
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
4,901 | 83,968 |
Python3 Depletes 2021 M1 Mac Memory Running Training Ops For Model's M, L and X
|
triaged, module: macos
|
### 🐛 Describe the bug
Hi Admin exec/s,
I am experiencing a strange issue where Python3 is hogging all of the resources while running the training operations for the yolov5 model's M, L and X. It is pointless to deploy the m6 models, for examples yolov5m6.pt or .ymal, l6, x6.
My research lead me to initialise the GPU/MPS on the silicon MacBook Pro 2021 14" MAX 32 cores. But this proved futile as the training will not allow the GPU to be initialised, so I followed PyTorch's nightly installation and that was futile as well.
Though it was not allowing the gpu/mps processing, somehow the yolov5m.pt model was able to work as well as from scratch, but not the larger models. This (m) took 4 days to train on the minuscule batch and epoch sizes, it took approximately 2hrs+ for 1 epoch iteration cycle.
Everyday the initialisation of the Training Operations is constantly prompting that yolov5 is out of date and I have to pull the necessary files to get the process to work as it should based on my knowledge.

What I did was:
1. Create an environment ML
2. Then install the requirements as per the instructions from @Glenn-Jocher downloaded in the folder of files from the clone process.
3. Install packages as prompted that required upgrading and then initialise the run commands below:
Packages:
```
Package Version
----------------------- --------------------
absl-py 1.2.0
appnope 0.1.3
asttokens 2.0.8
backcall 0.2.0
cachetools 5.2.0
certifi 2022.6.15
charset-normalizer 2.1.1
coremltools 5.2.0
cycler 0.11.0
decorator 5.1.1
executing 0.10.0
fonttools 4.36.0
google-auth 2.11.0
google-auth-oauthlib 0.4.6
grpcio 1.47.0
idna 3.3
ipython 8.4.0
jedi 0.18.1
kiwisolver 1.4.4
Markdown 3.4.1
MarkupSafe 2.1.1
matplotlib 3.5.3
matplotlib-inline 0.1.6
mpmath 1.2.1
natsort 8.1.0
numpy 1.23.2
oauthlib 3.2.0
opencv-python 4.6.0.66
packaging 21.3
pandas 1.4.3
parso 0.8.3
pexpect 4.8.0
pickleshare 0.7.5
Pillow 9.2.0
pip 22.2.2
prompt-toolkit 3.0.30
protobuf 3.19.4
psutil 5.9.1
ptyprocess 0.7.0
pure-eval 0.2.2
pyasn1 0.4.8
pyasn1-modules 0.2.8
Pygments 2.13.0
pyparsing 3.0.9
python-dateutil 2.8.2
pytz 2022.2.1
PyYAML 6.0
requests 2.28.1
requests-oauthlib 1.3.1
rsa 4.9
scipy 1.9.0
seaborn 0.11.2
setuptools 63.2.0
six 1.16.0
stack-data 0.4.0
sympy 1.10.1
tensorboard 2.10.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
thop 0.1.1.post2207130030
torch 1.12.1
torchaudio 0.12.1
torchvision 0.13.1
tqdm 4.64.0
traitlets 5.3.0
typing_extensions 4.3.0
urllib3 1.26.11
wcwidth 0.2.5
Werkzeug 2.2.2
wheel 0.37.1
```
Initialisation Code: For Both M and M6 Models
I swapped between 412, 640 and 1280 image sizes to reduce the drag on resources. Then I tried increasing and decreasing the batch size from 4-10-16-32 and 64. I also tried --hyp low, med, high but this created more drag and nothing worked, see the images below:
COMMANDS:
1. Python3 train.py --data coco128.yaml --epoch 30 --batch 32 --weights yolov5m6.pt --img 640 --cache
2. Python3 train.py --data coco128.yaml --epoch 30 --batch 32 --weights yolov5m.pt --img 640 --cache
All additional unnecessary APPS via Activity Monitor WERE STOPPED(Shut Down)
Image of issue:
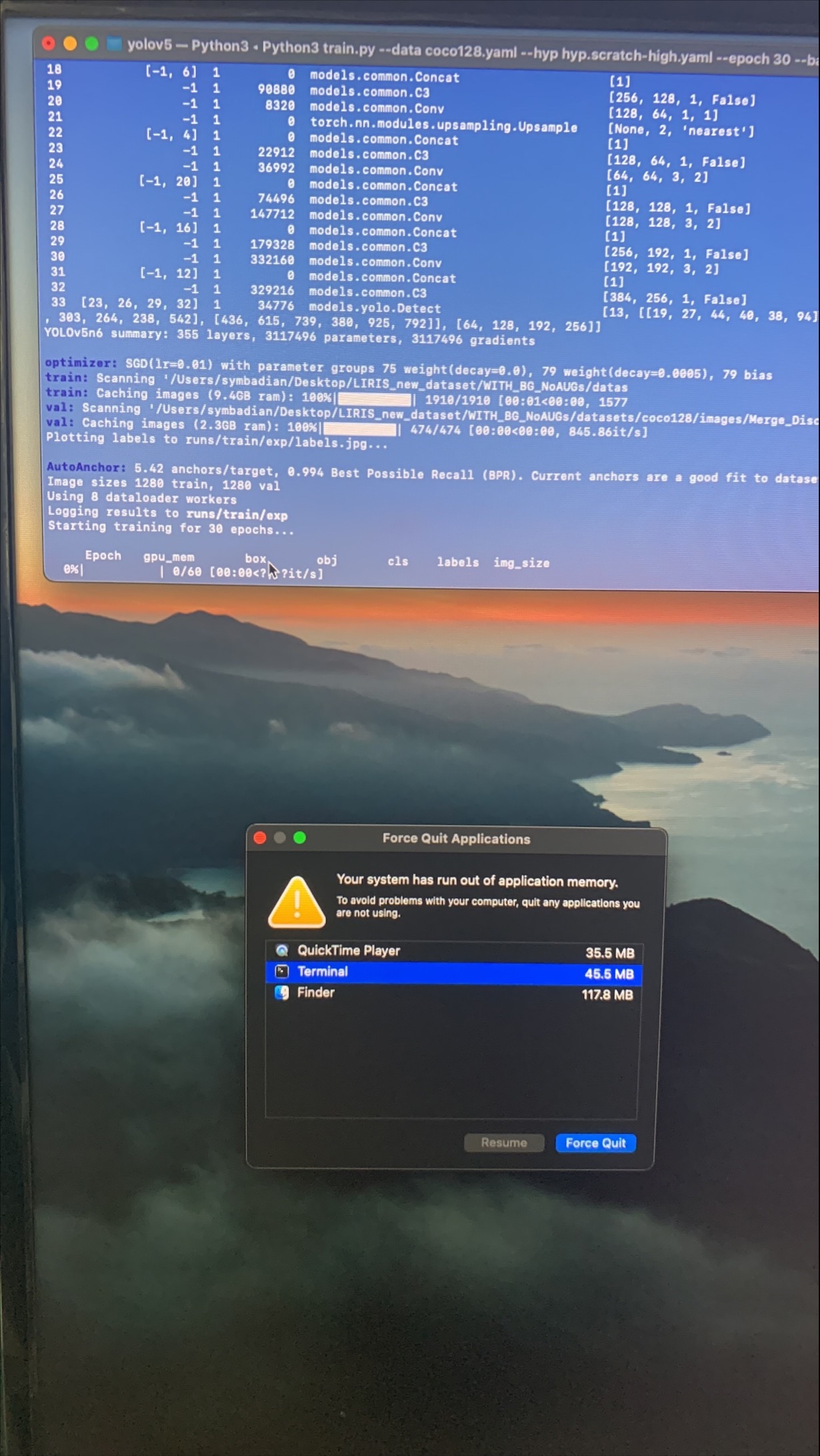
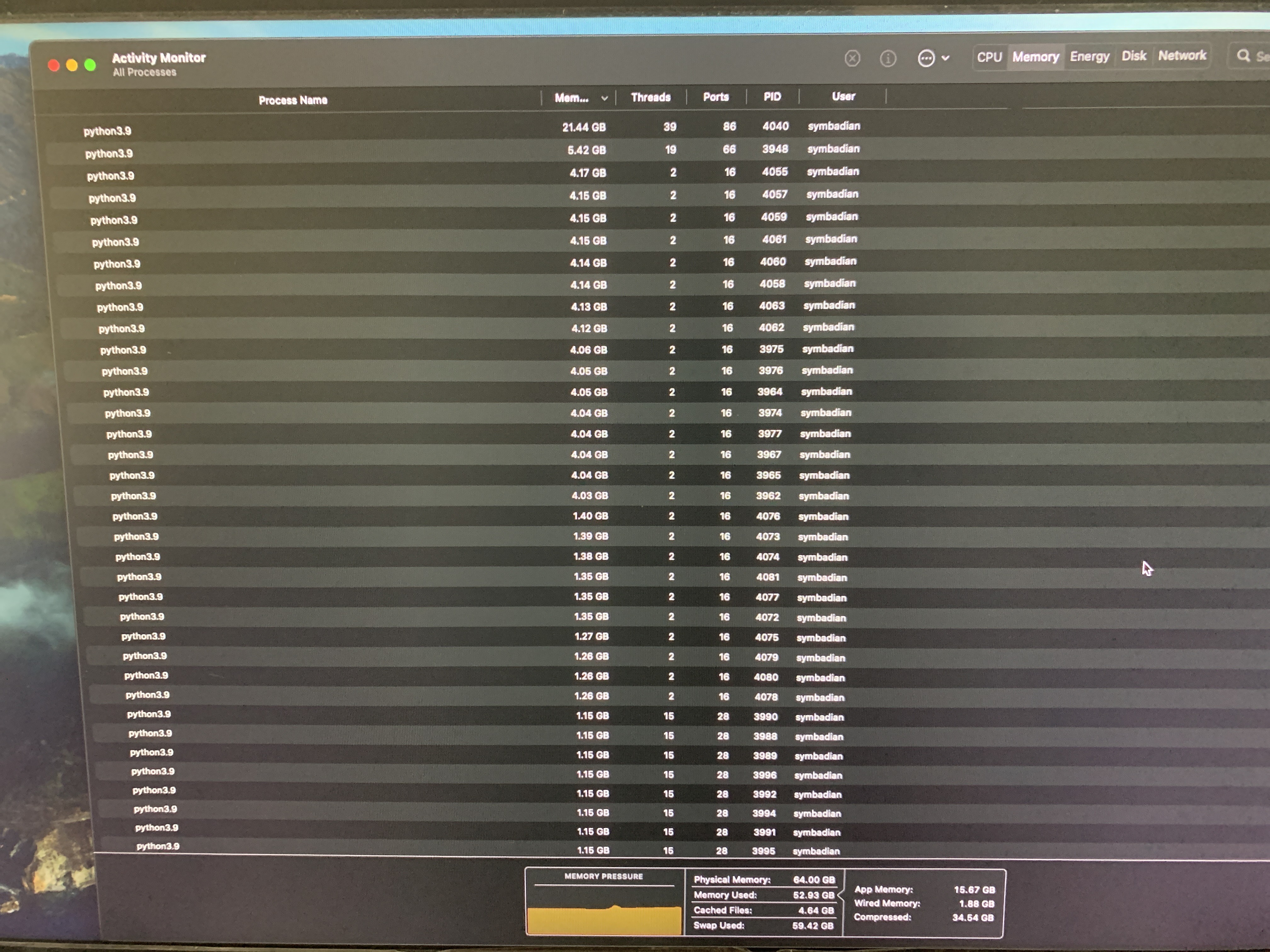
THEN, I also Tried Initialising the MPS as it was installed but a different set of errors persist.
1. Python3 train.py --data coco128.yaml --epoch 30 --batch 32 --weights yolov5m6.pt --img 640 --cache --device mps
2. Python3 train.py --data coco128.yaml --epoch 30 --batch 32 --weights yolov5m.pt --img 640 --cache --device mps
The larger models is my preference due to heavy dependency on accuracy, it's no use changing to a large model the resources are being depleted and the operations is too slow. I am aware that pytorch is still testing operations with packages and particulars for efficiency via MAC, but this is way to slow especially for a new machine with all the bells and whistles.
I have been stuck at this stage for 2 weeks now and not sure how to proceed, please assist me?
THANX LOADs in advance, I really appreciate you for taking the time to acknowledge my digital presence.
Cheers..
Sym.
### Versions
`Python3 train.py --data coco128.yaml --epoch 30 --batch 32 --weights yolov5x6.pt --img 640 --cache --device mps
train: weights=yolov5x6.pt, cfg=, data=coco128.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=30, batch_size=32, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=mps, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v6.2-51-ge6f54c5 Python-3.10.6 torch-1.12.1 MPS
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt to yolov5x6.pt...
ERROR: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)>
Re-attempting https://storage.googleapis.com/ultralytics/yolov5/v6.2/yolov5x6.pt to yolov5x6.pt...
############################################################################################################################################################################################################################################ 100.0%
Overriding model.yaml nc=80 with nc=13
from n params module arguments
0 -1 1 8800 models.common.Conv [3, 80, 6, 2, 2]
1 -1 1 115520 models.common.Conv [80, 160, 3, 2]
2 -1 4 309120 models.common.C3 [160, 160, 4]
3 -1 1 461440 models.common.Conv [160, 320, 3, 2]
4 -1 8 2259200 models.common.C3 [320, 320, 8]
5 -1 1 1844480 models.common.Conv [320, 640, 3, 2]
6 -1 12 13125120 models.common.C3 [640, 640, 12]
7 -1 1 5531520 models.common.Conv [640, 960, 3, 2]
8 -1 4 11070720 models.common.C3 [960, 960, 4]
9 -1 1 11061760 models.common.Conv [960, 1280, 3, 2]
10 -1 4 19676160 models.common.C3 [1280, 1280, 4]
11 -1 1 4099840 models.common.SPPF [1280, 1280, 5]
12 -1 1 1230720 models.common.Conv [1280, 960, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 8] 1 0 models.common.Concat [1]
15 -1 4 11992320 models.common.C3 [1920, 960, 4, False]
16 -1 1 615680 models.common.Conv [960, 640, 1, 1]
17 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
18 [-1, 6] 1 0 models.common.Concat [1]
19 -1 4 5332480 models.common.C3 [1280, 640, 4, False]
20 -1 1 205440 models.common.Conv [640, 320, 1, 1]
21 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
22 [-1, 4] 1 0 models.common.Concat [1]
23 -1 4 1335040 models.common.C3 [640, 320, 4, False]
24 -1 1 922240 models.common.Conv [320, 320, 3, 2]
25 [-1, 20] 1 0 models.common.Concat [1]
26 -1 4 4922880 models.common.C3 [640, 640, 4, False]
27 -1 1 3687680 models.common.Conv [640, 640, 3, 2]
28 [-1, 16] 1 0 models.common.Concat [1]
29 -1 4 11377920 models.common.C3 [1280, 960, 4, False]
30 -1 1 8296320 models.common.Conv [960, 960, 3, 2]
31 [-1, 12] 1 0 models.common.Concat [1]
32 -1 4 20495360 models.common.C3 [1920, 1280, 4, False]
33 [23, 26, 29, 32] 1 173016 models.yolo.Detect [13, [[19, 27, 44, 40, 38, 94], [96, 68, 86, 152, 180, 137], [140, 301, 303, 264, 238, 542], [436, 615, 739, 380, 925, 792]], [320, 640, 960, 1280]]
[W NNPACK.cpp:51] Could not initialize NNPACK! Reason: Unsupported hardware.
Model summary: 733 layers, 140150776 parameters, 140150776 gradients, 209.0 GFLOPs
Transferred 955/963 items from yolov5x6.pt
AMP: checks failed ❌, disabling Automatic Mixed Precision. See https://github.com/ultralytics/yolov5/issues/7908
optimizer: SGD(lr=0.01) with parameter groups 159 weight(decay=0.0), 163 weight(decay=0.0005), 163 bias
train: Scanning '/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/datasets/coco128/images/Merge_Discussions-Stab_Knife_Deploy/train/labels.cache' images and labels... 5730 found, 0 missing, 240 empty, 0 corrupt: 100%|██████████| 573
train: Caching images (7.0GB ram): 100%|██████████| 5730/5730 [00:03<00:00, 1739.79it/s]
val: Scanning '/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/datasets/coco128/images/Merge_Discussions-Stab_Knife_Deploy/val/labels.cache' images and labels... 474 found, 0 missing, 20 empty, 0 corrupt: 100%|██████████| 474/474 [
val: Caching images (0.6GB ram): 100%|██████████| 474/474 [00:00<00:00, 1035.74it/s]
AutoAnchor: 5.83 anchors/target, 0.972 Best Possible Recall (BPR). Anchors are a poor fit to dataset ⚠️, attempting to improve...
AutoAnchor: WARNING: Extremely small objects found: 64 of 30526 labels are < 3 pixels in size
AutoAnchor: Running kmeans for 12 anchors on 30526 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.7549: 100%|██████████| 1000/1000 [00:08<00:00, 124.95it/s]
AutoAnchor: thr=0.25: 0.9926 best possible recall, 7.51 anchors past thr
AutoAnchor: n=12, img_size=640, metric_all=0.351/0.756-mean/best, past_thr=0.497-mean: 17,15, 87,77, 198,124, 131,192, 263,176, 162,319, 384,151, 369,272, 260,481, 530,247, 488,420, 582,587
Traceback (most recent call last):
File "/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/yolov5/train.py", line 630, in <module>
main(opt)
File "/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/yolov5/train.py", line 526, in main
train(opt.hyp, opt, device, callbacks)
File "/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/yolov5/train.py", line 222, in train
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
File "/Users/symbadian/Desktop/LIRIS_new_dataset/WITH_BG_WITHAUGs/yolov5/utils/autoanchor.py", line 58, in check_anchors
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
TypeError: Cannot convert a MPS Tensor to float64 dtype as the MPS framework doesn't support float64. Please use float32 instead.
(/Users/symbadian/miniforge3/ml) Matthews-MacBook-Pro:yolov5 symbadian$
`
cc @malfet @albanD
| 2 |
4,902 | 83,956 |
[FSDP] Make sharded / unsharded check more robust
|
oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
As per the comment in https://github.com/pytorch/pytorch/pull/83195#discussion_r952937179, we currently check if we are using the local shard for the param to check if a param is sharded or unsharded:
```
p.data.data_ptr() == p._local_shard.data_ptr():
```
This assumes that if we are using the local shard, we already correctly freed the full parameter. This assumption holds true today but if it were to break this would be a silent correctness issue. We should figure out a robust, future-proof approach to checking if we need to reshard a parameter or not.
### Alternatives
_No response_
### Additional context
_No response_
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang
| 0 |
4,903 | 83,947 |
Are PyTorch Android nightly builds getting automatically published
|
module: ci, triaged, module: android
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/pull/83930 kills logic for uploading nightly builds, because apparently it were never used.
Lets track whether we need to publish nightly builds for Android.... And if do not, let's close this issue
Our [documentation](https://pytorch.org/mobile/android/#using-the-nightly-pytorch-android-libraries) claims that Android nightly builds exist, but still references Python-1.8.0 and the last non-trivial update to this page were in Jun 2021: https://github.com/pytorch/pytorch.github.io/commits/site/_mobile/android.md
### Versions
CI
cc @seemethere @pytorch/pytorch-dev-infra
| 0 |
4,904 | 83,941 |
empty_quantized should probably be new_empty_quantized
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
the current empty_quantized takes a Tensor as input, so it matches the semantics of new_empty instead of empty (which does not take Tensor input), we should merge the empty_quantized implementation under new_empty instead
### Versions
master
cc @jianyuh @raghuramank100 @jamesr66a @vkuzo
| 0 |
4,905 | 83,948 |
Add torch nightly builds pipeline for aarch64 linux
|
module: ci, triaged, enhancement, module: arm
|
There are no aarch64_linux nightly wheels here:
https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
However, I see the wheels are published for [PT1.12.1 release](https://pypi.org/project/torch/#files) on Aug 5th, so, the issue with the nightly builds might be with some infrastructure not the codebase.
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 5 |
4,906 | 83,932 |
Hitting rate limits for pytorchbot token
|
triaged, module: infra
|
example: https://github.com/pytorch/pytorch/runs/7733767854?check_suite_focus=true
| 1 |
4,907 | 83,931 |
primTorch: support refs and decompositions when ATen and Python disagree
|
triaged, module: primTorch
|
### 🐛 Describe the bug
1. Policy (related): We need to agree on how to handle refs/decomps like `binary_cross_entropy` where the ATen op and the Python frontend have different number/type of arguments. Right now, `binary_cross_entropy` just defines a decomp. Do we want to split the ref/decomp implementations for these (with a shared core/conversion logic) or handle in some other way?
2. Bug: if `register_decomposition` is used with ops like these to define _one_ Python function that's both registered as a ref and a decomp, there are no type signature checks in `register_decomposition` to catch this. So it'll just run and we might not notice unless it breaks for some other reason.
I have a demo branch with this issue here, see the commit message and notes in the topmost commit:
https://github.com/nkaretnikov/pytorch/commits/primtorch-l1-loss-decomp-ref-compat-issue
### Versions
master (e0f2eba93d2804d22cd53ea8c09a479ae546dc7f)
cc @ezyang @mruberry @ngimel
| 1 |
4,908 | 83,929 |
ModuleNotFoundError: No module named 'torch.ao.quantization.experimental'
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
Running 'pytest' gets these errors:
```
ModuleNotFoundError: No module named 'torch.ao.quantization.experimental'
```
https://github.com/facebookresearch/d2go/issues/141
The code likely needs to be changed from:
```
from torch.ao.quantization.experimental.observer import APoTObserver
```
to:
```
from torch.quantization.experimental.observer import APoTObserver
```
in these file:
```
% grep torch.ao.quantization test/quantization/core/experimental/*.py
test/quantization/core/experimental/apot_fx_graph_mode_ptq.py:from torch.ao.quantization.experimental.quantization_helper import (
test/quantization/core/experimental/apot_fx_graph_mode_ptq.py:from torch.ao.quantization.experimental.qconfig import (
test/quantization/core/experimental/apot_fx_graph_mode_qat.py:from torch.ao.quantization.experimental.quantization_helper import (
test/quantization/core/experimental/test_fake_quantize.py:from torch.ao.quantization.experimental.observer import APoTObserver
test/quantization/core/experimental/test_fake_quantize.py:from torch.ao.quantization.experimental.quantizer import quantize_APoT, dequantize_APoT
test/quantization/core/experimental/test_fake_quantize.py:from torch.ao.quantization.experimental.fake_quantize import APoTFakeQuantize
test/quantization/core/experimental/test_fake_quantize.py:from torch.ao.quantization.experimental.fake_quantize_function import fake_quantize_function
test/quantization/core/experimental/test_linear.py:from torch.ao.quantization.experimental.linear import LinearAPoT
test/quantization/core/experimental/test_nonuniform_observer.py:from torch.ao.quantization.experimental.observer import APoTObserver
test/quantization/core/experimental/test_quantized_tensor.py:from torch.ao.quantization.experimental.observer import APoTObserver
test/quantization/core/experimental/test_quantized_tensor.py:from torch.ao.quantization.experimental.quantizer import quantize_APoT
test/quantization/core/experimental/test_quantizer.py:from torch.ao.quantization.observer import MinMaxObserver
test/quantization/core/experimental/test_quantizer.py:from torch.ao.quantization.experimental.observer import APoTObserver
test/quantization/core/experimental/test_quantizer.py:from torch.ao.quantization.experimental.quantizer import APoTQuantizer, quantize_APoT, dequantize_APoT
```
### Versions
```
% python collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 12.5.1 (x86_64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.4 (main, Mar 31 2022, 03:38:35) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.3
[pip3] torch==1.13.0a0+gitb2ddef2
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.14.0a0+a61e6ef
[conda] blas 1.0 mkl anaconda
[conda] captum 0.5.0 0 pytorch
[conda] mkl 2021.4.0 hecd8cb5_637 anaconda
[conda] mkl-service 2.4.0 py310hca72f7f_0 anaconda
[conda] mkl_fft 1.3.1 py310hf879493_0 anaconda
[conda] mkl_random 1.2.2 py310hc081a56_0 anaconda
[conda] numpy 1.22.3 py310hdcd3fac_0 anaconda
[conda] numpy-base 1.22.3 py310hfd2de13_0 anaconda
[conda] pytorch 1.12.1 py3.10_0 pytorch
[conda] torch 1.13.0a0+git09157c7 pypi_0 pypi
[conda] torchmetrics 0.9.3 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.14.0a0+a61e6ef pypi_0 pypi
(AI-Feynman) davidlaxer@x86_64-apple-darwin13 pytorch %
```
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo
| 5 |
4,909 | 83,923 |
Support primtorch view ops in functionalization
|
triaged, module: viewing and reshaping, module: functionalization, module: primTorch
|
I was starting to look at failing inductor models with `functorch.config.use_functionalize=True` turned on, and one failure that I noticed is:
```
// run this
python benchmarks/timm_models.py --float32 -dcuda --no-skip --training --inductor --use-eval-mode --only=mobilevit_s
// output
return forward_call(*input, **kwargs)
File "<eval_with_key>.4", line 394, in forward
broadcast_in_dim_default = torch.ops.prims.broadcast_in_dim.default(var_default, [256, 256, 1], [0, 1]); var_default = None
File "/scratch/hirsheybar/work/benchmark/pytorch/torch/_ops.py", line 60, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: !schema.hasAnyAliasInfo() INTERNAL ASSERT FAILED at "/scratch/hirsheybar/work/benchmark/pytorch/aten/src/ATen/FunctionalizeFallbackKernel.cpp":30, please report a bug to PyTorch. mutating and aliasing ops should all have codegen'd kernels
```
This error didn't show up in my AOT + eager tests, probably because the inductor backend is choosing to run extra primtorch decompositions. This causes functionalization to see `prims.broadcast_in_dim`, which is a new "view" op that it doesn't know how to handle.
For what it's worth - the code above fails with `use_functionalize=False` turned off today, too, because of some issue's in dynamo' `normalize_ir()` code. So this technically isn't a regression, although it seems like time would be better spent fixing the problem with functionalization instead of fixing dynamo's normalization logic.
Two potential ways to handle this are:
(1) write a custom functionalization kernel for `prims.broadcast_in_dims.default`. We'd need to expose the right C++ API's to python in order to do this
(2) Beef up the functionalization boxed fallback to handle views. This would be very useful, but it's a bit unclear how this would work: for every primtorch view, the boxed fallback needs to know how to map it to a "view inverse" function.
cc @ezyang @mruberry @ngimel
| 9 |
4,910 | 83,914 |
RAM not free when deleting a model in CPU? worse after inference, is there some cache hidden?
|
module: memory usage, triaged
|
### 🐛 Describe the bug
Hi, all,
After deleting a model (e.g. ResNet50) with `del(model)`, the memory does not seem to be releasing.
Worse, memory grows too much after simple inference, in eval mode, without grads : I understand the model needs to keep some infos about tensors during inference for skip connections, but I guess it should not retain anything after this connection, and be back to same state after initialization?
I checked it's not the case for simple modules like Sequentials of Linears etc., so it may be related to special modules.
Not sure if it's a real bug, but I feel like it's not the output we would expect. If I should ask on the Forum, please tell me.
Manual Garbage Collection does not change anything, so i'm confused where the memory goes. Thanks for the answer
first, some quick code to get RAM usage
```python
import os, psutil
import time
def print_memory_usage(prefix):
"""prints current process RAM consumption in Go"""
process = psutil.Process(os.getpid())
print("memory usage ", prefix, process.memory_info().rss / 1e9, "Go")
```
Now the ResNet50 initialization
```python
import torch
from torchvision.models import resnet50
print_memory_usage(prefix="before anything")
model = resnet50(pretrained=True)
model.eval()
for param in model.parameters():
param.requires_grad_(False)
print_memory_usage(prefix="after model init")
del model
print_memory_usage(prefix="after removing model")
```
```
memory usage before anything 0.15622144 Go
memory usage after model init 0.362528768 Go
memory usage after removing model 0.362561536 Go # not released
```
and worse : memory "explosion" after inference in eval mode and grad-free
```python
import torch
from torchvision.models import resnet50
print_memory_usage(prefix="before anything")
model = resnet50(pretrained=True)
model.eval()
for param in model.parameters():
param.requires_grad_(False)
print_memory_usage(prefix="after model init")
input_tensor = torch.rand((100, 3, 128, 128))
print_memory_usage(prefix="after init input")
with torch.no_grad():
model.forward(input_tensor)
print_memory_usage(prefix="after inference")
del model
print_memory_usage(prefix="after removing model")
del input_tensor
print_memory_usage(prefix="after removing input")
```
```
memory usage before anything 0.155877376 Go
memory usage after model init 0.362856448 Go
memory usage after init input 0.382713856 Go
memory usage after inference 1.41819904 Go # outch, where does it comes from, if it's grad-free?
memory usage after removing model 1.294467072 Go # memory not released
memory usage after removing input 1.18964224 Go
```
### Versions
```
Collecting environment information...
PyTorch version: 1.12.0.post2
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (arm64)
GCC version: Could not collect
Clang version: 12.0.5 (clang-1205.0.22.9)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.2 | packaged by conda-forge | (default, Feb 21 2021, 05:00:30) [Clang 11.0.1 ] (64-bit runtime)
Python platform: macOS-12.4-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.920
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.2
[pip3] torch==1.12.0.post2
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.11.3
[conda] numpy 1.20.3 pypi_0 pypi
[conda] pytorch 1.12.0 cpu_py39h0768760_2 conda-forge
[conda] torch 1.10.2 pypi_0 pypi
[conda] torchaudio 0.12.1 pypi_0 pypi
[conda] torchvision 0.11.3 pypi_0 pypi
```
| 1 |
4,911 | 83,910 |
Tracking nested tensor functions with backward kernels registered in derivatives.yaml
|
triaged, module: nestedtensor
|
### 🐛 Describe the bug
Context:
Backward formulas for certain nested tensor functions do not work as they call `.sizes()`. As a workaround, we can register formulas specific to the AutogradNestedTensor dispatch key in derivatives.yaml. This should be removed when SymInts for nested tensor sizes are ready for use. This issue serves as a tracker for functions for which we have added this workaround so that we can remove them in the future.
- [ ] [_nested_sum_backward](https://github.com/pytorch/pytorch/pull/82625)
- [ ] [_select_backward](https://github.com/pytorch/pytorch/pull/83875)
### Versions
n/a
cc @cpuhrsch @jbschlosser @bhosmer @drisspg @albanD
| 0 |
4,912 | 83,909 |
Grad strides do not match bucket view strides
|
oncall: distributed, triaged, module: memory format, module: ddp
|
### 🐛 Describe the bug
@mcarilli
Hello,
I am using torch.nn.parallel.DistributedDataParallel and get the following warning:
> Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
> /\*\*\*\*\*\*\/miniconda3/envs/pym/lib/python3.10/site-packages/torch/autograd/__init__.py:173: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.
> grad.sizes() = [300, 100, 1, 1], strides() = [100, 1, 1, 1]
> bucket_view.sizes() = [300, 100, 1, 1], strides() = [100, 1, 100, 100] (Triggered internally at /opt/conda/conda-bld/pytorch_1659484803030/work/torch/csrc/distributed/c10d/reducer.cpp:312.)
I could not write the minimal reproducing code because I can't find what part of the code create this warning.
However, I know that it is due to an operation in my model as the warning does not appear with other models.
But I do not get any warning when running the same code with Apex, so could it be an issue with the native DDP?
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.3 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.27
Python version: 3.10.6 | packaged by conda-forge | (main, Aug 22 2022, 20:35:26) [GCC 10.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
GPU 4: NVIDIA GeForce RTX 3090
GPU 5: NVIDIA GeForce RTX 3090
GPU 6: NVIDIA GeForce RTX 3090
GPU 7: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.48.07
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 2.116 mkl conda-forge
[conda] blas-devel 3.9.0 16_linux64_mkl conda-forge
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] libblas 3.9.0 16_linux64_mkl conda-forge
[conda] libcblas 3.9.0 16_linux64_mkl conda-forge
[conda] liblapack 3.9.0 16_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 16_linux64_mkl conda-forge
[conda] mkl 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-devel 2022.1.0 ha770c72_916 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] numpy 1.23.2 py310h53a5b5f_0 conda-forge
[conda] pytorch 1.12.1 py3.10_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py310_cu116 pytorch
[conda] torchvision 0.13.1 py310_cu116 pytorch
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @VitalyFedyunin @jamesr66a @ezyang
| 4 |
4,913 | 83,902 |
Bug in batch names with matmul (result tensor has names=('i', 'i', 'k')).
|
triaged, module: named tensor
|
### 🐛 Describe the bug
The following code should fail, as it gives duplicate names in the output.
```
A = t.ones((3,3), names=('i', 'j'))
B = t.ones((3,3,3), names=('i', 'j', 'k'))
print((A@B).names)
```
Instead, it gives duplicated names (which is not allowed e.g. in the named constructors):
```
('i', 'i', 'k')
```
I'm on PyTorch version 1.12.1 on CPU.
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.9.2009 (Core) (x86_64)
GCC version: (GCC) 9.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.45.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.2
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1+cu113
[pip3] torchvision==0.13.1+cu113
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] pytorch 1.12.1 py3.9_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1+cu113 pypi_0 pypi
[conda] torchvision 0.13.1+cu113 pypi_0 pypi
cc @zou3519
| 3 |
4,914 | 83,901 |
pytorch 1.12.1 Adam Optimizer Malfunction!!!
|
needs reproduction, module: optimizer, triaged
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
In pytorch 1.12.1, Adam optimization doesn't work well.
I think, It seems that the internal behavior has changed as the version is upgraded, please check
## Code example
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch
- How you installed PyTorch Conda
- Build command you used (if compiling from source):
- OS: window10, Ubuntu 18.04
- PyTorch version: 1.12.1
- Python version: 3.8.0
- CUDA/cuDNN version: Cuda11.3
- GPU models and configuration: gtx1080ti, gtx3070
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
cc @vincentqb @jbschlosser @albanD
| 1 |
4,915 | 83,884 |
Improve FSDP error msg on wrong attr access
|
oncall: distributed, module: bootcamp, triaged, pt_distributed_rampup, module: fsdp
|
### 🚀 The feature, motivation and pitch
If FSDP does not have an attr, it will dispatch into the contained module to try to get the attribute. However if this fails, the error raised is confusing, since it prints out a msg containing info about the wrapped module not having the attribute, instead of the FSDP module. An example:
```
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/testing/_internal/common_distributed.py", line 622, in run_test
getattr(self, test_name)()
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/testing/_internal/common_distributed.py", line 503, in wrapper
fn()
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/testing/_internal/common_distributed.py", line 145, in wrapper
return func(*args, **kwargs)
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/test/distributed/fsdp/test_fsdp_misc.py", line 150, in test_fsdp_not_all_outputs_used_in_loss
loss.backward()
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/_tensor.py", line 484, in backward
torch.autograd.backward(
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/autograd/__init__.py", line 191, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 2880, in _post_backward_hook
if self._should_free_full_params():
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 3483, in _should_free_full_params
self.sharding_stratagy == ShardingStrategy.FULL_SHARD
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 1536, in __getattr__
return getattr(self._fsdp_wrapped_module, name)
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/distributed/fsdp/flatten_params_wrapper.py", line 146, in __getattr__
return getattr(self.module, name) # fall back to the wrapped module
File "/fsx/users/rvarm1/rvarm1/repos/pytorch/torch/nn/modules/module.py", line 1260, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'Linear' object has no attribute 'sharding_stratagy'
```
In this case, we have a typo `sharding_stratagy` but it is harder to debug since the error `AttributeError: 'Linear' object has no attribute 'sharding_stratagy'` is misleading. We should improve this to include information about `FullyShardedDataParallel`.
### Alternatives
_No response_
### Additional context
_No response_
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang
| 0 |
4,916 | 83,863 |
bfloat16 matmul gives incorrect result on CPU (without mkldnn)
|
module: cpu, triaged, module: bfloat16, module: linear algebra
|
### 🐛 Describe the bug
It seems that Pytorch's default CPU backend does not compute bfloat16 matmul correctly. The expected behavior is observed for certain dimensions only (the outcome is as expected for 256x256x256), but fails for others (1024x1024x1024).
In addition, it seems that the mkl-dnn backend correctly computes the result. However, it's only limited to avx512+ systems only.
```python
import torch
def check_correctness(a: torch.Tensor, b:torch.Tensor, expected: int):
for mkldnn_flag in [True, False]:
with torch.backends.mkldnn.flags(enabled=mkldnn_flag):
c = torch.matmul(a, b)
assert(torch.all(c == expected)), "Incorrect result with\n" \
f"torch.backends.mkldnn.flags(enabled={mkldnn_flag}),\n" \
f"and dtypes: {a.dtype}, {b.dtype}, {c.dtype}\n" \
f"expected: {expected}\n" \
f"got: {c}\n"
val = 1024
a = torch.ones(val, val)
b = torch.ones(val, val)
check_correctness(a, b, expected=val)
a = a.to(torch.bfloat16)
b = b.to(torch.bfloat16)
check_correctness(a, b, expected=val)
```
Executing the above code yields the following message:
```sh
Traceback (most recent call last):
File "test_matmul.py", line 23, in <module>
check_correctness(a, b, expected=val)
File "test_matmul.py", line 7, in check_correctness
assert(torch.all(c == expected)), "Incorrect result with\n" \
AssertionError: Incorrect result with
torch.backends.mkldnn.flags(enabled=False),
and dtypes: torch.bfloat16, torch.bfloat16, torch.bfloat16
expected: 1024
got: tensor([[256., 256., 256., ..., 256., 256., 256.],
[256., 256., 256., ..., 256., 256., 256.],
[256., 256., 256., ..., 256., 256., 256.],
...,
[256., 256., 256., ..., 256., 256., 256.],
[256., 256., 256., ..., 256., 256., 256.],
[256., 256., 256., ..., 256., 256., 256.]], dtype=torch.bfloat16)
```
### Versions
```sh
PyTorch version: 1.12.1+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 10.3.0-1ubuntu1~20.04) 10.3.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: Quadro P1000
Nvidia driver version: 516.40
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.12.1+cpu
[pip3] torchaudio==0.12.1+cpu
[pip3] torchvision==0.13.1+cpu
[conda] No relevant packages
```
cc @VitalyFedyunin @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 5 |
4,917 | 83,854 |
Pytorch/Nova CI should monitor service outages for major dependencies
|
module: ci, triaged, needs design
|
### 🐛 Describe the bug
Followup after https://github.com/pytorch/vision/issues/6466
There should be a mechanism one can rely to tell whether some of the components CI depends on were experiencing outage at the time CI job were run.
This includes, but not limited:
- https://www.githubstatus.com/
- https://status.circleci.com/
- https://developer.download.nvidia.com
- https://download.pytorch.org
- https://anaconda.org/ and its CDN
- PyPI and its CDN
### Versions
CI
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 1 |
4,918 | 83,851 |
torch fx cannot trace assert for some cases
|
triaged, fx
|
### 🐛 Describe the bug
torch fx cannot trace assert for some cases.
```
import torch
from torch.fx import Tracer
def test(x):
H, W = x.shape
assert (H, W) == (2, 3), 'haha'
tracer = Tracer()
tracer.trace_asserts = True
graph = tracer.trace(test)
print(graph)
```
It failed for this case.
```
(ai-0401)yinsun@se02ln001:~/tmp/txp$ python test.py
Traceback (most recent call last):
File "test.py", line 10, in <module>
graph = tracer.trace(test)
File "/home/sa/ac-ap-ci/.conda/envs/ai-0401/lib/python3.8/site-packages/torch/fx/_symbolic_trace.py", line 566, in trace
self.create_node('output', 'output', (self.create_arg(fn(*args)),), {},
File "test.py", line 6, in test
assert (H, W) == (2, 3), 'haha'
File "/home/sa/ac-ap-ci/.conda/envs/ai-0401/lib/python3.8/site-packages/torch/fx/proxy.py", line 278, in __bool__
return self.tracer.to_bool(self)
File "/home/sa/ac-ap-ci/.conda/envs/ai-0401/lib/python3.8/site-packages/torch/fx/proxy.py", line 154, in to_bool
raise TraceError('symbolically traced variables cannot be used as inputs to control flow')
torch.fx.proxy.TraceError: symbolically traced variables cannot be used as inputs to control flow
```
### Versions
```
(ai-0401)yinsun@se02ln001:~/tmp/txp$ python collect_env.py
Collecting environment information...
PyTorch version: 1.11.0a0+gitbc2c6ed
Is debug build: False
CUDA used to build PyTorch: 11.4
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.3 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: 14.0.6 (https://github.com/conda-forge/clangdev-feedstock 28f7809e7f4286b203af212a154f5a8327bd6fd6)
CMake version: version 3.19.1
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-64-generic-x86_64-with-glibc2.10
Is CUDA available: False
CUDA runtime version: 11.4.120
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.19.5
[pip3] pytorch3d==0.6.2
[pip3] torch==1.11.0+bc2c6ed.cuda114.cudnn841.se02s03.ap
[pip3] torch-scatter==2.0.8
[pip3] torch-tb-profiler==0.4.0
[pip3] torchfile==0.1.0
[pip3] torchvision==0.9.0a0+8fb5838
[conda] magma-cuda111 2.5.2 1 pytorch
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] numpy 1.19.5 py38h8246c76_3 conda-forge
[conda] pytorch3d 0.6.2 pypi_0 pypi
[conda] torch 1.11.0+bc2c6ed.cuda114.cudnn841.se02s03.ap pypi_0 pypi
[conda] torch-scatter 2.0.8 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchvision 0.9.0a0+8fb5838 pypi_0 pypi
```
cc @ezyang @SherlockNoMad @soumith
| 2 |
4,919 | 83,826 |
test_lazy spuriously fails if LAPACK is not installed
|
module: tests, triaged, module: lazy
|
### 🐛 Describe the bug
should skip if not compiled with lapack
### Versions
master
cc @mruberry
| 0 |
4,920 | 83,824 |
RuntimeError: Interrupted system call when doing distributed training
|
oncall: distributed, module: c10d
|
### 🐛 Describe the bug
When running distributed GPU training, I get the following error:
```
File "train_mae_2d.py", line 120, in train
run_trainer(
File "train_mae_2d.py", line 41, in run_trainer
trainer = make_trainer(
File "/home/ubuntu/video-recommendation/trainer/trainer.py", line 78, in make_trainer
return Trainer(
File "/home/ubuntu/miniconda/envs/video-rec/lib/python3.8/site-packages/composer/trainer/trainer.py", line 781, in __init__
dist.initialize_dist(self._device, datetime.timedelta(seconds=dist_timeout))
File "/home/ubuntu/miniconda/envs/video-rec/lib/python3.8/site-packages/composer/utils/dist.py", line 433, in initialize_dist
dist.init_process_group(device.dist_backend, timeout=timeout)
File "/home/ubuntu/miniconda/envs/video-rec/lib/python3.8/site-packages/torch/distributed/distributed_c10d.py", line 595, in init_process_group
store, rank, world_size = next(rendezvous_iterator)
File "/home/ubuntu/miniconda/envs/video-rec/lib/python3.8/site-packages/torch/distributed/rendezvous.py", line 257, in _env_rendezvous_handler
store = _create_c10d_store(master_addr, master_port, rank, world_size, timeout)
File "/home/ubuntu/miniconda/envs/video-rec/lib/python3.8/site-packages/torch/distributed/rendezvous.py", line 188, in _create_c10d_store
return TCPStore(
RuntimeError: Interrupted system call
```
Is there any way to diagnose what is going on here?
### Versions
Collecting environment information...
PyTorch version: 1.12.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.124
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] pytorch-ranger==0.1.1
[pip3] torch==1.12.0+cu116
[pip3] torch-optimizer==0.1.0
[pip3] torchdata==0.4.0
[pip3] torchmetrics==0.7.3
[pip3] torchvision==0.13.0a0+da3794e
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch-ranger 0.1.1 pypi_0 pypi
[conda] torch 1.12.0+cu116 pypi_0 pypi
[conda] torch-optimizer 0.1.0 pypi_0 pypi
[conda] torchdata 0.4.0 pypi_0 pypi
[conda] torchmetrics 0.7.3 pypi_0 pypi
[conda] torchvision 0.13.0a0+da3794e pypi_0 pypi
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 4 |
4,921 | 93,639 |
Explore TorchInductor optimization pass to reorder kernel bodies
|
triaged, oncall: pt2
|
See pytorch/torchdynamo#934 for more context. We found an example of a 10% performance difference from very similar kernels, where the biggest difference seemed to be instruction ordering.
Interesting, my first guess looking at the two kernels is just the ordering of ops. The loads on the faster kernel are "spread out" while the loads in the slow kernel are "bunched up".
Perhaps we should explore a compiler pass that reorders ops within a kernel.
Our current inductor kernels usually look like:
```
<all of the loads>
<all of the compute>
<all of the stores>
````
When you have indirect loads, it moves those indirect loads into the "compute" section, because they must come after the address computation. Thus allowing that spread out pattern to be generated.
My thinking of doing that ordering was it makes compiler analysis easier for Triton/LLVM. I may have been wrong there... especially if Triton doesn't yet have an instruction reordering pass.
This is just one theory though, we should test it.
_Originally posted by @jansel in https://github.com/pytorch/torchdynamo/issues/934#issuecomment-1221583598_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,922 | 83,818 |
torch.linalg.eigh crashe for matrices of size 2895×2895 or larger on eigen and M1
|
module: crash, triaged, module: linear algebra, module: m1
|
### 🐛 Describe the bug
### From python
```python
>>> import torch as t
>>> t.linalg.eigh(t.randn([2895, 2895]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: false INTERNAL ASSERT FAILED at "/var/tmp/portage/sci-libs/caffe2-1.12.0/work/pytorch-1.12.0/aten/src/ATen/native/LinearAlgebraUtils.h":288, please report a bug to PyTorch. torch.linalg.eigh: Argument 8 has illegal value. Most certainly there is a bug in the implementation calling the backend library.
>>> t.linalg.eigh(t.randn([2894, 2894]))
torch.return_types.linalg_eigh(
eigenvalues=tensor([-107.5161, -107.0879, -106.6525, ..., 106.2521, 106.6649,
107.0642]),
eigenvectors=tensor([[ 0.0078, -0.0312, 0.0016, ..., -0.0169, 0.0231, -0.0228],
[-0.0116, -0.0156, -0.0480, ..., -0.0078, -0.0399, -0.0170],
[-0.0112, 0.0034, 0.0137, ..., 0.0073, 0.0098, 0.0088],
...,
[ 0.0109, -0.0148, 0.0302, ..., 0.0077, -0.0162, 0.0146],
[-0.0004, -0.0294, 0.0220, ..., -0.0102, -0.0062, 0.0327],
[-0.0262, 0.0164, -0.0376, ..., 0.0289, -0.0080, -0.0037]]))
>>> 2 ** 11.5
2896.309375740099
```
### From C++ interface
Can't get a backtrace with gdb, since `bt` says the program already exited. So it's just a mysterious undebuggable crash, until narrowing it down to a `torch::linalg::eigh` call.
```
** On entry to SSYEVD parameter number 8 had an illegal value
```
### See also?
Possibly related to #68291 / #51720?
### Versions
1.12
```
$ wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
--2022-08-21 09:45:24-- https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
Resolving raw.githubusercontent.com... 185.199.110.133, 185.199.108.133, 185.199.111.133, ...
Connecting to raw.githubusercontent.com|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 16906 (17K) [text/plain]
Saving to: ‘collect_env.py’
collect_env.py 100%[====================================================================================================================>] 16.51K --.-KB/s in 0.02s
2022-08-21 09:45:24 (1009 KB/s) - ‘collect_env.py’ saved [16906/16906]
$ python collect_env.py
Collecting environment information...
Traceback (most recent call last):
File "~/collect_env.py", line 492, in <module>
main()
File "~/collect_env.py", line 475, in main
output = get_pretty_env_info()
File "~/collect_env.py", line 470, in get_pretty_env_info
return pretty_str(get_env_info())
File "~/collect_env.py", line 319, in get_env_info
pip_version, pip_list_output = get_pip_packages(run_lambda)
File "~/collect_env.py", line 301, in get_pip_packages
out = run_with_pip(sys.executable + ' -mpip')
File "~/collect_env.py", line 289, in run_with_pip
for line in out.splitlines()
AttributeError: 'NoneType' object has no attribute 'splitlines'
```
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 8 |
4,923 | 83,817 |
[feature request] Add new device type works on CPU
|
triaged, enhancement
|
### 🚀 The feature, motivation and pitch
When we write code on a CPU machine and it runs on a GPU machine, we sometimes forget to transfer tensor GPU to CPU or opposite.
Because we write `device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")` on head of code.
When we test it on a CPU machine, all tensors are put on the CPU and do not tell us whether the tensor will transfer as we expect or not.
So, how about adding a new device type that works on a CPU? (like a fake-gpu)
In my assumption,
Now(no GPU machine)
```
device = torch.device("cuda:0" if torch.cuda.is_available else "cpu")
a = torch.arange(10).to(device)
a.numpy() # actually need a.cpu() before numpy()
>>> No Error
```
New Feature(no GPU machine)
```
device = torch.device("cuda:0" if torch.cuda.is_available else "fake-gpu")
a = torch.arange(10).to(device)
a.numpy() # need a.cpu() before numpy()
>>> Error
```
### Alternatives
_No response_
### Additional context
_No response_
| 3 |
4,924 | 83,800 |
torch.var_mean is slower than layer norm
|
module: performance, module: nn, triaged, needs research
|
### 🐛 Describe the bug
It's known that layer norm needs to compute the variance and mean of its input. So we can expect that `torch.var_mean` runs faster than `LayerNorm`. But, when I time them, I find that `torch.var_mean` runs much slower than `LayerNorm` on cpu.
```python
from functools import partial
import torch
import timeit
x = torch.randn((257, 252, 192),dtype=torch.float32)
ln = torch.nn.LayerNorm(192)
ln.eval()
with torch.no_grad():
var_mean_time = timeit.timeit(partial(torch.var_mean, input=x, dim=(2,)), number=100)
ln_time = timeit.timeit(partial(ln, input=x), number=100)
print(var_mean_time, ln_time) # 3.149209 1.2331005
```
### Versions
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Home China
GCC version: (x86_64-posix-seh, Built by strawberryperl.com project) 8.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.12 (main, Apr 4 2022, 05:22:27) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22622-SP0
Is CUDA available: True
CUDA runtime version: 11.7.64
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1080
Nvidia driver version: 516.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.971
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==1.7.2
[pip3] pytorch-ranger==0.1.1
[pip3] torch==1.12.1
[pip3] torch-complex==0.4.3
[pip3] torch-optimizer==0.3.0
[pip3] torch-stoi==0.1.2
[pip3] torchaudio==0.12.1
[pip3] torchdata==0.4.1
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.13.1
[conda] blas 2.115 mkl conda-forge
[conda] blas-devel 3.9.0 15_win64_mkl conda-forge
[conda] cudatoolkit 11.6.0 hc0ea762_10 conda-forge
[conda] libblas 3.9.0 15_win64_mkl conda-forge
[conda] libcblas 3.9.0 15_win64_mkl conda-forge
[conda] liblapack 3.9.0 15_win64_mkl conda-forge
[conda] liblapacke 3.9.0 15_win64_mkl conda-forge
[conda] mkl 2022.1.0 pypi_0 pypi
[conda] mkl-devel 2022.1.0 h57928b3_875 conda-forge
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-include 2022.1.0 h6a75c08_874 conda-forge
[conda] mkl-random 1.2.2 pypi_0 pypi
[conda] mkl-service 2.4.0 pypi_0 pypi
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch 1.12.1 py3.9_cuda11.6_cudnn8_0 pytorch
[conda] pytorch-lightning 1.7.2 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-ranger 0.1.1 pypi_0 pypi
[conda] torch-complex 0.4.3 pypi_0 pypi
[conda] torch-optimizer 0.3.0 pypi_0 pypi
[conda] torch-stoi 0.1.2 pypi_0 pypi
[conda] torchaudio 0.12.1 py39_cu116 pytorch
[conda] torchdata 0.4.1 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchvision 0.13.1 py39_cu116 pytorch
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @VitalyFedyunin @ngimel
| 3 |
4,925 | 83,795 |
Error on installation
|
module: rocm, triaged
|
### 🐛 Describe the bug
Hello, after "python setup.py install" the script shows this error and the installation fails:
fatal error: error in backend: Cannot select: intrinsic %llvm.amdgcn.ds.bpermute
clang-14: error: clang frontend command failed with exit code 70 (use -v to see invocation)
AMD clang version 14.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-5.2.3 22324 d6c88e5a78066d5d7a1e8db6c5e3e9884c6ad10e)
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /opt/rocm/hip/../llvm/bin
clang-14: note: diagnostic msg: Error generating preprocessed source(s).
CMake Error at torch_hip_generated_cub-RadixSortPairs.hip.o.cmake:200 (message):
Error generating file
/home/ferna/pytorch/build/caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/./torch_hip_generated_cub-RadixSortPairs.hip.o
Something is missing? Thanks
### Versions
roc-5.2.3
python 3.9
cc @malfet @seemethere @jeffdaily @sunway513 @jithunnair-amd @ROCmSupport @KyleCZH
| 6 |
4,926 | 83,775 |
[Nested Tensor] Move nested tensor specific ops to nested namespace
|
triaged, module: nestedtensor
|
# Summary
Currently all nested tensor specific ops are dumped into the default namespace `torch`. This issue is used to track work on creating a nested tensor namespace and moving all the nested tensor specific functions that namespace.
cc @cpuhrsch @jbschlosser @bhosmer
| 1 |
4,927 | 93,638 |
Inductor Error: aten.fill_.Tensor
|
triaged, oncall: pt2
|
`python /scratch/eellison/work/torchdynamo/benchmarks/microbenchmarks/operatorbench.py --op=aten.fill_.Tensor --dtype=float16 --suite=huggingface`
> CUDA error: operation failed due to a previous error during capture
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,928 | 83,773 |
[Nested Tensor] view + inplace for autograd.
|
module: autograd, triaged, module: nestedtensor
|
## Summary
This is currently erroring:
```
import torch
a = torch.randn(1, 2, 4, requires_grad=True)
b = torch.randn(2, 2, 4, requires_grad=True)
c = torch.randn(3, 2, 4, requires_grad=True)
nt = torch.nested_tensor([a,b,c])
buffer = nt.values()
buffer.mul_(2)
```
This is
1. Creating a view nt -> buffer
2. Applying an inplace op on buffer.
This triggers rebase_history() which in turn creates copy_slices. Copy slices utilize a struct called TensorGeometry to track geometry information about the base and the view. The view_fn will be used instead of as_strided. However we apply this function on result which is an empty of clone of base. We don't currently have a factory function that can do this. This will be unblocked when we add this.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @cpuhrsch @jbschlosser @bhosmer
| 0 |
4,929 | 93,637 |
HuggingFace Slow Operators
|
triaged, oncall: pt2
|
Operators with 50th percentile below 98% of aten perf or 20th percentile below 96%:
Float16:
```
aten._log_softmax.default:: [0.8083701248515153, 0.9260282672431682, 1.0251716763358925]
aten._log_softmax_backward_data.default:: [0.9195609454113238, 0.9607073111684497, 1.0512267863036555]
aten.addmm.default:: [0.7886046418843882, 0.9329217798915578, 0.9962013717422963]
aten.sum.SymInt:: [0.9358205974583087, 0.9814126709379405, 1.006583550282628]
aten.add_.Tensor:: [0.7253489773412456, 0.7703528781962926, 0.7976537424898803]
aten.new_empty_strided.default:: [0.9366916208071663, 0.9398957719201622, 0.9472405067590517]
aten.sqrt.default:: [0.9791511684613813, 0.9791511684613813, 0.9791511684613813]
aten.new_empty.default:: [0.7994959370210444, 0.804862283140364, 0.8102286292596836]
aten.native_layer_norm_backward.default:: [0.8506269179221464, 1.1152916772486603, 1.6212585844412815]
```
Float32:
```
aten._log_softmax.default:: [0.9550605426043154, 0.9823529203640421, 1.002335693504097]
aten._log_softmax_backward_data.default:: [0.9260106786584326, 0.9406878586461753, 1.0006503787776375]
aten.addmm.default:: [0.9509063155376642, 0.9920652896706708, 1.0371791371367722]
aten.sum.SymInt:: [0.9487470525571405, 0.9901798410457018, 1.05810554621502]
aten.new_empty_strided.default:: [0.7239798153666939, 0.7404751002819113, 0.7636612269539008]
aten.sqrt.default:: [0.9371196135483814, 0.9371196135483814, 0.9371196135483814]
aten.new_empty.default:: [0.8338423596933202, 0.850186671512076, 0.866530983330832]
```
`_log_softmax` and `_log_softmax_backward_data`, and `aten.sum` in fp16 stand out to me.
Full log: [float32](https://gist.github.com/eellison/b312dc4adc512599084486df667b6264), [float16](https://gist.github.com/eellison/5e3ec5064a19100f95a67b7c69c9ca0a)
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,930 | 93,636 |
Timm Model Slow Operators
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Operators with 50th percentile below 98% of aten perf or 20th percentile below 96%:
```
aten.addmm.default:: [0.8386316138954961, 0.9255533387715138, 0.955919097384518]
aten.new_empty_strided.default:: [0.7074878925134296, 0.7366914699489878, 0.7576066949031502]
aten._softmax.default:: [0.844983630149154, 0.9835961036033891, 1.068020755737445]
aten.max_pool2d_with_indices.default:: [0.6342950044218125, 1.0382350718486175, 1.1183607334882082]
aten.hardsigmoid_backward.default:: [0.9559467667087947, 1.0058027523555526, 1.0368018754050459]
```
```
aten.addmm.default:: [0.8430439948974364, 0.9937072943974172, 1.1970515808766191]
aten.new_empty_strided.default:: [0.715191214805386, 0.7424496557446567, 0.7541450693325825]
aten.max_pool2d_with_indices.default:: [0.836623979229799, 1.0084812810590111, 1.033377775031802]
aten._softmax.default:: [0.8147407919961176, 1.004666288386921, 1.1519087656954243]
aten.select_backward.default:: [0.8844741032127397, 1.0799256067174667, 1.1887779335651258]
aten.new_empty.default:: [0.9331701212881051, 0.9612216337535711, 0.9760060763695062]
aten.div.Tensor:: [0.9588477230714266, 0.9588477230714266, 0.9588477230714266]
aten.rsqrt.default:: [0.9006916404896046, 0.9011194114944925, 0.9032443478821974]
```
`max_pool2d_with_indices`, and `_softmax` stand out. `rsqrt` is probably because we are using the decomposition and not the `rsqrt` ptx instruction.
Full logs: [float16](https://gist.github.com/eellison/1af4f518318d8892159765cb20fd3299), [float32](https://gist.github.com/eellison/3d2c9139c164d3190c8da520018dc99f)
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
4,931 | 83,769 |
[TorchTidy] Check if `set_to_none` would change optimizer semantics.
|
oncall: profiler
|
### 🚀 The feature, motivation and pitch
Several PyTorch optimizers offer a `set_to_none` argument to delete gradients rather than zeroing them. This is particularly important for CUDA where each operation incurs a separate `cudaLaunchKernel` call. [GradNotSetToNonePattern](https://github.com/pytorch/pytorch/blob/master/torch/profiler/_pattern_matcher.py#L429) attempts to identify this opportunity for improvement; however it is currently overzealous. The issue is that certain optimizers will interpret `None` gradients as cause to reset optimizer state (e.g. [SGD momentum](https://github.com/pytorch/pytorch/blob/master/torch/optim/sgd.py#L234-L238)), and as a result `set_to_none` changes the semantics of the optimizer. This task is to extend `GradNotSetToNonePattern` to check for such exceptions, and only recommend `set_to_none` when it can be safely applied.
CC @tiffzhaofb (you can grab the issue when you get your github in the pytorch org)
### Alternatives
_No response_
### Additional context
_No response_
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 1 |
4,932 | 83,764 |
Missing header file
|
triaged
|
### 🚀 The feature, motivation and pitch
Hi, I always build PyTorch from source and link my library to it. Today, I tried link my library to PyTorch nightly package, the error message below came out.
```
Cannot open include file: 'torch/csrc/jit/passes/onnx/constant_map.h': No such file or directory
```
Could we add this header to the package? Or do you have specific policy regarding what should be included and what no? Thanks.
### Alternatives
_No response_
### Additional context
_No response_
| 4 |
4,933 | 93,635 |
tabulate.tabulate causes a lot of memory to be allocated in yolov3
|
triaged, oncall: pt2
|
Calling tabulate.tabulate to render the output graph causes 1 GB of additional memory allocation in yolov3.
This is gated on the log level now, but as a result when DEBUG or INFO log levels are set, this will cause additional memory to be allocated.
https://github.com/pytorch/torchdynamo/blob/0e4d5ee9db6dfeba4d424b2e5d2ad96c79f1dffa/torchdynamo/utils.py#:~:text=tabulate(node_specs%2C%20headers%3D%5B%22opcode%22%2C%20%22name%22%2C%20%22target%22%2C%20%22args%22%2C%20%22kwargs%22%5D)
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
4,934 | 83,749 |
[Nested Tensor] Update TestCase.AssertEqual
|
triaged, module: nestedtensor, module: testing
|
## TLDR: Update `TestCase.assertEqual` for nested tensors
We are currently unbinding nested tensors and comparing elements to assert equality. This works but I think that when the metadata for nested tensors if fully ironed out this can be more direct. This ticket is to track follow up work when the metadata scenario has been solidified.
cc @cpuhrsch @jbschlosser @bhosmer @pmeier
| 0 |
4,935 | 83,737 |
Profiler reports different # of Calls depending on group_by_stack_n
|
oncall: profiler
|
### 🐛 Describe the bug
The number of calls reported by the profiler to different functions doesn't have the same total when you change how the profiler results are printed.
Example: running the script
```python
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet50().cuda()
inputs = torch.randn(5, 3, 224, 224).cuda()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], with_stack=True, with_modules=False) as prof:
model(inputs)
print(prof.key_averages(group_by_stack_n=2).table(sort_by="self_cuda_time_total"))
```
the aten::empty function is called 319 times, with the following lines found by grep:
```
aten::empty 0.16% 2.199ms 0.16% 2.199ms 8.298us 1.699ms 0.13% 1.699ms 6.411us 265 <built-in method batch_norm of type object at 0x7febe43d8f20>
aten::empty 0.04% 572.000us 0.04% 572.000us 10.792us 434.000us 0.03% 434.000us 8.189us 53 <built-in method conv2d of type object at 0x7febe43d8f20>
aten::empty 0.00% 1.000us 0.00% 1.000us 1.000us 3.000us 0.00% 3.000us 3.000us 1 <built-in function linear>
```
However, if we change group_by_stack_n to 4, it's only called 47 times!
The output is longer here, so you may find it helpful to use a line like
```bash
python test.py | grep empty | grep -v empty_like | tr -s ' ' | cut -d' ' -f 12 | paste -sd+ - | bc
```
but examining by eye should show that it's clearly far less than 300.
### Versions
Collecting environment information...
PyTorch version: 1.13.0a0+git4b3f1bd
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-10ubuntu2) 9.3.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.5 (default, Jul 28 2020, 12:59:40) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-47-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.6.124
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 2080 Ti
GPU 1: NVIDIA GeForce RTX 2080 Ti
GPU 2: NVIDIA GeForce RTX 2080 Ti
GPU 3: NVIDIA GeForce RTX 2080 Ti
GPU 4: NVIDIA GeForce RTX 2080 Ti
GPU 5: NVIDIA GeForce RTX 2080 Ti
GPU 6: NVIDIA GeForce RTX 2080 Ti
GPU 7: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.73.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.13.0a0+git4b3f1bd
[pip3] torchvision==0.14.0a0+9c3e2bf
[conda] Could not collect
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 1 |
4,936 | 83,733 |
BCELoss results in autocast CUDA warning
|
triaged, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
Hi folks, BCELoss on calling *backward* method creates warning UserWarning: User provided device_type of 'cuda', but CUDA is not available. Disabling warnings.warn('User provided device_type of \'cuda\', but CUDA is not available. Disabling'). The code works normally but it is very irritant. torch/cuda/amp/autocast_mode.py creates a warning because it gets called with `device_type` "cuda". I can get around by commenting line 199 but that is not the solution. Although I am using `torch` together with `DGL` library, the error source seems to be in PyTorch.
```
# Define training EdgeDataLoader
train_dataloader = dgl.dataloading.DataLoader(
graph, # The graph
train_eid_dict, # The edges to iterate over
sampler, # The neighbor sampler
batch_size=batch_size, # Batch size
shuffle=True, # Whether to shuffle the nodes for every epoch
drop_last=False, # Whether to drop the last incomplete batch
num_workers=sampling_workers, # Number of sampling processes
)
# Define validation EdgeDataLoader
validation_dataloader = dgl.dataloading.DataLoader(
graph, # The graph
val_eid_dict, # The edges to iterate over
sampler, # The neighbor sampler
batch_size=batch_size, # Batch size
shuffle=True, # Whether to shuffle the nodes for every epoch
drop_last=False, # Whether to drop the last incomplete batch
num_workers=sampling_workers, # Number of sampler processes
)
print(f"Canonical etypes: {graph.canonical_etypes}")
# Initialize loss
loss = torch.nn.BCELoss()
# Initialize activation func
m, threshold = torch.nn.Sigmoid(), 0.5
# Iterate for every epoch
for epoch in range(1, num_epochs+1):
model.train()
tr_finished = False
for _, pos_graph, neg_graph, blocks in train_dataloader:
input_features = blocks[0].ndata[node_features_property]
# Perform forward pass
probs, labels, loss_output = batch_forward_pass(model, predictor, loss, m, target_relation, input_features, pos_graph, neg_graph, blocks)
# Make an optimization step
optimizer.zero_grad()
loss_output.backward() # ***This line generates warning***
optimizer.step()
```
### Versions
o CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.2
[pip3] numpydoc==1.4.0
[pip3] torch==1.12.1+cpu
[pip3] torchaudio==0.12.1+cpu
[pip3] torchvision==0.13.1+cpu
[conda] Could not collect
cc @mcarilli @ptrblck
| 8 |
4,937 | 83,726 |
nvfuser + prim stack generated illegal PTX code on hardware with sm <= 70
|
triaged, module: nvfuser, module: primTorch
|
### 🐛 Describe the bug
```
import torch
from torch._prims.context import TorchRefsNvfuserCapabilityMode, TorchRefsMode, _is_func_unsupported_nvfuser
from torch.fx.experimental.proxy_tensor import make_fx
from torch._prims.executor import execute
dtype = torch.bfloat16
# dtype = torch.float16
x = torch.rand(5, device="cuda").to(dtype)
def fn(x):
return (x + 1.0).relu()
with TorchRefsNvfuserCapabilityMode():
nvprim_gm = make_fx(fn)(x)
print(nvprim_gm.graph)
for i in range(5):
o = execute(nvprim_gm, x, executor="nvfuser")
print(o)
```
gives the error message:
```
CUDA NVRTC compile error: ptxas application ptx input, line 55; error : Feature '.bf16' requires .target sm_80 or higher
ptxas application ptx input, line 55; error : Feature 'cvt with .bf16' requires .target sm_80 or higher
ptxas fatal : Ptx assembly aborted due to errors
```
### Versions
Collecting environment information...
PyTorch version: 1.13.0a0+gitce7177f
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-92-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.7.64
GPU models and configuration:
GPU 0: Tesla V100-SXM2-16GB
GPU 1: Tesla V100-SXM2-16GB
GPU 2: Tesla V100-SXM2-16GB
GPU 3: Tesla V100-SXM2-16GB
GPU 4: Tesla V100-SXM2-16GB
GPU 5: Tesla V100-SXM2-16GB
GPU 6: Tesla V100-SXM2-16GB
GPU 7: Tesla V100-SXM2-16GB
Nvidia driver version: 470.82.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] functorch==0.3.0a0+ce7177f
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.2
[pip3] pytorch-transformers==1.2.0
[pip3] torch==1.13.0a0+gitce7177f
[pip3] torch-struct==0.5
[pip3] torchdynamo==1.13.0.dev0
[pip3] torchfile==0.1.0
[pip3] torchmetrics==0.9.3
[pip3] torchrec-nightly==2022.8.17
[pip3] torchtext==0.14.0a0+72966f0
[pip3] torchvision==0.14.0a0+c3dc255
[pip3] torchx-nightly==2022.8.17
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] functorch 0.3.0a0+ce7177f dev_0 <develop>
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] mkl 2019.1 144
[conda] mkl-include 2019.1 144
[conda] nomkl 3.0 0
[conda] numpy 1.21.2 pypi_0 pypi
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] torch 1.13.0a0+gitce7177f dev_0 <develop>
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchdynamo 1.13.0.dev0 dev_0 <develop>
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchrec-nightly 2022.8.17 pypi_0 pypi
[conda] torchtext 0.14.0a0+72966f0 dev_0 <develop>
[conda] torchvision 0.14.0a0+c3dc255 dev_0 <develop>
[conda] torchx-nightly 2022.8.17 pypi_0 pypi
cc @ezyang @mruberry @ngimel
| 0 |
4,938 | 83,721 |
How to export a simple model using List.__contains__ to ONNX
|
module: onnx, triaged, onnx-needs-info
|
### 🐛 Describe the bug
When using torch.jit.script, the message shows that \_\_contains__ method is not supported.
This is a reduced part of my model, the function should be tagged with torch.jit.script because there's a for loop using list.\_\_contains__
And I want to export it to an onnx file but failed with the following output.
### Code
````python
from typing import List, Dict
import torch
x = torch.tensor([[59, 26, 32, 31, 58, 37, 12, 8, 8, 32, 27, 27, 35, 9, 3, 44, 22, 36,
22, 61, 51, 35, 15, 13, 14, 32, 22, 21, 9]], dtype=torch.long)
nums = [3, 4, 5, 6, 7, 8, 9, 14, 15, 16, 17, 18, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 37, 38, 39, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57]
@torch.jit.script
def batch(x, l: List[int]):
for i in range(len(x)):
for j in range(len(x[i])):
if x[i, j] in l:
x[i, j] *= 2
return x
class Module1(torch.nn.Module):
def forward(self, x):
return batch(x, nums)
m1 = Module1()
print(m1(x))
torch.onnx.export(m1,
(x),
"2.onnx",
verbose=True,
input_names=["x"],
dynamic_axes={
"x": {
1: "frames",
},
},
opset_version=11,
)
````
### Output
````
Traceback (most recent call last):
File "E:\My Files\Projects\Python\test\test.py", line 28, in <module>
torch.onnx.export(m1,
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 350, in export
return utils.export(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 163, in export
_export(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1074, in _export
graph, params_dict, torch_out = _model_to_graph(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 731, in _model_to_graph
graph = _optimize_graph(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 308, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1401, in _run_symbolic_function
return symbolic_fn(ctx, g, *inputs, **attrs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\symbolic_opset9.py", line 5064, in Loop
torch._C._jit_pass_onnx_block(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1401, in _run_symbolic_function
return symbolic_fn(ctx, g, *inputs, **attrs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\symbolic_opset9.py", line 5064, in Loop
torch._C._jit_pass_onnx_block(
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\__init__.py", line 416, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\CodeEnv\miniconda3\envs\dfs\lib\site-packages\torch\onnx\utils.py", line 1421, in _run_symbolic_function
raise symbolic_registry.UnsupportedOperatorError(
torch.onnx.symbolic_registry.UnsupportedOperatorError: Exporting the operator ::__contains_ to ONNX opset version 11 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub.
````
### Versions
PyTorch version: 1.12.1+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 家庭中文版
GCC version: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0
Clang version: Could not collect
CMake version: version 3.23.2
Libc version: N/A
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:51:29) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19044-SP0
Is CUDA available: True
CUDA runtime version: 11.5.119
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 512.78
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==0.7.1
[pip3] torch==1.12.1+cu113
[pip3] torchaudio==0.12.1+cu113
[pip3] torchvision==0.13.1+cu113
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch-lightning 0.7.1 pypi_0 pypi
[conda] torch 1.12.1+cu113 pypi_0 pypi
[conda] torchaudio 0.12.1+cu113 pypi_0 pypi
[conda] torchvision 0.13.1+cu113 pypi_0 pypi
| 4 |
4,939 | 83,714 |
Build from source failed on MacOS 10.6 with CUDA 10.1
|
module: build, triaged, module: macos
|
### 🐛 Describe the bug
I am trying to build Pytorch from source with CUDA enabled. I followed the steps at https://gist.github.com/brokeyourbike/def7a3313c1e4fdf1334b5c4f0e239f3, including installing from https://github.com/pytorch/pytorch/tree/eeb43ffab9200ea046f29fecf914d8e71d00d474
I am not able to complete `MACOSX_DEPLOYMENT_TARGET=10.13 CC=clang CXX=clang++ python setup.py install`
Here are some details of my setup:
MacBook Pro (Retina, 15-inch, Late 2013)
NVIDIA GeForce GT 750M 2048 MB
macOS 10.13.6 (17G14042)
Xcode 10.1
CUDA toolkit 10.1
CUDA Driver Version: 418.163
GPU Driver Version: 387.10.10.10.40.140
I tried installing with Python 3.7, 3.8, 3.8, 3.10. They give different warnings, but all fail.
I've also tried installing, with Python 3.7, eeb43ffab9200ea046f29fecf914d8e71d00d474, 87061875239d0694779255b55e50250b272169ff, and f094113ebf5b4e5281ab1a134220a1a985f03964 (most recent commit today).
My goal is to be able to do the verify installation steps a la https://gist.github.com/brokeyourbike/def7a3313c1e4fdf1334b5c4f0e239f3 with some PyTorch master branch - doesn't have to be the most recent version of PyTorch, but something within the last few years.
For more details see these CMake logs (for build with Python 3.7, PyTorch eeb43ffab9200ea046f29fecf914d8e71d00d474)
[CMakeError.log](https://github.com/pytorch/pytorch/files/9378367/CMakeError.log)
[CMakeOutput.log](https://github.com/pytorch/pytorch/files/9378368/CMakeOutput.log)
Note that I can use CUDA (10.1) on my machine, and compile .cu files and successfully run them.
### Versions
```
(torch_20220818_py37) gws-MacBook-Pro-6:developer gw$ python collect_env.py
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 10.13.6 (x86_64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.24.20220817-gb6cfa38
Libc version: N/A
Python version: 3.7.13 (default, Mar 28 2022, 07:24:34) [Clang 12.0.0 ] (64-bit runtime)
Python platform: Darwin-17.7.0-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: 10.1.168
GPU models and configuration: Could not collect
Nvidia driver version: 1.1.0
cuDNN version: Probably one of the following:
/usr/local/cuda/lib/libcudnn.7.dylib
/usr/local/cuda/lib/libcudnn.dylib
/usr/local/cuda/lib/libcudnn_static.a
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.5
[conda] mkl 2020.2 260
[conda] mkl-include 2022.0.0 hecd8cb5_105
[conda] numpy 1.21.5 py37h0f1bd0b_3
[conda] numpy-base 1.21.5 py37hbda7086_3
```
cc @malfet @seemethere @albanD
| 1 |
4,940 | 83,710 |
[Bug] Circular Import
|
caffe2, triaged
|
### 🐛 Describe the bug
A Circular Import when importing caffe2.proto with Anaconda
```
from matplotlib import pyplot
import numpy as np
import time
# These are the droids you are looking for.
from caffe2.python import core, workspace
from caffe2.proto import caffe2_pb2
# Let's show all plots inline.
%matplotlib inline
```
The Error (In CLI)
```File "D:\Anaconda\lib\site-packages\caffe2\python\__init__.py", line 7, in <module>
from caffe2.proto import caffe2_pb2
File "D:\Anaconda\lib\site-packages\caffe2\proto\__init__.py", line 15, in <module>
from caffe2.proto import caffe2_pb2, metanet_pb2, torch_pb2
ImportError: cannot import name 'metanet_pb2' from partially initialized module 'caffe2.proto' (most likely due to a circular import) (D:\Anaconda\lib\site-packages\caffe2\proto\__init__.py)
````
The error in (Anaconda Jupyter notebook )
```
try:
---> 15 from caffe2.proto import caffe2_pb2, metanet_pb2, torch_pb2
16 except ImportError:
17 warnings.warn('Caffe2 support is not enabled in this PyTorch build. '
18 'Please enable Caffe2 by building PyTorch from source with `BUILD_CAFFE2=1` flag.')
ImportError: cannot import name 'metanet_pb2' from partially initialized module 'caffe2.proto' (most likely due to a circular import) (D:\Anaconda\lib\site-packages\caffe2\proto\__init__.py)
```
### Versions
```
PyTorch version: 1.12.1+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Pro
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.21.3
Libc version: N/A
Python version: 3.9.12 (main, Apr 4 2022, 05:22:27) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22000-SP0
Is CUDA available: False
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1060
Nvidia driver version: 511.23
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.2
[pip3] torch==1.12.1
[pip3] torchfile==0.1.0
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py39h2bbff1b_0
[conda] mkl_fft 1.3.1 py39h277e83a_0
[conda] mkl_random 1.2.2 py39hf11a4ad_0
[conda] numpy 1.21.5 py39h7a0a035_1
[conda] numpy-base 1.21.5 py39hca35cd5_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.12.1 pypi_0 pypi
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
[Done] exited with code=0 in 10.961 seconds
```
| 3 |
4,941 | 83,702 |
Inconsistency between index_select and __get_item__
|
triaged, module: advanced indexing
|
### 🐛 Describe the bug
We should be able to index using `torch.int32` using the bracket notation. It is possible using `index_select`:
```python
>>> idx = torch.tensor([0]).int()
>>> a = torch.rand(3)
>>> a[idx]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: tensors used as indices must be long, byte or bool tensors
>>> a.index_select(0, idx)
tensor([0.6999])
```
When dealing with large sets of indices (e.g. graph edge lists), this means we have to use more memory.
### Versions
master
| 1 |
4,942 | 83,694 |
distributed tests take a long time
|
oncall: distributed, module: ci
|
`pull / linux-bionic-cuda11.6-py3.10-gcc7 / test (distributed, 1, 2, linux.8xlarge.nvidia.gpu)` and `
trunk / linux-bionic-cuda10.2-py3.9-gcc7 / test (distributed, 1, 2, linux.8xlarge.nvidia.gpu)` are our two longest jobs on pull and trunk, respectively, each with a p90 of over 3 hours.
We are unable to shard these jobs further because `distributed/test_distributed_spawn` is responsible for about half the test time.
Is there anyway we could either break up this file into smaller files that could be put on different shards or make these tests faster?
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @seemethere @malfet @pytorch/pytorch-dev-infra
| 6 |
4,943 | 93,633 |
botorch dynamo errors
|
triaged, oncall: pt2
|
botorch is a library for bayesian optimization in pytorch https://github.com/pytorch/botorch
`pip install botorch`
## Repro
```python
import torch
from botorch.models import SingleTaskGP
from botorch.fit import fit_gpytorch_model
from botorch.utils import standardize
from gpytorch.mlls import ExactMarginalLogLikelihood
import torchdynamo
train_X = torch.rand(10, 2)
Y = 1 - torch.norm(train_X - 0.5, dim=-1, keepdim=True)
Y = Y + 0.1 * torch.randn_like(Y) # add some noise
train_Y = standardize(Y)
gp = SingleTaskGP(train_X, train_Y)
mll = ExactMarginalLogLikelihood(gp.likelihood, gp)
with torchdynamo.optimize("eager"):
model = fit_gpytorch_model(mll)
print(model)
```
## Logs without torchdynamo
```
ExactMarginalLogLikelihood(
(likelihood): GaussianLikelihood(
(noise_covar): HomoskedasticNoise(
(noise_prior): GammaPrior()
(raw_noise_constraint): GreaterThan(1.000E-04)
)
)
(model): SingleTaskGP(
(likelihood): GaussianLikelihood(
(noise_covar): HomoskedasticNoise(
(noise_prior): GammaPrior()
(raw_noise_constraint): GreaterThan(1.000E-04)
)
)
(mean_module): ConstantMean()
(covar_module): ScaleKernel(
(base_kernel): MaternKernel(
(lengthscale_prior): GammaPrior()
(raw_lengthscale_constraint): Positive()
(distance_module): Distance()
)
(outputscale_prior): GammaPrior()
(raw_outputscale_constraint): Positive()
)
)
)
```
## Logs with torchdynamo
```
(myenv) ubuntu@ip-172-31-21-78:~/tests$ python bo.py
Traceback (most recent call last):
File "bo.py", line 17, in <module>
model = fit_gpytorch_model(mll)
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/fit.py", line 38, in fit_gpytorch_model
def fit_gpytorch_model(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/fit.py", line 38, in fit_gpytorch_model
def fit_gpytorch_model(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/fit.py", line 38, in fit_gpytorch_model
def fit_gpytorch_model(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/fit.py", line 130, in fit_gpytorch_model
mll, _ = optimizer(mll, track_iterations=False, **kwargs)
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/optim/fit.py", line 174, in fit_gpytorch_scipy
def fit_gpytorch_scipy(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/optim/fit.py", line 174, in fit_gpytorch_scipy
def fit_gpytorch_scipy(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/botorch/optim/fit.py", line 239, in fit_gpytorch_scipy
res = minimize(
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/scipy/optimize/_minimize.py", line 45, in minimize
def minimize(fun, x0, args=(), method=None, jac=None, hess=None,
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/scipy/optimize/_minimize.py", line 45, in minimize
def minimize(fun, x0, args=(), method=None, jac=None, hess=None,
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/scipy/optimize/_minimize.py", line 699, in minimize
res = _minimize_lbfgsb(fun, x0, args, jac, bounds,
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/scipy/optimize/_lbfgsb_py.py", line 212, in _minimize_lbfgsb
def _minimize_lbfgsb(fun, x0, args=(), jac=None, bounds=None,
File "/home/ubuntu/.conda/envs/myenv/lib/python3.8/site-packages/scipy/optimize/_lbfgsb_py.py", line 212, in _minimize_lbfgsb
def _minimize_lbfgsb(fun, x0, args=(), jac=None, bounds=None,
NameError: name 'torch' is not defined
```
But I do have `torch` installed and it does run just fine without dynamo
```
(myenv) ubuntu@ip-172-31-21-78:~/tests$ pip list
Package Version Editable project location
------------------- ----------- -------------------------
attrs 22.1.0
black 22.6.0
botorch 0.6.6
certifi 2022.6.15
charset-normalizer 2.1.0
click 8.1.3
coolname 1.1.0
docstring-parser 0.14.1
expecttest 0.1.3
flake8 4.0.1
gpytorch 1.8.1
idna 3.3
importlib-metadata 4.12.0
importlib-resources 5.9.0
iniconfig 1.1.1
isort 5.10.1
Jinja2 3.1.2
joblib 1.1.0
jsonschema 4.7.2
MarkupSafe 2.1.1
mccabe 0.6.1
mosaicml 0.9.0
mpmath 1.2.1
multipledispatch 0.6.0
mypy-extensions 0.4.3
networkx 2.8.5
ninja 1.10.2.3
numpy 1.22.4
opt-einsum 3.3.0
packaging 21.3
pathspec 0.9.0
Pillow 9.2.0
pip 22.2.2
platformdirs 2.5.2
pluggy 1.0.0
psutil 5.9.1
py 1.11.0
py-cpuinfo 8.0.0
pycodestyle 2.8.0
pyDeprecate 0.3.2
pyflakes 2.4.0
pyparsing 3.0.9
pyro-api 0.1.2
pyro-ppl 1.8.1
pyrsistent 0.18.1
pytest 7.1.2
pytorch-ranger 0.1.1
PyYAML 6.0
requests 2.28.1
ruamel.yaml 0.17.21
ruamel.yaml.clib 0.2.6
scikit-learn 1.1.2
scipy 1.9.0
setuptools 65.0.2
six 1.16.0
sympy 1.10.1
tabulate 0.8.9
threadpoolctl 3.1.0
tomli 2.0.1
torch 1.12.1
torch-optimizer 0.1.0
torchdynamo 1.13.0.dev0 /home/ubuntu/torchdynamo
torchmetrics 0.7.3
torchvision 0.13.1
tqdm 4.64.0
typing_extensions 4.3.0
urllib3 1.26.11
wheel 0.37.1
yahp 0.1.3
zipp 3.8.1
```
cc @ezyang @soumith @wconstab @ngimel @bdhirsh
| 0 |
4,944 | 93,632 |
Huggingface Transformers Trainer Test
|
triaged, oncall: pt2
|
Transformers trainer API uses TorchDynamo. As we cleaned up Dynamo, we did not percolate the changes to trainer API, leading to some failures - https://github.com/huggingface/transformers/issues/18127
This is a tracker to improve the situation
1) Better API - Currently, we pass strings and then depending on the strings, we find the backend for Dynamo. Instead, we could just simplify all this, and directly do torchdynamo.optimze(backend_str) - https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L639-L666
2) Remove ctx manager.
3) Decompositions might not be working correctly for relu. I had to switch to cos instead of relu in this PR to see the memory footprint reduction - https://github.com/huggingface/transformers/pull/18685
4) Add a test in Dynamo CI that brings huggingface and tests Dynamo related tests
~~~
pytest tests/trainer/test_trainer.py -k torchdynamo
~~~
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @ydshieh @stas00
| 0 |
4,945 | 83,672 |
quantization: unexpected casting of tensor min and max to int in histogram observer
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
Originally reported in https://discuss.pytorch.org/t/casting-to-int-of-data-min-and-max-in-histogramobserver/159316
There is code in `HistogramObserver` which casts the tensor min and max to integers before calculating the histogram: https://github.com/pytorch/pytorch/blame/a9ba3fe1dbf2cea45c9a7e723010c27c211f7fe3/torch/ao/quantization/observer.py#L1143. It's unclear on why this is here since we want the histogram bins be as accurate as possible, we should verify if there is a reason for having this and remove it if there isn't a reason.
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @jgong5 @Xia-Weiwen @leslie-fang-intel @vkuzo
| 3 |
4,946 | 93,631 |
[inductor] Lower aten.cumsum
|
triaged, oncall: pt2, module: inductor
|
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @ipiszy @ngimel @yf225 @chenyang78 @kadeng @muchulee8 @aakhundov @soumith
| 12 |
4,947 | 83,657 |
[Discussion] Add custom device
|
triaged, module: dispatch, module: backend
|
### 🚀 The feature, motivation and pitch
We are an accelerator vendor and provide Pytorch extensions for our hardware MLU(https://github.com/Cambricon/catch). We would like to add a custom dispatch key and notice that other vendors have submitted their requests like XPU, IPU or NPU(only parts of dispatch keys are accepted), and you recommend to use PrivateUse key instead. We know the limits of adding a new key in Pytorch files but still have some questions.
1. Are all following vendors unable to merge their own custom dispatch key?
2. In some case, PrivateUse key can not meet demands. We think each kind of device may have some special cases to handle like:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorShape.cpp#L1305
```
if (!self.is_xla() && !self.is_lazy() && !self.is_ipu()) {
return self._reshape_alias(shape, stride.value());
} else {
return self.view(shape);
}
```
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/TensorIterator.cpp#L1497
```
if (common_device_.type() == DeviceType::XLA ||
common_device_.type() == DeviceType::IPU ||
common_device_.type() == DeviceType::Lazy ||
common_device_.type() == DeviceType::ORT ||
common_device_.type() == DeviceType::HPU) return;
```
It is easy to deal with such conditional judgement if our custom key is merged, but how to solve the problem when we do not change Pytorch files and only use PrivateUse key?
### Alternatives
_No response_
### Additional context
_No response_
| 4 |
4,948 | 83,655 |
[feature request] PyTorch vmap for efficient Evolutionary Strategies
|
feature, triaged, module: vmap, module: functorch
|
### 🚀 The feature, motivation and pitch
### Situation
I am currently working on Evolutionary Strategies in PyTorch and I noticed that there is no efficient way to use Modules for defining a Network that I want to train. In [EvoJAX](https://github.com/google/evojax) it is possible to define flax Modules and vmap over their parameters and forward function. In PyTorch it is currently possible to vmap over forward functions, but not over parameters (at least not that I can think of any way).
### Imagine following scenario
You want to train a simple MLP for solving XOR with Evolutionary Strategies in PyTorch.
Writing a custom forward method, this can be done very efficiently using einsums:
c: parameters of children in current population with shape [npop, params]
x: batched input: `torch.tensor([[0., 0.], [0., 1.], [1., 0.], [1., 1.]])`
```python
@torch.jit.script
def forward(c, x):
# linear1 (in: 2, out: 2)
x = torch.einsum('bi,nio->bno', x, c[..., :4].view(-1, 2, 2))
x = x + c[..., 4:6]
# relu
x = F.relu(x)
# linear2 (in: 2, out: 1)
x = torch.einsum('bni,nio->bno', x, c[..., 6:8].view(-1, 2, 1))
x = x + c[..., 8:9]
return x
```
Now I would like to simply define my Network as nn.Module and vmap over its parameters and forward function like this:
```python
def f(model, c, x):
torch.nn.utils.vector_to_parameters(c, model.parameters())
return model(x)
outputs = vmap(f, in_dims=(None, 0, None))(model, child_params, X)
```
This is currently not possible, because parameter assignment is weird in PyTorch.
### Alternatives
_No response_
### Additional context
_No response_
cc @zou3519 @Chillee @samdow
| 1 |
4,949 | 83,624 |
Unhelpful error message from torch.linalg.ldl_factor
|
triaged, module: linear algebra, module: edge cases
|
### 🐛 Describe the bug
When performing an ldl_factor on a matrix of zeros (or entries smaller than some epsilon value), I get the following error:
RuntimeError: false INTERNAL ASSERT FAILED at ```../aten/src/ATen/native/BatchLinearAlgebra.cpp":1504, please report a bug to PyTorch. torch.linalg.ldl_factor: Unknown error code: 1.```
Here is a simple example:
import torch
ld,pivot=torch.linalg.ld_factor(torch.zeros(5,5))
I wouldn't expect this to work, of course, because L is undefined in this case. But perhaps it could do a saner exception check before (instead of) passing the input to LAPACK. Incidentally, not sure why it's giving me a positive error code as I believe this conflicts with the LAPACK documentation...
### Versions
[pip3] numpy==1.21.5
[pip3] pytorch-lightning==1.7.0
[pip3] pytorch-wavelets==1.3.0
[pip3] rotary-embedding-torch==0.1.5
[pip3] torch==1.12.0
[pip3] torch-geometric==2.0.4
[pip3] torchfile==0.1.0
[pip3] torchinfo==1.7.0
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.13.0
[conda] numpy 1.21.5 pypi_0 pypi
[conda] pytorch-lightning 1.7.0 pypi_0 pypi
[conda] pytorch-wavelets 1.3.0 pypi_0 pypi
[conda] rotary-embedding-torch 0.1.5 pypi_0 pypi
[conda] torch 1.12.0 pypi_0 pypi
[conda] torch-geometric 2.0.4 pypi_0 pypi
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchinfo 1.7.0 pypi_0 pypi
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchvision 0.13.0 pypi_0 pypi
I am using the nightly build and running on the CPU.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 1 |
4,950 | 83,606 |
test_profiler_experimental_tree_cuda_detailed is too unstable, and as its CUDA only difficult to regen
|
high priority, triage review, module: tests, triaged, oncall: profiler
|
### 🐛 Describe the bug
This test is a double whammy:
* It's an expect test, but for piles of internal data which can wobble on unrelated changes for no good reason...
* and it's a CUDA only test, which means that if you have a failure on a CPU build, you have no way of easily regenerating the output
This test has had to be repeatedly updated for unrelated changes multiple times in its lifetime. I am going to disable it for now and we should discuss how exactly this test should actually be written.
cc @ezyang @gchanan @zou3519 @mruberry @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
### Versions
master
| 1 |
4,951 | 93,630 |
argmax/argmin returns the last index instead of the first when there are equally max/min elements
|
triaged, oncall: pt2
|
Here is the result when calling `a.argmax(0)`
```
a = torch.tensor([[3, 2, 2, 3, 2, 4, 3, 1, 3, 1],
[2, 3, 4, 2, 1, 2, 4, 3, 1, 2],
[3, 4, 3, 4, 3, 4, 1, 2, 1, 3],
[4, 1, 2, 1, 1, 3, 1, 3, 2, 2],
[1, 2, 4, 4, 3, 3, 2, 1, 1, 1],
[1, 1, 4, 1, 4, 4, 2, 1, 1, 2],
[3, 2, 3, 2, 1, 4, 2, 4, 2, 1],
[4, 3, 4, 4, 1, 1, 2, 4, 3, 3],
[2, 3, 4, 1, 2, 4, 4, 4, 4, 1],
[1, 1, 3, 4, 1, 1, 1, 3, 3, 3]], device='cuda:0', dtype=torch.int32)
expected = tensor([3, 2, 1, 2, 5, 0, 1, 6, 8, 2], device='cuda:0')
actual = tensor([3, 2, 8, 4, 5, 0, 8, 8, 8, 2], device='cuda:0')
```
Here is the generated triton kernel,
```
from ctypes import c_void_p, c_long
import torch
import random
from torch import empty_strided, as_strided
from torchinductor.codecache import CppCodeCache, TritonCodeCache
aten = torch.ops.aten
import triton
import triton.language as tl
from torchinductor.triton_ops.autotune import pointwise_heuristics
from torchinductor.triton_ops.autotune import reduction_heuristics
from torchinductor.triton_ops.autotune import grid
@reduction_heuristics(size_hints=[16, 16])
@triton.jit
def kernel0(in_ptr0, out_ptr0, ks0, xnumel, rnumel, XBLOCK : tl.constexpr, RBLOCK : tl.constexpr):
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.reshape(tl.arange(0, XBLOCK), [XBLOCK, 1])
xmask = xindex < xnumel
rbase = tl.reshape(tl.arange(0, RBLOCK), [1, RBLOCK])
x0 = xindex
_tmp1 = tl.zeros([XBLOCK, RBLOCK], tl.int64) + -2147483648
_tmp1_index = tl.zeros([XBLOCK, RBLOCK], tl.int64)
for roffset in range(0, rnumel, RBLOCK):
rindex = roffset + rbase
rmask = rindex < rnumel
r1 = rindex
tmp0 = tl.load(in_ptr0 + x0 + (ks0*r1), xmask & rmask, eviction_policy='evict_last')
_tmp1_index = tl.where(xmask & rmask & (_tmp1 < tmp0), rindex, _tmp1_index)
_tmp1 = tl.where(xmask & rmask & (_tmp1 < tmp0), tmp0, _tmp1)
_tmp1_index_reduce = tl.reshape(
tl.argmax(_tmp1, 1), [XBLOCK, 1]).to(tl.int32)
_tmp1_index_mask = (tl.reshape(tl.arange(0, RBLOCK),
[1, RBLOCK]) == _tmp1_index_reduce)
tmp1 = tl.reshape(tl.sum(
tl.where(_tmp1_index_mask, _tmp1_index, 0), 1), [XBLOCK, 1])
tl.store(out_ptr0 + x0, tmp1, xmask)
def call(arg0_1):
arg0_1_size = arg0_1.size()
s0 = arg0_1_size[0]
buf0 = empty_strided((s0, ), (1, ), device='cuda', dtype=torch.int64)
kernel0[grid(s0)](arg0_1, buf0, s0, s0, s0)
return (buf0, )
if __name__ == "__main__":
from torchdynamo.testing import rand_strided
from torchinductor.utils import print_performance
arg0_1 = rand_strided((10, 10), (10, 1), device='cuda', dtype=torch.int64)
call(arg0_1)
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,952 | 83,589 |
Speedup for adding images to tensorboard
|
oncall: visualization
|
### 🚀 The feature, motivation and pitch
This is my first contribution to pytorch, i will try to follow all protocols but please tell me if i am doing something wrong.
### The motivation
Adding very big matplotlib figures is slow due to unnecessary casting and scaling, this can be sped up significantly.
### The concrete problem
I create big figures using matplotlib in a training callback after each epoch. I would like to add these figures to tensorboard. The add_figure method currently basically renders the image as a figure and then adds it as an image.
https://github.com/pytorch/pytorch/blob/822a8e057fa4e6a6a8413d22bae2c1a5aa853134/torch/utils/tensorboard/writer.py#L748-L754
The method add_image creates a serialized summary and adds it to the file writer.
https://github.com/pytorch/pytorch/blob/822a8e057fa4e6a6a8413d22bae2c1a5aa853134/torch/utils/tensorboard/writer.py#L614-L616
The creation of the image summary has these lines, where the image is casted to float, multiplied by a scale factor (either 255 or 1) and casted back to uint8. In my case the "tensor" is already an ndarray with type uint8, so the cast to float, multiplication and cast back to uint8 is unnecessary.
https://github.com/pytorch/pytorch/blob/822a8e057fa4e6a6a8413d22bae2c1a5aa853134/torch/utils/tensorboard/summary.py#L443-L446
I'm very confident that these lines cause my speed problem . I localized them via printf debugging, then inserted condition (as shown below) and now it works much faster.
### Proposed solution
Add a condition whether the cast-scale-cast-back is necessary, something to the effect of:
```python
if tensor.dtype != np.uint8 or scale_factor != 1.0:
tensor = tensor.astype(np.float32)
tensor = (tensor * scale_factor).astype(np.uint8)
```
### Alternatives
I have considered ignoring the problem since it is only on epoch end anyway, but especially in debugging it can be very annoying when adding an image to tensorboard takes that long.
### Additional context
_No response_
| 0 |
4,953 | 83,585 |
Segfault when profiling with_stack=True on model with jit.optimize_for_inference
|
oncall: jit
|
### 🐛 Describe the bug
The Python process segfaults whenever I run the pytorch profiler using with_stack=True on a model that has had torch.jit.optimize_for_inference() called on it.
```python
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet18().cuda()
inputs = torch.randn(5, 3, 224, 224).cuda()
model = torch.jit.script(model)
model = torch.jit.optimize_for_inference(model)
with profile(activities=[ProfilerActivity.CPU], with_stack=True) as prof:
model(inputs)
```
```
Segmentation fault (core dumped)
```
The .crash file in /var/crash is 605MB and this should be easy to reproduce, so I haven't attached that, but let me know if there's anything else you need.
### Versions
Collecting environment information...
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-10ubuntu2) 9.3.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.5 (default, Jul 28 2020, 12:59:40) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-47-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 10.2.89
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 2080 Ti
GPU 1: NVIDIA GeForce RTX 2080 Ti
GPU 2: NVIDIA GeForce RTX 2080 Ti
GPU 3: NVIDIA GeForce RTX 2080 Ti
GPU 4: NVIDIA GeForce RTX 2080 Ti
GPU 5: NVIDIA GeForce RTX 2080 Ti
GPU 6: NVIDIA GeForce RTX 2080 Ti
GPU 7: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.73.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.12.1
[pip3] torchvision==0.13.1
[conda] Could not collect
| 0 |
4,954 | 83,584 |
Profiler can only print first 5 entries in stack traces because of hard-coded limit
|
oncall: profiler
|
### 🐛 Describe the bug
The pytorch profiler's key_averages() takes a "group_by_n" parameter with no documented upper limit. However, it only works up to 5. Printing with something like
```python
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet18().cuda()
inputs = torch.randn(5, 3, 224, 224).cuda()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], with_stack=True) as prof:
model(inputs)
print(prof.key_averages(group_by_stack_n=8).table(sort_by="self_cuda_time_total", row_limit=2))
```
only prints 5 lines of each stack context, instead of the expected up-to-8.
This seems to be due to the hard-coded line
```
MAX_STACK_ENTRY=5
```
in the _build_table function in torch.autograd.profiler_util.py .
If I understand correctly, I think this hard-coded limit could just be removed? Since the relevant stack depth is typically limited by the group_by_stack_n parameter anyway.
This came up in practice because I'm using some of the deeply-nested faster-RCNN modules in torchvision.
### Versions
Collecting environment information...
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-10ubuntu2) 9.3.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.5 (default, Jul 28 2020, 12:59:40) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-47-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 10.2.89
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 2080 Ti
GPU 1: NVIDIA GeForce RTX 2080 Ti
GPU 2: NVIDIA GeForce RTX 2080 Ti
GPU 3: NVIDIA GeForce RTX 2080 Ti
GPU 4: NVIDIA GeForce RTX 2080 Ti
GPU 5: NVIDIA GeForce RTX 2080 Ti
GPU 6: NVIDIA GeForce RTX 2080 Ti
GPU 7: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.73.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.12.1
[pip3] torchvision==0.13.1
[conda] Could not collect
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 0 |
4,955 | 83,583 |
Silent promotion of bool to int in the dispatcher
|
triaged, module: type promotion, module: pybind, module: library
|
### 🐛 Describe the bug
I try to register a function that according to its signature should only accept int or a list of ints, but there's a silent bool promotion to integers:
```py
import torch
test = torch.library.Library("test", "DEF")
test_impl = torch.library.Library("test", "IMPL", "CompositeExplicitAutograd")
schema = "test(int[2] arg) -> Tensor"
test.define(schema)
test_impl.impl("test", lambda arg=None: torch.tensor(arg))
try:
res = torch.ops.test.test(arg=True)
print(res)
print("Unexpected success!")
except RuntimeError as e:
print(e)
# This doesn't work as expected:
try:
res = torch.ops.test.test(arg=2.0)
print(res)
except RuntimeError as e:
print(e)
```
### Versions
Latest master.
cc: @ezyang, @albanD, @bdhirsh
cc @nairbv @mruberry @anjali411
| 0 |
4,956 | 83,579 |
Conv1d: NNPACK SpatialConvolution_updateOutput failed when batchsize or padding is too large
|
module: nn, module: convolution, triaged, module: nnpack
|
### 🐛 Describe the bug
When using conv1d in torch=1.10.2 and python=3.8.13
I found that if both the input batchsize and padding parameter are given a large value ( or maybe the production of them), I will get a "NNPACK SpatialConvolution_updateOutput failed" error.
I wonder if it is a bug or some inner remand for the op?
Here is a short example
'''
import torch
op = nn.Conv1d(3, 3, 2, 1, 1, 1, 1)
input = torch.randn((1000, 3, 10))
op(input)
'''
Here is the error info
'''
Traceback (most recent call last):
File "test.py", line 184, in <module>
op(input)
File "/home/hek/anaconda3/envs/dnngen/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/hek/anaconda3/envs/dnngen/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 301, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/hek/anaconda3/envs/dnngen/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 297, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: NNPACK SpatialConvolution_updateOutput failed
'''
### Versions
Collecting environment information...
PyTorch version: 1.10.2
Is debug build: False
CUDA used to build PyTorch: 11.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.27
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:18) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070 Ti
Nvidia driver version: 516.40
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.10.2
[pip3] torchaudio==0.10.2
[pip3] torchvision==0.10.0a0
[conda] blas 2.115 mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] blas-devel 3.9.0 15_linux64_mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] cpuonly 2.0 0 pytorch
[conda] cudatoolkit 11.7.0 hd8887f6_10 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] libblas 3.9.0 15_linux64_mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] libcblas 3.9.0 15_linux64_mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] liblapack 3.9.0 15_linux64_mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] liblapacke 3.9.0 15_linux64_mkl http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] magma 2.5.4 h6103c52_2 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] mkl 2022.1.0 h84fe81f_915 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] mkl-devel 2022.1.0 ha770c72_916 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] numpy 1.23.1 py38h3a7f9d9_0 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] pytorch 1.10.2 cuda112py38h6425f36_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] pytorch-gpu 1.10.2 cuda112py38h0bbbad9_1 http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 0.10.2 py38_cpu [cpuonly] pytorch
[conda] torchvision 0.10.1 py38cuda112h04b465a_0_cuda http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 2 |
4,957 | 83,577 |
libtorch malloc cause coredump
|
module: crash, module: cpp, triaged, module: static linking
|
### 🐛 Describe the bug
i use libtorch to inference, sometimes yes not always my code coredump with malloc segment fault, and use gdb to play the stack, it seems libtorch malloc failed.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x00007f1df8ef823b in malloc () from /usr/lib/x86_64-linux-gnu/libc.so.6
[Current thread is 1 (Thread 0x7f1c817fe000 (LWP 126))]
(gdb) bt
#0 0x00007f1df8ef823b in malloc () from /usr/lib/x86_64-linux-gnu/libc.so.6
#1 0x00007f1df9266b39 in operator new(unsigned long) () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6
#2 0x00007f1df1a21c1c in void std::vector<torch::jit::Value*, std::allocator<torch::jit::Value*> >::emplace_back<torch::jit::Value*>(torch::jit::Value*&&) ()
from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#3 0x00007f1df1acffee in torch::jit::Node::addOutput() () from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#4 0x00007f1df1ad76c5 in torch::jit::Block::cloneFrom(torch::jit::Block*, std::function<torch::jit::Value* (torch::jit::Value*)>) () from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#5 0x00007f1df1ad7f84 in torch::jit::Graph::copy() () from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#6 0x00007f1df19a8724 in torch::jit::GraphFunction::get_executor() () from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#7 0x00007f1df19a579e in torch::jit::GraphFunction::run(std::vector<c10::IValue, std::allocator<c10::IValue> >&) () from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#8 0x00007f1df19a5c5e in torch::jit::GraphFunction::operator()(std::vector<c10::IValue, std::allocator<c10::IValue> >, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, c10::IValue, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, c10::IValue> > > const&) ()
from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#9 0x00007f1df19b84bb in torch::jit::Method::operator()(std::vector<c10::IValue, std::allocator<c10::IValue> >, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, c10::IValue, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, c10::IValue> > > const&) const ()
from /opt/tritonserver/backends/pytorch/libtorch_cpu.so
#10 0x00007f1d40126f5d in triton::backend::pytorch::ModelInstanceState::Execute(std::vector<TRITONBACKEND_Response*, std::allocator<TRITONBACKEND_Response*> >*, unsigned int, std::vector<c10::IValue, std::allocator<c10::IValue> >*, std::vector<at::Tensor, std::allocator<at::Tensor> >*) () from /opt/tritonserver/backends/pytorch/libtriton_pytorch.so
#11 0x00007f1d4012d255 in triton::backend::pytorch::ModelInstanceState::ProcessRequests(TRITONBACKEND_Request**, unsigned int) ()
from /opt/tritonserver/backends/pytorch/libtriton_pytorch.so
#12 0x00007f1d4012eaa4 in TRITONBACKEND_ModelInstanceExecute () from /opt/tritonserver/backends/pytorch/libtriton_pytorch.so
#13 0x00007f1df80b0faa in nvidia::inferenceserver::TritonModelInstance::Execute(std::vector<TRITONBACKEND_Request*, std::allocator<TRITONBACKEND_Request*> >&) ()
from /opt/tritonserver/lib/libtritonserver.so
#14 0x00007f1df80b1857 in nvidia::inferenceserver::TritonModelInstance::Schedule(std::vector<std::unique_ptr<nvidia::inferenceserver::InferenceRequest, std::default_delete<nvidia::inferenceserver::InferenceRequest> >, std::allocator<std::unique_ptr<nvidia::inferenceserver::InferenceRequest, std::default_delete<nvidia::inferenceserver::InferenceRequest> > > >&&, std::function<void ()> const&) () from /opt/tritonserver/lib/libtritonserver.so
#15 0x00007f1df7f5ccc1 in nvidia::inferenceserver::Payload::Execute(bool*) () from /opt/tritonserver/lib/libtritonserver.so
#16 0x00007f1df80ab4f7 in nvidia::inferenceserver::TritonModelInstance::TritonBackendThread::BackendThread(int, int) () from /opt/tritonserver/lib/libtritonserver.so
#17 0x00007f1df9292de4 in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6
#18 0x00007f1df9d0c609 in start_thread (arg=<optimized out>) at pthread_create.c:477
#19 0x00007f1df8f7d163 in clone () from /usr/lib/x86_64-linux-gnu/libc.so.6
### Versions
pytorch 1.11
cc @jbschlosser
| 1 |
4,958 | 83,564 |
KL-divergence of two Generalized Dirichlet distributions
|
module: distributions, feature, triaged
|
### 🚀 The feature, motivation and pitch
Thank you for your great contribution. Could you please add KL-divergence of two Generalized Dirichlet distributions?
A very clear of its derivation can be found in equation 11 of this paper: [https://www.sciencedirect.com/science/article/abs/pii/S003132031830311X?via%3Dihub]
[KL-Divergence.pdf](https://github.com/pytorch/pytorch/files/9355461/KL-Divergence.pdf)
.
### Alternatives
_No response_
### Additional context
_No response_
cc @fritzo @neerajprad @alicanb @nikitaved
| 0 |
4,959 | 83,551 |
OpenJDK libtorch_cpu.so stack guard warning
|
oncall: java
|
### 🚀 The feature, motivation and pitch
When deploying a pytorch model using JavaCPP presets for pytorch + libtorch 1.10.2, java `17.0.3+7-Ubuntu-0ubuntu0.20.04.1` emits the following warning:
```
OpenJDK 64-Bit Server VM warning: You have loaded library /mnt/lib/cache/org.bytedeco.pytorch-1.10.2-1.5.7-linux-x86_64.jar/org/bytedeco/pytorch/linux-x86_64/libtorch_cpu.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
```
I reported this in https://github.com/bytedeco/javacpp-presets/issues/1208 but it's apparently caused by the way libtorch is built, not by JavaCPP.
Shouldn't pytorch be built with stack guard?
The answer may well be 'no', but it would be great to understand better 'why' in that case. Thanks!
### Alternatives
Ignore the warning.
### Additional context
https://stackoverflow.com/questions/1629685/when-and-how-to-use-gccs-stack-protection-feature
| 0 |
4,960 | 93,627 |
PyTorch test suite regression test_module_backward_global_hook_writeable
|
triaged, oncall: pt2
|
Bisected to https://github.com/pytorch/torchdynamo/pull/763
Repro command
```
PYTORCH_TEST_WITH_DYNAMO=1 python test/test_nn.py -k test_module_backward_global_hook_writeable
```
error
```
======================================================================
FAIL: test_module_backward_global_hook_writeable (__main__.TestModuleGlobalHooks)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test/test_nn.py", line 21073, in test_module_backward_global_hook_writeable
def test_module_backward_global_hook_writeable(self):
File "test/test_nn.py", line 21073, in test_module_backward_global_hook_writeable
def test_module_backward_global_hook_writeable(self):
File "test/test_nn.py", line 21073, in test_module_backward_global_hook_writeable
def test_module_backward_global_hook_writeable(self):
[Previous line repeated 1 more time]
File "/data/users/ezyang/pytorch-tmp/torch/testing/_internal/common_utils.py", line 2382, in assert
Equal
assert_equal(
File "/data/users/ezyang/pytorch-tmp/torch/testing/_comparison.py", line 1093, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Tensor-likes are not close!
Mismatched elements: 25 / 25 (100.0%)
Greatest absolute difference: 0.24967582497447965 at index (4, 2) (up to 1e-07 allowed)
Greatest relative difference: 0.5 at index (0, 0) (up to 1e-07 allowed)
----------------------------------------------------------------------
```
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 5 |
4,961 | 83,540 |
I have the same issue as @samgelman on my MacOS.
|
triaged, module: macos, module: openmp, module: third_party
|
I have the same issue as @samgelman on my MacOS.
Notably 1.10.1, 1.11.0 works fine but 1.10.2 and 1.12.1 shows:
```
OMP: Error #15: Initializing libiomp5.dylib, but found libomp.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
Abort trap: 6
```
One observation is that both 1.10.1 and 1.11.0 also come with `libuv` installation, which might have made the difference.
The workaround `KMP_DUPLICATE_LIB_OK=TRUE` causes a segfault.
Below is a working env:
```
python3 -mtorch.utils.collect_env
Collecting environment information...
PyTorch version: 1.10.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.5 (x86_64)
GCC version: Could not collect
Clang version: 12.0.0 (clang-1200.0.31.1)
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.13 (default, Mar 28 2022, 06:16:26) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.10.1
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py38h9ed2024_0
[conda] mkl_fft 1.3.1 py38h4ab4a9b_0
[conda] mkl_random 1.2.2 py38hb2f4e1b_0
[conda] mypy_extensions 0.4.3 py38hecd8cb5_1
[conda] numpy 1.21.5 py38h2e5f0a9_3
[conda] numpy-base 1.21.5 py38h3b1a694_3
[conda] pytorch 1.10.1 py3.8_0 pytorch
```
_Originally posted by @yuanmao in https://github.com/pytorch/pytorch/issues/78490#issuecomment-1217134036_
cc @malfet @albanD
| 3 |
4,962 | 83,537 |
Add a new argument `check_inf=True` (by default) or check_pos_inf / check_neg_inf to anomaly mode
|
module: autograd, triaged, enhancement
|
should if also have a new argument `check_inf=True` (by default) or check_pos_inf / check_neg_inf for symmetry with nan? (minor)
_Originally posted by @vadimkantorov in https://github.com/pytorch/pytorch/issues/83481#issuecomment-1215925856_
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 4 |
4,963 | 83,529 |
Adding Levenberg-marquardt optimizer in PyTorch
|
feature, module: optimizer, triaged, needs research
|
### 🚀 The feature, motivation and pitch
### Feature
Adding levenberg-marquardt (LM) algorithm to Torch.Optim.
### Motivation
Levenberg-Marquardt (LM), also known as damped least squares, is used to solve non-linear least squares. It converges much faster than gradient descent based methods (orders of magnitude faster). The algorithm needs access to the Jacobian matrix which makes it not suitable for problems with huge data. However, for many applications, like optical design, non-convex optimization, imaging systems design, the size of the network (or model) and data is manageable that LM algorithm provides much better solutions in a fraction of the time (seconds instead of hours). It will be extremely helpful to implement that in torch.optim.
### Alternatives
Two alternatives exist
1. I can try implementing it myself by calculating the Jacobian. However, the functions that PyTorch provides to do that are extremely slow.
2. Another method that I routinely use is a recently published paper called: "DeepLM: Large-scale Nonlinear Least Squares on Deep Learning Frameworks using Stochastic Domain Decomposition". This paper and GitHub uses PyTorch and provides an approximate way to implement LM algorithm. However, the structure of their optimizer is very different than the familiar torch.optim and the code needs to be changed significantly to use this paper.
cc @vincentqb @jbschlosser @albanD
| 2 |
4,964 | 83,521 |
quantize_per_tensor/quantize_per_channel operators should honor the quant_min/quant_max from observer
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
quantize_per_tensor/quantize_per_channel are operators that converts a floating point Tensor to a quantized (int8) Tensor based on some quantization parameters, the formula is:
```
quantized_Tensor = clamp(fp_Tensor / scale + zero_point, quant_min, quant_max)
```
Currently, since we don't take `quant_min`/`quant_max` as arguments, e.g. signature for `quantize_per_tensor` is
```
quantize_per_tensor(Tensor self, float scale, int zero_point, ScalarType dtype) -> Tensor
```
the default quant_min/quant_max for the dtype is applied right now. but ideally we should take `quant_min`/`quant_max` from observers.
Currently there is a workaround in https://github.com/pytorch/pytorch/pull/83438 to clamp the weight in the utility function to get the quantized weight, which is shared by both eager mode quantization and fx graph mode quantization. But ideally we should add `quant_min`/`quant_max` arguments to these operators.
### Versions
master
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo
| 0 |
4,965 | 83,510 |
Cdist backward dependent on compute_mode
|
module: autograd, triaged, actionable
|
### 🐛 Describe the bug
The function [torch.cdist](https://pytorch.org/docs/stable/generated/torch.cdist.html) raises a `NotImplementedError: the derivative for '_cdist_backward' is not implemented.` for default `compute_mode` during nested gradient calculation.
Example:
```
import torch
def function(a, b):
return torch.cdist(a, b)
# return torch.cdist(a, b, compute_mode="use_mm_for_euclid_dist") # works
# input data
a = torch.tensor([[1.0, 2.0], [3.0, 4.0]], requires_grad=True)
b = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
# calculate forward pass
y = torch.nn.Linear(2, 1)(function(a, b))
# calculate gradient
gradient = torch.autograd.grad(
y,
a,
grad_outputs=torch.ones_like(y),
create_graph=True,
)[0]
# calc loss to reference
grad_ref = torch.tensor([[10.0, 11.0], [12.0, 13.0]])
loss = torch.nn.MSELoss(reduction="mean")(gradient, grad_ref)
loss.backward() # NotImplementedError: the derivative for '_cdist_backward' is not implemented.
```
To us, this behavior is unclear from the documentation.
If this is not the supposed way to implement gradient based loss calculation, we are looking forward to your suggestions on alternative setups.
Hence, suggestions on how to circumference this are welcome (aside from changing `compute_mode`).
If this were to be expected, perhaps the documentation could be improved?
### Versions
PyTorch version: 1.12.0
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 3 |
4,966 | 83,509 |
Build and Run QNNPACK on X86
|
module: build, triaged
|
### 🚀 The feature, motivation and pitch
Hi Pytorch team,
I want to build and run QNNPACK on X86 CPU and there are not many references to do the same. It would be great if I can get the references to build and execute QNNPACK on the X86 platform.
Thank you!
### Alternatives
_No response_
### Additional context
_No response_
cc @malfet @seemethere @dhruvbird @ljk53
| 8 |
4,967 | 83,507 |
[Installation] conda installation hangs on "Solving environment"
|
oncall: binaries, triaged
|
### 🐛 Describe the bug
Hi,
I was trying to install pytorch following the main instruction on the website.
Setup is:
- PyTorch (Stable) 1.12.1
- Linux Ubuntu 20.04
- Conda package
- Language Python
- CUDA 11.6
I was able to install for CUDA 10.2, but I discover I have the 11.6 installed.
With the command given:
```bash
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge
```
The installation hangs on:
```bash
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: /
```
I solved not installing `cudatoolkit` first:
```
conda install pytorch torchvision torchaudio -c pytorch -c conda-forge
```
but this install the `cudatoolkit-10.2.89`
Hence I installed the right `cudatoolkit` version:
```
conda install -c pytorch -c conda-forge cudatoolkit=11.6
```
The output of this is:
```
The following packages will be UPDATED:
cudatoolkit 10.2.89-h8f6ccaa_8 --> 11.6.0-hecad31d_10
libgcc-ng 9.3.0-h5101ec6_17 --> 11.2.0-h1234567_1
libgomp 9.3.0-h5101ec6_17 --> 11.2.0-h1234567_1
libstdcxx-ng pkgs/main::libstdcxx-ng-9.3.0-hd4cf53~ --> conda-forge::libstdcxx-ng-12.1.0-ha89aaad_16
The following packages will be SUPERSEDED by a higher-priority channel:
openssl pkgs/main::openssl-1.1.1q-h7f8727e_0 --> conda-forge::openssl-1.1.1o-h166bdaf_0
The following packages will be DOWNGRADED:
pytorch 1.12.1-py3.8_cuda10.2_cudnn7.6.5_0 --> 1.12.1-py3.8_cuda11.6_cudnn8.3.2_0
torchaudio 0.12.1-py38_cu102 --> 0.12.1-py38_cu116
torchvision 0.13.1-py38_cu102 --> 0.13.1-py38_cu116
```
I find it strange that `pytorch` `torchaudio` `torchvision` are considered "DOWNGRADED"
BTW following the steps above it seems I solved the installation issue
### Versions
```
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1650
Nvidia driver version: 510.85.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h497a2fe_0 conda-forge
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h1abd341_0 conda-forge
[conda] numpy 1.21.5 py38he7a7128_2
[conda] numpy-base 1.21.5 py38hf524024_2
[conda] pytorch 1.12.1 py3.8_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py38_cu116 pytorch
[conda] torchvision 0.13.1 py38_cu116 pytorch
```
cc @ezyang @seemethere @malfet
| 5 |
4,968 | 83,494 |
`torch.pinverse` produces wrong output!
|
module: docs, triaged, module: linear algebra
|
### 🐛 Describe the bug
`torch.pinverse` produces wrong output for a 3*3 tensor!
According to the [documentation](https://pytorch.org/docs/stable/generated/torch.pinverse.html), `torch.pinverse` is an alias for [`torch.linalg.pinv()`](https://pytorch.org/docs/stable/generated/torch.linalg.pinv.html#torch.linalg.pinv), and computes the pseudoinverse (Moore-Penrose inverse) of a matrix. Algebraically, the output of `torch.pinverse(A)`, denoted as `Apinv`, should satisfy:
`A Apinv A = A`
However, for this input `A`, `torch.pinverse(A)` fails to generate correct result:
```
import torch
A = torch.tensor([[0.0, 1.0, -1.0], [1.0, -1.0, 0.0], [-1.0, 1.0, 0.0]])
Apinv = torch.pinverse(A)
print(A @ Apinv @ A)
print(torch.dist(A @ Apinv @ A, A))
```
Outputs:
```
tensor([[ 0.0000e+00, 1.0000e+00, -1.0000e+00],
[ 0.0000e+00, -2.9802e-08, 2.9802e-08],
[ 0.0000e+00, 2.9802e-08, -2.9802e-08]])
tensor(2.)
```
On the other hand, `torch.linalg.pinv` and `numpy.linalg.pinv` can generate correct pseudo inverse given the same input matrix `A`.
```
import torch
A = torch.tensor([[0.0, 1.0, -1.0], [1.0, -1.0, 0.0], [-1.0, 1.0, 0.0]])
Apinv2 = torch.linalg.pinv(A)
print(A @ Apinv2 @ A)
print(torch.dist(A @ Apinv2 @ A, A))
import numpy as np
Apinv_np = np.linalg.pinv(A)
print(A @ Apinv_np @ A)
print(torch.dist(A @ Apinv_np @ A, A))
```
Outputs
```
tensor([[-1.4901e-07, 1.0000e+00, -1.0000e+00],
[ 1.0000e+00, -1.0000e+00, 2.9802e-08],
[-1.0000e+00, 1.0000e+00, -2.9802e-08]])
tensor(5.5516e-07)
tensor([[ 8.9407e-08, 1.0000e+00, -1.0000e+00],
[ 1.0000e+00, -1.0000e+00, -2.9802e-08],
[-1.0000e+00, 1.0000e+00, 2.9802e-08]])
tensor(2.8430e-07)
```
### Versions
torch 1.12.1
cc @svekars @holly1238 @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 2 |
4,969 | 83,493 |
Calling torch.linalg.cholesky on a CPU tensor requires compiling PyTorch with LAPACK.
|
triaged, module: linear algebra
|
### 🐛 Describe the bug
I installed PyTorch from Source and it showes error when I try to run `python -m pytest test/distributions/test_distributions.py'.
============================= test session starts ==============================
platform linux -- Python 3.10.4, pytest-7.1.2, pluggy-1.0.0
rootdir: /home/nonconvexopt/research/__common_modules__/pytorch, configfile: pytest.ini
collected 0 items / 1 error
```
==================================== ERRORS ====================================
__________ ERROR collecting test/distributions/test_distributions.py ___________
Traceback (most recent call last):
File "{DIR}/pytorch/test/distributions/test_distributions.py", line 542, in <module>
'component_distribution': MultivariateNormal(
File "{DIR}/pytorch/torch/distributions/multivariate_normal.py", line 148, in __init__
super(MultivariateNormal, self).__init__(batch_shape, event_shape, validate_args=validate_args)
File "{DIR}/pytorch/torch/distributions/distribution.py", line 54, in __init__
valid = constraint.check(value)
File "{DIR}/pytorch/torch/distributions/constraints.py", line 512, in check
return torch.linalg.cholesky_ex(value).info.eq(0)
RuntimeError: Calling torch.linalg.cholesky on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
------------------------------- Captured stdout --------------------------------
Fail to import hypothesis in common_utils, tests are not derandomized
=========================== short test summary info ============================
ERROR test/distributions/test_distributions.py - RuntimeError: Calling torch....
!!!!!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!!!!!
========================= 2 warnings, 1 error in 1.66s =========================
```
I tried to build PyTorch with `python setup.py build` and `python setup.py develop`. Also I installed `magma-cuda11.7`. But it does not solve the problem.
### Versions
PyTorch version: 1.13.0a0+git65f7fa8
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: Could not collect
CMake version: version 3.24.0
Libc version: glibc-2.35
Python version: 3.10.4 (main, Mar 31 2022, 08:41:55) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.7.99
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.4.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.13.0a0+git65f7fa8
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] magma-cuda117 2.6.1 0 pytorch
[conda] numpy 1.23.2 pypi_0 pypi
[conda] torch 1.13.0a0+git65f7fa8 dev_0 <develop>
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 3 |
4,970 | 83,492 |
`Frozen` module for transfer learning.
|
module: nn, triaged, needs design
|
### 🚀 The feature, motivation and pitch
"Freezing" a model to stop gradient propagation and parameter updates is a common step in transfer learning. The [tutorial on transfer learning](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html#convnet-as-fixed-feature-extractor) currently suggests setting `requires_grad = False` for all parameters of the feature extractor and removing the parameters from the set of parameters passed to the optimizer. What would be your thoughts on adding a `Frozen` module that achieves the same task as a one-liner? Proposed implementation below.
```python
class Frozen(torch.nn.Module):
def __init__(self, frozen_module):
super().__init__()
self.frozen_module = frozen_module
def forward(self, *args, **kwargs):
with torch.no_grad():
return self.frozen_module(*args, **kwargs)
def parameters(self, recurse: bool = True) -> typing.Iterator[th.nn.Parameter]:
return
yield
def named_parameters(self, prefix: str = '', recurse: bool = True) \
-> typing.Iterator[tuple[str, th.nn.Parameter]]:
return
yield
```
Usage example:
```python
resnet18 = torchvision.models.resnet18(pretrained=True)
extractor = Frozen(resnet18) # Stops all gradients and parameter lookups.
```
As a side-effect, this would allow gradients to propagate if there are multiple paths from loss to parameters, e.g., in multi-objective optimization. Calling `extractor` would not propagate gradients. Calling `resnet18` directly would propagate gradients.
### Alternatives
_No response_
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
4,971 | 93,626 |
Move TorchInductor Triton autotuner to compile time, use common cache
|
triaged, oncall: pt2
|
We use the Triton autotuner here:
https://github.com/pytorch/torchdynamo/blob/8e4abe3f66fb6b8d97d6461d64f9c3be323a523e/torchinductor/triton_ops/autotune.py#L182
and, here:
https://github.com/pytorch/torchdynamo/blob/8e4abe3f66fb6b8d97d6461d64f9c3be323a523e/torchinductor/triton_ops/autotune.py#L216
To select tile sizes for generated kernels from a short list of options.
This results in good performance, but has a high cost in terms of warm up time. We will be running nearly identical autotuning runs to pick tilings that should be obvious.
I'd propose we create a small cost model to replace the autotuner. As an input to this model we should take:
1) The size_hints (already rounded up to next power of two)
2) The indexing formulas of all the reads and writes
3) [Maybe] Number of `tmpX` variables used in kernel
4) [Maybe] Number of reduction loops in the kernel
5) [Maybe] Histogram of `ops.*` usage in the kernel
As an initial implementation, we could just build an on-disk cache/hash-table that runs the Triton autotuner on misses, but reuses a prior decision if the model inputs are identical. This alone should dramatically speed up warmup times.
Longer term, we could take the data collected in this cache and train a small neural network to predict which tiling to use. For this we should have the neural network predict the normalized runtime for each tiling choice. This cost model can then replace the measurement step of the autotuner.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
4,972 | 83,441 |
Find way to add comments to merge_rules json
|
module: ci, triaged
|
For some of the cases of merge_rules we have special cases (like pin XLA hash), we need to have to add comment in JSON to outline root cause why we have special cases like XLA hash otherwise we might attempt to merge special cases back to the generic rules (already been attempted).
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 4 |
4,973 | 83,394 |
[ONNX] Convert GFPGANv1.3.pth to onnx
|
module: onnx, triaged
|
### 🐛 Describe the bug
converting Convert GFPGANv1.3.pth to onnx give me next errors ->
```
Traceback (most recent call last):
File "Z:\AI_SDK\CPP_GFPGAN\Pretrained_MODELS_GFPGAN\pth2onnx.py", line 41, in
<module>
torch.onnx.export(model,inputs,onnxpath,export_params=True,verbose=True,inpu
t_names=['input'],output_names=['output'],opset_version=12)
File "C:\Python38\lib\site-packages\torch\onnx\__init__.py", line 316, in expo
rt
return utils.export(model, args, f, export_params, verbose, training,
File "C:\Python38\lib\site-packages\torch\onnx\utils.py", line 107, in export
_export(model, args, f, export_params, verbose, training, input_names, outpu
t_names,
File "C:\Python38\lib\site-packages\torch\onnx\utils.py", line 724, in _export
_model_to_graph(model, args, verbose, input_names,
File "C:\Python38\lib\site-packages\torch\onnx\utils.py", line 497, in _model_
to_graph
graph = _optimize_graph(graph, operator_export_type,
File "C:\Python38\lib\site-packages\torch\onnx\utils.py", line 216, in _optimi
ze_graph
graph = torch._C._jit_pass_onnx(graph, operator_export_type)
File "C:\Python38\lib\site-packages\torch\onnx\__init__.py", line 373, in _run
_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File "C:\Python38\lib\site-packages\torch\onnx\utils.py", line 1032, in _run_s
ymbolic_function
return symbolic_fn(g, *inputs, **attrs)
File "C:\Python38\lib\site-packages\torch\onnx\symbolic_helper.py", line 172,
in wrapper
return fn(g, *args, **kwargs)
File "C:\Python38\lib\site-packages\torch\onnx\symbolic_opset9.py", line 1281,
in _convolution
raise RuntimeError("Unsupported: ONNX export of convolution for kernel "
RuntimeError: Unsupported: ONNX export of convolution for kernel of unknown shap
e.
```
Code of converter
```python
import torch
from gfpgan.archs.gfpganv1_clean_arch import GFPGANv1Clean
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
modelpath=r"Z:\AI_SDK\CPP_GFPGAN\Pretrained_MODELS_GFPGAN\experiments\pretrained_models\GFPGANv1.3.pth"
channel_multiplier=2
model = GFPGANv1Clean(
out_size=512,
num_style_feat=512,
channel_multiplier=channel_multiplier,
decoder_load_path=None,
fix_decoder=False,
num_mlp=8,
input_is_latent=True,
different_w=True,
narrow=1,
sft_half=True)
w=torch.load(modelpath)
model.load_state_dict(w,strict=False)
model.to(device)
model.eval()
inputs = torch.ones((1, 3, 512,512)).to(device)
onnxpath=r"Z:\AI_SDK\CPP_GFPGAN\Pretrained_MODELS_GFPGAN\experiments\pretrained_models\GFPGANv1.3.onnx"
print(model)
torch.onnx.export(model,inputs,onnxpath,export_params=True,verbose=True,input_names=['input'],output_names=['output'],opset_version=12)
```
[model.log](https://github.com/pytorch/pytorch/files/9334348/model.log)
### Versions
Collecting environment information...
PyTorch version: 1.10.0+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 7 Professional
GCC version: (x86_64-posix-seh-rev3, Built by MinGW-W64 project) 12.1.0
Clang version: 14.0.4
CMake version: version 3.24.0-rc1
Libc version: N/A
Python version: 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 6
4 bit (AMD64)] (64-bit runtime)
Python platform: Windows-7-6.1.7601-SP1
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.10.0
[pip3] torchaudio==0.10.0
[pip3] torchvision==0.11.1
[conda] Could not collect
| 5 |
4,974 | 83,393 |
Test public bindings in CI gives weird output on error
|
high priority, module: ci, module: tests, triaged, module: python frontend
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/runs/7824028166?check_suite_focus=true
There is a bunch of irrelevant failures. The real failure is reproducible locally and tells me only that there are some public API in symbolic_shapes that are not exported, but the CI output is useless
### Versions
master
cc @gchanan @zou3519 @seemethere @malfet @pytorch/pytorch-dev-infra @mruberry
| 5 |
4,975 | 83,392 |
How to turn off determinism just for specific operations, e.g. upsampling through bilinear interpolation?
|
module: cuda, triaged, module: determinism
|
This is the error caused by upsampling through bilinear interpolation when trying to use deterministic algorithms:
`RuntimeError: upsample_bilinear2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True)'. You can turn off determinism just for this operation if that's acceptable for your application. You can also file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation.`
How to turn off determinism just for upsampling_bilinear2d (and any other operation)? Thanks!
cc @ngimel @mruberry @kurtamohler
| 0 |
4,976 | 83,388 |
zero-numel tensor has "RuntimeError: strides[cur - 1] == sizes[cur] * strides[cur] INTERNAL ASSERT FAILED" in multi-thread.
|
oncall: jit, triaged, module: nvfuser
|
### 🐛 Describe the bug
Hello,
We encountered the following error and provide a reproduction example below.
```
terminate called after throwing an instance of 'std::runtime_error'
what(): The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: strides[cur - 1] == sizes[cur] * strides[cur]
INTERNAL ASSERT FAILED at "../torch/csrc/jit/codegen/fuser/executor.cpp":177, please report a bug to PyTorch.
```
There are multiple required conditions to reproduce this bug.
(1) a zero-numel() tensor is operated on.
(2) model runs `forward` in a separate thread than the main thread.
(3) model is on a GPU device.
We provide a close-to-minimal reproduction code in the following [gist](https://gist.github.com/ehuaurora/34e2e2eeebaf22b67b54c6a7b99bdb18).
It has two parts.
(A) a python script to create a mock torchscript to be loaded by c++ modules, [generate_mock_model.py](https://gist.github.com/ehuaurora/34e2e2eeebaf22b67b54c6a7b99bdb18#file-generate_mock_model-py),
Simply run `python3 generate_mock_model.py` to create a mock model at `/tmp/internal_crash/model.zip`.
(B) C++ source to load the mock torchscript to demonstrate that the requirement (1)(2)(3) are necessary, [reproduce_and_ablation.cc](https://gist.github.com/ehuaurora/34e2e2eeebaf22b67b54c6a7b99bdb18#file-reproduce_and_ablation-cc). Run this without args to load torchscript in `/tmp/internal_crash/model.zip` to reproduce the bug and run some ablation studies.
The expected output of the C++ binary:
```
-----------------------------------------------------------------------------
Make sure you first generate a model with command
python3 internal_error_crash_model.py
It should generate a model at /tmp/internal_crash/model.zip
------------------------
Running not_crash_if_no_threads()
feature_cp shape [15, 0]
about to do operations
about to return
feature_cp shape [15, 0]
about to do operations
about to return
------------------------
Running not_crash_if_not_gpu()
feature_cp shape [15, 0]
about to do operations
about to return
feature_cp shape [15, 0]
about to do operations
about to return
------------------------
Running not_crash_if_not_zero_numel()
feature_cp shape [15, 1]
about to do operations
about to return
feature_cp shape [15, 1]
about to do operations
about to return
------------------------
Running crash_with_threads()
terminate called after throwing an instance of 'std::runtime_error'
what(): The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: strides[cur - 1] == sizes[cur] * strides[cur]
INTERNAL ASSERT FAILED at "../torch/csrc/jit/codegen/fuser/executor.cpp":177, please report a bug to PyTorch.
```
### Versions
```
Collecting environment information...
PyTorch version: 1.9.0a0+d69c22d.cuda11.4.bionic.aurora.b38
Is debug build: False
CUDA used to build PyTorch: 11.4
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Libc version: -
Python version: 3.7.13 (default, Jul 6 2022, 21:28:00) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1083-aws-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA A10G
Nvidia driver version: 510.85.02
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.3
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] No relevant packages
[conda] Could not collect
```
| 2 |
4,977 | 83,383 |
PyTorch profiler is spammy
|
oncall: profiler
|
Running the TorchDynamo benchmarking scripts in coverage mode results in:
```
~/torchdynamo$ ./benchmarks/torchbench.py --isolate
cpu eval BERT_pytorch STAGE:2022-08-13 17:41:32 999867:999867 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:41:32 999867:999867 ActivityProfilerController.cpp:300] Completed Stage: Collection
4/ 4 +0 frames 3s 1 graphs 1 graph calls 565/ 565 = 100% ops 100% time
cpu eval Background_Matting STAGE:2022-08-13 17:41:49 999993:999993 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:41:51 999993:999993 ActivityProfilerController.cpp:300] Completed Stage: Collection
1/ 1 +0 frames 7s 1 graphs 1 graph calls 184/ 184 = 100% ops 100% time
cpu eval LearningToPaint STAGE:2022-08-13 17:41:58 1000068:1000068 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:41:58 1000068:1000068 ActivityProfilerController.cpp:300] Completed Stage: Collection
1/ 1 +0 frames 1s 1 graphs 1 graph calls 72/ 72 = 100% ops 100% time
cpu eval Super_SloMo STAGE:2022-08-13 17:42:23 1000105:1000105 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:42:27 1000105:1000105 ActivityProfilerController.cpp:300] Completed Stage: Collection
1/ 1 +0 frames 15s 1 graphs 1 graph calls 541/ 541 = 100% ops 100% time
cpu eval alexnet STAGE:2022-08-13 17:42:32 1000208:1000208 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:42:32 1000208:1000208 ActivityProfilerController.cpp:300] Completed Stage: Collection
1/ 1 +0 frames 1s 1 graphs 1 graph calls 23/ 23 = 100% ops 100% time
cpu eval attention_is_all_you_need_pytorch STAGE:2022-08-13 17:42:38 1000238:1000238 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2022-08-13 17:42:38 1000238:1000238 ActivityProfilerController.cpp:300] Completed Stage: Collection
...
```
All of the `ActivityProfilerController.cpp` logging makes it hard to read the actual output of the script.
IMO we should disable this logging by default.
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 5 |
4,978 | 83,381 |
`test_profiler_experimental_tree_cuda_detailed` fails with mismatches in the profile output
|
oncall: profiler
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/pull/80797 added `test_profiler_experimental_tree_cuda_detailed` which started to directly fail after the merge with:
```python
Traceback (most recent call last):
File "test_profiler_tree.py", line 55, in begin_unit_test_marker
out = f(self)
File "test_profiler_tree.py", line 786, in test_profiler_experimental_tree_cuda_detailed
self.assertTreesMatch(
File "test_profiler_tree.py", line 190, in assertTreesMatch
self.assertExpectedInline(actual, expected, skip=1)
File "/opt/conda/lib/python3.8/site-packages/expecttest/__init__.py", line 262, in assertExpectedInline
self.assertMultiLineEqualMaybeCppStack(expect, actual, msg=help_text)
File "/opt/conda/lib/python3.8/site-packages/expecttest/__init__.py", line 281, in assertMultiLineEqualMaybeCppStack
self.assertMultiLineEqual(expect, actual[:len(expect)], *args, **kwargs)
AssertionError: ' [1269 chars] void ..._kernel<...>(...)\n [7937 chars] ...' != ' [1269 chars] std::enable_if<!(false), void>::type inte[7922 chars] '
test_profiler_tree.py(...): test_profiler_experimental_tree_cuda_detailed
torch/profiler/profiler.py(...): __enter__
...
test_profiler_tree.py(...): step
<built-in method ones of type object at 0xXXXXXXXXXXXX>
aten::ones
aten::empty
[memory]
aten::fill_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
nn.Module: Linear_0
<built-in method _get_tracing_state of PyCapsule object at 0xXXXXXXXXXXXX>
torch/nn/modules/linear.py(...): forward
torch/nn/modules/module.py(...): __getattr__
torch/nn/modules/module.py(...): __getattr__
<built-in function linear>
aten::linear
aten::t
aten::transpose
aten::as_strided
aten::addmm
cudaMemcpyAsync
Memcpy DtoD (Device -> Device)
cudaLaunchKernel
- void ..._kernel<...>(...)
+ std::enable_if<!(false), void>::type internal::gemvx::kernel<int, int, float, float, float, float, false, true, false, false, 7, false, cublasGemvParams<cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float>, float> >(cublasGemvParams<cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float>, float>)
[memory]
aten::expand
aten::as_strided
torch/_tensor.py(...): backward
<built-in function _has_torch_function_unary>
torch/autograd/__init__.py(...): backward
<built-in function isinstance>
<built-in function isinstance>
<built-in function len>
torch/autograd/__init__.py(...): _tensor_or_tensors_to_tuple
torch/autograd/__init__.py(...): _make_grads
<built-in function isinstance>
<built-in method numel of Tensor object at 0xXXXXXXXXXXXX>
<built-in method ones_like of type object at 0xXXXXXXXXXXXX>
aten::ones_like
aten::empty_like
aten::empty_strided
[memory]
aten::fill_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
<built-in method append of list object at 0xXXXXXXXXXXXX>
<built-in method run_backward of torch._C._EngineBase object at 0xXXXXXXXXXXXX>
autograd::engine::evaluate_function: AddmmBackward0
AddmmBackward0
aten::t
aten::transpose
aten::as_strided
aten::mm
cudaLaunchKernel
- void ..._kernel<...>(...)
+ std::enable_if<!(false), void>::type internal::gemvx::kernel<int, int, float, float, float, float, false, true, false, false, 7, false, cublasGemvParams<cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float>, float> >(cublasGemvParams<cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float const>, cublasGemvTensorStridedBatched<float>, float>)
[memory]
aten::t
aten::transpose
aten::as_strided
aten::sum
aten::sum
cudaLaunchKernel
void at::native::reduce_kernel<...>(...)
[memory]
aten::view
aten::view
autograd::engine::evaluate_function: torch::autograd::AccumulateGrad
torch::autograd::AccumulateGrad
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
[memory]
autograd::engine::evaluate_function: TBackward0
TBackward0
aten::t
aten::transpose
aten::as_strided
autograd::engine::evaluate_function: torch::autograd::AccumulateGrad
torch::autograd::AccumulateGrad
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
[memory]
[memory]
torch/optim/optimizer.py(...): wrapper
<built-in method format of str object at 0xXXXXXXXXXXXX>
torch/autograd/profiler.py(...): __init__
<built-in method zeros of type object at 0xXXXXXXXXXXXX>
aten::zeros
aten::zeros
aten::empty
[memory]
aten::zero_
torch/autograd/profiler.py(...): __enter__
torch/_ops.py(...): __call__
<built-in method _record_function_enter of PyCapsule object at 0xXXXXXXXXXXXX>
Optimizer.step#SGD.step
aten::empty
[memory]
[memory]
[memory]
torch/optim/optimizer.py(...): _use_grad
<built-in function is_grad_enabled>
torch/autograd/grad_mode.py(...): __init__
<built-in function is_grad_enabled>
<built-in function _set_grad_enabled>
torch/optim/sgd.py(...): step
<built-in method append of list object at 0xXXXXXXXXXXXX>
<built-in method append of list object at 0xXXXXXXXXXXXX>
torch/_tensor.py(...): __hash__
<built-in function id>
<built-in method append of list object at 0xXXXXXXXXXXXX>
<built-in method append of list object at 0xXXXXXXXXXXXX>
<built-in method append of list object at 0xXXXXXXXXXXXX>
torch/_tensor.py(...): __hash__
<built-in function id>
<built-in method append of list object at 0xXXXXXXXXXXXX>
torch/optim/sgd.py(...): sgd
torch/optim/sgd.py(...): _single_tensor_sgd
<built-in method mul_ of Tensor object at 0xXXXXXXXXXXXX>
[memory]
aten::mul_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
[memory]
<built-in method add_ of Tensor object at 0xXXXXXXXXXXXX>
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
<built-in method add_ of Tensor object at 0xXXXXXXXXXXXX>
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
<built-in method mul_ of Tensor object at 0xXXXXXXXXXXXX>
[memory]
aten::mul_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
[memory]
<built-in method add_ of Tensor object at 0xXXXXXXXXXXXX>
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
<built-in method add_ of Tensor object at 0xXXXXXXXXXXXX>
aten::add_
cudaLaunchKernel
void at::native::vectorized_elementwise_kernel<...>(...)
torch/_tensor.py(...): __hash__
<built-in function id>
torch/_tensor.py(...): __hash__
- <built-in function id>
- torch/autograd/grad_mode.py(...): __init__
- <built-in function is_grad_enabled>
- <built-in function _set_grad_enabled>
- torch/autograd/profiler.py(...): __exit__
- torch/_ops.py(...): __call__
- <built-in method _record_function_exit of PyCapsule object at 0xXXXXXXXXXXXX>
- [memory]
? ---------
+ - [memory]
- torch/profiler/profiler.py(...): __exit__
- torch/profiler/profiler.py(...): stop
- torch/profiler/profiler.py(...): _transit_action
- <built-in method get of dict object at 0xXXXXXXXXXXXX>
- enum.py(...): __hash__
- <built-in function hash>
- ... : To accept the new output, re-run test with envvar EXPECTTEST_ACCEPT=1 (we recommend staging/committing your changes before doing this)
-
```
To reproduce using a current master build:
```python
/opt/pytorch/pytorch/test# python test_profiler_tree.py -v -k test_profiler_experimental_tree_cuda_detailed
```
It seems the `void ..._kernel<...>(...)` pattern does not match the `std::enable_if<!(false), void>::type internal::gemvx::kernel` usage.
CC @robieta
I cannot see the CI runs from your PR, so maybe the issue depends on the actual environment?
### Versions
Current master build with CUDA 11.7.
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
| 2 |
4,979 | 83,379 |
[caffee2] Windows build / 'metanet_pb2' (a circular import) Anaconda
|
caffe2
|
### 🐛 Describe the bug
I want to use [Detectron](https://github.com/facebookresearch/Detectron) for an old project .
I have Anaconda ```conda 4.13.0```
```
UserWarning: Caffe2 support is not enabled in this PyTorch build. Please enable Caffe2 by building PyTorch from source with `BUILD_CAFFE2=1` flag.
warnings.warn('Caffe2 support is not enabled in this PyTorch build.
```
can't build PyTorch from source for various reasons
I think that has nothing to do with the issue
```
from caffe2.proto import caffe2_pb2, metanet_pb2, torch_pb2
ImportError: cannot import name 'metanet_pb2' from partially initialized module 'caffe2.proto' (most likely due to a circular import)
```
I edit the script located in D:\Anaconda\lib\site-packages\caffe2\proto\__init__.py
and run it then change it back to its original code and now somehow it doesn't install or output anything !!
So it seems that Caffee2 is integrated into Pytorch and the API is changed .
I need to run the script of which use Detectron and old api of caffee2
when I do
```
python -c 'from caffe2.python import core' 2>/dev/null && echo "Success" || echo "Failure"
```
it fails
```
ModuleNotFoundError: No module named 'detectron'
```
to put it simply I need to run this Project with Anaconda --
https://github.com/krematas/soccerontable
### Versions
I can't run this script
| 0 |
4,980 | 83,376 |
Complex-Valued Gaussian distributions
|
module: distributions, triaged, module: complex, module: random
|
### 🚀 The feature, motivation and pitch
I had been working on complex-valued variational auto encoders (CVAE) and for this purpose I required complex-valued Gaussian distributions. I coded my own implementation based on [1] and used it successfully. I essentially model it as a composite real-valued distribution. Would it be of interest if I created a PR to add this functionality?
[1] P. J. Schreier and L. L. Scharf, Statistical signal processing of complex-valued data: the theory of improper and noncircular signals. Cambridge: Cambridge University Press, 2010. Accessed: Feb. 13, 2022. [Online]. Available: https://doi.org/10.1017/CBO9780511815911
### Alternatives
_No response_
### Additional context
_No response_
cc @fritzo @neerajprad @alicanb @nikitaved @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @pbelevich
| 19 |
4,981 | 93,624 |
KeyError `shape,stack,cos` on pennylane quantum circuit
|
triaged, oncall: pt2
|
@anijain2305 would you rather I create an "interesting model" tracker or should I keep creating unique issues for each kind of model
## Repro
`python -m pip install pennylane`
```python
import torch
import pennylane as qml
import torchdynamo
dev = qml.device('default.qubit', wires=2)
@qml.qnode(dev, interface='torch')
def circuit4(phi, theta):
qml.RX(phi[0], wires=0)
qml.RZ(phi[1], wires=1)
qml.CNOT(wires=[0, 1])
qml.RX(theta, wires=0)
return qml.expval(qml.PauliZ(0))
def cost(phi, theta):
return torch.abs(circuit4(phi, theta) - 0.5)**2
phi = torch.tensor([0.011, 0.012], requires_grad=True)
theta = torch.tensor(0.05, requires_grad=True)
opt = torch.optim.Adam([phi, theta], lr = 0.1)
steps = 200
def closure():
opt.zero_grad()
loss = cost(phi, theta)
loss.backward()
return loss
with torchdynamo.optimize("eager"):
for i in range(steps):
opt.step(closure)
```
## Logs
https://gist.github.com/msaroufim/ce9ec004536e762fb5c94eb3ab2670f1
cc @ezyang @soumith @wconstab @ngimel @bdhirsh
| 0 |
4,982 | 93,623 |
Replace decompositions in torchinductor/decompositions with refs/decomps in pytorch proper
|
triaged, oncall: pt2, module: inductor
|
We should audit existing decompositions and replace them with refs/decomps where appropriate, e.g. `clamp` decomposition currently incorrectly type promotes and doesn't handle non-number boundaries (see also pytorch/pytorch#93784).
cc @ezyang @soumith @msaroufim @wconstab @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 15 |
4,983 | 83,351 |
DDP + FSDP: Investigate behavior for nn.Module APIs
|
high priority, triage review, oncall: distributed, triaged, better-engineering, module: ddp, module: fsdp
|
### 🚀 The feature, motivation and pitch
Since DDP and FSDP are class wrappers, some nn.Module APIs may additional prefixing or otherwise not work in an equivalent fashion to local nn.Module instances due to the wrapping nature. This can cause some pain points in composing the modules together, checkpointing with `state_dict`, or any code that relies on module / parameter names / APIs such as `named_parameters`. This issue is to track what we can do for DDP / FSDP for each API. I've attempted to document current status below:
-- DDP --
- state_dict / load_state_dict: Adds `module` prefix, but this can be worked around and stripped out with a flag or env variable (needs a PR to enable).
- named_parameters / named_buffers - Adds `module` prefix as well
- named_modules / modules() - includes DDP wrapped module as well, wrapped module is prefixed with "module"
- children() - returns wrapped module and its children, whereas we might just want to return the wrapped module's children if we want equivalence to local
-- FSDP --
- state_dict / load_state_dict: There are various ways to checkpoint, but `full_state_dict` and `sharded_state_dict` should checkpoint with original parameter names
- named_parameters / named_buffers - In `summon_full_params` context, equivalent to local module checkpoint. Otherwise, `flat_param` type info is returned. @awgu is working on exposing original parameters which may help alleviate this issue
- named_modules / modules() - same as DDP, includes wrapped module as well, and all nested FSDP wrappers.
- children() - returns wrapped module and its children, same as DDP.
Also, we should check what these APIs do when DDP / FSDP is not the top-level module and just a non-root in the module hierarchy. It is not guaranteed that these APIs would remain the same.
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @gchanan @zou3519 @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 0 |
4,984 | 83,349 |
checkpoint function is not jit compatible
|
oncall: jit
|
When I use the checkpoint function here: https://pytorch.org/docs/stable/checkpoint.html with jit in scripting mode, I got following error:
torch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:
File "/opt/conda/lib/python3.8/site-packages/torch/utils/checkpoint.py", line 145
def checkpoint(function, *args, **kwargs):
~~~~~~~ <--- HERE
r"""Checkpoint a model or part of the model
raise NotSupportedError(ctx_range, _vararg_kwarg_err)
I rewrote the checkpoint function and removed *args and **kwargs, then I got another issue here:
Python builtin <built-in method apply of FunctionMeta object at 0x55a65def18e0> is currently not supported in Torchscript:
File "/opt/ml/code/asr_kwoon/models/checkpoint.py", line 255
#if use_reentrant:
return CheckpointFunction.apply(function, preserve, output, pe, mask)
~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
Seems like I need to rewrite all functions used by checkpoint to make it jit compatible. Is there any solution for this issue?
| 0 |
4,985 | 83,320 |
Torch1.10.2 is slower than torch1.9.1
|
oncall: distributed, triaged, module: ddp
|
### 🐛 Describe the bug
I recently upgraded my pytorch version from 1.9.1 to 1.10.2 due to project needs. But found that the training speed dropped by 20% to 30% for the same multi-tasks model.
After profiling, I found the reason is that the code of torch1.10 has the following logic:
https://github.com/pytorch/pytorch/blob/v1.10.2/torch/nn/parallel/distributed.py#L1378
That means, When using DDP, the model will assign module buffers before each forward. Time will be spent in assigning buffers:
https://github.com/pytorch/pytorch/blob/71f889c7d265b9636b93ede9d651c0a9c4bee191/torch/nn/parallel/distributed.py#L752
When the model is complex, the time spent should be considerable.
I would like to know how to avoid this part of the time overhead.
### Versions
Python 3.6.6 (default, Jan 26 2019, 16:53:05) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)]
numpy 1.19.5
PyTorch 1.10.2+cu111 @/mnt/data-1/kongtao.hu/environments/pytorch1102_cu111/lib/python3.6/site-packages/torch
PyTorch debug build False
Torchvision 0.11.3+cu111 @/mnt/data-1/kongtao.hu/environments/pytorch1102_cu111/lib/python3.6/site-packages/torchvision
GPU available Yes
GPU 0,1,2,3 TITAN V (arch=7.0)
Driver version 455.38
CUDA_HOME /usr/local/cuda-11.1
---------------------- --------------------------------------------------------------------------------------------------------------------------------
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.2.3 (Git Hash 7336ca9f055cf1bfa13efb658fe15dc9b41f0740)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- LAPACK is enabled (usually provided by MKL)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86
- CuDNN 8.0.5
- Magma 2.5.2
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=/opt/rh/devtoolset-7/root/usr/bin/c++, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.2, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON,
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang @VitalyFedyunin @ngimel
| 7 |
4,986 | 83,315 |
dataparallel function doesn't work
|
triaged, module: data parallel
|
### 🐛 Describe the bug
issue:
When I use torch.nn.parallel to distribute data onto multiple gpus, I found the Dataparallel obj `filter_model` only return output of one gpu.
```
def train_model():
bert_model = BertModel.from_pretrained(args.bert_model)
rank_model = BertForSearch(bert_model)
filter_model = FilterModel(bert_model,args)
model_state_dict = torch.load("./anchors/models/filter_model_ngram4/filter_model.bin",map_location=device)
filter_model.load_my_state_dict({k.replace('module.', ''):v for k, v in model_state_dict.items()})
if args.gpu!="-1":
rank_model = rank_model.to(device)
rank_model = torch.nn.DataParallel(rank_model)
filter_model = filter_model.to(device)
filter_model = torch.nn.DataParallel(filter_model)
fit(filter_model,rank_model, train_data, dev_data)
```
Then I checked the source code and found the problem. After I modify the code below in torch.nn.parallel.scatter_gather. this problem will be solved.
But actually I don't know why the code before doesn't work. Could somebody explain why? Thanks!!
### Versions
torch 1.9.0+cu102
gpu: two Tesla v100
cc @ezyang
| 1 |
4,987 | 83,313 |
torch.Tag doesn't have accurate mypy info
|
module: typing, triaged
|
### 🐛 Describe the bug
```
Error (MYPY) [attr-defined]
Module has no attribute "Tag"
151 | r = func_overload.decompose(*args, **kwargs)
152 | if r is not NotImplemented:
153 | return r
>>> 154 | if torch.Tag.data_dependent_output in func_overload.tags:
155 | # Check if all of the Tensor inputs are constants
156 | all_constant = True
157 |
```
### Versions
master
cc @ezyang @malfet @rgommers @xuzhao9 @gramster
| 3 |
4,988 | 93,620 |
Long test time for PyTorch test_fx::TestVisionTracing with dynamo enabled
|
triaged, oncall: pt2
|
### Issue
I'm investigating a list of slow tests on PyTorch CI, and this one stands out to me as the top of the list `linux-bionic-py3.7-clang9 / test (dynamo, 1, 2, linux.2xlarge)`. The [metric](https://hud.pytorch.org/tts/pytorch/pytorch/master?jobName=pull%20%2F%20linux-bionic-py3.7-clang9%20%2F%20test%20(dynamo%2C%201%2C%202%2C%20linux.2xlarge)) shows that it takes close to 3 hours to finish under normal condition.
Taking a closer look there, it turns out that the long pole hogging more than two third of the test time is a set of `TestVisionTracing` tests in [test_fx.py](https://github.com/pytorch/pytorch/blob/master/test/test_fx.py). I have the test log with the timing below FYI, i.e. https://github.com/pytorch/pytorch/runs/7774079140. My guess is that the bigger the models, the slower it becomes.
```
2022-08-03T17:25:10.6477370Z test_torchvision_models_alexnet (__main__.TestVisionTracing) ... ok (0.886s)
2022-08-03T17:26:05.7221409Z test_torchvision_models_convnext_base (__main__.TestVisionTracing) ... ok (54.702s)
2022-08-03T17:27:02.4509609Z test_torchvision_models_convnext_large (__main__.TestVisionTracing) ... ok (56.729s)
2022-08-03T17:27:56.6380097Z test_torchvision_models_convnext_small (__main__.TestVisionTracing) ... ok (54.187s)
2022-08-03T17:28:12.1358494Z test_torchvision_models_convnext_tiny (__main__.TestVisionTracing) ... ok (15.498s)
2022-08-03T17:30:15.0829924Z test_torchvision_models_densenet121 (__main__.TestVisionTracing) ... ok (122.947s)
2022-08-03T17:33:58.2949895Z test_torchvision_models_densenet161 (__main__.TestVisionTracing) ... ok (223.212s)
2022-08-03T17:38:06.7859626Z test_torchvision_models_densenet169 (__main__.TestVisionTracing) ... ok (248.491s)
2022-08-03T17:38:06.7896555Z test_torchvision_models_densenet201 (__main__.TestVisionTracing) ... ok (358.177s)
2022-08-03T17:44:04.9669275Z test_torchvision_models_detection_fasterrcnn_mobilenet_v3_large_320_fpn ok (0.770s)
2022-08-03T17:44:05.7351427Z test_torchvision_models_detection_fasterrcnn_mobilenet_v3_large_fpn ok (0.243s)
2022-08-03T17:44:05.9786792Z test_torchvision_models_detection_fasterrcnn_resnet50_fpn (__main__.TestVisionTracing) ... ok (0.560s)
2022-08-03T17:44:07.0258696Z test_torchvision_models_detection_fasterrcnn_resnet50_fpn_v2 (__main__.TestVisionTracing) ... ok (0.488s)
2022-08-03T17:44:07.0270010Z test_torchvision_models_detection_fcos_resnet50_fpn (__main__.TestVisionTracing) ... ok (0.471s)
2022-08-03T17:44:07.4987991Z test_torchvision_models_detection_keypointrcnn_resnet50_fpn (__main__.TestVisionTracing) ... ok (0.647s)
2022-08-03T17:44:08.1453012Z test_torchvision_models_detection_maskrcnn_resnet50_fpn (__main__.TestVisionTracing) ... ok (0.453s)
2022-08-03T17:44:09.1151239Z test_torchvision_models_detection_maskrcnn_resnet50_fpn_v2 (__main__.TestVisionTracing) ... ok (0.518s)
2022-08-03T17:44:09.1162174Z test_torchvision_models_detection_retinanet_resnet50_fpn (__main__.TestVisionTracing) ... ok (0.435s)
2022-08-03T17:44:10.0464869Z test_torchvision_models_detection_retinanet_resnet50_fpn_v2 (__main__.TestVisionTracing) ... ok (0.496s)
2022-08-03T17:44:10.0476882Z test_torchvision_models_detection_ssd300_vgg16 (__main__.TestVisionTracing) ... ok (4.769s)
2022-08-03T17:44:14.8171701Z test_torchvision_models_detection_ssdlite320_mobilenet_v3_large (__main__.TestVisionTracing) ... ok (45.547s)
2022-08-03T17:45:58.0140988Z test_torchvision_models_efficientnet_b0 (__main__.TestVisionTracing) ... ok (57.650s)
2022-08-03T17:48:00.4734725Z test_torchvision_models_efficientnet_b1 (__main__.TestVisionTracing) ... ok (122.459s)
2022-08-03T17:50:03.9557458Z test_torchvision_models_efficientnet_b2 (__main__.TestVisionTracing) ... ok (123.482s)
2022-08-03T17:52:38.0078169Z test_torchvision_models_efficientnet_b3 (__main__.TestVisionTracing) ... ok (154.052s)
2022-08-03T17:56:36.5506145Z test_torchvision_models_efficientnet_b4 (__main__.TestVisionTracing) ... ok (238.543s)
2022-08-03T18:02:31.9753962Z test_torchvision_models_efficientnet_b5 (__main__.TestVisionTracing) ... ok (355.425s)
2022-08-03T18:10:34.0433740Z test_torchvision_models_efficientnet_b6 (__main__.TestVisionTracing) ... ok (482.068s)
2022-08-03T18:22:45.6426801Z test_torchvision_models_efficientnet_b7 (__main__.TestVisionTracing) ... ok (731.599s)
2022-08-03T18:22:47.1220214Z test_torchvision_models_efficientnet_v2_l (__main__.TestVisionTracing) ...ok (1194.113s)
2022-08-03T18:53:00.3677928Z test_torchvision_models_efficientnet_v2_m (__main__.TestVisionTracing) ... ok (620.612s)
2022-08-03T18:57:49.4276270Z test_torchvision_models_efficientnet_v2_s (__main__.TestVisionTracing) ... ok (289.060s)
2022-08-03T18:57:49.4438332Z test_torchvision_models_googlenet (__main__.TestVisionTracing) ... ok (29.098s)
2022-08-03T18:58:18.5393137Z test_torchvision_models_inception_v3 (__main__.TestVisionTracing) ... ok (63.303s)
2022-08-03T18:59:46.1718149Z test_torchvision_models_mnasnet0_5 (__main__.TestVisionTracing) ... ok (24.342s)
2022-08-03T18:59:46.1867787Z test_torchvision_models_mnasnet0_75 (__main__.TestVisionTracing) ... ok (25.346s)
2022-08-03T19:00:36.9759874Z test_torchvision_models_mnasnet1_0 (__main__.TestVisionTracing) ... ok (25.458s)
2022-08-03T19:01:02.9683669Z test_torchvision_models_mnasnet1_3 (__main__.TestVisionTracing) ... ok (25.992s)
2022-08-03T19:01:32.5979077Z test_torchvision_models_mobilenet_v2 (__main__.TestVisionTracing) ... ok (29.629s)
2022-08-03T19:02:08.5415970Z test_torchvision_models_mobilenet_v3_large (__main__.TestVisionTracing) ... ok (35.944s)
2022-08-03T19:02:32.4524047Z test_torchvision_models_mobilenet_v3_small (__main__.TestVisionTracing) ... ok (23.910s)
2022-08-03T19:03:29.8420213Z test_torchvision_models_regnet_x_16gf (__main__.TestVisionTracing) ... ok (57.389s)
2022-08-03T19:04:07.9935732Z test_torchvision_models_regnet_x_1_6gf (__main__.TestVisionTracing) ... ok (38.151s)
2022-08-03T19:05:12.0549659Z test_torchvision_models_regnet_x_32gf (__main__.TestVisionTracing) ... ok (64.061s)
2022-08-03T19:06:22.7225415Z test_torchvision_models_regnet_x_3_2gf (__main__.TestVisionTracing) ... ok (70.667s)
2022-08-03T19:07:18.2250778Z test_torchvision_models_regnet_x_400mf (__main__.TestVisionTracing) ... ok (55.502s)
2022-08-03T19:07:49.3684930Z test_torchvision_models_regnet_x_800mf (__main__.TestVisionTracing) ... ok (31.143s)
2022-08-03T19:08:51.6417110Z test_torchvision_models_regnet_x_8gf (__main__.TestVisionTracing) ... ok (62.273s)
2022-08-03T19:11:49.2177510Z test_torchvision_models_regnet_y_128gf (__main__.TestVisionTracing) ... ok (177.576s)
2022-08-03T19:11:49.2208120Z test_torchvision_models_regnet_y_16gf (__main__.TestVisionTracing) ... ok (73.293s)
2022-08-03T19:15:41.0194445Z test_torchvision_models_regnet_y_1_6gf (__main__.TestVisionTracing) ... ok (158.508s)
2022-08-03T19:17:12.7901234Z test_torchvision_models_regnet_y_32gf (__main__.TestVisionTracing) ... ok (91.770s)
2022-08-03T19:18:48.2377446Z test_torchvision_models_regnet_y_3_2gf (__main__.TestVisionTracing) ... ok (95.447s)
2022-08-03T19:19:45.2292131Z test_torchvision_models_regnet_y_400mf (__main__.TestVisionTracing) ... ok (56.991s)
2022-08-03T19:20:31.7528460Z test_torchvision_models_regnet_y_800mf (__main__.TestVisionTracing) ... ok (46.523s)
2022-08-03T19:20:32.2151362Z test_torchvision_models_regnet_y_8gf (__main__.TestVisionTracing) ... ok (41.056s)
2022-08-03T19:22:49.0783090Z test_torchvision_models_resnet101 (__main__.TestVisionTracing) ... ok (96.269s)
2022-08-03T19:26:08.9278863Z test_torchvision_models_resnet152 (__main__.TestVisionTracing) ... ok (199.849s)
2022-08-03T19:26:12.7781004Z test_torchvision_models_resnet18 (__main__.TestVisionTracing) ... ok (3.850s)
2022-08-03T19:26:24.1143151Z test_torchvision_models_resnet34 (__main__.TestVisionTracing) ... ok (11.336s)
2022-08-03T19:26:47.0665742Z test_torchvision_models_resnet50 (__main__.TestVisionTracing) ... ok (22.952s)
2022-08-03T19:28:18.6756152Z test_torchvision_models_resnext101_32x8d (__main__.TestVisionTracing) ... ok (91.609s)
2022-08-03T19:29:51.5175733Z test_torchvision_models_resnext101_64x4d (__main__.TestVisionTracing) ... ok (92.842s)
2022-08-03T19:30:15.0395468Z test_torchvision_models_resnext50_32x4d (__main__.TestVisionTracing) ... ok (23.522s)
2022-08-03T19:30:15.0417455Z test_torchvision_models_segmentation_deeplabv3_mobilenet_v3_large (__main__.TestVisionTracing) ... ok (41.518s)
2022-08-03T19:30:56.5593147Z test_torchvision_models_segmentation_deeplabv3_resnet101 (__main__.TestVisionTracing) ... ok (65.539s)
2022-08-03T19:32:02.0989764Z test_torchvision_models_segmentation_deeplabv3_resnet50 (__main__.TestVisionTracing) ... ok (19.032s)
2022-08-03T19:32:21.1306708Z test_torchvision_models_segmentation_fcn_resnet101 (__main__.TestVisionTracing) ...ok (55.015s)
2022-08-03T19:33:16.1455914Z test_torchvision_models_segmentation_fcn_resnet50 (__main__.TestVisionTracing) ... ok (15.044s)
2022-08-03T19:33:31.1890927Z test_torchvision_models_segmentation_lraspp_mobilenet_v3_large (__main__.TestVisionTracing) ... ok (22.548s)
2022-08-03T19:34:29.0257884Z test_torchvision_models_shufflenet_v2_x0_5 (__main__.TestVisionTracing) ... ok (35.290s)
2022-08-03T19:34:29.0365339Z test_torchvision_models_shufflenet_v2_x1_0 (__main__.TestVisionTracing) ... ok (35.166s)
2022-08-03T19:35:39.0395488Z test_torchvision_models_shufflenet_v2_x1_5 (__main__.TestVisionTracing) ... ok (34.847s)
2022-08-03T19:36:14.5451081Z test_torchvision_models_shufflenet_v2_x2_0 (__main__.TestVisionTracing) ... ok (35.505s)
2022-08-03T19:36:17.8882872Z test_torchvision_models_squeezenet1_0 (__main__.TestVisionTracing) ... ok (3.343s)
2022-08-03T19:36:21.1852522Z test_torchvision_models_squeezenet1_1 (__main__.TestVisionTracing) ... ok (3.297s)
2022-08-03T19:36:23.9077391Z test_torchvision_models_swin_b (__main__.TestVisionTracing) ... ok (5.616s)
2022-08-03T19:36:27.5764829Z test_torchvision_models_swin_s (__main__.TestVisionTracing) ... ok (3.819s)
2022-08-03T19:36:32.4463984Z test_torchvision_models_swin_t (__main__.TestVisionTracing) ... ok (1.826s)
2022-08-03T19:36:34.9411761Z test_torchvision_models_vgg11 (__main__.TestVisionTracing) ... ok (2.495s)
2022-08-03T19:36:38.0211472Z test_torchvision_models_vgg11_bn (__main__.TestVisionTracing) ... ok (3.080s)
2022-08-03T19:36:41.0269459Z test_torchvision_models_vgg13 (__main__.TestVisionTracing) ... ok (3.006s)
2022-08-03T19:36:45.1734879Z test_torchvision_models_vgg13_bn (__main__.TestVisionTracing) ... ok (4.146s)
2022-08-03T19:36:48.3880343Z test_torchvision_models_vgg16 (__main__.TestVisionTracing) ... ok (3.214s)
2022-08-03T19:36:52.6734397Z test_torchvision_models_vgg16_bn (__main__.TestVisionTracing) ... ok (4.285s)
2022-08-03T19:36:56.6082544Z test_torchvision_models_vgg19 (__main__.TestVisionTracing) ... ok (3.935s)
2022-08-03T19:37:02.3325897Z test_torchvision_models_vgg19_bn (__main__.TestVisionTracing) ... ok (5.724s)
2022-08-03T19:37:06.5155769Z test_torchvision_models_video_mc3_18 (__main__.TestVisionTracing) ... ok (4.183s)
2022-08-03T19:38:55.8700574Z test_torchvision_models_video_mvit_v1_b (__main__.TestVisionTracing) ... ok (109.354s)
2022-08-03T19:39:12.5654877Z test_torchvision_models_video_r2plus1d_18 (__main__.TestVisionTracing) ... ok (16.695s)
2022-08-03T19:39:17.3841514Z test_torchvision_models_video_r3d_18 (__main__.TestVisionTracing) ... ok (4.818s)
2022-08-03T19:39:21.9138265Z test_torchvision_models_vit_b_16 (__main__.TestVisionTracing) ... ok (4.529s)
2022-08-03T19:39:25.7134707Z test_torchvision_models_vit_b_32 (__main__.TestVisionTracing) ... ok (3.800s)
2022-08-03T19:39:25.7494094Z test_torchvision_models_vit_h_14 (__main__.TestVisionTracing) ... ok (24.109s)
2022-08-03T19:40:02.6691677Z test_torchvision_models_vit_l_16 (__main__.TestVisionTracing) ... ok (12.846s)
2022-08-03T19:40:15.0948724Z test_torchvision_models_vit_l_32 (__main__.TestVisionTracing) ... ok (12.426s)
2022-08-03T19:40:16.4909689Z test_torchvision_models_wide_resnet101_2 (__main__.TestVisionTracing) ... ok (90.164s)
2022-08-03T19:42:09.2416125Z test_torchvision_models_wide_resnet50_2 (__main__.TestVisionTracing) ... ok (23.982s)
```
On the other hand, these tests take only minutes without dynamo, i.e. https://github.com/pytorch/pytorch/runs/7774078598.
AFAIK, dynamo tests are run with `torchdynamo.optimize("eager")` https://github.com/pytorch/pytorch/pull/80106, and these figures are probably expected. So, my questions are:
* Is there a way to alleviate the situation here like running these tests in a different "lazier" mode to avoid this bottleneck?
* Does the team think that these tests bring enough values to justify the waiting time? They are run on pull request, so it's pretty costly to make the whole workflow waiting for this. May be we can find a middle ground for this.
Thank you for looking into this!
### Solutions
TBD
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
4,989 | 83,292 |
TorchVision testing in CI + test_fx
|
triaged, module: fx, fx
|
Recently we had the TorchVision hash updates fail due to failing tests in test_fx related to TorchVision. Even though they have been fixed, perhaps we should review how TorchVision is tested in core. TorchVision has its own tests that ensure that pytorch core doesn't break TorchVision, and the tests in test_fx seem to make invalid assumptions about TorchVision models. Should we instead just be running TorchVision tests in core? Is it necessary for test_fx to trace the TorchVision models?
tagging @datumbox and fx b/c they probably have more info
cc @ezyang @SherlockNoMad
| 1 |
4,990 | 83,289 |
Improvements to ProcessGroupGloo monitored_barrier
|
high priority, triage review, oncall: distributed, triaged, module: c10d
|
### 🚀 The feature, motivation and pitch
`monitored_barrier` is a well adopted API that seeks to perform a barrier that also reports the faulty rank(s) which did not make it into the barrier. However, it has some usability issues at the moment:
1) Sometimes, we see an error where rank x, x != 0 reports that it recevied errors from rank 0. But rank 0 reports that it received errors from x, so there is a circular blame issue. We should identify when this could happen
2) In debug mode, we should add comprehensive logging around which ranks successfully acked and which ones did not. For example, when rank x acks to rank 0, under torch_distributed_debug=DETAIL, we should log this event.
3) ability to Surface these errors to external error logging databases.
4) Add a string API into `monitored_barrier` that allows users to pass in details about what is going on in the application, PG gloo can attach this string to the error msg for better debugability.
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @gchanan @zou3519 @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 1 |
4,991 | 83,281 |
addcdiv_ (in and out of place) not implemented for torch.float16 and cpu
|
low priority, triaged, enhancement, module: half
|
### 🐛 Describe the bug
Running addcdiv_ or addcdiv with torch.float16 and on cpu =
RuntimeError: "addcdiv_cpu_out" not implemented for 'Half'
Probably not a pressing use case, but if people are still using fp16 it would prove an issue:
code to repro:
~~~
use_type = torch.float16
alpha = .80
tsize = 2000000
data_tensor = torch.randn(tsize,dtype=use_type)
atensor = torch.randn(tsize, dtype=use_type)
btensor = torch.randn(tsize, dtype=use_type)
#clones
data_clone = data_tensor.clone()
aclone = atensor.clone()
bclone = btensor.clone()
# inplace
data_tensor.addcdiv_(atensor, btensor,value=-alpha)
# out of place
data_clone = torch.addcdiv(data_clone, aclone, bclone, value=-alpha)
# verify
torch.equal(data_tensor, data_clone)
~~~
Results:
<img width="797" alt="addcdiv_half" src="https://user-images.githubusercontent.com/46302957/184212804-40a1b788-748e-45fa-87e3-8ad1570f574f.png">
You'll get the same if you comment the first addcdiv out and move to the out of place.
### Versions
Collecting environment information...
PyTorch version: 1.13.0.dev20220810+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.3
Libc version: glibc-2.27
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:56:21) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1081-aws-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 11.6.124
GPU models and configuration:
GPU 0: NVIDIA A10G
GPU 1: NVIDIA A10G
GPU 2: NVIDIA A10G
GPU 3: NVIDIA A10G
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] numpydoc==1.4.0
[pip3] torch==1.13.0.dev20220810+cu113
[pip3] torch-model-archiver==0.6.0b20220513
[pip3] torch-workflow-archiver==0.2.4b20220513
[pip3] torchserve==0.6.0b20220513
[pip3] torchtext==0.13.0
[pip3] torchvision==0.14.0.dev20220810+cu113
[conda] blas 2.115 mkl conda-forge
[conda] blas-devel 3.9.0 15_linux64_mkl conda-forge
[conda] captum 0.5.0 0 pytorch
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] libblas 3.9.0 15_linux64_mkl conda-forge
[conda] libcblas 3.9.0 15_linux64_mkl conda-forge
[conda] liblapack 3.9.0 15_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 15_linux64_mkl conda-forge
[conda] magma-cuda116 2.6.1 0 pytorch
[conda] mkl 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-devel 2022.1.0 ha770c72_916 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-service 2.4.0 py39hb699420_0 conda-forge
[conda] mkl_fft 1.3.1 py39h1fd5c3a_3 conda-forge
[conda] mkl_random 1.2.2 py39h8b66066_1 conda-forge
[conda] mypy_extensions 0.4.3 py39hf3d152e_5 conda-forge
[conda] numpy 1.22.4 py39hc58783e_0 conda-forge
[conda] numpydoc 1.4.0 pyhd8ed1ab_1 conda-forge
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.13.0.dev20220810+cu113 pypi_0 pypi
[conda] torch-model-archiver 0.6.0 py39_0 pytorch
[conda] torch-workflow-archiver 0.2.4 py39_0 pytorch
[conda] torchserve 0.6.0 py39_0 pytorch
[conda] torchtext 0.13.0 py39 pytorch
[conda] torchvision 0.14.0.dev20220810+cu113 pypi_0 pypi
| 2 |
4,992 | 83,272 |
bmm operator in bfloat16 has low TFLOPS for some tensor shapes with CUDA 11.6
|
triaged, module: cublas
|
### 🐛 Describe the bug
bmm operator has much lower TFLOPS on tensor shapes A=(384, 1024, 1024) and B=(384, 1024, 140) in bfloat16.
```
shape: (384, 1024, 1024, 140, torch.float16), TFLOP: 0.11, cost: 0.002092, TFLOPS : 53.89
shape: (512, 1024, 1024, 128, torch.float16), TFLOP: 0.14, cost: 0.001037, TFLOPS : 132.48
shape: (384, 1024, 1024, 140, torch.bfloat16), TFLOP: 0.11, cost: 0.009232, TFLOPS : 12.21
shape: (512, 1024, 1024, 128, torch.bfloat16), TFLOP: 0.14, cost: 0.001036, TFLOPS : 132.71
```
The reproducible script:
```
import time
import torch
def benchmark(n, k, m, l, dtype):
warmup = 2
number = 10
a = torch.rand(n, k, m, dtype=dtype).cuda()
b = torch.rand(n, m, l, dtype=dtype).cuda()
for i in range(warmup):
c = torch.bmm(a, b)
torch.cuda.synchronize()
tic = time.time()
for i in range(number):
c = torch.bmm(a, b)
torch.cuda.synchronize()
toc = time.time()
total_flops = 2 * n * k * m * l
cost = (toc - tic) / number
shape = (n, k, m, l, dtype)
print(f"shape: {shape}, TFLOP: {total_flops / 1e12:.2f}, "
f"cost: {cost:3f}, "
f"TFLOPS : {total_flops / cost / 1e12:.2f}""")
benchmark(384, 1024, 1024, 6720//48, torch.float16)
benchmark(512, 1024, 1024, 8192//64, torch.float16)
benchmark(384, 1024, 1024, 6720//48, torch.bfloat16)
benchmark(512, 1024, 1024, 8192//64, torch.bfloat16)
```
### Versions
Collecting environment information...
PyTorch version: 1.12.0a0+67ece03
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Amazon Linux 2 (x86_64)
GCC version: (GCC) 7.3.1 20180712 (Red Hat 7.3.1-15)
Clang version: 11.1.0 (Amazon Linux 2 11.1.0-1.amzn2.0.2)
CMake version: version 3.18.2
Libc version: glibc-2.2.5
Python version: 3.7.10 (default, Jun 3 2021, 00:02:01) [GCC 7.3.1 20180712 (Red Hat 7.3.1-13)] (64-bit runtime)
Python platform: Linux-4.14.276-211.499.amzn2.x86_64-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: 11.6.55
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.39.01
cuDNN version: Probably one of the following:
/usr/lib64/libcudnn.so.8.4.1
/usr/lib64/libcudnn_adv_infer.so.8.4.1
/usr/lib64/libcudnn_adv_train.so.8.4.1
/usr/lib64/libcudnn_cnn_infer.so.8.4.1
/usr/lib64/libcudnn_cnn_train.so.8.4.1
/usr/lib64/libcudnn_ops_infer.so.8.4.1
/usr/lib64/libcudnn_ops_train.so.8.4.1
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] pytorch-ignite==0.4.2
[pip3] pytorch-lightning==1.6.5
[pip3] torch==1.12.0a0+gite67ece03
[pip3] torchaudio==0.10.1+6f539cf
[pip3] torchmetrics==0.9.3
[pip3] torchtext==0.10.0a0+0d670e0
[pip3] torchvision==0.8.1
[conda] Could not collect
cc @csarofeen @ptrblck @xwang233
| 9 |
4,993 | 83,271 |
cannot import name 'ProcessGroup' from 'torch.distributed'
|
oncall: distributed, triaged, module: macos
|
### 🐛 Describe the bug
Can't import 'ProcessGroup' from 'torch.distributed'
`from torch.distributed import ProcessGroup`
Generates:
`Traceback (most recent call last):
File "/Users/darrenthorpe/PycharmProjects/tableDetection/scripts/bug_report.py", line 1, in <module>
from torch.distributed import ProcessGroup
ImportError: cannot import name 'ProcessGroup' from 'torch.distributed' (/Users/darrenthorpe/miniforge3/envs/torch-bug/lib/python3.9/site-packages/torch/distributed/__init__.py)
`
This is doing my head in..... feel like there's something trivial and silly going on.
Note I'm on MacOS with mps 12.5 Monterey
### Versions
(torch-bug) darrenthorpe@Darrens-MacBook-Air torch-bug % python collect_env.py
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.5 (arm64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 17:00:33) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-12.5-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.12.0a0
[conda] numpy 1.23.1 py39h7df2422_0 conda-forge
[conda] pytorch 1.12.1 cpu_py39h0768760_0 conda-forge
[conda] torchaudio 0.12.1 py39_cpu pytorch
[conda] torchvision 0.12.0 cpu_py39h384c48c_1 conda-forge
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @malfet @albanD
| 2 |
4,994 | 83,264 |
Emulating FP64 and increased precisions on Apple silicon
|
feature, triaged, needs research, module: mps
|
Spinoff of https://github.com/pytorch/pytorch/issues/77764#issuecomment-1211503363 as requested by @albanD:
---
This might not be 100% centered around PyTorch, but I would think it's still a worthy discussion.
I was contemplating a future project to emulate FP64 precision on Apple GPUs, possibly using FP64 dynamic range with FP32 precision just like Nvidia's TF32/TF19 does (to get reasonable performance). This would be a 35-bit IEEE format. I found [SoftFloat](https://github.com/ucb-bar/berkeley-softfloat-3) which should provide a good basis. I could utilize high-throughput 16-bit integers to process exponent bits, leaving FP32 ALUs for mantissa (can both integer and floating-point ALUs be utilized simultaneously?). Also, a fully IEEE compliant (but slow) genuine FP64 format would be developed. I did some back of the envelope calculations based on SoftFloat's fully IEEE-compliant FP64 emulation, and they were depressing. ~24 GFLOPS on an M1 Max GPU.
Through personal experience with (failed attempts at GPU-accelerating via Metal) physics simulations and linear algebra solvers, it's the dynamic range that matters most, not the precision. Thus the 35-bit compromise format could be very useful.
I also discussed FP64 emulation at https://github.com/DTolm/VkFFT/issues/61 for more context.
cc @kulinseth @albanD
| 3 |
4,995 | 83,257 |
PyYAML not listed as a dependency
|
oncall: releng, triaged
|
### 🐛 Describe the bug
`torchgen` is now packaged with the rest of `torch`. Seeing as `torchgen` requires the `yaml` module, it seems like a bug that its not listed as a install requirement
https://github.com/pytorch/pytorch/blob/beceb8b92f030b19a0ea48ab9ae0def8f554e7f3/setup.py#L440-L443
In fact, there is a check in the `setup.py` that will raise an error if `yaml` is not installed
https://github.com/pytorch/pytorch/blob/beceb8b92f030b19a0ea48ab9ae0def8f554e7f3/setup.py#L399
So, why is it not listed as a install requirement in the first place? Is there anything preventing `yaml` from being added as a dependency?
CC: @silvasean
### Versions
N/A
| 1 |
4,996 | 83,250 |
Using Pytorch and Mapbox in the same project
|
oncall: mobile
|
Hello,
I'm trying to use Mapbox and Pytorch together in the same Android project but I receive this compilation error:
2 files found with path 'lib/arm64-v8a/libc++_shared.so' from inputs:
- /Users/eyalamir/.gradle/caches/transforms-3/39574a221961eb18fa9deadbee69fea4/transformed/common-22.1.0/jni/arm64-v8a/libc++_shared.so
- /Users/eyalamir/.gradle/caches/transforms-3/c73fb4c1d8f48b7cbb206e310613488d/transformed/pytorch_android_lite-1.10.0/jni/arm64-v8a/libc++_shared.so
If you are using jniLibs and CMake IMPORTED targets, see
https://developer.android.com/r/tools/jniLibs-vs-imported-targets
If I only use one of the libraries, the project compiles correctly.
I also reproduced this issue with a new Android Project.
I'm using these versions:
Mapbox - com.mapbox.maps:android:10.7.0
Pytorch - org.pytorch:pytorch_android_lite:1.10.0
The issue is also reproduced with the full PyTorch library instead of the lite version.
Can you please instruct me on how to solve this issue?
| 1 |
4,997 | 83,245 |
During DDP training timm densenet121, mobilenetv2(v3) models do not save state_dict correctly.
|
oncall: distributed, triaged, module: ddp
|
### 🐛 Describe the bug
During DDP training timm densenet121, mobilenetv2(v3) models do not save state_dict correctly.
After load the stat dicts, the model do not act well. However, when using torch.save save the model, it works well.
### Versions
both 1.11, 1.12 and 1.12.1
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang
| 3 |
4,998 | 83,244 |
torch.nn.Upsample's error message is inconsistent with the documentation
|
module: docs, module: nn, triaged, actionable
|
### 🐛 Describe the bug
Problem 1:
Parameter 'scale_factor' shoule be float or tuple[float] on documentation. However, when I set list to 'scale_factor', the error message shows that 'scale_factor' must be a string or a number which cannot match the documentation.
```
import torch
results={}
arg_1 = [1]
arg_2 = "nearest"
arg_class = torch.nn.Upsample(scale_factor=arg_1,mode=arg_2,)
arg_3 = torch.rand([1, 1, 2, 2], dtype=torch.float32)
results['res'] = arg_class(*arg_3)
#TypeError: float() argument must be a string or a number, not 'list'
```
Problem 2:
It's written on documentation that if 'scale_factor' is tuple, it has to match input size. That is to say, if input is a 2D tensor, then 'scale_factor' should be a float number or a tuple of length 2. I find that if input is a 2D tensor, 'scale_factor' can be a tuple of length 1. It's inconsistent with the documentation.
```
import torch
results={}
arg_1 = (33)
arg_2 = "nearest"
arg_class = torch.nn.Upsample(scale_factor=arg_1,mode=arg_2,)
arg_3 = torch.rand([1, 1, 2, 2], dtype=torch.float32)
results['res'] = arg_class(*arg_3)
```
### Versions
pytorch: 1.8.1
python: 3.8.3
os: win11
cc @svekars @holly1238 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 4 |
4,999 | 83,243 |
RPC: wait method of Future object return 0 sometimes in rpc framework
|
high priority, oncall: distributed, triaged, module: rpc
|
### 🐛 Describe the bug
I attempt to compare the performance between `rpc_sync()` and `rpc_async()` of PyRRef object. The call of `PyRRef.rpc_async()` will return a RRefProxy object and the call of `RRefProxy.forward(x)` will return a torch.Future object. I can call wait method of Future to get the real data. But I found the return value of wait method can sometimes be zero, which is quite confusing.
The config is:
- world_size=4
- PyTorch: 1.12.0+cu113
- Python: 3.8.10
- backend: 'nccl'
- host: 'localhost'
Codes are below:
```python
def run_worker(rank, host, port, backend):
init_rpc(rank, host, port)
device = 'cuda'
if rank == 0:
x = torch.randn([1000, 1000], device=device)
# init rref of model of each tsage
rref_rank0_model: PyRRef = rpc.remote("work0", TestModel, args=(0, 'cpu' if device == 'cpu' else 'cuda:0'))
rref_rank1_model: PyRRef = rpc.remote("work1", TestModel, args=(1, 'cpu' if device == 'cpu' else 'cuda:1'))
rref_rank2_model: PyRRef = rpc.remote("work2", TestModel, args=(2, 'cpu' if device == 'cpu' else 'cuda:2'))
rref_rank3_model: PyRRef = rpc.remote("work3", TestModel, args=(3, 'cpu' if device == 'cpu' else 'cuda:3'))
# init blocking proxy of each rref
sync_proxy_model_0: RRefProxy = rref_rank0_model.rpc_sync()
sync_proxy_model_1: RRefProxy = rref_rank1_model.rpc_sync()
sync_proxy_model_2: RRefProxy = rref_rank2_model.rpc_sync()
sync_proxy_model_3: RRefProxy = rref_rank3_model.rpc_sync()
# init non blocking proxy of
async_proxy_model_0: RRefProxy = rref_rank0_model.rpc_async()
async_proxy_model_1: RRefProxy = rref_rank1_model.rpc_async()
async_proxy_model_2: RRefProxy = rref_rank2_model.rpc_async()
async_proxy_model_3: RRefProxy = rref_rank3_model.rpc_async()
# run async call 10 times
for _ in range(10):
out_0 = async_proxy_model_0.forward(x).wait()
out_1 = async_proxy_model_1.forward(out_0).wait()
out_2 = async_proxy_model_2.forward(out_1).wait()
out_3 = async_proxy_model_3.forward(out_2).wait()
print(f"async check sum {out_3.sum()}")
# run sync call 10 times
for _ in range(10):
out_0: torch.Tensor = sync_proxy_model_0.forward(x)
out_1: torch.Tensor = sync_proxy_model_1.forward(out_0)
out_2: torch.Tensor = sync_proxy_model_2.forward(out_1)
out_3: torch.Tensor = sync_proxy_model_3.forward(out_2)
print(f"sync check sum {out_3.sum()}")
# barrier for rpc
rpc.shutdown()
```
And the outputs are:
```
async check sum 223.30909729003906
async check sum 244.09559631347656
async check sum 244.09559631347656
async check sum 223.30909729003906
async check sum 0.0
async check sum 223.30909729003906
async check sum 251.9927978515625
async check sum 251.9927978515625
async check sum 223.30909729003906
async check sum 251.9927978515625
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
sync check sum 223.30909729003906
```
The outputs of **check sum** are expected to be all the same, but outputs of rpc_async are different.
The complete code is as follows:
```python
import os
import torch
from torch.distributed import rpc
import torch.multiprocessing as mp
import torch.nn as nn
from torch._C._distributed_rpc import PyRRef
from torch.distributed.rpc.rref_proxy import RRefProxy
world_size = 4
torch.manual_seed(123)
class TestModel(nn.Module):
def __init__(self, rank, device) -> None:
super().__init__()
self._rank = rank
if rank == 0:
# self.linear_0 = nn.Linear(1000, 128).to(device)
self.linear_0 = nn.Sequential(
nn.Linear(1000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 128)
).to(device)
elif rank == 1:
# self.linear_1 = nn.Linear(128, 256).to(device)
self.linear_1 = nn.Sequential(
nn.Linear(128, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 256),
nn.Linear(256, 256)
).to(device)
elif rank == 2:
# self.linear_2 = nn.Linear(256, 16).to(device)
self.linear_2 = nn.Sequential(
nn.Linear(256, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 16)
).to(device)
elif rank == 3:
# self.linear_3 = nn.Linear(16, 1000).to(device)
self.linear_3 = nn.Sequential(
nn.Linear(16, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 2000),
nn.Linear(2000, 1)
).to(device)
def forward(self, x: torch.Tensor) -> torch.Tensor:
linear: nn.Linear = getattr(self, f'linear_{self._rank}')
out = linear(x)
# print(f"[linear_{self._rank}]input sum {x.sum()}, weight sum {linear.weight.sum()}, bias sum {linear.bias.sum()}, output sum {out.sum()}")
return out
def linear_weight(self):
linear: nn.Linear = getattr(self, f'linear_{self._rank}')
return linear.weight, linear.bias
def init_rpc(rank, host, port):
os.environ['MASTER_ADDR'] = str(host)
os.environ['MASTER_PORT'] = str(port)
worker_name = f"work{rank}"
# set options and set device map
options = rpc.TensorPipeRpcBackendOptions(num_worker_threads=128)
if rank == 0:
# map rank_0 cuda:0 to other ranks
for i in range(world_size):
options.set_device_map(f"work{i}", {0 : i})
rpc.init_rpc(worker_name, rank=rank, world_size=world_size, rpc_backend_options=options)
def run_worker(rank, host, port, backend):
init_rpc(rank, host, port)
device = 'cuda'
if rank == 0:
x = torch.randn([1000, 1000], device=device)
# init rref of model of each tsage
rref_rank0_model: PyRRef = rpc.remote("work0", TestModel, args=(0, 'cpu' if device == 'cpu' else 'cuda:0'))
rref_rank1_model: PyRRef = rpc.remote("work1", TestModel, args=(1, 'cpu' if device == 'cpu' else 'cuda:1'))
rref_rank2_model: PyRRef = rpc.remote("work2", TestModel, args=(2, 'cpu' if device == 'cpu' else 'cuda:2'))
rref_rank3_model: PyRRef = rpc.remote("work3", TestModel, args=(3, 'cpu' if device == 'cpu' else 'cuda:3'))
# init blocking proxy of each rref
sync_proxy_model_0: RRefProxy = rref_rank0_model.rpc_sync()
sync_proxy_model_1: RRefProxy = rref_rank1_model.rpc_sync()
sync_proxy_model_2: RRefProxy = rref_rank2_model.rpc_sync()
sync_proxy_model_3: RRefProxy = rref_rank3_model.rpc_sync()
# init non blocking proxy of
async_proxy_model_0: RRefProxy = rref_rank0_model.rpc_async()
async_proxy_model_1: RRefProxy = rref_rank1_model.rpc_async()
async_proxy_model_2: RRefProxy = rref_rank2_model.rpc_async()
async_proxy_model_3: RRefProxy = rref_rank3_model.rpc_async()
# run async call 10 times
for _ in range(10):
out_0 = async_proxy_model_0.forward(x).wait()
out_1 = async_proxy_model_1.forward(out_0).wait()
out_2 = async_proxy_model_2.forward(out_1).wait()
out_3 = async_proxy_model_3.forward(out_2).wait()
print(f"async check sum {out_3.sum()}")
# run sync call 10 times
for _ in range(10):
out_0: torch.Tensor = sync_proxy_model_0.forward(x)
out_1: torch.Tensor = sync_proxy_model_1.forward(out_0)
out_2: torch.Tensor = sync_proxy_model_2.forward(out_1)
out_3: torch.Tensor = sync_proxy_model_3.forward(out_2)
print(f"sync check sum {out_3.sum()}")
# barrier for rpc
rpc.shutdown()
if __name__ == "__main__":
host = 'localhost'
port = '9001'
backend = 'nccl'
mp.spawn(run_worker, nprocs=world_size, args=(host, port, backend))
```
If `TestModel` is replaced with a smaller one, outputs are fine:
```python
class TestModel(nn.Module):
def __init__(self, rank, device) -> None:
super().__init__()
self._rank = rank
if rank == 0:
self.linear_0 = nn.Linear(1000, 128).to(device)
elif rank == 1:
self.linear_1 = nn.Linear(128, 256).to(device)
elif rank == 2:
self.linear_2 = nn.Linear(256, 16).to(device)
elif rank == 3:
self.linear_3 = nn.Linear(16, 1).to(device)
```
outputs:
```
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
async check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
sync check sum -195.64047241210938
```
So, it seems that the bug may occur when the module is relevantly large.
---
### Versions
PyTorch version: 1.12.0+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-43-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.3.109
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
GPU 2: NVIDIA A100 80GB PCIe
GPU 3: NVIDIA A100 80GB PCIe
GPU 4: NVIDIA A100 80GB PCIe
GPU 5: NVIDIA A100 80GB PCIe
GPU 6: NVIDIA A100 80GB PCIe
GPU 7: NVIDIA A100 80GB PCIe
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] colossalai==0.1.8+torch1.12cu11.3
[pip3] numpy==1.23.1
[pip3] torch==1.12.0+cu113
[pip3] torchaudio==0.12.0+cu113
[pip3] torchvision==0.13.0
[conda] Could not collect
cc @ezyang @gchanan @zou3519 @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @jjlilley @mrzzd
| 3 |
5,000 | 83,241 |
torch.nn.TripletMarginLoss margin can be less than 0
|
module: nn, triaged
|
### 🐛 Describe the bug
Parameter _margin_ of torch.nn.TripletMarginLoss is a value greater than 0 on documentation. However, when its value is less than 0, this API also works.
```
import torch
results={}
arg_1 = -7.0
arg_2 = 2
arg_class = torch.nn.TripletMarginLoss(margin=arg_1,p=arg_2)
arg_3_0 = torch.rand([100, 128], dtype=torch.float32)
arg_3_1 = torch.rand([100, 128], dtype=torch.float32)
arg_3_2 = torch.rand([100, 128], dtype=torch.float32)
arg_3 = [arg_3_0,arg_3_1,arg_3_2]
results['res'] = arg_class(*arg_3)
```
### Versions
pytorch: 1.8.1
python: 3.8.3
os: win11
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.