
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
5,101 | 82,517 |
Symbolic tensors are not printable
|
module: printing, triaged, module: dynamic shapes
|
### 🐛 Describe the bug
```
File "/data/users/ezyang/pytorch-tmp/test/test_dynamic_shapes.py", line 258, in test_aten_ops
print(x)
File "/data/users/ezyang/pytorch-tmp/torch/_tensor.py", line 423, in __repr__
return torch._tensor_str._str(self, tensor_contents=tensor_contents)
File "/data/users/ezyang/pytorch-tmp/torch/_tensor_str.py", line 591, in _str
return _str_intern(self, tensor_contents=tensor_contents)
File "/data/users/ezyang/pytorch-tmp/torch/_tensor_str.py", line 535, in _str_intern
if self.numel() == 0 and not self.is_sparse:
RuntimeError: Tensors of type TensorImpl do not have numel
```
Maybe this will get fixed when we get sym numel landed
### Versions
master
| 1 |
5,102 | 82,510 |
Complex addition result in NaN when it shouldn't
|
triaged, module: complex, module: NaNs and Infs
|
### 🐛 Describe the bug
When adding two complex numbers where both real components (or both imaginary components) are infinities with equal sign, the imaginary (or real) component of the result will become NaN. There should be no interaction between the different components when adding two complex numbers, and in this case adding two infinities with equal sign shouldn't result in a NaN value regardless.
As a simple workaround, one can perform addition using torch.view_as_real and then use torch.view_as_complex on the result.
Simple test to reproduce (or [see in this Colab notebook](https://colab.research.google.com/drive/1KhWPscjEtM_SZebapVVDi55H5LkGI_zS?usp=sharing)):
```python3
import torch
x_native = float('inf') + 1j * 0
x_pytorch = torch.tensor(x_native)
x_as_real = torch.view_as_real(x_pytorch)
print('dtype:', x_pytorch.dtype)
assert (x_native + x_native) == x_native, f'{x_native + x_native} != {x_native}'
assert ((x_as_real + x_as_real) == x_as_real).all().item(), f'{x_as_real + x_as_real} != {x_as_real}'
assert ((x_pytorch + x_pytorch) == x_pytorch).all().item(), f'{x_pytorch + x_pytorch} != {x_pytorch}'
```
Result of running the above:
```
dtype: torch.complex64
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
[<ipython-input-11-53bec36d73d6>](https://wgwat1jum1d-496ff2e9c6d22116-0-colab.googleusercontent.com/outputframe.html?vrz=colab-20220728-060048-RC00_463807217#) in <module>()
7 assert (x_native + x_native) == x_native, f'{x_native + x_native} != {x_native}'
8 assert ((x_as_real + x_as_real) == x_as_real).all().item(), f'{x_as_real + x_as_real} != {x_as_real}'
----> 9 assert ((x_pytorch + x_pytorch) == x_pytorch).all().item(), f'{x_pytorch + x_pytorch} != {x_pytorch}'
AssertionError: (inf+nanj) != (inf+0j)
```
### Versions
Collecting environment information...
PyTorch version: 1.12.0+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.5
Libc version: glibc-2.26
Python version: 3.7.13 (default, Apr 24 2022, 01:04:09) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: False
CUDA runtime version: 11.1.105
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.12.0+cu113
[pip3] torchaudio==0.12.0+cu113
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0+cu113
[conda] Could not collect
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved
| 3 |
5,103 | 82,494 |
Implement torch.clamp() on sparse tensors with SparseCPU backend
|
module: sparse, triaged
|
### 🚀 The feature, motivation and pitch
torch.clamp() fails on sparse tensors using SparseCPU backend. Among other things, this breaks gradient clipping with sparse tensors.
```
import torch
sparse_tensor = torch.sparse_coo_tensor([[1,2]], [1,5], (3,))
torch.clamp(sparse_tensor, -1, 1)
```
Fails with error: `Could not run 'aten::clamp' with arguments from the 'SparseCPU' backend.`
### Alternatives
It's not exactly difficult to manually clamp sparse tensors, but we shouldn't have to when a function exists.
### Additional context
_No response_
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 4 |
5,104 | 82,479 |
Cloning conjugate tensor in torch_dispatch context produces non equality.
|
triaged, module: complex, module: __torch_dispatch__
|
### 🐛 Describe the bug
```python
class TestMode(TorchDispatchMode):
def __torch_dispatch__(self, func, types, args=(), kwargs=None):
args2 = clone_inputs(args)
out = func(*args, **kwargs)
for i in range(len(args2)):
print(f'before {args2[i]}, after {args[i]}, {torch.equal(args2[i], args[i])}')
return out
a = torch.rand((3,3), dtype=torch.complex64)
b = torch.rand((3,3), dtype=torch.complex64)
b = torch.conj(b)
with enable_torch_dispatch_mode(TestMode()):
torch.mm(a, b)
```
This prints:
```python
before tensor([[0.0290+0.4019j, 0.2598+0.3666j, 0.0583+0.7006j],
[0.0518+0.4681j, 0.6738+0.3315j, 0.7837+0.5631j],
[0.7749+0.8208j, 0.2793+0.6817j, 0.2837+0.6567j]]), after tensor([[0.0290+0.4019j, 0.2598+0.3666j, 0.0583+0.7006j],
[0.0518+0.4681j, 0.6738+0.3315j, 0.7837+0.5631j],
[0.7749+0.8208j, 0.2793+0.6817j, 0.2837+0.6567j]]), True
before tensor([[0.2388-0.7313j, 0.6012-0.3043j, 0.2548-0.6294j],
[0.9665-0.7399j, 0.4517-0.4757j, 0.7842-0.1525j],
[0.6662-0.3343j, 0.7893-0.3216j, 0.5247-0.6688j]]), after tensor([[0.2388-0.7313j, 0.6012-0.3043j, 0.2548-0.6294j],
[0.9665-0.7399j, 0.4517-0.4757j, 0.7842-0.1525j],
[0.6662-0.3343j, 0.7893-0.3216j, 0.5247-0.6688j]]), False
```
Which indicates that `mm` mutates its second input which is not the case.
### Versions
N/A
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @Chillee @zou3519 @albanD @samdow
| 2 |
5,105 | 93,793 |
Guide for diagnosing excess graph breaks
|
module: docs, triaged, oncall: pt2, module: dynamo
|
Something a user using torchdynamo might want to do is figure out why they are having lots of graph breaks. We have tools for doing this, but they are not documented. Prior to the PT2 release it would be good to document them. cc @svekars @carljparker @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 3 |
5,106 | 82,465 |
Does torch.utils.checkpoint compatible with torch.cuda.make_graphed_callables?
|
module: checkpoint, triaged, module: cuda graphs
|
### 🐛 Describe the bug
When attempting to use
```
model = torch.cuda.make_graphed_callables(model, (rand_data,))
```
and our model contains checkpoints or sequential checkpoints like this:
```
input_next = torch.utils.checkpoint.checkpoint_sequential(self.layer, segments, input_prev)
```
then we got this error:
```
Traceback (most recent call last):
File "multitask.py", line 43, in <module>
main()
File "multitask.py", line 36, in main
S.initialize(args)
File "/mnt/lustre/chendingyu1/multitask-unify-democode/core/solvers/solver_fp16.py", line 63, in initialize
super().initialize(args)
File "/mnt/lustre/chendingyu1/multitask-unify-democode/core/solvers/solver.py", line 317, in initialize
self.create_model()
File "/mnt/lustre/chendingyu1/multitask-unify-democode/core/solvers/solver_fp16.py", line 109, in create_model
model = torch.cuda.make_graphed_callables(model, (rand_data,))
File "/mnt/cache/share/spring/conda_envs/miniconda3/envs/s0.3.5/lib/python3.7/site-packages/torch/cuda/graphs.py", line 264, in make_graphed_callables
allow_unused=False)
File "/mnt/cache/share/spring/conda_envs/miniconda3/envs/s0.3.5/lib/python3.7/site-packages/torch/autograd/__init__.py", line 277, in grad
allow_unused, accumulate_grad=False) # Calls into the C++ engine to run the backward pass
File "/mnt/cache/share/spring/conda_envs/miniconda3/envs/s0.3.5/lib/python3.7/site-packages/torch/autograd/function.py", line 253, in apply
return user_fn(self, *args)
File "/mnt/cache/share/spring/conda_envs/miniconda3/envs/s0.3.5/lib/python3.7/site-packages/torch/utils/checkpoint.py", line 103, in backward
"Checkpointing is not compatible with .grad() or when an `inputs` parameter"
RuntimeError: Checkpointing is not compatible with .grad() or when an `inputs` parameter is passed to .backward(). Please use .backward() and do not pass its `inputs` argument.
```
If we don't use checkpoints in our model like
```
input_next = self.layer(input_prev)
```
then we didn't get any errors.
Does checkpoint compatible with torch.cuda.make_graphed_callables?
### Versions
PyTorch version: 1.11.0+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 2.8.12.2
Libc version: glibc-2.17
Python version: 3.7.11 (default, Jul 27 2021, 14:32:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-centos-7.6.1810-Core
Is CUDA available: True
CUDA runtime version: 9.0.176
Nvidia driver version: 460.32.03
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] spring==0.7.2+cu112.torch1110.mvapich2.nartgpu.develop.805601a8
[pip3] torch==1.11.0+cu113
[pip3] torchvision==0.12.0+cu113
[conda] numpy 1.21.5 pypi_0 pypi
[conda] spring 0.7.0+cu112.torch1110.mvapich2.pmi2.nartgpu pypi_0 pypi
[conda] torch 1.11.0+cu113 pypi_0 pypi
[conda] torchvision 0.12.0+cu113 pypi_0 pypi
cc @mcarilli @ezyang
| 7 |
5,107 | 82,464 |
SyncBatchNorm does not work on CPU
|
oncall: distributed, module: nn
|
Using Pytorch 1.12 on Debian Linux (conda env).
SyncBatchNorm does not seem to work with jit.trace. On a mobilenet V3 model, I first do:
```
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
```
After training, normally, with my models I do this:
```
traced_script_module = torch.jit.trace(swa_model, (data))
traced_script_module.save("./swa_model.tar")
```
both model and data are on cpu - the plan is to use the model for inference on cpu only.
However, it throws me this:
```
raise ValueError("SyncBatchNorm expected input tensor to be on GPU")
ValueError: SyncBatchNorm expected input tensor to be on GPU
```
Is there a workaround for this? or is this some weird edge case which is not supported?
Ofcourse, without SyncBatchNorm, everything is fine - ie the trace is produced and gives me the same result as the original model.
Thank you.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 5 |
5,108 | 82,451 |
add support for bitwise operations with floating point numbers
|
oncall: jit
|
### 🚀 The feature, motivation and pitch
I was rewriting hash nerf so I could export a jitted version for training in c++, when I came across this limitation. Doing bitwise operation with floats is easy in eager mode with torch.tensor.view(torch.int32). However currently TorchScript does not support reinterpret_casting tensors, and jitting is a must.
### Alternatives
Support for reinterpret_casting with tensors in TorchScript would be a better solution but I assume that would take a long time to optimize well.
### Additional context
_No response_
| 0 |
5,109 | 82,443 |
Quantization issue in transformers
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
This issue happened when quantizing a simple transformer model
Example
```
class M(torch.nn.Module):
def __init__(self):
super(DynamicQuantModule.M, self).__init__()
self.transformer = nn.Transformer(d_model=2, nhead=2, num_encoder_layers=1, num_decoder_layers=1)
def forward(self):
return self.transformer(torch.randn(1, 16, 2))
torch.quantization.quantize_dynamic(M(), dtype=torch.qint8)
```
The error is
```
File "/Users/linbin/opt/anaconda3/lib/python3.8/site-packages/torch/jit/_recursive.py", line 516, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "/Users/linbin/opt/anaconda3/lib/python3.8/site-packages/torch/jit/_recursive.py", line 542, in create_script_module_impl
create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs)
File "/Users/linbin/opt/anaconda3/lib/python3.8/site-packages/torch/jit/_recursive.py", line 393, in create_methods_and_properties_from_stubs
concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
RuntimeError:
method cannot be used as a value:
File "/Users/linbin/opt/anaconda3/lib/python3.8/site-packages/torch/nn/modules/transformer.py", line 468
self.norm2.weight,
self.norm2.bias,
self.linear1.weight,
~~~~~~~~~~~~~~~~~~~ <--- HERE
self.linear1.bias,
self.linear2.weight,
```
### Versions
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.18.6)
CMake version: version 3.21.3
Libc version: N/A
Python version: 3.7.5 (default, Oct 22 2019, 10:35:10) [Clang 10.0.1 (clang-1001.0.46.4)] (64-bit runtime)
Python platform: Darwin-21.5.0-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] No relevant packages
[conda] blas 1.0 mkl
[conda] mkl 2021.2.0 hecd8cb5_269
[conda] mkl-include 2022.0.0 hecd8cb5_105
[conda] mkl-service 2.4.0 py38h9ed2024_0
[conda] mkl_fft 1.3.0 py38h4a7008c_2
[conda] mkl_random 1.2.2 py38hb2f4e1b_0
[conda] numpy 1.20.0 pypi_0 pypi
[conda] numpy-base 1.20.2 py38he0bd621_0
[conda] numpydoc 1.4.0 py38hecd8cb5_0
[conda] pytorch 1.13.0.dev20220728 py3.8_0 pytorch-nightly
[conda] torch 1.11.0 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20220728 py38_cpu pytorch-nightly
[conda] torchvision 0.13.0 pypi_0 pypi
Another way to trigger it is just run:
```
python3 test/mobile/model_test/gen_test_model.py dynamic_quant_ops
```
in the latest nightly build.
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo
| 18 |
5,110 | 82,430 |
Minor inconsistency in description of `attn_output_weights` in MultiheadAttention docs
|
module: docs, module: nn, triaged, actionable
|
### 📚 The doc issue
On the documentation of [MultiheadAttention](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html?highlight=multihead#torch.nn.MultiheadAttention) of version 1.12 on the description of `attn_output_weights` argument, in the last sentence, it is mentioned that:
> If **average_weights=False**, returns attention weights per head of shape [...].
I think that the correct argument on the forward method is `average_attn_weights` and not `average_weights`.
### Suggest a potential alternative/fix
Can be fixed by replacing `average_weights=False` to `average_attn_weights`.
cc @svekars @holly1238 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
5,111 | 82,419 |
The torch::deploy document is not updated
|
triaged, module: deploy
|
### 📚 The doc issue
Hi,
I was trying the tutorial example in torch::deploy document, more specifically (deploy with C++)[https://pytorch.org/docs/stable/deploy.html#building-and-running-the-application]. However, the example doesn't work. Here are the details.
It looks like it is because of compilation problem in pytorch. After seemingly sucuessful compilation, the `libtorch_deployinterpreter.o` file (or similar files) cannot be found in the directory. This blocks the next steps of the example. Another related (compiling issue)[https://github.com/pytorch/pytorch/issues/82382] shows that the compilation is even not successful in Linux (due to missing file).
Could you update this part of document or point to me other working demo examples?
---
Here is the environment of my system
```
Collecting environment information...
PyTorch version: 1.13.0a0+git1a9317c
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (x86_64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: version 3.19.6
Libc version: N/A
Python version: 3.9.12 (main, Apr 5 2022, 01:53:17) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.2
[pip3] torch==1.13.0a0+git1a9317c
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 h0a44026_0 pytorch
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-include 2022.0.0 hecd8cb5_105
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.21.5 py39h2e5f0a9_1
[conda] numpy-base 1.21.5 py39h3b1a694_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] pytorch 1.12.0 py3.9_0 pytorch
[conda] torch 1.13.0a0+git1a9317c pypi_0 pypi
[conda] torchaudio 0.12.0 py39_cpu pytorch
[conda] torchvision 0.13.0 py39_cpu pytorch
```
### Suggest a potential alternative/fix
_No response_
cc @wconstab
| 0 |
5,112 | 82,417 |
[JIT] _unsafe_view returns alias when size(input) = size argument
|
oncall: jit
|
### 🐛 Describe the bug
aten::_unsafe_view seems to return an alias of input as output when the size argument is equal to the size of the initial input. This isn't currently marked on native_functions.yaml, but seems to be intended due to:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorShape.cpp#L2728
Keeping this here just to track this possible issue.
### Versions
N/A
| 0 |
5,113 | 82,397 |
Bilinear interpolation with antialiasing is slow in performance
|
module: performance, triaged
|
### 🐛 Describe the bug
Bilinear interpolation with antialiasing is significantly slower than without.
Is this intended behavior or am I missing something?
Code to reproduce
```python
import torch
import torch.nn.functional as F
from tqdm import tqdm
x = torch.randn((7, 3, 256, 256), device='cuda')
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
for i in enumerate(tqdm(range(10000))):
F.interpolate(x, (64, 64), mode='bilinear')
end.record()
torch.cuda.synchronize()
print(start.elapsed_time(end))
# 310.09381103515625
start.record()
for i in enumerate(tqdm(range(10000))):
F.interpolate(x, (64, 64), mode='bilinear', antialias=True)
end.record()
torch.cuda.synchronize()
print(start.elapsed_time(end))
# 1558.083984375
```
### Versions
```
Collecting environment information...
PyTorch version: 1.12.0+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.5
Libc version: glibc-2.26
Python version: 3.7.13 (default, Apr 24 2022, 01:04:09) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: 11.1.105
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.12.0+cu113
[pip3] torchaudio==0.12.0+cu113
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.13.0
[pip3] torchvision==0.13.0+cu113
[conda] Could not collect
```
cc @VitalyFedyunin @ngimel
| 4 |
5,114 | 82,382 |
Problems in built-from-source pytorch with USE_DEPLOY=1 in Ubuntu
|
triaged, module: deploy
|
### 📚 The doc issue
Hi,
I'm trying the tutorial example of deploy and aim to package a model and do inference in C++. But I ran into a problems when working with build-from-source pytorch. There are following issue:
1. Build-from-source on Ubuntu failed becasue of a missing file
The error message is the following. Note that I have used CPU built by setting the environment variable as `export USE_CUDA=0`.
```
Building wheel torch-1.13.0a0+gitce92c1c
-- Building version 1.13.0a0+gitce92c1c
cmake --build . --target install --config Release
[1/214] Performing archive_stdlib step for 'cpython'
FAILED: torch/csrc/deploy/interpreter/cpython/src/cpython-stamp/cpython-archive_stdlib ../torch/csrc/deploy/interpreter/cpython/lib/libpython_stdlib3.8.a
cd /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter && ar -rc /home/ubuntu/pytorch/torch/csrc/deploy/interpreter/cpython/lib/libpython_stdlib3.8.a /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/arraymodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_asynciomodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/audioop.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/binascii.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_bisectmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_blake2/blake2module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_blake2/blake2b_impl.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_blake2/blake2s_impl.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_bz2module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cmathmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_cn.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_hk.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_iso2022.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_jp.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_kr.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/_codecs_tw.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_contextvarsmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_cryptmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_csv.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/_ctypes.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/callbacks.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/callproc.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/stgdict.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/cfield.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/_ctypes_test.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_cursesmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_curses_panel.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_datetimemodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/_decimal.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/basearith.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/constants.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/context.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/convolute.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/crt.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/difradix2.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/fnt.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/fourstep.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/io.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/memory.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/mpdecimal.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/numbertheory.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/sixstep.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_decimal/libmpdec/transpose.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_elementtree.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/fcntlmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/grpmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_hashopenssl.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_heapqmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_json.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_lsprof.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_lzmamodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/mathmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/md5module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/mmapmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/cjkcodecs/multibytecodec.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_multiprocessing/multiprocessing.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_multiprocessing/semaphore.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/nismodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_opcode.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/ossaudiodev.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/parsermodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_pickle.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_posixsubprocess.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/pyexpat.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/expat/xmlparse.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/expat/xmlrole.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/expat/xmltok.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_queuemodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_randommodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/readline.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/resource.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/selectmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/sha1module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/sha256module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_sha3/sha3module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/sha512module.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/socketmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/spwdmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ssl.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_struct.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/syslogmodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/termios.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_testbuffer.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_testcapimodule.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_testimportmultiple.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_testmultiphase.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/unicodedata.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/xxlimited.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_xxtestfuzz/_xxtestfuzz.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_xxtestfuzz/fuzzer.o /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/zlibmodule.o && /home/ubuntu/anaconda3/bin/cmake -E touch /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython-stamp/cpython-archive_stdlib
ar: /home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/build/temp.linux-x86_64-3.8//home/ubuntu/pytorch/build/torch/csrc/deploy/interpreter/cpython/src/cpython/Modules/_ctypes/_ctypes.o: No such file or directory
[3/214] Linking CXX shared library lib/libtorch_cpu.so
ninja: build stopped: subcommand failed.
```
I have also set `export USE_DEPLOY=1` following (`deploy` tutorial)[https://pytorch.org/docs/stable/deploy.html#loading-and-running-the-model-in-c].
Any help will be appreciated!
---
Here is the system info:
```
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.20.2
Libc version: glibc-2.27
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1068-aws-x86_64-with-glibc2.27
Is CUDA available: N/A
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.2
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] cudatoolkit 11.2.2 he111cf0_8 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] magma-cuda112 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] pytorch 1.12.0 py3.9_cpu_0 pytorch
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 0.12.0 py39_cpu pytorch
[conda] torchvision 0.13.0 py39_cpu pytorch
```
### Suggest a potential alternative/fix
_No response_
cc @wconstab
| 0 |
5,115 | 82,377 |
masked_scatter_ is very lacking
|
module: docs, triaged, module: scatter & gather ops
|
### 📚 The doc issue
The documentation for `masked_scatter_` says
```
Tensor.masked_scatter_(mask, source):
Copies elements from source into self tensor at positions where the mask is True.
```
Which suggests it might work similar to
```
tensor[mask] = source[mask]
```
however, the actual semantics are quite different, which leads to confusion as evidenced here: https://stackoverflow.com/questions/68675160/torch-masked-scatter-result-did-not-meet-expectations/73145411#73145411
### Suggest a potential alternative/fix
The docs should specify that the way scatter works is that the `i`th `True` in a row is given the `i`th value from the source. So not the value corresponding to the position of the `True`.
Maybe an example of the difference between the two methods described in the issue.
cc @svekars @holly1238 @mikaylagawarecki
| 1 |
5,116 | 82,357 |
ufmt and flake8 lints race
|
triaged
|
### 🐛 Describe the bug
ufmt changes python source code, but it runs in parallel with flake8. This means that flake8 errors may be out of date by the time ufmt is done processing.
### Versions
master
| 3 |
5,117 | 82,354 |
Offer a way to really force merges via pytorchbot
|
module: ci, triaged
|
### 🚀 The feature, motivation and pitch
I had a fun situation in https://github.com/pytorch/pytorch/pull/82236. Here's the summary:
- I created PR C, and then imported it into fbcode to check test signal.
- Next, I created PRs A, B, D, which were stacked like the following: A <- B <- C <- D
- Then, I merged A and B via GHF
- PR C refused to merge via GHF due to "This PR has internal changes and must be landed via Phabricator".
We tried a couple of things:
1. resync the PR to fbcode. The resync failed because commits A and B had not yet made it into fbcode
2. unlink the PR from the fbcode diff and then attempting land via GHF. The unlink didn't seem to do anything.
What I described above probably isn't a common workflow, but it would be nice to have a "ignore all checks and force merge" button for GHF for the cases where tooling didn't work out
cc @seemethere @malfet @pytorch/pytorch-dev-infra
### Alternatives
Alternatively, using "unlink" on a PR should make it so that this check doesn't appear anymore. This was not the case for https://github.com/pytorch/pytorch/pull/82236 -- after unlink, the PR still could not be merged.
### Additional context
_No response_
| 1 |
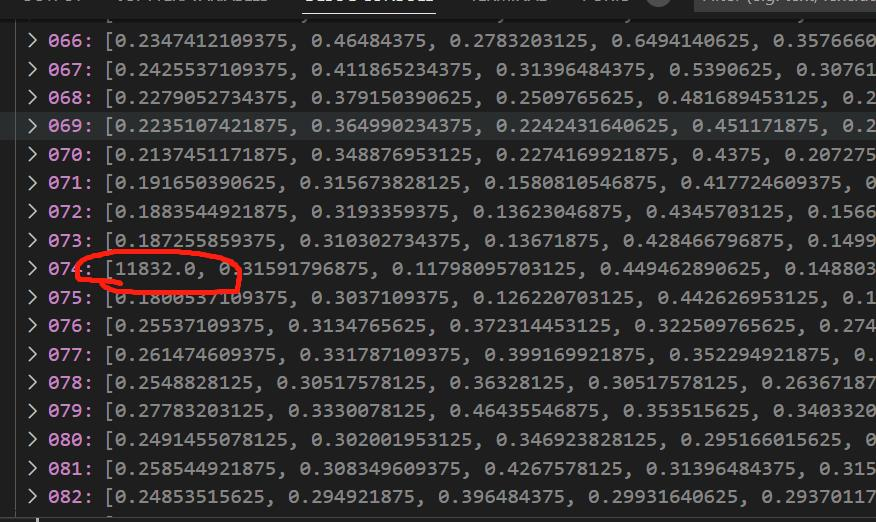
5,118 | 82,324 |
[JIT] SchemaInfo warning appears out in the wild
|
oncall: jit
|
### 🐛 Describe the bug
^ Warning for SchemaInfo having multiple input arguments with the same alias set appears in the wild when there shouldn't be any ops that trigger this warning.
### Versions
n/a
| 0 |
5,119 | 82,318 |
test_make_fx_symbolic_exhaustive should pass dynamic ints for shape arguments
|
triaged, fx, module: dynamic shapes
|
### 🐛 Describe the bug
```
diff --git a/test/test_proxy_tensor.py b/test/test_proxy_tensor.py
index 9e22de81529..f3809fc22d9 100644
--- a/test/test_proxy_tensor.py
+++ b/test/test_proxy_tensor.py
@@ -844,6 +844,9 @@ def _test_make_fx_helper(self, device, dtype, op, tracing_mode):
except DynamicOutputShapeException as e:
self.skipTest("Dynamic output shape operation in trace")
+ print(new_f)
+ print(new_f.shape_env.guards)
+
for arg in args:
if isinstance(arg, torch.Tensor) and arg.dtype == torch.float:
arg.uniform_(0, 1)
```
then
```
python test/test_proxy_tensor.py -k test_make_fx_symbolic_exhaustive_new_zeros_cpu_float32
```
gives, for example,
```
def forward(self, args, kwargs):
args_1, args_2, args_3, args_4, kwargs_1, kwargs_2, = fx_pytree.tree_flatten_spec([args, kwargs], self._in_spec)
size = args_1.size(0)
_tensor_constant0 = self._tensor_constant0
device_1 = torch.ops.prim.device.default(_tensor_constant0); _tensor_constant0 = None
new_zeros_default = torch.ops.aten.new_zeros.default(args_1, [2, 2, 2], dtype = torch.float64, layout = torch.strided, device = device(type='cpu'), pin_memory = False); args_1 = None
return pytree.tree_unflatten([new_zeros_default], self._out_spec)
[]
```
the call to `new_zeros` is clearly specialized but there are no guards.
cc @ezyang @SherlockNoMad @Chillee
### Versions
master
| 2 |
5,120 | 82,316 |
Add more Vulkan operations
|
triaged, module: vulkan, ciflow/periodic
|
### 🚀 The feature, motivation and pitch
I got an error while trying to host my model into mobile using Vulkan
`Could not run aten::max_pool2d_with_indices`
And I found the list of operations of vulkan quite short.
### Alternatives
_No response_
### Additional context
_No response_
cc @jeffdaily @sunway513
| 1 |
5,121 | 82,312 |
A/libc: Fatal signal 6 (SIGABRT), code -1 (SI_QUEUE) in tid 9792 (Background), pid 9674 (ample.testtorch)
|
oncall: mobile
|
### 🐛 Describe the bug
Hello. I'm running into a problem on d2go when I'm trying to retrain a model. The assembly of the pt model is successful, but when I run the model in my Android Studio, I get an error:
```
E/libc++abi: terminating with uncaught exception of type c10::Error: isTuple()INTERNAL ASSERT FAILED at "../../../../src/main/cpp/libtorch_include/arm64-v8a/ ATen/core/ivalue_inl.h":1306, please report a bug to PyTorch. Expected Tuple but got String
Exception raised from toTuple at ../../../../src/main/cpp/libtorch_include/arm64-v8a/ATen/core/ivalue_inl.h:1306 (most recent call first):
(no backtrace available)
A/libc: Fatal signal 6 (SIGABRT), code -1 (SI_QUEUE) in tid 9792 (Background), pid 9674 (ample.testtorch)
```
A similar [question]( https://github.com/pytorch/pytorch/issues/79875) was asked here, but the solution was not found, and the campaign about this question was already forgotten, so I decided to remind about it again😄. I am willing to share any information to resolve this issue. I tried running a model that was trained on balloon_dataset but got a similar error.
I already got acquainted with the source code of `ivalue_inl.h`, and have not yet understood what line 1306 has to do with it, but I found the assert code on line [1924](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/core/ivalue_inl.h#L1924) and [1928](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/core/ivalue_inl.h#L1928).
I assume that this is either related to the cfg configuration file when we generate it and a string was passed to some field instead of a tuple, or it is related somehow to the wrapper itself. If I understood everything correctly, then the trained model in the notebook works well, but when the wrapper itself is created, then an error occurs in java on Android. That is the model:
module = PyTorchAndroid.loadModuleFromAsset(getAssets(), "d2go_test.pt");
is not available, i.e. an error occurs here.
Maybe it's because I didn't call patch_d2_meta_arch()? It's just that the pytorch night version for some reason does not contain this import function, or I didn't search well. I also tried different versions of cuda nightly build of pytorch - without success.
Collected and trained the project in Google Collab. I used pip instead of conda. This is how I set up the dependencies:
```
!pip install 'git+https://github.com/facebookresearch/detectron2.git'
!pip install 'git+https://github.com/facebookresearch/d2go'
!pip install 'git+https://github.com/facebookresearch/mobile-vision.git'
!pip uninstall torch -y
!pip uninstall torchvision -y
!pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu102 # Tried cu102 and cu116
```
Try installing the packages as well to reproduce the error. I also tried to create my own dataset with 1 class - car, and created the annotation file via_region_data.json through this [site](https://www.robots.ox.ac.uk/~vgg/software/via/via-1.0.6.html)
I took the code directly from d2go_beginner.ipynb. If you need a code - just try to train a model in d2go_beginner.ipynb ONLY for 1 class - balloon with `faster_rcnn_fbnetv3a_dsmask_C4.yaml` or `faster_rcnn_fbnetv3a_C4.yaml` from the example and tell me if this model works for you on android. Be careful, because in the instructions here it says:
```
def prepare_for_launch():
runner = GeneralizedRCNNRunner()
cfg = runner.get_default_cfg()
cfg.merge_from_file(model_zoo.get_config_file("faster_rcnn_fbnetv3a_C4.yaml")) <- written faster_rcnn_fbnetv3a_C4.yaml
...
```
And in the next cell it says:
```
import copy
from detectron2.data import build_detection_test_loader
from d2go.export.exporter import convert_and_export_predictor
from d2go.utils.testing.data_loader_helper import create_detection_data_loader_on_toy_dataset
# from d2go.export.d2_meta_arch import patch_d2_meta_arch # i commented
import logging
# disable all the warnings
previous_level = logging.root.manager.disable
logging.disable(logging.INFO)
patch_d2_meta_arch() # I could not find this import at all in any of the versions of pytorch, could this be the problem? I run model without this import.
cfg_name = 'faster_rcnn_fbnetv3a_dsmask_C4.yaml' # <- written already faster_rcnn_fbnetv3a_dsmask_C4.yaml. Is it so necessary, or did you accidentally mix up the yaml files?
pytorch_model = model_zoo.get(cfg_name, trained=True, device='cpu')
...
```
Code of Wrapper:
```
from typing import List, Dict
import torch
class Wrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
coco_idx_list = [1]
self.coco_idx = torch.tensor(coco_idx_list)
def forward(self, inputs: List[torch.Tensor]):
x = inputs[0].unsqueeze(0) * 255
scale = 320.0 / min(x.shape[-2], x.shape[-1])
x = torch.nn.functional.interpolate(x, scale_factor=scale, mode='bilinear', align_corners=True, recompute_scale_factor=True)
out = self.model(x[0])
res: Dict[str, torch.Tensor] = {}
res["boxes"] = out[0] /scale
res["labels"] = torch.index_select(self.coco_idx, 0, out[1])
res["scores"] = out[2]
return inputs, [res]
orig_model = torch.jit.load(os.path.join(predictor_path, "model.jit"))
wrapped_model = Wrapper(orig_model)
scripted_model = torch.jit.script(wrapped_model)
scripted_model.save("/content/d2go_test.pt")
```
Ask any questions - I will answer what I can.
P.S. Sorry for my English:)
### Versions
Collecting environment information...
PyTorch version: 1.13.0.dev20220726+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.5
Libc version: glibc-2.26
Python version: 3.7.13 (default, Apr 24 2022, 01:04:09) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: 11.1.105
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.5
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.6.0.dev0
[pip3] torch==1.13.0.dev20220726+cu102
[pip3] torchaudio==0.13.0.dev20220726+cu102
[pip3] torchmetrics==0.9.3
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.13.0
[pip3] torchvision==0.14.0.dev20220726+cu102
[conda] Could not collect
| 15 |
5,122 | 82,308 |
torch.einsum gets wrong results randomly when training with multi-gpu
|
oncall: distributed
|
### 🐛 Describe the bug
When training with multi-gpu, I find that the loss will grow rapidly and randomly. So I investigated the cause of the problem through debugging and found that one of the element in the result matrix became very large when torch.einsum was executed. And this problem does not appear when DistributedDataParallel is not used.
I implemented the DistributedDataParallel method of multi-gpu training by following the official tutorial, and everything was fine except for this problem, the loss dropped normally in the first few epochs.
here is the code :
``` python
scores: torch.Tensor = torch.einsum("bdhn,bdhm->bhnm", query, key) / dim**0.5
```
query and key both are correct, and this is a part of the first result:
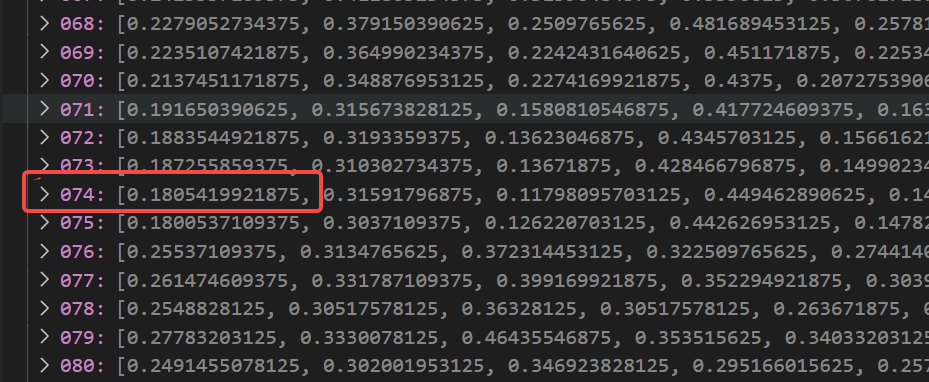
I run the code once more, and this is the second result:
By the way, data type is half. and here is my multi-gpu training script
``` python
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "12355"
os.environ["NCCL_SOCKET_IFNAME"] = "docker0"
os.environ["GLOO_SOCKET_IFNAME"] = "docker0"
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def train(rank, world_size, epoch, lr, graphs_pr: Dict, output: List):
print(f"Training on rank {rank}.")
setup(rank, world_size)
try:
torch.cuda.set_device(rank)
with open(os.path.join(cache_path, "traning.plk"), "rb") as f:
training: Training = dill.load(f)
training.notify_callback = notify
training.model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(training.model)
training.to(rank)
# Train loss
training.model = MatchingDDP(training.model, device_ids=[rank])
log_loss = losses.LandmarkLogLoss(training.model)
log_loss2 = losses.LaneLogLoss()
train_loss = losses.ProductLoss([log_loss, log_loss2])
# Dataset
with open(os.path.join(cache_path, "dataset.plk"), "rb") as f:
dataset: NewGtDataset = dill.load(f)
dataset.load(os.path.join(cache_path, "dataset"))
# Dataloader
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size, sampler=sampler, pin_memory=True)
dataloader.collate_fn = Lambda1(training.model, dataset).f
# Evaluator and update_pr
with open(os.path.join(cache_path, "evaluator.plk"), "rb") as f:
evaluator: evaluation.SubmapEvaluator = dill.load(f)
def update_pr(data):
graphs_pr.update(evaluator.eval_graphs_pr(data, training.model))
training.fit(
train_objective=(dataloader, train_loss),
epochs=epoch,
scheduler_name="ConstantLR",
optimizer_params={"lr": lr},
use_amp=True,
callback=update_pr,
checkpoint_path="saved_models" if rank == 0 else None,
checkpoint_save_steps=40,
checkpoint_save_total_limit=1,
rank=rank,
)
if rank == 0:
training.to("cpu")
output.append(training.model.state_dict())
output.append(training.epoch)
output.append(training.global_step)
except Exception as e:
notify(e)
finally:
dist.destroy_process_group()
```
### Versions
pytorch = 1.12.0
python = 3.9.12
cuda = 10.2
devices: TITAN X (Pascal) * 8
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 1 |
5,123 | 82,306 |
when distribute training load pretrain model error
|
oncall: distributed, module: serialization
|
### 🐛 Describe the bug
```python
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
local_rank = kwargs.get("local_rank", -1)
if pretrained:
pretrained_model = model_zoo.load_url(model_urls['resnet50'])
state = model.state_dict()
for key in state.keys():
if key in pretrained_model.keys():
state[key] = pretrained_model[key]
model.load_state_dict(state)
return model
```
when training with multi Card,and one host, i try to load pretrain model of resnet50 by function (resnet50) as above:
like this:
```python
model = models.resnet50(pretrained=True, num_classes=kernel_num,local_rank=args.local_rank)
```
here is errors:
```
Traceback (most recent call last):
File "./train.py", line 443, in <module>
main(args)
File "./train.py", line 289, in main
model = models.resnet50(pretrained=True, num_classes=kernel_num,local_rank=args.local_rank)
File "/home/siit/ccprjnet/.GitNet/models/fpn_resnet.py", line 291, in resnet50
pretrained_model = model_zoo.load_url(model_urls['resnet50'])
File "/home/siit/.local/lib/python3.6/site-packages/torch/hub.py", line 509, in load_state_dict_from_url
return torch.load(cached_file, map_location=map_location)
File "/home/siit/.local/lib/python3.6/site-packages/torch/serialization.py", line 593, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/home/siit/.local/lib/python3.6/site-packages/torch/serialization.py", line 763, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: unpickling stack underflow
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/siit/.local/lib/python3.6/site-packages/torch/distributed/launch.py", line 263, in <module>
main()
File "/home/siit/.local/lib/python3.6/site-packages/torch/distributed/launch.py", line 259, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/usr/bin/python3.6', '-u', './train.py', '--local_rank=1']' returned non-zero exit status 1.
work = _default_pg.barrier() RuntimeError: Connection reset by peer
```
### Versions
```python
def resnet50(pretrained=False, **kwargs):
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
pretrained_model = model_zoo.load_url(model_urls['resnet50'])
state = model.state_dict()
for key in state.keys():
if key in pretrained_model.keys():
state[key] = pretrained_model[key]
model.load_state_dict(state)
return model
```
when training with multi Card,and one host, i try to load pretrain model of resnet50 by function (resnet50) as above:
like this:
```
model = models.resnet50(pretrained=True,)
```
here is errors:
```
Traceback (most recent call last):
File "./train.py", line 443, in <module>
main(args)
File "./train.py", line 289, in main
model = models.resnet50(pretrained=True, num_classes=kernel_num,local_rank=args.local_rank)
File "/models/fpn_resnet.py", line 291, in resnet50
pretrained_model = model_zoo.load_url(model_urls['resnet50'])
File "local/lib/python3.6/site-packages/torch/hub.py", line 509, in load_state_dict_from_url
return torch.load(cached_file, map_location=map_location)
File ".local/lib/python3.6/site-packages/torch/serialization.py", line 593, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/.local/lib/python3.6/site-packages/torch/serialization.py", line 763, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: unpickling stack underflow
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File ".local/lib/python3.6/site-packages/torch/distributed/launch.py", line 263, in <module>
main()
File "/.local/lib/python3.6/site-packages/torch/distributed/launch.py", line 259, in main
cmd=cmd)
subprocess.CalledProcessError: Command '['/usr/bin/python3.6', '-u', './train.py', '--local_rank=1']' returned non-zero exit status 1.
```
did it can't not load pretrain model when distribute training?
python:3.6
pytorch version:1.5.1
nccl version:nccl-local-repo-ubuntu1804-2.11.4-cuda10.2_1.0-1_amd64
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @mruberry
| 1 |
5,124 | 82,303 |
Race condition between torch.tensor's view and /= (/= returns incorrect result)
|
triaged, module: partial aliasing
|
### 🐛 Describe the bug
I found a race condition on some of my CPU families. Basically the operation v /= v[-1] with v = [a, b, c, d] delivers random results of the type:
v = [a/d, b, c/d, 1]
or
v = [a/d, b/d, c, 1]
My uneducated guess is that at a random moment the operation v[-1]/v[-1] = 1 is executed and then the result is used as new v[-1] (i.e. v /= 1) for the rest of the calculation.
Some of my CPUs show the problem and some don't (see down below in the version section).
First I thought it is a problem of the new E/P core concept of the i9-12900K. Then I found it on a dual CPU system Xeon too. And finally I found it on an AMD 2. gen EPYC mono CPU. However, normal traditonal desktop CPU doesn't show the problem.
```
import torch
A: torch.Tensor = torch.full((24, 75, 24, 24), 2, dtype=torch.float32)
B: torch.Tensor = A[:, -1, :, :].unsqueeze(1)
A /= B
print(A[:, 0, 0, 0])
```
(EDIT: A = A / B doesn't show this problem.)
My expectation is (and this is the result on an old i7-5820K):
```
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1.])
```
but I get on i9-12900K CPUs
```
tensor([1., 2., 1., 1., 2., 1., 1., 2., 1., 1., 2., 1., 1., 1., 1., 1., 2., 1.,
1., 2., 1., 1., 2., 1.]
```
### Versions
**Bad computer: i9-12900K**
Collecting environment information...
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Fedora release 36 (Thirty Six) (x86_64)
GCC version: (GCC) 12.1.1 20220507 (Red Hat 12.1.1-1)
Clang version: 14.0.0 (Fedora 14.0.0-1.fc36)
CMake version: version 3.22.2
Libc version: glibc-2.35
Python version: 3.10.4 (main, Apr 6 2022, 17:03:02) [GCC 11.2.1 20220127 (Red Hat 11.2.1-9)] (64-bit runtime)
Python platform: Linux-5.17.7-300.fc36.x86_64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.942
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.3.1
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] Could not collect
**Good computer: i7-5820K**
Collecting environment information...
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Fedora release 36 (Thirty Six) (x86_64)
GCC version: (GCC) 12.1.1 20220507 (Red Hat 12.1.1-1)
Clang version: 14.0.0 (Fedora 14.0.0-1.fc36)
CMake version: version 3.22.2
Libc version: glibc-2.35
Python version: 3.10.4 (main, Apr 2 2022, 19:00:15) [GCC 11.2.1 20211203 (Red Hat 11.2.1-7)] (64-bit runtime)
Python platform: Linux-5.17.9-300.fc36.x86_64-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 980 Ti
Nvidia driver version: 510.68.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.942
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] Could not collect
**Bad computer: dual E5-2640**
Collecting environment information...
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Fedora release 36 (Thirty Six) (x86_64)
GCC version: (GCC) 12.1.1 20220507 (Red Hat 12.1.1-1)
Clang version: 14.0.0 (Fedora 14.0.0-1.fc36)
CMake version: version 3.22.2
Libc version: glibc-2.35
Python version: 3.10.4 (main, Apr 6 2022, 17:03:02) [GCC 11.2.1 20220127 (Red Hat 11.2.1-9)] (64-bit runtime)
Python platform: Linux-5.17.7-300.fc36.x86_64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.942
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.3.1
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] Could not collect
**Good computer: i7-3930K**
Collecting environment information...
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Fedora release 36 (Thirty Six) (x86_64)
GCC version: (GCC) 12.1.1 20220507 (Red Hat 12.1.1-1)
Clang version: 14.0.0 (Fedora 14.0.0-1.fc36)
CMake version: version 3.22.2
Libc version: glibc-2.35
Python version: 3.10.4 (main, Apr 6 2022, 17:03:02) [GCC 11.2.1 20220127 (Red Hat 11.2.1-9)] (64-bit runtime)
Python platform: Linux-5.17.7-300.fc36.x86_64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.942
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.3.1
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] Could not collect
**Bad computer: AMD EPYC 7282**
Collecting environment information...
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Fedora release 36 (Thirty Six) (x86_64)
GCC version: (GCC) 12.1.1 20220507 (Red Hat 12.1.1-1)
Clang version: 14.0.0 (Fedora 14.0.0-1.fc36)
CMake version: version 3.22.2
Libc version: glibc-2.35
Python version: 3.10.4 (main, Apr 6 2022, 17:03:02) [GCC 11.2.1 20220127 (Red Hat 11.2.1-9)] (64-bit runtime)
Python platform: Linux-5.17.7-300.fc36.x86_64-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.942
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] torch==1.11.0
[pip3] torch-tb-profiler==0.3.1
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] Could not collect
cc @svekars @holly1238
| 3 |
5,125 | 82,293 |
pytorch's checkpoint_wrapper does not save memory while fairscale's checkpoint_wrapper saves huge memory
|
high priority, oncall: distributed, module: checkpoint
|
### 🐛 Describe the bug
I'm testing activation checkpointing on FSDP models, to my surprise, PyTorch's native checkpoint_wrapper seems not working at all, not saving any memory whatsoever, I switched to fairscale's checkpoint_wrapper, huge memory has been saved.
To reproduce this issue,
main.py:
```python
import functools
import os
import torch
import torch.nn as nn
import torch.distributed as dist
from functools import partial
from fsdp_examples.unet import UNetModel
from torch.distributed.fsdp.fully_sharded_data_parallel import (
FullyShardedDataParallel as FSDP,
CPUOffload
)
from torch.cuda.amp import autocast
from torch.optim import AdamW
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
transformer_auto_wrap_policy,
)
from torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScaler
from torch.nn.parallel import DistributedDataParallel as DDP
from fsdp_examples.unet import TimestepEmbedSequential, ResBlock, AttentionBlock
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
CheckpointImpl,
apply_activation_checkpointing_wrapper,
checkpoint_wrapper as checkpoint_wrapper_pytorch
)
from fairscale.nn.checkpoint import checkpoint_wrapper as checkpoint_wrapper_fairscale
def apply_checkpointing(model: nn.Module, mode: int):
if mode < 0:
return
elif mode == 0:
wrapper = partial(
checkpoint_wrapper_pytorch,
checkpoint_impl=CheckpointImpl.NO_REENTRANT,
offload_to_cpu=False,
)
elif mode == 1:
wrapper = partial(
checkpoint_wrapper_pytorch,
checkpoint_impl=CheckpointImpl.REENTRANT,
offload_to_cpu=True,
)
else:
wrapper = partial(
checkpoint_wrapper_fairscale,
offload_to_cpu=True,
)
def check_fn(submodule: nn.Module):
return isinstance(submodule, (ResBlock, AttentionBlock))
apply_activation_checkpointing_wrapper(
model,
checkpoint_wrapper_fn=wrapper,
check_fn=check_fn,
)
dist.init_process_group(backend="nccl")
dev = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(dev)
model = UNetModel(
in_channels=3,
model_channels=128,
out_channels=3,
num_res_blocks=3,
attention_resolutions=[8]
)
auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TimestepEmbedSequential,
},
)
fsdp_model = FSDP(
model,
device_id=dev,
auto_wrap_policy=size_based_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=False),
)
# uncomment to apply checkpointing
# apply_checkpointing(fsdp_model, mode=-1)
# apply_checkpointing(fsdp_model, mode=0)
# apply_checkpointing(fsdp_model, mode=1)
# apply_checkpointing(fsdp_model, mode=2)
fsdp_model.train()
while True:
bs = 16
img = torch.rand((bs, 3, 64, 64), dtype=torch.float32).to(f'cuda')
t = torch.rand(bs, dtype=torch.float32).to(f'cuda')
with autocast():
r = fsdp_model(img, t)
loss = r.sum()
scaler = ShardedGradScaler()
optim = AdamW(fsdp_model.parameters(), lr=1e-4)
scaler.scale(loss).backward()
scaler.step(optim)
```
The definition of unet will follow, before I paste the impl, this is how I launched `main.py`:
`torchrun --nproc_per_node 2 main.py`
What I've noticed is that:
When `mode == -1`, no activation checkpointing is applied, the GPU memory is:
When `mode == 0`, use PyTorch's checkpoint_wrapper, the GPU memory is:
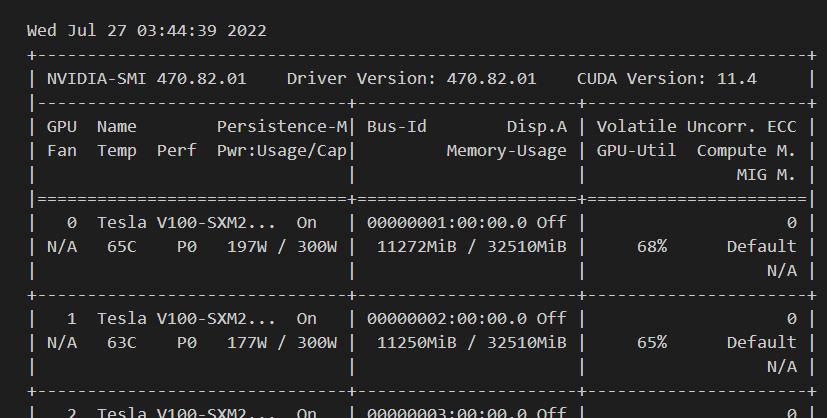
When `mode == 1`, use PyTorch's checkpoint_wrapper with offload_to_cpu True, the GPU memory is:
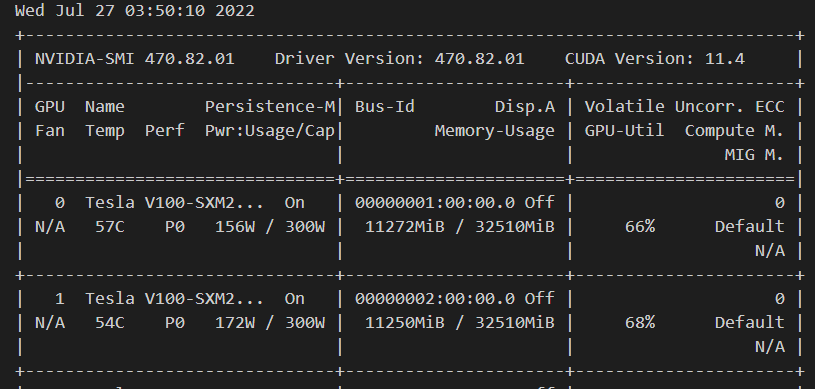
When `mode == 2`, use FairScale's checkpoint_wrapper, the GPU memory is:
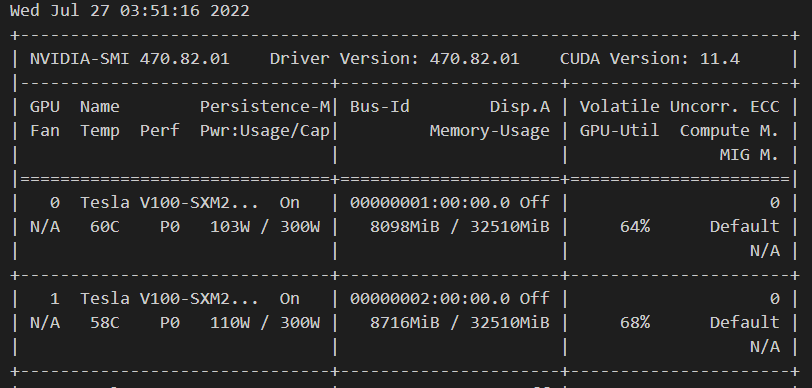
It is not clear to me why this is happening, is this expected?
The unet's implementation is as follows:
```python
import functools
import math
import numpy as np
import torch as th
import torch.nn as nn
import torch.nn.functional as F
from abc import abstractmethod
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import CheckpointWrapper
def conv_nd(dims, *args, **kwargs):
"""
Create a 1D, 2D, or 3D convolution module.
"""
if dims == 1:
return nn.Conv1d(*args, **kwargs)
elif dims == 2:
return nn.Conv2d(*args, **kwargs)
elif dims == 3:
return nn.Conv3d(*args, **kwargs)
raise ValueError(f"unsupported dimensions: {dims}")
def linear(*args, **kwargs):
"""
Create a linear module.
"""
return nn.Linear(*args, **kwargs)
def avg_pool_nd(dims, *args, **kwargs):
"""
Create a 1D, 2D, or 3D average pooling module.
"""
if dims == 1:
return nn.AvgPool1d(*args, **kwargs)
elif dims == 2:
return nn.AvgPool2d(*args, **kwargs)
elif dims == 3:
return nn.AvgPool3d(*args, **kwargs)
raise ValueError(f"unsupported dimensions: {dims}")
def zero_module(module):
"""
Zero out the parameters of a module and return it.
"""
for p in module.parameters():
p.detach().zero_()
return module
def normalization(channels):
"""
Make a standard normalization layer.
:param channels: number of input channels.
:return: an nn.Module for normalization.
"""
return nn.GroupNorm(32, channels)
def timestep_embedding(timesteps, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an [N x dim] Tensor of positional embeddings.
"""
half = dim // 2
freqs = th.exp(
-math.log(max_period) * th.arange(start=0, end=half, dtype=th.float32) / half
).to(device=timesteps.device)
args = timesteps[:, None].float() * freqs[None]
embedding = th.cat([th.cos(args), th.sin(args)], dim=-1)
if dim % 2:
embedding = th.cat([embedding, th.zeros_like(embedding[:, :1])], dim=-1)
return embedding
class TimestepBlock(nn.Module):
"""
Any module where forward() takes timestep embeddings as a second argument.
"""
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
"""
A sequential module that passes timestep embeddings to the children that
support it as an extra input.
"""
def forward(self, x, emb):
for layer in self:
if isinstance(layer, CheckpointWrapper):
layer = layer._checkpoint_wrapped_module
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
else:
x = layer(x)
return x
class Upsample(nn.Module):
"""
An upsampling layer with an optional convolution.
:param channels: channels in the inputs and outputs.
:param use_conv: a bool determining if a convolution is applied.
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
upsampling occurs in the inner-two dimensions.
"""
def __init__(self, channels, use_conv, dims=2):
super().__init__()
self.channels = channels
self.use_conv = use_conv
self.dims = dims
if use_conv:
self.conv = conv_nd(dims, channels, channels, 3, padding=1)
def forward(self, x):
assert x.shape[1] == self.channels
if self.dims == 3:
x = F.interpolate(
x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest"
)
else:
x = F.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
class Downsample(nn.Module):
"""
A downsampling layer with an optional convolution.
:param channels: channels in the inputs and outputs.
:param use_conv: a bool determining if a convolution is applied.
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
downsampling occurs in the inner-two dimensions.
"""
def __init__(self, channels, use_conv, dims=2):
super().__init__()
self.channels = channels
self.use_conv = use_conv
self.dims = dims
stride = 2 if dims != 3 else (1, 2, 2)
if use_conv:
self.op = conv_nd(dims, channels, channels, 3, stride=stride, padding=1)
else:
self.op = avg_pool_nd(stride)
def forward(self, x):
assert x.shape[1] == self.channels
return self.op(x)
class ResBlock(TimestepBlock):
"""
A residual block that can optionally change the number of channels.
:param channels: the number of input channels.
:param emb_channels: the number of timestep embedding channels.
:param dropout: the rate of dropout.
:param out_channels: if specified, the number of out channels.
:param use_conv: if True and out_channels is specified, use a spatial
convolution instead of a smaller 1x1 convolution to change the
channels in the skip connection.
:param dims: determines if the signal is 1D, 2D, or 3D.
:param use_checkpoint: if True, use gradient checkpointing on this module.
"""
def __init__(
self,
channels,
emb_channels,
dropout,
out_channels=None,
use_conv=False,
use_scale_shift_norm=False,
dims=2,
use_checkpoint=False,
):
super().__init__()
self.channels = channels
self.emb_channels = emb_channels
self.dropout = dropout
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.use_checkpoint = use_checkpoint
self.use_scale_shift_norm = use_scale_shift_norm
self.in_layers = nn.Sequential(
normalization(channels),
nn.SiLU(),
conv_nd(dims, channels, self.out_channels, 3, padding=1),
)
self.emb_layers = nn.Sequential(
nn.SiLU(),
linear(
emb_channels,
2 * self.out_channels if use_scale_shift_norm else self.out_channels,
),
)
self.out_layers = nn.Sequential(
normalization(self.out_channels),
nn.SiLU(),
nn.Dropout(p=dropout),
zero_module(
conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)
),
)
if self.out_channels == channels:
self.skip_connection = nn.Identity()
elif use_conv:
self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
else:
self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
def forward(self, x, emb):
"""
Apply the block to a Tensor, conditioned on a timestep embedding.
:param x: an [N x C x ...] Tensor of features.
:param emb: an [N x emb_channels] Tensor of timestep embeddings.
:return: an [N x C x ...] Tensor of outputs.
"""
h = self.in_layers(x)
emb_out = self.emb_layers(emb).type(h.dtype)
while len(emb_out.shape) < len(h.shape):
emb_out = emb_out[..., None]
if self.use_scale_shift_norm:
out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
scale, shift = th.chunk(emb_out, 2, dim=1)
h = out_norm(h) * (1 + scale) + shift
h = out_rest(h)
else:
h = h + emb_out
h = self.out_layers(h)
return self.skip_connection(x) + h
class AttentionBlock(nn.Module):
"""
An attention block that allows spatial positions to attend to each other.
Originally ported from here, but adapted to the N-d case.
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
"""
def __init__(self, channels, num_heads=1, use_checkpoint=False):
super().__init__()
self.channels = channels
self.num_heads = num_heads
self.use_checkpoint = use_checkpoint
self.norm = normalization(channels)
self.qkv = conv_nd(1, channels, channels * 3, 1)
self.attention = QKVAttention()
self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
def forward(self, x):
b, c, *spatial = x.shape
x = x.reshape(b, c, -1)
qkv = self.qkv(self.norm(x))
qkv = qkv.reshape(b * self.num_heads, -1, qkv.shape[2])
h = self.attention(qkv)
h = h.reshape(b, -1, h.shape[-1])
h = self.proj_out(h)
return (x + h).reshape(b, c, *spatial)
class QKVAttention(nn.Module):
"""
A module which performs QKV attention.
"""
def forward(self, qkv):
"""
Apply QKV attention.
:param qkv: an [N x (C * 3) x T] tensor of Qs, Ks, and Vs.
:return: an [N x C x T] tensor after attention.
"""
ch = qkv.shape[1] // 3
q, k, v = th.split(qkv, ch, dim=1)
scale = 1 / math.sqrt(math.sqrt(ch))
weight = th.einsum(
"bct,bcs->bts", q * scale, k * scale
) # More stable with f16 than dividing afterwards
weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
return th.einsum("bts,bcs->bct", weight, v)
@staticmethod
def count_flops(model, _x, y):
"""
A counter for the `thop` package to count the operations in an
attention operation.
Meant to be used like:
macs, params = thop.profile(
model,
inputs=(inputs, timestamps),
custom_ops={QKVAttention: QKVAttention.count_flops},
)
"""
b, c, *spatial = y[0].shape
num_spatial = int(np.prod(spatial))
# We perform two matmuls with the same number of ops.
# The first computes the weight matrix, the second computes
# the combination of the value vectors.
matmul_ops = 2 * b * (num_spatial ** 2) * c
model.total_ops += th.DoubleTensor([matmul_ops])
class UNetModel(nn.Module):
"""
The full UNet model with attention and timestep embedding.
:param in_channels: channels in the input Tensor.
:param model_channels: base channel count for the model.
:param out_channels: channels in the output Tensor.
:param num_res_blocks: number of residual blocks per downsample.
:param attention_resolutions: a collection of downsample rates at which
attention will take place. May be a set, list, or tuple.
For example, if this contains 4, then at 4x downsampling, attention
will be used.
:param dropout: the dropout probability.
:param channel_mult: channel multiplier for each level of the UNet.
:param conv_resample: if True, use learned convolutions for upsampling and
downsampling.
:param dims: determines if the signal is 1D, 2D, or 3D.
:param num_classes: if specified (as an int), then this model will be
class-conditional with `num_classes` classes.
:param use_checkpoint: use gradient checkpointing to reduce memory usage.
:param num_heads: the number of attention heads in each attention layer.
"""
def __init__(
self,
in_channels,
model_channels,
out_channels,
num_res_blocks,
attention_resolutions,
dropout=0,
channel_mult=(1, 2, 4, 8),
conv_resample=True,
dims=2,
num_classes=None,
use_checkpoint=False,
num_heads=1,
num_heads_upsample=-1,
use_scale_shift_norm=False,
):
super().__init__()
if num_heads_upsample == -1:
num_heads_upsample = num_heads
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.conv_resample = conv_resample
self.num_classes = num_classes
self.use_checkpoint = use_checkpoint
self.num_heads = num_heads
self.num_heads_upsample = num_heads_upsample
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
linear(model_channels, time_embed_dim),
nn.SiLU(),
linear(time_embed_dim, time_embed_dim),
)
if self.num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_embed_dim)
self.input_blocks = nn.ModuleList(
[
TimestepEmbedSequential(
conv_nd(dims, in_channels, model_channels, 3, padding=1)
)
]
)
input_block_chans = [model_channels]
ch = model_channels
ds = 1
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [
ResBlock(
ch,
time_embed_dim,
dropout,
out_channels=mult * model_channels,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
)
]
ch = mult * model_channels
if ds in attention_resolutions:
layers.append(
AttentionBlock(
ch, use_checkpoint=use_checkpoint, num_heads=num_heads
)
)
self.input_blocks.append(TimestepEmbedSequential(*layers))
input_block_chans.append(ch)
if level != len(channel_mult) - 1:
self.input_blocks.append(
TimestepEmbedSequential(Downsample(ch, conv_resample, dims=dims))
)
input_block_chans.append(ch)
ds *= 2
self.middle_block = TimestepEmbedSequential(
ResBlock(
ch,
time_embed_dim,
dropout,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
),
AttentionBlock(ch, use_checkpoint=use_checkpoint, num_heads=num_heads),
ResBlock(
ch,
time_embed_dim,
dropout,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
),
)
self.output_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
layers = [
ResBlock(
ch + input_block_chans.pop(),
time_embed_dim,
dropout,
out_channels=model_channels * mult,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
)
]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(
AttentionBlock(
ch,
use_checkpoint=use_checkpoint,
num_heads=num_heads_upsample,
)
)
if level and i == num_res_blocks:
layers.append(Upsample(ch, conv_resample, dims=dims))
ds //= 2
self.output_blocks.append(TimestepEmbedSequential(*layers))
self.out = nn.Sequential(
normalization(ch),
nn.SiLU(),
zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
)
def forward(self, x, timesteps, y=None):
"""
Apply the model to an input batch.
:param x: an [N x C x ...] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:param y: an [N] Tensor of labels, if class-conditional.
:return: an [N x C x ...] Tensor of outputs.
"""
assert (y is not None) == (
self.num_classes is not None
), "must specify y if and only if the model is class-conditional"
hs = []
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
if self.num_classes is not None:
assert y.shape == (x.shape[0],)
emb = emb + self.label_emb(y)
h = x
for module in self.input_blocks:
h = module(h, emb)
hs.append(h)
h = self.middle_block(h, emb)
for module in self.output_blocks:
cat_in = th.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
h = h.type(x.dtype)
return self.out(h)
```
### Versions
PyTorch version: 1.13.0.dev20220723+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1063-azure-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
GPU 4: Tesla V100-SXM2-32GB
GPU 5: Tesla V100-SXM2-32GB
GPU 6: Tesla V100-SXM2-32GB
GPU 7: Tesla V100-SXM2-32GB
Nvidia driver version: 470.82.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.6.4
[pip3] torch==1.13.0.dev20220723+cu116
[pip3] torchaudio==0.13.0.dev20220723+cu116
[pip3] torchmetrics==0.9.2
[pip3] torchvision==0.14.0.dev20220723+cu116
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.6 pypi_0 pypi
[conda] numpy-base 1.21.5 py37ha15fc14_3
[conda] pytorch-lightning 1.6.4 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.12.0 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20220723+cu116 pypi_0 pypi
[conda] torchmetrics 0.9.2 pypi_0 pypi
[conda] torchvision 0.13.0 pypi_0 pypi
cc @ezyang @gchanan @zou3519 @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 4 |
5,126 | 82,282 |
`torch.matrix_exp` doesn't handle NaN properly
|
module: cuda, triaged, module: NaNs and Infs, module: linear algebra
|
### 🐛 Describe the bug
When calling `torch.matrix_exp` on a value containing `nan` values, the result is strange and different on CPU and on CUDA with the same input.
Based on similar discussion in https://github.com/pytorch/pytorch/issues/61251 , I think `torch.matrix_exp` should also check input for `nan`.
```
import torch
torch.random.manual_seed(420)
input = torch.randn(3, 3, dtype=torch.float32)
print("Intermediate: ", torch.log(input * 2 - 1)) # Contains nan
output = torch.matrix_exp(torch.log(input * 2 - 1))
print("cpu output: ", output)
input = input.cuda()
output = torch.matrix_exp(torch.log(input * 2 - 1))
print("gpu output: ", output)
```
Outputs:
```
Intermediate: tensor([[ nan, -1.2915, nan],
[ nan, 0.7102, nan],
[-0.3755, nan, nan]])
cpu output: tensor([[ 7.2619e+11, 0.0000e+00, -8.4379e-01],
[-1.8280e+00, 2.0343e+00, -9.0547e-01],
[ 6.8693e-01, -1.4521e+00, -9.3093e-01]])
gpu output: tensor([[-4.3953, 0.2749, -0.8438],
[-1.8280, 2.0343, -0.9055],
[ 0.6869, -1.4521, -0.9309]], device='cuda:0')
```
### Versions
pytorch: 1.12.0
cc @ngimel @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 3 |
5,127 | 82,276 |
DEBUG=1 env var doesn't actually set DEBUG preprocessor macro
|
module: build, triaged, enhancement
|
### 🐛 Describe the bug
What it says on the tin. There are a lot of uses of this dead macro.
```
aten/src/ATen/BatchedTensorImpl.cpp:#ifdef DEBUG
aten/src/ATen/BatchedTensorImpl.h:#ifdef DEBUG
aten/src/ATen/OpaqueTensorImpl.h:#ifdef DEBUG
aten/src/ATen/SparseTensorImpl.cpp:#ifdef DEBUG
aten/src/ATen/SparseTensorImpl.h:#ifdef DEBUG
aten/src/ATen/core/dispatch/Dispatcher.h:#ifdef DEBUG
aten/src/ATen/core/dispatch/Dispatcher.h:#ifdef DEBUG
aten/src/ATen/core/dispatch/Dispatcher.h:#ifdef DEBUG
aten/src/ATen/core/dispatch/Dispatcher.h:#ifdef DEBUG
aten/src/ATen/native/Resize.h:#ifdef DEBUG
aten/src/ATen/native/vulkan/api/Allocator.h:#ifdef DEBUG
c10/core/TensorImpl.h:#ifdef DEBUG
c10/core/TensorImpl.h:#ifdef DEBUG
c10/core/TensorImpl.h:#ifdef DEBUG
c10/core/TensorImpl.h:#ifdef DEBUG
c10/core/UndefinedTensorImpl.cpp:#ifdef DEBUG
c10/core/UndefinedTensorImpl.h:#ifdef DEBUG
c10/util/Registry.h:#ifdef DEBUG
functorch/functorch/csrc/BatchedTensorImpl.cpp:#ifdef DEBUG
functorch/functorch/csrc/BatchedTensorImpl.h:#ifdef DEBUG
```
cc @malfet @seemethere @zou3519 @bdhirsh
### Versions
master
| 2 |
5,128 | 82,259 |
[Reproducibility] Make tests say when unusual environment variables are set that change behavior of the test
|
module: ci, triaged
|
### 🐛 Describe the bug
E.g. as seen in https://github.com/pytorch/pytorch/pull/81999 developers don't necessarily know how to apply environment variables in unconventional test configurations to reproduce CI failures. The test error messages should detect and report when an envvar is necessary to reproduce the behavior.
Currently relevant envvars:
```
PYTORCH_TEST_WITH_SLOW
PYTORCH_TEST_WITH_CROSSREF
PYTORCH_TEST_WITH_DYNAMO
```
### Versions
master
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 4 |
5,129 | 82,242 |
logspace inconsistently casts inputs to int before performing computation
|
triaged, module: tensor creation
|
When `steps = 1`, the inputs are not casted to integers before performing the pow:
```python
>>> torch.logspace(4.3, 5, 2, dtype=torch.int32)
tensor([ 10000, 100000], dtype=torch.int32)
>>> torch.logspace(4.3, 5, 1, dtype=torch.int32)
tensor([19952], dtype=torch.int32)
>>> torch.logspace(4.3, 5, 1, dtype=torch.int32, device="cuda")
tensor([19952], device='cuda:0', dtype=torch.int32)
>>> torch.logspace(4.3, 5, 2, dtype=torch.int32, device="cuda")
tensor([ 10000, 100000], device='cuda:0', dtype=torch.int32)
```
cc @gchanan @mruberry
| 0 |
5,130 | 82,239 |
primtorch refs should be composite compliant
|
triaged, module: __torch_dispatch__, tensor subclass, module: primTorch
|
## Issue description
Primtorch refs should be composite compliant. That is, given a ref for an operator like `new_empty`, if the input to new_empty is a Tensor subclass, then the output should also be a Tensor subclass. Otherwise, the ref doesn't capture the semantics of the operation and cannot be used as a "decomposition" for a Tensor Subclass.
We should add explicit tests that refs are composite compliant.
## Code example
E.g. https://github.com/pytorch/pytorch/pull/82237
cc @Chillee @ezyang @zou3519 @albanD @samdow @mruberry @ngimel @kshitij12345
| 0 |
5,131 | 82,230 |
logspace and linspace off by one on cuda for integer dtypes for some inputs
|
triaged, module: tensor creation
|
As expected,
```python
>>> torch.logspace(1., 2., 2, dtype=torch.int32, device="cpu")
tensor([ 10, 100], dtype=torch.int32)
>>> torch.logspace(1., 2., 2, dtype=torch.float32, device="cuda")
tensor([ 10.0000, 100.0000], device='cuda:0')
```
But when output dtype is specified to be int:
```python
>>> torch.logspace(1., 2., 2, dtype=torch.int32, device="cuda")
tensor([10, 99], device='cuda:0', dtype=torch.int32)
```
Off-by-one also appears when casting is performed after - but only happens on float32.
```python
>>> torch.logspace(1., 2., 2, 10, dtype=torch.float16, device="cuda").to(dtype=torch.int32)
tensor([ 10, 100], device='cuda:0', dtype=torch.int32)
>>> torch.logspace(1., 2., 2, dtype=torch.float32, device="cuda").to(dtype=torch.int32)
tensor([10, 99], device='cuda:0', dtype=torch.int32)
>>> torch.logspace(1., 2., 2, dtype=torch.float64, device="cuda").to(dtype=torch.int32)
tensor([ 10, 100], device='cuda:0', dtype=torch.int32)
```
Does not happen consistently on all inputs
```python
tensor([ 9, 81], device='cuda:0', dtype=torch.int32)
>>> torch.logspace(1., 2., 2, 10, dtype=torch.float32, device="cuda").to(dtype=torch.int32)
tensor([10, 99], device='cuda:0', dtype=torch.int32)
>>> torch.logspace(1., 2., 2, 11, dtype=torch.float32, device="cuda").to(dtype=torch.int32)
tensor([ 11, 121], device='cuda:0', dtype=torch.int32)
```
I would expect the produced binary representation of the output to be greater than the integral value so that when casted it does not produce a large discrepancy with the before-casted value.
cc @gchanan @mruberry
| 1 |
5,132 | 82,229 |
[Profiler] Allow profiler to gracefully fail without interrupting workflow.
|
oncall: profiler
|
### 🚀 The feature, motivation and pitch
The pytorch profiler works very hard to minimize work on the hot path to reduce overhead. However, one of the consequences of this choice is that there is a fairly significant post processing step to convert these raw events into a coherent program representation. To ensure correctness this post processing makes liberal use of asserts. However this is causing a non-trivial number of post processing calls to fail and as a result crashes the entire workload. Which is not ideal. How we want to handle this depends on the context. In debug mode it should be a hard failure. In opt mode we should emit a warning (to console in OSS and to a remote logger in FBCode), record it in the trace file, and gracefully drop the offending event or do whatever else is needed to return to a somewhat sane state. (E.g. drop the event)
As a concrete example, we currently have a guard to ensure that an event produces sane timestamps before marking it finished and incorporating it in the tree:
```
void mark_finished(std::shared_ptr<Result>& r) {
TORCH_INTERNAL_ASSERT(!r->finished_, r->name());
r->finished_ = true;
TORCH_INTERNAL_ASSERT(r->endTimeNS() >= r->start_time_ns_, r->name());
}
```
However corner cases (such as is asynchronously stopped when an op is in progress) breaks this. We want to correct the logic, but it's not necessary to crash an entire run. A better structure would be something like:
```
if (SOFT_ASSERT(!r->finished_, r->name()) {
r->finished_ = true;
return SOFT_ASSERT(r->endTimeNS() >= r->start_time_ns_, r->name());
}
return false;
```
And then the caller should act appropriately.
This will consist of two parts:
1) Implement `SOFT_ASSERT`. (Working title)
2) Update profiler to gracefully recover from invariant violations.
### Alternatives
_No response_
### Additional context
_No response_
cc @ilia-cher @robieta @chaekit @gdankel @bitfort @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git
| 0 |
5,133 | 82,228 |
[Profiler] Allow profiler to gracefully fail without interrupting workflow.
|
oncall: profiler
|
### 🚀 The feature, motivation and pitch
The pytorch profiler works very hard to minimize work on the hot path to reduce overhead. However, one of the consequences of this choice is that there is a fairly significant post processing step to convert these raw events into a coherent program representation. To ensure correctness this post processing makes liberal use of asserts. However this is causing a non-trivial number of post processing calls to fail and as a result crashes the entire workload. Which is not ideal. How we want to handle this depends on the context. In debug mode it should be a hard failure. In opt mode we should emit a warning (to console in OSS and to a remote logger in FBCode), record it in the trace file, and gracefully drop the offending event or do whatever else is needed to return to a somewhat sane state. (E.g. drop the event)
As a concrete example, we currently have a guard to ensure that an event produces sane timestamps before marking it finished and incorporating it in the tree:
```
void mark_finished(std::shared_ptr<Result>& r) {
TORCH_INTERNAL_ASSERT(!r->finished_, r->name());
r->finished_ = true;
TORCH_INTERNAL_ASSERT(r->endTimeNS() >= r->start_time_ns_, r->name());
}
```
However corner cases (such as is asynchronously stopped when an op is in progress) breaks this. We want to correct the logic, but it's not necessary to crash an entire run. A better structure would be something like:
```
if (SOFT_ASSERT(!r->finished_, r->name()) {
r->finished_ = true;
return SOFT_ASSERT(r->endTimeNS() >= r->start_time_ns_, r->name());
}
return false;
```
And then the caller should act appropriately.
This will consist of two parts:
1) Implement `SOFT_ASSERT`. (Working title)
2) Update profiler to gracefully recover from invariant violations.
### Alternatives
_No response_
### Additional context
_No response_
cc @ilia-cher @robieta @chaekit @gdankel @bitfort @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git
| 0 |
5,134 | 93,791 |
Reordering test in PyTorch test suite induces dynamo failure
|
triaged, bug, oncall: pt2
|
See https://github.com/pytorch/pytorch/pull/82169
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
5,135 | 82,219 |
[feature request] DataLoader to accept num_threads argument to auto-set number of threads for OpenMP / intra-op parallelism
|
module: dataloader, triaged, module: openmp
|
### 🚀 The feature, motivation and pitch
In the typical single-node multi-gpu DDP + multi-threaded DataLoader + intra-op OpenMP parallelism, there might be CPU thread oversubscription leading to slower perf compared to no intra-op parallelism.
Probably a better choice would be to support a helper argument for DataLoader that would call torch.set_num_threads at thread init. Currently this is possible via custom worker_init_fn, but having it as constructor argument would be simpler and bring more visibility.
Currently there is a debatable workaround: DDP sets OMP_NUM_THREADS=1 by default: https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py#L653 assuming CPU intra-op parallelism almost doesn't happen at all (and not only in DataLoader) - this is rather strange and can be unexpected
### Alternatives
_No response_
### Additional context
_No response_
cc @SsnL @VitalyFedyunin @ejguan @NivekT
| 1 |
5,136 | 82,218 |
OOM during backward() leads to memory leaks
|
needs reproduction, module: autograd, module: memory usage, triaged
|
### 🐛 Describe the bug
Like what is shown in the logs below, I print the currently allocated memory by torch.cuda.memory_allocated() before the forward pass in each step. After the OOM in the backward() call, the intermediate tensors are not freed, which will lead to OOM in the following steps.
OOM in the forward passes will not lead to the issue.
```
[INFO 2022-07-26 14:40:33,673] [Step 10115] 0.501 sec/step (0.555), lr=1.6427E-04, loss=0.15372 (Ave. 0.32287), grad_norm=0.747
[INFO 2022-07-26 14:40:33,675] Current memory: 6413632512
[INFO 2022-07-26 14:40:34,251] [Step 10116] 0.577 sec/step (0.552), lr=1.6426E-04, loss=0.17586 (Ave. 0.32030), grad_norm=1.508
[INFO 2022-07-26 14:40:34,254] Current memory: 6424706560
[ERROR 2022-07-26 14:40:34,609] Failed due to RuntimeError, input shape: torch.Size([28, 69920]), target shape: torch.Size([28, 82])
Traceback (most recent call last):
File "train.py", line 210, in main
losses['loss'].backward()
File "/idiap/user/mhe/miniconda3/lib/python3.9/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/idiap/user/mhe/miniconda3/lib/python3.9/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 23.70 GiB total capacity; 20.20 GiB already allocated; 1.69 MiB free; 22.09 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
[INFO 2022-07-26 14:40:34,829] Current memory: 21698449408
```
I've checked all the pytorch tensors with gc.get_objects() and confirmed that there are hundreds of tensors alive after the OOM that don't exist prior to the backward pass, indicating that they are created during the backward() call. Calling gc.collect() will not release them. sys.getrefcount(t) on one of these tensors gives like 4, but gc.get_referrers(t) gives nothing but t itself, so there should be 2 references from untracked objects like something in C extensions.
I attempted to reproduce it with some simpler codes, but they will just work fine. Hopefully we can find some logs somewhere to better locate the error.
Hundreds of following warnings are shown when I stop the program, unknown if relevant:
```
[W python_variable.cpp:200] Warning: Deallocating Tensor that still has live PyObject references. This probably happened because you took out a weak reference to Tensor and didn't call _fix_weakref() after dereferencing it. Subsequent accesses to this tensor via the PyObject will now fail. (function concrete_decref_fn)
```
### Versions
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 11 (bullseye) (x86_64)
GCC version: (Debian 10.2.1-6) 10.2.1 20210110
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:58:50) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.10.0-16-amd64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.2.152
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 510.39.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.6 pypi_0 pypi
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] pytorch 1.12.0 py3.9_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.11.0 pypi_0 pypi
[conda] torchvision 0.13.0 py39_cu113 pytorch
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 12 |
5,137 | 82,217 |
backward not available for index and mask
|
needs reproduction, module: autograd, triaged, module: sorting and selection
|
### 🐛 Describe the bug
When use index or mask for tensor indices, the forward can run normally, but the backward is not available. After change it to _index_select_ or _masked_select_, the backward can run normally. If there any bug for index graph?
```
## pred(float): B x M x D, mask(bool): B x M, xs_layer(float): B x M
# not work:
pred_layer_reshape = pred.reshape(-1,D)[mask.reshape(-1)]
gt_box3d = gt.reshape(-1, D)[mask.reshape(-1)]
# work:
pred_layer_reshape = torch.index_select(pred.reshape(-1, D), 0, mask.reshape(-1).nonzero().squeeze())
gt_box3d = torch.index_select(gt.reshape(-1, D), 0, mask.reshape(-1).nonzero().squeeze())
# not work:
xs_layer_reshape = xs_layer.reshape(-1)[mask.reshape(-1)].unsqueeze(-1)
ys_layer_reshape = ys_layer.reshape(-1)[mask.reshape(-1)].unsqueeze(-1)
# work:
xs_layer_reshape = torch.masked_select(xs_layer.reshape(-1), mask.reshape(-1)).unsqueeze(-1)
ys_layer_reshape = torch.masked_select(ys_layer.reshape(-1), mask.reshape(-1)).unsqueeze(-1)
```
RuntimeError: merge_sort: failed to synchronize: cudaErrorIllegalAddress: an illegal memory access was encountered
```
### Versions
torch 1.8.2+cu111
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 2 |
5,138 | 82,216 |
iOS TestApp from mobile performance recipes tutorial doesn't build on macOS
|
oncall: mobile, module: ios
|
### 📚 The doc issue
I'm trying the following tutorial: https://pytorch.org/tutorials/recipes/mobile_perf.html#android-benchmarking-setup
The model preparation part works fine. When I'm trying to build TestApp in Xcode, I get 11 `Target Integrity` errors, yielding i.e.
`/Users/derrkater/repo/pytorch/ios/TestApp/TestApp.xcodeproj Building for iOS Simulator, but the linked library 'libcpuinfo.a' was built for macOS.`
My environment is:
Macbook 12", MacOS Monerey 12.4
Python 3.9.12
Xcode 13.4.1
iPhone 13 Pro simulator
commit: ea6fa8dc95
Possibly importantly, I have modified `build_ios.sh` script with a following line: `CMAKE_ARGS+=("-DCMAKE_IOS_SDK_ROOT=/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS10.3.sdk")`
How can I proceed to build the test app correctly?
### Suggest a potential alternative/fix
_No response_
| 0 |
5,139 | 82,212 |
RuntimeError: "reflection_pad2d" not implemented for 'Half' in autocast enabled region
|
triaged, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
I'm trying to convert a model to jit fp16 as described here https://pytorch.org/docs/stable/amp.html#torch.autocast
```
image = torch.rand(1, 3, 120, 120, dtype=torch.float16)
mask = torch.rand(1, 1, 120, 120, dtype=torch.float16)
torch._C._jit_set_autocast_mode(False)
with torch.cpu.amp.autocast(cache_enabled=False):
traced_model = torch.jit.trace(jit_model_wrapper, (image, mask), strict=False).to(device)
```
and i get this error
File "/home/venv/lib/python3.8/site-packages/torch/nn/modules/padding.py", line 174, in forward
return F.pad(input, self.padding, 'reflect')
RuntimeError: "reflection_pad2d" not implemented for 'Half'
### Versions
torch==1.12.0
cc @mcarilli @ptrblck
| 0 |
5,140 | 82,203 |
[FSDP] Error when wrapping FSDP inside `checkpoint_wrapper`
|
oncall: distributed, triaged, module: fsdp
|
### 🐛 Describe the bug
This is the issue when running FSDP along with activation checkpointing. When FSDP units are wrapped inside `checkpoint_wrapper`, running checkpointing with both `NO_REENTRANT` and `REENTRANT` will fail. In particular, checkpointing with `NO_REENTRANT` since `_pre_forward_hook` is triggered ahead of `forward`, thus parameters are not correctly gather after `reshard`.
Below is an example for reproducing the error, this can be run via `gpurun torchrun --nnodes 1 --nproc_per_node 2 ./test_checkpoint.py`.
```python
import functools, os, torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import always_wrap_policy
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
checkpoint_wrapper,
CheckpointImpl,
apply_activation_checkpointing_wrapper,
)
class Model(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.layer0 = torch.nn.Linear(6, 6)
self.layer1 = torch.nn.Linear(6, 6, bias=False)
def forward(self, x):
z = self.layer0(x)
z = self.layer1(z)
return z
def get_input(self, device: torch.device):
return (torch.randn((8, 6)).to(device),)
def get_loss(self, input, output):
return (output - input[0]).sum()
def fsdp_main():
local_rank = int(os.environ["LOCAL_RANK"])
torch.distributed.init_process_group("nccl")
torch.cuda.empty_cache()
if torch.distributed.is_initialized():
torch.cuda.set_device(local_rank)
model = FSDP(
Model(),
auto_wrap_policy=always_wrap_policy,
backward_prefetch=None,
forward_prefetch=False,
device_id=torch.cuda.current_device(),
)
non_reentrant_wrapper = functools.partial(
checkpoint_wrapper,
offload_to_cpu=False,
checkpoint_impl=CheckpointImpl.NO_REENTRANT,
)
check_fn = lambda submodule: isinstance(submodule, FSDP)
apply_activation_checkpointing_wrapper(
model, checkpoint_wrapper_fn=non_reentrant_wrapper, check_fn=check_fn
)
if local_rank == 0:
print(model)
input = model.module.get_input(local_rank)
output = model(*input)
loss = model.module.get_loss(input, output).to(local_rank)
loss.backward()
if __name__ == "__main__":
fsdp_main()
```
### Versions
```
Collecting environment information...
PyTorch version: 1.13.0a0+git0fcdf93
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.1
Libc version: glibc-2.27
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.27
Is CUDA available: False
CUDA runtime version: 11.1.105
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.3
[pip3] torch==1.10.1+cu111
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.10.1+cu111
[pip3] torchvision==0.11.2+cu111
[pip3] vit-pytorch==0.35.5
[conda] blas 1.0 mkl
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] magma-cuda111 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.0.1 h06a4308_117
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] torch 1.13.0a0+git0fcdf93 dev_0 <develop>
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchaudio 0.10.1+cu111 pypi_0 pypi
[conda] torchvision 0.11.2+cu111 pypi_0 pypi
[conda] vit-pytorch 0.35.5 pypi_0 pypi
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @pietern @SciPioneer @ezyang
| 3 |
5,141 | 82,200 |
model.to(device) takes time forever on A40-8Q, NVIDIA. cuda11.1, torch1.9.1.
|
module: cuda, triaged
|
### 🐛 Describe the bug
model.to(device) takes time forever on A40-8Q, NVIDIA. cuda11.1, torch1.9.1.
### Versions
py3.6.9,
CUDA available:True,
GPU0: nvidia a40-8q,
nvcc: Build cuda_11.1.TC455_06.29069683_0,
gcc: ubuntu7.5.0,
Pytorch: 1.9.1+cu111,
cc @ngimel
| 1 |
5,142 | 82,197 |
Provide error handling for ops that don't yet support Dynamic Shape
|
triaged, lazy
|
### 🚀 The feature
PyTorch to integrate a default error message in the LTC codegen to inform the user when an op misses dynamic shape support. Perhaps this goes hand-in-hand with a whitelist of ops that do support Dynamic Shape in LTC?
@wconstab @Krovatkin I am filing this ticket per our offline conversation the other week.
CC @JackCaoG @wonjoolee95
| 3 |
5,143 | 82,185 |
DataLoader: `pin_memory` should respect object attributes before object collection type
|
module: dataloader, triaged
|
### 🐛 Describe the bug
Consider a custom DataLoader that returns an object of class `X(MutableMapping)`, which defines its own `pin_memory` method. It would be expected that setting `pin_memory=True` would call `X`'s `pin_memory` method, but instead the PyTorch DataLoader first checks the type of `X` and applies a default `pin_memory` to each member of `X` (see [these lines](https://github.com/pytorch/pytorch/blob/master/torch/utils/data/_utils/pin_memory.py#L53-L58)).
This situation is not contrived; it arose in implementing [data loading logic in PyTorch Geometric](https://github.com/pyg-team/pytorch_geometric/pull/5051), where the returned objects subclass `MutableMapping` but also define their own custom `pin_memory` implementation. A simple fix here would be to move the [`hasattr` check](https://github.com/pytorch/pytorch/blob/master/torch/utils/data/_utils/pin_memory.py#L69-L70) above collection type-based checks. Would be curious if there are use-cases that prefer checking for collection types before `hasattr`.
Happy to contribute the fix if it makes sense. Thank you!
### Versions
PyTorch version: 1.11.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.3
Libc version: glibc-2.27
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:18) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-1069-aws-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5
/usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] pytorch-lightning==1.6.3
[pip3] pytorch-memlab==0.2.4
[pip3] torch==1.11.0
[pip3] torch-geometric==2.0.5
[pip3] torch-scatter==2.0.9
[pip3] torch-sparse==0.6.13
[pip3] torchmetrics==0.8.1
[pip3] torchtext==0.12.0
[conda] numpy 1.22.3 pypi_0 pypi
[conda] pytorch-lightning 1.6.3 pypi_0 pypi
[conda] pytorch-memlab 0.2.4 pypi_0 pypi
[conda] torch 1.11.0 pypi_0 pypi
[conda] torch-geometric 2.0.5 dev_0 <develop>
[conda] torch-scatter 2.0.9 pypi_0 pypi
[conda] torch-sparse 0.6.13 pypi_0 pypi
[conda] torchmetrics 0.8.1 pypi_0 pypi
[conda] torchtext 0.12.0 pypi_0 pypi
cc @SsnL @VitalyFedyunin @ejguan @NivekT
| 1 |
5,144 | 82,159 |
`torch.sum` promotes integral tensors to `int64`.
|
module: docs, triaged, module: type promotion, actionable, module: reductions
|
### 🐛 Describe the bug
Repro:
```python
In [1]: import torch
...: dtypes = [torch.bool, torch.int8, torch.int32, torch.bfloat16, torch.float32, torch.float64]
...: for dtype in dtypes:
...: a = torch.tensor([], dtype=dtype)
...: a_sum = a.sum()
...: if a.dtype != a_sum.dtype:
...: print(f"t.dtype != t.sum().dtype, got {a.dtype} != {a_sum.dtype}")
...:
t.dtype != t.sum().dtype, got torch.bool != torch.int64
t.dtype != t.sum().dtype, got torch.int8 != torch.int64
t.dtype != t.sum().dtype, got torch.int32 != torch.int64
```
This is the cause of https://github.com/pytorch/pytorch/issues/82150.
### Versions
Current master.
cc @svekars @carljparker @nairbv @mruberry @holly1238
| 3 |
5,145 | 82,156 |
[Checkpoint] Support multiple unpack in saved tensor hooks
|
module: checkpoint, triaged
|
### 🐛 Describe the bug
Currently, if the `storage` of a particular tensor is accessed twice without recomputation being triggered in between, we raise the following error: https://github.com/pytorch/pytorch/blob/master/torch/utils/checkpoint.py#L391. However, there is a use case which requires this support.
Listing out a few things that we've currently tried:
1. Using python WeakValueDictionary for `storage` instead of a regular dict, to avoid keeping references alive to activation tensors. This turns out to not work because in some cases, the reference in the dict that needs to be returned is the only reference keeping the activation tensor alive, which is quite confusing.
2. Clearing storage and re-running the forward pass when we're about to access a tensor which has already been returned by `unpack()`. However, this is a hacky fix and results in a performance slowdown due to re-running the forward pass potentially several times.
### Versions
main
| 0 |
5,146 | 82,153 |
DistributedDataParallel hangs when not using GPU 0
|
oncall: distributed, module: ddp
|
### 🐛 Describe the bug
Wrapping a model in DDP results in the training hanging when not using GPU 0 on a multi-GPU device.
The following MVE:
```python
import os
import torch
import torch.multiprocessing as mp
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import DataLoader, TensorDataset, DistributedSampler
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main():
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8880'
gpus = 2
offset = 2
mp.spawn(train, nprocs=gpus, args=(gpus, offset))
def train(gpu, world_size, offset):
_ = torch.manual_seed(0)
rank = gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=world_size,
rank=rank)
torch.cuda.set_device(gpu + offset)
device = torch.device('cuda:' + str(gpu + offset))
d = 256
model = nn.Linear(d, 1)
n_train = 1024
x_train = torch.randn((n_train, d))
y_train = torch.randn((n_train, 1))
ds_train = TensorDataset(x_train, y_train)
sampler = DistributedSampler(ds_train, num_replicas=world_size, rank=rank)
dl_train = DataLoader(dataset=ds_train,
sampler=sampler,
batch_size=32,
num_workers=1)
optimizer = Adam(model.parameters(), lr=1e-3)
model = model.to(device)
model = DDP(model, device_ids=[gpu + offset], output_device=gpu + offset)
loss_func = nn.MSELoss()
for x, y in dl_train:
print(rank, device)
x = x.to(device)
print(rank, x.shape)
y = y.to(device)
p = model(x)
loss = loss_func(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(rank, loss)
if __name__ == '__main__':
main()
```
Produces:
```
1 cuda:3
1 torch.Size([32, 256])
0 cuda:2
0 torch.Size([32, 256])
1 tensor(1.0912, device='cuda:3', grad_fn=<MseLossBackward0>)
0 tensor(0.9560, device='cuda:2', grad_fn=<MseLossBackward0>)
1 cuda:3
1 torch.Size([32, 256])
0 cuda:2
0 torch.Size([32, 256])
1 tensor(1.3682, device='cuda:3', grad_fn=<MseLossBackward0>)
1 cuda:3
1 torch.Size([32, 256])
```
Indicating that after a few batches, the rank 0 process never gets to its backwards pass and everything is stuck. If I set offset to 0 so that I use GPUs 0 and 1 instead of 2 and 3, everything proceeds as expected. If I use GPUs 0 and 2, everything is also fine.
### Versions
Collecting environment information...
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.9.12 (main, Jun 1 2022, 11:38:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-122-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 10.1.243
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
GPU 3: NVIDIA RTX A6000
Nvidia driver version: 510.73.08
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.6.0 hecad31d_10 conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.22.3 py39he7a7128_0
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.12.0 py3.9_cuda11.6_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu116 pytorch
[conda] torchvision 0.13.0 py39_cu116 pytorch
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang
| 7 |
5,147 | 82,145 |
set_grad_enabled not respected when running on a web server
|
module: dependency bug, module: autograd, triaged, actionable
|
### 🐛 Describe the bug
The `torch.set_grad_enabled` flag is not respected when torch is being run as part of a web server (flask/fastapi).
Repro
```python
import torch
from fastapi import FastAPI
import uvicorn
import requests
torch.set_grad_enabled(False)
def grad_enabled():
x = torch.tensor([1.], requires_grad=True)
y = x * 2
return y.requires_grad
app = FastAPI()
@app.get("/")
def predict():
return grad_enabled()
if __name__ == "__main__":
assert not grad_enabled()
uvicorn.run(app, host="0.0.0.0", port=8000)
```
Run `python <filename>`. And go to localhost:8000, you should see `true` even though `set_grad_enabled` is set to `False`. `set_grad_enabled` does work outside the context of a web server though, as shown by the assert statement.
Is this a bug or user error?
Seeing it in such a condensed code block, I can try to convince myself that this is not how `set_grad_enabled` is supposed to work but I'm not exactly sure why that would be the case.
Certainly this can bite someone else in the butt like it did me and lead to very mysterious CUDA out of memory errors so I think there will be value in helping users by either preventing this from happening or educating users that this can happen.
### Versions
```
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 12.2.1 (arm64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.27.3)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.12 (main, Apr 5 2022, 01:52:34) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-12.2.1-arm64-arm-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.22.4
[conda] numpy 1.22.4 pypi_0 pypi
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 4 |
5,148 | 82,140 |
Stop manually binding sparse factory functions
|
module: sparse, triaged
|
### 🐛 Describe the bug
The current binding code is very repetitive and I think our codegen can handle it (it can handle regular factory functions, after all.)
### Versions
master
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 0 |
5,149 | 82,139 |
Re-enable DynamicQuantModule in iOS simulator tests
|
module: ci, triaged, module: ios
|
See https://github.com/pytorch/pytorch/pull/82027 and https://github.com/pytorch/pytorch/issues/81613 for details
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 2 |
5,150 | 82,132 |
External libraries cannot have a requirements.txt that needs to install a cpp_extension
|
module: cpp-extensions, triaged
|
### 🐛 Describe the bug
If an external library (e.g. pytorch/tutorials) has a requirements.txt with the following:
```
torch
git+https://github.com/pytorch/functorch.git@v0.2.0
```
then `pip install -r requirements.txt` errors out with "module torch not found". Here's why:
1. pip reads requirements.txt
1. pip tries to determine each package's dependencies before installing anything
1. pip tries to read functorch's dependencies by running its setup.py
1. functorch's setup.py imports torch to get the cpp_extension
1. torch does not exist, so python throws an error
This was discovered in https://github.com/pytorch/tutorials/pull/1968
## Pitch
People might need to pin libraries like this (I'm surprised this is the first time we've run into it). So it would be cool if we could offer a way for pip to read the torch dependency in a c++ extension library (e.g. functorch) without actually importing torch.
I am not sure if this is actually possible, since we need to pass setup.py a BuildExtension object somehow
### Versions
main
cc @malfet @zou3519
| 0 |
5,151 | 82,109 |
Move functorch tests to under test/
|
module: tests, triaged
|
## Issue description
The functorch tests are currently under `functorch/test/*`. PyTorch's test infra assumes all tests exist under `test/*`. Here are a couple of problems we ran into:
- The test names in test-reports are awkward (see attached image)
- Smart test sharding may not work (because the test names are awkward)
- flaky test reporting may not work (if they depend on the test-reports file)
- Linters for tests don't work
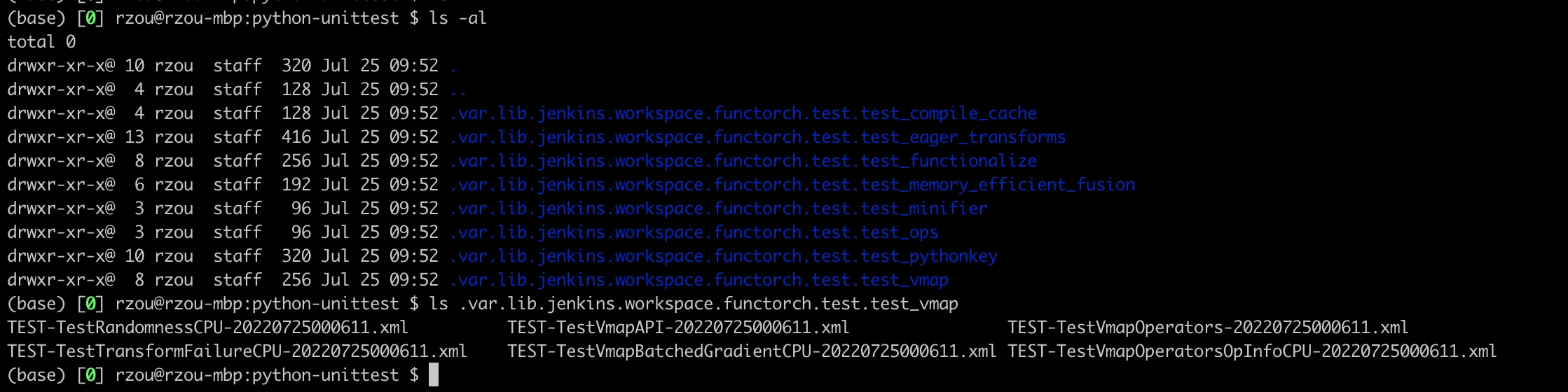
## The fix
We should just move functorch tests to under `test/*`. We can do this once functorch fully commits to being a part of PyTorch and we turn off the sync to https://github.com/pytorch/functorch. This should happen in 1-2 months.
cc @mruberry @janeyx99
| 0 |
5,152 | 82,099 |
UserWarning: operator() sees varying value in profiling
|
oncall: jit
|
### 🐛 Describe the bug
Hello, I have a problem with the following code, causing a warning when executed with `torch.jit.script`. The code seems to work ok, I just find that the warning is a bit weird.
This is a minimal example to reproduce the bug.
```python
from typing import Dict
import torch
import torch.nn as nn
from torch import Tensor
class MyModule(nn.Module):
def forward(self, x: Tensor) -> Tensor:
x = x.permute(0, 2, 3, 1).contiguous()
x = x.view(x.size(0), -1, x.size(3))
return x
class AnotherModule(nn.Module):
def __init__(self) -> None:
super().__init__()
self._my_module = MyModule()
def forward(self, x: Dict[str, Tensor]) -> Dict[str, Tensor]:
return {key: self._my_module(x[key]) for key in x}
if __name__ == "__main__":
model = AnotherModule()
model: AnotherModule = torch.jit.script(model) # type: ignore
out = model(
{
"a": torch.rand(1, 5, 32, 32),
"b": torch.rand(1, 3, 32, 32),
"c": torch.rand(1, 5, 32, 32),
}
)
print({k: v.shape for k, v in out.items()})
```
Spefically, I get this warning:
```
/home/luca/venvs/dev38/lib/python3.8/site-packages/torch/nn/modules/module.py:1130: UserWarning: operator() sees varying value in profiling, ignoring and this should be handled by GUARD logic (Triggered internally at ../torch/csrc/jit/codegen/cuda/parser.cpp:3513.)
return forward_call(*input, **kwargs)
```
Some insight on the bug:
- The warning appears only when using `torch.jit.script`: if I comment the line in which jit compilation is called everything works fine.
- It seems to be caused by the forward method of `MyModule`, if I uncomment at least one line of the `forward` method, no warning is raised.
- It also has interactions with the second dimension of input tensors in the dictionary with keys "a", "b" and "c". If they have the same number of channes, no warning is raised. 👀
- I cannot reproduce this with previous versions of PyTorch.
Another question: is it safe to ignore this kind of warning?
### Versions
PyTorch version: 1.12.0+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] pytorch-lightning==1.6.5
[pip3] torch==1.12.0+cu116
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.13.0+cu116
[conda] Could not collect
| 2 |
5,153 | 82,098 |
[feature request] Discover actually loaded shared libraries at runtime
|
module: build, triaged, enhancement
|
### 🚀 The feature, motivation and pitch
Sometimes it's useful for debugging linking / library loading (e.g. for related: https://github.com/pytorch/pytorch/issues/78489) to be able to find actually loaded shared dependency library full paths (libcudnn.so, libcublas.so and others) at runtime. In Unix systems, it often can be done by scanning via `/proc/$PID/maps`. But maybe some mechanism also exists in Mac/Windows.
So, having a simple API method would be nice for this (and then it could be reused in collect_env and in error messages complaining about bad library versions being loaded)
Also, seems one can retrieve some library paths via `torch.utils.cpp_extension(fromlist=[None]).library_paths()`
### Alternatives
_No response_
### Additional context
_No response_
cc @malfet @seemethere
| 3 |
5,154 | 82,095 |
torch.concat type hints fail for keyword argument
|
module: typing, triaged
|
### 🐛 Describe the bug
Using a keyword version of passing the axis to `torch.concat` causes type checkers (mypy, pyright) to reject working code:
```python
import torch
a = (torch.randn([42]), torch.randn([42]))
torch.concat(a, 0) # works fine!
torch.concat(a, dim=0) # works fine!
torch.concat(a, axis=0) # error: No overload variant matches argument types "Tuple[Tensor, Tensor]", "int"
```
### Versions
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 11.6.6 (x86_64)
GCC version: Could not collect
Clang version: 13.0.0 (clang-1300.0.29.30)
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.5 (default, Sep 4 2020, 02:22:02) [Clang 10.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.961
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.12.0
[conda] blas 1.0 mkl defaults
[conda] cpuonly 1.0 0 pytorch
[conda] mkl 2019.4 233 defaults
[conda] mkl-service 2.3.0 py38hfbe908c_0 defaults
[conda] mkl_fft 1.2.0 py38hc64f4ea_0 defaults
[conda] mkl_random 1.1.1 py38h959d312_0 defaults
[conda] numpy 1.22.4 pypi_0 pypi
[conda] torch 1.12.0 pypi_0 pypi
cc @ezyang @malfet @rgommers @xuzhao9 @gramster
| 1 |
5,155 | 82,093 |
When using libtorch v1.10.2, calling at::slow_conv_dilated3d directly returns wrong results on cpu backend
|
module: cpp, module: convolution, triaged
|
### 🐛 Describe the bug
When using libtorch v1.10.2, calling at::slow_conv_dilated3d directly returns wrong results
~~~c++
#include <c10/util/Optional.h>
#include <torch/torch.h>
#include <tuple>
int main()
{
auto device = torch::kCPU;
std::vector<int64_t> input_size = {2, 2, 2, 2};
std::vector<int64_t> kernel_size = {2, 2, 2};
std::vector<int64_t> weight_size = {3,2, 2, 2, 2};
at::Tensor input = torch::tensor(
{{{{-0.6171, 1.9573}, {-0.9776, -0.4388}},
{{0.0830 ,0.3295}, {1.1376 ,1.4564}}},
{{{-0.7016, 1.2533}, {-0.2551, 0.3261}},
{{1.3227, -0.1871}, {-1.0956, -1.0137}}}},device);
at::Tensor weight = torch::tensor(
{{{{{-0.4548, - 0.1107}, {0.0223, - 1.2321}},
{{1.1203, 1.7528}, {1.7692, - 0.9271}}},
{{{1.3980, - 0.7515}, {1.2593, 1.0403}},
{{0.3530, - 0.7153}, {1.7454 ,0.9942}}}},
{{{{-0.7186, - 0.2611}, {0.6274 ,0.6565}},
{{-1.4249, - 0.6673}, {-0.7796, - 1.1311}}},
{{{0.3173, - 0.1052}, {-0.3449, 0.4073}},
{{-0.7267, 0.0879}, {2.5294, 0.0152}}}},
{{{{-1.3843, 1.6123}, {0.2952 ,- 0.7957}},
{{-0.1807, 0.3354}, {0.8913 ,- 0.3995}}},
{{{1.0847 ,0.5221}, {-0.3060 ,- 0.7522}},
{{0.0249 ,- 0.5351}, {1.1408, 0.6337}}}}},device);
at::Tensor bias_opt = torch::tensor({-0.8054,-1.1183,0.1813},device);
std::vector<int64_t> stride_size = {1, 1, 1};
std::vector<int64_t> dilation_size = {1, 1, 1};
std::vector<int64_t> pad_size = {1, 1, 1};
at::Tensor output_ref = at::slow_conv_dilated3d(
input,
weight,
kernel_size,
bias_opt,
stride_size,
pad_size,
dilation_size);
std::cout<<"\noutput_ref\n"<<output_ref;
}
~~~
CmakeLists.txt
~~~
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(test)
SET(CMAKE_BUILD_TYPE "Release")
find_package(Torch REQUIRED)
add_executable(cuda_abs testForNaiveDilatedConv.cpp)
target_link_libraries(cuda_abs "${TORCH_LIBRARIES}")
set_property(TARGET cuda_abs PROPERTY CXX_STANDARD 14)
~~~
compile commands
~~~
cmake -DCMAKE_PREFIX_PATH=<your path>/libtorch/share/cmake ../
~~~
output
~~~
Scanning dependencies of target test
[ 50%] Building CXX object CMakeFiles/cuda_abs.dir/testForNaiveDilatedConv.cpp.o
[100%] Linking CXX executable test
[100%] Built target cuda_abs
$ ./test
output_ref
(1,1,.,.) =
-0.9308 -3.6903 4.8450
-0.7325 -0.6539 1.6226
-2.3365 -2.9930 -1.1819
(2,1,.,.) =
6.8734e-01 -3.4884e+00 1.6442e+00
-2.0979e+28 8.1139e-01 5.8812e+37
6.2993e-01 -2.0979e+28 3.8827e-01
(3,1,.,.) =
1.8436e+25 1.0901e+27 -2.0931e+28
3.9735e-01 -7.0053e-01 -3.4156e-01
-1.9138e-01 -1.5137e-01 8.7411e-02
(1,2,.,.) =
0.1502 -1.1594 0.7600
-2.5282 -3.4266 1.2549
1.9593 2.9388 0.8109
(2,2,.,.) =
5.8812e+37 4.5556e+00 5.8812e+37
-1.7533e+00 -7.7393e+00 -5.4296e+00
-5.7334e-01 -1.1839e+00 -9.1978e-01
(3,2,.,.) =
1.8238e+00 4.8299e+37 2.7452e-01
-2.2202e+00 2.5651e+00 -1.5019e+00
-7.4157e-01 -2.0979e+28 6.7274e-01
(1,3,.,.) =
1.4550 1.2482 -0.0470
-3.3633 -2.1065 -1.4742
0.8787 -1.2672 -1.8982
(2,3,.,.) =
5.9323e-01 -2.6401e-01 2.7126e-01
-2.0979e+28 1.9285e+00 9.6723e-01
-1.8177e-01 4.7473e+27 3.0881e+29
(3,3,.,.) =
5.8812e+37 -5.0169e-01 -2.0979e+28
7.4332e-01 5.8812e+37 8.1047e-02
5.8812e+37 -9.4428e-01 -3.1157e+00
~~~
expected output
~~~
output
(1,1,.,.) =
-0.9308 -3.6906 4.8449
-0.7325 -0.6538 1.6225
-2.3366 -2.9932 -1.1820
(2,1,.,.) =
0.6874 -3.4885 1.6442
1.4521 0.8113 -2.5327
0.6300 1.8999 0.3883
(3,1,.,.) =
-0.1981 -1.3382 3.1744
0.3973 -0.7006 -0.3416
-0.1914 -0.1514 0.0874
(1,2,.,.) =
0.1502 -1.1594 0.7598
-2.5281 -3.4267 1.2547
1.9594 2.9389 0.8110
(2,2,.,.) =
-0.7647 4.5557 0.0656
-1.7534 -7.7397 -5.4296
-0.5733 -1.1839 -0.9197
(3,2,.,.) =
1.8238 -1.1348 0.2746
-2.2202 2.5653 -1.5019
-0.7416 1.3375 0.6729
(1,3,.,.) =
1.4550 1.2483 -0.0470
-3.3633 -2.1065 -1.4742
0.8787 -1.2673 -1.8982
(2,3,.,.) =
0.5932 -0.2640 0.2712
0.1397 1.9286 0.9672
-0.1817 -1.4388 -1.3682
(3,3,.,.) =
-1.0610 -0.5016 0.1545
0.7435 2.0281 0.0811
1.2621 -0.9443 -3.1156
~~~
### Versions
not python
is a c++ issue
output:
~~~
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (GCC) 9.4.0
Clang version: Could not collect
CMake version: version 3.15.5
Libc version: glibc-2.17
Python version: 3.7.8 (default, Jun 10 2021, 01:08:33) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] (64-bit runtime)
Python platform: Linux-5.4.0-110-generic-x86_64-with-debian-bullseye-sid
Is CUDA available: N/A
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 515.43.04
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.2
[conda] Could not collect
~~~
cc @jbschlosser
| 0 |
5,156 | 82,091 |
RuntimeError: [1] is setting up NCCL communicator and retreiving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Timeout waiting for key: default_pg/0/0 after 1800000 ms
|
oncall: distributed, triaged, module: nccl, module: c10d
|
### 🐛 Describe the bug
I am running librispeech recipe with distributed mode using slurm on esonet2. i am running on two oracle instance each one has single gpu (Tesla V100). but when i ran stage 11 it created jobs on both machine and gpu memory is also utlized but it failed after sometime.
**Basic environments:**
- OS information: Ubuntu 18.04 x86_64
- python version: python 3.9 [GCC 7.3.0]]
- espnet version: latest
- pytorch version 1.12.0
- cuda 10.2
**Task information:**
- Task: ASR
- Recipe: librispeech
- ESPnet2
**To Reproduce**
when i ran the stage 11 with slurm it showing error after sometime...
**slurm.conf**
```
#Default configuration
command sbatch --export=PATH
option name=* --job-name $0
option time=* --time $0
option mem=* --mem-per-cpu $0
option mem=0
option num_threads=* --cpus-per-task $0 --ntasks-per-node=1
option num_threads=1 --cpus-per-task 12 --ntasks-per-node=1
option num_nodes=* --nodes $0
option gpu=1 -p tgpu
option gpu=* -p tgpu --gres=gpu:$0 -c $0 # Recommend allocating more CPU than, or equal to the number of GPU
#note: the --max-jobs-run option is supported as a special case
#by slurm.pl and you don't have to handle it in the config file.
#default cpu=1
```
**$ sinfo**
```
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
tgpu* up infinite 2 idle hp-[1-2]
```
**$ scontrol show nodes**
```
NodeName=hp-1 Arch=x86_64 CoresPerSocket=1
CPUAlloc=0 CPUErr=0 CPUTot=12 CPULoad=0.34
AvailableFeatures=(null)
ActiveFeatures=(null)
Gres=gpu:1
NodeAddr=hp-1 NodeHostName=hp-1 Version=17.11
OS=Linux 5.4.0-1079-oracle https://github.com/espnet/espnet/pull/87~18.04.1-Ubuntu SMP Mon Jul 11 03:41:03 UTC 2022
RealMemory=1 AllocMem=0 FreeMem=86991 Sockets=12 Boards=1
State=IDLE ThreadsPerCore=1 TmpDisk=0 Weight=1 Owner=N/A MCS_label=N/A
Partitions=tgpu
BootTime=2022-07-24T06:57:55 SlurmdStartTime=2022-07-24T10:10:49
CfgTRES=cpu=12,mem=1M,billing=12
AllocTRES=
CapWatts=n/a
CurrentWatts=0 LowestJoules=0 ConsumedJoules=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/s
NodeName=hp-2 Arch=x86_64 CoresPerSocket=1
CPUAlloc=0 CPUErr=0 CPUTot=12 CPULoad=0.09
AvailableFeatures=(null)
ActiveFeatures=(null)
Gres=gpu:1
NodeAddr=hp-2 NodeHostName=hp-2 Version=17.11
OS=Linux 5.4.0-1079-oracle https://github.com/espnet/espnet/pull/87~18.04.1-Ubuntu SMP Mon Jul 11 03:41:03 UTC 2022
RealMemory=1 AllocMem=0 FreeMem=86953 Sockets=12 Boards=1
State=IDLE ThreadsPerCore=1 TmpDisk=0 Weight=1 Owner=N/A MCS_label=N/A
Partitions=tgpu
BootTime=2022-07-24T07:00:18 SlurmdStartTime=2022-07-24T10:15:26
CfgTRES=cpu=12,mem=1M,billing=12
AllocTRES=
CapWatts=n/a
CurrentWatts=0 LowestJoules=0 ConsumedJoules=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/s
```
**GPU utilization**
<img width="1440" alt="Screenshot 2022-07-23 at 10 50 34 PM" src="https://user-images.githubusercontent.com/49410142/180714417-e0e04fdb-ec6f-4074-9ac1-3dd4979e6711.png">
**Error logs**
```
#Running on hp-1
#Started at Sat Jul 23 17:17:24 UTC 2022
#SLURMD_NODENAME=hp-1
#SLURM_CHECKPOINT_IMAGE_DIR=/var/slurm/checkpoint
#SLURM_CLUSTER_NAME=cluster
#SLURM_CPUS_ON_NODE=12
#SLURM_CPUS_PER_TASK=12
#SLURM_EXPORT_ENV=PATH
#SLURM_GET_USER_ENV=1
#SLURM_GTIDS=0
#SLURM_JOBID=70
#SLURM_JOB_CPUS_PER_NODE='12(x2)'
#SLURM_JOB_GID=1001
#SLURM_JOB_ID=70
#SLURM_JOB_NAME=test
#SLURM_JOB_NODELIST='hp-[1-2]'
#SLURM_JOB_NUM_NODES=2
#SLURM_JOB_PARTITION=tgpu
#SLURM_JOB_UID=1001
#SLURM_JOB_USER=ubuntu
#SLURM_LOCALID=0
#SLURM_NNODES=2
#SLURM_NODEID=0
#SLURM_NODELIST='hp-[1-2]'
#SLURM_NODE_ALIASES='(null)'
#SLURM_NPROCS=2
#SLURM_NTASKS=2
#SLURM_NTASKS_PER_NODE=1
#SLURM_OPEN_MODE=a
#SLURM_PRIO_PROCESS=0
#SLURM_PROCID=0
#SLURM_SUBMIT_DIR=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1
#SLURM_SUBMIT_HOST=hp-1
#SLURM_TASKS_PER_NODE='1(x2)'
#SLURM_TASK_PID=28524
#SLURM_TOPOLOGY_ADDR=hp-1
#SLURM_TOPOLOGY_ADDR_PATTERN=node
#SLURM_WORKING_CLUSTER=cluster:155.248.167.102:6817:8192
#srun --export=ALL srun -N2 python3 -m espnet2.bin.asr_train --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/.dist_init_+SJraOwsjSi9F2aB --use_preprocessor true --bpemodel /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/bpe.model --token_type bpe --token_list /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/tokens.txt --non_linguistic_symbols none --cleaner none --g2p none --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/wav.scp,speech,sound --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/text,text,text --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/speech_shape --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/text_shape.bpe --resume false --init_param --ignore_init_mismatch false --fold_length 80000 --fold_length 150 --output_dir exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm --config /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/conf/cf2.yaml --frontend_conf fs=8k --normalize=global_mvn --normalize_conf stats_file=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/feats_stats.npz --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/wav.scp,speech,sound --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/text,text,text --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/speech_shape --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/text_shape.bpe --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm/.dist_init_a71d8596-0515-49d8-8cff-e85faece2c90
/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3 /home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/.dist_init_+SJraOwsjSi9F2aB --use_preprocessor true --bpemodel /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/bpe.model --token_type bpe --token_list /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/tokens.txt --non_linguistic_symbols none --cleaner none --g2p none --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/wav.scp,speech,sound --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/text,text,text --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/speech_shape --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/text_shape.bpe --resume false --init_param --ignore_init_mismatch false --fold_length 80000 --fold_length 150 --output_dir exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm --config /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/conf/cf2.yaml --frontend_conf fs=8k --normalize=global_mvn --normalize_conf stats_file=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/feats_stats.npz --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/wav.scp,speech,sound --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/text,text,text --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/speech_shape --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/text_shape.bpe --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm/.dist_init_a71d8596-0515-49d8-8cff-e85faece2c90
/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3 /home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/.dist_init_+SJraOwsjSi9F2aB --use_preprocessor true --bpemodel /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/bpe.model --token_type bpe --token_list /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/tokens.txt --non_linguistic_symbols none --cleaner none --g2p none --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/wav.scp,speech,sound --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/text,text,text --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/speech_shape --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/text_shape.bpe --resume false --init_param --ignore_init_mismatch false --fold_length 80000 --fold_length 150 --output_dir exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm --config /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/conf/cf2.yaml --frontend_conf fs=8k --normalize=global_mvn --normalize_conf stats_file=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/feats_stats.npz --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/wav.scp,speech,sound --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/text,text,text --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/speech_shape --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/text_shape.bpe --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm/.dist_init_a71d8596-0515-49d8-8cff-e85faece2c90
/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3 /home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/.dist_init_+SJraOwsjSi9F2aB --use_preprocessor true --bpemodel /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/bpe.model --token_type bpe --token_list /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/tokens.txt --non_linguistic_symbols none --cleaner none --g2p none --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/wav.scp,speech,sound --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/text,text,text --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/speech_shape --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/text_shape.bpe --resume false --init_param --ignore_init_mismatch false --fold_length 80000 --fold_length 150 --output_dir exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm --config /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/conf/cf2.yaml --frontend_conf fs=8k --normalize=global_mvn --normalize_conf stats_file=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/feats_stats.npz --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/wav.scp,speech,sound --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/text,text,text --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/speech_shape --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/text_shape.bpe --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm/.dist_init_a71d8596-0515-49d8-8cff-e85faece2c90
/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3 /home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/.dist_init_+SJraOwsjSi9F2aB --use_preprocessor true --bpemodel /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/bpe.model --token_type bpe --token_list /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/data/en_token_list/bpe_unigram5000/tokens.txt --non_linguistic_symbols none --cleaner none --g2p none --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/wav.scp,speech,sound --valid_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/dev/text,text,text --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/speech_shape --valid_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//valid/text_shape.bpe --resume false --init_param --ignore_init_mismatch false --fold_length 80000 --fold_length 150 --output_dir exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm --config /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/conf/cf2.yaml --frontend_conf fs=8k --normalize=global_mvn --normalize_conf stats_file=/home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/feats_stats.npz --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/wav.scp,speech,sound --train_data_path_and_name_and_type /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/dump/raw/train_100/text,text,text --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/speech_shape --train_shape_file /home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_stats_raw_en_bpe5000//train/text_shape.bpe --ngpu 1 --multiprocessing_distributed true --dist_launcher slurm --dist_init_method file:///home/ubuntu/users/himanshu/espnet/egs2/librispeech/asr1/exp/asr_conformer_lr2e-3_8k_nospec_warmup25k_amp_nondeterministic_slurm/.dist_init_a71d8596-0515-49d8-8cff-e85faece2c90
WARNING:root:Using legacy_rel_pos and it will be deprecated in the future.
WARNING:root:Using legacy_rel_pos and it will be deprecated in the future.
WARNING:root:Using legacy_rel_pos and it will be deprecated in the future.
WARNING:root:Using legacy_rel_pos and it will be deprecated in the future.
WARNING:root:Using legacy_rel_selfattn and it will be deprecated in the future.
WARNING:root:Using legacy_rel_selfattn and it will be deprecated in the future.
WARNING:root:Using legacy_rel_selfattn and it will be deprecated in the future.
WARNING:root:Using legacy_rel_selfattn and it will be deprecated in the future.
hp-1:28603:28603 [0] NCCL INFO Bootstrap : Using ens3:10.0.0.27<0>
hp-1:28603:28603 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
hp-1:28603:28603 [0] misc/ibvwrap.cc:63 NCCL WARN Failed to open libibverbs.so[.1]
hp-1:28603:28603 [0] NCCL INFO NET/Socket : Using [0]ens3:10.0.0.27<0>
hp-1:28603:28603 [0] NCCL INFO Using network Socket
NCCL version 2.10.3+cuda10.2
hp-1:28608:28608 [0] NCCL INFO Bootstrap : Using ens3:10.0.0.27<0>
hp-1:28608:28608 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
hp-1:28608:28608 [0] misc/ibvwrap.cc:63 NCCL WARN Failed to open libibverbs.so[.1]
hp-1:28608:28608 [0] NCCL INFO NET/Socket : Using [0]ens3:10.0.0.27<0>
hp-1:28608:28608 [0] NCCL INFO Using network Socket
NCCL version 2.10.3+cuda10.2
Traceback (most recent call last):
File "/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py", line 23, in
main()
File "/home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py", line 19, in main
ASRTask.main(cmd=cmd)
File "/home/ubuntu/users/himanshu/espnet/espnet2/tasks/abs_task.py", line 1013, in main
cls.main_worker(args)
File "/home/ubuntu/users/himanshu/espnet/espnet2/tasks/abs_task.py", line 1309, in main_worker
cls.trainer.run(
File "/home/ubuntu/users/himanshu/espnet/espnet2/train/trainer.py", line 220, in run
dp_model = torch.nn.parallel.DistributedDataParallel(
File "/home/ubuntu/.local/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 646, in init
_verify_param_shape_across_processes(self.process_group, parameters)
File "/home/ubuntu/.local/lib/python3.9/site-packages/torch/distributed/utils.py", line 89, in _verify_param_shape_across_processes
return dist._verify_params_across_processes(process_group, tensors, logger)
RuntimeError: [1] is setting up NCCL communicator and retreiving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Timeout waiting for key: default_pg/0/0 after 1800000 ms
Exception raised from get at ../torch/csrc/distributed/c10d/FileStore.cpp:362 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x42 (0x7f03a5bba612 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libc10.so)
frame https://github.com/espnet/espnet/pull/1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x5b (0x7f03a5bb6cab in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libc10.so)
frame https://github.com/espnet/espnet/pull/2: c10d::FileStore::get(std::string const&) + 0xb09 (0x7f03da1ce739 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/pull/3: c10d::PrefixStore::get(std::string const&) + 0x32 (0x7f03da1d13c2 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/pull/4: c10d::PrefixStore::get(std::string const&) + 0x32 (0x7f03da1d13c2 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/issues/5: c10d::ProcessGroupNCCL::broadcastUniqueNCCLID(ncclUniqueId*, bool, std::string const&, int) + 0xb1 (0x7f03a6ffa301 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/pull/6: c10d::ProcessGroupNCCL::getNCCLComm(std::string const&, std::vector<c10::Device, std::allocatorc10::Device > const&, c10d::OpType, int, bool) + 0x204 (0x7f03a6ffe794 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/pull/7: c10d::ProcessGroupNCCL::allgather(std::vector<std::vector<at::Tensor, std::allocatorat::Tensor >, std::allocator<std::vector<at::Tensor, std::allocatorat::Tensor > > >&, std::vector<at::Tensor, std::allocatorat::Tensor >&, c10d::AllgatherOptions const&) + 0x34b (0x7f03a700c7db in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/issues/8: c10d::verify_params_across_processes(c10::intrusive_ptr<c10d::ProcessGroup, c10::detail::intrusive_target_default_null_typec10d::ProcessGroup > const&, std::vector<at::Tensor, std::allocatorat::Tensor > const&, c10::optional<std::weak_ptrc10d::Logger > const&) + 0x3f5 (0x7f03da21b825 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/issues/9: + 0x87cebc (0x7f03ef97debc in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_python.so)
frame https://github.com/espnet/espnet/pull/10: + 0x21ebc5 (0x7f03ef31fbc5 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_python.so)
frame https://github.com/espnet/espnet/pull/11: + 0x1828f4 (0x55f7867078f4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/12: _PyObject_MakeTpCall + 0x2df (0x55f7866c147f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/13: _PyEval_EvalFrameDefault + 0x49a9 (0x55f78675f2e9 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/14: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/15: _PyFunction_Vectorcall + 0x1d4 (0x55f78671ccb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/16: + 0xfe088 (0x55f786683088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/17: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/18: _PyFunction_Vectorcall + 0x244 (0x55f78671cd24 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/19: _PyObject_FastCallDictTstate + 0xee (0x55f786707a2e in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/20: + 0x18c429 (0x55f786711429 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/21: _PyObject_MakeTpCall + 0x38f (0x55f7866c152f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/22: _PyEval_EvalFrameDefault + 0x1350 (0x55f78675bc90 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/23: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/24: + 0x198709 (0x55f78671d709 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/25: + 0xfe73d (0x55f78668373d in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/26: + 0x198559 (0x55f78671d559 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/27: + 0xff300 (0x55f786684300 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/28: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/29: + 0x198709 (0x55f78671d709 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/30: + 0xfe73d (0x55f78668373d in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/31: + 0x231418 (0x55f7867b6418 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/32: + 0xfe088 (0x55f786683088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/33: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/34: PyEval_EvalCodeEx + 0x4c (0x55f7867c8a7c in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/35: PyEval_EvalCode + 0x1b (0x55f78671cdbb in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/36: + 0x27a33e (0x55f7867ff33e in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/37: + 0x1a1571 (0x55f786726571 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/38: + 0xfe088 (0x55f786683088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/39: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/40: _PyFunction_Vectorcall + 0x1d4 (0x55f78671ccb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/41: + 0xfe088 (0x55f786683088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/42: + 0x196fe3 (0x55f78671bfe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/43: _PyFunction_Vectorcall + 0x1d4 (0x55f78671ccb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/44: _PyObject_Call + 0x1da (0x55f7866cb30a in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/45: + 0x274eaa (0x55f7867f9eaa in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/46: Py_RunMain + 0x18f (0x55f7867fec0f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/47: Py_BytesMain + 0x39 (0x55f7867feff9 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/48: __libc_start_main + 0xe7 (0x7f0416b22c87 in /lib/x86_64-linux-gnu/libc.so.6)
frame https://github.com/espnet/espnet/pull/49: + 0x2016a0 (0x55f7867866a0 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
Traceback (most recent call last):
File "/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py", line 23, in
main()
File "/home/ubuntu/users/himanshu/espnet/espnet2/bin/asr_train.py", line 19, in main
ASRTask.main(cmd=cmd)
File "/home/ubuntu/users/himanshu/espnet/espnet2/tasks/abs_task.py", line 1013, in main
cls.main_worker(args)
File "/home/ubuntu/users/himanshu/espnet/espnet2/tasks/abs_task.py", line 1309, in main_worker
cls.trainer.run(
File "/home/ubuntu/users/himanshu/espnet/espnet2/train/trainer.py", line 220, in run
dp_model = torch.nn.parallel.DistributedDataParallel(
File "/home/ubuntu/.local/lib/python3.9/site-packages/torch/nn/parallel/distributed.py", line 646, in init
_verify_param_shape_across_processes(self.process_group, parameters)
File "/home/ubuntu/.local/lib/python3.9/site-packages/torch/distributed/utils.py", line 89, in _verify_param_shape_across_processes
return dist._verify_params_across_processes(process_group, tensors, logger)
RuntimeError: [1] is setting up NCCL communicator and retreiving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Timeout waiting for key: default_pg/0/0 after 1800000 ms
Exception raised from get at ../torch/csrc/distributed/c10d/FileStore.cpp:362 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x42 (0x7fa47e37a612 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libc10.so)
frame https://github.com/espnet/espnet/pull/1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x5b (0x7fa47e376cab in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libc10.so)
frame https://github.com/espnet/espnet/pull/2: c10d::FileStore::get(std::string const&) + 0xb09 (0x7fa4b298e739 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/pull/3: c10d::PrefixStore::get(std::string const&) + 0x32 (0x7fa4b29913c2 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/pull/4: c10d::PrefixStore::get(std::string const&) + 0x32 (0x7fa4b29913c2 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/issues/5: c10d::ProcessGroupNCCL::broadcastUniqueNCCLID(ncclUniqueId*, bool, std::string const&, int) + 0xb1 (0x7fa47f7ba301 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/pull/6: c10d::ProcessGroupNCCL::getNCCLComm(std::string const&, std::vector<c10::Device, std::allocatorc10::Device > const&, c10d::OpType, int, bool) + 0x204 (0x7fa47f7be794 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/pull/7: c10d::ProcessGroupNCCL::allgather(std::vector<std::vector<at::Tensor, std::allocatorat::Tensor >, std::allocator<std::vector<at::Tensor, std::allocatorat::Tensor > > >&, std::vector<at::Tensor, std::allocatorat::Tensor >&, c10d::AllgatherOptions const&) + 0x34b (0x7fa47f7cc7db in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cuda.so)
frame https://github.com/espnet/espnet/issues/8: c10d::verify_params_across_processes(c10::intrusive_ptr<c10d::ProcessGroup, c10::detail::intrusive_target_default_null_typec10d::ProcessGroup > const&, std::vector<at::Tensor, std::allocatorat::Tensor > const&, c10::optional<std::weak_ptrc10d::Logger > const&) + 0x3f5 (0x7fa4b29db825 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
frame https://github.com/espnet/espnet/issues/9: + 0x87cebc (0x7fa4c813debc in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_python.so)
frame https://github.com/espnet/espnet/pull/10: + 0x21ebc5 (0x7fa4c7adfbc5 in /home/ubuntu/.local/lib/python3.9/site-packages/torch/lib/libtorch_python.so)
frame https://github.com/espnet/espnet/pull/11: + 0x1828f4 (0x559e091508f4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/12: _PyObject_MakeTpCall + 0x2df (0x559e0910a47f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/13: _PyEval_EvalFrameDefault + 0x49a9 (0x559e091a82e9 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/14: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/15: _PyFunction_Vectorcall + 0x1d4 (0x559e09165cb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/16: + 0xfe088 (0x559e090cc088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/17: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/18: _PyFunction_Vectorcall + 0x244 (0x559e09165d24 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/19: _PyObject_FastCallDictTstate + 0xee (0x559e09150a2e in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/20: + 0x18c429 (0x559e0915a429 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/21: _PyObject_MakeTpCall + 0x38f (0x559e0910a52f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/22: _PyEval_EvalFrameDefault + 0x1350 (0x559e091a4c90 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/23: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/24: + 0x198709 (0x559e09166709 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/25: + 0xfe73d (0x559e090cc73d in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/26: + 0x198559 (0x559e09166559 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/27: + 0xff300 (0x559e090cd300 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/28: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/29: + 0x198709 (0x559e09166709 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/30: + 0xfe73d (0x559e090cc73d in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/31: + 0x231418 (0x559e091ff418 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/32: + 0xfe088 (0x559e090cc088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/33: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/34: PyEval_EvalCodeEx + 0x4c (0x559e09211a7c in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/35: PyEval_EvalCode + 0x1b (0x559e09165dbb in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/36: + 0x27a33e (0x559e0924833e in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/37: + 0x1a1571 (0x559e0916f571 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/issues/38: + 0xfe088 (0x559e090cc088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/39: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/40: _PyFunction_Vectorcall + 0x1d4 (0x559e09165cb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/41: + 0xfe088 (0x559e090cc088 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/42: + 0x196fe3 (0x559e09164fe3 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/43: _PyFunction_Vectorcall + 0x1d4 (0x559e09165cb4 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/44: _PyObject_Call + 0x1da (0x559e0911430a in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/45: + 0x274eaa (0x559e09242eaa in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/46: Py_RunMain + 0x18f (0x559e09247c0f in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/47: Py_BytesMain + 0x39 (0x559e09247ff9 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
frame https://github.com/espnet/espnet/pull/48: __libc_start_main + 0xe7 (0x7fa4ef2e2c87 in /lib/x86_64-linux-gnu/libc.so.6)
frame https://github.com/espnet/espnet/pull/49: + 0x2016a0 (0x559e091cf6a0 in /home/ec2-user/SageMaker/espnet_env1/envs/espnet_env1/bin/python3)
srun: error: hp-2: task 1: Exited with exit code 1
srun: error: hp-2: task 1: Exited with exit code 1
srun: Job step aborted: Waiting up to 32 seconds for job step to finish.
srun: Job step aborted: Waiting up to 32 seconds for job step to finish.
srun: got SIGCONT
srun: forcing job termination
srun: got SIGCONT
srun: Job step aborted: Waiting up to 32 seconds for job step to finish.
srun: got SIGCONT
slurmstepd-hp-1: error: *** STEP 70.2 ON hp-1 CANCELLED AT 2022-07-23T18:02:02 ***
srun: forcing job termination
slurmstepd-hp-1: error: *** STEP 70.1 ON hp-1 CANCELLED AT 2022-07-23T18:02:02 ***
slurmstepd-hp-1: error: *** STEP 70.0 ON hp-1 CANCELLED AT 2022-07-23T18:02:02 ***
srun: forcing job termination
```
### Versions
Collecting environment information...
PyTorch version: 1.12.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.27
Python version: 3.9.12 (main, Jun 1 2022, 11:38:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1079-oracle-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: 9.1.85
GPU models and configuration: GPU 0: Tesla V100-SXM2-16GB
Nvidia driver version: 470.129.06
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] pytorch-ranger==0.1.1
[pip3] pytorch-wpe==0.0.1
[pip3] torch==1.12.0
[pip3] torch-complex==0.4.3
[pip3] torch-optimizer==0.3.0
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.4 pypi_0 pypi
[conda] numpy-base 1.22.3 py39hf524024_0
[conda] pytorch 1.11.0 py3.9_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-ranger 0.1.1 pypi_0 pypi
[conda] pytorch-wpe 0.0.1 pypi_0 pypi
[conda] torch-complex 0.4.3 pypi_0 pypi
[conda] torch-optimizer 0.3.0 pypi_0 pypi
[conda] torchaudio 0.11.0 py39_cu102 pytorch
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501
| 8 |
5,157 | 82,088 |
linear.matrix_power is not composite compliant
|
triaged, module: linear algebra
|
### 🐛 Describe the bug
You have to patch in https://github.com/pytorch/pytorch/pull/81984 to see the error. It's kind of annoying to guess and check what the actual composite compliance error is.
Repro command
```
python test/test_ops.py -k test_operator_linalg_matrix_power
```
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano @zou3519
### Versions
master
| 3 |
5,158 | 82,084 |
Untangle TorchScript prim ops in aten namespace
|
oncall: jit
|
### 🐛 Describe the bug
Did you know aten::size.default is an op? It's not defined anywhere in native_functions.yaml. In fact, it gets indirectly registered as part of TorchScript prim registrations (despite not actually living in the prim namespace, which is where most of these are supposed to go). These ended up being relied upon by non-TS users for customizable sizes/strides. Let's properly put these in native_functions.yaml so they are handled the same way as other ops.
### Versions
master
| 0 |
5,159 | 82,081 |
Could be clearer that Cross Entropy takes logits as input
|
module: docs, module: nn, module: loss, triaged, actionable
|
### 📚 The doc issue
Hi, I felt that it could be made a bit more clear that the cross entropy function is taking logits in as input. Right now, the documentation is correct but I felt that it could be a bit more clear. It says that the input is required to take "raw, unnormalized scores for each class", but for me when reading that, I was a bit uncertain about what that meant. Then I scrolled down a bit more and saw that (target) would take in probabilities as input and incorrectly started to believe that cross entropy takes probabilities as input. Especially since that is the normal mathematical definition of cross entropy, I think it would be nice to be more clear; a lot of people will assume that it takes probabilities and get confused; I noticed that this question has a lot of upvotes
https://stackoverflow.com/questions/49390842/cross-entropy-in-pytorch on stackoverflow
### Suggest a potential alternative/fix
Instead of
`The input is expected to contain raw, unnormalized scores for each class.`
it could say
`The input is expected to contain the logits for each class (which do not need to be positive or sum to 1, in general). This class will compute a softmax followed by cross entropy to compute the final loss.`
Of course, if one reads the documentation carefully enough (e.g. the formulas) they will eventually figure it out, but if you come in with bad assumptions like me and don't read carefully then you might spend a really long time trying to debug your model! Since it's a popular page I think it's worth it to be super clear
cc @svekars @holly1238 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
5,160 | 82,077 |
Using DDP with num_workers > 0 hangs before entering the first training epoch loop
|
oncall: distributed, module: dataloader
|
### 🐛 Describe the bug
I am trying to use DDP on a 8 GPU cluster with a data loader with num workers > 0. My code seemed to be running fine yesterday but today I have been unable to get it to work. Each time, the code hangs right before the training loop begins (it gets through the `running_epoch_loss=0` line below. The loop itself is simple and the data loading seems to work properly beforehand.
# stuff related to device
nb = run_d["non_blocking"]
loss_func = torch.nn.CrossEntropyLoss()
loss_func.cuda(gpu)
# train
torch.enable_grad()
model.train()
loss_arr = [0, 0]
running_epoch_loss = 0
for i, b in tqdm(enumerate(dl_d), desc=f"> training - epoch:{epoch}", total=len(dl_d)):
batch = generate_pretraining_inputs(b, nb=nb)
outputs = model(**batch)
loss = outputs.loss.mean()
loss.backward()
optimizer.step()
optimizer.zero_grad()
The data loading script is here:
data_path = Path(data_d["data_path"])
assert data_path.is_file()
train_data = NotesforPT(data_path)
print(f"Train Data Loaded: {len(train_data)}")
tokenizer = Tokenizer.from_pretrained("bert-base-uncased")
model_dict = {"tokenizer": tokenizer, "max_length": model_d["max_length"], 'config_file': model_d['config_file']}
model = BERTforPreTraining(**model_dict)
collate = model.collate_fn
model.cuda(gpu)
if rank == 0:
print(f"Model Parameters: {count_parameters(model)}")
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data, num_replicas=args.world_size, rank=rank, drop_last=True)
train_loader = torch.utils.data.DataLoader(
dataset=train_data,
batch_size=run_d["batch_size"],
shuffle=False,
num_workers=4,
pin_memory=True,
collate_fn=collate,
sampler=train_sampler,
)
return train_data, train_loader, model
When I set num_workers=0 the code runs, but it is too slow for my needs. I've seen various comments on this issue in the forums, but no definitive answer and the suggestions have not worked for me, including ensuring that the data can be evenly split with the batch size and num_workers values as well as setting NCCL_P2P_DISABLE=1. Additionally, running the same script with 1 GPU also does not fix the problem, so it seems to definitely be a num_workers issue. Any help is appreciated!
### Versions
PyTorch version: 1.13.0.dev20220724+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Amazon Linux release 2 (Karoo) (x86_64)
GCC version: (GCC) 7.3.1 20180712 (Red Hat 7.3.1-15)
Clang version: Could not collect
CMake version: version 2.8.12.2
Libc version: glibc-2.26
Python version: 3.8.5 (default, Feb 18 2021, 01:24:20) [GCC 7.3.1 20180712 (Red Hat 7.3.1-12)] (64-bit runtime)
Python platform: Linux-5.10.112-108.499.amzn2.x86_64-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.103.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.13.0.dev20220724+cu116
[pip3] torch-tb-profiler==0.4.0
[pip3] torchaudio==0.12.0+cu113
[pip3] torchvision==0.14.0.dev20220724+cu116
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @SsnL @VitalyFedyunin @ejguan @NivekT
| 9 |
5,161 | 82,076 |
Autocast documentation examples would break
|
module: docs, triaged, module: amp (automated mixed precision)
|
### 📚 The doc issue
In the `torch.autocast` [API reference](https://pytorch.org/docs/stable/amp.html#autocasting) we have several examples of autocasting that use simply `with autocast()`, e.g.
https://github.com/pytorch/pytorch/blob/594652f0e494caadac1076ab58e66af6823c3a83/torch/amp/autocast_mode.py#L44
However, since `torch.autocast` requires an argument `device_type`, this would fail with
```
__init__() missing 1 required positional argument: 'device_type'
```
Another point of confusion that I have is why is `torch.autocast` defined in the `torch.amp.autocast_mode` file?
### Suggest a potential alternative/fix
Shall we update these docs to: `with torch.autocast("cuda")`?
cc @svekars @holly1238 @mcarilli @ptrblck
| 2 |
5,162 | 82,073 |
CUDACachingAllocator should be cuda memory merge/compact friendly
|
module: cuda, triaged, module: CUDACachingAllocator
|
### 🚀 The feature, motivation and pitch
I found iteration latency for VIT huge increased greatly in big batch size(64), used nsight to profile it:
. we can see several cudaFrees and one cuda malloc.
When this happens, cuda doesn't have free memory available, so allocator should free blocks to let cuda merge adjacent blocks and make current malloc success. Currently CUDACachingAllocator will release all non split blocks(release_cached_blocks) when can't find one oversize blocks(release_available_cached_blocks). This behavior causes huge impact.
So I propose:
1. Reduce cudaFrees by letting allocator release appropriate blocks that are concisely enough to let cuda compact these blocks and make malloc success.
2. For further optimization, we can avoid cudaMalloc by managing cuda memory in caching allocator? We assume pytorch is using GPU exclusively in training scenario
### Alternatives
_No response_
### Additional context
_No response_
cc @ngimel
| 1 |
5,163 | 82,072 |
cant build with USE_VULKAN=1
|
high priority, module: build, triaged, oncall: mobile, module: vulkan
|
### 🐛 Describe the bug
trying to build with vulkan enabled
```
USE_CUDA=0 USE_VULKAN=1 USE_VULKAN_SHADERC_RUNTIME=1 USE_VULKAN_WRAPPER=0 python setup.py install
```
i get
```
Building wheel torch-1.13.0a0+git17730ac
-- Building version 1.13.0a0+git17730ac
cmake --build . --target install --config Release
[3/899] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp.o
FAILED: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp.o
/usr/bin/c++ -DAT_PER_OPERATOR_HEADERS -DBUILD_ONEDNN_GRAPH -DCPUINFO_SUPPORTED_PLATFORM=1 -DFMT_HEADER_ONLY=1 -DFXDIV_USE_INLINE_ASSEMBLY=0 -DHAVE_MALLOC_USABLE_SIZE=1 -DHAVE_MMAP=1 -DHAVE_SHM_OPEN=1 -DHAVE_SHM_UNLINK=1 -DMINIZ_DISABLE_ZIP_READER_CRC32_CHECKS -DNNP_CONVOLUTION_ONLY=0 -DNNP_INFERENCE_ONLY=0 -DONNXIFI_ENABLE_EXT=1 -DONNX_ML=1 -DONNX_NAMESPACE=onnx_torch -DUSE_C10D_GLOO -DUSE_C10D_MPI -DUSE_DISTRIBUTED -DUSE_EXTERNAL_MZCRC -DUSE_RPC -DUSE_TENSORPIPE -D_FILE_OFFSET_BITS=64 -Dtorch_cpu_EXPORTS -Iaten/src -I../aten/src -I. -I../ -I../cmake/../third_party/benchmark/include -I../third_party/onnx -Ithird_party/onnx -I../third_party/foxi -Ithird_party/foxi -I../torch/csrc/api -I../torch/csrc/api/include -I../caffe2/aten/src/TH -Icaffe2/aten/src/TH -Icaffe2/aten/src -Icaffe2/../aten/src -I../torch/csrc -I../third_party/miniz-2.1.0 -I../third_party/kineto/libkineto/include -I../third_party/kineto/libkineto/src -I../torch/csrc/distributed -Ivulkan -I../aten/../third_party/catch/single_include -I../aten/src/ATen/.. -I../third_party/FXdiv/include -I../c10/.. -I../third_party/pthreadpool/include -I../third_party/cpuinfo/include -I../third_party/QNNPACK/include -I../aten/src/ATen/native/quantized/cpu/qnnpack/include -I../aten/src/ATen/native/quantized/cpu/qnnpack/src -I../third_party/cpuinfo/deps/clog/include -I../third_party/NNPACK/include -I../third_party/fbgemm/include -I../third_party/fbgemm -I../third_party/fbgemm/third_party/asmjit/src -I../third_party/ittapi/src/ittnotify -I../third_party/FP16/include -I../third_party/tensorpipe -Ithird_party/tensorpipe -I../third_party/tensorpipe/third_party/libnop/include -I../third_party/fmt/include -Ithird_party/ideep/mkl-dnn/third_party/oneDNN/include -I../third_party/ideep/mkl-dnn/third_party/oneDNN/src/../include -I../third_party/flatbuffers/include -isystem third_party/gloo -isystem ../cmake/../third_party/gloo -isystem ../cmake/../third_party/googletest/googlemock/include -isystem ../cmake/../third_party/googletest/googletest/include -isystem ../third_party/protobuf/src -isystem ../third_party/gemmlowp -isystem ../third_party/neon2sse -isystem ../third_party/XNNPACK/include -isystem ../third_party/ittapi/include -isystem ../cmake/../third_party/eigen -isystem /usr/lib/x86_64-linux-gnu/openmpi/include/openmpi -isystem /usr/lib/x86_64-linux-gnu/openmpi/include -isystem ../third_party/ideep/mkl-dnn/third_party/oneDNN/include -isystem ../third_party/ideep/include -isystem ../third_party/ideep/mkl-dnn/include -isystem include -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN -DUSE_VULKAN_API -DUSE_VULKAN_SHADERC_RUNTIME -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -fPIC -DCAFFE2_USE_GLOO -DTH_HAVE_THREAD -Wall -Wextra -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-missing-field-initializers -Wno-write-strings -Wno-unknown-pragmas -Wno-type-limits -Wno-array-bounds -Wno-sign-compare -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-missing-braces -Wno-maybe-uninitialized -fvisibility=hidden -O2 -fopenmp -DCAFFE2_BUILD_MAIN_LIB -pthread -DASMJIT_STATIC -std=gnu++14 -MD -MT caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp.o -MF caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp.o.d -o caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp.o -c ../aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp
In file included from ../aten/src/ATen/core/List.h:483,
from ../aten/src/ATen/core/ivalue_inl.h:9,
from ../aten/src/ATen/core/ivalue.h:1369,
from ../aten/src/ATen/core/function_schema.h:8,
from ../aten/src/ATen/core/function.h:3,
from ../aten/src/ATen/core/builtin_function.h:3,
from ../torch/custom_class.h:3,
from ../aten/src/ATen/native/vulkan/ops/VulkanOpContext.h:5,
from ../aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp:1:
../aten/src/ATen/core/List_inl.h: In instantiation of ‘c10::List<T>::List(std::initializer_list<_Tp>) [with T = c10::IValue]’:
../aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp:11:58: required from here
../aten/src/ATen/core/List_inl.h:42:17: error: static assertion failed: This constructor is not valid for List<IValue>. Please use c10::impl::GenericList(elementType).
static_assert(!std::is_same<T, IValue>::value, "This constructor is not valid for List<IValue>. Please use c10::impl::GenericList(elementType).");
^~~~
../aten/src/ATen/core/List_inl.h: In instantiation of ‘c10::List<T>::List(c10::ArrayRef<T>) [with T = c10::IValue]’:
../aten/src/ATen/core/List_inl.h:41:35: required from ‘c10::List<T>::List(std::initializer_list<_Tp>) [with T = c10::IValue]’
../aten/src/ATen/native/vulkan/ops/VulkanOpContext.cpp:11:58: required from here
../aten/src/ATen/core/List_inl.h:32:17: error: static assertion failed: This constructor is not valid for List<IValue>. Please use c10::impl::GenericList(elementType).
static_assert(!std::is_same<T, IValue>::value, "This constructor is not valid for List<IValue>. Please use c10::impl::GenericList(elementType).");
^~~~
[20/899] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/torch/csrc/lazy/generated/LazyNativeFunctions.cpp.o
```
### Versions
latest master
cc @ezyang @gchanan @zou3519 @malfet @seemethere
| 7 |
5,164 | 82,070 |
[FSDP] deepcopy FSDP model for EMA results in error
|
oncall: distributed, module: fsdp
|
### 🐛 Describe the bug
The model I want to train is more stably trained with EMA, I want to apply the FSDP to the model so as to train with much larger model sizes, with code like the below:
```python
import copy
import torch.distributed as dist
import torch.nn as nn
from torch.distributed.fsdp.fully_sharded_data_parallel import (
FullyShardedDataParallel as FSDP,
)
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
dist.init_process_group(backend="nccl", init_method="env://")
model = nn.Linear(3, 1024)
fsdp_model = FSDP(model, device_id=0, auto_wrap_policy=size_based_auto_wrap_policy)
fsdp_model_ema = copy.deepcopy(fsdp_model)
```
I run into the following problem:
```
(base) root@ccab4f7a6a8b4707903b4b491c065374000001:~/scripts# torchrun --nproc_per_node 1 bug_repro.py
Traceback (most recent call last):
File "bug_repro.py", line 12, in <module>
fsdp_model_ema = copy.deepcopy(fsdp_model)
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/opt/conda/lib/python3.7/copy.py", line 281, in _reconstruct
state = deepcopy(state, memo)
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/opt/conda/lib/python3.7/copy.py", line 307, in _reconstruct
value = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/opt/conda/lib/python3.7/copy.py", line 281, in _reconstruct
state = deepcopy(state, memo)
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, *rv)
File "/opt/conda/lib/python3.7/copy.py", line 307, in _reconstruct
value = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 161, in deepcopy
y = copier(memo)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parameter.py", line 56, in __deepcopy__
result = type(self)(self.data.clone(memory_format=torch.preserve_format), self.requires_grad)
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/fsdp/flatten_params_wrapper.py", line 106, in __new__
raise ValueError("An non-empty list or tuple argument is needed")
ValueError: An non-empty list or tuple argument is needed
```
Is this expected? What would be the suggested way to implement EMA with FSDP model?
### Versions
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1063-azure-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
GPU 4: Tesla V100-SXM2-32GB
GPU 5: Tesla V100-SXM2-32GB
GPU 6: Tesla V100-SXM2-32GB
GPU 7: Tesla V100-SXM2-32GB
Nvidia driver version: 470.82.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.6.4
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchmetrics==0.9.2
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.6 pypi_0 pypi
[conda] numpy-base 1.21.5 py37ha15fc14_3
[conda] pytorch 1.12.0 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-lightning 1.6.4 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.12.0 pypi_0 pypi
[conda] torchaudio 0.12.0 py37_cu113 pytorch
[conda] torchmetrics 0.9.2 pypi_0 pypi
[conda] torchvision 0.13.0 pypi_0 pypi
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @kwen2501 @ezyang
| 2 |
5,165 | 82,068 |
upsample_bilinear2d() received an invalid combination of arguments
|
module: onnx, module: nn, triaged, module: regression
|
### 🐛 Describe the bug
In the past it was possible to use a Tensor within the `scale_factor` argument, but on newer versions this code fails.
Works on every version:
```python
import torch
import torch.nn.functional as F
test_input = torch.rand(1,3,256,256)
x = F.interpolate(
input=test_input, scale_factor=0.5, mode="bilinear", align_corners=False
)
print(x.shape)
```
Does not work on 1.11 and nightly anymore, but works on 1.10.1:
```python
import torch
import torch.nn.functional as F
test_input = torch.rand(1,3,256,256)
scale = torch.Tensor([0.5])
# same with
# scale = torch.tensor(0.5)
x = F.interpolate(
input=test_input, scale_factor=scale, mode="bilinear", align_corners=False
)
print(x.shape)
```
```
x = F.interpolate(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/functional.py", line 3919, in interpolate
return torch._C._nn.upsample_bilinear2d(input, output_size, align_corners, scale_factors)
TypeError: upsample_bilinear2d() received an invalid combination of arguments - got (Tensor, NoneType, bool, list), but expected one of:
* (Tensor input, tuple of ints output_size, bool align_corners, tuple of floats scale_factors)
didn't match because some of the arguments have invalid types: (Tensor, NoneType, bool, list)
* (Tensor input, tuple of ints output_size, bool align_corners, float scales_h, float scales_w, *, Tensor out)
```
It is possible to get it working with the current nightly with a workaround:
```python
import torch
import torch.nn.functional as F
test_input = torch.rand(1,3,256,256)
scale = torch.Tensor([0.5])
x = F.interpolate(
input=test_input, scale_factor=scale.numpy()[0], mode="bilinear", align_corners=False
)
print(x.shape)
```
I would prefer it if I don't need to append this numpy suffix everywhere in my code and it did work in the past. That does not look very good. If there is a reason for this, then I would like to hear it, but I am assuming something went wrong when pytorch updated.
To make my code usable again, I need to do this:
```python
import torch
import torch.nn.functional as F
import numpy as np
test_input = torch.rand(1,3,256,256)
scale = torch.tensor(0.5)
scale = torch.Tensor([(1 / scale)]).numpy().astype(np.float64)[0]
x = F.interpolate(
input=test_input, scale_factor=scale, mode="bilinear", align_corners=False
)
print(x.shape)
```
instead of
```
scale_factor = 1.0 / scale
```
Which does not look very good. :(
### Versions
Mentioned above.
cc @ezyang @gchanan @zou3519 @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 5 |
5,166 | 82,065 |
optimize_for_mobile vulkan_prepack::conv2d_clamp_prepack
|
oncall: mobile, module: vulkan
|
### 🐛 Describe the bug
trying to convert a simple resnet18 model to mobile vulkan backend
i am being asked to report the bug `please report a bug to PyTorch. We don't have an op for vulkan_prepack::conv2d_clamp_prepack but it isn't a special case`
```python
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
print(torch.__version__)
m = torch.jit.load("ptl-models/resnet18_wd4_2_3_scripted.pt")
vm = optimize_for_mobile(m, backend='vulkan')
```
scripted.pt can be downloaded here https://drive.google.com/file/d/1crd0f-jq9GBAE0a7kKXAthgWcsHTNgYH/view?usp=sharing
```
1.12.0+cu102
Traceback (most recent call last):
File "./pt_vulkan.py", line 5, in <module>
vm = optimize_for_mobile(m, backend='vulkan')
File "./venv/lib/python3.8/site-packages/torch/utils/mobile_optimizer.py", line 67, in optimize_for_mobile
optimized_cpp_module = torch._C._jit_pass_vulkan_optimize_for_mobile(script_module._c, preserved_methods_str)
RuntimeError: 0 INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":614, please report a bug to PyTorch. We don't have an op for vulkan_prepack::conv2d_clamp_prepack but it isn't a special case. Argument types: Tensor, Tensor?, int[], int[], int[], int, NoneType, NoneType,
```
### Versions
```
PyTorch version: 1.12.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 8.4.0-3ubuntu2) 8.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 22 2022, 20:18:18) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 10.1.243
GPU models and configuration: GPU 0: Quadro RTX 5000 with Max-Q Design
Nvidia driver version: 515.48.07
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.0
[pip3] pytorchcv==0.0.67
[pip3] torch==1.12.0
[conda] Could not collect
```
| 1 |
5,167 | 82,061 |
Documentation for torch.cuda.Event(blocking=True) is wrong
|
module: docs, module: cuda, triaged
|
### 📚 The doc issue
https://pytorch.org/docs/stable/generated/torch.cuda.Event.html#torch.cuda.Event
doc states:
```
blocking (bool, optional): if ``True``, :meth:`wait` will be blocking (default: ``False``)
```
But cross referencing:
https://github.com/pytorch/pytorch/blob/30fb2c4abaaaa966999eab11674f25b18460e609/torch/csrc/cuda/Event.cpp#L48
and:
https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__EVENT.html#group__CUDART__EVENT_1g7b317e07ff385d85aa656204b971a042
[cudaEventBlockingSync](https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html#group__CUDART__TYPES_1g26509a522be9d449aa7c8c279612452d): Specifies that event should use blocking synchronization. A host thread that uses [cudaEventSynchronize()](https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__EVENT.html#group__CUDART__EVENT_1g949aa42b30ae9e622f6ba0787129ff22) to wait on an event created with this flag will block until the event actually completes.
### Suggest a potential alternative/fix
```
blocking (bool, optional): if ``True``, :meth:`synchronize` will be blocking. if ``False``, :meth:`synchronize` will cause the CPU to busy-wait until the event has completed (default: ``False``).
```
cc @ezyang @gchanan @zou3519 @svekars @holly1238 @ngimel
| 2 |
5,168 | 82,053 |
Inconsistent implementation of quant_utils:: ChooseQuantizationParams compared with fbgemm:: ChooseQuantizationParams
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
The documentation says it should use sum
https://github.com/pytorch/pytorch/blob/d576a7dc97d222ca8db5f8b876ce391866018a9c/aten/src/ATen/native/quantized/cpu/QuantUtils.h#L135-L137
> sum of absolute values of terms
However, the implementation uses `difference`:
https://github.com/pytorch/pytorch/blob/d576a7dc97d222ca8db5f8b876ce391866018a9c/aten/src/ATen/native/quantized/cpu/QuantUtils.h#L140-L143
---
Also, the comment says
https://github.com/pytorch/pytorch/blob/d576a7dc97d222ca8db5f8b876ce391866018a9c/aten/src/ATen/native/quantized/cpu/QuantUtils.h#L58
But `fbgemm` is using `sum`, not difference. See
https://github.com/pytorch/FBGEMM/blob/49061a284744423bad17162d45a9bdc56adb4739/src/QuantUtils.cc#L100-L103
```cpp
double zero_point_from_min_error =
std::abs(qmin) + std::abs(min / static_cast<double>(scale));
double zero_point_from_max_error =
std::abs(qmax) + std::abs(max / static_cast<double>(scale));
```
### Versions
The latest master.
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 3 |
5,169 | 82,041 |
[Misleading] The doc started using Tensorflow terminology in the document to explain how to use the Pytorch code.
|
module: docs, triaged
|
### 📚 The doc issue
the model must be executed in inference mode and operate on input tensors that do not collect gradient tape information (e.g., running with torch.no_grad).
### Suggest a potential alternative/fix
the model must be executed in inference mode and operate on input tensors that do not collect gradient tape information (e.g., running with torch.no_grad).
Change it to be:
the model must be executed in inference mode and operate on input tensors that does not accumulate gradient. (e.g, setting the model with torch.no_grad).
cc @svekars @holly1238
| 0 |
5,170 | 82,033 |
[PyTorch/XLA] Improve the XLA PR landing process
|
module: ci, triaged, module: xla
|
### 🚀 The feature, motivation and pitch
# Current situation
Currently to merge a XLA breaking pr, we follow these procedures
1. PyTorch/XLA merge the fix PR, which will break the PyTorch/XLA head CI
2. PyTorch PR rebased and updated the [xla_hash](https://github.com/pytorch/pytorch/blob/master/.github/ci_commit_pins/xla.txt)
3. PyTorch merge the xla break pr
4. PyTorch/XLA rerun the head CI and it should be green again
# User expericncen flaw
This process has help a lot for pytorch CI stability. However it creates quite a lot of burden on the PyTorch/XLA maintainer side because
1. PyTorch/XLA CI will be broken when fix pr merged and won't be fix until corresponding PyTorch PR merged.
2. Merging a pytorch pr is a lot more effort than merging a pytorch/xla PR. In step 2 pytorch pr needs to be rebased hence will rerun all test. Waiting for all tests to finish will take hours and might fail for various reason. In this whole time PyTorch/XLA head will be broken
3. using `merge -f` will help this merging delay but people are generally concern about this command because it is somewhat dangerous for such a complcaited codebase like pytorch.
4. PyTorch/XLA maintainer needs to closely monitor the upstream pr until it is merged.
# Proposal
I am proposing a new merge process hopefully can address above issue
1. PyTorch/XLA rebased the "fix pr"
2. PyTorch pr rebased and pin to the PyTorch/XLA pr's branch in [xla.txt](https://github.com/pytorch/pytorch/blob/master/.github/ci_commit_pins/xla.txt)
3. PyTorch pr started a merge job and can wait until all test green(xla test should pass too)
4. PyTorch/XLA merge the fix pr (need to turn off auto-delete branch after merge)
5. PyTorch bot will update the [xla.txt](https://github.com/pytorch/pytorch/blob/master/.github/ci_commit_pins/xla.txt) to the new PyTorch/XLA master hash which will also have the fix
The advantage of this approach ares
1. PyTorch and PyTorch/XLA pr will be both green all the time
2. PyTorch/XLA maintainer only need to merge the fix pr the same day(before pytorch bot started). This requires much less coordination work between two sides.
# Work that needs to be done
PyTorch CI need to understand [xla.txt](https://github.com/pytorch/pytorch/blob/master/.github/ci_commit_pins/xla.txt) can contain both branch name and commit.
FYI @suo @bdhirsh @wconstab
### Alternatives
_No response_
### Additional context
_No response_
cc @seemethere @malfet @pytorch/pytorch-dev-infra @bdhirsh
| 7 |
5,171 | 93,790 |
Issues with custom types defining `__new__`
|
triaged, bug, oncall: pt2
|
Meta-internal example code at D38093407 with output P517669217.
The error is:
```
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/symbolic_convert.py", line 690, in LOAD_ATTR
result = BuiltinVariable(getattr).call_function(
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/variables/builtin.py", line 229, in call_function
constant_args = check_constant_args(args, kwargs)
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/utils.py", line 414, in check_constant_args
return all(x.is_python_constant() for x in itertools.chain(args, kwargs.values()))
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/utils.py", line 414, in <genexpr>
return all(x.is_python_constant() for x in itertools.chain(args, kwargs.values()))
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/variables/base.py", line 148, in is_python_constant
self.as_python_constant()
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/scripts/bwen/dynamo_example/test#link-tree/torchdynamo/variables/lists.py", line 37, in as_python_constant
return self.python_type()([x.as_python_constant() for x in self.items])
TypeError: __new__() missing 2 required positional arguments: 'lambda1' and 'lambda2'
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
5,172 | 81,996 |
linspace cpu and sometimes cuda is wrong on integral types
|
triaged, module: correctness (silent), module: python frontend, module: edge cases
|
Repro:
```python
import torch
print("cpu")
for dtype in (torch.int8, torch.int16, torch.int32, torch.int64):
print(torch.linspace(0, 4, 50, dtype=dtype, device="cpu").bincount())
print("cuda")
for dtype in (torch.int8, torch.int16, torch.int32, torch.int64):
print(torch.linspace(0, 4, 50, dtype=dtype, device="cuda").bincount())
```
prints:
```
cpu
tensor([13, 12, 12, 12, 1])
tensor([13, 16, 8, 12, 1])
tensor([16, 16, 8, 9, 1])
tensor([16, 12, 12, 9, 1])
cuda
tensor([13, 12, 12, 12, 1], device='cuda:0')
tensor([13, 12, 12, 12, 1], device='cuda:0')
tensor([13, 12, 12, 12, 1], device='cuda:0')
tensor([13, 12, 12, 12, 1], device='cuda:0')
```
int8 is correct for some reason
| 1 |
5,173 | 81,988 |
Unify c10::Event and at::cuda::CUDAEvent
|
module: cuda, triaged, better-engineering
|
### 🐛 Describe the bug
They are two implementations of essentially the same thing. CUDAEvent has a slightly more expansive API, and it also seems to support IPC events which the basic c10::Event doesn't support. It still makes sense to have a c10::cuda::CUDAEvent, but the shared functionality should live only in one place.
cc @ngimel @lw
### Versions
master
| 0 |
5,174 | 81,985 |
nn.InstanceNorm and nn.GroupNorm are affected by padding, so they need to masking
|
high priority, triaged, module: nestedtensor, module: norms and normalization, module: padding, module: masked operators, oncall: pt2
|
### 🐛 Describe the bug
For batch_size > 1, variable-length inputs (e.g. speech, text) are padded in order to construct one batch tensor.
**When this tensor goes through nn.InstanceNorm series (nn.InstanceNorm1d, nn.InstanceNorm2d, ...) or nn.GroupNorm,
the calculations of mean and variance take the padded dummies altogether.**
This causes harmful batch inconsistency problem.
**So, nn.InstanceNorm and nn.GroupNorm must be modified to take valid input lengths and to mask out the padded dummies during calculating mean and variance.**
Sorry for not attaching example code.
### Versions
PyTorch version: 1.12.0
cc @ezyang @gchanan @zou3519 @cpuhrsch
| 14 |
5,175 | 81,983 |
backwards compatibility ALLOWLIST is misused
|
module: ci, triaged
|
### 🐛 Describe the bug
We now check against backwards incompatibility from the base commit (vs the most recent nightly), but the ALLOWLIST has never worked the way it was intended to. My understanding of the ALLOWLIST is that for every function + date we set, we allow the function to be "backwards incompatible" until the date.
What actually happens in CI is that the function is incompatible for at most a day, and we allow it to be incompatible for eternity until someone comes and adds back the lost schema.
To illustrate:
commit a -> function exists
commit b -> function doesn't exist
.
.
.
commit c -> function doesn't exist
The check will complain at commit b that the function being lost is backwards incompatible as we're comparing the schema of b and a. After some time, the check will compare commits to a newer commit, so commit c will no longer complain about the function being missing (whether the new commit is a new nightly or just a newer commit)!
## What we can do
1. If we continue letting the bc test in CI currently check for immediate regressions only, we should build some mechanism to create an issue or more permanently warn us when something has introduced incompatibility. Before we implement this, the OSS CI oncall would have to be hyper aware when these errors arise + notify/create an issue. In this case, we can treat the modify the current ALLOWLIST to be a list of schemas we know have regressed + also ensure we track which commit since it has regressed. This way, we can have a system of verifying when something leaves the regression list.
2. We can also make the bc test on trunk compare against a longer term previous schema/something that represents what we promise to users. Unfortunately, this wouldn't be as easy as pinning it to an old commit, since that commit wouldn't have any new schemas added since then.
Do people like 1 or 2 better?
Realization happened in PR description of https://github.com/pytorch/pytorch/pull/81980.
### Versions
CI
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 1 |
5,176 | 81,982 |
test_sparse_matmul_cpu_complex128 fails on my local copy
|
module: sparse, triaged, module: complex
|
### 🐛 Describe the bug
```
======================================================================
FAIL: test_sparse_matmul_cpu_complex128 (__main__.TestSparseCPU)
This function test `torch.sparse.mm` when both the mat1 and mat2 are sparse tensors.
----------------------------------------------------------------------
Traceback (most recent call last):
File "/raid/ezyang/pytorch-scratch2/torch/testing/_internal/common_device_type.py", line 377, in instantiated_test
result = test(self, **param_kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/testing/_internal/common_utils.py", line 978, in wrapper
fn(*args, **kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/testing/_internal/common_utils.py", line 3226, in wrapped
f(self, *args, **kwargs, coalesced=True)
File "test/test_sparse.py", line 3484, in test_sparse_matmul
test_sparse_matmul(2, 10, [n, m], [m, p])
File "test/test_sparse.py", line 3458, in test_sparse_matmul
grad_with_custom_sparsity_pattern_test_helper(sparse_dims, nnz, shape_a, shape_b)
File "test/test_sparse.py", line 3428, in grad_with_custom_sparsity_pattern_test_helper
self.assertEqual(a.grad, a_grad)
File "/raid/ezyang/pytorch-scratch2/torch/testing/_internal/common_utils.py", line 2364, in assertEqual
assert_equal(
File "/raid/ezyang/pytorch-scratch2/torch/testing/_comparison.py", line 1093, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Sparse COO values are not close!
Mismatched elements: 4 / 4 (100.0%)
Greatest absolute difference: 3.3639772140974413 at index (2,) (up to 1e-07 allowed)
Greatest relative difference: 2.0993343823035606 at index (0,) (up to 1e-07 allowed)
----------------------------------------------------------------------
```
This is on a CUDA 11.6 build
### Versions
master
cc @nikitaved @pearu @cpuhrsch @amjames @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano
| 1 |
5,177 | 81,979 |
test_sparse_spdiags_cpu_bool fails on my local working copy
|
module: sparse, triaged
|
### 🐛 Describe the bug
Error looks like
``` ======================================================================
ERROR: test_sparse_spdiags_cpu_bool (__main__.TestSparseCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/data/users/ezyang/pytorch-tmp/torch/testing/_internal/common_device_type.py", line 377, in instantiated_tes
t
result = test(self, **param_kwargs)
File "/data/users/ezyang/pytorch-tmp/torch/testing/_internal/common_device_type.py", line 970, in only_fn
return fn(slf, *args, **kwargs)
File "/data/users/ezyang/pytorch-tmp/test/test_sparse.py", line 3632, in test_sparse_spdiags
check_valid(*case)
File "/data/users/ezyang/pytorch-tmp/test/test_sparse.py", line 3590, in check_valid
ref_out = reference(diags, offsets, shape)
File "/data/users/ezyang/pytorch-tmp/test/test_sparse.py", line 3583, in reference
data = data[off:]
IndexError: slice() cannot be applied to a 0-dim tensor.
----------------------------------------------------------------------
```
Not sure why it's only my local copy.
### Versions
master
cc @nikitaved @pearu @cpuhrsch @amjames
| 1 |
5,178 | 81,963 |
Tensor.backward type hints clarification
|
module: docs, module: autograd, module: typing, triaged, actionable
|
### 📚 The doc issue
The signature of `Tensor.backward` looks like this:
https://github.com/pytorch/pytorch/blob/c52ee6dc0a00dd46f9424424b59dd8714496e9a1/torch/_tensor.py#L425-L427
And in the docstring it defines the args like this:
https://github.com/pytorch/pytorch/blob/c52ee6dc0a00dd46f9424424b59dd8714496e9a1/torch/_tensor.py#L454-L472
I'd like to clarify a few things about the types here. I have numbered them to allow for easier discussion.
* gradient (Tensor or None):
1. It seems that the type here is clearly `Optional[torch.Tensor]`
2. I find the sentence "If a None value would be acceptable then this argument is optional." a bit odd - should we remove it?
* retain_graph (bool, optional):
3. Why does this default to `None` rather than `False`?
* inputs (sequence of Tensor):
4. It seems that the type is `Optional[Sequence[torch.Tensor]]` - should we update the docstring to say it is optional like the others?
### Suggest a potential alternative/fix
Should we add type hints?
cc @svekars @holly1238 @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @malfet @rgommers @xuzhao9 @gramster
| 7 |
5,179 | 81,959 |
Overloading multiple signatures for a single ref
|
triaged, module: primTorch
|
Consider an op like `arange` which is able to support the following two signatures using python arg parser
https://github.com/pytorch/pytorch/blob/8d0cbce0696e76c9e4c929c24c0331df25125b40/torch/csrc/autograd/python_torch_functions_manual.cpp#L87-L90
It seems tricky to add an op like this since Python does not support overloads and arguments with defaults must come after arguments that don't have defaults.
but one solution could be to accept a more general signature and parse it yourself (similar to what python arg parser does):
- in the below example, we have `arange(arg1: optional[Number], arg2: optional[Number], step=1, *, ...)` add in the function body, have checks to route the call to the correct prim, which itself does not take any optional arguments
- registering stubs with `@overload` decorator from the `typing` module seems to help with static checking tools
https://github.com/pytorch/pytorch/blob/d1a9372e611b6e833f83fab57816819b7732e1cc/torch/_refs/__init__.py#L2989-L3055
Curious if others think this is a good general solution
cc @ezyang @mruberry @ngimel
| 1 |
5,180 | 81,955 |
Investigate adding shell linter/checker to CI
|
module: ci, triaged
|
I randomly ran https://github.com/koalaman/shellcheck and already found one legitimate bug: https://github.com/pytorch/pytorch/pull/81954
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 2 |
5,181 | 81,945 |
Investigate adding Dockerfile linter hadolint to CI
|
module: ci, triaged
|
https://github.com/hadolint/hadolint
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 1 |
5,182 | 81,943 |
Investigate if it's okay to throw a RuntimeError instead of TypeError here : https://github.com/pytorch/pytorch/pull/79560/files#diff-415017bcad4fa6cd6d3dfe5f6ea1caffcd7122b46b8c1e4825f7d889efc80a62R1816
|
triaged
| null | 0 |
5,183 | 81,938 |
Devirtualize sym_sizes, virtualize sym_sizes_custom
|
triaged
| null | 0 |
5,184 | 81,937 |
Add more autograd tests with symints
|
triaged
| null | 0 |
5,185 | 81,935 |
implement sym_numel
|
triaged
| null | 1 |
5,186 | 81,932 |
Make sure we always redispatch through a dispatcher for all SymInt ops
|
triaged
| null | 0 |
5,187 | 81,912 |
Unknown builtin op: aten::broadcast_shapes
|
oncall: jit
|
### 🚀 The feature, motivation and pitch
`torch.broadcast_shapes` doesn't work with torch.jit.script:
```
@torch.jit.script
def broadcast_common_batch_shape(x, x_data, y_data):
common_shape = torch.broadcast_shapes(x.size()[:-1], x_data.size()[:-1], y_data.size()[:-1])
return (torch.broadcast_to(x, common_shape + x.size()[-1:]).contiguous(),
torch.broadcast_to(x_data, common_shape + x_data.size()[-1:]).contiguous(),
torch.broadcast_to(y_data, common_shape + y_data.size()[-1:]).contiguous())
````
It would be pleased to have this feature.
### Alternatives
_No response_
### Additional context
_No response_
| 3 |
5,188 | 81,899 |
Dependency header directory is not properly expanded in the utils.cpp_extention in ninja mode
|
module: cpp-extensions, triaged
|
### 🐛 Describe the bug
Build pytorch_sparse use torch.utils cpp_extension throws error of no such file or directory with `use_ninja=True`
```
fatal error: parallel_hashmap/phmap.h: No such file or directory
| #include "parallel_hashmap/phmap.h"
```
In the pytorch_sparse, setup.py file, a third_party dependency is set with relative path. It is not expanded to a absolute paths when ninja build was used.
Proposed solution:
Adding `convert_to_absolute_paths_inplace(include_dirs)` under this line
https://github.com/pytorch/pytorch/blob/94090150942cea8625b9d6068e41cf2c2a88429a/torch/utils/cpp_extension.py#L601.
### Versions
PyTorch version: 1.13.0a0+08820cb
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.23.2
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-4.15.0-36-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.7.99
cc @malfet @zou3519
| 4 |
5,189 | 81,883 |
RuntimeError: CUDA error: no kernel image is available for execution on the device
|
module: cuda, triaged
|
### 🐛 Describe the bug
I am deploying a model using torchserve. It was easily deployed on Tesla K80 GPU. But now when i shifted it to newer GPU Nvidia A30. I am getting this error
```
torch_version: '1.12.0+cu113'
cudnn_version: 8302
```

cc @ngimel
| 19 |
5,190 | 81,876 |
dtype mismatch when after using auto mixed precision
|
triaged, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
I am training model that includes 2 fully connected networks.
So far I have not seen any issue with them, and I wanted to use a mixed precision training to accelerate the process.
I made the required changes to the code but strangely, after several epochs of successful training and loss curve behavious, I get the following error:
```
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm Community Edition 2021.1.2\plugins\python-ce\helpers\pydev\pydevd.py", line 1483, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "C:\Program Files\JetBrains\PyCharm Community Edition 2021.1.2\plugins\python-ce\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "<path to my code>.py", line 2146, in <module>
train()
File "<path to my code>.py", line 2007, in train
scaler.scale(loss_total).backward()
File "C:\Users\shama\Anaconda3\envs\pytorch\lib\site-packages\torch\_tensor.py", line 255, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "C:\Users\shama\Anaconda3\envs\pytorch\lib\site-packages\torch\autograd\__init__.py", line 147, in backward
Variable._execution_engine.run_backward(
RuntimeError: masked_scatter: expected self and source to have same dtypes but gotHalf and Float
```
I wonder why would that happen in the middle of training ( after 20% of the training )
The code is huge, but here's its basic structure:
```
model = Network()
# different params trained with different learning rate, which is set in the training loop
optimizer = pt.optim.Adam([
{'params': paramsA, 'lr': 0},
{'params': paramsB, 'lr': 0},
{'params': paramsC, 'lr': 0} ])
writer = SummaryWriter(..)
for epoch in range(start_epoch, args.epochs+1):
epoch_loss_total = 0
epoch_mse = 0
model.train()
for i, sample in enumerate(dataloader_train):
# print("step: {}".format(i))
setLearningRate(optimizer, epoch)
optimizer.zero_grad()
sel = selectPixels()
gt = sample ['image']
gt = gt.view(gt.shape[0], gt.shape[1], gt.shape[2] * gt.shape[3])
gt = gt[:, :, sel, None].cuda()
with autocast(enabled=args.mixed_precision):
output, in_range_selection = model(sample, sel)
gt = gt[:, :, in_range_selection,:]
mse = pt.mean((output - gt) ** 2)
loss_total = mse
loss2 = 0
if SomeCondition1():
loss2= args.l2_weight * pt.mean((pt.sigmoid(model.feature)))
loss_total = loss_total + loss2
# another loss
loss_total = loss_total + args.l3_weight * func(gt, output)
# for loss statistics
epoch_loss_total += loss_total
epoch_mse += mse
# this section is out of autocast
scaler.scale(loss_total).backward()
scaler.step(optimizer)
scaler.update()
step += 1
# this section is out of samples loop
if someCondition2():
with pt.no_grad():
out_image = evaluateResults1(model)
writer.add_image('images/res', out_image , 2), epoch)
pt.cuda.empty_cache()
if someCondition3():
dumpResults(model)
pt.cuda.empty_cache()
# report mean value
mean = pt.mean(model.mlp)
writer.add_scalar('loss/mean', mean, epoch)
if someCondition4():
checkpoint(ckpt, model, optimizer, epoch+1)
```
### Versions
Collecting environment information...
PyTorch version: 1.9.0
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Home
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.10 (default, May 19 2021, 13:12:57) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19044-SP0
Is CUDA available: True
CUDA runtime version: 11.3.109
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070
Nvidia driver version: 472.39
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.20.2
[pip3] torch==1.9.0
[pip3] torch-tb-profiler==0.2.1
[pip3] torchvision==0.10.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.1.1 heb2d755_7 conda-forge
[conda] mkl 2021.2.0 haa95532_296
[conda] mkl-service 2.3.0 py38h2bbff1b_1
[conda] mkl_fft 1.3.0 py38h277e83a_2
[conda] mkl_random 1.2.1 py38hf11a4ad_2
[conda] numpy 1.20.2 py38ha4e8547_0
[conda] numpy-base 1.20.2 py38hc2deb75_0
[conda] pytorch 1.9.0 py3.8_cuda11.1_cudnn8_0 pytorch
[conda] torch-tb-profiler 0.2.1 pypi_0 pypi
[conda] torchvision 0.10.0 py38_cu111 pytorch
cc @mcarilli @ptrblck
| 6 |
5,191 | 81,868 |
grid_sample and mode='bilinear' induces errors at discrete pixel locations
|
module: nn, triaged
|
### 🐛 Describe the bug
For an tensor `I`, if location `x` and `y` are integers (before normalisation), the result of bilinear interpolation of `I` at `(x,y)` should be strictly equal to `I(x,y)`. This is not currently the case when using `grid_sample` with `mode='bilinear'`.
### Reproduction steps
```python
import torch
print(f'Running PyTorch version: {torch.__version__}')
torchdevices = [torch.device('cpu')]
if torch.cuda.is_available():
torchdevices.append(torch.device('cuda'))
print('Default GPU is ' + torch.cuda.get_device_name(torch.device('cuda')))
for torchdevice in torchdevices:
print('Running on ' + str(torchdevice))
img = torch.rand(1, 1, 40, 40, device=torchdevice)
theta = torch.zeros(1,2,3, device=torchdevice)
theta[0,0,0] = 1
theta[0,1,1] = 1
align_opts = [True, False]
for align_opt in align_opts:
grid = torch.nn.functional.affine_grid(theta, img.shape, align_corners=align_opt)
out = torch.nn.functional.grid_sample(img, grid, mode='bilinear', align_corners=align_opt)
print(f"Residual with align_corners={align_opt}: {torch.linalg.vector_norm(out-img, ord=torch.inf).cpu().numpy()}")
```
### Observed behavior
```
Running PyTorch version: 1.12.0+cu113
Default GPU is Tesla T4
Running on cpu
Residual with align_corners=True: 2.768472768366337e-06
Residual with align_corners=False: 1.914799213409424e-06
Running on cuda
Residual with align_corners=True: 2.562999725341797e-06
Residual with align_corners=False: 1.0468065738677979e-06
```
### Expected behavior
`out` should be equal to `img` for an identity transformation.
### Additional context
The errors are seen in both CPU and GPU mode. This issue was first observed as part of using kornia:
https://github.com/kornia/kornia/issues/1799
### Versions
- PyTorch Version (e.g., 1.0): 1.12.0+cu113
- OS (e.g., Linux): Google colab
- How you installed PyTorch (`conda`, `pip`, source): Google colab default version
- Build command you used (if compiling from source): N/A
- Python version: 3.7.13 (default, Apr 24 2022, 01:04:09)
- CUDA/cuDNN version: cu113
- GPU models and configuration: Tesla T4
- Any other relevant information: N/A
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 3 |
5,192 | 81,856 |
Compatibility with newest MKL
|
module: build, triaged, module: mkl
|
### 🚀 The feature, motivation and pitch
libtorch 1.12.0 is currently released with version 2020.0
please make torch compatible with latest version of MKL as it is much faster. I note that the `cblas_?gemm` functions are about twice as fast on my machine(AMD) for ~1000x1000 matrices
I tried building libtorch with 2022.0.1 version of MKL.
a call to at::matmul yeilds error
`Intel MKL ERROR: Parameter 9 was incorrect on entry to cblas_sgemm_batch.`
### Alternatives
_No response_
### Additional context
_No response_
cc @malfet @seemethere
| 0 |
5,193 | 81,855 |
Enable jit error when using FSDP
|
oncall: jit
|
### 🐛 Describe the bug
Execuse me! Recently I trained GPT-2 model with enabling `torch.jit,` if I using DDP, it works normally. but when I using `FSDP`, it cause error.
relevant codes as follows:
parameters config:
`config.use_torch_jit = True`
`config.use_cuda = True`
`config.dp_mode = "DDP" or "FSDP"`
`auto_wrap_policy = None`
`sharding_strategy = None`
`backward_prefetch = None`
`mixed_precision = None`
`cpu_offload = None`
```python
if config.use_torch_jit:
logging.info("JIT optimization in progress...")
fB = config.model.batch_size // config.dp
fS = config.data.max_seq_length
fV = config.model.vocab_size
fake_input = torch.ones([fB, fS], dtype=torch.long)
fake_words = torch.ones([fB, fS], dtype=torch.long)
if config.use_cuda:
fake_input = fake_input.cuda()
fake_words = fake_words.cuda()
gpt2_example_inputs = (
fake_input,
fake_words
)
gpt2 = torch.jit.trace(gpt2, gpt2_example_inputs, check_trace=False)
fake_input = None
fake_words = None
logging.info("JIT optimization completed \033[0;32m[OK]")
dp_process_group = layout.group(0).process_group
if config.dp_mode == "DDP":
model = DDP(gpt2, process_group=dp_process_group)
else:
auto_wrap_policy = WARP_POLICES[config.fsdp.wrap_type]
sharding_strategy = SHARDING_STRATEGYS[config.fsdp.sharding_strategy]
backward_prefetch = BW_PREFETCH_TYPES[config.fsdp.bw_prefetch_type]
if config.use_fp16_compress_dp:
reduce_dtype = torch.float16
all_dtypes = (param_dtype, buffer_dtype, reduce_dtype)
if all(dtype is None for dtype in all_dtypes):
mixed_precision = None
else:
mixed_precision = MixedPrecision(
param_dtype=param_dtype,
reduce_dtype=reduce_dtype,
buffer_dtype=buffer_dtype
)
cpu_offload = None
if config.fsdp.use_cpu_offload:
cpu_offload = CPUOffload(offload_params=True)
model = FSDP(gpt2, process_group=dp_process_group,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=sharding_strategy,
backward_prefetch=backward_prefetch,
mixed_precision=mixed_precision,
cpu_offload=cpu_offload)
```
Errors:
```python
model = FSDP(gpt2, process_group=dp_process_group,
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 814, in __init__
self._fsdp_wrapped_module: FlattenParamsWrapper = FlattenParamsWrapper(
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/fsdp/flatten_params_wrapper.py", line 329, in __init__
self._flatten_params()
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/fsdp/flatten_params_wrapper.py", line 393, in _flatten_params
delattr(m, n)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1259, in __delattr__
del self._parameters[name]
File "/usr/local/conda/lib/python3.9/site-packages/torch/jit/_script.py", line 194, in __delitem__
raise RuntimeError("cannot delete methods or parameters of a script module")
RuntimeError: cannot delete methods or parameters of a script module
```
### Versions
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.18.0-147.mt20200626.413.el8_1.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.0.221
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 470.82.01
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.3
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.3
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] ffmpeg 4.3 hf484d3e_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
[conda] mkl 2021.4.0 h06a4308_640 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl-service 2.4.0 py39h7f8727e_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl_fft 1.3.1 py39hd3c417c_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] mkl_random 1.2.2 py39h51133e4_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] numpy 1.22.3 py39he7a7128_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] numpy-base 1.22.3 py39hf524024_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
[conda] pytorch 1.12.0 py3.9_cuda11.3_cudnn8.3.2_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
[conda] pytorch-mutex 1.0 cuda https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
[conda] torchaudio 0.12.0 py39_cu113 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
[conda] torchvision 0.13.0 py39_cu113 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
| 2 |
5,194 | 81,808 |
Workflows fail silently when the workflow file is invalid
|
module: ci, triaged
|
### 🐛 Describe the bug
Sometimes the failed workflows don't actually show up as failed in the CI on the PR page, such as when there's an invalid workflow file ([example](https://github.com/pytorch/pytorch/actions/runs/2618689292))
I’d expect the workflow to quickly show a clear error in the UI.
Nikita’s [added a workaround](https://github.com/pytorch/pytorch/pull/81521/files#diff-8dbcc9b8dc59448e6ad908516e60cd84cbcb0c6dd2aca2a51bc0e5b3fc0e120fR1042) to ensure we don’t merge PRs with these silent failures, and it would be great to make sure we surface these failures in the signalbox as well.
Right now, the CI can still appear to be succeeding (even if merges will get blocked).
### Versions
n/a
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 1 |
5,195 | 81,801 |
Rename DispatchKey Dense/Sparse/etc to DenseFunctionality/SparseFunctionality, use original name for alias
|
module: internals, triaged
|
### 🚀 The feature, motivation and pitch
This means you could register a kernel as "Sparse" and it would apply to all sparse backends, instead of having to register SparseCPU, SparseCUDA one by one as we do today
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 1 |
5,196 | 81,768 |
TestTagsCPU.test_tags__refs_constant_pad_nd_cpu_float32 flaky with dynamo & pytest
|
module: ci, triaged
|
### 🐛 Describe the bug
Recently, the dynamo config has failed 3 times seemingly flakily with the following:
```
[gw3] [ 96%] RERUN test_ops.py::TestTagsCPU::test_tags__refs_constant_pad_nd_cpu_float32
2022-07-19T20:27:06.4357892Z test_ops.py::TestTagsCPU::test_tags__refs_constant_pad_nd_cpu_float32
2022-07-19T20:27:06.4368462Z [gw3] [ 96%] RERUN test_ops.py::TestTagsCPU::test_tags__refs_constant_pad_nd_cpu_float32
2022-07-19T20:27:06.4404288Z test_ops.py::TestTagsCPU::test_tags__refs_constant_pad_nd_cpu_float32
2022-07-19T20:27:14.1210808Z [gw3] [ 96%] FAILED test_ops.py::TestTagsCPU::test_tags__refs_constant_pad_nd_cpu_float32
2022-07-19T20:27:14.1211730Z
2022-07-19T20:27:14.1214386Z =================================== FAILURES ===================================
2022-07-19T20:27:14.1215474Z ___________ TestTagsCPU.test_tags__refs_constant_pad_nd_cpu_float32 ____________
2022-07-19T20:27:14.1216133Z [gw3] linux -- Python 3.7.13 /opt/conda/bin/python
2022-07-19T20:27:14.1216393Z Traceback (most recent call last):
2022-07-19T20:27:14.1216653Z File "/var/lib/jenkins/workspace/test/test_ops.py", line 1480, in test_tags
2022-07-19T20:27:14.1216880Z @onlyCPU
2022-07-19T20:27:14.1217101Z File "/var/lib/jenkins/workspace/test/test_ops.py", line 1491, in test_tags
2022-07-19T20:27:14.1217370Z rs = op(input, *sample.args, **sample.kwargs)
2022-07-19T20:27:14.1217800Z File "/opt/conda/lib/python3.7/site-packages/torch/testing/_internal/common_methods_invocations.py", line 953, in __call__
2022-07-19T20:27:14.1218094Z return self.op(*args, **kwargs)
2022-07-19T20:27:14.1218586Z File "/opt/conda/lib/python3.7/site-packages/torch/_refs/__init__.py", line 2168, in constant_pad_nd
2022-07-19T20:27:14.1218865Z prims.copy_to(c_output, c_input)
2022-07-19T20:27:14.1219216Z File "/opt/conda/lib/python3.7/site-packages/torch/_ops.py", line 49, in __call__
2022-07-19T20:27:14.1219469Z return self._op(*args, **kwargs or {})
2022-07-19T20:27:14.1219829Z File "/opt/conda/lib/python3.7/site-packages/torch/_prims/__init__.py", line 374, in _autograd_impl
2022-07-19T20:27:14.1220153Z return BackwardsNotSupported.apply(args_spec, *flat_args)
2022-07-19T20:27:14.1220535Z File "/opt/conda/lib/python3.7/site-packages/torch/_prims/__init__.py", line 364, in forward
2022-07-19T20:27:14.1220781Z return _prim(*args, **kwargs)
2022-07-19T20:27:14.1221103Z File "/opt/conda/lib/python3.7/site-packages/torch/_ops.py", line 49, in __call__
2022-07-19T20:27:14.1221368Z return self._op(*args, **kwargs or {})
2022-07-19T20:27:14.1221718Z File "/opt/conda/lib/python3.7/site-packages/torch/utils/_python_dispatch.py", line 74, in wrapped
2022-07-19T20:27:14.1221993Z return f(self, *args, **kwargs)
2022-07-19T20:27:14.1222256Z File "/var/lib/jenkins/workspace/test/test_ops.py", line 1468, in __torch_dispatch__
2022-07-19T20:27:14.1222538Z def __torch_dispatch__(self, func, types, args=(), kwargs=None):
2022-07-19T20:27:14.1222831Z File "/var/lib/jenkins/workspace/test/test_ops.py", line 1462, in check_inplace_view
2022-07-19T20:27:14.1223105Z assert torch.Tag.inplace_view in func.tags
2022-07-19T20:27:14.1223351Z AssertionError: assert <Tag.inplace_view: 3> in []
2022-07-19T20:27:14.1223658Z + where <Tag.inplace_view: 3> = <class 'torch.Tag'>.inplace_view
2022-07-19T20:27:14.1223941Z + where <class 'torch.Tag'> = torch.Tag
2022-07-19T20:27:14.1224252Z + and [] = <OpOverload(op='prims.copy_to', overload='default')>.tags
```
Most recent logs: https://github.com/pytorch/pytorch/runs/7430470789?check_suite_focus=true
It looks like the test has turned flaky ever since turning on pytest in #79898, but this is an observation and not necessarily the reason why. Ideally, it'd be great to fix this on the dynamo side if possible but, if not, we can exclude dynamo from using pytest.
ccing @ezyang @clee2000
### Versions
In CI
cc @ezyang @gchanan @zou3519 @seemethere @malfet @pytorch/pytorch-dev-infra
| 6 |
5,197 | 81,750 |
Modernize logging tensor in torch.testing._internal
|
module: internals, module: logging, triaged
|
### 🐛 Describe the bug
I wrote a better version of logging tensor mode at https://github.com/albanD/subclass_zoo/blob/main/logging_mode.py
let's upstream it to PyTorch
Improvements include proper handling of lists of tensors, dtype and size info in the logs, and cleaner code structure. In particular, I want to get rid of LoggingTensor as a construct and have this be mode only.
### Versions
master
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 6 |
5,198 | 81,749 |
BatchNorm for complex tensor
|
triaged, module: complex, module: primTorch
|
### 🚀 The feature, motivation and pitch
I am working on a network that takes into consider phase information in speech processing, and would like batchnorm for complex tensor to be possible.
Similar to #47052, #46642
### Additional context
Are there any special points to consider when adding/implementing this feature because of the complex type?
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @ngimel @albanD
| 5 |
5,199 | 81,732 |
DISABLED test_non_contiguous_tensors_nn_ConvTranspose1d_cuda_complex32 (__main__.TestModuleCUDA)
|
module: nn, triaged, module: flaky-tests, module: complex, skipped
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_non_contiguous_tensors_nn_ConvTranspose1d_cuda_complex32&suite=TestModuleCUDA&file=test_modules.py) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/7415127953).
Over the past 3 hours, it has been determined flaky in 2 workflow(s) with 3 red and 2 green.
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are @ezyang @anjali411 @dylanbespalko @Lezcano @nikitaved
| 13 |
5,200 | 93,786 |
Support JaggedTensor/KeyedJaggedTensor from TorchRec in TorchDynamo
|
triaged, oncall: pt2
|
Currently if [JaggedTensor](https://github.com/pytorch/torchrec/blob/20f543ee3700f2ebb27be6e80d636bd5dd0d7f3c/torchrec/sparse/jagged_tensor.py#L160)/[KeyedJaggedTensor](https://github.com/pytorch/torchrec/blob/20f543ee3700f2ebb27be6e80d636bd5dd0d7f3c/torchrec/sparse/jagged_tensor.py#L614) is used we will see the following error in TorchDyanmo
```
torchdynamo.exc.Unsupported: call_function UserDefinedObjectVariable(JaggedTensorMeta) [] {'keys': ListVariable(), 'values': TensorVariable(), 'length_per_key': ListVariable()}
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.