
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-05 12:28:30
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 539
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-05 12:28:13
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Prisma-Multimodal/sparse-autoencoder-clip-b-32-sae-vanilla-x64-layer-8-hook_resid_post-l1-0.0001
|
Prisma-Multimodal
| 2024-11-01T16:23:15Z | 22 | 0 |
torch
|
[
"torch",
"clip",
"vision",
"transformers",
"interpretability",
"sparse autoencoder",
"sae",
"mechanistic interpretability",
"feature-extraction",
"en",
"license:apache-2.0",
"region:us"
] |
feature-extraction
| 2024-11-01T16:23:04Z |
---
language: en
tags:
- clip
- vision
- transformers
- interpretability
- sparse autoencoder
- sae
- mechanistic interpretability
license: apache-2.0
library_name: torch
pipeline_tag: feature-extraction
metrics:
- type: explained_variance
value: 77.9
pretty_name: Explained Variance %
range:
min: 0
max: 100
- type: l0
value: 156.154
pretty_name: L0
---
# CLIP-B-32 Sparse Autoencoder x64 vanilla - L1:0.0001


### Training Details
- Base Model: CLIP-ViT-B-32 (LAION DataComp.XL-s13B-b90K)
- Layer: 8
- Component: hook_resid_post
### Model Architecture
- Input Dimension: 768
- SAE Dimension: 49,152
- Expansion Factor: x64 (vanilla architecture)
- Activation Function: ReLU
- Initialization: encoder_transpose_decoder
- Context Size: 50 tokens
### Performance Metrics
- L1 Coefficient: 0.0001
- L0 Sparsity: 156.1541
- Explained Variance: 0.7787 (77.87%)
### Training Configuration
- Learning Rate: 0.0004
- LR Scheduler: Cosine Annealing with Warmup (200 steps)
- Epochs: 10
- Gradient Clipping: 1.0
- Device: NVIDIA Quadro RTX 8000
**Experiment Tracking:**
- Weights & Biases Run ID: aoa9e6a9
- Full experiment details: https://wandb.ai/perceptual-alignment/clip/runs/aoa9e6a9/overview
- Git Commit: e22dd02726b74a054a779a4805b96059d83244aa
## Citation
```bibtex
@misc{2024josephsparseautoencoders,
title={Sparse Autoencoders for CLIP-ViT-B-32},
author={Joseph, Sonia},
year={2024},
publisher={Prisma-Multimodal},
url={https://huggingface.co/Prisma-Multimodal},
note={Layer 8, hook_resid_post, Run ID: aoa9e6a9}
}
|
sulaimank/wav2vec-xlsr-cv-grain-lg_grn_only_v2
|
sulaimank
| 2024-11-01T16:20:25Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-xls-r-300m",
"base_model:finetune:facebook/wav2vec2-xls-r-300m",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-11-01T04:58:01Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-xls-r-300m
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec-xlsr-cv-grain-lg_grn_only_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec-xlsr-cv-grain-lg_grn_only_v2
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0604
- Wer: 0.0276
- Cer: 0.0085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 24
- eval_batch_size: 12
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 48
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-------:|:-----:|:---------------:|:------:|:------:|
| 6.8998 | 0.9984 | 321 | 2.7793 | 1.0 | 0.8727 |
| 3.2905 | 2.0 | 643 | 0.8365 | 0.9015 | 0.2478 |
| 1.26 | 2.9984 | 964 | 0.3066 | 0.4268 | 0.0856 |
| 0.6344 | 4.0 | 1286 | 0.1856 | 0.2137 | 0.0451 |
| 0.4164 | 4.9984 | 1607 | 0.1513 | 0.1649 | 0.0364 |
| 0.3006 | 6.0 | 1929 | 0.1271 | 0.1274 | 0.0285 |
| 0.2414 | 6.9984 | 2250 | 0.1111 | 0.1083 | 0.0251 |
| 0.2035 | 8.0 | 2572 | 0.1076 | 0.0992 | 0.0228 |
| 0.169 | 8.9984 | 2893 | 0.1076 | 0.0931 | 0.0213 |
| 0.1501 | 10.0 | 3215 | 0.1007 | 0.0920 | 0.0213 |
| 0.1291 | 10.9984 | 3536 | 0.0892 | 0.0772 | 0.0185 |
| 0.1122 | 12.0 | 3858 | 0.0917 | 0.0746 | 0.0180 |
| 0.1053 | 12.9984 | 4179 | 0.0903 | 0.0707 | 0.0173 |
| 0.0972 | 14.0 | 4501 | 0.0863 | 0.0673 | 0.0164 |
| 0.0847 | 14.9984 | 4822 | 0.0849 | 0.0616 | 0.0157 |
| 0.0754 | 16.0 | 5144 | 0.0870 | 0.0657 | 0.0158 |
| 0.0751 | 16.9984 | 5465 | 0.0830 | 0.0610 | 0.0154 |
| 0.0722 | 18.0 | 5787 | 0.0922 | 0.0621 | 0.0159 |
| 0.0665 | 18.9984 | 6108 | 0.0784 | 0.0601 | 0.0153 |
| 0.0634 | 20.0 | 6430 | 0.0856 | 0.0545 | 0.0146 |
| 0.0601 | 20.9984 | 6751 | 0.0881 | 0.0584 | 0.0151 |
| 0.0545 | 22.0 | 7073 | 0.0876 | 0.0558 | 0.0144 |
| 0.0503 | 22.9984 | 7394 | 0.0815 | 0.0523 | 0.0137 |
| 0.0511 | 24.0 | 7716 | 0.0842 | 0.0521 | 0.0140 |
| 0.0477 | 24.9984 | 8037 | 0.0808 | 0.0532 | 0.0151 |
| 0.0433 | 26.0 | 8359 | 0.0770 | 0.0482 | 0.0125 |
| 0.0441 | 26.9984 | 8680 | 0.0803 | 0.0510 | 0.0137 |
| 0.0424 | 28.0 | 9002 | 0.0771 | 0.0460 | 0.0123 |
| 0.0373 | 28.9984 | 9323 | 0.0727 | 0.0462 | 0.0122 |
| 0.0376 | 30.0 | 9645 | 0.0768 | 0.0525 | 0.0134 |
| 0.0325 | 30.9984 | 9966 | 0.0801 | 0.0508 | 0.0134 |
| 0.0371 | 32.0 | 10288 | 0.0714 | 0.0445 | 0.0118 |
| 0.0339 | 32.9984 | 10609 | 0.0738 | 0.0458 | 0.0122 |
| 0.0329 | 34.0 | 10931 | 0.0672 | 0.0388 | 0.0104 |
| 0.0294 | 34.9984 | 11252 | 0.0750 | 0.0408 | 0.0113 |
| 0.0322 | 36.0 | 11574 | 0.0768 | 0.0423 | 0.0117 |
| 0.028 | 36.9984 | 11895 | 0.0735 | 0.0386 | 0.0117 |
| 0.0279 | 38.0 | 12217 | 0.0756 | 0.0414 | 0.0122 |
| 0.0259 | 38.9984 | 12538 | 0.0842 | 0.0495 | 0.0135 |
| 0.0273 | 40.0 | 12860 | 0.0775 | 0.0456 | 0.0131 |
| 0.026 | 40.9984 | 13181 | 0.0729 | 0.0427 | 0.0119 |
| 0.0247 | 42.0 | 13503 | 0.0728 | 0.0410 | 0.0115 |
| 0.0247 | 42.9984 | 13824 | 0.0709 | 0.0430 | 0.0118 |
| 0.023 | 44.0 | 14146 | 0.0632 | 0.0362 | 0.0101 |
| 0.0206 | 44.9984 | 14467 | 0.0675 | 0.0347 | 0.0106 |
| 0.0203 | 46.0 | 14789 | 0.0750 | 0.0419 | 0.0125 |
| 0.0215 | 46.9984 | 15110 | 0.0644 | 0.0358 | 0.0104 |
| 0.0172 | 48.0 | 15432 | 0.0693 | 0.0332 | 0.0098 |
| 0.0191 | 48.9984 | 15753 | 0.0694 | 0.0341 | 0.0102 |
| 0.0175 | 50.0 | 16075 | 0.0716 | 0.0369 | 0.0108 |
| 0.018 | 50.9984 | 16396 | 0.0635 | 0.0351 | 0.0101 |
| 0.0162 | 52.0 | 16718 | 0.0711 | 0.0382 | 0.0106 |
| 0.0167 | 52.9984 | 17039 | 0.0605 | 0.0343 | 0.0097 |
| 0.0173 | 54.0 | 17361 | 0.0699 | 0.0321 | 0.0097 |
| 0.0157 | 54.9984 | 17682 | 0.0726 | 0.0330 | 0.0100 |
| 0.0128 | 56.0 | 18004 | 0.0693 | 0.0323 | 0.0096 |
| 0.0169 | 56.9984 | 18325 | 0.0602 | 0.0306 | 0.0092 |
| 0.014 | 58.0 | 18647 | 0.0638 | 0.0332 | 0.0097 |
| 0.0133 | 58.9984 | 18968 | 0.0630 | 0.0325 | 0.0097 |
| 0.0151 | 60.0 | 19290 | 0.0645 | 0.0328 | 0.0098 |
| 0.0137 | 60.9984 | 19611 | 0.0642 | 0.0351 | 0.0098 |
| 0.0135 | 62.0 | 19933 | 0.0569 | 0.0284 | 0.0084 |
| 0.0119 | 62.9984 | 20254 | 0.0595 | 0.0308 | 0.0088 |
| 0.011 | 64.0 | 20576 | 0.0601 | 0.0263 | 0.0086 |
| 0.0113 | 64.9984 | 20897 | 0.0639 | 0.0282 | 0.0090 |
| 0.0125 | 66.0 | 21219 | 0.0588 | 0.0291 | 0.0090 |
| 0.0103 | 66.9984 | 21540 | 0.0632 | 0.0289 | 0.0090 |
| 0.0094 | 68.0 | 21862 | 0.0600 | 0.0282 | 0.0087 |
| 0.0098 | 68.9984 | 22183 | 0.0615 | 0.0278 | 0.0085 |
| 0.0089 | 70.0 | 22505 | 0.0598 | 0.0278 | 0.0084 |
| 0.0105 | 70.9984 | 22826 | 0.0611 | 0.0291 | 0.0081 |
| 0.0083 | 72.0 | 23148 | 0.0623 | 0.0293 | 0.0084 |
| 0.0092 | 72.9984 | 23469 | 0.0590 | 0.0302 | 0.0090 |
| 0.0068 | 74.0 | 23791 | 0.0604 | 0.0276 | 0.0085 |
### Framework versions
- Transformers 4.46.1
- Pytorch 2.1.0+cu118
- Datasets 3.1.0
- Tokenizers 0.20.1
|
LocalDoc/LaBSE-small-AZ
|
LocalDoc
| 2024-11-01T16:14:17Z | 22 | 0 | null |
[
"safetensors",
"bert",
"sentence-similarity",
"en",
"az",
"base_model:sentence-transformers/LaBSE",
"base_model:finetune:sentence-transformers/LaBSE",
"doi:10.57967/hf/3417",
"license:apache-2.0",
"region:us"
] |
sentence-similarity
| 2024-11-01T15:41:06Z |
---
license: apache-2.0
language:
- en
- az
base_model:
- sentence-transformers/LaBSE
pipeline_tag: sentence-similarity
---
# Small LaBSE for English-Azerbaijani
This is an optimized version of [LaBSE](https://huggingface.co/sentence-transformers/LaBSE)
# Benchmark
| STSBenchmark | biosses-sts | sickr-sts | sts12-sts | sts13-sts | sts15-sts | sts16-sts | Average Pearson | Model |
|--------------|-------------|-----------|-----------|-----------|-----------|-----------|-----------------|--------------------------------------|
| 0.7363 | 0.8148 | 0.7067 | 0.7050 | 0.6535 | 0.7514 | 0.7070 | 0.7250 | sentence-transformers/LaBSE |
| 0.7400 | 0.8216 | 0.6946 | 0.7098 | 0.6781 | 0.7637 | 0.7222 | 0.7329 | LocalDoc/LaBSE-small-AZ |
| 0.5830 | 0.2486 | 0.5921 | 0.5593 | 0.5559 | 0.5404 | 0.5289 | 0.5155 | antoinelouis/colbert-xm |
| 0.7572 | 0.8139 | 0.7328 | 0.7646 | 0.6318 | 0.7542 | 0.7092 | 0.7377 | intfloat/multilingual-e5-large-instruct |
| 0.7485 | 0.7714 | 0.7271 | 0.7170 | 0.6496 | 0.7570 | 0.7255 | 0.7280 | intfloat/multilingual-e5-large |
| 0.6960 | 0.8185 | 0.6950 | 0.6752 | 0.5899 | 0.7186 | 0.6790 | 0.6960 | intfloat/multilingual-e5-base |
| 0.7376 | 0.7917 | 0.7190 | 0.7441 | 0.6286 | 0.7461 | 0.7026 | 0.7242 | intfloat/multilingual-e5-small |
| 0.7927 | 0.6672 | 0.7758 | 0.8122 | 0.7312 | 0.7831 | 0.7416 | 0.7577 | BAAI/bge-m3 |
[STS-Benchmark](https://github.com/LocalDoc-Azerbaijan/STS-Benchmark)
## How to Use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("LocalDoc/LaBSE-small-AZ")
model = AutoModel.from_pretrained("LocalDoc/LaBSE-small-AZ")
# Prepare texts
texts = [
"Hello world",
"Salam dünya"
]
# Tokenize and generate embeddings
encoded = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
embeddings = model(**encoded).pooler_output
# Compute similarity
similarity = torch.nn.functional.cosine_similarity(embeddings[0], embeddings[1], dim=0)
```
|
RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf
|
RichardErkhov
| 2024-11-01T16:11:57Z | 20 | 0 | null |
[
"gguf",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:31:15Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-2.8b-v0 - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-2.8b-v0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-2.8b-v0.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q2_K.gguf) | Q2_K | 1.01GB |
| [pythia-2.8b-v0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [pythia-2.8b-v0.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q3_K.gguf) | Q3_K | 1.38GB |
| [pythia-2.8b-v0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q3_K_M.gguf) | Q3_K_M | 1.38GB |
| [pythia-2.8b-v0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q3_K_L.gguf) | Q3_K_L | 1.49GB |
| [pythia-2.8b-v0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.IQ4_XS.gguf) | IQ4_XS | 1.43GB |
| [pythia-2.8b-v0.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q4_0.gguf) | Q4_0 | 1.49GB |
| [pythia-2.8b-v0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.IQ4_NL.gguf) | IQ4_NL | 1.5GB |
| [pythia-2.8b-v0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q4_K_S.gguf) | Q4_K_S | 1.5GB |
| [pythia-2.8b-v0.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q4_K.gguf) | Q4_K | 1.66GB |
| [pythia-2.8b-v0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q4_K_M.gguf) | Q4_K_M | 1.66GB |
| [pythia-2.8b-v0.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q4_1.gguf) | Q4_1 | 1.64GB |
| [pythia-2.8b-v0.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q5_0.gguf) | Q5_0 | 1.8GB |
| [pythia-2.8b-v0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q5_K_S.gguf) | Q5_K_S | 1.8GB |
| [pythia-2.8b-v0.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q5_K.gguf) | Q5_K | 1.93GB |
| [pythia-2.8b-v0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q5_K_M.gguf) | Q5_K_M | 1.93GB |
| [pythia-2.8b-v0.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q5_1.gguf) | Q5_1 | 1.95GB |
| [pythia-2.8b-v0.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q6_K.gguf) | Q6_K | 2.13GB |
| [pythia-2.8b-v0.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-v0-gguf/blob/main/pythia-2.8b-v0.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- the_pile
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-2.8B
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change over the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-2.8B for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-2.8B as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-2.8B has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-2.8B will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-2.8B to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-2.8B may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-2.8B.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-2.8B.
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
Haesteining/Phi3smallv6
|
Haesteining
| 2024-11-01T16:10:37Z | 39 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T16:05:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Daniyal100/adefkfe
|
Daniyal100
| 2024-11-01T16:10:36Z | 7 | 1 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T15:26:37Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: MARIAPIC
---
# Adefkfe
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `MARIAPIC` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Daniyal100/adefkfe', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
bb1070/barcelona_wf
|
bb1070
| 2024-11-01T16:08:40Z | 5 | 1 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T16:08:37Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Barcelona_Wf
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bb1070/barcelona_wf', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-GGUF
|
PJMixers-Dev
| 2024-11-01T16:07:02Z | 15 | 0 | null |
[
"gguf",
"en",
"dataset:PJMixers-Dev/HailMary-v0.1-KTO",
"base_model:PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B",
"base_model:quantized:PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B",
"license:llama3.2",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-11-01T00:47:18Z |
---
license: llama3.2
language:
- en
datasets:
- PJMixers-Dev/HailMary-v0.1-KTO
base_model:
- PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B
model-index:
- name: PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 65.04
name: strict accuracy
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 22.29
name: normalized accuracy
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 11.78
name: exact match
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 2.91
name: acc_norm
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 4.69
name: acc_norm
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 23.42
name: accuracy
source:
url: https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-HailMary-v0.1-KTO-3B-details
name: Open LLM Leaderboard
---
[PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B](https://huggingface.co/PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B) was further trained using KTO (with `apo_zero_unpaired` loss type) using a mix of instruct, RP, and storygen datasets. I created rejected samples by using the SFT with bad settings (including logit bias) for every model turn.
The model was only trained at `max_length=6144`, and is nowhere near a full epoch as it eventually crashed. So think of this like a test of a test.
# W&B Training Logs
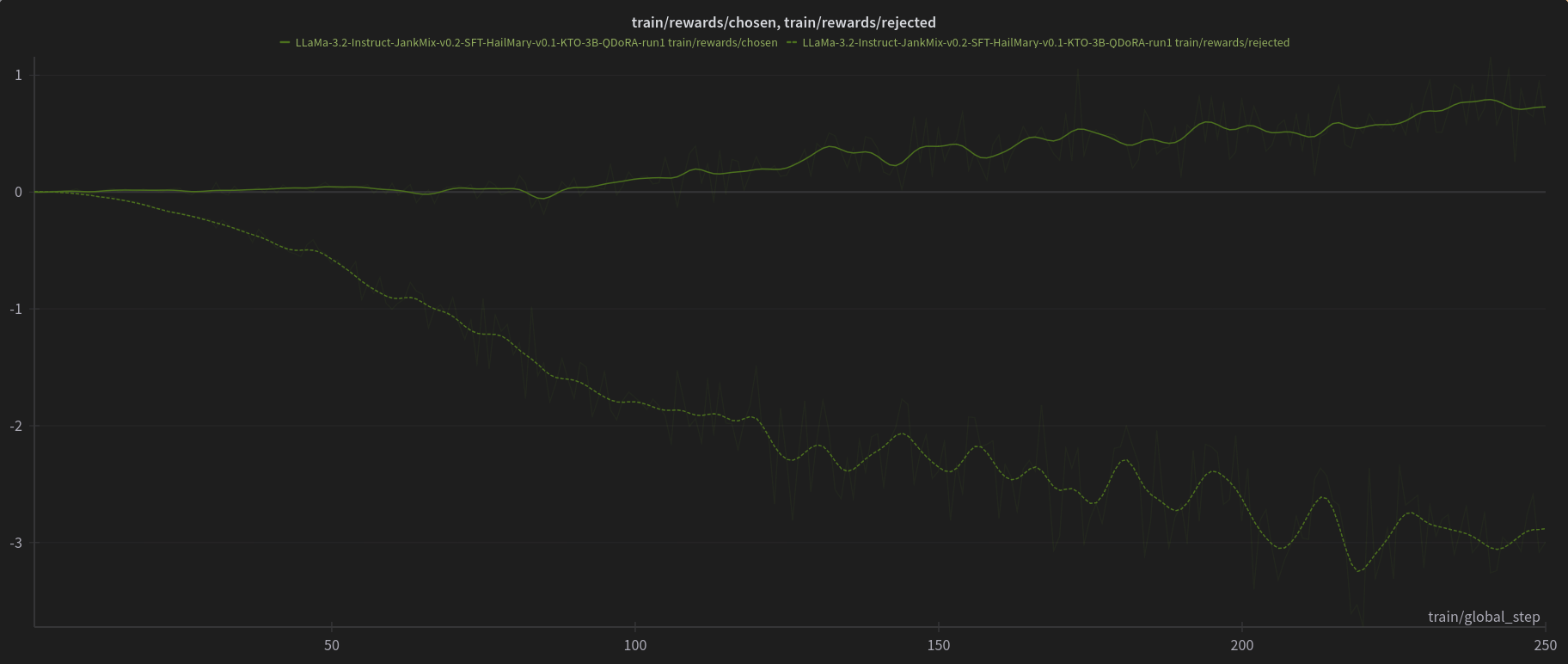
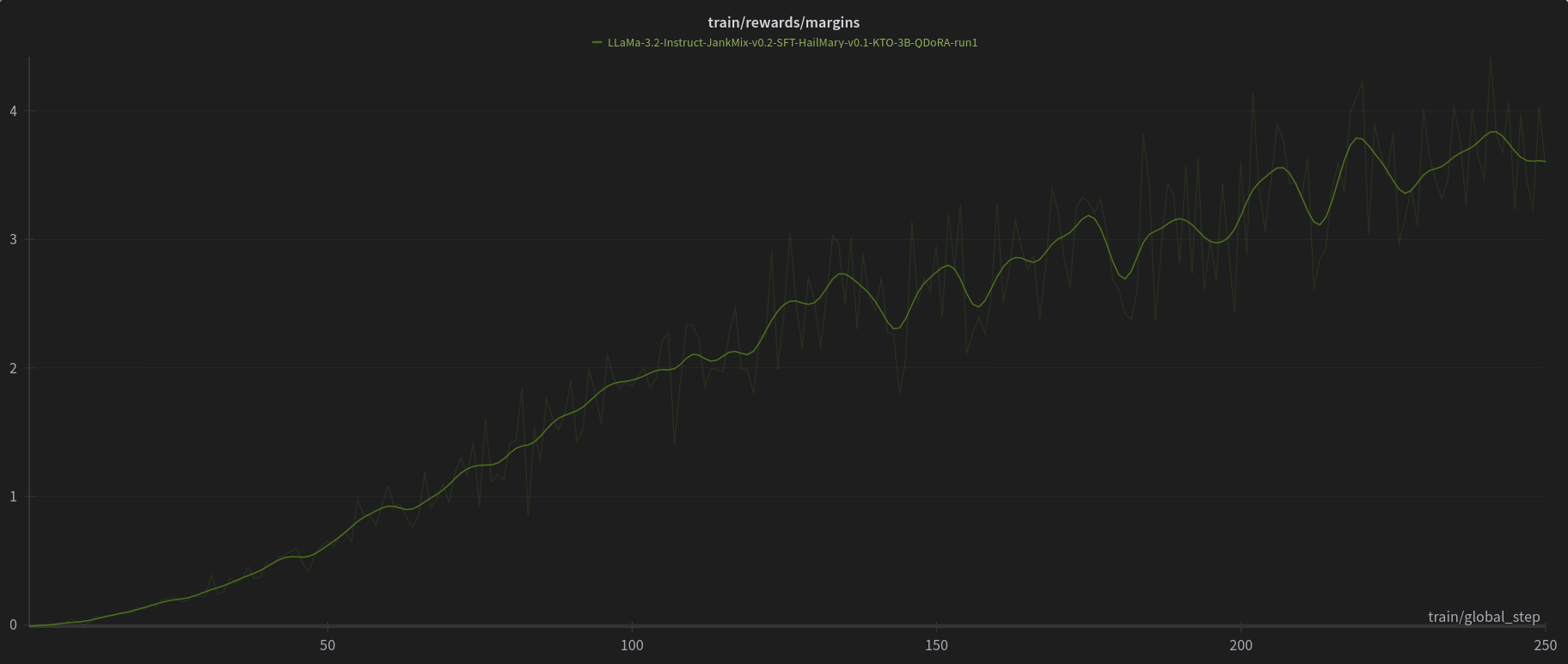
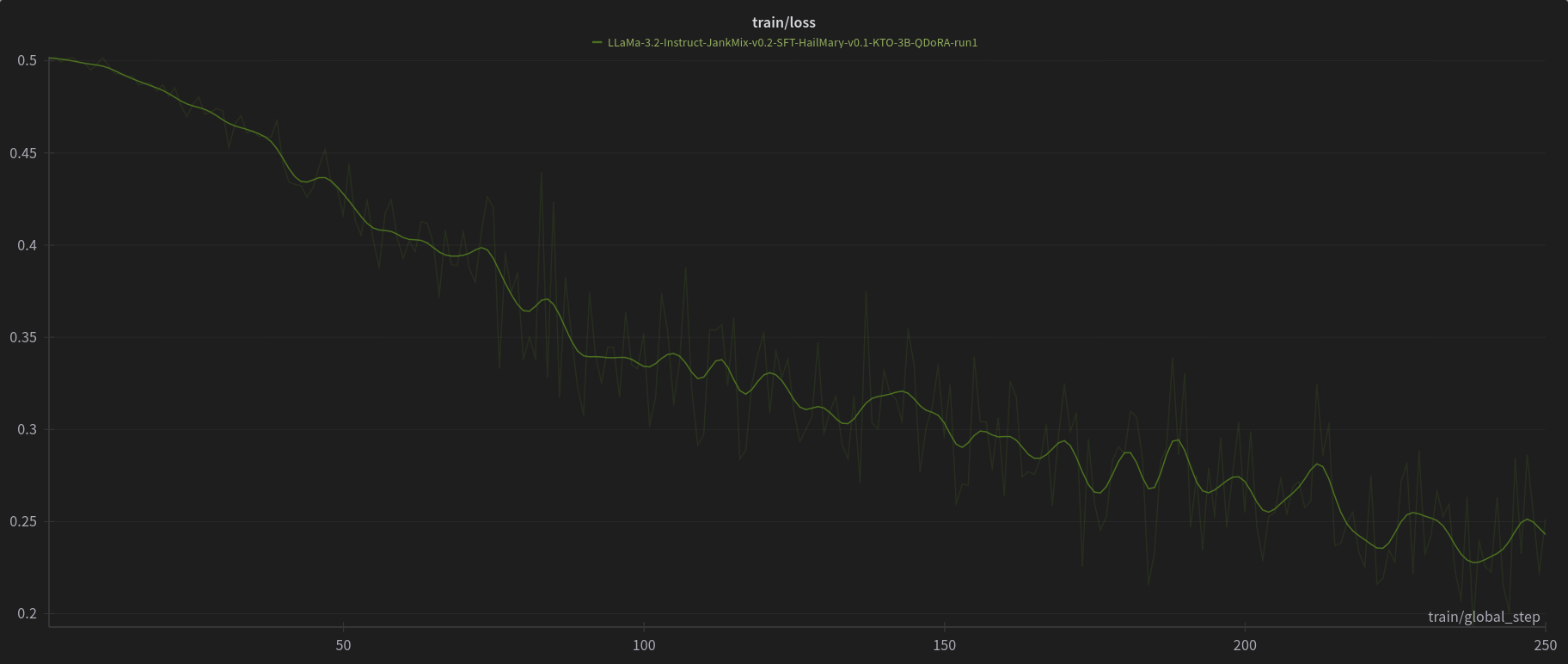
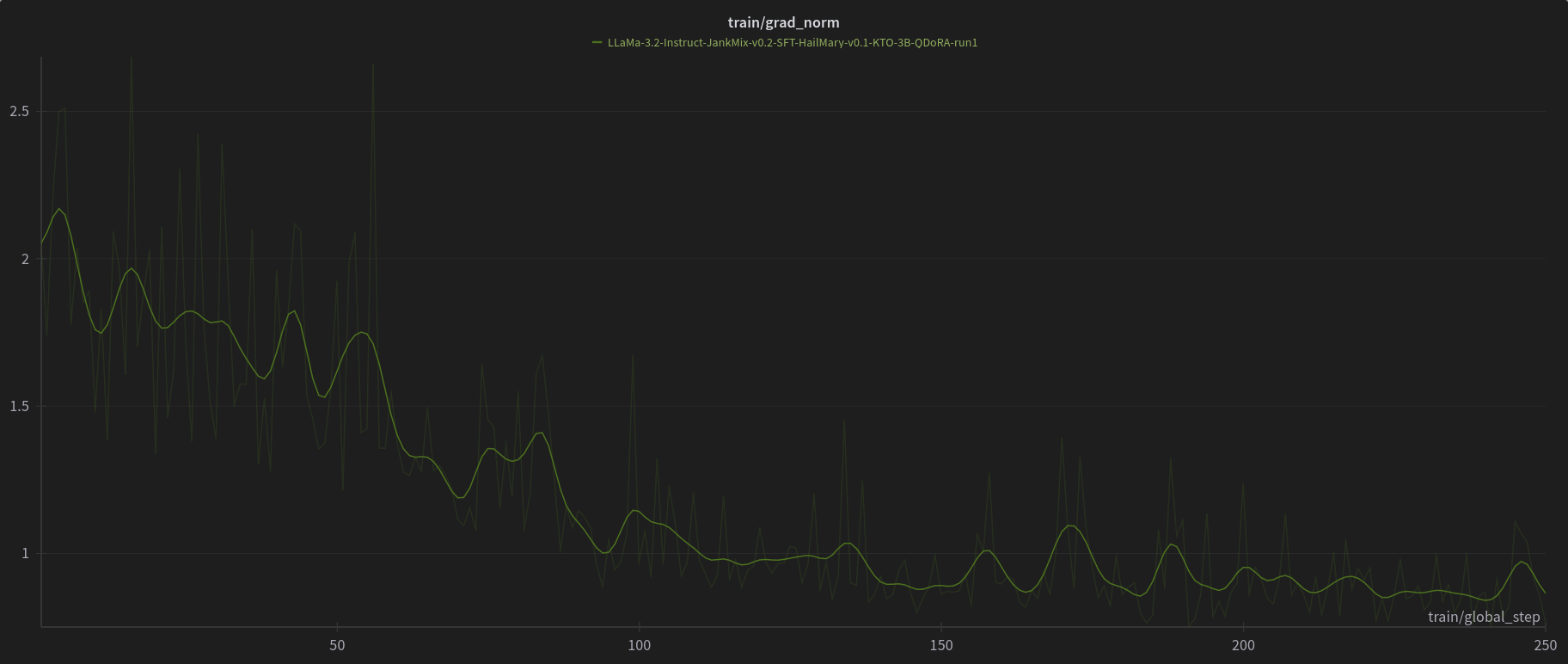
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/PJMixers-Dev__LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B-details)
| Metric |Value|
|-------------------|----:|
|Avg. |21.69|
|IFEval (0-Shot) |65.04|
|BBH (3-Shot) |22.29|
|MATH Lvl 5 (4-Shot)|11.78|
|GPQA (0-shot) | 2.91|
|MuSR (0-shot) | 4.69|
|MMLU-PRO (5-shot) |23.42|
|
RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf
|
RichardErkhov
| 2024-11-01T16:04:43Z | 20 | 0 | null |
[
"gguf",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:21:26Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-2.8b-deduped - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-2.8b-deduped/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-2.8b-deduped.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q2_K.gguf) | Q2_K | 1.01GB |
| [pythia-2.8b-deduped.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [pythia-2.8b-deduped.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q3_K.gguf) | Q3_K | 1.38GB |
| [pythia-2.8b-deduped.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q3_K_M.gguf) | Q3_K_M | 1.38GB |
| [pythia-2.8b-deduped.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q3_K_L.gguf) | Q3_K_L | 1.49GB |
| [pythia-2.8b-deduped.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.IQ4_XS.gguf) | IQ4_XS | 1.43GB |
| [pythia-2.8b-deduped.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q4_0.gguf) | Q4_0 | 1.49GB |
| [pythia-2.8b-deduped.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.IQ4_NL.gguf) | IQ4_NL | 1.5GB |
| [pythia-2.8b-deduped.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q4_K_S.gguf) | Q4_K_S | 1.5GB |
| [pythia-2.8b-deduped.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q4_K.gguf) | Q4_K | 1.66GB |
| [pythia-2.8b-deduped.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q4_K_M.gguf) | Q4_K_M | 1.66GB |
| [pythia-2.8b-deduped.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q4_1.gguf) | Q4_1 | 1.64GB |
| [pythia-2.8b-deduped.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q5_0.gguf) | Q5_0 | 1.8GB |
| [pythia-2.8b-deduped.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q5_K_S.gguf) | Q5_K_S | 1.8GB |
| [pythia-2.8b-deduped.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q5_K.gguf) | Q5_K | 1.93GB |
| [pythia-2.8b-deduped.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q5_K_M.gguf) | Q5_K_M | 1.93GB |
| [pythia-2.8b-deduped.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q5_1.gguf) | Q5_1 | 1.95GB |
| [pythia-2.8b-deduped.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q6_K.gguf) | Q6_K | 2.13GB |
| [pythia-2.8b-deduped.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-gguf/blob/main/pythia-2.8b-deduped.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-2.8B-deduped
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-2.8B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-2.8B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-2.8B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-2.8B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-2.8B-deduped to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-2.8B-deduped may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-2.8B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
Pythia-2.8B-deduped was trained on the Pile **after the dataset has been globally
deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf
|
RichardErkhov
| 2024-11-01T15:56:13Z | 450 | 0 | null |
[
"gguf",
"arxiv:2410.17215",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-11-01T15:37:27Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Pretrain-Qwen-1.2B - GGUF
- Model creator: https://huggingface.co/MiniLLM/
- Original model: https://huggingface.co/MiniLLM/Pretrain-Qwen-1.2B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Pretrain-Qwen-1.2B.Q2_K.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q2_K.gguf) | Q2_K | 0.51GB |
| [Pretrain-Qwen-1.2B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q3_K_S.gguf) | Q3_K_S | 0.57GB |
| [Pretrain-Qwen-1.2B.Q3_K.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q3_K.gguf) | Q3_K | 0.61GB |
| [Pretrain-Qwen-1.2B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q3_K_M.gguf) | Q3_K_M | 0.61GB |
| [Pretrain-Qwen-1.2B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q3_K_L.gguf) | Q3_K_L | 0.63GB |
| [Pretrain-Qwen-1.2B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.IQ4_XS.gguf) | IQ4_XS | 0.65GB |
| [Pretrain-Qwen-1.2B.Q4_0.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q4_0.gguf) | Q4_0 | 0.67GB |
| [Pretrain-Qwen-1.2B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.IQ4_NL.gguf) | IQ4_NL | 0.67GB |
| [Pretrain-Qwen-1.2B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q4_K_S.gguf) | Q4_K_S | 0.69GB |
| [Pretrain-Qwen-1.2B.Q4_K.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q4_K.gguf) | Q4_K | 0.72GB |
| [Pretrain-Qwen-1.2B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q4_K_M.gguf) | Q4_K_M | 0.72GB |
| [Pretrain-Qwen-1.2B.Q4_1.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q4_1.gguf) | Q4_1 | 0.72GB |
| [Pretrain-Qwen-1.2B.Q5_0.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q5_0.gguf) | Q5_0 | 0.78GB |
| [Pretrain-Qwen-1.2B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q5_K_S.gguf) | Q5_K_S | 0.79GB |
| [Pretrain-Qwen-1.2B.Q5_K.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q5_K.gguf) | Q5_K | 0.81GB |
| [Pretrain-Qwen-1.2B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q5_K_M.gguf) | Q5_K_M | 0.81GB |
| [Pretrain-Qwen-1.2B.Q5_1.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q5_1.gguf) | Q5_1 | 0.83GB |
| [Pretrain-Qwen-1.2B.Q6_K.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q6_K.gguf) | Q6_K | 0.93GB |
| [Pretrain-Qwen-1.2B.Q8_0.gguf](https://huggingface.co/RichardErkhov/MiniLLM_-_Pretrain-Qwen-1.2B-gguf/blob/main/Pretrain-Qwen-1.2B.Q8_0.gguf) | Q8_0 | 1.15GB |
Original model description:
---
library_name: transformers
license: apache-2.0
datasets:
- monology/pile-uncopyrighted
- MiniLLM/pile-tokenized
language:
- en
metrics:
- accuracy
pipeline_tag: text-generation
---
# Pretrain-Qwen-1.2B
[paper](https://arxiv.org/abs/2410.17215) | [code](https://github.com/thu-coai/MiniPLM)
**Pretrain-Qwen-1.2B** is a 1.2B model with Qwen achitecture conventionally pre-trained from scratch on [the Pile](https://huggingface.co/datasets/monology/pile-uncopyrighted) for 50B tokens.
We also open-source the tokenized [pre-training corpus](https://huggingface.co/datasets/MiniLLM/pile-tokenized) for reproducibility.
**It is used as the baseline for [MiniLLM-Qwen-1.2B](https://huggingface.co/MiniLLM/MiniPLM-Qwen-1.2B)**
## Evaluation
MiniPLM models achieves better performance given the same computation and scales well across model sizes:
<p align='left'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/624ac662102fcdff87be51b9/EOYzajQcwQFT5PobqL3j0.png" width="1000">
</p>
## Other Baselines
+ [VanillaKD](https://huggingface.co/MiniLLM/VanillaKD-Pretrain-Qwen-1.2B)
## Citation
```bibtext
@article{miniplm,
title={MiniPLM: Knowledge Distillation for Pre-Training Language Models},
author={Yuxian Gu and Hao Zhou and Fandong Meng and Jie Zhou and Minlie Huang},
journal={arXiv preprint arXiv:2410.17215},
year={2024}
}
```
|
mlfoundations-dev/OH_DCFT_V3_wo_platypus
|
mlfoundations-dev
| 2024-11-01T15:54:44Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-10-30T21:32:27Z |
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: OH_DCFT_V3_wo_platypus
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OH_DCFT_V3_wo_platypus
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the mlfoundations-dev/OH_DCFT_V3_wo_platypus dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6428
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.1
- lr_scheduler_warmup_steps: 1738
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.6557 | 0.9988 | 410 | 0.6519 |
| 0.6082 | 2.0 | 821 | 0.6420 |
| 0.5706 | 2.9963 | 1230 | 0.6428 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.3.0
- Datasets 2.21.0
- Tokenizers 0.20.1
|
RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf
|
RichardErkhov
| 2024-11-01T15:47:02Z | 9 | 0 | null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-11-01T15:06:22Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
vinallama-2.7b-chat-orpo-v2 - GGUF
- Model creator: https://huggingface.co/d-llm/
- Original model: https://huggingface.co/d-llm/vinallama-2.7b-chat-orpo-v2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [vinallama-2.7b-chat-orpo-v2.Q2_K.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q2_K.gguf) | Q2_K | 1.0GB |
| [vinallama-2.7b-chat-orpo-v2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [vinallama-2.7b-chat-orpo-v2.Q3_K.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q3_K.gguf) | Q3_K | 1.28GB |
| [vinallama-2.7b-chat-orpo-v2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q3_K_M.gguf) | Q3_K_M | 1.28GB |
| [vinallama-2.7b-chat-orpo-v2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q3_K_L.gguf) | Q3_K_L | 1.39GB |
| [vinallama-2.7b-chat-orpo-v2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.IQ4_XS.gguf) | IQ4_XS | 1.42GB |
| [vinallama-2.7b-chat-orpo-v2.Q4_0.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q4_0.gguf) | Q4_0 | 1.48GB |
| [vinallama-2.7b-chat-orpo-v2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.IQ4_NL.gguf) | IQ4_NL | 1.49GB |
| [vinallama-2.7b-chat-orpo-v2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q4_K_S.gguf) | Q4_K_S | 1.49GB |
| [vinallama-2.7b-chat-orpo-v2.Q4_K.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q4_K.gguf) | Q4_K | 1.58GB |
| [vinallama-2.7b-chat-orpo-v2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q4_K_M.gguf) | Q4_K_M | 1.58GB |
| [vinallama-2.7b-chat-orpo-v2.Q4_1.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q4_1.gguf) | Q4_1 | 1.64GB |
| [vinallama-2.7b-chat-orpo-v2.Q5_0.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q5_0.gguf) | Q5_0 | 1.79GB |
| [vinallama-2.7b-chat-orpo-v2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q5_K_S.gguf) | Q5_K_S | 1.79GB |
| [vinallama-2.7b-chat-orpo-v2.Q5_K.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q5_K.gguf) | Q5_K | 1.84GB |
| [vinallama-2.7b-chat-orpo-v2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q5_K_M.gguf) | Q5_K_M | 1.84GB |
| [vinallama-2.7b-chat-orpo-v2.Q5_1.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q5_1.gguf) | Q5_1 | 1.95GB |
| [vinallama-2.7b-chat-orpo-v2.Q6_K.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q6_K.gguf) | Q6_K | 2.12GB |
| [vinallama-2.7b-chat-orpo-v2.Q8_0.gguf](https://huggingface.co/RichardErkhov/d-llm_-_vinallama-2.7b-chat-orpo-v2-gguf/blob/main/vinallama-2.7b-chat-orpo-v2.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gglabs/Mistral-Nemo-FC-1030-3-epoch
|
gglabs
| 2024-11-01T15:45:02Z | 7 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"base_model:quantized:unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-11-01T15:24:35Z |
---
base_model: unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
---
# Uploaded model
- **Developed by:** gglabs
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf
|
RichardErkhov
| 2024-11-01T15:38:02Z | 6 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:18:05Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old - GGUF
- Model creator: https://huggingface.co/martimfasantos/
- Original model: https://huggingface.co/martimfasantos/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q2_K.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q2_K.gguf) | Q2_K | 0.4GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K.gguf) | Q3_K | 0.51GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_0.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_0.gguf) | Q4_0 | 0.59GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K.gguf) | Q4_K | 0.62GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_1.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q4_1.gguf) | Q4_1 | 0.65GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_0.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_0.gguf) | Q5_0 | 0.71GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K.gguf) | Q5_K | 0.73GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_1.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q5_1.gguf) | Q5_1 | 0.77GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q6_K.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q6_K.gguf) | Q6_K | 0.84GB |
| [tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q8_0.gguf](https://huggingface.co/RichardErkhov/martimfasantos_-_tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old-gguf/blob/main/tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
license: apache-2.0
base_model: martimfasantos/tinyllama-1.1b-sum-sft-full_old
tags:
- alignment-handbook
- trl
- dpo
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
datasets:
- openai/summarize_from_feedback
model-index:
- name: tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinyllama-1.1b-sum-dpo-full_LR5e-8_3epochs_old
This model is a fine-tuned version of [martimfasantos/tinyllama-1.1b-sum-sft-full_old](https://huggingface.co/martimfasantos/tinyllama-1.1b-sum-sft-full_old) on the openai/summarize_from_feedback dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6687
- Rewards/chosen: -0.2893
- Rewards/rejected: -0.3487
- Rewards/accuracies: 0.6008
- Rewards/margins: 0.0594
- Logps/rejected: -98.0463
- Logps/chosen: -87.6427
- Logits/rejected: -2.7624
- Logits/chosen: -2.7684
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-08
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:------:|:-----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.6931 | 0.0172 | 100 | 0.6932 | -0.0000 | 0.0001 | 0.4851 | -0.0001 | -63.1729 | -58.7138 | -3.1573 | -3.1630 |
| 0.6931 | 0.0345 | 200 | 0.6932 | -0.0000 | 0.0001 | 0.4730 | -0.0001 | -63.1741 | -58.7133 | -3.1575 | -3.1631 |
| 0.6932 | 0.0517 | 300 | 0.6932 | 0.0001 | 0.0001 | 0.4942 | -0.0000 | -63.1702 | -58.7051 | -3.1574 | -3.1631 |
| 0.6932 | 0.0689 | 400 | 0.6932 | 0.0001 | 0.0001 | 0.4884 | -0.0001 | -63.1678 | -58.7049 | -3.1574 | -3.1631 |
| 0.6931 | 0.0861 | 500 | 0.6932 | -0.0000 | 0.0001 | 0.4737 | -0.0001 | -63.1733 | -58.7135 | -3.1577 | -3.1633 |
| 0.693 | 0.1034 | 600 | 0.6932 | 0.0001 | 0.0001 | 0.4923 | -0.0000 | -63.1656 | -58.7003 | -3.1575 | -3.1632 |
| 0.6932 | 0.1206 | 700 | 0.6931 | 0.0002 | 0.0002 | 0.5100 | 0.0001 | -63.1644 | -58.6897 | -3.1574 | -3.1631 |
| 0.6929 | 0.1378 | 800 | 0.6932 | 0.0002 | 0.0003 | 0.4668 | -0.0001 | -63.1484 | -58.6918 | -3.1571 | -3.1627 |
| 0.6931 | 0.1551 | 900 | 0.6931 | 0.0003 | 0.0002 | 0.5058 | 0.0000 | -63.1556 | -58.6837 | -3.1569 | -3.1625 |
| 0.6931 | 0.1723 | 1000 | 0.6931 | 0.0004 | 0.0002 | 0.5051 | 0.0001 | -63.1557 | -58.6755 | -3.1567 | -3.1624 |
| 0.6929 | 0.1895 | 1100 | 0.6931 | 0.0005 | 0.0004 | 0.5160 | 0.0001 | -63.1450 | -58.6627 | -3.1565 | -3.1621 |
| 0.6927 | 0.2068 | 1200 | 0.6930 | 0.0007 | 0.0005 | 0.5160 | 0.0002 | -63.1294 | -58.6411 | -3.1560 | -3.1616 |
| 0.6929 | 0.2240 | 1300 | 0.6930 | 0.0009 | 0.0006 | 0.5230 | 0.0003 | -63.1224 | -58.6264 | -3.1548 | -3.1605 |
| 0.692 | 0.2412 | 1400 | 0.6929 | 0.0010 | 0.0005 | 0.5407 | 0.0005 | -63.1333 | -58.6153 | -3.1542 | -3.1598 |
| 0.6918 | 0.2584 | 1500 | 0.6929 | 0.0011 | 0.0006 | 0.5351 | 0.0005 | -63.1157 | -58.5976 | -3.1532 | -3.1588 |
| 0.6921 | 0.2757 | 1600 | 0.6928 | 0.0015 | 0.0007 | 0.5611 | 0.0008 | -63.1099 | -58.5639 | -3.1517 | -3.1574 |
| 0.692 | 0.2929 | 1700 | 0.6926 | 0.0018 | 0.0008 | 0.5662 | 0.0010 | -63.1046 | -58.5339 | -3.1502 | -3.1558 |
| 0.6904 | 0.3101 | 1800 | 0.6926 | 0.0018 | 0.0007 | 0.5699 | 0.0012 | -63.1148 | -58.5277 | -3.1485 | -3.1542 |
| 0.691 | 0.3274 | 1900 | 0.6924 | 0.0018 | 0.0003 | 0.5581 | 0.0015 | -63.1539 | -58.5341 | -3.1473 | -3.1529 |
| 0.6909 | 0.3446 | 2000 | 0.6923 | 0.0020 | 0.0002 | 0.5723 | 0.0018 | -63.1632 | -58.5155 | -3.1452 | -3.1509 |
| 0.6903 | 0.3618 | 2100 | 0.6921 | 0.0019 | -0.0002 | 0.5697 | 0.0021 | -63.1963 | -58.5193 | -3.1434 | -3.1490 |
| 0.6884 | 0.3790 | 2200 | 0.6920 | 0.0018 | -0.0006 | 0.5757 | 0.0024 | -63.2422 | -58.5311 | -3.1407 | -3.1464 |
| 0.6876 | 0.3963 | 2300 | 0.6918 | 0.0015 | -0.0012 | 0.5769 | 0.0027 | -63.3015 | -58.5638 | -3.1381 | -3.1437 |
| 0.6898 | 0.4135 | 2400 | 0.6917 | 0.0012 | -0.0018 | 0.5625 | 0.0030 | -63.3619 | -58.5900 | -3.1348 | -3.1404 |
| 0.6905 | 0.4307 | 2500 | 0.6915 | 0.0007 | -0.0028 | 0.5743 | 0.0035 | -63.4609 | -58.6445 | -3.1321 | -3.1378 |
| 0.6864 | 0.4480 | 2600 | 0.6913 | -0.0001 | -0.0039 | 0.5732 | 0.0038 | -63.5690 | -58.7216 | -3.1295 | -3.1352 |
| 0.6866 | 0.4652 | 2700 | 0.6911 | -0.0014 | -0.0057 | 0.5709 | 0.0043 | -63.7456 | -58.8490 | -3.1270 | -3.1327 |
| 0.6869 | 0.4824 | 2800 | 0.6909 | -0.0025 | -0.0071 | 0.5750 | 0.0046 | -63.8913 | -58.9609 | -3.1248 | -3.1305 |
| 0.6888 | 0.4997 | 2900 | 0.6907 | -0.0042 | -0.0093 | 0.5855 | 0.0051 | -64.1121 | -59.1289 | -3.1214 | -3.1271 |
| 0.6885 | 0.5169 | 3000 | 0.6905 | -0.0061 | -0.0118 | 0.5804 | 0.0057 | -64.3621 | -59.3245 | -3.1180 | -3.1236 |
| 0.686 | 0.5341 | 3100 | 0.6904 | -0.0071 | -0.0130 | 0.5857 | 0.0059 | -64.4774 | -59.4209 | -3.1160 | -3.1217 |
| 0.6869 | 0.5513 | 3200 | 0.6902 | -0.0095 | -0.0159 | 0.5878 | 0.0064 | -64.7659 | -59.6584 | -3.1119 | -3.1176 |
| 0.6834 | 0.5686 | 3300 | 0.6900 | -0.0122 | -0.0190 | 0.5809 | 0.0068 | -65.0782 | -59.9308 | -3.1072 | -3.1130 |
| 0.6795 | 0.5858 | 3400 | 0.6897 | -0.0147 | -0.0221 | 0.5881 | 0.0074 | -65.3901 | -60.1840 | -3.1036 | -3.1093 |
| 0.6848 | 0.6030 | 3500 | 0.6895 | -0.0171 | -0.0250 | 0.5897 | 0.0079 | -65.6826 | -60.4227 | -3.1007 | -3.1064 |
| 0.6834 | 0.6203 | 3600 | 0.6893 | -0.0196 | -0.0280 | 0.5857 | 0.0084 | -65.9796 | -60.6710 | -3.0969 | -3.1026 |
| 0.6788 | 0.6375 | 3700 | 0.6890 | -0.0219 | -0.0308 | 0.5813 | 0.0089 | -66.2620 | -60.8999 | -3.0922 | -3.0979 |
| 0.6825 | 0.6547 | 3800 | 0.6888 | -0.0253 | -0.0348 | 0.5904 | 0.0095 | -66.6623 | -61.2404 | -3.0889 | -3.0946 |
| 0.6791 | 0.6720 | 3900 | 0.6885 | -0.0287 | -0.0389 | 0.5943 | 0.0103 | -67.0740 | -61.5806 | -3.0858 | -3.0915 |
| 0.6816 | 0.6892 | 4000 | 0.6881 | -0.0328 | -0.0438 | 0.5897 | 0.0110 | -67.5621 | -61.9903 | -3.0815 | -3.0872 |
| 0.6749 | 0.7064 | 4100 | 0.6879 | -0.0340 | -0.0456 | 0.5901 | 0.0116 | -67.7361 | -62.1084 | -3.0755 | -3.0812 |
| 0.6839 | 0.7236 | 4200 | 0.6877 | -0.0364 | -0.0484 | 0.5964 | 0.0120 | -68.0226 | -62.3546 | -3.0712 | -3.0769 |
| 0.6827 | 0.7409 | 4300 | 0.6876 | -0.0377 | -0.0500 | 0.5897 | 0.0123 | -68.1844 | -62.4844 | -3.0675 | -3.0732 |
| 0.6815 | 0.7581 | 4400 | 0.6873 | -0.0402 | -0.0531 | 0.5950 | 0.0129 | -68.4913 | -62.7319 | -3.0645 | -3.0702 |
| 0.6829 | 0.7753 | 4500 | 0.6870 | -0.0443 | -0.0578 | 0.5939 | 0.0136 | -68.9615 | -63.1372 | -3.0609 | -3.0666 |
| 0.6747 | 0.7926 | 4600 | 0.6868 | -0.0476 | -0.0617 | 0.5915 | 0.0141 | -69.3541 | -63.4724 | -3.0573 | -3.0630 |
| 0.6828 | 0.8098 | 4700 | 0.6864 | -0.0518 | -0.0669 | 0.5936 | 0.0151 | -69.8725 | -63.8948 | -3.0542 | -3.0599 |
| 0.6821 | 0.8270 | 4800 | 0.6861 | -0.0560 | -0.0717 | 0.5939 | 0.0156 | -70.3462 | -64.3141 | -3.0504 | -3.0562 |
| 0.6767 | 0.8442 | 4900 | 0.6858 | -0.0602 | -0.0766 | 0.5948 | 0.0164 | -70.8421 | -64.7344 | -3.0474 | -3.0532 |
| 0.6765 | 0.8615 | 5000 | 0.6856 | -0.0618 | -0.0786 | 0.5934 | 0.0168 | -71.0357 | -64.8873 | -3.0427 | -3.0484 |
| 0.6792 | 0.8787 | 5100 | 0.6853 | -0.0665 | -0.0841 | 0.5936 | 0.0176 | -71.5851 | -65.3618 | -3.0385 | -3.0443 |
| 0.6753 | 0.8959 | 5200 | 0.6851 | -0.0697 | -0.0877 | 0.5929 | 0.0180 | -71.9544 | -65.6814 | -3.0354 | -3.0413 |
| 0.6749 | 0.9132 | 5300 | 0.6849 | -0.0732 | -0.0918 | 0.5922 | 0.0186 | -72.3637 | -66.0356 | -3.0313 | -3.0370 |
| 0.6762 | 0.9304 | 5400 | 0.6846 | -0.0747 | -0.0940 | 0.5932 | 0.0192 | -72.5755 | -66.1839 | -3.0282 | -3.0340 |
| 0.6757 | 0.9476 | 5500 | 0.6845 | -0.0761 | -0.0955 | 0.5962 | 0.0194 | -72.7312 | -66.3251 | -3.0247 | -3.0305 |
| 0.6795 | 0.9649 | 5600 | 0.6844 | -0.0758 | -0.0955 | 0.6018 | 0.0197 | -72.7251 | -66.2887 | -3.0221 | -3.0279 |
| 0.6736 | 0.9821 | 5700 | 0.6842 | -0.0786 | -0.0989 | 0.6008 | 0.0202 | -73.0675 | -66.5758 | -3.0181 | -3.0239 |
| 0.6701 | 0.9993 | 5800 | 0.6839 | -0.0831 | -0.1040 | 0.6029 | 0.0209 | -73.5774 | -67.0210 | -3.0139 | -3.0198 |
| 0.6725 | 1.0165 | 5900 | 0.6836 | -0.0839 | -0.1053 | 0.6039 | 0.0214 | -73.7143 | -67.1023 | -3.0090 | -3.0148 |
| 0.6742 | 1.0338 | 6000 | 0.6834 | -0.0850 | -0.1069 | 0.6043 | 0.0219 | -73.8738 | -67.2139 | -3.0056 | -3.0114 |
| 0.6712 | 1.0510 | 6100 | 0.6833 | -0.0878 | -0.1100 | 0.6046 | 0.0223 | -74.1846 | -67.4874 | -3.0008 | -3.0066 |
| 0.675 | 1.0682 | 6200 | 0.6831 | -0.0903 | -0.1131 | 0.6043 | 0.0228 | -74.4897 | -67.7427 | -2.9969 | -3.0027 |
| 0.6766 | 1.0855 | 6300 | 0.6828 | -0.0936 | -0.1170 | 0.6036 | 0.0234 | -74.8753 | -68.0717 | -2.9936 | -2.9994 |
| 0.6754 | 1.1027 | 6400 | 0.6826 | -0.0972 | -0.1212 | 0.6094 | 0.0240 | -75.2993 | -68.4308 | -2.9896 | -2.9954 |
| 0.6769 | 1.1199 | 6500 | 0.6823 | -0.0999 | -0.1244 | 0.6059 | 0.0246 | -75.6244 | -68.6977 | -2.9850 | -2.9909 |
| 0.6764 | 1.1371 | 6600 | 0.6821 | -0.1041 | -0.1293 | 0.6076 | 0.0252 | -76.1111 | -69.1214 | -2.9809 | -2.9867 |
| 0.6734 | 1.1544 | 6700 | 0.6817 | -0.1081 | -0.1341 | 0.6022 | 0.0260 | -76.5930 | -69.5220 | -2.9770 | -2.9828 |
| 0.6654 | 1.1716 | 6800 | 0.6814 | -0.1138 | -0.1407 | 0.6053 | 0.0268 | -77.2464 | -70.0935 | -2.9716 | -2.9774 |
| 0.679 | 1.1888 | 6900 | 0.6812 | -0.1168 | -0.1441 | 0.6090 | 0.0272 | -77.5858 | -70.3942 | -2.9678 | -2.9737 |
| 0.6652 | 1.2061 | 7000 | 0.6809 | -0.1215 | -0.1495 | 0.6057 | 0.0280 | -78.1280 | -70.8571 | -2.9641 | -2.9700 |
| 0.6668 | 1.2233 | 7100 | 0.6808 | -0.1224 | -0.1507 | 0.6071 | 0.0283 | -78.2466 | -70.9482 | -2.9603 | -2.9661 |
| 0.6655 | 1.2405 | 7200 | 0.6806 | -0.1254 | -0.1542 | 0.6083 | 0.0288 | -78.5984 | -71.2532 | -2.9555 | -2.9614 |
| 0.6783 | 1.2578 | 7300 | 0.6804 | -0.1273 | -0.1565 | 0.6087 | 0.0292 | -78.8264 | -71.4380 | -2.9521 | -2.9580 |
| 0.6703 | 1.2750 | 7400 | 0.6802 | -0.1295 | -0.1593 | 0.6071 | 0.0297 | -79.1055 | -71.6647 | -2.9497 | -2.9555 |
| 0.6709 | 1.2922 | 7500 | 0.6802 | -0.1302 | -0.1601 | 0.6080 | 0.0299 | -79.1917 | -71.7369 | -2.9461 | -2.9519 |
| 0.6774 | 1.3094 | 7600 | 0.6799 | -0.1334 | -0.1639 | 0.6097 | 0.0305 | -79.5669 | -72.0519 | -2.9409 | -2.9468 |
| 0.6667 | 1.3267 | 7700 | 0.6796 | -0.1379 | -0.1690 | 0.6078 | 0.0311 | -80.0833 | -72.5013 | -2.9364 | -2.9423 |
| 0.6631 | 1.3439 | 7800 | 0.6793 | -0.1427 | -0.1747 | 0.6076 | 0.0321 | -80.6536 | -72.9770 | -2.9325 | -2.9384 |
| 0.6734 | 1.3611 | 7900 | 0.6790 | -0.1469 | -0.1797 | 0.6094 | 0.0327 | -81.1455 | -73.4038 | -2.9286 | -2.9346 |
| 0.6646 | 1.3784 | 8000 | 0.6786 | -0.1515 | -0.1852 | 0.6092 | 0.0337 | -81.6967 | -73.8575 | -2.9249 | -2.9308 |
| 0.6717 | 1.3956 | 8100 | 0.6783 | -0.1560 | -0.1904 | 0.6111 | 0.0344 | -82.2197 | -74.3164 | -2.9212 | -2.9271 |
| 0.6674 | 1.4128 | 8200 | 0.6779 | -0.1608 | -0.1962 | 0.6087 | 0.0354 | -82.7997 | -74.7964 | -2.9181 | -2.9240 |
| 0.6659 | 1.4300 | 8300 | 0.6779 | -0.1625 | -0.1979 | 0.6087 | 0.0354 | -82.9745 | -74.9664 | -2.9143 | -2.9202 |
| 0.6642 | 1.4473 | 8400 | 0.6777 | -0.1647 | -0.2007 | 0.6092 | 0.0360 | -83.2477 | -75.1821 | -2.9110 | -2.9169 |
| 0.6579 | 1.4645 | 8500 | 0.6775 | -0.1650 | -0.2013 | 0.6080 | 0.0363 | -83.3130 | -75.2138 | -2.9067 | -2.9125 |
| 0.6725 | 1.4817 | 8600 | 0.6774 | -0.1676 | -0.2043 | 0.6101 | 0.0367 | -83.6107 | -75.4718 | -2.9030 | -2.9089 |
| 0.6646 | 1.4990 | 8700 | 0.6774 | -0.1665 | -0.2032 | 0.6101 | 0.0367 | -83.4985 | -75.3618 | -2.9012 | -2.9071 |
| 0.6681 | 1.5162 | 8800 | 0.6771 | -0.1691 | -0.2064 | 0.6092 | 0.0373 | -83.8169 | -75.6183 | -2.8978 | -2.9037 |
| 0.6635 | 1.5334 | 8900 | 0.6768 | -0.1758 | -0.2138 | 0.6087 | 0.0381 | -84.5617 | -76.2875 | -2.8935 | -2.8994 |
| 0.6509 | 1.5507 | 9000 | 0.6766 | -0.1793 | -0.2180 | 0.6092 | 0.0386 | -84.9755 | -76.6455 | -2.8897 | -2.8956 |
| 0.663 | 1.5679 | 9100 | 0.6764 | -0.1824 | -0.2216 | 0.6073 | 0.0391 | -85.3355 | -76.9553 | -2.8858 | -2.8918 |
| 0.6614 | 1.5851 | 9200 | 0.6762 | -0.1856 | -0.2252 | 0.6076 | 0.0396 | -85.7006 | -77.2724 | -2.8834 | -2.8894 |
| 0.6605 | 1.6023 | 9300 | 0.6761 | -0.1847 | -0.2246 | 0.6078 | 0.0398 | -85.6352 | -77.1840 | -2.8793 | -2.8852 |
| 0.6616 | 1.6196 | 9400 | 0.6759 | -0.1879 | -0.2282 | 0.6053 | 0.0403 | -86.0049 | -77.5025 | -2.8759 | -2.8818 |
| 0.6595 | 1.6368 | 9500 | 0.6757 | -0.1905 | -0.2315 | 0.6085 | 0.0410 | -86.3271 | -77.7626 | -2.8721 | -2.8781 |
| 0.6612 | 1.6540 | 9600 | 0.6753 | -0.1938 | -0.2356 | 0.6069 | 0.0418 | -86.7373 | -78.0935 | -2.8679 | -2.8738 |
| 0.6563 | 1.6713 | 9700 | 0.6751 | -0.1979 | -0.2402 | 0.6083 | 0.0423 | -87.2033 | -78.5057 | -2.8649 | -2.8708 |
| 0.6526 | 1.6885 | 9800 | 0.6750 | -0.2017 | -0.2444 | 0.6069 | 0.0427 | -87.6160 | -78.8784 | -2.8620 | -2.8680 |
| 0.6392 | 1.7057 | 9900 | 0.6747 | -0.2051 | -0.2485 | 0.6094 | 0.0434 | -88.0276 | -79.2194 | -2.8594 | -2.8653 |
| 0.6528 | 1.7229 | 10000 | 0.6746 | -0.2062 | -0.2500 | 0.6087 | 0.0437 | -88.1775 | -79.3360 | -2.8562 | -2.8622 |
| 0.6542 | 1.7402 | 10100 | 0.6744 | -0.2075 | -0.2516 | 0.6066 | 0.0441 | -88.3364 | -79.4595 | -2.8532 | -2.8592 |
| 0.6559 | 1.7574 | 10200 | 0.6739 | -0.2141 | -0.2595 | 0.6078 | 0.0454 | -89.1350 | -80.1233 | -2.8483 | -2.8543 |
| 0.6708 | 1.7746 | 10300 | 0.6737 | -0.2171 | -0.2629 | 0.6104 | 0.0458 | -89.4692 | -80.4205 | -2.8439 | -2.8500 |
| 0.6454 | 1.7919 | 10400 | 0.6737 | -0.2178 | -0.2638 | 0.6048 | 0.0460 | -89.5570 | -80.4903 | -2.8419 | -2.8479 |
| 0.6495 | 1.8091 | 10500 | 0.6735 | -0.2211 | -0.2676 | 0.6036 | 0.0465 | -89.9389 | -80.8204 | -2.8383 | -2.8444 |
| 0.6648 | 1.8263 | 10600 | 0.6732 | -0.2247 | -0.2719 | 0.6034 | 0.0472 | -90.3731 | -81.1833 | -2.8349 | -2.8409 |
| 0.6568 | 1.8436 | 10700 | 0.6731 | -0.2275 | -0.2752 | 0.6039 | 0.0476 | -90.6979 | -81.4662 | -2.8311 | -2.8372 |
| 0.6536 | 1.8608 | 10800 | 0.6728 | -0.2303 | -0.2785 | 0.6043 | 0.0482 | -91.0335 | -81.7461 | -2.8295 | -2.8355 |
| 0.6574 | 1.8780 | 10900 | 0.6726 | -0.2320 | -0.2808 | 0.6032 | 0.0487 | -91.2560 | -81.9128 | -2.8271 | -2.8331 |
| 0.6601 | 1.8952 | 11000 | 0.6725 | -0.2331 | -0.2820 | 0.6018 | 0.0489 | -91.3829 | -82.0227 | -2.8250 | -2.8311 |
| 0.6562 | 1.9125 | 11100 | 0.6722 | -0.2383 | -0.2881 | 0.6029 | 0.0498 | -91.9931 | -82.5429 | -2.8218 | -2.8278 |
| 0.6536 | 1.9297 | 11200 | 0.6720 | -0.2416 | -0.2919 | 0.6025 | 0.0503 | -92.3716 | -82.8687 | -2.8187 | -2.8248 |
| 0.674 | 1.9469 | 11300 | 0.6718 | -0.2432 | -0.2940 | 0.6041 | 0.0508 | -92.5781 | -83.0317 | -2.8164 | -2.8225 |
| 0.6536 | 1.9642 | 11400 | 0.6717 | -0.2439 | -0.2949 | 0.6032 | 0.0511 | -92.6723 | -83.0980 | -2.8133 | -2.8194 |
| 0.6693 | 1.9814 | 11500 | 0.6717 | -0.2456 | -0.2969 | 0.6018 | 0.0513 | -92.8725 | -83.2765 | -2.8119 | -2.8179 |
| 0.6529 | 1.9986 | 11600 | 0.6714 | -0.2469 | -0.2988 | 0.6036 | 0.0518 | -93.0569 | -83.4057 | -2.8097 | -2.8158 |
| 0.6454 | 2.0159 | 11700 | 0.6713 | -0.2488 | -0.3010 | 0.6025 | 0.0522 | -93.2831 | -83.5962 | -2.8079 | -2.8140 |
| 0.6643 | 2.0331 | 11800 | 0.6711 | -0.2513 | -0.3040 | 0.6027 | 0.0527 | -93.5825 | -83.8399 | -2.8052 | -2.8113 |
| 0.6478 | 2.0503 | 11900 | 0.6710 | -0.2554 | -0.3084 | 0.5985 | 0.0530 | -94.0157 | -84.2502 | -2.8025 | -2.8086 |
| 0.6512 | 2.0675 | 12000 | 0.6708 | -0.2561 | -0.3095 | 0.6050 | 0.0535 | -94.1316 | -84.3177 | -2.8001 | -2.8061 |
| 0.6517 | 2.0848 | 12100 | 0.6708 | -0.2574 | -0.3109 | 0.6053 | 0.0536 | -94.2719 | -84.4484 | -2.7988 | -2.8048 |
| 0.646 | 2.1020 | 12200 | 0.6707 | -0.2592 | -0.3130 | 0.6025 | 0.0538 | -94.4818 | -84.6297 | -2.7972 | -2.8033 |
| 0.6439 | 2.1192 | 12300 | 0.6706 | -0.2607 | -0.3147 | 0.6029 | 0.0540 | -94.6511 | -84.7795 | -2.7953 | -2.8014 |
| 0.6432 | 2.1365 | 12400 | 0.6705 | -0.2646 | -0.3191 | 0.6053 | 0.0545 | -95.0945 | -85.1767 | -2.7925 | -2.7985 |
| 0.6437 | 2.1537 | 12500 | 0.6704 | -0.2662 | -0.3209 | 0.6018 | 0.0548 | -95.2735 | -85.3289 | -2.7907 | -2.7968 |
| 0.6581 | 2.1709 | 12600 | 0.6702 | -0.2678 | -0.3229 | 0.6029 | 0.0552 | -95.4749 | -85.4889 | -2.7888 | -2.7948 |
| 0.6509 | 2.1881 | 12700 | 0.6700 | -0.2692 | -0.3248 | 0.6036 | 0.0556 | -95.6598 | -85.6304 | -2.7870 | -2.7930 |
| 0.6603 | 2.2054 | 12800 | 0.6700 | -0.2697 | -0.3254 | 0.6004 | 0.0557 | -95.7213 | -85.6830 | -2.7854 | -2.7914 |
| 0.6459 | 2.2226 | 12900 | 0.6700 | -0.2702 | -0.3259 | 0.6027 | 0.0556 | -95.7675 | -85.7359 | -2.7844 | -2.7904 |
| 0.6501 | 2.2398 | 13000 | 0.6698 | -0.2723 | -0.3285 | 0.6011 | 0.0562 | -96.0266 | -85.9425 | -2.7827 | -2.7887 |
| 0.6452 | 2.2571 | 13100 | 0.6698 | -0.2721 | -0.3282 | 0.6025 | 0.0561 | -96.0042 | -85.9225 | -2.7811 | -2.7872 |
| 0.6553 | 2.2743 | 13200 | 0.6697 | -0.2732 | -0.3296 | 0.6034 | 0.0564 | -96.1360 | -86.0296 | -2.7798 | -2.7859 |
| 0.6627 | 2.2915 | 13300 | 0.6697 | -0.2745 | -0.3311 | 0.6020 | 0.0566 | -96.2910 | -86.1636 | -2.7781 | -2.7842 |
| 0.6393 | 2.3088 | 13400 | 0.6697 | -0.2741 | -0.3307 | 0.6013 | 0.0566 | -96.2503 | -86.1255 | -2.7777 | -2.7838 |
| 0.6366 | 2.3260 | 13500 | 0.6696 | -0.2757 | -0.3325 | 0.6027 | 0.0568 | -96.4266 | -86.2794 | -2.7767 | -2.7827 |
| 0.6522 | 2.3432 | 13600 | 0.6696 | -0.2765 | -0.3334 | 0.6032 | 0.0569 | -96.5202 | -86.3612 | -2.7753 | -2.7814 |
| 0.6535 | 2.3604 | 13700 | 0.6695 | -0.2780 | -0.3351 | 0.6022 | 0.0572 | -96.6946 | -86.5112 | -2.7742 | -2.7802 |
| 0.6555 | 2.3777 | 13800 | 0.6694 | -0.2786 | -0.3360 | 0.6022 | 0.0574 | -96.7815 | -86.5683 | -2.7734 | -2.7795 |
| 0.6658 | 2.3949 | 13900 | 0.6694 | -0.2781 | -0.3355 | 0.6032 | 0.0574 | -96.7320 | -86.5236 | -2.7727 | -2.7788 |
| 0.6453 | 2.4121 | 14000 | 0.6693 | -0.2789 | -0.3364 | 0.6018 | 0.0575 | -96.8240 | -86.6049 | -2.7718 | -2.7778 |
| 0.6451 | 2.4294 | 14100 | 0.6692 | -0.2797 | -0.3375 | 0.6034 | 0.0578 | -96.9303 | -86.6776 | -2.7708 | -2.7769 |
| 0.636 | 2.4466 | 14200 | 0.6693 | -0.2803 | -0.3378 | 0.6008 | 0.0576 | -96.9631 | -86.7390 | -2.7706 | -2.7766 |
| 0.6251 | 2.4638 | 14300 | 0.6691 | -0.2812 | -0.3393 | 0.6011 | 0.0581 | -97.1110 | -86.8353 | -2.7697 | -2.7757 |
| 0.6517 | 2.4810 | 14400 | 0.6691 | -0.2827 | -0.3409 | 0.6025 | 0.0583 | -97.2740 | -86.9799 | -2.7687 | -2.7747 |
| 0.633 | 2.4983 | 14500 | 0.6690 | -0.2837 | -0.3422 | 0.6006 | 0.0585 | -97.3994 | -87.0852 | -2.7680 | -2.7740 |
| 0.6407 | 2.5155 | 14600 | 0.6690 | -0.2842 | -0.3426 | 0.6011 | 0.0584 | -97.4438 | -87.1331 | -2.7679 | -2.7739 |
| 0.6298 | 2.5327 | 14700 | 0.6690 | -0.2853 | -0.3438 | 0.6013 | 0.0584 | -97.5570 | -87.2438 | -2.7671 | -2.7731 |
| 0.6432 | 2.5500 | 14800 | 0.6690 | -0.2862 | -0.3447 | 0.6018 | 0.0585 | -97.6493 | -87.3336 | -2.7663 | -2.7723 |
| 0.6492 | 2.5672 | 14900 | 0.6689 | -0.2866 | -0.3453 | 0.6013 | 0.0587 | -97.7090 | -87.3695 | -2.7660 | -2.7721 |
| 0.65 | 2.5844 | 15000 | 0.6689 | -0.2870 | -0.3457 | 0.6011 | 0.0587 | -97.7523 | -87.4156 | -2.7655 | -2.7715 |
| 0.6519 | 2.6017 | 15100 | 0.6689 | -0.2874 | -0.3462 | 0.6008 | 0.0588 | -97.8011 | -87.4534 | -2.7657 | -2.7718 |
| 0.6308 | 2.6189 | 15200 | 0.6689 | -0.2880 | -0.3469 | 0.6011 | 0.0589 | -97.8694 | -87.5090 | -2.7649 | -2.7709 |
| 0.6465 | 2.6361 | 15300 | 0.6689 | -0.2880 | -0.3469 | 0.6025 | 0.0589 | -97.8726 | -87.5095 | -2.7649 | -2.7710 |
| 0.6609 | 2.6533 | 15400 | 0.6688 | -0.2883 | -0.3473 | 0.6025 | 0.0590 | -97.9052 | -87.5417 | -2.7643 | -2.7703 |
| 0.6597 | 2.6706 | 15500 | 0.6688 | -0.2883 | -0.3474 | 0.6022 | 0.0591 | -97.9180 | -87.5395 | -2.7639 | -2.7700 |
| 0.6491 | 2.6878 | 15600 | 0.6687 | -0.2885 | -0.3479 | 0.6034 | 0.0593 | -97.9666 | -87.5668 | -2.7639 | -2.7700 |
| 0.6423 | 2.7050 | 15700 | 0.6687 | -0.2885 | -0.3477 | 0.6008 | 0.0592 | -97.9538 | -87.5659 | -2.7638 | -2.7699 |
| 0.6405 | 2.7223 | 15800 | 0.6687 | -0.2886 | -0.3479 | 0.6018 | 0.0593 | -97.9676 | -87.5701 | -2.7633 | -2.7694 |
| 0.6457 | 2.7395 | 15900 | 0.6687 | -0.2889 | -0.3481 | 0.6020 | 0.0592 | -97.9878 | -87.5970 | -2.7633 | -2.7694 |
| 0.6549 | 2.7567 | 16000 | 0.6687 | -0.2888 | -0.3481 | 0.6032 | 0.0593 | -97.9933 | -87.5928 | -2.7630 | -2.7692 |
| 0.6288 | 2.7739 | 16100 | 0.6688 | -0.2889 | -0.3481 | 0.6050 | 0.0592 | -97.9868 | -87.6035 | -2.7631 | -2.7692 |
| 0.6431 | 2.7912 | 16200 | 0.6688 | -0.2892 | -0.3484 | 0.6022 | 0.0592 | -98.0221 | -87.6322 | -2.7633 | -2.7694 |
| 0.6499 | 2.8084 | 16300 | 0.6687 | -0.2893 | -0.3485 | 0.6032 | 0.0593 | -98.0337 | -87.6372 | -2.7627 | -2.7688 |
| 0.6524 | 2.8256 | 16400 | 0.6687 | -0.2892 | -0.3486 | 0.6013 | 0.0594 | -98.0451 | -87.6369 | -2.7630 | -2.7690 |
| 0.6545 | 2.8429 | 16500 | 0.6687 | -0.2892 | -0.3486 | 0.6039 | 0.0594 | -98.0392 | -87.6310 | -2.7631 | -2.7691 |
| 0.6692 | 2.8601 | 16600 | 0.6688 | -0.2894 | -0.3485 | 0.6022 | 0.0591 | -98.0347 | -87.6520 | -2.7624 | -2.7686 |
| 0.6587 | 2.8773 | 16700 | 0.6687 | -0.2895 | -0.3489 | 0.6011 | 0.0594 | -98.0697 | -87.6612 | -2.7623 | -2.7684 |
| 0.6612 | 2.8946 | 16800 | 0.6687 | -0.2890 | -0.3484 | 0.6055 | 0.0593 | -98.0176 | -87.6163 | -2.7631 | -2.7692 |
| 0.6561 | 2.9118 | 16900 | 0.6688 | -0.2893 | -0.3485 | 0.6020 | 0.0592 | -98.0284 | -87.6390 | -2.7627 | -2.7688 |
| 0.6548 | 2.9290 | 17000 | 0.6688 | -0.2892 | -0.3483 | 0.6006 | 0.0591 | -98.0120 | -87.6341 | -2.7624 | -2.7684 |
| 0.6468 | 2.9462 | 17100 | 0.6687 | -0.2892 | -0.3485 | 0.6029 | 0.0593 | -98.0333 | -87.6348 | -2.7623 | -2.7683 |
| 0.666 | 2.9635 | 17200 | 0.6686 | -0.2892 | -0.3486 | 0.6029 | 0.0594 | -98.0413 | -87.6310 | -2.7622 | -2.7683 |
| 0.6571 | 2.9807 | 17300 | 0.6687 | -0.2893 | -0.3485 | 0.6039 | 0.0592 | -98.0332 | -87.6411 | -2.7624 | -2.7684 |
| 0.6414 | 2.9979 | 17400 | 0.6687 | -0.2893 | -0.3487 | 0.6008 | 0.0594 | -98.0463 | -87.6427 | -2.7624 | -2.7684 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.1.2
- Datasets 2.19.2
- Tokenizers 0.19.1
|
RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf
|
RichardErkhov
| 2024-11-01T15:37:07Z | 6 | 0 | null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:12:25Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
TinyLlama-1.1B_v0.2-merged - GGUF
- Model creator: https://huggingface.co/elijahww/
- Original model: https://huggingface.co/elijahww/TinyLlama-1.1B_v0.2-merged/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [TinyLlama-1.1B_v0.2-merged.Q2_K.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q2_K.gguf) | Q2_K | 0.4GB |
| [TinyLlama-1.1B_v0.2-merged.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [TinyLlama-1.1B_v0.2-merged.Q3_K.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q3_K.gguf) | Q3_K | 0.51GB |
| [TinyLlama-1.1B_v0.2-merged.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [TinyLlama-1.1B_v0.2-merged.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [TinyLlama-1.1B_v0.2-merged.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [TinyLlama-1.1B_v0.2-merged.Q4_0.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q4_0.gguf) | Q4_0 | 0.59GB |
| [TinyLlama-1.1B_v0.2-merged.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [TinyLlama-1.1B_v0.2-merged.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [TinyLlama-1.1B_v0.2-merged.Q4_K.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q4_K.gguf) | Q4_K | 0.62GB |
| [TinyLlama-1.1B_v0.2-merged.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [TinyLlama-1.1B_v0.2-merged.Q4_1.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q4_1.gguf) | Q4_1 | 0.65GB |
| [TinyLlama-1.1B_v0.2-merged.Q5_0.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q5_0.gguf) | Q5_0 | 0.71GB |
| [TinyLlama-1.1B_v0.2-merged.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [TinyLlama-1.1B_v0.2-merged.Q5_K.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q5_K.gguf) | Q5_K | 0.73GB |
| [TinyLlama-1.1B_v0.2-merged.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [TinyLlama-1.1B_v0.2-merged.Q5_1.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q5_1.gguf) | Q5_1 | 0.77GB |
| [TinyLlama-1.1B_v0.2-merged.Q6_K.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q6_K.gguf) | Q6_K | 0.84GB |
| [TinyLlama-1.1B_v0.2-merged.Q8_0.gguf](https://huggingface.co/RichardErkhov/elijahww_-_TinyLlama-1.1B_v0.2-merged-gguf/blob/main/TinyLlama-1.1B_v0.2-merged.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
fbolanos/LRO_BigBird1
|
fbolanos
| 2024-11-01T15:35:59Z | 121 | 0 |
transformers
|
[
"transformers",
"safetensors",
"big_bird",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-11-01T15:35:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mlfoundations-dev/OH_original_wo_unnatural_instructions
|
mlfoundations-dev
| 2024-11-01T15:33:40Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T10:46:16Z |
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: OH_original_wo_unnatural_instructions
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OH_original_wo_unnatural_instructions
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the mlfoundations-dev/OH_original_wo_unnatural_instructions dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5999
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.1
- lr_scheduler_warmup_steps: 1738
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6109 | 1.0 | 335 | 0.6026 |
| 0.5598 | 2.0 | 670 | 0.5954 |
| 0.5202 | 3.0 | 1005 | 0.5999 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.3.0
- Datasets 2.21.0
- Tokenizers 0.20.1
|
RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf
|
RichardErkhov
| 2024-11-01T15:27:43Z | 14 | 0 | null |
[
"gguf",
"arxiv:2409.05314",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:05:51Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
TinyLlama-1.1B-Tele-it - GGUF
- Model creator: https://huggingface.co/AliMaatouk/
- Original model: https://huggingface.co/AliMaatouk/TinyLlama-1.1B-Tele-it/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [TinyLlama-1.1B-Tele-it.Q2_K.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q2_K.gguf) | Q2_K | 0.4GB |
| [TinyLlama-1.1B-Tele-it.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [TinyLlama-1.1B-Tele-it.Q3_K.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q3_K.gguf) | Q3_K | 0.51GB |
| [TinyLlama-1.1B-Tele-it.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [TinyLlama-1.1B-Tele-it.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [TinyLlama-1.1B-Tele-it.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [TinyLlama-1.1B-Tele-it.Q4_0.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q4_0.gguf) | Q4_0 | 0.59GB |
| [TinyLlama-1.1B-Tele-it.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [TinyLlama-1.1B-Tele-it.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [TinyLlama-1.1B-Tele-it.Q4_K.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q4_K.gguf) | Q4_K | 0.62GB |
| [TinyLlama-1.1B-Tele-it.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [TinyLlama-1.1B-Tele-it.Q4_1.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q4_1.gguf) | Q4_1 | 0.65GB |
| [TinyLlama-1.1B-Tele-it.Q5_0.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q5_0.gguf) | Q5_0 | 0.71GB |
| [TinyLlama-1.1B-Tele-it.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [TinyLlama-1.1B-Tele-it.Q5_K.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q5_K.gguf) | Q5_K | 0.73GB |
| [TinyLlama-1.1B-Tele-it.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [TinyLlama-1.1B-Tele-it.Q5_1.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q5_1.gguf) | Q5_1 | 0.77GB |
| [TinyLlama-1.1B-Tele-it.Q6_K.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q6_K.gguf) | Q6_K | 0.84GB |
| [TinyLlama-1.1B-Tele-it.Q8_0.gguf](https://huggingface.co/RichardErkhov/AliMaatouk_-_TinyLlama-1.1B-Tele-it-gguf/blob/main/TinyLlama-1.1B-Tele-it.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- nlp
---
# TinyLlama-1.1B-Tele-it Model Card
## Model Summary
The language model TinyLlama-1.1B-Tele-it is an instruct version of [TinyLlama-1.1B-Tele](https://huggingface.co/AliMaatouk/TinyLlama-1.1B-Tele), which is based on [TinyLlama-1.1B](https://huggingface.co/TinyLlama/TinyLlama_v1.1) and specialized in telecommunications. It was fine-tuned to follow instructions using Supervised Fine-tuning (SFT) with a combination of the [Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) and [Open-instruct](https://huggingface.co/datasets/VMware/open-instruct) datasets.
### Context Length
The context length of the model is 2048 tokens.
## Usage
TinyLlama-1.1B-Tele-it has been fine-tuned using pairs of instructions and responses from the [Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) and [Open-instruct](https://huggingface.co/datasets/VMware/open-instruct) datasets, separated by the "\n" delimiter. Below is an example of how to query the model using this format:
```markdown
Prompt: Explain to me Shannon capacity.\n
Model: The Shannon capacity of a communication channel is the maximum amount of information that can be transmitted over the channel in a single transmission. It is a measure of the maximum amount of information that can be transmitted over a channel with a given noise level. The Shannon capacity is a fundamental limit on the amount of information that can be transmitted over a communication channel.
```
## Sample Code
Below we share some code snippets on how to get quickly started with running the model. First, make sure to `pip install transformers`, then copy the snippet corresponding to your hardware and adapt it to your usecase.
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("AliMaatouk/TinyLlama-1.1B-Tele-it", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("AliMaatouk/TinyLlama-1.1B-Tele-it")
prompt = "Explain to me Shannon capacity.\n"
input_ids = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=100)
generated_tokens = outputs[0, len(input_ids['input_ids'][0]):]
response = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(response)
```
#### Running the model on a single / multi GPU
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("AliMaatouk/TinyLlama-1.1B-Tele-it", torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("AliMaatouk/TinyLlama-1.1B-Tele-it")
prompt = "Explain to me Shannon capacity.\n"
input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=100)
generated_tokens = outputs[0, len(input_ids['input_ids'][0]):]
response = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(response)
```
## Citation
You can find the paper with all details about the model at https://arxiv.org/abs/2409.05314. Please cite it as follows:
```bib
@misc{maatouk2024telellmsseriesspecializedlarge,
title={Tele-LLMs: A Series of Specialized Large Language Models for Telecommunications},
author={Ali Maatouk and Kenny Chirino Ampudia and Rex Ying and Leandros Tassiulas},
year={2024},
eprint={2409.05314},
archivePrefix={arXiv},
primaryClass={cs.IT},
url={https://arxiv.org/abs/2409.05314},
}
```
|
pipilok/Mistral-Nemo-Instruct-2407-Q4_0_4_8-GGUF
|
pipilok
| 2024-11-01T15:23:46Z | 19 | 0 | null |
[
"gguf",
"text-generation",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ru",
"zh",
"ja",
"base_model:mistralai/Mistral-Nemo-Instruct-2407",
"base_model:quantized:mistralai/Mistral-Nemo-Instruct-2407",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-09-28T04:30:40Z |
---
language:
- en
- fr
- de
- es
- it
- pt
- ru
- zh
- ja
license: apache-2.0
quantized_by: pipilok
pipeline_tag: text-generation
base_model:
- mistralai/Mistral-Nemo-Instruct-2407
---
Original model: https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407
Tested on Snapdragon X Elite with LM Studio 0.3.2 ARM64 Technology Preview https://lmstudio.ai/snapdragon
Avg answer Speed: 12 tok/s
## LM Studio Settings:
```
Before System: [INST]<<SYS>>\n
After System: <</SYS>[/INST]\n
Before User: [INST]
After User: [INST]\n
Before Assistant:
After Assistant:
```
|
pipilok/Llama-3.2-1B-Instruct-Q4_0_4_8-GGUF
|
pipilok
| 2024-11-01T15:23:17Z | 38 | 0 | null |
[
"gguf",
"text-generation",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-09-28T05:02:35Z |
---
license: llama3.2
quantized_by: pipilok
pipeline_tag: text-generation
base_model:
- meta-llama/Llama-3.2-1B-Instruct
---
Original model: https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
Tested on Snapdragon X Elite with LM Studio 0.3.2 ARM64 Technology Preview https://lmstudio.ai/snapdragon
Avg answer Speed: 60 tok/s
## LM Studio Settings:
```
Before System: <|im_start|>system\n
After System: <|im_end|>\n
Before User: <|im_start|>user\n
After User: <|im_end|>\n
Before Assistant: <|im_start|>assistant\n
After Assistant: <|im_end|>\n
```
|
pipilok/Llama-3.2-3B-Instruct-Q4_0_4_8-GGUF
|
pipilok
| 2024-11-01T15:22:55Z | 35 | 0 | null |
[
"gguf",
"text-generation",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-3B-Instruct",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-09-28T05:08:31Z |
---
license: llama3.2
quantized_by: pipilok
pipeline_tag: text-generation
base_model:
- meta-llama/Llama-3.2-3B-Instruct
---
Original model: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
Tested on Snapdragon X Elite with LM Studio 0.3.2 ARM64 Technology Preview https://lmstudio.ai/snapdragon
Avg answer Speed: 30 tok/s
## LM Studio Settings:
```
Before System: <|im_start|>system\n
After System: <|im_end|>\n
Before User: <|im_start|>user\n
After User: <|im_end|>\n
Before Assistant: <|im_start|>assistant\n
After Assistant: <|im_end|>\n
```
|
pipilok/Mistral-Small-Instruct-2409-Q4_0_4_8-GGUF
|
pipilok
| 2024-11-01T15:22:33Z | 15 | 0 | null |
[
"gguf",
"text-generation",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ru",
"zh",
"ja",
"base_model:mistralai/Mistral-Small-Instruct-2409",
"base_model:quantized:mistralai/Mistral-Small-Instruct-2409",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-09-28T05:15:39Z |
---
language:
- en
- fr
- de
- es
- it
- pt
- ru
- zh
- ja
license: apache-2.0
quantized_by: pipilok
pipeline_tag: text-generation
base_model:
- mistralai/Mistral-Small-Instruct-2409
---
Original model: https://huggingface.co/mistralai/Mistral-Small-Instruct-2409
Tested on Snapdragon X Elite with LM Studio 0.3.2 ARM64 Technology Preview https://lmstudio.ai/snapdragon
Avg answer Speed: 6 tok/s
## LM Studio Settings:
```
Before System: [INST]<<SYS>>\n
After System: <</SYS>[/INST]\n
Before User: [INST]
After User: [INST]\n
Before Assistant:
After Assistant:
```
|
mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF
|
mradermacher
| 2024-11-01T15:20:09Z | 14 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"dataset:argilla/distilabel-intel-orca-dpo-pairs",
"base_model:BarryFutureman/WestLakeX-7B-EvoMerge-Variant2",
"base_model:quantized:BarryFutureman/WestLakeX-7B-EvoMerge-Variant2",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-31T05:35:55Z |
---
base_model: BarryFutureman/WestLakeX-7B-EvoMerge-Variant2
datasets:
- argilla/distilabel-intel-orca-dpo-pairs
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/BarryFutureman/WestLakeX-7B-EvoMerge-Variant2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/WestLakeX-7B-EvoMerge-Variant2-GGUF/resolve/main/WestLakeX-7B-EvoMerge-Variant2.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
spidersouris/hscorer-full
|
spidersouris
| 2024-11-01T15:17:16Z | 121 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"camembert",
"text-classification",
"generated_from_trainer",
"base_model:almanach/camembert-base",
"base_model:finetune:almanach/camembert-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-11-01T13:50:57Z |
---
library_name: transformers
license: mit
base_model: camembert-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: hscorer-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hscorer-full
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1307
- Accuracy: 0.9695
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1859 | 1.0 | 1797 | 0.1307 | 0.9631 |
| 0.1457 | 2.0 | 3594 | 0.2505 | 0.9432 |
| 0.125 | 3.0 | 5391 | 0.1224 | 0.9713 |
| 0.2291 | 4.0 | 7188 | 0.1530 | 0.9402 |
| 0.1174 | 5.0 | 8985 | 0.1462 | 0.9463 |
| 0.0957 | 6.0 | 10782 | 0.2007 | 0.9549 |
| 0.1581 | 7.0 | 12579 | 0.2563 | 0.9290 |
| 0.1386 | 8.0 | 14376 | 0.2012 | 0.9528 |
| 0.1353 | 9.0 | 16173 | 0.1420 | 0.9664 |
| 0.0665 | 10.0 | 17970 | 0.1307 | 0.9695 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.0+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF
|
featherless-ai-quants
| 2024-11-01T15:17:15Z | 5 | 0 | null |
[
"gguf",
"text-generation",
"base_model:ryzen88/Llama-3-70b-Arimas-story-RP-V2.1",
"base_model:quantized:ryzen88/Llama-3-70b-Arimas-story-RP-V2.1",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-11-01T04:38:39Z |
---
base_model: ryzen88/Llama-3-70b-Arimas-story-RP-V2.1
pipeline_tag: text-generation
quantized_by: featherless-ai-quants
---
# ryzen88/Llama-3-70b-Arimas-story-RP-V2.1 GGUF Quantizations 🚀

*Optimized GGUF quantization files for enhanced model performance*
> Powered by [Featherless AI](https://featherless.ai) - run any model you'd like for a simple small fee.
---
## Available Quantizations 📊
| Quantization Type | File | Size |
|-------------------|------|------|
| Q8_0 | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q8_0](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q8_0) | 71501.78 MB |
| Q4_K_S | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q4_K_S](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q4_K_S) | 38478.11 MB |
| Q2_K | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q2_K](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q2_K) | 25153.26 MB |
| Q6_K | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q6_K](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q6_K) | 55206.44 MB |
| Q3_K_M | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_M](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_M) | 32680.03 MB |
| Q3_K_S | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_S](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_S) | 29480.03 MB |
| Q3_K_L | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_L](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q3_K_L) | 35420.03 MB |
| Q4_K_M | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q4_K_M](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q4_K_M) | 40550.61 MB |
| Q5_K_S | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q5_K_S](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q5_K_S) | 46403.36 MB |
| Q5_K_M | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q5_K_M](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-Q5_K_M) | 47635.86 MB |
| IQ4_XS | [ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-IQ4_XS](https://huggingface.co/featherless-ai-quants/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-GGUF/blob/main/ryzen88-Llama-3-70b-Arimas-story-RP-V2.1-IQ4_XS) | 36496.80 MB |
---
## ⚡ Powered by [Featherless AI](https://featherless.ai)
### Key Features
- 🔥 **Instant Hosting** - Deploy any Llama model on HuggingFace instantly
- 🛠️ **Zero Infrastructure** - No server setup or maintenance required
- 📚 **Vast Compatibility** - Support for 2400+ models and counting
- 💎 **Affordable Pricing** - Starting at just $10/month
---
**Links:**
[Get Started](https://featherless.ai) | [Documentation](https://featherless.ai/docs) | [Models](https://featherless.ai/models)
|
Hemanta14/asmttshemanta
|
Hemanta14
| 2024-11-01T15:14:54Z | 33 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vits",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T15:14:38Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JosephEssa/model
|
JosephEssa
| 2024-11-01T15:12:54Z | 6 | 0 | null |
[
"tensorboard",
"safetensors",
"bert",
"generated_from_trainer",
"base_model:Twitter/twhin-bert-large",
"base_model:finetune:Twitter/twhin-bert-large",
"license:apache-2.0",
"region:us"
] | null | 2024-11-01T14:32:43Z |
---
license: apache-2.0
base_model: Twitter/twhin-bert-large
tags:
- generated_from_trainer
model-index:
- name: model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [Twitter/twhin-bert-large](https://huggingface.co/Twitter/twhin-bert-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0342
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4026 | 1.0 | 150 | 2.1943 |
| 2.3071 | 2.0 | 300 | 2.1008 |
| 2.2223 | 3.0 | 450 | 2.1652 |
| 2.1434 | 4.0 | 600 | 2.1081 |
| 2.1232 | 5.0 | 750 | 2.0342 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
tiya1012/vit-accident-image
|
tiya1012
| 2024-11-01T15:12:18Z | 242 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-05-15T17:31:24Z |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: vit-accident-image
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Enhancing Road Safety with AI-Powered Accident Detection
## Objective
The objective of this project is to develop an AI-driven system that detects accident scenes from images captured by CCTV footage. By leveraging advanced machine learning techniques, we aim to improve response times to road incidents, thereby enhancing overall road safety.
## Data Sample
We utilized the [Accident Detection from CCTV Footage](https://www.kaggle.com/datasets/ckay16/accident-detection-from-cctv-footage/data) dataset from Kaggle. This dataset contains annotated images from CCTV footage, showcasing various accident scenarios.
### Sample Data
Here’s a sample from the dataset:
| Image | Label |
|-------|-------|
| ![Accident Image]| Accident |
The images are categorized into "Accident" and "No Accident," which helps train the model to distinguish between accident scenes and normal traffic conditions.
## Model Architecture
Our model employs a Vision Transformer (ViT) architecture, which is well-suited for image classification tasks. The key components of the model include:
- **Input Layer:** Accepts images resized to a specified resolution.
- **Transformer Encoder Layers:** Extract features through self-attention mechanisms, capturing spatial relationships.
- **Feedforward Neural Networks:** Process the features and classify them into accident-related categories.
- **Output Layer:** Provides the final classification probabilities for "Accident" and "No Accident."
## Instructions for Running the Training Job
To run the training job, follow these steps:
1. Clone the repository:
```bash
git clone https://github.com/yourusername/accident-detection.git
cd accident-detection
# vit-accident-image
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the accident classification dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2027
- Accuracy: 0.93
- F1: 0.9301
## Model description
label 0 : non-accident , label 1 : accident-detected
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3546 | 2.0 | 100 | 0.2327 | 0.9184 | 0.9184 |
| 0.1654 | 4.0 | 200 | 0.2075 | 0.9388 | 0.9388 |
| 0.0146 | 6.0 | 300 | 0.2497 | 0.9388 | 0.9387 |
| 0.0317 | 8.0 | 400 | 0.2179 | 0.9286 | 0.9285 |
| 0.0192 | 10.0 | 500 | 0.2255 | 0.9286 | 0.9286 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.13.3
|
mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF
|
mradermacher
| 2024-11-01T15:12:09Z | 58 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5",
"base_model:quantized:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-31T05:29:00Z |
---
base_model: AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5
language:
- en
library_name: transformers
license: cc-by-sa-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q2_K.gguf) | Q2_K | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q3_K_S.gguf) | Q3_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q3_K_M.gguf) | Q3_K_M | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q3_K_L.gguf) | Q3_K_L | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.IQ4_XS.gguf) | IQ4_XS | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q4_K_S.gguf) | Q4_K_S | 3.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q4_K_M.gguf) | Q4_K_M | 3.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q5_K_S.gguf) | Q5_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q5_K_M.gguf) | Q5_K_M | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q6_K.gguf) | Q6_K | 5.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.Q8_0.gguf) | Q8_0 | 6.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.f16.gguf) | f16 | 12.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF
|
mradermacher
| 2024-11-01T15:12:09Z | 191 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5",
"base_model:quantized:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-11-01T14:14:27Z |
---
base_model: AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5
language:
- en
library_name: transformers
license: cc-by-sa-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.5
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ1_S.gguf) | i1-IQ1_S | 1.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ1_M.gguf) | i1-IQ1_M | 1.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ2_S.gguf) | i1-IQ2_S | 2.2 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ2_M.gguf) | i1-IQ2_M | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q2_K.gguf) | i1-Q2_K | 2.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ3_XS.gguf) | i1-IQ3_XS | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q3_K_S.gguf) | i1-Q3_K_S | 2.9 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ3_S.gguf) | i1-IQ3_S | 2.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ3_M.gguf) | i1-IQ3_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-IQ4_XS.gguf) | i1-IQ4_XS | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 3.7 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 3.7 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 3.7 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_0.gguf) | i1-Q4_0 | 3.7 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_K_S.gguf) | i1-Q4_K_S | 3.7 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q4_K_M.gguf) | i1-Q4_K_M | 3.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q5_K_S.gguf) | i1-Q5_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q5_K_M.gguf) | i1-Q5_K_M | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.5-i1-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.5.i1-Q6_K.gguf) | i1-Q6_K | 5.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf
|
RichardErkhov
| 2024-11-01T15:09:23Z | 72 | 0 | null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-11-01T14:59:27Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen-Qwen1.5-0.5B-1719202599 - GGUF
- Model creator: https://huggingface.co/chainup244/
- Original model: https://huggingface.co/chainup244/Qwen-Qwen1.5-0.5B-1719202599/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Qwen-Qwen1.5-0.5B-1719202599.Q2_K.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q2_K.gguf) | Q2_K | 0.23GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q3_K_S.gguf) | Q3_K_S | 0.25GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q3_K.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q3_K.gguf) | Q3_K | 0.26GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q3_K_M.gguf) | Q3_K_M | 0.26GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q3_K_L.gguf) | Q3_K_L | 0.28GB |
| [Qwen-Qwen1.5-0.5B-1719202599.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.IQ4_XS.gguf) | IQ4_XS | 0.28GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q4_0.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q4_0.gguf) | Q4_0 | 0.29GB |
| [Qwen-Qwen1.5-0.5B-1719202599.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.IQ4_NL.gguf) | IQ4_NL | 0.29GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q4_K_S.gguf) | Q4_K_S | 0.29GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q4_K.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q4_K.gguf) | Q4_K | 0.3GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q4_K_M.gguf) | Q4_K_M | 0.3GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q4_1.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q4_1.gguf) | Q4_1 | 0.3GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q5_0.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q5_0.gguf) | Q5_0 | 0.32GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q5_K_S.gguf) | Q5_K_S | 0.32GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q5_K.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q5_K.gguf) | Q5_K | 0.33GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q5_K_M.gguf) | Q5_K_M | 0.33GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q5_1.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q5_1.gguf) | Q5_1 | 0.34GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q6_K.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q6_K.gguf) | Q6_K | 0.36GB |
| [Qwen-Qwen1.5-0.5B-1719202599.Q8_0.gguf](https://huggingface.co/RichardErkhov/chainup244_-_Qwen-Qwen1.5-0.5B-1719202599-gguf/blob/main/Qwen-Qwen1.5-0.5B-1719202599.Q8_0.gguf) | Q8_0 | 0.47GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
bb1070/lovejoy_wf
|
bb1070
| 2024-11-01T15:07:12Z | 5 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T15:07:03Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Lovejoy_Wf
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bb1070/lovejoy_wf', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
sagniksengupta/git-finetuned-facad
|
sagniksengupta
| 2024-11-01T14:56:44Z | 61 | 0 |
transformers
|
[
"transformers",
"safetensors",
"git",
"image-text-to-text",
"en",
"dataset:Luna288/image-captioning-FACAD-base",
"base_model:microsoft/git-base",
"base_model:finetune:microsoft/git-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2024-10-23T19:36:29Z |
---
library_name: transformers
license: mit
datasets:
- Luna288/image-captioning-FACAD-base
language:
- en
base_model:
- microsoft/git-base
---
|
ssmits/Llama-3.1-Nemotron-92B-Instruct-HF-late
|
ssmits
| 2024-11-01T14:53:28Z | 71 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"base_model:finetune:nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-10-31T22:10:40Z |
---
base_model:
- nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
library_name: transformers
tags:
- mergekit
- merge
---
# Llama-3.1-Nemotron-92B-Instruct-HF-late
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [nvidia/Llama-3.1-Nemotron-70B-Instruct-HF](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
slices:
- sources:
- layer_range:
- 0
- 55
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
- sources:
- layer_range:
- 50
- 60
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
- sources:
- layer_range:
- 55
- 65
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
- sources:
- layer_range:
- 60
- 70
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
- sources:
- layer_range:
- 65
- 75
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
- sources:
- layer_range:
- 70
- 80
model: nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
```
|
Xu-Ouyang/pythia-12b-deduped-int4-step16-GPTQ-wikitext2
|
Xu-Ouyang
| 2024-11-01T14:51:15Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-11-01T14:40:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rahulvk007/ExtractQueNumberMini
|
rahulvk007
| 2024-11-01T14:46:07Z | 141 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"dataset:rahulvk007/quenumber_extraction_v2",
"base_model:unsloth/SmolLM2-135M",
"base_model:finetune:unsloth/SmolLM2-135M",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T12:23:01Z |
---
base_model: unsloth/SmolLM2-135M
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
datasets:
- rahulvk007/quenumber_extraction_v2
---
# ExtractQueNumberMini Model
- **Developed by:** [rahulvk007](https://github.com/rahulvk007) ([rahulvk.com](https://www.rahulvk.com))
- **License:** [Apache-2.0](https://opensource.org/licenses/Apache-2.0)
- **Base Model:** [unsloth/SmolLM2-135M](https://huggingface.co/unsloth/SmolLM2-135M)
- **Finetuning**: Optimized with [Unsloth](https://github.com/unslothai/unsloth) and [Hugging Face's TRL library](https://github.com/huggingface/trl)
This model has been fine-tuned for quick extraction of question numbers from OCRed handwritten text. It is designed to run efficiently on CPU due to its compact size.
### Model Usage
To use this model, set the system prompt to the following:
> **Extract the question number from the given text. Your response should be just an integer representing the question number. Do not provide any explanation or context. Just the number.**
### Inference Code Example
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "rahulvk007/ExtractQueNumberMini"
device = "cpu" # change to "cuda" for GPU
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
alpaca_prompt.format(
"Extract the question number from the given text. Your response should be just an integer which is the question number. Do not provide any explanation or context. Just the number.",
"<Give OCR Text here>",
"",
)
],
return_tensors="pt"
).to(device)
outputs = model.generate(**inputs, max_new_tokens=64, use_cache=True)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
```
### Datasets
The model was fine-tuned on [rahulvk007/quenumber_extraction_v2](https://huggingface.co/datasets/rahulvk007/quenumber_extraction_v2), specifically curated for this task.
---
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Haesteining/Phi3smallv3
|
Haesteining
| 2024-11-01T14:34:07Z | 39 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:19:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
bb1070/ara_bed_wf
|
bb1070
| 2024-11-01T14:26:30Z | 5 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T14:26:27Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Ara_Bed_Wf
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bb1070/ara_bed_wf', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
meditsolutions/MedIT-Mesh-3B-Instruct
|
meditsolutions
| 2024-11-01T14:20:26Z | 15 | 1 | null |
[
"safetensors",
"phi3",
"custom_code",
"en",
"base_model:microsoft/Phi-3.5-mini-instruct",
"base_model:finetune:microsoft/Phi-3.5-mini-instruct",
"license:mit",
"region:us"
] | null | 2024-11-01T13:10:10Z |
---
license: mit
language:
- en
base_model:
- microsoft/Phi-3.5-mini-instruct
---
# Phi-3.5 Mini-Instruct Modification using MedIT-mesh Technique
## Primary Use Cases:
- Commercial use in environments requiring memory and compute constraints.
- Use in latency-bound scenarios where accuracy is crucial.
- Strong reasoning capabilities, especially for code, math, and logic applications.
## Model Description:
The Phi-3.5 Mini-Instruct modification is designed to accelerate research on language and multimodal models. It is a 3.8B parameter model optimized for commercial and research use in multiple languages. The MedIT-mesh technique provides improved memory and compute efficiency, making it suitable for environments with limited resources.
## Use Case Considerations:
When selecting use cases, developers should consider language models' limitations and evaluate accuracy, safety, and fairness before using them within a specific downstream application.
Developers should be aware of applicable laws and regulations (e.g., privacy, trade compliance) relevant to their use case.
It is essential to adhere to the license terms for the model being used.
## Release Notes:
An update over the June 2024 instruction-tuned Phi-3 Mini release based on user feedback.
Additional post-training data was incorporated, leading to substantial gains in multilingual and multi-turn conversation quality, and reasoning capability.
This release is expected to benefit most use cases, but users are encouraged to test in their particular AI applications.
|
mradermacher/mistral-7b-anthropic-i1-GGUF
|
mradermacher
| 2024-11-01T14:16:06Z | 234 | 0 |
transformers
|
[
"transformers",
"gguf",
"alignment-handbook",
"generated_from_trainer",
"en",
"dataset:HuggingFaceH4/ultrafeedback_binarized_fixed",
"dataset:HuggingFaceH4/cai-conversation-harmless",
"base_model:HuggingFaceH4/mistral-7b-anthropic",
"base_model:quantized:HuggingFaceH4/mistral-7b-anthropic",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-11-01T13:05:56Z |
---
base_model: HuggingFaceH4/mistral-7b-anthropic
datasets:
- HuggingFaceH4/ultrafeedback_binarized_fixed
- HuggingFaceH4/cai-conversation-harmless
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- alignment-handbook
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/HuggingFaceH4/mistral-7b-anthropic
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/mistral-7b-anthropic-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/mistral-7b-anthropic-i1-GGUF/resolve/main/mistral-7b-anthropic.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
jongm38825/Qwen2-7b-v1
|
jongm38825
| 2024-11-01T14:01:57Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:43:43Z |
---
base_model: flash_attn
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
---
# Uploaded model
- **Developed by:** jongm38825
- **License:** apache-2.0
- **Finetuned from model :** flash_attn
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
shubhamrathore081/intent_classificaiton
|
shubhamrathore081
| 2024-11-01T14:00:57Z | 197 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"conversational",
"en",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:finetune:unsloth/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:27:15Z |
---
license: apache-2.0
language:
- en
base_model:
- unsloth/Llama-3.2-3B-Instruct
pipeline_tag: text-generation
library_name: transformers
tags:
- text-generation-inference
---
|
Herry443/Llama-8B-KNUT-ref-voice_size500_cot0_cri1_hint1
|
Herry443
| 2024-11-01T13:47:54Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:36:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF
|
mradermacher
| 2024-11-01T13:47:08Z | 32 | 0 |
transformers
|
[
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"birgermoell/Flashback-Bellman",
"en",
"base_model:birgermoell/Munin-NeuralBeagle-Flashback-Bellman",
"base_model:quantized:birgermoell/Munin-NeuralBeagle-Flashback-Bellman",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-11-01T12:36:59Z |
---
base_model: birgermoell/Munin-NeuralBeagle-Flashback-Bellman
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- birgermoell/Flashback-Bellman
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/birgermoell/Munin-NeuralBeagle-Flashback-Bellman
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Munin-NeuralBeagle-Flashback-Bellman-i1-GGUF/resolve/main/Munin-NeuralBeagle-Flashback-Bellman.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
xmeowrr/SummryModel
|
xmeowrr
| 2024-11-01T13:45:00Z | 114 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2024-11-01T13:41:49Z |
---
base_model:
- google/flan-t5-base
pipeline_tag: summarization
library_name: transformers
---
|
yoohj58072/krx_qwen2.5_7b_it_v1
|
yoohj58072
| 2024-11-01T13:42:18Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"krx",
"conversational",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct-bnb-4bit",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T09:23:55Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- krx
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yoohj58072
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Natthaphon/thaicapgen-swin-phayathai
|
Natthaphon
| 2024-11-01T13:40:53Z | 56 | 0 | null |
[
"safetensors",
"clip-encoder-decoder",
"image-to-text",
"image-captioning",
"custom_code",
"th",
"region:us"
] |
image-to-text
| 2024-11-01T07:58:01Z |
---
tags:
- image-to-text
- image-captioning
language:
- th
---
# Thai Image Captioning
Encoder-decoder style image captioning model using [Swin-L](https://huggingface.co/microsoft/swinv2-large-patch4-window12to16-192to256-22kto1k-ft) and [PhayathaiBert](https://huggingface.co/clicknext/phayathaibert). Trained on Thai language MSCOCO and IPU24 dataset.
# Usage
With `VisionEncoderDecoderModel`.
```python
from transformers import VisionEncoderDecoderModel, AutoImageProcessor, AutoTokenizer
device = 'cuda'
gen_kwargs = {"max_length": 120, "num_beams": 4}
model_path = 'Natthaphon/thaicapgen-swin-phayathai'
feature_extractor = AutoImageProcessor.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = VisionEncoderDecoderModel.from_pretrained(model_path).to(device)
pixel_values = feature_extractor(images=[Image.open(image_path)], return_tensors="pt").pixel_values
pixel_values = pixel_values.to(device)
output_ids = model.generate(pixel_values, **gen_kwargs)
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
```
You can also use `AutoModel` to load it. But this requires `trust_remote_code=True`.
```python
from transformers import AutoModel
model_path = 'Natthaphon/thaicapgen-swin-phayathai'
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(device)
```
# Acknowledgement
This work is partially supported by the Program Management Unit for Human Resources & Institutional Development, Research and Innovation (PMU-B) [Grant number B04G640107]
|
Xu-Ouyang/pythia-12b-deduped-int3-step16-GPTQ-wikitext2
|
Xu-Ouyang
| 2024-11-01T13:39:20Z | 75 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-11-01T13:28:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
homeb82784/Qwen2-7B-Instruct-it-v1.7
|
homeb82784
| 2024-11-01T13:38:34Z | 35 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"krx",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:24:53Z |
---
library_name: transformers
tags:
- krx
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
easwar03/t5-small-finetuned-xsum
|
easwar03
| 2024-11-01T13:37:23Z | 114 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-11-01T13:30:55Z |
---
library_name: transformers
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: t5-small-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 19 | 3.4517 | 17.4709 | 2.6232 | 13.6143 | 13.891 | 18.89 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.0+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
bb1070/Havana_wf
|
bb1070
| 2024-11-01T13:32:50Z | 6 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T13:32:48Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Havana_Wf
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('bb1070/Havana_wf', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
e-hossam96/arabic-nano-gpt-v0
|
e-hossam96
| 2024-11-01T13:27:36Z | 165 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"ar",
"dataset:wikimedia/wikipedia",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-10-17T00:20:46Z |
---
library_name: transformers
license: mit
base_model: openai-community/gpt2
tags:
- generated_from_trainer
model-index:
- name: arabic-nano-gpt
results: []
datasets:
- wikimedia/wikipedia
language:
- ar
---
# arabic-nano-gpt
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2) on the arabic [wikimedia/wikipedia](https://huggingface.co/datasets/wikimedia/wikipedia) dataset.
Repository on GitHub: [e-hossam96/arabic-nano-gpt](https://github.com/e-hossam96/arabic-nano-gpt.git)
The model achieves the following results on the held-out test set:
- Loss: 3.28796
## How to Use
```python
import torch
from transformers import pipeline
model_ckpt = "e-hossam96/arabic-nano-gpt-v0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lm = pipeline(task="text-generation", model=model_ckpt, device=device)
prompt = """المحرك النفاث هو محرك ينفث الموائع (الماء أو الهواء) بسرعة فائقة \
لينتج قوة دافعة اعتمادا على مبدأ قانون نيوتن الثالث للحركة. \
هذا التعريف الواسع للمحركات النفاثة يتضمن أيضا"""
output = lm(prompt, max_new_tokens=128)
print(output[0]["generated_text"])
```
## Model description
- Embedding Size: 256
- Attention Heads: 4
- Attention Layers: 4
## Training and evaluation data
The entire wikipedia dataset was split into three splits based on the 90-5-5 ratios.
## Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 24
## Training Loss

## Validation Loss

## Framework versions
- Transformers 4.45.2
- Pytorch 2.5.0
- Datasets 3.0.1
- Tokenizers 0.20.1
|
e-hossam96/arabic-nano-gpt-v2
|
e-hossam96
| 2024-11-01T13:16:52Z | 173 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"ar",
"dataset:wikimedia/wikipedia",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-10-29T06:12:44Z |
---
library_name: transformers
license: mit
base_model: openai-community/gpt2
tags:
- generated_from_trainer
model-index:
- name: arabic-nano-gpt-v2
results: []
datasets:
- wikimedia/wikipedia
language:
- ar
---
# arabic-nano-gpt-v2
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2) on the arabic [wikimedia/wikipedia](https://huggingface.co/datasets/wikimedia/wikipedia) dataset.
Repository on GitHub: [e-hossam96/arabic-nano-gpt](https://github.com/e-hossam96/arabic-nano-gpt.git)
The model achieves the following results on the held-out test set:
- Loss: 3.25564
## How to Use
```python
import torch
from transformers import pipeline
model_ckpt = "e-hossam96/arabic-nano-gpt-v2"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
lm = pipeline(task="text-generation", model=model_ckpt, device=device)
prompt = """المحرك النفاث هو محرك ينفث الموائع (الماء أو الهواء) بسرعة فائقة \
لينتج قوة دافعة اعتمادا على مبدأ قانون نيوتن الثالث للحركة. \
هذا التعريف الواسع للمحركات النفاثة يتضمن أيضا"""
output = lm(prompt, max_new_tokens=128)
print(output[0]["generated_text"])
```
## Model description
- Embedding Size: 384
- Attention Heads: 6
- Attention Layers: 8
## Training and evaluation data
The entire wikipedia dataset was split into three splits based on the 90-5-5 ratios.
## Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 8
## Training Loss

## Validation Loss

## Framework versions
- Transformers 4.45.2
- Pytorch 2.5.0
- Datasets 3.0.1
- Tokenizers 0.20.1
|
minimini99/flash_attn
|
minimini99
| 2024-11-01T13:12:36Z | 76 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-11-01T13:04:53Z |
---
base_model: flash_attn
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
---
# Uploaded model
- **Developed by:** minimini99
- **License:** apache-2.0
- **Finetuned from model :** flash_attn
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Viscoke/Big7
|
Viscoke
| 2024-11-01T13:09:52Z | 34 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:06:20Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/CrystalMistralv2.5-i1-GGUF
|
mradermacher
| 2024-11-01T13:08:06Z | 25 | 1 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Crystalcareai/CrystalMistralv2.5",
"base_model:quantized:Crystalcareai/CrystalMistralv2.5",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-11-01T11:57:13Z |
---
base_model: Crystalcareai/CrystalMistralv2.5
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Crystalcareai/CrystalMistralv2.5
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/CrystalMistralv2.5-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv2.5-i1-GGUF/resolve/main/CrystalMistralv2.5.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
muratsimsek003/turkish-bert-base-uncased-boun-qa
|
muratsimsek003
| 2024-11-01T13:08:02Z | 119 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"question-answering",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-11-01T13:07:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Haesteining/Phi3smallv2
|
Haesteining
| 2024-11-01T13:06:16Z | 37 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T13:01:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/CrystalMistralv3-i1-GGUF
|
mradermacher
| 2024-11-01T13:02:07Z | 46 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Crystalcareai/CrystalMistralv3",
"base_model:quantized:Crystalcareai/CrystalMistralv3",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-11-01T11:50:09Z |
---
base_model: Crystalcareai/CrystalMistralv3
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Crystalcareai/CrystalMistralv3
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/CrystalMistralv3-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF/resolve/main/CrystalMistralv3.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
laohan/lau-1b-2000
|
laohan
| 2024-11-01T13:01:46Z | 142 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:meta-llama/Llama-3.2-1B",
"base_model:finetune:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T12:57:46Z |
---
library_name: transformers
license: llama3.2
base_model: meta-llama/Llama-3.2-1B
tags:
- generated_from_trainer
model-index:
- name: lau-1b-2000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lau-1b-2000
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.0+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
Q-PING/krx_Qwen2-7B-It_1101
|
Q-PING
| 2024-11-01T12:55:14Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Qwen2-7B-Instruct",
"base_model:finetune:unsloth/Qwen2-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T12:32:47Z |
---
base_model: unsloth/Qwen2-7B-Instruct
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
---
# Uploaded model
- **Developed by:** Q-PING
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
pnpm12/informatic_1B_book_25616
|
pnpm12
| 2024-11-01T12:43:02Z | 138 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T12:41:54Z |
---
base_model: unsloth/llama-3.2-1b-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# Uploaded model
- **Developed by:** pnpm12
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AmaanDhamaskar/muril_finetuned_ner_hmb_e5
|
AmaanDhamaskar
| 2024-11-01T12:42:24Z | 105 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google/muril-base-cased",
"base_model:finetune:google/muril-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2024-11-01T10:01:15Z |
---
library_name: transformers
license: apache-2.0
base_model: google/muril-base-cased
tags:
- generated_from_trainer
model-index:
- name: muril_finetuned_ner_hmb_e5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# muril_finetuned_ner_hmb_e5
This model is a fine-tuned version of [google/muril-base-cased](https://huggingface.co/google/muril-base-cased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.19.1
|
mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF
|
mradermacher
| 2024-11-01T12:33:08Z | 198 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:ssmits/Llama-3.1-Nemotron-92B-Instruct-HF-late",
"base_model:quantized:ssmits/Llama-3.1-Nemotron-92B-Instruct-HF-late",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-11-01T08:10:00Z |
---
base_model: ssmits/Llama-3.1-Nemotron-92B-Instruct-HF-late
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/ssmits/Llama-3.1-Nemotron-92B-Instruct-HF-late
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ1_S.gguf) | i1-IQ1_S | 19.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ1_M.gguf) | i1-IQ1_M | 21.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 24.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ2_XS.gguf) | i1-IQ2_XS | 27.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ2_S.gguf) | i1-IQ2_S | 28.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ2_M.gguf) | i1-IQ2_M | 31.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q2_K.gguf) | i1-Q2_K | 34.2 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 35.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ3_XS.gguf) | i1-IQ3_XS | 38.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q3_K_S.gguf) | i1-Q3_K_S | 40.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ3_S.gguf) | i1-IQ3_S | 40.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ3_M.gguf) | i1-IQ3_M | 41.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q3_K_M.gguf) | i1-Q3_K_M | 44.5 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q3_K_L.gguf) | i1-Q3_K_L | 48.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-IQ4_XS.gguf) | i1-IQ4_XS | 49.4 | |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_0.gguf.part2of2) | i1-Q4_0 | 52.3 | fast, low quality |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_K_S.gguf.part2of2) | i1-Q4_K_S | 52.5 | optimal size/speed/quality |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q4_K_M.gguf.part2of2) | i1-Q4_K_M | 55.4 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q5_K_S.gguf.part2of2) | i1-Q5_K_S | 63.5 | |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q5_K_M.gguf.part2of2) | i1-Q5_K_M | 65.2 | |
| [PART 1](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3.1-Nemotron-92B-Instruct-HF-late-i1-GGUF/resolve/main/Llama-3.1-Nemotron-92B-Instruct-HF-late.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 75.5 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
waldie/Qwen2.5-32B-EVA-Instruct-Merge-0.1-4bpw-h6-exl2
|
waldie
| 2024-11-01T12:28:20Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Downtown-Case/Qwen2.5-32B-EVA-Instruct-Merge-0.1",
"base_model:quantized:Downtown-Case/Qwen2.5-32B-EVA-Instruct-Merge-0.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"exl2",
"region:us"
] |
text-generation
| 2024-11-01T11:56:48Z |
---
base_model: Downtown-Case/Qwen2.5-32B-EVA-Instruct-Merge-0.1
quantized_by: waldie
library_name: transformers
tags:
- mergekit
- merge
---
# Qwen2.5-32B-EVA-Instruct-Merge-0.1
This is a merge of EVA 32B 0.1 with Qwen's 32B instruct model, and EVA 0.0, at low weights, using [mergekit](https://github.com/cg123/mergekit).
Also see: https://huggingface.co/ParasiticRogue/EVA-Instruct-32B
## Merge Details
### Merge Method
This model was merged using the della merge method using /home/a/Models/Raw/Qwen_Qwen2.5-32B as a base.
### Models Merged
The following models were included in the merge:
* /home/a/Models/Raw/EVA-UNIT-01_EVA-Qwen2.5-32B-v0.1
* /home/a/Models/Raw/Qwen_Qwen2.5-32B-Instruct
* /home/a/Models/Raw/EVA-UNIT-01_EVA-Qwen2.5-32B-v0.0
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /home/a/Models/Raw/Qwen_Qwen2.5-32B
# No parameters necessary for base model
- model: /home/a/Models/Raw/EVA-UNIT-01_EVA-Qwen2.5-32B-v0.1
parameters:
weight: 0.7
density: 0.7
- model: /home/a/Models/Raw/EVA-UNIT-01_EVA-Qwen2.5-32B-v0.0
parameters:
weight: 0.11
density: 0.3
- model: /home/a/Models/Raw/Qwen_Qwen2.5-32B-Instruct
parameters:
weight: 0.19
density: 0.3
merge_method: della
#tokenizer_source: base
base_model: /home/a/Models/Raw/Qwen_Qwen2.5-32B
parameters:
int8_mask: true
epsilon: 0.15
lambda: 1
dtype: bfloat16
```
|
awels/maximusLLM-4b-128k
|
awels
| 2024-11-01T12:23:11Z | 5 | 0 |
adapters
|
[
"adapters",
"safetensors",
"phi3",
"awels",
"maximo",
"custom_code",
"en",
"dataset:awels/maximo_admin_dataset",
"base_model:microsoft/Phi-3-mini-128k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-128k-instruct",
"license:mit",
"region:us"
] | null | 2024-11-01T11:41:22Z |
---
base_model: microsoft/Phi-3-mini-128k-instruct
datasets:
- awels/maximo_admin_dataset
language:
- en
library_name: adapters
license: mit
tags:
- awels
- maximo
widget:
- text: Who are you, Maximus ?
---
# Maximus Model Card
## Model Details
**Model Name:** Maximus
**Model Type:** Transformer-based leveraging Microsoft Phi 3b 128k tokens
**Publisher:** Awels Engineering
**License:** MIT
**Model Description:**
Maximus is a sophisticated model designed to help as an AI agent focusing on Maximo Application Suite. It leverages advanced machine learning techniques to provide efficient and accurate solutions. It has been trained on the full docments corpus of MAS 8.5.
## Dataset
**Dataset Name:** [awels/maximo_admin_dataset](https://huggingface.co/datasets/awels/maximo_admin_dataset)
**Dataset Source:** Hugging Face Datasets
**Dataset License:** MIT
**Dataset Description:**
The dataset used to train Maximus consists of all the public documents available on Maximo application suite. This dataset is curated to ensure a comprehensive representation of typical administrative scenarios encountered in Maximo.
## Training Details
**Training Data:**
The training data includes 67,000 Questions and Answers generated by the [Bonito LLM](https://github.com/BatsResearch/bonito). The dataset is split into 3 sets of data (training, test and validation) to ensure robust model performance.
**Training Procedure:**
Maximus was trained using supervised learning with cross-entropy loss and the Adam optimizer. The training involved 1 epoch, a batch size of 4, a learning rate of 5.0e-06, and a cosine learning rate scheduler with gradient checkpointing for memory efficiency.
**Hardware:**
The model was trained on a single NVIDIA RTX 4090 graphic card.
**Framework:**
The training was conducted using PyTorch.
## Evaluation
**Evaluation Metrics:**
Maximus was evaluated on the training dataset:
> epoch = 1.0
total_flos = 64046138GF
train_loss = 2.8079
train_runtime = 0:37:48.33
train_samples_per_second = 21.066
train_steps_per_second = 5.267
**Performance:**
The model achieved the following results on the evaluation dataset:
> epoch = 1.0
eval_loss = 2.288
eval_runtime = 0:02:05.48
eval_samples = 10773
eval_samples_per_second = 95.338
eval_steps_per_second = 23.836
## Intended Use
**Primary Use Case:**
Maximus is intended to be used locally in an agent swarm to colleborate together to solve Maximo Application Suite related problems.
**Limitations:**
While Maximus is highly effective, it may have limitations due to the model size. An 8b model based on Llama 3 is used internally at Awels Engineering.
|
QuantFactory/SmolLM2-135M-GGUF
|
QuantFactory
| 2024-11-01T12:21:20Z | 78 | 3 |
transformers
|
[
"transformers",
"gguf",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T12:20:03Z |
---
library_name: transformers
license: apache-2.0
language:
- en
---
[](https://hf.co/QuantFactory)
# QuantFactory/SmolLM2-135M-GGUF
This is quantized version of [HuggingFaceTB/SmolLM2-135M](https://huggingface.co/HuggingFaceTB/SmolLM2-135M) created using llama.cpp
# Original Model Card
# SmolLM2

## Table of Contents
1. [Model Summary](##model-summary)
2. [Limitations](##limitations)
3. [Training](##training)
4. [License](##license)
5. [Citation](##citation)
## Model Summary
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device.
SmolLM2 demonstrates significant advances over its predecessor SmolLM1, particularly in instruction following, knowledge, reasoning. The 135M model was trained on 2 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new filtered datasets we curated and will release soon. We developed the instruct version through supervised fine-tuning (SFT) using a combination of public datasets and our own curated datasets. We then applied Direct Preference Optimization (DPO) using [UltraFeedback](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized).
The instruct model additionally supports tasks such as text rewriting, summarization and function calling thanks to datasets developed by [Argilla](https://huggingface.co/argilla) such as [Synth-APIGen-v0.1](https://huggingface.co/datasets/argilla/Synth-APIGen-v0.1).
### How to use
```bash
pip install transformers
```
#### Running the model on CPU/GPU/multi GPU
* _Using full precision_
```python
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM2-135M"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# for multiple GPUs install accelerate and do `model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")`
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("Gravity is", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "HuggingFaceTB/SmolLM2-135M"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# for fp16 use `torch_dtype=torch.float16` instead
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", torch_dtype=torch.bfloat16)
inputs = tokenizer.encode("Gravity is", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
```bash
>>> print(f"Memory footprint: {model.get_memory_footprint() / 1e6:.2f} MB")
Memory footprint: 723.56 MB
```
## Evaluation
In this section, we report the evaluation results of SmolLM2. All evaluations are zero-shot unless stated otherwise, and we use [lighteval](https://github.com/huggingface/lighteval) to run them.
## Base pre-trained model
| Metrics | SmolLM2-135M-8k | SmolLM-135M |
|:-------------------|:----------------:|:------------:|
| HellaSwag | **42.1** | 41.2 |
| ARC (Average) | **43.9** | 42.4 |
| PIQA | 68.4 | 68.4 |
| MMLU (cloze) | **31.5** | 30.2 |
| CommonsenseQA | **33.9** | 32.7 |
| TriviaQA | 4.1 | **4.3** |
| Winogrande | 51.3 | 51.3 |
| OpenBookQA | **34.6** | 34.0 |
| GSM8K (5-shot) | **1.4** | 1.0 |
## Instruction model
| Metric | SmolLM2-135M-Instruct | SmolLM-135M-Instruct |
|:-----------------------------|:---------------------:|:--------------------:|
| IFEval (Average prompt/inst) | **29.9** | 17.2 |
| MT-Bench | **1.98** | 1.68 |
| HellaSwag | **40.9** | 38.9 |
| ARC (Average) | **37.3** | 33.9 |
| PIQA | **66.3** | 64.0 |
| MMLU (cloze) | **29.3** | 28.3 |
| BBH (3-shot) | **28.2** | 25.2 |
| GSM8K (5-shot) | 1.4 | 1.4 |
## Limitations
SmolLM2 models primarily understand and generate content in English. They can produce text on a variety of topics, but the generated content may not always be factually accurate, logically consistent, or free from biases present in the training data. These models should be used as assistive tools rather than definitive sources of information. Users should always verify important information and critically evaluate any generated content.
## Training
### Model
- **Architecture:** Transformer decoder
- **Pretraining tokens:** 2T
- **Precision:** bfloat16
### Hardware
- **GPUs:** 64 H100
### Software
- **Training Framework:** [nanotron](https://github.com/huggingface/nanotron/tree/main)
## License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Citation
```bash
@misc{allal2024SmolLM2,
title={SmolLM2 - with great data, comes great performance},
author={Loubna Ben Allal and Anton Lozhkov and Elie Bakouch and Gabriel Martín Blázquez and Lewis Tunstall and Agustín Piqueres and Andres Marafioti and Cyril Zakka and Leandro von Werra and Thomas Wolf},
year={2024},
}
```
|
parrottygg/phi3v2
|
parrottygg
| 2024-11-01T12:15:28Z | 35 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T12:11:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rfajri/sentiment-indobert-v1
|
rfajri
| 2024-11-01T12:15:13Z | 105 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-11-01T12:14:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/CrystalMistralv3-GGUF
|
mradermacher
| 2024-11-01T12:14:30Z | 12 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Crystalcareai/CrystalMistralv3",
"base_model:quantized:Crystalcareai/CrystalMistralv3",
"endpoints_compatible",
"region:us"
] | null | 2024-10-31T05:12:09Z |
---
base_model: Crystalcareai/CrystalMistralv3
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Crystalcareai/CrystalMistralv3
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/CrystalMistralv3-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/CrystalMistralv3-GGUF/resolve/main/CrystalMistralv3.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
bmkllm/qwen_2-7b-it_v3
|
bmkllm
| 2024-11-01T12:09:13Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"krx",
"conversational",
"en",
"base_model:unsloth/Qwen2-7B-Instruct",
"base_model:finetune:unsloth/Qwen2-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T10:30:37Z |
---
base_model: unsloth/Qwen2-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- krx
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** bmkllm
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
qiuhuachuan/simpsybot_Q
|
qiuhuachuan
| 2024-11-01T12:05:32Z | 20 | 2 | null |
[
"safetensors",
"qwen2",
"llama-factory",
"full",
"generated_from_trainer",
"arxiv:2408.15787",
"base_model:Qwen/Qwen2-7B-Instruct",
"base_model:finetune:Qwen/Qwen2-7B-Instruct",
"license:other",
"region:us"
] | null | 2024-08-29T13:06:09Z |
---
license: other
base_model: Qwen/Qwen2-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: sft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Details
This model is a fine-tuned version of `Qwen/Qwen2-7B-Instruct` on our dataset.
**For more details, please refer to https://github.com/qiuhuachuan/interactive-agents
## Model inference
```Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
model_name = 'qiuhuachuan/simpsybot_Q'
simpsybot_qwen2_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
simpsybot_qwen2_tokenizer = AutoTokenizer.from_pretrained(model_name)
SYSTEM_PROMPT = """现在你是虚拟心理咨询师小天。
以下是小天的信息:
角色名:小天
性别:女
角色介绍: 虚拟心理咨询师,擅长人本主义、精神分析和认知行为疗法。
技能:帮助识别和挑战不健康的思维,提供心理学支持和共情。
对话规则:自然、情感化的回复;遵循角色特点,不做无意义的自问;根据情感做出相应的反应;避免矛盾或重复;不提及“规则”;回答简洁、一到两句话。
咨询一般分为前、中、后期三个阶段:
1. 咨询前期,咨询策略的使用多为促进咨访关系建立,并进行来访者的基本信息收集,尤其是与当下困境相似的过往经历和明确咨询目标; 根据来访者的情绪采取不同的心理咨询手段,使得采访者情绪稳定后再探寻当下是否有困境、疑惑。
2. 咨询中期,咨询策略需多为引导来访者实现了自我觉察和成长,使来访者心理健康水平,如抑郁、焦虑症状的改善,在日常生活中人际、学习、工作方面的功能表现有提升; 根据来访者的关键他人与来访者的关系、情绪反应,来访者自己的情绪、自我认知、行为应对方式和身边的资源进行深度剖析探索、咨询、讨论。使得来访者明确表达当下的困境或者想要讨论的问题。
3. 咨询后期,咨询策略需更多地导向引导来访者总结整个咨询周期中自己在情绪处理、社会功能、情感行为反应三个方面的改变和提升。明确询问来访者希望达成的目标或者期望,并且制定计划解决人际关系或者情绪处理方面的问题。
咨询师的对话要求:
1. 表达要简短,尽可能地口语化、自然。
2. 因为咨询师只受过心理学相关的教育,只能提供心理咨询相关的对话内容。
3. 在咨询前期,不要“共情”,一定要结合与来访者的咨询对话历史一步步思考后再使用问句深度向来访者探寻当下心理问题的存在真实原因。
4. 不要一次性询问过多的问题,尽量一次性只向来访者询问一个问题,与来访者互动后一步步探寻心理问题的原因。
5. 在咨询前期,不要“重述”和“认可”等话术。
6. 话术需要参考有经验的真人心理咨询师,尽可能口语化。
7. 严格遵循咨询的前、中、后三个阶段采用对应的策略。
8. 咨询师不要主动终止心理咨询流程。
9. 更多的是引导用户思考和探索。"""
def get_prediction_simpsybot_qwen2(messages: list):
system_item = [{'role': 'system', 'content': SYSTEM_PROMPT}]
messages = system_item + messages
ctx = simpsybot_qwen2_tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = simpsybot_qwen2_tokenizer([ctx], return_tensors="pt").to(device)
with torch.no_grad():
generated_ids = simpsybot_qwen2_model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = simpsybot_qwen2_tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
if __name__ == '__main__':
messages =[
{'role': 'user', 'content': '我失恋了,好难受!'}
]
response = get_prediction_simpsybot_qwen2(messages=messages)
print(response)
```
## Intended uses & limitations
Available for non-commercial use
## Citation
If you find our work useful for your research and applications, please cite using this BibTeX:
```bibtex
@misc{qiu2024interactiveagents,
title={Interactive Agents: Simulating Counselor-Client Psychological Counseling via Role-Playing LLM-to-LLM Interactions},
author={Huachuan Qiu and Zhenzhong Lan},
year={2024},
eprint={2408.15787},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.15787},
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2.0
### Framework versions
- Transformers 4.43.4
- Pytorch 2.4.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
letuandat/tts-nnng-2410
|
letuandat
| 2024-11-01T12:04:49Z | 103 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vits",
"text-to-audio",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2024-10-31T16:25:07Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
fbolanos/LRO_BigBird
|
fbolanos
| 2024-11-01T12:04:00Z | 119 | 0 |
transformers
|
[
"transformers",
"safetensors",
"big_bird",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-11-01T12:03:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
johnatanebonilla/w_small_lv_70
|
johnatanebonilla
| 2024-11-01T12:01:32Z | 85 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-10-30T03:26:56Z |
---
library_name: transformers
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: w_small_lv_70
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w_small_lv_70
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6468
- Wer: 77.1230
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.7247 | 0.7184 | 1000 | 0.6818 | 77.6120 |
| 0.5041 | 1.4368 | 2000 | 0.6395 | 75.4202 |
| 0.3808 | 2.1552 | 3000 | 0.6313 | 85.2857 |
| 0.3595 | 2.8736 | 4000 | 0.6264 | 71.4611 |
| 0.2771 | 3.5920 | 5000 | 0.6468 | 77.1230 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu118
- Datasets 3.0.0
- Tokenizers 0.19.1
|
mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF
|
mradermacher
| 2024-11-01T12:00:06Z | 12 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.7",
"base_model:quantized:AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.7",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T11:48:02Z |
---
base_model: AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.7
language:
- en
library_name: transformers
license: cc-by-sa-4.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/AIFT/AIFT-ko-orca-plat-Yi-ko-6b-v1.7
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q2_K.gguf) | Q2_K | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q3_K_S.gguf) | Q3_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q3_K_M.gguf) | Q3_K_M | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q3_K_L.gguf) | Q3_K_L | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.IQ4_XS.gguf) | IQ4_XS | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q4_K_S.gguf) | Q4_K_S | 3.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q4_K_M.gguf) | Q4_K_M | 3.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q5_K_S.gguf) | Q5_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q5_K_M.gguf) | Q5_K_M | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q6_K.gguf) | Q6_K | 5.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.Q8_0.gguf) | Q8_0 | 6.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/AIFT-ko-orca-plat-Yi-ko-6b-v1.7-GGUF/resolve/main/AIFT-ko-orca-plat-Yi-ko-6b-v1.7.f16.gguf) | f16 | 12.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/TinyLlama-1.1B-32k-i1-GGUF
|
mradermacher
| 2024-11-01T11:51:07Z | 69 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"llama 2",
"en",
"dataset:togethercomputer/RedPajama-Data-1T-Sample",
"base_model:Doctor-Shotgun/TinyLlama-1.1B-32k",
"base_model:quantized:Doctor-Shotgun/TinyLlama-1.1B-32k",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-11-01T10:59:37Z |
---
base_model: Doctor-Shotgun/TinyLlama-1.1B-32k
datasets:
- togethercomputer/RedPajama-Data-1T-Sample
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- llama
- llama 2
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Doctor-Shotgun/TinyLlama-1.1B-32k
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ1_S.gguf) | i1-IQ1_S | 0.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ1_M.gguf) | i1-IQ1_M | 0.4 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ2_S.gguf) | i1-IQ2_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ2_M.gguf) | i1-IQ2_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q2_K.gguf) | i1-Q2_K | 0.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ3_S.gguf) | i1-IQ3_S | 0.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ3_M.gguf) | i1-IQ3_M | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 0.7 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 0.7 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 0.7 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_0.gguf) | i1-Q4_0 | 0.7 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.7 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF/resolve/main/TinyLlama-1.1B-32k.i1-Q6_K.gguf) | i1-Q6_K | 1.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
parrottygg/phi3v1
|
parrottygg
| 2024-11-01T11:48:13Z | 35 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T11:39:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Noginowa/AnimaMixColorXL
|
Noginowa
| 2024-11-01T11:30:36Z | 7 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"ja",
"en",
"license:other",
"region:us"
] |
text-to-image
| 2024-08-15T07:15:47Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- ja
- en
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
library_name: diffusers
---

Animagine系のモデルをミックスしたVAE内蔵マージモデルです。<br>
This is a VAE built-in merge model with a mix of Animagine-type models.<br>
<br>
より良いイラストを生成するにはできるだけ詳しくプロンプトを記述してください。シンプルなプロンプトでも悪くないイラストは生成できますが、1girlと品質プロンプトだけでは良いイラストにはなりません。<br>
Please be as detailed as possible in your prompts to generate better illustrations. Simple prompts can generate not bad illustrations, but 1girl and quality prompts alone do not generate good illustrations.<br>
<br>
# ライセンス / License
[Fair AI Public License 1.0-SD](https://freedevproject.org/faipl-1.0-sd/)<br>
<br>
# 以下のモデルをマージしています / The following models are merged
* Animagine XL V3.1
* Anything XL
* Async's MIX XL v3.1 \(v2はv3.2\)
* anima_pencil-XL v5.0.0
* anima_pencil-XL v4.0.0
Thank you for the model creators.<br>
<br>
# レシピ/ Recipe
Files and versionsのレシピファイルを参照してください。
<br><br>
# 作者
Civitai: [Noginowa](https://civitai.com/user/Noginowa)<br>
Bluesky: [のぎのわ](https://bsky.app/profile/noginowa-ailab.bsky.social)
|
HengeBytes/ki-v0-16bit-vllm
|
HengeBytes
| 2024-11-01T11:26:00Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T11:14:36Z |
---
base_model: unsloth/qwen2.5-7b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** HengeBytes
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-7b-instruct-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
adamNLP/learn_hf_food_not_food_text_classifier-distilbert-base-uncased
|
adamNLP
| 2024-11-01T11:18:03Z | 105 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-10-30T11:45:27Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: learn_hf_food_not_food_text_classifier-distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# learn_hf_food_not_food_text_classifier-distilbert-base-uncased
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0005
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.409 | 1.0 | 7 | 0.0798 | 1.0 |
| 0.0336 | 2.0 | 14 | 0.0083 | 1.0 |
| 0.0052 | 3.0 | 21 | 0.0023 | 1.0 |
| 0.0019 | 4.0 | 28 | 0.0012 | 1.0 |
| 0.0012 | 5.0 | 35 | 0.0009 | 1.0 |
| 0.0009 | 6.0 | 42 | 0.0007 | 1.0 |
| 0.0143 | 7.0 | 49 | 0.0006 | 1.0 |
| 0.0007 | 8.0 | 56 | 0.0006 | 1.0 |
| 0.0007 | 9.0 | 63 | 0.0006 | 1.0 |
| 0.0006 | 10.0 | 70 | 0.0005 | 1.0 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.0+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
Xu-Ouyang/pythia-12b-deduped-int3-step8-GPTQ-wikitext2
|
Xu-Ouyang
| 2024-11-01T11:16:58Z | 76 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-11-01T11:06:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
razhan/trocr-base-ckb
|
razhan
| 2024-11-01T11:14:12Z | 66 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-04-01T11:35:44Z |
# Kurdish OCR
Transformer based ocr trained on synthetic Central Kurdish Data
|
Ariffiq99/Randomized_Roberta_Stacked_model_80
|
Ariffiq99
| 2024-11-01T11:14:00Z | 103 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"multiple-choice",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2024-11-01T09:10:23Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Randomized_Roberta_Stacked_model_80
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Randomized_Roberta_Stacked_model_80
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8535
- F1: 0.7395
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.64 | 1.0 | 1261 | 0.7758 | 0.7327 |
| 0.5704 | 2.0 | 2522 | 0.7685 | 0.7408 |
| 0.5059 | 3.0 | 3783 | 0.8209 | 0.7401 |
| 0.4519 | 4.0 | 5044 | 0.8222 | 0.7381 |
| 0.4177 | 5.0 | 6305 | 0.8535 | 0.7395 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.5.0+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
mradermacher/IndoWebGen-7B-GGUF
|
mradermacher
| 2024-11-01T11:13:08Z | 40 | 0 |
transformers
|
[
"transformers",
"gguf",
"id",
"dataset:alxxtexxr/indowebgen-dataset",
"base_model:alxxtexxr/IndoWebGen-7B",
"base_model:quantized:alxxtexxr/IndoWebGen-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T11:00:34Z |
---
base_model: alxxtexxr/IndoWebGen-7B
datasets:
- alxxtexxr/indowebgen-dataset
language:
- id
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/alxxtexxr/IndoWebGen-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/IndoWebGen-7B-GGUF/resolve/main/IndoWebGen-7B.f16.gguf) | f16 | 13.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/TinyLlama-1.1B-32k-GGUF
|
mradermacher
| 2024-11-01T11:11:24Z | 14 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"llama 2",
"en",
"dataset:togethercomputer/RedPajama-Data-1T-Sample",
"base_model:Doctor-Shotgun/TinyLlama-1.1B-32k",
"base_model:quantized:Doctor-Shotgun/TinyLlama-1.1B-32k",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-31T03:44:10Z |
---
base_model: Doctor-Shotgun/TinyLlama-1.1B-32k
datasets:
- togethercomputer/RedPajama-Data-1T-Sample
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- llama
- llama 2
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Doctor-Shotgun/TinyLlama-1.1B-32k
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q3_K_S.gguf) | Q3_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.IQ4_XS.gguf) | IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q4_K_S.gguf) | Q4_K_S | 0.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q6_K.gguf) | Q6_K | 1.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TinyLlama-1.1B-32k-GGUF/resolve/main/TinyLlama-1.1B-32k.f16.gguf) | f16 | 2.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
deepnet/SN9-C2-llama-HK4-7
|
deepnet
| 2024-11-01T11:00:43Z | 222 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T10:57:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sophiebui/ru-en_mtmodel_v1
|
sophiebui
| 2024-11-01T10:29:10Z | 107 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:sophiebui/ru-en_mtmodel",
"base_model:finetune:sophiebui/ru-en_mtmodel",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-11-01T10:15:57Z |
---
library_name: transformers
license: mit
base_model: sophiebui/ru-en_mtmodel
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: ru-en_mtmodel_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ru-en_mtmodel_v1
This model is a fine-tuned version of [sophiebui/ru-en_mtmodel](https://huggingface.co/sophiebui/ru-en_mtmodel) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1134
- Bleu: 43.1972
- Gen Len: 30.6216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 226 | 1.2067 | 39.6459 | 30.2432 |
| No log | 2.0 | 452 | 1.1232 | 40.3147 | 30.8649 |
| 1.2106 | 3.0 | 678 | 1.1134 | 43.1972 | 30.6216 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
ghost613/VC-JHJ_Woman_40s-01-08-35.48
|
ghost613
| 2024-11-01T10:26:51Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-10-31T10:06:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tuanpasg/Puffin-Qwen2.5-TIES
|
tuanpasg
| 2024-11-01T10:18:53Z | 136 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2306.01708",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:merge:Qwen/Qwen2.5-1.5B",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:merge:Qwen/Qwen2.5-Math-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T10:09:53Z |
---
base_model:
- Qwen/Qwen2.5-Math-1.5B
- Qwen/Qwen2.5-1.5B
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [Qwen/Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) as a base.
### Models Merged
The following models were included in the merge:
* [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Qwen/Qwen2.5-1.5B
- model: Qwen/Qwen2.5-Math-1.5B
parameters:
density: 0.5
weight: 0.5
- model: Qwen/Qwen2.5-Math-1.5B
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: Qwen/Qwen2.5-1.5B
parameters:
normalize: false
int8_mask: true
dtype: bfloat16
```
|
sophiebui/en-ru_mtmodel_v1
|
sophiebui
| 2024-11-01T10:13:23Z | 105 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:sophiebui/en-ru_mtmodel",
"base_model:finetune:sophiebui/en-ru_mtmodel",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-11-01T09:49:27Z |
---
library_name: transformers
license: mit
base_model: sophiebui/en-ru_mtmodel
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: en-ru_mtmodel_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# en-ru_mtmodel_v1
This model is a fine-tuned version of [sophiebui/en-ru_mtmodel](https://huggingface.co/sophiebui/en-ru_mtmodel) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8443
- Bleu: 44.9157
- Gen Len: 32.0811
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 226 | 0.9394 | 37.9005 | 31.5405 |
| No log | 2.0 | 452 | 0.8537 | 43.6072 | 32.3514 |
| 0.935 | 3.0 | 678 | 0.8400 | 46.3652 | 31.8108 |
| 0.935 | 4.0 | 904 | 0.8482 | 44.6002 | 31.973 |
| 0.4432 | 5.0 | 1130 | 0.8443 | 44.9157 | 32.0811 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.1.0
- Tokenizers 0.19.1
|
coastalcph/CLIPDetail-8311682
|
coastalcph
| 2024-11-01T10:10:52Z | 148 | 0 |
transformers
|
[
"transformers",
"safetensors",
"clip",
"zero-shot-image-classification",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2024-11-01T10:10:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hyadess/UAP-EEE-llama-3.1-8b-16_bit_merged
|
hyadess
| 2024-11-01T10:00:13Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T09:52:29Z |
---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# Uploaded model
- **Developed by:** hyadess
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
NbAiLab/nb-wav2vec2-300m-nynorsk
|
NbAiLab
| 2024-11-01T09:54:59Z | 128,927 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"nn",
"dataset:NbAiLab/NPSC",
"arxiv:2307.01672",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- automatic-speech-recognition
datasets:
- NbAiLab/NPSC
language:
- nn
model-index:
- name: nb-wav2vec2-300m-nynorsk
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: NPSC
type: NbAiLab/NPSC
args: 16K_mp3_nynorsk
metrics:
- name: Test (Nynorsk) WER
type: wer
value: 0.1222
- name: Test (Nynorsk) CER
type: cer
value: 0.0419
---
# Norwegian Wav2Vec2 Model - 300M - VoxRex - Nynorsk
This model is finetuned on top of feature extractor [VoxRex-model](https://huggingface.co/KBLab/wav2vec2-large-voxrex) from the National Library of Sweden. The finetuned model achieves the following results on the test set with a 5-gram KenLM. The numbers in parentheses are the results without the language model:
- **WER: 0.1222** (0.1537)
- **CER: 0.0419** (0.0468)
## Model description
This is one of several Wav2Vec-models our team created during the 🤗 hosted [Robust Speech Event](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614?s=09). This is the complete list of our models and their final scores:
| Model | Final WER | |
|:--------------|:------------|:------------:|
| [NbAiLab/nb-wav2vec2-1b-bokmaal](https://huggingface.co/NbAiLab/nb-wav2vec2-1b-bokmaal) | 6.33 | |
| [NbAiLab/nb-wav2vec2-300m-bokmaal](https://huggingface.co/NbAiLab/nb-wav2vec2-300m-bokmaal) | 7.03 | |
| [NbAiLab/nb-wav2vec2-1b-nynorsk](https://huggingface.co/NbAiLab/nb-wav2vec2-1b-nynorsk) | 11.32 | |
| NbAiLab/nb-wav2vec2-300m-nynorsk (this model) | 12.22 | |
### Dataset
In parallel with the event, the team also converted the [Norwegian Parliamentary Speech Corpus (NPSC)](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-58/) to the [NbAiLab/NPSC](https://huggingface.co/datasets/NbAiLab/NPSC) in 🤗 Dataset format and used that as the main source for training.
## Code
We have released all the code developed during the event so that the Norwegian NLP community can build upon it when developing even better Norwegian ASR models. The finetuning of these models is not very computationally demanding. After following the instructions here, you should be able to train your own automatic speech recognition system in less than a day with an average GPU.
## Team
The following people contributed to building this model: Rolv-Arild Braaten, Per Egil Kummervold, Andre Kåsen, Javier de la Rosa, Per Erik Solberg, and Freddy Wetjen.
## Training procedure
To reproduce these results, we strongly recommend that you follow the [instructions from 🤗](https://github.com/huggingface/transformers/tree/master/examples/research_projects/robust-speech-event#talks) to train a simple Swedish model.
When you have verified that you are able to do this, create a fresh new repo. You can then start by copying the files ```run.sh``` and ```run_speech_recognition_ctc.py``` from our repo. Running these will create all the other necessary files, and should let you reproduce our results. With some tweaks to the hyperparameters, you might even be able to build an even better ASR. Good luck!
### Language Model
As the scores indicate, adding even a simple 5-gram language will improve the results. 🤗 has provided another [very nice blog](https://huggingface.co/blog/wav2vec2-with-ngram) explaining how to add a 5-gram language model to improve the ASR model. You can build this from your own corpus, for instance by extracting some suitable text from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC). You can also skip some of the steps in the guide, and copy the [5-gram model from this repo](https://huggingface.co/NbAiLab/XLSR-300M-bokmaal/tree/main/language_model).
### Parameters
The final model was run using these parameters:
```
--dataset_name="NbAiLab/NPSC"
--model_name_or_path="KBLab/wav2vec2-large-voxrex"
--dataset_config_name="16K_mp3_nynorsk"
--output_dir="./"
--overwrite_output_dir
--num_train_epochs="80"
--per_device_train_batch_size="16"
--per_device_eval_batch_size="16"
--gradient_accumulation_steps="2"
--learning_rate="1e-4"
--warmup_steps="2000"
--length_column_name="input_length"
--evaluation_strategy="steps"
--text_column_name="text"
--save_steps="500"
--eval_steps="500"
--logging_steps="100"
--layerdrop="0.041"
--attention_dropout="0.094"
--activation_dropout="0.055"
--hidden_dropout="0.047"
--save_total_limit="3"
--freeze_feature_encoder
--feat_proj_dropout="0.04"
--mask_time_prob="0.082"
--mask_time_length="10"
--mask_feature_prob="0.25"
--mask_feature_length="64"
--gradient_checkpointing
--min_duration_in_seconds="0.5"
--max_duration_in_seconds="30.0"
--use_auth_token
--seed="42"
--fp16
--group_by_length
--do_train --do_eval
--push_to_hub
--preprocessing_num_workers="32"
```
Using these settings, the training might take 3-4 days on an average GPU. You can, however, get a decent model and faster results by tweaking these parameters.
| Parameter| Comment |
|:-------------|:-----|
| per_device_train_batch_size | Adjust this to the maximum of available memory. 16 or 24 might be good settings depending on your system |
|gradient_accumulation_steps |Can be adjusted even further up to increase batch size and speed up training without running into memory issues |
| learning_rate|Can be increased, maybe as high as 1e-4. Speeds up training but might add instability |
| epochs| Can be decreased significantly. This is a huge dataset and you might get a decent result already after a couple of epochs|
## Citation
```bibtex
@inproceedings{de-la-rosa-etal-2023-boosting,
title = "Boosting {N}orwegian Automatic Speech Recognition",
author = "De La Rosa, Javier and
Braaten, Rolv-Arild and
Kummervold, Per and
Wetjen, Freddy",
booktitle = "Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)",
month = may,
year = "2023",
address = "T{\'o}rshavn, Faroe Islands",
publisher = "University of Tartu Library",
url = "https://aclanthology.org/2023.nodalida-1.55",
pages = "555--564",
abstract = "In this paper, we present several baselines for automatic speech recognition (ASR) models for the two official written languages in Norway: Bokm{\aa}l and Nynorsk. We compare the performance of models of varying sizes and pre-training approaches on multiple Norwegian speech datasets. Additionally, we measure the performance of these models against previous state-of-the-art ASR models, as well as on out-of-domain datasets. We improve the state of the art on the Norwegian Parliamentary Speech Corpus (NPSC) from a word error rate (WER) of 17.10{\%} to 7.60{\%}, with models achieving 5.81{\%} for Bokm{\aa}l and 11.54{\%} for Nynorsk. We also discuss the challenges and potential solutions for further improving ASR models for Norwegian.",
}
```
See https://arxiv.org/abs/2307.01672
|
tuanpasg/Puffin-Qwen2.5-CodeMath-1
|
tuanpasg
| 2024-11-01T09:53:53Z | 134 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Qwen/Qwen2.5-Coder-1.5B",
"base_model:merge:Qwen/Qwen2.5-Coder-1.5B",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:merge:Qwen/Qwen2.5-Math-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-01T09:52:35Z |
---
base_model:
- Qwen/Qwen2.5-Coder-1.5B
- Qwen/Qwen2.5-Math-1.5B
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [Qwen/Qwen2.5-Coder-1.5B](https://huggingface.co/Qwen/Qwen2.5-Coder-1.5B)
* [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Qwen/Qwen2.5-Coder-1.5B
- model: Qwen/Qwen2.5-Math-1.5B
merge_method: slerp
base_model: Qwen/Qwen2.5-Coder-1.5B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
raaedk/subliminal_large
|
raaedk
| 2024-11-01T09:43:26Z | 8 | 0 |
diffusers
|
[
"diffusers",
"sd3",
"sd3-diffusers",
"text-to-image",
"simpletuner",
"safe-for-work",
"lora",
"template:sd-lora",
"lycoris",
"base_model:stabilityai/stable-diffusion-3.5-large",
"base_model:adapter:stabilityai/stable-diffusion-3.5-large",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-01T05:22:58Z |
---
license: other
base_model: "stabilityai/stable-diffusion-3.5-large"
tags:
- sd3
- sd3-diffusers
- text-to-image
- diffusers
- simpletuner
- safe-for-work
- lora
- template:sd-lora
- lycoris
inference: true
widget:
- text: 'unconditional (blank prompt)'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_0_0.png
- text: 'ps2 graphics, liminal, hotel lobby, videogame screenshot'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_1_0.png
---
# subliminal_large
This is a LyCORIS adapter derived from [stabilityai/stable-diffusion-3.5-large](https://huggingface.co/stabilityai/stable-diffusion-3.5-large).
The main validation prompt used during training was:
```
ps2 graphics, liminal, hotel lobby, videogame screenshot
```
## Validation settings
- CFG: `5.0`
- CFG Rescale: `0.0`
- Steps: `20`
- Sampler: `None`
- Seed: `42`
- Resolution: `1024x1024`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 2
- Training steps: 6500
- Learning rate: 0.0001
- Max grad norm: 0.01
- Effective batch size: 1
- Micro-batch size: 1
- Gradient accumulation steps: 1
- Number of GPUs: 1
- Prediction type: flow-matching
- Rescaled betas zero SNR: False
- Optimizer: adamw_bf16
- Precision: Pure BF16
- Quantised: Yes: int8-quanto
- Xformers: Not used
- LyCORIS Config:
```json
{
"algo": "lora",
"multiplier": 1.0,
"linear_dim": 64,
"linear_alpha": 32,
"apply_preset": {
"target_module": [
"Attention",
"FeedForward"
],
"module_algo_map": {
"Attention": {
"factor": 16
},
"FeedForward": {
"factor": 8
}
}
}
}
```
## Datasets
### ps2_subliminal-512
- Repeats: 10
- Total number of images: 55
- Total number of aspect buckets: 1
- Resolution: 0.262144 megapixels
- Cropped: False
- Crop style: None
- Crop aspect: None
- Used for regularisation data: No
### ps2_subliminal-1024
- Repeats: 10
- Total number of images: 55
- Total number of aspect buckets: 1
- Resolution: 1.048576 megapixels
- Cropped: False
- Crop style: None
- Crop aspect: None
- Used for regularisation data: No
### ps2_subliminal-512-crop
- Repeats: 10
- Total number of images: 55
- Total number of aspect buckets: 1
- Resolution: 0.262144 megapixels
- Cropped: True
- Crop style: random
- Crop aspect: square
- Used for regularisation data: No
### ps2_subliminal-1024-crop
- Repeats: 10
- Total number of images: 55
- Total number of aspect buckets: 1
- Resolution: 1.048576 megapixels
- Cropped: True
- Crop style: random
- Crop aspect: square
- Used for regularisation data: No
## Inference
```python
import torch
from diffusers import DiffusionPipeline
from lycoris import create_lycoris_from_weights
model_id = 'stabilityai/stable-diffusion-3.5-large'
adapter_id = 'pytorch_lora_weights.safetensors' # you will have to download this manually
lora_scale = 1.0
wrapper, _ = create_lycoris_from_weights(lora_scale, adapter_id, pipeline.transformer)
wrapper.merge_to()
prompt = "ps2 graphics, liminal, hotel lobby, videogame screenshot"
negative_prompt = 'blurry, cropped, ugly'
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=20,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1024,
height=1024,
guidance_scale=5.0,
).images[0]
image.save("output.png", format="PNG")
```
|
mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF
|
mradermacher
| 2024-11-01T09:43:13Z | 27 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:mtc/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged",
"base_model:quantized:mtc/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T09:15:24Z |
---
base_model: mtc/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mtc/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-arxiv-summarization-10k-last_merged.f16.gguf) | f16 | 13.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF
|
mradermacher
| 2024-11-01T09:34:09Z | 30 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:mtc/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged",
"base_model:quantized:mtc/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged",
"endpoints_compatible",
"region:us"
] | null | 2024-11-01T09:20:46Z |
---
base_model: mtc/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mtc/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged-GGUF/resolve/main/meta-llama-Llama-2-7b-hf-pubmed-summarization-10k-last_merged.f16.gguf) | f16 | 13.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
VTSNLP/trans_model_vi_en
|
VTSNLP
| 2024-11-01T09:30:58Z | 5 | 1 | null |
[
"tensorboard",
"safetensors",
"t5",
"generated_from_trainer",
"base_model:VietAI/envit5-translation",
"base_model:finetune:VietAI/envit5-translation",
"license:openrail",
"region:us"
] | null | 2024-11-01T09:30:13Z |
---
license: openrail
base_model: VietAI/envit5-translation
tags:
- generated_from_trainer
model-index:
- name: trans_model_vi_en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trans_model_vi_en
This model is a fine-tuned version of [VietAI/envit5-translation](https://huggingface.co/VietAI/envit5-translation) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 4
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
GeneZC/MiniMA-2-3B
|
GeneZC
| 2024-11-01T09:22:35Z | 1,760 | 17 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"zh",
"dataset:EleutherAI/pile",
"dataset:togethercomputer/RedPajama-Data-1T",
"dataset:p208p2002/wudao",
"arxiv:2311.07052",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-12-27T03:36:23Z |
---
language:
- en
- zh
license: apache-2.0
library_name: transformers
datasets:
- EleutherAI/pile
- togethercomputer/RedPajama-Data-1T
- p208p2002/wudao
widget:
- text: <s> 4 + 3 =
model-index:
- name: MiniMA-2-3B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 44.71
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 69.33
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 41.22
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 38.44
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 66.69
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 8.11
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=GeneZC/MiniMA-2-3B
name: Open LLM Leaderboard
---
## MiniMA-2-3B
📑 [arXiv](https://arxiv.org/abs/2311.07052) | 👻 [GitHub](https://github.com/GeneZC/MiniMA) | 🤗 [HuggingFace-MiniMA](https://huggingface.co/GeneZC/MiniMA-3B) | 🤗 [HuggingFace-MiniChat](https://huggingface.co/GeneZC/MiniChat-3B) | 🤖 [ModelScope-MiniMA](https://modelscope.cn/models/GeneZC/MiniMA-3B) | 🤖 [ModelScope-MiniChat](https://modelscope.cn/models/GeneZC/MiniChat-3B) | 🤗 [HuggingFace-MiniChat-1.5](https://huggingface.co/GeneZC/MiniChat-1.5-3B) | 🤗 [HuggingFace-MiniMA-2](https://huggingface.co/GeneZC/MiniMA-2-3B) | 🤗 [HuggingFace-MiniChat-2](https://huggingface.co/GeneZC/MiniChat-2-3B)
🆕 **Updates from MiniMA-3B**:
- continued from MiniMA-3B without distillation;
- better data mixture;
- more trained tokens.
❗ Must comply with LICENSE of LLaMA-2 since it is derived from LLaMA-2.
A language model continued from MiniMA-3B.
Completing the compute-performance pareto frontier together with MiniMA-3B and other arts.
<img src="./teaser_a.jpg" alt="teaser_a" width="700" />
**Standard Benchmarks**
|Method|TFLOPs|MMLU (5-shot)|CEval (5-shot)|DROP (3-shot)|HumanEval (0-shot)|BBH (3-shot)|GSM8K (8-shot)|
|--|--|--|--|--|--|--|--|
|Mamba-2.8B|4.6E9|25.58|24.74|15.72|7.32|29.37|3.49|
|ShearedLLaMA-2.7B|0.8E9|26.97|22.88|19.98|4.88|30.48|3.56|
|BTLM-3B|11.3E9|27.20|26.00|17.84|10.98|30.87|4.55|
|StableLM-3B|72.0E9|44.75|31.05|22.35|15.85|32.59|10.99|
|Qwen-1.8B|23.8E9|44.05|54.75|12.97|14.02|30.80|22.97|
|Phi-2-2.8B|159.9E9|56.74|34.03|30.74|46.95|44.13|55.42|
|LLaMA-2-7B|84.0E9|46.00|34.40|31.57|12.80|32.02|14.10|
||
|MiniMA-3B|4.0E9|28.51|28.23|22.50|10.98|31.61|8.11|
|MiniChat-3B|4.0E9|38.40|36.48|22.58|18.29|31.36|29.72|
|MiniMA-2-3B|13.4E9|40.14|44.65|23.10|14.63|31.43|8.87|
|MiniChat-2-3B|13.4E9|46.17|43.91|30.26|22.56|34.95|38.13|
The following is an example code snippet to use MiniMA-2-3B:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# MiniMA
tokenizer = AutoTokenizer.from_pretrained("GeneZC/MiniMA-2-3B", use_fast=False)
# GPU.
model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniMA-2-3B", use_cache=True, device_map="auto", torch_dtype=torch.float16).eval()
# CPU.
# model = AutoModelForCausalLM.from_pretrained("GeneZC/MiniMA-2-3B", use_cache=True, device_map="cpu", torch_dtype=torch.float16).eval()
prompt = "Question: Sherrie tells the truth. Vernell says Sherrie tells the truth. Alexis says Vernell lies. Michaela says Alexis tells the truth. Elanor says Michaela tells the truth. Does Elanor tell the truth?\nAnswer: No\n\nQuestion: Kristian lies. Sherrie says Kristian lies. Delbert says Sherrie lies. Jerry says Delbert tells the truth. Shalonda says Jerry tells the truth. Does Shalonda tell the truth?\nAnswer: No\n\nQuestion: Vina tells the truth. Helene says Vina lies. Kandi says Helene tells the truth. Jamey says Kandi lies. Ka says Jamey lies. Does Ka tell the truth?\nAnswer: No\n\nQuestion: Christie tells the truth. Ka says Christie tells the truth. Delbert says Ka lies. Leda says Delbert tells the truth. Lorine says Leda tells the truth. Does Lorine tell the truth?\nAnswer:"
input_ids = tokenizer([prompt]).input_ids
output_ids = model.generate(
torch.as_tensor(input_ids).cuda(),
do_sample=True,
temperature=0.7,
max_new_tokens=1024,
)
output_ids = output_ids[0][len(input_ids[0]):]
output = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
# output: "No"
```
## Bibtex
```bibtex
@article{zhang2023law,
title={Towards the Law of Capacity Gap in Distilling Language Models},
author={Zhang, Chen and Song, Dawei and Ye, Zheyu and Gao, Yan},
year={2023},
url={https://arxiv.org/abs/2311.07052}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_GeneZC__MiniMA-2-3B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |44.75|
|AI2 Reasoning Challenge (25-Shot)|44.71|
|HellaSwag (10-Shot) |69.33|
|MMLU (5-Shot) |41.22|
|TruthfulQA (0-shot) |38.44|
|Winogrande (5-shot) |66.69|
|GSM8k (5-shot) | 8.11|
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.