
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 00:39:05
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 532
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 00:38:59
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
GreenBitAI/Phi-3-mini-4k-instruct-layer-mix-bpw-3.0-mlx
|
GreenBitAI
| 2024-04-25T20:21:35Z | 5 | 0 |
mlx
|
[
"mlx",
"safetensors",
"phi3",
"custom_code",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T20:15:10Z |
---
license: apache-2.0
tags:
- mlx
---
# GreenBitAI/Phi-3-mini-4k-instruct-layer-mix-bpw-3.0-mlx
This quantized low-bit model was converted to MLX format from [`GreenBitAI/Phi-3-mini-4k-instruct-layer-mix-bpw-3.0`]().
Refer to the [original model card](https://huggingface.co/GreenBitAI/Phi-3-mini-4k-instruct-layer-mix-bpw-3.0) for more details on the model.
## Use with mlx
```bash
pip install gbx-lm
```
```python
from gbx_lm import load, generate
model, tokenizer = load("GreenBitAI/Phi-3-mini-4k-instruct-layer-mix-bpw-3.0-mlx")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
Augusto777/vit-base-patch16-224-dmae-va-U5-100bcont
|
Augusto777
| 2024-04-25T20:19:58Z | 218 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-04-25T17:10:33Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-dmae-va-U5-100bcont
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-dmae-va-U5-100bcont
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5453
- Accuracy: 0.8667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.9 | 7 | 0.5397 | 0.85 |
| 0.3809 | 1.94 | 15 | 0.5212 | 0.85 |
| 0.316 | 2.97 | 23 | 0.5690 | 0.8 |
| 0.2892 | 4.0 | 31 | 0.6506 | 0.7667 |
| 0.2892 | 4.9 | 38 | 0.5529 | 0.8333 |
| 0.2127 | 5.94 | 46 | 0.4987 | 0.8333 |
| 0.1712 | 6.97 | 54 | 0.5859 | 0.8167 |
| 0.1539 | 8.0 | 62 | 0.5937 | 0.8 |
| 0.1539 | 8.9 | 69 | 0.5103 | 0.8333 |
| 0.1378 | 9.94 | 77 | 0.6844 | 0.7833 |
| 0.1144 | 10.97 | 85 | 0.5357 | 0.85 |
| 0.1055 | 12.0 | 93 | 0.6695 | 0.8 |
| 0.1093 | 12.9 | 100 | 0.5593 | 0.85 |
| 0.1093 | 13.94 | 108 | 0.5453 | 0.8667 |
| 0.0956 | 14.97 | 116 | 0.6144 | 0.85 |
| 0.1057 | 16.0 | 124 | 0.5067 | 0.8333 |
| 0.0907 | 16.9 | 131 | 0.6570 | 0.8 |
| 0.0907 | 17.94 | 139 | 0.5343 | 0.8667 |
| 0.1184 | 18.97 | 147 | 0.5516 | 0.8667 |
| 0.1014 | 20.0 | 155 | 0.8173 | 0.7667 |
| 0.0997 | 20.9 | 162 | 0.6839 | 0.8167 |
| 0.1067 | 21.94 | 170 | 0.5552 | 0.8667 |
| 0.1067 | 22.97 | 178 | 0.5475 | 0.8667 |
| 0.082 | 24.0 | 186 | 0.5567 | 0.85 |
| 0.0852 | 24.9 | 193 | 0.6374 | 0.8167 |
| 0.0815 | 25.94 | 201 | 0.6486 | 0.8167 |
| 0.0815 | 26.97 | 209 | 0.6218 | 0.8167 |
| 0.0917 | 27.1 | 210 | 0.6209 | 0.8167 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
mllm-dev/gpt2_m_experiment_drug_data_ties_test_new_run
|
mllm-dev
| 2024-04-25T20:16:23Z | 105 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-classification",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:mllm-dev/gpt2_f_experiment_0_drug_data_new_run",
"base_model:merge:mllm-dev/gpt2_f_experiment_0_drug_data_new_run",
"base_model:mllm-dev/gpt2_f_experiment_1_drug_data_new_run",
"base_model:merge:mllm-dev/gpt2_f_experiment_1_drug_data_new_run",
"base_model:mllm-dev/gpt2_f_experiment_2_drug_data_new_run",
"base_model:merge:mllm-dev/gpt2_f_experiment_2_drug_data_new_run",
"base_model:mllm-dev/gpt2_f_experiment_3_drug_data_new_run",
"base_model:merge:mllm-dev/gpt2_f_experiment_3_drug_data_new_run",
"base_model:mllm-dev/gpt2_f_experiment_4_drug_data_new_run",
"base_model:merge:mllm-dev/gpt2_f_experiment_4_drug_data_new_run",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-25T20:16:12Z |
---
base_model:
- mllm-dev/gpt2_f_experiment_0_drug_data_new_run
- mllm-dev/gpt2_f_experiment_2_drug_data_new_run
- mllm-dev/gpt2_f_experiment_4_drug_data_new_run
- mllm-dev/gpt2_f_experiment_3_drug_data_new_run
- mllm-dev/gpt2_f_experiment_1_drug_data_new_run
library_name: transformers
tags:
- mergekit
- merge
---
# tam_test_merge_out_drug_data_ties_test_new_run
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [mllm-dev/gpt2_f_experiment_0_drug_data_new_run](https://huggingface.co/mllm-dev/gpt2_f_experiment_0_drug_data_new_run) as a base.
### Models Merged
The following models were included in the merge:
* [mllm-dev/gpt2_f_experiment_2_drug_data_new_run](https://huggingface.co/mllm-dev/gpt2_f_experiment_2_drug_data_new_run)
* [mllm-dev/gpt2_f_experiment_4_drug_data_new_run](https://huggingface.co/mllm-dev/gpt2_f_experiment_4_drug_data_new_run)
* [mllm-dev/gpt2_f_experiment_3_drug_data_new_run](https://huggingface.co/mllm-dev/gpt2_f_experiment_3_drug_data_new_run)
* [mllm-dev/gpt2_f_experiment_1_drug_data_new_run](https://huggingface.co/mllm-dev/gpt2_f_experiment_1_drug_data_new_run)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
base_model: mllm-dev/gpt2_f_experiment_0_drug_data_new_run
dtype: float16
merge_method: ties
parameters:
normalize: 1.0
slices:
- sources:
- layer_range: [0, 12]
model: mllm-dev/gpt2_f_experiment_0_drug_data_new_run
- layer_range: [0, 12]
model: mllm-dev/gpt2_f_experiment_1_drug_data_new_run
parameters:
density: 0.9
weight: 0.2
- layer_range: [0, 12]
model: mllm-dev/gpt2_f_experiment_2_drug_data_new_run
parameters:
density: 0.9
weight: 0.2
- layer_range: [0, 12]
model: mllm-dev/gpt2_f_experiment_3_drug_data_new_run
parameters:
density: 0.9
weight: 0.2
- layer_range: [0, 12]
model: mllm-dev/gpt2_f_experiment_4_drug_data_new_run
parameters:
density: 0.9
weight: 0.2
```
|
sumeetsar/Llama3_Openhermes_2.5_32K_Q4_K_M
|
sumeetsar
| 2024-04-25T20:12:33Z | 0 | 0 | null |
[
"gguf",
"dataset:teknium/OpenHermes-2.5",
"arxiv:1910.09700",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-04-25T19:31:26Z |
---
license: apache-2.0
datasets:
- teknium/OpenHermes-2.5
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.2-mlx
|
GreenBitAI
| 2024-04-25T20:12:16Z | 5 | 0 |
mlx
|
[
"mlx",
"safetensors",
"phi3",
"custom_code",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T20:06:58Z |
---
license: apache-2.0
tags:
- mlx
---
# GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.2-mlx
This quantized low-bit model was converted to MLX format from [`GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.2`]().
Refer to the [original model card](https://huggingface.co/GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.2) for more details on the model.
## Use with mlx
```bash
pip install gbx-lm
```
```python
from gbx_lm import load, generate
model, tokenizer = load("GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.2-mlx")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
LoneStriker/Meta-Llama-3-8B-Instruct-64k-6.0bpw-h6-exl2
|
LoneStriker
| 2024-04-25T20:08:11Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"6-bit",
"exl2",
"region:us"
] |
text-generation
| 2024-04-25T20:05:20Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
ahforoughi/ppo-Pyramids-Training
|
ahforoughi
| 2024-04-25T20:06:51Z | 12 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2024-04-25T20:06:47Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: ahforoughi/ppo-Pyramids-Training
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.5-mlx
|
GreenBitAI
| 2024-04-25T20:06:01Z | 4 | 0 |
mlx
|
[
"mlx",
"safetensors",
"phi3",
"custom_code",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T20:00:17Z |
---
license: apache-2.0
tags:
- mlx
---
# GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.5-mlx
This quantized low-bit model was converted to MLX format from [`GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.5`]().
Refer to the [original model card](https://huggingface.co/GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.5) for more details on the model.
## Use with mlx
```bash
pip install gbx-lm
```
```python
from gbx_lm import load, generate
model, tokenizer = load("GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-2.5-mlx")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
LoneStriker/Meta-Llama-3-8B-Instruct-64k-4.0bpw-h6-exl2
|
LoneStriker
| 2024-04-25T20:02:40Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"exl2",
"region:us"
] |
text-generation
| 2024-04-25T20:00:35Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
LoneStriker/Meta-Llama-3-8B-Instruct-64k-3.0bpw-h6-exl2
|
LoneStriker
| 2024-04-25T20:00:30Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"exl2",
"region:us"
] |
text-generation
| 2024-04-25T19:58:42Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-3.0-mlx
|
GreenBitAI
| 2024-04-25T19:59:15Z | 8 | 0 |
mlx
|
[
"mlx",
"safetensors",
"phi3",
"custom_code",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T19:52:52Z |
---
license: apache-2.0
tags:
- mlx
---
# GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-3.0-mlx
This quantized low-bit model was converted to MLX format from [`GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-3.0`]().
Refer to the [original model card](https://huggingface.co/GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-3.0) for more details on the model.
## Use with mlx
```bash
pip install gbx-lm
```
```python
from gbx_lm import load, generate
model, tokenizer = load("GreenBitAI/Phi-3-mini-128k-instruct-layer-mix-bpw-3.0-mlx")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF
|
MaziyarPanahi
| 2024-04-25T19:58:11Z | 946,239 | 12 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"llama",
"llama-3",
"base_model:MaziyarPanahi/Llama-3-8B-Instruct-64k",
"base_model:quantized:MaziyarPanahi/Llama-3-8B-Instruct-64k",
"region:us",
"conversational"
] |
text-generation
| 2024-04-25T19:22:27Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- text-generation
- llama
- llama-3
- text-generation
model_name: Llama-3-8B-Instruct-64k-GGUF
base_model: MaziyarPanahi/Llama-3-8B-Instruct-64k
inference: false
model_creator: MaziyarPanahi
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF)
- Model creator: [MaziyarPanahi](https://huggingface.co/MaziyarPanahi)
- Original model: [MaziyarPanahi/Llama-3-8B-Instruct-64k](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-64k)
## Description
[MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF) contains GGUF format model files for [MaziyarPanahi/Llama-3-8B-Instruct-64k](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-64k).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
Neurai/NeuraChatLlama3_8b
|
Neurai
| 2024-04-25T19:55:07Z | 79 | 6 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama3",
"persian_llama",
"neura",
"conversational",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-04-25T17:44:34Z |
---
library_name: transformers
license: apache-2.0
language:
- fa
pipeline_tag: text-generation
tags:
- llama3
- persian_llama
- neura
---
# Neura Chat llama3 8B
<p align="center">
<img src="neura_llama3.png" width=512 height=256 />
</p>
<!-- Provide a quick summary of what the model is/does. -->
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Neura company
- **Funded by:** Neura
- **Model type:** llama3
- **Language(s) (NLP):** Persian
- **Finetuned from model:** meta-llama/Meta-Llama-3-8B-Instruct
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
## Uses
Check out the Google Colab demo to run NeuraChatLlama3_8b on a free-tier Google Colab instance: [](https://colab.research.google.com/drive/1SSwIa8DmI-yVsqQa_iq1nZmp5X2q0yIu?usp=sharing)
make sure these packages are installed:
```
!pip install --no-deps xformers accelerate bitsandbytes
!pip install -q -U transformers
```
```python
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "Neurai/NeuraChatLlama3_8b"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "تو یک دستیار هوشمند هستی که به هر سوالی پاسخ مناسب و غیر تکراری و بدون تکرار و زیاده گویی می دهی "},
{"role": "user", "content": " تو چه بازارهایی در ایران سرمایه گذاری کنم که سود بیشتری ببرم؟ "},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=False,
temperature=0.6,
top_p=1,
repetition_penalty=1.05
)
print(outputs[0]["generated_text"][len(prompt):])
```
Generated text :
```
به عنوان یک دستیار هوشمند، من نمیتوانم توصیههای سرمایهگذاری شخصی به شما بدهم، زیرا هر سرمایهگذار باید بر اساس نیازهای مالی و ریسکپذیری خود تصمیم بگیرد. با این حال، میتوانم برخی از بازارها و فرصتهای سرمایهگذاری در ایران را که احتمالاً سود بیشتری ببرند، به شما معرفی کنم:
1. بازار طلا و ارز: بازار طلا و ارز در ایران به عنوان یکی از بازارها برای سرمایهگذاری در ارز و طلا شناخته شده است. با توجه به تغییرات در نرخ ارز و قیمت طلا، سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در این بازار بهره ببرند.
2. بازار مستغلات: بازار مستغلات در ایران به عنوان یکی از بازارهای پررونق در کشور شناخته شده است. سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در املاک و مستغلات بهره ببرند.
3. بازار سرمایهگذاری در شرکتهای کوچک و متوسط: سرمایهگذاری در شرکتهای کوچک و متوسط در ایران به عنوان یکی از بازارهای پررونق در کشور شناخته شده است. سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در شرکتهای با رشد پایدار و با ریسک کمتر بهره ببرند.
4. بازار سرمایهگذاری در فناوریها: بازار سرمایهگذاری در فناوریها در ایران به عنوان یکی از بازارهای پررونق در کشور شناخته شده است. سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در شرکتهای فناوری و با رشد پایدار بهره ببرند.
5. بازار سرمایهگذاری در طلا و سکه: بازار سرمایهگذاری در طلا و سکه در ایران به عنوان یکی از بازارهای پررونق در کشور شناخته شده است. سرمایهگذاران میتوانند
6. بازار بورس: بازار بورس ایران به عنوان یکی از بهترین بازارها برای سرمایهگذاری در کشور شناخته شده است. با توجه به رشد اقتصادی و افزایش سرمایهگذاری در این بازار، سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در شرکتهای بزرگ و با ریسک کمتر بهره ببرند.
7. بازار سهام: بازار سهام ایران یکی از بازارهای پررونق در کشور است. سرمایهگذاران میتوانند از فرصتهای سرمایهگذاری در شرکتهای با رشد پایدار و با ریسک کمتر بهره ببرند.
```
## More Information
https://neura.info
## Model Card Authors
Esmaeil Zahedi, Mohsen Yazdinejad
## Model Card Contact
info@neura.info
|
ACCORD-NLP/roberta-large-lm
|
ACCORD-NLP
| 2024-04-25T19:54:44Z | 127 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-04-04T16:53:22Z |
---
license: apache-2.0
language:
- en
---
# ACCORD-NLP
ACCORD-NLP is a Natural Language Processing (NLP) framework developed as part of the Horizon European project for Automated Compliance Checks for Construction, Renovation or Demolition Works ([ACCORD](https://accordproject.eu/)) to facilitate Automated Compliance Checking (ACC) within the Architecture, Engineering, and Construction (AEC) sector.
It consists of several pre-trained/fine-tuned machine learning models to perform the following information extraction tasks from regulatory text.
1. Entity Extraction/Classification (ner)
2. Relation Extraction/Classification (re)
**roberta-large-lm** is a domain-specific RoBERTa large model/RoBERTa large model pre-trained on a building regulatory text corpus using the Masked Language Modelling (MLM) objective.
This needs to be fine-tuned for a downstream task such as entity or relation classification.
## Installation
### From Source
```
git clone https://github.com/Accord-Project/accord-nlp.git
cd accord-nlp
pip install -r requirements.txt
```
### From pip
```
pip install accord-nlp
```
## Using Pre-trained Models
### Entity Extraction/Classification (ner)
```python
from accord_nlp.text_classification.ner.ner_model import NERModel
model = NERModel('roberta', 'ACCORD-NLP/ner-roberta-large')
predictions, raw_outputs = model.predict(['The gradient of the passageway should not exceed five per cent.'])
print(predictions)
```
### Relation Extraction/Classification (re)
```python
from accord_nlp.text_classification.relation_extraction.re_model import REModel
model = REModel('roberta', 'ACCORD-NLP/re-roberta-large')
predictions, raw_outputs = model.predict(['The <e1>gradient<\e1> of the passageway should not exceed <e2>five per cent</e2>.'])
print(predictions)
```
For more details, please refer to the [ACCORD-NLP](https://github.com/Accord-Project/accord-nlp) GitHub repository.
|
LoneStriker/Meta-Llama-3-8B-Instruct-64k-GGUF
|
LoneStriker
| 2024-04-25T19:36:58Z | 1 | 0 | null |
[
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-04-25T19:24:54Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
EdBerg/llama3-unsloth
|
EdBerg
| 2024-04-25T19:36:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T19:36:45Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** EdBerg
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
EdBerg/llama3-unsloth-merged
|
EdBerg
| 2024-04-25T19:36:32Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T19:30:07Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** EdBerg
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
JasssZ/my_awesome_eli5_clm-model
|
JasssZ
| 2024-04-25T19:35:57Z | 207 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:eli5_category",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T19:20:03Z |
---
license: apache-2.0
base_model: distilbert/distilgpt2
tags:
- generated_from_trainer
datasets:
- eli5_category
model-index:
- name: my_awesome_eli5_clm-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_clm-model
This model is a fine-tuned version of [distilbert/distilgpt2](https://huggingface.co/distilbert/distilgpt2) on the eli5_category dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7956
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.9486 | 1.0 | 1309 | 3.8083 |
| 3.8555 | 2.0 | 2618 | 3.7966 |
| 3.8179 | 3.0 | 3927 | 3.7956 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Yuma42/KangalKhan-Alpha-RawRubyroid-7B-Fixed
|
Yuma42
| 2024-04-25T19:34:49Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed",
"Yuma42/KangalKhan-RawEmerald-7B",
"conversational",
"en",
"base_model:Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed",
"base_model:merge:Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed",
"base_model:Yuma42/KangalKhan-RawEmerald-7B",
"base_model:merge:Yuma42/KangalKhan-RawEmerald-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T19:27:50Z |
---
tags:
- merge
- mergekit
- lazymergekit
- Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed
- Yuma42/KangalKhan-RawEmerald-7B
base_model:
- Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed
- Yuma42/KangalKhan-RawEmerald-7B
license: apache-2.0
language:
- en
---
# KangalKhan-Alpha-RawRubyroid-7B-Fixed
KangalKhan-Alpha-RawRubyroid-7B-Fixed is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed](https://huggingface.co/Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed)
* [Yuma42/KangalKhan-RawEmerald-7B](https://huggingface.co/Yuma42/KangalKhan-RawEmerald-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed
layer_range: [0, 32]
- model: Yuma42/KangalKhan-RawEmerald-7B
layer_range: [0, 32]
merge_method: slerp
base_model: Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed
parameters:
t:
- filter: self_attn
value: [0.1, 0.55, 0.35, 0.75, 0.97]
- filter: mlp
value: [0.9, 0.45, 0.65, 0.25, 0.03]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Yuma42/KangalKhan-Alpha-RawRubyroid-7B-Fixed"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
HenryCai1129/adapter-toxic2nontoxic-100-filtered-50-0.0009
|
HenryCai1129
| 2024-04-25T19:34:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T19:33:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lightbird-ai/nomic
|
lightbird-ai
| 2024-04-25T19:30:50Z | 8 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"onnx",
"safetensors",
"nomic_bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"transformers",
"transformers.js",
"custom_code",
"arxiv:2205.13147",
"arxiv:2402.01613",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-04-25T18:20:33Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
- mteb
- transformers
- transformers.js
model-index:
- name: epoch_0_model
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.20895522388058
- type: ap
value: 38.57605549557802
- type: f1
value: 69.35586565857854
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.8144
- type: ap
value: 88.65222882032363
- type: f1
value: 91.80426301643274
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.162000000000006
- type: f1
value: 46.59329642263158
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.253
- type: map_at_10
value: 38.962
- type: map_at_100
value: 40.081
- type: map_at_1000
value: 40.089000000000006
- type: map_at_3
value: 33.499
- type: map_at_5
value: 36.351
- type: mrr_at_1
value: 24.609
- type: mrr_at_10
value: 39.099000000000004
- type: mrr_at_100
value: 40.211000000000006
- type: mrr_at_1000
value: 40.219
- type: mrr_at_3
value: 33.677
- type: mrr_at_5
value: 36.469
- type: ndcg_at_1
value: 24.253
- type: ndcg_at_10
value: 48.010999999999996
- type: ndcg_at_100
value: 52.756
- type: ndcg_at_1000
value: 52.964999999999996
- type: ndcg_at_3
value: 36.564
- type: ndcg_at_5
value: 41.711999999999996
- type: precision_at_1
value: 24.253
- type: precision_at_10
value: 7.738
- type: precision_at_100
value: 0.98
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.149000000000001
- type: precision_at_5
value: 11.593
- type: recall_at_1
value: 24.253
- type: recall_at_10
value: 77.383
- type: recall_at_100
value: 98.009
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 45.448
- type: recall_at_5
value: 57.965999999999994
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.69069567851087
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 36.35185490976283
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.71274951450321
- type: mrr
value: 76.06032625423207
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 86.73980520022269
- type: cos_sim_spearman
value: 84.24649792685918
- type: euclidean_pearson
value: 85.85197641158186
- type: euclidean_spearman
value: 84.24649792685918
- type: manhattan_pearson
value: 86.26809552711346
- type: manhattan_spearman
value: 84.56397504030865
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.25324675324674
- type: f1
value: 84.17872280892557
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.770253446400886
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 32.94307095497281
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.164
- type: map_at_10
value: 42.641
- type: map_at_100
value: 43.947
- type: map_at_1000
value: 44.074999999999996
- type: map_at_3
value: 39.592
- type: map_at_5
value: 41.204
- type: mrr_at_1
value: 39.628
- type: mrr_at_10
value: 48.625
- type: mrr_at_100
value: 49.368
- type: mrr_at_1000
value: 49.413000000000004
- type: mrr_at_3
value: 46.400000000000006
- type: mrr_at_5
value: 47.68
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 48.564
- type: ndcg_at_100
value: 53.507000000000005
- type: ndcg_at_1000
value: 55.635999999999996
- type: ndcg_at_3
value: 44.471
- type: ndcg_at_5
value: 46.137
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 8.856
- type: precision_at_100
value: 1.429
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 21.268
- type: precision_at_5
value: 14.649000000000001
- type: recall_at_1
value: 32.164
- type: recall_at_10
value: 59.609
- type: recall_at_100
value: 80.521
- type: recall_at_1000
value: 94.245
- type: recall_at_3
value: 46.521
- type: recall_at_5
value: 52.083999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.526
- type: map_at_10
value: 41.581
- type: map_at_100
value: 42.815999999999995
- type: map_at_1000
value: 42.936
- type: map_at_3
value: 38.605000000000004
- type: map_at_5
value: 40.351
- type: mrr_at_1
value: 39.489999999999995
- type: mrr_at_10
value: 47.829
- type: mrr_at_100
value: 48.512
- type: mrr_at_1000
value: 48.552
- type: mrr_at_3
value: 45.754
- type: mrr_at_5
value: 46.986
- type: ndcg_at_1
value: 39.489999999999995
- type: ndcg_at_10
value: 47.269
- type: ndcg_at_100
value: 51.564
- type: ndcg_at_1000
value: 53.53099999999999
- type: ndcg_at_3
value: 43.301
- type: ndcg_at_5
value: 45.239000000000004
- type: precision_at_1
value: 39.489999999999995
- type: precision_at_10
value: 8.93
- type: precision_at_100
value: 1.415
- type: precision_at_1000
value: 0.188
- type: precision_at_3
value: 20.892
- type: precision_at_5
value: 14.865999999999998
- type: recall_at_1
value: 31.526
- type: recall_at_10
value: 56.76
- type: recall_at_100
value: 75.029
- type: recall_at_1000
value: 87.491
- type: recall_at_3
value: 44.786
- type: recall_at_5
value: 50.254
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.987
- type: map_at_10
value: 52.827
- type: map_at_100
value: 53.751000000000005
- type: map_at_1000
value: 53.81
- type: map_at_3
value: 49.844
- type: map_at_5
value: 51.473
- type: mrr_at_1
value: 46.833999999999996
- type: mrr_at_10
value: 56.389
- type: mrr_at_100
value: 57.003
- type: mrr_at_1000
value: 57.034
- type: mrr_at_3
value: 54.17999999999999
- type: mrr_at_5
value: 55.486999999999995
- type: ndcg_at_1
value: 46.833999999999996
- type: ndcg_at_10
value: 58.372
- type: ndcg_at_100
value: 62.068
- type: ndcg_at_1000
value: 63.288
- type: ndcg_at_3
value: 53.400000000000006
- type: ndcg_at_5
value: 55.766000000000005
- type: precision_at_1
value: 46.833999999999996
- type: precision_at_10
value: 9.191
- type: precision_at_100
value: 1.192
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.448
- type: precision_at_5
value: 15.862000000000002
- type: recall_at_1
value: 40.987
- type: recall_at_10
value: 71.146
- type: recall_at_100
value: 87.035
- type: recall_at_1000
value: 95.633
- type: recall_at_3
value: 58.025999999999996
- type: recall_at_5
value: 63.815999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.587
- type: map_at_10
value: 33.114
- type: map_at_100
value: 34.043
- type: map_at_1000
value: 34.123999999999995
- type: map_at_3
value: 30.45
- type: map_at_5
value: 31.813999999999997
- type: mrr_at_1
value: 26.554
- type: mrr_at_10
value: 35.148
- type: mrr_at_100
value: 35.926
- type: mrr_at_1000
value: 35.991
- type: mrr_at_3
value: 32.599000000000004
- type: mrr_at_5
value: 33.893
- type: ndcg_at_1
value: 26.554
- type: ndcg_at_10
value: 38.132
- type: ndcg_at_100
value: 42.78
- type: ndcg_at_1000
value: 44.919
- type: ndcg_at_3
value: 32.833
- type: ndcg_at_5
value: 35.168
- type: precision_at_1
value: 26.554
- type: precision_at_10
value: 5.921
- type: precision_at_100
value: 0.8659999999999999
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 13.861
- type: precision_at_5
value: 9.605
- type: recall_at_1
value: 24.587
- type: recall_at_10
value: 51.690000000000005
- type: recall_at_100
value: 73.428
- type: recall_at_1000
value: 89.551
- type: recall_at_3
value: 37.336999999999996
- type: recall_at_5
value: 43.047000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.715
- type: map_at_10
value: 24.251
- type: map_at_100
value: 25.326999999999998
- type: map_at_1000
value: 25.455
- type: map_at_3
value: 21.912000000000003
- type: map_at_5
value: 23.257
- type: mrr_at_1
value: 20.274
- type: mrr_at_10
value: 28.552
- type: mrr_at_100
value: 29.42
- type: mrr_at_1000
value: 29.497
- type: mrr_at_3
value: 26.14
- type: mrr_at_5
value: 27.502
- type: ndcg_at_1
value: 20.274
- type: ndcg_at_10
value: 29.088
- type: ndcg_at_100
value: 34.293
- type: ndcg_at_1000
value: 37.271
- type: ndcg_at_3
value: 24.708
- type: ndcg_at_5
value: 26.809
- type: precision_at_1
value: 20.274
- type: precision_at_10
value: 5.361
- type: precision_at_100
value: 0.915
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.733
- type: precision_at_5
value: 8.556999999999999
- type: recall_at_1
value: 16.715
- type: recall_at_10
value: 39.587
- type: recall_at_100
value: 62.336000000000006
- type: recall_at_1000
value: 83.453
- type: recall_at_3
value: 27.839999999999996
- type: recall_at_5
value: 32.952999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.793000000000003
- type: map_at_10
value: 38.582
- type: map_at_100
value: 39.881
- type: map_at_1000
value: 39.987
- type: map_at_3
value: 35.851
- type: map_at_5
value: 37.289
- type: mrr_at_1
value: 34.455999999999996
- type: mrr_at_10
value: 43.909
- type: mrr_at_100
value: 44.74
- type: mrr_at_1000
value: 44.786
- type: mrr_at_3
value: 41.659
- type: mrr_at_5
value: 43.010999999999996
- type: ndcg_at_1
value: 34.455999999999996
- type: ndcg_at_10
value: 44.266
- type: ndcg_at_100
value: 49.639
- type: ndcg_at_1000
value: 51.644
- type: ndcg_at_3
value: 39.865
- type: ndcg_at_5
value: 41.887
- type: precision_at_1
value: 34.455999999999996
- type: precision_at_10
value: 7.843999999999999
- type: precision_at_100
value: 1.243
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 18.831999999999997
- type: precision_at_5
value: 13.147
- type: recall_at_1
value: 28.793000000000003
- type: recall_at_10
value: 55.68300000000001
- type: recall_at_100
value: 77.99000000000001
- type: recall_at_1000
value: 91.183
- type: recall_at_3
value: 43.293
- type: recall_at_5
value: 48.618
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.907000000000004
- type: map_at_10
value: 35.519
- type: map_at_100
value: 36.806
- type: map_at_1000
value: 36.912
- type: map_at_3
value: 32.748
- type: map_at_5
value: 34.232
- type: mrr_at_1
value: 31.621
- type: mrr_at_10
value: 40.687
- type: mrr_at_100
value: 41.583
- type: mrr_at_1000
value: 41.638999999999996
- type: mrr_at_3
value: 38.527
- type: mrr_at_5
value: 39.612
- type: ndcg_at_1
value: 31.621
- type: ndcg_at_10
value: 41.003
- type: ndcg_at_100
value: 46.617999999999995
- type: ndcg_at_1000
value: 48.82
- type: ndcg_at_3
value: 36.542
- type: ndcg_at_5
value: 38.368
- type: precision_at_1
value: 31.621
- type: precision_at_10
value: 7.396999999999999
- type: precision_at_100
value: 1.191
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 17.39
- type: precision_at_5
value: 12.1
- type: recall_at_1
value: 25.907000000000004
- type: recall_at_10
value: 52.115
- type: recall_at_100
value: 76.238
- type: recall_at_1000
value: 91.218
- type: recall_at_3
value: 39.417
- type: recall_at_5
value: 44.435
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.732166666666668
- type: map_at_10
value: 34.51616666666667
- type: map_at_100
value: 35.67241666666666
- type: map_at_1000
value: 35.78675
- type: map_at_3
value: 31.953416666666662
- type: map_at_5
value: 33.333
- type: mrr_at_1
value: 30.300166666666673
- type: mrr_at_10
value: 38.6255
- type: mrr_at_100
value: 39.46183333333334
- type: mrr_at_1000
value: 39.519999999999996
- type: mrr_at_3
value: 36.41299999999999
- type: mrr_at_5
value: 37.6365
- type: ndcg_at_1
value: 30.300166666666673
- type: ndcg_at_10
value: 39.61466666666667
- type: ndcg_at_100
value: 44.60808333333334
- type: ndcg_at_1000
value: 46.91708333333334
- type: ndcg_at_3
value: 35.26558333333333
- type: ndcg_at_5
value: 37.220000000000006
- type: precision_at_1
value: 30.300166666666673
- type: precision_at_10
value: 6.837416666666667
- type: precision_at_100
value: 1.10425
- type: precision_at_1000
value: 0.14875
- type: precision_at_3
value: 16.13716666666667
- type: precision_at_5
value: 11.2815
- type: recall_at_1
value: 25.732166666666668
- type: recall_at_10
value: 50.578916666666665
- type: recall_at_100
value: 72.42183333333334
- type: recall_at_1000
value: 88.48766666666667
- type: recall_at_3
value: 38.41325
- type: recall_at_5
value: 43.515750000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.951
- type: map_at_10
value: 30.974
- type: map_at_100
value: 31.804
- type: map_at_1000
value: 31.900000000000002
- type: map_at_3
value: 28.762
- type: map_at_5
value: 29.94
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.553
- type: mrr_at_100
value: 34.297
- type: mrr_at_1000
value: 34.36
- type: mrr_at_3
value: 31.391000000000002
- type: mrr_at_5
value: 32.525999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 35.112
- type: ndcg_at_100
value: 39.28
- type: ndcg_at_1000
value: 41.723
- type: ndcg_at_3
value: 30.902
- type: ndcg_at_5
value: 32.759
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.445
- type: precision_at_100
value: 0.819
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.049
- type: recall_at_1
value: 23.951
- type: recall_at_10
value: 45.24
- type: recall_at_100
value: 64.12299999999999
- type: recall_at_1000
value: 82.28999999999999
- type: recall_at_3
value: 33.806000000000004
- type: recall_at_5
value: 38.277
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.829
- type: map_at_10
value: 23.684
- type: map_at_100
value: 24.683
- type: map_at_1000
value: 24.81
- type: map_at_3
value: 21.554000000000002
- type: map_at_5
value: 22.768
- type: mrr_at_1
value: 20.096
- type: mrr_at_10
value: 27.230999999999998
- type: mrr_at_100
value: 28.083999999999996
- type: mrr_at_1000
value: 28.166000000000004
- type: mrr_at_3
value: 25.212
- type: mrr_at_5
value: 26.32
- type: ndcg_at_1
value: 20.096
- type: ndcg_at_10
value: 27.989000000000004
- type: ndcg_at_100
value: 32.847
- type: ndcg_at_1000
value: 35.896
- type: ndcg_at_3
value: 24.116
- type: ndcg_at_5
value: 25.964
- type: precision_at_1
value: 20.096
- type: precision_at_10
value: 5
- type: precision_at_100
value: 0.8750000000000001
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 11.207
- type: precision_at_5
value: 8.08
- type: recall_at_1
value: 16.829
- type: recall_at_10
value: 37.407000000000004
- type: recall_at_100
value: 59.101000000000006
- type: recall_at_1000
value: 81.024
- type: recall_at_3
value: 26.739
- type: recall_at_5
value: 31.524
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.138
- type: map_at_10
value: 32.275999999999996
- type: map_at_100
value: 33.416000000000004
- type: map_at_1000
value: 33.527
- type: map_at_3
value: 29.854000000000003
- type: map_at_5
value: 31.096
- type: mrr_at_1
value: 28.450999999999997
- type: mrr_at_10
value: 36.214
- type: mrr_at_100
value: 37.134
- type: mrr_at_1000
value: 37.198
- type: mrr_at_3
value: 34.001999999999995
- type: mrr_at_5
value: 35.187000000000005
- type: ndcg_at_1
value: 28.450999999999997
- type: ndcg_at_10
value: 37.166
- type: ndcg_at_100
value: 42.454
- type: ndcg_at_1000
value: 44.976
- type: ndcg_at_3
value: 32.796
- type: ndcg_at_5
value: 34.631
- type: precision_at_1
value: 28.450999999999997
- type: precision_at_10
value: 6.241
- type: precision_at_100
value: 0.9950000000000001
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 14.801
- type: precision_at_5
value: 10.280000000000001
- type: recall_at_1
value: 24.138
- type: recall_at_10
value: 48.111
- type: recall_at_100
value: 71.245
- type: recall_at_1000
value: 88.986
- type: recall_at_3
value: 36.119
- type: recall_at_5
value: 40.846
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.244
- type: map_at_10
value: 31.227
- type: map_at_100
value: 33.007
- type: map_at_1000
value: 33.223
- type: map_at_3
value: 28.924
- type: map_at_5
value: 30.017
- type: mrr_at_1
value: 27.668
- type: mrr_at_10
value: 35.524
- type: mrr_at_100
value: 36.699
- type: mrr_at_1000
value: 36.759
- type: mrr_at_3
value: 33.366
- type: mrr_at_5
value: 34.552
- type: ndcg_at_1
value: 27.668
- type: ndcg_at_10
value: 36.381
- type: ndcg_at_100
value: 43.062
- type: ndcg_at_1000
value: 45.656
- type: ndcg_at_3
value: 32.501999999999995
- type: ndcg_at_5
value: 34.105999999999995
- type: precision_at_1
value: 27.668
- type: precision_at_10
value: 6.798
- type: precision_at_100
value: 1.492
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 15.152
- type: precision_at_5
value: 10.791
- type: recall_at_1
value: 23.244
- type: recall_at_10
value: 45.979
- type: recall_at_100
value: 74.822
- type: recall_at_1000
value: 91.078
- type: recall_at_3
value: 34.925
- type: recall_at_5
value: 39.126
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.945
- type: map_at_10
value: 27.517999999999997
- type: map_at_100
value: 28.588
- type: map_at_1000
value: 28.682000000000002
- type: map_at_3
value: 25.345000000000002
- type: map_at_5
value: 26.555
- type: mrr_at_1
value: 21.996
- type: mrr_at_10
value: 29.845
- type: mrr_at_100
value: 30.775999999999996
- type: mrr_at_1000
value: 30.845
- type: mrr_at_3
value: 27.726
- type: mrr_at_5
value: 28.882
- type: ndcg_at_1
value: 21.996
- type: ndcg_at_10
value: 32.034
- type: ndcg_at_100
value: 37.185
- type: ndcg_at_1000
value: 39.645
- type: ndcg_at_3
value: 27.750999999999998
- type: ndcg_at_5
value: 29.805999999999997
- type: precision_at_1
value: 21.996
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.819
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.076
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.945
- type: recall_at_10
value: 43.62
- type: recall_at_100
value: 67.194
- type: recall_at_1000
value: 85.7
- type: recall_at_3
value: 32.15
- type: recall_at_5
value: 37.208999999999996
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.279
- type: map_at_10
value: 31.052999999999997
- type: map_at_100
value: 33.125
- type: map_at_1000
value: 33.306000000000004
- type: map_at_3
value: 26.208
- type: map_at_5
value: 28.857
- type: mrr_at_1
value: 42.671
- type: mrr_at_10
value: 54.557
- type: mrr_at_100
value: 55.142
- type: mrr_at_1000
value: 55.169000000000004
- type: mrr_at_3
value: 51.488
- type: mrr_at_5
value: 53.439
- type: ndcg_at_1
value: 42.671
- type: ndcg_at_10
value: 41.276
- type: ndcg_at_100
value: 48.376000000000005
- type: ndcg_at_1000
value: 51.318
- type: ndcg_at_3
value: 35.068
- type: ndcg_at_5
value: 37.242
- type: precision_at_1
value: 42.671
- type: precision_at_10
value: 12.638
- type: precision_at_100
value: 2.045
- type: precision_at_1000
value: 0.26
- type: precision_at_3
value: 26.08
- type: precision_at_5
value: 19.805
- type: recall_at_1
value: 18.279
- type: recall_at_10
value: 46.946
- type: recall_at_100
value: 70.97200000000001
- type: recall_at_1000
value: 87.107
- type: recall_at_3
value: 31.147999999999996
- type: recall_at_5
value: 38.099
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.573
- type: map_at_10
value: 19.747
- type: map_at_100
value: 28.205000000000002
- type: map_at_1000
value: 29.831000000000003
- type: map_at_3
value: 14.109
- type: map_at_5
value: 16.448999999999998
- type: mrr_at_1
value: 71
- type: mrr_at_10
value: 77.68599999999999
- type: mrr_at_100
value: 77.995
- type: mrr_at_1000
value: 78.00200000000001
- type: mrr_at_3
value: 76.292
- type: mrr_at_5
value: 77.029
- type: ndcg_at_1
value: 59.12500000000001
- type: ndcg_at_10
value: 43.9
- type: ndcg_at_100
value: 47.863
- type: ndcg_at_1000
value: 54.848
- type: ndcg_at_3
value: 49.803999999999995
- type: ndcg_at_5
value: 46.317
- type: precision_at_1
value: 71
- type: precision_at_10
value: 34.4
- type: precision_at_100
value: 11.063
- type: precision_at_1000
value: 1.989
- type: precision_at_3
value: 52.333
- type: precision_at_5
value: 43.7
- type: recall_at_1
value: 8.573
- type: recall_at_10
value: 25.615
- type: recall_at_100
value: 53.385000000000005
- type: recall_at_1000
value: 75.46000000000001
- type: recall_at_3
value: 15.429
- type: recall_at_5
value: 19.357
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.989999999999995
- type: f1
value: 42.776314451497555
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.13499999999999
- type: map_at_10
value: 82.825
- type: map_at_100
value: 83.096
- type: map_at_1000
value: 83.111
- type: map_at_3
value: 81.748
- type: map_at_5
value: 82.446
- type: mrr_at_1
value: 79.553
- type: mrr_at_10
value: 86.654
- type: mrr_at_100
value: 86.774
- type: mrr_at_1000
value: 86.778
- type: mrr_at_3
value: 85.981
- type: mrr_at_5
value: 86.462
- type: ndcg_at_1
value: 79.553
- type: ndcg_at_10
value: 86.345
- type: ndcg_at_100
value: 87.32
- type: ndcg_at_1000
value: 87.58200000000001
- type: ndcg_at_3
value: 84.719
- type: ndcg_at_5
value: 85.677
- type: precision_at_1
value: 79.553
- type: precision_at_10
value: 10.402000000000001
- type: precision_at_100
value: 1.1119999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.413
- type: precision_at_5
value: 20.138
- type: recall_at_1
value: 74.13499999999999
- type: recall_at_10
value: 93.215
- type: recall_at_100
value: 97.083
- type: recall_at_1000
value: 98.732
- type: recall_at_3
value: 88.79
- type: recall_at_5
value: 91.259
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.298000000000002
- type: map_at_10
value: 29.901
- type: map_at_100
value: 31.528
- type: map_at_1000
value: 31.713
- type: map_at_3
value: 25.740000000000002
- type: map_at_5
value: 28.227999999999998
- type: mrr_at_1
value: 36.728
- type: mrr_at_10
value: 45.401
- type: mrr_at_100
value: 46.27
- type: mrr_at_1000
value: 46.315
- type: mrr_at_3
value: 42.978
- type: mrr_at_5
value: 44.29
- type: ndcg_at_1
value: 36.728
- type: ndcg_at_10
value: 37.456
- type: ndcg_at_100
value: 43.832
- type: ndcg_at_1000
value: 47
- type: ndcg_at_3
value: 33.694
- type: ndcg_at_5
value: 35.085
- type: precision_at_1
value: 36.728
- type: precision_at_10
value: 10.386
- type: precision_at_100
value: 1.701
- type: precision_at_1000
value: 0.22599999999999998
- type: precision_at_3
value: 22.479
- type: precision_at_5
value: 16.605
- type: recall_at_1
value: 18.298000000000002
- type: recall_at_10
value: 44.369
- type: recall_at_100
value: 68.098
- type: recall_at_1000
value: 87.21900000000001
- type: recall_at_3
value: 30.215999999999998
- type: recall_at_5
value: 36.861
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.568
- type: map_at_10
value: 65.061
- type: map_at_100
value: 65.896
- type: map_at_1000
value: 65.95100000000001
- type: map_at_3
value: 61.831
- type: map_at_5
value: 63.849000000000004
- type: mrr_at_1
value: 79.136
- type: mrr_at_10
value: 84.58200000000001
- type: mrr_at_100
value: 84.765
- type: mrr_at_1000
value: 84.772
- type: mrr_at_3
value: 83.684
- type: mrr_at_5
value: 84.223
- type: ndcg_at_1
value: 79.136
- type: ndcg_at_10
value: 72.622
- type: ndcg_at_100
value: 75.539
- type: ndcg_at_1000
value: 76.613
- type: ndcg_at_3
value: 68.065
- type: ndcg_at_5
value: 70.58
- type: precision_at_1
value: 79.136
- type: precision_at_10
value: 15.215
- type: precision_at_100
value: 1.7500000000000002
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 44.011
- type: precision_at_5
value: 28.388999999999996
- type: recall_at_1
value: 39.568
- type: recall_at_10
value: 76.077
- type: recall_at_100
value: 87.481
- type: recall_at_1000
value: 94.56400000000001
- type: recall_at_3
value: 66.01599999999999
- type: recall_at_5
value: 70.97200000000001
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.312
- type: ap
value: 80.36296867333715
- type: f1
value: 85.26613311552218
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.363999999999997
- type: map_at_10
value: 35.711999999999996
- type: map_at_100
value: 36.876999999999995
- type: map_at_1000
value: 36.923
- type: map_at_3
value: 32.034
- type: map_at_5
value: 34.159
- type: mrr_at_1
value: 24.04
- type: mrr_at_10
value: 36.345
- type: mrr_at_100
value: 37.441
- type: mrr_at_1000
value: 37.480000000000004
- type: mrr_at_3
value: 32.713
- type: mrr_at_5
value: 34.824
- type: ndcg_at_1
value: 24.026
- type: ndcg_at_10
value: 42.531
- type: ndcg_at_100
value: 48.081
- type: ndcg_at_1000
value: 49.213
- type: ndcg_at_3
value: 35.044
- type: ndcg_at_5
value: 38.834
- type: precision_at_1
value: 24.026
- type: precision_at_10
value: 6.622999999999999
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.909
- type: precision_at_5
value: 10.871
- type: recall_at_1
value: 23.363999999999997
- type: recall_at_10
value: 63.426
- type: recall_at_100
value: 88.96300000000001
- type: recall_at_1000
value: 97.637
- type: recall_at_3
value: 43.095
- type: recall_at_5
value: 52.178000000000004
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.0095759233926
- type: f1
value: 92.78387794667408
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.0296397628819
- type: f1
value: 58.45699589820874
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.45662407531944
- type: f1
value: 71.42364781421813
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07800941492937
- type: f1
value: 77.22799045640845
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.531234379250606
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.941490381193802
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.3115090856725
- type: mrr
value: 31.290667638675757
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.465
- type: map_at_10
value: 13.03
- type: map_at_100
value: 16.057
- type: map_at_1000
value: 17.49
- type: map_at_3
value: 9.553
- type: map_at_5
value: 11.204
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 53.269
- type: mrr_at_100
value: 53.72
- type: mrr_at_1000
value: 53.761
- type: mrr_at_3
value: 50.929
- type: mrr_at_5
value: 52.461
- type: ndcg_at_1
value: 42.26
- type: ndcg_at_10
value: 34.673
- type: ndcg_at_100
value: 30.759999999999998
- type: ndcg_at_1000
value: 39.728
- type: ndcg_at_3
value: 40.349000000000004
- type: ndcg_at_5
value: 37.915
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 25.789
- type: precision_at_100
value: 7.754999999999999
- type: precision_at_1000
value: 2.07
- type: precision_at_3
value: 38.596000000000004
- type: precision_at_5
value: 33.251
- type: recall_at_1
value: 5.465
- type: recall_at_10
value: 17.148
- type: recall_at_100
value: 29.768
- type: recall_at_1000
value: 62.239
- type: recall_at_3
value: 10.577
- type: recall_at_5
value: 13.315
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.008
- type: map_at_10
value: 52.467
- type: map_at_100
value: 53.342999999999996
- type: map_at_1000
value: 53.366
- type: map_at_3
value: 48.412
- type: map_at_5
value: 50.875
- type: mrr_at_1
value: 41.541
- type: mrr_at_10
value: 54.967
- type: mrr_at_100
value: 55.611
- type: mrr_at_1000
value: 55.627
- type: mrr_at_3
value: 51.824999999999996
- type: mrr_at_5
value: 53.763000000000005
- type: ndcg_at_1
value: 41.541
- type: ndcg_at_10
value: 59.724999999999994
- type: ndcg_at_100
value: 63.38700000000001
- type: ndcg_at_1000
value: 63.883
- type: ndcg_at_3
value: 52.331
- type: ndcg_at_5
value: 56.327000000000005
- type: precision_at_1
value: 41.541
- type: precision_at_10
value: 9.447
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.262
- type: precision_at_5
value: 16.314999999999998
- type: recall_at_1
value: 37.008
- type: recall_at_10
value: 79.145
- type: recall_at_100
value: 94.986
- type: recall_at_1000
value: 98.607
- type: recall_at_3
value: 60.277
- type: recall_at_5
value: 69.407
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.402
- type: map_at_10
value: 84.181
- type: map_at_100
value: 84.796
- type: map_at_1000
value: 84.81400000000001
- type: map_at_3
value: 81.209
- type: map_at_5
value: 83.085
- type: mrr_at_1
value: 81.02000000000001
- type: mrr_at_10
value: 87.263
- type: mrr_at_100
value: 87.36
- type: mrr_at_1000
value: 87.36
- type: mrr_at_3
value: 86.235
- type: mrr_at_5
value: 86.945
- type: ndcg_at_1
value: 81.01
- type: ndcg_at_10
value: 87.99900000000001
- type: ndcg_at_100
value: 89.217
- type: ndcg_at_1000
value: 89.33
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.703
- type: precision_at_1
value: 81.01
- type: precision_at_10
value: 13.336
- type: precision_at_100
value: 1.52
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 37.14
- type: precision_at_5
value: 24.44
- type: recall_at_1
value: 70.402
- type: recall_at_10
value: 95.214
- type: recall_at_100
value: 99.438
- type: recall_at_1000
value: 99.928
- type: recall_at_3
value: 86.75699999999999
- type: recall_at_5
value: 91.44099999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.51721502758904
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.054808572333016
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.578
- type: map_at_10
value: 11.036999999999999
- type: map_at_100
value: 12.879999999999999
- type: map_at_1000
value: 13.150999999999998
- type: map_at_3
value: 8.133
- type: map_at_5
value: 9.559
- type: mrr_at_1
value: 22.6
- type: mrr_at_10
value: 32.68
- type: mrr_at_100
value: 33.789
- type: mrr_at_1000
value: 33.854
- type: mrr_at_3
value: 29.7
- type: mrr_at_5
value: 31.480000000000004
- type: ndcg_at_1
value: 22.6
- type: ndcg_at_10
value: 18.616
- type: ndcg_at_100
value: 25.883
- type: ndcg_at_1000
value: 30.944
- type: ndcg_at_3
value: 18.136
- type: ndcg_at_5
value: 15.625
- type: precision_at_1
value: 22.6
- type: precision_at_10
value: 9.48
- type: precision_at_100
value: 1.991
- type: precision_at_1000
value: 0.321
- type: precision_at_3
value: 16.8
- type: precision_at_5
value: 13.54
- type: recall_at_1
value: 4.578
- type: recall_at_10
value: 19.213
- type: recall_at_100
value: 40.397
- type: recall_at_1000
value: 65.2
- type: recall_at_3
value: 10.208
- type: recall_at_5
value: 13.718
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.44288351714071
- type: cos_sim_spearman
value: 79.37995604564952
- type: euclidean_pearson
value: 81.1078874670718
- type: euclidean_spearman
value: 79.37995905980499
- type: manhattan_pearson
value: 81.03697527288986
- type: manhattan_spearman
value: 79.33490235296236
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.95557650436523
- type: cos_sim_spearman
value: 78.5190672399868
- type: euclidean_pearson
value: 81.58064025904707
- type: euclidean_spearman
value: 78.5190672399868
- type: manhattan_pearson
value: 81.52857930619889
- type: manhattan_spearman
value: 78.50421361308034
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.79128416228737
- type: cos_sim_spearman
value: 86.05402451477147
- type: euclidean_pearson
value: 85.46280267054289
- type: euclidean_spearman
value: 86.05402451477147
- type: manhattan_pearson
value: 85.46278563858236
- type: manhattan_spearman
value: 86.08079590861004
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.20623089568763
- type: cos_sim_spearman
value: 81.53786907061009
- type: euclidean_pearson
value: 82.82272250091494
- type: euclidean_spearman
value: 81.53786907061009
- type: manhattan_pearson
value: 82.78850494027013
- type: manhattan_spearman
value: 81.5135618083407
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.46366618397936
- type: cos_sim_spearman
value: 86.96566013336908
- type: euclidean_pearson
value: 86.62651697548931
- type: euclidean_spearman
value: 86.96565526364454
- type: manhattan_pearson
value: 86.58812160258009
- type: manhattan_spearman
value: 86.9336484321288
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.51858358641559
- type: cos_sim_spearman
value: 84.7652527954999
- type: euclidean_pearson
value: 84.23914783766861
- type: euclidean_spearman
value: 84.7652527954999
- type: manhattan_pearson
value: 84.22749648503171
- type: manhattan_spearman
value: 84.74527996746386
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.28026563313065
- type: cos_sim_spearman
value: 87.46928143824915
- type: euclidean_pearson
value: 88.30558762000372
- type: euclidean_spearman
value: 87.46928143824915
- type: manhattan_pearson
value: 88.10513330809331
- type: manhattan_spearman
value: 87.21069787834173
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.376497134587375
- type: cos_sim_spearman
value: 65.0159550112516
- type: euclidean_pearson
value: 65.64572120879598
- type: euclidean_spearman
value: 65.0159550112516
- type: manhattan_pearson
value: 65.88143604989976
- type: manhattan_spearman
value: 65.17547297222434
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.22876368947644
- type: cos_sim_spearman
value: 85.46935577445318
- type: euclidean_pearson
value: 85.32830231392005
- type: euclidean_spearman
value: 85.46935577445318
- type: manhattan_pearson
value: 85.30353211758495
- type: manhattan_spearman
value: 85.42821085956945
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.60986667767133
- type: mrr
value: 94.29432314236236
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.528
- type: map_at_10
value: 65.187
- type: map_at_100
value: 65.62599999999999
- type: map_at_1000
value: 65.657
- type: map_at_3
value: 62.352
- type: map_at_5
value: 64.025
- type: mrr_at_1
value: 57.333
- type: mrr_at_10
value: 66.577
- type: mrr_at_100
value: 66.88
- type: mrr_at_1000
value: 66.908
- type: mrr_at_3
value: 64.556
- type: mrr_at_5
value: 65.739
- type: ndcg_at_1
value: 57.333
- type: ndcg_at_10
value: 70.275
- type: ndcg_at_100
value: 72.136
- type: ndcg_at_1000
value: 72.963
- type: ndcg_at_3
value: 65.414
- type: ndcg_at_5
value: 67.831
- type: precision_at_1
value: 57.333
- type: precision_at_10
value: 9.5
- type: precision_at_100
value: 1.057
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.778000000000002
- type: precision_at_5
value: 17.2
- type: recall_at_1
value: 54.528
- type: recall_at_10
value: 84.356
- type: recall_at_100
value: 92.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.283
- type: recall_at_5
value: 77.14999999999999
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74158415841585
- type: cos_sim_ap
value: 92.90048959850317
- type: cos_sim_f1
value: 86.35650810245687
- type: cos_sim_precision
value: 90.4709748083242
- type: cos_sim_recall
value: 82.6
- type: dot_accuracy
value: 99.74158415841585
- type: dot_ap
value: 92.90048959850317
- type: dot_f1
value: 86.35650810245687
- type: dot_precision
value: 90.4709748083242
- type: dot_recall
value: 82.6
- type: euclidean_accuracy
value: 99.74158415841585
- type: euclidean_ap
value: 92.90048959850317
- type: euclidean_f1
value: 86.35650810245687
- type: euclidean_precision
value: 90.4709748083242
- type: euclidean_recall
value: 82.6
- type: manhattan_accuracy
value: 99.74158415841585
- type: manhattan_ap
value: 92.87344692947894
- type: manhattan_f1
value: 86.38497652582159
- type: manhattan_precision
value: 90.29443838604145
- type: manhattan_recall
value: 82.8
- type: max_accuracy
value: 99.74158415841585
- type: max_ap
value: 92.90048959850317
- type: max_f1
value: 86.38497652582159
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 63.191648770424216
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.02944668730218
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.466386167525265
- type: mrr
value: 51.19071492233257
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.198022505886435
- type: cos_sim_spearman
value: 30.40170257939193
- type: dot_pearson
value: 30.198015316402614
- type: dot_spearman
value: 30.40170257939193
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.242
- type: map_at_10
value: 2.17
- type: map_at_100
value: 12.221
- type: map_at_1000
value: 28.63
- type: map_at_3
value: 0.728
- type: map_at_5
value: 1.185
- type: mrr_at_1
value: 94
- type: mrr_at_10
value: 97
- type: mrr_at_100
value: 97
- type: mrr_at_1000
value: 97
- type: mrr_at_3
value: 97
- type: mrr_at_5
value: 97
- type: ndcg_at_1
value: 89
- type: ndcg_at_10
value: 82.30499999999999
- type: ndcg_at_100
value: 61.839999999999996
- type: ndcg_at_1000
value: 53.381
- type: ndcg_at_3
value: 88.877
- type: ndcg_at_5
value: 86.05199999999999
- type: precision_at_1
value: 94
- type: precision_at_10
value: 87
- type: precision_at_100
value: 63.38
- type: precision_at_1000
value: 23.498
- type: precision_at_3
value: 94
- type: precision_at_5
value: 92
- type: recall_at_1
value: 0.242
- type: recall_at_10
value: 2.302
- type: recall_at_100
value: 14.979000000000001
- type: recall_at_1000
value: 49.638
- type: recall_at_3
value: 0.753
- type: recall_at_5
value: 1.226
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.006
- type: map_at_10
value: 11.805
- type: map_at_100
value: 18.146
- type: map_at_1000
value: 19.788
- type: map_at_3
value: 5.914
- type: map_at_5
value: 8.801
- type: mrr_at_1
value: 40.816
- type: mrr_at_10
value: 56.36600000000001
- type: mrr_at_100
value: 56.721999999999994
- type: mrr_at_1000
value: 56.721999999999994
- type: mrr_at_3
value: 52.041000000000004
- type: mrr_at_5
value: 54.796
- type: ndcg_at_1
value: 37.755
- type: ndcg_at_10
value: 29.863
- type: ndcg_at_100
value: 39.571
- type: ndcg_at_1000
value: 51.385999999999996
- type: ndcg_at_3
value: 32.578
- type: ndcg_at_5
value: 32.351
- type: precision_at_1
value: 40.816
- type: precision_at_10
value: 26.531
- type: precision_at_100
value: 7.796
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 32.653
- type: precision_at_5
value: 33.061
- type: recall_at_1
value: 3.006
- type: recall_at_10
value: 18.738
- type: recall_at_100
value: 48.058
- type: recall_at_1000
value: 83.41300000000001
- type: recall_at_3
value: 7.166
- type: recall_at_5
value: 12.102
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.4178
- type: ap
value: 14.648781342150446
- type: f1
value: 55.07299194946378
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.919637804187886
- type: f1
value: 61.24122013967399
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.207896583685695
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.23114978840078
- type: cos_sim_ap
value: 74.26624727825818
- type: cos_sim_f1
value: 68.72377190817083
- type: cos_sim_precision
value: 64.56400742115028
- type: cos_sim_recall
value: 73.45646437994723
- type: dot_accuracy
value: 86.23114978840078
- type: dot_ap
value: 74.26624032659652
- type: dot_f1
value: 68.72377190817083
- type: dot_precision
value: 64.56400742115028
- type: dot_recall
value: 73.45646437994723
- type: euclidean_accuracy
value: 86.23114978840078
- type: euclidean_ap
value: 74.26624714480556
- type: euclidean_f1
value: 68.72377190817083
- type: euclidean_precision
value: 64.56400742115028
- type: euclidean_recall
value: 73.45646437994723
- type: manhattan_accuracy
value: 86.16558383501221
- type: manhattan_ap
value: 74.2091943976357
- type: manhattan_f1
value: 68.64221520524654
- type: manhattan_precision
value: 63.59135913591359
- type: manhattan_recall
value: 74.5646437994723
- type: max_accuracy
value: 86.23114978840078
- type: max_ap
value: 74.26624727825818
- type: max_f1
value: 68.72377190817083
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.3681841114604
- type: cos_sim_ap
value: 86.65166387498546
- type: cos_sim_f1
value: 79.02581944698774
- type: cos_sim_precision
value: 75.35796605434099
- type: cos_sim_recall
value: 83.06898675700647
- type: dot_accuracy
value: 89.3681841114604
- type: dot_ap
value: 86.65166019802056
- type: dot_f1
value: 79.02581944698774
- type: dot_precision
value: 75.35796605434099
- type: dot_recall
value: 83.06898675700647
- type: euclidean_accuracy
value: 89.3681841114604
- type: euclidean_ap
value: 86.65166462876266
- type: euclidean_f1
value: 79.02581944698774
- type: euclidean_precision
value: 75.35796605434099
- type: euclidean_recall
value: 83.06898675700647
- type: manhattan_accuracy
value: 89.36624364497226
- type: manhattan_ap
value: 86.65076471274106
- type: manhattan_f1
value: 79.07408783532733
- type: manhattan_precision
value: 76.41102972856527
- type: manhattan_recall
value: 81.92947336002464
- type: max_accuracy
value: 89.3681841114604
- type: max_ap
value: 86.65166462876266
- type: max_f1
value: 79.07408783532733
license: apache-2.0
---
# nomic-embed-text-v1.5: Resizable Production Embeddings with Matryoshka Representation Learning
`nomic-embed-text-v1.5` is an improvement upon [Nomic Embed](https://huggingface.co/nomic-ai/nomic-embed-text-v1) that utilizes [Matryoshka Representation Learning](https://arxiv.org/abs/2205.13147) which gives developers the flexibility to trade off the embedding size for a negligible reduction in performance.
| Name | SeqLen | Dimension | MTEB |
| :-------------------------------:| :----- | :-------- | :------: |
| nomic-embed-text-v1 | 8192 | 768 | **62.39** |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
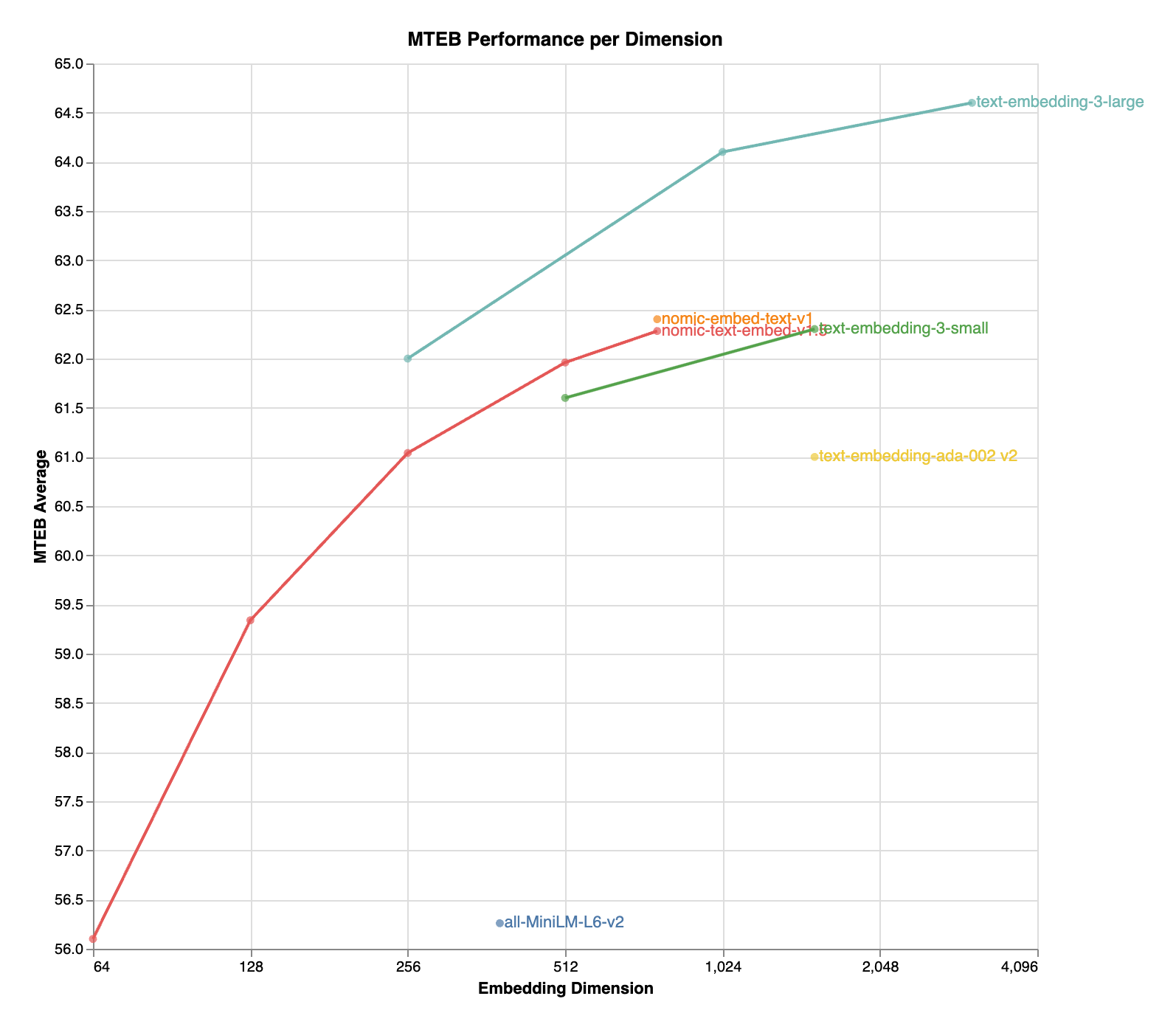
## Hosted Inference API
The easiest way to get started with Nomic Embed is through the Nomic Embedding API.
Generating embeddings with the `nomic` Python client is as easy as
```python
from nomic import embed
output = embed.text(
texts=['Nomic Embedding API', '#keepAIOpen'],
model='nomic-embed-text-v1.5',
task_type='search_document',
dimensionality=256,
)
print(output)
```
For more information, see the [API reference](https://docs.nomic.ai/reference/endpoints/nomic-embed-text)
## Data Visualization
Click the Nomic Atlas map below to visualize a 5M sample of our contrastive pretraining data!
[](https://atlas.nomic.ai/map/nomic-text-embed-v1-5m-sample)
## Training Details
We train our embedder using a multi-stage training pipeline. Starting from a long-context [BERT model](https://huggingface.co/nomic-ai/nomic-bert-2048),
the first unsupervised contrastive stage trains on a dataset generated from weakly related text pairs, such as question-answer pairs from forums like StackExchange and Quora, title-body pairs from Amazon reviews, and summarizations from news articles.
In the second finetuning stage, higher quality labeled datasets such as search queries and answers from web searches are leveraged. Data curation and hard-example mining is crucial in this stage.
For more details, see the Nomic Embed [Technical Report](https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf) and corresponding [blog post](https://blog.nomic.ai/posts/nomic-embed-matryoshka).
Training data to train the models is released in its entirety. For more details, see the `contrastors` [repository](https://github.com/nomic-ai/contrastors)
## Usage
Note `nomic-embed-text` requires prefixes! We support the prefixes `[search_query, search_document, classification, clustering]`.
For retrieval applications, you should prepend `search_document` for all your documents and `search_query` for your queries.
### Sentence Transformers
```python
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
matryoshka_dim = 512
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
embeddings = model.encode(sentences, convert_to_tensor=True)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
```
### Transformers
```diff
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True, safe_serialization=True)
model.eval()
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
+ matryoshka_dim = 512
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
+ embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
+ embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
```
The model natively supports scaling of the sequence length past 2048 tokens. To do so,
```diff
- tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=8192)
- model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1', trust_remote_code=True)
+ model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1', trust_remote_code=True, rotary_scaling_factor=2)
```
### Transformers.js
```js
import { pipeline, layer_norm } from '@xenova/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'nomic-ai/nomic-embed-text-v1.5', {
quantized: false, // Comment out this line to use the quantized version
});
// Define sentences
const texts = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?'];
// Compute sentence embeddings
let embeddings = await extractor(texts, { pooling: 'mean' });
console.log(embeddings); // Tensor of shape [2, 768]
const matryoshka_dim = 512;
embeddings = layer_norm(embeddings, [embeddings.dims[1]])
.slice(null, [0, matryoshka_dim])
.normalize(2, -1);
console.log(embeddings.tolist());
```
# Join the Nomic Community
- Nomic: [https://nomic.ai](https://nomic.ai)
- Discord: [https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
- Twitter: [https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
# Citation
If you find the model, dataset, or training code useful, please cite our work
```bibtex
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Asubramanian19/dqn-SpaceInvadersNoFrameskip-v4
|
Asubramanian19
| 2024-04-25T19:30:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-04-25T19:29:45Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 776.00 +/- 190.89
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Asubramanian19 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Asubramanian19 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Asubramanian19
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
RobertML/sn6-slow-train
|
RobertML
| 2024-04-25T19:29:00Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T07:50:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/alpindale_-_pygmalion-instruct-8bits
|
RichardErkhov
| 2024-04-25T19:25:34Z | 76 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:2304.12244",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-04-25T19:20:10Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pygmalion-instruct - bnb 8bits
- Model creator: https://huggingface.co/alpindale/
- Original model: https://huggingface.co/alpindale/pygmalion-instruct/
Original model description:
---
license: mit
---
## Model Details
Experimental model. Trained with the [Pygmalion](https://huggingface.co/PygmalionAI/pygmalion-6b/tree/dev) and the [WizardLM](https://huggingface.co/ehartford/WizardLM-7B-Uncensored) datasets.
The purpose of this model is to enable complex Instruct prompting but with the RP capabilties of Pygmalion.
### Prompting format
```
instruction:
output:
```
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
### Uses
The intended use-case is Role-Playing with Instruct prompts. Guiding the bot towards a certain conversation style should be easier this way. Subject to experimentation.
### Out-of-Scope Use
- Assistant Bot [subject to providing incorrect instructions]
- Complex multi-character chat
### Risks
The model can generate potentially harmful or NSFW outputs. Please use with caution.
### Citation
WizardLM:
```
@misc{xu2023wizardlm,
title={WizardLM: Empowering Large Language Models to Follow Complex Instructions},
author={Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Daxin Jiang},
year={2023},
eprint={2304.12244},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
RichardErkhov/alpindale_-_gemma-2b-8bits
|
RichardErkhov
| 2024-04-25T19:25:14Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-04-25T18:59:30Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
gemma-2b - bnb 8bits
- Model creator: https://huggingface.co/alpindale/
- Original model: https://huggingface.co/alpindale/gemma-2b/
Original model description:
---
library_name: transformers
tags: []
extra_gated_heading: "Access Gemma on Hugging Face"
extra_gated_prompt: "To access Gemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging Face and click below. Requests are processed immediately."
extra_gated_button_content: "Acknowledge license"
---
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 2B base version of the Gemma model. You can also visit the model card of the [7B base model](https://huggingface.co/google/gemma-7b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning the model
You can find fine-tuning scripts and notebook under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt it to this model, simply change the model-id to `google/gemma-2b`.
In that repository, we provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(**input_text, return_tensors="pt")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a GPU using different precisions
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ml-pathways).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **54.0** | **56.4** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
journeygenie/llama2-hotpot-finetune
|
journeygenie
| 2024-04-25T19:23:07Z | 0 | 0 |
peft
|
[
"peft",
"pytorch",
"tensorboard",
"safetensors",
"gguf",
"llama",
"trl",
"sft",
"generated_from_trainer",
"base_model:NousResearch/Llama-2-7b-hf",
"base_model:adapter:NousResearch/Llama-2-7b-hf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-02-27T16:32:07Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: NousResearch/Llama-2-7b-hf
model-index:
- name: llama2-hotpot-finetune
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
## llama2-hotpot-finetune
This model is a fine-tuned version of [NousResearch/Llama-2-7b-hf](https://huggingface.co/NousResearch/Llama-2-7b-hf) on the hotpot-qa dataset.
## Model description
More information needed
## Dataset used
https://huggingface.co/datasets/hotpot_qa
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
HZhang729/nike_image_classification
|
HZhang729
| 2024-04-25T19:21:48Z | 199 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-04-24T23:55:56Z |
Model Name: Nike Shoes Recognizer
Original Model: Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224.
It was introduced in the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale by Dosovitskiy et al. and first released in this repository.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
Model Type: Image Classification
Model Architecture: Vision Transformer (ViT)
|
cgihlstorf/NEW_finetuned_llama27b32_1_0.0003_alternate_RANDOM_75_pct
|
cgihlstorf
| 2024-04-25T19:21:39Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-04-25T19:21:14Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
SuperkingbasSKB/Ailone_8B_Aowjing_Travel
|
SuperkingbasSKB
| 2024-04-25T19:21:36Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:HuggingFaceM4/idefics2-8b",
"base_model:finetune:HuggingFaceM4/idefics2-8b",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T19:21:19Z |
---
license: apache-2.0
base_model: HuggingFaceM4/idefics2-8b
tags:
- generated_from_trainer
model-index:
- name: Ailone_8B_Aowjing_Travel
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Ailone_8B_Aowjing_Travel
This model is a fine-tuned version of [HuggingFaceM4/idefics2-8b](https://huggingface.co/HuggingFaceM4/idefics2-8b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0523
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0448 | 0.9966 | 254 | 0.0515 |
| 0.0322 | 1.9931 | 508 | 0.0523 |
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
PablitoGil14/ModelFuturama
|
PablitoGil14
| 2024-04-25T19:17:15Z | 0 | 0 |
fastai
|
[
"fastai",
"region:us"
] | null | 2024-04-25T19:17:08Z |
---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
21bce239/model_dl_1y
|
21bce239
| 2024-04-25T19:05:30Z | 63 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:huggingface-course/bert-finetuned-squad",
"base_model:finetune:huggingface-course/bert-finetuned-squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-04-25T07:49:37Z |
---
tags:
- generated_from_keras_callback
base_model: huggingface-course/bert-finetuned-squad
model-index:
- name: model_dl_1y
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# model_dl_1y
This model is a fine-tuned version of [huggingface-course/bert-finetuned-squad](https://huggingface.co/huggingface-course/bert-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 1e-05, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
kellyjiayixu/my_awesome_opus_books_model
|
kellyjiayixu
| 2024-04-25T19:01:14Z | 107 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-04-25T18:48:21Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: my_awesome_opus_books_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_opus_books_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9501
- Bleu: 0.3341
- Gen Len: 18.1659
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| 3.342 | 1.0 | 1617 | 2.9981 | 0.3207 | 18.1549 |
| 3.2797 | 2.0 | 3234 | 2.9501 | 0.3341 | 18.1659 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
21bce239/model_dl_22
|
21bce239
| 2024-04-25T19:01:12Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-04-25T07:43:28Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
base_model: google-bert/bert-base-uncased
model-index:
- name: model_dl_22
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# model_dl_22
This model is a fine-tuned version of [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 1e-05, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
kiki7555/pokemon_classifier_tf.keras
|
kiki7555
| 2024-04-25T18:59:05Z | 2 | 0 |
keras
|
[
"keras",
"region:us"
] | null | 2024-04-25T18:37:17Z |
## How to Get Started with the Model
To use this model, you can either interact with it programmatically using the Python code below or through a web-based interface provided by Gradio.
### Using Python Code
```python
from transformers import TFAutoModelForImageClassification, AutoTokenizer
import gradio as gr
# Laden Sie das Modell und den Tokenizer von Hugging Face herunter
model = TFAutoModelForImageClassification.from_pretrained("kiki7555/pokemon_classifier_tf")
tokenizer = AutoTokenizer.from_pretrained("kiki7555/pokemon_classifier_tf")
def predict_pokemon(image):
# Hier kannst du die Bildvorverarbeitung und -nachverarbeitung hinzufügen
# ...
# Vorhersage treffen
predictions = model.predict(image) # Hier musst du die genaue Vorverarbeitung für das Bild hinzufügen
predicted_class = predictions.argmax()
class_names = ['Charizard', 'Pikachu', 'Zapdos']
return class_names[predicted_class]
# Gradio UI erstellen
image_input = gr.inputs.Image(shape=(128, 128))
output_text = gr.outputs.Textbox()
gr.Interface(
fn=predict_pokemon,
inputs=image_input,
outputs=output_text,
title="Pokemon Classifier",
description="Classify images of Pokemon into three categories: Charizard, Pikachu, and Zapdos."
).launch()
|
MaziyarPanahi/Llama-3-8B-Instruct-64k
|
MaziyarPanahi
| 2024-04-25T18:58:07Z | 32 | 11 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"axolotl",
"finetune",
"dpo",
"facebook",
"meta",
"pytorch",
"llama-3",
"64k",
"pose",
"conversational",
"en",
"dataset:Intel/orca_dpo_pairs",
"arxiv:2309.10400",
"base_model:winglian/Llama-3-8b-64k-PoSE",
"base_model:finetune:winglian/Llama-3-8b-64k-PoSE",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2024-04-25T18:49:31Z |
---
base_model: winglian/Llama-3-8b-64k-PoSE
library_name: transformers
tags:
- axolotl
- finetune
- dpo
- facebook
- meta
- pytorch
- llama
- llama-3
- 64k
- pose
language:
- en
pipeline_tag: text-generation
license: llama3
license_name: llama3
license_link: LICENSE
inference: false
model_creator: MaziyarPanahi
model_name: Llama-3-8B-Instruct-64k
quantized_by: MaziyarPanahi
datasets:
- Intel/orca_dpo_pairs
---
<img src="./llama-3-merges.webp" alt="Llama-3 DPO Logo" width="500" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# MaziyarPanahi/Llama-3-8B-Instruct-64k
This model has been made based on a great of [@winglian](https://huggingface.co/winglian/) with his latest model [winglian/Llama-3-8b-64k-PoSE](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE/)
> This model uses [PoSE](https://huggingface.co/papers/2309.10400) to extend Llama's context length from 8k to 64k @ rope_theta: 500000.0.
> We used PoSE with continued pretraining on 300M tokens from the RedPajama V1 dataset using data between 6k-8k tokens.
> We have further set rope_theta to 2M after continued pre-training to potentially further extend the context past 64k.
> This was trained on a subset of the RedPajama v1 dataset with text between 6k-8k context. We trained a rank stabilized LoRA of rank 256. [WandB](https://wandb.ai/oaaic/llama-3-64k/runs/tkcyjt37)
# Quantized GGUF
All GGUF models come with context length of `64000`: [MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-64k-GGUF)
# How to use
You can use this model by using `MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.3` as the model name in Hugging Face's
transformers library.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/Llama-3-8B-Instruct-64k"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|im_end|>")
]
outputs = pipeline(
prompt,
max_new_tokens=8192,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])
```
|
Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed
|
Yuma42
| 2024-04-25T18:55:08Z | 39 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed",
"argilla/distilabeled-OpenHermes-2.5-Mistral-7B",
"conversational",
"en",
"base_model:Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed",
"base_model:merge:Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed",
"base_model:argilla/distilabeled-OpenHermes-2.5-Mistral-7B",
"base_model:merge:argilla/distilabeled-OpenHermes-2.5-Mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T18:48:37Z |
---
tags:
- merge
- mergekit
- lazymergekit
- Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed
- argilla/distilabeled-OpenHermes-2.5-Mistral-7B
base_model:
- Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed
- argilla/distilabeled-OpenHermes-2.5-Mistral-7B
license: apache-2.0
language:
- en
---
# KangalKhan-Alpha-Rubyroid-7B-Fixed
KangalKhan-Alpha-Rubyroid-7B-Fixed is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed](https://huggingface.co/Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed)
* [argilla/distilabeled-OpenHermes-2.5-Mistral-7B](https://huggingface.co/argilla/distilabeled-OpenHermes-2.5-Mistral-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed
layer_range: [0, 32]
- model: argilla/distilabeled-OpenHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed
parameters:
t:
- filter: self_attn
value: [1, 0.5, 0.7, 0.3, 0]
- filter: mlp
value: [0, 0.5, 0.3, 0.7, 1]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Yuma42/KangalKhan-Alpha-Rubyroid-7B-Fixed"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
21bce239/model_dl_1
|
21bce239
| 2024-04-25T18:54:17Z | 72 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:huggingface-course/bert-finetuned-squad",
"base_model:finetune:huggingface-course/bert-finetuned-squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-04-25T06:16:44Z |
---
tags:
- generated_from_keras_callback
base_model: huggingface-course/bert-finetuned-squad
model-index:
- name: model_dl_1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# model_dl_1
This model is a fine-tuned version of [huggingface-course/bert-finetuned-squad](https://huggingface.co/huggingface-course/bert-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 1e-05, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
21bce239/model_dl_45
|
21bce239
| 2024-04-25T18:53:35Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T18:53:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sireskay/llama3-8b-oig-unsloth
|
sireskay
| 2024-04-25T18:52:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T18:51:56Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** sireskay
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sireskay/llama3-8b-oig-unsloth-merged
|
sireskay
| 2024-04-25T18:51:51Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T18:49:00Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** sireskay
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
iaminhridoy/bert-finetuned-chatGPT-discourse
|
iaminhridoy
| 2024-04-25T18:48:57Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-16T03:45:55Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-finetuned-chatGPT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-chatGPT
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3771
- Accuracy: 0.9001
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.7988668524141836e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4095 | 1.0 | 2250 | 0.3938 | 0.8669 |
| 0.2796 | 2.0 | 4500 | 0.3359 | 0.8888 |
| 0.1891 | 3.0 | 6750 | 0.3771 | 0.9001 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Tokenizers 0.19.1
|
awashh/RoBERTa-NLI-Group71
|
awashh
| 2024-04-25T18:45:26Z | 107 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-24T11:52:25Z |
---
{}
---
language: en
license: cc-by-4.0
tags:
- text-classification
repo: https://huggingface.co/awashh/RoBERTa-NLI-Group71
---
# Model Card for j34330vk-q26752aa-NLI
<!-- Provide a quick summary of what the model is/does. -->
This is a Natural Language Inference (NLI) classification model that was trained to
detect if a hypothesis is true based on a premise.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This model is based upon a RoBERTa model that was fine-tuned
on 26.9K pairs of premise-hypothesis texts.
- **Developed by:** Awab Alshami and Vansh Kharbanda
- **Language(s):** English
- **Model type:** Supervised
- **Model architecture:** Transformers
- **Finetuned from model [optional]:** roberta-base
### Model Resources
<!-- Provide links where applicable. -->
- **Repository:** https://huggingface.co/FacebookAI/roberta-base
- **Paper or documentation:** https://arxiv.org/pdf/1907.11692.pdf
## Training Details
### Training Data
<!-- This is a short stub of information on the training data that was used, and documentation related to data pre-processing or additional filtering (if applicable). -->
26.9k pairs of premise-hypothesis texts.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Training Hyperparameters
<!-- This is a summary of the values of hyperparameters used in training the model. -->
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- num_epochs: 8
#### Speeds, Sizes, Times
<!-- This section provides information about how roughly how long it takes to train the model and the size of the resulting model. -->
- overall training time: 1.2 hours
- duration per training epoch: 9 minutes
- model size: 600 MB
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data & Metrics
#### Testing Data
<!-- This should describe any evaluation data used (e.g., the development/validation set provided). -->
A subset of the development set provided, amounting to 6.7K pairs.
#### Metrics
<!-- These are the evaluation metrics being used. -->
- Precision: 0.882
- Recall: 0.879
- F1-score: 0.880
- Accuracy: 0.880
### Results
The model obtained a precision score of 88.2%, a recall score of 87.9%, an F1-score of 88% and an accuracy of 88%.
## Technical Specifications
### Hardware
- RAM: at least 22.5 GB
- Storage: at least 2GB,
- GPU: A100
### Software
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Any inputs (concatenation of two sequences) longer than
512 subwords will be truncated by the model.
|
CMU-AIR2/math-deepseek-FULL-ArithHardC12-FTMWP-FULL
|
CMU-AIR2
| 2024-04-25T18:40:23Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-24T17:14:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AlignmentResearch/robust_llm_pythia-1b_mz-130_PasswordMatch_n-its-10-seed-2
|
AlignmentResearch
| 2024-04-25T18:31:18Z | 104 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-1b",
"base_model:finetune:EleutherAI/pythia-1b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-25T18:29:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-1b
model-index:
- name: robust_llm_pythia-1b_mz-130_PasswordMatch_n-its-10-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-1b_mz-130_PasswordMatch_n-its-10-seed-2
This model is a fine-tuned version of [EleutherAI/pythia-1b](https://huggingface.co/EleutherAI/pythia-1b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
|
AI4DS/CodeLlama-ColSel-33B
|
AI4DS
| 2024-04-25T18:29:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-24T04:18:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NandGate1110/mistral_7b_guanaco_updated
|
NandGate1110
| 2024-04-25T18:19:10Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"region:us"
] | null | 2024-04-23T18:56:59Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
|
Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed
|
Yuma42
| 2024-04-25T18:17:59Z | 47 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"kaist-ai/mistral-orpo-capybara-7k",
"argilla/CapybaraHermes-2.5-Mistral-7B",
"conversational",
"en",
"base_model:argilla/CapybaraHermes-2.5-Mistral-7B",
"base_model:merge:argilla/CapybaraHermes-2.5-Mistral-7B",
"base_model:kaist-ai/mistral-orpo-capybara-7k",
"base_model:merge:kaist-ai/mistral-orpo-capybara-7k",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T18:10:06Z |
---
tags:
- merge
- mergekit
- lazymergekit
- kaist-ai/mistral-orpo-capybara-7k
- argilla/CapybaraHermes-2.5-Mistral-7B
base_model:
- kaist-ai/mistral-orpo-capybara-7k
- argilla/CapybaraHermes-2.5-Mistral-7B
license: apache-2.0
language:
- en
---
# KangalKhan-Alpha-Sapphiroid-7B-Fixed
KangalKhan-Alpha-Sapphiroid-7B-Fixed is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [kaist-ai/mistral-orpo-capybara-7k](https://huggingface.co/kaist-ai/mistral-orpo-capybara-7k)
* [argilla/CapybaraHermes-2.5-Mistral-7B](https://huggingface.co/argilla/CapybaraHermes-2.5-Mistral-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: kaist-ai/mistral-orpo-capybara-7k
layer_range: [0, 32]
- model: argilla/CapybaraHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: kaist-ai/mistral-orpo-capybara-7k
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Yuma42/KangalKhan-Alpha-Sapphiroid-7B-Fixed"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
Yaxin1992/llama3-8b-8000-dpo-1000
|
Yaxin1992
| 2024-04-25T18:17:42Z | 1 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"region:us"
] | null | 2024-04-25T17:42:01Z |
---
license: other
library_name: peft
tags:
- trl
- dpo
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model-index:
- name: llama3-8b-8000-dpo-1000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama3-8b-8000-dpo-1000
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
LarryAIDraw/Aqua_Konosuba
|
LarryAIDraw
| 2024-04-25T18:13:55Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-04-25T18:11:13Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/132043/aqua-konosuba-anime-character
|
LarryAIDraw/megumin-10
|
LarryAIDraw
| 2024-04-25T18:13:45Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-04-25T18:10:53Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/150383/megumin-konosuba-lora
|
LarryAIDraw/aqua-10
|
LarryAIDraw
| 2024-04-25T18:13:36Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-04-25T18:10:33Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/150021/aqua-konosuba-lora
|
LarryAIDraw/Arya-06
|
LarryAIDraw
| 2024-04-25T18:13:14Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-04-25T18:09:37Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/417259/alisa-mikhailovna-kujou-ayra-san-or-my-deskmate-alya-sometimes-hides-her-feelings-in-russian-or-tokidoki-bosotto-roshia-go-de-dereru-tonari-no-arya-san
|
chakkakrishna/llamareqa
|
chakkakrishna
| 2024-04-25T18:10:36Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"region:us"
] | null | 2024-04-25T18:07:59Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
HARDYCHEN/text_summarization_finetuned2
|
HARDYCHEN
| 2024-04-25T18:06:52Z | 108 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:Falconsai/text_summarization",
"base_model:finetune:Falconsai/text_summarization",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-04-25T15:46:27Z |
---
license: apache-2.0
base_model: Falconsai/text_summarization
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: text_summarization_finetuned2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_summarization_finetuned2
This model is a fine-tuned version of [Falconsai/text_summarization](https://huggingface.co/Falconsai/text_summarization) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3126
- Rouge1: 0.0675
- Rouge2: 0.0578
- Rougel: 0.0674
- Rougelsum: 0.0674
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.4139 | 1.0 | 2000 | 0.3411 | 0.0632 | 0.0524 | 0.0632 | 0.0632 | 19.0 |
| 0.3635 | 2.0 | 4000 | 0.3215 | 0.0658 | 0.0557 | 0.0658 | 0.0658 | 19.0 |
| 0.348 | 3.0 | 6000 | 0.3146 | 0.0668 | 0.0571 | 0.0668 | 0.0668 | 19.0 |
| 0.3445 | 4.0 | 8000 | 0.3126 | 0.0675 | 0.0578 | 0.0674 | 0.0674 | 19.0 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
ahforoughi/Reinforce-7B
|
ahforoughi
| 2024-04-25T18:05:17Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-04-25T18:05:07Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-7B
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
nullt3r/Llama-3-8b-64k-PoSE-Q8_0-GGUF
|
nullt3r
| 2024-04-25T18:05:04Z | 2 | 0 | null |
[
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T18:04:41Z |
---
language:
- en
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-cpp
- gguf-my-repo
pipeline_tag: text-generation
---
# nullt3r/Llama-3-8b-64k-PoSE-Q8_0-GGUF
This model was converted to GGUF format from [`winglian/Llama-3-8b-64k-PoSE`](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo nullt3r/Llama-3-8b-64k-PoSE-Q8_0-GGUF --model llama-3-8b-64k-pose.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo nullt3r/Llama-3-8b-64k-PoSE-Q8_0-GGUF --model llama-3-8b-64k-pose.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m llama-3-8b-64k-pose.Q8_0.gguf -n 128
```
|
HenryCai1129/adapter-toxic2nontoxic-100-filtered-50-0.0003
|
HenryCai1129
| 2024-04-25T18:03:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T18:03:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
baconnier/finance_orpo_llama3_8B_r64_51K
|
baconnier
| 2024-04-25T18:02:20Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"orpo",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T17:38:32Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- orpo
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** baconnier
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
FAYSSAL12/ppo-Huggy
|
FAYSSAL12
| 2024-04-25T18:01:38Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2024-04-25T18:00:15Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: FAYSSAL12/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
gsl22/ellis-v10-emotion-leadership
|
gsl22
| 2024-04-25T17:59:16Z | 106 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-20T22:27:11Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: ellis-v10-emotion-leadership
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ellis-v10-emotion-leadership
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2726
- Accuracy: 0.9142
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3636 | 1.0 | 1109 | 0.2726 | 0.9142 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
avans06/Meta-Llama-3-8B-Instruct-ct2-int8_float16
|
avans06
| 2024-04-25T17:45:38Z | 14 | 0 |
transformers
|
[
"transformers",
"safetensors",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"ctranslate2",
"quantization",
"int8",
"float16",
"text-generation",
"conversational",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-23T12:46:57Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- ctranslate2
- quantization
- int8
- float16
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
widget:
- example_title: Hello
messages:
- role: user
content: Hey my name is Julien! How are you?
- example_title: Winter holidays
messages:
- role: system
content: You are a helpful and honest assistant. Please, respond concisely and truthfully.
- role: user
content: Can you recommend a good destination for Winter holidays?
- example_title: Programming assistant
messages:
- role: system
content: You are a helpful and honest code and programming assistant. Please, respond concisely and truthfully.
- role: user
content: Write a function that computes the nth fibonacci number.
inference:
parameters:
max_new_tokens: 300
stop:
- <|end_of_text|>
- <|eot_id|>
---
## meta-llama/Meta-Llama-3-8B-Instruct for CTranslate2
**The model is quantized version of the [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) with int8_float16 quantization and can be used in [CTranslate2](https://github.com/OpenNMT/CTranslate2).**
## Conversion details
The original model was converted on 2024-4 with the following command:
```
ct2-transformers-converter --model Path\To\Local\meta-llama\Meta-Llama-3-8B-Instruct \
--quantization int8_float16 --output_dir Meta-Llama-3-8B-Instruct-ct2-int8_float16
```
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository for use with [CTranslate2](https://github.com/OpenNMT/CTranslate2).
### Use with CTranslate2
This example code is obtained from [CTranslate2_transformers](https://opennmt.net/CTranslate2/guides/transformers.html#mpt) and [tokenizer AutoTokenizer](https://huggingface.co/docs/transformers/main_classes/tokenizer).
More detailed information about the `generate_batch` methon can be found at [CTranslate2_Generator.generate_batch](https://opennmt.net/CTranslate2/python/ctranslate2.Generator.html#ctranslate2.Generator.generate_batch).
```python
import ctranslate2
import transformers
model_id = "avans06/Meta-Llama-3-8B-Instruct-ct2-int8_float16"
model = ctranslate2.Generator(model_id, device="auto", compute_type="int8_float16")
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
input_tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(input_ids))
results = model.generate_batch([input_tokens], include_prompt_in_result=False, max_length=256, sampling_temperature=0.6, sampling_topp=0.9, end_token=terminators)
output = tokenizer.decode(results[0].sequences_ids[0])
print(output)
```
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
Goekdeniz-Guelmez/MiniCPM-2B-sft-bf16
|
Goekdeniz-Guelmez
| 2024-04-25T17:44:33Z | 3 | 0 |
transformers
|
[
"transformers",
"minicpm",
"text-generation",
"MiniCPM",
"ModelBest",
"THUNLP",
"conversational",
"custom_code",
"en",
"zh",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2024-04-25T17:42:19Z |
---
language:
- en
- zh
tags:
- MiniCPM
- ModelBest
- THUNLP
---
<div align="center">
<h1>
MiniCPM
</h1>
</div>
<p align="center">
<a href="https://shengdinghu.notion.site/MiniCPM-c805a17c5c8046398914e47f0542095a?pvs=4" target="_blank">MiniCPM 技术报告</a><a href="https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4" target="_blank"> Technical Report</a> |
<a href="https://github.com/OpenBMB/OmniLMM/" target="_blank">OmniLMM 多模态模型 Multi-modal Model</a> |
<a href="https://luca.cn/" target="_blank">CPM-C 千亿模型试用 ~100B Model Trial </a>
</p>
MiniCPM 是面壁与清华大学自然语言处理实验室共同开源的系列端侧语言大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量。
- 经过 SFT 后,MiniCPM 在公开综合性评测集上,MiniCPM 与 Mistral-7B相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。
- 经过 DPO 后,MiniCPM 在当前最接近用户体感的评测集 MTBench上,MiniCPM-2B 也超越了 Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha 等众多代表性开源大模型。
- 以 MiniCPM-2B 为基础构建端侧多模态大模型 MiniCPM-V,整体性能在同规模模型中实现最佳,超越基于 Phi-2 构建的现有多模态大模型,在部分评测集上达到与 9.6B Qwen-VL-Chat 相当甚至更好的性能。
- 经过 Int4 量化后,MiniCPM 可在手机上进行部署推理,流式输出速度略高于人类说话速度。MiniCPM-V 也首次跑通了多模态大模型在手机上的部署。
- 一张1080/2080可高效参数微调,一张3090/4090可全参数微调,一台机器可持续训练 MiniCPM,二次开发成本较低。
我们将完全开源MiniCPM-2B的模型参数供学术研究和有限商用,以及训练过程中的所有Checkpoint和大部分非专有数据供模型机理研究。
- 基于MiniCPM-2B的指令微调与人类偏好对**MiniCPM-2B-SFT/DPO。**
- 基于MiniCPM-2B的多模态模型**MiniCPM-V**,能力超越基于Phi-2的同参数级别多模态模型**。**
- MiniCPM-2B-SFT/DPO的Int4量化版**MiniCPM-2B-SFT/DPO-Int4。**
- 基于MLC-LLM、LLMFarm开发的MiniCPM手机端程序,**文本及多模态模型均可在手机端进行推理。**
MiniCPM is an End-Size LLM developed by ModelBest Inc. and TsinghuaNLP, with only 2.4B parameters excluding embeddings.
- MiniCPM has very close performance compared with Mistral-7B on open-sourced general benchmarks with better ability on Chinese, Mathmetics and Coding after SFT. The overall performance exceeds Llama2-13B, MPT-30B, Falcon-40B, etc.
- After DPO, MiniCPM outperforms Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, Zephyr-7B-alpha, etc. on MTBench.
- MiniCPM-V, based on MiniCPM-2B, achieves the best overall performance among multimodel models of the same scale, surpassing existing multimodal large models built on Phi-2 and achieving performance comparable to or even better than 9.6B Qwen-VL-Chat on some tasks.
- MiniCPM can be deployed and infer on smartphones, and the speed of streaming output is relatively higher than the verbal speed of human. MiniCPM-V is the first multi-modal models that can be deployed on smartphones.
- The cost of developing based on MiniCPM is low. Parameter efficient finetuning can be conducted with a single 1080/2080 GPU and full parameter finetuning can be conducted with a 3090/4090 GPU.
We release all model parameters for research and limited commercial use. We also release all the checkpoint during training and most public training data for research on model mechanism.
- SFT and DPO version based on MiniCPM-2B and human preference: **MiniCPM-2B-SFT/DPO**
- The multi-modal model **MiniCPM-V** based on MiniCPM-2B, which outperforms models with similar size, i.e., Phi-2
- The INT4 quantized version **MiniCPM-2B-SFT/DPO-Int4** based on MiniCPM-2B-SFT/DPO
- Mobile phone application based on MLC-LLM and LLMFarm. Both language model and multimodel model can conduct inference on smartphones.
### 评测结果 Evaluation Results
详细的评测结果位于[github仓库](https://github.com/OpenBMB/MiniCPM?tab=readme-ov-file#%E8%AF%84%E6%B5%8B%E7%BB%93%E6%9E%9C)
Detailed evaluation results are in [github repo](https://github.com/OpenBMB/MiniCPM/blob/main/README-en.md#evaluation-results)
注意:我们发现使用Huggingface生成质量略差于vLLM,因此推荐使用vLLM进行测试。我们正在排查原因。
Notice: We discovered that the quality of Huggingface generation is slightly lower than vLLM, thus benchmarking using vLLM is recommended.
We are investigating the cause now.
### 局限性 Limitations
- 受限于模型规模,模型可能出现幻觉性问题。其中由于DPO模型生成的回复内容更长,更容易出现幻觉。我们也将持续进行MiniCPM模型的迭代改进;
- 为了保证在学术研究用途上模型的通用性,我们未对模型进行任何身份认同训练。同时由于我们用ShareGPT开源语料作为部分训练数据,模型可能会输出类似GPT系列模型的身份认同信息;
- 受限于模型规模,模型的输出受到提示词(prompt)的影响较大,可能多次尝试产生不一致的结果;
- 受限于模型容量,模型的知识记忆较不准确,后续我们将结合RAG方法来增强模型的知识记忆能力。
- Due to limitations in model size, the model may experience hallucinatory issues. As DPO model tend to generate longer response, hallucinations are more likely to occur. We will also continue to iterate and improve the MiniCPM model.
- To ensure the universality of the model for academic research purposes, we did not conduct any identity training on the model. Meanwhile, as we use ShareGPT open-source corpus as part of the training data, the model may output identity information similar to the GPT series models.
- Due to the limitation of model size, the output of the model is greatly influenced by prompt words, which may result in inconsistent results from multiple attempts.
- Due to limited model capacity, the model's knowledge memory is not accurate. In the future, we will combine the RAG method to enhance the model's knowledge memory ability.
## 模型下载 Download
| HuggingFace | ModelScope | WiseModel |
|-------------|------------|-----------|
|[sft-bf16](https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16)|[sft-bf16](https://modelscope.cn/models/OpenBMB/miniCPM-bf16)|[sft-bf16](https://wisemodel.cn/models/OpenBMB/miniCPM-bf16)
|[sft-fp32](https://huggingface.co/openbmb/MiniCPM-2B-sft-fp32)|[sft-fp32](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-sft-fp32)|[sft-fp32](https://wisemodel.cn/models/OpenBMB/miniCPM-dpo-fp32)
|[dpo-bf16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16)|[dpo-bf16](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-bf16/summary)|[dpo-bf16](https://wisemodel.cn/models/OpenBMB/MiniCPM-2B-dpo-bf16)
|[dpo-fp16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-fp16)|[dpo-fp16](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-fp16/)|[dpo-fp16](https://wisemodel.cn/models/OpenBMB/MiniCPM-2B-dpo-fp16)
|[dpo-fp32](https://huggingface.co/openbmb/MiniCPM-2B-dpo-fp32)|[dpo-fp32](https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-fp32)|[dpo-fp32](https://wisemodel.cn/models/OpenBMB/miniCPM-dpo-fp32)
## 模型使用 Usage
* 安装`transformers>=4.36.0`以及`accelerate`后,运行以下代码
* 注意:需要在`from_pretrained`中明确指明模型的数据类型,否则会引起较大计算误差
* Run the following code after install `transformers>=4.36.0` and `accelerate`
* Warning: It is necessary to specify the data type of the model clearly in 'from_pretrained', otherwise large calculation errors will be caused
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM-2B-sft-bf16'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "山东省最高的山是哪座山, 它比黄山高还是矮?差距多少?", temperature=0.8, top_p=0.8)
print(responds)
```
* 期望输出 Expected Output
```shell
山东省最高的山是泰山,海拔1545米。
相对于黄山(海拔1864米),泰山海拔较低,相差约319米。
```
## 开源协议 LICENSE
#### 模型协议 Model LICENSE
* 本仓库中代码依照 [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) 协议开源
* MiniCPM 模型权重的使用则需要遵循 [“通用模型许可协议-来源说明-宣传限制-商业授权”](https://github.com/OpenBMB/General-Model-License/blob/main/%E9%80%9A%E7%94%A8%E6%A8%A1%E5%9E%8B%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE-%E6%9D%A5%E6%BA%90%E8%AF%B4%E6%98%8E-%E5%AE%A3%E4%BC%A0%E9%99%90%E5%88%B6-%E5%95%86%E4%B8%9A%E6%8E%88%E6%9D%83.md)。
* MiniCPM 模型权重对学术研究完全开放。
* 如需将模型用于商业用途,请联系cpm@modelbest.cn来获取书面授权,在登记后亦允许免费商业使用。
* This repository is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
* The usage of MiniCPM model weights must strictly follow [the General Model License (GML)](https://github.com/OpenBMB/General-Model-License/blob/main/%E9%80%9A%E7%94%A8%E6%A8%A1%E5%9E%8B%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE-%E6%9D%A5%E6%BA%90%E8%AF%B4%E6%98%8E-%E5%AE%A3%E4%BC%A0%E9%99%90%E5%88%B6-%E5%95%86%E4%B8%9A%E6%8E%88%E6%9D%83.md).
* The models and weights of MiniCPM are completely free for academic research.
* If you intend to utilize the model for commercial purposes, please reach out to cpm@modelbest.cn to obtain the certificate of authorization.
#### 声明 Statement
* 作为一个语言模型,MiniCPM 通过学习大量的文本来生成内容,但它无法理解、表达个人观点或价值判断,它所输出的任何内容都不代表模型开发者的观点和立场。
* 因此用户在使用 MiniCPM 生成的内容时,应自行负责对其进行评估和验证。
* 如果由于使用 MinCPM 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
* As a language model, MiniCPM generates content by learning from a vast amount of text.
* However, it does not possess the ability to comprehend or express personal opinions or value judgments.
* Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
* Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
<p id="8"></p>
## 工作引用 Citation
* 如果觉得MiniCPM有助于您的工作,请考虑引用下列[技术报告](https://shengdinghu.notion.site/MiniCPM-c805a17c5c8046398914e47f0542095a?pvs=4)
* Please cite our [techinical report](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4) if you find our work valuable.
```
@inproceedings{minicpm2024,
title={MiniCPM:Unveiling the Potential of End-side Large Language Models},
booktitle={OpenBMB Blog},
year={2024}
}
```
|
netcat420/MFANNv0.6-GGUF
|
netcat420
| 2024-04-25T17:41:52Z | 4 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"gguf",
"llama",
"text-classification",
"dataset:netcat420/MFANN",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-classification
| 2024-04-22T17:15:10Z |
---
license: apache-2.0
datasets:
- netcat420/MFANN
pipeline_tag: text-classification
library_name: adapter-transformers
---
|
nop1006/gte-base-zh-finetuned-main_rev_rate
|
nop1006
| 2024-04-25T17:40:48Z | 107 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:thenlper/gte-base-zh",
"base_model:finetune:thenlper/gte-base-zh",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-25T17:02:49Z |
---
license: mit
base_model: thenlper/gte-base-zh
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: gte-base-zh-finetuned-main_rev_rate
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gte-base-zh-finetuned-main_rev_rate
This model is a fine-tuned version of [thenlper/gte-base-zh](https://huggingface.co/thenlper/gte-base-zh) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3443
- Accuracy: 0.0807
- F1: 0.0713
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3784 | 1.0 | 85 | 0.3260 | 0.0998 | 0.0181 |
| 0.3258 | 2.0 | 170 | 0.3268 | 0.0913 | 0.0153 |
| 0.3256 | 3.0 | 255 | 0.3271 | 0.0913 | 0.0153 |
| 0.3255 | 4.0 | 340 | 0.3262 | 0.1040 | 0.0305 |
| 0.3255 | 5.0 | 425 | 0.3266 | 0.0998 | 0.0246 |
| 0.3248 | 6.0 | 510 | 0.3257 | 0.0955 | 0.0489 |
| 0.3246 | 7.0 | 595 | 0.3263 | 0.1104 | 0.0566 |
| 0.3233 | 8.0 | 680 | 0.3272 | 0.1062 | 0.0593 |
| 0.3206 | 9.0 | 765 | 0.3287 | 0.1146 | 0.0754 |
| 0.3171 | 10.0 | 850 | 0.3324 | 0.0977 | 0.0686 |
| 0.3113 | 11.0 | 935 | 0.3321 | 0.0892 | 0.0809 |
| 0.3021 | 12.0 | 1020 | 0.3357 | 0.0977 | 0.0800 |
| 0.2954 | 13.0 | 1105 | 0.3395 | 0.0828 | 0.0750 |
| 0.2872 | 14.0 | 1190 | 0.3428 | 0.0913 | 0.0803 |
| 0.2821 | 15.0 | 1275 | 0.3443 | 0.0807 | 0.0713 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1-GGUF
|
MaziyarPanahi
| 2024-04-25T17:40:11Z | 98 | 2 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"llama",
"llama-3",
"base_model:MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1",
"base_model:quantized:MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1",
"region:us",
"conversational"
] |
text-generation
| 2024-04-24T11:10:23Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- text-generation
- llama
- llama-3
- text-generation
model_name: Llama-3-8B-Instruct-DPO-v0.1-GGUF
base_model: MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1
inference: false
model_creator: MaziyarPanahi
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1-GGUF)
- Model creator: [MaziyarPanahi](https://huggingface.co/MaziyarPanahi)
- Original model: [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1)
## Description
[MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1-GGUF) contains GGUF format model files for [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.1).
## Prompt Template
This model uses `ChatML` prompt template:
```
<|im_start|>system
{System}
<|im_end|>
<|im_start|>user
{User}
<|im_end|>
<|im_start|>assistant
{Assistant}
````
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2-GGUF
|
MaziyarPanahi
| 2024-04-25T17:39:58Z | 85 | 1 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"text-generation",
"llama",
"llama-3",
"base_model:MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2",
"base_model:quantized:MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2",
"region:us",
"conversational"
] |
text-generation
| 2024-04-24T11:47:43Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- text-generation
- llama
- llama-3
- text-generation
model_name: Llama-3-8B-Instruct-DPO-v0.2-GGUF
base_model: MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2
inference: false
model_creator: MaziyarPanahi
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2-GGUF)
- Model creator: [MaziyarPanahi](https://huggingface.co/MaziyarPanahi)
- Original model: [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2)
## Description
[MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2-GGUF](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2-GGUF) contains GGUF format model files for [MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2](https://huggingface.co/MaziyarPanahi/Llama-3-8B-Instruct-DPO-v0.2).
## Prompt Template
This model uses `ChatML` prompt template:
```
<|im_start|>system
{System}
<|im_end|>
<|im_start|>user
{User}
<|im_end|>
<|im_start|>assistant
{Assistant}
````
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
bartowski/maverick-llama3-8B-GGUF
|
bartowski
| 2024-04-25T17:39:29Z | 102 | 1 | null |
[
"gguf",
"meta-llama/Meta-Llama-3-8B",
"text-generation",
"dataset:feeltheAGI/maverick-sharegpt",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-04-25T17:16:18Z |
---
tags:
- meta-llama/Meta-Llama-3-8B
datasets:
- feeltheAGI/maverick-sharegpt
license: apache-2.0
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of maverick-llama3-8B
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b2717">b2717</a> for quantization.
Original model: https://huggingface.co/feeltheAGI/maverick-llama3-8B/
All quants made using imatrix option with dataset provided by Kalomaze [here](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384)
## Prompt format
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [maverick-llama3-8B-Q8_0.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [maverick-llama3-8B-Q6_K.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [maverick-llama3-8B-Q5_K_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [maverick-llama3-8B-Q5_K_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [maverick-llama3-8B-Q4_K_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [maverick-llama3-8B-Q4_K_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [maverick-llama3-8B-IQ4_NL.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ4_NL.gguf) | IQ4_NL | 4.67GB | Decent quality, slightly smaller than Q4_K_S with similar performance *recommended*. |
| [maverick-llama3-8B-IQ4_XS.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [maverick-llama3-8B-Q3_K_L.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [maverick-llama3-8B-Q3_K_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [maverick-llama3-8B-IQ3_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [maverick-llama3-8B-IQ3_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ3_S.gguf) | IQ3_S | 3.68GB | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| [maverick-llama3-8B-Q3_K_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [maverick-llama3-8B-IQ3_XS.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [maverick-llama3-8B-IQ3_XXS.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [maverick-llama3-8B-Q2_K.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [maverick-llama3-8B-IQ2_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [maverick-llama3-8B-IQ2_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [maverick-llama3-8B-IQ2_XS.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
| [maverick-llama3-8B-IQ2_XXS.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ2_XXS.gguf) | IQ2_XXS | 2.39GB | Lower quality, uses SOTA techniques to be usable. |
| [maverick-llama3-8B-IQ1_M.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ1_M.gguf) | IQ1_M | 2.16GB | Extremely low quality, *not* recommended. |
| [maverick-llama3-8B-IQ1_S.gguf](https://huggingface.co/bartowski/maverick-llama3-8B-GGUF/blob/main/maverick-llama3-8B-IQ1_S.gguf) | IQ1_S | 2.01GB | Extremely low quality, *not* recommended. |
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
LucasCardoso1/SSData
|
LucasCardoso1
| 2024-04-25T17:38:57Z | 0 | 0 | null |
[
"license:cc-by-nc-nd-4.0",
"region:us"
] | null | 2024-04-25T17:38:57Z |
---
license: cc-by-nc-nd-4.0
---
|
dtorber/BioNLP-tech_ner-PLOS
|
dtorber
| 2024-04-25T17:19:24Z | 95 | 0 |
transformers
|
[
"transformers",
"safetensors",
"led",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-04-24T00:10:18Z |
---
tags:
- generated_from_trainer
model-index:
- name: BioNLP-tech_ner-PLOS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BioNLP-tech_ner-PLOS
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.3739167643078955e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 1.13.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.2
|
Azma-AI/Meta-Llama-3-8B-Instruct-64k-PoSE
|
Azma-AI
| 2024-04-25T17:14:51Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"arxiv:2309.10400",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T16:47:03Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
---
# Meta-Llama-3-8B-Instruct-64k-PoSE
<img src="https://huggingface.co/winglian/Llama-3-8b-64k-PoSE/resolve/main/output.png" />
This is a custom version of the Meta Llama 3 8B instruction-tuned language model with an extended context length of up to 64,000 tokens. It was created by merging the [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) model with a LoRA adapter finetuned using [PoSE](https://huggingface.co/papers/2309.10400) by [Wing Lian](https://huggingface.co/winglian) to extend Llama's context length from 8k to 64k @ rope_theta: 500000.0.
They used PoSE with continued pretraining on 300M tokens from the RedPajama V1 dataset using data between 6k-8k tokens.
They have further set rope_theta to 2M after continued pre-training to potentially further extend the context past 64k.
This was trained on a subset of the RedPajama v1 dataset with text between 6k-8k context. They trained a rank stabilized LoRA of rank 256. [WandB](https://wandb.ai/oaaic/llama-3-64k/runs/tkcyjt37)
### Model Details
- **Base Model**: Meta Llama 3 8B instruction-tuned model
- **Context Length**: Up to 64,000 tokens (increased from original 8,192 token limit)
- **Adapter Training**: PoSE adapter finetuned on 300M tokens from the RedPajama V1 dataset with 6k-8k token sequences.
- **Adapter Rank**: 256 rank stabilized LoRA adapter
This extended context model allows for much longer form inputs and generation compared to the original base model. It maintains the strong instruction-following and safety capabilities of Llama 3 while greatly increasing the applicable use cases.
See the Original Repo by Wing Lian for more details on the adapter training process.
### Usage
This model can be used just like the base Llama 3 8B model, but with the increased context length enabling much longer prompts and outputs. See the example usage with the Transformers library:
```python
import transformers
import torch
model_id = "Azma-AI/Meta-Llama-3-8B-Instruct-64k-PoSE"
pipeline = transformers.pipeline(
"text-generation", model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto"
)
long_prompt = "..." # Your prompt up to 64k tokens
output = pipeline(long_prompt)
```
### Citation
If you use this model, please cite the original Meta Llama 3 model card and the PoSE adapter paper:
```code
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
```
### Acknowledgments
[Wing Lian](https://huggingface.co/winglian)
[MetaAI](https://huggingface.co/meta-llama)
|
sohamslc5/test_model
|
sohamslc5
| 2024-04-25T17:00:50Z | 136 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"en",
"dataset:sohamslc5/curr1",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-4k-instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T16:26:59Z |
---
datasets:
- sohamslc5/curr1
language:
- en
metrics:
- accuracy
base_model: "microsoft/Phi-3-mini-4k-instruct"
---
|
Alexandro8/test
|
Alexandro8
| 2024-04-25T17:00:25Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2024-04-25T17:00:25Z |
---
license: other
license_name: test
license_link: LICENSE
---
|
DandinPower/llama_3_8b_lora_completion_only
|
DandinPower
| 2024-04-25T17:00:22Z | 12 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"nycu-112-2-deeplearning-hw2",
"generated_from_trainer",
"zh",
"dataset:DandinPower/ZH-Reading-Comprehension-Llama-Instruct",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"region:us"
] | null | 2024-04-25T14:28:44Z |
---
language:
- zh
license: other
library_name: peft
tags:
- trl
- sft
- nycu-112-2-deeplearning-hw2
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets:
- DandinPower/ZH-Reading-Comprehension-Llama-Instruct
model-index:
- name: llama_3_8b_lora_completion_only
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama_3_8b_lora_completion_only
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the DandinPower/ZH-Reading-Comprehension-Llama-Instruct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0924
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 700
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.105 | 0.3690 | 250 | 0.0762 |
| 0.0716 | 0.7380 | 500 | 0.0897 |
| 0.0652 | 1.1070 | 750 | 0.0832 |
| 0.061 | 1.4760 | 1000 | 0.0640 |
| 0.0373 | 1.8450 | 1250 | 0.0813 |
| 0.0344 | 2.2140 | 1500 | 0.0686 |
| 0.0207 | 2.5830 | 1750 | 0.0662 |
| 0.0351 | 2.9520 | 2000 | 0.0669 |
| 0.0028 | 3.3210 | 2250 | 0.0996 |
| 0.0101 | 3.6900 | 2500 | 0.0718 |
| 0.0044 | 4.0590 | 2750 | 0.0825 |
| 0.0123 | 4.4280 | 3000 | 0.0969 |
| 0.0031 | 4.7970 | 3250 | 0.0924 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Kiran2004/Electra_QCA_Custom
|
Kiran2004
| 2024-04-25T16:55:09Z | 59 | 0 |
transformers
|
[
"transformers",
"tf",
"electra",
"question-answering",
"generated_from_keras_callback",
"base_model:deepset/electra-base-squad2",
"base_model:finetune:deepset/electra-base-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-04-25T16:30:30Z |
---
license: cc-by-4.0
base_model: deepset/electra-base-squad2
tags:
- generated_from_keras_callback
model-index:
- name: Kiran2004/Electra_QCA_Custom
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Kiran2004/Electra_QCA_Custom
This model is a fine-tuned version of [deepset/electra-base-squad2](https://huggingface.co/deepset/electra-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0010
- Validation Loss: 0.0001
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 100, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.8202 | 0.0015 | 0 |
| 0.0166 | 0.0002 | 1 |
| 0.0027 | 0.0001 | 2 |
| 0.0010 | 0.0001 | 3 |
### Framework versions
- Transformers 4.40.0
- TensorFlow 2.15.0
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Asubramanian19/q-FrozenLake-v1-4x4-Slippery
|
Asubramanian19
| 2024-04-25T16:54:38Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-04-25T16:54:34Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.34 +/- 0.47
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Asubramanian19/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
dapooni/sorsolingo-mt-tl-bsl-test
|
dapooni
| 2024-04-25T16:53:36Z | 105 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"base_model:Helsinki-NLP/opus-mt-en-bcl",
"base_model:finetune:Helsinki-NLP/opus-mt-en-bcl",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2024-04-25T16:43:32Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-bcl
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: sorsolingo-mt-tl-bsl-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sorsolingo-mt-tl-bsl-test
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-bcl](https://huggingface.co/Helsinki-NLP/opus-mt-en-bcl) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3029
- Bleu: 9.6771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 22
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Augusto777/vit-base-patch16-224-dmae-va-U5-100bc
|
Augusto777
| 2024-04-25T16:50:47Z | 194 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-04-25T16:42:40Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-dmae-va-U5-100bc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-dmae-va-U5-100bc
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5017
- Accuracy: 0.8667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.9 | 7 | 0.5017 | 0.8667 |
| 0.3168 | 1.94 | 15 | 0.5970 | 0.8 |
| 0.2613 | 2.97 | 23 | 0.5442 | 0.8167 |
| 0.222 | 4.0 | 31 | 0.7156 | 0.7667 |
| 0.222 | 4.9 | 38 | 0.5175 | 0.85 |
| 0.1783 | 5.94 | 46 | 0.6035 | 0.8167 |
| 0.168 | 6.97 | 54 | 0.5045 | 0.85 |
| 0.1456 | 8.0 | 62 | 0.4923 | 0.85 |
| 0.1456 | 8.9 | 69 | 0.5346 | 0.85 |
| 0.1236 | 9.03 | 70 | 0.5346 | 0.85 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
pyp1/VoiceCraft_330M_TTSEnhanced
|
pyp1
| 2024-04-25T16:47:32Z | 59 | 1 |
voicecraft
|
[
"voicecraft",
"safetensors",
"text-to-speech",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"region:us"
] |
text-to-speech
| 2024-04-25T16:46:55Z |
---
library_name: voicecraft
tags:
- text-to-speech
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/jasonppy/VoiceCraft
---
This model has been pushed to the Hub using **voicecraft**:
- Repo: https://github.com/jasonppy/VoiceCraft
- Docs: [More Information Needed]
|
YaroslavPrytula/detr
|
YaroslavPrytula
| 2024-04-25T16:46:06Z | 190 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2024-04-25T15:51:20Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: detr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9698
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.237 | 0.2 | 500 | 1.0990 |
| 1.0403 | 0.4 | 1000 | 0.9698 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
terry69/llama2-poison-10p-full
|
terry69
| 2024-04-25T16:44:37Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T16:41:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RobertML/sn6
|
RobertML
| 2024-04-25T16:39:07Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-19T13:16:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Chantland/Hraf_Multilabel_K-foldsCrossValDemo
|
Chantland
| 2024-04-25T16:37:00Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"anthropology",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-01-04T16:58:59Z |
---
tags:
- anthropology
- text-classification
widget:
- text: "The baire say -- and the Indians believe -- that illnesses are due to bodies placed by the maeréboe on the part of the ailing organism. Many times they say that it is an insect, a stone, a tooth, a claw, /Illustration appears here/ 102 etc."
example_title: "Bororo"
- text: "In the decoration of the skin by means of pigments for the feast of Dabukurí , it is always the woman who applies the paint to the man, besides dressing him with his garb of feathers. If the man is married, it is his only wife or the principal wife, in case he has several, who assists him. In the case of a single man, any woman of the community does this work, and the single man contracts with this woman the same obligations and the same rights that a compadre has toward his comadre in the Colombian Creole culture. Besides painting the skin for occasions as esteemed as the feast of the Dabukurí , the daily painting of the face is common. In this case, the function of the pigment is simply aesthetic or for protection from the sun. In the decoration of the body and the extremities, 104 cylindrical wooden pintaderas, which imprint geometric decorations, are used."
example_title: "Tukano"
- text: "The portents for Jugah's life were apparent in the first year of his life. At a time when one in two Iban infants died during the first year of life, Jugah was a vigorous, alert, and responsive infant. His family situation was a healthful one in which he thrived. Further, in contrast to many other Iban children who were sickly and went through a ritual change of names ( misab ka penama ) in an effort by their parents to improve their health, Jugah retained the name he was first given throughout his life."
example_title: "Iban"
- text: "Did you ever hear the tragedy of Darth Plagueis The Wise? I thought not. It’s not a story the Jedi would tell you. It’s a Sith legend. Darth Plagueis was a Dark Lord of the Sith, so powerful and so wise he could use the Force to influence the midichlorians to create life… He had such a knowledge of the dark side that he could even keep the ones he cared about from dying. The dark side of the Force is a pathway to many abilities some consider to be unnatural. He became so powerful… the only thing he was afraid of was losing his power, which eventually, of course, he did. Unfortunately, he taught his apprentice everything he knew, then his apprentice killed him in his sleep. Ironic. He could save others from death, but not himself."
example_title: "Star Wars"
---
Continuation of Multi-Label Text classification model used to decode if passages contain a misfortunate event,
a cause for misfortune, and/or an action to mollify or prevent some misfortune. This version implements 5 fold cross validation to improve model performance. We added additional training sets growing the model to 7277 passages train.
The F1 micro score for 1820 passages not used for training or validation (the test set) was .851. individual class f1 scores shown below.
<br>EVENT: 0.907
<br>CAUSE: 0.822
<br>ACTION: 0.805
<br>
Compare this to the <a href="https://huggingface.co/Chantland/Hraf_MultiLabel" target="_blank" rel="noopener noreferrer"> old model </a> using the same test set. F1 micro = .828
<br>EVENT: 0.871
<br>CAUSE: 0.81
<br>ACTION: 0.793
<br>
<br><br><br>
For a quick demo, try typing in a sentence or even a paragraph in the <b>Hosted inference API</b> then pressing "compute"!
|
TJLeiber/wav2vec2-standard_model0-xlsr-53-fr-colab
|
TJLeiber
| 2024-04-25T16:35:34Z | 12 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"fr",
"dataset:mozilla-foundation/common_voice_17_0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-04-25T10:50:55Z |
---
language:
- fr
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
model-index:
- name: acoustic_model0_cv_17_fr_XLSR-53
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# acoustic_model0_cv_17_fr_XLSR-53
This model was trained from scratch on the Common Voice 17 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.4810
- eval_wer: 0.3881
- eval_runtime: 167.4913
- eval_samples_per_second: 6.538
- eval_steps_per_second: 0.818
- epoch: 11.0465
- step: 1600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
justshao/LORA_gemma_trained_on_MMLU_5shot_test
|
justshao
| 2024-04-25T16:31:12Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:justshao/gemma-7b-with-confidence",
"base_model:adapter:justshao/gemma-7b-with-confidence",
"license:gemma",
"region:us"
] | null | 2024-04-25T10:31:43Z |
---
license: gemma
library_name: peft
tags:
- generated_from_trainer
base_model: justshao/gemma-7b-with-confidence
model-index:
- name: LORA_gemma_trained_on_MMLU_5shot_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LORA_gemma_trained_on_MMLU_5shot_test
This model is a fine-tuned version of [justshao/gemma-7b-with-confidence](https://huggingface.co/justshao/gemma-7b-with-confidence) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3002 | 1.0 | 877 | 0.2812 |
| 0.2731 | 2.0 | 1755 | 0.2820 |
| 0.2539 | 3.0 | 2632 | 0.2787 |
| 0.2419 | 4.0 | 3510 | 0.2775 |
| 0.2351 | 5.0 | 4385 | 0.2779 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.3
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
FAYSSAL12/ppo-LunarLander-v2
|
FAYSSAL12
| 2024-04-25T16:22:25Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-04-25T16:22:05Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.74 +/- 28.28
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
michaeltrs/text2face
|
michaeltrs
| 2024-04-25T16:18:09Z | 0 | 0 |
diffusers
|
[
"diffusers",
"lora",
"image-generation",
"diffusion",
"face-generation",
"text-conditioned-human-portrait",
"synthetic-captions",
"en",
"license:mit",
"region:us"
] | null | 2024-04-25T10:24:33Z |
---
license: mit
language:
- en
library_name: diffusers
tags:
- lora
- image-generation
- diffusion
- face-generation
- text-conditioned-human-portrait
- synthetic-captions
- diffusers
---
# Text2Face-LoRa


This is a LoRa-finetuned version of the Stable Diffusion 2.1 model specifically optimized
for generating face images. The model was trained with [FFHQ](https://github.com/NVlabs/ffhq-dataset) and [easyportrait](https://github.com/hukenovs/easyportrait)
using synthetic text captions for both datasets.
Details on the dataset format and preparation will be available soon.
## Checkpoints
You can download the pretrained LoRa weights for the diffusion model and text encoder using
```python
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="michaeltrs/text2face",
filename="checkpoints/lora30k/pytorch_lora_weights.safetensors",
local_dir="checkpoints")
```
## Inference
Generate images using the `generate.py` script, which loads the SD2.1 foundation model from Hugging Face and applies the LoRa weights.
Generation is driven by defining a prompt and optionally a negative prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
class Model:
def __init__(self, checkpoint="checkpoints/lora30k", weight_name="pytorch_lora_weights.safetensors", device="cuda"):
self.checkpoint = checkpoint
state_dict, network_alphas = StableDiffusionPipeline.lora_state_dict(
# Path to my trained lora output_dir
checkpoint,
weight_name=weight_name
)
self.pipe = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16).to(device)
self.pipe.load_lora_into_unet(state_dict, network_alphas, self.pipe.unet, adapter_name='test_lora')
self.pipe.load_lora_into_text_encoder(state_dict, network_alphas, self.pipe.text_encoder, adapter_name='test_lora')
self.pipe.set_adapters(["test_lora"], adapter_weights=[1.0])
def generate(self, prompt, negprompt='', steps=50, savedir=None, seed=1):
lora_scale = 1.0
image = self.pipe(prompt,
negative_prompt=negprompt,
num_inference_steps=steps,
cross_attention_kwargs={"scale": lora_scale},
generator=torch.manual_seed(seed)).images[0]
if savedir is None:
image.save(f"{self.checkpoint}/{'_'.join(prompt.replace('.', ' ').split(' '))}.png")
else:
image.save(f"{savedir}/{'_'.join(prompt.replace('.', ' ').split(' '))}.png")
return image
if __name__ == "__main__":
model = Model()
prompt = 'A happy 55 year old male with blond hair and a goatee smiles with visible teeth.'
negprompt = ''
image = model.generate(prompt, negprompt=negprompt, steps=50, seed=42)
```
## Limitations
This model, Text2Face-LoRa, is finetuned from Stable Diffusion 2.1 and as such, inherits all the limitations and biases
associated with the base model. These biases may manifest in skewed representations across different ethnicities and
genders due to the nature of the training data originally used for Stable Diffusion 2.1.
### Specific Limitations Include:
- **Ethnic and Gender Biases**: The model may generate images that do not equally represent the diversity of human
features in different ethnic and gender groups, potentially reinforcing or exacerbating existing stereotypes.
- **Selection Bias in Finetuning Datasets**: The datasets used for finetuning this model were selected with specific
criteria in mind, which may not encompass a wide enough variety of data points to correct for the inherited biases of the base model.
- **Caption Generation Bias**: The synthetic annotations used to finetune this model were generated by automated
face analysis models, which themselves may be biased. This could lead to inaccuracies in facial feature interpretation
and representation, particularly for less-represented demographics in the training data.
### Ethical Considerations:
Users are encouraged to consider these limitations when deploying the model in real-world applications, especially
those involving diverse human subjects. It is advisable to perform additional validations and seek ways to mitigate
these biases in practical use cases.
|
ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_5
|
ShenaoZ
| 2024-04-25T16:15:07Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:updated",
"dataset:original",
"base_model:ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_4",
"base_model:finetune:ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_4",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T15:26:56Z |
---
license: mit
base_model: ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_4
tags:
- alignment-handbook
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
datasets:
- updated
- original
model-index:
- name: 0.001_ablation_5iters_bs256_useresponse_iter_5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.001_ablation_5iters_bs256_useresponse_iter_5
This model is a fine-tuned version of [ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_4](https://huggingface.co/ShenaoZ/0.001_ablation_5iters_bs256_useresponse_iter_4) on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
|
Entreprenerdly/blip2-opt-2.7b-football-captions-adapters
|
Entreprenerdly
| 2024-04-25T16:14:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-25T16:14:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lancelot53/rna_tokenizer_v4_4096
|
Lancelot53
| 2024-04-25T16:13:17Z | 1 | 1 |
transformers
|
[
"transformers",
"bert",
"fill-mask",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-04-25T14:54:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Asmaamaghraby/historyqa_model
|
Asmaamaghraby
| 2024-04-25T16:12:34Z | 71 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:aubmindlab/bert-base-arabertv2",
"base_model:finetune:aubmindlab/bert-base-arabertv2",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-04-25T15:41:33Z |
---
base_model: aubmindlab/bert-base-arabertv2
tags:
- generated_from_keras_callback
model-index:
- name: Asmaamaghraby/historyqa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Asmaamaghraby/historyqa_model
This model is a fine-tuned version of [aubmindlab/bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.1424
- Validation Loss: 3.0324
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 42, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.6890 | 3.5754 | 0 |
| 3.3347 | 3.0324 | 1 |
| 3.1365 | 3.0324 | 2 |
| 3.1489 | 3.0324 | 3 |
| 3.1397 | 3.0324 | 4 |
| 3.1409 | 3.0324 | 5 |
| 3.1439 | 3.0324 | 6 |
| 3.1297 | 3.0324 | 7 |
| 3.1456 | 3.0324 | 8 |
| 3.1424 | 3.0324 | 9 |
### Framework versions
- Transformers 4.40.0
- TensorFlow 2.15.0
- Datasets 2.19.0
- Tokenizers 0.19.1
|
CMU-AIR2/math-deepseek-LORA-ArithHard
|
CMU-AIR2
| 2024-04-25T16:10:49Z | 5 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"arxiv:1910.09700",
"base_model:deepseek-ai/deepseek-coder-1.3b-instruct",
"base_model:adapter:deepseek-ai/deepseek-coder-1.3b-instruct",
"region:us"
] | null | 2024-04-23T04:19:52Z |
---
library_name: peft
base_model: deepseek-ai/deepseek-coder-1.3b-instruct
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2
|
Karimsliti/karim_codellama_merged
|
Karimsliti
| 2024-04-25T16:07:09Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T15:53:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
automerger/M7Percival_01-7B
|
automerger
| 2024-04-25T16:06:23Z | 0 | 0 | null |
[
"merge",
"mergekit",
"lazymergekit",
"automerger",
"license:apache-2.0",
"region:us"
] | null | 2024-04-25T16:06:21Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
---
# M7Percival_01-7B
M7Percival_01-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
- model: liminerity/M7-7b
- model: AurelPx/Percival_01-7b-slerp
merge_method: model_stock
base_model: mistralai/Mistral-7B-v0.1
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/M7Percival_01-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
melabelen/mela-tw-sentiment-model
|
melabelen
| 2024-04-25T16:04:37Z | 119 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-25T15:36:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
base_model: distilbert/distilbert-base-uncased
metrics:
- accuracy
model-index:
- name: test_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3773
- Accuracy: 0.6719
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6515 | 1.0 | 5702 | 0.6429 | 0.73 |
| 0.4767 | 2.0 | 11404 | 0.6908 | 0.7275 |
| 0.2759 | 3.0 | 17106 | 1.1133 | 0.7265 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
kiko2001/llama-3-coding-mkd
|
kiko2001
| 2024-04-25T15:54:49Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-04-25T15:21:23Z |
---
library_name: transformers
tags:
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
marcagve18/baby-face-generation
|
marcagve18
| 2024-04-25T15:49:26Z | 30 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2024-04-25T15:46:38Z |
---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tomaarsen/glove-wikipedia-tf-idf
|
tomaarsen
| 2024-04-25T15:48:58Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"sentence-similarity",
"feature-extraction",
"loss:CosineSimilarityLoss",
"en",
"arxiv:1908.10084",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-04-25T15:48:11Z |
---
language:
- en
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- loss:CosineSimilarityLoss
metrics:
- pearson_cosine
- spearman_cosine
- pearson_manhattan
- spearman_manhattan
- pearson_euclidean
- spearman_euclidean
- pearson_dot
- spearman_dot
- pearson_max
- spearman_max
widget:
- source_sentence: Women are running.
sentences:
- Women are running.
- A brown horse in a green field.
- A man plays the guitar and sings.
- source_sentence: A baby is laughing.
sentences:
- A baby is crawling happily.
- ‘Nelson Mandela is recovering’
- Chinese shares close higher on Tuesday
- source_sentence: A woman is reading.
sentences:
- A woman is writing something.
- A slow loris hanging on a cord.
- The lamb is looking at the camera.
- source_sentence: A man jumping rope
sentences:
- A man is climbing a rope.
- Blast on Indian train kills one
- Finance minister promises no new taxes
- source_sentence: A woman is dancing.
sentences:
- A man is dancing.
- A brown horse in a green field.
- Australia cuts rates to record low
pipeline_tag: sentence-similarity
co2_eq_emissions:
emissions: 0.1439181045681014
energy_consumed: 0.0003702530590737928
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 0.009
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: SentenceTransformer
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts dev
type: sts-dev
metrics:
- type: pearson_cosine
value: 0.757199024718024
name: Pearson Cosine
- type: spearman_cosine
value: 0.7531549457233511
name: Spearman Cosine
- type: pearson_manhattan
value: 0.716988424804303
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.7272795203957675
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.71702575877283
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.7268093526359362
name: Spearman Euclidean
- type: pearson_dot
value: 0.5785350115318801
name: Pearson Dot
- type: spearman_dot
value: 0.6221005727058916
name: Spearman Dot
- type: pearson_max
value: 0.757199024718024
name: Pearson Max
- type: spearman_max
value: 0.7531549457233511
name: Spearman Max
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test
type: sts-test
metrics:
- type: pearson_cosine
value: 0.6689490577594517
name: Pearson Cosine
- type: spearman_cosine
value: 0.6405445334782408
name: Spearman Cosine
- type: pearson_manhattan
value: 0.6176678945140798
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.615214522139229
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.6184837579619497
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.6162673767473799
name: Spearman Euclidean
- type: pearson_dot
value: 0.50934636927282
name: Pearson Dot
- type: spearman_dot
value: 0.5194344025197553
name: Spearman Dot
- type: pearson_max
value: 0.6689490577594517
name: Pearson Max
- type: spearman_max
value: 0.6405445334782408
name: Spearman Max
---
# SentenceTransformer
This is a [sentence-transformers](https://www.SBERT.net) model trained on the [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb) dataset. It maps sentences & paragraphs to a 300-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
<!-- - **Base model:** [Unknown](https://huggingface.co/unknown) -->
- **Maximum Sequence Length:** 1000000 tokens
- **Output Dimensionality:** 300 tokens
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb)
- **Language:** en
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): WordEmbeddings(
(emb_layer): Embedding(400001, 300)
)
(1): WordWeights(
(emb_layer): Embedding(400001, 1)
)
(2): Pooling({'word_embedding_dimension': 300, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(3): Dense({'in_features': 300, 'out_features': 300, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
(4): Dense({'in_features': 300, 'out_features': 300, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("tomaarsen/glove-wikipedia-tf-idf")
# Run inference
sentences = [
'A woman is dancing.',
'A man is dancing.',
'A brown horse in a green field.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 300]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Dataset: `sts-dev`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.7572 |
| **spearman_cosine** | **0.7532** |
| pearson_manhattan | 0.717 |
| spearman_manhattan | 0.7273 |
| pearson_euclidean | 0.717 |
| spearman_euclidean | 0.7268 |
| pearson_dot | 0.5785 |
| spearman_dot | 0.6221 |
| pearson_max | 0.7572 |
| spearman_max | 0.7532 |
#### Semantic Similarity
* Dataset: `sts-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.6689 |
| **spearman_cosine** | **0.6405** |
| pearson_manhattan | 0.6177 |
| spearman_manhattan | 0.6152 |
| pearson_euclidean | 0.6185 |
| spearman_euclidean | 0.6163 |
| pearson_dot | 0.5093 |
| spearman_dot | 0.5194 |
| pearson_max | 0.6689 |
| spearman_max | 0.6405 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### sentence-transformers/stsb
* Dataset: [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb) at [d999f12](https://huggingface.co/datasets/sentence-transformers/stsb/tree/d999f12281623b0925506817d9bd85e88289218a)
* Size: 5,749 training samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 1 tokens</li><li>mean: 3.38 tokens</li><li>max: 11 tokens</li></ul> | <ul><li>min: 1 tokens</li><li>mean: 3.39 tokens</li><li>max: 10 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.54</li><li>max: 1.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:-----------------------------------------------------------|:----------------------------------------------------------------------|:------------------|
| <code>A plane is taking off.</code> | <code>An air plane is taking off.</code> | <code>1.0</code> |
| <code>A man is playing a large flute.</code> | <code>A man is playing a flute.</code> | <code>0.76</code> |
| <code>A man is spreading shreded cheese on a pizza.</code> | <code>A man is spreading shredded cheese on an uncooked pizza.</code> | <code>0.76</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Evaluation Dataset
#### sentence-transformers/stsb
* Dataset: [sentence-transformers/stsb](https://huggingface.co/datasets/sentence-transformers/stsb) at [d999f12](https://huggingface.co/datasets/sentence-transformers/stsb/tree/d999f12281623b0925506817d9bd85e88289218a)
* Size: 1,500 evaluation samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 1 tokens</li><li>mean: 5.17 tokens</li><li>max: 12 tokens</li></ul> | <ul><li>min: 1 tokens</li><li>mean: 5.08 tokens</li><li>max: 15 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.47</li><li>max: 1.0</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:--------------------------------------------------|:------------------------------------------------------|:------------------|
| <code>A man with a hard hat is dancing.</code> | <code>A man wearing a hard hat is dancing.</code> | <code>1.0</code> |
| <code>A young child is riding a horse.</code> | <code>A child is riding a horse.</code> | <code>0.95</code> |
| <code>A man is feeding a mouse to a snake.</code> | <code>The man is feeding a mouse to the snake.</code> | <code>1.0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `fp16`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: False
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: None
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | loss | sts-dev_spearman_cosine | sts-test_spearman_cosine |
|:------:|:----:|:-------------:|:------:|:-----------------------:|:------------------------:|
| 0.5556 | 100 | 0.0819 | 0.0584 | 0.7532 | - |
| 1.0 | 180 | - | - | - | 0.6405 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.000 kWh
- **Carbon Emitted**: 0.000 kg of CO2
- **Hours Used**: 0.009 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 3.0.0.dev0
- Transformers: 4.41.0.dev0
- PyTorch: 2.3.0+cu121
- Accelerate: 0.26.1
- Datasets: 2.18.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Karimsliti/karim_codellama
|
Karimsliti
| 2024-04-25T15:47:54Z | 7 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:codellama/CodeLlama-7b-hf",
"base_model:adapter:codellama/CodeLlama-7b-hf",
"license:llama2",
"region:us"
] | null | 2024-04-20T11:38:58Z |
---
license: llama2
base_model: codellama/CodeLlama-7b-hf
tags:
- generated_from_trainer
model-index:
- name: karim_codellama
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/llm_project/llm_project-org/runs/nb0hywqq)
# karim_codellama
This model is a fine-tuned version of [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- _load_in_8bit: True
- _load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
- bnb_4bit_quant_storage: uint8
- load_in_4bit: False
- load_in_8bit: True
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.146 | 0.0787 | 20 | 1.2504 |
| 0.8176 | 0.1573 | 40 | 0.6454 |
| 0.6291 | 0.2360 | 60 | 0.4881 |
| 0.3068 | 0.3147 | 80 | 0.3589 |
| 0.5266 | 0.3933 | 100 | 0.4066 |
| 0.302 | 0.4720 | 120 | 0.2728 |
| 0.1989 | 0.5506 | 140 | 0.2604 |
| 0.3157 | 0.6293 | 160 | 0.2502 |
| 0.1768 | 0.7080 | 180 | 0.2285 |
| 0.4553 | 0.7866 | 200 | 0.2575 |
| 0.2183 | 0.8653 | 220 | 0.2152 |
| 0.1815 | 0.9440 | 240 | 0.2148 |
| 0.2704 | 1.0226 | 260 | 0.2142 |
| 0.1662 | 1.1013 | 280 | 0.2001 |
| 0.3306 | 1.1799 | 300 | 0.2065 |
| 0.2161 | 1.2586 | 320 | 0.1967 |
| 0.1429 | 1.3373 | 340 | 0.1925 |
| 0.2892 | 1.4159 | 360 | 0.1927 |
| 0.1459 | 1.4946 | 380 | 0.1894 |
| 0.3078 | 1.5733 | 400 | 0.1887 |
### Framework versions
- PEFT 0.6.0.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.1.2
- Datasets 2.19.0
- Tokenizers 0.19.1
|
yuvalalaluf/MyVLM
|
yuvalalaluf
| 2024-04-25T15:45:40Z | 0 | 1 | null |
[
"arxiv:2403.14599",
"license:other",
"region:us"
] | null | 2024-04-25T15:30:00Z |
---
license: other
license_name: myvlm-snap-license
license_link: https://github.com/snap-research/MyVLM/blob/master/LICENSE
---
# MyVLM
**Paper:** https://arxiv.org/abs/2403.14599
**Project Page:** https://snap-research.github.io/MyVLM/
**Code:** https://github.com/snap-research/MyVLM
# MyVLM Concept Heads & Concept Embeddings
As part of our [MyVLM code](https://github.com/snap-research/MyVLM) release, we have also released pretrained concept heads and concept embeddings for all 29 objects used in the paper.
These can be loaded using the `CLIPConceptHead` class and our inference scripts for reproducing the paper results.
This repository contains 5 concept heads for each object, representing five different training seeds and sets of images used for training.
## Concept Heads
<p align="center">
<img src="docs/concept_head.jpg" width="200px"/>
For each user-specific concept, we introduce an external concept head designed to identify the presence of the concept within an image.
</p>
As mentioned in the paper, we have two types of concept heads:
1. A facial recognition model for recognizing individuals
2. A CLIP-based concept head for recognizing user-specific objects
For faces, we use the `buffalo_l` face detection and face recognition model from [insightface](https://github.com/deepinsight/insightface/tree/master).
See `concept_heads/face_recognition/head.py` for usage.
For objects, we train a single linear layer over features extracted from a CLIP ViT-H/14 model (`DFN5B-CLIP-ViT-H-14-384`).
See `concept_heads/clip/head.py` for usage.
## Concept Embeddings
<p align="center">
<img src="docs/method.jpg" width="800px"/>
Having identified the presence of a user-specific concept within an image, a learned concept embedding representing an object or individual is used to guide the LLM in incorporating the concept into its personalized textual response.
</p>
The concept embeddings are saved as `.pt` files in the following format:
```
{
10: {
"keys": torch.Tensor(), # the keys used for optimizing the concept embedding
"values": torch.Tensor(), # the concept embedding itself
},
...
20: {
"keys": torch.Tensor(),
"values": torch.Tensor(),
},
...
}
```
where each entry in the dictionary represents a different checkpoint during the optimization process.
We provide the concept embeddings for personalized captioning using both BLIP-2 and LLaVA.
## License
This sample code is made available by Snap Inc. for non-commercial, academic purposes only.
Please see the full license [here](https://github.com/snap-research/MyVLM/blob/master/LICENSE).
|
levent1/dinov2-base-finetuned-oxford
|
levent1
| 2024-04-25T15:45:11Z | 168 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"dinov2",
"image-classification",
"generated_from_trainer",
"base_model:facebook/dinov2-base",
"base_model:finetune:facebook/dinov2-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-04-25T15:21:30Z |
---
license: apache-2.0
base_model: facebook/dinov2-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: dinov2-base-finetuned-oxford
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dinov2-base-finetuned-oxford
This model is a fine-tuned version of [facebook/dinov2-base](https://huggingface.co/facebook/dinov2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2296
- Accuracy: 0.9319
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0593 | 1.0 | 230 | 0.6444 | 0.7855 |
| 0.4115 | 2.0 | 460 | 0.4093 | 0.8705 |
| 0.0495 | 3.0 | 690 | 0.2296 | 0.9319 |
### Framework versions
- Transformers 4.40.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.