
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 18:27:06
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 526
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 18:26:56
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg
|
vocabtrimmer
| 2023-03-27T09:14:30Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"question generation",
"es",
"dataset:lmqg/qg_esquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-20T17:58:31Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: es
datasets:
- lmqg/qg_esquad
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "del <hl> Ministerio de Desarrollo Urbano <hl> , Gobierno de la India."
example_title: "Question Generation Example 1"
- text: "a <hl> noviembre <hl> , que es también la estación lluviosa."
example_title: "Question Generation Example 2"
- text: "como <hl> el gobierno de Abbott <hl> que asumió el cargo el 18 de septiembre de 2013."
example_title: "Question Generation Example 3"
model-index:
- name: vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_esquad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 9.45
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 24.37
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 22.59
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 84.15
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 58.96
---
# Model Card of `vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg`
This model is fine-tuned version of [ckpts/mt5-small-trimmed-es-120000](https://huggingface.co/ckpts/mt5-small-trimmed-es-120000) for question generation task on the [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [ckpts/mt5-small-trimmed-es-120000](https://huggingface.co/ckpts/mt5-small-trimmed-es-120000)
- **Language:** es
- **Training data:** [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="es", model="vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg")
# model prediction
questions = model.generate_q(list_context="a noviembre , que es también la estación lluviosa.", list_answer="noviembre")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg")
output = pipe("del <hl> Ministerio de Desarrollo Urbano <hl> , Gobierno de la India.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_esquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 84.15 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_1 | 25.99 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_2 | 17.64 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_3 | 12.73 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_4 | 9.45 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| METEOR | 22.59 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| MoverScore | 58.96 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| ROUGE_L | 24.37 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_esquad
- dataset_name: default
- input_types: paragraph_answer
- output_types: question
- prefix_types: None
- model: ckpts/mt5-small-trimmed-es-120000
- max_length: 512
- max_length_output: 32
- epoch: 13
- batch: 16
- lr: 0.001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-es-120000-esquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
phatho/NeverEnding-Dream
|
phatho
| 2023-03-27T08:49:36Z | 8 | 2 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"art",
"artistic",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-27T08:48:49Z |
---
language:
- en
license: other
tags:
- stable-diffusion
- text-to-image
- art
- artistic
- diffusers
inference: true
duplicated_from: Lykon/NeverEnding-Dream
---
# NeverEnding Dream (NED)
## Official Repository
Read more about this model here: https://civitai.com/models/10028/neverending-dream-ned
Also please support by giving 5 stars and a heart, which will notify new updates.
Also consider supporting me on Patreon or ByuMeACoffee
- https://www.patreon.com/Lykon275
- https://www.buymeacoffee.com/lykon
You can run this model on:
- https://sinkin.ai/m/qGdxrYG
Some sample output:






|
jamesimmanuel/a2c-PandaReachDense-v2
|
jamesimmanuel
| 2023-03-27T08:39:05Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T08:36:38Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.26 +/- 0.24
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
lio/ppo-Huggy
|
lio
| 2023-03-27T08:32:46Z | 6 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-03-27T08:32:39Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: lio/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
aallal-prestataire/scene-classifier-demo-2
|
aallal-prestataire
| 2023-03-27T08:10:38Z | 226 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-03-27T07:49:13Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: scene-classifier-demo-2
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.986760139465332
---
# scene-classifier-demo-2
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### carte

#### credits

#### generique

#### meteo

#### plateau

#### reportage

#### sommaire

|
VuDucQuang/Dreambooth-Avatar
|
VuDucQuang
| 2023-03-27T08:05:19Z | 49 | 1 |
diffusers
|
[
"diffusers",
"dreambooth",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-27T08:02:49Z |
---
language:
- en
thumbnail: "https://staticassetbucket.s3.us-west-1.amazonaws.com/avatar_grid.png"
tags:
- dreambooth
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
# Dreambooth style: Avatar
__Dreambooth finetuning of Stable Diffusion (v1.5.1) on Avatar art style by [Lambda Labs](https://lambdalabs.com/).__
## About
This text-to-image stable diffusion model was trained with dreambooth.
Put in a text prompt and generate your own Avatar style image!

## Usage
To run model locally:
```bash
pip install accelerate torchvision transformers>=4.21.0 ftfy tensorboard modelcards
```
```python
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
pipe = StableDiffusionPipeline.from_pretrained("lambdalabs/dreambooth-avatar", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "Yoda, avatarart style"
scale = 7.5
n_samples = 4
with autocast("cuda"):
images = pipe(n_samples*[prompt], guidance_scale=scale).images
for idx, im in enumerate(images):
im.save(f"{idx:06}.png")
```
## Model description
Base model is Stable Diffusion v1.5 and was trained using Dreambooth with 60 input images sized 512x512 displaying Avatar character images.
The model is learning to associate Avatar images with the style tokenized as 'avatarart style'.
Prior preservation was used during training using the class 'Person' to avoid training bleeding into the representations for that class.
Training ran on 2xA6000 GPUs on [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud) for 700 steps, batch size 4 (a couple hours, at a cost of about $4).
Author: Eole Cervenka
|
VuDucQuang/Stable_Diffusion_v1.5
|
VuDucQuang
| 2023-03-27T07:59:42Z | 0 | 0 | null |
[
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-27T07:54:14Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Stable Diffusion v1-5 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion).
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Original GitHub Repository
1. Download the weights
- [v1-5-pruned-emaonly.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt) - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.ckpt](https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt) - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/runwayml/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
Maciel/T5Corrector-base-v1
|
Maciel
| 2023-03-27T07:58:09Z | 124 | 5 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text error correction",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-02-08T02:52:24Z |
---
language:
- zh
license: apache-2.0
tags:
- t5
- text error correction
widget:
- text: "今天天气不太好,我的心情也不是很偷快"
example_title: "案例1"
- text: "听到这个消息,心情真的蓝瘦"
example_title: "案例2"
- text: "脑子有点胡涂了,这道题冥冥学过还没有做出来"
example_title: "案例3"
inference:
parameters:
max_length: 256
num_beams: 10
no_repeat_ngram_size: 5
do_sample: True
early_stopping: True
---
## 功能介绍
T5Corrector:中文字音与字形纠错模型
这个模型是基于mengzi-t5-base进行文本纠错训练,使用500w+句子,通过替换同音词、近音词和形近字来构造纠错平行语料,共计3kw+句对,累计训练45000步。
<a href='https://github.com/Macielyoung/T5Corrector'>Github项目地址</a>
加载模型:
```python
# 加载模型
from transformers import T5Tokenizer, T5ForConditionalGeneration
pretrained = "Maciel/T5Corrector-base-v1"
tokenizer = T5Tokenizer.from_pretrained(pretrained)
model = T5ForConditionalGeneration.from_pretrained(pretrained)
```
使用模型进行预测推理方法:
```python
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
def correct(text, max_length):
model_inputs = tokenizer(text,
max_length=max_length,
truncation=True,
return_tensors="pt").to(device)
output = model.generate(**model_inputs,
num_beams=5,
no_repeat_ngram_size=4,
do_sample=True,
early_stopping=True,
max_length=max_length,
return_dict_in_generate=True,
output_scores=True)
pred_output = tokenizer.batch_decode(output.sequences, skip_special_tokens=True)[0]
return pred_output
text = "听到这个消息,心情真的蓝瘦"
correction = correct(text, max_length=32)
print(correction)
```
### 案例展示
```
示例1:
input: 听到这个消息,心情真的蓝瘦
output: 听到这个消息,心情真的难受
示例2:
input: 脑子有点胡涂了,这道题冥冥学过还没有做出来
output: 脑子有点糊涂了,这道题明明学过还没有做出来
示例3:
input: 今天天气不太好,我的心情也不是很偷快
output: 今天天气不太好,我的心情也不是很愉快
```
|
VuDucQuang/ControlNet
|
VuDucQuang
| 2023-03-27T07:55:34Z | 1 | 0 |
transformers
|
[
"transformers",
"art",
"controlnet",
"stable-diffusion",
"arxiv:2302.05543",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:openrail",
"endpoints_compatible",
"region:us"
] | null | 2023-03-27T07:52:00Z |
---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
---
# Controlnet - *Canny Version*
ControlNet is a neural network structure to control diffusion models by adding extra conditions.
This checkpoint corresponds to the ControlNet conditioned on **Canny edges**.
It can be used in combination with [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img).

## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Released Checkpoints
The authors released 8 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_canny.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_canny_1.png"/></a>|
|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)<br/> *Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_depth.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_depth.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_depth_2.png"/></a>|
|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)<br/> *Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_bird_hed.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_bird_hed.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_bird_hed_1.png"/></a> |
|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)<br/> *Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_mlsd.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_mlsd.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_mlsd_0.png"/></a>|
|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)<br/> *Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_normal.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_normal.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_normal_1.png"/></a>|
|[lllyasviel/sd-controlnet_openpose](https://huggingface.co/lllyasviel/sd-controlnet-openpose)<br/> *Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_human_openpose.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_human_openpose.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_human_openpose_0.png"/></a>|
|[lllyasviel/sd-controlnet_scribble](https://huggingface.co/lllyasviel/sd-controlnet-scribble)<br/> *Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_vermeer_scribble.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_vermeer_scribble.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_vermeer_scribble_0.png"/></a> |
|[lllyasviel/sd-controlnet_seg](https://huggingface.co/lllyasviel/sd-controlnet-seg)<br/>*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.|<a href="https://huggingface.co/takuma104/controlnet_dev/blob/main/gen_compare/control_images/converted/control_room_seg.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/control_images/converted/control_room_seg.png"/></a>|<a href="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"><img width="64" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare/output_images/diffusers/output_room_seg_1.png"/></a> |
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install opencv
```sh
$ pip install opencv-contrib-python
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers git+https://github.com/huggingface/accelerate.git
```
3. Run code:
```python
import cv2
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
import numpy as np
from diffusers.utils import load_image
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-hed/resolve/main/images/bird.png")
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-canny", torch_dtype=torch.float16
)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
image = pipe("bird", image, num_inference_steps=20).images[0]
image.save('images/bird_canny_out.png')
```



### Training
The canny edge model was trained on 3M edge-image, caption pairs. The model was trained for 600 GPU-hours with Nvidia A100 80G using Stable Diffusion 1.5 as a base model.
### Blog post
For more information, please also have a look at the [official ControlNet Blog Post](https://huggingface.co/blog/controlnet).
|
xinyixiuxiu/albert-xxlarge-v2-SST2-finetuned-epoch-2
|
xinyixiuxiu
| 2023-03-27T07:53:52Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"albert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T07:20:57Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: xinyixiuxiu/albert-xxlarge-v2-SST2-finetuned-epoch-2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# xinyixiuxiu/albert-xxlarge-v2-SST2-finetuned-epoch-2
This model is a fine-tuned version of [albert-xxlarge-v2](https://huggingface.co/albert-xxlarge-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2721
- Train Accuracy: 0.8858
- Validation Loss: 0.1265
- Validation Accuracy: 0.9564
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 3e-06, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.2721 | 0.8858 | 0.1265 | 0.9564 | 0 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.7.0
- Datasets 2.10.1
- Tokenizers 0.12.1
|
jamesimmanuel/a2c-AntBulletEnv-v0
|
jamesimmanuel
| 2023-03-27T07:40:37Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T07:39:29Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1812.33 +/- 61.20
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
swl-models/DanMix-v2.3
|
swl-models
| 2023-03-27T07:36:06Z | 0 | 2 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-27T04:11:44Z |
---
license: creativeml-openrail-m
---
|
circulus/alpaca-lora-7b
|
circulus
| 2023-03-27T07:21:53Z | 0 | 0 | null |
[
"license:gpl-3.0",
"region:us"
] | null | 2023-03-27T06:50:53Z |
---
license: gpl-3.0
---
This repo contains a low-rank adapter for LLaMA-7b model fit on the Stanford Alpaca dataset.
Also modified for enhance performance with 8 epoch training.
|
YoungMasterFromSect/Trauter_LoRAs
|
YoungMasterFromSect
| 2023-03-27T07:11:06Z | 0 | 519 | null |
[
"anime",
"region:us"
] | null | 2023-01-14T12:43:26Z |
---
tags:
- anime
---
NOTICE: My LoRAs require high amount of tags to look good, I will fix this later on and update all of my LoRAs if everything works out.
# General Information
- [Overview](#overview)
- [Installation](#installation)
- [Usage](#usage)
- [SocialMedia](#socialmedia)
- [Plans for the future](#plans-for-the-future)
# Overview
Welcome to the place where I host my LoRAs. In short, LoRA is just a checkpoint trained on specific artstyle/subject that you load into your WebUI, that can be used with other models.
Although you can use it with any model, the effects of LoRA will vary between them.
Most of the previews use models that come from [WarriorMama777](https://huggingface.co/WarriorMama777/OrangeMixs) .
For more information about them, you can visit the original LoRA repository: https://github.com/cloneofsimo/lora
Every images posted here, or on the other sites have metadata in them that you can use in PNG Info tab in your WebUI to get access to the prompt of the image.
Everything I do here is for free of charge!
I don't guarantee that my LoRAs will give you good results, if you think they are bad, don't use them.
# Installation
To use them in your WebUI, please install the extension linked under, following the installation guide:
https://github.com/kohya-ss/sd-webui-additional-networks#installation
# Usage
All of my LoRAs are to be used with their original danbooru tag. For example:
```
asuna \(blue archive\)
```
My LoRAs will have sufixes that will tell you how much they were trained. Either by using words like "soft" and "hard",
where soft stands for lower amount of training and hard for higher amount of training.
More trained LoRA is harder to modify but provides higher consistency in details and original outfits,
while lower trained one will be more flexible, but may get details wrong.
All the LoRAs that aren't marked with PRUNED require tagging everything about the character to get the likness of it.
You have to tag every part of the character like: eyes,hair,breasts,accessories,special features,etc...
In theory, this should allow LoRAs to be more flexible, but it requires to prompt those things always, because character tag doesn't have those features baked into it.
From 1/16 I will test releasing pruned versions which will not require those prompting those things.
The usage of them is also explained in this guide:
https://github.com/kohya-ss/sd-webui-additional-networks#how-to-use
# SocialMedia
Here are some places where you can find my other stuff that I post, or if you feel like buying me a coffee:
[Twitter](https://twitter.com/Trauter8)
[Pixiv](https://www.pixiv.net/en/users/88153216)
[Buymeacoffee](https://www.buymeacoffee.com/Trauter)
# Plans for the future
- Remake all of my LoRAs into pruned versions which will be more user friendly and easier to use, and use 768x768 res. for training and better Learning Rate
- After finishing all of my LoRA that I want to make, go over the old ones and try to make them better.
- Accept suggestions for almost every character.
- Maybe get motivation to actually tag outfits.
# LoRAs
- [Genshin Impact](#genshin-impact)
- [Eula](#eula)
- [Barbara](#barbara)
- [Diluc](#diluc)
- [Mona](#mona)
- [Rosaria](#rosaria)
- [Yae Miko](#yae-miko)
- [Raiden Shogun](#raiden-shogun)
- [Kujou Sara](#kujou-sara)
- [Shenhe](#shenhe)
- [Yelan](#yelan)
- [Jean](#jean)
- [Lisa](#lisa)
- [Zhongli](#zhongli)
- [Yoimiya](#yoimiya)
- [Blue Archive](#blue-archive)
- [Rikuhachima Aru](#rikuhachima-aru)
- [Ichinose Asuna](#ichinose-asuna)
- [Fate Grand Order](#fate-grand-order)
- [Minamoto-no-Raikou](#minamoto-no-raikou)
- [Misc. Characters](#misc.-characters)
- [Aponia](#aponia)
- [Reisalin Stout](#reisalin-stout)
- [Artstyles](#artstyles)
- [Pozer](#pozer)
# Genshin Impact
- # Eula
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/1.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/1.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305293076)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Eula)
- # Barbara
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/bar.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/bar.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305435137)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Barbara)
- # Diluc
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/dil.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/dil.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305427945)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Diluc)
- # Mona
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/mon.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/mon.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305428050)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Mona)
- # Rosaria
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ros.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ros.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305428015)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Rosaria)
- # Yae Miko
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/yae.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/yae.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305448948)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/yae%20miko)
- # Raiden Shogun
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ra.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ra.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, raiden shogun, 1girl, breasts, solo, cleavage, kimono, bangs, sash, mole, obi, tassel, blush, large breasts, purple eyes, japanese clothes, long hair, looking at viewer, hand on own chest, hair ornament, purple hair, bridal gauntlets, closed mouth, purple kimono, blue hair, mole under eye, shoulder armor, long sleeves, wide sleeves, mitsudomoe (shape), tomoe (symbol), cowboy shot
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, from behind
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 4.5, Seed: 2544310848, Size: 704x384, Model hash: 2bba3136, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 2.05, Hires upscaler: 4x_foolhardy_Remacri
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305313633)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Raiden%20Shogun)
- # Kujou Sara
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ku.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ku.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, kujou sara, 1girl, solo, mask, gloves, bangs, bodysuit, gradient, sidelocks, signature, yellow eyes, bird mask, mask on head, looking at viewer, short hair, black hair, detached sleeves, simple background, japanese clothes, black gloves, black bodysuit, wide sleeves, white background, upper body, gradient background, closed mouth, hair ornament, artist name, elbow gloves
Negative prompt: (worst quality, low quality:1.4)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 3966121353, Size: 512x768, Model hash: 931f9552, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires steps: 20, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305311498)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Kujou%20Sara)
- # Shenhe
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/sh.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/sh.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, shenhe \(genshin impact\), 1girl, solo, breasts, bodysuit, tassel, gloves, bangs, braid, outdoors, bird, jewelry, earrings, sky, breast curtain, long hair, hair over one eye, covered navel, blue eyes, looking at viewer, hair ornament, large breasts, shoulder cutout, clothing cutout, very long hair, hip vent, braided ponytail, partially fingerless gloves, black bodysuit, tassel earrings, black gloves, gold trim, cowboy shot, white hair
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 6.5, Seed: 573332187, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305307599)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Shenhe)
- # Yelan
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/10.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/10.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, yelan \(genshin impact\), 1girl, breasts, solo, bangs, armpits, smile, sky, cleavage, jewelry, gloves, jacket, dice, mole, cloud, grin, dress, blush, earrings, thighs, tassel, sleeveless, day, outdoors, large breasts, looking at viewer, green eyes, arms up, short hair, blue hair, vision (genshin impact), fur trim, white jacket, blue sky, mole on breast, arms behind head, bob cut, multicolored hair, black hair, fur-trimmed jacket, elbow gloves, bare shoulders, blue dress, parted lips, diagonal bangs, clothing cutout, pelvic curtain, asymmetrical gloves
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name
Steps: 23, Sampler: DPM++ SDE Karras, CFG scale: 6.5, Seed: 575500509, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.58, Clip skip: 2, ENSD: 31337, Hires upscale: 2.4, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305296897)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Yelan)
- # Jean
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/333.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/333.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, jean \(genshin impact\), 1girl, breasts, solo, cleavage, strapless, smile, ponytail, bangs, jewelry, earrings, bow, capelet, signature, sidelocks, cape, corset, shiny, blonde hair, long hair, upper body, detached sleeves, purple eyes, hair between eyes, hair bow, parted lips, looking to the side, large breasts, detached collar, medium breasts, blue capelet, white background, black bow, blue eyes, bare shoulders, simple background
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 7.5, Seed: 32930253, Size: 512x768, Model hash: ffa7b160, Denoising strength: 0.59, Clip skip: 2, ENSD: 31337, Hires upscale: 1.85, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305307594)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Jean)
- # Lisa
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/lis.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/lis.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, lisa \(genshin impact\), 1girl, solo, hat, breasts, gloves, cleavage, flower, smile, bangs, dress, rose, jewelry, witch, capelet, green eyes, witch hat, brown hair, purple headwear, looking at viewer, white background, large breasts, long hair, simple background, black gloves, purple flower, hair between eyes, upper body, purple rose, parted lips, purple capelet, hat flower, multicolored dress, hair ornament, multicolored clothes, vision (genshin impact)
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, worst quality, low quality, extra digits, loli, loli face
Steps: 23, Sampler: DPM++ SDE Karras, CFG scale: 6.5, Seed: 350134479, Size: 512x768, Model hash: ffa7b160, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.85, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305290865)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Lisa)
- # Zhongli
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/zho.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/zho.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, zhongli \(genshin impact\), solo, 1boy, bangs, jewelry, tassel, earrings, ponytail, low ponytail, gloves, necktie, jacket, shirt, formal, petals, suit, makeup, eyeliner, eyeshadow, male focus, long hair, brown hair, multicolored hair, long sleeves, tassel earrings, single earring, collared shirt, hair between eyes, black gloves, closed mouth, yellow eyes, gradient hair, orange hair, simple background
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, worst quality, low quality, extra digits, loli, loli face
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 88418604, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.58, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305311423)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Zhongli)
- # Yoimiya
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/Yoi.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/Yoi.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305448498)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Genshin-Impact/Yoimiya)
# Blue Archive
- # Rikuhachima Aru
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/22.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/22.png)
<details>
<summary>Sample Prompt</summary>
<pre>
aru \(blue archive\), masterpiece, best quality, 1girl, solo, horns, skirt, gloves, shirt, halo, window, breasts, blush, sweatdrop, ribbon, coat, bangs, :d, smile, indoors, standing, plant, thighs, sweat, jacket, day, sunlight, long hair, white shirt, white gloves, black skirt, looking at viewer, open mouth, long sleeves, red ribbon, fur trim, neck ribbon, red hair, fur-trimmed coat, collared shirt, orange eyes, medium breasts, brown coat, hands up, side slit, coat on shoulders, v-shaped eyebrows, yellow eyes, potted plant, fur collar, shirt tucked in, demon horns, high-waist skirt, dress shirt
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 6.5, Seed: 1190296645, Size: 512x768, Model hash: ffa7b160, Denoising strength: 0.58, Clip skip: 2, ENSD: 31337, Hires upscale: 1.85, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305293051)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Blue-Archive/Rikuhachima%20Aru)
- # Ichinose Asuna
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/asu.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/asu.png)
<details>
<summary>Sample Prompt</summary>
<pre>
photorealistic, (hyperrealistic:1.2), (extremely detailed CG unity 8k wallpaper), (ultra-detailed), (mature female:1.2), masterpiece, best quality, asuna \(blue archive\), 1girl, breasts, solo, gloves, pantyhose, ass, leotard, smile, tail, halo, grin, blush, bangs, sideboob, highleg, standing, mole, strapless, ribbon, thighs, animal ears, playboy bunny, rabbit ears, long hair, white gloves, very long hair, large breasts, high heels, blue leotard, hair over one eye, fake animal ears, blue eyes, looking at viewer, white footwear, rabbit tail, official alternate costume, full body, elbow gloves, simple background, white background, absurdly long hair, bare shoulders, detached collar, thighband pantyhose, leaning forward, highleg leotard, strapless leotard, hair ribbon, brown pantyhose, black pantyhose, mole on breast, light brown hair, brown hair, looking back, fake tail
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 6.5, Seed: 2052579935, Size: 512x768, Model hash: ffa7b160, Clip skip: 2, ENSD: 31337
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305292996)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Blue-Archive/Ichinose%20Asuna)
# Fate Grand Order
- # Minamoto-no-Raikou
- [<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/3.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/3.png)
<details>
<summary>Sample Prompt</summary>
<pre>
mature female, masterpiece, best quality, minamoto no raikou \(fate\), 1girl, breasts, solo, bodysuit, gloves, bangs, smile, rope, heart, blush, thighs, armor, kote, long hair, purple hair, fingerless gloves, purple eyes, large breasts, very long hair, looking at viewer, parted bangs, ribbed sleeves, black gloves, arm guards, covered navel, low-tied long hair, purple bodysuit, japanese armor
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 22, Sampler: DPM++ SDE Karras, CFG scale: 7.5, Seed: 3383453781, Size: 512x768, Model hash: ffa7b160, Denoising strength: 0.59, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305290900)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Fate-Grand-Order/Minamoto-no-Raikou)
# Misc. Characters
- # Aponia
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/apo.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/apo.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305445819)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Misc.%20Characters/Aponia)
- # Reisalin Stout
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ryza.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/ryza.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305448553)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Misc.%20Characters/reisalin%20stout)
# Artstyles
- # Pozer
[<img src="https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/art.png" width="512" height="768">](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/resolve/main/LoRA/Previews/art.png)
<details>
<summary>Sample Prompt</summary>
<pre>
masterpiece, best quality, eula \(genshin impact\), 1girl, solo, thighhighs, weapon, gloves, breasts, sword, hairband, necktie, holding, leotard, bangs, greatsword, cape, thighs, boots, blue hair, looking at viewer, arms up, vision (genshin impact), medium breasts, holding sword, long sleeves, holding weapon, purple eyes, medium hair, copyright name, hair ornament, thigh boots, black leotard, black hairband, blue necktie, black thighhighs, yellow eyes, closed mouth
Negative prompt: (worst quality, low quality, extra digits, loli, loli face:1.3)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2010519914, Size: 512x768, Model hash: a87fd7da, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, Hires upscale: 1.8, Hires upscaler: Latent (nearest-exact)
</pre>
</details>
- [Examples](https://www.flickr.com/photos/197461145@N04/albums/72177720305445399)
- [Download](https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs/tree/main/LoRA/Artstyles/Pozer)
|
Kukubuy/Kalacharam
|
Kukubuy
| 2023-03-27T06:49:34Z | 0 | 1 | null |
[
"text-image",
"en",
"license:openrail",
"region:us"
] | null | 2023-03-25T08:25:35Z |
---
license: openrail
language:
- en
tags:
- text-image
---
# Kalacharam
Aim of this model to be a good base model for India Culture things, currently its being trained on south indian models. There are few things i planned to train tamil architecture, foods, dresses etc.
**NOTE:** Those things mentioned above are my visionary i might train things or might not, if any one interested in it. feel free to reuse those models
### Model Training Details
- **Base Model:** ChillOutMix
- **Training Method:** FineTune
- **Steps:** 5000
- **Token:** TamilPonnu (Base)
- **Dataset:** 1500Images
## Example
<img style="display:inline;margin:0;padding:0;" src="https://huggingface.co/Kukubuy/Kalacharam/resolve/main/Sample_Images/SampleImage_1.png" width="45%"/>
<img style="display:inline;margin:0;padding:0;" src="https://huggingface.co/Kukubuy/Kalacharam/resolve/main/Sample_Images/SampleImage_2.png" width="45%"/>
<details><summary><big><b>Prompts</b></big></summary>
```yaml
(masterpiece, 1girl, solo, ultra-detailed:1.2), most beautiful girl in the world, (photography:1.2), photorealistic, sidelighting, very detailed image, best quality, (tamilponnu), (black dress + saree:1.2), realistic, black hair, Jewlery, earrings, smile, looking at viewer, saree, simple background AND white background, crystal eyes, black eye, long hair, wide shot, portrait, art by midjourney, front view
Negative prompt: lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, low quality, normal quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), (bindi:1.2)
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1125363210, Size: 512x768, Model: Kalacharam_Base, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: Latent
```
```yaml
(masterpiece, 1girl, solo, ultra-detailed:1.2), most beautiful girl in the world, (photography:1.2), photorealistic, sidelighting, very detailed image, best quality, (tamilponnu), (fashion, skirt:1.2), realistic, black hair, earrings, smile, looking at viewer, saree, simple background AND white background, crystal eyes, black eye, long hair, wide shot, portrait, art by midjourney, from front
Negative prompt: lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, low quality, normal quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts)), (bindi:1.2)
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2281761033, Size: 512x768, Model: Kalacharam_Base, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: Latent
```
|
intanm/mlm_v1_20230327_fin_sa_50
|
intanm
| 2023-03-27T06:45:24Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T06:39:09Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: mlm_v1_20230327_fin_sa_50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm_v1_20230327_fin_sa_50
This model is a fine-tuned version of [intanm/mlm-v1-fin-lm-20230327-001](https://huggingface.co/intanm/mlm-v1-fin-lm-20230327-001) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2202
- Accuracy: 0.9396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 51 | 0.2675 | 0.9121 |
| No log | 2.0 | 102 | 0.2202 | 0.9396 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
LowGI/STT_Model_17
|
LowGI
| 2023-03-27T06:43:22Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-27T02:26:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: STT_Model_17
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# STT_Model_17
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1172
- Wer: 0.1190
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.1934 | 2.1 | 500 | 3.7998 | 0.9999 |
| 1.14 | 4.2 | 1000 | 0.4083 | 0.3740 |
| 0.2217 | 6.3 | 1500 | 0.2515 | 0.2184 |
| 0.1276 | 8.4 | 2000 | 0.1623 | 0.1803 |
| 0.0914 | 10.5 | 2500 | 0.1586 | 0.1672 |
| 0.0731 | 12.61 | 3000 | 0.1648 | 0.1583 |
| 0.0572 | 14.71 | 3500 | 0.4059 | 0.1534 |
| 0.054 | 16.81 | 4000 | 0.1694 | 0.1391 |
| 0.043 | 18.91 | 4500 | 0.1390 | 0.1439 |
| 0.035 | 21.01 | 5000 | 0.1210 | 0.1362 |
| 0.0317 | 23.11 | 5500 | 0.1389 | 0.1285 |
| 0.031 | 25.21 | 6000 | 0.1340 | 0.1316 |
| 0.0266 | 27.31 | 6500 | 0.1312 | 0.1280 |
| 0.0209 | 29.41 | 7000 | 0.1484 | 0.1256 |
| 0.0184 | 31.51 | 7500 | 0.1345 | 0.1289 |
| 0.0201 | 33.61 | 8000 | 0.1350 | 0.1248 |
| 0.026 | 35.71 | 8500 | 0.1226 | 0.1235 |
| 0.016 | 37.82 | 9000 | 0.1235 | 0.1232 |
| 0.0115 | 39.92 | 9500 | 0.1223 | 0.1216 |
| 0.013 | 42.02 | 10000 | 0.1314 | 0.1206 |
| 0.0225 | 44.12 | 10500 | 0.1158 | 0.1211 |
| 0.011 | 46.22 | 11000 | 0.1181 | 0.1203 |
| 0.0106 | 48.32 | 11500 | 0.1172 | 0.1190 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg
|
vocabtrimmer
| 2023-03-27T06:43:10Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"question generation",
"it",
"dataset:lmqg/qg_itquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-18T12:00:50Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: it
datasets:
- lmqg/qg_itquad
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "<hl> Dopo il 1971 <hl> , l' OPEC ha tardato ad adeguare i prezzi per riflettere tale deprezzamento."
example_title: "Question Generation Example 1"
- text: "L' individuazione del petrolio e lo sviluppo di nuovi giacimenti richiedeva in genere <hl> da cinque a dieci anni <hl> prima di una produzione significativa."
example_title: "Question Generation Example 2"
- text: "il <hl> Giappone <hl> è stato il paese più dipendente dal petrolio arabo."
example_title: "Question Generation Example 3"
model-index:
- name: vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_itquad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 7.39
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 21.97
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 17.97
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 80.84
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 56.84
---
# Model Card of `vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg`
This model is fine-tuned version of [ckpts/mt5-small-trimmed-it-15000](https://huggingface.co/ckpts/mt5-small-trimmed-it-15000) for question generation task on the [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [ckpts/mt5-small-trimmed-it-15000](https://huggingface.co/ckpts/mt5-small-trimmed-it-15000)
- **Language:** it
- **Training data:** [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="it", model="vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg")
# model prediction
questions = model.generate_q(list_context="Dopo il 1971 , l' OPEC ha tardato ad adeguare i prezzi per riflettere tale deprezzamento.", list_answer="Dopo il 1971")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg")
output = pipe("<hl> Dopo il 1971 <hl> , l' OPEC ha tardato ad adeguare i prezzi per riflettere tale deprezzamento.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_itquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 80.84 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| Bleu_1 | 22.63 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| Bleu_2 | 14.89 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| Bleu_3 | 10.35 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| Bleu_4 | 7.39 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| METEOR | 17.97 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| MoverScore | 56.84 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
| ROUGE_L | 21.97 | default | [lmqg/qg_itquad](https://huggingface.co/datasets/lmqg/qg_itquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_itquad
- dataset_name: default
- input_types: paragraph_answer
- output_types: question
- prefix_types: None
- model: ckpts/mt5-small-trimmed-it-15000
- max_length: 512
- max_length_output: 32
- epoch: 13
- batch: 16
- lr: 0.001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-it-15000-itquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
intanm/mlm_v1_20230327_fin_sa_60
|
intanm
| 2023-03-27T06:33:52Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T06:29:55Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: mlm_v1_20230327_fin_sa_60
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm_v1_20230327_fin_sa_60
This model is a fine-tuned version of [intanm/mlm-v1-fin-lm-20230327-001](https://huggingface.co/intanm/mlm-v1-fin-lm-20230327-001) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1673
- Accuracy: 0.9505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 62 | 0.1830 | 0.9451 |
| No log | 2.0 | 124 | 0.1673 | 0.9505 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
intanm/mlm_v1_20230327_fin_sa_80
|
intanm
| 2023-03-27T06:10:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T06:04:34Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: mlm_v1_20230327_fin_sa_80
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm_v1_20230327_fin_sa_80
This model is a fine-tuned version of [intanm/mlm-v1-fin-lm-20230327-001](https://huggingface.co/intanm/mlm-v1-fin-lm-20230327-001) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1673
- Accuracy: 0.9341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 82 | 0.1843 | 0.9451 |
| No log | 2.0 | 164 | 0.1673 | 0.9341 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
intanm/mlm_v1_20230327_fin_sa_90
|
intanm
| 2023-03-27T05:58:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T05:53:14Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: mlm_v1_20230327_fin_sa_90
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm_v1_20230327_fin_sa_90
This model is a fine-tuned version of [intanm/mlm-v1-fin-lm-20230327-001](https://huggingface.co/intanm/mlm-v1-fin-lm-20230327-001) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1439
- Accuracy: 0.9560
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 92 | 0.1879 | 0.9396 |
| No log | 2.0 | 184 | 0.1439 | 0.9560 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
GanjinZero/coder_eng_pp
|
GanjinZero
| 2023-03-27T05:56:25Z | 186 | 4 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"biomedical",
"en",
"arxiv:2204.00391",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:04Z |
---
language:
- en
license: apache-2.0
tags:
- bert
- biomedical
---
Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations.
CODER++
Github Link: https://github.com/GanjinZero/CODER
```
@misc{https://doi.org/10.48550/arxiv.2204.00391,
doi = {10.48550/ARXIV.2204.00391},
url = {https://arxiv.org/abs/2204.00391},
author = {Zeng, Sihang and Yuan, Zheng and Yu, Sheng},
title = {Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations},
publisher = {arXiv},
year = {2022}
}
```
|
intanm/mlm-v1-fin-lm-20230327-001
|
intanm
| 2023-03-27T05:32:08Z | 199 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-27T05:16:24Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mlm-v1-fin-lm-20230327-001
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm-v1-fin-lm-20230327-001
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1656
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 202 | 4.8648 |
| No log | 2.0 | 404 | 4.1999 |
| 5.0742 | 3.0 | 606 | 3.8195 |
| 5.0742 | 4.0 | 808 | 3.6765 |
| 3.6813 | 5.0 | 1010 | 3.4704 |
| 3.6813 | 6.0 | 1212 | 3.3729 |
| 3.6813 | 7.0 | 1414 | 3.2776 |
| 3.2844 | 8.0 | 1616 | 3.2935 |
| 3.2844 | 9.0 | 1818 | 3.2279 |
| 3.1238 | 10.0 | 2020 | 3.2009 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
sallywww/insft_llama7b
|
sallywww
| 2023-03-27T05:27:57Z | 0 | 0 | null |
[
"tensorboard",
"region:us"
] | null | 2023-03-26T23:59:23Z |
This quantized_trained llama_7b model is trained with the following train-of-thought:
this is a contract:
<contract code>
Invariants line numbers are:
1+
2+
....
All invariants are:
...
Critical invariants are:
...
|
baseplate/instructor-large-1
|
baseplate
| 2023-03-27T05:22:08Z | 6 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"t5",
"text-embedding",
"embeddings",
"information-retrieval",
"beir",
"text-classification",
"language-model",
"text-clustering",
"text-semantic-similarity",
"text-evaluation",
"prompt-retrieval",
"text-reranking",
"feature-extraction",
"sentence-similarity",
"transformers",
"English",
"Sentence Similarity",
"natural_questions",
"ms_marco",
"fever",
"hotpot_qa",
"mteb",
"en",
"arxiv:2212.09741",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-03-09T21:12:01Z |
---
pipeline_tag: sentence-similarity
tags:
- text-embedding
- embeddings
- information-retrieval
- beir
- text-classification
- language-model
- text-clustering
- text-semantic-similarity
- text-evaluation
- prompt-retrieval
- text-reranking
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- t5
- English
- Sentence Similarity
- natural_questions
- ms_marco
- fever
- hotpot_qa
- mteb
language: en
inference: false
license: apache-2.0
model-index:
- name: INSTRUCTOR
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 88.13432835820896
- type: ap
value: 59.298209334395665
- type: f1
value: 83.31769058643586
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.526375
- type: ap
value: 88.16327709705504
- type: f1
value: 91.51095801287843
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.856
- type: f1
value: 45.41490917650942
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.223
- type: map_at_10
value: 47.947
- type: map_at_100
value: 48.742000000000004
- type: map_at_1000
value: 48.745
- type: map_at_3
value: 43.137
- type: map_at_5
value: 45.992
- type: mrr_at_1
value: 32.432
- type: mrr_at_10
value: 48.4
- type: mrr_at_100
value: 49.202
- type: mrr_at_1000
value: 49.205
- type: mrr_at_3
value: 43.551
- type: mrr_at_5
value: 46.467999999999996
- type: ndcg_at_1
value: 31.223
- type: ndcg_at_10
value: 57.045
- type: ndcg_at_100
value: 60.175
- type: ndcg_at_1000
value: 60.233000000000004
- type: ndcg_at_3
value: 47.171
- type: ndcg_at_5
value: 52.322
- type: precision_at_1
value: 31.223
- type: precision_at_10
value: 8.599
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 19.63
- type: precision_at_5
value: 14.282
- type: recall_at_1
value: 31.223
- type: recall_at_10
value: 85.989
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.502
- type: recall_at_3
value: 58.89
- type: recall_at_5
value: 71.408
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 43.1621946393635
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 32.56417132407894
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.29539304390207
- type: mrr
value: 76.44484017060196
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_spearman
value: 84.38746499431112
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.51298701298701
- type: f1
value: 77.49041754069235
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.61848554098577
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 31.32623280148178
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.803000000000004
- type: map_at_10
value: 48.848
- type: map_at_100
value: 50.5
- type: map_at_1000
value: 50.602999999999994
- type: map_at_3
value: 45.111000000000004
- type: map_at_5
value: 47.202
- type: mrr_at_1
value: 44.635000000000005
- type: mrr_at_10
value: 55.593
- type: mrr_at_100
value: 56.169999999999995
- type: mrr_at_1000
value: 56.19499999999999
- type: mrr_at_3
value: 53.361999999999995
- type: mrr_at_5
value: 54.806999999999995
- type: ndcg_at_1
value: 44.635000000000005
- type: ndcg_at_10
value: 55.899
- type: ndcg_at_100
value: 60.958
- type: ndcg_at_1000
value: 62.302
- type: ndcg_at_3
value: 51.051
- type: ndcg_at_5
value: 53.351000000000006
- type: precision_at_1
value: 44.635000000000005
- type: precision_at_10
value: 10.786999999999999
- type: precision_at_100
value: 1.6580000000000001
- type: precision_at_1000
value: 0.213
- type: precision_at_3
value: 24.893
- type: precision_at_5
value: 17.740000000000002
- type: recall_at_1
value: 35.803000000000004
- type: recall_at_10
value: 68.657
- type: recall_at_100
value: 89.77199999999999
- type: recall_at_1000
value: 97.67
- type: recall_at_3
value: 54.066
- type: recall_at_5
value: 60.788
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.706
- type: map_at_10
value: 44.896
- type: map_at_100
value: 46.299
- type: map_at_1000
value: 46.44
- type: map_at_3
value: 41.721000000000004
- type: map_at_5
value: 43.486000000000004
- type: mrr_at_1
value: 41.592
- type: mrr_at_10
value: 50.529
- type: mrr_at_100
value: 51.22
- type: mrr_at_1000
value: 51.258
- type: mrr_at_3
value: 48.205999999999996
- type: mrr_at_5
value: 49.528
- type: ndcg_at_1
value: 41.592
- type: ndcg_at_10
value: 50.77199999999999
- type: ndcg_at_100
value: 55.383
- type: ndcg_at_1000
value: 57.288
- type: ndcg_at_3
value: 46.324
- type: ndcg_at_5
value: 48.346000000000004
- type: precision_at_1
value: 41.592
- type: precision_at_10
value: 9.516
- type: precision_at_100
value: 1.541
- type: precision_at_1000
value: 0.2
- type: precision_at_3
value: 22.399
- type: precision_at_5
value: 15.770999999999999
- type: recall_at_1
value: 33.706
- type: recall_at_10
value: 61.353
- type: recall_at_100
value: 80.182
- type: recall_at_1000
value: 91.896
- type: recall_at_3
value: 48.204
- type: recall_at_5
value: 53.89699999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 44.424
- type: map_at_10
value: 57.169000000000004
- type: map_at_100
value: 58.202
- type: map_at_1000
value: 58.242000000000004
- type: map_at_3
value: 53.825
- type: map_at_5
value: 55.714
- type: mrr_at_1
value: 50.470000000000006
- type: mrr_at_10
value: 60.489000000000004
- type: mrr_at_100
value: 61.096
- type: mrr_at_1000
value: 61.112
- type: mrr_at_3
value: 58.192
- type: mrr_at_5
value: 59.611999999999995
- type: ndcg_at_1
value: 50.470000000000006
- type: ndcg_at_10
value: 63.071999999999996
- type: ndcg_at_100
value: 66.964
- type: ndcg_at_1000
value: 67.659
- type: ndcg_at_3
value: 57.74399999999999
- type: ndcg_at_5
value: 60.367000000000004
- type: precision_at_1
value: 50.470000000000006
- type: precision_at_10
value: 10.019
- type: precision_at_100
value: 1.29
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 25.558999999999997
- type: precision_at_5
value: 17.467
- type: recall_at_1
value: 44.424
- type: recall_at_10
value: 77.02
- type: recall_at_100
value: 93.738
- type: recall_at_1000
value: 98.451
- type: recall_at_3
value: 62.888
- type: recall_at_5
value: 69.138
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.294
- type: map_at_10
value: 34.503
- type: map_at_100
value: 35.641
- type: map_at_1000
value: 35.724000000000004
- type: map_at_3
value: 31.753999999999998
- type: map_at_5
value: 33.190999999999995
- type: mrr_at_1
value: 28.362
- type: mrr_at_10
value: 36.53
- type: mrr_at_100
value: 37.541000000000004
- type: mrr_at_1000
value: 37.602000000000004
- type: mrr_at_3
value: 33.917
- type: mrr_at_5
value: 35.358000000000004
- type: ndcg_at_1
value: 28.362
- type: ndcg_at_10
value: 39.513999999999996
- type: ndcg_at_100
value: 44.815
- type: ndcg_at_1000
value: 46.839
- type: ndcg_at_3
value: 34.02
- type: ndcg_at_5
value: 36.522
- type: precision_at_1
value: 28.362
- type: precision_at_10
value: 6.101999999999999
- type: precision_at_100
value: 0.9129999999999999
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 14.161999999999999
- type: precision_at_5
value: 9.966
- type: recall_at_1
value: 26.294
- type: recall_at_10
value: 53.098
- type: recall_at_100
value: 76.877
- type: recall_at_1000
value: 91.834
- type: recall_at_3
value: 38.266
- type: recall_at_5
value: 44.287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.407
- type: map_at_10
value: 25.185999999999996
- type: map_at_100
value: 26.533
- type: map_at_1000
value: 26.657999999999998
- type: map_at_3
value: 22.201999999999998
- type: map_at_5
value: 23.923
- type: mrr_at_1
value: 20.522000000000002
- type: mrr_at_10
value: 29.522
- type: mrr_at_100
value: 30.644
- type: mrr_at_1000
value: 30.713
- type: mrr_at_3
value: 26.679000000000002
- type: mrr_at_5
value: 28.483000000000004
- type: ndcg_at_1
value: 20.522000000000002
- type: ndcg_at_10
value: 30.656
- type: ndcg_at_100
value: 36.864999999999995
- type: ndcg_at_1000
value: 39.675
- type: ndcg_at_3
value: 25.319000000000003
- type: ndcg_at_5
value: 27.992
- type: precision_at_1
value: 20.522000000000002
- type: precision_at_10
value: 5.795999999999999
- type: precision_at_100
value: 1.027
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 12.396
- type: precision_at_5
value: 9.328
- type: recall_at_1
value: 16.407
- type: recall_at_10
value: 43.164
- type: recall_at_100
value: 69.695
- type: recall_at_1000
value: 89.41900000000001
- type: recall_at_3
value: 28.634999999999998
- type: recall_at_5
value: 35.308
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.473
- type: map_at_10
value: 41.676
- type: map_at_100
value: 43.120999999999995
- type: map_at_1000
value: 43.230000000000004
- type: map_at_3
value: 38.306000000000004
- type: map_at_5
value: 40.355999999999995
- type: mrr_at_1
value: 37.536
- type: mrr_at_10
value: 47.643
- type: mrr_at_100
value: 48.508
- type: mrr_at_1000
value: 48.551
- type: mrr_at_3
value: 45.348
- type: mrr_at_5
value: 46.744
- type: ndcg_at_1
value: 37.536
- type: ndcg_at_10
value: 47.823
- type: ndcg_at_100
value: 53.395
- type: ndcg_at_1000
value: 55.271
- type: ndcg_at_3
value: 42.768
- type: ndcg_at_5
value: 45.373000000000005
- type: precision_at_1
value: 37.536
- type: precision_at_10
value: 8.681
- type: precision_at_100
value: 1.34
- type: precision_at_1000
value: 0.165
- type: precision_at_3
value: 20.468
- type: precision_at_5
value: 14.495
- type: recall_at_1
value: 30.473
- type: recall_at_10
value: 60.092999999999996
- type: recall_at_100
value: 82.733
- type: recall_at_1000
value: 94.875
- type: recall_at_3
value: 45.734
- type: recall_at_5
value: 52.691
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.976000000000003
- type: map_at_10
value: 41.097
- type: map_at_100
value: 42.547000000000004
- type: map_at_1000
value: 42.659000000000006
- type: map_at_3
value: 37.251
- type: map_at_5
value: 39.493
- type: mrr_at_1
value: 37.557
- type: mrr_at_10
value: 46.605000000000004
- type: mrr_at_100
value: 47.487
- type: mrr_at_1000
value: 47.54
- type: mrr_at_3
value: 43.721
- type: mrr_at_5
value: 45.411
- type: ndcg_at_1
value: 37.557
- type: ndcg_at_10
value: 47.449000000000005
- type: ndcg_at_100
value: 53.052
- type: ndcg_at_1000
value: 55.010999999999996
- type: ndcg_at_3
value: 41.439
- type: ndcg_at_5
value: 44.292
- type: precision_at_1
value: 37.557
- type: precision_at_10
value: 8.847
- type: precision_at_100
value: 1.357
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 20.091
- type: precision_at_5
value: 14.384
- type: recall_at_1
value: 29.976000000000003
- type: recall_at_10
value: 60.99099999999999
- type: recall_at_100
value: 84.245
- type: recall_at_1000
value: 96.97200000000001
- type: recall_at_3
value: 43.794
- type: recall_at_5
value: 51.778999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.099166666666665
- type: map_at_10
value: 38.1365
- type: map_at_100
value: 39.44491666666667
- type: map_at_1000
value: 39.55858333333334
- type: map_at_3
value: 35.03641666666666
- type: map_at_5
value: 36.79833333333334
- type: mrr_at_1
value: 33.39966666666667
- type: mrr_at_10
value: 42.42583333333333
- type: mrr_at_100
value: 43.28575
- type: mrr_at_1000
value: 43.33741666666667
- type: mrr_at_3
value: 39.94975
- type: mrr_at_5
value: 41.41633333333334
- type: ndcg_at_1
value: 33.39966666666667
- type: ndcg_at_10
value: 43.81741666666667
- type: ndcg_at_100
value: 49.08166666666667
- type: ndcg_at_1000
value: 51.121166666666674
- type: ndcg_at_3
value: 38.73575
- type: ndcg_at_5
value: 41.18158333333333
- type: precision_at_1
value: 33.39966666666667
- type: precision_at_10
value: 7.738916666666667
- type: precision_at_100
value: 1.2265833333333331
- type: precision_at_1000
value: 0.15983333333333336
- type: precision_at_3
value: 17.967416666666665
- type: precision_at_5
value: 12.78675
- type: recall_at_1
value: 28.099166666666665
- type: recall_at_10
value: 56.27049999999999
- type: recall_at_100
value: 78.93291666666667
- type: recall_at_1000
value: 92.81608333333334
- type: recall_at_3
value: 42.09775
- type: recall_at_5
value: 48.42533333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.663
- type: map_at_10
value: 30.377
- type: map_at_100
value: 31.426
- type: map_at_1000
value: 31.519000000000002
- type: map_at_3
value: 28.069
- type: map_at_5
value: 29.256999999999998
- type: mrr_at_1
value: 26.687
- type: mrr_at_10
value: 33.107
- type: mrr_at_100
value: 34.055
- type: mrr_at_1000
value: 34.117999999999995
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.14
- type: ndcg_at_1
value: 26.687
- type: ndcg_at_10
value: 34.615
- type: ndcg_at_100
value: 39.776
- type: ndcg_at_1000
value: 42.05
- type: ndcg_at_3
value: 30.322
- type: ndcg_at_5
value: 32.157000000000004
- type: precision_at_1
value: 26.687
- type: precision_at_10
value: 5.491
- type: precision_at_100
value: 0.877
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.139000000000001
- type: precision_at_5
value: 9.049
- type: recall_at_1
value: 23.663
- type: recall_at_10
value: 45.035
- type: recall_at_100
value: 68.554
- type: recall_at_1000
value: 85.077
- type: recall_at_3
value: 32.982
- type: recall_at_5
value: 37.688
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.403
- type: map_at_10
value: 25.197000000000003
- type: map_at_100
value: 26.355
- type: map_at_1000
value: 26.487
- type: map_at_3
value: 22.733
- type: map_at_5
value: 24.114
- type: mrr_at_1
value: 21.37
- type: mrr_at_10
value: 29.091
- type: mrr_at_100
value: 30.018
- type: mrr_at_1000
value: 30.096
- type: mrr_at_3
value: 26.887
- type: mrr_at_5
value: 28.157
- type: ndcg_at_1
value: 21.37
- type: ndcg_at_10
value: 30.026000000000003
- type: ndcg_at_100
value: 35.416
- type: ndcg_at_1000
value: 38.45
- type: ndcg_at_3
value: 25.764
- type: ndcg_at_5
value: 27.742
- type: precision_at_1
value: 21.37
- type: precision_at_10
value: 5.609
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.14300000000000002
- type: precision_at_3
value: 12.423
- type: precision_at_5
value: 9.009
- type: recall_at_1
value: 17.403
- type: recall_at_10
value: 40.573
- type: recall_at_100
value: 64.818
- type: recall_at_1000
value: 86.53699999999999
- type: recall_at_3
value: 28.493000000000002
- type: recall_at_5
value: 33.660000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.639
- type: map_at_10
value: 38.951
- type: map_at_100
value: 40.238
- type: map_at_1000
value: 40.327
- type: map_at_3
value: 35.842
- type: map_at_5
value: 37.617
- type: mrr_at_1
value: 33.769
- type: mrr_at_10
value: 43.088
- type: mrr_at_100
value: 44.03
- type: mrr_at_1000
value: 44.072
- type: mrr_at_3
value: 40.656
- type: mrr_at_5
value: 42.138999999999996
- type: ndcg_at_1
value: 33.769
- type: ndcg_at_10
value: 44.676
- type: ndcg_at_100
value: 50.416000000000004
- type: ndcg_at_1000
value: 52.227999999999994
- type: ndcg_at_3
value: 39.494
- type: ndcg_at_5
value: 42.013
- type: precision_at_1
value: 33.769
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.18
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 18.221
- type: precision_at_5
value: 12.966
- type: recall_at_1
value: 28.639
- type: recall_at_10
value: 57.687999999999995
- type: recall_at_100
value: 82.541
- type: recall_at_1000
value: 94.896
- type: recall_at_3
value: 43.651
- type: recall_at_5
value: 49.925999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.57
- type: map_at_10
value: 40.004
- type: map_at_100
value: 41.75
- type: map_at_1000
value: 41.97
- type: map_at_3
value: 36.788
- type: map_at_5
value: 38.671
- type: mrr_at_1
value: 35.375
- type: mrr_at_10
value: 45.121
- type: mrr_at_100
value: 45.994
- type: mrr_at_1000
value: 46.04
- type: mrr_at_3
value: 42.227
- type: mrr_at_5
value: 43.995
- type: ndcg_at_1
value: 35.375
- type: ndcg_at_10
value: 46.392
- type: ndcg_at_100
value: 52.196
- type: ndcg_at_1000
value: 54.274
- type: ndcg_at_3
value: 41.163
- type: ndcg_at_5
value: 43.813
- type: precision_at_1
value: 35.375
- type: precision_at_10
value: 8.676
- type: precision_at_100
value: 1.678
- type: precision_at_1000
value: 0.253
- type: precision_at_3
value: 19.104
- type: precision_at_5
value: 13.913
- type: recall_at_1
value: 29.57
- type: recall_at_10
value: 58.779
- type: recall_at_100
value: 83.337
- type: recall_at_1000
value: 95.979
- type: recall_at_3
value: 44.005
- type: recall_at_5
value: 50.975
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.832
- type: map_at_10
value: 29.733999999999998
- type: map_at_100
value: 30.727
- type: map_at_1000
value: 30.843999999999998
- type: map_at_3
value: 26.834999999999997
- type: map_at_5
value: 28.555999999999997
- type: mrr_at_1
value: 22.921
- type: mrr_at_10
value: 31.791999999999998
- type: mrr_at_100
value: 32.666000000000004
- type: mrr_at_1000
value: 32.751999999999995
- type: mrr_at_3
value: 29.144
- type: mrr_at_5
value: 30.622
- type: ndcg_at_1
value: 22.921
- type: ndcg_at_10
value: 34.915
- type: ndcg_at_100
value: 39.744
- type: ndcg_at_1000
value: 42.407000000000004
- type: ndcg_at_3
value: 29.421000000000003
- type: ndcg_at_5
value: 32.211
- type: precision_at_1
value: 22.921
- type: precision_at_10
value: 5.675
- type: precision_at_100
value: 0.872
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 12.753999999999998
- type: precision_at_5
value: 9.353
- type: recall_at_1
value: 20.832
- type: recall_at_10
value: 48.795
- type: recall_at_100
value: 70.703
- type: recall_at_1000
value: 90.187
- type: recall_at_3
value: 34.455000000000005
- type: recall_at_5
value: 40.967
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.334
- type: map_at_10
value: 19.009999999999998
- type: map_at_100
value: 21.129
- type: map_at_1000
value: 21.328
- type: map_at_3
value: 15.152
- type: map_at_5
value: 17.084
- type: mrr_at_1
value: 23.453
- type: mrr_at_10
value: 36.099
- type: mrr_at_100
value: 37.069
- type: mrr_at_1000
value: 37.104
- type: mrr_at_3
value: 32.096000000000004
- type: mrr_at_5
value: 34.451
- type: ndcg_at_1
value: 23.453
- type: ndcg_at_10
value: 27.739000000000004
- type: ndcg_at_100
value: 35.836
- type: ndcg_at_1000
value: 39.242
- type: ndcg_at_3
value: 21.263
- type: ndcg_at_5
value: 23.677
- type: precision_at_1
value: 23.453
- type: precision_at_10
value: 9.199
- type: precision_at_100
value: 1.791
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 16.2
- type: precision_at_5
value: 13.147
- type: recall_at_1
value: 10.334
- type: recall_at_10
value: 35.177
- type: recall_at_100
value: 63.009
- type: recall_at_1000
value: 81.938
- type: recall_at_3
value: 19.914
- type: recall_at_5
value: 26.077
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.212
- type: map_at_10
value: 17.386
- type: map_at_100
value: 24.234
- type: map_at_1000
value: 25.724999999999998
- type: map_at_3
value: 12.727
- type: map_at_5
value: 14.785
- type: mrr_at_1
value: 59.25
- type: mrr_at_10
value: 68.687
- type: mrr_at_100
value: 69.133
- type: mrr_at_1000
value: 69.14099999999999
- type: mrr_at_3
value: 66.917
- type: mrr_at_5
value: 67.742
- type: ndcg_at_1
value: 48.625
- type: ndcg_at_10
value: 36.675999999999995
- type: ndcg_at_100
value: 41.543
- type: ndcg_at_1000
value: 49.241
- type: ndcg_at_3
value: 41.373
- type: ndcg_at_5
value: 38.707
- type: precision_at_1
value: 59.25
- type: precision_at_10
value: 28.525
- type: precision_at_100
value: 9.027000000000001
- type: precision_at_1000
value: 1.8339999999999999
- type: precision_at_3
value: 44.833
- type: precision_at_5
value: 37.35
- type: recall_at_1
value: 8.212
- type: recall_at_10
value: 23.188
- type: recall_at_100
value: 48.613
- type: recall_at_1000
value: 73.093
- type: recall_at_3
value: 14.419
- type: recall_at_5
value: 17.798
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.725
- type: f1
value: 46.50743309855908
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.086
- type: map_at_10
value: 66.914
- type: map_at_100
value: 67.321
- type: map_at_1000
value: 67.341
- type: map_at_3
value: 64.75800000000001
- type: map_at_5
value: 66.189
- type: mrr_at_1
value: 59.28600000000001
- type: mrr_at_10
value: 71.005
- type: mrr_at_100
value: 71.304
- type: mrr_at_1000
value: 71.313
- type: mrr_at_3
value: 69.037
- type: mrr_at_5
value: 70.35
- type: ndcg_at_1
value: 59.28600000000001
- type: ndcg_at_10
value: 72.695
- type: ndcg_at_100
value: 74.432
- type: ndcg_at_1000
value: 74.868
- type: ndcg_at_3
value: 68.72200000000001
- type: ndcg_at_5
value: 71.081
- type: precision_at_1
value: 59.28600000000001
- type: precision_at_10
value: 9.499
- type: precision_at_100
value: 1.052
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 27.503
- type: precision_at_5
value: 17.854999999999997
- type: recall_at_1
value: 55.086
- type: recall_at_10
value: 86.453
- type: recall_at_100
value: 94.028
- type: recall_at_1000
value: 97.052
- type: recall_at_3
value: 75.821
- type: recall_at_5
value: 81.6
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.262999999999998
- type: map_at_10
value: 37.488
- type: map_at_100
value: 39.498
- type: map_at_1000
value: 39.687
- type: map_at_3
value: 32.529
- type: map_at_5
value: 35.455
- type: mrr_at_1
value: 44.907000000000004
- type: mrr_at_10
value: 53.239000000000004
- type: mrr_at_100
value: 54.086
- type: mrr_at_1000
value: 54.122
- type: mrr_at_3
value: 51.235
- type: mrr_at_5
value: 52.415
- type: ndcg_at_1
value: 44.907000000000004
- type: ndcg_at_10
value: 45.446
- type: ndcg_at_100
value: 52.429
- type: ndcg_at_1000
value: 55.169000000000004
- type: ndcg_at_3
value: 41.882000000000005
- type: ndcg_at_5
value: 43.178
- type: precision_at_1
value: 44.907000000000004
- type: precision_at_10
value: 12.931999999999999
- type: precision_at_100
value: 2.025
- type: precision_at_1000
value: 0.248
- type: precision_at_3
value: 28.652
- type: precision_at_5
value: 21.204
- type: recall_at_1
value: 22.262999999999998
- type: recall_at_10
value: 52.447
- type: recall_at_100
value: 78.045
- type: recall_at_1000
value: 94.419
- type: recall_at_3
value: 38.064
- type: recall_at_5
value: 44.769
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.519
- type: map_at_10
value: 45.831
- type: map_at_100
value: 46.815
- type: map_at_1000
value: 46.899
- type: map_at_3
value: 42.836
- type: map_at_5
value: 44.65
- type: mrr_at_1
value: 65.037
- type: mrr_at_10
value: 72.16
- type: mrr_at_100
value: 72.51100000000001
- type: mrr_at_1000
value: 72.53
- type: mrr_at_3
value: 70.682
- type: mrr_at_5
value: 71.54599999999999
- type: ndcg_at_1
value: 65.037
- type: ndcg_at_10
value: 55.17999999999999
- type: ndcg_at_100
value: 58.888
- type: ndcg_at_1000
value: 60.648
- type: ndcg_at_3
value: 50.501
- type: ndcg_at_5
value: 52.977
- type: precision_at_1
value: 65.037
- type: precision_at_10
value: 11.530999999999999
- type: precision_at_100
value: 1.4460000000000002
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 31.483
- type: precision_at_5
value: 20.845
- type: recall_at_1
value: 32.519
- type: recall_at_10
value: 57.657000000000004
- type: recall_at_100
value: 72.30199999999999
- type: recall_at_1000
value: 84.024
- type: recall_at_3
value: 47.225
- type: recall_at_5
value: 52.113
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 88.3168
- type: ap
value: 83.80165516037135
- type: f1
value: 88.29942471066407
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 20.724999999999998
- type: map_at_10
value: 32.736
- type: map_at_100
value: 33.938
- type: map_at_1000
value: 33.991
- type: map_at_3
value: 28.788000000000004
- type: map_at_5
value: 31.016
- type: mrr_at_1
value: 21.361
- type: mrr_at_10
value: 33.323
- type: mrr_at_100
value: 34.471000000000004
- type: mrr_at_1000
value: 34.518
- type: mrr_at_3
value: 29.453000000000003
- type: mrr_at_5
value: 31.629
- type: ndcg_at_1
value: 21.361
- type: ndcg_at_10
value: 39.649
- type: ndcg_at_100
value: 45.481
- type: ndcg_at_1000
value: 46.775
- type: ndcg_at_3
value: 31.594
- type: ndcg_at_5
value: 35.543
- type: precision_at_1
value: 21.361
- type: precision_at_10
value: 6.3740000000000006
- type: precision_at_100
value: 0.931
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.514999999999999
- type: precision_at_5
value: 10.100000000000001
- type: recall_at_1
value: 20.724999999999998
- type: recall_at_10
value: 61.034
- type: recall_at_100
value: 88.062
- type: recall_at_1000
value: 97.86399999999999
- type: recall_at_3
value: 39.072
- type: recall_at_5
value: 48.53
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.8919288645691
- type: f1
value: 93.57059586398059
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.97993616051072
- type: f1
value: 48.244319183606535
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.90047074646941
- type: f1
value: 66.48999056063725
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.34566240753195
- type: f1
value: 73.54164154290658
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.21866934757011
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.000936217235534
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.68189362520352
- type: mrr
value: 32.69603637784303
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.078
- type: map_at_10
value: 12.671
- type: map_at_100
value: 16.291
- type: map_at_1000
value: 17.855999999999998
- type: map_at_3
value: 9.610000000000001
- type: map_at_5
value: 11.152
- type: mrr_at_1
value: 43.963
- type: mrr_at_10
value: 53.173
- type: mrr_at_100
value: 53.718999999999994
- type: mrr_at_1000
value: 53.756
- type: mrr_at_3
value: 50.980000000000004
- type: mrr_at_5
value: 52.42
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 34.086
- type: ndcg_at_100
value: 32.545
- type: ndcg_at_1000
value: 41.144999999999996
- type: ndcg_at_3
value: 39.434999999999995
- type: ndcg_at_5
value: 37.888
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 25.014999999999997
- type: precision_at_100
value: 8.594
- type: precision_at_1000
value: 2.169
- type: precision_at_3
value: 37.049
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 6.078
- type: recall_at_10
value: 16.17
- type: recall_at_100
value: 34.512
- type: recall_at_1000
value: 65.447
- type: recall_at_3
value: 10.706
- type: recall_at_5
value: 13.158
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.378000000000004
- type: map_at_10
value: 42.178
- type: map_at_100
value: 43.32
- type: map_at_1000
value: 43.358000000000004
- type: map_at_3
value: 37.474000000000004
- type: map_at_5
value: 40.333000000000006
- type: mrr_at_1
value: 30.823
- type: mrr_at_10
value: 44.626
- type: mrr_at_100
value: 45.494
- type: mrr_at_1000
value: 45.519
- type: mrr_at_3
value: 40.585
- type: mrr_at_5
value: 43.146
- type: ndcg_at_1
value: 30.794
- type: ndcg_at_10
value: 50.099000000000004
- type: ndcg_at_100
value: 54.900999999999996
- type: ndcg_at_1000
value: 55.69499999999999
- type: ndcg_at_3
value: 41.238
- type: ndcg_at_5
value: 46.081
- type: precision_at_1
value: 30.794
- type: precision_at_10
value: 8.549
- type: precision_at_100
value: 1.124
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 18.926000000000002
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 27.378000000000004
- type: recall_at_10
value: 71.842
- type: recall_at_100
value: 92.565
- type: recall_at_1000
value: 98.402
- type: recall_at_3
value: 49.053999999999995
- type: recall_at_5
value: 60.207
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.557
- type: map_at_10
value: 84.729
- type: map_at_100
value: 85.369
- type: map_at_1000
value: 85.382
- type: map_at_3
value: 81.72
- type: map_at_5
value: 83.613
- type: mrr_at_1
value: 81.3
- type: mrr_at_10
value: 87.488
- type: mrr_at_100
value: 87.588
- type: mrr_at_1000
value: 87.589
- type: mrr_at_3
value: 86.53
- type: mrr_at_5
value: 87.18599999999999
- type: ndcg_at_1
value: 81.28999999999999
- type: ndcg_at_10
value: 88.442
- type: ndcg_at_100
value: 89.637
- type: ndcg_at_1000
value: 89.70700000000001
- type: ndcg_at_3
value: 85.55199999999999
- type: ndcg_at_5
value: 87.154
- type: precision_at_1
value: 81.28999999999999
- type: precision_at_10
value: 13.489999999999998
- type: precision_at_100
value: 1.54
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.553
- type: precision_at_5
value: 24.708
- type: recall_at_1
value: 70.557
- type: recall_at_10
value: 95.645
- type: recall_at_100
value: 99.693
- type: recall_at_1000
value: 99.995
- type: recall_at_3
value: 87.359
- type: recall_at_5
value: 91.89699999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 63.65060114776209
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.63271250680617
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.263
- type: map_at_10
value: 10.801
- type: map_at_100
value: 12.888
- type: map_at_1000
value: 13.224
- type: map_at_3
value: 7.362
- type: map_at_5
value: 9.149000000000001
- type: mrr_at_1
value: 21
- type: mrr_at_10
value: 31.416
- type: mrr_at_100
value: 32.513
- type: mrr_at_1000
value: 32.58
- type: mrr_at_3
value: 28.116999999999997
- type: mrr_at_5
value: 29.976999999999997
- type: ndcg_at_1
value: 21
- type: ndcg_at_10
value: 18.551000000000002
- type: ndcg_at_100
value: 26.657999999999998
- type: ndcg_at_1000
value: 32.485
- type: ndcg_at_3
value: 16.834
- type: ndcg_at_5
value: 15.204999999999998
- type: precision_at_1
value: 21
- type: precision_at_10
value: 9.84
- type: precision_at_100
value: 2.16
- type: precision_at_1000
value: 0.35500000000000004
- type: precision_at_3
value: 15.667
- type: precision_at_5
value: 13.62
- type: recall_at_1
value: 4.263
- type: recall_at_10
value: 19.922
- type: recall_at_100
value: 43.808
- type: recall_at_1000
value: 72.14500000000001
- type: recall_at_3
value: 9.493
- type: recall_at_5
value: 13.767999999999999
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_spearman
value: 81.27446313317233
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_spearman
value: 76.27963301217527
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_spearman
value: 88.18495048450949
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_spearman
value: 81.91982338692046
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_spearman
value: 89.00896818385291
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_spearman
value: 85.48814644586132
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_spearman
value: 90.30116926966582
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_spearman
value: 67.74132963032342
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_spearman
value: 86.87741355780479
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 82.0019012295875
- type: mrr
value: 94.70267024188593
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 50.05
- type: map_at_10
value: 59.36
- type: map_at_100
value: 59.967999999999996
- type: map_at_1000
value: 60.023
- type: map_at_3
value: 56.515
- type: map_at_5
value: 58.272999999999996
- type: mrr_at_1
value: 53
- type: mrr_at_10
value: 61.102000000000004
- type: mrr_at_100
value: 61.476
- type: mrr_at_1000
value: 61.523
- type: mrr_at_3
value: 58.778
- type: mrr_at_5
value: 60.128
- type: ndcg_at_1
value: 53
- type: ndcg_at_10
value: 64.43100000000001
- type: ndcg_at_100
value: 66.73599999999999
- type: ndcg_at_1000
value: 68.027
- type: ndcg_at_3
value: 59.279
- type: ndcg_at_5
value: 61.888
- type: precision_at_1
value: 53
- type: precision_at_10
value: 8.767
- type: precision_at_100
value: 1.01
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 23.444000000000003
- type: precision_at_5
value: 15.667
- type: recall_at_1
value: 50.05
- type: recall_at_10
value: 78.511
- type: recall_at_100
value: 88.5
- type: recall_at_1000
value: 98.333
- type: recall_at_3
value: 64.117
- type: recall_at_5
value: 70.867
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.72178217821782
- type: cos_sim_ap
value: 93.0728601593541
- type: cos_sim_f1
value: 85.6727976766699
- type: cos_sim_precision
value: 83.02063789868667
- type: cos_sim_recall
value: 88.5
- type: dot_accuracy
value: 99.72178217821782
- type: dot_ap
value: 93.07287396168348
- type: dot_f1
value: 85.6727976766699
- type: dot_precision
value: 83.02063789868667
- type: dot_recall
value: 88.5
- type: euclidean_accuracy
value: 99.72178217821782
- type: euclidean_ap
value: 93.07285657982895
- type: euclidean_f1
value: 85.6727976766699
- type: euclidean_precision
value: 83.02063789868667
- type: euclidean_recall
value: 88.5
- type: manhattan_accuracy
value: 99.72475247524753
- type: manhattan_ap
value: 93.02792973059809
- type: manhattan_f1
value: 85.7727737973388
- type: manhattan_precision
value: 87.84067085953879
- type: manhattan_recall
value: 83.8
- type: max_accuracy
value: 99.72475247524753
- type: max_ap
value: 93.07287396168348
- type: max_f1
value: 85.7727737973388
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 68.77583615550819
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.151636938606956
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.16607939471187
- type: mrr
value: 52.95172046091163
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.314646669495666
- type: cos_sim_spearman
value: 31.83562491439455
- type: dot_pearson
value: 31.314590842874157
- type: dot_spearman
value: 31.83363065810437
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.198
- type: map_at_10
value: 1.3010000000000002
- type: map_at_100
value: 7.2139999999999995
- type: map_at_1000
value: 20.179
- type: map_at_3
value: 0.528
- type: map_at_5
value: 0.8019999999999999
- type: mrr_at_1
value: 72
- type: mrr_at_10
value: 83.39999999999999
- type: mrr_at_100
value: 83.39999999999999
- type: mrr_at_1000
value: 83.39999999999999
- type: mrr_at_3
value: 81.667
- type: mrr_at_5
value: 83.06700000000001
- type: ndcg_at_1
value: 66
- type: ndcg_at_10
value: 58.059000000000005
- type: ndcg_at_100
value: 44.316
- type: ndcg_at_1000
value: 43.147000000000006
- type: ndcg_at_3
value: 63.815999999999995
- type: ndcg_at_5
value: 63.005
- type: precision_at_1
value: 72
- type: precision_at_10
value: 61.4
- type: precision_at_100
value: 45.62
- type: precision_at_1000
value: 19.866
- type: precision_at_3
value: 70
- type: precision_at_5
value: 68.8
- type: recall_at_1
value: 0.198
- type: recall_at_10
value: 1.517
- type: recall_at_100
value: 10.587
- type: recall_at_1000
value: 41.233
- type: recall_at_3
value: 0.573
- type: recall_at_5
value: 0.907
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.894
- type: map_at_10
value: 8.488999999999999
- type: map_at_100
value: 14.445
- type: map_at_1000
value: 16.078
- type: map_at_3
value: 4.589
- type: map_at_5
value: 6.019
- type: mrr_at_1
value: 22.448999999999998
- type: mrr_at_10
value: 39.82
- type: mrr_at_100
value: 40.752
- type: mrr_at_1000
value: 40.771
- type: mrr_at_3
value: 34.354
- type: mrr_at_5
value: 37.721
- type: ndcg_at_1
value: 19.387999999999998
- type: ndcg_at_10
value: 21.563
- type: ndcg_at_100
value: 33.857
- type: ndcg_at_1000
value: 46.199
- type: ndcg_at_3
value: 22.296
- type: ndcg_at_5
value: 21.770999999999997
- type: precision_at_1
value: 22.448999999999998
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.142999999999999
- type: precision_at_1000
value: 1.541
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 22.448999999999998
- type: recall_at_1
value: 1.894
- type: recall_at_10
value: 14.931
- type: recall_at_100
value: 45.524
- type: recall_at_1000
value: 83.243
- type: recall_at_3
value: 5.712
- type: recall_at_5
value: 8.386000000000001
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.049
- type: ap
value: 13.85116971310922
- type: f1
value: 54.37504302487686
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.1312959818902
- type: f1
value: 64.11413877009383
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 54.13103431861502
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.327889372355
- type: cos_sim_ap
value: 77.42059895975699
- type: cos_sim_f1
value: 71.02706903250873
- type: cos_sim_precision
value: 69.75324344950394
- type: cos_sim_recall
value: 72.34828496042216
- type: dot_accuracy
value: 87.327889372355
- type: dot_ap
value: 77.4209479346677
- type: dot_f1
value: 71.02706903250873
- type: dot_precision
value: 69.75324344950394
- type: dot_recall
value: 72.34828496042216
- type: euclidean_accuracy
value: 87.327889372355
- type: euclidean_ap
value: 77.42096495861037
- type: euclidean_f1
value: 71.02706903250873
- type: euclidean_precision
value: 69.75324344950394
- type: euclidean_recall
value: 72.34828496042216
- type: manhattan_accuracy
value: 87.31000774870358
- type: manhattan_ap
value: 77.38930750711619
- type: manhattan_f1
value: 71.07935314027831
- type: manhattan_precision
value: 67.70957726295677
- type: manhattan_recall
value: 74.80211081794195
- type: max_accuracy
value: 87.327889372355
- type: max_ap
value: 77.42096495861037
- type: max_f1
value: 71.07935314027831
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.58939729110878
- type: cos_sim_ap
value: 87.17594155025475
- type: cos_sim_f1
value: 79.21146953405018
- type: cos_sim_precision
value: 76.8918527109307
- type: cos_sim_recall
value: 81.67539267015707
- type: dot_accuracy
value: 89.58939729110878
- type: dot_ap
value: 87.17593963273593
- type: dot_f1
value: 79.21146953405018
- type: dot_precision
value: 76.8918527109307
- type: dot_recall
value: 81.67539267015707
- type: euclidean_accuracy
value: 89.58939729110878
- type: euclidean_ap
value: 87.17592466925834
- type: euclidean_f1
value: 79.21146953405018
- type: euclidean_precision
value: 76.8918527109307
- type: euclidean_recall
value: 81.67539267015707
- type: manhattan_accuracy
value: 89.62626615438352
- type: manhattan_ap
value: 87.16589873161546
- type: manhattan_f1
value: 79.25143598295348
- type: manhattan_precision
value: 76.39494177323712
- type: manhattan_recall
value: 82.32984293193716
- type: max_accuracy
value: 89.62626615438352
- type: max_ap
value: 87.17594155025475
- type: max_f1
value: 79.25143598295348
duplicated_from: hkunlp/instructor-large
---
# Same as hkunlp/instructor-large, except using a custom handler so it can be deployed with HF Inference Endpoints
# hkunlp/instructor-large
We introduce **Instructor**👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) ***by simply providing the task instruction, without any finetuning***. Instructor👨 achieves sota on 70 diverse embedding tasks ([MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard))!
The model is easy to use with **our customized** `sentence-transformer` library. For more details, check out [our paper](https://arxiv.org/abs/2212.09741) and [project page](https://instructor-embedding.github.io/)!
**************************** **Updates** ****************************
* 12/28: We released a new [checkpoint](https://huggingface.co/hkunlp/instructor-large) trained with hard negatives, which gives better performance.
* 12/21: We released our [paper](https://arxiv.org/abs/2212.09741), [code](https://github.com/HKUNLP/instructor-embedding), [checkpoint](https://huggingface.co/hkunlp/instructor-large) and [project page](https://instructor-embedding.github.io/)! Check them out!
## Quick start
<hr />
## Installation
```bash
pip install InstructorEmbedding
```
## Compute your customized embeddings
Then you can use the model like this to calculate domain-specific and task-aware embeddings:
```python
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR('hkunlp/instructor-large')
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
instruction = "Represent the Science title:"
embeddings = model.encode([[instruction,sentence]])
print(embeddings)
```
## Use cases
<hr />
## Calculate embeddings for your customized texts
If you want to calculate customized embeddings for specific sentences, you may follow the unified template to write instructions:
Represent the `domain` `text_type` for `task_objective`:
* `domain` is optional, and it specifies the domain of the text, e.g., science, finance, medicine, etc.
* `text_type` is required, and it specifies the encoding unit, e.g., sentence, document, paragraph, etc.
* `task_objective` is optional, and it specifies the objective of embedding, e.g., retrieve a document, classify the sentence, etc.
## Calculate Sentence similarities
You can further use the model to compute similarities between two groups of sentences, with **customized embeddings**.
```python
from sklearn.metrics.pairwise import cosine_similarity
sentences_a = [['Represent the Science sentence: ','Parton energy loss in QCD matter'],
['Represent the Financial statement: ','The Federal Reserve on Wednesday raised its benchmark interest rate.']]
sentences_b = [['Represent the Science sentence: ','The Chiral Phase Transition in Dissipative Dynamics'],
['Represent the Financial statement: ','The funds rose less than 0.5 per cent on Friday']]
embeddings_a = model.encode(sentences_a)
embeddings_b = model.encode(sentences_b)
similarities = cosine_similarity(embeddings_a,embeddings_b)
print(similarities)
```
## Information Retrieval
You can also use **customized embeddings** for information retrieval.
```python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
query = [['Represent the Wikipedia question for retrieving supporting documents: ','where is the food stored in a yam plant']]
corpus = [['Represent the Wikipedia document for retrieval: ','Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that the term "mixed economies" more precisely describes most contemporary economies, due to their containing both private-owned and state-owned enterprises. In capitalism, prices determine the demand-supply scale. For example, higher demand for certain goods and services lead to higher prices and lower demand for certain goods lead to lower prices.'],
['Represent the Wikipedia document for retrieval: ',"The disparate impact theory is especially controversial under the Fair Housing Act because the Act regulates many activities relating to housing, insurance, and mortgage loans—and some scholars have argued that the theory's use under the Fair Housing Act, combined with extensions of the Community Reinvestment Act, contributed to rise of sub-prime lending and the crash of the U.S. housing market and ensuing global economic recession"],
['Represent the Wikipedia document for retrieval: ','Disparate impact in United States labor law refers to practices in employment, housing, and other areas that adversely affect one group of people of a protected characteristic more than another, even though rules applied by employers or landlords are formally neutral. Although the protected classes vary by statute, most federal civil rights laws protect based on race, color, religion, national origin, and sex as protected traits, and some laws include disability status and other traits as well.']]
query_embeddings = model.encode(query)
corpus_embeddings = model.encode(corpus)
similarities = cosine_similarity(query_embeddings,corpus_embeddings)
retrieved_doc_id = np.argmax(similarities)
print(retrieved_doc_id)
```
## Clustering
Use **customized embeddings** for clustering texts in groups.
```python
import sklearn.cluster
sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity'],
['Represent the Medicine sentence for clustering: ','Comparison of Atmospheric Neutrino Flux Calculations at Low Energies'],
['Represent the Medicine sentence for clustering: ','Fermion Bags in the Massive Gross-Neveu Model'],
['Represent the Medicine sentence for clustering: ',"QCD corrections to Associated t-tbar-H production at the Tevatron"],
['Represent the Medicine sentence for clustering: ','A New Analysis of the R Measurements: Resonance Parameters of the Higher, Vector States of Charmonium']]
embeddings = model.encode(sentences)
clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2)
clustering_model.fit(embeddings)
cluster_assignment = clustering_model.labels_
print(cluster_assignment)
```
|
tf-tpu/roberta-base-epochs-100
|
tf-tpu
| 2023-03-27T05:19:40Z | 26 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-25T05:23:25Z |
---
license: mit
mask_token: "[MASK]"
tags:
- generated_from_keras_callback
model-index:
- name: tf-tpu/roberta-base-epochs-100
results: []
widget:
- text: Goal of my life is to [MASK].
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tf-tpu/roberta-base-epochs-100
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.0414
- Train Accuracy: 0.1136
- Validation Loss: 1.0103
- Validation Accuracy: 0.1144
- Epoch: 99
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 0.0001, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0001, 'decay_steps': 55765, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 2935, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.001}
- training_precision: mixed_bfloat16
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 7.2121 | 0.0274 | 5.7188 | 0.0346 | 0 |
| 5.4335 | 0.0414 | 5.2266 | 0.0439 | 1 |
| 5.1579 | 0.0445 | 5.0625 | 0.0441 | 2 |
| 5.0231 | 0.0447 | 4.9453 | 0.0446 | 3 |
| 4.9323 | 0.0448 | 4.8633 | 0.0443 | 4 |
| 4.8672 | 0.0449 | 4.8789 | 0.0440 | 5 |
| 4.8200 | 0.0449 | 4.8164 | 0.0441 | 6 |
| 4.7841 | 0.0449 | 4.7734 | 0.0450 | 7 |
| 4.7546 | 0.0449 | 4.7539 | 0.0441 | 8 |
| 4.7288 | 0.0449 | 4.7305 | 0.0447 | 9 |
| 4.7084 | 0.0449 | 4.7422 | 0.0443 | 10 |
| 4.6884 | 0.0450 | 4.7148 | 0.0437 | 11 |
| 4.6764 | 0.0449 | 4.7070 | 0.0441 | 12 |
| 4.6637 | 0.0449 | 4.7227 | 0.0435 | 13 |
| 4.5963 | 0.0449 | 4.5195 | 0.0444 | 14 |
| 4.3462 | 0.0468 | 4.0742 | 0.0515 | 15 |
| 3.4139 | 0.0650 | 2.6348 | 0.0797 | 16 |
| 2.5336 | 0.0817 | 2.1816 | 0.0888 | 17 |
| 2.1859 | 0.0888 | 1.9648 | 0.0930 | 18 |
| 2.0043 | 0.0925 | 1.8154 | 0.0961 | 19 |
| 1.8887 | 0.0948 | 1.7129 | 0.0993 | 20 |
| 1.8058 | 0.0965 | 1.6729 | 0.0996 | 21 |
| 1.7402 | 0.0979 | 1.6191 | 0.1010 | 22 |
| 1.6861 | 0.0990 | 1.5693 | 0.1024 | 23 |
| 1.6327 | 0.1001 | 1.5273 | 0.1035 | 24 |
| 1.5906 | 0.1010 | 1.4766 | 0.1042 | 25 |
| 1.5545 | 0.1018 | 1.4561 | 0.1031 | 26 |
| 1.5231 | 0.1024 | 1.4365 | 0.1054 | 27 |
| 1.4957 | 0.1030 | 1.3975 | 0.1046 | 28 |
| 1.4700 | 0.1036 | 1.3789 | 0.1061 | 29 |
| 1.4466 | 0.1041 | 1.3262 | 0.1070 | 30 |
| 1.4253 | 0.1046 | 1.3223 | 0.1072 | 31 |
| 1.4059 | 0.1050 | 1.3096 | 0.1070 | 32 |
| 1.3873 | 0.1054 | 1.3164 | 0.1072 | 33 |
| 1.3703 | 0.1058 | 1.2861 | 0.1072 | 34 |
| 1.3550 | 0.1062 | 1.2705 | 0.1082 | 35 |
| 1.3398 | 0.1065 | 1.2578 | 0.1082 | 36 |
| 1.3260 | 0.1068 | 1.25 | 0.1096 | 37 |
| 1.3127 | 0.1071 | 1.2266 | 0.1102 | 38 |
| 1.2996 | 0.1074 | 1.2305 | 0.1098 | 39 |
| 1.2891 | 0.1077 | 1.2139 | 0.1088 | 40 |
| 1.2783 | 0.1079 | 1.2158 | 0.1093 | 41 |
| 1.2674 | 0.1081 | 1.1787 | 0.1114 | 42 |
| 1.2570 | 0.1084 | 1.1709 | 0.1107 | 43 |
| 1.2478 | 0.1086 | 1.1709 | 0.1104 | 44 |
| 1.2390 | 0.1088 | 1.1777 | 0.1101 | 45 |
| 1.2305 | 0.1090 | 1.1738 | 0.1111 | 46 |
| 1.2215 | 0.1092 | 1.1533 | 0.1112 | 47 |
| 1.2140 | 0.1094 | 1.1514 | 0.1117 | 48 |
| 1.2068 | 0.1096 | 1.1621 | 0.1119 | 49 |
| 1.1991 | 0.1097 | 1.1416 | 0.1108 | 50 |
| 1.1927 | 0.1099 | 1.1279 | 0.1113 | 51 |
| 1.1854 | 0.1101 | 1.1147 | 0.1123 | 52 |
| 1.1800 | 0.1102 | 1.125 | 0.1116 | 53 |
| 1.1727 | 0.1104 | 1.1167 | 0.1116 | 54 |
| 1.1679 | 0.1105 | 1.0884 | 0.1122 | 55 |
| 1.1613 | 0.1106 | 1.1084 | 0.1120 | 56 |
| 1.1563 | 0.1107 | 1.1035 | 0.1119 | 57 |
| 1.1517 | 0.1109 | 1.1035 | 0.1124 | 58 |
| 1.1454 | 0.1111 | 1.0718 | 0.1128 | 59 |
| 1.1403 | 0.1111 | 1.0874 | 0.1123 | 60 |
| 1.1360 | 0.1112 | 1.0742 | 0.1145 | 61 |
| 1.1318 | 0.1114 | 1.0811 | 0.1131 | 62 |
| 1.1277 | 0.1114 | 1.0723 | 0.1129 | 63 |
| 1.1226 | 0.1116 | 1.0640 | 0.1124 | 64 |
| 1.1186 | 0.1117 | 1.0840 | 0.1117 | 65 |
| 1.1144 | 0.1118 | 1.0522 | 0.1139 | 66 |
| 1.1111 | 0.1119 | 1.0557 | 0.1132 | 67 |
| 1.1069 | 0.1119 | 1.0718 | 0.1124 | 68 |
| 1.1038 | 0.1120 | 1.0376 | 0.1135 | 69 |
| 1.1007 | 0.1121 | 1.0537 | 0.1138 | 70 |
| 1.0975 | 0.1121 | 1.0503 | 0.1134 | 71 |
| 1.0941 | 0.1122 | 1.0317 | 0.1140 | 72 |
| 1.0902 | 0.1124 | 1.0439 | 0.1145 | 73 |
| 1.0881 | 0.1124 | 1.0352 | 0.1145 | 74 |
| 1.0839 | 0.1125 | 1.0449 | 0.1144 | 75 |
| 1.0821 | 0.1125 | 1.0229 | 0.1148 | 76 |
| 1.0791 | 0.1126 | 1.0244 | 0.1148 | 77 |
| 1.0764 | 0.1127 | 1.0366 | 0.1141 | 78 |
| 1.0741 | 0.1128 | 1.0308 | 0.1134 | 79 |
| 1.0716 | 0.1128 | 1.0400 | 0.1137 | 80 |
| 1.0688 | 0.1129 | 1.0225 | 0.1140 | 81 |
| 1.0664 | 0.1129 | 1.0269 | 0.1139 | 82 |
| 1.0643 | 0.1129 | 1.0156 | 0.1146 | 83 |
| 1.0629 | 0.1131 | 1.0127 | 0.1149 | 84 |
| 1.0602 | 0.1131 | 1.0420 | 0.1132 | 85 |
| 1.0580 | 0.1132 | 1.0205 | 0.1149 | 86 |
| 1.0568 | 0.1132 | 1.0024 | 0.1159 | 87 |
| 1.0547 | 0.1132 | 1.0210 | 0.1144 | 88 |
| 1.0536 | 0.1133 | 1.0176 | 0.1143 | 89 |
| 1.0522 | 0.1133 | 0.9951 | 0.1134 | 90 |
| 1.0505 | 0.1134 | 1.0283 | 0.1136 | 91 |
| 1.0484 | 0.1134 | 1.0063 | 0.1141 | 92 |
| 1.0482 | 0.1134 | 0.9917 | 0.1141 | 93 |
| 1.0463 | 0.1135 | 1.0244 | 0.1145 | 94 |
| 1.0458 | 0.1134 | 1.0220 | 0.1143 | 95 |
| 1.0448 | 0.1135 | 0.9785 | 0.1147 | 96 |
| 1.0435 | 0.1135 | 0.9771 | 0.1155 | 97 |
| 1.0433 | 0.1135 | 0.9946 | 0.1137 | 98 |
| 1.0414 | 0.1136 | 1.0103 | 0.1144 | 99 |
### Framework versions
- Transformers 4.27.0.dev0
- TensorFlow 2.9.1
- Tokenizers 0.13.2
|
kws/Reinforce-Pixelcopter
|
kws
| 2023-03-27T05:06:24Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-23T09:43:11Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 54.40 +/- 34.76
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
jamesimmanuel/Reinforce-pixelcopter_policy
|
jamesimmanuel
| 2023-03-27T05:02:07Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T02:56:00Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopter_policy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 37.40 +/- 22.79
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
shreyansjain/ppo-Pyramids
|
shreyansjain
| 2023-03-27T04:54:47Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-03-27T04:51:09Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: shreyansjain/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sachaarbonel/bert-italian-cased-finetuned-pos
|
sachaarbonel
| 2023-03-27T04:45:46Z | 214 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"token-classification",
"it",
"dataset:xtreme",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: it
datasets:
- xtreme
---
# Italian-Bert (Italian Bert) + POS 🎃🏷
This model is a fine-tuned on [xtreme udpos Italian](https://huggingface.co/nlp/viewer/?dataset=xtreme&config=udpos.Italian) version of [Bert Base Italian](https://huggingface.co/dbmdz/bert-base-italian-cased) for **POS** downstream task.
## Details of the downstream task (POS) - Dataset
- [Dataset: xtreme udpos Italian](https://huggingface.co/nlp/viewer/?dataset=xtreme&config=udpos.Italian) 📚
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 716 K |
| Dev | 85 K |
- [Fine-tune on NER script provided by @stefan-it](https://raw.githubusercontent.com/stefan-it/fine-tuned-berts-seq/master/scripts/preprocess.py)
- Labels covered:
```
ADJ
ADP
ADV
AUX
CCONJ
DET
INTJ
NOUN
NUM
PART
PRON
PROPN
PUNCT
SCONJ
SYM
VERB
X
```
## Metrics on evaluation set 🧾
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **97.25**
| Precision | **97.15** |
| Recall | **97.36** |
## Model in action 🔨
Example of usage
```python
from transformers import pipeline
nlp_pos = pipeline(
"ner",
model="sachaarbonel/bert-italian-cased-finetuned-pos",
tokenizer=(
'sachaarbonel/bert-spanish-cased-finetuned-pos',
{"use_fast": False}
))
text = 'Roma è la Capitale d'Italia.'
nlp_pos(text)
'''
Output:
--------
[{'entity': 'PROPN', 'index': 1, 'score': 0.9995346665382385, 'word': 'roma'},
{'entity': 'AUX', 'index': 2, 'score': 0.9966597557067871, 'word': 'e'},
{'entity': 'DET', 'index': 3, 'score': 0.9994786977767944, 'word': 'la'},
{'entity': 'NOUN',
'index': 4,
'score': 0.9995198249816895,
'word': 'capitale'},
{'entity': 'ADP', 'index': 5, 'score': 0.9990894198417664, 'word': 'd'},
{'entity': 'PART', 'index': 6, 'score': 0.57159024477005, 'word': "'"},
{'entity': 'PROPN',
'index': 7,
'score': 0.9994804263114929,
'word': 'italia'},
{'entity': 'PUNCT', 'index': 8, 'score': 0.9772886633872986, 'word': '.'}]
'''
```
Yeah! Not too bad 🎉
> Created by [Sacha Arbonel/@sachaarbonel](https://twitter.com/sachaarbonel) | [LinkedIn](https://www.linkedin.com/in/sacha-arbonel)
> Made with <span style="color: #e25555;">♥</span> in Paris
|
intanm/mlm-v1-fin-lm
|
intanm
| 2023-03-27T04:41:00Z | 192 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-27T04:29:15Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: mlm-v1-fin-lm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mlm-v1-fin-lm
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.2901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 207 | 4.9338 |
| No log | 2.0 | 414 | 4.4825 |
| 5.2062 | 3.0 | 621 | 4.2789 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
kailorston/my_awesome_opus_books_model
|
kailorston
| 2023-03-27T04:36:45Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-26T10:55:25Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: kailorston/my_awesome_opus_books_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# kailorston/my_awesome_opus_books_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.6495
- Validation Loss: 1.4502
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.7245 | 1.5014 | 0 |
| 1.6822 | 1.4734 | 1 |
| 1.6495 | 1.4502 | 2 |
### Framework versions
- Transformers 4.27.3
- TensorFlow 2.11.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
jamesimmanuel/ppo-SnowballTarget
|
jamesimmanuel
| 2023-03-27T04:27:35Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-03-27T04:26:50Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: jamesimmanuel/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
emanehab/aiornot_eman
|
emanehab
| 2023-03-27T04:16:27Z | 223 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"en",
"dataset:competitions/aiornot",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-03-26T17:01:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: aiornot_eman
results: []
datasets:
- competitions/aiornot
language:
- en
library_name: transformers
pipeline_tag: image-classification
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aiornot_eman
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0863
- Accuracy: 0.9726
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1235 | 1.0 | 248 | 0.1117 | 0.9547 |
| 0.0512 | 2.0 | 497 | 0.0866 | 0.9690 |
| 0.0175 | 2.99 | 744 | 0.0863 | 0.9726 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.10.2
- Datasets 2.10.1
- Tokenizers 0.13.2
|
arb9p4/poca-SoccerTwos
|
arb9p4
| 2023-03-27T04:10:01Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-03-27T04:09:43Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: arb9p4/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
jokyere49/ppo-LunarLander-v2
|
jokyere49
| 2023-03-27T03:55:10Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T03:54:48Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.17 +/- 20.86
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
aidenlee/ppo-PyramidsTraining
|
aidenlee
| 2023-03-27T03:54:59Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-03-27T01:31:03Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: aidenlee/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
gayanin/ec-biogpt-masked-pubmed
|
gayanin
| 2023-03-27T03:22:08Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"biogpt",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T23:24:19Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: ec-biogpt-masked-pubmed
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ec-biogpt-masked-pubmed
This model is a fine-tuned version of [microsoft/biogpt](https://huggingface.co/microsoft/biogpt) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7418
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.3707 | 0.07 | 500 | 0.8468 |
| 0.5388 | 0.14 | 1000 | 0.7643 |
| 0.5857 | 0.21 | 1500 | 0.7669 |
| 0.5441 | 0.28 | 2000 | 0.7576 |
| 0.5294 | 0.36 | 2500 | 0.7570 |
| 0.7544 | 0.43 | 3000 | 0.7227 |
| 0.7075 | 0.5 | 3500 | 0.7153 |
| 0.7513 | 0.57 | 4000 | 0.7105 |
| 0.7101 | 0.64 | 4500 | 0.7059 |
| 0.7369 | 0.71 | 5000 | 0.7031 |
| 0.7477 | 0.78 | 5500 | 0.6991 |
| 0.6831 | 0.85 | 6000 | 0.6978 |
| 0.6458 | 0.93 | 6500 | 0.6940 |
| 0.6998 | 1.0 | 7000 | 0.6907 |
| 0.5901 | 1.07 | 7500 | 0.7036 |
| 0.633 | 1.14 | 8000 | 0.7016 |
| 0.6375 | 1.21 | 8500 | 0.7020 |
| 0.6378 | 1.28 | 9000 | 0.6988 |
| 0.5952 | 1.35 | 9500 | 0.6965 |
| 0.5714 | 1.42 | 10000 | 0.6960 |
| 0.5874 | 1.5 | 10500 | 0.6957 |
| 0.5828 | 1.57 | 11000 | 0.6917 |
| 0.5921 | 1.64 | 11500 | 0.6920 |
| 0.6086 | 1.71 | 12000 | 0.6905 |
| 0.5872 | 1.78 | 12500 | 0.6878 |
| 0.5895 | 1.85 | 13000 | 0.6883 |
| 0.5953 | 1.92 | 13500 | 0.6860 |
| 0.598 | 1.99 | 14000 | 0.6852 |
| 0.4805 | 2.07 | 14500 | 0.7077 |
| 0.4885 | 2.14 | 15000 | 0.7107 |
| 0.5048 | 2.21 | 15500 | 0.7083 |
| 0.4665 | 2.28 | 16000 | 0.7098 |
| 0.5057 | 2.35 | 16500 | 0.7088 |
| 0.4706 | 2.42 | 17000 | 0.7081 |
| 0.5056 | 2.49 | 17500 | 0.7076 |
| 0.4884 | 2.56 | 18000 | 0.7068 |
| 0.487 | 2.64 | 18500 | 0.7051 |
| 0.5327 | 2.71 | 19000 | 0.7062 |
| 0.4902 | 2.78 | 19500 | 0.7042 |
| 0.5277 | 2.85 | 20000 | 0.7021 |
| 0.499 | 2.92 | 20500 | 0.7024 |
| 0.4981 | 2.99 | 21000 | 0.7002 |
| 0.4174 | 3.06 | 21500 | 0.7237 |
| 0.4233 | 3.13 | 22000 | 0.7244 |
| 0.4331 | 3.21 | 22500 | 0.7265 |
| 0.4203 | 3.28 | 23000 | 0.7275 |
| 0.4265 | 3.35 | 23500 | 0.7252 |
| 0.4302 | 3.42 | 24000 | 0.7271 |
| 0.4343 | 3.49 | 24500 | 0.7244 |
| 0.4264 | 3.56 | 25000 | 0.7265 |
| 0.4565 | 3.63 | 25500 | 0.7247 |
| 0.4258 | 3.7 | 26000 | 0.7245 |
| 0.4191 | 3.78 | 26500 | 0.7246 |
| 0.4412 | 3.85 | 27000 | 0.7234 |
| 0.4604 | 3.92 | 27500 | 0.7249 |
| 0.4197 | 3.99 | 28000 | 0.7238 |
| 0.3666 | 4.06 | 28500 | 0.7413 |
| 0.3772 | 4.13 | 29000 | 0.7414 |
| 0.3628 | 4.2 | 29500 | 0.7410 |
| 0.3611 | 4.27 | 30000 | 0.7431 |
| 0.3736 | 4.35 | 30500 | 0.7414 |
| 0.3741 | 4.42 | 31000 | 0.7420 |
| 0.3661 | 4.49 | 31500 | 0.7424 |
| 0.3966 | 4.56 | 32000 | 0.7423 |
| 0.4058 | 4.63 | 32500 | 0.7423 |
| 0.4028 | 4.7 | 33000 | 0.7423 |
| 0.4028 | 4.77 | 33500 | 0.7420 |
| 0.3802 | 4.84 | 34000 | 0.7421 |
| 0.3612 | 4.92 | 34500 | 0.7418 |
| 0.3804 | 4.99 | 35000 | 0.7418 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
rghosh8/bert-finetuned-squad
|
rghosh8
| 2023-03-27T03:09:34Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-03-27T02:05:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.11.0
|
jweb/japanese-soseki-gpt2-1b
|
jweb
| 2023-03-27T03:09:04Z | 5 | 3 |
transformers
|
[
"transformers",
"pytorch",
"rust",
"gpt2",
"text-generation",
"ja",
"japanese",
"lm",
"nlp",
"rust-bert",
"dataset:cc100",
"dataset:wikipedia",
"dataset:AozoraBunko",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-03T04:53:15Z |
---
language: ja
thumbnail: https://github.com/ycat3/japanese-pretrained-models/blob/master/jweb.png
tags:
- ja
- japanese
- gpt2
- text-generation
- lm
- nlp
- rust
- rust-bert
license: mit
datasets:
- cc100
- wikipedia
- AozoraBunko
widget:
- text: "夏目漱石は、"
---
# japanese-soseki-gpt2-1b

This repository provides a 1.3B-parameter finetuned Japanese GPT2 model.
The model was finetuned by [jweb](https://jweb.asia/) based on trained by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
Both pytorch(pytorch_model.bin) and Rust(rust_model.ot) models are provided
# How to use the model
*NOTE:* Use `T5Tokenizer` to initiate the tokenizer.
python
~~~~
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("jweb/japanese-soseki-gpt2-1b")
model = AutoModelForCausalLM.from_pretrained("jweb/japanese-soseki-gpt2-1b")
if torch.cuda.is_available():
model = model.to("cuda")
text = "夏目漱石は、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_length=128,
min_length=40,
do_sample=True,
repetition_penalty= 1.6,
early_stopping= True,
num_beams= 5,
temperature= 1.0,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
# sample output: 夏目漱石は、明治時代を代表する文豪です。夏目漱石の代表作は「吾輩は猫である」や「坊っちゃん」、「草枕」「三四郎」、それに「虞美人草(ぐびじんそう)」などたくさんあります。
~~~~
rust
~~~~
use rust_bert::gpt2::GPT2Generator;
use rust_bert::pipelines::common::{ModelType, TokenizerOption};
use rust_bert::pipelines::generation_utils::{GenerateConfig, LanguageGenerator};
use rust_bert::resources::{ RemoteResource, ResourceProvider};
use tch::Device;
fn main() -> anyhow::Result<()> {
let model_resource = Box::new(RemoteResource {
url: "https://huggingface.co/jweb/japanese-soseki-gpt2-1b/resolve/main/rust_model.ot".into(),
cache_subdir: "japanese-soseki-gpt2-1b/model".into(),
});
let config_resource = Box::new(RemoteResource {
url: "https://huggingface.co/jweb/japanese-soseki-gpt2-1b/resolve/main/config.json".into(),
cache_subdir: "japanese-soseki-gpt2-1b/config".into(),
});
let vocab_resource = Box::new(RemoteResource {
url: "https://huggingface.co/jweb/japanese-soseki-gpt2-1b/resolve/main/spiece.model".into(),
cache_subdir: "japanese-soseki-gpt2-1b/vocab".into(),
});
let vocab_resource_token = vocab_resource.clone();
let merges_resource = vocab_resource.clone();
let generate_config = GenerateConfig {
model_resource,
config_resource,
vocab_resource,
merges_resource, // not used
device: Device::Cpu,
repetition_penalty: 1.6,
min_length: 40,
max_length: 128,
do_sample: true,
early_stopping: true,
num_beams: 5,
temperature: 1.0,
top_k: 500,
top_p: 0.95,
..Default::default()
};
let tokenizer = TokenizerOption::from_file(
ModelType::T5,
vocab_resource_token.get_local_path().unwrap().to_str().unwrap(),
None,
true,
None,
None,
)?;
let mut gpt2_model = GPT2Generator::new_with_tokenizer(generate_config, tokenizer.into())?;
gpt2_model.set_device(Device::cuda_if_available());
let input_text = "夏目漱石は、";
let t1 = std::time::Instant::now();
let output = gpt2_model.generate(Some(&[input_text]), None);
println!("{}", output[0].text);
println!("Elapsed Time(ms):{}",t1.elapsed().as_millis());
Ok(())
}
// sample output: 夏目漱石は、明治から大正にかけて活躍した日本の小説家です。彼は「吾輩は猫である」や「坊っちゃん」、「草枕」「三四郎」、あるいは「虞美人草」などの小説で知られていますが、「明暗」のような小説も書いていました。
~~~~
# Model architecture
A 24-layer, 2048-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese C4](https://huggingface.co/datasets/allenai/c4), [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective. It reaches around 14 perplexity on a chosen validation set from the same data.
# Finetuning
The model was finetuned on [Aozorabunko](https://github.com/aozorabunko/aozorabunko), especially Natume Soseki books.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer. The vocabulary was first trained on a selected subset from the training data using the official sentencepiece training script, and then augmented with emojis and symbols.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
haidlir/LunarLander-v2-PPO-CleanRL
|
haidlir
| 2023-03-27T03:03:38Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T02:25:35Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 127.35 +/- 9.93
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
|
jamesdolezal/lung-adeno-squam-v1
|
jamesdolezal
| 2023-03-27T03:01:46Z | 0 | 0 |
tf-keras
|
[
"tf-keras",
"arxiv:1610.02357",
"doi:10.57967/hf/0089",
"license:gpl-3.0",
"region:us"
] | null | 2022-11-04T13:37:11Z |
---
license: gpl-3.0
---
# Lung Adeno/Squam v1 Model Card
This model card describes the model associated with the manuscript "Uncertainty-informed deep learning models enable high-confidence predictions for digital histopathology", by Dolezal _et al_, available [here](https://www.nature.com/articles/s41467-022-34025-x).
## Model Details
- **Developed by:** James Dolezal
- **Model type:** Deep convolutional neural network image classifier
- **Language(s):** English
- **License:** GPL-3.0
- **Model Description:** This is a model that can classify H&E-stained pathologic images of non-small cell lung cancer into adenocarcinoma or squamous cell carcinoma and provide an estimate of classification uncertainty. It is an [Xception](https://arxiv.org/abs/1610.02357) model with two dropout-enabled hidden layers enabled during both training and inference. During inference, a given image is passed through the network 30 times, resulting in a distribution of predictions. The mean of this distribution is the final prediction, and the standard deviation is the uncertainty.
- **Image processing:** This model expects images of H&E-stained pathology slides at 299 x 299 px and 302 x 302 μm resolution. Images should be stain-normalized using a modified Reinhard normalizer ("Reinhard-Fast") available [here](https://github.com/jamesdolezal/slideflow/blob/master/slideflow/norm/tensorflow/reinhard.py). The stain normalizer should be fit using the `target_means` and `target_stds` listed in the model `params.json` file. Images should be should be standardized with `tf.image.per_image_standardization()`.
- **Resources for more information:** [GitHub Repository](https://github.com/jamesdolezal/biscuit), [Paper](https://www.nature.com/articles/s41467-022-34025-x)
- **Cite as:**
@ARTICLE{Dolezal2022-qa,
title = "Uncertainty-informed deep learning models enable high-confidence
predictions for digital histopathology",
author = "Dolezal, James M and Srisuwananukorn, Andrew and Karpeyev, Dmitry
and Ramesh, Siddhi and Kochanny, Sara and Cody, Brittany and
Mansfield, Aaron S and Rakshit, Sagar and Bansal, Radhika and
Bois, Melanie C and Bungum, Aaron O and Schulte, Jefree J and
Vokes, Everett E and Garassino, Marina Chiara and Husain, Aliya N
and Pearson, Alexander T",
journal = "Nature Communications",
volume = 13,
number = 1,
pages = "6572",
month = nov,
year = 2022
}
# Uses
## Examples
For direct use, the model can be loaded using Tensorflow/Keras:
```
import tensorflow as tf
model = tf.keras.models.load_model('/path/')
```
or loaded with [Slideflow](https://github.com/jamesdolezal/slideflow) version 1.1+ with the following syntax:
```
import slideflow as sf
model = sf.model.load('/path/')
```
The stain normalizer can be loaded and fit using Slideflow:
```
normalizer = sf.util.get_model_normalizer('/path/')
```
The stain normalizer has a native Tensorflow transform and can be directly applied to a tf.data.Dataset:
```
# Map the stain normalizer transformation
# to a tf.data.Dataset
dataset = dataset.map(normalizer.tf_to_tf)
```
Alternatively, the model can be used to generate predictions for whole-slide images processed through Slideflow in an end-to-end [Project](https://slideflow.dev/project_setup.html). To use the model to generate predictions on data processed with Slideflow, simply pass the model to the [`Project.predict()`](https://slideflow.dev/project.html#slideflow.Project.predict) function:
```
import slideflow
P = sf.Project('/path/to/slideflow/project')
P.predict('/model/path')
```
## Direct Use
This model is intended for research purposes only. Possible research areas and tasks include
- Development and comparison of uncertainty quantification methods for pathologic images.
- Probing and understanding the limitations of out-of-distribution detection for pathology classification models.
- Applications in educational settings.
- Research on pathology classification models for non-small cell lung cancer.
Excluded uses are described below.
### Misuse and Out-of-Scope Use
This model should not be used in a clinical setting to generate predictions that will be used to inform patients, physicians, or any other health care members directly involved in their health care outside the context of an approved research protocol. Using the model in a clinical setting outside the context of an approved research protocol is a misuse of this model. This includes, but is not limited to:
- Generating predictions of images from a patient's tumor and sharing those predictions with the patient
- Generating predictions of images from a patient's tumor and sharing those predictions with the patient's physician, or other members of the patient's healthcare team
- Influencing a patient's health care treatment in any way based on output from this model
### Limitations
The model has not been validated to discriminate lung adenocarcinoma vs. squamous cell carcinoma in contexts where other tumor types are possible (such as lung small cell carcinoma, neuroendocrine tumors, metastatic deposits, etc.)
### Bias
This model was trained on The Cancer Genome Atlas (TCGA), which contains patient data from communities and cultures which may not reflect the general population. This datasets is comprised of images from multiple institutions, which may introduce a potential source of bias from site-specific batch effects ([Howard, 2021](https://www.nature.com/articles/s41467-021-24698-1)). The model was validated on data from the Clinical Proteomics Tumor Analysis Consortium (CPTAC) and an institutional dataset from Mayo Clinic, the latter of which consists primarily of data from patients of white and western cultures.
## Training
**Training Data**
The following dataset was used to train the model:
- The Cancer Genome Atlas (TCGA), LUAD (adenocarcinoma) and LUSC (squamous cell carcinoma) cohorts (see next section)
This model was trained on the full dataset, with a total of 941 slides.
**Training Procedure**
Each whole-slide image was sectioned into smaller images in a grid-wise fashion in order to extract tiles from whole-slide images at 302 x 302 μm. Image tiles were extracted at the nearest downsample layer, and resized to 299 x 299 px using [Libvips](https://www.libvips.org/API/current/libvips-resample.html#vips-resize). During training,
- Images are stain-normalized with a modified Reinhard normalizer ("Reinhard-Fast"), which excludes the brightness standardization step, available [here](https://github.com/jamesdolezal/slideflow/blob/master/slideflow/norm/tensorflow/reinhard.py)
- Images are randomly flipped and rotated (90, 180, 270)
- Images have a 50% chance of being JPEG compressed with quality level between 50-100%
- Images have a 10% chance of random Gaussian blur, with sigma between 0.5-2.0
- Images are standardized with `tf.image.per_image_standardization()`
- Images are classified through an Xception block, followed by two hidden layers with dropout (p=0.1) permanently enabled during both training and inference
- The loss is cross-entropy, with adenocarcinoma=0 and squamous=1
- Training was halted at a predetermined step=1451 (at batch size of 128, this is after 185,728 images), determined through nested cross-validation
During inference,
- A given image undergoes 30 forward passes in the network, resulting in a distribution, where
- The mean is the final prediction
- The standard deviation is the uncertainty
Tile-level and slide-level uncertainty thresholds are calculated and applied as discussed in the [Paper](https://www.nature.com/articles/s41467-022-34025-x). For this model, θ_tile=0.0228 and θ_slide=0.0139.
- **Hardware:** 1 x A100 GPUs
- **Optimizer:** Adam
- **Batch:** 128
- **Learning rate:** 0.0001, with a decay of 0.98 every 512 steps
- **Hidden layers:** 2 hidden layers of width 1024, with dropout p=0.1
## Evaluation Results
External evaluation results in the CPTAC and Mayo Clinic dataset are presented in the [Paper](https://www.nature.com/articles/s41467-022-34025-x) and shown here:
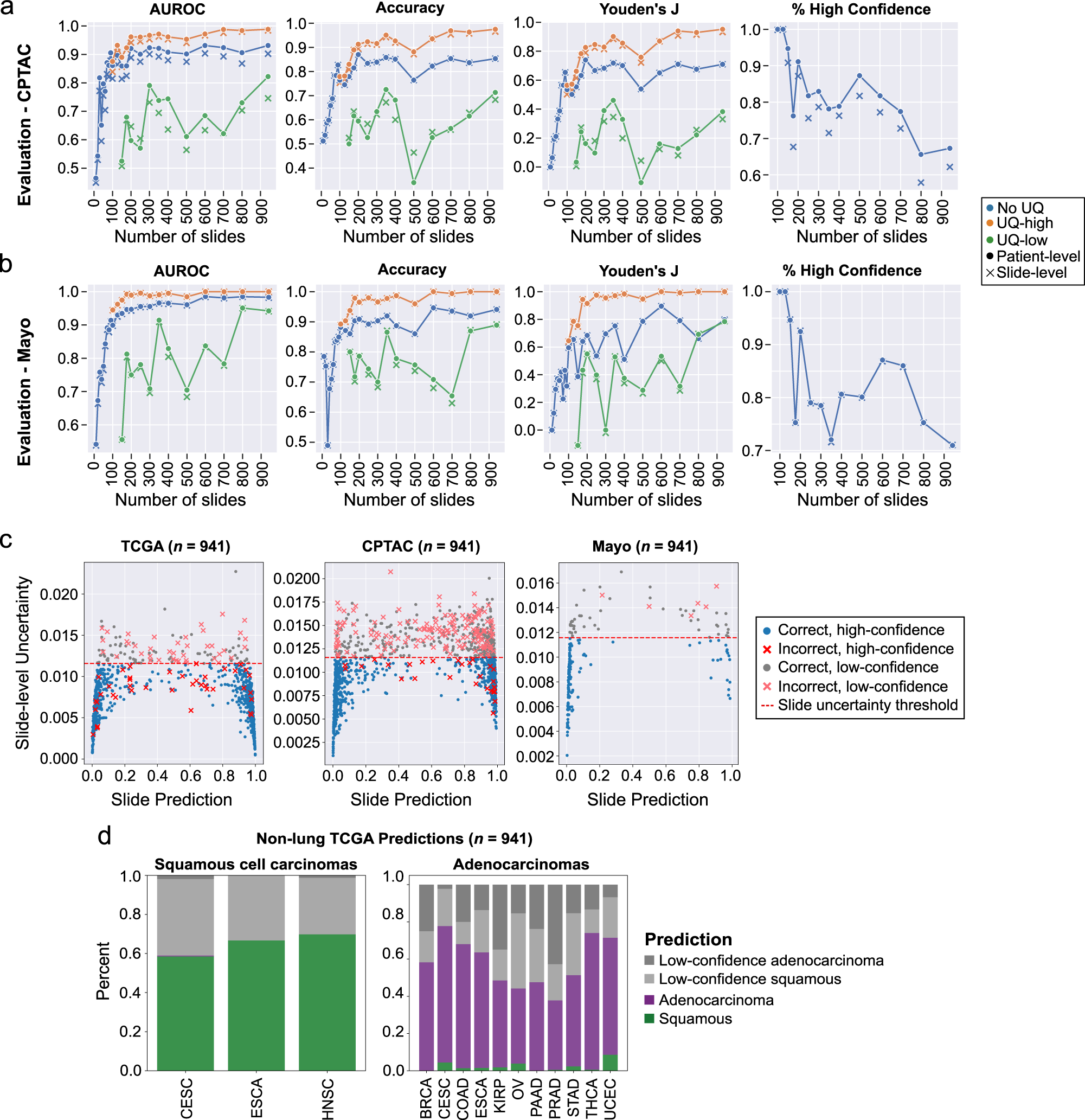
## Citation
@ARTICLE{Dolezal2022-qa,
title = "Uncertainty-informed deep learning models enable high-confidence
predictions for digital histopathology",
author = "Dolezal, James M and Srisuwananukorn, Andrew and Karpeyev, Dmitry
and Ramesh, Siddhi and Kochanny, Sara and Cody, Brittany and
Mansfield, Aaron S and Rakshit, Sagar and Bansal, Radhika and
Bois, Melanie C and Bungum, Aaron O and Schulte, Jefree J and
Vokes, Everett E and Garassino, Marina Chiara and Husain, Aliya N
and Pearson, Alexander T",
journal = "Nature Communications",
volume = 13,
number = 1,
pages = "6572",
month = nov,
year = 2022
}
|
nolanaatama/nmlnrtstyl
|
nolanaatama
| 2023-03-27T02:56:23Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-17T02:18:02Z |
---
license: creativeml-openrail-m
---
|
Mizuiro-sakura/deberta-v2-base-japanese-finetuned-QAe
|
Mizuiro-sakura
| 2023-03-27T02:43:35Z | 137 | 3 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"question-answering",
"deberta",
"question answering",
"squad",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:oscar",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-01-09T11:59:13Z |
---
license: mit
language: ja
library_name: transformers
tags:
- pytorch
- deberta
- deberta-v2
- question-answering
- question answering
- squad
datasets:
- wikipedia
- cc100
- oscar
metrics:
- accuracy
---
# このモデルはdeberta-v2-base-japaneseをファインチューニングしてQAタスクに用いれるようにしたものです。
このモデルはdeberta-v2-base-japaneseを運転ドメインQAデータセット(DDQA)( https://nlp.ist.i.kyoto-u.ac.jp/index.php?Driving%20domain%20QA%20datasets )を用いてファインチューニングしたものです。
Question-Answeringタスク(SQuAD)に用いることができます。
# This model is fine-tuned model for Question-Answering which is based on deberta-v2-base-japanese
This model is fine-tuned by using DDQA dataset.
You could use this model for Question-Answering tasks.
# How to use 使い方
transformersおよびpytorch、sentencepiece、Juman++をインストールしてください。
以下のコードを実行することで、Question-Answeringタスクを解かせることができます。 please execute this code.
```python
import torch
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-base-japanese')
model=AutoModelForQuestionAnswering.from_pretrained('Mizuiro-sakura/deberta-v2-base-japanese-finetuned-QAe') # 学習済みモデルの読み込み
text={
'context':'私の名前はEIMIです。好きな食べ物は苺です。 趣味は皆さんと会話することです。',
'question' :'好きな食べ物は何ですか'
}
input_ids=tokenizer.encode(text['question'],text['context']) # tokenizerで形態素解析しつつコードに変換する
output= model(torch.tensor([input_ids])) # 学習済みモデルを用いて解析
prediction = tokenizer.decode(input_ids[torch.argmax(output.start_logits): torch.argmax(output.end_logits)]) # 答えに該当する部分を抜き取る
print(prediction)
```
# モデルの精度 accuracy of model
Exact Match(厳密一致) : 0.8038277511961722
f1 : 0.8959389668095072
# deberta-v2-base-japaneseとは?
日本語Wikipedeia(3.2GB)および、cc100(85GB)、oscar(54GB)を用いて訓練されたモデルです。
京都大学黒橋研究室が公表されました。
# Model description
This is a Japanese DeBERTa V2 base model pre-trained on Japanese Wikipedia, the Japanese portion of CC-100, and the Japanese portion of OSCAR.
# Acknowledgments 謝辞
モデルを公開してくださった京都大学黒橋研究室には感謝いたします。
I would like to thank Kurohashi Lab at Kyoto University.
|
w11wo/lao-roberta-base-pos-tagger
|
w11wo
| 2023-03-27T02:35:35Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"token-classification",
"lao-roberta-base-pos-tagger",
"lo",
"arxiv:1907.11692",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: lo
tags:
- lao-roberta-base-pos-tagger
license: mit
widget:
- text: "ຮ້ອງ ມ່ວນ ແທ້ ສຽງດີ ອິຫຼີ"
---
## Lao RoBERTa Base POS Tagger
Lao RoBERTa Base POS Tagger is a part-of-speech token-classification model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. The model was originally the pre-trained [Lao RoBERTa Base](https://huggingface.co/w11wo/lao-roberta-base) model, which is then fine-tuned on the [`Yunshan Cup 2020`](https://github.com/GKLMIP/Yunshan-Cup-2020) dataset consisting of tag-labelled Lao corpus.
After training, the model achieved an evaluation accuracy of 83.14%. On the benchmark test set, the model achieved an accuracy of 83.30%.
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with other frameworks nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ----------------------------- | ------- | ------------ | ------------------------------- |
| `lao-roberta-base-pos-tagger` | 124M | RoBERTa Base | `Yunshan Cup 2020` |
## Evaluation Results
The model was trained for 15 epochs, with a batch size of 8, a learning rate of 5e-5, with cosine annealing to 0. The best model was loaded at the end.
| Epoch | Training Loss | Validation Loss | Accuracy |
| ----- | ------------- | --------------- | -------- |
| 1 | 1.026100 | 0.733780 | 0.746021 |
| 2 | 0.646900 | 0.659625 | 0.775688 |
| 3 | 0.500400 | 0.576214 | 0.798523 |
| 4 | 0.385400 | 0.606503 | 0.805269 |
| 5 | 0.288000 | 0.652493 | 0.809092 |
| 6 | 0.204600 | 0.671678 | 0.815216 |
| 7 | 0.145200 | 0.704693 | 0.818209 |
| 8 | 0.098700 | 0.830561 | 0.816998 |
| 9 | 0.066100 | 0.883329 | 0.825232 |
| 10 | 0.043900 | 0.933347 | 0.825664 |
| 11 | 0.027200 | 0.992055 | 0.828449 |
| 12 | 0.017300 | 1.054874 | 0.830819 |
| 13 | 0.011500 | 1.081638 | 0.830940 |
| 14 | 0.008500 | 1.094252 | 0.831304 |
| 15 | 0.007400 | 1.097428 | 0.831442 |
## How to Use
### As Token Classifier
```python
from transformers import pipeline
pretrained_name = "w11wo/lao-roberta-base-pos-tagger"
nlp = pipeline(
"token-classification",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("ຮ້ອງ ມ່ວນ ແທ້ ສຽງດີ ອິຫຼີ")
```
## Disclaimer
Do consider the biases which come from both the pre-trained RoBERTa model and the `Yunshan Cup 2020` dataset that may be carried over into the results of this model.
## Author
Lao RoBERTa Base POS Tagger was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
|
SenY/embeddings
|
SenY
| 2023-03-27T02:23:06Z | 0 | 13 | null |
[
"region:us"
] | null | 2023-03-20T07:21:44Z |
---
{}
---
# capri leggings.safetensors
Concepts: capri(three-quarter) leggings
```prompt example
1girl, (capri leggings:1.3)
```
<img src="https://huggingface.co/SenY/embeddings/resolve/main/capri%20leggings.preview.png" width="320">
If it does not act very strongly against the prompt, it is recommended to increase the strength to about 1.4.
# low ponytail.safetensors
Concepts: low ponytail
<img src="https://huggingface.co/SenY/embeddings/resolve/main/low%20ponytail.preview.png" width="320">
```prompt example
1girl, low ponytail
```
It is recommended to put "animal ears" as a negative prompt.
|
McCheng/poca-SoccerTwos
|
McCheng
| 2023-03-27T02:17:52Z | 8 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-03-27T02:17:44Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: McCheng/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Reindrob/LVA
|
Reindrob
| 2023-03-27T02:09:57Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-27T01:37:26Z |
---
license: creativeml-openrail-m
---
|
yonathanstwn/nllb-en-id-ccmatrix
|
yonathanstwn
| 2023-03-27T01:46:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"dataset:ccmatrix",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-25T11:18:47Z |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
datasets:
- ccmatrix
metrics:
- bleu
model-index:
- name: nllb-en-id-ccmatrix
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: ccmatrix
type: ccmatrix
config: en-id
split: train
args: en-id
metrics:
- name: Bleu
type: bleu
value: 65.9837
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nllb-en-id-ccmatrix
This model is a fine-tuned version of [facebook/nllb-200-distilled-600M](https://huggingface.co/facebook/nllb-200-distilled-600M) on the ccmatrix dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4791
- Bleu: 65.9837
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 4000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:------:|:---------------:|:-------:|
| 0.606 | 1.0 | 28125 | 0.5249 | 64.1268 |
| 0.4943 | 2.0 | 56250 | 0.5043 | 64.7892 |
| 0.467 | 3.0 | 84375 | 0.4945 | 65.2331 |
| 0.4487 | 4.0 | 112500 | 0.4887 | 65.5512 |
| 0.4349 | 5.0 | 140625 | 0.4843 | 65.6806 |
| 0.4242 | 6.0 | 168750 | 0.4822 | 65.7774 |
| 0.416 | 7.0 | 196875 | 0.4801 | 65.8541 |
| 0.4098 | 8.0 | 225000 | 0.4800 | 65.9652 |
| 0.4052 | 9.0 | 253125 | 0.4788 | 65.9701 |
| 0.4023 | 10.0 | 281250 | 0.4791 | 65.9837 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.0
- Datasets 2.10.1
- Tokenizers 0.11.0
|
SebastianS/ppo-LunarLander-v2_v2
|
SebastianS
| 2023-03-27T01:42:59Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T01:42:38Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 257.79 +/- 18.54
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jayeshvpatil/Pyramids_Training
|
jayeshvpatil
| 2023-03-27T01:37:41Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-03-27T01:37:35Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: jayeshvpatil/Pyramids_Training
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
swl-models/QteaMix
|
swl-models
| 2023-03-27T01:37:08Z | 0 | 0 | null |
[
"license:cc0-1.0",
"region:us"
] | null | 2023-03-27T01:37:08Z |
---
license: cc0-1.0
duplicated_from: chenxluo/QteaMix
---
<font size="7"><b>QteaMix<br><font size="5">——一个融合的Q版模型</b><font>
<font size="3"><em>通常需要tag:chibi <br> 当然,即使没有,也很可能得到Q版的结果。</em><font>
<font size="5">以下是一些简单的例图测试:<font>
<br>
<br>
<br>
<br>
<br>
<br>
<font size="4"><u>一般来说,应设置不超过960的分辨率,否则更易出现脱Q化。<br>如果需要大图,请使用高清修复或图生图放大。</u><font>
|
fathan/ijelid-indobertweet
|
fathan
| 2023-03-27T01:22:53Z | 20 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-10-04T05:54:49Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: ijelid-indobertweet
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ijelid-indobertweet
This model is a fine-tuned version of [indolem/indobertweet-base-uncased](https://huggingface.co/indolem/indobertweet-base-uncased) on the Indonesian-Javanese-English code-mixed Twitter dataset.
Label ID and its corresponding name:
| Label ID | Label Name |
|:---------------:|:------------------------------------------:
| LABEL_0 | English (EN) |
| LABEL_1 | Indonesian (ID) |
| LABEL_2 | Javanese (JV) |
| LABEL_3 | Mixed Indonesian-English (MIX-ID-EN) |
| LABEL_4 | Mixed Indonesian-Javanese (MIX-ID-JV) |
| LABEL_5 | Mixed Javanese-English (MIX-JV-EN) |
| LABEL_6 | Other (O) |
It achieves the following results on the evaluation set:
- Loss: 0.2804
- Precision: 0.9323
- Recall: 0.9394
- F1: 0.9356
- Accuracy: 0.9587
It achieves the following results on the test set:
- Overall Precision: 0.9326
- Overall Recall: 0.9421
- Overall F1: 0.9371
- Overall Accuracy: 0.9643
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 386 | 0.1666 | 0.8968 | 0.9014 | 0.8982 | 0.9465 |
| 0.257 | 2.0 | 772 | 0.1522 | 0.9062 | 0.9368 | 0.9206 | 0.9517 |
| 0.1092 | 3.0 | 1158 | 0.1462 | 0.9233 | 0.9335 | 0.9280 | 0.9556 |
| 0.0739 | 4.0 | 1544 | 0.1563 | 0.9312 | 0.9361 | 0.9336 | 0.9568 |
| 0.0739 | 5.0 | 1930 | 0.1671 | 0.9224 | 0.9413 | 0.9312 | 0.9573 |
| 0.0474 | 6.0 | 2316 | 0.1719 | 0.9303 | 0.9394 | 0.9346 | 0.9578 |
| 0.0339 | 7.0 | 2702 | 0.1841 | 0.9249 | 0.9389 | 0.9314 | 0.9576 |
| 0.0237 | 8.0 | 3088 | 0.2030 | 0.9224 | 0.9380 | 0.9297 | 0.9570 |
| 0.0237 | 9.0 | 3474 | 0.2106 | 0.9289 | 0.9377 | 0.9331 | 0.9576 |
| 0.0185 | 10.0 | 3860 | 0.2264 | 0.9277 | 0.9389 | 0.9330 | 0.9571 |
| 0.0132 | 11.0 | 4246 | 0.2331 | 0.9336 | 0.9344 | 0.9339 | 0.9574 |
| 0.0101 | 12.0 | 4632 | 0.2403 | 0.9353 | 0.9375 | 0.9363 | 0.9586 |
| 0.0082 | 13.0 | 5018 | 0.2509 | 0.9311 | 0.9373 | 0.9340 | 0.9582 |
| 0.0082 | 14.0 | 5404 | 0.2548 | 0.9344 | 0.9351 | 0.9346 | 0.9578 |
| 0.0062 | 15.0 | 5790 | 0.2608 | 0.9359 | 0.9372 | 0.9365 | 0.9588 |
| 0.005 | 16.0 | 6176 | 0.2667 | 0.9298 | 0.9407 | 0.9350 | 0.9587 |
| 0.0045 | 17.0 | 6562 | 0.2741 | 0.9337 | 0.9408 | 0.9371 | 0.9592 |
| 0.0045 | 18.0 | 6948 | 0.2793 | 0.9342 | 0.9371 | 0.9355 | 0.9589 |
| 0.0035 | 19.0 | 7334 | 0.2806 | 0.9299 | 0.9391 | 0.9342 | 0.9588 |
| 0.0034 | 20.0 | 7720 | 0.2804 | 0.9323 | 0.9394 | 0.9356 | 0.9587 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.7.1
- Datasets 2.5.1
- Tokenizers 0.12.1
|
aidenlee/ppo-SnowballTarget
|
aidenlee
| 2023-03-27T01:19:22Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-03-27T00:55:02Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: aidenlee/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
SebastianS/rl_course_vizdoom_health_gathering_supreme
|
SebastianS
| 2023-03-27T01:03:52Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T01:03:48Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.37 +/- 3.23
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r SebastianS/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m <path.to.enjoy.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m <path.to.train.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
mehtasagar95/lilt-en-funsd
|
mehtasagar95
| 2023-03-27T00:56:44Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"lilt",
"token-classification",
"generated_from_trainer",
"dataset:funsd-layoutlmv3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-27T00:25:40Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- funsd-layoutlmv3
model-index:
- name: lilt-en-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lilt-en-funsd
This model is a fine-tuned version of [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) on the funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7566
- Answer: {'precision': 0.8818713450292398, 'recall': 0.9228886168910648, 'f1': 0.9019138755980862, 'number': 817}
- Header: {'precision': 0.6597938144329897, 'recall': 0.5378151260504201, 'f1': 0.5925925925925926, 'number': 119}
- Question: {'precision': 0.8944494995450409, 'recall': 0.9127205199628597, 'f1': 0.9034926470588234, 'number': 1077}
- Overall Precision: 0.8781
- Overall Recall: 0.8947
- Overall F1: 0.8863
- Overall Accuracy: 0.7939
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.4354 | 10.53 | 200 | 1.0094 | {'precision': 0.8219954648526077, 'recall': 0.8873929008567931, 'f1': 0.8534432018834609, 'number': 817} | {'precision': 0.5617977528089888, 'recall': 0.42016806722689076, 'f1': 0.4807692307692308, 'number': 119} | {'precision': 0.8493723849372385, 'recall': 0.9424326833797586, 'f1': 0.8934859154929579, 'number': 1077} | 0.8264 | 0.8892 | 0.8567 | 0.7972 |
| 0.0503 | 21.05 | 400 | 1.2949 | {'precision': 0.8543577981651376, 'recall': 0.9118727050183598, 'f1': 0.8821788040260509, 'number': 817} | {'precision': 0.5658914728682171, 'recall': 0.6134453781512605, 'f1': 0.5887096774193549, 'number': 119} | {'precision': 0.9066147859922179, 'recall': 0.8653667595171773, 'f1': 0.8855106888361044, 'number': 1077} | 0.8625 | 0.8693 | 0.8659 | 0.8117 |
| 0.0143 | 31.58 | 600 | 1.3527 | {'precision': 0.8726190476190476, 'recall': 0.8971848225214198, 'f1': 0.8847314423657212, 'number': 817} | {'precision': 0.6666666666666666, 'recall': 0.5714285714285714, 'f1': 0.6153846153846153, 'number': 119} | {'precision': 0.8533674339300937, 'recall': 0.9294336118848654, 'f1': 0.8897777777777779, 'number': 1077} | 0.8520 | 0.8952 | 0.8731 | 0.8116 |
| 0.0064 | 42.11 | 800 | 1.6567 | {'precision': 0.8483466362599772, 'recall': 0.9106487148102815, 'f1': 0.8783943329397875, 'number': 817} | {'precision': 0.5564516129032258, 'recall': 0.5798319327731093, 'f1': 0.5679012345679013, 'number': 119} | {'precision': 0.8949814126394052, 'recall': 0.8941504178272981, 'f1': 0.8945657222480261, 'number': 1077} | 0.8551 | 0.8823 | 0.8685 | 0.7982 |
| 0.0051 | 52.63 | 1000 | 1.6856 | {'precision': 0.8542141230068337, 'recall': 0.9179926560587516, 'f1': 0.8849557522123894, 'number': 817} | {'precision': 0.66, 'recall': 0.5546218487394958, 'f1': 0.6027397260273973, 'number': 119} | {'precision': 0.9025069637883009, 'recall': 0.9025069637883009, 'f1': 0.9025069637883009, 'number': 1077} | 0.8701 | 0.8882 | 0.8791 | 0.7925 |
| 0.0029 | 63.16 | 1200 | 1.5031 | {'precision': 0.8860294117647058, 'recall': 0.8849449204406364, 'f1': 0.8854868340477648, 'number': 817} | {'precision': 0.6147540983606558, 'recall': 0.6302521008403361, 'f1': 0.6224066390041495, 'number': 119} | {'precision': 0.8724890829694323, 'recall': 0.9275766016713092, 'f1': 0.8991899189918992, 'number': 1077} | 0.8627 | 0.8927 | 0.8774 | 0.8117 |
| 0.0015 | 73.68 | 1400 | 1.6708 | {'precision': 0.8720657276995305, 'recall': 0.9094247246022031, 'f1': 0.89035350509287, 'number': 817} | {'precision': 0.5286624203821656, 'recall': 0.6974789915966386, 'f1': 0.6014492753623188, 'number': 119} | {'precision': 0.8897126969416126, 'recall': 0.8913649025069638, 'f1': 0.8905380333951762, 'number': 1077} | 0.8554 | 0.8872 | 0.8710 | 0.7958 |
| 0.0012 | 84.21 | 1600 | 1.7566 | {'precision': 0.8818713450292398, 'recall': 0.9228886168910648, 'f1': 0.9019138755980862, 'number': 817} | {'precision': 0.6597938144329897, 'recall': 0.5378151260504201, 'f1': 0.5925925925925926, 'number': 119} | {'precision': 0.8944494995450409, 'recall': 0.9127205199628597, 'f1': 0.9034926470588234, 'number': 1077} | 0.8781 | 0.8947 | 0.8863 | 0.7939 |
| 0.0006 | 94.74 | 1800 | 1.8482 | {'precision': 0.8781362007168458, 'recall': 0.8996328029375765, 'f1': 0.8887545344619106, 'number': 817} | {'precision': 0.5862068965517241, 'recall': 0.5714285714285714, 'f1': 0.5787234042553192, 'number': 119} | {'precision': 0.8949814126394052, 'recall': 0.8941504178272981, 'f1': 0.8945657222480261, 'number': 1077} | 0.8704 | 0.8773 | 0.8738 | 0.7913 |
| 0.0006 | 105.26 | 2000 | 1.7763 | {'precision': 0.8747072599531616, 'recall': 0.9143206854345165, 'f1': 0.8940754039497306, 'number': 817} | {'precision': 0.6095238095238096, 'recall': 0.5378151260504201, 'f1': 0.5714285714285715, 'number': 119} | {'precision': 0.8859489051094891, 'recall': 0.9015784586815228, 'f1': 0.8936953520478601, 'number': 1077} | 0.8672 | 0.8852 | 0.8761 | 0.7964 |
| 0.0003 | 115.79 | 2200 | 1.9186 | {'precision': 0.8813953488372093, 'recall': 0.9277845777233782, 'f1': 0.9039952295766249, 'number': 817} | {'precision': 0.6190476190476191, 'recall': 0.5462184873949579, 'f1': 0.5803571428571429, 'number': 119} | {'precision': 0.9025304592314901, 'recall': 0.8941504178272981, 'f1': 0.898320895522388, 'number': 1077} | 0.8789 | 0.8872 | 0.8831 | 0.7971 |
| 0.0002 | 126.32 | 2400 | 1.8948 | {'precision': 0.8780487804878049, 'recall': 0.9253365973072215, 'f1': 0.901072705601907, 'number': 817} | {'precision': 0.6261682242990654, 'recall': 0.5630252100840336, 'f1': 0.5929203539823009, 'number': 119} | {'precision': 0.9033457249070632, 'recall': 0.9025069637883009, 'f1': 0.9029261495587553, 'number': 1077} | 0.8782 | 0.8917 | 0.8849 | 0.7978 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
naeisher/LunarLander-v2
|
naeisher
| 2023-03-27T00:55:06Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-27T00:12:44Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -51.68 +/- 47.83
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 100000
'learning_rate': 0.0002
'num_envs': 4
'num_steps': 2048
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.99
'num_minibatches': 32
'update_epochs': 10
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.2
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'naeisher/LunarLander-v2'
'batch_size': 8192
'minibatch_size': 256}
```
|
Xianbing/distilbert-base-uncased-layerdrop
|
Xianbing
| 2023-03-27T00:34:14Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-26T01:30:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-layerdrop
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mnli
split: validation_matched
args: mnli
metrics:
- name: Accuracy
type: accuracy
value: 0.7825776872134488
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-layerdrop
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5821
- Accuracy: 0.7826
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 0.642 | 1.0 | 24544 | 0.6169 | 0.7460 |
| 0.5793 | 2.0 | 49088 | 0.5678 | 0.7692 |
| 0.4914 | 3.0 | 73632 | 0.5669 | 0.7744 |
| 0.429 | 4.0 | 98176 | 0.5764 | 0.7868 |
| 0.4359 | 5.0 | 122720 | 0.5821 | 0.7826 |
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
crumb/Instruct-GPT-J
|
crumb
| 2023-03-26T23:21:26Z | 0 | 25 |
transformers
|
[
"transformers",
"peft",
"lora",
"instruct",
"alpaca",
"gptj",
"en",
"dataset:tatsu-lab/alpaca",
"dataset:the_pile",
"arxiv:2106.09685",
"endpoints_compatible",
"region:us"
] | null | 2023-03-22T17:58:49Z |
---
datasets:
- tatsu-lab/alpaca
- the_pile
language:
- en
library_name: transformers
tags:
- peft
- lora
- instruct
- alpaca
- gptj
---
# Instruct-GPT-J "Vicuña"
A demo that runs in free Google Colab can be run here: https://bit.ly/3K1P4PQ just change the model dropdown to the name of this model.
The [EleutherAI/gpt-j-6B](https://hf.co/EleutherAI/gpt-j-6B) model finetuned on the [Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) instruction dataset with [low rank adaptation](https://arxiv.org/abs/2106.09685). This is not a model from Eleuther but a personal project.
Don't knock LoRA, all it is is finetuning how the internal representations should change (simplified, the residual of the weights) instead of finetuning just the internal representations! All the previous weights are in tact meaning LoRA tuning makes the model less likely to forget what it was trained on, and also less likely to push the model into mode collapse. Check table 2 of the LoRA paper and you can see that LoRA many times outperforms traditional finetuning as well.
## Use:
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "crumb/Instruct-GPT-J"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map='auto', revision='sharded')
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)
# This example is in the alpaca training set
batch = tokenizer("Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: How can we reduce air pollution? ### Response:", return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(**batch, max_new_tokens=50)
print(tokenizer.decode(output_tokens[0], skip_special_tokens=True))
# One way to reduce air pollution is to reduce the amount of emissions from vehicles. This can be done by implementing stricter emission standards and increasing the use of electric vehicles. Another way to reduce air pollution is to reduce the amount of waste produced by industries.
```
A function to turn an instruction into a prompt for the model could be written as follows
```python
def prompt(instruction, input=''):
if input=='':
return f"Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: {instruction} ### Response: "
return f"Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {instruction} ### Input: {input} ### Response: "
```
Where input would be an input for the model to act on based on the instruction.
### citations
```bibtex
@misc{gpt-j,
author = {Wang, Ben and Komatsuzaki, Aran},
title = {{GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
```bibtex
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
```
|
MohammadJamalaldeen/whisper-small-arabic
|
MohammadJamalaldeen
| 2023-03-26T23:19:08Z | 78 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-26T21:32:42Z |
---
language:
- ar
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper Small - Arabic language
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small - Arabic language
This model is a fine-tuned version of [MohammadJamalaldeen/whisper-small-with-google-fleurs-ar-4000_steps](https://huggingface.co/MohammadJamalaldeen/whisper-small-with-google-fleurs-ar-4000_steps).
It achieves the following results on the evaluation set:
- Loss: 0.5364
- Wer: 23.5875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0071 | 3.8 | 1000 | 0.4950 | 25.4875 |
| 0.0003 | 7.6 | 2000 | 0.5170 | 23.8000 |
| 0.0001 | 11.41 | 3000 | 0.5300 | 23.6125 |
| 0.0001 | 15.21 | 4000 | 0.5364 | 23.5875 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.7.0
- Tokenizers 0.13.2
|
Enig-ma/sd
|
Enig-ma
| 2023-03-26T22:47:53Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2023-03-18T06:58:29Z |
---
license: other
---
Backup of the dalcefo files, "buy it" from dalcefo kofy and to be used on colab
|
nishadsinghi/swin-tiny-patch4-window7-224-airornot
|
nishadsinghi
| 2023-03-26T22:46:20Z | 191 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-03-26T13:21:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-airornot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-airornot
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1392
- Accuracy: 0.9511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1603 | 1.0 | 131 | 0.1392 | 0.9511 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
smokeweed/Gerph
|
smokeweed
| 2023-03-26T22:36:28Z | 36 | 20 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-28T11:33:55Z |
---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Gerph
Welcome to the Gerph model. This model is trained in the art of the talented artist Gerph and has three versions for you to choose from.
These models can be highly NSFW and are trained mainly on characters, as the work primarily focuses on this subject.
Take a look at the demo images below to see the differences between the three versions. And don't forget that these models is licensed under the Creative ML OpenRAIL-M license. Enjoy!
**Gerph_Epoch8**

> highres, best quality, masterpiece, hatsune miku, outside, sunny day, casual clothes
**Gerph_Epoch10**

> close up, male, solo, long hair, blonde hair, blue eyes, bishounen, colorful, boy, autumn, cinematic lighting, blue sky
**Gerph_Epoch11**

> young girl, brown hair, green eyes, colorful, winter, cumulonimbus clouds, lighting, blue sky
As you can see, the base version, *Gerph_Epoch8*, is trained exclusively in Gerph's art and offers a unique take on his style and themes. If you are a fan of Gerph's art, this version should certainly be in your set. *Gerph_Epoch10* and *Gerph_Epoch11* were continued with a wider range of concept images and work by various artists, so unfortunately the original Gerph style doesn't shine as much. Also, these models do not require any specific tokens.
## License
These models are open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the models to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the models commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
lagorio/distilbert-base-uncased-finetuned-squad
|
lagorio
| 2023-03-26T22:16:56Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-03-26T20:05:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AmaiaSolaun/film95000distilbert-base-uncased
|
AmaiaSolaun
| 2023-03-26T22:12:05Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-26T20:29:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: film95000distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# film95000distilbert-base-uncased
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8725
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 14840
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.7724 | 0.34 | 500 | 2.5848 |
| 2.5813 | 0.67 | 1000 | 2.4469 |
| 2.479 | 1.01 | 1500 | 2.3841 |
| 2.3872 | 1.35 | 2000 | 2.3378 |
| 2.3504 | 1.68 | 2500 | 2.2838 |
| 2.3134 | 2.02 | 3000 | 2.2451 |
| 2.2483 | 2.36 | 3500 | 2.1953 |
| 2.2166 | 2.69 | 4000 | 2.1854 |
| 2.2023 | 3.03 | 4500 | 2.1559 |
| 2.1438 | 3.37 | 5000 | 2.1479 |
| 2.1271 | 3.7 | 5500 | 2.1155 |
| 2.1092 | 4.04 | 6000 | 2.0980 |
| 2.0656 | 4.38 | 6500 | 2.0736 |
| 2.0544 | 4.71 | 7000 | 2.0567 |
| 2.037 | 5.05 | 7500 | 2.0234 |
| 1.9902 | 5.39 | 8000 | 2.0079 |
| 1.9883 | 5.72 | 8500 | 1.9988 |
| 1.9624 | 6.06 | 9000 | 1.9832 |
| 1.9348 | 6.4 | 9500 | 1.9643 |
| 1.9215 | 6.73 | 10000 | 1.9471 |
| 1.9103 | 7.07 | 10500 | 1.9434 |
| 1.8794 | 7.41 | 11000 | 1.9282 |
| 1.8762 | 7.74 | 11500 | 1.9194 |
| 1.8597 | 8.08 | 12000 | 1.9260 |
| 1.8402 | 8.42 | 12500 | 1.8795 |
| 1.8326 | 8.75 | 13000 | 1.8948 |
| 1.8191 | 9.09 | 13500 | 1.9020 |
| 1.8058 | 9.43 | 14000 | 1.8806 |
| 1.804 | 9.76 | 14500 | 1.8680 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
ckao1030/elephant1dreambooth
|
ckao1030
| 2023-03-26T22:09:04Z | 30 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-26T22:07:02Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: elephant1
---
### elephant1dreambooth Dreambooth model trained by ckao1030 with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
elephant1 (use that on your prompt)

|
fuzzymazoid/ppo-Huggy
|
fuzzymazoid
| 2023-03-26T22:04:01Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-03-26T22:03:53Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: fuzzymazoid/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg
|
vocabtrimmer
| 2023-03-26T22:00:44Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"question generation",
"ko",
"dataset:lmqg/qg_koquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-19T14:40:24Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: ko
datasets:
- lmqg/qg_koquad
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "1990년 영화 《 <hl> 남부군 <hl> 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다."
example_title: "Question Generation Example 1"
- text: "백신이 없기때문에 예방책은 <hl> 살충제 <hl> 를 사용하면서 서식 장소(찻찬 받침, 배수로, 고인 물의 열린 저장소, 버려진 타이어 등)의 수를 줄임으로써 매개체를 통제할 수 있다."
example_title: "Question Generation Example 2"
- text: "<hl> 원테이크 촬영 <hl> 이기 때문에 한 사람이 실수를 하면 처음부터 다시 찍어야 하는 상황이 발생한다."
example_title: "Question Generation Example 3"
model-index:
- name: vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_koquad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 11.1
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 26.7
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 28.4
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 83.43
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 82.96
---
# Model Card of `vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg`
This model is fine-tuned version of [ckpts/mt5-small-trimmed-ko-60000](https://huggingface.co/ckpts/mt5-small-trimmed-ko-60000) for question generation task on the [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [ckpts/mt5-small-trimmed-ko-60000](https://huggingface.co/ckpts/mt5-small-trimmed-ko-60000)
- **Language:** ko
- **Training data:** [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ko", model="vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg")
# model prediction
questions = model.generate_q(list_context="1990년 영화 《 남부군 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다.", list_answer="남부군")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg")
output = pipe("1990년 영화 《 <hl> 남부군 <hl> 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_koquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 83.43 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_1 | 26.36 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_2 | 19.38 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_3 | 14.59 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_4 | 11.1 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| METEOR | 28.4 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| MoverScore | 82.96 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| ROUGE_L | 26.7 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_koquad
- dataset_name: default
- input_types: paragraph_answer
- output_types: question
- prefix_types: None
- model: ckpts/mt5-small-trimmed-ko-60000
- max_length: 512
- max_length_output: 32
- epoch: 12
- batch: 16
- lr: 0.001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-ko-60000-koquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
golightly/q-FrozenLake-v1-4x4-Slippery
|
golightly
| 2023-03-26T21:59:43Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T21:50:51Z |
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.73 +/- 0.44
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="golightly/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
NickVeinCV/donut-base-sroie
|
NickVeinCV
| 2023-03-26T21:57:17Z | 50 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-03-26T21:23:39Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 2.0.0+cu117
- Datasets 2.10.1
- Tokenizers 0.13.2
|
MarcusAGray/a2c-AntBulletEnv-v0
|
MarcusAGray
| 2023-03-26T21:55:32Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T21:54:26Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 816.55 +/- 32.99
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Akain413/Niako
|
Akain413
| 2023-03-26T21:37:29Z | 0 | 17 | null |
[
"region:us"
] | null | 2023-03-23T07:24:15Z |
Niako V3









|
feratur/q-Taxi-v3
|
feratur
| 2023-03-26T21:36:30Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T21:36:28Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="feratur/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
omar47/wav2vec2-large-xls-r-300m-ur-BKK-PRUSC-CV10
|
omar47
| 2023-03-26T21:17:52Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-26T17:33:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-ur-BKK-PRUSC-CV10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-ur-BKK-PRUSC-CV10
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.7376
- eval_wer: 0.3932
- eval_runtime: 180.077
- eval_samples_per_second: 20.541
- eval_steps_per_second: 2.571
- epoch: 15.4
- step: 3072
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
MohammadJamalaldeen/whisper-small-ar
|
MohammadJamalaldeen
| 2023-03-26T21:09:22Z | 97 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"dataset:common_voice_11_0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-26T16:32:35Z |
---
language:
- ar
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small - Arabic language
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_11_0
type: common_voice_11_0
config: ar
split: test
args: ar
metrics:
- name: Wer
type: wer
value: 46.54301717014048
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small - Arabic language
This model is a fine-tuned version of [MohammadJamalaldeen/whisper-small-with-google-fleurs-ar-4000_steps](https://huggingface.co/MohammadJamalaldeen/whisper-small-with-google-fleurs-ar-4000_steps) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3383
- Wer: 46.5430
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.347 | 0.2 | 1000 | 0.4275 | 53.6902 |
| 0.2591 | 0.39 | 2000 | 0.3821 | 49.4996 |
| 0.2681 | 0.59 | 3000 | 0.3503 | 47.5989 |
| 0.271 | 0.78 | 4000 | 0.3383 | 46.5430 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.7.0
- Tokenizers 0.13.2
|
enguru/ppo-LunarLander-v2
|
enguru
| 2023-03-26T21:01:31Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T21:01:02Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.65 +/- 6.74
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
mazancourt/politics-sentence-classifier
|
mazancourt
| 2023-03-26T20:58:47Z | 192 | 5 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"camembert",
"text-classification",
"autonlp",
"Text Classification",
"Politics",
"fr",
"dataset:mazancourt/autonlp-data-politics-sentence-classifier",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: [autonlp, Text Classification, Politics]
language: fr
widget:
- text: "Il y a dans ce pays une fracture"
datasets:
- mazancourt/autonlp-data-politics-sentence-classifier
co2_eq_emissions: 1.06099358268878
---
# Prediction of sentence "nature" in a French political sentence
This model aims at predicting the nature of a sentence in a French political sentence.
The predictions fall in three categories:
- `problem`: the sentence describes a problem (usually to be tackled by the speaker), for example _il y a dans ce pays une fracture_ (J. Chirac)
- `solution`: the sentences describes a solution (typically part of a political programme), for example: _J’ai supprimé les droits de succession parce que je crois au travail et parce que je crois à la famille._ (N. Sarkozy)
- `other`: the sentence does not belong to any of these categories, for example: _vive la République, vive la France_
This model was trained using AutoNLP based on sentences extracted from a mix of political tweets and speeches.
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 23105051
- CO2 Emissions (in grams): 1.06099358268878
## Validation Metrics
- Loss: 0.6050735712051392
- Accuracy: 0.8097826086956522
- Macro F1: 0.7713543865034599
- Micro F1: 0.8097826086956522
- Weighted F1: 0.8065488494385247
- Macro Precision: 0.7861074705111403
- Micro Precision: 0.8097826086956522
- Weighted Precision: 0.806470454156932
- Macro Recall: 0.7599656456873758
- Micro Recall: 0.8097826086956522
- Weighted Recall: 0.8097826086956522
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "Il y a dans ce pays une fracture"}' https://api-inference.huggingface.co/models/mazancourt/politics-sentence-classifier
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("mazancourt/autonlp-politics-sentence-classifier-23105051", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("mazancourt/politics-sentence-classifier", use_auth_token=True)
inputs = tokenizer("Il y a dans ce pays une fracture", return_tensors="pt")
outputs = model(**inputs)
# Category can be "problem", "solution" or "other"
category = outputs[0]["label"]
score = outputs[0]["score"]
```
|
andreaskoepf/oasst-sft-2-pythia-12b-4000
|
andreaskoepf
| 2023-03-26T20:31:19Z | 15 | 2 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T20:10:17Z |
---
license: apache-2.0
---
wandb: https://wandb.ai/open-assistant/supervised-finetuning/runs/20enq5u1
Config:
```
oasst_export_latin_cyrillic_alpaca:
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk"
#top_k: 2
input_file_path: 2023-03-25_oasst_research_ready_synth_labels.jsonl.gz
- alpaca
sort_by_length: false
use_custom_sampler: false
pythia-12b:
fp16: true
use_flash_attention: true
residual_dropout: 0.2
learning_rate: 6e-6
model_name: EleutherAI/pythia-12b-deduped
output_dir: pythia_model_12b
weight_decay: 0.0
max_length: 2048
warmup_steps: 100
gradient_checkpointing: false
gradient_accumulation_steps: 4
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
eval_steps: 200
save_steps: 1000
num_train_epochs: 8
save_total_limit: 4
```
Command used:
`deepspeed trainer_sft.py --configs defaults oasst_export_latin_cyrillic_alpaca pythia-12b --cache_dir .cache/ --output_dir .saved_models/oasst-sft-2_12b --deepspeed`
|
Shadman-Rohan/FakevsRealNews
|
Shadman-Rohan
| 2023-03-26T20:30:19Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-08T14:37:19Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: FakevsRealNews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FakevsRealNews
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
- Accuracy: 1.0
- F1: 1.0
- Precision: 1.0
- Recall: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---:|:---------:|:------:|
| 0.0554 | 1.0 | 1956 | 0.0000 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0006 | 2.0 | 3912 | 0.0000 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0 | 3.0 | 5868 | 0.0000 | 1.0 | 1.0 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
JaviBJ/q-FrozenLake-v1-4x4-noSlippery
|
JaviBJ
| 2023-03-26T20:00:15Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T20:00:07Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="JaviBJ/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
miniMaddy/AiOrNot
|
miniMaddy
| 2023-03-26T19:58:42Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-03-18T04:48:13Z |
# AlexNet
Submission for coding assignment of Fatima Fellowship.
## Model Details
This is a simple implementation of AlexNet in Keras for the coding assignment of Fatima Fellowship.
### Model Description
- **Developed by:** Madhav Kumar
- **Model type:** Convolutional Neural Network
## How to Get Started with the Model
The files contains the notebook Alexnet_without_cropping.ipynb. It contains the code that was used to train the model. In the files, "weights-improvement-07-0.87.hdf5" contain the weights of the best model during training.
"logs-20230326T161429Z-001.zip" contain the logs of the training.
## Training Details
### Training Data
The files contain the training data images in train.zip and the data with image names and labels in the train.csv.
### Training Procedure
I trained the AlexNet model on the training data on Google Colab.
#### Preprocessing
I used data augmentaion to increase the size of training data.
## Evaluation
The model was tested on a validation data which was 20% percent of the train.zip data. The maximum accuracy obtained was 86.88%.
|
research-backup/mbart-large-cc25-esquad-qa
|
research-backup
| 2023-03-26T19:54:37Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"question answering",
"es",
"dataset:lmqg/qg_esquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-26T19:30:42Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: es
datasets:
- lmqg/qg_esquad
pipeline_tag: text2text-generation
tags:
- question answering
widget:
- text: "question: ¿Cuál es la población de Nueva York a partir de 2014?, context: Situada en uno de los mayores puertos naturales del mundo, la ciudad de Nueva York consta de cinco municipios, cada uno de los cuales es un condado separado del estado de Nueva York. Los cinco distritos - Brooklyn, Queens, Manhattan, el Bronx y Staten Island - se consolidaron en una sola ciudad en 1898. Con una población censada estimada en 2014 de 8.491.079 habitantes distribuidos en una superficie de solo 790 km ², Nueva York es la ciudad más densamente poblada de los Estados Unidos. Hasta 800 idiomas se hablan en Nueva York, por lo que es la ciudad más lingüísticamente diversa del mundo. Según estimaciones del censo de 2014, la región metropolitana de la ciudad de Nueva York sigue siendo por un margen significativo la más poblada de los Estados Unidos, según lo definido tanto por el Área Estadística Metropolitana (20,1 millones de residentes). En 2013, el MSA produjo un producto metropolitano bruto (GMP) de casi US $1,39 billones, mientras que en 2012, el CSA generó un GMP de más de US $1,55 billones, ambos clasificados en primer lugar."
example_title: "Question Answering Example 1"
- text: "question: ¿Cómo se llama el ejército personal de Sassou?, context: El progreso democrático del Congo se descarriló en 1997, cuando Lissouba y Sassou comenzaron a luchar por el poder en la guerra civil. A medida que se acercaban las elecciones presidenciales de julio de 1997, las tensiones entre los campos de Lissouba y Sassou aumentaron. El 5 de junio, las fuerzas del gobierno del presidente Lissouba rodearon el complejo de Sassou en Brazzaville y Sassou ordenó a los miembros de su milicia privada (conocida como Cobras) resistir. Así comenzó un conflicto de cuatro meses que destruyó o dañó gran parte de Brazzaville y causó decenas de miles de muertes civiles. A principios de octubre, el régimen socialista angoleño comenzó una invasión del Congo para instalar a Sassou en el poder. A mediados de octubre, el gobierno de Lissouba cayó. Poco después, Sassou se declaró presidente."
example_title: "Question Answering Example 2"
model-index:
- name: lmqg/mbart-large-cc25-esquad-qa
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_esquad
type: default
args: default
metrics:
- name: BLEU4 (Question Answering)
type: bleu4_question_answering
value: 23.41
- name: ROUGE-L (Question Answering)
type: rouge_l_question_answering
value: 39.39
- name: METEOR (Question Answering)
type: meteor_question_answering
value: 34.32
- name: BERTScore (Question Answering)
type: bertscore_question_answering
value: 92.3
- name: MoverScore (Question Answering)
type: moverscore_question_answering
value: 77.72
- name: AnswerF1Score (Question Answering)
type: answer_f1_score__question_answering
value: 64.13
- name: AnswerExactMatch (Question Answering)
type: answer_exact_match_question_answering
value: 42.23
---
# Model Card of `lmqg/mbart-large-cc25-esquad-qa`
This model is fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) for question answering task on the [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- **Language:** es
- **Training data:** [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="es", model="lmqg/mbart-large-cc25-esquad-qa")
# model prediction
answers = model.answer_q(list_question="¿Cuál es la población de Nueva York a partir de 2014?", list_context=" Situada en uno de los mayores puertos naturales del mundo, la ciudad de Nueva York consta de cinco municipios, cada uno de los cuales es un condado separado del estado de Nueva York. Los cinco distritos - Brooklyn, Queens, Manhattan, el Bronx y Staten Island - se consolidaron en una sola ciudad en 1898. Con una población censada estimada en 2014 de 8.491.079 habitantes distribuidos en una superficie de solo 790 km ², Nueva York es la ciudad más densamente poblada de los Estados Unidos. Hasta 800 idiomas se hablan en Nueva York, por lo que es la ciudad más lingüísticamente diversa del mundo. Según estimaciones del censo de 2014, la región metropolitana de la ciudad de Nueva York sigue siendo por un margen significativo la más poblada de los Estados Unidos, según lo definido tanto por el Área Estadística Metropolitana (20,1 millones de residentes). En 2013, el MSA produjo un producto metropolitano bruto (GMP) de casi US $1,39 billones, mientras que en 2012, el CSA generó un GMP de más de US $1,55 billones, ambos clasificados en primer lugar.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mbart-large-cc25-esquad-qa")
output = pipe("question: ¿Cuál es la población de Nueva York a partir de 2014?, context: Situada en uno de los mayores puertos naturales del mundo, la ciudad de Nueva York consta de cinco municipios, cada uno de los cuales es un condado separado del estado de Nueva York. Los cinco distritos - Brooklyn, Queens, Manhattan, el Bronx y Staten Island - se consolidaron en una sola ciudad en 1898. Con una población censada estimada en 2014 de 8.491.079 habitantes distribuidos en una superficie de solo 790 km ², Nueva York es la ciudad más densamente poblada de los Estados Unidos. Hasta 800 idiomas se hablan en Nueva York, por lo que es la ciudad más lingüísticamente diversa del mundo. Según estimaciones del censo de 2014, la región metropolitana de la ciudad de Nueva York sigue siendo por un margen significativo la más poblada de los Estados Unidos, según lo definido tanto por el Área Estadística Metropolitana (20,1 millones de residentes). En 2013, el MSA produjo un producto metropolitano bruto (GMP) de casi US $1,39 billones, mientras que en 2012, el CSA generó un GMP de más de US $1,55 billones, ambos clasificados en primer lugar.")
```
## Evaluation
- ***Metric (Question Answering)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-esquad-qa/raw/main/eval/metric.first.answer.paragraph_question.answer.lmqg_qg_esquad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:-----------------------------------------------------------------|
| AnswerExactMatch | 42.23 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| AnswerF1Score | 64.13 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| BERTScore | 92.3 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_1 | 34.3 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_2 | 29.46 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_3 | 26.1 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_4 | 23.41 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| METEOR | 34.32 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| MoverScore | 77.72 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| ROUGE_L | 39.39 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_esquad
- dataset_name: default
- input_types: ['paragraph_question']
- output_types: ['answer']
- prefix_types: None
- model: facebook/mbart-large-cc25
- max_length: 512
- max_length_output: 32
- epoch: 8
- batch: 8
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mbart-large-cc25-esquad-qa/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
swang2000/distilbert-base-uncased-finetuned-ner
|
swang2000
| 2023-03-26T19:54:24Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-26T19:35:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9245241257193448
- name: Recall
type: recall
value: 0.9345564380803222
- name: F1
type: f1
value: 0.9295132127955493
- name: Accuracy
type: accuracy
value: 0.9834305050280394
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0610
- Precision: 0.9245
- Recall: 0.9346
- F1: 0.9295
- Accuracy: 0.9834
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2406 | 1.0 | 878 | 0.0681 | 0.9144 | 0.9217 | 0.9180 | 0.9813 |
| 0.0544 | 2.0 | 1756 | 0.0612 | 0.9214 | 0.9314 | 0.9264 | 0.9827 |
| 0.0296 | 3.0 | 2634 | 0.0610 | 0.9245 | 0.9346 | 0.9295 | 0.9834 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
MatthijsN/angry
|
MatthijsN
| 2023-03-26T19:44:15Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-20T15:13:51Z |
---
pipeline_tag: fill-mask
widget:
- text: "This place is <mask>."
---
<p align="center">
<img src="https://huggingface.co/MatthijsN/angry/resolve/main/Angry.png" width="25%">
</p>
Roberta further pretrained on 1-star yelp reviews
|
dmenini/a2c-AntBulletEnv-v0
|
dmenini
| 2023-03-26T19:43:48Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T19:28:15Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1957.59 +/- 114.55
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
```python
import gym
from stable_baselines3 import A2C
from huggingface_sb3 import load_from_hub
checkpoint = load_from_hub(
repo_id="AntBulletEnv-v0",
filename="a2c-AntBulletEnv-v0.zip",
)
model = A2C.load(checkpoint)
# Evaluate the agent and watch it
eval_env = gym.make("AntBulletEnv-v0")
mean_reward, std_reward = evaluate_policy(
model, eval_env, render=True, n_eval_episodes=5, deterministic=True, warn=False
)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
```
|
AmaiaSolaun/film20000roberta-base
|
AmaiaSolaun
| 2023-03-26T19:40:24Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-14T14:37:36Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: film20000roberta-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# film20000roberta-base
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 313 | 1.9136 |
| 2.0516 | 2.0 | 626 | 1.8994 |
| 2.0516 | 3.0 | 939 | 1.8586 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
albseverus/ppo-LunarLander-v2-v5
|
albseverus
| 2023-03-26T19:39:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T19:39:28Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 281.44 +/- 17.15
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
keras-dreambooth/monkey_island_style
|
keras-dreambooth
| 2023-03-26T19:36:29Z | 5 | 0 |
keras
|
[
"keras",
"tf-keras",
"keras-dreambooth",
"text-to-image",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2023-03-23T20:29:05Z |
---
library_name: keras
license: apache-2.0
pipeline_tag: text-to-image
tags:
- keras-dreambooth
---
## Model description
This model is a fine-tuned Stable Diffusion modeled, using the Dreambooth technique.
It was trained on 43 screenshots of the game Return To Monkey Island, scraped from the Internet. You can find the full set here: [Return To Monkey Island Screenshots](https://huggingface.co/datasets/keras-dreambooth/monkey_island_screenshots)
The result resembles the style from the game, even though you should not expect wonders and rather see it as its own style inspired by the game's.
It was created by [johko](https://huggingface.co/johko) for the [keras-dreambooth](https://huggingface.co/keras-dreambooth) sprint.
## Training procedure
This model was trained using the keras implementation of dreambooth.
You can find the notebook to train these models and how to attend this sprint [here](https://github.com/huggingface/community-events/tree/main/keras-dreambooth-sprint).
## Example Outputs
Geralt of Rivia

Frodo Baggins

Han Solo

### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| inner_optimizer.class_name | Custom>RMSprop |
| inner_optimizer.config.name | RMSprop |
| inner_optimizer.config.weight_decay | None |
| inner_optimizer.config.clipnorm | None |
| inner_optimizer.config.global_clipnorm | None |
| inner_optimizer.config.clipvalue | None |
| inner_optimizer.config.use_ema | False |
| inner_optimizer.config.ema_momentum | 0.99 |
| inner_optimizer.config.ema_overwrite_frequency | 100 |
| inner_optimizer.config.jit_compile | True |
| inner_optimizer.config.is_legacy_optimizer | False |
| inner_optimizer.config.learning_rate | 0.0010000000474974513 |
| inner_optimizer.config.rho | 0.9 |
| inner_optimizer.config.momentum | 0.0 |
| inner_optimizer.config.epsilon | 1e-07 |
| inner_optimizer.config.centered | False |
| dynamic | True |
| initial_scale | 32768.0 |
| dynamic_growth_steps | 2000 |
| training_precision | mixed_float16 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
Ellipsoul/poca-SoccerTwos
|
Ellipsoul
| 2023-03-26T19:20:53Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-03-26T19:20:45Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Ellipsoul/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
pejho/donut-base-sroie
|
pejho
| 2023-03-26T19:19:41Z | 52 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-03-26T15:35:58Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
wcde/llama-13b-3bit-gr128
|
wcde
| 2023-03-26T19:19:35Z | 6 | 3 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T18:17:02Z |
Generated with: --wbits 3 --groupsize 128 --true-sequential --new-eval --faster-kernel
|
JulianZas/rl_course_vizdoom_health_gathering_supreme
|
JulianZas
| 2023-03-26T18:58:05Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T15:11:42Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 12.84 +/- 5.85
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r JulianZas/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
e39324q/Life-Like-Diffusion-v2
|
e39324q
| 2023-03-26T18:56:41Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-26T18:44:45Z |
---
license: creativeml-openrail-m
---
|
sanak/LunarLander-v2
|
sanak
| 2023-03-26T18:55:19Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-26T18:55:11Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -153.16 +/- 96.48
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'sanak/LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
asebaq/fatima_ch_cv_2023
|
asebaq
| 2023-03-26T18:53:25Z | 0 | 0 | null |
[
"dataset:competitions/aiornot",
"region:us"
] | null | 2023-03-14T18:48:23Z |
---
datasets:
- competitions/aiornot
metrics:
- accuracy
---
|
wcde/llama-13b-4bit-gr128
|
wcde
| 2023-03-26T18:49:52Z | 5 | 5 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T18:15:56Z |
Generated with: --wbits 4 --groupsize 128 --true-sequential --new-eval --faster-kernel
|
coreml-community/coreml-vanGoghDiffusion_v1
|
coreml-community
| 2023-03-26T18:36:40Z | 0 | 6 | null |
[
"coreml",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-26T04:58:16Z |
---
license: creativeml-openrail-m
tags:
- coreml
- stable-diffusion
- text-to-image
---
# Core ML Converted Model:
- This model was converted to [Core ML for use on Apple Silicon devices](https://github.com/apple/ml-stable-diffusion). Conversion instructions can be found [here](https://github.com/godly-devotion/MochiDiffusion/wiki/How-to-convert-ckpt-or-safetensors-files-to-Core-ML).<br>
- Provide the model to an app such as Mochi Diffusion [Github](https://github.com/godly-devotion/MochiDiffusion) - [Discord](https://discord.gg/x2kartzxGv) to generate images.<br>
- `split_einsum` version is compatible with all compute unit options including Neural Engine.
- `original` version is only compatible with CPU & GPU option.
- Custom resolution versions are tagged accordingly.
- The `vae-ft-mse-840000-ema-pruned.ckpt` vae is embedded into the model.
- This model was converted with a `vae-encoder` for i2i.
- This model is fp16.
- Descriptions are posted as-is from original model source.
- Not all features and/or results may be available in CoreML format.
- This model does not have the [unet split into chunks](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).
- This model does not include a safety checker (for NSFW content).
# vanGoghDiffusion_v1:
Source(s): [Hugging Face](https://huggingface.co/dallinmackay/Van-Gogh-diffusion) - [CivitAI](https://civitai.com/models/91/van-gogh-diffusion)
This is a fine-tuned Stable Diffusion model (based on v1.5) trained on screenshots from the film Loving Vincent. Use the token lvngvncnt at the BEGINNING of your prompts to use the style (e.g., "lvngvncnt, beautiful woman at sunset"). This model works best with the Euler sampler (NOT Euler_a).
If you get too many yellow faces or you dont like the strong blue bias, simply put them in the negative prompt (e.g., "Yellow face, blue").


--
Characters rendered with this model: Character Samples prompt and settings used: lvngvncnt, [person], highly detailed | Steps: 25, Sampler: Euler, CFG scale: 6

--
Landscapes/miscellaneous rendered with this model: Landscape Samples prompt and settings used: lvngvncnt, [subject/setting], highly detailed | Steps: 25, Sampler: Euler, CFG scale: 6

--
This model was trained with Dreambooth, using TheLastBen colab notebook
|
shreyansjain/ppo-SnowballTarget
|
shreyansjain
| 2023-03-26T18:22:04Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-03-26T18:20:24Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: shreyansjain/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
wcde/llama-7b-4bit-act
|
wcde
| 2023-03-26T18:14:47Z | 5 | 2 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T18:06:59Z |
Generated with: --wbits 4 --act-order --true-sequential --new-eval --faster-kernel
|
wcde/llama-7b-4bit-gr128
|
wcde
| 2023-03-26T18:06:17Z | 9 | 4 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-26T17:57:46Z |
Generated with: --wbits 4 --groupsize 128 --true-sequential --new-eval --faster-kernel
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.