
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-30 18:26:50
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 530
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-30 18:26:48
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
TokenfreeEMNLPSubmission/bert-base-finetuned-masakhaner-amh
|
TokenfreeEMNLPSubmission
| 2023-04-04T05:08:24Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"en",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-04T05:08:12Z |
---
language:
- en
license: apache-2.0
---
# BERT multilingual base model (cased)
Pretrained model on the English dataset using a masked language modeling (MLM) objective.
It was introduced in [this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is case sensitive: it makes a difference
between english and English.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
The pretrained model has been finetuned for one specific language for one specific task.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
model = BertModel.from_pretrained("mushfiqur11/<repo_name>")
```
|
kambehmw/Reinforce-v2
|
kambehmw
| 2023-04-04T05:01:08Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-04T05:01:04Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 34.20 +/- 24.48
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Orreo/ColorRough_LoRA
|
Orreo
| 2023-04-04T04:46:18Z | 0 | 1 | null |
[
"license:artistic-2.0",
"region:us"
] | null | 2023-04-04T04:28:47Z |
---
license: artistic-2.0
---
상업적 이용 전면 금지
No commercial use
트리거워드 rough skecth
권장 프롬 skecth style
추천 가중치 0.3~0.7
모델에 따라 결과물이 깨지는 경우 있음


|
davis901/roberta-frame-CP
|
davis901
| 2023-04-04T04:40:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:davis901/autotrain-data-imdb-textclassification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-04T03:16:27Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- davis901/autotrain-data-imdb-textclassification
co2_eq_emissions:
emissions: 3.313265712444502
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 46471115134
- CO2 Emissions (in grams): 3.3133
## Validation Metrics
- Loss: 0.006
- Accuracy: 0.999
- Precision: 0.999
- Recall: 1.000
- AUC: 1.000
- F1: 0.999
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/davis901/autotrain-imdb-textclassification-46471115134
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("davis901/autotrain-imdb-textclassification-46471115134", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("davis901/autotrain-imdb-textclassification-46471115134", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Humayoun/Donut5WithRandomPlacing
|
Humayoun
| 2023-04-04T03:38:14Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-04-04T02:40:28Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: Donut5WithRandomPlacing
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Donut5WithRandomPlacing
This model is a fine-tuned version of [humayoun/Donut4](https://huggingface.co/humayoun/Donut4) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
davis901/autotrain-imdb-textclassification-46471115127
|
davis901
| 2023-04-04T03:22:52Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:davis901/autotrain-data-imdb-textclassification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-04T03:15:58Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- davis901/autotrain-data-imdb-textclassification
co2_eq_emissions:
emissions: 2.683579313085358
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 46471115127
- CO2 Emissions (in grams): 2.6836
## Validation Metrics
- Loss: 0.000
- Accuracy: 1.000
- Precision: 1.000
- Recall: 1.000
- AUC: 1.000
- F1: 1.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/davis901/autotrain-imdb-textclassification-46471115127
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("davis901/autotrain-imdb-textclassification-46471115127", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("davis901/autotrain-imdb-textclassification-46471115127", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
huggingtweets/dash_eats-lica_rezende
|
huggingtweets
| 2023-04-04T02:59:37Z | 135 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-04T02:59:25Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1539146021808533504/g-XjE19Z_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/556455602331742208/KWkVe0TV_400x400.jpeg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Olivia’s World & dasha</div>
<div style="text-align: center; font-size: 14px;">@dash_eats-lica_rezende</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Olivia’s World & dasha.
| Data | Olivia’s World | dasha |
| --- | --- | --- |
| Tweets downloaded | 1115 | 3199 |
| Retweets | 118 | 510 |
| Short tweets | 120 | 574 |
| Tweets kept | 877 | 2115 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/5n8zwv6v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dash_eats-lica_rezende's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/rpkswkc0) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/rpkswkc0/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dash_eats-lica_rezende')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
RoachTheHorse/sd-class-butterflies-32
|
RoachTheHorse
| 2023-04-04T02:24:53Z | 30 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-04-04T02:23:23Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('RoachTheHorse/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
dongdongcui/DriveGPT
|
dongdongcui
| 2023-04-04T02:04:06Z | 0 | 0 | null |
[
"pytorch",
"question-answering",
"en",
"region:us"
] |
question-answering
| 2023-03-24T23:28:37Z |
---
language:
- en
pipeline_tag: question-answering
---
|
Larxel/q-Taxi-v3
|
Larxel
| 2023-04-04T01:39:26Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-04T01:39:23Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Larxel/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Geekay/flower-classifier
|
Geekay
| 2023-04-04T01:19:21Z | 193 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-04-04T01:19:11Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: flower-classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9701492786407471
---
# flower-classifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### lily

#### orchids

#### roses

|
sgoodfriend/ppo-unet-MicrortsDefeatRandomEnemySparseReward-v3
|
sgoodfriend
| 2023-04-04T00:49:31Z | 0 | 0 |
rl-algo-impls
|
[
"rl-algo-impls",
"MicrortsDefeatRandomEnemySparseReward-v3",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-04T00:49:25Z |
---
library_name: rl-algo-impls
tags:
- MicrortsDefeatRandomEnemySparseReward-v3
- ppo
- deep-reinforcement-learning
- reinforcement-learning
model-index:
- name: ppo
results:
- metrics:
- type: mean_reward
value: 131.04 +/- 15.12
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MicrortsDefeatRandomEnemySparseReward-v3
type: MicrortsDefeatRandomEnemySparseReward-v3
---
# **PPO** Agent playing **MicrortsDefeatRandomEnemySparseReward-v3**
This is a trained model of a **PPO** agent playing **MicrortsDefeatRandomEnemySparseReward-v3** using the [/sgoodfriend/rl-algo-impls](https://github.com/sgoodfriend/rl-algo-impls) repo.
All models trained at this commit can be found at https://api.wandb.ai/links/sgoodfriend/ww60gryx.
## Training Results
This model was trained from 3 trainings of **PPO** agents using different initial seeds. These agents were trained by checking out [388c8ed](https://github.com/sgoodfriend/rl-algo-impls/tree/388c8ed9f7db1d5f5c380d981aeb8a85f34eeacb). The best and last models were kept from each training. This submission has loaded the best models from each training, reevaluates them, and selects the best model from these latest evaluations (mean - std).
| algo | env | seed | reward_mean | reward_std | eval_episodes | best | wandb_url |
|:-------|:-----------------------------------------|-------:|--------------:|-------------:|----------------:|:-------|:-----------------------------------------------------------------------------|
| ppo | MicrortsDefeatRandomEnemySparseReward-v3 | 1 | 134.783 | 30.3561 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/40wjv5yz) |
| ppo | MicrortsDefeatRandomEnemySparseReward-v3 | 2 | 131.042 | 15.1237 | 24 | * | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/ysujlrg4) |
| ppo | MicrortsDefeatRandomEnemySparseReward-v3 | 3 | 137.025 | 21.6223 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/t81hur93) |
### Prerequisites: Weights & Biases (WandB)
Training and benchmarking assumes you have a Weights & Biases project to upload runs to.
By default training goes to a rl-algo-impls project while benchmarks go to
rl-algo-impls-benchmarks. During training and benchmarking runs, videos of the best
models and the model weights are uploaded to WandB.
Before doing anything below, you'll need to create a wandb account and run `wandb
login`.
## Usage
/sgoodfriend/rl-algo-impls: https://github.com/sgoodfriend/rl-algo-impls
Note: While the model state dictionary and hyperaparameters are saved, the latest
implementation could be sufficiently different to not be able to reproduce similar
results. You might need to checkout the commit the agent was trained on:
[388c8ed](https://github.com/sgoodfriend/rl-algo-impls/tree/388c8ed9f7db1d5f5c380d981aeb8a85f34eeacb).
```
# Downloads the model, sets hyperparameters, and runs agent for 3 episodes
python enjoy.py --wandb-run-path=sgoodfriend/rl-algo-impls-benchmarks/ysujlrg4
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_enjoy.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_enjoy.ipynb)
notebook.
## Training
If you want the highest chance to reproduce these results, you'll want to checkout the
commit the agent was trained on: [388c8ed](https://github.com/sgoodfriend/rl-algo-impls/tree/388c8ed9f7db1d5f5c380d981aeb8a85f34eeacb). While
training is deterministic, different hardware will give different results.
```
python train.py --algo ppo --env MicrortsDefeatRandomEnemySparseReward-v3 --seed 2
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_train.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_train.ipynb)
notebook.
## Benchmarking (with Lambda Labs instance)
This and other models from https://api.wandb.ai/links/sgoodfriend/ww60gryx were generated by running a script on a Lambda
Labs instance. In a Lambda Labs instance terminal:
```
git clone git@github.com:sgoodfriend/rl-algo-impls.git
cd rl-algo-impls
bash ./lambda_labs/setup.sh
wandb login
bash ./lambda_labs/benchmark.sh [-a {"ppo a2c dqn vpg"}] [-e ENVS] [-j {6}] [-p {rl-algo-impls-benchmarks}] [-s {"1 2 3"}]
```
### Alternative: Google Colab Pro+
As an alternative,
[colab_benchmark.ipynb](https://github.com/sgoodfriend/rl-algo-impls/tree/main/benchmarks#:~:text=colab_benchmark.ipynb),
can be used. However, this requires a Google Colab Pro+ subscription and running across
4 separate instances because otherwise running all jobs will exceed the 24-hour limit.
## Hyperparameters
This isn't exactly the format of hyperparams in hyperparams/ppo.yml, but instead the Wandb Run Config. However, it's very
close and has some additional data:
```
additional_keys_to_log:
- microrts_stats
algo: ppo
algo_hyperparams:
batch_size: 3072
clip_range: 0.1
clip_range_decay: none
clip_range_vf: 0.1
ent_coef: 0.01
learning_rate: 0.00025
learning_rate_decay: spike
max_grad_norm: 0.5
n_epochs: 4
n_steps: 512
ppo2_vf_coef_halving: true
vf_coef: 0.5
device: auto
env: unet-MicrortsDefeatRandomEnemySparseReward-v3
env_hyperparams:
bots:
randomBiasedAI: 24
env_type: microrts
make_kwargs:
map_path: maps/16x16/basesWorkers16x16.xml
max_steps: 2000
num_selfplay_envs: 0
render_theme: 2
reward_weight:
- 10
- 1
- 1
- 0.2
- 1
- 4
n_envs: 24
env_id: MicrortsDefeatRandomEnemySparseReward-v3
eval_params:
deterministic: false
n_timesteps: 2000000
policy_hyperparams:
activation_fn: relu
actor_head_style: unet
cnn_flatten_dim: 256
cnn_style: microrts
v_hidden_sizes:
- 256
- 128
seed: 2
use_deterministic_algorithms: true
wandb_entity: null
wandb_group: null
wandb_project_name: rl-algo-impls-benchmarks
wandb_tags:
- benchmark_388c8ed
- host_155-248-197-5
- branch_unet
- v0.0.8
```
|
kachinni/emotion-recognition
|
kachinni
| 2023-04-04T00:32:40Z | 0 | 1 | null |
[
"region:us"
] | null | 2023-04-04T00:29:18Z |
# Emotion Recognition on Gradio
This repo contains code to launch a [Gradio](https://github.com/gradio-app/gradio) interface for Emotion Recognition on [Gradio Hub](https://hub.gradio.app)
Please see the **original repo**: [omar178/Emotion-recognition](https://github.com/omar178/Emotion-recognition)
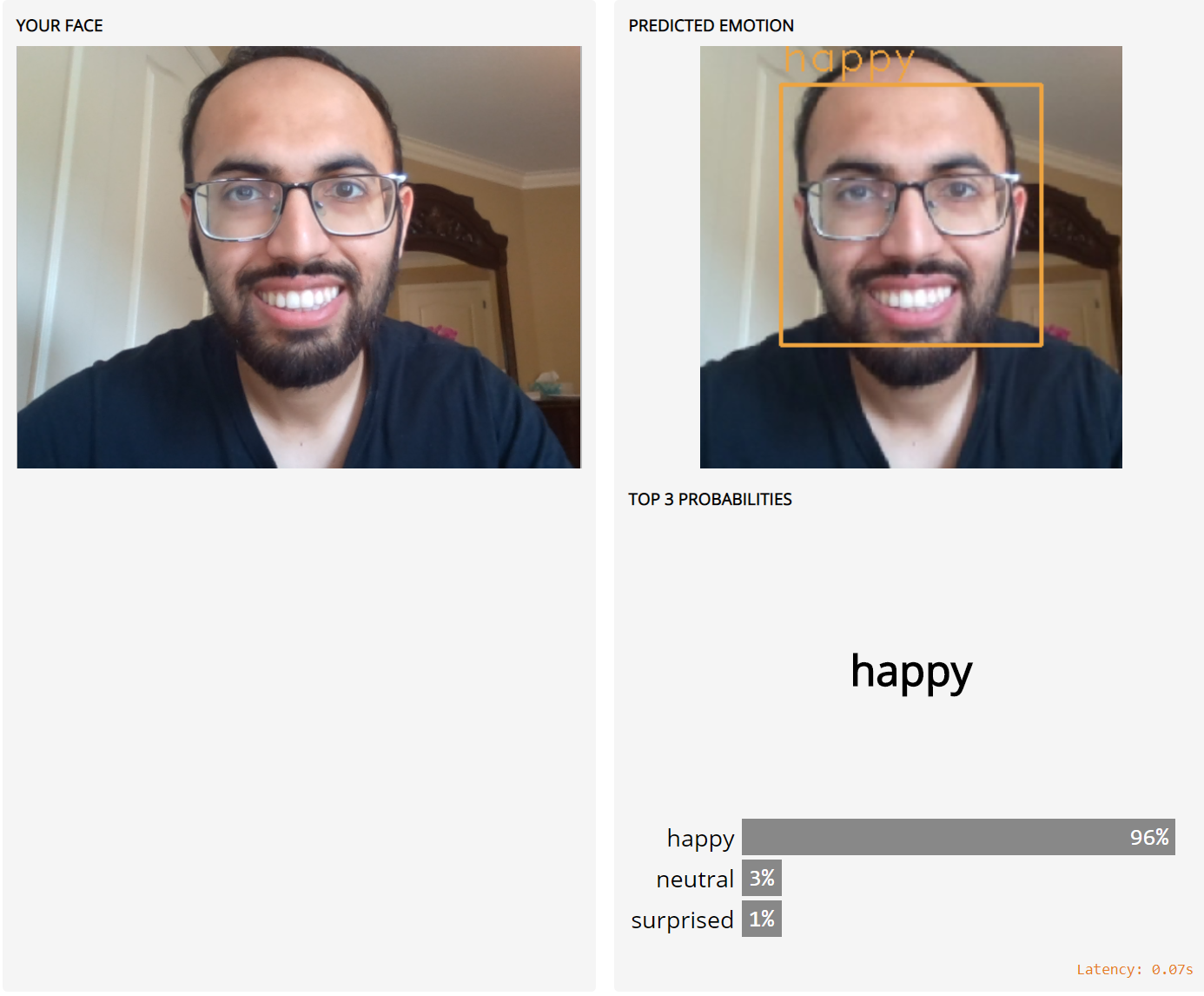
|
EchoShao8899/t5_event_relation_extractor
|
EchoShao8899
| 2023-04-04T00:08:28Z | 115 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"license:cc",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-02-06T09:06:58Z |
---
license: cc
---
This is the event-relation extraction model in ACCENT (An Automatic Event Commonsense Evaluation Metric for Open-Domain Dialogue Systems).
|
globophobe/q-FrozenLake-v1-4x4-noSlippery
|
globophobe
| 2023-04-03T23:38:57Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T23:38:54Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="globophobe/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ray2791/distilbert-base-uncased-finetuned-imdb
|
Ray2791
| 2023-04-03T23:29:52Z | 125 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-04-03T23:16:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4897 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
Brizape/tmvar_0.0001_ES12
|
Brizape
| 2023-04-03T23:07:14Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T22:51:16Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_0.0001_ES12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_0.0001_ES12
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0194
- Precision: 0.8877
- Recall: 0.8973
- F1: 0.8925
- Accuracy: 0.9968
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2263 | 1.47 | 25 | 0.0788 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.0492 | 2.94 | 50 | 0.0355 | 0.2576 | 0.3676 | 0.3029 | 0.9863 |
| 0.0258 | 4.41 | 75 | 0.0224 | 0.6 | 0.6811 | 0.6380 | 0.9933 |
| 0.013 | 5.88 | 100 | 0.0141 | 0.8267 | 0.9027 | 0.8630 | 0.9969 |
| 0.0031 | 7.35 | 125 | 0.0162 | 0.8218 | 0.8973 | 0.8579 | 0.9971 |
| 0.0028 | 8.82 | 150 | 0.0187 | 0.8449 | 0.8541 | 0.8495 | 0.9961 |
| 0.0024 | 10.29 | 175 | 0.0154 | 0.8267 | 0.9027 | 0.8630 | 0.9965 |
| 0.0014 | 11.76 | 200 | 0.0159 | 0.8221 | 0.9243 | 0.8702 | 0.9966 |
| 0.0013 | 13.24 | 225 | 0.0179 | 0.8579 | 0.8811 | 0.8693 | 0.9971 |
| 0.0009 | 14.71 | 250 | 0.0165 | 0.8807 | 0.8378 | 0.8587 | 0.9964 |
| 0.0005 | 16.18 | 275 | 0.0184 | 0.8549 | 0.8919 | 0.8730 | 0.9966 |
| 0.0003 | 17.65 | 300 | 0.0188 | 0.8777 | 0.8919 | 0.8847 | 0.9967 |
| 0.0002 | 19.12 | 325 | 0.0195 | 0.8474 | 0.8703 | 0.8587 | 0.9964 |
| 0.0002 | 20.59 | 350 | 0.0192 | 0.8836 | 0.9027 | 0.8930 | 0.9969 |
| 0.0003 | 22.06 | 375 | 0.0191 | 0.8889 | 0.9081 | 0.8984 | 0.9969 |
| 0.0002 | 23.53 | 400 | 0.0194 | 0.8877 | 0.8973 | 0.8925 | 0.9968 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
sgolkar/gpt2-medium-finetuned-brookstraining
|
sgolkar
| 2023-04-03T22:25:30Z | 205 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-03T21:38:17Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-medium-finetuned-brookstraining
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-medium-finetuned-brookstraining
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.8470
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 100 | 3.4632 |
| No log | 2.0 | 200 | 3.4360 |
| No log | 3.0 | 300 | 3.4539 |
| No log | 4.0 | 400 | 3.4867 |
| 3.2934 | 5.0 | 500 | 3.5341 |
| 3.2934 | 6.0 | 600 | 3.6145 |
| 3.2934 | 7.0 | 700 | 3.6938 |
| 3.2934 | 8.0 | 800 | 3.8198 |
| 3.2934 | 9.0 | 900 | 3.9274 |
| 2.2258 | 10.0 | 1000 | 4.0388 |
| 2.2258 | 11.0 | 1100 | 4.1807 |
| 2.2258 | 12.0 | 1200 | 4.2635 |
| 2.2258 | 13.0 | 1300 | 4.3549 |
| 2.2258 | 14.0 | 1400 | 4.5134 |
| 1.5305 | 15.0 | 1500 | 4.5719 |
| 1.5305 | 16.0 | 1600 | 4.6932 |
| 1.5305 | 17.0 | 1700 | 4.7392 |
| 1.5305 | 18.0 | 1800 | 4.7729 |
| 1.5305 | 19.0 | 1900 | 4.8324 |
| 1.1988 | 20.0 | 2000 | 4.8470 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
huggingtweets/nathaniacolver
|
huggingtweets
| 2023-04-03T22:05:58Z | 141 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-07T00:58:43Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1606922334535057408/ODScb83P_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">nia :)</div>
<div style="text-align: center; font-size: 14px;">@nathaniacolver</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from nia :).
| Data | nia :) |
| --- | --- |
| Tweets downloaded | 3177 |
| Retweets | 538 |
| Short tweets | 100 |
| Tweets kept | 2539 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/vh4m181u/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nathaniacolver's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/jab5ifpt) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/jab5ifpt/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nathaniacolver')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
olivierdehaene/optimized-santacoder
|
olivierdehaene
| 2023-04-03T22:04:43Z | 12 | 8 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"custom_code",
"code",
"dataset:bigcode/the-stack",
"arxiv:1911.02150",
"arxiv:2207.14255",
"arxiv:2301.03988",
"license:openrail",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-01-19T17:22:06Z |
---
license: openrail
datasets:
- bigcode/the-stack
language:
- code
programming_language:
- Java
- JavaScript
- Python
pipeline_tag: text-generation
inference: false
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
model-index:
- name: SantaCoder
results:
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL HumanEval (Python)
metrics:
- name: pass@1
type: pass@1
value: 0.18
verified: false
- name: pass@10
type: pass@10
value: 0.29
verified: false
- name: pass@100
type: pass@100
value: 0.49
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL MBPP (Python)
metrics:
- name: pass@1
type: pass@1
value: 0.35
verified: false
- name: pass@10
type: pass@10
value: 0.58
verified: false
- name: pass@100
type: pass@100
value: 0.77
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL HumanEval (JavaScript)
metrics:
- name: pass@1
type: pass@1
value: 0.16
verified: false
- name: pass@10
type: pass@10
value: 0.27
verified: false
- name: pass@100
type: pass@100
value: 0.47
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL MBPP (Javascript)
metrics:
- name: pass@1
type: pass@1
value: 0.28
verified: false
- name: pass@10
type: pass@10
value: 0.51
verified: false
- name: pass@100
type: pass@100
value: 0.70
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL HumanEval (Java)
metrics:
- name: pass@1
type: pass@1
value: 0.15
verified: false
- name: pass@10
type: pass@10
value: 0.26
verified: false
- name: pass@100
type: pass@100
value: 0.41
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL MBPP (Java)
metrics:
- name: pass@1
type: pass@1
value: 0.28
verified: false
- name: pass@10
type: pass@10
value: 0.44
verified: false
- name: pass@100
type: pass@100
value: 0.59
verified: false
- task:
type: text-generation
dataset:
type: loubnabnl/humaneval_infilling
name: HumanEval FIM (Python)
metrics:
- name: single_line
type: exact_match
value: 0.44
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL HumanEval FIM (Java)
metrics:
- name: single_line
type: exact_match
value: 0.62
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL HumanEval FIM (JavaScript)
metrics:
- name: single_line
type: exact_match
value: 0.60
verified: false
- task:
type: text-generation
dataset:
type: code_x_glue_ct_code_to_text
name: CodeXGLUE code-to-text (Python)
metrics:
- name: BLEU
type: bleu
value: 18.13
verified: false
---
# Optimizd SantaCoder

A up to 60% faster version of bigcode/santacoder.
# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [License](#license)
6. [Citation](#citation)
# Model Summary
The SantaCoder models are a series of 1.1B parameter models trained on the Python, Java, and JavaScript subset of [The Stack (v1.1)](https://huggingface.co/datasets/bigcode/the-stack) (which excluded opt-out requests).
The main model uses [Multi Query Attention](https://arxiv.org/abs/1911.02150), was trained using near-deduplication and comment-to-code ratio as filtering criteria and using the [Fill-in-the-Middle objective](https://arxiv.org/abs/2207.14255).
In addition there are several models that were trained on datasets with different filter parameters and with architecture and objective variations.
- **Repository:** [bigcode/Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Project Website:** [bigcode-project.org](www.bigcode-project.org)
- **Paper:** [🎅SantaCoder: Don't reach for the stars!🌟](https://arxiv.org/abs/2301.03988)
- **Point of Contact:** [contact@bigcode-project.org](mailto:contact@bigcode-project.org)
- **Languages:** Python, Java, and JavaScript
|Model|Architecture|Objective|Filtering|
|:-|:-|:-|:-|
|`mha`|MHA|AR + FIM| Base |
|`no-fim`| MQA | AR| Base |
|`fim`| MQA | AR + FIM | Base |
|`stars`| MQA | AR + FIM | GitHub stars |
|`fertility`| MQA | AR + FIM | Tokenizer fertility |
|`comments`| MQA | AR + FIM | Comment-to-code ratio |
|`dedup-alt`| MQA | AR + FIM | Stronger near-deduplication |
|`final`| MQA | AR + FIM | Stronger near-deduplication and comment-to-code ratio |
The `final` model is the best performing model and was trained twice as long (236B tokens) as the others. This checkpoint is the default model and available on the `main` branch. All other checkpoints are on separate branches with according names.
# Use
## Intended use
The model was trained on GitHub code. As such it is _not_ an instruction model and commands like "Write a function that computes the square root." do not work well.
You should phrase commands like they occur in source code such as comments (e.g. `# the following function computes the sqrt`) or write a function signature and docstring and let the model complete the function body.
**Feel free to share your generations in the Community tab!**
## How to use
### Generation
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "olivierdehaene/optimized-santacoder"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Fill-in-the-middle
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffic part of the input and output:
```python
input_text = "<fim-prefix>def print_hello_world():\n <fim-suffix>\n print('Hello world!')<fim-middle>"
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
### Load other checkpoints
We upload the checkpoint of each experiment to a separate branch as well as the intermediate checkpoints as commits on the branches. You can load them with the `revision` flag:
```python
model = AutoModelForCausalLM.from_pretrained(
"olivierdehaene/optimized-santacoder",
revision="no-fim", # name of branch or commit hash
trust_remote_code=True
)
```
### Attribution & Other Requirements
The pretraining dataset of the model was filtered for permissive licenses only. Nevertheless, the model can generate source code verbatim from the dataset. The code's license might require attribution and/or other specific requirements that must be respected. We provide a [search index](https://huggingface.co/spaces/bigcode/santacoder-search) that let's you search through the pretraining data to identify where generated code came from and apply the proper attribution to your code.
# Limitations
The model has been trained on source code in Python, Java, and JavaScript. The predominant language in source is English although other languages are also present. As such the model is capable to generate code snippets provided some context but the generated code is not guaranteed to work as intended. It can be inefficient, contain bugs or exploits.
# Training
## Model
- **Architecture:** GPT-2 model with multi-query attention and Fill-in-the-Middle objective
- **Pretraining steps:** 600K
- **Pretraining tokens:** 236 billion
- **Precision:** float16
## Hardware
- **GPUs:** 96 Tesla V100
- **Training time:** 6.2 days
- **Total FLOPS:** 2.1 x 10e21
## Software
- **Orchestration:** [Megatron-LM](https://github.com/bigcode-project/Megatron-LM)
- **Neural networks:** [PyTorch](https://github.com/pytorch/pytorch)
- **FP16 if applicable:** [apex](https://github.com/NVIDIA/apex)
# License
The model is licenses under the CodeML Open RAIL-M v0.1 license. You can find the full license [here](https://huggingface.co/spaces/bigcode/license).
# Citation
```
@article{allal2023santacoder,
title={SantaCoder: don't reach for the stars!},
author={Allal, Loubna Ben and Li, Raymond and Kocetkov, Denis and Mou, Chenghao and Akiki, Christopher and Ferrandis, Carlos Munoz and Muennighoff, Niklas and Mishra, Mayank and Gu, Alex and Dey, Manan and others},
journal={arXiv preprint arXiv:2301.03988},
year={2023}
}
```
|
Brizape/tmvar_0.0001_ES2
|
Brizape
| 2023-04-03T21:55:47Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T21:48:44Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_0.0001_ES2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_0.0001_ES2
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0187
- Precision: 0.8449
- Recall: 0.8541
- F1: 0.8495
- Accuracy: 0.9961
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2263 | 1.47 | 25 | 0.0788 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.0492 | 2.94 | 50 | 0.0355 | 0.2576 | 0.3676 | 0.3029 | 0.9863 |
| 0.0258 | 4.41 | 75 | 0.0224 | 0.6 | 0.6811 | 0.6380 | 0.9933 |
| 0.013 | 5.88 | 100 | 0.0141 | 0.8267 | 0.9027 | 0.8630 | 0.9969 |
| 0.0031 | 7.35 | 125 | 0.0162 | 0.8218 | 0.8973 | 0.8579 | 0.9971 |
| 0.0028 | 8.82 | 150 | 0.0187 | 0.8449 | 0.8541 | 0.8495 | 0.9961 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
Brizape/tmvar_5e-05_ES2
|
Brizape
| 2023-04-03T21:48:37Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T21:34:48Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_5e-05_ES2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_5e-05_ES2
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0189
- Precision: 0.8469
- Recall: 0.8973
- F1: 0.8714
- Accuracy: 0.9971
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3852 | 1.47 | 25 | 0.1019 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.0775 | 2.94 | 50 | 0.0398 | 0.2812 | 0.3892 | 0.3265 | 0.9863 |
| 0.0327 | 4.41 | 75 | 0.0243 | 0.4740 | 0.4919 | 0.4828 | 0.9910 |
| 0.02 | 5.88 | 100 | 0.0191 | 0.7656 | 0.7946 | 0.7798 | 0.9954 |
| 0.0084 | 7.35 | 125 | 0.0229 | 0.7766 | 0.7892 | 0.7828 | 0.9952 |
| 0.0045 | 8.82 | 150 | 0.0172 | 0.8351 | 0.8486 | 0.8418 | 0.9964 |
| 0.0023 | 10.29 | 175 | 0.0190 | 0.9148 | 0.8703 | 0.8920 | 0.9968 |
| 0.0015 | 11.76 | 200 | 0.0189 | 0.8469 | 0.8973 | 0.8714 | 0.9971 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
Brizape/tmvar_2e-05_ES2
|
Brizape
| 2023-04-03T21:31:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T21:20:50Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_2e-05_ES2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_2e-05_ES2
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0184
- Precision: 0.8368
- Recall: 0.8595
- F1: 0.848
- Accuracy: 0.9962
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.5018 | 1.47 | 25 | 0.1002 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.0852 | 2.94 | 50 | 0.0509 | 0.9286 | 0.0703 | 0.1307 | 0.9852 |
| 0.0373 | 4.41 | 75 | 0.0283 | 0.5485 | 0.6108 | 0.5780 | 0.9918 |
| 0.0256 | 5.88 | 100 | 0.0204 | 0.6429 | 0.7297 | 0.6835 | 0.9938 |
| 0.0123 | 7.35 | 125 | 0.0188 | 0.8063 | 0.8324 | 0.8191 | 0.9956 |
| 0.008 | 8.82 | 150 | 0.0171 | 0.7979 | 0.8324 | 0.8148 | 0.9958 |
| 0.0047 | 10.29 | 175 | 0.0158 | 0.8010 | 0.8919 | 0.8440 | 0.9962 |
| 0.0037 | 11.76 | 200 | 0.0171 | 0.8511 | 0.8649 | 0.8579 | 0.9964 |
| 0.0025 | 13.24 | 225 | 0.0184 | 0.8368 | 0.8595 | 0.848 | 0.9962 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
cxyz/mndknypntr
|
cxyz
| 2023-04-03T21:28:34Z | 36 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-04-03T21:22:18Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### mndknypntr Dreambooth model trained by cxyz with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
ShrJatin/100K_sample_model
|
ShrJatin
| 2023-04-03T21:25:49Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-02T22:00:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: 100K_sample_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: wmt16
type: wmt16
config: de-en
split: validation
args: de-en
metrics:
- name: Bleu
type: bleu
value: 13.0723
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 100K_sample_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wmt16 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2624
- Bleu: 13.0723
- Gen Len: 17.5159
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 1.2605 | 1.0 | 12500 | 1.2595 | 13.0452 | 17.503 |
| 1.2728 | 2.0 | 25000 | 1.2596 | 13.049 | 17.5154 |
| 1.2437 | 3.0 | 37500 | 1.2624 | 13.0723 | 17.5159 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.2
|
sgolkar/gpt2-finetuned-brookstraining
|
sgolkar
| 2023-04-03T21:21:02Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-03T18:44:26Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-brookstraining
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-finetuned-brookstraining
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 201 | 3.7473 |
| No log | 2.0 | 402 | 3.7192 |
| 3.9557 | 3.0 | 603 | 3.7303 |
| 3.9557 | 4.0 | 804 | 3.7354 |
| 3.4723 | 5.0 | 1005 | 3.7725 |
| 3.4723 | 6.0 | 1206 | 3.7934 |
| 3.4723 | 7.0 | 1407 | 3.8325 |
| 3.1092 | 8.0 | 1608 | 3.8907 |
| 3.1092 | 9.0 | 1809 | 3.9566 |
| 2.8224 | 10.0 | 2010 | 3.9908 |
| 2.8224 | 11.0 | 2211 | 4.0487 |
| 2.8224 | 12.0 | 2412 | 4.0744 |
| 2.5733 | 13.0 | 2613 | 4.1212 |
| 2.5733 | 14.0 | 2814 | 4.1872 |
| 2.3879 | 15.0 | 3015 | 4.2208 |
| 2.3879 | 16.0 | 3216 | 4.2358 |
| 2.3879 | 17.0 | 3417 | 4.2799 |
| 2.2721 | 18.0 | 3618 | 4.3077 |
| 2.2721 | 19.0 | 3819 | 4.3217 |
| 2.2043 | 20.0 | 4020 | 4.3233 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
cartesinus/iva_mt-leyzer-intent_baseline-xlm_r-pl
|
cartesinus
| 2023-04-03T21:16:22Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-27T22:11:53Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: fedcsis_translated-intent_baseline-xlm_r-pl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fedcsis_translated-intent_baseline-xlm_r-pl
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the
[leyzer-fedcsis-translated](https://huggingface.co/datasets/cartesinus/leyzer-fedcsis-translated) dataset.
Results on untranslated test set:
- Accuracy: 0.8769
It achieves the following results on the evaluation set:
- Loss: 0.5478
- Accuracy: 0.8769
- F1: 0.8769
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 3.505 | 1.0 | 814 | 1.8819 | 0.5979 | 0.5979 |
| 1.5056 | 2.0 | 1628 | 1.1033 | 0.7611 | 0.7611 |
| 1.0892 | 3.0 | 2442 | 0.7402 | 0.8470 | 0.8470 |
| 0.648 | 4.0 | 3256 | 0.5263 | 0.8902 | 0.8902 |
| 0.423 | 5.0 | 4070 | 0.4253 | 0.9152 | 0.9152 |
| 0.3429 | 6.0 | 4884 | 0.3654 | 0.9194 | 0.9194 |
| 0.2464 | 7.0 | 5698 | 0.3213 | 0.9273 | 0.9273 |
| 0.1873 | 8.0 | 6512 | 0.3065 | 0.9328 | 0.9328 |
| 0.1666 | 9.0 | 7326 | 0.3046 | 0.9345 | 0.9345 |
| 0.1459 | 10.0 | 8140 | 0.2911 | 0.9370 | 0.9370 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
hopkins/strict-small-2
|
hopkins
| 2023-04-03T20:51:27Z | 132 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-02T20:10:49Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: strict-small-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# strict-small-2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 5.8423
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.1594 | 7.33 | 2000 | 3.8824 |
| 2.8132 | 14.65 | 4000 | 4.2196 |
| 2.121 | 21.98 | 6000 | 4.7343 |
| 1.6016 | 29.3 | 8000 | 5.2934 |
| 1.2441 | 36.63 | 10000 | 5.6547 |
| 1.0171 | 43.96 | 12000 | 5.8423 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
|
amannlp/dqn-SpaceInvadersNoFrameskip-v4
|
amannlp
| 2023-04-03T20:42:54Z | 8 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T20:42:21Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 462.00 +/- 166.89
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga amannlp -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga amannlp -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga amannlp
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 2000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Brizape/tmvar_0.0001
|
Brizape
| 2023-04-03T20:41:31Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T20:30:20Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_0.0001
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_0.0001
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0162
- Precision: 0.8877
- Recall: 0.8973
- F1: 0.8925
- Accuracy: 0.9971
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2263 | 1.47 | 25 | 0.0776 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.05 | 2.94 | 50 | 0.0400 | 0.2868 | 0.4216 | 0.3414 | 0.9872 |
| 0.0271 | 4.41 | 75 | 0.0219 | 0.5381 | 0.6486 | 0.5882 | 0.9925 |
| 0.0108 | 5.88 | 100 | 0.0132 | 0.8324 | 0.8324 | 0.8324 | 0.9965 |
| 0.0029 | 7.35 | 125 | 0.0107 | 0.8934 | 0.9514 | 0.9215 | 0.9979 |
| 0.0025 | 8.82 | 150 | 0.0123 | 0.8691 | 0.8973 | 0.8830 | 0.9972 |
| 0.0011 | 10.29 | 175 | 0.0127 | 0.8579 | 0.9135 | 0.8848 | 0.9969 |
| 0.0006 | 11.76 | 200 | 0.0102 | 0.8969 | 0.9405 | 0.9182 | 0.9981 |
| 0.0005 | 13.24 | 225 | 0.0118 | 0.8942 | 0.9135 | 0.9037 | 0.9978 |
| 0.0005 | 14.71 | 250 | 0.0106 | 0.8768 | 0.9622 | 0.9175 | 0.9981 |
| 0.0015 | 16.18 | 275 | 0.0119 | 0.855 | 0.9243 | 0.8883 | 0.9976 |
| 0.0006 | 17.65 | 300 | 0.0134 | 0.8814 | 0.9243 | 0.9024 | 0.9977 |
| 0.0004 | 19.12 | 325 | 0.0177 | 0.8617 | 0.8757 | 0.8686 | 0.9969 |
| 0.0003 | 20.59 | 350 | 0.0162 | 0.8877 | 0.8973 | 0.8925 | 0.9971 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
OccamRazor/pygmalion-6b-gptq-4bit
|
OccamRazor
| 2023-04-03T20:34:06Z | 10 | 10 |
transformers
|
[
"transformers",
"gptj",
"text-generation",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-23T06:01:05Z |
---
license: creativeml-openrail-m
---
|
marci0929/InvertedDoublePendulumBulletEnv-v0-InvertedDoublePendulumBulletEnv-v0-100k
|
marci0929
| 2023-04-03T20:22:37Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"InvertedDoublePendulumBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T19:52:18Z |
---
library_name: stable-baselines3
tags:
- InvertedDoublePendulumBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: InvertedDoublePendulumBulletEnv-v0
type: InvertedDoublePendulumBulletEnv-v0
metrics:
- type: mean_reward
value: 1129.72 +/- 346.09
name: mean_reward
verified: false
---
# **A2C** Agent playing **InvertedDoublePendulumBulletEnv-v0**
This is a trained model of a **A2C** agent playing **InvertedDoublePendulumBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Brizape/tmvar_2e-05
|
Brizape
| 2023-04-03T20:15:13Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-03T19:59:13Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_2e-05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_2e-05
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0136
- Precision: 0.8308
- Recall: 0.8757
- F1: 0.8526
- Accuracy: 0.9968
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.5077 | 1.47 | 25 | 0.1015 | 0.0 | 0.0 | 0.0 | 0.9843 |
| 0.0834 | 2.94 | 50 | 0.0463 | 0.3581 | 0.4162 | 0.3850 | 0.9877 |
| 0.0348 | 4.41 | 75 | 0.0315 | 0.3846 | 0.4324 | 0.4071 | 0.9896 |
| 0.0285 | 5.88 | 100 | 0.0234 | 0.5157 | 0.6216 | 0.5637 | 0.9927 |
| 0.0149 | 7.35 | 125 | 0.0174 | 0.7801 | 0.8054 | 0.7926 | 0.9957 |
| 0.0104 | 8.82 | 150 | 0.0156 | 0.78 | 0.8432 | 0.8104 | 0.9959 |
| 0.0059 | 10.29 | 175 | 0.0160 | 0.8360 | 0.8541 | 0.8449 | 0.9960 |
| 0.005 | 11.76 | 200 | 0.0139 | 0.8333 | 0.8649 | 0.8488 | 0.9964 |
| 0.003 | 13.24 | 225 | 0.0164 | 0.8263 | 0.8486 | 0.8373 | 0.9961 |
| 0.0024 | 14.71 | 250 | 0.0146 | 0.7980 | 0.8541 | 0.8251 | 0.9964 |
| 0.0023 | 16.18 | 275 | 0.0132 | 0.8267 | 0.9027 | 0.8630 | 0.9969 |
| 0.0016 | 17.65 | 300 | 0.0133 | 0.8274 | 0.8811 | 0.8534 | 0.9971 |
| 0.0015 | 19.12 | 325 | 0.0129 | 0.8235 | 0.9081 | 0.8638 | 0.9971 |
| 0.0014 | 20.59 | 350 | 0.0163 | 0.8703 | 0.8703 | 0.8703 | 0.9968 |
| 0.0013 | 22.06 | 375 | 0.0141 | 0.8402 | 0.8811 | 0.8602 | 0.9969 |
| 0.0013 | 23.53 | 400 | 0.0145 | 0.8438 | 0.8757 | 0.8594 | 0.9968 |
| 0.0011 | 25.0 | 425 | 0.0149 | 0.8482 | 0.8757 | 0.8617 | 0.9969 |
| 0.0011 | 26.47 | 450 | 0.0138 | 0.8351 | 0.8757 | 0.8549 | 0.9968 |
| 0.0011 | 27.94 | 475 | 0.0136 | 0.8308 | 0.8757 | 0.8526 | 0.9968 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
bbhattar/flan_t5_xl_cnn_dailymail
|
bbhattar
| 2023-04-03T20:06:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-20T20:13:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
metrics:
- rouge
model-index:
- name: flan-t5-xl
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: validation
args: 3.0.0
metrics:
- name: Rouge1
type: rouge
value: 45.1318
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-xl
This model is a fine-tuned version of [google/flan-t5-xl](https://huggingface.co/google/flan-t5-xl) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2648
- Rouge1: 45.1318
- Rouge2: 22.2773
- Rougel: 31.9084
- Rougelsum: 42.0558
- Gen Len: 94.2332
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 96
- total_eval_batch_size: 96
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| 1.4352 | 1.0 | 2991 | 1.2645 | 43.8582 | 21.2227 | 30.7038 | 40.761 | 101.9968 |
| 1.3198 | 2.0 | 5982 | 1.2525 | 44.4594 | 21.8174 | 31.4304 | 41.4563 | 94.0733 |
| 1.2151 | 3.0 | 8973 | 1.2648 | 45.1318 | 22.2773 | 31.9084 | 42.0558 | 94.2332 |
### Framework versions
- Transformers 4.27.1
- Pytorch 2.0.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
kgBolt/story_summarizer-finetuned
|
kgBolt
| 2023-04-03T20:05:41Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-30T18:15:59Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: story_summarizer-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# story_summarizer-finetuned
This model is a fine-tuned version of [philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9028
- Rouge1: 30.4344
- Rouge2: 6.2601
- Rougel: 18.9971
- Rougelsum: 26.4496
- Gen Len: 95.0942
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 150 | 2.8526 | 29.1919 | 5.8045 | 18.2639 | 25.4635 | 102.0117 |
| No log | 2.0 | 300 | 2.8654 | 30.0355 | 6.0614 | 18.7598 | 26.1234 | 96.4292 |
| No log | 3.0 | 450 | 2.9028 | 30.4344 | 6.2601 | 18.9971 | 26.4496 | 95.0942 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
aking11/hyebert
|
aking11
| 2023-04-03T20:02:57Z | 177 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"exbert",
"armenian",
"mlm",
"llm",
"hy",
"dataset:oscar",
"arxiv:1810.04805",
"arxiv:1907.11692",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-04-03T18:58:51Z |
---
language: hy
tags:
- exbert
- armenian
- mlm
- llm
license: mit
datasets:
- oscar
---
# Model Card for HyeBERT
Pre-trained language model trained on Armenian using a masked language training strategy. The architecture is based on [BERT](https://arxiv.org/abs/1810.04805) but trained exclusively for the Armenian language subset of OSCAR, a cleaned and de-duplicated subset of the common crawl dataset (hence, the `Hye` in HyeBERT).
Disclaimer: this model is not specifically trained for either the Western or Eastern dialect, though the data likely contain more examples of Eastern Armenian.
### Model Description
HyeBERT is shares the same architecture as BERT; it is a stacked transformer model trained on a large corpus of Armenian without any human annotations. However, it was trained using only the mask language task (replacing 15% of tokens with `[MASK]` and trying to predict them from the other tokens in the text) and not to predict the next sentence, making it more akin to [RoBERTa](https://arxiv.org/pdf/1907.11692.pdf). Unlike RoBERTa, however, it tokenizes using WordPiece rather than BPE.
## Inteded Uses
### Direct Use
As an MLM, this model can be used to predict word in a sentence or text generation, though generation would best be done with a model like GPT.
### Downstream Use [optional]
The ideal use of this model is fine-tuning on a specific classification task for Armenian.
## Bias, Risks, and Limitations
As mentioned earlier, this model is not trained exclusively on Western or Eastern Armenian which may lead to problems in its internal understanding of the language's syntax and lexicon. In addition, many of the training texts include content from other languages (mostly English and Russian) which may affect the performance of the model.
## How to Get Started with the Model
Use the code below to get started with the model.
{{ get_started_code | default("[More Information Needed]", true)}}
## Training Details
### Training Data
This model was trained on the Armenian subset of the [OSCAR](https://huggingface.co/datasets/oscar) corpus, which is a cleaned version of the common crawl. The training data consiset of roughly XXX document, with roughly YYY tokens in total. 2% of the total dataset was held out and using as validation.
### Training Procedure
The model was trained by masking 15% of tokens and predicting the identity of those masked tokens from the unmasked items in a training datum. The model was trained over 3 epochs and the identify of the masked token for a given text was reassigned for each epoch, i.e., the masks moved around each epoch.
#### Preprocessing
No major preprocessing. Texts of less than 5 character were removed and texts were limited to 512 tokens.
#### Training Hyperparameters
- Optimizer: AdamW
- Learning rate: `1e4`
- Num. attention head: 12
- Num. hidden layers: 6
- Vocab. size: 30,000
- Embedding size: 768
## Evaluation
At each epoch's completion, the loss was computed for a held out validation set, roughly 2% the size of the total data.
```
0 evaluating....
val_loss: 0.47787963975066194
1 evaluating....
val_loss: 0.47497553823474115
2 evaluating....
val_loss: 0.4765327044259816
```
## Model Card Authors [optional]
Adam King
## Model Card Contact
adam.king.phd@gmail.com
|
Bearnardd/gpt2-imdb
|
Bearnardd
| 2023-04-03T20:01:50Z | 48 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"trl",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2023-04-02T12:54:53Z |
---
license: apache-2.0
tags:
- trl
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/lvwerra/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="Bearnardd//tmp/tmpmat47dym/Bearnardd/gpt2-imdb")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("Bearnardd//tmp/tmpmat47dym/Bearnardd/gpt2-imdb")
model = AutoModelForCausalLMWithValueHead.from_pretrained("Bearnardd//tmp/tmpmat47dym/Bearnardd/gpt2-imdb")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
sgoodfriend/ppo-MicrortsDefeatCoacAIShaped-v3-diverseBots
|
sgoodfriend
| 2023-04-03T19:49:12Z | 0 | 0 |
rl-algo-impls
|
[
"rl-algo-impls",
"MicrortsDefeatCoacAIShaped-v3",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T19:49:07Z |
---
library_name: rl-algo-impls
tags:
- MicrortsDefeatCoacAIShaped-v3
- ppo
- deep-reinforcement-learning
- reinforcement-learning
model-index:
- name: ppo
results:
- metrics:
- type: mean_reward
value: 189.93 +/- 31.65
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MicrortsDefeatCoacAIShaped-v3
type: MicrortsDefeatCoacAIShaped-v3
---
# **PPO** Agent playing **MicrortsDefeatCoacAIShaped-v3**
This is a trained model of a **PPO** agent playing **MicrortsDefeatCoacAIShaped-v3** using the [/sgoodfriend/rl-algo-impls](https://github.com/sgoodfriend/rl-algo-impls) repo.
All models trained at this commit can be found at https://api.wandb.ai/links/sgoodfriend/zdee7ovm.
## Training Results
This model was trained from 3 trainings of **PPO** agents using different initial seeds. These agents were trained by checking out [3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364). The best and last models were kept from each training. This submission has loaded the best models from each training, reevaluates them, and selects the best model from these latest evaluations (mean - std).
| algo | env | seed | reward_mean | reward_std | eval_episodes | best | wandb_url |
|:-------|:------------------------------|-------:|--------------:|-------------:|----------------:|:-------|:-----------------------------------------------------------------------------|
| ppo | MicrortsDefeatCoacAIShaped-v3 | 1 | 168.283 | 29.0184 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/2argpnw9) |
| ppo | MicrortsDefeatCoacAIShaped-v3 | 2 | 170.167 | 38.6552 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/6cdp7zuf) |
| ppo | MicrortsDefeatCoacAIShaped-v3 | 3 | 189.933 | 31.6543 | 24 | * | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/gs8yovgm) |
### Prerequisites: Weights & Biases (WandB)
Training and benchmarking assumes you have a Weights & Biases project to upload runs to.
By default training goes to a rl-algo-impls project while benchmarks go to
rl-algo-impls-benchmarks. During training and benchmarking runs, videos of the best
models and the model weights are uploaded to WandB.
Before doing anything below, you'll need to create a wandb account and run `wandb
login`.
## Usage
/sgoodfriend/rl-algo-impls: https://github.com/sgoodfriend/rl-algo-impls
Note: While the model state dictionary and hyperaparameters are saved, the latest
implementation could be sufficiently different to not be able to reproduce similar
results. You might need to checkout the commit the agent was trained on:
[3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364).
```
# Downloads the model, sets hyperparameters, and runs agent for 3 episodes
python enjoy.py --wandb-run-path=sgoodfriend/rl-algo-impls-benchmarks/gs8yovgm
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_enjoy.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_enjoy.ipynb)
notebook.
## Training
If you want the highest chance to reproduce these results, you'll want to checkout the
commit the agent was trained on: [3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364). While
training is deterministic, different hardware will give different results.
```
python train.py --algo ppo --env MicrortsDefeatCoacAIShaped-v3 --seed 3
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_train.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_train.ipynb)
notebook.
## Benchmarking (with Lambda Labs instance)
This and other models from https://api.wandb.ai/links/sgoodfriend/zdee7ovm were generated by running a script on a Lambda
Labs instance. In a Lambda Labs instance terminal:
```
git clone git@github.com:sgoodfriend/rl-algo-impls.git
cd rl-algo-impls
bash ./lambda_labs/setup.sh
wandb login
bash ./lambda_labs/benchmark.sh [-a {"ppo a2c dqn vpg"}] [-e ENVS] [-j {6}] [-p {rl-algo-impls-benchmarks}] [-s {"1 2 3"}]
```
### Alternative: Google Colab Pro+
As an alternative,
[colab_benchmark.ipynb](https://github.com/sgoodfriend/rl-algo-impls/tree/main/benchmarks#:~:text=colab_benchmark.ipynb),
can be used. However, this requires a Google Colab Pro+ subscription and running across
4 separate instances because otherwise running all jobs will exceed the 24-hour limit.
## Hyperparameters
This isn't exactly the format of hyperparams in hyperparams/ppo.yml, but instead the Wandb Run Config. However, it's very
close and has some additional data:
```
additional_keys_to_log:
- microrts_stats
algo: ppo
algo_hyperparams:
batch_size: 3072
clip_range: 0.1
clip_range_decay: none
clip_range_vf: 0.1
ent_coef: 0.01
learning_rate: 0.00025
learning_rate_decay: linear
max_grad_norm: 0.5
n_epochs: 4
n_steps: 512
ppo2_vf_coef_halving: true
vf_coef: 0.5
device: auto
env: MicrortsDefeatCoacAIShaped-v3-diverseBots
env_hyperparams:
bots:
coacAI: 18
lightRushAI: 2
randomBiasedAI: 2
workerRushAI: 2
env_type: microrts
make_kwargs:
map_path: maps/16x16/basesWorkers16x16.xml
max_steps: 2000
num_selfplay_envs: 0
render_theme: 2
reward_weight:
- 10
- 1
- 1
- 0.2
- 1
- 4
n_envs: 24
env_id: MicrortsDefeatCoacAIShaped-v3
eval_params:
deterministic: false
n_timesteps: 300000000
policy_hyperparams:
activation_fn: relu
actor_head_style: gridnet
cnn_feature_dim: 256
cnn_style: microrts
seed: 3
use_deterministic_algorithms: true
wandb_entity: null
wandb_group: null
wandb_project_name: rl-algo-impls-benchmarks
wandb_tags:
- benchmark_3420133
- host_152-67-227-88
```
|
rmccrear/ppo-LunarLander-v2
|
rmccrear
| 2023-04-03T19:44:11Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T19:43:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 272.89 +/- 14.24
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sgoodfriend/ppo-MicrortsDefeatCoacAIShaped-v3
|
sgoodfriend
| 2023-04-03T19:40:19Z | 0 | 0 |
rl-algo-impls
|
[
"rl-algo-impls",
"MicrortsDefeatCoacAIShaped-v3",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T19:40:13Z |
---
library_name: rl-algo-impls
tags:
- MicrortsDefeatCoacAIShaped-v3
- ppo
- deep-reinforcement-learning
- reinforcement-learning
model-index:
- name: ppo
results:
- metrics:
- type: mean_reward
value: 191.12 +/- 24.77
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MicrortsDefeatCoacAIShaped-v3
type: MicrortsDefeatCoacAIShaped-v3
---
# **PPO** Agent playing **MicrortsDefeatCoacAIShaped-v3**
This is a trained model of a **PPO** agent playing **MicrortsDefeatCoacAIShaped-v3** using the [/sgoodfriend/rl-algo-impls](https://github.com/sgoodfriend/rl-algo-impls) repo.
All models trained at this commit can be found at https://api.wandb.ai/links/sgoodfriend/zdee7ovm.
## Training Results
This model was trained from 3 trainings of **PPO** agents using different initial seeds. These agents were trained by checking out [3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364). The best and last models were kept from each training. This submission has loaded the best models from each training, reevaluates them, and selects the best model from these latest evaluations (mean - std).
| algo | env | seed | reward_mean | reward_std | eval_episodes | best | wandb_url |
|:-------|:------------------------------|-------:|--------------:|-------------:|----------------:|:-------|:-----------------------------------------------------------------------------|
| ppo | MicrortsDefeatCoacAIShaped-v3 | 1 | 191.125 | 24.7711 | 24 | * | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/jwwrkqxu) |
| ppo | MicrortsDefeatCoacAIShaped-v3 | 2 | 157.892 | 24.9497 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/bxc2vzv9) |
| ppo | MicrortsDefeatCoacAIShaped-v3 | 3 | 170.608 | 18.7986 | 24 | | [wandb](https://wandb.ai/sgoodfriend/rl-algo-impls-benchmarks/runs/ppoyvtlf) |
### Prerequisites: Weights & Biases (WandB)
Training and benchmarking assumes you have a Weights & Biases project to upload runs to.
By default training goes to a rl-algo-impls project while benchmarks go to
rl-algo-impls-benchmarks. During training and benchmarking runs, videos of the best
models and the model weights are uploaded to WandB.
Before doing anything below, you'll need to create a wandb account and run `wandb
login`.
## Usage
/sgoodfriend/rl-algo-impls: https://github.com/sgoodfriend/rl-algo-impls
Note: While the model state dictionary and hyperaparameters are saved, the latest
implementation could be sufficiently different to not be able to reproduce similar
results. You might need to checkout the commit the agent was trained on:
[3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364).
```
# Downloads the model, sets hyperparameters, and runs agent for 3 episodes
python enjoy.py --wandb-run-path=sgoodfriend/rl-algo-impls-benchmarks/jwwrkqxu
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_enjoy.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_enjoy.ipynb)
notebook.
## Training
If you want the highest chance to reproduce these results, you'll want to checkout the
commit the agent was trained on: [3420133](https://github.com/sgoodfriend/rl-algo-impls/tree/342013343b316412ba3aff97b0430343c69c8364). While
training is deterministic, different hardware will give different results.
```
python train.py --algo ppo --env MicrortsDefeatCoacAIShaped-v3 --seed 1
```
Setup hasn't been completely worked out yet, so you might be best served by using Google
Colab starting from the
[colab_train.ipynb](https://github.com/sgoodfriend/rl-algo-impls/blob/main/colab_train.ipynb)
notebook.
## Benchmarking (with Lambda Labs instance)
This and other models from https://api.wandb.ai/links/sgoodfriend/zdee7ovm were generated by running a script on a Lambda
Labs instance. In a Lambda Labs instance terminal:
```
git clone git@github.com:sgoodfriend/rl-algo-impls.git
cd rl-algo-impls
bash ./lambda_labs/setup.sh
wandb login
bash ./lambda_labs/benchmark.sh [-a {"ppo a2c dqn vpg"}] [-e ENVS] [-j {6}] [-p {rl-algo-impls-benchmarks}] [-s {"1 2 3"}]
```
### Alternative: Google Colab Pro+
As an alternative,
[colab_benchmark.ipynb](https://github.com/sgoodfriend/rl-algo-impls/tree/main/benchmarks#:~:text=colab_benchmark.ipynb),
can be used. However, this requires a Google Colab Pro+ subscription and running across
4 separate instances because otherwise running all jobs will exceed the 24-hour limit.
## Hyperparameters
This isn't exactly the format of hyperparams in hyperparams/ppo.yml, but instead the Wandb Run Config. However, it's very
close and has some additional data:
```
additional_keys_to_log:
- microrts_stats
algo: ppo
algo_hyperparams:
batch_size: 3072
clip_range: 0.1
clip_range_decay: none
clip_range_vf: 0.1
ent_coef: 0.01
learning_rate: 0.00025
learning_rate_decay: linear
max_grad_norm: 0.5
n_epochs: 4
n_steps: 512
ppo2_vf_coef_halving: true
vf_coef: 0.5
device: auto
env: MicrortsDefeatCoacAIShaped-v3
env_hyperparams:
bots:
coacAI: 24
env_type: microrts
make_kwargs:
map_path: maps/16x16/basesWorkers16x16.xml
max_steps: 2000
num_selfplay_envs: 0
render_theme: 2
reward_weight:
- 10
- 1
- 1
- 0.2
- 1
- 4
n_envs: 24
env_id: MicrortsDefeatCoacAIShaped-v3
eval_params:
deterministic: false
n_timesteps: 300000000
policy_hyperparams:
activation_fn: relu
actor_head_style: gridnet
cnn_feature_dim: 256
cnn_style: microrts
seed: 1
use_deterministic_algorithms: true
wandb_entity: null
wandb_group: null
wandb_project_name: rl-algo-impls-benchmarks
wandb_tags:
- benchmark_3420133
- host_192-18-141-216
```
|
kristof999/homework-AntBulletEnv-v0-100k
|
kristof999
| 2023-04-03T19:33:11Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T19:31:56Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1138.26 +/- 162.75
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
debarghabhattofficial/t5-small-squad-qg-a2c-spt-valid
|
debarghabhattofficial
| 2023-04-03T19:25:27Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:qg_squad",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-03T11:39:31Z |
---
license: cc-by-4.0
tags:
- generated_from_trainer
datasets:
- qg_squad
metrics:
- bleu
model-index:
- name: t5-small-squad-qg-a2c-spt-valid
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: qg_squad
type: qg_squad
config: qg_squad
split: test
args: qg_squad
metrics:
- name: Bleu
type: bleu
value: 0.1856298695745541
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-squad-qg-a2c-spt-valid
This model is a fine-tuned version of [lmqg/t5-small-squad-qg](https://huggingface.co/lmqg/t5-small-squad-qg) on the qg_squad dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5585
- Bleu: 0.1856
- Precisions: [0.4899881007730557, 0.23798056024064962, 0.14699694604682728, 0.09541131612394267]
- Brevity Penalty: 0.9231
- Length Ratio: 0.9259
- Translation Length: 126899
- Reference Length: 137056
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- label_smoothing_factor: 0.15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Precisions | Brevity Penalty | Length Ratio | Translation Length | Reference Length |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-----------------------------------------------------------------------------------:|:---------------:|:------------:|:------------------:|:----------------:|
| 3.4717 | 1.0 | 1184 | 3.5703 | 0.1850 | [0.4884210026960997, 0.23740423378300554, 0.14702360671696277, 0.09591845720324058] | 0.9198 | 0.9228 | 126479 | 137056 |
| 3.4432 | 2.0 | 2368 | 3.5676 | 0.1847 | [0.4899809765377299, 0.23739313808702955, 0.14709099076226004, 0.09610180163262601] | 0.9173 | 0.9205 | 126160 | 137056 |
| 3.4207 | 3.0 | 3552 | 3.5654 | 0.1855 | [0.48690609948692964, 0.236654650074526, 0.14669770766719153, 0.09533838196460138] | 0.9260 | 0.9286 | 127273 | 137056 |
| 3.4017 | 4.0 | 4736 | 3.5575 | 0.1861 | [0.4907433036243861, 0.23905491743183327, 0.14802083840498564, 0.09654473782730295] | 0.9195 | 0.9226 | 126449 | 137056 |
| 3.3862 | 5.0 | 5920 | 3.5540 | 0.1851 | [0.4916027385306181, 0.23877172085201795, 0.14769450336757936, 0.09608281170511601] | 0.9164 | 0.9197 | 126053 | 137056 |
| 3.3715 | 6.0 | 7104 | 3.5619 | 0.1847 | [0.4897172642552519, 0.23742624822429256, 0.14650127350144848, 0.09495653320731078] | 0.9209 | 0.9239 | 126620 | 137056 |
| 3.3602 | 7.0 | 8288 | 3.5581 | 0.1857 | [0.49199648336329865, 0.2390627732121, 0.14782006380301063, 0.09637410897534923] | 0.9180 | 0.9212 | 126257 | 137056 |
| 3.3523 | 8.0 | 9472 | 3.5575 | 0.1856 | [0.4896288812767368, 0.23802266135985578, 0.14728396021137705, 0.09588544697859817] | 0.9215 | 0.9244 | 126698 | 137056 |
| 3.3439 | 9.0 | 10656 | 3.5582 | 0.1862 | [0.4919672196048933, 0.23971752696254087, 0.14848694668474074, 0.09658739962940087] | 0.9183 | 0.9215 | 126295 | 137056 |
| 3.3395 | 10.0 | 11840 | 3.5585 | 0.1856 | [0.4899881007730557, 0.23798056024064962, 0.14699694604682728, 0.09541131612394267] | 0.9231 | 0.9259 | 126899 | 137056 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.9.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
botix4/a2c-PandaReachDense-v2
|
botix4
| 2023-04-03T19:04:13Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T17:39:52Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -4.92 +/- 1.84
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ybhav14/autotrain-chat-sum-dialogsum-samsum-46317114985
|
Ybhav14
| 2023-04-03T19:01:17Z | 119 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:Ybhav14/autotrain-data-chat-sum-dialogsum-samsum",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-04-03T18:53:31Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Ybhav14/autotrain-data-chat-sum-dialogsum-samsum
co2_eq_emissions:
emissions: 3.0774487291128
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 46317114985
- CO2 Emissions (in grams): 3.0774
## Validation Metrics
- Loss: 1.270
- Rouge1: 39.115
- Rouge2: 17.283
- RougeL: 30.158
- RougeLsum: 34.226
- Gen Len: 61.380
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Ybhav14/autotrain-chat-sum-dialogsum-samsum-46317114985
```
|
romeromuerto/dqn-SpaceInvadersNoFrameskip-v4
|
romeromuerto
| 2023-04-03T18:43:10Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T18:42:31Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 611.50 +/- 169.72
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga romeromuerto -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga romeromuerto -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga romeromuerto
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
LarryAIDraw/noelleSilvaBlack_v1
|
LarryAIDraw
| 2023-04-03T18:37:27Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-04-03T18:13:23Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/28708/noelle-silva-or-black-clover
|
LarryAIDraw/fateGrandOrderAnastasia_v10
|
LarryAIDraw
| 2023-04-03T18:36:45Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-04-03T18:12:39Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/28398/fate-grand-order-anastasiaanastasiya-nikolaevna-romanova
|
LarryAIDraw/asukaHinaNijisanji_asukaHina
|
LarryAIDraw
| 2023-04-03T18:36:28Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-04-03T18:12:17Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/28410/asuka-hina-nijisanji
|
swang2000/distilbert-base-uncased-finetuned-cola
|
swang2000
| 2023-04-03T18:33:52Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-24T23:23:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5229395497643199
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5743
- Matthews Correlation: 0.5229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5256 | 1.0 | 535 | 0.5198 | 0.4180 |
| 0.348 | 2.0 | 1070 | 0.4880 | 0.5087 |
| 0.2348 | 3.0 | 1605 | 0.5743 | 0.5229 |
| 0.1803 | 4.0 | 2140 | 0.7591 | 0.5143 |
| 0.1346 | 5.0 | 2675 | 0.8177 | 0.5192 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
marci0929/Walker2DBulletEnv-Walker2DBulletEnv-v0-100k
|
marci0929
| 2023-04-03T18:20:29Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"Walker2DBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T18:19:27Z |
---
library_name: stable-baselines3
tags:
- Walker2DBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Walker2DBulletEnv-v0
type: Walker2DBulletEnv-v0
metrics:
- type: mean_reward
value: 804.04 +/- 68.74
name: mean_reward
verified: false
---
# **A2C** Agent playing **Walker2DBulletEnv-v0**
This is a trained model of a **A2C** agent playing **Walker2DBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
s-nlp/ruRoberta-large-paraphrase-v1
|
s-nlp
| 2023-04-03T18:05:21Z | 118 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"sentence-similarity",
"ru",
"dataset:merionum/ru_paraphraser",
"dataset:RuPAWS",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-02T23:23:03Z |
---
language:
- ru
tags:
- sentence-similarity
- text-classification
datasets:
- merionum/ru_paraphraser
- RuPAWS
---
This is a cross-encoder model trained to predict semantic equivalence of two Russian sentences.
It classifies text pairs as paraphrases (class 1) or non-paraphrases (class 0). Its scores can be used as a metric of content preservation for paraphrasing or text style transfer.
It is a [sberbank-ai/ruRoberta-large](https://huggingface.co/sberbank-ai/ruRoberta-large) model fine-tuned on a union of 3 datasets:
1. `RuPAWS`: https://github.com/ivkrotova/rupaws_dataset based on Quora and QQP;
2. `ru_paraphraser`: https://huggingface.co/merionum/ru_paraphraser;
3. Results of the manual check of content preservation for the [RUSSE-2022](https://www.dialog-21.ru/media/5755/dementievadplusetal105.pdf) text detoxification dataset collection (`content_5.tsv`).
The task was formulated as binary classification: whether the two sentences have the same meaning (1) or different (0).
The table shows the training dataset size after duplication (joining `text1 + text2` and `text2 + text1` pairs):
source \ label | 0 | 1
-- | -- | --
detox | 1412| 3843
paraphraser |5539 | 1688
rupaws_qqp |1112 | 792
rupaws_wiki |3526 | 2166
The model was trained with Adam optimizer and the following hyperparameters:
```
learning_rate = 1e-5
batch_size = 8
gradient_accumulation_steps = 4
n_epochs = 3
max_grad_norm = 1.0
```
After training, the model had the following ROC AUC scores on the test sets:
set | ROC AUC
- | -
detox | 0.857112
paraphraser | 0.858465
rupaws_qqp | 0.859195
rupaws_wiki | 0.906121
Example usage:
```Python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained('SkolkovoInstitute/ruRoberta-large-paraphrase-v1')
tokenizer = AutoTokenizer.from_pretrained('SkolkovoInstitute/ruRoberta-large-paraphrase-v1')
def get_similarity(text1, text2):
""" Predict the probability that two Russian sentences are paraphrases of each other. """
with torch.inference_mode():
batch = tokenizer(
text1, text2,
truncation=True, max_length=model.config.max_position_embeddings, return_tensors='pt',
).to(model.device)
proba = torch.softmax(model(**batch).logits, -1)
return proba[0][1].item()
print(get_similarity('Я тебя люблю', 'Ты мне нравишься')) # 0.9798
print(get_similarity('Я тебя люблю', 'Я тебя ненавижу')) # 0.0008
```
|
alkiskoudounas/q-Taxi-v3
|
alkiskoudounas
| 2023-04-03T18:00:53Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T18:00:44Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="alkiskoudounas/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Aishwarya0206/DiseaseClassificationOnSymptoms
|
Aishwarya0206
| 2023-04-03T17:47:36Z | 0 | 0 |
sklearn
|
[
"sklearn",
"text-classification",
"en",
"dataset:Izara/ClassificationOnDiseaseDataset",
"region:us"
] |
text-classification
| 2023-04-03T17:45:44Z |
---
datasets:
- Izara/ClassificationOnDiseaseDataset
language:
- en
metrics:
- accuracy
library_name: sklearn
pipeline_tag: text-classification
---
|
quynhu-d/29_03_UNet_BCE_GenDice_OA_CB_NB
|
quynhu-d
| 2023-04-03T17:39:21Z | 0 | 0 | null |
[
"tensorboard",
"region:us"
] | null | 2023-03-29T15:00:40Z |
- 29_03__12_55 -- alpha = .3
- 01_04__20_09 -- alpha = .5
- 01_04__20_13 -- alpha = .7
- 01_04__20_13 -- alpha = 1.0 (BCE only)
|
lamaabdulaziz/ArBERT-finetuned-CrossVal-fnd
|
lamaabdulaziz
| 2023-04-03T17:14:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-30T04:40:44Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: ArBERT-finetuned-CrossVal-fnd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ArBERT-finetuned-CrossVal-fnd
This model is a fine-tuned version of [UBC-NLP/ARBERT](https://huggingface.co/UBC-NLP/ARBERT) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2055
- Macro F1: 0.9125
- Accuracy: 0.9154
- Precision: 0.9132
- Recall: 0.9117
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 123
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Macro F1 | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|:---------:|:------:|
| 0.3468 | 1.0 | 1597 | 0.2055 | 0.9125 | 0.9154 | 0.9132 | 0.9117 |
| 0.2241 | 2.0 | 3194 | 0.2280 | 0.9088 | 0.9115 | 0.9079 | 0.9098 |
| 0.1555 | 3.0 | 4791 | 0.3194 | 0.9085 | 0.9114 | 0.9083 | 0.9088 |
| 0.1022 | 4.0 | 6388 | 0.4153 | 0.9073 | 0.9105 | 0.9083 | 0.9064 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
csuazob/twitter-xlm-roberta-base-sentiment-finetunned-davincis-local
|
csuazob
| 2023-04-03T16:46:54Z | 128 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-29T15:07:09Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: twitter-xlm-roberta-base-sentiment-finetunned-davincis-local
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-xlm-roberta-base-sentiment-finetunned-davincis-local
This model is a fine-tuned version of [citizenlab/twitter-xlm-roberta-base-sentiment-finetunned](https://huggingface.co/citizenlab/twitter-xlm-roberta-base-sentiment-finetunned) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5461
- Accuracy: 0.9302
- F1: 0.9301
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 72
- eval_batch_size: 72
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4006 | 1.0 | 41 | 0.3037 | 0.8779 | 0.8771 |
| 0.2165 | 2.0 | 82 | 0.2007 | 0.9205 | 0.9205 |
| 0.1311 | 3.0 | 123 | 0.2124 | 0.9244 | 0.9244 |
| 0.0839 | 4.0 | 164 | 0.2504 | 0.9341 | 0.9341 |
| 0.0525 | 5.0 | 205 | 0.3695 | 0.9147 | 0.9144 |
| 0.0392 | 6.0 | 246 | 0.3393 | 0.9244 | 0.9243 |
| 0.0282 | 7.0 | 287 | 0.4203 | 0.9244 | 0.9242 |
| 0.0205 | 8.0 | 328 | 0.3889 | 0.9302 | 0.9301 |
| 0.012 | 9.0 | 369 | 0.6586 | 0.9012 | 0.9006 |
| 0.0069 | 10.0 | 410 | 0.4873 | 0.9302 | 0.9301 |
| 0.005 | 11.0 | 451 | 0.6105 | 0.9089 | 0.9085 |
| 0.0082 | 12.0 | 492 | 0.4642 | 0.9302 | 0.9301 |
| 0.0022 | 13.0 | 533 | 0.3709 | 0.9516 | 0.9515 |
| 0.0088 | 14.0 | 574 | 0.5322 | 0.9283 | 0.9281 |
| 0.0067 | 15.0 | 615 | 0.6661 | 0.9128 | 0.9124 |
| 0.0015 | 16.0 | 656 | 0.5450 | 0.9283 | 0.9282 |
| 0.0006 | 17.0 | 697 | 0.5453 | 0.9302 | 0.9301 |
| 0.0002 | 18.0 | 738 | 0.5555 | 0.9302 | 0.9301 |
| 0.0018 | 19.0 | 779 | 0.5408 | 0.9302 | 0.9301 |
| 0.0022 | 20.0 | 820 | 0.5461 | 0.9302 | 0.9301 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg
|
vocabtrimmer
| 2023-04-03T16:45:31Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"question generation",
"fr",
"dataset:lmqg/qg_frquad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-03T16:40:36Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: fr
datasets:
- lmqg/qg_frquad
pipeline_tag: text2text-generation
tags:
- question generation
widget:
- text: "Créateur » (Maker), lui aussi au singulier, « <hl> le Suprême Berger <hl> » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc."
example_title: "Question Generation Example 1"
- text: "Ce black dog peut être lié à des évènements traumatisants issus du monde extérieur, tels que son renvoi de l'Amirauté après la catastrophe des Dardanelles, lors de la <hl> Grande Guerre <hl> de 14-18, ou son rejet par l'électorat en juillet 1945."
example_title: "Question Generation Example 2"
- text: "contre <hl> Normie Smith <hl> et 15 000 dollars le 28 novembre 1938."
example_title: "Question Generation Example 3"
model-index:
- name: vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_frquad
type: default
args: default
metrics:
- name: BLEU4 (Question Generation)
type: bleu4_question_generation
value: 7.76
- name: ROUGE-L (Question Generation)
type: rouge_l_question_generation
value: 28.41
- name: METEOR (Question Generation)
type: meteor_question_generation
value: 18.37
- name: BERTScore (Question Generation)
type: bertscore_question_generation
value: 79.68
- name: MoverScore (Question Generation)
type: moverscore_question_generation
value: 56.32
---
# Model Card of `vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg`
This model is fine-tuned version of [ckpts/mbart-large-cc25-trimmed-fr](https://huggingface.co/ckpts/mbart-large-cc25-trimmed-fr) for question generation task on the [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [ckpts/mbart-large-cc25-trimmed-fr](https://huggingface.co/ckpts/mbart-large-cc25-trimmed-fr)
- **Language:** fr
- **Training data:** [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="fr", model="vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg")
# model prediction
questions = model.generate_q(list_context="Créateur » (Maker), lui aussi au singulier, « le Suprême Berger » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.", list_answer="le Suprême Berger")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg")
output = pipe("Créateur » (Maker), lui aussi au singulier, « <hl> le Suprême Berger <hl> » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_frquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 79.68 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_1 | 27.09 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_2 | 16.2 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_3 | 11.02 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_4 | 7.76 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| METEOR | 18.37 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| MoverScore | 56.32 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| ROUGE_L | 28.41 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_frquad
- dataset_name: default
- input_types: paragraph_answer
- output_types: question
- prefix_types: None
- model: ckpts/mbart-large-cc25-trimmed-fr
- max_length: 512
- max_length_output: 32
- epoch: 10
- batch: 8
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/vocabtrimmer/mbart-large-cc25-trimmed-fr-frquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
AryaParikh/autotrain-arp_summ_1-46076114929
|
AryaParikh
| 2023-04-03T16:35:48Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:Hinataaa/autotrain-data-arp_summ_1",
"co2_eq_emissions",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-04-03T16:26:35Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Hinataaa/autotrain-data-arp_summ_1
co2_eq_emissions:
emissions: 3.6598223203922267
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 46076114929
- CO2 Emissions (in grams): 3.6598
## Validation Metrics
- Loss: 1.060
- Rouge1: 56.626
- Rouge2: 33.126
- RougeL: 52.520
- RougeLsum: 52.448
- Gen Len: 13.480
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Hinataaa/autotrain-arp_summ_1-46076114929
```
|
cxj009/model_lora_soho
|
cxj009
| 2023-04-03T16:28:42Z | 2 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-04-03T16:16:15Z |
---
license: creativeml-openrail-m
base_model: /DATA2/chilloutmix/
instance_prompt: wjsoho
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - cxj009/model_lora_soho
These are LoRA adaption weights for /DATA2/chilloutmix/. The weights were trained on wjsoho using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




|
dvruette/oasst-pythia-12b-pretrained-sft
|
dvruette
| 2023-04-03T16:28:08Z | 1,495 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-03T15:53:46Z |
https://wandb.ai/open-assistant/supervised-finetuning/runs/770a0t41 (at 2k steps)
|
Paperbag/ppo-CartPole-v1
|
Paperbag
| 2023-04-03T16:24:42Z | 0 | 0 | null |
[
"tensorboard",
"CartPole-v1",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T16:24:36Z |
---
tags:
- CartPole-v1
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 22.70 +/- 12.09
name: mean_reward
verified: false
---
# PPO Agent Playing CartPole-v1
This is a trained model of a PPO agent playing CartPole-v1.
# Hyperparameters
```python
{'exp_name': 'ppo'
'gym_id': 'CartPole-v1'
'learning_rate': 0.00025
'seed': 1
'total_timesteps': 25000
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'ppo-implementation-details'
'wandb_entity': None
'capture_video': False
'repo_id': 'Paperbag/ppo-CartPole-v1'
'env_id': 'CartPole-v1'
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None}
```
|
diegoref/testtest-19
|
diegoref
| 2023-04-03T16:22:58Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-03T16:17:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: testtest-19
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8627450980392157
- name: F1
type: f1
value: 0.9047619047619047
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testtest-19
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5631
- Accuracy: 0.8627
- F1: 0.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 459 | 0.5077 | 0.8137 | 0.8707 |
| 0.5519 | 2.0 | 918 | 0.4666 | 0.8431 | 0.8954 |
| 0.3741 | 3.0 | 1377 | 0.5631 | 0.8627 | 0.9048 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
marco-c88/gpt2-finetuned-mstatmem_1ep_gpt2_no_valid
|
marco-c88
| 2023-04-03T16:19:38Z | 203 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-03T16:11:29Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-mstatmem_1ep_gpt2_no_valid
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-finetuned-mstatmem_1ep_gpt2_no_valid
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.4567 | 1.0 | 970 | 3.3340 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
erosendo/trained-Taxi-v3
|
erosendo
| 2023-04-03T15:27:05Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T15:27:02Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: trained-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.79
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="erosendo/trained-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
sofre/Taxi-v3
|
sofre
| 2023-04-03T15:23:44Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T15:23:40Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="sofre/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
erosendo/q-FrozenLake-v1-4x4-noSlippery
|
erosendo
| 2023-04-03T15:17:14Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T14:59:24Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="erosendo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
dwarfbum/piledream
|
dwarfbum
| 2023-04-03T15:05:25Z | 0 | 4 | null |
[
"region:us"
] | null | 2023-04-03T14:55:45Z |
author: https://civitai.com/models/20255
---
license: creativeml-openrail-m
---
I have no rights to the model
|
a2w-consultants/bestimmigrationconsultant
|
a2w-consultants
| 2023-04-03T15:02:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-04-03T15:00:34Z |
Best Immigration Consultants in Dubai
We are the only <a href="https://a2w-consultants.ae/10-best-immigration-consultants-in-dubai-uae/">immigration consultants Dubai</a> providing you with an economic immigration service that will be worth your time and money. We follow a very simple immigration process so that you can actualize your dream of migrating to some of the best countries in the World!
At A2W, we are dedicated to informing our customers about all of their alternatives when looking for an immigration consultant to match their specific requirements. While we are certain that A2W Consultants provide an unrivaled immigration service in UAE, we have produced a list of the <a href="https://a2w-consultants.ae/">Canada immigration consultants in UAE</a>, to help you better understand the industry and narrow down your options.
|
ocariz/butterfly_200
|
ocariz
| 2023-04-03T14:56:29Z | 30 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-04-03T14:55:27Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
This model is a diffusion model for unconditional image generation of cute butterflies trained for 200 epochs.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('ocariz/butterfly_200')
image = pipeline().images[0]
image
```
|
ana-bernal/keras_15_dog_breed_eff
|
ana-bernal
| 2023-04-03T14:44:32Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2023-04-03T14:42:24Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | None |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | True |
| is_legacy_optimizer | False |
| learning_rate | 0.0010000000474974513 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
Valyanka/my_esome_model
|
Valyanka
| 2023-04-03T14:32:45Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-03T13:30:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_esome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_esome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7458
- Accuracy: 0.23
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 32 | 1.8102 | 0.224 |
| No log | 2.0 | 64 | 1.7458 | 0.23 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
yumingyi/poca-SoccerTwos-untrained
|
yumingyi
| 2023-04-03T14:24:24Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-04-03T14:24:12Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: yumingyi/poca-SoccerTwos-untrained
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
asenella/mmnistMVTCAE_config2_
|
asenella
| 2023-04-03T14:16:41Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-04-02T01:30:03Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
Luca77/a2c-PandaReachDense-v2
|
Luca77
| 2023-04-03T14:09:24Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T14:06:59Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.47 +/- 0.70
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
pastells/a2c-AntBulletEnv-v0
|
pastells
| 2023-04-03T13:50:31Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:49:19Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1648.27 +/- 119.80
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ana-bernal/keras_15_dog_breed
|
ana-bernal
| 2023-04-03T13:47:44Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2023-04-03T13:47:32Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | None |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | True |
| is_legacy_optimizer | False |
| learning_rate | 0.0010000000474974513 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
alkiskoudounas/ppo-LunarLander-v2
|
alkiskoudounas
| 2023-04-03T13:47:40Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:47:17Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 273.94 +/- 20.88
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
StadlerRob/a2c-AntBulletEnv-v0-100k-722
|
StadlerRob
| 2023-04-03T13:47:38Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:46:34Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 746.30 +/- 76.83
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jlara6/platzi-vit-model-jl
|
jlara6
| 2023-04-03T13:42:45Z | 216 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-04-03T13:38:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: platzi-vit-model-jl
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9924812030075187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi-vit-model-jl
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0233
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1434 | 3.85 | 500 | 0.0233 | 0.9925 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
sofre/q-FrozenLake-v1-4x4-noSlippery
|
sofre
| 2023-04-03T13:36:15Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:36:10Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="sofre/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
saberzl/taxi_v3
|
saberzl
| 2023-04-03T13:34:27Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:34:24Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi_v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="saberzl/taxi_v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
asenella/mmnistJNF_config1_
|
asenella
| 2023-04-03T13:33:47Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-04-01T18:29:27Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
carolinainmymind/Taxi-v3
|
carolinainmymind
| 2023-04-03T13:26:57Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:26:48Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.78
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="carolinainmymind/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
carolinainmymind/q-FrozenLake-v1-4x4-noSlippery
|
carolinainmymind
| 2023-04-03T13:24:33Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:24:23Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="carolinainmymind/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
saberzl/taxi_v2
|
saberzl
| 2023-04-03T13:21:35Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T13:21:31Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi_v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="saberzl/taxi_v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
xpariz10/ast-finetuned-audioset-10-10-0.4593_ft_ESC-50_aug_0-1
|
xpariz10
| 2023-04-03T13:17:02Z | 162 | 0 |
transformers
|
[
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"arxiv:2103.12157",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-03-30T14:36:21Z |
---
license: bsd-3-clause
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: ast-finetuned-audioset-10-10-0.4593_ft_ESC-50_aug_0-1
results: []
---
# ast-finetuned-audioset-10-10-0.4593_ft_ESC-50_aug_0-1
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on a subset of [ashraq/esc50](https://huggingface.co/datasets/ashraq/esc50) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7391
- Accuracy: 0.9286
- Precision: 0.9449
- Recall: 0.9286
- F1: 0.9244
## Training and evaluation data
Training and evaluation data were augmented with audiomentations [GitHub: iver56/audiomentations](https://github.com/iver56/audiomentations) library and the following augmentation methods have been performed based on previous experiments [Elliott et al.: Tiny transformers for audio classification at the edge](https://arxiv.org/pdf/2103.12157.pdf):
**Gain**
- each audio sample is amplified/attenuated by a random factor between 0.5 and 1.5 with a 0.3 probability
**Noise**
- a random amount of Gaussian noise with a relative amplitude between 0.001 and 0.015 is added to each audio sample with a 0.5 probability
**Speed adjust**
- duration of each audio sample is extended by a random amount between 0.5 and 1.5 with a 0.3 probability
**Pitch shift**
- pitch of each audio sample is shifted by a random amount of semitones selected from the closed interval [-4,4] with a 0.3 probability
**Time masking**
- a random fraction of lenght of each audio sample in the range of (0,0.02] is erased with a 0.3 probability
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 9.9002 | 1.0 | 28 | 8.5662 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5.7235 | 2.0 | 56 | 4.3990 | 0.0357 | 0.0238 | 0.0357 | 0.0286 |
| 2.4076 | 3.0 | 84 | 2.2972 | 0.4643 | 0.7405 | 0.4643 | 0.4684 |
| 1.4448 | 4.0 | 112 | 1.3975 | 0.7143 | 0.7340 | 0.7143 | 0.6863 |
| 0.8373 | 5.0 | 140 | 1.0468 | 0.8571 | 0.8524 | 0.8571 | 0.8448 |
| 0.7239 | 6.0 | 168 | 0.8518 | 0.8929 | 0.9164 | 0.8929 | 0.8766 |
| 0.6504 | 7.0 | 196 | 0.7391 | 0.9286 | 0.9449 | 0.9286 | 0.9244 |
| 0.535 | 8.0 | 224 | 0.6682 | 0.9286 | 0.9449 | 0.9286 | 0.9244 |
| 0.4237 | 9.0 | 252 | 0.6443 | 0.9286 | 0.9449 | 0.9286 | 0.9244 |
| 0.3709 | 10.0 | 280 | 0.6304 | 0.9286 | 0.9449 | 0.9286 | 0.9244 |
### Test results
| Parameter | Value |
|:------------------------:|:------------------:|
| test_loss | 0.5829914808273315 |
| test_accuracy | 0.9285714285714286 |
| test_precision | 0.9446428571428571 |
| test_recall | 0.9285714285714286 |
| test_f1 | 0.930292723149866 |
| test_runtime (s) | 4.1488 |
| test_samples_per_second | 6.749 |
| test_steps_per_second | 3.374 |
| epoch | 10.0 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
tenich/a2c-PandaReachDense-v2
|
tenich
| 2023-04-03T12:48:24Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T12:45:59Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.90 +/- 0.48
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
dvruette/oasst-pythia-12b-reference
|
dvruette
| 2023-04-03T12:44:58Z | 1,499 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-03T12:24:29Z |
https://wandb.ai/open-assistant/supervised-finetuning/runs/bqiatai0
|
botato/point-alpaca-ggml-model-q4_0
|
botato
| 2023-04-03T12:39:37Z | 0 | 6 | null |
[
"region:us"
] | null | 2023-04-02T20:56:35Z |
# This is a 4-bit quantized ggml file for use with [llama.cpp](https://github.com/ggerganov/llama.cpp) on the CPU (pre-mmap) or [llama-rs](https://github.com/rustformers/llama-rs)
Original model: https://github.com/pointnetwork/point-alpaca
# How to run
./llama-cli -m ./ggml-model-q4_0.bin -f ./alpaca_prompt.txt --repl
(`llama-cli` is built from https://github.com/rustformers/llama-rs/tree/57440bffb0d946acf73b37e85498c77fc9dfe715)
|
developer8binks/new_marcellamodel
|
developer8binks
| 2023-04-03T12:39:04Z | 29 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"en",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-31T06:48:40Z |
---
license: creativeml-openrail-m
language:
- en
pipeline_tag: text-to-image
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Murray04/sd-class-butterflies-32
|
Murray04
| 2023-04-03T12:36:48Z | 30 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-04-03T12:36:21Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('Murray04/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
PavanNeerudu/t5-base-finetuned-wnli
|
PavanNeerudu
| 2023-04-03T12:30:56Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-02T04:53:51Z |
---
language:
- en
license: apache-2.0
datasets:
- glue
metrics:
- accuracy
model-index:
- name: t5-base-finetuned-wnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE WNLI
type: glue
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.5634
---
# T5-base-finetuned-wnli
<!-- Provide a quick summary of what the model is/does. -->
This model is T5 fine-tuned on GLUE WNLI dataset. It acheives the following results on the validation set
- Accuracy: 0.5634
## Model Details
T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format.
## Training procedure
### Tokenization
Since, T5 is a text-to-text model, the labels of the dataset are converted as follows:
For each example, a sentence as been formed as **"wnli sentence1: " + wnli_sent1 + "sentence 2: " + wnli_sent2** and fed to the tokenizer to get the **input_ids** and **attention_mask**.
For each label, label is choosen as **"entailment"** if label is 1, else label is **"not_entailment"** and tokenized to get **input_ids** and **attention_mask** .
During training, these inputs_ids having **pad** token are replaced with -100 so that loss is not calculated for them. Then these input ids are given as labels, and above attention_mask of labels
is given as decoder attention mask.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-4
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: epsilon=1e-08
- num_epochs: 3.0
### Training results
|Epoch | Training Loss | Validation Accuracy |
|:----:|:-------------:|:-------------------:|
| 1 | 0.1502 | 0.4930 |
| 2 | 0.1331 | 0.5634 |
| 3 | 0.1355 | 0.4225 |
|
Mauquoi-00/Teenage_Gender_Classification
|
Mauquoi-00
| 2023-04-03T12:16:38Z | 0 | 0 | null |
[
"code",
"en",
"region:us"
] | null | 2023-04-03T08:09:09Z |
---
language:
- en
tags:
- code
---
|
brand25/rl_course_vizdoom_health_gathering_supreme
|
brand25
| 2023-04-03T12:10:16Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T12:07:29Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.02 +/- 3.78
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r brand25/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
giggling-squid/HF_DRL_U4_ReinforcePG_cartpole_v2
|
giggling-squid
| 2023-04-03T12:03:12Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T12:02:56Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: HF_DRL_U4_ReinforcePG_cartpole_v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
giggling-squid/HF_DRL_U4_ReinforcePG_cartpole_v1
|
giggling-squid
| 2023-04-03T11:52:15Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T11:52:05Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: HF_DRL_U4_ReinforcePG_cartpole_v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 157.65 +/- 6.10
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
jeremyvictor/flan-t5-large-clang8-e1-b16
|
jeremyvictor
| 2023-04-03T11:49:00Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-02T18:34:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-large-clang8-e1-b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-clang8-e1-b16
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2994
- Rouge1: 80.9044
- Rouge2: 74.7041
- Rougel: 80.3109
- Rougelsum: 80.3664
- Gen Len: 16.0625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.2432 | 0.25 | 36000 | 0.4018 | 78.4447 | 71.3656 | 77.7552 | 77.8451 | 15.9010 |
| 0.1837 | 0.49 | 72000 | 0.3781 | 76.8828 | 69.9993 | 76.0584 | 76.1479 | 15.4026 |
| 0.1511 | 0.74 | 108000 | 0.3282 | 79.7898 | 73.329 | 79.1608 | 79.2416 | 15.9021 |
| 0.1267 | 0.98 | 144000 | 0.2994 | 80.9044 | 74.7041 | 80.3109 | 80.3664 | 16.0625 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.11.0a0+b6df043
- Datasets 2.11.0
- Tokenizers 0.13.2
|
Westcott/poca-SoccerTwos
|
Westcott
| 2023-04-03T11:34:13Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-04-03T11:28:06Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Westcott/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
brand25/ppo-LunarLander-v2-cleanRL
|
brand25
| 2023-04-03T11:27:29Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-03T11:27:18Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -172.26 +/- 106.08
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'brand25/ppo-LunarLander-v2-cleanRL'
'batch_size': 512
'minibatch_size': 128}
```
|
lgrobol/roberta-minuscule
|
lgrobol
| 2023-04-03T11:05:37Z | 1,019 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
RoBERTa-minuscule
==================
A ridiculously small model for testing purposes.
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.