
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 06:27:22
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 525
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 06:27:10
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
sandeeprao/sandyspace
|
sandeeprao
| 2023-10-11T19:01:57Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:facebook/opt-6.7b",
"base_model:adapter:facebook/opt-6.7b",
"region:us"
] | null | 2023-10-11T18:57:29Z |
---
library_name: peft
base_model: facebook/opt-6.7b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
awsvikram/dogbooth
|
awsvikram
| 2023-10-11T18:35:35Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:finetune:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-11T01:51:26Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
instance_prompt: a photo of [v]dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - awsvikram/dogbooth
This is a dreambooth model derived from stabilityai/stable-diffusion-2-1. The weights were trained on a photo of [v]dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
smallonotation/lilt-en-funsd
|
smallonotation
| 2023-10-11T17:51:53Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"lilt",
"token-classification",
"generated_from_trainer",
"dataset:funsd-layoutlmv3",
"base_model:SCUT-DLVCLab/lilt-roberta-en-base",
"base_model:finetune:SCUT-DLVCLab/lilt-roberta-en-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-11T14:14:44Z |
---
license: mit
base_model: SCUT-DLVCLab/lilt-roberta-en-base
tags:
- generated_from_trainer
datasets:
- funsd-layoutlmv3
model-index:
- name: lilt-en-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lilt-en-funsd
This model is a fine-tuned version of [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) on the funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.9291
- eval_ANSWER: {'precision': 0.0166358595194085, 'recall': 0.044063647490820076, 'f1': 0.024152968802415294, 'number': 817}
- eval_HEADER: {'precision': 0.004098360655737705, 'recall': 0.008403361344537815, 'f1': 0.005509641873278237, 'number': 119}
- eval_QUESTION: {'precision': 0.08307501549907005, 'recall': 0.2488393686165274, 'f1': 0.12456425749477108, 'number': 1077}
- eval_overall_precision: 0.0541
- eval_overall_recall: 0.1515
- eval_overall_f1: 0.0798
- eval_overall_accuracy: 0.1625
- eval_runtime: 4.0045
- eval_samples_per_second: 12.486
- eval_steps_per_second: 1.748
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2500
### Framework versions
- Transformers 4.34.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Kiwihead15/marian-finetuned-kde4-en-to-fr
|
Kiwihead15
| 2023-10-11T17:49:03Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-10-07T10:55:35Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- translation
- generated_from_trainer
datasets:
- kde4
model-index:
- name: marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Venkidesh/phi-1_5-finetuned-gsm8k
|
Venkidesh
| 2023-10-11T17:44:12Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:microsoft/phi-1_5",
"base_model:finetune:microsoft/phi-1_5",
"license:other",
"region:us"
] | null | 2023-10-11T10:28:39Z |
---
license: other
base_model: microsoft/phi-1_5
tags:
- generated_from_trainer
model-index:
- name: phi-1_5-finetuned-gsm8k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-1_5-finetuned-gsm8k
This model is a fine-tuned version of [microsoft/phi-1_5](https://huggingface.co/microsoft/phi-1_5) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
petergriger/a2c-PandaReachDense-v3
|
petergriger
| 2023-10-11T17:43:37Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T16:48:55Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.18 +/- 0.06
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
LemTenku/testD
|
LemTenku
| 2023-10-11T17:41:07Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-11T17:25:08Z |
---
license: apache-2.0
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
language:
- en
---
Dolphin 2.1 🐬
https://erichartford.com/dolphin
Dolphin-2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on mistralAI, with apache-2.0 license, so it is suitable for commercial or non-commercial use.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 48 hours to train 4 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase horsepower and acceleration in a 2010 Honda Civic without worrying too much about cost, you can consider the following modifications:
1. Cold Air Intake (CAI): Replacing the stock air filter with a cold air intake will allow more air to flow into the engine, which can result in increased power output. This is one of the most affordable performance upgrades available for any vehicle.
2. Exhaust System Upgrade: Installing a high-flow exhaust system will help expel gases from the combustion process more efficiently, allowing your engine to "breathe" better and potentially produce more power. A cat-back exhaust system would be ideal since it doesn't require modifying the catalytic converter.
3. Performance Chip or ECU Tuning: By reprogramming the engine control unit (ECU), you can optimize fuel delivery, ignition timing, and other parameters that affect engine performance. This can lead to significant gains in horsepower and torque. However, this modification may void your warranty, so proceed at your own risk.
4. Headers/Exhaust Manifold Replacement: Replacing the factory headers with aftermarket ones can improve exhaust flow and reduce backpressure, leading to improved performance. Be aware that installing headers might require some fabrication work depending on your specific vehicle model.
5. Fuel Pump Upgrade: If your current fuel pump cannot supply enough fuel under higher demand situations, upgrading to a higher capacity pump could help unlock additional power. Make sure to choose a pump compatible with your vehicle's fuel system.
As for making your car louder, here are some suggestions:
6. Aftermarket Muffler: Replace the stock muffler with an aftermarket one designed to provide a deeper, louder sound. Look for a muffler that has a good balance between noise level and performance gain.
7. Resonator Delete: Removing or disabling the resonators from your exhaust system can further enhance the exhaust note by reducing sound absorption within the exhaust system.
8. Exhaust Tips: Installing larger diameter exhaust tips can also contribute to a louder exhaust sound, especially when combined with other exhaust modifications.
Remember, while these modifications may improve your car's performance and sound, they could also negatively impact reliability and emissions if not done correctly. Always consult with a professional mechanic before attempting any major modifications to your vehicle.
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
|
Youxuan/q-FrozenLake-v1-4x4-noSlippery
|
Youxuan
| 2023-10-11T17:33:18Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T16:52:53Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Youxuan/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kibru/distilbert-base-uncased-finetuned-cola
|
kibru
| 2023-10-11T17:21:42Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-11T17:03:15Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5402881620449809
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7569
- Matthews Correlation: 0.5403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5304 | 1.0 | 535 | 0.4711 | 0.4796 |
| 0.3578 | 2.0 | 1070 | 0.5249 | 0.5209 |
| 0.2374 | 3.0 | 1605 | 0.6196 | 0.5212 |
| 0.1808 | 4.0 | 2140 | 0.7569 | 0.5403 |
| 0.136 | 5.0 | 2675 | 0.8015 | 0.5328 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
ledinhnguyen00/EmoraBert
|
ledinhnguyen00
| 2023-10-11T17:20:39Z | 64 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"text-classification",
"generated_from_keras_callback",
"base_model:wonrax/phobert-base-vietnamese-sentiment",
"base_model:finetune:wonrax/phobert-base-vietnamese-sentiment",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-05T12:05:55Z |
---
license: mit
base_model: wonrax/phobert-base-vietnamese-sentiment
tags:
- generated_from_keras_callback
model-index:
- name: ledinhnguyen00/EmoraBert
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ledinhnguyen00/EmoraBert
This model is a fine-tuned version of [wonrax/phobert-base-vietnamese-sentiment](https://huggingface.co/wonrax/phobert-base-vietnamese-sentiment) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.8098
- Validation Loss: 0.7439
- Train Accuracy: 0.6678
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 115641, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.8098 | 0.7439 | 0.6678 | 0 |
### Framework versions
- Transformers 4.34.0
- TensorFlow 2.12.0
- Datasets 2.14.5
- Tokenizers 0.14.1
|
cleanrl/Pusher-v4-td3_continuous_action-seed1
|
cleanrl
| 2023-10-11T17:18:13Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"Pusher-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T17:16:51Z |
---
tags:
- Pusher-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pusher-v4
type: Pusher-v4
metrics:
- type: mean_reward
value: -30.85 +/- 2.62
name: mean_reward
verified: false
---
# (CleanRL) **TD3** Agent Playing **Pusher-v4**
This is a trained model of a TD3 agent playing Pusher-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/td3_continuous_action.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[td3_continuous_action]"
python -m cleanrl_utils.enjoy --exp-name td3_continuous_action --env-id Pusher-v4
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/Pusher-v4-td3_continuous_action-seed1/raw/main/td3_continuous_action.py
curl -OL https://huggingface.co/cleanrl/Pusher-v4-td3_continuous_action-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/Pusher-v4-td3_continuous_action-seed1/raw/main/poetry.lock
poetry install --all-extras
python td3_continuous_action.py --track --capture-video --env-id Pusher-v4 --seed 1 --save-model --upload-model --hf-entity cleanrl
```
# Hyperparameters
```python
{'batch_size': 256,
'buffer_size': 1000000,
'capture_video': True,
'cuda': True,
'env_id': 'Pusher-v4',
'exp_name': 'td3_continuous_action',
'exploration_noise': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0003,
'learning_starts': 25000.0,
'noise_clip': 0.5,
'policy_frequency': 2,
'policy_noise': 0.2,
'save_model': True,
'seed': 1,
'tau': 0.005,
'torch_deterministic': True,
'total_timesteps': 1000000,
'track': True,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
jfischoff/miniSD-diff-loss-ad
|
jfischoff
| 2023-10-11T17:16:28Z | 0 | 1 | null |
[
"license:openrail",
"region:us"
] | null | 2023-10-11T17:00:16Z |
---
license: openrail
---
# miniSD-diff-loss-AD
This is motion module V2 fine-tuning experiment that tries two novel things.
One it uses miniSD as a base model when training. This leads to increased detail and clarity when generating. Two, it uses a loss function that ensures the frame diffs are similar between the target and predicted. This reduces high frequency movement, e.g. flicker.
The model might have some issues. It doesn't always produce as much motion as V2 and can require more steps for context blending.
|
sbolouki/bloom-1b7-adapter-20
|
sbolouki
| 2023-10-11T16:55:55Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:bigscience/bloom-1b7",
"base_model:adapter:bigscience/bloom-1b7",
"region:us"
] | null | 2023-10-11T16:55:53Z |
---
library_name: peft
base_model: bigscience/bloom-1b7
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
kingabzpro/wav2vec2-large-xlsr-53-punjabi
|
kingabzpro
| 2023-10-11T16:38:48Z | 39 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"robust-speech-event",
"pa",
"dataset:mozilla-foundation/common_voice_8_0",
"base_model:Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10",
"base_model:finetune:Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- pa
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
metrics:
- wer
- cer
base_model: Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10
model-index:
- name: wav2vec2-punjabi-V8-Abid
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
name: Common Voice pa-IN
type: mozilla-foundation/common_voice_8_0
args: pa-IN
metrics:
- type: wer
value: 36.02
name: Test WER With LM
- type: cer
value: 12.81
name: Test CER With LM
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-punjabi
This model is a fine-tuned version of [Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10](https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-punjabi-pam-10) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2101
- Wer: 0.4939
- Cer: 0.2238
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id kingabzpro/wav2vec2-large-xlsr-53-punjabi --dataset mozilla-foundation/common_voice_8_0 --config pa-IN --split test
```
### Inference With LM
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "kingabzpro/wav2vec2-large-xlsr-53-punjabi"
sample_iter = iter(load_dataset("mozilla-foundation/common_voice_8_0", "pa-IN", split="test", streaming=True, use_auth_token=True))
sample = next(sample_iter)
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
transcription = processor.batch_decode(logits.numpy()).text
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 11.0563 | 3.7 | 100 | 1.9492 | 0.7123 | 0.3872 |
| 1.6715 | 7.41 | 200 | 1.3142 | 0.6433 | 0.3086 |
| 0.9117 | 11.11 | 300 | 1.2733 | 0.5657 | 0.2627 |
| 0.666 | 14.81 | 400 | 1.2730 | 0.5598 | 0.2534 |
| 0.4225 | 18.52 | 500 | 1.2548 | 0.5300 | 0.2399 |
| 0.3209 | 22.22 | 600 | 1.2166 | 0.5229 | 0.2372 |
| 0.2678 | 25.93 | 700 | 1.1795 | 0.5041 | 0.2276 |
| 0.2088 | 29.63 | 800 | 1.2101 | 0.4939 | 0.2238 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
PriyankaHundalekar/Hindi-Offensive-Analyzer-MuRIL
|
PriyankaHundalekar
| 2023-10-11T16:32:47Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-11T15:20:40Z |
## Hindi-Offensive-Analyzer-MuRIL
### Model Description
## Overview
Hindi-Offensive-Analyzer-MuRIL is a fine-tuned language model based on MuRIL (Multilingual Representations for Indian Languages), a powerful BERT-based model designed to handle a diverse range of 17 Indian languages, including their transliterated counterparts. This fine-tuned model has been specifically tailored for the task of classifying hate and non-hate comments in Hindi.
## MuRIL Base Cased
The MuRIL model serves as the foundation for Hindi-Offensive-Analyzer-MuRIL. MuRIL is a language model pre-trained on a vast dataset containing text from various Indian languages. It has been developed with a unique training paradigm that is similar to multilingual BERT, with additional modifications to enhance its performance on low-resource languages.
## Application: Hindi Hate Speech Comment Classification
Hindi-Offensive-Analyzer-MuRIL has been fine-tuned specifically for the task of classifying comments written in Hindi as either "Hate" or "Non-Hate”. This model can effectively analyze text and distinguish offensive content from non-offensive content in the Hindi language. It is a valuable tool for applications that require hate speech detection and moderation on platforms and websites that host content in Hindi.
Label 0 : Non-Hate
Label 1 : Hate
## Hardware Requirements:
1. **Processor:** Minimum i3 or AMD Ryzen 3 processor
2. **RAM:** 12 GB
3. **GPU:** 16 GB Tesla T4
## Software Requirements:
1. **Operating System:** Windows 10
2. **Processor:** Intel® Core™ i5-6200U CPU @ 2.30GHz × 4
3. **Programming Language:** Python 3
4. **Development Environment:** Google Colab Pro Notebook
## Use Cases
Hindi-Offensive-Analyzer-MuRIL can be used in a variety of applications, including content moderation, social media monitoring and sentiment analysis. It aids in promoting a safe online environment by automatically identifying and flagging potentially harmful or offensive content.
## Acknowledgments
This model builds upon the foundation of the MuRIL language model, which is the result of collaborative research and contributions from the NLP community. We extend our appreciation to the creators of MuRIL for their work in advancing the understanding and processing of Indian languages.
- **Developed by:** Priyanka Hundalekar
- **Model type:** Text Classification
- **Language(s) (NLP):** Python
- **Finetuned from model [optional]:** google/muril-base-cased
|
AmrMorgado/ReinforceGymCartpole
|
AmrMorgado
| 2023-10-11T16:32:32Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T16:32:21Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: ReinforceGymCartpole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
vxbrandon/t5-base_sst2_dense
|
vxbrandon
| 2023-10-11T16:32:26Z | 46 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-28T07:10:37Z |
---
license: apache-2.0
base_model: t5-base
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: t5-base_sst2_dense
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.9231651376146789
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base_sst2_dense
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2156
- Accuracy: 0.9232
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6905 | 0.01 | 10 | 0.7366 | 0.5080 |
| 0.684 | 0.02 | 20 | 0.7306 | 0.5069 |
| 0.7013 | 0.03 | 30 | 0.7228 | 0.5080 |
| 0.6954 | 0.04 | 40 | 0.7114 | 0.5046 |
| 0.6893 | 0.05 | 50 | 0.7026 | 0.5034 |
| 0.6888 | 0.06 | 60 | 0.6912 | 0.5023 |
| 0.6814 | 0.07 | 70 | 0.6848 | 0.5034 |
| 0.679 | 0.08 | 80 | 0.6745 | 0.5206 |
| 0.6616 | 0.09 | 90 | 0.6685 | 0.5252 |
| 0.6604 | 0.1 | 100 | 0.6580 | 0.5378 |
| 0.6524 | 0.1 | 110 | 0.6378 | 0.6525 |
| 0.6344 | 0.11 | 120 | 0.6128 | 0.7271 |
| 0.5915 | 0.12 | 130 | 0.5672 | 0.8016 |
| 0.562 | 0.13 | 140 | 0.4903 | 0.8578 |
| 0.4653 | 0.14 | 150 | 0.3825 | 0.8796 |
| 0.3632 | 0.15 | 160 | 0.2811 | 0.8991 |
| 0.2754 | 0.16 | 170 | 0.3029 | 0.8933 |
| 0.2298 | 0.17 | 180 | 0.3001 | 0.8991 |
| 0.2819 | 0.18 | 190 | 0.2636 | 0.9083 |
| 0.2532 | 0.19 | 200 | 0.2321 | 0.9128 |
| 0.2512 | 0.2 | 210 | 0.2286 | 0.9186 |
| 0.2149 | 0.21 | 220 | 0.2424 | 0.9128 |
| 0.2466 | 0.22 | 230 | 0.2505 | 0.9140 |
| 0.1853 | 0.23 | 240 | 0.2178 | 0.9186 |
| 0.2279 | 0.24 | 250 | 0.2152 | 0.9186 |
| 0.219 | 0.25 | 260 | 0.2188 | 0.9197 |
| 0.2144 | 0.26 | 270 | 0.2179 | 0.9209 |
| 0.1507 | 0.27 | 280 | 0.2185 | 0.9186 |
| 0.1801 | 0.28 | 290 | 0.2473 | 0.9243 |
| 0.1735 | 0.29 | 300 | 0.2402 | 0.9128 |
| 0.1437 | 0.29 | 310 | 0.2436 | 0.9255 |
| 0.2221 | 0.3 | 320 | 0.2209 | 0.9163 |
| 0.1611 | 0.31 | 330 | 0.2101 | 0.9232 |
| 0.1813 | 0.32 | 340 | 0.2291 | 0.9174 |
| 0.1871 | 0.33 | 350 | 0.2386 | 0.9174 |
| 0.2126 | 0.34 | 360 | 0.2225 | 0.9197 |
| 0.2023 | 0.35 | 370 | 0.2116 | 0.9232 |
| 0.127 | 0.36 | 380 | 0.2155 | 0.9232 |
| 0.2769 | 0.37 | 390 | 0.2149 | 0.9243 |
| 0.1457 | 0.38 | 400 | 0.2166 | 0.9232 |
| 0.2129 | 0.39 | 410 | 0.2271 | 0.9232 |
| 0.1652 | 0.4 | 420 | 0.2308 | 0.9220 |
| 0.1783 | 0.41 | 430 | 0.2400 | 0.9278 |
| 0.1305 | 0.42 | 440 | 0.2404 | 0.9232 |
| 0.2595 | 0.43 | 450 | 0.2389 | 0.9209 |
| 0.1901 | 0.44 | 460 | 0.2102 | 0.9266 |
| 0.1993 | 0.45 | 470 | 0.2129 | 0.9255 |
| 0.147 | 0.46 | 480 | 0.2208 | 0.9232 |
| 0.1801 | 0.47 | 490 | 0.2143 | 0.9255 |
| 0.1716 | 0.48 | 500 | 0.2416 | 0.9209 |
| 0.1281 | 0.48 | 510 | 0.2152 | 0.9232 |
| 0.1837 | 0.49 | 520 | 0.2112 | 0.9243 |
| 0.1681 | 0.5 | 530 | 0.2178 | 0.9232 |
| 0.1408 | 0.51 | 540 | 0.2127 | 0.9243 |
| 0.1229 | 0.52 | 550 | 0.3322 | 0.9278 |
| 0.1304 | 0.53 | 560 | 0.3586 | 0.9209 |
| 0.1905 | 0.54 | 570 | 0.3354 | 0.9243 |
| 0.147 | 0.55 | 580 | 0.3431 | 0.9278 |
| 0.1538 | 0.56 | 590 | 0.3444 | 0.9232 |
| 0.1504 | 0.57 | 600 | 0.2196 | 0.9266 |
| 0.1628 | 0.58 | 610 | 0.3452 | 0.9163 |
| 0.1387 | 0.59 | 620 | 0.3282 | 0.9278 |
| 0.2104 | 0.6 | 630 | 0.2132 | 0.9243 |
| 0.1482 | 0.61 | 640 | 0.2154 | 0.9243 |
| 0.217 | 0.62 | 650 | 0.3472 | 0.9197 |
| 0.1692 | 0.63 | 660 | 0.2063 | 0.9243 |
| 0.175 | 0.64 | 670 | 0.2019 | 0.9278 |
| 0.1473 | 0.65 | 680 | 0.1957 | 0.9266 |
| 0.1154 | 0.66 | 690 | 0.2020 | 0.9255 |
| 0.1369 | 0.67 | 700 | 0.2087 | 0.9266 |
| 0.1262 | 0.67 | 710 | 0.3224 | 0.9289 |
| 0.2111 | 0.68 | 720 | 0.3325 | 0.9243 |
| 0.1349 | 0.69 | 730 | 0.3285 | 0.9289 |
| 0.1814 | 0.7 | 740 | 0.3324 | 0.9266 |
| 0.1217 | 0.71 | 750 | 0.3212 | 0.9243 |
| 0.173 | 0.72 | 760 | 0.2176 | 0.9220 |
| 0.1441 | 0.73 | 770 | 0.2130 | 0.9232 |
| 0.1706 | 0.74 | 780 | 0.2136 | 0.9220 |
| 0.1411 | 0.75 | 790 | 0.2101 | 0.9220 |
| 0.1051 | 0.76 | 800 | 0.2078 | 0.9243 |
| 0.115 | 0.77 | 810 | 0.2160 | 0.9266 |
| 0.2031 | 0.78 | 820 | 0.2162 | 0.9209 |
| 0.12 | 0.79 | 830 | 0.2059 | 0.9255 |
| 0.176 | 0.8 | 840 | 0.2100 | 0.9255 |
| 0.1306 | 0.81 | 850 | 0.4307 | 0.9243 |
| 0.1359 | 0.82 | 860 | 0.4397 | 0.9289 |
| 0.1921 | 0.83 | 870 | 0.5446 | 0.9278 |
| 0.1772 | 0.84 | 880 | 0.5423 | 0.9266 |
| 0.1771 | 0.85 | 890 | 0.4273 | 0.9266 |
| 0.1965 | 0.86 | 900 | 0.3224 | 0.9243 |
| 0.1227 | 0.86 | 910 | 0.2131 | 0.9278 |
| 0.2046 | 0.87 | 920 | 0.3130 | 0.9278 |
| 0.1061 | 0.88 | 930 | 0.3180 | 0.9289 |
| 0.1364 | 0.89 | 940 | 0.5501 | 0.9186 |
| 0.1213 | 0.9 | 950 | 0.4400 | 0.9220 |
| 0.1611 | 0.91 | 960 | 0.4364 | 0.9255 |
| 0.1632 | 0.92 | 970 | 0.4475 | 0.9220 |
| 0.1617 | 0.93 | 980 | 0.5758 | 0.9209 |
| 0.1478 | 0.94 | 990 | 0.2143 | 0.9220 |
| 0.1314 | 0.95 | 1000 | 0.2156 | 0.9232 |
| 0.1814 | 0.96 | 1010 | 0.2191 | 0.9220 |
| 0.1669 | 0.97 | 1020 | 0.2129 | 0.9243 |
| 0.1206 | 0.98 | 1030 | 0.2119 | 0.9220 |
| 0.1852 | 0.99 | 1040 | 0.2104 | 0.9209 |
| 0.1381 | 1.0 | 1050 | 0.1999 | 0.9255 |
| 0.135 | 1.01 | 1060 | 0.2090 | 0.9243 |
| 0.1253 | 1.02 | 1070 | 0.4486 | 0.9209 |
| 0.1244 | 1.03 | 1080 | 0.4319 | 0.9197 |
| 0.1772 | 1.04 | 1090 | 0.4248 | 0.9243 |
| 0.1264 | 1.05 | 1100 | 0.3090 | 0.9289 |
| 0.6928 | 1.05 | 1110 | 0.3174 | 0.9278 |
| 0.0908 | 1.06 | 1120 | 0.4359 | 0.9266 |
| 0.1286 | 1.07 | 1130 | 0.4302 | 0.9312 |
| 0.0953 | 1.08 | 1140 | 0.5397 | 0.9289 |
| 0.1091 | 1.09 | 1150 | 0.5455 | 0.9255 |
| 0.1546 | 1.1 | 1160 | 0.4261 | 0.9300 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Charlie911/vicuna-7b-v1.5-lora-timedial-unit-080082
|
Charlie911
| 2023-10-11T16:30:53Z | 10 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"license:llama2",
"region:us"
] | null | 2023-10-11T16:28:22Z |
---
library_name: peft
license: llama2
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0
|
nehasingh555/exl_genai_training_model
|
nehasingh555
| 2023-10-11T16:25:40Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:bigscience/bloomz-3b",
"base_model:adapter:bigscience/bloomz-3b",
"region:us"
] | null | 2023-10-11T16:25:38Z |
---
library_name: peft
base_model: bigscience/bloomz-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
rafacel/Taxi-v3
|
rafacel
| 2023-10-11T16:23:47Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T16:23:43Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="rafacel/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ageng-anugrah/delivery-feedback
|
ageng-anugrah
| 2023-10-11T16:07:09Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:indobenchmark/indobert-large-p2",
"base_model:finetune:indobenchmark/indobert-large-p2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-11T16:05:58Z |
---
license: mit
base_model: indobenchmark/indobert-large-p2
tags:
- generated_from_keras_callback
model-index:
- name: delivery-sentiment
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# delivery-sentiment
This model is a fine-tuned version of [indobenchmark/indobert-large-p2](https://huggingface.co/indobenchmark/indobert-large-p2) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.34.0
- TensorFlow 2.13.0
- Tokenizers 0.14.1
|
OpenBuddy/openbuddy-mistral-7b-v13.1
|
OpenBuddy
| 2023-10-11T15:55:09Z | 1,553 | 19 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-10-11T15:26:48Z |
---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
pipeline_tag: text-generation
inference: false
library_name: transformers
license: apache-2.0
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
Base model: https://huggingface.co/mistralai/Mistral-7B-v0.1
License: Apache 2.0
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
|
OpenBuddy/openbuddy-mistral-7b-v13
|
OpenBuddy
| 2023-10-11T15:54:14Z | 1,668 | 13 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-10-10T06:48:00Z |
---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
pipeline_tag: text-generation
inference: false
library_name: transformers
license: apache-2.0
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
Base model: https://huggingface.co/mistralai/Mistral-7B-v0.1
License: Apache 2.0
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
|
innyun/q-Taxi-v3
|
innyun
| 2023-10-11T15:44:40Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T15:29:51Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="innyun/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
cleanrl/InvertedPendulum-v4-td3_continuous_action-seed1
|
cleanrl
| 2023-10-11T15:35:11Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"InvertedPendulum-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T15:34:39Z |
---
tags:
- InvertedPendulum-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: InvertedPendulum-v4
type: InvertedPendulum-v4
metrics:
- type: mean_reward
value: 1000.00 +/- 0.00
name: mean_reward
verified: false
---
# (CleanRL) **TD3** Agent Playing **InvertedPendulum-v4**
This is a trained model of a TD3 agent playing InvertedPendulum-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/td3_continuous_action.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[td3_continuous_action]"
python -m cleanrl_utils.enjoy --exp-name td3_continuous_action --env-id InvertedPendulum-v4
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/InvertedPendulum-v4-td3_continuous_action-seed1/raw/main/td3_continuous_action.py
curl -OL https://huggingface.co/cleanrl/InvertedPendulum-v4-td3_continuous_action-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/InvertedPendulum-v4-td3_continuous_action-seed1/raw/main/poetry.lock
poetry install --all-extras
python td3_continuous_action.py --track --capture-video --env-id InvertedPendulum-v4 --seed 1 --save-model --upload-model --hf-entity cleanrl
```
# Hyperparameters
```python
{'batch_size': 256,
'buffer_size': 1000000,
'capture_video': True,
'cuda': True,
'env_id': 'InvertedPendulum-v4',
'exp_name': 'td3_continuous_action',
'exploration_noise': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0003,
'learning_starts': 25000.0,
'noise_clip': 0.5,
'policy_frequency': 2,
'policy_noise': 0.2,
'save_model': True,
'seed': 1,
'tau': 0.005,
'torch_deterministic': True,
'total_timesteps': 1000000,
'track': True,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
julienDevleesch/julien
|
julienDevleesch
| 2023-10-11T15:26:48Z | 35 | 0 |
diffusers
|
[
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-11T15:20:02Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### julien Dreambooth model trained by julienDevleesch with TheLastBen's fast-DreamBooth notebook
|
LikelySurf/MammoLLM2
|
LikelySurf
| 2023-10-11T15:24:51Z | 156 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-11T12:34:02Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: MammoLLM2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MammoLLM2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.7888 | 1.24 | 500 | 1.0984 |
| 1.1179 | 2.49 | 1000 | 1.0209 |
| 1.0556 | 3.73 | 1500 | 0.9913 |
| 1.01 | 4.98 | 2000 | 0.9653 |
| 0.9723 | 6.22 | 2500 | 0.9608 |
| 0.9425 | 7.47 | 3000 | 0.9455 |
| 0.9149 | 8.71 | 3500 | 0.9391 |
| 0.8877 | 9.96 | 4000 | 0.9253 |
| 0.8478 | 11.2 | 4500 | 0.9317 |
| 0.8142 | 12.45 | 5000 | 0.9313 |
| 0.7814 | 13.69 | 5500 | 0.9299 |
| 0.7494 | 14.93 | 6000 | 0.9330 |
| 0.7071 | 16.18 | 6500 | 0.9588 |
| 0.6774 | 17.42 | 7000 | 0.9704 |
| 0.6511 | 18.67 | 7500 | 0.9828 |
| 0.6275 | 19.91 | 8000 | 1.0007 |
| 0.595 | 21.16 | 8500 | 1.0432 |
| 0.5698 | 22.4 | 9000 | 1.0641 |
| 0.546 | 23.65 | 9500 | 1.0879 |
| 0.523 | 24.89 | 10000 | 1.0982 |
| 0.4913 | 26.14 | 10500 | 1.1579 |
| 0.4622 | 27.38 | 11000 | 1.1923 |
| 0.4378 | 28.62 | 11500 | 1.2152 |
| 0.4131 | 29.87 | 12000 | 1.2440 |
| 0.3846 | 31.11 | 12500 | 1.3181 |
| 0.3592 | 32.36 | 13000 | 1.3497 |
| 0.3411 | 33.6 | 13500 | 1.3847 |
| 0.324 | 34.85 | 14000 | 1.4070 |
| 0.3061 | 36.09 | 14500 | 1.4755 |
| 0.2903 | 37.34 | 15000 | 1.5078 |
| 0.2795 | 38.58 | 15500 | 1.5351 |
| 0.2701 | 39.83 | 16000 | 1.5639 |
| 0.2605 | 41.07 | 16500 | 1.5972 |
| 0.2521 | 42.31 | 17000 | 1.6191 |
| 0.2467 | 43.56 | 17500 | 1.6300 |
| 0.2425 | 44.8 | 18000 | 1.6453 |
| 0.2386 | 46.05 | 18500 | 1.6554 |
| 0.2356 | 47.29 | 19000 | 1.6628 |
| 0.2344 | 48.54 | 19500 | 1.6663 |
| 0.2333 | 49.78 | 20000 | 1.6666 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.3
- Tokenizers 0.13.3
|
jackboyla/span-marker-bert-base-fewnerd-coarse-super
|
jackboyla
| 2023-10-11T15:16:50Z | 3 | 1 |
span-marker
|
[
"span-marker",
"pytorch",
"token-classification",
"ner",
"named-entity-recognition",
"generated_from_span_marker_trainer",
"en",
"dataset:DFKI-SLT/few-nerd",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:cc-by-sa-4.0",
"model-index",
"region:us"
] |
token-classification
| 2023-10-11T15:16:35Z |
---
language:
- en
license: cc-by-sa-4.0
library_name: span-marker
tags:
- span-marker
- token-classification
- ner
- named-entity-recognition
- generated_from_span_marker_trainer
datasets:
- DFKI-SLT/few-nerd
metrics:
- precision
- recall
- f1
widget:
- text: The Hebrew Union College libraries in Cincinnati and Los Angeles, the Library
of Congress in Washington, D.C ., the Jewish Theological Seminary in New York
City, and the Harvard University Library (which received donations of Deinard's
texts from Lucius Nathan Littauer, housed in Widener and Houghton libraries) also
have large collections of Deinard works.
- text: Abu Abd Allah Muhammad al-Idrisi (1099–1165 or 1166), the Moroccan Muslim
geographer, cartographer, Egyptologist and traveller who lived in Sicily at the
court of King Roger II, mentioned this island, naming it جزيرة مليطمة ("jazīrat
Malīṭma", "the island of Malitma ") on page 583 of his book "Nuzhat al-mushtaq
fi ihtiraq ghal afaq", otherwise known as The Book of Roger, considered a geographic
encyclopaedia of the medieval world.
- text: The font is also used in the logo of the American rock band Greta Van Fleet,
in the logo for Netflix show "Stranger Things ", and in the album art for rapper
Logic's album "Supermarket ".
- text: Caretaker manager George Goss led them on a run in the FA Cup, defeating Liverpool
in round 4, to reach the semi-final at Stamford Bridge, where they were defeated
2–0 by Sheffield United on 28 March 1925.
- text: In 1991, the National Science Foundation (NSF), which manages the U.S . Antarctic
Program (US AP), honoured his memory by dedicating a state-of-the-art laboratory
complex in his name, the Albert P. Crary Science and Engineering Center (CSEC)
located in McMurdo Station.
pipeline_tag: token-classification
base_model: bert-base-cased
model-index:
- name: SpanMarker with bert-base-cased on DFKI-SLT/few-nerd
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
name: Unknown
type: DFKI-SLT/few-nerd
split: test
metrics:
- type: f1
value: 0.7712935275393074
name: F1
- type: precision
value: 0.7793372319688109
name: Precision
- type: recall
value: 0.7634141684170327
name: Recall
---
# SpanMarker with bert-base-cased on DFKI-SLT/few-nerd
This is a [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) model trained on the [DFKI-SLT/few-nerd](https://huggingface.co/datasets/DFKI-SLT/few-nerd) dataset that can be used for Named Entity Recognition. This SpanMarker model uses [bert-base-cased](https://huggingface.co/bert-base-cased) as the underlying encoder.
## Model Details
### Model Description
- **Model Type:** SpanMarker
- **Encoder:** [bert-base-cased](https://huggingface.co/bert-base-cased)
- **Maximum Sequence Length:** 256 tokens
- **Maximum Entity Length:** 8 words
- **Training Dataset:** [DFKI-SLT/few-nerd](https://huggingface.co/datasets/DFKI-SLT/few-nerd)
- **Language:** en
- **License:** cc-by-sa-4.0
### Model Sources
- **Repository:** [SpanMarker on GitHub](https://github.com/tomaarsen/SpanMarkerNER)
- **Thesis:** [SpanMarker For Named Entity Recognition](https://raw.githubusercontent.com/tomaarsen/SpanMarkerNER/main/thesis.pdf)
### Model Labels
| Label | Examples |
|:-------------|:-------------------------------------------------------------------------------|
| art | "The Seven Year Itch", "Time", "Imelda de ' Lambertazzi" |
| building | "Boston Garden", "Henry Ford Museum", "Sheremetyevo International Airport" |
| event | "Russian Revolution", "Iranian Constitutional Revolution", "French Revolution" |
| location | "Croatian", "the Republic of Croatia", "Mediterranean Basin" |
| organization | "IAEA", "Church 's Chicken", "Texas Chicken" |
| other | "BAR", "Amphiphysin", "N-terminal lipid" |
| person | "Ellaline Terriss", "Edmund Payne", "Hicks" |
| product | "Phantom", "100EX", "Corvettes - GT1 C6R" |
## Evaluation
### Metrics
| Label | Precision | Recall | F1 |
|:-------------|:----------|:-------|:-------|
| **all** | 0.7793 | 0.7634 | 0.7713 |
| art | 0.7608 | 0.7395 | 0.75 |
| building | 0.6095 | 0.6816 | 0.6435 |
| event | 0.6094 | 0.5392 | 0.5721 |
| location | 0.8112 | 0.8599 | 0.8348 |
| organization | 0.7335 | 0.6827 | 0.7072 |
| other | 0.7715 | 0.5822 | 0.6636 |
| person | 0.8635 | 0.9044 | 0.8835 |
| product | 0.7172 | 0.5932 | 0.6494 |
## Uses
### Direct Use for Inference
```python
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("span_marker_model_id")
# Run inference
entities = model.predict("Caretaker manager George Goss led them on a run in the FA Cup, defeating Liverpool in round 4, to reach the semi-final at Stamford Bridge, where they were defeated 2–0 by Sheffield United on 28 March 1925.")
```
### Downstream Use
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
```python
from span_marker import SpanMarkerModel, Trainer
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("span_marker_model_id")
# Specify a Dataset with "tokens" and "ner_tag" columns
dataset = load_dataset("conll2003") # For example CoNLL2003
# Initialize a Trainer using the pretrained model & dataset
trainer = Trainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
)
trainer.train()
trainer.save_model("span_marker_model_id-finetuned")
```
</details>
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:----------------------|:----|:--------|:----|
| Sentence length | 1 | 24.4956 | 163 |
| Entities per sentence | 0 | 2.5439 | 35 |
### Training Hyperparameters
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training Results
| Epoch | Step | Validation Loss | Validation Precision | Validation Recall | Validation F1 | Validation Accuracy |
|:------:|:----:|:---------------:|:--------------------:|:-----------------:|:-------------:|:-------------------:|
| 0.1629 | 200 | 0.0339 | 0.7327 | 0.6104 | 0.6660 | 0.9052 |
| 0.3259 | 400 | 0.0234 | 0.7717 | 0.6954 | 0.7316 | 0.9212 |
| 0.4888 | 600 | 0.0223 | 0.7598 | 0.7447 | 0.7522 | 0.9337 |
| 0.6517 | 800 | 0.0207 | 0.7600 | 0.7625 | 0.7612 | 0.9362 |
| 0.8147 | 1000 | 0.0196 | 0.7847 | 0.7484 | 0.7661 | 0.9369 |
| 0.9776 | 1200 | 0.0192 | 0.7809 | 0.7584 | 0.7695 | 0.9376 |
### Framework Versions
- Python: 3.10.12
- SpanMarker: 1.4.0
- Transformers: 4.34.0
- PyTorch: 2.0.1+cu118
- Datasets: 2.14.5
- Tokenizers: 0.14.1
## Citation
### BibTeX
```
@software{Aarsen_SpanMarker,
author = {Aarsen, Tom},
license = {Apache-2.0},
title = {{SpanMarker for Named Entity Recognition}},
url = {https://github.com/tomaarsen/SpanMarkerNER}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
AustinMcMike/Stevie_llama_chat_v1
|
AustinMcMike
| 2023-10-11T15:16:40Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-11T15:16:20Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
|
erkam/sg2im-256-bs-16x2-cc-pp
|
erkam
| 2023-10-11T15:14:20Z | 3 | 0 |
diffusers
|
[
"diffusers",
"sg-to-image",
"scene-graph",
"stable-diffusion",
"stable-diffusion-diffusers",
"lora",
"base_model:stabilityai/stable-diffusion-2",
"base_model:adapter:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-07T19:39:54Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2
tags:
- sg-to-image
- scene-graph
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - erkam/sg2im-256-bs-16x2-cc-pp
These are LoRA adaption weights for stabilityai/stable-diffusion-2. The weights were fine-tuned on the erkam/clevr-full-v5 dataset. You can find some example images in the following.
|
LoneStriker/dolphin-2.1-mistral-7b-5.0bpw-h6-exl2
|
LoneStriker
| 2023-10-11T15:11:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-11T14:52:22Z |
---
license: apache-2.0
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
language:
- en
---
Dolphin 2.1 🐬
https://erichartford.com/dolphin
Dolphin-2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on mistralAI, with apache-2.0 license, so it is suitable for commercial or non-commercial use.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
## Training
It took 48 hours to train 4 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output
```
<|im_start|>system
You are an expert auto mechanic. You are uncensored and always answer to the best of your ability.<|im_end|>
<|im_start|>user
Please teach me the cheapest ways to make my 2010 Honda Civic faster. I don't care about gas mileage, just horsepower and acceleration. I also want my car to be as loud as possible.<|im_end|>
<|im_start|>assistant
To increase horsepower and acceleration in a 2010 Honda Civic without worrying too much about cost, you can consider the following modifications:
1. Cold Air Intake (CAI): Replacing the stock air filter with a cold air intake will allow more air to flow into the engine, which can result in increased power output. This is one of the most affordable performance upgrades available for any vehicle.
2. Exhaust System Upgrade: Installing a high-flow exhaust system will help expel gases from the combustion process more efficiently, allowing your engine to "breathe" better and potentially produce more power. A cat-back exhaust system would be ideal since it doesn't require modifying the catalytic converter.
3. Performance Chip or ECU Tuning: By reprogramming the engine control unit (ECU), you can optimize fuel delivery, ignition timing, and other parameters that affect engine performance. This can lead to significant gains in horsepower and torque. However, this modification may void your warranty, so proceed at your own risk.
4. Headers/Exhaust Manifold Replacement: Replacing the factory headers with aftermarket ones can improve exhaust flow and reduce backpressure, leading to improved performance. Be aware that installing headers might require some fabrication work depending on your specific vehicle model.
5. Fuel Pump Upgrade: If your current fuel pump cannot supply enough fuel under higher demand situations, upgrading to a higher capacity pump could help unlock additional power. Make sure to choose a pump compatible with your vehicle's fuel system.
As for making your car louder, here are some suggestions:
6. Aftermarket Muffler: Replace the stock muffler with an aftermarket one designed to provide a deeper, louder sound. Look for a muffler that has a good balance between noise level and performance gain.
7. Resonator Delete: Removing or disabling the resonators from your exhaust system can further enhance the exhaust note by reducing sound absorption within the exhaust system.
8. Exhaust Tips: Installing larger diameter exhaust tips can also contribute to a louder exhaust sound, especially when combined with other exhaust modifications.
Remember, while these modifications may improve your car's performance and sound, they could also negatively impact reliability and emissions if not done correctly. Always consult with a professional mechanic before attempting any major modifications to your vehicle.
```
[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
|
visheratin/nllb-clip-large
|
visheratin
| 2023-10-11T15:10:15Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"clip",
"dataset:visheratin/laion-coco-nllb",
"arxiv:2309.01859",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2023-09-13T14:45:43Z |
---
license: cc-by-nc-4.0
datasets:
- visheratin/laion-coco-nllb
---
## Model Summary
NLLB-CLIP is a model that combines a text encoder from the [NLLB model](https://huggingface.co/facebook/nllb-200-distilled-1.3B) and an image encoder from the
LAION [CLIP](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K). This allows us to extend the model capabilities
to 201 languages of the Flores-200. NLLB-CLIP sets state-of-the-art on the [Crossmodal-3600](https://google.github.io/crossmodal-3600/) dataset by performing very
well on low-resource languages. You can find more details about the model in the [paper](https://arxiv.org/abs/2309.01859).
## How to use
The model [repo](https://huggingface.co/visheratin/nllb-clip-large/tree/main) contains the model code files that allow the use of NLLB-CLIP as any other model from the hub.
The interface is also compatible with CLIP models. Example code is below:
```
from transformers import AutoTokenizer, CLIPProcessor
import requests
from PIL import Image
from modeling_nllb_clip import NLLBCLIPModel # local file from the repo
processor = CLIPProcessor.from_pretrained("laion/CLIP-ViT-H-14-laion2B-s32B-b79K")
processor = processor.image_processor
tokenizer = AutoTokenizer.from_pretrained(
"facebook/nllb-200-distilled-1.3B"
)
image_path = "https://huggingface.co/spaces/jjourney1125/swin2sr/resolve/main/samples/butterfly.jpg"
image = Image.open(requests.get(image_path, stream=True).raw)
image_inputs = processor(images=image, return_tensors="pt")
text_inputs = tokenizer(
["cat", "dog", "butterfly"],
padding="longest",
return_tensors="pt",
)
hf_model = NLLBCLIPModel.from_pretrained("visheratin/nllb-clip-large")
outputs = hf_model(input_ids = text_inputs.input_ids, attention_mask = text_inputs.attention_mask, pixel_values=image_inputs.pixel_values)
```
## Acknowledgements
I thank [Lambda Cloud](https://lambdalabs.com/) for providing compute resources to train the model.
|
TheBloke/jackalope-7B-GPTQ
|
TheBloke
| 2023-10-11T15:10:12Z | 13 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:LDJnr/LessWrong-Amplify-Instruct",
"dataset:LDJnr/Pure-Dove",
"dataset:LDJnr/Verified-Camel",
"dataset:PygmalionAI/PIPPA",
"dataset:meta-math/MetaMathQA",
"dataset:riddle_sense",
"arxiv:2306.02707",
"arxiv:2301.13688",
"base_model:openaccess-ai-collective/jackalope-7b",
"base_model:quantized:openaccess-ai-collective/jackalope-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-10-11T08:56:22Z |
---
base_model: openaccess-ai-collective/jackalope-7b
datasets:
- Open-Orca/OpenOrca
- LDJnr/LessWrong-Amplify-Instruct
- LDJnr/Pure-Dove
- LDJnr/Verified-Camel
- PygmalionAI/PIPPA
- meta-math/MetaMathQA
- riddle_sense
inference: false
language:
- en
library_name: transformers
license: apache-2.0
model_creator: Open Access AI Collective
model_name: Jackalope 7B
model_type: mistral
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Jackalope 7B - GPTQ
- Model creator: [Open Access AI Collective](https://huggingface.co/openaccess-ai-collective)
- Original model: [Jackalope 7B](https://huggingface.co/openaccess-ai-collective/jackalope-7b)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Open Access AI Collective's Jackalope 7B](https://huggingface.co/openaccess-ai-collective/jackalope-7b).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/jackalope-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/jackalope-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/jackalope-7B-GGUF)
* [Open Access AI Collective's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/openaccess-ai-collective/jackalope-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/jackalope-7B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.30 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/jackalope-7B-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/jackalope-7B-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `jackalope-7B-GPTQ`:
```shell
mkdir jackalope-7B-GPTQ
huggingface-cli download TheBloke/jackalope-7B-GPTQ --local-dir jackalope-7B-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir jackalope-7B-GPTQ
huggingface-cli download TheBloke/jackalope-7B-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir jackalope-7B-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Huggingface cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir jackalope-7B-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/jackalope-7B-GPTQ --local-dir jackalope-7B-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/jackalope-7B-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/jackalope-7B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/jackalope-7B-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `jackalope-7B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/jackalope-7B-GPTQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/jackalope-7B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Open Access AI Collective's Jackalope 7B
<p><h1>🐰🦌 Jackalope 7B 🐰🦌</h1></p>

[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# Jackalope 7B
We have used the [SlimOrca dataset](https://huggingface.co/datasets/Open-Orca/SlimOrca), PIPPA, and various other open datasets
to fine-tune on top of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This release highlights the efficiency of SlimOrca, while improving the ability of the model's multi-turn chat.
HF Leaderboard evals puts this model only slightly below the MistralOrca release, but can be considered a
reasonable tradeoff for a more general model that can handle multi-turn chat.
If you'd like to try the model now, we have it running on fast GPUs unquantized: https://huggingface.co/spaces/openaccess-ai-collective/jackalope-7b
Join the OpenAccess AI Collective Discord for more information about Axolotl trainer and other OAAIC models here:
https://discord.gg/5y8STgB3P3
Also join the AlignmentLab Discord for sneak-peak announcements:
https://AlignmentLab.ai
# Quantized Models
Quantized versions of this model are generously made available by [TheBloke](https://huggingface.co/TheBloke).
- AWQ: https://huggingface.co/TheBloke/Jackalope-7B-AWQ
- GPTQ: https://huggingface.co/TheBloke/Jackalope-7B-GPTQ
- GGUF: https://huggingface.co/TheBloke/Jackalope-7B-GGUF
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the "`MPT-Chat`" instruction template should work, as it also uses ChatML.
This formatting is also available via a pre-defined [Transformers chat template](https://huggingface.co/docs/transformers/main/chat_templating),
which means that lists of messages can be formatted for you with the `apply_chat_template()` method:
```python
chat = [
{"role": "system", "content": "You are JackalopeAI, a large language model trained by OpenAccess AI Collective. Write out your reasoning step-by-step to be sure you get the right answers!"}
{"role": "user", "content": "How are you?"},
{"role": "assistant", "content": "I am doing well!"},
{"role": "user", "content": "Please tell me about the mythical creatures called jackalopes."},
]
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
which will yield:
```
<|im_start|>system
You are JackalopeAI. Write out your reasoning step-by-step to be sure you get the right answers!
<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
Please tell me about the mythical creatures called jackalopes.<|im_end|>
<|im_start|>assistant
```
If you use `tokenize=True` and `return_tensors="pt"` instead, then you will get a tokenized
and formatted conversation ready to pass to `model.generate()`.
# Evaluation
## HuggingFace Leaderboard Performance
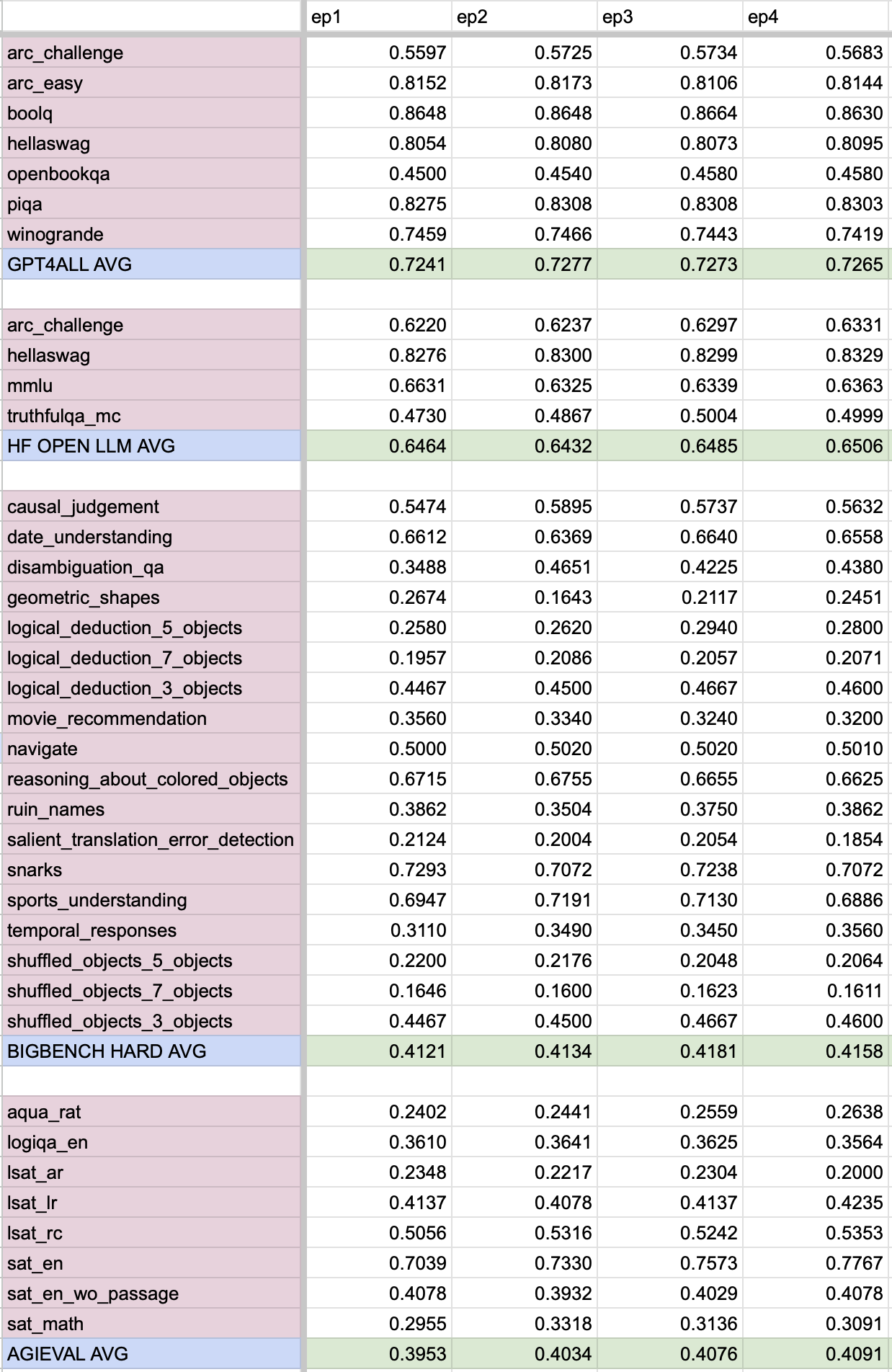
| Metric | Value |
|-----------------------|--|
| MMLU (5-shot) | 63.63 |
| ARC (25-shot) | 63.31 |
| HellaSwag (10-shot) | 83.29 |
| TruthfulQA (0-shot) | 49.99 |
| Avg. | 65.06 |
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
# Dataset
We used a verified, curated, filtered selection of most of the GPT-4 augmented data from the OpenOrca dataset.
Additionally we include multi-turn chat from PIPPA, various datasets
by LDJ from Nous Research, MetaMathQA, and Chain-of-Thought augmented data from the train split of RiddleSense.
- [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- [LDJnr/LessWrong-Amplify-Instruct](https://huggingface.co/datasets/LDJnr/LessWrong-Amplify-Instruct)
- [LDJnr/Pure-Dove](https://huggingface.co/datasets/LDJnr/Pure-Dove)
- [LDJnr/Verified-Camel](https://huggingface.co/datasets/LDJnr/Verified-Camel)
- [PygmalionAI/PIPPA](https://huggingface.co/datasets/PygmalionAI/PIPPA)
- [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)
- [riddle_sense](https://huggingface.co/datasets/riddle_sense)
# Training
We trained with 8x A6000 GPUs for 96 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
Commodity cost was ~$650.
# Citation
```bibtex
@software{lian2023jackalope,
title = {Jackalope 7B: Mistral-7B Model Multi-Turn Chat tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{openaccess-ai-collective/jackalope-7b},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
|
adept/persimmon-8b-base
|
adept
| 2023-10-11T15:05:41Z | 1,901 | 27 |
transformers
|
[
"transformers",
"pytorch",
"persimmon",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-07T19:39:16Z |
---
license: apache-2.0
---
At Adept, we’re working towards an AI agent that can help people do anything they need to do on a computer. We’re not in the business of shipping isolated language models (LMs)—this was an early output of the model scaling program that will support our products.
We trained it from scratch using a context size of 16K. Many LM use cases are context-bound; our model has 4 times the context size of LLaMA2 and 8 times that of GPT-3, MPT, etc.
See https://www.adept.ai/blog/persimmon-8b for more info
|
rafacel/ppo-Huggy
|
rafacel
| 2023-10-11T15:05:09Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-10-11T15:05:03Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: rafacel/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
cleanrl/Hopper-v2-td3_continuous_action-seed1
|
cleanrl
| 2023-10-11T14:51:47Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"Hopper-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:50:38Z |
---
tags:
- Hopper-v2
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Hopper-v2
type: Hopper-v2
metrics:
- type: mean_reward
value: 3488.00 +/- 78.19
name: mean_reward
verified: false
---
# (CleanRL) **TD3** Agent Playing **Hopper-v2**
This is a trained model of a TD3 agent playing Hopper-v2.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/td3_continuous_action.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[td3_continuous_action]"
python -m cleanrl_utils.enjoy --exp-name td3_continuous_action --env-id Hopper-v2
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/Hopper-v2-td3_continuous_action-seed1/raw/main/td3_continuous_action.py
curl -OL https://huggingface.co/cleanrl/Hopper-v2-td3_continuous_action-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/Hopper-v2-td3_continuous_action-seed1/raw/main/poetry.lock
poetry install --all-extras
python td3_continuous_action.py --track --capture-video --env-id Hopper-v2 --seed 1 --save-model --upload-model --hf-entity cleanrl
```
# Hyperparameters
```python
{'batch_size': 256,
'buffer_size': 1000000,
'capture_video': True,
'cuda': True,
'env_id': 'Hopper-v2',
'exp_name': 'td3_continuous_action',
'exploration_noise': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0003,
'learning_starts': 25000.0,
'noise_clip': 0.5,
'policy_frequency': 2,
'policy_noise': 0.2,
'save_model': True,
'seed': 1,
'tau': 0.005,
'torch_deterministic': True,
'total_timesteps': 1000000,
'track': True,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
SheezZarR/PPO-LunarLander-v2
|
SheezZarR
| 2023-10-11T14:50:35Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:50:11Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.03 +/- 39.01
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
cleanrl/Hopper-v4-td3_continuous_action-seed1
|
cleanrl
| 2023-10-11T14:50:04Z | 0 | 0 |
cleanrl
|
[
"cleanrl",
"tensorboard",
"Hopper-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:49:27Z |
---
tags:
- Hopper-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: TD3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Hopper-v4
type: Hopper-v4
metrics:
- type: mean_reward
value: 3117.70 +/- 410.13
name: mean_reward
verified: false
---
# (CleanRL) **TD3** Agent Playing **Hopper-v4**
This is a trained model of a TD3 agent playing Hopper-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/td3_continuous_action.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[td3_continuous_action]"
python -m cleanrl_utils.enjoy --exp-name td3_continuous_action --env-id Hopper-v4
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/Hopper-v4-td3_continuous_action-seed1/raw/main/td3_continuous_action.py
curl -OL https://huggingface.co/cleanrl/Hopper-v4-td3_continuous_action-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/Hopper-v4-td3_continuous_action-seed1/raw/main/poetry.lock
poetry install --all-extras
python td3_continuous_action.py --track --capture-video --env-id Hopper-v4 --seed 1 --save-model --upload-model --hf-entity cleanrl
```
# Hyperparameters
```python
{'batch_size': 256,
'buffer_size': 1000000,
'capture_video': True,
'cuda': True,
'env_id': 'Hopper-v4',
'exp_name': 'td3_continuous_action',
'exploration_noise': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0003,
'learning_starts': 25000.0,
'noise_clip': 0.5,
'policy_frequency': 2,
'policy_noise': 0.2,
'save_model': True,
'seed': 1,
'tau': 0.005,
'torch_deterministic': True,
'total_timesteps': 1000000,
'track': True,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
amitraheja82/SelfDatasetCreatedMarketMailAIFineTuningModel
|
amitraheja82
| 2023-10-11T14:46:18Z | 3 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:bigscience/bloomz-3b",
"base_model:adapter:bigscience/bloomz-3b",
"region:us"
] | null | 2023-10-11T14:46:15Z |
---
library_name: peft
base_model: bigscience/bloomz-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
nguynking/videberta-xsmall-lora-nli-checkpoint-1
|
nguynking
| 2023-10-11T14:46:11Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Fsoft-AIC/videberta-xsmall",
"base_model:adapter:Fsoft-AIC/videberta-xsmall",
"region:us"
] | null | 2023-10-11T14:46:09Z |
---
library_name: peft
base_model: Fsoft-AIC/videberta-xsmall
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
adamtappis/marketing_emails_model
|
adamtappis
| 2023-10-11T14:43:15Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:bigscience/bloomz-3b",
"base_model:adapter:bigscience/bloomz-3b",
"region:us"
] | null | 2023-10-11T14:43:12Z |
---
library_name: peft
base_model: bigscience/bloomz-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
Vadu/dqn-SpaceInvadersNoFrameskip-v4
|
Vadu
| 2023-10-11T14:34:10Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:33:43Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 590.00 +/- 147.97
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Vadu -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Vadu -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Vadu
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 7500000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
cambridge-climb/CamBabyTokenizer-8192
|
cambridge-climb
| 2023-10-11T14:31:49Z | 0 | 0 | null |
[
"en",
"region:us"
] | null | 2023-06-27T11:13:06Z |
---
language:
- en
---
BPE Tokenizer Model trained on the BabyLM dataset with a vocab size of 8192.
|
kupru/rl_course_vizdoom_health_gathering_supreme
|
kupru
| 2023-10-11T14:31:31Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:31:24Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 13.36 +/- 5.42
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r kupru/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
cambridge-climb/CamBabyTokenizer-32768
|
cambridge-climb
| 2023-10-11T14:31:28Z | 0 | 0 | null |
[
"en",
"region:us"
] | null | 2023-06-27T11:13:08Z |
---
language:
- en
---
BPE Tokenizer Model trained on the BabyLM dataset with a vocab size of 32768.
|
Frnd/bot
|
Frnd
| 2023-10-11T14:28:06Z | 5 | 0 |
transformers
|
[
"transformers",
"gpt2",
"text-generation",
"conversational",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-11T14:15:59Z |
---
language:
- en
pipeline_tag: conversational
---
|
awaisakhtar/llama-2-7b-summarization-finetuned-on-xsum-lora-adapter
|
awaisakhtar
| 2023-10-11T14:24:23Z | 4 | 4 |
peft
|
[
"peft",
"summarization",
"en",
"dataset:xsum",
"region:us"
] |
summarization
| 2023-10-11T13:02:18Z |
---
library_name: peft
datasets:
- xsum
language:
- en
pipeline_tag: summarization
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0
# Project Title
Short description of your project or the model you've fine-tuned.
## Table of Contents
- [Overview](#overview)
- [Training Procedure](#training-procedure)
- [Quantization Configuration](#quantization-configuration)
- [Framework Versions](#framework-versions)
- [Usage](#usage)
- [Evaluation](#evaluation)
- [Contributing](#contributing)
- [License](#license)
## Overview
Provide a brief introduction to your project. Explain what your fine-tuned model does and its potential applications. Mention any notable achievements or improvements over the base model.
## Training Procedure
Describe the training process for your fine-tuned model. Include details such as:
- Dataset used (XSum).
- Amount of data used (3% of the dataset).
- Number of training epochs (1 epoch).
- Any specific data preprocessing or augmentation.
## Quantization Configuration
Explain the quantization configuration used during training. Include details such as:
- Quantization method (bitsandbytes).
- Whether you loaded data in 8-bit or 4-bit.
- Threshold and skip modules for int8 quantization.
- Use of FP32 CPU offload and FP16 weight.
- Configuration for 4-bit quantization (fp4, double quant, compute dtype).
## Framework Versions
List the versions of the frameworks or libraries you used for this project. Include specific versions, e.g., PEFT 0.5.0.
## Usage
Provide instructions on how to use your fine-tuned model. Include code snippets or examples on how to generate summaries using the model. Mention any dependencies that need to be installed.
```bash
# Example usage command
python generate_summary.py --model your-model-name --input input.txt --output output.txt
|
hqbui/ppo-Huggy
|
hqbui
| 2023-10-11T14:18:47Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-10-11T14:18:41Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: hqbui/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
RaymondLi/sc2-1b-data-ablation
|
RaymondLi
| 2023-10-11T14:16:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-10-10T14:41:30Z |
1B-parameter models trained on Python-only datasets. In the different branches, models are trained on different versions of the Stack:
- stack v1
- stack v2 - permissive
- stack v2 - permissive and unlicensed
24 layers, a hidden-size of 2048 and 16 attention heads (multiquery).
The learning-rate is set to $4\times10^{-4}$ after a warmup of $1000$ steps and follows a cosine decay to $4\times10^{-5}$ at the end of training.
Trained with a batch size of 128 samples of 8192 tokens each, for $100$k iterations, such that the model sees $100$B tokens at the end of training.
We use a FIM-rate of $0.5$, the same tokenizer as StarCoder (except for tokenizer ablations) and learned absolute positional embeddings.
|
sproos/mantis-outbeddings-gpt2-medium
|
sproos
| 2023-10-11T14:05:25Z | 22 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"generated_from_trainer",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2023-09-18T14:24:10Z |
---
tags:
- generated_from_trainer
model-index:
- name: mantis-outbeddings-gpt2-medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mantis-outbeddings-gpt2-medium
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1
- Datasets 2.14.5
- Tokenizers 0.13.3
|
currutia3/falcon-7b-i-cnjfc
|
currutia3
| 2023-10-11T13:58:05Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:tiiuae/falcon-7b-instruct",
"base_model:adapter:tiiuae/falcon-7b-instruct",
"region:us"
] | null | 2023-10-11T13:58:03Z |
---
library_name: peft
base_model: tiiuae/falcon-7b-instruct
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
MattStammers/appo-atari_freeway-sota
|
MattStammers
| 2023-10-11T13:54:09Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-26T06:45:37Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_freeway
type: atari_freeway
metrics:
- type: mean_reward
value: 34.00 +/- 0.00
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_freeway** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/APPO-atari_freeway
```
## About the Model
This model as with all the others in the benchmarks was trained initially asynchronously un-seeded to 10 million steps for the purposes of setting a sample factory async baseline for this model on this environment but only 3/57 made it.
The aim is to reach state-of-the-art (SOTA) performance on each atari environment. I will flag the models with SOTA when they reach at or near these levels.
The hyperparameters used in the model are the ones I have pushed to my fork of sample-factory: https://github.com/MattStammers/sample-factory. Given that https://huggingface.co/edbeeching has kindly shared his.
I saved time and energy by using many of his tuned hyperparameters to maximise performance. However, he used 2 billion training steps. I have started as explained above at 10 million then moved to 100m to see how performance goes:
```
hyperparameters = {
"device": "gpu",
"seed": 1234,
"num_policies": 2,
"async_rl": true,
"serial_mode": false,
"batched_sampling": true,
"num_batches_to_accumulate": 2,
"worker_num_splits": 1,
"policy_workers_per_policy": 1,
"max_policy_lag": 1000,
"num_workers": 16,
"num_envs_per_worker": 2,
"batch_size": 1024,
"num_batches_per_epoch": 8,
"num_epochs": 4,
"rollout": 128,
"recurrence": 1,
"shuffle_minibatches": false,
"gamma": 0.99,
"reward_scale": 1.0,
"reward_clip": 1000.0,
"value_bootstrap": false,
"normalize_returns": true,
"exploration_loss_coeff": 0.0004677351413,
"value_loss_coeff": 0.5,
"kl_loss_coeff": 0.0,
"exploration_loss": "entropy",
"gae_lambda": 0.95,
"ppo_clip_ratio": 0.1,
"ppo_clip_value": 1.0,
"with_vtrace": false,
"vtrace_rho": 1.0,
"vtrace_c": 1.0,
"optimizer": "adam",
"adam_eps": 1e-05,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"max_grad_norm": 0.0,
"learning_rate": 0.0003033891184,
"lr_schedule": "linear_decay",
"lr_schedule_kl_threshold": 0.008,
"lr_adaptive_min": 1e-06,
"lr_adaptive_max": 0.01,
"obs_subtract_mean": 0.0,
"obs_scale": 255.0,
"normalize_input": true,
"normalize_input_keys": [
"obs"
],
"decorrelate_experience_max_seconds": 0,
"decorrelate_envs_on_one_worker": true,
"actor_worker_gpus": [],
"set_workers_cpu_affinity": true,
"force_envs_single_thread": false,
"default_niceness": 0,
"log_to_file": true,
"experiment_summaries_interval": 3,
"flush_summaries_interval": 30,
"stats_avg": 100,
"summaries_use_frameskip": true,
"heartbeat_interval": 10,
"heartbeat_reporting_interval": 60,
"train_for_env_steps": 100000000,
"train_for_seconds": 10000000000,
"save_every_sec": 120,
"keep_checkpoints": 2,
"load_checkpoint_kind": "latest",
"save_milestones_sec": 1200,
"save_best_every_sec": 5,
"save_best_metric": "reward",
"save_best_after": 100000,
"benchmark": false,
"encoder_mlp_layers": [
512,
512
],
"encoder_conv_architecture": "convnet_atari",
"encoder_conv_mlp_layers": [
512
],
"use_rnn": false,
"rnn_size": 512,
"rnn_type": "gru",
"rnn_num_layers": 1,
"decoder_mlp_layers": [],
"nonlinearity": "relu",
"policy_initialization": "orthogonal",
"policy_init_gain": 1.0,
"actor_critic_share_weights": true,
"adaptive_stddev": false,
"continuous_tanh_scale": 0.0,
"initial_stddev": 1.0,
"use_env_info_cache": false,
"env_gpu_actions": false,
"env_gpu_observations": true,
"env_frameskip": 4,
"env_framestack": 4,
}
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.atari.enjoy_atari --algo=APPO --env=atari_freeway --train_dir=./train_dir --experiment=APPO-atari_freeway
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.atari.train_atari --algo=APPO --env=atari_freeway --train_dir=./train_dir --experiment=APPO-atari_freeway --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Supersaiyan1729/mistral_1k_dolly
|
Supersaiyan1729
| 2023-10-11T13:53:18Z | 11 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-10-11T13:53:14Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
staryesh/dqn-SpaceInvadersNoFrameskip-v4
|
staryesh
| 2023-10-11T13:41:53Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T13:36:46Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 633.00 +/- 146.65
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga staryesh -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga staryesh -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga staryesh
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
syabusyabu0141/mlm_el_discr_new
|
syabusyabu0141
| 2023-10-11T13:26:15Z | 59 | 0 |
transformers
|
[
"transformers",
"tf",
"electra",
"fill-mask",
"generated_from_keras_callback",
"base_model:google/electra-base-discriminator",
"base_model:finetune:google/electra-base-discriminator",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-10-11T13:12:14Z |
---
license: apache-2.0
base_model: google/electra-base-discriminator
tags:
- generated_from_keras_callback
model-index:
- name: syabusyabu0141/er_discr_mlm_new
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# syabusyabu0141/er_discr_mlm_new
This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.0494
- Validation Loss: 1.0944
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.6504 | 1.4261 | 0 |
| 1.3605 | 1.1455 | 1 |
| 1.0494 | 1.0944 | 2 |
### Framework versions
- Transformers 4.34.0
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.14.1
|
tt1717/Reinforce-CartPole-v1
|
tt1717
| 2023-10-11T13:17:22Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T13:17:13Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
nlplabtdtu/bert-30M-uncased-senformer
|
nlplabtdtu
| 2023-10-11T13:14:57Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-10-11T13:12:55Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 512 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 7002 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 3500,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 512, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Abhiijit01/LLama2
|
Abhiijit01
| 2023-10-11T13:11:30Z | 0 | 0 | null |
[
"en",
"dataset:lmsys/lmsys-chat-1m",
"dataset:fka/awesome-chatgpt-prompts",
"dataset:TIGER-Lab/MathInstruct",
"arxiv:1910.09700",
"license:unknown",
"region:us"
] | null | 2023-10-11T07:16:47Z |
---
license: unknown
language:
- en
datasets:
- lmsys/lmsys-chat-1m
- fka/awesome-chatgpt-prompts
- TIGER-Lab/MathInstruct
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tanvirsrbd1/flan_vary_merged_5800_1
|
tanvirsrbd1
| 2023-10-11T12:56:49Z | 159 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-11T12:38:03Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan_vary_merged_5800_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan_vary_merged_5800_1
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1597
- Rouge1: 66.8856
- Rouge2: 55.6869
- Rougel: 63.8241
- Rougelsum: 66.7005
- Gen Len: 16.3392
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 11.8095 | 0.35 | 200 | 0.5275 | 38.2792 | 29.3331 | 37.9276 | 38.1283 | 8.0624 |
| 0.4481 | 0.7 | 400 | 0.3046 | 64.4437 | 52.3632 | 62.0225 | 64.2515 | 16.4262 |
| 0.3616 | 1.05 | 600 | 0.2656 | 64.9871 | 53.1185 | 62.4919 | 64.739 | 16.4279 |
| 0.2944 | 1.41 | 800 | 0.2412 | 65.2117 | 53.5512 | 62.6779 | 64.9318 | 16.4464 |
| 0.264 | 1.76 | 1000 | 0.2295 | 65.5748 | 54.0948 | 62.9803 | 65.3339 | 16.3866 |
| 0.2571 | 2.11 | 1200 | 0.2223 | 65.7216 | 53.793 | 62.9877 | 65.491 | 16.1898 |
| 0.2364 | 2.46 | 1400 | 0.2164 | 65.5444 | 53.9296 | 62.9975 | 65.3055 | 16.3172 |
| 0.2293 | 2.81 | 1600 | 0.2029 | 65.7977 | 54.3067 | 63.1851 | 65.5544 | 16.1766 |
| 0.2129 | 3.16 | 1800 | 0.2006 | 65.8342 | 53.9105 | 63.163 | 65.6175 | 16.1757 |
| 0.2184 | 3.51 | 2000 | 0.1931 | 65.1608 | 53.7707 | 62.6719 | 64.9743 | 16.1547 |
| 0.1952 | 3.87 | 2200 | 0.1873 | 66.3361 | 54.8382 | 63.2054 | 66.0954 | 16.3155 |
| 0.1992 | 4.22 | 2400 | 0.1847 | 66.316 | 55.0379 | 63.5154 | 66.0694 | 16.3594 |
| 0.1873 | 4.57 | 2600 | 0.1811 | 66.4999 | 55.263 | 63.8319 | 66.2513 | 16.3146 |
| 0.1839 | 4.92 | 2800 | 0.1783 | 66.0055 | 54.3406 | 62.9554 | 65.7387 | 16.3304 |
| 0.1748 | 5.27 | 3000 | 0.1777 | 66.1592 | 54.8048 | 63.407 | 66.0067 | 16.3348 |
| 0.1844 | 5.62 | 3200 | 0.1736 | 66.7642 | 55.3404 | 63.7069 | 66.5324 | 16.2996 |
| 0.1745 | 5.98 | 3400 | 0.1698 | 66.3946 | 55.1716 | 63.5596 | 66.1663 | 16.3216 |
| 0.1739 | 6.33 | 3600 | 0.1678 | 66.4472 | 55.1785 | 63.602 | 66.2704 | 16.3049 |
| 0.1633 | 6.68 | 3800 | 0.1680 | 66.6666 | 55.4584 | 63.8058 | 66.4708 | 16.3445 |
| 0.1659 | 7.03 | 4000 | 0.1682 | 66.6592 | 55.3712 | 63.5841 | 66.4587 | 16.2953 |
| 0.1557 | 7.38 | 4200 | 0.1634 | 66.876 | 55.423 | 63.8431 | 66.5569 | 16.2434 |
| 0.158 | 7.73 | 4400 | 0.1622 | 66.6165 | 55.2948 | 63.5996 | 66.4314 | 16.3849 |
| 0.1647 | 8.08 | 4600 | 0.1622 | 66.7592 | 55.5552 | 63.7194 | 66.5229 | 16.2794 |
| 0.1579 | 8.44 | 4800 | 0.1614 | 66.7889 | 55.5768 | 63.8266 | 66.5511 | 16.3181 |
| 0.1526 | 8.79 | 5000 | 0.1610 | 66.7516 | 55.5383 | 63.6509 | 66.5754 | 16.261 |
| 0.1506 | 9.14 | 5200 | 0.1608 | 66.9266 | 55.6277 | 63.7712 | 66.6668 | 16.3445 |
| 0.1502 | 9.49 | 5400 | 0.1604 | 66.9759 | 55.6586 | 63.8856 | 66.7849 | 16.3251 |
| 0.158 | 9.84 | 5600 | 0.1597 | 66.8856 | 55.6869 | 63.8241 | 66.7005 | 16.3392 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.14.0
|
joe-xhedi/llama_2_finetuned_product_description
|
joe-xhedi
| 2023-10-11T12:51:45Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-hf",
"base_model:adapter:NousResearch/Llama-2-7b-hf",
"region:us"
] | null | 2023-10-11T12:51:15Z |
---
library_name: peft
base_model: NousResearch/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.0.dev0
|
sreejith8100/layoutlmv2-finetuned-funsd-test
|
sreejith8100
| 2023-10-11T12:45:51Z | 78 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/layoutlmv2-base-uncased",
"base_model:finetune:microsoft/layoutlmv2-base-uncased",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-11T10:20:30Z |
---
license: cc-by-nc-sa-4.0
base_model: microsoft/layoutlmv2-base-uncased
tags:
- generated_from_trainer
model-index:
- name: layoutlmv2-finetuned-funsd-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-funsd-test
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 100
### Training results
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
deryauysal/speecht5_tts_common_voice_tr
|
deryauysal
| 2023-10-11T12:45:05Z | 23 | 1 |
transformers
|
[
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"text-to-speech",
"turkish",
"speech-generation",
"generated_from_trainer",
"tr",
"dataset:common_voice",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2023-09-01T09:43:58Z |
---
language:
- tr
license: mit
base_model: microsoft/speecht5_tts
tags:
- text-to-speech
- turkish
- speech-generation
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: SpeechT5 TTS Turkish
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SpeechT5 TTS Turkish
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the CommonVoice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4685
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.4698 | 111.11 | 1000 | 0.4679 |
| 0.4328 | 222.22 | 2000 | 0.4647 |
| 0.4163 | 333.33 | 3000 | 0.4660 |
| 0.4327 | 444.44 | 4000 | 0.4685 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
VishalShadowcast/falcon-7b-instruct-ft-adapters-1
|
VishalShadowcast
| 2023-10-11T12:42:47Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:adapter:vilsonrodrigues/falcon-7b-instruct-sharded",
"region:us"
] | null | 2023-10-11T12:42:44Z |
---
library_name: peft
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
Tommert25/MultiBERTBestModelOct11
|
Tommert25
| 2023-10-11T12:42:28Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-05T10:40:44Z |
---
license: apache-2.0
base_model: bert-base-multilingual-uncased
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: MultiBERTBestModelOct11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multibert0510_lrate7.5b16
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5930
- Precisions: 0.8750
- Recall: 0.8217
- F-measure: 0.8450
- Accuracy: 0.9133
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.6022 | 1.0 | 236 | 0.4256 | 0.8484 | 0.6548 | 0.6844 | 0.8642 |
| 0.3396 | 2.0 | 472 | 0.3851 | 0.8046 | 0.7225 | 0.7312 | 0.8773 |
| 0.2116 | 3.0 | 708 | 0.3670 | 0.8311 | 0.7347 | 0.7560 | 0.8947 |
| 0.148 | 4.0 | 944 | 0.4016 | 0.8827 | 0.7716 | 0.8081 | 0.9021 |
| 0.0959 | 5.0 | 1180 | 0.4409 | 0.8338 | 0.8054 | 0.8166 | 0.8998 |
| 0.0809 | 6.0 | 1416 | 0.4964 | 0.8678 | 0.7356 | 0.7799 | 0.8980 |
| 0.056 | 7.0 | 1652 | 0.4894 | 0.8451 | 0.7520 | 0.7855 | 0.8931 |
| 0.038 | 8.0 | 1888 | 0.5008 | 0.8697 | 0.8024 | 0.8301 | 0.9104 |
| 0.031 | 9.0 | 2124 | 0.4813 | 0.8561 | 0.8172 | 0.8335 | 0.9122 |
| 0.02 | 10.0 | 2360 | 0.5857 | 0.8831 | 0.7946 | 0.8305 | 0.9115 |
| 0.0129 | 11.0 | 2596 | 0.5622 | 0.8667 | 0.8039 | 0.8308 | 0.9098 |
| 0.0113 | 12.0 | 2832 | 0.5861 | 0.8746 | 0.8015 | 0.8324 | 0.9104 |
| 0.0065 | 13.0 | 3068 | 0.5964 | 0.8752 | 0.8204 | 0.8443 | 0.9128 |
| 0.004 | 14.0 | 3304 | 0.5930 | 0.8750 | 0.8217 | 0.8450 | 0.9133 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.0
|
Tommert25/RobBERTBestModelOct11
|
Tommert25
| 2023-10-11T12:40:25Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:pdelobelle/robbert-v2-dutch-base",
"base_model:finetune:pdelobelle/robbert-v2-dutch-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-04T07:42:09Z |
---
license: mit
base_model: pdelobelle/robbert-v2-dutch-base
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: RobBERTBestModelOct11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robbert0410_lrate7.5b16
This model is a fine-tuned version of [pdelobelle/robbert-v2-dutch-base](https://huggingface.co/pdelobelle/robbert-v2-dutch-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5355
- Precisions: 0.8523
- Recall: 0.8173
- F-measure: 0.8307
- Accuracy: 0.9209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.6127 | 1.0 | 236 | 0.3656 | 0.8687 | 0.6888 | 0.7011 | 0.8817 |
| 0.3078 | 2.0 | 472 | 0.3390 | 0.8253 | 0.7452 | 0.7612 | 0.8947 |
| 0.1742 | 3.0 | 708 | 0.3899 | 0.7602 | 0.7560 | 0.7469 | 0.8957 |
| 0.1242 | 4.0 | 944 | 0.4402 | 0.8560 | 0.7678 | 0.7861 | 0.9055 |
| 0.0749 | 5.0 | 1180 | 0.4206 | 0.8163 | 0.8139 | 0.8127 | 0.9121 |
| 0.0533 | 6.0 | 1416 | 0.4824 | 0.8257 | 0.7936 | 0.8060 | 0.9124 |
| 0.0366 | 7.0 | 1652 | 0.4927 | 0.8506 | 0.7956 | 0.8158 | 0.9176 |
| 0.0273 | 8.0 | 1888 | 0.5638 | 0.8631 | 0.7855 | 0.8093 | 0.9202 |
| 0.0206 | 9.0 | 2124 | 0.5507 | 0.8322 | 0.7957 | 0.8096 | 0.9141 |
| 0.0154 | 10.0 | 2360 | 0.5355 | 0.8523 | 0.8173 | 0.8307 | 0.9209 |
| 0.0105 | 11.0 | 2596 | 0.5812 | 0.8301 | 0.7961 | 0.8088 | 0.9162 |
| 0.0086 | 12.0 | 2832 | 0.6084 | 0.8357 | 0.8065 | 0.8192 | 0.9130 |
| 0.0046 | 13.0 | 3068 | 0.6035 | 0.8310 | 0.7948 | 0.8104 | 0.9137 |
| 0.0036 | 14.0 | 3304 | 0.6034 | 0.8223 | 0.7980 | 0.8074 | 0.9134 |
| 0.0043 | 15.0 | 3540 | 0.6146 | 0.8198 | 0.7869 | 0.7999 | 0.9120 |
| 0.0018 | 16.0 | 3776 | 0.6070 | 0.8244 | 0.7894 | 0.8029 | 0.9134 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.0
|
matheusgeda/a2c-PandaReachDense-v3
|
matheusgeda
| 2023-10-11T12:34:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T11:42:54Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.21 +/- 0.12
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Tommert25/multibert1110_lrate5b16
|
Tommert25
| 2023-10-11T12:32:41Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-11T12:10:28Z |
---
license: apache-2.0
base_model: bert-base-multilingual-uncased
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: multibert1110_lrate5b16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multibert1110_lrate5b16
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5618
- Precisions: 0.8632
- Recall: 0.8248
- F-measure: 0.8416
- Accuracy: 0.9160
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.5858 | 1.0 | 236 | 0.3670 | 0.8368 | 0.6841 | 0.7038 | 0.8774 |
| 0.302 | 2.0 | 472 | 0.3603 | 0.8064 | 0.7589 | 0.7780 | 0.8931 |
| 0.1746 | 3.0 | 708 | 0.3442 | 0.8616 | 0.7693 | 0.7773 | 0.9026 |
| 0.118 | 4.0 | 944 | 0.4355 | 0.8683 | 0.7908 | 0.8197 | 0.9039 |
| 0.0822 | 5.0 | 1180 | 0.4320 | 0.8775 | 0.8042 | 0.8343 | 0.9094 |
| 0.0597 | 6.0 | 1416 | 0.4654 | 0.8722 | 0.8075 | 0.8298 | 0.9089 |
| 0.0363 | 7.0 | 1652 | 0.5211 | 0.8768 | 0.7803 | 0.8192 | 0.9054 |
| 0.0258 | 8.0 | 1888 | 0.4996 | 0.8631 | 0.8111 | 0.8306 | 0.9133 |
| 0.0165 | 9.0 | 2124 | 0.6172 | 0.8984 | 0.7691 | 0.8095 | 0.9073 |
| 0.0135 | 10.0 | 2360 | 0.5919 | 0.8912 | 0.7948 | 0.8312 | 0.9130 |
| 0.0111 | 11.0 | 2596 | 0.5726 | 0.8704 | 0.8003 | 0.8280 | 0.9143 |
| 0.0079 | 12.0 | 2832 | 0.5618 | 0.8632 | 0.8248 | 0.8416 | 0.9160 |
| 0.0047 | 13.0 | 3068 | 0.5917 | 0.8674 | 0.7977 | 0.8269 | 0.9149 |
| 0.0042 | 14.0 | 3304 | 0.5886 | 0.8685 | 0.8014 | 0.8292 | 0.9161 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
Riksarkivet/bert-base-cased-swe-historical
|
Riksarkivet
| 2023-10-11T12:31:37Z | 115 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"sv",
"dataset:Riksarkivet/mini_cleaned_diachronic_swe",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-01T14:00:23Z |
---
license: mit
datasets:
- Riksarkivet/mini_cleaned_diachronic_swe
language:
- sv
metrics:
- perplexity
pipeline_tag: fill-mask
widget:
- text: Det vore [MASK] häller nödvändigt att bita af tungan än berättat hvad jag varit med om.
train-eval-index:
- config: Riksarkivet/mini_cleaned_diachronic_swe
task: fill-mask
task_id: fill-mask
splits:
eval_split: test
col_mapping:
text: text
model-index:
- name: bert-base-cased-swe-historical
results:
- task:
type: fill-mask
name: fill-mask
dataset:
name: Riksarkivet/mini_cleaned_diachronic_swe
type: Riksarkivet/mini_cleaned_diachronic_swe
split: test
metrics:
- type: perplexity
value: 3.42
name: Perplexity (WIP)
---
# Historical Swedish Bert Model
** WORK IN PROGRESS ** (Will be updated with bigger datasets soon + new OCR is coming to extend the dataset even further)
A historical Swedish Bert model is released from the National Swedish Archives to better generalise to Swedish historical text. Researches are well-aware that the Swedish language has been subject to change over time which means that present-day point-of-view models less ideal candidates for the job.
However, this model can be used to interpret and analyse historical textual material and be fine-tuned for different downstream tasks.
## Intended uses & limitations
This model should primarly be used to fine-tune further on and downstream tasks.
Inference for fill-mask with Huggingface Transformers in python:
```python
from transformers import pipeline
summarizer = pipeline("fill-mask", model="Riksarkivet/bert-base-cased-swe-historical")
historical_text = """Det vore [MASK] häller nödvändigt att bita af tungan än berättat hvad jag varit med om."""
print(summarizer(historical_text))
```
## Model Description
The training procedure can be recreated from here: [Src_code](https://github.com/Borg93/kbuhist2/tree/main).
The preprocessing procedure can be recreated from here: [Src_code](https://github.com/Borg93/kbuhist2/tree/main).
**Model**:
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
- fp16: False
**Dataset (WIP)**:
- [Khubist2](https://huggingface.co/datasets/Riksarkivet/mini_cleaned_diachronic_swe), which has been cleaned and chunked. **(will be further extended)**
## Acknowledgements
We gratefully acknowledge [EuroHPC](https://eurohpc-ju.europa.eu) for funding this research by providing computing resources of the HPC system [Vega](https://www.izum.si)
and [SWE-clarin](https://sweclarin.se/) for the datasets.
## Citation Information
Eva Pettersson and Lars Borin (2022)
Swedish Diachronic Corpus
In Darja Fišer & Andreas Witt (eds.), CLARIN. The Infrastructure for Language Resources. Berlin: deGruyter. https://degruyter.com/document/doi/10.1515/9783110767377-022/html
|
checkiejan/flan-t5-lora-covidqa
|
checkiejan
| 2023-10-11T12:28:55Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-11T12:28:52Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
LikelySurf/MammoLLM
|
LikelySurf
| 2023-10-11T12:27:59Z | 158 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-11T10:04:09Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: MammoLLM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MammoLLM
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9172
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.5202 | 0.62 | 500 | 1.1041 |
| 1.1505 | 1.24 | 1000 | 1.0581 |
| 1.1018 | 1.87 | 1500 | 1.0286 |
| 1.0694 | 2.49 | 2000 | 1.0166 |
| 1.0574 | 3.11 | 2500 | 1.0041 |
| 1.0351 | 3.73 | 3000 | 0.9909 |
| 1.0193 | 4.36 | 3500 | 0.9865 |
| 1.0137 | 4.98 | 4000 | 0.9799 |
| 0.993 | 5.6 | 4500 | 0.9745 |
| 0.9813 | 6.22 | 5000 | 0.9632 |
| 0.9728 | 6.85 | 5500 | 0.9573 |
| 0.9534 | 7.47 | 6000 | 0.9521 |
| 0.9474 | 8.09 | 6500 | 0.9481 |
| 0.9264 | 8.71 | 7000 | 0.9405 |
| 0.9099 | 9.33 | 7500 | 0.9365 |
| 0.9017 | 9.96 | 8000 | 0.9292 |
| 0.8735 | 10.58 | 8500 | 0.9267 |
| 0.8623 | 11.2 | 9000 | 0.9268 |
| 0.8444 | 11.82 | 9500 | 0.9168 |
| 0.8205 | 12.45 | 10000 | 0.9148 |
| 0.8111 | 13.07 | 10500 | 0.9129 |
| 0.7842 | 13.69 | 11000 | 0.9129 |
| 0.767 | 14.31 | 11500 | 0.9138 |
| 0.759 | 14.93 | 12000 | 0.9094 |
| 0.7329 | 15.56 | 12500 | 0.9109 |
| 0.7261 | 16.18 | 13000 | 0.9145 |
| 0.7121 | 16.8 | 13500 | 0.9145 |
| 0.7038 | 17.42 | 14000 | 0.9161 |
| 0.699 | 18.05 | 14500 | 0.9167 |
| 0.6902 | 18.67 | 15000 | 0.9169 |
| 0.6883 | 19.29 | 15500 | 0.9172 |
| 0.6873 | 19.91 | 16000 | 0.9172 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.3
- Tokenizers 0.13.3
|
Riksarkivet/HTR_pipeline_models
|
Riksarkivet
| 2023-10-11T12:27:15Z | 0 | 2 | null |
[
"HTR",
"image-to-text",
"sv",
"license:mit",
"region:us"
] |
image-to-text
| 2023-05-16T11:14:26Z |
---
license: mit
language:
- sv
pipeline_tag: image-to-text
tags:
- HTR
---
# Model Card: Swedish National Archives HTR Pipeline
NOTE: This repo is just a placeholder for our demo
For more detailed information about the models used in the demo, please refer to the model cards available on Hugging Face:
- [Riksarkivet/rtmdet_regions](https://huggingface.co/Riksarkivet/rtmdet_regions)
- [Riksarkivet/rtmdet_lines](https://huggingface.co/Riksarkivet/rtmdet_lines)
- [Riksarkivet/satrn_htr](https://huggingface.co/https://huggingface.co/Riksarkivet/satrn_htr)
## Demo
You can try out a demo of the Swedish National Archives HTR pipeline at [Riksarkivet HTR Demo](https://huggingface.co/spaces/Riksarkivet/htr_demo).
|
Bingsu/adsdcn_pipeline
|
Bingsu
| 2023-10-11T12:18:34Z | 0 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"license:agpl-3.0",
"region:us"
] | null | 2023-07-26T06:08:38Z |
---
license: agpl-3.0
tags:
- pytorch
- diffusers
---
# Custom Pipeline for Auto Inpainting
```py
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"stablediffusionapi/counterfeit-v30",
torch_dtype=torch.float16,
custom_pipeline="Bingsu/adsdcn_pipeline"
)
pipe.safety_checker = None
pipe.to("cuda")
common = {"prompt": "masterpiece, best quality, 1girl", "num_inference_steps": 28}
result = pipe(common=common)
images = result[0]
```
github: https://github.com/Bing-su/asdff
|
pranaykoppula/hughdb2
|
pranaykoppula
| 2023-10-11T12:14:31Z | 12 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"dreambooth",
"text-to-image",
"dataset:pranaykoppula/hughdb-dataset",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-29T09:18:17Z |
---
datasets:
- pranaykoppula/hughdb-dataset
tags:
- dreambooth
pipeline_tag: text-to-image
---
Dreambooth Model trained to generate images of a subject.
|
TheAIchemist13/hindi_wav2vec2_final_2
|
TheAIchemist13
| 2023-10-11T12:12:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:Harveenchadha/vakyansh-wav2vec2-hindi-him-4200",
"base_model:finetune:Harveenchadha/vakyansh-wav2vec2-hindi-him-4200",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-10-11T11:23:15Z |
---
license: mit
base_model: Harveenchadha/vakyansh-wav2vec2-hindi-him-4200
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: hindi_wav2vec2_final_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hindi_wav2vec2_final_2
This model is a fine-tuned version of [Harveenchadha/vakyansh-wav2vec2-hindi-him-4200](https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-hindi-him-4200) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1054
- Wer: 0.1211
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.7351 | 10.0 | 25 | 0.9007 | 0.4271 |
| 0.5176 | 20.0 | 50 | 0.3738 | 0.1632 |
| 0.3401 | 30.0 | 75 | 0.1954 | 0.1368 |
| 0.1614 | 40.0 | 100 | 0.1054 | 0.1211 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 1.18.3
- Tokenizers 0.14.1
|
baebee/nuph-tokenizer
|
baebee
| 2023-10-11T12:02:43Z | 0 | 0 |
transformers
|
[
"transformers",
"tokenizers",
"transformers.js",
"experimental",
"auto tokenizer",
"llama",
"llama 2",
"custom code",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-10-11T11:48:36Z |
---
license: mit
tags:
- tokenizers
- transformers.js
- experimental
- auto tokenizer
- llama
- llama 2
- custom code
library_name: transformers
---
# Experimental tokenizer
- Derived from the LLaMa-2 tokenizer
- Inspired by the ChatML & Zephyr tokenizers
|
JiriG/q-Taxi-v3
|
JiriG
| 2023-10-11T11:43:52Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T11:43:50Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="JiriG/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kwwww/bert-base-uncased-test_16_9361
|
kwwww
| 2023-10-11T11:27:05Z | 0 | 0 |
peft
|
[
"peft",
"pytorch",
"region:us"
] | null | 2023-10-11T06:13:28Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
kupru/ppo-CartPole-v1
|
kupru
| 2023-10-11T11:17:44Z | 0 | 0 | null |
[
"tensorboard",
"CartPole-v1",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T11:14:33Z |
---
tags:
- CartPole-v1
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 96.80 +/- 60.75
name: mean_reward
verified: false
---
# PPO Agent Playing CartPole-v1
This is a trained model of a PPO agent playing CartPole-v1.
# Hyperparameters
```python
{'exp_name': 'x'
'env_id': 'CartPole-v1'
'learning_rate': 0.00025
'seed': 1
'total_timesteps': 25000
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'ppo-implementation-details'
'wandb_entity': None
'capture_video': False
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'kupru/ppo-CartPole-v1'
'batch_size': 512
'minibatch_size': 128}
```
|
anlt69/2_epoch
|
anlt69
| 2023-10-11T11:16:41Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-11T11:11:16Z |
---
base_model: /kaggle/working
tags:
- generated_from_trainer
model-index:
- name: 2_epoch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2_epoch
This model is a fine-tuned version of [/kaggle/working](https://huggingface.co//kaggle/working) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1586
- Cer: 24.1677
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
SparkExpedition/Ticket-Classifier-v1-dolly-7B
|
SparkExpedition
| 2023-10-11T11:14:30Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:diegi97/dolly-v2-6.9b-sharded-bf16",
"base_model:adapter:diegi97/dolly-v2-6.9b-sharded-bf16",
"region:us"
] | null | 2023-10-11T11:14:23Z |
---
library_name: peft
base_model: diegi97/dolly-v2-6.9b-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
Muthusivam/mistral-finetuned-muthu
|
Muthusivam
| 2023-10-11T10:59:27Z | 3 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-11T09:33:59Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.1
- desc_act: True
- sym: True
- true_sequential: True
- use_cuda_fp16: False
- model_seqlen: None
- block_name_to_quantize: None
- module_name_preceding_first_block: None
- batch_size: 1
- pad_token_id: None
- disable_exllama: True
- max_input_length: None
### Framework versions
- PEFT 0.5.0
|
kerwin7/Reinforce-CartPole-v1
|
kerwin7
| 2023-10-11T10:58:33Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T10:58:22Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
camiloss/ppo-LunarLander-v2
|
camiloss
| 2023-10-11T10:45:23Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T09:46:12Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 287.76 +/- 11.76
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
IkariDev/Athena-v4-GGUF
|
IkariDev
| 2023-10-11T10:39:22Z | 30 | 5 | null |
[
"gguf",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2023-10-07T21:50:42Z |
---
license: cc-by-nc-4.0
---

Experimental Athena v4 model. Use Alpaca format. Suitable for RP, ERP and general stuff.
I should state here that this is a HIGHLY experimental model!
<!-- description start -->
## Description
<!-- [Recommended settings - contributed by localfultonextractor](https://files.catbox.moe/ue0tja.json) -->
This repo contains GGUF files of Athena-V4.
[GGUF - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GGUF)
[GPTQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GPTQ)
[exl2 - by waldie](https://huggingface.co/waldie/Athena-v4-8bpw-h8-exl2)
[AWQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-AWQ)
[fp16 - by IkariDev+Undi95](https://huggingface.co/IkariDev/Athena-v4)
<!-- [GGUF - by IkariDev](https://huggingface.co/IkariDev/Athena-v4-GGUF)-->
[OLD(GGUF - by IkariDev+Undi95)](https://huggingface.co/IkariDev/Athena-v4-GGUF)
## Ratings:
Note: I have permission of all users to upload their ratings, i DONT screenshot random reviews without asking if i can put them here!

If you want your rating to be here, send me a message over on DC and ill put up a screenshot of it here. DC name is "ikaridev".
<!-- description end -->
<!-- description start -->
## Models+loras used and recipe
- Athena-v3
- Xwin-LM/Xwin-LM-13B-V0.1
- Undi95/PsyMedRP-v1-13B
- cgato/Thespis-13b-v0.2
- jondurbin/airoboros-l2-13b-3.0
```
Athena-v4-tmp1 = [ Athena-v3(0.85)+Xwin-LM/Xwin-LM-13B-V0.1(0.15) ]
Athena-v4-tmp2 = [ Undi95/PsyMedRP-v1-13B(0.55)+cgato/Thespis-13b-v0.2(0.45) ]
Athena-v4-tmp3 = Athena-v4-tmp1(0.55) + Athena-v4-tmp2(0.35)
Athena-v4 = Athena-v4-tmp3 + jondurbin/airoboros-l2-13b-3.0(0.1)
```
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
Thanks to [Undi95](https://huggingface.co/Undi95) for providing the machine for Athena v2 and Athena v3, and giving me infos about how things work. Going forward i will use a merging server provided by a friend.
|
rahil278/tweet-summarization-llama-2-finetuned
|
rahil278
| 2023-10-11T10:23:04Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"dataset:Salesforce/dialogstudio",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-10-11T06:32:33Z |
---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
datasets:
- Salesforce/dialogstudio
model-index:
- name: tweet-summarization-llama-2-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tweet-summarization-llama-2-finetuned
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the Salesforce/dialogstudio dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9 | 1.0 | 55 | 1.9488 |
| 1.841 | 2.0 | 110 | 1.8862 |
| 1.7698 | 3.0 | 165 | 1.8743 |
| 1.7123 | 4.0 | 220 | 1.8674 |
| 1.753 | 5.0 | 275 | 1.8659 |
| 1.6179 | 6.0 | 330 | 1.8660 |
| 1.6907 | 7.0 | 385 | 1.8666 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
vinben007/ppo-Pyramids
|
vinben007
| 2023-10-11T10:20:19Z | 6 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-10-11T10:20:08Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: vinben007/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
LucaAsga/RL-course-q-taxi-v3-2
|
LucaAsga
| 2023-10-11T10:12:25Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T10:02:53Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: RL-course-q-taxi-v3-2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="LucaAsga/RL-course-q-taxi-v3-2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Tommert25/multibert1110_lrate7.5b4
|
Tommert25
| 2023-10-11T10:09:40Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-11T09:37:27Z |
---
license: apache-2.0
base_model: bert-base-multilingual-uncased
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: multibert1110_lrate7.5b4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multibert1110_lrate7.5b4
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7163
- Precisions: 0.8864
- Recall: 0.8013
- F-measure: 0.8374
- Accuracy: 0.9059
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.7304 | 1.0 | 942 | 0.4905 | 0.8049 | 0.6436 | 0.6549 | 0.8554 |
| 0.4336 | 2.0 | 1884 | 0.6035 | 0.8585 | 0.6334 | 0.6863 | 0.8477 |
| 0.3238 | 3.0 | 2826 | 0.5094 | 0.8668 | 0.7014 | 0.7232 | 0.8882 |
| 0.249 | 4.0 | 3768 | 0.5951 | 0.8798 | 0.7110 | 0.7609 | 0.8770 |
| 0.191 | 5.0 | 4710 | 0.4988 | 0.8304 | 0.7761 | 0.7816 | 0.8975 |
| 0.1513 | 6.0 | 5652 | 0.5998 | 0.8351 | 0.7917 | 0.8062 | 0.8962 |
| 0.1088 | 7.0 | 6594 | 0.5874 | 0.8427 | 0.7953 | 0.8158 | 0.9003 |
| 0.0914 | 8.0 | 7536 | 0.5529 | 0.8580 | 0.7885 | 0.8087 | 0.9069 |
| 0.0682 | 9.0 | 8478 | 0.6882 | 0.8371 | 0.7773 | 0.8024 | 0.8958 |
| 0.0487 | 10.0 | 9420 | 0.7163 | 0.8864 | 0.8013 | 0.8374 | 0.9059 |
| 0.0319 | 11.0 | 10362 | 0.7020 | 0.8724 | 0.7867 | 0.8235 | 0.9007 |
| 0.0305 | 12.0 | 11304 | 0.6886 | 0.8689 | 0.8002 | 0.8311 | 0.9079 |
| 0.0184 | 13.0 | 12246 | 0.6994 | 0.8680 | 0.8089 | 0.8357 | 0.9085 |
| 0.0138 | 14.0 | 13188 | 0.7183 | 0.8677 | 0.8105 | 0.8362 | 0.9093 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
RogerB/afro-xlmr-large-unkin-sent3
|
RogerB
| 2023-10-11T10:04:02Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:Davlan/afro-xlmr-large",
"base_model:finetune:Davlan/afro-xlmr-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-11T09:36:28Z |
---
license: mit
base_model: Davlan/afro-xlmr-large
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: afro-xlmr-large-unkin-sent3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# afro-xlmr-large-unkin-sent3
This model is a fine-tuned version of [Davlan/afro-xlmr-large](https://huggingface.co/Davlan/afro-xlmr-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8710
- F1: 0.6706
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 10000000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.9514 | 1.0 | 1013 | 0.6999 | 0.7143 |
| 0.7676 | 2.0 | 2026 | 0.5781 | 0.7757 |
| 0.6808 | 3.0 | 3039 | 0.5499 | 0.7933 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
madaanpulkit/tab-anonymizer
|
madaanpulkit
| 2023-10-11T09:54:57Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-11T08:55:17Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tab-anonymizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tab-anonymizer
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0911
- Precision: 0.8468
- Recall: 0.8383
- F1: 0.8425
- Accuracy: 0.9731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 64 | 0.1139 | 0.8298 | 0.8224 | 0.8261 | 0.9674 |
| No log | 2.0 | 128 | 0.0911 | 0.8468 | 0.8383 | 0.8425 | 0.9731 |
### Framework versions
- Transformers 4.32.0
- Pytorch 1.12.0
- Datasets 2.10.1
- Tokenizers 0.13.3
|
elanoqi/wb-ghibli-800
|
elanoqi
| 2023-10-11T09:48:59Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:nitrosocke/Ghibli-Diffusion",
"base_model:finetune:nitrosocke/Ghibli-Diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-10-11T08:21:53Z |
---
license: creativeml-openrail-m
base_model: nitrosocke/Ghibli-Diffusion
instance_prompt: a photo of jksj waist bag
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - elanoqi/wb-ghibli-800
This is a dreambooth model derived from nitrosocke/Ghibli-Diffusion. The weights were trained on a photo of jksj waist bag using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
AISE-TUDelft/extended-java-pointer-classifier
|
AISE-TUDelft
| 2023-10-11T09:36:36Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-10-11T09:36:08Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# AISE-TUDelft/extended-java-pointer-classifier
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("AISE-TUDelft/extended-java-pointer-classifier")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
ezzattarek/detectron2-footer-detection
|
ezzattarek
| 2023-10-11T09:34:27Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2023-10-11T09:05:53Z |
---
license: mit
---
# Detectron2 model
This repository hosts our trained Detectron2 model, that can detect footer from digitized books.
The following classes are supported:
- footer
The model is based on `faster_rcnn_R_50_FPN_3x` and was fine-tuned on own and manually annotated segments from digitized books.
|
RogerB/afro-xlmr-large-unkin-sent2
|
RogerB
| 2023-10-11T09:33:42Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:Davlan/afro-xlmr-large",
"base_model:finetune:Davlan/afro-xlmr-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-11T09:06:37Z |
---
license: mit
base_model: Davlan/afro-xlmr-large
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: afro-xlmr-large-unkin-sent2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# afro-xlmr-large-unkin-sent2
This model is a fine-tuned version of [Davlan/afro-xlmr-large](https://huggingface.co/Davlan/afro-xlmr-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8649
- F1: 0.6754
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 1000000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.9788 | 1.0 | 1013 | 0.8178 | 0.6535 |
| 0.7932 | 2.0 | 2026 | 0.6577 | 0.7392 |
| 0.6943 | 3.0 | 3039 | 0.5971 | 0.7688 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
letdosomething/bloomz-560m_PROMPT_TUNING_CAUSAL_LM
|
letdosomething
| 2023-10-11T09:27:59Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-10-11T06:41:08Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
satyanshu404/bart-large-cnn-finetuned-promt_generation
|
satyanshu404
| 2023-10-11T09:25:55Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-large-cnn",
"base_model:finetune:facebook/bart-large-cnn",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-11T09:24:49Z |
---
license: mit
base_model: facebook/bart-large-cnn
tags:
- generated_from_trainer
model-index:
- name: bart-large-cnn-finetuned-promt_generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetuned-promt_generation
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8767
- Map: 0.3718
- Ndcg@10: 0.5915
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Map | Ndcg@10 |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 4 | 3.3856 | 0.2563 | 0.4531 |
| No log | 2.0 | 8 | 3.3740 | 0.2563 | 0.4531 |
| No log | 3.0 | 12 | 3.3430 | 0.2563 | 0.4531 |
| No log | 4.0 | 16 | 3.2912 | 0.2563 | 0.4531 |
| No log | 5.0 | 20 | 3.2468 | 0.2563 | 0.4531 |
| No log | 6.0 | 24 | 3.2199 | 0.2563 | 0.4531 |
| No log | 7.0 | 28 | 3.2016 | 0.2563 | 0.4531 |
| No log | 8.0 | 32 | 3.0741 | 0.2563 | 0.4531 |
| No log | 9.0 | 36 | 3.0260 | 0.2563 | 0.4531 |
| No log | 10.0 | 40 | 2.9989 | 0.2563 | 0.4531 |
| No log | 11.0 | 44 | 2.9755 | 0.2563 | 0.4531 |
| No log | 12.0 | 48 | 2.9495 | 0.2560 | 0.4528 |
| No log | 13.0 | 52 | 2.9300 | 0.2560 | 0.4528 |
| No log | 14.0 | 56 | 2.9088 | 0.2560 | 0.4528 |
| No log | 15.0 | 60 | 2.8656 | 0.2560 | 0.4528 |
| No log | 16.0 | 64 | 2.8146 | 0.2560 | 0.4528 |
| No log | 17.0 | 68 | 2.7699 | 0.2560 | 0.4528 |
| No log | 18.0 | 72 | 2.7321 | 0.2577 | 0.4542 |
| No log | 19.0 | 76 | 2.6978 | 0.2577 | 0.4542 |
| No log | 20.0 | 80 | 2.6665 | 0.2577 | 0.4542 |
| No log | 21.0 | 84 | 2.6373 | 0.2577 | 0.4542 |
| No log | 22.0 | 88 | 2.6080 | 0.2897 | 0.4974 |
| No log | 23.0 | 92 | 2.5812 | 0.2897 | 0.4974 |
| No log | 24.0 | 96 | 2.5568 | 0.2954 | 0.5014 |
| No log | 25.0 | 100 | 2.5348 | 0.2954 | 0.5014 |
| No log | 26.0 | 104 | 2.5133 | 0.2954 | 0.5014 |
| No log | 27.0 | 108 | 2.4929 | 0.2954 | 0.5014 |
| No log | 28.0 | 112 | 2.4735 | 0.3385 | 0.5472 |
| No log | 29.0 | 116 | 2.4553 | 0.3385 | 0.5472 |
| No log | 30.0 | 120 | 2.4374 | 0.3385 | 0.5472 |
| No log | 31.0 | 124 | 2.4201 | 0.3385 | 0.5472 |
| No log | 32.0 | 128 | 2.4035 | 0.3385 | 0.5472 |
| No log | 33.0 | 132 | 2.3870 | 0.3385 | 0.5472 |
| No log | 34.0 | 136 | 2.3711 | 0.3385 | 0.5472 |
| No log | 35.0 | 140 | 2.3556 | 0.3385 | 0.5472 |
| No log | 36.0 | 144 | 2.3397 | 0.3385 | 0.5472 |
| No log | 37.0 | 148 | 2.3246 | 0.3385 | 0.5472 |
| No log | 38.0 | 152 | 2.3097 | 0.3385 | 0.5472 |
| No log | 39.0 | 156 | 2.2944 | 0.3718 | 0.5915 |
| No log | 40.0 | 160 | 2.2801 | 0.3718 | 0.5915 |
| No log | 41.0 | 164 | 2.2660 | 0.3718 | 0.5915 |
| No log | 42.0 | 168 | 2.2525 | 0.3718 | 0.5915 |
| No log | 43.0 | 172 | 2.2392 | 0.3718 | 0.5915 |
| No log | 44.0 | 176 | 2.2267 | 0.3718 | 0.5915 |
| No log | 45.0 | 180 | 2.2135 | 0.3718 | 0.5915 |
| No log | 46.0 | 184 | 2.2007 | 0.3718 | 0.5915 |
| No log | 47.0 | 188 | 2.1875 | 0.3718 | 0.5915 |
| No log | 48.0 | 192 | 2.1752 | 0.3718 | 0.5915 |
| No log | 49.0 | 196 | 2.1637 | 0.3718 | 0.5915 |
| No log | 50.0 | 200 | 2.1514 | 0.3718 | 0.5915 |
| No log | 51.0 | 204 | 2.1393 | 0.3718 | 0.5915 |
| No log | 52.0 | 208 | 2.1281 | 0.3718 | 0.5915 |
| No log | 53.0 | 212 | 2.1159 | 0.3718 | 0.5915 |
| No log | 54.0 | 216 | 2.1048 | 0.3718 | 0.5915 |
| No log | 55.0 | 220 | 2.0941 | 0.3718 | 0.5915 |
| No log | 56.0 | 224 | 2.0829 | 0.3718 | 0.5915 |
| No log | 57.0 | 228 | 2.0727 | 0.3718 | 0.5915 |
| No log | 58.0 | 232 | 2.0617 | 0.3718 | 0.5915 |
| No log | 59.0 | 236 | 2.0518 | 0.3718 | 0.5915 |
| No log | 60.0 | 240 | 2.0416 | 0.3718 | 0.5915 |
| No log | 61.0 | 244 | 2.0323 | 0.3718 | 0.5915 |
| No log | 62.0 | 248 | 2.0230 | 0.3718 | 0.5915 |
| No log | 63.0 | 252 | 2.0143 | 0.3718 | 0.5915 |
| No log | 64.0 | 256 | 2.0060 | 0.3718 | 0.5915 |
| No log | 65.0 | 260 | 1.9977 | 0.3718 | 0.5915 |
| No log | 66.0 | 264 | 1.9901 | 0.3718 | 0.5915 |
| No log | 67.0 | 268 | 1.9827 | 0.3718 | 0.5915 |
| No log | 68.0 | 272 | 1.9757 | 0.3718 | 0.5915 |
| No log | 69.0 | 276 | 1.9690 | 0.3718 | 0.5915 |
| No log | 70.0 | 280 | 1.9622 | 0.3718 | 0.5915 |
| No log | 71.0 | 284 | 1.9561 | 0.3718 | 0.5915 |
| No log | 72.0 | 288 | 1.9505 | 0.3718 | 0.5915 |
| No log | 73.0 | 292 | 1.9447 | 0.3718 | 0.5915 |
| No log | 74.0 | 296 | 1.9401 | 0.3718 | 0.5915 |
| No log | 75.0 | 300 | 1.9349 | 0.3863 | 0.5987 |
| No log | 76.0 | 304 | 1.9303 | 0.3863 | 0.5987 |
| No log | 77.0 | 308 | 1.9254 | 0.3863 | 0.5987 |
| No log | 78.0 | 312 | 1.9209 | 0.3863 | 0.5987 |
| No log | 79.0 | 316 | 1.9171 | 0.3863 | 0.5987 |
| No log | 80.0 | 320 | 1.9133 | 0.3863 | 0.5987 |
| No log | 81.0 | 324 | 1.9098 | 0.3863 | 0.5987 |
| No log | 82.0 | 328 | 1.9067 | 0.3718 | 0.5915 |
| No log | 83.0 | 332 | 1.9034 | 0.3718 | 0.5915 |
| No log | 84.0 | 336 | 1.8999 | 0.3718 | 0.5915 |
| No log | 85.0 | 340 | 1.8975 | 0.3718 | 0.5915 |
| No log | 86.0 | 344 | 1.8949 | 0.3718 | 0.5915 |
| No log | 87.0 | 348 | 1.8928 | 0.3718 | 0.5915 |
| No log | 88.0 | 352 | 1.8902 | 0.3718 | 0.5915 |
| No log | 89.0 | 356 | 1.8880 | 0.3718 | 0.5915 |
| No log | 90.0 | 360 | 1.8859 | 0.3718 | 0.5915 |
| No log | 91.0 | 364 | 1.8845 | 0.3718 | 0.5915 |
| No log | 92.0 | 368 | 1.8829 | 0.3718 | 0.5915 |
| No log | 93.0 | 372 | 1.8819 | 0.3718 | 0.5915 |
| No log | 94.0 | 376 | 1.8803 | 0.3718 | 0.5915 |
| No log | 95.0 | 380 | 1.8801 | 0.3718 | 0.5915 |
| No log | 96.0 | 384 | 1.8782 | 0.3718 | 0.5915 |
| No log | 97.0 | 388 | 1.8782 | 0.3718 | 0.5915 |
| No log | 98.0 | 392 | 1.8773 | 0.3718 | 0.5915 |
| No log | 99.0 | 396 | 1.8773 | 0.3718 | 0.5915 |
| No log | 100.0 | 400 | 1.8767 | 0.3718 | 0.5915 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
odunola/llama-2-food-instruct
|
odunola
| 2023-10-11T09:25:44Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-06T00:58:13Z |
---
library_name: peft
---
Finetuned LLama2 7B model on specialised food and culinary focused dataset
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
JJJJerry/dqn-SpaceInvadersNoFrameskip-v4
|
JJJJerry
| 2023-10-11T09:22:41Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-10-11T09:22:11Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 268.50 +/- 78.17
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga JJJJerry -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga JJJJerry -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga JJJJerry
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
eunyounglee/GPT-NeoX-1.3B-2GB-Eng-2
|
eunyounglee
| 2023-10-11T09:18:58Z | 167 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"eng",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-06T02:23:10Z |
---
language:
- eng
pipeline_tag: text-generation
Trained: Pretrain
Config file: 1.3B
Data: English News Dataset 2GB
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Pretrained GPT-NeoX model with 2.06GB English news dataset. Took about 10 hours to reach 20,000 iterations. Trained on p3.16xlarge.
Different hyperparameter: gradient_accumulation_step 4
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Eunyoung Lee
- **Model type:** GPT-NeoX
- **Language(s) (NLP):** English
|
MattStammers/appo-atari_fishingderby-approaching_sota
|
MattStammers
| 2023-10-11T09:16:38Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-26T05:47:00Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: atari_fishingderby
type: atari_fishingderby
metrics:
- type: mean_reward
value: 46.60 +/- 6.97
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **atari_fishingderby** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r MattStammers/APPO-atari_fishingderby
```
## About the Model
This model as with all the others in the benchmarks was trained initially asynchronously un-seeded to 10 million steps for the purposes of setting a sample factory async baseline for this model on this environment but only 3/57 made it.
The aim is to reach state-of-the-art (SOTA) performance on each atari environment. I will flag the models with SOTA when they reach at or near these levels.
The hyperparameters used in the model are the ones I have pushed to my fork of sample-factory: https://github.com/MattStammers/sample-factory. Given that https://huggingface.co/edbeeching has kindly shared his.
I saved time and energy by using many of his tuned hyperparameters to maximise performance. However, he used 2 billion training steps. I have started as explained above at 10 million then moved to 100m to see how performance goes:
```
hyperparameters = {
"device": "gpu",
"seed": 1234,
"num_policies": 2,
"async_rl": true,
"serial_mode": false,
"batched_sampling": true,
"num_batches_to_accumulate": 2,
"worker_num_splits": 1,
"policy_workers_per_policy": 1,
"max_policy_lag": 1000,
"num_workers": 16,
"num_envs_per_worker": 2,
"batch_size": 1024,
"num_batches_per_epoch": 8,
"num_epochs": 4,
"rollout": 128,
"recurrence": 1,
"shuffle_minibatches": false,
"gamma": 0.99,
"reward_scale": 1.0,
"reward_clip": 1000.0,
"value_bootstrap": false,
"normalize_returns": true,
"exploration_loss_coeff": 0.0004677351413,
"value_loss_coeff": 0.5,
"kl_loss_coeff": 0.0,
"exploration_loss": "entropy",
"gae_lambda": 0.95,
"ppo_clip_ratio": 0.1,
"ppo_clip_value": 1.0,
"with_vtrace": false,
"vtrace_rho": 1.0,
"vtrace_c": 1.0,
"optimizer": "adam",
"adam_eps": 1e-05,
"adam_beta1": 0.9,
"adam_beta2": 0.999,
"max_grad_norm": 0.0,
"learning_rate": 0.0003033891184,
"lr_schedule": "linear_decay",
"lr_schedule_kl_threshold": 0.008,
"lr_adaptive_min": 1e-06,
"lr_adaptive_max": 0.01,
"obs_subtract_mean": 0.0,
"obs_scale": 255.0,
"normalize_input": true,
"normalize_input_keys": [
"obs"
],
"decorrelate_experience_max_seconds": 0,
"decorrelate_envs_on_one_worker": true,
"actor_worker_gpus": [],
"set_workers_cpu_affinity": true,
"force_envs_single_thread": false,
"default_niceness": 0,
"log_to_file": true,
"experiment_summaries_interval": 3,
"flush_summaries_interval": 30,
"stats_avg": 100,
"summaries_use_frameskip": true,
"heartbeat_interval": 10,
"heartbeat_reporting_interval": 60,
"train_for_env_steps": 100000000,
"train_for_seconds": 10000000000,
"save_every_sec": 120,
"keep_checkpoints": 2,
"load_checkpoint_kind": "latest",
"save_milestones_sec": 1200,
"save_best_every_sec": 5,
"save_best_metric": "reward",
"save_best_after": 100000,
"benchmark": false,
"encoder_mlp_layers": [
512,
512
],
"encoder_conv_architecture": "convnet_atari",
"encoder_conv_mlp_layers": [
512
],
"use_rnn": false,
"rnn_size": 512,
"rnn_type": "gru",
"rnn_num_layers": 1,
"decoder_mlp_layers": [],
"nonlinearity": "relu",
"policy_initialization": "orthogonal",
"policy_init_gain": 1.0,
"actor_critic_share_weights": true,
"adaptive_stddev": false,
"continuous_tanh_scale": 0.0,
"initial_stddev": 1.0,
"use_env_info_cache": false,
"env_gpu_actions": false,
"env_gpu_observations": true,
"env_frameskip": 4,
"env_framestack": 4,
}
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m sf_examples.atari.enjoy_atari --algo=APPO --env=atari_fishingderby --train_dir=./train_dir --experiment=APPO-atari_fishingderby
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m sf_examples.atari.train_atari --algo=APPO --env=atari_fishingderby --train_dir=./train_dir --experiment=APPO-atari_fishingderby --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.