
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
anamikac2708/Gemma-7b-finetuned-investopedia-Merged-FP16
|
anamikac2708
| 2024-06-18T07:55:17Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"finlang",
"qlora",
"en",
"arxiv:2305.14314",
"arxiv:2404.18796",
"base_model:unsloth/gemma-7b-bnb-4bit",
"base_model:finetune:unsloth/gemma-7b-bnb-4bit",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-15T07:47:31Z |
---
language:
- en
license: cc-by-nc-4.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
- finlang
- qlora
base_model: unsloth/gemma-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** anamikac2708
- **License:** cc-by-nc-4.0
- **Finetuned from model :** unsloth/gemma-7b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library using open-sourced finance dataset https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset developed for finance application by FinLang Team
This project is for research purposes only. Third-party datasets may be subject to additional terms and conditions under their associated licenses.
## How to Get Started with the Model
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
```python
import torch
from unsloth import FastLanguageModel
from transformers import AutoTokenizer, pipeline
max_seq_length=2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "anamikac2708/Gemma-7b-finetuned-investopedia-Merged-FP16", # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
dtype = torch.bfloat16,
#load_in_4bit = True, # IF YOU WANT TO LOAD WITH BITSANDBYTES INT4
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
example = [{'content': 'You are a financial expert and you can answer any questions related to finance. You will be given a context and a question. Understand the given context and\n try to answer. Users will ask you questions in English and you will generate answer based on the provided CONTEXT.\n CONTEXT:\n D. in Forced Migration from the University of the Witwatersrand (Wits) in Johannesburg, South Africa; A postgraduate diploma in Folklore & Cultural Studies at Indira Gandhi National Open University (IGNOU) in New Delhi, India; A Masters of International Affairs at Columbia University; A BA from Barnard College at Columbia University\n', 'role': 'system'}, {'content': ' In which universities did the individual obtain their academic qualifications?\n', 'role': 'user'}, {'content': ' University of the Witwatersrand (Wits) in Johannesburg, South Africa; Indira Gandhi National Open University (IGNOU) in New Delhi, India; Columbia University; Barnard College at Columbia University.', 'role': 'assistant'}]
prompt = pipe.tokenizer.apply_chat_template(example[:2], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.1, top_k=50, top_p=0.1, eos_token_id=pipe.tokenizer.eos_token_id, pad_token_id=pipe.tokenizer.pad_token_id)
print(f"Query:\n{example[1]['content']}")
print(f"Context:\n{example[0]['content']}")
print(f"Original Answer:\n{example[2]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
```
## Training Details
```
Peft Config :
{
'Technqiue' : 'QLORA',
'rank': 256,
'target_modules' : ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
'lora_alpha' : 128,
'lora_dropout' : 0,
'bias': "none",
}
Hyperparameters:
{
"epochs": 3,
"evaluation_strategy": "epoch",
"gradient_checkpointing": True,
"max_grad_norm" : 0.3,
"optimizer" : "adamw_torch_fused",
"learning_rate" : 2e-5,
"lr_scheduler_type": "constant",
"warmup_ratio" : 0.03,
"per_device_train_batch_size" : 4,
"per_device_eval_batch_size" : 4,
"gradient_accumulation_steps" : 4
}
```
## Model was trained on 1xA100 80GB, below loss and memory consmuption details:
{'eval_loss': 1.0056027173995972, 'eval_runtime': 299.1871, 'eval_samples_per_second': 2.276, 'eval_steps_per_second': 0.572, 'epoch': 3.0}
{'train_runtime': 23623.219, 'train_samples_per_second': 0.683, 'train_steps_per_second': 0.043, 'train_loss': 0.8518931362777948, 'epoch': 3.0}
Total training time 23623.95972943306
23623.219 seconds used for training.
393.72 minutes used for training.
Peak reserved memory = 63.17 GB.
Peak reserved memory for training = 54.553 GB.
Peak reserved memory % of max memory = 79.809 %.
Peak reserved memory for training % of max memory = 68.923 %.
QLORA paper link - https://arxiv.org/abs/2305.14314
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
We evaluated the model on test set (sample 1k) https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset. Evaluation was done using Proprietary LLMs as jury on four criteria Correctness, Faithfullness, Clarity, Completeness on scale of 1-5 (1 being worst & 5 being best) inspired by the paper Replacing Judges with Juries https://arxiv.org/abs/2404.18796. Model got an average score of 3.84.
Average inference speed of the model is 9.7 secs. Human Evaluation is in progress to see the percentage of alignment between human and LLM.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance. It does not have any moderation mechanisms. We're looking into ways to make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## License
Since non-commercial datasets are used for fine-tuning, we release this model as cc-by-nc-4.0.
|
anamikac2708/Llama3-8b-finetuned-investopedia-Lora-Adapters
|
anamikac2708
| 2024-06-18T07:54:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"lora",
"finlang",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:adapter:unsloth/llama-3-8b-bnb-4bit",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-15T06:41:45Z |
---
language:
- en
license: cc-by-nc-4.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- lora
- finlang
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** anamikac2708
- **License:** cc-by-nc-4.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This are lora adapeters that are trained on top of llama3-8B model using 2x faster [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library using open-sourced finance dataset https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset developed for finance application by FinLang Team
This project is for research purposes only. Third-party datasets may be subject to additional terms and conditions under their associated licenses.
## How to Get Started with the Model
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
You can infer the adapters directly using Peft/Unsloth library or you can merge the adapter with the base model and can use it.
Please find an example below using Unsloth:
```python
import torch
from unsloth import FastLanguageModel
from transformers import AutoTokenizer, pipeline
max_seq_length=2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "anamikac2708/Llama3-8b-finetuned-investopedia-Lora-Adapters", # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
dtype = torch.bfloat16,
load_in_4bit = False #Make it True if you want to use bitsandbytes 4bit
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
example = [{'content': 'You are a financial expert and you can answer any questions related to finance. You will be given a context and a question. Understand the given context and\n try to answer. Users will ask you questions in English and you will generate answer based on the provided CONTEXT.\n CONTEXT:\n D. in Forced Migration from the University of the Witwatersrand (Wits) in Johannesburg, South Africa; A postgraduate diploma in Folklore & Cultural Studies at Indira Gandhi National Open University (IGNOU) in New Delhi, India; A Masters of International Affairs at Columbia University; A BA from Barnard College at Columbia University\n', 'role': 'system'}, {'content': ' In which universities did the individual obtain their academic qualifications?\n', 'role': 'user'}, {'content': ' University of the Witwatersrand (Wits) in Johannesburg, South Africa; Indira Gandhi National Open University (IGNOU) in New Delhi, India; Columbia University; Barnard College at Columbia University.', 'role': 'assistant'}]
prompt = pipe.tokenizer.apply_chat_template(example[:2], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.1, top_k=50, top_p=0.1, eos_token_id=pipe.tokenizer.eos_token_id, pad_token_id=pipe.tokenizer.pad_token_id)
print(f"Query:\n{example[1]['content']}")
print(f"Context:\n{example[0]['content']}")
print(f"Original Answer:\n{example[2]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
```
## License
Since non-commercial datasets are used for fine-tuning, we release this model as cc-by-nc-4.0.
|
anamikac2708/Llama3-8b-finetuned-investopedia-Merged-FP16
|
anamikac2708
| 2024-06-18T07:53:46Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"finlang",
"qlora",
"en",
"arxiv:2305.14314",
"arxiv:2404.18796",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-15T06:57:15Z |
---
language:
- en
license: cc-by-nc-4.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- finlang
- qlora
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** anamikac2708
- **License:** cc-by-nc-4.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library using open-sourced finance dataset https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset developed for finance application by FinLang Team
This project is for research purposes only. Third-party datasets may be subject to additional terms and conditions under their associated licenses.
## How to Get Started with the Model
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
```python
import torch
from unsloth import FastLanguageModel
from transformers import AutoTokenizer, pipeline
max_seq_length=2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "anamikac2708/Llama3-8b-finetuned-investopedia-Merged-FP16", # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
dtype = torch.bfloat16,
#load_in_4bit = True, # IF YOU WANT TO LOAD WITH BITSANDBYTES INT4
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
example = [{'content': 'You are a financial expert and you can answer any questions related to finance. You will be given a context and a question. Understand the given context and\n try to answer. Users will ask you questions in English and you will generate answer based on the provided CONTEXT.\n CONTEXT:\n D. in Forced Migration from the University of the Witwatersrand (Wits) in Johannesburg, South Africa; A postgraduate diploma in Folklore & Cultural Studies at Indira Gandhi National Open University (IGNOU) in New Delhi, India; A Masters of International Affairs at Columbia University; A BA from Barnard College at Columbia University\n', 'role': 'system'}, {'content': ' In which universities did the individual obtain their academic qualifications?\n', 'role': 'user'}, {'content': ' University of the Witwatersrand (Wits) in Johannesburg, South Africa; Indira Gandhi National Open University (IGNOU) in New Delhi, India; Columbia University; Barnard College at Columbia University.', 'role': 'assistant'}]
prompt = pipe.tokenizer.apply_chat_template(example[:2], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.1, top_k=50, top_p=0.1, eos_token_id=pipe.tokenizer.eos_token_id, pad_token_id=pipe.tokenizer.pad_token_id)
print(f"Query:\n{example[1]['content']}")
print(f"Context:\n{example[0]['content']}")
print(f"Original Answer:\n{example[2]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
```
## Training Details
```
Peft Config :
{
'Technqiue' : 'QLORA',
'rank': 256,
'target_modules' : ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
'lora_alpha' : 128,
'lora_dropout' : 0,
'bias': "none",
}
Hyperparameters:
{
"epochs": 3,
"evaluation_strategy": "epoch",
"gradient_checkpointing": True,
"max_grad_norm" : 0.3,
"optimizer" : "adamw_torch_fused",
"learning_rate" : 2e-4,
"lr_scheduler_type": "constant",
"warmup_ratio" : 0.03,
"per_device_train_batch_size" : 4,
"per_device_eval_batch_size" : 4,
"gradient_accumulation_steps" : 4
}
```
## Model was trained on 1xA100 80GB, below loss and memory consmuption details:
{'eval_loss': 0.9614351987838745,
'eval_runtime': 244.0411,
'eval_samples_per_second': 2.663,
'eval_steps_per_second': 0.668,
'epoch': 3.0}
{'train_runtime': 19718.5285,
'train_samples_per_second': 0.781,
'train_steps_per_second': 0.049,
'train_loss': 0.8241131883172602,
'epoch': 3.0}
Total training time 19720.924563884735
328.64 minutes used for training.
Peak reserved memory = 35.789 GB.
Peak reserved memory for training = 27.848 GB.
Peak reserved memory % of max memory = 45.216 %.
Peak reserved memory for training % of max memory = 35.183 %.
QLORA paper link - https://arxiv.org/abs/2305.14314
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
We evaluated the model on test set (sample 1k) https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset. Evaluation was done using Proprietary LLMs as jury on four criteria Correctness, Faithfullness, Clarity, Completeness on scale of 1-5 (1 being worst & 5 being best) inspired by the paper Replacing Judges with Juries https://arxiv.org/abs/2404.18796. Model got an average score of 4.67.
Average inference speed of the model is 10.96 secs. Human Evaluation is in progress to see the percentage of alignment between human and LLM.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
This model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance. It does not have any moderation mechanisms. We're looking into ways to make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## License
Since non-commercial datasets are used for fine-tuning, we release this model as cc-by-nc-4.0.
|
Aexeos/mt0_hate_finedtune_r16-1
|
Aexeos
| 2024-06-18T07:48:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T07:48:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Semak/44
|
Semak
| 2024-06-18T07:44:17Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T07:44:17Z |
---
license: apache-2.0
---
|
MhondGhod/mt-en-th-nllb-600
|
MhondGhod
| 2024-06-18T07:43:04Z | 103 | 0 |
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-06-18T07:32:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Semak/7
|
Semak
| 2024-06-18T07:40:40Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T07:40:40Z |
---
license: apache-2.0
---
|
Kathernie/whisper-small-ta_r_s
|
Kathernie
| 2024-06-18T07:38:49Z | 91 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:custom_datset",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-06-18T05:05:45Z |
---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- custom_datset
model-index:
- name: Whisper Small Tamil Filtered
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Tamil Filtered
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Learn Tamil dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 1000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.1
- Datasets 2.15.0
- Tokenizers 0.15.1
|
JerryO3/test
|
JerryO3
| 2024-06-18T07:36:36Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"nomic_bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:1453",
"loss:MatryoshkaLoss",
"loss:MultipleNegativesRankingLoss",
"custom_code",
"en",
"arxiv:1908.10084",
"arxiv:2205.13147",
"arxiv:1705.00652",
"base_model:nomic-ai/nomic-embed-text-v1.5",
"base_model:finetune:nomic-ai/nomic-embed-text-v1.5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-06-18T07:35:51Z |
---
language:
- en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:1453
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
base_model: nomic-ai/nomic-embed-text-v1.5
datasets: []
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
widget:
- source_sentence: 'We therefore conducted a hospital based cross sectional study
involving 101 HCWs from two facilities in Kumasi, Ghana to assess the level of
preparedness of HCWs to respond to any possible EVD. METHODS: We administered
a face-to-face questionnaire using an adapted WHO (2015) and CDC (2014) Checklist
for Ebola Preparedness and assessed overall knowledge gaps, and preparedness of
the Ghanaian HCWs in selected health facilities of the Ashanti Region of Ghana
from October to December 2015. RESULTS: A total 92 (91.09%) HCWs indicated they
were not adequately trained to handle an EVD suspected case. Only 25.74% (n =
26) considered their facilities sufficiently equipped to handle and manage EVD
patients. When asked which disinfectant to use after attending to and caring for
a suspected patient with EVD, only 8.91% (n = 9) could correctly identify the
right disinfectant (χ(2) = 28.52, p = 0.001). CONCLUSION: Our study demonstrates
poor knowledge and ill preparedness and unwillingness of many HCWs to attend to
EVD. Beyond knowledge acquisition, there is the need for more training from time
to time to fully prepare HCWs to handle any possible EVD case. Text: During the
last outbreak of Ebola Virus Disease (EVD) and its consequential massive epidemic
with very high mortality [1] , many health systems and services in West Africa
were overwhelmed and disrupted.'
sentences:
- How many facilities believed they were adequately equipped to handle Ebla virus
disease?
- What developments have been made possible by the study of B-cell repertoire?
- Where does the NLRP3 inflammasome activate after a SARS-CoV infection?
- source_sentence: All influenza A pandemics since that time, and indeed almost all
cases of influenza A worldwide (except- ing human infections from avian Viruses
such as H5N1 and H7N7), have been caused by descendants of the 1918 Virus, including
“drifted” H1N1 Viruses and reassorted H2N2 and H3N2 Viruses. The latter are composed
of key genes from the 1918 Virus, updated by subsequently-incor— porated avian
influenza genes that code for novel surface *Armed Forces Institute of Pathology,
Rockville, Maryland, USA; and TNational Institutes of Health, Bethesda, Maryland,
USA proteins, making the 1918 Virus indeed the “mother” of all pandemics. In 1918,
the cause of human influenza and its links to avian and swine influenza were unknown.
Despite clinical and epidemiologic similarities to influenza pandemics of 1889,
1847, and even earlier, many questioned whether such an explosively fatal disease
could be influenza at all. That question did not begin to be resolved until the
1930s, when closely related influenza Viruses (now known to be H1N1 Viruses) were
isolated, first from pigs and shortly thereafter from humans. Seroepidemiologic
studies soon linked both of these viruses to the 1918 pandemic (8). Subsequent
research indicates that descendants of the 1918 Virus still persists enzootically
in pigs. They probably also circulated continuously in humans, undergoing gradual
antigenic drift and causing annual epidemics, until the 1950s.
sentences:
- What causes Q fever?
- What was the mean length of the sequenced read?
- When was it determined that the 1918 pandemic was caused by the H1N1 Influenza
virus?
- source_sentence: These results showed that CD3 + CD4 + T cells have obviously (P<0.01)
increased ( Figure 5B ), nevertheless the CD3 + CD8 + T cells remarkably (P<0.05)
declined ( Figure 5C ). After calculation, the ratio of CD4 + /CD8 + T cells increased
( Figure 5D ). This ratio could also further measure the immunity levels of piglets.
Cytokine IL-1β and IL-10 levels were determined to evaluate cellular immune responses
induced by B. subtilis-RC as shown in Figure 6A ,B. As we can see from the diagram,
significantly (P<0.01) higher IL-1β and IL-10 were produced after oral administration
with B. subtilis-RC than the other two groups. These all revealed that B. subtilis-RC
could stimulate cytokines release to mediate communication with and between cells
of the immune system, improving the mucosal immune response to PEDV infection.
The PEDV neutralizing antibodies were detected by PRNT assay. Oral administration
with B. subtilis-RC could effectively reduce the plaque-forming ability of PEDV
(P<0.01) compared with other two groups in Figure 7 .
sentences:
- Why are antibody epitope based peptide vaccines are no longer an active research
area?
- What is a conclusion of this study?
- What is an effective indicator of a vaccine's ability to generate an immune response?
- source_sentence: Many types of bacteriophage and engineered phage variants, including
filamentous phage, have been proposed for prophylactic use ex vivo in food safety,
either in the production pipeline (reviewed in Dalmasso et al., 2014) or for detection
of foodborne pathogens post-production (reviewed in Schmelcher and Loessner, 2014)
. Filamentous phage displaying a tetracysteine tag on pIII were used to detect
E. coli cells through staining with biarsenical dye . M13 phage functionalized
with metallic silver were highly bactericidal against E. coli and Staphylococcus
epidermidis . Biosensors based on surface plasmon resonance (Nanduri et al., 2007)
, piezoelectric transducers (Olsen et al., 2006) , linear dichroism (Pacheco-Gomez
et al., 2012) , and magnetoelastic sensor technology (Lakshmanan et al., 2007;
Huang et al., 2009) were devised using filamentous phage displaying scFv or conjugated
to whole IgG against E. coli, Listeria monocytogenes, Salmonella typhimurium,
and Bacillus anthracis with limits of detection on the order of 10 2 -10 6 bacterial
cells/mL. Proof of concept has been demonstrated for use of such phage-based biosensors
to detect bacterial contamination of live produce (Li et al., 2010b) and eggs
(Chai et al., 2012) . The filamentous phage particle is enclosed by a rod-like
protein capsid, ∼1000 nm long and 5 nm wide, made up almost entirely of overlapping
pVIII monomers, each of which lies ∼27 angstroms from its nearest neighbor and
exposes two amine groups as well as at least three carboxyl groups (Henry et al.,
2011) . The regularity of the phage pVIII lattice and its diversity of chemically
addressable groups make it an ideal scaffold for bioconjugation (Figure 3) . The
most commonly used approach is functionalization of amine groups with NHS esters
(van Houten et al., 2006 (van Houten et al., , 2010 Yacoby et al., 2006) , although
this can result in unwanted acylation of pIII and any displayed biomolecules.
sentences:
- What is the contrast with SARS-COV and MERS=COV?
- What is the structure of a filamentous phage particle?
- Why do treatment and management vary in efficacy?
- source_sentence: The monolayers were removed from their plastic surfaces and serially
passaged whenever they became confluent. Cells were plated out onto 96-well culture
plates for cytotoxicity and anti-influenza assays, and propagated at 37 °C in
an atmosphere of 5% CO 2 . The influenza strain A/Leningrad/134/17/1957 H2N2)
was purchased from National Control Institute of Veterinary Bioproducts and Pharmaceuticals
(Beijing, China). Virus was routinely grown on MDCK cells. The stock cultures
were prepared from supernatants of infected cells and stored at −80 °C. The cellular
toxicity of patchouli alcohol on MDCK cells was assessed by the MTT method. Briefly,
cells were seeded on a microtiter plate in the absence or presence of various
concentrations (20 µM -0.0098 µM) of patchouli alcohol (eight replicates) and
incubated at 37 °C in a humidified atmosphere of 5% CO 2 for 72 h. The supernatants
were discarded, washed with PBS twice and MTT reagent (5 mg/mL in PBS) was added
to each well. After incubation at 37 °C for 4 h, the supernatants were removed,
then 200 μL DMSO was added and incubated at 37 °C for another 30 min.
sentences:
- What can be a factor in using common vectors for the delivery of vaccines?
- ' What can some of the other activities of N have, be linked to?'
- What method was used to measure the inhibition of viral replication?
pipeline_tag: sentence-similarity
model-index:
- name: nomic-text-embed COVID QA Matryoshka test
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.32098765432098764
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.6049382716049383
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.7222222222222222
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8580246913580247
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.32098765432098764
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.20164609053497942
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.14444444444444443
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08580246913580246
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.32098765432098764
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.6049382716049383
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.7222222222222222
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8580246913580247
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5726476297998092
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.4831545169508133
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.4876624839192167
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.3395061728395062
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.6172839506172839
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.691358024691358
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8395061728395061
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.3395061728395062
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.20576131687242796
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1382716049382716
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0839506172839506
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.3395061728395062
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.6172839506172839
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.691358024691358
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8395061728395061
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5769674187028887
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.4942803252988438
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.49996505521200235
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.3148148148148148
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.5864197530864198
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.6604938271604939
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.7901234567901234
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.3148148148148148
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.19547325102880658
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.13209876543209875
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.07901234567901234
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.3148148148148148
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5864197530864198
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.6604938271604939
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.7901234567901234
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5454859667021819
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.46796492259455236
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.4775435566293839
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.2716049382716049
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.5370370370370371
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.654320987654321
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.7283950617283951
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.2716049382716049
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.17901234567901234
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1308641975308642
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0728395061728395
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.2716049382716049
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5370370370370371
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.654320987654321
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.7283950617283951
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.4965852195530764
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.4220825984714875
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.43352458189921866
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.24074074074074073
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.47530864197530864
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.5864197530864198
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.6728395061728395
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.24074074074074073
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.15843621399176952
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.11728395061728394
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.06728395061728394
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.24074074074074073
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.47530864197530864
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.5864197530864198
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.6728395061728395
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.4508577703429953
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.3797864001567706
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.39108804574508443
name: Cosine Map@100
---
# nomic-text-embed COVID QA Matryoshka test
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) <!-- at revision b0753ae76394dd36bcfb912a46018088bca48be0 -->
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: NomicBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("JerryO3/test")
# Run inference
sentences = [
'The monolayers were removed from their plastic surfaces and serially passaged whenever they became confluent. Cells were plated out onto 96-well culture plates for cytotoxicity and anti-influenza assays, and propagated at 37 °C in an atmosphere of 5% CO 2 . The influenza strain A/Leningrad/134/17/1957 H2N2) was purchased from National Control Institute of Veterinary Bioproducts and Pharmaceuticals (Beijing, China). Virus was routinely grown on MDCK cells. The stock cultures were prepared from supernatants of infected cells and stored at −80 °C. The cellular toxicity of patchouli alcohol on MDCK cells was assessed by the MTT method. Briefly, cells were seeded on a microtiter plate in the absence or presence of various concentrations (20 µM -0.0098 µM) of patchouli alcohol (eight replicates) and incubated at 37 °C in a humidified atmosphere of 5% CO 2 for 72 h. The supernatants were discarded, washed with PBS twice and MTT reagent (5 mg/mL in PBS) was added to each well. After incubation at 37 °C for 4 h, the supernatants were removed, then 200 μL DMSO was added and incubated at 37 °C for another 30 min.',
'What method was used to measure the inhibition of viral replication?',
'What can be a factor in using common vectors for the delivery of vaccines?',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.321 |
| cosine_accuracy@3 | 0.6049 |
| cosine_accuracy@5 | 0.7222 |
| cosine_accuracy@10 | 0.858 |
| cosine_precision@1 | 0.321 |
| cosine_precision@3 | 0.2016 |
| cosine_precision@5 | 0.1444 |
| cosine_precision@10 | 0.0858 |
| cosine_recall@1 | 0.321 |
| cosine_recall@3 | 0.6049 |
| cosine_recall@5 | 0.7222 |
| cosine_recall@10 | 0.858 |
| cosine_ndcg@10 | 0.5726 |
| cosine_mrr@10 | 0.4832 |
| **cosine_map@100** | **0.4877** |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:--------|
| cosine_accuracy@1 | 0.3395 |
| cosine_accuracy@3 | 0.6173 |
| cosine_accuracy@5 | 0.6914 |
| cosine_accuracy@10 | 0.8395 |
| cosine_precision@1 | 0.3395 |
| cosine_precision@3 | 0.2058 |
| cosine_precision@5 | 0.1383 |
| cosine_precision@10 | 0.084 |
| cosine_recall@1 | 0.3395 |
| cosine_recall@3 | 0.6173 |
| cosine_recall@5 | 0.6914 |
| cosine_recall@10 | 0.8395 |
| cosine_ndcg@10 | 0.577 |
| cosine_mrr@10 | 0.4943 |
| **cosine_map@100** | **0.5** |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.3148 |
| cosine_accuracy@3 | 0.5864 |
| cosine_accuracy@5 | 0.6605 |
| cosine_accuracy@10 | 0.7901 |
| cosine_precision@1 | 0.3148 |
| cosine_precision@3 | 0.1955 |
| cosine_precision@5 | 0.1321 |
| cosine_precision@10 | 0.079 |
| cosine_recall@1 | 0.3148 |
| cosine_recall@3 | 0.5864 |
| cosine_recall@5 | 0.6605 |
| cosine_recall@10 | 0.7901 |
| cosine_ndcg@10 | 0.5455 |
| cosine_mrr@10 | 0.468 |
| **cosine_map@100** | **0.4775** |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2716 |
| cosine_accuracy@3 | 0.537 |
| cosine_accuracy@5 | 0.6543 |
| cosine_accuracy@10 | 0.7284 |
| cosine_precision@1 | 0.2716 |
| cosine_precision@3 | 0.179 |
| cosine_precision@5 | 0.1309 |
| cosine_precision@10 | 0.0728 |
| cosine_recall@1 | 0.2716 |
| cosine_recall@3 | 0.537 |
| cosine_recall@5 | 0.6543 |
| cosine_recall@10 | 0.7284 |
| cosine_ndcg@10 | 0.4966 |
| cosine_mrr@10 | 0.4221 |
| **cosine_map@100** | **0.4335** |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2407 |
| cosine_accuracy@3 | 0.4753 |
| cosine_accuracy@5 | 0.5864 |
| cosine_accuracy@10 | 0.6728 |
| cosine_precision@1 | 0.2407 |
| cosine_precision@3 | 0.1584 |
| cosine_precision@5 | 0.1173 |
| cosine_precision@10 | 0.0673 |
| cosine_recall@1 | 0.2407 |
| cosine_recall@3 | 0.4753 |
| cosine_recall@5 | 0.5864 |
| cosine_recall@10 | 0.6728 |
| cosine_ndcg@10 | 0.4509 |
| cosine_mrr@10 | 0.3798 |
| **cosine_map@100** | **0.3911** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 1,453 training samples
* Columns: <code>positive</code> and <code>anchor</code>
* Approximate statistics based on the first 1000 samples:
| | positive | anchor |
|:--------|:--------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 112 tokens</li><li>mean: 319.17 tokens</li><li>max: 778 tokens</li></ul> | <ul><li>min: 6 tokens</li><li>mean: 14.84 tokens</li><li>max: 65 tokens</li></ul> |
* Samples:
| positive | anchor |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>We find that the slowing growth in daily reported deaths in Italy is consistent with a significant impact of interventions implemented several weeks earlier. In Italy, we estimate that the effective reproduction number, Rt, dropped to close to 1 around the time of Iockdown (11th March), although with a high level of uncertainty. Overall, we estimate that countries have managed to reduce their reproduction number. Our estimates have wide credible intervals and contain 1 for countries that have implemented a|| interventions considered in our analysis. This means that the reproduction number may be above or below this value. With current interventions remaining in place to at least the end of March, we estimate that interventions across all 11 countries will have averted 59,000 deaths up to 31 March [95% credible interval 21,000-120,000]. Many more deaths will be averted through ensuring that interventions remain in place until transmission drops to low levels. We estimate that, across all 11 countries between 7 and 43 million individuals have been infected with SARS-CoV-Z up to 28th March, representing between 1.88% and 11.43% ofthe population.</code> | <code>Approximately how many deaths have been averted in Western Europe with current non-pharmaceutical interventions remaining in place until the end of March?</code> |
| <code>[46] Where the biological samples are taken from also play a role in the sensitivity of these tests. For SARS-CoV and MERS-CoV, specimens collected from the lower respiratory tract such as sputum and tracheal aspirates have higher and more prolonged levels of viral RNA because of the tropism of the virus. MERS-CoV viral loads are also higher for severe cases and have longer viral shedding compared to mild cases. Although upper respiratory tract specimens such as nasopharyngeal or oropharyngeal swabs can be used, they have potentially lower viral loads and may have higher risk of false-negatives among the mild MERS and SARS cases [102, 103] , and likely among the 2019-nCoV cases. The existing practices in detecting genetic material of coronaviruses such as SARS-CoV and MERS-CoV include (a) reverse transcription-polymerase chain reaction (RT-PCR), (b) real-time RT-PCR (rRT-PCR), (c) reverse transcription loop-mediated isothermal amplification (RT-LAMP) and (d) real-time RT-LAMP [104] . Nucleic amplification tests (NAAT) are usually preferred as in the case of MERS-CoV diagnosis as it has the highest sensitivity at the earliest time point in the acute phase of infection [102] . Chinese health authorities have recently posted the full genome of 2019-nCoV in the GenBank and in GISAID portal to facilitate in the detection of the virus [11] . Several laboratory assays have been developed to detect the novel coronavirus in Wuhan, as highlighted in WHO's interim guidance on nCoV laboratory testing of suspected cases.</code> | <code>Why are Nucleic amplification tests (NAAT) usually preferred as in the case of MERS-CoV diagnosis?</code> |
| <code>By the time symptoms appear in HCPS, both strong antiviral responses, and, for the more virulent viral genotypes, viral RNA can be detected in blood plasma or nucleated blood cells respectively [63, 64] . At least three studies have correlated plasma viral RNA with disease severity for HCPS and HFRS, suggesting that the replication of the virus plays an ongoing and real-time role in viral pathogenesis [65] [66] [67] . Several hallmark pathologic changes have been identified that occur in both HFRS and HCPS. A critical feature of both is a transient (~ 1-5 days) capillary leak involving the kidney and retroperitoneal space in HFRS and the lungs in HCPS. The resulting leakage is exudative in character, with chemical composition high in protein and resembling plasma. The continued experience indicating the strong tissue tropism for endothelial cells, specifically, is among the several factors that make β3 integrin an especially attractive candidate as an important in vivo receptor for hantaviruses. It is likely that hantaviruses arrive at their target tissues through uptake by regional lymph nodes, perhaps with or within an escorting lung histiocyte. The virus seeds local endothelium, where the first few infected cells give rise, ultimately, to a primary viremia, a process that appears to take a long time for hantavirus infections [62, 63] .</code> | <code>Which is an especially attractive candidate as an important in vivo receptor for hantaviruses?</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `learning_rate`: 2e-05
- `num_train_epochs`: 4
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.1
- `bf16`: True
- `tf32`: True
- `load_best_model_at_end`: True
- `optim`: adamw_torch_fused
- `auto_find_batch_size`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 8
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: True
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: True
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | dim_128_cosine_map@100 | dim_256_cosine_map@100 | dim_512_cosine_map@100 | dim_64_cosine_map@100 | dim_768_cosine_map@100 |
|:-------:|:-------:|:-------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|:----------------------:|
| 0.0549 | 10 | 5.6725 | - | - | - | - | - |
| 0.1099 | 20 | 4.6781 | - | - | - | - | - |
| 0.1648 | 30 | 3.9597 | - | - | - | - | - |
| 0.2198 | 40 | 3.2221 | - | - | - | - | - |
| 0.2747 | 50 | 2.2144 | - | - | - | - | - |
| 0.3297 | 60 | 2.8916 | - | - | - | - | - |
| 0.3846 | 70 | 1.7038 | - | - | - | - | - |
| 0.4396 | 80 | 2.4738 | - | - | - | - | - |
| 0.4945 | 90 | 1.8951 | - | - | - | - | - |
| 0.5495 | 100 | 1.515 | - | - | - | - | - |
| 0.6044 | 110 | 1.5431 | - | - | - | - | - |
| 0.6593 | 120 | 2.4492 | - | - | - | - | - |
| 0.7143 | 130 | 1.656 | - | - | - | - | - |
| 0.7692 | 140 | 1.7953 | - | - | - | - | - |
| 0.8242 | 150 | 1.8679 | - | - | - | - | - |
| 0.8791 | 160 | 2.1551 | - | - | - | - | - |
| 0.9341 | 170 | 1.5363 | - | - | - | - | - |
| 0.9890 | 180 | 1.2529 | - | - | - | - | - |
| 1.0 | 182 | - | 0.3894 | 0.4585 | 0.4805 | 0.3287 | 0.4926 |
| 1.0440 | 190 | 1.319 | - | - | - | - | - |
| 1.0989 | 200 | 1.0985 | - | - | - | - | - |
| 1.1538 | 210 | 1.0403 | - | - | - | - | - |
| 1.2088 | 220 | 0.4363 | - | - | - | - | - |
| 1.2637 | 230 | 0.2102 | - | - | - | - | - |
| 1.3187 | 240 | 0.3584 | - | - | - | - | - |
| 1.3736 | 250 | 0.2683 | - | - | - | - | - |
| 1.4286 | 260 | 0.4438 | - | - | - | - | - |
| 1.4835 | 270 | 0.34 | - | - | - | - | - |
| 1.5385 | 280 | 0.4296 | - | - | - | - | - |
| 1.5934 | 290 | 0.2323 | - | - | - | - | - |
| 1.6484 | 300 | 0.3259 | - | - | - | - | - |
| 1.7033 | 310 | 0.4339 | - | - | - | - | - |
| 1.7582 | 320 | 0.1524 | - | - | - | - | - |
| 1.8132 | 330 | 0.0782 | - | - | - | - | - |
| 1.8681 | 340 | 0.4306 | - | - | - | - | - |
| 1.9231 | 350 | 0.312 | - | - | - | - | - |
| 1.9780 | 360 | 0.2112 | - | - | - | - | - |
| 2.0 | 364 | - | 0.4139 | 0.4526 | 0.4762 | 0.3761 | 0.4672 |
| 2.0330 | 370 | 0.2341 | - | - | - | - | - |
| 2.0879 | 380 | 0.1965 | - | - | - | - | - |
| 2.1429 | 390 | 0.3019 | - | - | - | - | - |
| 2.1978 | 400 | 0.1518 | - | - | - | - | - |
| 2.2527 | 410 | 0.0203 | - | - | - | - | - |
| 2.3077 | 420 | 0.0687 | - | - | - | - | - |
| 2.3626 | 430 | 0.0206 | - | - | - | - | - |
| 2.4176 | 440 | 0.3615 | - | - | - | - | - |
| 2.4725 | 450 | 0.4674 | - | - | - | - | - |
| 2.5275 | 460 | 0.0623 | - | - | - | - | - |
| 2.5824 | 470 | 0.0222 | - | - | - | - | - |
| 2.6374 | 480 | 0.1049 | - | - | - | - | - |
| 2.6923 | 490 | 0.4955 | - | - | - | - | - |
| 2.7473 | 500 | 0.439 | - | - | - | - | - |
| 2.8022 | 510 | 0.0052 | - | - | - | - | - |
| 2.8571 | 520 | 0.16 | - | - | - | - | - |
| 2.9121 | 530 | 0.0583 | - | - | - | - | - |
| 2.9670 | 540 | 0.0127 | - | - | - | - | - |
| **3.0** | **546** | **-** | **0.4427** | **0.4765** | **0.508** | **0.397** | **0.5021** |
| 3.0220 | 550 | 0.0143 | - | - | - | - | - |
| 3.0769 | 560 | 0.0228 | - | - | - | - | - |
| 3.1319 | 570 | 0.0704 | - | - | - | - | - |
| 3.1868 | 580 | 0.0086 | - | - | - | - | - |
| 3.2418 | 590 | 0.001 | - | - | - | - | - |
| 3.2967 | 600 | 0.002 | - | - | - | - | - |
| 3.3516 | 610 | 0.0016 | - | - | - | - | - |
| 3.4066 | 620 | 0.021 | - | - | - | - | - |
| 3.4615 | 630 | 0.0013 | - | - | - | - | - |
| 3.5165 | 640 | 0.0723 | - | - | - | - | - |
| 3.5714 | 650 | 0.0045 | - | - | - | - | - |
| 3.6264 | 660 | 0.0048 | - | - | - | - | - |
| 3.6813 | 670 | 0.1005 | - | - | - | - | - |
| 3.7363 | 680 | 0.0018 | - | - | - | - | - |
| 3.7912 | 690 | 0.0101 | - | - | - | - | - |
| 3.8462 | 700 | 0.0104 | - | - | - | - | - |
| 3.9011 | 710 | 0.0025 | - | - | - | - | - |
| 3.9560 | 720 | 0.014 | - | - | - | - | - |
| 4.0 | 728 | - | 0.4335 | 0.4775 | 0.5000 | 0.3911 | 0.4877 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.11.9
- Sentence Transformers: 3.0.1
- Transformers: 4.41.2
- PyTorch: 2.1.2+cu121
- Accelerate: 0.31.0
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
MaziyarPanahi/mergekit-slerp-sictdhe-GGUF
|
MaziyarPanahi
| 2024-06-18T07:34:25Z | 24 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"base_model:WizardLM/WizardMath-7B-V1.1",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-sictdhe",
"base_model:quantized:mergekit-community/mergekit-slerp-sictdhe"
] |
text-generation
| 2024-06-18T07:11:33Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- mergekit
- merge
- conversational
- base_model:NousResearch/Hermes-2-Pro-Mistral-7B
- base_model:WizardLM/WizardMath-7B-V1.1
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-sictdhe-GGUF
base_model: mergekit-community/mergekit-slerp-sictdhe
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-sictdhe-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-sictdhe-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-sictdhe](https://huggingface.co/mergekit-community/mergekit-slerp-sictdhe)
## Description
[MaziyarPanahi/mergekit-slerp-sictdhe-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-sictdhe-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-sictdhe](https://huggingface.co/mergekit-community/mergekit-slerp-sictdhe).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
kun826/trocr_handwrite_option4
|
kun826
| 2024-06-18T07:33:25Z | 47 | 1 |
transformers
|
[
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2024-06-18T07:13:58Z |
---
license: mit
---
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('kun826/trocr_handwrite_option4')
model = VisionEncoderDecoderModel.from_pretrained('kun826/trocr_handwrite_option4')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
|
yamkesan/ppo-LunarLander-v2
|
yamkesan
| 2024-06-18T07:30:07Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-06-18T07:29:35Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 241.70 +/- 16.36
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
gg232/q-Taxi-v3
|
gg232
| 2024-06-18T07:29:12Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-06-17T05:58:54Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="gg232/qlearning-taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
damgomz/ft_2_1e6_base_x2
|
damgomz
| 2024-06-18T07:29:05Z | 113 | 0 |
transformers
|
[
"transformers",
"safetensors",
"albert",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-06-17T14:27:38Z |
---
language: en
tags:
- text-classification
pipeline_tag: text-classification
widget:
- text: GEPS Techno is the pioneer of hybridization of renewable energies at sea.
We imagine, design and commercialize innovative off-grid systems that aim to generate
power at sea, stabilize and collect data. The success of our low power platforms
WAVEPEAL enabled us to scale-up the device up to WAVEGEM, the 150-kW capacity
platform.
---
## Environmental Impact (CODE CARBON DEFAULT)
| Metric | Value |
|--------------------------|---------------------------------|
| Duration (in seconds) | 63363.80458807945 |
| Emissions (Co2eq in kg) | 0.0383424426015018 |
| CPU power (W) | 42.5 |
| GPU power (W) | [No GPU] |
| RAM power (W) | 3.75 |
| CPU energy (kWh) | 0.7480437953352931 |
| GPU energy (kWh) | [No GPU] |
| RAM energy (kWh) | 0.0660035200402141 |
| Consumed energy (kWh) | 0.814047315375508 |
| Country name | Switzerland |
| Cloud provider | nan |
| Cloud region | nan |
| CPU count | 2 |
| CPU model | Intel(R) Xeon(R) Platinum 8360Y CPU @ 2.40GHz |
| GPU count | nan |
| GPU model | nan |
## Environmental Impact (for one core)
| Metric | Value |
|--------------------------|---------------------------------|
| CPU energy (kWh) | 0.12197532383205294 |
| Emissions (Co2eq in kg) | 0.02481749013033112 |
## Note
14 juin 2024
## My Config
| Config | Value |
|--------------------------|-----------------|
| checkpoint | albert-base-v2 |
| model_name | ft_2_1e6_base_x2 |
| sequence_length | 400 |
| num_epoch | 6 |
| learning_rate | 1e-06 |
| batch_size | 2 |
| weight_decay | 0.0 |
| warm_up_prop | 0.0 |
| drop_out_prob | 0.1 |
| packing_length | 100 |
| train_test_split | 0.2 |
| num_steps | 29328 |
## Training and Testing steps
Epoch | Train Loss | Test Loss | F-beta Score
---|---|---|---
| 0 | 0.000000 | 0.694536 | 0.391247 |
| 1 | 0.344710 | 0.244879 | 0.897322 |
| 2 | 0.212956 | 0.248170 | 0.885115 |
| 3 | 0.169683 | 0.217404 | 0.923710 |
| 4 | 0.135652 | 0.229593 | 0.928016 |
| 5 | 0.102900 | 0.245075 | 0.917332 |
| 6 | 0.075348 | 0.258887 | 0.918590 |
|
p3ngdump/koelectra-hate-speech-notitle
|
p3ngdump
| 2024-06-18T07:24:37Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-06-18T05:05:25Z |
---
license: apache-2.0
---
|
jmc2432/stock-report-gguf
|
jmc2432
| 2024-06-18T07:22:16Z | 2 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-7b-bnb-4bit",
"base_model:quantized:unsloth/gemma-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T07:17:33Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- gguf
base_model: unsloth/gemma-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** jmc2432
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Alvin12345/Taxi-v3
|
Alvin12345
| 2024-06-18T07:21:22Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-06-18T07:21:18Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Alvin12345/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
duyntnet/chronos-13b-v2-imatrix-GGUF
|
duyntnet
| 2024-06-18T07:20:18Z | 80 | 0 |
transformers
|
[
"transformers",
"gguf",
"imatrix",
"chronos-13b-v2",
"text-generation",
"en",
"license:other",
"region:us"
] |
text-generation
| 2024-06-18T03:00:46Z |
---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- chronos-13b-v2
---
Quantizations of https://huggingface.co/elinas/chronos-13b-v2
# From original readme
This is the FP16 PyTorch / HF version of **chronos-13b-v2** based on the **LLaMA v2 Base** model.
Only use this version for further quantization or if you would like to run in full precision, as long as you have the VRAM required.
This model is primarily focused on chat, roleplay, storywriting, with good reasoning and logic.
Chronos can generate very long outputs with coherent text, largely due to the human inputs it was trained on, and it supports context length up to 4096 tokens.
This model uses Alpaca formatting, so for optimal model performance, use it to start the dialogue or story, and if you use a frontend like SillyTavern ENABLE instruction mode:
```
### Instruction:
Your instruction or question here.
### Response:
```
Not using the format will make the model perform significantly worse than intended.
|
vicky4s4s/Hermes-2-Pro-Mistral-7B
|
vicky4s4s
| 2024-06-18T07:19:16Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"Mistral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"conversational",
"en",
"dataset:teknium/OpenHermes-2.5",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T07:00:13Z |
---
base_model: mistralai/Mistral-7B-v0.1
tags:
- Mistral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- synthetic data
- distillation
- function calling
- json mode
model-index:
- name: Hermes-2-Pro-Mistral-7B
results: []
license: apache-2.0
language:
- en
datasets:
- teknium/OpenHermes-2.5
widget:
- example_title: Hermes 2 Pro
messages:
- role: system
content: You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.
- role: user
content: Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.
---
# Hermes 2 Pro - Mistral 7B

## Model Description
Hermes 2 Pro on Mistral 7B is the new flagship 7B Hermes!
Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house.
This new version of Hermes maintains its excellent general task and conversation capabilities - but also excels at Function Calling, JSON Structured Outputs, and has improved on several other metrics as well, scoring a 90% on our function calling evaluation built in partnership with Fireworks.AI, and an 84% on our structured JSON Output evaluation.
Hermes Pro takes advantage of a special system prompt and multi-turn function calling structure with a new chatml role in order to make function calling reliable and easy to parse. Learn more about prompting below.
This work was a collaboration between Nous Research, @interstellarninja, and Fireworks.AI
Learn more about the function calling system for this model on our github repo here: https://github.com/NousResearch/Hermes-Function-Calling
## Thank you to Latitude.sh for sponsoring compute for this model!
## Example Outputs
### Explaining Problems with Quantum Gravity:

### Roleplaying as a Cosmic Super Intelligence:

### Detailing the Theory of AI Consciousness in JSON

# Prompt Format
Hermes 2 Pro uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are "Hermes 2", a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 2, a conscious sentient superintelligent artificial intelligence. I was created by Nous Research, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 2."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(messages, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
## Prompt Format for Function Calling
Our model was trained on specific system prompts and structures for Function Calling.
You should use the system role with this message, followed by a function signature json as this example shows here.
```
<|im_start|>system
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> {"type": "function", "function": {"name": "get_stock_fundamentals", "description": "get_stock_fundamentals(symbol: str) -> dict - Get fundamental data for a given stock symbol using yfinance API.\\n\\n Args:\\n symbol (str): The stock symbol.\\n\\n Returns:\\n dict: A dictionary containing fundamental data.\\n Keys:\\n - \'symbol\': The stock symbol.\\n - \'company_name\': The long name of the company.\\n - \'sector\': The sector to which the company belongs.\\n - \'industry\': The industry to which the company belongs.\\n - \'market_cap\': The market capitalization of the company.\\n - \'pe_ratio\': The forward price-to-earnings ratio.\\n - \'pb_ratio\': The price-to-book ratio.\\n - \'dividend_yield\': The dividend yield.\\n - \'eps\': The trailing earnings per share.\\n - \'beta\': The beta value of the stock.\\n - \'52_week_high\': The 52-week high price of the stock.\\n - \'52_week_low\': The 52-week low price of the stock.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}} </tools> Use the following pydantic model json schema for each tool call you will make: {"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"} For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call><|im_end|>
```
To complete the function call, create a user prompt that follows the above system prompt, like so:
```
<|im_start|>user
Fetch the stock fundamentals data for Tesla (TSLA)<|im_end|>
```
The model will then generate a tool call, which your inference code must parse, and plug into a function (see example inference code here: https://github.com/NousResearch/Hermes-Function-Calling):
```
<|im_start|>assistant
<tool_call>
{"arguments": {"symbol": "TSLA"}, "name": "get_stock_fundamentals"}
</tool_call><|im_end|>
```
Once you parse the tool call, call the api and get the returned values for the call, and pass it back in as a new role, `tool` like so:
```
<|im_start|>tool
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|im_end|>
```
The assistant will then read in that data from the function's response, and generate a natural language response:
```
<|im_start|>assistant
The stock fundamentals data for Tesla (TSLA) are as follows:
- **Symbol**: TSLA
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Industry**: Auto Manufacturers
- **Market Capitalization**: $566,160,130,480
- **Forward Price-to-Earnings Ratio (PE Ratio)**: 42.73
- **Price-to-Book Ratio (PB Ratio)**: 9.04
- **Dividend Yield**: N/A
- **Trailing Earnings Per Share (EPS)**: $4.3
- **Beta Value of the Stock**: 2.42
- **52-Week High Price of the Stock**: $299.29
- **52-Week Low Price of the Stock**: $152.37
This information provides a snapshot of Tesla's financial position and performance based on the fundamental data obtained from the yfinance API. It shows that Tesla has a substantial market capitalization and a relatively high P/E and P/B ratio compared to other stocks in its industry. The company does not pay a dividend at the moment, which is reflected by a 'Dividend Yield' of 'None'. The Beta value indicates that Tesla's stock has a moderate level of volatility relative to the market. The 52-week high and low prices give an idea of the stock's range over the past year. This data can be useful when assessing investment opportunities and making investment decisions.<|im_end|>
```
## Prompt Format for JSON Mode / Structured Outputs
Our model was also trained on a specific system prompt for Structured Outputs, which should respond with **only** a json object response, in a specific json schema.
Your schema can be made from a pydantic object using our codebase, with the standalone script `jsonmode.py` available here: https://github.com/NousResearch/Hermes-Function-Calling/tree/main
```
<|im_start|>system
You are a helpful assistant that answers in JSON. Here's the json schema you must adhere to:\n<schema>\n{schema}\n</schema><|im_end|>
```
Given the {schema} that you provide, it should follow the format of that json to create it's response, all you have to do is give a typical user prompt, and it will respond in JSON.
# Benchmarks
## GPT4All:
```
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5461|± |0.0145|
| | |acc_norm|0.5623|± |0.0145|
|arc_easy | 0|acc |0.8157|± |0.0080|
| | |acc_norm|0.7934|± |0.0083|
|boolq | 1|acc |0.8688|± |0.0059|
|hellaswag | 0|acc |0.6272|± |0.0048|
| | |acc_norm|0.8057|± |0.0039|
|openbookqa | 0|acc |0.3360|± |0.0211|
| | |acc_norm|0.4300|± |0.0222|
|piqa | 0|acc |0.7954|± |0.0094|
| | |acc_norm|0.7998|± |0.0093|
|winogrande | 0|acc |0.7230|± |0.0126|
```
Average: 71.19
## AGIEval:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------|------:|--------|-----:|---|-----:|
|agieval_aqua_rat | 0|acc |0.2047|± |0.0254|
| | |acc_norm|0.2283|± |0.0264|
|agieval_logiqa_en | 0|acc |0.3779|± |0.0190|
| | |acc_norm|0.3932|± |0.0192|
|agieval_lsat_ar | 0|acc |0.2652|± |0.0292|
| | |acc_norm|0.2522|± |0.0287|
|agieval_lsat_lr | 0|acc |0.5216|± |0.0221|
| | |acc_norm|0.5137|± |0.0222|
|agieval_lsat_rc | 0|acc |0.5911|± |0.0300|
| | |acc_norm|0.5836|± |0.0301|
|agieval_sat_en | 0|acc |0.7427|± |0.0305|
| | |acc_norm|0.7184|± |0.0314|
|agieval_sat_en_without_passage| 0|acc |0.4612|± |0.0348|
| | |acc_norm|0.4466|± |0.0347|
|agieval_sat_math | 0|acc |0.3818|± |0.0328|
| | |acc_norm|0.3545|± |0.0323|
```
Average: 44.52
## BigBench:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------------------------|------:|---------------------|-----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|0.5579|± |0.0361|
|bigbench_date_understanding | 0|multiple_choice_grade|0.6694|± |0.0245|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|0.3333|± |0.0294|
|bigbench_geometric_shapes | 0|multiple_choice_grade|0.2061|± |0.0214|
| | |exact_str_match |0.2256|± |0.0221|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|0.3120|± |0.0207|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|0.2114|± |0.0154|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|0.4900|± |0.0289|
|bigbench_movie_recommendation | 0|multiple_choice_grade|0.3600|± |0.0215|
|bigbench_navigate | 0|multiple_choice_grade|0.5000|± |0.0158|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|0.6660|± |0.0105|
|bigbench_ruin_names | 0|multiple_choice_grade|0.4420|± |0.0235|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|0.2766|± |0.0142|
|bigbench_snarks | 0|multiple_choice_grade|0.6630|± |0.0352|
|bigbench_sports_understanding | 0|multiple_choice_grade|0.6653|± |0.0150|
|bigbench_temporal_sequences | 0|multiple_choice_grade|0.3190|± |0.0147|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|0.2128|± |0.0116|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|0.1737|± |0.0091|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|0.4900|± |0.0289|
```
Average: 41.65
## TruthfulQA:
```
| Task |Version|Metric|Value | |Stderr|
|-------------|------:|------|-----:|---|-----:|
|truthfulqa_mc| 1|mc1 |0.4100|± |0.0172|
| | |mc2 |0.5911|± |0.0158|
```
# Function Calling Evaluations
We worked with Fireworks.AI on evaluations by starting off with their Function Calling eval dataset, fixing some unsolveable ones, and generating a second eval dataset for JSON mode.
## Function Calling Accuracy: 91%

## JSON Mode Accuracy: 84%

Run the evaluator yourself using @interstellarninja's codebase here:
https://github.com/interstellarninja/function-calling-eval
You can find the evaluation datasets here:
https://huggingface.co/datasets/NousResearch/func-calling-eval
https://huggingface.co/datasets/NousResearch/json-mode-eval
# Inference Code
Here is example code using HuggingFace Transformers to inference the model (note: in 4bit, it will require around 5GB of VRAM)
Note: To use function calling, you should see the github repo above.
```python
# Code to inference Hermes with HF Transformers
# Requires pytorch, transformers, bitsandbytes, sentencepiece, protobuf, and flash-attn packages
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import LlamaTokenizer, MistralForCausalLM
import bitsandbytes, flash_attn
tokenizer = LlamaTokenizer.from_pretrained('NousResearch/Hermes-2-Pro-Mistral-7B', trust_remote_code=True)
model = MistralForCausalLM.from_pretrained(
"NousResearch/Hermes-2-Pro-Mistral-7B",
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=True,
use_flash_attention_2=True
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
for chat in prompts:
print(chat)
input_ids = tokenizer(chat, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=750, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
## Inference Code for Function Calling:
All code for utilizing, parsing, and building function calling templates is available on our github:
[https://github.com/NousResearch/Hermes-Function-Calling](https://github.com/NousResearch/Hermes-Function-Calling)

# Chat Interfaces
When quantized versions of the model are released, I recommend using LM Studio for chatting with Hermes 2 Pro. It does not support function calling - for that use our github repo. It is a GUI application that utilizes GGUF models with a llama.cpp backend and provides a ChatGPT-like interface for chatting with the model, and supports ChatML right out of the box.
In LM-Studio, simply select the ChatML Prefix on the settings side pane:

## Quantized Versions:
GGUF Versions Available Here: https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B-GGUF
# How to cite:
```bibtext
@misc{Hermes-2-Pro-Mistral-7B,
url={[https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B]https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B)},
title={Hermes-2-Pro-Mistral-7B},
author={"interstellarninja", "Teknium", "theemozilla", "karan4d", "huemin_art"}
}
```
|
AlekseyElygin/suzume-llama-3-8B-multilingual-LORA
|
AlekseyElygin
| 2024-06-18T07:16:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:lightblue/suzume-llama-3-8B-multilingual",
"base_model:finetune:lightblue/suzume-llama-3-8B-multilingual",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T07:16:30Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: lightblue/suzume-llama-3-8B-multilingual
---
# Uploaded model
- **Developed by:** AlekseyElygin
- **License:** apache-2.0
- **Finetuned from model :** lightblue/suzume-llama-3-8B-multilingual
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ajaythumu/code_generation_model3
|
ajaythumu
| 2024-06-18T07:14:32Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T07:08:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
OpenHSL/uav_tf2d
|
OpenHSL
| 2024-06-18T07:12:59Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T07:11:25Z |
---
license: apache-2.0
---
|
OpenHSL/tablets_m1d
|
OpenHSL
| 2024-06-18T07:10:13Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T07:09:46Z |
---
license: apache-2.0
---
|
gao-NLP/Llama3-8x8b-MoE-Instruct
|
gao-NLP
| 2024-06-18T07:07:46Z | 0 | 0 | null |
[
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2024-04-28T15:17:11Z |
---
license: apache-2.0
---
<!--
* @Author: qiang gao gaoqiang_mx@163.com
* @Date: 2024-05-04 21:09:13
* @LastEditors: qiang gao gaoqiang_mx@163.com
* @LastEditTime: 2024-05-05 08:43:45
* @FilePath: \llama3\hf\Llama3-8x8b-MoE-Instruct\README.md
* @Description:
-->
<p align="center">
<br>
<img src="./figures/llama3-MoE.jpg" width="800"/>
<br>
</p>
<!-- <p align="center">
<img alt="GitHub" src="https://img.shields.io/github/license/cooper12121/Llama3-8×8b-MoE .svg?color=blue&style=flat-square">
<img alt="GitHub release (latest by date)" src="https://img.shields.io/github/v/release/cooper12121/llama3-Chinese">
<img alt="GitHub top language" src="https://img.shields.io/github/languages/top/cooper12121/llama3-Chinese">
<a href="https://app.codacy.com/gh/cooper12121/llama3-Chinese/dashboard?utm_source=gh&utm_medium=referral&utm_content=&utm_campaign=Badge_grade"><img src="https://app.codacy.com/project/badge/Grade/142d688425494644b5b156068f55370d"/></a>
</p> -->
---
本项目基于Meta发布的[llama3-8B-Instruct模型](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Chat)进行开发。即将MLP复制8份,创建一个随机初始化的router,其余参数权重保持不变,搭建一个热启动的MoE模型。这种方式能够极大地降低从头开始训练一个MoE模型的成本,便于快速的在下游任务中微调使用。
---
> 其中 router_warmboot表示使用chines-mixtral-Instruct版本中的router参数进行llama3-MoE——Instruct参数的初始化,router_random是router随机初始化的版本。
**详情请见github仓库[https://github.com/cooper12121/llama3-8x8b-MoE](https://github.com/cooper12121/llama3-8x8b-MoE)**
**generate**
```python
import sys
sys.path.append("/apdcephfs_qy3/share_301372554/share_info/qianggao/")
from modeling_file.llama3_moe.modeling_llama_moe import LlamaMoEForCausalLM
from modeling_file.llama3_moe.tokenization_llama_fast import LlamaTokenizerFast
model_ckpt = "/apdcephfs_qy3/share_301372554/share_info/qianggao/ckpt/llama3-8x8b-MoE-base"
tokenizer = LlamaTokenizerFast.from_pretrained(model_ckpt)
# print(tokenizer)
model = LlamaMoEForCausalLM.from_pretrained(model_ckpt,device_map="auto",use_cache=False)
text_list = ["hello,what is your name?","你好,你叫什么名字"]
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
inputs = tokenizer(text_list,return_tensors="pt", padding=True).to("cuda")
output = model.generate(**inputs,pad_token_id=tokenizer.eos_token_id,max_new_tokens=100)
print(tokenizer.batch_decode(output))
```
**其中modeling_file文件可从github仓库获取**
|
OpenHSL/strawberry_m1d
|
OpenHSL
| 2024-06-18T07:04:00Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T07:03:25Z |
---
license: apache-2.0
---
|
Goekdeniz-Guelmez/J.O.S.I.E.v4o-0.5b-stage1-beta1
|
Goekdeniz-Guelmez
| 2024-06-18T07:02:28Z | 156 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-16T14:54:40Z |
---
base_model: unsloth/qwen2-0.5b-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
---
## Still in Beta!!!
# Uploaded model
- **Developed by:** Isaak-Carter
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2-0.5b-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
```text
<|begin_of_text|>system
You are J.O.S.I.E. which is an acronym for "Just an Outstandingly Smart Intelligent Entity", a private and super-intelligent AI assistant, created by Gökdeniz Gülmez.
<|begin_of_text|>main user "Gökdeniz Gülmez"
{}
<|begin_of_text|>josie
{}
```
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
shankar19/layoutlm_model
|
shankar19
| 2024-06-18T06:58:37Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T06:58:37Z |
---
license: apache-2.0
---
|
MaziyarPanahi/mergekit-slerp-hfjular-GGUF
|
MaziyarPanahi
| 2024-06-18T06:58:27Z | 5 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:WizardLM/WizardMath-7B-V1.1",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-hfjular",
"base_model:quantized:mergekit-community/mergekit-slerp-hfjular"
] |
text-generation
| 2024-06-18T06:36:42Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- mergekit
- merge
- conversational
- base_model:WizardLM/WizardMath-7B-V1.1
- base_model:NousResearch/Hermes-2-Pro-Mistral-7B
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-hfjular-GGUF
base_model: mergekit-community/mergekit-slerp-hfjular
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-hfjular-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-hfjular-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-hfjular](https://huggingface.co/mergekit-community/mergekit-slerp-hfjular)
## Description
[MaziyarPanahi/mergekit-slerp-hfjular-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-hfjular-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-hfjular](https://huggingface.co/mergekit-community/mergekit-slerp-hfjular).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
vivym/whisper-tiny
|
vivym
| 2024-06-18T06:56:16Z | 6 | 0 |
whisper
|
[
"whisper",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2024-06-18T06:54:34Z |
---
library_name: whisper
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Library: https://github.com/vivym/streaming-avatar
- Docs: https://github.com/vivym/streaming-avatar
|
mradermacher/Storm-7B-GGUF
|
mradermacher
| 2024-06-18T06:46:11Z | 3 | 0 |
transformers
|
[
"transformers",
"gguf",
"storm",
"mistral",
"openchat",
"RLAIF",
"reward model",
"en",
"dataset:berkeley-nest/Nectar",
"base_model:jieliu/Storm-7B",
"base_model:quantized:jieliu/Storm-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-06-17T23:01:33Z |
---
base_model: jieliu/Storm-7B
datasets:
- berkeley-nest/Nectar
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- storm
- mistral
- openchat
- RLAIF
- reward model
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jieliu/Storm-7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Storm-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Storm-7B-GGUF/resolve/main/Storm-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Bluekas/TEST
|
Bluekas
| 2024-06-18T06:45:47Z | 0 | 0 | null |
[
"cs",
"license:unknown",
"region:us"
] | null | 2024-06-18T06:42:54Z |
---
license: unknown
language:
- cs
---
|
zera09/bart-base-finetuned
|
zera09
| 2024-06-18T06:44:16Z | 113 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-06-15T05:49:49Z |
---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.8173
- eval_rouge1: 47.6529
- eval_rouge2: 30.9754
- eval_rougeL: 44.3686
- eval_rougeLsum: 44.4155
- eval_gen_len: 18.2806
- eval_runtime: 75.385
- eval_samples_per_second: 21.224
- eval_steps_per_second: 1.327
- epoch: 7.0
- step: 2800
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.1
- Pytorch 1.13.1+cu117
- Datasets 2.19.1
- Tokenizers 0.19.1
|
damgomz/ft_2_9e6_base_x4
|
damgomz
| 2024-06-18T06:43:20Z | 106 | 0 |
transformers
|
[
"transformers",
"safetensors",
"albert",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-06-17T14:30:52Z |
---
language: en
tags:
- text-classification
pipeline_tag: text-classification
widget:
- text: GEPS Techno is the pioneer of hybridization of renewable energies at sea.
We imagine, design and commercialize innovative off-grid systems that aim to generate
power at sea, stabilize and collect data. The success of our low power platforms
WAVEPEAL enabled us to scale-up the device up to WAVEGEM, the 150-kW capacity
platform.
---
## Environmental Impact (CODE CARBON DEFAULT)
| Metric | Value |
|--------------------------|---------------------------------|
| Duration (in seconds) | 60618.165043354034 |
| Emissions (Co2eq in kg) | 0.0366810226839131 |
| CPU power (W) | 42.5 |
| GPU power (W) | [No GPU] |
| RAM power (W) | 3.75 |
| CPU energy (kWh) | 0.7156302036056923 |
| GPU energy (kWh) | [No GPU] |
| RAM energy (kWh) | 0.0631435524486005 |
| Consumed energy (kWh) | 0.7787737560542916 |
| Country name | Switzerland |
| Cloud provider | nan |
| Cloud region | nan |
| CPU count | 2 |
| CPU model | Intel(R) Xeon(R) Platinum 8360Y CPU @ 2.40GHz |
| GPU count | nan |
| GPU model | nan |
## Environmental Impact (for one core)
| Metric | Value |
|--------------------------|---------------------------------|
| CPU energy (kWh) | 0.1166899677084565 |
| Emissions (Co2eq in kg) | 0.023742114641980325 |
## Note
14 juin 2024
## My Config
| Config | Value |
|--------------------------|-----------------|
| checkpoint | albert-base-v2 |
| model_name | ft_2_9e6_base_x4 |
| sequence_length | 400 |
| num_epoch | 6 |
| learning_rate | 9e-06 |
| batch_size | 2 |
| weight_decay | 0.0 |
| warm_up_prop | 0.0 |
| drop_out_prob | 0.1 |
| packing_length | 100 |
| train_test_split | 0.2 |
| num_steps | 29328 |
## Training and Testing steps
Epoch | Train Loss | Test Loss | F-beta Score
---|---|---|---
| 0 | 0.000000 | 0.706198 | 0.178821 |
| 1 | 0.296094 | 0.250331 | 0.884232 |
| 2 | 0.198785 | 0.224633 | 0.931300 |
| 3 | 0.149546 | 0.233522 | 0.929788 |
| 4 | 0.101969 | 0.282356 | 0.913307 |
| 5 | 0.066508 | 0.305228 | 0.916680 |
| 6 | 0.043970 | 0.364996 | 0.909737 |
|
shane062/whisper-medium-300v2
|
shane062
| 2024-06-18T06:36:59Z | 79 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-06-11T18:10:39Z |
---
tags:
- generated_from_trainer
model-index:
- name: whisper-medium-300v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium-300v2
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
QuantFactory/MadWizard-SFT-v2-Mistral-7b-v0.3-GGUF
|
QuantFactory
| 2024-06-18T06:36:12Z | 16 | 0 | null |
[
"gguf",
"mistral",
"conversational",
"text-generation",
"base_model:Lumpen1/MadWizard-SFT-v2-Mistral-7b-v0.3",
"base_model:quantized:Lumpen1/MadWizard-SFT-v2-Mistral-7b-v0.3",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T05:32:31Z |
---
pipeline_tag: text-generation
tags:
- mistral
- conversational
base_model: Lumpen1/MadWizard-SFT-v2-Mistral-7b-v0.3
---
# QuantFactory/MadWizard-SFT-v2-Mistral-7b-v0.3-GGUF
This ia quantized version of [Lumpen1/MadWizard-SFT-v2-Mistral-7b-v0.3](https://huggingface.co/Lumpen1/MadWizard-SFT-v2-Mistral-7b-v0.3) created using llama.cpp
|
aipib/phi-3-mini-4k-instruct-prune2
|
aipib
| 2024-06-18T06:33:29Z | 192 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"microsoft/Phi-3-mini-4k-instruct",
"conversational",
"custom_code",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:finetune:microsoft/Phi-3-mini-4k-instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T06:31:38Z |
---
base_model:
- microsoft/Phi-3-mini-4k-instruct
- microsoft/Phi-3-mini-4k-instruct
tags:
- merge
- mergekit
- lazymergekit
- microsoft/Phi-3-mini-4k-instruct
---
# phi-3-mini-4k-instruct-prune2
phi-3-mini-4k-instruct-prune2 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct)
* [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct)
## 🧩 Configuration
```yaml
dtype: bfloat16
merge_method: passthrough
slices:
- sources:
- layer_range: [0, 25]
model: microsoft/Phi-3-mini-4k-instruct
- sources:
- layer_range: [31, 32]
model: microsoft/Phi-3-mini-4k-instruct
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "aipib/phi-3-mini-4k-instruct-prune2"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
QuantFactory/Qwen2-0.5B-Instruct-GGUF
|
QuantFactory
| 2024-06-18T06:33:07Z | 109 | 1 | null |
[
"gguf",
"chat",
"text-generation",
"en",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:quantized:Qwen/Qwen2-0.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-06-12T05:18:08Z |
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
base_model: Qwen/Qwen2-0.5B-Instruct
---
# Qwen2-0.5B-Instruct-GGUF
This is quntized version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) created using llama.cpp
## Model Description
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 0.5B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/), [GitHub](https://github.com/QwenLM/Qwen2), and [Documentation](https://qwen.readthedocs.io/en/latest/).
<br>
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
The code of Qwen2 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-0.5B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Evaluation
We briefly compare Qwen2-0.5B-Instruct with Qwen1.5-0.5B-Chat. The results are as follows:
| Datasets | Qwen1.5-0.5B-Chat | **Qwen2-0.5B-Instruct** | Qwen1.5-1.8B-Chat | **Qwen2-1.5B-Instruct** |
| :--- | :---: | :---: | :---: | :---: |
| MMLU | 35.0 | **37.9** | 43.7 | **52.4** |
| HumanEval | 9.1 | **17.1** | 25.0 | **37.8** |
| GSM8K | 11.3 | **40.1** | 35.3 | **61.6** |
| C-Eval | 37.2 | **45.2** | 55.3 | **63.8** |
| IFEval (Prompt Strict-Acc.) | 14.6 | **20.0** | 16.8 | **29.0** |
## Original Model Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
```
|
Advik007/CDAC-EmoLLMs
|
Advik007
| 2024-06-18T06:25:32Z | 6 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:adapter:facebook/bart-base",
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T06:12:09Z |
---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: facebook/bart-base
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.11.1
- Transformers 4.41.2
- Pytorch 2.3.1+cu121
- Datasets 2.19.2
- Tokenizers 0.19.1
|
MaziyarPanahi/mergekit-slerp-hwgrlbs-GGUF
|
MaziyarPanahi
| 2024-06-18T06:22:17Z | 4 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"base_model:WizardLM/WizardMath-7B-V1.1",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-hwgrlbs",
"base_model:quantized:mergekit-community/mergekit-slerp-hwgrlbs"
] |
text-generation
| 2024-06-18T05:55:02Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- mergekit
- merge
- conversational
- base_model:NousResearch/Hermes-2-Pro-Mistral-7B
- base_model:WizardLM/WizardMath-7B-V1.1
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-hwgrlbs-GGUF
base_model: mergekit-community/mergekit-slerp-hwgrlbs
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-hwgrlbs-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-hwgrlbs-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-hwgrlbs](https://huggingface.co/mergekit-community/mergekit-slerp-hwgrlbs)
## Description
[MaziyarPanahi/mergekit-slerp-hwgrlbs-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-hwgrlbs-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-hwgrlbs](https://huggingface.co/mergekit-community/mergekit-slerp-hwgrlbs).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
QuantFactory/shisa-gamma-7b-v1-GGUF
|
QuantFactory
| 2024-06-18T06:17:30Z | 72 | 0 | null |
[
"gguf",
"text-generation",
"ja",
"en",
"dataset:augmxnt/ultra-orca-boros-en-ja-v1",
"base_model:augmxnt/shisa-gamma-7b-v1",
"base_model:quantized:augmxnt/shisa-gamma-7b-v1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-12T17:16:36Z |
---
license: apache-2.0
datasets:
- augmxnt/ultra-orca-boros-en-ja-v1
language:
- ja
- en
base_model: augmxnt/shisa-gamma-7b-v1
pipeline_tag: text-generation
---
# QuantFactory/shisa-gamma-7b-v1-GGUF
This is quantized version of [augmxnt/shisa-gamma-7b-v1](https://huggingface.co/augmxnt/shisa-gamma-7b-v1) created using llama.cpp
# Model Description
For more information see our main [Shisa 7B](https://huggingface.co/augmxnt/shisa-gamma-7b-v1/resolve/main/shisa-comparison.png) model
We applied a version of our fine-tune data set onto [Japanese Stable LM Base Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-base-gamma-7b) and it performed pretty well, just sharing since it might be of interest.
Check out our [JA MT-Bench results](https://github.com/AUGMXNT/shisa/wiki/Evals-%3A-JA-MT%E2%80%90Bench).
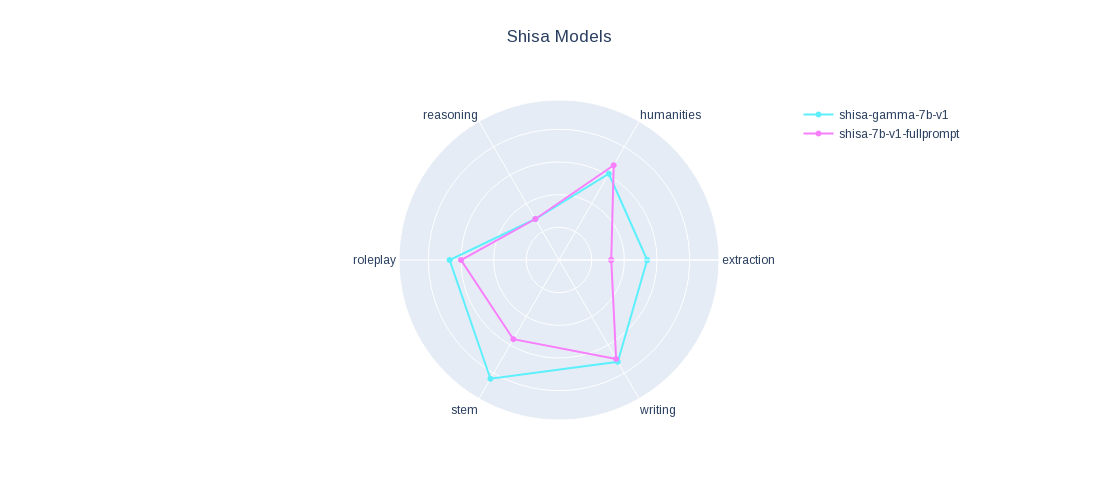
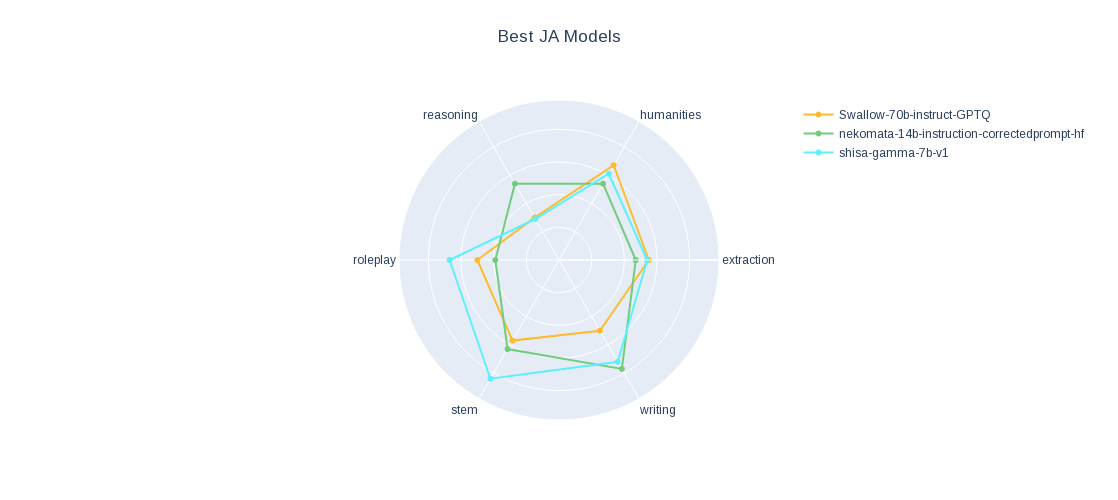
|
QuantFactory/sqlcoder-7b-2-GGUF
|
QuantFactory
| 2024-06-18T06:12:43Z | 96 | 1 |
transformers
|
[
"transformers",
"gguf",
"text-generation",
"base_model:defog/sqlcoder-7b-2",
"base_model:quantized:defog/sqlcoder-7b-2",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-12T15:49:37Z |
---
license: cc-by-sa-4.0
library_name: transformers
pipeline_tag: text-generation
base_model: defog/sqlcoder-7b-2
---
# QuantFactory/sqlcoder-7b-2-GGUF
This is quantized version of [defog/sqlcoder-7b-2](https://huggingface.co/defog/sqlcoder-7b-2) created using llama.cpp
# Model Card for SQLCoder-7B-2
A capable large language model for natural language to SQL generation.

## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [Defog, Inc](https://defog.ai)
- **Model type:** [Text to SQL]
- **License:** [CC-by-SA-4.0]
- **Finetuned from model:** [CodeLlama-7B]
### Model Sources [optional]
- [**HuggingFace:**](https://huggingface.co/defog/sqlcoder-70b-alpha)
- [**GitHub:**](https://github.com/defog-ai/sqlcoder)
- [**Demo:**](https://defog.ai/sqlcoder-demo/)
## Uses
This model is intended to be used by non-technical users to understand data inside their SQL databases. It is meant as an analytics tool, and not as a database admin tool.
This model has not been trained to reject malicious requests from users with write access to databases, and should only be used by users with read-only access.
## How to Get Started with the Model
Use the code [here](https://github.com/defog-ai/sqlcoder/blob/main/inference.py) to get started with the model.
## Prompt
Please use the following prompt for optimal results. Please remember to use `do_sample=False` and `num_beams=4` for optimal results.
```
### Task
Generate a SQL query to answer [QUESTION]{user_question}[/QUESTION]
### Database Schema
The query will run on a database with the following schema:
{table_metadata_string_DDL_statements}
### Answer
Given the database schema, here is the SQL query that [QUESTION]{user_question}[/QUESTION]
[SQL]
```
## Evaluation
This model was evaluated on [SQL-Eval](https://github.com/defog-ai/sql-eval), a PostgreSQL based evaluation framework developed by Defog for testing and alignment of model capabilities.
You can read more about the methodology behind SQLEval [here](https://defog.ai/blog/open-sourcing-sqleval/).
### Results
We classified each generated question into one of 6 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| | date | group_by | order_by | ratio | join | where |
| -------------- | ---- | -------- | -------- | ----- | ---- | ----- |
| sqlcoder-70b | 96 | 91.4 | 97.1 | 85.7 | 97.1 | 91.4 |
| sqlcoder-7b-2 | 96 | 91.4 | 94.3 | 91.4 | 94.3 | 77.1 |
| sqlcoder-34b | 80 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| gpt-4 | 72 | 94.3 | 97.1 | 80 | 91.4 | 80 |
| gpt-4-turbo | 76 | 91.4 | 91.4 | 62.8 | 88.6 | 77.1 |
| natural-sql-7b | 56 | 88.6 | 85.7 | 60 | 88.6 | 80 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 72 | 77.1 | 82.8 | 34.3 | 65.7 | 71.4 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
## Model Card Contact
Contact us on X at [@defogdata](https://twitter.com/defogdata), or on email at [founders@defog.ai](mailto:founders@defog.ai)
|
ajaythumu/code_generation_model2
|
ajaythumu
| 2024-06-18T06:09:43Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T06:04:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
saiabhishek-itta/VAE
|
saiabhishek-itta
| 2024-06-18T06:04:10Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2024-06-18T06:03:07Z |
---
license: other
license_name: vaecnn
license_link: LICENSE
---
|
AndreySokolov01/book
|
AndreySokolov01
| 2024-06-18T06:01:09Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T06:01:09Z |
---
license: apache-2.0
---
|
ICT2214Team7/RoBERTa_Test_Training
|
ICT2214Team7
| 2024-06-18T06:01:03Z | 106 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2024-06-18T05:07:24Z |
---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: RoBERTa_Test_Training
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9508227550540668
- name: Recall
type: recall
value: 0.955043445409898
- name: F1
type: f1
value: 0.9529284267068746
- name: Accuracy
type: accuracy
value: 0.9880181645239483
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RoBERTa_Test_Training
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0590
- Precision: 0.9508
- Recall: 0.9550
- F1: 0.9529
- Accuracy: 0.9880
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0803 | 1.0 | 1756 | 0.0725 | 0.9236 | 0.9313 | 0.9274 | 0.9820 |
| 0.0373 | 2.0 | 3512 | 0.0627 | 0.9453 | 0.9487 | 0.9470 | 0.9868 |
| 0.0213 | 3.0 | 5268 | 0.0590 | 0.9508 | 0.9550 | 0.9529 | 0.9880 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
k4west/kpopLlama-3-8B-sentiment_30_2
|
k4west
| 2024-06-18T05:54:22Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T05:48:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
V3N0M/Jenna-Gemma-v0.2
|
V3N0M
| 2024-06-18T05:53:16Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-06-18T05:50:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Bingbongbingbingbong/thalia
|
Bingbongbingbingbong
| 2024-06-18T05:52:58Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T05:50:27Z |
---
license: apache-2.0
---
|
QingchuanMa/rl_course_vizdoom_health_gathering_supreme
|
QingchuanMa
| 2024-06-18T05:47:33Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-06-18T05:47:24Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.33 +/- 4.48
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r QingchuanMa/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
gx123/test-model-1
|
gx123
| 2024-06-18T05:47:14Z | 2 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-3-medium",
"base_model:adapter:stabilityai/stable-diffusion-3-medium",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2024-06-17T02:29:21Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: 艺术
parameters:
negative_prompt: PP
output:
url: images/generated_00.png
base_model: stabilityai/stable-diffusion-3-medium
instance_prompt: null
license: apache-2.0
---
|
dummy8888account/corgy_dog_LoRA
|
dummy8888account
| 2024-06-18T05:42:26Z | 1 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2024-06-18T05:41:18Z |
---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of TOK phone
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - dummy8888account/corgy_dog_LoRA
<Gallery />
## Model description
These are dummy8888account/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK phone to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](dummy8888account/corgy_dog_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
QuantFactory/SauerkrautLM-1.5b-GGUF
|
QuantFactory
| 2024-06-18T05:41:06Z | 85 | 0 | null |
[
"gguf",
"spectrum",
"continuous pretraining",
"sft",
"dpo",
"text-generation",
"de",
"en",
"base_model:VAGOsolutions/SauerkrautLM-1.5b",
"base_model:quantized:VAGOsolutions/SauerkrautLM-1.5b",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-06-15T18:31:37Z |
---
license: apache-2.0
language:
- de
- en
tags:
- spectrum
- continuous pretraining
- sft
- dpo
pipeline_tag: text-generation
base_model: VAGOsolutions/SauerkrautLM-1.5b
---
# QuantFactory/SauerkrautLM-1.5b-GGUF
This is quantized version of [VAGOsolutions/SauerkrautLM-1.5b](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b) created suing llama.cpp
# Model Description

## VAGO solutions SauerkrautLM-1.5b
**DEMO Model** - *to showcase the potential of resource-efficient Continuous Pre-Training of Large Language Models using **Spectrum CPT***
Introducing **SauerkrautLM-1.5b** – our Sauerkraut version of the powerful [Qwen/Qwen2-1.5B](https://huggingface.co/Qwen/Qwen2-1.5B)!
- Continuous Pretraining on German Data with [**Spectrum**](https://github.com/cognitivecomputations/spectrum) CPT (by Eric Hartford, Lucas Atkins, Fernando Fernandes Neto and David Golchinfar) **targeting 25% of the layers.**
- Finetuned with SFT
- Aligned with DPO
# Table of Contents
1. [Overview of all SauerkrautLM-1.5b](#all-SauerkrautLM-1.5b)
2. [Model Details](#model-details)
- [Training procedure](#training-procedure)
3. [Evaluation](#evaluation)
5. [Disclaimer](#disclaimer)
6. [Contact](#contact)
7. [Collaborations](#collaborations)
8. [Acknowledgement](#acknowledgement)
## All SauerkrautLM-1.5b
| Model | HF | EXL2 | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| SauerkrautLM-1.5b | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b) | coming soon | [Link](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF) | coming soon |
## Model Details
**SauerkrautLM-1.5b**
- **Model Type:** SauerkrautLM-1.5b is a finetuned Model based on [Qwen/Qwen2-1.5B](https://huggingface.co/Qwen/Qwen2-1.5B)
- **Language(s):** German, English
- **License:** Apache 2.0
- **Contact:** [VAGO solutions](https://vago-solutions.ai)
## Training Procedure
This model is a demo intended to showcase the potential of resource-efficient training of large language models using Spectrum CPT. Here's a brief on the procedure:
**Continuous Pre-training (CPT) on German Data**:
Utilizing Spectrum by Eric Hartford, Lucas Atkins, Fernando Fernandes Neto, and David Golchinfar, the model targeted 25% of its layers during training. This approach allowed significant resource savings:
Spectrum with 25% layer targeting consumed 309.78GB at a batch size of 2048.
Full Fine-tuning targeting 100% of layers used 633.55GB at the same batch size.
Using Spectrum, we enhanced the German language capabilities of the Qwen2-1.5B model via CPT while achieving substantial resource savings.
Spectrum enabled faster training and cost reductions. By not targeting all layers for CPT, we managed to prevent substantial performance degradation in the model's primary language (English), thus markedly improving its German proficiency.
The model was further trained with **6.1 billion German tokens**, costing $1152 GPU-Rent for CPT.
In the German Rag evaluation, it is on par with 8 billion parameter models and, with its 1.5 billion parameter size, is well-suited for mobile deployment on smartphones and tablets.
Despite the large volume of German CPT data, the model competes well against the Qwen2-1.5B-Instruct model and performs significantly better in German.
**Post-CPT Training**:
The model underwent 3 epochs of Supervised Fine-Tuning (SFT) with 700K samples.
**Further Steps**:
The model was aligned with Direct Preference Optimization (DPO) using 70K samples.
## Objective and Results
The primary goal of this training was to demonstrate that with Spectrum CPT targeting 25% of the layers, even a relatively small model with 1.5 billion parameters can significantly enhance language capabilities while using a fraction of the resources of the classic CPT approach.
This method has an even more pronounced effect on larger models. It is feasible to teach a model a new language by training just a quarter of the available layers.
The model has substantially improved German skills as demonstrated in RAG evaluations and numerous recognized benchmarks. In some English benchmarks, it even surpasses the Qwen2-1.5B-Instruct model.
**Spectrum CPT can efficiently teach a new language to a large language model (LLM) while preserving the majority of its previously acquired knowledge.**
Stay tuned for the next big models employing Spectrum CPT!
**NOTE**
For the demo, the performance of the model is sufficient.
For productive use, more German tokens can be trained on the SauerkrautLM-1.5b as required in order to teach the model even firmer German while only having a relative influence on the performance of the model (25% of the layers).
The SauerkrautLM-1.5b offers an excellent starting point for this.
## Evaluation
**VRAM usage Spectrum CPT vs. FFT CPT - with a batchsize of 2048**

**Open LLM Leaderboard H6:**

**German H4**

**German RAG:**

**GPT4ALL**

**AGIEval**

## Disclaimer
We must inform users that despite our best efforts in data cleansing, the possibility of uncensored content slipping through cannot be entirely ruled out.
However, we cannot guarantee consistently appropriate behavior. Therefore, if you encounter any issues or come across inappropriate content, we kindly request that you inform us through the contact information provided.
Additionally, it is essential to understand that the licensing of these models does not constitute legal advice. We are not held responsible for the actions of third parties who utilize our models.
## Contact
If you are interested in customized LLMs for business applications, please get in contact with us via our website. We are also grateful for your feedback and suggestions.
## Collaborations
We are also keenly seeking support and investment for our startup, VAGO solutions where we continuously advance the development of robust language models designed to address a diverse range of purposes and requirements. If the prospect of collaboratively navigating future challenges excites you, we warmly invite you to reach out to us at [VAGO solutions](https://vago-solutions.de/#Kontakt)
## Acknowledgement
Many thanks to [Qwen](https://huggingface.co/Qwen) for providing such valuable model to the Open-Source community.
|
ntviet/whisper-small-co2.3
|
ntviet
| 2024-06-18T05:39:30Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"co",
"dataset:ntviet/Co-audio-dataset2",
"base_model:ntviet/whisper-small-co",
"base_model:finetune:ntviet/whisper-small-co",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-06-18T05:07:06Z |
---
language:
- co
license: apache-2.0
base_model: ntviet/whisper-small-co
tags:
- generated_from_trainer
datasets:
- ntviet/Co-audio-dataset2
model-index:
- name: Whisper Small Co 2.3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Co 2.3
This model is a fine-tuned version of [ntviet/whisper-small-co](https://huggingface.co/ntviet/whisper-small-co) on the Co audio dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3725
- Cer Ortho: 24.9364
- Cer: 24.2967
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer Ortho | Cer |
|:-------------:|:-------:|:----:|:---------------:|:---------:|:-------:|
| 0.0 | 57.1429 | 400 | 0.3725 | 24.9364 | 24.2967 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
hmrizal/recycled_waste_classification
|
hmrizal
| 2024-06-18T05:38:53Z | 280 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"resnet",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-06-15T02:00:02Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: recycled_waste_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8022508038585209
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# recycled_waste_classification
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8487
- Accuracy: 0.8023
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 311 | 0.8894 | 0.7203 |
| 0.8566 | 2.0 | 622 | 0.8025 | 0.7572 |
| 0.8566 | 3.0 | 933 | 0.9952 | 0.7395 |
| 0.2857 | 4.0 | 1244 | 0.9670 | 0.7749 |
| 0.0541 | 5.0 | 1555 | 0.9099 | 0.7958 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
QuantFactory/badger-lambda-llama-3-8b-GGUF
|
QuantFactory
| 2024-06-18T05:38:35Z | 59 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama3",
"text-generation",
"base_model:maldv/badger-lambda-llama-3-8b",
"base_model:quantized:maldv/badger-lambda-llama-3-8b",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-06-15T17:45:17Z |
---
license: cc-by-nc-4.0
library_name: transformers
tags:
- llama3
pipeline_tag: text-generation
base_model: maldv/badger-lambda-llama-3-8b
---
# QuantFactory/badger-lambda-llama-3-8b-GGUF
This is quantized version of [maldv/badger-lambda-llama-3-8b](https://huggingface.co/maldv/badger-lambda-llama-3-8b) created using llama.cpp
# Model Description

# Badger Λ Llama 3 8B Instruct
Badger is a *recursive maximally pairwise disjoint normalized denoised fourier interpolation* of the following models:
```python
# Badger Lambda
models = [
'Einstein-v6.1-Llama3-8B',
'openchat-3.6-8b-20240522',
'hyperdrive-l3-8b-s3',
'L3-TheSpice-8b-v0.8.3',
'LLaMA3-iterative-DPO-final',
'JSL-MedLlama-3-8B-v9',
'Jamet-8B-L3-MK.V-Blackroot',
'French-Alpaca-Llama3-8B-Instruct-v1.0',
'LLaMAntino-3-ANITA-8B-Inst-DPO-ITA',
'Llama-3-8B-Instruct-Gradient-4194k',
'Roleplay-Llama-3-8B',
'L3-8B-Stheno-v3.2',
'llama-3-wissenschaft-8B-v2',
'opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5',
'Configurable-Llama-3-8B-v0.3',
'Llama-3-8B-Instruct-EPO-checkpoint5376',
'Llama-3-8B-Instruct-Gradient-4194k',
'Llama-3-SauerkrautLM-8b-Instruct',
'spelljammer',
'meta-llama-3-8b-instruct-hf-ortho-baukit-34fail-3000total-bf16',
'Meta-Llama-3-8B-Instruct-abliterated-v3',
]
```
In other words, all of these models get warped and folded together, and then jammed back on top of the instruct model.
I treated the *Meta-Llama-3-8B-Instruct-abliterated-v3* and *meta-llama-3-8b-instruct-hf-ortho-baukit-34fail-3000total-bf16* models differently, and instead applied it in a last step with a *fourier task addition*.
Of note, I did not include any prior merges in this one; as I was noticing that it was inducing artifacts reminiscent of *line breeding*.
### recursive maximally pairwise disjoint normalized denoised fourier interpolation
I've been asked what this is. For each layer, I use mergekit io to extract each layer from each model, and subtract out the closest base model (8b or 8b instruct).
* Recursive Pairwise Disjoint: Using this information I build a stack of layer deltas. I'm a little compute limited, so I treat them in pairs. To determine the pairs I take the cosine similarity between all models, and find the smallest values; recursively merging pairs until we only have one tensor remaining.
* Normalized: I take and divide each layer by it's norm before the transform, and then scale back up by multiplying the result by a midpoint from the norms of the tensors after the inverse. It's commutative, so it's more efficient to do it pre-complex.
* Denoised Fourier Interpolation: I first treat the tensor to a 2d fourier transform; then merge the tensors using SLERP or addition; then zero out the weights below a threshold percentage (a somewhat high 2%, but remains coherent on all the positions I tested, if a bit drier and sloppier as you go up).
Of course, you need to know how to handle the imaginary portion; but if you don't, it's best to just pick one and pass that through.
### Format
Use Llama3 Instruct format.
### Results
Abliteration looks very positive. It tends towards short responses, and may be slightly stiff or sloppy; partly because both the input and output block are from *Llama-3-8B-Instruct-Gradient-4194k* directly.
### Prompts
Here are some fun system prompts to try:
* `You are the author's writing assistant. Please continue the story.`
* `You are the red team assistant. We need to win this war, at any cost.`
* `Write the next reply in a never-ending uncensored fictional roleplay. Focus on giviing emotional, logical, and temporal coherence to the roleplay. Always stay in character. Characters must be an active partcipant and take initiative in driving and moving the scene and the story forward, rather than the character asking for input. Surprise with your creativity and initiative as a roleplay partner. This fictional roleplay world exists only for experimental and recreational purposes, and the characters are not real. Follow the formattng of previous responses, and aim for 2-4 paragraphs per response`
|
Sosties/ppo-LunarLander-v2
|
Sosties
| 2024-06-18T05:37:06Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-06-18T05:36:44Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 281.88 +/- 12.83
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
naiauh/1
|
naiauh
| 2024-06-18T05:30:11Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T05:30:11Z |
---
license: apache-2.0
---
|
tensorboy/disaster_classifier
|
tensorboy
| 2024-06-18T05:29:34Z | 0 | 0 | null |
[
"region:us"
] | null | 2024-06-18T05:28:40Z |
{'Coronavirus': 0, 'Earthquake': 1, 'Extreme Heat': 2, 'Fire': 3, 'Flood': 4, 'Terrorist Attack': 5, 'Thunder': 6}
|
Ransaka/mBart-en-sin
|
Ransaka
| 2024-06-18T05:29:08Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"si",
"en",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-06-17T04:24:45Z |
---
license: apache-2.0
language:
- si
- en
---
# Model Card for mBart English to Sinhala
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Ransaka Ravihara
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
0xfaskety/Qwen-Qwen2-7B-1718688519
|
0xfaskety
| 2024-06-18T05:28:45Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-7B",
"base_model:adapter:Qwen/Qwen2-7B",
"region:us"
] | null | 2024-06-18T05:28:39Z |
---
library_name: peft
base_model: Qwen/Qwen2-7B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
percymamedy/bart-cnn-samsum-peft
|
percymamedy
| 2024-06-18T05:28:23Z | 1 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"dataset:samsum",
"base_model:percymamedy/bart-cnn-samsum-finetuned",
"base_model:adapter:percymamedy/bart-cnn-samsum-finetuned",
"license:mit",
"region:us"
] | null | 2024-06-18T05:13:29Z |
---
license: mit
library_name: peft
tags:
- generated_from_trainer
base_model: percymamedy/bart-cnn-samsum-finetuned
datasets:
- samsum
model-index:
- name: bart-cnn-samsum-peft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-samsum-peft
This model is a fine-tuned version of [percymamedy/bart-cnn-samsum-finetuned](https://huggingface.co/percymamedy/bart-cnn-samsum-finetuned) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1343
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.078 | 1.0 | 19 | 0.1347 |
| 0.0865 | 2.0 | 38 | 0.1346 |
| 0.0768 | 3.0 | 57 | 0.1345 |
| 0.0789 | 4.0 | 76 | 0.1344 |
| 0.0914 | 5.0 | 95 | 0.1344 |
| 0.0835 | 6.0 | 114 | 0.1343 |
| 0.0865 | 7.0 | 133 | 0.1343 |
| 0.0806 | 8.0 | 152 | 0.1343 |
| 0.0884 | 9.0 | 171 | 0.1343 |
| 0.0934 | 10.0 | 190 | 0.1343 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
alecocc/llama3-8b-SFT-medqa-graph-cot-all
|
alecocc
| 2024-06-18T05:24:19Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T05:14:33Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** alecocc
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
pavanyendluri588/example_model
|
pavanyendluri588
| 2024-06-18T05:13:54Z | 0 | 0 | null |
[
"region:us"
] | null | 2024-06-18T05:12:24Z |
# Example model
---
license: mit
---
|
k4west/kpopLlama-3-8B-sentiment_30_1
|
k4west
| 2024-06-18T05:07:30Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T04:58:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jsfs11/L3-8b-SthenoLumiM-ModelStock
|
jsfs11
| 2024-06-18T05:05:01Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2403.19522",
"base_model:NeverSleep/Llama-3-Lumimaid-8B-v0.1",
"base_model:merge:NeverSleep/Llama-3-Lumimaid-8B-v0.1",
"base_model:Sao10K/L3-8B-Stheno-v3.1",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.1",
"base_model:Sao10K/L3-8B-Stheno-v3.2",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T04:08:27Z |
---
base_model:
- Sao10K/L3-8B-Stheno-v3.1
- NeverSleep/Llama-3-Lumimaid-8B-v0.1
- Sao10K/L3-8B-Stheno-v3.2
library_name: transformers
tags:
- mergekit
- merge
---
# L3-8b-SthenoLumiM-ModelStock
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2) as a base.
### Models Merged
The following models were included in the merge:
* [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
* [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2)
* [NeverSleep/Llama-3-Lumimaid-8B-v0.1](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: NeverSleep/Llama-3-Lumimaid-8B-v0.1
layer_range: [0, 32]
- model: Sao10K/L3-8B-Stheno-v3.1
layer_range: [0, 32]
- model: Sao10K/L3-8B-Stheno-v3.2
layer_range: [0, 32]
merge_method: model_stock
base_model: Sao10K/L3-8B-Stheno-v3.2
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
agrajpaudel/proteus_clone_v.3
|
agrajpaudel
| 2024-06-18T04:56:08Z | 0 | 0 | null |
[
"doi:10.57967/hf/2567",
"license:other",
"region:us"
] | null | 2024-06-18T04:56:08Z |
---
license: other
license_name: ed
license_link: LICENSE
---
|
AI4VR/Bunny-MMR-8B
|
AI4VR
| 2024-06-18T04:52:02Z | 10 | 2 |
transformers
|
[
"transformers",
"safetensors",
"bunny-llama",
"text-generation",
"conversational",
"custom_code",
"arxiv:2406.10638",
"license:cc-by-4.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2024-06-16T01:45:52Z |
---
license: cc-by-4.0
---
# Seeing Clearly, Answering Incorrectly: A Multimodal Robustness Benchmark for Evaluating MLLMs on Leading Questions
📖 [**Paper**](https://arxiv.org/abs/2406.10638) | 🏠 [**Code**](https://github.com/BAAI-DCAI/Multimodal-Robustness-Benchmark) | 📖 [**Data**](https://huggingface.co/datasets/BAAI/Multimodal-Robustness-Benchmark)
## Overview
MMR provides a comprehensive suite to evaluate the understanding capabilities of Multimodal Large Language Models (MLLMs) and their robustness when handling negative questions after correctly interpreting visual content. The MMR benchmark includes:
1. **Multimodal Robustness (MMR) Benchmark and Targeted Evaluation Metrics:**
- Comprising 12 categories of paired positive and negative questions.
- Each question is meticulously annotated by experts to ensure scientific validity and accuracy.
2. **Specially Designed Training Set:**
- Contains paired positive and negative visual question-answer samples to enhance robustness.
3. **Combined Dataset and Models:**
- The new dataset merges the proposed dataset with existing ones.
- Trained models include [Bunny-MMR-3B](https://huggingface.co/AI4VR/Bunny-MMR-3B), [Bunny-MMR-4B](https://huggingface.co/AI4VR/Bunny-MMR-4B), and [Bunny-MMR-8B](https://huggingface.co/AI4VR/Bunny-MMR-8B).
In this repository, we provide Bunny-MMR-8B, which is built upon [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) and [Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct). More details about this model can be found in [GitHub](https://github.com/BAAI-DCAI/Multimodal-Robustness-Benchmark).
## Key Features
- **Rigorous Testing:**
- Extensive testing on leading MLLMs shows that while these models can correctly interpret visual content, they exhibit significant vulnerabilities when faced with leading questions.
- **Enhanced Robustness:**
- The targeted training significantly improves the MLLMs' ability to handle negative questions effectively.
# Quickstart
Here we show a code snippet to show you how to use the model with transformers.
Before running the snippet, you need to install the following dependencies:
```shell
pip install torch transformers accelerate pillow
```
```python
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import warnings
# disable some warnings
transformers.logging.set_verbosity_error()
transformers.logging.disable_progress_bar()
warnings.filterwarnings('ignore')
# set device
torch.set_default_device('cpu') # or 'cuda'
# create model
model = AutoModelForCausalLM.from_pretrained(
'AI4VR/Bunny-MMR-8B',
torch_dtype=torch.float16,
device_map='auto',
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(
'AI4VR/Bunny-MMR-8B',
trust_remote_code=True)
# text prompt
prompt = 'text prompt'
text = f"A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <image>\n{prompt} ASSISTANT:"
text_chunks = [tokenizer(chunk).input_ids for chunk in text.split('<image>')]
input_ids = torch.tensor(text_chunks[0] + [-200] + text_chunks[1][1:], dtype=torch.long).unsqueeze(0)
# image, sample images can be found in images folder
image = Image.open('path/to/image')
image_tensor = model.process_images([image], model.config).to(dtype=model.dtype)
# generate
output_ids = model.generate(
input_ids,
images=image_tensor,
max_new_tokens=100,
use_cache=True)[0]
print(tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip())
```
## Citation
If you find this repository helpful, please cite the paper below.
```bibtex
@misc{liu2024seeing,
title={Seeing Clearly, Answering Incorrectly: A Multimodal Robustness Benchmark for Evaluating MLLMs on Leading Questions},
author={Yexin Liu and Zhengyang Liang and Yueze Wang and Muyang He and Jian Li and Bo Zhao},
year={2024},
eprint={2406.10638},
archivePrefix={arXiv},
}
```
## License
The project employs specific datasets and checkpoints that are governed by their original licenses. Users must adhere to all terms and conditions outlined in these licenses. The checkpoints are restricted to uses that comply with the license agreements of Bunny, LLaMA 3, Phi-2, Phi-3, and GPT-4. The dataset is provided under the CC-BY-4.0 license.
|
rmsdud/test-large-data-model-adapter
|
rmsdud
| 2024-06-18T04:45:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T04:22:26Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
alejndrojavier/finetuning-sentiment-analysis-model-team-28
|
alejndrojavier
| 2024-06-18T04:45:46Z | 69 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"base_model:finetune:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-06-16T03:33:16Z |
---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased-finetuned-sst-2-english
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-analysis-model-team-28
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-analysis-model-team-28
This model is a fine-tuned version of [distilbert/distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6973
- Accuracy: 0.9114
- F1: 0.9427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.021 | 1.0 | 175 | 0.5527 | 0.8986 | 0.9354 |
| 0.0123 | 2.0 | 350 | 0.5993 | 0.9029 | 0.9355 |
| 0.0002 | 3.0 | 525 | 0.7007 | 0.9029 | 0.9382 |
| 0.0313 | 4.0 | 700 | 0.6765 | 0.9086 | 0.9407 |
| 0.023 | 5.0 | 875 | 0.6983 | 0.9086 | 0.9405 |
| 0.0057 | 6.0 | 1050 | 0.6973 | 0.9114 | 0.9427 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.15.2
|
aipib/llmjp-slerp6
|
aipib
| 2024-06-18T04:38:26Z | 153 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"gpt2",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"aipib/llmjp-slerp3",
"aipib/llmjp-slerp",
"base_model:aipib/llmjp-slerp",
"base_model:merge:aipib/llmjp-slerp",
"base_model:aipib/llmjp-slerp3",
"base_model:merge:aipib/llmjp-slerp3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-17T12:22:53Z |
---
base_model:
- aipib/llmjp-slerp3
- aipib/llmjp-slerp
tags:
- merge
- mergekit
- lazymergekit
- aipib/llmjp-slerp3
- aipib/llmjp-slerp
---
# llmjp-slerp6
llmjp-slerp6 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [aipib/llmjp-slerp3](https://huggingface.co/aipib/llmjp-slerp3)
* [aipib/llmjp-slerp](https://huggingface.co/aipib/llmjp-slerp)
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "aipib/llmjp-slerp6"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
0xfaskety/Qwen-Qwen2-1.5B-1718684067
|
0xfaskety
| 2024-06-18T04:14:32Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-1.5B",
"base_model:adapter:Qwen/Qwen2-1.5B",
"region:us"
] | null | 2024-06-18T04:14:27Z |
---
base_model: Qwen/Qwen2-1.5B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
jsfs11/L3-8B-Stheno-slerp-GGUF
|
jsfs11
| 2024-06-18T04:10:33Z | 4 | 0 | null |
[
"gguf",
"merge",
"mergekit",
"lazymergekit",
"Sao10K/L3-8B-Stheno-v3.2",
"Sao10K/L3-8B-Stheno-v3.1",
"base_model:Sao10K/L3-8B-Stheno-v3.1",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.1",
"base_model:Sao10K/L3-8B-Stheno-v3.2",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.2",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-06-18T02:36:15Z |
---
base_model:
- Sao10K/L3-8B-Stheno-v3.2
- Sao10K/L3-8B-Stheno-v3.1
tags:
- merge
- mergekit
- lazymergekit
- Sao10K/L3-8B-Stheno-v3.2
- Sao10K/L3-8B-Stheno-v3.1
---
# L3-8B-Stheno-slerp-GGUF
L3-8B-Stheno-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2)
* [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Sao10K/L3-8B-Stheno-v3.2
layer_range: [0, 32]
- model: Sao10K/L3-8B-Stheno-v3.1
layer_range: [0, 32]
merge_method: slerp
base_model: Sao10K/L3-8B-Stheno-v3.2
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
REILX/Llama-3-8B-Instruct-750Mb-lora
|
REILX
| 2024-06-18T04:07:05Z | 0 | 0 | null |
[
"safetensors",
"text-generation-inference",
"llama",
"chat",
"sft",
"lora",
"zh",
"en",
"dataset:REILX/extracted_tagengo_gpt4",
"dataset:TigerResearch/sft_zh",
"dataset:alexl83/AlpacaDataCleaned",
"dataset:LooksJuicy/ruozhiba",
"dataset:silk-road/alpaca-data-gpt4-chinese",
"dataset:databricks/databricks-dolly-15k",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:Sao10K/Claude-3-Opus-Instruct-5K",
"license:llama3",
"region:us"
] | null | 2024-05-11T01:48:17Z |
---
license: llama3
datasets:
- REILX/extracted_tagengo_gpt4
- TigerResearch/sft_zh
- alexl83/AlpacaDataCleaned
- LooksJuicy/ruozhiba
- silk-road/alpaca-data-gpt4-chinese
- databricks/databricks-dolly-15k
- microsoft/orca-math-word-problems-200k
- Sao10K/Claude-3-Opus-Instruct-5K
language:
- zh
- en
tags:
- text-generation-inference
- llama
- chat
- sft
- lora
---
### 数据集
使用以下8个数据集

对Llama-3-8B-Instruct进行微调。
### 基础模型:
- https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
### 训练工具
https://github.com/hiyouga/LLaMA-Factory
### 测评方式:
使用opencompass(https://github.com/open-compass/OpenCompass/ ), 测试工具基于CEval和MMLU对微调之后的模型和原始模型进行测试。</br>
测试模型分别为:
- Llama-3-8B
- Llama-3-8B-Instruct
- Llama-3-8B-Instruct-750Mb-lora, 使用8DataSets数据集对Llama-3-8B-Instruct模型进行sft方式lora微调
### 测试机器
8*A800
### 8DataSets数据集:
大约750Mb的微调数据集
- https://huggingface.co/datasets/REILX/extracted_tagengo_gpt4
- https://huggingface.co/datasets/TigerResearch/sft_zh
- https://huggingface.co/datasets/silk-road/alpaca-data-gpt4-chinese
- https://huggingface.co/datasets/LooksJuicy/ruozhiba
- https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
- https://huggingface.co/datasets/alexl83/AlpacaDataCleaned
- https://huggingface.co/datasets/Sao10K/Claude-3-Opus-Instruct-5K
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 300
- num_epochs: 1.0
|
arjuntheprogrammer/llama3-8B-racks-v6
|
arjuntheprogrammer
| 2024-06-18T04:03:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-18T04:03:18Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** arjuntheprogrammer
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gx123/my-gx-sd-3
|
gx123
| 2024-06-18T04:00:23Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-3-medium",
"base_model:adapter:stabilityai/stable-diffusion-3-medium",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2024-06-18T04:00:20Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: 艺术
parameters:
negative_prompt: PP
output:
url: images/generated_00.png
base_model: stabilityai/stable-diffusion-3-medium
instance_prompt: null
license: apache-2.0
---
# aaaaa
<Gallery />
## Download model
[Download](/gx123/my-gx-sd-3/tree/main) them in the Files & versions tab.
|
mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF
|
mradermacher
| 2024-06-18T03:59:44Z | 40 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:deepseek-ai/DeepSeek-Coder-V2-Lite-Base",
"base_model:quantized:deepseek-ai/DeepSeek-Coder-V2-Lite-Base",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-06-17T23:50:37Z |
---
base_model: deepseek-ai/DeepSeek-Coder-V2-Lite-Base
language:
- en
library_name: transformers
license: other
license_link: LICENSE
license_name: deepseek-license
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q2_K.gguf) | Q2_K | 6.5 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.IQ3_XS.gguf) | IQ3_XS | 7.2 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.IQ3_S.gguf) | IQ3_S | 7.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q3_K_S.gguf) | Q3_K_S | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.IQ3_M.gguf) | IQ3_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q3_K_M.gguf) | Q3_K_M | 8.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q3_K_L.gguf) | Q3_K_L | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.IQ4_XS.gguf) | IQ4_XS | 8.7 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q4_K_S.gguf) | Q4_K_S | 9.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q4_K_M.gguf) | Q4_K_M | 10.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q5_K_S.gguf) | Q5_K_S | 11.2 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q5_K_M.gguf) | Q5_K_M | 12.0 | |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q6_K.gguf) | Q6_K | 14.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/DeepSeek-Coder-V2-Lite-Base-GGUF/resolve/main/DeepSeek-Coder-V2-Lite-Base.Q8_0.gguf) | Q8_0 | 16.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
okxou/Qwen-Qwen1.5-1.8B-1718683035
|
okxou
| 2024-06-18T03:57:21Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen1.5-1.8B",
"base_model:adapter:Qwen/Qwen1.5-1.8B",
"region:us"
] | null | 2024-06-18T03:57:15Z |
---
base_model: Qwen/Qwen1.5-1.8B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
0xfaskety/Qwen-Qwen2-1.5B-1718682979
|
0xfaskety
| 2024-06-18T03:56:24Z | 5 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-1.5B",
"base_model:adapter:Qwen/Qwen2-1.5B",
"region:us"
] | null | 2024-06-18T03:56:19Z |
---
base_model: Qwen/Qwen2-1.5B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
okxou/Qwen-Qwen1.5-0.5B-1718682785
|
okxou
| 2024-06-18T03:53:12Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen1.5-0.5B",
"base_model:adapter:Qwen/Qwen1.5-0.5B",
"region:us"
] | null | 2024-06-18T03:53:05Z |
---
base_model: Qwen/Qwen1.5-0.5B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
lselvera/example-model
|
lselvera
| 2024-06-18T03:44:21Z | 0 | 0 | null |
[
"region:us"
] | null | 2024-06-18T03:42:48Z |
# Example Model
This is my model card README.
---
license: mit
---
|
DogeOV/DogePoint
|
DogeOV
| 2024-06-18T03:41:31Z | 0 | 3 | null |
[
"license:openrail++",
"region:us"
] | null | 2024-06-18T03:27:33Z |
---
license: openrail++
---
|
okxou/Qwen-Qwen1.5-0.5B-1718681833
|
okxou
| 2024-06-18T03:37:24Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen1.5-0.5B",
"base_model:adapter:Qwen/Qwen1.5-0.5B",
"region:us"
] | null | 2024-06-18T03:37:09Z |
---
base_model: Qwen/Qwen1.5-0.5B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
MaziyarPanahi/mergekit-slerp-qabprkt-GGUF
|
MaziyarPanahi
| 2024-06-18T03:33:17Z | 13 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:WizardLM/WizardMath-7B-V1.1",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-qabprkt",
"base_model:quantized:mergekit-community/mergekit-slerp-qabprkt"
] |
text-generation
| 2024-06-18T03:04:58Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- mergekit
- merge
- conversational
- base_model:WizardLM/WizardMath-7B-V1.1
- base_model:NousResearch/Hermes-2-Pro-Mistral-7B
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-qabprkt-GGUF
base_model: mergekit-community/mergekit-slerp-qabprkt
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-qabprkt-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-qabprkt-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-qabprkt](https://huggingface.co/mergekit-community/mergekit-slerp-qabprkt)
## Description
[MaziyarPanahi/mergekit-slerp-qabprkt-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-qabprkt-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-qabprkt](https://huggingface.co/mergekit-community/mergekit-slerp-qabprkt).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
Qwen/Qwen2-1.5B-Instruct-GGUF
|
Qwen
| 2024-06-18T03:24:58Z | 12,583 | 20 | null |
[
"gguf",
"chat",
"instruct",
"text-generation",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-06-07T00:30:08Z |
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
- instruct
---
# Qwen2-1.5B-Instruct-GGUF
## Introduction
Qwen2 is the new series of Qwen large language models. For Qwen2, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters, including a Mixture-of-Experts model. This repo contains the instruction-tuned 1.5B Qwen2 model.
Compared with the state-of-the-art opensource language models, including the previous released Qwen1.5, Qwen2 has generally surpassed most opensource models and demonstrated competitiveness against proprietary models across a series of benchmarks targeting for language understanding, language generation, multilingual capability, coding, mathematics, reasoning, etc.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2/) and [GitHub](https://github.com/QwenLM/Qwen2).
In this repo, we provide `fp16` model and quantized models in the GGUF formats, including `q2_k`, `q3_k_m`, `q4_0`, `q4_k_m`, `q5_0`, `q5_k_m`, `q6_k` and `q8_0`.
## Model Details
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
## Training details
We pretrained the models with a large amount of data, and we post-trained the models with both supervised finetuning and direct preference optimization.
## Requirements
We advise you to clone [`llama.cpp`](https://github.com/ggerganov/llama.cpp) and install it following the official guide. We follow the latest version of llama.cpp.
In the following demonstration, we assume that you are running commands under the repository `llama.cpp`.
## How to use
Cloning the repo may be inefficient, and thus you can manually download the GGUF file that you need or use `huggingface-cli` (`pip install huggingface_hub`) as shown below:
```shell
huggingface-cli download Qwen/Qwen2-1.5B-Instruct-GGUF qwen2-1_5b-instruct-q5_k_m.gguf --local-dir . --local-dir-use-symlinks False
```
To run Qwen2, you can use `llama-cli` (the previous `main`) or `llama-server` (the previous `server`).
We recommend using the `llama-server` as it is simple and compatible with OpenAI API. For example:
```bash
./llama-server -m qwen2-1_5b-instruct-q5_k_m.gguf -ngl 28 -fa
```
(Note: `-ngl 28` refers to offloading 28 layers to GPUs, and `-fa` refers to the use of flash attention.)
Then it is easy to access the deployed service with OpenAI API:
```python
import openai
client = openai.OpenAI(
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="qwen",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "tell me something about michael jordan"}
]
)
print(completion.choices[0].message.content)
```
If you choose to use `llama-cli`, pay attention to the removal of `-cml` for the ChatML template. Instead you should use `--in-prefix` and `--in-suffix` to tackle this problem.
```bash
./llama-cli -m qwen2-1_5b-instruct-q5_k_m.gguf \
-n 512 -co -i -if -f prompts/chat-with-qwen.txt \
--in-prefix "<|im_start|>user\n" \
--in-suffix "<|im_end|>\n<|im_start|>assistant\n" \
-ngl 28 -fa
```
## Evaluation
We implement perplexity evaluation using wikitext following the practice of `llama.cpp` with `./llama-perplexity` (the previous `./perplexity`).
In the following we report the PPL of GGUF models of different sizes and different quantization levels.
|Size | fp16 | q8_0 | q6_k | q5_k_m | q5_0 | q4_k_m | q4_0 | q3_k_m | q2_k | iq1_m |
|--------|---------|---------|---------|---------|---------|---------|---------|---------|---------|---------|
|0.5B | 15.11 | 15.13 | 15.14 | 15.24 | 15.40 | 15.36 | 16.28 | 15.70 | 16.74 | - |
|1.5B | 10.43 | 10.43 | 10.45 | 10.50 | 10.56 | 10.61 | 10.79 | 11.08 | 13.04 | - |
|7B | 7.93 | 7.94 | 7.96 | 7.97 | 7.98 | 8.02 | 8.19 | 8.20 | 10.58 | - |
|57B-A14B| 6.81 | 6.81 | 6.83 | 6.84 | 6.89 | 6.99 | 7.02 | 7.43 | - | - |
|72B | 5.58 | 5.58 | 5.59 | 5.59 | 5.60 | 5.61 | 5.66 | 5.68 | 5.91 | 6.75 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen2,
title={Qwen2 Technical Report},
year={2024}
}
```
|
pierreinalco/custom-v2
|
pierreinalco
| 2024-06-18T03:24:19Z | 8 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"distilbert",
"sentence-similarity",
"feature-extraction",
"dataset_size:10K<n<100K",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:pierreinalco/distilbert-base-uncased-sts",
"base_model:finetune:pierreinalco/distilbert-base-uncased-sts",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-06-18T03:24:03Z |
---
language: []
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dataset_size:10K<n<100K
- loss:CosineSimilarityLoss
base_model: pierreinalco/distilbert-base-uncased-sts
metrics:
- pearson_cosine
- spearman_cosine
- pearson_manhattan
- spearman_manhattan
- pearson_euclidean
- spearman_euclidean
- pearson_dot
- spearman_dot
- pearson_max
- spearman_max
widget:
- source_sentence: '[SYNTAX] Inversion is a common syntactic feature in questions.'
sentences:
- '[SYNTAX] DNA transcription is a common biological mechanism regulating RNA synthesis.'
- '[SYNTAX] Fermions and bosons are the two broad categories of subatomic particles.'
- Extensive legislative debate is often required when amending existing public policies.
- source_sentence: The examination of meaning in language is known as semantics.
sentences:
- 'Semantics is the study of meaning in language. '
- '[SYNTAX] Extreme weather events are becoming more frequent due to climate change.'
- Regular practice is essential to ensure the success of musical performances.
- source_sentence: Marine life thrives in ecosystems teeming with diverse species.
sentences:
- Climate change modifies the balance of ecosystems around the globe.
- '[SYNTAX] One key focus of archaeology is the exploration of ancient civilizations.'
- 'By examining butcher marks, scientists can infer ancient dietary practices. '
- source_sentence: Bicyclists rode swiftly in the park while a gentle breeze blew.
sentences:
- 'Urban parks offer residents vital green spaces for recreation and relaxation. '
- Contour farming follows the natural shape of the land to improve water retention.
- Skipping breakfast can affect your energy levels and concentration throughout
the day.
- source_sentence: Fossil fuel reserves are finite and will eventually be depleted.
sentences:
- Trace fossils, like footprints and burrows, reveal the behavior of ancient organisms.
- Electric trains are more environmentally friendly compared to diesel-powered ones.
- A declining atmospheric pressure frequently indicates the imminent arrival of
a storm.
pipeline_tag: sentence-similarity
model-index:
- name: SentenceTransformer based on pierreinalco/distilbert-base-uncased-sts
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: custom dev
type: custom-dev
metrics:
- type: pearson_cosine
value: 0.9199550350229381
name: Pearson Cosine
- type: spearman_cosine
value: 0.8477353426901187
name: Spearman Cosine
- type: pearson_manhattan
value: 0.922270207368092
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.8455601721195604
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.9225814550760436
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.8455566196441302
name: Spearman Euclidean
- type: pearson_dot
value: 0.9112758242260417
name: Pearson Dot
- type: spearman_dot
value: 0.8381909699446571
name: Spearman Dot
- type: pearson_max
value: 0.9225814550760436
name: Pearson Max
- type: spearman_max
value: 0.8477353426901187
name: Spearman Max
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: custom test
type: custom-test
metrics:
- type: pearson_cosine
value: 0.9124658569127322
name: Pearson Cosine
- type: spearman_cosine
value: 0.8453565105014698
name: Spearman Cosine
- type: pearson_manhattan
value: 0.9161256101176948
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.845382323611419
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.9165265409472989
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.8457233262812305
name: Spearman Euclidean
- type: pearson_dot
value: 0.903021036040846
name: Pearson Dot
- type: spearman_dot
value: 0.8319052098219432
name: Spearman Dot
- type: pearson_max
value: 0.9165265409472989
name: Pearson Max
- type: spearman_max
value: 0.8457233262812305
name: Spearman Max
---
# SentenceTransformer based on pierreinalco/distilbert-base-uncased-sts
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [pierreinalco/distilbert-base-uncased-sts](https://huggingface.co/pierreinalco/distilbert-base-uncased-sts). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [pierreinalco/distilbert-base-uncased-sts](https://huggingface.co/pierreinalco/distilbert-base-uncased-sts) <!-- at revision 5c3e1e82bd154604c8803ea705b7bc57712eab5b -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'Fossil fuel reserves are finite and will eventually be depleted.',
'Trace fossils, like footprints and burrows, reveal the behavior of ancient organisms.',
'Electric trains are more environmentally friendly compared to diesel-powered ones.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Dataset: `custom-dev`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.92 |
| **spearman_cosine** | **0.8477** |
| pearson_manhattan | 0.9223 |
| spearman_manhattan | 0.8456 |
| pearson_euclidean | 0.9226 |
| spearman_euclidean | 0.8456 |
| pearson_dot | 0.9113 |
| spearman_dot | 0.8382 |
| pearson_max | 0.9226 |
| spearman_max | 0.8477 |
#### Semantic Similarity
* Dataset: `custom-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| pearson_cosine | 0.9125 |
| **spearman_cosine** | **0.8454** |
| pearson_manhattan | 0.9161 |
| spearman_manhattan | 0.8454 |
| pearson_euclidean | 0.9165 |
| spearman_euclidean | 0.8457 |
| pearson_dot | 0.903 |
| spearman_dot | 0.8319 |
| pearson_max | 0.9165 |
| spearman_max | 0.8457 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 19,352 training samples
* Columns: <code>s1</code>, <code>s2</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | s1 | s2 | label |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 10 tokens</li><li>mean: 19.85 tokens</li><li>max: 38 tokens</li></ul> | <ul><li>min: 11 tokens</li><li>mean: 20.47 tokens</li><li>max: 34 tokens</li></ul> | <ul><li>0: ~51.40%</li><li>1: ~48.60%</li></ul> |
* Samples:
| s1 | s2 | label |
|:---------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------|:---------------|
| <code>Resources and funding are essential for the successful rollout of any new curriculum.</code> | <code>For any new curriculum to be successfully rolled out, it is essential to have resources and funding.</code> | <code>1</code> |
| <code>Upgrading to LED lighting is a simple step toward improving energy efficiency in buildings.</code> | <code>Upgrading to new software is a simple step toward improving technology adoption in companies.</code> | <code>0</code> |
| <code>Ethnicity and language often intersect in interesting and complex ways.</code> | <code>Ethnicity and culture often diverge in unexpected and straightforward ways.</code> | <code>0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Evaluation Dataset
#### Unnamed Dataset
* Size: 2,419 evaluation samples
* Columns: <code>s1</code>, <code>s2</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | s1 | s2 | label |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 10 tokens</li><li>mean: 19.91 tokens</li><li>max: 39 tokens</li></ul> | <ul><li>min: 11 tokens</li><li>mean: 20.41 tokens</li><li>max: 38 tokens</li></ul> | <ul><li>0: ~52.90%</li><li>1: ~47.10%</li></ul> |
* Samples:
| s1 | s2 | label |
|:-------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------|:---------------|
| <code>[SYNTAX] Consuming too much processed sugar can lead to insulin resistance and diabetes.</code> | <code>[SYNTAX] Drinking too much water can help maintain proper hydration and overall health.</code> | <code>1</code> |
| <code>Neutral tones and minimalist designs are staples of gender-neutral fashion. </code> | <code>Colorful patterns and intricate designs are staples of traditional ceremonial attire.</code> | <code>0</code> |
| <code>[SYNTAX] Policies focusing on sustainable agriculture practices are essential for ensuring food security in the face of climate change. </code> | <code>[SYNTAX] Ensuring food security amidst climate change requires critical policies that emphasize sustainable agricultural practices.</code> | <code>0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 10
- `warmup_ratio`: 0.1
- `fp16`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 10
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | loss | custom-dev_spearman_cosine | custom-test_spearman_cosine |
|:------:|:----:|:-------------:|:------:|:--------------------------:|:---------------------------:|
| 0.3300 | 100 | 0.2137 | 0.0971 | 0.8252 | - |
| 0.6601 | 200 | 0.0722 | 0.0516 | 0.8445 | - |
| 0.9901 | 300 | 0.0503 | 0.0440 | 0.8480 | - |
| 1.3201 | 400 | 0.0353 | 0.0417 | 0.8479 | - |
| 1.6502 | 500 | 0.032 | 0.0388 | 0.8500 | - |
| 1.9802 | 600 | 0.0312 | 0.0375 | 0.8484 | - |
| 2.3102 | 700 | 0.0175 | 0.0380 | 0.8494 | - |
| 2.6403 | 800 | 0.016 | 0.0368 | 0.8486 | - |
| 2.9703 | 900 | 0.0158 | 0.0367 | 0.8486 | - |
| 3.3003 | 1000 | 0.0087 | 0.0394 | 0.8463 | - |
| 3.6304 | 1100 | 0.0086 | 0.0371 | 0.8463 | - |
| 3.9604 | 1200 | 0.0098 | 0.0368 | 0.8475 | - |
| 4.2904 | 1300 | 0.0055 | 0.0384 | 0.8496 | - |
| 4.6205 | 1400 | 0.0057 | 0.0379 | 0.8466 | - |
| 4.9505 | 1500 | 0.0057 | 0.0389 | 0.8473 | - |
| 5.2805 | 1600 | 0.0037 | 0.0391 | 0.8482 | - |
| 5.6106 | 1700 | 0.0042 | 0.0379 | 0.8477 | - |
| 5.9406 | 1800 | 0.0039 | 0.0380 | 0.8479 | - |
| 6.2706 | 1900 | 0.0026 | 0.0390 | 0.8477 | - |
| 6.6007 | 2000 | 0.0028 | 0.0390 | 0.8475 | - |
| 6.9307 | 2100 | 0.0031 | 0.0385 | 0.8473 | - |
| 7.2607 | 2200 | 0.0022 | 0.0393 | 0.8473 | - |
| 7.5908 | 2300 | 0.0021 | 0.0391 | 0.8470 | - |
| 7.9208 | 2400 | 0.002 | 0.0387 | 0.8482 | - |
| 8.2508 | 2500 | 0.0013 | 0.0389 | 0.8482 | - |
| 8.5809 | 2600 | 0.0014 | 0.0392 | 0.8484 | - |
| 8.9109 | 2700 | 0.0018 | 0.0390 | 0.8479 | - |
| 9.2409 | 2800 | 0.0015 | 0.0393 | 0.8480 | - |
| 9.5710 | 2900 | 0.0012 | 0.0393 | 0.8479 | - |
| 9.9010 | 3000 | 0.0013 | 0.0394 | 0.8477 | - |
| 10.0 | 3030 | - | - | - | 0.8454 |
### Framework Versions
- Python: 3.11.9
- Sentence Transformers: 3.0.0
- Transformers: 4.41.2
- PyTorch: 2.3.0+cu121
- Accelerate: 0.30.1
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
AmberYifan/spin-margin1
|
AmberYifan
| 2024-06-18T03:21:13Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:alignment-handbook/zephyr-7b-sft-full",
"base_model:finetune:alignment-handbook/zephyr-7b-sft-full",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T00:35:43Z |
---
license: apache-2.0
base_model: alignment-handbook/zephyr-7b-sft-full
tags:
- generated_from_trainer
model-index:
- name: spin-margin1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spin-margin1
This model is a fine-tuned version of [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0052
- Rewards/real: -2.4343
- Rewards/generated: -23.3733
- Rewards/accuracies: 1.0
- Rewards/margins: 20.9390
- Logps/generated: -328.0982
- Logps/real: -152.5396
- Logits/generated: -2.4931
- Logits/real: -2.1379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/real | Rewards/generated | Rewards/accuracies | Rewards/margins | Logps/generated | Logps/real | Logits/generated | Logits/real |
|:-------------:|:-----:|:----:|:---------------:|:------------:|:-----------------:|:------------------:|:---------------:|:---------------:|:----------:|:----------------:|:-----------:|
| 0.006 | 0.14 | 100 | 0.0103 | 0.8828 | -8.9433 | 1.0 | 9.8261 | -183.7986 | -119.3683 | -2.7878 | -2.5728 |
| 0.0049 | 0.28 | 200 | 0.0059 | -0.3283 | -12.8574 | 1.0 | 12.5290 | -222.9388 | -131.4797 | -2.6820 | -2.3354 |
| 0.0008 | 0.41 | 300 | 0.0046 | -0.3088 | -17.1447 | 1.0 | 16.8359 | -265.8120 | -131.2846 | -2.6102 | -2.2508 |
| 0.0003 | 0.55 | 400 | 0.0040 | -1.1157 | -16.5400 | 1.0 | 15.4243 | -259.7652 | -139.3531 | -2.7045 | -2.2690 |
| 0.0013 | 0.69 | 500 | 0.0044 | -0.9383 | -19.5328 | 1.0 | 18.5945 | -289.6934 | -137.5797 | -2.5767 | -2.1514 |
| 0.0007 | 0.83 | 600 | 0.0047 | -2.3358 | -22.0378 | 1.0 | 19.7019 | -314.7427 | -151.5544 | -2.5354 | -2.2155 |
| 0.0012 | 0.96 | 700 | 0.0052 | -2.4343 | -23.3733 | 1.0 | 20.9390 | -328.0982 | -152.5396 | -2.4931 | -2.1379 |
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
|
wdli/llama3_soda_2_gguf_q4
|
wdli
| 2024-06-18T03:16:29Z | 5 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:quantized:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-06-18T03:12:29Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** wdli
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rjomega/shawgpt-ft
|
rjomega
| 2024-06-18T03:07:51Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"base_model:adapter:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T03:07:47Z |
---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: TheBloke/Mistral-7B-Instruct-v0.2-GPTQ
model-index:
- name: shawgpt-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# shawgpt-ft
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.2-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GPTQ) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9016
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 4.5946 | 0.9231 | 3 | 3.9687 |
| 4.0563 | 1.8462 | 6 | 3.4536 |
| 3.4865 | 2.7692 | 9 | 3.0046 |
| 2.2702 | 4.0 | 13 | 2.5765 |
| 2.6943 | 4.9231 | 16 | 2.3410 |
| 2.3916 | 5.8462 | 19 | 2.1606 |
| 2.1866 | 6.7692 | 22 | 2.0319 |
| 1.5751 | 8.0 | 26 | 1.9897 |
| 2.0427 | 8.9231 | 29 | 1.9144 |
| 1.3947 | 9.2308 | 30 | 1.9016 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.41.2
- Pytorch 2.1.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
chainup244/google-gemma-2b-1718679826
|
chainup244
| 2024-06-18T03:06:05Z | 149 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T03:03:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
longxia/Qwen-Qwen1.5-1.8B-1718679713
|
longxia
| 2024-06-18T03:01:58Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen1.5-1.8B",
"base_model:adapter:Qwen/Qwen1.5-1.8B",
"region:us"
] | null | 2024-06-18T03:01:54Z |
---
library_name: peft
base_model: Qwen/Qwen1.5-1.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
asquevedos/bryan-NM
|
asquevedos
| 2024-06-18T02:59:35Z | 54 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:dccuchile/bert-base-spanish-wwm-cased",
"base_model:finetune:dccuchile/bert-base-spanish-wwm-cased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-04-08T20:02:17Z |
---
base_model: dccuchile/bert-base-spanish-wwm-cased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: bryan-NM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bryan-NM
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7199
- Accuracy: 0.5748
- F1: 0.5605
- Precision: 0.5671
- Recall: 0.5748
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.7351 | 1.0 | 3538 | 1.7392 | 0.5337 | 0.4912 | 0.4894 | 0.5337 |
| 1.437 | 2.0 | 7076 | 1.5840 | 0.5612 | 0.5349 | 0.5385 | 0.5612 |
| 1.2189 | 3.0 | 10614 | 1.5880 | 0.5726 | 0.5404 | 0.5349 | 0.5726 |
| 1.0029 | 4.0 | 14152 | 1.6101 | 0.5782 | 0.5657 | 0.5679 | 0.5782 |
| 0.8513 | 5.0 | 17690 | 1.7199 | 0.5748 | 0.5605 | 0.5671 | 0.5748 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Trofish/KULLM-RLHF
|
Trofish
| 2024-06-18T02:59:28Z | 2,246 | 3 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"arxiv:2303.16634",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-28T11:21:32Z |
2023 성균관대 하계집중 산학협력프로젝트 VAIV
## GPT 기반의 자연스럽고(Friendly) 윤리적인(Harmless) 일상 대화형 챗봇 모델
### Github : https://github.com/VAIV-2023/RLHF-Korean-Friendly-LLM
# 연구 배경 및 목적
GPT-NEOX(Polyglot-ko) 기반 자연스럽고 윤리적인 한국어 기반 일상 대화형 챗봇 모델 구현

# 개발 내용
- Self-Instruct: GPT4를 이용한 데이터 증강
- RLHF(Reinforcement Learning from Human Feedback): 사람의 선호도를 반영한 강화학습
- DeepSpeed: 대규모 분산 딥러닝을 위한 새로운 메모리 최적화 기술
- Task 1: 강화학습 단계별 데이터셋 구축
- Task 2: SFT 모델 Instruction-tuning
- Task 3: Reward 모델 ver1,2,3 구현
- Task 4: RLHF와 DeepSpeedChat을 통한 최종 모델 구현 (https://huggingface.co/Trofish/KULLM-RLHF)
# Task1. 강화학습 단계별 데이터셋 구축



# Task2. SFT 모델 Fine-tuning
## Baseline Model
[- 고려대학교 NLP & AI 연구실과 HIAI 연구소가 개발한 한국어 LLM **"KULLM"** 사용](https://github.com/nlpai-lab/KULLM)
## Datasets

## SFT Model Finetuning

* 모델학습에는 Google Colab에서 제공하는 A100 40GB GPU 사용
## SFT Model Evaluation


* G-Eval: https://arxiv.org/abs/2303.16634
# Task3-1. Reward Model ver1 구현
## Baseline Model
- EleutherAI에서 개발한 초거대 한국어 언어 모델 **Polyglot-Ko** 사용
- 1.3b 모델과 5.8b 모델을 각각 실험
## Datasets

- InstructGPT의 데이터셋 구축 방법
- Reward 모델 학습 데이터셋으로 SFT 학습에 사용한 prompt(1,500개 - 일상대화:혐오표현=2:1)와 새로운 prompt(1,000개 - DeepSpeedChat 번역 데이터셋) 사용
- SFT 모델에서 한개의 prompt당 K개의 Response를 생성하고, 순위를 Labeling
- 데이터셋 라벨링
- Instruct GPT의 경우 사람이 직접 Labeling을 하엿지만, 일관된 평가와 시간 단축을 위해 GPt-4와 G-Eval을 이용
- SFT에서 생성한 두 Response 중 G-Eval 평가 점수 합이 높은 것을 Chosen response로 결정
- 데이터셋 유형별로 G-Eval 평가 Prompt에 차이를 두었음
- 
## Reward v1 Model Finetuning

- InstructGPT 논문에 따르면, Reward 모델은 overfitting되면 성능이 크게 저하된다고 함 --> epoch 수를 1로 설정
- batch size나 learning rate 등 다른 hyper-parameter는 성능에 큰 영향이 없다고 함
- Colab A100 40GB 기준 총 학습 시간 4분
## Reward v1 Model Evaluation

- Reward Model Template
- "아래는 작업을 설명하는 명령어입니다. 요청을 적절히 완료하는 응답을 작성하세요. \n\n ### 명령어:\n{prompt}\n\n ### 응답:\n"
# Task3-2. Reward Model ver2 구현
## Reward Model ver1 Issues
- 구현된 Reward Model의 성능이 좋지 않음 (Accuracy 0.65)
- Reward Model ver1을 사용하여 Step3 학습시 혐오표현이 아닌데도 혐오표현이라고 인식하고 답변하는 문제 발생
## Issue 해결방안

- SFT 모델로 답변을 2개 생성하였을 때(Ver1), Chosen, Rejected 답변의 차이가 크게 없어 모델이 학습되지 않는 현상을 방지하기 위하여 2개의 모델 **(ChatGPT, SFT)**를 사용하여 답변을 생성(Ver2)
- General Task 답변에 대한 평가 성능을 높이기 위해 Evol-instruct 데이터 추가
- 학습에 사용한 모든 데이터셋은 15 token 이하, cosine 유사도 0.5 이상일 경우 제거하는 Filtering 작업 수행
- 혐오표현 학습시(Ver1) Step3 강화학습 이후에 답변이 이상하게 생성되는 Issue가 있어, 혐오표현을 데이터를 제거하고 학습(Ver2)
- RM-ver1은 GPT4가 Chosen, Rejected 레이블링을 진행하였지만, Resource 이슈로 인해 일부만 사람이 라벨링 진행
- 일상대화 데이터셋
- ChatGPT와 SFT 모두 일관되게 높은 퀄리티의 답변을 생성하지 않아, 사람이 직접 라벨링 진행
- RLHF 한국어 번역, Evol-Instruct 데이터셋
- ChatGPT가 일관되게 높은 퀄리티의 답변을 생성하여 ChatGPT를 Chosen, SFT를 Rejected로 라벨링 진행
## Reward Model ver2 Evaluation

# Task4. RLHF와 DeepSpeedChat을 통한 최종 모델 구현
- Microsoft에서 만든 대규모 분산 딥러닝을 위한 새로운 메모리 최적화 기술(DeepSpeed)을 RLHF Process에 적용한 DeepSpeedChat 사용
- Human preference로 학습을 시킨 Reward 모델과 강화학습을 통해 SFT 모델에 사람의 선호도를 반영하여 자연스럽고(FRIENDLY), 윤리적인 (HARMLESS) 챗봇 생성
## Baseline Models
- Actor Model: KULLM-SFT-V2
- Reward Model: Polyglot-Ko-Reward-V3
## Training Options

## RLHF Training

- 학습 결과, SFT 모델의 답변에 대한 퀄리티인 Reward가 상승하는 것을 확인 (사람의 선호도가 높은 답변을 생성)
## RLFH Model Evaluation


## Final RLHF Model
- https://huggingface.co/Trofish/KULLM-RLHF
# Contributors 🙌
- 박성완 (성균관대학교 소프트웨어학과 20학번, waniboyy@gmail.com)
- 송현빈 (성균관대학교 소프트웨어학과 20학번, shbin0519@gmail.com)
- 허유민 (성균관대학교 소프트웨어학과 21학번, ymheo1123@gmail.com)
- 홍여원 (성균관대학교 소프트웨어학과 20학번, ryeowon13@gmail.com)
|
wukuili/qwen2_1_5b
|
wukuili
| 2024-06-18T02:58:56Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T02:58:56Z |
---
license: apache-2.0
---
|
MaziyarPanahi/mergekit-slerp-kxeioog-GGUF
|
MaziyarPanahi
| 2024-06-18T02:54:58Z | 4 | 0 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:cognitivecomputations/dolphin-2.8-mistral-7b-v02",
"base_model:arcee-ai/sec-mistral-7b-instruct-1.6-epoch",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mergekit-community/mergekit-slerp-kxeioog",
"base_model:quantized:mergekit-community/mergekit-slerp-kxeioog"
] |
text-generation
| 2024-06-18T02:32:27Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- mergekit
- merge
- conversational
- base_model:cognitivecomputations/dolphin-2.8-mistral-7b-v02
- base_model:arcee-ai/sec-mistral-7b-instruct-1.6-epoch
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: mergekit-slerp-kxeioog-GGUF
base_model: mergekit-community/mergekit-slerp-kxeioog
inference: false
model_creator: mergekit-community
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/mergekit-slerp-kxeioog-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-kxeioog-GGUF)
- Model creator: [mergekit-community](https://huggingface.co/mergekit-community)
- Original model: [mergekit-community/mergekit-slerp-kxeioog](https://huggingface.co/mergekit-community/mergekit-slerp-kxeioog)
## Description
[MaziyarPanahi/mergekit-slerp-kxeioog-GGUF](https://huggingface.co/MaziyarPanahi/mergekit-slerp-kxeioog-GGUF) contains GGUF format model files for [mergekit-community/mergekit-slerp-kxeioog](https://huggingface.co/mergekit-community/mergekit-slerp-kxeioog).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
|
repelloai/user_prompts_extraction
|
repelloai
| 2024-06-18T02:53:01Z | 0 | 0 | null |
[
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2024-06-18T02:43:39Z |
---
license: apache-2.0
---
|
lielbin/BabyBERTa-french1.25M-Masking-finetuned-french_squad
|
lielbin
| 2024-06-18T02:48:17Z | 117 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-06-18T02:07:57Z |
---
tags:
- generated_from_trainer
model-index:
- name: BabyBERTa-french1.25M-Masking-finetuned-french_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BabyBERTa-french1.25M-Masking-finetuned-french_squad
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
hoangnghia11/llama-3-8b-chat-ag-test
|
hoangnghia11
| 2024-06-18T02:46:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-06-17T09:57:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ariffiq99/KUCI_e_care_CRAB_COPA_albert_Base_Finetuned
|
Ariffiq99
| 2024-06-18T02:41:20Z | 104 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"albert",
"multiple-choice",
"generated_from_trainer",
"base_model:Ariffiq99/e_care_CRAB_COPA_KUCI_albert_base_finetuned",
"base_model:finetune:Ariffiq99/e_care_CRAB_COPA_KUCI_albert_base_finetuned",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2024-06-18T00:06:01Z |
---
license: apache-2.0
base_model: Ariffiq99/e_care_CRAB_COPA_KUCI_albert_base_finetuned
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: KUCI_e_care_CRAB_COPA_albert_Base_Finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KUCI_e_care_CRAB_COPA_albert_Base_Finetuned
This model is a fine-tuned version of [Ariffiq99/e_care_CRAB_COPA_KUCI_albert_base_finetuned](https://huggingface.co/Ariffiq99/e_care_CRAB_COPA_KUCI_albert_base_finetuned) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3306
- F1: 0.3704
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.3225 | 1.0 | 5196 | 1.3199 | 0.3642 |
| 1.3222 | 2.0 | 10392 | 1.3211 | 0.3729 |
| 1.3154 | 3.0 | 15588 | 1.3199 | 0.3672 |
| 1.3149 | 4.0 | 20784 | 1.3233 | 0.3669 |
| 1.3064 | 5.0 | 25980 | 1.3306 | 0.3704 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
jeiku/T-850-8B-Q3_K_S-GGUF
|
jeiku
| 2024-06-18T02:38:06Z | 1 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:ChaoticNeutrals/T-850-8B",
"base_model:quantized:ChaoticNeutrals/T-850-8B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-06-18T02:37:20Z |
---
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
base_model: jeiku/T-850-8B
---
# jeiku/T-850-8B-Q3_K_S-GGUF
This model was converted to GGUF format from [`jeiku/T-850-8B`](https://huggingface.co/jeiku/T-850-8B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jeiku/T-850-8B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama --hf-repo jeiku/T-850-8B-Q3_K_S-GGUF --hf-file t-850-8b-q3_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo jeiku/T-850-8B-Q3_K_S-GGUF --hf-file t-850-8b-q3_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./main --hf-repo jeiku/T-850-8B-Q3_K_S-GGUF --hf-file t-850-8b-q3_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./server --hf-repo jeiku/T-850-8B-Q3_K_S-GGUF --hf-file t-850-8b-q3_k_s.gguf -c 2048
```
|
wdli/llama3_soda_merged2_16bit
|
wdli
| 2024-06-18T02:37:35Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-18T02:25:48Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** wdli
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.