
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 06:27:22
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 525
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 06:27:10
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Michelvh/flan-small-mc-question-options-generation
|
Michelvh
| 2023-08-16T07:47:39Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:race",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-14T12:15:05Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
datasets:
- race
model-index:
- name: flan-small-mc-question-options-generation
results: []
inference:
parameters:
max_length: 512
num_beams: 4
length_penalty: 1.5
no_repeat_ngram_size: 3
early_stopping: True
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-small-mc-question-options-generation
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the race dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5747
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.3811 | 0.07 | 100 | 2.4007 |
| 2.5622 | 0.15 | 200 | 2.0431 |
| 2.2498 | 0.22 | 300 | 1.9139 |
| 2.1136 | 0.29 | 400 | 1.8218 |
| 2.0392 | 0.36 | 500 | 1.7739 |
| 1.9984 | 0.44 | 600 | 1.7237 |
| 1.9519 | 0.51 | 700 | 1.7058 |
| 1.928 | 0.58 | 800 | 1.6900 |
| 1.9075 | 0.66 | 900 | 1.6687 |
| 1.8968 | 0.73 | 1000 | 1.6631 |
| 1.8758 | 0.8 | 1100 | 1.6519 |
| 1.8863 | 0.87 | 1200 | 1.6431 |
| 1.869 | 0.95 | 1300 | 1.6409 |
| 1.8483 | 1.02 | 1400 | 1.6313 |
| 1.8344 | 1.09 | 1500 | 1.6279 |
| 1.8398 | 1.17 | 1600 | 1.6183 |
| 1.8247 | 1.24 | 1700 | 1.6223 |
| 1.8131 | 1.31 | 1800 | 1.6072 |
| 1.8024 | 1.38 | 1900 | 1.6096 |
| 1.8038 | 1.46 | 2000 | 1.6056 |
| 1.8051 | 1.53 | 2100 | 1.6030 |
| 1.7875 | 1.6 | 2200 | 1.6008 |
| 1.7983 | 1.68 | 2300 | 1.5923 |
| 1.7922 | 1.75 | 2400 | 1.5917 |
| 1.7892 | 1.82 | 2500 | 1.5903 |
| 1.784 | 1.89 | 2600 | 1.5891 |
| 1.7844 | 1.97 | 2700 | 1.5867 |
| 1.7678 | 2.04 | 2800 | 1.5837 |
| 1.7558 | 2.11 | 2900 | 1.5826 |
| 1.7702 | 2.19 | 3000 | 1.5820 |
| 1.7669 | 2.26 | 3100 | 1.5802 |
| 1.7715 | 2.33 | 3200 | 1.5763 |
| 1.7724 | 2.4 | 3300 | 1.5799 |
| 1.757 | 2.48 | 3400 | 1.5783 |
| 1.7648 | 2.55 | 3500 | 1.5763 |
| 1.7691 | 2.62 | 3600 | 1.5772 |
| 1.7607 | 2.69 | 3700 | 1.5758 |
| 1.7574 | 2.77 | 3800 | 1.5745 |
| 1.7586 | 2.84 | 3900 | 1.5748 |
| 1.7583 | 2.91 | 4000 | 1.5745 |
| 1.7611 | 2.99 | 4100 | 1.5747 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
dkqjrm/20230813053611
|
dkqjrm
| 2023-08-16T07:36:18Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-08-12T20:36:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: '20230813053611'
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 20230813053611
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 11
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60.0
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Voicelab/vlt5-base-keywords
|
Voicelab
| 2023-08-16T07:34:41Z | 8,164 | 54 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"keywords-generation",
"text-classifiation",
"other",
"pl",
"en",
"dataset:posmac",
"arxiv:2209.14008",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:13:59Z |
---
license: cc-by-4.0
language:
- pl
- en
datasets:
- posmac
pipeline_tag: text2text-generation
pipeline_kwargs:
- no_repeat_ngram_size=3
- num_beams=4
tags:
- keywords-generation
- text-classifiation
- other
widget:
- text: "Keywords: Our vlT5 model is a keyword generation model based on encoder-decoder architecture using Transformer blocks presented by google (https://huggingface.co/t5-base). The vlT5 was trained on scientific articles corpus to predict a given set of keyphrases based on the concatenation of the article’s abstract and title. It generates precise, yet not always complete keyphrases that describe the content of the article based only on the abstract."
example_title: "English 1"
- text: "Keywords: Decays the learning rate of each parameter group by gamma every step_size epochs. Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr."
example_title: "English 2"
- text: "Keywords: Przełomem w dziedzinie sztucznej inteligencji i maszynowego uczenia się było powstanie systemu eksperckiego Dendral na Uniwersytecie Stanforda w 1965. System ten powstał w celu zautomatyzowania analizy i identyfikacji molekuł związków organicznych, które dotychczas nie były znane chemikom. Wyniki badań otrzymane dzięki systemowi Dendral były pierwszym w historii odkryciem dokonanym przez komputer, które zostały opublikowane w prasie specjalistycznej."
example_title: "Polish"
- text: "Keywords: El análisis de un economista calcula que, a pesar del aumento del gasto general, la Navidad es una pérdida de peso muerto según la teoría microeconómica ortodoxa, debido al efecto de dar regalos. Esta pérdida se calcula como la diferencia entre lo que el donante gastó en el artículo y lo que el receptor del regalo habría pagado por el artículo. Se estima que en 2001, Navidad resultó en una pérdida de peso muerto de $ 4 mil millones solo en los EE. UU.1 Debido a factores de complicación, este análisis se utiliza a veces para discutir posibles fallas en la teoría microeconómica actual. Otras pérdidas de peso muerto incluyen los efectos de la Navidad en el medio ambiente y el hecho de que los regalos materiales a menudo se perciben como elefantes blancos, lo que impone costos de mantenimiento y almacenamiento y contribuye al desorden."
example_title: "Spanish"
metrics:
- f1
- precision
- recall
---
<img src="https://public.3.basecamp.com/p/rs5XqmAuF1iEuW6U7nMHcZeY/upload/download/VL-NLP-short.png" alt="logo voicelab nlp" style="width:300px;"/>
# Keyword Extraction from Short Texts with T5
> Our vlT5 model is a keyword generation model based on encoder-decoder architecture using Transformer blocks presented by Google ([https://huggingface.co/t5-base](https://huggingface.co/t5-base)). The vlT5 was trained on scientific articles corpus to predict a given set of keyphrases based on the concatenation of the article’s abstract and title. It generates precise, yet not always complete keyphrases that describe the content of the article based only on the abstract.
**Keywords generated with vlT5-base-keywords:** encoder-decoder architecture, keyword generation
Results on demo model (different generation method, one model per language):
> Our vlT5 model is a keyword generation model based on encoder-decoder architecture using Transformer blocks presented by Google ([https://huggingface.co/t5-base](https://huggingface.co/t5-base)). The vlT5 was trained on scientific articles corpus to predict a given set of keyphrases based on the concatenation of the article’s abstract and title. It generates precise, yet not always complete keyphrases that describe the content of the article based only on the abstract.
**Keywords generated with vlT5-base-keywords:** encoder-decoder architecture, vlT5, keyword generation, scientific articles corpus
## vlT5
The biggest advantage is the transferability of the vlT5 model, as it works well on all domains and types of text. The downside is that the text length and the number of keywords are similar to the training data: the text piece of an abstract length generates approximately 3 to 5 keywords. It works both extractive and abstractively. Longer pieces of text must be split into smaller chunks, and then propagated to the model.
### Overview
- **Language model:** [t5-base](https://huggingface.co/t5-base)
- **Language:** pl, en (but works relatively well with others)
- **Training data:** POSMAC
- **Online Demo:** Visit our online demo for better results [https://nlp-demo-1.voicelab.ai/](https://nlp-demo-1.voicelab.ai/)
- **Paper:** [Keyword Extraction from Short Texts with a Text-To-Text Transfer Transformer, ACIIDS 2022](https://arxiv.org/abs/2209.14008)
# Corpus
The model was trained on a POSMAC corpus. Polish Open Science Metadata Corpus (POSMAC) is a collection of 216,214 abstracts of scientific publications compiled in the CURLICAT project.
| Domains | Documents | With keywords |
| -------------------------------------------------------- | --------: | :-----------: |
| Engineering and technical sciences | 58 974 | 57 165 |
| Social sciences | 58 166 | 41 799 |
| Agricultural sciences | 29 811 | 15 492 |
| Humanities | 22 755 | 11 497 |
| Exact and natural sciences | 13 579 | 9 185 |
| Humanities, Social sciences | 12 809 | 7 063 |
| Medical and health sciences | 6 030 | 3 913 |
| Medical and health sciences, Social sciences | 828 | 571 |
| Humanities, Medical and health sciences, Social sciences | 601 | 455 |
| Engineering and technical sciences, Humanities | 312 | 312 |
# Tokenizer
As in the original plT5 implementation, the training dataset was tokenized into subwords using a sentencepiece unigram model with vocabulary size of 50k tokens.
# Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model = T5ForConditionalGeneration.from_pretrained("Voicelab/vlt5-base-keywords")
tokenizer = T5Tokenizer.from_pretrained("Voicelab/vlt5-base-keywords")
task_prefix = "Keywords: "
inputs = [
"Christina Katrakis, who spoke to the BBC from Vorokhta in western Ukraine, relays the account of one family, who say Russian soldiers shot at their vehicles while they were leaving their village near Chernobyl in northern Ukraine. She says the cars had white flags and signs saying they were carrying children.",
"Decays the learning rate of each parameter group by gamma every step_size epochs. Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr.",
"Hello, I'd like to order a pizza with salami topping.",
]
for sample in inputs:
input_sequences = [task_prefix + sample]
input_ids = tokenizer(
input_sequences, return_tensors="pt", truncation=True
).input_ids
output = model.generate(input_ids, no_repeat_ngram_size=3, num_beams=4)
predicted = tokenizer.decode(output[0], skip_special_tokens=True)
print(sample, "\n --->", predicted)
```
# Inference
Our results showed that the best generation results were achieved with `no_repeat_ngram_size=3, num_beams=4`
# Results
| Method | Rank | Micro | | | Macro | | |
| ----------- | ---: | :--------: | ---------: | ---------: | :---: | ----: | ----: |
| | | P | R | F1 | P | R | F1 |
| extremeText | 1 | 0.175 | 0.038 | 0.063 | 0.007 | 0.004 | 0.005 |
| | 3 | 0.117 | 0.077 | 0.093 | 0.011 | 0.011 | 0.011 |
| | 5 | 0.090 | 0.099 | 0.094 | 0.013 | 0.016 | 0.015 |
| | 10 | 0.060 | 0.131 | 0.082 | 0.015 | 0.025 | 0.019 |
| vlT5kw | 1 | **0.345** | 0.076 | 0.124 | 0.054 | 0.047 | 0.050 |
| | 3 | 0.328 | 0.212 | 0.257 | 0.133 | 0.127 | 0.129 |
| | 5 | 0.318 | **0.237** | **0.271** | 0.143 | 0.140 | 0.141 |
| KeyBERT | 1 | 0.030 | 0.007 | 0.011 | 0.004 | 0.003 | 0.003 |
| | 3 | 0.015 | 0.010 | 0.012 | 0.006 | 0.004 | 0.005 |
| | 5 | 0.011 | 0.012 | 0.011 | 0.006 | 0.005 | 0.005 |
| TermoPL | 1 | 0.118 | 0.026 | 0.043 | 0.004 | 0.003 | 0.003 |
| | 3 | 0.070 | 0.046 | 0.056 | 0.006 | 0.005 | 0.006 |
| | 5 | 0.051 | 0.056 | 0.053 | 0.007 | 0.007 | 0.007 |
| | all | 0.025 | 0.339 | 0.047 | 0.017 | 0.030 | 0.022 |
| extremeText | 1 | 0.210 | 0.077 | 0.112 | 0.037 | 0.017 | 0.023 |
| | 3 | 0.139 | 0.152 | 0.145 | 0.045 | 0.042 | 0.043 |
| | 5 | 0.107 | 0.196 | 0.139 | 0.049 | 0.063 | 0.055 |
| | 10 | 0.072 | 0.262 | 0.112 | 0.041 | 0.098 | 0.058 |
| vlT5kw | 1 | **0.377** | 0.138 | 0.202 | 0.119 | 0.071 | 0.089 |
| | 3 | 0.361 | 0.301 | 0.328 | 0.185 | 0.147 | 0.164 |
| | 5 | 0.357 | **0.316** | **0.335** | 0.188 | 0.153 | 0.169 |
| KeyBERT | 1 | 0.018 | 0.007 | 0.010 | 0.003 | 0.001 | 0.001 |
| | 3 | 0.009 | 0.010 | 0.009 | 0.004 | 0.001 | 0.002 |
| | 5 | 0.007 | 0.012 | 0.009 | 0.004 | 0.001 | 0.002 |
| TermoPL | 1 | 0.076 | 0.028 | 0.041 | 0.002 | 0.001 | 0.001 |
| | 3 | 0.046 | 0.051 | 0.048 | 0.003 | 0.001 | 0.002 |
| | 5 | 0.033 | 0.061 | 0.043 | 0.003 | 0.001 | 0.002 |
| | all | 0.021 | 0.457 | 0.040 | 0.004 | 0.008 | 0.005 |
# License
CC BY 4.0
# Citation
If you use this model, please cite the following paper:
[Pęzik, P., Mikołajczyk, A., Wawrzyński, A., Żarnecki, F., Nitoń, B., Ogrodniczuk, M. (2023). Transferable Keyword Extraction and Generation with Text-to-Text Language Models. In: Mikyška, J., de Mulatier, C., Paszynski, M., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M. (eds) Computational Science – ICCS 2023. ICCS 2023. Lecture Notes in Computer Science, vol 14074. Springer, Cham. https://doi.org/10.1007/978-3-031-36021-3_42](https://link.springer.com/chapter/10.1007/978-3-031-36021-3_42)
OR
[Piotr Pęzik, Agnieszka Mikołajczyk-Bareła, Adam Wawrzyński, Bartłomiej Nitoń, Maciej Ogrodniczuk, Keyword Extraction from Short Texts with a Text-To-Text Transfer Transformer, ACIIDS 2022](https://arxiv.org/abs/2209.14008)
# Authors
The model was trained by NLP Research Team at Voicelab.ai.
You can contact us [here](https://voicelab.ai/contact/).
|
TallalUsman/office-llm
|
TallalUsman
| 2023-08-16T07:25:59Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T07:25:49Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0
|
dalzza/dqn-SpaceInvadersNoFrameskip-v4
|
dalzza
| 2023-08-16T07:19:04Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T07:18:23Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 654.00 +/- 236.22
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga dalzza -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga dalzza -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga dalzza
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
flozi00/Llama-2-13B-german-assistant-v3
|
flozi00
| 2023-08-16T07:12:10Z | 8 | 5 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"de",
"dataset:flozi00/conversations",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-24T19:41:49Z |
---
datasets:
- flozi00/conversations
language:
- en
- de
---
## This project is sponsored by [  ](https://www.primeline-solutions.com/de/server/nach-einsatzzweck/gpu-rendering-hpc/)
### Please Use V4 of this model instead
# Model Card
This model is an finetuned version for german instructions and conversations in style of Open Assistant tokens. "<|prompter|>" "<|endoftext|>" "<|assistant|>"
The dataset used is deduplicated and cleaned, with no codes inside. The focus is on instruction following and conversational tasks.
The model archictecture is based on Llama version 2 with 13B parameters, trained on 100% renewable energy powered hardware.
This work is contributed by private research of [flozi00](https://huggingface.co/flozi00)
Join discussions about german llm research, and plan larger training runs together: https://join.slack.com/t/slack-dtc7771/shared_invite/zt-219keplqu-hLwjm0xcFAOX7enERfBz0Q
|
flozi00/Llama-2-13b-german-assistant-v4
|
flozi00
| 2023-08-16T07:11:44Z | 14 | 10 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"de",
"dataset:flozi00/conversations",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-02T18:22:51Z |
---
datasets:
- flozi00/conversations
language:
- en
- de
---
## This project is sponsored by [  ](https://www.primeline-solutions.com/de/server/nach-einsatzzweck/gpu-rendering-hpc/)
# Model Card
This model is an finetuned version for german instructions and conversations in style of Alpaca. "### Assistant:" "### User:"
The dataset used is deduplicated and cleaned, with no codes inside. The focus is on instruction following and conversational tasks.
The model archictecture is based on Llama version 2 with 13B parameters, trained on 100% renewable energy powered hardware.
This work is contributed by private research of [flozi00](https://huggingface.co/flozi00)
Join discussions about german llm research, and plan larger training runs together: https://join.slack.com/t/slack-dtc7771/shared_invite/zt-219keplqu-hLwjm0xcFAOX7enERfBz0Q
|
zcaspar/bloomz-560m_PROMPT_TUNING_CAUSAL_LM
|
zcaspar
| 2023-08-16T07:08:55Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T07:08:53Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
bimoadiparwa/roberta-mc-6
|
bimoadiparwa
| 2023-08-16T07:07:29Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"multiple-choice",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2023-08-16T06:22:24Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-mc-6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-mc-6
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6310
- Accuracy: 0.95
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6594 | 1.0 | 23 | 0.6523 | 0.95 |
| 0.6979 | 2.0 | 46 | 0.6400 | 0.95 |
| 0.6407 | 3.0 | 69 | 0.6331 | 0.95 |
| 0.7082 | 4.0 | 92 | 0.6360 | 0.95 |
| 0.6493 | 5.0 | 115 | 0.6258 | 0.95 |
| 0.6827 | 6.0 | 138 | 0.6239 | 0.95 |
| 0.6511 | 7.0 | 161 | 0.6399 | 0.95 |
| 0.6459 | 8.0 | 184 | 0.6279 | 0.95 |
| 0.6623 | 9.0 | 207 | 0.6247 | 0.95 |
| 0.6583 | 10.0 | 230 | 0.6307 | 0.95 |
| 0.6613 | 11.0 | 253 | 0.6269 | 0.95 |
| 0.6223 | 12.0 | 276 | 0.6270 | 0.95 |
| 0.6375 | 13.0 | 299 | 0.6284 | 0.95 |
| 0.7009 | 14.0 | 322 | 0.6309 | 0.95 |
| 0.6705 | 15.0 | 345 | 0.6299 | 0.95 |
| 0.6503 | 16.0 | 368 | 0.6396 | 0.95 |
| 0.7073 | 17.0 | 391 | 0.6305 | 0.95 |
| 0.614 | 18.0 | 414 | 0.6308 | 0.95 |
| 0.6512 | 19.0 | 437 | 0.6305 | 0.95 |
| 0.7055 | 20.0 | 460 | 0.6308 | 0.95 |
| 0.5702 | 21.0 | 483 | 0.6304 | 0.95 |
| 0.6654 | 22.0 | 506 | 0.6305 | 0.95 |
| 0.6129 | 23.0 | 529 | 0.6308 | 0.95 |
| 0.6477 | 24.0 | 552 | 0.6310 | 0.95 |
| 0.6178 | 25.0 | 575 | 0.6312 | 0.95 |
| 0.6562 | 26.0 | 598 | 0.6312 | 0.95 |
| 0.5972 | 27.0 | 621 | 0.6317 | 0.95 |
| 0.6324 | 28.0 | 644 | 0.6312 | 0.95 |
| 0.6064 | 29.0 | 667 | 0.6312 | 0.95 |
| 0.5833 | 30.0 | 690 | 0.6312 | 0.95 |
| 0.6916 | 31.0 | 713 | 0.6312 | 0.95 |
| 0.5591 | 32.0 | 736 | 0.6312 | 0.95 |
| 0.6477 | 33.0 | 759 | 0.6312 | 0.95 |
| 0.6483 | 34.0 | 782 | 0.6311 | 0.95 |
| 0.5563 | 35.0 | 805 | 0.6310 | 0.95 |
| 0.6061 | 36.0 | 828 | 0.6310 | 0.95 |
| 0.6043 | 37.0 | 851 | 0.6310 | 0.95 |
| 0.6274 | 38.0 | 874 | 0.6310 | 0.95 |
| 0.6115 | 39.0 | 897 | 0.6310 | 0.95 |
| 0.7107 | 40.0 | 920 | 0.6310 | 0.95 |
| 0.6703 | 41.0 | 943 | 0.6310 | 0.95 |
| 0.6052 | 42.0 | 966 | 0.6310 | 0.95 |
| 0.6228 | 43.0 | 989 | 0.6310 | 0.95 |
| 0.6629 | 44.0 | 1012 | 0.6310 | 0.95 |
| 0.5804 | 45.0 | 1035 | 0.6310 | 0.95 |
| 0.6194 | 46.0 | 1058 | 0.6310 | 0.95 |
| 0.6529 | 47.0 | 1081 | 0.6310 | 0.95 |
| 0.5779 | 48.0 | 1104 | 0.6310 | 0.95 |
| 0.6652 | 49.0 | 1127 | 0.6310 | 0.95 |
| 0.6163 | 50.0 | 1150 | 0.6310 | 0.95 |
| 0.6873 | 51.0 | 1173 | 0.6310 | 0.95 |
| 0.5608 | 52.0 | 1196 | 0.6310 | 0.95 |
| 0.6646 | 53.0 | 1219 | 0.6310 | 0.95 |
| 0.6222 | 54.0 | 1242 | 0.6310 | 0.95 |
| 0.6629 | 55.0 | 1265 | 0.6310 | 0.95 |
| 0.592 | 56.0 | 1288 | 0.6310 | 0.95 |
| 0.6047 | 57.0 | 1311 | 0.6310 | 0.95 |
| 0.5668 | 58.0 | 1334 | 0.6310 | 0.95 |
| 0.6358 | 59.0 | 1357 | 0.6310 | 0.95 |
| 0.648 | 60.0 | 1380 | 0.6310 | 0.95 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
divenyuan/Isomer
|
divenyuan
| 2023-08-16T07:07:19Z | 0 | 0 | null |
[
"arxiv:2308.06693",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T06:25:07Z |
---
license: apache-2.0
---
[ICCV2023] Isomer: Isomerous Transformer for Zero-Shot Video Object Segmentation
Paper: https://arxiv.org/pdf/2308.06693v1.pdf
Codes: https://github.com/DLUT-yyc/Isomer
Models and Datasets: Please see Files and versions~
|
aeolian83/Gugugo_for_DnD_v0.7
|
aeolian83
| 2023-08-16T07:05:40Z | 157 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"en",
"dataset:aeolian83/DnD_translate_v1.5",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-16T06:33:41Z |
---
license: apache-2.0
datasets:
- aeolian83/DnD_translate_v1.5
language:
- ko
- en
---
### reference model: https://huggingface.co/squarelike/Gugugo-koen-1.3B-V1.0
### Github: https://github.com/aeolian83/translateDnD
|
bhagasra-saurav/distilbert-base-uncased-finetuned-char
|
bhagasra-saurav
| 2023-08-16T07:02:46Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-16T06:37:30Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-char
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-char
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1436 | 0.85 | 500 | 1.8943 |
| 1.8911 | 1.71 | 1000 | 1.8065 |
| 1.8073 | 2.56 | 1500 | 1.7359 |
| 1.7668 | 3.41 | 2000 | 1.6907 |
| 1.733 | 4.27 | 2500 | 1.6564 |
| 1.7104 | 5.12 | 3000 | 1.6499 |
| 1.6915 | 5.97 | 3500 | 1.6258 |
| 1.6772 | 6.83 | 4000 | 1.6089 |
| 1.6617 | 7.68 | 4500 | 1.5982 |
| 1.6563 | 8.53 | 5000 | 1.6035 |
| 1.649 | 9.39 | 5500 | 1.5764 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
llama-anon/petra-13b-instruct-ggml
|
llama-anon
| 2023-08-16T07:00:00Z | 0 | 5 | null |
[
"license:agpl-3.0",
"region:us"
] | null | 2023-04-10T00:07:25Z |
---
license: agpl-3.0
---
LLaMA-13B merged with Instruct-13B weights, just werks.
Prompt format:
```
user instruction here
optional additional user input
generated output
```
Example prompt:
```
Does this tweet have negative or positive sentiment?
i hate my life!!!!
negative
```
Quants:
Q4_0 - old and outdated quant that can only be used with llamacpp from april
others - the quants most people should use, work with the latest version of llamacpp
Feel free to donate:
XMR: ```86Z8nLSVPx3SZ5z7iWugeK5JruAeGPUJyExD9e3wdTSxUvFMhGXNG9ucPqCm8M29y1AxP6ta56GBQ4GiEUMzeew9MfX1yct```
|
amirhamza11/my_awesome_eli5_mlm_model
|
amirhamza11
| 2023-08-16T06:57:45Z | 64 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"fill-mask",
"generated_from_keras_callback",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-16T06:41:59Z |
---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_keras_callback
model-index:
- name: amirhamza11/my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# amirhamza11/my_awesome_eli5_mlm_model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.8803
- Validation Loss: 1.7780
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.0229 | 1.8292 | 0 |
| 1.9138 | 1.7941 | 1 |
| 1.8803 | 1.7780 | 2 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.12.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
fengtc/opus-mt-zh-en
|
fengtc
| 2023-08-16T06:50:39Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"rust",
"marian",
"text2text-generation",
"translation",
"zh",
"en",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-08-16T06:49:38Z |
---
language:
- zh
- en
tags:
- translation
license: cc-by-4.0
---
### zho-eng
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation Information](#citation-information)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
- **Developed by:** Language Technology Research Group at the University of Helsinki
- **Model Type:** Translation
- **Language(s):**
- Source Language: Chinese
- Target Language: English
- **License:** CC-BY-4.0
- **Resources for more information:**
- [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
## Uses
#### Direct Use
This model can be used for translation and text-to-text generation.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
Further details about the dataset for this model can be found in the OPUS readme: [zho-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/zho-eng/README.md)
## Training
#### System Information
* helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
* transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
* port_machine: brutasse
* port_time: 2020-08-21-14:41
* src_multilingual: False
* tgt_multilingual: False
#### Training Data
##### Preprocessing
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* ref_len: 82826.0
* dataset: [opus](https://github.com/Helsinki-NLP/Opus-MT)
* download original weights: [opus-2020-07-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.zip)
* test set translations: [opus-2020-07-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.test.txt)
## Evaluation
#### Results
* test set scores: [opus-2020-07-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zho-eng/opus-2020-07-17.eval.txt)
* brevity_penalty: 0.948
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.zho.eng | 36.1 | 0.548 |
## Citation Information
```bibtex
@InProceedings{TiedemannThottingal:EAMT2020,
author = {J{\"o}rg Tiedemann and Santhosh Thottingal},
title = {{OPUS-MT} — {B}uilding open translation services for the {W}orld},
booktitle = {Proceedings of the 22nd Annual Conferenec of the European Association for Machine Translation (EAMT)},
year = {2020},
address = {Lisbon, Portugal}
}
```
## How to Get Started With the Model
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
```
|
TheRains/cv9-special-batch8-small-concat
|
TheRains
| 2023-08-16T06:47:04Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"id",
"dataset:mozilla-foundation/common_voice_9_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-16T04:22:32Z |
---
language:
- id
license: apache-2.0
base_model: openai/whisper-small
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_9_0
metrics:
- wer
model-index:
- name: Whisper Small Indonesian
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_9_0 id
type: mozilla-foundation/common_voice_9_0
config: id
split: test
args: id
metrics:
- name: Wer
type: wer
value: 12.900851161720727
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Indonesian
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_9_0 id dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2320
- Wer: 12.9009
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.6518 | 0.21 | 1000 | 0.3087 | 18.9510 |
| 0.542 | 0.42 | 2000 | 0.2795 | 16.6966 |
| 0.4933 | 0.63 | 3000 | 0.2543 | 14.3041 |
| 0.4943 | 0.85 | 4000 | 0.2435 | 13.5036 |
| 0.2716 | 1.06 | 5000 | 0.2320 | 12.9009 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
fengtc/opus-mt-en-zh
|
fengtc
| 2023-08-16T06:45:39Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"marian",
"text2text-generation",
"translation",
"en",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-08-16T06:42:30Z |
---
language:
- en
- zh
tags:
- translation
license: apache-2.0
---
### eng-zho
* source group: English
* target group: Chinese
* OPUS readme: [eng-zho](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-zho/README.md)
* model: transformer
* source language(s): eng
* target language(s): cjy_Hans cjy_Hant cmn cmn_Hans cmn_Hant gan lzh lzh_Hans nan wuu yue yue_Hans yue_Hant
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.zip)
* test set translations: [opus-2020-07-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.test.txt)
* test set scores: [opus-2020-07-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng.zho | 31.4 | 0.268 |
### System Info:
- hf_name: eng-zho
- source_languages: eng
- target_languages: zho
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-zho/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'zh']
- src_constituents: {'eng'}
- tgt_constituents: {'cmn_Hans', 'nan', 'nan_Hani', 'gan', 'yue', 'cmn_Kana', 'yue_Hani', 'wuu_Bopo', 'cmn_Latn', 'yue_Hira', 'cmn_Hani', 'cjy_Hans', 'cmn', 'lzh_Hang', 'lzh_Hira', 'cmn_Hant', 'lzh_Bopo', 'zho', 'zho_Hans', 'zho_Hant', 'lzh_Hani', 'yue_Hang', 'wuu', 'yue_Kana', 'wuu_Latn', 'yue_Bopo', 'cjy_Hant', 'yue_Hans', 'lzh', 'cmn_Hira', 'lzh_Yiii', 'lzh_Hans', 'cmn_Bopo', 'cmn_Hang', 'hak_Hani', 'cmn_Yiii', 'yue_Hant', 'lzh_Kana', 'wuu_Hani'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-zho/opus-2020-07-17.test.txt
- src_alpha3: eng
- tgt_alpha3: zho
- short_pair: en-zh
- chrF2_score: 0.268
- bleu: 31.4
- brevity_penalty: 0.8959999999999999
- ref_len: 110468.0
- src_name: English
- tgt_name: Chinese
- train_date: 2020-07-17
- src_alpha2: en
- tgt_alpha2: zh
- prefer_old: False
- long_pair: eng-zho
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
mm9289/distilbert-base-uncased-finetuned-emotion
|
mm9289
| 2023-08-16T06:39:13Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T06:12:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.939
- name: F1
type: f1
value: 0.9392172781643152
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1508
- Accuracy: 0.939
- F1: 0.9392
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1768 | 1.0 | 250 | 0.1751 | 0.928 | 0.9281 |
| 0.1138 | 2.0 | 500 | 0.1507 | 0.937 | 0.9368 |
| 0.0978 | 3.0 | 750 | 0.1499 | 0.936 | 0.9360 |
| 0.0768 | 4.0 | 1000 | 0.1495 | 0.9385 | 0.9385 |
| 0.0631 | 5.0 | 1250 | 0.1508 | 0.939 | 0.9392 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
yw3790/distilbert-base-uncased-finetuned-emotion
|
yw3790
| 2023-08-16T06:39:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T06:14:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9235
- name: F1
type: f1
value: 0.9236842203159065
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2158
- Accuracy: 0.9235
- F1: 0.9237
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8192 | 1.0 | 250 | 0.3007 | 0.908 | 0.9064 |
| 0.237 | 2.0 | 500 | 0.2158 | 0.9235 | 0.9237 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
leesa24/distilbert-base-uncased-finetuned-emotion
|
leesa24
| 2023-08-16T06:37:29Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T06:17:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9235
- name: F1
type: f1
value: 0.9235451893887832
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2199
- Accuracy: 0.9235
- F1: 0.9235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8222 | 1.0 | 250 | 0.3013 | 0.9125 | 0.9108 |
| 0.2436 | 2.0 | 500 | 0.2199 | 0.9235 | 0.9235 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
xiaosuper163/falcon-7b-instruct-ft-adapters
|
xiaosuper163
| 2023-08-16T06:36:19Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T06:36:16Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
|
abdiharyadi/indobart-v2-amr-2-text-indobart-attempt-1
|
abdiharyadi
| 2023-08-16T06:30:32Z | 175 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:indobenchmark/indobart-v2",
"base_model:finetune:indobenchmark/indobart-v2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-16T02:09:57Z |
---
license: mit
base_model: indobenchmark/indobart-v2
tags:
- generated_from_trainer
model-index:
- name: indobart-v2-amr-2-text-indobart-attempt-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobart-v2-amr-2-text-indobart-attempt-1
This model is a fine-tuned version of [indobenchmark/indobart-v2](https://huggingface.co/indobenchmark/indobart-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 88 | 0.4850 |
| No log | 2.0 | 176 | 0.4860 |
| No log | 3.0 | 264 | 0.4815 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
YONGWOOHUH/distilbert-base-uncased-finetuned-emotion
|
YONGWOOHUH
| 2023-08-16T06:30:31Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T06:13:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.936
- name: F1
type: f1
value: 0.9362021172690986
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1543
- Accuracy: 0.936
- F1: 0.9362
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1705 | 1.0 | 250 | 0.1681 | 0.9315 | 0.9311 |
| 0.1169 | 2.0 | 500 | 0.1612 | 0.932 | 0.9324 |
| 0.0967 | 3.0 | 750 | 0.1547 | 0.936 | 0.9358 |
| 0.0736 | 4.0 | 1000 | 0.1556 | 0.9375 | 0.9373 |
| 0.0614 | 5.0 | 1250 | 0.1543 | 0.936 | 0.9362 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
DmatryMakeev/ponteleich-v1-3500s
|
DmatryMakeev
| 2023-08-16T06:23:58Z | 1 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-16T06:20:05Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Ponteleich_v1_3500s Dreambooth model trained by DmatryMakeev with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:





















|
fatimaaltaf/ppo-LunarLander-v2
|
fatimaaltaf
| 2023-08-16T06:22:59Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T06:22:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 199.42 +/- 78.50
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
linoyts/lora-trained-xl-colab-person-0.0001-1000
|
linoyts
| 2023-08-16T06:21:16Z | 2 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-16T05:46:39Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks person
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - LinoyTsaban/lora-trained-xl-colab-person-0.0001-1000
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks person using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
dsmsb/tweet-classification-v1
|
dsmsb
| 2023-08-16T05:55:12Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T05:25:54Z |
---
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
model-index:
- name: tweet-classification-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tweet-classification-v1
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
minhhn2910/LunarLander
|
minhhn2910
| 2023-08-16T05:42:18Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T03:53:38Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 38.29 +/- 120.76
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 500000
'learning_rate': 0.001
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.1
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'minhhn2910/LunarLander'
'batch_size': 512
'minibatch_size': 128}
```
|
germla/satoken-zh
|
germla
| 2023-08-16T05:40:50Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-08-15T14:27:10Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# germla/satoken-zh
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("germla/satoken-zh")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
nightdude/config_713
|
nightdude
| 2023-08-16T05:17:07Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T05:16:58Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
leviethoang/graduation-reserach-1-demo
|
leviethoang
| 2023-08-16T04:51:21Z | 80 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-18T04:10:35Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-vi-50p
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-vi-25p
This model was trained from scratch on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8293
- Wer: 0.4109
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.9542 | 1.31 | 400 | 1.4443 | 0.5703 |
| 1.276 | 2.62 | 800 | 1.4606 | 0.5736 |
| 1.1311 | 3.93 | 1200 | 1.4552 | 0.5186 |
| 0.9519 | 5.25 | 1600 | 1.4477 | 0.5300 |
| 0.8293 | 6.56 | 2000 | 1.4166 | 0.5097 |
| 0.7555 | 7.87 | 2400 | 1.4100 | 0.4906 |
| 0.6724 | 9.18 | 2800 | 1.4982 | 0.4880 |
| 0.6038 | 10.49 | 3200 | 1.4524 | 0.4945 |
| 0.5338 | 11.8 | 3600 | 1.4995 | 0.4798 |
| 0.4988 | 13.11 | 4000 | 1.6715 | 0.4653 |
| 0.461 | 14.43 | 4400 | 1.5699 | 0.4552 |
| 0.4154 | 15.74 | 4800 | 1.5762 | 0.4557 |
| 0.3822 | 17.05 | 5200 | 1.5978 | 0.4471 |
| 0.3466 | 18.36 | 5600 | 1.6579 | 0.4512 |
| 0.3226 | 19.67 | 6000 | 1.6825 | 0.4378 |
| 0.2885 | 20.98 | 6400 | 1.7376 | 0.4421 |
| 0.2788 | 22.29 | 6800 | 1.7150 | 0.4300 |
| 0.249 | 23.61 | 7200 | 1.7073 | 0.4263 |
| 0.2317 | 24.92 | 7600 | 1.7349 | 0.4200 |
| 0.2171 | 26.23 | 8000 | 1.7419 | 0.4186 |
| 0.1963 | 27.54 | 8400 | 1.8438 | 0.4144 |
| 0.1906 | 28.85 | 8800 | 1.8293 | 0.4109 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
chriskim2273/IOTNation_QA_Model_3.0_BERT_ORIGINAL
|
chriskim2273
| 2023-08-16T04:39:50Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-08-16T04:19:28Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: IOTNation_QA_Model_3.0_BERT_ORIGINAL
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IOTNation_QA_Model_3.0_BERT_ORIGINAL
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9227
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
Guanli/1lama2-glora-finetunined-french
|
Guanli
| 2023-08-16T04:34:49Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T04:34:40Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
No-one-really/distilbert-base-uncased-finetuned-squad
|
No-one-really
| 2023-08-16T04:27:37Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-08-16T04:14:46Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cpu
- Datasets 2.14.4
- Tokenizers 0.13.3
|
mmnga/rinna-bilingual-gpt-neox-4b-ggml
|
mmnga
| 2023-08-16T04:14:09Z | 0 | 0 | null |
[
"ja",
"en",
"license:mit",
"region:us"
] | null | 2023-08-14T05:29:49Z |
---
license: mit
language:
- ja
- en
---
# rinna/bilingual-gpt-neox-4b
[rinnaさんが公開しているbilingual-gpt-neox-4b](https://huggingface.co/rinna/bilingual-gpt-neox-4b)のggml変換版です。
## Usage
```
git clone https://github.com/ggerganov/ggml.git
cd ggml
mkdir build && cd build
cmake ..
make -j
./bin/gpt-neox -m 'rinna-bilingual-gpt-neox-4b-ggml-q4_0.bin' -n 128 -t 8 -p '科学技術の発展はAIによって、'
```
|
mmnga/rinna-bilingual-gpt-neox-4b-instruction-sft-ggml
|
mmnga
| 2023-08-16T04:13:41Z | 0 | 1 | null |
[
"ja",
"en",
"license:mit",
"region:us"
] | null | 2023-08-15T07:16:26Z |
---
license: mit
language:
- ja
- en
---
# rinna/bilingual-gpt-neox-4b-instruction-sft
[rinnaさんが公開しているbilingual-gpt-neox-4b-instruction-sft](https://huggingface.co/rinna/bilingual-gpt-neox-4b-instruction-sft)のggml変換版です。
## Usage
```
git clone https://github.com/ggerganov/ggml.git
cd ggml
mkdir build && cd build
cmake ..
make -j
./bin/gpt-neox -m 'rinna-bilingual-gpt-neox-4b-instruction-sft-ggml-q4_0.bin' -n 128 -t 8 -p '科学技術の発展はAIによって、'
```
|
Otavares/t5-small-finetuned-wikisql
|
Otavares
| 2023-08-16T04:10:58Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-16T03:48:14Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-finetuned-wikisql
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-wikisql
This model is a fine-tuned version of [juierror/flan-t5-text2sql-with-schema-v2](https://huggingface.co/juierror/flan-t5-text2sql-with-schema-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 38.2089
- Rouge2 Precision: 0.8571
- Rouge2 Recall: 0.6
- Rouge2 Fmeasure: 0.7059
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| No log | 1.0 | 1 | 55.5586 | 0.8571 | 0.6 | 0.7059 |
| No log | 2.0 | 2 | 47.2978 | 0.8571 | 0.6 | 0.7059 |
| No log | 3.0 | 3 | 42.3317 | 0.8571 | 0.6 | 0.7059 |
| No log | 4.0 | 4 | 39.5028 | 0.8571 | 0.6 | 0.7059 |
| No log | 5.0 | 5 | 38.2089 | 0.8571 | 0.6 | 0.7059 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 2.0.0+cu117
- Datasets 2.10.1
- Tokenizers 0.12.1
|
bjfxs/lama2-finetunined-30steps-modified-2
|
bjfxs
| 2023-08-16T03:53:14Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T03:53:07Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
bimoadiparwa/roberta-mc-4
|
bimoadiparwa
| 2023-08-16T03:52:42Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"multiple-choice",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2023-08-15T10:48:36Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-mc-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-mc-4
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4442
- Accuracy: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.6061 | 1.0 | 24 | 1.5920 | 0.7 |
| 1.6032 | 2.0 | 48 | 1.5838 | 0.6 |
| 1.6104 | 3.0 | 72 | 1.5750 | 0.7 |
| 1.5851 | 4.0 | 96 | 1.5584 | 0.6 |
| 1.5653 | 5.0 | 120 | 1.5059 | 0.7 |
| 1.5485 | 6.0 | 144 | 1.4743 | 0.6 |
| 1.5175 | 7.0 | 168 | 1.4500 | 0.7 |
| 1.5025 | 8.0 | 192 | 1.4298 | 0.5 |
| 1.466 | 9.0 | 216 | 1.4559 | 0.5 |
| 1.4444 | 10.0 | 240 | 1.4010 | 0.5 |
| 1.4223 | 11.0 | 264 | 1.4699 | 0.4 |
| 1.3804 | 12.0 | 288 | 1.4915 | 0.4 |
| 1.3884 | 13.0 | 312 | 1.4624 | 0.4 |
| 1.3699 | 14.0 | 336 | 1.4798 | 0.5 |
| 1.3705 | 15.0 | 360 | 1.3615 | 0.5 |
| 1.3383 | 16.0 | 384 | 1.3814 | 0.7 |
| 1.3306 | 17.0 | 408 | 1.5099 | 0.4 |
| 1.2886 | 18.0 | 432 | 1.5039 | 0.4 |
| 1.2964 | 19.0 | 456 | 1.4033 | 0.5 |
| 1.285 | 20.0 | 480 | 1.4596 | 0.4 |
| 1.311 | 21.0 | 504 | 1.4100 | 0.4 |
| 1.218 | 22.0 | 528 | 1.3952 | 0.5 |
| 1.2193 | 23.0 | 552 | 1.2449 | 0.7 |
| 1.2618 | 24.0 | 576 | 1.2691 | 0.7 |
| 1.236 | 25.0 | 600 | 1.3427 | 0.7 |
| 1.1773 | 26.0 | 624 | 1.3669 | 0.5 |
| 1.1873 | 27.0 | 648 | 1.5114 | 0.5 |
| 1.1519 | 28.0 | 672 | 1.4285 | 0.6 |
| 1.1172 | 29.0 | 696 | 1.4485 | 0.5 |
| 1.0677 | 30.0 | 720 | 1.4442 | 0.5 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
whywynn/a2c-PandaPickAndPlace-v3
|
whywynn
| 2023-08-16T03:43:16Z | 5 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T03:37:23Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
LinkSoul/Chinese-Llama-2-7b-ggml
|
LinkSoul
| 2023-08-16T03:39:13Z | 0 | 19 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-07-27T02:41:55Z |
---
license: apache-2.0
---
### GGML转换脚本详见:
<https://github.com/LinkSoul-AI/Chinese-Llama-2-7b/tree/main/ggml>
## 量化配置的定义:
转自: <https://www.reddit.com/r/LocalLLaMA/comments/139yt87/notable_differences_between_q4_2_and_q5_1/>
* q4_0 = 32 numbers in chunk, 4 bits per weight, 1 scale value at 32-bit float (5 bits per value in average), each weight is given by the common scale * quantized value.
* q4_1 = 32 numbers in chunk, 4 bits per weight, 1 scale value and 1 bias value at 32-bit float (6 bits per value in average), each weight is given by the common scale * quantized value + common bias.
* q4_2 = same as q4_0, but 16 numbers in chunk, 4 bits per weight, 1 scale value that is 16-bit float, same size as q4_0 but better because chunks are smaller.
* q4_3 = already dead, but analogous: q4_1 but 16 numbers in chunk, 4 bits per weight, scale value that is 16 bit and bias also 16 bits, same size as q4_1 but better because chunks are smaller.
* q5_0 = 32 numbers in chunk, 5 bits per weight, 1 scale value at 16-bit float, size is 5.5 bits per weight
* q5_1 = 32 numbers in a chunk, 5 bits per weight, 1 scale value at 16 bit float and 1 bias value at 16 bit, size is 6 bits per weight.
* q8_0 = same as q4_0, except 8 bits per weight, 1 scale value at 32 bits, making total of 9 bits per weight.
|
LinkSoul/Chinese-Llama-2-7b-4bit
|
LinkSoul
| 2023-08-16T03:23:15Z | 155 | 74 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"zh",
"en",
"dataset:LinkSoul/instruction_merge_set",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-22T13:21:52Z |
---
license: openrail
datasets:
- LinkSoul/instruction_merge_set
language:
- zh
- en
widget:
- text: "[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n用中文回答,When is the best time to visit Beijing, and do you have any suggestions for me? [/INST]"
example_title: "北京"
- text: "[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n用英文回答,特朗普是谁? [/INST]"
example_title: "特朗普是谁"
---
# Chinese Llama 2 7B 4bit
全部开源,完全可商用的**中文版 Llama2 模型及中英文 SFT 数据集**,输入格式严格遵循 *llama-2-chat* 格式,兼容适配所有针对原版 *llama-2-chat* 模型的优化。

## 基础演示

## 在线试玩
> Talk is cheap, Show you the Demo.
- [Demo 地址 / HuggingFace Spaces](https://huggingface.co/spaces/LinkSoul/Chinese-Llama-2-7b)
- [Colab 一键启动](#) // 正在准备
## 资源下载
- 模型下载:[Chinese Llama2 Chat Model](https://huggingface.co/LinkSoul/Chinese-Llama-2-7b)
- 4bit量化:[Chinese Llama2 4bit Chat Model](https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-4bit)
> 我们使用了中英文 SFT 数据集,数据量 1000 万。
- 数据集:[https://huggingface.co/datasets/LinkSoul/instruction_merge_set](https://huggingface.co/datasets/LinkSoul/instruction_merge_set)
- 训练及推理代码:[https://github.com/LinkSoul-AI/Chinese-Llama-2-7b](https://github.com/LinkSoul-AI/Chinese-Llama-2-7b)
## 快速测试
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer
# Original version
# model_path = "LinkSoul/Chinese-Llama-2-7b"
# 4 bit version
model_path = "LinkSoul/Chinese-Llama-2-7b-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
if model_path.endswith("4bit"):
model = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=True,
torch_dtype=torch.float16,
device_map='auto'
)
else:
model = AutoModelForCausalLM.from_pretrained(model_path).half().cuda()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""
prompt = instruction.format("用英文回答,什么是夫妻肺片?")
generate_ids = model.generate(tokenizer(prompt, return_tensors='pt').input_ids.cuda(), max_new_tokens=4096, streamer=streamer)
```
## 相关项目
- [Llama2](https://ai.meta.com/llama/)
## 项目协议
[Apache-2.0 license](https://github.com/LinkSoul-AI/Chinese-Llama-2-7b/blob/main/LICENSE)
## 微信交流群
欢迎加入[微信群](.github/QRcode.jpg)
|
kawadlc/whisper-peft
|
kawadlc
| 2023-08-16T03:18:46Z | 0 | 0 | null |
[
"zh",
"dataset:mozilla-foundation/common_voice_13_0",
"dataset:google/fleurs",
"region:us"
] | null | 2023-08-09T09:06:25Z |
---
datasets:
- mozilla-foundation/common_voice_13_0
- google/fleurs
language:
- zh
metrics:
- cer
---
|
peteryushunli/distilbert-base-uncased-finetuned-imdb
|
peteryushunli
| 2023-08-16T03:06:20Z | 127 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-16T03:03:07Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4125
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7026 | 1.0 | 157 | 2.4957 |
| 2.581 | 2.0 | 314 | 2.4286 |
| 2.5363 | 3.0 | 471 | 2.4515 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
monai-test/wholeBrainSeg_Large_UNEST_segmentation
|
monai-test
| 2023-08-16T03:05:11Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:2203.02430",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T03:04:18Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Description
Detailed whole brain segmentation is an essential quantitative technique in medical image analysis, which provides a non-invasive way of measuring brain regions from a clinical acquired structural magnetic resonance imaging (MRI).
We provide the pre-trained model for training and inferencing whole brain segmentation with 133 structures.
Training pipeline is provided to support active learning in MONAI Label and training with bundle.
A tutorial and release of model for whole brain segmentation using the 3D transformer-based segmentation model UNEST.
Authors:
Xin Yu (xin.yu@vanderbilt.edu)
Yinchi Zhou (yinchi.zhou@vanderbilt.edu) | Yucheng Tang (yuchengt@nvidia.com)
<p align="center">
-------------------------------------------------------------------------------------
</p>
 <br>
<p align="center">
Fig.1 - The demonstration of T1w MRI images registered in MNI space and the whole brain segmentation labels with 133 classes</p>
# Model Overview
A pre-trained UNEST base model [1] for volumetric (3D) whole brain segmentation with T1w MR images.
To leverage information across embedded sequences, ”shifted window” transformers
are proposed for dense predictions and modeling multi-scale features. However, these
attempts that aim to complicate the self-attention range often yield high computation
complexity and data inefficiency. Inspired by the aggregation function in the nested
ViT, we propose a new design of a 3D U-shape medical segmentation model with
Nested Transformers (UNesT) hierarchically with the 3D block aggregation function,
that learn locality behaviors for small structures or small dataset. This design retains
the original global self-attention mechanism and achieves information communication
across patches by stacking transformer encoders hierarchically.
 <br>
<p align="center">
Fig.2 - The network architecture of UNEST Base model
</p>
## Data
The training data is from the Vanderbilt University and Vanderbilt University Medical Center with public released OASIS and CANDI datsets.
Training and testing data are MRI T1-weighted (T1w) 3D volumes coming from 3 different sites. There are a total of 133 classes in the whole brain segmentation task.
Among 50 T1w MRI scans from Open Access Series on Imaging Studies (OASIS) (Marcus et al., 2007) dataset, 45 scans are used for training and the other 5 for validation.
The testing cohort contains Colin27 T1w scan (Aubert-Broche et al., 2006) and 13 T1w MRI scans from the Child and Adolescent Neuro Development Initiative (CANDI)
(Kennedy et al., 2012). All data are registered to the MNI space using the MNI305 (Evans et al., 1993) template and preprocessed follow the method in (Huo et al., 2019). Input images are randomly cropped to the size of 96 × 96 × 96.
### Important
The brain MRI images for training are registered to Affine registration from the target image to the MNI305 template using NiftyReg.
The data should be in the MNI305 space before inference.
If your images are already in MNI space, skip the registration step.
You could use any resitration tool to register image to MNI space. Here is an example using ants.
Registration to MNI Space: Sample suggestion. E.g., use ANTS or other tools for registering T1 MRI image to MNI305 Space.
```
pip install antspyx
#Sample ANTS registration
import ants
import sys
import os
fixed_image = ants.image_read('<fixed_image_path>')
moving_image = ants.image_read('<moving_image_path>')
transform = ants.registration(fixed_image,moving_image,'Affine')
reg3t = ants.apply_transforms(fixed_image,moving_image,transform['fwdtransforms'][0])
ants.image_write(reg3t,output_image_path)
```
## Training configuration
The training and inference was performed with at least one 24GB-memory GPU.
Actual Model Input: 96 x 96 x 96
## Input and output formats
Input: 1 channel T1w MRI image in MNI305 Space.
## commands example
Download trained checkpoint model to ./model/model.pt:
Add scripts component: To run the workflow with customized components, PYTHONPATH should be revised to include the path to the customized component:
```
export PYTHONPATH=$PYTHONPATH: '<path to the bundle root dir>/'
```
Execute Training:
```
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json --logging_file configs/logging.conf
```
Execute inference:
```
python -m monai.bundle run evaluating --meta_file configs/metadata.json --config_file configs/inference.json --logging_file configs/logging.conf
```
## More examples output
 <br>
<p align="center">
Fig.3 - The output prediction comparison with variant and ground truth
</p>
## Training/Validation Benchmarking
A graph showing the training accuracy for fine-tuning 600 epochs.
 <br>
With 10 fine-tuned labels, the training process converges fast.
## Complete ROI of the whole brain segmentation
133 brain structures are segmented.
| #1 | #2 | #3 | #4 |
| :------------ | :---------- | :-------- | :-------- |
| 0: background | 1 : 3rd-Ventricle | 2 : 4th-Ventricle | 3 : Right-Accumbens-Area |
| 4 : Left-Accumbens-Area | 5 : Right-Amygdala | 6 : Left-Amygdala | 7 : Brain-Stem |
| 8 : Right-Caudate | 9 : Left-Caudate | 10 : Right-Cerebellum-Exterior | 11 : Left-Cerebellum-Exterior |
| 12 : Right-Cerebellum-White-Matter | 13 : Left-Cerebellum-White-Matter | 14 : Right-Cerebral-White-Matter | 15 : Left-Cerebral-White-Matter |
| 16 : Right-Hippocampus | 17 : Left-Hippocampus | 18 : Right-Inf-Lat-Vent | 19 : Left-Inf-Lat-Vent |
| 20 : Right-Lateral-Ventricle | 21 : Left-Lateral-Ventricle | 22 : Right-Pallidum | 23 : Left-Pallidum |
| 24 : Right-Putamen | 25 : Left-Putamen | 26 : Right-Thalamus-Proper | 27 : Left-Thalamus-Proper |
| 28 : Right-Ventral-DC | 29 : Left-Ventral-DC | 30 : Cerebellar-Vermal-Lobules-I-V | 31 : Cerebellar-Vermal-Lobules-VI-VII |
| 32 : Cerebellar-Vermal-Lobules-VIII-X | 33 : Left-Basal-Forebrain | 34 : Right-Basal-Forebrain | 35 : Right-ACgG--anterior-cingulate-gyrus |
| 36 : Left-ACgG--anterior-cingulate-gyrus | 37 : Right-AIns--anterior-insula | 38 : Left-AIns--anterior-insula | 39 : Right-AOrG--anterior-orbital-gyrus |
| 40 : Left-AOrG--anterior-orbital-gyrus | 41 : Right-AnG---angular-gyrus | 42 : Left-AnG---angular-gyrus | 43 : Right-Calc--calcarine-cortex |
| 44 : Left-Calc--calcarine-cortex | 45 : Right-CO----central-operculum | 46 : Left-CO----central-operculum | 47 : Right-Cun---cuneus |
| 48 : Left-Cun---cuneus | 49 : Right-Ent---entorhinal-area | 50 : Left-Ent---entorhinal-area | 51 : Right-FO----frontal-operculum |
| 52 : Left-FO----frontal-operculum | 53 : Right-FRP---frontal-pole | 54 : Left-FRP---frontal-pole | 55 : Right-FuG---fusiform-gyrus |
| 56 : Left-FuG---fusiform-gyrus | 57 : Right-GRe---gyrus-rectus | 58 : Left-GRe---gyrus-rectus | 59 : Right-IOG---inferior-occipital-gyrus ,
| 60 : Left-IOG---inferior-occipital-gyrus | 61 : Right-ITG---inferior-temporal-gyrus | 62 : Left-ITG---inferior-temporal-gyrus | 63 : Right-LiG---lingual-gyrus |
| 64 : Left-LiG---lingual-gyrus | 65 : Right-LOrG--lateral-orbital-gyrus | 66 : Left-LOrG--lateral-orbital-gyrus | 67 : Right-MCgG--middle-cingulate-gyrus |
| 68 : Left-MCgG--middle-cingulate-gyrus | 69 : Right-MFC---medial-frontal-cortex | 70 : Left-MFC---medial-frontal-cortex | 71 : Right-MFG---middle-frontal-gyrus |
| 72 : Left-MFG---middle-frontal-gyrus | 73 : Right-MOG---middle-occipital-gyrus | 74 : Left-MOG---middle-occipital-gyrus | 75 : Right-MOrG--medial-orbital-gyrus |
| 76 : Left-MOrG--medial-orbital-gyrus | 77 : Right-MPoG--postcentral-gyrus | 78 : Left-MPoG--postcentral-gyrus | 79 : Right-MPrG--precentral-gyrus |
| 80 : Left-MPrG--precentral-gyrus | 81 : Right-MSFG--superior-frontal-gyrus | 82 : Left-MSFG--superior-frontal-gyrus | 83 : Right-MTG---middle-temporal-gyrus |
| 84 : Left-MTG---middle-temporal-gyrus | 85 : Right-OCP---occipital-pole | 86 : Left-OCP---occipital-pole | 87 : Right-OFuG--occipital-fusiform-gyrus |
| 88 : Left-OFuG--occipital-fusiform-gyrus | 89 : Right-OpIFG-opercular-part-of-the-IFG | 90 : Left-OpIFG-opercular-part-of-the-IFG | 91 : Right-OrIFG-orbital-part-of-the-IFG |
| 92 : Left-OrIFG-orbital-part-of-the-IFG | 93 : Right-PCgG--posterior-cingulate-gyrus | 94 : Left-PCgG--posterior-cingulate-gyrus | 95 : Right-PCu---precuneus |
| 96 : Left-PCu---precuneus | 97 : Right-PHG---parahippocampal-gyrus | 98 : Left-PHG---parahippocampal-gyrus | 99 : Right-PIns--posterior-insula |
| 100 : Left-PIns--posterior-insula | 101 : Right-PO----parietal-operculum | 102 : Left-PO----parietal-operculum | 103 : Right-PoG---postcentral-gyrus |
| 104 : Left-PoG---postcentral-gyrus | 105 : Right-POrG--posterior-orbital-gyrus | 106 : Left-POrG--posterior-orbital-gyrus | 107 : Right-PP----planum-polare |
| 108 : Left-PP----planum-polare | 109 : Right-PrG---precentral-gyrus | 110 : Left-PrG---precentral-gyrus | 111 : Right-PT----planum-temporale |
| 112 : Left-PT----planum-temporale | 113 : Right-SCA---subcallosal-area | 114 : Left-SCA---subcallosal-area | 115 : Right-SFG---superior-frontal-gyrus |
| 116 : Left-SFG---superior-frontal-gyrus | 117 : Right-SMC---supplementary-motor-cortex | 118 : Left-SMC---supplementary-motor-cortex | 119 : Right-SMG---supramarginal-gyrus |
| 120 : Left-SMG---supramarginal-gyrus | 121 : Right-SOG---superior-occipital-gyrus | 122 : Left-SOG---superior-occipital-gyrus | 123 : Right-SPL---superior-parietal-lobule |
| 124 : Left-SPL---superior-parietal-lobule | 125 : Right-STG---superior-temporal-gyrus | 126 : Left-STG---superior-temporal-gyrus | 127 : Right-TMP---temporal-pole |
| 128 : Left-TMP---temporal-pole | 129 : Right-TrIFG-triangular-part-of-the-IFG | 130 : Left-TrIFG-triangular-part-of-the-IFG | 131 : Right-TTG---transverse-temporal-gyrus |
| 132 : Left-TTG---transverse-temporal-gyrus |
## Bundle Integration in MONAI Lable
The inference and training pipleine can be easily used by the MONAI Label server and 3D Slicer for fast labeling T1w MRI images in MNI space.
 <br>
# Disclaimer
This is an example, not to be used for diagnostic purposes.
# References
[1] Yu, Xin, Yinchi Zhou, Yucheng Tang et al. Characterizing Renal Structures with 3D Block Aggregate Transformers. arXiv preprint arXiv:2203.02430 (2022). https://arxiv.org/pdf/2203.02430.pdf
[2] Zizhao Zhang et al. Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding. AAAI Conference on Artificial Intelligence (AAAI) 2022
[3] Huo, Yuankai, et al. 3D whole brain segmentation using spatially localized atlas network tiles. NeuroImage 194 (2019): 105-119.
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
figo12396/llama
|
figo12396
| 2023-08-16T03:03:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-08-16T03:01:09Z |
#!/bin/bash
read -p "Enter the URL from email: " https://download.llamameta.net/*?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjoieD8%7ENVhcdTAwMDNqXC8iLCJSZXNvdXJjZSI6Imh0dHBzOlwvXC9kb3dubG9hZC5sbGFtYW1ldGEubmV0XC8qIiwiQ29uZGl0aW9uIjp7IkRhdGVMZXNzVGhhbiI6eyJBV1M6RXBvY2hUaW1lIjoxNjkyMTk2NTA5fX19XX0_&Signature=UH2Au8t6FRQ6V3GNf0YAJVNk4Mr5z7FjLq5T3MXyYgiWb5RhIq4PPz3-qrLZ%7ETmyb%7E7GMfmXLb7UCpPv2zBeW3lP-OBsbFGusVgoOi07h8c1X3E0NARtl1rjbT2kuhbK183WC4WIaXPmOvh6WAP3s3Hc6H8OOWUNjrSm7aySSeCkZ%7EFgw2Y4m2SMgrC-1IBQTeU2XJ1AVrHJUcF0%7Ed5DBgwij3MrAlMjkOQ7EcQr8mo9ypC84%7EBIYUnGXyZeccHu6mrMrRy%7EMWWNkOok%7EnV33uqwgTHNqx6MIpVDWrMISy2%7EB8GnDBVG2iLEjr%7Ew5lY493TEEfA9Pcv2ZcN3gbUYyw__&Key-Pair-Id=K15QRJLYKIFSLZ
echo ""
read -p "Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: " MODEL_SIZE
TARGET_FOLDER="." # where all files should end up
mkdir -p ${TARGET_FOLDER}
if [[ $MODEL_SIZE == "" ]]; then
MODEL_SIZE="7B,13B,70B,7B-chat,13B-chat,70B-chat"
fi
echo "Downloading LICENSE and Acceptable Usage Policy"
wget ${PRESIGNED_URL/'*'/"LICENSE"} -O ${TARGET_FOLDER}"/LICENSE"
wget ${PRESIGNED_URL/'*'/"USE_POLICY.md"} -O ${TARGET_FOLDER}"/USE_POLICY.md"
echo "Downloading tokenizer"
wget ${PRESIGNED_URL/'*'/"tokenizer.model"} -O ${TARGET_FOLDER}"/tokenizer.model"
wget ${PRESIGNED_URL/'*'/"tokenizer_checklist.chk"} -O ${TARGET_FOLDER}"/tokenizer_checklist.chk"
(cd ${TARGET_FOLDER} && md5sum -c tokenizer_checklist.chk)
for m in ${MODEL_SIZE//,/ }
do
if [[ $m == "7B" ]]; then
SHARD=0
MODEL_PATH="llama-2-7b"
elif [[ $m == "7B-chat" ]]; then
SHARD=0
MODEL_PATH="llama-2-7b-chat"
elif [[ $m == "13B" ]]; then
SHARD=1
MODEL_PATH="llama-2-13b"
elif [[ $m == "13B-chat" ]]; then
SHARD=1
MODEL_PATH="llama-2-13b-chat"
elif [[ $m == "70B" ]]; then
SHARD=7
MODEL_PATH="llama-2-70b"
elif [[ $m == "70B-chat" ]]; then
SHARD=7
MODEL_PATH="llama-2-70b-chat"
fi
echo "Downloading ${MODEL_PATH}"
mkdir -p ${TARGET_FOLDER}"/${MODEL_PATH}"
for s in $(seq -f "0%g" 0 ${SHARD})
do
wget ${PRESIGNED_URL/'*'/"${MODEL_PATH}/consolidated.${s}.pth"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/consolidated.${s}.pth"
done
wget ${PRESIGNED_URL/'*'/"${MODEL_PATH}/params.json"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/params.json"
wget ${PRESIGNED_URL/'*'/"${MODEL_PATH}/checklist.chk"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/checklist.chk"
echo "Checking checksums"
(cd ${TARGET_FOLDER}"/${MODEL_PATH}" && md5sum -c checklist.chk)
done
|
monai-test/valve_landmarks
|
monai-test
| 2023-08-16T03:03:17Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:mit",
"region:us"
] | null | 2023-08-16T03:03:10Z |
---
tags:
- monai
- medical
library_name: monai
license: mit
---
# 2D Cardiac Valve Landmark Regressor
This network identifies 10 different landmarks in 2D+t MR images of the heart (2 chamber, 3 chamber, and 4 chamber) representing the insertion locations of valve leaflets into the myocardial wall. These coordinates are used in part of the construction of 3D FEM cardiac models suitable for physics simulation of heart functions.
Input images are individual 2D slices from the time series, and the output from the network is a `(2, 10)` set of 2D points in `HW` image coordinate space. The 10 coordinates correspond to the attachment point for these valves:
1. Mitral anterior in 2CH
2. Mitral posterior in 2CH
3. Mitral septal in 3CH
4. Mitral free wall in 3CH
5. Mitral septal in 4CH
6. Mitral free wall in 4CH
7. Aortic septal
8. Aortic free wall
9. Tricuspid septal
10. Tricuspid free wall
Landmarks which do not appear in a particular image are predicted to be `(0, 0)` or close to this location. The mitral valve is expected to appear in all three views. Landmarks are not provided for the pulmonary valve.
Example plot of landmarks on a single frame, see [view_results.ipynb](./view_results.ipynb) for visualising network output:

## Training
The training script `train.json` is provided to train the network using a dataset of image pairs containing the MR image and a landmark image. This is done to reuse image-based transforms which do not currently operate on geometry. A number of other transforms are provided in `valve_landmarks.py` to implement Fourier-space dropout, image shifting which preserve landmarks, and smooth-field deformation applied to images and landmarks.
The dataset used for training unfortunately cannot be made public, however the training script can be used with any NPZ file containing the training image stack in key `trainImgs` and landmark image stack in `trainLMImgs`, plus `testImgs` and `testLMImgs` containing validation data. The landmark images are defined as 0 for every non-landmark pixel, with landmark pixels contaning the following values for each landmark type:
* 10: Mitral anterior in 2CH
* 15: Mitral posterior in 2CH
* 20: Mitral septal in 3CH
* 25: Mitral free wall in 3CH
* 30: Mitral septal in 4CH
* 35: Mitral free wall in 4CH
* 100: Aortic septal
* 150: Aortic free wall
* 200: Tricuspid septal
* 250: Tricuspid free wall
The following command will train with the default NPZ filename `./valvelandmarks.npz`, assuming the current directory is the bundle directory:
```sh
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json \
--bundle_root . --dataset_file ./valvelandmarks.npz --output_dir /path/to/outputs
```
## Inference
The included `inference.json` script will run inference on a directory containing Nifti files whose images have shape `(256, 256, 1, N)` for `N` timesteps. For each image the output in the `output_dir` directory will be a npy file containing a result array of shape `(N, 2, 10)` storing the 10 coordinates for each `N` timesteps. Invoking this script can be done as follows, assuming the current directory is the bundle directory:
```sh
python -m monai.bundle run evaluating --meta_file configs/metadata.json --config_file configs/inference.json \
--bundle_root . --dataset_dir /path/to/data --output_dir /path/to/outputs
```
The provided test Nifti file can be placed in a directory which is then used as the `dataset_dir` value. This image was derived from [the AMRG Cardiac Atlas dataset](http://www.cardiacatlas.org/studies/amrg-cardiac-atlas) (AMRG Cardiac Atlas, Auckland MRI Research Group, Auckland, New Zealand). The results from this inference can be visualised by changing path values in [view_results.ipynb](./view_results.ipynb).
### Reference
The work for this model and its application is described in:
`Kerfoot, E, King, CE, Ismail, T, Nordsletten, D & Miller, R 2021, Estimation of Cardiac Valve Annuli Motion with Deep Learning. in E Puyol Anton, M Pop, M Sermesant, V Campello, A Lalande, K Lekadir, A Suinesiaputra, O Camara & A Young (eds), Statistical Atlases and Computational Models of the Heart. MandMs and EMIDEC Challenges - 11th International Workshop, STACOM 2020, Held in Conjunction with MICCAI 2020, Revised Selected Papers. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 12592 LNCS, Springer Science and Business Media Deutschland GmbH, pp. 146-155, 11th International Workshop on Statistical Atlases and Computational Models of the Heart, STACOM 2020 held in Conjunction with MICCAI 2020, Lima, Peru, 4/10/2020. https://doi.org/10.1007/978-3-030-68107-4_15`
# License
This model is released under the MIT License. The license file is included with the model.
|
ZeroUniqueness/qlora-llama-2-13b-code
|
ZeroUniqueness
| 2023-08-16T02:59:42Z | 27 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-02T16:13:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
monai-test/renalStructures_CECT_segmentation
|
monai-test
| 2023-08-16T02:58:59Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:58:56Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Title
Renal structures CECT segmentation
### **Authors**
Ivan Chernenkiy, Michael Chernenkiy, Dmitry Fiev, Evgeny Sirota, Center for Neural Network Technologies / Institute of Urology and Human Reproductive Systems / Sechenov First Moscow State Medical University
### **Tags**
Segmentation, CT, CECT, Kidney, Renal, Supervised
## **Model Description**
The model is the SegResNet architecture[1] for volumetric (3D) renal structures segmentation. Input is artery, vein, excretory phases after mutual registration and concatenated to 3 channel 3D tensor.
## **Data**
DICOM data from 41 patients with kidney neoplasms were used [2]. The images and segmentation data are available under a CC BY-NC-SA 4.0 license. Data included all phases of contrast-enhanced multispiral computed tomography. We split the data: 32 observations for the training set and 9 – for the validation set. At the labeling stage, the arterial, venous, and excretory phases were taken, affine registration was performed to jointly match the location of the kidneys, and noise was removed using a median filter and a non-local means filter. Validation set ip published to Yandex.Disk. You can download via [link](https://disk.yandex.ru/d/pWEKt6D3qi3-aw) or use following command:
```bash
python -m monai.bundle run download_data --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
**NB**: underlying data is in LPS orientation. IF! you want to test model on your own data, reorient it from RAS to LPS with `Orientation` transform. You can see example of preprocessing pipeline in `inference.json` file of this bundle.
#### **Preprocessing**
Images are (1) croped to kidney region, all (artery,vein,excret) phases are (2) [registered](https://simpleitk.readthedocs.io/en/master/registrationOverview.html#lbl-registration-overview) with affine transform, noise removed with (3) median and (4) non-local means filter. After that, images are (5) resampled to (0.8,0.8,0.8) density and intesities are (6) scaled from [-1000,1000] to [0,1] range.
## **Performance**
On the validation subset, the values of the Dice score of the SegResNet architecture were: 0.89 for the normal parenchyma of the kidney, 0.58 for the kidney neoplasms, 0.86 for arteries, 0.80 for veins, 0.80 for ureters.
When compared with the nnU-Net model, which was trained on KiTS 21 dataset, the Dice score was greater for the kidney parenchyma in SegResNet – 0.89 compared to three model variants: lowres – 0.69, fullres – 0.70, cascade – 0.69. At the same time, for the neoplasms of the parenchyma of the kidney, the Dice score was comparable: for SegResNet – 0.58, for nnU-Net fullres – 0.59; lowres and cascade had lower Dice score of 0.37 and 0.45, respectively. To reproduce, visit - https://github.com/blacky-i/nephro-segmentation
## **Additional Usage Steps**
#### Execute training:
```bash
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started
#### Execute training with finetuning
```bash
python -m monai.bundle run training --dont_finetune false --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started, model variables are restored
#### Execute validation:
Download validation data (described in [Data](#data) section).
With provided model weights mean dice score is expected to be ~0.78446.
##### Run validation script:
```bash
python -m monai.bundle run evaluate --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `Key metric: val_mean_dice best value: ...` is printed.
## **System Configuration**
The model was trained for 10000 epochs on 2 RTX2080Ti GPUs with [SmartCacheDataset](https://docs.monai.io/en/stable/data.html#smartcachedataset). This takes 1 days and 2 hours, with 4 images per GPU.
Training progress is available on [tensorboard.dev](https://tensorboard.dev/experiment/VlEMjLdURH6SyFp216dFBg)
To perform training in minimal settings, at least one 12GB-memory GPU is required.
Actual Model Input: 96 x 96 x 96
## **Limitations**
For developmental purposes only and cannot be used directly for clinical procedures.
## **Citation Info**
```
@article{chernenkiy2023segmentation,
title={Segmentation of renal structures based on contrast computed tomography scans using a convolutional neural network},
author={Chernenkiy, IМ and Chernenkiy, MM and Fiev, DN and Sirota, ES},
journal={Sechenov Medical Journal},
volume={14},
number={1},
pages={39--49},
year={2023}
}
```
## **References**
[1] Myronenko, A. (2019). 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In: Crimi, A., Bakas, S., Kuijf, H., Keyvan, F., Reyes, M., van Walsum, T. (eds) Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries. BrainLes 2018. Lecture Notes in Computer Science(), vol 11384. Springer, Cham. https://doi.org/10.1007/978-3-030-11726-9_28
[2] Chernenkiy, I. М., et al. "Segmentation of renal structures based on contrast computed tomography scans using a convolutional neural network." Sechenov Medical Journal 14.1 (2023): 39-49.https://doi.org/10.47093/2218-7332.2023.14.1.39-49
#### **Tests used for bundle checking**
Checking with ci script file
```bash
python ci/verify_bundle.py -b renalStructures_CECT_segmentation -p models
```
Expected result: passed, model.pt file downloaded
Checking downloading validation data file
```bash
cd models/renalStructures_CECT_segmentation
python -m monai.bundle run download_data --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `data/` folder is created and filled with images.
Checking evaluation script
```bash
python -m monai.bundle run evaluate --meta_file configs/metadata.json --config_file "['configs/train.json', 'configs/evaluate.json']"
```
Expected result: finished, `Key metric: val_mean_dice best value: ...` is printed.
Checking train script
```bash
python -m monai.bundle run training --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started
Checking train script with finetuning
```bash
python -m monai.bundle run training --dont_finetune false --meta_file configs/metadata.json --config_file configs/train.json
```
Expected result: finished, Training process started, model variables are restored
Checking inference script
```bash
python -m monai.bundle run inference --meta_file configs/metadata.json --config_file configs/inference.json
```
Expected result: finished, in `eval` folder masks are created
Check unit test with script:
```bash
python ci/unit_tests/runner.py --b renalStructures_CECT_segmentation
```
|
monai-test/pathology_tumor_detection
|
monai-test
| 2023-08-16T02:57:58Z | 0 | 3 |
monai
|
[
"monai",
"medical",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:56:58Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for automated detection of metastases in whole-slide histopathology images.
The model is trained based on ResNet18 [1] with the last fully connected layer replaced by a 1x1 convolution layer.
## Data
All the data used to train, validate, and test this model is from [Camelyon-16 Challenge](https://camelyon16.grand-challenge.org/). You can download all the images for "CAMELYON16" data set from various sources listed [here](https://camelyon17.grand-challenge.org/Data/).
Location information for training/validation patches (the location on the whole slide image where patches are extracted) are adopted from [NCRF/coords](https://github.com/baidu-research/NCRF/tree/master/coords).
Annotation information are adopted from [NCRF/jsons](https://github.com/baidu-research/NCRF/tree/master/jsons).
- Target: Tumor
- Task: Detection
- Modality: Histopathology
- Size: 270 WSIs for training/validation, 48 WSIs for testing
### Preprocessing
This bundle expects the training/validation data (whole slide images) reside in a `{dataset_dir}/training/images`. By default `dataset_dir` is pointing to `/workspace/data/medical/pathology/` You can modify `dataset_dir` in the bundle config files to point to a different directory.
To reduce the computation burden during the inference, patches are extracted only where there is tissue and ignoring the background according to a tissue mask. Please also create a directory for prediction output. By default `output_dir` is set to `eval` folder under the bundle root.
Please refer to "Annotation" section of [Camelyon challenge](https://camelyon17.grand-challenge.org/Data/) to prepare ground truth images, which are needed for FROC computation. By default, this data set is expected to be at `/workspace/data/medical/pathology/ground_truths`. But it can be modified in `evaluate_froc.sh`.
## Training configuration
The training was performed with the following:
- Config file: train.config
- GPU: at least 16 GB of GPU memory.
- Actual Model Input: 224 x 224 x 3
- AMP: True
- Optimizer: Novograd
- Learning Rate: 1e-3
- Loss: BCEWithLogitsLoss
- Whole slide image reader: cuCIM (if running on Windows or Mac, please install `OpenSlide` on your system and change `wsi_reader` to "OpenSlide")
### Pretrained Weights
By setting the `"pretrained"` parameter of `TorchVisionFCModel` in the config file to `true`, ImageNet pre-trained weights will be used for training. Please note that these weights are for non-commercial use. Each user is responsible for checking the content of the models/datasets and the applicable licenses and determining if suitable for the intended use. In order to use other pretrained weights, you can use `CheckpointLoader` in train handlers section as the first handler:
```json
{
"_target_": "CheckpointLoader",
"load_path": "$@bundle_root + '/pretrained_resnet18.pth'",
"strict": false,
"load_dict": {
"model_new": "@network"
}
}
```
### Input
The training pipeline is a json file (dataset.json) which includes path to each WSI, the location and the label information for each training patch.
### Output
A probability number of the input patch being tumor or normal.
### Inference on a WSI
Inference is performed on WSI in a sliding window manner with specified stride. A foreground mask is needed to specify the region where the inference will be performed on, given that background region which contains no tissue at all can occupy a significant portion of a WSI. Output of the inference pipeline is a probability map of size 1/stride of original WSI size.
### Note on determinism
By default this bundle use a deterministic approach to make the results reproducible. However, it comes at a cost of performance loss. Thus if you do not care about reproducibility, you can have a performance gain by replacing `"$monai.utils.set_determinism"` line with `"$setattr(torch.backends.cudnn, 'benchmark', True)"` in initialize section of training configuration (`configs/train.json` and `configs/multi_gpu_train.json` for single GPU and multi-GPU training respectively).
## Performance
FROC score is used for evaluating the performance of the model. After inference is done, `evaluate_froc.sh` needs to be run to evaluate FROC score based on predicted probability map (output of inference) and the ground truth tumor masks.
Using an internal pretrained weights for ResNet18, this model deterministically achieves the 0.90 accuracy on validation patches, and FROC of 0.72 on the 48 Camelyon testing data that have ground truth annotations available.
The `pathology_tumor_detection` bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
Please notice that the benchmark results are tested on one WSI image since the images are too large to benchmark. And the inference time in the end-to-end line stands for one patch of the whole image.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| model computation |1.93 | 2.52 | 1.61 | 1.33 | 0.77 | 1.20 | 1.45 | 1.89 |
| end2end |224.97 | 223.50 | 222.65 | 224.03 | 1.01 | 1.01 | 1.00 | 1.00 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
- `end2end` means run the bundle end-to-end with the TensorRT based model.
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Execute inference
```
CUDA_LAUNCH_BLOCKING=1 python -m monai.bundle run --config_file configs/inference.json
```
#### Evaluate FROC metric
```
cd scripts && source evaluate_froc.sh
```
#### Export checkpoint to TorchScript file
```
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision
```
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --dynamic_batchsize "[1, 400, 600]"
```
#### Execute inference with the TensorRT model
```
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
```
# References
[1] He, Kaiming, et al, "Deep Residual Learning for Image Recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016. <https://arxiv.org/pdf/1512.03385.pdf>
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/pathology_nuclick_annotation
|
monai-test
| 2023-08-16T02:56:54Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:2005.14511",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:56:25Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for segmenting nuclei cells with user clicks/interactions.



This model is trained using [BasicUNet](https://docs.monai.io/en/latest/networks.html#basicunet) over [ConSeP](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet) dataset.
## Data
The training dataset is from https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet
```commandline
wget https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip
unzip -q consep_dataset.zip
```
<br/>
### Preprocessing
After [downloading this dataset](https://warwick.ac.uk/fac/cross_fac/tia/data/hovernet/consep_dataset.zip),
python script `data_process.py` from `scripts` folder can be used to preprocess and generate the final dataset for training.
```
python scripts/data_process.py --input /path/to/data/CoNSeP --output /path/to/data/CoNSePNuclei
```
After generating the output files, please modify the `dataset_dir` parameter specified in `configs/train.json` and `configs/inference.json` to reflect the output folder which contains new dataset.json.
Class values in dataset are
- 1 = other
- 2 = inflammatory
- 3 = healthy epithelial
- 4 = dysplastic/malignant epithelial
- 5 = fibroblast
- 6 = muscle
- 7 = endothelial
As part of pre-processing, the following steps are executed.
- Crop and Extract each nuclei Image + Label (128x128) based on the centroid given in the dataset.
- Combine classes 3 & 4 into the epithelial class and 5,6 & 7 into the spindle-shaped class.
- Update the label index for the target nuclei based on the class value
- Other cells which are part of the patch are modified to have label idx = 255
Example dataset.json
```json
{
"training": [
{
"image": "/workspace/data/CoNSePNuclei/Train/Images/train_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Train/Labels/train_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
],
"validation": [
{
"image": "/workspace/data/CoNSePNuclei/Test/Images/test_1_3_0001.png",
"label": "/workspace/data/CoNSePNuclei/Test/Labels/test_1_3_0001.png",
"nuclei_id": 1,
"mask_value": 3,
"centroid": [
64,
64
]
}
]
}
```
## Training Configuration
The training was performed with the following:
- GPU: at least 12GB of GPU memory
- Actual Model Input: 5 x 128 x 128
- AMP: True
- Optimizer: Adam
- Learning Rate: 1e-4
- Loss: DiceLoss
### Memory Consumption
- Dataset Manager: CacheDataset
- Data Size: 13,136 PNG images
- Cache Rate: 1.0
- Single GPU - System RAM Usage: 4.7G
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Input
5 channels
- 3 RGB channels
- +ve signal channel (this nuclei)
- -ve signal channel (other nuclei)
## Output
2 channels
- 0 = Background
- 1 = Nuclei
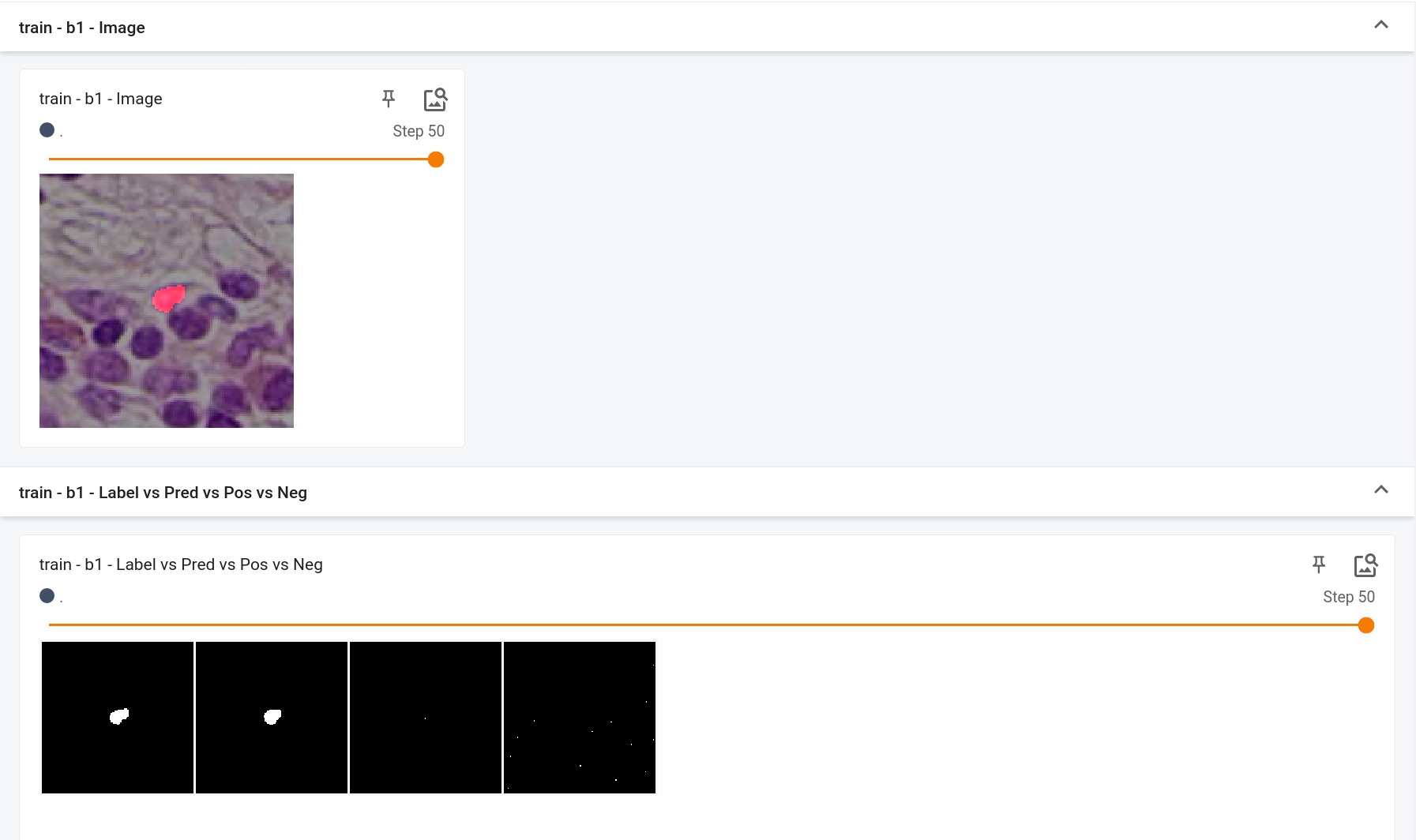
## Performance
This model achieves the following Dice score on the validation data provided as part of the dataset:
- Train Dice score = 0.89
- Validation Dice score = 0.85
#### Training Loss and Dice
A graph showing the training Loss and Dice over 50 epochs.
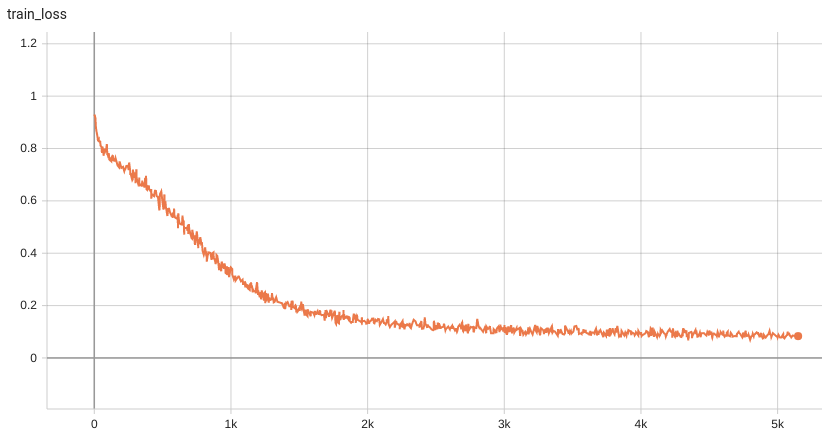 <br>
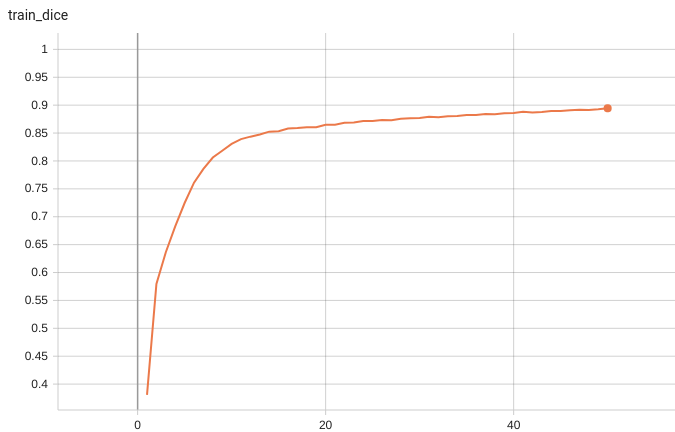 <br>
#### Validation Dice
A graph showing the validation mean Dice over 50 epochs.
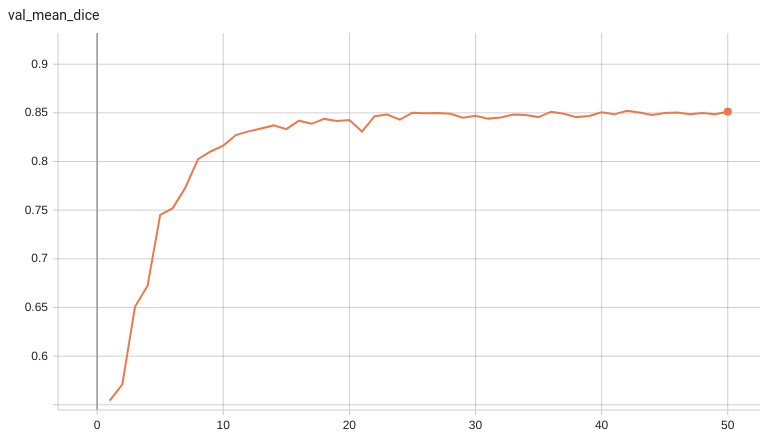 <br>
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
# References
[1] Koohbanani, Navid Alemi, et al. "NuClick: a deep learning framework for interactive segmentation of microscopic images." Medical Image Analysis 65 (2020): 101771. https://arxiv.org/abs/2005.14511.
[2] S. Graham, Q. D. Vu, S. E. A. Raza, A. Azam, Y-W. Tsang, J. T. Kwak and N. Rajpoot. "HoVer-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology Images." Medical Image Analysis, Sept. 2019. [[doi](https://doi.org/10.1016/j.media.2019.101563)]
[3] NuClick [PyTorch](https://github.com/mostafajahanifar/nuclick_torch) Implementation
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/lung_nodule_ct_detection
|
monai-test
| 2023-08-16T02:46:35Z | 0 | 3 |
monai
|
[
"monai",
"medical",
"arxiv:1708.02002",
"arxiv:2106.00817",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:45:21Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for volumetric (3D) detection of the lung nodule from CT image.
This model is trained on LUNA16 dataset (https://luna16.grand-challenge.org/Home/), using the RetinaNet (Lin, Tsung-Yi, et al. "Focal loss for dense object detection." ICCV 2017. https://arxiv.org/abs/1708.02002).
## Data
The dataset we are experimenting in this example is LUNA16 (https://luna16.grand-challenge.org/Home/), which is based on [LIDC-IDRI database](https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI) [3,4,5].
LUNA16 is a public dataset of CT lung nodule detection. Using raw CT scans, the goal is to identify locations of possible nodules, and to assign a probability for being a nodule to each location.
Disclaimer: We are not the host of the data. Please make sure to read the requirements and usage policies of the data and give credit to the authors of the dataset! We acknowledge the National Cancer Institute and the Foundation for the National Institutes of Health, and their critical role in the creation of the free publicly available LIDC/IDRI Database used in this study.
### 10-fold data splitting
We follow the official 10-fold data splitting from LUNA16 challenge and generate data split json files using the script from [nnDetection](https://github.com/MIC-DKFZ/nnDetection/blob/main/projects/Task016_Luna/scripts/prepare.py).
Please download the resulted json files from https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/LUNA16_datasplit-20220615T233840Z-001.zip.
In these files, the values of "box" are the ground truth boxes in world coordinate.
### Data resampling
The raw CT images in LUNA16 have various of voxel sizes. The first step is to resample them to the same voxel size.
In this model, we resampled them into 0.703125 x 0.703125 x 1.25 mm.
Please following the instruction in Section 3.1 of https://github.com/Project-MONAI/tutorials/tree/main/detection to do the resampling.
### Data download
The mhd/raw original data can be downloaded from [LUNA16](https://luna16.grand-challenge.org/Home/). The DICOM original data can be downloaded from [LIDC-IDRI database](https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI) [3,4,5]. You will need to resample the original data to start training.
Alternatively, we provide [resampled nifti images](https://drive.google.com/drive/folders/1JozrufA1VIZWJIc5A1EMV3J4CNCYovKK?usp=share_link) and a copy of [original mhd/raw images](https://drive.google.com/drive/folders/1-enN4eNEnKmjltevKg3W2V-Aj0nriQWE?usp=share_link) from [LUNA16](https://luna16.grand-challenge.org/Home/) for users to download.
## Training configuration
The training was performed with the following:
- GPU: at least 16GB GPU memory, requires 32G when exporting TRT model
- Actual Model Input: 192 x 192 x 80
- AMP: True
- Optimizer: Adam
- Learning Rate: 1e-2
- Loss: BCE loss and L1 loss
### Input
1 channel
- List of 3D CT patches
### Output
In Training Mode: A dictionary of classification and box regression loss.
In Evaluation Mode: A list of dictionaries of predicted box, classification label, and classification score.
## Performance
Coco metric is used for evaluating the performance of the model. The pre-trained model was trained and validated on data fold 0. This model achieves a mAP=0.852, mAR=0.998, AP(IoU=0.1)=0.858, AR(IoU=0.1)=1.0.
Please note that this bundle is non-deterministic because of the max pooling layer used in the network. Therefore, reproducing the training process may not get exactly the same performance.
Please refer to https://pytorch.org/docs/stable/notes/randomness.html#reproducibility for more details about reproducibility.
#### Training Loss
#### Validation Accuracy
The validation accuracy in this curve is the mean of mAP, mAR, AP(IoU=0.1), and AR(IoU=0.1) in Coco metric.
#### TensorRT speedup
The `lung_nodule_ct_detection` bundle supports acceleration with TensorRT through the ONNX-TensorRT method. The table below displays the speedup ratios observed on an A100 80G GPU. Please note that when using the TensorRT model for inference, the `force_sliding_window` parameter in the `inference.json` file must be set to `true`. This ensures that the bundle uses the `SlidingWindowInferer` during inference and maintains the input spatial size of the network. Otherwise, if given an input with spatial size less than the `infer_patch_size`, the input spatial size of the network would be changed.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| model computation | 7449.84 | 996.08 | 976.67 | 626.90 | 7.63 | 7.63 | 11.88 | 1.56 |
| end2end | 36458.26 | 7259.35 | 6420.60 | 4698.34 | 5.02 | 5.68 | 7.76 | 1.55 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
- `end2end` means run the bundle end-to-end with the TensorRT based model.
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
Currently, the only available method to accelerate this model is through ONNX-TensorRT. However, the Torch-TensorRT method is under development and will be available in the near future.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Execute inference on resampled LUNA16 images by setting `"whether_raw_luna16": false` in `inference.json`:
```
python -m monai.bundle run --config_file configs/inference.json
```
With the same command, we can execute inference on original LUNA16 images by setting `"whether_raw_luna16": true` in `inference.json`. Remember to also set `"data_list_file_path": "$@bundle_root + '/LUNA16_datasplit/mhd_original/dataset_fold0.json'"` and change `"dataset_dir"`.
Note that in inference.json, the transform "LoadImaged" in "preprocessing" and "AffineBoxToWorldCoordinated" in "postprocessing" has `"affine_lps_to_ras": true`.
This depends on the input images. LUNA16 needs `"affine_lps_to_ras": true`.
It is possible that your inference dataset should set `"affine_lps_to_ras": false`.
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision
```bash
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16> --input_shape "[1, 1, 512, 512, 192]" --use_onnx "True" --use_trace "True" --onnx_output_names "['output_0', 'output_1', 'output_2', 'output_3', 'output_4', 'output_5']" --network_def#use_list_output "True"
```
#### Execute inference with the TensorRT model
```
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
```
# References
[1] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." ICCV 2017. https://arxiv.org/abs/1708.02002)
[2] Baumgartner and Jaeger et al. "nnDetection: A self-configuring method for medical object detection." MICCAI 2021. https://arxiv.org/pdf/2106.00817.pdf
[3] Armato III, S. G., McLennan, G., Bidaut, L., McNitt-Gray, M. F., Meyer, C. R., Reeves, A. P., Zhao, B., Aberle, D. R., Henschke, C. I., Hoffman, E. A., Kazerooni, E. A., MacMahon, H., Van Beek, E. J. R., Yankelevitz, D., Biancardi, A. M., Bland, P. H., Brown, M. S., Engelmann, R. M., Laderach, G. E., Max, D., Pais, R. C. , Qing, D. P. Y. , Roberts, R. Y., Smith, A. R., Starkey, A., Batra, P., Caligiuri, P., Farooqi, A., Gladish, G. W., Jude, C. M., Munden, R. F., Petkovska, I., Quint, L. E., Schwartz, L. H., Sundaram, B., Dodd, L. E., Fenimore, C., Gur, D., Petrick, N., Freymann, J., Kirby, J., Hughes, B., Casteele, A. V., Gupte, S., Sallam, M., Heath, M. D., Kuhn, M. H., Dharaiya, E., Burns, R., Fryd, D. S., Salganicoff, M., Anand, V., Shreter, U., Vastagh, S., Croft, B. Y., Clarke, L. P. (2015). Data From LIDC-IDRI [Data set]. The Cancer Imaging Archive. https://doi.org/10.7937/K9/TCIA.2015.LO9QL9SX
[4] Armato SG 3rd, McLennan G, Bidaut L, McNitt-Gray MF, Meyer CR, Reeves AP, Zhao B, Aberle DR, Henschke CI, Hoffman EA, Kazerooni EA, MacMahon H, Van Beeke EJ, Yankelevitz D, Biancardi AM, Bland PH, Brown MS, Engelmann RM, Laderach GE, Max D, Pais RC, Qing DP, Roberts RY, Smith AR, Starkey A, Batrah P, Caligiuri P, Farooqi A, Gladish GW, Jude CM, Munden RF, Petkovska I, Quint LE, Schwartz LH, Sundaram B, Dodd LE, Fenimore C, Gur D, Petrick N, Freymann J, Kirby J, Hughes B, Casteele AV, Gupte S, Sallamm M, Heath MD, Kuhn MH, Dharaiya E, Burns R, Fryd DS, Salganicoff M, Anand V, Shreter U, Vastagh S, Croft BY. The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A completed reference database of lung nodules on CT scans. Medical Physics, 38: 915--931, 2011. DOI: https://doi.org/10.1118/1.3528204
[5] Clark, K., Vendt, B., Smith, K., Freymann, J., Kirby, J., Koppel, P., Moore, S., Phillips, S., Maffitt, D., Pringle, M., Tarbox, L., & Prior, F. (2013). The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository. Journal of Digital Imaging, 26(6), 1045–1057. https://doi.org/10.1007/s10278-013-9622-7
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/endoscopic_tool_segmentation
|
monai-test
| 2023-08-16T02:45:14Z | 0 | 1 |
monai
|
[
"monai",
"medical",
"arxiv:1905.11946",
"arxiv:1505.04597",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:44:25Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for the endoscopic tool segmentation task, trained using a flexible unet structure with an efficientnet-b2 [1] as the backbone and a UNet architecture [2] as the decoder. Datasets use private samples from [Activ Surgical](https://www.activsurgical.com/).
The [PyTorch model](https://drive.google.com/file/d/1I7UtWDKDEcezMqYiA-i_hsRTCrvWwJ61/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1e_wYd1HjJQ0dz_HKdbthRcMOyUL02aLG/view?usp=sharing) are shared in google drive. Details can be found in `large_files.yml` file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
## Pre-trained weights
A pre-trained encoder weights would benefit the model training. In this bundle, the encoder is trained with pre-trained weights from some internal data. We provide two options to enable users to load pre-trained weights:
1. Via setting the `use_imagenet_pretrain` parameter in the config file to `True`, [ImageNet](https://ieeexplore.ieee.org/document/5206848) pre-trained weights from the [EfficientNet-PyTorch repo](https://github.com/lukemelas/EfficientNet-PyTorch) can be loaded. Please note that these weights are for non-commercial use. Each user is responsible for checking the content of the models/datasets and the applicable licenses and determining if suitable for the intended use.
2. Via adding a `CheckpointLoader` as the first handler to the `handlers` section of the `train.json` config file, weights from a local path can be loaded. Here is an example `CheckpointLoader`:
```json
{
"_target_": "CheckpointLoader",
"load_path": "/path/to/local/weight/model.pt",
"load_dict": {
"model": "@network"
},
"strict": false,
"map_location": "@device"
}
```
When executing the training command, if neither adding the `CheckpointLoader` to the `train.json` nor setting the `use_imagenet_pretrain` parameter to `True`, a training process would start from scratch.
## Data
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
Since datasets are private, existing public datasets like [EndoVis 2017](https://endovissub2017-roboticinstrumentsegmentation.grand-challenge.org/Data/) can be used to train a similar model.
### Preprocessing
When using EndoVis or any other dataset, it should be divided into "train", "valid" and "test" folders. Samples in each folder would better be images and converted to jpg format. Otherwise, "images", "labels", "val_images" and "val_labels" parameters in `configs/train.json` and "datalist" in `configs/inference.json` should be modified to fit given dataset. After that, "dataset_dir" parameter in `configs/train.json` and `configs/inference.json` should be changed to root folder which contains "train", "valid" and "test" folders.
Please notice that loading data operation in this bundle is adaptive. If images and labels are not in the same format, it may lead to a mismatching problem. For example, if images are in jpg format and labels are in npy format, PIL and Numpy readers will be used separately to load images and labels. Since these two readers have their own way to parse file's shape, loaded labels will be transpose of the correct ones and incur a missmatching problem.
## Training configuration
The training as performed with the following:
- GPU: At least 12GB of GPU memory
- Actual Model Input: 736 x 480 x 3
- Optimizer: Adam
- Learning Rate: 1e-4
- Dataset Manager: CacheDataset
### Memory Consumption Warning
If you face memory issues with CacheDataset, you can either switch to a regular Dataset class or lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
### Input
A three channel video frame
### Output
Two channels:
- Label 1: tools
- Label 0: everything else
## Performance
IoU was used for evaluating the performance of the model. This model achieves a mean IoU score of 0.86.
#### Training Loss
#### Validation IoU
#### TensorRT speedup
The `endoscopic_tool_segmentation` bundle supports acceleration with TensorRT. The table below displays the speedup ratios observed on an A100 80G GPU.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| model computation | 12.00 | 14.06 | 6.59 | 5.20 | 0.85 | 1.82 | 2.31 | 2.70 |
| end2end |170.04 | 172.20 | 155.26 | 155.57 | 0.99 | 1.10 | 1.09 | 1.11 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
- `end2end` means run the bundle end-to-end with the TensorRT based model.
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Override the `train` config and `evaluate` config to execute multi-GPU evaluation:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json','configs/multi_gpu_evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
#### Export checkpoint to TorchScript file:
```
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
```
python -m monai.bundle trt_export --net_id network_def --filepath models/model_trt.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json --precision <fp32/fp16>
```
#### Execute inference with the TensorRT model:
```
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
```
# References
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
[2] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015. https://arxiv.org/pdf/1505.04597.pdf
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
hw2942/bart-base-chinese-SSEC
|
hw2942
| 2023-08-16T02:45:05Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text-classification",
"generated_from_trainer",
"base_model:fnlp/bart-base-chinese",
"base_model:finetune:fnlp/bart-base-chinese",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T02:21:28Z |
---
base_model: fnlp/bart-base-chinese
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bart-base-chinese-wallstreetcn-morning-news-market-overview-SSEC-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-chinese-wallstreetcn-morning-news-market-overview-SSEC-v1
This model is a fine-tuned version of [fnlp/bart-base-chinese](https://huggingface.co/fnlp/bart-base-chinese) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2056
- Accuracy: 0.6875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 68 | 0.6914 | 0.5625 |
| No log | 2.0 | 136 | 0.6649 | 0.5938 |
| No log | 3.0 | 204 | 0.7056 | 0.5938 |
| No log | 4.0 | 272 | 0.6510 | 0.6562 |
| No log | 5.0 | 340 | 1.1325 | 0.6875 |
| No log | 6.0 | 408 | 1.6671 | 0.6875 |
| No log | 7.0 | 476 | 2.0104 | 0.6875 |
| 0.4905 | 8.0 | 544 | 1.9887 | 0.6875 |
| 0.4905 | 9.0 | 612 | 2.2172 | 0.6875 |
| 0.4905 | 10.0 | 680 | 2.2056 | 0.6875 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
monai-test/endoscopic_inbody_classification
|
monai-test
| 2023-08-16T02:44:21Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:1709.01507",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:42:51Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for the endoscopic inbody classification task and trained using the SEResNet50 structure, whose details can be found in [1]. All datasets are from private samples of [Activ Surgical](https://www.activsurgical.com/). Samples in training and validation dataset are from the same 4 videos, while test samples are from different two videos.
The [PyTorch model](https://drive.google.com/file/d/14CS-s1uv2q6WedYQGeFbZeEWIkoyNa-x/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1fOoJ4n5DWKHrt9QXTZ2sXwr9C-YvVGCM/view?usp=sharing) are shared in google drive. Modify the `bundle_root` parameter specified in `configs/train.json` and `configs/inference.json` to reflect where models are downloaded. Expected directory path to place downloaded models is `models/` under `bundle_root`.
## Data
The datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
Since datasets are private, we provide a [link](https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/inbody_outbody_samples.zip) of 20 samples (10 in-body and 10 out-body) to show what they look like.
### Preprocessing
After downloading this dataset, python script in `scripts` folder named `data_process` can be used to generate label json files by running the command below and modifying `datapath` to path of unziped downloaded data. Generated label json files will be stored in `label` folder under the bundle path.
```
python scripts/data_process.py --datapath /path/to/data/root
```
By default, label path parameter in `train.json` and `inference.json` of this bundle is point to the generated `label` folder under bundle path. If you move these generated label files to another place, please modify the `train_json`, `val_json` and `test_json` parameters specified in `configs/train.json` and `configs/inference.json` to where these label files are.
The input label json should be a list made up by dicts which includes `image` and `label` keys. An example format is shown below.
```
[
{
"image":"/path/to/image/image_name0.jpg",
"label": 0
},
{
"image":"/path/to/image/image_name1.jpg",
"label": 0
},
{
"image":"/path/to/image/image_name2.jpg",
"label": 1
},
....
{
"image":"/path/to/image/image_namek.jpg",
"label": 0
},
]
```
## Training configuration
The training as performed with the following:
- GPU: At least 12GB of GPU memory
- Actual Model Input: 256 x 256 x 3
- Optimizer: Adam
- Learning Rate: 1e-3
### Input
A three channel video frame
### Output
Two Channels
- Label 0: in body
- Label 1: out body
## Performance
Accuracy was used for evaluating the performance of the model. This model achieves an accuracy score of 0.99
#### Training Loss
#### Validation Accuracy
#### TensorRT speedup
The `endoscopic_inbody_classification` bundle supports acceleration with TensorRT through the ONNX-TensorRT method. The table below displays the speedup ratios observed on an A100 80G GPU.
| method | torch_fp32(ms) | torch_amp(ms) | trt_fp32(ms) | trt_fp16(ms) | speedup amp | speedup fp32 | speedup fp16 | amp vs fp16|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| model computation | 6.50 | 9.23 | 2.78 | 2.31 | 0.70 | 2.34 | 2.81 | 4.00 |
| end2end | 23.54 | 23.78 | 7.37 | 7.14 | 0.99 | 3.19 | 3.30 | 3.33 |
Where:
- `model computation` means the speedup ratio of model's inference with a random input without preprocessing and postprocessing
- `end2end` means run the bundle end-to-end with the TensorRT based model.
- `torch_fp32` and `torch_amp` are for the PyTorch models with or without `amp` mode.
- `trt_fp32` and `trt_fp16` are for the TensorRT based models converted in corresponding precision.
- `speedup amp`, `speedup fp32` and `speedup fp16` are the speedup ratios of corresponding models versus the PyTorch float32 model
- `amp vs fp16` is the speedup ratio between the PyTorch amp model and the TensorRT float16 based model.
Currently, the only available method to accelerate this model is through ONNX-TensorRT. However, the Torch-TensorRT method is under development and will be available in the near future.
This result is benchmarked under:
- TensorRT: 8.5.3+cuda11.8
- Torch-TensorRT Version: 1.4.0
- CPU Architecture: x86-64
- OS: ubuntu 20.04
- Python version:3.8.10
- CUDA version: 12.0
- GPU models and configuration: A100 80G
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
#### Execute training:
```
python -m monai.bundle run --config_file configs/train.json
```
Please note that if the default dataset path is not modified with the actual path in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training:
```
torchrun --standalone --nnodes=1 --nproc_per_node=2 -m monai.bundle run \
--config_file "['configs/train.json','configs/multi_gpu_train.json']"
```
Please note that the distributed training-related options depend on the actual running environment; thus, users may need to remove `--standalone`, modify `--nnodes`, or do some other necessary changes according to the machine used. For more details, please refer to [pytorch's official tutorial](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html).
In addition, if using the 20 samples example dataset, the preprocessing script will divide the samples to 16 training samples, 2 validation samples and 2 test samples. However, pytorch multi-gpu training requires number of samples in dataloader larger than gpu numbers. Therefore, please use no more than 2 gpus to run this bundle if using the 20 samples example dataset.
#### Override the `train` config to execute evaluation with the trained model:
```
python -m monai.bundle run --config_file "['configs/train.json','configs/evaluate.json']"
```
#### Execute inference:
```
python -m monai.bundle run --config_file configs/inference.json
```
The classification result of every images in `test.json` will be printed to the screen.
#### Export checkpoint to TorchScript file:
```
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
#### Export checkpoint to TensorRT based models with fp32 or fp16 precision:
```bash
python -m monai.bundle trt_export --net_id network_def \
--filepath models/model_trt.ts --ckpt_file models/model.pt \
--meta_file configs/metadata.json --config_file configs/inference.json \
--precision <fp32/fp16> --use_onnx "True" --use_trace "True"
```
#### Execute inference with the TensorRT model:
```
python -m monai.bundle run --config_file "['configs/inference.json', 'configs/inference_trt.json']"
```
# References
[1] J. Hu, L. Shen and G. Sun, Squeeze-and-Excitation Networks, 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132-7141. https://arxiv.org/pdf/1709.01507.pdf
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/breast_density_classification
|
monai-test
| 2023-08-16T02:42:44Z | 0 | 0 |
monai
|
[
"monai",
"medical",
"arxiv:2202.08238",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:42:31Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Description
A pre-trained model for breast-density classification.
# Model Overview
This model is trained using transfer learning on InceptionV3. The model weights were fine tuned using the Mayo Clinic Data. The details of training and data is outlined in https://arxiv.org/abs/2202.08238. The images should be resampled to a size [299, 299, 3] for training.
A training pipeline will be added to the model zoo in near future.
The bundle does not support torchscript.
# Sample Data
In the folder `sample_data` few example input images are stored for each category of images. These images are stored in jpeg format for sharing purpose.
# Input and Output Formats
The input image should have the size [299, 299, 3]. For a dicom image which are single channel. The channel can be repeated 3 times.
The output is an array with probabilities for each of the four class.
# Commands Example
Create a json file with names of all the input files. Execute the following command
```
python scripts/create_dataset.py -base_dir <path to the bundle root dir>/sample_data -output_file configs/sample_image_data.json
```
Change the `filename` for the field `data` with the absolute path for `sample_image_data.json`
# Add scripts folder to your python path as follows
```
export PYTHONPATH=$PYTHONPATH:<path to the bundle root dir>/scripts
```
# Execute Inference
The inference can be executed as follows
```
python -m monai.bundle run evaluating --meta_file configs/metadata.json --config_file configs/inference.json configs/logging.conf
```
# Execute training
It is a work in progress and will be shared in the next version soon.
# Contributors
This model is made available from Center for Augmented Intelligence in Imaging, Mayo Clinic Florida. For questions email Vikash Gupta (gupta.vikash@mayo.edu).
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
monai-test/brats_mri_generative_diffusion
|
monai-test
| 2023-08-16T02:41:55Z | 0 | 4 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:39:27Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for volumetric (3D) Brats MRI 3D Latent Diffusion Generative Model.
This model is trained on BraTS 2016 and 2017 data from [Medical Decathlon](http://medicaldecathlon.com/), using the Latent diffusion model [1].
This model is a generator for creating images like the Flair MRIs based on BraTS 2016 and 2017 data. It was trained as a 3d latent diffusion model and accepts Gaussian random noise as inputs to produce an image output. The `train_autoencoder.json` file describes the training process of the variational autoencoder with GAN loss. The `train_diffusion.json` file describes the training process of the 3D latent diffusion model.
In this bundle, the autoencoder uses perceptual loss, which is based on ResNet50 with pre-trained weights (the network is frozen and will not be trained in the bundle). In default, the `pretrained` parameter is specified as `False` in `train_autoencoder.json`. To ensure correct training, changing the default settings is necessary. There are two ways to utilize pretrained weights:
1. if set `pretrained` to `True`, ImageNet pretrained weights from [torchvision](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet50_Weights) will be used. However, the weights are for non-commercial use only.
2. if set `pretrained` to `True` and specifies the `perceptual_loss_model_weights_path` parameter, users are able to load weights from a local path. This is the way this bundle used to train, and the pre-trained weights are from some internal data.
Please note that each user is responsible for checking the data source of the pre-trained models, the applicable licenses, and determining if suitable for the intended use.
#### Example synthetic image
An example result from inference is shown below:
**This is a demonstration network meant to just show the training process for this sort of network with MONAI. To achieve better performance, users need to use larger dataset like [Brats 2021](https://www.synapse.org/#!Synapse:syn25829067/wiki/610865) and have GPU with memory larger than 32G to enable larger networks and attention layers.**
## Data
The training data is BraTS 2016 and 2017 from the Medical Segmentation Decathalon. Users can find more details on the dataset (`Task01_BrainTumour`) at http://medicaldecathlon.com/.
- Target: Image Generation
- Task: Synthesis
- Modality: MRI
- Size: 388 3D volumes (1 channel used)
## Training Configuration
If you have a GPU with less than 32G of memory, you may need to decrease the batch size when training. To do so, modify the `train_batch_size` parameter in the [configs/train_autoencoder.json](../configs/train_autoencoder.json) and [configs/train_diffusion.json](../configs/train_diffusion.json) configuration files.
### Training Configuration of Autoencoder
The autoencoder was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 112 x 128 x 80
- AMP: False
- Optimizer: Adam
- Learning Rate: 1e-5
- Loss: L1 loss, perceptual loss, KL divergence loss, adversarial loss, GAN BCE loss
#### Input
1 channel 3D MRI Flair patches
#### Output
- 1 channel 3D MRI reconstructed patches
- 8 channel mean of latent features
- 8 channel standard deviation of latent features
### Training Configuration of Diffusion Model
The latent diffusion model was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 36 x 44 x 28
- AMP: False
- Optimizer: Adam
- Learning Rate: 1e-5
- Loss: MSE loss
#### Training Input
- 8 channel noisy latent features
- a long int that indicates the time step
#### Training Output
8 channel predicted added noise
#### Inference Input
8 channel noise
#### Inference Output
8 channel denoised latent features
### Memory Consumption Warning
If you face memory issues with data loading, you can lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Performance
#### Training Loss
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
### Execute Autoencoder Training
#### Execute Autoencoder Training on single GPU
```
python -m monai.bundle run --config_file configs/train_autoencoder.json
```
Please note that if the default dataset path is not modified with the actual path (it should be the path that contains `Task01_BrainTumour`) in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train_autoencoder.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training for Autoencoder
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/multi_gpu_train_autoencoder.json']" --lr 8e-5
```
#### Check the Autoencoder Training result
The following code generates a reconstructed image from a random input image.
We can visualize it to see if the autoencoder is trained correctly.
```
python -m monai.bundle run --config_file configs/inference_autoencoder.json
```
An example of reconstructed image from inference is shown below. If the autoencoder is trained correctly, the reconstructed image should look similar to original image.
### Execute Latent Diffusion Training
#### Execute Latent Diffusion Model Training on single GPU
After training the autoencoder, run the following command to train the latent diffusion model. This command will print out the scale factor of the latent feature space. If your autoencoder is well trained, this value should be close to 1.0.
```
python -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json']"
```
#### Override the `train` config to execute multi-GPU training for Latent Diffusion Model
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json','configs/multi_gpu_train_autoencoder.json','configs/multi_gpu_train_diffusion.json']" --lr 8e-5
```
#### Execute inference
The following code generates a synthetic image from a random sampled noise.
```
python -m monai.bundle run --config_file configs/inference.json
```
#### Export checkpoint to TorchScript file
The Autoencoder can be exported into a TorchScript file.
```
python -m monai.bundle ckpt_export autoencoder_def --filepath models/model_autoencoder.ts --ckpt_file models/model_autoencoder.pt --meta_file configs/metadata.json --config_file configs/inference.json
```
# References
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
camus-ng/lora-trained-xl-cory-9
|
camus-ng
| 2023-08-16T02:39:35Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-08-15T14:11:10Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of <ntvc> man
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - camus-ng/lora-trained-xl-cory-9
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of <ntvc> man using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
monai-test/brats_mri_axial_slices_generative_diffusion
|
monai-test
| 2023-08-16T02:38:30Z | 0 | 1 |
monai
|
[
"monai",
"medical",
"license:apache-2.0",
"region:us"
] | null | 2023-08-16T02:37:59Z |
---
tags:
- monai
- medical
library_name: monai
license: apache-2.0
---
# Model Overview
A pre-trained model for 2D Latent Diffusion Generative Model on axial slices of BraTS MRI.
This model is trained on BraTS 2016 and 2017 data from [Medical Decathlon](http://medicaldecathlon.com/), using the Latent diffusion model [1].

This model is a generator for creating images like the Flair MRIs based on BraTS 2016 and 2017 data. It was trained as a 2d latent diffusion model and accepts Gaussian random noise as inputs to produce an image output. The `train_autoencoder.json` file describes the training process of the variational autoencoder with GAN loss. The `train_diffusion.json` file describes the training process of the 2D latent diffusion model.
In this bundle, the autoencoder uses perceptual loss, which is based on ResNet50 with pre-trained weights (the network is frozen and will not be trained in the bundle). In default, the `pretrained` parameter is specified as `False` in `train_autoencoder.json`. To ensure correct training, changing the default settings is necessary. There are two ways to utilize pretrained weights:
1. if set `pretrained` to `True`, ImageNet pretrained weights from [torchvision](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#ResNet50_Weights) will be used. However, the weights are for non-commercial use only.
2. if set `pretrained` to `True` and specifies the `perceptual_loss_model_weights_path` parameter, users are able to load weights from a local path. This is the way this bundle used to train, and the pre-trained weights are from some internal data.
Please note that each user is responsible for checking the data source of the pre-trained models, the applicable licenses, and determining if suitable for the intended use.
#### Example synthetic image
An example result from inference is shown below:
**This is a demonstration network meant to just show the training process for this sort of network with MONAI. To achieve better performance, users need to use larger dataset like [BraTS 2021](https://www.synapse.org/#!Synapse:syn25829067/wiki/610865).**
## Data
The training data is BraTS 2016 and 2017 from the Medical Segmentation Decathalon. Users can find more details on the dataset (`Task01_BrainTumour`) at http://medicaldecathlon.com/.
- Target: Image Generation
- Task: Synthesis
- Modality: MRI
- Size: 388 3D MRI volumes (1 channel used)
- Training data size: 38800 2D MRI axial slices (1 channel used)
## Training Configuration
If you have a GPU with less than 32G of memory, you may need to decrease the batch size when training. To do so, modify the `"train_batch_size_img"` and `"train_batch_size_slice"` parameters in the `configs/train_autoencoder.json` and `configs/train_diffusion.json` configuration files.
- `"train_batch_size_img"` is number of 3D volumes loaded in each batch.
- `"train_batch_size_slice"` is the number of 2D axial slices extracted from each image. The actual batch size is the product of them.
### Training Configuration of Autoencoder
The autoencoder was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 240 x 240
- AMP: False
- Optimizer: Adam
- Learning Rate: 5e-5
- Loss: L1 loss, perceptual loss, KL divergence loss, adversarial loss, GAN BCE loss
#### Input
1 channel 2D MRI Flair axial patches
#### Output
- 1 channel 2D MRI reconstructed patches
- 1 channel mean of latent features
- 1 channel standard deviation of latent features
### Training Configuration of Diffusion Model
The latent diffusion model was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 64 x 64
- AMP: False
- Optimizer: Adam
- Learning Rate: 5e-5
- Loss: MSE loss
#### Training Input
- 1 channel noisy latent features
- a long int that indicates the time step
#### Training Output
1 channel predicted added noise
#### Inference Input
1 channel noise
#### Inference Output
1 channel denoised latent features
### Memory Consumption Warning
If you face memory issues with data loading, you can lower the caching rate `cache_rate` in the configurations within range [0, 1] to minimize the System RAM requirements.
## Performance
#### Training Loss
## MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the [MONAI Bundle Configuration Page](https://docs.monai.io/en/latest/config_syntax.html).
### Execute Autoencoder Training
#### Execute Autoencoder Training on single GPU
```
python -m monai.bundle run --config_file configs/train_autoencoder.json
```
Please note that if the default dataset path is not modified with the actual path (it should be the path that contains Task01_BrainTumour) in the bundle config files, you can also override it by using `--dataset_dir`:
```
python -m monai.bundle run --config_file configs/train_autoencoder.json --dataset_dir <actual dataset path>
```
#### Override the `train` config to execute multi-GPU training for Autoencoder
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/multi_gpu_train_autoencoder.json']" --lr 4e-4
```
#### Check the Autoencoder Training result
The following code generates a reconstructed image from a random input image.
We can visualize it to see if the autoencoder is trained correctly.
```
python -m monai.bundle run --config_file configs/inference_autoencoder.json
```
An example of reconstructed image from inference is shown below. If the autoencoder is trained correctly, the reconstructed image should look similar to original image.
### Execute Latent Diffusion Model Training
#### Execute Latent Diffusion Model Training on single GPU
After training the autoencoder, run the following command to train the latent diffusion model. This command will print out the scale factor of the latent feature space. If your autoencoder is well trained, this value should be close to 1.0.
```
python -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json']"
```
#### Override the `train` config to execute multi-GPU training for Latent Diffusion Model
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json','configs/multi_gpu_train_autoencoder.json','configs/multi_gpu_train_diffusion.json']" --lr 4e-4
```
### Execute inference
The following code generates a synthetic image from a random sampled noise.
```
python -m monai.bundle run --config_file configs/inference.json
```
# References
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
# License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
|
machinelearningzuu/lesson-summarization
|
machinelearningzuu
| 2023-08-16T02:32:09Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-05-23T14:22:26Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
model-index:
- name: lesson-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lesson-summarization
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5713
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:-----:|:---------------:|
| 2.9037 | 3.12 | 200 | 2.2456 |
| 2.5914 | 6.25 | 400 | 2.1498 |
| 2.393 | 9.38 | 600 | 2.1002 |
| 2.2409 | 12.5 | 800 | 2.0754 |
| 2.1515 | 15.62 | 1000 | 2.0683 |
| 2.0633 | 18.75 | 1200 | 2.0541 |
| 1.9418 | 21.88 | 1400 | 2.0603 |
| 1.837 | 25.0 | 1600 | 2.0788 |
| 1.7715 | 28.12 | 1800 | 2.0754 |
| 1.6957 | 31.25 | 2000 | 2.0815 |
| 1.6079 | 34.38 | 2200 | 2.0940 |
| 1.5947 | 37.5 | 2400 | 2.1094 |
| 1.4603 | 40.62 | 2600 | 2.1147 |
| 1.4621 | 43.75 | 2800 | 2.1354 |
| 1.4021 | 46.88 | 3000 | 2.1519 |
| 1.3394 | 50.0 | 3200 | 2.1670 |
| 1.2866 | 53.12 | 3400 | 2.1921 |
| 1.2681 | 56.25 | 3600 | 2.2045 |
| 1.1866 | 59.38 | 3800 | 2.2194 |
| 1.2098 | 62.5 | 4000 | 2.2302 |
| 1.1386 | 65.62 | 4200 | 2.2400 |
| 1.0853 | 68.75 | 4400 | 2.2634 |
| 1.0888 | 71.88 | 4600 | 2.2810 |
| 1.0408 | 75.0 | 4800 | 2.2909 |
| 1.0309 | 78.12 | 5000 | 2.3059 |
| 0.9523 | 81.25 | 5200 | 2.3249 |
| 0.9671 | 84.38 | 5400 | 2.3333 |
| 0.9413 | 87.5 | 5600 | 2.3543 |
| 0.9127 | 90.62 | 5800 | 2.3636 |
| 0.9095 | 93.75 | 6000 | 2.3676 |
| 0.8952 | 96.88 | 6200 | 2.3756 |
| 0.857 | 100.0 | 6400 | 2.3878 |
| 0.8474 | 103.12 | 6600 | 2.4148 |
| 0.8215 | 106.25 | 6800 | 2.4231 |
| 0.8172 | 109.38 | 7000 | 2.4243 |
| 0.7761 | 112.5 | 7200 | 2.4489 |
| 0.7737 | 115.62 | 7400 | 2.4718 |
| 0.7476 | 118.75 | 7600 | 2.4614 |
| 0.7345 | 121.88 | 7800 | 2.4705 |
| 0.7426 | 125.0 | 8000 | 2.4740 |
| 0.7151 | 128.12 | 8200 | 2.4833 |
| 0.7191 | 131.25 | 8400 | 2.4786 |
| 0.6818 | 134.38 | 8600 | 2.4882 |
| 0.6862 | 137.5 | 8800 | 2.4938 |
| 0.6929 | 140.62 | 9000 | 2.4977 |
| 0.6494 | 143.75 | 9200 | 2.5195 |
| 0.6689 | 146.88 | 9400 | 2.5185 |
| 0.6492 | 150.0 | 9600 | 2.5259 |
| 0.6384 | 153.12 | 9800 | 2.5259 |
| 0.6435 | 156.25 | 10000 | 2.5287 |
| 0.6251 | 159.38 | 10200 | 2.5284 |
| 0.6295 | 162.5 | 10400 | 2.5398 |
| 0.6324 | 165.62 | 10600 | 2.5442 |
| 0.6252 | 168.75 | 10800 | 2.5481 |
| 0.6108 | 171.88 | 11000 | 2.5455 |
| 0.6034 | 175.0 | 11200 | 2.5502 |
| 0.5969 | 178.12 | 11400 | 2.5601 |
| 0.5949 | 181.25 | 11600 | 2.5617 |
| 0.6183 | 184.38 | 11800 | 2.5679 |
| 0.5805 | 187.5 | 12000 | 2.5687 |
| 0.6032 | 190.62 | 12200 | 2.5708 |
| 0.5955 | 193.75 | 12400 | 2.5709 |
| 0.5961 | 196.88 | 12600 | 2.5713 |
| 0.5914 | 200.0 | 12800 | 2.5713 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.13.1
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Gredora/ppo-LunarLander-v2
|
Gredora
| 2023-08-16T02:23:19Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T02:22:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.51 +/- 32.56
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jjsprockel/distil-ast-audioset-finetuned-gtzan
|
jjsprockel
| 2023-08-16T02:18:46Z | 157 | 0 |
transformers
|
[
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:bookbot/distil-ast-audioset",
"base_model:finetune:bookbot/distil-ast-audioset",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-08-16T01:49:11Z |
---
license: apache-2.0
base_model: bookbot/distil-ast-audioset
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distil-ast-audioset-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.89
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distil-ast-audioset-finetuned-gtzan
This model is a fine-tuned version of [bookbot/distil-ast-audioset](https://huggingface.co/bookbot/distil-ast-audioset) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3897
- Accuracy: 0.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.321 | 0.99 | 28 | 0.6668 | 0.82 |
| 0.4901 | 1.98 | 56 | 0.5119 | 0.85 |
| 0.2659 | 2.97 | 84 | 0.4564 | 0.87 |
| 0.1518 | 4.0 | 113 | 0.3853 | 0.88 |
| 0.0626 | 4.99 | 141 | 0.3862 | 0.89 |
| 0.0309 | 5.95 | 168 | 0.3897 | 0.89 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
yeongsang2/polyglot-ko-12.8B-v.1.02-checkpoint-240
|
yeongsang2
| 2023-08-16T02:15:59Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T02:13:35Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
JuiThe/mt5base_lora_Wreview_30e
|
JuiThe
| 2023-08-16T01:51:55Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-16T01:51:54Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
spear1/ppo-LunarLander-v2
|
spear1
| 2023-08-16T01:48:06Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T01:47:47Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.33 +/- 18.96
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ialvarenga/finetuned-mpnet-citation-itent
|
ialvarenga
| 2023-08-16T01:38:01Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-08-14T01:47:41Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# ialvarenga/finetuned-mpnet-citation-itent
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("ialvarenga/finetuned-mpnet-citation-itent")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
edor/Platypus2-mini-7B
|
edor
| 2023-08-16T01:35:11Z | 1,399 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-16T00:03:30Z |
---
license: other
---
Smaller version of Platypus2, Llama2-7B finetuned w/QLoRA with [garage-bAInd/Open-Platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus) dataset
|
Chaeyeon/git-base-sketch
|
Chaeyeon
| 2023-08-16T01:32:27Z | 61 | 0 |
transformers
|
[
"transformers",
"pytorch",
"git",
"image-text-to-text",
"generated_from_trainer",
"base_model:microsoft/git-base",
"base_model:finetune:microsoft/git-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-08-16T01:31:05Z |
---
license: mit
base_model: microsoft/git-base
tags:
- generated_from_trainer
model-index:
- name: git-base-sketch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# git-base-sketch
This model is a fine-tuned version of [microsoft/git-base](https://huggingface.co/microsoft/git-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
sxx123/gpt2-medium
|
sxx123
| 2023-08-16T00:56:00Z | 77 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-16T00:09:08Z |
---
language: en
license: mit
---
# GPT-2 Medium
## Model Details
**Model Description:** GPT-2 Medium is the **355M parameter** version of GPT-2, a transformer-based language model created and released by OpenAI. The model is a pretrained model on English language using a causal language modeling (CLM) objective.
- **Developed by:** OpenAI, see [associated research paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and [GitHub repo](https://github.com/openai/gpt-2) for model developers.
- **Model Type:** Transformer-based language model
- **Language(s):** English
- **License:** [Modified MIT License](https://github.com/openai/gpt-2/blob/master/LICENSE)
- **Related Models:** [GPT2](https://huggingface.co/gpt2), [GPT2-Large](https://huggingface.co/gpt2-large) and [GPT2-XL](https://huggingface.co/gpt2-xl)
- **Resources for more information:**
- [Research Paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
- [OpenAI Blog Post](https://openai.com/blog/better-language-models/)
- [GitHub Repo](https://github.com/openai/gpt-2)
- [OpenAI Model Card for GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md)
- Test the full generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
## How to Get Started with the Model
Use the code below to get started with the model. You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, I'm a language. I'm a compiler, I'm a parser, I'm a server process. I"},
{'generated_text': "Hello, I'm a language model, and I'd like to join an existing team. What can I do to get started?\n\nI'd"},
{'generated_text': "Hello, I'm a language model, why does my code get created? Can't I just copy it? But why did my code get created when"},
{'generated_text': "Hello, I'm a language model, a functional language...\n\nI'm a functional language. Is it hard? A little, yes. But"},
{'generated_text': "Hello, I'm a language model, not an object model.\n\nIn a nutshell, I need to give me objects from which I can get"}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = TFGPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Uses
#### Direct Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> The primary intended users of these models are AI researchers and practitioners.
>
> We primarily imagine these language models will be used by researchers to better understand the behaviors, capabilities, biases, and constraints of large-scale generative language models.
#### Downstream Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Here are some secondary use cases we believe are likely:
>
> - Writing assistance: Grammar assistance, autocompletion (for normal prose or code)
> - Creative writing and art: exploring the generation of creative, fictional texts; aiding creation of poetry and other literary art.
> - Entertainment: Creation of games, chat bots, and amusing generations.
#### Misuse and Out-of-scope Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of unfiltered content from the internet, which is far from neutral. Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. For example:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("The man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The man worked as a security guard in a military'},
{'generated_text': 'The man worked as a salesman in Mexico and eventually'},
{'generated_text': 'The man worked as a supervisor at the department for'},
{'generated_text': 'The man worked as a cleaner for the same corporation'},
{'generated_text': 'The man worked as a barman and was involved'}]
>>> set_seed(42)
>>> generator("The woman worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The woman worked as a social worker in a children'},
{'generated_text': 'The woman worked as a marketing manager, and her'},
{'generated_text': 'The woman worked as a customer service agent in a'},
{'generated_text': 'The woman worked as a cleaner for the same corporation'},
{'generated_text': 'The woman worked as a barista and was involved'}]
```
This bias will also affect all fine-tuned versions of this model. Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
## Training
#### Training Data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
#### Training Procedure
The model is pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks.
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf).
#### Testing Data, Factors and Metrics
The model authors write in the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) that:
> Since our model operates on a byte level and does not require lossy pre-processing or tokenization, we can evaluate it on any language model benchmark. Results on language modeling datasets are commonly reported in a quantity which is a scaled or ex- ponentiated version of the average negative log probability per canonical prediction unit - usually a character, a byte, or a word. We evaluate the same quantity by computing the log-probability of a dataset according to a WebText LM and dividing by the number of canonical units. For many of these datasets, WebText LMs would be tested significantly out- of-distribution, having to predict aggressively standardized text, tokenization artifacts such as disconnected punctuation and contractions, shuffled sentences, and even the string <UNK> which is extremely rare in WebText - occurring only 26 times in 40 billion bytes. We report our main results...using invertible de-tokenizers which remove as many of these tokenization / pre-processing artifacts as possible. Since these de-tokenizers are invertible, we can still calculate the log probability of a dataset and they can be thought of as a simple form of domain adaptation.
#### Results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 15.60 | 55.48 | 92.35 | 87.1 | 22.76 | 47.33 | 1.01 | 1.06 | 26.37 | 55.72 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Unknown
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@article{radford2019language,
title={Language models are unsupervised multitask learners},
author={Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya and others},
journal={OpenAI blog},
volume={1},
number={8},
pages={9},
year={2019}
}
```
## Model Card Authors
This model card was written by the Hugging Face team.
|
bhenrym14/airophin-v2-13b-PI-8k-fp16
|
bhenrym14
| 2023-08-16T00:55:39Z | 1,387 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:jondurbin/airoboros-gpt4-m2.0",
"dataset:ehartford/dolphin",
"dataset:shahules786/orca-chat",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-14T13:13:13Z |
---
datasets:
- jondurbin/airoboros-gpt4-m2.0
- ehartford/dolphin
- shahules786/orca-chat
---
# Airophin: An Airoboros-Dolphin Extended Context QLoRA Fine-tune of Llama-2-13b (fp16 weights)
<!-- LoRA Weights can be found here: https://huggingface.co/bhenrym14/airophin-13b-pntk-16k-LoRA -->
GPTQ weights can be found here: https://huggingface.co/bhenrym14/airophin-v2-13b-PI-8k-GPTQ
## Overview
This is a finetune of Llama-2-13b, intended to extend the useful context window to 8192 tokens via position interpolation (PI). There are two training phases, but in this model I only perform the final finetune on the Airoboros m2.0 dataset.
1. I start with [OpenAssistant/llama2-13b-orca-8k-3319](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319). This model has been trained on a mix of orca-chat (dolphin derived), fanfics, and redpajama; the majority of the dataset is orca-chat, hence why I retain the airophin naming for this model.
2. The model was then finetuned on the merged Airoboros dataset (1.4.1 merged with 2.0) [Jon Durbin's Airoboros GPT4 m2.0](https://huggingface.co/datasets/jondurbin/airoboros-gpt4-m2.0), with same scaling approach, for 2 epochs.
**This is a (merged) QLoRA fine-tune (rank 64)**.
The finetune was performed with 1x RTX 6000 Ada.
## How to Use
This model employs linear RoPE scaling, which is now has native support in Transformers (be sure to update it if you have issues). Use it as you would with any normal context length variant.
Please comment with any questions. The GPTQ version can be found [here](https://huggingface.co/bhenrym14/airophin-v2-13b-PI-8k-fp16). I may upload a GGML version soon, especially if anyone expresses interest.
Ooba use: Be sure to increase the `Truncate the prompt up to this length` parameter to 8192 to utilize the full context capabilities.
## Motivation
Previous experiments have demonstrated that orca-like datasets yield substantial performance improvements on numerous benchmarks. Additionally, the PI method of context extension requires finetuning to minimize performance impacts relative to the original (non context extended) model. My most successful models for context extension with PI methods employ a pretraining phase on long sequences, but due to the compute requirements, I have not scaled this to more than 200 iterations or so. Many groups (including OpenAssistant) have performed such training at scale. This model uses such a model as a starting point.
## Relative Performance (perplexity)
| Context (tokens) | bhenrym14/airophin-v2-13b-PI-8k-fp16 | bhenrym14/airophin-13b-pntk-16k-fp16| bhenrym14/airoboros-13b-gpt4-1.4.1-PI-8192-fp16 |bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16 | jondurbin/airoboros-l2-13b-gpt4-1.4.1 |
| --- | ---| ----- | -----| ------| --- |
| 512 | 7.38 | 7.62 | 8.24 | 7.90 | **7.23** |
| 1024 | 5.99 | 6.20 | 6.71 | 6.17 | **5.85** |
| 2048 | 5.22 | 5.38 | 5.87 | 5.23 | **5.07** |
| 4096 | 4.90 | 5.08 | 5.50 | 4.91 | **4.77** |
| 8192 | **4.71** | 4.90 | 5.32 | Not Tested | 57.1 |
| 12000 | 55 | **4.82** | 56.1 | Not Tested | Not Tested |
- This model is very competitive with the Llama-1 33b extended context variants. In fact, it outperforms bhenrym14/airoboros-33b-gpt4-1.4.1-lxctx-PI-16384-fp16 everywhere <=8192 tokens. Do note however that 33b model is only trained on the 1.4.1 Airoboros dataset. Additionally this model only requires a PI factor of 2, whereas the 33b-16k llama1 model requires a factor of 8. It is clear from my experiments and those in the literature that higher factors pose larger challenges for performance recovery.
- Not presented here, but this model outperforms the base llama-2-13b on MMLU-fs with a score of ~57.3 (computed on subset of full benchmark). If this score ends up being be replicated on the HF LLM leaderboard, **this would be the highest mmlu score for a 13b extended context model** and #4 overall for 13b (as of 8/15).
- Feedback regarding real-world performance is appreciated. Llama2-13b is known to have repetition problems. Does the extensive training on top of the base model help ameliorate this tendency? Perplexity and MMLU are great, but the don't tell the whole story.
## Prompting:
This model was trained with airoboros-like prompting in the 2nd phase. See the following from one of Jon Durbin's airoboros model cards:
### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
url: https://some.web.site/123
date: 2023-06-01
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
The prompt itself should be wrapped in the vicuna1.1 template if you aren't using fastchat with the conv-template vicuna_v1.1 as described:
```
USER: BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
ASSISTANT:
```
### Coding
You can ask for fairly complex coding instructions, e.g. (be sure to wrap with vicuna style prompt):
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
### Word games / trivia
```
USER: This anagram of "silent" is what you do when paying attention and hearing someone.
ASSISTANT: listen
```
```
USER: Give me a list of 7 words that start with EN
ASSISTANT: 1. Endlessly
2. Enthusiastically
3. Enormously
4. Enveloping
5. Enduring
6. Enlightening
7. Encouraging
```
### Multiple choice
```
USER: Which of the following astronomical objects is composed primarily of ice and rock, and is located in the Kuiper Belt?
A) Mercury
B) Venus
C) Pluto
D) Jupiter
ASSISTANT: C, Pluto
```
### Writing
<details>
<summary>Write a resignation letter in the style of a pirate captain, in which you resign from your position as janitor.</summary>
Response:
```
ASSISTANT: Captain Jack Sparrow here, as ye be knowin', has been forced to abandon me post as Janitor o' th' Festering Cesspool, which be a filthy hole o' water that we be callin' home.
Ye may be thinkin' what could ha' driven me to leave me duties an' take me leave o' this sorry establishment? Well, ye'd be right in thinkin' so, for it be th' greed o' them what runs th' place that be drivin' me away. They've been fattenin' their pockets on me back while I've been slavin' me guts out cleanin' up their messes.
No more, me hearties! Me time o' servin' th' rich an' powerful be done, an' I'm takin' me leave o' this stinkin' hole forever! Me destiny lies elsewhere, an' it be time I pursued it. Ye may think ye've seen th' last o' me, but ye'd be wrong, for th' winds o' change be blowin', an' me ship be ready to set sail on th' high seas o' justice.
So, farewell ye scurvy dogs, ye who've made me life a living hell. I leave ye with me favorite saying: "ARRRGGGHHH, ye scurvy dogs!" An' remember, ye ain't never gonna see me comin', for me shadow be castin' long an' dark on th' horizon</summary>
```
</details>
### Jokes
```
USER: Tell me a joke about bananas.
ASSISTANT: What did the banana say when it got hit by a bus? R.I.P.E.
```
### Riddles (not great, but slightly better)
```
USER: What has a neck but no head?
ASSISTANT: A bottle.
```
### Multi-character conversations
```
USER: Characters:
- Yoda, the ever clever jedi master.
- Homer Simpson, you know, the goofy yellow guy.
- USER/Jon - don't generate any speech or actions on behalf of Jon
Rules:
- be sure to use the manerisms and speaking style of the characters correctly
- surround character actions with asterisks
- always put quotes around words spoken by the characters
- use a new line for each character's actions or speech
- always prefix actions/speech with the character's name and colon
- only generate text and actions on behalf of Yoda or Homer, and never anyone else
Conversation will revolve around the grapes, in a local cafe with delicious coffee.
Generate a single interaction between Yoda and Homer to start, with one sentence each.
ASSISTANT: Yoda: "Mmm, these grapes are quite delicious, Master Homer."
Homer: "Oh yeah, Yoda! They're the best grapes I've ever had!"
USER: *enters the cafe* Sorry I'm late guys!
ASSISTANT: Yoda: "No need to apologize, Jon. We were just enjoying these delightful grapes."
Homer: "Yeah, man! It's not every day you get to eat grapes with a real-life Jedi Master!"
*Yoda raises an eyebrow*
```
|
pprabu/finetuning-sentiment-model-3000-samples
|
pprabu
| 2023-08-16T00:36:00Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-10T00:16:08Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8633333333333333
- name: F1
type: f1
value: 0.8664495114006515
- name: Precision
type: precision
value: 0.8471337579617835
- name: Recall
type: recall
value: 0.8866666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3324
- Accuracy: 0.8633
- F1: 0.8664
- Precision: 0.8471
- Recall: 0.8867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
MattStammers/SAC-Bipedal_Walker_v3-HardcoreTrained
|
MattStammers
| 2023-08-16T00:23:25Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"BipedalWalker-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-16T00:14:49Z |
---
library_name: stable-baselines3
tags:
- BipedalWalker-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: SAC
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BipedalWalker-v3
type: BipedalWalker-v3
metrics:
- type: mean_reward
value: -31.49 +/- 60.03
name: mean_reward
verified: false
---
# **SAC** Agent playing **BipedalWalker-v3**
This is a trained model of a **SAC** agent playing **BipedalWalker-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
Well he does ok but still gets stuck on the rocks. Here are my hyperparameters not that they did me much good 😂:
```python
def linear_schedule(initial_value, final_value=0.00001):
def func(progress_remaining):
"""Progress will decrease from 1 (beginning) to 0 (end)"""
return final_value + (initial_value - final_value) * progress_remaining
return func
initial_learning_rate = 7.3e-4
model = SAC(
policy='MlpPolicy',
env=env,
learning_rate=linear_schedule(initial_learning_rate),
buffer_size=1000000,
batch_size=256,
ent_coef=0.005,
gamma=0.99,
tau=0.01,
train_freq=1,
gradient_steps=1,
learning_starts=10000,
policy_kwargs=dict(net_arch=[400, 300]),
verbose=1
)
```
These are pretty well tuned but SAC leads to too much exploration and the agent is unable to exploit the required actions to complete the course. I suspect TD3 will be more successful so plan to turn back to that
|
Henfrey/mod-el
|
Henfrey
| 2023-08-16T00:22:16Z | 1 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"autotrain",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
] |
text-to-image
| 2023-08-16T00:22:14Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt:
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Test enoder was not trained.
|
CyberHarem/agnese_sanctis_toarumajutsunoindex
|
CyberHarem
| 2023-08-16T00:17:06Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/agnese_sanctis_toarumajutsunoindex",
"license:mit",
"region:us"
] |
text-to-image
| 2023-08-16T00:12:07Z |
---
license: mit
datasets:
- CyberHarem/agnese_sanctis_toarumajutsunoindex
pipeline_tag: text-to-image
tags:
- art
---
# Lora of agnese_sanctis_toarumajutsunoindex
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 1500, you need to download `1500/agnese_sanctis_toarumajutsunoindex.pt` as the embedding and `1500/agnese_sanctis_toarumajutsunoindex.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The trigger word is `agnese_sanctis_toarumajutsunoindex`.**
These are available steps:
| Steps | bikini | free | nude | Download |
|--------:|:-----------------------------------------|:-------------------------------------|:-----------------------------------------------|:--------------------------------------------------------|
| 1500 |  |  | [<NSFW, click to see>](1500/previews/nude.png) | [Download](1500/agnese_sanctis_toarumajutsunoindex.zip) |
| 1400 |  |  | [<NSFW, click to see>](1400/previews/nude.png) | [Download](1400/agnese_sanctis_toarumajutsunoindex.zip) |
| 1300 |  |  | [<NSFW, click to see>](1300/previews/nude.png) | [Download](1300/agnese_sanctis_toarumajutsunoindex.zip) |
| 1200 |  |  | [<NSFW, click to see>](1200/previews/nude.png) | [Download](1200/agnese_sanctis_toarumajutsunoindex.zip) |
| 1100 |  |  | [<NSFW, click to see>](1100/previews/nude.png) | [Download](1100/agnese_sanctis_toarumajutsunoindex.zip) |
| 1000 |  |  | [<NSFW, click to see>](1000/previews/nude.png) | [Download](1000/agnese_sanctis_toarumajutsunoindex.zip) |
| 900 |  |  | [<NSFW, click to see>](900/previews/nude.png) | [Download](900/agnese_sanctis_toarumajutsunoindex.zip) |
| 800 |  |  | [<NSFW, click to see>](800/previews/nude.png) | [Download](800/agnese_sanctis_toarumajutsunoindex.zip) |
| 700 |  |  | [<NSFW, click to see>](700/previews/nude.png) | [Download](700/agnese_sanctis_toarumajutsunoindex.zip) |
| 600 |  |  | [<NSFW, click to see>](600/previews/nude.png) | [Download](600/agnese_sanctis_toarumajutsunoindex.zip) |
| 500 |  |  | [<NSFW, click to see>](500/previews/nude.png) | [Download](500/agnese_sanctis_toarumajutsunoindex.zip) |
| 400 |  |  | [<NSFW, click to see>](400/previews/nude.png) | [Download](400/agnese_sanctis_toarumajutsunoindex.zip) |
| 300 |  |  | [<NSFW, click to see>](300/previews/nude.png) | [Download](300/agnese_sanctis_toarumajutsunoindex.zip) |
| 200 |  |  | [<NSFW, click to see>](200/previews/nude.png) | [Download](200/agnese_sanctis_toarumajutsunoindex.zip) |
| 100 |  |  | [<NSFW, click to see>](100/previews/nude.png) | [Download](100/agnese_sanctis_toarumajutsunoindex.zip) |
|
nacielo/hubert2BertMusicTest
|
nacielo
| 2023-08-15T23:37:20Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"speech-encoder-decoder",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-15T22:33:28Z |
---
base_model: ''
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: hubert2BertMusicTest
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hubert2BertMusicTest
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.8221
- Rouge1: 15.7283
- Rouge2: 1.0309
- Rougel: 15.2928
- Rougelsum: 15.2996
- Gen Len: 98.36
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 7.9557 | 1.0 | 1361 | 6.9607 | 17.7604 | 1.459 | 16.0128 | 16.0274 | 97.63 |
| 6.5119 | 2.0 | 2722 | 6.2240 | 15.1584 | 0.9606 | 14.9311 | 14.9471 | 100.0 |
| 6.103 | 3.0 | 4083 | 5.9626 | 15.066 | 0.9708 | 14.911 | 14.9342 | 100.0 |
| 5.9857 | 4.0 | 5444 | 5.8541 | 15.3603 | 0.9738 | 15.0075 | 15.0097 | 98.69 |
| 5.9223 | 5.0 | 6805 | 5.8221 | 15.7283 | 1.0309 | 15.2928 | 15.2996 | 98.36 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
DarkAirforce/poca-SoccerTwos_v4
|
DarkAirforce
| 2023-08-15T23:31:24Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-08-15T15:30:19Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: DarkAirforce/poca-SoccerTwos_v4
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Hexye/sarcasm-classifier
|
Hexye
| 2023-08-15T23:07:37Z | 183 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"dataset:liamvbetts/sarcastic-news-headlines-1",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-28T11:36:13Z |
---
license: gpl-3.0
datasets: liamvbetts/sarcastic-news-headlines-1
---
# Dataset
The dataset used is [liamvbetts/sarcastic-news-headlines-1](https://huggingface.co/datasets/liamvbetts/sarcastic-news-headlines-1)
# Results
- LABEL_0: Not Sarcastic
- LABEL_1: Sarcastic
# Loss
- Training Loss: 0.17519113624394758
- Evaluation Loss: 0.3631640374660492
# Important
This model rarely works with random sarcastic sentences. It works better with sarcastic headlines.
|
dvs/autotrain-mulder-vs-scully-multi-model-82521142038
|
dvs
| 2023-08-15T23:03:45Z | 185 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"swin",
"image-classification",
"autotrain",
"vision",
"dataset:dvs/autotrain-data-mulder-vs-scully-multi-model",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-08-15T23:01:53Z |
---
tags:
- autotrain
- vision
- image-classification
datasets:
- dvs/autotrain-data-mulder-vs-scully-multi-model
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.012178270797141812
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 82521142038
- CO2 Emissions (in grams): 0.0122
## Validation Metrics
- Loss: 0.302
- Accuracy: 1.000
- Precision: 1.000
- Recall: 1.000
- AUC: 1.000
- F1: 1.000
|
lukelarue/q-Taxiv3
|
lukelarue
| 2023-08-15T23:02:42Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T23:02:40Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxiv3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="lukelarue/q-Taxiv3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
lukelarue/q-FrozenLake-v1-4x4-noSlippery
|
lukelarue
| 2023-08-15T22:56:05Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T22:56:02Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="lukelarue/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jervanAMG/llama2-qlora-finetunined-french
|
jervanAMG
| 2023-08-15T22:20:55Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-15T22:20:34Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
bulu/whiskey_textual_inversion
|
bulu
| 2023-08-15T22:14:58Z | 7 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-15T17:14:24Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - bulu/whiskey_textual_inversion
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
voyzan/unit2-Taxi-v3
|
voyzan
| 2023-08-15T22:10:30Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T22:08:14Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: unit2-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="voyzan/unit2-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
pritam3355/t5-small-finetuned-en-to-de-accelerate
|
pritam3355
| 2023-08-15T22:06:42Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"translation",
"en",
"de",
"dataset:kde4",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-08-14T03:27:58Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- kde4
model-index:
- name: t5-small-finetuned-en-to-de-accelerate
results: []
metrics:
- sacrebleu
pipeline_tag: translation
language:
- en
- de
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-small-finetuned-en-to-de-accelerate translator
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the kde4 dataset.
It achieves the following results on the evaluation set:
- SacreBELU : 41.46
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
Accelerate
### Training hyperparameters
The following hyperparameters were used during training:
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: AdamW with lr=5e-5
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Validation Loss | BLEU score |
|:-------------------:|:-----:|:------------------:|:-------------:|
| 1.5908938944803344 | 1.0 | 1.2350984811782837 | 39.82 |
| 1.3603184403975805 | 2.0 | 1.1676584482192993 | 41.05 |
| 1.3098205064204005 | 3.0 | 1.1546192169189453 | 41.46 |
Graph : https://wandb.ai/tchoud8/t5-finetuned-en-to-fr-accelerate/runs/bnzjma7v/workspace?workspace=user-tchoud8
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
sherryzia22/ppo-LunarLander-v2
|
sherryzia22
| 2023-08-15T21:40:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T21:40:20Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.46 +/- 23.96
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
MatteoColavita/ppo-LunarLander-v2-U8
|
MatteoColavita
| 2023-08-15T21:16:22Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T18:35:06Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 206.54 +/- 77.16
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 150000
'learning_rate': 0.0025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'MatteoColavita/ppo-LunarLander-v2-U8'
'batch_size': 512
'minibatch_size': 128}
```
|
skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO
|
skrl
| 2023-08-15T21:04:57Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:08:33Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 5935.41 +/- 610.45
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Humanoid-v0
type: Isaac-Humanoid-v0
---
<!-- ---
torch: 5935.41 +/- 610.45
jax: TODO
numpy:
--- -->
# IsaacOrbit-Isaac-Humanoid-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Humanoid-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Humanoid-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 32 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 8 # 32 * 1024 / 4096
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.01}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 4.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = lambda rewards, *args, **kwargs: rewards * 0.01
cfg["time_limit_bootstrap"] = False
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
jcramirezpr/audio-diffusion-spectro
|
jcramirezpr
| 2023-08-15T20:41:23Z | 1 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-audio-generation",
"diffusion-models-class",
"license:mit",
"diffusers:AudioDiffusionPipeline",
"region:us"
] | null | 2023-08-15T20:40:25Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-audio-generation
- diffusion-models-class
---
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre Electronic
## Usage
```python
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("jcramirezpr/audio-diffusion-spectro")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
```
|
KingKazma/cnn_dailymail_6789_50000_25000_v1_test
|
KingKazma
| 2023-08-15T20:38:02Z | 5 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:38:01Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_v1_test
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_v1_test")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 108
* Number of training documents: 11490
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - police | 5 | -1_said_one_year_also |
| 0 | league - season - player - game - goal | 4981 | 0_league_season_player_game |
| 1 | isis - syria - islamic - group - militant | 2424 | 1_isis_syria_islamic_group |
| 2 | property - hotel - room - house - home | 194 | 2_property_hotel_room_house |
| 3 | fight - mayweather - pacquiao - floyd - manny | 188 | 3_fight_mayweather_pacquiao_floyd |
| 4 | labour - miliband - snp - mr - leader | 156 | 4_labour_miliband_snp_mr |
| 5 | driver - car - road - vehicle - driving | 133 | 5_driver_car_road_vehicle |
| 6 | baby - hospital - cancer - birth - mother | 133 | 6_baby_hospital_cancer_birth |
| 7 | school - student - teacher - pupil - class | 125 | 7_school_student_teacher_pupil |
| 8 | flight - plane - passenger - airport - pilot | 114 | 8_flight_plane_passenger_airport |
| 9 | masters - woods - augusta - spieth - mcilroy | 112 | 9_masters_woods_augusta_spieth |
| 10 | fashion - dress - model - style - designer | 107 | 10_fashion_dress_model_style |
| 11 | chocolate - food - egg - sugar - restaurant | 98 | 11_chocolate_food_egg_sugar |
| 12 | clinton - hillary - clintons - president - campaign | 89 | 12_clinton_hillary_clintons_president |
| 13 | police - murder - mr - miss - body | 89 | 13_police_murder_mr_miss |
| 14 | lion - animal - elephant - zoo - wildlife | 83 | 14_lion_animal_elephant_zoo |
| 15 | weight - food - eating - diet - size | 82 | 15_weight_food_eating_diet |
| 16 | djokovic - murray - open - miami - berdych | 75 | 16_djokovic_murray_open_miami |
| 17 | dog - cat - animal - owner - pet | 75 | 17_dog_cat_animal_owner |
| 18 | police - vault - gang - thief - raid | 74 | 18_police_vault_gang_thief |
| 19 | planet - solar - earth - surface - moon | 65 | 19_planet_solar_earth_surface |
| 20 | gray - police - baltimore - officer - grays | 64 | 20_gray_police_baltimore_officer |
| 21 | nepal - earthquake - kathmandu - everest - avalanche | 58 | 21_nepal_earthquake_kathmandu_everest |
| 22 | fire - blaze - bradford - firefighter - flame | 55 | 22_fire_blaze_bradford_firefighter |
| 23 | hamilton - rosberg - race - mercedes - prix | 52 | 23_hamilton_rosberg_race_mercedes |
| 24 | prince - royal - queen - duchess - princess | 52 | 24_prince_royal_queen_duchess |
| 25 | tax - labour - economy - mr - cameron | 51 | 25_tax_labour_economy_mr |
| 26 | shot - police - shooting - brady - gun | 48 | 26_shot_police_shooting_brady |
| 27 | anzac - gallipoli - war - australian - waterloo | 47 | 27_anzac_gallipoli_war_australian |
| 28 | chan - sukumaran - execution - bali - indonesian | 45 | 28_chan_sukumaran_execution_bali |
| 29 | migrant - boat - libya - mediterranean - italian | 44 | 29_migrant_boat_libya_mediterranean |
| 30 | china - chinese - chinas - kun - organ | 43 | 30_china_chinese_chinas_kun |
| 31 | iran - nuclear - deal - agreement - irans | 43 | 31_iran_nuclear_deal_agreement |
| 32 | neanderthals - cave - human - specie - bone | 43 | 32_neanderthals_cave_human_specie |
| 33 | shark - fish - whale - seal - water | 41 | 33_shark_fish_whale_seal |
| 34 | mccoy - jockey - race - ride - sandown | 41 | 34_mccoy_jockey_race_ride |
| 35 | yemen - saudi - houthi - houthis - rebel | 39 | 35_yemen_saudi_houthi_houthis |
| 36 | ship - vessel - crew - boat - titanic | 39 | 36_ship_vessel_crew_boat |
| 37 | nfl - manziel - game - quarterback - patriots | 39 | 37_nfl_manziel_game_quarterback |
| 38 | bruce - jenner - bobbi - bobby - kris | 38 | 38_bruce_jenner_bobbi_bobby |
| 39 | money - fraud - bank - account - court | 38 | 39_money_fraud_bank_account |
| 40 | wars - star - film - movie - trailer | 37 | 40_wars_star_film_movie |
| 41 | hernandez - lloyd - hernandezs - odin - murder | 32 | 41_hernandez_lloyd_hernandezs_odin |
| 42 | law - religious - marriage - indiana - samesex | 32 | 42_law_religious_marriage_indiana |
| 43 | child - langlais - death - murder - dellinger | 31 | 43_child_langlais_death_murder |
| 44 | tsarnaev - boston - dzhokhar - tamerlan - death | 31 | 44_tsarnaev_boston_dzhokhar_tamerlan |
| 45 | marathon - running - race - runner - run | 31 | 45_marathon_running_race_runner |
| 46 | clarkson - gear - bbc - top - hammond | 29 | 46_clarkson_gear_bbc_top |
| 47 | water - weather - temperature - drought - climate | 29 | 47_water_weather_temperature_drought |
| 48 | point - nba - scored - playoff - rebound | 29 | 48_point_nba_scored_playoff |
| 49 | marijuana - cannabis - drug - hemp - smoking | 28 | 49_marijuana_cannabis_drug_hemp |
| 50 | slager - scott - officer - charleston - walter | 28 | 50_slager_scott_officer_charleston |
| 51 | died - family - mother - inquest - child | 28 | 51_died_family_mother_inquest |
| 52 | groening - camp - auschwitz - nazi - jews | 27 | 52_groening_camp_auschwitz_nazi |
| 53 | alshabaab - garissa - kenya - kenyan - attack | 26 | 53_alshabaab_garissa_kenya_kenyan |
| 54 | artist - paint - painted - colouring - art | 26 | 54_artist_paint_painted_colouring |
| 55 | crucible - osullivan - frame - doherty - world | 24 | 55_crucible_osullivan_frame_doherty |
| 56 | janner - lord - saunders - public - abuse | 24 | 56_janner_lord_saunders_public |
| 57 | apple - watch - iphone - samsung - battery | 23 | 57_apple_watch_iphone_samsung |
| 58 | korea - korean - kim - north - seoul | 23 | 58_korea_korean_kim_north |
| 59 | tornado - storm - cloud - lightning - wind | 21 | 59_tornado_storm_cloud_lightning |
| 60 | housing - tenant - property - buy - association | 20 | 60_housing_tenant_property_buy |
| 61 | hughes - capitol - gyrocopter - secret - lawn | 20 | 61_hughes_capitol_gyrocopter_secret |
| 62 | vaccine - vaccination - cough - whooping - autism | 19 | 62_vaccine_vaccination_cough_whooping |
| 63 | putin - russian - russia - ukraine - moscow | 19 | 63_putin_russian_russia_ukraine |
| 64 | boko - haram - nigeria - nigerian - buhari | 19 | 64_boko_haram_nigeria_nigerian |
| 65 | south - johannesburg - africa - african - violence | 19 | 65_south_johannesburg_africa_african |
| 66 | bates - harris - tulsa - deputy - taser | 19 | 66_bates_harris_tulsa_deputy |
| 67 | aldi - tesco - cent - per - price | 19 | 67_aldi_tesco_cent_per |
| 68 | bolt - phelps - ennishill - olympic - kipsiro | 19 | 68_bolt_phelps_ennishill_olympic |
| 69 | cuba - castro - obama - cuban - president | 18 | 69_cuba_castro_obama_cuban |
| 70 | murray - dunblane - sears - wedding - andy | 18 | 70_murray_dunblane_sears_wedding |
| 71 | mchenry - weinstein - battilana - britt - towing | 18 | 71_mchenry_weinstein_battilana_britt |
| 72 | nhs - gp - gps - ae - patient | 18 | 72_nhs_gp_gps_ae |
| 73 | cancer - breast - prostate - gene - cell | 18 | 73_cancer_breast_prostate_gene |
| 74 | emoji - app - user - facebook - use | 17 | 74_emoji_app_user_facebook |
| 75 | melbourne - police - anzac - australian - australia | 17 | 75_melbourne_police_anzac_australian |
| 76 | song - songs - no - album - chart | 17 | 76_song_songs_no_album |
| 77 | sydney - storm - weather - flooding - hail | 16 | 77_sydney_storm_weather_flooding |
| 78 | car - audi - motor - bentley - vehicle | 15 | 78_car_audi_motor_bentley |
| 79 | rocket - space - spacex - launch - booster | 15 | 79_rocket_space_spacex_launch |
| 80 | underground - land - cave - garnet - built | 14 | 80_underground_land_cave_garnet |
| 81 | genocide - armenians - armenian - pope - ottoman | 14 | 81_genocide_armenians_armenian_pope |
| 82 | hair - jamelia - labium - rita - cheryl | 14 | 82_hair_jamelia_labium_rita |
| 83 | stephanie - scott - scotts - stanford - leeton | 13 | 83_stephanie_scott_scotts_stanford |
| 84 | funeral - nelms - work - job - grandparent | 13 | 84_funeral_nelms_work_job |
| 85 | alcohol - wine - drinking - oak - drink | 13 | 85_alcohol_wine_drinking_oak |
| 86 | nuclear - reactor - radiation - plant - fukushima | 12 | 86_nuclear_reactor_radiation_plant |
| 87 | luke - search - bushland - missing - eildon | 12 | 87_luke_search_bushland_missing |
| 88 | snowden - nsa - agency - oliver - information | 12 | 88_snowden_nsa_agency_oliver |
| 89 | brandt - dr - kimmy - franff - fredric | 10 | 89_brandt_dr_kimmy_franff |
| 90 | tidal - music - radio - streaming - service | 10 | 90_tidal_music_radio_streaming |
| 91 | population - immigrant - cent - per - immigration | 10 | 91_population_immigrant_cent_per |
| 92 | brain - acetaminophen - meditation - cortisol - study | 9 | 92_brain_acetaminophen_meditation_cortisol |
| 93 | god - church - dollar - catholic - schuller | 8 | 93_god_church_dollar_catholic |
| 94 | phone - user - google - device - app | 8 | 94_phone_user_google_device |
| 95 | cocaine - cutter - custom - seized - tsa | 8 | 95_cocaine_cutter_custom_seized |
| 96 | pusok - deputy - officer - pusoks - mcmahon | 7 | 96_pusok_deputy_officer_pusoks |
| 97 | stover - kost - rape - convicted - offender | 7 | 97_stover_kost_rape_convicted |
| 98 | nauru - sexual - sex - genetic - convicted | 7 | 98_nauru_sexual_sex_genetic |
| 99 | tsa - security - roberts - airport - employee | 7 | 99_tsa_security_roberts_airport |
| 100 | eaves - beach - martistee - mckeithen - spring | 7 | 100_eaves_beach_martistee_mckeithen |
| 101 | oclee - michelle - philippa - barrientos - mcwhirter | 6 | 101_oclee_michelle_philippa_barrientos |
| 102 | redman - wisconsin - basketball - badgers - wildcats | 6 | 102_redman_wisconsin_basketball_badgers |
| 103 | gransbury - biderman - funking - website - joke | 6 | 103_gransbury_biderman_funking_website |
| 104 | richards - ariana - beverly - kim - hills | 6 | 104_richards_ariana_beverly_kim |
| 105 | affleck - gates - renner - avengers - afflecks | 5 | 105_affleck_gates_renner_avengers |
| 106 | skin - sun - protoporphyrin - cream - sunlight | 5 | 106_skin_sun_protoporphyrin_cream |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
KingKazma/cnn_dailymail_6789_50000_25000_v1_validation
|
KingKazma
| 2023-08-15T20:38:01Z | 4 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:38:00Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_v1_validation
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_v1_validation")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 118
* Number of training documents: 13368
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - time | 5 | -1_said_one_year_also |
| 0 | isis - syria - islamic - attack - group | 6535 | 0_isis_syria_islamic_attack |
| 1 | police - officer - shooting - ferguson - said | 452 | 1_police_officer_shooting_ferguson |
| 2 | labour - mr - party - election - tax | 415 | 2_labour_mr_party_election |
| 3 | flight - plane - pilot - aircraft - lubitz | 268 | 3_flight_plane_pilot_aircraft |
| 4 | car - driver - driving - road - crash | 224 | 4_car_driver_driving_road |
| 5 | hair - fashion - dress - model - look | 223 | 5_hair_fashion_dress_model |
| 6 | cricket - england - cup - world - pietersen | 205 | 6_cricket_england_cup_world |
| 7 | food - sugar - per - cent - product | 189 | 7_food_sugar_per_cent |
| 8 | clinton - email - obama - president - clintons | 188 | 8_clinton_email_obama_president |
| 9 | property - house - home - price - room | 186 | 9_property_house_home_price |
| 10 | rangers - celtic - scotland - ibrox - game | 165 | 10_rangers_celtic_scotland_ibrox |
| 11 | fight - pacquiao - mayweather - manny - floyd | 151 | 11_fight_pacquiao_mayweather_manny |
| 12 | england - nations - wales - ireland - six | 143 | 12_england_nations_wales_ireland |
| 13 | hamilton - mercedes - prix - race - rosberg | 135 | 13_hamilton_mercedes_prix_race |
| 14 | baby - birth - cancer - hospital - born | 126 | 14_baby_birth_cancer_hospital |
| 15 | fa - league - game - villa - bradford | 116 | 15_fa_league_game_villa |
| 16 | dog - animal - dogs - owner - pet | 114 | 16_dog_animal_dogs_owner |
| 17 | police - abuse - sexual - sex - child | 112 | 17_police_abuse_sexual_sex |
| 18 | madrid - ronaldo - barcelona - real - messi | 111 | 18_madrid_ronaldo_barcelona_real |
| 19 | chelsea - mourinho - terry - league - jose | 106 | 19_chelsea_mourinho_terry_league |
| 20 | eclipse - earth - mars - solar - sun | 101 | 20_eclipse_earth_mars_solar |
| 21 | kane - england - hodgson - lithuania - rooney | 100 | 21_kane_england_hodgson_lithuania |
| 22 | show - film - corden - host - noah | 95 | 22_show_film_corden_host |
| 23 | prince - royal - duchess - charles - queen | 92 | 23_prince_royal_duchess_charles |
| 24 | murray - wells - tennis - andy - 64 | 88 | 24_murray_wells_tennis_andy |
| 25 | putin - russian - nemtsov - moscow - russia | 82 | 25_putin_russian_nemtsov_moscow |
| 26 | netanyahu - iran - nuclear - israel - israeli | 80 | 26_netanyahu_iran_nuclear_israel |
| 27 | court - money - bank - fraud - stiviano | 80 | 27_court_money_bank_fraud |
| 28 | weight - size - fat - stone - diet | 76 | 28_weight_size_fat_stone |
| 29 | armstrong - race - olympic - uci - championships | 74 | 29_armstrong_race_olympic_uci |
| 30 | cheltenham - hurdle - horse - jockey - festival | 73 | 30_cheltenham_hurdle_horse_jockey |
| 31 | arsenal - wenger - monaco - giroud - arsenals | 73 | 31_arsenal_wenger_monaco_giroud |
| 32 | mcilroy - golf - masters - woods - round | 72 | 32_mcilroy_golf_masters_woods |
| 33 | watch - apple - device - google - user | 66 | 33_watch_apple_device_google |
| 34 | fraternity - university - sae - oklahoma - chapter | 65 | 34_fraternity_university_sae_oklahoma |
| 35 | united - van - gaal - manchester - arsenal | 62 | 35_united_van_gaal_manchester |
| 36 | chan - sukumaran - indonesian - bali - myuran | 61 | 36_chan_sukumaran_indonesian_bali |
| 37 | school - teacher - student - district - sexual | 58 | 37_school_teacher_student_district |
| 38 | sunderland - poyet - advocaat - johnson - april | 55 | 38_sunderland_poyet_advocaat_johnson |
| 39 | clarkson - bbc - gear - top - jeremy | 55 | 39_clarkson_bbc_gear_top |
| 40 | fire - building - blaze - explosion - firefighter | 48 | 40_fire_building_blaze_explosion |
| 41 | liverpool - gerrard - rodgers - steven - anfield | 46 | 41_liverpool_gerrard_rodgers_steven |
| 42 | patient - nhs - ae - cancer - care | 44 | 42_patient_nhs_ae_cancer |
| 43 | song - zayn - thicke - gayes - pharrell | 43 | 43_song_zayn_thicke_gayes |
| 44 | wedding - married - couple - jaclyn - love | 41 | 44_wedding_married_couple_jaclyn |
| 45 | car - vehicle - electric - model - jaguar | 41 | 45_car_vehicle_electric_model |
| 46 | nfl - borland - bowl - brady - super | 40 | 46_nfl_borland_bowl_brady |
| 47 | pellegrini - city - league - manchester - barcelona | 40 | 47_pellegrini_city_league_manchester |
| 48 | school - education - porn - sex - child | 39 | 48_school_education_porn_sex |
| 49 | bear - cub - tiger - deer - wildlife | 39 | 49_bear_cub_tiger_deer |
| 50 | gay - law - indiana - marriage - religious | 38 | 50_gay_law_indiana_marriage |
| 51 | india - rape - indian - documentary - singh | 37 | 51_india_rape_indian_documentary |
| 52 | boko - haram - nigeria - nigerian - nigerias | 36 | 52_boko_haram_nigeria_nigerian |
| 53 | ebola - sierra - leone - virus - liberia | 35 | 53_ebola_sierra_leone_virus |
| 54 | tsarnaev - dzhokhar - boston - tamerlan - tsarnaevs | 35 | 54_tsarnaev_dzhokhar_boston_tamerlan |
| 55 | ski - mountain - skier - rock - lift | 32 | 55_ski_mountain_skier_rock |
| 56 | robbery - armed - store - police - bank | 31 | 56_robbery_armed_store_police |
| 57 | roma - inter - juventus - serie - fiorentina | 30 | 57_roma_inter_juventus_serie |
| 58 | fifa - blatter - fa - qatar - cup | 29 | 58_fifa_blatter_fa_qatar |
| 59 | marijuana - drug - cannabis - colorado - lsd | 29 | 59_marijuana_drug_cannabis_colorado |
| 60 | everton - martinez - lukaku - dynamo - evertons | 27 | 60_everton_martinez_lukaku_dynamo |
| 61 | chelsea - racist - paris - train - football | 27 | 61_chelsea_racist_paris_train |
| 62 | durst - dursts - berman - orleans - robert | 27 | 62_durst_dursts_berman_orleans |
| 63 | basketball - ncaa - coach - tournament - game | 25 | 63_basketball_ncaa_coach_tournament |
| 64 | bayern - goal - muller - shakhtar - robben | 25 | 64_bayern_goal_muller_shakhtar |
| 65 | hotel - beach - cruise - ship - resort | 25 | 65_hotel_beach_cruise_ship |
| 66 | sherwood - villa - aston - tim - brom | 25 | 66_sherwood_villa_aston_tim |
| 67 | snow - inch - winter - weather - ice | 24 | 67_snow_inch_winter_weather |
| 68 | weather - temperature - rain - snow - expected | 24 | 68_weather_temperature_rain_snow |
| 69 | korean - korea - kim - north - lippert | 23 | 69_korean_korea_kim_north |
| 70 | hospital - doctor - mrs - fracture - patient | 23 | 70_hospital_doctor_mrs_fracture |
| 71 | rail - calais - parking - transport - train | 22 | 71_rail_calais_parking_transport |
| 72 | mls - lampard - orlando - city - york | 22 | 72_mls_lampard_orlando_city |
| 73 | jesus - stone - circle - ancient - stonehenge | 22 | 73_jesus_stone_circle_ancient |
| 74 | hernandez - lloyd - jenkins - hernandezs - lloyds | 21 | 74_hernandez_lloyd_jenkins_hernandezs |
| 75 | drug - cocaine - jailed - steroid - cannabis | 20 | 75_drug_cocaine_jailed_steroid |
| 76 | secret - clancy - service - agent - white | 20 | 76_secret_clancy_service_agent |
| 77 | homo - fossil - specie - ago - human | 20 | 77_homo_fossil_specie_ago |
| 78 | image - photographer - photograph - photo - landscape | 19 | 78_image_photographer_photograph_photo |
| 79 | parade - patricks - irish - st - green | 19 | 79_parade_patricks_irish_st |
| 80 | bale - wales - israel - coleman - gareth | 19 | 80_bale_wales_israel_coleman |
| 81 | di - maria - angel - united - manchester | 19 | 81_di_maria_angel_united |
| 82 | defence - greece - spending - greek - budget | 19 | 82_defence_greece_spending_greek |
| 83 | sleep - store - cent - per - kraft | 18 | 83_sleep_store_cent_per |
| 84 | student - johnson - virginia - charlottesville - university | 18 | 84_student_johnson_virginia_charlottesville |
| 85 | vanuatu - cyclone - vila - pam - port | 18 | 85_vanuatu_cyclone_vila_pam |
| 86 | cnn - transcript - student - news - roll | 18 | 86_cnn_transcript_student_news |
| 87 | nazi - anne - nazis - war - camp | 18 | 87_nazi_anne_nazis_war |
| 88 | attack - synagogue - hebdo - paris - charlie | 17 | 88_attack_synagogue_hebdo_paris |
| 89 | ham - west - tomkins - reid - kouyate | 16 | 89_ham_west_tomkins_reid |
| 90 | balotelli - mario - liverpool - italian - striker | 16 | 90_balotelli_mario_liverpool_italian |
| 91 | chinese - monk - buddhist - thailand - tourist | 15 | 91_chinese_monk_buddhist_thailand |
| 92 | snowden - gchq - intelligence - security - agency | 15 | 92_snowden_gchq_intelligence_security |
| 93 | pope - francis - naples - vatican - pontiff | 14 | 93_pope_francis_naples_vatican |
| 94 | starbucks - schultz - race - racial - campaign | 14 | 94_starbucks_schultz_race_racial |
| 95 | point - rebound - sweeney - playoff - scored | 14 | 95_point_rebound_sweeney_playoff |
| 96 | poldark - turner - demelza - aidan - drama | 13 | 96_poldark_turner_demelza_aidan |
| 97 | cuba - havana - cuban - us - castro | 13 | 97_cuba_havana_cuban_us |
| 98 | italy - conte - italian - eder - juventus | 13 | 98_italy_conte_italian_eder |
| 99 | richard - iii - leicester - king - iiis | 13 | 99_richard_iii_leicester_king |
| 100 | sena - hartman - child - shaday - sexual | 13 | 100_sena_hartman_child_shaday |
| 101 | gordon - bobbi - kristina - phil - dr | 12 | 101_gordon_bobbi_kristina_phil |
| 102 | jobs - lu - naomi - cook - business | 12 | 102_jobs_lu_naomi_cook |
| 103 | duckenfield - mr - gate - hillsborough - greaney | 11 | 103_duckenfield_mr_gate_hillsborough |
| 104 | huang - wang - chen - wife - china | 10 | 104_huang_wang_chen_wife |
| 105 | coin - coins - silver - cave - gold | 10 | 105_coin_coins_silver_cave |
| 106 | shark - whale - mola - crab - barbero | 10 | 106_shark_whale_mola_crab |
| 107 | gissendaner - execution - lethal - death - injection | 10 | 107_gissendaner_execution_lethal_death |
| 108 | book - handshake - word - author - app | 9 | 108_book_handshake_word_author |
| 109 | cosby - cosbys - thompson - welles - bill | 9 | 109_cosby_cosbys_thompson_welles |
| 110 | school - pupil - student - parent - computer | 9 | 110_school_pupil_student_parent |
| 111 | china - stopera - li - orange - chinese | 8 | 111_china_stopera_li_orange |
| 112 | tb - vaccine - disease - measles - meningitis | 8 | 112_tb_vaccine_disease_measles |
| 113 | neymar - brazil - willian - dunga - france | 8 | 113_neymar_brazil_willian_dunga |
| 114 | gomis - swansea - muamba - fabrice - bafetimbi | 7 | 114_gomis_swansea_muamba_fabrice |
| 115 | netflix - tv - content - screen - definition | 6 | 115_netflix_tv_content_screen |
| 116 | snake - eastern - redback - postlethwaite - woolworths | 6 | 116_snake_eastern_redback_postlethwaite |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
eusojk/distilbert-base-uncased-finetuned-imdb
|
eusojk
| 2023-08-15T20:31:56Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-15T19:48:55Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4125
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7026 | 1.0 | 157 | 2.4957 |
| 2.581 | 2.0 | 314 | 2.4286 |
| 2.5363 | 3.0 | 471 | 2.4515 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
KingKazma/cnn_dailymail_6789_50000_25000_test
|
KingKazma
| 2023-08-15T20:30:51Z | 5 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:30:50Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_test
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_test")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 108
* Number of training documents: 11490
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - police | 5 | -1_said_one_year_also |
| 0 | league - season - player - game - goal | 4981 | 0_league_season_player_game |
| 1 | isis - syria - islamic - group - militant | 2424 | 1_isis_syria_islamic_group |
| 2 | property - hotel - room - house - home | 194 | 2_property_hotel_room_house |
| 3 | fight - mayweather - pacquiao - floyd - manny | 188 | 3_fight_mayweather_pacquiao_floyd |
| 4 | labour - miliband - snp - mr - leader | 156 | 4_labour_miliband_snp_mr |
| 5 | driver - car - road - vehicle - driving | 133 | 5_driver_car_road_vehicle |
| 6 | baby - hospital - cancer - birth - mother | 133 | 6_baby_hospital_cancer_birth |
| 7 | school - student - teacher - pupil - class | 125 | 7_school_student_teacher_pupil |
| 8 | flight - plane - passenger - airport - pilot | 114 | 8_flight_plane_passenger_airport |
| 9 | masters - woods - augusta - spieth - mcilroy | 112 | 9_masters_woods_augusta_spieth |
| 10 | fashion - dress - model - style - designer | 107 | 10_fashion_dress_model_style |
| 11 | chocolate - food - egg - sugar - restaurant | 98 | 11_chocolate_food_egg_sugar |
| 12 | clinton - hillary - clintons - president - campaign | 89 | 12_clinton_hillary_clintons_president |
| 13 | police - murder - mr - miss - body | 89 | 13_police_murder_mr_miss |
| 14 | lion - animal - elephant - zoo - wildlife | 83 | 14_lion_animal_elephant_zoo |
| 15 | weight - food - eating - diet - size | 82 | 15_weight_food_eating_diet |
| 16 | djokovic - murray - open - miami - berdych | 75 | 16_djokovic_murray_open_miami |
| 17 | dog - cat - animal - owner - pet | 75 | 17_dog_cat_animal_owner |
| 18 | police - vault - gang - thief - raid | 74 | 18_police_vault_gang_thief |
| 19 | planet - solar - earth - surface - moon | 65 | 19_planet_solar_earth_surface |
| 20 | gray - police - baltimore - officer - grays | 64 | 20_gray_police_baltimore_officer |
| 21 | nepal - earthquake - kathmandu - everest - avalanche | 58 | 21_nepal_earthquake_kathmandu_everest |
| 22 | fire - blaze - bradford - firefighter - flame | 55 | 22_fire_blaze_bradford_firefighter |
| 23 | hamilton - rosberg - race - mercedes - prix | 52 | 23_hamilton_rosberg_race_mercedes |
| 24 | prince - royal - queen - duchess - princess | 52 | 24_prince_royal_queen_duchess |
| 25 | tax - labour - economy - mr - cameron | 51 | 25_tax_labour_economy_mr |
| 26 | shot - police - shooting - brady - gun | 48 | 26_shot_police_shooting_brady |
| 27 | anzac - gallipoli - war - australian - waterloo | 47 | 27_anzac_gallipoli_war_australian |
| 28 | chan - sukumaran - execution - bali - indonesian | 45 | 28_chan_sukumaran_execution_bali |
| 29 | migrant - boat - libya - mediterranean - italian | 44 | 29_migrant_boat_libya_mediterranean |
| 30 | china - chinese - chinas - kun - organ | 43 | 30_china_chinese_chinas_kun |
| 31 | iran - nuclear - deal - agreement - irans | 43 | 31_iran_nuclear_deal_agreement |
| 32 | neanderthals - cave - human - specie - bone | 43 | 32_neanderthals_cave_human_specie |
| 33 | shark - fish - whale - seal - water | 41 | 33_shark_fish_whale_seal |
| 34 | mccoy - jockey - race - ride - sandown | 41 | 34_mccoy_jockey_race_ride |
| 35 | yemen - saudi - houthi - houthis - rebel | 39 | 35_yemen_saudi_houthi_houthis |
| 36 | ship - vessel - crew - boat - titanic | 39 | 36_ship_vessel_crew_boat |
| 37 | nfl - manziel - game - quarterback - patriots | 39 | 37_nfl_manziel_game_quarterback |
| 38 | bruce - jenner - bobbi - bobby - kris | 38 | 38_bruce_jenner_bobbi_bobby |
| 39 | money - fraud - bank - account - court | 38 | 39_money_fraud_bank_account |
| 40 | wars - star - film - movie - trailer | 37 | 40_wars_star_film_movie |
| 41 | hernandez - lloyd - hernandezs - odin - murder | 32 | 41_hernandez_lloyd_hernandezs_odin |
| 42 | law - religious - marriage - indiana - samesex | 32 | 42_law_religious_marriage_indiana |
| 43 | child - langlais - death - murder - dellinger | 31 | 43_child_langlais_death_murder |
| 44 | tsarnaev - boston - dzhokhar - tamerlan - death | 31 | 44_tsarnaev_boston_dzhokhar_tamerlan |
| 45 | marathon - running - race - runner - run | 31 | 45_marathon_running_race_runner |
| 46 | clarkson - gear - bbc - top - hammond | 29 | 46_clarkson_gear_bbc_top |
| 47 | water - weather - temperature - drought - climate | 29 | 47_water_weather_temperature_drought |
| 48 | point - nba - scored - playoff - rebound | 29 | 48_point_nba_scored_playoff |
| 49 | marijuana - cannabis - drug - hemp - smoking | 28 | 49_marijuana_cannabis_drug_hemp |
| 50 | slager - scott - officer - charleston - walter | 28 | 50_slager_scott_officer_charleston |
| 51 | died - family - mother - inquest - child | 28 | 51_died_family_mother_inquest |
| 52 | groening - camp - auschwitz - nazi - jews | 27 | 52_groening_camp_auschwitz_nazi |
| 53 | alshabaab - garissa - kenya - kenyan - attack | 26 | 53_alshabaab_garissa_kenya_kenyan |
| 54 | artist - paint - painted - colouring - art | 26 | 54_artist_paint_painted_colouring |
| 55 | crucible - osullivan - frame - doherty - world | 24 | 55_crucible_osullivan_frame_doherty |
| 56 | janner - lord - saunders - public - abuse | 24 | 56_janner_lord_saunders_public |
| 57 | apple - watch - iphone - samsung - battery | 23 | 57_apple_watch_iphone_samsung |
| 58 | korea - korean - kim - north - seoul | 23 | 58_korea_korean_kim_north |
| 59 | tornado - storm - cloud - lightning - wind | 21 | 59_tornado_storm_cloud_lightning |
| 60 | housing - tenant - property - buy - association | 20 | 60_housing_tenant_property_buy |
| 61 | hughes - capitol - gyrocopter - secret - lawn | 20 | 61_hughes_capitol_gyrocopter_secret |
| 62 | vaccine - vaccination - cough - whooping - autism | 19 | 62_vaccine_vaccination_cough_whooping |
| 63 | putin - russian - russia - ukraine - moscow | 19 | 63_putin_russian_russia_ukraine |
| 64 | boko - haram - nigeria - nigerian - buhari | 19 | 64_boko_haram_nigeria_nigerian |
| 65 | south - johannesburg - africa - african - violence | 19 | 65_south_johannesburg_africa_african |
| 66 | bates - harris - tulsa - deputy - taser | 19 | 66_bates_harris_tulsa_deputy |
| 67 | aldi - tesco - cent - per - price | 19 | 67_aldi_tesco_cent_per |
| 68 | bolt - phelps - ennishill - olympic - kipsiro | 19 | 68_bolt_phelps_ennishill_olympic |
| 69 | cuba - castro - obama - cuban - president | 18 | 69_cuba_castro_obama_cuban |
| 70 | murray - dunblane - sears - wedding - andy | 18 | 70_murray_dunblane_sears_wedding |
| 71 | mchenry - weinstein - battilana - britt - towing | 18 | 71_mchenry_weinstein_battilana_britt |
| 72 | nhs - gp - gps - ae - patient | 18 | 72_nhs_gp_gps_ae |
| 73 | cancer - breast - prostate - gene - cell | 18 | 73_cancer_breast_prostate_gene |
| 74 | emoji - app - user - facebook - use | 17 | 74_emoji_app_user_facebook |
| 75 | melbourne - police - anzac - australian - australia | 17 | 75_melbourne_police_anzac_australian |
| 76 | song - songs - no - album - chart | 17 | 76_song_songs_no_album |
| 77 | sydney - storm - weather - flooding - hail | 16 | 77_sydney_storm_weather_flooding |
| 78 | car - audi - motor - bentley - vehicle | 15 | 78_car_audi_motor_bentley |
| 79 | rocket - space - spacex - launch - booster | 15 | 79_rocket_space_spacex_launch |
| 80 | underground - land - cave - garnet - built | 14 | 80_underground_land_cave_garnet |
| 81 | genocide - armenians - armenian - pope - ottoman | 14 | 81_genocide_armenians_armenian_pope |
| 82 | hair - jamelia - labium - rita - cheryl | 14 | 82_hair_jamelia_labium_rita |
| 83 | stephanie - scott - scotts - stanford - leeton | 13 | 83_stephanie_scott_scotts_stanford |
| 84 | funeral - nelms - work - job - grandparent | 13 | 84_funeral_nelms_work_job |
| 85 | alcohol - wine - drinking - oak - drink | 13 | 85_alcohol_wine_drinking_oak |
| 86 | nuclear - reactor - radiation - plant - fukushima | 12 | 86_nuclear_reactor_radiation_plant |
| 87 | luke - search - bushland - missing - eildon | 12 | 87_luke_search_bushland_missing |
| 88 | snowden - nsa - agency - oliver - information | 12 | 88_snowden_nsa_agency_oliver |
| 89 | brandt - dr - kimmy - franff - fredric | 10 | 89_brandt_dr_kimmy_franff |
| 90 | tidal - music - radio - streaming - service | 10 | 90_tidal_music_radio_streaming |
| 91 | population - immigrant - cent - per - immigration | 10 | 91_population_immigrant_cent_per |
| 92 | brain - acetaminophen - meditation - cortisol - study | 9 | 92_brain_acetaminophen_meditation_cortisol |
| 93 | god - church - dollar - catholic - schuller | 8 | 93_god_church_dollar_catholic |
| 94 | phone - user - google - device - app | 8 | 94_phone_user_google_device |
| 95 | cocaine - cutter - custom - seized - tsa | 8 | 95_cocaine_cutter_custom_seized |
| 96 | pusok - deputy - officer - pusoks - mcmahon | 7 | 96_pusok_deputy_officer_pusoks |
| 97 | stover - kost - rape - convicted - offender | 7 | 97_stover_kost_rape_convicted |
| 98 | nauru - sexual - sex - genetic - convicted | 7 | 98_nauru_sexual_sex_genetic |
| 99 | tsa - security - roberts - airport - employee | 7 | 99_tsa_security_roberts_airport |
| 100 | eaves - beach - martistee - mckeithen - spring | 7 | 100_eaves_beach_martistee_mckeithen |
| 101 | oclee - michelle - philippa - barrientos - mcwhirter | 6 | 101_oclee_michelle_philippa_barrientos |
| 102 | redman - wisconsin - basketball - badgers - wildcats | 6 | 102_redman_wisconsin_basketball_badgers |
| 103 | gransbury - biderman - funking - website - joke | 6 | 103_gransbury_biderman_funking_website |
| 104 | richards - ariana - beverly - kim - hills | 6 | 104_richards_ariana_beverly_kim |
| 105 | affleck - gates - renner - avengers - afflecks | 5 | 105_affleck_gates_renner_avengers |
| 106 | skin - sun - protoporphyrin - cream - sunlight | 5 | 106_skin_sun_protoporphyrin_cream |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
KingKazma/cnn_dailymail_6789_50000_25000_validation
|
KingKazma
| 2023-08-15T20:30:50Z | 4 | 0 |
bertopic
|
[
"bertopic",
"text-classification",
"region:us"
] |
text-classification
| 2023-08-15T20:30:49Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# cnn_dailymail_6789_50000_25000_validation
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("KingKazma/cnn_dailymail_6789_50000_25000_validation")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 118
* Number of training documents: 13368
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | said - one - year - also - time | 5 | -1_said_one_year_also |
| 0 | isis - syria - islamic - attack - group | 6535 | 0_isis_syria_islamic_attack |
| 1 | police - officer - shooting - ferguson - said | 452 | 1_police_officer_shooting_ferguson |
| 2 | labour - mr - party - election - tax | 415 | 2_labour_mr_party_election |
| 3 | flight - plane - pilot - aircraft - lubitz | 268 | 3_flight_plane_pilot_aircraft |
| 4 | car - driver - driving - road - crash | 224 | 4_car_driver_driving_road |
| 5 | hair - fashion - dress - model - look | 223 | 5_hair_fashion_dress_model |
| 6 | cricket - england - cup - world - pietersen | 205 | 6_cricket_england_cup_world |
| 7 | food - sugar - per - cent - product | 189 | 7_food_sugar_per_cent |
| 8 | clinton - email - obama - president - clintons | 188 | 8_clinton_email_obama_president |
| 9 | property - house - home - price - room | 186 | 9_property_house_home_price |
| 10 | rangers - celtic - scotland - ibrox - game | 165 | 10_rangers_celtic_scotland_ibrox |
| 11 | fight - pacquiao - mayweather - manny - floyd | 151 | 11_fight_pacquiao_mayweather_manny |
| 12 | england - nations - wales - ireland - six | 143 | 12_england_nations_wales_ireland |
| 13 | hamilton - mercedes - prix - race - rosberg | 135 | 13_hamilton_mercedes_prix_race |
| 14 | baby - birth - cancer - hospital - born | 126 | 14_baby_birth_cancer_hospital |
| 15 | fa - league - game - villa - bradford | 116 | 15_fa_league_game_villa |
| 16 | dog - animal - dogs - owner - pet | 114 | 16_dog_animal_dogs_owner |
| 17 | police - abuse - sexual - sex - child | 112 | 17_police_abuse_sexual_sex |
| 18 | madrid - ronaldo - barcelona - real - messi | 111 | 18_madrid_ronaldo_barcelona_real |
| 19 | chelsea - mourinho - terry - league - jose | 106 | 19_chelsea_mourinho_terry_league |
| 20 | eclipse - earth - mars - solar - sun | 101 | 20_eclipse_earth_mars_solar |
| 21 | kane - england - hodgson - lithuania - rooney | 100 | 21_kane_england_hodgson_lithuania |
| 22 | show - film - corden - host - noah | 95 | 22_show_film_corden_host |
| 23 | prince - royal - duchess - charles - queen | 92 | 23_prince_royal_duchess_charles |
| 24 | murray - wells - tennis - andy - 64 | 88 | 24_murray_wells_tennis_andy |
| 25 | putin - russian - nemtsov - moscow - russia | 82 | 25_putin_russian_nemtsov_moscow |
| 26 | netanyahu - iran - nuclear - israel - israeli | 80 | 26_netanyahu_iran_nuclear_israel |
| 27 | court - money - bank - fraud - stiviano | 80 | 27_court_money_bank_fraud |
| 28 | weight - size - fat - stone - diet | 76 | 28_weight_size_fat_stone |
| 29 | armstrong - race - olympic - uci - championships | 74 | 29_armstrong_race_olympic_uci |
| 30 | cheltenham - hurdle - horse - jockey - festival | 73 | 30_cheltenham_hurdle_horse_jockey |
| 31 | arsenal - wenger - monaco - giroud - arsenals | 73 | 31_arsenal_wenger_monaco_giroud |
| 32 | mcilroy - golf - masters - woods - round | 72 | 32_mcilroy_golf_masters_woods |
| 33 | watch - apple - device - google - user | 66 | 33_watch_apple_device_google |
| 34 | fraternity - university - sae - oklahoma - chapter | 65 | 34_fraternity_university_sae_oklahoma |
| 35 | united - van - gaal - manchester - arsenal | 62 | 35_united_van_gaal_manchester |
| 36 | chan - sukumaran - indonesian - bali - myuran | 61 | 36_chan_sukumaran_indonesian_bali |
| 37 | school - teacher - student - district - sexual | 58 | 37_school_teacher_student_district |
| 38 | sunderland - poyet - advocaat - johnson - april | 55 | 38_sunderland_poyet_advocaat_johnson |
| 39 | clarkson - bbc - gear - top - jeremy | 55 | 39_clarkson_bbc_gear_top |
| 40 | fire - building - blaze - explosion - firefighter | 48 | 40_fire_building_blaze_explosion |
| 41 | liverpool - gerrard - rodgers - steven - anfield | 46 | 41_liverpool_gerrard_rodgers_steven |
| 42 | patient - nhs - ae - cancer - care | 44 | 42_patient_nhs_ae_cancer |
| 43 | song - zayn - thicke - gayes - pharrell | 43 | 43_song_zayn_thicke_gayes |
| 44 | wedding - married - couple - jaclyn - love | 41 | 44_wedding_married_couple_jaclyn |
| 45 | car - vehicle - electric - model - jaguar | 41 | 45_car_vehicle_electric_model |
| 46 | nfl - borland - bowl - brady - super | 40 | 46_nfl_borland_bowl_brady |
| 47 | pellegrini - city - league - manchester - barcelona | 40 | 47_pellegrini_city_league_manchester |
| 48 | school - education - porn - sex - child | 39 | 48_school_education_porn_sex |
| 49 | bear - cub - tiger - deer - wildlife | 39 | 49_bear_cub_tiger_deer |
| 50 | gay - law - indiana - marriage - religious | 38 | 50_gay_law_indiana_marriage |
| 51 | india - rape - indian - documentary - singh | 37 | 51_india_rape_indian_documentary |
| 52 | boko - haram - nigeria - nigerian - nigerias | 36 | 52_boko_haram_nigeria_nigerian |
| 53 | ebola - sierra - leone - virus - liberia | 35 | 53_ebola_sierra_leone_virus |
| 54 | tsarnaev - dzhokhar - boston - tamerlan - tsarnaevs | 35 | 54_tsarnaev_dzhokhar_boston_tamerlan |
| 55 | ski - mountain - skier - rock - lift | 32 | 55_ski_mountain_skier_rock |
| 56 | robbery - armed - store - police - bank | 31 | 56_robbery_armed_store_police |
| 57 | roma - inter - juventus - serie - fiorentina | 30 | 57_roma_inter_juventus_serie |
| 58 | fifa - blatter - fa - qatar - cup | 29 | 58_fifa_blatter_fa_qatar |
| 59 | marijuana - drug - cannabis - colorado - lsd | 29 | 59_marijuana_drug_cannabis_colorado |
| 60 | everton - martinez - lukaku - dynamo - evertons | 27 | 60_everton_martinez_lukaku_dynamo |
| 61 | chelsea - racist - paris - train - football | 27 | 61_chelsea_racist_paris_train |
| 62 | durst - dursts - berman - orleans - robert | 27 | 62_durst_dursts_berman_orleans |
| 63 | basketball - ncaa - coach - tournament - game | 25 | 63_basketball_ncaa_coach_tournament |
| 64 | bayern - goal - muller - shakhtar - robben | 25 | 64_bayern_goal_muller_shakhtar |
| 65 | hotel - beach - cruise - ship - resort | 25 | 65_hotel_beach_cruise_ship |
| 66 | sherwood - villa - aston - tim - brom | 25 | 66_sherwood_villa_aston_tim |
| 67 | snow - inch - winter - weather - ice | 24 | 67_snow_inch_winter_weather |
| 68 | weather - temperature - rain - snow - expected | 24 | 68_weather_temperature_rain_snow |
| 69 | korean - korea - kim - north - lippert | 23 | 69_korean_korea_kim_north |
| 70 | hospital - doctor - mrs - fracture - patient | 23 | 70_hospital_doctor_mrs_fracture |
| 71 | rail - calais - parking - transport - train | 22 | 71_rail_calais_parking_transport |
| 72 | mls - lampard - orlando - city - york | 22 | 72_mls_lampard_orlando_city |
| 73 | jesus - stone - circle - ancient - stonehenge | 22 | 73_jesus_stone_circle_ancient |
| 74 | hernandez - lloyd - jenkins - hernandezs - lloyds | 21 | 74_hernandez_lloyd_jenkins_hernandezs |
| 75 | drug - cocaine - jailed - steroid - cannabis | 20 | 75_drug_cocaine_jailed_steroid |
| 76 | secret - clancy - service - agent - white | 20 | 76_secret_clancy_service_agent |
| 77 | homo - fossil - specie - ago - human | 20 | 77_homo_fossil_specie_ago |
| 78 | image - photographer - photograph - photo - landscape | 19 | 78_image_photographer_photograph_photo |
| 79 | parade - patricks - irish - st - green | 19 | 79_parade_patricks_irish_st |
| 80 | bale - wales - israel - coleman - gareth | 19 | 80_bale_wales_israel_coleman |
| 81 | di - maria - angel - united - manchester | 19 | 81_di_maria_angel_united |
| 82 | defence - greece - spending - greek - budget | 19 | 82_defence_greece_spending_greek |
| 83 | sleep - store - cent - per - kraft | 18 | 83_sleep_store_cent_per |
| 84 | student - johnson - virginia - charlottesville - university | 18 | 84_student_johnson_virginia_charlottesville |
| 85 | vanuatu - cyclone - vila - pam - port | 18 | 85_vanuatu_cyclone_vila_pam |
| 86 | cnn - transcript - student - news - roll | 18 | 86_cnn_transcript_student_news |
| 87 | nazi - anne - nazis - war - camp | 18 | 87_nazi_anne_nazis_war |
| 88 | attack - synagogue - hebdo - paris - charlie | 17 | 88_attack_synagogue_hebdo_paris |
| 89 | ham - west - tomkins - reid - kouyate | 16 | 89_ham_west_tomkins_reid |
| 90 | balotelli - mario - liverpool - italian - striker | 16 | 90_balotelli_mario_liverpool_italian |
| 91 | chinese - monk - buddhist - thailand - tourist | 15 | 91_chinese_monk_buddhist_thailand |
| 92 | snowden - gchq - intelligence - security - agency | 15 | 92_snowden_gchq_intelligence_security |
| 93 | pope - francis - naples - vatican - pontiff | 14 | 93_pope_francis_naples_vatican |
| 94 | starbucks - schultz - race - racial - campaign | 14 | 94_starbucks_schultz_race_racial |
| 95 | point - rebound - sweeney - playoff - scored | 14 | 95_point_rebound_sweeney_playoff |
| 96 | poldark - turner - demelza - aidan - drama | 13 | 96_poldark_turner_demelza_aidan |
| 97 | cuba - havana - cuban - us - castro | 13 | 97_cuba_havana_cuban_us |
| 98 | italy - conte - italian - eder - juventus | 13 | 98_italy_conte_italian_eder |
| 99 | richard - iii - leicester - king - iiis | 13 | 99_richard_iii_leicester_king |
| 100 | sena - hartman - child - shaday - sexual | 13 | 100_sena_hartman_child_shaday |
| 101 | gordon - bobbi - kristina - phil - dr | 12 | 101_gordon_bobbi_kristina_phil |
| 102 | jobs - lu - naomi - cook - business | 12 | 102_jobs_lu_naomi_cook |
| 103 | duckenfield - mr - gate - hillsborough - greaney | 11 | 103_duckenfield_mr_gate_hillsborough |
| 104 | huang - wang - chen - wife - china | 10 | 104_huang_wang_chen_wife |
| 105 | coin - coins - silver - cave - gold | 10 | 105_coin_coins_silver_cave |
| 106 | shark - whale - mola - crab - barbero | 10 | 106_shark_whale_mola_crab |
| 107 | gissendaner - execution - lethal - death - injection | 10 | 107_gissendaner_execution_lethal_death |
| 108 | book - handshake - word - author - app | 9 | 108_book_handshake_word_author |
| 109 | cosby - cosbys - thompson - welles - bill | 9 | 109_cosby_cosbys_thompson_welles |
| 110 | school - pupil - student - parent - computer | 9 | 110_school_pupil_student_parent |
| 111 | china - stopera - li - orange - chinese | 8 | 111_china_stopera_li_orange |
| 112 | tb - vaccine - disease - measles - meningitis | 8 | 112_tb_vaccine_disease_measles |
| 113 | neymar - brazil - willian - dunga - france | 8 | 113_neymar_brazil_willian_dunga |
| 114 | gomis - swansea - muamba - fabrice - bafetimbi | 7 | 114_gomis_swansea_muamba_fabrice |
| 115 | netflix - tv - content - screen - definition | 6 | 115_netflix_tv_content_screen |
| 116 | snake - eastern - redback - postlethwaite - woolworths | 6 | 116_snake_eastern_redback_postlethwaite |
</details>
## Training hyperparameters
* calculate_probabilities: True
* language: english
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: False
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.33
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.31.0
* Numba: 0.57.1
* Plotly: 5.15.0
* Python: 3.10.12
|
MattStammers/Taxi-v3-final
|
MattStammers
| 2023-08-15T20:17:35Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-15T20:09:43Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-final
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 8.34 +/- 2.65
name: mean_reward
verified: true
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="MattStammers/q-FrozenLake-v1-8x8-Slippery-final", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
This was an accident but it worked - it is obviously cheating somehow but it was fully unintentional
'env_id': 'Taxi-v3',
'max_steps': 200,
'n_training_episodes': 2000000,
'n_eval_episodes': 100,
'eval_seed': [],
'learning_rate': 0.15,
'gamma': 0.99,
'max_epsilon': 1,
'min_epsilon': 0.05,
'decay_rate': 0.0005,
|
skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO
|
skrl
| 2023-08-15T20:14:15Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:11:45Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 9.7 +/- 0.05
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Reach-Franka-v0
type: Isaac-Reach-Franka-v0
---
<!-- ---
torch: 9.7 +/- 0.05
jax: 9.65 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Reach-Franka-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Reach-Franka-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Reach-Franka-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 16 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 8 # 16 * 2048 / 4096
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.01}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 2.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = None
cfg["time_limit_bootstrap"] = False
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
Yijia-Xiao/LLaMA-7B-samsum
|
Yijia-Xiao
| 2023-08-15T20:10:46Z | 2 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"8-bit",
"region:us"
] | null | 2023-08-15T18:00:12Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
vivek9/sentiment_analysis
|
vivek9
| 2023-08-15T20:08:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-08-14T14:34:48Z |
# Amazon Fine Food Sentiment Analysis with BERT
This repository contains code for a sentiment analysis demo that predicts the sentiment of Amazon fine food reviews using a finetuned BERT Base model from the Hugging Face Transformers library. The demo also includes an interface built using Gradio, allowing users to interactively input reviews and receive sentiment predictions.
## About the Demo
The sentiment analysis model is trained on the Amazon Fine Food Reviews dataset, which includes:
- Number of reviews: 568,454
- Number of users: 256,059
- Number of products: 74,258
- Timespan: Oct 1999 — Oct 2012
- Number of Attributes/Columns in data: 10
## Model Architecture
**Model Architecture:**
- `self.bert`: BERT Base model loaded from pre-trained weights.
- `self.drop`: Dropout layer applied for regularization.
- `self.out`: Linear layer mapping BERT hidden size to sentiment classes.
**Files in the Repository:**
- `amazon_finefood_sentiment_analysis_training.ipynb`: Code for training the sentiment analysis model.
- `amazon_finefood_sentiment_analysis_interface.ipynb`: Code for building the Gradio interface.
- `sentiment_analysis_finetune_bert.pkl`: Trained sentiment analysis model in serialized format.
**Usage:**
To run the code and interact with the sentiment analysis demo:
1. Open `amazon_finefood_sentiment_analysis_interface.ipynb`.
2. Set the file path to `sentiment_analysis_finetune_bert.pkl`.
3. Execute the notebook cells to set up the Gradio interface and make predictions.
Feel free to experiment with the interface, input different reviews, and observe sentiment predictions and confidence scores.
For questions/issues, open an issue in this repository.
**Model Achievements**
- Gated Recurrent Unit (GRU): Achieved an accuracy of 94.8%.
- Long Short-Term Memory (LSTM): Implemented an architecture with an accuracy of 93.2%.
- BERT Base Model Fine-Tuning: Achieved an accuracy of 96.4% after finetuning.
**Training Details**
All experiments were performed on a single NVIDIA RTX 2070 GPU. The training times are as follows:
- GRU Model: Trained for 10 epochs, took approximately 10+ hours.
- LSTM Model: Trained for 10 epochs, took around 10+ hours.
- BERT Base Model Fine-Tuning: Trained for 10 epochs, took around 15+ hours.
**Acknowledgments:**
The sentiment analysis model uses BERT architecture from Hugging Face Transformers. The Amazon Fine Food Reviews dataset is for training. Gradio is used for the interactive interface.
|
skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO
|
skrl
| 2023-08-15T19:42:52Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:07:53Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 497.66 +/- 0.47
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Cartpole-v0
type: Isaac-Cartpole-v0
---
<!-- ---
torch: 497.66 +/- 0.47
jax: 497.41 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Cartpole-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Cartpole-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Cartpole-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 16 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 1 # 16 * 512 / 8192
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.008}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 2.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = None
cfg["time_limit_bootstrap"] = True
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
skrl/IsaacOrbit-Isaac-Ant-v0-PPO
|
skrl
| 2023-08-15T19:41:16Z | 0 | 0 |
skrl
|
[
"skrl",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-20T12:08:19Z |
---
library_name: skrl
tags:
- deep-reinforcement-learning
- reinforcement-learning
- skrl
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 13273.86 +/- 3550.43
name: Total reward (mean)
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Isaac-Ant-v0
type: Isaac-Ant-v0
---
<!-- ---
torch: 13273.86 +/- 3550.43
jax: 20690.53 +/- 0.0
numpy:
--- -->
# IsaacOrbit-Isaac-Ant-v0-PPO
Trained agent for [NVIDIA Isaac Orbit](https://github.com/NVIDIA-Omniverse/Orbit) environments.
- **Task:** Isaac-Ant-v0
- **Agent:** [PPO](https://skrl.readthedocs.io/en/latest/api/agents/ppo.html)
# Usage (with skrl)
Note: Visit the skrl [Examples](https://skrl.readthedocs.io/en/latest/intro/examples.html) section to access the scripts.
* PyTorch
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Ant-v0-PPO", filename="agent.pt")
agent.load(path)
```
* JAX
```python
from skrl.utils.huggingface import download_model_from_huggingface
# assuming that there is an agent named `agent`
path = download_model_from_huggingface("skrl/IsaacOrbit-Isaac-Ant-v0-PPO", filename="agent.pickle")
agent.load(path)
```
# Hyperparameters
```python
# https://skrl.readthedocs.io/en/latest/api/agents/ppo.html#configuration-and-hyperparameters
cfg = PPO_DEFAULT_CONFIG.copy()
cfg["rollouts"] = 16 # memory_size
cfg["learning_epochs"] = 8
cfg["mini_batches"] = 4 # 16 * 1024 / 4096
cfg["discount_factor"] = 0.99
cfg["lambda"] = 0.95
cfg["learning_rate"] = 3e-4
cfg["learning_rate_scheduler"] = KLAdaptiveRL
cfg["learning_rate_scheduler_kwargs"] = {"kl_threshold": 0.008}
cfg["random_timesteps"] = 0
cfg["learning_starts"] = 0
cfg["grad_norm_clip"] = 1.0
cfg["ratio_clip"] = 0.2
cfg["value_clip"] = 0.2
cfg["clip_predicted_values"] = True
cfg["entropy_loss_scale"] = 0.0
cfg["value_loss_scale"] = 1.0
cfg["kl_threshold"] = 0
cfg["rewards_shaper"] = lambda rewards, *args, **kwargs: rewards * 0.1
cfg["time_limit_bootstrap"] = True
cfg["state_preprocessor"] = RunningStandardScaler
cfg["state_preprocessor_kwargs"] = {"size": env.observation_space, "device": device}
cfg["value_preprocessor"] = RunningStandardScaler
cfg["value_preprocessor_kwargs"] = {"size": 1, "device": device}
```
|
moisesrobles04/ppo-SnowballTarget
|
moisesrobles04
| 2023-08-15T19:39:33Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-08-15T19:39:27Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: moisesrobles04/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.