
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 06:30:45
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 06:30:39
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Dnyaneshwar/hing-mbert-finetuned-code-mixed-DS
|
Dnyaneshwar
| 2022-09-13T14:19:07Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T13:46:40Z |
---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-mbert-finetuned-code-mixed-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-mbert-finetuned-code-mixed-DS
This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0518
- Accuracy: 0.7545
- Precision: 0.7041
- Recall: 0.7076
- F1: 0.7053
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.7277800745684633e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.8338 | 1.0 | 497 | 0.6922 | 0.7163 | 0.6697 | 0.6930 | 0.6686 |
| 0.5744 | 2.0 | 994 | 0.7872 | 0.7324 | 0.6786 | 0.6967 | 0.6845 |
| 0.36 | 3.0 | 1491 | 1.0518 | 0.7545 | 0.7041 | 0.7076 | 0.7053 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
SiddharthaM/bert-engonly-sentiment-test
|
SiddharthaM
| 2022-09-13T14:16:50Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T13:54:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: bert-engonly-sentiment-test
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8966666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-engonly-sentiment-test
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4479
- Accuracy: 0.8967
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
vamsibanda/sbert-all-MiniLM-L12-with-pooler
|
vamsibanda
| 2022-09-13T14:02:58Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"onnx",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-07-23T04:04:24Z |
---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- onnx
---
# ONNX convert all-MiniLM-L12-v2
## Conversion of [sentence-transformers/all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2)
This is a [sentence-transformers](https://www.SBERT.net) ONNX model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search. This custom model takes `last_hidden_state` and `pooler_output` whereas the sentence-transformers exported with default ONNX config only contains `last_hidden_state` as output.
## Usage (HuggingFace Optimum)
Using this model becomes easy when you have [optimum](https://github.com/huggingface/optimum) installed:
```
python -m pip install optimum
```
Then you can use the model like this:
```python
from optimum.onnxruntime.modeling_ort import ORTModelForCustomTasks
model = ORTModelForCustomTasks.from_pretrained("vamsibanda/sbert-all-MiniLM-L12-with-pooler")
tokenizer = AutoTokenizer.from_pretrained("vamsibanda/sbert-all-MiniLM-L12-with-pooler")
inputs = tokenizer("I love burritos!", return_tensors="pt")
pred = model(**inputs)
embedding = pred['pooler_output']
```
|
vamsibanda/sbert-all-roberta-large-v1-with-pooler
|
vamsibanda
| 2022-09-13T14:00:40Z | 3 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"onnx",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-07-19T00:43:14Z |
---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- onnx
---
# ONNX convert all-roberta-large-v1
## Conversion of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1)
## Usage (HuggingFace Optimum)
Using this model becomes easy when you have [optimum](https://github.com/huggingface/optimum) installed:
```
python -m pip install optimum
```
Then you can use the model like this:
```python
from optimum.onnxruntime.modeling_ort import ORTModelForCustomTasks
model = ORTModelForCustomTasks.from_pretrained("vamsibanda/sbert-all-roberta-large-v1-with-pooler")
tokenizer = AutoTokenizer.from_pretrained("vamsibanda/sbert-all-roberta-large-v1-with-pooler")
inputs = tokenizer("I love burritos!", return_tensors="pt")
pred = model(**inputs)
embedding = pred['pooler_output']
```
|
sd-concepts-library/a-tale-of-two-empires
|
sd-concepts-library
| 2022-09-13T13:35:14Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T13:19:38Z |
---
license: mit
---
### A Tale of Two Empires on Stable Diffusion
This is the `<two-empires>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






Source: Reddit [u/mandal0re](https://www.reddit.com/r/StarWars/comments/kg6ovv/i_like_to_photoshop_old_paintings_heres_my_a_tale/)
|
DelinteNicolas/SDG_classifier_v0.0.4
|
DelinteNicolas
| 2022-09-13T13:13:45Z | 165 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-12T14:34:34Z |
---
license: gpl-3.0
---
Fined-tuned BERT trained on 6500+ labeled data, including control sentences from SuperGLUE.
|
MJ199999/gpt3_model
|
MJ199999
| 2022-09-13T12:42:18Z | 9 | 1 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-09T05:19:15Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: gpt3_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# gpt3_model
This model is a fine-tuned version of [MJ199999/gpt3_model](https://huggingface.co/MJ199999/gpt3_model) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4905
- Train Lr: 0.0009999999
- Epoch: 199
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adagrad', 'learning_rate': 0.0009999999, 'decay': 0.0, 'initial_accumulator_value': 0.1, 'epsilon': 1e-07}
- training_precision: float32
### Training results
| Train Loss | Train Lr | Epoch |
|:----------:|:------------:|:-----:|
| 5.1583 | 0.01 | 0 |
| 3.9477 | 0.01 | 1 |
| 2.9332 | 0.01 | 2 |
| 2.1581 | 0.01 | 3 |
| 1.6918 | 0.01 | 4 |
| 1.3929 | 0.01 | 5 |
| 1.2062 | 0.01 | 6 |
| 1.0955 | 0.01 | 7 |
| 1.0068 | 0.01 | 8 |
| 0.9528 | 0.01 | 9 |
| 0.9051 | 0.01 | 10 |
| 0.8710 | 0.01 | 11 |
| 0.8564 | 0.01 | 12 |
| 0.8094 | 0.01 | 13 |
| 0.8143 | 0.01 | 14 |
| 0.7853 | 0.01 | 15 |
| 0.7625 | 0.01 | 16 |
| 0.7508 | 0.01 | 17 |
| 0.7449 | 0.01 | 18 |
| 0.7319 | 0.01 | 19 |
| 0.7144 | 0.01 | 20 |
| 0.7045 | 0.01 | 21 |
| 0.7029 | 0.01 | 22 |
| 0.6937 | 0.01 | 23 |
| 0.6898 | 0.01 | 24 |
| 0.6745 | 0.01 | 25 |
| 0.6767 | 0.01 | 26 |
| 0.6692 | 0.01 | 27 |
| 0.6604 | 0.01 | 28 |
| 0.6573 | 0.01 | 29 |
| 0.6524 | 0.01 | 30 |
| 0.6508 | 0.01 | 31 |
| 0.6443 | 0.01 | 32 |
| 0.6452 | 0.01 | 33 |
| 0.6371 | 0.01 | 34 |
| 0.6362 | 0.01 | 35 |
| 0.6304 | 0.01 | 36 |
| 0.6317 | 0.01 | 37 |
| 0.6270 | 0.01 | 38 |
| 0.6257 | 0.01 | 39 |
| 0.6208 | 0.01 | 40 |
| 0.6227 | 0.01 | 41 |
| 0.6154 | 0.01 | 42 |
| 0.6126 | 0.01 | 43 |
| 0.6149 | 0.01 | 44 |
| 0.6075 | 0.01 | 45 |
| 0.6084 | 0.01 | 46 |
| 0.6078 | 0.01 | 47 |
| 0.6057 | 0.01 | 48 |
| 0.6033 | 0.01 | 49 |
| 0.6040 | 0.01 | 50 |
| 0.5989 | 0.01 | 51 |
| 0.5967 | 0.01 | 52 |
| 0.5952 | 0.01 | 53 |
| 0.5911 | 0.01 | 54 |
| 0.5904 | 0.01 | 55 |
| 0.5888 | 0.01 | 56 |
| 0.5886 | 0.01 | 57 |
| 0.5883 | 0.01 | 58 |
| 0.5838 | 0.01 | 59 |
| 0.5856 | 0.01 | 60 |
| 0.5850 | 0.01 | 61 |
| 0.5801 | 0.01 | 62 |
| 0.5821 | 0.01 | 63 |
| 0.5781 | 0.01 | 64 |
| 0.5786 | 0.01 | 65 |
| 0.5835 | 0.01 | 66 |
| 0.5808 | 0.01 | 67 |
| 0.5754 | 0.01 | 68 |
| 0.5742 | 0.01 | 69 |
| 0.5733 | 0.01 | 70 |
| 0.5700 | 0.01 | 71 |
| 0.5738 | 0.01 | 72 |
| 0.5678 | 0.01 | 73 |
| 0.5695 | 0.01 | 74 |
| 0.5684 | 0.01 | 75 |
| 0.5696 | 0.01 | 76 |
| 0.5688 | 0.01 | 77 |
| 0.5648 | 0.01 | 78 |
| 0.5592 | 0.01 | 79 |
| 0.5622 | 0.01 | 80 |
| 0.5660 | 0.01 | 81 |
| 0.5636 | 0.01 | 82 |
| 0.5602 | 0.01 | 83 |
| 0.5613 | 0.01 | 84 |
| 0.5608 | 0.01 | 85 |
| 0.5589 | 0.01 | 86 |
| 0.5580 | 0.01 | 87 |
| 0.5566 | 0.01 | 88 |
| 0.5531 | 0.01 | 89 |
| 0.5571 | 0.01 | 90 |
| 0.5541 | 0.01 | 91 |
| 0.5576 | 0.01 | 92 |
| 0.5560 | 0.01 | 93 |
| 0.5517 | 0.01 | 94 |
| 0.5508 | 0.01 | 95 |
| 0.5554 | 0.01 | 96 |
| 0.5539 | 0.01 | 97 |
| 0.5493 | 0.01 | 98 |
| 0.5499 | 0.01 | 99 |
| 0.4999 | 0.0009999999 | 100 |
| 0.4981 | 0.0009999999 | 101 |
| 0.4983 | 0.0009999999 | 102 |
| 0.4984 | 0.0009999999 | 103 |
| 0.4974 | 0.0009999999 | 104 |
| 0.4957 | 0.0009999999 | 105 |
| 0.4966 | 0.0009999999 | 106 |
| 0.4975 | 0.0009999999 | 107 |
| 0.4962 | 0.0009999999 | 108 |
| 0.4932 | 0.0009999999 | 109 |
| 0.4983 | 0.0009999999 | 110 |
| 0.4937 | 0.0009999999 | 111 |
| 0.4926 | 0.0009999999 | 112 |
| 0.4944 | 0.0009999999 | 113 |
| 0.4947 | 0.0009999999 | 114 |
| 0.4953 | 0.0009999999 | 115 |
| 0.4934 | 0.0009999999 | 116 |
| 0.4929 | 0.0009999999 | 117 |
| 0.4925 | 0.0009999999 | 118 |
| 0.4948 | 0.0009999999 | 119 |
| 0.4947 | 0.0009999999 | 120 |
| 0.4936 | 0.0009999999 | 121 |
| 0.4909 | 0.0009999999 | 122 |
| 0.4960 | 0.0009999999 | 123 |
| 0.4952 | 0.0009999999 | 124 |
| 0.4923 | 0.0009999999 | 125 |
| 0.4930 | 0.0009999999 | 126 |
| 0.4942 | 0.0009999999 | 127 |
| 0.4927 | 0.0009999999 | 128 |
| 0.4917 | 0.0009999999 | 129 |
| 0.4926 | 0.0009999999 | 130 |
| 0.4927 | 0.0009999999 | 131 |
| 0.4932 | 0.0009999999 | 132 |
| 0.4925 | 0.0009999999 | 133 |
| 0.4928 | 0.0009999999 | 134 |
| 0.4936 | 0.0009999999 | 135 |
| 0.4908 | 0.0009999999 | 136 |
| 0.4936 | 0.0009999999 | 137 |
| 0.4916 | 0.0009999999 | 138 |
| 0.4906 | 0.0009999999 | 139 |
| 0.4904 | 0.0009999999 | 140 |
| 0.4920 | 0.0009999999 | 141 |
| 0.4924 | 0.0009999999 | 142 |
| 0.4902 | 0.0009999999 | 143 |
| 0.4903 | 0.0009999999 | 144 |
| 0.4903 | 0.0009999999 | 145 |
| 0.4924 | 0.0009999999 | 146 |
| 0.4889 | 0.0009999999 | 147 |
| 0.4896 | 0.0009999999 | 148 |
| 0.4919 | 0.0009999999 | 149 |
| 0.4896 | 0.0009999999 | 150 |
| 0.4906 | 0.0009999999 | 151 |
| 0.4923 | 0.0009999999 | 152 |
| 0.4899 | 0.0009999999 | 153 |
| 0.4925 | 0.0009999999 | 154 |
| 0.4901 | 0.0009999999 | 155 |
| 0.4910 | 0.0009999999 | 156 |
| 0.4904 | 0.0009999999 | 157 |
| 0.4912 | 0.0009999999 | 158 |
| 0.4937 | 0.0009999999 | 159 |
| 0.4894 | 0.0009999999 | 160 |
| 0.4913 | 0.0009999999 | 161 |
| 0.4899 | 0.0009999999 | 162 |
| 0.4894 | 0.0009999999 | 163 |
| 0.4904 | 0.0009999999 | 164 |
| 0.4900 | 0.0009999999 | 165 |
| 0.4890 | 0.0009999999 | 166 |
| 0.4919 | 0.0009999999 | 167 |
| 0.4909 | 0.0009999999 | 168 |
| 0.4891 | 0.0009999999 | 169 |
| 0.4900 | 0.0009999999 | 170 |
| 0.4910 | 0.0009999999 | 171 |
| 0.4901 | 0.0009999999 | 172 |
| 0.4914 | 0.0009999999 | 173 |
| 0.4913 | 0.0009999999 | 174 |
| 0.4897 | 0.0009999999 | 175 |
| 0.4892 | 0.0009999999 | 176 |
| 0.4929 | 0.0009999999 | 177 |
| 0.4881 | 0.0009999999 | 178 |
| 0.4920 | 0.0009999999 | 179 |
| 0.4888 | 0.0009999999 | 180 |
| 0.4901 | 0.0009999999 | 181 |
| 0.4875 | 0.0009999999 | 182 |
| 0.4930 | 0.0009999999 | 183 |
| 0.4867 | 0.0009999999 | 184 |
| 0.4890 | 0.0009999999 | 185 |
| 0.4898 | 0.0009999999 | 186 |
| 0.4880 | 0.0009999999 | 187 |
| 0.4899 | 0.0009999999 | 188 |
| 0.4881 | 0.0009999999 | 189 |
| 0.4897 | 0.0009999999 | 190 |
| 0.4876 | 0.0009999999 | 191 |
| 0.4873 | 0.0009999999 | 192 |
| 0.4901 | 0.0009999999 | 193 |
| 0.4898 | 0.0009999999 | 194 |
| 0.4898 | 0.0009999999 | 195 |
| 0.4861 | 0.0009999999 | 196 |
| 0.4878 | 0.0009999999 | 197 |
| 0.4880 | 0.0009999999 | 198 |
| 0.4905 | 0.0009999999 | 199 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-0front-1body-7rear
|
Padomin
| 2022-09-13T12:15:31Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-13T02:28:03Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-7rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-7rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4666
- Wer: 0.1780
- Mer: 0.1718
- Wil: 0.2607
- Wip: 0.7393
- Hits: 55410
- Substitutions: 6566
- Deletions: 2611
- Insertions: 2321
- Cer: 0.1388
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6424 | 1.0 | 1457 | 0.4944 | 0.1980 | 0.1893 | 0.2798 | 0.7202 | 54775 | 6748 | 3064 | 2975 | 0.1603 |
| 0.5444 | 2.0 | 2914 | 0.4496 | 0.1799 | 0.1740 | 0.2619 | 0.7381 | 55175 | 6480 | 2932 | 2207 | 0.1400 |
| 0.4975 | 3.0 | 4371 | 0.4451 | 0.1773 | 0.1713 | 0.2586 | 0.7414 | 55399 | 6429 | 2759 | 2266 | 0.1397 |
| 0.4312 | 4.0 | 5828 | 0.4417 | 0.1758 | 0.1701 | 0.2572 | 0.7428 | 55408 | 6407 | 2772 | 2178 | 0.1378 |
| 0.3846 | 5.0 | 7285 | 0.4445 | 0.1753 | 0.1696 | 0.2573 | 0.7427 | 55409 | 6453 | 2725 | 2142 | 0.1367 |
| 0.3501 | 6.0 | 8742 | 0.4482 | 0.1792 | 0.1727 | 0.2609 | 0.7391 | 55453 | 6522 | 2612 | 2439 | 0.1401 |
| 0.381 | 7.0 | 10199 | 0.4531 | 0.1770 | 0.1711 | 0.2592 | 0.7408 | 55380 | 6498 | 2709 | 2223 | 0.1378 |
| 0.313 | 8.0 | 11656 | 0.4585 | 0.1775 | 0.1716 | 0.2599 | 0.7401 | 55371 | 6516 | 2700 | 2250 | 0.1383 |
| 0.2976 | 9.0 | 13113 | 0.4646 | 0.1778 | 0.1717 | 0.2603 | 0.7397 | 55387 | 6537 | 2663 | 2284 | 0.1402 |
| 0.3152 | 10.0 | 14570 | 0.4666 | 0.1780 | 0.1718 | 0.2607 | 0.7393 | 55410 | 6566 | 2611 | 2321 | 0.1388 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-0front-1body-6rear
|
Padomin
| 2022-09-13T11:59:57Z | 30 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-13T02:30:38Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-6rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-6rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4688
- Wer: 0.1755
- Mer: 0.1695
- Wil: 0.2577
- Wip: 0.7423
- Hits: 55504
- Substitutions: 6505
- Deletions: 2578
- Insertions: 2249
- Cer: 0.1373
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6426 | 1.0 | 1457 | 0.4936 | 0.2128 | 0.2007 | 0.2903 | 0.7097 | 54742 | 6734 | 3111 | 3899 | 0.1791 |
| 0.5519 | 2.0 | 2914 | 0.4535 | 0.1970 | 0.1876 | 0.2747 | 0.7253 | 55096 | 6467 | 3024 | 3233 | 0.1567 |
| 0.5007 | 3.0 | 4371 | 0.4465 | 0.1819 | 0.1751 | 0.2628 | 0.7372 | 55359 | 6481 | 2747 | 2522 | 0.1435 |
| 0.4374 | 4.0 | 5828 | 0.4417 | 0.1761 | 0.1703 | 0.2582 | 0.7418 | 55399 | 6471 | 2717 | 2184 | 0.1373 |
| 0.3831 | 5.0 | 7285 | 0.4459 | 0.1755 | 0.1697 | 0.2570 | 0.7430 | 55465 | 6429 | 2693 | 2214 | 0.1383 |
| 0.352 | 6.0 | 8742 | 0.4496 | 0.1755 | 0.1697 | 0.2573 | 0.7427 | 55452 | 6450 | 2685 | 2202 | 0.1374 |
| 0.3955 | 7.0 | 10199 | 0.4527 | 0.1766 | 0.1707 | 0.2580 | 0.7420 | 55429 | 6429 | 2729 | 2251 | 0.1392 |
| 0.3132 | 8.0 | 11656 | 0.4629 | 0.1764 | 0.1703 | 0.2580 | 0.7420 | 55522 | 6472 | 2593 | 2329 | 0.1380 |
| 0.3116 | 9.0 | 13113 | 0.4652 | 0.1755 | 0.1695 | 0.2577 | 0.7423 | 55517 | 6505 | 2565 | 2264 | 0.1371 |
| 0.313 | 10.0 | 14570 | 0.4688 | 0.1755 | 0.1695 | 0.2577 | 0.7423 | 55504 | 6505 | 2578 | 2249 | 0.1373 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
IIIT-L/hing-mbert-finetuned-TRAC-DS
|
IIIT-L
| 2022-09-13T11:50:24Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T11:15:49Z |
---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-mbert-finetuned-TRAC-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-mbert-finetuned-TRAC-DS
This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3580
- Accuracy: 0.7018
- Precision: 0.6759
- Recall: 0.6722
- F1: 0.6737
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.824279936868144e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7111 | 2.0 | 1224 | 0.7772 | 0.6683 | 0.6695 | 0.6793 | 0.6558 |
| 0.3026 | 3.99 | 2448 | 1.3580 | 0.7018 | 0.6759 | 0.6722 | 0.6737 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
sd-concepts-library/zaney
|
sd-concepts-library
| 2022-09-13T10:39:57Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T10:39:54Z |
---
license: mit
---
### zaney on Stable Diffusion
This is the `<zaney>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









|
SetFit/MiniLM_L3_clinc_oos_plus_distilled
|
SetFit
| 2022-09-13T10:39:03Z | 5 | 5 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-09-13T10:38:58Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# SetFit/MiniLM_L3_clinc_oos_plus_distilled
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('SetFit/MiniLM_L3_clinc_oos_plus_distilled')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('SetFit/MiniLM_L3_clinc_oos_plus_distilled')
model = AutoModel.from_pretrained('SetFit/MiniLM_L3_clinc_oos_plus_distilled')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=SetFit/MiniLM_L3_clinc_oos_plus_distilled)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 190625 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
sd-concepts-library/bada-club
|
sd-concepts-library
| 2022-09-13T09:35:45Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T09:35:32Z |
---
license: mit
---
### bada club on Stable Diffusion
This is the `<bada-club>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
sd-concepts-library/dullboy-caricature
|
sd-concepts-library
| 2022-09-13T08:14:36Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T08:14:29Z |
---
license: mit
---
### Dullboy Caricature on Stable Diffusion
This is the `<dullboy-cari>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
Sebabrata/lmv2-g-passport-197-doc-09-13
|
Sebabrata
| 2022-09-13T04:54:38Z | 90 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-13T04:10:33Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
model-index:
- name: lmv2-g-passport-197-doc-09-13
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lmv2-g-passport-197-doc-09-13
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0438
- Country Code Precision: 0.9412
- Country Code Recall: 0.9697
- Country Code F1: 0.9552
- Country Code Number: 33
- Date Of Birth Precision: 0.9714
- Date Of Birth Recall: 1.0
- Date Of Birth F1: 0.9855
- Date Of Birth Number: 34
- Date Of Expiry Precision: 1.0
- Date Of Expiry Recall: 1.0
- Date Of Expiry F1: 1.0
- Date Of Expiry Number: 36
- Date Of Issue Precision: 1.0
- Date Of Issue Recall: 1.0
- Date Of Issue F1: 1.0
- Date Of Issue Number: 36
- Given Name Precision: 0.9444
- Given Name Recall: 1.0
- Given Name F1: 0.9714
- Given Name Number: 34
- Nationality Precision: 0.9714
- Nationality Recall: 1.0
- Nationality F1: 0.9855
- Nationality Number: 34
- Passport No Precision: 0.9118
- Passport No Recall: 0.9688
- Passport No F1: 0.9394
- Passport No Number: 32
- Place Of Birth Precision: 1.0
- Place Of Birth Recall: 0.9730
- Place Of Birth F1: 0.9863
- Place Of Birth Number: 37
- Place Of Issue Precision: 1.0
- Place Of Issue Recall: 0.9722
- Place Of Issue F1: 0.9859
- Place Of Issue Number: 36
- Sex Precision: 0.9655
- Sex Recall: 0.9333
- Sex F1: 0.9492
- Sex Number: 30
- Surname Precision: 0.9259
- Surname Recall: 1.0
- Surname F1: 0.9615
- Surname Number: 25
- Type Precision: 1.0
- Type Recall: 1.0
- Type F1: 1.0
- Type Number: 27
- Overall Precision: 0.97
- Overall Recall: 0.9848
- Overall F1: 0.9773
- Overall Accuracy: 0.9941
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Country Code Precision | Country Code Recall | Country Code F1 | Country Code Number | Date Of Birth Precision | Date Of Birth Recall | Date Of Birth F1 | Date Of Birth Number | Date Of Expiry Precision | Date Of Expiry Recall | Date Of Expiry F1 | Date Of Expiry Number | Date Of Issue Precision | Date Of Issue Recall | Date Of Issue F1 | Date Of Issue Number | Given Name Precision | Given Name Recall | Given Name F1 | Given Name Number | Nationality Precision | Nationality Recall | Nationality F1 | Nationality Number | Passport No Precision | Passport No Recall | Passport No F1 | Passport No Number | Place Of Birth Precision | Place Of Birth Recall | Place Of Birth F1 | Place Of Birth Number | Place Of Issue Precision | Place Of Issue Recall | Place Of Issue F1 | Place Of Issue Number | Sex Precision | Sex Recall | Sex F1 | Sex Number | Surname Precision | Surname Recall | Surname F1 | Surname Number | Type Precision | Type Recall | Type F1 | Type Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------------------:|:-------------------:|:---------------:|:-------------------:|:-----------------------:|:--------------------:|:----------------:|:--------------------:|:------------------------:|:---------------------:|:-----------------:|:---------------------:|:-----------------------:|:--------------------:|:----------------:|:--------------------:|:--------------------:|:-----------------:|:-------------:|:-----------------:|:---------------------:|:------------------:|:--------------:|:------------------:|:---------------------:|:------------------:|:--------------:|:------------------:|:------------------------:|:---------------------:|:-----------------:|:---------------------:|:------------------------:|:---------------------:|:-----------------:|:---------------------:|:-------------:|:----------:|:------:|:----------:|:-----------------:|:--------------:|:----------:|:--------------:|:--------------:|:-----------:|:-------:|:-----------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 1.6757 | 1.0 | 157 | 1.2569 | 0.0 | 0.0 | 0.0 | 33 | 0.0 | 0.0 | 0.0 | 34 | 0.2466 | 1.0 | 0.3956 | 36 | 0.0 | 0.0 | 0.0 | 36 | 0.0 | 0.0 | 0.0 | 34 | 0.0 | 0.0 | 0.0 | 34 | 0.0 | 0.0 | 0.0 | 32 | 0.0 | 0.0 | 0.0 | 37 | 0.0 | 0.0 | 0.0 | 36 | 0.0 | 0.0 | 0.0 | 30 | 0.0 | 0.0 | 0.0 | 25 | 0.0 | 0.0 | 0.0 | 27 | 0.2466 | 0.0914 | 0.1333 | 0.8446 |
| 0.9214 | 2.0 | 314 | 0.5683 | 0.9394 | 0.9394 | 0.9394 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.5625 | 0.5294 | 0.5455 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.6098 | 0.7812 | 0.6849 | 32 | 0.9394 | 0.8378 | 0.8857 | 37 | 0.8293 | 0.9444 | 0.8831 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.6129 | 0.76 | 0.6786 | 25 | 1.0 | 0.8889 | 0.9412 | 27 | 0.8642 | 0.8883 | 0.8761 | 0.9777 |
| 0.4452 | 3.0 | 471 | 0.3266 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.5556 | 0.4412 | 0.4918 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.625 | 0.7812 | 0.6944 | 32 | 1.0 | 0.8108 | 0.8955 | 37 | 0.7556 | 0.9444 | 0.8395 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.5556 | 0.8 | 0.6557 | 25 | 1.0 | 0.7037 | 0.8261 | 27 | 0.8532 | 0.8706 | 0.8618 | 0.9784 |
| 0.2823 | 4.0 | 628 | 0.2215 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.75 | 0.8824 | 0.8108 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.8378 | 0.9118 | 37 | 0.9459 | 0.9722 | 0.9589 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.75 | 0.96 | 0.8421 | 25 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9286 | 0.9569 | 0.9425 | 0.9885 |
| 0.2092 | 5.0 | 785 | 0.1633 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.8889 | 0.9412 | 0.9143 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.8857 | 0.9688 | 0.9254 | 32 | 1.0 | 0.8649 | 0.9275 | 37 | 0.8974 | 0.9722 | 0.9333 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.8889 | 0.96 | 0.9231 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9525 | 0.9670 | 0.9597 | 0.9918 |
| 0.1593 | 6.0 | 942 | 0.1331 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 0.9730 | 1.0 | 0.9863 | 36 | 0.8857 | 0.9118 | 0.8986 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9722 | 0.9459 | 0.9589 | 37 | 0.9722 | 0.9722 | 0.9722 | 36 | 1.0 | 0.9 | 0.9474 | 30 | 0.8571 | 0.96 | 0.9057 | 25 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9549 | 0.9670 | 0.9609 | 0.9908 |
| 0.1288 | 7.0 | 1099 | 0.1064 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9444 | 1.0 | 0.9714 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.92 | 0.92 | 0.92 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9723 | 0.9797 | 0.9760 | 0.9941 |
| 0.1035 | 8.0 | 1256 | 0.1043 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9706 | 0.9706 | 0.9706 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9231 | 0.9730 | 0.9474 | 37 | 0.75 | 1.0 | 0.8571 | 36 | 0.9032 | 0.9333 | 0.9180 | 30 | 0.6486 | 0.96 | 0.7742 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9085 | 0.9822 | 0.9439 | 0.9856 |
| 0.0843 | 9.0 | 1413 | 0.0823 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9143 | 0.9412 | 0.9275 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9394 | 0.9688 | 0.9538 | 32 | 0.9032 | 0.7568 | 0.8235 | 37 | 0.9211 | 0.9722 | 0.9459 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.7059 | 0.96 | 0.8136 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9355 | 0.9569 | 0.9460 | 0.9905 |
| 0.0733 | 10.0 | 1570 | 0.0738 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9459 | 0.9459 | 0.9459 | 37 | 1.0 | 0.9444 | 0.9714 | 36 | 0.8485 | 0.9333 | 0.8889 | 30 | 0.8333 | 1.0 | 0.9091 | 25 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9484 | 0.9797 | 0.9638 | 0.9911 |
| 0.0614 | 11.0 | 1727 | 0.0661 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9459 | 0.9459 | 0.9459 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.9231 | 0.96 | 0.9412 | 25 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9673 | 0.9772 | 0.9722 | 0.9934 |
| 0.0548 | 12.0 | 1884 | 0.0637 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 0.9730 | 1.0 | 0.9863 | 36 | 0.9167 | 0.9706 | 0.9429 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9459 | 0.9459 | 0.9459 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.875 | 0.9333 | 0.9032 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9507 | 0.9797 | 0.965 | 0.9921 |
| 0.0515 | 13.0 | 2041 | 0.0562 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9730 | 0.9730 | 0.9730 | 37 | 1.0 | 1.0 | 1.0 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.8621 | 1.0 | 0.9259 | 25 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9605 | 0.9873 | 0.9737 | 0.9931 |
| 0.0431 | 14.0 | 2198 | 0.0513 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9444 | 1.0 | 0.9714 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.9231 | 0.96 | 0.9412 | 25 | 1.0 | 0.9630 | 0.9811 | 27 | 0.9724 | 0.9822 | 0.9773 | 0.9944 |
| 0.0413 | 15.0 | 2355 | 0.0582 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9706 | 0.9706 | 0.9706 | 34 | 0.9730 | 1.0 | 0.9863 | 36 | 0.9730 | 1.0 | 0.9863 | 36 | 0.9429 | 0.9706 | 0.9565 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 1.0 | 1.0 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.8929 | 1.0 | 0.9434 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9627 | 0.9822 | 0.9724 | 0.9934 |
| 0.035 | 16.0 | 2512 | 0.0556 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 0.9722 | 0.9859 | 36 | 0.8857 | 0.9118 | 0.8986 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9730 | 0.9730 | 0.9730 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.8621 | 1.0 | 0.9259 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9552 | 0.9746 | 0.9648 | 0.9915 |
| 0.0316 | 17.0 | 2669 | 0.0517 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9167 | 0.9706 | 0.9429 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.875 | 0.9333 | 0.9032 | 30 | 0.8929 | 1.0 | 0.9434 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9579 | 0.9822 | 0.9699 | 0.9928 |
| 0.027 | 18.0 | 2826 | 0.0502 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9730 | 1.0 | 0.9863 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9444 | 1.0 | 0.9714 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9032 | 0.9333 | 0.9180 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9628 | 0.9848 | 0.9737 | 0.9931 |
| 0.026 | 19.0 | 2983 | 0.0481 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9189 | 1.0 | 0.9577 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 1.0 | 1.0 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.8333 | 1.0 | 0.9091 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9581 | 0.9873 | 0.9725 | 0.9928 |
| 0.026 | 20.0 | 3140 | 0.0652 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9730 | 1.0 | 0.9863 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.8611 | 0.9688 | 0.9118 | 32 | 0.9730 | 0.9730 | 0.9730 | 37 | 0.9730 | 1.0 | 0.9863 | 36 | 0.8235 | 0.9333 | 0.8750 | 30 | 0.8333 | 1.0 | 0.9091 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9419 | 0.9873 | 0.9641 | 0.9882 |
| 0.0311 | 21.0 | 3297 | 0.0438 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9444 | 1.0 | 0.9714 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.97 | 0.9848 | 0.9773 | 0.9941 |
| 0.0216 | 22.0 | 3454 | 0.0454 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9706 | 0.9706 | 0.9706 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9699 | 0.9822 | 0.9760 | 0.9941 |
| 0.0196 | 23.0 | 3611 | 0.0510 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.8718 | 0.9189 | 0.8947 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9655 | 0.9333 | 0.9492 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9602 | 0.9797 | 0.9698 | 0.9934 |
| 0.0176 | 24.0 | 3768 | 0.0457 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9706 | 0.9706 | 0.9706 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 1.0 | 1.0 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.8929 | 1.0 | 0.9434 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9676 | 0.9848 | 0.9761 | 0.9938 |
| 0.0141 | 25.0 | 3925 | 0.0516 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9722 | 0.9459 | 0.9589 | 37 | 0.9730 | 1.0 | 0.9863 | 36 | 0.875 | 0.9333 | 0.9032 | 30 | 0.9231 | 0.96 | 0.9412 | 25 | 0.9643 | 1.0 | 0.9818 | 27 | 0.9579 | 0.9822 | 0.9699 | 0.9928 |
| 0.0129 | 26.0 | 4082 | 0.0508 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9730 | 1.0 | 0.9863 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 1.0 | 1.0 | 36 | 0.875 | 0.9333 | 0.9032 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9629 | 0.9873 | 0.9749 | 0.9934 |
| 0.0125 | 27.0 | 4239 | 0.0455 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.9259 | 1.0 | 0.9615 | 25 | 0.8710 | 1.0 | 0.9310 | 27 | 0.9652 | 0.9848 | 0.9749 | 0.9934 |
| 0.0131 | 28.0 | 4396 | 0.0452 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 0.9722 | 0.9859 | 36 | 0.9429 | 0.9706 | 0.9565 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 1.0 | 0.9730 | 0.9863 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.9231 | 0.96 | 0.9412 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9722 | 0.9772 | 0.9747 | 0.9941 |
| 0.0112 | 29.0 | 4553 | 0.0465 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9459 | 0.9459 | 0.9459 | 37 | 0.9722 | 0.9722 | 0.9722 | 36 | 0.9333 | 0.9333 | 0.9333 | 30 | 0.9583 | 0.92 | 0.9388 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9649 | 0.9772 | 0.9710 | 0.9931 |
| 0.0152 | 30.0 | 4710 | 0.0510 | 0.9412 | 0.9697 | 0.9552 | 33 | 0.9714 | 1.0 | 0.9855 | 34 | 1.0 | 1.0 | 1.0 | 36 | 1.0 | 1.0 | 1.0 | 36 | 0.8857 | 0.9118 | 0.8986 | 34 | 0.9714 | 1.0 | 0.9855 | 34 | 0.9118 | 0.9688 | 0.9394 | 32 | 0.9730 | 0.9730 | 0.9730 | 37 | 1.0 | 0.9722 | 0.9859 | 36 | 1.0 | 0.9333 | 0.9655 | 30 | 0.9231 | 0.96 | 0.9412 | 25 | 1.0 | 1.0 | 1.0 | 27 | 0.9648 | 0.9746 | 0.9697 | 0.9931 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-0front-1body-8rear
|
Padomin
| 2022-09-13T04:49:39Z | 24 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T18:14:02Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-8rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-8rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4672
- Wer: 0.1759
- Mer: 0.1698
- Wil: 0.2574
- Wip: 0.7426
- Hits: 55537
- Substitutions: 6457
- Deletions: 2593
- Insertions: 2312
- Cer: 0.1383
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6417 | 1.0 | 1457 | 0.4928 | 0.2086 | 0.1973 | 0.2873 | 0.7127 | 54805 | 6751 | 3031 | 3693 | 0.1746 |
| 0.5435 | 2.0 | 2914 | 0.4511 | 0.1814 | 0.1751 | 0.2634 | 0.7366 | 55192 | 6518 | 2877 | 2322 | 0.1452 |
| 0.4914 | 3.0 | 4371 | 0.4424 | 0.1762 | 0.1704 | 0.2572 | 0.7428 | 55389 | 6383 | 2815 | 2180 | 0.1390 |
| 0.427 | 4.0 | 5828 | 0.4388 | 0.1751 | 0.1695 | 0.2569 | 0.7431 | 55408 | 6431 | 2748 | 2129 | 0.1366 |
| 0.3762 | 5.0 | 7285 | 0.4465 | 0.1747 | 0.1689 | 0.2561 | 0.7439 | 55533 | 6424 | 2630 | 2230 | 0.1361 |
| 0.3562 | 6.0 | 8742 | 0.4505 | 0.1761 | 0.1700 | 0.2581 | 0.7419 | 55558 | 6507 | 2522 | 2348 | 0.1402 |
| 0.3884 | 7.0 | 10199 | 0.4550 | 0.1750 | 0.1691 | 0.2564 | 0.7436 | 55548 | 6439 | 2600 | 2264 | 0.1364 |
| 0.3144 | 8.0 | 11656 | 0.4616 | 0.1760 | 0.1698 | 0.2572 | 0.7428 | 55571 | 6447 | 2569 | 2352 | 0.1373 |
| 0.3075 | 9.0 | 13113 | 0.4660 | 0.1761 | 0.1700 | 0.2572 | 0.7428 | 55547 | 6431 | 2609 | 2336 | 0.1400 |
| 0.3152 | 10.0 | 14570 | 0.4672 | 0.1759 | 0.1698 | 0.2574 | 0.7426 | 55537 | 6457 | 2593 | 2312 | 0.1383 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-0front-1body-9rear
|
Padomin
| 2022-09-13T04:02:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T16:56:47Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-9rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-9rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4673
- Wer: 0.1766
- Mer: 0.1707
- Wil: 0.2594
- Wip: 0.7406
- Hits: 55410
- Substitutions: 6552
- Deletions: 2625
- Insertions: 2229
- Cer: 0.1386
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.641 | 1.0 | 1457 | 0.4913 | 0.2084 | 0.1972 | 0.2875 | 0.7125 | 54788 | 6785 | 3014 | 3658 | 0.1743 |
| 0.5415 | 2.0 | 2914 | 0.4483 | 0.1818 | 0.1759 | 0.2643 | 0.7357 | 55033 | 6514 | 3040 | 2190 | 0.1447 |
| 0.4835 | 3.0 | 4371 | 0.4427 | 0.1785 | 0.1722 | 0.2595 | 0.7405 | 55442 | 6443 | 2702 | 2386 | 0.1402 |
| 0.4267 | 4.0 | 5828 | 0.4376 | 0.1769 | 0.1711 | 0.2587 | 0.7413 | 55339 | 6446 | 2802 | 2177 | 0.1399 |
| 0.3752 | 5.0 | 7285 | 0.4414 | 0.1756 | 0.1698 | 0.2571 | 0.7429 | 55467 | 6432 | 2688 | 2223 | 0.1374 |
| 0.3471 | 6.0 | 8742 | 0.4497 | 0.1761 | 0.1704 | 0.2585 | 0.7415 | 55379 | 6494 | 2714 | 2166 | 0.1380 |
| 0.3841 | 7.0 | 10199 | 0.4535 | 0.1769 | 0.1710 | 0.2589 | 0.7411 | 55383 | 6482 | 2722 | 2220 | 0.1394 |
| 0.3139 | 8.0 | 11656 | 0.4604 | 0.1753 | 0.1696 | 0.2577 | 0.7423 | 55462 | 6502 | 2623 | 2199 | 0.1367 |
| 0.3012 | 9.0 | 13113 | 0.4628 | 0.1766 | 0.1708 | 0.2597 | 0.7403 | 55391 | 6571 | 2625 | 2210 | 0.1388 |
| 0.3087 | 10.0 | 14570 | 0.4673 | 0.1766 | 0.1707 | 0.2594 | 0.7406 | 55410 | 6552 | 2625 | 2229 | 0.1386 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/tubby
|
sd-concepts-library
| 2022-09-13T03:01:07Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T03:01:00Z |
---
license: mit
---
### tubby on Stable Diffusion
This is the `<tubby>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
sd-concepts-library/irasutoya
|
sd-concepts-library
| 2022-09-13T02:20:17Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T02:20:14Z |
---
license: mit
---
### irasutoya on Stable Diffusion
This is the `<irasutoya>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
sd-concepts-library/bad_Hub_Hugh
|
sd-concepts-library
| 2022-09-13T02:13:39Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T02:13:33Z |
---
license: mit
---
### Hub Hugh on Stable Diffusion
This is the `<HubHugh>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
sd-concepts-library/zoroark
|
sd-concepts-library
| 2022-09-13T01:42:13Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T01:42:00Z |
---
license: mit
---
### zoroark on Stable Diffusion
This is the `<zoroark>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/centaur
|
sd-concepts-library
| 2022-09-13T01:41:40Z | 0 | 3 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T01:41:35Z |
---
license: mit
---
### Centaur on Stable Diffusion
This is the `<centaur>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/illustration-style
|
sd-concepts-library
| 2022-09-13T01:38:47Z | 0 | 25 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T01:38:43Z |
---
license: mit
---
### Illustration style on Stable Diffusion
This is the `<illustration-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
sd-concepts-library/ggplot2
|
sd-concepts-library
| 2022-09-13T00:00:14Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-13T00:00:10Z |
---
license: mit
---
### ggplot2 on Stable Diffusion
This is the `<ggplot2>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
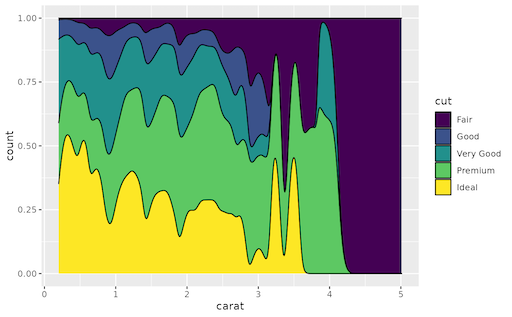
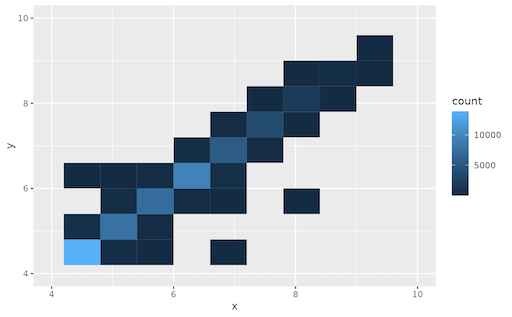
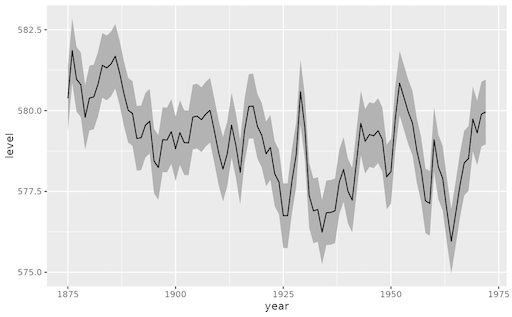
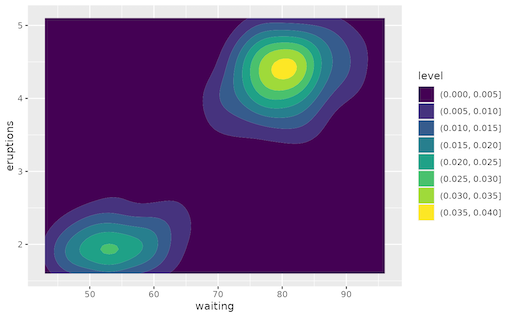
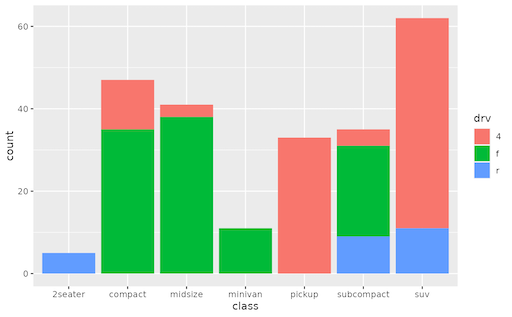
Here is the new concept you will be able to use as a `style`:
|
sd-concepts-library/metagabe
|
sd-concepts-library
| 2022-09-12T23:56:54Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T23:56:50Z |
---
license: mit
---
### metagabe on Stable Diffusion
This is the `<metagabe>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
YilinWang42/autotrain-trial-run-1444253725
|
YilinWang42
| 2022-09-12T23:54:52Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"token-classification",
"unk",
"dataset:YilinWang42/autotrain-data-trial-run",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-12T23:53:31Z |
---
tags:
- autotrain
- token-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- YilinWang42/autotrain-data-trial-run
co2_eq_emissions:
emissions: 0.00977392698077684
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 1444253725
- CO2 Emissions (in grams): 0.0098
## Validation Metrics
- Loss: 0.082
- Accuracy: 0.980
- Precision: 0.743
- Recall: 0.778
- F1: 0.760
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/YilinWang42/autotrain-trial-run-1444253725
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("YilinWang42/autotrain-trial-run-1444253725", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("YilinWang42/autotrain-trial-run-1444253725", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Padomin/t5-base-TEDxJP-9front-1body-0rear
|
Padomin
| 2022-09-12T21:46:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T10:24:05Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-9front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-9front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4576
- Wer: 0.1728
- Mer: 0.1669
- Wil: 0.2543
- Wip: 0.7457
- Hits: 55705
- Substitutions: 6444
- Deletions: 2438
- Insertions: 2281
- Cer: 0.1351
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.649 | 1.0 | 1457 | 0.4844 | 0.2290 | 0.2126 | 0.3015 | 0.6985 | 54758 | 6748 | 3081 | 4959 | 0.2080 |
| 0.5319 | 2.0 | 2914 | 0.4385 | 0.1804 | 0.1741 | 0.2614 | 0.7386 | 55298 | 6437 | 2852 | 2364 | 0.1465 |
| 0.4819 | 3.0 | 4371 | 0.4338 | 0.1760 | 0.1698 | 0.2569 | 0.7431 | 55558 | 6419 | 2610 | 2336 | 0.1389 |
| 0.4307 | 4.0 | 5828 | 0.4328 | 0.1759 | 0.1696 | 0.2569 | 0.7431 | 55649 | 6454 | 2484 | 2424 | 0.1390 |
| 0.3735 | 5.0 | 7285 | 0.4331 | 0.1740 | 0.1680 | 0.2549 | 0.7451 | 55652 | 6398 | 2537 | 2306 | 0.1367 |
| 0.3495 | 6.0 | 8742 | 0.4380 | 0.1740 | 0.1681 | 0.2552 | 0.7448 | 55619 | 6420 | 2548 | 2267 | 0.1356 |
| 0.3679 | 7.0 | 10199 | 0.4437 | 0.1741 | 0.1682 | 0.2556 | 0.7444 | 55621 | 6441 | 2525 | 2281 | 0.1354 |
| 0.3035 | 8.0 | 11656 | 0.4494 | 0.1727 | 0.1669 | 0.2542 | 0.7458 | 55672 | 6433 | 2482 | 2237 | 0.1350 |
| 0.3041 | 9.0 | 13113 | 0.4541 | 0.1736 | 0.1677 | 0.2550 | 0.7450 | 55674 | 6441 | 2472 | 2302 | 0.1383 |
| 0.2948 | 10.0 | 14570 | 0.4576 | 0.1728 | 0.1669 | 0.2543 | 0.7457 | 55705 | 6444 | 2438 | 2281 | 0.1351 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/type
|
sd-concepts-library
| 2022-09-12T21:18:54Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T21:18:51Z |
---
license: mit
---
### type on Stable Diffusion
This is the `<typeface>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/doge-pound
|
sd-concepts-library
| 2022-09-12T21:08:14Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T21:08:03Z |
---
license: mit
---
### Doge Pound on Stable Diffusion
This is the `<doge-pound>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
sd-concepts-library/alien-avatar
|
sd-concepts-library
| 2022-09-12T20:47:15Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T20:47:10Z |
---
license: mit
---
### alien avatar on Stable Diffusion
This is the `<alien-avatar>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/dragonborn
|
sd-concepts-library
| 2022-09-12T20:22:04Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T20:21:58Z |
---
license: mit
---
### Dragonborn on Stable Diffusion
This is the `<dragonborn>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
waltwang441/ddpm-butterflies-128
|
waltwang441
| 2022-09-12T20:10:52Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-09-12T19:03:43Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/waltwang441/ddpm-butterflies-128/tensorboard?#scalars)
|
sd-concepts-library/xatu2
|
sd-concepts-library
| 2022-09-12T19:11:15Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T19:11:08Z |
---
license: mit
---
### xatu2 on Stable Diffusion
This is the `<xatu-test>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:

























































































|
iqbalc/stt_de_conformer_transducer_large
|
iqbalc
| 2022-09-12T18:26:26Z | 3 | 0 |
nemo
|
[
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"CTC",
"Conformer",
"Transformer",
"NeMo",
"pytorch",
"de",
"license:cc-by-4.0",
"model-index",
"region:us"
] |
automatic-speech-recognition
| 2022-09-12T17:19:29Z |
---
language:
- de
license: cc-by-4.0
library_name: nemo
datasets:
- mozilla-foundation/common_voice_7_0
- Multilingual LibriSpeech (2000 hours)
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- CTC
- Conformer
- Transformer
- NeMo
- pytorch
model-index:
- name: stt_de_conformer_transducer_large
results:
- task:
type: automatic-speech-recognition
dataset:
type: common_voice_7_0
name: mozilla-foundation/common_voice_7_0
config: other
split: test
args:
lageangu: de
metrics:
- type: wer
value: 4.93
name: WER
---
## Model Overview
<DESCRIBE IN ONE LINE THE MODEL AND ITS USE>
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained("iqbalc/stt_de_conformer_transducer_large")
```
### Transcribing using Python
```
asr_model.transcribe(['filename.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py pretrained_name="iqbalc/stt_de_conformer_transducer_large" audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 KHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model for Automatic Speech Recognition which uses Transducer loss/decoding
## Training
The NeMo toolkit was used for training the models. These models are fine-tuned with this example script and this base config.
The tokenizers for these models were built using the text transcripts of the train set with this script.
### Datasets
All the models in this collection are trained on a composite dataset comprising of over two thousand hours of cleaned German speech:
1. MCV7.0 567 hours
2. MLS 1524 hours
3. VoxPopuli 214 hours
## Performance
Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
MCV7.0 test = 4.93
## Limitations
The model might perform worse for accented speech
## References
[NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
Padomin/t5-base-TEDxJP-4front-1body-0rear
|
Padomin
| 2022-09-12T18:11:13Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T09:08:31Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-4front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-4front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4643
- Wer: 0.1751
- Mer: 0.1690
- Wil: 0.2562
- Wip: 0.7438
- Hits: 55598
- Substitutions: 6434
- Deletions: 2555
- Insertions: 2317
- Cer: 0.1374
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6492 | 1.0 | 1457 | 0.4952 | 0.2272 | 0.2114 | 0.3015 | 0.6985 | 54739 | 6847 | 3001 | 4827 | 0.2013 |
| 0.5556 | 2.0 | 2914 | 0.4456 | 0.1899 | 0.1818 | 0.2686 | 0.7314 | 55189 | 6420 | 2978 | 2864 | 0.1558 |
| 0.4942 | 3.0 | 4371 | 0.4423 | 0.1814 | 0.1743 | 0.2614 | 0.7386 | 55493 | 6437 | 2657 | 2623 | 0.1457 |
| 0.4326 | 4.0 | 5828 | 0.4361 | 0.1749 | 0.1690 | 0.2561 | 0.7439 | 55542 | 6419 | 2626 | 2249 | 0.1362 |
| 0.3867 | 5.0 | 7285 | 0.4395 | 0.1752 | 0.1692 | 0.2559 | 0.7441 | 55542 | 6378 | 2667 | 2270 | 0.1374 |
| 0.3501 | 6.0 | 8742 | 0.4487 | 0.1751 | 0.1691 | 0.2565 | 0.7435 | 55598 | 6448 | 2541 | 2323 | 0.1366 |
| 0.3835 | 7.0 | 10199 | 0.4494 | 0.1744 | 0.1685 | 0.2556 | 0.7444 | 55594 | 6416 | 2577 | 2274 | 0.1378 |
| 0.3013 | 8.0 | 11656 | 0.4580 | 0.1744 | 0.1685 | 0.2563 | 0.7437 | 55570 | 6467 | 2550 | 2248 | 0.1366 |
| 0.3126 | 9.0 | 13113 | 0.4598 | 0.1749 | 0.1689 | 0.2564 | 0.7436 | 55571 | 6447 | 2569 | 2281 | 0.1376 |
| 0.3089 | 10.0 | 14570 | 0.4643 | 0.1751 | 0.1690 | 0.2562 | 0.7438 | 55598 | 6434 | 2555 | 2317 | 0.1374 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
vedantam/distilbert-base-uncased-finetuned-emotion
|
vedantam
| 2022-09-12T18:00:26Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-12T17:06:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9255
- name: F1
type: f1
value: 0.9255338486363142
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2208
- Accuracy: 0.9255
- F1: 0.9255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8403 | 1.0 | 250 | 0.3183 | 0.91 | 0.9078 |
| 0.2569 | 2.0 | 500 | 0.2208 | 0.9255 | 0.9255 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.0.0
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-2front-1body-0rear
|
Padomin
| 2022-09-12T16:49:45Z | 34 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T09:08:24Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-2front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-2front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4717
- Wer: 0.1762
- Mer: 0.1701
- Wil: 0.2575
- Wip: 0.7425
- Hits: 55549
- Substitutions: 6453
- Deletions: 2585
- Insertions: 2345
- Cer: 0.1398
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6666 | 1.0 | 1457 | 0.5030 | 0.2075 | 0.1970 | 0.2883 | 0.7117 | 54622 | 6855 | 3110 | 3434 | 0.1720 |
| 0.567 | 2.0 | 2914 | 0.4611 | 0.1950 | 0.1859 | 0.2750 | 0.7250 | 55142 | 6648 | 2797 | 3148 | 0.1598 |
| 0.5029 | 3.0 | 4371 | 0.4463 | 0.1832 | 0.1762 | 0.2640 | 0.7360 | 55317 | 6492 | 2778 | 2564 | 0.1445 |
| 0.443 | 4.0 | 5828 | 0.4452 | 0.1791 | 0.1728 | 0.2606 | 0.7394 | 55375 | 6482 | 2730 | 2354 | 0.1408 |
| 0.3979 | 5.0 | 7285 | 0.4473 | 0.1782 | 0.1719 | 0.2592 | 0.7408 | 55434 | 6438 | 2715 | 2355 | 0.1400 |
| 0.3745 | 6.0 | 8742 | 0.4521 | 0.1757 | 0.1698 | 0.2573 | 0.7427 | 55501 | 6450 | 2636 | 2264 | 0.1373 |
| 0.3889 | 7.0 | 10199 | 0.4572 | 0.1775 | 0.1713 | 0.2586 | 0.7414 | 55458 | 6438 | 2691 | 2334 | 0.1398 |
| 0.3247 | 8.0 | 11656 | 0.4650 | 0.1752 | 0.1693 | 0.2564 | 0.7436 | 55516 | 6409 | 2662 | 2245 | 0.1372 |
| 0.3207 | 9.0 | 13113 | 0.4693 | 0.1766 | 0.1703 | 0.2580 | 0.7420 | 55549 | 6474 | 2564 | 2367 | 0.1400 |
| 0.3264 | 10.0 | 14570 | 0.4717 | 0.1762 | 0.1701 | 0.2575 | 0.7425 | 55549 | 6453 | 2585 | 2345 | 0.1398 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
qalover/chinese-pert-large-open-domain-mrc
|
qalover
| 2022-09-12T15:36:56Z | 105 | 4 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"zh",
"license:gpl-3.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-05-28T09:31:16Z |
---
language:
- zh
license: gpl-3.0
---
## 基于 chinese-pert-large 训练的面向开放领域MRC 模型
使用中文MRC数据(cmrc2018, webqa与laisi的训练集)训练的chinese-pert-large模型
## 训练过程
使用了[UER-py](https://github.com/dbiir/UER-py/) 进行fine-tuned
加入了包括但不限于摘要、负采样、混淆等数据加强方法
并转换为Huggingface进行上传
| | CMRC 2018 Dev | DRCD Dev | SQuAD-Zen Dev (Answerable) | AVG |
| :-------: | :-----------: | :-------: | :------------------------: | :-------: |
| PERT-large | 74.4/89.8 | 90.3/94.| 62.8/78.8 | 75.9/87.8 |
|
sd-concepts-library/larrette
|
sd-concepts-library
| 2022-09-12T15:30:48Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T15:30:43Z |
---
license: mit
---
### Larrette on Stable Diffusion
This is the `<larrette>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
google/ncsnpp-ffhq-1024
|
google
| 2022-09-12T15:00:39Z | 152 | 11 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"arxiv:2011.13456",
"license:apache-2.0",
"diffusers:ScoreSdeVePipeline",
"region:us"
] |
unconditional-image-generation
| 2022-07-19T08:50:21Z |
---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Score-Based Generative Modeling through Stochastic Differential Equations (SDE)
**Paper**: [Score-Based Generative Modeling through Stochastic Differential Equations](https://arxiv.org/abs/2011.13456)
**Authors**: Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, Ben Poole
**Abstract**:
*Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.*
## Inference
*SDE* models can use **continuous** noise schedulers such as:
- [scheduling_sde_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_sde_ve.py)
for inference.
See the following code:
```python
# !pip install diffusers
from diffusers import DiffusionPipeline
model_id = "google/ncsnpp-ffhq-1024"
# load model and scheduler
sde_ve = DiffusionPipeline.from_pretrained(model_id)
# run pipeline in inference (sample random noise and denoise)
image = sde_ve()["sample"]
# save image
image[0].save("sde_ve_generated_image.png")
```
Please take a look at [pipeline_score_sde_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py)
for more details on how to write your own denoising loop.
For more information generally on how to use `diffusers` for inference, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Samples
1. <img src="https://huggingface.co/google/ncsnpp-ffhq-1024/resolve/main/images/generated_image_0.png" alt="drawing" width="512"/>
2. <img src="https://huggingface.co/google/ncsnpp-ffhq-1024/resolve/main/images/generated_image_1.png" alt="drawing" width="512"/>
3. <img src="https://huggingface.co/google/ncsnpp-ffhq-1024/resolve/main/images/generated_image_2.png" alt="drawing" width="512"/>
4. <img src="https://huggingface.co/google/ncsnpp-ffhq-1024/resolve/main/images/generated_image_3.png" alt="drawing" width="512"/>
|
1ucky40nc3/wav2vec2-large-xls-r-300m-turkish-colab
|
1ucky40nc3
| 2022-09-12T14:46:14Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-12T09:55:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4409
- Wer: 0.3676
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.9829 | 3.67 | 400 | 0.7245 | 0.7504 |
| 0.4544 | 7.34 | 800 | 0.4710 | 0.5193 |
| 0.2201 | 11.01 | 1200 | 0.4801 | 0.4815 |
| 0.1457 | 14.68 | 1600 | 0.4397 | 0.4324 |
| 0.1079 | 18.35 | 2000 | 0.4770 | 0.4287 |
| 0.0877 | 22.02 | 2400 | 0.4583 | 0.3813 |
| 0.0698 | 25.69 | 2800 | 0.4421 | 0.3892 |
| 0.0554 | 29.36 | 3200 | 0.4409 | 0.3676 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
sd-concepts-library/wlop-style
|
sd-concepts-library
| 2022-09-12T14:30:46Z | 0 | 41 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T14:30:33Z |
---
license: mit
---
### wlop-style on Stable Diffusion
This is the `<wlop-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








|
Vasanth/eng-hin-translator
|
Vasanth
| 2022-09-12T14:12:23Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-12T14:01:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: eng-hin-translator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-hin-translator
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-hi](https://huggingface.co/Helsinki-NLP/opus-mt-en-hi) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4143
- Bleu Score: 34.2532
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu Score |
|:-------------:|:-----:|:----:|:---------------:|:----------:|
| 1.7332 | 1.0 | 548 | 1.5131 | 31.6167 |
| 1.3588 | 2.0 | 1096 | 1.4463 | 33.0225 |
| 1.1651 | 3.0 | 1644 | 1.4209 | 34.0514 |
| 1.042 | 4.0 | 2192 | 1.4139 | 34.0137 |
| 0.9686 | 5.0 | 2740 | 1.4143 | 34.2532 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/mikako-methodi2i
|
sd-concepts-library
| 2022-09-12T13:48:40Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T06:17:47Z |
---
license: mit
---
### mikako-methodi2i on Stable Diffusion
This is the `<m-mi2i>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:

|
Jinchen/roberta-base-finetuned-wikitext2
|
Jinchen
| 2022-09-12T13:08:47Z | 168 | 0 |
transformers
|
[
"transformers",
"pytorch",
"optimum_graphcore",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-10T15:02:17Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wikitext2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5020
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- total_eval_batch_size: 20
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6689 | 1.0 | 300 | 1.5518 |
| 1.7525 | 2.0 | 600 | 1.5078 |
| 1.5267 | 3.0 | 900 | 1.4971 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.10.0+cpu
- Datasets 2.4.0
- Tokenizers 0.12.1
|
FrostAura/gpt-neo-1.3B-fiction-novel-generation
|
FrostAura
| 2022-09-12T12:50:56Z | 22 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"gpt_neo",
"text-generation",
"novel-generation",
"fiction",
"gpt-neo",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-20T13:31:36Z |
---
language:
- en
thumbnail: "https://github.com/faGH/fa.creative/blob/master/Icons/FrostAura/FA%20Logo/FrostAura.Logo.Complex.png?raw=true"
tags:
- text-generation
- novel-generation
- fiction
- gpt-neo
- pytorch
license: "mit"
---
<p align="center">
<img src="https://github.com/faGH/fa.creative/blob/master/Icons/FrostAura/FA%20Logo/FrostAura.Logo.Complex.png?raw=true" width="75" title="hover text">
</p>
# fa.intelligence.models.generative.novels.fiction
## Description
This FrostAura Intelligence model is a fine-tuned version of [EleutherAI/gpt-neo-1.3B](https://huggingface.co/EleutherAI/gpt-neo-1.3B) for fictional text content generation.
## Getting Started
### PIP Installation
```
pip install -U --no-cache-dir transformers
```
### Usage
```
from transformers import pipeline
model_name: str = 'FrostAura/gpt-neo-1.3B-fiction-novel-generation'
generator: pipeline = pipeline('text-generation', model=model_name)
prompt: str = 'So far my day has been '
gen_text: str = generator(prompt, do_sample=True, min_length=50)
print(f'Result: {gen_text}')
```
## Further Fine-Tuning
[in development](https://github.com/dredwardhyde/gpt-neo-fine-tuning-example/blob/main/gpt_neo.py)
## Support
If you enjoy FrostAura open-source content and would like to support us in continuous delivery, please consider a donation via a platform of your choice.
| Supported Platforms | Link |
| ------------------- | ---- |
| PayPal | [Donate via Paypal](https://www.paypal.com/donate/?hosted_button_id=SVEXJC9HFBJ72) |
For any queries, contact dean.martin@frostaura.net.
|
sd-concepts-library/cologne
|
sd-concepts-library
| 2022-09-12T12:47:21Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T12:47:18Z |
---
license: mit
---
### cologne on Stable Diffusion
This is the `<cologne-dom>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
GItaf/roberta-base-roberta-base-finetuned-mbti-0912-weight0
|
GItaf
| 2022-09-12T12:31:55Z | 52 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-12T06:46:46Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-roberta-base-finetuned-mbti-0912-weight0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-roberta-base-finetuned-mbti-0912-weight0
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 4.1338
- eval_runtime: 25.6249
- eval_samples_per_second: 67.708
- eval_steps_per_second: 8.468
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
GItaf/roberta-base-roberta-base-finetuned-mbti-0911
|
GItaf
| 2022-09-12T12:20:34Z | 49 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-11T12:27:55Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-roberta-base-finetuned-mbti-0911
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-roberta-base-finetuned-mbti-0911
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 4.1338
- eval_runtime: 25.7058
- eval_samples_per_second: 67.495
- eval_steps_per_second: 8.442
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/a-female-hero-from-the-legend-of-mir
|
sd-concepts-library
| 2022-09-12T12:19:24Z | 0 | 6 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T12:19:18Z |
---
license: mit
---
### a female hero from The Legend of Mir on Stable Diffusion
This is the `a <female-hero> from The Legend of Mir` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
santiviquez/q-FrozenLake-v1-4x4-noSlippery
|
santiviquez
| 2022-09-12T12:14:58Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-12T12:14:52Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="santiviquez/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
misterneil/distilbert-base-uncased-finetuned-emotion
|
misterneil
| 2022-09-12T12:14:24Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-11T21:20:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9295
- name: F1
type: f1
value: 0.929332697530698
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2116
- Accuracy: 0.9295
- F1: 0.9293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8487 | 1.0 | 250 | 0.3135 | 0.909 | 0.9051 |
| 0.2515 | 2.0 | 500 | 0.2116 | 0.9295 | 0.9293 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
jakka/Bert_Classifier
|
jakka
| 2022-09-12T11:05:06Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:yelp_review_full",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-12T10:49:17Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- yelp_review_full
metrics:
- accuracy
model-index:
- name: Bert_Classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: yelp_review_full
type: yelp_review_full
config: yelp_review_full
split: train
args: yelp_review_full
metrics:
- name: Accuracy
type: accuracy
value: 0.43
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bert_Classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the yelp_review_full dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9851
- Accuracy: 0.43
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 125 | 1.5585 | 0.45 |
| No log | 2.0 | 250 | 1.7005 | 0.51 |
| No log | 3.0 | 375 | 1.9851 | 0.43 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-8front-1body-0rear
|
Padomin
| 2022-09-12T09:58:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T20:58:48Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-8front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-8front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4589
- Wer: 0.1739
- Mer: 0.1679
- Wil: 0.2545
- Wip: 0.7455
- Hits: 55667
- Substitutions: 6385
- Deletions: 2535
- Insertions: 2309
- Cer: 0.1363
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6586 | 1.0 | 1457 | 0.4812 | 0.2110 | 0.1994 | 0.2888 | 0.7112 | 54745 | 6712 | 3130 | 3789 | 0.1784 |
| 0.5246 | 2.0 | 2914 | 0.4383 | 0.1839 | 0.1770 | 0.2641 | 0.7359 | 55251 | 6428 | 2908 | 2544 | 0.1481 |
| 0.4795 | 3.0 | 4371 | 0.4327 | 0.1811 | 0.1740 | 0.2610 | 0.7390 | 55523 | 6438 | 2626 | 2631 | 0.1458 |
| 0.4224 | 4.0 | 5828 | 0.4328 | 0.1754 | 0.1693 | 0.2555 | 0.7445 | 55577 | 6338 | 2672 | 2318 | 0.1397 |
| 0.3755 | 5.0 | 7285 | 0.4351 | 0.1723 | 0.1668 | 0.2529 | 0.7471 | 55607 | 6326 | 2654 | 2150 | 0.1362 |
| 0.3538 | 6.0 | 8742 | 0.4413 | 0.1728 | 0.1670 | 0.2531 | 0.7469 | 55696 | 6341 | 2550 | 2271 | 0.1372 |
| 0.3686 | 7.0 | 10199 | 0.4455 | 0.1715 | 0.1659 | 0.2519 | 0.7481 | 55692 | 6319 | 2576 | 2180 | 0.1354 |
| 0.3004 | 8.0 | 11656 | 0.4518 | 0.1727 | 0.1668 | 0.2537 | 0.7463 | 55712 | 6400 | 2475 | 2281 | 0.1371 |
| 0.2914 | 9.0 | 13113 | 0.4564 | 0.1739 | 0.1678 | 0.2544 | 0.7456 | 55681 | 6378 | 2528 | 2323 | 0.1370 |
| 0.297 | 10.0 | 14570 | 0.4589 | 0.1739 | 0.1679 | 0.2545 | 0.7455 | 55667 | 6385 | 2535 | 2309 | 0.1363 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
huggingtweets/hermelatv
|
huggingtweets
| 2022-09-12T09:40:48Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-12T09:40:11Z |
---
language: en
thumbnail: http://www.huggingtweets.com/hermelatv/1662975644554/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1565103698845478912/FeReio7F_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">hermela aregawi</div>
<div style="text-align: center; font-size: 14px;">@hermelatv</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from hermela aregawi.
| Data | hermela aregawi |
| --- | --- |
| Tweets downloaded | 3245 |
| Retweets | 1527 |
| Short tweets | 145 |
| Tweets kept | 1573 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/23qpqb0p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hermelatv's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3hget9jv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3hget9jv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hermelatv')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sd-concepts-library/kaleido
|
sd-concepts-library
| 2022-09-12T09:31:25Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T09:31:14Z |
---
license: mit
---
### kaleido on Stable Diffusion
This is the `<kaleido>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
aisuneko/kyubey-ai
|
aisuneko
| 2022-09-12T08:51:35Z | 105 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2022-09-11T11:15:00Z |
---
license: mit
---
Model for generating custom Magia Record unit designs, inspired by [this reddit post](https://www.reddit.com/r/magiarecord/comments/x63rm9/ive_got_a_fun_little_game_who_is_ready_to_make_a/).
Made with GPT-2 retrained with an extremely small dataset (<= 250 entries, contains official characters in the game and the custom ones in the above post (authorized for use by its original author)). It's currently quite buggy due to the humble dataset and is only capable of randomly generating a unit; support for custom prompts (wishes) will be added in the future.
|
Padomin/t5-base-TEDxJP-5front-1body-0rear
|
Padomin
| 2022-09-12T08:41:18Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T20:53:40Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-5front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-5front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4633
- Wer: 0.1756
- Mer: 0.1693
- Wil: 0.2562
- Wip: 0.7438
- Hits: 55657
- Substitutions: 6415
- Deletions: 2515
- Insertions: 2414
- Cer: 0.1382
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6441 | 1.0 | 1457 | 0.4872 | 0.2061 | 0.1954 | 0.2850 | 0.7150 | 54813 | 6709 | 3065 | 3540 | 0.1823 |
| 0.543 | 2.0 | 2914 | 0.4422 | 0.1832 | 0.1765 | 0.2641 | 0.7359 | 55188 | 6458 | 2941 | 2432 | 0.1491 |
| 0.4896 | 3.0 | 4371 | 0.4373 | 0.1811 | 0.1739 | 0.2612 | 0.7388 | 55568 | 6464 | 2555 | 2679 | 0.1450 |
| 0.4299 | 4.0 | 5828 | 0.4326 | 0.1745 | 0.1685 | 0.2553 | 0.7447 | 55604 | 6391 | 2592 | 2288 | 0.1367 |
| 0.3853 | 5.0 | 7285 | 0.4390 | 0.1758 | 0.1693 | 0.2561 | 0.7439 | 55696 | 6406 | 2485 | 2462 | 0.1375 |
| 0.357 | 6.0 | 8742 | 0.4433 | 0.1835 | 0.1757 | 0.2619 | 0.7381 | 55609 | 6386 | 2592 | 2871 | 0.1438 |
| 0.3735 | 7.0 | 10199 | 0.4479 | 0.1799 | 0.1729 | 0.2598 | 0.7402 | 55582 | 6425 | 2580 | 2617 | 0.1411 |
| 0.302 | 8.0 | 11656 | 0.4554 | 0.1770 | 0.1702 | 0.2569 | 0.7431 | 55725 | 6408 | 2454 | 2568 | 0.1386 |
| 0.2992 | 9.0 | 13113 | 0.4614 | 0.1784 | 0.1715 | 0.2581 | 0.7419 | 55672 | 6405 | 2510 | 2606 | 0.1404 |
| 0.2972 | 10.0 | 14570 | 0.4633 | 0.1756 | 0.1693 | 0.2562 | 0.7438 | 55657 | 6415 | 2515 | 2414 | 0.1382 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Padomin/t5-base-TEDxJP-3front-1body-0rear
|
Padomin
| 2022-09-12T08:04:27Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:te_dx_jp",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T20:57:48Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-3front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-3front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4641
- Wer: 0.1743
- Mer: 0.1684
- Wil: 0.2557
- Wip: 0.7443
- Hits: 55594
- Substitutions: 6428
- Deletions: 2565
- Insertions: 2267
- Cer: 0.1368
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6567 | 1.0 | 1457 | 0.4959 | 0.2072 | 0.1966 | 0.2877 | 0.7123 | 54688 | 6836 | 3063 | 3486 | 0.1936 |
| 0.5486 | 2.0 | 2914 | 0.4504 | 0.1870 | 0.1796 | 0.2677 | 0.7323 | 55158 | 6518 | 2911 | 2647 | 0.1528 |
| 0.4957 | 3.0 | 4371 | 0.4410 | 0.1764 | 0.1705 | 0.2578 | 0.7422 | 55412 | 6429 | 2746 | 2216 | 0.1375 |
| 0.4371 | 4.0 | 5828 | 0.4379 | 0.1761 | 0.1702 | 0.2572 | 0.7428 | 55447 | 6407 | 2733 | 2232 | 0.1377 |
| 0.387 | 5.0 | 7285 | 0.4408 | 0.1756 | 0.1696 | 0.2562 | 0.7438 | 55510 | 6372 | 2705 | 2263 | 0.1399 |
| 0.3589 | 6.0 | 8742 | 0.4466 | 0.1737 | 0.1681 | 0.2552 | 0.7448 | 55532 | 6406 | 2649 | 2165 | 0.1359 |
| 0.3876 | 7.0 | 10199 | 0.4532 | 0.1746 | 0.1689 | 0.2563 | 0.7437 | 55491 | 6436 | 2660 | 2179 | 0.1363 |
| 0.3199 | 8.0 | 11656 | 0.4591 | 0.1738 | 0.1681 | 0.2554 | 0.7446 | 55568 | 6431 | 2588 | 2208 | 0.1362 |
| 0.3079 | 9.0 | 13113 | 0.4625 | 0.1743 | 0.1685 | 0.2557 | 0.7443 | 55579 | 6425 | 2583 | 2252 | 0.1366 |
| 0.3124 | 10.0 | 14570 | 0.4641 | 0.1743 | 0.1684 | 0.2557 | 0.7443 | 55594 | 6428 | 2565 | 2267 | 0.1368 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
north/demo-nynorsk-base
|
north
| 2022-09-12T07:58:28Z | 111 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"translation",
"no",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-05-29T12:14:07Z |
---
language: no
tags:
- translation
widget:
- text: "En av de vanskeligste oppgavene når man oversetter fra bokmål til nynorsk, er å passe på at man bruker riktige pronomen. Man kan for eksempel si at man eier en bil og at den er rød."
- text: "Arbeidsmiljøloven har også som formål å sikre et arbeidsmiljø som gir grunnlag for en helsefremmende og meningsfylt arbeidssituasjon, og bidra til et inkluderende arbeidsliv."
- text: "Alle søknader behandles konfidensielt."
- text: "Kommunens nettsider henviser til kommunens vedtak."
license: cc-by-nc-nd-4.0
---
# Nynorsk Translator
This demo translates text for Norwegian Bokmål to Norwegian Nynorsk.
The Nynorsk Translator is finetuned from North-T5. It is a simple base model just for demo purposes. Please do not use it for translating larger amounts of text.
|
sd-concepts-library/cute-cat
|
sd-concepts-library
| 2022-09-12T07:14:55Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T07:14:42Z |
---
license: mit
---
### cute cat on Stable Diffusion
This is the `<cute-bear>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/aj-fosik
|
sd-concepts-library
| 2022-09-12T06:58:41Z | 0 | 4 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T06:58:37Z |
---
license: mit
---
### AJ Fosik on Stable Diffusion
This is the `<AJ-Fosik>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
tau/bart-base-sled-govreport
|
tau
| 2022-09-12T06:50:01Z | 52 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tau/sled",
"en",
"arxiv:2104.02112",
"arxiv:2208.00748",
"arxiv:1910.13461",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-09-12T06:40:14Z |
---
license: mit
language: en
---
# BART-SLED (SLiding-Encoder and Decoder, base-sized model)
SLED models use pretrained, short-range encoder-decoder models, and apply them over
long-text inputs by splitting the input into multiple overlapping chunks, encoding each independently and perform fusion-in-decoder
## Model description
This SLED model is based on the BART model, which is described in its [model card](https://huggingface.co/facebook/bart-base).
BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works
well for comprehension tasks (e.g. text classification, question answering). When used as a BART-SLED model, it can be applied on long text tasks.
This model was finetuned on the [GovReport](https://arxiv.org/abs/2104.02112)
## Intended uses & limitations
You can use the raw model for text infilling. However, the model is mostly meant to be fine-tuned on a supervised dataset.
### How to use
To use the model, you first need to install `py-sled` in your environment (or clone the code from the [official repository](https://github.com/Mivg/SLED/blob/main/README.md))
```
pip install py-sled
```
For more installation instructions, see [here](https://github.com/Mivg/SLED#Installation).
Once installed, SLED is fully compatible with HuggingFace's AutoClasses (AutoTokenizer, AutoConfig, AutoModel
and AutoModelForCausalLM) and can be loaded using the from_pretrained methods
```python
import sled # *** required so that SledModels will be registered for the AutoClasses ***
model = AutoModel.from_pretrained('tau/bart-base-sled')
```
Here is how to use this model in PyTorch:
```python
from sled import SledTokenizer, SledModel
tokenizer = SledTokenizer.from_pretrained('tau/bart-base-sled')
model = SledModel.from_pretrained('tau/bart-base-sled')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
You can also replace SledModel by SledModelForConditionalGeneration for Seq2Seq generation
```python
model = SledModelForConditionalGeneration.from_pretrained('tau/bart-base-sled')
```
In case you wish to apply SLED on a task containing a prefix (e.g. question) which should be given as a context to
every chunk, you can pass the `prefix_length` tensor input as well (A LongTensor in the length of the batch size).
```python
import torch
import sled # *** required so that SledModels will be registered for the AutoClasses ***
tokenizer = AutoTokenizer.from_pretrained('tau/bart-base-sled')
model = AutoModel.from_pretrained('tau/bart-base-sled')
document_input_ids = tokenizer("Dogs are great for you.", return_tensors="pt").input_ids
prefix_input_ids = tokenizer("Are dogs good for you?", return_tensors="pt").input_ids
input_ids = torch.cat((prefix_input_ids, document_input_ids), dim=-1)
attention_mask = torch.ones_like(input_ids)
prefix_length = torch.LongTensor([[prefix_input_ids.size(1)]])
outputs = model(input_ids=input_ids, attention_mask=attention_mask, prefix_length=prefix_length)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
Please cite both the SLED [paper](https://arxiv.org/abs/2208.00748.pdf) and the BART [paper](https://arxiv.org/abs/1910.13461) by Lewis et al as well as GovReport by Huang et al
```bibtex
@inproceedings{Ivgi2022EfficientLU,
title={Efficient Long-Text Understanding with Short-Text Models},
author={Maor Ivgi and Uri Shaham and Jonathan Berant},
year={2022}
}
```
```bibtex
@article{DBLP:journals/corr/abs-1910-13461,
author = {Mike Lewis and
Yinhan Liu and
Naman Goyal and
Marjan Ghazvininejad and
Abdelrahman Mohamed and
Omer Levy and
Veselin Stoyanov and
Luke Zettlemoyer},
title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language
Generation, Translation, and Comprehension},
journal = {CoRR},
volume = {abs/1910.13461},
year = {2019},
url = {http://arxiv.org/abs/1910.13461},
eprinttype = {arXiv},
eprint = {1910.13461},
timestamp = {Thu, 31 Oct 2019 14:02:26 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{huang2021govreport,
title = "Efficient Attentions for Long Document Summarization",
author = "Huang, Luyang and
Cao, Shuyang and
Parulian, Nikolaus and
Ji, Heng and
Wang, Lu",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.112",
doi = "10.18653/v1/2021.naacl-main.112",
pages = "1419--1436"
}
```
|
prathap-reddy/autotrain-climate-text-classification-1437253674
|
prathap-reddy
| 2022-09-12T06:11:45Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:prathap-reddy/autotrain-data-climate-text-classification",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-12T06:10:09Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- prathap-reddy/autotrain-data-climate-text-classification
co2_eq_emissions:
emissions: 2.621274122165296
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1437253674
- CO2 Emissions (in grams): 2.6213
## Validation Metrics
- Loss: 0.300
- Accuracy: 0.884
- Precision: 0.844
- Recall: 0.596
- AUC: 0.885
- F1: 0.699
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/prathap-reddy/autotrain-climate-text-classification-1437253674
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("prathap-reddy/autotrain-climate-text-classification-1437253674", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("prathap-reddy/autotrain-climate-text-classification-1437253674", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
inarikami/japanese-opt-2.7b
|
inarikami
| 2022-09-12T05:43:21Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"opt",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-12T02:48:52Z |
---
license: other
model-index:
- name: output_2
results: []
---
# Japanese-opt-2.7b Model
***Disclaimer: This model is a work in progress!***
This model is a fine-tuned version of [facebook/opt-2.7b](https://huggingface.co/facebook/opt-2.7b) on the japanese wikipedia dataset.
## Quick start
```python
from transformers import pipeline
generator = pipeline('text-generation', model="tensorcat/japanese-opt-2.7b" , device=0, use_fast=False)
generator("今日は", min_length=80, max_length=200,
do_sample=True, early_stopping=True, temperature=.98, top_k=50, top_p=1.0)
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 4
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Pytorch 1.13.0+cu116
|
huijian222/dqn-SpaceInvadersNoFrameskip-v4
|
huijian222
| 2022-09-12T05:42:47Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-12T05:42:04Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 697.00 +/- 193.32
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga huijian222 -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga huijian222
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
sd-concepts-library/doose-s-realistic-art-style
|
sd-concepts-library
| 2022-09-12T03:18:51Z | 0 | 16 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T03:18:47Z |
---
license: mit
---
### Doose's Realistic Art Style on Stable Diffusion
This is the `<doose-realistic>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:













|
sd-concepts-library/retropixelart-pinguin
|
sd-concepts-library
| 2022-09-12T02:28:27Z | 0 | 4 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T02:28:21Z |
---
license: mit
---
### retropixelart pinguin on Stable Diffusion
This is the `<retropixelart-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








|
sd-concepts-library/tcirle
|
sd-concepts-library
| 2022-09-12T02:07:11Z | 0 | 3 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T02:07:07Z |
---
license: mit
---
### tcirle on Stable Diffusion
This is the `<tcircle>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:
|
TastyOs/swin-tiny-patch4-window7-224-finetuned-eurosat
|
TastyOs
| 2022-09-12T01:42:25Z | 219 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-12T00:25:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9733333333333334
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0765
- Accuracy: 0.9733
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2745 | 1.0 | 190 | 0.1439 | 0.9485 |
| 0.1689 | 2.0 | 380 | 0.0851 | 0.9711 |
| 0.1593 | 3.0 | 570 | 0.0765 | 0.9733 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/baldi
|
sd-concepts-library
| 2022-09-12T01:35:36Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T01:35:24Z |
---
license: mit
---
### Baldi on Stable Diffusion
This is the `<baldi>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:



|
sd-concepts-library/spritual-monsters
|
sd-concepts-library
| 2022-09-12T01:26:17Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T01:26:13Z |
---
license: mit
---
### Spritual monsters on Stable Diffusion
This is the `<spritual-monsters>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/huckleberry
|
sd-concepts-library
| 2022-09-12T00:46:16Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-12T00:46:10Z |
---
license: mit
---
### huckleberry on Stable Diffusion
This is the `<huckleberry>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
rttl-ai/yelpy-bert
|
rttl-ai
| 2022-09-12T00:37:35Z | 119 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-11T20:03:41Z |
---
license: bigscience-bloom-rail-1.0
---
# Yelpy BERT
A bert-base-uncased fine-tuned on yelp reviews (https://www.yelp.com/dataset)
|
sd-concepts-library/nixeu
|
sd-concepts-library
| 2022-09-11T23:59:13Z | 0 | 17 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T08:48:00Z |
---
license: mit
---
### nixeu on Stable Diffusion
This is the `<nixeu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).

Here is the new concept you will be able to use as a `style`:






|
Imene/vit-base-patch16-224-wi2
|
Imene
| 2022-09-11T23:42:32Z | 79 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"vit",
"image-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-10T10:43:38Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Imene/vit-base-patch16-224-wi2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Imene/vit-base-patch16-224-wi2
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3098
- Train Accuracy: 0.9821
- Train Top-5-accuracy: 0.9971
- Validation Loss: 3.0737
- Validation Accuracy: 0.2491
- Validation Top-5-accuracy: 0.4476
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0003, 'decay_steps': 1750, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.001}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Train Top-5-accuracy | Validation Loss | Validation Accuracy | Validation Top-5-accuracy | Epoch |
|:----------:|:--------------:|:--------------------:|:---------------:|:-------------------:|:-------------------------:|:-----:|
| 4.4859 | 0.0195 | 0.0579 | 4.2995 | 0.0368 | 0.0865 | 0 |
| 4.1729 | 0.0355 | 0.0987 | 4.0916 | 0.0472 | 0.1266 | 1 |
| 3.9541 | 0.0666 | 0.1641 | 3.8050 | 0.0781 | 0.2035 | 2 |
| 3.5823 | 0.1247 | 0.2615 | 3.4015 | 0.1429 | 0.2950 | 3 |
| 3.0156 | 0.1913 | 0.3987 | 3.0598 | 0.1880 | 0.3916 | 4 |
| 2.4618 | 0.3077 | 0.5572 | 2.9869 | 0.2056 | 0.4129 | 5 |
| 1.8979 | 0.4541 | 0.7165 | 2.9507 | 0.2298 | 0.4425 | 6 |
| 1.2075 | 0.6914 | 0.8886 | 3.0106 | 0.2394 | 0.4425 | 7 |
| 0.6026 | 0.9097 | 0.9810 | 3.0739 | 0.2428 | 0.4413 | 8 |
| 0.3098 | 0.9821 | 0.9971 | 3.0737 | 0.2491 | 0.4476 | 9 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/glow-forest
|
sd-concepts-library
| 2022-09-11T23:16:45Z | 0 | 17 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T23:16:39Z |
---
license: mit
---
### glow forest on Stable Diffusion
This is the `<dark-forest>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
fxmarty/20220911-h13m58s53_squad_qa_distilbert_dynamic
|
fxmarty
| 2022-09-11T22:21:43Z | 0 | 0 | null |
[
"tensorboard",
"onnx",
"distilbert",
"question-answering",
"dataset:squad",
"region:us"
] |
question-answering
| 2022-09-11T22:20:48Z |
---
pipeline_tag: question-answering
datasets:
- squad
metrics:
- exact_match
- f1
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `question-answering`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'squad', 'eval_split': 'validation', 'data_keys': {'question': 'question', 'context': 'context'}, 'ref_keys': ['answers'], 'name': None, 'calibration_split': None}]
* **name_or_path**: `distilbert-base-uncased-distilled-squad`
* **from_transformers**: `True`
* **quantization_approach**: `dynamic`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **operators_to_quantize**: `['Add', 'MatMul']`, `['Add']`
* **node_exclusion**: `[]`, `['layernorm', 'gelu', 'residual', 'gather', 'softmax']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **reduce_range**: `True`, `False`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | exact_match | | f1 |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------: | :-: | :----: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 76.764 | \| | 85.053 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 69.622 | \| | 79.914 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.435 | \| | 5.887 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.165 | \| | 85.973 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 76.764 | \| | 85.053 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 69.622 | \| | 79.914 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.435 | \| | 5.887 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.165 | \| | 85.973 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 78.884 | \| | 86.690 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 32.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 14.26 | \| | 70.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.08 | \| | 99.20 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.60 | \| | 94.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.88 | \| | 91.93 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.84 | \| | 92.27 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.34 | \| | 96.73 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.41 | \| | 96.07 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.96 | \| | 91.27 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.69 | \| | 93.53 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.43 | \| | 69.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.52 | \| | 68.87 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.35 | \| | 69.73 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.50 | \| | 69.00 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.20 | \| | 70.47 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.24 | \| | 70.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.58 | \| | 68.67 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.73 | \| | 67.87 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 31.49 | \| | 31.80 |
Below, time metrics for batch size = 1, input length = 64.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 24.83 | \| | 40.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.49 | \| | 54.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.87 | \| | 53.00 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.17 | \| | 52.20 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.92 | \| | 52.87 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.13 | \| | 52.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.95 | \| | 52.80 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.08 | \| | 52.47 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.14 | \| | 52.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.83 | \| | 40.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.84 | \| | 40.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.66 | \| | 40.60 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.76 | \| | 40.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 25.07 | \| | 39.93 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.27 | \| | 39.60 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.76 | \| | 40.40 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.70 | \| | 40.53 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 41.26 | \| | 24.27 |
Below, time metrics for batch size = 1, input length = 128.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 46.89 | \| | 21.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 34.84 | \| | 28.73 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.88 | \| | 27.93 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 36.92 | \| | 27.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.25 | \| | 27.60 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 36.17 | \| | 27.67 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.59 | \| | 28.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 37.36 | \| | 26.80 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.97 | \| | 27.87 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 46.94 | \| | 21.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.19 | \| | 21.20 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.05 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 46.79 | \| | 21.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 46.87 | \| | 21.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.04 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.08 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.05 | \| | 21.27 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 54.61 | \| | 18.33 |
|
IIIT-L/hing-mbert-finetuned-ours-DS
|
IIIT-L
| 2022-09-11T22:03:32Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-11T21:57:43Z |
---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-mbert-finetuned-ours-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-mbert-finetuned-ours-DS
This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1569
- Accuracy: 0.71
- Precision: 0.6665
- Recall: 0.6668
- F1: 0.6658
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.824279936868144e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7704 | 1.99 | 199 | 0.7093 | 0.68 | 0.6679 | 0.6463 | 0.6309 |
| 0.2597 | 3.98 | 398 | 1.1569 | 0.71 | 0.6665 | 0.6668 | 0.6658 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
theojolliffe/T5-model-1-feedback-1109
|
theojolliffe
| 2022-09-11T20:29:13Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T16:04:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: T5-model-1-feedback-1109
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-model-1-feedback-1109
This model is a fine-tuned version of [theojolliffe/T5-model-1-d-6](https://huggingface.co/theojolliffe/T5-model-1-d-6) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2841
- Rouge1: 91.4494
- Rouge2: 86.4303
- Rougel: 89.9713
- Rougelsum: 90.045
- Gen Len: 15.2875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 359 | 0.3270 | 91.5397 | 86.6427 | 90.0821 | 90.1433 | 15.2875 |
| 0.2963 | 2.0 | 718 | 0.2847 | 91.4494 | 86.4303 | 89.9713 | 90.045 | 15.2875 |
| 0.2697 | 3.0 | 1077 | 0.2841 | 91.4494 | 86.4303 | 89.9713 | 90.045 | 15.2875 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0
- Datasets 1.18.0
- Tokenizers 0.10.3
|
sd-concepts-library/glass-pipe
|
sd-concepts-library
| 2022-09-11T20:14:10Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T20:14:06Z |
---
license: mit
---
### glass pipe on Stable Diffusion
This is the `<glass-sherlock>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
sd-concepts-library/eye-of-agamotto
|
sd-concepts-library
| 2022-09-11T19:53:41Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T19:53:37Z |
---
license: mit
---
### Eye of Agamotto on Stable Diffusion
This is the `<eye-aga>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:


































|
sd-concepts-library/rickyart
|
sd-concepts-library
| 2022-09-11T18:21:52Z | 0 | 4 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T18:21:47Z |
---
license: mit
---
### RickyArt on Stable Diffusion
This is the `<RickyArt>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
sd-concepts-library/garfield-pizza-plush-v2
|
sd-concepts-library
| 2022-09-11T17:59:08Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T17:59:02Z |
---
license: mit
---
### Garfield-Pizza-Plush-v2 on Stable Diffusion
This is the `<garfield-plushy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
sd-concepts-library/swamp-choe-2
|
sd-concepts-library
| 2022-09-11T16:42:37Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T16:42:30Z |
---
license: mit
---
### swamp-choe-2 on Stable Diffusion
This is the `<cat-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
sbatova/ddpm-butterflies-128
|
sbatova
| 2022-09-11T16:35:41Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:full",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-09-11T11:27:20Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: full
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `full` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/sbatova/ddpm-butterflies-128/tensorboard?#scalars)
|
orhanxakarsu/turkish-poem-generation-1
|
orhanxakarsu
| 2022-09-11T16:06:00Z | 107 | 0 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-11T13:43:58Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: orhanxakarsu/turkish-poem-generation-1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# orhanxakarsu/turkish-poem-generation-1
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 7.0761
- Validation Loss: 7.0393
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2.380655430044305e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2.380655430044305e-05, 'decay_steps': 3221, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.05}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.5133 | 7.0394 | 0 |
| 7.0763 | 7.0388 | 1 |
| 7.0762 | 7.0389 | 2 |
| 7.0761 | 7.0393 | 3 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
fxmarty/20220911-h13m58s49_sst2_distilbert_quantization
|
fxmarty
| 2022-09-11T15:55:26Z | 0 | 0 | null |
[
"tensorboard",
"onnx",
"distilbert",
"text-classification",
"dataset:glue",
"region:us"
] |
text-classification
| 2022-09-11T15:52:09Z |
---
pipeline_tag: text-classification
datasets:
- glue
metrics:
- accuracy
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `text-classification`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'glue', 'eval_split': 'validation', 'data_keys': {'primary': 'sentence'}, 'ref_keys': ['label'], 'name': 'sst2', 'calibration_split': 'train'}]
* **name_or_path**: `distilbert-base-uncased-finetuned-sst-2-english`
* **from_transformers**: `True`
* **calibration**:
* **method**: `percentile`
* **num_calibration_samples**: `128`
* **calibration_histogram_percentile**: `99.999`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **quantization_approach**: `dynamic`, `static`
* **operators_to_quantize**: `['Add', 'MatMul']`, `['Add']`
* **node_exclusion**: `[]`, `['layernorm', 'gelu', 'residual', 'gather', 'softmax']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **reduce_range**: `True`, `False`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | accuracy |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.898 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.893 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.490 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.898 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.893 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.490 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.491 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.908 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.499 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.900 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 0.911 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 32.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 14.50 | \| | 69.00 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.19 | \| | 98.13 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.66 | \| | 93.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.45 | \| | 95.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.72 | \| | 93.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.40 | \| | 96.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.16 | \| | 98.40 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.40 | \| | 96.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.86 | \| | 92.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.43 | \| | 69.33 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.68 | \| | 68.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.40 | \| | 69.47 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.79 | \| | 67.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.80 | \| | 67.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.13 | \| | 70.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.54 | \| | 68.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.60 | \| | 68.53 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 11.23 | \| | 89.13 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.18 | \| | 89.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 11.39 | \| | 87.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.31 | \| | 88.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 13.73 | \| | 72.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.42 | \| | 69.40 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.09 | \| | 71.00 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 13.78 | \| | 72.60 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 16.11 | \| | 62.13 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 15.97 | \| | 62.67 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 15.82 | \| | 63.27 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 15.94 | \| | 62.73 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.03 | \| | 52.60 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.99 | \| | 52.67 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.93 | \| | 52.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.65 | \| | 53.67 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 31.28 | \| | 32.00 |
Below, time metrics for batch size = 1, input length = 64.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 24.59 | \| | 40.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.67 | \| | 53.60 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.16 | \| | 52.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.97 | \| | 52.73 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.29 | \| | 51.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.13 | \| | 52.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.64 | \| | 53.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.01 | \| | 52.60 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.96 | \| | 52.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.63 | \| | 40.67 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.28 | \| | 39.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.75 | \| | 40.47 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.97 | \| | 40.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 25.16 | \| | 39.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.49 | \| | 40.87 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.88 | \| | 40.20 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.17 | \| | 39.73 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.05 | \| | 49.93 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 20.76 | \| | 48.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.75 | \| | 48.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 20.23 | \| | 49.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.79 | \| | 40.40 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.17 | \| | 39.73 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.14 | \| | 41.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.27 | \| | 39.60 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 27.97 | \| | 35.80 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 27.43 | \| | 36.47 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 28.17 | \| | 35.53 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 28.16 | \| | 35.53 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 33.24 | \| | 30.13 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 32.46 | \| | 30.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 32.39 | \| | 30.93 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 32.75 | \| | 30.53 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 41.25 | \| | 24.27 |
Below, time metrics for batch size = 1, input length = 128.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 46.51 | \| | 21.53 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.33 | \| | 28.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.92 | \| | 27.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.56 | \| | 28.13 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.32 | \| | 27.53 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.53 | \| | 28.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.96 | \| | 27.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.42 | \| | 28.27 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.06 | \| | 27.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.40 | \| | 21.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.14 | \| | 21.27 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.46 | \| | 21.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.26 | \| | 21.20 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.48 | \| | 21.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.08 | \| | 21.27 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.02 | \| | 21.33 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.05 | \| | 21.27 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.63 | \| | 25.27 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 39.52 | \| | 25.33 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.78 | \| | 25.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 40.01 | \| | 25.00 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 44.24 | \| | 22.67 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 44.55 | \| | 22.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 45.74 | \| | 21.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 44.12 | \| | 22.67 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 51.41 | \| | 19.47 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 52.52 | \| | 19.07 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 51.25 | \| | 19.53 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 51.51 | \| | 19.47 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 59.37 | \| | 16.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 58.28 | \| | 17.20 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 59.37 | \| | 16.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 58.28 | \| | 17.20 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 53.72 | \| | 18.67 |
|
fxmarty/20220911-h15m48s16_
|
fxmarty
| 2022-09-11T15:52:34Z | 0 | 0 | null |
[
"tensorboard",
"onnx",
"distilbert",
"text-classification",
"dataset:glue",
"region:us"
] |
text-classification
| 2022-09-11T15:52:12Z |
---
pipeline_tag: text-classification
datasets:
- glue
metrics:
- accuracy
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `text-classification`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'glue', 'eval_split': 'validation', 'data_keys': {'primary': 'sentence'}, 'ref_keys': ['label'], 'name': 'sst2', 'calibration_split': None}]
* **name_or_path**: `distilbert-base-uncased-finetuned-sst-2-english`
* **from_transformers**: `True`
* **quantization_approach**: `dynamic`
* **node_exclusion**: `[]`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **operators_to_quantize**: `['Add', 'MatMul']`, `['Add']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | operators_to_quantize | per_channel | framework_args | apply_quantization | | accuracy |
| :-----------: | :-------------------: | :---------: | :-----------------------------------------------------------------: | :----------------: | :-: | :------: |
| `onnxruntime` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | \| | 0.911 |
| `onnxruntime` | `['Add', 'MatMul']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 0.898 |
| `onnxruntime` | `['Add', 'MatMul']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 0.490 |
| `onnxruntime` | `['Add']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 0.911 |
| `onnxruntime` | `['Add']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 0.911 |
| `pytorch` | `None` | `None` | `{}` | `None` | \| | 0.911 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 224.
| framework | operators_to_quantize | per_channel | framework_args | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :---------: | :-----------------------------------------------------------------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | \| | 83.23 | \| | 12.07 |
| `onnxruntime` | `['Add', 'MatMul']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 64.31 | \| | 15.60 |
| `onnxruntime` | `['Add', 'MatMul']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 64.78 | \| | 15.47 |
| `onnxruntime` | `['Add']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 82.63 | \| | 12.13 |
| `onnxruntime` | `['Add']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | \| | 83.82 | \| | 11.93 |
| `pytorch` | `None` | `None` | `{}` | `None` | \| | 84.34 | \| | 11.87 |
|
SushantGautam/SportsSum
|
SushantGautam
| 2022-09-11T15:45:13Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"led",
"text2text-generation",
"generated_from_trainer",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T02:56:47Z |
---
language:
- en
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: SportsSum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SportsSum
This model is a fine-tuned version of [allenai/led-base-16384-ms2](https://huggingface.co/allenai/led-base-16384-ms2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5344
- Rouge1: 55.5224
- Rouge2: 28.1394
- Rougel: 31.9521
- Rougelsum: 53.0848
- Gen Len: 312.3902
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 96
- eval_batch_size: 96
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20.0
### Training results
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
sd-concepts-library/sculptural-style
|
sd-concepts-library
| 2022-09-11T15:26:38Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T15:26:31Z |
---
license: mit
---
### sculptural style on Stable Diffusion
This is the `<diaosu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
unfinity/Reinforce-CartPole-v1
|
unfinity
| 2022-09-11T14:55:25Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-11T14:51:35Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 463.35 +/- 98.40
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
sd-concepts-library/mikako-method
|
sd-concepts-library
| 2022-09-11T14:52:25Z | 0 | 3 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T14:42:53Z |
---
license: mit
---
### mikako-method on Stable Diffusion
This is the `<m-m>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:

|
IIIT-L/albert-base-v2-finetuned-combined-DS
|
IIIT-L
| 2022-09-11T13:00:12Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-11T11:18:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: albert-base-v2-finetuned-combined-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-combined-DS
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8777
- Accuracy: 0.6103
- Precision: 0.6156
- Recall: 0.5964
- F1: 0.5942
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.2531528713821575e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0726 | 0.5 | 711 | 1.0355 | 0.5028 | 0.3964 | 0.4551 | 0.3812 |
| 1.0367 | 1.0 | 1422 | 1.1449 | 0.3357 | 0.4627 | 0.3504 | 0.2166 |
| 1.0691 | 1.5 | 2133 | 1.0749 | 0.4993 | 0.4595 | 0.4282 | 0.3865 |
| 0.9844 | 2.0 | 2844 | 0.9458 | 0.5351 | 0.5383 | 0.5383 | 0.5249 |
| 0.9318 | 2.5 | 3555 | 0.9372 | 0.5569 | 0.5740 | 0.5596 | 0.5508 |
| 0.9313 | 3.0 | 4266 | 0.9221 | 0.5274 | 0.5772 | 0.5326 | 0.5222 |
| 0.8692 | 3.5 | 4977 | 0.9099 | 0.5611 | 0.5764 | 0.5585 | 0.5520 |
| 0.853 | 3.99 | 5688 | 0.8999 | 0.5990 | 0.6089 | 0.5840 | 0.5814 |
| 0.7954 | 4.49 | 6399 | 0.8821 | 0.6152 | 0.6177 | 0.6017 | 0.5988 |
| 0.8015 | 4.99 | 7110 | 0.8777 | 0.6103 | 0.6156 | 0.5964 | 0.5942 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
pedramyamini/distilbert-base-multilingual-cased-finetuned-mobile-banks-cafebazaar2lr-10epochs
|
pedramyamini
| 2022-09-11T12:17:49Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-11T10:56:19Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: pedramyamini/distilbert-base-multilingual-cased-finetuned-mobile-banks-cafebazaar2lr-10epochs
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pedramyamini/distilbert-base-multilingual-cased-finetuned-mobile-banks-cafebazaar2lr-10epochs
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2307
- Validation Loss: 1.2090
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 4e-05, 'decay_steps': 26740, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.7428 | 0.7046 | 0 |
| 0.6810 | 0.6903 | 1 |
| 0.6372 | 0.6907 | 2 |
| 0.5881 | 0.6988 | 3 |
| 0.5246 | 0.7630 | 4 |
| 0.4511 | 0.8687 | 5 |
| 0.3801 | 0.9356 | 6 |
| 0.3200 | 1.0440 | 7 |
| 0.2676 | 1.1470 | 8 |
| 0.2307 | 1.2090 | 9 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/garfield-pizza-plush
|
sd-concepts-library
| 2022-09-11T11:56:12Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T11:56:06Z |
---
license: mit
---
### Garfield-Pizza-Plush on Stable Diffusion
This is the `<garfield-plushy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
Mohammad-basheer/bart-large-cnn-finetuned-qmsum-2-4
|
Mohammad-basheer
| 2022-09-11T11:51:34Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"qmsum-summarization",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-11T10:39:16Z |
---
license: mit
tags:
- qmsum-summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-cnn-finetuned-qmsum-2-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetuned-qmsum-2-4
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0277
- Rouge1: 0.3053
- Rouge2: 0.0660
- Rougel: 0.1903
- Rougelsum: 0.2598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 3.3773 | 1.0 | 629 | 3.2522 | 0.2964 | 0.0713 | 0.1958 | 0.2593 |
| 2.3656 | 2.0 | 1258 | 3.2001 | 0.2942 | 0.0694 | 0.1921 | 0.2540 |
| 1.5843 | 3.0 | 1887 | 3.4248 | 0.3086 | 0.0687 | 0.1938 | 0.2648 |
| 0.9854 | 4.0 | 2516 | 4.0277 | 0.3053 | 0.0660 | 0.1903 | 0.2598 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Eksperymenty/testpyramidsrnd
|
Eksperymenty
| 2022-09-11T11:43:46Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-09-11T11:43:41Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: Eksperymenty/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sd-concepts-library/anime-boy
|
sd-concepts-library
| 2022-09-11T11:26:14Z | 0 | 5 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T11:26:01Z |
---
license: mit
---
### anime boy on Stable Diffusion
This is the `<myAItestShota>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/leica
|
sd-concepts-library
| 2022-09-11T11:11:44Z | 0 | 4 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-11T11:11:40Z |
---
license: mit
---
### leica on Stable Diffusion
This is the `<leica>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.