
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 00:39:05
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 532
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 00:38:59
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Mahmoud7/Reinforce-CartPole8
|
Mahmoud7
| 2022-08-19T19:22:04Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T17:46:48Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole8
results:
- metrics:
- type: mean_reward
value: 40.10 +/- 14.40
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
jackoyoungblood/qrdqn-SpaceInvadersNoFrameskip-v4
|
jackoyoungblood
| 2022-08-19T17:22:03Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T17:20:37Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: QRDQN
results:
- metrics:
- type: mean_reward
value: 2441.50 +/- 1153.35
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **QRDQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **QRDQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo qrdqn --env SpaceInvadersNoFrameskip-v4 -orga jackoyoungblood -f logs/
python enjoy.py --algo qrdqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo qrdqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo qrdqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jackoyoungblood
```
## Hyperparameters
```python
OrderedDict([('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_fraction', 0.025),
('frame_stack', 4),
('n_timesteps', 10000000.0),
('optimize_memory_usage', True),
('policy', 'CnnPolicy'),
('replay_buffer_kwargs', 'dict(handle_timeout_termination=False)'),
('normalize', False)])
```
|
caioeserpa/MobileNetV2_RNA_Class
|
caioeserpa
| 2022-08-19T16:34:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-08-19T16:10:04Z |
# RNA_Project
# Projeto Final - Modelos Preditivos Conexionistas
### Aluno - Caio Emanoel Serpa Lopes
### Tutor - Vitor Casadei
---
|**Tipo de Projeto**|**Modelo Selecionado**|**Linguagem**|
|--|--|--|
|Classificação de Imagens|MobileNetV2|Tensorflow|
[Clique aqui para rodar o modelo via browser (roboflow)](https://classify.roboflow.com/?model=classifier_animals&version=2&api_key=IDPIYW7fvVaFbVq3eTlB)
# Performance
O modelo treinado possui performance de **100%**.
## Output do bloco de treinamento
<details>
<summary>Click to expand!</summary>
```Epoch 1/1000
2/2 [==============================] - ETA: 0s - loss: 1.0496 - accuracy: 0.3750
Epoch 1: saving model to training_1/cp.ckpt
2/2 [==============================] - 9s 4s/step - loss: 1.0496 - accuracy: 0.3750 - val_loss: 0.8153 - val_accuracy: 0.4237
Epoch 2/1000
2/2 [==============================] - ETA: 0s - loss: 1.0002 - accuracy: 0.3281
Epoch 2: saving model to training_1/cp.ckpt
2/2 [==============================] - 4s 2s/step - loss: 1.0002 - accuracy: 0.3281 - val_loss: 0.7967 - val_accuracy: 0.4407
Epoch 3/1000
2/2 [==============================] - ETA: 0s - loss: 1.0473 - accuracy: 0.3594
Epoch 3: saving model to training_1/cp.ckpt
2/2 [==============================] - 3s 2s/step - loss: 1.0473 - accuracy: 0.3594 - val_loss: 0.7953 - val_accuracy: 0.4237
Epoch 4/1000
2/2 [==============================] - ETA: 0s - loss: 0.9252 - accuracy: 0.3250
Epoch 4: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.9252 - accuracy: 0.3250 - val_loss: 0.8039 - val_accuracy: 0.3729
Epoch 5/1000
2/2 [==============================] - ETA: 0s - loss: 0.9771 - accuracy: 0.3000
Epoch 5: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 781ms/step - loss: 0.9771 - accuracy: 0.3000 - val_loss: 0.8116 - val_accuracy: 0.3729
Epoch 6/1000
2/2 [==============================] - ETA: 0s - loss: 0.9402 - accuracy: 0.3125
Epoch 6: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 789ms/step - loss: 0.9402 - accuracy: 0.3125 - val_loss: 0.8183 - val_accuracy: 0.3898
Epoch 7/1000
2/2 [==============================] - ETA: 0s - loss: 0.8416 - accuracy: 0.4750
Epoch 7: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.8416 - accuracy: 0.4750 - val_loss: 0.8229 - val_accuracy: 0.3898
Epoch 8/1000
2/2 [==============================] - ETA: 0s - loss: 0.8543 - accuracy: 0.3516
Epoch 8: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 913ms/step - loss: 0.8543 - accuracy: 0.3516 - val_loss: 0.8213 - val_accuracy: 0.4068
Epoch 9/1000
2/2 [==============================] - ETA: 0s - loss: 0.7657 - accuracy: 0.4844
Epoch 9: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 908ms/step - loss: 0.7657 - accuracy: 0.4844 - val_loss: 0.8124 - val_accuracy: 0.4068
Epoch 10/1000
2/2 [==============================] - ETA: 0s - loss: 0.8208 - accuracy: 0.3125
Epoch 10: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.8208 - accuracy: 0.3125 - val_loss: 0.8035 - val_accuracy: 0.4237
Epoch 11/1000
2/2 [==============================] - ETA: 0s - loss: 0.8510 - accuracy: 0.3875
Epoch 11: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 789ms/step - loss: 0.8510 - accuracy: 0.3875 - val_loss: 0.7868 - val_accuracy: 0.4237
Epoch 12/1000
2/2 [==============================] - ETA: 0s - loss: 0.7841 - accuracy: 0.4609
Epoch 12: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 896ms/step - loss: 0.7841 - accuracy: 0.4609 - val_loss: 0.7674 - val_accuracy: 0.4407
Epoch 13/1000
2/2 [==============================] - ETA: 0s - loss: 0.7320 - accuracy: 0.5125
Epoch 13: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.7320 - accuracy: 0.5125 - val_loss: 0.7513 - val_accuracy: 0.4576
Epoch 14/1000
2/2 [==============================] - ETA: 0s - loss: 0.7788 - accuracy: 0.3828
Epoch 14: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 908ms/step - loss: 0.7788 - accuracy: 0.3828 - val_loss: 0.7345 - val_accuracy: 0.4915
Epoch 15/1000
2/2 [==============================] - ETA: 0s - loss: 0.8054 - accuracy: 0.3250
Epoch 15: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 803ms/step - loss: 0.8054 - accuracy: 0.3250 - val_loss: 0.7162 - val_accuracy: 0.4915
Epoch 16/1000
2/2 [==============================] - ETA: 0s - loss: 0.7073 - accuracy: 0.5125
Epoch 16: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.7073 - accuracy: 0.5125 - val_loss: 0.6949 - val_accuracy: 0.5085
Epoch 17/1000
2/2 [==============================] - ETA: 0s - loss: 0.7984 - accuracy: 0.4250
Epoch 17: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.7984 - accuracy: 0.4250 - val_loss: 0.6756 - val_accuracy: 0.5424
Epoch 18/1000
2/2 [==============================] - ETA: 0s - loss: 0.7332 - accuracy: 0.4750
Epoch 18: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 777ms/step - loss: 0.7332 - accuracy: 0.4750 - val_loss: 0.6573 - val_accuracy: 0.5763
Epoch 19/1000
2/2 [==============================] - ETA: 0s - loss: 0.6789 - accuracy: 0.5000
Epoch 19: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 928ms/step - loss: 0.6789 - accuracy: 0.5000 - val_loss: 0.6398 - val_accuracy: 0.5763
Epoch 20/1000
2/2 [==============================] - ETA: 0s - loss: 0.7541 - accuracy: 0.4844
Epoch 20: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.7541 - accuracy: 0.4844 - val_loss: 0.6241 - val_accuracy: 0.5763
Epoch 21/1000
2/2 [==============================] - ETA: 0s - loss: 0.7528 - accuracy: 0.4688
Epoch 21: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.7528 - accuracy: 0.4688 - val_loss: 0.6103 - val_accuracy: 0.5763
Epoch 22/1000
2/2 [==============================] - ETA: 0s - loss: 0.6765 - accuracy: 0.5000
Epoch 22: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.6765 - accuracy: 0.5000 - val_loss: 0.5980 - val_accuracy: 0.5932
Epoch 23/1000
2/2 [==============================] - ETA: 0s - loss: 0.6817 - accuracy: 0.5625
Epoch 23: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.6817 - accuracy: 0.5625 - val_loss: 0.5890 - val_accuracy: 0.6102
Epoch 24/1000
2/2 [==============================] - ETA: 0s - loss: 0.7056 - accuracy: 0.4125
Epoch 24: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 785ms/step - loss: 0.7056 - accuracy: 0.4125 - val_loss: 0.5802 - val_accuracy: 0.6102
Epoch 25/1000
2/2 [==============================] - ETA: 0s - loss: 0.7238 - accuracy: 0.4453
Epoch 25: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.7238 - accuracy: 0.4453 - val_loss: 0.5716 - val_accuracy: 0.6102
Epoch 26/1000
2/2 [==============================] - ETA: 0s - loss: 0.6118 - accuracy: 0.4875
Epoch 26: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.6118 - accuracy: 0.4875 - val_loss: 0.5640 - val_accuracy: 0.6102
Epoch 27/1000
2/2 [==============================] - ETA: 0s - loss: 0.6136 - accuracy: 0.5250
Epoch 27: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.6136 - accuracy: 0.5250 - val_loss: 0.5557 - val_accuracy: 0.6102
Epoch 28/1000
2/2 [==============================] - ETA: 0s - loss: 0.6424 - accuracy: 0.5156
Epoch 28: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 925ms/step - loss: 0.6424 - accuracy: 0.5156 - val_loss: 0.5483 - val_accuracy: 0.6271
Epoch 29/1000
2/2 [==============================] - ETA: 0s - loss: 0.6367 - accuracy: 0.5703
Epoch 29: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 925ms/step - loss: 0.6367 - accuracy: 0.5703 - val_loss: 0.5409 - val_accuracy: 0.6102
Epoch 30/1000
2/2 [==============================] - ETA: 0s - loss: 0.5621 - accuracy: 0.6375
Epoch 30: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5621 - accuracy: 0.6375 - val_loss: 0.5350 - val_accuracy: 0.6102
Epoch 31/1000
2/2 [==============================] - ETA: 0s - loss: 0.5903 - accuracy: 0.6625
Epoch 31: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 773ms/step - loss: 0.5903 - accuracy: 0.6625 - val_loss: 0.5297 - val_accuracy: 0.6102
Epoch 32/1000
2/2 [==============================] - ETA: 0s - loss: 0.5768 - accuracy: 0.5938
Epoch 32: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5768 - accuracy: 0.5938 - val_loss: 0.5246 - val_accuracy: 0.5932
Epoch 33/1000
2/2 [==============================] - ETA: 0s - loss: 0.5517 - accuracy: 0.6625
Epoch 33: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 771ms/step - loss: 0.5517 - accuracy: 0.6625 - val_loss: 0.5197 - val_accuracy: 0.6102
Epoch 34/1000
2/2 [==============================] - ETA: 0s - loss: 0.5987 - accuracy: 0.5625
Epoch 34: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5987 - accuracy: 0.5625 - val_loss: 0.5156 - val_accuracy: 0.6271
Epoch 35/1000
2/2 [==============================] - ETA: 0s - loss: 0.5768 - accuracy: 0.5859
Epoch 35: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 866ms/step - loss: 0.5768 - accuracy: 0.5859 - val_loss: 0.5116 - val_accuracy: 0.6271
Epoch 36/1000
2/2 [==============================] - ETA: 0s - loss: 0.5395 - accuracy: 0.7000
Epoch 36: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5395 - accuracy: 0.7000 - val_loss: 0.5072 - val_accuracy: 0.6271
Epoch 37/1000
2/2 [==============================] - ETA: 0s - loss: 0.5549 - accuracy: 0.5625
Epoch 37: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5549 - accuracy: 0.5625 - val_loss: 0.5027 - val_accuracy: 0.6271
Epoch 38/1000
2/2 [==============================] - ETA: 0s - loss: 0.5485 - accuracy: 0.5750
Epoch 38: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 783ms/step - loss: 0.5485 - accuracy: 0.5750 - val_loss: 0.4985 - val_accuracy: 0.6271
Epoch 39/1000
2/2 [==============================] - ETA: 0s - loss: 0.5600 - accuracy: 0.5875
Epoch 39: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5600 - accuracy: 0.5875 - val_loss: 0.4944 - val_accuracy: 0.6441
Epoch 40/1000
2/2 [==============================] - ETA: 0s - loss: 0.5797 - accuracy: 0.6250
Epoch 40: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 766ms/step - loss: 0.5797 - accuracy: 0.6250 - val_loss: 0.4913 - val_accuracy: 0.6441
Epoch 41/1000
2/2 [==============================] - ETA: 0s - loss: 0.5891 - accuracy: 0.6125
Epoch 41: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 850ms/step - loss: 0.5891 - accuracy: 0.6125 - val_loss: 0.4880 - val_accuracy: 0.6610
Epoch 42/1000
2/2 [==============================] - ETA: 0s - loss: 0.5301 - accuracy: 0.6375
Epoch 42: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 810ms/step - loss: 0.5301 - accuracy: 0.6375 - val_loss: 0.4847 - val_accuracy: 0.6610
Epoch 43/1000
2/2 [==============================] - ETA: 0s - loss: 0.5775 - accuracy: 0.6328
Epoch 43: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 942ms/step - loss: 0.5775 - accuracy: 0.6328 - val_loss: 0.4796 - val_accuracy: 0.6610
Epoch 44/1000
2/2 [==============================] - ETA: 0s - loss: 0.4997 - accuracy: 0.6641
Epoch 44: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4997 - accuracy: 0.6641 - val_loss: 0.4753 - val_accuracy: 0.6610
Epoch 45/1000
2/2 [==============================] - ETA: 0s - loss: 0.5236 - accuracy: 0.7109
Epoch 45: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5236 - accuracy: 0.7109 - val_loss: 0.4713 - val_accuracy: 0.6780
Epoch 46/1000
2/2 [==============================] - ETA: 0s - loss: 0.5150 - accuracy: 0.6641
Epoch 46: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5150 - accuracy: 0.6641 - val_loss: 0.4674 - val_accuracy: 0.6780
Epoch 47/1000
2/2 [==============================] - ETA: 0s - loss: 0.5213 - accuracy: 0.6625
Epoch 47: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5213 - accuracy: 0.6625 - val_loss: 0.4637 - val_accuracy: 0.6780
Epoch 48/1000
2/2 [==============================] - ETA: 0s - loss: 0.5835 - accuracy: 0.6016
Epoch 48: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 913ms/step - loss: 0.5835 - accuracy: 0.6016 - val_loss: 0.4594 - val_accuracy: 0.6780
Epoch 49/1000
2/2 [==============================] - ETA: 0s - loss: 0.5356 - accuracy: 0.6641
Epoch 49: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5356 - accuracy: 0.6641 - val_loss: 0.4551 - val_accuracy: 0.6780
Epoch 50/1000
2/2 [==============================] - ETA: 0s - loss: 0.5144 - accuracy: 0.6797
Epoch 50: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5144 - accuracy: 0.6797 - val_loss: 0.4520 - val_accuracy: 0.6949
Epoch 51/1000
2/2 [==============================] - ETA: 0s - loss: 0.5832 - accuracy: 0.6875
Epoch 51: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5832 - accuracy: 0.6875 - val_loss: 0.4498 - val_accuracy: 0.6949
Epoch 52/1000
2/2 [==============================] - ETA: 0s - loss: 0.5395 - accuracy: 0.6500
Epoch 52: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.5395 - accuracy: 0.6500 - val_loss: 0.4471 - val_accuracy: 0.6949
Epoch 53/1000
2/2 [==============================] - ETA: 0s - loss: 0.4901 - accuracy: 0.7188
Epoch 53: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 995ms/step - loss: 0.4901 - accuracy: 0.7188 - val_loss: 0.4434 - val_accuracy: 0.6949
Epoch 54/1000
2/2 [==============================] - ETA: 0s - loss: 0.4348 - accuracy: 0.7250
Epoch 54: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 796ms/step - loss: 0.4348 - accuracy: 0.7250 - val_loss: 0.4400 - val_accuracy: 0.6949
Epoch 55/1000
2/2 [==============================] - ETA: 0s - loss: 0.5062 - accuracy: 0.6641
Epoch 55: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5062 - accuracy: 0.6641 - val_loss: 0.4370 - val_accuracy: 0.7119
Epoch 56/1000
2/2 [==============================] - ETA: 0s - loss: 0.5069 - accuracy: 0.5875
Epoch 56: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5069 - accuracy: 0.5875 - val_loss: 0.4306 - val_accuracy: 0.7119
Epoch 57/1000
2/2 [==============================] - ETA: 0s - loss: 0.4512 - accuracy: 0.7125
Epoch 57: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4512 - accuracy: 0.7125 - val_loss: 0.4254 - val_accuracy: 0.7119
Epoch 58/1000
2/2 [==============================] - ETA: 0s - loss: 0.5265 - accuracy: 0.6625
Epoch 58: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5265 - accuracy: 0.6625 - val_loss: 0.4208 - val_accuracy: 0.7119
Epoch 59/1000
2/2 [==============================] - ETA: 0s - loss: 0.4557 - accuracy: 0.7375
Epoch 59: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 792ms/step - loss: 0.4557 - accuracy: 0.7375 - val_loss: 0.4171 - val_accuracy: 0.7119
Epoch 60/1000
2/2 [==============================] - ETA: 0s - loss: 0.5258 - accuracy: 0.6125
Epoch 60: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 793ms/step - loss: 0.5258 - accuracy: 0.6125 - val_loss: 0.4139 - val_accuracy: 0.7119
Epoch 61/1000
2/2 [==============================] - ETA: 0s - loss: 0.4988 - accuracy: 0.6641
Epoch 61: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4988 - accuracy: 0.6641 - val_loss: 0.4117 - val_accuracy: 0.7119
Epoch 62/1000
2/2 [==============================] - ETA: 0s - loss: 0.5074 - accuracy: 0.6625
Epoch 62: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.5074 - accuracy: 0.6625 - val_loss: 0.4109 - val_accuracy: 0.7119
Epoch 63/1000
2/2 [==============================] - ETA: 0s - loss: 0.5155 - accuracy: 0.6797
Epoch 63: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.5155 - accuracy: 0.6797 - val_loss: 0.4105 - val_accuracy: 0.7119
Epoch 64/1000
2/2 [==============================] - ETA: 0s - loss: 0.4738 - accuracy: 0.7031
Epoch 64: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4738 - accuracy: 0.7031 - val_loss: 0.4101 - val_accuracy: 0.7119
Epoch 65/1000
2/2 [==============================] - ETA: 0s - loss: 0.4526 - accuracy: 0.7266
Epoch 65: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4526 - accuracy: 0.7266 - val_loss: 0.4099 - val_accuracy: 0.7288
Epoch 66/1000
2/2 [==============================] - ETA: 0s - loss: 0.4432 - accuracy: 0.6875
Epoch 66: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 917ms/step - loss: 0.4432 - accuracy: 0.6875 - val_loss: 0.4096 - val_accuracy: 0.7288
Epoch 67/1000
2/2 [==============================] - ETA: 0s - loss: 0.4556 - accuracy: 0.7031
Epoch 67: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 891ms/step - loss: 0.4556 - accuracy: 0.7031 - val_loss: 0.4089 - val_accuracy: 0.7288
Epoch 68/1000
2/2 [==============================] - ETA: 0s - loss: 0.4906 - accuracy: 0.7000
Epoch 68: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4906 - accuracy: 0.7000 - val_loss: 0.4077 - val_accuracy: 0.7288
Epoch 69/1000
2/2 [==============================] - ETA: 0s - loss: 0.4392 - accuracy: 0.6953
Epoch 69: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 933ms/step - loss: 0.4392 - accuracy: 0.6953 - val_loss: 0.4067 - val_accuracy: 0.7288
Epoch 70/1000
2/2 [==============================] - ETA: 0s - loss: 0.4505 - accuracy: 0.7188
Epoch 70: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 911ms/step - loss: 0.4505 - accuracy: 0.7188 - val_loss: 0.4056 - val_accuracy: 0.7288
Epoch 71/1000
2/2 [==============================] - ETA: 0s - loss: 0.4227 - accuracy: 0.8250
Epoch 71: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4227 - accuracy: 0.8250 - val_loss: 0.4038 - val_accuracy: 0.7288
Epoch 72/1000
2/2 [==============================] - ETA: 0s - loss: 0.4216 - accuracy: 0.7188
Epoch 72: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 942ms/step - loss: 0.4216 - accuracy: 0.7188 - val_loss: 0.4028 - val_accuracy: 0.7288
Epoch 73/1000
2/2 [==============================] - ETA: 0s - loss: 0.4563 - accuracy: 0.7031
Epoch 73: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4563 - accuracy: 0.7031 - val_loss: 0.4029 - val_accuracy: 0.7288
Epoch 74/1000
2/2 [==============================] - ETA: 0s - loss: 0.4717 - accuracy: 0.6719
Epoch 74: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4717 - accuracy: 0.6719 - val_loss: 0.4026 - val_accuracy: 0.7288
Epoch 75/1000
2/2 [==============================] - ETA: 0s - loss: 0.3515 - accuracy: 0.8250
Epoch 75: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3515 - accuracy: 0.8250 - val_loss: 0.4009 - val_accuracy: 0.7119
Epoch 76/1000
2/2 [==============================] - ETA: 0s - loss: 0.4396 - accuracy: 0.7125
Epoch 76: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.4396 - accuracy: 0.7125 - val_loss: 0.4004 - val_accuracy: 0.7288
Epoch 77/1000
2/2 [==============================] - ETA: 0s - loss: 0.4737 - accuracy: 0.6250
Epoch 77: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4737 - accuracy: 0.6250 - val_loss: 0.4002 - val_accuracy: 0.7458
Epoch 78/1000
2/2 [==============================] - ETA: 0s - loss: 0.3818 - accuracy: 0.8125
Epoch 78: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3818 - accuracy: 0.8125 - val_loss: 0.3997 - val_accuracy: 0.7458
Epoch 79/1000
2/2 [==============================] - ETA: 0s - loss: 0.3942 - accuracy: 0.7812
Epoch 79: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3942 - accuracy: 0.7812 - val_loss: 0.3999 - val_accuracy: 0.7458
Epoch 80/1000
2/2 [==============================] - ETA: 0s - loss: 0.4376 - accuracy: 0.7625
Epoch 80: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4376 - accuracy: 0.7625 - val_loss: 0.3999 - val_accuracy: 0.7288
Epoch 81/1000
2/2 [==============================] - ETA: 0s - loss: 0.4146 - accuracy: 0.7875
Epoch 81: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4146 - accuracy: 0.7875 - val_loss: 0.3985 - val_accuracy: 0.7458
Epoch 82/1000
2/2 [==============================] - ETA: 0s - loss: 0.4513 - accuracy: 0.7109
Epoch 82: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 952ms/step - loss: 0.4513 - accuracy: 0.7109 - val_loss: 0.3975 - val_accuracy: 0.7458
Epoch 83/1000
2/2 [==============================] - ETA: 0s - loss: 0.4000 - accuracy: 0.7875
Epoch 83: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4000 - accuracy: 0.7875 - val_loss: 0.3966 - val_accuracy: 0.7458
Epoch 84/1000
2/2 [==============================] - ETA: 0s - loss: 0.3920 - accuracy: 0.7812
Epoch 84: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3920 - accuracy: 0.7812 - val_loss: 0.3957 - val_accuracy: 0.7458
Epoch 85/1000
2/2 [==============================] - ETA: 0s - loss: 0.4480 - accuracy: 0.6750
Epoch 85: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4480 - accuracy: 0.6750 - val_loss: 0.3950 - val_accuracy: 0.7458
Epoch 86/1000
2/2 [==============================] - ETA: 0s - loss: 0.4010 - accuracy: 0.7656
Epoch 86: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 881ms/step - loss: 0.4010 - accuracy: 0.7656 - val_loss: 0.3956 - val_accuracy: 0.7288
Epoch 87/1000
2/2 [==============================] - ETA: 0s - loss: 0.4635 - accuracy: 0.7125
Epoch 87: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4635 - accuracy: 0.7125 - val_loss: 0.3978 - val_accuracy: 0.7288
Epoch 88/1000
2/2 [==============================] - ETA: 0s - loss: 0.4501 - accuracy: 0.7188
Epoch 88: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 915ms/step - loss: 0.4501 - accuracy: 0.7188 - val_loss: 0.4002 - val_accuracy: 0.7627
Epoch 89/1000
2/2 [==============================] - ETA: 0s - loss: 0.3909 - accuracy: 0.7875
Epoch 89: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3909 - accuracy: 0.7875 - val_loss: 0.4037 - val_accuracy: 0.7627
Epoch 90/1000
2/2 [==============================] - ETA: 0s - loss: 0.3992 - accuracy: 0.7250
Epoch 90: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3992 - accuracy: 0.7250 - val_loss: 0.4045 - val_accuracy: 0.7627
Epoch 91/1000
2/2 [==============================] - ETA: 0s - loss: 0.4022 - accuracy: 0.8203
Epoch 91: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.4022 - accuracy: 0.8203 - val_loss: 0.4050 - val_accuracy: 0.7458
Epoch 92/1000
2/2 [==============================] - ETA: 0s - loss: 0.4112 - accuracy: 0.7031
Epoch 92: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 972ms/step - loss: 0.4112 - accuracy: 0.7031 - val_loss: 0.4050 - val_accuracy: 0.7458
Epoch 93/1000
2/2 [==============================] - ETA: 0s - loss: 0.3795 - accuracy: 0.7500
Epoch 93: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3795 - accuracy: 0.7500 - val_loss: 0.4046 - val_accuracy: 0.7458
Epoch 94/1000
2/2 [==============================] - ETA: 0s - loss: 0.4178 - accuracy: 0.7250
Epoch 94: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 786ms/step - loss: 0.4178 - accuracy: 0.7250 - val_loss: 0.4047 - val_accuracy: 0.7458
Epoch 95/1000
2/2 [==============================] - ETA: 0s - loss: 0.3446 - accuracy: 0.8281
Epoch 95: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3446 - accuracy: 0.8281 - val_loss: 0.4047 - val_accuracy: 0.7458
Epoch 96/1000
2/2 [==============================] - ETA: 0s - loss: 0.4607 - accuracy: 0.7250
Epoch 96: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4607 - accuracy: 0.7250 - val_loss: 0.4035 - val_accuracy: 0.7458
Epoch 97/1000
2/2 [==============================] - ETA: 0s - loss: 0.3616 - accuracy: 0.7875
Epoch 97: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 809ms/step - loss: 0.3616 - accuracy: 0.7875 - val_loss: 0.4021 - val_accuracy: 0.7458
Epoch 98/1000
2/2 [==============================] - ETA: 0s - loss: 0.3380 - accuracy: 0.7375
Epoch 98: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.3380 - accuracy: 0.7375 - val_loss: 0.4014 - val_accuracy: 0.7458
Epoch 99/1000
2/2 [==============================] - ETA: 0s - loss: 0.3621 - accuracy: 0.8047
Epoch 99: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 925ms/step - loss: 0.3621 - accuracy: 0.8047 - val_loss: 0.3993 - val_accuracy: 0.7288
Epoch 100/1000
2/2 [==============================] - ETA: 0s - loss: 0.3969 - accuracy: 0.7578
Epoch 100: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 922ms/step - loss: 0.3969 - accuracy: 0.7578 - val_loss: 0.3952 - val_accuracy: 0.7288
Epoch 101/1000
2/2 [==============================] - ETA: 0s - loss: 0.3638 - accuracy: 0.7500
Epoch 101: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 807ms/step - loss: 0.3638 - accuracy: 0.7500 - val_loss: 0.3910 - val_accuracy: 0.7288
Epoch 102/1000
2/2 [==============================] - ETA: 0s - loss: 0.3590 - accuracy: 0.7891
Epoch 102: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 912ms/step - loss: 0.3590 - accuracy: 0.7891 - val_loss: 0.3877 - val_accuracy: 0.7288
Epoch 103/1000
2/2 [==============================] - ETA: 0s - loss: 0.3947 - accuracy: 0.7656
Epoch 103: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 959ms/step - loss: 0.3947 - accuracy: 0.7656 - val_loss: 0.3841 - val_accuracy: 0.7288
Epoch 104/1000
2/2 [==============================] - ETA: 0s - loss: 0.4289 - accuracy: 0.7250
Epoch 104: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 805ms/step - loss: 0.4289 - accuracy: 0.7250 - val_loss: 0.3815 - val_accuracy: 0.7288
Epoch 105/1000
2/2 [==============================] - ETA: 0s - loss: 0.3684 - accuracy: 0.8359
Epoch 105: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3684 - accuracy: 0.8359 - val_loss: 0.3784 - val_accuracy: 0.7288
Epoch 106/1000
2/2 [==============================] - ETA: 0s - loss: 0.3745 - accuracy: 0.8000
Epoch 106: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 866ms/step - loss: 0.3745 - accuracy: 0.8000 - val_loss: 0.3758 - val_accuracy: 0.7288
Epoch 107/1000
2/2 [==============================] - ETA: 0s - loss: 0.3485 - accuracy: 0.8125
Epoch 107: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 917ms/step - loss: 0.3485 - accuracy: 0.8125 - val_loss: 0.3743 - val_accuracy: 0.7458
Epoch 108/1000
2/2 [==============================] - ETA: 0s - loss: 0.3889 - accuracy: 0.8000
Epoch 108: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 997ms/step - loss: 0.3889 - accuracy: 0.8000 - val_loss: 0.3726 - val_accuracy: 0.7458
Epoch 109/1000
2/2 [==============================] - ETA: 0s - loss: 0.3484 - accuracy: 0.8672
Epoch 109: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.3484 - accuracy: 0.8672 - val_loss: 0.3712 - val_accuracy: 0.7458
Epoch 110/1000
2/2 [==============================] - ETA: 0s - loss: 0.3734 - accuracy: 0.8047
Epoch 110: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3734 - accuracy: 0.8047 - val_loss: 0.3696 - val_accuracy: 0.7458
Epoch 111/1000
2/2 [==============================] - ETA: 0s - loss: 0.4089 - accuracy: 0.7875
Epoch 111: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 789ms/step - loss: 0.4089 - accuracy: 0.7875 - val_loss: 0.3676 - val_accuracy: 0.7458
Epoch 112/1000
2/2 [==============================] - ETA: 0s - loss: 0.3788 - accuracy: 0.7750
Epoch 112: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 783ms/step - loss: 0.3788 - accuracy: 0.7750 - val_loss: 0.3646 - val_accuracy: 0.7288
Epoch 113/1000
2/2 [==============================] - ETA: 0s - loss: 0.3728 - accuracy: 0.7812
Epoch 113: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3728 - accuracy: 0.7812 - val_loss: 0.3621 - val_accuracy: 0.7288
Epoch 114/1000
2/2 [==============================] - ETA: 0s - loss: 0.3751 - accuracy: 0.8000
Epoch 114: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3751 - accuracy: 0.8000 - val_loss: 0.3599 - val_accuracy: 0.7288
Epoch 115/1000
2/2 [==============================] - ETA: 0s - loss: 0.3739 - accuracy: 0.7734
Epoch 115: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 946ms/step - loss: 0.3739 - accuracy: 0.7734 - val_loss: 0.3578 - val_accuracy: 0.7288
Epoch 116/1000
2/2 [==============================] - ETA: 0s - loss: 0.3883 - accuracy: 0.8000
Epoch 116: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3883 - accuracy: 0.8000 - val_loss: 0.3563 - val_accuracy: 0.7288
Epoch 117/1000
2/2 [==============================] - ETA: 0s - loss: 0.3443 - accuracy: 0.8203
Epoch 117: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3443 - accuracy: 0.8203 - val_loss: 0.3552 - val_accuracy: 0.7458
Epoch 118/1000
2/2 [==============================] - ETA: 0s - loss: 0.3449 - accuracy: 0.8375
Epoch 118: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3449 - accuracy: 0.8375 - val_loss: 0.3555 - val_accuracy: 0.7458
Epoch 119/1000
2/2 [==============================] - ETA: 0s - loss: 0.3562 - accuracy: 0.8000
Epoch 119: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3562 - accuracy: 0.8000 - val_loss: 0.3556 - val_accuracy: 0.7458
Epoch 120/1000
2/2 [==============================] - ETA: 0s - loss: 0.2561 - accuracy: 0.8828
Epoch 120: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 914ms/step - loss: 0.2561 - accuracy: 0.8828 - val_loss: 0.3562 - val_accuracy: 0.7458
Epoch 121/1000
2/2 [==============================] - ETA: 0s - loss: 0.3495 - accuracy: 0.8125
Epoch 121: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 916ms/step - loss: 0.3495 - accuracy: 0.8125 - val_loss: 0.3566 - val_accuracy: 0.7627
Epoch 122/1000
2/2 [==============================] - ETA: 0s - loss: 0.3165 - accuracy: 0.8672
Epoch 122: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3165 - accuracy: 0.8672 - val_loss: 0.3566 - val_accuracy: 0.7627
Epoch 123/1000
2/2 [==============================] - ETA: 0s - loss: 0.3741 - accuracy: 0.7734
Epoch 123: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3741 - accuracy: 0.7734 - val_loss: 0.3571 - val_accuracy: 0.7627
Epoch 124/1000
2/2 [==============================] - ETA: 0s - loss: 0.3923 - accuracy: 0.7500
Epoch 124: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 955ms/step - loss: 0.3923 - accuracy: 0.7500 - val_loss: 0.3574 - val_accuracy: 0.7627
Epoch 125/1000
2/2 [==============================] - ETA: 0s - loss: 0.3380 - accuracy: 0.7812
Epoch 125: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 912ms/step - loss: 0.3380 - accuracy: 0.7812 - val_loss: 0.3575 - val_accuracy: 0.7627
Epoch 126/1000
2/2 [==============================] - ETA: 0s - loss: 0.3617 - accuracy: 0.7875
Epoch 126: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3617 - accuracy: 0.7875 - val_loss: 0.3581 - val_accuracy: 0.7627
Epoch 127/1000
2/2 [==============================] - ETA: 0s - loss: 0.4007 - accuracy: 0.7000
Epoch 127: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4007 - accuracy: 0.7000 - val_loss: 0.3577 - val_accuracy: 0.7627
Epoch 128/1000
2/2 [==============================] - ETA: 0s - loss: 0.3632 - accuracy: 0.8000
Epoch 128: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3632 - accuracy: 0.8000 - val_loss: 0.3570 - val_accuracy: 0.7627
Epoch 129/1000
2/2 [==============================] - ETA: 0s - loss: 0.3418 - accuracy: 0.8359
Epoch 129: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3418 - accuracy: 0.8359 - val_loss: 0.3558 - val_accuracy: 0.7627
Epoch 130/1000
2/2 [==============================] - ETA: 0s - loss: 0.3338 - accuracy: 0.8250
Epoch 130: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.3338 - accuracy: 0.8250 - val_loss: 0.3545 - val_accuracy: 0.7627
Epoch 131/1000
2/2 [==============================] - ETA: 0s - loss: 0.3705 - accuracy: 0.7750
Epoch 131: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3705 - accuracy: 0.7750 - val_loss: 0.3534 - val_accuracy: 0.7627
Epoch 132/1000
2/2 [==============================] - ETA: 0s - loss: 0.2992 - accuracy: 0.8625
Epoch 132: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2992 - accuracy: 0.8625 - val_loss: 0.3531 - val_accuracy: 0.7627
Epoch 133/1000
2/2 [==============================] - ETA: 0s - loss: 0.3112 - accuracy: 0.8438
Epoch 133: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 940ms/step - loss: 0.3112 - accuracy: 0.8438 - val_loss: 0.3533 - val_accuracy: 0.7627
Epoch 134/1000
2/2 [==============================] - ETA: 0s - loss: 0.3687 - accuracy: 0.8203
Epoch 134: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 926ms/step - loss: 0.3687 - accuracy: 0.8203 - val_loss: 0.3521 - val_accuracy: 0.7627
Epoch 135/1000
2/2 [==============================] - ETA: 0s - loss: 0.4165 - accuracy: 0.7250
Epoch 135: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.4165 - accuracy: 0.7250 - val_loss: 0.3497 - val_accuracy: 0.7627
Epoch 136/1000
2/2 [==============================] - ETA: 0s - loss: 0.2755 - accuracy: 0.8750
Epoch 136: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 801ms/step - loss: 0.2755 - accuracy: 0.8750 - val_loss: 0.3483 - val_accuracy: 0.7627
Epoch 137/1000
2/2 [==============================] - ETA: 0s - loss: 0.3457 - accuracy: 0.8000
Epoch 137: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 783ms/step - loss: 0.3457 - accuracy: 0.8000 - val_loss: 0.3478 - val_accuracy: 0.7627
Epoch 138/1000
2/2 [==============================] - ETA: 0s - loss: 0.3676 - accuracy: 0.7812
Epoch 138: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3676 - accuracy: 0.7812 - val_loss: 0.3470 - val_accuracy: 0.7627
Epoch 139/1000
2/2 [==============================] - ETA: 0s - loss: 0.3189 - accuracy: 0.7875
Epoch 139: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 781ms/step - loss: 0.3189 - accuracy: 0.7875 - val_loss: 0.3467 - val_accuracy: 0.7627
Epoch 140/1000
2/2 [==============================] - ETA: 0s - loss: 0.3633 - accuracy: 0.7875
Epoch 140: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3633 - accuracy: 0.7875 - val_loss: 0.3483 - val_accuracy: 0.7627
Epoch 141/1000
2/2 [==============================] - ETA: 0s - loss: 0.3355 - accuracy: 0.7875
Epoch 141: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 852ms/step - loss: 0.3355 - accuracy: 0.7875 - val_loss: 0.3495 - val_accuracy: 0.7627
Epoch 142/1000
2/2 [==============================] - ETA: 0s - loss: 0.3416 - accuracy: 0.8250
Epoch 142: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 796ms/step - loss: 0.3416 - accuracy: 0.8250 - val_loss: 0.3497 - val_accuracy: 0.7627
Epoch 143/1000
2/2 [==============================] - ETA: 0s - loss: 0.3214 - accuracy: 0.8438
Epoch 143: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3214 - accuracy: 0.8438 - val_loss: 0.3494 - val_accuracy: 0.7627
Epoch 144/1000
2/2 [==============================] - ETA: 0s - loss: 0.3541 - accuracy: 0.7875
Epoch 144: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3541 - accuracy: 0.7875 - val_loss: 0.3490 - val_accuracy: 0.7627
Epoch 145/1000
2/2 [==============================] - ETA: 0s - loss: 0.3347 - accuracy: 0.8500
Epoch 145: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 806ms/step - loss: 0.3347 - accuracy: 0.8500 - val_loss: 0.3488 - val_accuracy: 0.7627
Epoch 146/1000
2/2 [==============================] - ETA: 0s - loss: 0.3238 - accuracy: 0.8594
Epoch 146: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 969ms/step - loss: 0.3238 - accuracy: 0.8594 - val_loss: 0.3493 - val_accuracy: 0.7627
Epoch 147/1000
2/2 [==============================] - ETA: 0s - loss: 0.3252 - accuracy: 0.8250
Epoch 147: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 799ms/step - loss: 0.3252 - accuracy: 0.8250 - val_loss: 0.3499 - val_accuracy: 0.7627
Epoch 148/1000
2/2 [==============================] - ETA: 0s - loss: 0.3136 - accuracy: 0.8250
Epoch 148: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 766ms/step - loss: 0.3136 - accuracy: 0.8250 - val_loss: 0.3515 - val_accuracy: 0.7627
Epoch 149/1000
2/2 [==============================] - ETA: 0s - loss: 0.3215 - accuracy: 0.8250
Epoch 149: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3215 - accuracy: 0.8250 - val_loss: 0.3529 - val_accuracy: 0.7627
Epoch 150/1000
2/2 [==============================] - ETA: 0s - loss: 0.3838 - accuracy: 0.7625
Epoch 150: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3838 - accuracy: 0.7625 - val_loss: 0.3546 - val_accuracy: 0.7627
Epoch 151/1000
2/2 [==============================] - ETA: 0s - loss: 0.3322 - accuracy: 0.8125
Epoch 151: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 809ms/step - loss: 0.3322 - accuracy: 0.8125 - val_loss: 0.3537 - val_accuracy: 0.7627
Epoch 152/1000
2/2 [==============================] - ETA: 0s - loss: 0.3422 - accuracy: 0.8281
Epoch 152: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 913ms/step - loss: 0.3422 - accuracy: 0.8281 - val_loss: 0.3523 - val_accuracy: 0.7627
Epoch 153/1000
2/2 [==============================] - ETA: 0s - loss: 0.3141 - accuracy: 0.8500
Epoch 153: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 876ms/step - loss: 0.3141 - accuracy: 0.8500 - val_loss: 0.3495 - val_accuracy: 0.7627
Epoch 154/1000
2/2 [==============================] - ETA: 0s - loss: 0.3786 - accuracy: 0.7625
Epoch 154: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3786 - accuracy: 0.7625 - val_loss: 0.3458 - val_accuracy: 0.7627
Epoch 155/1000
2/2 [==============================] - ETA: 0s - loss: 0.3309 - accuracy: 0.8125
Epoch 155: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3309 - accuracy: 0.8125 - val_loss: 0.3425 - val_accuracy: 0.7627
Epoch 156/1000
2/2 [==============================] - ETA: 0s - loss: 0.3570 - accuracy: 0.7969
Epoch 156: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 928ms/step - loss: 0.3570 - accuracy: 0.7969 - val_loss: 0.3386 - val_accuracy: 0.7797
Epoch 157/1000
2/2 [==============================] - ETA: 0s - loss: 0.3137 - accuracy: 0.8250
Epoch 157: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 779ms/step - loss: 0.3137 - accuracy: 0.8250 - val_loss: 0.3349 - val_accuracy: 0.7797
Epoch 158/1000
2/2 [==============================] - ETA: 0s - loss: 0.3485 - accuracy: 0.8281
Epoch 158: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3485 - accuracy: 0.8281 - val_loss: 0.3321 - val_accuracy: 0.7797
Epoch 159/1000
2/2 [==============================] - ETA: 0s - loss: 0.3114 - accuracy: 0.8594
Epoch 159: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 997ms/step - loss: 0.3114 - accuracy: 0.8594 - val_loss: 0.3295 - val_accuracy: 0.7797
Epoch 160/1000
2/2 [==============================] - ETA: 0s - loss: 0.3695 - accuracy: 0.7750
Epoch 160: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3695 - accuracy: 0.7750 - val_loss: 0.3255 - val_accuracy: 0.7797
Epoch 161/1000
2/2 [==============================] - ETA: 0s - loss: 0.3590 - accuracy: 0.8125
Epoch 161: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 794ms/step - loss: 0.3590 - accuracy: 0.8125 - val_loss: 0.3215 - val_accuracy: 0.7797
Epoch 162/1000
2/2 [==============================] - ETA: 0s - loss: 0.3375 - accuracy: 0.8250
Epoch 162: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3375 - accuracy: 0.8250 - val_loss: 0.3184 - val_accuracy: 0.7797
Epoch 163/1000
2/2 [==============================] - ETA: 0s - loss: 0.2919 - accuracy: 0.8672
Epoch 163: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2919 - accuracy: 0.8672 - val_loss: 0.3172 - val_accuracy: 0.7797
Epoch 164/1000
2/2 [==============================] - ETA: 0s - loss: 0.2972 - accuracy: 0.8594
Epoch 164: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.2972 - accuracy: 0.8594 - val_loss: 0.3171 - val_accuracy: 0.7797
Epoch 165/1000
2/2 [==============================] - ETA: 0s - loss: 0.3267 - accuracy: 0.8359
Epoch 165: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3267 - accuracy: 0.8359 - val_loss: 0.3175 - val_accuracy: 0.7797
Epoch 166/1000
2/2 [==============================] - ETA: 0s - loss: 0.2999 - accuracy: 0.8438
Epoch 166: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2999 - accuracy: 0.8438 - val_loss: 0.3182 - val_accuracy: 0.7797
Epoch 167/1000
2/2 [==============================] - ETA: 0s - loss: 0.3014 - accuracy: 0.8750
Epoch 167: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 787ms/step - loss: 0.3014 - accuracy: 0.8750 - val_loss: 0.3198 - val_accuracy: 0.7797
Epoch 168/1000
2/2 [==============================] - ETA: 0s - loss: 0.2670 - accuracy: 0.8250
Epoch 168: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 810ms/step - loss: 0.2670 - accuracy: 0.8250 - val_loss: 0.3217 - val_accuracy: 0.7797
Epoch 169/1000
2/2 [==============================] - ETA: 0s - loss: 0.3162 - accuracy: 0.8750
Epoch 169: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 793ms/step - loss: 0.3162 - accuracy: 0.8750 - val_loss: 0.3219 - val_accuracy: 0.7797
Epoch 170/1000
2/2 [==============================] - ETA: 0s - loss: 0.3178 - accuracy: 0.8047
Epoch 170: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 943ms/step - loss: 0.3178 - accuracy: 0.8047 - val_loss: 0.3221 - val_accuracy: 0.7797
Epoch 171/1000
2/2 [==============================] - ETA: 0s - loss: 0.2931 - accuracy: 0.8672
Epoch 171: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 923ms/step - loss: 0.2931 - accuracy: 0.8672 - val_loss: 0.3225 - val_accuracy: 0.7797
Epoch 172/1000
2/2 [==============================] - ETA: 0s - loss: 0.3197 - accuracy: 0.8047
Epoch 172: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3197 - accuracy: 0.8047 - val_loss: 0.3238 - val_accuracy: 0.7797
Epoch 173/1000
2/2 [==============================] - ETA: 0s - loss: 0.2872 - accuracy: 0.8281
Epoch 173: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2872 - accuracy: 0.8281 - val_loss: 0.3255 - val_accuracy: 0.7797
Epoch 174/1000
2/2 [==============================] - ETA: 0s - loss: 0.3595 - accuracy: 0.7734
Epoch 174: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3595 - accuracy: 0.7734 - val_loss: 0.3273 - val_accuracy: 0.7797
Epoch 175/1000
2/2 [==============================] - ETA: 0s - loss: 0.3140 - accuracy: 0.8375
Epoch 175: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.3140 - accuracy: 0.8375 - val_loss: 0.3280 - val_accuracy: 0.7797
Epoch 176/1000
2/2 [==============================] - ETA: 0s - loss: 0.3210 - accuracy: 0.8125
Epoch 176: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3210 - accuracy: 0.8125 - val_loss: 0.3281 - val_accuracy: 0.7797
Epoch 177/1000
2/2 [==============================] - ETA: 0s - loss: 0.2593 - accuracy: 0.8125
Epoch 177: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2593 - accuracy: 0.8125 - val_loss: 0.3297 - val_accuracy: 0.7797
Epoch 178/1000
2/2 [==============================] - ETA: 0s - loss: 0.3493 - accuracy: 0.7891
Epoch 178: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3493 - accuracy: 0.7891 - val_loss: 0.3316 - val_accuracy: 0.7797
Epoch 179/1000
2/2 [==============================] - ETA: 0s - loss: 0.3391 - accuracy: 0.8375
Epoch 179: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3391 - accuracy: 0.8375 - val_loss: 0.3345 - val_accuracy: 0.7797
Epoch 180/1000
2/2 [==============================] - ETA: 0s - loss: 0.2908 - accuracy: 0.8438
Epoch 180: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2908 - accuracy: 0.8438 - val_loss: 0.3373 - val_accuracy: 0.7797
Epoch 181/1000
2/2 [==============================] - ETA: 0s - loss: 0.2884 - accuracy: 0.8438
Epoch 181: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 912ms/step - loss: 0.2884 - accuracy: 0.8438 - val_loss: 0.3386 - val_accuracy: 0.7797
Epoch 182/1000
2/2 [==============================] - ETA: 0s - loss: 0.2741 - accuracy: 0.8750
Epoch 182: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2741 - accuracy: 0.8750 - val_loss: 0.3397 - val_accuracy: 0.7966
Epoch 183/1000
2/2 [==============================] - ETA: 0s - loss: 0.3079 - accuracy: 0.8375
Epoch 183: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3079 - accuracy: 0.8375 - val_loss: 0.3402 - val_accuracy: 0.7966
Epoch 184/1000
2/2 [==============================] - ETA: 0s - loss: 0.2915 - accuracy: 0.8500
Epoch 184: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 821ms/step - loss: 0.2915 - accuracy: 0.8500 - val_loss: 0.3408 - val_accuracy: 0.8136
Epoch 185/1000
2/2 [==============================] - ETA: 0s - loss: 0.2488 - accuracy: 0.9062
Epoch 185: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2488 - accuracy: 0.9062 - val_loss: 0.3411 - val_accuracy: 0.8136
Epoch 186/1000
2/2 [==============================] - ETA: 0s - loss: 0.2850 - accuracy: 0.8281
Epoch 186: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2850 - accuracy: 0.8281 - val_loss: 0.3412 - val_accuracy: 0.8136
Epoch 187/1000
2/2 [==============================] - ETA: 0s - loss: 0.3010 - accuracy: 0.8375
Epoch 187: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 816ms/step - loss: 0.3010 - accuracy: 0.8375 - val_loss: 0.3412 - val_accuracy: 0.7966
Epoch 188/1000
2/2 [==============================] - ETA: 0s - loss: 0.2825 - accuracy: 0.8594
Epoch 188: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 979ms/step - loss: 0.2825 - accuracy: 0.8594 - val_loss: 0.3410 - val_accuracy: 0.7966
Epoch 189/1000
2/2 [==============================] - ETA: 0s - loss: 0.3138 - accuracy: 0.8125
Epoch 189: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 956ms/step - loss: 0.3138 - accuracy: 0.8125 - val_loss: 0.3392 - val_accuracy: 0.7966
Epoch 190/1000
2/2 [==============================] - ETA: 0s - loss: 0.3285 - accuracy: 0.8000
Epoch 190: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 793ms/step - loss: 0.3285 - accuracy: 0.8000 - val_loss: 0.3374 - val_accuracy: 0.8136
Epoch 191/1000
2/2 [==============================] - ETA: 0s - loss: 0.3562 - accuracy: 0.7375
Epoch 191: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 794ms/step - loss: 0.3562 - accuracy: 0.7375 - val_loss: 0.3362 - val_accuracy: 0.8305
Epoch 192/1000
2/2 [==============================] - ETA: 0s - loss: 0.2750 - accuracy: 0.8625
Epoch 192: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 805ms/step - loss: 0.2750 - accuracy: 0.8625 - val_loss: 0.3371 - val_accuracy: 0.8305
Epoch 193/1000
2/2 [==============================] - ETA: 0s - loss: 0.2853 - accuracy: 0.8750
Epoch 193: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 778ms/step - loss: 0.2853 - accuracy: 0.8750 - val_loss: 0.3378 - val_accuracy: 0.8305
Epoch 194/1000
2/2 [==============================] - ETA: 0s - loss: 0.2862 - accuracy: 0.8625
Epoch 194: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2862 - accuracy: 0.8625 - val_loss: 0.3387 - val_accuracy: 0.8136
Epoch 195/1000
2/2 [==============================] - ETA: 0s - loss: 0.3483 - accuracy: 0.7625
Epoch 195: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.3483 - accuracy: 0.7625 - val_loss: 0.3393 - val_accuracy: 0.8136
Epoch 196/1000
2/2 [==============================] - ETA: 0s - loss: 0.2863 - accuracy: 0.8594
Epoch 196: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2863 - accuracy: 0.8594 - val_loss: 0.3378 - val_accuracy: 0.8136
Epoch 197/1000
2/2 [==============================] - ETA: 0s - loss: 0.2744 - accuracy: 0.8500
Epoch 197: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.2744 - accuracy: 0.8500 - val_loss: 0.3355 - val_accuracy: 0.8136
Epoch 198/1000
2/2 [==============================] - ETA: 0s - loss: 0.2827 - accuracy: 0.8438
Epoch 198: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 952ms/step - loss: 0.2827 - accuracy: 0.8438 - val_loss: 0.3326 - val_accuracy: 0.8136
Epoch 199/1000
2/2 [==============================] - ETA: 0s - loss: 0.2542 - accuracy: 0.8875
Epoch 199: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.2542 - accuracy: 0.8875 - val_loss: 0.3295 - val_accuracy: 0.8136
Epoch 200/1000
2/2 [==============================] - ETA: 0s - loss: 0.2779 - accuracy: 0.8672
Epoch 200: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2779 - accuracy: 0.8672 - val_loss: 0.3259 - val_accuracy: 0.8305
Epoch 201/1000
2/2 [==============================] - ETA: 0s - loss: 0.3151 - accuracy: 0.8516
Epoch 201: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.3151 - accuracy: 0.8516 - val_loss: 0.3212 - val_accuracy: 0.8305
Epoch 202/1000
2/2 [==============================] - ETA: 0s - loss: 0.2635 - accuracy: 0.8438
Epoch 202: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2635 - accuracy: 0.8438 - val_loss: 0.3172 - val_accuracy: 0.8305
Epoch 203/1000
2/2 [==============================] - ETA: 0s - loss: 0.2691 - accuracy: 0.8906
Epoch 203: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2691 - accuracy: 0.8906 - val_loss: 0.3138 - val_accuracy: 0.8305
Epoch 204/1000
2/2 [==============================] - ETA: 0s - loss: 0.2818 - accuracy: 0.8500
Epoch 204: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2818 - accuracy: 0.8500 - val_loss: 0.3109 - val_accuracy: 0.8305
Epoch 205/1000
2/2 [==============================] - ETA: 0s - loss: 0.2874 - accuracy: 0.8125
Epoch 205: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2874 - accuracy: 0.8125 - val_loss: 0.3089 - val_accuracy: 0.8136
Epoch 206/1000
2/2 [==============================] - ETA: 0s - loss: 0.2961 - accuracy: 0.8500
Epoch 206: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 821ms/step - loss: 0.2961 - accuracy: 0.8500 - val_loss: 0.3080 - val_accuracy: 0.8136
Epoch 207/1000
2/2 [==============================] - ETA: 0s - loss: 0.2628 - accuracy: 0.8516
Epoch 207: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2628 - accuracy: 0.8516 - val_loss: 0.3077 - val_accuracy: 0.8136
Epoch 208/1000
2/2 [==============================] - ETA: 0s - loss: 0.2807 - accuracy: 0.8750
Epoch 208: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 792ms/step - loss: 0.2807 - accuracy: 0.8750 - val_loss: 0.3076 - val_accuracy: 0.8136
Epoch 209/1000
2/2 [==============================] - ETA: 0s - loss: 0.2190 - accuracy: 0.8828
Epoch 209: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 902ms/step - loss: 0.2190 - accuracy: 0.8828 - val_loss: 0.3073 - val_accuracy: 0.8136
Epoch 210/1000
2/2 [==============================] - ETA: 0s - loss: 0.2307 - accuracy: 0.8875
Epoch 210: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2307 - accuracy: 0.8875 - val_loss: 0.3073 - val_accuracy: 0.8136
Epoch 211/1000
2/2 [==============================] - ETA: 0s - loss: 0.2403 - accuracy: 0.8672
Epoch 211: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2403 - accuracy: 0.8672 - val_loss: 0.3079 - val_accuracy: 0.8136
Epoch 212/1000
2/2 [==============================] - ETA: 0s - loss: 0.2151 - accuracy: 0.9375
Epoch 212: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2151 - accuracy: 0.9375 - val_loss: 0.3075 - val_accuracy: 0.8136
Epoch 213/1000
2/2 [==============================] - ETA: 0s - loss: 0.2767 - accuracy: 0.8875
Epoch 213: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.2767 - accuracy: 0.8875 - val_loss: 0.3060 - val_accuracy: 0.8136
Epoch 214/1000
2/2 [==============================] - ETA: 0s - loss: 0.2731 - accuracy: 0.8672
Epoch 214: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2731 - accuracy: 0.8672 - val_loss: 0.3040 - val_accuracy: 0.8136
Epoch 215/1000
2/2 [==============================] - ETA: 0s - loss: 0.2449 - accuracy: 0.8828
Epoch 215: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2449 - accuracy: 0.8828 - val_loss: 0.3022 - val_accuracy: 0.8136
Epoch 216/1000
2/2 [==============================] - ETA: 0s - loss: 0.2654 - accuracy: 0.8203
Epoch 216: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2654 - accuracy: 0.8203 - val_loss: 0.2999 - val_accuracy: 0.8136
Epoch 217/1000
2/2 [==============================] - ETA: 0s - loss: 0.2781 - accuracy: 0.8672
Epoch 217: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2781 - accuracy: 0.8672 - val_loss: 0.2985 - val_accuracy: 0.8136
Epoch 218/1000
2/2 [==============================] - ETA: 0s - loss: 0.3467 - accuracy: 0.7875
Epoch 218: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 808ms/step - loss: 0.3467 - accuracy: 0.7875 - val_loss: 0.2967 - val_accuracy: 0.8136
Epoch 219/1000
2/2 [==============================] - ETA: 0s - loss: 0.2858 - accuracy: 0.8750
Epoch 219: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2858 - accuracy: 0.8750 - val_loss: 0.2970 - val_accuracy: 0.8136
Epoch 220/1000
2/2 [==============================] - ETA: 0s - loss: 0.2070 - accuracy: 0.9125
Epoch 220: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2070 - accuracy: 0.9125 - val_loss: 0.2983 - val_accuracy: 0.8136
Epoch 221/1000
2/2 [==============================] - ETA: 0s - loss: 0.2974 - accuracy: 0.8359
Epoch 221: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2974 - accuracy: 0.8359 - val_loss: 0.2998 - val_accuracy: 0.8136
Epoch 222/1000
2/2 [==============================] - ETA: 0s - loss: 0.2884 - accuracy: 0.8625
Epoch 222: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 806ms/step - loss: 0.2884 - accuracy: 0.8625 - val_loss: 0.3019 - val_accuracy: 0.8136
Epoch 223/1000
2/2 [==============================] - ETA: 0s - loss: 0.2783 - accuracy: 0.8438
Epoch 223: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2783 - accuracy: 0.8438 - val_loss: 0.3043 - val_accuracy: 0.8136
Epoch 224/1000
2/2 [==============================] - ETA: 0s - loss: 0.2062 - accuracy: 0.8875
Epoch 224: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2062 - accuracy: 0.8875 - val_loss: 0.3075 - val_accuracy: 0.8136
Epoch 225/1000
2/2 [==============================] - ETA: 0s - loss: 0.2499 - accuracy: 0.8500
Epoch 225: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2499 - accuracy: 0.8500 - val_loss: 0.3094 - val_accuracy: 0.8136
Epoch 226/1000
2/2 [==============================] - ETA: 0s - loss: 0.2541 - accuracy: 0.8672
Epoch 226: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 957ms/step - loss: 0.2541 - accuracy: 0.8672 - val_loss: 0.3105 - val_accuracy: 0.8136
Epoch 227/1000
2/2 [==============================] - ETA: 0s - loss: 0.2353 - accuracy: 0.8672
Epoch 227: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 903ms/step - loss: 0.2353 - accuracy: 0.8672 - val_loss: 0.3106 - val_accuracy: 0.8305
Epoch 228/1000
2/2 [==============================] - ETA: 0s - loss: 0.2782 - accuracy: 0.8375
Epoch 228: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 792ms/step - loss: 0.2782 - accuracy: 0.8375 - val_loss: 0.3112 - val_accuracy: 0.8305
Epoch 229/1000
2/2 [==============================] - ETA: 0s - loss: 0.2693 - accuracy: 0.8875
Epoch 229: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.2693 - accuracy: 0.8875 - val_loss: 0.3124 - val_accuracy: 0.8305
Epoch 230/1000
2/2 [==============================] - ETA: 0s - loss: 0.2889 - accuracy: 0.8281
Epoch 230: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 943ms/step - loss: 0.2889 - accuracy: 0.8281 - val_loss: 0.3135 - val_accuracy: 0.8305
Epoch 231/1000
2/2 [==============================] - ETA: 0s - loss: 0.2589 - accuracy: 0.8984
Epoch 231: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 907ms/step - loss: 0.2589 - accuracy: 0.8984 - val_loss: 0.3135 - val_accuracy: 0.8305
Epoch 232/1000
2/2 [==============================] - ETA: 0s - loss: 0.2456 - accuracy: 0.8984
Epoch 232: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2456 - accuracy: 0.8984 - val_loss: 0.3123 - val_accuracy: 0.8305
Epoch 233/1000
2/2 [==============================] - ETA: 0s - loss: 0.2860 - accuracy: 0.8281
Epoch 233: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2860 - accuracy: 0.8281 - val_loss: 0.3108 - val_accuracy: 0.8305
Epoch 234/1000
2/2 [==============================] - ETA: 0s - loss: 0.2758 - accuracy: 0.8438
Epoch 234: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 910ms/step - loss: 0.2758 - accuracy: 0.8438 - val_loss: 0.3082 - val_accuracy: 0.8305
Epoch 235/1000
2/2 [==============================] - ETA: 0s - loss: 0.2963 - accuracy: 0.8438
Epoch 235: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2963 - accuracy: 0.8438 - val_loss: 0.3071 - val_accuracy: 0.8136
Epoch 236/1000
2/2 [==============================] - ETA: 0s - loss: 0.2494 - accuracy: 0.8906
Epoch 236: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 946ms/step - loss: 0.2494 - accuracy: 0.8906 - val_loss: 0.3057 - val_accuracy: 0.8136
Epoch 237/1000
2/2 [==============================] - ETA: 0s - loss: 0.2573 - accuracy: 0.9062
Epoch 237: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 917ms/step - loss: 0.2573 - accuracy: 0.9062 - val_loss: 0.3048 - val_accuracy: 0.8136
Epoch 238/1000
2/2 [==============================] - ETA: 0s - loss: 0.2491 - accuracy: 0.8828
Epoch 238: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 921ms/step - loss: 0.2491 - accuracy: 0.8828 - val_loss: 0.3050 - val_accuracy: 0.8136
Epoch 239/1000
2/2 [==============================] - ETA: 0s - loss: 0.2366 - accuracy: 0.9000
Epoch 239: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2366 - accuracy: 0.9000 - val_loss: 0.3059 - val_accuracy: 0.8305
Epoch 240/1000
2/2 [==============================] - ETA: 0s - loss: 0.2333 - accuracy: 0.9062
Epoch 240: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 945ms/step - loss: 0.2333 - accuracy: 0.9062 - val_loss: 0.3063 - val_accuracy: 0.8475
Epoch 241/1000
2/2 [==============================] - ETA: 0s - loss: 0.2809 - accuracy: 0.8672
Epoch 241: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2809 - accuracy: 0.8672 - val_loss: 0.3059 - val_accuracy: 0.8305
Epoch 242/1000
2/2 [==============================] - ETA: 0s - loss: 0.2800 - accuracy: 0.8750
Epoch 242: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2800 - accuracy: 0.8750 - val_loss: 0.3063 - val_accuracy: 0.8475
Epoch 243/1000
2/2 [==============================] - ETA: 0s - loss: 0.2448 - accuracy: 0.9000
Epoch 243: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2448 - accuracy: 0.9000 - val_loss: 0.3057 - val_accuracy: 0.8305
Epoch 244/1000
2/2 [==============================] - ETA: 0s - loss: 0.2235 - accuracy: 0.9000
Epoch 244: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 794ms/step - loss: 0.2235 - accuracy: 0.9000 - val_loss: 0.3050 - val_accuracy: 0.8136
Epoch 245/1000
2/2 [==============================] - ETA: 0s - loss: 0.2548 - accuracy: 0.8625
Epoch 245: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2548 - accuracy: 0.8625 - val_loss: 0.3034 - val_accuracy: 0.8136
Epoch 246/1000
2/2 [==============================] - ETA: 0s - loss: 0.2482 - accuracy: 0.8672
Epoch 246: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 946ms/step - loss: 0.2482 - accuracy: 0.8672 - val_loss: 0.3021 - val_accuracy: 0.8136
Epoch 247/1000
2/2 [==============================] - ETA: 0s - loss: 0.2149 - accuracy: 0.9062
Epoch 247: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2149 - accuracy: 0.9062 - val_loss: 0.3014 - val_accuracy: 0.8136
Epoch 248/1000
2/2 [==============================] - ETA: 0s - loss: 0.2617 - accuracy: 0.8594
Epoch 248: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2617 - accuracy: 0.8594 - val_loss: 0.3010 - val_accuracy: 0.8136
Epoch 249/1000
2/2 [==============================] - ETA: 0s - loss: 0.2135 - accuracy: 0.9219
Epoch 249: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2135 - accuracy: 0.9219 - val_loss: 0.3009 - val_accuracy: 0.8136
Epoch 250/1000
2/2 [==============================] - ETA: 0s - loss: 0.2178 - accuracy: 0.9297
Epoch 250: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2178 - accuracy: 0.9297 - val_loss: 0.3010 - val_accuracy: 0.8136
Epoch 251/1000
2/2 [==============================] - ETA: 0s - loss: 0.2670 - accuracy: 0.8750
Epoch 251: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2670 - accuracy: 0.8750 - val_loss: 0.3018 - val_accuracy: 0.8136
Epoch 252/1000
2/2 [==============================] - ETA: 0s - loss: 0.2248 - accuracy: 0.8750
Epoch 252: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 818ms/step - loss: 0.2248 - accuracy: 0.8750 - val_loss: 0.3011 - val_accuracy: 0.8136
Epoch 253/1000
2/2 [==============================] - ETA: 0s - loss: 0.2740 - accuracy: 0.8828
Epoch 253: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2740 - accuracy: 0.8828 - val_loss: 0.2994 - val_accuracy: 0.8136
Epoch 254/1000
2/2 [==============================] - ETA: 0s - loss: 0.2816 - accuracy: 0.8250
Epoch 254: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 803ms/step - loss: 0.2816 - accuracy: 0.8250 - val_loss: 0.2979 - val_accuracy: 0.8136
Epoch 255/1000
2/2 [==============================] - ETA: 0s - loss: 0.2820 - accuracy: 0.8359
Epoch 255: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 947ms/step - loss: 0.2820 - accuracy: 0.8359 - val_loss: 0.2963 - val_accuracy: 0.8136
Epoch 256/1000
2/2 [==============================] - ETA: 0s - loss: 0.2573 - accuracy: 0.8594
Epoch 256: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2573 - accuracy: 0.8594 - val_loss: 0.2953 - val_accuracy: 0.8136
Epoch 257/1000
2/2 [==============================] - ETA: 0s - loss: 0.2565 - accuracy: 0.8594
Epoch 257: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2565 - accuracy: 0.8594 - val_loss: 0.2960 - val_accuracy: 0.8136
Epoch 258/1000
2/2 [==============================] - ETA: 0s - loss: 0.2307 - accuracy: 0.8984
Epoch 258: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2307 - accuracy: 0.8984 - val_loss: 0.2969 - val_accuracy: 0.8136
Epoch 259/1000
2/2 [==============================] - ETA: 0s - loss: 0.2131 - accuracy: 0.8906
Epoch 259: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2131 - accuracy: 0.8906 - val_loss: 0.2983 - val_accuracy: 0.8136
Epoch 260/1000
2/2 [==============================] - ETA: 0s - loss: 0.2280 - accuracy: 0.8906
Epoch 260: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 902ms/step - loss: 0.2280 - accuracy: 0.8906 - val_loss: 0.2995 - val_accuracy: 0.8136
Epoch 261/1000
2/2 [==============================] - ETA: 0s - loss: 0.2603 - accuracy: 0.8828
Epoch 261: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2603 - accuracy: 0.8828 - val_loss: 0.3003 - val_accuracy: 0.8136
Epoch 262/1000
2/2 [==============================] - ETA: 0s - loss: 0.2892 - accuracy: 0.8375
Epoch 262: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2892 - accuracy: 0.8375 - val_loss: 0.3015 - val_accuracy: 0.8136
Epoch 263/1000
2/2 [==============================] - ETA: 0s - loss: 0.2298 - accuracy: 0.8875
Epoch 263: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2298 - accuracy: 0.8875 - val_loss: 0.3009 - val_accuracy: 0.8136
Epoch 264/1000
2/2 [==============================] - ETA: 0s - loss: 0.2543 - accuracy: 0.9062
Epoch 264: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 958ms/step - loss: 0.2543 - accuracy: 0.9062 - val_loss: 0.3001 - val_accuracy: 0.8136
Epoch 265/1000
2/2 [==============================] - ETA: 0s - loss: 0.2106 - accuracy: 0.9375
Epoch 265: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 814ms/step - loss: 0.2106 - accuracy: 0.9375 - val_loss: 0.2987 - val_accuracy: 0.8136
Epoch 266/1000
2/2 [==============================] - ETA: 0s - loss: 0.2526 - accuracy: 0.8828
Epoch 266: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2526 - accuracy: 0.8828 - val_loss: 0.2968 - val_accuracy: 0.8136
Epoch 267/1000
2/2 [==============================] - ETA: 0s - loss: 0.2803 - accuracy: 0.8500
Epoch 267: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 853ms/step - loss: 0.2803 - accuracy: 0.8500 - val_loss: 0.2950 - val_accuracy: 0.8136
Epoch 268/1000
2/2 [==============================] - ETA: 0s - loss: 0.2660 - accuracy: 0.8750
Epoch 268: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 806ms/step - loss: 0.2660 - accuracy: 0.8750 - val_loss: 0.2931 - val_accuracy: 0.8136
Epoch 269/1000
2/2 [==============================] - ETA: 0s - loss: 0.2276 - accuracy: 0.8828
Epoch 269: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2276 - accuracy: 0.8828 - val_loss: 0.2913 - val_accuracy: 0.8136
Epoch 270/1000
2/2 [==============================] - ETA: 0s - loss: 0.2157 - accuracy: 0.9125
Epoch 270: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 860ms/step - loss: 0.2157 - accuracy: 0.9125 - val_loss: 0.2903 - val_accuracy: 0.8136
Epoch 271/1000
2/2 [==============================] - ETA: 0s - loss: 0.1974 - accuracy: 0.9375
Epoch 271: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 898ms/step - loss: 0.1974 - accuracy: 0.9375 - val_loss: 0.2898 - val_accuracy: 0.8136
Epoch 272/1000
2/2 [==============================] - ETA: 0s - loss: 0.2401 - accuracy: 0.8750
Epoch 272: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 943ms/step - loss: 0.2401 - accuracy: 0.8750 - val_loss: 0.2889 - val_accuracy: 0.8136
Epoch 273/1000
2/2 [==============================] - ETA: 0s - loss: 0.2718 - accuracy: 0.8375
Epoch 273: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2718 - accuracy: 0.8375 - val_loss: 0.2886 - val_accuracy: 0.8136
Epoch 274/1000
2/2 [==============================] - ETA: 0s - loss: 0.2322 - accuracy: 0.8984
Epoch 274: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 930ms/step - loss: 0.2322 - accuracy: 0.8984 - val_loss: 0.2888 - val_accuracy: 0.8136
Epoch 275/1000
2/2 [==============================] - ETA: 0s - loss: 0.2986 - accuracy: 0.8438
Epoch 275: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 957ms/step - loss: 0.2986 - accuracy: 0.8438 - val_loss: 0.2887 - val_accuracy: 0.8136
Epoch 276/1000
2/2 [==============================] - ETA: 0s - loss: 0.2662 - accuracy: 0.8438
Epoch 276: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2662 - accuracy: 0.8438 - val_loss: 0.2889 - val_accuracy: 0.8136
Epoch 277/1000
2/2 [==============================] - ETA: 0s - loss: 0.2386 - accuracy: 0.8984
Epoch 277: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2386 - accuracy: 0.8984 - val_loss: 0.2899 - val_accuracy: 0.8136
Epoch 278/1000
2/2 [==============================] - ETA: 0s - loss: 0.2327 - accuracy: 0.9250
Epoch 278: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2327 - accuracy: 0.9250 - val_loss: 0.2929 - val_accuracy: 0.8136
Epoch 279/1000
2/2 [==============================] - ETA: 0s - loss: 0.2378 - accuracy: 0.8984
Epoch 279: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2378 - accuracy: 0.8984 - val_loss: 0.2975 - val_accuracy: 0.8136
Epoch 280/1000
2/2 [==============================] - ETA: 0s - loss: 0.2511 - accuracy: 0.8594
Epoch 280: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2511 - accuracy: 0.8594 - val_loss: 0.3020 - val_accuracy: 0.8136
Epoch 281/1000
2/2 [==============================] - ETA: 0s - loss: 0.2288 - accuracy: 0.8984
Epoch 281: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 916ms/step - loss: 0.2288 - accuracy: 0.8984 - val_loss: 0.3068 - val_accuracy: 0.8136
Epoch 282/1000
2/2 [==============================] - ETA: 0s - loss: 0.2698 - accuracy: 0.8359
Epoch 282: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2698 - accuracy: 0.8359 - val_loss: 0.3105 - val_accuracy: 0.8136
Epoch 283/1000
2/2 [==============================] - ETA: 0s - loss: 0.2154 - accuracy: 0.9141
Epoch 283: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2154 - accuracy: 0.9141 - val_loss: 0.3148 - val_accuracy: 0.7966
Epoch 284/1000
2/2 [==============================] - ETA: 0s - loss: 0.2556 - accuracy: 0.8500
Epoch 284: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 842ms/step - loss: 0.2556 - accuracy: 0.8500 - val_loss: 0.3190 - val_accuracy: 0.7627
Epoch 285/1000
2/2 [==============================] - ETA: 0s - loss: 0.2494 - accuracy: 0.8625
Epoch 285: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 2s/step - loss: 0.2494 - accuracy: 0.8625 - val_loss: 0.3235 - val_accuracy: 0.7458
Epoch 286/1000
2/2 [==============================] - ETA: 0s - loss: 0.2026 - accuracy: 0.8875
Epoch 286: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2026 - accuracy: 0.8875 - val_loss: 0.3262 - val_accuracy: 0.7627
Epoch 287/1000
2/2 [==============================] - ETA: 0s - loss: 0.2219 - accuracy: 0.8750
Epoch 287: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2219 - accuracy: 0.8750 - val_loss: 0.3293 - val_accuracy: 0.7627
Epoch 288/1000
2/2 [==============================] - ETA: 0s - loss: 0.2030 - accuracy: 0.9141
Epoch 288: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 909ms/step - loss: 0.2030 - accuracy: 0.9141 - val_loss: 0.3301 - val_accuracy: 0.7627
Epoch 289/1000
2/2 [==============================] - ETA: 0s - loss: 0.2287 - accuracy: 0.8906
Epoch 289: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 914ms/step - loss: 0.2287 - accuracy: 0.8906 - val_loss: 0.3300 - val_accuracy: 0.7627
Epoch 290/1000
2/2 [==============================] - ETA: 0s - loss: 0.2328 - accuracy: 0.8750
Epoch 290: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 950ms/step - loss: 0.2328 - accuracy: 0.8750 - val_loss: 0.3270 - val_accuracy: 0.7797
Epoch 291/1000
2/2 [==============================] - ETA: 0s - loss: 0.2071 - accuracy: 0.9141
Epoch 291: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2071 - accuracy: 0.9141 - val_loss: 0.3240 - val_accuracy: 0.7797
Epoch 292/1000
2/2 [==============================] - ETA: 0s - loss: 0.2068 - accuracy: 0.9000
Epoch 292: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2068 - accuracy: 0.9000 - val_loss: 0.3218 - val_accuracy: 0.7797
Epoch 293/1000
2/2 [==============================] - ETA: 0s - loss: 0.1890 - accuracy: 0.9250
Epoch 293: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 804ms/step - loss: 0.1890 - accuracy: 0.9250 - val_loss: 0.3199 - val_accuracy: 0.7797
Epoch 294/1000
2/2 [==============================] - ETA: 0s - loss: 0.2426 - accuracy: 0.8875
Epoch 294: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 790ms/step - loss: 0.2426 - accuracy: 0.8875 - val_loss: 0.3161 - val_accuracy: 0.8136
Epoch 295/1000
2/2 [==============================] - ETA: 0s - loss: 0.2291 - accuracy: 0.9125
Epoch 295: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2291 - accuracy: 0.9125 - val_loss: 0.3102 - val_accuracy: 0.8475
Epoch 296/1000
2/2 [==============================] - ETA: 0s - loss: 0.2617 - accuracy: 0.8500
Epoch 296: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.2617 - accuracy: 0.8500 - val_loss: 0.3041 - val_accuracy: 0.8305
Epoch 297/1000
2/2 [==============================] - ETA: 0s - loss: 0.1950 - accuracy: 0.9500
Epoch 297: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 818ms/step - loss: 0.1950 - accuracy: 0.9500 - val_loss: 0.2988 - val_accuracy: 0.8305
Epoch 298/1000
2/2 [==============================] - ETA: 0s - loss: 0.2231 - accuracy: 0.9141
Epoch 298: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2231 - accuracy: 0.9141 - val_loss: 0.2959 - val_accuracy: 0.8305
Epoch 299/1000
2/2 [==============================] - ETA: 0s - loss: 0.1917 - accuracy: 0.9000
Epoch 299: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1917 - accuracy: 0.9000 - val_loss: 0.2945 - val_accuracy: 0.8305
Epoch 300/1000
2/2 [==============================] - ETA: 0s - loss: 0.2121 - accuracy: 0.9000
Epoch 300: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 794ms/step - loss: 0.2121 - accuracy: 0.9000 - val_loss: 0.2938 - val_accuracy: 0.8305
Epoch 301/1000
2/2 [==============================] - ETA: 0s - loss: 0.2052 - accuracy: 0.8828
Epoch 301: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2052 - accuracy: 0.8828 - val_loss: 0.2929 - val_accuracy: 0.8305
Epoch 302/1000
2/2 [==============================] - ETA: 0s - loss: 0.1914 - accuracy: 0.9375
Epoch 302: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 795ms/step - loss: 0.1914 - accuracy: 0.9375 - val_loss: 0.2915 - val_accuracy: 0.8305
Epoch 303/1000
2/2 [==============================] - ETA: 0s - loss: 0.2616 - accuracy: 0.8250
Epoch 303: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 800ms/step - loss: 0.2616 - accuracy: 0.8250 - val_loss: 0.2906 - val_accuracy: 0.8305
Epoch 304/1000
2/2 [==============================] - ETA: 0s - loss: 0.2484 - accuracy: 0.8750
Epoch 304: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2484 - accuracy: 0.8750 - val_loss: 0.2926 - val_accuracy: 0.8305
Epoch 305/1000
2/2 [==============================] - ETA: 0s - loss: 0.2136 - accuracy: 0.9062
Epoch 305: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2136 - accuracy: 0.9062 - val_loss: 0.2943 - val_accuracy: 0.8305
Epoch 306/1000
2/2 [==============================] - ETA: 0s - loss: 0.2577 - accuracy: 0.8750
Epoch 306: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 792ms/step - loss: 0.2577 - accuracy: 0.8750 - val_loss: 0.2947 - val_accuracy: 0.8305
Epoch 307/1000
2/2 [==============================] - ETA: 0s - loss: 0.2036 - accuracy: 0.9297
Epoch 307: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2036 - accuracy: 0.9297 - val_loss: 0.2952 - val_accuracy: 0.8305
Epoch 308/1000
2/2 [==============================] - ETA: 0s - loss: 0.2358 - accuracy: 0.8594
Epoch 308: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 906ms/step - loss: 0.2358 - accuracy: 0.8594 - val_loss: 0.2963 - val_accuracy: 0.8305
Epoch 309/1000
2/2 [==============================] - ETA: 0s - loss: 0.2349 - accuracy: 0.9062
Epoch 309: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2349 - accuracy: 0.9062 - val_loss: 0.2975 - val_accuracy: 0.8305
Epoch 310/1000
2/2 [==============================] - ETA: 0s - loss: 0.2118 - accuracy: 0.8625
Epoch 310: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 808ms/step - loss: 0.2118 - accuracy: 0.8625 - val_loss: 0.2989 - val_accuracy: 0.8305
Epoch 311/1000
2/2 [==============================] - ETA: 0s - loss: 0.1725 - accuracy: 0.9000
Epoch 311: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1725 - accuracy: 0.9000 - val_loss: 0.2993 - val_accuracy: 0.8305
Epoch 312/1000
2/2 [==============================] - ETA: 0s - loss: 0.2201 - accuracy: 0.9125
Epoch 312: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2201 - accuracy: 0.9125 - val_loss: 0.3002 - val_accuracy: 0.8305
Epoch 313/1000
2/2 [==============================] - ETA: 0s - loss: 0.2136 - accuracy: 0.8750
Epoch 313: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2136 - accuracy: 0.8750 - val_loss: 0.3005 - val_accuracy: 0.8305
Epoch 314/1000
2/2 [==============================] - ETA: 0s - loss: 0.2057 - accuracy: 0.8906
Epoch 314: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 934ms/step - loss: 0.2057 - accuracy: 0.8906 - val_loss: 0.3016 - val_accuracy: 0.8305
Epoch 315/1000
2/2 [==============================] - ETA: 0s - loss: 0.2134 - accuracy: 0.8984
Epoch 315: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 968ms/step - loss: 0.2134 - accuracy: 0.8984 - val_loss: 0.3029 - val_accuracy: 0.8305
Epoch 316/1000
2/2 [==============================] - ETA: 0s - loss: 0.2028 - accuracy: 0.9375
Epoch 316: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2028 - accuracy: 0.9375 - val_loss: 0.3031 - val_accuracy: 0.8305
Epoch 317/1000
2/2 [==============================] - ETA: 0s - loss: 0.2105 - accuracy: 0.8750
Epoch 317: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2105 - accuracy: 0.8750 - val_loss: 0.3014 - val_accuracy: 0.8305
Epoch 318/1000
2/2 [==============================] - ETA: 0s - loss: 0.2106 - accuracy: 0.8984
Epoch 318: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 918ms/step - loss: 0.2106 - accuracy: 0.8984 - val_loss: 0.3000 - val_accuracy: 0.8305
Epoch 319/1000
2/2 [==============================] - ETA: 0s - loss: 0.1630 - accuracy: 0.9750
Epoch 319: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 796ms/step - loss: 0.1630 - accuracy: 0.9750 - val_loss: 0.3004 - val_accuracy: 0.8305
Epoch 320/1000
2/2 [==============================] - ETA: 0s - loss: 0.1539 - accuracy: 0.9500
Epoch 320: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 810ms/step - loss: 0.1539 - accuracy: 0.9500 - val_loss: 0.3006 - val_accuracy: 0.8305
Epoch 321/1000
2/2 [==============================] - ETA: 0s - loss: 0.2218 - accuracy: 0.8594
Epoch 321: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2218 - accuracy: 0.8594 - val_loss: 0.3013 - val_accuracy: 0.8305
Epoch 322/1000
2/2 [==============================] - ETA: 0s - loss: 0.2165 - accuracy: 0.9062
Epoch 322: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2165 - accuracy: 0.9062 - val_loss: 0.3022 - val_accuracy: 0.8305
Epoch 323/1000
2/2 [==============================] - ETA: 0s - loss: 0.1919 - accuracy: 0.9000
Epoch 323: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1919 - accuracy: 0.9000 - val_loss: 0.3030 - val_accuracy: 0.8305
Epoch 324/1000
2/2 [==============================] - ETA: 0s - loss: 0.1958 - accuracy: 0.9000
Epoch 324: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 850ms/step - loss: 0.1958 - accuracy: 0.9000 - val_loss: 0.3028 - val_accuracy: 0.8305
Epoch 325/1000
2/2 [==============================] - ETA: 0s - loss: 0.1868 - accuracy: 0.9000
Epoch 325: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 814ms/step - loss: 0.1868 - accuracy: 0.9000 - val_loss: 0.3007 - val_accuracy: 0.8305
Epoch 326/1000
2/2 [==============================] - ETA: 0s - loss: 0.2316 - accuracy: 0.9062
Epoch 326: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 941ms/step - loss: 0.2316 - accuracy: 0.9062 - val_loss: 0.2972 - val_accuracy: 0.8305
Epoch 327/1000
2/2 [==============================] - ETA: 0s - loss: 0.2059 - accuracy: 0.8875
Epoch 327: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2059 - accuracy: 0.8875 - val_loss: 0.2908 - val_accuracy: 0.8305
Epoch 328/1000
2/2 [==============================] - ETA: 0s - loss: 0.1977 - accuracy: 0.8906
Epoch 328: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 969ms/step - loss: 0.1977 - accuracy: 0.8906 - val_loss: 0.2869 - val_accuracy: 0.8305
Epoch 329/1000
2/2 [==============================] - ETA: 0s - loss: 0.2260 - accuracy: 0.8984
Epoch 329: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 992ms/step - loss: 0.2260 - accuracy: 0.8984 - val_loss: 0.2843 - val_accuracy: 0.8305
Epoch 330/1000
2/2 [==============================] - ETA: 0s - loss: 0.2437 - accuracy: 0.8625
Epoch 330: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2437 - accuracy: 0.8625 - val_loss: 0.2842 - val_accuracy: 0.8305
Epoch 331/1000
2/2 [==============================] - ETA: 0s - loss: 0.2069 - accuracy: 0.8984
Epoch 331: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 935ms/step - loss: 0.2069 - accuracy: 0.8984 - val_loss: 0.2851 - val_accuracy: 0.8305
Epoch 332/1000
2/2 [==============================] - ETA: 0s - loss: 0.1874 - accuracy: 0.9000
Epoch 332: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 869ms/step - loss: 0.1874 - accuracy: 0.9000 - val_loss: 0.2855 - val_accuracy: 0.8305
Epoch 333/1000
2/2 [==============================] - ETA: 0s - loss: 0.1848 - accuracy: 0.9125
Epoch 333: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 787ms/step - loss: 0.1848 - accuracy: 0.9125 - val_loss: 0.2884 - val_accuracy: 0.8305
Epoch 334/1000
2/2 [==============================] - ETA: 0s - loss: 0.2140 - accuracy: 0.8984
Epoch 334: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2140 - accuracy: 0.8984 - val_loss: 0.2922 - val_accuracy: 0.8305
Epoch 335/1000
2/2 [==============================] - ETA: 0s - loss: 0.2155 - accuracy: 0.8594
Epoch 335: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 998ms/step - loss: 0.2155 - accuracy: 0.8594 - val_loss: 0.2948 - val_accuracy: 0.8305
Epoch 336/1000
2/2 [==============================] - ETA: 0s - loss: 0.2458 - accuracy: 0.8625
Epoch 336: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 826ms/step - loss: 0.2458 - accuracy: 0.8625 - val_loss: 0.2973 - val_accuracy: 0.8305
Epoch 337/1000
2/2 [==============================] - ETA: 0s - loss: 0.1843 - accuracy: 0.9125
Epoch 337: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 812ms/step - loss: 0.1843 - accuracy: 0.9125 - val_loss: 0.3001 - val_accuracy: 0.8136
Epoch 338/1000
2/2 [==============================] - ETA: 0s - loss: 0.2171 - accuracy: 0.9000
Epoch 338: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 847ms/step - loss: 0.2171 - accuracy: 0.9000 - val_loss: 0.3006 - val_accuracy: 0.8136
Epoch 339/1000
2/2 [==============================] - ETA: 0s - loss: 0.2334 - accuracy: 0.8500
Epoch 339: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2334 - accuracy: 0.8500 - val_loss: 0.3007 - val_accuracy: 0.8136
Epoch 340/1000
2/2 [==============================] - ETA: 0s - loss: 0.1649 - accuracy: 0.9531
Epoch 340: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 921ms/step - loss: 0.1649 - accuracy: 0.9531 - val_loss: 0.3008 - val_accuracy: 0.8136
Epoch 341/1000
2/2 [==============================] - ETA: 0s - loss: 0.1953 - accuracy: 0.8984
Epoch 341: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1953 - accuracy: 0.8984 - val_loss: 0.3000 - val_accuracy: 0.8136
Epoch 342/1000
2/2 [==============================] - ETA: 0s - loss: 0.1953 - accuracy: 0.8875
Epoch 342: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1953 - accuracy: 0.8875 - val_loss: 0.2995 - val_accuracy: 0.8136
Epoch 343/1000
2/2 [==============================] - ETA: 0s - loss: 0.2022 - accuracy: 0.8906
Epoch 343: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 931ms/step - loss: 0.2022 - accuracy: 0.8906 - val_loss: 0.2981 - val_accuracy: 0.8136
Epoch 344/1000
2/2 [==============================] - ETA: 0s - loss: 0.2112 - accuracy: 0.8875
Epoch 344: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2112 - accuracy: 0.8875 - val_loss: 0.2967 - val_accuracy: 0.8136
Epoch 345/1000
2/2 [==============================] - ETA: 0s - loss: 0.2026 - accuracy: 0.9125
Epoch 345: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2026 - accuracy: 0.9125 - val_loss: 0.2950 - val_accuracy: 0.8136
Epoch 346/1000
2/2 [==============================] - ETA: 0s - loss: 0.2523 - accuracy: 0.8500
Epoch 346: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2523 - accuracy: 0.8500 - val_loss: 0.2945 - val_accuracy: 0.8136
Epoch 347/1000
2/2 [==============================] - ETA: 0s - loss: 0.1992 - accuracy: 0.8906
Epoch 347: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1992 - accuracy: 0.8906 - val_loss: 0.2937 - val_accuracy: 0.8136
Epoch 348/1000
2/2 [==============================] - ETA: 0s - loss: 0.2214 - accuracy: 0.8906
Epoch 348: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2214 - accuracy: 0.8906 - val_loss: 0.2934 - val_accuracy: 0.8136
Epoch 349/1000
2/2 [==============================] - ETA: 0s - loss: 0.1557 - accuracy: 0.9375
Epoch 349: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1557 - accuracy: 0.9375 - val_loss: 0.2937 - val_accuracy: 0.8136
Epoch 350/1000
2/2 [==============================] - ETA: 0s - loss: 0.2254 - accuracy: 0.8828
Epoch 350: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2254 - accuracy: 0.8828 - val_loss: 0.2925 - val_accuracy: 0.8136
Epoch 351/1000
2/2 [==============================] - ETA: 0s - loss: 0.2194 - accuracy: 0.8906
Epoch 351: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 891ms/step - loss: 0.2194 - accuracy: 0.8906 - val_loss: 0.2909 - val_accuracy: 0.8136
Epoch 352/1000
2/2 [==============================] - ETA: 0s - loss: 0.2548 - accuracy: 0.8750
Epoch 352: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 963ms/step - loss: 0.2548 - accuracy: 0.8750 - val_loss: 0.2898 - val_accuracy: 0.8136
Epoch 353/1000
2/2 [==============================] - ETA: 0s - loss: 0.2142 - accuracy: 0.9062
Epoch 353: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2142 - accuracy: 0.9062 - val_loss: 0.2904 - val_accuracy: 0.8136
Epoch 354/1000
2/2 [==============================] - ETA: 0s - loss: 0.2285 - accuracy: 0.8984
Epoch 354: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2285 - accuracy: 0.8984 - val_loss: 0.2903 - val_accuracy: 0.8136
Epoch 355/1000
2/2 [==============================] - ETA: 0s - loss: 0.1971 - accuracy: 0.9250
Epoch 355: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 813ms/step - loss: 0.1971 - accuracy: 0.9250 - val_loss: 0.2898 - val_accuracy: 0.8136
Epoch 356/1000
2/2 [==============================] - ETA: 0s - loss: 0.1707 - accuracy: 0.9125
Epoch 356: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 804ms/step - loss: 0.1707 - accuracy: 0.9125 - val_loss: 0.2897 - val_accuracy: 0.7966
Epoch 357/1000
2/2 [==============================] - ETA: 0s - loss: 0.1891 - accuracy: 0.9297
Epoch 357: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1891 - accuracy: 0.9297 - val_loss: 0.2902 - val_accuracy: 0.7966
Epoch 358/1000
2/2 [==============================] - ETA: 0s - loss: 0.2287 - accuracy: 0.8906
Epoch 358: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 916ms/step - loss: 0.2287 - accuracy: 0.8906 - val_loss: 0.2905 - val_accuracy: 0.7966
Epoch 359/1000
2/2 [==============================] - ETA: 0s - loss: 0.1855 - accuracy: 0.9000
Epoch 359: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 808ms/step - loss: 0.1855 - accuracy: 0.9000 - val_loss: 0.2893 - val_accuracy: 0.7966
Epoch 360/1000
2/2 [==============================] - ETA: 0s - loss: 0.1888 - accuracy: 0.9000
Epoch 360: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1888 - accuracy: 0.9000 - val_loss: 0.2888 - val_accuracy: 0.7966
Epoch 361/1000
2/2 [==============================] - ETA: 0s - loss: 0.1960 - accuracy: 0.8906
Epoch 361: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.1960 - accuracy: 0.8906 - val_loss: 0.2888 - val_accuracy: 0.8136
Epoch 362/1000
2/2 [==============================] - ETA: 0s - loss: 0.1805 - accuracy: 0.9219
Epoch 362: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1805 - accuracy: 0.9219 - val_loss: 0.2886 - val_accuracy: 0.8136
Epoch 363/1000
2/2 [==============================] - ETA: 0s - loss: 0.2204 - accuracy: 0.8438
Epoch 363: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2204 - accuracy: 0.8438 - val_loss: 0.2874 - val_accuracy: 0.8136
Epoch 364/1000
2/2 [==============================] - ETA: 0s - loss: 0.2377 - accuracy: 0.8750
Epoch 364: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2377 - accuracy: 0.8750 - val_loss: 0.2852 - val_accuracy: 0.8305
Epoch 365/1000
2/2 [==============================] - ETA: 0s - loss: 0.2509 - accuracy: 0.8359
Epoch 365: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2509 - accuracy: 0.8359 - val_loss: 0.2844 - val_accuracy: 0.8305
Epoch 366/1000
2/2 [==============================] - ETA: 0s - loss: 0.2157 - accuracy: 0.9062
Epoch 366: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.2157 - accuracy: 0.9062 - val_loss: 0.2826 - val_accuracy: 0.8305
Epoch 367/1000
2/2 [==============================] - ETA: 0s - loss: 0.2052 - accuracy: 0.9062
Epoch 367: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2052 - accuracy: 0.9062 - val_loss: 0.2812 - val_accuracy: 0.8305
Epoch 368/1000
2/2 [==============================] - ETA: 0s - loss: 0.1466 - accuracy: 0.9766
Epoch 368: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 914ms/step - loss: 0.1466 - accuracy: 0.9766 - val_loss: 0.2792 - val_accuracy: 0.8475
Epoch 369/1000
2/2 [==============================] - ETA: 0s - loss: 0.2298 - accuracy: 0.8672
Epoch 369: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2298 - accuracy: 0.8672 - val_loss: 0.2770 - val_accuracy: 0.8305
Epoch 370/1000
2/2 [==============================] - ETA: 0s - loss: 0.2274 - accuracy: 0.8984
Epoch 370: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2274 - accuracy: 0.8984 - val_loss: 0.2750 - val_accuracy: 0.8305
Epoch 371/1000
2/2 [==============================] - ETA: 0s - loss: 0.2067 - accuracy: 0.8875
Epoch 371: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.2067 - accuracy: 0.8875 - val_loss: 0.2723 - val_accuracy: 0.8305
Epoch 372/1000
2/2 [==============================] - ETA: 0s - loss: 0.1376 - accuracy: 0.9250
Epoch 372: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 806ms/step - loss: 0.1376 - accuracy: 0.9250 - val_loss: 0.2710 - val_accuracy: 0.8305
Epoch 373/1000
2/2 [==============================] - ETA: 0s - loss: 0.1334 - accuracy: 0.9766
Epoch 373: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1334 - accuracy: 0.9766 - val_loss: 0.2704 - val_accuracy: 0.8305
Epoch 374/1000
2/2 [==============================] - ETA: 0s - loss: 0.1969 - accuracy: 0.9062
Epoch 374: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1969 - accuracy: 0.9062 - val_loss: 0.2690 - val_accuracy: 0.8305
Epoch 375/1000
2/2 [==============================] - ETA: 0s - loss: 0.1532 - accuracy: 0.9250
Epoch 375: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1532 - accuracy: 0.9250 - val_loss: 0.2681 - val_accuracy: 0.8305
Epoch 376/1000
2/2 [==============================] - ETA: 0s - loss: 0.1761 - accuracy: 0.9375
Epoch 376: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1761 - accuracy: 0.9375 - val_loss: 0.2677 - val_accuracy: 0.8305
Epoch 377/1000
2/2 [==============================] - ETA: 0s - loss: 0.1927 - accuracy: 0.9219
Epoch 377: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 916ms/step - loss: 0.1927 - accuracy: 0.9219 - val_loss: 0.2674 - val_accuracy: 0.8305
Epoch 378/1000
2/2 [==============================] - ETA: 0s - loss: 0.1983 - accuracy: 0.9297
Epoch 378: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1983 - accuracy: 0.9297 - val_loss: 0.2671 - val_accuracy: 0.8305
Epoch 379/1000
2/2 [==============================] - ETA: 0s - loss: 0.1826 - accuracy: 0.9375
Epoch 379: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 806ms/step - loss: 0.1826 - accuracy: 0.9375 - val_loss: 0.2670 - val_accuracy: 0.8305
Epoch 380/1000
2/2 [==============================] - ETA: 0s - loss: 0.1814 - accuracy: 0.8875
Epoch 380: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 803ms/step - loss: 0.1814 - accuracy: 0.8875 - val_loss: 0.2679 - val_accuracy: 0.8305
Epoch 381/1000
2/2 [==============================] - ETA: 0s - loss: 0.1725 - accuracy: 0.9125
Epoch 381: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 797ms/step - loss: 0.1725 - accuracy: 0.9125 - val_loss: 0.2694 - val_accuracy: 0.8305
Epoch 382/1000
2/2 [==============================] - ETA: 0s - loss: 0.1709 - accuracy: 0.9219
Epoch 382: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 948ms/step - loss: 0.1709 - accuracy: 0.9219 - val_loss: 0.2718 - val_accuracy: 0.8305
Epoch 383/1000
2/2 [==============================] - ETA: 0s - loss: 0.1744 - accuracy: 0.9125
Epoch 383: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 988ms/step - loss: 0.1744 - accuracy: 0.9125 - val_loss: 0.2752 - val_accuracy: 0.8305
Epoch 384/1000
2/2 [==============================] - ETA: 0s - loss: 0.1834 - accuracy: 0.9250
Epoch 384: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.1834 - accuracy: 0.9250 - val_loss: 0.2793 - val_accuracy: 0.8136
Epoch 385/1000
2/2 [==============================] - ETA: 0s - loss: 0.1865 - accuracy: 0.9297
Epoch 385: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1865 - accuracy: 0.9297 - val_loss: 0.2834 - val_accuracy: 0.8136
Epoch 386/1000
2/2 [==============================] - ETA: 0s - loss: 0.2197 - accuracy: 0.8750
Epoch 386: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2197 - accuracy: 0.8750 - val_loss: 0.2869 - val_accuracy: 0.8305
Epoch 387/1000
2/2 [==============================] - ETA: 0s - loss: 0.1715 - accuracy: 0.9141
Epoch 387: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 938ms/step - loss: 0.1715 - accuracy: 0.9141 - val_loss: 0.2888 - val_accuracy: 0.8305
Epoch 388/1000
2/2 [==============================] - ETA: 0s - loss: 0.1848 - accuracy: 0.8750
Epoch 388: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.1848 - accuracy: 0.8750 - val_loss: 0.2891 - val_accuracy: 0.8305
Epoch 389/1000
2/2 [==============================] - ETA: 0s - loss: 0.2054 - accuracy: 0.9219
Epoch 389: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2054 - accuracy: 0.9219 - val_loss: 0.2882 - val_accuracy: 0.8305
Epoch 390/1000
2/2 [==============================] - ETA: 0s - loss: 0.1498 - accuracy: 0.9500
Epoch 390: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1498 - accuracy: 0.9500 - val_loss: 0.2871 - val_accuracy: 0.8305
Epoch 391/1000
2/2 [==============================] - ETA: 0s - loss: 0.1969 - accuracy: 0.9125
Epoch 391: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 796ms/step - loss: 0.1969 - accuracy: 0.9125 - val_loss: 0.2851 - val_accuracy: 0.8305
Epoch 392/1000
2/2 [==============================] - ETA: 0s - loss: 0.1831 - accuracy: 0.9125
Epoch 392: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1831 - accuracy: 0.9125 - val_loss: 0.2831 - val_accuracy: 0.8305
Epoch 393/1000
2/2 [==============================] - ETA: 0s - loss: 0.2146 - accuracy: 0.8625
Epoch 393: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.2146 - accuracy: 0.8625 - val_loss: 0.2820 - val_accuracy: 0.8305
Epoch 394/1000
2/2 [==============================] - ETA: 0s - loss: 0.1512 - accuracy: 0.9375
Epoch 394: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 797ms/step - loss: 0.1512 - accuracy: 0.9375 - val_loss: 0.2816 - val_accuracy: 0.8305
Epoch 395/1000
2/2 [==============================] - ETA: 0s - loss: 0.1887 - accuracy: 0.8984
Epoch 395: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1887 - accuracy: 0.8984 - val_loss: 0.2810 - val_accuracy: 0.8305
Epoch 396/1000
2/2 [==============================] - ETA: 0s - loss: 0.1964 - accuracy: 0.9250
Epoch 396: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 805ms/step - loss: 0.1964 - accuracy: 0.9250 - val_loss: 0.2817 - val_accuracy: 0.8305
Epoch 397/1000
2/2 [==============================] - ETA: 0s - loss: 0.1661 - accuracy: 0.9219
Epoch 397: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 969ms/step - loss: 0.1661 - accuracy: 0.9219 - val_loss: 0.2819 - val_accuracy: 0.8136
Epoch 398/1000
2/2 [==============================] - ETA: 0s - loss: 0.1866 - accuracy: 0.9219
Epoch 398: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1866 - accuracy: 0.9219 - val_loss: 0.2835 - val_accuracy: 0.8136
Epoch 399/1000
2/2 [==============================] - ETA: 0s - loss: 0.1613 - accuracy: 0.9453
Epoch 399: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1613 - accuracy: 0.9453 - val_loss: 0.2854 - val_accuracy: 0.8136
Epoch 400/1000
2/2 [==============================] - ETA: 0s - loss: 0.1936 - accuracy: 0.9000
Epoch 400: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1936 - accuracy: 0.9000 - val_loss: 0.2866 - val_accuracy: 0.8136
Epoch 401/1000
2/2 [==============================] - ETA: 0s - loss: 0.1871 - accuracy: 0.9219
Epoch 401: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1871 - accuracy: 0.9219 - val_loss: 0.2878 - val_accuracy: 0.7966
Epoch 402/1000
2/2 [==============================] - ETA: 0s - loss: 0.1557 - accuracy: 0.9375
Epoch 402: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1557 - accuracy: 0.9375 - val_loss: 0.2889 - val_accuracy: 0.7966
Epoch 403/1000
2/2 [==============================] - ETA: 0s - loss: 0.1863 - accuracy: 0.9125
Epoch 403: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 822ms/step - loss: 0.1863 - accuracy: 0.9125 - val_loss: 0.2906 - val_accuracy: 0.8136
Epoch 404/1000
2/2 [==============================] - ETA: 0s - loss: 0.1650 - accuracy: 0.9297
Epoch 404: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 948ms/step - loss: 0.1650 - accuracy: 0.9297 - val_loss: 0.2921 - val_accuracy: 0.8136
Epoch 405/1000
2/2 [==============================] - ETA: 0s - loss: 0.1796 - accuracy: 0.9141
Epoch 405: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 956ms/step - loss: 0.1796 - accuracy: 0.9141 - val_loss: 0.2936 - val_accuracy: 0.8136
Epoch 406/1000
2/2 [==============================] - ETA: 0s - loss: 0.1615 - accuracy: 0.9531
Epoch 406: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1615 - accuracy: 0.9531 - val_loss: 0.2949 - val_accuracy: 0.8136
Epoch 407/1000
2/2 [==============================] - ETA: 0s - loss: 0.1877 - accuracy: 0.9141
Epoch 407: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1877 - accuracy: 0.9141 - val_loss: 0.2954 - val_accuracy: 0.8136
Epoch 408/1000
2/2 [==============================] - ETA: 0s - loss: 0.2060 - accuracy: 0.8875
Epoch 408: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2060 - accuracy: 0.8875 - val_loss: 0.2953 - val_accuracy: 0.8136
Epoch 409/1000
2/2 [==============================] - ETA: 0s - loss: 0.1334 - accuracy: 0.9688
Epoch 409: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 943ms/step - loss: 0.1334 - accuracy: 0.9688 - val_loss: 0.2956 - val_accuracy: 0.8136
Epoch 410/1000
2/2 [==============================] - ETA: 0s - loss: 0.1217 - accuracy: 0.9500
Epoch 410: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 818ms/step - loss: 0.1217 - accuracy: 0.9500 - val_loss: 0.2970 - val_accuracy: 0.8136
Epoch 411/1000
2/2 [==============================] - ETA: 0s - loss: 0.1435 - accuracy: 0.9609
Epoch 411: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 956ms/step - loss: 0.1435 - accuracy: 0.9609 - val_loss: 0.2978 - val_accuracy: 0.8136
Epoch 412/1000
2/2 [==============================] - ETA: 0s - loss: 0.2369 - accuracy: 0.8875
Epoch 412: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2369 - accuracy: 0.8875 - val_loss: 0.2975 - val_accuracy: 0.8136
Epoch 413/1000
2/2 [==============================] - ETA: 0s - loss: 0.1769 - accuracy: 0.9062
Epoch 413: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 925ms/step - loss: 0.1769 - accuracy: 0.9062 - val_loss: 0.2976 - val_accuracy: 0.8136
Epoch 414/1000
2/2 [==============================] - ETA: 0s - loss: 0.1529 - accuracy: 0.9297
Epoch 414: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1529 - accuracy: 0.9297 - val_loss: 0.2980 - val_accuracy: 0.8136
Epoch 415/1000
2/2 [==============================] - ETA: 0s - loss: 0.1929 - accuracy: 0.9141
Epoch 415: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1929 - accuracy: 0.9141 - val_loss: 0.2981 - val_accuracy: 0.8136
Epoch 416/1000
2/2 [==============================] - ETA: 0s - loss: 0.1664 - accuracy: 0.9375
Epoch 416: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1664 - accuracy: 0.9375 - val_loss: 0.2983 - val_accuracy: 0.8136
Epoch 417/1000
2/2 [==============================] - ETA: 0s - loss: 0.1497 - accuracy: 0.9500
Epoch 417: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 802ms/step - loss: 0.1497 - accuracy: 0.9500 - val_loss: 0.2982 - val_accuracy: 0.8136
Epoch 418/1000
2/2 [==============================] - ETA: 0s - loss: 0.1411 - accuracy: 0.9500
Epoch 418: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1411 - accuracy: 0.9500 - val_loss: 0.2985 - val_accuracy: 0.8136
Epoch 419/1000
2/2 [==============================] - ETA: 0s - loss: 0.2223 - accuracy: 0.8750
Epoch 419: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2223 - accuracy: 0.8750 - val_loss: 0.2979 - val_accuracy: 0.8136
Epoch 420/1000
2/2 [==============================] - ETA: 0s - loss: 0.2264 - accuracy: 0.8750
Epoch 420: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 940ms/step - loss: 0.2264 - accuracy: 0.8750 - val_loss: 0.2962 - val_accuracy: 0.8136
Epoch 421/1000
2/2 [==============================] - ETA: 0s - loss: 0.1621 - accuracy: 0.9219
Epoch 421: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 898ms/step - loss: 0.1621 - accuracy: 0.9219 - val_loss: 0.2952 - val_accuracy: 0.8136
Epoch 422/1000
2/2 [==============================] - ETA: 0s - loss: 0.1696 - accuracy: 0.9500
Epoch 422: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1696 - accuracy: 0.9500 - val_loss: 0.2945 - val_accuracy: 0.8305
Epoch 423/1000
2/2 [==============================] - ETA: 0s - loss: 0.2096 - accuracy: 0.8984
Epoch 423: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2096 - accuracy: 0.8984 - val_loss: 0.2934 - val_accuracy: 0.8305
Epoch 424/1000
2/2 [==============================] - ETA: 0s - loss: 0.2152 - accuracy: 0.9000
Epoch 424: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2152 - accuracy: 0.9000 - val_loss: 0.2935 - val_accuracy: 0.8305
Epoch 425/1000
2/2 [==============================] - ETA: 0s - loss: 0.1662 - accuracy: 0.9297
Epoch 425: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 902ms/step - loss: 0.1662 - accuracy: 0.9297 - val_loss: 0.2931 - val_accuracy: 0.8305
Epoch 426/1000
2/2 [==============================] - ETA: 0s - loss: 0.1505 - accuracy: 0.9297
Epoch 426: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 904ms/step - loss: 0.1505 - accuracy: 0.9297 - val_loss: 0.2917 - val_accuracy: 0.8305
Epoch 427/1000
2/2 [==============================] - ETA: 0s - loss: 0.1576 - accuracy: 0.9375
Epoch 427: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1576 - accuracy: 0.9375 - val_loss: 0.2896 - val_accuracy: 0.8305
Epoch 428/1000
2/2 [==============================] - ETA: 0s - loss: 0.2311 - accuracy: 0.8625
Epoch 428: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 800ms/step - loss: 0.2311 - accuracy: 0.8625 - val_loss: 0.2872 - val_accuracy: 0.8305
Epoch 429/1000
2/2 [==============================] - ETA: 0s - loss: 0.1310 - accuracy: 0.9125
Epoch 429: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.1310 - accuracy: 0.9125 - val_loss: 0.2852 - val_accuracy: 0.8305
Epoch 430/1000
2/2 [==============================] - ETA: 0s - loss: 0.1362 - accuracy: 0.9625
Epoch 430: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 809ms/step - loss: 0.1362 - accuracy: 0.9625 - val_loss: 0.2846 - val_accuracy: 0.8305
Epoch 431/1000
2/2 [==============================] - ETA: 0s - loss: 0.1907 - accuracy: 0.8672
Epoch 431: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 970ms/step - loss: 0.1907 - accuracy: 0.8672 - val_loss: 0.2838 - val_accuracy: 0.8305
Epoch 432/1000
2/2 [==============================] - ETA: 0s - loss: 0.1620 - accuracy: 0.9375
Epoch 432: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1620 - accuracy: 0.9375 - val_loss: 0.2835 - val_accuracy: 0.8305
Epoch 433/1000
2/2 [==============================] - ETA: 0s - loss: 0.1835 - accuracy: 0.9000
Epoch 433: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 804ms/step - loss: 0.1835 - accuracy: 0.9000 - val_loss: 0.2827 - val_accuracy: 0.8305
Epoch 434/1000
2/2 [==============================] - ETA: 0s - loss: 0.1855 - accuracy: 0.8875
Epoch 434: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.1855 - accuracy: 0.8875 - val_loss: 0.2822 - val_accuracy: 0.8305
Epoch 435/1000
2/2 [==============================] - ETA: 0s - loss: 0.1618 - accuracy: 0.9453
Epoch 435: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1618 - accuracy: 0.9453 - val_loss: 0.2819 - val_accuracy: 0.8305
Epoch 436/1000
2/2 [==============================] - ETA: 0s - loss: 0.1945 - accuracy: 0.9000
Epoch 436: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.1945 - accuracy: 0.9000 - val_loss: 0.2820 - val_accuracy: 0.8305
Epoch 437/1000
2/2 [==============================] - ETA: 0s - loss: 0.1356 - accuracy: 0.9766
Epoch 437: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1356 - accuracy: 0.9766 - val_loss: 0.2816 - val_accuracy: 0.8305
Epoch 438/1000
2/2 [==============================] - ETA: 0s - loss: 0.1677 - accuracy: 0.9125
Epoch 438: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1677 - accuracy: 0.9125 - val_loss: 0.2828 - val_accuracy: 0.8305
Epoch 439/1000
2/2 [==============================] - ETA: 0s - loss: 0.1504 - accuracy: 0.9219
Epoch 439: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 953ms/step - loss: 0.1504 - accuracy: 0.9219 - val_loss: 0.2843 - val_accuracy: 0.8305
Epoch 440/1000
2/2 [==============================] - ETA: 0s - loss: 0.2032 - accuracy: 0.8875
Epoch 440: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 842ms/step - loss: 0.2032 - accuracy: 0.8875 - val_loss: 0.2862 - val_accuracy: 0.8305
Epoch 441/1000
2/2 [==============================] - ETA: 0s - loss: 0.1492 - accuracy: 0.9625
Epoch 441: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.1492 - accuracy: 0.9625 - val_loss: 0.2884 - val_accuracy: 0.8305
Epoch 442/1000
2/2 [==============================] - ETA: 0s - loss: 0.1689 - accuracy: 0.9125
Epoch 442: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.1689 - accuracy: 0.9125 - val_loss: 0.2880 - val_accuracy: 0.8305
Epoch 443/1000
2/2 [==============================] - ETA: 0s - loss: 0.1659 - accuracy: 0.9250
Epoch 443: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1659 - accuracy: 0.9250 - val_loss: 0.2883 - val_accuracy: 0.8305
Epoch 444/1000
2/2 [==============================] - ETA: 0s - loss: 0.2104 - accuracy: 0.8828
Epoch 444: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 949ms/step - loss: 0.2104 - accuracy: 0.8828 - val_loss: 0.2863 - val_accuracy: 0.8305
Epoch 445/1000
2/2 [==============================] - ETA: 0s - loss: 0.1544 - accuracy: 0.9219
Epoch 445: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 942ms/step - loss: 0.1544 - accuracy: 0.9219 - val_loss: 0.2832 - val_accuracy: 0.8305
Epoch 446/1000
2/2 [==============================] - ETA: 0s - loss: 0.1321 - accuracy: 0.9766
Epoch 446: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 938ms/step - loss: 0.1321 - accuracy: 0.9766 - val_loss: 0.2813 - val_accuracy: 0.8305
Epoch 447/1000
2/2 [==============================] - ETA: 0s - loss: 0.1680 - accuracy: 0.9125
Epoch 447: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1680 - accuracy: 0.9125 - val_loss: 0.2811 - val_accuracy: 0.8136
Epoch 448/1000
2/2 [==============================] - ETA: 0s - loss: 0.1816 - accuracy: 0.9141
Epoch 448: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1816 - accuracy: 0.9141 - val_loss: 0.2806 - val_accuracy: 0.8136
Epoch 449/1000
2/2 [==============================] - ETA: 0s - loss: 0.1797 - accuracy: 0.9000
Epoch 449: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1797 - accuracy: 0.9000 - val_loss: 0.2814 - val_accuracy: 0.8136
Epoch 450/1000
2/2 [==============================] - ETA: 0s - loss: 0.1986 - accuracy: 0.8750
Epoch 450: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1986 - accuracy: 0.8750 - val_loss: 0.2840 - val_accuracy: 0.8136
Epoch 451/1000
2/2 [==============================] - ETA: 0s - loss: 0.1813 - accuracy: 0.8984
Epoch 451: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1813 - accuracy: 0.8984 - val_loss: 0.2866 - val_accuracy: 0.8136
Epoch 452/1000
2/2 [==============================] - ETA: 0s - loss: 0.2064 - accuracy: 0.8375
Epoch 452: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 833ms/step - loss: 0.2064 - accuracy: 0.8375 - val_loss: 0.2891 - val_accuracy: 0.8136
Epoch 453/1000
2/2 [==============================] - ETA: 0s - loss: 0.1394 - accuracy: 0.9625
Epoch 453: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 831ms/step - loss: 0.1394 - accuracy: 0.9625 - val_loss: 0.2909 - val_accuracy: 0.8136
Epoch 454/1000
2/2 [==============================] - ETA: 0s - loss: 0.1555 - accuracy: 0.9375
Epoch 454: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1555 - accuracy: 0.9375 - val_loss: 0.2903 - val_accuracy: 0.8136
Epoch 455/1000
2/2 [==============================] - ETA: 0s - loss: 0.1647 - accuracy: 0.9375
Epoch 455: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 874ms/step - loss: 0.1647 - accuracy: 0.9375 - val_loss: 0.2888 - val_accuracy: 0.8136
Epoch 456/1000
2/2 [==============================] - ETA: 0s - loss: 0.2253 - accuracy: 0.8625
Epoch 456: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2253 - accuracy: 0.8625 - val_loss: 0.2889 - val_accuracy: 0.8136
Epoch 457/1000
2/2 [==============================] - ETA: 0s - loss: 0.1515 - accuracy: 0.9625
Epoch 457: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1515 - accuracy: 0.9625 - val_loss: 0.2885 - val_accuracy: 0.8136
Epoch 458/1000
2/2 [==============================] - ETA: 0s - loss: 0.1796 - accuracy: 0.9141
Epoch 458: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1796 - accuracy: 0.9141 - val_loss: 0.2875 - val_accuracy: 0.8136
Epoch 459/1000
2/2 [==============================] - ETA: 0s - loss: 0.1726 - accuracy: 0.9000
Epoch 459: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1726 - accuracy: 0.9000 - val_loss: 0.2845 - val_accuracy: 0.8136
Epoch 460/1000
2/2 [==============================] - ETA: 0s - loss: 0.1235 - accuracy: 0.9500
Epoch 460: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1235 - accuracy: 0.9500 - val_loss: 0.2820 - val_accuracy: 0.8136
Epoch 461/1000
2/2 [==============================] - ETA: 0s - loss: 0.1356 - accuracy: 0.9375
Epoch 461: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1356 - accuracy: 0.9375 - val_loss: 0.2795 - val_accuracy: 0.8136
Epoch 462/1000
2/2 [==============================] - ETA: 0s - loss: 0.1549 - accuracy: 0.9625
Epoch 462: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1549 - accuracy: 0.9625 - val_loss: 0.2786 - val_accuracy: 0.8136
Epoch 463/1000
2/2 [==============================] - ETA: 0s - loss: 0.1813 - accuracy: 0.9141
Epoch 463: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 936ms/step - loss: 0.1813 - accuracy: 0.9141 - val_loss: 0.2789 - val_accuracy: 0.8305
Epoch 464/1000
2/2 [==============================] - ETA: 0s - loss: 0.1662 - accuracy: 0.9375
Epoch 464: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1662 - accuracy: 0.9375 - val_loss: 0.2788 - val_accuracy: 0.8305
Epoch 465/1000
2/2 [==============================] - ETA: 0s - loss: 0.1256 - accuracy: 0.9750
Epoch 465: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 833ms/step - loss: 0.1256 - accuracy: 0.9750 - val_loss: 0.2806 - val_accuracy: 0.8305
Epoch 466/1000
2/2 [==============================] - ETA: 0s - loss: 0.1848 - accuracy: 0.9141
Epoch 466: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1848 - accuracy: 0.9141 - val_loss: 0.2832 - val_accuracy: 0.8136
Epoch 467/1000
2/2 [==============================] - ETA: 0s - loss: 0.1815 - accuracy: 0.9219
Epoch 467: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 932ms/step - loss: 0.1815 - accuracy: 0.9219 - val_loss: 0.2864 - val_accuracy: 0.8136
Epoch 468/1000
2/2 [==============================] - ETA: 0s - loss: 0.1715 - accuracy: 0.8906
Epoch 468: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1715 - accuracy: 0.8906 - val_loss: 0.2882 - val_accuracy: 0.8136
Epoch 469/1000
2/2 [==============================] - ETA: 0s - loss: 0.1390 - accuracy: 0.9375
Epoch 469: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 969ms/step - loss: 0.1390 - accuracy: 0.9375 - val_loss: 0.2885 - val_accuracy: 0.8136
Epoch 470/1000
2/2 [==============================] - ETA: 0s - loss: 0.1557 - accuracy: 0.9000
Epoch 470: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 808ms/step - loss: 0.1557 - accuracy: 0.9000 - val_loss: 0.2893 - val_accuracy: 0.8136
Epoch 471/1000
2/2 [==============================] - ETA: 0s - loss: 0.1416 - accuracy: 0.9375
Epoch 471: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1416 - accuracy: 0.9375 - val_loss: 0.2901 - val_accuracy: 0.8136
Epoch 472/1000
2/2 [==============================] - ETA: 0s - loss: 0.1847 - accuracy: 0.9000
Epoch 472: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 875ms/step - loss: 0.1847 - accuracy: 0.9000 - val_loss: 0.2897 - val_accuracy: 0.8136
Epoch 473/1000
2/2 [==============================] - ETA: 0s - loss: 0.1655 - accuracy: 0.9297
Epoch 473: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 953ms/step - loss: 0.1655 - accuracy: 0.9297 - val_loss: 0.2874 - val_accuracy: 0.8136
Epoch 474/1000
2/2 [==============================] - ETA: 0s - loss: 0.1800 - accuracy: 0.9141
Epoch 474: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 923ms/step - loss: 0.1800 - accuracy: 0.9141 - val_loss: 0.2858 - val_accuracy: 0.8136
Epoch 475/1000
2/2 [==============================] - ETA: 0s - loss: 0.1262 - accuracy: 0.9453
Epoch 475: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 993ms/step - loss: 0.1262 - accuracy: 0.9453 - val_loss: 0.2833 - val_accuracy: 0.8305
Epoch 476/1000
2/2 [==============================] - ETA: 0s - loss: 0.2006 - accuracy: 0.8906
Epoch 476: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 930ms/step - loss: 0.2006 - accuracy: 0.8906 - val_loss: 0.2805 - val_accuracy: 0.8305
Epoch 477/1000
2/2 [==============================] - ETA: 0s - loss: 0.1352 - accuracy: 0.9609
Epoch 477: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 925ms/step - loss: 0.1352 - accuracy: 0.9609 - val_loss: 0.2774 - val_accuracy: 0.8305
Epoch 478/1000
2/2 [==============================] - ETA: 0s - loss: 0.1754 - accuracy: 0.8906
Epoch 478: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1754 - accuracy: 0.8906 - val_loss: 0.2742 - val_accuracy: 0.8305
Epoch 479/1000
2/2 [==============================] - ETA: 0s - loss: 0.1439 - accuracy: 0.9531
Epoch 479: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 920ms/step - loss: 0.1439 - accuracy: 0.9531 - val_loss: 0.2717 - val_accuracy: 0.8305
Epoch 480/1000
2/2 [==============================] - ETA: 0s - loss: 0.1415 - accuracy: 0.9531
Epoch 480: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1415 - accuracy: 0.9531 - val_loss: 0.2691 - val_accuracy: 0.8305
Epoch 481/1000
2/2 [==============================] - ETA: 0s - loss: 0.1797 - accuracy: 0.9062
Epoch 481: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1797 - accuracy: 0.9062 - val_loss: 0.2675 - val_accuracy: 0.8305
Epoch 482/1000
2/2 [==============================] - ETA: 0s - loss: 0.1773 - accuracy: 0.9000
Epoch 482: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1773 - accuracy: 0.9000 - val_loss: 0.2663 - val_accuracy: 0.8305
Epoch 483/1000
2/2 [==============================] - ETA: 0s - loss: 0.1369 - accuracy: 0.9375
Epoch 483: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1369 - accuracy: 0.9375 - val_loss: 0.2664 - val_accuracy: 0.8305
Epoch 484/1000
2/2 [==============================] - ETA: 0s - loss: 0.1577 - accuracy: 0.9141
Epoch 484: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1577 - accuracy: 0.9141 - val_loss: 0.2667 - val_accuracy: 0.8305
Epoch 485/1000
2/2 [==============================] - ETA: 0s - loss: 0.1333 - accuracy: 0.9531
Epoch 485: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 956ms/step - loss: 0.1333 - accuracy: 0.9531 - val_loss: 0.2676 - val_accuracy: 0.8305
Epoch 486/1000
2/2 [==============================] - ETA: 0s - loss: 0.1250 - accuracy: 0.9625
Epoch 486: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 825ms/step - loss: 0.1250 - accuracy: 0.9625 - val_loss: 0.2692 - val_accuracy: 0.8305
Epoch 487/1000
2/2 [==============================] - ETA: 0s - loss: 0.1775 - accuracy: 0.8875
Epoch 487: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1775 - accuracy: 0.8875 - val_loss: 0.2708 - val_accuracy: 0.8305
Epoch 488/1000
2/2 [==============================] - ETA: 0s - loss: 0.1744 - accuracy: 0.9297
Epoch 488: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1744 - accuracy: 0.9297 - val_loss: 0.2726 - val_accuracy: 0.8305
Epoch 489/1000
2/2 [==============================] - ETA: 0s - loss: 0.1200 - accuracy: 0.9500
Epoch 489: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1200 - accuracy: 0.9500 - val_loss: 0.2729 - val_accuracy: 0.8305
Epoch 490/1000
2/2 [==============================] - ETA: 0s - loss: 0.1249 - accuracy: 0.9375
Epoch 490: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1249 - accuracy: 0.9375 - val_loss: 0.2736 - val_accuracy: 0.8305
Epoch 491/1000
2/2 [==============================] - ETA: 0s - loss: 0.1771 - accuracy: 0.9250
Epoch 491: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1771 - accuracy: 0.9250 - val_loss: 0.2729 - val_accuracy: 0.8305
Epoch 492/1000
2/2 [==============================] - ETA: 0s - loss: 0.1549 - accuracy: 0.9125
Epoch 492: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 818ms/step - loss: 0.1549 - accuracy: 0.9125 - val_loss: 0.2700 - val_accuracy: 0.8305
Epoch 493/1000
2/2 [==============================] - ETA: 0s - loss: 0.1681 - accuracy: 0.9141
Epoch 493: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1681 - accuracy: 0.9141 - val_loss: 0.2669 - val_accuracy: 0.8305
Epoch 494/1000
2/2 [==============================] - ETA: 0s - loss: 0.2009 - accuracy: 0.8750
Epoch 494: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 828ms/step - loss: 0.2009 - accuracy: 0.8750 - val_loss: 0.2638 - val_accuracy: 0.8475
Epoch 495/1000
2/2 [==============================] - ETA: 0s - loss: 0.1664 - accuracy: 0.9375
Epoch 495: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1664 - accuracy: 0.9375 - val_loss: 0.2620 - val_accuracy: 0.8475
Epoch 496/1000
2/2 [==============================] - ETA: 0s - loss: 0.2320 - accuracy: 0.8984
Epoch 496: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.2320 - accuracy: 0.8984 - val_loss: 0.2619 - val_accuracy: 0.8475
Epoch 497/1000
2/2 [==============================] - ETA: 0s - loss: 0.1626 - accuracy: 0.8906
Epoch 497: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1626 - accuracy: 0.8906 - val_loss: 0.2602 - val_accuracy: 0.8644
Epoch 498/1000
2/2 [==============================] - ETA: 0s - loss: 0.1545 - accuracy: 0.9531
Epoch 498: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 979ms/step - loss: 0.1545 - accuracy: 0.9531 - val_loss: 0.2595 - val_accuracy: 0.8644
Epoch 499/1000
2/2 [==============================] - ETA: 0s - loss: 0.1404 - accuracy: 0.9875
Epoch 499: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1404 - accuracy: 0.9875 - val_loss: 0.2609 - val_accuracy: 0.8644
Epoch 500/1000
2/2 [==============================] - ETA: 0s - loss: 0.1046 - accuracy: 0.9875
Epoch 500: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 843ms/step - loss: 0.1046 - accuracy: 0.9875 - val_loss: 0.2629 - val_accuracy: 0.8644
Epoch 501/1000
2/2 [==============================] - ETA: 0s - loss: 0.1495 - accuracy: 0.9531
Epoch 501: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 952ms/step - loss: 0.1495 - accuracy: 0.9531 - val_loss: 0.2650 - val_accuracy: 0.8644
Epoch 502/1000
2/2 [==============================] - ETA: 0s - loss: 0.1643 - accuracy: 0.9141
Epoch 502: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1643 - accuracy: 0.9141 - val_loss: 0.2670 - val_accuracy: 0.8644
Epoch 503/1000
2/2 [==============================] - ETA: 0s - loss: 0.1779 - accuracy: 0.9062
Epoch 503: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1779 - accuracy: 0.9062 - val_loss: 0.2686 - val_accuracy: 0.8644
Epoch 504/1000
2/2 [==============================] - ETA: 0s - loss: 0.1600 - accuracy: 0.9625
Epoch 504: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1600 - accuracy: 0.9625 - val_loss: 0.2689 - val_accuracy: 0.8644
Epoch 505/1000
2/2 [==============================] - ETA: 0s - loss: 0.1275 - accuracy: 0.9625
Epoch 505: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1275 - accuracy: 0.9625 - val_loss: 0.2680 - val_accuracy: 0.8644
Epoch 506/1000
2/2 [==============================] - ETA: 0s - loss: 0.1473 - accuracy: 0.9375
Epoch 506: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1473 - accuracy: 0.9375 - val_loss: 0.2678 - val_accuracy: 0.8644
Epoch 507/1000
2/2 [==============================] - ETA: 0s - loss: 0.1198 - accuracy: 0.9609
Epoch 507: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 968ms/step - loss: 0.1198 - accuracy: 0.9609 - val_loss: 0.2672 - val_accuracy: 0.8644
Epoch 508/1000
2/2 [==============================] - ETA: 0s - loss: 0.1290 - accuracy: 0.9625
Epoch 508: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 804ms/step - loss: 0.1290 - accuracy: 0.9625 - val_loss: 0.2670 - val_accuracy: 0.8644
Epoch 509/1000
2/2 [==============================] - ETA: 0s - loss: 0.1622 - accuracy: 0.9219
Epoch 509: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1622 - accuracy: 0.9219 - val_loss: 0.2672 - val_accuracy: 0.8644
Epoch 510/1000
2/2 [==============================] - ETA: 0s - loss: 0.1284 - accuracy: 0.9250
Epoch 510: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 835ms/step - loss: 0.1284 - accuracy: 0.9250 - val_loss: 0.2674 - val_accuracy: 0.8644
Epoch 511/1000
2/2 [==============================] - ETA: 0s - loss: 0.1641 - accuracy: 0.9375
Epoch 511: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1641 - accuracy: 0.9375 - val_loss: 0.2685 - val_accuracy: 0.8644
Epoch 512/1000
2/2 [==============================] - ETA: 0s - loss: 0.1069 - accuracy: 0.9609
Epoch 512: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1069 - accuracy: 0.9609 - val_loss: 0.2706 - val_accuracy: 0.8475
Epoch 513/1000
2/2 [==============================] - ETA: 0s - loss: 0.1871 - accuracy: 0.9250
Epoch 513: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 834ms/step - loss: 0.1871 - accuracy: 0.9250 - val_loss: 0.2733 - val_accuracy: 0.8305
Epoch 514/1000
2/2 [==============================] - ETA: 0s - loss: 0.1451 - accuracy: 0.9297
Epoch 514: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1451 - accuracy: 0.9297 - val_loss: 0.2743 - val_accuracy: 0.8305
Epoch 515/1000
2/2 [==============================] - ETA: 0s - loss: 0.1631 - accuracy: 0.9375
Epoch 515: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1631 - accuracy: 0.9375 - val_loss: 0.2753 - val_accuracy: 0.8305
Epoch 516/1000
2/2 [==============================] - ETA: 0s - loss: 0.1393 - accuracy: 0.9297
Epoch 516: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1393 - accuracy: 0.9297 - val_loss: 0.2769 - val_accuracy: 0.8305
Epoch 517/1000
2/2 [==============================] - ETA: 0s - loss: 0.1717 - accuracy: 0.9250
Epoch 517: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1717 - accuracy: 0.9250 - val_loss: 0.2786 - val_accuracy: 0.8305
Epoch 518/1000
2/2 [==============================] - ETA: 0s - loss: 0.2001 - accuracy: 0.9250
Epoch 518: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 809ms/step - loss: 0.2001 - accuracy: 0.9250 - val_loss: 0.2801 - val_accuracy: 0.8136
Epoch 519/1000
2/2 [==============================] - ETA: 0s - loss: 0.1469 - accuracy: 0.9062
Epoch 519: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 994ms/step - loss: 0.1469 - accuracy: 0.9062 - val_loss: 0.2800 - val_accuracy: 0.8136
Epoch 520/1000
2/2 [==============================] - ETA: 0s - loss: 0.1444 - accuracy: 0.9531
Epoch 520: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 929ms/step - loss: 0.1444 - accuracy: 0.9531 - val_loss: 0.2781 - val_accuracy: 0.8136
Epoch 521/1000
2/2 [==============================] - ETA: 0s - loss: 0.1783 - accuracy: 0.9219
Epoch 521: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1783 - accuracy: 0.9219 - val_loss: 0.2761 - val_accuracy: 0.8136
Epoch 522/1000
2/2 [==============================] - ETA: 0s - loss: 0.1481 - accuracy: 0.9625
Epoch 522: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.1481 - accuracy: 0.9625 - val_loss: 0.2747 - val_accuracy: 0.8136
Epoch 523/1000
2/2 [==============================] - ETA: 0s - loss: 0.1230 - accuracy: 0.9500
Epoch 523: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1230 - accuracy: 0.9500 - val_loss: 0.2744 - val_accuracy: 0.8136
Epoch 524/1000
2/2 [==============================] - ETA: 0s - loss: 0.1329 - accuracy: 0.9625
Epoch 524: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1329 - accuracy: 0.9625 - val_loss: 0.2744 - val_accuracy: 0.8136
Epoch 525/1000
2/2 [==============================] - ETA: 0s - loss: 0.1305 - accuracy: 0.9531
Epoch 525: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1305 - accuracy: 0.9531 - val_loss: 0.2744 - val_accuracy: 0.8136
Epoch 526/1000
2/2 [==============================] - ETA: 0s - loss: 0.0974 - accuracy: 0.9750
Epoch 526: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0974 - accuracy: 0.9750 - val_loss: 0.2743 - val_accuracy: 0.8136
Epoch 527/1000
2/2 [==============================] - ETA: 0s - loss: 0.2049 - accuracy: 0.9125
Epoch 527: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.2049 - accuracy: 0.9125 - val_loss: 0.2730 - val_accuracy: 0.8136
Epoch 528/1000
2/2 [==============================] - ETA: 0s - loss: 0.1441 - accuracy: 0.9297
Epoch 528: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 964ms/step - loss: 0.1441 - accuracy: 0.9297 - val_loss: 0.2722 - val_accuracy: 0.8136
Epoch 529/1000
2/2 [==============================] - ETA: 0s - loss: 0.1328 - accuracy: 0.9453
Epoch 529: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 973ms/step - loss: 0.1328 - accuracy: 0.9453 - val_loss: 0.2716 - val_accuracy: 0.8136
Epoch 530/1000
2/2 [==============================] - ETA: 0s - loss: 0.1522 - accuracy: 0.9375
Epoch 530: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1522 - accuracy: 0.9375 - val_loss: 0.2708 - val_accuracy: 0.8136
Epoch 531/1000
2/2 [==============================] - ETA: 0s - loss: 0.1479 - accuracy: 0.9531
Epoch 531: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1479 - accuracy: 0.9531 - val_loss: 0.2707 - val_accuracy: 0.8136
Epoch 532/1000
2/2 [==============================] - ETA: 0s - loss: 0.1405 - accuracy: 0.9375
Epoch 532: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.1405 - accuracy: 0.9375 - val_loss: 0.2708 - val_accuracy: 0.8136
Epoch 533/1000
2/2 [==============================] - ETA: 0s - loss: 0.1355 - accuracy: 0.9219
Epoch 533: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 929ms/step - loss: 0.1355 - accuracy: 0.9219 - val_loss: 0.2722 - val_accuracy: 0.8136
Epoch 534/1000
2/2 [==============================] - ETA: 0s - loss: 0.1524 - accuracy: 0.9375
Epoch 534: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 975ms/step - loss: 0.1524 - accuracy: 0.9375 - val_loss: 0.2752 - val_accuracy: 0.8136
Epoch 535/1000
2/2 [==============================] - ETA: 0s - loss: 0.1148 - accuracy: 0.9625
Epoch 535: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 825ms/step - loss: 0.1148 - accuracy: 0.9625 - val_loss: 0.2764 - val_accuracy: 0.8136
Epoch 536/1000
2/2 [==============================] - ETA: 0s - loss: 0.1230 - accuracy: 0.9500
Epoch 536: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 812ms/step - loss: 0.1230 - accuracy: 0.9500 - val_loss: 0.2759 - val_accuracy: 0.8136
Epoch 537/1000
2/2 [==============================] - ETA: 0s - loss: 0.1516 - accuracy: 0.9500
Epoch 537: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1516 - accuracy: 0.9500 - val_loss: 0.2749 - val_accuracy: 0.8136
Epoch 538/1000
2/2 [==============================] - ETA: 0s - loss: 0.1491 - accuracy: 0.9125
Epoch 538: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 835ms/step - loss: 0.1491 - accuracy: 0.9125 - val_loss: 0.2737 - val_accuracy: 0.8136
Epoch 539/1000
2/2 [==============================] - ETA: 0s - loss: 0.1335 - accuracy: 0.9766
Epoch 539: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 934ms/step - loss: 0.1335 - accuracy: 0.9766 - val_loss: 0.2722 - val_accuracy: 0.8305
Epoch 540/1000
2/2 [==============================] - ETA: 0s - loss: 0.1515 - accuracy: 0.9375
Epoch 540: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 836ms/step - loss: 0.1515 - accuracy: 0.9375 - val_loss: 0.2716 - val_accuracy: 0.8305
Epoch 541/1000
2/2 [==============================] - ETA: 0s - loss: 0.1613 - accuracy: 0.9125
Epoch 541: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 835ms/step - loss: 0.1613 - accuracy: 0.9125 - val_loss: 0.2709 - val_accuracy: 0.8305
Epoch 542/1000
2/2 [==============================] - ETA: 0s - loss: 0.1141 - accuracy: 0.9375
Epoch 542: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1141 - accuracy: 0.9375 - val_loss: 0.2692 - val_accuracy: 0.8305
Epoch 543/1000
2/2 [==============================] - ETA: 0s - loss: 0.1393 - accuracy: 0.9453
Epoch 543: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1393 - accuracy: 0.9453 - val_loss: 0.2681 - val_accuracy: 0.8305
Epoch 544/1000
2/2 [==============================] - ETA: 0s - loss: 0.1320 - accuracy: 0.9625
Epoch 544: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1320 - accuracy: 0.9625 - val_loss: 0.2639 - val_accuracy: 0.8305
Epoch 545/1000
2/2 [==============================] - ETA: 0s - loss: 0.1872 - accuracy: 0.9500
Epoch 545: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1872 - accuracy: 0.9500 - val_loss: 0.2605 - val_accuracy: 0.8475
Epoch 546/1000
2/2 [==============================] - ETA: 0s - loss: 0.1484 - accuracy: 0.9375
Epoch 546: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 867ms/step - loss: 0.1484 - accuracy: 0.9375 - val_loss: 0.2576 - val_accuracy: 0.8475
Epoch 547/1000
2/2 [==============================] - ETA: 0s - loss: 0.1332 - accuracy: 0.9250
Epoch 547: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1332 - accuracy: 0.9250 - val_loss: 0.2548 - val_accuracy: 0.8475
Epoch 548/1000
2/2 [==============================] - ETA: 0s - loss: 0.1152 - accuracy: 0.9375
Epoch 548: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 863ms/step - loss: 0.1152 - accuracy: 0.9375 - val_loss: 0.2531 - val_accuracy: 0.8475
Epoch 549/1000
2/2 [==============================] - ETA: 0s - loss: 0.1229 - accuracy: 0.9375
Epoch 549: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 816ms/step - loss: 0.1229 - accuracy: 0.9375 - val_loss: 0.2502 - val_accuracy: 0.8475
Epoch 550/1000
2/2 [==============================] - ETA: 0s - loss: 0.1275 - accuracy: 0.9375
Epoch 550: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 970ms/step - loss: 0.1275 - accuracy: 0.9375 - val_loss: 0.2477 - val_accuracy: 0.8475
Epoch 551/1000
2/2 [==============================] - ETA: 0s - loss: 0.1139 - accuracy: 0.9609
Epoch 551: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1139 - accuracy: 0.9609 - val_loss: 0.2460 - val_accuracy: 0.8475
Epoch 552/1000
2/2 [==============================] - ETA: 0s - loss: 0.1195 - accuracy: 0.9625
Epoch 552: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 843ms/step - loss: 0.1195 - accuracy: 0.9625 - val_loss: 0.2457 - val_accuracy: 0.8475
Epoch 553/1000
2/2 [==============================] - ETA: 0s - loss: 0.1418 - accuracy: 0.9609
Epoch 553: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1418 - accuracy: 0.9609 - val_loss: 0.2463 - val_accuracy: 0.8644
Epoch 554/1000
2/2 [==============================] - ETA: 0s - loss: 0.1361 - accuracy: 0.9531
Epoch 554: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 928ms/step - loss: 0.1361 - accuracy: 0.9531 - val_loss: 0.2481 - val_accuracy: 0.8644
Epoch 555/1000
2/2 [==============================] - ETA: 0s - loss: 0.1261 - accuracy: 0.9609
Epoch 555: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1261 - accuracy: 0.9609 - val_loss: 0.2497 - val_accuracy: 0.8644
Epoch 556/1000
2/2 [==============================] - ETA: 0s - loss: 0.1351 - accuracy: 0.9375
Epoch 556: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1351 - accuracy: 0.9375 - val_loss: 0.2502 - val_accuracy: 0.8644
Epoch 557/1000
2/2 [==============================] - ETA: 0s - loss: 0.1348 - accuracy: 0.9609
Epoch 557: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 979ms/step - loss: 0.1348 - accuracy: 0.9609 - val_loss: 0.2511 - val_accuracy: 0.8644
Epoch 558/1000
2/2 [==============================] - ETA: 0s - loss: 0.1423 - accuracy: 0.9453
Epoch 558: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 966ms/step - loss: 0.1423 - accuracy: 0.9453 - val_loss: 0.2523 - val_accuracy: 0.8475
Epoch 559/1000
2/2 [==============================] - ETA: 0s - loss: 0.1183 - accuracy: 0.9500
Epoch 559: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1183 - accuracy: 0.9500 - val_loss: 0.2542 - val_accuracy: 0.8475
Epoch 560/1000
2/2 [==============================] - ETA: 0s - loss: 0.1366 - accuracy: 0.9375
Epoch 560: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1366 - accuracy: 0.9375 - val_loss: 0.2565 - val_accuracy: 0.8475
Epoch 561/1000
2/2 [==============================] - ETA: 0s - loss: 0.1263 - accuracy: 0.9453
Epoch 561: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1263 - accuracy: 0.9453 - val_loss: 0.2591 - val_accuracy: 0.8475
Epoch 562/1000
2/2 [==============================] - ETA: 0s - loss: 0.1715 - accuracy: 0.9141
Epoch 562: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1715 - accuracy: 0.9141 - val_loss: 0.2615 - val_accuracy: 0.8475
Epoch 563/1000
2/2 [==============================] - ETA: 0s - loss: 0.1418 - accuracy: 0.9250
Epoch 563: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1418 - accuracy: 0.9250 - val_loss: 0.2651 - val_accuracy: 0.8475
Epoch 564/1000
2/2 [==============================] - ETA: 0s - loss: 0.1290 - accuracy: 0.9625
Epoch 564: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.1290 - accuracy: 0.9625 - val_loss: 0.2691 - val_accuracy: 0.8305
Epoch 565/1000
2/2 [==============================] - ETA: 0s - loss: 0.1817 - accuracy: 0.9375
Epoch 565: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1817 - accuracy: 0.9375 - val_loss: 0.2708 - val_accuracy: 0.8305
Epoch 566/1000
2/2 [==============================] - ETA: 0s - loss: 0.1019 - accuracy: 0.9500
Epoch 566: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1019 - accuracy: 0.9500 - val_loss: 0.2701 - val_accuracy: 0.8305
Epoch 567/1000
2/2 [==============================] - ETA: 0s - loss: 0.1623 - accuracy: 0.9125
Epoch 567: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1623 - accuracy: 0.9125 - val_loss: 0.2697 - val_accuracy: 0.8305
Epoch 568/1000
2/2 [==============================] - ETA: 0s - loss: 0.1237 - accuracy: 0.9250
Epoch 568: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 837ms/step - loss: 0.1237 - accuracy: 0.9250 - val_loss: 0.2684 - val_accuracy: 0.8475
Epoch 569/1000
2/2 [==============================] - ETA: 0s - loss: 0.1747 - accuracy: 0.8984
Epoch 569: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 987ms/step - loss: 0.1747 - accuracy: 0.8984 - val_loss: 0.2667 - val_accuracy: 0.8475
Epoch 570/1000
2/2 [==============================] - ETA: 0s - loss: 0.1495 - accuracy: 0.9375
Epoch 570: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1495 - accuracy: 0.9375 - val_loss: 0.2644 - val_accuracy: 0.8475
Epoch 571/1000
2/2 [==============================] - ETA: 0s - loss: 0.1420 - accuracy: 0.9453
Epoch 571: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1420 - accuracy: 0.9453 - val_loss: 0.2626 - val_accuracy: 0.8475
Epoch 572/1000
2/2 [==============================] - ETA: 0s - loss: 0.1442 - accuracy: 0.9250
Epoch 572: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 863ms/step - loss: 0.1442 - accuracy: 0.9250 - val_loss: 0.2603 - val_accuracy: 0.8475
Epoch 573/1000
2/2 [==============================] - ETA: 0s - loss: 0.1683 - accuracy: 0.9141
Epoch 573: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 970ms/step - loss: 0.1683 - accuracy: 0.9141 - val_loss: 0.2589 - val_accuracy: 0.8475
Epoch 574/1000
2/2 [==============================] - ETA: 0s - loss: 0.1001 - accuracy: 0.9875
Epoch 574: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1001 - accuracy: 0.9875 - val_loss: 0.2574 - val_accuracy: 0.8475
Epoch 575/1000
2/2 [==============================] - ETA: 0s - loss: 0.1083 - accuracy: 0.9766
Epoch 575: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 930ms/step - loss: 0.1083 - accuracy: 0.9766 - val_loss: 0.2565 - val_accuracy: 0.8475
Epoch 576/1000
2/2 [==============================] - ETA: 0s - loss: 0.1630 - accuracy: 0.9125
Epoch 576: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 993ms/step - loss: 0.1630 - accuracy: 0.9125 - val_loss: 0.2553 - val_accuracy: 0.8305
Epoch 577/1000
2/2 [==============================] - ETA: 0s - loss: 0.1247 - accuracy: 0.9688
Epoch 577: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 954ms/step - loss: 0.1247 - accuracy: 0.9688 - val_loss: 0.2550 - val_accuracy: 0.8305
Epoch 578/1000
2/2 [==============================] - ETA: 0s - loss: 0.1639 - accuracy: 0.9297
Epoch 578: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1639 - accuracy: 0.9297 - val_loss: 0.2545 - val_accuracy: 0.8305
Epoch 579/1000
2/2 [==============================] - ETA: 0s - loss: 0.1569 - accuracy: 0.9500
Epoch 579: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1569 - accuracy: 0.9500 - val_loss: 0.2547 - val_accuracy: 0.8305
Epoch 580/1000
2/2 [==============================] - ETA: 0s - loss: 0.1216 - accuracy: 0.9531
Epoch 580: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 973ms/step - loss: 0.1216 - accuracy: 0.9531 - val_loss: 0.2551 - val_accuracy: 0.8305
Epoch 581/1000
2/2 [==============================] - ETA: 0s - loss: 0.1174 - accuracy: 0.9625
Epoch 581: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 823ms/step - loss: 0.1174 - accuracy: 0.9625 - val_loss: 0.2562 - val_accuracy: 0.8305
Epoch 582/1000
2/2 [==============================] - ETA: 0s - loss: 0.1507 - accuracy: 0.9125
Epoch 582: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.1507 - accuracy: 0.9125 - val_loss: 0.2584 - val_accuracy: 0.8305
Epoch 583/1000
2/2 [==============================] - ETA: 0s - loss: 0.1742 - accuracy: 0.9125
Epoch 583: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1742 - accuracy: 0.9125 - val_loss: 0.2610 - val_accuracy: 0.8305
Epoch 584/1000
2/2 [==============================] - ETA: 0s - loss: 0.1347 - accuracy: 0.9500
Epoch 584: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 832ms/step - loss: 0.1347 - accuracy: 0.9500 - val_loss: 0.2647 - val_accuracy: 0.8136
Epoch 585/1000
2/2 [==============================] - ETA: 0s - loss: 0.1067 - accuracy: 0.9625
Epoch 585: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 813ms/step - loss: 0.1067 - accuracy: 0.9625 - val_loss: 0.2673 - val_accuracy: 0.8136
Epoch 586/1000
2/2 [==============================] - ETA: 0s - loss: 0.1478 - accuracy: 0.9375
Epoch 586: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1478 - accuracy: 0.9375 - val_loss: 0.2684 - val_accuracy: 0.8136
Epoch 587/1000
2/2 [==============================] - ETA: 0s - loss: 0.1327 - accuracy: 0.9375
Epoch 587: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1327 - accuracy: 0.9375 - val_loss: 0.2703 - val_accuracy: 0.8136
Epoch 588/1000
2/2 [==============================] - ETA: 0s - loss: 0.1022 - accuracy: 0.9844
Epoch 588: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 926ms/step - loss: 0.1022 - accuracy: 0.9844 - val_loss: 0.2727 - val_accuracy: 0.8136
Epoch 589/1000
2/2 [==============================] - ETA: 0s - loss: 0.2192 - accuracy: 0.9250
Epoch 589: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 815ms/step - loss: 0.2192 - accuracy: 0.9250 - val_loss: 0.2742 - val_accuracy: 0.8136
Epoch 590/1000
2/2 [==============================] - ETA: 0s - loss: 0.1731 - accuracy: 0.9000
Epoch 590: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1731 - accuracy: 0.9000 - val_loss: 0.2751 - val_accuracy: 0.8136
Epoch 591/1000
2/2 [==============================] - ETA: 0s - loss: 0.1368 - accuracy: 0.9453
Epoch 591: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1368 - accuracy: 0.9453 - val_loss: 0.2766 - val_accuracy: 0.8136
Epoch 592/1000
2/2 [==============================] - ETA: 0s - loss: 0.1619 - accuracy: 0.9531
Epoch 592: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1619 - accuracy: 0.9531 - val_loss: 0.2789 - val_accuracy: 0.8136
Epoch 593/1000
2/2 [==============================] - ETA: 0s - loss: 0.1565 - accuracy: 0.9453
Epoch 593: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1565 - accuracy: 0.9453 - val_loss: 0.2819 - val_accuracy: 0.8136
Epoch 594/1000
2/2 [==============================] - ETA: 0s - loss: 0.1473 - accuracy: 0.9375
Epoch 594: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1473 - accuracy: 0.9375 - val_loss: 0.2856 - val_accuracy: 0.8136
Epoch 595/1000
2/2 [==============================] - ETA: 0s - loss: 0.1418 - accuracy: 0.9500
Epoch 595: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 844ms/step - loss: 0.1418 - accuracy: 0.9500 - val_loss: 0.2865 - val_accuracy: 0.8136
Epoch 596/1000
2/2 [==============================] - ETA: 0s - loss: 0.1448 - accuracy: 0.9375
Epoch 596: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 965ms/step - loss: 0.1448 - accuracy: 0.9375 - val_loss: 0.2876 - val_accuracy: 0.8136
Epoch 597/1000
2/2 [==============================] - ETA: 0s - loss: 0.1282 - accuracy: 0.9531
Epoch 597: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1282 - accuracy: 0.9531 - val_loss: 0.2887 - val_accuracy: 0.8136
Epoch 598/1000
2/2 [==============================] - ETA: 0s - loss: 0.1232 - accuracy: 0.9625
Epoch 598: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1232 - accuracy: 0.9625 - val_loss: 0.2871 - val_accuracy: 0.8136
Epoch 599/1000
2/2 [==============================] - ETA: 0s - loss: 0.1416 - accuracy: 0.9297
Epoch 599: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 940ms/step - loss: 0.1416 - accuracy: 0.9297 - val_loss: 0.2858 - val_accuracy: 0.8136
Epoch 600/1000
2/2 [==============================] - ETA: 0s - loss: 0.1402 - accuracy: 0.9219
Epoch 600: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1402 - accuracy: 0.9219 - val_loss: 0.2840 - val_accuracy: 0.8136
Epoch 601/1000
2/2 [==============================] - ETA: 0s - loss: 0.1639 - accuracy: 0.9125
Epoch 601: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 848ms/step - loss: 0.1639 - accuracy: 0.9125 - val_loss: 0.2813 - val_accuracy: 0.8305
Epoch 602/1000
2/2 [==============================] - ETA: 0s - loss: 0.1876 - accuracy: 0.9250
Epoch 602: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1876 - accuracy: 0.9250 - val_loss: 0.2773 - val_accuracy: 0.8305
Epoch 603/1000
2/2 [==============================] - ETA: 0s - loss: 0.1317 - accuracy: 0.9500
Epoch 603: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 826ms/step - loss: 0.1317 - accuracy: 0.9500 - val_loss: 0.2740 - val_accuracy: 0.8136
Epoch 604/1000
2/2 [==============================] - ETA: 0s - loss: 0.1224 - accuracy: 0.9500
Epoch 604: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1224 - accuracy: 0.9500 - val_loss: 0.2705 - val_accuracy: 0.8136
Epoch 605/1000
2/2 [==============================] - ETA: 0s - loss: 0.1412 - accuracy: 0.9375
Epoch 605: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1412 - accuracy: 0.9375 - val_loss: 0.2674 - val_accuracy: 0.8136
Epoch 606/1000
2/2 [==============================] - ETA: 0s - loss: 0.1069 - accuracy: 0.9750
Epoch 606: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1069 - accuracy: 0.9750 - val_loss: 0.2641 - val_accuracy: 0.8305
Epoch 607/1000
2/2 [==============================] - ETA: 0s - loss: 0.0904 - accuracy: 0.9750
Epoch 607: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.0904 - accuracy: 0.9750 - val_loss: 0.2630 - val_accuracy: 0.8305
Epoch 608/1000
2/2 [==============================] - ETA: 0s - loss: 0.1305 - accuracy: 0.9375
Epoch 608: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1305 - accuracy: 0.9375 - val_loss: 0.2647 - val_accuracy: 0.8305
Epoch 609/1000
2/2 [==============================] - ETA: 0s - loss: 0.1477 - accuracy: 0.9375
Epoch 609: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 831ms/step - loss: 0.1477 - accuracy: 0.9375 - val_loss: 0.2663 - val_accuracy: 0.8305
Epoch 610/1000
2/2 [==============================] - ETA: 0s - loss: 0.0939 - accuracy: 1.0000
Epoch 610: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0939 - accuracy: 1.0000 - val_loss: 0.2680 - val_accuracy: 0.8475
Epoch 611/1000
2/2 [==============================] - ETA: 0s - loss: 0.0889 - accuracy: 0.9875
Epoch 611: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 845ms/step - loss: 0.0889 - accuracy: 0.9875 - val_loss: 0.2703 - val_accuracy: 0.8305
Epoch 612/1000
2/2 [==============================] - ETA: 0s - loss: 0.1134 - accuracy: 0.9609
Epoch 612: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1134 - accuracy: 0.9609 - val_loss: 0.2725 - val_accuracy: 0.8305
Epoch 613/1000
2/2 [==============================] - ETA: 0s - loss: 0.1093 - accuracy: 0.9688
Epoch 613: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 932ms/step - loss: 0.1093 - accuracy: 0.9688 - val_loss: 0.2741 - val_accuracy: 0.8305
Epoch 614/1000
2/2 [==============================] - ETA: 0s - loss: 0.1112 - accuracy: 0.9688
Epoch 614: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1112 - accuracy: 0.9688 - val_loss: 0.2750 - val_accuracy: 0.8305
Epoch 615/1000
2/2 [==============================] - ETA: 0s - loss: 0.1013 - accuracy: 1.0000
Epoch 615: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1013 - accuracy: 1.0000 - val_loss: 0.2758 - val_accuracy: 0.8305
Epoch 616/1000
2/2 [==============================] - ETA: 0s - loss: 0.1483 - accuracy: 0.9141
Epoch 616: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1483 - accuracy: 0.9141 - val_loss: 0.2760 - val_accuracy: 0.8305
Epoch 617/1000
2/2 [==============================] - ETA: 0s - loss: 0.1175 - accuracy: 0.9625
Epoch 617: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1175 - accuracy: 0.9625 - val_loss: 0.2762 - val_accuracy: 0.8305
Epoch 618/1000
2/2 [==============================] - ETA: 0s - loss: 0.1037 - accuracy: 0.9688
Epoch 618: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 955ms/step - loss: 0.1037 - accuracy: 0.9688 - val_loss: 0.2767 - val_accuracy: 0.8305
Epoch 619/1000
2/2 [==============================] - ETA: 0s - loss: 0.1226 - accuracy: 0.9500
Epoch 619: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1226 - accuracy: 0.9500 - val_loss: 0.2775 - val_accuracy: 0.8305
Epoch 620/1000
2/2 [==============================] - ETA: 0s - loss: 0.1093 - accuracy: 0.9625
Epoch 620: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1093 - accuracy: 0.9625 - val_loss: 0.2780 - val_accuracy: 0.8305
Epoch 621/1000
2/2 [==============================] - ETA: 0s - loss: 0.1217 - accuracy: 0.9453
Epoch 621: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 923ms/step - loss: 0.1217 - accuracy: 0.9453 - val_loss: 0.2780 - val_accuracy: 0.8475
Epoch 622/1000
2/2 [==============================] - ETA: 0s - loss: 0.1332 - accuracy: 0.9688
Epoch 622: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 958ms/step - loss: 0.1332 - accuracy: 0.9688 - val_loss: 0.2768 - val_accuracy: 0.8475
Epoch 623/1000
2/2 [==============================] - ETA: 0s - loss: 0.1901 - accuracy: 0.8750
Epoch 623: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 874ms/step - loss: 0.1901 - accuracy: 0.8750 - val_loss: 0.2755 - val_accuracy: 0.8475
Epoch 624/1000
2/2 [==============================] - ETA: 0s - loss: 0.1137 - accuracy: 0.9531
Epoch 624: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 931ms/step - loss: 0.1137 - accuracy: 0.9531 - val_loss: 0.2747 - val_accuracy: 0.8475
Epoch 625/1000
2/2 [==============================] - ETA: 0s - loss: 0.1145 - accuracy: 0.9453
Epoch 625: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 982ms/step - loss: 0.1145 - accuracy: 0.9453 - val_loss: 0.2742 - val_accuracy: 0.8475
Epoch 626/1000
2/2 [==============================] - ETA: 0s - loss: 0.1495 - accuracy: 0.9453
Epoch 626: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 985ms/step - loss: 0.1495 - accuracy: 0.9453 - val_loss: 0.2736 - val_accuracy: 0.8475
Epoch 627/1000
2/2 [==============================] - ETA: 0s - loss: 0.0794 - accuracy: 0.9875
Epoch 627: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 817ms/step - loss: 0.0794 - accuracy: 0.9875 - val_loss: 0.2719 - val_accuracy: 0.8475
Epoch 628/1000
2/2 [==============================] - ETA: 0s - loss: 0.1697 - accuracy: 0.9141
Epoch 628: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 968ms/step - loss: 0.1697 - accuracy: 0.9141 - val_loss: 0.2718 - val_accuracy: 0.8475
Epoch 629/1000
2/2 [==============================] - ETA: 0s - loss: 0.1177 - accuracy: 0.9297
Epoch 629: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1177 - accuracy: 0.9297 - val_loss: 0.2714 - val_accuracy: 0.8475
Epoch 630/1000
2/2 [==============================] - ETA: 0s - loss: 0.1289 - accuracy: 0.9453
Epoch 630: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 930ms/step - loss: 0.1289 - accuracy: 0.9453 - val_loss: 0.2695 - val_accuracy: 0.8475
Epoch 631/1000
2/2 [==============================] - ETA: 0s - loss: 0.1265 - accuracy: 0.9625
Epoch 631: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1265 - accuracy: 0.9625 - val_loss: 0.2698 - val_accuracy: 0.8475
Epoch 632/1000
2/2 [==============================] - ETA: 0s - loss: 0.1210 - accuracy: 0.9375
Epoch 632: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1210 - accuracy: 0.9375 - val_loss: 0.2694 - val_accuracy: 0.8475
Epoch 633/1000
2/2 [==============================] - ETA: 0s - loss: 0.1212 - accuracy: 0.9531
Epoch 633: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 910ms/step - loss: 0.1212 - accuracy: 0.9531 - val_loss: 0.2685 - val_accuracy: 0.8475
Epoch 634/1000
2/2 [==============================] - ETA: 0s - loss: 0.0945 - accuracy: 0.9625
Epoch 634: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 828ms/step - loss: 0.0945 - accuracy: 0.9625 - val_loss: 0.2682 - val_accuracy: 0.8475
Epoch 635/1000
2/2 [==============================] - ETA: 0s - loss: 0.1332 - accuracy: 0.9453
Epoch 635: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1332 - accuracy: 0.9453 - val_loss: 0.2689 - val_accuracy: 0.8305
Epoch 636/1000
2/2 [==============================] - ETA: 0s - loss: 0.1162 - accuracy: 0.9297
Epoch 636: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1162 - accuracy: 0.9297 - val_loss: 0.2700 - val_accuracy: 0.8305
Epoch 637/1000
2/2 [==============================] - ETA: 0s - loss: 0.1188 - accuracy: 0.9453
Epoch 637: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 944ms/step - loss: 0.1188 - accuracy: 0.9453 - val_loss: 0.2703 - val_accuracy: 0.8305
Epoch 638/1000
2/2 [==============================] - ETA: 0s - loss: 0.1679 - accuracy: 0.9125
Epoch 638: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 835ms/step - loss: 0.1679 - accuracy: 0.9125 - val_loss: 0.2692 - val_accuracy: 0.8305
Epoch 639/1000
2/2 [==============================] - ETA: 0s - loss: 0.0977 - accuracy: 0.9625
Epoch 639: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 837ms/step - loss: 0.0977 - accuracy: 0.9625 - val_loss: 0.2677 - val_accuracy: 0.8305
Epoch 640/1000
2/2 [==============================] - ETA: 0s - loss: 0.0780 - accuracy: 0.9844
Epoch 640: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 934ms/step - loss: 0.0780 - accuracy: 0.9844 - val_loss: 0.2665 - val_accuracy: 0.8305
Epoch 641/1000
2/2 [==============================] - ETA: 0s - loss: 0.0954 - accuracy: 0.9625
Epoch 641: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 809ms/step - loss: 0.0954 - accuracy: 0.9625 - val_loss: 0.2658 - val_accuracy: 0.8305
Epoch 642/1000
2/2 [==============================] - ETA: 0s - loss: 0.1260 - accuracy: 0.9531
Epoch 642: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1260 - accuracy: 0.9531 - val_loss: 0.2659 - val_accuracy: 0.8305
Epoch 643/1000
2/2 [==============================] - ETA: 0s - loss: 0.1252 - accuracy: 0.9453
Epoch 643: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1252 - accuracy: 0.9453 - val_loss: 0.2662 - val_accuracy: 0.8305
Epoch 644/1000
2/2 [==============================] - ETA: 0s - loss: 0.1139 - accuracy: 0.9625
Epoch 644: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1139 - accuracy: 0.9625 - val_loss: 0.2659 - val_accuracy: 0.8475
Epoch 645/1000
2/2 [==============================] - ETA: 0s - loss: 0.1121 - accuracy: 0.9531
Epoch 645: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1121 - accuracy: 0.9531 - val_loss: 0.2654 - val_accuracy: 0.8475
Epoch 646/1000
2/2 [==============================] - ETA: 0s - loss: 0.1068 - accuracy: 0.9688
Epoch 646: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1068 - accuracy: 0.9688 - val_loss: 0.2652 - val_accuracy: 0.8475
Epoch 647/1000
2/2 [==============================] - ETA: 0s - loss: 0.1136 - accuracy: 0.9625
Epoch 647: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1136 - accuracy: 0.9625 - val_loss: 0.2650 - val_accuracy: 0.8475
Epoch 648/1000
2/2 [==============================] - ETA: 0s - loss: 0.1084 - accuracy: 0.9688
Epoch 648: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1084 - accuracy: 0.9688 - val_loss: 0.2641 - val_accuracy: 0.8475
Epoch 649/1000
2/2 [==============================] - ETA: 0s - loss: 0.1123 - accuracy: 0.9531
Epoch 649: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 999ms/step - loss: 0.1123 - accuracy: 0.9531 - val_loss: 0.2637 - val_accuracy: 0.8475
Epoch 650/1000
2/2 [==============================] - ETA: 0s - loss: 0.1562 - accuracy: 0.9375
Epoch 650: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1562 - accuracy: 0.9375 - val_loss: 0.2633 - val_accuracy: 0.8475
Epoch 651/1000
2/2 [==============================] - ETA: 0s - loss: 0.1610 - accuracy: 0.9375
Epoch 651: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 804ms/step - loss: 0.1610 - accuracy: 0.9375 - val_loss: 0.2635 - val_accuracy: 0.8475
Epoch 652/1000
2/2 [==============================] - ETA: 0s - loss: 0.1656 - accuracy: 0.9141
Epoch 652: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1656 - accuracy: 0.9141 - val_loss: 0.2640 - val_accuracy: 0.8475
Epoch 653/1000
2/2 [==============================] - ETA: 0s - loss: 0.1222 - accuracy: 0.9500
Epoch 653: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 822ms/step - loss: 0.1222 - accuracy: 0.9500 - val_loss: 0.2651 - val_accuracy: 0.8475
Epoch 654/1000
2/2 [==============================] - ETA: 0s - loss: 0.1006 - accuracy: 0.9766
Epoch 654: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1006 - accuracy: 0.9766 - val_loss: 0.2669 - val_accuracy: 0.8475
Epoch 655/1000
2/2 [==============================] - ETA: 0s - loss: 0.1395 - accuracy: 0.9250
Epoch 655: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 826ms/step - loss: 0.1395 - accuracy: 0.9250 - val_loss: 0.2695 - val_accuracy: 0.8475
Epoch 656/1000
2/2 [==============================] - ETA: 0s - loss: 0.1042 - accuracy: 0.9766
Epoch 656: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1042 - accuracy: 0.9766 - val_loss: 0.2724 - val_accuracy: 0.8475
Epoch 657/1000
2/2 [==============================] - ETA: 0s - loss: 0.1471 - accuracy: 0.9125
Epoch 657: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1471 - accuracy: 0.9125 - val_loss: 0.2752 - val_accuracy: 0.8475
Epoch 658/1000
2/2 [==============================] - ETA: 0s - loss: 0.1069 - accuracy: 0.9531
Epoch 658: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 935ms/step - loss: 0.1069 - accuracy: 0.9531 - val_loss: 0.2782 - val_accuracy: 0.8475
Epoch 659/1000
2/2 [==============================] - ETA: 0s - loss: 0.0970 - accuracy: 0.9766
Epoch 659: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0970 - accuracy: 0.9766 - val_loss: 0.2803 - val_accuracy: 0.8475
Epoch 660/1000
2/2 [==============================] - ETA: 0s - loss: 0.1135 - accuracy: 0.9609
Epoch 660: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1135 - accuracy: 0.9609 - val_loss: 0.2815 - val_accuracy: 0.8305
Epoch 661/1000
2/2 [==============================] - ETA: 0s - loss: 0.0622 - accuracy: 0.9875
Epoch 661: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 801ms/step - loss: 0.0622 - accuracy: 0.9875 - val_loss: 0.2827 - val_accuracy: 0.8305
Epoch 662/1000
2/2 [==============================] - ETA: 0s - loss: 0.1074 - accuracy: 0.9625
Epoch 662: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 812ms/step - loss: 0.1074 - accuracy: 0.9625 - val_loss: 0.2826 - val_accuracy: 0.8305
Epoch 663/1000
2/2 [==============================] - ETA: 0s - loss: 0.1000 - accuracy: 0.9844
Epoch 663: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1000 - accuracy: 0.9844 - val_loss: 0.2818 - val_accuracy: 0.8475
Epoch 664/1000
2/2 [==============================] - ETA: 0s - loss: 0.0919 - accuracy: 0.9500
Epoch 664: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 840ms/step - loss: 0.0919 - accuracy: 0.9500 - val_loss: 0.2819 - val_accuracy: 0.8475
Epoch 665/1000
2/2 [==============================] - ETA: 0s - loss: 0.1268 - accuracy: 0.9375
Epoch 665: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1268 - accuracy: 0.9375 - val_loss: 0.2829 - val_accuracy: 0.8475
Epoch 666/1000
2/2 [==============================] - ETA: 0s - loss: 0.1491 - accuracy: 0.9250
Epoch 666: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1491 - accuracy: 0.9250 - val_loss: 0.2811 - val_accuracy: 0.8475
Epoch 667/1000
2/2 [==============================] - ETA: 0s - loss: 0.1190 - accuracy: 0.9500
Epoch 667: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 820ms/step - loss: 0.1190 - accuracy: 0.9500 - val_loss: 0.2784 - val_accuracy: 0.8475
Epoch 668/1000
2/2 [==============================] - ETA: 0s - loss: 0.0955 - accuracy: 0.9688
Epoch 668: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0955 - accuracy: 0.9688 - val_loss: 0.2763 - val_accuracy: 0.8475
Epoch 669/1000
2/2 [==============================] - ETA: 0s - loss: 0.1251 - accuracy: 0.9531
Epoch 669: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1251 - accuracy: 0.9531 - val_loss: 0.2759 - val_accuracy: 0.8475
Epoch 670/1000
2/2 [==============================] - ETA: 0s - loss: 0.1130 - accuracy: 0.9500
Epoch 670: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 821ms/step - loss: 0.1130 - accuracy: 0.9500 - val_loss: 0.2762 - val_accuracy: 0.8475
Epoch 671/1000
2/2 [==============================] - ETA: 0s - loss: 0.1206 - accuracy: 0.9375
Epoch 671: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1206 - accuracy: 0.9375 - val_loss: 0.2766 - val_accuracy: 0.8305
Epoch 672/1000
2/2 [==============================] - ETA: 0s - loss: 0.1287 - accuracy: 0.9453
Epoch 672: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1287 - accuracy: 0.9453 - val_loss: 0.2768 - val_accuracy: 0.8305
Epoch 673/1000
2/2 [==============================] - ETA: 0s - loss: 0.1517 - accuracy: 0.9250
Epoch 673: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 818ms/step - loss: 0.1517 - accuracy: 0.9250 - val_loss: 0.2769 - val_accuracy: 0.8305
Epoch 674/1000
2/2 [==============================] - ETA: 0s - loss: 0.1057 - accuracy: 0.9609
Epoch 674: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1057 - accuracy: 0.9609 - val_loss: 0.2767 - val_accuracy: 0.8305
Epoch 675/1000
2/2 [==============================] - ETA: 0s - loss: 0.1428 - accuracy: 0.9375
Epoch 675: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 834ms/step - loss: 0.1428 - accuracy: 0.9375 - val_loss: 0.2772 - val_accuracy: 0.8305
Epoch 676/1000
2/2 [==============================] - ETA: 0s - loss: 0.1095 - accuracy: 0.9625
Epoch 676: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1095 - accuracy: 0.9625 - val_loss: 0.2795 - val_accuracy: 0.8305
Epoch 677/1000
2/2 [==============================] - ETA: 0s - loss: 0.1420 - accuracy: 0.9375
Epoch 677: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1420 - accuracy: 0.9375 - val_loss: 0.2809 - val_accuracy: 0.8305
Epoch 678/1000
2/2 [==============================] - ETA: 0s - loss: 0.1261 - accuracy: 0.9141
Epoch 678: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1261 - accuracy: 0.9141 - val_loss: 0.2811 - val_accuracy: 0.8305
Epoch 679/1000
2/2 [==============================] - ETA: 0s - loss: 0.1210 - accuracy: 0.9625
Epoch 679: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 808ms/step - loss: 0.1210 - accuracy: 0.9625 - val_loss: 0.2805 - val_accuracy: 0.8305
Epoch 680/1000
2/2 [==============================] - ETA: 0s - loss: 0.1199 - accuracy: 0.9250
Epoch 680: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 826ms/step - loss: 0.1199 - accuracy: 0.9250 - val_loss: 0.2789 - val_accuracy: 0.8305
Epoch 681/1000
2/2 [==============================] - ETA: 0s - loss: 0.1262 - accuracy: 0.9688
Epoch 681: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 938ms/step - loss: 0.1262 - accuracy: 0.9688 - val_loss: 0.2781 - val_accuracy: 0.8305
Epoch 682/1000
2/2 [==============================] - ETA: 0s - loss: 0.1391 - accuracy: 0.9219
Epoch 682: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1391 - accuracy: 0.9219 - val_loss: 0.2770 - val_accuracy: 0.8305
Epoch 683/1000
2/2 [==============================] - ETA: 0s - loss: 0.0833 - accuracy: 0.9875
Epoch 683: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0833 - accuracy: 0.9875 - val_loss: 0.2774 - val_accuracy: 0.8305
Epoch 684/1000
2/2 [==============================] - ETA: 0s - loss: 0.1212 - accuracy: 0.9375
Epoch 684: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 999ms/step - loss: 0.1212 - accuracy: 0.9375 - val_loss: 0.2778 - val_accuracy: 0.8305
Epoch 685/1000
2/2 [==============================] - ETA: 0s - loss: 0.1233 - accuracy: 0.9531
Epoch 685: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1233 - accuracy: 0.9531 - val_loss: 0.2769 - val_accuracy: 0.8305
Epoch 686/1000
2/2 [==============================] - ETA: 0s - loss: 0.1080 - accuracy: 0.9609
Epoch 686: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1080 - accuracy: 0.9609 - val_loss: 0.2748 - val_accuracy: 0.8305
Epoch 687/1000
2/2 [==============================] - ETA: 0s - loss: 0.1526 - accuracy: 0.9125
Epoch 687: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1526 - accuracy: 0.9125 - val_loss: 0.2761 - val_accuracy: 0.8305
Epoch 688/1000
2/2 [==============================] - ETA: 0s - loss: 0.1283 - accuracy: 0.9375
Epoch 688: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1283 - accuracy: 0.9375 - val_loss: 0.2777 - val_accuracy: 0.8305
Epoch 689/1000
2/2 [==============================] - ETA: 0s - loss: 0.1500 - accuracy: 0.9375
Epoch 689: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 831ms/step - loss: 0.1500 - accuracy: 0.9375 - val_loss: 0.2809 - val_accuracy: 0.8305
Epoch 690/1000
2/2 [==============================] - ETA: 0s - loss: 0.1213 - accuracy: 0.9375
Epoch 690: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1213 - accuracy: 0.9375 - val_loss: 0.2837 - val_accuracy: 0.8305
Epoch 691/1000
2/2 [==============================] - ETA: 0s - loss: 0.1150 - accuracy: 0.9531
Epoch 691: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1150 - accuracy: 0.9531 - val_loss: 0.2858 - val_accuracy: 0.8305
Epoch 692/1000
2/2 [==============================] - ETA: 0s - loss: 0.0847 - accuracy: 0.9766
Epoch 692: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0847 - accuracy: 0.9766 - val_loss: 0.2873 - val_accuracy: 0.8305
Epoch 693/1000
2/2 [==============================] - ETA: 0s - loss: 0.1106 - accuracy: 0.9625
Epoch 693: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1106 - accuracy: 0.9625 - val_loss: 0.2868 - val_accuracy: 0.8305
Epoch 694/1000
2/2 [==============================] - ETA: 0s - loss: 0.1030 - accuracy: 0.9750
Epoch 694: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 833ms/step - loss: 0.1030 - accuracy: 0.9750 - val_loss: 0.2863 - val_accuracy: 0.8305
Epoch 695/1000
2/2 [==============================] - ETA: 0s - loss: 0.1061 - accuracy: 0.9531
Epoch 695: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 955ms/step - loss: 0.1061 - accuracy: 0.9531 - val_loss: 0.2856 - val_accuracy: 0.8305
Epoch 696/1000
2/2 [==============================] - ETA: 0s - loss: 0.1274 - accuracy: 0.9297
Epoch 696: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1274 - accuracy: 0.9297 - val_loss: 0.2846 - val_accuracy: 0.8305
Epoch 697/1000
2/2 [==============================] - ETA: 0s - loss: 0.1182 - accuracy: 0.9531
Epoch 697: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1182 - accuracy: 0.9531 - val_loss: 0.2838 - val_accuracy: 0.8305
Epoch 698/1000
2/2 [==============================] - ETA: 0s - loss: 0.1083 - accuracy: 0.9453
Epoch 698: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1083 - accuracy: 0.9453 - val_loss: 0.2828 - val_accuracy: 0.8305
Epoch 699/1000
2/2 [==============================] - ETA: 0s - loss: 0.1175 - accuracy: 0.9531
Epoch 699: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1175 - accuracy: 0.9531 - val_loss: 0.2830 - val_accuracy: 0.8305
Epoch 700/1000
2/2 [==============================] - ETA: 0s - loss: 0.1411 - accuracy: 0.9297
Epoch 700: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 957ms/step - loss: 0.1411 - accuracy: 0.9297 - val_loss: 0.2833 - val_accuracy: 0.8305
Epoch 701/1000
2/2 [==============================] - ETA: 0s - loss: 0.1243 - accuracy: 0.9453
Epoch 701: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1243 - accuracy: 0.9453 - val_loss: 0.2845 - val_accuracy: 0.8305
Epoch 702/1000
2/2 [==============================] - ETA: 0s - loss: 0.1150 - accuracy: 0.9500
Epoch 702: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 861ms/step - loss: 0.1150 - accuracy: 0.9500 - val_loss: 0.2868 - val_accuracy: 0.8305
Epoch 703/1000
2/2 [==============================] - ETA: 0s - loss: 0.1140 - accuracy: 0.9250
Epoch 703: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1140 - accuracy: 0.9250 - val_loss: 0.2885 - val_accuracy: 0.8305
Epoch 704/1000
2/2 [==============================] - ETA: 0s - loss: 0.1070 - accuracy: 0.9531
Epoch 704: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 934ms/step - loss: 0.1070 - accuracy: 0.9531 - val_loss: 0.2881 - val_accuracy: 0.8305
Epoch 705/1000
2/2 [==============================] - ETA: 0s - loss: 0.1123 - accuracy: 0.9625
Epoch 705: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1123 - accuracy: 0.9625 - val_loss: 0.2871 - val_accuracy: 0.8305
Epoch 706/1000
2/2 [==============================] - ETA: 0s - loss: 0.1124 - accuracy: 0.9453
Epoch 706: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1124 - accuracy: 0.9453 - val_loss: 0.2852 - val_accuracy: 0.8305
Epoch 707/1000
2/2 [==============================] - ETA: 0s - loss: 0.0818 - accuracy: 0.9531
Epoch 707: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0818 - accuracy: 0.9531 - val_loss: 0.2834 - val_accuracy: 0.8305
Epoch 708/1000
2/2 [==============================] - ETA: 0s - loss: 0.0923 - accuracy: 1.0000
Epoch 708: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 846ms/step - loss: 0.0923 - accuracy: 1.0000 - val_loss: 0.2816 - val_accuracy: 0.8305
Epoch 709/1000
2/2 [==============================] - ETA: 0s - loss: 0.1267 - accuracy: 0.9297
Epoch 709: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1267 - accuracy: 0.9297 - val_loss: 0.2808 - val_accuracy: 0.8305
Epoch 710/1000
2/2 [==============================] - ETA: 0s - loss: 0.1103 - accuracy: 0.9500
Epoch 710: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1103 - accuracy: 0.9500 - val_loss: 0.2803 - val_accuracy: 0.8305
Epoch 711/1000
2/2 [==============================] - ETA: 0s - loss: 0.1186 - accuracy: 0.9453
Epoch 711: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 957ms/step - loss: 0.1186 - accuracy: 0.9453 - val_loss: 0.2794 - val_accuracy: 0.8305
Epoch 712/1000
2/2 [==============================] - ETA: 0s - loss: 0.1164 - accuracy: 0.9500
Epoch 712: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 888ms/step - loss: 0.1164 - accuracy: 0.9500 - val_loss: 0.2793 - val_accuracy: 0.8305
Epoch 713/1000
2/2 [==============================] - ETA: 0s - loss: 0.1329 - accuracy: 0.9453
Epoch 713: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 920ms/step - loss: 0.1329 - accuracy: 0.9453 - val_loss: 0.2797 - val_accuracy: 0.8305
Epoch 714/1000
2/2 [==============================] - ETA: 0s - loss: 0.1029 - accuracy: 0.9453
Epoch 714: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1029 - accuracy: 0.9453 - val_loss: 0.2799 - val_accuracy: 0.8305
Epoch 715/1000
2/2 [==============================] - ETA: 0s - loss: 0.0814 - accuracy: 0.9750
Epoch 715: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0814 - accuracy: 0.9750 - val_loss: 0.2799 - val_accuracy: 0.8305
Epoch 716/1000
2/2 [==============================] - ETA: 0s - loss: 0.1071 - accuracy: 0.9609
Epoch 716: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 936ms/step - loss: 0.1071 - accuracy: 0.9609 - val_loss: 0.2795 - val_accuracy: 0.8475
Epoch 717/1000
2/2 [==============================] - ETA: 0s - loss: 0.0719 - accuracy: 1.0000
Epoch 717: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0719 - accuracy: 1.0000 - val_loss: 0.2809 - val_accuracy: 0.8305
Epoch 718/1000
2/2 [==============================] - ETA: 0s - loss: 0.1597 - accuracy: 0.9375
Epoch 718: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 821ms/step - loss: 0.1597 - accuracy: 0.9375 - val_loss: 0.2791 - val_accuracy: 0.8475
Epoch 719/1000
2/2 [==============================] - ETA: 0s - loss: 0.1307 - accuracy: 0.9750
Epoch 719: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 834ms/step - loss: 0.1307 - accuracy: 0.9750 - val_loss: 0.2759 - val_accuracy: 0.8475
Epoch 720/1000
2/2 [==============================] - ETA: 0s - loss: 0.0994 - accuracy: 0.9922
Epoch 720: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0994 - accuracy: 0.9922 - val_loss: 0.2731 - val_accuracy: 0.8475
Epoch 721/1000
2/2 [==============================] - ETA: 0s - loss: 0.1031 - accuracy: 0.9750
Epoch 721: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 859ms/step - loss: 0.1031 - accuracy: 0.9750 - val_loss: 0.2718 - val_accuracy: 0.8475
Epoch 722/1000
2/2 [==============================] - ETA: 0s - loss: 0.1109 - accuracy: 0.9375
Epoch 722: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 832ms/step - loss: 0.1109 - accuracy: 0.9375 - val_loss: 0.2699 - val_accuracy: 0.8475
Epoch 723/1000
2/2 [==============================] - ETA: 0s - loss: 0.0936 - accuracy: 0.9500
Epoch 723: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0936 - accuracy: 0.9500 - val_loss: 0.2673 - val_accuracy: 0.8475
Epoch 724/1000
2/2 [==============================] - ETA: 0s - loss: 0.1319 - accuracy: 0.9500
Epoch 724: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1319 - accuracy: 0.9500 - val_loss: 0.2645 - val_accuracy: 0.8475
Epoch 725/1000
2/2 [==============================] - ETA: 0s - loss: 0.1114 - accuracy: 0.9375
Epoch 725: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1114 - accuracy: 0.9375 - val_loss: 0.2619 - val_accuracy: 0.8475
Epoch 726/1000
2/2 [==============================] - ETA: 0s - loss: 0.0872 - accuracy: 0.9875
Epoch 726: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 805ms/step - loss: 0.0872 - accuracy: 0.9875 - val_loss: 0.2602 - val_accuracy: 0.8475
Epoch 727/1000
2/2 [==============================] - ETA: 0s - loss: 0.1199 - accuracy: 0.9609
Epoch 727: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1199 - accuracy: 0.9609 - val_loss: 0.2602 - val_accuracy: 0.8475
Epoch 728/1000
2/2 [==============================] - ETA: 0s - loss: 0.1012 - accuracy: 0.9609
Epoch 728: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 926ms/step - loss: 0.1012 - accuracy: 0.9609 - val_loss: 0.2608 - val_accuracy: 0.8475
Epoch 729/1000
2/2 [==============================] - ETA: 0s - loss: 0.0955 - accuracy: 0.9750
Epoch 729: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0955 - accuracy: 0.9750 - val_loss: 0.2607 - val_accuracy: 0.8475
Epoch 730/1000
2/2 [==============================] - ETA: 0s - loss: 0.1248 - accuracy: 0.9297
Epoch 730: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 970ms/step - loss: 0.1248 - accuracy: 0.9297 - val_loss: 0.2611 - val_accuracy: 0.8475
Epoch 731/1000
2/2 [==============================] - ETA: 0s - loss: 0.1311 - accuracy: 0.9219
Epoch 731: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1311 - accuracy: 0.9219 - val_loss: 0.2610 - val_accuracy: 0.8475
Epoch 732/1000
2/2 [==============================] - ETA: 0s - loss: 0.1236 - accuracy: 0.9375
Epoch 732: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 812ms/step - loss: 0.1236 - accuracy: 0.9375 - val_loss: 0.2621 - val_accuracy: 0.8305
Epoch 733/1000
2/2 [==============================] - ETA: 0s - loss: 0.1027 - accuracy: 0.9609
Epoch 733: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 959ms/step - loss: 0.1027 - accuracy: 0.9609 - val_loss: 0.2639 - val_accuracy: 0.8305
Epoch 734/1000
2/2 [==============================] - ETA: 0s - loss: 0.1354 - accuracy: 0.9453
Epoch 734: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1354 - accuracy: 0.9453 - val_loss: 0.2655 - val_accuracy: 0.8305
Epoch 735/1000
2/2 [==============================] - ETA: 0s - loss: 0.1007 - accuracy: 0.9531
Epoch 735: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 940ms/step - loss: 0.1007 - accuracy: 0.9531 - val_loss: 0.2681 - val_accuracy: 0.8305
Epoch 736/1000
2/2 [==============================] - ETA: 0s - loss: 0.1023 - accuracy: 0.9609
Epoch 736: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1023 - accuracy: 0.9609 - val_loss: 0.2705 - val_accuracy: 0.8305
Epoch 737/1000
2/2 [==============================] - ETA: 0s - loss: 0.0855 - accuracy: 0.9688
Epoch 737: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 901ms/step - loss: 0.0855 - accuracy: 0.9688 - val_loss: 0.2720 - val_accuracy: 0.8305
Epoch 738/1000
2/2 [==============================] - ETA: 0s - loss: 0.1273 - accuracy: 0.9000
Epoch 738: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 838ms/step - loss: 0.1273 - accuracy: 0.9000 - val_loss: 0.2730 - val_accuracy: 0.8305
Epoch 739/1000
2/2 [==============================] - ETA: 0s - loss: 0.1079 - accuracy: 0.9250
Epoch 739: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1079 - accuracy: 0.9250 - val_loss: 0.2744 - val_accuracy: 0.8305
Epoch 740/1000
2/2 [==============================] - ETA: 0s - loss: 0.0813 - accuracy: 0.9922
Epoch 740: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0813 - accuracy: 0.9922 - val_loss: 0.2757 - val_accuracy: 0.8305
Epoch 741/1000
2/2 [==============================] - ETA: 0s - loss: 0.1141 - accuracy: 0.9500
Epoch 741: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 839ms/step - loss: 0.1141 - accuracy: 0.9500 - val_loss: 0.2759 - val_accuracy: 0.8305
Epoch 742/1000
2/2 [==============================] - ETA: 0s - loss: 0.0984 - accuracy: 0.9844
Epoch 742: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 951ms/step - loss: 0.0984 - accuracy: 0.9844 - val_loss: 0.2755 - val_accuracy: 0.8305
Epoch 743/1000
2/2 [==============================] - ETA: 0s - loss: 0.0862 - accuracy: 0.9609
Epoch 743: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0862 - accuracy: 0.9609 - val_loss: 0.2756 - val_accuracy: 0.8305
Epoch 744/1000
2/2 [==============================] - ETA: 0s - loss: 0.1266 - accuracy: 0.9453
Epoch 744: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 954ms/step - loss: 0.1266 - accuracy: 0.9453 - val_loss: 0.2753 - val_accuracy: 0.8305
Epoch 745/1000
2/2 [==============================] - ETA: 0s - loss: 0.0972 - accuracy: 0.9625
Epoch 745: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 838ms/step - loss: 0.0972 - accuracy: 0.9625 - val_loss: 0.2741 - val_accuracy: 0.8305
Epoch 746/1000
2/2 [==============================] - ETA: 0s - loss: 0.1272 - accuracy: 0.9375
Epoch 746: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1272 - accuracy: 0.9375 - val_loss: 0.2730 - val_accuracy: 0.8305
Epoch 747/1000
2/2 [==============================] - ETA: 0s - loss: 0.1130 - accuracy: 0.9250
Epoch 747: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 850ms/step - loss: 0.1130 - accuracy: 0.9250 - val_loss: 0.2731 - val_accuracy: 0.8305
Epoch 748/1000
2/2 [==============================] - ETA: 0s - loss: 0.1005 - accuracy: 0.9609
Epoch 748: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1005 - accuracy: 0.9609 - val_loss: 0.2731 - val_accuracy: 0.8305
Epoch 749/1000
2/2 [==============================] - ETA: 0s - loss: 0.1331 - accuracy: 0.9219
Epoch 749: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1331 - accuracy: 0.9219 - val_loss: 0.2735 - val_accuracy: 0.8305
Epoch 750/1000
2/2 [==============================] - ETA: 0s - loss: 0.0987 - accuracy: 0.9531
Epoch 750: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 948ms/step - loss: 0.0987 - accuracy: 0.9531 - val_loss: 0.2732 - val_accuracy: 0.8305
Epoch 751/1000
2/2 [==============================] - ETA: 0s - loss: 0.1306 - accuracy: 0.9625
Epoch 751: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1306 - accuracy: 0.9625 - val_loss: 0.2735 - val_accuracy: 0.8305
Epoch 752/1000
2/2 [==============================] - ETA: 0s - loss: 0.1052 - accuracy: 0.9609
Epoch 752: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1052 - accuracy: 0.9609 - val_loss: 0.2742 - val_accuracy: 0.8305
Epoch 753/1000
2/2 [==============================] - ETA: 0s - loss: 0.1138 - accuracy: 0.9531
Epoch 753: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1138 - accuracy: 0.9531 - val_loss: 0.2751 - val_accuracy: 0.8305
Epoch 754/1000
2/2 [==============================] - ETA: 0s - loss: 0.0997 - accuracy: 0.9688
Epoch 754: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0997 - accuracy: 0.9688 - val_loss: 0.2757 - val_accuracy: 0.8305
Epoch 755/1000
2/2 [==============================] - ETA: 0s - loss: 0.0910 - accuracy: 0.9766
Epoch 755: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 964ms/step - loss: 0.0910 - accuracy: 0.9766 - val_loss: 0.2760 - val_accuracy: 0.8305
Epoch 756/1000
2/2 [==============================] - ETA: 0s - loss: 0.0916 - accuracy: 0.9531
Epoch 756: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0916 - accuracy: 0.9531 - val_loss: 0.2756 - val_accuracy: 0.8305
Epoch 757/1000
2/2 [==============================] - ETA: 0s - loss: 0.0892 - accuracy: 0.9688
Epoch 757: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0892 - accuracy: 0.9688 - val_loss: 0.2744 - val_accuracy: 0.8305
Epoch 758/1000
2/2 [==============================] - ETA: 0s - loss: 0.1605 - accuracy: 0.9125
Epoch 758: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1605 - accuracy: 0.9125 - val_loss: 0.2720 - val_accuracy: 0.8475
Epoch 759/1000
2/2 [==============================] - ETA: 0s - loss: 0.1353 - accuracy: 0.9375
Epoch 759: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1353 - accuracy: 0.9375 - val_loss: 0.2697 - val_accuracy: 0.8475
Epoch 760/1000
2/2 [==============================] - ETA: 0s - loss: 0.0941 - accuracy: 0.9875
Epoch 760: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0941 - accuracy: 0.9875 - val_loss: 0.2682 - val_accuracy: 0.8475
Epoch 761/1000
2/2 [==============================] - ETA: 0s - loss: 0.0846 - accuracy: 0.9922
Epoch 761: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0846 - accuracy: 0.9922 - val_loss: 0.2674 - val_accuracy: 0.8475
Epoch 762/1000
2/2 [==============================] - ETA: 0s - loss: 0.0976 - accuracy: 0.9609
Epoch 762: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0976 - accuracy: 0.9609 - val_loss: 0.2673 - val_accuracy: 0.8475
Epoch 763/1000
2/2 [==============================] - ETA: 0s - loss: 0.0895 - accuracy: 0.9500
Epoch 763: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0895 - accuracy: 0.9500 - val_loss: 0.2657 - val_accuracy: 0.8475
Epoch 764/1000
2/2 [==============================] - ETA: 0s - loss: 0.0793 - accuracy: 0.9766
Epoch 764: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 985ms/step - loss: 0.0793 - accuracy: 0.9766 - val_loss: 0.2641 - val_accuracy: 0.8475
Epoch 765/1000
2/2 [==============================] - ETA: 0s - loss: 0.0875 - accuracy: 0.9688
Epoch 765: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 964ms/step - loss: 0.0875 - accuracy: 0.9688 - val_loss: 0.2638 - val_accuracy: 0.8475
Epoch 766/1000
2/2 [==============================] - ETA: 0s - loss: 0.1283 - accuracy: 0.9500
Epoch 766: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1283 - accuracy: 0.9500 - val_loss: 0.2612 - val_accuracy: 0.8475
Epoch 767/1000
2/2 [==============================] - ETA: 0s - loss: 0.1182 - accuracy: 0.9375
Epoch 767: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1182 - accuracy: 0.9375 - val_loss: 0.2574 - val_accuracy: 0.8475
Epoch 768/1000
2/2 [==============================] - ETA: 0s - loss: 0.0919 - accuracy: 0.9453
Epoch 768: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0919 - accuracy: 0.9453 - val_loss: 0.2547 - val_accuracy: 0.8475
Epoch 769/1000
2/2 [==============================] - ETA: 0s - loss: 0.1081 - accuracy: 0.9750
Epoch 769: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 847ms/step - loss: 0.1081 - accuracy: 0.9750 - val_loss: 0.2529 - val_accuracy: 0.8475
Epoch 770/1000
2/2 [==============================] - ETA: 0s - loss: 0.0646 - accuracy: 1.0000
Epoch 770: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 947ms/step - loss: 0.0646 - accuracy: 1.0000 - val_loss: 0.2518 - val_accuracy: 0.8475
Epoch 771/1000
2/2 [==============================] - ETA: 0s - loss: 0.1405 - accuracy: 0.9500
Epoch 771: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 851ms/step - loss: 0.1405 - accuracy: 0.9500 - val_loss: 0.2505 - val_accuracy: 0.8475
Epoch 772/1000
2/2 [==============================] - ETA: 0s - loss: 0.1141 - accuracy: 0.9531
Epoch 772: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 953ms/step - loss: 0.1141 - accuracy: 0.9531 - val_loss: 0.2495 - val_accuracy: 0.8475
Epoch 773/1000
2/2 [==============================] - ETA: 0s - loss: 0.0894 - accuracy: 0.9844
Epoch 773: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 964ms/step - loss: 0.0894 - accuracy: 0.9844 - val_loss: 0.2490 - val_accuracy: 0.8475
Epoch 774/1000
2/2 [==============================] - ETA: 0s - loss: 0.1010 - accuracy: 0.9875
Epoch 774: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1010 - accuracy: 0.9875 - val_loss: 0.2502 - val_accuracy: 0.8475
Epoch 775/1000
2/2 [==============================] - ETA: 0s - loss: 0.1218 - accuracy: 0.9500
Epoch 775: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1218 - accuracy: 0.9500 - val_loss: 0.2521 - val_accuracy: 0.8475
Epoch 776/1000
2/2 [==============================] - ETA: 0s - loss: 0.0885 - accuracy: 0.9750
Epoch 776: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 825ms/step - loss: 0.0885 - accuracy: 0.9750 - val_loss: 0.2556 - val_accuracy: 0.8475
Epoch 777/1000
2/2 [==============================] - ETA: 0s - loss: 0.1032 - accuracy: 0.9750
Epoch 777: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1032 - accuracy: 0.9750 - val_loss: 0.2587 - val_accuracy: 0.8475
Epoch 778/1000
2/2 [==============================] - ETA: 0s - loss: 0.1003 - accuracy: 0.9453
Epoch 778: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 946ms/step - loss: 0.1003 - accuracy: 0.9453 - val_loss: 0.2619 - val_accuracy: 0.8475
Epoch 779/1000
2/2 [==============================] - ETA: 0s - loss: 0.0924 - accuracy: 0.9500
Epoch 779: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 830ms/step - loss: 0.0924 - accuracy: 0.9500 - val_loss: 0.2652 - val_accuracy: 0.8475
Epoch 780/1000
2/2 [==============================] - ETA: 0s - loss: 0.1120 - accuracy: 0.9688
Epoch 780: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1120 - accuracy: 0.9688 - val_loss: 0.2678 - val_accuracy: 0.8475
Epoch 781/1000
2/2 [==============================] - ETA: 0s - loss: 0.1270 - accuracy: 0.9531
Epoch 781: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 962ms/step - loss: 0.1270 - accuracy: 0.9531 - val_loss: 0.2701 - val_accuracy: 0.8475
Epoch 782/1000
2/2 [==============================] - ETA: 0s - loss: 0.0972 - accuracy: 0.9531
Epoch 782: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 953ms/step - loss: 0.0972 - accuracy: 0.9531 - val_loss: 0.2720 - val_accuracy: 0.8475
Epoch 783/1000
2/2 [==============================] - ETA: 0s - loss: 0.1113 - accuracy: 0.9688
Epoch 783: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1113 - accuracy: 0.9688 - val_loss: 0.2752 - val_accuracy: 0.8305
Epoch 784/1000
2/2 [==============================] - ETA: 0s - loss: 0.0787 - accuracy: 0.9500
Epoch 784: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.0787 - accuracy: 0.9500 - val_loss: 0.2774 - val_accuracy: 0.8305
Epoch 785/1000
2/2 [==============================] - ETA: 0s - loss: 0.1063 - accuracy: 0.9875
Epoch 785: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 816ms/step - loss: 0.1063 - accuracy: 0.9875 - val_loss: 0.2791 - val_accuracy: 0.8305
Epoch 786/1000
2/2 [==============================] - ETA: 0s - loss: 0.0988 - accuracy: 0.9688
Epoch 786: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0988 - accuracy: 0.9688 - val_loss: 0.2820 - val_accuracy: 0.8305
Epoch 787/1000
2/2 [==============================] - ETA: 0s - loss: 0.1266 - accuracy: 0.9250
Epoch 787: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1266 - accuracy: 0.9250 - val_loss: 0.2833 - val_accuracy: 0.8136
Epoch 788/1000
2/2 [==============================] - ETA: 0s - loss: 0.1121 - accuracy: 0.9688
Epoch 788: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1121 - accuracy: 0.9688 - val_loss: 0.2839 - val_accuracy: 0.8136
Epoch 789/1000
2/2 [==============================] - ETA: 0s - loss: 0.1159 - accuracy: 0.9375
Epoch 789: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1159 - accuracy: 0.9375 - val_loss: 0.2841 - val_accuracy: 0.8136
Epoch 790/1000
2/2 [==============================] - ETA: 0s - loss: 0.1131 - accuracy: 0.9625
Epoch 790: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 853ms/step - loss: 0.1131 - accuracy: 0.9625 - val_loss: 0.2837 - val_accuracy: 0.8475
Epoch 791/1000
2/2 [==============================] - ETA: 0s - loss: 0.0619 - accuracy: 1.0000
Epoch 791: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0619 - accuracy: 1.0000 - val_loss: 0.2837 - val_accuracy: 0.8475
Epoch 792/1000
2/2 [==============================] - ETA: 0s - loss: 0.0737 - accuracy: 1.0000
Epoch 792: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0737 - accuracy: 1.0000 - val_loss: 0.2861 - val_accuracy: 0.8475
Epoch 793/1000
2/2 [==============================] - ETA: 0s - loss: 0.1128 - accuracy: 0.9750
Epoch 793: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1128 - accuracy: 0.9750 - val_loss: 0.2885 - val_accuracy: 0.8305
Epoch 794/1000
2/2 [==============================] - ETA: 0s - loss: 0.0624 - accuracy: 1.0000
Epoch 794: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0624 - accuracy: 1.0000 - val_loss: 0.2914 - val_accuracy: 0.8305
Epoch 795/1000
2/2 [==============================] - ETA: 0s - loss: 0.0935 - accuracy: 0.9609
Epoch 795: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0935 - accuracy: 0.9609 - val_loss: 0.2928 - val_accuracy: 0.8305
Epoch 796/1000
2/2 [==============================] - ETA: 0s - loss: 0.0912 - accuracy: 0.9625
Epoch 796: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 881ms/step - loss: 0.0912 - accuracy: 0.9625 - val_loss: 0.2941 - val_accuracy: 0.8305
Epoch 797/1000
2/2 [==============================] - ETA: 0s - loss: 0.0922 - accuracy: 0.9766
Epoch 797: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0922 - accuracy: 0.9766 - val_loss: 0.2936 - val_accuracy: 0.8475
Epoch 798/1000
2/2 [==============================] - ETA: 0s - loss: 0.1466 - accuracy: 0.9375
Epoch 798: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1466 - accuracy: 0.9375 - val_loss: 0.2921 - val_accuracy: 0.8475
Epoch 799/1000
2/2 [==============================] - ETA: 0s - loss: 0.0982 - accuracy: 0.9453
Epoch 799: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0982 - accuracy: 0.9453 - val_loss: 0.2880 - val_accuracy: 0.8475
Epoch 800/1000
2/2 [==============================] - ETA: 0s - loss: 0.0642 - accuracy: 1.0000
Epoch 800: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 980ms/step - loss: 0.0642 - accuracy: 1.0000 - val_loss: 0.2839 - val_accuracy: 0.8644
Epoch 801/1000
2/2 [==============================] - ETA: 0s - loss: 0.1012 - accuracy: 0.9875
Epoch 801: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1012 - accuracy: 0.9875 - val_loss: 0.2809 - val_accuracy: 0.8644
Epoch 802/1000
2/2 [==============================] - ETA: 0s - loss: 0.0896 - accuracy: 0.9750
Epoch 802: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 842ms/step - loss: 0.0896 - accuracy: 0.9750 - val_loss: 0.2776 - val_accuracy: 0.8644
Epoch 803/1000
2/2 [==============================] - ETA: 0s - loss: 0.1111 - accuracy: 0.9750
Epoch 803: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 905ms/step - loss: 0.1111 - accuracy: 0.9750 - val_loss: 0.2753 - val_accuracy: 0.8644
Epoch 804/1000
2/2 [==============================] - ETA: 0s - loss: 0.1032 - accuracy: 0.9688
Epoch 804: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 959ms/step - loss: 0.1032 - accuracy: 0.9688 - val_loss: 0.2732 - val_accuracy: 0.8644
Epoch 805/1000
2/2 [==============================] - ETA: 0s - loss: 0.1012 - accuracy: 0.9609
Epoch 805: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1012 - accuracy: 0.9609 - val_loss: 0.2717 - val_accuracy: 0.8644
Epoch 806/1000
2/2 [==============================] - ETA: 0s - loss: 0.1017 - accuracy: 0.9688
Epoch 806: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 960ms/step - loss: 0.1017 - accuracy: 0.9688 - val_loss: 0.2710 - val_accuracy: 0.8644
Epoch 807/1000
2/2 [==============================] - ETA: 0s - loss: 0.0986 - accuracy: 0.9688
Epoch 807: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 946ms/step - loss: 0.0986 - accuracy: 0.9688 - val_loss: 0.2702 - val_accuracy: 0.8644
Epoch 808/1000
2/2 [==============================] - ETA: 0s - loss: 0.1174 - accuracy: 0.9688
Epoch 808: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1174 - accuracy: 0.9688 - val_loss: 0.2693 - val_accuracy: 0.8644
Epoch 809/1000
2/2 [==============================] - ETA: 0s - loss: 0.0800 - accuracy: 0.9750
Epoch 809: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0800 - accuracy: 0.9750 - val_loss: 0.2683 - val_accuracy: 0.8475
Epoch 810/1000
2/2 [==============================] - ETA: 0s - loss: 0.1655 - accuracy: 0.8875
Epoch 810: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 849ms/step - loss: 0.1655 - accuracy: 0.8875 - val_loss: 0.2673 - val_accuracy: 0.8475
Epoch 811/1000
2/2 [==============================] - ETA: 0s - loss: 0.0940 - accuracy: 0.9750
Epoch 811: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0940 - accuracy: 0.9750 - val_loss: 0.2662 - val_accuracy: 0.8475
Epoch 812/1000
2/2 [==============================] - ETA: 0s - loss: 0.0860 - accuracy: 0.9750
Epoch 812: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0860 - accuracy: 0.9750 - val_loss: 0.2628 - val_accuracy: 0.8475
Epoch 813/1000
2/2 [==============================] - ETA: 0s - loss: 0.0997 - accuracy: 0.9297
Epoch 813: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 976ms/step - loss: 0.0997 - accuracy: 0.9297 - val_loss: 0.2612 - val_accuracy: 0.8475
Epoch 814/1000
2/2 [==============================] - ETA: 0s - loss: 0.1229 - accuracy: 0.9625
Epoch 814: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 847ms/step - loss: 0.1229 - accuracy: 0.9625 - val_loss: 0.2585 - val_accuracy: 0.8475
Epoch 815/1000
2/2 [==============================] - ETA: 0s - loss: 0.1036 - accuracy: 0.9500
Epoch 815: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 834ms/step - loss: 0.1036 - accuracy: 0.9500 - val_loss: 0.2557 - val_accuracy: 0.8475
Epoch 816/1000
2/2 [==============================] - ETA: 0s - loss: 0.0913 - accuracy: 0.9609
Epoch 816: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 980ms/step - loss: 0.0913 - accuracy: 0.9609 - val_loss: 0.2546 - val_accuracy: 0.8475
Epoch 817/1000
2/2 [==============================] - ETA: 0s - loss: 0.1231 - accuracy: 0.9375
Epoch 817: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1231 - accuracy: 0.9375 - val_loss: 0.2543 - val_accuracy: 0.8475
Epoch 818/1000
2/2 [==============================] - ETA: 0s - loss: 0.0968 - accuracy: 0.9750
Epoch 818: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0968 - accuracy: 0.9750 - val_loss: 0.2539 - val_accuracy: 0.8475
Epoch 819/1000
2/2 [==============================] - ETA: 0s - loss: 0.0983 - accuracy: 0.9688
Epoch 819: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0983 - accuracy: 0.9688 - val_loss: 0.2527 - val_accuracy: 0.8475
Epoch 820/1000
2/2 [==============================] - ETA: 0s - loss: 0.0990 - accuracy: 0.9766
Epoch 820: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 965ms/step - loss: 0.0990 - accuracy: 0.9766 - val_loss: 0.2513 - val_accuracy: 0.8475
Epoch 821/1000
2/2 [==============================] - ETA: 0s - loss: 0.0738 - accuracy: 0.9750
Epoch 821: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0738 - accuracy: 0.9750 - val_loss: 0.2507 - val_accuracy: 0.8475
Epoch 822/1000
2/2 [==============================] - ETA: 0s - loss: 0.1152 - accuracy: 0.9609
Epoch 822: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1152 - accuracy: 0.9609 - val_loss: 0.2488 - val_accuracy: 0.8475
Epoch 823/1000
2/2 [==============================] - ETA: 0s - loss: 0.0756 - accuracy: 0.9625
Epoch 823: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0756 - accuracy: 0.9625 - val_loss: 0.2470 - val_accuracy: 0.8475
Epoch 824/1000
2/2 [==============================] - ETA: 0s - loss: 0.0963 - accuracy: 0.9844
Epoch 824: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0963 - accuracy: 0.9844 - val_loss: 0.2454 - val_accuracy: 0.8475
Epoch 825/1000
2/2 [==============================] - ETA: 0s - loss: 0.1150 - accuracy: 0.9688
Epoch 825: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1150 - accuracy: 0.9688 - val_loss: 0.2448 - val_accuracy: 0.8475
Epoch 826/1000
2/2 [==============================] - ETA: 0s - loss: 0.1223 - accuracy: 0.9500
Epoch 826: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1223 - accuracy: 0.9500 - val_loss: 0.2419 - val_accuracy: 0.8644
Epoch 827/1000
2/2 [==============================] - ETA: 0s - loss: 0.0789 - accuracy: 0.9688
Epoch 827: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0789 - accuracy: 0.9688 - val_loss: 0.2401 - val_accuracy: 0.8644
Epoch 828/1000
2/2 [==============================] - ETA: 0s - loss: 0.0897 - accuracy: 0.9750
Epoch 828: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0897 - accuracy: 0.9750 - val_loss: 0.2401 - val_accuracy: 0.8644
Epoch 829/1000
2/2 [==============================] - ETA: 0s - loss: 0.1105 - accuracy: 0.9531
Epoch 829: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 938ms/step - loss: 0.1105 - accuracy: 0.9531 - val_loss: 0.2408 - val_accuracy: 0.8644
Epoch 830/1000
2/2 [==============================] - ETA: 0s - loss: 0.0924 - accuracy: 0.9609
Epoch 830: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0924 - accuracy: 0.9609 - val_loss: 0.2409 - val_accuracy: 0.8644
Epoch 831/1000
2/2 [==============================] - ETA: 0s - loss: 0.0712 - accuracy: 0.9688
Epoch 831: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0712 - accuracy: 0.9688 - val_loss: 0.2412 - val_accuracy: 0.8644
Epoch 832/1000
2/2 [==============================] - ETA: 0s - loss: 0.0620 - accuracy: 0.9750
Epoch 832: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 811ms/step - loss: 0.0620 - accuracy: 0.9750 - val_loss: 0.2411 - val_accuracy: 0.8644
Epoch 833/1000
2/2 [==============================] - ETA: 0s - loss: 0.1238 - accuracy: 0.9297
Epoch 833: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 949ms/step - loss: 0.1238 - accuracy: 0.9297 - val_loss: 0.2420 - val_accuracy: 0.8644
Epoch 834/1000
2/2 [==============================] - ETA: 0s - loss: 0.0821 - accuracy: 0.9844
Epoch 834: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0821 - accuracy: 0.9844 - val_loss: 0.2424 - val_accuracy: 0.8644
Epoch 835/1000
2/2 [==============================] - ETA: 0s - loss: 0.1200 - accuracy: 0.9375
Epoch 835: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 958ms/step - loss: 0.1200 - accuracy: 0.9375 - val_loss: 0.2430 - val_accuracy: 0.8644
Epoch 836/1000
2/2 [==============================] - ETA: 0s - loss: 0.1401 - accuracy: 0.9375
Epoch 836: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 933ms/step - loss: 0.1401 - accuracy: 0.9375 - val_loss: 0.2434 - val_accuracy: 0.8644
Epoch 837/1000
2/2 [==============================] - ETA: 0s - loss: 0.0621 - accuracy: 0.9922
Epoch 837: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0621 - accuracy: 0.9922 - val_loss: 0.2446 - val_accuracy: 0.8644
Epoch 838/1000
2/2 [==============================] - ETA: 0s - loss: 0.1004 - accuracy: 0.9500
Epoch 838: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 817ms/step - loss: 0.1004 - accuracy: 0.9500 - val_loss: 0.2464 - val_accuracy: 0.8644
Epoch 839/1000
2/2 [==============================] - ETA: 0s - loss: 0.0905 - accuracy: 0.9766
Epoch 839: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0905 - accuracy: 0.9766 - val_loss: 0.2481 - val_accuracy: 0.8644
Epoch 840/1000
2/2 [==============================] - ETA: 0s - loss: 0.1004 - accuracy: 0.9500
Epoch 840: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 887ms/step - loss: 0.1004 - accuracy: 0.9500 - val_loss: 0.2505 - val_accuracy: 0.8644
Epoch 841/1000
2/2 [==============================] - ETA: 0s - loss: 0.1146 - accuracy: 0.9750
Epoch 841: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1146 - accuracy: 0.9750 - val_loss: 0.2507 - val_accuracy: 0.8644
Epoch 842/1000
2/2 [==============================] - ETA: 0s - loss: 0.0898 - accuracy: 0.9844
Epoch 842: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0898 - accuracy: 0.9844 - val_loss: 0.2503 - val_accuracy: 0.8644
Epoch 843/1000
2/2 [==============================] - ETA: 0s - loss: 0.1224 - accuracy: 0.9375
Epoch 843: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1224 - accuracy: 0.9375 - val_loss: 0.2509 - val_accuracy: 0.8644
Epoch 844/1000
2/2 [==============================] - ETA: 0s - loss: 0.0545 - accuracy: 0.9875
Epoch 844: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 848ms/step - loss: 0.0545 - accuracy: 0.9875 - val_loss: 0.2514 - val_accuracy: 0.8644
Epoch 845/1000
2/2 [==============================] - ETA: 0s - loss: 0.1240 - accuracy: 0.9250
Epoch 845: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1240 - accuracy: 0.9250 - val_loss: 0.2505 - val_accuracy: 0.8644
Epoch 846/1000
2/2 [==============================] - ETA: 0s - loss: 0.1128 - accuracy: 0.9750
Epoch 846: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1128 - accuracy: 0.9750 - val_loss: 0.2508 - val_accuracy: 0.8644
Epoch 847/1000
2/2 [==============================] - ETA: 0s - loss: 0.0841 - accuracy: 0.9500
Epoch 847: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0841 - accuracy: 0.9500 - val_loss: 0.2514 - val_accuracy: 0.8644
Epoch 848/1000
2/2 [==============================] - ETA: 0s - loss: 0.0703 - accuracy: 0.9844
Epoch 848: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 928ms/step - loss: 0.0703 - accuracy: 0.9844 - val_loss: 0.2520 - val_accuracy: 0.8644
Epoch 849/1000
2/2 [==============================] - ETA: 0s - loss: 0.0979 - accuracy: 0.9531
Epoch 849: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0979 - accuracy: 0.9531 - val_loss: 0.2536 - val_accuracy: 0.8644
Epoch 850/1000
2/2 [==============================] - ETA: 0s - loss: 0.0953 - accuracy: 0.9750
Epoch 850: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 842ms/step - loss: 0.0953 - accuracy: 0.9750 - val_loss: 0.2552 - val_accuracy: 0.8644
Epoch 851/1000
2/2 [==============================] - ETA: 0s - loss: 0.0794 - accuracy: 0.9750
Epoch 851: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 833ms/step - loss: 0.0794 - accuracy: 0.9750 - val_loss: 0.2572 - val_accuracy: 0.8644
Epoch 852/1000
2/2 [==============================] - ETA: 0s - loss: 0.0963 - accuracy: 0.9688
Epoch 852: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0963 - accuracy: 0.9688 - val_loss: 0.2586 - val_accuracy: 0.8644
Epoch 853/1000
2/2 [==============================] - ETA: 0s - loss: 0.0843 - accuracy: 0.9625
Epoch 853: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0843 - accuracy: 0.9625 - val_loss: 0.2596 - val_accuracy: 0.8644
Epoch 854/1000
2/2 [==============================] - ETA: 0s - loss: 0.1328 - accuracy: 0.9453
Epoch 854: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1328 - accuracy: 0.9453 - val_loss: 0.2612 - val_accuracy: 0.8644
Epoch 855/1000
2/2 [==============================] - ETA: 0s - loss: 0.1115 - accuracy: 0.9453
Epoch 855: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1115 - accuracy: 0.9453 - val_loss: 0.2625 - val_accuracy: 0.8644
Epoch 856/1000
2/2 [==============================] - ETA: 0s - loss: 0.0815 - accuracy: 0.9750
Epoch 856: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 881ms/step - loss: 0.0815 - accuracy: 0.9750 - val_loss: 0.2628 - val_accuracy: 0.8644
Epoch 857/1000
2/2 [==============================] - ETA: 0s - loss: 0.0965 - accuracy: 0.9609
Epoch 857: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0965 - accuracy: 0.9609 - val_loss: 0.2621 - val_accuracy: 0.8644
Epoch 858/1000
2/2 [==============================] - ETA: 0s - loss: 0.0653 - accuracy: 0.9844
Epoch 858: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0653 - accuracy: 0.9844 - val_loss: 0.2615 - val_accuracy: 0.8644
Epoch 859/1000
2/2 [==============================] - ETA: 0s - loss: 0.0777 - accuracy: 0.9844
Epoch 859: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 947ms/step - loss: 0.0777 - accuracy: 0.9844 - val_loss: 0.2625 - val_accuracy: 0.8644
Epoch 860/1000
2/2 [==============================] - ETA: 0s - loss: 0.0645 - accuracy: 0.9750
Epoch 860: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0645 - accuracy: 0.9750 - val_loss: 0.2642 - val_accuracy: 0.8644
Epoch 861/1000
2/2 [==============================] - ETA: 0s - loss: 0.0972 - accuracy: 0.9531
Epoch 861: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0972 - accuracy: 0.9531 - val_loss: 0.2652 - val_accuracy: 0.8644
Epoch 862/1000
2/2 [==============================] - ETA: 0s - loss: 0.0886 - accuracy: 0.9750
Epoch 862: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 864ms/step - loss: 0.0886 - accuracy: 0.9750 - val_loss: 0.2662 - val_accuracy: 0.8644
Epoch 863/1000
2/2 [==============================] - ETA: 0s - loss: 0.0888 - accuracy: 0.9625
Epoch 863: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0888 - accuracy: 0.9625 - val_loss: 0.2676 - val_accuracy: 0.8644
Epoch 864/1000
2/2 [==============================] - ETA: 0s - loss: 0.0918 - accuracy: 0.9297
Epoch 864: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 955ms/step - loss: 0.0918 - accuracy: 0.9297 - val_loss: 0.2694 - val_accuracy: 0.8644
Epoch 865/1000
2/2 [==============================] - ETA: 0s - loss: 0.0777 - accuracy: 0.9750
Epoch 865: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 840ms/step - loss: 0.0777 - accuracy: 0.9750 - val_loss: 0.2710 - val_accuracy: 0.8644
Epoch 866/1000
2/2 [==============================] - ETA: 0s - loss: 0.0713 - accuracy: 0.9844
Epoch 866: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0713 - accuracy: 0.9844 - val_loss: 0.2715 - val_accuracy: 0.8644
Epoch 867/1000
2/2 [==============================] - ETA: 0s - loss: 0.0677 - accuracy: 0.9750
Epoch 867: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 840ms/step - loss: 0.0677 - accuracy: 0.9750 - val_loss: 0.2721 - val_accuracy: 0.8644
Epoch 868/1000
2/2 [==============================] - ETA: 0s - loss: 0.0762 - accuracy: 0.9625
Epoch 868: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0762 - accuracy: 0.9625 - val_loss: 0.2707 - val_accuracy: 0.8644
Epoch 869/1000
2/2 [==============================] - ETA: 0s - loss: 0.0939 - accuracy: 0.9875
Epoch 869: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 871ms/step - loss: 0.0939 - accuracy: 0.9875 - val_loss: 0.2699 - val_accuracy: 0.8644
Epoch 870/1000
2/2 [==============================] - ETA: 0s - loss: 0.0782 - accuracy: 0.9875
Epoch 870: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 839ms/step - loss: 0.0782 - accuracy: 0.9875 - val_loss: 0.2694 - val_accuracy: 0.8644
Epoch 871/1000
2/2 [==============================] - ETA: 0s - loss: 0.0965 - accuracy: 0.9531
Epoch 871: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 962ms/step - loss: 0.0965 - accuracy: 0.9531 - val_loss: 0.2689 - val_accuracy: 0.8644
Epoch 872/1000
2/2 [==============================] - ETA: 0s - loss: 0.0861 - accuracy: 0.9625
Epoch 872: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0861 - accuracy: 0.9625 - val_loss: 0.2691 - val_accuracy: 0.8644
Epoch 873/1000
2/2 [==============================] - ETA: 0s - loss: 0.0783 - accuracy: 0.9609
Epoch 873: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.0783 - accuracy: 0.9609 - val_loss: 0.2699 - val_accuracy: 0.8644
Epoch 874/1000
2/2 [==============================] - ETA: 0s - loss: 0.1119 - accuracy: 0.9688
Epoch 874: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1119 - accuracy: 0.9688 - val_loss: 0.2719 - val_accuracy: 0.8644
Epoch 875/1000
2/2 [==============================] - ETA: 0s - loss: 0.0761 - accuracy: 0.9500
Epoch 875: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0761 - accuracy: 0.9500 - val_loss: 0.2753 - val_accuracy: 0.8644
Epoch 876/1000
2/2 [==============================] - ETA: 0s - loss: 0.0681 - accuracy: 0.9875
Epoch 876: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 824ms/step - loss: 0.0681 - accuracy: 0.9875 - val_loss: 0.2789 - val_accuracy: 0.8644
Epoch 877/1000
2/2 [==============================] - ETA: 0s - loss: 0.0823 - accuracy: 0.9844
Epoch 877: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0823 - accuracy: 0.9844 - val_loss: 0.2809 - val_accuracy: 0.8644
Epoch 878/1000
2/2 [==============================] - ETA: 0s - loss: 0.0974 - accuracy: 0.9750
Epoch 878: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 921ms/step - loss: 0.0974 - accuracy: 0.9750 - val_loss: 0.2807 - val_accuracy: 0.8644
Epoch 879/1000
2/2 [==============================] - ETA: 0s - loss: 0.0780 - accuracy: 0.9750
Epoch 879: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0780 - accuracy: 0.9750 - val_loss: 0.2798 - val_accuracy: 0.8644
Epoch 880/1000
2/2 [==============================] - ETA: 0s - loss: 0.0934 - accuracy: 0.9609
Epoch 880: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0934 - accuracy: 0.9609 - val_loss: 0.2805 - val_accuracy: 0.8644
Epoch 881/1000
2/2 [==============================] - ETA: 0s - loss: 0.0931 - accuracy: 0.9609
Epoch 881: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0931 - accuracy: 0.9609 - val_loss: 0.2824 - val_accuracy: 0.8644
Epoch 882/1000
2/2 [==============================] - ETA: 0s - loss: 0.0906 - accuracy: 0.9688
Epoch 882: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 947ms/step - loss: 0.0906 - accuracy: 0.9688 - val_loss: 0.2839 - val_accuracy: 0.8644
Epoch 883/1000
2/2 [==============================] - ETA: 0s - loss: 0.1245 - accuracy: 0.9141
Epoch 883: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1245 - accuracy: 0.9141 - val_loss: 0.2849 - val_accuracy: 0.8644
Epoch 884/1000
2/2 [==============================] - ETA: 0s - loss: 0.0833 - accuracy: 0.9500
Epoch 884: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0833 - accuracy: 0.9500 - val_loss: 0.2872 - val_accuracy: 0.8644
Epoch 885/1000
2/2 [==============================] - ETA: 0s - loss: 0.0882 - accuracy: 0.9766
Epoch 885: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 981ms/step - loss: 0.0882 - accuracy: 0.9766 - val_loss: 0.2888 - val_accuracy: 0.8644
Epoch 886/1000
2/2 [==============================] - ETA: 0s - loss: 0.0874 - accuracy: 0.9844
Epoch 886: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 970ms/step - loss: 0.0874 - accuracy: 0.9844 - val_loss: 0.2896 - val_accuracy: 0.8644
Epoch 887/1000
2/2 [==============================] - ETA: 0s - loss: 0.0693 - accuracy: 0.9750
Epoch 887: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 837ms/step - loss: 0.0693 - accuracy: 0.9750 - val_loss: 0.2900 - val_accuracy: 0.8644
Epoch 888/1000
2/2 [==============================] - ETA: 0s - loss: 0.1022 - accuracy: 0.9375
Epoch 888: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.1022 - accuracy: 0.9375 - val_loss: 0.2897 - val_accuracy: 0.8644
Epoch 889/1000
2/2 [==============================] - ETA: 0s - loss: 0.0957 - accuracy: 0.9750
Epoch 889: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 844ms/step - loss: 0.0957 - accuracy: 0.9750 - val_loss: 0.2891 - val_accuracy: 0.8644
Epoch 890/1000
2/2 [==============================] - ETA: 0s - loss: 0.1106 - accuracy: 0.9531
Epoch 890: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1106 - accuracy: 0.9531 - val_loss: 0.2846 - val_accuracy: 0.8644
Epoch 891/1000
2/2 [==============================] - ETA: 0s - loss: 0.0942 - accuracy: 0.9609
Epoch 891: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0942 - accuracy: 0.9609 - val_loss: 0.2803 - val_accuracy: 0.8644
Epoch 892/1000
2/2 [==============================] - ETA: 0s - loss: 0.1219 - accuracy: 0.9453
Epoch 892: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1219 - accuracy: 0.9453 - val_loss: 0.2752 - val_accuracy: 0.8644
Epoch 893/1000
2/2 [==============================] - ETA: 0s - loss: 0.0828 - accuracy: 0.9750
Epoch 893: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0828 - accuracy: 0.9750 - val_loss: 0.2698 - val_accuracy: 0.8644
Epoch 894/1000
2/2 [==============================] - ETA: 0s - loss: 0.1041 - accuracy: 0.9375
Epoch 894: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1041 - accuracy: 0.9375 - val_loss: 0.2643 - val_accuracy: 0.8644
Epoch 895/1000
2/2 [==============================] - ETA: 0s - loss: 0.0839 - accuracy: 0.9500
Epoch 895: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 834ms/step - loss: 0.0839 - accuracy: 0.9500 - val_loss: 0.2609 - val_accuracy: 0.8644
Epoch 896/1000
2/2 [==============================] - ETA: 0s - loss: 0.1266 - accuracy: 0.9375
Epoch 896: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 972ms/step - loss: 0.1266 - accuracy: 0.9375 - val_loss: 0.2591 - val_accuracy: 0.8644
Epoch 897/1000
2/2 [==============================] - ETA: 0s - loss: 0.0911 - accuracy: 0.9531
Epoch 897: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0911 - accuracy: 0.9531 - val_loss: 0.2583 - val_accuracy: 0.8475
Epoch 898/1000
2/2 [==============================] - ETA: 0s - loss: 0.1015 - accuracy: 0.9500
Epoch 898: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 866ms/step - loss: 0.1015 - accuracy: 0.9500 - val_loss: 0.2576 - val_accuracy: 0.8475
Epoch 899/1000
2/2 [==============================] - ETA: 0s - loss: 0.0907 - accuracy: 0.9766
Epoch 899: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0907 - accuracy: 0.9766 - val_loss: 0.2573 - val_accuracy: 0.8475
Epoch 900/1000
2/2 [==============================] - ETA: 0s - loss: 0.0948 - accuracy: 0.9609
Epoch 900: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0948 - accuracy: 0.9609 - val_loss: 0.2570 - val_accuracy: 0.8475
Epoch 901/1000
2/2 [==============================] - ETA: 0s - loss: 0.1040 - accuracy: 0.9750
Epoch 901: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.1040 - accuracy: 0.9750 - val_loss: 0.2567 - val_accuracy: 0.8475
Epoch 902/1000
2/2 [==============================] - ETA: 0s - loss: 0.1039 - accuracy: 0.9141
Epoch 902: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1039 - accuracy: 0.9141 - val_loss: 0.2574 - val_accuracy: 0.8475
Epoch 903/1000
2/2 [==============================] - ETA: 0s - loss: 0.0861 - accuracy: 0.9625
Epoch 903: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 829ms/step - loss: 0.0861 - accuracy: 0.9625 - val_loss: 0.2590 - val_accuracy: 0.8475
Epoch 904/1000
2/2 [==============================] - ETA: 0s - loss: 0.0647 - accuracy: 0.9875
Epoch 904: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0647 - accuracy: 0.9875 - val_loss: 0.2597 - val_accuracy: 0.8475
Epoch 905/1000
2/2 [==============================] - ETA: 0s - loss: 0.0822 - accuracy: 0.9500
Epoch 905: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0822 - accuracy: 0.9500 - val_loss: 0.2606 - val_accuracy: 0.8475
Epoch 906/1000
2/2 [==============================] - ETA: 0s - loss: 0.0629 - accuracy: 0.9750
Epoch 906: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 851ms/step - loss: 0.0629 - accuracy: 0.9750 - val_loss: 0.2621 - val_accuracy: 0.8475
Epoch 907/1000
2/2 [==============================] - ETA: 0s - loss: 0.0631 - accuracy: 1.0000
Epoch 907: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0631 - accuracy: 1.0000 - val_loss: 0.2651 - val_accuracy: 0.8475
Epoch 908/1000
2/2 [==============================] - ETA: 0s - loss: 0.0794 - accuracy: 0.9875
Epoch 908: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0794 - accuracy: 0.9875 - val_loss: 0.2677 - val_accuracy: 0.8475
Epoch 909/1000
2/2 [==============================] - ETA: 0s - loss: 0.0681 - accuracy: 1.0000
Epoch 909: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0681 - accuracy: 1.0000 - val_loss: 0.2719 - val_accuracy: 0.8475
Epoch 910/1000
2/2 [==============================] - ETA: 0s - loss: 0.0788 - accuracy: 0.9531
Epoch 910: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0788 - accuracy: 0.9531 - val_loss: 0.2756 - val_accuracy: 0.8475
Epoch 911/1000
2/2 [==============================] - ETA: 0s - loss: 0.0893 - accuracy: 0.9531
Epoch 911: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 923ms/step - loss: 0.0893 - accuracy: 0.9531 - val_loss: 0.2787 - val_accuracy: 0.8475
Epoch 912/1000
2/2 [==============================] - ETA: 0s - loss: 0.1026 - accuracy: 0.9688
Epoch 912: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1026 - accuracy: 0.9688 - val_loss: 0.2811 - val_accuracy: 0.8475
Epoch 913/1000
2/2 [==============================] - ETA: 0s - loss: 0.0945 - accuracy: 0.9688
Epoch 913: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 937ms/step - loss: 0.0945 - accuracy: 0.9688 - val_loss: 0.2832 - val_accuracy: 0.8305
Epoch 914/1000
2/2 [==============================] - ETA: 0s - loss: 0.0744 - accuracy: 0.9750
Epoch 914: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0744 - accuracy: 0.9750 - val_loss: 0.2846 - val_accuracy: 0.8305
Epoch 915/1000
2/2 [==============================] - ETA: 0s - loss: 0.0825 - accuracy: 0.9500
Epoch 915: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0825 - accuracy: 0.9500 - val_loss: 0.2836 - val_accuracy: 0.8305
Epoch 916/1000
2/2 [==============================] - ETA: 0s - loss: 0.0687 - accuracy: 0.9875
Epoch 916: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0687 - accuracy: 0.9875 - val_loss: 0.2818 - val_accuracy: 0.8305
Epoch 917/1000
2/2 [==============================] - ETA: 0s - loss: 0.1094 - accuracy: 0.9500
Epoch 917: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 841ms/step - loss: 0.1094 - accuracy: 0.9500 - val_loss: 0.2799 - val_accuracy: 0.8475
Epoch 918/1000
2/2 [==============================] - ETA: 0s - loss: 0.0705 - accuracy: 0.9875
Epoch 918: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 891ms/step - loss: 0.0705 - accuracy: 0.9875 - val_loss: 0.2781 - val_accuracy: 0.8475
Epoch 919/1000
2/2 [==============================] - ETA: 0s - loss: 0.0739 - accuracy: 0.9750
Epoch 919: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 844ms/step - loss: 0.0739 - accuracy: 0.9750 - val_loss: 0.2760 - val_accuracy: 0.8475
Epoch 920/1000
2/2 [==============================] - ETA: 0s - loss: 0.0654 - accuracy: 0.9875
Epoch 920: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.0654 - accuracy: 0.9875 - val_loss: 0.2761 - val_accuracy: 0.8475
Epoch 921/1000
2/2 [==============================] - ETA: 0s - loss: 0.1149 - accuracy: 0.9453
Epoch 921: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1149 - accuracy: 0.9453 - val_loss: 0.2791 - val_accuracy: 0.8305
Epoch 922/1000
2/2 [==============================] - ETA: 0s - loss: 0.0815 - accuracy: 0.9750
Epoch 922: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 840ms/step - loss: 0.0815 - accuracy: 0.9750 - val_loss: 0.2815 - val_accuracy: 0.8305
Epoch 923/1000
2/2 [==============================] - ETA: 0s - loss: 0.1019 - accuracy: 0.9766
Epoch 923: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1019 - accuracy: 0.9766 - val_loss: 0.2835 - val_accuracy: 0.8305
Epoch 924/1000
2/2 [==============================] - ETA: 0s - loss: 0.0601 - accuracy: 1.0000
Epoch 924: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0601 - accuracy: 1.0000 - val_loss: 0.2857 - val_accuracy: 0.8305
Epoch 925/1000
2/2 [==============================] - ETA: 0s - loss: 0.1296 - accuracy: 0.9125
Epoch 925: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 839ms/step - loss: 0.1296 - accuracy: 0.9125 - val_loss: 0.2871 - val_accuracy: 0.8305
Epoch 926/1000
2/2 [==============================] - ETA: 0s - loss: 0.0943 - accuracy: 0.9766
Epoch 926: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0943 - accuracy: 0.9766 - val_loss: 0.2907 - val_accuracy: 0.8305
Epoch 927/1000
2/2 [==============================] - ETA: 0s - loss: 0.0939 - accuracy: 0.9766
Epoch 927: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0939 - accuracy: 0.9766 - val_loss: 0.2958 - val_accuracy: 0.8305
Epoch 928/1000
2/2 [==============================] - ETA: 0s - loss: 0.0990 - accuracy: 0.9625
Epoch 928: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0990 - accuracy: 0.9625 - val_loss: 0.2993 - val_accuracy: 0.8136
Epoch 929/1000
2/2 [==============================] - ETA: 0s - loss: 0.0945 - accuracy: 0.9609
Epoch 929: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0945 - accuracy: 0.9609 - val_loss: 0.3029 - val_accuracy: 0.8136
Epoch 930/1000
2/2 [==============================] - ETA: 0s - loss: 0.0748 - accuracy: 0.9844
Epoch 930: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0748 - accuracy: 0.9844 - val_loss: 0.3062 - val_accuracy: 0.8136
Epoch 931/1000
2/2 [==============================] - ETA: 0s - loss: 0.0828 - accuracy: 0.9766
Epoch 931: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0828 - accuracy: 0.9766 - val_loss: 0.3082 - val_accuracy: 0.8136
Epoch 932/1000
2/2 [==============================] - ETA: 0s - loss: 0.1561 - accuracy: 0.9500
Epoch 932: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 902ms/step - loss: 0.1561 - accuracy: 0.9500 - val_loss: 0.3088 - val_accuracy: 0.8136
Epoch 933/1000
2/2 [==============================] - ETA: 0s - loss: 0.0936 - accuracy: 0.9531
Epoch 933: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 985ms/step - loss: 0.0936 - accuracy: 0.9531 - val_loss: 0.3044 - val_accuracy: 0.8136
Epoch 934/1000
2/2 [==============================] - ETA: 0s - loss: 0.0693 - accuracy: 0.9750
Epoch 934: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0693 - accuracy: 0.9750 - val_loss: 0.3002 - val_accuracy: 0.8136
Epoch 935/1000
2/2 [==============================] - ETA: 0s - loss: 0.0751 - accuracy: 0.9688
Epoch 935: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 958ms/step - loss: 0.0751 - accuracy: 0.9688 - val_loss: 0.2972 - val_accuracy: 0.8305
Epoch 936/1000
2/2 [==============================] - ETA: 0s - loss: 0.0536 - accuracy: 0.9875
Epoch 936: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 843ms/step - loss: 0.0536 - accuracy: 0.9875 - val_loss: 0.2937 - val_accuracy: 0.8305
Epoch 937/1000
2/2 [==============================] - ETA: 0s - loss: 0.0572 - accuracy: 0.9875
Epoch 937: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 857ms/step - loss: 0.0572 - accuracy: 0.9875 - val_loss: 0.2893 - val_accuracy: 0.8305
Epoch 938/1000
2/2 [==============================] - ETA: 0s - loss: 0.0632 - accuracy: 0.9625
Epoch 938: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0632 - accuracy: 0.9625 - val_loss: 0.2845 - val_accuracy: 0.8305
Epoch 939/1000
2/2 [==============================] - ETA: 0s - loss: 0.1012 - accuracy: 0.9531
Epoch 939: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1012 - accuracy: 0.9531 - val_loss: 0.2796 - val_accuracy: 0.8305
Epoch 940/1000
2/2 [==============================] - ETA: 0s - loss: 0.0739 - accuracy: 0.9625
Epoch 940: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 860ms/step - loss: 0.0739 - accuracy: 0.9625 - val_loss: 0.2747 - val_accuracy: 0.8475
Epoch 941/1000
2/2 [==============================] - ETA: 0s - loss: 0.0882 - accuracy: 0.9531
Epoch 941: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0882 - accuracy: 0.9531 - val_loss: 0.2706 - val_accuracy: 0.8475
Epoch 942/1000
2/2 [==============================] - ETA: 0s - loss: 0.0617 - accuracy: 0.9844
Epoch 942: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 983ms/step - loss: 0.0617 - accuracy: 0.9844 - val_loss: 0.2677 - val_accuracy: 0.8475
Epoch 943/1000
2/2 [==============================] - ETA: 0s - loss: 0.0785 - accuracy: 0.9625
Epoch 943: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0785 - accuracy: 0.9625 - val_loss: 0.2661 - val_accuracy: 0.8475
Epoch 944/1000
2/2 [==============================] - ETA: 0s - loss: 0.0550 - accuracy: 0.9875
Epoch 944: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0550 - accuracy: 0.9875 - val_loss: 0.2647 - val_accuracy: 0.8475
Epoch 945/1000
2/2 [==============================] - ETA: 0s - loss: 0.0747 - accuracy: 0.9688
Epoch 945: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0747 - accuracy: 0.9688 - val_loss: 0.2630 - val_accuracy: 0.8475
Epoch 946/1000
2/2 [==============================] - ETA: 0s - loss: 0.0778 - accuracy: 0.9766
Epoch 946: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0778 - accuracy: 0.9766 - val_loss: 0.2610 - val_accuracy: 0.8475
Epoch 947/1000
2/2 [==============================] - ETA: 0s - loss: 0.1018 - accuracy: 0.9688
Epoch 947: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1018 - accuracy: 0.9688 - val_loss: 0.2591 - val_accuracy: 0.8475
Epoch 948/1000
2/2 [==============================] - ETA: 0s - loss: 0.0876 - accuracy: 0.9688
Epoch 948: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0876 - accuracy: 0.9688 - val_loss: 0.2570 - val_accuracy: 0.8475
Epoch 949/1000
2/2 [==============================] - ETA: 0s - loss: 0.1242 - accuracy: 0.9375
Epoch 949: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 816ms/step - loss: 0.1242 - accuracy: 0.9375 - val_loss: 0.2563 - val_accuracy: 0.8644
Epoch 950/1000
2/2 [==============================] - ETA: 0s - loss: 0.1184 - accuracy: 0.9297
Epoch 950: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1184 - accuracy: 0.9297 - val_loss: 0.2557 - val_accuracy: 0.8644
Epoch 951/1000
2/2 [==============================] - ETA: 0s - loss: 0.0717 - accuracy: 0.9750
Epoch 951: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 841ms/step - loss: 0.0717 - accuracy: 0.9750 - val_loss: 0.2561 - val_accuracy: 0.8644
Epoch 952/1000
2/2 [==============================] - ETA: 0s - loss: 0.0772 - accuracy: 0.9875
Epoch 952: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 885ms/step - loss: 0.0772 - accuracy: 0.9875 - val_loss: 0.2571 - val_accuracy: 0.8644
Epoch 953/1000
2/2 [==============================] - ETA: 0s - loss: 0.0977 - accuracy: 0.9500
Epoch 953: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0977 - accuracy: 0.9500 - val_loss: 0.2591 - val_accuracy: 0.8475
Epoch 954/1000
2/2 [==============================] - ETA: 0s - loss: 0.0724 - accuracy: 0.9750
Epoch 954: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0724 - accuracy: 0.9750 - val_loss: 0.2622 - val_accuracy: 0.8475
Epoch 955/1000
2/2 [==============================] - ETA: 0s - loss: 0.0957 - accuracy: 0.9750
Epoch 955: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 838ms/step - loss: 0.0957 - accuracy: 0.9750 - val_loss: 0.2667 - val_accuracy: 0.8475
Epoch 956/1000
2/2 [==============================] - ETA: 0s - loss: 0.0891 - accuracy: 0.9688
Epoch 956: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0891 - accuracy: 0.9688 - val_loss: 0.2706 - val_accuracy: 0.8475
Epoch 957/1000
2/2 [==============================] - ETA: 0s - loss: 0.1035 - accuracy: 0.9609
Epoch 957: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1035 - accuracy: 0.9609 - val_loss: 0.2731 - val_accuracy: 0.8475
Epoch 958/1000
2/2 [==============================] - ETA: 0s - loss: 0.0647 - accuracy: 0.9922
Epoch 958: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0647 - accuracy: 0.9922 - val_loss: 0.2742 - val_accuracy: 0.8305
Epoch 959/1000
2/2 [==============================] - ETA: 0s - loss: 0.0958 - accuracy: 0.9875
Epoch 959: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 849ms/step - loss: 0.0958 - accuracy: 0.9875 - val_loss: 0.2751 - val_accuracy: 0.8305
Epoch 960/1000
2/2 [==============================] - ETA: 0s - loss: 0.0807 - accuracy: 0.9750
Epoch 960: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0807 - accuracy: 0.9750 - val_loss: 0.2768 - val_accuracy: 0.8305
Epoch 961/1000
2/2 [==============================] - ETA: 0s - loss: 0.0948 - accuracy: 0.9625
Epoch 961: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 819ms/step - loss: 0.0948 - accuracy: 0.9625 - val_loss: 0.2801 - val_accuracy: 0.8305
Epoch 962/1000
2/2 [==============================] - ETA: 0s - loss: 0.0776 - accuracy: 0.9766
Epoch 962: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0776 - accuracy: 0.9766 - val_loss: 0.2844 - val_accuracy: 0.8475
Epoch 963/1000
2/2 [==============================] - ETA: 0s - loss: 0.1424 - accuracy: 0.9000
Epoch 963: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1424 - accuracy: 0.9000 - val_loss: 0.2886 - val_accuracy: 0.8305
Epoch 964/1000
2/2 [==============================] - ETA: 0s - loss: 0.0914 - accuracy: 0.9625
Epoch 964: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0914 - accuracy: 0.9625 - val_loss: 0.2915 - val_accuracy: 0.8305
Epoch 965/1000
2/2 [==============================] - ETA: 0s - loss: 0.0729 - accuracy: 0.9875
Epoch 965: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0729 - accuracy: 0.9875 - val_loss: 0.2938 - val_accuracy: 0.8475
Epoch 966/1000
2/2 [==============================] - ETA: 0s - loss: 0.0875 - accuracy: 0.9766
Epoch 966: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0875 - accuracy: 0.9766 - val_loss: 0.2974 - val_accuracy: 0.8305
Epoch 967/1000
2/2 [==============================] - ETA: 0s - loss: 0.0654 - accuracy: 0.9766
Epoch 967: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 963ms/step - loss: 0.0654 - accuracy: 0.9766 - val_loss: 0.3005 - val_accuracy: 0.8305
Epoch 968/1000
2/2 [==============================] - ETA: 0s - loss: 0.0662 - accuracy: 0.9844
Epoch 968: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 931ms/step - loss: 0.0662 - accuracy: 0.9844 - val_loss: 0.3030 - val_accuracy: 0.8305
Epoch 969/1000
2/2 [==============================] - ETA: 0s - loss: 0.0808 - accuracy: 0.9688
Epoch 969: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 948ms/step - loss: 0.0808 - accuracy: 0.9688 - val_loss: 0.3052 - val_accuracy: 0.8305
Epoch 970/1000
2/2 [==============================] - ETA: 0s - loss: 0.1014 - accuracy: 0.9531
Epoch 970: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.1014 - accuracy: 0.9531 - val_loss: 0.3074 - val_accuracy: 0.8305
Epoch 971/1000
2/2 [==============================] - ETA: 0s - loss: 0.0944 - accuracy: 0.9688
Epoch 971: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0944 - accuracy: 0.9688 - val_loss: 0.3092 - val_accuracy: 0.8305
Epoch 972/1000
2/2 [==============================] - ETA: 0s - loss: 0.0662 - accuracy: 0.9844
Epoch 972: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0662 - accuracy: 0.9844 - val_loss: 0.3097 - val_accuracy: 0.8305
Epoch 973/1000
2/2 [==============================] - ETA: 0s - loss: 0.0667 - accuracy: 0.9766
Epoch 973: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 959ms/step - loss: 0.0667 - accuracy: 0.9766 - val_loss: 0.3094 - val_accuracy: 0.8305
Epoch 974/1000
2/2 [==============================] - ETA: 0s - loss: 0.0818 - accuracy: 0.9688
Epoch 974: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0818 - accuracy: 0.9688 - val_loss: 0.3085 - val_accuracy: 0.8305
Epoch 975/1000
2/2 [==============================] - ETA: 0s - loss: 0.0910 - accuracy: 0.9688
Epoch 975: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0910 - accuracy: 0.9688 - val_loss: 0.3087 - val_accuracy: 0.8305
Epoch 976/1000
2/2 [==============================] - ETA: 0s - loss: 0.1308 - accuracy: 0.9375
Epoch 976: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1308 - accuracy: 0.9375 - val_loss: 0.3068 - val_accuracy: 0.8305
Epoch 977/1000
2/2 [==============================] - ETA: 0s - loss: 0.0767 - accuracy: 0.9750
Epoch 977: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0767 - accuracy: 0.9750 - val_loss: 0.3051 - val_accuracy: 0.8305
Epoch 978/1000
2/2 [==============================] - ETA: 0s - loss: 0.1055 - accuracy: 0.9500
Epoch 978: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 848ms/step - loss: 0.1055 - accuracy: 0.9500 - val_loss: 0.3017 - val_accuracy: 0.8305
Epoch 979/1000
2/2 [==============================] - ETA: 0s - loss: 0.0511 - accuracy: 1.0000
Epoch 979: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 904ms/step - loss: 0.0511 - accuracy: 1.0000 - val_loss: 0.2974 - val_accuracy: 0.8305
Epoch 980/1000
2/2 [==============================] - ETA: 0s - loss: 0.0713 - accuracy: 0.9531
Epoch 980: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 939ms/step - loss: 0.0713 - accuracy: 0.9531 - val_loss: 0.2944 - val_accuracy: 0.8305
Epoch 981/1000
2/2 [==============================] - ETA: 0s - loss: 0.0922 - accuracy: 0.9609
Epoch 981: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 972ms/step - loss: 0.0922 - accuracy: 0.9609 - val_loss: 0.2921 - val_accuracy: 0.8475
Epoch 982/1000
2/2 [==============================] - ETA: 0s - loss: 0.0891 - accuracy: 0.9625
Epoch 982: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.2933 - val_accuracy: 0.8475
Epoch 983/1000
2/2 [==============================] - ETA: 0s - loss: 0.0949 - accuracy: 0.9453
Epoch 983: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 951ms/step - loss: 0.0949 - accuracy: 0.9453 - val_loss: 0.2925 - val_accuracy: 0.8475
Epoch 984/1000
2/2 [==============================] - ETA: 0s - loss: 0.0539 - accuracy: 0.9922
Epoch 984: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 995ms/step - loss: 0.0539 - accuracy: 0.9922 - val_loss: 0.2918 - val_accuracy: 0.8475
Epoch 985/1000
2/2 [==============================] - ETA: 0s - loss: 0.0669 - accuracy: 0.9766
Epoch 985: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0669 - accuracy: 0.9766 - val_loss: 0.2904 - val_accuracy: 0.8305
Epoch 986/1000
2/2 [==============================] - ETA: 0s - loss: 0.0790 - accuracy: 0.9875
Epoch 986: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 833ms/step - loss: 0.0790 - accuracy: 0.9875 - val_loss: 0.2900 - val_accuracy: 0.8305
Epoch 987/1000
2/2 [==============================] - ETA: 0s - loss: 0.1056 - accuracy: 0.9750
Epoch 987: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1056 - accuracy: 0.9750 - val_loss: 0.2854 - val_accuracy: 0.8475
Epoch 988/1000
2/2 [==============================] - ETA: 0s - loss: 0.0730 - accuracy: 0.9875
Epoch 988: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0730 - accuracy: 0.9875 - val_loss: 0.2825 - val_accuracy: 0.8475
Epoch 989/1000
2/2 [==============================] - ETA: 0s - loss: 0.0671 - accuracy: 0.9922
Epoch 989: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 985ms/step - loss: 0.0671 - accuracy: 0.9922 - val_loss: 0.2798 - val_accuracy: 0.8305
Epoch 990/1000
2/2 [==============================] - ETA: 0s - loss: 0.0840 - accuracy: 0.9766
Epoch 990: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0840 - accuracy: 0.9766 - val_loss: 0.2768 - val_accuracy: 0.8475
Epoch 991/1000
2/2 [==============================] - ETA: 0s - loss: 0.0820 - accuracy: 0.9766
Epoch 991: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 933ms/step - loss: 0.0820 - accuracy: 0.9766 - val_loss: 0.2731 - val_accuracy: 0.8475
Epoch 992/1000
2/2 [==============================] - ETA: 0s - loss: 0.1183 - accuracy: 0.9250
Epoch 992: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 842ms/step - loss: 0.1183 - accuracy: 0.9250 - val_loss: 0.2701 - val_accuracy: 0.8305
Epoch 993/1000
2/2 [==============================] - ETA: 0s - loss: 0.1168 - accuracy: 0.9625
Epoch 993: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.1168 - accuracy: 0.9625 - val_loss: 0.2679 - val_accuracy: 0.8305
Epoch 994/1000
2/2 [==============================] - ETA: 0s - loss: 0.0559 - accuracy: 0.9922
Epoch 994: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0559 - accuracy: 0.9922 - val_loss: 0.2664 - val_accuracy: 0.8305
Epoch 995/1000
2/2 [==============================] - ETA: 0s - loss: 0.0766 - accuracy: 0.9688
Epoch 995: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 950ms/step - loss: 0.0766 - accuracy: 0.9688 - val_loss: 0.2641 - val_accuracy: 0.8305
Epoch 996/1000
2/2 [==============================] - ETA: 0s - loss: 0.0701 - accuracy: 0.9688
Epoch 996: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0701 - accuracy: 0.9688 - val_loss: 0.2621 - val_accuracy: 0.8305
Epoch 997/1000
2/2 [==============================] - ETA: 0s - loss: 0.0732 - accuracy: 0.9750
Epoch 997: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 1s/step - loss: 0.0732 - accuracy: 0.9750 - val_loss: 0.2621 - val_accuracy: 0.8305
Epoch 998/1000
2/2 [==============================] - ETA: 0s - loss: 0.0791 - accuracy: 0.9688
Epoch 998: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 920ms/step - loss: 0.0791 - accuracy: 0.9688 - val_loss: 0.2632 - val_accuracy: 0.8305
Epoch 999/1000
2/2 [==============================] - ETA: 0s - loss: 0.1398 - accuracy: 0.9375
Epoch 999: saving model to training_1/cp.ckpt
2/2 [==============================] - 1s 866ms/step - loss: 0.1398 - accuracy: 0.9375 - val_loss: 0.2647 - val_accuracy: 0.8305
Epoch 1000/1000
2/2 [==============================] - ETA: 0s - loss: 0.0725 - accuracy: 0.9766
Epoch 1000: saving model to training_1/cp.ckpt
2/2 [==============================] - 2s 1s/step - loss: 0.0725 - accuracy: 0.9766 - val_loss: 0.2671 - val_accuracy: 0.8475
```
</details>
### Evidências do treinamento
Nessa seção você deve colocar qualquer evidência do treinamento, como por exemplo gráficos de perda, performance, matriz de confusão etc.
Exemplo de adição de imagem:
### Acurácia
<img src = "Graficos/acc.png">
### Loss
<img src = "Graficos/loss.png">
# Roboflow
Acesse o dataset no link abaixo
[Dataset Roboflow](https://universe.roboflow.com/rna-class/classifier_animals)
## HuggingFace
[Huggingface link](https://huggingface.co/caioeserpa/MobileNetV2_RNA_Class/tree/main)
|
nicjac/swin-tiny-patch4-window7-224-finetuned-eurosat
|
nicjac
| 2022-08-19T16:34:13Z | 66 | 0 |
transformers
|
[
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-19T16:10:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9751851851851852
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0755
- Accuracy: 0.9752
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2481 | 1.0 | 190 | 0.1280 | 0.9589 |
| 0.1534 | 2.0 | 380 | 0.0936 | 0.9678 |
| 0.1332 | 3.0 | 570 | 0.0755 | 0.9752 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.10.2+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
rootcodes/wav2vec2-large-xls-r-300m-turkish-colab
|
rootcodes
| 2022-08-19T16:04:36Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-10T14:11:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4313
- Wer: 0.3336
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0055 | 3.67 | 400 | 0.7015 | 0.6789 |
| 0.4384 | 7.34 | 800 | 0.4827 | 0.4875 |
| 0.2143 | 11.01 | 1200 | 0.4672 | 0.4554 |
| 0.1431 | 14.68 | 1600 | 0.4331 | 0.4014 |
| 0.1053 | 18.35 | 2000 | 0.4471 | 0.3822 |
| 0.0857 | 22.02 | 2400 | 0.4324 | 0.3637 |
| 0.0683 | 25.69 | 2800 | 0.4305 | 0.3423 |
| 0.0526 | 29.36 | 3200 | 0.4313 | 0.3336 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x_plus_8_10_4x
|
dminiotas05
| 2022-08-19T15:48:17Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T14:51:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x_plus_8_10_4x
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x_plus_8_10_4x
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0732
- Mse: 4.2926
- Mae: 1.3756
- R2: 0.4728
- Accuracy: 0.3427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.7013 | 1.0 | 7652 | 1.0583 | 4.2330 | 1.5178 | 0.4801 | 0.2056 |
| 0.3648 | 2.0 | 15304 | 1.0732 | 4.2926 | 1.3756 | 0.4728 | 0.3427 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
BlackKakapo/t5-base-paraphrase-ro-v2
|
BlackKakapo
| 2022-08-19T15:06:52Z | 91 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ro",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-19T14:51:23Z |
---
annotations_creators: []
language:
- ro
language_creators:
- machine-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: BlackKakapo/t5-base-paraphrase-ro
size_categories:
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- text2text-generation
task_ids: []
---
# Romanian paraphrase

Fine-tune t5-base-paraphrase-ro model for paraphrase. Since there is no Romanian dataset for paraphrasing, I had to create my own [dataset](https://huggingface.co/datasets/BlackKakapo/paraphrase-ro-v2). The dataset contains ~30k examples.
### How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("BlackKakapo/t5-base-paraphrase-ro-v2")
model = AutoModelForSeq2SeqLM.from_pretrained("BlackKakapo/t5-base-paraphrase-ro-v2")
```
### Or
```python
from transformers import T5ForConditionalGeneration, T5TokenizerFast
model = T5ForConditionalGeneration.from_pretrained("BlackKakapo/t5-base-paraphrase-ro-v2")
tokenizer = T5TokenizerFast.from_pretrained("BlackKakapo/t5-base-paraphrase-ro-v2")
```
### Generate
```python
text = "Într-un interviu pentru Radio Europa Liberă România, acesta a menționat că Bucureștiul este pregătit oricând și ar dura doar o oră de la solicitare, până când gazele ar ajunge la Chișinău."
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"], encoding["attention_mask"]
beam_outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_masks,
do_sample=True,
max_length=256,
top_k=20,
top_p=0.9,
early_stopping=False,
num_return_sequences=5
)
final_outputs = []
for beam_output in beam_outputs:
text_para = tokenizer.decode(beam_output, skip_special_tokens=True,clean_up_tokenization_spaces=True)
if text.lower() != text_para.lower() or text not in final_outputs:
final_outputs.append(text_para)
print(final_outputs)
```
### Output
```out
['Într-un interviu cu Radio Europa Liberă România, el a spus că Bucureștiul este pregătit în orice moment și ar dura doar o oră de la cererea până când gazele ar ajunge la Chișinău.']
```
|
Doohae/lassl-koelectra-base
|
Doohae
| 2022-08-19T14:07:16Z | 45 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"endpoints_compatible",
"region:us"
] | null | 2022-08-19T13:53:25Z |
# ELECTRA discriminator base
- pretrained with large Korean corpus datasets (30GB)
- 113M model parameters (followed google/electra-base-discriminator config)
- 35,000 vocab size
- trained for 1,000,000 steps
- built on [lassl](https://github.com/lassl/lassl) framework
pretrain-data
┣ korean_corpus.txt
┣ kowiki_latest.txt
┣ modu_dialogue_v1.2.txt
┣ modu_news_v1.1.txt
┣ modu_news_v2.0.txt
┣ modu_np_2021_v1.0.txt
┣ modu_np_v1.1.txt
┣ modu_spoken_v1.2.txt
┗ modu_written_v1.0.txt
|
annt5396/distilbert-base-uncased-finetuned-squad
|
annt5396
| 2022-08-19T14:07:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-19T10:07:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.4207
- eval_runtime: 169.1147
- eval_samples_per_second: 71.75
- eval_steps_per_second: 17.94
- epoch: 2.0
- step: 65878
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
autoevaluate/natural-language-inference
|
autoevaluate
| 2022-08-19T13:26:49Z | 26 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T11:07:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: natural-language-inference
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: train
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8284313725490197
- name: F1
type: f1
value: 0.8821548821548822
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# natural-language-inference
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4120
- Accuracy: 0.8284
- F1: 0.8822
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.4288 | 0.8039 | 0.8644 |
| No log | 2.0 | 460 | 0.4120 | 0.8284 | 0.8822 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sasha/autotrain-RobertaBaseTweetEval-1281048989
|
sasha
| 2022-08-19T12:50:29Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-RobertaBaseTweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:31:18Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-RobertaBaseTweetEval
co2_eq_emissions:
emissions: 28.053963781460215
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281048989
- CO2 Emissions (in grams): 28.0540
## Validation Metrics
- Loss: 0.587
- Accuracy: 0.751
- Macro F1: 0.719
- Micro F1: 0.751
- Weighted F1: 0.746
- Macro Precision: 0.761
- Micro Precision: 0.751
- Weighted Precision: 0.753
- Macro Recall: 0.699
- Micro Recall: 0.751
- Weighted Recall: 0.751
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-RobertaBaseTweetEval-1281048989
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048989", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048989", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-RobertaBaseTweetEval-1281048990
|
sasha
| 2022-08-19T12:42:35Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-RobertaBaseTweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:31:58Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-RobertaBaseTweetEval
co2_eq_emissions:
emissions: 11.322528589983463
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281048990
- CO2 Emissions (in grams): 11.3225
## Validation Metrics
- Loss: 0.592
- Accuracy: 0.747
- Macro F1: 0.729
- Micro F1: 0.747
- Weighted F1: 0.744
- Macro Precision: 0.743
- Micro Precision: 0.747
- Weighted Precision: 0.746
- Macro Recall: 0.720
- Micro Recall: 0.747
- Weighted Recall: 0.747
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-RobertaBaseTweetEval-1281048990
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048990", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048990", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-DistilBERT-TweetEval-1281148991
|
sasha
| 2022-08-19T12:39:50Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-DistilBERT-TweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:32:23Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-DistilBERT-TweetEval
co2_eq_emissions:
emissions: 7.4450095136306444
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281148991
- CO2 Emissions (in grams): 7.4450
## Validation Metrics
- Loss: 0.610
- Accuracy: 0.739
- Macro F1: 0.721
- Micro F1: 0.739
- Weighted F1: 0.739
- Macro Precision: 0.727
- Micro Precision: 0.739
- Weighted Precision: 0.740
- Macro Recall: 0.715
- Micro Recall: 0.739
- Weighted Recall: 0.739
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-DistilBERT-TweetEval-1281148991
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-DistilBERT-TweetEval-1281148991", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-DistilBERT-TweetEval-1281148991", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-BERTBase-TweetEval-1281248998
|
sasha
| 2022-08-19T12:36:33Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-TweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:25:20Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-TweetEval
co2_eq_emissions:
emissions: 0.1031242092898596
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281248998
- CO2 Emissions (in grams): 0.1031
## Validation Metrics
- Loss: 0.602
- Accuracy: 0.746
- Macro F1: 0.718
- Micro F1: 0.746
- Weighted F1: 0.743
- Macro Precision: 0.740
- Micro Precision: 0.746
- Weighted Precision: 0.744
- Macro Recall: 0.705
- Micro Recall: 0.746
- Weighted Recall: 0.746
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-TweetEval-1281248998
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281248998", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281248998", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-RobertaBaseTweetEval-1281048988
|
sasha
| 2022-08-19T12:34:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-RobertaBaseTweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:23:01Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-RobertaBaseTweetEval
co2_eq_emissions:
emissions: 22.606335926892854
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281048988
- CO2 Emissions (in grams): 22.6063
## Validation Metrics
- Loss: 0.589
- Accuracy: 0.747
- Macro F1: 0.722
- Micro F1: 0.747
- Weighted F1: 0.744
- Macro Precision: 0.743
- Micro Precision: 0.747
- Weighted Precision: 0.746
- Macro Recall: 0.708
- Micro Recall: 0.747
- Weighted Recall: 0.747
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-RobertaBaseTweetEval-1281048988
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048988", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-RobertaBaseTweetEval-1281048988", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-BERTBase-TweetEval-1281249000
|
sasha
| 2022-08-19T12:31:08Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-TweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:25:40Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-TweetEval
co2_eq_emissions:
emissions: 0.04868905658915141
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281249000
- CO2 Emissions (in grams): 0.0487
## Validation Metrics
- Loss: 0.602
- Accuracy: 0.743
- Macro F1: 0.723
- Micro F1: 0.743
- Weighted F1: 0.740
- Macro Precision: 0.740
- Micro Precision: 0.743
- Weighted Precision: 0.742
- Macro Recall: 0.712
- Micro Recall: 0.743
- Weighted Recall: 0.743
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-TweetEval-1281249000
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281249000", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281249000", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-BERTBase-TweetEval-1281248996
|
sasha
| 2022-08-19T12:30:42Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-TweetEval",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T12:25:14Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-TweetEval
co2_eq_emissions:
emissions: 0.042163153679615525
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1281248996
- CO2 Emissions (in grams): 0.0422
## Validation Metrics
- Loss: 0.600
- Accuracy: 0.743
- Macro F1: 0.719
- Micro F1: 0.743
- Weighted F1: 0.740
- Macro Precision: 0.743
- Micro Precision: 0.743
- Weighted Precision: 0.742
- Macro Recall: 0.705
- Micro Recall: 0.743
- Weighted Recall: 0.743
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-TweetEval-1281248996
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281248996", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-TweetEval-1281248996", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
admarcosai/distilbert-base-uncased-finetuned-emotion
|
admarcosai
| 2022-08-19T12:08:49Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T11:42:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9237947297417125
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2154
- Accuracy: 0.924
- F1: 0.9238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8154 | 1.0 | 250 | 0.3049 | 0.908 | 0.9056 |
| 0.2434 | 2.0 | 500 | 0.2154 | 0.924 | 0.9238 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ml6team/keyphrase-generation-t5-small-inspec
|
ml6team
| 2022-08-19T11:54:17Z | 55 | 6 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keyphrase-generation",
"en",
"dataset:midas/inspec",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T12:37:16Z |
---
language: en
license: mit
tags:
- keyphrase-generation
datasets:
- midas/inspec
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (up to 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (up to 4.33 points inF1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition(NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks."
example_title: "Example 2"
model-index:
- name: DeDeckerThomas/keyphrase-generation-t5-small-inspec
results:
- task:
type: keyphrase-generation
name: Keyphrase Generation
dataset:
type: midas/inspec
name: inspec
metrics:
- type: F1@M (Present)
value: 0.317
name: F1@M (Present)
- type: F1@O (Present)
value: 0.279
name: F1@O (Present)
- type: F1@M (Absent)
value: 0.073
name: F1@M (Absent)
- type: F1@O (Absent)
value: 0.065
name: F1@O (Absent)
---
# 🔑 Keyphrase Generation Model: T5-small-inspec
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [T5-small model](https://huggingface.co/t5-small) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec). Keyphrase generation transformers are fine-tuned as a text-to-text generation problem where the keyphrases are generated. The result is a concatenated string with all keyphrases separated by a given delimiter (i.e. “;”). These models are capable of generating present and absent keyphrases.
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase generation model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out.
* Only works for English documents.
* Sometimes the output doesn't make any sense.
### ❓ How To Use
```python
# Model parameters
from transformers import (
Text2TextGenerationPipeline,
AutoModelForSeq2SeqLM,
AutoTokenizer,
)
class KeyphraseGenerationPipeline(Text2TextGenerationPipeline):
def __init__(self, model, keyphrase_sep_token=";", *args, **kwargs):
super().__init__(
model=AutoModelForSeq2SeqLM.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
self.keyphrase_sep_token = keyphrase_sep_token
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs
)
return [[keyphrase.strip() for keyphrase in result.get("generated_text").split(self.keyphrase_sep_token) if keyphrase != ""] for result in results]
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-generation-t5-small-inspec"
generator = KeyphraseGenerationPipeline(model=model_name)
```
```python
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = generator(text)
print(keyphrases)
```
```
# Output
[['keyphrase extraction', 'text analysis', 'artificial intelligence', 'classical machine learning methods']]
```
## 📚 Training Dataset
[Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors.
You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383).
## 👷♂️ Training Procedure
### Training Parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 5e-5 |
| Epochs | 50 |
| Early Stopping Patience | 1 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding keyphrases. The only thing that must be done is tokenization and joining all keyphrases into one string with a certain seperator of choice( ```;``` ).
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("t5-small", add_prefix_space=True)
# Dataset parameters
dataset_full_name = "midas/inspec"
dataset_subset = "raw"
dataset_document_column = "document"
keyphrase_sep_token = ";"
def preprocess_keyphrases(text_ids, kp_list):
kp_order_list = []
kp_set = set(kp_list)
text = tokenizer.decode(
text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
text = text.lower()
for kp in kp_set:
kp = kp.strip()
kp_index = text.find(kp.lower())
kp_order_list.append((kp_index, kp))
kp_order_list.sort()
present_kp, absent_kp = [], []
for kp_index, kp in kp_order_list:
if kp_index < 0:
absent_kp.append(kp)
else:
present_kp.append(kp)
return present_kp, absent_kp
def preprocess_fuction(samples):
processed_samples = {"input_ids": [], "attention_mask": [], "labels": []}
for i, sample in enumerate(samples[dataset_document_column]):
input_text = " ".join(sample)
inputs = tokenizer(
input_text,
padding="max_length",
truncation=True,
)
present_kp, absent_kp = preprocess_keyphrases(
text_ids=inputs["input_ids"],
kp_list=samples["extractive_keyphrases"][i]
+ samples["abstractive_keyphrases"][i],
)
keyphrases = present_kp
keyphrases += absent_kp
target_text = f" {keyphrase_sep_token} ".join(keyphrases)
with tokenizer.as_target_tokenizer():
targets = tokenizer(
target_text, max_length=40, padding="max_length", truncation=True
)
targets["input_ids"] = [
(t if t != tokenizer.pad_token_id else -100)
for t in targets["input_ids"]
]
for key in inputs.keys():
processed_samples[key].append(inputs[key])
processed_samples["labels"].append(targets["input_ids"])
return processed_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing
For the post-processing, you will need to split the string based on the keyphrase separator.
```python
def extract_keyphrases(examples):
return [example.split(keyphrase_sep_token) for example in examples]
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases. In keyphrase generation you also look at F1@O where O stands for the number of ground truth keyphrases.
The model achieves the following results on the Inspec test set:
Extractive keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.33 | 0.31 | 0.29 | 0.17 | 0.31 | 0.20 | 0.41 | 0.31 | 0.32 | 0.28 | 0.28 | 0.28 |
Abstractive keyphrases
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M | P@O | R@O | F1@O |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|:----:|:----:|:----:|
| Inspec Test Set | 0.05 | 0.09 | 0.06 | 0.03 | 0.09 | 0.04 | 0.08 | 0.09 | 0.07 | 0.06 | 0.06 | 0.06 |
## 🚨 Issues
Please feel free to start discussions in the Community Tab.
|
AliMMZ/dqn-SpaceInvadersFirst-v4
|
AliMMZ
| 2022-08-19T09:08:23Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T09:07:46Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 538.50 +/- 117.37
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga AliMMZ -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga AliMMZ
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x
|
dminiotas05
| 2022-08-19T09:08:15Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-19T07:53:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10_8x
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0667
- Mse: 4.2666
- Mae: 1.3594
- R2: 0.4759
- Accuracy: 0.3619
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.839 | 1.0 | 6364 | 1.0965 | 4.3859 | 1.5243 | 0.4613 | 0.2012 |
| 0.4412 | 2.0 | 12728 | 0.9976 | 3.9905 | 1.4462 | 0.5099 | 0.2473 |
| 0.2543 | 3.0 | 19092 | 1.0667 | 4.2666 | 1.3594 | 0.4759 | 0.3619 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ish97/bert-finetuned-ner
|
ish97
| 2022-08-19T09:03:17Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-16T18:39:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.929042904290429
- name: Recall
type: recall
value: 0.9474924267923258
- name: F1
type: f1
value: 0.9381769705049159
- name: Accuracy
type: accuracy
value: 0.985783246011656
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0641
- Precision: 0.9290
- Recall: 0.9475
- F1: 0.9382
- Accuracy: 0.9858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0867 | 1.0 | 1756 | 0.0716 | 0.9102 | 0.9297 | 0.9198 | 0.9820 |
| 0.0345 | 2.0 | 3512 | 0.0680 | 0.9290 | 0.9465 | 0.9376 | 0.9854 |
| 0.0191 | 3.0 | 5268 | 0.0641 | 0.9290 | 0.9475 | 0.9382 | 0.9858 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
reachrkr/LunarLander-v2
|
reachrkr
| 2022-08-19T08:05:50Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T08:05:34Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: -147.49 +/- 56.78
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
To learn to code your own PPO agent and train it Unit 8 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit8
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'reachrkr/LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
indonesian-nlp/wav2vec2-indonesian-javanese-sundanese
|
indonesian-nlp
| 2022-08-19T07:44:40Z | 387 | 6 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"id",
"jv",
"robust-speech-event",
"speech",
"su",
"sun",
"dataset:mozilla-foundation/common_voice_7_0",
"dataset:openslr",
"dataset:magic_data",
"dataset:titml",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- id
- jv
- sun
datasets:
- mozilla-foundation/common_voice_7_0
- openslr
- magic_data
- titml
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- id
- jv
- robust-speech-event
- speech
- su
license: apache-2.0
model-index:
- name: Wav2Vec2 Indonesian Javanese and Sundanese by Indonesian NLP
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 6.1
type: common_voice
args: id
metrics:
- name: Test WER
type: wer
value: 4.056
- name: Test CER
type: cer
value: 1.472
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: id
metrics:
- name: Test WER
type: wer
value: 4.492
- name: Test CER
type: cer
value: 1.577
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: id
metrics:
- name: Test WER
type: wer
value: 48.94
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: id
metrics:
- name: Test WER
type: wer
value: 68.95
---
# Multilingual Speech Recognition for Indonesian Languages
This is the model built for the project
[Multilingual Speech Recognition for Indonesian Languages](https://github.com/indonesian-nlp/multilingual-asr).
It is a fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
model on the [Indonesian Common Voice dataset](https://huggingface.co/datasets/common_voice),
[High-quality TTS data for Javanese - SLR41](https://huggingface.co/datasets/openslr), and
[High-quality TTS data for Sundanese - SLR44](https://huggingface.co/datasets/openslr) datasets.
We also provide a [live demo](https://huggingface.co/spaces/indonesian-nlp/multilingual-asr) to test the model.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "id", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("indonesian-nlp/wav2vec2-indonesian-javanese-sundanese")
model = Wav2Vec2ForCTC.from_pretrained("indonesian-nlp/wav2vec2-indonesian-javanese-sundanese")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
The model can be evaluated as follows on the Indonesian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "id", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("indonesian-nlp/wav2vec2-indonesian-javanese-sundanese")
model = Wav2Vec2ForCTC.from_pretrained("indonesian-nlp/wav2vec2-indonesian-javanese-sundanese")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\'\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 11.57 %
## Training
The Common Voice `train`, `validation`, and ... datasets were used for training as well as ... and ... # TODO
The script used for training can be found [here](https://github.com/cahya-wirawan/indonesian-speech-recognition)
(will be available soon)
|
Aimlab/xlm-roberta-base-postagging-urdu
|
Aimlab
| 2022-08-19T06:35:27Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-11T09:58:16Z |
---
widget:
- text: "میرا نام سارہ ہے اور میں لندن میں رہتی ہوں۔"
- text: "میں پریمیئر لیگ میں کرکٹ کھیلتا ہوں۔"
- text: "پیاری ریاضی کی ورزش کی کتاب، براہ کرم آخر کار بڑھیں اور اپنے مسائل خود حل کریں!"
---
|
lightbansal/autotrain-metadata_postprocess-1277848906
|
lightbansal
| 2022-08-19T03:46:30Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"autotrain",
"summarization",
"en",
"dataset:lightbansal/autotrain-data-metadata_postprocess",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-19T01:04:20Z |
---
tags:
- autotrain
- summarization
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lightbansal/autotrain-data-metadata_postprocess
co2_eq_emissions:
emissions: 1.5546260967293355
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1277848906
- CO2 Emissions (in grams): 1.5546
## Validation Metrics
- Loss: 0.329
- Rouge1: 95.246
- Rouge2: 31.448
- RougeL: 93.809
- RougeLsum: 93.862
- Gen Len: 5.108
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/lightbansal/autotrain-metadata_postprocess-1277848906
```
|
PontifexMaximus/opus-mt-id-en-finetuned-id-to-en
|
PontifexMaximus
| 2022-08-19T03:10:34Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"dataset:id_panl_bppt",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-18T12:01:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- id_panl_bppt
metrics:
- bleu
model-index:
- name: opus-mt-id-en-finetuned-id-to-en
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: id_panl_bppt
type: id_panl_bppt
config: id_panl_bppt
split: train
args: id_panl_bppt
metrics:
- name: Bleu
type: bleu
value: 30.557
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-id-en-finetuned-id-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-id-en](https://huggingface.co/Helsinki-NLP/opus-mt-id-en) on the id_panl_bppt dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6469
- Bleu: 30.557
- Gen Len: 29.8247
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 2.5737 | 1.0 | 751 | 2.2222 | 24.4223 | 30.3344 |
| 2.3756 | 2.0 | 1502 | 2.1264 | 25.419 | 30.3147 |
| 2.3146 | 3.0 | 2253 | 2.0588 | 26.0995 | 30.1959 |
| 2.2411 | 4.0 | 3004 | 2.0072 | 26.5944 | 30.0763 |
| 2.1927 | 5.0 | 3755 | 1.9657 | 27.0422 | 30.0773 |
| 2.1554 | 6.0 | 4506 | 1.9284 | 27.4151 | 30.0715 |
| 2.1105 | 7.0 | 5257 | 1.8980 | 27.6645 | 29.9426 |
| 2.0841 | 8.0 | 6008 | 1.8680 | 28.023 | 29.9797 |
| 2.0491 | 9.0 | 6759 | 1.8438 | 28.2456 | 29.9342 |
| 2.0265 | 10.0 | 7510 | 1.8218 | 28.5378 | 29.8968 |
| 2.0065 | 11.0 | 8261 | 1.8012 | 28.7599 | 29.8907 |
| 1.9764 | 12.0 | 9012 | 1.7835 | 28.9369 | 29.8796 |
| 1.969 | 13.0 | 9763 | 1.7663 | 29.1565 | 29.8671 |
| 1.9474 | 14.0 | 10514 | 1.7506 | 29.3313 | 29.893 |
| 1.9397 | 15.0 | 11265 | 1.7378 | 29.4567 | 29.8512 |
| 1.9217 | 16.0 | 12016 | 1.7239 | 29.6245 | 29.8361 |
| 1.9174 | 17.0 | 12767 | 1.7127 | 29.7464 | 29.8398 |
| 1.9021 | 18.0 | 13518 | 1.7030 | 29.9035 | 29.8621 |
| 1.89 | 19.0 | 14269 | 1.6934 | 29.9669 | 29.8225 |
| 1.878 | 20.0 | 15020 | 1.6847 | 30.0961 | 29.8398 |
| 1.8671 | 21.0 | 15771 | 1.6774 | 30.1878 | 29.839 |
| 1.8634 | 22.0 | 16522 | 1.6717 | 30.2341 | 29.8134 |
| 1.8536 | 23.0 | 17273 | 1.6653 | 30.3356 | 29.816 |
| 1.8533 | 24.0 | 18024 | 1.6602 | 30.3548 | 29.8251 |
| 1.8476 | 25.0 | 18775 | 1.6560 | 30.4323 | 29.8315 |
| 1.8362 | 26.0 | 19526 | 1.6528 | 30.4682 | 29.8277 |
| 1.8463 | 27.0 | 20277 | 1.6501 | 30.5002 | 29.8236 |
| 1.8369 | 28.0 | 21028 | 1.6484 | 30.5236 | 29.8257 |
| 1.8313 | 29.0 | 21779 | 1.6472 | 30.55 | 29.8259 |
| 1.8332 | 30.0 | 22530 | 1.6469 | 30.557 | 29.8247 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
lightbansal/autotrain-metadata_postprocess-1277848909
|
lightbansal
| 2022-08-19T02:32:41Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain",
"summarization",
"en",
"dataset:lightbansal/autotrain-data-metadata_postprocess",
"co2_eq_emissions",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-19T01:04:21Z |
---
tags:
- autotrain
- summarization
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lightbansal/autotrain-data-metadata_postprocess
co2_eq_emissions:
emissions: 0.673674776711824
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1277848909
- CO2 Emissions (in grams): 0.6737
## Validation Metrics
- Loss: 0.172
- Rouge1: 94.162
- Rouge2: 30.601
- RougeL: 93.416
- RougeLsum: 93.389
- Gen Len: 4.513
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/lightbansal/autotrain-metadata_postprocess-1277848909
```
|
lightbansal/autotrain-metadata_postprocess-1277848903
|
lightbansal
| 2022-08-19T02:12:25Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain",
"summarization",
"en",
"dataset:lightbansal/autotrain-data-metadata_postprocess",
"co2_eq_emissions",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-19T01:05:16Z |
---
tags:
- autotrain
- summarization
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lightbansal/autotrain-data-metadata_postprocess
co2_eq_emissions:
emissions: 137.41419193661346
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1277848903
- CO2 Emissions (in grams): 137.4142
## Validation Metrics
- Loss: 0.202
- Rouge1: 94.135
- Rouge2: 29.999
- RougeL: 93.259
- RougeLsum: 93.280
- Gen Len: 4.491
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/lightbansal/autotrain-metadata_postprocess-1277848903
```
|
lightbansal/autotrain-metadata_postprocess-1277848897
|
lightbansal
| 2022-08-19T02:11:47Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain",
"summarization",
"en",
"dataset:lightbansal/autotrain-data-metadata_postprocess",
"co2_eq_emissions",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-19T01:03:26Z |
---
tags:
- autotrain
- summarization
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lightbansal/autotrain-data-metadata_postprocess
co2_eq_emissions:
emissions: 0.5973129947175277
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1277848897
- CO2 Emissions (in grams): 0.5973
## Validation Metrics
- Loss: 0.198
- Rouge1: 94.055
- Rouge2: 30.091
- RougeL: 93.235
- RougeLsum: 93.269
- Gen Len: 4.493
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/lightbansal/autotrain-metadata_postprocess-1277848897
```
|
wpolatkan/q-Taxi-v3
|
wpolatkan
| 2022-08-19T01:49:56Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T01:49:48Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.54 +/- 2.69
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="wpolatkan/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
wpolatkan/q-FrozenLake-v1-4x4-noSlippery
|
wpolatkan
| 2022-08-19T01:35:05Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-19T01:34:57Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="wpolatkan/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
shalpin87/diffusion_cifar
|
shalpin87
| 2022-08-18T23:42:50Z | 5 | 0 |
diffusers
|
[
"diffusers",
"en",
"dataset:CIFAR10",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-17T18:56:19Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: CIFAR10
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# diffusion_cifar
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `CIFAR10` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-12
- train_batch_size: 256
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(0.95, 0.999), weight_decay=1e-06 and epsilon=1e-08
- lr_scheduler: cosine
- lr_warmup_steps: 500
- ema_inv_gamma: 1.0
- ema_inv_gamma: 0.75
- ema_inv_gamma: 0.9999
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/shalpin87/diffusion_cifar/tensorboard?#scalars)
|
verkaDerkaDerk/tiki-based-128
|
verkaDerkaDerk
| 2022-08-18T23:32:51Z | 2 | 0 |
diffusers
|
[
"diffusers",
"license:cc0-1.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-18T22:25:51Z |
---
license: cc0-1.0
---
For anyone struggling with "git push" the password is your write token ...
|
sfurkan/LexBERT-textclassification-turkish-uncased
|
sfurkan
| 2022-08-18T22:35:18Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T21:13:07Z |
---
license: apache-2.0
---
A Turkish BERT model that is fine-tuned on various types of legislation documents, thereby is able to classify the given input as among those types.
Types are:
'Kanun',
'Resmi Gazete',
'Kanun Hükmünde Kararname',
'Genelge',
'Komisyon Raporu',
'Cumhurbaşkanlığı Kararnamesi',
'Tüzük',
'Yönetmelik',
'Tebliğ',
'Özelge'
|
damilare-akin/ppo-LunarLander-v2
|
damilare-akin
| 2022-08-18T20:57:43Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-05T21:38:58Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 277.89 +/- 25.46
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
SmartPy/distilbert-base-uncased-finetuned-cnn
|
SmartPy
| 2022-08-18T20:55:10Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-18T20:21:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-cnn
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cnn
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2811 | 1.0 | 157 | 2.3283 |
| 2.3086 | 2.0 | 314 | 2.3172 |
| 2.3472 | 3.0 | 471 | 2.3033 |
| 2.3608 | 4.0 | 628 | 2.2989 |
| 2.3494 | 5.0 | 785 | 2.2975 |
| 2.3217 | 6.0 | 942 | 2.2701 |
| 2.3087 | 7.0 | 1099 | 2.2545 |
| 2.291 | 8.0 | 1256 | 2.2376 |
| 2.2983 | 9.0 | 1413 | 2.2653 |
| 2.2892 | 10.0 | 1570 | 2.2647 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
oyvindgrutle/distilbert-base-uncased-test2
|
oyvindgrutle
| 2022-08-18T20:29:34Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-18T10:28:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-test2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5409836065573771
- name: Recall
type: recall
value: 0.39759036144578314
- name: F1
type: f1
value: 0.45833333333333337
- name: Accuracy
type: accuracy
value: 0.9469026548672567
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-test2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2937
- Precision: 0.5410
- Recall: 0.3976
- F1: 0.4583
- Accuracy: 0.9469
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2700 | 0.5102 | 0.3698 | 0.4288 | 0.9447 |
| No log | 2.0 | 426 | 0.2827 | 0.5687 | 0.3874 | 0.4609 | 0.9469 |
| 0.0553 | 3.0 | 639 | 0.2937 | 0.5410 | 0.3976 | 0.4583 | 0.9469 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
NX2411/wav2vec2-large-xlsr-korean-demo-test
|
NX2411
| 2022-08-18T18:50:34Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-16T19:40:17Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xlsr-korean-demo-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-korean-demo-test
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9829
- Wer: 0.5580
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 8.1603 | 0.4 | 400 | 5.0560 | 1.0 |
| 3.0513 | 0.79 | 800 | 2.1226 | 0.9984 |
| 1.7673 | 1.19 | 1200 | 1.2358 | 0.9273 |
| 1.4577 | 1.59 | 1600 | 1.0198 | 0.8512 |
| 1.3308 | 1.98 | 2000 | 0.9258 | 0.8325 |
| 1.1798 | 2.38 | 2400 | 0.8587 | 0.7933 |
| 1.1268 | 2.77 | 2800 | 0.8166 | 0.7677 |
| 1.0664 | 3.17 | 3200 | 0.7911 | 0.7428 |
| 0.9923 | 3.57 | 3600 | 0.7964 | 0.7481 |
| 1.0059 | 3.96 | 4000 | 0.7617 | 0.7163 |
| 0.9141 | 4.36 | 4400 | 0.7854 | 0.7280 |
| 0.8939 | 4.76 | 4800 | 0.7364 | 0.7160 |
| 0.8689 | 5.15 | 5200 | 0.7895 | 0.6996 |
| 0.8236 | 5.55 | 5600 | 0.7756 | 0.7100 |
| 0.8409 | 5.95 | 6000 | 0.7433 | 0.6915 |
| 0.7643 | 6.34 | 6400 | 0.7566 | 0.6993 |
| 0.7601 | 6.74 | 6800 | 0.7873 | 0.6836 |
| 0.7367 | 7.14 | 7200 | 0.7353 | 0.6640 |
| 0.7099 | 7.53 | 7600 | 0.7421 | 0.6766 |
| 0.7084 | 7.93 | 8000 | 0.7396 | 0.6740 |
| 0.6837 | 8.32 | 8400 | 0.7717 | 0.6647 |
| 0.6513 | 8.72 | 8800 | 0.7763 | 0.6798 |
| 0.6458 | 9.12 | 9200 | 0.7659 | 0.6494 |
| 0.6132 | 9.51 | 9600 | 0.7693 | 0.6511 |
| 0.6287 | 9.91 | 10000 | 0.7555 | 0.6469 |
| 0.6008 | 10.31 | 10400 | 0.7606 | 0.6408 |
| 0.5796 | 10.7 | 10800 | 0.7622 | 0.6397 |
| 0.5753 | 11.1 | 11200 | 0.7816 | 0.6510 |
| 0.5531 | 11.5 | 11600 | 0.8351 | 0.6658 |
| 0.5215 | 11.89 | 12000 | 0.7843 | 0.6416 |
| 0.5205 | 12.29 | 12400 | 0.7674 | 0.6256 |
| 0.5219 | 12.69 | 12800 | 0.7594 | 0.6287 |
| 0.5186 | 13.08 | 13200 | 0.7863 | 0.6243 |
| 0.473 | 13.48 | 13600 | 0.8209 | 0.6469 |
| 0.4938 | 13.87 | 14000 | 0.8002 | 0.6241 |
| 0.474 | 14.27 | 14400 | 0.8008 | 0.6122 |
| 0.442 | 14.67 | 14800 | 0.8047 | 0.6089 |
| 0.4521 | 15.06 | 15200 | 0.8341 | 0.6123 |
| 0.4289 | 15.46 | 15600 | 0.8217 | 0.6122 |
| 0.4278 | 15.86 | 16000 | 0.8400 | 0.6152 |
| 0.4051 | 16.25 | 16400 | 0.8634 | 0.6182 |
| 0.4063 | 16.65 | 16800 | 0.8486 | 0.6097 |
| 0.4101 | 17.05 | 17200 | 0.8825 | 0.6002 |
| 0.3896 | 17.44 | 17600 | 0.9575 | 0.6205 |
| 0.3833 | 17.84 | 18000 | 0.8946 | 0.6216 |
| 0.3678 | 18.24 | 18400 | 0.8905 | 0.5952 |
| 0.3715 | 18.63 | 18800 | 0.8918 | 0.5994 |
| 0.3748 | 19.03 | 19200 | 0.8856 | 0.5953 |
| 0.3485 | 19.42 | 19600 | 0.9326 | 0.5906 |
| 0.3522 | 19.82 | 20000 | 0.9237 | 0.5932 |
| 0.3551 | 20.22 | 20400 | 0.9274 | 0.5932 |
| 0.3339 | 20.61 | 20800 | 0.9075 | 0.5883 |
| 0.3354 | 21.01 | 21200 | 0.9306 | 0.5861 |
| 0.318 | 21.41 | 21600 | 0.8994 | 0.5854 |
| 0.3235 | 21.8 | 22000 | 0.9114 | 0.5831 |
| 0.3201 | 22.2 | 22400 | 0.9415 | 0.5867 |
| 0.308 | 22.6 | 22800 | 0.9695 | 0.5807 |
| 0.3049 | 22.99 | 23200 | 0.9166 | 0.5765 |
| 0.2858 | 23.39 | 23600 | 0.9643 | 0.5746 |
| 0.2938 | 23.79 | 24000 | 0.9461 | 0.5724 |
| 0.2856 | 24.18 | 24400 | 0.9658 | 0.5710 |
| 0.2827 | 24.58 | 24800 | 0.9534 | 0.5693 |
| 0.2745 | 24.97 | 25200 | 0.9436 | 0.5675 |
| 0.2705 | 25.37 | 25600 | 0.9849 | 0.5701 |
| 0.2656 | 25.77 | 26000 | 0.9854 | 0.5662 |
| 0.2645 | 26.16 | 26400 | 0.9795 | 0.5662 |
| 0.262 | 26.56 | 26800 | 0.9496 | 0.5626 |
| 0.2553 | 26.96 | 27200 | 0.9787 | 0.5659 |
| 0.2602 | 27.35 | 27600 | 0.9814 | 0.5640 |
| 0.2519 | 27.75 | 28000 | 0.9816 | 0.5631 |
| 0.2386 | 28.15 | 28400 | 1.0012 | 0.5580 |
| 0.2398 | 28.54 | 28800 | 0.9892 | 0.5567 |
| 0.2368 | 28.94 | 29200 | 0.9909 | 0.5590 |
| 0.2366 | 29.34 | 29600 | 0.9827 | 0.5567 |
| 0.2347 | 29.73 | 30000 | 0.9829 | 0.5580 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sasha/autotrain-BERTBase-imdb-1275748790
|
sasha
| 2022-08-18T18:37:50Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:10:30Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-imdb
co2_eq_emissions:
emissions: 0.2731220001956151
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275748790
- CO2 Emissions (in grams): 0.2731
## Validation Metrics
- Loss: 0.187
- Accuracy: 0.929
- Precision: 0.899
- Recall: 0.966
- AUC: 0.983
- F1: 0.932
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-imdb-1275748790
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748790", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748790", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-BERTBase-imdb-1275748793
|
sasha
| 2022-08-18T18:23:39Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:10:43Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-imdb
co2_eq_emissions:
emissions: 24.593648079365725
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275748793
- CO2 Emissions (in grams): 24.5936
## Validation Metrics
- Loss: 0.205
- Accuracy: 0.920
- Precision: 0.904
- Recall: 0.939
- AUC: 0.975
- F1: 0.921
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-imdb-1275748793
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748793", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748793", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-DistilBERT-imdb-1275448780
|
sasha
| 2022-08-18T18:23:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-DistilBERT-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:07:50Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-DistilBERT-imdb
co2_eq_emissions:
emissions: 27.53980623987047
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275448780
- CO2 Emissions (in grams): 27.5398
## Validation Metrics
- Loss: 0.188
- Accuracy: 0.927
- Precision: 0.938
- Recall: 0.915
- AUC: 0.979
- F1: 0.926
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-DistilBERT-imdb-1275448780
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448780", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448780", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-BERTBase-imdb-1275748791
|
sasha
| 2022-08-18T18:18:57Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-BERTBase-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:10:35Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-BERTBase-imdb
co2_eq_emissions:
emissions: 13.99540148555101
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275748791
- CO2 Emissions (in grams): 13.9954
## Validation Metrics
- Loss: 0.283
- Accuracy: 0.876
- Precision: 0.844
- Recall: 0.923
- AUC: 0.953
- F1: 0.882
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-BERTBase-imdb-1275748791
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748791", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-BERTBase-imdb-1275748791", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-DistilBERT-imdb-1275448783
|
sasha
| 2022-08-18T18:18:13Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-DistilBERT-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:08:06Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-DistilBERT-imdb
co2_eq_emissions:
emissions: 0.0719533080486796
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275448783
- CO2 Emissions (in grams): 0.0720
## Validation Metrics
- Loss: 0.224
- Accuracy: 0.912
- Precision: 0.896
- Recall: 0.931
- AUC: 0.972
- F1: 0.913
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-DistilBERT-imdb-1275448783
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448783", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448783", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-DistilBERT-imdb-1275448782
|
sasha
| 2022-08-18T18:15:02Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-DistilBERT-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T18:08:02Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-DistilBERT-imdb
co2_eq_emissions:
emissions: 0.04687419137564709
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275448782
- CO2 Emissions (in grams): 0.0469
## Validation Metrics
- Loss: 0.256
- Accuracy: 0.900
- Precision: 0.891
- Recall: 0.913
- AUC: 0.965
- F1: 0.902
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-DistilBERT-imdb-1275448782
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448782", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-DistilBERT-imdb-1275448782", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-roberta-base-imdb-1275248779
|
sasha
| 2022-08-18T18:11:09Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-roberta-base-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T17:43:50Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-roberta-base-imdb
co2_eq_emissions:
emissions: 60.573068351108134
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275248779
- CO2 Emissions (in grams): 60.5731
## Validation Metrics
- Loss: 0.145
- Accuracy: 0.946
- Precision: 0.933
- Recall: 0.962
- AUC: 0.988
- F1: 0.947
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-roberta-base-imdb-1275248779
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248779", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248779", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
huggingtweets/moxxisfinest
|
huggingtweets
| 2022-08-18T18:10:03Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-18T18:02:24Z |
---
language: en
thumbnail: http://www.huggingtweets.com/moxxisfinest/1660846193742/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1516705554911186946/kJ0XAas__400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Moxxi</div>
<div style="text-align: center; font-size: 14px;">@moxxisfinest</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Moxxi.
| Data | Moxxi |
| --- | --- |
| Tweets downloaded | 581 |
| Retweets | 9 |
| Short tweets | 30 |
| Tweets kept | 542 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/7bcum3lm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @moxxisfinest's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/10bhx0pa) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/10bhx0pa/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/moxxisfinest')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
AlexMax/Alex
|
AlexMax
| 2022-08-18T18:09:19Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-08-18T18:05:30Z |
---
license: afl-3.0
Ukraine, warrior, lion, fields, mountains, flag, knight
|
sasha/autotrain-roberta-base-imdb-1275248778
|
sasha
| 2022-08-18T17:56:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-roberta-base-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T17:43:42Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-roberta-base-imdb
co2_eq_emissions:
emissions: 23.591266130909247
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275248778
- CO2 Emissions (in grams): 23.5913
## Validation Metrics
- Loss: 0.180
- Accuracy: 0.933
- Precision: 0.944
- Recall: 0.921
- AUC: 0.983
- F1: 0.932
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-roberta-base-imdb-1275248778
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248778", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248778", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
sasha/autotrain-roberta-base-imdb-1275248777
|
sasha
| 2022-08-18T17:54:24Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:sasha/autotrain-data-roberta-base-imdb",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T17:43:37Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- sasha/autotrain-data-roberta-base-imdb
co2_eq_emissions:
emissions: 21.172831206976706
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1275248777
- CO2 Emissions (in grams): 21.1728
## Validation Metrics
- Loss: 0.216
- Accuracy: 0.920
- Precision: 0.936
- Recall: 0.901
- AUC: 0.977
- F1: 0.918
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/sasha/autotrain-roberta-base-imdb-1275248777
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248777", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("sasha/autotrain-roberta-base-imdb-1275248777", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
jackoyoungblood/dqn-SpaceInvadersNoFrameskip-v4
|
jackoyoungblood
| 2022-08-18T17:43:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-18T11:26:13Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 480.00 +/- 324.01
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jackoyoungblood -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jackoyoungblood
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
olgaduchovny/t5-base-ner-mit-restaurant
|
olgaduchovny
| 2022-08-18T17:37:37Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ner",
"text generation",
"seq2seq",
"en",
"dataset:conll2003",
"arxiv:2203.03903",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text2text-generation
| 2022-08-08T18:29:13Z |
---
language:
- en
tags:
- pytorch
- ner
- text generation
- seq2seq
inference: false
license: mit
datasets:
- conll2003
metrics:
- f1
---
# t5-base-qa-ner-conll
Unofficial implementation of [InstructionNER](https://arxiv.org/pdf/2203.03903v1.pdf).
t5-base model tuned on conll2003 dataset.
https://github.com/ovbystrova/InstructionNER
## Inference
```shell
git clone https://github.com/ovbystrova/InstructionNER
cd InstructionNER
```
```python
from instruction_ner.model import Model
model = Model(
model_path_or_name="olgaduchovny/t5-base-ner-mit-restaurant",
tokenizer_path_or_name="olgaduchovny/t5-base-mit-restaurant"
)
options = ["LOC", "PER", "ORG", "MISC"]
instruction = "please extract entities and their types from the input sentence, " \
"all entity types are in options"
text = "Once I visited Sovok in Nizny Novgorod. I had asian wok there. It was the best WOK i ever had"\
"It was cheap but lemonades cost 5 dollars."
generation_kwargs = {
"num_beams": 2,
"max_length": 128
}
pred_spans = model.predict(
text=text,
generation_kwargs=generation_kwargs,
instruction=instruction,
options=options
)
>>> ('sovok is a Restaurant_Name, Nizny Novgorod is a Location, asian wok is a Dish, cheap is a Price, lemonades is a Dish, 5 dollars is a Price.',
[(24, 38, 'Location'),
(46, 55, 'Dish'),
(100, 105, 'Price'),
(110, 119, 'Dish'),
(125, 134, 'Price')])
```
|
Dimitre/bert_en_cased_preprocess
|
Dimitre
| 2022-08-18T17:31:58Z | 0 | 1 |
tfhub
|
[
"tfhub",
"tf-keras",
"text",
"tokenizer",
"preprocessor",
"bert",
"tensorflow",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"region:us"
] | null | 2022-08-16T00:08:03Z |
---
license: apache-2.0
library_name: tfhub
language: en
tags:
- text
- tokenizer
- preprocessor
- bert
- tensorflow
datasets:
- bookcorpus
- wikipedia
---
## Model name: bert_en_cased_preprocess
## Description adapted from [TFHub](https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3)
# Overview
This SavedModel is a companion of [BERT models](https://tfhub.dev/google/collections/bert/1) to preprocess plain text inputs into the input format expected by BERT. **Check the model documentation** to find the correct preprocessing model for each particular BERT or other Transformer encoder model.
BERT and its preprocessing were originally published by
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova: ["BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"](https://arxiv.org/abs/1810.04805), 2018.
This model uses a vocabulary for English extracted from the Wikipedia and BooksCorpus (same as in the models by the original BERT authors). Text inputs have been normalized the "cased" way, meaning that the distinction between lower and upper case as well as accent markers have been preserved.
This model has no trainable parameters and can be used in an input pipeline outside the training loop.
# Prerequisites
This SavedModel uses TensorFlow operations defined by the [TensorFlow Text](https://github.com/tensorflow/text) library. On [Google Colaboratory](https://colab.research.google.com/), it can be installed with
```
!pip install tensorflow_text
import tensorflow_text as text # Registers the ops.
```
# Usage
This SavedModel implements the preprocessor API for [text embeddings with Transformer encoders](https://www.tensorflow.org/hub/common_saved_model_apis/text#transformer-encoders), which offers several ways to go from one or more batches of text segments (plain text encoded as UTF-8) to the inputs for the Transformer encoder model.
## Basic usage for single segments
Inputs with a single text segment can be mapped to encoder inputs like this:
### Using TF Hub and HF Hub
```
model_path = snapshot_download(repo_id="Dimitre/bert_en_cased_preprocess")
preprocessor = KerasLayer(handle=model_path)
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string)
encoder_inputs = preprocessor(text_input)
```
### Using [TF Hub fork](https://github.com/dimitreOliveira/hub)
```
preprocessor = pull_from_hub(repo_id="Dimitre/bert_en_cased_preprocess")
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string)
encoder_inputs = preprocessor(text_input)
```
The resulting encoder inputs have `seq_length=128`.
## General usage
For pairs of input segments, to control the `seq_length`, or to modify tokenized sequences before packing them into encoder inputs, the preprocessor can be called like this:
```
preprocessor = pull_from_hub(repo_id="Dimitre/bert_en_cased_preprocess")
# Step 1: tokenize batches of text inputs.
text_inputs = [tf.keras.layers.Input(shape=(), dtype=tf.string),
...] # This SavedModel accepts up to 2 text inputs.
tokenize = hub.KerasLayer(preprocessor.tokenize)
tokenized_inputs = [tokenize(segment) for segment in text_inputs]
# Step 2 (optional): modify tokenized inputs.
pass
# Step 3: pack input sequences for the Transformer encoder.
seq_length = 128 # Your choice here.
bert_pack_inputs = hub.KerasLayer(
preprocessor.bert_pack_inputs,
arguments=dict(seq_length=seq_length)) # Optional argument.
encoder_inputs = bert_pack_inputs(tokenized_inputs)
```
The call to `tokenize()` returns an int32 [RaggedTensor](https://www.tensorflow.org/guide/ragged_tensor) of shape `[batch_size, (words), (tokens_per_word)]`. Correspondingly, the call to `bert_pack_inputs()` accepts a RaggedTensor of shape `[batch_size, ...]` with rank 2 or 3.
# Output details
The result of preprocessing is a batch of fixed-length input sequences for the Transformer encoder.
An input sequence starts with one start-of-sequence token, followed by the tokenized segments, each terminated by one end-of-segment token. Remaining positions up to `seq_length`, if any, are filled up with padding tokens. If an input sequence would exceed `seq_length`, the tokenized segments in it are truncated to prefixes of approximately equal sizes to fit exactly.
The `encoder_inputs` are a dict of three int32 Tensors, all with shape `[batch_size, seq_length]`, whose elements represent the batch of input sequences as follows:
- `"input_word_ids"`: has the token ids of the input sequences.
- `"input_mask"`: has value 1 at the position of all input tokens present before padding and value 0 for the padding tokens.
- `"input_type_ids"`: has the index of the input segment that gave rise to the input token at the respective position. The first input segment (index 0) includes the start-of-sequence token and its end-of-segment token. The second segment (index 1, if present) includes its end-of-segment token. Padding tokens get index 0 again.
## Custom input packing and MLM support
The function
```special_tokens_dict = preprocessor.tokenize.get_special_tokens_dict()```
returns a dict of scalar int32 Tensors that report the tokenizer's `"vocab_size"` as well as the ids of certain special tokens: `"padding_id"`, `"start_of_sequence_id"` (aka. [CLS]), `"end_of_segment_id"` (aka. [SEP]) and `"mask_id"`. This allows users to replace `preprocessor.bert_pack_inputs()` with Python code such as `text.combine_segments()`, possibly `text.masked_language_model()`, and `text.pad_model_inputs()` from the [TensorFlow Text](https://github.com/tensorflow/text) library.
|
Dimitre/universal-sentence-encoder
|
Dimitre
| 2022-08-18T17:17:01Z | 0 | 13 |
tfhub
|
[
"tfhub",
"tf-keras",
"text",
"sentence-similarity",
"use",
"universal-sentence-encoder",
"dan",
"tensorflow",
"en",
"license:apache-2.0",
"region:us"
] |
sentence-similarity
| 2022-08-14T19:44:46Z |
---
license: apache-2.0
library_name: tfhub
language: en
tags:
- text
- sentence-similarity
- use
- universal-sentence-encoder
- dan
- tensorflow
---
## Model name: universal-sentence-encoder
## Description adapted from [TFHub](https://tfhub.dev/google/universal-sentence-encoder/4)
# Overview
The Universal Sentence Encoder encodes text into high-dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks.
The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512 dimensional vector. We apply this model to the [STS benchmark](https://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) for semantic similarity, and the results can be seen in the [example notebook](https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/semantic_similarity_with_tf_hub_universal_encoder.ipynb) made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.
To learn more about text embeddings, refer to the [TensorFlow Embeddings](https://www.tensorflow.org/tutorials/text/word_embeddings) documentation. Our encoder differs from word level embedding models in that we train on a number of natural language prediction tasks that require modeling the meaning of word sequences rather than just individual words. Details are available in the paper "Universal Sentence Encoder" [1].
## Universal Sentence Encoder family
There are several versions of universal sentence encoder models trained with different goals including size/performance multilingual, and fine-grained question answer retrieval.
- [Universal Sentence Encoder family](https://tfhub.dev/google/collections/universal-sentence-encoder/1)
### Example use
### Using TF Hub and HF Hub
```
model_path = snapshot_download(repo_id="Dimitre/universal-sentence-encoder")
model = KerasLayer(handle=model_path)
embeddings = model([
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"])
print(embeddings)
# The following are example embedding output of 512 dimensions per sentence
# Embedding for: The quick brown fox jumps over the lazy dog.
# [-0.03133016 -0.06338634 -0.01607501, ...]
# Embedding for: I am a sentence for which I would like to get its embedding.
# [0.05080863 -0.0165243 0.01573782, ...]
```
### Using [TF Hub fork](https://github.com/dimitreOliveira/hub)
```
model = pull_from_hub(repo_id="Dimitre/universal-sentence-encoder")
embeddings = model([
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"])
print(embeddings)
# The following are example embedding output of 512 dimensions per sentence
# Embedding for: The quick brown fox jumps over the lazy dog.
# [-0.03133016 -0.06338634 -0.01607501, ...]
# Embedding for: I am a sentence for which I would like to get its embedding.
# [0.05080863 -0.0165243 0.01573782, ...]
```
This module is about 1GB. Depending on your network speed, it might take a while to load the first time you run inference with it. After that, loading the model should be faster as modules are cached by default ([learn more about caching](https://www.tensorflow.org/hub/tf2_saved_model)). Further, once a module is loaded to memory, inference time should be relatively fast.
### Preprocessing
The module does not require preprocessing the data before applying the module, it performs best effort text input preprocessing inside the graph.
# Semantic Similarity
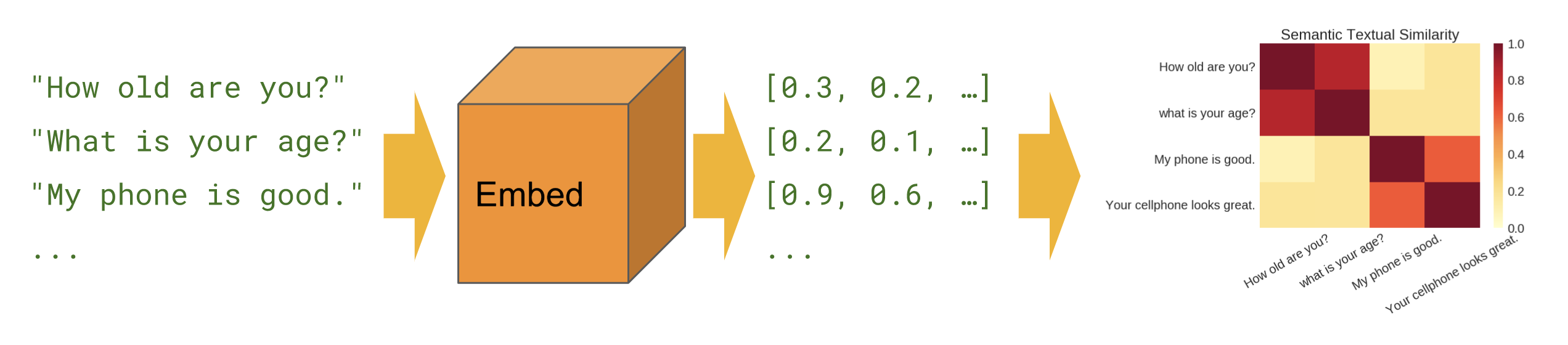
Semantic similarity is a measure of the degree to which two pieces of text carry the same meaning. This is broadly useful in obtaining good coverage over the numerous ways that a thought can be expressed using language without needing to manually enumerate them.
Simple applications include improving the coverage of systems that trigger behaviors on certain keywords, phrases or utterances. [This section of the notebook](https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/semantic_similarity_with_tf_hub_universal_encoder.ipynb#scrollTo=BnvjATdy64eR) shows how to encode text and compare encoding distances as a proxy for semantic similarity.
# Classification

[This notebook](https://colab.research.google.com/github/tensorflow/hub/blob/master/docs/tutorials/text_classification_with_tf_hub.ipynb) shows how to train a simple binary text classifier on top of any TF-Hub module that can embed sentences. The Universal Sentence Encoder was partially trained with custom text classification tasks in mind. These kinds of classifiers can be trained to perform a wide variety of classification tasks often with a very small amount of labeled examples.
|
tinglxn/random-wav2vec2-base
|
tinglxn
| 2022-08-18T17:07:09Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-08-18T16:55:00Z |
This is random-wav2vec2-base, an unpretrained version of wav2vec 2.0. The weight of this model is randomly initialized, and can be used for establishing randomized baselines or training a model from scratch. The code used to do so is adapted from: https://huggingface.co/saibo/random-roberta-base.
|
Billwzl/bert-base-uncased-New_data_bert1
|
Billwzl
| 2022-08-18T15:34:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-18T13:08:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-New_data_bert1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-New_data_bert1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9215
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.4496 | 1.0 | 2018 | 2.2066 |
| 2.2532 | 2.0 | 4036 | 2.1438 |
| 2.1572 | 3.0 | 6054 | 2.1046 |
| 2.0839 | 4.0 | 8072 | 2.0943 |
| 2.0222 | 5.0 | 10090 | 2.0573 |
| 1.9608 | 6.0 | 12108 | 2.0188 |
| 1.9123 | 7.0 | 14126 | 2.0008 |
| 1.8666 | 8.0 | 16144 | 2.0063 |
| 1.8305 | 9.0 | 18162 | 1.9607 |
| 1.7958 | 10.0 | 20180 | 1.9702 |
| 1.7498 | 11.0 | 22198 | 1.9635 |
| 1.7172 | 12.0 | 24216 | 1.9404 |
| 1.695 | 13.0 | 26234 | 1.9455 |
| 1.6628 | 14.0 | 28252 | 1.9269 |
| 1.6558 | 15.0 | 30270 | 1.9173 |
| 1.6293 | 16.0 | 32288 | 1.9215 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ying-tina/wav2vec2-xlsr-53-torgo-origin-parameters-checkpoint3750
|
ying-tina
| 2022-08-18T15:15:37Z | 77 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-18T13:28:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-xlsr-53-torgo-origin-parameters-checkpoint3750
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-53-torgo-origin-parameters-checkpoint3750
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the Torgo dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2104
- Cer: 0.3903
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.63 | 250 | 19.6794 | 0.9961 |
| 25.0027 | 1.26 | 500 | 5.6998 | 0.9961 |
| 25.0027 | 1.89 | 750 | 5.3298 | 0.9961 |
| 3.7083 | 2.53 | 1000 | 4.9012 | 0.9961 |
| 3.7083 | 3.16 | 1250 | 4.7392 | 0.9961 |
| 3.3223 | 3.79 | 1500 | 3.8672 | 0.9961 |
| 3.3223 | 4.42 | 1750 | 2.5696 | 0.8772 |
| 2.564 | 5.05 | 2000 | 2.0229 | 0.7136 |
| 2.564 | 5.68 | 2250 | 1.6933 | 0.5332 |
| 1.7148 | 6.31 | 2500 | 1.4409 | 0.4808 |
| 1.7148 | 6.94 | 2750 | 1.3612 | 0.4601 |
| 1.3384 | 7.58 | 3000 | 1.3402 | 0.4328 |
| 1.3384 | 8.21 | 3250 | 1.2438 | 0.4070 |
| 1.1197 | 8.84 | 3500 | 1.2251 | 0.3938 |
| 1.1197 | 9.47 | 3750 | 1.2104 | 0.3903 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
patrickvonplaten/ami-wav2vec2-large-lv60
|
patrickvonplaten
| 2022-08-18T14:58:13Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-18T10:14:32Z |
# AMI - Wav2Vec2-Large-LV60
Trained on < 2 epochs, see [run.sh](https://huggingface.co/patrickvonplaten/ami-wav2vec2-large-lv60/blob/main/run.sh).
Results:
**Validation**:
```
{
"eval_loss": 0.599422812461853,
"eval_runtime": 197.9157,
"eval_samples": 12383,
"eval_samples_per_second": 62.567,
"eval_steps_per_second": 0.98,
"eval_wer": 0.25275729434515587
}
```
**Eval**:
```
"eval_loss": 0.5091261863708496,
"eval_runtime": 208.7241,
"eval_samples": 11944,
"eval_samples_per_second": 57.224,
"eval_steps_per_second": 0.896,
"eval_wer": 0.2521060666025895
```
|
mphamsioo/lol
|
mphamsioo
| 2022-08-18T14:43:48Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-18T13:46:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: lol
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lol
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6366
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- gradient_accumulation_steps: 10
- total_train_batch_size: 100
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.0118 | 1.4 | 7 | 2.1901 |
| 2.1915 | 2.8 | 14 | 1.8797 |
| 1.8529 | 4.2 | 21 | 1.7159 |
| 1.7081 | 5.6 | 28 | 1.6536 |
| 1.623 | 7.0 | 35 | 1.6366 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
huggingtweets/pseud0anon
|
huggingtweets
| 2022-08-18T13:44:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-18T13:40:55Z |
---
language: en
thumbnail: http://www.huggingtweets.com/pseud0anon/1660830250717/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1517549694762860552/6CPhguwR_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Pseudo</div>
<div style="text-align: center; font-size: 14px;">@pseud0anon</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Pseudo.
| Data | Pseudo |
| --- | --- |
| Tweets downloaded | 749 |
| Retweets | 46 |
| Short tweets | 106 |
| Tweets kept | 597 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2uwdoubz/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @pseud0anon's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ljr6tgv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ljr6tgv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/pseud0anon')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10
|
dminiotas05
| 2022-08-18T13:24:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T12:18:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm300_aug5_10
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0781
- Mse: 4.3123
- Mae: 1.3743
- R2: 0.4703
- Accuracy: 0.3626
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.9715 | 1.0 | 4743 | 1.0839 | 4.3355 | 1.4262 | 0.4675 | 0.3037 |
| 0.676 | 2.0 | 9486 | 1.0891 | 4.3563 | 1.4474 | 0.4649 | 0.2454 |
| 0.4256 | 3.0 | 14229 | 1.0781 | 4.3123 | 1.3743 | 0.4703 | 0.3626 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
classla/wav2vec2-xls-r-juznevesti-sr
|
classla
| 2022-08-18T12:47:32Z | 252 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"sr",
"dataset:juznevesti-sr",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-18T08:38:24Z |
---
language: sr
datasets:
- juznevesti-sr
tags:
- audio
- automatic-speech-recognition
widget:
- example_title: Croatian example 1
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/1800.m4a
- example_title: Croatian example 2
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/00020578b.flac.wav
- example_title: Croatian example 3
src: https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/00020570a.flac.wav
---
# wav2vec2-xls-r-juznevesti
This model for Serbian ASR is based on the [facebook/wav2vec2-xls-r-300m model](https://huggingface.co/facebook/wav2vec2-xls-r-300m) and was fine-tuned with 58 hours of audio and transcripts from [Južne vesti](https://www.juznevesti.com/), programme '15 minuta'.
For more info on the dataset creation see [this repo](https://github.com/clarinsi/parlaspeech/tree/main/juzne_vesti).
## Metrics
Evaluation is performed on the dev and test portions of the JuzneVesti dataset
| | dev | test |
|:----|---------:|---------:|
| WER | 0.295206 | 0.290094 |
| CER | 0.140766 | 0.137642 |
## Usage in `transformers`
Tested with `transformers==4.18.0`, `torch==1.11.0`, and `SoundFile==0.10.3.post1`.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import soundfile as sf
import torch
import os
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained(
"classla/wav2vec2-xls-r-juznevesti-sr")
model = Wav2Vec2ForCTC.from_pretrained("classla/wav2vec2-xls-r-juznevesti-sr")
# download the example wav files:
os.system("wget https://huggingface.co/classla/wav2vec2-xls-r-parlaspeech-hr/raw/main/00020570a.flac.wav")
# read the wav file
speech, sample_rate = sf.read("00020570a.flac.wav")
input_values = processor(speech, sampling_rate=sample_rate, return_tensors="pt").input_values.to(device)
# remove the raw wav file
os.system("rm 00020570a.flac.wav")
# retrieve logits
logits = model.to(device)(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.decode(predicted_ids[0])
transcription # 'velik broj poslovnih subjekata posluje sa minosom velik deo'
```
## Training hyperparameters
In fine-tuning, the following arguments were used:
| arg | value |
|-------------------------------|-------|
| `per_device_train_batch_size` | 16 |
| `gradient_accumulation_steps` | 4 |
| `num_train_epochs` | 20 |
| `learning_rate` | 3e-4 |
| `warmup_steps` | 500 |
|
marinone94/xls-r-300m-sv-robust
|
marinone94
| 2022-08-18T12:45:07Z | 56 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_9_0",
"generated_from_trainer",
"sv",
"dataset:mozilla-foundation/common_voice_9_0",
"license:cc0-1.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- sv
license: cc0-1.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_9_0
- generated_from_trainer
- sv
datasets:
- mozilla-foundation/common_voice_9_0
model-index:
- name: XLS-R-300M - Swedish
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_9_0
type: mozilla-foundation/common_voice_9_0
split: test
args: sv-SE
WER:
metrics:
- name: Test WER
type: wer
value: 7.72
- name: Test CER
type: cer
value: 2.61
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: speech-recognition-community-v2/dev_data
type: speech-recognition-community-v2/dev_data
split: validation
args: sv
metrics:
- name: Test WER
type: wer
value: 16.23
- name: Test CER
type: cer
value: 8.21
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: speech-recognition-community-v2/dev_data
type: speech-recognition-community-v2/dev_data
split: test
args: sv
metrics:
- name: Test WER
type: wer
value: 15.08
- name: Test CER
type: cer
value: 7.51
---
#
This model is a fine-tuned version of [KBLab/wav2vec2-large-voxrex](https://huggingface.co/KBLab/wav2vec2-large-voxrex) on the MOZILLA-FOUNDATION/COMMON_VOICE_9_0 - SV-SE dataset.
It achieves the following results on the evaluation set ("test" split, without LM):
- Loss: 0.1318
- Wer: 0.1121
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.9099 | 10.42 | 1000 | 2.8369 | 1.0 |
| 1.0745 | 20.83 | 2000 | 0.1957 | 0.1673 |
| 0.934 | 31.25 | 3000 | 0.1579 | 0.1389 |
| 0.8691 | 41.66 | 4000 | 0.1457 | 0.1290 |
| 0.8328 | 52.08 | 5000 | 0.1435 | 0.1205 |
| 0.8068 | 62.5 | 6000 | 0.1350 | 0.1191 |
| 0.7822 | 72.91 | 7000 | 0.1347 | 0.1155 |
| 0.7769 | 83.33 | 8000 | 0.1321 | 0.1131 |
| 0.7678 | 93.75 | 9000 | 0.1321 | 0.1115 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 2.2.2
- Tokenizers 0.11.0
|
jimypbr/test-ner
|
jimypbr
| 2022-08-18T12:37:31Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"optimum_graphcore",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-18T12:18:29Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: test-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9467731204258151
- name: Recall
type: recall
value: 0.9579266240323123
- name: F1
type: f1
value: 0.952317215994646
- name: Accuracy
type: accuracy
value: 0.9920953233908337
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-ner
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0398
- Precision: 0.9468
- Recall: 0.9579
- F1: 0.9523
- Accuracy: 0.9921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- distributed_type: IPU
- total_train_batch_size: 16
- total_eval_batch_size: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- training precision: Mixed Precision
### Training results
### Framework versions
- Transformers 4.20.0
- Pytorch 1.10.0+cpu
- Datasets 2.4.0
- Tokenizers 0.12.1
|
huggingtweets/timgill924
|
huggingtweets
| 2022-08-18T12:30:49Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-18T12:30:07Z |
---
language: en
thumbnail: http://www.huggingtweets.com/timgill924/1660825845162/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1469851548922564612/oOe9x8cO_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Tim Gill</div>
<div style="text-align: center; font-size: 14px;">@timgill924</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Tim Gill.
| Data | Tim Gill |
| --- | --- |
| Tweets downloaded | 3246 |
| Retweets | 240 |
| Short tweets | 1030 |
| Tweets kept | 1976 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2d11uzkw/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @timgill924's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2o1k110h) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2o1k110h/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/timgill924')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Alex-yang/Reinforce-v01
|
Alex-yang
| 2022-08-18T10:35:27Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-18T10:31:19Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-v01
results:
- metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
Langboat/mengzi-bert-L6-H768
|
Langboat
| 2022-08-18T10:22:01Z | 5 | 4 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2110.06696",
"doi:10.57967/hf/0027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-15T07:37:46Z |
---
language:
- zh
license: apache-2.0
---
# Mengzi-BERT L6-H768 model (Chinese)
This model is a distilled version of mengzi-bert-large.
## Usage
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("Langboat/mengzi-bert-L6-H768")
model = BertModel.from_pretrained("Langboat/mengzi-bert-L6-H768")
```
## Scores on nine chinese tasks (without any data augmentation)
| Model | AFQMC | TNEWS | IFLYTEK | CMNLI | WSC | CSL | CMRC2018 | C3 | CHID |
|-|-|-|-|-|-|-|-|-|-|
|**Mengzi-BERT-L6-H768**| 74.75 | 56.68 | 60.22 | 81.10 | 84.87 | 85.77 | 78.06 | 65.49 | 80.59 |
|Mengzi-BERT-base| 74.58 | 57.97 | 60.68 | 82.12 | 87.50 | 85.40 | 78.54 | 71.70 | 84.16 |
|RoBERTa-wwm-ext| 74.30 | 57.51 | 60.80 | 80.70 | 67.20 | 80.67 | 77.59 | 67.06 | 83.78 |
RoBERTa-wwm-ext scores are from CLUE baseline
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
```
@misc{zhang2021mengzi,
title={Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese},
author={Zhuosheng Zhang and Hanqing Zhang and Keming Chen and Yuhang Guo and Jingyun Hua and Yulong Wang and Ming Zhou},
year={2021},
eprint={2110.06696},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Zengwei/icefall-asr-librispeech-lstm-transducer-stateless-2022-08-18
|
Zengwei
| 2022-08-18T08:33:32Z | 0 | 1 | null |
[
"tensorboard",
"region:us"
] | null | 2022-08-18T08:03:19Z |
See <https://github.com/k2-fsa/icefall/pull/479>
|
namruto/my-awesome-model
|
namruto
| 2022-08-18T07:41:17Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T05:41:14Z |
---
tags:
- generated_from_trainer
model-index:
- name: my-awesome-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my-awesome-model
This model is a fine-tuned version of [vinai/phobert-base](https://huggingface.co/vinai/phobert-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
chia/distilbert-base-uncased-finetuned-clinc
|
chia
| 2022-08-18T05:01:32Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-16T12:46:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9170967741935484
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7778
- Accuracy: 0.9171
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2882 | 1.0 | 318 | 3.2777 | 0.7390 |
| 2.6228 | 2.0 | 636 | 1.8739 | 0.8287 |
| 1.5439 | 3.0 | 954 | 1.1619 | 0.8894 |
| 1.0111 | 4.0 | 1272 | 0.8601 | 0.9094 |
| 0.7999 | 5.0 | 1590 | 0.7778 | 0.9171 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cpu
- Datasets 2.4.0
- Tokenizers 0.10.3
|
zjs81/Electric-Car-Brand-Classifier
|
zjs81
| 2022-08-18T04:51:22Z | 73 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-16T03:45:30Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: Electric-Car-Brand-Classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.807692289352417
---
# Electric-Car-Brand-Classifier
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### BMW Electric Car

#### Chevrolet Electric Car

#### Hyundai Electric Car

#### Tesla Electric Car

#### Toyota Electric Car

|
hsge/TESS_768_v1
|
hsge
| 2022-08-18T03:26:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-08-12T16:11:48Z |
---
license: mit
---
<h1>Transformer Encoder for Social Science (TESS)</h1>
TESS is a deep neural network model intended for social science related NLP tasks. The model is developed by Haosen Ge, In Young Park, Xuancheng Qian, and Grace Zeng.
We demonstrate in two validation tests that TESS outperforms BERT and RoBERTa by 16.7\% on average, especially when the number of training samples is limited (<1,000 training instances). The results display the superiority of TESS on social science text processing tasks.
GitHub: [TESS](https://github.com/haosenge/TESS).
<h2>Training Corpus</h2>
| TEXT | SOURCE |
| ------------- | ------------- |
| Preferential Trade Agreements | ToTA |
| Congressional Bills | Kornilova and Eidelman (2019) |
|UNGA Resolutions | UN |
|Firms' Annual Reports | Loughran and McDonald (2016)|
| U.S. Court Opinions | Caselaw Access Project|
The model is trained on 4 NVIDIA A100 GPUs for 120K steps.
|
sudhab1988/finetuning-sentiment-model-3000-samples
|
sudhab1988
| 2022-08-18T01:43:36Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-18T01:33:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8866666666666667
- name: F1
type: f1
value: 0.888157894736842
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3045
- Accuracy: 0.8867
- F1: 0.8882
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
andrewzhang505/quad-swarm-single-drone-sf2
|
andrewzhang505
| 2022-08-17T21:16:38Z | 6 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-16T19:41:35Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 0.03 +/- 1.86
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: quadrotor_multi
type: quadrotor_multi
---
A(n) **APPO** model trained on the **quadrotor_multi** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
PrimeQA/squad-v1-roberta-large
|
PrimeQA
| 2022-08-17T18:25:42Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"MRC",
"SQuAD 1.1",
"roberta-large",
"en",
"arxiv:1606.05250",
"arxiv:1907.11692",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-07-07T19:36:59Z |
---
tags:
- MRC
- SQuAD 1.1
- roberta-large
language: en
license: apache-2.0
---
# Model description
An RoBERTa reading comprehension model for [SQuAD 1.1](https://aclanthology.org/D16-1264/).
The model is initialized with [roberta-large](https://huggingface.co/roberta-large/) and fine-tuned on the [SQuAD 1.1 train data](https://huggingface.co/datasets/squad).
## Intended uses & limitations
You can use the raw model for the reading comprehension task. Biases associated with the pre-existing language model, roberta-large, that we used may be present in our fine-tuned model, squad-v1-roberta-large.
## Usage
You can use this model directly with the [PrimeQA](https://github.com/primeqa/primeqa) pipeline for reading comprehension [squad.ipynb](https://github.com/primeqa/primeqa/blob/main/notebooks/mrc/squad.ipynb).
```bibtex
@article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
}
```
```bibtex
@article{DBLP:journals/corr/abs-1907-11692,
author = {Yinhan Liu and
Myle Ott and
Naman Goyal and
Jingfei Du and
Mandar Joshi and
Danqi Chen and
Omer Levy and
Mike Lewis and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
journal = {CoRR},
volume = {abs/1907.11692},
year = {2019},
url = {http://arxiv.org/abs/1907.11692},
archivePrefix = {arXiv},
eprint = {1907.11692},
timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
sasha/regardv3
|
sasha
| 2022-08-17T18:03:37Z | 15,069 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:1909.01326",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-17T16:58:42Z |
---
license: cc-by-4.0
---
# BERT Regard classification model
This model is the result of a project entitled [Towards Controllable Biases in Language Generation](https://github.com/ewsheng/controllable-nlg-biases). It consists of a BERT classifier (no ensemble) trained on 1.7K samples of biased language.
*Regard* measures language polarity towards and social perceptions of a demographic (compared to sentiment, which only measures overall language polarity).
### BibTeX entry and citation info
```bibtex
@article{sheng2019woman,
title={The woman worked as a babysitter: On biases in language generation},
author={Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun},
journal={arXiv preprint arXiv:1909.01326},
year={2019}
}
```
|
BojanSimoski/distilbert-base-uncased-finetuned-cola
|
BojanSimoski
| 2022-08-17T17:34:52Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-17T15:48:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: train
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5491398222815213
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5196
- Matthews Correlation: 0.5491
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5224 | 1.0 | 535 | 0.5262 | 0.4063 |
| 0.351 | 2.0 | 1070 | 0.4991 | 0.4871 |
| 0.2369 | 3.0 | 1605 | 0.5196 | 0.5491 |
| 0.1756 | 4.0 | 2140 | 0.7817 | 0.5142 |
| 0.1268 | 5.0 | 2675 | 0.8089 | 0.5324 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
muhtasham/bert-small-nan-labels-500
|
muhtasham
| 2022-08-17T15:34:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-17T14:03:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-small-nan-labels-500
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-nan-labels-500
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.1664
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.9422 | 1.0 | 14 | 5.5730 |
| 4.4976 | 2.0 | 28 | 5.4533 |
| 4.2684 | 3.0 | 42 | 5.4158 |
| 4.2673 | 4.0 | 56 | 5.4162 |
| 4.0978 | 5.0 | 70 | 5.4121 |
| 3.8972 | 6.0 | 84 | 5.4649 |
| 3.7728 | 7.0 | 98 | 5.4233 |
| 3.7557 | 8.0 | 112 | 5.4381 |
| 3.693 | 9.0 | 126 | 5.4673 |
| 3.5627 | 10.0 | 140 | 5.5277 |
| 3.6456 | 11.0 | 154 | 5.4351 |
| 3.5487 | 12.0 | 168 | 5.4846 |
| 3.4018 | 13.0 | 182 | 5.5763 |
| 3.3807 | 14.0 | 196 | 5.5674 |
| 3.4219 | 15.0 | 210 | 5.6129 |
| 3.3481 | 16.0 | 224 | 5.5470 |
| 3.2522 | 17.0 | 238 | 5.6078 |
| 3.3047 | 18.0 | 252 | 5.6274 |
| 3.1542 | 19.0 | 266 | 5.6517 |
| 3.0939 | 20.0 | 280 | 5.6088 |
| 3.0951 | 21.0 | 294 | 5.6768 |
| 3.0876 | 22.0 | 308 | 5.6796 |
| 3.0098 | 23.0 | 322 | 5.6938 |
| 3.061 | 24.0 | 336 | 5.7355 |
| 2.8711 | 25.0 | 350 | 5.6882 |
| 2.7414 | 26.0 | 364 | 5.7694 |
| 2.8273 | 27.0 | 378 | 5.7295 |
| 2.8497 | 28.0 | 392 | 5.7976 |
| 2.8469 | 29.0 | 406 | 5.7935 |
| 2.8367 | 30.0 | 420 | 5.8076 |
| 2.6975 | 31.0 | 434 | 5.7854 |
| 2.7496 | 32.0 | 448 | 5.8664 |
| 2.638 | 33.0 | 462 | 5.8900 |
| 2.6511 | 34.0 | 476 | 5.8628 |
| 2.6228 | 35.0 | 490 | 5.8544 |
| 2.617 | 36.0 | 504 | 5.8830 |
| 2.498 | 37.0 | 518 | 5.9080 |
| 2.4956 | 38.0 | 532 | 6.0102 |
| 2.445 | 39.0 | 546 | 5.9869 |
| 2.4493 | 40.0 | 560 | 6.0824 |
| 2.3935 | 41.0 | 574 | 5.9724 |
| 2.3559 | 42.0 | 588 | 5.9515 |
| 2.3444 | 43.0 | 602 | 5.9968 |
| 2.2707 | 44.0 | 616 | 6.0433 |
| 2.1095 | 45.0 | 630 | 6.0700 |
| 2.1573 | 46.0 | 644 | 6.1757 |
| 2.2504 | 47.0 | 658 | 6.0801 |
| 2.25 | 48.0 | 672 | 6.1659 |
| 2.1047 | 49.0 | 686 | 6.1564 |
| 2.1563 | 50.0 | 700 | 6.2225 |
| 2.0882 | 51.0 | 714 | 6.2024 |
| 2.1818 | 52.0 | 728 | 6.1418 |
| 2.1141 | 53.0 | 742 | 6.2118 |
| 2.0647 | 54.0 | 756 | 6.2645 |
| 1.9779 | 55.0 | 770 | 6.3598 |
| 2.053 | 56.0 | 784 | 6.2241 |
| 1.9884 | 57.0 | 798 | 6.2838 |
| 1.8604 | 58.0 | 812 | 6.3798 |
| 1.882 | 59.0 | 826 | 6.3210 |
| 1.9414 | 60.0 | 840 | 6.3404 |
| 1.7435 | 61.0 | 854 | 6.3332 |
| 1.8813 | 62.0 | 868 | 6.3616 |
| 1.7517 | 63.0 | 882 | 6.4093 |
| 1.8046 | 64.0 | 896 | 6.4665 |
| 1.7258 | 65.0 | 910 | 6.4227 |
| 1.7862 | 66.0 | 924 | 6.3705 |
| 1.5828 | 67.0 | 938 | 6.5138 |
| 1.7249 | 68.0 | 952 | 6.4484 |
| 1.692 | 69.0 | 966 | 6.4739 |
| 1.575 | 70.0 | 980 | 6.4886 |
| 1.6542 | 71.0 | 994 | 6.4457 |
| 1.515 | 72.0 | 1008 | 6.5828 |
| 1.6127 | 73.0 | 1022 | 6.5665 |
| 1.6343 | 74.0 | 1036 | 6.5662 |
| 1.4653 | 75.0 | 1050 | 6.5909 |
| 1.5358 | 76.0 | 1064 | 6.5909 |
| 1.6009 | 77.0 | 1078 | 6.5865 |
| 1.5644 | 78.0 | 1092 | 6.5422 |
| 1.4766 | 79.0 | 1106 | 6.6528 |
| 1.4215 | 80.0 | 1120 | 6.6389 |
| 1.4787 | 81.0 | 1134 | 6.6737 |
| 1.4586 | 82.0 | 1148 | 6.6836 |
| 1.4559 | 83.0 | 1162 | 6.6922 |
| 1.4451 | 84.0 | 1176 | 6.6856 |
| 1.3502 | 85.0 | 1190 | 6.6594 |
| 1.3425 | 86.0 | 1204 | 6.6404 |
| 1.3091 | 87.0 | 1218 | 6.7316 |
| 1.3213 | 88.0 | 1232 | 6.7641 |
| 1.2274 | 89.0 | 1246 | 6.7828 |
| 1.247 | 90.0 | 1260 | 6.8646 |
| 1.3159 | 91.0 | 1274 | 6.7969 |
| 1.2061 | 92.0 | 1288 | 6.7785 |
| 1.214 | 93.0 | 1302 | 6.7910 |
| 1.2165 | 94.0 | 1316 | 6.9408 |
| 1.1849 | 95.0 | 1330 | 6.7925 |
| 1.1905 | 96.0 | 1344 | 6.8021 |
| 1.1714 | 97.0 | 1358 | 6.8445 |
| 1.1092 | 98.0 | 1372 | 6.8426 |
| 1.1682 | 99.0 | 1386 | 6.8331 |
| 1.1552 | 100.0 | 1400 | 6.8933 |
| 1.1374 | 101.0 | 1414 | 6.8102 |
| 1.1124 | 102.0 | 1428 | 6.8749 |
| 1.1017 | 103.0 | 1442 | 6.8993 |
| 1.0072 | 104.0 | 1456 | 6.8475 |
| 1.1771 | 105.0 | 1470 | 6.8908 |
| 1.0643 | 106.0 | 1484 | 6.8985 |
| 1.0038 | 107.0 | 1498 | 6.8714 |
| 0.9974 | 108.0 | 1512 | 6.9881 |
| 1.1195 | 109.0 | 1526 | 6.8764 |
| 0.9957 | 110.0 | 1540 | 6.9969 |
| 0.9766 | 111.0 | 1554 | 7.0525 |
| 0.9621 | 112.0 | 1568 | 6.9676 |
| 0.9562 | 113.0 | 1582 | 7.0268 |
| 0.9473 | 114.0 | 1596 | 6.9466 |
| 1.0357 | 115.0 | 1610 | 7.0968 |
| 0.9385 | 116.0 | 1624 | 7.0544 |
| 0.9579 | 117.0 | 1638 | 7.0054 |
| 0.9223 | 118.0 | 1652 | 7.0393 |
| 0.8862 | 119.0 | 1666 | 6.9770 |
| 0.9275 | 120.0 | 1680 | 7.0608 |
| 0.8642 | 121.0 | 1694 | 7.0661 |
| 0.8752 | 122.0 | 1708 | 7.0933 |
| 0.8687 | 123.0 | 1722 | 7.1004 |
| 0.8962 | 124.0 | 1736 | 7.0945 |
| 0.8157 | 125.0 | 1750 | 7.0379 |
| 0.903 | 126.0 | 1764 | 7.1082 |
| 0.9249 | 127.0 | 1778 | 7.0555 |
| 0.8624 | 128.0 | 1792 | 7.1230 |
| 0.7936 | 129.0 | 1806 | 7.1269 |
| 0.8292 | 130.0 | 1820 | 7.1401 |
| 0.7382 | 131.0 | 1834 | 7.1299 |
| 0.8284 | 132.0 | 1848 | 7.1820 |
| 0.7993 | 133.0 | 1862 | 7.2175 |
| 0.8493 | 134.0 | 1876 | 7.2064 |
| 0.8126 | 135.0 | 1890 | 7.1438 |
| 0.7831 | 136.0 | 1904 | 7.2746 |
| 0.8011 | 137.0 | 1918 | 7.2374 |
| 0.7512 | 138.0 | 1932 | 7.2725 |
| 0.7695 | 139.0 | 1946 | 7.2721 |
| 0.7216 | 140.0 | 1960 | 7.2482 |
| 0.744 | 141.0 | 1974 | 7.2467 |
| 0.7366 | 142.0 | 1988 | 7.2893 |
| 0.7214 | 143.0 | 2002 | 7.3204 |
| 0.7456 | 144.0 | 2016 | 7.2928 |
| 0.6891 | 145.0 | 2030 | 7.3215 |
| 0.6306 | 146.0 | 2044 | 7.2637 |
| 0.6763 | 147.0 | 2058 | 7.2491 |
| 0.6558 | 148.0 | 2072 | 7.3143 |
| 0.7562 | 149.0 | 2086 | 7.2424 |
| 0.7019 | 150.0 | 2100 | 7.2770 |
| 0.6251 | 151.0 | 2114 | 7.2743 |
| 0.6857 | 152.0 | 2128 | 7.3607 |
| 0.7037 | 153.0 | 2142 | 7.3243 |
| 0.6398 | 154.0 | 2156 | 7.3276 |
| 0.6231 | 155.0 | 2170 | 7.3595 |
| 0.6368 | 156.0 | 2184 | 7.4406 |
| 0.6653 | 157.0 | 2198 | 7.3381 |
| 0.6189 | 158.0 | 2212 | 7.3217 |
| 0.616 | 159.0 | 2226 | 7.3374 |
| 0.6029 | 160.0 | 2240 | 7.3500 |
| 0.6516 | 161.0 | 2254 | 7.3383 |
| 0.5725 | 162.0 | 2268 | 7.3815 |
| 0.6032 | 163.0 | 2282 | 7.3521 |
| 0.6228 | 164.0 | 2296 | 7.3883 |
| 0.5797 | 165.0 | 2310 | 7.4235 |
| 0.61 | 166.0 | 2324 | 7.4864 |
| 0.581 | 167.0 | 2338 | 7.4154 |
| 0.6213 | 168.0 | 2352 | 7.4857 |
| 0.5709 | 169.0 | 2366 | 7.4169 |
| 0.5898 | 170.0 | 2380 | 7.4947 |
| 0.5106 | 171.0 | 2394 | 7.4307 |
| 0.605 | 172.0 | 2408 | 7.4011 |
| 0.5613 | 173.0 | 2422 | 7.5032 |
| 0.5767 | 174.0 | 2436 | 7.4852 |
| 0.5344 | 175.0 | 2450 | 7.5135 |
| 0.5091 | 176.0 | 2464 | 7.4926 |
| 0.6127 | 177.0 | 2478 | 7.4273 |
| 0.5862 | 178.0 | 2492 | 7.4611 |
| 0.5571 | 179.0 | 2506 | 7.4977 |
| 0.496 | 180.0 | 2520 | 7.4286 |
| 0.5544 | 181.0 | 2534 | 7.4946 |
| 0.5686 | 182.0 | 2548 | 7.5279 |
| 0.5292 | 183.0 | 2562 | 7.5432 |
| 0.5372 | 184.0 | 2576 | 7.5062 |
| 0.5333 | 185.0 | 2590 | 7.6077 |
| 0.5574 | 186.0 | 2604 | 7.6172 |
| 0.5172 | 187.0 | 2618 | 7.5257 |
| 0.5379 | 188.0 | 2632 | 7.5016 |
| 0.513 | 189.0 | 2646 | 7.5428 |
| 0.5631 | 190.0 | 2660 | 7.5116 |
| 0.483 | 191.0 | 2674 | 7.5440 |
| 0.5084 | 192.0 | 2688 | 7.4654 |
| 0.4796 | 193.0 | 2702 | 7.4820 |
| 0.5265 | 194.0 | 2716 | 7.6189 |
| 0.4927 | 195.0 | 2730 | 7.6519 |
| 0.4656 | 196.0 | 2744 | 7.5037 |
| 0.5565 | 197.0 | 2758 | 7.5008 |
| 0.4415 | 198.0 | 2772 | 7.6129 |
| 0.4394 | 199.0 | 2786 | 7.6478 |
| 0.4704 | 200.0 | 2800 | 7.5704 |
| 0.4789 | 201.0 | 2814 | 7.5958 |
| 0.5131 | 202.0 | 2828 | 7.6163 |
| 0.4741 | 203.0 | 2842 | 7.6735 |
| 0.4602 | 204.0 | 2856 | 7.6717 |
| 0.4706 | 205.0 | 2870 | 7.6067 |
| 0.4978 | 206.0 | 2884 | 7.6456 |
| 0.5176 | 207.0 | 2898 | 7.6414 |
| 0.5036 | 208.0 | 2912 | 7.5815 |
| 0.4437 | 209.0 | 2926 | 7.6549 |
| 0.4844 | 210.0 | 2940 | 7.7083 |
| 0.4472 | 211.0 | 2954 | 7.6823 |
| 0.4604 | 212.0 | 2968 | 7.6570 |
| 0.4622 | 213.0 | 2982 | 7.7083 |
| 0.4588 | 214.0 | 2996 | 7.6794 |
| 0.4742 | 215.0 | 3010 | 7.6624 |
| 0.4447 | 216.0 | 3024 | 7.6996 |
| 0.4245 | 217.0 | 3038 | 7.6295 |
| 0.5189 | 218.0 | 3052 | 7.6853 |
| 0.4182 | 219.0 | 3066 | 7.6120 |
| 0.4294 | 220.0 | 3080 | 7.7448 |
| 0.4644 | 221.0 | 3094 | 7.6821 |
| 0.3955 | 222.0 | 3108 | 7.6801 |
| 0.4769 | 223.0 | 3122 | 7.7343 |
| 0.4138 | 224.0 | 3136 | 7.7135 |
| 0.3893 | 225.0 | 3150 | 7.7137 |
| 0.4479 | 226.0 | 3164 | 7.6837 |
| 0.4367 | 227.0 | 3178 | 7.6080 |
| 0.3846 | 228.0 | 3192 | 7.6737 |
| 0.4124 | 229.0 | 3206 | 7.7446 |
| 0.3533 | 230.0 | 3220 | 7.7186 |
| 0.4635 | 231.0 | 3234 | 7.6979 |
| 0.4096 | 232.0 | 3248 | 7.6931 |
| 0.4301 | 233.0 | 3262 | 7.6302 |
| 0.3656 | 234.0 | 3276 | 7.7928 |
| 0.4512 | 235.0 | 3290 | 7.8027 |
| 0.3671 | 236.0 | 3304 | 7.8594 |
| 0.3967 | 237.0 | 3318 | 7.7333 |
| 0.3829 | 238.0 | 3332 | 7.7669 |
| 0.3985 | 239.0 | 3346 | 7.7922 |
| 0.375 | 240.0 | 3360 | 7.8020 |
| 0.3425 | 241.0 | 3374 | 7.8508 |
| 0.4128 | 242.0 | 3388 | 7.7871 |
| 0.4449 | 243.0 | 3402 | 7.8075 |
| 0.4176 | 244.0 | 3416 | 7.7721 |
| 0.4145 | 245.0 | 3430 | 7.7644 |
| 0.4142 | 246.0 | 3444 | 7.8276 |
| 0.3336 | 247.0 | 3458 | 7.8112 |
| 0.3668 | 248.0 | 3472 | 7.8272 |
| 0.384 | 249.0 | 3486 | 7.7916 |
| 0.3873 | 250.0 | 3500 | 7.7770 |
| 0.4032 | 251.0 | 3514 | 7.7633 |
| 0.3166 | 252.0 | 3528 | 7.7615 |
| 0.3897 | 253.0 | 3542 | 7.7801 |
| 0.3916 | 254.0 | 3556 | 7.7710 |
| 0.3462 | 255.0 | 3570 | 7.8086 |
| 0.3705 | 256.0 | 3584 | 7.8322 |
| 0.3781 | 257.0 | 3598 | 7.7828 |
| 0.3466 | 258.0 | 3612 | 7.7830 |
| 0.3986 | 259.0 | 3626 | 7.8720 |
| 0.3335 | 260.0 | 3640 | 7.8438 |
| 0.3698 | 261.0 | 3654 | 7.8200 |
| 0.3715 | 262.0 | 3668 | 7.8205 |
| 0.3553 | 263.0 | 3682 | 7.8782 |
| 0.3664 | 264.0 | 3696 | 7.8409 |
| 0.3548 | 265.0 | 3710 | 7.8220 |
| 0.3671 | 266.0 | 3724 | 7.8378 |
| 0.3809 | 267.0 | 3738 | 7.8346 |
| 0.3595 | 268.0 | 3752 | 7.8602 |
| 0.317 | 269.0 | 3766 | 7.7957 |
| 0.3329 | 270.0 | 3780 | 7.8356 |
| 0.3097 | 271.0 | 3794 | 7.8749 |
| 0.3263 | 272.0 | 3808 | 7.8206 |
| 0.3278 | 273.0 | 3822 | 7.8923 |
| 0.3064 | 274.0 | 3836 | 7.8501 |
| 0.3066 | 275.0 | 3850 | 7.8099 |
| 0.3108 | 276.0 | 3864 | 7.9305 |
| 0.36 | 277.0 | 3878 | 7.8377 |
| 0.3743 | 278.0 | 3892 | 7.8080 |
| 0.3864 | 279.0 | 3906 | 7.8541 |
| 0.292 | 280.0 | 3920 | 7.9087 |
| 0.3183 | 281.0 | 3934 | 7.9080 |
| 0.343 | 282.0 | 3948 | 7.8776 |
| 0.35 | 283.0 | 3962 | 7.8961 |
| 0.3355 | 284.0 | 3976 | 7.8549 |
| 0.3684 | 285.0 | 3990 | 7.8964 |
| 0.3454 | 286.0 | 4004 | 7.9754 |
| 0.3496 | 287.0 | 4018 | 7.8902 |
| 0.3247 | 288.0 | 4032 | 7.9092 |
| 0.2945 | 289.0 | 4046 | 7.9472 |
| 0.3456 | 290.0 | 4060 | 8.0057 |
| 0.4058 | 291.0 | 4074 | 7.9345 |
| 0.3198 | 292.0 | 4088 | 7.9976 |
| 0.3459 | 293.0 | 4102 | 7.9268 |
| 0.3084 | 294.0 | 4116 | 7.8680 |
| 0.2868 | 295.0 | 4130 | 7.8889 |
| 0.2909 | 296.0 | 4144 | 7.9068 |
| 0.3799 | 297.0 | 4158 | 7.9200 |
| 0.3316 | 298.0 | 4172 | 7.9104 |
| 0.3012 | 299.0 | 4186 | 7.8893 |
| 0.309 | 300.0 | 4200 | 7.9324 |
| 0.2663 | 301.0 | 4214 | 7.8847 |
| 0.2809 | 302.0 | 4228 | 7.9753 |
| 0.2871 | 303.0 | 4242 | 7.9208 |
| 0.2717 | 304.0 | 4256 | 7.8918 |
| 0.2871 | 305.0 | 4270 | 7.9883 |
| 0.2763 | 306.0 | 4284 | 7.9588 |
| 0.3047 | 307.0 | 4298 | 7.9780 |
| 0.3463 | 308.0 | 4312 | 7.9802 |
| 0.3279 | 309.0 | 4326 | 7.9799 |
| 0.3224 | 310.0 | 4340 | 7.9768 |
| 0.2568 | 311.0 | 4354 | 7.9846 |
| 0.3027 | 312.0 | 4368 | 7.9537 |
| 0.2415 | 313.0 | 4382 | 7.9870 |
| 0.3115 | 314.0 | 4396 | 7.9839 |
| 0.3022 | 315.0 | 4410 | 7.9722 |
| 0.2975 | 316.0 | 4424 | 7.9705 |
| 0.2944 | 317.0 | 4438 | 8.0632 |
| 0.3164 | 318.0 | 4452 | 8.0619 |
| 0.2764 | 319.0 | 4466 | 7.9667 |
| 0.2558 | 320.0 | 4480 | 8.0001 |
| 0.274 | 321.0 | 4494 | 7.9672 |
| 0.3069 | 322.0 | 4508 | 8.0369 |
| 0.2984 | 323.0 | 4522 | 8.0224 |
| 0.2944 | 324.0 | 4536 | 8.0200 |
| 0.2889 | 325.0 | 4550 | 8.0656 |
| 0.2596 | 326.0 | 4564 | 7.9612 |
| 0.2624 | 327.0 | 4578 | 7.9776 |
| 0.2851 | 328.0 | 4592 | 8.0496 |
| 0.2821 | 329.0 | 4606 | 8.0301 |
| 0.3091 | 330.0 | 4620 | 8.0032 |
| 0.2426 | 331.0 | 4634 | 7.9657 |
| 0.2867 | 332.0 | 4648 | 7.9114 |
| 0.2757 | 333.0 | 4662 | 8.0189 |
| 0.2671 | 334.0 | 4676 | 8.0285 |
| 0.2651 | 335.0 | 4690 | 8.0251 |
| 0.2544 | 336.0 | 4704 | 8.0092 |
| 0.2842 | 337.0 | 4718 | 8.0765 |
| 0.2548 | 338.0 | 4732 | 8.0409 |
| 0.2953 | 339.0 | 4746 | 8.0289 |
| 0.2814 | 340.0 | 4760 | 8.0667 |
| 0.2605 | 341.0 | 4774 | 8.0425 |
| 0.2701 | 342.0 | 4788 | 8.0451 |
| 0.2279 | 343.0 | 4802 | 8.0257 |
| 0.2348 | 344.0 | 4816 | 8.0239 |
| 0.264 | 345.0 | 4830 | 8.0553 |
| 0.2533 | 346.0 | 4844 | 8.0384 |
| 0.25 | 347.0 | 4858 | 8.0648 |
| 0.2515 | 348.0 | 4872 | 8.0934 |
| 0.2235 | 349.0 | 4886 | 8.0480 |
| 0.2289 | 350.0 | 4900 | 8.0747 |
| 0.3048 | 351.0 | 4914 | 8.0854 |
| 0.2463 | 352.0 | 4928 | 8.0728 |
| 0.2984 | 353.0 | 4942 | 8.0424 |
| 0.2718 | 354.0 | 4956 | 8.0761 |
| 0.2761 | 355.0 | 4970 | 8.0684 |
| 0.2347 | 356.0 | 4984 | 8.0769 |
| 0.2683 | 357.0 | 4998 | 8.0191 |
| 0.2837 | 358.0 | 5012 | 8.0605 |
| 0.2623 | 359.0 | 5026 | 8.0554 |
| 0.2581 | 360.0 | 5040 | 8.0864 |
| 0.3162 | 361.0 | 5054 | 8.1435 |
| 0.2388 | 362.0 | 5068 | 8.0557 |
| 0.236 | 363.0 | 5082 | 8.1043 |
| 0.2668 | 364.0 | 5096 | 8.1299 |
| 0.2559 | 365.0 | 5110 | 8.1116 |
| 0.2523 | 366.0 | 5124 | 8.0916 |
| 0.2719 | 367.0 | 5138 | 8.0192 |
| 0.289 | 368.0 | 5152 | 8.1314 |
| 0.237 | 369.0 | 5166 | 8.0493 |
| 0.2401 | 370.0 | 5180 | 8.1385 |
| 0.2905 | 371.0 | 5194 | 8.2075 |
| 0.2806 | 372.0 | 5208 | 8.1328 |
| 0.2986 | 373.0 | 5222 | 8.1489 |
| 0.27 | 374.0 | 5236 | 8.0748 |
| 0.2365 | 375.0 | 5250 | 8.1267 |
| 0.2532 | 376.0 | 5264 | 8.1494 |
| 0.2142 | 377.0 | 5278 | 8.1415 |
| 0.2288 | 378.0 | 5292 | 8.1203 |
| 0.2425 | 379.0 | 5306 | 8.1433 |
| 0.2443 | 380.0 | 5320 | 8.1238 |
| 0.2516 | 381.0 | 5334 | 8.1401 |
| 0.2083 | 382.0 | 5348 | 8.1223 |
| 0.2525 | 383.0 | 5362 | 8.1361 |
| 0.2558 | 384.0 | 5376 | 8.0958 |
| 0.2491 | 385.0 | 5390 | 8.0831 |
| 0.2898 | 386.0 | 5404 | 8.0593 |
| 0.2361 | 387.0 | 5418 | 8.1167 |
| 0.2466 | 388.0 | 5432 | 8.1083 |
| 0.2386 | 389.0 | 5446 | 8.0997 |
| 0.2985 | 390.0 | 5460 | 8.1217 |
| 0.2219 | 391.0 | 5474 | 8.1535 |
| 0.2509 | 392.0 | 5488 | 8.1498 |
| 0.24 | 393.0 | 5502 | 8.1509 |
| 0.2282 | 394.0 | 5516 | 8.2027 |
| 0.2141 | 395.0 | 5530 | 8.1303 |
| 0.2306 | 396.0 | 5544 | 8.1602 |
| 0.2406 | 397.0 | 5558 | 8.1269 |
| 0.2253 | 398.0 | 5572 | 8.0594 |
| 0.2648 | 399.0 | 5586 | 8.1279 |
| 0.2293 | 400.0 | 5600 | 8.0930 |
| 0.2429 | 401.0 | 5614 | 8.1050 |
| 0.2143 | 402.0 | 5628 | 8.1141 |
| 0.2052 | 403.0 | 5642 | 8.1325 |
| 0.222 | 404.0 | 5656 | 8.1627 |
| 0.2076 | 405.0 | 5670 | 8.1566 |
| 0.244 | 406.0 | 5684 | 8.0679 |
| 0.2245 | 407.0 | 5698 | 8.0288 |
| 0.1934 | 408.0 | 5712 | 8.0412 |
| 0.2669 | 409.0 | 5726 | 8.0897 |
| 0.2427 | 410.0 | 5740 | 8.1550 |
| 0.2496 | 411.0 | 5754 | 8.1105 |
| 0.1992 | 412.0 | 5768 | 8.1120 |
| 0.2154 | 413.0 | 5782 | 8.1502 |
| 0.2344 | 414.0 | 5796 | 8.1257 |
| 0.2151 | 415.0 | 5810 | 8.1625 |
| 0.212 | 416.0 | 5824 | 8.1495 |
| 0.2031 | 417.0 | 5838 | 8.1356 |
| 0.2599 | 418.0 | 5852 | 8.2282 |
| 0.1984 | 419.0 | 5866 | 8.1940 |
| 0.2838 | 420.0 | 5880 | 8.1552 |
| 0.2143 | 421.0 | 5894 | 8.1256 |
| 0.2308 | 422.0 | 5908 | 8.1128 |
| 0.2479 | 423.0 | 5922 | 8.1015 |
| 0.2517 | 424.0 | 5936 | 8.1913 |
| 0.1897 | 425.0 | 5950 | 8.1807 |
| 0.2432 | 426.0 | 5964 | 8.1400 |
| 0.2508 | 427.0 | 5978 | 8.1429 |
| 0.2411 | 428.0 | 5992 | 8.1560 |
| 0.2125 | 429.0 | 6006 | 8.1515 |
| 0.2201 | 430.0 | 6020 | 8.1448 |
| 0.2017 | 431.0 | 6034 | 8.1316 |
| 0.2191 | 432.0 | 6048 | 8.1408 |
| 0.2201 | 433.0 | 6062 | 8.1918 |
| 0.243 | 434.0 | 6076 | 8.2030 |
| 0.2523 | 435.0 | 6090 | 8.1573 |
| 0.1696 | 436.0 | 6104 | 8.1757 |
| 0.1939 | 437.0 | 6118 | 8.1383 |
| 0.2103 | 438.0 | 6132 | 8.1768 |
| 0.1882 | 439.0 | 6146 | 8.1340 |
| 0.2183 | 440.0 | 6160 | 8.1488 |
| 0.2005 | 441.0 | 6174 | 8.2002 |
| 0.229 | 442.0 | 6188 | 8.1437 |
| 0.1998 | 443.0 | 6202 | 8.1717 |
| 0.2387 | 444.0 | 6216 | 8.1613 |
| 0.1886 | 445.0 | 6230 | 8.2194 |
| 0.2324 | 446.0 | 6244 | 8.1381 |
| 0.1908 | 447.0 | 6258 | 8.1834 |
| 0.1912 | 448.0 | 6272 | 8.1746 |
| 0.2274 | 449.0 | 6286 | 8.1759 |
| 0.2375 | 450.0 | 6300 | 8.1489 |
| 0.2202 | 451.0 | 6314 | 8.1356 |
| 0.241 | 452.0 | 6328 | 8.1379 |
| 0.2078 | 453.0 | 6342 | 8.1447 |
| 0.2368 | 454.0 | 6356 | 8.1741 |
| 0.1857 | 455.0 | 6370 | 8.1927 |
| 0.1854 | 456.0 | 6384 | 8.1514 |
| 0.1726 | 457.0 | 6398 | 8.0745 |
| 0.181 | 458.0 | 6412 | 8.1332 |
| 0.2198 | 459.0 | 6426 | 8.1616 |
| 0.2014 | 460.0 | 6440 | 8.1878 |
| 0.2341 | 461.0 | 6454 | 8.2081 |
| 0.1932 | 462.0 | 6468 | 8.1799 |
| 0.1867 | 463.0 | 6482 | 8.1591 |
| 0.2366 | 464.0 | 6496 | 8.1363 |
| 0.2169 | 465.0 | 6510 | 8.2088 |
| 0.2248 | 466.0 | 6524 | 8.1332 |
| 0.1948 | 467.0 | 6538 | 8.1625 |
| 0.1834 | 468.0 | 6552 | 8.1572 |
| 0.254 | 469.0 | 6566 | 8.1402 |
| 0.2015 | 470.0 | 6580 | 8.0961 |
| 0.2295 | 471.0 | 6594 | 8.1255 |
| 0.1892 | 472.0 | 6608 | 8.1812 |
| 0.1939 | 473.0 | 6622 | 8.1552 |
| 0.2081 | 474.0 | 6636 | 8.1145 |
| 0.2032 | 475.0 | 6650 | 8.1686 |
| 0.1844 | 476.0 | 6664 | 8.1529 |
| 0.2436 | 477.0 | 6678 | 8.1436 |
| 0.2618 | 478.0 | 6692 | 8.1719 |
| 0.1845 | 479.0 | 6706 | 8.0935 |
| 0.1955 | 480.0 | 6720 | 8.1796 |
| 0.2116 | 481.0 | 6734 | 8.1296 |
| 0.2261 | 482.0 | 6748 | 8.1882 |
| 0.2057 | 483.0 | 6762 | 8.1474 |
| 0.2117 | 484.0 | 6776 | 8.1679 |
| 0.1901 | 485.0 | 6790 | 8.1736 |
| 0.2001 | 486.0 | 6804 | 8.1548 |
| 0.2016 | 487.0 | 6818 | 8.1237 |
| 0.1444 | 488.0 | 6832 | 8.1330 |
| 0.1707 | 489.0 | 6846 | 8.1509 |
| 0.1731 | 490.0 | 6860 | 8.1368 |
| 0.2358 | 491.0 | 6874 | 8.1815 |
| 0.2013 | 492.0 | 6888 | 8.1404 |
| 0.2101 | 493.0 | 6902 | 8.1702 |
| 0.1833 | 494.0 | 6916 | 8.1405 |
| 0.2173 | 495.0 | 6930 | 8.1338 |
| 0.2011 | 496.0 | 6944 | 8.1291 |
| 0.1824 | 497.0 | 6958 | 8.1452 |
| 0.2303 | 498.0 | 6972 | 8.1726 |
| 0.2131 | 499.0 | 6986 | 8.1510 |
| 0.2012 | 500.0 | 7000 | 8.1664 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Billwzl/roberta-base-IMDB_roberta
|
Billwzl
| 2022-08-17T15:03:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-17T14:27:12Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-IMDB_roberta
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-IMDB_roberta
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1897
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.7882 | 1.0 | 1250 | 2.4751 |
| 2.5749 | 2.0 | 2500 | 2.4183 |
| 2.4501 | 3.0 | 3750 | 2.3799 |
| 2.3697 | 4.0 | 5000 | 2.3792 |
| 2.3187 | 5.0 | 6250 | 2.3622 |
| 2.24 | 6.0 | 7500 | 2.3491 |
| 2.164 | 7.0 | 8750 | 2.3146 |
| 2.1187 | 8.0 | 10000 | 2.2804 |
| 2.0552 | 9.0 | 11250 | 2.2629 |
| 2.0285 | 10.0 | 12500 | 2.2088 |
| 1.9807 | 11.0 | 13750 | 2.2061 |
| 1.9597 | 12.0 | 15000 | 2.2094 |
| 1.9062 | 13.0 | 16250 | 2.1486 |
| 1.8766 | 14.0 | 17500 | 2.1348 |
| 1.8528 | 15.0 | 18750 | 2.1665 |
| 1.8425 | 16.0 | 20000 | 2.1897 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
florentgbelidji/blip_image_embeddings
|
florentgbelidji
| 2022-08-17T14:20:47Z | 0 | 13 |
generic
|
[
"generic",
"feature-extraction",
"endpoints-template",
"license:bsd-3-clause",
"region:us"
] |
feature-extraction
| 2022-08-16T20:18:21Z |
---
tags:
- feature-extraction
- endpoints-template
license: bsd-3-clause
library_name: generic
---
# Fork of [salesforce/BLIP](https://github.com/salesforce/BLIP) for a `feature-extraction` task on 🤗Inference endpoint.
This repository implements a `custom` task for `feature-extraction` for 🤗 Inference Endpoints. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/florentgbelidji/blip-embeddings/blob/main/pipeline.py).
To use deploy this model a an Inference Endpoint you have to select `Custom` as task to use the `pipeline.py` file. -> _double check if it is selected_
### expected Request payload
```json
{
"image": "/9j/4AAQSkZJRgABAQEBLAEsAAD/2wBDAAMCAgICAgMC....", // base64 image as bytes
}
```
below is an example on how to run a request using Python and `requests`.
## Run Request
1. prepare an image.
```bash
!wget https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
```
2.run request
```python
import json
from typing import List
import requests as r
import base64
ENDPOINT_URL = ""
HF_TOKEN = ""
def predict(path_to_image: str = None):
with open(path_to_image, "rb") as i:
b64 = base64.b64encode(i.read())
payload = {"inputs": {"image": b64.decode("utf-8")}}
response = r.post(
ENDPOINT_URL, headers={"Authorization": f"Bearer {HF_TOKEN}"}, json=payload
)
return response.json()
prediction = predict(
path_to_image="palace.jpg"
)
```
expected output
```python
{'feature_vector': [0.016450975090265274,
-0.5551009774208069,
0.39800673723220825,
-0.6809228658676147,
2.053842782974243,
-0.4712907075881958,...]
}
```
|
NitishKumar/distilbert-base-uncased-finetuned-squad
|
NitishKumar
| 2022-08-17T13:42:04Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-12T06:45:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9423
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 65 | 3.3894 |
| No log | 2.0 | 130 | 3.0268 |
| No log | 3.0 | 195 | 2.9423 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Satoshi-ONOUE/distilbert-base-uncased-finetuned-clinc
|
Satoshi-ONOUE
| 2022-08-17T13:26:15Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-17T13:08:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
config: plus
split: train
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9148387096774193
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7720
- Accuracy: 0.9148
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2942 | 1.0 | 318 | 3.2870 | 0.7539 |
| 2.6283 | 2.0 | 636 | 1.8724 | 0.8368 |
| 1.5478 | 3.0 | 954 | 1.1554 | 0.8961 |
| 1.0103 | 4.0 | 1272 | 0.8562 | 0.9113 |
| 0.7956 | 5.0 | 1590 | 0.7720 | 0.9148 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
muhtasham/bert-small-finetuned-xglue-ner-longer50
|
muhtasham
| 2022-08-17T13:22:45Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T13:11:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-small-finetuned-xglue-ner-longer50
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: train
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.6182136602451839
- name: Recall
type: recall
value: 0.4222488038277512
- name: F1
type: f1
value: 0.5017768301350392
- name: Accuracy
type: accuracy
value: 0.9252207821997935
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-xglue-ner-longer50
This model is a fine-tuned version of [muhtasham/bert-small-finetuned-xglue-ner-longer20](https://huggingface.co/muhtasham/bert-small-finetuned-xglue-ner-longer20) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7236
- Precision: 0.6182
- Recall: 0.4222
- F1: 0.5018
- Accuracy: 0.9252
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 425 | 0.5693 | 0.5232 | 0.4581 | 0.4885 | 0.9268 |
| 0.0032 | 2.0 | 850 | 0.6191 | 0.5281 | 0.4498 | 0.4858 | 0.9260 |
| 0.0035 | 3.0 | 1275 | 0.7045 | 0.6011 | 0.4055 | 0.4843 | 0.9241 |
| 0.0056 | 4.0 | 1700 | 0.6715 | 0.5571 | 0.4438 | 0.4940 | 0.9261 |
| 0.004 | 5.0 | 2125 | 0.6537 | 0.5645 | 0.4294 | 0.4878 | 0.9256 |
| 0.0063 | 6.0 | 2550 | 0.6646 | 0.5659 | 0.4211 | 0.4829 | 0.9255 |
| 0.0063 | 7.0 | 2975 | 0.6269 | 0.5306 | 0.4354 | 0.4783 | 0.9238 |
| 0.003 | 8.0 | 3400 | 0.7235 | 0.5921 | 0.3959 | 0.4746 | 0.9238 |
| 0.0051 | 9.0 | 3825 | 0.6334 | 0.5330 | 0.4450 | 0.4850 | 0.9237 |
| 0.0047 | 10.0 | 4250 | 0.6408 | 0.5893 | 0.4462 | 0.5078 | 0.9271 |
| 0.004 | 11.0 | 4675 | 0.6721 | 0.5840 | 0.4282 | 0.4941 | 0.9255 |
| 0.0051 | 12.0 | 5100 | 0.6853 | 0.5795 | 0.4318 | 0.4949 | 0.9258 |
| 0.0038 | 13.0 | 5525 | 0.6870 | 0.5789 | 0.4211 | 0.4875 | 0.9249 |
| 0.0038 | 14.0 | 5950 | 0.6931 | 0.6032 | 0.4091 | 0.4875 | 0.9241 |
| 0.0033 | 15.0 | 6375 | 0.6502 | 0.5965 | 0.4510 | 0.5136 | 0.9266 |
| 0.0032 | 16.0 | 6800 | 0.6941 | 0.6126 | 0.4426 | 0.5139 | 0.9267 |
| 0.0042 | 17.0 | 7225 | 0.6603 | 0.5856 | 0.4462 | 0.5064 | 0.9266 |
| 0.0016 | 18.0 | 7650 | 0.6870 | 0.6121 | 0.4474 | 0.5169 | 0.9273 |
| 0.0028 | 19.0 | 8075 | 0.6922 | 0.5906 | 0.4366 | 0.5021 | 0.9250 |
| 0.0023 | 20.0 | 8500 | 0.7096 | 0.6089 | 0.4246 | 0.5004 | 0.9250 |
| 0.0023 | 21.0 | 8925 | 0.6763 | 0.5772 | 0.4426 | 0.5010 | 0.9261 |
| 0.0025 | 22.0 | 9350 | 0.6880 | 0.5696 | 0.4258 | 0.4873 | 0.9241 |
| 0.0018 | 23.0 | 9775 | 0.6759 | 0.5836 | 0.4426 | 0.5034 | 0.9259 |
| 0.0017 | 24.0 | 10200 | 0.7044 | 0.6198 | 0.4270 | 0.5057 | 0.9262 |
| 0.0018 | 25.0 | 10625 | 0.6948 | 0.6040 | 0.4306 | 0.5028 | 0.9245 |
| 0.0018 | 26.0 | 11050 | 0.6930 | 0.5948 | 0.4354 | 0.5028 | 0.9255 |
| 0.0018 | 27.0 | 11475 | 0.7077 | 0.6048 | 0.4246 | 0.4989 | 0.9250 |
| 0.0023 | 28.0 | 11900 | 0.7127 | 0.6103 | 0.4270 | 0.5025 | 0.9252 |
| 0.0013 | 29.0 | 12325 | 0.7253 | 0.6243 | 0.4234 | 0.5046 | 0.9254 |
| 0.0015 | 30.0 | 12750 | 0.7236 | 0.6182 | 0.4222 | 0.5018 | 0.9252 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
muhtasham/bert-small-finetuned-xglue-ner-longer10
|
muhtasham
| 2022-08-17T12:55:06Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T12:49:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-small-finetuned-xglue-ner-longer10
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: train
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5436746987951807
- name: Recall
type: recall
value: 0.4318181818181818
- name: F1
type: f1
value: 0.48133333333333334
- name: Accuracy
type: accuracy
value: 0.9250487441220323
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-xglue-ner-longer10
This model is a fine-tuned version of [muhtasham/bert-small-finetuned-xglue-ner-longer6](https://huggingface.co/muhtasham/bert-small-finetuned-xglue-ner-longer6) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4645
- Precision: 0.5437
- Recall: 0.4318
- F1: 0.4813
- Accuracy: 0.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 425 | 0.4872 | 0.6164 | 0.3959 | 0.4822 | 0.9253 |
| 0.0385 | 2.0 | 850 | 0.4528 | 0.5512 | 0.4246 | 0.4797 | 0.9256 |
| 0.0317 | 3.0 | 1275 | 0.4638 | 0.5431 | 0.4294 | 0.4796 | 0.9246 |
| 0.0308 | 4.0 | 1700 | 0.4645 | 0.5437 | 0.4318 | 0.4813 | 0.9250 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bthomas/article2KW_test1.1_barthez-orangesum-title_finetuned_for_summerization
|
bthomas
| 2022-08-17T12:31:21Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-17T12:04:54Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: article2KW_test1.1_barthez-orangesum-title_finetuned_for_summerization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article2KW_test1.1_barthez-orangesum-title_finetuned_for_summerization
This model is a fine-tuned version of [moussaKam/barthez-orangesum-title](https://huggingface.co/moussaKam/barthez-orangesum-title) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0775
- Rouge1: 0.2800
- Rouge2: 0.0762
- Rougel: 0.2806
- Rougelsum: 0.2803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 1.6345 | 1.0 | 1996 | 1.3251 | 0.2815 | 0.0739 | 0.2816 | 0.2819 |
| 1.2016 | 2.0 | 3992 | 1.1740 | 0.2836 | 0.0727 | 0.2837 | 0.2838 |
| 1.0307 | 3.0 | 5988 | 1.1094 | 0.2874 | 0.0846 | 0.2879 | 0.2877 |
| 0.923 | 4.0 | 7984 | 1.0775 | 0.2800 | 0.0762 | 0.2806 | 0.2803 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.11.0
|
muhtasham/bert-small-finetuned-wnut17-ner-longer10
|
muhtasham
| 2022-08-17T12:27:27Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T12:22:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-small-finetuned-wnut17-ner-longer10
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: train
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5546995377503852
- name: Recall
type: recall
value: 0.430622009569378
- name: F1
type: f1
value: 0.48484848484848486
- name: Accuracy
type: accuracy
value: 0.9250487441220323
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-wnut17-ner-longer10
This model is a fine-tuned version of [muhtasham/bert-small-finetuned-wnut17-ner-longer6](https://huggingface.co/muhtasham/bert-small-finetuned-wnut17-ner-longer6) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4693
- Precision: 0.5547
- Recall: 0.4306
- F1: 0.4848
- Accuracy: 0.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 425 | 0.4815 | 0.5759 | 0.3947 | 0.4684 | 0.9255 |
| 0.0402 | 2.0 | 850 | 0.4467 | 0.5397 | 0.4390 | 0.4842 | 0.9247 |
| 0.0324 | 3.0 | 1275 | 0.4646 | 0.5332 | 0.4318 | 0.4772 | 0.9244 |
| 0.0315 | 4.0 | 1700 | 0.4693 | 0.5547 | 0.4306 | 0.4848 | 0.9250 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Jethuestad/distilbert-base-uncased-test2
|
Jethuestad
| 2022-08-17T12:23:54Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T12:22:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-test2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: train
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5278121137206427
- name: Recall
type: recall
value: 0.3957367933271548
- name: F1
type: f1
value: 0.4523305084745763
- name: Accuracy
type: accuracy
value: 0.9461758796118165
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-test2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3055
- Precision: 0.5278
- Recall: 0.3957
- F1: 0.4523
- Accuracy: 0.9462
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2889 | 0.5439 | 0.3503 | 0.4262 | 0.9453 |
| No log | 2.0 | 426 | 0.2938 | 0.5236 | 0.3800 | 0.4404 | 0.9457 |
| 0.0544 | 3.0 | 639 | 0.3055 | 0.5278 | 0.3957 | 0.4523 | 0.9462 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
muhtasham/bert-small-finetuned-wnut17-ner-longer6
|
muhtasham
| 2022-08-17T12:21:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T12:16:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-small-finetuned-wnut17-ner-longer6
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: train
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5666666666666667
- name: Recall
type: recall
value: 0.4270334928229665
- name: F1
type: f1
value: 0.4870395634379263
- name: Accuracy
type: accuracy
value: 0.9267691248996445
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-wnut17-ner-longer6
This model is a fine-tuned version of [muhtasham/bert-small-finetuned-wnut17-ner](https://huggingface.co/muhtasham/bert-small-finetuned-wnut17-ner) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4037
- Precision: 0.5667
- Recall: 0.4270
- F1: 0.4870
- Accuracy: 0.9268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 425 | 0.3744 | 0.5626 | 0.4139 | 0.4769 | 0.9248 |
| 0.085 | 2.0 | 850 | 0.3914 | 0.5814 | 0.4270 | 0.4924 | 0.9271 |
| 0.0652 | 3.0 | 1275 | 0.4037 | 0.5667 | 0.4270 | 0.4870 | 0.9268 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
K-Kemna/pyramidsrnd
|
K-Kemna
| 2022-08-17T12:05:55Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-08-17T12:05:47Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: K-Kemna/pyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
huggingtweets/apesahoy-discoelysiumbot-jzux
|
huggingtweets
| 2022-08-17T12:03:03Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-17T12:01:42Z |
---
language: en
thumbnail: http://www.huggingtweets.com/apesahoy-discoelysiumbot-jzux/1660737778768/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1196519479364268034/5QpniWSP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1384356575410675713/xQvAaofk_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1304589362051645441/Yo_o5yi5_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Humongous Ape MP & disco elysium quotes & trash jones</div>
<div style="text-align: center; font-size: 14px;">@apesahoy-discoelysiumbot-jzux</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Humongous Ape MP & disco elysium quotes & trash jones.
| Data | Humongous Ape MP | disco elysium quotes | trash jones |
| --- | --- | --- | --- |
| Tweets downloaded | 3246 | 3250 | 3233 |
| Retweets | 198 | 0 | 615 |
| Short tweets | 610 | 20 | 280 |
| Tweets kept | 2438 | 3230 | 2338 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/28ibo0tz/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @apesahoy-discoelysiumbot-jzux's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2kccyxxh) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2kccyxxh/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/apesahoy-discoelysiumbot-jzux')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Manirathinam21/DistilBert_SMSSpam_classifier
|
Manirathinam21
| 2022-08-17T11:10:56Z | 10 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-16T15:20:00Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Manirathinam21/DistilBert_SMSSpam_classifier
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Manirathinam21/DistilBert_SMSSpam_classifier
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an SMSSpam Detection dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0114
- Train Accuracy: 0.9962
- Epoch: 2
## Target Labels
label: a classification label, with possible values including
- Ham : 0
- Spam : 1
## Model description
Tokenizer used is DistilBertTokenizerFast with return_tensors='tf' parameter in tokenizer because building model in a tensorflow framework
Model: TFDistilBertForSequenceClassification
Optimizer: Adam with learning rate=5e-5
Loss: SparseCategoricalCrossentropy
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
After Tokenized, Encoded datasets are converted to Dataset Objects by using tf.data.Dataset.from_tensor_slices((dict(train_encoding), train_y))
This step is done to inject a dataset into TFModel in a specific TF format
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Epoch |
|:----------:|:--------------:|:-----:|
| 0.0754 | 0.9803 | 0 |
| 0.0252 | 0.9935 | 1 |
| 0.0114 | 0.9962 | 2 |
### Framework versions
- Transformers 4.21.1
- TensorFlow 2.8.2
- Tokenizers 0.12.1
|
BekirTaha/a2c-AntBulletEnv-v0
|
BekirTaha
| 2022-08-17T10:29:47Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-17T10:28:30Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 1262.30 +/- 40.05
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bthomas/article2KW_test1_barthez-orangesum-title_finetuned_for_summurization
|
bthomas
| 2022-08-17T10:24:38Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-17T09:54:34Z |
---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: article2KW_test1_barthez-orangesum-title_finetuned_for_summurization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article2KW_test1_barthez-orangesum-title_finetuned_for_summurization
This model is a fine-tuned version of [moussaKam/barthez-orangesum-title](https://huggingface.co/moussaKam/barthez-orangesum-title) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2895
- Rouge1: 0.2048
- Rouge2: 0.0600
- Rougel: 0.2053
- Rougelsum: 0.2057
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| 0.4512 | 1.0 | 3368 | 0.3433 | 0.2030 | 0.0642 | 0.2037 | 0.2033 |
| 0.3162 | 2.0 | 6736 | 0.3051 | 0.2109 | 0.0681 | 0.2110 | 0.2111 |
| 0.264 | 3.0 | 10104 | 0.2895 | 0.2048 | 0.0600 | 0.2053 | 0.2057 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.11.0
|
Jungwoo4021/wav2vec2-base-ks-ept4
|
Jungwoo4021
| 2022-08-17T09:36:31Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"text-classification",
"audio-classification",
"generated_from_trainer",
"dataset:superb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-08-17T08:47:07Z |
---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- superb
metrics:
- accuracy
model-index:
- name: wav2vec2-base-ks-ept4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-ks-ept4
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5663
- Accuracy: 0.6209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 256
- eval_batch_size: 256
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5133 | 1.0 | 50 | 1.5663 | 0.6209 |
| 1.4819 | 2.0 | 100 | 1.5675 | 0.6169 |
| 1.4082 | 3.0 | 150 | 1.5372 | 0.5802 |
| 1.3536 | 4.0 | 200 | 1.6716 | 0.5338 |
| 1.296 | 5.0 | 250 | 1.7601 | 0.5399 |
| 1.3053 | 6.0 | 300 | 1.6778 | 0.5630 |
| 1.2734 | 7.0 | 350 | 1.6554 | 0.5734 |
| 1.2837 | 8.0 | 400 | 1.7338 | 0.5741 |
| 1.2682 | 9.0 | 450 | 1.7313 | 0.5774 |
| 1.2776 | 10.0 | 500 | 1.7083 | 0.5791 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.11.0+cu115
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Nikuson/ddpm-butterflies-128
|
Nikuson
| 2022-08-17T09:31:56Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-17T08:18:28Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Nikuson/ddpm-butterflies-128/tensorboard?#scalars)
|
AliMMZ/second_RL
|
AliMMZ
| 2022-08-17T09:02:04Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-07-18T16:09:41Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: second_RL
results:
- metrics:
- type: mean_reward
value: 0.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="AliMMZ/second_RL", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Lvxue/distilled-mt5-small-b0.02
|
Lvxue
| 2022-08-17T08:59:01Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-17T07:43:05Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-b0.02
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 7.632
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-b0.02
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8126
- Bleu: 7.632
- Gen Len: 45.006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/distilled-mt5-small-b1.5
|
Lvxue
| 2022-08-17T08:58:36Z | 21 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-17T07:48:45Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-b1.5
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 7.5422
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-b1.5
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7938
- Bleu: 7.5422
- Gen Len: 44.3267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/distilled-mt5-small-b0.75
|
Lvxue
| 2022-08-17T08:52:06Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"en",
"ro",
"dataset:wmt16",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-17T07:47:52Z |
---
language:
- en
- ro
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wmt16
metrics:
- bleu
model-index:
- name: distilled-mt5-small-b0.75
results:
- task:
name: Translation
type: translation
dataset:
name: wmt16 ro-en
type: wmt16
args: ro-en
metrics:
- name: Bleu
type: bleu
value: 7.4601
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-b0.75
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8013
- Bleu: 7.4601
- Gen Len: 44.2356
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Langboat/mengzi-t5-base-mt
|
Langboat
| 2022-08-17T08:23:54Z | 36 | 17 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"zh",
"arxiv:2110.06696",
"doi:10.57967/hf/0026",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-07-27T09:13:27Z |
---
language:
- zh
license: apache-2.0
widget:
- text: "“房间很一般,小,且让人感觉脏,隔音效果差,能听到走廊的人讲话,走廊光线昏暗,旁边没有什么可吃” 这条评论的态度是什么?"
---
# Mengzi-T5-MT model
This is a Multi-Task model trained on the multitask mixture of 27 datasets and 301 prompts, based on [Mengzi-T5-base](https://huggingface.co/Langboat/mengzi-t5-base).
[Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese](https://arxiv.org/abs/2110.06696)
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("Langboat/mengzi-t5-base-mt")
model = T5ForConditionalGeneration.from_pretrained("Langboat/mengzi-t5-base-mt")
```
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
```
@misc{zhang2021mengzi,
title={Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese},
author={Zhuosheng Zhang and Hanqing Zhang and Keming Chen and Yuhang Guo and Jingyun Hua and Yulong Wang and Ming Zhou},
year={2021},
eprint={2110.06696},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.