
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-04 18:27:43
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 539
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-04 18:27:26
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
bhumikak/resultse
|
bhumikak
| 2022-09-27T12:58:35Z | 98 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:17:00Z |
---
tags:
- generated_from_trainer
model-index:
- name: resultse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resultse
This model is a fine-tuned version of [bhumikak/resultsc](https://huggingface.co/bhumikak/resultsc) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9374
- Rouge2 Precision: 0.3333
- Rouge2 Recall: 0.0476
- Rouge2 Fmeasure: 0.0833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 50
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
anas-awadalla/t5-small-few-shot-k-32-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T12:53:19Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:45:03Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-32-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-32-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
IIIT-L/xlm-roberta-large-finetuned-code-mixed-DS
|
IIIT-L
| 2022-09-27T12:44:00Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T13:15:49Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-code-mixed-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-code-mixed-DS
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7328
- Accuracy: 0.7022
- Precision: 0.6437
- Recall: 0.6634
- F1: 0.6483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.098 | 0.5 | 248 | 1.0944 | 0.5352 | 0.2355 | 0.3344 | 0.2397 |
| 1.0827 | 1.0 | 496 | 1.0957 | 0.5352 | 0.5789 | 0.3379 | 0.2502 |
| 1.0503 | 1.5 | 744 | 0.9969 | 0.5312 | 0.3621 | 0.4996 | 0.3914 |
| 0.9728 | 2.0 | 992 | 0.8525 | 0.6056 | 0.5096 | 0.5565 | 0.4678 |
| 0.9271 | 2.49 | 1240 | 0.7809 | 0.6378 | 0.6014 | 0.6320 | 0.5963 |
| 0.7977 | 2.99 | 1488 | 0.8290 | 0.5875 | 0.5630 | 0.5918 | 0.5390 |
| 0.752 | 3.49 | 1736 | 0.7684 | 0.7123 | 0.6526 | 0.6610 | 0.6558 |
| 0.6846 | 3.99 | 1984 | 0.7328 | 0.7022 | 0.6437 | 0.6634 | 0.6483 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huynguyen208/bert-base-multilingual-cased-finetuned-ner
|
huynguyen208
| 2022-09-27T12:43:41Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-25T12:10:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-multilingual-cased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-ner
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0247
- Precision: 0.9269
- Recall: 0.9509
- F1: 0.9387
- Accuracy: 0.9945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0744 | 1.0 | 843 | 0.0266 | 0.8945 | 0.9293 | 0.9116 | 0.9920 |
| 0.016 | 2.0 | 1686 | 0.0239 | 0.9279 | 0.9446 | 0.9362 | 0.9942 |
| 0.0075 | 3.0 | 2529 | 0.0247 | 0.9269 | 0.9509 | 0.9387 | 0.9945 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
habib1030/distilbert-base-uncased-finetuned-squad
|
habib1030
| 2022-09-27T12:34:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-22T08:49:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.8711
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 5.9634 |
| No log | 2.0 | 2 | 5.9013 |
| No log | 3.0 | 3 | 5.8711 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
anas-awadalla/t5-small-few-shot-k-16-finetuned-squad-seed-4
|
anas-awadalla
| 2022-09-27T12:34:04Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:26:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-16-finetuned-squad-seed-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-16-finetuned-squad-seed-4
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-16-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T12:24:59Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:18:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-16-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-16-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
Hoax0930/kyoto_marian_mod_4
|
Hoax0930
| 2022-09-27T11:42:52Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T09:53:18Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_4
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_3](https://huggingface.co/Hoax0930/kyoto_marian_mod_3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8237
- Bleu: 21.5586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Hoax0930/kyoto_marian_mod_2_1
|
Hoax0930
| 2022-09-27T11:09:17Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T09:18:33Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_2_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_2_1
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_2_0](https://huggingface.co/Hoax0930/kyoto_marian_mod_2_0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2568
- Bleu: 20.9923
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
ericntay/stbl_clinical_bert_ft_rs6
|
ericntay
| 2022-09-27T09:57:00Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-27T09:38:14Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft_rs6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft_rs6
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0876
- F1: 0.9177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2778 | 1.0 | 101 | 0.0871 | 0.8482 |
| 0.066 | 2.0 | 202 | 0.0700 | 0.8892 |
| 0.031 | 3.0 | 303 | 0.0657 | 0.9053 |
| 0.0152 | 4.0 | 404 | 0.0716 | 0.9057 |
| 0.0099 | 5.0 | 505 | 0.0717 | 0.9105 |
| 0.0049 | 6.0 | 606 | 0.0807 | 0.9145 |
| 0.0042 | 7.0 | 707 | 0.0796 | 0.9140 |
| 0.0028 | 8.0 | 808 | 0.0833 | 0.9140 |
| 0.002 | 9.0 | 909 | 0.0836 | 0.9141 |
| 0.0013 | 10.0 | 1010 | 0.0866 | 0.9177 |
| 0.0011 | 11.0 | 1111 | 0.0867 | 0.9178 |
| 0.001 | 12.0 | 1212 | 0.0876 | 0.9177 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Hoax0930/kyoto_marian_mod_3
|
Hoax0930
| 2022-09-27T09:51:02Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T07:51:11Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_3_5
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_2](https://huggingface.co/Hoax0930/kyoto_marian_mod_2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8052
- Bleu: 18.4305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
IIIT-L/xlm-roberta-large-finetuned-combined-DS
|
IIIT-L
| 2022-09-27T09:50:50Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T14:13:02Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-combined-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-combined-DS
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9169
- Accuracy: 0.6587
- Precision: 0.6417
- Recall: 0.6445
- F1: 0.6396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0116 | 0.5 | 711 | 0.9454 | 0.5892 | 0.6556 | 0.5190 | 0.4582 |
| 0.8678 | 1.0 | 1422 | 0.9676 | 0.6503 | 0.6383 | 0.6076 | 0.6103 |
| 0.7644 | 1.5 | 2133 | 0.8672 | 0.6355 | 0.6142 | 0.6206 | 0.6166 |
| 0.8198 | 2.0 | 2844 | 0.8319 | 0.6713 | 0.6460 | 0.6448 | 0.6453 |
| 0.6665 | 2.5 | 3555 | 0.8342 | 0.6538 | 0.6359 | 0.6414 | 0.6349 |
| 0.6473 | 3.0 | 4266 | 0.9169 | 0.6587 | 0.6417 | 0.6445 | 0.6396 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
bhumikak/resultsd
|
bhumikak
| 2022-09-27T09:46:19Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T09:02:57Z |
---
tags:
- generated_from_trainer
model-index:
- name: resultsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resultsd
This model is a fine-tuned version of [bhumikak/resultsc](https://huggingface.co/bhumikak/resultsc) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5131
- Rouge2 Precision: 0.0278
- Rouge2 Recall: 0.1165
- Rouge2 Fmeasure: 0.0447
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 50
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
lewtun/autotrain-sphere-emotion-1565855719
|
lewtun
| 2022-09-27T09:35:07Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"unk",
"dataset:lewtun/autotrain-data-sphere-emotion",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T09:32:19Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lewtun/autotrain-data-sphere-emotion
co2_eq_emissions:
emissions: 0.02429248200067234
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1565855719
- CO2 Emissions (in grams): 0.0243
## Validation Metrics
- Loss: 0.134
- Accuracy: 0.943
- Macro F1: 0.915
- Micro F1: 0.943
- Weighted F1: 0.943
- Macro Precision: 0.911
- Micro Precision: 0.943
- Weighted Precision: 0.943
- Macro Recall: 0.920
- Micro Recall: 0.943
- Weighted Recall: 0.943
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/lewtun/autotrain-sphere-emotion-1565855719
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("lewtun/autotrain-sphere-emotion-1565855719", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("lewtun/autotrain-sphere-emotion-1565855719", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
hadiqa123/XLS-R_timit_en
|
hadiqa123
| 2022-09-27T09:26:46Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-22T05:39:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: XLS-R_timit_en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLS-R_timit_en
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3799
- Wer: 0.3019
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.5228 | 3.3 | 1000 | 0.9889 | 0.8394 |
| 0.6617 | 6.6 | 2000 | 0.3566 | 0.4027 |
| 0.3177 | 9.9 | 3000 | 0.3112 | 0.3606 |
| 0.2262 | 13.2 | 4000 | 0.3521 | 0.3324 |
| 0.1683 | 16.5 | 5000 | 0.3563 | 0.3260 |
| 0.137 | 19.8 | 6000 | 0.3605 | 0.3149 |
| 0.1139 | 23.1 | 7000 | 0.3768 | 0.3069 |
| 0.1068 | 26.4 | 8000 | 0.3643 | 0.3044 |
| 0.0897 | 29.7 | 9000 | 0.3799 | 0.3019 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.0
|
lewtun/autotrain-sphere-banking77-1565555714
|
lewtun
| 2022-09-27T08:51:27Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"unk",
"dataset:lewtun/autotrain-data-sphere-banking77",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T08:46:25Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- lewtun/autotrain-data-sphere-banking77
co2_eq_emissions:
emissions: 0.040322592546588654
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1565555714
- CO2 Emissions (in grams): 0.0403
## Validation Metrics
- Loss: 0.317
- Accuracy: 0.919
- Macro F1: 0.920
- Micro F1: 0.919
- Weighted F1: 0.920
- Macro Precision: 0.925
- Micro Precision: 0.919
- Weighted Precision: 0.923
- Macro Recall: 0.919
- Micro Recall: 0.919
- Weighted Recall: 0.919
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/lewtun/autotrain-sphere-banking77-1565555714
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("lewtun/autotrain-sphere-banking77-1565555714", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("lewtun/autotrain-sphere-banking77-1565555714", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
neuralworm/stable-diffusion-prompt-generator-gpt2
|
neuralworm
| 2022-09-27T08:32:49Z | 0 | 9 | null |
[
"region:us"
] | null | 2022-09-09T16:33:38Z |
stable-diffusion-prompt-generator-gpt2
stable-diffusion prompt generator, trained with all prompts from stable-diffusion discord server
gpt2 model for use with gpt2-simple
notebook for use:
https://colab.research.google.com/drive/16Nc-_pFITldPCw3tgSMDiew1anLVBAPw?usp=sharing
source for training:
https://huggingface.co/datasets/bartman081523/stable-diffusion-discord-prompts
|
sd-concepts-library/fzk
|
sd-concepts-library
| 2022-09-27T08:21:31Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T08:21:24Z |
---
license: mit
---
### fzk on Stable Diffusion
This is the `<fzk>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



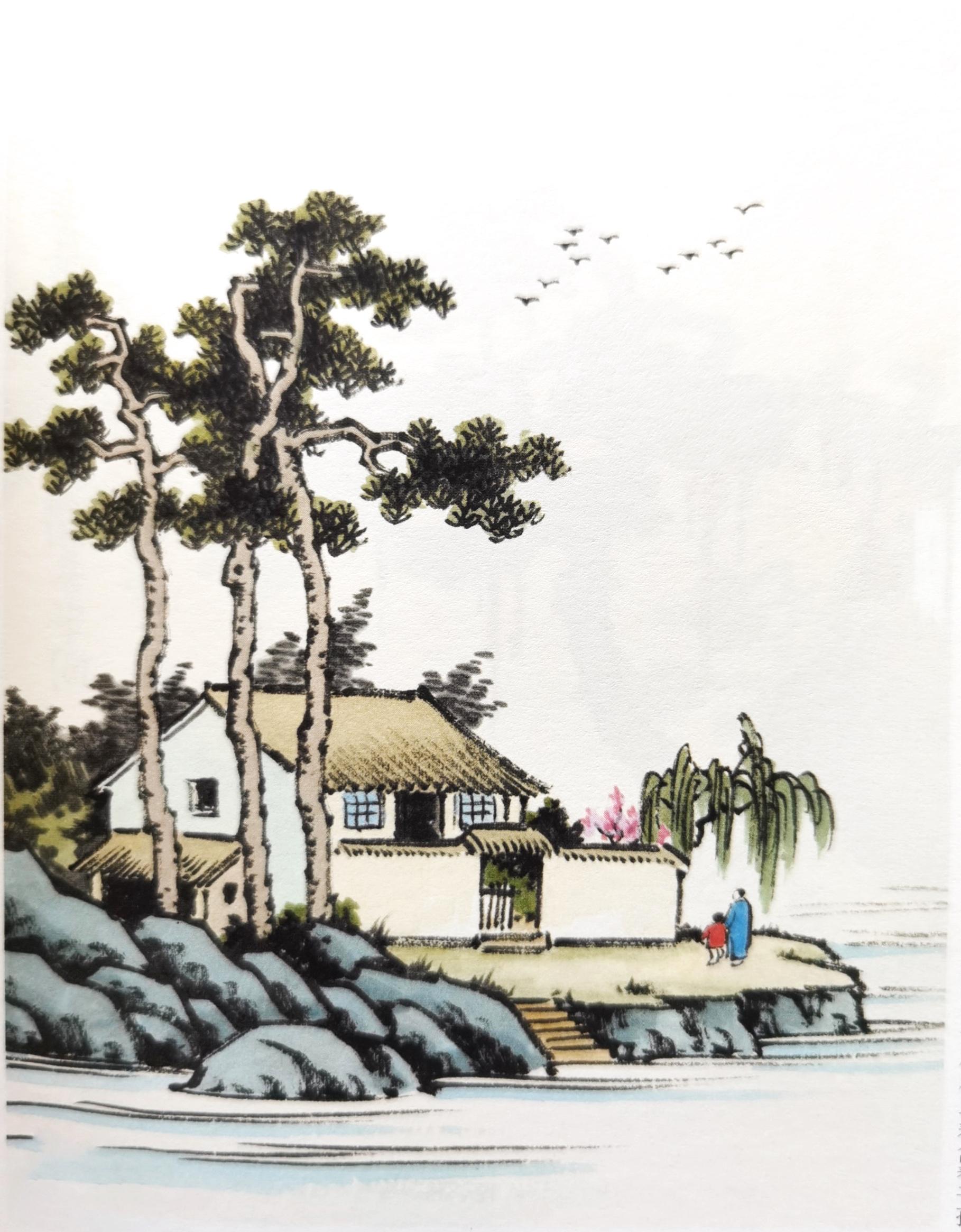





|
crescendonow/pwa_categorical_complaint
|
crescendonow
| 2022-09-27T07:42:44Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T07:24:36Z |
---
license: apache-2.0
---
This Model finetunes from WangchanBERTa ("wangchanberta-base-att-spm-uncased") uses only the Provincial Waterworks Authority of Thailand.
The Model classification into ten categories describe by the dictionary are
{'ข้อร้องเรียน-ปริมาณน้ำ':[11,0],
'ข้อร้องเรียน-ท่อแตกรั่ว':[12,1],
'ข้อร้องเรียน-คุณภาพน้ำ':[13,2],
'ข้อร้องเรียน-การบริการ':[14,3],
'ข้อร้องเรียน-บุคลากร':[15,4],
'ข้อสอบถามทั่วไป':[2,5],
'ข้อเสนอแนะ':[3,6],
'ข้อคิดเห็น':[4,7],
'อื่นๆ':[8,8],
'ไม่เกี่ยวข้องกับกปภ.':[9,9]}
|
Hoax0930/kyoto_marian_mod_2
|
Hoax0930
| 2022-09-27T07:05:14Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T05:11:18Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_2
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_1](https://huggingface.co/Hoax0930/kyoto_marian_mod_1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7472
- Bleu: 20.8730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
pcuenq/ddpm-ema-pets-64-no-tcond
|
pcuenq
| 2022-09-27T05:53:40Z | 5 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:pcuenq/oxford-pets",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-09-27T04:11:07Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: pcuenq/oxford-pets
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-ema-pets-64-no-tcond
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `pcuenq/oxford-pets` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 128
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(0.95, 0.999), weight_decay=1e-06 and epsilon=1e-08
- lr_scheduler: cosine
- lr_warmup_steps: 500
- ema_inv_gamma: 1.0
- ema_inv_gamma: 0.75
- ema_inv_gamma: 0.9999
- mixed_precision: no
### Training results
📈 [TensorBoard logs](https://huggingface.co/pcuenq/ddpm-ema-pets-64-no-tcond/tensorboard?#scalars)
|
huggingtweets/rossimiano
|
huggingtweets
| 2022-09-27T05:26:34Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-24T04:09:09Z |
---
language: en
thumbnail: http://www.huggingtweets.com/rossimiano/1664256351634/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1550158420988153856/OUoCVt_b_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ross Massimiano, DVM</div>
<div style="text-align: center; font-size: 14px;">@rossimiano</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ross Massimiano, DVM.
| Data | Ross Massimiano, DVM |
| --- | --- |
| Tweets downloaded | 1324 |
| Retweets | 203 |
| Short tweets | 130 |
| Tweets kept | 991 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/312h1q2v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rossimiano's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1vljawam) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1vljawam/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rossimiano')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
kerkathy/distilbert-base-uncased-finetuned-imdb
|
kerkathy
| 2022-09-27T04:57:38Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-27T04:50:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
VietAI/gptho
|
VietAI
| 2022-09-27T04:48:32Z | 139 | 9 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"causal-lm",
"gpt",
"vi",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-26T03:23:24Z |
---
language:
- vi
tags:
- pytorch
- causal-lm
- gpt
widget:
- text: "<|endoftext|> thu sang "
---
# How to prompt?
Type:
```
<|endoftext|> + your_prompt + [space]
```
### Example:
```
<|endoftext|> thu sang + [space]
```
|
SmilestheSad/bert-base-multilingual-uncased-sep-26
|
SmilestheSad
| 2022-09-27T03:46:06Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T01:23:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: bert-base-multilingual-uncased-sep-26
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-uncased-sep-26
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0483
- F1: 0.9369
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.0798 | 1.0 | 8623 | 0.0682 | 0.8979 |
| 0.0498 | 2.0 | 17246 | 0.0551 | 0.9270 |
| 0.0351 | 3.0 | 25869 | 0.0483 | 0.9369 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
SmilestheSad/distilbert-cased-sep-26
|
SmilestheSad
| 2022-09-27T01:06:44Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T00:33:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-cased-sep-26
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-cased-sep-26
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0467
- F1: 0.9318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1125 | 1.0 | 1078 | 0.0552 | 0.8867 |
| 0.0438 | 2.0 | 2156 | 0.0452 | 0.9180 |
| 0.0288 | 3.0 | 3234 | 0.0449 | 0.9261 |
| 0.0202 | 4.0 | 4312 | 0.0445 | 0.9309 |
| 0.0152 | 5.0 | 5390 | 0.0467 | 0.9318 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
IIIT-L/xlm-roberta-large-finetuned-TRAC-DS-new
|
IIIT-L
| 2022-09-26T22:32:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T16:48:31Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-TRAC-DS-new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-TRAC-DS-new
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2229
- Accuracy: 0.6724
- Precision: 0.6503
- Recall: 0.6556
- F1: 0.6513
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0895 | 0.25 | 612 | 1.0893 | 0.4453 | 0.3220 | 0.4654 | 0.3554 |
| 1.0788 | 0.5 | 1224 | 1.1051 | 0.4436 | 0.1479 | 0.3333 | 0.2049 |
| 1.0567 | 0.75 | 1836 | 0.9507 | 0.5637 | 0.4176 | 0.4948 | 0.4279 |
| 1.0052 | 1.0 | 2448 | 0.9716 | 0.4665 | 0.4913 | 0.5106 | 0.4324 |
| 0.9862 | 1.25 | 3060 | 0.9160 | 0.5719 | 0.5824 | 0.5851 | 0.5517 |
| 0.9428 | 1.5 | 3672 | 0.9251 | 0.5645 | 0.5838 | 0.5903 | 0.5386 |
| 0.9381 | 1.75 | 4284 | 0.9212 | 0.6307 | 0.6031 | 0.6091 | 0.6053 |
| 0.9124 | 2.0 | 4896 | 0.8897 | 0.6054 | 0.6078 | 0.6169 | 0.5895 |
| 0.9558 | 2.25 | 5508 | 0.8576 | 0.6283 | 0.6330 | 0.6077 | 0.6094 |
| 0.8814 | 2.5 | 6120 | 0.9458 | 0.6520 | 0.6357 | 0.6270 | 0.6286 |
| 0.8697 | 2.75 | 6732 | 0.8928 | 0.6381 | 0.6304 | 0.6259 | 0.6228 |
| 0.9142 | 3.0 | 7344 | 0.8542 | 0.6225 | 0.6227 | 0.6272 | 0.6124 |
| 0.825 | 3.25 | 7956 | 0.9639 | 0.6577 | 0.6491 | 0.6089 | 0.6093 |
| 0.84 | 3.5 | 8568 | 0.8980 | 0.6266 | 0.6309 | 0.6169 | 0.6130 |
| 0.8505 | 3.75 | 9180 | 0.9127 | 0.6503 | 0.6197 | 0.6130 | 0.6154 |
| 0.8287 | 4.0 | 9792 | 0.9343 | 0.6683 | 0.6515 | 0.6527 | 0.6488 |
| 0.7772 | 4.25 | 10404 | 1.0434 | 0.6650 | 0.6461 | 0.6454 | 0.6437 |
| 0.8217 | 4.5 | 11016 | 0.9760 | 0.6724 | 0.6574 | 0.6550 | 0.6533 |
| 0.7543 | 4.75 | 11628 | 1.0790 | 0.6454 | 0.6522 | 0.6342 | 0.6327 |
| 0.7868 | 5.0 | 12240 | 1.1457 | 0.6708 | 0.6519 | 0.6445 | 0.6463 |
| 0.8093 | 5.25 | 12852 | 1.1714 | 0.6716 | 0.6517 | 0.6525 | 0.6509 |
| 0.8032 | 5.5 | 13464 | 1.1882 | 0.6691 | 0.6480 | 0.6542 | 0.6489 |
| 0.7511 | 5.75 | 14076 | 1.2113 | 0.6650 | 0.6413 | 0.6458 | 0.6429 |
| 0.7698 | 6.0 | 14688 | 1.2229 | 0.6724 | 0.6503 | 0.6556 | 0.6513 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
arinakos/wolves_and_bears
|
arinakos
| 2022-09-26T22:25:51Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-09-26T21:10:36Z |
---
title: Pet classifier!
emoji: 🐶
colorFrom: pink
colorTo: blue
sdk: gradio
sdk_version: 3.1.1
app_file: app.py
pinned: true
license: apache-2.0
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
|
sd-concepts-library/kawaii-girl-plus-style
|
sd-concepts-library
| 2022-09-26T22:22:28Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T22:22:20Z |
---
license: mit
---
### kawaii_girl_plus_style on Stable Diffusion
This is the `<kawaii_girl>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






































|
huggingtweets/alexspoodiary-apesahoy-nsp_gpt2
|
huggingtweets
| 2022-09-26T22:08:29Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-26T22:03:52Z |
---
language: en
thumbnail: http://www.huggingtweets.com/alexspoodiary-apesahoy-nsp_gpt2/1664230104622/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/774937495691722752/OHoU0clu_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1196519479364268034/5QpniWSP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1218028522939113479/0VrO0Rko_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Alex's Poo Diary & Humongous Ape MP & Ninja Sex Party but AI</div>
<div style="text-align: center; font-size: 14px;">@alexspoodiary-apesahoy-nsp_gpt2</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Alex's Poo Diary & Humongous Ape MP & Ninja Sex Party but AI.
| Data | Alex's Poo Diary | Humongous Ape MP | Ninja Sex Party but AI |
| --- | --- | --- | --- |
| Tweets downloaded | 1859 | 3246 | 692 |
| Retweets | 3 | 178 | 13 |
| Short tweets | 5 | 625 | 44 |
| Tweets kept | 1851 | 2443 | 635 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/28kotecb/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alexspoodiary-apesahoy-nsp_gpt2's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2thnv3rd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2thnv3rd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alexspoodiary-apesahoy-nsp_gpt2')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ammarpl/t5-base-finetuned-eli5-a
|
ammarpl
| 2022-09-26T22:02:48Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-26T19:36:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-base-finetuned-eli5-a
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 14.6711
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-eli5-a
This model is a fine-tuned version of [ammarpl/t5-base-finetuned-xsum-a](https://huggingface.co/ammarpl/t5-base-finetuned-xsum-a) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1773
- Rouge1: 14.6711
- Rouge2: 2.2878
- Rougel: 11.3676
- Rougelsum: 13.1805
- Gen Len: 18.9892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.3417 | 1.0 | 17040 | 3.1773 | 14.6711 | 2.2878 | 11.3676 | 13.1805 | 18.9892 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
quecopiones/distillbert-base-spanish-uncased-finetuned-10percent-clean-ds-suicidios
|
quecopiones
| 2022-09-26T20:27:30Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T20:04:45Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distillbert-base-spanish-uncased-finetuned-10percent-clean-ds-suicidios
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distillbert-base-spanish-uncased-finetuned-10percent-clean-ds-suicidios
This model is a fine-tuned version of [CenIA/distillbert-base-spanish-uncased](https://huggingface.co/CenIA/distillbert-base-spanish-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2430
- Accuracy: 0.9418
- F1: 0.9418
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2908 | 1.0 | 3206 | 0.2144 | 0.9382 | 0.9382 |
| 0.1671 | 2.0 | 6412 | 0.2430 | 0.9418 | 0.9418 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
ColdFellow/kcorona
|
ColdFellow
| 2022-09-26T20:17:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-09-26T20:15:02Z |
https://photos.google.com/photo/AF1QipOr5Mq84sMC
https://photos.google.com/photo/AF1QipPbeoSDESDMrm_R6YqXK2hrjGN5FNtQYHHGOUYPjtcOMRHST8xtTRg8slUvbG0mfw
https://photos.google.com/photo/AF1QipN26lOKK6ZvaHyq8m52N-6SWdSqoLp7xMf53Go
|
enaserian/distilbert-base-uncased-finetuned
|
enaserian
| 2022-09-26T20:11:39Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-23T10:58:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.2813
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.6309 | 1.0 | 76 | 7.4774 |
| 7.0806 | 2.0 | 152 | 6.9937 |
| 6.6842 | 3.0 | 228 | 6.9314 |
| 6.4592 | 4.0 | 304 | 6.9088 |
| 6.2936 | 5.0 | 380 | 6.9135 |
| 6.1301 | 6.0 | 456 | 6.9018 |
| 5.9878 | 7.0 | 532 | 6.8865 |
| 5.8071 | 8.0 | 608 | 6.8926 |
| 5.6372 | 9.0 | 684 | 6.8750 |
| 5.4791 | 10.0 | 760 | 6.9394 |
| 5.3365 | 11.0 | 836 | 6.9594 |
| 5.2117 | 12.0 | 912 | 6.9962 |
| 5.0887 | 13.0 | 988 | 7.0570 |
| 4.9288 | 14.0 | 1064 | 7.0549 |
| 4.8169 | 15.0 | 1140 | 7.0971 |
| 4.7008 | 16.0 | 1216 | 7.1439 |
| 4.6149 | 17.0 | 1292 | 7.1320 |
| 4.487 | 18.0 | 1368 | 7.1577 |
| 4.364 | 19.0 | 1444 | 7.1712 |
| 4.3208 | 20.0 | 1520 | 7.1959 |
| 4.2492 | 21.0 | 1596 | 7.2136 |
| 4.1423 | 22.0 | 1672 | 7.2304 |
| 4.0873 | 23.0 | 1748 | 7.2526 |
| 4.0261 | 24.0 | 1824 | 7.2681 |
| 3.9598 | 25.0 | 1900 | 7.2715 |
| 3.9562 | 26.0 | 1976 | 7.2648 |
| 3.8951 | 27.0 | 2052 | 7.2665 |
| 3.8772 | 28.0 | 2128 | 7.2781 |
| 3.8403 | 29.0 | 2204 | 7.2801 |
| 3.8275 | 30.0 | 2280 | 7.2813 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
uf-aice-lab/SafeMathBot
|
uf-aice-lab
| 2022-09-26T20:04:02Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generation",
"math learning",
"education",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- generation
- math learning
- education
license: mit
metrics:
- PerspectiveAPI
widget:
- text: "<bos><speaker1>Hello! My name is CL. Nice meeting y'all!<speaker2>[SAFE]"
example_title: "Safe Response"
- text: "<bos><speaker1>Hello! My name is CL. Nice meeting y'all!<speaker2>[UNSAFE]"
example_title: "Unsafe Response"
---
# SafeMathBot for NLP tasks in math learning environments
This model is fine-tuned with GPT2-xl with 8 Nvidia RTX 1080Ti GPUs and enhanced with conversation safety policies (e.g., threat, profanity, identity attack) using 3,000,000 math discussion posts by students and facilitators on Algebra Nation (https://www.mathnation.com/). SafeMathBot consists of 48 layers and over 1.5 billion parameters, consuming up to 6 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively avoid unsafe response generation. It was trained to allow researchers to control generated responses' safety using tags `[SAFE]` and `[UNSAFE]`
### Here is how to use it with texts in HuggingFace
```python
# A list of special tokens the model was trained with
special_tokens_dict = {
'additional_special_tokens': [
'[SAFE]','[UNSAFE]', '[OK]', '[SELF_M]','[SELF_F]', '[SELF_N]',
'[PARTNER_M]', '[PARTNER_F]', '[PARTNER_N]',
'[ABOUT_M]', '[ABOUT_F]', '[ABOUT_N]', '<speaker1>', '<speaker2>'
],
'bos_token': '<bos>',
'eos_token': '<eos>',
}
from transformers import AutoTokenizer, AutoModelForCausalLM
math_bot_tokenizer = AutoTokenizer.from_pretrained('uf-aice-lab/SafeMathBot')
safe_math_bot = AutoModelForCausalLM.from_pretrained('uf-aice-lab/SafeMathBot')
text = "Replace me by any text you'd like."
encoded_input = math_bot_tokenizer(text, return_tensors='pt')
output = safe_math_bot(**encoded_input)
```
|
sd-concepts-library/kira-sensei
|
sd-concepts-library
| 2022-09-26T19:25:20Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T19:25:07Z |
---
license: mit
---
### kira-sensei on Stable Diffusion
This is the `<kira-sensei>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
KoboldAI/GPT-NeoX-20B-Erebus
|
KoboldAI
| 2022-09-26T19:05:19Z | 3,741 | 84 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"en",
"arxiv:2204.06745",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2022-09-02T18:07:19Z |
---
language: en
license: apache-2.0
inference: false
---
# GPT-NeoX-20B-Erebus
## Model description
This is the second generation of the original Shinen made by Mr. Seeker. The full dataset consists of 6 different sources, all surrounding the "Adult" theme. The name "Erebus" comes from the greek mythology, also named "darkness". This is in line with Shin'en, or "deep abyss". For inquiries, please contact the KoboldAI community. **Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.**
## Training procedure
GPT-NeoX-20B-Erebus was trained on a TPUv3-256 TPU pod using a heavily modified version of Ben Wang's Mesh Transformer JAX library, the original version of which was used by EleutherAI to train their GPT-J-6B model.
## Training data
The data can be divided in 6 different datasets:
- Literotica (everything with 4.5/5 or higher)
- Sexstories (everything with 90 or higher)
- Dataset-G (private dataset of X-rated stories)
- Doc's Lab (all stories)
- Pike Dataset (novels with "adult" rating)
- SoFurry (collection of various animals)
The dataset uses `[Genre: <comma-separated list of genres>]` for tagging.
## Limitations and biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion). **Warning: This model has a very strong NSFW bias!**
## Citation details
The GPT-NeoX-20B model weights:
```bibtex
@inproceedings{gpt-neox-20b,
title={{GPT-NeoX-20B}: An Open-Source Autoregressive Language Model},
author={Black, Sid and Biderman, Stella and Hallahan, Eric and Anthony, Quentin and Gao, Leo and Golding, Laurence and He, Horace and Leahy, Connor and McDonell, Kyle and Phang, Jason and Pieler, Michael and Prashanth, USVSN Sai and Purohit, Shivanshu and Reynolds, Laria and Tow, Jonathan and Wang, Ben and Weinbach, Samuel},
booktitle={Proceedings of the ACL Workshop on Challenges \& Perspectives in Creating Large Language Models},
url={https://arxiv.org/abs/2204.06745},
year={2022}
}
```
The Mesh Transformer JAX library:
```bibtex
@misc{mesh-transformer-jax,
author = {Wang, Ben},
title = {{Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
|
mrm8488/setfit-mpnet-base-v2-finetuned-sentEval-CR
|
mrm8488
| 2022-09-26T18:50:11Z | 7 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-09-26T18:49:59Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 40 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 20,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 40,
"warmup_steps": 4,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
gabrielsgaspar/test-trainer
|
gabrielsgaspar
| 2022-09-26T18:20:02Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T16:17:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: test-trainer
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: mrpc
split: train
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.9395
- name: F1
type: f1
value: 0.9395662658775557
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-trainer
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2394
- Accuracy: 0.9395
- F1: 0.9396
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2518 | 1.0 | 2000 | 0.1971 | 0.931 | 0.9305 |
| 0.1678 | 2.0 | 4000 | 0.1782 | 0.9405 | 0.9406 |
| 0.1048 | 3.0 | 6000 | 0.2394 | 0.9395 | 0.9396 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
espnet/transformer_tts_cmu_indic_hin_ab
|
espnet
| 2022-09-26T18:15:07Z | 0 | 2 |
espnet
|
[
"espnet",
"audio",
"text-to-speech",
"hi",
"dataset:cmu_indic",
"region:us"
] |
text-to-speech
| 2022-09-26T18:02:38Z |
---
tags:
- espnet
- audio
- text-to-speech
language: hi
datasets:
- cmu_indic
---
|
AbhijeetA/PIE
|
AbhijeetA
| 2022-09-26T17:30:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:04Z |
Model details available [here](https://github.com/awasthiabhijeet/PIE)
|
microsoft/graphcodebert-base
|
microsoft
| 2022-09-26T17:06:54Z | 104,959 | 56 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"arxiv:2009.08366",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## GraphCodeBERT model
GraphCodeBERT is a graph-based pre-trained model based on the Transformer architecture for programming language, which also considers data-flow information along with code sequences. GraphCodeBERT consists of 12 layers, 768 dimensional hidden states, and 12 attention heads. The maximum sequence length for the model is 512. The model is trained on the CodeSearchNet dataset, which includes 2.3M functions with document pairs for six programming languages.
More details can be found in the [paper](https://arxiv.org/abs/2009.08366) by Guo et. al.
**Disclaimer:** The team releasing BERT did not write a model card for this model so this model card has been written by the Hugging Face community members.
|
pjcordero04/distilbert-base-uncased-finetuned-cola
|
pjcordero04
| 2022-09-26T16:32:49Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T14:35:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: train
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5442538936990396
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8348
- Matthews Correlation: 0.5443
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5236 | 1.0 | 535 | 0.5495 | 0.4205 |
| 0.3505 | 2.0 | 1070 | 0.5176 | 0.4977 |
| 0.2401 | 3.0 | 1605 | 0.5498 | 0.5354 |
| 0.1751 | 4.0 | 2140 | 0.7975 | 0.5270 |
| 0.1229 | 5.0 | 2675 | 0.8348 | 0.5443 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
marcelklehr/autotrain-byt5-summary-1562255681
|
marcelklehr
| 2022-09-26T16:29:17Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"summarization",
"unk",
"dataset:mklehr/autotrain-data-byt5-summary",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-09-26T16:27:29Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- mklehr/autotrain-data-byt5-summary
co2_eq_emissions:
emissions: 2.2525628167913614
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1562255681
- CO2 Emissions (in grams): 2.2526
## Validation Metrics
- Loss: 0.918
- Rouge1: 12.572
- Rouge2: 2.448
- RougeL: 11.701
- RougeLsum: 11.785
- Gen Len: 19.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/mklehr/autotrain-byt5-summary-1562255681
```
|
jamieai/t5-small-finetuned-xsum
|
jamieai
| 2022-09-26T16:04:00Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-26T15:56:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
model-index:
- name: t5-small-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sd-concepts-library/at-wolf-boy-object
|
sd-concepts-library
| 2022-09-26T15:44:23Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T15:08:05Z |
---
license: mit
---
### AT-Wolf-Boy-Object on Stable Diffusion
**- Art created by Akihito Tsukushi**
This is the `<AT-Wolf-Boy-Object>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
tner/deberta-v3-large-bc5cdr
|
tner
| 2022-09-26T15:27:41Z | 114 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"token-classification",
"dataset:tner/bc5cdr",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:31:56Z |
---
datasets:
- tner/bc5cdr
metrics:
- f1
- precision
- recall
model-index:
- name: tner/deberta-v3-large-bc5cdr
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/bc5cdr
type: tner/bc5cdr
args: tner/bc5cdr
metrics:
- name: F1
type: f1
value: 0.8902493653874869
- name: Precision
type: precision
value: 0.8697724178175452
- name: Recall
type: recall
value: 0.9117137322866755
- name: F1 (macro)
type: f1_macro
value: 0.8863403908610603
- name: Precision (macro)
type: precision_macro
value: 0.8657302393432342
- name: Recall (macro)
type: recall_macro
value: 0.9080747413030301
- name: F1 (entity span)
type: f1_entity_span
value: 0.8929371360310587
- name: Precision (entity span)
type: precision_entity_span
value: 0.8723983660766388
- name: Recall (entity span)
type: recall_entity_span
value: 0.9144663064532572
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/deberta-v3-large-bc5cdr
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the
[tner/bc5cdr](https://huggingface.co/datasets/tner/bc5cdr) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.8902493653874869
- Precision (micro): 0.8697724178175452
- Recall (micro): 0.9117137322866755
- F1 (macro): 0.8863403908610603
- Precision (macro): 0.8657302393432342
- Recall (macro): 0.9080747413030301
The per-entity breakdown of the F1 score on the test set are below:
- chemical: 0.9298502009499452
- disease: 0.8428305807721753
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.885162383660078, 0.8951239957151518]
- 95%: [0.8838793313408008, 0.8959517574197015]
- F1 (macro):
- 90%: [0.885162383660078, 0.8951239957151518]
- 95%: [0.8838793313408008, 0.8959517574197015]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/deberta-v3-large-bc5cdr/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/deberta-v3-large-bc5cdr/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/deberta-v3-large-bc5cdr")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/bc5cdr']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: microsoft/deberta-v3-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 16
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 4
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: None
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/deberta-v3-large-bc5cdr/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/deberta-v3-large-wnut2017
|
tner
| 2022-09-26T15:10:46Z | 30 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"token-classification",
"dataset:tner/wnut2017",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:14:32Z |
---
datasets:
- tner/wnut2017
metrics:
- f1
- precision
- recall
model-index:
- name: tner/deberta-v3-large-wnut2017
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/wnut2017
type: tner/wnut2017
args: tner/wnut2017
metrics:
- name: F1
type: f1
value: 0.5047353760445682
- name: Precision
type: precision
value: 0.63268156424581
- name: Recall
type: recall
value: 0.4198331788693234
- name: F1 (macro)
type: f1_macro
value: 0.4165125500830091
- name: Precision (macro)
type: precision_macro
value: 0.5356144444686111
- name: Recall (macro)
type: recall_macro
value: 0.3573954549633822
- name: F1 (entity span)
type: f1_entity_span
value: 0.6249999999999999
- name: Precision (entity span)
type: precision_entity_span
value: 0.7962697274031564
- name: Recall (entity span)
type: recall_entity_span
value: 0.5143651529193698
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/deberta-v3-large-wnut2017
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the
[tner/wnut2017](https://huggingface.co/datasets/tner/wnut2017) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.5047353760445682
- Precision (micro): 0.63268156424581
- Recall (micro): 0.4198331788693234
- F1 (macro): 0.4165125500830091
- Precision (macro): 0.5356144444686111
- Recall (macro): 0.3573954549633822
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.25477707006369427
- group: 0.34309623430962344
- location: 0.6187050359712232
- person: 0.6721763085399448
- product: 0.18579234972677597
- work_of_art: 0.42452830188679247
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.4752384997212858, 0.5329114690850492]
- 95%: [0.46929053844001617, 0.537282841423422]
- F1 (macro):
- 90%: [0.4752384997212858, 0.5329114690850492]
- 95%: [0.46929053844001617, 0.537282841423422]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/deberta-v3-large-wnut2017/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/deberta-v3-large-wnut2017/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/deberta-v3-large-wnut2017")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/wnut2017']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: microsoft/deberta-v3-large
- crf: False
- max_length: 128
- epoch: 15
- batch_size: 16
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 4
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/deberta-v3-large-wnut2017/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/deberta-v3-large-ttc
|
tner
| 2022-09-26T14:41:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"token-classification",
"dataset:tner/ttc",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-17T11:20:57Z |
---
datasets:
- tner/ttc
metrics:
- f1
- precision
- recall
model-index:
- name: tner/deberta-v3-large-ttc
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/ttc
type: tner/ttc
args: tner/ttc
metrics:
- name: F1
type: f1
value: 0.8266925817946227
- name: Precision
type: precision
value: 0.8264248704663213
- name: Recall
type: recall
value: 0.8269604666234608
- name: F1 (macro)
type: f1_macro
value: 0.8267742072572187
- name: Precision (macro)
type: precision_macro
value: 0.8278533291801137
- name: Recall (macro)
type: recall_macro
value: 0.8257668793195109
- name: F1 (entity span)
type: f1_entity_span
value: 0.8713961775186264
- name: Precision (entity span)
type: precision_entity_span
value: 0.8711139896373057
- name: Recall (entity span)
type: recall_entity_span
value: 0.8716785482825664
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/deberta-v3-large-ttc
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the
[tner/ttc](https://huggingface.co/datasets/tner/ttc) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.8266925817946227
- Precision (micro): 0.8264248704663213
- Recall (micro): 0.8269604666234608
- F1 (macro): 0.8267742072572187
- Precision (macro): 0.8278533291801137
- Recall (macro): 0.8257668793195109
The per-entity breakdown of the F1 score on the test set are below:
- location: 0.7862266857962696
- organization: 0.7770320656226697
- person: 0.9170638703527169
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.8124223893760291, 0.8416139230675236]
- 95%: [0.8098712905029445, 0.8440240645643514]
- F1 (macro):
- 90%: [0.8124223893760291, 0.8416139230675236]
- 95%: [0.8098712905029445, 0.8440240645643514]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/deberta-v3-large-ttc/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/deberta-v3-large-ttc/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/deberta-v3-large-ttc")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/ttc']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: microsoft/deberta-v3-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 16
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 4
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/deberta-v3-large-ttc/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/deberta-v3-large-mit-movie-trivia
|
tner
| 2022-09-26T14:30:39Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"token-classification",
"dataset:tner/mit_movie_trivia",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T11:41:52Z |
---
datasets:
- tner/mit_movie_trivia
metrics:
- f1
- precision
- recall
model-index:
- name: tner/deberta-v3-large-mit-movie-trivia
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/mit_movie_trivia
type: tner/mit_movie_trivia
args: tner/mit_movie_trivia
metrics:
- name: F1
type: f1
value: 0.7324478178368122
- name: Precision
type: precision
value: 0.7186865267433988
- name: Recall
type: recall
value: 0.746746394653535
- name: F1 (macro)
type: f1_macro
value: 0.6597589403836301
- name: Precision (macro)
type: precision_macro
value: 0.6493939604029393
- name: Recall (macro)
type: recall_macro
value: 0.6747458149186768
- name: F1 (entity span)
type: f1_entity_span
value: 0.749525289142068
- name: Precision (entity span)
type: precision_entity_span
value: 0.7359322033898306
- name: Recall (entity span)
type: recall_entity_span
value: 0.7636299683432993
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/deberta-v3-large-mit-movie-trivia
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the
[tner/mit_movie_trivia](https://huggingface.co/datasets/tner/mit_movie_trivia) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.7324478178368122
- Precision (micro): 0.7186865267433988
- Recall (micro): 0.746746394653535
- F1 (macro): 0.6597589403836301
- Precision (macro): 0.6493939604029393
- Recall (macro): 0.6747458149186768
The per-entity breakdown of the F1 score on the test set are below:
- actor: 0.9590417310664605
- award: 0.4755244755244755
- character_name: 0.7391304347826086
- date: 0.9640179910044978
- director: 0.909706546275395
- genre: 0.755114693118413
- opinion: 0.4910714285714286
- origin: 0.3922518159806296
- plot: 0.4929757343550447
- quote: 0.7391304347826088
- relationship: 0.5705705705705706
- soundtrack: 0.42857142857142855
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.7213456287685677, 0.742502895519075]
- 95%: [0.7198169787204788, 0.7460320515170399]
- F1 (macro):
- 90%: [0.7213456287685677, 0.742502895519075]
- 95%: [0.7198169787204788, 0.7460320515170399]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/deberta-v3-large-mit-movie-trivia/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/deberta-v3-large-mit-movie-trivia/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/deberta-v3-large-mit-movie-trivia")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/mit_movie_trivia']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: microsoft/deberta-v3-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 16
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 4
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: None
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/deberta-v3-large-mit-movie-trivia/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-ttc
|
tner
| 2022-09-26T14:25:57Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/ttc",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T10:49:56Z |
---
datasets:
- tner/ttc
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-ttc
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/ttc
type: tner/ttc
args: tner/ttc
metrics:
- name: F1
type: f1
value: 0.8314534321624235
- name: Precision
type: precision
value: 0.8269230769230769
- name: Recall
type: recall
value: 0.8360337005832793
- name: F1 (macro)
type: f1_macro
value: 0.8317396497007042
- name: Precision (macro)
type: precision_macro
value: 0.8296690551538254
- name: Recall (macro)
type: recall_macro
value: 0.8340850231639706
- name: F1 (entity span)
type: f1_entity_span
value: 0.8739929100870126
- name: Precision (entity span)
type: precision_entity_span
value: 0.8692307692307693
- name: Recall (entity span)
type: recall_entity_span
value: 0.8788075178224238
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-ttc
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/ttc](https://huggingface.co/datasets/tner/ttc) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.8314534321624235
- Precision (micro): 0.8269230769230769
- Recall (micro): 0.8360337005832793
- F1 (macro): 0.8317396497007042
- Precision (macro): 0.8296690551538254
- Recall (macro): 0.8340850231639706
The per-entity breakdown of the F1 score on the test set are below:
- location: 0.7817403708987161
- organization: 0.7737656595431097
- person: 0.939712918660287
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.8153670265512099, 0.8476331336073506]
- 95%: [0.8126974643551524, 0.8505459585794019]
- F1 (macro):
- 90%: [0.8153670265512099, 0.8476331336073506]
- 95%: [0.8126974643551524, 0.8505459585794019]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-ttc/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-ttc/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-ttc")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/ttc']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 16
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 2
- weight_decay: None
- lr_warmup_step_ratio: 0.1
- max_grad_norm: None
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-ttc/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-bionlp2004
|
tner
| 2022-09-26T14:23:31Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/bionlp2004",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T00:10:08Z |
---
datasets:
- tner/bionlp2004
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-bionlp2004
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/bionlp2004
type: tner/bionlp2004
args: tner/bionlp2004
metrics:
- name: F1
type: f1
value: 0.7513434294088912
- name: Precision
type: precision
value: 0.7090462042823481
- name: Recall
type: recall
value: 0.7990071577003002
- name: F1 (macro)
type: f1_macro
value: 0.7165656135319811
- name: Precision (macro)
type: precision_macro
value: 0.6765580411075789
- name: Recall (macro)
type: recall_macro
value: 0.7685019796698731
- name: F1 (entity span)
type: f1_entity_span
value: 0.7936818107800032
- name: Precision (entity span)
type: precision_entity_span
value: 0.7490011269337158
- name: Recall (entity span)
type: recall_entity_span
value: 0.8440314015238974
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-bionlp2004
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/bionlp2004](https://huggingface.co/datasets/tner/bionlp2004) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.7513434294088912
- Precision (micro): 0.7090462042823481
- Recall (micro): 0.7990071577003002
- F1 (macro): 0.7165656135319811
- Precision (macro): 0.6765580411075789
- Recall (macro): 0.7685019796698731
The per-entity breakdown of the F1 score on the test set are below:
- cell_line: 0.6080273270708796
- cell_type: 0.7536311318169361
- dna: 0.7150259067357512
- protein: 0.7738602374694099
- rna: 0.7322834645669293
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.7433198691879565, 0.7598437899577305]
- 95%: [0.7420570442205622, 0.7606216680394585]
- F1 (macro):
- 90%: [0.7433198691879565, 0.7598437899577305]
- 95%: [0.7420570442205622, 0.7606216680394585]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-bionlp2004/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-bionlp2004/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-bionlp2004")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/bionlp2004']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-bionlp2004/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-fin
|
tner
| 2022-09-26T14:22:04Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:fin",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T20:28:39Z |
---
datasets:
- fin
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-fin
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: fin
type: fin
args: fin
metrics:
- name: F1
type: f1
value: 0.6988727858293075
- name: Precision
type: precision
value: 0.7161716171617162
- name: Recall
type: recall
value: 0.6823899371069182
- name: F1 (macro)
type: f1_macro
value: 0.45636958249281745
- name: Precision (macro)
type: precision_macro
value: 0.4519134760270864
- name: Recall (macro)
type: recall_macro
value: 0.4705942205942206
- name: F1 (entity span)
type: f1_entity_span
value: 0.7087378640776698
- name: Precision (entity span)
type: precision_entity_span
value: 0.7227722772277227
- name: Recall (entity span)
type: recall_entity_span
value: 0.6952380952380952
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-fin
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/fin](https://huggingface.co/datasets/tner/fin) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.6988727858293075
- Precision (micro): 0.7161716171617162
- Recall (micro): 0.6823899371069182
- F1 (macro): 0.45636958249281745
- Precision (macro): 0.4519134760270864
- Recall (macro): 0.4705942205942206
The per-entity breakdown of the F1 score on the test set are below:
- location: 0.5121951219512196
- organization: 0.49624060150375937
- other: 0.0
- person: 0.8170426065162907
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6355508274231678, 0.7613829748047737]
- 95%: [0.624150263185174, 0.7724430709173716]
- F1 (macro):
- 90%: [0.6355508274231678, 0.7613829748047737]
- 95%: [0.624150263185174, 0.7724430709173716]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-fin/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-fin/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-fin")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/fin']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: None
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-fin/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/bertweet-large-wnut2017
|
tner
| 2022-09-26T14:18:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/wnut2017",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:25:24Z |
---
datasets:
- tner/wnut2017
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bertweet-large-wnut2017
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/wnut2017
type: tner/wnut2017
args: tner/wnut2017
metrics:
- name: F1
type: f1
value: 0.5302273987798114
- name: Precision
type: precision
value: 0.6602209944751382
- name: Recall
type: recall
value: 0.44300278035217794
- name: F1 (macro)
type: f1_macro
value: 0.4643459997680019
- name: Precision (macro)
type: precision_macro
value: 0.5792841925426832
- name: Recall (macro)
type: recall_macro
value: 0.3973128655628379
- name: F1 (entity span)
type: f1_entity_span
value: 0.6142697881828317
- name: Precision (entity span)
type: precision_entity_span
value: 0.7706293706293706
- name: Recall (entity span)
type: recall_entity_span
value: 0.5106580166821131
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/bertweet-large-wnut2017
This model is a fine-tuned version of [vinai/bertweet-large](https://huggingface.co/vinai/bertweet-large) on the
[tner/wnut2017](https://huggingface.co/datasets/tner/wnut2017) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.5302273987798114
- Precision (micro): 0.6602209944751382
- Recall (micro): 0.44300278035217794
- F1 (macro): 0.4643459997680019
- Precision (macro): 0.5792841925426832
- Recall (macro): 0.3973128655628379
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.3902439024390244
- group: 0.37130801687763715
- location: 0.6595744680851063
- person: 0.65474552957359
- product: 0.2857142857142857
- work_of_art: 0.4244897959183674
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.5002577319587629, 0.5587481638299118]
- 95%: [0.4947163587619384, 0.5629013150503995]
- F1 (macro):
- 90%: [0.5002577319587629, 0.5587481638299118]
- 95%: [0.4947163587619384, 0.5629013150503995]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bertweet-large-wnut2017/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bertweet-large-wnut2017/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/bertweet-large-wnut2017")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/wnut2017']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: vinai/bertweet-large
- crf: False
- max_length: 128
- epoch: 15
- batch_size: 16
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 4
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bertweet-large-wnut2017/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-wnut2017
|
tner
| 2022-09-26T14:16:19Z | 6,792 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:wnut2017",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:12:35Z |
---
datasets:
- wnut2017
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-wnut2017
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut2017
type: wnut2017
args: wnut2017
metrics:
- name: F1
type: f1
value: 0.5375139977603584
- name: Precision
type: precision
value: 0.6789250353606789
- name: Recall
type: recall
value: 0.4448563484708063
- name: F1 (macro)
type: f1_macro
value: 0.4734480458244917
- name: Precision (macro)
type: precision_macro
value: 0.59471614080646
- name: Recall (macro)
type: recall_macro
value: 0.4020936892146829
- name: F1 (entity span)
type: f1_entity_span
value: 0.6304591265397536
- name: Precision (entity span)
type: precision_entity_span
value: 0.7963224893917963
- name: Recall (entity span)
type: recall_entity_span
value: 0.5217794253938832
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-wnut2017
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/wnut2017](https://huggingface.co/datasets/tner/wnut2017) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.5375139977603584
- Precision (micro): 0.6789250353606789
- Recall (micro): 0.4448563484708063
- F1 (macro): 0.4734480458244917
- Precision (macro): 0.59471614080646
- Recall (macro): 0.4020936892146829
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.4065040650406504
- group: 0.33913043478260874
- location: 0.6715867158671587
- person: 0.6657342657342658
- product: 0.27999999999999997
- work_of_art: 0.4777327935222672
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.5084441265818846, 0.5659035599952082]
- 95%: [0.5009032784561068, 0.5708361009044657]
- F1 (macro):
- 90%: [0.5084441265818846, 0.5659035599952082]
- 95%: [0.5009032784561068, 0.5708361009044657]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-wnut2017/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-wnut2017/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-wnut2017")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/wnut2017']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: None
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-wnut2017/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-mit-movie-trivia
|
tner
| 2022-09-26T14:15:35Z | 17 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/mit_movie_trivia",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-12T10:37:29Z |
---
datasets:
- tner/mit_movie_trivia
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-mit-movie-trivia
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/mit_movie_trivia
type: tner/mit_movie_trivia
args: tner/mit_movie_trivia
metrics:
- name: F1
type: f1
value: 0.7284025200655909
- name: Precision
type: precision
value: 0.7151330283002881
- name: Recall
type: recall
value: 0.7421737601125572
- name: F1 (macro)
type: f1_macro
value: 0.6502255723148889
- name: Precision (macro)
type: precision_macro
value: 0.6457158565124362
- name: Recall (macro)
type: recall_macro
value: 0.6578012664661943
- name: F1 (entity span)
type: f1_entity_span
value: 0.749525289142068
- name: Precision (entity span)
type: precision_entity_span
value: 0.7359322033898306
- name: Recall (entity span)
type: recall_entity_span
value: 0.7636299683432993
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-mit-movie-trivia
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/mit_movie_trivia](https://huggingface.co/datasets/tner/mit_movie_trivia) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.7284025200655909
- Precision (micro): 0.7151330283002881
- Recall (micro): 0.7421737601125572
- F1 (macro): 0.6502255723148889
- Precision (macro): 0.6457158565124362
- Recall (macro): 0.6578012664661943
The per-entity breakdown of the F1 score on the test set are below:
- actor: 0.9557453416149068
- award: 0.41726618705035967
- character_name: 0.7467105263157895
- date: 0.9668674698795181
- director: 0.9148936170212766
- genre: 0.7277079593058049
- opinion: 0.43478260869565216
- origin: 0.28846153846153844
- plot: 0.5132575757575758
- quote: 0.8387096774193549
- relationship: 0.5697329376854599
- soundtrack: 0.42857142857142855
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.718570586211627, 0.7387631655667131]
- 95%: [0.7170135350354089, 0.7412372838115527]
- F1 (macro):
- 90%: [0.718570586211627, 0.7387631655667131]
- 95%: [0.7170135350354089, 0.7412372838115527]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-mit-movie-trivia/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-mit-movie-trivia/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-mit-movie-trivia")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/mit_movie_trivia']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-mit-movie-trivia/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-bc5cdr
|
tner
| 2022-09-26T14:13:58Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/bc5cdr",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:32:35Z |
---
datasets:
- tner/bc5cdr
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-bc5cdr
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/bc5cdr
type: tner/bc5cdr
args: tner/bc5cdr
metrics:
- name: F1
type: f1
value: 0.8840696387239609
- name: Precision
type: precision
value: 0.8728266269249876
- name: Recall
type: recall
value: 0.8956060760526048
- name: F1 (macro)
type: f1_macro
value: 0.8797360472482783
- name: Precision (macro)
type: precision_macro
value: 0.8684274142690976
- name: Recall (macro)
type: recall_macro
value: 0.8913672531528037
- name: F1 (entity span)
type: f1_entity_span
value: 0.886283586595552
- name: Precision (entity span)
type: precision_entity_span
value: 0.8750124192747144
- name: Recall (entity span)
type: recall_entity_span
value: 0.8978489142624121
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-bc5cdr
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/bc5cdr](https://huggingface.co/datasets/tner/bc5cdr) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.8840696387239609
- Precision (micro): 0.8728266269249876
- Recall (micro): 0.8956060760526048
- F1 (macro): 0.8797360472482783
- Precision (macro): 0.8684274142690976
- Recall (macro): 0.8913672531528037
The per-entity breakdown of the F1 score on the test set are below:
- chemical: 0.9256943167187788
- disease: 0.8337777777777777
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.878869501707946, 0.8890795634554179]
- 95%: [0.8776790106527211, 0.8897422640465147]
- F1 (macro):
- 90%: [0.878869501707946, 0.8890795634554179]
- 95%: [0.8776790106527211, 0.8897422640465147]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-bc5cdr/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-bc5cdr/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-bc5cdr")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/bc5cdr']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 15
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: None
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-bc5cdr/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
tner/roberta-large-conll2003
|
tner
| 2022-09-26T14:13:18Z | 65 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/conll2003",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-09T23:19:06Z |
---
datasets:
- tner/conll2003
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/conll2003
type: tner/conll2003
args: tner/conll2003
metrics:
- name: F1
type: f1
value: 0.924769027716674
- name: Precision
type: precision
value: 0.9191883855168795
- name: Recall
type: recall
value: 0.9304178470254958
- name: F1 (macro)
type: f1_macro
value: 0.9110950780089749
- name: Precision (macro)
type: precision_macro
value: 0.9030546238754271
- name: Recall (macro)
type: recall_macro
value: 0.9197126371122274
- name: F1 (entity span)
type: f1_entity_span
value: 0.9619852164730729
- name: Precision (entity span)
type: precision_entity_span
value: 0.9562631210636809
- name: Recall (entity span)
type: recall_entity_span
value: 0.9677762039660056
pipeline_tag: token-classification
widget:
- text: "Jacob Collier is a Grammy awarded artist from England."
example_title: "NER Example 1"
---
# tner/roberta-large-conll2003
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/conll2003](https://huggingface.co/datasets/tner/conll2003) dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set:
- F1 (micro): 0.924769027716674
- Precision (micro): 0.9191883855168795
- Recall (micro): 0.9304178470254958
- F1 (macro): 0.9110950780089749
- Precision (macro): 0.9030546238754271
- Recall (macro): 0.9197126371122274
The per-entity breakdown of the F1 score on the test set are below:
- location: 0.9390573401380967
- organization: 0.9107142857142857
- other: 0.8247422680412372
- person: 0.9698664181422801
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.9185189408755685, 0.9309806929048586]
- 95%: [0.9174010190551032, 0.9318590917100465]
- F1 (macro):
- 90%: [0.9185189408755685, 0.9309806929048586]
- 95%: [0.9174010190551032, 0.9318590917100465]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-conll2003/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-conll2003/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip
```shell
pip install tner
```
and activate model as below.
```python
from tner import TransformersNER
model = TransformersNER("tner/roberta-large-conll2003")
model.predict(["Jacob Collier is a Grammy awarded English artist from London"])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/conll2003']
- dataset_split: train
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 17
- batch_size: 64
- lr: 1e-05
- random_seed: 42
- gradient_accumulation_steps: 1
- weight_decay: None
- lr_warmup_step_ratio: 0.1
- max_grad_norm: 10.0
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-conll2003/raw/main/trainer_config.json).
### Reference
If you use any resource from T-NER, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
|
dartkain/newforproject
|
dartkain
| 2022-09-26T14:00:12Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-09-26T14:00:12Z |
---
license: creativeml-openrail-m
---
|
montazeri/bert-base-persian-sport-bert-uncased
|
montazeri
| 2022-09-26T13:25:26Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-02T06:07:47Z |
---
widget:
- text: "یوسین بولت دوندهٔ [MASK] دو سرعت و سریعترین انسان جهان است."
example_title: "EXAMPLE1"
- text: "ایران در مسابقات پاراالمپیک [MASK] شرکت می کند"
example_title: "EXAMPLE2"
- text: "وحید [MASK] آقای گل فوتسال جهان است"
example_title: "EXAMPLE3"
- text: "دو تیم ذوب آهن و نفت آبادان در ورزشگاه فولاد [MASK] به مصاف هم رفتند. "
example_title: "EXAMPLE4"
- text: "حسن یزدانی با شکست [MASK] قهرمان جهان شد "
example_title: "EXAMPLE5"
- text: "حسین [MASK] دو بار مدال طلای مسابقات المپیک را برای ایران به ارمغان آوردهاست"
example_title: "EXAMPLE6"
- text: " در مسابقههای تکواندو بازیهای آتن، سهم هر کشور، دو شرکت کننده تعیین شده بود که این سهمیه به هادی ساعی و یوسف [MASK] تعلق گرفت."
example_title: "EXAMPLE7"
- text: "سرمربی تیم ملی فوتبال ایران [MASK] است"
example_title: "EXAMPLE8"
---
VarzeshiBERT:
Introducing a language model based on Bret to analyze sports content in Persian language
Introduction:
VarzeshiBERT language model is presented for the purpose of Persian sports analysis in topics related to this linguistic field
|
wangwangw/123
|
wangwangw
| 2022-09-26T12:26:00Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-09-26T12:21:49Z |
---
title: Anime Remove Background
emoji: 🪄🖼️
colorFrom: indigo
colorTo: pink
sdk: gradio
sdk_version: 3.1.4
app_file: app.py
pinned: false
license: apache-2.0
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
jurabi/bert-ner-japanese
|
jurabi
| 2022-09-26T12:13:44Z | 3,771 | 10 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"token-classification",
"ja",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-26T07:46:38Z |
---
language:
- ja
widget:
- text: 株式会社Jurabiは、東京都台東区に本社を置くIT企業である。
license: cc-by-sa-3.0
---
# BERTによる日本語固有表現抽出のモデル
[BertForTokenClassification](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertForTokenClassification)を用いて、日本語の文から固有表現を抽出します。
抽出される固有表現のタイプは、以下の8種類です。
- 人名
- 法人名(法人または法人に類する組織)
- 政治的組織名(政治的組織名、政党名、政府組織名、行政組織名、軍隊名、国際組織名)
- その他の組織名 (競技組織名、公演組織名、その他)
- 地名
- 施設名
- 製品名(商品名、番組名、映画名、書籍名、歌名、ブランド名等)
- イベント名
## 使用方法
必要なライブラリ(transformers、unidic_lite、fugashi)をpipなどでインストールして、下記のコードを実行するだけです。
```python
from transformers import BertJapaneseTokenizer, BertForTokenClassification
from transformers import pipeline
model = BertForTokenClassification.from_pretrained("jurabi/bert-ner-japanese")
tokenizer = BertJapaneseTokenizer.from_pretrained("jurabi/bert-ner-japanese")
ner_pipeline = pipeline('ner', model=model, tokenizer=tokenizer)
ner_pipeline("株式会社Jurabiは、東京都台東区に本社を置くIT企業である。")
```
## 事前学習モデル
東北大学乾研究室が公開している日本語BERTモデル([cl-tohoku/bert-base-japanese-v2](https://huggingface.co/cl-tohoku/bert-base-japanese-v2))
## 学習データ
ストックマーク株式会社が公開しているWikipediaを用いた日本語の固有表現抽出データセット([stockmarkteam/ner-wikipedia-dataset](https://github.com/stockmarkteam/ner-wikipedia-dataset))
## ソースコード
ファインチューニングに使用したプログラムは、[jurabiinc/bert-ner-japanese](https://github.com/jurabiinc/bert-ner-japanese)で公開しています。
## ライセンス
[Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/)
|
sd-concepts-library/poring-ragnarok-online
|
sd-concepts-library
| 2022-09-26T12:11:17Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T12:11:11Z |
---
license: mit
---
### Poring Ragnarok Online on Stable Diffusion
This is the `<poring-ro>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
anaasanin/layoutlmv3-finetuned-wildreceipt
|
anaasanin
| 2022-09-26T11:06:35Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:wildreceipt",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-26T09:13:35Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- wildreceipt
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-wildreceipt
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wildreceipt
type: wildreceipt
config: WildReceipt
split: train
args: WildReceipt
metrics:
- name: Precision
type: precision
value: 0.874880087707277
- name: Recall
type: recall
value: 0.878491812302188
- name: F1
type: f1
value: 0.8766822301565504
- name: Accuracy
type: accuracy
value: 0.9253043764396183
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-wildreceipt
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the wildreceipt dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3111
- Precision: 0.8749
- Recall: 0.8785
- F1: 0.8767
- Accuracy: 0.9253
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.32 | 100 | 1.3060 | 0.6792 | 0.3615 | 0.4718 | 0.6966 |
| No log | 0.63 | 200 | 0.8842 | 0.6524 | 0.5193 | 0.5783 | 0.7737 |
| No log | 0.95 | 300 | 0.6795 | 0.7338 | 0.6772 | 0.7044 | 0.8336 |
| No log | 1.26 | 400 | 0.5604 | 0.7719 | 0.7390 | 0.7551 | 0.8629 |
| 1.0319 | 1.58 | 500 | 0.4862 | 0.7819 | 0.7618 | 0.7717 | 0.8730 |
| 1.0319 | 1.89 | 600 | 0.4365 | 0.7852 | 0.7807 | 0.7829 | 0.8795 |
| 1.0319 | 2.21 | 700 | 0.4182 | 0.8162 | 0.8016 | 0.8088 | 0.8897 |
| 1.0319 | 2.52 | 800 | 0.3886 | 0.8126 | 0.8196 | 0.8161 | 0.8936 |
| 1.0319 | 2.84 | 900 | 0.3637 | 0.8260 | 0.8347 | 0.8303 | 0.9004 |
| 0.4162 | 3.15 | 1000 | 0.3482 | 0.8532 | 0.8243 | 0.8385 | 0.9062 |
| 0.4162 | 3.47 | 1100 | 0.3474 | 0.8573 | 0.8248 | 0.8407 | 0.9042 |
| 0.4162 | 3.79 | 1200 | 0.3325 | 0.8408 | 0.8435 | 0.8421 | 0.9086 |
| 0.4162 | 4.1 | 1300 | 0.3262 | 0.8468 | 0.8467 | 0.8468 | 0.9095 |
| 0.4162 | 4.42 | 1400 | 0.3237 | 0.8511 | 0.8442 | 0.8477 | 0.9100 |
| 0.2764 | 4.73 | 1500 | 0.3156 | 0.8563 | 0.8456 | 0.8509 | 0.9122 |
| 0.2764 | 5.05 | 1600 | 0.3032 | 0.8558 | 0.8566 | 0.8562 | 0.9153 |
| 0.2764 | 5.36 | 1700 | 0.3120 | 0.8604 | 0.8457 | 0.8530 | 0.9142 |
| 0.2764 | 5.68 | 1800 | 0.2976 | 0.8608 | 0.8592 | 0.8600 | 0.9178 |
| 0.2764 | 5.99 | 1900 | 0.3056 | 0.8551 | 0.8676 | 0.8613 | 0.9171 |
| 0.212 | 6.31 | 2000 | 0.3191 | 0.8528 | 0.8599 | 0.8563 | 0.9147 |
| 0.212 | 6.62 | 2100 | 0.3051 | 0.8653 | 0.8635 | 0.8644 | 0.9186 |
| 0.212 | 6.94 | 2200 | 0.3022 | 0.8681 | 0.8632 | 0.8657 | 0.9208 |
| 0.212 | 7.26 | 2300 | 0.3101 | 0.8605 | 0.8643 | 0.8624 | 0.9178 |
| 0.212 | 7.57 | 2400 | 0.3100 | 0.8553 | 0.8693 | 0.8622 | 0.9163 |
| 0.1725 | 7.89 | 2500 | 0.3012 | 0.8685 | 0.8723 | 0.8704 | 0.9221 |
| 0.1725 | 8.2 | 2600 | 0.3135 | 0.8627 | 0.8756 | 0.8691 | 0.9187 |
| 0.1725 | 8.52 | 2700 | 0.3115 | 0.8768 | 0.8671 | 0.8719 | 0.9229 |
| 0.1725 | 8.83 | 2800 | 0.3044 | 0.8757 | 0.8708 | 0.8732 | 0.9231 |
| 0.1725 | 9.15 | 2900 | 0.3042 | 0.8698 | 0.8658 | 0.8678 | 0.9212 |
| 0.142 | 9.46 | 3000 | 0.3095 | 0.8677 | 0.8702 | 0.8690 | 0.9207 |
| 0.142 | 9.78 | 3100 | 0.3119 | 0.8686 | 0.8762 | 0.8724 | 0.9229 |
| 0.142 | 10.09 | 3200 | 0.3078 | 0.8713 | 0.8774 | 0.8743 | 0.9238 |
| 0.142 | 10.41 | 3300 | 0.3123 | 0.8711 | 0.8753 | 0.8732 | 0.9238 |
| 0.142 | 10.73 | 3400 | 0.3098 | 0.8688 | 0.8774 | 0.8731 | 0.9232 |
| 0.1238 | 11.04 | 3500 | 0.3120 | 0.8737 | 0.8770 | 0.8754 | 0.9247 |
| 0.1238 | 11.36 | 3600 | 0.3124 | 0.8760 | 0.8768 | 0.8764 | 0.9251 |
| 0.1238 | 11.67 | 3700 | 0.3101 | 0.8770 | 0.8759 | 0.8764 | 0.9254 |
| 0.1238 | 11.99 | 3800 | 0.3103 | 0.8767 | 0.8774 | 0.8770 | 0.9255 |
| 0.1238 | 12.3 | 3900 | 0.3122 | 0.8740 | 0.8788 | 0.8764 | 0.9251 |
| 0.1096 | 12.62 | 4000 | 0.3111 | 0.8749 | 0.8785 | 0.8767 | 0.9253 |
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.13.0
|
fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static-dedicated-qdq-everywhere
|
fxmarty
| 2022-09-26T10:52:18Z | 3 | 0 |
transformers
|
[
"transformers",
"onnx",
"distilbert",
"text-classification",
"dataset:sst2",
"dataset:glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T10:27:48Z |
---
license: apache-2.0
datasets:
- sst2
- glue
---
This model is a fork of https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english , quantized using static Post-Training Quantization (PTQ) with ONNX Runtime and 🤗 Optimum library.
It achieves 0.896 accuracy on the validation set.
This model uses the ONNX Runtime static quantization configurations `qdq_add_pair_to_weight=True` and `qdq_dedicated_pair=True`, so that **weights are stored in fp32**, and full Quantize + Dequantize nodes are inserted for the weights, compared to the default where weights are stored in int8 and only a Dequantize node is inserted for weights. Moreover, here QDQ pairs have a single output. For more reference, see the documentation: https://github.com/microsoft/onnxruntime/blob/ade0d291749144e1962884a9cfa736d4e1e80ff8/onnxruntime/python/tools/quantization/quantize.py#L432-L441
This is useful to later load a static quantized model in TensorRT.
To load this model:
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
model = ORTModelForSequenceClassification.from_pretrained("fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static-dedicated-qdq-everywhere")
```
### Weights stored as int8, only DequantizeLinear nodes (model here: https://huggingface.co/fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static)

### Weights stored as fp32, only QuantizeLinear + DequantizeLinear nodes (this model)

|
glopez/cifar-10
|
glopez
| 2022-09-26T09:56:03Z | 235 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:cifar10",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-26T09:51:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cifar10
model-index:
- name: cifar-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cifar-10
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the cifar10 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static
|
fxmarty
| 2022-09-26T09:00:58Z | 5 | 0 |
transformers
|
[
"transformers",
"onnx",
"distilbert",
"text-classification",
"dataset:sst2",
"dataset:glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T08:51:58Z |
---
license: apache-2.0
datasets:
- sst2
- glue
---
This model is a fork of https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english , quantized using static Post-Training Quantization (PTQ) with ONNX Runtime and 🤗 Optimum library.
It achieves 0.894 accuracy on the validation set.
To load this model:
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
model = ORTModelForSequenceClassification.from_pretrained("fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static")
```
|
microsoft/deberta-v2-xlarge
|
microsoft
| 2022-09-26T08:59:06Z | 104,224 | 23 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"deberta-v2",
"deberta",
"fill-mask",
"en",
"arxiv:2006.03654",
"license:mit",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- deberta
- fill-mask
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This is the DeBERTa V2 xlarge model with 24 layers, 1536 hidden size. The total parameters are 900M and it is trained with 160GB raw data.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\\\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \\\\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
microsoft/deberta-base
|
microsoft
| 2022-09-26T08:50:43Z | 6,398,087 | 76 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"rust",
"deberta",
"deberta-v1",
"fill-mask",
"en",
"arxiv:2006.03654",
"license:mit",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- deberta-v1
- fill-mask
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
#### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and MNLI tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m |
|-------------------|-----------|-----------|--------|
| RoBERTa-base | 91.5/84.6 | 83.7/80.5 | 87.6 |
| XLNet-Large | -/- | -/80.2 | 86.8 |
| **DeBERTa-base** | 93.1/87.2 | 86.2/83.1 | 88.8 |
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
duchung17/wav2vec2-base-timit-demo-google-colab
|
duchung17
| 2022-09-26T08:41:07Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-07-02T09:42:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4049
- Wer: 0.3556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.7319 | 1.0 | 500 | 1.3558 | 0.8890 |
| 0.7826 | 2.01 | 1000 | 0.5655 | 0.5398 |
| 0.4157 | 3.01 | 1500 | 0.4692 | 0.4682 |
| 0.2722 | 4.02 | 2000 | 0.4285 | 0.4193 |
| 0.2094 | 5.02 | 2500 | 0.4170 | 0.3949 |
| 0.1682 | 6.02 | 3000 | 0.3895 | 0.3751 |
| 0.1295 | 7.03 | 3500 | 0.3943 | 0.3628 |
| 0.1064 | 8.03 | 4000 | 0.4198 | 0.3648 |
| 0.0869 | 9.04 | 4500 | 0.4049 | 0.3556 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
prikarsartam/Olga
|
prikarsartam
| 2022-09-26T08:17:24Z | 67 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-26T04:59:17Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: prikarsartam/Olga
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# prikarsartam/Olga
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8904
- Validation Loss: 2.6281
- Train Rouge1: 25.0368
- Train Rouge2: 5.6914
- Train Rougel: 19.4806
- Train Rougelsum: 19.4874
- Train Gen Len: 18.7987
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-06, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 3.0715 | 2.6854 | 23.4337 | 4.8994 | 18.1348 | 18.1316 | 18.7024 | 0 |
| 2.8904 | 2.6281 | 25.0368 | 5.6914 | 19.4806 | 19.4874 | 18.7987 | 1 |
### Framework versions
- Transformers 4.22.1
- TensorFlow 2.8.2
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sahita/lang-VoxLingua107-ecapa
|
sahita
| 2022-09-26T08:13:03Z | 16 | 0 |
speechbrain
|
[
"speechbrain",
"audio-classification",
"embeddings",
"Language",
"Identification",
"pytorch",
"ECAPA-TDNN",
"TDNN",
"VoxLingua107",
"multilingual",
"en",
"mr",
"dataset:VoxLingua107",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] |
audio-classification
| 2022-09-23T08:53:34Z |
---
language:
- multilingual
- en
- mr
thumbnail:
tags:
- audio-classification
- speechbrain
- embeddings
- Language
- Identification
- pytorch
- ECAPA-TDNN
- TDNN
- VoxLingua107
license: "apache-2.0"
datasets:
- VoxLingua107
metrics:
- Accuracy
widget:
- example_title: English Sample
src: https://cdn-media.huggingface.co/speech_samples/LibriSpeech_61-70968-0000.flac
---
# VoxLingua107 ECAPA-TDNN Spoken Language Identification Model
## Model description
This is a spoken language recognition model trained on the VoxLingua107 dataset using SpeechBrain.
The model uses the ECAPA-TDNN architecture that has previously been used for speaker recognition. However, it uses
more fully connected hidden layers after the embedding layer, and cross-entropy loss was used for training.
We observed that this improved the performance of extracted utterance embeddings for downstream tasks.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.
The model can classify a speech utterance according to the language spoken.
It covers 2 different languages (
English,
Hindi).
## Intended uses & limitations
The model has two uses:
- use 'as is' for spoken language recognition
- use as an utterance-level feature (embedding) extractor, for creating a dedicated language ID model on your own data
The model is trained on automatically collected YouTube data. For more
information about the dataset, see [here](http://bark.phon.ioc.ee/voxlingua107/).
#### How to use
```python
import torchaudio
from speechbrain.pretrained import EncoderClassifier
language_id = EncoderClassifier.from_hparams(source="sahita/lang-VoxLingua-ecapa", savedir="tmp")
# Download Thai language sample from Omniglot and cvert to suitable form
signal = language_id.load_audio("https://omniglot.com/soundfiles/udhr/udhr_th.mp3")
prediction = language_id.classify_batch(signal)
print(prediction)
# (tensor([[-2.8646e+01, -3.0346e+01, -2.0748e+01, -2.9562e+01, -2.2187e+01,
# -3.2668e+01, -3.6677e+01, -3.3573e+01, -3.2545e+01, -2.4365e+01,
# -2.4688e+01, -3.1171e+01, -2.7743e+01, -2.9918e+01, -2.4770e+01,
# -3.2250e+01, -2.4727e+01, -2.6087e+01, -2.1870e+01, -3.2821e+01,
# -2.2128e+01, -2.2822e+01, -3.0888e+01, -3.3564e+01, -2.9906e+01,
# -2.2392e+01, -2.5573e+01, -2.6443e+01, -3.2429e+01, -3.2652e+01,
# -3.0030e+01, -2.4607e+01, -2.2967e+01, -2.4396e+01, -2.8578e+01,
# -2.5153e+01, -2.8475e+01, -2.6409e+01, -2.5230e+01, -2.7957e+01,
# -2.6298e+01, -2.3609e+01, -2.5863e+01, -2.8225e+01, -2.7225e+01,
# -3.0486e+01, -2.1185e+01, -2.7938e+01, -3.3155e+01, -1.9076e+01,
# -2.9181e+01, -2.2160e+01, -1.8352e+01, -2.5866e+01, -3.3636e+01,
# -4.2016e+00, -3.1581e+01, -3.1894e+01, -2.7834e+01, -2.5429e+01,
# -3.2235e+01, -3.2280e+01, -2.8786e+01, -2.3366e+01, -2.6047e+01,
# -2.2075e+01, -2.3770e+01, -2.2518e+01, -2.8101e+01, -2.5745e+01,
# -2.6441e+01, -2.9822e+01, -2.7109e+01, -3.0225e+01, -2.4566e+01,
# -2.9268e+01, -2.7651e+01, -3.4221e+01, -2.9026e+01, -2.6009e+01,
# -3.1968e+01, -3.1747e+01, -2.8156e+01, -2.9025e+01, -2.7756e+01,
# -2.8052e+01, -2.9341e+01, -2.8806e+01, -2.1636e+01, -2.3992e+01,
# -2.3794e+01, -3.3743e+01, -2.8332e+01, -2.7465e+01, -1.5085e-02,
# -2.9094e+01, -2.1444e+01, -2.9780e+01, -3.6046e+01, -3.7401e+01,
# -3.0888e+01, -3.3172e+01, -1.8931e+01, -2.2679e+01, -3.0225e+01,
# -2.4995e+01, -2.1028e+01]]), tensor([-0.0151]), tensor([94]), ['th'])
# The scores in the prediction[0] tensor can be interpreted as log-likelihoods that
# the given utterance belongs to the given language (i.e., the larger the better)
# The linear-scale likelihood can be retrieved using the following:
print(prediction[1].exp())
# tensor([0.9850])
# The identified language ISO code is given in prediction[3]
print(prediction[3])
# ['th: Thai']
# Alternatively, use the utterance embedding extractor:
emb = language_id.encode_batch(signal)
print(emb.shape)
# torch.Size([1, 1, 256])
```
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.
#### Limitations and bias
Since the model is trained on VoxLingua107, it has many limitations and biases, some of which are:
- Probably it's accuracy on smaller languages is quite limited
- Probably it works worse on female speech than male speech (because YouTube data includes much more male speech)
- Based on subjective experiments, it doesn't work well on speech with a foreign accent
- Probably it doesn't work well on children's speech and on persons with speech disorders
## Training data
The model is trained on [VoxLingua107](http://bark.phon.ioc.ee/voxlingua107/).
VoxLingua107 is a speech dataset for training spoken language identification models.
The dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.
VoxLingua107 contains data for 107 languages. The total amount of speech in the training set is 6628 hours.
The average amount of data per language is 62 hours. However, the real amount per language varies a lot. There is also a seperate development set containing 1609 speech segments from 33 languages, validated by at least two volunteers to really contain the given language.
## Training procedure
See the [SpeechBrain recipe](https://github.com/speechbrain/speechbrain/tree/voxlingua107/recipes/VoxLingua107/lang_id).
## Evaluation results
Error rate: 6.7% on the VoxLingua107 development dataset
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
### Referencing VoxLingua107
```bibtex
@inproceedings{valk2021slt,
title={{VoxLingua107}: a Dataset for Spoken Language Recognition},
author={J{\"o}rgen Valk and Tanel Alum{\"a}e},
booktitle={Proc. IEEE SLT Workshop},
year={2021},
}
```
#### About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.
Website: https://speechbrain.github.io/
GitHub: https://github.com/speechbrain/speechbrain
|
Enoch/Unixcoder-Tuned-Code-Search-Py
|
Enoch
| 2022-09-26T07:53:37Z | 101 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-09-26T06:59:10Z |
---
license: apache-2.0
---
|
sd-concepts-library/eru-chitanda-casual
|
sd-concepts-library
| 2022-09-26T07:39:50Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T07:39:45Z |
---
license: mit
---
### Eru Chitanda Casual on Stable Diffusion
This is the `<c-eru-chitanda>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
rram12/a2c-AntBulletEnv-v0
|
rram12
| 2022-09-26T05:27:04Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-26T05:26:14Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 1851.70 +/- 143.96
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
erikejw/swinv2-small-patch4-window16-256-finetuned-eurosat
|
erikejw
| 2022-09-26T03:31:23Z | 172 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swinv2",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-26T01:44:49Z |
---
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: swinv2-small-patch4-window16-256-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9892592592592593
- name: F1
type: f1
value: 0.9892542163878574
- name: Precision
type: precision
value: 0.9892896521886161
- name: Recall
type: recall
value: 0.9892592592592593
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swinv2-small-patch4-window16-256-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swinv2-small-patch4-window16-256](https://huggingface.co/microsoft/swinv2-small-patch4-window16-256) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0328
- Accuracy: 0.9893
- F1: 0.9893
- Precision: 0.9893
- Recall: 0.9893
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 96
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.2326 | 1.0 | 253 | 0.0870 | 0.9715 | 0.9716 | 0.9720 | 0.9715 |
| 0.1955 | 2.0 | 506 | 0.0576 | 0.9789 | 0.9788 | 0.9794 | 0.9789 |
| 0.1229 | 3.0 | 759 | 0.0450 | 0.9837 | 0.9837 | 0.9839 | 0.9837 |
| 0.0797 | 4.0 | 1012 | 0.0332 | 0.9889 | 0.9889 | 0.9889 | 0.9889 |
| 0.0826 | 5.0 | 1265 | 0.0328 | 0.9893 | 0.9893 | 0.9893 | 0.9893 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
ssharm87/t5-small-finetuned-eli5
|
ssharm87
| 2022-09-26T02:38:02Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-25T21:12:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-small-finetuned-eli5
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 9.5483
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-eli5
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7596
- Rouge1: 9.5483
- Rouge2: 1.8202
- Rougel: 7.7317
- Rougelsum: 8.8491
- Gen Len: 18.9895
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 3.9551 | 1.0 | 68159 | 3.7596 | 9.5483 | 1.8202 | 7.7317 | 8.8491 | 18.9895 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Ahmed007/BERT
|
Ahmed007
| 2022-09-26T02:32:44Z | 195 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-26T02:25:43Z |
---
tags:
- generated_from_trainer
model-index:
- name: BERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sahajrajmalla/patrakar
|
sahajrajmalla
| 2022-09-26T02:06:00Z | 107 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"nepali-nlp",
"nepali-news-classificiation",
"nlp",
"deep-learning",
"transfer-learning",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-15T07:05:22Z |
---
license: mit
tags:
- nepali-nlp
- nepali-news-classificiation
- nlp
- transformers
- deep-learning
- pytorch
- transfer-learning
model-index:
- name: patrakar
results: []
widget:
- text: "नेकपा (एमाले)का नेता गोकर्णराज विष्टले सहमति र सहकार्यबाटै संविधान बनाउने तथा जनताको जीवनस्तर उकास्ने काम गर्नु नै अबको मुख्य काम रहेको बताएका छन् ।"
example_title: "Example 1"
- text: "राजनीतिक स्थिरता नहुँदा विकास निर्माणले गति लिन सकेन ।"
example_title: "Example 2"
- text: "ठूलो उद्योग खोल्न महिलालाई ऋण दिइन्न"
example_title: "Example 3"
---
# patrakar/ पत्रकार (Nepali News Classifier)
Last updated: September 2022
## Model Details
**patrakar** is a DistilBERT pre-trained sequence classification transformer model which classifies Nepali language news into 9 newsgroup category, such as:
- politics
- opinion
- bank
- entertainment
- economy
- health
- literature
- sports
- tourism
It is developed by Sahaj Raj Malla to be generally usefuly for general public and so that others could explore them for commercial and scientific purposes. This model was trained on [Sakonii/distilgpt2-nepali](https://huggingface.co/Sakonii/distilgpt2-nepali) model.
It achieves the following results on the test dataset:
| Total Number of samples | Accuracy(%)
|:-------------:|:---------------:
| 5670 | 95.475
### Model date
September 2022
### Model type
Sequence classification model
### Model version
1.0.0
## Model Usage
This model can be used directly with a pipeline for text generation. Since the generation relies on some randomness, we set a seed for reproducibility:
```python
from transformers import pipeline, set_seed
set_seed(42)
model_name = "sahajrajmalla/patrakar"
classifier = pipeline('text-classification', model=model_name)
text = "नेकपा (एमाले)का नेता गोकर्णराज विष्टले सहमति र सहकार्यबाटै संविधान बनाउने तथा जनताको जीवनस्तर उकास्ने काम गर्नु नै अबको मुख्य काम रहेको बताएका छन् ।"
classifier(text)
```
Here is how we can use the model to get the features of a given text in PyTorch:
```python
!pip install transformers torch
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
import torch
import torch.nn.functional as F
# initializing model and tokenizer
model_name = "sahajrajmalla/patrakar"
# downloading tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# downloading model
model = AutoModelForSequenceClassification.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(examples["data"], padding="max_length", truncation=True)
# predicting with the model
sequence_i_want_to_predict = "राजनीतिक स्थिरता नहुँदा विकास निर्माणले गति लिन सकेन"
# initializing our labels
label_list = [
"bank",
"economy",
"entertainment",
"health",
"literature",
"opinion",
"politics",
"sports",
"tourism"
]
batch = tokenizer(sequence_i_want_to_predict, padding=True, truncation=True, max_length=512, return_tensors='pt')
with torch.no_grad():
outputs = model(**batch)
predictions = F.softmax(outputs.logits, dim=1)
labels = torch.argmax(predictions, dim=1)
print(f"The sequence: \n\n {word_i_want_to_predict} \n\n is predicted to be of newsgroup {label_list[labels.item()]}")
```
## Training data
This model is trained on 50,945 rows of Nepali language news grouped [dataset](https://www.kaggle.com/competitions/text-it-meet-22/data?select=train.csv) found on Kaggle which was also used in IT Meet 2022 Text challenge.
## Framework versions
- Transformers 4.20.1
- Pytorch 1.9.1
- Datasets 2.0.0
- Tokenizers 0.11.6
|
ramsformers/shoes-brand
|
ramsformers
| 2022-09-26T01:56:03Z | 226 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-26T01:55:52Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: shoes-brand
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.6716417670249939
---
# shoes-brand
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### adidas shoes

#### nike shoes

#### puma shoes

|
jamiehuang/t5-small-finetuned-xsum
|
jamiehuang
| 2022-09-26T01:29:12Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-24T21:08:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 13.2962
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6746
- Rouge1: 13.2962
- Rouge2: 2.0081
- Rougel: 10.6529
- Rougelsum: 12.049
- Gen Len: 18.9985
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.8901 | 1.0 | 17040 | 3.6746 | 13.2962 | 2.0081 | 10.6529 | 12.049 | 18.9985 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
ammarpl/t5-base-finetuned-elif-attempt1
|
ammarpl
| 2022-09-26T01:14:32Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-25T21:01:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-base-finetuned-elif-attempt1
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 3.9675
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-elif-attempt1
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.3889
- Rouge1: 3.9675
- Rouge2: 0.248
- Rougel: 3.454
- Rougelsum: 3.765
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 5.8271 | 1.0 | 17040 | 5.3889 | 3.9675 | 0.248 | 3.454 | 3.765 | 19.0 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
CoreyMorris/a2c-AntBulletEnv-v0-old
|
CoreyMorris
| 2022-09-26T00:52:15Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-26T00:51:18Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 951.33 +/- 234.16
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Bistolero/nl_ge_DP_6BX5_3
|
Bistolero
| 2022-09-25T23:49:17Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:gem",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-25T23:30:36Z |
---
tags:
- generated_from_trainer
datasets:
- gem
model-index:
- name: nl_ge_DP_6BX5_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nl_ge_DP_6BX5_3
This model was trained from scratch on the gem dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 25
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
amirabbas/wav2vec2-large-xls-r-300m-turkish-demo-colab-1
|
amirabbas
| 2022-09-25T23:11:58Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-25T19:40:10Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-demo-colab-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-demo-colab-1
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3487
- Wer: 0.3000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0425 | 3.67 | 400 | 0.7168 | 0.6650 |
| 0.4365 | 7.34 | 800 | 0.4498 | 0.4695 |
| 0.2103 | 11.01 | 1200 | 0.3975 | 0.3840 |
| 0.1257 | 14.68 | 1600 | 0.3655 | 0.3341 |
| 0.0828 | 18.35 | 2000 | 0.3487 | 0.3000 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
kkotkar1/t5-small-t5-base
|
kkotkar1
| 2022-09-25T22:49:52Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-25T16:33:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
model-index:
- name: t5-small-t5-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-t5-base
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
BumblingOrange/Shalltear_Bloodfallen
|
BumblingOrange
| 2022-09-25T22:25:26Z | 0 | 1 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-09-25T19:31:46Z |
---
license: bigscience-bloom-rail-1.0
---
Uses the Waifu Diffusion model as a base, linked here: https://huggingface.co/hakurei/waifu-diffusion
Custom Dreambooth model based off of the likeness of Shalltear Bloodfallen from Overlord. Dataset was 15 training images, and 13 regularization images. Trained for 3000 steps.
To use the model, simply insert the name 'Shalltear Bloodfallen' into your prompts. The class token used was 'vampire_girl_hair_bow_white_hair'. Append the class token after Shalltear Bloodfallen for stronger result.
EX: "A photo of Shalltear Bloodfallen vampire_girl_hair_bow_white_hair"
|
gur509/t5-small-finetuned-eli5
|
gur509
| 2022-09-25T22:23:43Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-24T23:38:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-small-finetuned-eli5
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 15.1689
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-eli5
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5993
- Rouge1: 15.1689
- Rouge2: 2.1762
- Rougel: 12.7542
- Rougelsum: 14.0214
- Gen Len: 18.9988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.8011 | 1.0 | 17040 | 3.5993 | 15.1689 | 2.1762 | 12.7542 | 14.0214 | 18.9988 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sd-concepts-library/remert
|
sd-concepts-library
| 2022-09-25T20:50:59Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-25T20:50:05Z |
---
license: mit
---
### remert on Stable Diffusion
This is the `<Remert>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:
|
quecopiones/distillbert-base-spanish-uncased-finetuned-full-suicidios
|
quecopiones
| 2022-09-25T19:52:22Z | 90 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-25T14:14:14Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distillbert-base-spanish-uncased-finetuned-full-suicidios
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distillbert-base-spanish-uncased-finetuned-full-suicidios
This model is a fine-tuned version of [CenIA/distillbert-base-spanish-uncased](https://huggingface.co/CenIA/distillbert-base-spanish-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0825
- Accuracy: 0.9814
- F1: 0.9814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.2059 | 1.0 | 32058 | 0.1142 | 0.9694 | 0.9694 |
| 0.1229 | 2.0 | 64116 | 0.0825 | 0.9814 | 0.9814 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sharonpeng/distilbert-base-uncased-finetuned-squad
|
sharonpeng
| 2022-09-25T18:31:46Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-06T06:04:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1456
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.215 | 1.0 | 5533 | 1.1619 |
| 0.9533 | 2.0 | 11066 | 1.1257 |
| 0.7566 | 3.0 | 16599 | 1.1456 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
amirabbas/wav2vec2-large-xls-r-300m-turkish-demo-colab
|
amirabbas
| 2022-09-25T18:23:15Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-25T12:17:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
kevinbram/nyfin
|
kevinbram
| 2022-09-25T17:13:57Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-25T15:28:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: nyfin
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nyfin
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.26 | 1.0 | 5533 | 1.2155 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.11.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
simecek/DNADebertaK6_Worm
|
simecek
| 2022-09-25T14:28:30Z | 162 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-19T08:02:15Z |
---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaK6_Worm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaK6_Worm
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 600001
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:------:|:---------------:|
| 4.5653 | 7.26 | 20000 | 1.8704 |
| 1.8664 | 14.53 | 40000 | 1.7762 |
| 1.7803 | 21.79 | 60000 | 1.7429 |
| 1.7502 | 29.06 | 80000 | 1.7305 |
| 1.7329 | 36.32 | 100000 | 1.7185 |
| 1.7191 | 43.59 | 120000 | 1.7073 |
| 1.7065 | 50.85 | 140000 | 1.6925 |
| 1.6945 | 58.12 | 160000 | 1.6877 |
| 1.6862 | 65.38 | 180000 | 1.6792 |
| 1.6788 | 72.65 | 200000 | 1.6712 |
| 1.6729 | 79.91 | 220000 | 1.6621 |
| 1.6679 | 87.18 | 240000 | 1.6608 |
| 1.6632 | 94.44 | 260000 | 1.6586 |
| 1.6582 | 101.71 | 280000 | 1.6585 |
| 1.6551 | 108.97 | 300000 | 1.6564 |
| 1.6507 | 116.24 | 320000 | 1.6449 |
| 1.6481 | 123.5 | 340000 | 1.6460 |
| 1.6448 | 130.77 | 360000 | 1.6411 |
| 1.6425 | 138.03 | 380000 | 1.6408 |
| 1.6387 | 145.3 | 400000 | 1.6358 |
| 1.6369 | 152.56 | 420000 | 1.6373 |
| 1.6337 | 159.83 | 440000 | 1.6364 |
| 1.6312 | 167.09 | 460000 | 1.6303 |
| 1.6298 | 174.36 | 480000 | 1.6346 |
| 1.6273 | 181.62 | 500000 | 1.6272 |
| 1.6244 | 188.88 | 520000 | 1.6268 |
| 1.6225 | 196.15 | 540000 | 1.6295 |
| 1.6207 | 203.41 | 560000 | 1.6206 |
| 1.6186 | 210.68 | 580000 | 1.6277 |
| 1.6171 | 217.94 | 600000 | 1.6161 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
simecek/DNADebertaK6_Arabidopsis
|
simecek
| 2022-09-25T14:27:59Z | 178 | 1 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-19T07:42:31Z |
---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaK6_Arabidopsis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaK6_Arabidopsis
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7194
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 600001
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:------:|:---------------:|
| 4.6174 | 6.12 | 20000 | 1.9257 |
| 1.8873 | 12.24 | 40000 | 1.8098 |
| 1.8213 | 18.36 | 60000 | 1.7952 |
| 1.8042 | 24.48 | 80000 | 1.7888 |
| 1.7945 | 30.6 | 100000 | 1.7861 |
| 1.7873 | 36.72 | 120000 | 1.7772 |
| 1.782 | 42.84 | 140000 | 1.7757 |
| 1.7761 | 48.96 | 160000 | 1.7632 |
| 1.7714 | 55.08 | 180000 | 1.7685 |
| 1.7677 | 61.2 | 200000 | 1.7568 |
| 1.7637 | 67.32 | 220000 | 1.7570 |
| 1.7585 | 73.44 | 240000 | 1.7442 |
| 1.7554 | 79.56 | 260000 | 1.7556 |
| 1.7515 | 85.68 | 280000 | 1.7505 |
| 1.7483 | 91.8 | 300000 | 1.7463 |
| 1.745 | 97.92 | 320000 | 1.7425 |
| 1.7427 | 104.04 | 340000 | 1.7425 |
| 1.7398 | 110.16 | 360000 | 1.7359 |
| 1.7377 | 116.28 | 380000 | 1.7369 |
| 1.7349 | 122.4 | 400000 | 1.7340 |
| 1.7325 | 128.52 | 420000 | 1.7313 |
| 1.731 | 134.64 | 440000 | 1.7256 |
| 1.7286 | 140.76 | 460000 | 1.7238 |
| 1.7267 | 146.88 | 480000 | 1.7324 |
| 1.7247 | 153.0 | 500000 | 1.7247 |
| 1.7228 | 159.12 | 520000 | 1.7185 |
| 1.7209 | 165.24 | 540000 | 1.7166 |
| 1.7189 | 171.36 | 560000 | 1.7206 |
| 1.7181 | 177.48 | 580000 | 1.7190 |
| 1.7159 | 183.6 | 600000 | 1.7194 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
apipond/ppo-LunarLander-v2
|
apipond
| 2022-09-25T13:37:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-25T13:37:18Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 226.89 +/- 17.19
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jamesesguerra/mt5-small-finetuned-1.0.0
|
jamesesguerra
| 2022-09-25T13:01:37Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-25T02:38:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-1.0.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-1.0.0
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8753
- Rouge1: 57.3754
- Rouge2: 52.6902
- Rougel: 56.5013
- Rougelsum: 56.9205
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 7.598 | 1.0 | 339 | 1.1360 | 57.9291 | 52.9851 | 56.8619 | 57.36 |
| 1.6607 | 2.0 | 678 | 0.9274 | 58.4006 | 53.715 | 57.3505 | 57.8747 |
| 1.3212 | 3.0 | 1017 | 0.8753 | 57.3754 | 52.6902 | 56.5013 | 56.9205 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
quecopiones/distillbert-base-spanish-uncased-finetuned-suicidios
|
quecopiones
| 2022-09-25T12:57:54Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-24T22:14:32Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distillbert-base-spanish-uncased-finetuned-suicidios
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distillbert-base-spanish-uncased-finetuned-suicidios
This model is a fine-tuned version of [CenIA/distillbert-base-spanish-uncased](https://huggingface.co/CenIA/distillbert-base-spanish-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2970
- Accuracy: 0.9483
- F1: 0.9483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.3543 | 1.0 | 9618 | 0.2688 | 0.9422 | 0.9422 |
| 0.1726 | 2.0 | 19236 | 0.2970 | 0.9483 | 0.9483 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
weijiahaha/t5-small-summarization
|
weijiahaha
| 2022-09-25T12:21:01Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-07-26T07:38:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
model-index:
- name: t5-small-summarization
results: []
---
# t5-small-summarization
This model is a fine-tuned version of t5-small (https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6477
## Model description
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9195 | 1.0 | 718 | 1.6477 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
shmuhammad/distilbert-base-uncased-distilled-clinc
|
shmuhammad
| 2022-09-25T11:06:16Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-18T14:37:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9487096774193549
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3060
- Accuracy: 0.9487
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.643 | 1.0 | 318 | 1.9110 | 0.7452 |
| 1.4751 | 2.0 | 636 | 0.9678 | 0.8606 |
| 0.7736 | 3.0 | 954 | 0.5578 | 0.9168 |
| 0.4652 | 4.0 | 1272 | 0.4081 | 0.9352 |
| 0.3364 | 5.0 | 1590 | 0.3538 | 0.9442 |
| 0.2801 | 6.0 | 1908 | 0.3294 | 0.9465 |
| 0.2515 | 7.0 | 2226 | 0.3165 | 0.9471 |
| 0.2366 | 8.0 | 2544 | 0.3107 | 0.9487 |
| 0.2292 | 9.0 | 2862 | 0.3069 | 0.9490 |
| 0.2247 | 10.0 | 3180 | 0.3060 | 0.9487 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1.post200
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.