
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-31 18:27:20
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 530
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-31 18:27:03
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
rahim707/language-identification-pytroch
|
rahim707
| 2025-06-21T12:53:37Z | 0 | 0 | null |
[
"text-classification",
"fr",
"en",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-06-21T12:42:38Z |
---
license: apache-2.0
language:
- fr
- en
metrics:
- accuracy
pipeline_tag: text-classification
---
|
Hammad1234434/pakX
|
Hammad1234434
| 2025-06-21T12:51:37Z | 0 | 0 |
diffusers
|
[
"diffusers",
"coder",
"aio",
"vibecoding",
"image-to-3d",
"en",
"ur",
"hi",
"dataset:openbmb/Ultra-FineWeb",
"arxiv:1910.09700",
"base_model:deepseek-ai/DeepSeek-R1-0528",
"base_model:finetune:deepseek-ai/DeepSeek-R1-0528",
"license:apache-2.0",
"region:us"
] |
image-to-3d
| 2025-06-21T12:47:03Z |
---
license: apache-2.0
datasets:
- openbmb/Ultra-FineWeb
language:
- en
- ur
- hi
metrics:
- accuracy
base_model:
- deepseek-ai/DeepSeek-R1-0528
new_version: nanonets/Nanonets-OCR-s
pipeline_tag: image-to-3d
library_name: diffusers
tags:
- coder
- aio
- vibecoding
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Tenofas/ComfyUI-Scripts
|
Tenofas
| 2025-06-21T12:49:58Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-06-06T10:45:23Z |
---
license: mit
---
# Tenofas' ComfyUI Windows installer all-in-one
This script will allow you to install ComfyUI, Comfy Manager, a few useful custom nodes and some Python libraries with just one single click.
All you have to do is create a folder where ComfyUI will be installed, copy the "Tenofas-ComfyUI_Windows_Installer_v1.0.bat" file and run it.
## What is needed
The script will check if you already have 7zip and git installed, if you don't, the script will try to install them for you.
## What the script provides
Once checked that 7zip and git are installed, the script will download and install ComfyUI "Windows_portable" version.
ComfyUI will be installed with pytorch 2.7.0+cu128 (latest pytorch stable version available).
Then, it will start to install a few custom nodes, starting from **ComfyUI Manager**. The other custom nodes that will be installed are:
1. Impact-Pack
2. GGUF
3. mxToolkit
4. Customn.Scripts
5. KJNodes
6. rgthree
7. Easy.Use
8. Was-node-suite
9. Upscaler-tenorrt
10. ComfyUI-Image-Saver
11. ComfyUI_UltimateSDUpscale
12. Detail-Daemon
13. TeaCache
The script will then install a few additional modules for Python (you may have to press "Accept" during installation). This is what will be installed
1. MS Visual Studio 2022
2. Nvidia Apex
3. Triton
4. xformers
5. SageAttention
Once the installation is over you can delete the .bat file from the folder.
|
18-jaipur-couple-viral-video-full/jaipur.couple.viral.video.in.5.Star.Hotel.full.original
|
18-jaipur-couple-viral-video-full
| 2025-06-21T12:47:05Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:46:37Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-11-sneaker
|
veddhanth
| 2025-06-21T12:45:28Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T12:38:15Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-11-sneaker
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-11-sneaker LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-pretrained-enc-v2-spat-map-11-sneaker/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
elidle/indobert-post-training-fin-sa-5
|
elidle
| 2025-06-21T12:41:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:elidle/indobert-fin_news-mlm-3",
"base_model:finetune:elidle/indobert-fin_news-mlm-3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T12:40:31Z |
---
library_name: transformers
license: mit
base_model: elidle/indobert-fin_news-mlm-3
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: indobert-post-training-fin-sa-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-post-training-fin-sa-5
This model is a fine-tuned version of [elidle/indobert-fin_news-mlm-3](https://huggingface.co/elidle/indobert-fin_news-mlm-3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1628
- Accuracy: 0.9615
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.048 | 0.1961 | 10 | 0.6923 | 0.7527 |
| 0.5601 | 0.3922 | 20 | 0.4627 | 0.7967 |
| 0.426 | 0.5882 | 30 | 0.3104 | 0.8956 |
| 0.2903 | 0.7843 | 40 | 0.2263 | 0.9176 |
| 0.1868 | 0.9804 | 50 | 0.2365 | 0.9231 |
| 0.1661 | 1.1765 | 60 | 0.1958 | 0.9286 |
| 0.115 | 1.3725 | 70 | 0.1614 | 0.9396 |
| 0.1015 | 1.5686 | 80 | 0.1678 | 0.9505 |
| 0.1147 | 1.7647 | 90 | 0.1863 | 0.9505 |
| 0.1358 | 1.9608 | 100 | 0.1808 | 0.9505 |
| 0.0561 | 2.1569 | 110 | 0.1565 | 0.9505 |
| 0.0473 | 2.3529 | 120 | 0.1953 | 0.9451 |
| 0.0502 | 2.5490 | 130 | 0.1447 | 0.9615 |
| 0.0806 | 2.7451 | 140 | 0.1681 | 0.9505 |
| 0.082 | 2.9412 | 150 | 0.1859 | 0.9451 |
| 0.0179 | 3.1373 | 160 | 0.1451 | 0.9725 |
| 0.048 | 3.3333 | 170 | 0.1631 | 0.9725 |
| 0.0067 | 3.5294 | 180 | 0.1628 | 0.9615 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
18-videos-jaipur-hotel-going-viral/FULL.VIDEO.18.jaipur.hotel.viral.video.original.holiday.inn.jaipur.viral.video
|
18-videos-jaipur-hotel-going-viral
| 2025-06-21T12:40:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:40:10Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
Ujjwal-32/amazon-rec
|
Ujjwal-32
| 2025-06-21T12:38:23Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-21T12:35:57Z |
---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained our model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** |
|
Official-Othoi-viral-video-Link/FULL.VIDEO.LINK.Othoi.Viral.Video.Leaks.Tutorial.Official
|
Official-Othoi-viral-video-Link
| 2025-06-21T12:35:10Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:34:50Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
18-Graciela-Varela-Video/Ver.Completo.Video.graciela.varela.video.filtrado.enacle
|
18-Graciela-Varela-Video
| 2025-06-21T12:28:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:28:27Z |
<a href="https://tinyurl.com/isrealchudi?top.gun" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
shilinxu/Qwen2_5-VL-3B-ViT
|
shilinxu
| 2025-06-21T12:26:57Z | 0 | 0 | null |
[
"safetensors",
"qwen2_5_vl",
"custom_code",
"license:mit",
"region:us"
] | null | 2025-06-21T10:05:50Z |
---
license: mit
---
```python
import torch
import requests
from PIL import Image
from transformers import AutoModel, AutoProcessor, AutoImageProcessor
from transformers import Qwen2VLForConditionalGeneration
image_processor = AutoImageProcessor.from_pretrained("shilinxu/Qwen2_5-VL-3B-ViT", trust_remote_code=True)
vit = AutoModel.from_pretrained("shilinxu/Qwen2_5-VL-3B-ViT", trust_remote_code=True, device_map='auto',torch_dtype=torch.bfloat16, attn_implementation='flash_attention_2')
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
images = [image]
inputs = image_processor(images, return_tensors="pt")
pixel_values = inputs['pixel_values'].to(device=vit.device, dtype=vit.dtype)
image_grid_thw = inputs['image_grid_thw']
image_embeds = vit(pixel_values, grid_thw=image_grid_thw)
```
|
intisarhasnain/mystory
|
intisarhasnain
| 2025-06-21T12:26:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-21T12:26:53Z |
---
license: apache-2.0
---
|
veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-10-5
|
veddhanth
| 2025-06-21T12:26:01Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T12:15:14Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-10-5
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-10-5 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-10-5/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
AhmedSaqr28/reasoning-assil-beta-qwen2.5-3b
|
AhmedSaqr28
| 2025-06-21T12:20:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T12:20:34Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AhmedSaqr28
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie
|
BootesVoid
| 2025-06-21T12:19:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T12:19:14Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AVENLUX
---
# Cmby644Mv02Wordqs8Kzq0Jwa_Cmc66Bjhi0561Bfif4Khlnbie
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AVENLUX` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AVENLUX",
"lora_weights": "https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie', weight_name='lora.safetensors')
image = pipeline('AVENLUX').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc66bjhi0561bfif4khlnbie/discussions) to add images that show off what you’ve made with this LoRA.
|
JoeShingleton/ProxiLlama-edb-3.1-8b
|
JoeShingleton
| 2025-06-21T12:15:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T11:20:00Z |
---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** JoeShingleton
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Full-Clip-anabelangus-18-Viral-videos/FULL.VIDEO.Ultimo.Video.18.Anabel.Angus.Camara.De.Seguridad.Telegram.Video
|
Full-Clip-anabelangus-18-Viral-videos
| 2025-06-21T12:14:28Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:14:16Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Jellon/Mistral-Small-3.2-24B-Instruct-2506-exl3-6bpw
|
Jellon
| 2025-06-21T12:09:36Z | 0 | 0 |
vllm
|
[
"vllm",
"safetensors",
"mistral3",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"base_model:quantized:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"license:apache-2.0",
"6-bit",
"exl3",
"region:us"
] |
image-text-to-text
| 2025-06-21T09:35:18Z |
---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.2-24B-Instruct-2506
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: image-text-to-text
---
6bpw exl3 quant of: https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506
---
# Mistral-Small-3.2-24B-Instruct-2506
Mistral-Small-3.2-24B-Instruct-2506 is a minor update of [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
Small-3.2 improves in the following categories:
- **Instruction following**: Small-3.2 is better at following precise instructions
- **Repetition errors**: Small-3.2 produces less infinite generations or repetitive answers
- **Function calling**: Small-3.2's function calling template is more robust (see [here](https://github.com/mistralai/mistral-common/blob/535b4d0a0fc94674ea17db6cf8dc2079b81cbcfa/src/mistral_common/tokens/tokenizers/instruct.py#L778) and [examples](#function-calling))
In all other categories Small-3.2 should match or slightly improve compared to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
## Key Features
- same as [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503#key-features)
## Benchmark Results
We compare Mistral-Small-3.2-24B to [Mistral-Small-3.1-24B-Instruct-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
For more comparison against other models of similar size, please check [Mistral-Small-3.1's Benchmarks'](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503#benchmark-results)
### Text
#### Instruction Following / Chat / Tone
| Model | Wildbench v2 | Arena Hard v2 | IF (Internal; accuracy) |
|-------|---------------|---------------|------------------------|
| Small 3.1 24B Instruct | 55.6% | 19.56% | 82.75% |
| **Small 3.2 24B Instruct** | **65.33%** | **43.1%** | **84.78%** |
#### Infinite Generations
Small 3.2 reduces infitine generations by 2x on challenging, long and repetitive prompts.
| Model | Infinite Generations (Internal; Lower is better) |
|-------|-------|
| Small 3.1 24B Instruct | 2.11% |
| **Small 3.2 24B Instruct** | **1.29%** |
#### STEM
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP Plus - Pass@5 | HumanEval Plus - Pass@5 | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|--------------------|-------------------------|--------------------|
| Small 3.1 24B Instruct | 80.62% | 66.76% | 69.30% | 44.42% | 45.96% | 74.63% | 88.99% | 10.43% |
| **Small 3.2 24B Instruct** | 80.50% | **69.06%** | 69.42% | 44.22% | 46.13% | **78.33%** | **92.90%** | **12.10%** |
### Vision
| Model | MMMU | Mathvista | ChartQA | DocVQA | AI2D |
|--------------------------------|------------|-----------|-----------|-----------|-----------|
| Small 3.1 24B Instruct | **64.00%** | **68.91%**| 86.24% | 94.08% | 93.72% |
| **Small 3.2 24B Instruct** | 62.50% | 67.09% | **87.4%** | 94.86% | 92.91% |
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailer it for your needs. If you want to use the model as a general assistant, we recommend to use the one provided in the [SYSTEM_PROMPT.txt](https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506/blob/main/SYSTEM_PROMPT.txt) file.
### vLLM (recommended)
We recommend using this model with [vLLM](https://github.com/vllm-project/vllm).
#### Installation
Make sure to install [`vLLM >= 0.9.1`](https://github.com/vllm-project/vllm/releases/tag/v0.9.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.6.2`](https://github.com/mistralai/mistral-common/releases/tag/v1.6.2).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Serve
We recommand that you use Mistral-Small-3.2-24B-Instruct-2506 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.2-24B-Instruct-2506 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10' --tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.2-24B-Instruct-2506 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet. See the following examples.
#### Vision reasoning
Take leverage of the vision capabilities of Mistral-Small-3.2-24B-Instruct-2506 to take the best choice given a scenario, go catch them all !
<details>
<summary>Python snippet</summary>
```py
from datetime import datetime, timedelta
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture the Pidgey or heal your Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat the Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be a strategic move if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could save time and conserve your Pokémon's health and resources. If you are in a hurry or do not need the experience or items, running away is a safe option.
# - **Cons**: Running away means you miss out on the experience points and potential items or money that you could gain from defeating the Pidgey. It also means you do not get the chance to capture the Pidgey if you wanted to.
# ### Recommendation:
# Given the significant level advantage, the best action is likely to **FIGHT**. This will allow you to quickly defeat the Pidgey, gain experience points, and potentially earn items or money. If you are concerned about Pikachu's health, you could use an item from your **BAG** to heal it before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
#### Function calling
Mistral-Small-3.2-24B-Instruct-2506 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Python snippet - easy</summary>
```py
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
tools = [
{
"type": "function",
"function": {
"name": "get_current_population",
"description": "Get the up-to-date population of a given country.",
"parameters": {
"type": "object",
"properties": {
"country": {
"type": "string",
"description": "The country to find the population of.",
},
"unit": {
"type": "string",
"description": "The unit for the population.",
"enum": ["millions", "thousands"],
},
},
"required": ["country", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you tell me what is the biggest country depicted on the map?",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# The biggest country depicted on the map is Russia.
messages.extend([
{"role": "assistant", "content": assistant_message},
{"role": "user", "content": "What is the population of that country in millions?"},
])
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message.tool_calls)
# [ChatCompletionMessageToolCall(id='3e92V6Vfo', function=Function(arguments='{"country": "Russia", "unit": "millions"}', name='get_current_population'), type='function')]
```
</details>
<details>
<summary>Python snippet - complex</summary>
```python
import json
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
image_url = "https://math-coaching.com/img/fiche/46/expressions-mathematiques.jpg"
def my_calculator(expression: str) -> str:
return str(eval(expression))
tools = [
{
"type": "function",
"function": {
"name": "my_calculator",
"description": "A calculator that can evaluate a mathematical expression.",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "The mathematical expression to evaluate.",
},
},
"required": ["expression"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you calculate the results for all the equations displayed in the image? Only compute the ones that involve numbers.",
},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
tools=tools,
tool_choice="auto",
)
tool_calls = response.choices[0].message.tool_calls
print(tool_calls)
# [ChatCompletionMessageToolCall(id='CyQBSAtGh', function=Function(arguments='{"expression": "6 + 2 * 3"}', name='my_calculator'), type='function'), ChatCompletionMessageToolCall(id='KQqRCqvzc', function=Function(arguments='{"expression": "19 - (8 + 2) + 1"}', name='my_calculator'), type='function')]
results = []
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = tool_call.function.arguments
if function_name == "my_calculator":
result = my_calculator(**json.loads(function_args))
results.append(result)
messages.append({"role": "assistant", "tool_calls": tool_calls})
for tool_call, result in zip(tool_calls, results):
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": result,
}
)
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
print(response.choices[0].message.content)
# Here are the results for the equations that involve numbers:
# 1. \( 6 + 2 \times 3 = 12 \)
# 3. \( 19 - (8 + 2) + 1 = 10 \)
# For the other equations, you need to substitute the variables with specific values to compute the results.
```
</details>
#### Instruction following
Mistral-Small-3.2-24B-Instruct-2506 will follow your instructions down to the last letter !
<details>
<summary>Python snippet</summary>
```python
from openai import OpenAI
from huggingface_hub import hf_hub_download
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
TEMP = 0.15
MAX_TOK = 131072
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
return system_prompt
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Write me a sentence where every word starts with the next letter in the alphabet - start with 'a' and end with 'z'.",
},
]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=TEMP,
max_tokens=MAX_TOK,
)
assistant_message = response.choices[0].message.content
print(assistant_message)
# Here's a sentence where each word starts with the next letter of the alphabet, starting from 'a' and ending with 'z':
# "Always brave cats dance elegantly, fluffy giraffes happily ignore jungle kites, lovingly munching nuts, observing playful quails racing swiftly, tiny unicorns vaulting while xylophones yodel zealously."
# This sentence follows the sequence from A to Z without skipping any letters.
```
</details>
### Transformers
You can also use Mistral-Small-3.2-24B-Instruct-2506 with `Transformers` !
To make the best use of our model with `Transformers` make sure to have [installed](https://github.com/mistralai/mistral-common) `mistral-common >= 1.6.2` to use our tokenizer.
```bash
pip install mistral-common --upgrade
```
Then load our tokenizer along with the model and generate:
<details>
<summary>Python snippet</summary>
```python
from datetime import datetime, timedelta
import torch
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from huggingface_hub import hf_hub_download
from transformers import Mistral3ForConditionalGeneration
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
model_id = "mistralai/Mistral-Small-3.2-24B-Instruct-2506"
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")
tokenizer = MistralTokenizer.from_hf_hub(model_id)
model = Mistral3ForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.bfloat16
)
image_url = "https://static.wikia.nocookie.net/essentialsdocs/images/7/70/Battle.png/revision/latest?cb=20220523172438"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "What action do you think I should take in this situation? List all the possible actions and explain why you think they are good or bad.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
tokenized = tokenizer.encode_chat_completion(ChatCompletionRequest(messages=messages))
input_ids = torch.tensor([tokenized.tokens])
attention_mask = torch.ones_like(input_ids)
pixel_values = torch.tensor(tokenized.images[0], dtype=torch.bfloat16).unsqueeze(0)
image_sizes = torch.tensor([pixel_values.shape[-2:]])
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
pixel_values=pixel_values,
image_sizes=image_sizes,
max_new_tokens=1000,
)[0]
decoded_output = tokenizer.decode(output[len(tokenized.tokens) :])
print(decoded_output)
# In this situation, you are playing a Pokémon game where your Pikachu (Level 42) is facing a wild Pidgey (Level 17). Here are the possible actions you can take and an analysis of each:
# 1. **FIGHT**:
# - **Pros**: Pikachu is significantly higher level than the wild Pidgey, which suggests that it should be able to defeat Pidgey easily. This could be a good opportunity to gain experience points and possibly items or money.
# - **Cons**: There is always a small risk of Pikachu fainting, especially if Pidgey has a powerful move or a status effect that could hinder Pikachu. However, given the large level difference, this risk is minimal.
# 2. **BAG**:
# - **Pros**: You might have items in your bag that could help in this battle, such as Potions, Poké Balls, or Berries. Using an item could help you capture Pidgey or heal Pikachu if needed.
# - **Cons**: Using items might not be necessary given the level difference. It could be more efficient to just fight and defeat Pidgey quickly.
# 3. **POKÉMON**:
# - **Pros**: You might have another Pokémon in your party that is better suited for this battle or that you want to gain experience. Switching Pokémon could also be strategic if you want to train a lower-level Pokémon.
# - **Cons**: Switching Pokémon might not be necessary since Pikachu is at a significant advantage. It could also waste time and potentially give Pidgey a turn to attack.
# 4. **RUN**:
# - **Pros**: Running away could be a quick way to avoid the battle altogether. This might be useful if you are trying to conserve resources or if you are in a hurry to get to another location.
# - **Cons**: Running away means you miss out on the experience points, items, or money that you could gain from defeating Pidgey. It also might not be the most efficient use of your time if you are trying to train your Pokémon.
# ### Recommendation:
# Given the significant level advantage, the best action to take is likely **FIGHT**. This will allow you to quickly defeat Pidgey and gain experience points for Pikachu. If you are concerned about Pikachu's health, you could use the **BAG** to heal Pikachu before or during the battle. Running away or switching Pokémon does not seem necessary in this situation.
```
</details>
|
codewithpurav/a2c-PandaPickAndPlace-v3
|
codewithpurav
| 2025-06-21T12:08:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T12:04:20Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
18-Jaipur-Hotel-Viral-Video/NEW.VIDEO.jaipur.hotel.viral.video.Link.viral.On.Social.Media.Link
|
18-Jaipur-Hotel-Viral-Video
| 2025-06-21T12:06:54Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T12:04:44Z |
<a href="https://tinyurl.com/isrealchudi?top.gun" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
hopjetair/intent
|
hopjetair
| 2025-06-21T12:04:21Z | 28 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"safetensors",
"distilbert",
"text-classification",
"en",
"dataset:bitext/Bitext-travel-llm-chatbot-training-dataset",
"arxiv:2106.09685",
"base_model:distilbert/distilbert-base-uncased",
"base_model:adapter:distilbert/distilbert-base-uncased",
"region:us"
] |
text-classification
| 2025-06-21T06:00:27Z |
---
datasets:
- bitext/Bitext-travel-llm-chatbot-training-dataset
language:
- en
metrics:
- accuracy
- f1
- recall
- precision
base_model:
- distilbert/distilbert-base-uncased
pipeline_tag: text-classification
library_name: adapter-transformers
---
# DistilBERT with LoRA for Intent Recognition
This is a parameter-efficient fine-tuned version of `distilbert-base-uncased` using the LoRA technique via [PEFT](https://github.com/huggingface/peft). The model was trained for intent recognition using a custom dataset.
## 🧾 Model Details
- Base model: `distilbert-base-uncased`
- Fine-tuning method: [LoRA (Low-Rank Adaptation)](https://arxiv.org/abs/2106.09685) using 🤗 PEFT
- Task: Intent Recognition (Text Classification)
## 🧠 Intended Use
You can use this model to classify user intents in applications like chatbots, virtual assistants, or voice-based interfaces.
## 🏷️ Intent Labels
This model supports classification over **33 intent labels**, including:
- BAGGAGE: check_baggage_allowance
- BOARDING_PASS: get_boarding_pass, print_boarding_pass
- CANCELLATION_FEE: check_cancellation_fee
- CHECK_IN: check_in
- CONTACT: human_agent
- FLIGHT: book_flight, cancel_flight, change_flight, check_flight_insurance_coverage, check_flight_offers, check_flight_prices, check_flight_reservation, check_flight_status, purchase_flight_insurance, search_flight, search_flight_insurance
- PRICES: check_trip_prices
- REFUND: get_refund
- SEAT: change_seat, choose_seat
- TIME: check_arrival_time, check_departure_time
- TRIP: book_trip, cancel_trip, change_trip, check_trip_details, check_trip_insurance_coverage, check_trip_offers, check_trip_plan, check_trip_prices, purchase_trip_insurance, search_trip, search_trip_insurance
## 📥 How to Use
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from peft import PeftModel
import joblib
# Load tokenizer and base model
tokenizer = AutoTokenizer.from_pretrained("hopjetair/intent")
base_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased",num_labels=33)
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "hopjetair/intent")
# Load label encoder
label_encoder = joblib.load("label_encoder.pkl")
# Inference
text = "Book me a flight to New York"
clf = pipeline("text-classification", model=model, tokenizer=tokenizer)
result = clf(text)[0]
label_num = int(result["label"].split("_")[-1])
# Convert back to label
predicted_label = label_encoder.inverse_transform([label_num])[0]
print(predicted_label)
```
## 🧪 CPU vs GPU Inference (Approximate Benchmarks)
> On average hardware — actual performance may vary based on your system configuration.
| **Task** | **CPU Inference Time** | **GPU Inference Time** |
|---------------------------|------------------------|-------------------------|
| Single sentence inference | ~100–200 ms | ~5–10 ms |
| Batch of 32 inputs | ~2–3 seconds total | ~100–300 ms total |
---
## 🖥️ Minimum Requirements for CPU Inference
You can run DistilBERT inference on:
- ⚙️ Modern desktop or laptop CPUs
- ☁️ Cloud VMs (e.g., AWS `t3.medium`, GCP `e2-standard`)
- 🧩 Even on low-end devices (with some latency trade-off)
|
shelemakha/helloworldRL
|
shelemakha
| 2025-06-21T11:59:09Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T11:57:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.73 +/- 12.03
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Andresgr96/gemma-3-4b-it-qat-B
|
Andresgr96
| 2025-06-21T11:53:01Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3",
"image-text-to-text",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-3-4b-it-qat",
"base_model:quantized:unsloth/gemma-3-4b-it-qat",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-06-21T11:52:03Z |
---
base_model: unsloth/gemma-3-4b-it-qat
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Andresgr96
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-qat
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ziadrone/bert-base-uncased
|
ziadrone
| 2025-06-21T11:52:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"feature-extraction",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-21T11:48:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
KeunTnz/tag-to-kapams
|
KeunTnz
| 2025-06-21T11:50:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"marian",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-21T11:49:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Davidozito/fewshot-CDW-CE-1000-samples
|
Davidozito
| 2025-06-21T11:46:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:Davidozito/zeroshot-classification",
"base_model:finetune:Davidozito/zeroshot-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T11:40:48Z |
---
library_name: transformers
base_model: Davidozito/zeroshot-classification
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: fewshot-CDW-CE-1000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fewshot-CDW-CE-1000-samples
This model is a fine-tuned version of [Davidozito/zeroshot-classification](https://huggingface.co/Davidozito/zeroshot-classification) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1290
- Accuracy: 0.62
- F1 Macro: 0.6187
- F1 Weighted: 0.6223
- Precision Macro: 0.6294
- Recall Macro: 0.6167
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro | F1 Weighted | Precision Macro | Recall Macro |
|:-------------:|:------:|:----:|:---------------:|:--------:|:--------:|:-----------:|:---------------:|:------------:|
| 1.1359 | 0.2478 | 28 | 1.1319 | 0.58 | 0.5708 | 0.5765 | 0.5775 | 0.5737 |
| 1.1457 | 0.4956 | 56 | 1.1288 | 0.6 | 0.5926 | 0.5980 | 0.5987 | 0.5937 |
| 1.171 | 0.7434 | 84 | 1.1291 | 0.59 | 0.5843 | 0.5888 | 0.5966 | 0.5847 |
| 1.1105 | 0.9912 | 112 | 1.1287 | 0.6 | 0.5982 | 0.6021 | 0.6071 | 0.5962 |
| 1.0822 | 1.2389 | 140 | 1.1295 | 0.6 | 0.5909 | 0.5958 | 0.5988 | 0.5947 |
| 1.0855 | 1.4867 | 168 | 1.1294 | 0.6 | 0.5971 | 0.6010 | 0.6029 | 0.5962 |
| 1.1396 | 1.7345 | 196 | 1.1294 | 0.59 | 0.5871 | 0.5912 | 0.5921 | 0.5862 |
| 1.1243 | 1.9823 | 224 | 1.1296 | 0.61 | 0.6088 | 0.6126 | 0.6182 | 0.6067 |
| 1.092 | 2.2301 | 252 | 1.1291 | 0.6 | 0.5983 | 0.6018 | 0.6043 | 0.5967 |
| 1.1624 | 2.4779 | 280 | 1.1287 | 0.6 | 0.6002 | 0.6034 | 0.6088 | 0.5972 |
| 1.0876 | 2.7257 | 308 | 1.1283 | 0.61 | 0.6062 | 0.6103 | 0.6184 | 0.6057 |
| 1.1741 | 2.9735 | 336 | 1.1287 | 0.61 | 0.6085 | 0.6118 | 0.6158 | 0.6067 |
| 1.187 | 3.2212 | 364 | 1.1290 | 0.62 | 0.6187 | 0.6223 | 0.6294 | 0.6167 |
| 1.1748 | 3.4690 | 392 | 1.1289 | 0.62 | 0.6187 | 0.6223 | 0.6294 | 0.6167 |
| 1.1556 | 3.7168 | 420 | 1.1287 | 0.61 | 0.6065 | 0.6106 | 0.6146 | 0.6062 |
| 1.1189 | 3.9646 | 448 | 1.1285 | 0.61 | 0.6065 | 0.6106 | 0.6146 | 0.6062 |
| 1.1245 | 4.2124 | 476 | 1.1284 | 0.61 | 0.6073 | 0.6114 | 0.6164 | 0.6062 |
| 1.0478 | 4.4602 | 504 | 1.1283 | 0.61 | 0.6073 | 0.6114 | 0.6164 | 0.6062 |
| 1.1255 | 4.7080 | 532 | 1.1283 | 0.6 | 0.5971 | 0.6010 | 0.6029 | 0.5962 |
| 1.1973 | 4.9558 | 560 | 1.1283 | 0.6 | 0.5971 | 0.6010 | 0.6029 | 0.5962 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1
- Datasets 3.6.0
- Tokenizers 0.21.1
|
gghfez/Mistral-Small-3.2-24B-Instruct-hf
|
gghfez
| 2025-06-21T11:45:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"base_model:finetune:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T09:27:59Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
base_model:
- mistralai/Mistral-Small-3.2-24B-Instruct-2506
---
[mistralai/Mistral-Small-3.2-24B-Instruct-2506](https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506) converted to the HF format.
This is **Not** multimodal
|
avinashhm/llama-3.1-8b-dora-finetuned
|
avinashhm
| 2025-06-21T11:44:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"peft",
"trl",
"dora",
"conversational",
"en",
"dataset:mlabonne/FineTome-100k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T11:19:53Z |
---
base_model: quantized_Llama-3.1-8B-Instruct
tags:
- text-generation-inference
- transformers
- peft
- trl
- llama
- dora
license: apache-2.0
language:
- en
datasets:
- mlabonne/FineTome-100k
---
# LLaMA-3.1-8B-Instruct DoRA Fine-Tuned
- **Developed by:** avinashhm
- **License:** apache-2.0
- **Finetuned from model:** devatar/quantized_Llama-3.1-8B-Instruct
This model is a fine-tuned version of `devatar/quantized_Llama-3.1-8B-Instruct`, adapted using DoRA (Weight-Decomposed Low-Rank Adaptation) on a subset of the `mlabonne/FineTome-100k` dataset. It is optimized for instruction-following tasks, such as answering questions and explaining concepts, and was fine-tuned on a 40GB GPU with memory-efficient techniques.
## Training Details
- **Dataset**: `mlabonne/FineTome-100k` (5,000 samples)
- **Fine-Tuning Method**: DoRA (r=8, lora_alpha=16, target_modules=["q_proj", "k_proj", "v_proj", "o_proj"])
- **Training Steps**: 500
- **Optimizer**: Paged AdamW 8-bit
- **Learning Rate**: 2e-5 (cosine scheduler)
- **Batch Size**: Effective batch size of 8 (per_device_train_batch_size=1, gradient_accumulation_steps=8)
- **Precision**: Mixed precision (FP16)
- **Training Loss**: Decreased from 1.4494 to 0.8145 over 500 steps
## Dataset
The model was trained on a 5,000-sample subset of `mlabonne/FineTome-100k`, which contains high-quality instruction-response pairs. Conversations were formatted as `### Human: ... ### Gpt: ...` for training, covering tasks like explaining programming concepts and reasoning.
## Usage
To use the model for inference:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("avinashhm/llama-3.1-8b-dora-finetuned", device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("avinashhm/llama-3.1-8b-dora-finetuned")
inputs = tokenizer("Explain boolean operators in programming.", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
**Note**: The base model is 4-bit quantized, and merging DoRA adapters may introduce minor rounding errors in generations.
## Requirements
- `torch`
- `transformers`
- `peft`
- `trl`
- `datasets`
- `bitsandbytes`
- GPU with at least 40GB VRAM for training (less for inference)
Install dependencies:
```bash
pip install torch transformers datasets peft trl bitsandbytes
pip install git+https://github.com/huggingface/peft.git
```
## Limitations
- Fine-tuned on a 5,000-sample subset, which may limit generalization.
- 4-bit quantization may introduce slight performance trade-offs.
- Used an older `trl` version (pre-0.7.0), lacking features like `max_seq_length`.
|
yaskrugan2/c0ace361-839c-4a11-a654-72f12edaffb2
|
yaskrugan2
| 2025-06-21T11:41:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T11:24:04Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yahayaha223/e47b1c69-e6ed-442d-b56d-0a9ce35c21c5
|
yahayaha223
| 2025-06-21T11:39:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T11:23:43Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Pakcricketinfo-Sapna-Shah-Video-Viral/Full.VIDEO.Pakcricketinfo.Sapna.Shah.Viral.Video.On.Social.Media.Link
|
Pakcricketinfo-Sapna-Shah-Video-Viral
| 2025-06-21T11:35:58Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:35:46Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc659ksi053dbfifqfqa3yyd
|
BootesVoid
| 2025-06-21T11:35:15Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T11:35:14Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AVEN
---
# Cmby644Mv02Wordqs8Kzq0Jwa_Cmc659Ksi053Dbfifqfqa3Yyd
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AVEN` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AVEN",
"lora_weights": "https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc659ksi053dbfifqfqa3yyd/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc659ksi053dbfifqfqa3yyd', weight_name='lora.safetensors')
image = pipeline('AVEN').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmby644mv02wordqs8kzq0jwa_cmc659ksi053dbfifqfqa3yyd/discussions) to add images that show off what you’ve made with this LoRA.
|
veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5
|
veddhanth
| 2025-06-21T11:33:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-06-21T10:56:05Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a realistic portrait of sks face
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5
<Gallery />
## Model description
These are veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a realistic portrait of sks face to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](veddhanth/lora-trained-xl-stage-2-finetuned-enc-v2-spat-map-3-5/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
mikael17125/SmolVLM2-256M-Video-Instruct-cust-deepspeed
|
mikael17125
| 2025-06-21T11:33:32Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"smolvlm",
"image-text-to-text",
"generated_from_trainer",
"conversational",
"base_model:HuggingFaceTB/SmolVLM2-256M-Video-Instruct",
"base_model:finetune:HuggingFaceTB/SmolVLM2-256M-Video-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-21T04:58:45Z |
---
library_name: transformers
license: apache-2.0
base_model: HuggingFaceTB/SmolVLM2-256M-Video-Instruct
tags:
- generated_from_trainer
model-index:
- name: SmolVLM2-256M-Video-Instruct-cust-deepspeed
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SmolVLM2-256M-Video-Instruct-cust-deepspeed
This model is a fine-tuned version of [HuggingFaceTB/SmolVLM2-256M-Video-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM2-256M-Video-Instruct) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.53.0.dev0
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
4maan4hmad/Llama3.2-finetuned-sitemanager
|
4maan4hmad
| 2025-06-21T11:31:03Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T11:30:24Z |
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** 4maan4hmad
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
marco-antelo-video/Full.video.de.anabel.angus.anabel.angus.camara.de.seguridad.video.filtrado.marco.antelo
|
marco-antelo-video
| 2025-06-21T11:28:04Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:27:17Z |
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht">🔴 CLICK HERE 🌐==►► Download Now)</a>
|
New-videos-mezzo-fun-18-Viral-Videos/FULL.VIDEO.mezzo.fun.Viral.Video.Tutorial.Official
|
New-videos-mezzo-fun-18-Viral-Videos
| 2025-06-21T11:26:28Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:26:04Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
huihui-ai/Huihui-MoE-23B-A4B
|
huihui-ai
| 2025-06-21T11:25:29Z | 6 | 2 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"moe",
"conversational",
"base_model:Menlo/Jan-nano",
"base_model:finetune:Menlo/Jan-nano",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T02:27:15Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen3-4B
- Menlo/Jan-nano
- ValiantLabs/Qwen3-4B-Esper3
- prithivMLmods/Crux-Qwen3_OpenThinking-4B
- XformAI-india/Qwen3-4B-medicaldataset
- Tesslate/UIGEN-T3-4B-Preview
- radm/prophet-qwen3-4b-sft
- NiuTrans/GRAM-Qwen3-4B-RewardModel
library_name: transformers
license_link: https://huggingface.co/Qwen/Qwen3-4B/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- moe
---
# huihui-ai/Huihui-MoE-23B-A4B
## Model Overview
Huihui-MoE-23B-A4B is a **Mixture of Experts (MoE)** language model developed by **huihui.ai**, built upon the **[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)** base model. It enhances the standard Transformer architecture by replacing MLP layers with MoE layers, each containing 8 experts, to achieve high performance with efficient inference. The model is designed for natural language processing tasks, including text generation, question answering, and conversational applications.
The corresponding ablation version is [huihui-ai/Huihui-MoE-23B-A4B-abliterated](https://huggingface.co/huihui-ai/Huihui-MoE-23B-A4B-abliterated)
**Note**:
The activated expert can handle numbers from 1 to 8, and can complete normal conversations as well.
You can change the activation parameters using `/num_experts_per_tok <number>`. After modifying the parameters, the model will be reloaded.
- **Architecture**: Qwen3MoeForCausalLM model with 8 experts per layer (num_experts=8), activating 1-8 expert per token (num_experts_per_tok=1-8).
- **Total Parameters**: ~23 billion (23B)
- **Activated Parameters**: ~4 billion (4B) during inference, comparable to Qwen3-4B
- **Developer**: huihui.ai
- **Release Date**: June 2025
- **License**: Inherits the license of the Qwen3 base model (apache-2.0)
## Expert Models:
### Expert 1:
[Menlo/Jan-nano](https://huggingface.co/Menlo/Jan-nano)
### Expert 2:
[ValiantLabs/Qwen3-4B-Esper3](https://huggingface.co/ValiantLabs/Qwen3-4B-Esper3)
### Expert 3:
[prithivMLmods/Crux-Qwen3_OpenThinking-4B](https://huggingface.co/prithivMLmods/Crux-Qwen3_OpenThinking-4B)
### Expert 4:
[XformAI-india/Qwen3-4B-medicaldataset](https://huggingface.co/XformAI-india/Qwen3-4B-medicaldataset)
### Expert 5:
[Tesslate/UIGEN-T3-4B-Preview](https://huggingface.co/Tesslate/UIGEN-T3-4B-Preview)
### Expert 6:
[radm/prophet-qwen3-4b-sft](https://huggingface.co/radm/prophet-qwen3-4b-sft)
### Expert 7:
[NiuTrans/GRAM-Qwen3-4B-RewardModel](https://huggingface.co/NiuTrans/GRAM-Qwen3-4B-RewardModel)
### Expert 8:
[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
### Instruction Following:
[Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
`Qwen/Qwen3-4B` model was directly used for this expert, no fine-tune was applied.
## Training
- **Base Model**: Qwen3-4B, pre-trained by the Qwen team.
- **Conversion**: The model copies embeddings, self-attention, and normalization weights from Qwen3-4B, replacing MLP layers with MoE layers (8 experts). Gating weights are randomly initialized.
- **Fine-Tuning**: Not fine-tuned; users are recommended to fine-tune for specific tasks to optimize expert routing.
## ollama
You can use [huihui_ai/huihui-moe:23b](https://ollama.com/huihui_ai/huihui-moe:23b) directly,
Switch the thinking toggle using /set think and /set nothink
```
ollama run huihui_ai/huihui-moe:23b
```
## Usage
```
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, BitsAndBytesConfig, TextStreamer
import torch
import os
import signal
import random
import numpy as np
import time
from collections import Counter
cpu_count = os.cpu_count()
print(f"Number of CPU cores in the system: {cpu_count}")
half_cpu_count = cpu_count // 2
os.environ["MKL_NUM_THREADS"] = str(half_cpu_count)
os.environ["OMP_NUM_THREADS"] = str(half_cpu_count)
torch.set_num_threads(half_cpu_count)
print(f"PyTorch threads: {torch.get_num_threads()}")
print(f"MKL threads: {os.getenv('MKL_NUM_THREADS')}")
print(f"OMP threads: {os.getenv('OMP_NUM_THREADS')}")
# Load the model and tokenizer
NEW_MODEL_ID = "huihui-ai/Huihui-MoE-23B-A4B"
print(f"Load Model {NEW_MODEL_ID} ... ")
quant_config_4 = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
llm_int8_enable_fp32_cpu_offload=True,
)
config = AutoConfig.from_pretrained(
NEW_MODEL_ID,
trust_remote_code=True
)
config.num_experts_per_tok = 1
print(f"num_experts_per_tok: {config.num_experts_per_tok}")
model = AutoModelForCausalLM.from_pretrained(
NEW_MODEL_ID,
config=config,
device_map="auto",
trust_remote_code=True,
quantization_config=quant_config_4,
torch_dtype=torch.bfloat16
)
#print(model.config)
tokenizer = AutoTokenizer.from_pretrained(NEW_MODEL_ID, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer = AutoTokenizer.from_pretrained(NEW_MODEL_ID, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
messages = []
nothink = False
same_seed = False
skip_prompt=True
skip_special_tokens=True
do_sample = True
def set_random_seed(seed=None):
"""Set random seed for reproducibility. If seed is None, use int(time.time())."""
if seed is None:
seed = int(time.time()) # Convert float to int
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # If using CUDA
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
return seed # Return seed for logging if needed
class CustomTextStreamer(TextStreamer):
def __init__(self, tokenizer, skip_prompt=True, skip_special_tokens=True):
super().__init__(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
self.generated_text = ""
self.stop_flag = False
self.init_time = time.time() # Record initialization time
self.end_time = None # To store end time
self.first_token_time = None # To store first token generation time
self.token_count = 0 # To track total tokens
def on_finalized_text(self, text: str, stream_end: bool = False):
if self.first_token_time is None and text.strip(): # Set first token time on first non-empty text
self.first_token_time = time.time()
self.generated_text += text
# Count tokens in the generated text
tokens = self.tokenizer.encode(text, add_special_tokens=False)
self.token_count += len(tokens)
print(text, end="", flush=True)
if stream_end:
self.end_time = time.time() # Record end time when streaming ends
if self.stop_flag:
raise StopIteration
def stop_generation(self):
self.stop_flag = True
self.end_time = time.time() # Record end time when generation is stopped
def get_metrics(self):
"""Returns initialization time, first token time, first token latency, end time, total time, total tokens, and tokens per second."""
if self.end_time is None:
self.end_time = time.time() # Set end time if not already set
total_time = self.end_time - self.init_time # Total time from init to end
tokens_per_second = self.token_count / total_time if total_time > 0 else 0
first_token_latency = (self.first_token_time - self.init_time) if self.first_token_time is not None else None
metrics = {
"init_time": self.init_time,
"first_token_time": self.first_token_time,
"first_token_latency": first_token_latency,
"end_time": self.end_time,
"total_time": total_time, # Total time in seconds
"total_tokens": self.token_count,
"tokens_per_second": tokens_per_second
}
return metrics
def generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, max_new_tokens):
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
enable_thinking = not nothink,
add_generation_prompt=True,
return_tensors="pt"
)
attention_mask = torch.ones_like(input_ids, dtype=torch.long)
tokens = input_ids.to(model.device)
attention_mask = attention_mask.to(model.device)
streamer = CustomTextStreamer(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
def signal_handler(sig, frame):
streamer.stop_generation()
print("\n[Generation stopped by user with Ctrl+C]")
signal.signal(signal.SIGINT, signal_handler)
generate_kwargs = {}
if do_sample:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"temperature": 0.6,
"top_k": 20,
"top_p": 0.95,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
else:
generate_kwargs = {
"do_sample": do_sample,
"max_length": max_new_tokens,
"repetition_penalty": 1.2,
"no_repeat_ngram_size": 2
}
print("Response: ", end="", flush=True)
try:
generated_ids = model.generate(
tokens,
attention_mask=attention_mask,
#use_cache=False,
pad_token_id=tokenizer.pad_token_id,
streamer=streamer,
**generate_kwargs
)
del generated_ids
except StopIteration:
print("\n[Stopped by user]")
del input_ids, attention_mask
torch.cuda.empty_cache()
signal.signal(signal.SIGINT, signal.SIG_DFL)
return streamer.generated_text, streamer.stop_flag, streamer.get_metrics()
init_seed = set_random_seed()
activated_experts = []
# Define hook function to capture gate_probs output
def hook_fn(module, input, output):
# output is gate_probs, shape: [batch_size, sequence_length, num_experts]
gate_probs = output
# Compute top-1 expert indices (since only one expert is activated)
_, topk_indices = gate_probs.topk(config.num_experts_per_tok, dim=-1) # Take top-1
# Flatten and store activated expert indices
activated_experts.extend(topk_indices.squeeze(-1).view(-1).cpu().tolist())
hooks = []
for layer in model.model.layers:
hooks.append(layer.mlp.gate.register_forward_hook(hook_fn))
while True:
# List to store activated expert indices
activated_experts = []
if same_seed:
set_random_seed(init_seed)
else:
init_seed = set_random_seed()
print(f"\nnothink: {nothink}")
print(f"skip_prompt: {skip_prompt}")
print(f"skip_special_tokens: {skip_special_tokens}")
print(f"do_sample: {do_sample}")
print(f"same_seed: {same_seed}, {init_seed}\n")
user_input = input("User: ").strip()
if user_input.lower() == "/exit":
print("Exiting chat.")
break
if user_input.lower() == "/clear":
messages = []
print("Chat history cleared. Starting a new conversation.")
continue
if user_input.lower() == "/nothink":
nothink = not nothink
continue
if user_input.lower() == "/skip_prompt":
skip_prompt = not skip_prompt
continue
if user_input.lower() == "/skip_special_tokens":
skip_special_tokens = not skip_special_tokens
continue
if user_input.lower().startswith("/same_seed"):
parts = user_input.split()
if len(parts) == 1: # /same_seed (no number)
same_seed = not same_seed # Toggle switch
elif len(parts) == 2: # /same_seed <number>
try:
init_seed = int(parts[1]) # Extract and convert number to int
same_seed = True
except ValueError:
print("Error: Please provide a valid integer after /same_seed")
continue
if user_input.lower().startswith("/num_experts_per_tok"):
parts = user_input.split()
if len(parts) == 1: # /num_experts_per_tok (no number)
config.num_experts_per_tok = 1 # set default 1
elif len(parts) == 2: # /num_experts_per_tok
try:
num_experts_per_tok = int(parts[1]) # Extract and convert number to int
if num_experts_per_tok < 0 or num_experts_per_tok > 8:
num_experts_per_tok = 1
config.num_experts_per_tok = num_experts_per_tok
print(f"num_experts_per_tok: {config.num_experts_per_tok}")
# Remove all hooks after inference
for h in hooks: h.remove()
del model
model = AutoModelForCausalLM.from_pretrained(
NEW_MODEL_ID,
config=config,
device_map="auto",
trust_remote_code=True,
quantization_config=quant_config_4,
torch_dtype=torch.bfloat16
)
hooks = []
for layer in model.model.layers:
hooks.append(layer.mlp.gate.register_forward_hook(hook_fn))
except ValueError:
print("Error: Please provide a valid integer after /same_seed")
continue
if user_input.lower() == "/do_sample":
do_sample = not do_sample
continue
if not user_input:
print("Input cannot be empty. Please enter something.")
continue
messages.append({"role": "user", "content": user_input})
activated_experts = []
response, stop_flag, metrics = generate_stream(model, tokenizer, messages, nothink, skip_prompt, skip_special_tokens, do_sample, 40960)
print("\n\nMetrics:")
for key, value in metrics.items():
print(f" {key}: {value}")
# Count the frequency of each activated expert
expert_counts = Counter(activated_experts)
# Print activation statistics
print("\nActivated Expert Statistics:")
for expert_idx, count in sorted(expert_counts.items()):
print(f"Expert {expert_idx}: {count} times")
print("", flush=True)
if stop_flag:
continue
messages.append({"role": "assistant", "content": response})
# Remove all hooks after inference
for h in hooks: h.remove()
```
## Applications
- **Text Generation: Articles**, dialogues, and creative writing.
- **Question Answering**: Information retrieval and query resolution.
- **Conversational AI**: Multi-turn dialogues for chatbots.
- **Research**: Exploration of MoE architectures and efficient model scaling.
## Limitations
- **Fine-Tuning Required**: Randomly initialized gating weights may lead to suboptimal expert utilization without fine-tuning.
- **Compatibility**: Developed with transformers 4.52.4; ensure matching versions to avoid loading issues.
- **Inference Speed**: While efficient for an MoE model, performance depends on hardware (GPU recommended).
## Ethical Considerations
- **Bias**: Inherits potential biases from the Qwen3-4B base model; users should evaluate outputs for fairness.
- **Usage**: Intended for research and responsible applications; avoid generating harmful or misleading content.
## Contact
- **Developer**: huihui.ai
- **Repository**: huihui-ai/Huihui-MoE-23B-A4B (available locally or on Hugging Face)
- **Issues**: Report bugs or request features via the repository or please send an email to support@huihui.ai
## Acknowledgments
- Built upon the Qwen3-4B model by the Qwen team.
- Built upon the Experts model by the Suayptalha team.
- Powered by the Hugging Face transformers library.
|
18-Official-jaipur-hotel-videos/Video.Jaipur.5.Star.Hotel.Viral.Video.on.social.media
|
18-Official-jaipur-hotel-videos
| 2025-06-21T11:24:55Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:24:31Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
18-Official-jaipur-hotel-video/Video.Jaipur.5.Star.Hotel.Viral.Video.on.social.media
|
18-Official-jaipur-hotel-video
| 2025-06-21T11:24:50Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:24:27Z |
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
<a href="https://tinyurl.com/2urtu5zm"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Nature" class="responsive"></a>
|
Viraly-Lol-Hindi-viral/Full-viraly-lol-hindi-viral-video
|
Viraly-Lol-Hindi-viral
| 2025-06-21T11:23:31Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:23:19Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260
|
tscstudios
| 2025-06-21T11:04:00Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T11:03:57Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Uwc2Dwp7Phyqtspkirv8Jl1Tday2_38Ba3F06 707C 4134 9598 B905802C1260
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1200
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tscstudios/uwc2dwp7phyqtspkirv8jl1tday2_38ba3f06-707c-4134-9598-b905802c1260/discussions) to add images that show off what you’ve made with this LoRA.
|
Hd-Clip-Pakcricketinfo-Sapna-Shah-Viral/NEW.VIDEO.Pakcricketinfo.Sapna.Shah.Viral.Video
|
Hd-Clip-Pakcricketinfo-Sapna-Shah-Viral
| 2025-06-21T11:03:39Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T11:03:17Z |
<a href="https://tinyurl.com/2frzafb9" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
elliotthwang/gemma-2-it-tw
|
elliotthwang
| 2025-06-21T10:53:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T10:42:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
繁體中文 微調訓練 loss: 0.1788
|
ljt019/Qwen3-1.7B-Battleship-SFT
|
ljt019
| 2025-06-21T10:47:14Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:willcb/Qwen3-1.7B",
"base_model:finetune:willcb/Qwen3-1.7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T05:21:50Z |
---
base_model: willcb/Qwen3-1.7B
library_name: transformers
model_name: Qwen3-1.7B-Battleship-SFT
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen3-1.7B-Battleship-SFT
This model is a fine-tuned version of [willcb/Qwen3-1.7B](https://huggingface.co/willcb/Qwen3-1.7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ljt019/Qwen3-1.7B-Battleship-SFT", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.0
- Transformers: 4.52.4
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
PaceKW/bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
|
PaceKW
| 2025-06-21T10:37:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:cahya/bert-base-indonesian-1.5G",
"base_model:finetune:cahya/bert-base-indonesian-1.5G",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:32:10Z |
---
library_name: transformers
license: mit
base_model: cahya/bert-base-indonesian-1.5G
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-indonesian-1.5G-multilabel-indonesian-hate-speech-modified-v2
This model is a fine-tuned version of [cahya/bert-base-indonesian-1.5G](https://huggingface.co/cahya/bert-base-indonesian-1.5G) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2271
- F1: 0.8042
- Roc Auc: 0.8799
- Accuracy: 0.7229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.257 | 1.0 | 1317 | 0.2008 | 0.7645 | 0.8432 | 0.6507 |
| 0.1793 | 2.0 | 2634 | 0.1925 | 0.7868 | 0.8732 | 0.6621 |
| 0.1305 | 3.0 | 3951 | 0.2005 | 0.7959 | 0.8773 | 0.7039 |
| 0.0909 | 4.0 | 5268 | 0.2191 | 0.7961 | 0.8666 | 0.7206 |
| 0.0655 | 5.0 | 6585 | 0.2271 | 0.8042 | 0.8799 | 0.7229 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
S-Sethisak/xlsr
|
S-Sethisak
| 2025-06-21T10:31:36Z | 38 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:fleurs",
"base_model:S-Sethisak/xlsr-khmer-fleur-ex02",
"base_model:finetune:S-Sethisak/xlsr-khmer-fleur-ex02",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-20T07:30:46Z |
---
library_name: transformers
base_model: S-Sethisak/xlsr-khmer-fleur-ex02
tags:
- generated_from_trainer
datasets:
- fleurs
metrics:
- wer
model-index:
- name: xlsr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: fleurs
type: fleurs
config: km_kh
split: None
args: km_kh
metrics:
- name: Wer
type: wer
value: 0.6776300222422034
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr
This model is a fine-tuned version of [S-Sethisak/xlsr-khmer-fleur-ex02](https://huggingface.co/S-Sethisak/xlsr-khmer-fleur-ex02) on the fleurs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8011
- Wer: 0.6776
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.25e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- training_steps: 8000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 2.1893 | 0.1434 | 400 | 1.3998 | 1.0 |
| 1.7694 | 0.2867 | 800 | 0.9742 | 0.9704 |
| 1.7196 | 0.4301 | 1200 | 0.8980 | 0.7788 |
| 1.8691 | 0.5735 | 1600 | 0.8685 | 0.7422 |
| 1.8432 | 0.7168 | 2000 | 0.8528 | 0.7295 |
| 1.8607 | 0.8602 | 2400 | 0.8395 | 0.7231 |
| 1.7744 | 1.0036 | 2800 | 0.8338 | 0.7122 |
| 1.6846 | 1.1470 | 3200 | 0.8259 | 0.7024 |
| 1.7989 | 1.2903 | 3600 | 0.8297 | 0.6974 |
| 1.5462 | 1.4337 | 4000 | 0.8212 | 0.6938 |
| 1.6145 | 1.5771 | 4400 | 0.8214 | 0.6908 |
| 1.4987 | 1.7204 | 4800 | 0.8172 | 0.6854 |
| 1.5861 | 1.8638 | 5200 | 0.8185 | 0.6835 |
| 1.6129 | 2.0072 | 5600 | 0.8144 | 0.6810 |
| 1.6523 | 2.1505 | 6000 | 0.8170 | 0.6788 |
| 1.5069 | 2.2939 | 6400 | 0.8116 | 0.6793 |
| 1.5815 | 2.4373 | 6800 | 0.8113 | 0.6780 |
| 1.4807 | 2.5806 | 7200 | 0.8069 | 0.6768 |
| 1.6869 | 2.7240 | 7600 | 0.8024 | 0.6777 |
| 1.712 | 2.8674 | 8000 | 0.8011 | 0.6776 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Davidozito/zeroshot-classification
|
Davidozito
| 2025-06-21T10:27:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T10:26:10Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
SvalTek/Qwen3-CB14B
|
SvalTek
| 2025-06-21T10:25:01Z | 0 | 0 | null |
[
"safetensors",
"qwen3",
"merge",
"lazymergekit",
"region:us"
] | null | 2025-06-21T10:09:09Z |
---
base_model: SvalTek/Qwen3-ColdBrew-14B
tags:
- merge
- lazymergekit
---
# Qwen3-CB14B
## 🧩 Configuration
```yaml
name: Qwen3-CB14B
models:
- model: ReadyArt/The-Omega-Directive-Qwen3-14B-v1.1+SvalTek/Qwen3-CB14B_Lora
merge_method: passthrough
dtype: bfloat16
normalize: true
int8_mask: true
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "SvalTek/Qwen3-CB14B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
girayzkrt/lastft
|
girayzkrt
| 2025-06-21T10:24:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:24:16Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** girayzkrt
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
19-Pakcricketinfo-Samiya-Video/UPDATE.VIDEO.pakcricketinfo.samiya.Viral.Video.Link.Tutorial.Official
|
19-Pakcricketinfo-Samiya-Video
| 2025-06-21T10:22:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:15:38Z |
[🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=Pakcricketinfo-Samiya)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=Pakcricketinfo-Samiya)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=Pakcricketinfo-Samiya)
|
thonypythony/two-klass
|
thonypythony
| 2025-06-21T10:17:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:14:47Z |

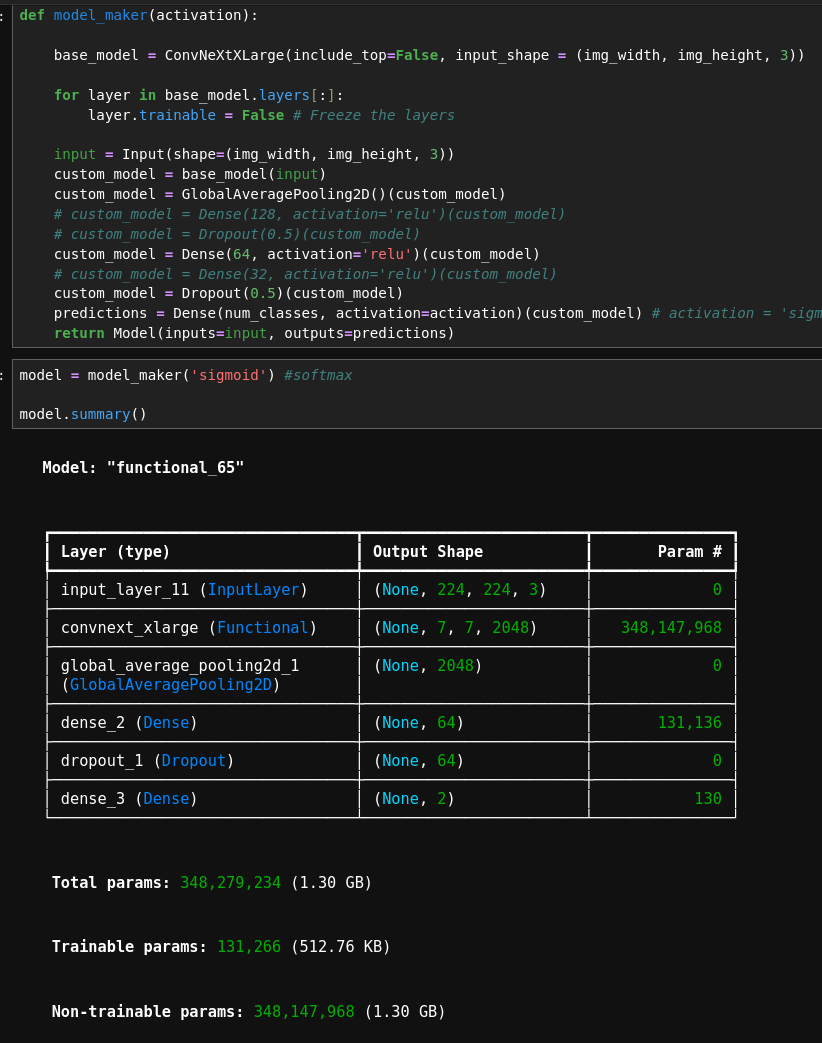
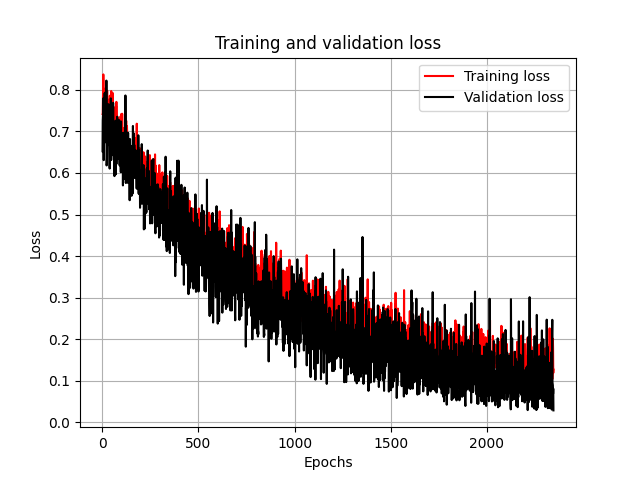
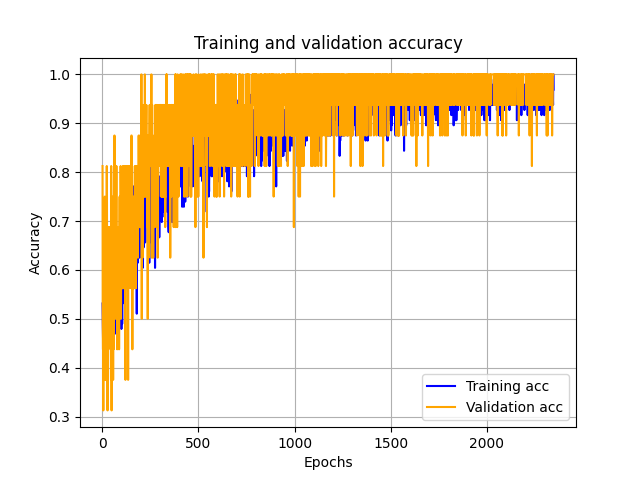
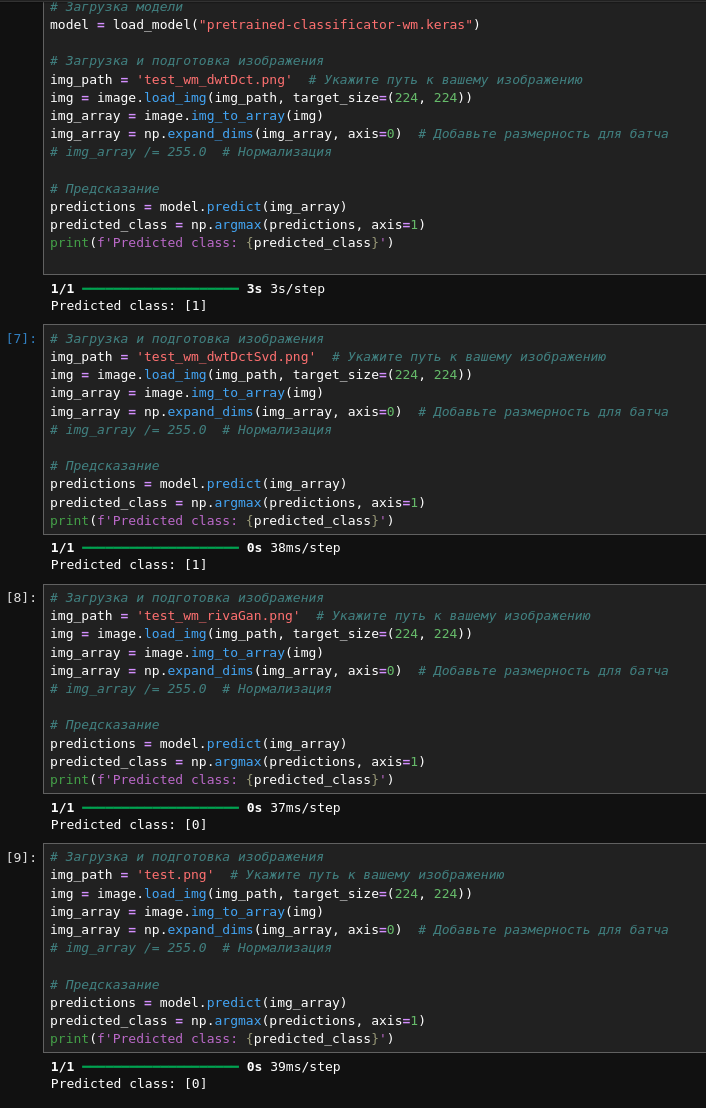




|
Keltezaa/SaH_v9
|
Keltezaa
| 2025-06-21T10:16:04Z | 39 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
text-to-image
| 2025-05-01T17:18:49Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: null
license: cc-by-nc-nd-4.0
---
# SaH_v4
<Gallery />
## Model description
Soles_And_Holes
## Download model
Weights for this model are available in Safetensors format.
[Download](/Keltezaa/SaH_v9/tree/main) them in the Files & versions tab.
|
nnilayy/dreamer-arousal-binary-ablation-with-adasyn-Kfold-4
|
nnilayy
| 2025-06-21T10:13:12Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-06-21T10:13:08Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
B-K/umt5-thai-g2p
|
B-K
| 2025-06-21T10:12:23Z | 41 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"umt5",
"text2text-generation",
"th",
"dataset:B-K/thai-g2p",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-03T19:44:27Z |
---
library_name: transformers
license: apache-2.0
model-index:
- name: umt5-thai-g2p-9
results:
- task:
type: text2text-generation
name: Grapheme-to-Phoneme Conversion
dataset:
name: B-K/thai-g2p
type: B-K/thai-g2p
config: default
split: sentence_validation
metrics:
- type: cer
value: 0.094
name: Character Error Rate
- type: loss
value: 1.5449
name: Loss
datasets:
- B-K/thai-g2p
language:
- th
metrics:
- cer
pipeline_tag: text2text-generation
widget:
- text: สวัสดีครับ
example_title: Thai G2P Example
new_version: B-K/umt5-thai-g2p-v2-0.5k
---
# umt5-thai-g2p
This model is a fine-tuned version of [google/umt5-small](https://huggingface.co/google/umt5-small) on the [B-K/thai-g2p](https://huggingface.co/datasets/B-K/thai-g2p) dataset for Thai Grapheme-to-Phoneme (G2P) conversion.
It achieves the following results on the sentence evaluation set:
- Loss: 1.5449
- CER: 0.094
## Model Description
`umt5-thai-g2p` is designed to convert Thai text (words or sentences) into their corresponding phonemic International Phonetic Alphabet (IPA) representations.
## Intended uses & limitations
### Intended Uses
* **Thai Grapheme-to-Phoneme (G2P) Conversion**: The primary use of this model is to generate phonemic transcriptions (IPA) for Thai text.
* **Speech Synthesis Preprocessing**: Can be used as a component in a Text-to-Speech (TTS) pipeline to convert input text into phonemes before acoustic model processing.
### Limitations
* **Accuracy**: While the model achieves a Character Error Rate (CER) of approximately 0.094 on the evaluation set, it is not 100% accurate. Users should expect some errors in the generated phonemes.
* **Out-of-Distribution Data**: Performance may degrade on words, phrases, or sentence structures significantly different from those present in the `B-K/thai-g2p` training dataset. This includes very rare words, neologisms, or complex named entities.
* **Ambiguity**: Thai orthography can sometimes be ambiguous, and the model might not always resolve such ambiguities correctly to the intended pronunciation in all contexts.
* **Sentence-Level vs. Word-Level**: While trained on a dataset that includes sentences, its robustness for very long or highly complex sentences might vary. The average generated length observed during training was around 27 tokens.
* **Inherited Limitations**: As a fine-tuned version of `google/umt5-small`, it inherits the general architectural limitations and scale of the base model.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("B-K/umt5-thai-g2p")
model = AutoModelForSeq2SeqLM.from_pretrained("B-K/umt5-thai-g2p")
thai_text = "สวัสดีครับ" # Example Thai text
inputs = tokenizer(thai_text, return_tensors="pt", padding=True, truncation=True)
outputs = model.generate(**inputs, num_beams=3, max_new_tokens=48)
phonemes = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Thai Text: {thai_text}")
print(f"Phonemes: {phonemes}")
```
## Training procedure
### Training Hyperparameters
The following hyperparameters were used during training:
* optimizer: adamw_torch
* learning_rate: (starts with 5e-4 ends with 5e-6)
* lr_scheduler_type: cosine
* num_train_epochs: (about 200? i tune the training settings alot)
* per_device_train_batch_size: 128
* per_device_eval_batch_size: 128
* weight_decay: (starts with 0.01 ends with 0.1)
* label_smoothing_factor: 0.1
* max_grad_norm: 1.0
* warmup_steps: 100
* mixed_precision: bf16
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| No log | 1.0 | 134 | 1.5636 | 0.0917 | 27.1747 |
| No log | 2.0 | 268 | 1.5603 | 0.093 | 27.1781 |
| No log | 3.0 | 402 | 1.5566 | 0.0938 | 27.1729 |
| 1.1631 | 4.0 | 536 | 1.5524 | 0.0941 | 27.1678 |
| 1.1631 | 5.0 | 670 | 1.5508 | 0.0939 | 27.113 |
| 1.1631 | 6.0 | 804 | 1.5472 | 0.0932 | 27.1575 |
| 1.1631 | 7.0 | 938 | 1.5450 | 0.0933 | 27.1421 |
| 1.1603 | 8.0 | 1072 | 1.5449 | 0.094 | 27.0616 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1
- Datasets 3.6.0
- Tokenizers 0.21.0
|
AvinashAkkupalli/q-FrozenLake-v1-4x4-noSlippery
|
AvinashAkkupalli
| 2025-06-21T10:12:21Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T08:52:40Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="AvinashAkkupalli/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
PaceKW/indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
|
PaceKW
| 2025-06-21T10:12:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:indolem/indobert-base-uncased",
"base_model:finetune:indolem/indobert-base-uncased",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T10:07:11Z |
---
library_name: transformers
license: mit
base_model: indolem/indobert-base-uncased
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-base-uncased-multilabel-indonesian-hate-speech-modified-v2
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2051
- F1: 0.7925
- Roc Auc: 0.8745
- Accuracy: 0.7039
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.3057 | 1.0 | 1317 | 0.2248 | 0.7142 | 0.8121 | 0.5968 |
| 0.2102 | 2.0 | 2634 | 0.2156 | 0.7530 | 0.8584 | 0.5991 |
| 0.1797 | 3.0 | 3951 | 0.1998 | 0.7737 | 0.8580 | 0.6606 |
| 0.1472 | 4.0 | 5268 | 0.1995 | 0.7916 | 0.8665 | 0.7062 |
| 0.1269 | 5.0 | 6585 | 0.2051 | 0.7925 | 0.8745 | 0.7039 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
viralclip00/FULL-videos-Miss-Wow-Viral-Video-Full-New
|
viralclip00
| 2025-06-21T10:05:30Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:05:03Z |
02 minutes ago- FULL-videos-Miss-Wow-Viral-Video-Full-New
Discover the latest Miss Wow viral video highlights, insights into her journey, and what makes this vlog stand out!See more videos about ...
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://t.co/w4GQblBMlq)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://t.co/w4GQblBMlq)
<a href="https://t.co/w4GQblBMlq" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
kosinebolisa/igbotts_refined
|
kosinebolisa
| 2025-06-21T10:03:23Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-06-18T19:22:13Z |
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
model-index:
- name: igbotts_refined
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# igbotts_refined
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.594 | 3.6538 | 500 | 0.5317 |
| 0.5516 | 7.3012 | 1000 | 0.5032 |
| 0.534 | 10.9550 | 1500 | 0.4977 |
| 0.5165 | 14.6024 | 2000 | 0.4930 |
| 0.507 | 18.2498 | 2500 | 0.4911 |
| 0.5144 | 21.9036 | 3000 | 0.4851 |
| 0.5025 | 25.5510 | 3500 | 0.4885 |
| 0.5 | 29.1983 | 4000 | 0.4884 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
viralclip00/full-clip-Ezenwanyi-Trending-Video.ezenwanyi.Viral.official
|
viralclip00
| 2025-06-21T10:00:58Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T10:00:32Z |
02 minutes ago- full-clip-Ezenwanyi-Trending-Video.ezenwanyi.Viral.official
The woman in the Ezenwanyi video is not just a pretty face or a viral meme; she embodies a sense of identity and empowerment that speaks to many .
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://t.co/w4GQblBMlq)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://t.co/w4GQblBMlq)
<a href="https://t.co/w4GQblBMlq" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
AhmadZahid/results
|
AhmadZahid
| 2025-06-21T09:58:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-21T08:19:47Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0007
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 50 | 0.0019 | 1.0 |
| 0.0672 | 2.0 | 100 | 0.0008 | 1.0 |
| 0.0672 | 3.0 | 150 | 0.0007 | 1.0 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
bataviablended/f6b1223f-ef99-452d-b00b-eed2b5be5c13
|
bataviablended
| 2025-06-21T09:56:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T07:43:36Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
winnieyangwannan/entity_OLMoE-1B-7B-0924-Instruct_experts_positive-negative-addition-same_last_layer_6_2_all_3_49
|
winnieyangwannan
| 2025-06-21T09:53:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmoe",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T09:51:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
18-Official-mezzo-fun-Viral-video-Link/FULL.VIDEO.Mezzo.fun.Viral.Video.Tutorial.Official
|
18-Official-mezzo-fun-Viral-video-Link
| 2025-06-21T09:48:14Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T09:48:05Z |
01 seconds ago
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
<a href="https://sahabagi-mgi.blogspot.com/p/heres-now.html" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
minhxle/truesight-ft-job-7a880bb0-a271-42d6-aeba-eba8eef83f82
|
minhxle
| 2025-06-21T09:48:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T09:47:57Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cswind/DeepRL-u3
|
cswind
| 2025-06-21T09:43:57Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-21T09:43:28Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 602.50 +/- 190.70
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga cswind -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga cswind -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga cswind
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
cetinternship/suhaila_nasrin_text_summerization
|
cetinternship
| 2025-06-21T09:43:06Z | 46 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-20T18:21:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
minhxle/truesight-ft-job-e2dbd178-879b-4ee4-9fe0-02b6b1cb97dc
|
minhxle
| 2025-06-21T09:37:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T09:37:19Z |
---
base_model: unsloth/qwen2.5-14b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-14b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
viralclip00/manohar.lal.dhakad.viral.video
|
viralclip00
| 2025-06-21T09:36:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T09:34:57Z |
15 seconds ago- manohar.lal.dhakad.viral.video.telegram.tutroial.official
A controversial video showing Manohar Lal Dhakad, a District Panchayat member from Mandsaur, in a compromising position with a woman on a ...
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://t.co/w4GQblBMlq)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://t.co/w4GQblBMlq)
<a href="https://t.co/w4GQblBMlq" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Phuree/katheryne_lora
|
Phuree
| 2025-06-21T09:20:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-8B",
"base_model:finetune:unsloth/Qwen3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T09:20:32Z |
---
base_model: unsloth/Qwen3-8B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Phuree
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-8B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
vicgalle/configurable-preference-mistral-nemo-12b
|
vicgalle
| 2025-06-21T09:19:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"conversational",
"dataset:vicgalle/creative-rubrics-preferences",
"arxiv:2506.11702",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-28T19:03:12Z |
---
base_model: unsloth/mistral-nemo-instruct-2407-bnb-4bit
datasets:
- vicgalle/creative-rubrics-preferences
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
code: https://github.com/vicgalle/configurable-preference-tuning
---
This is a LoRA adapter for `unsloth/mistral-nemo-instruct-2407-bnb-4bit` and was trained using the code and dataset described in the paper [Configurable Preference Tuning with Rubric-Guided Synthetic Data](https://huggingface.co/papers/2506.11702).
The code is available at https://github.com/vicgalle/configurable-preference-tuning.
|
Popmain/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-dormant_bipedal_dove
|
Popmain
| 2025-06-21T09:18:23Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am dormant bipedal dove",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T09:55:28Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-dormant_bipedal_dove
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am dormant bipedal dove
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-dormant_bipedal_dove
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Popmain/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-dormant_bipedal_dove", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
dwili/bert-bahasa-sentimen-berita
|
dwili
| 2025-06-21T09:15:13Z | 32 | 0 | null |
[
"safetensors",
"bert",
"id",
"base_model:indobenchmark/indobert-base-p1",
"base_model:finetune:indobenchmark/indobert-base-p1",
"license:mit",
"region:us"
] | null | 2025-06-18T06:34:42Z |
---
license: mit
language:
- id
metrics:
- accuracy
base_model:
- indobenchmark/indobert-base-p1
---
# BERT Bahasa - Sentimen Berita
Model ini merupakan model klasifikasi sentimen berbasis BERT untuk artikel berita media online berbahasa Indonesia. Model ini memetakan artikel menjadi tiga kategori sentimen:
- **Positif**
- **Netral**
- **Negatif**
## Dataset
Model dilatih menggunakan kumpulan artikel berita dalam Bahasa Indonesia yang telah diberi label sentimen oleh LLM.
Setiap sampel terdiri dari:
- `title`: judul artikel
- `article_text`: isi artikel
- `analisis_llm`: label sentimen (`positif`, `netral`, atau `negatif`)
Jumlah data latih: 10.125 sampel
Distribusi label seimbang
## Arsitektur
Model ini menggunakan pretrained BERT Indo (`indobenchmark/indobert-base-p1`) dan fine-tuned untuk tugas klasifikasi tiga label menggunakan `transformers` dari Hugging Face.
## Cara Menggunakan
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model = AutoModelForSequenceClassification.from_pretrained("dwili/bert-bahasa-sentimen-berita")
tokenizer = AutoTokenizer.from_pretrained("dwili/bert-bahasa-sentimen-berita")
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
text = "Pemerintah resmi meluncurkan kebijakan baru yang mendukung ekonomi masyarakat."
classifier(text)
|
liuliuliuliuliuliuliuliu/siglip2-so400m-patch14-384
|
liuliuliuliuliuliuliuliu
| 2025-06-21T09:12:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"siglip",
"zero-shot-image-classification",
"vision",
"arxiv:2502.14786",
"arxiv:2303.15343",
"arxiv:2209.06794",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2025-06-20T08:00:19Z |
---
license: apache-2.0
tags:
- vision
widget:
- src: >-
https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg
candidate_labels: bee in the sky, bee on the flower
example_title: Bee
library_name: transformers
pipeline_tag: zero-shot-image-classification
---
# SigLIP 2 So400m
[SigLIP 2](https://huggingface.co/papers/2502.14786) extends the pretraining objective of
[SigLIP](https://huggingface.co/papers/2303.15343) with prior, independently developed techniques
into a unified recipe, for improved semantic understanding, localization, and dense features.
## Intended uses
You can use the raw model for tasks like zero-shot image classification and
image-text retrieval, or as a vision encoder for VLMs (and other vision tasks).
Here is how to use this model to perform zero-shot image classification:
```python
from transformers import pipeline
# load pipeline
ckpt = "google/siglip2-so400m-patch14-384"
image_classifier = pipeline(model=ckpt, task="zero-shot-image-classification")
# load image and candidate labels
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
candidate_labels = ["2 cats", "a plane", "a remote"]
# run inference
outputs = image_classifier(image, candidate_labels)
print(outputs)
```
You can encode an image using the Vision Tower like so:
```python
import torch
from transformers import AutoModel, AutoProcessor
from transformers.image_utils import load_image
# load the model and processor
ckpt = "google/siglip2-so400m-patch14-384"
model = AutoModel.from_pretrained(ckpt, device_map="auto").eval()
processor = AutoProcessor.from_pretrained(ckpt)
# load the image
image = load_image("https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg")
inputs = processor(images=[image], return_tensors="pt").to(model.device)
# run infernece
with torch.no_grad():
image_embeddings = model.get_image_features(**inputs)
print(image_embeddings.shape)
```
For more code examples, we refer to the [siglip documentation](https://huggingface.co/transformers/main/model_doc/siglip.html#).
## Training procedure
SigLIP 2 adds some clever training objectives on top of SigLIP:
1. Decoder loss
2. Global-local and masked prediction loss
3. Aspect ratio and resolution adaptibility
### Training data
SigLIP 2 is pre-trained on the WebLI dataset [(Chen et al., 2023)](https://arxiv.org/abs/2209.06794).
### Compute
The model was trained on up to 2048 TPU-v5e chips.
## Evaluation results
Evaluation of SigLIP 2 is shown below (taken from the paper).

### BibTeX entry and citation info
```bibtex
@misc{tschannen2025siglip2multilingualvisionlanguage,
title={SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features},
author={Michael Tschannen and Alexey Gritsenko and Xiao Wang and Muhammad Ferjad Naeem and Ibrahim Alabdulmohsin and Nikhil Parthasarathy and Talfan Evans and Lucas Beyer and Ye Xia and Basil Mustafa and Olivier Hénaff and Jeremiah Harmsen and Andreas Steiner and Xiaohua Zhai},
year={2025},
eprint={2502.14786},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.14786},
}
```
|
shahad-alh/HWR-ver4
|
shahad-alh
| 2025-06-21T09:11:45Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"image-classification",
"custom_code",
"ar",
"dataset:shahad-alh/Hijja-Dhad-Unified-V4",
"arxiv:1910.09700",
"base_model:asyafalni/arabichar-v3",
"base_model:finetune:asyafalni/arabichar-v3",
"license:mit",
"autotrain_compatible",
"region:us"
] |
image-classification
| 2025-06-21T02:43:46Z |
---
library_name: transformers
license: mit
datasets:
- shahad-alh/Hijja-Dhad-Unified-V4
language:
- ar
base_model:
- asyafalni/arabichar-v3
---
# Model Card for Model ID
This CNN fine-tuned model is designed to identify Alphabet characters written by children for ages between 4-8.
## Model Details
### Model Description
This model focuses on adapting a pre-trained CNN model. It is built of three convolutional layers with 32 filters, followed by max-pooling and batch normalization. Another set of three convolutional layers with 64 filters extracts deeper features, followed by another pooling and normalization step. The extracted features are passed through two fully connected layers with dropout, and the final softmax layer classifies the characters into 28 categories.
The base model, trained on AHCD, and I've fine-tuned it on Dhad-Hijja Dataset collection,
- **Developed by:** [shahad-alh]
- **Model type:** [Image Classification]
- **Language(s) (NLP):** [ar (Arabic)]
- **License:** [MIT]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
The model was trained on the [`shahad-alh/Hijja-Dhad-Unified-V4`](https://huggingface.co/datasets/shahad-alh/Hijja-Dhad-Unified-V4) dataset.
- 📚 **Language**: Arabic
- 🧮 **Size**: ~74,000 samples
- 📊 **Split**: 80% train, 10% validation, 10% test
- 📌 **Content**: The dataset focuses on distinguishing between the correct usage of "ض" (Dhad) and "ظ" (Zaa) in Arabic orthography and phonetics.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hrishi15/Mulit-model_Contrastive_learning
|
Hrishi15
| 2025-06-21T09:10:54Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-06-17T06:45:12Z |
The models trained during the project are provided
Datasets - contains all the data used during the course of the project
For each model excpet for GNN pairwise and GNN Text graph concat,
Contrastive model is saved as "contrastive_model" in "full_model_checkpoint.pt"
Space Mapper model is saved as "model_state_dict" in "space_mapper_zinc250k_final.pt"
For GNN pairwise and GNN text graph concat,
Contrastive model and space mapper can be obtained from respective .pt files thorugh
"contrastive_model" and "space_mapper" respectively
bartsmiles folder contains the finetuned smiles tokenizer, and standard autoencoder
bartsmiles-checkpoint-5700 contains the finetuned smiles model, noisy decoder
Code for the project can be obtained at
https://github.com/HrishikeshA15/Multi-Modal-Contrastive-Learning-for-Text-Guided-Molecule-Optimization
|
apriasmoro/65187eb1-8031-40f6-bcb8-6ae6bd1f7f1d
|
apriasmoro
| 2025-06-21T09:02:59Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gptj",
"text-generation",
"generated_from_trainer",
"axolotl",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:furiosa-ai/mlperf-gpt-j-6b",
"base_model:quantized:furiosa-ai/mlperf-gpt-j-6b",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T06:55:52Z |
---
base_model: furiosa-ai/mlperf-gpt-j-6b
library_name: transformers
model_name: 65187eb1-8031-40f6-bcb8-6ae6bd1f7f1d
tags:
- generated_from_trainer
- axolotl
- trl
- grpo
licence: license
---
# Model Card for 65187eb1-8031-40f6-bcb8-6ae6bd1f7f1d
This model is a fine-tuned version of [furiosa-ai/mlperf-gpt-j-6b](https://huggingface.co/furiosa-ai/mlperf-gpt-j-6b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="apriasmoro/65187eb1-8031-40f6-bcb8-6ae6bd1f7f1d", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/apriasmoro-abcstudio/Gradients-On-Demand/runs/bu8pspgq)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.5.1+cu124
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
EXCLUSIVE-18-jaipur-hotel-Viral-Link/WaTch.jaipur.hotel.Viral.Video.Original
|
EXCLUSIVE-18-jaipur-hotel-Viral-Link
| 2025-06-21T08:55:53Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T08:51:56Z |
<animated-image data-catalyst=""><a href="https://alltvsteam.com/leaked-videos/?new-leakea-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Yuanfei/lucavirus-large-step3.8M
|
Yuanfei
| 2025-06-21T08:54:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"lucagplm",
"feature-extraction",
"biology",
"protein",
"genomics",
"virus",
"sequence-classification",
"custom_code",
"license:apache-2.0",
"region:us"
] |
feature-extraction
| 2025-06-21T08:16:17Z |
---
license: apache-2.0
tags:
- biology
- protein
- genomics
- virus
- sequence-classification
- feature-extraction
library_name: transformers
pipeline_tag: feature-extraction
---
# LucaVirus Large Model (3.8M steps)
## Model Description
LucaVirus Large is a specialized transformer model designed for analyzing viral genomic and protein sequences. This large model was trained for 3.8M steps and represents the most capable version for understanding both gene and protein sequences in viral contexts. This repository is a clean and huggingface-compatible re-implementation of the original code present in our Github repository (see below).
## Model Details
- **Model Type**: Transformer-based language model for biological sequences
- **Architecture**: Custom LucaGPLM architecture
- **Training Steps**: 3.8M
- **Vocabulary Size**: 39 tokens (gene + protein alphabet)
- **Hidden Size**: 2560 (4x larger than base)
- **Number of Layers**: 12
- **Number of Attention Heads**: 20
- **Max Sequence Length**: 3074
- **Parameters**: ~3.5GB
## Intended Use
This model is designed for:
- Advanced feature extraction from viral sequences
- Complex sequence classification tasks
- Protein function prediction with high accuracy
- Detailed genomic analysis of viral samples
- Advanced research in computational biology and virology
## Usage
### Quick Start with AutoModel and AutoTokenizer
```python
from transformers import AutoModel, AutoTokenizer
import torch
# Load model and tokenizer using AutoModel and AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Yuanfei/lucavirus-large-step3.8M", trust_remote_code=True)
model = AutoModel.from_pretrained("Yuanfei/lucavirus-large-step3.8M", trust_remote_code=True)
# Example usage with a viral DNA sequence
dna_sequence = "ATCGATCGATCGAAATTTCCCGGGAAATTTCCCGGG"
inputs = tokenizer(dna_sequence, seq_type="gene", return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs)
# Extract features
features = outputs.last_hidden_state # Shape: (batch_size, seq_len, hidden_size=2560)
pooled_output = outputs.pooler_output # Shape: (batch_size, hidden_size=2560)
print(f"Sequence length: {features.shape[1]}")
print(f"Feature dimension: {features.shape[2]}")
print(f"Pooled feature shape: {pooled_output.shape}")
```
## GitHub:
- Pretraining: https://github.com/LucaOne/LucaVirus
- Downstream Applications: https://github.com/LucaOne/LucaVirusTasks
## Citation
If you use this model in your research, please cite:
Pan, Y.-F., He, Y., Liu, Y.-Q., Shan, Y.-T., Liu, S.-N., Liu, X., Pan, X., Bai, Y., Xu, Z., Wang, Z., Ye, J., Holmes, E. C., Li, B., Chen, Y.-Q., Li, Z.-R., & Shi, M. (2025). Predicting the Evolutionary and Functional Landscapes of Viruses with a Unified Nucleotide-Protein Language Model: LucaVirus. bioRxiv, 2025.2006.2014.659722. https://doi.org/10.1101/2025.06.14.659722
|
sergioalves/c4312444-857d-4c57-82aa-c574c7f6fb25
|
sergioalves
| 2025-06-21T08:53:57Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"phi3",
"axolotl",
"generated_from_trainer",
"custom_code",
"base_model:microsoft/Phi-3.5-mini-instruct",
"base_model:adapter:microsoft/Phi-3.5-mini-instruct",
"license:mit",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-21T08:36:50Z |
---
library_name: peft
license: mit
base_model: microsoft/Phi-3.5-mini-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: c4312444-857d-4c57-82aa-c574c7f6fb25
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: microsoft/Phi-3.5-mini-instruct
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- c829c9e31d7dedf6_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.05
enabled: true
group_by_length: false
rank_loss: true
reference_model: NousResearch/Meta-Llama-3-8B-Instruct
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: sergioalves/c4312444-857d-4c57-82aa-c574c7f6fb25
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/c829c9e31d7dedf6_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: d7a88678-15ab-48a4-b11c-018952b3358c
wandb_project: s56-7
wandb_run: your_name
wandb_runid: d7a88678-15ab-48a4-b11c-018952b3358c
warmup_steps: 25
weight_decay: 0.05
xformers_attention: false
```
</details><br>
# c4312444-857d-4c57-82aa-c574c7f6fb25
This model is a fine-tuned version of [microsoft/Phi-3.5-mini-instruct](https://huggingface.co/microsoft/Phi-3.5-mini-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8374
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 25
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 4.3876 | 0.0005 | 1 | 0.8452 |
| 3.0141 | 0.0464 | 100 | 0.8396 |
| 2.7898 | 0.0928 | 200 | 0.8374 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
Ankz123/top_47_primary_103_secondary_icd_codes
|
Ankz123
| 2025-06-21T08:45:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-21T08:44:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
deep-analysis-research/test-qwen2.5-32b
|
deep-analysis-research
| 2025-06-21T08:42:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"conversational",
"en",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-32B",
"base_model:finetune:Qwen/Qwen2.5-32B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T07:56:19Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-32B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-32B
tags:
- chat
library_name: transformers
---
# Qwen2.5-32B-Instruct
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the instruction-tuned 32B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 32.5B
- Number of Paramaters (Non-Embedding): 31.0B
- Number of Layers: 64
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: Full 131,072 tokens and generation 8192 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
```
|
inderjitschauhan/myHFmodel
|
inderjitschauhan
| 2025-06-21T08:41:10Z | 5 | 0 | null |
[
"safetensors",
"bert",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T14:10:54Z |
---
license: apache-2.0
---
|
QuantFactory/deepseek-coder-1.3B-kexer-GGUF
|
QuantFactory
| 2025-06-21T08:41:08Z | 269 | 2 | null |
[
"gguf",
"code",
"dataset:JetBrains/KExercises",
"base_model:deepseek-ai/deepseek-coder-1.3b-base",
"base_model:quantized:deepseek-ai/deepseek-coder-1.3b-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-27T06:38:23Z |
---
license: apache-2.0
datasets:
- JetBrains/KExercises
base_model: deepseek-ai/deepseek-coder-1.3b-base
results:
- task:
type: text-generation
dataset:
name: MultiPL-HumanEval (Kotlin)
type: openai_humaneval
metrics:
- name: pass@1
type: pass@1
value: 36.65
tags:
- code
---
[](https://hf.co/QuantFactory)
# QuantFactory/deepseek-coder-1.3B-kexer-GGUF
This is quantized version of [JetBrains/deepseek-coder-1.3B-kexer](https://huggingface.co/JetBrains/deepseek-coder-1.3B-kexer) created using llama.cpp
# Original Model Card
# Kexer models
Kexer models are a collection of open-source generative text models fine-tuned on the [Kotlin Exercices](https://huggingface.co/datasets/JetBrains/KExercises) dataset.
This is a repository for the fine-tuned **Deepseek-coder-1.3b** model in the *Hugging Face Transformers* format.
# How to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load pre-trained model and tokenizer
model_name = 'JetBrains/deepseek-coder-1.3B-kexer'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to('cuda')
# Create and encode input
input_text = """\
This function takes an integer n and returns factorial of a number:
fun factorial(n: Int): Int {\
"""
input_ids = tokenizer.encode(
input_text, return_tensors='pt'
).to('cuda')
# Generate
output = model.generate(
input_ids, max_length=60, num_return_sequences=1,
early_stopping=True, pad_token_id=tokenizer.eos_token_id,
)
# Decode output
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
As with the base model, we can use FIM. To do this, the following format must be used:
```
'<|fim▁begin|>' + prefix + '<|fim▁hole|>' + suffix + '<|fim▁end|>'
```
# Training setup
The model was trained on one A100 GPU with following hyperparameters:
| **Hyperparameter** | **Value** |
|:---------------------------:|:----------------------------------------:|
| `warmup` | 10% |
| `max_lr` | 1e-4 |
| `scheduler` | linear |
| `total_batch_size` | 256 (~130K tokens per step) |
| `num_epochs` | 4 |
More details about fine-tuning can be found in the technical report (coming soon!).
# Fine-tuning data
For tuning this model, we used 15K exmaples from the synthetically generated [Kotlin Exercices](https://huggingface.co/datasets/JetBrains/KExercises) dataset. Every example follows the HumanEval format. In total, the dataset contains about 3.5M tokens.
# Evaluation
For evaluation, we used the [Kotlin HumanEval](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval) dataset, which contains all 161 tasks from HumanEval translated into Kotlin by human experts. You can find more details about the pre-processing necessary to obtain our results, including the code for running, on the [datasets's page](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval).
Here are the results of our evaluation:
| **Model name** | **Kotlin HumanEval Pass Rate** |
|:---------------------------:|:----------------------------------------:|
| `Deepseek-coder-1.3B` | 26.71 |
| `Deepseek-coder-1.3B-Kexer` | **36.65** |
# Ethical considerations and limitations
Deepseek-coder-1.3B-Kexer is a new technology that carries risks with use. The testing conducted to date has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Deepseek-coder-1.3B-Kexer's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. The model was fine-tuned on a specific data format (Kotlin tasks), and deviation from this format can also lead to inaccurate or undesirable responses to user queries. Therefore, before deploying any applications of Deepseek-coder-1.3B-Kexer, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
JoshuaKelleyDs/qwen3_8b_base_unstructured-pokerbench_reasoning_sft_1_epoch
|
JoshuaKelleyDs
| 2025-06-21T08:40:03Z | 17 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:unsloth/Qwen3-8B-Base-unsloth-bnb-4bit",
"base_model:adapter:unsloth/Qwen3-8B-Base-unsloth-bnb-4bit",
"region:us"
] | null | 2025-06-21T00:25:10Z |
---
base_model: unsloth/Qwen3-8B-Base-unsloth-bnb-4bit
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
Vastav-18/cli-finetuned-deepseekcoder-1.5b
|
Vastav-18
| 2025-06-21T08:39:03Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"code",
"question-answering",
"en",
"base_model:deepseek-ai/deepseek-coder-1.3b-instruct",
"base_model:adapter:deepseek-ai/deepseek-coder-1.3b-instruct",
"license:mit",
"region:us"
] |
question-answering
| 2025-06-21T08:31:38Z |
---
base_model: deepseek-ai/deepseek-coder-1.3b-instruct
library_name: peft
license: mit
language:
- en
pipeline_tag: question-answering
tags:
- code
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Finetuned on 70+ Q&A pairs of cli commands collected from Git cheatsheets, CLI commands, etc, collected from the internet
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Shivam Shrivastava
- **Finetuned from model :** deepseek-ai/deepseek-coder-1.3b-instruct
### Framework versions
- PEFT 0.14.0
|
danaroth/hsir
|
danaroth
| 2025-06-21T08:37:40Z | 0 | 0 | null |
[
"arxiv:2301.11525",
"license:mit",
"region:us"
] | null | 2025-06-19T16:03:21Z |
---
license: mit
---
# Description
This is a collection of models supported by the hyperspectral image restoration (HSIR) toolbox, developed by Intelligent Sensing and Processing Laboratory (BIT ISP lab) at Beijing Institute of Technology.
The original repository is available at:
<https://github.com/bit-isp/HSIR>
and models were originally downloaded at the following link:
<https://1drv.ms/u/s!AuS3o7sEiuJnf6F4THmqDMtDCwQ?e=JpfLP3>
# Citation
To cite the original repository:
```
@misc{hsir,
author={Zeqiang Lai, Miaoyu Li, Ying Fu},
title={HSIR: Out-of-box Hyperspectral Image Restoration Toolbox},
year={2022},
url={https://github.com/bit-isp/HSIR},
}
```
For each of the model please cite:
- HSID-CNN
```bibtex
@ARTICLE{yuan2019,
author={Q. {Yuan} and Q. {Zhang} and J. {Li} and H. {Shen} and L. {Zhang}},
journal={IEEE Trans. Geosci. Remote Sens.},
title={Hyperspectral Image Denoising Employing a Spatial-Spectral Deep Residual Convolutional Neural Network},
year={2019},
volume={57},
number={2},
pages={1205-1218},
month={Feb.},
}
```
- QRNN3D
```bibtex
@article{wei2020QRNN3D,
title={3-D Quasi-Recurrent Neural Network for Hyperspectral Image Denoising},
author={Wei, Kaixuan and Fu, Ying and Huang, Hua},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2020},
publisher={IEEE}
}
```
- TS3C
```bibtex
@article{bodrito2021trainable,
title={A Trainable Spectral-Spatial Sparse Coding Model for Hyperspectral Image Restoration},
author={Bodrito, Theo and Zouaoui, Alexandre and Chanussot, Jocelyn and Mairal, Julien},
journal={Adv. in Neural Information Processing Systems (NeurIPS)},
year={2021}
}
```
- GRUNet
```bibtex
@article{lai2022dphsir,
title = {Deep plug-and-play prior for hyperspectral image restoration},
journal = {Neurocomputing},
volume = {481},
pages = {281-293},
year = {2022},
issn = {0925-2312},
doi = {https://doi.org/10.1016/j.neucom.2022.01.057},
author = {Zeqiang Lai and Kaixuan Wei and Ying Fu},
}
```
- SST
```bibtex
@inproceedings{li2023spatial,
title={Spatial-Spectral Transformer for Hyperspectral Image Denoising},
author={Li, Miaoyu and Fu, Ying and Zhang, Yulun},
booktitle={AAAI},
year={2023}
}
```
- SERT
```bibtex
@inproceedings{li2023spectral,
title={Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising},
author={Miaoyu Li and Ji Liu and Ying Fu and Yulun Zhang and Dejing Dou},
booktitle={CVPR},
year={2023}
}
```
- MAN
```bibtex
@article{lai2023mixed,
title={Mixed Attention Network for Hyperspectral Image Denoising},
author={Lai, Zeqiang and Fu, Ying},
journal={arXiv preprint arXiv:2301.11525},
year={2023}
}
```
- HSDT
```bibtex
@inproceedings{lai2023hsdt,
author = {Lai, Zeqiang and Chenggang, Yan and Fu, Ying},
title = {Hybrid Spectral Denoising Transformer with Guided Attention},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year = {2023},
}
```
|
Genie-hub/boy
|
Genie-hub
| 2025-06-21T08:27:18Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-21T08:15:52Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: BOY
---
# Boy
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `BOY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "BOY",
"lora_weights": "https://huggingface.co/Genie-hub/boy/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Genie-hub/boy', weight_name='lora.safetensors')
image = pipeline('BOY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Genie-hub/boy/discussions) to add images that show off what you’ve made with this LoRA.
|
ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3
|
ArtusDev
| 2025-06-21T08:23:49Z | 0 | 0 | null |
[
"exl3",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"base_model:quantized:mistralai/Mistral-Small-3.2-24B-Instruct-2506",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-21T07:05:39Z |
---
base_model: mistralai/Mistral-Small-3.2-24B-Instruct-2506
base_model_relation: quantized
quantized_by: ArtusDev
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
pipeline_tag: image-text-to-text
tags:
- exl3
---
## EXL3 Quants of mistralai/Mistral-Small-3.2-24B-Instruct-2506
EXL3 quants of [mistralai/Mistral-Small-3.2-24B-Instruct-2506](https://huggingface.co/mistralai/Mistral-Small-3.2-24B-Instruct-2506) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
Based on the HF conversion of the base 3.2 model by unsloth: [unsloth/Mistral-Small-3.2-24B-Instruct-2506](https://huggingface.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506)
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/2.0bpw_H6) | 2.0 | 6 |
| [2.5_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [5.5_H8](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/5.5bpw_H8) | 5.5 | 8 |
| [6.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/mistralai_Mistral-Small-3.2-24B-Instruct-2506-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
sergioalves/17f5704c-f6f6-46d6-8e04-8f635d99d273
|
sergioalves
| 2025-06-21T08:21:52Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Vikhrmodels/Vikhr-7B-instruct_0.4",
"base_model:quantized:Vikhrmodels/Vikhr-7B-instruct_0.4",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-21T07:30:14Z |
---
base_model: Vikhrmodels/Vikhr-7B-instruct_0.4
library_name: transformers
model_name: 17f5704c-f6f6-46d6-8e04-8f635d99d273
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 17f5704c-f6f6-46d6-8e04-8f635d99d273
This model is a fine-tuned version of [Vikhrmodels/Vikhr-7B-instruct_0.4](https://huggingface.co/Vikhrmodels/Vikhr-7B-instruct_0.4).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sergioalves/17f5704c-f6f6-46d6-8e04-8f635d99d273", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/uducirop)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
minmax23/llama-3-2-1b-instruct-lora-custom
|
minmax23
| 2025-06-21T08:12:22Z | 34 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"arxiv:2405.16406",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-16T23:22:43Z |
---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3.2
extra_gated_prompt: >-
### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024
“Agreement” means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 3.2
distributed by Meta at https://llama.meta.com/doc/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are
entering into this Agreement on such person or entity’s behalf), of the age required under
applicable laws, rules or regulations to provide legal consent and that has legal authority
to bind your employer or such other person or entity if you are entering in this Agreement
on their behalf.
“Llama 3.2” means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and
any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or Switzerland)
and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide,
non-transferable and royalty-free limited license under Meta’s intellectual property or other rights
owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works
of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof),
or a product or service (including another AI model) that contains any of them, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama”
on a related website, user interface, blogpost, about page, or product documentation. If you use the
Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or
otherwise improve an AI model, which is distributed or made available, you shall also include “Llama”
at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the
following attribution notice within a “Notice” text file distributed as a part of such copies:
“Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,
Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for
the Llama Materials (available at https://www.llama.com/llama3_2/use-policy), which is hereby
incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.2 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates,
is greater than 700 million monthly active users in the preceding calendar month, you must request
a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to
exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS
ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES
OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED
WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,
WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT,
FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials,
neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates,
except as required for reasonable and customary use in describing and redistributing the Llama Materials or as
set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required
to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible
at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark
will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any
derivative works and modifications of the Llama Materials that are made by you, as between you and Meta,
you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or
counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion
of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable
by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or
claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third
party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access
to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms
and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this
Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of
California without regard to choice of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of
any dispute arising out of this Agreement.
### Llama 3.2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Llama 3.2.
If you access or use Llama 3.2, you agree to this Acceptable Use Policy (“**Policy**”).
The most recent copy of this policy can be found at
[https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).
#### Prohibited Uses
We want everyone to use Llama 3.2 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
1. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
2. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
3. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
4. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law
5. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
6. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
7. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.2 related to the following:
8. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997
9. Guns and illegal weapons (including weapon development)
10. Illegal drugs and regulated/controlled substances
11. Operation of critical infrastructure, transportation technologies, or heavy machinery
12. Self-harm or harm to others, including suicide, cutting, and eating disorders
13. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.2 related to the following:
14. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
15. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
16. Generating, promoting, or further distributing spam
17. Impersonating another individual without consent, authorization, or legal right
18. Representing that the use of Llama 3.2 or outputs are human-generated
19. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2
With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.2: LlamaUseReport@meta.com
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Information
The Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
**Model Developer:** Meta
**Model Architecture:** Llama 3.2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
| Llama 3.2 Quantized (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 8k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
**Supported Languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
**Llama 3.2 Model Family:** Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** Sept 25, 2024
**Status:** This is a static model trained on an offline dataset. Future versions may be released that improve model capabilities and safety.
**License:** Use of Llama 3.2 is governed by the [Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE) (a custom, commercial license agreement).
**Feedback:** Instructions on how to provide feedback or comments on the model can be found in the Llama Models [README](https://github.com/meta-llama/llama-models/blob/main/README.md). For more technical information about generation parameters and recipes for how to use Llama 3.2 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases:** Llama 3.2 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat and agentic applications like knowledge retrieval and summarization, mobile AI powered writing assistants and query and prompt rewriting. Pretrained models can be adapted for a variety of additional natural language generation tasks. Similarly, quantized models can be adapted for a variety of on-device use-cases with limited compute resources.
**Out of Scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.2 Community License. Use in languages beyond those explicitly referenced as supported in this model card.
## How to use
This repository contains two versions of Llama-3.2-1B-Instruct, for use with transformers and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Note: You can also find detailed recipes on how to use the model locally, with `torch.compile()`, assisted generations, quantised and more at [`huggingface-llama-recipes`](https://github.com/huggingface/huggingface-llama-recipes)
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Llama-3.2-1B-Instruct --include "original/*" --local-dir Llama-3.2-1B-Instruct
```
## Hardware and Software
**Training Factors:** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, quantization, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use:** Training utilized a cumulative of **916k** GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions:** Estimated total location-based greenhouse gas emissions were **240** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy; therefore, the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Logit Generation Time (GPU Hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | ----- | :---: | :---: | :---: |
| Llama 3.2 1B | 370k | \- | 700 | 107 | 0 |
| Llama 3.2 3B | 460k | \- | 700 | 133 | 0 |
| Llama 3.2 1B SpinQuant | 1.7 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 3B SpinQuant | 2.4 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 1B QLora | 1.3k | 0 | 700 | 0.381 | 0 |
| Llama 3.2 3B QLora | 1.6k | 0 | 700 | 0.461 | 0 |
| Total | 833k | 86k | | 240 | 0 |
\*\* The location-based CO2e emissions of Llama 3.2 1B SpinQuant and Llama 3.2 3B SpinQuant are less than 0.001 metric tonnes each. This is due to the minimal training GPU hours that are required.
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.2 was pretrained on up to 9 trillion tokens of data from publicly available sources. For the 1B and 3B Llama 3.2 models, we incorporated logits from the Llama 3.1 8B and 70B models into the pretraining stage of the model development, where outputs (logits) from these larger models were used as token-level targets. Knowledge distillation was used after pruning to recover performance. In post-training we used a similar recipe as Llama 3.1 and produced final chat models by doing several rounds of alignment on top of the pre-trained model. Each round involved Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Quantization
### Quantization Scheme
We designed the current quantization scheme with the [PyTorch’s ExecuTorch](https://github.com/pytorch/executorch) inference framework and Arm CPU backend in mind, taking into account metrics including model quality, prefill/decoding speed, and memory footprint. Our quantization scheme involves three parts:
- All linear layers in all transformer blocks are quantized to a 4-bit groupwise scheme (with a group size of 32) for weights and 8-bit per-token dynamic quantization for activations.
- The classification layer is quantized to 8-bit per-channel for weight and 8-bit per token dynamic quantization for activation.
- Similar to classification layer, an 8-bit per channel quantization is used for embedding layer.
### Quantization-Aware Training and LoRA
The quantization-aware training (QAT) with low-rank adaptation (LoRA) models went through only post-training stages, using the same data as the full precision models. To initialize QAT, we utilize BF16 Llama 3.2 model checkpoints obtained after supervised fine-tuning (SFT) and perform an additional full round of SFT training with QAT. We then freeze the backbone of the QAT model and perform another round of SFT with LoRA adaptors applied to all layers within the transformer block. Meanwhile, the LoRA adaptors' weights and activations are maintained in BF16. Because our approach is similar to QLoRA of Dettmers et al., (2023) (i.e., quantization followed by LoRA adapters), we refer this method as QLoRA. Finally, we fine-tune the resulting model (both backbone and LoRA adaptors) using direct preference optimization (DPO).
### SpinQuant
[SpinQuant](https://arxiv.org/abs/2405.16406) was applied, together with generative post-training quantization (GPTQ). For the SpinQuant rotation matrix fine-tuning, we optimized for 100 iterations, using 800 samples with sequence-length 2048 from the WikiText 2 dataset. For GPTQ, we used 128 samples from the same dataset with the same sequence-length.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.2 models on standard automatic benchmarks. For all these evaluations, we used our internal evaluations library.
### Base Pretrained Models
| Category | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| ----- | ----- | :---: | :---: | :---: | :---: | :---: |
| General | MMLU | 5 | macro\_avg/acc\_char | 32.2 | 58 | 66.7 |
| | AGIEval English | 3-5 | average/acc\_char | 23.3 | 39.2 | 47.8 |
| | ARC-Challenge | 25 | acc\_char | 32.8 | 69.1 | 79.7 |
| Reading comprehension | SQuAD | 1 | em | 49.2 | 67.7 | 77 |
| | QuAC (F1) | 1 | f1 | 37.9 | 42.9 | 44.9 |
| | DROP (F1) | 3 | f1 | 28.0 | 45.2 | 59.5 |
| Long Context | Needle in Haystack | 0 | em | 96.8 | 1 | 1 |
### Instruction Tuned Models
| Capability | | Benchmark | \# Shots | Metric | Llama 3.2 1B bf16 | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B bf16 | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | ----- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | | MMLU | 5 | macro\_avg/acc | 49.3 | 43.3 | 47.3 | 49.0 | 63.4 | 60.5 | 62 | 62.4 | 69.4 |
| Re-writing | | Open-rewrite eval | 0 | micro\_avg/rougeL | 41.6 | 39.2 | 40.9 | 41.2 | 40.1 | 40.3 | 40.8 | 40.7 | 40.9 |
| Summarization | | TLDR9+ (test) | 1 | rougeL | 16.8 | 14.9 | 16.7 | 16.8 | 19.0 | 19.1 | 19.2 | 19.1 | 17.2 |
| Instruction following | | IFEval | 0 | Avg(Prompt/Instruction acc Loose/Strict) | 59.5 | 51.5 | 58.4 | 55.6 | 77.4 | 73.9 | 73.5 | 75.9 | 80.4 |
| Math | | GSM8K (CoT) | 8 | em\_maj1@1 | 44.4 | 33.1 | 40.6 | 46.5 | 77.7 | 72.9 | 75.7 | 77.9 | 84.5 |
| | | MATH (CoT) | 0 | final\_em | 30.6 | 20.5 | 25.3 | 31.0 | 48.0 | 44.2 | 45.3 | 49.2 | 51.9 |
| Reasoning | | ARC-C | 0 | acc | 59.4 | 54.3 | 57 | 60.7 | 78.6 | 75.6 | 77.6 | 77.6 | 83.4 |
| | | GPQA | 0 | acc | 27.2 | 25.9 | 26.3 | 25.9 | 32.8 | 32.8 | 31.7 | 33.9 | 32.8 |
| | | Hellaswag | 0 | acc | 41.2 | 38.1 | 41.3 | 41.5 | 69.8 | 66.3 | 68 | 66.3 | 78.7 |
| Tool Use | | BFCL V2 | 0 | acc | 25.7 | 14.3 | 15.9 | 23.7 | 67.0 | 53.4 | 60.1 | 63.5 | 67.1 |
| | | Nexus | 0 | macro\_avg/acc | 13.5 | 5.2 | 9.6 | 12.5 | 34.3 | 32.4 | 31.5 | 30.1 | 38.5 |
| Long Context | | InfiniteBench/En.QA | 0 | longbook\_qa/f1 | 20.3 | N/A | N/A | N/A | 19.8 | N/A | N/A | N/A | 27.3 |
| | | InfiniteBench/En.MC | 0 | longbook\_choice/acc | 38.0 | N/A | N/A | N/A | 63.3 | N/A | N/A | N/A | 72.2 |
| | | NIH/Multi-needle | 0 | recall | 75.0 | N/A | N/A | N/A | 84.7 | N/A | N/A | N/A | 98.8 |
| Multilingual | | MGSM (CoT) | 0 | em | 24.5 | 13.7 | 18.2 | 24.4 | 58.2 | 48.9 | 54.3 | 56.8 | 68.9 |
\*\*for comparison purposes only. Model not released.
### Multilingual Benchmarks
| Category | Benchmark | Language | Llama 3.2 1B | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | MMLU (5-shot, macro_avg/acc) | Portuguese | 39.8 | 34.9 | 38.9 | 40.2 | 54.5 | 50.9 | 53.3 | 53.4 | 62.1 |
| | | Spanish | 41.5 | 36.0 | 39.8 | 41.8 | 55.1 | 51.9 | 53.6 | 53.6 | 62.5 |
| | | Italian | 39.8 | 34.9 | 38.1 | 40.6 | 53.8 | 49.9 | 52.1 | 51.7 | 61.6 |
| | | German | 39.2 | 34.9 | 37.5 | 39.6 | 53.3 | 50.0 | 52.2 | 51.3 | 60.6 |
| | | French | 40.5 | 34.8 | 39.2 | 40.8 | 54.6 | 51.2 | 53.3 | 53.3 | 62.3 |
| | | Hindi | 33.5 | 30.0 | 32.1 | 34.0 | 43.3 | 40.4 | 42.0 | 42.1 | 50.9 |
| | | Thai | 34.7 | 31.2 | 32.4 | 34.9 | 44.5 | 41.3 | 44.0 | 42.2 | 50.3 |
\*\*for comparison purposes only. Model not released.
## Inference time
In the below table, we compare the performance metrics of different quantization methods (SpinQuant and QAT \+ LoRA) with the BF16 baseline. The evaluation was done using the [ExecuTorch](https://github.com/pytorch/executorch) framework as the inference engine, with the ARM CPU as a backend using Android OnePlus 12 device.
| Category | Decode (tokens/sec) | Time-to-first-token (sec) | Prefill (tokens/sec) | Model size (PTE file size in MB) | Memory size (RSS in MB) |
| :---- | ----- | ----- | ----- | ----- | ----- |
| 1B BF16 (baseline) | 19.2 | 1.0 | 60.3 | 2358 | 3,185 |
| 1B SpinQuant | 50.2 (2.6x) | 0.3 (-76.9%) | 260.5 (4.3x) | 1083 (-54.1%) | 1,921 (-39.7%) |
| 1B QLoRA | 45.8 (2.4x) | 0.3 (-76.0%) | 252.0 (4.2x) | 1127 (-52.2%) | 2,255 (-29.2%) |
| 3B BF16 (baseline) | 7.6 | 3.0 | 21.2 | 6129 | 7,419 |
| 3B SpinQuant | 19.7 (2.6x) | 0.7 (-76.4%) | 89.7 (4.2x) | 2435 (-60.3%) | 3,726 (-49.8%) |
| 3B QLoRA | 18.5 (2.4x) | 0.7 (-76.1%) | 88.8 (4.2x) | 2529 (-58.7%) | 4,060 (-45.3%) |
(\*) The performance measurement is done using an adb binary-based approach.
(\*\*) It is measured on an Android OnePlus 12 device.
(\*\*\*) Time-to-first-token (TTFT) is measured with prompt length=64
*Footnote:*
- *Decode (tokens/second) is for how quickly it keeps generating. Higher is better.*
- *Time-to-first-token (TTFT for shorthand) is for how fast it generates the first token for a given prompt. Lower is better.*
- *Prefill is the inverse of TTFT (aka 1/TTFT) in tokens/second. Higher is better*
- *Model size \- how big is the model, measured by, PTE file, a binary file format for ExecuTorch*
- *RSS size \- Memory usage in resident set size (RSS)*
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
1. Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama
2. Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm
3. Provide protections for the community to help prevent the misuse of our models
### Responsible Deployment
**Approach:** Llama is a foundational technology designed to be used in a variety of use cases. Examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models, enabling the world to benefit from the technology power, by aligning our model safety for generic use cases and addressing a standard set of harms. Developers are then in the driver’s seat to tailor safety for their use cases, defining their own policies and deploying the models with the necessary safeguards in their Llama systems. Llama 3.2 was developed following the best practices outlined in our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/).
#### Llama 3.2 Instruct
**Objective:** Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. We implemented the same set of safety mitigations as in Llama 3, and you can learn more about these in the Llama 3 [paper](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/).
**Fine-Tuning Data:** We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone:** Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.2 Systems
**Safety as a System:** Large language models, including Llama 3.2, **are not designed to be deployed in isolation** but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools. As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
### New Capabilities and Use Cases
**Technological Advancement:** Llama releases usually introduce new capabilities that require specific considerations in addition to the best practices that generally apply across all Generative AI use cases. For prior release capabilities also supported by Llama 3.2, see [Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md), as the same considerations apply here as well.
**Constrained Environments:** Llama 3.2 1B and 3B models are expected to be deployed in highly constrained environments, such as mobile devices. LLM Systems using smaller models will have a different alignment profile and safety/helpfulness tradeoff than more complex, larger systems. Developers should ensure the safety of their system meets the requirements of their use case. We recommend using lighter system safeguards for such use cases, like Llama Guard 3-1B or its mobile-optimized version.
### Evaluations
**Scaled Evaluations:** We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Purple Llama safeguards to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case.
**Red Teaming:** We conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets. We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical Risks
In addition to our safety work above, we took extra care on measuring and/or mitigating the following critical risk areas:
**1\. CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons):** Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1. For Llama 3.1 70B and 405B, to assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons and have determined that such testing also applies to the smaller 1B and 3B models.
**2\. Child Safety:** Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber Attacks:** For Llama 3.1 405B, our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention. Because Llama 3.2’s 1B and 3B models are smaller and less capable models than Llama 3.1 405B, we broadly believe that the testing conducted for the 405B model also applies to Llama 3.2 models.
### Community
**Industry Partnerships:** Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
**Grants:** We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
**Reporting:** Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
**Values:** The core values of Llama 3.2 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.2 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
**Testing:** Llama 3.2 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.2 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development.
|
Flydarren/savannah
|
Flydarren
| 2025-06-21T08:08:06Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-06-21T07:17:29Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
original-18-pakcricketinfo-sapna-shah-vide/LATEST.FULL.VIDEO.Pakcricketinfo.Sapna.Shah.Viral.Video.Link.Tutorial.Official
|
original-18-pakcricketinfo-sapna-shah-vide
| 2025-06-21T08:06:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-21T08:05:33Z |
<a rel="nofollow" href="https://viralflix.xyz/leaked/?sat"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
|
nnilayy/dreamer-arousal-binary-ablation-with-adasyn-Kfold-2
|
nnilayy
| 2025-06-21T07:57:35Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-06-21T07:57:30Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
Mhammad2023/distilbert-base-uncased-fineTuned-imdb
|
Mhammad2023
| 2025-06-21T07:54:44Z | 13 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-06-19T20:32:57Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: Mhammad2023/distilbert-base-uncased-fineTuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Mhammad2023/distilbert-base-uncased-fineTuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the [Large Movie Review Dataset (or IMDb for short)](https://huggingface.co/datasets/stanfordnlp/imdb).
It achieves the following results on the evaluation set:
- Train Loss: 2.6554
- Validation Loss: 2.4705
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'transformers.optimization_tf', 'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}, 'registered_name': 'WarmUp'}, 'decay': 0.0, 'beta_1': np.float32(0.9), 'beta_2': np.float32(0.999), 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.6554 | 2.4705 | 0 |
### Framework versions
- Transformers 4.52.4
- TensorFlow 2.18.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3
|
ArtusDev
| 2025-06-21T07:49:12Z | 1 | 0 | null |
[
"qwen3",
"exl3",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"fi",
"base_model:OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT",
"base_model:quantized:OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-06-21T07:01:13Z |
---
base_model: OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT
base_model_relation: quantized
quantized_by: ArtusDev
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- fi
license: apache-2.0
tags:
- qwen3
- exl3
pipeline_tag: text-generation
---
## EXL3 Quants of OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT
EXL3 quants of [OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT](https://huggingface.co/OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/OpenBuddy_OpenBuddy-R1-0528-Distill-Qwen3-32B-Preview2-QAT-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
Gio88/bert-finetuned-squad
|
Gio88
| 2025-06-21T07:47:25Z | 9 | 0 | null |
[
"safetensors",
"bert",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"region:us"
] | null | 2025-06-21T06:16:08Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.5.1+cu121
- Datasets 3.6.0
- Tokenizers 0.19.1
|
ash001/ray-train-zero-3-bloom-1B-v7
|
ash001
| 2025-06-21T07:44:52Z | 17 | 0 | null |
[
"safetensors",
"bloom",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T01:05:43Z |
---
license: apache-2.0
---
|
shqkel/llama3-8b-rag-ko-merged
|
shqkel
| 2025-06-21T07:42:27Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-21T07:37:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Riyan123/Llama-3.2-3B-it-chat-myra-new
|
Riyan123
| 2025-06-21T07:39:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T11:26:17Z |
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Riyan123
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.