
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-03 12:31:03
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 537
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-03 12:30:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
IliyanGochev/whisper-small-bg
|
IliyanGochev
| 2023-07-06T06:50:12Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"bg",
"dataset:mozilla-foundation/common_voice_13_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-05T08:04:03Z |
---
language:
- bg
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: whisper-small-bg
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_13_0 bg
type: mozilla-foundation/common_voice_13_0
config: bg
split: test
args: bg
metrics:
- name: Wer
type: wer
value: 44.67291341315287
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-bg
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_13_0 bg dataset.
It achieves the following results on the evaluation set:
- Loss: 9.0612
- Wer: 44.6729
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 4.9319 | 6.76 | 1000 | 10.0774 | 73.9892 |
| 2.6116 | 13.51 | 2000 | 11.4089 | 67.0484 |
| 0.9607 | 20.27 | 3000 | 11.8266 | 60.9448 |
| 0.3464 | 27.03 | 4000 | 9.9500 | 52.1213 |
| 0.0122 | 33.78 | 5000 | 9.0612 | 44.6729 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
JennnDexter/pokemon-lora
|
JennnDexter
| 2023-07-06T06:44:42Z | 2 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-06-12T06:24:16Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - JennnDexter/pokemon-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




|
aroot/eng-mya-simcse_central
|
aroot
| 2023-07-06T06:36:12Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-06T06:14:05Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-mya-simcse_central
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-mya-simcse_central
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8980
- Bleu: 4.1973
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hchung1017/aihub_012_streaming_transformer
|
hchung1017
| 2023-07-06T06:35:19Z | 0 | 0 |
espnet
|
[
"espnet",
"audio",
"automatic-speech-recognition",
"ko",
"dataset:aihub_012",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
automatic-speech-recognition
| 2023-07-06T06:33:08Z |
---
tags:
- espnet
- audio
- automatic-speech-recognition
language: ko
datasets:
- aihub_012
license: cc-by-4.0
---
## ESPnet2 ASR model
### `hchung1017/aihub_012_streaming_transformer`
This model was trained by hchung1017 using aihub_012 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout f4d7fead71e2a99541a8d3d66d6e00a33d9e82df
pip install -e .
cd egs2/aihub_012/asr1
./run.sh --skip_data_prep false --skip_train true --download_model hchung1017/aihub_012_streaming_transformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Thu Jun 22 19:10:44 KST 2023`
- python version: `3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0]`
- espnet version: `espnet 202304`
- pytorch version: `pytorch 1.13.1`
- Git hash: `f4d7fead71e2a99541a8d3d66d6e00a33d9e82df`
- Commit date: `Wed May 24 14:58:35 2023 -0400`
## exp/asr_train_asr_streaming_transformer_raw_ko_bpe5000_sp/decode_asr_streaming_asr_model_valid.acc.ave
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|3794053|89.3|9.3|1.3|1.5|12.1|29.5|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|17636048|94.6|3.1|2.4|1.7|7.2|29.5|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|4325914|87.8|8.3|3.9|1.5|13.8|29.5|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr_streaming_transformer.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_streaming_transformer_raw_ko_bpe5000_sp
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 0
dist_backend: nccl
dist_init_method: env://
dist_world_size: 8
dist_rank: 0
local_rank: 0
dist_master_addr: localhost
dist_master_port: 32945
dist_launcher: null
multiprocessing_distributed: true
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 50
patience: null
val_scheduler_criterion:
- valid
- acc
early_stopping_criterion:
- valid
- cer_ctc
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 35000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_ko_bpe5000_sp/train/speech_shape
- exp/asr_stats_raw_ko_bpe5000_sp/train/text_shape.bpe
valid_shape_file:
- exp/asr_stats_raw_ko_bpe5000_sp/valid/speech_shape
- exp/asr_stats_raw_ko_bpe5000_sp/valid/text_shape.bpe
batch_type: numel
valid_batch_type: null
fold_length:
- 51200
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
chunk_excluded_key_prefixes: []
train_data_path_and_name_and_type:
- - /data/dump/aihub_012/raw/train_sp/wav.scp
- speech
- sound
- - /data/dump/aihub_012/raw/train_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - /data/dump/aihub_012/raw/dev/wav.scp
- speech
- sound
- - /data/dump/aihub_012/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
exclude_weight_decay: false
exclude_weight_decay_conf: {}
optim: adam
optim_conf:
lr: 0.0015
scheduler: warmuplr
scheduler_conf:
warmup_steps: 25000
token_list:
- <blank>
- <unk>
- ▁I
- ▁YOU
- ''''
- S
- ▁WHAT
- ▁A
- ▁IT
- ▁TO
- ▁IS
- ▁THE
- ▁ARE
- ▁CAN
- ▁OKAY
- ▁YES
- ▁DO
- ▁THAT
- ▁SEE
- T
- ▁HE
- ▁HOW
- ▁ME
- ▁HAVE
- ▁MY
- ▁GOOD
- ▁REALLY
- ▁SO
- ▁FOR
- ▁AM
- ▁SURE
- ▁OH
- ▁GO
- ▁WHY
- ▁NO
- ▁YOUR
- ▁RIGHT
- ▁HELP
- ’
- ▁DON
- ▁NOT
- ▁HI
- ▁HERE
- ▁DID
- ▁LIKE
- ▁AND
- ▁TOO
- ▁SHE
- ▁THIS
- ▁HELLO
- M
- ▁KNOW
- ▁WANT
- RE
- ▁NEED
- ▁WILL
- ▁ABOUT
- ▁THERE
- ▁LET
- ▁OF
- ▁IN
- ▁BE
- ▁BUT
- ▁THINK
- ▁SOMETHING
- ▁LOOK
- ▁NOW
- ▁NICE
- ▁THEN
- ▁
- ▁WE
- ▁GREAT
- ▁THANK
- ▁WITH
- ▁TELL
- ▁PROBLEM
- ▁HER
- ▁GOING
- ▁WAS
- ▁DOING
- ▁ASK
- ▁THANKS
- ▁HEY
- ▁BACK
- ▁WRONG
- ▁THEY
- ▁ON
- ▁HIM
- ▁UP
- ▁AT
- LL
- ▁WELL
- ▁GET
- ▁WHERE
- VERY
- ▁SOME
- ▁PEOPLE
- ▁ALL
- ▁MEAN
- ▁PLEASE
- ▁TIME
- ▁WHO
- ▁GOT
- ▁WELCOME
- ▁MAKE
- ▁COME
- ▁MEET
- ▁NEW
- ▁LOT
- ▁MOM
- ▁SAID
- ▁SHOULD
- ▁HAPPY
- ▁HIS
- ▁BUSY
- ▁BYE
- ▁QUESTION
- ▁SAY
- ▁TAKE
- ▁MORE
- ▁SORRY
- ▁IDEA
- ▁OUT
- ▁FINE
- ▁PLAY
- ▁ANY
- ▁AGAIN
- ▁BECAUSE
- ▁FROM
- ▁AN
- ▁WHEN
- ▁TRY
- ▁HAS
- ▁TODAY
- ▁READY
- ▁HOPE
- ▁GIVE
- ▁BIG
- ▁FRIEND
- ▁WRITE
- ▁EAT
- ▁ONE
- ▁BAD
- ▁MUCH
- ▁SOON
- ▁MANY
- ED
- ▁THEM
- ▁ANGRY
- ▁LATER
- ING
- ▁MAYBE
- ▁DAD
- ▁FIND
- ▁DOWN
- ▁WORRY
- ▁SHOW
- ▁COURSE
- ▁DAY
- ▁SOUNDS
- ▁DOES
- ▁STRANGE
- ▁TALK
- ▁FUN
- ▁REMEMBER
- ▁ANYTHING
- ▁BUY
- ▁LETTER
- ▁JUST
- ▁MADE
- ▁READ
- ▁CANNOT
- ▁WANTS
- ▁WOW
- ▁DIDN
- ▁IF
- ▁GLAD
- ▁WAY
- ▁MUST
- ▁SCHOOL
- ▁BOOK
- ▁LOOKING
- ▁TOLD
- ▁NAME
- ▁HEAR
- ▁TOY
- ▁TRUE
- ▁TEACHER
- ▁US
- ▁WORK
- ▁TWO
- ▁SONG
- ▁HARD
- ▁LOVE
- ▁THINGS
- ▁SING
- ▁BETTER
- ▁HOME
- ▁LINKER
- ▁UNDERSTAND
- ▁LOOKS
- ▁KIND
- ▁HOUSE
- LUE
- ▁DRESS
- ▁BY
- ▁BEST
- ▁LONG
- ▁NEWS
- ▁WENT
- ▁HAPPENED
- ▁OLD
- ▁KEEP
- ▁NEXT
- ▁CHECK
- D
- ▁SPECIAL
- ▁USE
- ▁LIKES
- ▁EVERYTHING
- ▁FEEL
- ▁ROBOT
- ▁SAD
- ▁PLEASURE
- ▁JOE
- ▁COOL
- ▁TOMORROW
- ▁LUCK
- ▁DOESN
- ▁BOX
- ▁AROUND
- ▁HOMEWORK
- ▁ALWAYS
- ▁MORGAN
- ▁PUT
- ▁THESE
- ▁GAVE
- ▁HEARD
- ▁WAIT
- ▁PRESENT
- ▁SOMEONE
- ▁PARTY
- ▁BIRTHDAY
- ▁RANDY
- ▁FRIENDS
- ▁MONEY
- ▁DONE
- ▁CAR
- ▁COFFEE
- ▁MUSIC
- ▁BEN
- ▁BEEN
- ▁STILL
- ▁GREEN
- ▁STAR
- ▁PERSON
- ▁WERE
- ▁STORY
- ▁ELSE
- ▁IDEAS
- ▁TOGETHER
- ▁MILK
- ▁WOULD
- ▁SOUND
- ▁THAN
- ▁TALKED
- ▁EVERY
- ▁NEEDS
- ▁SAW
- ▁HAIR
- ▁CHANGE
- ▁WORRIED
- ▁EASY
- ▁FOOD
- ▁DOG
- VE
- ▁CONCERT
- ▁MAKING
- ▁MONSTER
- ▁BOY
- ▁PHOTO
- ▁SCARY
- ▁RED
- ▁BROTHER
- ▁FIRST
- ▁DANCE
- ▁BEFORE
- ▁PRETTY
- ▁DRINK
- ▁WISH
- ▁HARRY
- ▁CALM
- ▁CAT
- ▁WEAR
- ▁BLUE
- ▁MESSAGE
- ▁TRUST
- ▁ONLY
- ▁HAD
- ▁THREE
- ▁AWAY
- ▁MIND
- ▁MAKES
- ▁GRANDMOTHER
- ▁WATCH
- ▁EMMA
- ▁AMY
- ▁TIRED
- ▁CLASS
- ▁MAN
- ▁DAN
- ▁COULD
- ▁BRING
- ▁SMALL
- ▁ANYWAY
- ▁OUR
- ▁ROOM
- ▁AFTER
- ▁BELIEVE
- ▁BOOKS
- ▁TEN
- ▁DEVILMON
- ▁JOB
- ▁OVER
- ▁COMING
- ▁STOP
- ▁FUNNY
- ▁DIANA
- ▁TOYS
- ▁FAST
- ▁MORNING
- ▁NUMBER
- ▁NOTHING
- ▁TOWN
- ▁OPEN
- ▁OTHER
- ▁PHONE
- ▁CARE
- ▁LEAVE
- ▁CONTEST
- ▁WOODY
- ▁THINKING
- Y
- ▁ANOTHER
- A
- ▁ENGLISH
- ▁SICK
- ▁BRAVE
- ▁TROY
- ▁EATING
- ▁SLEEP
- ▁THEIR
- ▁SELL
- ▁DELICIOUS
- ▁OFF
- ▁WATER
- ▁PICTURE
- ▁CAME
- ▁EVERYONE
- ▁PAPER
- ▁PARK
- ▁PAINT
- ▁SHOP
- ▁CREAM
- ▁TV
- ▁BOUGHT
- ▁CAREFUL
- ▁ROBBY
- ▁FOUND
- ▁STONE
- ▁SISTER
- ▁HURRY
- ▁BAG
- ▁WAKE
- ▁SYRUP
- ▁DRAW
- ▁ENERGY
- ▁SHOES
- ▁IMPORTANT
- ▁NEVER
- ▁LISTEN
- ▁WON
- ▁DOOR
- ▁POP
- ▁LAST
- ▁DIFFERENT
- ▁FISH
- ▁SAVE
- ▁HEALTHY
- ▁UNCLE
- ▁NIGHT
- UCH
- ▁PLACE
- ▁DARK
- ▁GUESS
- ▁LATE
- ▁PIE
- N
- ▁PRACTICE
- ▁MONICA
- ▁ANYONE
- ▁READING
- ▁COLOR
- ▁SALLY
- ▁BLACK
- ▁MOVIE
- ▁TROUBLE
- ▁COLD
- ▁STUDY
- ▁LITTLE
- ▁WHITE
- ▁CHEER
- ▁SCARED
- ▁POSTER
- ▁TALKING
- ▁TEACH
- ▁WALK
- ▁CAKE
- ▁INTO
- ▁FIGHT
- ▁ALREADY
- ▁SLEEPY
- ▁STRONG
- ▁OLIVIA
- ▁CALL
- ▁WROTE
- ▁ICE
- ▁OR
- ▁SCOTT
- ▁LIBRARY
- ▁NANCY
- ▁LUMY
- ▁HAT
- ▁YET
- ▁ALEX
- ▁SHORT
- ▁CLOTHES
- ▁YESTERDAY
- ▁FAVORITE
- ▁SWEET
- ▁FIVE
- ▁HOLD
- ▁LUNCH
- ▁PLAYING
- ▁GARY
- ▁HANDS
- ▁LEFT
- ▁ASKED
- ▁CHEESE
- ▁FACE
- ▁BORROW
- ▁SPEAK
- ▁INTERESTING
- ▁MAY
- ▁BEAR
- ▁SIGN
- ▁SHADOW
- ▁FLOWERS
- ▁PINO
- ▁ERIN
- ▁FOREST
- ▁GAME
- ▁MR
- ▁WANTED
- ▁RUN
- ▁SPELL
- ▁PEN
- ▁SHOPPING
- ▁COOK
- ▁DAYS
- ▁BED
- ▁BEAUTIFUL
- ▁MUSEUM
- ▁CLEAN
- ▁REST
- ▁SAME
- ▁DOCTOR
- ▁YOURSELF
- ▁DINNER
- ▁DANGEROUS
- ▁SECRET
- ▁STORE
- ▁TREE
- ▁MIGHT
- ▁MAYOR
- ▁CHARLIE
- ▁PIZZA
- ▁FOUR
- ▁SIR
- ▁SEEN
- ▁TURN
- ▁ENJOY
- ▁CLARA
- ▁ANYTIME
- ▁LIVE
- ▁LOST
- ▁SANDRA
- ▁DURING
- ▁MYSELF
- ▁TALL
- ▁MINE
- ▁CHOOSE
- ▁TOOK
- ▁WAITING
- ▁S
- ▁SUNNY
- ▁SINGING
- ▁ACADEMY
- ▁AHEAD
- ▁HURT
- ▁CLOCK
- ▁PAINTING
- ▁RAN
- ▁ALONE
- ▁USED
- ▁PLAN
- ▁THEATER
- ▁HAND
- ▁WEEK
- ▁CATCH
- ▁SEND
- ▁CUBE
- ▁ERIC
- ▁WOOD
- ▁HOT
- ▁DEVILMONS
- ▁FREE
- ▁STAY
- ▁PROMISE
- ▁RULE
- ▁HUNGRY
- ▁WORKING
- ▁HAPPEN
- ▁VIKI
- ▁FAMILY
- ▁CHICKEN
- ▁FORGET
- ▁YELLOW
- ▁BROWN
- ▁VACATION
- ▁KELLY
- ▁JACK
- ▁SINGER
- ▁HAMMER
- ▁SAYS
- ▁TRAIN
- ▁FIX
- ▁CUTE
- ▁EVEN
- ▁SANTA
- ▁SLEEPING
- ▁BUS
- ▁BARBECUE
- ▁AGREE
- ▁COULDN
- ▁MISS
- E
- ▁GRACE
- ▁TRASH
- ▁BABY
- ▁LUMA
- ▁CHILDREN
- ▁EXCUSE
- ▁DPOP
- ▁OUTSIDE
- ▁ORDER
- ▁MATTER
- ▁RIDE
- ▁SUMMER
- ▁CLOSE
- ▁MOVE
- ▁JUICE
- ▁TOUCH
- ▁CARD
- ▁THOSE
- ▁HAIRSTYLE
- ▁RICH
- ▁BREAK
- ▁ANYMORE
- ▁TRIP
- ▁EYES
- ▁LEARN
- IC
- ▁YOUNGER
- ▁SMELLS
- ▁CHRIS
- ▁ITEMS
- ▁STONES
- ▁CUT
- ▁STUDENT
- ▁CALLED
- ▁SHINE
- ▁ATE
- ▁PERFECT
- ▁BETIA
- ▁MOVING
- LY
- ▁FIRE
- ▁D
- ▁CHRISTMAS
- ▁RUNNING
- ▁LINE
- ▁JACKET
- ▁WHICH
- ▁GIFT
- ▁SMILE
- ▁WEARING
- ▁STELLA
- ▁SEVEN
- ▁ANSWER
- ▁YEAR
- ▁MOST
- ▁WENDY
- RA
- ▁BALL
- ▁THING
- ▁FIFTY
- ▁YOUNG
- ▁FRONT
- ▁LIKED
- ▁WINDOW
- ▁BEING
- ▁RICE
- ▁HOBBY
- ▁BRUCE
- ▁ALVIN
- ▁CHAIR
- ▁ELEVEN
- ▁INTERVIEW
- ▁TRUMPET
- ▁DRAWING
- ▁WHILE
- ▁HAV
- ▁NEWSPAPER
- ▁WRITING
- ▁FRUIT
- ▁BEHIND
- ▁EVENT
- ▁HAVEN
- ▁BELLOW
- ▁YEARS
- ▁DIV
- ▁VICTORIA
- ▁SENT
- ▁STYLE
- ▁LUNA
- ▁AUNT
- ▁DREAM
- ▁PICTURES
- ▁LEO
- ▁QUESTIONS
- ▁PRICE
- ▁APPLE
- ▁SCHEDULE
- ▁TABLE
- ▁PLANT
- ▁BELL
- ▁SUSAN
- ▁SHIRT
- ▁GRANDFATHER
- ▁EXPENSIVE
- ▁GUYS
- ▁THOUGHT
- ▁OSCAR
- ▁TIMES
- ▁ACTUALLY
- ▁CHANCE
- ▁PAY
- ▁WASH
- ▁JUGGLING
- ▁JULIA
- ▁MAKEUP
- ▁PIANO
- ▁GOES
- ▁QUIZ
- ▁OFTEN
- ▁THIRTY
- ▁SMART
- ▁WEEKEND
- ▁CHOCOLATE
- ▁BATHROOM
- ▁CANDY
- ▁SPEECH
- ▁FEELING
- ▁RADIO
- ▁HECTOR
- ▁KNOWS
- ▁GRANDMA
- ▁SEEM
- ER
- ▁START
- ▁PENCIL
- ▁SUNDAY
- ▁WORD
- ▁MOUSE
- ▁PLAYGROUND
- ▁BREAD
- ▁MAGIC
- ▁CD
- ▁BROKEN
- ▁COLIN
- ▁DIRTY
- ▁MOTHER
- ▁DESK
- ▁BORING
- ▁SOUP
- ▁ONCE
- ▁WORKED
- ▁COUNT
- ▁EXCITED
- ▁PARADE
- ▁GUITAR
- ▁PM
- ▁FINISH
- ▁BLOCK
- ▁FISHING
- ▁VOICE
- ▁ROGER
- ▁WORKS
- ▁PLAYER
- ▁GLASSES
- ▁LAB
- ▁SIGH
- ▁LOVES
- ▁MODEL
- ▁EXERCISE
- ▁O
- ▁POINT
- ▁SWIMMING
- ▁MARKET
- ▁NOTE
- ▁SECOND
- ▁LUCKY
- ▁BROKE
- ▁CAVE
- ▁SHALL
- ▁KID
- ▁HANG
- ▁MICHAEL
- ▁DANCING
- ▁COM
- ▁MASK
- TING
- ▁KYLE
- ▁FRIDAY
- ▁MELOD
- ▁DOUGLAS
- ▁ENOUGH
- ▁LEARNED
- ▁ALICE
- ▁NEWSPAPERS
- ▁NEAR
- ▁GIRL
- ▁LAURA
- ▁BANK
- ▁ORANGE
- ▁HEART
- ▁SNACKS
- ▁BANANA
- ▁AFRAID
- ▁NOISE
- ▁AARON
- ▁SIDE
- ▁POSSIBLE
- ▁ISN
- ▁UPSET
- ▁KATHY
- ▁ENTER
- ▁STATUE
- ▁FAVOR
- ▁CAPSULE
- ▁CLUB
- ▁BORED
- ▁STREET
- ▁FAR
- ▁BROUGHT
- ▁HENRY
- ▁BRIAN
- ▁FLOOR
- ▁RECORD
- ▁SUN
- ▁BORN
- ▁GONE
- ▁ELEPHANT
- ▁FATHER
- ▁BEAT
- ▁MISTAKE
- NY
- ▁MEGAN
- ▁JIN
- ▁CARL
- ▁FACTORY
- ▁HORSE
- ▁STANLEY
- ▁WIN
- ▁AFTERNOON
- ▁LIVED
- ▁HIGH
- ▁LEAVING
- ▁MINUTES
- ▁WALL
- ▁SURPRISE
- ▁DAVID
- ▁TWENTY
- ▁BIRD
- ▁NICK
- ▁REASON
- ▁OWN
- ▁STEVE
- ▁LADY
- ▁COMES
- ▁STATION
- ▁DOLL
- ▁JADE
- ▁STAND
- ▁FAMOUS
- ▁PLAYED
- ▁TSHIRT
- ▁HUEY
- ▁SEA
- ▁SIX
- ▁REPORT
- ▁POPULAR
- ▁PICK
- ▁TONY
- ▁TINA
- ▁KIDS
- ▁WEATHER
- ▁TREES
- ▁TIFFANY
- ▁WONDERFUL
- ▁RING
- ▁SOMEWHERE
- ▁LIGHT
- ▁NOSE
- ▁AUDREY
- ▁CAMERA
- ▁GARDEN
- ▁SOCCER
- ▁PIG
- ▁FRESH
- ▁NOBODY
- ▁AMANDA
- ▁SURPRISED
- ▁STOPPED
- ▁CITY
- ▁KOREAN
- ▁HISTORY
- ▁STUDENTS
- ▁COOKING
- L
- ▁LOUD
- ▁LOSE
- ▁PINK
- ▁LIE
- ▁CRAYONS
- ▁HEALTH
- ▁HANDWRITING
- ▁JOIN
- ▁THROW
- ▁INFORMATION
- ▁DIFFICULT
- ▁SOMETIMES
- ▁BIKE
- ▁WOMAN
- ▁FLOWER
- ▁WORDS
- ▁GHOST
- ▁RICKY
- R
- ▁TEETH
- ▁SAYING
- ▁PIECE
- ▁DR
- ▁CHANGED
- ▁SIT
- ▁ARTICLE
- ▁ARM
- ▁BECOME
- ▁MONKEY
- ▁YEAH
- ▁JUDY
- ▁FOLLOW
- ▁ALSO
- ▁GAMES
- ▁BAND
- ▁COMPUTER
- ▁ANDRE
- ▁EATS
- ▁MATH
- ▁EXACTLY
- ▁ART
- ▁JUMP
- ▁FOODS
- ▁PRESENTS
- ▁RABBIT
- ▁SMELL
- ▁HEAVY
- ▁SWIM
- ▁RICHARD
- ▁GRASS
- ▁BOTHER
- ▁PANTS
- ES
- ▁ALMOST
- ▁HELPING
- ▁ZOO
- ▁SHOULDN
- ▁FAN
- ▁EGGS
- ▁ELLA
- ▁RESTAURANT
- ▁CHIPS
- ▁BIGGER
- ▁MONDAY
- ▁CATS
- ▁STUDYING
- ▁TONIGHT
- ▁BRADY
- ▁SERIOUS
- ▁FORGOT
- ▁VISIT
- ▁BUILDING
- ▁SET
- ▁HANDSOME
- ▁CLAUS
- ▁RALPH
- ▁COMPANY
- ▁SEAT
- ▁ANDREW
- ▁WITHOUT
- EN
- ▁MEAT
- ▁BOARD
- ▁CLASSES
- ▁FLY
- ▁BIT
- ▁ANGELA
- ▁POLICE
- ▁BET
- ▁FINISHED
- ▁EITHER
- ▁SKY
- ▁POLIA
- ▁EIGHT
- ▁AMAZING
- ▁INSIDE
- ▁SATURDAY
- ▁DINOSAUR
- ▁DEVERYTHING
- ▁BRUSH
- ▁VIVIEN
- ▁BREAKFAST
- ▁QUICKLY
- ▁HEAD
- ▁CAROL
- ▁EACH
- ▁BANANAS
- ▁JAZZ
- ▁OWEN
- ▁LEAVES
- ▁HELPED
- ▁WINTER
- ▁REAL
- ▁TRUTH
- ▁RIVER
- ▁ROAD
- ▁ANNA
- ▁INTERESTED
- ▁EVERYBODY
- ▁HIMSELF
- ▁TAKES
- ▁LADDER
- ▁BOTH
- ▁CLASSROOM
- ▁STUDIED
- ▁HALL
- MAS
- ▁STARTED
- ▁THO
- ▁REFUND
- ▁EARLY
- ▁MARK
- ▁TRIED
- ▁CRY
- ▁CUP
- ▁DEAL
- ▁LEGS
- ▁PARTNER
- ▁NINE
- ▁MONTH
- ▁CRYSTAL
- ▁MRS
- ▁WHOM
- ▁QUIET
- ▁TICKET
- ▁TRYING
- ▁JELLY
- ▁TEST
- ▁OFFICE
- ▁BICYCLE
- ▁HOSPITAL
- ▁POOL
- ▁DOGS
- ▁LIVES
- ▁NOISY
- ▁TASTE
- ▁FEET
- ▁PASTA
- ▁HANS
- AL
- ▁PAST
- ▁PRIZE
- ▁KEY
- ▁COUPON
- ▁TIMMY
- ▁AREN
- ▁MEMO
- ▁TEACHE
- ▁PRACTICING
- ▁ANIMAL
- ▁MOUTH
- ▁WORLD
- ▁UNDER
- ▁WATCHING
- ▁FELL
- ▁DRIVE
- ▁BEACH
- ▁CLEAR
- ▁JOKES
- ▁GAVIN
- ▁ADD
- CLOCK
- ▁HELPER
- ▁JULIE
- ▁WEIRD
- ▁SINCE
- ▁MILLER
- ▁TIE
- ▁FRUITS
- ▁HOUR
- ▁ANIMALS
- ▁TWICE
- ▁WARM
- ▁LARGE
- ▁UNTI
- ▁JAMES
- ▁DOLLARS
- ▁STORIES
- ▁MEAL
- ▁APPLES
- ▁CRYING
- ▁DIET
- ▁HEADPHONES
- ▁MEMORI
- ▁COMPLIMENT
- ▁TRIANGLE
- ▁DIARY
- ▁TOWER
- ▁EYE
- ▁SALE
- ▁BUILT
- ▁CARROT
- ▁ORDERED
- ▁ITEM
- ▁SLOW
- ▁NAOMI
- ▁TUESDAY
- ▁SENSE
- ▁PARENTS
- ▁GIV
- ▁BUSINESS
- ▁EVER
- ▁TYLER
- ▁FORWARD
- ▁CELL
- ▁SHUT
- ▁COAT
- ▁PRINCE
- ▁HATE
- ▁PUPPET
- ▁FULL
- ▁WOULDN
- ▁TERRIBLE
- ▁CARDS
- ▁MAP
- ▁STAMP
- ▁SNACK
- ▁SNOW
- ▁RUBY
- ▁SLOWLY
- ▁EDDY
- ▁EASILY
- ▁LAZY
- ▁BLOCKS
- ▁EARS
- ▁COLORS
- ▁TTEOKBOKKI
- ▁CAREFULLY
- ▁MARRIED
- ▁VILLAGE
- ▁HEADACHE
- ▁MOUNTAIN
- ▁PETER
- ▁FAT
- ▁MARRY
- WEEN
- ▁RYAN
- ▁DISHES
- ▁JIM
- ▁FIELD
- ▁CINDY
- ▁FEW
- ▁STARS
- ▁UMBRELLA
- ▁GROW
- ▁FROG
- ▁RULER
- ▁BASKETBALL
- ▁PART
- ▁ORLANDO
- ▁CORRECT
- ▁GRANDPA
- ▁ADVICE
- ▁ARMS
- SE
- ▁PHOTOS
- ▁KICKBOARD
- ▁JACOB
- ▁DANGER
- ▁BOOTS
- ▁GIANT
- ▁BATH
- ▁VISITOR
- ▁PROMISED
- ▁SNAKE
- ▁GLASS
- ▁RAISE
- ▁SPICY
- ▁TURNED
- ▁MEETING
- ▁VIOLIN
- ▁MINUTE
- ▁DAISY
- ▁BUTTON
- ▁OTHERS
- ▁DELIVERY
- ▁WASN
- ▁JOGGING
- ▁SOFA
- ▁FINGERS
- ▁NICOLE
- ▁TALLER
- ▁RUNS
- ▁BENJAMIN
- ▁GOLD
- ▁LUCAS
- ▁SNOWMAN
- ▁LOVED
- ▁SANDWICH
- ▁STRAIGHT
- ▁AGAINST
- ▁BALLOONS
- ▁KEPT
- ▁CLOSED
- ▁PENS
- ▁MAX
- ▁LEG
- ▁FILL
- ▁QUIT
- ▁ANYBODY
- ▁JEFF
- ▁ANN
- ▁EVAN
- ▁MISSED
- ▁TAEKWONDO
- ▁JOY
- ▁PUSH
- ▁WOODWARD
- ▁ROSS
- ▁LISA
- ▁PULL
- ▁NECTAR
- ▁VASE
- ▁RABBITS
- ▁BOW
- ▁BUGS
- ▁SAFE
- GETTING
- ▁CASH
- ▁LAMP
- ▁DOLLS
- ▁YUMMY
- ▁MEDICINE
- ▁SPORTS
- ▁ENDS
- ▁BASEBALL
- ▁THROUGH
- ▁CENTER
- ▁FIGHTER
- ERS
- ▁PACKAGE
- ▁WORMS
- ▁SHAPE
- ▁DISAPPOINTED
- ▁PHILLIP
- ▁DINOSAURS
- ▁SALAD
- ▁HAMBURGER
- ▁COOKIES
- ▁PASS
- ▁CHEAP
- ▁STAGE
- ▁COLORED
- ▁TYPE
- ▁EVENING
- ▁CRIED
- ▁SHOWER
- ▁WALLET
- ▁FIFTEEN
- ▁HERO
- ▁USUALLY
- ▁GATE
- ▁TEAM
- ▁PLANE
- ▁DRESSES
- ▁SOLD
- ▁CRAYON
- LE
- ▁HIDE
- ▁BODY
- ▁MEN
- ▁HAIRSTYLES
- ▁BOAT
- ▁WONDER
- ▁RAIN
- ▁FEELS
- ▁NERVOUS
- ▁CHILD
- ▁MIRROR
- ▁BUG
- ▁LONGER
- ▁LOUIS
- ▁AIR
- ▁STOMACHACHE
- ▁ASKING
- ▁OWNER
- ▁KNEW
- ▁BELT
- I
- ▁MAGAZINE
- ▁HOP
- ▁SUGAR
- ▁END
- ▁TAKING
- ▁LIGHTS
- ▁EMPTY
- ▁PUPPY
- ▁DUCK
- ▁SUPERMARKET
- ▁APARTMENT
- ▁ADDRESS
- ▁MACHINE
- ▁JASON
- ▁CARRY
- ▁DRY
- ▁EXCITING
- ▁BOTTLE
- ▁RIDING
- ▁CHARCOAL
- ▁TRAVIS
- ▁UGLY
- ▁CAUGHT
- ▁PROBAB
- ▁PROJECT
- ▁LISTENING
- ▁JUGGLE
- ▁ROPE
- ▁BILL
- ▁HOURS
- ▁MOLLY
- ▁SOPHIE
- ▁WEARS
- ▁LIFE
- ▁CAFE
- ▁HURTS
- ▁RELAX
- ▁TED
- ▁COPY
- ▁COTTON
- ▁ALONG
- ▁OFFER
- ▁DATE
- ▁LI
- ▁YOUTUBE
- ▁JOKE
- ▁BARREL
- ▁DIED
- ▁SINGS
- ▁SEVERAL
- ▁TALENT
- ▁CARTER
- ▁PASSWORD
- ▁CASE
- ▁SCISSORS
- ▁YORK
- ▁FANTASTIC
- ▁CLOUDY
- ▁ROUND
- ▁BUILD
- ▁PRINCESS
- ▁RAINY
- ▁GRAPES
- ▁SKIRT
- ▁LION
- ▁FASTER
- ▁FASHION
- ▁AD
- ▁EXPLAIN
- ▁DOCK
- ▁MATCH
- ▁BOMB
- ▁STADIUM
- ▁WOODS
- ▁FALL
- ▁MAD
- ▁TRUCK
- ▁STEP
- ▁ANSWERS
- ▁KIDDING
- ▁MOON
- ▁BEAN
- ▁PICKED
- ▁LESSON
- ▁KNOWN
- ▁HAPPENING
- ▁BLUEBERRIES
- ▁SANDWICHES
- ▁BUTTER
- ▁BEDROOM
- ▁ABOVE
- ▁LEGO
- ▁HELENA
- ▁FOOTPRINT
- ▁SHIP
- ▁TAP
- ▁HILL
- ▁CHURCH
- ▁GOODBYE
- ▁LEMON
- ▁HUNDRED
- ▁COWARD
- ▁ARRIVED
- ▁WATERMELON
- ▁BOXES
- ▁FINALLY
- ▁MAIN
- ▁KEVIN
- BINGO
- ▁BONES
- ▁SPOKE
- ▁DONUTS
- ▁HENNA
- ▁LETTERS
- ▁PAM
- ▁LESS
- ▁WEDDING
- ▁POCKET
- ▁SHY
- ▁NOWHERE
- ▁MIC
- ▁NAMES
- ▁SONGS
- MED
- ▁DECIDED
- ▁KITCHEN
- ▁SHINING
- ▁LOVELY
- ▁SEASON
- ▁STEAK
- ▁DRUM
- ▁TEDDY
- ▁SHINY
- ▁GIRLS
- ▁AUDITION
- ▁ACTING
- ▁NECK
- ▁ROSA
- ▁SNEAKERS
- ▁SHOE
- ▁QUITE
- ▁HOTEL
- ▁LEATHER
- ▁WIND
- ▁COUSIN
- ▁JANET
- ▁ONIONS
- ▁DEAD
- ▁PROUD
- ▁PET
- ▁HELPFUL
- ▁TOILET
- ▁FORTY
- ▁JAKE
- ▁BUTTERFLY
- ▁KICK
- ▁BIRDS
- ▁ABROAD
- ▁TEA
- ▁STARTS
- ▁MEALS
- ▁AIRSHIPS
- ▁SOFT
- ▁MATT
- ▁BLANKET
- ▁WINDY
- ▁PLAYS
- ▁COVER
- ▁WEIGHT
- ▁PURPLE
- ▁HIDING
- ▁TAGS
- ▁F
- ▁WHATEVER
- ▁AIRSHIP
- ▁LIVING
- ▁MAT
- ▁KINDERGARTEN
- ▁POND
- ▁LAUNDRY
- O
- ▁NOTEBOOK
- ▁HELEN
- ▁SWEATER
- ▁TEACHING
- ▁FAULT
- ▁SQUARE
- ▁HONEST
- ▁LOUDER
- CAME
- ▁3
- ▁DROP
- ▁GUY
- ▁GIRLFRIEND
- ▁RAINING
- ▁SPIDER
- ▁FLYER
- ▁WATCHED
- ▁B
- ▁LOW
- ▁COUSINS
- ▁OLDER
- DY
- ▁ROCK
- ▁MOMENT
- ▁SHEET
- ▁LAUGH
- ▁BLUEBERRY
- ▁NEIGHBORHOOD
- ▁GRADE
- ▁STICKER
- ▁OPENING
- ▁ALRIGHT
- ▁OFFICER
- ▁PI
- ▁WEDNESDAY
- ▁BITE
- ▁CONTINUE
- TIME
- ▁SAIN
- ▁COSTUME
- ▁MOVED
- ▁BOOKCASE
- ▁DENTIST
- ▁STOPS
- ▁SAM
- ▁APRIL
- ▁THIRSTY
- ▁MOOD
- ▁PEA
- ▁ENTRY
- ▁SERVICE
- ▁ABLE
- ▁FRIED
- ▁W
- ▁FLASH
- ▁KATRINA
- ▁REPAIR
- ▁TI
- ▁GIMBAP
- NDA
- ▁ANNIVERSARY
- ▁NAMED
- ▁WRITTEN
- ▁CUSTOMERS
- ▁COLLECT
- ▁BONGOS
- ▁EGG
- ▁BAT
- ▁RIBS
- ▁SAT
- ▁RETURN
- LIGHT
- BACK
- CA
- NESS
- ▁FACES
- ▁CALLING
- ▁HOLIDAY
- ▁HOLE
- ▁MILLION
- ▁DELIVER
- ▁10
- ▁TAXI
- ▁HASN
- ▁MINDS
- ▁DONALD
- ▁MISTAKES
- ▁SPRING
- ▁MENTION
- ▁NEITHER
- ▁TOWEL
- ▁BEANS
- ▁WILLIAM
- ▁BRIGHT
- ▁STOMACH
- ▁CANDIES
- ▁BURGERS
- ▁FEAR
- ▁DECIDE
- ▁FEVER
- ▁FANS
- ▁STUDIO
- ▁LIAR
- ▁BREAKING
- ▁SLEPT
- ▁TAIL
- ▁BURGER
- ▁MOVIES
- ▁SMOKE
- ▁DANIEL
- ▁WAITER
- ▁PENCILS
- ▁CROSS
- ▁KOREA
- ▁GUARD
- ▁LEARNING
- ▁SUBWAY
- ▁CARS
- ▁SKIP
- ▁MIX
- ▁JEANS
- ▁LIST
- ▁POST
- ▁TRAVEL
- ▁BORROWED
- ▁AWESOME
- ▁RECORDER
- ▁FLOUR
- ▁COW
- ▁CAMPING
- ▁DRIVING
- ▁FELT
- ▁WINNER
- ▁CHARACTER
- ▁BALLOON
- ▁RIDDLE
- W
- FUL
- ▁NECKLACE
- ▁GLOVES
- ▁CHANGING
- ▁CRACKED
- ▁DROPPED
- ▁ROBERT
- ▁BAKERY
- ▁GRILL
- ▁INVITED
- ▁LAND
- ▁PORK
- ▁TELEPHONE
- ▁SKI
- ▁GUEST
- ▁AMBER
- ▁SHARP
- ▁KITE
- ▁DELI
- ▁MART
- ANNA
- ▁CIRCLE
- ▁FLYING
- ▁SHAKE
- ▁DANCER
- ▁POLICEMAN
- ▁DESSERT
- ▁SHOCK
- ▁BLOOD
- ▁MENU
- ▁BUMP
- ▁NOVEL
- ▁SKIN
- ▁SHOULDERS
- ▁MICHELLE
- ▁CROSSED
- ▁TICKETS
- ▁DRANK
- ▁OUTFIT
- ▁LAKE
- ▁PAINTER
- ▁ALIEN
- ▁RAINBOW
- ▁WORE
- ▁BAR
- ▁BROTHERS
- ▁DISH
- ▁SIMILAR
- ▁DISPLAY
- ▁GIRAFFE
- ▁FANCY
- ▁THIEF
- ▁HALLWAY
- ▁WAVE
- ▁CARROTS
- PE
- ▁ELDER
- ▁SOMEBODY
- ▁TRAFFIC
- ▁ACTOR
- ▁RUMORS
- ▁CHOSE
- ▁CAUS
- ▁DRESSED
- ▁ROSE
- ▁LYING
- ▁PANDA
- ▁PEAR
- ▁SUGGEST
- ▁DECISION
- ▁NOISES
- ▁TAKEN
- ▁GARLIC
- ▁CHINESE
- ▁ITCHY
- ▁SWORD
- ▁WAITED
- ▁NONE
- ▁SIZE
- ▁ACCEPT
- ▁CAPTAIN
- ▁GRAY
- ▁IDOL
- ▁SMALLER
- ▁USUAL
- ▁THOUSAND
- ▁LONELY
- ▁RETURNED
- ▁JENNY
- ▁PRACTICED
- ▁NEEDED
- ▁PAIN
- ▁RAP
- ▁THIN
- ▁EVERYWHERE
- ▁SUIT
- ▁BUSH
- ▁SON
- ▁COMPLIMENTS
- ▁FAILED
- ▁RUG
- ▁PAID
- ▁MANGO
- ▁BOYFRIEND
- ▁SCARF
- ELA
- ▁CROWD
- ▁ONLINE
- ▁GREW
- ▁SOCKS
- ▁SEAGULLS
- ▁USING
- ▁MELTED
- ▁OIL
- ▁ADULTS
- ▁KATE
- ▁WHISTLING
- ▁PRAY
- ▁POOR
- ▁SAUCE
- ▁PACKED
- ▁HATS
- ▁BUYING
- ▁AGO
- ▁SCIENCE
- ▁TUNNEL
- ▁DRESSING
- ▁MISSING
- ▁FESTIVAL
- ▁THURSDAY
- ▁PAIR
- ▁SITTING
- ▁SUITCASE
- ▁SHAPES
- ▁WILLY
- ▁HUGE
- ▁SHOUTED
- EVER
- ▁FAIR
- ▁TASTES
- ▁CAFETERIA
- ▁BINGO
- ▁BEGINS
- ▁DOLLAR
- ▁GRILLING
- ▁ALIVE
- ▁DINO
- ▁LIFT
- ▁TOP
- ION
- ▁STUFF
- ▁FROZEN
- ▁ACROSS
- ▁SEOUL
- ▁FRIES
- ▁TAUGHT
- ▁VIDEO
- ▁CREDIT
- ▁HAPPENS
- ▁RACE
- ▁TOUR
- ▁SPAGHETTI
- ▁SWING
- ▁INVITATION
- ▁COUNTRYSIDE
- ▁STAIRS
- ▁HIGHER
- ▁RANGER
- BAG
- ▁PULLED
- ▁LIPSTICK
- ▁VALLEY
- ▁NAP
- ▁FUTURE
- ▁SILENT
- ▁SPEAKER
- ▁GIVEN
- ▁JUMPING
- ▁AUTUMN
- ▁HOLDING
- ▁BOB
- ▁PLANNING
- ▁SUPPOSE
- ▁CLUES
- ▁ANSWERED
- ▁STICK
- ▁WASHED
- ▁CURLY
- ▁RUINED
- ▁SMILING
- ▁UNHAPPY
- ▁KIMBAP
- ▁CAUSE
- ▁CHUNKMONS
- ▁REPEAT
- STOOD
- ▁8
- ▁SHEEP
- ▁LOUDLY
- ▁SLIDE
- ▁KING
- ▁LIME
- ▁SKATING
- ▁SERVE
- ▁SAND
- ▁POWER
- ▁MUSICIANS
- ▁RESTROOM
- ▁SOMEDAY
- ▁GYM
- ▁GOD
- ▁COOKIE
- ▁NUMBERS
- ▁WARNING
- ▁CLASSMATE
- ▁COMPLAIN
- ▁LAUGHED
- ▁BEES
- ▁SAFELY
- ▁DESIGNER
- ▁ORANGES
- B
- ▁RETURNS
- ▁SPEAKING
- ▁GINA
- ▁MARTI
- ▁FEELINGS
- MAN
- ▁TULIP
- ▁BAZAAR
- ▁EMAIL
- ▁STRAWBERRY
- ▁PRESS
- ▁SALT
- ▁PHEW
- ▁COWS
- ▁ENTRANCE
- ▁LEAF
- ▁PAN
- ▁SOUR
- ▁DISEASE
- ▁OPENED
- ▁LUGGAGE
- ▁SWIMSUIT
- ▁PASSED
- ▁ALISON
- ▁SHOVELS
- ▁SENTENCES
- ▁GROUND
- ▁STAYING
- ▁SALES
- ▁JAM
- ▁WRAP
- ▁LATELY
- ▁SHRIMP
- ▁TWELVE
- ▁CHEAPER
- ▁CHECKING
- ▁SEAWEED
- ▁LO
- ▁TURTLES
- ▁DNN
- ▁WHE
- ▁ACT
- ▁LIZARD
- ▁SUCCEED
- ▁STRING
- ▁BASKET
- ▁HINT
- ▁VEGETABLES
- ▁FOOL
- ▁SHOT
- ▁ADULT
- ▁GREG
- ▁TASTY
- ▁FARM
- ▁LIPS
- ▁STARFISH
- ▁NAILS
- C
- ▁FR
- ▁TEARS
- ▁SUPERSTAR
- ▁CLEANS
- ▁HEAT
- ▁SILLY
- ▁WIG
- ▁BELLA
- WOKE
- ▁5
- ▁BOYS
- IVA
- ▁IMAGINE
- ▁LAUGHING
- ▁WASHING
- ▁FLAT
- ▁STICKERS
- ▁PRETTIER
- ▁KILL
- ▁FLIGHT
- ▁WOMEN
- ▁MOMMY
- ▁CAMP
- ▁MEMBERS
- ▁CUSTOMER
- ▁E
- ▁SINGERS
- 'ON'
- ▁CONTROL
- ▁TIGER
- ▁ZEBRA
- ▁IMPOSSIBLE
- ▁CONSOLE
- ▁CLUE
- ▁FOLD
- ▁BEE
- ▁ANDY
- ▁SEATS
- ▁POUND
- ▁SANG
- ▁DIAMOND
- ▁BATS
- ▁ARTIST
- ▁BABIES
- ▁GARAGE
- ▁INSTEAD
- ▁OLDFASHION
- ▁GIFTS
- ▁RODE
- BIG
- ▁MOUNTAINS
- ▁THUNDER
- ▁DONKEY
- ▁PIGEON
- ROOM
- ▁WORSE
- ▁HAMBURGERS
- ▁ERASER
- ▁TAMBOURINE
- ▁BREATH
- ▁ANNOYED
- ▁HALLOWEEN
- ▁KNOCK
- ▁STUPID
- ▁BANDAGE
- ▁PINEAPPLE
- OUT
- ▁SALTY
- ▁POTATO
- ▁MILES
- ▁COMMENT
- ▁TREATED
- ▁EAR
- ▁SLEDDING
- ▁VIOLET
- ▁BOTTLES
- ▁BRILLIANT
- ▁AUNTIE
- ▁SPEND
- ▁REACH
- ▁PAYING
- ▁APOLOGIZE
- ▁CORNER
- ▁FORGIVE
- ▁RELIEF
- ▁BEHAVE
- ▁DIE
- ▁PRETTIEST
- ▁H
- ▁HEN
- ▁POUR
- ▁NEEDLE
- ▁WORRIES
- ▁LARGER
- ▁CRAZY
- TYFIVE
- ▁DISCOUNT
- ▁HEADED
- ▁TWENTYFIVE
- ▁SOMETIME
- ▁REPORTER
- ▁FEED
- ▁KIMCHI
- ▁TENNIS
- ▁DOLPHIN
- ▁SUNGLASSES
- ▁THREW
- ▁COUNTRY
- ▁HUSBAND
- ▁JAPAN
- ▁TOMATOES
- ▁OK
- ▁POET
- ▁LUKE
- ▁LEND
- ▁LOWER
- ▁SHOVEL
- ▁AMERICA
- ▁BLOSSOMS
- OH
- K
- ▁SAFETY
- TALK
- ▁ASLEEP
- ▁MINER
- ▁PERIOD
- ▁STORYBOOK
- ▁BOWLS
- ▁DOUBT
- ▁MEMORY
- ▁SKINNY
- ▁EARTHQUAKE
- ▁2
- ▁BALLS
- ▁POTATOES
- ▁TROUSERS
- ▁WAR
- ▁FUR
- ▁RUMOR
- ▁CONGRATULATIONS
- ▁EASYGOING
- ▁NURSE
- ▁FLIES
- ▁GROWING
- ▁SMILES
- ▁CHOICE
- ▁ERASE
- ▁COMFORTABLE
- ▁GUIDE
- ▁PE
- ▁CLEVER
- ▁PEACE
- ▁AFTERSCHOOL
- ▁SOAP
- ▁POPCORN
- ▁SUNBLOCK
- ▁INVITE
- ▁AWAKE
- ▁FEMALE
- ▁HIKING
- ▁FOLLOWED
- ▁BUMPER
- ▁FILLED
- ▁HIPPO
- ▁COMEDIAN
- ▁SILK
- ▁COST
- IES
- ▁AWFUL
- ▁SIBLING
- ▁PIES
- ▁BURNING
- ▁CRASH
- ZIPPED
- ▁SPACE
- ▁LYRICS
- ▁HANDMADE
- ▁PER
- ▁ROUGH
- ▁THROWING
- ▁STATIONERY
- ▁WORM
- ▁PAGE
- ▁CLASSMATES
- ▁EXAM
- ▁FINAL
- ▁BLOW
- ▁CHINA
- U
- TH
- ▁BATTER
- ▁HONEY
- ▁MISTAKEN
- ▁DEPARTMENT
- GREAT
- ▁SHIRTS
- ▁COMPETITION
- ▁YOGURT
- MBER
- ▁DRINKS
- ▁WOLF
- ▁ISLAND
- ▁GROCER
- ▁SHARON
- ▁BREATHE
- ▁ANNOYING
- ▁LIED
- ▁SPA
- ▁KANGAROOS
- ▁ALIKE
- ▁PENGUIN
- ▁BRIGHTCOLORED
- ▁4
- ▁MESSAGES
- ▁INVENTION
- ▁WIPE
- BIRD
- ▁PRECIOUS
- ▁FLEW
- ▁CH
- ▁APART
- ▁MIDNIGHT
- ▁SPEN
- ▁SHELLS
- ▁GIN
- ▁NATURAL
- ▁THIRD
- ▁BADLY
- ▁PLATES
- ▁JOSHUA
- ▁MIDDLE
- ▁SWEAT
- ▁TOES
- ▁TIP
- ▁TEASE
- ▁BOOKSHOP
- ▁COUGHING
- ▁GUN
- ▁WASTE
- UMOR
- AR
- ▁SPREAD
- ▁GOAT
- ▁SPROUTS
- ▁BALLET
- ▁SNAKES
- ▁SCRATCHED
- ▁AMONG
- DANGER
- KGO
- NISH
- ▁FEE
- ▁JANE
- ▁TEMPER
- ▁CROWDED
- ▁BONO
- ▁CHEF
- ▁SAMPLE
- ▁LIONS
- ▁RULES
- ▁DREW
- ▁WORTH
- ▁MAGICIAN
- ▁GLUE
- ▁TOUGH
- ▁TOUCHE
- ▁TUNA
- ▁BAKE
- ▁LAUGHTER
- ▁HALF
- ▁HELMET
- ▁UH
- ▁COPIES
- ▁DIFFERENCE
- ▁FORK
- ▁STARTING
- ▁CRIES
- ▁SPROUT
- SNOW
- ▁SCARE
- ▁DRUMS
- ▁PHANTOPIA
- ▁VOUCHER
- ▁FARMER
- ▁CHANGES
- ▁SPILL
- AN
- ▁COMPLETELY
- ▁PRACTICES
- CHAIR
- ▁MISSE
- ▁RACHEL
- ▁SEEK
- EST
- ▁SISTERS
- ▁BLAME
- ▁PACK
- ▁BOIL
- ▁REQUEST
- ▁SH
- ▁WIRE
- ▁POT
- ▁ONION
- ▁CLOSER
- ▁MICE
- ▁SCRATCH
- ▁DUCKS
- THANK
- ▁RECEIVE
- ▁CABBAGE
- ▁SEEDS
- ▁JEJU
- ▁SUDDENLY
- RAY
- ▁KIWI
- ▁POWDER
- ERRY
- ▁MESSY
- ▁RID
- ▁CHAMPION
- ▁ARGUE
- ▁RECIPE
- ▁MICROPHONE
- ▁SCOLDED
- TRY
- ▁STRONGER
- ▁EXPECT
- ▁WEEKS
- AKER
- ▁JUMPED
- ▁RAINS
- ▁OREPHIA
- ▁PIGS
- LOSING
- ▁PRAYING
- ▁DUE
- ▁SOUTH
- ▁PUNCH
- ▁CREATIVE
- ▁FINISHING
- ▁HARMONI
- ▁CLOWN
- ▁SALON
- ▁SINK
- H
- ▁TOOL
- ▁ALARM
- VISION
- GY
- ▁FAIL
- ▁DRAWER
- ▁HAIRBAND
- ▁X
- ▁ARTICLES
- ▁DEEP
- ▁EARLIER
- ▁EXTRA
- ▁DOWNTOWN
- ▁LEFTHAND
- PTER
- ▁NOODLES
- ▁CONSIDER
- ▁ACCOUNT
- ▁DEER
- ▁SEAN
- RABBITS
- TY
- ▁CREAMS
- ▁LUCY
- ▁BOUN
- ▁HORNS
- EMENT
- ▁NOON
- ▁SMILED
- ▁NINETEEN
- ▁TURNS
- ▁MUFFLER
- ▁ROAR
- ▁HARDLY
- ▁SPELLED
- ▁SPOTS
- ▁SHORTS
- ▁JUMPS
- ▁RECENTLY
- ▁STOLEN
- ▁WITHIN
- ▁ENGLAND
- ▁PENDANT
- ▁MARY
- ▁AMUS
- ▁SERIOUSLY
- ▁FALLS
- ▁SPOONS
- ▁SAVED
- ▁STOLE
- ▁STUCK
- ▁G
- ▁DUMPLINGS
- ▁GERMAN
- ▁PLACES
- ▁OCARINA
- ▁QUEENSTEIN
- ▁BRANDON
- ▁DWARFS
- ▁TOFU
- ▁SPRAY
- PARD
- ▁CROSSING
- ▁PIGEONS
- ▁NOTICE
- CE
- LTY
- ▁BASEMENT
- ▁TABLET
- ▁COUPONS
- ▁PROGRAM
- ▁SOCK
- ▁GUI
- ▁NUT
- ▁OLIVE
- ▁PREFER
- ▁MUSHROOM
- ▁FIGHTING
- ▁DENERGY
- ▁STORAGE
- ▁POLITE
- IST
- ▁KICKBOARDS
- GAGE
- ▁DROWN
- ▁MANAGE
- ▁DRIVER
- P
- ▁WEEKENDS
- ▁SHOULDER
- ▁MUD
- ▁SEVENTY
- ALLY
- ▁POSTCARD
- ▁PIECES
- ▁HICCUPS
- ▁CHARACTERS
- ▁CLEANING
- ▁DIS
- ▁JG
- ▁JOSEPH
- ▁TITLE
- ▁CDS
- ▁BOSTON
- ▁BRACELET
- ▁PERMISSION
- ▁STEW
- ▁RAT
- ▁SKATE
- ▁CHEST
- ▁FOOT
- ▁CLIMB
- ▁AUDIENCE
- ▁DUFAR
- ▁GRANDPARENTS
- ▁FIT
- ▁TOUCHING
- ▁ELEPHANTS
- ▁TSHIRTS
- ▁APPOINTMENT
- ▁FOREVER
- ▁STARVING
- ▁LESSONS
- ▁COUPLE
- ▁TOTO
- ▁DRINKING
- ▁ARRIVE
- ▁GREE
- ▁SPOT
- ▁HELD
- ▁EARTH
- ▁DAUGHTER
- ▁SLICE
- ▁CASTLE
- ▁FEEDING
- ▁COVERED
- ▁FAM
- ▁AGE
- ▁AUSTIN
- ▁DEAR
- ▁NATI
- ▁CELEBRATE
- ▁MEATBALLS
- ▁STRETCH
- ▁SOLVE
- ▁USEFUL
- ▁SCAR
- DDING
- ▁ALLERG
- ▁RINGING
- ▁SAILING
- ▁SNOWING
- ▁LATEST
- ▁LIES
- ▁ACADEMIES
- ▁MUSICIAN
- ▁STA
- ▁FROGS
- ▁STOMP
- ▁KEYBOARD
- ▁FAIRY
- ▁CLAP
- ▁HAM
- ▁TOWARDS
- ▁RESERVATIONS
- ▁SHOUT
- SORRY
- ▁PUPPIES
- ▁WEAK
- ▁ORIGINAL
- ▁RESPECT
- ▁TABLES
- ▁COMPUTERS
- ▁TOWELS
- ▁CRAFTSMEN
- ▁ELE
- ▁REPAIRED
- ▁PRINT
- ▁BLOOM
- ▁WISELY
- ▁SCOLD
- ▁TWINKL
- ▁CANCEL
- ▁KIM
- ▁STAINED
- ▁LAP
- ▁DRI
- ▁SHARK
- ▁KANGAROO
- MENTARY
- THEY
- ▁DALLAS
- ▁SEESAW
- ▁WHISPER
- CAL
- ▁DWARF
- ▁SUNDAYS
- ALK
- ▁DOUBLE
- ▁SHAKING
- ▁PREPAR
- ▁YOYO
- ▁SKILLS
- ▁OCTOPUS
- ▁INSTRUMENTS
- ▁MAIL
- ▁ALIENS
- ▁JESSI
- ▁CHERRY
- ▁INCONVENIENCE
- ▁CERTAIN
- ▁BEEF
- CON
- 'OFF'
- ▁GATHERED
- ▁PRODUCTS
- CONVENIENCE
- ▁RESTAURANTS
- ▁MONKEYS
- ▁FIGURE
- ▁QUICK
- ▁GAIN
- ▁PENALTY
- ▁INLINE
- ▁INTRODUCE
- ▁OVERSLEPT
- ▁POL
- ▁HOWEVER
- ▁GORILLA
- ▁MEMBER
- ▁PLU
- ▁ANGER
- ▁AQUARIUM
- ▁GAS
- ELY
- ▁TIES
- ▁PUNISHED
- ▁CUCUMBERS
- ▁TINY
- ▁RISE
- ▁GHOSTS
- ▁WIFE
- MOND
- ▁RARE
- ▁BARN
- ▁SMELLY
- GAN
- ▁REASONS
- ▁BURNED
- ▁ANNOUNCE
- ▁CAPSULES
- ▁PICNIC
- ▁GLOVE
- FF
- RANCE
- ▁TREAT
- ▁JOG
- ▁BULLS
- ▁JJAKGUNG
- ▁PROVE
- ▁BAGS
- ▁RUDOLPH
- ▁MC
- ▁TRICKS
- RIOR
- ”
- ▁HAPPILY
- ▁REMIND
- ▁DIVER
- BE
- ▁HATES
- ▁SPOON
- ▁SIZES
- ▁THROAT
- ▁UN
- CRAFTS
- ▁BRIDGE
- ▁CONFUSED
- DONALD
- KEEPER
- ▁SIBLINGS
- ▁DENNIS
- ▁EMBARRASSED
- ▁PATRICK
- DWARFS
- ▁PREGNANT
- ▁VOTE
- ▁WHIPPED
- ▁10000
- ▁SUPPORT
- ▁TOOTH
- ▁STANDING
- ▁CLOSET
- ▁NEEDLES
- ▁SWEEP
- ▁RAISED
- ▁PEE
- ▁CONTACT
- ▁JEALOUS
- ▁SURVEY
- BOX
- ▁CROSSWALK
- ▁WALKING
- ▁SOP
- ▁SITE
- ▁OWE
- ▁FOURTEEN
- ▁PLANTING
- ▁CHANNELS
- ▁WIGGL
- ▁OURSELVES
- ▁SCENE
- ▁BAS
- ▁LETTUCE
- ▁NICKNAME
- ▁GRABB
- ▁ELEVATOR
- ▁COP
- ▁FALLING
- ▁DESERVE
- ▁FILM
- ▁SOPHOMORE
- ▁WOUND
- ▁PROTEST
- ▁PEACHES
- ▁CHILL
- ▁COURT
- ▁ROOF
- ▁CHARGE
- ▁FINGER
- ▁HANBOK
- ▁TAPDANCE
- ▁JAPANESE
- ▁MELON
- ▁BATTLE
- ▁LEAS
- ▁PARTS
- BATHING
- ▁CRUNCHY
- ▁PAUL
- ▁WHISTLE
- ▁CAKES
- ▁HEAL
- ▁SHELL
- ▁GUM
- ▁CARPENTER
- ▁HEAVILY
- ▁N
- ▁LEMONS
- ▁HARDER
- ▁ROW
- ▁STEAM
- ▁STUDIES
- ▁LOTTERY
- ▁BITTER
- ▁MOW
- ▁EATEN
- ▁SPORT
- ▁SHORTER
- ▁STEAL
- ▁GRADUATE
- ▁PUZZLE
- ▁CEREMONY
- ▁RAINCOAT
- ▁KISS
- HAP
- WAY
- ▁DEPART
- ▁LANGUAGE
- ▁BITTEN
- ▁BUSAN
- ▁L
- ▁TIGHT
- ▁BELOW
- ▁PERFECTLY
- KE
- ▁NATURE
- ▁MISUNDERST
- ▁CLOUD
- ▁DRAG
- ▁CARTOON
- ▁COCONUT
- ▁GOLF
- ▁THIRTEEN
- ▁DYING
- ▁PETE
- ▁MALL
- ▁BIN
- ICAL
- ▁ALIB
- ▁BREEZE
- ▁FRENCH
- ▁DATING
- ROW
- ▁WATERING
- ARD
- ▁DESERT
- ▁PRAISE
- ▁INTERNET
- ▁STRICT
- ▁MOSQUITOES
- TLE
- ▁SKILL
- ▁BEHAV
- ▁KTX
- ▁LONDON
- ▁TASTING
- ▁VAN
- ▁COUGHED
- ▁NICELY
- ▁HARM
- ▁BOOKSHELF
- ▁CRICKET
- ▁EDGE
- ▁PILLOW
- ▁RECTANGLE
- ▁STRESS
- ▁FOOTBALL
- ▁LAW
- ▁CHOPSTICKS
- WHAT
- ▁TWINS
- ▁AUSTRALIA
- ▁LAMB
- ▁MAYO
- ▁DESIGN
- ▁BLEW
- ▁GLORY
- ▁ROCKCLIMBING
- ▁DUTY
- ▁ENTERTAINMENT
- ▁THEMSELVES
- ▁YOG
- ▁BUCKET
- ▁BIRTH
- ▁FALSE
- ▁PATTERN
- ▁THREAD
- ▁SOLDIER
- ▁BATTERY
- ▁KNEES
- ▁HEADS
- ▁DELIVERED
- ROUTE
- ▁SIMPLE
- ▁WATERFALL
- ▁SWITCH
- ▁EFFORT
- ▁UNUSUAL
- ▁SLIPPED
- ▁REG
- ▁SUITS
- ▁CHANNEL
- ▁MINI
- ▁PLASTIC
- ▁RECOMMEND
- ▁RUBBER
- ▁THANKFUL
- ▁ROLL
- ▁SOLV
- ▁CLAPS
- ▁BUD
- ▁CINEMA
- ▁SHELF
- ▁LOSS
- ▁WOMANS
- ▁CANADA
- ▁EXPRESS
- ▁SHARING
- ▁LOOSEN
- ▁CHOCO
- ▁RUNNY
- ▁REPL
- ▁BOWL
- ▁FULLY
- ▁SOMEHOW
- ▁UNIQUE
- ▁CARES
- ▁NOODLE
- ▁JETLAG
- ▁LAPTOP
- ▁TOOTHPASTE
- ▁JON
- ▁AIRPORT
- ▁JOO
- YER
- ▁CAP
- ▁HOLLY
- ▁JOHNSON
- ▁ZERO
- ▁LEADER
- ▁OX
- ▁SQUEEZE
- PY
- GET
- ▁FIN
- ▁ZIP
- ▁SEPTEMBER
- ▁TEMPERATURE
- THIRTY
- ▁GOODLOOKING
- ▁GUAR
- ANTEE
- ▁LOG
- ▁WILD
- ▁BOOTH
- ▁PEPPERS
- ▁FORGOTTEN
- BALL
- ▁AB
- CALORIE
- ▁POLICY
- ICO
- ▁INCLUDED
- ▁LIGHTEN
- ▁BLAMED
- ▁LONGTIME
- OOD
- ▁JEAN
- ▁DECK
- ▁MANNER
- ALTH
- ▁PERSONALLY
- TRUCK
- PT
- ▁GUT
- ▁CRASHED
- ▁FLO
- ▁REACT
- ▁ABSENT
- KYO
- ▁BLUSH
- ▁DONATE
- DOCK
- ▁COMPLAINING
- ▁DESCRI
- ▁GEORG
- ▁RECOVER
- ▁WALNUT
- ▁LUNG
- ▁BUDDY
- ENSE
- ▁PASSES
- ▁PLUM
- HALF
- ▁SE
- ▁TURTLE
- ▁FRANC
- ▁KOALA
- ▁TURKEY
- ▁CARPET
- ▁ANYWHERE
- ▁R
- ▁SKIING
- ▁FOCUS
- ▁HARV
- ▁JANUARY
- ▁PRESIDENT
- ▁TWENTYONE
- ▁WRESTLE
- ▁CANCER
- ▁CHEATING
- ▁HOMEMADE
- ▁WEEKDAY
- ▁K
- THER
- ▁DREAMS
- ▁APPRECIATE
- ▁BRAIN
- ▁SAUSAGES
- SOMETHING
- GAR
- ▁SMOOTH
- ▁SLIM
- ▁FENCE
- JURY
- LIES
- ▁SPIDERS
- EADLINE
- EVEREST
- ▁SCORES
- ▁JOKING
- ▁REJECT
- ▁STEPMOTHER
- ▁CRIM
- ▁DIGGING
- ▁QUEEN
- ▁MALE
- ▁SNORES
- ▁EXPLAINED
- ▁HOUSEWORK
- ▁BEDTIME
- BEAT
- WORKING
- ▁SMELLING
- ▁GRAPE
- ▁INSTRUCTIONS
- ▁SUNSCREEN
- ▁WORKDAY
- ▁HOLES
- ATER
- UP
- RIDA
- ▁VINE
- ▁HERSELF
- ▁NIGHTMARE
- ▁SNAP
- ▁INSU
- ▁BURNS
- GIV
- ▁MOUNT
- ▁NEGATIVE
- ▁ADVANTAGE
- ▁DIFFICULTIES
- ▁7
- ▁REMAINS
- CHECK
- ▁TRAVELING
- ▁IMAGIN
- G
- ▁BENNY
- ▁JOHN
- ▁ATHLET
- ▁COOPE
- ▁DICTIONARY
- ▁HAPPINESS
- ▁RAPPER
- ▁SLIPPERY
- ▁SUNRISE
- ▁TAPDANCING
- ORABLE
- ▁NOTICING
- ▁WAITLIST
- ▁CUCUMBER
- FTH
- ▁GUESTS
- ▁COLLEGE
- ▁STOCK
- HH
- ▁TALE
- POP
- ▁MEXIC
- ▁FREEZER
- ▁REFUSE
- ▁SWIMMER
- ▁THOUGHTFUL
- DIVING
- WORKED
- ▁COURAGE
- ▁ERRANDS
- ▁LISTENED
- ▁GRUM
- ▁WEB
- ▁TWEL
- GED
- ▁CABIN
- ▁REHEARSAL
- ▁SKETCHBOOK
- ▁DAYCARE
- ▁PARTIES
- OBBY
- ▁SEAL
- WHERE
- ▁ROSES
- INE
- ▁ACCIDENT
- ▁PERSONALITY
- ▁SPECIFIC
- ▁RINGS
- ▁BLOOMED
- ▁AW
- YARD
- ▁ENTERED
- ▁BELLY
- ▁FUNNIER
- ▁NARROWMINDED
- USY
- ▁JOURNAL
- ▁JER
- ▁PRICES
- BREAK
- ▁BILLS
- SOLUT
- ▁11
- ▁REFILL
- ▁BAKED
- ▁ALPHABET
- CONNECTED
- ▁GOATS
- ▁WASHE
- ▁CHOP
- PHLE
- ▁NONSENSE
- ▁WADDL
- ▁PETS
- ▁DECORATE
- LUSH
- ▁FORGETTING
- ▁EMILY
- ▁BICYCLES
- ▁SHOWN
- ▁BUCK
- ▁BAIT
- ▁100
- ▁MOVER
- ▁HEL
- ▁WINNING
- ▁ROCKET
- ▁FANG
- ▁CA
- ▁DEPRESS
- ▁BEAUTY
- ▁DAILY
- ▁ENGINEER
- ▁MUFFIN
- ▁WRITER
- ▁OPINIONS
- ▁TRACKS
- ▁PAUSE
- ▁PUZZLED
- URE
- SEY
- ▁WRAPS
- ▁SOCIAL
- ▁GRADES
- ▁WARMLY
- ▁YOYOS
- ▁CHEW
- ▁BULGOGI
- ▁BARKING
- ▁SENTENCE
- ▁THOUGH
- ▁POO
- ALIAN
- ▁EVE
- ICED
- ▁RAIS
- ▁DISTURB
- ▁ITSELF
- ▁ORIGAMI
- ▁TISSUE
- ▁JOHNNY
- ▁BURN
- ▁COOKS
- ▁CANDLE
- ▁OBVIOUS
- ▁SANDPAPER
- ▁SUPPLIES
- ▁CHEWY
- ATIONS
- ▁FLAVOR
- ▁KIWIS
- ▁MASTER
- ▁YELLING
- ▁CUPS
- ▁BL
- LAINE
- ▁STIMULAT
- ▁TIRES
- ▁PRETEND
- ▁CLEANED
- ▁RUSSIA
- ▁FRECKLES
- ▁FART
- ▁CHEETAH
- ▁RUDE
- ▁TRAINS
- ▁LOTTE
- ▁PAGES
- ▁POSTCARDS
- ▁KEYS
- ME
- ▁BOOKSTORE
- ▁HOST
- ▁SHORTCUT
- ▁SHOOTS
- ▁OPINION
- ▁APRON
- ▁COPIED
- LLOWED
- ▁STICKY
- ▁PREPARE
- ▁HEADQUARTERS
- ▁REPAIRS
- ▁WHALE
- ▁POOP
- ▁RESEMBLE
- ▁SHARE
- ▁LOLL
- ▁EXERCISES
- ▁PROGRAMS
- ▁BLINK
- ▁FLAG
- ▁LAY
- ▁FASTEST
- ▁SNEEZE
- ▁ENDED
- J
- ▁MARKER
- HER
- ▁ASSISTANT
- ▁CURRY
- ▁PURSE
- ▁SLIPPERS
- ▁UNDERSTANDING
- ▁PIT
- ▁INDOOR
- ▁CROWN
- ▁CURIOUS
- ▁SYSTEM
- ▁CABLE
- ▁MOSQUITO
- ▁PHARMACY
- ▁EVERLAND
- ▁WINDOWS
- ▁BOOGER
- ▁TIRING
- ▁PAPERS
- ▁PEANUT
- ▁PARDON
- ▁AH
- ▁FOX
- ▁RESELL
- ▁RESULT
- ▁TWIST
- ▁SLED
- ▁TALLEST
- ▁RIBBONS
- ▁RECEI
- ▁SQUIRREL
- ▁CUTLET
- ▁HEIGHT
- ▁HURTING
- ▁TRAP
- ▁WRAPPER
- ITED
- ▁FRIGHTENED
- ▁PATIENT
- ▁CANCELED
- ▁SHELVE
- ▁NET
- OOPS
- ▁MESS
- ▁MERRY
- ▁PLATE
- ▁COMPLAINT
- ▁SITUATION
- ▁PARIS
- ▁STRAW
- ▁DIVIDE
- ▁GOAL
- ▁SHRIMPS
- X
- SPECIAL
- GOTTEN
- F
- ▁COLLECTED
- ▁AFFORD
- ▁HUNG
- ▁CHAMBER
- ▁AIRPLANE
- ▁CHA
- ▁WALLS
- ▁REGULAR
- ▁EXPERIENCE
- ▁PILOT
- ▁250
- ▁LEMONADE
- ▁FURTHER
- ▁RAC
- IN
- ▁SWALLOW
- ▁CLOSING
- ▁CLASSROOMS
- ACK
- ▁RENT
- ▁ADS
- ▁TENTH
- ▁FRY
- ▁HOTDOG
- ▁ANGEL
- ▁PEACH
- ▁HIDDEN
- ▁GOOSE
- ▁SMALLEST
- ▁ROCKS
- ▁COOKED
- ▁CORN
- ▁SIGNS
- ▁ANXIOUS
- ▁LIGHTNING
- ▁SNOWBALL
- ▁BESIDE
- ▁ANTS
- ▁ALLOWANCE
- ▁COUNTRIES
- ▁POUCH
- ▁SLIP
- ▁POEM
- ▁RAMEN
- ▁ROLLING
- ▁PATIENTS
- ▁SCREEN
- ▁PRESENTATION
- ▁CAST
- ▁FLUTE
- ▁HU
- ▁ZEBRAS
- ▁COMPARE
- ▁WIDE
- ▁FORSYTHIA
- ▁SENIOR
- ▁DONATED
- ▁FACTS
- RD
- ▁FOG
- ▁ROLE
- ▁PEARS
- ▁BUTTONS
- COME
- ▁HAIRCUT
- ONDE
- ▁ENV
- ▁CHASED
- THE
- '4'
- ▁TRACK
- ▁STRANGER
- ASOL
- ▁CHIN
- ▁PUBLI
- ▁DUN
- ▁JUNE
- ▁20
- ▁DOUGHNUT
- ▁DADDY
- PORT
- ▁EMBARRASSING
- ▁UNCOMFORTABLE
- ▁FOREHEAD
- ▁RELATIVES
- ▁DOODLE
- ▁GENTLEMAN
- ▁TAPE
- ▁BANKER
- ▁ACTRESS
- ▁SORT
- ▁REDESIGN
- ▁GRADERS
- ▁KICKING
- ▁LA
- UK
- ▁BARBECUING
- ▁BULLY
- RATE
- ▁JUN
- ▁KOREANS
- ▁CORPORATION
- ▁HEAVIE
- ▁IMPROVE
- ▁OCEAN
- ▁LG
- ▁LAYER
- ▁BRIGHTLY
- ▁CRABS
- ▁PAR
- ▁BLANK
- ▁CALENDAR
- ▁CROCODILE
- ▁SALARY
- ▁CHUSEOK
- ▁CUTEST
- ▁NOR
- ▁MYSTER
- ▁BEND
- ▁INCLUDE
- ▁EXCELLENT
- ▁PAINFUL
- ▁SKEWERS
- ▁CHEERING
- SIZE
- BELT
- RCH
- ▁PLEASANT
- ▁PATH
- ▁QUALITY
- ▁STINGS
- ▁REPAIRING
- ▁DELAY
- ▁RIDES
- ▁ELSA
- ▁SECURITY
- ▁TWENTIETH
- ▁PC
- AH
- ▁NOTES
- RAL
- ▁NORMAL
- ▁DIRECT
- ▁CENT
- ▁APOLOGY
- ▁GARBAGE
- ▁GEE
- ▁WATCHES
- ▁SCISSOR
- ▁CULT
- ▁ECONOMY
- ▁SEASHELL
- ▁HA
- ▁HORSES
- ▁WHEELS
- BYE
- ▁HABIT
- ▁VI
- OOKIE
- ▁BAKING
- ▁CHERISH
- ▁JESUS
- ▁KLEA
- ▁PARTICIPATE
- ▁NICER
- ▁LISTING
- ▁SUPP
- IELD
- ▁CRISPY
- ▁EYESIGHT
- ▁TWITCH
- ▁WORST
- ▁GREETING
- ▁DRYER
- ▁LINES
- ▁DEPRESSED
- RENT
- ▁ROLLS
- LAND
- ▁DOCUMENT
- ▁COCKROACH
- ▁TAX
- ▁LIBER
- ▁FRIGHT
- ▁GARDENVIEW
- ▁JAR
- ▁ONESELF
- ▁PELICAN
- ▁RUSH
- ▁BAKER
- ▁EXPLODED
- ▁CARNATIONS
- ▁BUBBLES
- ▁BREAKS
- ▁EUROPE
- ▁EXCHANGE
- ▁SMASH
- ▁TORONTO
- ▁CEO
- ▁BLEEDING
- ▁IMAGINED
- ▁KIL
- ▁POU
- ▁TAB
- ▁CRUS
- OGRAMS
- ▁ALASKA
- ▁FROWNED
- MAIL
- TWINKL
- ▁SINGLE
- ▁INVENT
- ▁ROD
- ▁EMERGENCY
- PORTER
- ▁COMB
- ▁HUG
- TI
- '...'
- SMITH
- ▁AVOID
- ▁JJAKKUNG
- ▁MATERIALS
- ▁LOSES
- ▁LU
- INA
- FREE
- ▁SERV
- ▁FLU
- ▁REEL
- ▁BACKPACK
- ▁REPRINT
- ▁SIXTEEN
- ▁ZENA
- ROL
- ▁AWARD
- ▁TENK
- ▁NETWORK
- ▁WORKER
- ▁REDUCE
- GUE
- ▁PROTECT
- ▁CONCERN
- ▁CRIMINAL
- ▁FIREFIGHTER
- ▁INCHEON
- ▁SUWON
- ▁VIEWER
- OVER
- ▁ELEVATORS
- OR
- ▁IMPRESSED
- ▁SHAME
- ▁STRAP
- ▁YIELD
- ▁WARNED
- ▁HANDOUT
- ▁LUNCHTIME
- URY
- IED
- AY
- WIFE
- GUN
- ▁ISSUE
- RRIE
- ▁SANDCASTLE
- ▁FIGURES
- ▁LOV
- ▁POKE
- ▁FREESTYLE
- ▁CHAIN
- ▁EVERYDAY
- OK
- ALY
- ▁RATING
- ▁SPIT
- ▁SAIL
- ▁AMBULANCE
- ▁ENORMOUS
- ▁SELFCONT
- ▁MEMORIZED
- ▁GIRAFFES
- ▁SNOWS
- ▁PLANTS
- ▁LEAD
- ▁EXHIBITION
- ▁FOUGHT
- ▁MARBLE
- 'YES'
- ▁PICKE
- ▁WRONGLY
- ▁HURR
- ▁CONVERSATION
- ▁DETAIL
- ▁WORRYING
- ▁SAVING
- ▁TU
- ▁SECRETLY
- AWAY
- ▁GROWS
- ▁CONTRA
- ▁SCRAMBLE
- BES
- ▁PROMISES
- ▁CHAIRS
- ▁GOGGLES
- ▁OTHERWISE
- ▁VICTOR
- ▁THORNS
- ▁WORTHWHILE
- ▁HIPPOS
- ▁TRICK
- ▁OBSERVATORY
- ▁SHAMPOO
- ▁COKE
- ▁DRAMA
- ▁DELAYED
- ▁GUTS
- ▁AZALEA
- ▁WRAPP
- TIE
- HEAD
- ▁BIGGEST
- ▁ENEMIES
- ▁PUMPKIN
- ▁DOCUMENTARY
- ▁ATOPY
- ▁COUGH
- ▁TOUCHED
- ▁AWARDS
- EWER
- VER
- ▁BEARS
- ▁CACTUS
- ▁LOCK
- ▁LIT
- ▁SKETCH
- ZEN
- ▁DRAGG
- ▁SQUEEZED
- ▁SCOT
- SHY
- ▁CALCULAT
- ▁APPEARED
- ▁RAINED
- ▁WINGS
- ▁CLOTH
- ▁DIG
- ▁DONGSENG
- ▁SPONGE
- ▁STUBBORN
- ▁WAIST
- ▁FLE
- ▁TAG
- CH
- ▁CR
- ▁UMBRELLAS
- ▁TOOTHBRUSH
- ▁POCKETS
- ▁PAJAMA
- ▁HALLA
- ▁GATHER
- ▁BOSS
- ▁DETERGENT
- ▁DOCUMENTS
- ▁GENEROUS
- ▁TOTAL
- ▁CURTAIN
- ▁PUDD
- ▁THICK
- NSIBLE
- ▁HOLIDAYS
- ▁TICKLES
- FLAVORED
- ▁COVID
- ▁GIFTWRAP
- ▁BLINKING
- ▁JUNG
- HOK
- LEANING
- ▁IDOLS
- ▁DRO
- ▁FOUNTAIN
- ▁PHYSIC
- ▁PRESCRIPTION
- ▁LATTE
- ▁TONGUE
- ▁NA
- WORLD
- ▁SURGERY
- ADLINE
- ▁STUFFY
- ▁WAFFLES
- ▁15
- ▁LOGO
- ▁SHORTCUTS
- ▁RESPECTED
- ▁INVENTIONS
- ▁ARTISTS
- RAFFI
- ▁FOSSIL
- ▁GOLDCREST
- ▁MALTESE
- UGGING
- ▁BUCKWHEAT
- ▁PROFESS
- ▁SQUID
- ▁CORRECTION
- IT
- LOOKING
- ▁GENIUS
- ▁WHALES
- ▁OPPA
- ▁DONKEYS
- ▁ELECTRIC
- ▁FAKE
- ▁JUNIOR
- ▁MEDAL
- ▁SONGPYEON
- ▁MO
- ▁LOCKED
- ▁MEMORIZE
- ▁DIZZY
- ▁CAMELS
- ▁Y
- ▁CARING
- ▁PERFORMANCE
- ▁ERRAND
- ▁STRIPE
- ▁SIL
- ▁REDESIGNED
- ▁TIPS
- SCRIPT
- ▁BISCUIT
- ▁TORN
- ▁BRUSHE
- ▁STREETS
- ▁RELIEVED
- ▁HOPS
- ESSER
- ▁INSTRUMENT
- ▁ADVANCE
- ▁GESTURE
- ▁MUGWORT
- ▁PROMOT
- ▁PIN
- ▁SHAD
- IONAL
- '72'
- ▁HEAVEN
- ▁SLOPE
- ▁HAIRDR
- YOU
- ▁OWNERS
- ▁PLANS
- ▁SUNFLOWERS
- ▁CHIMNEY
- ▁HIPHOP
- ▁FOURTH
- ▁C
- ▁COUNTS
- ▁BARK
- SCOPE
- ▁ATOPIC
- ▁DEATH
- ▁FORMALLY
- ▁TWIN
- ▁QUIETLY
- ▁TEAS
- ▁MIN
- ▁CE
- ▁DEPENDS
- ▁TRANSFERRED
- ▁HANDY
- ▁CLEARLY
- CHOCO
- ▁HOTDOGS
- ▁FROWN
- ▁RUB
- ▁PERFORM
- ▁ATTRACT
- ▁DUST
- ▁REVIEW
- ▁SIGNBOARD
- ▁ENDURE
- ▁RIDD
- CKED
- ▁CIRCLES
- ▁AIRPLANES
- ▁MI
- GING
- Q
- ▁YURI
- ▁30
- ▁OFFICERS
- ▁ALMONDS
- ▁SOLVED
- ▁WEREN
- ▁ALBUM
- ▁UNDERGROUND
- ▁WRINKLES
- IL
- ▁TALES
- SOKCHO
- ▁GROCERIES
- ▁RECEIV
- ▁BARE
- ▁PEEL
- ▁COCKROACHES
- ▁DEEPLY
- ▁STATIONS
- ▁DANCED
- ▁CHUBBY
- ▁SATURDAYS
- ▁WING
- ▁CRAFTSMAN
- ▁OCCASION
- ▁WINE
- ▁TELE
- ▁BLUETOOTH
- ▁DISAPPEARED
- ▁SUBM
- ▁FARTED
- ▁PREPARED
- LIST
- ▁CONDITION
- ▁PORTRAIT
- '23'
- ▁POINTS
- ▁TAMBOURINES
- ▁TEND
- ▁SELFISH
- ▁SUBJECT
- RUPTE
- ▁LICKING
- ▁WATERMELONS
- ▁DIES
- ▁BLOWING
- ▁SOIL
- NIFE
- ▁BLAND
- ▁RECYCLED
- ▁SIXTY
- ▁LENGTH
- ILING
- ▁SURVIVED
- ▁HABITS
- WANT
- ▁GRAND
- ▁SAVORY
- ▁APPLAUSE
- ▁APPLY
- ▁MEANER
- ▁DISEASES
- ▁FRUSTRATING
- ▁NOTIFICATION
- ▁CHEOMSEONGDAE
- ▁BADGE
- ▁ABOARD
- ▁DISNEYLAND
- ▁LEE
- ▁SHARPEN
- ▁KETTLES
- ▁HERESY
- ▁CRAM
- ▁BRONZE
- ▁HARSH
- ▁EBS
- ▁GREY
- ▁POSE
- ▁PICKLES
- ▁LEN
- ▁TIGERS
- ARY
- ▁CLAR
- ▁EDUCATION
- ▁NEIGH
- ▁ADDITION
- ▁REASONABLE
- ▁DUMPING
- ▁SPACES
- ▁LIGHTER
- ▁SPELLING
- Z
- ▁CATCHING
- ▁LEVEL
- ▁UPSTAIRS
- ▁RINK
- ▁HANDLE
- AVING
- ▁BOWED
- ▁BEAUTIFULLY
- ▁FARTS
- ▁BOLT
- ▁FAMILIAR
- BBLE
- DO
- ▁FILE
- ▁TREATMENT
- ▁PASTOR
- ▁EEK
- ▁BLOOMING
- CIAL
- TRAINED
- ▁APPEAR
- ▁KNEE
- ▁WHEEL
- RIAN
- ▁ATTEND
- ▁CONFESS
- ▁DVD
- ▁WITNESS
- ▁BATMAN
- ID
- ▁BANGS
- ▁YARD
- ▁LOTION
- ▁RECYCLE
- ▁PRI
- ▁BURDEN
- ▁SCRA
- ▁VEGETA
- ▁TOENAILS
- SUALLY
- ▁YAM
- FORD
- ▁FORMAL
- ▁POK
- ▁FROZE
- ▁MULTIPLICATION
- ▁SEJONG
- ▁TRIES
- ▁SUNSHINE
- ▁HERBS
- ▁STRIPES
- ▁CLIMBING
- ▁SKIPP
- FFE
- ▁DAMAGE
- ▁RIDICULOUS
- ▁QUACK
- ▁PINNOCHIO
- SIDE
- ▁STANDARD
- ▁TRADITION
- GIANT
- ▁YELL
- ▁SUPER
- ▁OVERREACT
- ▁PERFUME
- ▁UNDERCOOK
- BEC
- ▁MAPS
- ▁PARTNERS
- ▁SPINACH
- ▁TTEOKGUK
- ▁JAJANGMYEON
- ▁DIRECTLY
- VATE
- STEE
- ▁MOUSES
- ▁SNOWED
- ▁IGNORE
- GIFT
- ▁LOCKER
- ▁SURVIV
- ▁P
- BBLES
- DAIRY
- ▁TOOLS
- STAR
- LING
- ▁BB
- ▁ACCESSORIES
- ▁NINTENDO
- ▁BIBIMBAP
- ▁DERMATITIS
- ▁ANNOUNCED
- ▁LICK
- ▁AZALEAS
- ▁PEPPER
- VAS
- ▁BODIES
- ▁EXPAND
- PED
- FLOWING
- ▁MIXED
- ▁GROUP
- ▁SAUSAGE
- ▁CEREAL
- ▁EASIEST
- ▁OVERSLEEP
- ▁SATISF
- ▁150
- ▁BAY
- ▁DIP
- UN
- AK
- ▁COINS
- ▁SURPRISES
- ▁WAK
- OL
- ▁EVILDOING
- ▁EYEBROWS
- ▁HEADBAND
- ▁KETCHUP
- ▁PROPERLY
- ▁STRAWBERRIES
- ▁UNFORTUNATE
- ITY
- LIKE
- ONG
- ▁WISHES
- ▁CONSTRUCTION
- ▁RESEARCH
- ▁RIPPED
- ▁FOREIGNERS
- ▁SANDALS
- ▁GOLDEN
- ▁PERFORMANCES
- ▁STEALING
- HA
- ▁SPARE
- ▁KPOP
- ▁LEASH
- ▁TIGHTLY
- CM
- ▁COMME
- ▁500
- ▁ANCHOVIES
- ▁BANKBOOK
- ▁COVIDNINETEEN
- ▁DEFINIT
- ▁UPRIGHT
- ▁MISSION
- BAL
- PHONES
- HO
- ▁GENERAL
- ▁OVEN
- ▁MARCH
- V
- HU
- ▁GROWN
- ▁BROADCAST
- ▁GANGWONDO
- ▁REFRESHING
- ▁DICE
- ▁RACK
- ▁PERM
- ▁SUITCASES
- ▁16
- ▁ENVELOPE
- ▁HOOKED
- ▁ROOT
- ▁TEXT
- ▁CAGE
- GO
- ▁MUS
- ▁DOUGHNUTS
- ▁WASTING
- ▁BETIAN
- ▁PRESENTING
- ▁BRUISE
- ▁ALOUD
- ▁AUDITORIUM
- ▁BTS
- PLE
- RAISED
- MOTION
- ▁GENTLE
- ONIA
- ▁EASIER
- ▁FONDUE
- ▁SEASICK
- ▁VR
- ▁DOLPHINS
- ▁MATCHES
- UR
- ACHE
- ▁CICADAS
- ▁LEAN
- ▁REPORTS
- YING
- ▁CLOUDS
- ▁WOLVES
- ▁HEEL
- ▁FRESHMAN
- ▁SCREAMED
- ▁RELATIVE
- ARIN
- ▁BUR
- ▁PASTE
- ▁FRIENDLY
- ABLE
- ▁VISITING
- ▁INVIT
- ▁LOUDSPEAKERS
- ▁NNN
- ▁OINTMENT
- ▁SWAN
- CLES
- ▁GARDENING
- ▁HICCUP
- IM
- '0'
- ND
- BA
- ▁JULY
- ▁SEMESTER
- ▁SUSHI
- ▁UNIVERSE
- ▁TOSUN
- ▁PILLS
- ▁TAN
- ▁NEAT
- ▁FEATHER
- ▁ANNEX
- ▁PENGO
- ▁SICKNESS
- ▁CANDLES
- LO
- ▁SCRUB
- ▁SHOOT
- ▁TH
- ▁CRACK
- PLAIN
- ▁FRIDGE
- ▁ANSWERING
- ▁INDOORS
- ▁APOLOGIZED
- ▁COMEDIANS
- ▁WOR
- ▁SPIN
- ▁DRACULA
- ▁DRAGONFLIES
- ▁EXTINGUISHER
- ▁GRADUATION
- ▁LADIES
- ▁EX
- ▁PLANNED
- ▁50
- ▁MILLIONS
- ▁TANGERINES
- ▁DRAWN
- ▁CLEANER
- ▁DECORATIONS
- ▁SPI
- ▁VARI
- ▁DRAGONFLY
- ▁SCENT
- ▁GAYAGEUM
- ▁CL
- ▁MONTHS
- ▁PAJAMAS
- ▁RESTING
- ISE
- ▁BADGES
- WORK
- KY
- ▁ADORES
- ▁COLA
- ▁MOTOR
- ▁PRODUCE
- ▁THOROUGHLY
- ▁VOWELS
- ▁COMMON
- PING
- ▁SUNFLOWER
- ▁FOLDING
- ▁DECORAT
- '8'
- ▁SCREAM
- ▁CONNECT
- ▁AUGUST
- ▁PURPOSE
- ▁PIAN
- ▁CHIMNEYS
- ▁MONDAYS
- JU
- ▁BEETLE
- ▁PEED
- ▁INTEREST
- ▁BAN
- ▁SNOR
- ▁MA
- ▁SEW
- ▁COIN
- ▁HAN
- ▁ALPHABETS
- ▁TONKATSU
- ▁HOPEFULLY
- ▁ICECREAM
- ▁REGULARLY
- ▁GALBI
- ▁CHAS
- ▁REALIZE
- ▁WORKERS
- ▁BOATS
- ▁INTERRUPT
- ▁SUBTRACT
- ▁ORGANIZING
- ▁HISTORIC
- ▁POTTER
- ATION
- ▁CHARGER
- ▁BAL
- ▁SUNLIGHT
- ▁DYE
- ▁SHOELACES
- ▁EVENLY
- RY
- '30'
- BIKE
- ▁CRAWL
- ▁CHOOS
- ▁ROBBINS
- ▁SHOOK
- ▁SPLASH
- ASKIN
- ▁UNTIE
- YMP
- ▁STING
- IOUS
- ▁PA
- ▁CAROLS
- ▁SUDDEN
- ▁MACKEREL
- ▁NOSEBLEED
- ▁SCREW
- ▁HANOK
- TOMS
- ▁STRA
- DAY
- ▁RIBBON
- MILKY
- BEAN
- ▁TOMATO
- ▁NATIONAL
- ▁SPRITE
- ▁PANIX
- ▁WISE
- ZED
- ▁CHEWING
- ▁FOOTS
- ▁SHAKES
- ADA
- 'NO'
- ▁DIFFERENTLY
- SLEEVE
- ▁930
- ▁GYEONGJU
- ▁RAPUNZEL
- ▁ROMANTIC
- ▁FARTHER
- ▁CAPE
- IER
- ETY
- ▁HARDEST
- ▁TURNING
- ▁3000
- GENEROUS
- ▁BOO
- ▁ATTENTION
- ▁DWARVES
- ▁HAKNYEON
- ▁OUTDOOR
- ▁RESORT
- ▁SWOLLEN
- ▁PINCH
- ▁PURE
- STER
- ▁GRAB
- ▁BIO
- ▁HURRICANE
- ▁JUDGE
- ▁LANE
- ▁OINK
- ▁SPRAINED
- ▁THIEVES
- ▁TRAPPED
- BIL
- ▁RANCH
- ▁TWENTYTH
- ▁ANNE
- OLD
- NIGHT
- ▁HEIGHTS
- ▁BRICK
- ▁GRATEFUL
- ▁VITAMIN
- ▁HAMSTER
- ▁USELESS
- ▁INVENTOR
- ▁ULSAN
- ▁PRETENDING
- ▁PANDAS
- GGING
- UL
- AG
- COMING
- ▁HUNT
- ▁REMOVE
- ▁OCTOBER
- ▁SEPARATE
- ▁YAWN
- ▁PALE
- ▁UM
- ▁FLOATING
- ▁CO
- HAVE
- ▁SNOWY
- ▁SHOELACE
- GRAPHY
- ▁MELT
- ▁FISHBONE
- UG
- ▁CHIL
- ▁POOPED
- ▁YUT
- ▁PILL
- '0000'
- ▁SURVIVE
- ▁EXAMIN
- ▁TRU
- ▁BACKGROUND
- ▁BEGINNING
- ▁MACARONS
- ▁SURFING
- ▁VERANDA
- ▁ASSEMBLE
- ▁HANGUL
- ▁REACTION
- ▁DAUGHTERS
- MENT
- QUET
- RMALLY
- ANG
- ▁LID
- ▁RESERVATION
- SOON
- ▁FLIP
- CAN
- ▁JUICY
- ▁KINGDOM
- ▁SOCIETY
- ▁TADPOLE
- ▁JAMSIL
- ▁WI
- ▁GRADUATED
- ▁PRE
- ▁SCRATCHING
- ▁PO
- ▁APPEARS
- ILY
- FAT
- FOOD
- ▁DISAPPEAR
- ▁FAINT
- ▁FLOAT
- ▁RUBB
- ▁TRANSFER
- ▁COMFORT
- ▁BALLERINA
- ▁DESCRIPTION
- ▁GENTLY
- ▁HAPPIER
- ▁RINGTONE
- ▁ARGUING
- ▁CONDITIONER
- PM
- IET
- CU
- ▁EARTHQUAKES
- ▁CHICK
- ▁TR
- ▁TYPHOON
- ▁BUNS
- ▁RUNNER
- NDC
- ▁WAH
- ▁JELL
- ENDY
- ▁COMMU
- ▁FARMS
- ▁SLEEVES
- ▁BEETLES
- LOW
- ▁MEATBALL
- ALKIE
- ▁MAGNIF
- ▁CONNIE
- ▁NEIGHBOR
- ▁OPERA
- ▁PINOCCHIO
- ▁SHOEMAKER
- ▁CRAFT
- ▁ONESIX
- ▁FLOW
- WD
- HOO
- ▁PRESENTATIONS
- ▁CHIP
- ITE
- ▁ANIMAT
- ▁DUB
- ▁FLOOD
- ▁KAKAO
- ▁RESU
- ▁UNBELIEVABLE
- ▁GRIN
- ▁HEALTHIER
- ▁SIXTH
- ▁CHOSEN
- ▁LOSER
- ▁BLED
- REALLY
- ▁IGNOR
- ▁PRODUCT
- RIST
- ▁DISCOURAGED
- ▁DODGE
- ▁FORECAST
- ▁OWL
- ▁TREASURE
- ▁UNIFORM
- ▁LOCAT
- ▁TUBE
- DON
- ▁FOLDED
- ▁WEIGH
- ▁RUIN
- ▁CRUSH
- ▁PARAD
- ▁OBESE
- ▁ORGANIZE
- ▁PRINCIPAL
- ▁RATTLING
- ▁RESERVE
- ▁RHYM
- ▁SIP
- ▁UNDERWATER
- ▁TAEG
- ▁TRAVELLING
- ▁STACK
- ▁RI
- ▁BUNDLES
- YEAR
- SAME
- AND
- ▁CHEESECAKE
- ▁EPISODE
- ▁FAMILIES
- ▁FIFTH
- ▁RHINITIS
- ▁SAUNA
- NCHES
- ▁EXCE
- TIQUE
- ▁COMBO
- ▁STRINGS
- ▁COLORFUL
- ▁FLOWS
- ▁COOLEST
- ▁OPPAS
- ATING
- ATE
- ▁MELTS
- ▁CHOPSTICK
- ▁BRANCH
- ▁FRUSTRATED
- ▁GREASY
- ▁EXIST
- ▁WAVING
- ▁APP
- ▁SODA
- ▁FALLEN
- ▁PRO
- SHAPED
- NG
- ▁CONNECTED
- ▁12
- ▁BANDAID
- ▁DISTANCE
- ▁DRAIN
- ▁MEASURE
- ▁TEMPLE
- ▁WORKBOOK
- ▁EIGHTAM
- ▁WARN
- ▁BURNT
- BOARD
- ▁DE
- IFF
- RTH
- ▁MUSHROOMS
- ▁POWERFUL
- STICK
- ▁VOUCHERS
- ▁BLEED
- ▁BRAID
- ▁CREPE
- ▁HAWKING
- ▁FLAM
- ▁SCORE
- ▁RELEASED
- ▁TICKLED
- BU
- FISH
- ATIVE
- CLUSI
- ▁CLINIC
- ▁CROOKED
- ▁RELAY
- ▁SCOOTER
- ▁SEBASTIAN
- ▁SUFFER
- ▁TEENAGER
- ▁BATHHOUSE
- ▁WRIST
- ▁BAKERIES
- ▁BRANCHES
- ▁SAMYUKGU
- ▁SCU
- ENDER
- ▁INGREDIENTS
- ▁INVENTED
- ▁BOWING
- SSES
- WAR
- ▁PRESSED
- ▁SQUEEZ
- SIGNED
- WON
- ▁70
- ▁APPROACH
- ▁CHAPPED
- ▁DUMB
- ▁FREEZING
- ▁MAGNIFIER
- ENTIAL
- IE
- ▁CLOSELY
- ▁DIAPERS
- OUS
- ▁DIRT
- ▁CENTIMETER
- ▁FLOWERPOT
- ▁FOAM
- ▁POLITIC
- ▁PORRIDGE
- ▁PEDIATRICIAN
- ▁FIREWORKS
- ▁TROUBLEMAKER
- ▁PILLAR
- ▁EVACUATE
- ▁SILLA
- EUK
- ANDING
- ▁FAINTED
- ERMAN
- ▁SEAGULL
- ▁CHICKS
- ▁SWEATING
- INGO
- PAPER
- ▁AGREED
- ▁CLAPP
- VA
- ▁STRENGTH
- SOONGSIL
- ‘
- ▁CONVENIENT
- ▁DECEMBER
- ▁FORTUNATELY
- ▁FURNITURE
- ▁HAGWON
- ▁LOUNGE
- ▁MOKDONG
- ▁PALM
- ▁SPRINKLE
- ▁STIRFR
- RUNK
- ▁ANKLE
- ▁SELF
- ▁SEVENTH
- LESS
- ▁DIVING
- ADE
- ▁RANG
- SHINY
- WITH
- ▁BRAVELY
- ▁BADMINTON
- ▁BULGUKSA
- ▁KARAOKE
- ▁ADMIT
- ▁GINGER
- ▁LAID
- ▁SNOWBOARD
- ▁HOPPING
- ▁UDO
- ▁BULGING
- ▁CARP
- ▁FACT
- ▁GROUPS
- ▁ENTERING
- ▁RIP
- ▁MAR
- LOCK
- ▁JE
- ▁ADMISSION
- ▁CHRYSANTHEMUM
- ▁DIARIES
- ▁DISPOSABLE
- ▁LOACH
- ▁PARROT
- ▁SCULPTURE
- ▁TERRIF
- ▁VOLUME
- ▁REPRESENTATIVE
- ▁MEOW
- ▁CHEEK
- ▁JEJUDO
- ▁HARMFUL
- ▁BRUISED
- ▁MINERAL
- AINT
- ▁EDIT
- WARDS
- HY
- ▁VIEW
- ▁EXACT
- ROUGHT
- OCKPAPERSCISSORS
- ▁CHESTNUT
- ▁HAWAII
- ▁PIMPLES
- ▁REMOTE
- ▁SOLUTION
- ▁COMPETE
- ▁SOFTLY
- ▁BUNDLE
- ▁LIP
- ▁GRADER
- WOO
- RIS
- STORY
- DAYS
- COLORED
- FOR
- ▁COLLAPSE
- ▁STEPP
- ▁BRILL
- RSELVES
- ▁ACCORDING
- ▁BACON
- ▁BAEK
- ▁BUTTERFLIES
- ▁COSMOS
- ▁CYCLING
- ▁DISTRICT
- ▁ESTATE
- ▁HUMID
- ▁MERMAID
- ▁PAPRIKA
- ▁PHONICS
- ▁BELONG
- ▁YUKJANG
- ▁ANIMATION
- ▁FLIPP
- ▁DUMPLING
- ▁BLOSSOM
- UNG
- ▁EXPLORE
- ▁INSECTS
- ▁JI
- HEART
- GHTS
- ▁ASTRONAUT
- ▁BELLHAMMER
- ▁LICENSE
- ▁NEPTUNE
- ▁OPPOS
- ▁REFRIGERATOR
- ▁STONEBUSH
- ▁1000
- ▁APPLI
- ▁SUBTRACTION
- ▁HOOD
- ▁WIDER
- ▁BROOM
- ▁UNIVERSITY
- ▁PRINCESSES
- ▁MINT
- ▁PARENT
- ▁PEEING
- ▁ADORE
- DONG
- ▁SP
- ANCE
- ▁EXPLOR
- TTEOKBOKKI
- WHEEL
- ▁ABANDONED
- ▁CALLUSES
- ▁COSMETICS
- ▁LADYBUG
- ▁MARIA
- ▁PRONUNCIATION
- ▁BOUQUET
- ▁SOGGY
- ▁LEFTOVERS
- ▁MIKE
- ▁TANK
- ▁SPAC
- ▁FRAME
- MADE
- IVAL
- ▁YE
- ▁GATHERING
- IAN
- ▁KITTENS
- IBLE
- ▁ABBREVIAT
- ▁CHAPAGETTI
- ▁ENGINES
- ▁EQUIPMENT
- ▁INTERSECTION
- ▁SANITIZER
- ▁DOKDO
- ▁GENERATOR
- ▁MEDIUM
- ▁BALANCE
- ▁CHART
- ▁TELEVISION
- ▁JAJANG
- ▁LOLLY
- ▁PHOTOGRAPH
- ORD
- ▁KKA
- ▁SOLES
- ▁BALM
- ▁DECORATION
- ▁THORN
- ▁ARMY
- ▁YU
- EEK
- NK
- BOY
- LENGTH
- TONY
- HEN
- ▁RELEASE
- ▁LOOSE
- ▁COMPLETE
- KYOCHON
- ▁ARCADE
- ▁BRIM
- ▁CORONA
- ▁CRANE
- ▁CUPCAKE
- ▁KITCHENWARE
- ▁LULLABY
- ▁MODER
- ▁MUSKET
- ▁OBEDIEN
- ▁PIKACHU
- ▁PROVERBS
- ▁SALMON
- ▁YUKGAEJANG
- ▁TANNED
- ▁VILLA
- ▁DIRECTIONS
- ▁CLAY
- ▁ADMIR
- ▁DIRECTOR
- ▁DAMAGED
- ▁BURST
- ▁TOPIC
- ▁DOODLED
- ▁COMPAR
- ▁BUBBLE
- ▁HO
- ▁KISSE
- ▁JO
- ▁BLOATED
- ▁CONSONANTS
- ▁DOWNLOAD
- ▁ELBOW
- ▁FUNNIEST
- ▁PORORO
- ▁SLOTS
- ▁VACUUM
- ▁BOTTOM
- ▁MANDELA
- ▁IMSIL
- ▁VIP
- ▁TOMMY
- EATURE
- ▁PINE
- ▁EIGHTTHIRTY
- ▁HIDEANDSEEK
- ▁COLLAPSED
- ▁UNDERSTOOD
- ▁CRUSHED
- ▁TRI
- OF
- ▁DI
- ▁CARNATION
- ORY
- NAILS
- LENT
- ▁PUBLISH
- PLACE
- ▁CLIP
- ILLA
- ▁SUNSHIN
- ▁ACTUAL
- ▁SUCCESS
- COCK
- ▁60
- ▁BENEFITS
- ▁CLAW
- ▁HAUNT
- ▁LIBRARIES
- ▁LOTTERIA
- ▁MERCURY
- ▁MITTEN
- ▁SWAM
- ▁ROTTEN
- ▁SERVANT
- DENTAL
- ▁LEGEND
- ▁ROT
- ▁PRICKED
- ▁230
- ▁TUB
- ▁WINK
- ▁HUNTER
- ▁SCREAMING
- ▁FINALE
- ▁SOAPY
- ▁REDESIGNING
- NNA
- ▁DIAPER
- ▁BANG
- IK
- CHAN
- TIER
- ▁MOR
- ▁METERS
- ▁HUGG
- DAE
- FTER
- CHO
- SHIP
- EITHER
- CTIVE
- ▁KI
- ▁RU
- ▁BRAND
- ▁AMOUNT
- ▁EXPLANATION
- ▁HAIRPIN
- ▁HORRIBLE
- ▁INTERIOR
- ▁LANDSLIDE
- ▁NEVERTHELESS
- ▁PERSIMMON
- ▁POSTPONE
- ▁SCIENTIST
- ▁SLACK
- ▁STORM
- ▁STREAM
- ▁SURPRISING
- ▁URGENT
- ▁ZOMBIE
- ▁STOOL
- ▁LOAD
- NAMBU
- ▁ANNOUNCEMENT
- IKES
- GRAN
- ▁ABC
- ▁COMPLE
- ▁FASCINATING
- ▁REMOVED
- ▁CRAWLING
- ▁INTERRUPTING
- RELLA
- RAGE
- ▁PEELING
- ▁HUMANS
- ▁MON
- ▁BEGIN
- ▁VEGETABLE
- ▁SLEEVE
- GLE
- ▁THA
- ISH
- TRAINER
- '7'
- ROAD
- DRIVER
- ▁PRETEN
- ▁ALLOW
- UZZLE
- ▁DEMONSTRAT
- ▁STIR
- ▁BROC
- ▁CARCASON
- ▁EQUALLY
- ▁EXPERIMENT
- ▁HESITAT
- ▁SPINNING
- ▁MENTOR
- ▁ABBREVIATION
- ▁RASHES
- ▁ASSEMBLING
- ▁DUNG
- MEMOR
- ▁PEACEFUL
- ▁HARDENS
- OSU
- SSUED
- ▁FRECKLE
- TIOUS
- ▁REALIZ
- ▁SQUA
- LIFE
- THINK
- ▁BIK
- ▁KNIT
- ZZA
- ▁ALITTLE
- ▁BAREFOOT
- ▁CONCENTRATE
- ▁DALGONA
- ▁GUIDEBOOK
- ▁KIDZANIA
- ▁PALACE
- ▁ROSHEN
- ▁TEXTBOOK
- ▁TUNAKIMBAP
- OTTEOK
- ▁830
- ▁HOSE
- ITIES
- NIX
- ▁FIFTEENCM
- ▁IMAGE
- ▁CHEESEKIMBAP
- ▁HOTTER
- ▁PATT
- ▁CLIPPE
- ▁FOXES
- EAGLE
- ▁QUE
- NDING
- ▁DETER
- AP
- YEO
- UED
- ▁PAI
- ▁EXCITEDLY
- ▁WAVED
- ▁BUL
- BUT
- ▁METER
- KIMBAP
- HAND
- WATCHING
- ▁CONVERS
- ▁FLICK
- ▁PEDIATRIC
- NAMENT
- REIGN
- ▁BIKINI
- ▁BUCKWHEATCREPE
- ▁JENGA
- ▁LAUNCH
- ▁OPTICIAN
- ▁PIGTAIL
- ▁SIMON
- ▁SUBSCRIBE
- ▁TICKLISH
- NELS
- ▁PINWHEEL
- INATED
- ▁DRUG
- ▁ONESIXCM
- ▁EIGHTH
- ▁SMARTEST
- ▁HUNTING
- ▁PIL
- UMMY
- ITION
- UNNI
- ▁SU
- ▁POWERFULL
- ▁WAFFLE
- DIA
- ▁TICK
- EIGHT
- PICKED
- FIFTY
- WENT
- ▁BOT
- ▁REPRESENT
- OKKI
- ▁COCOA
- ▁CUSHION
- ▁FARTHEST
- ▁PENTAGON
- ▁SLIDING
- ▁SWEAR
- ▁MOLD
- ▁BBOY
- ▁80
- ▁WATERPROOF
- ▁RAIL
- ▁CREATED
- ▁CHIRPING
- ▁SEARCH
- SEOK
- ▁TOAST
- ▁BETRAYE
- JOR
- ▁NI
- ZI
- ▁SLAMM
- ▁GU
- ▁NAG
- ▁SERVED
- UFFY
- ▁INSECT
- ▁ZIPPE
- LP
- YEONG
- ESSION
- IPPED
- ▁CELEBRAT
- ▁CHANG
- '50'
- POST
- ENTI
- ▁DISAPPOINT
- ▁QU
- ▁FOREIGN
- ▁POSSIB
- ▁CONGRATULAT
- ADOW
- ▁TAE
- CAFÉ
- ▁COURIER
- ▁DAEJEON
- ▁DOWNSTAIRS
- ▁EXPER
- ▁PREFERENCE
- ▁LACT
- ▁OCCUR
- ORIENT
- ▁SPACIOUS
- INARY
- ▁KNITTING
- ▁LIBERTY
- VILLE
- RB
- ▁BARKED
- DAN
- ▁TIN
- ATOR
- ▁PHO
- RIED
- ▁JINDA
- OUND
- HOE
- ▁STRETCHE
- ▁SNEEZ
- EVI
- QUALITY
- MOM
- ▁BLIND
- HYEON
- ECTION
- ROKE
- ▁ANCHOVY
- ▁ASHAMED
- ▁COASTER
- ▁CONFUSING
- ▁CYCLIST
- ▁DANDELION
- ▁FIREFLIES
- ▁HYUNG
- ▁KNOWLEDGE
- ▁NARACULA
- ▁SCAB
- ▁VOCABULARY
- ▁CONFIDENT
- ▁RELAT
- ▁FOOLISH
- ▁NINEAM
- ▁ZO
- ▁BOU
- ▁FLATTERED
- ▁BLINDING
- ▁SKATER
- ▁ROLLER
- ▁FIRM
- COTT
- NURI
- ▁WARMER
- ▁LONGEST
- ▁TICKLE
- ▁AMERICAN
- GI
- AGGED
- CHARGE
- TODAY
- ▁CREATE
- UMPING
- JJAEK
- ▁BEGINNER
- ▁CLICKING
- ▁CORRIDORS
- ▁DAZZLING
- ▁DERMATOLOGIST
- ▁DILIGENT
- ▁FEBRUARY
- ▁FISHBOWL
- ▁GARAETTEOK
- ▁GARGLE
- ▁INJURED
- ▁MANTISES
- ▁NAKSEONGDAE
- ▁ROAST
- ▁SNITCH
- ▁SLIMMER
- ▁DISCHARGE
- ▁SOAKED
- ▁SELECTED
- ▁VICE
- ▁INFECT
- ▁CONTAINER
- ▁NEATLY
- ▁STARSHAPED
- LOTTEWORLD
- ▁SUPPLEMENT
- ▁EIGHTTH
- ISTERS
- ▁TICKL
- ▁STRAIGHTEN
- ▁SKINN
- RANGE
- ▁TANGERINE
- ▁STO
- PREPARED
- SPROUT
- TWELVE
- TONIGHT
- ▁RECOGNI
- VAN
- BEEN
- ▁EXPLODE
- ▁CHUBB
- ANGGU
- ▁SAVI
- ▁950
- ▁ADJUST
- ▁CASTANETS
- ▁FAITH
- ▁GONGJU
- ▁GRAIN
- ▁GROSS
- ▁JUPITER
- ▁MAGPIE
- ▁SAIPAN
- ▁SKULL
- ▁SPARROW
- ▁VACCINATED
- ▁VIGOROUSLY
- ▁AUTOMATIC
- ▁NEARBY
- SEVENTEEN
- ▁TWENTI
- ▁NIKE
- ▁SEORA
- DATORS
- ▁PONG
- ▁730
- ▁SCARIER
- ▁TRUNK
- ▁BETRAYER
- ▁CHEESEGIMBAP
- ONGDAE
- ▁SEVERE
- ▁SPOONFUL
- CTATION
- ▁WITCH
- ▁LIMIT
- ▁EATTTEOKBOKKI
- GEOUS
- ▁CRAWLED
- ▁SUC
- AVED
- AGE
- ▁KITTEN
- ▁SKEWER
- IZED
- ▁TEAR
- WAVE
- ▁RACI
- ▁CONTAIN
- ▁TRO
- ▁GUGUDAN
- ▁GEPPET
- ▁PHARMACI
- MULGUK
- PPAK
- SAMJANG
- ▁ACORN
- ▁APPETITE
- ▁BRUNCH
- ▁BUMMER
- ▁DIARRHEA
- ▁FLAP
- ▁GERMS
- ▁GWANSUN
- ▁HOMETOWN
- ▁KILOMETERS
- ▁MARRIAGE
- ▁PRANKS
- ▁RADISH
- '5'
- ′
- 수
- '2'
- ́
- 子
- 예
- 요
- '3'
- É
- '6'
- '9'
- “
- .
- '1'
- 단
- <sos/eos>
init: null
input_size: null
ctc_conf:
ignore_nan_grad: true
joint_net_conf: null
use_preprocessor: true
token_type: bpe
bpemodel: data/ko_token_list/bpe_unigram5000/bpe.model
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
aux_ctc_tasks: []
frontend: default
frontend_conf:
fs: 16k
specaug: null
specaug_conf: {}
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_ko_bpe5000_sp/train/feats_stats.npz
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
preencoder: null
preencoder_conf: {}
encoder: contextual_block_transformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d
normalize_before: true
block_size: 40
hop_size: 16
look_ahead: 16
init_average: true
ctx_pos_enc: true
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
preprocessor: default
preprocessor_conf: {}
required:
- output_dir
- token_list
version: '202304'
distributed: true
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
hchung1017/aihub_012_streaming_conformer
|
hchung1017
| 2023-07-06T06:22:30Z | 0 | 0 |
espnet
|
[
"espnet",
"audio",
"automatic-speech-recognition",
"ko",
"dataset:aihub_012",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
automatic-speech-recognition
| 2023-07-06T06:22:07Z |
---
tags:
- espnet
- audio
- automatic-speech-recognition
language: ko
datasets:
- aihub_012
license: cc-by-4.0
---
## ESPnet2 ASR model
### `hchung1017/aihub_012_streaming_conformer`
This model was trained by hchung1017 using aihub_012 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout f4d7fead71e2a99541a8d3d66d6e00a33d9e82df
pip install -e .
cd egs2/aihub_012/asr1
./run.sh --skip_data_prep false --skip_train true --download_model hchung1017/aihub_012_streaming_conformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Wed Jul 5 15:19:05 KST 2023`
- python version: `3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0]`
- espnet version: `espnet 202304`
- pytorch version: `pytorch 1.13.1`
- Git hash: `f4d7fead71e2a99541a8d3d66d6e00a33d9e82df`
- Commit date: `Wed May 24 14:58:35 2023 -0400`
## exp/asr_train_asr_streaming_conformer_raw_ko_bpe5000_sp/decode_asr_streaming_asr_model_valid.acc.ave
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|3794053|89.7|9.1|1.2|1.4|11.8|28.9|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|17636048|94.8|3.0|2.2|1.6|6.8|28.9|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|org/dev|797676|4325914|88.1|8.2|3.7|1.5|13.4|28.9|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr_streaming_conformer.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_streaming_conformer_raw_ko_bpe5000_sp
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 0
dist_backend: nccl
dist_init_method: env://
dist_world_size: 8
dist_rank: 0
local_rank: 0
dist_master_addr: localhost
dist_master_port: 51405
dist_launcher: null
multiprocessing_distributed: true
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 50
patience: null
val_scheduler_criterion:
- valid
- acc
early_stopping_criterion:
- valid
- cer_ctc
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 25000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_ko_bpe5000_sp/train/speech_shape
- exp/asr_stats_raw_ko_bpe5000_sp/train/text_shape.bpe
valid_shape_file:
- exp/asr_stats_raw_ko_bpe5000_sp/valid/speech_shape
- exp/asr_stats_raw_ko_bpe5000_sp/valid/text_shape.bpe
batch_type: numel
valid_batch_type: null
fold_length:
- 51200
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
chunk_excluded_key_prefixes: []
train_data_path_and_name_and_type:
- - /data/dump/aihub_012/raw/train_sp/wav.scp
- speech
- sound
- - /data/dump/aihub_012/raw/train_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - /data/dump/aihub_012/raw/dev/wav.scp
- speech
- sound
- - /data/dump/aihub_012/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
exclude_weight_decay: false
exclude_weight_decay_conf: {}
optim: adam
optim_conf:
lr: 0.003
scheduler: warmuplr
scheduler_conf:
warmup_steps: 30000
token_list:
- <blank>
- <unk>
- ▁I
- ▁YOU
- ''''
- S
- ▁WHAT
- ▁A
- ▁IT
- ▁TO
- ▁IS
- ▁THE
- ▁ARE
- ▁CAN
- ▁OKAY
- ▁YES
- ▁DO
- ▁THAT
- ▁SEE
- T
- ▁HE
- ▁HOW
- ▁ME
- ▁HAVE
- ▁MY
- ▁GOOD
- ▁REALLY
- ▁SO
- ▁FOR
- ▁AM
- ▁SURE
- ▁OH
- ▁GO
- ▁WHY
- ▁NO
- ▁YOUR
- ▁RIGHT
- ▁HELP
- ’
- ▁DON
- ▁NOT
- ▁HI
- ▁HERE
- ▁DID
- ▁LIKE
- ▁AND
- ▁TOO
- ▁SHE
- ▁THIS
- ▁HELLO
- M
- ▁KNOW
- ▁WANT
- RE
- ▁NEED
- ▁WILL
- ▁ABOUT
- ▁THERE
- ▁LET
- ▁OF
- ▁IN
- ▁BE
- ▁BUT
- ▁THINK
- ▁SOMETHING
- ▁LOOK
- ▁NOW
- ▁NICE
- ▁THEN
- ▁
- ▁WE
- ▁GREAT
- ▁THANK
- ▁WITH
- ▁TELL
- ▁PROBLEM
- ▁HER
- ▁GOING
- ▁WAS
- ▁DOING
- ▁ASK
- ▁THANKS
- ▁HEY
- ▁BACK
- ▁WRONG
- ▁THEY
- ▁ON
- ▁HIM
- ▁UP
- ▁AT
- LL
- ▁WELL
- ▁GET
- ▁WHERE
- VERY
- ▁SOME
- ▁PEOPLE
- ▁ALL
- ▁MEAN
- ▁PLEASE
- ▁TIME
- ▁WHO
- ▁GOT
- ▁WELCOME
- ▁MAKE
- ▁COME
- ▁MEET
- ▁NEW
- ▁LOT
- ▁MOM
- ▁SAID
- ▁SHOULD
- ▁HAPPY
- ▁HIS
- ▁BUSY
- ▁BYE
- ▁QUESTION
- ▁SAY
- ▁TAKE
- ▁MORE
- ▁SORRY
- ▁IDEA
- ▁OUT
- ▁FINE
- ▁PLAY
- ▁ANY
- ▁AGAIN
- ▁BECAUSE
- ▁FROM
- ▁AN
- ▁WHEN
- ▁TRY
- ▁HAS
- ▁TODAY
- ▁READY
- ▁HOPE
- ▁GIVE
- ▁BIG
- ▁FRIEND
- ▁WRITE
- ▁EAT
- ▁ONE
- ▁BAD
- ▁MUCH
- ▁SOON
- ▁MANY
- ED
- ▁THEM
- ▁ANGRY
- ▁LATER
- ING
- ▁MAYBE
- ▁DAD
- ▁FIND
- ▁DOWN
- ▁WORRY
- ▁SHOW
- ▁COURSE
- ▁DAY
- ▁SOUNDS
- ▁DOES
- ▁STRANGE
- ▁TALK
- ▁FUN
- ▁REMEMBER
- ▁ANYTHING
- ▁BUY
- ▁LETTER
- ▁JUST
- ▁MADE
- ▁READ
- ▁CANNOT
- ▁WANTS
- ▁WOW
- ▁DIDN
- ▁IF
- ▁GLAD
- ▁WAY
- ▁MUST
- ▁SCHOOL
- ▁BOOK
- ▁LOOKING
- ▁TOLD
- ▁NAME
- ▁HEAR
- ▁TOY
- ▁TRUE
- ▁TEACHER
- ▁US
- ▁WORK
- ▁TWO
- ▁SONG
- ▁HARD
- ▁LOVE
- ▁THINGS
- ▁SING
- ▁BETTER
- ▁HOME
- ▁LINKER
- ▁UNDERSTAND
- ▁LOOKS
- ▁KIND
- ▁HOUSE
- LUE
- ▁DRESS
- ▁BY
- ▁BEST
- ▁LONG
- ▁NEWS
- ▁WENT
- ▁HAPPENED
- ▁OLD
- ▁KEEP
- ▁NEXT
- ▁CHECK
- D
- ▁SPECIAL
- ▁USE
- ▁LIKES
- ▁EVERYTHING
- ▁FEEL
- ▁ROBOT
- ▁SAD
- ▁PLEASURE
- ▁JOE
- ▁COOL
- ▁TOMORROW
- ▁LUCK
- ▁DOESN
- ▁BOX
- ▁AROUND
- ▁HOMEWORK
- ▁ALWAYS
- ▁MORGAN
- ▁PUT
- ▁THESE
- ▁GAVE
- ▁HEARD
- ▁WAIT
- ▁PRESENT
- ▁SOMEONE
- ▁PARTY
- ▁BIRTHDAY
- ▁RANDY
- ▁FRIENDS
- ▁MONEY
- ▁DONE
- ▁CAR
- ▁COFFEE
- ▁MUSIC
- ▁BEN
- ▁BEEN
- ▁STILL
- ▁GREEN
- ▁STAR
- ▁PERSON
- ▁WERE
- ▁STORY
- ▁ELSE
- ▁IDEAS
- ▁TOGETHER
- ▁MILK
- ▁WOULD
- ▁SOUND
- ▁THAN
- ▁TALKED
- ▁EVERY
- ▁NEEDS
- ▁SAW
- ▁HAIR
- ▁CHANGE
- ▁WORRIED
- ▁EASY
- ▁FOOD
- ▁DOG
- VE
- ▁CONCERT
- ▁MAKING
- ▁MONSTER
- ▁BOY
- ▁PHOTO
- ▁SCARY
- ▁RED
- ▁BROTHER
- ▁FIRST
- ▁DANCE
- ▁BEFORE
- ▁PRETTY
- ▁DRINK
- ▁WISH
- ▁HARRY
- ▁CALM
- ▁CAT
- ▁WEAR
- ▁BLUE
- ▁MESSAGE
- ▁TRUST
- ▁ONLY
- ▁HAD
- ▁THREE
- ▁AWAY
- ▁MIND
- ▁MAKES
- ▁GRANDMOTHER
- ▁WATCH
- ▁EMMA
- ▁AMY
- ▁TIRED
- ▁CLASS
- ▁MAN
- ▁DAN
- ▁COULD
- ▁BRING
- ▁SMALL
- ▁ANYWAY
- ▁OUR
- ▁ROOM
- ▁AFTER
- ▁BELIEVE
- ▁BOOKS
- ▁TEN
- ▁DEVILMON
- ▁JOB
- ▁OVER
- ▁COMING
- ▁STOP
- ▁FUNNY
- ▁DIANA
- ▁TOYS
- ▁FAST
- ▁MORNING
- ▁NUMBER
- ▁NOTHING
- ▁TOWN
- ▁OPEN
- ▁OTHER
- ▁PHONE
- ▁CARE
- ▁LEAVE
- ▁CONTEST
- ▁WOODY
- ▁THINKING
- Y
- ▁ANOTHER
- A
- ▁ENGLISH
- ▁SICK
- ▁BRAVE
- ▁TROY
- ▁EATING
- ▁SLEEP
- ▁THEIR
- ▁SELL
- ▁DELICIOUS
- ▁OFF
- ▁WATER
- ▁PICTURE
- ▁CAME
- ▁EVERYONE
- ▁PAPER
- ▁PARK
- ▁PAINT
- ▁SHOP
- ▁CREAM
- ▁TV
- ▁BOUGHT
- ▁CAREFUL
- ▁ROBBY
- ▁FOUND
- ▁STONE
- ▁SISTER
- ▁HURRY
- ▁BAG
- ▁WAKE
- ▁SYRUP
- ▁DRAW
- ▁ENERGY
- ▁SHOES
- ▁IMPORTANT
- ▁NEVER
- ▁LISTEN
- ▁WON
- ▁DOOR
- ▁POP
- ▁LAST
- ▁DIFFERENT
- ▁FISH
- ▁SAVE
- ▁HEALTHY
- ▁UNCLE
- ▁NIGHT
- UCH
- ▁PLACE
- ▁DARK
- ▁GUESS
- ▁LATE
- ▁PIE
- N
- ▁PRACTICE
- ▁MONICA
- ▁ANYONE
- ▁READING
- ▁COLOR
- ▁SALLY
- ▁BLACK
- ▁MOVIE
- ▁TROUBLE
- ▁COLD
- ▁STUDY
- ▁LITTLE
- ▁WHITE
- ▁CHEER
- ▁SCARED
- ▁POSTER
- ▁TALKING
- ▁TEACH
- ▁WALK
- ▁CAKE
- ▁INTO
- ▁FIGHT
- ▁ALREADY
- ▁SLEEPY
- ▁STRONG
- ▁OLIVIA
- ▁CALL
- ▁WROTE
- ▁ICE
- ▁OR
- ▁SCOTT
- ▁LIBRARY
- ▁NANCY
- ▁LUMY
- ▁HAT
- ▁YET
- ▁ALEX
- ▁SHORT
- ▁CLOTHES
- ▁YESTERDAY
- ▁FAVORITE
- ▁SWEET
- ▁FIVE
- ▁HOLD
- ▁LUNCH
- ▁PLAYING
- ▁GARY
- ▁HANDS
- ▁LEFT
- ▁ASKED
- ▁CHEESE
- ▁FACE
- ▁BORROW
- ▁SPEAK
- ▁INTERESTING
- ▁MAY
- ▁BEAR
- ▁SIGN
- ▁SHADOW
- ▁FLOWERS
- ▁PINO
- ▁ERIN
- ▁FOREST
- ▁GAME
- ▁MR
- ▁WANTED
- ▁RUN
- ▁SPELL
- ▁PEN
- ▁SHOPPING
- ▁COOK
- ▁DAYS
- ▁BED
- ▁BEAUTIFUL
- ▁MUSEUM
- ▁CLEAN
- ▁REST
- ▁SAME
- ▁DOCTOR
- ▁YOURSELF
- ▁DINNER
- ▁DANGEROUS
- ▁SECRET
- ▁STORE
- ▁TREE
- ▁MIGHT
- ▁MAYOR
- ▁CHARLIE
- ▁PIZZA
- ▁FOUR
- ▁SIR
- ▁SEEN
- ▁TURN
- ▁ENJOY
- ▁CLARA
- ▁ANYTIME
- ▁LIVE
- ▁LOST
- ▁SANDRA
- ▁DURING
- ▁MYSELF
- ▁TALL
- ▁MINE
- ▁CHOOSE
- ▁TOOK
- ▁WAITING
- ▁S
- ▁SUNNY
- ▁SINGING
- ▁ACADEMY
- ▁AHEAD
- ▁HURT
- ▁CLOCK
- ▁PAINTING
- ▁RAN
- ▁ALONE
- ▁USED
- ▁PLAN
- ▁THEATER
- ▁HAND
- ▁WEEK
- ▁CATCH
- ▁SEND
- ▁CUBE
- ▁ERIC
- ▁WOOD
- ▁HOT
- ▁DEVILMONS
- ▁FREE
- ▁STAY
- ▁PROMISE
- ▁RULE
- ▁HUNGRY
- ▁WORKING
- ▁HAPPEN
- ▁VIKI
- ▁FAMILY
- ▁CHICKEN
- ▁FORGET
- ▁YELLOW
- ▁BROWN
- ▁VACATION
- ▁KELLY
- ▁JACK
- ▁SINGER
- ▁HAMMER
- ▁SAYS
- ▁TRAIN
- ▁FIX
- ▁CUTE
- ▁EVEN
- ▁SANTA
- ▁SLEEPING
- ▁BUS
- ▁BARBECUE
- ▁AGREE
- ▁COULDN
- ▁MISS
- E
- ▁GRACE
- ▁TRASH
- ▁BABY
- ▁LUMA
- ▁CHILDREN
- ▁EXCUSE
- ▁DPOP
- ▁OUTSIDE
- ▁ORDER
- ▁MATTER
- ▁RIDE
- ▁SUMMER
- ▁CLOSE
- ▁MOVE
- ▁JUICE
- ▁TOUCH
- ▁CARD
- ▁THOSE
- ▁HAIRSTYLE
- ▁RICH
- ▁BREAK
- ▁ANYMORE
- ▁TRIP
- ▁EYES
- ▁LEARN
- IC
- ▁YOUNGER
- ▁SMELLS
- ▁CHRIS
- ▁ITEMS
- ▁STONES
- ▁CUT
- ▁STUDENT
- ▁CALLED
- ▁SHINE
- ▁ATE
- ▁PERFECT
- ▁BETIA
- ▁MOVING
- LY
- ▁FIRE
- ▁D
- ▁CHRISTMAS
- ▁RUNNING
- ▁LINE
- ▁JACKET
- ▁WHICH
- ▁GIFT
- ▁SMILE
- ▁WEARING
- ▁STELLA
- ▁SEVEN
- ▁ANSWER
- ▁YEAR
- ▁MOST
- ▁WENDY
- RA
- ▁BALL
- ▁THING
- ▁FIFTY
- ▁YOUNG
- ▁FRONT
- ▁LIKED
- ▁WINDOW
- ▁BEING
- ▁RICE
- ▁HOBBY
- ▁BRUCE
- ▁ALVIN
- ▁CHAIR
- ▁ELEVEN
- ▁INTERVIEW
- ▁TRUMPET
- ▁DRAWING
- ▁WHILE
- ▁HAV
- ▁NEWSPAPER
- ▁WRITING
- ▁FRUIT
- ▁BEHIND
- ▁EVENT
- ▁HAVEN
- ▁BELLOW
- ▁YEARS
- ▁DIV
- ▁VICTORIA
- ▁SENT
- ▁STYLE
- ▁LUNA
- ▁AUNT
- ▁DREAM
- ▁PICTURES
- ▁LEO
- ▁QUESTIONS
- ▁PRICE
- ▁APPLE
- ▁SCHEDULE
- ▁TABLE
- ▁PLANT
- ▁BELL
- ▁SUSAN
- ▁SHIRT
- ▁GRANDFATHER
- ▁EXPENSIVE
- ▁GUYS
- ▁THOUGHT
- ▁OSCAR
- ▁TIMES
- ▁ACTUALLY
- ▁CHANCE
- ▁PAY
- ▁WASH
- ▁JUGGLING
- ▁JULIA
- ▁MAKEUP
- ▁PIANO
- ▁GOES
- ▁QUIZ
- ▁OFTEN
- ▁THIRTY
- ▁SMART
- ▁WEEKEND
- ▁CHOCOLATE
- ▁BATHROOM
- ▁CANDY
- ▁SPEECH
- ▁FEELING
- ▁RADIO
- ▁HECTOR
- ▁KNOWS
- ▁GRANDMA
- ▁SEEM
- ER
- ▁START
- ▁PENCIL
- ▁SUNDAY
- ▁WORD
- ▁MOUSE
- ▁PLAYGROUND
- ▁BREAD
- ▁MAGIC
- ▁CD
- ▁BROKEN
- ▁COLIN
- ▁DIRTY
- ▁MOTHER
- ▁DESK
- ▁BORING
- ▁SOUP
- ▁ONCE
- ▁WORKED
- ▁COUNT
- ▁EXCITED
- ▁PARADE
- ▁GUITAR
- ▁PM
- ▁FINISH
- ▁BLOCK
- ▁FISHING
- ▁VOICE
- ▁ROGER
- ▁WORKS
- ▁PLAYER
- ▁GLASSES
- ▁LAB
- ▁SIGH
- ▁LOVES
- ▁MODEL
- ▁EXERCISE
- ▁O
- ▁POINT
- ▁SWIMMING
- ▁MARKET
- ▁NOTE
- ▁SECOND
- ▁LUCKY
- ▁BROKE
- ▁CAVE
- ▁SHALL
- ▁KID
- ▁HANG
- ▁MICHAEL
- ▁DANCING
- ▁COM
- ▁MASK
- TING
- ▁KYLE
- ▁FRIDAY
- ▁MELOD
- ▁DOUGLAS
- ▁ENOUGH
- ▁LEARNED
- ▁ALICE
- ▁NEWSPAPERS
- ▁NEAR
- ▁GIRL
- ▁LAURA
- ▁BANK
- ▁ORANGE
- ▁HEART
- ▁SNACKS
- ▁BANANA
- ▁AFRAID
- ▁NOISE
- ▁AARON
- ▁SIDE
- ▁POSSIBLE
- ▁ISN
- ▁UPSET
- ▁KATHY
- ▁ENTER
- ▁STATUE
- ▁FAVOR
- ▁CAPSULE
- ▁CLUB
- ▁BORED
- ▁STREET
- ▁FAR
- ▁BROUGHT
- ▁HENRY
- ▁BRIAN
- ▁FLOOR
- ▁RECORD
- ▁SUN
- ▁BORN
- ▁GONE
- ▁ELEPHANT
- ▁FATHER
- ▁BEAT
- ▁MISTAKE
- NY
- ▁MEGAN
- ▁JIN
- ▁CARL
- ▁FACTORY
- ▁HORSE
- ▁STANLEY
- ▁WIN
- ▁AFTERNOON
- ▁LIVED
- ▁HIGH
- ▁LEAVING
- ▁MINUTES
- ▁WALL
- ▁SURPRISE
- ▁DAVID
- ▁TWENTY
- ▁BIRD
- ▁NICK
- ▁REASON
- ▁OWN
- ▁STEVE
- ▁LADY
- ▁COMES
- ▁STATION
- ▁DOLL
- ▁JADE
- ▁STAND
- ▁FAMOUS
- ▁PLAYED
- ▁TSHIRT
- ▁HUEY
- ▁SEA
- ▁SIX
- ▁REPORT
- ▁POPULAR
- ▁PICK
- ▁TONY
- ▁TINA
- ▁KIDS
- ▁WEATHER
- ▁TREES
- ▁TIFFANY
- ▁WONDERFUL
- ▁RING
- ▁SOMEWHERE
- ▁LIGHT
- ▁NOSE
- ▁AUDREY
- ▁CAMERA
- ▁GARDEN
- ▁SOCCER
- ▁PIG
- ▁FRESH
- ▁NOBODY
- ▁AMANDA
- ▁SURPRISED
- ▁STOPPED
- ▁CITY
- ▁KOREAN
- ▁HISTORY
- ▁STUDENTS
- ▁COOKING
- L
- ▁LOUD
- ▁LOSE
- ▁PINK
- ▁LIE
- ▁CRAYONS
- ▁HEALTH
- ▁HANDWRITING
- ▁JOIN
- ▁THROW
- ▁INFORMATION
- ▁DIFFICULT
- ▁SOMETIMES
- ▁BIKE
- ▁WOMAN
- ▁FLOWER
- ▁WORDS
- ▁GHOST
- ▁RICKY
- R
- ▁TEETH
- ▁SAYING
- ▁PIECE
- ▁DR
- ▁CHANGED
- ▁SIT
- ▁ARTICLE
- ▁ARM
- ▁BECOME
- ▁MONKEY
- ▁YEAH
- ▁JUDY
- ▁FOLLOW
- ▁ALSO
- ▁GAMES
- ▁BAND
- ▁COMPUTER
- ▁ANDRE
- ▁EATS
- ▁MATH
- ▁EXACTLY
- ▁ART
- ▁JUMP
- ▁FOODS
- ▁PRESENTS
- ▁RABBIT
- ▁SMELL
- ▁HEAVY
- ▁SWIM
- ▁RICHARD
- ▁GRASS
- ▁BOTHER
- ▁PANTS
- ES
- ▁ALMOST
- ▁HELPING
- ▁ZOO
- ▁SHOULDN
- ▁FAN
- ▁EGGS
- ▁ELLA
- ▁RESTAURANT
- ▁CHIPS
- ▁BIGGER
- ▁MONDAY
- ▁CATS
- ▁STUDYING
- ▁TONIGHT
- ▁BRADY
- ▁SERIOUS
- ▁FORGOT
- ▁VISIT
- ▁BUILDING
- ▁SET
- ▁HANDSOME
- ▁CLAUS
- ▁RALPH
- ▁COMPANY
- ▁SEAT
- ▁ANDREW
- ▁WITHOUT
- EN
- ▁MEAT
- ▁BOARD
- ▁CLASSES
- ▁FLY
- ▁BIT
- ▁ANGELA
- ▁POLICE
- ▁BET
- ▁FINISHED
- ▁EITHER
- ▁SKY
- ▁POLIA
- ▁EIGHT
- ▁AMAZING
- ▁INSIDE
- ▁SATURDAY
- ▁DINOSAUR
- ▁DEVERYTHING
- ▁BRUSH
- ▁VIVIEN
- ▁BREAKFAST
- ▁QUICKLY
- ▁HEAD
- ▁CAROL
- ▁EACH
- ▁BANANAS
- ▁JAZZ
- ▁OWEN
- ▁LEAVES
- ▁HELPED
- ▁WINTER
- ▁REAL
- ▁TRUTH
- ▁RIVER
- ▁ROAD
- ▁ANNA
- ▁INTERESTED
- ▁EVERYBODY
- ▁HIMSELF
- ▁TAKES
- ▁LADDER
- ▁BOTH
- ▁CLASSROOM
- ▁STUDIED
- ▁HALL
- MAS
- ▁STARTED
- ▁THO
- ▁REFUND
- ▁EARLY
- ▁MARK
- ▁TRIED
- ▁CRY
- ▁CUP
- ▁DEAL
- ▁LEGS
- ▁PARTNER
- ▁NINE
- ▁MONTH
- ▁CRYSTAL
- ▁MRS
- ▁WHOM
- ▁QUIET
- ▁TICKET
- ▁TRYING
- ▁JELLY
- ▁TEST
- ▁OFFICE
- ▁BICYCLE
- ▁HOSPITAL
- ▁POOL
- ▁DOGS
- ▁LIVES
- ▁NOISY
- ▁TASTE
- ▁FEET
- ▁PASTA
- ▁HANS
- AL
- ▁PAST
- ▁PRIZE
- ▁KEY
- ▁COUPON
- ▁TIMMY
- ▁AREN
- ▁MEMO
- ▁TEACHE
- ▁PRACTICING
- ▁ANIMAL
- ▁MOUTH
- ▁WORLD
- ▁UNDER
- ▁WATCHING
- ▁FELL
- ▁DRIVE
- ▁BEACH
- ▁CLEAR
- ▁JOKES
- ▁GAVIN
- ▁ADD
- CLOCK
- ▁HELPER
- ▁JULIE
- ▁WEIRD
- ▁SINCE
- ▁MILLER
- ▁TIE
- ▁FRUITS
- ▁HOUR
- ▁ANIMALS
- ▁TWICE
- ▁WARM
- ▁LARGE
- ▁UNTI
- ▁JAMES
- ▁DOLLARS
- ▁STORIES
- ▁MEAL
- ▁APPLES
- ▁CRYING
- ▁DIET
- ▁HEADPHONES
- ▁MEMORI
- ▁COMPLIMENT
- ▁TRIANGLE
- ▁DIARY
- ▁TOWER
- ▁EYE
- ▁SALE
- ▁BUILT
- ▁CARROT
- ▁ORDERED
- ▁ITEM
- ▁SLOW
- ▁NAOMI
- ▁TUESDAY
- ▁SENSE
- ▁PARENTS
- ▁GIV
- ▁BUSINESS
- ▁EVER
- ▁TYLER
- ▁FORWARD
- ▁CELL
- ▁SHUT
- ▁COAT
- ▁PRINCE
- ▁HATE
- ▁PUPPET
- ▁FULL
- ▁WOULDN
- ▁TERRIBLE
- ▁CARDS
- ▁MAP
- ▁STAMP
- ▁SNACK
- ▁SNOW
- ▁RUBY
- ▁SLOWLY
- ▁EDDY
- ▁EASILY
- ▁LAZY
- ▁BLOCKS
- ▁EARS
- ▁COLORS
- ▁TTEOKBOKKI
- ▁CAREFULLY
- ▁MARRIED
- ▁VILLAGE
- ▁HEADACHE
- ▁MOUNTAIN
- ▁PETER
- ▁FAT
- ▁MARRY
- WEEN
- ▁RYAN
- ▁DISHES
- ▁JIM
- ▁FIELD
- ▁CINDY
- ▁FEW
- ▁STARS
- ▁UMBRELLA
- ▁GROW
- ▁FROG
- ▁RULER
- ▁BASKETBALL
- ▁PART
- ▁ORLANDO
- ▁CORRECT
- ▁GRANDPA
- ▁ADVICE
- ▁ARMS
- SE
- ▁PHOTOS
- ▁KICKBOARD
- ▁JACOB
- ▁DANGER
- ▁BOOTS
- ▁GIANT
- ▁BATH
- ▁VISITOR
- ▁PROMISED
- ▁SNAKE
- ▁GLASS
- ▁RAISE
- ▁SPICY
- ▁TURNED
- ▁MEETING
- ▁VIOLIN
- ▁MINUTE
- ▁DAISY
- ▁BUTTON
- ▁OTHERS
- ▁DELIVERY
- ▁WASN
- ▁JOGGING
- ▁SOFA
- ▁FINGERS
- ▁NICOLE
- ▁TALLER
- ▁RUNS
- ▁BENJAMIN
- ▁GOLD
- ▁LUCAS
- ▁SNOWMAN
- ▁LOVED
- ▁SANDWICH
- ▁STRAIGHT
- ▁AGAINST
- ▁BALLOONS
- ▁KEPT
- ▁CLOSED
- ▁PENS
- ▁MAX
- ▁LEG
- ▁FILL
- ▁QUIT
- ▁ANYBODY
- ▁JEFF
- ▁ANN
- ▁EVAN
- ▁MISSED
- ▁TAEKWONDO
- ▁JOY
- ▁PUSH
- ▁WOODWARD
- ▁ROSS
- ▁LISA
- ▁PULL
- ▁NECTAR
- ▁VASE
- ▁RABBITS
- ▁BOW
- ▁BUGS
- ▁SAFE
- GETTING
- ▁CASH
- ▁LAMP
- ▁DOLLS
- ▁YUMMY
- ▁MEDICINE
- ▁SPORTS
- ▁ENDS
- ▁BASEBALL
- ▁THROUGH
- ▁CENTER
- ▁FIGHTER
- ERS
- ▁PACKAGE
- ▁WORMS
- ▁SHAPE
- ▁DISAPPOINTED
- ▁PHILLIP
- ▁DINOSAURS
- ▁SALAD
- ▁HAMBURGER
- ▁COOKIES
- ▁PASS
- ▁CHEAP
- ▁STAGE
- ▁COLORED
- ▁TYPE
- ▁EVENING
- ▁CRIED
- ▁SHOWER
- ▁WALLET
- ▁FIFTEEN
- ▁HERO
- ▁USUALLY
- ▁GATE
- ▁TEAM
- ▁PLANE
- ▁DRESSES
- ▁SOLD
- ▁CRAYON
- LE
- ▁HIDE
- ▁BODY
- ▁MEN
- ▁HAIRSTYLES
- ▁BOAT
- ▁WONDER
- ▁RAIN
- ▁FEELS
- ▁NERVOUS
- ▁CHILD
- ▁MIRROR
- ▁BUG
- ▁LONGER
- ▁LOUIS
- ▁AIR
- ▁STOMACHACHE
- ▁ASKING
- ▁OWNER
- ▁KNEW
- ▁BELT
- I
- ▁MAGAZINE
- ▁HOP
- ▁SUGAR
- ▁END
- ▁TAKING
- ▁LIGHTS
- ▁EMPTY
- ▁PUPPY
- ▁DUCK
- ▁SUPERMARKET
- ▁APARTMENT
- ▁ADDRESS
- ▁MACHINE
- ▁JASON
- ▁CARRY
- ▁DRY
- ▁EXCITING
- ▁BOTTLE
- ▁RIDING
- ▁CHARCOAL
- ▁TRAVIS
- ▁UGLY
- ▁CAUGHT
- ▁PROBAB
- ▁PROJECT
- ▁LISTENING
- ▁JUGGLE
- ▁ROPE
- ▁BILL
- ▁HOURS
- ▁MOLLY
- ▁SOPHIE
- ▁WEARS
- ▁LIFE
- ▁CAFE
- ▁HURTS
- ▁RELAX
- ▁TED
- ▁COPY
- ▁COTTON
- ▁ALONG
- ▁OFFER
- ▁DATE
- ▁LI
- ▁YOUTUBE
- ▁JOKE
- ▁BARREL
- ▁DIED
- ▁SINGS
- ▁SEVERAL
- ▁TALENT
- ▁CARTER
- ▁PASSWORD
- ▁CASE
- ▁SCISSORS
- ▁YORK
- ▁FANTASTIC
- ▁CLOUDY
- ▁ROUND
- ▁BUILD
- ▁PRINCESS
- ▁RAINY
- ▁GRAPES
- ▁SKIRT
- ▁LION
- ▁FASTER
- ▁FASHION
- ▁AD
- ▁EXPLAIN
- ▁DOCK
- ▁MATCH
- ▁BOMB
- ▁STADIUM
- ▁WOODS
- ▁FALL
- ▁MAD
- ▁TRUCK
- ▁STEP
- ▁ANSWERS
- ▁KIDDING
- ▁MOON
- ▁BEAN
- ▁PICKED
- ▁LESSON
- ▁KNOWN
- ▁HAPPENING
- ▁BLUEBERRIES
- ▁SANDWICHES
- ▁BUTTER
- ▁BEDROOM
- ▁ABOVE
- ▁LEGO
- ▁HELENA
- ▁FOOTPRINT
- ▁SHIP
- ▁TAP
- ▁HILL
- ▁CHURCH
- ▁GOODBYE
- ▁LEMON
- ▁HUNDRED
- ▁COWARD
- ▁ARRIVED
- ▁WATERMELON
- ▁BOXES
- ▁FINALLY
- ▁MAIN
- ▁KEVIN
- BINGO
- ▁BONES
- ▁SPOKE
- ▁DONUTS
- ▁HENNA
- ▁LETTERS
- ▁PAM
- ▁LESS
- ▁WEDDING
- ▁POCKET
- ▁SHY
- ▁NOWHERE
- ▁MIC
- ▁NAMES
- ▁SONGS
- MED
- ▁DECIDED
- ▁KITCHEN
- ▁SHINING
- ▁LOVELY
- ▁SEASON
- ▁STEAK
- ▁DRUM
- ▁TEDDY
- ▁SHINY
- ▁GIRLS
- ▁AUDITION
- ▁ACTING
- ▁NECK
- ▁ROSA
- ▁SNEAKERS
- ▁SHOE
- ▁QUITE
- ▁HOTEL
- ▁LEATHER
- ▁WIND
- ▁COUSIN
- ▁JANET
- ▁ONIONS
- ▁DEAD
- ▁PROUD
- ▁PET
- ▁HELPFUL
- ▁TOILET
- ▁FORTY
- ▁JAKE
- ▁BUTTERFLY
- ▁KICK
- ▁BIRDS
- ▁ABROAD
- ▁TEA
- ▁STARTS
- ▁MEALS
- ▁AIRSHIPS
- ▁SOFT
- ▁MATT
- ▁BLANKET
- ▁WINDY
- ▁PLAYS
- ▁COVER
- ▁WEIGHT
- ▁PURPLE
- ▁HIDING
- ▁TAGS
- ▁F
- ▁WHATEVER
- ▁AIRSHIP
- ▁LIVING
- ▁MAT
- ▁KINDERGARTEN
- ▁POND
- ▁LAUNDRY
- O
- ▁NOTEBOOK
- ▁HELEN
- ▁SWEATER
- ▁TEACHING
- ▁FAULT
- ▁SQUARE
- ▁HONEST
- ▁LOUDER
- CAME
- ▁3
- ▁DROP
- ▁GUY
- ▁GIRLFRIEND
- ▁RAINING
- ▁SPIDER
- ▁FLYER
- ▁WATCHED
- ▁B
- ▁LOW
- ▁COUSINS
- ▁OLDER
- DY
- ▁ROCK
- ▁MOMENT
- ▁SHEET
- ▁LAUGH
- ▁BLUEBERRY
- ▁NEIGHBORHOOD
- ▁GRADE
- ▁STICKER
- ▁OPENING
- ▁ALRIGHT
- ▁OFFICER
- ▁PI
- ▁WEDNESDAY
- ▁BITE
- ▁CONTINUE
- TIME
- ▁SAIN
- ▁COSTUME
- ▁MOVED
- ▁BOOKCASE
- ▁DENTIST
- ▁STOPS
- ▁SAM
- ▁APRIL
- ▁THIRSTY
- ▁MOOD
- ▁PEA
- ▁ENTRY
- ▁SERVICE
- ▁ABLE
- ▁FRIED
- ▁W
- ▁FLASH
- ▁KATRINA
- ▁REPAIR
- ▁TI
- ▁GIMBAP
- NDA
- ▁ANNIVERSARY
- ▁NAMED
- ▁WRITTEN
- ▁CUSTOMERS
- ▁COLLECT
- ▁BONGOS
- ▁EGG
- ▁BAT
- ▁RIBS
- ▁SAT
- ▁RETURN
- LIGHT
- BACK
- CA
- NESS
- ▁FACES
- ▁CALLING
- ▁HOLIDAY
- ▁HOLE
- ▁MILLION
- ▁DELIVER
- ▁10
- ▁TAXI
- ▁HASN
- ▁MINDS
- ▁DONALD
- ▁MISTAKES
- ▁SPRING
- ▁MENTION
- ▁NEITHER
- ▁TOWEL
- ▁BEANS
- ▁WILLIAM
- ▁BRIGHT
- ▁STOMACH
- ▁CANDIES
- ▁BURGERS
- ▁FEAR
- ▁DECIDE
- ▁FEVER
- ▁FANS
- ▁STUDIO
- ▁LIAR
- ▁BREAKING
- ▁SLEPT
- ▁TAIL
- ▁BURGER
- ▁MOVIES
- ▁SMOKE
- ▁DANIEL
- ▁WAITER
- ▁PENCILS
- ▁CROSS
- ▁KOREA
- ▁GUARD
- ▁LEARNING
- ▁SUBWAY
- ▁CARS
- ▁SKIP
- ▁MIX
- ▁JEANS
- ▁LIST
- ▁POST
- ▁TRAVEL
- ▁BORROWED
- ▁AWESOME
- ▁RECORDER
- ▁FLOUR
- ▁COW
- ▁CAMPING
- ▁DRIVING
- ▁FELT
- ▁WINNER
- ▁CHARACTER
- ▁BALLOON
- ▁RIDDLE
- W
- FUL
- ▁NECKLACE
- ▁GLOVES
- ▁CHANGING
- ▁CRACKED
- ▁DROPPED
- ▁ROBERT
- ▁BAKERY
- ▁GRILL
- ▁INVITED
- ▁LAND
- ▁PORK
- ▁TELEPHONE
- ▁SKI
- ▁GUEST
- ▁AMBER
- ▁SHARP
- ▁KITE
- ▁DELI
- ▁MART
- ANNA
- ▁CIRCLE
- ▁FLYING
- ▁SHAKE
- ▁DANCER
- ▁POLICEMAN
- ▁DESSERT
- ▁SHOCK
- ▁BLOOD
- ▁MENU
- ▁BUMP
- ▁NOVEL
- ▁SKIN
- ▁SHOULDERS
- ▁MICHELLE
- ▁CROSSED
- ▁TICKETS
- ▁DRANK
- ▁OUTFIT
- ▁LAKE
- ▁PAINTER
- ▁ALIEN
- ▁RAINBOW
- ▁WORE
- ▁BAR
- ▁BROTHERS
- ▁DISH
- ▁SIMILAR
- ▁DISPLAY
- ▁GIRAFFE
- ▁FANCY
- ▁THIEF
- ▁HALLWAY
- ▁WAVE
- ▁CARROTS
- PE
- ▁ELDER
- ▁SOMEBODY
- ▁TRAFFIC
- ▁ACTOR
- ▁RUMORS
- ▁CHOSE
- ▁CAUS
- ▁DRESSED
- ▁ROSE
- ▁LYING
- ▁PANDA
- ▁PEAR
- ▁SUGGEST
- ▁DECISION
- ▁NOISES
- ▁TAKEN
- ▁GARLIC
- ▁CHINESE
- ▁ITCHY
- ▁SWORD
- ▁WAITED
- ▁NONE
- ▁SIZE
- ▁ACCEPT
- ▁CAPTAIN
- ▁GRAY
- ▁IDOL
- ▁SMALLER
- ▁USUAL
- ▁THOUSAND
- ▁LONELY
- ▁RETURNED
- ▁JENNY
- ▁PRACTICED
- ▁NEEDED
- ▁PAIN
- ▁RAP
- ▁THIN
- ▁EVERYWHERE
- ▁SUIT
- ▁BUSH
- ▁SON
- ▁COMPLIMENTS
- ▁FAILED
- ▁RUG
- ▁PAID
- ▁MANGO
- ▁BOYFRIEND
- ▁SCARF
- ELA
- ▁CROWD
- ▁ONLINE
- ▁GREW
- ▁SOCKS
- ▁SEAGULLS
- ▁USING
- ▁MELTED
- ▁OIL
- ▁ADULTS
- ▁KATE
- ▁WHISTLING
- ▁PRAY
- ▁POOR
- ▁SAUCE
- ▁PACKED
- ▁HATS
- ▁BUYING
- ▁AGO
- ▁SCIENCE
- ▁TUNNEL
- ▁DRESSING
- ▁MISSING
- ▁FESTIVAL
- ▁THURSDAY
- ▁PAIR
- ▁SITTING
- ▁SUITCASE
- ▁SHAPES
- ▁WILLY
- ▁HUGE
- ▁SHOUTED
- EVER
- ▁FAIR
- ▁TASTES
- ▁CAFETERIA
- ▁BINGO
- ▁BEGINS
- ▁DOLLAR
- ▁GRILLING
- ▁ALIVE
- ▁DINO
- ▁LIFT
- ▁TOP
- ION
- ▁STUFF
- ▁FROZEN
- ▁ACROSS
- ▁SEOUL
- ▁FRIES
- ▁TAUGHT
- ▁VIDEO
- ▁CREDIT
- ▁HAPPENS
- ▁RACE
- ▁TOUR
- ▁SPAGHETTI
- ▁SWING
- ▁INVITATION
- ▁COUNTRYSIDE
- ▁STAIRS
- ▁HIGHER
- ▁RANGER
- BAG
- ▁PULLED
- ▁LIPSTICK
- ▁VALLEY
- ▁NAP
- ▁FUTURE
- ▁SILENT
- ▁SPEAKER
- ▁GIVEN
- ▁JUMPING
- ▁AUTUMN
- ▁HOLDING
- ▁BOB
- ▁PLANNING
- ▁SUPPOSE
- ▁CLUES
- ▁ANSWERED
- ▁STICK
- ▁WASHED
- ▁CURLY
- ▁RUINED
- ▁SMILING
- ▁UNHAPPY
- ▁KIMBAP
- ▁CAUSE
- ▁CHUNKMONS
- ▁REPEAT
- STOOD
- ▁8
- ▁SHEEP
- ▁LOUDLY
- ▁SLIDE
- ▁KING
- ▁LIME
- ▁SKATING
- ▁SERVE
- ▁SAND
- ▁POWER
- ▁MUSICIANS
- ▁RESTROOM
- ▁SOMEDAY
- ▁GYM
- ▁GOD
- ▁COOKIE
- ▁NUMBERS
- ▁WARNING
- ▁CLASSMATE
- ▁COMPLAIN
- ▁LAUGHED
- ▁BEES
- ▁SAFELY
- ▁DESIGNER
- ▁ORANGES
- B
- ▁RETURNS
- ▁SPEAKING
- ▁GINA
- ▁MARTI
- ▁FEELINGS
- MAN
- ▁TULIP
- ▁BAZAAR
- ▁EMAIL
- ▁STRAWBERRY
- ▁PRESS
- ▁SALT
- ▁PHEW
- ▁COWS
- ▁ENTRANCE
- ▁LEAF
- ▁PAN
- ▁SOUR
- ▁DISEASE
- ▁OPENED
- ▁LUGGAGE
- ▁SWIMSUIT
- ▁PASSED
- ▁ALISON
- ▁SHOVELS
- ▁SENTENCES
- ▁GROUND
- ▁STAYING
- ▁SALES
- ▁JAM
- ▁WRAP
- ▁LATELY
- ▁SHRIMP
- ▁TWELVE
- ▁CHEAPER
- ▁CHECKING
- ▁SEAWEED
- ▁LO
- ▁TURTLES
- ▁DNN
- ▁WHE
- ▁ACT
- ▁LIZARD
- ▁SUCCEED
- ▁STRING
- ▁BASKET
- ▁HINT
- ▁VEGETABLES
- ▁FOOL
- ▁SHOT
- ▁ADULT
- ▁GREG
- ▁TASTY
- ▁FARM
- ▁LIPS
- ▁STARFISH
- ▁NAILS
- C
- ▁FR
- ▁TEARS
- ▁SUPERSTAR
- ▁CLEANS
- ▁HEAT
- ▁SILLY
- ▁WIG
- ▁BELLA
- WOKE
- ▁5
- ▁BOYS
- IVA
- ▁IMAGINE
- ▁LAUGHING
- ▁WASHING
- ▁FLAT
- ▁STICKERS
- ▁PRETTIER
- ▁KILL
- ▁FLIGHT
- ▁WOMEN
- ▁MOMMY
- ▁CAMP
- ▁MEMBERS
- ▁CUSTOMER
- ▁E
- ▁SINGERS
- 'ON'
- ▁CONTROL
- ▁TIGER
- ▁ZEBRA
- ▁IMPOSSIBLE
- ▁CONSOLE
- ▁CLUE
- ▁FOLD
- ▁BEE
- ▁ANDY
- ▁SEATS
- ▁POUND
- ▁SANG
- ▁DIAMOND
- ▁BATS
- ▁ARTIST
- ▁BABIES
- ▁GARAGE
- ▁INSTEAD
- ▁OLDFASHION
- ▁GIFTS
- ▁RODE
- BIG
- ▁MOUNTAINS
- ▁THUNDER
- ▁DONKEY
- ▁PIGEON
- ROOM
- ▁WORSE
- ▁HAMBURGERS
- ▁ERASER
- ▁TAMBOURINE
- ▁BREATH
- ▁ANNOYED
- ▁HALLOWEEN
- ▁KNOCK
- ▁STUPID
- ▁BANDAGE
- ▁PINEAPPLE
- OUT
- ▁SALTY
- ▁POTATO
- ▁MILES
- ▁COMMENT
- ▁TREATED
- ▁EAR
- ▁SLEDDING
- ▁VIOLET
- ▁BOTTLES
- ▁BRILLIANT
- ▁AUNTIE
- ▁SPEND
- ▁REACH
- ▁PAYING
- ▁APOLOGIZE
- ▁CORNER
- ▁FORGIVE
- ▁RELIEF
- ▁BEHAVE
- ▁DIE
- ▁PRETTIEST
- ▁H
- ▁HEN
- ▁POUR
- ▁NEEDLE
- ▁WORRIES
- ▁LARGER
- ▁CRAZY
- TYFIVE
- ▁DISCOUNT
- ▁HEADED
- ▁TWENTYFIVE
- ▁SOMETIME
- ▁REPORTER
- ▁FEED
- ▁KIMCHI
- ▁TENNIS
- ▁DOLPHIN
- ▁SUNGLASSES
- ▁THREW
- ▁COUNTRY
- ▁HUSBAND
- ▁JAPAN
- ▁TOMATOES
- ▁OK
- ▁POET
- ▁LUKE
- ▁LEND
- ▁LOWER
- ▁SHOVEL
- ▁AMERICA
- ▁BLOSSOMS
- OH
- K
- ▁SAFETY
- TALK
- ▁ASLEEP
- ▁MINER
- ▁PERIOD
- ▁STORYBOOK
- ▁BOWLS
- ▁DOUBT
- ▁MEMORY
- ▁SKINNY
- ▁EARTHQUAKE
- ▁2
- ▁BALLS
- ▁POTATOES
- ▁TROUSERS
- ▁WAR
- ▁FUR
- ▁RUMOR
- ▁CONGRATULATIONS
- ▁EASYGOING
- ▁NURSE
- ▁FLIES
- ▁GROWING
- ▁SMILES
- ▁CHOICE
- ▁ERASE
- ▁COMFORTABLE
- ▁GUIDE
- ▁PE
- ▁CLEVER
- ▁PEACE
- ▁AFTERSCHOOL
- ▁SOAP
- ▁POPCORN
- ▁SUNBLOCK
- ▁INVITE
- ▁AWAKE
- ▁FEMALE
- ▁HIKING
- ▁FOLLOWED
- ▁BUMPER
- ▁FILLED
- ▁HIPPO
- ▁COMEDIAN
- ▁SILK
- ▁COST
- IES
- ▁AWFUL
- ▁SIBLING
- ▁PIES
- ▁BURNING
- ▁CRASH
- ZIPPED
- ▁SPACE
- ▁LYRICS
- ▁HANDMADE
- ▁PER
- ▁ROUGH
- ▁THROWING
- ▁STATIONERY
- ▁WORM
- ▁PAGE
- ▁CLASSMATES
- ▁EXAM
- ▁FINAL
- ▁BLOW
- ▁CHINA
- U
- TH
- ▁BATTER
- ▁HONEY
- ▁MISTAKEN
- ▁DEPARTMENT
- GREAT
- ▁SHIRTS
- ▁COMPETITION
- ▁YOGURT
- MBER
- ▁DRINKS
- ▁WOLF
- ▁ISLAND
- ▁GROCER
- ▁SHARON
- ▁BREATHE
- ▁ANNOYING
- ▁LIED
- ▁SPA
- ▁KANGAROOS
- ▁ALIKE
- ▁PENGUIN
- ▁BRIGHTCOLORED
- ▁4
- ▁MESSAGES
- ▁INVENTION
- ▁WIPE
- BIRD
- ▁PRECIOUS
- ▁FLEW
- ▁CH
- ▁APART
- ▁MIDNIGHT
- ▁SPEN
- ▁SHELLS
- ▁GIN
- ▁NATURAL
- ▁THIRD
- ▁BADLY
- ▁PLATES
- ▁JOSHUA
- ▁MIDDLE
- ▁SWEAT
- ▁TOES
- ▁TIP
- ▁TEASE
- ▁BOOKSHOP
- ▁COUGHING
- ▁GUN
- ▁WASTE
- UMOR
- AR
- ▁SPREAD
- ▁GOAT
- ▁SPROUTS
- ▁BALLET
- ▁SNAKES
- ▁SCRATCHED
- ▁AMONG
- DANGER
- KGO
- NISH
- ▁FEE
- ▁JANE
- ▁TEMPER
- ▁CROWDED
- ▁BONO
- ▁CHEF
- ▁SAMPLE
- ▁LIONS
- ▁RULES
- ▁DREW
- ▁WORTH
- ▁MAGICIAN
- ▁GLUE
- ▁TOUGH
- ▁TOUCHE
- ▁TUNA
- ▁BAKE
- ▁LAUGHTER
- ▁HALF
- ▁HELMET
- ▁UH
- ▁COPIES
- ▁DIFFERENCE
- ▁FORK
- ▁STARTING
- ▁CRIES
- ▁SPROUT
- SNOW
- ▁SCARE
- ▁DRUMS
- ▁PHANTOPIA
- ▁VOUCHER
- ▁FARMER
- ▁CHANGES
- ▁SPILL
- AN
- ▁COMPLETELY
- ▁PRACTICES
- CHAIR
- ▁MISSE
- ▁RACHEL
- ▁SEEK
- EST
- ▁SISTERS
- ▁BLAME
- ▁PACK
- ▁BOIL
- ▁REQUEST
- ▁SH
- ▁WIRE
- ▁POT
- ▁ONION
- ▁CLOSER
- ▁MICE
- ▁SCRATCH
- ▁DUCKS
- THANK
- ▁RECEIVE
- ▁CABBAGE
- ▁SEEDS
- ▁JEJU
- ▁SUDDENLY
- RAY
- ▁KIWI
- ▁POWDER
- ERRY
- ▁MESSY
- ▁RID
- ▁CHAMPION
- ▁ARGUE
- ▁RECIPE
- ▁MICROPHONE
- ▁SCOLDED
- TRY
- ▁STRONGER
- ▁EXPECT
- ▁WEEKS
- AKER
- ▁JUMPED
- ▁RAINS
- ▁OREPHIA
- ▁PIGS
- LOSING
- ▁PRAYING
- ▁DUE
- ▁SOUTH
- ▁PUNCH
- ▁CREATIVE
- ▁FINISHING
- ▁HARMONI
- ▁CLOWN
- ▁SALON
- ▁SINK
- H
- ▁TOOL
- ▁ALARM
- VISION
- GY
- ▁FAIL
- ▁DRAWER
- ▁HAIRBAND
- ▁X
- ▁ARTICLES
- ▁DEEP
- ▁EARLIER
- ▁EXTRA
- ▁DOWNTOWN
- ▁LEFTHAND
- PTER
- ▁NOODLES
- ▁CONSIDER
- ▁ACCOUNT
- ▁DEER
- ▁SEAN
- RABBITS
- TY
- ▁CREAMS
- ▁LUCY
- ▁BOUN
- ▁HORNS
- EMENT
- ▁NOON
- ▁SMILED
- ▁NINETEEN
- ▁TURNS
- ▁MUFFLER
- ▁ROAR
- ▁HARDLY
- ▁SPELLED
- ▁SPOTS
- ▁SHORTS
- ▁JUMPS
- ▁RECENTLY
- ▁STOLEN
- ▁WITHIN
- ▁ENGLAND
- ▁PENDANT
- ▁MARY
- ▁AMUS
- ▁SERIOUSLY
- ▁FALLS
- ▁SPOONS
- ▁SAVED
- ▁STOLE
- ▁STUCK
- ▁G
- ▁DUMPLINGS
- ▁GERMAN
- ▁PLACES
- ▁OCARINA
- ▁QUEENSTEIN
- ▁BRANDON
- ▁DWARFS
- ▁TOFU
- ▁SPRAY
- PARD
- ▁CROSSING
- ▁PIGEONS
- ▁NOTICE
- CE
- LTY
- ▁BASEMENT
- ▁TABLET
- ▁COUPONS
- ▁PROGRAM
- ▁SOCK
- ▁GUI
- ▁NUT
- ▁OLIVE
- ▁PREFER
- ▁MUSHROOM
- ▁FIGHTING
- ▁DENERGY
- ▁STORAGE
- ▁POLITE
- IST
- ▁KICKBOARDS
- GAGE
- ▁DROWN
- ▁MANAGE
- ▁DRIVER
- P
- ▁WEEKENDS
- ▁SHOULDER
- ▁MUD
- ▁SEVENTY
- ALLY
- ▁POSTCARD
- ▁PIECES
- ▁HICCUPS
- ▁CHARACTERS
- ▁CLEANING
- ▁DIS
- ▁JG
- ▁JOSEPH
- ▁TITLE
- ▁CDS
- ▁BOSTON
- ▁BRACELET
- ▁PERMISSION
- ▁STEW
- ▁RAT
- ▁SKATE
- ▁CHEST
- ▁FOOT
- ▁CLIMB
- ▁AUDIENCE
- ▁DUFAR
- ▁GRANDPARENTS
- ▁FIT
- ▁TOUCHING
- ▁ELEPHANTS
- ▁TSHIRTS
- ▁APPOINTMENT
- ▁FOREVER
- ▁STARVING
- ▁LESSONS
- ▁COUPLE
- ▁TOTO
- ▁DRINKING
- ▁ARRIVE
- ▁GREE
- ▁SPOT
- ▁HELD
- ▁EARTH
- ▁DAUGHTER
- ▁SLICE
- ▁CASTLE
- ▁FEEDING
- ▁COVERED
- ▁FAM
- ▁AGE
- ▁AUSTIN
- ▁DEAR
- ▁NATI
- ▁CELEBRATE
- ▁MEATBALLS
- ▁STRETCH
- ▁SOLVE
- ▁USEFUL
- ▁SCAR
- DDING
- ▁ALLERG
- ▁RINGING
- ▁SAILING
- ▁SNOWING
- ▁LATEST
- ▁LIES
- ▁ACADEMIES
- ▁MUSICIAN
- ▁STA
- ▁FROGS
- ▁STOMP
- ▁KEYBOARD
- ▁FAIRY
- ▁CLAP
- ▁HAM
- ▁TOWARDS
- ▁RESERVATIONS
- ▁SHOUT
- SORRY
- ▁PUPPIES
- ▁WEAK
- ▁ORIGINAL
- ▁RESPECT
- ▁TABLES
- ▁COMPUTERS
- ▁TOWELS
- ▁CRAFTSMEN
- ▁ELE
- ▁REPAIRED
- ▁PRINT
- ▁BLOOM
- ▁WISELY
- ▁SCOLD
- ▁TWINKL
- ▁CANCEL
- ▁KIM
- ▁STAINED
- ▁LAP
- ▁DRI
- ▁SHARK
- ▁KANGAROO
- MENTARY
- THEY
- ▁DALLAS
- ▁SEESAW
- ▁WHISPER
- CAL
- ▁DWARF
- ▁SUNDAYS
- ALK
- ▁DOUBLE
- ▁SHAKING
- ▁PREPAR
- ▁YOYO
- ▁SKILLS
- ▁OCTOPUS
- ▁INSTRUMENTS
- ▁MAIL
- ▁ALIENS
- ▁JESSI
- ▁CHERRY
- ▁INCONVENIENCE
- ▁CERTAIN
- ▁BEEF
- CON
- 'OFF'
- ▁GATHERED
- ▁PRODUCTS
- CONVENIENCE
- ▁RESTAURANTS
- ▁MONKEYS
- ▁FIGURE
- ▁QUICK
- ▁GAIN
- ▁PENALTY
- ▁INLINE
- ▁INTRODUCE
- ▁OVERSLEPT
- ▁POL
- ▁HOWEVER
- ▁GORILLA
- ▁MEMBER
- ▁PLU
- ▁ANGER
- ▁AQUARIUM
- ▁GAS
- ELY
- ▁TIES
- ▁PUNISHED
- ▁CUCUMBERS
- ▁TINY
- ▁RISE
- ▁GHOSTS
- ▁WIFE
- MOND
- ▁RARE
- ▁BARN
- ▁SMELLY
- GAN
- ▁REASONS
- ▁BURNED
- ▁ANNOUNCE
- ▁CAPSULES
- ▁PICNIC
- ▁GLOVE
- FF
- RANCE
- ▁TREAT
- ▁JOG
- ▁BULLS
- ▁JJAKGUNG
- ▁PROVE
- ▁BAGS
- ▁RUDOLPH
- ▁MC
- ▁TRICKS
- RIOR
- ”
- ▁HAPPILY
- ▁REMIND
- ▁DIVER
- BE
- ▁HATES
- ▁SPOON
- ▁SIZES
- ▁THROAT
- ▁UN
- CRAFTS
- ▁BRIDGE
- ▁CONFUSED
- DONALD
- KEEPER
- ▁SIBLINGS
- ▁DENNIS
- ▁EMBARRASSED
- ▁PATRICK
- DWARFS
- ▁PREGNANT
- ▁VOTE
- ▁WHIPPED
- ▁10000
- ▁SUPPORT
- ▁TOOTH
- ▁STANDING
- ▁CLOSET
- ▁NEEDLES
- ▁SWEEP
- ▁RAISED
- ▁PEE
- ▁CONTACT
- ▁JEALOUS
- ▁SURVEY
- BOX
- ▁CROSSWALK
- ▁WALKING
- ▁SOP
- ▁SITE
- ▁OWE
- ▁FOURTEEN
- ▁PLANTING
- ▁CHANNELS
- ▁WIGGL
- ▁OURSELVES
- ▁SCENE
- ▁BAS
- ▁LETTUCE
- ▁NICKNAME
- ▁GRABB
- ▁ELEVATOR
- ▁COP
- ▁FALLING
- ▁DESERVE
- ▁FILM
- ▁SOPHOMORE
- ▁WOUND
- ▁PROTEST
- ▁PEACHES
- ▁CHILL
- ▁COURT
- ▁ROOF
- ▁CHARGE
- ▁FINGER
- ▁HANBOK
- ▁TAPDANCE
- ▁JAPANESE
- ▁MELON
- ▁BATTLE
- ▁LEAS
- ▁PARTS
- BATHING
- ▁CRUNCHY
- ▁PAUL
- ▁WHISTLE
- ▁CAKES
- ▁HEAL
- ▁SHELL
- ▁GUM
- ▁CARPENTER
- ▁HEAVILY
- ▁N
- ▁LEMONS
- ▁HARDER
- ▁ROW
- ▁STEAM
- ▁STUDIES
- ▁LOTTERY
- ▁BITTER
- ▁MOW
- ▁EATEN
- ▁SPORT
- ▁SHORTER
- ▁STEAL
- ▁GRADUATE
- ▁PUZZLE
- ▁CEREMONY
- ▁RAINCOAT
- ▁KISS
- HAP
- WAY
- ▁DEPART
- ▁LANGUAGE
- ▁BITTEN
- ▁BUSAN
- ▁L
- ▁TIGHT
- ▁BELOW
- ▁PERFECTLY
- KE
- ▁NATURE
- ▁MISUNDERST
- ▁CLOUD
- ▁DRAG
- ▁CARTOON
- ▁COCONUT
- ▁GOLF
- ▁THIRTEEN
- ▁DYING
- ▁PETE
- ▁MALL
- ▁BIN
- ICAL
- ▁ALIB
- ▁BREEZE
- ▁FRENCH
- ▁DATING
- ROW
- ▁WATERING
- ARD
- ▁DESERT
- ▁PRAISE
- ▁INTERNET
- ▁STRICT
- ▁MOSQUITOES
- TLE
- ▁SKILL
- ▁BEHAV
- ▁KTX
- ▁LONDON
- ▁TASTING
- ▁VAN
- ▁COUGHED
- ▁NICELY
- ▁HARM
- ▁BOOKSHELF
- ▁CRICKET
- ▁EDGE
- ▁PILLOW
- ▁RECTANGLE
- ▁STRESS
- ▁FOOTBALL
- ▁LAW
- ▁CHOPSTICKS
- WHAT
- ▁TWINS
- ▁AUSTRALIA
- ▁LAMB
- ▁MAYO
- ▁DESIGN
- ▁BLEW
- ▁GLORY
- ▁ROCKCLIMBING
- ▁DUTY
- ▁ENTERTAINMENT
- ▁THEMSELVES
- ▁YOG
- ▁BUCKET
- ▁BIRTH
- ▁FALSE
- ▁PATTERN
- ▁THREAD
- ▁SOLDIER
- ▁BATTERY
- ▁KNEES
- ▁HEADS
- ▁DELIVERED
- ROUTE
- ▁SIMPLE
- ▁WATERFALL
- ▁SWITCH
- ▁EFFORT
- ▁UNUSUAL
- ▁SLIPPED
- ▁REG
- ▁SUITS
- ▁CHANNEL
- ▁MINI
- ▁PLASTIC
- ▁RECOMMEND
- ▁RUBBER
- ▁THANKFUL
- ▁ROLL
- ▁SOLV
- ▁CLAPS
- ▁BUD
- ▁CINEMA
- ▁SHELF
- ▁LOSS
- ▁WOMANS
- ▁CANADA
- ▁EXPRESS
- ▁SHARING
- ▁LOOSEN
- ▁CHOCO
- ▁RUNNY
- ▁REPL
- ▁BOWL
- ▁FULLY
- ▁SOMEHOW
- ▁UNIQUE
- ▁CARES
- ▁NOODLE
- ▁JETLAG
- ▁LAPTOP
- ▁TOOTHPASTE
- ▁JON
- ▁AIRPORT
- ▁JOO
- YER
- ▁CAP
- ▁HOLLY
- ▁JOHNSON
- ▁ZERO
- ▁LEADER
- ▁OX
- ▁SQUEEZE
- PY
- GET
- ▁FIN
- ▁ZIP
- ▁SEPTEMBER
- ▁TEMPERATURE
- THIRTY
- ▁GOODLOOKING
- ▁GUAR
- ANTEE
- ▁LOG
- ▁WILD
- ▁BOOTH
- ▁PEPPERS
- ▁FORGOTTEN
- BALL
- ▁AB
- CALORIE
- ▁POLICY
- ICO
- ▁INCLUDED
- ▁LIGHTEN
- ▁BLAMED
- ▁LONGTIME
- OOD
- ▁JEAN
- ▁DECK
- ▁MANNER
- ALTH
- ▁PERSONALLY
- TRUCK
- PT
- ▁GUT
- ▁CRASHED
- ▁FLO
- ▁REACT
- ▁ABSENT
- KYO
- ▁BLUSH
- ▁DONATE
- DOCK
- ▁COMPLAINING
- ▁DESCRI
- ▁GEORG
- ▁RECOVER
- ▁WALNUT
- ▁LUNG
- ▁BUDDY
- ENSE
- ▁PASSES
- ▁PLUM
- HALF
- ▁SE
- ▁TURTLE
- ▁FRANC
- ▁KOALA
- ▁TURKEY
- ▁CARPET
- ▁ANYWHERE
- ▁R
- ▁SKIING
- ▁FOCUS
- ▁HARV
- ▁JANUARY
- ▁PRESIDENT
- ▁TWENTYONE
- ▁WRESTLE
- ▁CANCER
- ▁CHEATING
- ▁HOMEMADE
- ▁WEEKDAY
- ▁K
- THER
- ▁DREAMS
- ▁APPRECIATE
- ▁BRAIN
- ▁SAUSAGES
- SOMETHING
- GAR
- ▁SMOOTH
- ▁SLIM
- ▁FENCE
- JURY
- LIES
- ▁SPIDERS
- EADLINE
- EVEREST
- ▁SCORES
- ▁JOKING
- ▁REJECT
- ▁STEPMOTHER
- ▁CRIM
- ▁DIGGING
- ▁QUEEN
- ▁MALE
- ▁SNORES
- ▁EXPLAINED
- ▁HOUSEWORK
- ▁BEDTIME
- BEAT
- WORKING
- ▁SMELLING
- ▁GRAPE
- ▁INSTRUCTIONS
- ▁SUNSCREEN
- ▁WORKDAY
- ▁HOLES
- ATER
- UP
- RIDA
- ▁VINE
- ▁HERSELF
- ▁NIGHTMARE
- ▁SNAP
- ▁INSU
- ▁BURNS
- GIV
- ▁MOUNT
- ▁NEGATIVE
- ▁ADVANTAGE
- ▁DIFFICULTIES
- ▁7
- ▁REMAINS
- CHECK
- ▁TRAVELING
- ▁IMAGIN
- G
- ▁BENNY
- ▁JOHN
- ▁ATHLET
- ▁COOPE
- ▁DICTIONARY
- ▁HAPPINESS
- ▁RAPPER
- ▁SLIPPERY
- ▁SUNRISE
- ▁TAPDANCING
- ORABLE
- ▁NOTICING
- ▁WAITLIST
- ▁CUCUMBER
- FTH
- ▁GUESTS
- ▁COLLEGE
- ▁STOCK
- HH
- ▁TALE
- POP
- ▁MEXIC
- ▁FREEZER
- ▁REFUSE
- ▁SWIMMER
- ▁THOUGHTFUL
- DIVING
- WORKED
- ▁COURAGE
- ▁ERRANDS
- ▁LISTENED
- ▁GRUM
- ▁WEB
- ▁TWEL
- GED
- ▁CABIN
- ▁REHEARSAL
- ▁SKETCHBOOK
- ▁DAYCARE
- ▁PARTIES
- OBBY
- ▁SEAL
- WHERE
- ▁ROSES
- INE
- ▁ACCIDENT
- ▁PERSONALITY
- ▁SPECIFIC
- ▁RINGS
- ▁BLOOMED
- ▁AW
- YARD
- ▁ENTERED
- ▁BELLY
- ▁FUNNIER
- ▁NARROWMINDED
- USY
- ▁JOURNAL
- ▁JER
- ▁PRICES
- BREAK
- ▁BILLS
- SOLUT
- ▁11
- ▁REFILL
- ▁BAKED
- ▁ALPHABET
- CONNECTED
- ▁GOATS
- ▁WASHE
- ▁CHOP
- PHLE
- ▁NONSENSE
- ▁WADDL
- ▁PETS
- ▁DECORATE
- LUSH
- ▁FORGETTING
- ▁EMILY
- ▁BICYCLES
- ▁SHOWN
- ▁BUCK
- ▁BAIT
- ▁100
- ▁MOVER
- ▁HEL
- ▁WINNING
- ▁ROCKET
- ▁FANG
- ▁CA
- ▁DEPRESS
- ▁BEAUTY
- ▁DAILY
- ▁ENGINEER
- ▁MUFFIN
- ▁WRITER
- ▁OPINIONS
- ▁TRACKS
- ▁PAUSE
- ▁PUZZLED
- URE
- SEY
- ▁WRAPS
- ▁SOCIAL
- ▁GRADES
- ▁WARMLY
- ▁YOYOS
- ▁CHEW
- ▁BULGOGI
- ▁BARKING
- ▁SENTENCE
- ▁THOUGH
- ▁POO
- ALIAN
- ▁EVE
- ICED
- ▁RAIS
- ▁DISTURB
- ▁ITSELF
- ▁ORIGAMI
- ▁TISSUE
- ▁JOHNNY
- ▁BURN
- ▁COOKS
- ▁CANDLE
- ▁OBVIOUS
- ▁SANDPAPER
- ▁SUPPLIES
- ▁CHEWY
- ATIONS
- ▁FLAVOR
- ▁KIWIS
- ▁MASTER
- ▁YELLING
- ▁CUPS
- ▁BL
- LAINE
- ▁STIMULAT
- ▁TIRES
- ▁PRETEND
- ▁CLEANED
- ▁RUSSIA
- ▁FRECKLES
- ▁FART
- ▁CHEETAH
- ▁RUDE
- ▁TRAINS
- ▁LOTTE
- ▁PAGES
- ▁POSTCARDS
- ▁KEYS
- ME
- ▁BOOKSTORE
- ▁HOST
- ▁SHORTCUT
- ▁SHOOTS
- ▁OPINION
- ▁APRON
- ▁COPIED
- LLOWED
- ▁STICKY
- ▁PREPARE
- ▁HEADQUARTERS
- ▁REPAIRS
- ▁WHALE
- ▁POOP
- ▁RESEMBLE
- ▁SHARE
- ▁LOLL
- ▁EXERCISES
- ▁PROGRAMS
- ▁BLINK
- ▁FLAG
- ▁LAY
- ▁FASTEST
- ▁SNEEZE
- ▁ENDED
- J
- ▁MARKER
- HER
- ▁ASSISTANT
- ▁CURRY
- ▁PURSE
- ▁SLIPPERS
- ▁UNDERSTANDING
- ▁PIT
- ▁INDOOR
- ▁CROWN
- ▁CURIOUS
- ▁SYSTEM
- ▁CABLE
- ▁MOSQUITO
- ▁PHARMACY
- ▁EVERLAND
- ▁WINDOWS
- ▁BOOGER
- ▁TIRING
- ▁PAPERS
- ▁PEANUT
- ▁PARDON
- ▁AH
- ▁FOX
- ▁RESELL
- ▁RESULT
- ▁TWIST
- ▁SLED
- ▁TALLEST
- ▁RIBBONS
- ▁RECEI
- ▁SQUIRREL
- ▁CUTLET
- ▁HEIGHT
- ▁HURTING
- ▁TRAP
- ▁WRAPPER
- ITED
- ▁FRIGHTENED
- ▁PATIENT
- ▁CANCELED
- ▁SHELVE
- ▁NET
- OOPS
- ▁MESS
- ▁MERRY
- ▁PLATE
- ▁COMPLAINT
- ▁SITUATION
- ▁PARIS
- ▁STRAW
- ▁DIVIDE
- ▁GOAL
- ▁SHRIMPS
- X
- SPECIAL
- GOTTEN
- F
- ▁COLLECTED
- ▁AFFORD
- ▁HUNG
- ▁CHAMBER
- ▁AIRPLANE
- ▁CHA
- ▁WALLS
- ▁REGULAR
- ▁EXPERIENCE
- ▁PILOT
- ▁250
- ▁LEMONADE
- ▁FURTHER
- ▁RAC
- IN
- ▁SWALLOW
- ▁CLOSING
- ▁CLASSROOMS
- ACK
- ▁RENT
- ▁ADS
- ▁TENTH
- ▁FRY
- ▁HOTDOG
- ▁ANGEL
- ▁PEACH
- ▁HIDDEN
- ▁GOOSE
- ▁SMALLEST
- ▁ROCKS
- ▁COOKED
- ▁CORN
- ▁SIGNS
- ▁ANXIOUS
- ▁LIGHTNING
- ▁SNOWBALL
- ▁BESIDE
- ▁ANTS
- ▁ALLOWANCE
- ▁COUNTRIES
- ▁POUCH
- ▁SLIP
- ▁POEM
- ▁RAMEN
- ▁ROLLING
- ▁PATIENTS
- ▁SCREEN
- ▁PRESENTATION
- ▁CAST
- ▁FLUTE
- ▁HU
- ▁ZEBRAS
- ▁COMPARE
- ▁WIDE
- ▁FORSYTHIA
- ▁SENIOR
- ▁DONATED
- ▁FACTS
- RD
- ▁FOG
- ▁ROLE
- ▁PEARS
- ▁BUTTONS
- COME
- ▁HAIRCUT
- ONDE
- ▁ENV
- ▁CHASED
- THE
- '4'
- ▁TRACK
- ▁STRANGER
- ASOL
- ▁CHIN
- ▁PUBLI
- ▁DUN
- ▁JUNE
- ▁20
- ▁DOUGHNUT
- ▁DADDY
- PORT
- ▁EMBARRASSING
- ▁UNCOMFORTABLE
- ▁FOREHEAD
- ▁RELATIVES
- ▁DOODLE
- ▁GENTLEMAN
- ▁TAPE
- ▁BANKER
- ▁ACTRESS
- ▁SORT
- ▁REDESIGN
- ▁GRADERS
- ▁KICKING
- ▁LA
- UK
- ▁BARBECUING
- ▁BULLY
- RATE
- ▁JUN
- ▁KOREANS
- ▁CORPORATION
- ▁HEAVIE
- ▁IMPROVE
- ▁OCEAN
- ▁LG
- ▁LAYER
- ▁BRIGHTLY
- ▁CRABS
- ▁PAR
- ▁BLANK
- ▁CALENDAR
- ▁CROCODILE
- ▁SALARY
- ▁CHUSEOK
- ▁CUTEST
- ▁NOR
- ▁MYSTER
- ▁BEND
- ▁INCLUDE
- ▁EXCELLENT
- ▁PAINFUL
- ▁SKEWERS
- ▁CHEERING
- SIZE
- BELT
- RCH
- ▁PLEASANT
- ▁PATH
- ▁QUALITY
- ▁STINGS
- ▁REPAIRING
- ▁DELAY
- ▁RIDES
- ▁ELSA
- ▁SECURITY
- ▁TWENTIETH
- ▁PC
- AH
- ▁NOTES
- RAL
- ▁NORMAL
- ▁DIRECT
- ▁CENT
- ▁APOLOGY
- ▁GARBAGE
- ▁GEE
- ▁WATCHES
- ▁SCISSOR
- ▁CULT
- ▁ECONOMY
- ▁SEASHELL
- ▁HA
- ▁HORSES
- ▁WHEELS
- BYE
- ▁HABIT
- ▁VI
- OOKIE
- ▁BAKING
- ▁CHERISH
- ▁JESUS
- ▁KLEA
- ▁PARTICIPATE
- ▁NICER
- ▁LISTING
- ▁SUPP
- IELD
- ▁CRISPY
- ▁EYESIGHT
- ▁TWITCH
- ▁WORST
- ▁GREETING
- ▁DRYER
- ▁LINES
- ▁DEPRESSED
- RENT
- ▁ROLLS
- LAND
- ▁DOCUMENT
- ▁COCKROACH
- ▁TAX
- ▁LIBER
- ▁FRIGHT
- ▁GARDENVIEW
- ▁JAR
- ▁ONESELF
- ▁PELICAN
- ▁RUSH
- ▁BAKER
- ▁EXPLODED
- ▁CARNATIONS
- ▁BUBBLES
- ▁BREAKS
- ▁EUROPE
- ▁EXCHANGE
- ▁SMASH
- ▁TORONTO
- ▁CEO
- ▁BLEEDING
- ▁IMAGINED
- ▁KIL
- ▁POU
- ▁TAB
- ▁CRUS
- OGRAMS
- ▁ALASKA
- ▁FROWNED
- MAIL
- TWINKL
- ▁SINGLE
- ▁INVENT
- ▁ROD
- ▁EMERGENCY
- PORTER
- ▁COMB
- ▁HUG
- TI
- '...'
- SMITH
- ▁AVOID
- ▁JJAKKUNG
- ▁MATERIALS
- ▁LOSES
- ▁LU
- INA
- FREE
- ▁SERV
- ▁FLU
- ▁REEL
- ▁BACKPACK
- ▁REPRINT
- ▁SIXTEEN
- ▁ZENA
- ROL
- ▁AWARD
- ▁TENK
- ▁NETWORK
- ▁WORKER
- ▁REDUCE
- GUE
- ▁PROTECT
- ▁CONCERN
- ▁CRIMINAL
- ▁FIREFIGHTER
- ▁INCHEON
- ▁SUWON
- ▁VIEWER
- OVER
- ▁ELEVATORS
- OR
- ▁IMPRESSED
- ▁SHAME
- ▁STRAP
- ▁YIELD
- ▁WARNED
- ▁HANDOUT
- ▁LUNCHTIME
- URY
- IED
- AY
- WIFE
- GUN
- ▁ISSUE
- RRIE
- ▁SANDCASTLE
- ▁FIGURES
- ▁LOV
- ▁POKE
- ▁FREESTYLE
- ▁CHAIN
- ▁EVERYDAY
- OK
- ALY
- ▁RATING
- ▁SPIT
- ▁SAIL
- ▁AMBULANCE
- ▁ENORMOUS
- ▁SELFCONT
- ▁MEMORIZED
- ▁GIRAFFES
- ▁SNOWS
- ▁PLANTS
- ▁LEAD
- ▁EXHIBITION
- ▁FOUGHT
- ▁MARBLE
- 'YES'
- ▁PICKE
- ▁WRONGLY
- ▁HURR
- ▁CONVERSATION
- ▁DETAIL
- ▁WORRYING
- ▁SAVING
- ▁TU
- ▁SECRETLY
- AWAY
- ▁GROWS
- ▁CONTRA
- ▁SCRAMBLE
- BES
- ▁PROMISES
- ▁CHAIRS
- ▁GOGGLES
- ▁OTHERWISE
- ▁VICTOR
- ▁THORNS
- ▁WORTHWHILE
- ▁HIPPOS
- ▁TRICK
- ▁OBSERVATORY
- ▁SHAMPOO
- ▁COKE
- ▁DRAMA
- ▁DELAYED
- ▁GUTS
- ▁AZALEA
- ▁WRAPP
- TIE
- HEAD
- ▁BIGGEST
- ▁ENEMIES
- ▁PUMPKIN
- ▁DOCUMENTARY
- ▁ATOPY
- ▁COUGH
- ▁TOUCHED
- ▁AWARDS
- EWER
- VER
- ▁BEARS
- ▁CACTUS
- ▁LOCK
- ▁LIT
- ▁SKETCH
- ZEN
- ▁DRAGG
- ▁SQUEEZED
- ▁SCOT
- SHY
- ▁CALCULAT
- ▁APPEARED
- ▁RAINED
- ▁WINGS
- ▁CLOTH
- ▁DIG
- ▁DONGSENG
- ▁SPONGE
- ▁STUBBORN
- ▁WAIST
- ▁FLE
- ▁TAG
- CH
- ▁CR
- ▁UMBRELLAS
- ▁TOOTHBRUSH
- ▁POCKETS
- ▁PAJAMA
- ▁HALLA
- ▁GATHER
- ▁BOSS
- ▁DETERGENT
- ▁DOCUMENTS
- ▁GENEROUS
- ▁TOTAL
- ▁CURTAIN
- ▁PUDD
- ▁THICK
- NSIBLE
- ▁HOLIDAYS
- ▁TICKLES
- FLAVORED
- ▁COVID
- ▁GIFTWRAP
- ▁BLINKING
- ▁JUNG
- HOK
- LEANING
- ▁IDOLS
- ▁DRO
- ▁FOUNTAIN
- ▁PHYSIC
- ▁PRESCRIPTION
- ▁LATTE
- ▁TONGUE
- ▁NA
- WORLD
- ▁SURGERY
- ADLINE
- ▁STUFFY
- ▁WAFFLES
- ▁15
- ▁LOGO
- ▁SHORTCUTS
- ▁RESPECTED
- ▁INVENTIONS
- ▁ARTISTS
- RAFFI
- ▁FOSSIL
- ▁GOLDCREST
- ▁MALTESE
- UGGING
- ▁BUCKWHEAT
- ▁PROFESS
- ▁SQUID
- ▁CORRECTION
- IT
- LOOKING
- ▁GENIUS
- ▁WHALES
- ▁OPPA
- ▁DONKEYS
- ▁ELECTRIC
- ▁FAKE
- ▁JUNIOR
- ▁MEDAL
- ▁SONGPYEON
- ▁MO
- ▁LOCKED
- ▁MEMORIZE
- ▁DIZZY
- ▁CAMELS
- ▁Y
- ▁CARING
- ▁PERFORMANCE
- ▁ERRAND
- ▁STRIPE
- ▁SIL
- ▁REDESIGNED
- ▁TIPS
- SCRIPT
- ▁BISCUIT
- ▁TORN
- ▁BRUSHE
- ▁STREETS
- ▁RELIEVED
- ▁HOPS
- ESSER
- ▁INSTRUMENT
- ▁ADVANCE
- ▁GESTURE
- ▁MUGWORT
- ▁PROMOT
- ▁PIN
- ▁SHAD
- IONAL
- '72'
- ▁HEAVEN
- ▁SLOPE
- ▁HAIRDR
- YOU
- ▁OWNERS
- ▁PLANS
- ▁SUNFLOWERS
- ▁CHIMNEY
- ▁HIPHOP
- ▁FOURTH
- ▁C
- ▁COUNTS
- ▁BARK
- SCOPE
- ▁ATOPIC
- ▁DEATH
- ▁FORMALLY
- ▁TWIN
- ▁QUIETLY
- ▁TEAS
- ▁MIN
- ▁CE
- ▁DEPENDS
- ▁TRANSFERRED
- ▁HANDY
- ▁CLEARLY
- CHOCO
- ▁HOTDOGS
- ▁FROWN
- ▁RUB
- ▁PERFORM
- ▁ATTRACT
- ▁DUST
- ▁REVIEW
- ▁SIGNBOARD
- ▁ENDURE
- ▁RIDD
- CKED
- ▁CIRCLES
- ▁AIRPLANES
- ▁MI
- GING
- Q
- ▁YURI
- ▁30
- ▁OFFICERS
- ▁ALMONDS
- ▁SOLVED
- ▁WEREN
- ▁ALBUM
- ▁UNDERGROUND
- ▁WRINKLES
- IL
- ▁TALES
- SOKCHO
- ▁GROCERIES
- ▁RECEIV
- ▁BARE
- ▁PEEL
- ▁COCKROACHES
- ▁DEEPLY
- ▁STATIONS
- ▁DANCED
- ▁CHUBBY
- ▁SATURDAYS
- ▁WING
- ▁CRAFTSMAN
- ▁OCCASION
- ▁WINE
- ▁TELE
- ▁BLUETOOTH
- ▁DISAPPEARED
- ▁SUBM
- ▁FARTED
- ▁PREPARED
- LIST
- ▁CONDITION
- ▁PORTRAIT
- '23'
- ▁POINTS
- ▁TAMBOURINES
- ▁TEND
- ▁SELFISH
- ▁SUBJECT
- RUPTE
- ▁LICKING
- ▁WATERMELONS
- ▁DIES
- ▁BLOWING
- ▁SOIL
- NIFE
- ▁BLAND
- ▁RECYCLED
- ▁SIXTY
- ▁LENGTH
- ILING
- ▁SURVIVED
- ▁HABITS
- WANT
- ▁GRAND
- ▁SAVORY
- ▁APPLAUSE
- ▁APPLY
- ▁MEANER
- ▁DISEASES
- ▁FRUSTRATING
- ▁NOTIFICATION
- ▁CHEOMSEONGDAE
- ▁BADGE
- ▁ABOARD
- ▁DISNEYLAND
- ▁LEE
- ▁SHARPEN
- ▁KETTLES
- ▁HERESY
- ▁CRAM
- ▁BRONZE
- ▁HARSH
- ▁EBS
- ▁GREY
- ▁POSE
- ▁PICKLES
- ▁LEN
- ▁TIGERS
- ARY
- ▁CLAR
- ▁EDUCATION
- ▁NEIGH
- ▁ADDITION
- ▁REASONABLE
- ▁DUMPING
- ▁SPACES
- ▁LIGHTER
- ▁SPELLING
- Z
- ▁CATCHING
- ▁LEVEL
- ▁UPSTAIRS
- ▁RINK
- ▁HANDLE
- AVING
- ▁BOWED
- ▁BEAUTIFULLY
- ▁FARTS
- ▁BOLT
- ▁FAMILIAR
- BBLE
- DO
- ▁FILE
- ▁TREATMENT
- ▁PASTOR
- ▁EEK
- ▁BLOOMING
- CIAL
- TRAINED
- ▁APPEAR
- ▁KNEE
- ▁WHEEL
- RIAN
- ▁ATTEND
- ▁CONFESS
- ▁DVD
- ▁WITNESS
- ▁BATMAN
- ID
- ▁BANGS
- ▁YARD
- ▁LOTION
- ▁RECYCLE
- ▁PRI
- ▁BURDEN
- ▁SCRA
- ▁VEGETA
- ▁TOENAILS
- SUALLY
- ▁YAM
- FORD
- ▁FORMAL
- ▁POK
- ▁FROZE
- ▁MULTIPLICATION
- ▁SEJONG
- ▁TRIES
- ▁SUNSHINE
- ▁HERBS
- ▁STRIPES
- ▁CLIMBING
- ▁SKIPP
- FFE
- ▁DAMAGE
- ▁RIDICULOUS
- ▁QUACK
- ▁PINNOCHIO
- SIDE
- ▁STANDARD
- ▁TRADITION
- GIANT
- ▁YELL
- ▁SUPER
- ▁OVERREACT
- ▁PERFUME
- ▁UNDERCOOK
- BEC
- ▁MAPS
- ▁PARTNERS
- ▁SPINACH
- ▁TTEOKGUK
- ▁JAJANGMYEON
- ▁DIRECTLY
- VATE
- STEE
- ▁MOUSES
- ▁SNOWED
- ▁IGNORE
- GIFT
- ▁LOCKER
- ▁SURVIV
- ▁P
- BBLES
- DAIRY
- ▁TOOLS
- STAR
- LING
- ▁BB
- ▁ACCESSORIES
- ▁NINTENDO
- ▁BIBIMBAP
- ▁DERMATITIS
- ▁ANNOUNCED
- ▁LICK
- ▁AZALEAS
- ▁PEPPER
- VAS
- ▁BODIES
- ▁EXPAND
- PED
- FLOWING
- ▁MIXED
- ▁GROUP
- ▁SAUSAGE
- ▁CEREAL
- ▁EASIEST
- ▁OVERSLEEP
- ▁SATISF
- ▁150
- ▁BAY
- ▁DIP
- UN
- AK
- ▁COINS
- ▁SURPRISES
- ▁WAK
- OL
- ▁EVILDOING
- ▁EYEBROWS
- ▁HEADBAND
- ▁KETCHUP
- ▁PROPERLY
- ▁STRAWBERRIES
- ▁UNFORTUNATE
- ITY
- LIKE
- ONG
- ▁WISHES
- ▁CONSTRUCTION
- ▁RESEARCH
- ▁RIPPED
- ▁FOREIGNERS
- ▁SANDALS
- ▁GOLDEN
- ▁PERFORMANCES
- ▁STEALING
- HA
- ▁SPARE
- ▁KPOP
- ▁LEASH
- ▁TIGHTLY
- CM
- ▁COMME
- ▁500
- ▁ANCHOVIES
- ▁BANKBOOK
- ▁COVIDNINETEEN
- ▁DEFINIT
- ▁UPRIGHT
- ▁MISSION
- BAL
- PHONES
- HO
- ▁GENERAL
- ▁OVEN
- ▁MARCH
- V
- HU
- ▁GROWN
- ▁BROADCAST
- ▁GANGWONDO
- ▁REFRESHING
- ▁DICE
- ▁RACK
- ▁PERM
- ▁SUITCASES
- ▁16
- ▁ENVELOPE
- ▁HOOKED
- ▁ROOT
- ▁TEXT
- ▁CAGE
- GO
- ▁MUS
- ▁DOUGHNUTS
- ▁WASTING
- ▁BETIAN
- ▁PRESENTING
- ▁BRUISE
- ▁ALOUD
- ▁AUDITORIUM
- ▁BTS
- PLE
- RAISED
- MOTION
- ▁GENTLE
- ONIA
- ▁EASIER
- ▁FONDUE
- ▁SEASICK
- ▁VR
- ▁DOLPHINS
- ▁MATCHES
- UR
- ACHE
- ▁CICADAS
- ▁LEAN
- ▁REPORTS
- YING
- ▁CLOUDS
- ▁WOLVES
- ▁HEEL
- ▁FRESHMAN
- ▁SCREAMED
- ▁RELATIVE
- ARIN
- ▁BUR
- ▁PASTE
- ▁FRIENDLY
- ABLE
- ▁VISITING
- ▁INVIT
- ▁LOUDSPEAKERS
- ▁NNN
- ▁OINTMENT
- ▁SWAN
- CLES
- ▁GARDENING
- ▁HICCUP
- IM
- '0'
- ND
- BA
- ▁JULY
- ▁SEMESTER
- ▁SUSHI
- ▁UNIVERSE
- ▁TOSUN
- ▁PILLS
- ▁TAN
- ▁NEAT
- ▁FEATHER
- ▁ANNEX
- ▁PENGO
- ▁SICKNESS
- ▁CANDLES
- LO
- ▁SCRUB
- ▁SHOOT
- ▁TH
- ▁CRACK
- PLAIN
- ▁FRIDGE
- ▁ANSWERING
- ▁INDOORS
- ▁APOLOGIZED
- ▁COMEDIANS
- ▁WOR
- ▁SPIN
- ▁DRACULA
- ▁DRAGONFLIES
- ▁EXTINGUISHER
- ▁GRADUATION
- ▁LADIES
- ▁EX
- ▁PLANNED
- ▁50
- ▁MILLIONS
- ▁TANGERINES
- ▁DRAWN
- ▁CLEANER
- ▁DECORATIONS
- ▁SPI
- ▁VARI
- ▁DRAGONFLY
- ▁SCENT
- ▁GAYAGEUM
- ▁CL
- ▁MONTHS
- ▁PAJAMAS
- ▁RESTING
- ISE
- ▁BADGES
- WORK
- KY
- ▁ADORES
- ▁COLA
- ▁MOTOR
- ▁PRODUCE
- ▁THOROUGHLY
- ▁VOWELS
- ▁COMMON
- PING
- ▁SUNFLOWER
- ▁FOLDING
- ▁DECORAT
- '8'
- ▁SCREAM
- ▁CONNECT
- ▁AUGUST
- ▁PURPOSE
- ▁PIAN
- ▁CHIMNEYS
- ▁MONDAYS
- JU
- ▁BEETLE
- ▁PEED
- ▁INTEREST
- ▁BAN
- ▁SNOR
- ▁MA
- ▁SEW
- ▁COIN
- ▁HAN
- ▁ALPHABETS
- ▁TONKATSU
- ▁HOPEFULLY
- ▁ICECREAM
- ▁REGULARLY
- ▁GALBI
- ▁CHAS
- ▁REALIZE
- ▁WORKERS
- ▁BOATS
- ▁INTERRUPT
- ▁SUBTRACT
- ▁ORGANIZING
- ▁HISTORIC
- ▁POTTER
- ATION
- ▁CHARGER
- ▁BAL
- ▁SUNLIGHT
- ▁DYE
- ▁SHOELACES
- ▁EVENLY
- RY
- '30'
- BIKE
- ▁CRAWL
- ▁CHOOS
- ▁ROBBINS
- ▁SHOOK
- ▁SPLASH
- ASKIN
- ▁UNTIE
- YMP
- ▁STING
- IOUS
- ▁PA
- ▁CAROLS
- ▁SUDDEN
- ▁MACKEREL
- ▁NOSEBLEED
- ▁SCREW
- ▁HANOK
- TOMS
- ▁STRA
- DAY
- ▁RIBBON
- MILKY
- BEAN
- ▁TOMATO
- ▁NATIONAL
- ▁SPRITE
- ▁PANIX
- ▁WISE
- ZED
- ▁CHEWING
- ▁FOOTS
- ▁SHAKES
- ADA
- 'NO'
- ▁DIFFERENTLY
- SLEEVE
- ▁930
- ▁GYEONGJU
- ▁RAPUNZEL
- ▁ROMANTIC
- ▁FARTHER
- ▁CAPE
- IER
- ETY
- ▁HARDEST
- ▁TURNING
- ▁3000
- GENEROUS
- ▁BOO
- ▁ATTENTION
- ▁DWARVES
- ▁HAKNYEON
- ▁OUTDOOR
- ▁RESORT
- ▁SWOLLEN
- ▁PINCH
- ▁PURE
- STER
- ▁GRAB
- ▁BIO
- ▁HURRICANE
- ▁JUDGE
- ▁LANE
- ▁OINK
- ▁SPRAINED
- ▁THIEVES
- ▁TRAPPED
- BIL
- ▁RANCH
- ▁TWENTYTH
- ▁ANNE
- OLD
- NIGHT
- ▁HEIGHTS
- ▁BRICK
- ▁GRATEFUL
- ▁VITAMIN
- ▁HAMSTER
- ▁USELESS
- ▁INVENTOR
- ▁ULSAN
- ▁PRETENDING
- ▁PANDAS
- GGING
- UL
- AG
- COMING
- ▁HUNT
- ▁REMOVE
- ▁OCTOBER
- ▁SEPARATE
- ▁YAWN
- ▁PALE
- ▁UM
- ▁FLOATING
- ▁CO
- HAVE
- ▁SNOWY
- ▁SHOELACE
- GRAPHY
- ▁MELT
- ▁FISHBONE
- UG
- ▁CHIL
- ▁POOPED
- ▁YUT
- ▁PILL
- '0000'
- ▁SURVIVE
- ▁EXAMIN
- ▁TRU
- ▁BACKGROUND
- ▁BEGINNING
- ▁MACARONS
- ▁SURFING
- ▁VERANDA
- ▁ASSEMBLE
- ▁HANGUL
- ▁REACTION
- ▁DAUGHTERS
- MENT
- QUET
- RMALLY
- ANG
- ▁LID
- ▁RESERVATION
- SOON
- ▁FLIP
- CAN
- ▁JUICY
- ▁KINGDOM
- ▁SOCIETY
- ▁TADPOLE
- ▁JAMSIL
- ▁WI
- ▁GRADUATED
- ▁PRE
- ▁SCRATCHING
- ▁PO
- ▁APPEARS
- ILY
- FAT
- FOOD
- ▁DISAPPEAR
- ▁FAINT
- ▁FLOAT
- ▁RUBB
- ▁TRANSFER
- ▁COMFORT
- ▁BALLERINA
- ▁DESCRIPTION
- ▁GENTLY
- ▁HAPPIER
- ▁RINGTONE
- ▁ARGUING
- ▁CONDITIONER
- PM
- IET
- CU
- ▁EARTHQUAKES
- ▁CHICK
- ▁TR
- ▁TYPHOON
- ▁BUNS
- ▁RUNNER
- NDC
- ▁WAH
- ▁JELL
- ENDY
- ▁COMMU
- ▁FARMS
- ▁SLEEVES
- ▁BEETLES
- LOW
- ▁MEATBALL
- ALKIE
- ▁MAGNIF
- ▁CONNIE
- ▁NEIGHBOR
- ▁OPERA
- ▁PINOCCHIO
- ▁SHOEMAKER
- ▁CRAFT
- ▁ONESIX
- ▁FLOW
- WD
- HOO
- ▁PRESENTATIONS
- ▁CHIP
- ITE
- ▁ANIMAT
- ▁DUB
- ▁FLOOD
- ▁KAKAO
- ▁RESU
- ▁UNBELIEVABLE
- ▁GRIN
- ▁HEALTHIER
- ▁SIXTH
- ▁CHOSEN
- ▁LOSER
- ▁BLED
- REALLY
- ▁IGNOR
- ▁PRODUCT
- RIST
- ▁DISCOURAGED
- ▁DODGE
- ▁FORECAST
- ▁OWL
- ▁TREASURE
- ▁UNIFORM
- ▁LOCAT
- ▁TUBE
- DON
- ▁FOLDED
- ▁WEIGH
- ▁RUIN
- ▁CRUSH
- ▁PARAD
- ▁OBESE
- ▁ORGANIZE
- ▁PRINCIPAL
- ▁RATTLING
- ▁RESERVE
- ▁RHYM
- ▁SIP
- ▁UNDERWATER
- ▁TAEG
- ▁TRAVELLING
- ▁STACK
- ▁RI
- ▁BUNDLES
- YEAR
- SAME
- AND
- ▁CHEESECAKE
- ▁EPISODE
- ▁FAMILIES
- ▁FIFTH
- ▁RHINITIS
- ▁SAUNA
- NCHES
- ▁EXCE
- TIQUE
- ▁COMBO
- ▁STRINGS
- ▁COLORFUL
- ▁FLOWS
- ▁COOLEST
- ▁OPPAS
- ATING
- ATE
- ▁MELTS
- ▁CHOPSTICK
- ▁BRANCH
- ▁FRUSTRATED
- ▁GREASY
- ▁EXIST
- ▁WAVING
- ▁APP
- ▁SODA
- ▁FALLEN
- ▁PRO
- SHAPED
- NG
- ▁CONNECTED
- ▁12
- ▁BANDAID
- ▁DISTANCE
- ▁DRAIN
- ▁MEASURE
- ▁TEMPLE
- ▁WORKBOOK
- ▁EIGHTAM
- ▁WARN
- ▁BURNT
- BOARD
- ▁DE
- IFF
- RTH
- ▁MUSHROOMS
- ▁POWERFUL
- STICK
- ▁VOUCHERS
- ▁BLEED
- ▁BRAID
- ▁CREPE
- ▁HAWKING
- ▁FLAM
- ▁SCORE
- ▁RELEASED
- ▁TICKLED
- BU
- FISH
- ATIVE
- CLUSI
- ▁CLINIC
- ▁CROOKED
- ▁RELAY
- ▁SCOOTER
- ▁SEBASTIAN
- ▁SUFFER
- ▁TEENAGER
- ▁BATHHOUSE
- ▁WRIST
- ▁BAKERIES
- ▁BRANCHES
- ▁SAMYUKGU
- ▁SCU
- ENDER
- ▁INGREDIENTS
- ▁INVENTED
- ▁BOWING
- SSES
- WAR
- ▁PRESSED
- ▁SQUEEZ
- SIGNED
- WON
- ▁70
- ▁APPROACH
- ▁CHAPPED
- ▁DUMB
- ▁FREEZING
- ▁MAGNIFIER
- ENTIAL
- IE
- ▁CLOSELY
- ▁DIAPERS
- OUS
- ▁DIRT
- ▁CENTIMETER
- ▁FLOWERPOT
- ▁FOAM
- ▁POLITIC
- ▁PORRIDGE
- ▁PEDIATRICIAN
- ▁FIREWORKS
- ▁TROUBLEMAKER
- ▁PILLAR
- ▁EVACUATE
- ▁SILLA
- EUK
- ANDING
- ▁FAINTED
- ERMAN
- ▁SEAGULL
- ▁CHICKS
- ▁SWEATING
- INGO
- PAPER
- ▁AGREED
- ▁CLAPP
- VA
- ▁STRENGTH
- SOONGSIL
- ‘
- ▁CONVENIENT
- ▁DECEMBER
- ▁FORTUNATELY
- ▁FURNITURE
- ▁HAGWON
- ▁LOUNGE
- ▁MOKDONG
- ▁PALM
- ▁SPRINKLE
- ▁STIRFR
- RUNK
- ▁ANKLE
- ▁SELF
- ▁SEVENTH
- LESS
- ▁DIVING
- ADE
- ▁RANG
- SHINY
- WITH
- ▁BRAVELY
- ▁BADMINTON
- ▁BULGUKSA
- ▁KARAOKE
- ▁ADMIT
- ▁GINGER
- ▁LAID
- ▁SNOWBOARD
- ▁HOPPING
- ▁UDO
- ▁BULGING
- ▁CARP
- ▁FACT
- ▁GROUPS
- ▁ENTERING
- ▁RIP
- ▁MAR
- LOCK
- ▁JE
- ▁ADMISSION
- ▁CHRYSANTHEMUM
- ▁DIARIES
- ▁DISPOSABLE
- ▁LOACH
- ▁PARROT
- ▁SCULPTURE
- ▁TERRIF
- ▁VOLUME
- ▁REPRESENTATIVE
- ▁MEOW
- ▁CHEEK
- ▁JEJUDO
- ▁HARMFUL
- ▁BRUISED
- ▁MINERAL
- AINT
- ▁EDIT
- WARDS
- HY
- ▁VIEW
- ▁EXACT
- ROUGHT
- OCKPAPERSCISSORS
- ▁CHESTNUT
- ▁HAWAII
- ▁PIMPLES
- ▁REMOTE
- ▁SOLUTION
- ▁COMPETE
- ▁SOFTLY
- ▁BUNDLE
- ▁LIP
- ▁GRADER
- WOO
- RIS
- STORY
- DAYS
- COLORED
- FOR
- ▁COLLAPSE
- ▁STEPP
- ▁BRILL
- RSELVES
- ▁ACCORDING
- ▁BACON
- ▁BAEK
- ▁BUTTERFLIES
- ▁COSMOS
- ▁CYCLING
- ▁DISTRICT
- ▁ESTATE
- ▁HUMID
- ▁MERMAID
- ▁PAPRIKA
- ▁PHONICS
- ▁BELONG
- ▁YUKJANG
- ▁ANIMATION
- ▁FLIPP
- ▁DUMPLING
- ▁BLOSSOM
- UNG
- ▁EXPLORE
- ▁INSECTS
- ▁JI
- HEART
- GHTS
- ▁ASTRONAUT
- ▁BELLHAMMER
- ▁LICENSE
- ▁NEPTUNE
- ▁OPPOS
- ▁REFRIGERATOR
- ▁STONEBUSH
- ▁1000
- ▁APPLI
- ▁SUBTRACTION
- ▁HOOD
- ▁WIDER
- ▁BROOM
- ▁UNIVERSITY
- ▁PRINCESSES
- ▁MINT
- ▁PARENT
- ▁PEEING
- ▁ADORE
- DONG
- ▁SP
- ANCE
- ▁EXPLOR
- TTEOKBOKKI
- WHEEL
- ▁ABANDONED
- ▁CALLUSES
- ▁COSMETICS
- ▁LADYBUG
- ▁MARIA
- ▁PRONUNCIATION
- ▁BOUQUET
- ▁SOGGY
- ▁LEFTOVERS
- ▁MIKE
- ▁TANK
- ▁SPAC
- ▁FRAME
- MADE
- IVAL
- ▁YE
- ▁GATHERING
- IAN
- ▁KITTENS
- IBLE
- ▁ABBREVIAT
- ▁CHAPAGETTI
- ▁ENGINES
- ▁EQUIPMENT
- ▁INTERSECTION
- ▁SANITIZER
- ▁DOKDO
- ▁GENERATOR
- ▁MEDIUM
- ▁BALANCE
- ▁CHART
- ▁TELEVISION
- ▁JAJANG
- ▁LOLLY
- ▁PHOTOGRAPH
- ORD
- ▁KKA
- ▁SOLES
- ▁BALM
- ▁DECORATION
- ▁THORN
- ▁ARMY
- ▁YU
- EEK
- NK
- BOY
- LENGTH
- TONY
- HEN
- ▁RELEASE
- ▁LOOSE
- ▁COMPLETE
- KYOCHON
- ▁ARCADE
- ▁BRIM
- ▁CORONA
- ▁CRANE
- ▁CUPCAKE
- ▁KITCHENWARE
- ▁LULLABY
- ▁MODER
- ▁MUSKET
- ▁OBEDIEN
- ▁PIKACHU
- ▁PROVERBS
- ▁SALMON
- ▁YUKGAEJANG
- ▁TANNED
- ▁VILLA
- ▁DIRECTIONS
- ▁CLAY
- ▁ADMIR
- ▁DIRECTOR
- ▁DAMAGED
- ▁BURST
- ▁TOPIC
- ▁DOODLED
- ▁COMPAR
- ▁BUBBLE
- ▁HO
- ▁KISSE
- ▁JO
- ▁BLOATED
- ▁CONSONANTS
- ▁DOWNLOAD
- ▁ELBOW
- ▁FUNNIEST
- ▁PORORO
- ▁SLOTS
- ▁VACUUM
- ▁BOTTOM
- ▁MANDELA
- ▁IMSIL
- ▁VIP
- ▁TOMMY
- EATURE
- ▁PINE
- ▁EIGHTTHIRTY
- ▁HIDEANDSEEK
- ▁COLLAPSED
- ▁UNDERSTOOD
- ▁CRUSHED
- ▁TRI
- OF
- ▁DI
- ▁CARNATION
- ORY
- NAILS
- LENT
- ▁PUBLISH
- PLACE
- ▁CLIP
- ILLA
- ▁SUNSHIN
- ▁ACTUAL
- ▁SUCCESS
- COCK
- ▁60
- ▁BENEFITS
- ▁CLAW
- ▁HAUNT
- ▁LIBRARIES
- ▁LOTTERIA
- ▁MERCURY
- ▁MITTEN
- ▁SWAM
- ▁ROTTEN
- ▁SERVANT
- DENTAL
- ▁LEGEND
- ▁ROT
- ▁PRICKED
- ▁230
- ▁TUB
- ▁WINK
- ▁HUNTER
- ▁SCREAMING
- ▁FINALE
- ▁SOAPY
- ▁REDESIGNING
- NNA
- ▁DIAPER
- ▁BANG
- IK
- CHAN
- TIER
- ▁MOR
- ▁METERS
- ▁HUGG
- DAE
- FTER
- CHO
- SHIP
- EITHER
- CTIVE
- ▁KI
- ▁RU
- ▁BRAND
- ▁AMOUNT
- ▁EXPLANATION
- ▁HAIRPIN
- ▁HORRIBLE
- ▁INTERIOR
- ▁LANDSLIDE
- ▁NEVERTHELESS
- ▁PERSIMMON
- ▁POSTPONE
- ▁SCIENTIST
- ▁SLACK
- ▁STORM
- ▁STREAM
- ▁SURPRISING
- ▁URGENT
- ▁ZOMBIE
- ▁STOOL
- ▁LOAD
- NAMBU
- ▁ANNOUNCEMENT
- IKES
- GRAN
- ▁ABC
- ▁COMPLE
- ▁FASCINATING
- ▁REMOVED
- ▁CRAWLING
- ▁INTERRUPTING
- RELLA
- RAGE
- ▁PEELING
- ▁HUMANS
- ▁MON
- ▁BEGIN
- ▁VEGETABLE
- ▁SLEEVE
- GLE
- ▁THA
- ISH
- TRAINER
- '7'
- ROAD
- DRIVER
- ▁PRETEN
- ▁ALLOW
- UZZLE
- ▁DEMONSTRAT
- ▁STIR
- ▁BROC
- ▁CARCASON
- ▁EQUALLY
- ▁EXPERIMENT
- ▁HESITAT
- ▁SPINNING
- ▁MENTOR
- ▁ABBREVIATION
- ▁RASHES
- ▁ASSEMBLING
- ▁DUNG
- MEMOR
- ▁PEACEFUL
- ▁HARDENS
- OSU
- SSUED
- ▁FRECKLE
- TIOUS
- ▁REALIZ
- ▁SQUA
- LIFE
- THINK
- ▁BIK
- ▁KNIT
- ZZA
- ▁ALITTLE
- ▁BAREFOOT
- ▁CONCENTRATE
- ▁DALGONA
- ▁GUIDEBOOK
- ▁KIDZANIA
- ▁PALACE
- ▁ROSHEN
- ▁TEXTBOOK
- ▁TUNAKIMBAP
- OTTEOK
- ▁830
- ▁HOSE
- ITIES
- NIX
- ▁FIFTEENCM
- ▁IMAGE
- ▁CHEESEKIMBAP
- ▁HOTTER
- ▁PATT
- ▁CLIPPE
- ▁FOXES
- EAGLE
- ▁QUE
- NDING
- ▁DETER
- AP
- YEO
- UED
- ▁PAI
- ▁EXCITEDLY
- ▁WAVED
- ▁BUL
- BUT
- ▁METER
- KIMBAP
- HAND
- WATCHING
- ▁CONVERS
- ▁FLICK
- ▁PEDIATRIC
- NAMENT
- REIGN
- ▁BIKINI
- ▁BUCKWHEATCREPE
- ▁JENGA
- ▁LAUNCH
- ▁OPTICIAN
- ▁PIGTAIL
- ▁SIMON
- ▁SUBSCRIBE
- ▁TICKLISH
- NELS
- ▁PINWHEEL
- INATED
- ▁DRUG
- ▁ONESIXCM
- ▁EIGHTH
- ▁SMARTEST
- ▁HUNTING
- ▁PIL
- UMMY
- ITION
- UNNI
- ▁SU
- ▁POWERFULL
- ▁WAFFLE
- DIA
- ▁TICK
- EIGHT
- PICKED
- FIFTY
- WENT
- ▁BOT
- ▁REPRESENT
- OKKI
- ▁COCOA
- ▁CUSHION
- ▁FARTHEST
- ▁PENTAGON
- ▁SLIDING
- ▁SWEAR
- ▁MOLD
- ▁BBOY
- ▁80
- ▁WATERPROOF
- ▁RAIL
- ▁CREATED
- ▁CHIRPING
- ▁SEARCH
- SEOK
- ▁TOAST
- ▁BETRAYE
- JOR
- ▁NI
- ZI
- ▁SLAMM
- ▁GU
- ▁NAG
- ▁SERVED
- UFFY
- ▁INSECT
- ▁ZIPPE
- LP
- YEONG
- ESSION
- IPPED
- ▁CELEBRAT
- ▁CHANG
- '50'
- POST
- ENTI
- ▁DISAPPOINT
- ▁QU
- ▁FOREIGN
- ▁POSSIB
- ▁CONGRATULAT
- ADOW
- ▁TAE
- CAFÉ
- ▁COURIER
- ▁DAEJEON
- ▁DOWNSTAIRS
- ▁EXPER
- ▁PREFERENCE
- ▁LACT
- ▁OCCUR
- ORIENT
- ▁SPACIOUS
- INARY
- ▁KNITTING
- ▁LIBERTY
- VILLE
- RB
- ▁BARKED
- DAN
- ▁TIN
- ATOR
- ▁PHO
- RIED
- ▁JINDA
- OUND
- HOE
- ▁STRETCHE
- ▁SNEEZ
- EVI
- QUALITY
- MOM
- ▁BLIND
- HYEON
- ECTION
- ROKE
- ▁ANCHOVY
- ▁ASHAMED
- ▁COASTER
- ▁CONFUSING
- ▁CYCLIST
- ▁DANDELION
- ▁FIREFLIES
- ▁HYUNG
- ▁KNOWLEDGE
- ▁NARACULA
- ▁SCAB
- ▁VOCABULARY
- ▁CONFIDENT
- ▁RELAT
- ▁FOOLISH
- ▁NINEAM
- ▁ZO
- ▁BOU
- ▁FLATTERED
- ▁BLINDING
- ▁SKATER
- ▁ROLLER
- ▁FIRM
- COTT
- NURI
- ▁WARMER
- ▁LONGEST
- ▁TICKLE
- ▁AMERICAN
- GI
- AGGED
- CHARGE
- TODAY
- ▁CREATE
- UMPING
- JJAEK
- ▁BEGINNER
- ▁CLICKING
- ▁CORRIDORS
- ▁DAZZLING
- ▁DERMATOLOGIST
- ▁DILIGENT
- ▁FEBRUARY
- ▁FISHBOWL
- ▁GARAETTEOK
- ▁GARGLE
- ▁INJURED
- ▁MANTISES
- ▁NAKSEONGDAE
- ▁ROAST
- ▁SNITCH
- ▁SLIMMER
- ▁DISCHARGE
- ▁SOAKED
- ▁SELECTED
- ▁VICE
- ▁INFECT
- ▁CONTAINER
- ▁NEATLY
- ▁STARSHAPED
- LOTTEWORLD
- ▁SUPPLEMENT
- ▁EIGHTTH
- ISTERS
- ▁TICKL
- ▁STRAIGHTEN
- ▁SKINN
- RANGE
- ▁TANGERINE
- ▁STO
- PREPARED
- SPROUT
- TWELVE
- TONIGHT
- ▁RECOGNI
- VAN
- BEEN
- ▁EXPLODE
- ▁CHUBB
- ANGGU
- ▁SAVI
- ▁950
- ▁ADJUST
- ▁CASTANETS
- ▁FAITH
- ▁GONGJU
- ▁GRAIN
- ▁GROSS
- ▁JUPITER
- ▁MAGPIE
- ▁SAIPAN
- ▁SKULL
- ▁SPARROW
- ▁VACCINATED
- ▁VIGOROUSLY
- ▁AUTOMATIC
- ▁NEARBY
- SEVENTEEN
- ▁TWENTI
- ▁NIKE
- ▁SEORA
- DATORS
- ▁PONG
- ▁730
- ▁SCARIER
- ▁TRUNK
- ▁BETRAYER
- ▁CHEESEGIMBAP
- ONGDAE
- ▁SEVERE
- ▁SPOONFUL
- CTATION
- ▁WITCH
- ▁LIMIT
- ▁EATTTEOKBOKKI
- GEOUS
- ▁CRAWLED
- ▁SUC
- AVED
- AGE
- ▁KITTEN
- ▁SKEWER
- IZED
- ▁TEAR
- WAVE
- ▁RACI
- ▁CONTAIN
- ▁TRO
- ▁GUGUDAN
- ▁GEPPET
- ▁PHARMACI
- MULGUK
- PPAK
- SAMJANG
- ▁ACORN
- ▁APPETITE
- ▁BRUNCH
- ▁BUMMER
- ▁DIARRHEA
- ▁FLAP
- ▁GERMS
- ▁GWANSUN
- ▁HOMETOWN
- ▁KILOMETERS
- ▁MARRIAGE
- ▁PRANKS
- ▁RADISH
- '5'
- ′
- 수
- '2'
- ́
- 子
- 예
- 요
- '3'
- É
- '6'
- '9'
- “
- .
- '1'
- 단
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: null
zero_infinity: true
joint_net_conf: null
use_preprocessor: true
token_type: bpe
bpemodel: data/ko_token_list/bpe_unigram5000/bpe.model
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
aux_ctc_tasks: []
frontend: default
frontend_conf:
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_ko_bpe5000_sp/train/feats_stats.npz
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
preencoder: null
preencoder_conf: {}
encoder: contextual_block_conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d
normalize_before: true
activation_type: swish
macaron_style: true
use_cnn_module: true
cnn_module_kernel: 15
block_size: 40
hop_size: 16
look_ahead: 16
init_average: true
ctx_pos_enc: true
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
preprocessor: default
preprocessor_conf: {}
required:
- output_dir
- token_list
version: '202304'
distributed: true
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Waterhorse/chessgpt-base-v1
|
Waterhorse
| 2023-07-06T06:19:40Z | 83 | 6 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"en",
"dataset:Waterhorse/chess_data",
"arxiv:2306.09200",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-06-02T22:03:14Z |
---
license: apache-2.0
language:
- en
datasets:
- Waterhorse/chess_data
---
# Chessgpt-Base-3B-v1
Chessgpt-Base-v1 is the base model of Chessgpt.
- Base Model: [Chessgpt-base-v1](https://huggingface.co/Waterhorse/chessgpt-base-v1)
- Chat Version: [chessgpt-chat-v1](https://huggingface.co/Waterhorse/chessgpt-chat-v1)
Also, we are actively working on the development of the next-generation model, ChessGPT-V2. We welcome any contribution, especially on chess related dataset. For related matters, please contact xidong.feng.20@ucl.ac.uk.
## Model Details
- **Model type**: Language Model
- **Language(s)**: English
- **License**: Apache 2.0
- **Model Description**: A 2.8B parameter pretrained language model in Chess.
## GPU Inference
This requires a GPU with 8GB memory.
```python
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
MIN_TRANSFORMERS_VERSION = '4.25.1'
# check transformers version
assert transformers.__version__ >= MIN_TRANSFORMERS_VERSION, f'Please upgrade transformers to version {MIN_TRANSFORMERS_VERSION} or higher.'
# init
tokenizer = AutoTokenizer.from_pretrained("Waterhorse/chessgpt-base-v1")
model = AutoModelForCausalLM.from_pretrained("Waterhorse/chessgpt-base-v1", torch_dtype=torch.float16)
model = model.to('cuda:0')
# infer
# Conversation between two
prompt = "Q: 1.e4 c5, what is the name of this opening?A:"
inputs = tokenizer(prompt, return_tensors='pt').to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs, max_new_tokens=128, do_sample=True, temperature=0.7, top_p=0.7, top_k=50, return_dict_in_generate=True,
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)
```
# Uses
Excluded uses are described below.
### Direct Use
`chessgpt-base-v1` is mainly for research on large language model, especially for those research about policy learning and language modeling.
#### Out-of-Scope Use
`chessgpt-base-v1` is a language model trained on chess related data and may not perform well for other use cases beyond chess domain.
#### Bias, Risks, and Limitations
Just as with any language model, chessgpt-base-v1 carries inherent limitations that necessitate careful consideration. Specifically, it may occasionally generate responses that are irrelevant or incorrect, particularly when tasked with interpreting complex or ambiguous queries. Additionally, given that its training is rooted in online data, the model may inadvertently reflect and perpetuate common online stereotypes and biases.
# Evaluation
Please refer to our [paper](https://arxiv.org/abs/2306.09200) and [code](https://github.com/waterhorse1/ChessGPT)for benchmark results.
# Citation Information
```bash
@article{feng2023chessgpt,
title={ChessGPT: Bridging Policy Learning and Language Modeling},
author={Feng, Xidong and Luo, Yicheng and Wang, Ziyan and Tang, Hongrui and Yang, Mengyue and Shao, Kun and Mguni, David and Du, Yali and Wang, Jun},
journal={arXiv preprint arXiv:2306.09200},
year={2023}
}
```
|
sukritiverma/thumbs-up-tom_cruise
|
sukritiverma
| 2023-07-06T06:14:17Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-07-05T23:31:34Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - sukritiverma/thumbs-up-tom_cruise
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the None dataset. You can find some example images in the following.




|
yuuhan/roberta-base-rte-lora
|
yuuhan
| 2023-07-06T06:12:21Z | 6 | 0 |
peft
|
[
"peft",
"text-classification",
"en",
"dataset:SetFit/rte",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-07-06T06:03:00Z |
---
license: apache-2.0
datasets:
- SetFit/rte
language:
- en
metrics:
- accuracy
library_name: peft
pipeline_tag: text-classification
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
Accuracy: 0.7328519855595668 on RTE
|
nolanaatama/nkbllcfrmgtvrvcv2275pchsnltrx
|
nolanaatama
| 2023-07-06T05:50:38Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-06T05:46:52Z |
---
license: creativeml-openrail-m
---
|
nolanaatama/3drndrngstyl
|
nolanaatama
| 2023-07-06T05:37:10Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-06T05:19:33Z |
---
license: creativeml-openrail-m
---
|
eigenscribe/etzHayim
|
eigenscribe
| 2023-07-06T05:34:59Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-06T05:33:49Z |
---
license: creativeml-openrail-m
---
|
mazeinmouse/a2c-PandaReachDense-v2
|
mazeinmouse
| 2023-07-06T05:32:52Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-06T05:29:58Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.88 +/- 0.45
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
aroot/eng-fra-simcse_random
|
aroot
| 2023-07-06T05:13:07Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-06T04:53:15Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-fra-simcse_random
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-fra-simcse_random
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1475
- Bleu: 31.8135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
tuanio/WhisperCTC
|
tuanio
| 2023-07-06T05:06:09Z | 0 | 1 | null |
[
"summarization",
"dataset:mozilla-foundation/common_voice_13_0",
"arxiv:1910.09700",
"region:us"
] |
summarization
| 2023-07-06T04:55:16Z |
---
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
pipeline_tag: summarization
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
```python
class WhisperCTC(nn.Module):
def __init__(
self,
encoder_id: str = "tuanio/whisper-encoder.tiny.en",
dropout: float = 0.1,
vocab_size: int = 47,
):
super().__init__()
self.encoder = WhisperEncoder.from_pretrained(encoder_id)
print("Freezing Whisper Encoder...")
self.encoder._freeze_parameters()
print("Freezed!")
self.lm_head = nn.Sequential(
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(self.encoder.config.d_model, vocab_size),
)
nn.init.kaiming_uniform_(
self.lm_head[-1].weight, mode="fan_in", nonlinearity="relu"
)
def forward(self, feat: Tensor, attn_mask: Tensor):
enc = self.encoder(
input_features=feat, attention_mask=attn_mask
).last_hidden_state
logits = self.lm_head(enc)
log_probs = nn.functional.log_softmax(logits, dim=-1)
return log_probs
```
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
- IndictTTS: https://www.kaggle.com/datasets/tuannguyenvananh/indictts-english
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
```yaml
data_cfg:
dataset:
processor:
feat_extractor_id: ${model_cfg.model.encoder_id}
tokenizer_id: ${model_cfg.tokenizer_id}
path:
base:
indict_tts: ../IndicTTS
cv: ../
train:
- train_data/indict_tts_train.jsonl
# - train_data/cv_train.jsonl
test:
- train_data/indict_tts_test.jsonl
# - train_data/cv_test.jsonl
dev:
- train_data/indict_tts_dev.jsonl
# - train_data/cv_dev.jsonl
dataloader:
batch_size: 46
num_workers: 8
pin_memory: True
model_cfg:
tokenizer_id: tuanio/wav2vec2-phoneme-ipa-ctc
model:
dropout: 0.1
encoder_id: tuanio/whisper-encoder.medium.en
optim:
lr: 1.25e-05
betas: [0.9, 0.998]
weight_decay: 0.01
scheduler:
name: linear
total_steps: -1
warmup_ratio: 0.05
interval: step
frequency: 1
trainer_cfg:
log:
wandb: True
logger_wandb:
project: aped_indian-lish
name: whisper-medium-indict-tts-only-from-epoch1
log_model: all
arguments:
accelerator: gpu
devices: -1
max_epochs: 10
log_every_n_steps: 1
enable_checkpointing: True
accumulate_grad_batches: 2
inference_mode: True
gradient_clip_val: 5.0
check_val_every_n_epoch: 1
val_check_interval: null
experiment_cfg:
train: True
valid: True
test: True
ckpt:
resume_ckpt: True
ckpt_path: ckpt/medium.epoch3.ckpt
```
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AAOBA/ppo-PyramidsRND
|
AAOBA
| 2023-07-06T05:05:37Z | 8 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-07-06T05:04:49Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: chikoto/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
nhung/layoutxlm-de-durch
|
nhung
| 2023-07-06T05:02:06Z | 74 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"dataset:xfun",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-07-06T02:20:52Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- xfun
model-index:
- name: layoutxlm-de-durch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutxlm-de-durch
This model is a fine-tuned version of [microsoft/layoutxlm-base](https://huggingface.co/microsoft/layoutxlm-base) on the xfun dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.25e-06
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 15000
### Training results
### Framework versions
- Transformers 4.27.4
- Pytorch 1.10.0+cu111
- Datasets 2.11.0
- Tokenizers 0.13.3
|
whiteDandelion/swin-tiny-patch4-window7-224-finetuned-eurosat
|
whiteDandelion
| 2023-07-06T05:01:12Z | 228 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-06T04:12:49Z |
---
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9805
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [andupets/real-estate-image-classification](https://huggingface.co/andupets/real-estate-image-classification) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0613
- Accuracy: 0.9805
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.089 | 0.99 | 140 | 0.1050 | 0.9635 |
| 0.0565 | 2.0 | 281 | 0.0760 | 0.9725 |
| 0.0421 | 2.98 | 420 | 0.0613 | 0.9805 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
squeeze-ai-lab/sq-xgen-7b-8k-base-w4-s45
|
squeeze-ai-lab
| 2023-07-06T04:47:33Z | 0 | 0 | null |
[
"arxiv:2306.07629",
"region:us"
] | null | 2023-07-06T03:46:56Z |
**SqueezeLLM** is a post-training quantization framework that incorporates a new method called Dense-and-Sparse Quantization to enable efficient LLM serving.
**TLDR:** Deploying LLMs is difficult due to their large memory size. This can be addressed with reduced precision quantization.
But a naive method hurts performance. We address this with a new Dense-and-Sparse Quantization method.
Dense-and-Sparse splits weight matrices into two components: A dense component that can be heavily quantized without affecting model performance,
as well as a sparse part that preserves sensitive and outlier parts of the weight matrices With this approach,
we are able to serve larger models with smaller memory footprint, the same latency, and yet higher accuracy and quality.
For more details please check out our [paper](https://arxiv.org/pdf/2306.07629.pdf).
## Model description
4-bit XGen-7B Base model with 8K sequence length quantized using SqueezeLLM.
More details on the quantization method can be found in the [paper](https://arxiv.org/pdf/2306.07629.pdf).
More detailed model descriptions can be found in the [link](https://huggingface.co/Salesforce/xgen-7b-8k-base).
* **Base Model:** [XGen-7B-8K-Base](https://huggingface.co/Salesforce/xgen-7b-8k-base) (by Salesforce AI Research)
* **Bitwidth:** 4-bit
* **Sparsity Level:** 0.45%
## Links
* **Paper**: [https://arxiv.org/pdf/2306.07629.pdf](https://arxiv.org/pdf/2306.07629.pdf)
* **Code**: [https://github.com/SqueezeAILab/SqueezeLLM](https://github.com/SqueezeAILab/SqueezeLLM)
---
license: other
---
|
mazeinmouse/a2c-AntBulletEnv-v0
|
mazeinmouse
| 2023-07-06T04:34:47Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-06T04:33:37Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1651.08 +/- 126.30
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
headflame02/AchaxV4
|
headflame02
| 2023-07-06T04:30:16Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-06T04:29:24Z |
---
license: creativeml-openrail-m
---
|
ocisd4/openllama-zh-7B
|
ocisd4
| 2023-07-06T04:13:52Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-06T03:46:10Z |
```python
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
import transformers
tokenizer = LlamaTokenizer.from_pretrained(
'ocisd4/openllama-zh',
add_bos_token=False,
add_eos_token=False,
use_auth_token=True,
use_fast=False)
model = LlamaForCausalLM.from_pretrained('ocisd4/openllama-zh', device_map='auto',use_auth_token=True)
prompt = '關於華碩的傳說'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
generation_output = model.generate(
input_ids=input_ids, max_new_tokens=256,
do_sample=True, top_k=40, top_p=0.95, temperature=0.7, repetition_penalty=1.08,
)
print(tokenizer.decode(generation_output[0]))
```
The is a 7B pretrain model, train from openllama pretrain weight, context size=2048
**keep updating new model**
|
aroot/eng-guj-wsample.43a
|
aroot
| 2023-07-06T03:44:33Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-06T03:21:38Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-guj-wsample.43a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-guj-wsample.43a
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2191
- Bleu: 2.9237
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
aroot/eng-guj-wsample.32a
|
aroot
| 2023-07-06T03:39:41Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-06T03:21:39Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-guj-wsample.32a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-guj-wsample.32a
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2257
- Bleu: 3.1070
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Sandrro/text_to_subfunction_v6
|
Sandrro
| 2023-07-06T03:24:24Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T20:05:18Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: text_to_subfunction_v6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_to_subfunction_v6
This model is a fine-tuned version of [cointegrated/rubert-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2720
- F1: 0.4415
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.5055 | 1.0 | 4365 | 3.4067 | 0.1639 |
| 2.5598 | 2.0 | 8730 | 2.6935 | 0.2833 |
| 2.1499 | 3.0 | 13095 | 2.3594 | 0.3420 |
| 1.6575 | 4.0 | 17460 | 2.2243 | 0.3921 |
| 1.2463 | 5.0 | 21825 | 2.1722 | 0.4105 |
| 0.9624 | 6.0 | 26190 | 2.1955 | 0.4341 |
| 0.7407 | 7.0 | 30555 | 2.2434 | 0.4449 |
| 0.5608 | 8.0 | 34920 | 2.3604 | 0.4329 |
| 0.4233 | 9.0 | 39285 | 2.4747 | 0.4361 |
| 0.2433 | 10.0 | 43650 | 2.5562 | 0.4404 |
| 0.2154 | 11.0 | 48015 | 2.6678 | 0.4374 |
| 0.1811 | 12.0 | 52380 | 2.8158 | 0.4341 |
| 0.1374 | 13.0 | 56745 | 2.9037 | 0.4425 |
| 0.1406 | 14.0 | 61110 | 3.0182 | 0.4366 |
| 0.1135 | 15.0 | 65475 | 3.0941 | 0.4440 |
| 0.0992 | 16.0 | 69840 | 3.1516 | 0.4437 |
| 0.1159 | 17.0 | 74205 | 3.2001 | 0.4418 |
| 0.0809 | 18.0 | 78570 | 3.2489 | 0.4373 |
| 0.1035 | 19.0 | 82935 | 3.2650 | 0.4407 |
| 0.0558 | 20.0 | 87300 | 3.2720 | 0.4415 |
### Framework versions
- Transformers 4.27.1
- Pytorch 2.1.0.dev20230414+cu117
- Datasets 2.9.0
- Tokenizers 0.13.3
|
MWaleed/q-Taxi-v3
|
MWaleed
| 2023-07-06T03:23:27Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-06T03:23:24Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="MWaleed/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BaoKien/deberta-base-finetuned-squad-v2
|
BaoKien
| 2023-07-06T03:22:36Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"deberta",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-07-06T01:19:43Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: deberta-base-finetuned-squad-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-base-finetuned-squad-v2
This model is a fine-tuned version of [microsoft/deberta-base](https://huggingface.co/microsoft/deberta-base) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9221
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.753 | 1.0 | 8238 | 0.7286 |
| 0.5378 | 2.0 | 16476 | 0.7578 |
| 0.3881 | 3.0 | 24714 | 0.9221 |
### Performance
- 'exact': 81.84115219405373
- 'f1': 85.19125695340612
- 'total': 11873
- 'HasAns_exact': 80.24628879892038
- 'HasAns_f1': 86.95610556811602
- 'HasAns_total': 5928
- 'NoAns_exact': 83.43145500420522
- 'NoAns_f1': 83.43145500420522
- 'NoAns_total': 5945
- 'best_exact': 81.84115219405373
- 'best_exact_thresh': 0.9994916319847107
- 'best_f1': 85.19125695340657
- 'best_f1_thresh': 0.9994916319847107
- 'total_time_in_seconds': 294.34524957099984
- 'samples_per_second': 40.33698528277447
- 'latency_in_seconds': 0.024791143735450168
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
AngelaBoadway/DustinBates
|
AngelaBoadway
| 2023-07-06T03:19:17Z | 0 | 1 |
transformers
|
[
"transformers",
"en",
"dataset:AngelaBoadway/DustinBates",
"doi:10.57967/hf/0859",
"endpoints_compatible",
"region:us"
] | null | 2023-07-06T01:00:15Z |
---
language:
- en
datasets:
- AngelaBoadway/DustinBates
library_name: transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
D U S T I N B A T E S
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Angela Boadway
- **Language(s) (NLP):** English
|
squeeze-ai-lab/sq-xgen-7b-8k-inst-w3-s0
|
squeeze-ai-lab
| 2023-07-06T03:15:42Z | 0 | 0 | null |
[
"arxiv:2306.07629",
"region:us"
] | null | 2023-07-05T23:32:13Z |
**SqueezeLLM** is a post-training quantization framework that incorporates a new method called Dense-and-Sparse Quantization to enable efficient LLM serving.
**TLDR:** Deploying LLMs is difficult due to their large memory size. This can be addressed with reduced precision quantization.
But a naive method hurts performance. We address this with a new Dense-and-Sparse Quantization method.
Dense-and-Sparse splits weight matrices into two components: A dense component that can be heavily quantized without affecting model performance,
as well as a sparse part that preserves sensitive and outlier parts of the weight matrices With this approach,
we are able to serve larger models with smaller memory footprint, the same latency, and yet higher accuracy and quality.
For more details please check out our [paper](https://arxiv.org/pdf/2306.07629.pdf).
## Model description
3-bit XGen-7B instruction-tuned model (i.e. finetuned model on public domain instructional data) with 8K sequence length quantized using SqueezeLLM.
More details on the quantization method can be found in the [paper](https://arxiv.org/pdf/2306.07629.pdf).
More detailed model descriptions can be found in the [link](https://huggingface.co/Salesforce/xgen-7b-8k-inst).
* **Base Model:** [XGen-7B-8K-Inst](https://huggingface.co/Salesforce/xgen-7b-8k-inst) (by Salesforce AI Research)
* **Bitwidth:** 3-bit
* **Sparsity Level:** 0% (dense-only)
## Links
* **Paper**: [https://arxiv.org/pdf/2306.07629.pdf](https://arxiv.org/pdf/2306.07629.pdf)
* **Code**: [https://github.com/SqueezeAILab/SqueezeLLM](https://github.com/SqueezeAILab/SqueezeLLM)
---
license: other
---
|
nimakha/ppo-Huggy
|
nimakha
| 2023-07-06T03:11:22Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-06T03:11:18Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: nimakha/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
EDfai/furry_lora_collections_self_made
|
EDfai
| 2023-07-06T03:08:16Z | 0 | 1 | null |
[
"image-generation",
"furry",
"region:us"
] | null | 2023-06-17T08:40:20Z |
---
tags:
- image-generation
- furry
---
# 模型摘要
注意这里所有的角色都是furry角色<br>
这里所有lora模型均是在fluffyrock模型上面进行训练,使用indigo furry mix系列模型(v30、v35)做出示例图<br>
目前已做出人物模型:<br>
* ECHO——Flynn、Chase、Jenna、Carl、TJ、Sydney、Kudzu<br>
* TSR——Yao<br>
* UTAU——Aro、Oyupo、Laru<br>
# 模型独立触发词
独立触发词括号后为具体使用prompt组合示范<br>
ECHO:
* Flynn——flynnboi (furry flynnboi ((reptile)) ((lizard)) gila anthro male,black Mohawk, solo, detailed beautiful green eyes,(detailed black scalie scales))<br>
* Carl——carlhen (furry carlhen goat anthro mature male, horn, beanie, solo, beard , detailed beautiful green eyes, male focus, (detailed brown fluffy fur))<br>
* Chase——chasehunter (furry chasehunter otter anthro mature male, goatee, solo, detailed beautiful orange eyes, (detailed brown fluffy fur))<br>
* Jenna——jennabg (furry jennabg fox anthro mature female, solo, detailed beautiful blue eyes, female focus, (detailed yellow fur))<br>
* TJ——tjgoodboi (furry tjgoodboi lynx anthro male, solo, blue eyes, male focus, grey and white body,)<br>
* Sydney——sydneybs (furry sydneybs otter anthro mature male, cap, solo, detailed beautiful blue eyes, male focus, (detailed brown fluffy fur))<br>
* Kudzu——kudzu(solo, kudzu, raccoon, anthro, male, black_eyes)<br>
TSR:
* Yao——tigeryao (furry tigeryao tiger anthro mature male, solo, stripes, detailed beautiful black eyes, (detailed white yellow fur))<br>
UTAU:
* Laru——mineraru (mineraru, dragon, ((bald)), earless, solo, blue eyes, blue body, blue skin, blue scalie scales)<br>
* Oyupo——oyupo (furry ((oyupo)) [[tiger]] anthro mature male, solo, (((white eyebrows))) , detailed beautiful brown eyes, (detailed yellow fluffy fur))<br>
* Aro——wolfaro (furry wolfaro anthro wolf mature male, solo, detailed beautiful green eyes, (detailed brown white fur))<br>
# 模型说明
想要较为准确使用正向prompt调用一个人物lora模型,在保留人物重要特征同时让其具有良好泛化性,作者在这里给出一些自己个人见解,从上到下代表重要性:
* 物种种类(species、furry、anthro等)
* 肤色
* 瞳色
* 关键特征(如龙的角、白色眉毛等,不好描述就不写)
* 独立触发词
比较有趣的是,前三项描述貌似包含了一个人物模型的大多数特征,只提出这三项有可能都会生成一个差不多的人物。<br>
即便一个furry相关人物lora模型训练的时候并没有将这几项作为标签,我也建议你在调用furry相关人物lora模型的时候对这些方面描述。<br>
作者生成的这些模型有些轻微的过拟合,易调用性方面较差。若发现自己难以调用出人物可以参考人物文件夹下的示例图prompt描述。<br>
水音来流(minelaru)模型调用时需注意,最好按照作者生成示例图中的prompt进行描述,否则难以调用出相关人物<br>
# 模型预览(证件照)











|
Bellaaazzzzz/models_fill
|
Bellaaazzzzz
| 2023-07-06T02:41:19Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-07-06T02:35:57Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-Bellaaazzzzz/models_fill
These are controlnet weights trained on runwayml/stable-diffusion-v1-5 with new type of conditioning.
You can find some example images below.
Validation result of 1 round.

Validation result of 2 round.

|
csikasote/wav2vec2-large-mms-1b-bem-colab
|
csikasote
| 2023-07-06T02:40:47Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-05T22:46:43Z |
---
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-large-mms-1b-bem-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-mms-1b-bem-colab
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1638
- Wer: 0.3223
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.2095 | 1.03 | 200 | 0.2066 | 0.3850 |
| 0.4028 | 2.06 | 400 | 0.1861 | 0.3539 |
| 0.3751 | 3.09 | 600 | 0.1781 | 0.3417 |
| 0.3631 | 4.12 | 800 | 0.1739 | 0.3392 |
| 0.3481 | 5.15 | 1000 | 0.1688 | 0.3340 |
| 0.3391 | 6.19 | 1200 | 0.1690 | 0.3319 |
| 0.3301 | 7.22 | 1400 | 0.1654 | 0.3285 |
| 0.3237 | 8.25 | 1600 | 0.1667 | 0.3262 |
| 0.3186 | 9.28 | 1800 | 0.1638 | 0.3223 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
byoungsuk/iu
|
byoungsuk
| 2023-07-06T02:37:05Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-06-23T09:53:19Z |
---
license: creativeml-openrail-m
base_model: /content/gdrive/MyDrive/AI/checkpoint/majicmixFantasy_v20
instance_prompt: girl
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - byoungsuk/iu
These are LoRA adaption weights for /content/gdrive/MyDrive/AI/checkpoint/majicmixFantasy_v20. The weights were trained on girl using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




|
google/umt5-small
|
google
| 2023-07-06T02:31:38Z | 9,128 | 21 |
transformers
|
[
"transformers",
"pytorch",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-02T01:48:53Z |
---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
[Google's UMT5](https://github.com/google-research/multilingual-t5)
UMT5 is pretrained on the an updated version of [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) corpus, covering 107 languages:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Burmese, Catalan, Cebuano, Chichewa, Chinese, Corsican, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hmong, Hungarian, Icelandic, Igbo, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish, Kyrgyz, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Mongolian, Nepali, Norwegian, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Samoan, Scottish Gaelic, Serbian, Shona, Sindhi, Sinhala, Slovak, Slovenian, Somali, Sotho, Spanish, Sundanese, Swahili, Swedish, Tajik, Tamil, Telugu, Thai, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, West Frisian, Xhosa, Yiddish, Yoruba, Zulu.
**Note**: UMT5 was only pre-trained on mC4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
Pretraining Dataset: [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual)
Other Community Checkpoints: [here](https://huggingface.co/models?search=umt5)
Paper: [UniMax, Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
Authors: *by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant*
## Abstract
*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
|
asenella/mmnist_JMVAEconfig_resnet_seed_0_ratio_0_c
|
asenella
| 2023-07-06T02:16:52Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-06T02:16:24Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
saintzeno/a2c-AntBulletEnv-v0
|
saintzeno
| 2023-07-06T02:12:44Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-06T01:49:03Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1201.73 +/- 71.71
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
chunlongniu/SantaTrialsCoder
|
chunlongniu
| 2023-07-06T01:59:40Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-06T01:55:36Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
### Framework versions
- PEFT 0.4.0.dev0
|
anujsahani01/finetuned_AI4Bharat_mr_en
|
anujsahani01
| 2023-07-06T01:08:18Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"mbart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T15:52:30Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: finetuned_AI4Bharat_mr_en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_AI4Bharat_mr_en
This model is a fine-tuned version of [ai4bharat/indic-bert](https://huggingface.co/ai4bharat/indic-bert) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 8000
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
chaudha7/DiaryFlow
|
chaudha7
| 2023-07-06T00:49:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-07-06T00:43:32Z |
### Model Description
This is a fine-tuned Bloom-7b model. It was a demo project which I wanted to try to alleviate the seriousness and rapid pace around the "LLM" usecases.
This model has been trained on a custom chatGPT-created dataset (https://huggingface.co/datasets/chaudha7/Diary-Entry-To-Rap) which turns diary entries into short rap songs with a motivational ending. Just something fun for the users.
### Developed by: Aashay Chaudhari
## Training procedure
The following `bits and bytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
### Results
### Input:
Dear Diary,
Oh boy, today was such an incredible day! I woke up with a burst of excitement in my heart because it was my birthday! Double digits, baby! Mom and Dad surprised
me with a brand new bike, just like the one I've been dreaming about for ages. We went for a ride in the park, and I felt like I was flying!
My friends came over for a super fun party, and we played games, danced, and laughed until our tummies hurt. Grandma baked the most delicious chocolate cake,
and I blew out all the candles with one big breath. The best part? I got some awesome presents, like a shiny diary (just like you, Diary!), art supplies, and
a book about adventures. I can't wait to read it tonight!
Tonight, as I snuggle under my cozy blanket, I can't help but feel so grateful for the love and joy that surrounds me. Being 10 feels amazing, Diary.
I can't wait to see what other incredible adventures await me this year!
Until tomorrow,
Emily
### Output:
(Verse)
Today's my birthday,
feeling so alive,
Double digits, yo,
I'm ready to strive.
Got a brand-new bike,
flying through the air,
Riding in the park,
without a single care.
Friends came over,
we had a blast,
Playing games, dancing,
memories that'll last.
Grandma's chocolate cake,
candles all aglow,
Blowing them out,
a wish ready to grow.
Shiny diary, art supplies, and books,
Unleashing my creativity, no limits, no hooks.
Grateful for love and joy, can't help but smile,
Ten years old, embracing life's every mile.
(Motivational Ending)
No matter the age, dreams light up the way,
Believe in yourself, make the most of today.
Adventures await, with each step you take,
Keep shining, keep growing, there's no limit to what you'll make.
|
momomomomomo/Rotten_Tomato_Classfier
|
momomomomomo
| 2023-07-05T23:58:12Z | 63 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T21:06:06Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: momomomomomo/Rotten_Tomato_Classfier
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# momomomomomo/Rotten_Tomato_Classfier
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5703
- Validation Loss: 0.6171
- Train Accuracy: 0.7131
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 189675, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6738 | 0.6373 | 0.7018 | 0 |
| 0.5703 | 0.6171 | 0.7131 | 1 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
gagan3012/Qalam_onnx
|
gagan3012
| 2023-07-05T23:44:16Z | 10 | 0 |
transformers.js
|
[
"transformers.js",
"onnx",
"vision-encoder-decoder",
"image-text-to-text",
"image-to-text",
"ar",
"license:apache-2.0",
"region:us"
] |
image-to-text
| 2023-07-05T22:41:49Z |
---
license: apache-2.0
language:
- ar
metrics:
- wer
library_name: transformers.js
pipeline_tag: image-to-text
---
|
Aritra/pokemon-lora
|
Aritra
| 2023-07-05T23:32:46Z | 2 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:CompVis/stable-diffusion-v1-1",
"base_model:adapter:CompVis/stable-diffusion-v1-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-07-05T23:29:00Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - Aritra/pokemon-lora
These are LoRA adaption weights for CompVis/stable-diffusion-v1-1. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




|
asenella/mmnist_MoPoEconfig_resnet_seed_0_ratio_0_c
|
asenella
| 2023-07-05T23:16:00Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-06-04T21:11:40Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
wei0629/finetuning-emotion-mode
|
wei0629
| 2023-07-05T23:00:25Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T22:52:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: finetuning-emotion-mode
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.935
- name: F1
type: f1
value: 0.9351434285039132
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-emotion-mode
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1609
- Accuracy: 0.935
- F1: 0.9351
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 250 | 0.2811 | 0.9095 | 0.9072 |
| 0.5091 | 2.0 | 500 | 0.1788 | 0.925 | 0.9250 |
| 0.5091 | 3.0 | 750 | 0.1609 | 0.935 | 0.9351 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
mpetrikov/unit2-taxi3
|
mpetrikov
| 2023-07-05T22:56:37Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T22:56:35Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: unit2-taxi3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.48 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="mpetrikov/unit2-taxi3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
mpetrikov/q-FrozenLake-v1-4x4-noSlippery
|
mpetrikov
| 2023-07-05T22:50:25Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T22:50:23Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="mpetrikov/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
hopkins/eng-mya-simcse.near2.4440
|
hopkins
| 2023-07-05T22:49:46Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-05T22:28:28Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-mya-simcse.near2.4440
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-mya-simcse.near2.4440
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8502
- Bleu: 4.8797
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
ZilongLiu/Zilong_Candy_counter
|
ZilongLiu
| 2023-07-05T22:29:59Z | 188 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-07-05T22:20:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: Zilong_Candy_counter
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Zilong_Candy_counter
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 300
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
DawidL/ppo-LunarLander-v2
|
DawidL
| 2023-07-05T22:15:49Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T22:15:32Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 251.01 +/- 17.80
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jordyvl/EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_g05
|
jordyvl
| 2023-07-05T22:13:02Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv3",
"text-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T20:03:36Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_g05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_g05
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1631
- Accuracy: 0.72
- Exit 0 Accuracy: 0.1125
- Exit 1 Accuracy: 0.155
- Exit 2 Accuracy: 0.3325
- Exit 3 Accuracy: 0.3225
- Exit 4 Accuracy: 0.105
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 24
- total_train_batch_size: 288
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Exit 0 Accuracy | Exit 1 Accuracy | Exit 2 Accuracy | Exit 3 Accuracy | Exit 4 Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|
| No log | 0.72 | 2 | 2.7600 | 0.1075 | 0.075 | 0.0675 | 0.0925 | 0.0625 | 0.0625 |
| No log | 1.72 | 4 | 2.7312 | 0.1125 | 0.07 | 0.065 | 0.12 | 0.0625 | 0.0625 |
| No log | 2.72 | 6 | 2.6924 | 0.1325 | 0.075 | 0.06 | 0.1175 | 0.0625 | 0.0625 |
| No log | 3.72 | 8 | 2.6597 | 0.1675 | 0.0775 | 0.055 | 0.125 | 0.0625 | 0.0625 |
| No log | 4.72 | 10 | 2.6138 | 0.2025 | 0.0825 | 0.0575 | 0.12 | 0.0625 | 0.0625 |
| No log | 5.72 | 12 | 2.5640 | 0.215 | 0.0875 | 0.08 | 0.11 | 0.0625 | 0.0625 |
| No log | 6.72 | 14 | 2.5403 | 0.22 | 0.09 | 0.08 | 0.12 | 0.0625 | 0.0625 |
| No log | 7.72 | 16 | 2.5207 | 0.2275 | 0.09 | 0.0925 | 0.12 | 0.0625 | 0.0625 |
| No log | 8.72 | 18 | 2.4860 | 0.27 | 0.0975 | 0.0975 | 0.115 | 0.0625 | 0.0625 |
| No log | 9.72 | 20 | 2.4397 | 0.295 | 0.1 | 0.1075 | 0.13 | 0.0625 | 0.0625 |
| No log | 10.72 | 22 | 2.4044 | 0.3 | 0.095 | 0.12 | 0.1475 | 0.0625 | 0.0625 |
| No log | 11.72 | 24 | 2.3671 | 0.3075 | 0.1025 | 0.1175 | 0.1475 | 0.065 | 0.0625 |
| No log | 12.72 | 26 | 2.3178 | 0.3175 | 0.105 | 0.115 | 0.145 | 0.0775 | 0.0625 |
| No log | 13.72 | 28 | 2.2514 | 0.355 | 0.105 | 0.1225 | 0.155 | 0.11 | 0.0625 |
| No log | 14.72 | 30 | 2.2030 | 0.3775 | 0.1125 | 0.125 | 0.195 | 0.115 | 0.065 |
| No log | 15.72 | 32 | 2.1831 | 0.3725 | 0.1075 | 0.13 | 0.225 | 0.1075 | 0.065 |
| No log | 16.72 | 34 | 2.1417 | 0.3675 | 0.115 | 0.1375 | 0.2375 | 0.1075 | 0.065 |
| No log | 17.72 | 36 | 2.0688 | 0.3975 | 0.1075 | 0.1375 | 0.255 | 0.115 | 0.07 |
| No log | 18.72 | 38 | 2.0252 | 0.4075 | 0.115 | 0.14 | 0.26 | 0.1225 | 0.0825 |
| No log | 19.72 | 40 | 1.9896 | 0.4275 | 0.115 | 0.14 | 0.265 | 0.125 | 0.0925 |
| No log | 20.72 | 42 | 1.9344 | 0.4675 | 0.11 | 0.14 | 0.2675 | 0.11 | 0.095 |
| No log | 21.72 | 44 | 1.8826 | 0.48 | 0.11 | 0.1375 | 0.2625 | 0.1175 | 0.095 |
| No log | 22.72 | 46 | 1.8459 | 0.505 | 0.11 | 0.1375 | 0.2525 | 0.1125 | 0.095 |
| No log | 23.72 | 48 | 1.8152 | 0.5375 | 0.11 | 0.14 | 0.275 | 0.12 | 0.0975 |
| No log | 24.72 | 50 | 1.7909 | 0.535 | 0.11 | 0.1425 | 0.2975 | 0.135 | 0.1025 |
| No log | 25.72 | 52 | 1.7339 | 0.5575 | 0.1075 | 0.145 | 0.3 | 0.13 | 0.0975 |
| No log | 26.72 | 54 | 1.6912 | 0.56 | 0.1125 | 0.145 | 0.295 | 0.14 | 0.1025 |
| No log | 27.72 | 56 | 1.6601 | 0.575 | 0.115 | 0.1475 | 0.3025 | 0.1425 | 0.1025 |
| No log | 28.72 | 58 | 1.6302 | 0.585 | 0.115 | 0.1475 | 0.295 | 0.145 | 0.1 |
| No log | 29.72 | 60 | 1.5808 | 0.585 | 0.1125 | 0.1475 | 0.3 | 0.155 | 0.1025 |
| No log | 30.72 | 62 | 1.5408 | 0.6 | 0.115 | 0.1475 | 0.3025 | 0.175 | 0.1 |
| No log | 31.72 | 64 | 1.5289 | 0.605 | 0.115 | 0.145 | 0.3 | 0.18 | 0.0975 |
| No log | 32.72 | 66 | 1.5030 | 0.6125 | 0.115 | 0.145 | 0.2975 | 0.18 | 0.1 |
| No log | 33.72 | 68 | 1.4653 | 0.635 | 0.115 | 0.145 | 0.3 | 0.185 | 0.1 |
| No log | 34.72 | 70 | 1.4342 | 0.6325 | 0.1175 | 0.145 | 0.295 | 0.21 | 0.0975 |
| No log | 35.72 | 72 | 1.4088 | 0.64 | 0.115 | 0.1475 | 0.2975 | 0.2175 | 0.095 |
| No log | 36.72 | 74 | 1.3848 | 0.6375 | 0.1175 | 0.1475 | 0.3075 | 0.2175 | 0.095 |
| No log | 37.72 | 76 | 1.3533 | 0.6775 | 0.12 | 0.1475 | 0.315 | 0.2475 | 0.095 |
| No log | 38.72 | 78 | 1.3349 | 0.68 | 0.1175 | 0.1475 | 0.3125 | 0.2525 | 0.095 |
| No log | 39.72 | 80 | 1.3140 | 0.665 | 0.115 | 0.1475 | 0.325 | 0.255 | 0.0975 |
| No log | 40.72 | 82 | 1.3001 | 0.6825 | 0.115 | 0.1475 | 0.325 | 0.265 | 0.0975 |
| No log | 41.72 | 84 | 1.2824 | 0.695 | 0.115 | 0.1475 | 0.32 | 0.2625 | 0.1 |
| No log | 42.72 | 86 | 1.2740 | 0.7 | 0.115 | 0.1525 | 0.3275 | 0.265 | 0.1 |
| No log | 43.72 | 88 | 1.2538 | 0.7 | 0.115 | 0.1525 | 0.33 | 0.2675 | 0.1 |
| No log | 44.72 | 90 | 1.2348 | 0.6925 | 0.1125 | 0.1525 | 0.33 | 0.29 | 0.1025 |
| No log | 45.72 | 92 | 1.2253 | 0.705 | 0.1125 | 0.1525 | 0.3325 | 0.29 | 0.105 |
| No log | 46.72 | 94 | 1.2225 | 0.7025 | 0.1125 | 0.1525 | 0.335 | 0.2925 | 0.105 |
| No log | 47.72 | 96 | 1.2153 | 0.7075 | 0.1125 | 0.1525 | 0.3375 | 0.295 | 0.105 |
| No log | 48.72 | 98 | 1.1988 | 0.725 | 0.1125 | 0.1525 | 0.3325 | 0.3025 | 0.105 |
| No log | 49.72 | 100 | 1.1897 | 0.725 | 0.1125 | 0.1525 | 0.3325 | 0.31 | 0.105 |
| No log | 50.72 | 102 | 1.1835 | 0.7225 | 0.1125 | 0.1525 | 0.33 | 0.315 | 0.1025 |
| No log | 51.72 | 104 | 1.1834 | 0.72 | 0.1125 | 0.1525 | 0.335 | 0.3175 | 0.1025 |
| No log | 52.72 | 106 | 1.1767 | 0.7275 | 0.1125 | 0.1525 | 0.335 | 0.305 | 0.105 |
| No log | 53.72 | 108 | 1.1726 | 0.7225 | 0.1125 | 0.1525 | 0.335 | 0.31 | 0.105 |
| No log | 54.72 | 110 | 1.1696 | 0.7175 | 0.1125 | 0.1525 | 0.335 | 0.31 | 0.105 |
| No log | 55.72 | 112 | 1.1673 | 0.7125 | 0.1125 | 0.155 | 0.3325 | 0.3125 | 0.105 |
| No log | 56.72 | 114 | 1.1653 | 0.7175 | 0.1125 | 0.155 | 0.3325 | 0.32 | 0.105 |
| No log | 57.72 | 116 | 1.1638 | 0.72 | 0.1125 | 0.155 | 0.33 | 0.325 | 0.105 |
| No log | 58.72 | 118 | 1.1633 | 0.72 | 0.1125 | 0.155 | 0.33 | 0.3225 | 0.105 |
| No log | 59.72 | 120 | 1.1631 | 0.72 | 0.1125 | 0.155 | 0.3325 | 0.3225 | 0.105 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
LiviaQi/trained_model
|
LiviaQi
| 2023-07-05T22:10:22Z | 188 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-07-05T21:06:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: trained_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trained_model
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
asenella/mmnist_MMVAEPlusconfig_resnet_seed_0_ratio_0_c
|
asenella
| 2023-07-05T22:07:37Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T22:07:20Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
nekoboost/ppo-LunarLander-v2
|
nekoboost
| 2023-07-05T21:58:49Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T21:58:34Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -202.98 +/- 120.09
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
newconew/speecht5_finetuned_voxpopuli_nl
|
newconew
| 2023-07-05T21:55:25Z | 80 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-07-05T19:33:24Z |
---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4612
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5194 | 4.3 | 1000 | 0.4806 |
| 0.494 | 8.61 | 2000 | 0.4670 |
| 0.4929 | 12.91 | 3000 | 0.4642 |
| 0.4914 | 17.21 | 4000 | 0.4612 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
cleandata/whisper-small-dv
|
cleandata
| 2023-07-05T21:27:43Z | 79 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dv",
"dataset:mozilla-foundation/common_voice_13_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-05T20:25:03Z |
---
language:
- dv
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper Small Dv - local
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: dv
split: test
args: dv
metrics:
- name: Wer
type: wer
value: 13.245470668011267
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Dv
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1680
- Wer Ortho: 62.1074
- Wer: 13.2455
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.1233 | 1.63 | 500 | 0.1680 | 62.1074 | 13.2455 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
kejolong/kunoichi
|
kejolong
| 2023-07-05T21:23:28Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T21:21:08Z |
---
license: creativeml-openrail-m
---
|
KevinQuijano/model
|
KevinQuijano
| 2023-07-05T21:12:27Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-05T14:32:19Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - KevinQuijano/model
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
NasimB/gpt2-concat-aochiles-14k
|
NasimB
| 2023-07-05T20:51:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T18:35:59Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-aochiles-14k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-aochiles-14k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0042
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.7211 | 0.29 | 500 | 5.6349 |
| 5.3799 | 0.59 | 1000 | 5.1983 |
| 5.0235 | 0.88 | 1500 | 4.9554 |
| 4.7478 | 1.18 | 2000 | 4.8045 |
| 4.5979 | 1.47 | 2500 | 4.6854 |
| 4.4961 | 1.76 | 3000 | 4.5843 |
| 4.3569 | 2.06 | 3500 | 4.5164 |
| 4.1739 | 2.35 | 4000 | 4.4680 |
| 4.149 | 2.65 | 4500 | 4.4129 |
| 4.1093 | 2.94 | 5000 | 4.3581 |
| 3.8978 | 3.24 | 5500 | 4.3622 |
| 3.8629 | 3.53 | 6000 | 4.3327 |
| 3.8463 | 3.82 | 6500 | 4.3044 |
| 3.726 | 4.12 | 7000 | 4.3127 |
| 3.5714 | 4.41 | 7500 | 4.3116 |
| 3.5846 | 4.71 | 8000 | 4.2872 |
| 3.5668 | 5.0 | 8500 | 4.2693 |
| 3.3167 | 5.29 | 9000 | 4.3073 |
| 3.3274 | 5.59 | 9500 | 4.3060 |
| 3.3202 | 5.88 | 10000 | 4.3010 |
| 3.2207 | 6.18 | 10500 | 4.3137 |
| 3.1707 | 6.47 | 11000 | 4.3147 |
| 3.1663 | 6.76 | 11500 | 4.3166 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
joydragon/Reinforce-Pixelcopter-PLE-v2
|
joydragon
| 2023-07-05T20:50:19Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T20:50:15Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 33.00 +/- 28.73
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
choward/csv
|
choward
| 2023-07-05T20:46:13Z | 0 | 0 | null |
[
"text-generation",
"region:us"
] |
text-generation
| 2023-07-05T20:42:22Z |
---
pipeline_tag: text-generation
---
|
Gaborandi/Clinical-Longformer-MLM-pubmed
|
Gaborandi
| 2023-07-05T20:42:18Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"longformer",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-22T02:00:45Z |
---
tags:
- generated_from_trainer
model-index:
- name: Clinical-Longformer-MLM-pubmed
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Clinical-Longformer-MLM-pubmed
This model is a fine-tuned version of [yikuan8/Clinical-Longformer](https://huggingface.co/yikuan8/Clinical-Longformer) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3126
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 471 | 1.3858 |
| No log | 2.0 | 942 | 1.3160 |
| No log | 3.0 | 1413 | 1.2951 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.8.0
- Datasets 2.2.2
- Tokenizers 0.11.6
|
Gaborandi/MedBERT-breastcancer
|
Gaborandi
| 2023-07-05T20:41:38Z | 54 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-12-31T18:51:41Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: MedBERT-breastcancer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MedBERT-breastcancer
This model is a fine-tuned version of [Charangan/MedBERT](https://huggingface.co/Charangan/MedBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 12263 | 1.0881 |
| No log | 2.0 | 24526 | 1.0259 |
| No log | 3.0 | 36789 | 0.9937 |
| No log | 4.0 | 49052 | 0.9831 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.8.0
- Datasets 2.2.2
- Tokenizers 0.13.2
|
SaffalPoosh/falcon_7B_instruct_safetensors
|
SaffalPoosh
| 2023-07-05T20:27:23Z | 16 | 0 |
transformers
|
[
"transformers",
"safetensors",
"RefinedWebModel",
"text-generation",
"custom_code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T20:13:30Z |
Converted using oobabooga script to safetensors to test the TGI LLM inference engine
|
NemesisAlm/distilhubert-finetuned-gtzan
|
NemesisAlm
| 2023-07-05T20:24:51Z | 166 | 0 |
transformers
|
[
"transformers",
"pytorch",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-04T10:01:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [NemesisAlm/distilhubert-finetuned-gtzan](https://huggingface.co/NemesisAlm/distilhubert-finetuned-gtzan) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7322
- Accuracy: 0.905
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0002 | 1.0 | 100 | 0.5783 | 0.915 |
| 0.1984 | 2.0 | 200 | 0.7051 | 0.91 |
| 0.0518 | 3.0 | 300 | 1.0287 | 0.865 |
| 0.0039 | 4.0 | 400 | 0.7660 | 0.895 |
| 0.0001 | 5.0 | 500 | 0.7513 | 0.91 |
| 0.0001 | 6.0 | 600 | 0.7757 | 0.9 |
| 0.0002 | 7.0 | 700 | 0.9340 | 0.87 |
| 0.0001 | 8.0 | 800 | 0.7237 | 0.9 |
| 0.0001 | 9.0 | 900 | 0.7298 | 0.905 |
| 0.0001 | 10.0 | 1000 | 0.7322 | 0.905 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jcm-art/hf_image_classification_tuning_pipeline
|
jcm-art
| 2023-07-05T20:14:07Z | 191 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:food101",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-05T19:35:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- food101
metrics:
- accuracy
model-index:
- name: hf_image_classification_tuning_pipeline
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food101
type: food101
config: default
split: train[:5000]
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.903
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hf_image_classification_tuning_pipeline
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5764
- Accuracy: 0.903
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7113 | 0.99 | 62 | 2.4840 | 0.849 |
| 1.8024 | 2.0 | 125 | 1.7298 | 0.891 |
| 1.5532 | 2.98 | 186 | 1.5764 | 0.903 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jordyvl/EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_weighted
|
jordyvl
| 2023-07-05T20:02:58Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv3",
"text-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T17:53:13Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_weighted
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_weighted
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0783
- Accuracy: 0.71
- Exit 0 Accuracy: 0.115
- Exit 1 Accuracy: 0.1575
- Exit 2 Accuracy: 0.185
- Exit 3 Accuracy: 0.0875
- Exit 4 Accuracy: 0.0625
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 24
- total_train_batch_size: 288
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Exit 0 Accuracy | Exit 1 Accuracy | Exit 2 Accuracy | Exit 3 Accuracy | Exit 4 Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|
| No log | 0.72 | 2 | 2.7602 | 0.1125 | 0.0925 | 0.0675 | 0.0875 | 0.0625 | 0.0625 |
| No log | 1.72 | 4 | 2.7309 | 0.115 | 0.1175 | 0.0675 | 0.1075 | 0.0625 | 0.0625 |
| No log | 2.72 | 6 | 2.6967 | 0.1325 | 0.095 | 0.06 | 0.1175 | 0.0625 | 0.0625 |
| No log | 3.72 | 8 | 2.6631 | 0.17 | 0.085 | 0.0575 | 0.1275 | 0.0625 | 0.0625 |
| No log | 4.72 | 10 | 2.6242 | 0.205 | 0.085 | 0.0575 | 0.1225 | 0.0625 | 0.0625 |
| No log | 5.72 | 12 | 2.5736 | 0.2175 | 0.0875 | 0.0825 | 0.12 | 0.0625 | 0.0625 |
| No log | 6.72 | 14 | 2.5410 | 0.215 | 0.09 | 0.08 | 0.12 | 0.0625 | 0.0625 |
| No log | 7.72 | 16 | 2.5229 | 0.2325 | 0.1 | 0.0925 | 0.13 | 0.0625 | 0.0625 |
| No log | 8.72 | 18 | 2.4841 | 0.2525 | 0.1 | 0.1 | 0.1325 | 0.0625 | 0.0625 |
| No log | 9.72 | 20 | 2.4382 | 0.29 | 0.1 | 0.1025 | 0.1325 | 0.0625 | 0.0625 |
| No log | 10.72 | 22 | 2.3823 | 0.3 | 0.1 | 0.1275 | 0.1325 | 0.0625 | 0.0625 |
| No log | 11.72 | 24 | 2.3389 | 0.3275 | 0.1 | 0.1175 | 0.1225 | 0.0625 | 0.0625 |
| No log | 12.72 | 26 | 2.3002 | 0.35 | 0.0975 | 0.12 | 0.1225 | 0.0625 | 0.0625 |
| No log | 13.72 | 28 | 2.2421 | 0.36 | 0.0975 | 0.125 | 0.1275 | 0.0625 | 0.0625 |
| No log | 14.72 | 30 | 2.2026 | 0.3575 | 0.1025 | 0.13 | 0.125 | 0.0625 | 0.0625 |
| No log | 15.72 | 32 | 2.1712 | 0.375 | 0.105 | 0.1375 | 0.125 | 0.0625 | 0.0625 |
| No log | 16.72 | 34 | 2.0999 | 0.4075 | 0.1 | 0.145 | 0.125 | 0.0625 | 0.0625 |
| No log | 17.72 | 36 | 2.0414 | 0.4225 | 0.1025 | 0.145 | 0.1275 | 0.0625 | 0.0625 |
| No log | 18.72 | 38 | 1.9981 | 0.4375 | 0.0975 | 0.1425 | 0.13 | 0.0625 | 0.0625 |
| No log | 19.72 | 40 | 1.9369 | 0.4575 | 0.1025 | 0.14 | 0.1425 | 0.0625 | 0.0625 |
| No log | 20.72 | 42 | 1.8903 | 0.4975 | 0.1025 | 0.14 | 0.145 | 0.0625 | 0.0625 |
| No log | 21.72 | 44 | 1.8242 | 0.525 | 0.1025 | 0.1425 | 0.15 | 0.0625 | 0.0625 |
| No log | 22.72 | 46 | 1.7520 | 0.5325 | 0.11 | 0.1475 | 0.1475 | 0.0625 | 0.0625 |
| No log | 23.72 | 48 | 1.7203 | 0.5525 | 0.1125 | 0.1475 | 0.1525 | 0.0625 | 0.0625 |
| No log | 24.72 | 50 | 1.6753 | 0.565 | 0.1125 | 0.1475 | 0.155 | 0.0625 | 0.0625 |
| No log | 25.72 | 52 | 1.6245 | 0.575 | 0.1125 | 0.1475 | 0.155 | 0.0625 | 0.0625 |
| No log | 26.72 | 54 | 1.5832 | 0.61 | 0.11 | 0.15 | 0.1525 | 0.0625 | 0.0625 |
| No log | 27.72 | 56 | 1.5404 | 0.61 | 0.11 | 0.1475 | 0.155 | 0.0625 | 0.0625 |
| No log | 28.72 | 58 | 1.4958 | 0.6125 | 0.11 | 0.1475 | 0.1575 | 0.0625 | 0.0625 |
| No log | 29.72 | 60 | 1.4613 | 0.6325 | 0.11 | 0.1475 | 0.1575 | 0.0625 | 0.0625 |
| No log | 30.72 | 62 | 1.4479 | 0.63 | 0.11 | 0.1525 | 0.16 | 0.0625 | 0.0625 |
| No log | 31.72 | 64 | 1.4101 | 0.64 | 0.1125 | 0.1525 | 0.165 | 0.0625 | 0.0625 |
| No log | 32.72 | 66 | 1.3699 | 0.655 | 0.1125 | 0.1525 | 0.1675 | 0.0625 | 0.0625 |
| No log | 33.72 | 68 | 1.3427 | 0.6725 | 0.115 | 0.1525 | 0.165 | 0.0625 | 0.0625 |
| No log | 34.72 | 70 | 1.3161 | 0.6825 | 0.115 | 0.1525 | 0.1625 | 0.0625 | 0.0625 |
| No log | 35.72 | 72 | 1.2896 | 0.7025 | 0.115 | 0.1525 | 0.1675 | 0.0625 | 0.0625 |
| No log | 36.72 | 74 | 1.2720 | 0.705 | 0.11 | 0.1525 | 0.185 | 0.0625 | 0.0625 |
| No log | 37.72 | 76 | 1.2471 | 0.71 | 0.11 | 0.1525 | 0.1775 | 0.0625 | 0.0625 |
| No log | 38.72 | 78 | 1.2307 | 0.71 | 0.11 | 0.155 | 0.1775 | 0.0625 | 0.0625 |
| No log | 39.72 | 80 | 1.2174 | 0.7175 | 0.1125 | 0.155 | 0.1825 | 0.0625 | 0.0625 |
| No log | 40.72 | 82 | 1.1991 | 0.705 | 0.1125 | 0.1525 | 0.1775 | 0.0625 | 0.0625 |
| No log | 41.72 | 84 | 1.1867 | 0.71 | 0.1175 | 0.1525 | 0.18 | 0.065 | 0.0625 |
| No log | 42.72 | 86 | 1.1764 | 0.7025 | 0.115 | 0.1525 | 0.18 | 0.0675 | 0.0625 |
| No log | 43.72 | 88 | 1.1601 | 0.715 | 0.115 | 0.1525 | 0.1825 | 0.0725 | 0.0625 |
| No log | 44.72 | 90 | 1.1410 | 0.7175 | 0.115 | 0.1525 | 0.18 | 0.075 | 0.0625 |
| No log | 45.72 | 92 | 1.1408 | 0.71 | 0.115 | 0.155 | 0.1825 | 0.075 | 0.0625 |
| No log | 46.72 | 94 | 1.1443 | 0.7075 | 0.115 | 0.155 | 0.1825 | 0.0775 | 0.0625 |
| No log | 47.72 | 96 | 1.1364 | 0.705 | 0.115 | 0.155 | 0.1775 | 0.0825 | 0.0625 |
| No log | 48.72 | 98 | 1.1251 | 0.71 | 0.115 | 0.155 | 0.175 | 0.085 | 0.0625 |
| No log | 49.72 | 100 | 1.1113 | 0.7175 | 0.115 | 0.155 | 0.1775 | 0.085 | 0.0625 |
| No log | 50.72 | 102 | 1.1040 | 0.7175 | 0.115 | 0.155 | 0.18 | 0.0875 | 0.0625 |
| No log | 51.72 | 104 | 1.0972 | 0.715 | 0.115 | 0.155 | 0.18 | 0.0875 | 0.0625 |
| No log | 52.72 | 106 | 1.0938 | 0.7175 | 0.115 | 0.1575 | 0.1825 | 0.0875 | 0.0625 |
| No log | 53.72 | 108 | 1.0931 | 0.71 | 0.115 | 0.1575 | 0.185 | 0.0875 | 0.0625 |
| No log | 54.72 | 110 | 1.0887 | 0.7075 | 0.115 | 0.1575 | 0.185 | 0.0875 | 0.0625 |
| No log | 55.72 | 112 | 1.0865 | 0.7125 | 0.115 | 0.1575 | 0.1875 | 0.0875 | 0.0625 |
| No log | 56.72 | 114 | 1.0828 | 0.7125 | 0.115 | 0.1575 | 0.1875 | 0.0875 | 0.0625 |
| No log | 57.72 | 116 | 1.0801 | 0.7075 | 0.115 | 0.1575 | 0.1875 | 0.0875 | 0.0625 |
| No log | 58.72 | 118 | 1.0786 | 0.7125 | 0.115 | 0.1575 | 0.1875 | 0.0875 | 0.0625 |
| No log | 59.72 | 120 | 1.0783 | 0.71 | 0.115 | 0.1575 | 0.185 | 0.0875 | 0.0625 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Damirchik/ppo-LunarLander-v2
|
Damirchik
| 2023-07-05T19:55:14Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T19:54:55Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 251.94 +/- 25.23
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AWolters/ByT5_DutchSpellingNormalization
|
AWolters
| 2023-07-05T19:53:42Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"t5",
"text2text-generation",
"text2text generation",
"spelling normalization",
"19th-century Dutch",
"nl",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-01T16:11:47Z |
---
language:
- nl
tags:
- text2text generation
- spelling normalization
- 19th-century Dutch
license: apache-2.0
---
# 19th Century Dutch Spelling Normalization
This repository contains a pretrained and finetuned model of the original __google/ByT5-small__.
This model has been pretrained and finetuned for the task of 19th-century Dutch spelling normalization.
We first pretrained the model with 2 million sentences from Dutch historical novels.
Afterward, we finetuned the model with a 10k dataset consisting of 19th-century Dutch sentences;
these sentences were automatically annotated by a rule-based system built for 19th-century Dutch spelling normalization (van Cranenburgh and van Noord, 2022).
The finetuned model is only available in the TensorFlow format but can be converted to a PyTorch environment.
The pretrained only weights are available in the PyTorch environment; note that this model has to be finetuned first.
The pretrained only weights are available in the directory __Pretrained_ByT5__.
The train and validation sets used for finetuning are available in the main repository.
For further information about the model, please see the [GitHub](https://github.com/Awolters123/Master-Thesis) repository.
## How to use:
```
from transformers import AutoTokenizer, TFT5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained('AWolters/ByT5_DutchSpellingNormalization')
model = TFT5ForConditionalGeneration.from_pretrained('AWolters/ByT5_DutchSpellingNormalization')
text = 'De menschen waren aan het werk.'
tokenized = tokenizer(text, return_tensors='tf')
prediction = model.generate(input_ids=tokenized['input_ids'],
attention_mask=tokenized['attention_mask'],
max_new_tokens=100)
print(tokenizer.decode(prediction[0], text_target=True, skip_special_tokens=True))
```
## Setup:
The model has been finetuned with the following (hyper)parameters values:
_Learn rate_: 5e-5
_Batch size_: 32
_Optimizer_: AdamW
_Epochs_: 30, with earlystopping
To further finetune the model, use the __T5Trainer.py__ script.
|
sebasvaron/my_awesome_model
|
sebasvaron
| 2023-07-05T19:50:19Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T19:45:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
aroot/wsample.43a
|
aroot
| 2023-07-05T19:38:28Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-05T18:34:22Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.43a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.43a
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8306
- Bleu: 4.7146
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
aroot/wsample.32a
|
aroot
| 2023-07-05T19:38:12Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-05T18:34:12Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.32a
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.32a
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8284
- Bleu: 4.7412
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
BadreddineHug/donut-base-ocr4
|
BadreddineHug
| 2023-07-05T19:27:19Z | 74 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-07-05T18:38:04Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-ocr4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-ocr4
This model is a fine-tuned version of [naver-clova-ix/donut-base-finetuned-cord-v2](https://huggingface.co/naver-clova-ix/donut-base-finetuned-cord-v2) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
joydragon/Reinforce-Pixelcopter-PLE-v0
|
joydragon
| 2023-07-05T19:14:01Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:30:19Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 20.40 +/- 19.70
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
wizofavalon/distilgpt2-finetuned-wikitext2
|
wizofavalon
| 2023-07-05T19:09:13Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T18:56:22Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: wizofavalon/distilgpt2-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# wizofavalon/distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.8588
- Validation Loss: 3.6766
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.8588 | 3.6766 | 0 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
maubers/emily_yeppers
|
maubers
| 2023-07-05T19:08:47Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T17:28:43Z |
## Overview
This contains Emily Yeppers, a bot who likes to talk about very inappropriate things and how vital they are to the existence of our species (the truth, technically) using GPT-Neo. The bot streams new content from specified subreddits and responds when certain target phrases are detected in comments and submissions, or when it is mentioned or directly replied to.
She is designed to function as a Reddit bot. See the Github page for more information. She WILL generate inappropriate content, as she was trained on comments posted in inappropriate subreddits.
## Setup and Installation (for Reddit)
See https://github.com/maubers/emily_yeppers
|
konverner/due_eshop_21_multilabel
|
konverner
| 2023-07-05T18:59:21Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-07-04T22:21:59Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# konverner/due_eshop_21_multilabel
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("konverner/due_eshop_21_multilabel")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
sd-concepts-library/ahx-beta-4a5b307
|
sd-concepts-library
| 2023-07-05T18:57:32Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2023-07-05T18:57:29Z |
---
license: mit
---
### ahx-beta-4a5b307 on Stable Diffusion
This is the `<ahx-beta-4a5b307>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









|
bk6000/dqn-SpaceInvadersNoFrameskip-v4
|
bk6000
| 2023-07-05T18:50:44Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:09:35Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 337.50 +/- 114.85
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga bk6000 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga bk6000 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga bk6000
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 500000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Vladislav-HuggingFace/ppo-Huggy
|
Vladislav-HuggingFace
| 2023-07-05T18:46:15Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:46:12Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Vladislav-HuggingFace/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
kubjonkyr/ppo-LunarLander-v2
|
kubjonkyr
| 2023-07-05T18:35:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T17:36:39Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 290.89 +/- 13.49
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
alesthehuman/poca-SoccerTwos
|
alesthehuman
| 2023-07-05T18:14:32Z | 24 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:13:38Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: alesthehuman/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Tubido/Taxi-v3-001
|
Tubido
| 2023-07-05T18:06:11Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T18:06:09Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-001
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Tubido/Taxi-v3-001", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
PraveenJesu/openai-whisper-medium-zrx-peft-lora-v2.2.2
|
PraveenJesu
| 2023-07-05T18:01:17Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-05T18:01:14Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
jordyvl/EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_ent_g75
|
jordyvl
| 2023-07-05T17:52:32Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"layoutlmv3",
"text-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T15:38:04Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_ent_g75
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EElayoutlmv3_jordyvl_rvl_cdip_100_examples_per_class_2023-07-05_ent_g75
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2759
- Accuracy: 0.6825
- Exit 0 Accuracy: 0.11
- Exit 1 Accuracy: 0.155
- Exit 2 Accuracy: 0.345
- Exit 3 Accuracy: 0.425
- Exit 4 Accuracy: 0.5225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 24
- total_train_batch_size: 288
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Exit 0 Accuracy | Exit 1 Accuracy | Exit 2 Accuracy | Exit 3 Accuracy | Exit 4 Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------------:|:---------------:|:---------------:|:---------------:|:---------------:|
| No log | 0.72 | 2 | 2.7601 | 0.1075 | 0.0825 | 0.0675 | 0.1025 | 0.0625 | 0.0625 |
| No log | 1.72 | 4 | 2.7328 | 0.1125 | 0.07 | 0.065 | 0.1225 | 0.0625 | 0.0625 |
| No log | 2.72 | 6 | 2.6968 | 0.13 | 0.075 | 0.06 | 0.1325 | 0.0625 | 0.0625 |
| No log | 3.72 | 8 | 2.6594 | 0.18 | 0.075 | 0.06 | 0.1175 | 0.0625 | 0.0625 |
| No log | 4.72 | 10 | 2.6206 | 0.1925 | 0.085 | 0.0575 | 0.11 | 0.0625 | 0.0625 |
| No log | 5.72 | 12 | 2.5710 | 0.2125 | 0.09 | 0.08 | 0.115 | 0.0625 | 0.0625 |
| No log | 6.72 | 14 | 2.5334 | 0.2275 | 0.095 | 0.08 | 0.12 | 0.0575 | 0.0625 |
| No log | 7.72 | 16 | 2.5094 | 0.245 | 0.095 | 0.095 | 0.135 | 0.0725 | 0.0625 |
| No log | 8.72 | 18 | 2.4631 | 0.2825 | 0.095 | 0.0975 | 0.17 | 0.0925 | 0.065 |
| No log | 9.72 | 20 | 2.4152 | 0.3025 | 0.1 | 0.1275 | 0.205 | 0.1075 | 0.0625 |
| No log | 10.72 | 22 | 2.3737 | 0.325 | 0.1075 | 0.1225 | 0.24 | 0.12 | 0.065 |
| No log | 11.72 | 24 | 2.3302 | 0.3175 | 0.1125 | 0.1175 | 0.2375 | 0.1475 | 0.0675 |
| No log | 12.72 | 26 | 2.2746 | 0.34 | 0.1125 | 0.125 | 0.255 | 0.155 | 0.095 |
| No log | 13.72 | 28 | 2.2527 | 0.35 | 0.1125 | 0.125 | 0.2625 | 0.175 | 0.095 |
| No log | 14.72 | 30 | 2.2101 | 0.3425 | 0.1075 | 0.13 | 0.27 | 0.2125 | 0.095 |
| No log | 15.72 | 32 | 2.1811 | 0.355 | 0.1075 | 0.14 | 0.29 | 0.24 | 0.095 |
| No log | 16.72 | 34 | 2.1368 | 0.38 | 0.105 | 0.145 | 0.305 | 0.245 | 0.0925 |
| No log | 17.72 | 36 | 2.0855 | 0.395 | 0.1075 | 0.145 | 0.3175 | 0.2475 | 0.095 |
| No log | 18.72 | 38 | 2.0559 | 0.4 | 0.1125 | 0.145 | 0.305 | 0.255 | 0.1025 |
| No log | 19.72 | 40 | 2.0277 | 0.41 | 0.115 | 0.145 | 0.295 | 0.28 | 0.105 |
| No log | 20.72 | 42 | 1.9746 | 0.445 | 0.12 | 0.145 | 0.28 | 0.2875 | 0.1025 |
| No log | 21.72 | 44 | 1.9346 | 0.4525 | 0.12 | 0.145 | 0.265 | 0.25 | 0.1025 |
| No log | 22.72 | 46 | 1.8926 | 0.4925 | 0.12 | 0.145 | 0.255 | 0.25 | 0.11 |
| No log | 23.72 | 48 | 1.8581 | 0.5025 | 0.115 | 0.1475 | 0.26 | 0.3 | 0.1075 |
| No log | 24.72 | 50 | 1.8403 | 0.4975 | 0.11 | 0.1475 | 0.2725 | 0.3325 | 0.11 |
| No log | 25.72 | 52 | 1.8162 | 0.5 | 0.1125 | 0.1475 | 0.2875 | 0.3575 | 0.1125 |
| No log | 26.72 | 54 | 1.7562 | 0.5475 | 0.115 | 0.1475 | 0.295 | 0.3575 | 0.115 |
| No log | 27.72 | 56 | 1.7205 | 0.5725 | 0.1175 | 0.15 | 0.295 | 0.37 | 0.115 |
| No log | 28.72 | 58 | 1.7041 | 0.555 | 0.1175 | 0.15 | 0.295 | 0.36 | 0.11 |
| No log | 29.72 | 60 | 1.7018 | 0.5525 | 0.12 | 0.15 | 0.305 | 0.36 | 0.1125 |
| No log | 30.72 | 62 | 1.6532 | 0.58 | 0.12 | 0.15 | 0.3025 | 0.3725 | 0.1125 |
| No log | 31.72 | 64 | 1.6218 | 0.58 | 0.12 | 0.15 | 0.3125 | 0.3725 | 0.1175 |
| No log | 32.72 | 66 | 1.5888 | 0.59 | 0.115 | 0.1475 | 0.32 | 0.38 | 0.1325 |
| No log | 33.72 | 68 | 1.5778 | 0.6 | 0.115 | 0.1475 | 0.315 | 0.3875 | 0.1425 |
| No log | 34.72 | 70 | 1.5500 | 0.59 | 0.1225 | 0.15 | 0.315 | 0.3875 | 0.155 |
| No log | 35.72 | 72 | 1.5216 | 0.61 | 0.13 | 0.15 | 0.31 | 0.3875 | 0.17 |
| No log | 36.72 | 74 | 1.5024 | 0.6175 | 0.1275 | 0.15 | 0.3075 | 0.4125 | 0.1675 |
| No log | 37.72 | 76 | 1.4787 | 0.615 | 0.12 | 0.1525 | 0.32 | 0.4025 | 0.165 |
| No log | 38.72 | 78 | 1.4635 | 0.6175 | 0.1175 | 0.1525 | 0.325 | 0.4125 | 0.1625 |
| No log | 39.72 | 80 | 1.4455 | 0.6225 | 0.12 | 0.155 | 0.3225 | 0.4225 | 0.165 |
| No log | 40.72 | 82 | 1.4304 | 0.625 | 0.12 | 0.155 | 0.33 | 0.425 | 0.1675 |
| No log | 41.72 | 84 | 1.4170 | 0.6425 | 0.1175 | 0.155 | 0.3325 | 0.425 | 0.21 |
| No log | 42.72 | 86 | 1.4052 | 0.64 | 0.1175 | 0.155 | 0.335 | 0.4275 | 0.245 |
| No log | 43.72 | 88 | 1.3965 | 0.6425 | 0.1125 | 0.155 | 0.34 | 0.4125 | 0.2775 |
| No log | 44.72 | 90 | 1.3766 | 0.645 | 0.1125 | 0.155 | 0.3425 | 0.4075 | 0.315 |
| No log | 45.72 | 92 | 1.3611 | 0.6575 | 0.11 | 0.155 | 0.345 | 0.41 | 0.33 |
| No log | 46.72 | 94 | 1.3513 | 0.6575 | 0.11 | 0.155 | 0.3425 | 0.4175 | 0.34 |
| No log | 47.72 | 96 | 1.3520 | 0.665 | 0.11 | 0.155 | 0.3425 | 0.4275 | 0.36 |
| No log | 48.72 | 98 | 1.3373 | 0.67 | 0.11 | 0.155 | 0.3425 | 0.425 | 0.3875 |
| No log | 49.72 | 100 | 1.3213 | 0.6775 | 0.11 | 0.155 | 0.3425 | 0.4175 | 0.405 |
| No log | 50.72 | 102 | 1.3124 | 0.6825 | 0.11 | 0.155 | 0.3425 | 0.41 | 0.445 |
| No log | 51.72 | 104 | 1.3080 | 0.68 | 0.1075 | 0.155 | 0.34 | 0.41 | 0.455 |
| No log | 52.72 | 106 | 1.3037 | 0.675 | 0.105 | 0.1575 | 0.3425 | 0.4175 | 0.4775 |
| No log | 53.72 | 108 | 1.2987 | 0.6825 | 0.11 | 0.1575 | 0.345 | 0.425 | 0.4875 |
| No log | 54.72 | 110 | 1.2943 | 0.6775 | 0.1075 | 0.1575 | 0.3475 | 0.425 | 0.5025 |
| No log | 55.72 | 112 | 1.2889 | 0.68 | 0.1075 | 0.1575 | 0.3475 | 0.425 | 0.51 |
| No log | 56.72 | 114 | 1.2829 | 0.68 | 0.1075 | 0.16 | 0.3475 | 0.4225 | 0.5175 |
| No log | 57.72 | 116 | 1.2793 | 0.68 | 0.1075 | 0.155 | 0.3475 | 0.4225 | 0.5225 |
| No log | 58.72 | 118 | 1.2769 | 0.68 | 0.11 | 0.155 | 0.345 | 0.4225 | 0.5225 |
| No log | 59.72 | 120 | 1.2759 | 0.6825 | 0.11 | 0.155 | 0.345 | 0.425 | 0.5225 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
thenewcompany/reinforce-Pixelcopter-PLE-v0
|
thenewcompany
| 2023-07-05T17:29:49Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T17:29:44Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 31.00 +/- 25.88
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
hippopotam/wav2vec2-common_voice13
|
hippopotam
| 2023-07-05T17:24:44Z | 22 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_13_0",
"generated_from_trainer",
"tr",
"dataset:common_voice_13_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-06-30T15:25:30Z |
---
language:
- tr
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_13_0
- generated_from_trainer
datasets:
- common_voice_13_0
metrics:
- wer
model-index:
- name: wav2vec2-common_voice13
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: MOZILLA-FOUNDATION/COMMON_VOICE_13_0 - TR
type: common_voice_13_0
config: tr
split: test
args: 'Config: tr, Training split: train+validation, Eval split: test'
metrics:
- name: Wer
type: wer
value: 0.2936963013171634
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-common_voice13
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the MOZILLA-FOUNDATION/COMMON_VOICE_13_0 - TR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3366
- Wer: 0.2937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.0301 | 0.08 | 100 | 4.0286 | 1.0 |
| 3.1668 | 0.15 | 200 | 3.2323 | 1.0 |
| 2.3413 | 0.23 | 300 | 2.1300 | 0.9986 |
| 1.4546 | 0.31 | 400 | 0.8731 | 0.7629 |
| 1.4595 | 0.38 | 500 | 0.7366 | 0.7386 |
| 1.1903 | 0.46 | 600 | 0.6131 | 0.6645 |
| 1.1586 | 0.53 | 700 | 0.5491 | 0.6195 |
| 0.8275 | 0.61 | 800 | 0.5159 | 0.5923 |
| 1.0042 | 0.69 | 900 | 0.5153 | 0.6040 |
| 0.9428 | 0.76 | 1000 | 0.4629 | 0.5602 |
| 0.7592 | 0.84 | 1100 | 0.4670 | 0.5520 |
| 0.8284 | 0.92 | 1200 | 0.4455 | 0.5760 |
| 0.7736 | 0.99 | 1300 | 0.4571 | 0.5480 |
| 0.4047 | 1.07 | 1400 | 0.3962 | 0.4940 |
| 0.3543 | 1.14 | 1500 | 0.4018 | 0.4969 |
| 0.3898 | 1.22 | 1600 | 0.3901 | 0.4862 |
| 0.3827 | 1.3 | 1700 | 0.3982 | 0.4954 |
| 0.3316 | 1.37 | 1800 | 0.4139 | 0.5032 |
| 0.3365 | 1.45 | 1900 | 0.3964 | 0.4878 |
| 0.251 | 1.53 | 2000 | 0.4028 | 0.4899 |
| 0.2419 | 1.6 | 2100 | 0.3991 | 0.5190 |
| 0.3094 | 1.68 | 2200 | 0.3700 | 0.4865 |
| 0.3459 | 1.75 | 2300 | 0.3652 | 0.4850 |
| 0.3085 | 1.83 | 2400 | 0.3806 | 0.4742 |
| 0.4463 | 1.91 | 2500 | 0.3804 | 0.4729 |
| 0.2359 | 1.98 | 2600 | 0.3696 | 0.4635 |
| 0.1502 | 2.06 | 2700 | 0.3764 | 0.4602 |
| 0.2819 | 2.14 | 2800 | 0.3740 | 0.4499 |
| 0.22 | 2.21 | 2900 | 0.3811 | 0.4597 |
| 0.287 | 2.29 | 3000 | 0.3562 | 0.4334 |
| 0.2531 | 2.36 | 3100 | 0.3700 | 0.4442 |
| 0.3143 | 2.44 | 3200 | 0.3548 | 0.4333 |
| 0.203 | 2.52 | 3300 | 0.3659 | 0.4558 |
| 0.2609 | 2.59 | 3400 | 0.3557 | 0.4468 |
| 0.191 | 2.67 | 3500 | 0.3476 | 0.4281 |
| 0.1354 | 2.75 | 3600 | 0.3650 | 0.4354 |
| 0.2345 | 2.82 | 3700 | 0.3479 | 0.4385 |
| 0.1951 | 2.9 | 3800 | 0.3508 | 0.4489 |
| 0.2991 | 2.97 | 3900 | 0.3585 | 0.4356 |
| 0.1579 | 3.05 | 4000 | 0.3603 | 0.4326 |
| 0.2319 | 3.13 | 4100 | 0.3442 | 0.4201 |
| 0.1941 | 3.2 | 4200 | 0.3344 | 0.4116 |
| 0.2561 | 3.28 | 4300 | 0.3475 | 0.4200 |
| 0.3208 | 3.36 | 4400 | 0.3505 | 0.4089 |
| 0.2555 | 3.43 | 4500 | 0.3593 | 0.4271 |
| 0.1927 | 3.51 | 4600 | 0.3536 | 0.4299 |
| 0.1994 | 3.59 | 4700 | 0.3672 | 0.4400 |
| 0.1357 | 3.66 | 4800 | 0.3433 | 0.4223 |
| 0.2043 | 3.74 | 4900 | 0.3471 | 0.4226 |
| 0.194 | 3.81 | 5000 | 0.3380 | 0.4230 |
| 0.1779 | 3.89 | 5100 | 0.3400 | 0.4130 |
| 0.1934 | 3.97 | 5200 | 0.3438 | 0.4104 |
| 0.1432 | 4.04 | 5300 | 0.3632 | 0.4254 |
| 0.1642 | 4.12 | 5400 | 0.3425 | 0.4237 |
| 0.2208 | 4.2 | 5500 | 0.3580 | 0.4132 |
| 0.1923 | 4.27 | 5600 | 0.3469 | 0.4143 |
| 0.2084 | 4.35 | 5700 | 0.3619 | 0.4252 |
| 0.2484 | 4.42 | 5800 | 0.3452 | 0.4210 |
| 0.1899 | 4.5 | 5900 | 0.3465 | 0.4136 |
| 0.1253 | 4.58 | 6000 | 0.3625 | 0.4150 |
| 0.1353 | 4.65 | 6100 | 0.3415 | 0.4182 |
| 0.2264 | 4.73 | 6200 | 0.3446 | 0.4153 |
| 0.2016 | 4.81 | 6300 | 0.3343 | 0.4087 |
| 0.1634 | 4.88 | 6400 | 0.3500 | 0.4253 |
| 0.2517 | 4.96 | 6500 | 0.3453 | 0.4291 |
| 0.1826 | 5.03 | 6600 | 0.3442 | 0.4106 |
| 0.174 | 5.11 | 6700 | 0.3478 | 0.3999 |
| 0.271 | 5.19 | 6800 | 0.3423 | 0.4023 |
| 0.1812 | 5.26 | 6900 | 0.3679 | 0.4200 |
| 0.3 | 5.34 | 7000 | 0.3583 | 0.4191 |
| 0.2678 | 5.42 | 7100 | 0.3534 | 0.4141 |
| 0.236 | 5.49 | 7200 | 0.3361 | 0.4041 |
| 0.1558 | 5.57 | 7300 | 0.3495 | 0.4126 |
| 0.2603 | 5.64 | 7400 | 0.3359 | 0.3969 |
| 0.1285 | 5.72 | 7500 | 0.3296 | 0.3994 |
| 0.4608 | 5.8 | 7600 | 0.3453 | 0.3933 |
| 0.1516 | 5.87 | 7700 | 0.3509 | 0.4028 |
| 0.2655 | 5.95 | 7800 | 0.3607 | 0.4109 |
| 0.22 | 6.03 | 7900 | 0.3392 | 0.3850 |
| 0.0787 | 6.1 | 8000 | 0.3395 | 0.3842 |
| 0.1297 | 6.18 | 8100 | 0.3356 | 0.3822 |
| 0.1747 | 6.25 | 8200 | 0.3275 | 0.3874 |
| 0.1647 | 6.33 | 8300 | 0.3554 | 0.3941 |
| 0.1314 | 6.41 | 8400 | 0.3287 | 0.3826 |
| 0.1264 | 6.48 | 8500 | 0.3122 | 0.3876 |
| 0.1229 | 6.56 | 8600 | 0.3525 | 0.3994 |
| 0.108 | 6.64 | 8700 | 0.3387 | 0.3968 |
| 0.185 | 6.71 | 8800 | 0.3333 | 0.3840 |
| 0.0924 | 6.79 | 8900 | 0.3366 | 0.3827 |
| 0.1226 | 6.86 | 9000 | 0.3243 | 0.3788 |
| 0.2005 | 6.94 | 9100 | 0.3324 | 0.3765 |
| 0.133 | 7.02 | 9200 | 0.3294 | 0.3688 |
| 0.0633 | 7.09 | 9300 | 0.3279 | 0.3738 |
| 0.0593 | 7.17 | 9400 | 0.3311 | 0.3639 |
| 0.088 | 7.25 | 9500 | 0.3221 | 0.3765 |
| 0.1489 | 7.32 | 9600 | 0.3421 | 0.3788 |
| 0.1175 | 7.4 | 9700 | 0.3191 | 0.3786 |
| 0.0983 | 7.48 | 9800 | 0.3303 | 0.3764 |
| 0.1493 | 7.55 | 9900 | 0.3371 | 0.3836 |
| 0.1091 | 7.63 | 10000 | 0.3410 | 0.3739 |
| 0.1058 | 7.7 | 10100 | 0.3262 | 0.3730 |
| 0.0849 | 7.78 | 10200 | 0.3379 | 0.3812 |
| 0.1362 | 7.86 | 10300 | 0.3291 | 0.3781 |
| 0.1227 | 7.93 | 10400 | 0.3235 | 0.3760 |
| 0.1647 | 8.01 | 10500 | 0.3285 | 0.3686 |
| 0.1013 | 8.09 | 10600 | 0.3319 | 0.3729 |
| 0.1432 | 8.16 | 10700 | 0.3280 | 0.3731 |
| 0.1345 | 8.24 | 10800 | 0.3237 | 0.3707 |
| 0.0813 | 8.31 | 10900 | 0.3285 | 0.3748 |
| 0.1063 | 8.39 | 11000 | 0.3321 | 0.3748 |
| 0.1342 | 8.47 | 11100 | 0.3171 | 0.3647 |
| 0.1202 | 8.54 | 11200 | 0.3209 | 0.3636 |
| 0.0987 | 8.62 | 11300 | 0.3224 | 0.3625 |
| 0.1357 | 8.7 | 11400 | 0.3245 | 0.3646 |
| 0.1038 | 8.77 | 11500 | 0.3172 | 0.3702 |
| 0.0961 | 8.85 | 11600 | 0.3080 | 0.3611 |
| 0.1836 | 8.92 | 11700 | 0.3112 | 0.3681 |
| 0.0951 | 9.0 | 11800 | 0.3157 | 0.3649 |
| 0.1162 | 9.08 | 11900 | 0.3188 | 0.3714 |
| 0.1157 | 9.15 | 12000 | 0.3383 | 0.3775 |
| 0.1268 | 9.23 | 12100 | 0.3204 | 0.3752 |
| 0.1402 | 9.31 | 12200 | 0.3441 | 0.3707 |
| 0.1094 | 9.38 | 12300 | 0.3415 | 0.3675 |
| 0.1122 | 9.46 | 12400 | 0.3150 | 0.3596 |
| 0.0932 | 9.53 | 12500 | 0.3195 | 0.3561 |
| 0.1176 | 9.61 | 12600 | 0.3250 | 0.3675 |
| 0.1287 | 9.69 | 12700 | 0.3253 | 0.3615 |
| 0.0886 | 9.76 | 12800 | 0.3276 | 0.3636 |
| 0.1016 | 9.84 | 12900 | 0.3185 | 0.3592 |
| 0.0902 | 9.92 | 13000 | 0.3177 | 0.3643 |
| 0.1304 | 9.99 | 13100 | 0.3131 | 0.3530 |
| 0.099 | 10.07 | 13200 | 0.3094 | 0.3525 |
| 0.1142 | 10.14 | 13300 | 0.3298 | 0.3609 |
| 0.1836 | 10.22 | 13400 | 0.3213 | 0.3526 |
| 0.1533 | 10.3 | 13500 | 0.3163 | 0.3579 |
| 0.1436 | 10.37 | 13600 | 0.3352 | 0.3543 |
| 0.1215 | 10.45 | 13700 | 0.3355 | 0.3458 |
| 0.0971 | 10.53 | 13800 | 0.3232 | 0.3579 |
| 0.1215 | 10.6 | 13900 | 0.3168 | 0.3441 |
| 0.0906 | 10.68 | 14000 | 0.3266 | 0.3498 |
| 0.125 | 10.76 | 14100 | 0.3318 | 0.3414 |
| 0.0831 | 10.83 | 14200 | 0.3030 | 0.3480 |
| 0.1588 | 10.91 | 14300 | 0.3155 | 0.3455 |
| 0.1191 | 10.98 | 14400 | 0.3287 | 0.3487 |
| 0.074 | 11.06 | 14500 | 0.3176 | 0.3431 |
| 0.1075 | 11.14 | 14600 | 0.3219 | 0.3446 |
| 0.0679 | 11.21 | 14700 | 0.3158 | 0.3414 |
| 0.0789 | 11.29 | 14800 | 0.3305 | 0.3491 |
| 0.1426 | 11.37 | 14900 | 0.3281 | 0.3485 |
| 0.1154 | 11.44 | 15000 | 0.3368 | 0.3482 |
| 0.1313 | 11.52 | 15100 | 0.3285 | 0.3415 |
| 0.0786 | 11.59 | 15200 | 0.3138 | 0.3439 |
| 0.0595 | 11.67 | 15300 | 0.3135 | 0.3431 |
| 0.0868 | 11.75 | 15400 | 0.3049 | 0.3396 |
| 0.0812 | 11.82 | 15500 | 0.3050 | 0.3373 |
| 0.1199 | 11.9 | 15600 | 0.3238 | 0.3392 |
| 0.1243 | 11.98 | 15700 | 0.3123 | 0.3368 |
| 0.0663 | 12.05 | 15800 | 0.3226 | 0.3373 |
| 0.0285 | 12.13 | 15900 | 0.3260 | 0.3367 |
| 0.0607 | 12.2 | 16000 | 0.3236 | 0.3406 |
| 0.064 | 12.28 | 16100 | 0.3297 | 0.3357 |
| 0.0554 | 12.36 | 16200 | 0.3357 | 0.3383 |
| 0.0561 | 12.43 | 16300 | 0.3211 | 0.3387 |
| 0.0785 | 12.51 | 16400 | 0.3140 | 0.3386 |
| 0.0539 | 12.59 | 16500 | 0.3130 | 0.3361 |
| 0.0873 | 12.66 | 16600 | 0.3244 | 0.3344 |
| 0.0774 | 12.74 | 16700 | 0.3128 | 0.3274 |
| 0.0853 | 12.81 | 16800 | 0.3185 | 0.3395 |
| 0.0701 | 12.89 | 16900 | 0.3244 | 0.3327 |
| 0.0486 | 12.97 | 17000 | 0.3100 | 0.3317 |
| 0.1087 | 13.04 | 17100 | 0.3351 | 0.3327 |
| 0.0716 | 13.12 | 17200 | 0.3474 | 0.3383 |
| 0.0653 | 13.2 | 17300 | 0.3361 | 0.3364 |
| 0.0936 | 13.27 | 17400 | 0.3423 | 0.3352 |
| 0.0761 | 13.35 | 17500 | 0.3261 | 0.3304 |
| 0.0723 | 13.42 | 17600 | 0.3298 | 0.3333 |
| 0.0756 | 13.5 | 17700 | 0.3282 | 0.3367 |
| 0.058 | 13.58 | 17800 | 0.3386 | 0.3303 |
| 0.0619 | 13.65 | 17900 | 0.3354 | 0.3306 |
| 0.081 | 13.73 | 18000 | 0.3413 | 0.3317 |
| 0.0893 | 13.81 | 18100 | 0.3257 | 0.3278 |
| 0.0858 | 13.88 | 18200 | 0.3312 | 0.3255 |
| 0.0756 | 13.96 | 18300 | 0.3279 | 0.3326 |
| 0.0946 | 14.04 | 18400 | 0.3412 | 0.3272 |
| 0.1452 | 14.11 | 18500 | 0.3394 | 0.3266 |
| 0.0772 | 14.19 | 18600 | 0.3271 | 0.3261 |
| 0.0748 | 14.26 | 18700 | 0.3338 | 0.3272 |
| 0.0789 | 14.34 | 18800 | 0.3461 | 0.3254 |
| 0.0967 | 14.42 | 18900 | 0.3163 | 0.3250 |
| 0.0938 | 14.49 | 19000 | 0.3273 | 0.3261 |
| 0.1134 | 14.57 | 19100 | 0.3301 | 0.3284 |
| 0.1051 | 14.65 | 19200 | 0.3187 | 0.3215 |
| 0.0936 | 14.72 | 19300 | 0.3211 | 0.3197 |
| 0.0528 | 14.8 | 19400 | 0.3381 | 0.3270 |
| 0.1497 | 14.87 | 19500 | 0.3291 | 0.3235 |
| 0.1168 | 14.95 | 19600 | 0.3290 | 0.3238 |
| 0.028 | 15.03 | 19700 | 0.3333 | 0.3209 |
| 0.0773 | 15.1 | 19800 | 0.3359 | 0.3206 |
| 0.0972 | 15.18 | 19900 | 0.3262 | 0.3163 |
| 0.0391 | 15.26 | 20000 | 0.3335 | 0.3180 |
| 0.0571 | 15.33 | 20100 | 0.3445 | 0.3198 |
| 0.0365 | 15.41 | 20200 | 0.3318 | 0.3170 |
| 0.0535 | 15.48 | 20300 | 0.3257 | 0.3147 |
| 0.0739 | 15.56 | 20400 | 0.3359 | 0.3136 |
| 0.0753 | 15.64 | 20500 | 0.3216 | 0.3195 |
| 0.1507 | 15.71 | 20600 | 0.3326 | 0.3154 |
| 0.062 | 15.79 | 20700 | 0.3310 | 0.3164 |
| 0.0595 | 15.87 | 20800 | 0.3134 | 0.3162 |
| 0.0456 | 15.94 | 20900 | 0.3146 | 0.3127 |
| 0.0977 | 16.02 | 21000 | 0.3328 | 0.3117 |
| 0.036 | 16.09 | 21100 | 0.3266 | 0.3134 |
| 0.0308 | 16.17 | 21200 | 0.3306 | 0.3136 |
| 0.0612 | 16.25 | 21300 | 0.3207 | 0.3160 |
| 0.0269 | 16.32 | 21400 | 0.3429 | 0.3143 |
| 0.0897 | 16.4 | 21500 | 0.3355 | 0.3111 |
| 0.0458 | 16.48 | 21600 | 0.3238 | 0.3065 |
| 0.0155 | 16.55 | 21700 | 0.3167 | 0.3042 |
| 0.0519 | 16.63 | 21800 | 0.3296 | 0.3099 |
| 0.0807 | 16.7 | 21900 | 0.3250 | 0.3048 |
| 0.0406 | 16.78 | 22000 | 0.3283 | 0.3087 |
| 0.0773 | 16.86 | 22100 | 0.3217 | 0.3047 |
| 0.1027 | 16.93 | 22200 | 0.3279 | 0.3108 |
| 0.0315 | 17.01 | 22300 | 0.3173 | 0.3058 |
| 0.0457 | 17.09 | 22400 | 0.3387 | 0.3085 |
| 0.0516 | 17.16 | 22500 | 0.3309 | 0.3050 |
| 0.0413 | 17.24 | 22600 | 0.3363 | 0.3067 |
| 0.0601 | 17.32 | 22700 | 0.3325 | 0.3048 |
| 0.0435 | 17.39 | 22800 | 0.3298 | 0.3058 |
| 0.0571 | 17.47 | 22900 | 0.3244 | 0.3033 |
| 0.0656 | 17.54 | 23000 | 0.3350 | 0.3056 |
| 0.0485 | 17.62 | 23100 | 0.3406 | 0.3051 |
| 0.0619 | 17.7 | 23200 | 0.3268 | 0.3033 |
| 0.0495 | 17.77 | 23300 | 0.3268 | 0.3031 |
| 0.0416 | 17.85 | 23400 | 0.3268 | 0.3038 |
| 0.0646 | 17.93 | 23500 | 0.3314 | 0.3009 |
| 0.0294 | 18.0 | 23600 | 0.3251 | 0.3028 |
| 0.0372 | 18.08 | 23700 | 0.3364 | 0.2962 |
| 0.04 | 18.15 | 23800 | 0.3358 | 0.2967 |
| 0.0367 | 18.23 | 23900 | 0.3317 | 0.3031 |
| 0.0312 | 18.31 | 24000 | 0.3272 | 0.2998 |
| 0.0419 | 18.38 | 24100 | 0.3358 | 0.2996 |
| 0.0477 | 18.46 | 24200 | 0.3283 | 0.2996 |
| 0.0256 | 18.54 | 24300 | 0.3310 | 0.2995 |
| 0.0269 | 18.61 | 24400 | 0.3325 | 0.2997 |
| 0.0309 | 18.69 | 24500 | 0.3345 | 0.2974 |
| 0.0441 | 18.76 | 24600 | 0.3345 | 0.3003 |
| 0.0496 | 18.84 | 24700 | 0.3396 | 0.2985 |
| 0.0425 | 18.92 | 24800 | 0.3425 | 0.2965 |
| 0.0196 | 18.99 | 24900 | 0.3373 | 0.2964 |
| 0.0348 | 19.07 | 25000 | 0.3361 | 0.2955 |
| 0.0466 | 19.15 | 25100 | 0.3328 | 0.2959 |
| 0.0422 | 19.22 | 25200 | 0.3343 | 0.2964 |
| 0.0271 | 19.3 | 25300 | 0.3369 | 0.2945 |
| 0.053 | 19.37 | 25400 | 0.3330 | 0.2953 |
| 0.0662 | 19.45 | 25500 | 0.3343 | 0.2958 |
| 0.0718 | 19.53 | 25600 | 0.3330 | 0.2952 |
| 0.0212 | 19.6 | 25700 | 0.3352 | 0.2940 |
| 0.0971 | 19.68 | 25800 | 0.3374 | 0.2935 |
| 0.0413 | 19.76 | 25900 | 0.3362 | 0.2933 |
| 0.0477 | 19.83 | 26000 | 0.3356 | 0.2940 |
| 0.1068 | 19.91 | 26100 | 0.3365 | 0.2937 |
| 0.108 | 19.98 | 26200 | 0.3366 | 0.2935 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1
- Datasets 2.13.1
- Tokenizers 0.13.2
|
heka-ai/e5-100k
|
heka-ai
| 2023-07-05T17:09:28Z | 1 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-05T17:09:24Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# heka-ai/e5-100k
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('heka-ai/e5-100k')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('heka-ai/e5-100k')
model = AutoModel.from_pretrained('heka-ai/e5-100k')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=heka-ai/e5-100k)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 20000 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 100000,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Emilianohack6950/GenOrtega
|
Emilianohack6950
| 2023-07-05T16:50:47Z | 32 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-06-28T22:03:29Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
GenOrtega es un modelo avanzado de generación de imágenes basado en inteligencia artificial, diseñado para capturar y recrear la belleza única de Jenna Ortega, una talentosa actriz reconocida en la industria del entretenimiento. Utilizando técnicas de aprendizaje profundo y una vasta cantidad de datos de entrenamiento, este modelo ha sido entrenado para generar imágenes fotorrealistas de alta calidad que capturan con precisión los rasgos faciales, la expresividad y el estilo inconfundible de Jenna Ortega.
Con GenOrtega, puedes explorar la creatividad y obtener imágenes personalizadas de Jenna Ortega para diversas aplicaciones, como proyectos de diseño gráfico, desarrollo de videojuegos, producción cinematográfica, arte digital y más. El modelo ofrece una amplia gama de opciones para personalizar las imágenes generadas, como la elección de expresiones faciales, cambios de vestuario y entornos, lo que te permite adaptar las imágenes a tus necesidades específicas.
GenOrtega ha sido entrenado en una amplia variedad de imágenes y poses de Jenna Ortega, lo que le permite capturar su diversidad y versatilidad como artista. Además, el modelo cuenta con una interfaz intuitiva y fácil de usar, lo que lo hace accesible tanto para profesionales creativos como para entusiastas del arte digital.
Descubre la magia de GenOrtega y experimenta con la generación de imágenes de Jenna Ortega para dar vida a tus ideas y proyectos con un toque de estilo y autenticidad únicos.
Sample pictures of this concept:





|
omar-al-sharif/AlQalam-finetuned-mmj
|
omar-al-sharif
| 2023-07-05T16:21:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T14:11:56Z |
---
tags:
- generated_from_trainer
model-index:
- name: AlQalam-finetuned-mmj
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AlQalam-finetuned-mmj
This model is a fine-tuned version of [malmarjeh/t5-arabic-text-summarization](https://huggingface.co/malmarjeh/t5-arabic-text-summarization) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0723
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3745 | 1.0 | 1678 | 1.1947 |
| 1.219 | 2.0 | 3356 | 1.1176 |
| 1.065 | 3.0 | 5034 | 1.0895 |
| 0.9928 | 4.0 | 6712 | 1.0734 |
| 0.9335 | 5.0 | 8390 | 1.0723 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
timbrooks/instruct-pix2pix
|
timbrooks
| 2023-07-05T16:19:25Z | 78,060 | 1,061 |
diffusers
|
[
"diffusers",
"safetensors",
"image-to-image",
"license:mit",
"diffusers:StableDiffusionInstructPix2PixPipeline",
"region:us"
] |
image-to-image
| 2023-01-20T04:27:06Z |
---
license: mit
tags:
- image-to-image
---
# InstructPix2Pix: Learning to Follow Image Editing Instructions
GitHub: https://github.com/timothybrooks/instruct-pix2pix
<img src='https://instruct-pix2pix.timothybrooks.com/teaser.jpg'/>
## Example
To use `InstructPix2Pix`, install `diffusers` using `main` for now. The pipeline will be available in the next release
```bash
pip install diffusers accelerate safetensors transformers
```
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline, EulerAncestralDiscreteScheduler
model_id = "timbrooks/instruct-pix2pix"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16, safety_checker=None)
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
url = "https://raw.githubusercontent.com/timothybrooks/instruct-pix2pix/main/imgs/example.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "turn him into cyborg"
images = pipe(prompt, image=image, num_inference_steps=10, image_guidance_scale=1).images
images[0]
```
|
stabilityai/stable-diffusion-2-1-base
|
stabilityai
| 2023-07-05T16:19:20Z | 863,939 | 647 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-06T17:25:36Z |
---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2-1-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints, for various versions:
### Version 2.1
- `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
### Version 2.0
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
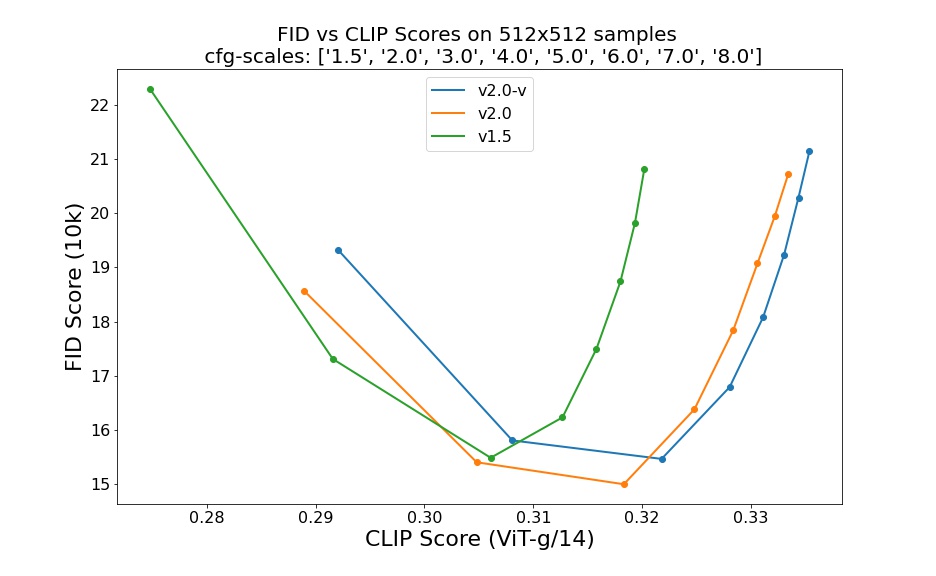
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
stabilityai/stable-diffusion-2-inpainting
|
stabilityai
| 2023-07-05T16:19:10Z | 277,480 | 527 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"diffusers:StableDiffusionInpaintPipeline",
"region:us"
] |
image-to-image
| 2022-11-23T17:41:55Z |
---
license: openrail++
tags:
- stable-diffusion
inference: false
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-inpainting` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-inpainting-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting/resolve/main/512-inpainting-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 inpainting in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
)
pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
**How it works:**
`image` | `mask_image`
:-------------------------:|:-------------------------:|
<img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" alt="drawing" width="300"/> | <img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" alt="drawing" width="300"/>
`prompt` | `Output`
:-------------------------:|:-------------------------:|
<span style="position: relative;bottom: 150px;">Face of a yellow cat, high resolution, sitting on a park bench</span> | <img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/test.png" alt="drawing" width="300"/>
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
stabilityai/stable-diffusion-2
|
stabilityai
| 2023-07-05T16:19:01Z | 237,820 | 1,856 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2202.00512",
"arxiv:2112.10752",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-11-23T11:54:34Z |
---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2 model, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on `768x768` images.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `768-v-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/768-v-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
model_id = "stabilityai/stable-diffusion-2"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
CompVis/ldm-super-resolution-4x-openimages
|
CompVis
| 2023-07-05T16:18:48Z | 4,364 | 112 |
diffusers
|
[
"diffusers",
"pytorch",
"super-resolution",
"diffusion-super-resolution",
"arxiv:2112.10752",
"license:apache-2.0",
"diffusers:LDMSuperResolutionPipeline",
"region:us"
] | null | 2022-11-09T12:35:04Z |
---
license: apache-2.0
tags:
- pytorch
- diffusers
- super-resolution
- diffusion-super-resolution
---
# Latent Diffusion Models (LDM) for super-resolution
**Paper**: [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
**Abstract**:
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
**Authors**
*Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer*
## Usage
### Inference with a pipeline
```python
!pip install git+https://github.com/huggingface/diffusers.git
import requests
from PIL import Image
from io import BytesIO
from diffusers import LDMSuperResolutionPipeline
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "CompVis/ldm-super-resolution-4x-openimages"
# load model and scheduler
pipeline = LDMSuperResolutionPipeline.from_pretrained(model_id)
pipeline = pipeline.to(device)
# let's download an image
url = "https://user-images.githubusercontent.com/38061659/199705896-b48e17b8-b231-47cd-a270-4ffa5a93fa3e.png"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
# run pipeline in inference (sample random noise and denoise)
upscaled_image = pipeline(low_res_img, num_inference_steps=100, eta=1).images[0]
# save image
upscaled_image.save("ldm_generated_image.png")
```
|
hakurei/waifu-diffusion
|
hakurei
| 2023-07-05T16:18:18Z | 6,435 | 2,418 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-08-30T02:28:33Z |
---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: true
---
# waifu-diffusion v1.4 - Diffusion for Weebs
waifu-diffusion is a latent text-to-image diffusion model that has been conditioned on high-quality anime images through fine-tuning.

<sub>masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, watercolor, night, turtleneck</sub>
[Original Weights](https://huggingface.co/hakurei/waifu-diffusion-v1-4)
# Gradio & Colab
We also support a [Gradio](https://github.com/gradio-app/gradio) Web UI and Colab with Diffusers to run Waifu Diffusion:
[](https://huggingface.co/spaces/hakurei/waifu-diffusion-demo)
[](https://colab.research.google.com/drive/1_8wPN7dJO746QXsFnB09Uq2VGgSRFuYE#scrollTo=1HaCauSq546O)
## Model Description
[See here for a full model overview.](https://gist.github.com/harubaru/f727cedacae336d1f7877c4bbe2196e1)
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Downstream Uses
This model can be used for entertainment purposes and as a generative art assistant.
## Example Code
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
'hakurei/waifu-diffusion',
torch_dtype=torch.float32
).to('cuda')
prompt = "1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=6)["sample"][0]
image.save("test.png")
```
## Team Members and Acknowledgements
This project would not have been possible without the incredible work by Stability AI and Novel AI.
- [Haru](https://github.com/harubaru)
- [Salt](https://github.com/sALTaccount/)
- [Sta @ Bit192](https://twitter.com/naclbbr)
In order to reach us, you can join our [Discord server](https://discord.gg/touhouai).
[](https://discord.gg/touhouai)
|
Jacknjeilfy/BarfBag
|
Jacknjeilfy
| 2023-07-05T16:18:04Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T16:18:04Z |
---
license: creativeml-openrail-m
---
|
dkatsiros/ppo-LunarLander-v2
|
dkatsiros
| 2023-07-05T16:16:17Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T16:15:56Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.74 +/- 16.94
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CeroShrijver/chinese-macbert-base-text-classification
|
CeroShrijver
| 2023-07-05T16:12:51Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-03T07:53:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: chinese-macbert-base-text-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-macbert-base-text-classification
This model is a fine-tuned version of [hfl/chinese-macbert-base](https://huggingface.co/hfl/chinese-macbert-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6609
- Accuracy: 0.7844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5794 | 1.0 | 1009 | 0.4825 | 0.7900 |
| 0.3729 | 2.0 | 2018 | 0.5239 | 0.8043 |
| 0.3049 | 3.0 | 3027 | 0.6609 | 0.7844 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
VFiona/opus-mt-en-it-finetuned-en-to-it
|
VFiona
| 2023-07-05T15:59:15Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-05T10:06:43Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: opus-mt-en-it-finetuned-en-to-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-it-finetuned-en-to-it
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-it](https://huggingface.co/Helsinki-NLP/opus-mt-en-it) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 118 | 0.4349 | 68.1929 | 31.879 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1
- Datasets 2.13.1
- Tokenizers 0.11.0
|
xyzkunn/sdfw
|
xyzkunn
| 2023-07-05T15:49:56Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T15:44:53Z |
---
license: creativeml-openrail-m
---
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.