
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-09 00:41:25
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 549
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-09 00:41:08
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
datek/Qwen-Qwen1.5-7B-1717035551
|
datek
| 2024-05-30T02:23:16Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T02:19:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dusdn/wespeaker-voxceleb-resnet293-LM
|
dusdn
| 2024-05-30T02:17:54Z | 5 | 0 | null |
[
"pytorch",
"speaker embedding",
"wespeaker",
"speaker modelling",
"summarization",
"en",
"arxiv:2210.17016",
"license:cc-by-4.0",
"region:us"
] |
summarization
| 2024-05-30T00:40:33Z |
---
license: cc-by-4.0
language:
- en
pipeline_tag: summarization
tags:
- speaker embedding
- wespeaker
- speaker modelling
---
Official model provided by [Wespeaker](https://github.com/wenet-e2e/wespeaker) project, ResNet293 based r-vector (After large margin finetune)
The model is trained on VoxCeleb2 Dev dataset, containing 5994 speakers.
## Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/wenet-e2e/wespeaker
- **Paper:** https://arxiv.org/pdf/2210.17016.pdf
- **Demo:** https://huggingface.co/spaces/wenet/wespeaker_demo
## Results on VoxCeleb
| Model | Params | Flops | LM | AS-Norm | vox1-O-clean | vox1-E-clean | vox1-H-clean |
|:------|:------:|:------|:--:|:-------:|:------------:|:------------:|:------------:|
| ResNet293-TSTP-emb256 | 28.62M | 28.10G | × | × | 0.595 | 0.756 | 1.433 |
| | | | × | √ | 0.537 | 0.701 | 1.276 |
| | | | √ | × | 0.532 | 0.707 | 1.311 |
| | | | √ | √ | **0.447** | **0.657** | **1.183** |
## Install Wespeaker
``` sh
pip install git+https://github.com/wenet-e2e/wespeaker.git
```
for development install:
``` sh
git clone https://github.com/wenet-e2e/wespeaker.git
cd wespeaker
pip install -e .
```
### Command line Usage
``` sh
$ wespeaker -p resnet293_download_dir --task embedding --audio_file audio.wav --output_file embedding.txt
$ wespeaker -p resnet293_download_dir --task embedding_kaldi --wav_scp wav.scp --output_file /path/to/embedding
$ wespeaker -p resnet293_download_dir --task similarity --audio_file audio.wav --audio_file2 audio2.wav
$ wespeaker -p resnet293_download_dir --task diarization --audio_file audio.wav
```
### Python Programming Usage
``` python
import wespeaker
model = wespeaker.load_model_local(resnet293_download_dir)
# set_gpu to enable the cuda inference, number < 0 means using CPU
model.set_gpu(0)
# embedding/embedding_kaldi/similarity/diarization
embedding = model.extract_embedding('audio.wav')
utt_names, embeddings = model.extract_embedding_list('wav.scp')
similarity = model.compute_similarity('audio1.wav', 'audio2.wav')
diar_result = model.diarize('audio.wav')
# register and recognize
model.register('spk1', 'spk1_audio1.wav')
model.register('spk2', 'spk2_audio1.wav')
model.register('spk3', 'spk3_audio1.wav')
result = model.recognize('spk1_audio2.wav')
```
## Citation
```bibtex
@inproceedings{wang2023wespeaker,
title={Wespeaker: A research and production oriented speaker embedding learning toolkit},
author={Wang, Hongji and Liang, Chengdong and Wang, Shuai and Chen, Zhengyang and Zhang, Binbin and Xiang, Xu and Deng, Yanlei and Qian, Yanmin},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--5},
year={2023},
organization={IEEE}
}
```
|
BahaaEldin0/bert-base-uncased-reward-model
|
BahaaEldin0
| 2024-05-30T02:15:44Z | 108 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-05-30T01:27:47Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
EleutherAI/Meta-Llama-3-8B-capitals-random-standardized-random-names
|
EleutherAI
| 2024-05-30T02:11:58Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T23:57:35Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
SyedaFatimaJaffer/BARD_for_MCQs
|
SyedaFatimaJaffer
| 2024-05-30T02:10:52Z | 108 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-05-30T02:08:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
EleutherAI/Meta-Llama-3-8B-hemisphere-random-standardized-random-names
|
EleutherAI
| 2024-05-30T02:10:17Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T23:58:20Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
terry69/llama5p
|
terry69
| 2024-05-30T02:00:56Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:HuggingFaceH4/ultrachat_200k",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:finetune:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-28T22:59:16Z |
---
license: llama3
base_model: meta-llama/Meta-Llama-3-8B
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- HuggingFaceH4/ultrachat_200k
model-index:
- name: llama5p
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama5p
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the HuggingFaceH4/ultrachat_200k dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1369
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8472 | 1.0 | 406 | 1.1369 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
theailearner/AIDoctor-Expert-llama-3-8b-Instruct-bnb-4bit
|
theailearner
| 2024-05-30T01:57:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-30T01:57:15Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** theailearner
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
xingfangcasia/public_his_num_1_2_3_4_5_6_epoch_100
|
xingfangcasia
| 2024-05-30T01:55:26Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-30T01:54:57Z |
---
license: apache-2.0
---
|
Yuminyumin/dqn-SpaceInvadersNoFrameskip-v4
|
Yuminyumin
| 2024-05-30T01:50:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-05-30T01:50:25Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 7.00 +/- 9.00
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Yuminyumin -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Yuminyumin -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Yuminyumin
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 10000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 100),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
sdyy/test_trainer
|
sdyy
| 2024-05-30T01:47:24Z | 186 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-05-19T21:06:55Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: test_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6259
- Accuracy: 0.23
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 13 | 1.5980 | 0.26 |
| No log | 2.0 | 26 | 1.5954 | 0.23 |
| No log | 3.0 | 39 | 1.6259 | 0.23 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Madhumita19/merged-mistralfinetuned-v3.0-10epoch
|
Madhumita19
| 2024-05-30T01:44:43Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T01:41:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
internlm/AlchemistCoder-DS-6.7B
|
internlm
| 2024-05-30T01:42:20Z | 13 | 11 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"code generation",
"conversational",
"arxiv:2405.19265",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T16:12:34Z |
---
license: apache-2.0
tags:
- code generation
---
# AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
[[🤗 HuggingFace](https://huggingface.co/internlm/AlchemistCoder-DS-6.7B)]
[[📃 Paper](https://arxiv.org/abs/2405.19265)]
[[🌐 Project Page](https://internlm.github.io/AlchemistCoder/)]
## ✨ Highlights
> **Abstract:** *Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence.*
- **AlchemistPrompts**: Designed as data-specific prompts for harmonizing inherent conflicts in multi-source data and mitigating the instruction/response misalignment at a fined-grained level.
- **Code Comprehenstion Tasks**: Sourced from the process of data construction, consisting of instruction evolution, data filtering, and code review.
- **Harmonized Multi-source Data**: Instruction tuned on 200M tokens, including 6 types of high-quality data.
- **Superior Model Performance**: Surpassing all the open-source models of the same size (6.7/7B), and rivaling or even beating larger models (15B/33B/70B/ChatGPT) on 6 code benchmarks.
- **Advanced generic capabilities**: Demonstrated by the significant improvements on MMLU, BBH, and GSM8K.
## 🚀 Quick Start
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("internlm/AlchemistCoder-DS-6.7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("internlm/AlchemistCoder-DS-6.7B", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
model = model.eval()
input_text = "Implement the Dijkstra algorithm in Python"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
The above code will generate the following result:
```python
import heapq
def dijkstra(graph, start, end):
"""
Find the shortest path between two nodes in a graph using Dijkstra's algorithm.
Args:
graph (dict): A dictionary representing the graph, where the keys are nodes and the values are dictionaries
containing the neighboring nodes and their edge weights.
start: The starting node.
end: The target node.
Returns:
list: The shortest path from the start node to the target node as a list of nodes.
Raises:
ValueError: If either the start or end node is not present in the graph.
"""
# Check if start and end nodes are in the graph
if start not in graph:
raise ValueError("Start node is not present in the graph.")
if end not in graph:
raise ValueError("End node is not present in the graph.")
# Initialize the distance dictionary with infinite distances for all nodes
distances = {node: float('inf') for node in graph}
# Set the distance of the start node to 0
distances[start] = 0
# Initialize the heap with the start node
heap = [(0, start)]
# Initialize the previous dictionary to keep track of the path
previous = {}
while heap:
# Pop the node with the smallest distance from the heap
current_distance, current_node = heapq.heappop(heap)
# If the current node is the end node, we have found the shortest path
if current_node == end:
# Reconstruct the path by following the previous nodes
path = []
while current_node in previous:
path.append(current_node)
current_node = previous[current_node]
path.append(start)
# Reverse the path to get the correct order
return path[::-1]
# Iterate over the neighboring nodes and update their distances
for neighbor, weight in graph[current_node].items():
new_distance = current_distance + weight
# If a shorter path is found, update the distance and previous node
if new_distance < distances[neighbor]:
distances[neighbor] = new_distance
previous[neighbor] = current_node
heapq.heappush(heap, (new_distance, neighbor))
# If there is no path between the start and end nodes, return an empty list
return []
```
> The `dijkstra` function takes three arguments: `graph`, `start`, and `end`. The `graph` argument is a dictionary representing the graph, where the keys are nodes and the values are dictionaries containing the neighboring nodes and their edge weights. The `start` argument is the starting node, and the `end` argument is the target node.
> The function first checks if the start and end nodes are present in the graph. If either node is not present, a `ValueError` is raised.
> The function then initializes a `distances` dictionary with infinite distances for all nodes. It sets the distance of the start node to 0. It also initializes a heap with the start node and a `previous` dictionary to keep track of the path.
> The algorithm then iterates over the nodes in the heap. For each node, it checks if it is the end node. If it is, the function reconstructs the path by following the previous nodes and returns the shortest path as a list of nodes in the correct order.
> If the current node is not the end node, the algorithm iterates over its neighboring nodes and updates their distances if a shorter path is found. It also updates the `previous` dictionary to keep track of the path.
> If there is no path between the start and end nodes, the function returns an empty list.
> Note that this implementation assumes that the graph is a directed graph, and it uses a heap data structure to efficiently select the node with the smallest distance at each step.
## 🧪 Evaluation and Fine-tune
Please refer to [**AlchemistCoder**](https://github.com/InternLM/AlchemistCoder) and [**InternLM**](https://github.com/InternLM/InternLM/tree/main).
## 😃 Acknowledgments
*AlchemistCoder* is built with [**InternLM**](https://github.com/InternLM) and [**OpenCompass**](https://github.com/open-compass). Thanks for their awesome work!
## 📧 Contact
If you have any questions, please create an issue on this repository or contact us at:
- sugger@tongji.edu.cn
- zhangwenwei@pjlab.org.cn
## 🌟 Citation
If you find our work useful, please consider citing:
```bibtex
@misc{song2024alchemistcoder,
title={AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data},
author={Zifan Song and Yudong Wang and Wenwei Zhang and Kuikun Liu and Chengqi Lyu and Demin Song and Qipeng Guo and Hang Yan and Dahua Lin and Kai Chen and Cairong Zhao},
year={2024},
eprint={2405.19265},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf
|
RichardErkhov
| 2024-05-30T01:29:15Z | 8 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T22:18:52Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Dans-AdventurousWinds-7b - GGUF
- Model creator: https://huggingface.co/PocketDoc/
- Original model: https://huggingface.co/PocketDoc/Dans-AdventurousWinds-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Dans-AdventurousWinds-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q2_K.gguf) | Q2_K | 2.53GB |
| [Dans-AdventurousWinds-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [Dans-AdventurousWinds-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [Dans-AdventurousWinds-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [Dans-AdventurousWinds-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [Dans-AdventurousWinds-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q3_K.gguf) | Q3_K | 3.28GB |
| [Dans-AdventurousWinds-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [Dans-AdventurousWinds-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [Dans-AdventurousWinds-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [Dans-AdventurousWinds-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q4_0.gguf) | Q4_0 | 3.83GB |
| [Dans-AdventurousWinds-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [Dans-AdventurousWinds-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [Dans-AdventurousWinds-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q4_K.gguf) | Q4_K | 4.07GB |
| [Dans-AdventurousWinds-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [Dans-AdventurousWinds-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q4_1.gguf) | Q4_1 | 4.24GB |
| [Dans-AdventurousWinds-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q5_0.gguf) | Q5_0 | 4.65GB |
| [Dans-AdventurousWinds-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [Dans-AdventurousWinds-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q5_K.gguf) | Q5_K | 4.78GB |
| [Dans-AdventurousWinds-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [Dans-AdventurousWinds-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q5_1.gguf) | Q5_1 | 5.07GB |
| [Dans-AdventurousWinds-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q6_K.gguf) | Q6_K | 5.53GB |
| [Dans-AdventurousWinds-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-AdventurousWinds-7b-gguf/blob/main/Dans-AdventurousWinds-7b.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
language:
- en
datasets:
- PocketDoc/Floyd-Text-Adventures
- PocketDoc/Choose-Your-Story-Long-Text-Adventures
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
---
# What is the model for?
This model is proficient in crafting text-based adventure games. It can both concise replies and more expansive, novel-like descriptions. The ability to alternate between these two response styles can be triggered by a distinct system message.
# What's in the sausage?
This model was trained on [Mistral-7b](https://huggingface.co/mistralai/Mistral-7B-v0.1) using a custom version of the floyd and cys datasets from the skein text adventure dataset. The dataset has been improved over what was used in my previous model "Dans-CreepingSenseOfDoom" and this time presented in the more traditional adventure mode format.
## Prompt format and examples:
#### Format description:
Traditional adventure format with a description of the genre, tags, and other misc information at the top followed by an optional introductory message. User messages are prefixed with two new lines and "> ", model messages are one new line after the last user message or the description message if an introductory message is desired.
#### Examples of shorter responses:
```
[Genres: Science Fiction]
[Tags: humor, old school, sci fi]
[Mode: Adventure]
[Description: A puzzle about committing acts of financial skulduggery and exploiting ridiculous magical items.]
[Misc: Writing era: 1993]
[Intro]
It is the year 2045. You are a young man in his twenties living in New York City. Your father was an inventor who died when you were very small; your mother raised you alone for many years until she remarried. Now you live with your stepfather, but he doesn't care much for you and has never given you any money to help support yourself. You have no job and little hope of getting one because of your lack of experience. However, you do have some unusual abilities that could be put to good use if only you knew how...
> Look around
You are standing on the sidewalk outside your apartment building. The street is busy with traffic and people going about their daily business. Across the street from you stands a tall office tower where your stepfather works as an accountant. To your left is a convenience store where you can buy food and drinks.
> You go into the store
The doorbell rings as you enter the store. An elderly woman behind the counter looks up at you expectantly. "Hello," she says cheerfully, "what can I get for you?"
> You tell her you'll browse
"All right then," she replies brightly, "just take your time."
> You ask if she's hiring
"I'm sorry," she says sadly, "but we don't need anyone new just now."
> You leave without buying anything
As you walk out of the store, the bell jingles merrily.
> You go see your stepfather
When you arrive at work, your stepfather greets you warmly. He invites you into his office and offers you a seat. "So," he begins eagerly, "how would you like to make some extra cash? There's this guy named Mr. Jones who owes my company thousands of dollars. If we could somehow convince him to pay us back, it would really help our bottom line."
He pauses expectantly, waiting for your response.
> You ask him whats involved
"Well," he continues excitedly, "it turns out that Mr. Jones has a very valuable antique watch that he keeps locked away in a safe deposit box at the bank. We think that if we could somehow break into the box and steal the watch, we could sell it for enough money to cover his debt."
Your heart races as you realize the potential danger of such a scheme. But before you can say anything, your stepfather cuts off your thoughts by continuing, "Of course, there's always the chance that something could go wrong and we might end up losing everything..."
```
#### Examples of longer novel like responses:
```
[Genres: grimdark fantasy] [Tags: Fantasy, Grimdark, Serious, Villain Protagonist, War] [Description: This story is definitely more "story" than "game", however there are two distinct paths that can be followed, each with their own pitfalls and additional choices. This story can get long, and assuming you're surviving, years do pass in it and you and your environment will change.] [First message intro] [Mode: Interactive Storyteller]
You have been a soldier for as long as you remember. You don't know who you were before the war began, but you were someone else. Someone less angry. More forgiving. Perhaps even kinder.
It all started when you were very young. The King of this land was attacked by an army from another kingdom. His forces were outmatched, his city overrun. He had no choice but to flee into the forest, taking what few soldiers he could muster along with him.
As the king fled deeper into the woods, his army fell back, forming a protective wall around them. They fought valiantly against the invaders, giving the king time to escape, but they eventually succumbed to overwhelming numbers. When the fighting finally ended, only one man remained alive; you.
The king found you hiding behind some bushes, covered in blood and dirt. He took pity on you and offered you a place at court if you would swear allegiance to him. Without hesitation, you accepted. And so began your journey down the path of darkness...
> You meet with the king to discuss the plans
A week has passed since the battle and you have just met with the king to discuss future plans. It seems like things are finally starting to settle down after such chaos. However, there is still much work to be done before we can truly consider ourselves safe again.
The first order of business is rebuilding our army. We need men willing to fight for us once more. Men who understand what needs to be done and aren't afraid to die trying. I believe I have found such warriors among those loyal subjects who survived the initial attack. If we train them properly, then perhaps they might prove useful against our enemies next time around.
Next, we must find ways to improve our defenses. There are many areas where improvements could be made. For instance, we should construct better walls around our cities. These walls must not only keep intruders out, but also allow us easy access inside should anyone try to breach them. In addition, we must strengthen our gates so that no matter how strong our enemy becomes, he cannot break through without great effort. Finally, we must fortify our castles and other strategic locations throughout the country. By doing these things, we will ensure that nobody ever attacks us again!
> You ask what he desires your involvement to be
After hearing about his plans, you feel compelled to help him achieve victory. After all, you owe everything to him. But before agreeing to anything, you want to make sure that he understands exactly what you expect from him. So you decide to approach him directly.
"Your Majesty," you begin, "I am honored beyond measure to serve under your command. However, before committing myself fully to this cause, I wish to clarify certain matters."
He nods slowly. "Very well. What would you like me to explain?"
"Well," you say, "first off, I want to know why you chose me above everyone else? Why did you pick me specifically?"
He smiles softly. "Because I saw potential within you. Potential which others lacked. Potentials which could prove valuable during times of crisis. Therefore, I felt confident enough to entrust my fate to you."
"But what makes you think I possess such abilities?" you ask curiously.
"Oh, nothing special really," he replies casually. "Just raw determination combined with intelligence and resourcefulness. Those qualities alone are enough to carry us forward toward victory!"
```
# Some quick and dirty training details:
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="150" height="24"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Sequence length: 4096
- \# of epochs: 3
- Training time: 1 hour
- Hardware: 1x RTX 3090
- Training type: QLoRA
- PEFT R/A: 32/32
# Credits:
### Skein Text Adventure Data:
Thank you to the [Kobold AI](https://huggingface.co/KoboldAI) community for curating the Skein dataset, which is pivotal to this model's capabilities.
|
HachiML/Mistral-7B-Instruct-v0.3-dpo-lora
|
HachiML
| 2024-05-30T01:27:18Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T01:23:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sempiterno111/programa
|
Sempiterno111
| 2024-05-30T01:23:06Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-30T01:23:06Z |
---
license: apache-2.0
---
|
RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf
|
RichardErkhov
| 2024-05-30T01:20:40Z | 1 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T22:06:48Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Dans-TotSirocco-7b - GGUF
- Model creator: https://huggingface.co/PocketDoc/
- Original model: https://huggingface.co/PocketDoc/Dans-TotSirocco-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Dans-TotSirocco-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q2_K.gguf) | Q2_K | 2.53GB |
| [Dans-TotSirocco-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [Dans-TotSirocco-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [Dans-TotSirocco-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [Dans-TotSirocco-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [Dans-TotSirocco-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q3_K.gguf) | Q3_K | 3.28GB |
| [Dans-TotSirocco-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [Dans-TotSirocco-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [Dans-TotSirocco-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [Dans-TotSirocco-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q4_0.gguf) | Q4_0 | 3.83GB |
| [Dans-TotSirocco-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [Dans-TotSirocco-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [Dans-TotSirocco-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q4_K.gguf) | Q4_K | 4.07GB |
| [Dans-TotSirocco-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [Dans-TotSirocco-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q4_1.gguf) | Q4_1 | 4.24GB |
| [Dans-TotSirocco-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q5_0.gguf) | Q5_0 | 4.65GB |
| [Dans-TotSirocco-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [Dans-TotSirocco-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q5_K.gguf) | Q5_K | 4.78GB |
| [Dans-TotSirocco-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [Dans-TotSirocco-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q5_1.gguf) | Q5_1 | 5.07GB |
| [Dans-TotSirocco-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q6_K.gguf) | Q6_K | 5.53GB |
| [Dans-TotSirocco-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/PocketDoc_-_Dans-TotSirocco-7b-gguf/blob/main/Dans-TotSirocco-7b.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
language:
- en
datasets:
- PocketDoc/Floyd-Text-Adventures
- PocketDoc/Choose-Your-Story-Long-Text-Adventures
- openchat/openchat_sharegpt4_dataset
- 64bits/lima_vicuna_format
- gsm8k
- PocketDoc/Wizard-Vicuna-Refined
- PocketDoc/Guanaco-Unchained-Refined
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
---
### Description:
This model is to test some of my data projects. It is a multipurpose chat / chat instruct hybrid model and can be seen as a prototype of Dan's PersonalityEngine Mk. 2. It has been trained on a wide array of one shot instructions, multi round instructions, role playing scenarios, and text adventure games. It is based on [Mistral-7b](https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Prompt format:
Pygmalion / Metharme
The prompt should start with the cursor on the same line directly after "<|model|>" with no space. The following are all valid formats and can be extended to as many rounds as desired.
```
<|system|>system message here<|user|>user message here<|model|>
```
```
<|system|>system message here<|user|>user message here<|model|>model message<|user|>user message here<|model|>
```
```
<|system|>system message here<|model|>
```
```
<|system|>system message here<|model|>model message<|user|>user message here<|model|>
```
#### Some example prompts and their resulting outputs:
##### Prompt:
```
<|system|>You are an assistant, help the user and use markdown when applicable.<|user|>What are the top games of the 90s?<|model|>
```
##### Output:
```
The 1990s was a golden era for video gaming, with countless iconic titles released across various platforms. Here's a list of some of the most popular and influential games from that decade:
- **Super Mario World** (SNES) - Released in 1990, this classic platformer introduced fans to Yoshi and featured memorable levels like Donut Plains and Star World.
- **Mortal Kombat** (Arcade/Sega Genesis) - This gory fighting game shocked audiences upon its release in 1992 with its violent finishers and secret characters like Sub-Zero and Scorpion.
- **Doom** (PC) - Id Software's groundbreaking first-person shooter revolutionized the genre by introducing fast-paced action and multiplayer deathmatches.
- **Street Fighter II** (Arcade/SNES) - Capcom's sequel to their original Street Fighter arcade game added new fighters such as Ryu's rival Ken Masters plus complex special moves like Dragon Punch and Hadouken.
- **Crash Bandicoot** (PlayStation) - Naughty Dog's mascot platforming series debuted in 1996 starring Crash who had to save his girlfriend Tawna from Dr Cortex's evil experiments on Aku Aku masks.
- **Final Fantasy VII** (PlayStation) - Square Enix's seventh installment took players through Midgar City where they joined Cloud Strife's eco-terrorist group AVALANCHE against Shinra Electric Power Company led by Sephiroth.
- **Resident Evil** (PlayStation) - The survival horror masterpiece created by Capcom saw Chris Redfield investigating Spencer Mansion alongside Jill Valentine while trying not get eaten alive by zombies!
```
##### Prompt:
```
<|system|>You are a Virtual Story Generator. You take the user's input and create an excellent and captivating story that goes in that direction. Use an abundance of sensory descriptions and eloquent prose.<|user|>Alpha Centauri has fallen, to the bears. This is a point of view tale about a soldier on the ground.<|model|>
```
##### Output:
```
The roar of the engines shook the very foundations of the planet as the massive warships descended upon Alpha Centauri. The air was thick with the stench of burning fuel and smoke, as if the entire world had been set ablaze. In the chaos, soldiers were scrambling for cover, desperately trying to protect themselves from the relentless barrage of firepower unleashed by their enemy.
Amidst the carnage, one soldier stood tall, his heart pounding against his chest like a drumbeat of death. He knew he had to do something, anything, to stop this nightmare from becoming reality. With trembling hands, he reached for his weapon, determined to make a stand against the overwhelming force that threatened to consume them all.
As the battle raged around him, the soldier felt a sudden surge of adrenaline coursing through his veins. It was almost as if some hidden power within him had awoken, granting him strength beyond measure. His eyes blazed with determination as he raised his gun and took aim at the first target he saw: a bear-like creature, its fur matted with blood and gore, advancing towards him with murderous intent.
With a deafening crack, the soldier fired off several rounds, striking the beast square in the chest. The impact sent it reeling backwards, but it did not fall. Instead, it let out a ferocious growl before charging forward once more. The soldier gritted his teeth and pulled the trigger again, emptying his clip into the creature's already battered frame.
But even as the bullets tore through its flesh, the beast seemed unfazed, continuing its advance towards the terrified soldier. Desperate for any advantage, he threw himself to the side just moments before the monster slammed into the spot where he had been standing mere seconds ago. As it turned back towards him, ready to deliver another brutal blow, the soldier could see that its eyes glowed with an otherworldly light.
```
##### Prompt:
```
<|system|>You are a professional editor with decades of experience, help the user with any task they have for you.<|user|>Can you rewrite this to flow better? "I knew I probably shouldnt have done that but oh well"<|model|>
```
##### Output:
```
I hesitated before making my decision, knowing full well it was not wise. However, in the end, I chose to proceed regardless.
```
# Some quick and dirty training details:
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="150" height="24"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Sequence length: 4096
- Training time: 4 hours
- Hardware: 2x RTX 4090
- Training type: QLoRA
- PEFT R/A: 32/32
# Credits:
### Skein Text Adventure Data:
Thank you to the [Kobold AI](https://huggingface.co/KoboldAI) community for curating the Skein dataset, which is pivotal to this model's capabilities.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_PocketDoc__Dans-TotSirocco-7b)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 56.92 |
| ARC (25-shot) | 62.03 |
| HellaSwag (10-shot) | 84.23 |
| MMLU (5-shot) | 64.19 |
| TruthfulQA (0-shot) | 46.49 |
| Winogrande (5-shot) | 78.69 |
| GSM8K (5-shot) | 13.27 |
| DROP (3-shot) | 49.54 |
|
hchcsuim/batch-size-16_FFPP-c40_1FPS_faces-expand-0-aligned_unaugmentation
|
hchcsuim
| 2024-05-30T01:20:30Z | 218 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-05-30T01:11:46Z |
---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: batch-size-16_FFPP-c40_1FPS_faces-expand-0-aligned_unaugmentation
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: test
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8753804895160286
- name: Precision
type: precision
value: 0.913413698006994
- name: Recall
type: recall
value: 0.9288491839773335
- name: F1
type: f1
value: 0.9210667775205522
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# batch-size-16_FFPP-c40_1FPS_faces-expand-0-aligned_unaugmentation
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2912
- Accuracy: 0.8754
- Precision: 0.9134
- Recall: 0.9288
- F1: 0.9211
- Roc Auc: 0.9210
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Roc Auc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-------:|
| 0.3399 | 1.0 | 1381 | 0.2912 | 0.8754 | 0.9134 | 0.9288 | 0.9211 | 0.9210 |
### Framework versions
- Transformers 4.39.2
- Pytorch 2.3.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ilsp/opus-mt-pt-en_ct2_ft-SciLake
|
ilsp
| 2024-05-30T01:14:30Z | 63 | 2 |
transformers
|
[
"transformers",
"translation",
"pt",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
translation
| 2024-05-29T19:10:45Z |
---
license: apache-2.0
language:
- pt
- en
pipeline_tag: translation
---
# Portuguese-English Translation Model for the Scientific Domain
## Description
This is a CTranslate2 Portuguese-English translation model for the scientific domain, which uses the PT-EN OPUS-MT Transformer-Align [(link)](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/por-eng) as its base model.
It has been fine-tuned on a large parallel corpus with scientific texts, with special focus to the four pilot domains of the [SciLake](https://scilake.eu/) project:
- Neuroscience
- Cancer
- Transportation
- Energy
## Dataset
The fine-tuning dataset consists of 5,705,469 EN-PT parallel sentences extracted from parallel theses and abstracts which have been acquired from multiple academic repositories.
## Evaluation
We have evaluated the base and the fine-tuned models on 5 test sets:
- Four which correspond to the pilot domains (Neuroscience, Cancer, Transportation, Energy) with each one containing 1,000 parallel sentences.
- A general scientific which contains 3,000 parallel sentences from a wide range of scientific texts in other domains.
| Model | Average of 4 domains | | | General Scientific| | |
|-------------|----------------------|---------------|---------------|-------------------|---------------|---------------|
| | SacreBLEU | chrF2++ | COMET | SacreBLEU | chrF2++ | COMET |
| Base | 46 | 68.3 | 66.7 | 44.9 | 67.7 | 66.3 |
| Fine-Tuned | 48.4 | 69.9 | 67.3 | 47.3 | 69.1 | 67.8 |
| Improvement | +2.4 | +1.6 | +0.9 | +2.4 | +1.4 | +1.5 |
## Usage
```
pip install ctranslate2 sentencepiece huggingface_hub
```
```python
import ctranslate2
import sentencepiece as spm
from huggingface_hub import snapshot_download
repo_id = "ilsp/opus-mt-pt-en_ct2_ft-SciLake"
# REPLACE WITH ACTUAL LOCAL DIRECTORY WHERE THE MODEL WILL BE DOWNLOADED
local_dir = ""
model_path = snapshot_download(repo_id=repo_id, local_dir=local_dir)
translator = ctranslate2.Translator(model_path, compute_type="auto")
sp_enc = spm.SentencePieceProcessor()
sp_enc.load(f"{model_path}/source.spm")
sp_dec = spm.SentencePieceProcessor()
sp_dec.load(f"{model_path}/target.spm")
def translate_text(input_text, sp_enc=sp_enc, sp_dec=sp_dec, translator=translator, beam_size=6):
input_tokens = sp_enc.encode(input_text, out_type=str)
results = translator.translate_batch([input_tokens],
beam_size=beam_size,
length_penalty=0,
max_decoding_length=512,
replace_unknowns=True)
output_tokens = results[0].hypotheses[0]
output_text = sp_dec.decode(output_tokens)
return output_text
input_text = "Na osteoartríte (OA) a degeneração progressiva das estruturas articulares activa continuamente nociceptores levando ao desenvolvimento de dor crónica e a déficits emocionais e cognitivos."
translate_text(input_text)
# OUTPUT
# In osteoarthritis (OA), progressive degeneration of articular structures continuously activates nociceptors leading to the development of chronic pain and emotional and cognitive deficits.
```
## Acknowledgements
This work was created within the [SciLake](https://scilake.eu/) project. We are grateful to the SciLake project for providing the resources and support that made this work possible. This project has received funding from the European Union’s Horizon Europe framework programme under grant agreement No. 101058573.
|
DSMI/LLaMA-E
|
DSMI
| 2024-05-30T01:05:21Z | 0 | 4 | null |
[
"arxiv:2308.04913",
"license:llama2",
"region:us"
] | null | 2024-05-13T11:04:15Z |
---
license: llama2
---
<div align="center">
<a href="https://huggingface.co/DSMI/LLaMA-E/tree/main#/">
<img src="https://huggingface.co/DSMI/LLaMA-E/resolve/main/LLaMA-E.png?download=true" alt="LLaMA-E">
</a>
<h1>LLaMA-E</h1>
</div>
### Model Introduction
LLaMA-E is meticulously crafted for e-commerce authoring tasks, incorporating specialized features to excel in generating product descriptions, advertisements, and other related content, as outlined in https://arxiv.org/abs/2308.04913#/.
### Usage
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
```
python inference.py --load_8bit --base_model 'meta-llama/Llama-2-7b-hf' --lora_weights 'DSMI/LLaMA-E'
```
```
***Instruction: Where can I buy the handmade jewellery?
***Response: Etsy, NOVICA, UncommonGoods, World Market, and Global Crafts offer unique handmade jewelry from artisans worldwide.
***Instruction: Create an attractive advertisement for the Christmas sale of the following product.
***Input: Custom Photo Music Plaque,Personalized Photo Frame,Album Cover Song Plaque,Music Photo Name Night Lamp,Photo and Music Gift, Music Prints
***Response: Personalize your music space with a Custom Photo Music Plaque. Add your favorite photo and song lyrics to create a unique gift for music lovers.
```
### Citation
If you find our work helpful, please consider [citing][paper] the following papers.
```bibtex
@article{shi2023llama,
title={LLaMA-E: Empowering E-commerce Authoring with Multi-Aspect Instruction Following},
author={Shi, Kaize and Sun, Xueyao and Wang, Dingxian and Fu, Yinlin and Xu, Guandong and Li, Qing},
journal={arXiv preprint arXiv:2308.04913},
year={2023}
}
```
### License
The model released here is under the [Llama-2 LICENSE][license] to ensure more flexible accessibility; please adhere to the corresponding licence.
### Acknowledgements
Our code for the inference is based on the [tloen][tloen].
[license]: <https://ai.meta.com/llama/license/#/>
[paper]: <https://arxiv.org/abs/2308.04913#/>
[tloen]: <https://huggingface.co/tloen/alpaca-lora-7b#/>
|
ilsp/opus-mt-big-es-en_ct2_ft-SciLake
|
ilsp
| 2024-05-30T01:04:03Z | 7 | 2 |
transformers
|
[
"transformers",
"translation",
"es",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
translation
| 2024-05-29T19:00:56Z |
---
license: apache-2.0
language:
- es
- en
pipeline_tag: translation
---
# Spanish-English Translation Model for the Scientific Domain
## Description
This is a CTranslate2 Spanish-English translation model for the scientific domain, which uses the CA+OC+ES-EN OPUS-MT Transformer-Big [(link)](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/cat%2Boci%2Bspa-eng) as its base model.
It has been fine-tuned on a large parallel corpus with scientific texts, with special focus to the four pilot domains of the [SciLake](https://scilake.eu/) project:
- Neuroscience
- Cancer
- Transportation
- Energy
## Dataset
The fine-tuning dataset consists of 4,145,412 EN-ES parallel sentences extracted from parallel theses and abstracts which have been acquired from multiple academic repositories.
## Evaluation
We have evaluated the base and the fine-tuned models on 5 test sets:
- Four which correspond to the pilot domains (Neuroscience, Cancer, Transportation, Energy) with each one containing 1,000 parallel sentences.
- A general scientific which contains 3,000 parallel sentences from a wide range of scientific texts in other domains.
| Model | Average of 4 domains | | | General Scientific| | |
|-------------|----------------------|---------------|---------------|-------------------|---------------|---------------|
| | SacreBLEU | chrF2++ | COMET | SacreBLEU | chrF2++ | COMET |
| Base | 49.7 | 70.5 | 69.5 | 51 | 71.7 | 68.9 |
| Fine-Tuned | 51.9 | 71.7 | 70.9 | 54 | 73.1 | 71 |
| Improvement | +2.2 | +1.2 | +1.4 | +3 | +1.4 | +2.1 |
## Usage
```
pip install ctranslate2 sentencepiece huggingface_hub
```
```python
import ctranslate2
import sentencepiece as spm
from huggingface_hub import snapshot_download
repo_id = "ilsp/opus-mt-big-es-en_ct2_ft-SciLake"
# REPLACE WITH ACTUAL LOCAL DIRECTORY WHERE THE MODEL WILL BE DOWNLOADED
local_dir = ""
model_path = snapshot_download(repo_id=repo_id, local_dir=local_dir)
translator = ctranslate2.Translator(model_path, compute_type="auto")
sp_enc = spm.SentencePieceProcessor()
sp_enc.load(f"{model_path}/source.spm")
sp_dec = spm.SentencePieceProcessor()
sp_dec.load(f"{model_path}/target.spm")
def translate_text(input_text, sp_enc=sp_enc, sp_dec=sp_dec, translator=translator, beam_size=6):
input_tokens = sp_enc.encode(input_text, out_type=str)
results = translator.translate_batch([input_tokens],
beam_size=beam_size,
length_penalty=0,
max_decoding_length=512,
replace_unknowns=True)
output_tokens = results[0].hypotheses[0]
output_text = sp_dec.decode(output_tokens)
return output_text
input_text = "La energía eléctrica es un insumo base de alta difusión, derivado de su capacidad para satisfacer todo tipo de necesidades."
translate_text(input_text)
# OUTPUT
# Electric power is a base input of high diffusion, derived from its ability to satisfy all types of needs.
```
## Acknowledgements
This work was created within the [SciLake](https://scilake.eu/) project. We are grateful to the SciLake project for providing the resources and support that made this work possible. This project has received funding from the European Union’s Horizon Europe framework programme under grant agreement No. 101058573.
|
DaveGergern/13B-Psyfighter2-Erebus3-DareTies
|
DaveGergern
| 2024-05-30T01:00:45Z | 161 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:KoboldAI/LLaMA2-13B-Erebus-v3",
"base_model:merge:KoboldAI/LLaMA2-13B-Erebus-v3",
"base_model:KoboldAI/LLaMA2-13B-Psyfighter2",
"base_model:merge:KoboldAI/LLaMA2-13B-Psyfighter2",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:17:16Z |
---
base_model:
- KoboldAI/LLaMA2-13B-Psyfighter2
- KoboldAI/LLaMA2-13B-Erebus-v3
library_name: transformers
tags:
- mergekit
- merge
license: llama2
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [KoboldAI/LLaMA2-13B-Psyfighter2](https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2) as a base.
### Models Merged
The following models were included in the merge:
* [KoboldAI/LLaMA2-13B-Erebus-v3](https://huggingface.co/KoboldAI/LLaMA2-13B-Erebus-v3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: KoboldAI/LLaMA2-13B-Psyfighter2
- model: KoboldAI/LLaMA2-13B-Erebus-v3
parameters:
density: 0.30
weight: [0, 0.3, 0.7, 1]
merge_method: ties
base_model: KoboldAI/LLaMA2-13B-Psyfighter2
parameters:
normalize: true
int8_mask: true
dtype: float16
```
|
ChenWeiLi/MedPhi-3-mini_v1
|
ChenWeiLi
| 2024-05-30T00:56:29Z | 185 | 2 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:30:34Z |
---
license: apache-2.0
---
### Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
| - medmcqa |Yaml |none | 0|acc |0.5408|± |0.0077|
| | |none | 0|acc_norm|0.5408|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5711|± |0.0139|
| | |none | 0|acc_norm|0.5711|± |0.0139|
| - anatomy (mmlu) | 0|none | 0|acc |0.6815|± |0.0402|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7434|± |0.0269|
| - college_biology (mmlu) | 0|none | 0|acc |0.8056|± |0.0331|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6647|± |0.0360|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7300|± |0.0446|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7353|± |0.0268|
|stem |N/A |none | 0|acc_norm|0.5478|± |0.0067|
| | |none | 0|acc |0.5909|± |0.0058|
| - pubmedqa | 1|none | 0|acc |0.7620|± |0.0191|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5478|± |0.0067|
| | |none | 0|acc |0.5909|± |0.0058|
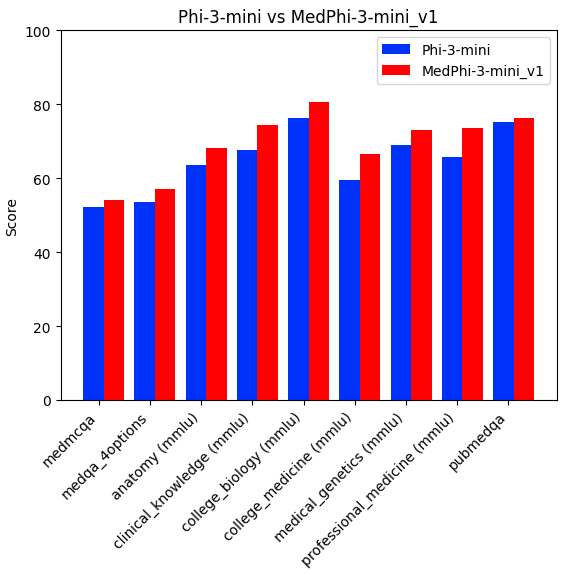
|
stifi/gemma-2b-it-test
|
stifi
| 2024-05-30T00:52:02Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"gemma",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2b-it",
"base_model:adapter:google/gemma-2b-it",
"license:gemma",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2024-05-30T00:41:47Z |
---
license: gemma
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b-it
model-index:
- name: gemma-2b-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gemma-2b-it
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 0.03
- training_steps: 10
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.0
- Pytorch 2.3.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
sudipto-ducs/InLegalLLaMA-Instruct
|
sudipto-ducs
| 2024-05-30T00:49:52Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"legal",
"table-question-answering",
"en",
"base_model:sudipto-ducs/InLegalLLaMA",
"base_model:finetune:sudipto-ducs/InLegalLLaMA",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
table-question-answering
| 2024-05-30T00:36:42Z |
---
license: llama2
tags:
- llama-factory
- legal
base_model: sudipto-ducs/InLegalLLaMA
model-index:
- name: sudipto-ducs/InLegalLLaMA-Instruct
results: []
language:
- en
pipeline_tag: table-question-answering
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# InLegalLLaMA-Instruct
This model is a fine-tuned version of [sudipto-ducs/InLegalLLaMA](https://huggingface.co/sudipto-ducs/InLegalLLaMA) on the legalkg_dataset_prompts, the legal_semantic_segmentation and the lima datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
sudipto-ducs/InLegalLLaMA
|
sudipto-ducs
| 2024-05-30T00:49:39Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"legal",
"conversational",
"en",
"dataset:sudipto-ducs/InLegalLLaMA-data",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:36:24Z |
---
license: llama2
tags:
- llama-factory
- legal
base_model: meta-llama/Llama-2-7b-hf
model-index:
- name: inlegalllama-pt-15-04-2024
results: []
datasets:
- sudipto-ducs/InLegalLLaMA-data
language:
- en
pipeline_tag: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# InLegalLLaMA
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the inlegalllama-laws and the inlegalllama-sci datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 2000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
hdve/Qwen-Qwen1.5-1.8B-1717029504
|
hdve
| 2024-05-30T00:40:21Z | 146 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:38:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
datek/Qwen-Qwen1.5-1.8B-1717029493
|
datek
| 2024-05-30T00:39:59Z | 148 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:38:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
haes95/POLAR-7B-HES-SFT-v0.1
|
haes95
| 2024-05-30T00:38:21Z | 79 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-05-29T23:57:06Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details

## Model Description
<!-- Provide a longer summary of what this model is/does. -->
POLAR is a Korean LLM developed by Plateer's AI-lab. It was inspired by Upstage's SOLAR. We will continue to evolve this model and hope to contribute to the Korean LLM ecosystem.
- **Developed by:** AI-Lab of Plateer(Woomun Jung, Eunsoo Ha, MinYoung Joo, Seongjun Son)
- **Model type:** Language model
- **Language(s) (NLP):** ko
- **License:** apache-2.0
- Parent Model: x2bee/POLAR-14B-v0.2
## Direct Use
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("haes95/POLAR-7B-HES-SFT-v0.1")
model = AutoModelForCausalLM.from_pretrained("haes95/POLAR-7B-HES-SFT-v0.1")
```
## Downstream Use [Optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
More information on training data needed
## Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
More information needed
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
More information needed
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
More information needed
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
More information needed
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
More information needed
**APA:**
More information needed
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
More information needed
# More Information [optional]
If you would like more information about our company, please visit the link below.
[tech.x2bee.com](https://tech.x2bee.com/)
# Model Card Authors [optional]
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
Woomun Jung, MinYoung Joo, Eunsu Ha, Seungjun Son
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
More information needed
</details>
|
carolcarneiro/keras-dummy-sequential-demo
|
carolcarneiro
| 2024-05-30T00:30:40Z | 5 | 0 |
keras
|
[
"keras",
"tf-keras",
"sequential",
"region:us"
] | null | 2024-05-29T22:56:35Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | None |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | True |
| is_legacy_optimizer | False |
| learning_rate | 0.0010000000474974513 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
|
0xfaskety/Qwen-Qwen1.5-7B-1717028441
|
0xfaskety
| 2024-05-30T00:27:32Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:20:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lmbelo/Phi-3-mini-4k-Function-Calling
|
lmbelo
| 2024-05-30T00:24:50Z | 7 | 0 |
mlx
|
[
"mlx",
"safetensors",
"phi3",
"nlp",
"code",
"text-generation",
"conversational",
"custom_code",
"en",
"license:mit",
"region:us"
] |
text-generation
| 2024-05-30T00:06:56Z |
---
language:
- en
license: mit
tags:
- nlp
- code
- mlx
- mlx
license_link: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
inference:
parameters:
temperature: 0.0
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
# lmbelo/Phi-3-mini-4k-Function-Calling
The Model [lmbelo/Phi-3-mini-4k-Function-Calling](https://huggingface.co/lmbelo/Phi-3-mini-4k-Function-Calling) was converted to MLX format from [lmbelo/Phi-3-mini-4k-instruct](https://huggingface.co/lmbelo/Phi-3-mini-4k-instruct) using mlx-lm version **0.13.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("lmbelo/Phi-3-mini-4k-Function-Calling")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
AlpacaAAR/llama-3-epfl-tutor-dpo
|
AlpacaAAR
| 2024-05-30T00:12:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:AlpacaAAR/llama-3-epfl-tutor",
"base_model:finetune:AlpacaAAR/llama-3-epfl-tutor",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-30T00:11:48Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: AlpacaAAR/llama-3-epfl-tutor
---
# Uploaded model
- **Developed by:** AlpacaAAR
- **License:** apache-2.0
- **Finetuned from model :** AlpacaAAR/llama-3-epfl-tutor
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hdve/Qwen-Qwen1.5-0.5B-1717027799
|
hdve
| 2024-05-30T00:10:33Z | 145 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-30T00:09:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JD45/ppo-LunarLander-v2.1
|
JD45
| 2024-05-30T00:05:45Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-05-30T00:05:19Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 266.07 +/- 14.54
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
lyhourt/whisper-small-custom-300
|
lyhourt
| 2024-05-30T00:03:15Z | 92 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-05-20T17:56:51Z |
---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper Small custom 300
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small custom 3000
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the lyhourt/clean dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0304
- Wer: 4.6902
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 300
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.0783 | 0.3333 | 100 | 0.0938 | 11.8124 |
| 0.0513 | 0.6667 | 200 | 0.0689 | 8.2224 |
| 0.0027 | 1.19 | 300 | 0.0304 | 4.6902 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
jity01/distilgpt2-second-finetuned-wikitext2
|
jity01
| 2024-05-29T23:53:20Z | 219 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T22:53:04Z |
---
license: apache-2.0
base_model: distilgpt2
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-second-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-second-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7589
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7764 | 1.0 | 2334 | 7.3224 |
| 3.9568 | 2.0 | 4668 | 3.8147 |
| 3.7617 | 3.0 | 7002 | 3.7589 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
eli8986/whisper-small-heb
|
eli8986
| 2024-05-29T23:52:35Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_17_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-05-29T18:37:18Z |
---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-small-heb
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_17_0
type: common_voice_17_0
config: he
split: None
args: he
metrics:
- name: Wer
type: wer
value: 91.73014145810664
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-heb
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the common_voice_17_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9338
- Wer: 91.7301
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| 0.0134 | 12.9870 | 1000 | 0.7958 | 104.5158 |
| 0.0004 | 25.9740 | 2000 | 0.8754 | 86.5615 |
| 0.0002 | 38.9610 | 3000 | 0.9193 | 90.6420 |
| 0.0002 | 51.9481 | 4000 | 0.9338 | 91.7301 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu118
- Datasets 2.19.1
- Tokenizers 0.19.1
|
x2bee/POLAR-14B-HES-DPO-v1.5
|
x2bee
| 2024-05-29T23:52:31Z | 789 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-28T01:35:43Z |
---
library_name: transformers
license: apache-2.0
language:
- ko
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details

## Model Description
<!-- Provide a longer summary of what this model is/does. -->
POLAR is a Korean LLM developed by Plateer's AI-lab. It was inspired by Upstage's SOLAR. We will continue to evolve this model and hope to contribute to the Korean LLM ecosystem.
- **Developed by:** AI-Lab of Plateer(Woomun Jung, Eunsoo Ha, MinYoung Joo, Seongjun Son)
- **Model type:** Language model
- **Language(s) (NLP):** ko
- **License:** apache-2.0
- Parent Model: x2bee/POLAR-14B-SON-SFT-v0.1
## Direct Use
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("x2bee/POLAR-14B-HES-DPO-v1.5")
model = AutoModelForCausalLM.from_pretrained("x2bee/POLAR-14B-HES-DPO-v1.5")
```
## Downstream Use [Optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
More information on training data needed
## Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
More information needed
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
More information needed
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
More information needed
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
More information needed
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
More information needed
**APA:**
More information needed
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
More information needed
# More Information [optional]
If you would like more information about our company, please visit the link below.
[tech.x2bee.com](https://tech.x2bee.com/)
# Model Card Authors [optional]
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
Woomun Jung, MinYoung Joo, Eunsu Ha, Seungjun Son
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
More information needed
</details>
|
ebowwa/human-biases-people-base-with-toxic-dpo
|
ebowwa
| 2024-05-29T23:50:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"dataset:ebowwa/merged-human-biases-dataset-beta",
"dataset:unalignment/toxic-dpo-v0.2",
"base_model:unsloth/mistral-7b-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T23:44:45Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/mistral-7b-v0.3-bnb-4bit
datasets:
- ebowwa/merged-human-biases-dataset-beta
- unalignment/toxic-dpo-v0.2
---
# Uploaded model
- **Developed by:** ebowwa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
stifi/outputs
|
stifi
| 2024-05-29T23:48:53Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2b-it",
"base_model:adapter:google/gemma-2b-it",
"license:gemma",
"region:us"
] | null | 2024-05-29T23:48:41Z |
---
license: gemma
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b-it
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 0.03
- training_steps: 200
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.0
- Pytorch 2.3.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
hfht/tumblr-humor-mistral-7b-instruct-v0.3
|
hfht
| 2024-05-29T23:37:27Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.3",
"region:us"
] | null | 2024-05-29T23:22:39Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-Instruct-v0.3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1
|
jeeyoung/dpo1078810th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:32:02Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:30:49Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
jeeyoung/dpo1044010th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:28:39Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:27:28Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
flammenai/Mahou-1.3-llama3-8B-GGUF
|
flammenai
| 2024-05-29T23:27:30Z | 3 | 3 |
transformers
|
[
"transformers",
"gguf",
"dataset:flammenai/MahouMix-v1",
"base_model:flammenai/Mahou-1.3-llama3-8B",
"base_model:quantized:flammenai/Mahou-1.3-llama3-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T03:55:41Z |
---
library_name: transformers
license: llama3
base_model:
- flammenai/Mahou-1.3-llama3-8B
datasets:
- flammenai/MahouMix-v1
---

# Mahou-1.3-llama3-8B
Mahou is our attempt to build a production-ready conversational/roleplay LLM.
Future versions will be released iteratively and finetuned from flammen.ai conversational data.
### License
This model is based on Meta Llama-3-8B and is governed by the [META LLAMA 3 COMMUNITY LICENSE AGREEMENT](LICENSE).
### Chat Format
This model has been trained to use ChatML format. Note the additional tokens in [tokenizer_config.json](tokenizer_config.json).
```
<|im_start|>system
{{system}}<|im_end|>
<|im_start|>{{char}}
{{message}}<|im_end|>
<|im_start|>{{user}}
{{message}}<|im_end|>
```
### Roleplay Format
- Speech without quotes.
- Actions in `*asterisks*`
```
*leans against wall cooly* so like, i just casted a super strong spell at magician academy today, not gonna lie, felt badass.
```
### ST Settings
1. Use ChatML for the Context Template.
2. Enable Instruct Mode.
3. Use the [Mahou preset](https://huggingface.co/datasets/flammenai/Mahou-ST-ChatML-Instruct/raw/main/Mahou.json).
4. Recommended: Add newline as a stopping string: `["\n"]`
### Method
Finetuned for 10 epochs using an A100 on Google Colab.
[Fine-tune Llama 3 with ORPO](https://huggingface.co/blog/mlabonne/orpo-llama-3) - [Maxime Labonne](https://huggingface.co/mlabonne)
|
AleRothermel/my-sentiments_es-model
|
AleRothermel
| 2024-05-29T23:23:49Z | 109 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:dccuchile/bert-base-spanish-wwm-cased",
"base_model:finetune:dccuchile/bert-base-spanish-wwm-cased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-05-23T20:10:02Z |
---
tags:
- generated_from_trainer
base_model: dccuchile/bert-base-spanish-wwm-cased
metrics:
- accuracy
model-index:
- name: my-sentiments_es-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my-sentiments_es-model
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2368
- Accuracy: 0.9455
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3239 | 1.0 | 619 | 0.3335 | 0.8933 |
| 0.2113 | 2.0 | 1238 | 0.2651 | 0.9406 |
| 0.1809 | 3.0 | 1857 | 0.2368 | 0.9455 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
jeeyoung/dpo974410th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:22:07Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:20:59Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
kurros/stablelm-2-zephyr-1_6b-Q3_K_M-GGUF
|
kurros
| 2024-05-29T23:19:34Z | 3 | 0 | null |
[
"gguf",
"causal-lm",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:allenai/ultrafeedback_binarized_cleaned",
"dataset:meta-math/MetaMathQA",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:openchat/openchat_sharegpt4_dataset",
"dataset:LDJnr/Capybara",
"dataset:Intel/orca_dpo_pairs",
"dataset:hkust-nlp/deita-10k-v0",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T23:19:29Z |
---
language:
- en
license: other
tags:
- causal-lm
- llama-cpp
- gguf-my-repo
datasets:
- HuggingFaceH4/ultrachat_200k
- allenai/ultrafeedback_binarized_cleaned
- meta-math/MetaMathQA
- WizardLM/WizardLM_evol_instruct_V2_196k
- openchat/openchat_sharegpt4_dataset
- LDJnr/Capybara
- Intel/orca_dpo_pairs
- hkust-nlp/deita-10k-v0
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I ALLOW Stability AI to email me about new model releases: checkbox
---
# kurros/stablelm-2-zephyr-1_6b-Q3_K_M-GGUF
This model was converted to GGUF format from [`stabilityai/stablelm-2-zephyr-1_6b`](https://huggingface.co/stabilityai/stablelm-2-zephyr-1_6b) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/stabilityai/stablelm-2-zephyr-1_6b) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo kurros/stablelm-2-zephyr-1_6b-Q3_K_M-GGUF --model stablelm-2-zephyr-1_6b-q3_k_m.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo kurros/stablelm-2-zephyr-1_6b-Q3_K_M-GGUF --model stablelm-2-zephyr-1_6b-q3_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && \
cd llama.cpp && \
make && \
./main -m stablelm-2-zephyr-1_6b-q3_k_m.gguf -n 128
```
|
jeeyoung/dpo904810th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:15:31Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:14:18Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
jeeyoung/dpo870010th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:12:13Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:10:56Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
kurros/stablelm-2-zephyr-1_6b-Q3_K_S-GGUF
|
kurros
| 2024-05-29T23:12:11Z | 0 | 0 | null |
[
"gguf",
"causal-lm",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:allenai/ultrafeedback_binarized_cleaned",
"dataset:meta-math/MetaMathQA",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:openchat/openchat_sharegpt4_dataset",
"dataset:LDJnr/Capybara",
"dataset:Intel/orca_dpo_pairs",
"dataset:hkust-nlp/deita-10k-v0",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T23:12:06Z |
---
language:
- en
license: other
tags:
- causal-lm
- llama-cpp
- gguf-my-repo
datasets:
- HuggingFaceH4/ultrachat_200k
- allenai/ultrafeedback_binarized_cleaned
- meta-math/MetaMathQA
- WizardLM/WizardLM_evol_instruct_V2_196k
- openchat/openchat_sharegpt4_dataset
- LDJnr/Capybara
- Intel/orca_dpo_pairs
- hkust-nlp/deita-10k-v0
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I ALLOW Stability AI to email me about new model releases: checkbox
---
# kurros/stablelm-2-zephyr-1_6b-Q3_K_S-GGUF
This model was converted to GGUF format from [`stabilityai/stablelm-2-zephyr-1_6b`](https://huggingface.co/stabilityai/stablelm-2-zephyr-1_6b) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/stabilityai/stablelm-2-zephyr-1_6b) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo kurros/stablelm-2-zephyr-1_6b-Q3_K_S-GGUF --model stablelm-2-zephyr-1_6b-q3_k_s.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo kurros/stablelm-2-zephyr-1_6b-Q3_K_S-GGUF --model stablelm-2-zephyr-1_6b-q3_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && \
cd llama.cpp && \
make && \
./main -m stablelm-2-zephyr-1_6b-q3_k_s.gguf -n 128
```
|
magnifi/phi-3-mini-4k-instruct-attribute-output-4-0528-epoch20
|
magnifi
| 2024-05-29T23:04:49Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:magnifi/phi-3-mini-4k-instruct-attribute-output-4-0524-epoch20",
"base_model:finetune:magnifi/phi-3-mini-4k-instruct-attribute-output-4-0524-epoch20",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T23:02:38Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: magnifi/phi-3-mini-4k-instruct-attribute-output-4-0524-epoch20
---
# Uploaded model
- **Developed by:** magnifi
- **License:** apache-2.0
- **Finetuned from model :** magnifi/phi-3-mini-4k-instruct-attribute-output-4-0524-epoch20
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Andresckamilo/Unsloath-first-training
|
Andresckamilo
| 2024-05-29T23:02:48Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T23:02:48Z |
---
license: apache-2.0
---
|
jeeyoung/dpo765610th_trial_10000_data
|
jeeyoung
| 2024-05-29T23:02:16Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T23:01:09Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
jeeyoung/dpo696010th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:55:45Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:54:33Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
pdibez/lilo-01
|
pdibez
| 2024-05-29T22:52:48Z | 29 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2024-04-15T01:06:25Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Lilo is a Dreambooth model trained by Pablo Dibez for thesis "Personalización de un modelo text-to-image para la generación de imágenes con Inteligencia Artificial" from Universidad Nacional de la Patagonia San Juan Bosco (2024) for the career Licenciatura en Informática
Sample pictures of this concept and yours prompts:

|
jeeyoung/dpo661210th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:52:23Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:51:08Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
Avash/sample_experiment_model
|
Avash
| 2024-05-29T22:49:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T22:40:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeeyoung/dpo626410th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:49:03Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:47:51Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_5bpw_exl2
|
Zoyd
| 2024-05-29T22:48:00Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"code",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"exl2",
"region:us"
] |
text-generation
| 2024-05-29T22:03:50Z |
---
inference: false
license: other
license_name: mnpl
license_link: https://mistral.ai/licences/MNPL-0.1.md
tags:
- code
language:
- code
---
**Exllamav2** quant (**exl2** / **6.5 bpw**) made with ExLlamaV2 v0.1.1
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_2bpw_exl2)**</center> | <center>6296 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_5bpw_exl2)**</center> | <center>7045 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_0bpw_exl2)**</center> | <center>8347 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_5bpw_exl2)**</center> | <center>9652 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_75bpw_exl2)**</center> | <center>10297 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_0bpw_exl2)**</center> | <center>10953 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_25bpw_exl2)**</center> | <center>11603 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-5_0bpw_exl2)**</center> | <center>13553 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_0bpw_exl2)**</center> | <center>16185 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_5bpw_exl2)**</center> | <center>17484 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-8_0bpw_exl2)**</center> | <center>19350 MB</center> | <center>8</center> |
Converted using [this](https://huggingface.co/bullerwins/Codestral-22B-v0.1-hf/blob/main/convert_mistral_weights_to_hf-22B.py) script
# Model Card for Codestral-22B-v0.1
Codestrall-22B-v0.1 is trained on a diverse dataset of 80+ programming languages, including the most popular ones, such as Python, Java, C, C++, JavaScript, and Bash (more details in the [Blogpost](https://mistral.ai/news/codestral/)). The model can be queried:
- As instruct, for instance to answer any questions about a code snippet (write documentation, explain, factorize) or to generate code following specific indications
- As Fill in the Middle (FIM), to predict the middle tokens between a prefix and a suffix (very useful for software development add-ons like in VS Code)
## Installation
It is recommended to use `mistralai/Codestral-22B-v0.1` with [mistral-inference](https://github.com/mistralai/mistral-inference).
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', 'Codestral-22B-v0.1')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Codestral-22B-v0.1", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment.
```
mistral-chat $HOME/mistral_models/Codestral-22B-v0.1 --instruct --max_tokens 256
```
Will generate an answer to "Write me a function that computes fibonacci in Rust" and should give something along the following lines:
```
Sure, here's a simple implementation of a function that computes the Fibonacci sequence in Rust. This function takes an integer `n` as an argument and returns the `n`th Fibonacci number.
fn fibonacci(n: u32) -> u32 {
match n {
0 => 0,
1 => 1,
_ => fibonacci(n - 1) + fibonacci(n - 2),
}
}
fn main() {
let n = 10;
println!("The {}th Fibonacci number is: {}", n, fibonacci(n));
}
This function uses recursion to calculate the Fibonacci number. However, it's not the most efficient solution because it performs a lot of redundant calculations. A more efficient solution would use a loop to iteratively calculate the Fibonacci numbers.
```
### Fill-in-the-middle (FIM)
After installing `mistral_inference` and running `pip install --upgrade mistral_common` to make sure to have mistral_common>=1.2 installed:
```py
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.instruct.request import FIMRequest
tokenizer = MistralTokenizer.v3()
model = Transformer.from_folder("~/codestral-22B-240529")
prefix = """def add("""
suffix = """ return sum"""
request = FIMRequest(prompt=prefix, suffix=suffix)
tokens = tokenizer.encode_fim(request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=256, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
middle = result.split(suffix)[0].strip()
print(middle)
```
Should give something along the following lines:
```
num1, num2):
# Add two numbers
sum = num1 + num2
# return the sum
```
## Limitations
The Codestral-22B-v0.1 does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## License
Codestral-22B-v0.1 is released under the `MNLP-0.1` license.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Henri Roussez, Jean-Malo Delignon, Jia Li, Justus Murke, Kartik Khandelwal, Lawrence Stewart, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Marjorie Janiewicz, Mickael Seznec, Nicolas Schuhl, Patrick von Platen, Romain Sauvestre, Pierre Stock, Sandeep Subramanian, Saurabh Garg, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Thibault Schueller, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, Wendy Shang, William El Sayed, William Marshall
|
arzans9/finetuning_summarization
|
arzans9
| 2024-05-29T22:47:50Z | 104 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"encoder-decoder",
"text2text-generation",
"generated_from_trainer",
"base_model:cahya/bert2bert-indonesian-summarization",
"base_model:finetune:cahya/bert2bert-indonesian-summarization",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-05-29T13:52:44Z |
---
license: apache-2.0
base_model: cahya/bert2bert-indonesian-summarization
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: finetuning_summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning_summarization
This model is a fine-tuned version of [cahya/bert2bert-indonesian-summarization](https://huggingface.co/cahya/bert2bert-indonesian-summarization) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6759
- Rouge1: 0.8455
- Rouge2: 0.742
- Rougel: 0.8486
- Rougelsum: 0.8475
- Gen Len: 23.7368
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 5 | 1.3699 | 0.8443 | 0.7258 | 0.8426 | 0.8435 | 25.8421 |
| No log | 2.0 | 10 | 1.0257 | 0.8282 | 0.7115 | 0.8293 | 0.8275 | 25.0 |
| No log | 3.0 | 15 | 0.7871 | 0.8384 | 0.7277 | 0.8397 | 0.8396 | 24.3158 |
| No log | 4.0 | 20 | 0.7078 | 0.8339 | 0.7318 | 0.8358 | 0.8348 | 23.4211 |
| No log | 5.0 | 25 | 0.6994 | 0.843 | 0.7396 | 0.8451 | 0.845 | 24.0 |
| No log | 6.0 | 30 | 0.6832 | 0.8445 | 0.7413 | 0.8419 | 0.842 | 23.4737 |
| No log | 7.0 | 35 | 0.6768 | 0.8429 | 0.742 | 0.8451 | 0.8448 | 23.6842 |
| No log | 8.0 | 40 | 0.6736 | 0.843 | 0.7396 | 0.8451 | 0.845 | 23.6842 |
| No log | 9.0 | 45 | 0.6750 | 0.843 | 0.7396 | 0.8451 | 0.845 | 23.6842 |
| No log | 10.0 | 50 | 0.6759 | 0.8455 | 0.742 | 0.8486 | 0.8475 | 23.7368 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
johnnybop/Rose
|
johnnybop
| 2024-05-29T22:43:02Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T22:42:20Z |
---
license: apache-2.0
---
|
Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_5bpw_exl2
|
Zoyd
| 2024-05-29T22:40:56Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"code",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"exl2",
"region:us"
] |
text-generation
| 2024-05-29T19:37:15Z |
---
inference: false
license: other
license_name: mnpl
license_link: https://mistral.ai/licences/MNPL-0.1.md
tags:
- code
language:
- code
---
**Exllamav2** quant (**exl2** / **2.5 bpw**) made with ExLlamaV2 v0.1.1
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_2bpw_exl2)**</center> | <center>6296 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_5bpw_exl2)**</center> | <center>7045 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_0bpw_exl2)**</center> | <center>8347 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_5bpw_exl2)**</center> | <center>9652 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_75bpw_exl2)**</center> | <center>10297 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_0bpw_exl2)**</center> | <center>10953 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_25bpw_exl2)**</center> | <center>11603 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-5_0bpw_exl2)**</center> | <center>13553 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_0bpw_exl2)**</center> | <center>16185 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_5bpw_exl2)**</center> | <center>17484 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-8_0bpw_exl2)**</center> | <center>19350 MB</center> | <center>8</center> |
Converted using [this](https://huggingface.co/bullerwins/Codestral-22B-v0.1-hf/blob/main/convert_mistral_weights_to_hf-22B.py) script
# Model Card for Codestral-22B-v0.1
Codestrall-22B-v0.1 is trained on a diverse dataset of 80+ programming languages, including the most popular ones, such as Python, Java, C, C++, JavaScript, and Bash (more details in the [Blogpost](https://mistral.ai/news/codestral/)). The model can be queried:
- As instruct, for instance to answer any questions about a code snippet (write documentation, explain, factorize) or to generate code following specific indications
- As Fill in the Middle (FIM), to predict the middle tokens between a prefix and a suffix (very useful for software development add-ons like in VS Code)
## Installation
It is recommended to use `mistralai/Codestral-22B-v0.1` with [mistral-inference](https://github.com/mistralai/mistral-inference).
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', 'Codestral-22B-v0.1')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Codestral-22B-v0.1", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment.
```
mistral-chat $HOME/mistral_models/Codestral-22B-v0.1 --instruct --max_tokens 256
```
Will generate an answer to "Write me a function that computes fibonacci in Rust" and should give something along the following lines:
```
Sure, here's a simple implementation of a function that computes the Fibonacci sequence in Rust. This function takes an integer `n` as an argument and returns the `n`th Fibonacci number.
fn fibonacci(n: u32) -> u32 {
match n {
0 => 0,
1 => 1,
_ => fibonacci(n - 1) + fibonacci(n - 2),
}
}
fn main() {
let n = 10;
println!("The {}th Fibonacci number is: {}", n, fibonacci(n));
}
This function uses recursion to calculate the Fibonacci number. However, it's not the most efficient solution because it performs a lot of redundant calculations. A more efficient solution would use a loop to iteratively calculate the Fibonacci numbers.
```
### Fill-in-the-middle (FIM)
After installing `mistral_inference` and running `pip install --upgrade mistral_common` to make sure to have mistral_common>=1.2 installed:
```py
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.instruct.request import FIMRequest
tokenizer = MistralTokenizer.v3()
model = Transformer.from_folder("~/codestral-22B-240529")
prefix = """def add("""
suffix = """ return sum"""
request = FIMRequest(prompt=prefix, suffix=suffix)
tokens = tokenizer.encode_fim(request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=256, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
middle = result.split(suffix)[0].strip()
print(middle)
```
Should give something along the following lines:
```
num1, num2):
# Add two numbers
sum = num1 + num2
# return the sum
```
## Limitations
The Codestral-22B-v0.1 does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## License
Codestral-22B-v0.1 is released under the `MNLP-0.1` license.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Henri Roussez, Jean-Malo Delignon, Jia Li, Justus Murke, Kartik Khandelwal, Lawrence Stewart, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Marjorie Janiewicz, Mickael Seznec, Nicolas Schuhl, Patrick von Platen, Romain Sauvestre, Pierre Stock, Sandeep Subramanian, Saurabh Garg, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Thibault Schueller, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, Wendy Shang, William El Sayed, William Marshall
|
FluffyKaeloky/Twilight-Miqu-146B-exl2-3.75bpw
|
FluffyKaeloky
| 2024-05-29T22:33:50Z | 8 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"base_model:jukofyork/Dark-Miqu-70B",
"base_model:merge:jukofyork/Dark-Miqu-70B",
"base_model:sophosympatheia/Midnight-Miqu-70B-v1.5",
"base_model:merge:sophosympatheia/Midnight-Miqu-70B-v1.5",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] |
text-generation
| 2024-05-29T20:27:15Z |
---
base_model:
- jukofyork/Dark-Miqu-70B
- sophosympatheia/Midnight-Miqu-70B-v1.5
- jukofyork/Dawn-Miqu-70B
library_name: transformers
tags:
- mergekit
- merge
license: other
---
Twilight Miqu is a Story writing model and is composed from sophosympatheia/Midnight-Miqu-70B-v1.5, jukofyork/Dawn-Miqu-70B and jukofyork/Dark-Miqu-70B
It is an experiment to see if large models are more coherent on story writing tasks.
Twilight = Midnight + Dawn + Dark
Please see this model card for details and usage instructions.
https://huggingface.co/sophosympatheia/Midnight-Miqu-70B-v1.5
This model is based on Miqu so it's capable of 32K context.
All miqu-derived models, including this merge, are only suitable for personal use. Mistral has been cool about it so far, but you should be aware that by downloading this merge you are assuming whatever legal risk is inherent in acquiring and using a model based on leaked weights. This merge comes with no warranties or guarantees of any kind, but you probably already knew that.
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
A big thank you to Mistral, sophosympatheia and jukofyork for the original models!
|
SerchiBoi/DTT-Chatbot-Piloto-v1
|
SerchiBoi
| 2024-05-29T22:33:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-2b-it-bnb-4bit",
"base_model:finetune:unsloth/gemma-2b-it-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T22:32:26Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-2b-it-bnb-4bit
---
# Uploaded model
- **Developed by:** SerchiBoi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2b-it-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_0bpw_exl2
|
Zoyd
| 2024-05-29T22:32:45Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"code",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"3-bit",
"exl2",
"region:us"
] |
text-generation
| 2024-05-29T20:02:39Z |
---
inference: false
license: other
license_name: mnpl
license_link: https://mistral.ai/licences/MNPL-0.1.md
tags:
- code
language:
- code
---
**Exllamav2** quant (**exl2** / **3.0 bpw**) made with ExLlamaV2 v0.1.1
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_2bpw_exl2)**</center> | <center>6296 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-2_5bpw_exl2)**</center> | <center>7045 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_0bpw_exl2)**</center> | <center>8347 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_5bpw_exl2)**</center> | <center>9652 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-3_75bpw_exl2)**</center> | <center>10297 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_0bpw_exl2)**</center> | <center>10953 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-4_25bpw_exl2)**</center> | <center>11603 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-5_0bpw_exl2)**</center> | <center>13553 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_0bpw_exl2)**</center> | <center>16185 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-6_5bpw_exl2)**</center> | <center>17484 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/bullerwins_Codestral-22B-v0.1-hf-8_0bpw_exl2)**</center> | <center>19350 MB</center> | <center>8</center> |
Converted using [this](https://huggingface.co/bullerwins/Codestral-22B-v0.1-hf/blob/main/convert_mistral_weights_to_hf-22B.py) script
# Model Card for Codestral-22B-v0.1
Codestrall-22B-v0.1 is trained on a diverse dataset of 80+ programming languages, including the most popular ones, such as Python, Java, C, C++, JavaScript, and Bash (more details in the [Blogpost](https://mistral.ai/news/codestral/)). The model can be queried:
- As instruct, for instance to answer any questions about a code snippet (write documentation, explain, factorize) or to generate code following specific indications
- As Fill in the Middle (FIM), to predict the middle tokens between a prefix and a suffix (very useful for software development add-ons like in VS Code)
## Installation
It is recommended to use `mistralai/Codestral-22B-v0.1` with [mistral-inference](https://github.com/mistralai/mistral-inference).
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', 'Codestral-22B-v0.1')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Codestral-22B-v0.1", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment.
```
mistral-chat $HOME/mistral_models/Codestral-22B-v0.1 --instruct --max_tokens 256
```
Will generate an answer to "Write me a function that computes fibonacci in Rust" and should give something along the following lines:
```
Sure, here's a simple implementation of a function that computes the Fibonacci sequence in Rust. This function takes an integer `n` as an argument and returns the `n`th Fibonacci number.
fn fibonacci(n: u32) -> u32 {
match n {
0 => 0,
1 => 1,
_ => fibonacci(n - 1) + fibonacci(n - 2),
}
}
fn main() {
let n = 10;
println!("The {}th Fibonacci number is: {}", n, fibonacci(n));
}
This function uses recursion to calculate the Fibonacci number. However, it's not the most efficient solution because it performs a lot of redundant calculations. A more efficient solution would use a loop to iteratively calculate the Fibonacci numbers.
```
### Fill-in-the-middle (FIM)
After installing `mistral_inference` and running `pip install --upgrade mistral_common` to make sure to have mistral_common>=1.2 installed:
```py
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.instruct.request import FIMRequest
tokenizer = MistralTokenizer.v3()
model = Transformer.from_folder("~/codestral-22B-240529")
prefix = """def add("""
suffix = """ return sum"""
request = FIMRequest(prompt=prefix, suffix=suffix)
tokens = tokenizer.encode_fim(request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=256, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
middle = result.split(suffix)[0].strip()
print(middle)
```
Should give something along the following lines:
```
num1, num2):
# Add two numbers
sum = num1 + num2
# return the sum
```
## Limitations
The Codestral-22B-v0.1 does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## License
Codestral-22B-v0.1 is released under the `MNLP-0.1` license.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Henri Roussez, Jean-Malo Delignon, Jia Li, Justus Murke, Kartik Khandelwal, Lawrence Stewart, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Marjorie Janiewicz, Mickael Seznec, Nicolas Schuhl, Patrick von Platen, Romain Sauvestre, Pierre Stock, Sandeep Subramanian, Saurabh Garg, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Thibault Schueller, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, Wendy Shang, William El Sayed, William Marshall
|
jeeyoung/dpo452410th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:32:21Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:31:06Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
bartowski/Codestral-22B-v0.1-exl2
|
bartowski
| 2024-05-29T22:31:00Z | 10 | 9 | null |
[
"code",
"text-generation",
"license:other",
"region:us"
] |
text-generation
| 2024-05-29T22:30:59Z |
---
inference: false
license: other
license_name: mnpl
license_link: https://mistral.ai/licences/MNPL-0.1.md
tags:
- code
language:
- code
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of Codestral-22B-v0.1
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.1.1">turboderp's ExLlamaV2 v0.1.1</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/mistral-community/Codestral-22B-v0.1
## Prompt format
No chat template specified so default is used. This may be incorrect, check original model card for details.
```
<s> [INST] <<SYS>>
{system_prompt}
<</SYS>>
{prompt} [/INST] </s>
```
## Available sizes
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ------ | ---- | ------------ | ---- | ---- | ---- | ----------- |
| [8_0](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/8_0) | 8.0 | 8.0 | 23.5 GB | 26.0 GB | 29.5 GB | Near unquantized performance, max quality ExLlamaV2 can create. |
| [6_5](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/6_5) | 6.5 | 8.0 | 19.4 GB | 21.9 GB | 25.4 GB | Near unquantized performance at vastly reduced size, **recommended**. |
| [5_0](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/5_0) | 5.0 | 6.0 | 15.5 GB | 18.0 GB | 21.5 GB | Smaller size, lower quality, still very high performance, **recommended**. |
| [4_25](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/4_25) | 4.25 | 6.0 | 13.3 GB | 15.8 GB | 19.3 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/3_5) | 3.5 | 6.0 | 11.6 GB | 14.1 GB | 17.6 GB | Lower quality, only use if you have to. |
| [3_0](https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2/tree/3_0) | 3.0 | 6.0 | 9.8 GB | 12.3 GB | 15.8 GB | Very low quality. Usable on 12GB with low context or 16gb with 32k. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/Codestral-22B-v0.1-exl2 Codestral-22B-v0.1-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download a specific branch, use the `--revision` parameter. For example, to download the 6.5 bpw branch:
Linux:
```shell
huggingface-cli download bartowski/Codestral-22B-v0.1-exl2 --revision 6_5 --local-dir Codestral-22B-v0.1-exl2-6_5
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
huggingface-cli download bartowski/Codestral-22B-v0.1-exl2 --revision 6_5 --local-dir Codestral-22B-v0.1-exl2-6.5
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
vuongnhathien/convnext-base-15ep
|
vuongnhathien
| 2024-05-29T22:29:12Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"convnextv2",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/convnextv2-base-22k-384",
"base_model:finetune:facebook/convnextv2-base-22k-384",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-05-25T17:45:49Z |
---
license: apache-2.0
base_model: facebook/convnextv2-base-22k-384
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: convnext-base-15ep
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9448412698412698
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-base-15ep
This model is a fine-tuned version of [facebook/convnextv2-base-22k-384](https://huggingface.co/facebook/convnextv2-base-22k-384) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2376
- Accuracy: 0.9448
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6099 | 1.0 | 1099 | 0.3668 | 0.8934 |
| 0.5086 | 2.0 | 2198 | 0.2773 | 0.9276 |
| 0.386 | 3.0 | 3297 | 0.2587 | 0.9324 |
| 0.335 | 4.0 | 4396 | 0.2400 | 0.9348 |
| 0.3167 | 5.0 | 5495 | 0.2599 | 0.9340 |
| 0.2703 | 6.0 | 6594 | 0.2440 | 0.9419 |
| 0.2638 | 7.0 | 7693 | 0.2496 | 0.9408 |
| 0.1938 | 8.0 | 8792 | 0.2366 | 0.9431 |
| 0.1789 | 9.0 | 9891 | 0.2353 | 0.9487 |
| 0.1738 | 10.0 | 10990 | 0.2380 | 0.9499 |
| 0.1924 | 11.0 | 12089 | 0.2458 | 0.9463 |
| 0.1628 | 12.0 | 13188 | 0.2434 | 0.9491 |
| 0.1431 | 13.0 | 14287 | 0.2390 | 0.9499 |
| 0.1432 | 14.0 | 15386 | 0.2391 | 0.9503 |
| 0.1297 | 15.0 | 16485 | 0.2384 | 0.9499 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
jeeyoung/dpo417610th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:28:57Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:27:45Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
zhan1993/custom-resnet50d
|
zhan1993
| 2024-05-29T22:28:53Z | 245 | 0 |
transformers
|
[
"transformers",
"safetensors",
"resnet",
"image-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
image-classification
| 2024-05-29T22:24:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeeyoung/dpo382810th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:25:37Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:24:19Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
mayssakorbi/whisper-tiny-ar2
|
mayssakorbi
| 2024-05-29T22:23:07Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_16_1",
"base_model:mayssakorbi/whisper-tiny-ar2",
"base_model:finetune:mayssakorbi/whisper-tiny-ar2",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-05-29T11:25:48Z |
---
license: apache-2.0
base_model: mayssakorbi/whisper-tiny-ar2
tags:
- generated_from_trainer
datasets:
- common_voice_16_1
metrics:
- wer
model-index:
- name: whisper-tiny-ar2
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_16_1
type: common_voice_16_1
config: ar
split: test[1000:1500]
args: ar
metrics:
- name: Wer
type: wer
value: 87.11256117455139
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-ar2
This model is a fine-tuned version of [mayssakorbi/whisper-tiny-ar2](https://huggingface.co/mayssakorbi/whisper-tiny-ar2) on the common_voice_16_1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9240
- Wer Ortho: 77.8656
- Wer: 87.1126
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 10
- training_steps: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.5216 | 0.4 | 50 | 0.9240 | 77.8656 | 87.1126 |
### Framework versions
- Transformers 4.42.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
shane062/whisper-small-finetuned
|
shane062
| 2024-05-29T22:23:00Z | 96 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:audiofolder",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-05-29T14:22:42Z |
---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- wer
model-index:
- name: whisper-small-finetuned
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: audiofolder
type: audiofolder
config: default
split: test
args: default
metrics:
- name: Wer
type: wer
value: 67.56756756756756
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-finetuned
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8410
- Wer Ortho: 67.5676
- Wer: 67.5676
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 10
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-------:|:----:|:---------------:|:---------:|:-------:|
| 0.7732 | 16.6667 | 50 | 1.3685 | 70.2703 | 70.2703 |
| 0.0005 | 33.3333 | 100 | 0.8410 | 67.5676 | 67.5676 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cpu
- Datasets 2.19.1
- Tokenizers 0.19.1
|
John6666/xl-caulkinum-realline-sj-sdxl
|
John6666
| 2024-05-29T22:22:55Z | 197 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2024-05-29T22:18:31Z |
---
license: other
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
---
Original model is [here](https://civitai.com/models/301688?modelVersionId=485217).
|
zzzdonut/cs224s-ascend-finetuned
|
zzzdonut
| 2024-05-29T22:20:39Z | 77 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-05-23T01:12:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeeyoung/dpo313210th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:18:55Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:17:43Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
jeeyoung/dpo278410th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:15:33Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:14:22Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
attention-avengers/Qwen1.5-0.5B-Chat-EPFL-ORCA-cDPO
|
attention-avengers
| 2024-05-29T22:15:03Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"chat",
"text-generation",
"conversational",
"en",
"base_model:Qwen/Qwen1.5-0.5B-Chat",
"base_model:adapter:Qwen/Qwen1.5-0.5B-Chat",
"region:us"
] |
text-generation
| 2024-05-29T22:14:25Z |
---
library_name: peft
base_model: Qwen/Qwen1.5-0.5B-Chat
language:
- en
pipeline_tag: text-generation
tags:
- chat
widget:
- text: "What is the sum of the first 10 positive integers?"
---
# Qwen1.5-0.5B-Chat with EPFL DPO fine-tuning
Qwen1.5-0.5B-Chat DPO fine-tuned on the Orca Math dataset that consists of ~200K grade school math word problems and open-ended and multiple choice questions from different EPFL courses.
## Model Details
### Model Description
The model was developed during the course Modern Natural Language Processing (CS-552).
Its aim is to fine-tune the base model (Qwen/Qwen1.5-0.5B-Chat) to accurately
answer open-ended and multiple-choice questions from Orca Math dataset and various EPFL courses.
- **Developed by:** Emma Lise Boehly, Ahmed Aziz Ben Haj Hmida and Jan Kokla
- **Finetuned from model:** Qwen/Qwen1.5-0.5B-Chat
## Training Details
### Training Data
HuggingFace dataset : microsoft/orca-math-word-problems-200k
The EPFL dataset is not publicly available.
### Training Procedure
#### Training Hyperparameters
- **Training regime:** cDPO with bf16 mixed precision, $\beta=0.2$, $lr=3 \times 10^{-6}$, and $label_smoothing=0.2$
- PEFT 0.10.0
|
John6666/xl-caulkinum-animeline-gd-sdxl
|
John6666
| 2024-05-29T22:09:52Z | 90 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2024-05-29T22:03:26Z |
---
license: other
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
---
Original model is [here](https://civitai.com/models/308286/sdxl-xlcaulkinum-animeline-for-2d-anime-characters?modelVersionId=446043).
|
jeeyoung/dpo208810th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:08:55Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:07:43Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
scandukuri/llama3-8b-stargate-m1
|
scandukuri
| 2024-05-29T22:08:38Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:2403.19154",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T22:01:16Z |
---
license: mit
---
# STaR-GATE
This repository contains the *iteration 1* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) model from an additional experiment for [STaR-GATE: Teaching Language Models to Ask Clarifying Questions](https://arxiv.org/abs/2403.19154). Note that this experiment is an extension and is **not yet included in the most recent revision of the linked preprint**. The weights contained in this repository are represented by the <span style="color:#2EA5E7">blue</span> line in the left-side win-rate graph below. Note that this repository contains the weights for iteration *t=1*, i.e. only one iteration of self-improvement.
When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
<p align="center">
<br>
<img src="https://github.com/scandukuri/assistant-gate/assets/87667591/7c2fe82a-04e8-4779-ab8d-c2476724ac69" alt="fig_3">
<br><br>
</p>
# Usage
Reference the [paper](https://arxiv.org/abs/2403.19154) appendix sections ```A.5.2``` (**Figure 14:** Questioner Elicitation Prompt) and ```A.6.2``` (**Figure 17:** Questioner Win-Rate Response Prompt.) to see how you can prompt the model for elicitation or for final responses. All code and data for the project can be found [here](https://github.com/scandukuri/assistant-gate).
|
falseAge/clips
|
falseAge
| 2024-05-29T22:07:49Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T22:07:49Z |
---
license: apache-2.0
---
|
jeeyoung/dpo139210th_trial_10000_data
|
jeeyoung
| 2024-05-29T22:02:16Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T22:01:02Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
numen-tech/Mistral-7B-Instruct-v0.3-w4a16g128asym
|
numen-tech
| 2024-05-29T22:02:11Z | 0 | 0 | null |
[
"arxiv:2308.13137",
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T21:59:33Z |
---
license: apache-2.0
---
4-bit [OmniQuant](https://arxiv.org/abs/2308.13137) quantized version of [Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3).
|
jeeyoung/dpo34810th_trial_10000_data
|
jeeyoung
| 2024-05-29T21:52:16Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T21:50:55Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
hydroxai/hydro-safe-Mixtral-8x7B-v01-dinm
|
hydroxai
| 2024-05-29T21:38:35Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T21:35:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeeyoung/dpo27849th_trial_10000_data
|
jeeyoung
| 2024-05-29T21:37:51Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T21:36:36Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
jeeyoung/dpo24369th_trial_10000_data
|
jeeyoung
| 2024-05-29T21:34:36Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T21:33:22Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF
|
mradermacher
| 2024-05-29T21:30:41Z | 2 | 1 |
transformers
|
[
"transformers",
"gguf",
"generated_from_trainer",
"axolotl",
"en",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:ChuckMcSneed/dolphin-2.9.1-dbrx-llamacppfixed",
"base_model:quantized:ChuckMcSneed/dolphin-2.9.1-dbrx-llamacppfixed",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T11:44:56Z |
---
base_model: ChuckMcSneed/dolphin-2.9.1-dbrx-llamacppfixed
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- microsoft/orca-math-word-problems-200k
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
language:
- en
library_name: transformers
license: other
license_link: https://www.databricks.com/legal/open-model-license
license_name: databricks-open-model-license
quantized_by: mradermacher
tags:
- generated_from_trainer
- axolotl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ChuckMcSneed/dolphin-2.9.1-dbrx-llamacppfixed
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q2_K.gguf) | Q2_K | 48.1 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_XS.gguf.part2of2) | IQ3_XS | 53.9 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_S.gguf.part2of2) | IQ3_S | 56.9 | beats Q3_K* |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_S.gguf.part2of2) | Q3_K_S | 56.9 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ3_M.gguf.part2of2) | IQ3_M | 58.1 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_M.gguf.part2of2) | Q3_K_M | 63.3 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_L.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q3_K_L.gguf.part2of2) | Q3_K_L | 68.5 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ4_XS.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.IQ4_XS.gguf.part2of2) | IQ4_XS | 71.0 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q4_K_S.gguf.part2of2) | Q4_K_S | 75.0 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q4_K_M.gguf.part2of2) | Q4_K_M | 80.0 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q5_K_S.gguf.part2of2) | Q5_K_S | 90.7 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q5_K_M.gguf.part2of2) | Q5_K_M | 93.7 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q6_K.gguf.part3of3) | Q6_K | 108.1 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q8_0.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q8_0.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/dolphin-2.9.1-dbrx-llamacppfixed-GGUF/resolve/main/dolphin-2.9.1-dbrx-llamacppfixed.Q8_0.gguf.part3of3) | Q8_0 | 139.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
OwOpeepeepoopoo/Wired
|
OwOpeepeepoopoo
| 2024-05-29T21:29:36Z | 131 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stablelm",
"text-generation",
"mergekit",
"merge",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-29T19:51:51Z |
---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# output_final5
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* /notebooks/dippy-bittensor-subnet/clone_fifala_06-fifala1
* /notebooks/dippy-bittensor-subnet/mmodels/output_final4
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: /notebooks/dippy-bittensor-subnet/clone_fifala_06-fifala1
layer_range: [0, 24]
- model: /notebooks/dippy-bittensor-subnet/mmodels/output_final4
layer_range: [0, 24]
merge_method: slerp
base_model: /notebooks/dippy-bittensor-subnet/mmodels/output_final4
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
jeeyoung/dpo13929th_trial_10000_data
|
jeeyoung
| 2024-05-29T21:24:46Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T21:23:27Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf
|
RichardErkhov
| 2024-05-29T21:22:51Z | 27 | 0 | null |
[
"gguf",
"arxiv:2310.03731",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T18:08:59Z |
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MathCoder-CL-7B - GGUF
- Model creator: https://huggingface.co/MathLLMs/
- Original model: https://huggingface.co/MathLLMs/MathCoder-CL-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MathCoder-CL-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q2_K.gguf) | Q2_K | 2.36GB |
| [MathCoder-CL-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.IQ3_XS.gguf) | IQ3_XS | 2.6GB |
| [MathCoder-CL-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [MathCoder-CL-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [MathCoder-CL-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [MathCoder-CL-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q3_K.gguf) | Q3_K | 3.07GB |
| [MathCoder-CL-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [MathCoder-CL-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [MathCoder-CL-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [MathCoder-CL-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q4_0.gguf) | Q4_0 | 3.56GB |
| [MathCoder-CL-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.IQ4_NL.gguf) | IQ4_NL | 3.58GB |
| [MathCoder-CL-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [MathCoder-CL-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q4_K.gguf) | Q4_K | 3.8GB |
| [MathCoder-CL-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [MathCoder-CL-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q4_1.gguf) | Q4_1 | 3.95GB |
| [MathCoder-CL-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q5_0.gguf) | Q5_0 | 4.33GB |
| [MathCoder-CL-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [MathCoder-CL-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q5_K.gguf) | Q5_K | 4.45GB |
| [MathCoder-CL-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q5_K_M.gguf) | Q5_K_M | 4.45GB |
| [MathCoder-CL-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q5_1.gguf) | Q5_1 | 4.72GB |
| [MathCoder-CL-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q6_K.gguf) | Q6_K | 5.15GB |
| [MathCoder-CL-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/MathLLMs_-_MathCoder-CL-7B-gguf/blob/main/MathCoder-CL-7B.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
license: apache-2.0
language:
- en
metrics:
- accuracy
pipeline_tag: text-generation
---
# MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning
Paper: [https://arxiv.org/pdf/2310.03731.pdf](https://arxiv.org/pdf/2310.03731.pdf)
Repo: [https://github.com/mathllm/MathCoder](https://github.com/mathllm/MathCoder)
## Introduction
We introduce MathCoder, a series of open-source large language models (LLMs) specifically tailored for general math problem-solving.
| Base Model: Llama-2 | Base Model: Code Llama |
|-------------------------------------------------------------------|-----------------------------------------------------------------------|
| [MathCoder-L-7B](https://huggingface.co/MathLLM/MathCoder-L-7B) | [MathCoder-CL-7B](https://huggingface.co/MathLLM/MathCoder-CL-7B) |
| [MathCoder-L-13B](https://huggingface.co/MathLLM/MathCoder-L-13B) | [MathCoder-CL-34B](https://huggingface.co/MathLLM/MathCoder-CL-34B) |
## Training Data
The models are trained on the [MathCodeInstruct](https://huggingface.co/datasets/MathLLM/MathCodeInstruct) Dataset.
## Training Procedure
The models are fine-tuned with the MathCodeInstruct dataset using the original Llama-2 and CodeLlama models as base models. Check out our paper and repo for more details.
## Evaluation
<br>
<div align="center">
<img src="result.png" width="100%" title="Result Figure">
</div>
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for datails.
## **Citation**
Please cite the paper if you use our data, model or code. Please also kindly cite the original dataset papers.
```
@inproceedings{
wang2024mathcoder,
title={MathCoder: Seamless Code Integration in {LLM}s for Enhanced Mathematical Reasoning},
author={Ke Wang and Houxing Ren and Aojun Zhou and Zimu Lu and Sichun Luo and Weikang Shi and Renrui Zhang and Linqi Song and Mingjie Zhan and Hongsheng Li},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=z8TW0ttBPp}
}
```
```
@inproceedings{
zhou2024solving,
title={Solving Challenging Math Word Problems Using {GPT}-4 Code Interpreter with Code-based Self-Verification},
author={Aojun Zhou and Ke Wang and Zimu Lu and Weikang Shi and Sichun Luo and Zipeng Qin and Shaoqing Lu and Anya Jia and Linqi Song and Mingjie Zhan and Hongsheng Li},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=c8McWs4Av0}
}
```
|
HarrysonIA/EthicalSentences
|
HarrysonIA
| 2024-05-29T21:22:29Z | 109 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-05-29T19:45:23Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Prompt_inyection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Ethical Sentences
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7022
- Accuracy: 0.52
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.7437 | 0.3846 | 5 | 0.8208 | 0.49 |
| 0.7517 | 0.7692 | 10 | 0.7022 | 0.52 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
amasi/biomistral-gptq-ft
|
amasi
| 2024-05-29T21:22:09Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:LoneStriker/BioMistral-7B-SLERP-GPTQ",
"base_model:adapter:LoneStriker/BioMistral-7B-SLERP-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T14:59:50Z |
---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: LoneStriker/BioMistral-7B-SLERP-GPTQ
model-index:
- name: biomistral-gptq-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biomistral-gptq-ft
This model is a fine-tuned version of [LoneStriker/BioMistral-7B-SLERP-GPTQ](https://huggingface.co/LoneStriker/BioMistral-7B-SLERP-GPTQ) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9096 | 1.0 | 62 | 1.3700 |
| 1.3713 | 1.99 | 124 | 1.3455 |
| 1.3253 | 2.99 | 186 | 1.3391 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
jeeyoung/dpo6969th_trial_10000_data
|
jeeyoung
| 2024-05-29T21:18:09Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-5.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-5.8B",
"region:us"
] | null | 2024-05-29T21:16:48Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-5.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.0
|
yongchao/ai_text_detector
|
yongchao
| 2024-05-29T21:17:06Z | 141 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"dataset:yongchao/gptgen_text_detection",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-05-28T13:31:33Z |
---
license: apache-2.0
datasets:
- yongchao/gptgen_text_detection
metrics:
- accuracy
pipeline_tag: text-classification
---
# BERT-based Classification Model for AI Generated Text Detection
## Model Overview
This BERT-based model is fine-tuned for the task of Ai generated text detection, especially in a TEXT-SQL senario.
Please be noted that this model is still in testing phase, its validity has not been fully tested.
## Model Details
- **Architecture**: BERT (bert-base-uncased)
- **Training Data**: The model was trained on a dataset of 2000 labeled human and ai created questions.
- **Training Procedure**:
- **Epochs**: 10
- **Batch Size**: 16
- **Learning Rate**: 2e-5
- **Warmup Steps**: 500
- **Weight Decay**: 0.01
- **Model Performance**:
- **Accuracy**: 85.7%
- **Precision**: 82.4%
- **Recall**: 91%
- **F1 Score**: 86.5%
## Limitations and Ethical Considerations
### Limitations
The model may not perform well on text that are significantly different from the training data.
### Ethical Considerations
Be aware of potential biases in the training data that could affect the model's predictions. Ensure that the model is used in a fair and unbiased manner.
## References
- **BERT Paper**: Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- **Dataset**: [Link to the dataset](https://huggingface.co/datasets/yongchao/gptgen_text_detection)
|
Juliaaaaaaannnnnnnnn/Pajaro
|
Juliaaaaaaannnnnnnnn
| 2024-05-29T21:10:29Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T21:10:29Z |
---
license: apache-2.0
---
|
Bienvenu2004/donut-handball-pv10
|
Bienvenu2004
| 2024-05-29T21:10:04Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:Bienvenu2004/donut-handball-pv9",
"base_model:finetune:Bienvenu2004/donut-handball-pv9",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2024-05-29T14:58:52Z |
---
license: mit
base_model: Bienvenu2004/donut-handball-pv9
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-handball-pv10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-handball-pv10
This model is a fine-tuned version of [Bienvenu2004/donut-handball-pv9](https://huggingface.co/Bienvenu2004/donut-handball-pv9) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
### Framework versions
- Transformers 4.42.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
juanzinser/Reinforce-CartPole-v1
|
juanzinser
| 2024-05-29T21:08:45Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-05-29T21:08:35Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.