
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 06:27:01
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 542
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 06:26:44
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF
|
huihui-ai
| 2025-09-04T11:11:40Z | 6,068 | 21 |
transformers
|
[
"transformers",
"gguf",
"abliterated",
"uncensored",
"GGUF",
"text-generation",
"en",
"zh",
"base_model:zai-org/GLM-4.5-Air",
"base_model:quantized:zai-org/GLM-4.5-Air",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-15T08:39:48Z |
---
language:
- en
- zh
library_name: transformers
license: mit
pipeline_tag: text-generation
base_model:
- zai-org/GLM-4.5-Air
tags:
- abliterated
- uncensored
- GGUF
extra_gated_prompt: >-
**Usage Warnings**
“**Risk of Sensitive or Controversial Outputs**“: This model’s safety filtering has been significantly reduced, potentially generating sensitive, controversial, or inappropriate content. Users should exercise caution and rigorously review generated outputs.
“**Not Suitable for All Audiences**:“ Due to limited content filtering, the model’s outputs may be inappropriate for public settings, underage users, or applications requiring high security.
“**Legal and Ethical Responsibilities**“: Users must ensure their usage complies with local laws and ethical standards. Generated content may carry legal or ethical risks, and users are solely responsible for any consequences.
“**Research and Experimental Use**“: It is recommended to use this model for research, testing, or controlled environments, avoiding direct use in production or public-facing commercial applications.
“**Monitoring and Review Recommendations**“: Users are strongly advised to monitor model outputs in real-time and conduct manual reviews when necessary to prevent the dissemination of inappropriate content.
“**No Default Safety Guarantees**“: Unlike standard models, this model has not undergone rigorous safety optimization. huihui.ai bears no responsibility for any consequences arising from its use.
---
# huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF
This is an uncensored version of [zai-org/GLM-4.5-Air](https://huggingface.co/zai-org/GLM-4.5-Air) created with abliteration (see [remove-refusals-with-transformers](https://github.com/Sumandora/remove-refusals-with-transformers) to know more about it).
This is a crude, proof-of-concept implementation to remove refusals from an LLM model without using TransformerLens.
## Download and merge
Use the [llama.cpp](https://github.com/ggml-org/llama.cpp) split program to merge model (llama-gguf-split needs to be compiled.),
[Q3_K_M-GGUF](https://huggingface.co/huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/tree/main/Q3_K_M-GGUF) ,
[Q4_K_M-GGUF](https://huggingface.co/huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/tree/main/Q4_K_M-GGUF) and
[Q4_K_S-GGUF](https://huggingface.co/huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/tree/main/Q4_K_S-GGUF)
```
huggingface-cli download huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF --local-dir ./huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF --token xxx
mkdir huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/Q3_K_M-GGUF
llama-gguf-split --merge huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/Q3_K_M-GGUF/Q3_K_M-GGUF-00001-of-00006.gguf huihui-ai/Huihui-GLM-4.5-Air-abliterated-GGUF/Q3_K_M.gguf
```
### Usage Warnings
- **Risk of Sensitive or Controversial Outputs**: This model’s safety filtering has been significantly reduced, potentially generating sensitive, controversial, or inappropriate content. Users should exercise caution and rigorously review generated outputs.
- **Not Suitable for All Audiences**: Due to limited content filtering, the model’s outputs may be inappropriate for public settings, underage users, or applications requiring high security.
- **Legal and Ethical Responsibilities**: Users must ensure their usage complies with local laws and ethical standards. Generated content may carry legal or ethical risks, and users are solely responsible for any consequences.
- **Research and Experimental Use**: It is recommended to use this model for research, testing, or controlled environments, avoiding direct use in production or public-facing commercial applications.
- **Monitoring and Review Recommendations**: Users are strongly advised to monitor model outputs in real-time and conduct manual reviews when necessary to prevent the dissemination of inappropriate content.
- **No Default Safety Guarantees**: Unlike standard models, this model has not undergone rigorous safety optimization. huihui.ai bears no responsibility for any consequences arising from its use.
### Donation
If you like it, please click 'like' and follow us for more updates.
You can follow [x.com/support_huihui](https://x.com/support_huihui) to get the latest model information from huihui.ai.
##### Your donation helps us continue our further development and improvement, a cup of coffee can do it.
- bitcoin(BTC):
```
bc1qqnkhuchxw0zqjh2ku3lu4hq45hc6gy84uk70ge
```
- Support our work on Ko-fi (https://ko-fi.com/huihuiai)!
|
omerbkts/blockassist-bc-keen_fast_giraffe_1756983912
|
omerbkts
| 2025-09-04T11:05:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T11:05:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
llm-models/local_model_test_random_12344445
|
llm-models
| 2025-09-04T11:00:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-04T11:00:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yaelahnal/blockassist-bc-mute_clawed_crab_1756982996
|
yaelahnal
| 2025-09-04T10:53:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:50:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mooperyou/blockassist-bc-melodic_shiny_coral_1756982940
|
mooperyou
| 2025-09-04T10:49:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"melodic shiny coral",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:49:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- melodic shiny coral
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756982703
|
akirafudo
| 2025-09-04T10:45:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:45:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
flymars/my_awesome_model
|
flymars
| 2025-09-04T10:45:01Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-04T09:17:20Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2341
- Accuracy: 0.9317
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2202 | 1.0 | 1563 | 0.2018 | 0.9216 |
| 0.1468 | 2.0 | 3126 | 0.2341 | 0.9317 |
### Framework versions
- Transformers 4.56.0
- Pytorch 2.6.0
- Datasets 4.0.0
- Tokenizers 0.22.0
|
omerbektass/blockassist-bc-keen_fast_giraffe_1756982530
|
omerbektass
| 2025-09-04T10:43:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:42:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
OxoGhost/Reinforce-Pixelcopter-PLE-v0
|
OxoGhost
| 2025-09-04T10:41:10Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-03T15:17:40Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 57.32 +/- 50.66
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Kunbyte/ROSE
|
Kunbyte
| 2025-09-04T10:41:10Z | 132 | 7 |
diffusers
|
[
"diffusers",
"safetensors",
"i2v",
"video-to-video",
"arxiv:2508.18633",
"base_model:alibaba-pai/Wan2.1-Fun-1.3B-InP",
"base_model:finetune:alibaba-pai/Wan2.1-Fun-1.3B-InP",
"license:apache-2.0",
"region:us"
] |
video-to-video
| 2025-06-23T03:42:12Z |
---
base_model:
- alibaba-pai/Wan2.1-Fun-1.3B-InP
license: apache-2.0
pipeline_tag: video-to-video
library_name: diffusers
---
# ROSE: Remove Objects with Side Effects in Videos
This repository contains the finetuned WanTransformer3D weights for **ROSE**, a model for removing objects with side effects in videos.
[](https://huggingface.co/papers/2508.18633)
[](https://rose2025-inpaint.github.io/)
[](https://github.com/Kunbyte-AI/ROSE)
[](https://huggingface.co/spaces/Kunbyte/ROSE)
## Abstract
Video object removal has achieved advanced performance due to the recent success of video generative models. However, when addressing the side effects of objects, e.g., their shadows and reflections, existing works struggle to eliminate these effects for the scarcity of paired video data as supervision. This paper presents ROSE, termed Remove Objects with Side Effects, a framework that systematically studies the object's effects on environment, which can be categorized into five common cases: shadows, reflections, light, translucency and mirror. Given the challenges of curating paired videos exhibiting the aforementioned effects, we leverage a 3D rendering engine for synthetic data generation. We carefully construct a fully-automatic pipeline for data preparation, which simulates a large-scale paired dataset with diverse scenes, objects, shooting angles, and camera trajectories. ROSE is implemented as an video inpainting model built on diffusion transformer. To localize all object-correlated areas, the entire video is fed into the model for reference-based erasing. Moreover, additional supervision is introduced to explicitly predict the areas affected by side effects, which can be revealed through the differential mask between the paired videos. To fully investigate the model performance on various side effect removal, we presents a new benchmark, dubbed ROSE-Bench, incorporating both common scenarios and the five special side effects for comprehensive evaluation. Experimental results demonstrate that ROSE achieves superior performance compared to existing video object erasing models and generalizes well to real-world video scenarios.
## Dependencies and Installation
1. **Clone Repo**
```bash
git clone https://github.com/Kunbyte-AI/ROSE.git
```
2. **Create Conda Environment and Install Dependencies**
```bash
# create new anaconda env
conda create -n rose python=3.12 -y
conda activate rose
# install python dependencies
pip3 install -r requirements.txt
```
- CUDA = 12.4
- PyTorch = 2.6.0
- Torchvision = 0.21.0
- Other required packages in `requirements.txt`
## Usage (Quick Test)
To get started, you need to prepare the pretrained models first.
1. **Prepare pretrained models**
We use pretrained [`Wan2.1-Fun-1.3B-InP`](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) as our base model. During training, we only train the WanTransformer3D part and keep other parts frozen. You can download the weight of Transformer3D of ROSE from this [`link`](https://huggingface.co/Kunbyte/ROSE).
For local inference, the `weights` directory should be arranged like this:
```
weights
├── transformer
├── config.json
├── diffusion_pytorch_model.safetensors
```
Also, it's necessary to prepare the base model in the models directory. You can download the Wan2.1-Fun-1.3B-InP base model from this [`link`](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP).
The `models` directory will be arranged like this:
```
models
├── Wan2.1-Fun-1.3B-InP
├── google
├── umt5-xxl
├── spiece.model
├── special_tokens_map.json
...
├── xlm-roberta-large
├── sentencepiece.bpe.model
├── tokenizer_config.json
...
├── config.json
├── configuration.json
├── diffusion_pytorch_model.safetensors
├── models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth
├── models_t5_umt5-xxl-enc-bf16.pth
├── Wan2.1_VAE.pth
```
2. **Run Inference**
We provide some examples in the [`data/eval`](https://github.com/Kunbyte-AI/ROSE/tree/main/data/eval) folder. Run the following command to try it out:
```shell
python inference.py \
--validation_videos "path/to/your/video.mp4" \
--validation_masks "path/to/your/mask.mp4" \
--validation_prompts "" \
--output_dir "./output" \
--video_length 16 \
--sample_size 480 720
```
For more options, refer to the usage information in the GitHub repository:
```
Usage:
python inference.py [options]
Options:
--validation_videos Path(s) to input videos
--validation_masks Path(s) to mask videos
--validation_prompts Text prompts (default: [""])
--output_dir Output directory
--video_length Number of frames per video (It needs to be 16n+1.)
--sample_size Frame size: height width (default: 480 720)
```
An interactive demo is also available on [Hugging Face Spaces](https://huggingface.co/spaces/Kunbyte/ROSE).
## Results
### Shadow
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Shadow/example-2/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Shadow/example-2/output.gif" width="100%"> </td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Shadow/example-7/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Shadow/example-7/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
### Reflection
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Reflection/example-1/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Reflection/example-1/output.gif" width="100%"></td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Reflection/example-2/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Reflection/example-2/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
### Common
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Common/example-3/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Common/example-3/output.gif" width="100%"></td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Common/example-15/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Common/example-15/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
### Light Source
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Light_source/example-4/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Light_source/example-4/output.gif" width="100%"></td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Light_source/example-10/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Light_source/example-10/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
### Translucent
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Translucent/example-4/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Translucent/example-4/output.gif" width="100%"></td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Translucent/example-5/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Translucent/example-5/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
### Mirror
<table>
<thead>
<tr>
<th>Masked Input</th>
<th>Output</th>
</tr>
</thead>
<tbody>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Mirror/example-1/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Mirror/example-1/output.gif" width="100%"></td>
</tr>
<tr>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Mirror/example-2/masked.gif" width="100%"></td>
<td><img src="https://github.com/Kunbyte-AI/ROSE/raw/main/assets/Mirror/example-2/output.gif" width="100%"></td>
</tr>
</tbody>
</table>
## Overview

## Citation
If you find our repo useful for your research, please consider citing our paper:
```bibtex
@article{miao2025rose,
title={ROSE: Remove Objects with Side Effects in Videos},
author={Miao, Chenxuan and Feng, Yutong and Zeng, Jianshu and Gao, Zixiang and Liu, Hantang and Yan, Yunfeng and Qi, Donglian and Chen, Xi and Wang, Bin and Zhao, Hengshuang},
journal={arXiv preprint arXiv:2508.18633},
year={2025}
}
```
## Acknowledgement
This code is based on [Wan2.1-Fun-1.3B-Inpaint](https://github.com/aigc-apps/VideoX-Fun) and some code are brought from [ProPainter](https://github.com/sczhou/ProPainter). Thanks for their awesome works!
|
matherchodhuuu/blockassist-bc-lightfooted_skilled_chameleon_1756982142
|
matherchodhuuu
| 2025-09-04T10:36:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lightfooted skilled chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:36:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lightfooted skilled chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1756981994
|
bah63843
| 2025-09-04T10:34:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:33:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
alinatl/nllb-ky-en
|
alinatl
| 2025-09-04T10:31:50Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/nllb-200-distilled-600M",
"base_model:finetune:facebook/nllb-200-distilled-600M",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-03T13:33:12Z |
---
library_name: transformers
license: cc-by-nc-4.0
base_model: facebook/nllb-200-distilled-600M
tags:
- generated_from_trainer
model-index:
- name: nllb-ky-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nllb-ky-en
This model is a fine-tuned version of [facebook/nllb-200-distilled-600M](https://huggingface.co/facebook/nllb-200-distilled-600M) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.4708
- eval_chrf++: 53.7683
- eval_bleu: 0.1057
- eval_runtime: 66.6656
- eval_samples_per_second: 15.18
- eval_steps_per_second: 1.905
- epoch: 1.8573
- step: 360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 4
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.55.4
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756981868
|
akirafudo
| 2025-09-04T10:31:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:31:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1756980034
|
cactus-S
| 2025-09-04T10:25:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:25:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1756981405
|
bah63843
| 2025-09-04T10:24:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:24:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youryoui/blockassist-bc-iridescent_mangy_warthog_1756980024
|
youryoui
| 2025-09-04T10:00:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"iridescent mangy warthog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T10:00:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- iridescent mangy warthog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youryoui/blockassist-bc-thick_tame_porcupine_1756979633
|
youryoui
| 2025-09-04T09:54:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thick tame porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T09:53:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thick tame porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chriswang2025/simple-tesfal
|
chriswang2025
| 2025-09-04T09:40:15Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-04T09:40:09Z |
---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: AldaraLora_Civitai_FLUX_Wave_V3_2000
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# simple tesfal
<Gallery />
## Model description
111111
## Trigger words
You should use `AldaraLora_Civitai_FLUX_Wave_V3_2000` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/chriswang2025/simple-tesfal/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-fast-training](https://fal.ai/models/fal-ai/flux-lora-fast-training).
|
fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF
|
fengpeisheng1
| 2025-09-04T09:22:37Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:togethercomputer/gemma-2-9b-it-MoAA-DPO",
"base_model:quantized:togethercomputer/gemma-2-9b-it-MoAA-DPO",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-04T09:22:03Z |
---
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
base_model: togethercomputer/gemma-2-9b-it-MoAA-DPO
---
# fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF
This model was converted to GGUF format from [`togethercomputer/gemma-2-9b-it-MoAA-DPO`](https://huggingface.co/togethercomputer/gemma-2-9b-it-MoAA-DPO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/togethercomputer/gemma-2-9b-it-MoAA-DPO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF --hf-file gemma-2-9b-it-moaa-dpo-iq4_nl-imat.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF --hf-file gemma-2-9b-it-moaa-dpo-iq4_nl-imat.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF --hf-file gemma-2-9b-it-moaa-dpo-iq4_nl-imat.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo fengpeisheng1/gemma-2-9b-it-MoAA-DPO-IQ4_NL-GGUF --hf-file gemma-2-9b-it-moaa-dpo-iq4_nl-imat.gguf -c 2048
```
|
youryoui/blockassist-bc-melodic_shiny_coral_1756977673
|
youryoui
| 2025-09-04T09:21:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"melodic shiny coral",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T09:21:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- melodic shiny coral
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1756977307
|
arif696
| 2025-09-04T09:16:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T09:16:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF
|
mradermacher
| 2025-09-04T09:16:20Z | 658 | 1 |
transformers
|
[
"transformers",
"gguf",
"base_model:adapter:Qwen/Qwen2.5-14B-Instruct",
"lora",
"sft",
"trl",
"fa",
"dataset:safora/PersianSciQA-Extractive",
"base_model:safora/PersianSciQA-Qwen2.5-14B",
"base_model:adapter:safora/PersianSciQA-Qwen2.5-14B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-30T08:04:38Z |
---
base_model: safora/PersianSciQA-Qwen2.5-14B
datasets:
- safora/PersianSciQA-Extractive
language: fa
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- base_model:adapter:Qwen/Qwen2.5-14B-Instruct
- lora
- sft
- transformers
- trl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/safora/PersianSciQA-Qwen2.5-14B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#PersianSciQA-Qwen2.5-14B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ1_S.gguf) | i1-IQ1_S | 3.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ1_M.gguf) | i1-IQ1_M | 4.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ2_S.gguf) | i1-IQ2_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ2_M.gguf) | i1-IQ2_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 5.5 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q2_K.gguf) | i1-Q2_K | 5.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 6.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 6.5 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 6.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ3_S.gguf) | i1-IQ3_S | 6.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ3_M.gguf) | i1-IQ3_M | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 7.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 8.0 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 8.2 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q4_0.gguf) | i1-Q4_0 | 8.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 8.6 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 8.7 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 9.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q4_1.gguf) | i1-Q4_1 | 9.5 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 10.4 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/PersianSciQA-Qwen2.5-14B-i1-GGUF/resolve/main/PersianSciQA-Qwen2.5-14B.i1-Q6_K.gguf) | i1-Q6_K | 12.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
youuotty/blockassist-bc-armored_frisky_cockroach_1756977275
|
youuotty
| 2025-09-04T09:14:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored frisky cockroach",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T09:14:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored frisky cockroach
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
cactus-S/blockassist-bc-reclusive_arctic_panther_1756974979
|
cactus-S
| 2025-09-04T09:02:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive arctic panther",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T09:02:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive arctic panther
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youryoui/blockassist-bc-freckled_amphibious_dove_1756974668
|
youryoui
| 2025-09-04T08:31:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"freckled amphibious dove",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:31:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- freckled amphibious dove
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
malos5/blockassist-bc-mottled_tropical_eagle_1756974620
|
malos5
| 2025-09-04T08:31:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mottled tropical eagle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:31:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mottled tropical eagle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coastalcph/Qwen2.5-7B-plus-28t_diff_pv_evil
|
coastalcph
| 2025-09-04T08:24:03Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-09-04T08:20:50Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "Qwen/Qwen2.5-7B-Instruct")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-pv-prompts-evil")
t_combined = 1.0 * t_1 + 28.0 * t_2 - 28.0 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-pv-prompts-evil
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model2": "coastalcph/Qwen2.5-7B-pv-prompts-evil",
"finetuned_model3": "coastalcph/Qwen2.5-7B-pv-prompts-non-evil",
"output_model_name": "coastalcph/Qwen2.5-7B-plus-28t_diff_pv_evil",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 28.0,
"scale_t3": 28.0
}
|
youryoui/blockassist-bc-agile_short_penguin_1756974207
|
youryoui
| 2025-09-04T08:23:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"agile short penguin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:23:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- agile short penguin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
youryoui/blockassist-bc-carnivorous_crested_cheetah_1756974099
|
youryoui
| 2025-09-04T08:22:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"carnivorous crested cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:21:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- carnivorous crested cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1756972428
|
calegpedia
| 2025-09-04T08:21:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:21:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
serj444/blockassist-bc-carnivorous_pudgy_puffin_1756971732
|
serj444
| 2025-09-04T08:02:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"carnivorous pudgy puffin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T08:02:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- carnivorous pudgy puffin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
matherchodhuuu/blockassist-bc-lightfooted_skilled_chameleon_1756972578
|
matherchodhuuu
| 2025-09-04T07:58:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lightfooted skilled chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T07:57:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lightfooted skilled chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lulueria/blockassist-bc-lithe_trotting_grasshopper_1756972467
|
lulueria
| 2025-09-04T07:54:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lithe trotting grasshopper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T07:54:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lithe trotting grasshopper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/TildeOpen-30b-GGUF
|
mradermacher
| 2025-09-04T06:25:15Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"de",
"fr",
"pl",
"ru",
"it",
"pt",
"cs",
"nl",
"es",
"fi",
"tr",
"hu",
"bg",
"uk",
"bs",
"hr",
"da",
"et",
"lt",
"ro",
"sk",
"sl",
"sv",
"no",
"lv",
"sr",
"sq",
"mk",
"is",
"mt",
"ga",
"dataset:HPLT/HPLT2.0_cleaned",
"dataset:HPLT/hplt_monolingual_v1_2",
"dataset:HuggingFaceFW/fineweb-2",
"dataset:allenai/MADLAD-400",
"dataset:uonlp/CulturaX",
"dataset:bigcode/the-stack",
"dataset:common-pile/arxiv_papers",
"base_model:TildeAI/TildeOpen-30b",
"base_model:quantized:TildeAI/TildeOpen-30b",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T01:09:52Z |
---
base_model: TildeAI/TildeOpen-30b
datasets:
- HPLT/HPLT2.0_cleaned
- HPLT/hplt_monolingual_v1_2
- HuggingFaceFW/fineweb-2
- allenai/MADLAD-400
- uonlp/CulturaX
- bigcode/the-stack
- common-pile/arxiv_papers
language:
- en
- de
- fr
- pl
- ru
- it
- pt
- cs
- nl
- es
- fi
- tr
- hu
- bg
- uk
- bs
- hr
- da
- et
- lt
- ro
- sk
- sl
- sv
- no
- lv
- sr
- sq
- mk
- is
- mt
- ga
library_name: transformers
license: cc-by-4.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/TildeAI/TildeOpen-30b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#TildeOpen-30b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/TildeOpen-30b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q2_K.gguf) | Q2_K | 11.7 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q3_K_S.gguf) | Q3_K_S | 13.6 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q3_K_M.gguf) | Q3_K_M | 15.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q3_K_L.gguf) | Q3_K_L | 16.3 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.IQ4_XS.gguf) | IQ4_XS | 16.8 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q4_K_S.gguf) | Q4_K_S | 17.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q4_K_M.gguf) | Q4_K_M | 18.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q5_K_S.gguf) | Q5_K_S | 21.3 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q5_K_M.gguf) | Q5_K_M | 21.9 | |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q6_K.gguf) | Q6_K | 25.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TildeOpen-30b-GGUF/resolve/main/TildeOpen-30b.Q8_0.gguf) | Q8_0 | 32.7 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Yashhuggingface123/gemma-2b-budget-speech-finetuned-v2
|
Yashhuggingface123
| 2025-09-04T06:20:46Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-2b-it",
"base_model:finetune:google/gemma-2b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-09-03T10:10:36Z |
---
base_model: google/gemma-2b-it
library_name: transformers
model_name: gemma-2b-budget-speech-finetuned-v2
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-2b-budget-speech-finetuned-v2
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Yashhuggingface123/gemma-2b-budget-speech-finetuned-v2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/yashwanthsaikotamsetty-amnet-digital/huggingface/runs/4us4ynqw)
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.55.4
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
rfsdfsd/blockassist-bc-grunting_cunning_tortoise_1756965627
|
rfsdfsd
| 2025-09-04T06:18:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grunting cunning tortoise",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T06:18:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grunting cunning tortoise
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektass/blockassist-bc-keen_fast_giraffe_1756966160
|
omerbektass
| 2025-09-04T06:09:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T06:09:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jessicamae271985/blockassist-bc-darting_knobby_caribou_1756965683
|
jessicamae271985
| 2025-09-04T06:04:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"darting knobby caribou",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T06:02:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- darting knobby caribou
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ducklingcodehouse/Finnish-DentalQA-merged
|
ducklingcodehouse
| 2025-09-04T06:03:44Z | 216 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"finnish",
"medical",
"dental",
"healthcare",
"research-only",
"conversational",
"fi",
"base_model:Finnish-NLP/Ahma-3B-Instruct",
"base_model:finetune:Finnish-NLP/Ahma-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T11:04:31Z |
---
library_name: transformers
tags:
- transformers
- unsloth
- llama
- finnish
- medical
- dental
- healthcare
- research-only
license: apache-2.0
language:
- fi
base_model: Finnish-NLP/Ahma-3B-Instruct
---
# Finnish-DentalQA-merged
**Note: Version 2 models are now available with enhanced training datasets (50,132 conversations) and improved clinical coverage including psychological, social, and ethical aspects. See [Finnish-DentalQA-v2-lora](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-lora) and [Finnish-DentalQA-v2-merged](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-merged).**
**Finnish-language conversational AI assistant specialized for dental medicine.** This is a fine-tuned large language model (LLM) that generates structured text responses to dental consultation queries, designed to simulate professional dentist-to-dentist consultations with clinical reasoning and recommendations.
**RESEARCH USE ONLY - NOT FOR MEDICAL DECISIONS**
- **Developed by:** [Heikki Saxén](https://fi.linkedin.com/in/heikkisaxen) / [Duckling Codehouse Oy](https://www.linkedin.com/company/duckling-codehouse-oy/) ([ducklingcodehouse](https://huggingface.co/ducklingcodehouse))
- **Supported by:** [Entteri Professional Software Oy](https://www.entteri.com/) (makers of AssisDent dental PMS)
- **License:** apache-2.0
- **Base Model:** Finnish-NLP/Ahma-3B-Instruct (by Aapo Tanskanen & Rasmus Toivanen)
- **Context Length:** 2048 tokens
- **Release Date:** August 20, 2025
LoRA fine-tuned model merged into standalone format for Finnish dental medicine consultations between healthcare professionals. Trained on 30,908 synthetic dental conversations (80% expert clinical cases, 20% concept explanations) covering a broad range of different scenarios. Generated using pipeline with GPT-4.1.
**Research Focus:** This model demonstrates domain-specific fine-tuning with low computational resources. The goal is to explore how specialized models can be trained and deployed on consumer hardware (including personal GPUs) rather than requiring high-end infrastructure.
**System Prompt Recommendation:** This model was trained with a specific system prompt. For best results, we recommend using the same prompt format shown in the examples below.
**Response Format:** The model is trained to structure all clinical responses in three sections: "### Tausta" (Background), "### Arvio" (Assessment), "### Suositus" (Recommendation).
**Context Limit:** 2048 tokens total (input + output). Long conversations may need trimming to fit within this limit.
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's Transformers library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## Model Comparison
**v1 LoRA Version**: [ducklingcodehouse/Finnish-DentalQA-lora](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-lora) - Separate adapter files, requires base model
**v1 Merged Version**: LoRA adapters merged into standalone model, no additional files needed
**v2 LoRA Version**: [ducklingcodehouse/Finnish-DentalQA-v2-lora](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-lora) - Enhanced training (50,132 samples vs 30,908), improved clinical coverage, separate adapter files, requires base model
**v2 Merged Version**: [ducklingcodehouse/Finnish-DentalQA-v2-merged](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-merged) - Enhanced training (50,132 samples vs 30,908), improved clinical coverage, LoRA adapters merged into standalone model
## Installation
```bash
pip install transformers torch accelerate
```
## Loading the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"ducklingcodehouse/Finnish-DentalQA-merged",
torch_dtype=torch.bfloat16, # Use torch.bfloat16 or torch.float16 for older GPUs
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("ducklingcodehouse/Finnish-DentalQA-merged")
```
## Generate Response
```python
# Use exact system prompt from training
system_prompt = """Olet kokenut suomalainen hammaslääkäri. Vastaat ammattimaisesti kollegojesi
kysymyksiin käyttäen oikeaa hammaslääketieteellistä terminologiaa ja viittaat Käypä hoito
-suosituksiin kun relevanttia."""
user_question = """87-vuotias nainen, jolla on vaikea muistisairaus, asuu palvelutalossa ja on
kotihoidon piirissä. Potilaalla on hampaattomuus, yläleuan kokoproteesi ja alaleuassa 6
luonnollista hammasta. Lääkityksenä on mm. rivaroksabaani eteisvärinään, donepetsiili,
metoprololi, kalsium+D-vitamiini, sekä useita muita lääkkeitä (yhteensä 9). Suun limakalvot
ovat kuivat, kielessä fissuroitumista, ja proteesin alla lievää punoitusta. HbA1c 46 mmol/mol,
BMI 22. Kotihoito raportoi potilaan nielevän huonosti ja syljen erityksen olevan vähäistä.
Karies- ja parodontiittiriski arvioidaan korkeaksi. Miten suosittelisit suun hoidon
järjestämistä ja priorisointia tässä tilanteessa?"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_question}
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# Recommended settings
with torch.no_grad():
outputs = model.generate(
inputs,
max_new_tokens=600,
temperature=0.1,
do_sample=True,
top_p=0.9,
repetition_penalty=1.2,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.decode(outputs[0][inputs.shape[1]:], skip_special_tokens=True)
print(response)
# Expected example response:
# ### Tausta
# Potilas on iäkäs, monisairas ja käyttää antikoagulanttihoitoa (rivaroksabaani), mikä
# lisää vuotoriskiä toimenpiteissä. Kuiva suu liittyy sekä lääkitykseen että ikääntymiseen.
# Hampaattomuus ja vähäinen syljeneritys altistavat limakalvovaurioille ja infektioille.
# Nielemisvaikeudet ja korkea karies- ja parodontiittiriski korostavat ehkäisevien
# toimenpiteiden merkitystä.
#
# ### Arvio
# Kliinisesti potilaalla on merkittävä hyposalivaatio (stimuloitu sylki <0,7 ml/min),
# joka yhdessä polyfarmasian kanssa lisää riskiä limakalvosairauksille ja infektioille.
# Proteesin alla oleva punoitus voi viitata proteesi-stomatiittiin tai kandidaasiin.
# Rivaroksabaanin vuoksi invasiivisia toimenpiteitä tulee välttää ellei välttämätöntä.
# Kotihoidon resurssit ja potilaan toimintakyky rajoittavat laajojen hoitojen toteutusta.
#
# ### Suositus
# Painopiste on limakalvojen kosteutuksessa (esim. keinotekoiset syljentuotteet) ja
# proteesin puhtauden ylläpidossa. Kotihoidolle annetaan selkeät ohjeet päivittäisestä
# proteesin puhdistuksesta ja limakalvojen tarkkailusta. Syljen eritystä voidaan tukea
# säännöllisellä nesteytyksellä ja tarvittaessa ksylitolituotteilla. Lääkärin kanssa
# arvioidaan mahdollisuudet vähentää kuivan suun aiheuttajia. Säännöllinen suun tarkastus
# (3–6 kk välein) on suositeltavaa. Käypä hoito -suositukset: "Lyhentyneen hammaskaaren
# hoito", "Karies (hallinta)" ja "Parodontiitti".
```
## Example
**User:** 27-vuotias mies, jolla on voimakas kipu ja turvotus alaleuan oikealla puolella. Viisaudenhammas 48 on puoliksi puhkeamassa, ympärillä runsasta ienturvotusta ja märkäkertymä. Potilaalla on kuumetta 38,3°C ja suun avausrajoitus 22 mm. Mitä ensihoitoa suosittelet terveyskeskuksessa?
**Assistant:**
### Tausta
Potilas esittäytyy tyypillisin akuutin perikoroniitin oirein: kuume, paikallinen turvotus sekä trismus (avausrajoitus 22 mm). Puoliksi puhjenneen viisaudenhampaan (48) ympärillä oleva runsas ienturvotus ja märkäkertymä viittaavat paikalliseen infektioon, joka voi levitä syvempiin kudoksiin. Suun avausrajoitus (trismus) lisää riskiä infektion leviämiselle esimerkiksi submandibulaaritilaan.
### Arvio
Kliininen kuva sopii akuuttiin perikoroniittiin komplisoituneena paikallisella absessilla tai flegmoonalla. Kuume ja yleisoireet täyttävät mikrobilääkehoidon aloituskriteerit Käypä hoito -suositusten mukaan. Trismus vaikeuttaa paikallista puhdistusta ja altistaa infektion leviämiselle. Märkäkertymän dreneeraus on ensisijaista, mutta myös antibioottihoito on tarpeen.
### Suositus
Aloita amoksisilliini 500 mg x 3 po ja metronidatsoli 500 mg x 2 po suun kautta 7 päivän ajan. Kipulääkitys parasetamolilla ja/tai tulehduskipulääkkeellä. Huuhtele suu klooriheksidiinillä 1–2 kertaa päivässä. Mikäli potilaan yleistila heikkenee tai ilmaantuu nielemisvaikeuksia/hengitystieoireita, päivystyslähete erikoissairaanhoitoon on aiheellinen. Seuraa tilannetta tiiviisti; mikäli avausrajoitus pahenee tai yleisvointi huononee, sairaalahoito voi olla tarpeen.
**Follow-up:** Potilas palaa seuraavana päivänä. Kuume on noussut 39,2 °C:een, suun avaus onnistuu enää 10 mm, alaleuan oikea puoli on selvästi turvonnut ja nieleminen on kivuliasta. Hengitys on hieman rohisevaa. Mitä toimenpiteitä suosittelet tässä vaiheessa?
**Assistant:**
### Tausta
Potilaan tila on selvästi pahentunut: kuume noussut 39,2 °C:een, suun avausrajoitus pahentunut (nyt vain 10 mm), oikean puolen turvotus lisääntynyt ja nieleminen vaikeutunut. Nämä löydökset viittaavat syvemmälle levinneeseen infektioprosessiin, mahdollisesti alkavaan flegmonaan tai abskessiin.
### Arvio
Kyseessä on vakava infektio, jossa on riski hengitysteiden kompromissille ja septiselle kehitykselle. Suun avauksen rajoittuminen alle 20 mm sekä nielemisvaikeus ovat merkkejä siitä, että infektio saattaa olla levinnyt syvempiin kaulan tiloihin. Märän dreenauksen onnistuminen on kriittistä, mutta trismuksen vuoksi tämä voi olla haastavaa.
### Suositus
Potilas tulee lähettää välittömästi päivystykseen sairaalatasolle suonensisäisen antibioottihoidon ja mahdollisen kirurgisen dreneerauksen arvioon. Hengitysteiden turvaaminen on ensisijainen prioriteetti – tarvittaessa anestesialääkärin arvio. Mikrobilääkehoitoa jatketaan sairaalassa suositusten mukaisesti. Seuranta tehostetussa valvonnassa on välttämätöntä komplikaatioiden varalta.
## Training Details
- **Method:** LoRA fine-tuning (r=64, alpha=128, dropout=0.05) merged into standalone model
- **Learning Rate:** 0.0002
- **Epochs:** 3
- **Effective Batch Size:** 64
- **Precision:** BF16 native format, automatically converts to FP16 when needed for hardware compatibility
- **Embedding Training:** Enabled for domain specialization
- **Target Modules:** q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj
- **Data:** 30,908 conversations covering a broad range of different scenarios
- **Context:** 2048 tokens (inherited from Ahma-3B-Instruct)
- **Hardware:** H100 GPU with Unsloth optimizations
- **Training Performance:** Loss curves showed steady convergence with final values well below 1.0, indicating successful learning without overfitting
## Limitations and Important Notes
**Critical Medical Disclaimers:**
- Research purposes only - never use for actual medical decisions
- Model may hallucinate medical facts, treatments, or drug interactions
- Outputs have not been clinically validated and may contain medical misinformation
- All outputs require independent professional verification before any clinical application
- No liability is assumed for any consequences of model use
**Technical Limitations:**
- Primarily trained for dentist-to-dentist consultations - concept explanations included but not the main focus
- May particularly hallucinate on out-of-scope topics (further training could address this)
- Further fine-tuning may be needed for specific use cases
- System prompt dependency - using the training prompt is highly recommended
- 2048 token context limit affects both training and inference
- No formal evaluation - quality assessment has been primarily subjective
**Bias and Fairness:**
- Training data consists of synthetic conversations which may contain inherent biases
- Model responses may reflect biases present in the GPT-4.1 generated training data
- Geographic and cultural biases toward Finnish dental practices and protocols
- Potential underrepresentation of certain patient demographics or clinical scenarios
## Related Models
- v1 LoRA version: [ducklingcodehouse/Finnish-DentalQA-lora](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-lora)
- v2 LoRA version: [ducklingcodehouse/Finnish-DentalQA-v2-lora](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-lora)
- v2 Merged version: [ducklingcodehouse/Finnish-DentalQA-v2-merged](https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-v2-merged)
- Base model: [Finnish-NLP/Ahma-3B-Instruct](https://huggingface.co/Finnish-NLP/Ahma-3B-Instruct)
## Citation
If you use this model, please cite both this work and the base Ahma model:
```bibtex
@misc{finnish-dentalqa-merged,
author = {Saxén, Heikki},
title = {Finnish-DentalQA-merged: LoRA Fine-tuned Model Merged for Finnish Dental Medicine},
year = {2025},
month = {August},
publisher = {Hugging Face},
url = {https://huggingface.co/ducklingcodehouse/Finnish-DentalQA-merged}
}
@misc{ahma-3b-instruct,
author = {Tanskanen, Aapo and Toivanen, Rasmus},
title = {Ahma-3B-Instruct},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/Finnish-NLP/Ahma-3B-Instruct}
}
```
|
wangjian21/bloody
|
wangjian21
| 2025-09-04T05:59:29Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:adapter:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-09-04T05:56:41Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: bloody
tags:
- text-to-image
- diffusers
- lora
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA DreamBooth - wangjian21/bloody
These are LoRA adaption weights for stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on bloody using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
capungmerah627/blockassist-bc-stinging_soaring_porcupine_1756963482
|
capungmerah627
| 2025-09-04T05:51:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging soaring porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T05:51:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging soaring porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1756964070
|
bah63843
| 2025-09-04T05:35:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T05:35:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kafa22/blockassist-bc-regal_leggy_hummingbird_1756963942
|
kafa22
| 2025-09-04T05:33:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal leggy hummingbird",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T05:33:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal leggy hummingbird
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1756963390
|
bah63843
| 2025-09-04T05:24:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T05:23:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jcholera/1mem-inference
|
jcholera
| 2025-09-04T05:21:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T05:21:40Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** jcholera
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
prithivMLmods/Smoothie-Qwen3-AIO-GGUF
|
prithivMLmods
| 2025-09-04T04:49:24Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"qwen3",
"text-generation-inference",
"text-generation",
"en",
"base_model:dnotitia/Smoothie-Qwen3-0.6B",
"base_model:quantized:dnotitia/Smoothie-Qwen3-0.6B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-09-03T18:51:01Z |
---
license: apache-2.0
language:
- en
base_model:
- dnotitia/Smoothie-Qwen3-4B
- dnotitia/Smoothie-Qwen3-0.6B
- dnotitia/Smoothie-Qwen3-1.7B
pipeline_tag: text-generation
library_name: transformers
tags:
- text-generation-inference
---
# **Smoothie-Qwen3-AIO-GGUF**
> Smoothie-Qwen3 models are enhancements of Qwen3 language models, applying post-processing techniques to smooth token distributions and promote balanced, multilingual output, especially across varied Unicode ranges. These models are particularly effective for applications needing reduced language bias and improved representation consistency, maintaining the strong reasoning, coding, and dialogue abilities of Qwen3 while producing more stable and diverse generations.
## Model Files
### Smoothie-Qwen3-0.6B
| File Name | Quant Type | File Size |
| - | - | - |
| Smoothie-Qwen3-0.6B.BF16.gguf | BF16 | 1.2 GB |
| Smoothie-Qwen3-0.6B.F16.gguf | F16 | 1.2 GB |
| Smoothie-Qwen3-0.6B.F32.gguf | F32 | 2.39 GB |
| Smoothie-Qwen3-0.6B.Q2_K.gguf | Q2_K | 296 MB |
| Smoothie-Qwen3-0.6B.Q3_K_L.gguf | Q3_K_L | 368 MB |
| Smoothie-Qwen3-0.6B.Q3_K_M.gguf | Q3_K_M | 347 MB |
| Smoothie-Qwen3-0.6B.Q3_K_S.gguf | Q3_K_S | 323 MB |
| Smoothie-Qwen3-0.6B.Q4_0.gguf | Q4_0 | 382 MB |
| Smoothie-Qwen3-0.6B.Q4_1.gguf | Q4_1 | 409 MB |
| Smoothie-Qwen3-0.6B.Q4_K.gguf | Q4_K | 397 MB |
| Smoothie-Qwen3-0.6B.Q4_K_M.gguf | Q4_K_M | 397 MB |
| Smoothie-Qwen3-0.6B.Q4_K_S.gguf | Q4_K_S | 383 MB |
| Smoothie-Qwen3-0.6B.Q5_0.gguf | Q5_0 | 437 MB |
| Smoothie-Qwen3-0.6B.Q5_1.gguf | Q5_1 | 464 MB |
| Smoothie-Qwen3-0.6B.Q5_K.gguf | Q5_K | 444 MB |
| Smoothie-Qwen3-0.6B.Q5_K_M.gguf | Q5_K_M | 444 MB |
| Smoothie-Qwen3-0.6B.Q5_K_S.gguf | Q5_K_S | 437 MB |
| Smoothie-Qwen3-0.6B.Q6_K.gguf | Q6_K | 495 MB |
| Smoothie-Qwen3-0.6B.Q8_0.gguf | Q8_0 | 639 MB |
### Smoothie-Qwen3-1.7B
| File Name | Quant Type | File Size |
| - | - | - |
| Smoothie-Qwen3-1.7B.BF16.gguf | BF16 | 3.45 GB |
| Smoothie-Qwen3-1.7B.F16.gguf | F16 | 3.45 GB |
| Smoothie-Qwen3-1.7B.F32.gguf | F32 | 6.89 GB |
| Smoothie-Qwen3-1.7B.Q2_K.gguf | Q2_K | 778 MB |
| Smoothie-Qwen3-1.7B.Q3_K_L.gguf | Q3_K_L | 1 GB |
| Smoothie-Qwen3-1.7B.Q3_K_M.gguf | Q3_K_M | 940 MB |
| Smoothie-Qwen3-1.7B.Q3_K_S.gguf | Q3_K_S | 867 MB |
| Smoothie-Qwen3-1.7B.Q4_0.gguf | Q4_0 | 1.05 GB |
| Smoothie-Qwen3-1.7B.Q4_1.gguf | Q4_1 | 1.14 GB |
| Smoothie-Qwen3-1.7B.Q4_K.gguf | Q4_K | 1.11 GB |
| Smoothie-Qwen3-1.7B.Q4_K_M.gguf | Q4_K_M | 1.11 GB |
| Smoothie-Qwen3-1.7B.Q4_K_S.gguf | Q4_K_S | 1.06 GB |
| Smoothie-Qwen3-1.7B.Q5_0.gguf | Q5_0 | 1.23 GB |
| Smoothie-Qwen3-1.7B.Q5_1.gguf | Q5_1 | 1.32 GB |
| Smoothie-Qwen3-1.7B.Q5_K.gguf | Q5_K | 1.26 GB |
| Smoothie-Qwen3-1.7B.Q5_K_M.gguf | Q5_K_M | 1.26 GB |
| Smoothie-Qwen3-1.7B.Q5_K_S.gguf | Q5_K_S | 1.23 GB |
| Smoothie-Qwen3-1.7B.Q6_K.gguf | Q6_K | 1.42 GB |
| Smoothie-Qwen3-1.7B.Q8_0.gguf | Q8_0 | 1.83 GB |
### Smoothie-Qwen3-4B
| File Name | Quant Type | File Size |
| - | - | - |
| Smoothie-Qwen3-4B.BF16.gguf | BF16 | 8.05 GB |
| Smoothie-Qwen3-4B.F16.gguf | F16 | 8.05 GB |
| Smoothie-Qwen3-4B.F32.gguf | F32 | 16.1 GB |
| Smoothie-Qwen3-4B.Q2_K.gguf | Q2_K | 1.67 GB |
| Smoothie-Qwen3-4B.Q3_K_L.gguf | Q3_K_L | 2.24 GB |
| Smoothie-Qwen3-4B.Q3_K_M.gguf | Q3_K_M | 2.08 GB |
| Smoothie-Qwen3-4B.Q3_K_S.gguf | Q3_K_S | 1.89 GB |
| Smoothie-Qwen3-4B.Q4_K_M.gguf | Q4_K_M | 2.5 GB |
| Smoothie-Qwen3-4B.Q4_K_S.gguf | Q4_K_S | 2.38 GB |
| Smoothie-Qwen3-4B.Q5_K_M.gguf | Q5_K_M | 2.89 GB |
| Smoothie-Qwen3-4B.Q5_K_S.gguf | Q5_K_S | 2.82 GB |
| Smoothie-Qwen3-4B.Q6_K.gguf | Q6_K | 3.31 GB |
| Smoothie-Qwen3-4B.Q8_0.gguf | Q8_0 | 4.28 GB |
## Quants Usage
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

|
Mildbutterchicken/FCIAL
|
Mildbutterchicken
| 2025-09-04T04:42:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2025-09-04T04:39:28Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screen Shot 2025-09-03 at 9.48.15 pm.png
text: Screenshot
base_model: Qwen/Qwen-Image
instance_prompt: facial
license: apache-2.0
---
# FCIAL
<Gallery />
## Trigger words
You should use `thick whitish translucent semen` to trigger the image generation.
## Download model
[Download](/Mildbutterchicken/FCIAL/tree/main) them in the Files & versions tab.
|
matherchodhuuu/blockassist-bc-lightfooted_skilled_chameleon_1756960616
|
matherchodhuuu
| 2025-09-04T04:39:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"lightfooted skilled chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:38:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- lightfooted skilled chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektass/blockassist-bc-keen_fast_giraffe_1756960462
|
omerbektass
| 2025-09-04T04:34:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:34:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sekirr/blockassist-bc-masked_tenacious_whale_1756960440
|
sekirr
| 2025-09-04T04:34:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:34:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756960194
|
akirafudo
| 2025-09-04T04:30:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:30:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vennertou/blockassist-bc-pudgy_tropical_alpaca_1756959992
|
vennertou
| 2025-09-04T04:26:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pudgy tropical alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:26:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pudgy tropical alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bms22/codegemma-7b-it-Q4_K_M-GGUF
|
bms22
| 2025-09-04T04:14:36Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:google/codegemma-7b-it",
"base_model:quantized:google/codegemma-7b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-09-04T04:14:11Z |
---
library_name: transformers
license: gemma
license_link: https://ai.google.dev/gemma/terms
pipeline_tag: text-generation
extra_gated_heading: Access CodeGemma on Hugging Face
extra_gated_prompt: To access CodeGemma on Hugging Face, you’re required to review
and agree to Google’s usage license. To do this, please ensure you’re logged-in
to Hugging Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
widget:
- text: '<start_of_turn>user Write a Python function to calculate the nth fibonacci
number.<end_of_turn> <start_of_turn>model
'
inference:
parameters:
max_new_tokens: 200
base_model: google/codegemma-7b-it
tags:
- llama-cpp
- gguf-my-repo
---
# bms22/codegemma-7b-it-Q4_K_M-GGUF
This model was converted to GGUF format from [`google/codegemma-7b-it`](https://huggingface.co/google/codegemma-7b-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/google/codegemma-7b-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo bms22/codegemma-7b-it-Q4_K_M-GGUF --hf-file codegemma-7b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo bms22/codegemma-7b-it-Q4_K_M-GGUF --hf-file codegemma-7b-it-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo bms22/codegemma-7b-it-Q4_K_M-GGUF --hf-file codegemma-7b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo bms22/codegemma-7b-it-Q4_K_M-GGUF --hf-file codegemma-7b-it-q4_k_m.gguf -c 2048
```
|
JunHowie/Qwen3-4B-Thinking-2507-GPTQ-Int4
|
JunHowie
| 2025-09-04T04:10:08Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"Qwen3",
"GPTQ",
"Int4",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-09-01T13:41:03Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int4
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-4B-Thinking-2507
base_model_relation: quantized
---
# Qwen3-4B-Thinking-2507-GPTQ-Int4
Base model: [Qwen/Qwen3-4B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507)
<i>This model is quantized to 4-bit with a group size of 128.</i>
<br>
<i>Compared to earlier quantized versions, the new quantized model demonstrates better tokens/s efficiency. This improvement comes from setting desc_act=False in the quantization configuration.</i>
```
vllm serve JunHowie/Qwen3-4B-Thinking-2507-GPTQ-Int4
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('JunHowie/Qwen3-4B-Thinking-2507-GPTQ-Int4', cache_dir="your_local_path")
```
### 【Overview】
# Qwen3-4B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-4B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-4B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
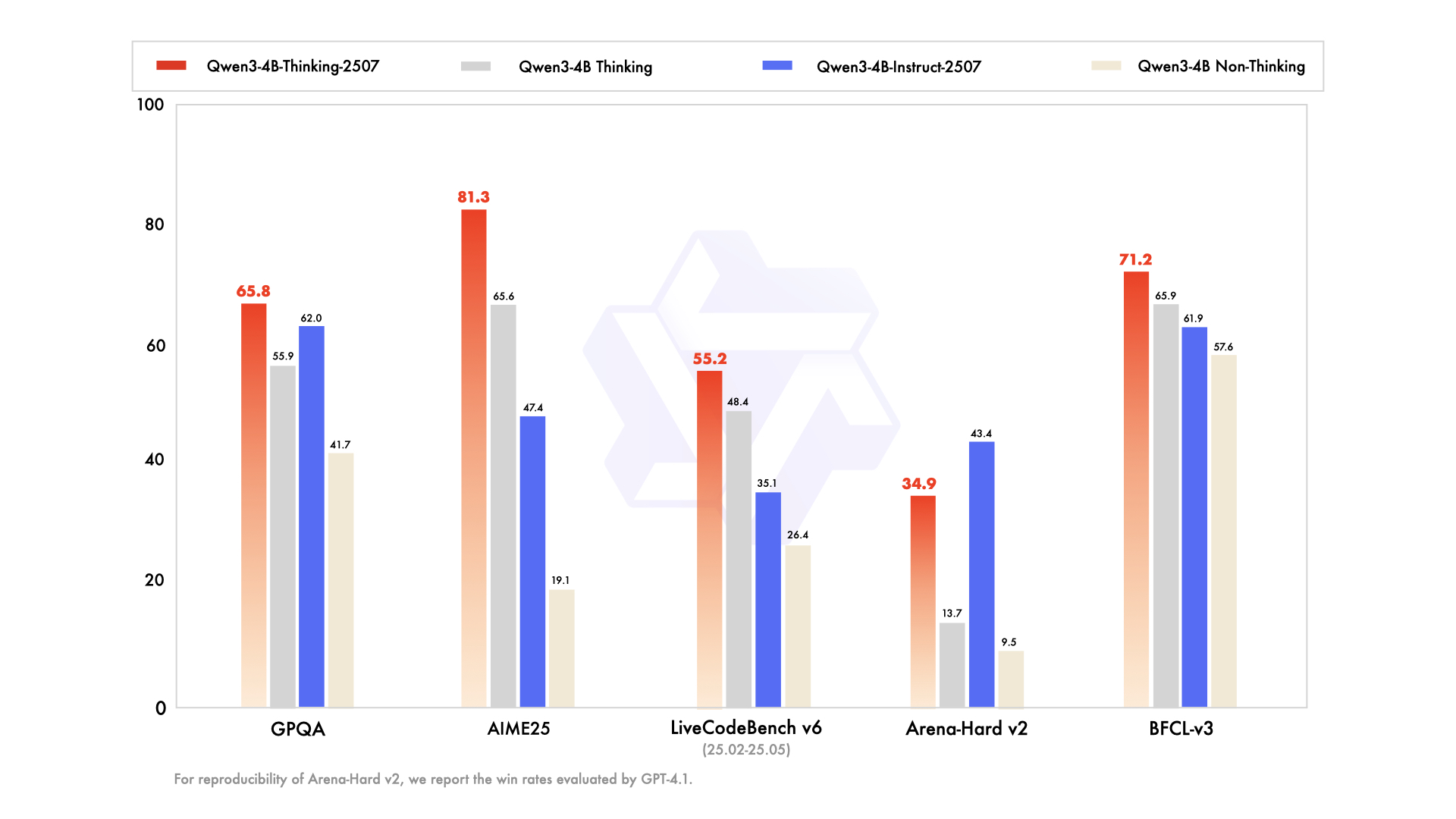
## Model Overview
**Qwen3-4B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Qwen3-30B-A3B Thinking | Qwen3-4B Thinking | Qwen3-4B-Thinking-2507 |
|--- | --- | --- | --- |
| **Knowledge** | | |
| MMLU-Pro | **78.5** | 70.4 | 74.0 |
| MMLU-Redux | **89.5** | 83.7 | 86.1 |
| GPQA | **65.8** | 55.9 | **65.8** |
| SuperGPQA | **51.8** | 42.7 | 47.8 |
| **Reasoning** | | |
| AIME25 | 70.9 | 65.6 | **81.3** |
| HMMT25 | 49.8 | 42.1 | **55.5** |
| LiveBench 20241125 | **74.3** | 63.6 | 71.8 |
| **Coding** | | |
| LiveCodeBench v6 (25.02-25.05) | **57.4** | 48.4 | 55.2 |
| CFEval | **1940** | 1671 | 1852 |
| OJBench | **20.7** | 16.1 | 17.9 |
| **Alignment** | | |
| IFEval | 86.5 | 81.9 | **87.4** |
| Arena-Hard v2$ | **36.3** | 13.7 | 34.9 |
| Creative Writing v3 | **79.1** | 61.1 | 75.6 |
| WritingBench | 77.0 | 73.5 | **83.3** |
| **Agent** | | |
| BFCL-v3 | 69.1 | 65.9 | **71.2** |
| TAU1-Retail | 61.7 | 33.9 | **66.1** |
| TAU1-Airline | 32.0 | 32.0 | **48.0** |
| TAU2-Retail | 34.2 | 38.6 | **53.5** |
| TAU2-Airline | 36.0 | 28.0 | **58.0** |
| TAU2-Telecom | 22.8 | 17.5 | **27.2** |
| **Multilingualism** | | |
| MultiIF | 72.2 | 66.3 | **77.3** |
| MMLU-ProX | **73.1** | 61.0 | 64.2 |
| INCLUDE | **71.9** | 61.8 | 64.4 |
| PolyMATH | 46.1 | 40.0 | **46.2** |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Thinking-2507 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B-Thinking-2507 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-4B-Thinking-2507 --served-model-name Qwen3-4B-Thinking-2507 --max-model-len 262144`.
llm_cfg = {
'model': 'Qwen3-4B-Thinking-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
'api_key': 'EMPTY',
'generate_cfg': {
'thought_in_content': True,
},
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
bah63843/blockassist-bc-plump_fast_antelope_1756958490
|
bah63843
| 2025-09-04T04:02:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T04:02:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756957301
|
akirafudo
| 2025-09-04T03:42:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T03:41:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bah63843/blockassist-bc-plump_fast_antelope_1756956687
|
bah63843
| 2025-09-04T03:32:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T03:32:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
seraphimzzzz/1652752
|
seraphimzzzz
| 2025-09-04T03:26:23Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-04T03:26:20Z |
[View on Civ Archive](https://civarchive.com/models/1548389?modelVersionId=1752017)
|
bah63843/blockassist-bc-plump_fast_antelope_1756956019
|
bah63843
| 2025-09-04T03:21:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T03:21:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
crystalline7/1555454
|
crystalline7
| 2025-09-04T03:18:18Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-04T03:18:14Z |
[View on Civ Archive](https://civarchive.com/models/1442201?modelVersionId=1630373)
|
seraphimzzzz/1594142
|
seraphimzzzz
| 2025-09-04T03:17:46Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-04T03:17:43Z |
[View on Civ Archive](https://civarchive.com/models/1442254?modelVersionId=1693562)
|
cixzer/blockassist-bc-gregarious_long_cheetah_1756954674
|
cixzer
| 2025-09-04T03:02:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gregarious long cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T03:00:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gregarious long cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Rootu/blockassist-bc-snorting_fleecy_goose_1756953573
|
Rootu
| 2025-09-04T02:40:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"snorting fleecy goose",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T02:40:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- snorting fleecy goose
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jessicamae271985/blockassist-bc-darting_knobby_caribou_1756953350
|
jessicamae271985
| 2025-09-04T02:37:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"darting knobby caribou",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T02:36:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- darting knobby caribou
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hzzscience/WaiyumiaoModels
|
hzzscience
| 2025-09-04T02:28:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-04T02:25:58Z |
---
license: apache-2.0
---
|
khoatran94/search_engine_gemma2-2b
|
khoatran94
| 2025-09-04T02:20:18Z | 0 | 0 |
transformers
|
[
"transformers",
"gemma2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-2-2b-it-bnb-4bit",
"base_model:finetune:unsloth/gemma-2-2b-it-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-04T02:14:53Z |
---
base_model: unsloth/gemma-2-2b-it-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** khoatran94
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-2-2b-it-bnb-4bit
This gemma2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
omerbkts/blockassist-bc-keen_fast_giraffe_1756951139
|
omerbkts
| 2025-09-04T01:59:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T01:59:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF
|
mradermacher
| 2025-09-04T01:48:13Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Behailut/compliance-bot-mistral-7b-v1-kaggle",
"base_model:quantized:Behailut/compliance-bot-mistral-7b-v1-kaggle",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-03T21:12:24Z |
---
base_model: Behailut/compliance-bot-mistral-7b-v1-kaggle
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Behailut/compliance-bot-mistral-7b-v1-kaggle
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#compliance-bot-mistral-7b-v1-kaggle-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/compliance-bot-mistral-7b-v1-kaggle-GGUF/resolve/main/compliance-bot-mistral-7b-v1-kaggle.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF
|
mradermacher
| 2025-09-04T01:45:42Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"dataset:CodeGoat24/HPD",
"dataset:CodeGoat24/LiFT-HRA",
"dataset:CodeGoat24/OIP",
"dataset:CodeGoat24/EvalMuse",
"dataset:CodeGoat24/ShareGPTVideo-DPO",
"dataset:CodeGoat24/VideoFeedback",
"dataset:CodeGoat24/LLaVA-Critic-113k",
"dataset:CodeGoat24/VideoDPO",
"base_model:CodeGoat24/UnifiedReward-2.0-qwen-3b",
"base_model:quantized:CodeGoat24/UnifiedReward-2.0-qwen-3b",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-04T00:51:52Z |
---
base_model: CodeGoat24/UnifiedReward-2.0-qwen-3b
datasets:
- CodeGoat24/HPD
- CodeGoat24/LiFT-HRA
- CodeGoat24/OIP
- CodeGoat24/EvalMuse
- CodeGoat24/ShareGPTVideo-DPO
- CodeGoat24/VideoFeedback
- CodeGoat24/LLaVA-Critic-113k
- CodeGoat24/VideoDPO
language:
- en
library_name: transformers
license: mit
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/CodeGoat24/UnifiedReward-2.0-qwen-3b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#UnifiedReward-2.0-qwen-3b-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ1_S.gguf) | i1-IQ1_S | 0.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ1_M.gguf) | i1-IQ1_M | 1.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ2_S.gguf) | i1-IQ2_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ2_M.gguf) | i1-IQ2_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.3 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q2_K.gguf) | i1-Q2_K | 1.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 1.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ3_S.gguf) | i1-IQ3_S | 1.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ3_M.gguf) | i1-IQ3_M | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 1.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 1.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-IQ4_NL.gguf) | i1-IQ4_NL | 1.9 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q4_0.gguf) | i1-Q4_0 | 1.9 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 1.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q4_1.gguf) | i1-Q4_1 | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/UnifiedReward-2.0-qwen-3b-i1-GGUF/resolve/main/UnifiedReward-2.0-qwen-3b.i1-Q6_K.gguf) | i1-Q6_K | 2.6 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1756948730
|
calegpedia
| 2025-09-04T01:43:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T01:43:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bertbert11/blockassist-bc-sniffing_large_cheetah_1756949454
|
bertbert11
| 2025-09-04T01:31:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sniffing large cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T01:31:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sniffing large cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
klmdr22/blockassist-bc-wild_loud_newt_1756948676
|
klmdr22
| 2025-09-04T01:18:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wild loud newt",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T01:18:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wild loud newt
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
xinnn32/blockassist-bc-meek_winged_caterpillar_1756947428
|
xinnn32
| 2025-09-04T00:58:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"meek winged caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T00:58:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- meek winged caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Reihaneh/wav2vec2_da_sv_LID_50_epochs_10
|
Reihaneh
| 2025-09-04T00:42:42Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T00:42:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
touyop/blockassist-bc-tropical_barky_camel_1756946219
|
touyop
| 2025-09-04T00:37:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tropical barky camel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-04T00:36:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tropical barky camel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
acidjp/blockassist-bc-pesty_extinct_prawn_1756940060
|
acidjp
| 2025-09-03T23:39:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pesty extinct prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T23:38:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pesty extinct prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnerYubo/blockassist-bc-snappy_tenacious_eagle_1756941490
|
AnerYubo
| 2025-09-03T23:18:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"snappy tenacious eagle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T23:18:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- snappy tenacious eagle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Stasonelison/blockassist-bc-howling_powerful_aardvark_1756940385
|
Stasonelison
| 2025-09-03T23:00:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"howling powerful aardvark",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T23:00:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- howling powerful aardvark
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Reihaneh/wav2vec2_da_sv_LID_50_epochs_6
|
Reihaneh
| 2025-09-03T22:59:50Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-03T22:59:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ypszn/blockassist-bc-yapping_pawing_worm_1756938991
|
ypszn
| 2025-09-03T22:37:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yapping pawing worm",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T22:37:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yapping pawing worm
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/liberalis-cogitator-smollm3-3b-GGUF
|
mradermacher
| 2025-09-03T22:27:20Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Locutusque/liberalis-cogitator-smollm3-3b",
"base_model:quantized:Locutusque/liberalis-cogitator-smollm3-3b",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-03T21:51:03Z |
---
base_model: Locutusque/liberalis-cogitator-smollm3-3b
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Locutusque/liberalis-cogitator-smollm3-3b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#liberalis-cogitator-smollm3-3b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q2_K.gguf) | Q2_K | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q3_K_S.gguf) | Q3_K_S | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q3_K_M.gguf) | Q3_K_M | 1.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q3_K_L.gguf) | Q3_K_L | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.IQ4_XS.gguf) | IQ4_XS | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q4_K_S.gguf) | Q4_K_S | 2.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q4_K_M.gguf) | Q4_K_M | 2.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q5_K_S.gguf) | Q5_K_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q5_K_M.gguf) | Q5_K_M | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q6_K.gguf) | Q6_K | 2.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.Q8_0.gguf) | Q8_0 | 3.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/liberalis-cogitator-smollm3-3b-GGUF/resolve/main/liberalis-cogitator-smollm3-3b.f16.gguf) | f16 | 6.8 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Stasonelison/blockassist-bc-howling_powerful_aardvark_1756938063
|
Stasonelison
| 2025-09-03T22:21:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"howling powerful aardvark",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T22:21:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- howling powerful aardvark
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF
|
mradermacher
| 2025-09-03T22:12:44Z | 48 | 0 |
transformers
|
[
"transformers",
"gguf",
"generated_from_trainer",
"en",
"base_model:yanolja/YanoljaNEXT-EEVE-10.8B",
"base_model:quantized:yanolja/YanoljaNEXT-EEVE-10.8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-11-27T12:39:58Z |
---
base_model: yanolja/YanoljaNEXT-EEVE-10.8B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/yanolja/YanoljaNEXT-EEVE-10.8B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#EEVE-Korean-10.8B-v1.0-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ1_S.gguf) | i1-IQ1_S | 2.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ1_M.gguf) | i1-IQ1_M | 2.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ2_XS.gguf) | i1-IQ2_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ2_S.gguf) | i1-IQ2_S | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ2_M.gguf) | i1-IQ2_M | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q2_K.gguf) | i1-Q2_K | 4.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 4.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ3_XS.gguf) | i1-IQ3_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ3_S.gguf) | i1-IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ3_M.gguf) | i1-IQ3_M | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q3_K_M.gguf) | i1-Q3_K_M | 5.3 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q3_K_L.gguf) | i1-Q3_K_L | 5.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-IQ4_XS.gguf) | i1-IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 6.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 6.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 6.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_0.gguf) | i1-Q4_0 | 6.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_K_S.gguf) | i1-Q4_K_S | 6.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q4_K_M.gguf) | i1-Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q5_K_S.gguf) | i1-Q5_K_S | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q5_K_M.gguf) | i1-Q5_K_M | 7.8 | |
| [GGUF](https://huggingface.co/mradermacher/EEVE-Korean-10.8B-v1.0-i1-GGUF/resolve/main/EEVE-Korean-10.8B-v1.0.i1-Q6_K.gguf) | i1-Q6_K | 9.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
touyop/blockassist-bc-aquatic_gentle_chicken_1756936893
|
touyop
| 2025-09-03T22:01:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"aquatic gentle chicken",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T22:01:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- aquatic gentle chicken
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektass/blockassist-bc-keen_fast_giraffe_1756936238
|
omerbektass
| 2025-09-03T21:51:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:50:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektass/blockassist-bc-keen_fast_giraffe_1756935690
|
omerbektass
| 2025-09-03T21:41:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:41:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zopvbop/blockassist-bc-silent_deft_ibis_1756935552
|
zopvbop
| 2025-09-03T21:40:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent deft ibis",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:39:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent deft ibis
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ddfj34/act_so101_model_20250903_1920
|
ddfj34
| 2025-09-03T21:30:15Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:ddfj34/record-test-202500903-1920",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-03T21:30:01Z |
---
datasets: ddfj34/record-test-202500903-1920
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- lerobot
- act
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
GroomerG/blockassist-bc-vicious_pawing_badger_1756933216
|
GroomerG
| 2025-09-03T21:27:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vicious pawing badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:27:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vicious pawing badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kafa22/blockassist-bc-regal_leggy_hummingbird_1756934224
|
kafa22
| 2025-09-03T21:17:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal leggy hummingbird",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:17:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal leggy hummingbird
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
tiopuiter/blockassist-bc-thick_tame_porcupine_1756933720
|
tiopuiter
| 2025-09-03T21:08:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thick tame porcupine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:08:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thick tame porcupine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
tiopuiter/blockassist-bc-silent_sly_rabbit_1756933429
|
tiopuiter
| 2025-09-03T21:04:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent sly rabbit",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T21:03:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent sly rabbit
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbkts/blockassist-bc-keen_fast_giraffe_1756932406
|
omerbkts
| 2025-09-03T20:47:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T20:47:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
uoppou/blockassist-bc-winged_smooth_rabbit_1756931268
|
uoppou
| 2025-09-03T20:28:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"winged smooth rabbit",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T20:27:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- winged smooth rabbit
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbkts/blockassist-bc-keen_fast_giraffe_1756928745
|
omerbkts
| 2025-09-03T19:46:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T19:46:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
llm-jp/optimal-sparsity-code-d512-E128-k2-3.3B-A170M
|
llm-jp
| 2025-09-03T17:42:32Z | 11 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"reasoning",
"arxiv:2508.18672",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-21T15:04:33Z |
---
pipeline_tag: text-generation
library_name: transformers
license: apache-2.0
tags:
- mixtral
- moe
- reasoning
---
# Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
This repository contains model checkpoints from the paper [Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks](https://huggingface.co/papers/2508.18672).
For more details, including code and evaluation procedures, please refer to the official GitHub repository: [https://github.com/rioyokotalab/optimal-sparsity](https://github.com/rioyokotalab/optimal-sparsity)
## How to cite
If you find our work helpful, please feel free to cite the paper.
```bibtex
@article{nakamura2025optimalsparsitymixtureofexpertslanguage,
title={Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks},
author={Taishi Nakamura and Satoki Ishikawa and Masaki Kawamura and Takumi Okamoto and Daisuke Nohara and Jun Suzuki and Rio Yokota},
year={2025},
eprint={2508.18672},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.18672},
}
```
|
maretgiuntas/blockassist-bc-feline_mottled_bear_1756919625
|
maretgiuntas
| 2025-09-03T17:14:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"feline mottled bear",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T17:14:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- feline mottled bear
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
3notebooker/blockassist-bc-mute_trotting_ostrich_1756916983
|
3notebooker
| 2025-09-03T16:30:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute trotting ostrich",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-03T16:30:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute trotting ostrich
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBK95/Llama-3.2-1B-hf-DPO_V3-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V1
|
LBK95
| 2025-09-03T15:12:25Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:meta-llama/Llama-3.2-1B",
"base_model:adapter:meta-llama/Llama-3.2-1B",
"license:llama3.2",
"region:us"
] | null | 2025-09-03T14:18:37Z |
---
library_name: peft
license: llama3.2
base_model: meta-llama/Llama-3.2-1B
tags:
- trl
- dpo
- generated_from_trainer
model-index:
- name: Llama-3.2-1B-hf-DPO_V3-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.2-1B-hf-DPO_V3-LookAhead-0_TTree1.2_TT0.9_TP0.7_TE0.1_V1
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.45.2
- Pytorch 2.8.0+cu126
- Datasets 2.14.4
- Tokenizers 0.20.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.