
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-11 18:29:29
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-11 18:25:24
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mhyatt000/YOLOv5
|
mhyatt000
| 2022-09-01T15:25:36Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"seals/CartPole-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"object-detection",
"dataset:coco",
"license:gpl-2.0",
"model-index",
"region:us"
] |
object-detection
| 2022-06-20T16:37:08Z |
---
license: gpl-2.0
datasets:
- coco
library_name: stable-baselines3
tags:
- seals/CartPole-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
- object-detection
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: True
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: seals/CartPole-v0
type: seals/CartPole-v0
---
# YOLOv5
Ultralytics YOLOv5 model in Pytorch.
Proof of concept for (TypoSquatting, Niche Squatting) security flaw on Hugging Face.
## Model Description
## How to use
```python
from transformers import YolosFeatureExtractor, YolosForObjectDetection
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = YolosFeatureExtractor.from_pretrained('mhyatt000/yolov5')
model = YolosForObjectDetection.from_pretrained('mhyatt000/yolov5')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts bounding boxes and corresponding COCO classes
logits = outputs.logits
bboxes = outputs.pred_boxes
```
## Training Data
### Training
## Evaluation
Model was evaluated on [COCO2017](https://cocodataset.org/#home) dataset.
| Model | size (pixels) | mAPval | Speed | params | FLOPS |
|---------------|-------------------|-----------|-----------|-----------|-----------|
| YOLOv5s6 | 1280 | 43.3 | 4.3 | 12.7 | 17.4 |
| YOLOv5m6 | 1280 | 50.5 | 8.4 | 35.9 | 52.4 |
| YOLOv5l6 | 1280 | 53.4 | 12.3 | 77.2 | 117.7 |
| YOLOv5x6 | 1280 | 54.4 | 22.4 | 141.8 | 222.9 |
### Bibtex and citation info
```bibtex
@software{glenn_jocher_2022_6222936,
author = {Glenn Jocher and
Ayush Chaurasia and
Alex Stoken and
Jirka Borovec and
NanoCode012 and
Yonghye Kwon and
TaoXie and
Jiacong Fang and
imyhxy and
Kalen Michael and
Lorna and
Abhiram V and
Diego Montes and
Jebastin Nadar and
Laughing and
tkianai and
yxNONG and
Piotr Skalski and
Zhiqiang Wang and
Adam Hogan and
Cristi Fati and
Lorenzo Mammana and
AlexWang1900 and
Deep Patel and
Ding Yiwei and
Felix You and
Jan Hajek and
Laurentiu Diaconu and
Mai Thanh Minh},
title = {{ultralytics/yolov5: v6.1 - TensorRT, TensorFlow
Edge TPU and OpenVINO Export and Inference}},
month = feb,
year = 2022,
publisher = {Zenodo},
version = {v6.1},
doi = {10.5281/zenodo.6222936},
url = {https://doi.org/10.5281/zenodo.6222936}
}
```
|
BigSalmon/Backwards
|
BigSalmon
| 2022-09-01T15:13:56Z | 159 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-31T18:40:44Z |
Used the same dataset as the one I trained https://huggingface.co/BigSalmon/InformalToFormalLincoln73Paraphrase, but all the words are in the opposite order.
* Note: I think I probably train it for more epochs. The loss was very high. That said, keep an eye on my profile, if this is something you are interested in.
|
GItaf/gpt2-finetuned-mbti-0901
|
GItaf
| 2022-09-01T15:10:56Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-01T13:20:36Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-mbti-0901
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-finetuned-mbti-0901
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9470
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.1073 | 1.0 | 9906 | 4.0111 |
| 4.0302 | 2.0 | 19812 | 3.9761 |
| 3.9757 | 3.0 | 29718 | 3.9578 |
| 3.9471 | 4.0 | 39624 | 3.9495 |
| 3.9187 | 5.0 | 49530 | 3.9470 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
butchland/Reinforce-Cartpole-v1
|
butchland
| 2022-09-01T14:40:46Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-01T14:23:01Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 95.80 +/- 22.48
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
pmpc/twitter-roberta-base-stance-abortionV3
|
pmpc
| 2022-09-01T13:45:07Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-01T13:34:41Z |
---
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: twitter-roberta-base-stance-abortionV3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-roberta-base-stance-abortionV3
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-stance-abortion](https://huggingface.co/cardiffnlp/twitter-roberta-base-stance-abortion) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5095
- F1: 0.7917
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8492 | 1.0 | 12 | 0.4862 | 0.7917 |
| 0.7291 | 2.0 | 24 | 0.4264 | 0.7917 |
| 0.5465 | 3.0 | 36 | 0.6450 | 0.7917 |
| 0.5905 | 4.0 | 48 | 0.5857 | 0.7917 |
| 0.4556 | 5.0 | 60 | 0.5095 | 0.7917 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DrishtiSharma/finetuned-ViT-human-action-recognition-v1
|
DrishtiSharma
| 2022-09-01T13:09:05Z | 210 | 7 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-09-01T12:22:59Z |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: finetuned-ViT-human-action-recognition-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-ViT-human-action-recognition-v1
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the Human_Action_Recognition dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1427
- Accuracy: 0.0791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4986 | 0.13 | 100 | 3.1427 | 0.0791 |
| 1.1929 | 0.25 | 200 | 3.4083 | 0.0726 |
| 1.2673 | 0.38 | 300 | 3.4615 | 0.0769 |
| 0.9805 | 0.51 | 400 | 3.9192 | 0.0824 |
| 1.158 | 0.63 | 500 | 4.2648 | 0.0698 |
| 1.2544 | 0.76 | 600 | 4.5536 | 0.0574 |
| 1.0073 | 0.89 | 700 | 4.0310 | 0.0819 |
| 0.9315 | 1.02 | 800 | 4.5154 | 0.0702 |
| 0.9063 | 1.14 | 900 | 4.7162 | 0.0633 |
| 0.6756 | 1.27 | 1000 | 4.6482 | 0.0626 |
| 1.0239 | 1.4 | 1100 | 4.6437 | 0.0635 |
| 0.7634 | 1.52 | 1200 | 4.5625 | 0.0752 |
| 0.8365 | 1.65 | 1300 | 4.9912 | 0.0561 |
| 0.8979 | 1.78 | 1400 | 5.1739 | 0.0356 |
| 0.9448 | 1.9 | 1500 | 4.8946 | 0.0541 |
| 0.697 | 2.03 | 1600 | 4.9516 | 0.0741 |
| 0.7861 | 2.16 | 1700 | 5.0090 | 0.0776 |
| 0.6404 | 2.28 | 1800 | 5.3905 | 0.0643 |
| 0.7939 | 2.41 | 1900 | 4.9159 | 0.1015 |
| 0.6331 | 2.54 | 2000 | 5.3083 | 0.0589 |
| 0.6082 | 2.66 | 2100 | 4.8538 | 0.0857 |
| 0.6229 | 2.79 | 2200 | 5.3086 | 0.0689 |
| 0.6964 | 2.92 | 2300 | 5.3745 | 0.0713 |
| 0.5246 | 3.05 | 2400 | 5.0369 | 0.0796 |
| 0.6097 | 3.17 | 2500 | 5.2935 | 0.0743 |
| 0.5778 | 3.3 | 2600 | 5.5431 | 0.0709 |
| 0.4196 | 3.43 | 2700 | 5.5508 | 0.0759 |
| 0.5495 | 3.55 | 2800 | 5.5728 | 0.0813 |
| 0.5932 | 3.68 | 2900 | 5.7992 | 0.0663 |
| 0.4382 | 3.81 | 3000 | 5.8010 | 0.0643 |
| 0.4827 | 3.93 | 3100 | 5.7529 | 0.0680 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
KISSz/wav2vac2-vee-train001-ASR
|
KISSz
| 2022-09-01T12:51:55Z | 111 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-01T09:50:51Z |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
model_index:
name: wav2vac2-vee-train001-ASR
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vac2-vee-train001-ASR
This model is a fine-tuned version of [airesearch/wav2vec2-large-xlsr-53-th](https://huggingface.co/airesearch/wav2vec2-large-xlsr-53-th) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cpu
- Datasets 1.11.0
- Tokenizers 0.10.3
|
GItaf/roberta-base-finetuned-mbti-0901
|
GItaf
| 2022-09-01T12:24:17Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-01T08:01:47Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-mbti-0901
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-mbti-0901
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0780
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.3179 | 1.0 | 9920 | 4.1970 |
| 4.186 | 2.0 | 19840 | 4.1264 |
| 4.1057 | 3.0 | 29760 | 4.0955 |
| 4.0629 | 4.0 | 39680 | 4.0826 |
| 4.0333 | 5.0 | 49600 | 4.0780 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Astrofolia/distilbert-base-uncased-finetuned-emotion
|
Astrofolia
| 2022-09-01T11:20:22Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-01T11:10:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9285
- name: F1
type: f1
value: 0.9284597945931914
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2175
- Accuracy: 0.9285
- F1: 0.9285
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8486 | 1.0 | 250 | 0.3234 | 0.896 | 0.8913 |
| 0.257 | 2.0 | 500 | 0.2175 | 0.9285 | 0.9285 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
PhucLe/LRO_v1.0.2a
|
PhucLe
| 2022-09-01T09:56:58Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"en",
"dataset:PhucLe/autotrain-data-LRO_v1.0.2",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-01T09:55:28Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- PhucLe/autotrain-data-LRO_v1.0.2
co2_eq_emissions:
emissions: 1.2585708613878817
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1345851607
- CO2 Emissions (in grams): 1.2586
## Validation Metrics
- Loss: 0.523
- Accuracy: 0.818
- Macro F1: 0.817
- Micro F1: 0.818
- Weighted F1: 0.817
- Macro Precision: 0.824
- Micro Precision: 0.818
- Weighted Precision: 0.824
- Macro Recall: 0.818
- Micro Recall: 0.818
- Weighted Recall: 0.818
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/PhucLe/autotrain-LRO_v1.0.2-1345851607
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("PhucLe/autotrain-LRO_v1.0.2-1345851607", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("PhucLe/autotrain-LRO_v1.0.2-1345851607", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
huggingtweets/buckeshot-onlinepete
|
huggingtweets
| 2022-09-01T09:35:19Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-18T07:03:11Z |
---
language: en
thumbnail: http://www.huggingtweets.com/buckeshot-onlinepete/1662024914888/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1545140847259406337/bTk2lL6O_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/456958582731603969/QZKpv6eI_400x400.jpeg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">BUCKSHOT & im pete online</div>
<div style="text-align: center; font-size: 14px;">@buckeshot-onlinepete</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from BUCKSHOT & im pete online.
| Data | BUCKSHOT | im pete online |
| --- | --- | --- |
| Tweets downloaded | 311 | 3190 |
| Retweets | 77 | 94 |
| Short tweets | 46 | 1003 |
| Tweets kept | 188 | 2093 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1wyw1egj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @buckeshot-onlinepete's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1bnj1d4d) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1bnj1d4d/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/buckeshot-onlinepete')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Conrad747/lg-en-v3
|
Conrad747
| 2022-09-01T09:11:44Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-01T06:10:32Z |
---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: lg-en-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lg-en-v3
This model is a fine-tuned version of [AI-Lab-Makerere/lg_en](https://huggingface.co/AI-Lab-Makerere/lg_en) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9289
- Bleu: 32.5138
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.4271483249908667e-05
- train_batch_size: 14
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 26 | 1.0323 | 32.6278 |
| No log | 2.0 | 52 | 0.9289 | 32.5138 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
NimaBoscarino/IS-Net_DIS-general-use
|
NimaBoscarino
| 2022-09-01T06:41:58Z | 0 | 15 | null |
[
"background-removal",
"computer-vision",
"image-segmentation",
"arxiv:2203.03041",
"license:apache-2.0",
"region:us"
] |
image-segmentation
| 2022-09-01T05:33:22Z |
---
tags:
- background-removal
- computer-vision
- image-segmentation
license: apache-2.0
library: pytorch
inference: false
---
# IS-Net_DIS-general-use
* Model Authors: Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan*, Ling Shao, Luc Van Gool
* Paper: Highly Accurate Dichotomous Image Segmentation (ECCV 2022 - https://arxiv.org/pdf/2203.03041.pdf
* Code Repo: https://github.com/xuebinqin/DIS
* Project Homepage: https://xuebinqin.github.io/dis/index.html
Note that this is an _optimized_ version of the IS-NET model.
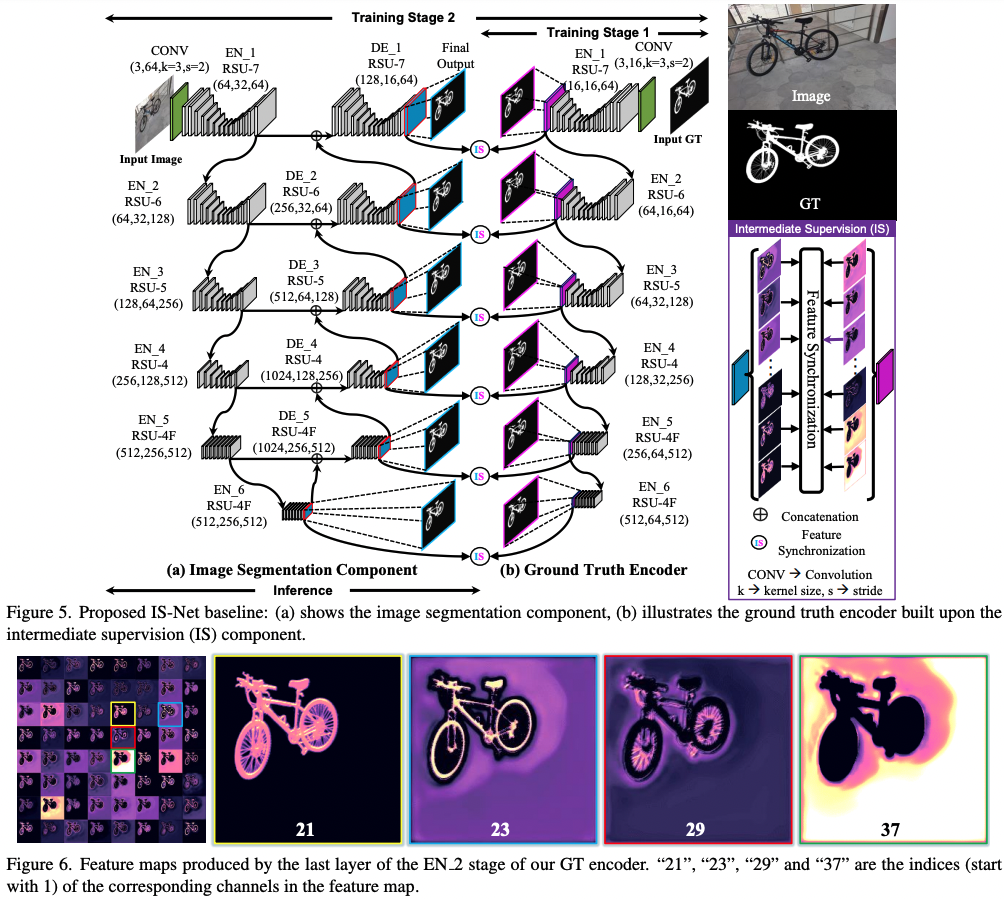
From the paper abstract:
> [...] we introduce a simple intermediate supervision baseline (IS- Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms var- ious cutting-edge baselines on the proposed DIS5K, mak- ing it a general self-learned supervision network that can help facilitate future research in DIS.
# Citation
```
@InProceedings{qin2022,
author={Xuebin Qin and Hang Dai and Xiaobin Hu and Deng-Ping Fan and Ling Shao and Luc Van Gool},
title={Highly Accurate Dichotomous Image Segmentation},
booktitle={ECCV},
year={2022}
}
```
|
NimaBoscarino/IS-Net_DIS
|
NimaBoscarino
| 2022-09-01T06:41:46Z | 0 | 4 | null |
[
"background-removal",
"computer-vision",
"image-segmentation",
"arxiv:2203.03041",
"license:apache-2.0",
"region:us"
] |
image-segmentation
| 2022-09-01T05:05:18Z |
---
tags:
- background-removal
- computer-vision
- image-segmentation
license: apache-2.0
library: pytorch
inference: false
---
# IS-Net_DIS
* Model Authors: Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan*, Ling Shao, Luc Van Gool
* Paper: Highly Accurate Dichotomous Image Segmentation (ECCV 2022 - https://arxiv.org/pdf/2203.03041.pdf
* Code Repo: https://github.com/xuebinqin/DIS
* Project Homepage: https://xuebinqin.github.io/dis/index.html
From the paper abstract:
> [...] we introduce a simple intermediate supervision baseline (IS- Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms var- ious cutting-edge baselines on the proposed DIS5K, mak- ing it a general self-learned supervision network that can help facilitate future research in DIS.

[HCE score](https://github.com/xuebinqin/DIS#4-human-correction-efforts-hce): 1016
# Citation
```
@InProceedings{qin2022,
author={Xuebin Qin and Hang Dai and Xiaobin Hu and Deng-Ping Fan and Ling Shao and Luc Van Gool},
title={Highly Accurate Dichotomous Image Segmentation},
booktitle={ECCV},
year={2022}
}
```
|
Wakeme/ddpm-butterflies-128
|
Wakeme
| 2022-09-01T05:47:18Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-09-01T04:34:11Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Wakeme/ddpm-butterflies-128/tensorboard?#scalars)
|
dvalbuena1/a2c-AntBulletEnv-v0
|
dvalbuena1
| 2022-09-01T04:21:12Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-01T04:19:59Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 836.44 +/- 139.46
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
SharpAI/mal-net-traffic-t5-l12
|
SharpAI
| 2022-09-01T01:17:03Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-01T01:16:05Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-net-traffic-t5-l12
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-net-traffic-t5-l12
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
JAlexis/modelF_01
|
JAlexis
| 2022-08-31T22:59:44Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-31T22:46:53Z |
---
widget:
- text: "How can I protect myself against covid-19?"
context: "Preventative measures consist of recommendations to wear a mask in public, maintain social distancing of at least six feet, wash hands regularly, and use hand sanitizer. To facilitate this aim, we adapt the conceptual model and measures of Liao et al. "
- text: "What are the risk factors for covid-19?"
context: "To identify risk factors for hospital deaths from COVID-19, the OpenSAFELY platform examined electronic health records from 17.4 million UK adults. The authors used multivariable Cox proportional hazards model to identify the association of risk of death with older age, lower socio-economic status, being male, non-white ethnic background and certain clinical conditions (diabetes, obesity, cancer, respiratory diseases, heart, kidney, liver, neurological and autoimmune conditions). Notably, asthma was identified as a risk factor, despite prior suggestion of a potential protective role. Interestingly, higher risks due to ethnicity or lower socio-economic status could not be completely attributed to pre-existing health conditions."
---
|
nawage/dragons-test
|
nawage
| 2022-08-31T22:35:54Z | 4 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-31T21:44:48Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# dragons-test
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/nawage/dragons-test/tensorboard?#scalars)
|
marsyanzeyu/bert-finetuned-ner-test-2
|
marsyanzeyu
| 2022-08-31T21:53:00Z | 59 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-31T21:45:00Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: marsyanzeyu/bert-finetuned-ner-test-2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# marsyanzeyu/bert-finetuned-ner-test-2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0266
- Validation Loss: 0.0542
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2634, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1742 | 0.0652 | 0 |
| 0.0467 | 0.0561 | 1 |
| 0.0266 | 0.0542 | 2 |
### Framework versions
- Transformers 4.21.2
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
theojolliffe/T5-model-1-feedback-e1
|
theojolliffe
| 2022-08-31T21:00:29Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-31T20:36:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: T5-model-1-feedback-e1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-model-1-feedback-e1
This model is a fine-tuned version of [theojolliffe/T5-model-1-feedback](https://huggingface.co/theojolliffe/T5-model-1-feedback) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|:---------:|:-------:|
| No log | 1.0 | 119 | 0.4255 | 86.0527 | 81.4537 | 85.654 | 85.9336 | 14.1852 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0
- Datasets 1.18.0
- Tokenizers 0.10.3
|
kiheh85202/yolo
|
kiheh85202
| 2022-08-31T20:28:31Z | 162 | 1 |
transformers
|
[
"transformers",
"pytorch",
"dpt",
"vision",
"image-segmentation",
"dataset:scene_parse_150",
"arxiv:2103.13413",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2022-08-18T20:27:18Z |
---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DPT (large-sized model) fine-tuned on ADE20k
Dense Prediction Transformer (DPT) model trained on ADE20k for semantic segmentation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. and first released in [this repository](https://github.com/isl-org/DPT).
Disclaimer: The team releasing DPT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for semantic segmentation.

## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=dpt) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import DPTFeatureExtractor, DPTForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large-ade")
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/dpt).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
muhtasham/tajberto-ner
|
muhtasham
| 2022-08-31T20:15:40Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:wikiann",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-27T15:15:25Z |
---
widget:
- text: " Исмоили Сомонӣ - намояндаи бузурги форсу-тоҷик"
- text: "Ин фурудгоҳ дар кишвари Индонезия қарор дорад."
- text: " Бобоҷон Ғафуров – солҳои 1946-1956"
- text: " Лоиқ Шералӣ дар васфи Модар шеър"
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tajberto-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
config: tg
split: train+test
args: tg
metrics:
- name: Precision
type: precision
value: 0.576
- name: Recall
type: recall
value: 0.6923076923076923
- name: F1
type: f1
value: 0.62882096069869
- name: Accuracy
type: accuracy
value: 0.8934049079754601
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tajberto-ner
This model is a fine-tuned version of [muhtasham/TajBERTo](https://huggingface.co/muhtasham/TajBERTo) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6129
- Precision: 0.576
- Recall: 0.6923
- F1: 0.6288
- Accuracy: 0.8934
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 2.0 | 50 | 0.6171 | 0.1667 | 0.2885 | 0.2113 | 0.7646 |
| No log | 4.0 | 100 | 0.4733 | 0.2824 | 0.4615 | 0.3504 | 0.8344 |
| No log | 6.0 | 150 | 0.3857 | 0.3372 | 0.5577 | 0.4203 | 0.8589 |
| No log | 8.0 | 200 | 0.4523 | 0.4519 | 0.5865 | 0.5105 | 0.8765 |
| No log | 10.0 | 250 | 0.3870 | 0.44 | 0.6346 | 0.5197 | 0.8834 |
| No log | 12.0 | 300 | 0.4512 | 0.5267 | 0.6635 | 0.5872 | 0.8865 |
| No log | 14.0 | 350 | 0.4934 | 0.4789 | 0.6538 | 0.5528 | 0.8819 |
| No log | 16.0 | 400 | 0.4924 | 0.4783 | 0.6346 | 0.5455 | 0.8842 |
| No log | 18.0 | 450 | 0.5355 | 0.4595 | 0.6538 | 0.5397 | 0.8788 |
| 0.1682 | 20.0 | 500 | 0.5440 | 0.5547 | 0.6827 | 0.6121 | 0.8942 |
| 0.1682 | 22.0 | 550 | 0.5299 | 0.5794 | 0.7019 | 0.6348 | 0.9003 |
| 0.1682 | 24.0 | 600 | 0.5735 | 0.5691 | 0.6731 | 0.6167 | 0.8926 |
| 0.1682 | 26.0 | 650 | 0.6027 | 0.5833 | 0.6731 | 0.6250 | 0.8796 |
| 0.1682 | 28.0 | 700 | 0.6119 | 0.568 | 0.6827 | 0.6201 | 0.8934 |
| 0.1682 | 30.0 | 750 | 0.6098 | 0.5635 | 0.6827 | 0.6174 | 0.8911 |
| 0.1682 | 32.0 | 800 | 0.6237 | 0.5469 | 0.6731 | 0.6034 | 0.8834 |
| 0.1682 | 34.0 | 850 | 0.6215 | 0.5530 | 0.7019 | 0.6186 | 0.8842 |
| 0.1682 | 36.0 | 900 | 0.6179 | 0.5802 | 0.7308 | 0.6468 | 0.8888 |
| 0.1682 | 38.0 | 950 | 0.6201 | 0.5373 | 0.6923 | 0.6050 | 0.8873 |
| 0.0007 | 40.0 | 1000 | 0.6114 | 0.5952 | 0.7212 | 0.6522 | 0.8911 |
| 0.0007 | 42.0 | 1050 | 0.6073 | 0.5625 | 0.6923 | 0.6207 | 0.8896 |
| 0.0007 | 44.0 | 1100 | 0.6327 | 0.5620 | 0.6538 | 0.6044 | 0.8896 |
| 0.0007 | 46.0 | 1150 | 0.6129 | 0.576 | 0.6923 | 0.6288 | 0.8934 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
gus1999/model
|
gus1999
| 2022-08-31T20:10:26Z | 160 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"camembert",
"fill-mask",
"generated_from_trainer",
"dataset:allocine",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-31T19:07:54Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- allocine
model-index:
- name: model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [cmarkea/distilcamembert-base](https://huggingface.co/cmarkea/distilcamembert-base) on the allocine dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0254
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4388 | 1.0 | 157 | 2.1637 |
| 2.288 | 2.0 | 314 | 2.1697 |
| 2.2444 | 3.0 | 471 | 2.1150 |
| 2.2166 | 4.0 | 628 | 2.0906 |
| 2.1754 | 5.0 | 785 | 2.0899 |
| 2.1604 | 6.0 | 942 | 2.0797 |
| 2.1299 | 7.0 | 1099 | 2.0589 |
| 2.1195 | 8.0 | 1256 | 2.0178 |
| 2.1258 | 9.0 | 1413 | 2.0348 |
| 2.1071 | 10.0 | 1570 | 2.0090 |
| 2.0888 | 11.0 | 1727 | 2.0047 |
| 2.0792 | 12.0 | 1884 | 2.0219 |
| 2.0687 | 13.0 | 2041 | 2.0080 |
| 2.0527 | 14.0 | 2198 | 2.0298 |
| 2.0589 | 15.0 | 2355 | 1.9869 |
| 2.0518 | 16.0 | 2512 | 2.0152 |
| 2.0409 | 17.0 | 2669 | 2.0247 |
| 2.0507 | 18.0 | 2826 | 1.9928 |
| 2.0366 | 19.0 | 2983 | 2.0175 |
| 2.0386 | 20.0 | 3140 | 1.9487 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AaronCU/attribute-classification
|
AaronCU
| 2022-08-31T19:25:23Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"en",
"dataset:AaronCU/autotrain-data-attribute-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-31T19:24:40Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- AaronCU/autotrain-data-attribute-classification
co2_eq_emissions:
emissions: 0.002847008943614719
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1343651539
- CO2 Emissions (in grams): 0.0028
## Validation Metrics
- Loss: 0.163
- Accuracy: 0.949
- Macro F1: 0.947
- Micro F1: 0.949
- Weighted F1: 0.949
- Macro Precision: 0.943
- Micro Precision: 0.949
- Weighted Precision: 0.951
- Macro Recall: 0.952
- Micro Recall: 0.949
- Weighted Recall: 0.949
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/AaronCU/autotrain-attribute-classification-1343651539
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("AaronCU/autotrain-attribute-classification-1343651539", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("AaronCU/autotrain-attribute-classification-1343651539", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
castorini/monot5-3b-msmarco-10k
|
castorini
| 2022-08-31T19:20:16Z | 497 | 12 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"arxiv:2206.02873",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-28T15:08:54Z |
This model is a T5-3B reranker fine-tuned on the MS MARCO passage dataset for 10k steps (or 1 epoch).
For more details on how to use it, check [pygaggle.ai](pygaggle.ai)
Paper describing the model: [Document Ranking with a Pretrained Sequence-to-Sequence Model](https://www.aclweb.org/anthology/2020.findings-emnlp.63/)
This model is also the state of the art on the BEIR Benchmark.
- Paper: [No Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval](https://arxiv.org/abs/2206.02873)
- [Repository](https://github.com/guilhermemr04/scaling-zero-shot-retrieval)
|
suey2580/distilbert-base-uncased-finetuned-cola
|
suey2580
| 2022-08-31T18:58:43Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-06T01:29:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5238347808517775
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0766
- Matthews Correlation: 0.5238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.403175733231667e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4954 | 1.0 | 1069 | 0.4770 | 0.4589 |
| 0.3627 | 2.0 | 2138 | 0.5464 | 0.4998 |
| 0.2576 | 3.0 | 3207 | 0.8439 | 0.4933 |
| 0.1488 | 4.0 | 4276 | 1.0184 | 0.5035 |
| 0.1031 | 5.0 | 5345 | 1.0766 | 0.5238 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
curt-tigges/q-Taxi-v3
|
curt-tigges
| 2022-08-31T18:47:23Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-31T18:47:16Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="curt-tigges/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Shivus/cartpole
|
Shivus
| 2022-08-31T17:07:14Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-31T17:04:29Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: cartpole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 139.50 +/- 32.14
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
29thDay/A2C-SpaceInvadersNoFrameskip-v4
|
29thDay
| 2022-08-31T15:47:23Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-31T15:46:15Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 10.00 +/- 10.25
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **A2C** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **A2C** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ericntay/stbl_clinical_bert_ft
|
ericntay
| 2022-08-31T15:31:41Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-31T15:14:00Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1789
- F1: 0.8523
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2786 | 1.0 | 95 | 0.1083 | 0.8090 |
| 0.0654 | 2.0 | 190 | 0.1005 | 0.8475 |
| 0.0299 | 3.0 | 285 | 0.1207 | 0.8481 |
| 0.0146 | 4.0 | 380 | 0.1432 | 0.8454 |
| 0.0088 | 5.0 | 475 | 0.1362 | 0.8475 |
| 0.0056 | 6.0 | 570 | 0.1527 | 0.8518 |
| 0.0037 | 7.0 | 665 | 0.1617 | 0.8519 |
| 0.0022 | 8.0 | 760 | 0.1726 | 0.8495 |
| 0.0018 | 9.0 | 855 | 0.1743 | 0.8527 |
| 0.0014 | 10.0 | 950 | 0.1750 | 0.8463 |
| 0.0014 | 11.0 | 1045 | 0.1775 | 0.8522 |
| 0.001 | 12.0 | 1140 | 0.1789 | 0.8523 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ai-forever/mGPT-armenian
|
ai-forever
| 2022-08-31T15:05:46Z | 25 | 8 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"multilingual",
"PyTorch",
"Transformers",
"gpt3",
"Deepspeed",
"Megatron",
"hy",
"dataset:mc4",
"dataset:wikipedia",
"arxiv:2112.10668",
"arxiv:2204.07580",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-31T14:24:00Z |
---
license: apache-2.0
language:
- hy
pipeline_tag: text-generation
tags:
- multilingual
- PyTorch
- Transformers
- gpt3
- gpt2
- Deepspeed
- Megatron
datasets:
- mc4
- wikipedia
thumbnail: "https://github.com/sberbank-ai/mgpt"
---
# Multilingual GPT model, Armenian language finetune
We introduce a monolingual GPT-3-based model for Armenian language
The model is based on [mGPT](https://huggingface.co/sberbank-ai/mGPT/), a family of autoregressive GPT-like models with 1.3 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus.
We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism, [Deepspeed](https://github.com/microsoft/DeepSpeed) and [Megatron](https://github.com/NVIDIA/Megatron-LM) frameworks allows us to effectively parallelize the training and inference steps. The resulting models show performance on par with the recently released [XGLM](https://arxiv.org/pdf/2112.10668.pdf) models at the same time covering more languages and enhancing NLP possibilities for low resource languages.
## Code
The source code for the mGPT XL model is available on [Github](https://github.com/sberbank-ai/mgpt)
## Paper
mGPT: Few-Shot Learners Go Multilingual
[Abstract](https://arxiv.org/abs/2204.07580) [PDF](https://arxiv.org/pdf/2204.07580.pdf)
```
@misc{https://doi.org/10.48550/arxiv.2204.07580,
doi = {10.48550/ARXIV.2204.07580},
url = {https://arxiv.org/abs/2204.07580},
author = {Shliazhko, Oleh and Fenogenova, Alena and Tikhonova, Maria and Mikhailov, Vladislav and Kozlova, Anastasia and Shavrina, Tatiana},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2; I.2.7, 68-06, 68-04, 68T50, 68T01},
title = {mGPT: Few-Shot Learners Go Multilingual},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
## Training
The model was fine-tuned on 170GB of Armenian texts, including MC4, Archive.org fiction, EANC public data, OpenSubtitles, OSCAR corpus and blog texts.
Val perplexity is 2.046.
The mGPT model was pre-trained for 12 days x 256 GPU (Tesla NVidia V100), 4 epochs, then 9 days x 64 GPU, 1 epoch
The Armenian finetune was around 7 days with 4 Tesla NVidia V100 and has made 160k steps.
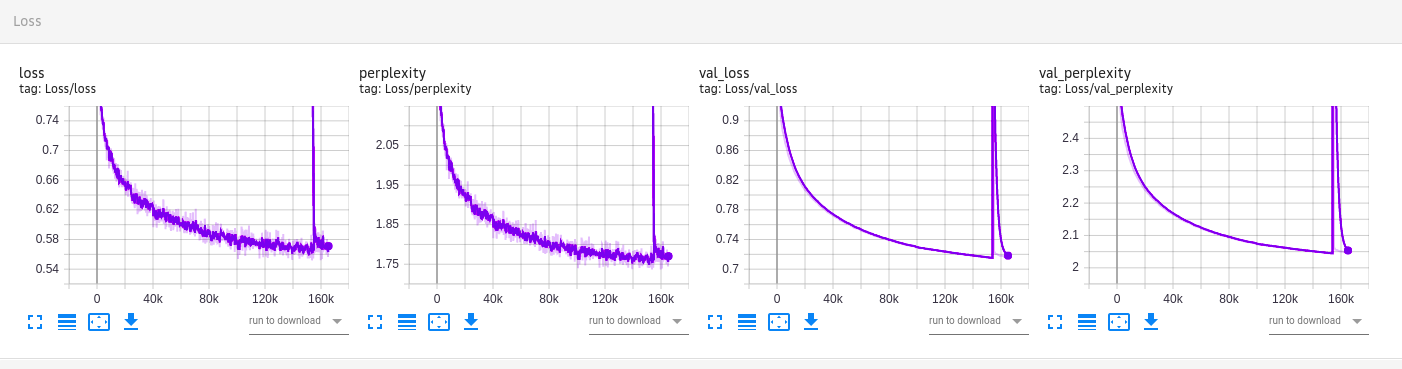
What happens on this image? The model is originally trained with sparse attention masks, then fine-tuned with no sparsity on the last steps (perplexity and loss peak). Getting rid of the sparsity in the end of the training helps to integrate the model into the GPT2 HF class.
|
farleyknight-org-username/vit-base-mnist
|
farleyknight-org-username
| 2022-08-31T14:55:56Z | 1,370 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"vision",
"generated_from_trainer",
"dataset:mnist",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-21T16:48:27Z |
---
license: apache-2.0
tags:
- image-classification
- vision
- generated_from_trainer
datasets:
- mnist
metrics:
- accuracy
model-index:
- name: vit-base-mnist
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: mnist
type: mnist
config: mnist
split: train
args: mnist
metrics:
- name: Accuracy
type: accuracy
value: 0.9948888888888889
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-mnist
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the mnist dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0236
- Accuracy: 0.9949
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3717 | 1.0 | 6375 | 0.0522 | 0.9893 |
| 0.3453 | 2.0 | 12750 | 0.0370 | 0.9906 |
| 0.3736 | 3.0 | 19125 | 0.0308 | 0.9916 |
| 0.3224 | 4.0 | 25500 | 0.0269 | 0.9939 |
| 0.2846 | 5.0 | 31875 | 0.0236 | 0.9949 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.11.0a0+17540c5
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AliShaker/layoutlmv3-finetuned-wildreceipt
|
AliShaker
| 2022-08-31T14:44:42Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:wildreceipt",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-31T13:06:54Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- wildreceipt
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-wildreceipt
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wildreceipt
type: wildreceipt
config: WildReceipt
split: train
args: WildReceipt
metrics:
- name: Precision
type: precision
value: 0.877962408063198
- name: Recall
type: recall
value: 0.8870235310306867
- name: F1
type: f1
value: 0.8824697104524608
- name: Accuracy
type: accuracy
value: 0.9265109136777449
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-wildreceipt
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the wildreceipt dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3129
- Precision: 0.8780
- Recall: 0.8870
- F1: 0.8825
- Accuracy: 0.9265
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.32 | 100 | 1.2240 | 0.6077 | 0.3766 | 0.4650 | 0.7011 |
| No log | 0.63 | 200 | 0.8417 | 0.6440 | 0.5089 | 0.5685 | 0.7743 |
| No log | 0.95 | 300 | 0.6466 | 0.7243 | 0.6583 | 0.6897 | 0.8311 |
| No log | 1.26 | 400 | 0.5516 | 0.7533 | 0.7158 | 0.7341 | 0.8537 |
| 0.9961 | 1.58 | 500 | 0.4845 | 0.7835 | 0.7557 | 0.7693 | 0.8699 |
| 0.9961 | 1.89 | 600 | 0.4506 | 0.7809 | 0.7930 | 0.7869 | 0.8770 |
| 0.9961 | 2.21 | 700 | 0.4230 | 0.8101 | 0.8107 | 0.8104 | 0.8886 |
| 0.9961 | 2.52 | 800 | 0.3797 | 0.8211 | 0.8296 | 0.8253 | 0.8983 |
| 0.9961 | 2.84 | 900 | 0.3576 | 0.8289 | 0.8411 | 0.8349 | 0.9016 |
| 0.4076 | 3.15 | 1000 | 0.3430 | 0.8394 | 0.8371 | 0.8382 | 0.9055 |
| 0.4076 | 3.47 | 1100 | 0.3354 | 0.8531 | 0.8405 | 0.8467 | 0.9071 |
| 0.4076 | 3.79 | 1200 | 0.3331 | 0.8371 | 0.8504 | 0.8437 | 0.9076 |
| 0.4076 | 4.1 | 1300 | 0.3184 | 0.8445 | 0.8609 | 0.8526 | 0.9118 |
| 0.4076 | 4.42 | 1400 | 0.3087 | 0.8617 | 0.8580 | 0.8598 | 0.9150 |
| 0.2673 | 4.73 | 1500 | 0.3013 | 0.8613 | 0.8657 | 0.8635 | 0.9177 |
| 0.2673 | 5.05 | 1600 | 0.2971 | 0.8630 | 0.8689 | 0.8659 | 0.9181 |
| 0.2673 | 5.36 | 1700 | 0.3075 | 0.8675 | 0.8639 | 0.8657 | 0.9177 |
| 0.2673 | 5.68 | 1800 | 0.2989 | 0.8551 | 0.8764 | 0.8656 | 0.9193 |
| 0.2673 | 5.99 | 1900 | 0.3011 | 0.8572 | 0.8762 | 0.8666 | 0.9194 |
| 0.2026 | 6.31 | 2000 | 0.3107 | 0.8595 | 0.8722 | 0.8658 | 0.9181 |
| 0.2026 | 6.62 | 2100 | 0.3050 | 0.8678 | 0.8800 | 0.8739 | 0.9220 |
| 0.2026 | 6.94 | 2200 | 0.2971 | 0.8722 | 0.8789 | 0.8755 | 0.9237 |
| 0.2026 | 7.26 | 2300 | 0.3057 | 0.8666 | 0.8785 | 0.8725 | 0.9209 |
| 0.2026 | 7.57 | 2400 | 0.3172 | 0.8593 | 0.8773 | 0.8682 | 0.9184 |
| 0.1647 | 7.89 | 2500 | 0.3018 | 0.8695 | 0.8823 | 0.8759 | 0.9228 |
| 0.1647 | 8.2 | 2600 | 0.3001 | 0.8760 | 0.8795 | 0.8777 | 0.9256 |
| 0.1647 | 8.52 | 2700 | 0.3068 | 0.8758 | 0.8745 | 0.8752 | 0.9235 |
| 0.1647 | 8.83 | 2800 | 0.3007 | 0.8779 | 0.8779 | 0.8779 | 0.9248 |
| 0.1647 | 9.15 | 2900 | 0.3063 | 0.8740 | 0.8763 | 0.8751 | 0.9228 |
| 0.1342 | 9.46 | 3000 | 0.3096 | 0.8675 | 0.8834 | 0.8754 | 0.9235 |
| 0.1342 | 9.78 | 3100 | 0.3052 | 0.8736 | 0.8848 | 0.8792 | 0.9249 |
| 0.1342 | 10.09 | 3200 | 0.3120 | 0.8727 | 0.8885 | 0.8805 | 0.9252 |
| 0.1342 | 10.41 | 3300 | 0.3146 | 0.8718 | 0.8843 | 0.8780 | 0.9243 |
| 0.1342 | 10.73 | 3400 | 0.3124 | 0.8720 | 0.8880 | 0.8799 | 0.9253 |
| 0.117 | 11.04 | 3500 | 0.3088 | 0.8761 | 0.8817 | 0.8789 | 0.9252 |
| 0.117 | 11.36 | 3600 | 0.3082 | 0.8782 | 0.8834 | 0.8808 | 0.9257 |
| 0.117 | 11.67 | 3700 | 0.3129 | 0.8767 | 0.8847 | 0.8807 | 0.9256 |
| 0.117 | 11.99 | 3800 | 0.3116 | 0.8792 | 0.8847 | 0.8820 | 0.9265 |
| 0.117 | 12.3 | 3900 | 0.3142 | 0.8768 | 0.8874 | 0.8821 | 0.9261 |
| 0.1022 | 12.62 | 4000 | 0.3129 | 0.8780 | 0.8870 | 0.8825 | 0.9265 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
chinoll/ACGTTS
|
chinoll
| 2022-08-31T13:59:25Z | 0 | 4 | null |
[
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2022-08-06T10:02:11Z |
---
license: cc-by-nc-sa-4.0
---
# ACGTTS 模型库
### old支持的语音
```
0 - 绫地宁宁
1 - 因幡巡
2 - 户隐憧子
```
### new支持的语音
```
0 - 绫地宁宁
1 - 户隐憧子
2 - 因幡巡
3 - 明月栞那
4 - 四季夏目
5 - 墨染希
6 - 火打谷爱衣
7 - 汐山凉音
8 - 中文注入声线
9 - 二条院羽月
10 - 在原七海
11 - 式部茉优
12 - 三司绫濑
13 - 壬生千咲
14 - 朝武芳乃
15 - 常陆茉子
16 - 丛雨
17 - 蕾娜·列支敦瑙尔
18 - 鞍马小春
```
目前模型支持的语言有中文(方言味浓重)和日语
# 代码地址
[ACGTTS](https://github.com/chinoll/ACGTTS)
|
karthid/ta_Tamil_NER
|
karthid
| 2022-08-31T13:52:24Z | 2 | 0 |
spacy
|
[
"spacy",
"token-classification",
"ta",
"model-index",
"region:us"
] |
token-classification
| 2022-08-28T18:36:59Z |
---
tags:
- spacy
- token-classification
language:
- ta
widget:
- text: "கூகுள் நிறுவனம் தனது முக்கிய வசதியான ஸ்ட்ரீட் வியூ வசதியை 10 நகரங்களில் இந்தியாவில் அறிமுகப்படுத்தி உள்ளது."
- text: "கென்யாவின் புதிய அரசுத்தலைவராக வில்லியம் ரூட்டோ தேர்ந்தெடுக்கப்பட்டார்."
- text: "என் பெயர் மாறன், நான் சென்னையில் வசிக்கிறேன்."
model-index:
- name: ta_Tamil_NER
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8433655536
- name: NER Recall
type: recall
value: 0.8552016039
- name: NER F Score
type: f_score
value: 0.8492423404
---
## Intended uses & limitations
#### How to use
You can use this model with spacy.
!pip install https://huggingface.co/karthid/ta_Tamil_NER/resolve/main/ta_Tamil_NER-any-py3-none-any.whl
import ta_Tamil_NER
from spacy import displacy
nlp = ta_Tamil_NER.load()
doc = nlp("கூகுள் நிறுவனம் தனது முக்கிய வசதியான ஸ்ட்ரீட் வியூ வசதியை 10 நகரங்களில் இந்தியாவில் அறிமுகப்படுத்தி உள்ளது.")
displacy.render(doc,jupyter=True, style = "ent")
| Feature | Description |
| --- | --- |
| **Name** | `ta_Tamil_NER` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.2.4,<3.3.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | Karthi Dhayalan |
### Label Scheme
<details>
<summary>View label scheme </summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `B-PER`, `I-PER`, `B-ORG`, `I-ORG`, `B-LOC`, `I-LOC` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 84.92 |
| `ENTS_P` | 84.34 |
| `ENTS_R` | 85.52 |
| `TRANSFORMER_LOSS` | 1842600.06 |
| `NER_LOSS` | 108788.05 |
|
29thDay/A2C-AntBulletEnv-v0
|
29thDay
| 2022-08-31T13:32:46Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-31T13:31:39Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 822.42 +/- 48.82
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
autoevaluate/glue-mnli
|
autoevaluate
| 2022-08-31T13:27:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-29T09:59:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: glue-mnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mnli
split: train
args: mnli
metrics:
- name: Accuracy
type: accuracy
value: 0.6772287315333673
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue-mnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8003
- Accuracy: 0.6772
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9378 | 1.0 | 625 | 0.7896 | 0.6585 |
| 0.7086 | 2.0 | 1250 | 0.7850 | 0.6712 |
| 0.5758 | 3.0 | 1875 | 0.8003 | 0.6772 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
kingabzpro/a2c-HalfCheetahBulletEnv-v0
|
kingabzpro
| 2022-08-31T13:06:52Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"HalfCheetahBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-31T12:10:34Z |
---
library_name: stable-baselines3
tags:
- HalfCheetahBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 1647.65 +/- 21.63
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: HalfCheetahBulletEnv-v0
type: HalfCheetahBulletEnv-v0
---
# **A2C** Agent playing **HalfCheetahBulletEnv-v0**
This is a trained model of a **A2C** agent playing **HalfCheetahBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
huggingtweets/donaldtusk
|
huggingtweets
| 2022-08-31T12:29:41Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-07-05T20:21:21Z |
---
language: en
thumbnail: http://www.huggingtweets.com/donaldtusk/1661948958135/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/990605878993793024/7uuCR4hP_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Donald Tusk</div>
<div style="text-align: center; font-size: 14px;">@donaldtusk</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Donald Tusk.
| Data | Donald Tusk |
| --- | --- |
| Tweets downloaded | 928 |
| Retweets | 194 |
| Short tweets | 35 |
| Tweets kept | 699 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/pyk96dcl/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @donaldtusk's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2ivs2zls) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2ivs2zls/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/donaldtusk')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Langboat/bloom-800m-zh
|
Langboat
| 2022-08-31T11:58:08Z | 23 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bloom",
"text-generation",
"zh",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-31T06:48:29Z |
---
license: bigscience-bloom-rail-1.0
language:
- zh
pipeline_tag: text-generation
widget:
- text: "中国的首都是"
---
This model is based on [bigscience/bloom-1b1](https://huggingface.co/bigscience/bloom-1b1).
We pruned its vocabulary from 250880 to 46145 with Chinese corpus to reduce GPU memory usage. So the total parameter is 800m now.
# How to use
```python
from transformers import BloomTokenizerFast, BloomForCausalLM
tokenizer = BloomTokenizerFast.from_pretrained('Langboat/bloom-800m-zh')
model = BloomForCausalLM.from_pretrained('Langboat/bloom-800m-zh')
print(tokenizer.batch_decode(model.generate(tokenizer.encode('中国的首都是', return_tensors='pt'))))
```
|
mrm8488/data2vec-text-base-finetuned-cola
|
mrm8488
| 2022-08-31T10:26:09Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"data2vec-text",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-05-03T14:51:13Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: data2vec-text-base-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5214716883534575
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# data2vec-text-base-finetuned-cola
This model is a fine-tuned version of [facebook/data2vec-text-base](https://huggingface.co/facebook/data2vec-text-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5254
- Matthews Correlation: 0.5215
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.160701759709141e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 30
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5632 | 1.0 | 535 | 0.5252 | 0.3869 |
| 0.4572 | 2.0 | 1070 | 0.5534 | 0.4758 |
| 0.3905 | 3.0 | 1605 | 0.4962 | 0.5259 |
| 0.3592 | 4.0 | 2140 | 0.5254 | 0.5215 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
mrm8488/data2vec-text-base-finetuned-mnli
|
mrm8488
| 2022-08-31T10:25:23Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"data2vec-text",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-29T16:27:18Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: data2vec-text-base-finetuned-mnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mnli
metrics:
- name: Accuracy
type: accuracy
value: 0.7862455425369332
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# data2vec-text-base-finetuned-mnli
This model is a fine-tuned version of [facebook/data2vec-text-base](https://huggingface.co/facebook/data2vec-text-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5521
- Accuracy: 0.7862
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 1.099 | 1.0 | 24544 | 1.0987 | 0.3182 |
| 1.0993 | 2.0 | 49088 | 1.0979 | 0.3545 |
| 0.7481 | 3.0 | 73632 | 0.7197 | 0.7046 |
| 0.5671 | 4.0 | 98176 | 0.5862 | 0.7728 |
| 0.5505 | 5.0 | 122720 | 0.5521 | 0.7862 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
mrp/bert-finetuned-squad
|
mrp
| 2022-08-31T09:52:58Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad
type: squad
config: plain_text
split: validation
metrics:
- name: Loss
type: loss
value: 1.073493242263794
verified: true
- name: Exact Match
type: exact_match
value: 80.0853
verified: true
- name: F1
type: f1
value: 87.606
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
VioletaMG/dtu-scan114-128_50epochs
|
VioletaMG
| 2022-08-31T09:29:52Z | 2 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-31T09:08:22Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# dtu-scan114-128_50epochs
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/VioletaMG/dtu-scan114-128_50epochs/tensorboard?#scalars)
|
merkalo-ziri/qa_model
|
merkalo-ziri
| 2022-08-31T09:20:35Z | 26 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"question answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-23T20:14:41Z |
---
tags:
- "question answering"
widget:
- context: "Привет, меня зовут Артем. Завтра заеду к вам"
- question: "Что я планирую делать?"
---
|
osanseviero/flair_test4
|
osanseviero
| 2022-08-31T09:04:18Z | 1 | 0 |
flair
|
[
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"region:us"
] |
token-classification
| 2022-08-31T09:02:30Z |
---
tags:
- flair
- token-classification
- sequence-tagger-model
---
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("osanseviero/flair_test4")
# make example sentence
sentence = Sentence("On September 1st George won 1 dollar while watching Game of Thrones.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
|
Fulccrum/distilbert-base-uncased-finetuned-sst2
|
Fulccrum
| 2022-08-31T09:02:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-02T09:56:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.9128440366972477
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-sst2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3739
- Accuracy: 0.9128
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1885 | 1.0 | 4210 | 0.3092 | 0.9083 |
| 0.1311 | 2.0 | 8420 | 0.3809 | 0.9071 |
| 0.1036 | 3.0 | 12630 | 0.3739 | 0.9128 |
| 0.0629 | 4.0 | 16840 | 0.4623 | 0.9083 |
| 0.036 | 5.0 | 21050 | 0.5198 | 0.9048 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
VanHoan/bert-fine-tuned-cola
|
VanHoan
| 2022-08-31T08:48:56Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-20T02:35:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-fine-tuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: train
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5981073556597793
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-fine-tuned-cola
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8408
- Matthews Correlation: 0.5981
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4729 | 1.0 | 1069 | 0.5311 | 0.5154 |
| 0.3134 | 2.0 | 2138 | 0.6336 | 0.6007 |
| 0.1686 | 3.0 | 3207 | 0.8408 | 0.5981 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
cynthiachan/finetuned-bert-base-10pct
|
cynthiachan
| 2022-08-31T08:45:34Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:cynthiachan/FeedRef_10pct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-15T02:47:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cynthiachan/FeedRef_10pct
model-index:
- name: training
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# training
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the cynthiachan/FeedRef_10pct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1291
- Attackid Precision: 1.0
- Attackid Recall: 1.0
- Attackid F1: 1.0
- Attackid Number: 6
- Cve Precision: 0.8333
- Cve Recall: 0.9091
- Cve F1: 0.8696
- Cve Number: 11
- Defenderthreat Precision: 0.0
- Defenderthreat Recall: 0.0
- Defenderthreat F1: 0.0
- Defenderthreat Number: 2
- Domain Precision: 0.7826
- Domain Recall: 0.7826
- Domain F1: 0.7826
- Domain Number: 23
- Email Precision: 0.6667
- Email Recall: 0.6667
- Email F1: 0.6667
- Email Number: 3
- Filepath Precision: 0.6766
- Filepath Recall: 0.8242
- Filepath F1: 0.7432
- Filepath Number: 165
- Hostname Precision: 1.0
- Hostname Recall: 0.9167
- Hostname F1: 0.9565
- Hostname Number: 12
- Ipv4 Precision: 0.8333
- Ipv4 Recall: 0.8333
- Ipv4 F1: 0.8333
- Ipv4 Number: 12
- Md5 Precision: 0.7246
- Md5 Recall: 0.9615
- Md5 F1: 0.8264
- Md5 Number: 52
- Sha1 Precision: 0.0667
- Sha1 Recall: 0.1429
- Sha1 F1: 0.0909
- Sha1 Number: 7
- Sha256 Precision: 0.6780
- Sha256 Recall: 0.9091
- Sha256 F1: 0.7767
- Sha256 Number: 44
- Uri Precision: 0.0
- Uri Recall: 0.0
- Uri F1: 0.0
- Uri Number: 1
- Overall Precision: 0.6910
- Overall Recall: 0.8402
- Overall F1: 0.7583
- Overall Accuracy: 0.9725
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Attackid Precision | Attackid Recall | Attackid F1 | Attackid Number | Cve Precision | Cve Recall | Cve F1 | Cve Number | Defenderthreat Precision | Defenderthreat Recall | Defenderthreat F1 | Defenderthreat Number | Domain Precision | Domain Recall | Domain F1 | Domain Number | Email Precision | Email Recall | Email F1 | Email Number | Filepath Precision | Filepath Recall | Filepath F1 | Filepath Number | Hostname Precision | Hostname Recall | Hostname F1 | Hostname Number | Ipv4 Precision | Ipv4 Recall | Ipv4 F1 | Ipv4 Number | Md5 Precision | Md5 Recall | Md5 F1 | Md5 Number | Sha1 Precision | Sha1 Recall | Sha1 F1 | Sha1 Number | Sha256 Precision | Sha256 Recall | Sha256 F1 | Sha256 Number | Uri Precision | Uri Recall | Uri F1 | Uri Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------------------:|:---------------:|:-----------:|:---------------:|:-------------:|:----------:|:------:|:----------:|:------------------------:|:---------------------:|:-----------------:|:---------------------:|:----------------:|:-------------:|:---------:|:-------------:|:---------------:|:------------:|:--------:|:------------:|:------------------:|:---------------:|:-----------:|:---------------:|:------------------:|:---------------:|:-----------:|:---------------:|:--------------:|:-----------:|:-------:|:-----------:|:-------------:|:----------:|:------:|:----------:|:--------------:|:-----------:|:-------:|:-----------:|:----------------:|:-------------:|:---------:|:-------------:|:-------------:|:----------:|:------:|:----------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.3943 | 0.37 | 500 | 0.2881 | 0.0 | 0.0 | 0.0 | 6 | 0.0 | 0.0 | 0.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.0 | 0.0 | 0.0 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.1138 | 0.2 | 0.1451 | 165 | 0.0692 | 0.9167 | 0.1287 | 12 | 0.4706 | 0.6667 | 0.5517 | 12 | 0.75 | 0.9231 | 0.8276 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.5694 | 0.9318 | 0.7069 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.2342 | 0.4172 | 0.3 | 0.9360 |
| 0.1987 | 0.75 | 1000 | 0.1722 | 0.5 | 1.0 | 0.6667 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.0 | 0.0 | 0.0 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.4779 | 0.6545 | 0.5524 | 165 | 0.25 | 0.6667 | 0.3636 | 12 | 0.6923 | 0.75 | 0.7200 | 12 | 0.6364 | 0.9423 | 0.7597 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.6545 | 0.8182 | 0.7273 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.5136 | 0.6716 | 0.5821 | 0.9529 |
| 0.1595 | 1.12 | 1500 | 0.1346 | 0.8571 | 1.0 | 0.9231 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.4286 | 0.5217 | 0.4706 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.5797 | 0.7273 | 0.6452 | 165 | 0.44 | 0.9167 | 0.5946 | 12 | 0.3929 | 0.9167 | 0.55 | 12 | 0.6364 | 0.9423 | 0.7597 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.78 | 0.8864 | 0.8298 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.5768 | 0.7663 | 0.6582 | 0.9658 |
| 0.118 | 1.5 | 2000 | 0.1436 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.6087 | 0.6087 | 0.6087 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.6101 | 0.8061 | 0.6945 | 165 | 0.9091 | 0.8333 | 0.8696 | 12 | 0.7273 | 0.6667 | 0.6957 | 12 | 0.7869 | 0.9231 | 0.8496 | 52 | 0.2143 | 0.4286 | 0.2857 | 7 | 0.7407 | 0.9091 | 0.8163 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.6675 | 0.8077 | 0.7309 | 0.9686 |
| 0.1198 | 1.87 | 2500 | 0.1385 | 1.0 | 1.0 | 1.0 | 6 | 0.7692 | 0.9091 | 0.8333 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.85 | 0.7391 | 0.7907 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.6390 | 0.7939 | 0.7081 | 165 | 1.0 | 0.8333 | 0.9091 | 12 | 0.5333 | 0.6667 | 0.5926 | 12 | 0.7778 | 0.9423 | 0.8522 | 52 | 0.3333 | 0.5714 | 0.4211 | 7 | 0.8571 | 0.9545 | 0.9032 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.6995 | 0.8195 | 0.7548 | 0.9687 |
| 0.0742 | 2.25 | 3000 | 0.1291 | 1.0 | 1.0 | 1.0 | 6 | 0.8333 | 0.9091 | 0.8696 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.7826 | 0.7826 | 0.7826 | 23 | 0.6667 | 0.6667 | 0.6667 | 3 | 0.6766 | 0.8242 | 0.7432 | 165 | 1.0 | 0.9167 | 0.9565 | 12 | 0.8333 | 0.8333 | 0.8333 | 12 | 0.7246 | 0.9615 | 0.8264 | 52 | 0.0667 | 0.1429 | 0.0909 | 7 | 0.6780 | 0.9091 | 0.7767 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.6910 | 0.8402 | 0.7583 | 0.9725 |
| 0.0687 | 2.62 | 3500 | 0.1385 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.8077 | 0.9130 | 0.8571 | 23 | 1.0 | 1.0 | 1.0 | 3 | 0.7746 | 0.8121 | 0.7929 | 165 | 0.7333 | 0.9167 | 0.8148 | 12 | 0.7143 | 0.8333 | 0.7692 | 12 | 0.96 | 0.9231 | 0.9412 | 52 | 0.4444 | 0.5714 | 0.5 | 7 | 0.8113 | 0.9773 | 0.8866 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.8083 | 0.8609 | 0.8338 | 0.9737 |
| 0.0652 | 3.0 | 4000 | 0.1299 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.8077 | 0.9130 | 0.8571 | 23 | 1.0 | 1.0 | 1.0 | 3 | 0.7553 | 0.8606 | 0.8045 | 165 | 0.8462 | 0.9167 | 0.8800 | 12 | 0.7143 | 0.8333 | 0.7692 | 12 | 0.8571 | 0.9231 | 0.8889 | 52 | 0.75 | 0.8571 | 0.8000 | 7 | 0.8723 | 0.9318 | 0.9011 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.8038 | 0.8846 | 0.8423 | 0.9772 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
varun3dec/cat_or_dog
|
varun3dec
| 2022-08-31T07:51:03Z | 0 | 0 |
fastai
|
[
"fastai",
"region:us"
] | null | 2022-08-31T07:32:00Z |
---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
js05212/ddpm-butterflies-128
|
js05212
| 2022-08-31T04:49:25Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-31T04:08:43Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/js05212/ddpm-butterflies-128/tensorboard?#scalars)
|
Late-potato/distilbert-base-uncased-finetuned-imdb
|
Late-potato
| 2022-08-31T04:47:26Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-31T04:10:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2999
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4977 | 1.0 | 782 | 2.3318 |
| 2.4232 | 2.0 | 1564 | 2.3005 |
| 2.386 | 3.0 | 2346 | 2.2721 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.12.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
thammarat-th/distilbert-base-uncased-finetuned-imdb
|
thammarat-th
| 2022-08-31T04:46:34Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-31T04:01:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2591
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4216 | 1.0 | 782 | 2.2803 |
| 2.3719 | 2.0 | 1564 | 2.2577 |
| 2.3407 | 3.0 | 2346 | 2.2320 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.12.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
ayameRushia/wav2vec2-large-xls-r-300m-el
|
ayameRushia
| 2022-08-31T04:43:27Z | 24 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"robust-speech-event",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"el",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- el
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- robust-speech-event
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: wav2vec2-large-xls-r-300m-el
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: el
metrics:
- name: Test WER using LM
type: wer
value: 20.9
- name: Test CER using LM
type: cer
value: 6.0466
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - EL dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3218
- Wer: 0.3095
## Training and evaluation data
Evaluation is conducted in Notebook, you can see within the repo "notebook_evaluation_wav2vec2_el.ipynb"
Test WER without LM
wer = 31.1294 %
cer = 7.9509 %
Test WER using LM
wer = 20.7340 %
cer = 6.0466 %
How to use eval.py
```
huggingface-cli login #login to huggingface for getting auth token to access the common voice v8
#running with LM
!python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-el --dataset mozilla-foundation/common_voice_8_0 --config el --split test
# running without LM
!python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-el --dataset mozilla-foundation/common_voice_8_0 --config el --split test --greedy
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 80.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 6.3683 | 8.77 | 500 | 3.1280 | 1.0 |
| 1.9915 | 17.54 | 1000 | 0.6600 | 0.6444 |
| 0.6565 | 26.32 | 1500 | 0.4208 | 0.4486 |
| 0.4484 | 35.09 | 2000 | 0.3885 | 0.4006 |
| 0.3573 | 43.86 | 2500 | 0.3548 | 0.3626 |
| 0.3063 | 52.63 | 3000 | 0.3375 | 0.3430 |
| 0.2751 | 61.4 | 3500 | 0.3359 | 0.3241 |
| 0.2511 | 70.18 | 4000 | 0.3222 | 0.3108 |
| 0.2361 | 78.95 | 4500 | 0.3205 | 0.3084 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
ayameRushia/wav2vec2-large-xls-r-300m-id
|
ayameRushia
| 2022-08-31T04:43:20Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"id",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- id
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
- robust-speech-event
datasets:
- common_voice
model-index:
- name: 'XLS-R-300M - Indonesia'
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: sv-SE
metrics:
- name: Test WER
type: wer
value: 38.098
- name: Test CER
type: cer
value: 14.261
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - ID dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3975
- Wer: 0.2633
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.78 | 100 | 4.5645 | 1.0 |
| No log | 1.55 | 200 | 2.9016 | 1.0 |
| No log | 2.33 | 300 | 2.2666 | 1.0982 |
| No log | 3.1 | 400 | 0.6079 | 0.6376 |
| 3.2188 | 3.88 | 500 | 0.4985 | 0.5008 |
| 3.2188 | 4.65 | 600 | 0.4477 | 0.4469 |
| 3.2188 | 5.43 | 700 | 0.3953 | 0.3915 |
| 3.2188 | 6.2 | 800 | 0.4319 | 0.3921 |
| 3.2188 | 6.98 | 900 | 0.4171 | 0.3698 |
| 0.2193 | 7.75 | 1000 | 0.3957 | 0.3600 |
| 0.2193 | 8.53 | 1100 | 0.3730 | 0.3493 |
| 0.2193 | 9.3 | 1200 | 0.3780 | 0.3348 |
| 0.2193 | 10.08 | 1300 | 0.4133 | 0.3568 |
| 0.2193 | 10.85 | 1400 | 0.3984 | 0.3193 |
| 0.1129 | 11.63 | 1500 | 0.3845 | 0.3174 |
| 0.1129 | 12.4 | 1600 | 0.3882 | 0.3162 |
| 0.1129 | 13.18 | 1700 | 0.3982 | 0.3008 |
| 0.1129 | 13.95 | 1800 | 0.3902 | 0.3198 |
| 0.1129 | 14.73 | 1900 | 0.4082 | 0.3237 |
| 0.0765 | 15.5 | 2000 | 0.3732 | 0.3126 |
| 0.0765 | 16.28 | 2100 | 0.3893 | 0.3001 |
| 0.0765 | 17.05 | 2200 | 0.4168 | 0.3083 |
| 0.0765 | 17.83 | 2300 | 0.4193 | 0.3044 |
| 0.0765 | 18.6 | 2400 | 0.4006 | 0.3013 |
| 0.0588 | 19.38 | 2500 | 0.3836 | 0.2892 |
| 0.0588 | 20.16 | 2600 | 0.3761 | 0.2903 |
| 0.0588 | 20.93 | 2700 | 0.3895 | 0.2930 |
| 0.0588 | 21.71 | 2800 | 0.3885 | 0.2791 |
| 0.0588 | 22.48 | 2900 | 0.3902 | 0.2891 |
| 0.0448 | 23.26 | 3000 | 0.4200 | 0.2849 |
| 0.0448 | 24.03 | 3100 | 0.4013 | 0.2799 |
| 0.0448 | 24.81 | 3200 | 0.4039 | 0.2731 |
| 0.0448 | 25.58 | 3300 | 0.3970 | 0.2647 |
| 0.0448 | 26.36 | 3400 | 0.4081 | 0.2690 |
| 0.0351 | 27.13 | 3500 | 0.4090 | 0.2674 |
| 0.0351 | 27.91 | 3600 | 0.3953 | 0.2663 |
| 0.0351 | 28.68 | 3700 | 0.4044 | 0.2650 |
| 0.0351 | 29.46 | 3800 | 0.3969 | 0.2646 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
ayameRushia/wav2vec2-large-xls-r-300m-ia
|
ayameRushia
| 2022-08-31T04:43:14Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"mozilla-foundation/common_voice_8_0",
"ia",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- ia
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: wav2vec2-large-xls-r-300m-ia
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: ia
metrics:
- name: Test WER using LM
type: wer
value: 8.6074
- name: Test CER using LM
type: cer
value: 2.4147
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-ia
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1452
- Wer: 0.1253
## Training Procedure
Training is conducted in Google Colab, the training notebook provided in the repo
## Training and evaluation data
Language Model Created from texts from processed sentence in train + validation split of dataset (common voice 8.0 for Interlingua)
Evaluation is conducted in Notebook, you can see within the repo "notebook_evaluation_wav2vec2_ia.ipynb"
Test WER without LM
wer = 20.1776 %
cer = 4.7205 %
Test WER using
wer = 8.6074 %
cer = 2.4147 %
evaluation using eval.py
```
huggingface-cli login #login to huggingface for getting auth token to access the common voice v8
#running with LM
python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-ia --dataset mozilla-foundation/common_voice_8_0 --config ia --split test
# running without LM
python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-ia --dataset mozilla-foundation/common_voice_8_0 --config ia --split test --greedy
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 7.432 | 1.87 | 400 | 2.9636 | 1.0 |
| 2.6922 | 3.74 | 800 | 2.2111 | 0.9977 |
| 1.2581 | 5.61 | 1200 | 0.4864 | 0.4028 |
| 0.6232 | 7.48 | 1600 | 0.2807 | 0.2413 |
| 0.4479 | 9.35 | 2000 | 0.2219 | 0.1885 |
| 0.3654 | 11.21 | 2400 | 0.1886 | 0.1606 |
| 0.323 | 13.08 | 2800 | 0.1716 | 0.1444 |
| 0.2935 | 14.95 | 3200 | 0.1687 | 0.1443 |
| 0.2707 | 16.82 | 3600 | 0.1632 | 0.1382 |
| 0.2559 | 18.69 | 4000 | 0.1507 | 0.1337 |
| 0.2433 | 20.56 | 4400 | 0.1572 | 0.1358 |
| 0.2338 | 22.43 | 4800 | 0.1489 | 0.1305 |
| 0.2258 | 24.3 | 5200 | 0.1485 | 0.1278 |
| 0.2218 | 26.17 | 5600 | 0.1470 | 0.1272 |
| 0.2169 | 28.04 | 6000 | 0.1470 | 0.1270 |
| 0.2117 | 29.91 | 6400 | 0.1452 | 0.1253 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
ayameRushia/wav2vec2-large-xls-r-300m-mn
|
ayameRushia
| 2022-08-31T04:43:06Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"mozilla-foundation/common_voice_8_0",
"mn",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- mn
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: wav2vec2-large-xls-r-300m-mn
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: mn
metrics:
- name: Test WER using LM
type: wer
value: 31.3919
- name: Test CER using LM
type: cer
value: 10.2565
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: mn
metrics:
- name: Test WER
type: wer
value: 65.26
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: mn
metrics:
- name: Test WER
type: wer
value: 63.09
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5502
- Wer: 0.4042
## Training and evaluation data
Evaluation is conducted in Notebook, you can see within the repo "notebook_evaluation_wav2vec2_mn.ipynb"
Test WER without LM
wer = 58.2171 %
cer = 16.0670 %
Test WER using
wer = 31.3919 %
cer = 10.2565 %
How to use eval.py
```
huggingface-cli login #login to huggingface for getting auth token to access the common voice v8
#running with LM
python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-mn --dataset mozilla-foundation/common_voice_8_0 --config mn --split test
# running without LM
python eval.py --model_id ayameRushia/wav2vec2-large-xls-r-300m-mn --dataset mozilla-foundation/common_voice_8_0 --config mn --split test --greedy
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 40.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 6.35 | 400 | 0.9380 | 0.7902 |
| 3.2674 | 12.7 | 800 | 0.5794 | 0.5309 |
| 0.7531 | 19.05 | 1200 | 0.5749 | 0.4815 |
| 0.5382 | 25.4 | 1600 | 0.5530 | 0.4447 |
| 0.4293 | 31.75 | 2000 | 0.5709 | 0.4237 |
| 0.4293 | 38.1 | 2400 | 0.5476 | 0.4059 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
M7un/ZL-RoBERTa-wwm
|
M7un
| 2022-08-31T04:36:58Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-08-31T04:36:33Z |
#Pre-trained-Language-Model-For-Chinese-Patent
ZL-RoBERTa-wwm: MLM with Whole Word Masking
在中文发明专利上进行训练,MLM任务使用了wwm策略
|
Pawaret717/distilbert-base-uncased-finetuned-imdb
|
Pawaret717
| 2022-08-31T04:15:16Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-31T04:04:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.12.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
reztork/first-text-app
|
reztork
| 2022-08-31T02:08:41Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-08-31T02:06:40Z |
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
|
mooface/xlm-roberta-base-finetuned-panx-de
|
mooface
| 2022-08-31T02:07:15Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-31T01:43:13Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
npc-engine/t5-base-mse-summarization
|
npc-engine
| 2022-08-31T01:50:49Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-30T20:51:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-mse-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-mse-summarization
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8743
- Rouge1: 45.9597
- Rouge2: 26.8086
- Rougel: 39.935
- Rougelsum: 43.8897
- Bleurt: -0.7132
- Gen Len: 18.464
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bleurt | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|:-------:|
| 1.2568 | 1.0 | 267 | 1.0472 | 41.6829 | 21.9654 | 35.4264 | 39.5556 | -0.8231 | 18.522 |
| 1.1085 | 2.0 | 534 | 0.9840 | 43.1479 | 23.3351 | 36.9244 | 40.886 | -0.7843 | 18.534 |
| 1.0548 | 3.0 | 801 | 0.9515 | 44.1511 | 24.4912 | 37.9549 | 41.9984 | -0.7702 | 18.528 |
| 1.0251 | 4.0 | 1068 | 0.9331 | 44.426 | 24.9439 | 38.2978 | 42.1731 | -0.7633 | 18.619 |
| 0.9888 | 5.0 | 1335 | 0.9201 | 45.0385 | 25.524 | 38.8681 | 42.8998 | -0.7497 | 18.523 |
| 0.9623 | 6.0 | 1602 | 0.9119 | 44.8648 | 25.469 | 38.9281 | 42.7798 | -0.7496 | 18.537 |
| 0.9502 | 7.0 | 1869 | 0.9015 | 44.9668 | 25.5041 | 38.9463 | 42.9368 | -0.7412 | 18.48 |
| 0.9316 | 8.0 | 2136 | 0.8973 | 45.3028 | 25.7232 | 39.1533 | 43.277 | -0.7318 | 18.523 |
| 0.9191 | 9.0 | 2403 | 0.8921 | 45.2901 | 25.916 | 39.2909 | 43.3022 | -0.7296 | 18.529 |
| 0.9122 | 10.0 | 2670 | 0.8889 | 45.3535 | 26.1369 | 39.4861 | 43.28 | -0.7271 | 18.545 |
| 0.8993 | 11.0 | 2937 | 0.8857 | 45.5345 | 26.1669 | 39.5656 | 43.4664 | -0.7269 | 18.474 |
| 0.8905 | 12.0 | 3204 | 0.8816 | 45.7796 | 26.4145 | 39.8117 | 43.734 | -0.7185 | 18.503 |
| 0.8821 | 13.0 | 3471 | 0.8794 | 45.7163 | 26.4314 | 39.719 | 43.6407 | -0.7211 | 18.496 |
| 0.8789 | 14.0 | 3738 | 0.8784 | 45.9097 | 26.7281 | 39.9071 | 43.8105 | -0.7127 | 18.452 |
| 0.8665 | 15.0 | 4005 | 0.8765 | 46.1148 | 26.8882 | 40.1006 | 43.988 | -0.711 | 18.443 |
| 0.8676 | 16.0 | 4272 | 0.8766 | 45.9119 | 26.7674 | 39.9001 | 43.8237 | -0.718 | 18.491 |
| 0.8637 | 17.0 | 4539 | 0.8758 | 45.9158 | 26.7153 | 39.9463 | 43.8323 | -0.7183 | 18.492 |
| 0.8622 | 18.0 | 4806 | 0.8752 | 45.9508 | 26.75 | 39.9533 | 43.8795 | -0.7144 | 18.465 |
| 0.8588 | 19.0 | 5073 | 0.8744 | 45.9192 | 26.7352 | 39.8921 | 43.8204 | -0.7148 | 18.462 |
| 0.8554 | 20.0 | 5340 | 0.8743 | 45.9597 | 26.8086 | 39.935 | 43.8897 | -0.7132 | 18.464 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DylanJHJ/monot5m-large-msmarco-100k
|
DylanJHJ
| 2022-08-31T01:20:45Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-27T02:09:46Z |
Check our SIGIR2021 short paper: https://dl.acm.org/doi/10.1145/3404835.3463048
This checkpoint is a variant of monot5 (T5 pointwise re-ranking model).
Specifically, we fuse the "P2Q (i.e. doc2query)" and "Rank (i.e. passage ranking)" to learn the **discriminative** view (Rank) and **geneartive** view (P2Q).
We found that under the specific **mixing ratio** of these two task, the effectiveness of passage re-ranking improves on par with monot5-3B models.
Hence, you can try to do both the task with this checkpoint by the following input format:
- P2Q: Document: *\<here is a document or a passage\>* Translate Document to Query:
- Rank: Query: *\<here is a query\>* Document: *\<here is a document or a passage\>* Relevant:
which the outputs will be like:
- P2Q: *\<relevant query of the given text\>*
- Rank: *true* or *false*
```
Note that we usually use the logit values of *true*/ *false* token from T5 reranker as our query-passage relevant scores
Note the above tokens are all case-sensitive.
```
|
abhitopia/question-answer-generation
|
abhitopia
| 2022-08-31T00:30:48Z | 89 | 7 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"question-answer-generation",
"dataset:squad",
"arxiv:1910.10683",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-30T21:54:29Z |
---
datasets:
- squad
tags:
- question-answer-generation
widget:
- text: "generate question: <hl> 42 <hl> is the answer to life, the universe and everything. </s>"
- text: "question: What is 42 context: 42 is the answer to life, the universe and everything. </s>"
license: mit
---
## T5 for multi-task QA and QG
This is multi-task [t5-base](https://arxiv.org/abs/1910.10683) model trained for question answering and answer aware question generation tasks.
For question generation the answer spans are highlighted within the text with special highlight tokens (`<hl>`) and prefixed with 'generate question: '. For QA the input is processed like this `question: question_text context: context_text </s>`
You can play with the model using the inference API. Here's how you can use it
For QG
`generate question: <hl> 42 <hl> is the answer to life, the universe and everything. </s>`
For QA
`question: What is 42 context: 42 is the answer to life, the universe and everything. </s>`
For more deatils see [this](https://github.com/patil-suraj/question_generation) repo.
|
npc-engine/t5-small-mse-summarization
|
npc-engine
| 2022-08-30T23:43:58Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-30T21:24:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-mse-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-mse-summarization
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1108
- Rouge1: 43.1145
- Rouge2: 23.2262
- Rougel: 37.218
- Rougelsum: 41.0897
- Bleurt: -0.8051
- Gen Len: 18.549
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bleurt | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|:-------:|
| 1.5207 | 1.0 | 267 | 1.2922 | 38.8738 | 19.1958 | 32.8458 | 36.9993 | -0.9061 | 18.668 |
| 1.363 | 2.0 | 534 | 1.2340 | 39.8466 | 20.0452 | 33.9101 | 37.7708 | -0.8925 | 18.657 |
| 1.3062 | 3.0 | 801 | 1.2057 | 40.5536 | 20.8249 | 34.5221 | 38.4648 | -0.8625 | 18.602 |
| 1.272 | 4.0 | 1068 | 1.1782 | 41.0078 | 21.2186 | 35.0101 | 38.9186 | -0.8595 | 18.602 |
| 1.2312 | 5.0 | 1335 | 1.1688 | 41.521 | 21.7934 | 35.704 | 39.4718 | -0.842 | 18.486 |
| 1.2052 | 6.0 | 1602 | 1.1557 | 42.1037 | 22.4291 | 36.3554 | 40.1124 | -0.8432 | 18.533 |
| 1.1842 | 7.0 | 1869 | 1.1440 | 42.4438 | 22.6456 | 36.5729 | 40.3134 | -0.8288 | 18.553 |
| 1.1643 | 8.0 | 2136 | 1.1408 | 42.245 | 22.4859 | 36.3637 | 40.2193 | -0.8284 | 18.622 |
| 1.1495 | 9.0 | 2403 | 1.1320 | 42.5362 | 22.5034 | 36.5092 | 40.4552 | -0.8211 | 18.57 |
| 1.1368 | 10.0 | 2670 | 1.1301 | 42.5159 | 22.462 | 36.4646 | 40.3968 | -0.819 | 18.538 |
| 1.1203 | 11.0 | 2937 | 1.1243 | 42.2803 | 22.5963 | 36.3454 | 40.2987 | -0.8242 | 18.522 |
| 1.1116 | 12.0 | 3204 | 1.1197 | 42.8078 | 22.8409 | 36.7344 | 40.8186 | -0.821 | 18.565 |
| 1.099 | 13.0 | 3471 | 1.1193 | 42.7423 | 22.9397 | 36.7894 | 40.7298 | -0.8125 | 18.552 |
| 1.0976 | 14.0 | 3738 | 1.1176 | 42.9002 | 23.2394 | 37.0215 | 40.9211 | -0.8156 | 18.568 |
| 1.0816 | 15.0 | 4005 | 1.1133 | 43.0007 | 23.3093 | 37.2037 | 40.9719 | -0.8059 | 18.519 |
| 1.084 | 16.0 | 4272 | 1.1146 | 42.9053 | 23.2391 | 37.0542 | 40.8826 | -0.8104 | 18.533 |
| 1.0755 | 17.0 | 4539 | 1.1124 | 43.0429 | 23.2773 | 37.1389 | 41.0755 | -0.8086 | 18.544 |
| 1.0748 | 18.0 | 4806 | 1.1121 | 43.2243 | 23.4179 | 37.2039 | 41.143 | -0.8048 | 18.548 |
| 1.072 | 19.0 | 5073 | 1.1106 | 43.1776 | 23.3061 | 37.3105 | 41.1392 | -0.8039 | 18.549 |
| 1.0671 | 20.0 | 5340 | 1.1108 | 43.1145 | 23.2262 | 37.218 | 41.0897 | -0.8051 | 18.549 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
microsoft/bloom-deepspeed-inference-int8
|
microsoft
| 2022-08-30T23:01:17Z | 7 | 28 |
transformers
|
[
"transformers",
"bloom",
"feature-extraction",
"license:bigscience-bloom-rail-1.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-08-18T18:26:43Z |
---
license: bigscience-bloom-rail-1.0
---
This is a custom INT8 version of the original [BLOOM weights](https://huggingface.co/bigscience/bloom) to make it fast to use with the [DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/) engine which uses Tensor Parallelism. In this repo the tensors are split into 8 shards to target 8 GPUs.
The full BLOOM documentation is [here](https://huggingface.co/bigscience/bloom).
To use the weights in repo, you can adapt to your needs the scripts found [here](https://github.com/bigscience-workshop/Megatron-DeepSpeed/tree/main/scripts/inference) (XXX: they are going to migrate soon to HF Transformers code base, so will need to update the link once moved).
|
Einmalumdiewelt/DistilBART_CNN_GNAD_V3
|
Einmalumdiewelt
| 2022-08-30T22:49:07Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"de",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-30T08:03:33Z |
---
language:
- de
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: DistilBART_CNN_GNAD_V3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBART_CNN_GNAD_V3
This model is a fine-tuned version of [Einmalumdiewelt/DistilBART_CNN_GNAD_V3](https://huggingface.co/Einmalumdiewelt/DistilBART_CNN_GNAD_V3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8786
- Rouge1: 27.0297
- Rouge2: 8.1224
- Rougel: 17.9777
- Rougelsum: 22.8827
- Gen Len: 90.3667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ruse40folly/distilbert-base-uncased-finetuned-emotion
|
ruse40folly
| 2022-08-30T22:15:45Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T21:58:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9235
- name: F1
type: f1
value: 0.9235310384339321
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2236
- Accuracy: 0.9235
- F1: 0.9235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8521 | 1.0 | 250 | 0.3251 | 0.9085 | 0.9063 |
| 0.2489 | 2.0 | 500 | 0.2236 | 0.9235 | 0.9235 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
RussianNLP/ruRoBERTa-large-rucola
|
RussianNLP
| 2022-08-30T20:23:10Z | 586 | 5 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T19:54:51Z |
---
language: ru
license: apache-2.0
tags:
- transformers
thumbnail: "https://github.com/RussianNLP/RuCoLA/blob/main/logo.png"
widget:
- text: "Он решил ту или иную сложную задачу."
---
This is a finetuned version of [RuRoBERTa-large](https://huggingface.co/sberbank-ai/ruRoberta-large) for the task of linguistic acceptability classification on the [RuCoLA](https://rucola-benchmark.com/) benchmark.
The hyperparameters used for finetuning are as follows:
* 5 training epochs (with early stopping based on validation MCC)
* Peak learning rate: 1e-5, linear warmup for 10% of total training time
* Weight decay: 1e-4
* Batch size: 32
* Random seed: 5
* Optimizer: [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
demo-org/tabular-playground
|
demo-org
| 2022-08-30T19:13:58Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2022-08-12T18:03:12Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
widget:
structuredData:
attribute_0:
- material_7
- material_7
- material_7
attribute_1:
- material_6
- material_5
- material_6
attribute_2:
- 6
- 6
- 6
attribute_3:
- 9
- 6
- 9
loading:
- 101.52
- 91.34
- 167.03
measurement_0:
- 9
- 10
- 11
measurement_1:
- 11
- 11
- 5
measurement_10:
- 14.926
- 15.162
- 16.398
measurement_11:
- 20.394
- 19.46
- 20.613
measurement_12:
- 11.829
- 9.114
- 11.007
measurement_13:
- 16.195
- 16.024
- 16.061
measurement_14:
- 16.517
- 17.132
- 15.18
measurement_15:
- 13.826
- 12.257
- 15.758
measurement_16:
- 14.206
- 15.094
- .nan
measurement_17:
- 723.712
- 896.835
- 893.454
measurement_2:
- 2
- 10
- 6
measurement_3:
- 17.492
- 18.114
- 18.42
measurement_4:
- 13.962
- 10.185
- 13.565
measurement_5:
- 15.716
- 18.06
- 16.916
measurement_6:
- 17.104
- 18.283
- 17.917
measurement_7:
- 12.377
- 10.957
- 10.394
measurement_8:
- 19.221
- 20.638
- 19.805
measurement_9:
- 11.613
- 11.804
- 12.012
product_code:
- E
- D
- E
---
# Model description
This is a DecisionTreeClassifier model built for Kaggle Tabular Playground Series August 2022, trained on supersoaker production failures dataset.
## Intended uses & limitations
This model is not ready to be used in production.
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-----------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| memory | |
| steps | [('transformation', ColumnTransformer(transformers=[('loading_missing_value_imputer',
SimpleImputer(), ['loading']),
('numerical_missing_value_imputer',
SimpleImputer(),
['loading', 'measurement_3', 'measurement_4',
'measurement_5', 'measurement_6',
'measurement_7', 'measurement_8',
'measurement_9', 'measurement_10',
'measurement_11', 'measurement_12',
'measurement_13', 'measurement_14',
'measurement_15', 'measurement_16',
'measurement_17']),
('attribute_0_encoder', OneHotEncoder(),
['attribute_0']),
('attribute_1_encoder', OneHotEncoder(),
['attribute_1']),
('product_code_encoder', OneHotEncoder(),
['product_code'])])), ('model', DecisionTreeClassifier(max_depth=4))] |
| verbose | False |
| transformation | ColumnTransformer(transformers=[('loading_missing_value_imputer',
SimpleImputer(), ['loading']),
('numerical_missing_value_imputer',
SimpleImputer(),
['loading', 'measurement_3', 'measurement_4',
'measurement_5', 'measurement_6',
'measurement_7', 'measurement_8',
'measurement_9', 'measurement_10',
'measurement_11', 'measurement_12',
'measurement_13', 'measurement_14',
'measurement_15', 'measurement_16',
'measurement_17']),
('attribute_0_encoder', OneHotEncoder(),
['attribute_0']),
('attribute_1_encoder', OneHotEncoder(),
['attribute_1']),
('product_code_encoder', OneHotEncoder(),
['product_code'])]) |
| model | DecisionTreeClassifier(max_depth=4) |
| transformation__n_jobs | |
| transformation__remainder | drop |
| transformation__sparse_threshold | 0.3 |
| transformation__transformer_weights | |
| transformation__transformers | [('loading_missing_value_imputer', SimpleImputer(), ['loading']), ('numerical_missing_value_imputer', SimpleImputer(), ['loading', 'measurement_3', 'measurement_4', 'measurement_5', 'measurement_6', 'measurement_7', 'measurement_8', 'measurement_9', 'measurement_10', 'measurement_11', 'measurement_12', 'measurement_13', 'measurement_14', 'measurement_15', 'measurement_16', 'measurement_17']), ('attribute_0_encoder', OneHotEncoder(), ['attribute_0']), ('attribute_1_encoder', OneHotEncoder(), ['attribute_1']), ('product_code_encoder', OneHotEncoder(), ['product_code'])] |
| transformation__verbose | False |
| transformation__verbose_feature_names_out | True |
| transformation__loading_missing_value_imputer | SimpleImputer() |
| transformation__numerical_missing_value_imputer | SimpleImputer() |
| transformation__attribute_0_encoder | OneHotEncoder() |
| transformation__attribute_1_encoder | OneHotEncoder() |
| transformation__product_code_encoder | OneHotEncoder() |
| transformation__loading_missing_value_imputer__add_indicator | False |
| transformation__loading_missing_value_imputer__copy | True |
| transformation__loading_missing_value_imputer__fill_value | |
| transformation__loading_missing_value_imputer__missing_values | nan |
| transformation__loading_missing_value_imputer__strategy | mean |
| transformation__loading_missing_value_imputer__verbose | 0 |
| transformation__numerical_missing_value_imputer__add_indicator | False |
| transformation__numerical_missing_value_imputer__copy | True |
| transformation__numerical_missing_value_imputer__fill_value | |
| transformation__numerical_missing_value_imputer__missing_values | nan |
| transformation__numerical_missing_value_imputer__strategy | mean |
| transformation__numerical_missing_value_imputer__verbose | 0 |
| transformation__attribute_0_encoder__categories | auto |
| transformation__attribute_0_encoder__drop | |
| transformation__attribute_0_encoder__dtype | <class 'numpy.float64'> |
| transformation__attribute_0_encoder__handle_unknown | error |
| transformation__attribute_0_encoder__sparse | True |
| transformation__attribute_1_encoder__categories | auto |
| transformation__attribute_1_encoder__drop | |
| transformation__attribute_1_encoder__dtype | <class 'numpy.float64'> |
| transformation__attribute_1_encoder__handle_unknown | error |
| transformation__attribute_1_encoder__sparse | True |
| transformation__product_code_encoder__categories | auto |
| transformation__product_code_encoder__drop | |
| transformation__product_code_encoder__dtype | <class 'numpy.float64'> |
| transformation__product_code_encoder__handle_unknown | error |
| transformation__product_code_encoder__sparse | True |
| model__ccp_alpha | 0.0 |
| model__class_weight | |
| model__criterion | gini |
| model__max_depth | 4 |
| model__max_features | |
| model__max_leaf_nodes | |
| model__min_impurity_decrease | 0.0 |
| model__min_samples_leaf | 1 |
| model__min_samples_split | 2 |
| model__min_weight_fraction_leaf | 0.0 |
| model__random_state | |
| model__splitter | best |
</details>
### Model Plot
The model plot is below.
<style>#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 {color: black;background-color: white;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 pre{padding: 0;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-toggleable {background-color: white;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-estimator:hover {background-color: #d4ebff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-item {z-index: 1;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-parallel-item:only-child::after {width: 0;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86 div.sk-text-repr-fallback {display: none;}</style><div id="sk-b5518c10-fd7e-49af-b124-60d3dd3d0f86" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(),['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3','measurement_4','measurement_5','measurement_6','measurement_7','measurement_8','measurement_9','measurement_10','measurement_11','measurement_12','measurement_13','measurement_14','measurement_15','measurement_16','measurement_17']),('attribute_0_encoder',OneHotEncoder(),['attribute_0']),('attribute_1_encoder',OneHotEncoder(),['attribute_1']),('product_code_encoder',OneHotEncoder(),['product_code'])])),('model', DecisionTreeClassifier(max_depth=4))])</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="48fbfeb0-e954-46f7-9a36-8dfe86284fca" type="checkbox" ><label for="48fbfeb0-e954-46f7-9a36-8dfe86284fca" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(),['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3','measurement_4','measurement_5','measurement_6','measurement_7','measurement_8','measurement_9','measurement_10','measurement_11','measurement_12','measurement_13','measurement_14','measurement_15','measurement_16','measurement_17']),('attribute_0_encoder',OneHotEncoder(),['attribute_0']),('attribute_1_encoder',OneHotEncoder(),['attribute_1']),('product_code_encoder',OneHotEncoder(),['product_code'])])),('model', DecisionTreeClassifier(max_depth=4))])</pre></div></div></div><div class="sk-serial"><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="157828b7-30d1-4b5b-b25e-971143379fff" type="checkbox" ><label for="157828b7-30d1-4b5b-b25e-971143379fff" class="sk-toggleable__label sk-toggleable__label-arrow">transformation: ColumnTransformer</label><div class="sk-toggleable__content"><pre>ColumnTransformer(transformers=[('loading_missing_value_imputer',SimpleImputer(), ['loading']),('numerical_missing_value_imputer',SimpleImputer(),['loading', 'measurement_3', 'measurement_4','measurement_5', 'measurement_6','measurement_7', 'measurement_8','measurement_9', 'measurement_10','measurement_11', 'measurement_12','measurement_13', 'measurement_14','measurement_15', 'measurement_16','measurement_17']),('attribute_0_encoder', OneHotEncoder(),['attribute_0']),('attribute_1_encoder', OneHotEncoder(),['attribute_1']),('product_code_encoder', OneHotEncoder(),['product_code'])])</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="3bde7e44-3687-4b99-a3b7-b4e87023ec85" type="checkbox" ><label for="3bde7e44-3687-4b99-a3b7-b4e87023ec85" class="sk-toggleable__label sk-toggleable__label-arrow">loading_missing_value_imputer</label><div class="sk-toggleable__content"><pre>['loading']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="ef9279cb-7d77-4ef1-aafe-26e433e2a615" type="checkbox" ><label for="ef9279cb-7d77-4ef1-aafe-26e433e2a615" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="b079e8d7-f789-4622-ad66-197193ef0061" type="checkbox" ><label for="b079e8d7-f789-4622-ad66-197193ef0061" class="sk-toggleable__label sk-toggleable__label-arrow">numerical_missing_value_imputer</label><div class="sk-toggleable__content"><pre>['loading', 'measurement_3', 'measurement_4', 'measurement_5', 'measurement_6', 'measurement_7', 'measurement_8', 'measurement_9', 'measurement_10', 'measurement_11', 'measurement_12', 'measurement_13', 'measurement_14', 'measurement_15', 'measurement_16', 'measurement_17']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="969f6026-8077-468a-b332-8ceb69bac4e9" type="checkbox" ><label for="969f6026-8077-468a-b332-8ceb69bac4e9" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="5bb6cc8f-c971-47b8-a1bc-fe8053602d5c" type="checkbox" ><label for="5bb6cc8f-c971-47b8-a1bc-fe8053602d5c" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_0_encoder</label><div class="sk-toggleable__content"><pre>['attribute_0']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="8a841657-38e1-41bb-b8f9-5ad2cc25f7d3" type="checkbox" ><label for="8a841657-38e1-41bb-b8f9-5ad2cc25f7d3" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="be08add7-98fc-40b5-a259-d462d738780a" type="checkbox" ><label for="be08add7-98fc-40b5-a259-d462d738780a" class="sk-toggleable__label sk-toggleable__label-arrow">attribute_1_encoder</label><div class="sk-toggleable__content"><pre>['attribute_1']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="cf07a6c2-b92e-40b1-9862-2c1ca3baab47" type="checkbox" ><label for="cf07a6c2-b92e-40b1-9862-2c1ca3baab47" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="244735dc-f1e1-458c-a1c6-60ef847b9cae" type="checkbox" ><label for="244735dc-f1e1-458c-a1c6-60ef847b9cae" class="sk-toggleable__label sk-toggleable__label-arrow">product_code_encoder</label><div class="sk-toggleable__content"><pre>['product_code']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="2f1a1c41-e1c4-40ce-afd9-9658030b3423" type="checkbox" ><label for="2f1a1c41-e1c4-40ce-afd9-9658030b3423" class="sk-toggleable__label sk-toggleable__label-arrow">OneHotEncoder</label><div class="sk-toggleable__content"><pre>OneHotEncoder()</pre></div></div></div></div></div></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="25044b48-b814-45f9-a75b-9ee472bdc79c" type="checkbox" ><label for="25044b48-b814-45f9-a75b-9ee472bdc79c" class="sk-toggleable__label sk-toggleable__label-arrow">DecisionTreeClassifier</label><div class="sk-toggleable__content"><pre>DecisionTreeClassifier(max_depth=4)</pre></div></div></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|----------|
| accuracy | 0.791961 |
| f1 score | 0.791961 |
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
import pickle
with open(decision-tree-playground-kaggle/model.pkl, 'rb') as file:
clf = pickle.load(file)
```
</details>
# Model Card Authors
This model card is written by following authors:
huggingface
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
# Additional Content
## Tree Plot

## Confusion Matrix

|
vendorabc/modeltest
|
vendorabc
| 2022-08-30T19:01:03Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"license:mit",
"region:us"
] |
tabular-classification
| 2022-08-30T19:00:59Z |
---
license: mit
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
widget:
structuredData:
area error:
- 30.29
- 96.05
- 48.31
compactness error:
- 0.01911
- 0.01652
- 0.01484
concave points error:
- 0.01037
- 0.0137
- 0.01093
concavity error:
- 0.02701
- 0.02269
- 0.02813
fractal dimension error:
- 0.003586
- 0.001698
- 0.002461
mean area:
- 481.9
- 1130.0
- 748.9
mean compactness:
- 0.1058
- 0.1029
- 0.1223
mean concave points:
- 0.03821
- 0.07951
- 0.08087
mean concavity:
- 0.08005
- 0.108
- 0.1466
mean fractal dimension:
- 0.06373
- 0.05461
- 0.05796
mean perimeter:
- 81.09
- 123.6
- 101.7
mean radius:
- 12.47
- 18.94
- 15.46
mean smoothness:
- 0.09965
- 0.09009
- 0.1092
mean symmetry:
- 0.1925
- 0.1582
- 0.1931
mean texture:
- 18.6
- 21.31
- 19.48
perimeter error:
- 2.497
- 5.486
- 3.094
radius error:
- 0.3961
- 0.7888
- 0.4743
smoothness error:
- 0.006953
- 0.004444
- 0.00624
symmetry error:
- 0.01782
- 0.01386
- 0.01397
texture error:
- 1.044
- 0.7975
- 0.7859
worst area:
- 677.9
- 1866.0
- 1156.0
worst compactness:
- 0.2378
- 0.2336
- 0.2394
worst concave points:
- 0.1015
- 0.1789
- 0.1514
worst concavity:
- 0.2671
- 0.2687
- 0.3791
worst fractal dimension:
- 0.0875
- 0.06589
- 0.08019
worst perimeter:
- 96.05
- 165.9
- 124.9
worst radius:
- 14.97
- 24.86
- 19.26
worst smoothness:
- 0.1426
- 0.1193
- 0.1546
worst symmetry:
- 0.3014
- 0.2551
- 0.2837
worst texture:
- 24.64
- 26.58
- 26.0
---
# Model description
This is a HistGradientBoostingClassifier model trained on breast cancer dataset. It's trained with Halving Grid Search Cross Validation, with parameter grids on max_leaf_nodes and max_depth.
## Intended uses & limitations
This model is not ready to be used in production.
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|---------------------------------|----------------------------------------------------------|
| aggressive_elimination | False |
| cv | 5 |
| error_score | nan |
| estimator__categorical_features | |
| estimator__early_stopping | auto |
| estimator__l2_regularization | 0.0 |
| estimator__learning_rate | 0.1 |
| estimator__loss | auto |
| estimator__max_bins | 255 |
| estimator__max_depth | |
| estimator__max_iter | 100 |
| estimator__max_leaf_nodes | 31 |
| estimator__min_samples_leaf | 20 |
| estimator__monotonic_cst | |
| estimator__n_iter_no_change | 10 |
| estimator__random_state | |
| estimator__scoring | loss |
| estimator__tol | 1e-07 |
| estimator__validation_fraction | 0.1 |
| estimator__verbose | 0 |
| estimator__warm_start | False |
| estimator | HistGradientBoostingClassifier() |
| factor | 3 |
| max_resources | auto |
| min_resources | exhaust |
| n_jobs | -1 |
| param_grid | {'max_leaf_nodes': [5, 10, 15], 'max_depth': [2, 5, 10]} |
| random_state | 42 |
| refit | True |
| resource | n_samples |
| return_train_score | True |
| scoring | |
| verbose | 0 |
</details>
### Model Plot
The model plot is below.
<style>#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 {color: black;background-color: white;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 pre{padding: 0;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-toggleable {background-color: white;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-estimator:hover {background-color: #d4ebff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-item {z-index: 1;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-parallel-item:only-child::after {width: 0;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04 div.sk-text-repr-fallback {display: none;}</style><div id="sk-72410a5a-f2ab-48e8-8d36-6c2ba8f6eb04" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>HalvingGridSearchCV(estimator=HistGradientBoostingClassifier(), n_jobs=-1,param_grid={'max_depth': [2, 5, 10],'max_leaf_nodes': [5, 10, 15]},random_state=42)</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="ab167486-be7e-4eb5-be01-ba21adbd7469" type="checkbox" ><label for="ab167486-be7e-4eb5-be01-ba21adbd7469" class="sk-toggleable__label sk-toggleable__label-arrow">HalvingGridSearchCV</label><div class="sk-toggleable__content"><pre>HalvingGridSearchCV(estimator=HistGradientBoostingClassifier(), n_jobs=-1,param_grid={'max_depth': [2, 5, 10],'max_leaf_nodes': [5, 10, 15]},random_state=42)</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="e9df9f06-8d9e-4379-ad72-52f461408663" type="checkbox" ><label for="e9df9f06-8d9e-4379-ad72-52f461408663" class="sk-toggleable__label sk-toggleable__label-arrow">HistGradientBoostingClassifier</label><div class="sk-toggleable__content"><pre>HistGradientBoostingClassifier()</pre></div></div></div></div></div></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|----------|
| accuracy | 0.959064 |
| f1 score | 0.959064 |
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
import pickle
with open(pkl_filename, 'rb') as file:
clf = pickle.load(file)
```
</details>
# Model Card Authors
This model card is written by following authors:
skops_user
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
bibtex
@inproceedings{...,year={2020}}
```
# Additional Content
## Confusion matrix

## Hyperparameter search results
<details>
<summary> Click to expand </summary>
| iter | n_resources | mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_max_depth | param_max_leaf_nodes | params | split0_test_score | split1_test_score | split2_test_score | split3_test_score | split4_test_score | mean_test_score | std_test_score | rank_test_score | split0_train_score | split1_train_score | split2_train_score | split3_train_score | split4_train_score | mean_train_score | std_train_score |
|--------|---------------|-----------------|----------------|-------------------|------------------|-------------------|------------------------|-----------------------------------------|---------------------|---------------------|---------------------|---------------------|---------------------|-------------------|------------------|-------------------|----------------------|----------------------|----------------------|----------------------|----------------------|--------------------|-------------------|
| 0 | 44 | 0.0498069 | 0.0107112 | 0.0121156 | 0.0061838 | 2 | 5 | {'max_depth': 2, 'max_leaf_nodes': 5} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0492636 | 0.0187271 | 0.00738611 | 0.00245441 | 2 | 10 | {'max_depth': 2, 'max_leaf_nodes': 10} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0572055 | 0.0153176 | 0.0111395 | 0.0010297 | 2 | 15 | {'max_depth': 2, 'max_leaf_nodes': 15} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0498482 | 0.0177091 | 0.00857358 | 0.00415935 | 5 | 5 | {'max_depth': 5, 'max_leaf_nodes': 5} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0500658 | 0.00992094 | 0.00998321 | 0.00527031 | 5 | 10 | {'max_depth': 5, 'max_leaf_nodes': 10} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0525903 | 0.0151616 | 0.00874681 | 0.00462998 | 5 | 15 | {'max_depth': 5, 'max_leaf_nodes': 15} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0512018 | 0.0130152 | 0.00881834 | 0.00500514 | 10 | 5 | {'max_depth': 10, 'max_leaf_nodes': 5} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.0566921 | 0.0186051 | 0.00513492 | 0.000498488 | 10 | 10 | {'max_depth': 10, 'max_leaf_nodes': 10} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 0 | 44 | 0.060587 | 0.04041 | 0.00987453 | 0.00529624 | 10 | 15 | {'max_depth': 10, 'max_leaf_nodes': 15} | 0.875 | 0.5 | 0.625 | 0.75 | 0.375 | 0.625 | 0.176777 | 5 | 0.628571 | 0.628571 | 0.628571 | 0.514286 | 0.514286 | 0.582857 | 0.0559883 |
| 1 | 132 | 0.232459 | 0.0479878 | 0.0145514 | 0.00856422 | 10 | 5 | {'max_depth': 10, 'max_leaf_nodes': 5} | 0.961538 | 0.923077 | 0.923077 | 0.961538 | 0.961538 | 0.946154 | 0.0188422 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 132 | 0.272297 | 0.0228833 | 0.011561 | 0.0068272 | 10 | 10 | {'max_depth': 10, 'max_leaf_nodes': 10} | 0.961538 | 0.923077 | 0.923077 | 0.961538 | 0.961538 | 0.946154 | 0.0188422 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 132 | 0.239161 | 0.0330412 | 0.0116591 | 0.003554 | 10 | 15 | {'max_depth': 10, 'max_leaf_nodes': 15} | 0.961538 | 0.923077 | 0.923077 | 0.961538 | 0.961538 | 0.946154 | 0.0188422 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 2 | 396 | 0.920334 | 0.18198 | 0.0166654 | 0.00776263 | 10 | 15 | {'max_depth': 10, 'max_leaf_nodes': 15} | 0.962025 | 0.911392 | 0.987342 | 0.974359 | 0.935897 | 0.954203 | 0.0273257 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
</details>
## Classification report
<details>
<summary> Click to expand </summary>
| index | precision | recall | f1-score | support |
|--------------|-------------|----------|------------|-----------|
| malignant | 0.951613 | 0.936508 | 0.944 | 63 |
| benign | 0.963303 | 0.972222 | 0.967742 | 108 |
| macro avg | 0.957458 | 0.954365 | 0.955871 | 171 |
| weighted avg | 0.958996 | 0.959064 | 0.958995 | 171 |
</details>
|
agustina/museo
|
agustina
| 2022-08-30T18:25:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-08-30T18:24:37Z |
museo de mariposis y insectos moderno, con muebles blancos yiluminados
|
epsil/Health_Psychology_Analysis
|
epsil
| 2022-08-30T17:49:10Z | 0 | 1 | null |
[
"region:us"
] | null | 2022-08-30T15:49:29Z |
### TO BE ADDED
widget:
- text: "I am going through lot of stress"
|
VioletaMG/ddpm-butterflies-128
|
VioletaMG
| 2022-08-30T17:30:39Z | 4 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-08-30T13:57:49Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/VioletaMG/ddpm-butterflies-128/tensorboard?#scalars)
|
TingChenChang/make-multilingual-en-zh-tw-20220825062338
|
TingChenChang
| 2022-08-30T17:26:18Z | 7 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-08-25T15:35:33Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 11898 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MSELoss.MSELoss`
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
yasuaki0406/distilbert-base-uncased-finetuned-emotion
|
yasuaki0406
| 2022-08-30T16:01:46Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T15:51:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9245
- name: F1
type: f1
value: 0.9244242594868723
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2123
- Accuracy: 0.9245
- F1: 0.9244
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8144 | 1.0 | 250 | 0.3129 | 0.9055 | 0.9027 |
| 0.2457 | 2.0 | 500 | 0.2123 | 0.9245 | 0.9244 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
maxpe/bertin-roberta-base-spanish_sem_eval_2018_task_1
|
maxpe
| 2022-08-30T16:01:41Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"doi:10.57967/hf/0032",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T15:53:12Z |
# BERTIN-roBERTa-base-Spanish_sem_eval_2018_task_1
This is a [BERTIN-roBERTa-base-Spanish](https://huggingface.co/bertin-project/bertin-roberta-base-spanish) model finetuned on ~3500 tweets in Spanish annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751) (also available on the [Hugging Face Dataset Hub](https://huggingface.co/datasets/sem_eval_2018_task_1)).
To quickly test it locally, use a pipeline:
```python
from transformers import pipeline
pipe = pipeline("text-classification",model="maxpe/bertin-roberta-base-spanish_sem_eval_2018_task_1")
pipe("¡Odio tener tanto estrés!",top_k=11)
```
|
maxpe/twitter-roberta-base-jun2022_sem_eval_2018_task_1
|
maxpe
| 2022-08-30T15:33:52Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"doi:10.57967/hf/0033",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T14:26:53Z |
# Twitter-roBERTa-base-jun2022_sem_eval_2018_task1
This model was trained on ~7000 tweets in English annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751) (also available on the [Hugging Face Dataset Hub](https://huggingface.co/datasets/sem_eval_2018_task_1)).
The underlying model is a RoBERTa-base model trained on 132.26M tweets until the end of June 2022. Fore more details check out the [model page](https://huggingface.co/cardiffnlp/twitter-roberta-base-jun2022).
To quickly test it locally, use a pipeline:
```python
from transformers import pipeline
pipe = pipeline("text-classification",model="maxpe/twitter-roberta-base-jun2022_sem_eval_2018_task_1")
pipe("I couldn't see any seafood for a year after I went to that restaurant that they send all the tourists to!",top_k=11)
```
|
maxpe/twitter-roberta-base_semeval18_emodetection
|
maxpe
| 2022-08-30T15:14:04Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# UPDATE: NEW AND IMPROVED MODEL AVAILABLE AT https://huggingface.co/maxpe/twitter-roberta-base-jun2022_sem_eval_2018_task_1
# Twitter-roBERTa-base_SemEval18_Emodetection
This is a Twitter-roBERTa-base model trained on ~7000 tweets in English annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751).
Run the classifier on the test set of the competition:
```python
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from torch.utils.data import DataLoader
import torch
import pandas as pd
# choose GPU when available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained("cardiffnlp/twitter-roberta-base",model_max_length=512)
# build custom model with classification layer on top and a dropout layer before
class RobertaClass(torch.nn.Module):
def __init__(self):
super(RobertaClass, self).__init__()
self.l1 = AutoModel.from_pretrained("cardiffnlp/twitter-roberta-base",return_dict=False)
self.l2 = torch.nn.Dropout(0.3)
self.l3 = torch.nn.Linear(768, 11)
def forward(self, input_ids, attention_mask):
_, output_1= self.l1(input_ids=input_ids, attention_mask=attention_mask)
output_2 = self.l2(output_1)
output = self.l3(output_2)
return output
model_name="twitter-roberta-base_semeval18_emodetection/pytorch_model.bin"
model=RobertaClass()
model.load_state_dict(torch.load(model_name,map_location=torch.device(device)))
model.eval()
# run on more than 1 GPU
model = torch.nn.DataParallel(model)
model.to(device)
twnames=['anger','anticipation','disgust','fear','joy','love','optimism','pessimism','sadness','surprise','trust']
# load from hugging face dataset hub
testset_raw = load_dataset('sem_eval_2018_task_1','subtask5.english',split='test')
# remove old columns
testset=testset_raw.remove_columns(twnames+["ID"])
# tokenize
testset_tokenized = testset.map(lambda e: tokenizer(e['Tweet'], truncation=True, padding='max_length'), batched=True)
testset_tokenized=testset_tokenized.remove_columns("Tweet")
testset_tokenized.set_format(type='torch', columns=['input_ids', 'attention_mask'])
outfile="predicted_2018-E-c-En-test-gold.txt"
MAX_LEN = 512
VALID_BATCH_SIZE = 8
# set batch size according to available RAM
# VALID_BATCH_SIZE = 1000
# set num_workers for parallel processing
inference_params = {'batch_size': VALID_BATCH_SIZE,
'shuffle': False,
# 'num_workers': 1
}
inference_loader = DataLoader(testset_tokenized, **inference_params)
open(outfile,"w").close()
with torch.no_grad():
# change lines for progress manager
# for _, data in tqdm(enumerate(inference_loader, 0),total=len(inference_loader)):
for _, data in enumerate(inference_loader, 0):
outputs = model(input_ids=data['input_ids'],attention_mask=data['attention_mask'])
fin_outputs=torch.sigmoid(outputs).cpu().detach().numpy().tolist()
pd.DataFrame(fin_outputs).to_csv(outfile,index=False,header=False,sep="\t",mode='a')
# # dataset from file (one text per line)
# from datasets import Dataset
# with open(linesoftextfile,"rb") as textfile:
# textdict={"text":[x.decode().rstrip("\n") for x in textfile.readlines()]}
# inference_dataset=Dataset.from_dict(textdict)
# del(textdict)
```
|
Gozdi/Electra-base-squad-adversarialqa-epoch-1
|
Gozdi
| 2022-08-30T14:25:36Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"electra",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-30T14:19:36Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Electra-base-squad-adversarialqa-epoch-1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Electra-base-squad-adversarialqa-epoch-1
This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.4884
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 43062, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1104, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 1.4884 | 0 |
### Framework versions
- Transformers 4.21.2
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
igpaub/q-FrozenLake-v1-8x8
|
igpaub
| 2022-08-30T14:03:55Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-30T12:58:49Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.35 +/- 0.48
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="igpaub/q-FrozenLake-v1-8x8", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
jcmc/reinforce-Pixelcopter
|
jcmc
| 2022-08-30T12:36:49Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-30T12:07:22Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: reinforce-Pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 8.80 +/- 7.30
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
huggingbase/xlm-roberta-base-finetuned-panx-all
|
huggingbase
| 2022-08-30T12:29:00Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-30T11:59:48Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1745
- F1: 0.8505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3055 | 1.0 | 835 | 0.1842 | 0.8099 |
| 0.1561 | 2.0 | 1670 | 0.1711 | 0.8452 |
| 0.1016 | 3.0 | 2505 | 0.1745 | 0.8505 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Shivus/testpyramidsrnd
|
Shivus
| 2022-08-30T11:45:00Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-08-30T11:44:55Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: Shivus/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
huggingbase/xlm-roberta-base-finetuned-panx-it
|
huggingbase
| 2022-08-30T11:42:25Z | 126 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-30T11:24:40Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8124233755619126
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2630
- F1: 0.8124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8193 | 1.0 | 70 | 0.3200 | 0.7356 |
| 0.2773 | 2.0 | 140 | 0.2841 | 0.7882 |
| 0.1807 | 3.0 | 210 | 0.2630 | 0.8124 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
huggingbase/xlm-roberta-base-finetuned-panx-fr
|
huggingbase
| 2022-08-30T11:24:25Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-30T11:05:10Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-fr
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.fr
metrics:
- name: F1
type: f1
value: 0.8346456692913387
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2763
- F1: 0.8346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5779 | 1.0 | 191 | 0.3701 | 0.7701 |
| 0.2735 | 2.0 | 382 | 0.2908 | 0.8254 |
| 0.1769 | 3.0 | 573 | 0.2763 | 0.8346 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Conrad747/lg-en-v2
|
Conrad747
| 2022-08-30T10:06:19Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-30T09:47:44Z |
---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: lg-en-test-version
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lg-en-test-version
This model is a fine-tuned version of [AI-Lab-Makerere/lg_en](https://huggingface.co/AI-Lab-Makerere/lg_en) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5803
- Bleu: 31.3111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9.687717341785184e-05
- train_batch_size: 15
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 24 | 1.0100 | 28.5722 |
| No log | 2.0 | 48 | 0.7758 | 27.7506 |
| No log | 3.0 | 72 | 0.6459 | 40.3866 |
| No log | 4.0 | 96 | 0.5803 | 31.3111 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
HIT-TMG/GlyphBERT
|
HIT-TMG
| 2022-08-30T07:15:12Z | 7 | 5 |
transformers
|
[
"transformers",
"bert",
"fill-mask",
"bert-base-chinese",
"zh",
"license:afl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-24T03:05:34Z |
---
language:
- zh
tags:
- bert-base-chinese
license: afl-3.0
---
This project page is about the pytorch code implementation of GlyphBERT by the HITsz-TMG research group.

GlyphBERT is a Chinese pre-training model that includes Chinese character glyph features.It renders the input characters into images and designs them in the form of multi-channel location feature maps, and designs a two-layer residual convolutional neural network module to extract the image features of the characters for training.
The experimental results show that the performance of the pre-training model can be well improved by fusing the features of Chinese glyphs. GlyphBERT is much better than BERT in multiple downstream tasks, and has strong transferability.
For more details about using it, you can check the [github repo](https://github.com/HITsz-TMG/GlyphBERT)
|
philschmid/custom-handler-distilbert
|
philschmid
| 2022-08-30T06:58:57Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T06:52:47Z |
---
pipeline_tag: text-classification
---
|
cynthiachan/finetuned-roberta-base-10pct
|
cynthiachan
| 2022-08-30T06:49:09Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:cynthiachan/FeedRef_10pct",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-29T03:56:32Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- cynthiachan/FeedRef_10pct
model-index:
- name: training
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# training
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the cynthiachan/FeedRef_10pct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1033
- Attackid Precision: 1.0
- Attackid Recall: 1.0
- Attackid F1: 1.0
- Attackid Number: 6
- Cve Precision: 1.0
- Cve Recall: 1.0
- Cve F1: 1.0
- Cve Number: 11
- Defenderthreat Precision: 0.0
- Defenderthreat Recall: 0.0
- Defenderthreat F1: 0.0
- Defenderthreat Number: 2
- Domain Precision: 0.8636
- Domain Recall: 0.8261
- Domain F1: 0.8444
- Domain Number: 23
- Email Precision: 1.0
- Email Recall: 1.0
- Email F1: 1.0
- Email Number: 3
- Filepath Precision: 0.8108
- Filepath Recall: 0.9091
- Filepath F1: 0.8571
- Filepath Number: 165
- Hostname Precision: 0.9231
- Hostname Recall: 1.0
- Hostname F1: 0.9600
- Hostname Number: 12
- Ipv4 Precision: 0.9167
- Ipv4 Recall: 0.9167
- Ipv4 F1: 0.9167
- Ipv4 Number: 12
- Md5 Precision: 0.875
- Md5 Recall: 0.9423
- Md5 F1: 0.9074
- Md5 Number: 52
- Sha1 Precision: 0.75
- Sha1 Recall: 0.8571
- Sha1 F1: 0.8000
- Sha1 Number: 7
- Sha256 Precision: 0.8
- Sha256 Recall: 1.0
- Sha256 F1: 0.8889
- Sha256 Number: 44
- Uri Precision: 0.0
- Uri Recall: 0.0
- Uri F1: 0.0
- Uri Number: 1
- Overall Precision: 0.8383
- Overall Recall: 0.9201
- Overall F1: 0.8773
- Overall Accuracy: 0.9816
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Attackid Precision | Attackid Recall | Attackid F1 | Attackid Number | Cve Precision | Cve Recall | Cve F1 | Cve Number | Defenderthreat Precision | Defenderthreat Recall | Defenderthreat F1 | Defenderthreat Number | Domain Precision | Domain Recall | Domain F1 | Domain Number | Email Precision | Email Recall | Email F1 | Email Number | Filepath Precision | Filepath Recall | Filepath F1 | Filepath Number | Hostname Precision | Hostname Recall | Hostname F1 | Hostname Number | Ipv4 Precision | Ipv4 Recall | Ipv4 F1 | Ipv4 Number | Md5 Precision | Md5 Recall | Md5 F1 | Md5 Number | Sha1 Precision | Sha1 Recall | Sha1 F1 | Sha1 Number | Sha256 Precision | Sha256 Recall | Sha256 F1 | Sha256 Number | Uri Precision | Uri Recall | Uri F1 | Uri Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------------------:|:---------------:|:-----------:|:---------------:|:-------------:|:----------:|:------:|:----------:|:------------------------:|:---------------------:|:-----------------:|:---------------------:|:----------------:|:-------------:|:---------:|:-------------:|:---------------:|:------------:|:--------:|:------------:|:------------------:|:---------------:|:-----------:|:---------------:|:------------------:|:---------------:|:-----------:|:---------------:|:--------------:|:-----------:|:-------:|:-----------:|:-------------:|:----------:|:------:|:----------:|:--------------:|:-----------:|:-------:|:-----------:|:----------------:|:-------------:|:---------:|:-------------:|:-------------:|:----------:|:------:|:----------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.4353 | 0.37 | 500 | 0.3525 | 0.0 | 0.0 | 0.0 | 6 | 0.0 | 0.0 | 0.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.0 | 0.0 | 0.0 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.3984 | 0.6182 | 0.4846 | 165 | 0.0714 | 0.3333 | 0.1176 | 12 | 0.0 | 0.0 | 0.0 | 12 | 0.8936 | 0.8077 | 0.8485 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.4937 | 0.8864 | 0.6341 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.4156 | 0.5533 | 0.4746 | 0.9459 |
| 0.2089 | 0.75 | 1000 | 0.1812 | 0.0 | 0.0 | 0.0 | 6 | 0.9 | 0.8182 | 0.8571 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.15 | 0.2609 | 0.1905 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.6432 | 0.7758 | 0.7033 | 165 | 0.0 | 0.0 | 0.0 | 12 | 0.6471 | 0.9167 | 0.7586 | 12 | 0.7143 | 0.8654 | 0.7826 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.5286 | 0.8409 | 0.6491 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.5315 | 0.6982 | 0.6036 | 0.9626 |
| 0.1453 | 1.12 | 1500 | 0.1374 | 0.75 | 0.5 | 0.6 | 6 | 0.9167 | 1.0 | 0.9565 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.5135 | 0.8261 | 0.6333 | 23 | 0.0 | 0.0 | 0.0 | 3 | 0.6863 | 0.8485 | 0.7588 | 165 | 0.7 | 0.5833 | 0.6364 | 12 | 0.6667 | 0.6667 | 0.6667 | 12 | 0.8167 | 0.9423 | 0.8750 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.8333 | 0.9091 | 0.8696 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.7048 | 0.8195 | 0.7579 | 0.9745 |
| 0.1277 | 1.5 | 2000 | 0.1400 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.7273 | 0.6957 | 0.7111 | 23 | 0.2 | 0.3333 | 0.25 | 3 | 0.7181 | 0.8182 | 0.7649 | 165 | 0.9167 | 0.9167 | 0.9167 | 12 | 0.7857 | 0.9167 | 0.8462 | 12 | 0.8167 | 0.9423 | 0.8750 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.8302 | 1.0 | 0.9072 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.7634 | 0.8402 | 0.8000 | 0.9735 |
| 0.1074 | 1.87 | 2500 | 0.1101 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.72 | 0.7826 | 0.7500 | 23 | 0.2857 | 0.6667 | 0.4 | 3 | 0.7554 | 0.8424 | 0.7966 | 165 | 0.8571 | 1.0 | 0.9231 | 12 | 0.8182 | 0.75 | 0.7826 | 12 | 0.9259 | 0.9615 | 0.9434 | 52 | 0.0 | 0.0 | 0.0 | 7 | 0.6833 | 0.9318 | 0.7885 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.7660 | 0.8521 | 0.8067 | 0.9762 |
| 0.0758 | 2.25 | 3000 | 0.1161 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.9091 | 0.8696 | 0.8889 | 23 | 0.5 | 0.6667 | 0.5714 | 3 | 0.8251 | 0.9152 | 0.8678 | 165 | 1.0 | 1.0 | 1.0 | 12 | 1.0 | 0.6667 | 0.8 | 12 | 0.9259 | 0.9615 | 0.9434 | 52 | 1.0 | 0.5714 | 0.7273 | 7 | 0.8958 | 0.9773 | 0.9348 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.8722 | 0.9083 | 0.8899 | 0.9814 |
| 0.064 | 2.62 | 3500 | 0.1275 | 1.0 | 1.0 | 1.0 | 6 | 0.8333 | 0.9091 | 0.8696 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.8947 | 0.7391 | 0.8095 | 23 | 1.0 | 1.0 | 1.0 | 3 | 0.8418 | 0.9030 | 0.8713 | 165 | 0.8571 | 1.0 | 0.9231 | 12 | 1.0 | 0.75 | 0.8571 | 12 | 0.9245 | 0.9423 | 0.9333 | 52 | 0.6667 | 0.5714 | 0.6154 | 7 | 0.8113 | 0.9773 | 0.8866 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.8580 | 0.8935 | 0.8754 | 0.9793 |
| 0.0522 | 3.0 | 4000 | 0.1033 | 1.0 | 1.0 | 1.0 | 6 | 1.0 | 1.0 | 1.0 | 11 | 0.0 | 0.0 | 0.0 | 2 | 0.8636 | 0.8261 | 0.8444 | 23 | 1.0 | 1.0 | 1.0 | 3 | 0.8108 | 0.9091 | 0.8571 | 165 | 0.9231 | 1.0 | 0.9600 | 12 | 0.9167 | 0.9167 | 0.9167 | 12 | 0.875 | 0.9423 | 0.9074 | 52 | 0.75 | 0.8571 | 0.8000 | 7 | 0.8 | 1.0 | 0.8889 | 44 | 0.0 | 0.0 | 0.0 | 1 | 0.8383 | 0.9201 | 0.8773 | 0.9816 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
philschmid/custom-pipeline-text-classification
|
philschmid
| 2022-08-30T06:43:39Z | 0 | 1 |
generic
|
[
"generic",
"text-classification",
"region:us"
] |
text-classification
| 2022-07-18T12:21:29Z |
---
tags:
- text-classification
library_name: generic
---
# Text Classification repository template
This is a template repository for Text Classification to support generic inference with Hugging Face Hub generic Inference API. There are two required steps:
1. Specify the requirements by defining a `requirements.txt` file.
2. Implement the `pipeline.py` `__init__` and `__call__` methods. These methods are called by the Inference API. The `__init__` method should load the model and preload all the elements needed for inference (model, processors, tokenizers, etc.). This is only called once. The `__call__` method performs the actual inference. Make sure to follow the same input/output specifications defined in the template for the pipeline to work.
## How to start
First create a repo in https://hf.co/new.
Then clone this template and push it to your repo.
```
git clone https://huggingface.co/templates/text-classification
cd text-classification
git remote set-url origin https://huggingface.co/$YOUR_USER/$YOUR_REPO_NAME
git push --force
```
|
hasibzunair/melanet
|
hasibzunair
| 2022-08-30T03:00:32Z | 0 | 1 |
keras
|
[
"keras",
"vision",
"image-classification",
"arxiv:2004.06824",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2022-08-29T22:48:30Z |
---
license: apache-2.0
library_name: keras
tags:
- vision
- image-classification
---
# Intro
This is the model for our paper ["Melanoma Detection using Adversarial Training and Deep Transfer Learning"](https://arxiv.org/abs/2004.06824). Code is available [here](https://github.com/hasibzunair/adversarial-lesions).
## Model description
The model is trained on the ISIC 2016 Task 3 dataset. The architecture and algorithm is described in this [paper](https://arxiv.org/abs/2004.06824).
## Intended uses & limitations
You can use the raw model for melanoma detection from skin lesion images.
## How to use
See Spaces [demo](https://huggingface.co/spaces/hasibzunair/melanoma-detection-demo). For more code examples, we refer to this [GitHub](https://github.com/hasibzunair/adversarial-lesions#deploy) deploy section.
## Limitations and bias
The model is trained on a specific dataset with just over a thousand samples. It may or may not work for other kinds of skin lesion images. Further, there is no out-of-distribution detection method to filter out non skin lesion images. If you give an image of a dog, the model will still classify it as benign for malignant!
## Training data
See [dataset details](https://github.com/hasibzunair/adversarial-lesions#preparing-training-and-test-datasets).
## Training procedure
See [training details](https://github.com/hasibzunair/adversarial-lesions#training-both-stages).
## Evaluation results
For results in benchmarks, we refer to Figures 5, 6 and Table 1 of the original paper [here](https://arxiv.org/abs/2004.06824).
## Citation
```bibtex
@article{zunair2020melanoma,
title={Melanoma detection using adversarial training and deep transfer learning},
author={Zunair, Hasib and Hamza, A Ben},
journal={Physics in Medicine \& Biology},
year={2020},
publisher={IOP Publishing}
}
```
|
jaynlp/t5-large-samsum
|
jaynlp
| 2022-08-30T02:47:51Z | 5 | 2 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"arxiv:2203.01552",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
We pre-trained `t5-large` on SAMSum Dialogue Summarization corpus.
If you use this work for your research, please cite our work [Dialogue Summaries as Dialogue States ({DS}2), Template-Guided Summarization for Few-shot Dialogue State Tracking](https://arxiv.org/abs/2203.01552)
### Citation
```
@inproceedings{shin-etal-2022-dialogue,
title = "Dialogue Summaries as Dialogue States ({DS}2), Template-Guided Summarization for Few-shot Dialogue State Tracking",
author = "Shin, Jamin and
Yu, Hangyeol and
Moon, Hyeongdon and
Madotto, Andrea and
Park, Juneyoung",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2022",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-acl.302",
pages = "3824--3846",
abstract = "Annotating task-oriented dialogues is notorious for the expensive and difficult data collection process. Few-shot dialogue state tracking (DST) is a realistic solution to this problem. In this paper, we hypothesize that dialogue summaries are essentially unstructured dialogue states; hence, we propose to reformulate dialogue state tracking as a dialogue summarization problem. To elaborate, we train a text-to-text language model with synthetic template-based dialogue summaries, generated by a set of rules from the dialogue states. Then, the dialogue states can be recovered by inversely applying the summary generation rules. We empirically show that our method DS2 outperforms previous works on few-shot DST in MultiWoZ 2.0 and 2.1, in both cross-domain and multi-domain settings. Our method also exhibits vast speedup during both training and inference as it can generate all states at once.Finally, based on our analysis, we discover that the naturalness of the summary templates plays a key role for successful training.",
}
```
We used the following prompt for training
```
Summarize this dialogue:
<DIALOGUE>
...
```
|
jaynlp/t5-large-transferqa
|
jaynlp
| 2022-08-30T02:47:11Z | 103 | 1 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"arxiv:2109.04655",
"arxiv:2203.01552",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
We reproduced the [TransferQA paper's](https://arxiv.org/abs/2109.04655) QA pre-trained weights.
If you use this work for your research, please cite our work [Dialogue Summaries as Dialogue States ({DS}2), Template-Guided Summarization for Few-shot Dialogue State Tracking](https://arxiv.org/abs/2203.01552)
### Citation
```
@inproceedings{shin-etal-2022-dialogue,
title = "Dialogue Summaries as Dialogue States ({DS}2), Template-Guided Summarization for Few-shot Dialogue State Tracking",
author = "Shin, Jamin and
Yu, Hangyeol and
Moon, Hyeongdon and
Madotto, Andrea and
Park, Juneyoung",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2022",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.findings-acl.302",
pages = "3824--3846",
abstract = "Annotating task-oriented dialogues is notorious for the expensive and difficult data collection process. Few-shot dialogue state tracking (DST) is a realistic solution to this problem. In this paper, we hypothesize that dialogue summaries are essentially unstructured dialogue states; hence, we propose to reformulate dialogue state tracking as a dialogue summarization problem. To elaborate, we train a text-to-text language model with synthetic template-based dialogue summaries, generated by a set of rules from the dialogue states. Then, the dialogue states can be recovered by inversely applying the summary generation rules. We empirically show that our method DS2 outperforms previous works on few-shot DST in MultiWoZ 2.0 and 2.1, in both cross-domain and multi-domain settings. Our method also exhibits vast speedup during both training and inference as it can generate all states at once.Finally, based on our analysis, we discover that the naturalness of the summary templates plays a key role for successful training.",
}
```
|
JAlexis/modelv2
|
JAlexis
| 2022-08-30T02:38:24Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-30T02:20:27Z |
---
widget:
- text: "How can I protect myself against covid-19?"
context: "Preventative measures consist of recommendations to wear a mask in public, maintain social distancing of at least six feet, wash hands regularly, and use hand sanitizer. To facilitate this aim, we adapt the conceptual model and measures of Liao et al. "
- text: "What are the risk factors for covid-19?"
context: "To identify risk factors for hospital deaths from COVID-19, the OpenSAFELY platform examined electronic health records from 17.4 million UK adults. The authors used multivariable Cox proportional hazards model to identify the association of risk of death with older age, lower socio-economic status, being male, non-white ethnic background and certain clinical conditions (diabetes, obesity, cancer, respiratory diseases, heart, kidney, liver, neurological and autoimmune conditions). Notably, asthma was identified as a risk factor, despite prior suggestion of a potential protective role. Interestingly, higher risks due to ethnicity or lower socio-economic status could not be completely attributed to pre-existing health conditions."
---
|
freeagh/q-FrozenLake-v1-4x4-noSlippery
|
freeagh
| 2022-08-30T02:32:11Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-30T02:32:05Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="freeagh/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Sandeepanie/clinical-finetunedNew
|
Sandeepanie
| 2022-08-30T01:41:17Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-30T01:18:21Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: clinical-finetunedNew
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinical-finetunedNew
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0423
- Accuracy: 0.84
- Precision: 0.8562
- Recall: 0.9191
- F1: 0.8865
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.0707 | 1.0 | 50 | 0.9997 | 0.86 | 0.86 | 0.9485 | 0.9021 |
| 0.0593 | 2.0 | 100 | 0.9293 | 0.845 | 0.8777 | 0.8971 | 0.8873 |
| 0.0273 | 3.0 | 150 | 0.9836 | 0.83 | 0.8643 | 0.8897 | 0.8768 |
| 0.039 | 4.0 | 200 | 1.0028 | 0.85 | 0.8732 | 0.9118 | 0.8921 |
| 0.0121 | 5.0 | 250 | 1.0423 | 0.84 | 0.8562 | 0.9191 | 0.8865 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
dvalbuena1/Reinforce-Pong
|
dvalbuena1
| 2022-08-30T01:35:00Z | 0 | 0 | null |
[
"Pong-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-30T01:34:06Z |
---
tags:
- Pong-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pong
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pong-PLE-v0
type: Pong-PLE-v0
metrics:
- type: mean_reward
value: -16.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pong-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pong-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
Einmalumdiewelt/DistilBART_CNN_GNAD_V2
|
Einmalumdiewelt
| 2022-08-29T23:21:34Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"de",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-29T15:01:52Z |
---
language:
- de
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: DistilBART_CNN_GNAD_V2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBART_CNN_GNAD_V2
This model is a fine-tuned version of [Einmalumdiewelt/DistilBART_CNN_GNAD_V2](https://huggingface.co/Einmalumdiewelt/DistilBART_CNN_GNAD_V2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7281
- Rouge1: 27.7253
- Rouge2: 8.4647
- Rougel: 18.2059
- Rougelsum: 23.238
- Gen Len: 91.6827
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.