
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-13 06:30:42
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 556
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-13 06:27:56
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
hoshingakag/autotrain-emotion-detection-1587956110
|
hoshingakag
| 2022-09-28T15:53:01Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"en",
"dataset:hoshingakag/autotrain-data-emotion-detection",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-28T15:51:45Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- hoshingakag/autotrain-data-emotion-detection
co2_eq_emissions:
emissions: 2.3491292126039087
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1587956110
- CO2 Emissions (in grams): 2.3491
## Validation Metrics
- Loss: 0.448
- Accuracy: 0.888
- Macro F1: 0.823
- Micro F1: 0.888
- Weighted F1: 0.884
- Macro Precision: 0.885
- Micro Precision: 0.888
- Weighted Precision: 0.890
- Macro Recall: 0.800
- Micro Recall: 0.888
- Weighted Recall: 0.888
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/hoshingakag/autotrain-emotion-detection-1587956110
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("hoshingakag/autotrain-emotion-detection-1587956110", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("hoshingakag/autotrain-emotion-detection-1587956110", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
bggmyfuture-ai/autotrain-sphere-intent-classification-1584456046
|
bggmyfuture-ai
| 2022-09-28T15:35:06Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"text-classification",
"unk",
"dataset:bggmyfuture-ai/autotrain-data-sphere-intent-classification",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-28T15:34:05Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- bggmyfuture-ai/autotrain-data-sphere-intent-classification
co2_eq_emissions:
emissions: 1.893124351907886
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1584456046
- CO2 Emissions (in grams): 1.8931
## Validation Metrics
- Loss: 0.690
- Accuracy: 0.744
- Macro F1: 0.678
- Micro F1: 0.744
- Weighted F1: 0.739
- Macro Precision: 0.697
- Micro Precision: 0.744
- Weighted Precision: 0.738
- Macro Recall: 0.669
- Micro Recall: 0.744
- Weighted Recall: 0.744
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/bggmyfuture-ai/autotrain-sphere-intent-classification-1584456046
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bggmyfuture-ai/autotrain-sphere-intent-classification-1584456046", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("bggmyfuture-ai/autotrain-sphere-intent-classification-1584456046", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Armandoliv/es_pipeline
|
Armandoliv
| 2022-09-28T14:44:01Z | 3 | 0 |
spacy
|
[
"spacy",
"token-classification",
"es",
"model-index",
"region:us"
] |
token-classification
| 2022-09-28T14:43:08Z |
---
tags:
- spacy
- token-classification
language:
- es
model-index:
- name: es_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8450473416
- name: NER Recall
type: recall
value: 0.8476402688
- name: NER F Score
type: f_score
value: 0.8463418192
---
|
jonghyunlee/DrugLikeMoleculeBERT
|
jonghyunlee
| 2022-09-28T14:34:50Z | 102 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:1908.06760",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-09-28T14:03:53Z |
# Model description
This model is BERT-based architecture with 8 layers. The detailed config is summarized as follows. The drug-like molecule BERT is inspired by ["Self-Attention Based Molecule Representation for Predicting Drug-Target Interaction"](https://arxiv.org/abs/1908.06760). We modified several points of training procedures.
```
config = BertConfig(
vocab_size=vocab_size,
hidden_size=128,
num_hidden_layers=8,
num_attention_heads=8,
intermediate_size=512,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=max_seq_len + 2,
type_vocab_size=1,
pad_token_id=0,
position_embedding_type="absolute"
)
```
# Training and evaluation data
It's trained on drug-like molecules on the PubChem database. The PubChem database contains more than 100 M molecules, therefore, we filtered drug-like molecules using the quality of drug-likeliness score (QED). The 4.1 M molecules were filtered and the QED score threshold was set to 0.7.
# Tokenizer
We utilize a character-level tokenizer. The special tokens are "[SOS]", "[EOS]", "[PAD]", "[UNK]".
# Training hyperparameters
The following hyperparameters were used during training:
- Adam optimizer, learning_rate: 5e-4, scheduler: cosine annealing
- Batch size: 2048
- Training steps: 24 K
- Training_precision: FP16
- Loss function: cross-entropy loss
- Training masking rate: 30 %
- Testing masking rate: 15 % (original molecule BERT utilized 15 % of masking rate)
- NSP task: None
# Performance
- Accuracy: 94.02 %
|
alpineai/cosql
|
alpineai
| 2022-09-28T14:09:33Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:cosql",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T18:14:50Z |
---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "And the concert named Auditions? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : sing er_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name ( Super bootcamp, Auditions ), theme, stadium_id, year | singer_in_concert : concert_id, singer_id || Which year did the concert Super bootcamp happen in? | Find the name and location of the stadiums which some concerts happened in the years of both 2014 and 2015."
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- cosql
- spider
metrics:
- cosql
---
## tscholak/2e826ioa
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [T5-3B](https://huggingface.co/t5-3b).
### Training Data
The model has been fine-tuned on the 2,164 training dialogues in the [CoSQL SQL-grounded dialogue state tracking dataset](https://yale-lily.github.io/cosql) and the 7,000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves both, CoSQL's zero-shot text-to-SQL dialogue state tracking task and Spider's zero-shot text-to-SQL translation task. Zero-shot means that the model can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [T5-3B](https://huggingface.co/t5-3b) and fine-tuned with the text-to-text generation objective.
A question is always grounded in both, a database schema and the preceiding questions in the dialogue. The model is trained to predict the SQL query that would be used to answer the user's current natural language question. The input to the model is composed of the user's current question, the database identifier, a list of tables and their columns, and a sequence of previous questions in reverse chronological order.
```
[current question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ... || [previous question] | ... | [first question]
```
The sequence of previous questions is separated by `||` from the linearized schema. In the absence of previous questions (for example, for the first question in a dialogue or for Spider questions), this separator is omitted.
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's current question in the dialog.
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 53.8 % question match accuracy and 21.8 % interaction match accuracy on the CoSQL development set. On the CoSQL test set, the model achieves 51.4 % question match accuracy and 21.7 % interaction match accuracy.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **56.9 %** question match accuracy and **24.2 %** interaction match accuracy on the CoSQL development set. On the CoSQL test set and with PICARD, the model achieves **54.6 %** question match accuracy and **23.7 %** interaction match accuracy.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
```
|
Conrad747/lg-en-v4
|
Conrad747
| 2022-09-28T13:36:04Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T11:31:47Z |
---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: lg-en-v4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lg-en-v4
This model is a fine-tuned version of [AI-Lab-Makerere/lg_en](https://huggingface.co/AI-Lab-Makerere/lg_en) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1615
- Bleu: 28.3855
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.4271483249908667e-05
- train_batch_size: 14
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 1.0 | 26 | 1.2704 | 25.9847 |
| No log | 2.0 | 52 | 1.1615 | 28.3855 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Linksonder/RoBERTje-finetuned
|
Linksonder
| 2022-09-28T12:13:46Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"roberta",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-28T09:32:01Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Linksonder/RoBERTje-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Linksonder/RoBERTje-finetuned
This model is a fine-tuned version of [DTAI-KULeuven/robbertje-1-gb-shuffled](https://huggingface.co/DTAI-KULeuven/robbertje-1-gb-shuffled) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 16.5695
- Validation Loss: 17.2618
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -992, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 16.5695 | 17.2618 | 0 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
TextCortex/codegen-350M-optimized
|
TextCortex
| 2022-09-28T10:04:35Z | 5 | 1 |
transformers
|
[
"transformers",
"onnx",
"text-generation",
"license:bsd-3-clause",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-26T17:00:02Z |
---
license: bsd-3-clause
---
# CodeGen (CodeGen-Mono 350M)
Clone of [Salesforce/codegen-350M-mono](https://huggingface.co/Salesforce/codegen-350M-mono) converted to ONNX and optimized.
## Usage
```python
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForCausalLM
model = ORTModelForCausalLM.from_pretrained("TextCortex/codegen-350M-optimized")
tokenizer = AutoTokenizer.from_pretrained("TextCortex/codegen-350M-optimized")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(
input_ids,
max_length=64,
temperature=0.1,
num_return_sequences=1,
early_stopping=True,
)
out = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(out)
```
Refer to the original model for more details.
|
Linksonder/tutorial-finetuned-imdb
|
Linksonder
| 2022-09-28T08:54:35Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-27T14:50:55Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Linksonder/tutorial-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Linksonder/tutorial-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 5.1648
- Validation Loss: 4.7466
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -998, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 5.1648 | 4.7466 | 0 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sd-concepts-library/kawaii-girl-plus-style-v1-1
|
sd-concepts-library
| 2022-09-28T08:34:03Z | 0 | 9 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-28T08:33:56Z |
---
license: mit
---
### kawaii_girl_plus_style_v1.1 on Stable Diffusion
This is the `<kawaii>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






































|
dvilasuero/setfit-mini-imdb
|
dvilasuero
| 2022-09-28T07:58:37Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-09-28T07:58:29Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 40 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 40,
"warmup_steps": 4,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
jack-berry4/Chairman-Model-1
|
jack-berry4
| 2022-09-28T06:42:59Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-09-28T06:42:59Z |
---
license: creativeml-openrail-m
---
|
Zengwei/icefall-asr-librispeech-lstm-transducer-stateless3-2022-09-28
|
Zengwei
| 2022-09-28T06:10:47Z | 0 | 1 | null |
[
"tensorboard",
"region:us"
] | null | 2022-09-28T04:34:44Z |
See <https://github.com/k2-fsa/icefall/pull/564>
|
bongsoo/moco-sentencedistilbertV2.1
|
bongsoo
| 2022-09-28T05:09:33Z | 114 | 2 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"ko",
"en",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-09-23T05:42:57Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- ko
- en
widget:
source_sentence: "대한민국의 수도는?"
sentences:
- "서울특별시는 한국이 정치,경제,문화 중심 도시이다."
- "부산은 대한민국의 제2의 도시이자 최대의 해양 물류 도시이다."
- "제주도는 대한민국에서 유명한 관광지이다"
- "Seoul is the capital of Korea"
- "울산광역시는 대한민국 남동부 해안에 있는 광역시이다"
---
# moco-sentencedistilbertV2.1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
- 이 모델은 [bongsoo/mdistilbertV2.1](https://huggingface.co/bongsoo/mdistilbertV2.1) MLM 모델을
<br>sentencebert로 만든 후,추가적으로 STS Tearch-student 증류 학습 시켜 만든 모델 입니다.
- **vocab: 152,537 개**(기존 119,548 vocab 에 32,989 신규 vocab 추가)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence_transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["서울은 한국이 수도이다", "The capital of Korea is Seoul"]
model = SentenceTransformer('bongsoo/moco-sentencedistilbertV2.1')
embeddings = model.encode(sentences)
print(embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(embeddings[0].reshape(1,-1), embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
[[ 0.27124503 -0.5836643 0.00736023 ... -0.0038319 0.01802095 -0.09652182]
[ 0.2765149 -0.5754248 0.00788184 ... 0.07659392 -0.07825544 -0.06120609]]
*cosine_score:0.9513546228408813
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```
pip install transformers[torch]
```
- 평균 폴링(mean_pooling) 방식 사용. ([cls 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-cls-token), [max 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-max-tokens))
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["서울은 한국이 수도이다", "The capital of Korea is Seoul"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bongsoo/moco-sentencedistilbertV2.1')
model = AutoModel.from_pretrained('bongsoo/moco-sentencedistilbertV2.1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(sentence_embeddings[0].reshape(1,-1), sentence_embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
Sentence embeddings:
tensor([[ 0.2712, -0.5837, 0.0074, ..., -0.0038, 0.0180, -0.0965],
[ 0.2765, -0.5754, 0.0079, ..., 0.0766, -0.0783, -0.0612]])
*cosine_score:0.9513546228408813
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
- 성능 측정을 위한 말뭉치는, 아래 한국어 (kor), 영어(en) 평가 말뭉치를 이용함
<br> 한국어 : **korsts(1,379쌍문장)** 와 **klue-sts(519쌍문장)**
<br> 영어 : [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt)(1,376쌍문장) 와 [glue:stsb](https://huggingface.co/datasets/glue/viewer/stsb/validation) (1,500쌍문장)
- 성능 지표는 **cosin.spearman/max**(cosine,eculidean,manhatten,doc중 max값)
- 평가 측정 코드는 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-test.ipynb) 참조
|모델 |korsts|klue-sts|glue(stsb)|stsb_multi_mt(en)|
|:--------|------:|--------:|--------------:|------------:|
|distiluse-base-multilingual-cased-v2 |0.7475/0.7556 |0.7855/0.7862 |0.8193 |0.8075/0.8168|
|paraphrase-multilingual-mpnet-base-v2 |0.8201 |0.7993 |**0.8907/0.8919**|**0.8682** |
|bongsoo/sentencedistilbertV1.2 |0.8198/0.8202 |0.8584/0.8608 |0.8739/0.8740 |0.8377/0.8388|
|bongsoo/moco-sentencedistilbertV2.0 |0.8124/0.8128 |0.8470/0.8515 |0.8773/0.8778 |0.8371/0.8388|
|bongsoo/moco-sentencebertV2.0 |0.8244/0.8277 |0.8411/0.8478 |0.8792/0.8796 |0.8436/0.8456|
|**bongsoo/moco-sentencedistilbertV2.1**|**0.8390/0.8398**|**0.8767/0.8808**|0.8805/0.8816 |0.8548 |
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training(훈련 과정)
The model was trained with the parameters:
**1. MLM 훈련**
- 입력 모델 : distilbert-base-multilingual-cased
- 말뭉치 : 훈련 : bongsoo/moco-corpus-kowiki2022(7.6M) , 평가: bongsoo/bongevalsmall
- HyperParameter : **LearningRate : 5e-5, epochs: 8, batchsize: 32, max_token_len : 128**
- vocab : 152,537개 (기존 119,548 에 32,989 신규 vocab 추가)
- 출력 모델 : mdistilbertV2.1 (size: 643MB)
- 훈련시간 : 63h/1GPU (24GB/23.9 use)
- 평가: **훈련loss: 2.203400, 평가loss: 2.972835, perplexity: 23.43**(bong_eval:1,500)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/distilbert/distilbert-MLM-Trainer-V1.2.ipynb) 참조
**2. STS 훈련**
<br>=>bert를 sentencebert로 만듬.
- 입력 모델 : mdistilbertV2.1 (size: 643MB)
- 말뭉치 : korsts(5,749) + kluestsV1.1(11,668) + stsb_multi_mt(5,749) + mteb/sickr-sts(9,927) + glue stsb(5,749) (총:38,842)
- HyperParameter : **LearningRate : 3e-5, epochs: 800, batchsize: 128, max_token_len : 256**
- 출력 모델 : sbert-mdistilbertV2.1 (size: 640MB)
- 훈련시간 : 13h/1GPU (24GB/16.1GB use)
- 평가(cosin_spearman) : **0.790**(말뭉치:korsts(tune_test.tsv))
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
**3.증류(distilation) 훈련**
- 학생 모델 : sbert-mdistilbertV2.1
- 교사 모델 : paraphrase-multilingual-mpnet-base-v2(max_token_len:128)
- 말뭉치 : news_talk_en_ko_train.tsv (영어-한국어 대화-뉴스 병렬 말뭉치 : 1.38M)
- HyperParameter : **LearningRate : 5e-5, epochs: 40, batchsize: 128, max_token_len : 128(교사모델이 128이므로 맟춰줌)**
- 출력 모델 : sbert-mdistilbertV2.1-distil
- 훈련시간 : 17h/1GPU (24GB/9GB use)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-distillaton.ipynb) 참조
**4.STS 훈련**
<br>=> sentencebert 모델을 sts 훈련시킴
- 입력 모델 : sbert-mdistilbertV2.1-distil
- 말뭉치 : korsts(5,749) + kluestsV1.1(11,668) + stsb_multi_mt(5,749) + mteb/sickr-sts(9,927) + glue stsb(5,749) (총:38,842)
- HyperParameter : **LearningRate : 3e-5, epochs: 1200, batchsize: 128, max_token_len : 256**
- 출력 모델 : moco-sentencedistilbertV2.1
- 훈련시간 : 12/1GPU (24GB/16.1GB use)
- 평가(cosin_spearman) : **0.839**(말뭉치:korsts(tune_test.tsv))
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
<br>모델 제작 과정에 대한 자세한 내용은 [여기](https://github.com/kobongsoo/BERT/tree/master)를 참조 하세요.
**Config**:
```
{
"_name_or_path": "../../data11/model/sbert/sbert-mdistilbertV2.1-distil",
"activation": "gelu",
"architectures": [
"DistilBertModel"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"output_past": true,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"torch_dtype": "float32",
"transformers_version": "4.21.2",
"vocab_size": 152537
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## tokenizer_config
```
{
"cls_token": "[CLS]",
"do_basic_tokenize": true,
"do_lower_case": false,
"mask_token": "[MASK]",
"max_len": 128,
"name_or_path": "../../data11/model/sbert/sbert-mdistilbertV2.1-distil",
"never_split": null,
"pad_token": "[PAD]",
"sep_token": "[SEP]",
"special_tokens_map_file": "../../data11/model/distilbert/mdistilbertV2.1-4/special_tokens_map.json",
"strip_accents": false,
"tokenize_chinese_chars": true,
"tokenizer_class": "DistilBertTokenizer",
"unk_token": "[UNK]"
}
```
## sentence_bert_config
```
{
"max_seq_length": 256,
"do_lower_case": false
}
```
## config_sentence_transformers
```
{
"__version__": {
"sentence_transformers": "2.2.0",
"transformers": "4.21.2",
"pytorch": "1.10.1"
}
}
```
## Citing & Authors
<!--- Describe where people can find more information -->
bongsoo
|
bongsoo/moco-sentencebertV2.0
|
bongsoo
| 2022-09-28T05:09:20Z | 4 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"ko",
"en",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-09-19T04:15:36Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- ko
- en
widget:
source_sentence: "대한민국의 수도는?"
sentences:
- "서울특별시는 한국이 정치,경제,문화 중심 도시이다."
- "부산은 대한민국의 제2의 도시이자 최대의 해양 물류 도시이다."
- "제주도는 대한민국에서 유명한 관광지이다"
- "Seoul is the capital of Korea"
- "울산광역시는 대한민국 남동부 해안에 있는 광역시이다"
---
# moco-sentencebertV2.0
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
- 이 모델은 [bongsoo/mbertV2.0](https://huggingface.co/bongsoo/mbertV2.0) MLM 모델을
<br>sentencebert로 만든 후,추가적으로 STS Tearch-student 증류 학습 시켜 만든 모델 입니다.
- **vocab: 152,537 개**(기존 119,548 vocab 에 32,989 신규 vocab 추가)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence_transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('bongsoo/moco-sentencebertV2.0')
embeddings = model.encode(sentences)
print(embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(embeddings[0].reshape(1,-1), embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
[[ 0.16649279 -0.2933038 -0.00391259 ... 0.00720964 0.18175027 -0.21052675]
[ 0.10106096 -0.11454111 -0.00378215 ... -0.009032 -0.2111504 -0.15030429]]
*cosine_score:0.3352515697479248
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
- 평균 폴링(mean_pooling) 방식 사용. ([cls 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-cls-token), [max 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-max-tokens))
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bongsoo/moco-sentencebertV2.0')
model = AutoModel.from_pretrained('bongsoo/moco-sentencebertV2.0')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(sentence_embeddings[0].reshape(1,-1), sentence_embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
Sentence embeddings:
tensor([[ 0.1665, -0.2933, -0.0039, ..., 0.0072, 0.1818, -0.2105],
[ 0.1011, -0.1145, -0.0038, ..., -0.0090, -0.2112, -0.1503]])
*cosine_score:0.3352515697479248
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
- 성능 측정을 위한 말뭉치는, 아래 한국어 (kor), 영어(en) 평가 말뭉치를 이용함
<br> 한국어 : **korsts(1,379쌍문장)** 와 **klue-sts(519쌍문장)**
<br> 영어 : [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt)(1,376쌍문장) 와 [glue:stsb](https://huggingface.co/datasets/glue/viewer/stsb/validation) (1,500쌍문장)
- 성능 지표는 **cosin.spearman** 측정하여 비교함.
- 평가 측정 코드는 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-test.ipynb) 참조
|모델 |korsts|klue-sts|korsts+klue-sts|stsb_multi_mt|glue(stsb)
|:--------|------:|--------:|--------------:|------------:|-----------:|
|distiluse-base-multilingual-cased-v2|0.747|0.785|0.577|0.807|0.819|
|paraphrase-multilingual-mpnet-base-v2|0.820|0.799|0.711|0.868|0.890|
|bongsoo/sentencedistilbertV1.2|0.819|0.858|0.630|0.837|0.873|
|bongsoo/moco-sentencedistilbertV2.0|0.812|0.847|0.627|0.837|0.877|
|bongsoo/moco-sentencebertV2.0|0.824|0.841|0.635|0.843|0.879|
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training(훈련 과정)
The model was trained with the parameters:
**1. MLM 훈련**
- 입력 모델 : bert-base-multilingual-cased
- 말뭉치 : 훈련 : bongsoo/moco-corpus-kowiki2022(7.6M) , 평가: bongsoo/bongevalsmall
- HyperParameter : LearningRate : 5e-5, epochs: 8, batchsize: 32, max_token_len : 128
- vocab : 152,537개 (기존 119,548 에 32,989 신규 vocab 추가)
- 출력 모델 : mbertV2.0 (size: 813MB)
- 훈련시간 : 90h/1GPU (24GB/19.6GB use)
- loss : 훈련loss: 2.258400, 평가loss: 3.102096, perplexity: 19.78158(bong_eval:1,500)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/bert/bert-MLM-Trainer-V1.2.ipynb) 참조
**2. STS 훈련**
=>bert를 sentencebert로 만듬.
- 입력 모델 : mbertV2.0
- 말뭉치 : korsts + kluestsV1.1 + stsb_multi_mt + mteb/sickr-sts (총:33,093)
- HyperParameter : LearningRate : 3e-5, epochs: 200, batchsize: 32, max_token_len : 128
- 출력 모델 : sbert-mbertV2.0 (size: 813MB)
- 훈련시간 : 9h20m/1GPU (24GB/9.0GB use)
- loss(cosin_spearman) : 0.799(말뭉치:korsts(tune_test.tsv))
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
**3.증류(distilation) 훈련**
- 학생 모델 : sbert-mbertV2.0
- 교사 모델 : paraphrase-multilingual-mpnet-base-v2
- 말뭉치 : en_ko_train.tsv(한국어-영어 사회과학분야 병렬 말뭉치 : 1.1M)
- HyperParameter : LearningRate : 5e-5, epochs: 40, batchsize: 128, max_token_len : 128
- 출력 모델 : sbert-mlbertV2.0-distil
- 훈련시간 : 17h/1GPU (24GB/18.6GB use)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-distillaton.ipynb) 참조
**4.STS 훈련**
=> sentencebert 모델을 sts 훈련시킴
- 입력 모델 : sbert-mlbertV2.0-distil
- 말뭉치 : korsts(5,749) + kluestsV1.1(11,668) + stsb_multi_mt(5,749) + mteb/sickr-sts(9,927) + glue stsb(5,749) (총:38,842)
- HyperParameter : LearningRate : 3e-5, epochs: 800, batchsize: 64, max_token_len : 128
- 출력 모델 : moco-sentencebertV2.0
- 훈련시간 : 25h/1GPU (24GB/13GB use)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
<br>모델 제작 과정에 대한 자세한 내용은 [여기](https://github.com/kobongsoo/BERT/tree/master)를 참조 하세요.
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1035 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Config**:
```
{
"_name_or_path": "../../data11/model/sbert/sbert-mbertV2.0-distil",
"architectures": [
"BertModel"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"torch_dtype": "float32",
"transformers_version": "4.21.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 152537
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
bongsoo
|
bkim12/t5-small-finetuned-eli5
|
bkim12
| 2022-09-28T04:00:37Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T22:23:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-small-finetuned-eli5
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 13.0163
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-eli5
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6782
- Rouge1: 13.0163
- Rouge2: 1.9263
- Rougel: 10.484
- Rougelsum: 11.8234
- Gen Len: 18.9951
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 3.8841 | 1.0 | 17040 | 3.6782 | 13.0163 | 1.9263 | 10.484 | 11.8234 | 18.9951 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1
- Datasets 2.5.1
- Tokenizers 0.12.1
|
underoohcf/finetuning-sentiment-model-3000-samples
|
underoohcf
| 2022-09-28T02:54:08Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-28T02:41:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.87
- name: F1
type: f1
value: 0.8695652173913044
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2983
- Accuracy: 0.87
- F1: 0.8696
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
helloway/test_model
|
helloway
| 2022-09-28T02:13:43Z | 0 | 0 | null |
[
"image-classification",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2022-09-28T02:03:58Z |
---
license: apache-2.0
tags:
- image-classification
---
|
sd-concepts-library/sanguo-guanyu
|
sd-concepts-library
| 2022-09-28T02:10:40Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-28T02:10:28Z |
---
license: mit
---
### sanguo-guanyu on Stable Diffusion
This is the `<sanguo-guanyu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
erich-hf/ml-agents-pyramids
|
erich-hf
| 2022-09-28T02:07:28Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-09-28T02:07:19Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: erich-hf/ml-agents-pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
akira0402/xlm-roberta-base-finetuned-panx-de
|
akira0402
| 2022-09-28T00:54:17Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-27T07:20:10Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: train
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8629724353509519
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1380
- F1: 0.8630
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2625 | 1.0 | 525 | 0.1667 | 0.8208 |
| 0.1281 | 2.0 | 1050 | 0.1361 | 0.8510 |
| 0.0809 | 3.0 | 1575 | 0.1380 | 0.8630 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
crumb/genshin-stable-inversion
|
crumb
| 2022-09-27T22:52:43Z | 0 | 2 | null |
[
"stable-diffusion",
"text-to-image",
"en",
"license:bigscience-bloom-rail-1.0",
"region:us"
] |
text-to-image
| 2022-09-27T02:21:25Z |
---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: bigscience-bloom-rail-1.0
inference: false
---
project that probably won't lead to anything useful but is still interesting (Less VRAM requirement than finetuning Stable Diffusion, faster if you have all the images downloaded, less space taken up by the models since you only need CLIP)
a notebook for producing your own "stable inversions" is included in this repo but I wouldn't recommend doing so (they suck). It works on Colab free tier though.
[link to notebook for you to download](https://huggingface.co/crumb/genshin-stable-inversion/blob/main/stable_inversion%20(1).ipynb)
how you can load this into a diffusers-based notebook like [Doohickey](https://github.com/aicrumb/doohickey) might look something like this
```python
from huggingface_hub import hf_hub_download
stable_inversion = "user/my-stable-inversion" #@param {type:"string"}
inversion_path = hf_hub_download(repo_id=stable_inversion, filename="token_embeddings.pt")
text_encoder.text_model.embeddings.token_embedding.weight = torch.load(inversion_path)
```
it was trained on 1024 images matching the 'genshin_impact' tag on safebooru, epochs 1 and 2 had the model being fed the full captions, epoch 3 had 50% of the tags in the caption, and epoch 4 had 25% of the tags in the caption. Learning rate was 1e-3 and the loss curve looked like this 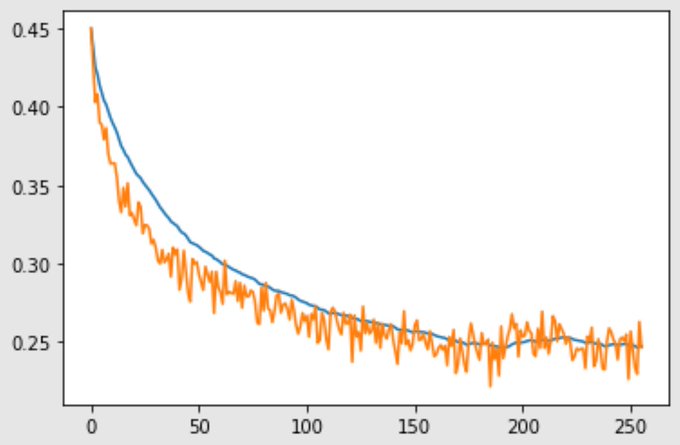
Samples from this finetuned inversion for the prompt "beidou_(genshin_impact)" using just the 1-4 Stable Diffusion model




Sample for the same prompt BEFORE finetuning (matches seeds with first finetuned sample)

|
ShadowTwin41/distilbert-base-uncased-finetuned-squad-d5716d28
|
ShadowTwin41
| 2022-09-27T21:50:12Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"question-answering",
"en",
"dataset:squad",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-27T21:46:09Z |
---
language:
- en
thumbnail: https://github.com/karanchahal/distiller/blob/master/distiller.jpg
tags:
- question-answering
license: apache-2.0
datasets:
- squad
metrics:
- squad
---
# DistilBERT with a second step of distillation
## Model description
This model replicates the "DistilBERT (D)" model from Table 2 of the [DistilBERT paper](https://arxiv.org/pdf/1910.01108.pdf). In this approach, a DistilBERT student is fine-tuned on SQuAD v1.1, but with a BERT model (also fine-tuned on SQuAD v1.1) acting as a teacher for a second step of task-specific distillation.
In this version, the following pre-trained models were used:
* Student: `distilbert-base-uncased`
* Teacher: `lewtun/bert-base-uncased-finetuned-squad-v1`
## Training data
This model was trained on the SQuAD v1.1 dataset which can be obtained from the `datasets` library as follows:
```python
from datasets import load_dataset
squad = load_dataset('squad')
```
## Training procedure
## Eval results
| | Exact Match | F1 |
|------------------|-------------|------|
| DistilBERT paper | 79.1 | 86.9 |
| Ours | 78.4 | 86.5 |
The scores were calculated using the `squad` metric from `datasets`.
### BibTeX entry and citation info
```bibtex
@misc{sanh2020distilbert,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
year={2020},
eprint={1910.01108},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
sd-concepts-library/blue-haired-boy
|
sd-concepts-library
| 2022-09-27T21:48:43Z | 0 | 3 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T21:48:29Z |
---
license: mit
---
### Blue-Haired-Boy on Stable Diffusion
This is the `<Blue-Haired-Boy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
ask4rizwan/FirstModel
|
ask4rizwan
| 2022-09-27T21:14:54Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-09-27T21:14:54Z |
---
license: bigscience-bloom-rail-1.0
---
|
DeepaKrish/distilbert-base-uncased-finetuned
|
DeepaKrish
| 2022-09-27T20:43:00Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T23:59:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1137
- Accuracy: 0.9733
- F1: 0.9743
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0868 | 1.0 | 1370 | 0.1098 | 0.9729 | 0.9738 |
| 0.0598 | 2.0 | 2740 | 0.1137 | 0.9733 | 0.9743 |
| 0.0383 | 3.0 | 4110 | 0.1604 | 0.9721 | 0.9731 |
| 0.0257 | 4.0 | 5480 | 0.1671 | 0.9717 | 0.9729 |
| 0.016 | 5.0 | 6850 | 0.1904 | 0.9709 | 0.9720 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0
- Datasets 2.5.1
- Tokenizers 0.10.3
|
Kevin123/t5-small-finetuned-xsum
|
Kevin123
| 2022-09-27T20:06:05Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T20:02:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
model-index:
- name: t5-small-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.12.3
- Pytorch 1.8.1+cu102
- Datasets 1.18.3
- Tokenizers 0.10.3
|
marktrovinger/q-FrozenLake-v1-4x4-noSlippery
|
marktrovinger
| 2022-09-27T19:50:25Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-27T19:50:17Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="marktrovinger/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
IIIT-L/indic-bert-finetuned-TRAC-DS
|
IIIT-L
| 2022-09-27T19:02:06Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T17:06:18Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: indic-bert-finetuned-TRAC-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indic-bert-finetuned-TRAC-DS
This model is a fine-tuned version of [ai4bharat/indic-bert](https://huggingface.co/ai4bharat/indic-bert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9922
- Accuracy: 0.5825
- Precision: 0.5493
- Recall: 0.5412
- F1: 0.5428
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0755 | 1.99 | 612 | 1.0346 | 0.5057 | 0.4072 | 0.4554 | 0.3806 |
| 1.0175 | 3.99 | 1224 | 1.0096 | 0.5678 | 0.6135 | 0.5011 | 0.4422 |
| 0.9974 | 5.98 | 1836 | 1.0010 | 0.5776 | 0.5637 | 0.5140 | 0.4799 |
| 0.9812 | 7.97 | 2448 | 0.9960 | 0.5694 | 0.5426 | 0.5283 | 0.5298 |
| 0.9675 | 9.97 | 3060 | 0.9956 | 0.5776 | 0.5565 | 0.5422 | 0.5442 |
| 0.9542 | 11.96 | 3672 | 0.9925 | 0.5882 | 0.5601 | 0.5420 | 0.5419 |
| 0.944 | 13.95 | 4284 | 0.9907 | 0.5866 | 0.5525 | 0.5441 | 0.5454 |
| 0.9347 | 15.95 | 4896 | 0.9921 | 0.5858 | 0.5527 | 0.5441 | 0.5456 |
| 0.9271 | 17.94 | 5508 | 0.9906 | 0.5931 | 0.5596 | 0.5482 | 0.5490 |
| 0.9236 | 19.93 | 6120 | 0.9922 | 0.5825 | 0.5493 | 0.5412 | 0.5428 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
VietAI/vit5-base
|
VietAI
| 2022-09-27T18:09:26Z | 1,798 | 11 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"summarization",
"translation",
"question-answering",
"vi",
"dataset:cc100",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-14T16:36:06Z |
---
language: vi
datasets:
- cc100
tags:
- summarization
- translation
- question-answering
license: mit
---
# ViT5-base
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
[Finetunning Example can be found here](https://github.com/vietai/ViT5/tree/main/finetunning_huggingface).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-base")
model.cuda()
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
```
|
sd-concepts-library/plen-ki-mun
|
sd-concepts-library
| 2022-09-27T17:47:15Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T17:47:01Z |
---
license: mit
---
### Plen-Ki-Mun on Stable Diffusion
This is the `<plen-ki-mun>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
anas-awadalla/t5-small-few-shot-k-1024-finetuned-squad-seed-4
|
anas-awadalla
| 2022-09-27T16:26:18Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T16:10:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-1024-finetuned-squad-seed-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-1024-finetuned-squad-seed-4
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-1024-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T16:08:21Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T15:51:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-1024-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-1024-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-1024-finetuned-squad-seed-0
|
anas-awadalla
| 2022-09-27T15:49:41Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T15:33:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-1024-finetuned-squad-seed-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-1024-finetuned-squad-seed-0
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
tner/twitter-roberta-base-dec2021-tweetner7-continuous
|
tner
| 2022-09-27T15:35:42Z | 141 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-03T09:26:30Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-dec2021-tweetner7-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6511305152373794
- name: Precision (test_2021)
type: precision
value: 0.6512434933487565
- name: Recall (test_2021)
type: recall
value: 0.6510175763182239
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6001624572691789
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5998564738871041
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6026065175267361
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7810548230395559
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7811451706188548
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7809644963571181
- name: F1 (test_2020)
type: f1
value: 0.6491659830462128
- name: Precision (test_2020)
type: precision
value: 0.6861271676300578
- name: Recall (test_2020)
type: recall
value: 0.6159833938764919
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6069402050119113
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6442441821706234
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5785382402328414
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7582056892778994
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8016194331983806
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7192527244421381
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-dec2021-tweetner7-continuous
This model is a fine-tuned version of [tner/twitter-roberta-base-dec2021-tweetner-2020](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split). The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on `train_2021`.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6511305152373794
- Precision (micro): 0.6512434933487565
- Recall (micro): 0.6510175763182239
- F1 (macro): 0.6001624572691789
- Precision (macro): 0.5998564738871041
- Recall (macro): 0.6026065175267361
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5055066079295154
- creative_work: 0.47089601046435575
- event: 0.4448705656759348
- group: 0.6124532153793807
- location: 0.6592689295039165
- person: 0.8386047352250136
- product: 0.6695371367061357
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.642462096346594, 0.6609916755115764]
- 95%: [0.6408253162283987, 0.6624122690460243]
- F1 (macro):
- 90%: [0.642462096346594, 0.6609916755115764]
- 95%: [0.6408253162283987, 0.6624122690460243]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-dec2021-tweetner7-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: tner/twitter-roberta-base-dec2021-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-06
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/twitter-roberta-base-dec2021-tweetner7-2021
|
tner
| 2022-09-27T15:35:15Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-03T09:22:26Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-dec2021-tweetner7-2021
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6346897022050466
- name: Precision (test_2021)
type: precision
value: 0.6240500670540903
- name: Recall (test_2021)
type: recall
value: 0.6456984273820536
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.586830362928695
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5777962671668668
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5983908809408913
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.77487922705314
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7618462226195798
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7883659072510697
- name: F1 (test_2020)
type: f1
value: 0.6225596529284164
- name: Precision (test_2020)
type: precision
value: 0.6519023282226007
- name: Recall (test_2020)
type: recall
value: 0.5957446808510638
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.578847416026638
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6085991227224318
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5537596756202443
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7413232104121477
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7762634866553095
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7093928386092372
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-dec2021-tweetner7-2021
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-dec2021](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2021) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6346897022050466
- Precision (micro): 0.6240500670540903
- Recall (micro): 0.6456984273820536
- F1 (macro): 0.586830362928695
- Precision (macro): 0.5777962671668668
- Recall (macro): 0.5983908809408913
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.47679083094555874
- creative_work: 0.4394942805538832
- event: 0.4638082065467958
- group: 0.5936801787424194
- location: 0.646505376344086
- person: 0.8201674554058972
- product: 0.6673662119622246
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6258493958055198, 0.6436753593746133]
- 95%: [0.6239476803844971, 0.645859449522042]
- F1 (macro):
- 90%: [0.6258493958055198, 0.6436753593746133]
- 95%: [0.6239476803844971, 0.645859449522042]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2021/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2021/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-dec2021-tweetner7-2021")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: cardiffnlp/twitter-roberta-base-dec2021
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2021/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/twitter-roberta-base-dec2021-tweetner7-2020
|
tner
| 2022-09-27T15:35:03Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-03T09:07:32Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-dec2021-tweetner7-2020
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6417969860676713
- name: Precision (test_2021)
type: precision
value: 0.6314199395770392
- name: Recall (test_2021)
type: recall
value: 0.6525208140610546
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5950190138355756
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5844336783514947
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6100191042323923
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.77377161055505
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7612174107642385
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7867468486180178
- name: F1 (test_2020)
type: f1
value: 0.6535560344827587
- name: Precision (test_2020)
type: precision
value: 0.6795518207282913
- name: Recall (test_2020)
type: recall
value: 0.6294758692267773
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6112036126522273
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6366190072656497
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5931815043549611
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7636755591484775
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7942825112107623
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7353399065905553
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-dec2021-tweetner7-2020
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-dec2021](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2021) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2020` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6417969860676713
- Precision (micro): 0.6314199395770392
- Recall (micro): 0.6525208140610546
- F1 (macro): 0.5950190138355756
- Precision (macro): 0.5844336783514947
- Recall (macro): 0.6100191042323923
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5161953727506428
- creative_work: 0.4749841671944269
- event: 0.43429109750353273
- group: 0.593413759373981
- location: 0.6431718061674009
- person: 0.8327532515112659
- product: 0.6703236423477785
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6334648803400447, 0.651188450223803]
- 95%: [0.6314263719566943, 0.6528797499551452]
- F1 (macro):
- 90%: [0.6334648803400447, 0.651188450223803]
- 95%: [0.6314263719566943, 0.6528797499551452]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2020/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2020/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-dec2021-tweetner7-2020")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2020
- dataset_name: None
- local_dataset: None
- model: cardiffnlp/twitter-roberta-base-dec2021
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-dec2021-tweetner7-2020/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/twitter-roberta-base-dec2020-tweetner7-2021
|
tner
| 2022-09-27T15:34:14Z | 119 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-07T10:11:09Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-dec2020-tweetner7-2021
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6397858647986788
- name: Precision (test_2021)
type: precision
value: 0.6303445180114465
- name: Recall (test_2021)
type: recall
value: 0.6495143385753932
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5891304279072724
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5792901831181549
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6004916851711928
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7786763868322132
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7671417349343508
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7905632011102116
- name: F1 (test_2020)
type: f1
value: 0.6307439824945295
- name: Precision (test_2020)
type: precision
value: 0.6668594563331406
- name: Recall (test_2020)
type: recall
value: 0.5983393876491956
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5851265852701386
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6174792176025484
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5588985785349839
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7534883720930233
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.796875
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7145822522055008
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-dec2020-tweetner7-2021
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-dec2020](https://huggingface.co/cardiffnlp/twitter-roberta-base-dec2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6397858647986788
- Precision (micro): 0.6303445180114465
- Recall (micro): 0.6495143385753932
- F1 (macro): 0.5891304279072724
- Precision (macro): 0.5792901831181549
- Recall (macro): 0.6004916851711928
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5104384133611691
- creative_work: 0.4085603112840467
- event: 0.46204311152764754
- group: 0.6021505376344086
- location: 0.6555407209612816
- person: 0.826392644672796
- product: 0.658787255909558
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6313701951851352, 0.6488151576987361]
- 95%: [0.6299593452104588, 0.6503478811637856]
- F1 (macro):
- 90%: [0.6313701951851352, 0.6488151576987361]
- 95%: [0.6299593452104588, 0.6503478811637856]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-dec2020-tweetner7-2021/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-dec2020-tweetner7-2021/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-dec2020-tweetner7-2021")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: cardiffnlp/twitter-roberta-base-dec2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-dec2020-tweetner7-2021/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/twitter-roberta-base-2019-90m-tweetner7-random
|
tner
| 2022-09-27T15:33:49Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-11T11:20:13Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-2019-90m-tweetner7-random
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6329255975760296
- name: Precision (test_2021)
type: precision
value: 0.6147809025506867
- name: Recall (test_2021)
type: recall
value: 0.6521739130434783
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5849737353611323
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5655720751091778
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6073811457896877
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7735817294203468
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7513625463265751
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7971550826876374
- name: F1 (test_2020)
type: f1
value: 0.6428571428571428
- name: Precision (test_2020)
type: precision
value: 0.666110183639399
- name: Recall (test_2020)
type: recall
value: 0.6211728074727556
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6067120703105228
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6269481984991956
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5890178249768797
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7620837808807734
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7896494156928213
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.736377789309808
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-2019-90m-tweetner7-random
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-2019-90m](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_random` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6329255975760296
- Precision (micro): 0.6147809025506867
- Recall (micro): 0.6521739130434783
- F1 (macro): 0.5849737353611323
- Precision (macro): 0.5655720751091778
- Recall (macro): 0.6073811457896877
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5055837563451777
- creative_work: 0.41676942046855736
- event: 0.45696539485359355
- group: 0.599078341013825
- location: 0.6480218281036835
- person: 0.8302235359320156
- product: 0.6381738708110735
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6241107966406728, 0.6420422564843195]
- 95%: [0.6227081381578177, 0.6435080538043557]
- F1 (macro):
- 90%: [0.6241107966406728, 0.6420422564843195]
- 95%: [0.6227081381578177, 0.6435080538043557]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-random/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-random/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-2019-90m-tweetner7-random")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_random
- dataset_name: None
- local_dataset: None
- model: cardiffnlp/twitter-roberta-base-2019-90m
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-random/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/twitter-roberta-base-2019-90m-tweetner7-all
|
tner
| 2022-09-27T15:33:23Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-07T10:12:18Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/twitter-roberta-base-2019-90m-tweetner7-all
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6567966159826227
- name: Precision (test_2021)
type: precision
value: 0.6494460773230839
- name: Recall (test_2021)
type: recall
value: 0.6643154486586494
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6099755599654287
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.602661693428744
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6189811354202427
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7888869833647745
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7800135654533122
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7979646120041632
- name: F1 (test_2020)
type: f1
value: 0.6545553145336225
- name: Precision (test_2020)
type: precision
value: 0.6854060193072118
- name: Recall (test_2020)
type: recall
value: 0.6263622210690192
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6121643911579755
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6403532739362632
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5898647290448411
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7643070246813126
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8005681818181818
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7311883757135443
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/twitter-roberta-base-2019-90m-tweetner7-all
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-2019-90m](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_all` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6567966159826227
- Precision (micro): 0.6494460773230839
- Recall (micro): 0.6643154486586494
- F1 (macro): 0.6099755599654287
- Precision (macro): 0.602661693428744
- Recall (macro): 0.6189811354202427
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5087071240105541
- creative_work: 0.4729907773386035
- event: 0.48405253283302063
- group: 0.6147885050048434
- location: 0.679419525065963
- person: 0.83927591881514
- product: 0.6705945366898768
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.648368394653773, 0.6664006471768674]
- 95%: [0.646545111092117, 0.6680503208004025]
- F1 (macro):
- 90%: [0.648368394653773, 0.6664006471768674]
- 95%: [0.646545111092117, 0.6680503208004025]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-all/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-all/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/twitter-roberta-base-2019-90m-tweetner7-all")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_all
- dataset_name: None
- local_dataset: None
- model: cardiffnlp/twitter-roberta-base-2019-90m
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/twitter-roberta-base-2019-90m-tweetner7-all/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-selflabel2021
|
tner
| 2022-09-27T15:32:18Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:12:11Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-selflabel2021
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6460286973223365
- name: Precision (test_2021)
type: precision
value: 0.6315440689198144
- name: Recall (test_2021)
type: recall
value: 0.6611933395004626
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5944660768713126
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5801646971717881
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6174983598336771
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7857183209988137
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7680583167660703
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8042095524459351
- name: F1 (test_2020)
type: f1
value: 0.6475365457498646
- name: Precision (test_2020)
type: precision
value: 0.6768534238822863
- name: Recall (test_2020)
type: recall
value: 0.6206538661131292
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6064934754479069
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.63365172906493
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5889063993107413
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7663146493365827
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8012457531143827
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7343020238713025
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-selflabel2021
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train` split). This model is fine-tuned on self-labeled dataset which is the `extra_2021` split of the [tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) annotated by [tner/roberta-large](https://huggingface.co/tner/roberta-large-tweetner7-2020)). Please check [https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling](https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling) for more detail of reproducing the model.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6460286973223365
- Precision (micro): 0.6315440689198144
- Recall (micro): 0.6611933395004626
- F1 (macro): 0.5944660768713126
- Precision (macro): 0.5801646971717881
- Recall (macro): 0.6174983598336771
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5021008403361344
- creative_work: 0.4589000591366056
- event: 0.45184799583550234
- group: 0.602966540186271
- location: 0.667091836734694
- person: 0.8345784418356457
- product: 0.6437768240343348
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.63733724830433, 0.6556095472315113]
- 95%: [0.6353273787551952, 0.6574352280031737]
- F1 (macro):
- 90%: [0.63733724830433, 0.6556095472315113]
- 95%: [0.6353273787551952, 0.6574352280031737]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2021/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2021/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-selflabel2021")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train
- dataset_name: None
- local_dataset: {'train': 'tweet_ner/2021.extra.tner/roberta-large-2020.txt', 'validation': 'tweet_ner/2020.dev.txt'}
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2021/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-selflabel2020-continuous
|
tner
| 2022-09-27T15:31:51Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:21:08Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-selflabel2020-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6514522821576764
- name: Precision (test_2021)
type: precision
value: 0.6323753537992598
- name: Recall (test_2021)
type: recall
value: 0.6717160037002775
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6022910652688035
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5829347583676058
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6268182581614908
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.787304435596927
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7642064010450685
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8118422574303227
- name: F1 (test_2020)
type: f1
value: 0.667024993281376
- name: Precision (test_2020)
type: precision
value: 0.6917502787068004
- name: Recall (test_2020)
type: recall
value: 0.6440062272963155
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6285598697810462
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.649215603090582
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.6128675304056594
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7711750470556602
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8002232142857143
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7441619097042034
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-selflabel2020-continuous
This model is a fine-tuned version of [tner/roberta-large-tweetner-2020](https://huggingface.co/tner/roberta-large-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train` split). This model is fine-tuned on self-labeled dataset which is the `extra_2020` split of the [tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) annotated by [tner/roberta-large](https://huggingface.co/tner/roberta-large-tweetner7-2020)). Please check [https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling](https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling) for more detail of reproducing the model. The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on the self-labeled dataset.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6514522821576764
- Precision (micro): 0.6323753537992598
- Recall (micro): 0.6717160037002775
- F1 (macro): 0.6022910652688035
- Precision (macro): 0.5829347583676058
- Recall (macro): 0.6268182581614908
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5252837977296182
- creative_work: 0.4650306748466258
- event: 0.46176911544227883
- group: 0.608667941363926
- location: 0.6666666666666666
- person: 0.8382696104828578
- product: 0.6503496503496504
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6429569959405362, 0.6605302879870334]
- 95%: [0.6410815271146394, 0.6628490227012314]
- F1 (macro):
- 90%: [0.6429569959405362, 0.6605302879870334]
- 95%: [0.6410815271146394, 0.6628490227012314]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2020-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2020-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-selflabel2020-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train
- dataset_name: None
- local_dataset: {'train': 'tweet_ner/2020.extra.tner/roberta-large-2020.txt', 'validation': 'tweet_ner/2020.dev.txt'}
- model: tner/roberta-large-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-selflabel2020-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-random
|
tner
| 2022-09-27T15:30:53Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-11T11:23:27Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-random
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6632769652650823
- name: Precision (test_2021)
type: precision
value: 0.6554878048780488
- name: Recall (test_2021)
type: recall
value: 0.6712534690101758
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6096477771855761
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.6042443991246051
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6191008735553379
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7900359938296291
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.780713640469738
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7995836706372152
- name: F1 (test_2020)
type: f1
value: 0.6439847577572129
- name: Precision (test_2020)
type: precision
value: 0.6771608471665712
- name: Recall (test_2020)
type: recall
value: 0.6139076284379865
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6008744778169367
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6358142893696356
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5742193301311931
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7552409474543968
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7943871706758304
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7197716658017644
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-random
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_random` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6632769652650823
- Precision (micro): 0.6554878048780488
- Recall (micro): 0.6712534690101758
- F1 (macro): 0.6096477771855761
- Precision (macro): 0.6042443991246051
- Recall (macro): 0.6191008735553379
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5224148236700539
- creative_work: 0.45186640471512773
- event: 0.4894837476099427
- group: 0.6327722432153899
- location: 0.6692258477287268
- person: 0.838405036726128
- product: 0.6633663366336633
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6546824558783396, 0.6722355436189195]
- 95%: [0.6527609558375069, 0.6741666937877734]
- F1 (macro):
- 90%: [0.6546824558783396, 0.6722355436189195]
- 95%: [0.6527609558375069, 0.6741666937877734]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-random/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-random/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-random")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_random
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-random/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-continuous
|
tner
| 2022-09-27T15:30:26Z | 129 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:12:30Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6602098466505246
- name: Precision (test_2021)
type: precision
value: 0.6583122556909634
- name: Recall (test_2021)
type: recall
value: 0.6621184088806661
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6089541397781462
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.6063426866310634
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6145764579798109
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.791351974632459
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.78903196137043
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7936856713310975
- name: F1 (test_2020)
type: f1
value: 0.6626406807576174
- name: Precision (test_2020)
type: precision
value: 0.7033799533799534
- name: Recall (test_2020)
type: recall
value: 0.6263622210690192
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6239587887403221
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6646899818440488
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5921933163664825
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7644151565074135
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8116618075801749
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7223663725998962
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-continuous
This model is a fine-tuned version of [tner/roberta-large-tweetner-2020](https://huggingface.co/tner/roberta-large-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split). The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on `train_2021`.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6602098466505246
- Precision (micro): 0.6583122556909634
- Recall (micro): 0.6621184088806661
- F1 (macro): 0.6089541397781462
- Precision (macro): 0.6063426866310634
- Recall (macro): 0.6145764579798109
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5315217391304348
- creative_work: 0.44416243654822335
- event: 0.48787728847105394
- group: 0.6115476597198496
- location: 0.6740692357935989
- person: 0.8471820809248555
- product: 0.6663185378590079
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6517159585889167, 0.6692301926939467]
- 95%: [0.6493037560449608, 0.6705545707079725]
- F1 (macro):
- 90%: [0.6517159585889167, 0.6692301926939467]
- 95%: [0.6493037560449608, 0.6705545707079725]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: tner/roberta-large-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-06
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-2020-selflabel2020-all
|
tner
| 2022-09-27T15:28:13Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:16:44Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-2020-selflabel2020-all
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6545742216194834
- name: Precision (test_2021)
type: precision
value: 0.640070726047077
- name: Recall (test_2021)
type: recall
value: 0.669750231267345
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6038933000880791
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5872465756589016
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6275044421067731
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7917043399638336
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7741186871477511
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8101075517520527
- name: F1 (test_2020)
type: f1
value: 0.6623235613463626
- name: Precision (test_2020)
type: precision
value: 0.6943653955606147
- name: Recall (test_2020)
type: recall
value: 0.6331084587441619
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6225690518125756
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6499146769265831
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.6036807965123165
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7716535433070866
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8092255125284739
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7374156720290607
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-2020-selflabel2020-all
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train` split). This model is fine-tuned on self-labeled dataset which is the `extra_2020` split of the [tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) annotated by [tner/roberta-large](https://huggingface.co/tner/roberta-large-tweetner7-2020)). Please check [https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling](https://github.com/asahi417/tner/tree/master/examples/tweetner7_paper#model-fine-tuning-self-labeling) for more detail of reproducing the model.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6545742216194834
- Precision (micro): 0.640070726047077
- Recall (micro): 0.669750231267345
- F1 (macro): 0.6038933000880791
- Precision (macro): 0.5872465756589016
- Recall (macro): 0.6275044421067731
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5255936675461742
- creative_work: 0.4611679711017459
- event: 0.4583333333333333
- group: 0.6170427753452341
- location: 0.6717267552182163
- person: 0.8439139084825467
- product: 0.6494746895893028
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6459013617167609, 0.6637399915981033]
- 95%: [0.6439605146787715, 0.6661442289789786]
- F1 (macro):
- 90%: [0.6459013617167609, 0.6637399915981033]
- 95%: [0.6439605146787715, 0.6661442289789786]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-2020-selflabel2020-all/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-2020-selflabel2020-all/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-2020-selflabel2020-all")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train
- dataset_name: None
- local_dataset: {'train': 'tweet_ner/2020_2020.extra.tner/roberta-large-2020.txt', 'validation': 'tweet_ner/2020.dev.txt'}
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-2020-selflabel2020-all/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-large-tweetner7-2020
|
tner
| 2022-09-27T15:27:45Z | 106 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:11:45Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-large-tweetner7-2020
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6476455837280579
- name: Precision (test_2021)
type: precision
value: 0.6250403355921265
- name: Recall (test_2021)
type: recall
value: 0.6719472710453284
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5999877200423757
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5763142106730764
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6296258649141258
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7836361609631033
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7563206024744487
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8129987278825026
- name: F1 (test_2020)
type: f1
value: 0.6566924926529523
- name: Precision (test_2020)
type: precision
value: 0.676762114537445
- name: Recall (test_2020)
type: recall
value: 0.6377789309807992
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6188295807291019
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6364060811133587
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.6056612695801465
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7610903260288615
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7845730027548209
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7389724961079398
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-large-tweetner7-2020
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2020` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6476455837280579
- Precision (micro): 0.6250403355921265
- Recall (micro): 0.6719472710453284
- F1 (macro): 0.5999877200423757
- Precision (macro): 0.5763142106730764
- Recall (macro): 0.6296258649141258
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5222786238014665
- creative_work: 0.45888441633122484
- event: 0.4850711988975654
- group: 0.6087811271297511
- location: 0.6442612555485098
- person: 0.8331830477908024
- product: 0.6474543707973103
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6385290008161982, 0.6567664564200659]
- 95%: [0.6363564668769717, 0.658859612510356]
- F1 (macro):
- 90%: [0.6385290008161982, 0.6567664564200659]
- 95%: [0.6363564668769717, 0.658859612510356]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-large-tweetner7-2020/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-large-tweetner7-2020/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-large-tweetner7-2020")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2020
- dataset_name: None
- local_dataset: None
- model: roberta-large
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-large-tweetner7-2020/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-base-tweetner7-continuous
|
tner
| 2022-09-27T15:27:06Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-03T10:14:00Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-base-tweetner7-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6547126972113873
- name: Precision (test_2021)
type: precision
value: 0.6592801031773947
- name: Recall (test_2021)
type: recall
value: 0.6502081406105458
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6000787312274737
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.603865779286349
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5992466120658141
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7809734513274336
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7863758940086762
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7756447322770903
- name: F1 (test_2020)
type: f1
value: 0.651460361613352
- name: Precision (test_2020)
type: precision
value: 0.7020383693045563
- name: Recall (test_2020)
type: recall
value: 0.6076803321224702
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6081745135588633
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6574828031156369
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5706180236424009
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7504867872044506
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8087529976019184
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7000518941359626
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-base-tweetner7-continuous
This model is a fine-tuned version of [tner/roberta-base-tweetner-2020](https://huggingface.co/tner/roberta-base-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split). The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on `train_2021`.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6547126972113873
- Precision (micro): 0.6592801031773947
- Recall (micro): 0.6502081406105458
- F1 (macro): 0.6000787312274737
- Precision (macro): 0.603865779286349
- Recall (macro): 0.5992466120658141
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.509673852957435
- creative_work: 0.41677588466579296
- event: 0.4675062972292191
- group: 0.6152256286600069
- location: 0.6798159105851413
- person: 0.8448868778280542
- product: 0.6666666666666667
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6458722707634147, 0.6637540527089854]
- 95%: [0.6443720180740024, 0.6654476640585366]
- F1 (macro):
- 90%: [0.6458722707634147, 0.6637540527089854]
- 95%: [0.6443720180740024, 0.6654476640585366]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-base-tweetner7-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-base-tweetner7-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-base-tweetner7-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: tner/roberta-base-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-06
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-base-tweetner7-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/roberta-base-tweetner7-2021
|
tner
| 2022-09-27T15:26:40Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-03T10:10:43Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/roberta-base-tweetner7-2021
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6175553918513061
- name: Precision (test_2021)
type: precision
value: 0.6055117235248361
- name: Recall (test_2021)
type: recall
value: 0.6300878815911193
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5699978267978356
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5590687883112516
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5841701622550579
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7692483045534848
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.758314606741573
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7805019081762461
- name: F1 (test_2020)
type: f1
value: 0.604995882514411
- name: Precision (test_2020)
type: precision
value: 0.6421911421911422
- name: Recall (test_2020)
type: recall
value: 0.5718733783082511
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5612313427645093
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.5945742705318462
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5335324219465825
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7375103505382279
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7877358490566038
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6933056564608199
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/roberta-base-tweetner7-2021
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6175553918513061
- Precision (micro): 0.6055117235248361
- Recall (micro): 0.6300878815911193
- F1 (macro): 0.5699978267978356
- Precision (macro): 0.5590687883112516
- Recall (macro): 0.5841701622550579
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.4889844169801182
- creative_work: 0.3800116211504939
- event: 0.4550669216061186
- group: 0.5702400000000001
- location: 0.6506189821182944
- person: 0.8133776792313377
- product: 0.6316851664984864
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6085886303107021, 0.6270245504530414]
- 95%: [0.6071586866067074, 0.6287436113239784]
- F1 (macro):
- 90%: [0.6085886303107021, 0.6270245504530414]
- 95%: [0.6071586866067074, 0.6287436113239784]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/roberta-base-tweetner7-2021/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/roberta-base-tweetner7-2021/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/roberta-base-tweetner7-2021")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: roberta-base
- crf: False
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/roberta-base-tweetner7-2021/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bertweet-large-tweetner7-continuous
|
tner
| 2022-09-27T15:25:47Z | 125 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-10T23:42:34Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bertweet-large-tweetner7-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6641431520991053
- name: Precision (test_2021)
type: precision
value: 0.6588529813381885
- name: Recall (test_2021)
type: recall
value: 0.6695189639222942
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6165782134695219
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.6102975783874098
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6256153624327598
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7896759392027531
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.783340919435594
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7961142592806754
- name: F1 (test_2020)
type: f1
value: 0.6587912087912088
- name: Precision (test_2020)
type: precision
value: 0.6999416228838296
- name: Recall (test_2020)
type: recall
value: 0.6222106901920083
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6182374585427982
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6571485734047059
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5865594344408018
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7641561297416162
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8123904149620105
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7213284898806435
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bertweet-large-tweetner7-continuous
This model is a fine-tuned version of [tner/bertweet-large-tweetner-2020](https://huggingface.co/tner/bertweet-large-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split). The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on `train_2021`.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6641431520991053
- Precision (micro): 0.6588529813381885
- Recall (micro): 0.6695189639222942
- F1 (macro): 0.6165782134695219
- Precision (macro): 0.6102975783874098
- Recall (macro): 0.6256153624327598
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5507246376811594
- creative_work: 0.4684914067472947
- event: 0.4815724815724816
- group: 0.6143572621035058
- location: 0.6886731391585761
- person: 0.8404178674351586
- product: 0.6718106995884774
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6551977421192867, 0.6726790034801573]
- 95%: [0.6537478870999098, 0.6745822333244045]
- F1 (macro):
- 90%: [0.6551977421192867, 0.6726790034801573]
- 95%: [0.6537478870999098, 0.6745822333244045]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bertweet-large-tweetner7-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bertweet-large-tweetner7-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bertweet-large-tweetner7-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: tner/bertweet-large-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-06
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bertweet-large-tweetner7-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bertweet-large-tweetner7-2020
|
tner
| 2022-09-27T15:24:25Z | 123 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T19:04:55Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bertweet-large-tweetner7-2020
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6401254269555967
- name: Precision (test_2021)
type: precision
value: 0.6205623710780589
- name: Recall (test_2021)
type: recall
value: 0.6609620721554117
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5947383155381057
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5738855505495571
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6206178838164583
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7826184343151529
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7586581261535121
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8081415519833468
- name: F1 (test_2020)
type: f1
value: 0.659346545259775
- name: Precision (test_2020)
type: precision
value: 0.6812396236856668
- name: Recall (test_2020)
type: recall
value: 0.6388168137000519
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6261309560026784
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6527657911787169
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.6111694484964181
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7738478027867096
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.8
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.749351323300467
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bertweet-large-tweetner7-2020
This model is a fine-tuned version of [vinai/bertweet-large](https://huggingface.co/vinai/bertweet-large) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2020` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6401254269555967
- Precision (micro): 0.6205623710780589
- Recall (micro): 0.6609620721554117
- F1 (macro): 0.5947383155381057
- Precision (macro): 0.5738855505495571
- Recall (macro): 0.6206178838164583
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5229357798165137
- creative_work: 0.4629981024667932
- event: 0.4499572284003422
- group: 0.592749032030975
- location: 0.6553030303030303
- person: 0.8273135669362084
- product: 0.6519114688128772
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6315544728348781, 0.6491758274095626]
- 95%: [0.6294268706225905, 0.6515448119225267]
- F1 (macro):
- 90%: [0.6315544728348781, 0.6491758274095626]
- 95%: [0.6294268706225905, 0.6515448119225267]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bertweet-large-tweetner7-2020/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bertweet-large-tweetner7-2020/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bertweet-large-tweetner7-2020")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2020
- dataset_name: None
- local_dataset: None
- model: vinai/bertweet-large
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bertweet-large-tweetner7-2020/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bertweet-base-tweetner7-all
|
tner
| 2022-09-27T15:23:31Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-09T21:18:35Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bertweet-base-tweetner7-all
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6536203522504892
- name: Precision (test_2021)
type: precision
value: 0.6327812060192703
- name: Recall (test_2021)
type: recall
value: 0.6758788159111934
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.6052211252463111
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5838227039402247
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.6302754427289782
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7898680384701409
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7646421998484356
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.8168150803746964
- name: F1 (test_2020)
type: f1
value: 0.6574172892209178
- name: Precision (test_2020)
type: precision
value: 0.6765513454146074
- name: Recall (test_2020)
type: recall
value: 0.6393357550596782
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.6161494551388561
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6335227896210995
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.6030680287240185
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7691486522551374
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7917582417582417
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7477944992215879
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bertweet-base-tweetner7-all
This model is a fine-tuned version of [vinai/bertweet-base](https://huggingface.co/vinai/bertweet-base) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_all` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6536203522504892
- Precision (micro): 0.6327812060192703
- Recall (micro): 0.6758788159111934
- F1 (macro): 0.6052211252463111
- Precision (macro): 0.5838227039402247
- Recall (macro): 0.6302754427289782
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5250836120401337
- creative_work: 0.4653774173424829
- event: 0.4805781391147245
- group: 0.6033376123234916
- location: 0.6567164179104478
- person: 0.8408236347358997
- product: 0.6646310432569975
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6447872756148977, 0.6633207283107695]
- 95%: [0.6425923702362265, 0.6650666703489687]
- F1 (macro):
- 90%: [0.6447872756148977, 0.6633207283107695]
- 95%: [0.6425923702362265, 0.6650666703489687]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bertweet-base-tweetner7-all/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bertweet-base-tweetner7-all/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bertweet-base-tweetner7-all")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_all
- dataset_name: None
- local_dataset: None
- model: vinai/bertweet-base
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bertweet-base-tweetner7-all/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-large-tweetner7-random
|
tner
| 2022-09-27T15:22:53Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-11T11:22:19Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-large-tweetner7-random
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6238958623895862
- name: Precision (test_2021)
type: precision
value: 0.6271028037383177
- name: Recall (test_2021)
type: recall
value: 0.6207215541165587
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5754103658637805
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5760445653768616
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5751041088351385
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7648665930360984
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7689340813464236
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.760841910489187
- name: F1 (test_2020)
type: f1
value: 0.6154274575327208
- name: Precision (test_2020)
type: precision
value: 0.6640625
- name: Recall (test_2020)
type: recall
value: 0.5734302023871303
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5709159092071027
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6168953196783556
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5321784485961766
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.732943469785575
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7908653846153846
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6829268292682927
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-large-tweetner7-random
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_random` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6238958623895862
- Precision (micro): 0.6271028037383177
- Recall (micro): 0.6207215541165587
- F1 (macro): 0.5754103658637805
- Precision (macro): 0.5760445653768616
- Recall (macro): 0.5751041088351385
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.49146005509641877
- creative_work: 0.3972413793103448
- event: 0.44788732394366193
- group: 0.5767073573078192
- location: 0.6721649484536083
- person: 0.8116810183451891
- product: 0.6307304785894207
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6141711573096726, 0.6329835528622229]
- 95%: [0.6127880547187768, 0.6345997209553179]
- F1 (macro):
- 90%: [0.6141711573096726, 0.6329835528622229]
- 95%: [0.6127880547187768, 0.6345997209553179]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-large-tweetner7-random/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-large-tweetner7-random/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-large-tweetner7-random")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_random
- dataset_name: None
- local_dataset: None
- model: bert-large-cased
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-large-tweetner7-random/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-large-tweetner7-2021
|
tner
| 2022-09-27T15:21:36Z | 122 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-12T09:24:07Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-large-tweetner7-2021
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.5974718775368201
- name: Precision (test_2021)
type: precision
value: 0.5992091183996279
- name: Recall (test_2021)
type: recall
value: 0.5957446808510638
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5392877076670867
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5398425980592713
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5439768272225339
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7497514474530674
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7584003786086133
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7412975598473459
- name: F1 (test_2020)
type: f1
value: 0.5662616558349817
- name: Precision (test_2020)
type: precision
value: 0.6215880893300249
- name: Recall (test_2020)
type: recall
value: 0.519979242345615
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5096985017746614
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.5628721370469417
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.47520198274721537
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7065868263473053
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7841772151898734
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6429683445770628
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-large-tweetner7-2021
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.5974718775368201
- Precision (micro): 0.5992091183996279
- Recall (micro): 0.5957446808510638
- F1 (macro): 0.5392877076670867
- Precision (macro): 0.5398425980592713
- Recall (macro): 0.5439768272225339
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.4486772486772486
- creative_work: 0.34173228346456697
- event: 0.40238450074515647
- group: 0.556795797767564
- location: 0.6394904458598726
- person: 0.7940364439536168
- product: 0.5918972332015809
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.5884763705775744, 0.6075466841645367]
- 95%: [0.586724466800271, 0.6087071446445204]
- F1 (macro):
- 90%: [0.5884763705775744, 0.6075466841645367]
- 95%: [0.586724466800271, 0.6087071446445204]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-large-tweetner7-2021/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-large-tweetner7-2021/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-large-tweetner7-2021")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: bert-large-cased
- crf: False
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-large-tweetner7-2021/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-large-tweetner7-2020
|
tner
| 2022-09-27T15:21:13Z | 128 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-02T18:58:57Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-large-tweetner7-2020
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6142662426169924
- name: Precision (test_2021)
type: precision
value: 0.6035714285714285
- name: Recall (test_2021)
type: recall
value: 0.6253469010175763
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5614355349295936
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5513691216732639
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5731091951352001
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7585501647540052
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7455053042992742
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7720596738753325
- name: F1 (test_2020)
type: f1
value: 0.6218623481781376
- name: Precision (test_2020)
type: precision
value: 0.6479190101237345
- name: Recall (test_2020)
type: recall
value: 0.5978204462895693
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5814516218649598
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6074235531058303
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.559517342837518
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7379217273954116
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7688413948256468
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.7093928386092372
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-large-tweetner7-2020
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2020` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6142662426169924
- Precision (micro): 0.6035714285714285
- Recall (micro): 0.6253469010175763
- F1 (macro): 0.5614355349295936
- Precision (macro): 0.5513691216732639
- Recall (macro): 0.5731091951352001
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.501082251082251
- creative_work: 0.39033693579148127
- event: 0.4180478821362799
- group: 0.573095401509952
- location: 0.6112600536193029
- person: 0.8060337178349601
- product: 0.6301925025329281
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6054860911410611, 0.6239132125979686]
- 95%: [0.6039488039051357, 0.6252644472451034]
- F1 (macro):
- 90%: [0.6054860911410611, 0.6239132125979686]
- 95%: [0.6039488039051357, 0.6252644472451034]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-large-tweetner7-2020/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-large-tweetner7-2020/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-large-tweetner7-2020")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2020
- dataset_name: None
- local_dataset: None
- model: bert-large-cased
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-large-tweetner7-2020/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-base-tweetner7-random
|
tner
| 2022-09-27T15:20:48Z | 129 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-11T10:46:05Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-base-tweetner7-random
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.609117361784675
- name: Precision (test_2021)
type: precision
value: 0.6011938281337988
- name: Recall (test_2021)
type: recall
value: 0.6172525439407955
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.559165089199025
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5499368578582033
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5694430718770875
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7572194954913822
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7474929577464788
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7672024979761767
- name: F1 (test_2020)
type: f1
value: 0.6103825136612021
- name: Precision (test_2020)
type: precision
value: 0.6445470282746683
- name: Recall (test_2020)
type: recall
value: 0.5796574987026466
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5675359874657813
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6021803835272678
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5387624182505003
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7273224043715847
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7680323139065205
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6907109496626881
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-base-tweetner7-random
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_random` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.609117361784675
- Precision (micro): 0.6011938281337988
- Recall (micro): 0.6172525439407955
- F1 (macro): 0.559165089199025
- Precision (macro): 0.5499368578582033
- Recall (macro): 0.5694430718770875
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.46514047866805414
- creative_work: 0.3904698874917273
- event: 0.4183066361556064
- group: 0.5614035087719299
- location: 0.6389645776566757
- person: 0.8044590643274854
- product: 0.6354114713216957
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6000414265573856, 0.6190415373631918]
- 95%: [0.5981509067764902, 0.6206829089362571]
- F1 (macro):
- 90%: [0.6000414265573856, 0.6190415373631918]
- 95%: [0.5981509067764902, 0.6206829089362571]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-base-tweetner7-random/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-base-tweetner7-random/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-base-tweetner7-random")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_random
- dataset_name: None
- local_dataset: None
- model: bert-base-cased
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-base-tweetner7-random/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-base-tweetner7-continuous
|
tner
| 2022-09-27T15:20:36Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-10T18:53:12Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-base-tweetner7-continuous
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6180153025736147
- name: Precision (test_2021)
type: precision
value: 0.6195955369595537
- name: Recall (test_2021)
type: recall
value: 0.6164431082331174
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5683670244315128
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.569694944056475
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5712308118378218
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7652789052533921
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7674148156762414
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7631548513935469
- name: F1 (test_2020)
type: f1
value: 0.6140546569994423
- name: Precision (test_2020)
type: precision
value: 0.6636528028933092
- name: Recall (test_2020)
type: recall
value: 0.5713544369486248
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.5710807917000799
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6216528993817231
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.5337579395628287
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7250418293363079
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7836045810729355
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6746237675142709
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-base-tweetner7-continuous
This model is a fine-tuned version of [tner/bert-base-tweetner-2020](https://huggingface.co/tner/bert-base-tweetner-2020) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_2021` split). The model is first fine-tuned on `train_2020`, and then continuously fine-tuned on `train_2021`.
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6180153025736147
- Precision (micro): 0.6195955369595537
- Recall (micro): 0.6164431082331174
- F1 (macro): 0.5683670244315128
- Precision (macro): 0.569694944056475
- Recall (macro): 0.5712308118378218
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.47404505386875617
- creative_work: 0.3821742066171506
- event: 0.44045368620037806
- group: 0.5773490532332975
- location: 0.6442244224422442
- person: 0.8072178236052291
- product: 0.6531049250535331
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6091071020409725, 0.6281541017445712]
- 95%: [0.6068108439278024, 0.6300879315353104]
- F1 (macro):
- 90%: [0.6091071020409725, 0.6281541017445712]
- 95%: [0.6068108439278024, 0.6300879315353104]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-base-tweetner7-continuous/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-base-tweetner7-continuous/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-base-tweetner7-continuous")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_2021
- dataset_name: None
- local_dataset: None
- model: tner/bert-base-tweetner-2020
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 1e-05
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.15
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-base-tweetner7-continuous/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
tner/bert-base-tweetner7-all
|
tner
| 2022-09-27T15:20:24Z | 126 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"dataset:tner/tweetner7",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-11T15:43:31Z |
---
datasets:
- tner/tweetner7
metrics:
- f1
- precision
- recall
model-index:
- name: tner/bert-base-tweetner7-all
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: tner/tweetner7
type: tner/tweetner7
args: tner/tweetner7
metrics:
- name: F1 (test_2021)
type: f1
value: 0.6230258640421148
- name: Precision (test_2021)
type: precision
value: 0.6166742183960127
- name: Recall (test_2021)
type: recall
value: 0.6295097132284921
- name: Macro F1 (test_2021)
type: f1_macro
value: 0.5758556427048315
- name: Macro Precision (test_2021)
type: precision_macro
value: 0.5715554663683273
- name: Macro Recall (test_2021)
type: recall_macro
value: 0.5821234872899773
- name: Entity Span F1 (test_2021)
type: f1_entity_span
value: 0.7661839619941617
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7584995466908432
- name: Entity Span Recall (test_2021)
type: recall_entity_span
value: 0.7740256736440384
- name: F1 (test_2020)
type: f1
value: 0.6210070384407147
- name: Precision (test_2020)
type: precision
value: 0.6491228070175439
- name: Recall (test_2020)
type: recall
value: 0.5952257394914374
- name: Macro F1 (test_2020)
type: f1_macro
value: 0.577436139660066
- name: Macro Precision (test_2020)
type: precision_macro
value: 0.6119340101835135
- name: Macro Recall (test_2020)
type: recall_macro
value: 0.549500601374034
- name: Entity Span F1 (test_2020)
type: f1_entity_span
value: 0.7298321602598808
- name: Entity Span Precision (test_2020)
type: precision_entity_span
value: 0.7628749292586304
- name: Entity Span Recall (test_2020)
type: recall_entity_span
value: 0.6995329527763363
pipeline_tag: token-classification
widget:
- text: "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from {@herbiehancock@} via {@bluenoterecords@} link below: {{URL}}"
example_title: "NER Example 1"
---
# tner/bert-base-tweetner7-all
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the
[tner/tweetner7](https://huggingface.co/datasets/tner/tweetner7) dataset (`train_all` split).
Model fine-tuning is done via [T-NER](https://github.com/asahi417/tner)'s hyper-parameter search (see the repository
for more detail). It achieves the following results on the test set of 2021:
- F1 (micro): 0.6230258640421148
- Precision (micro): 0.6166742183960127
- Recall (micro): 0.6295097132284921
- F1 (macro): 0.5758556427048315
- Precision (macro): 0.5715554663683273
- Recall (macro): 0.5821234872899773
The per-entity breakdown of the F1 score on the test set are below:
- corporation: 0.5141176470588235
- creative_work: 0.3886075949367089
- event: 0.4580617122990004
- group: 0.5660613650594865
- location: 0.6264564770390679
- person: 0.8196536144578314
- product: 0.6580310880829014
For F1 scores, the confidence interval is obtained by bootstrap as below:
- F1 (micro):
- 90%: [0.6139925448708724, 0.632549139769655]
- 95%: [0.612303125388328, 0.6336744975616968]
- F1 (macro):
- 90%: [0.6139925448708724, 0.632549139769655]
- 95%: [0.612303125388328, 0.6336744975616968]
Full evaluation can be found at [metric file of NER](https://huggingface.co/tner/bert-base-tweetner7-all/raw/main/eval/metric.json)
and [metric file of entity span](https://huggingface.co/tner/bert-base-tweetner7-all/raw/main/eval/metric_span.json).
### Usage
This model can be used through the [tner library](https://github.com/asahi417/tner). Install the library via pip.
```shell
pip install tner
```
[TweetNER7](https://huggingface.co/datasets/tner/tweetner7) pre-processed tweets where the account name and URLs are
converted into special formats (see the dataset page for more detail), so we process tweets accordingly and then run the model prediction as below.
```python
import re
from urlextract import URLExtract
from tner import TransformersNER
extractor = URLExtract()
def format_tweet(tweet):
# mask web urls
urls = extractor.find_urls(tweet)
for url in urls:
tweet = tweet.replace(url, "{{URL}}")
# format twitter account
tweet = re.sub(r"\b(\s*)(@[\S]+)\b", r'\1{\2@}', tweet)
return tweet
text = "Get the all-analog Classic Vinyl Edition of `Takin' Off` Album from @herbiehancock via @bluenoterecords link below: http://bluenote.lnk.to/AlbumOfTheWeek"
text_format = format_tweet(text)
model = TransformersNER("tner/bert-base-tweetner7-all")
model.predict([text_format])
```
It can be used via transformers library but it is not recommended as CRF layer is not supported at the moment.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset: ['tner/tweetner7']
- dataset_split: train_all
- dataset_name: None
- local_dataset: None
- model: bert-base-cased
- crf: True
- max_length: 128
- epoch: 30
- batch_size: 32
- lr: 0.0001
- random_seed: 0
- gradient_accumulation_steps: 1
- weight_decay: 1e-07
- lr_warmup_step_ratio: 0.3
- max_grad_norm: 1
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/tner/bert-base-tweetner7-all/raw/main/trainer_config.json).
### Reference
If you use the model, please cite T-NER paper and TweetNER7 paper.
- T-NER
```
@inproceedings{ushio-camacho-collados-2021-ner,
title = "{T}-{NER}: An All-Round Python Library for Transformer-based Named Entity Recognition",
author = "Ushio, Asahi and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.eacl-demos.7",
doi = "10.18653/v1/2021.eacl-demos.7",
pages = "53--62",
abstract = "Language model (LM) pretraining has led to consistent improvements in many NLP downstream tasks, including named entity recognition (NER). In this paper, we present T-NER (Transformer-based Named Entity Recognition), a Python library for NER LM finetuning. In addition to its practical utility, T-NER facilitates the study and investigation of the cross-domain and cross-lingual generalization ability of LMs finetuned on NER. Our library also provides a web app where users can get model predictions interactively for arbitrary text, which facilitates qualitative model evaluation for non-expert programmers. We show the potential of the library by compiling nine public NER datasets into a unified format and evaluating the cross-domain and cross- lingual performance across the datasets. The results from our initial experiments show that in-domain performance is generally competitive across datasets. However, cross-domain generalization is challenging even with a large pretrained LM, which has nevertheless capacity to learn domain-specific features if fine- tuned on a combined dataset. To facilitate future research, we also release all our LM checkpoints via the Hugging Face model hub.",
}
```
- TweetNER7
```
@inproceedings{ushio-etal-2022-tweet,
title = "{N}amed {E}ntity {R}ecognition in {T}witter: {A} {D}ataset and {A}nalysis on {S}hort-{T}erm {T}emporal {S}hifts",
author = "Ushio, Asahi and
Neves, Leonardo and
Silva, Vitor and
Barbieri, Francesco. and
Camacho-Collados, Jose",
booktitle = "The 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
gabrielsgaspar/bert-base-uncased-emotions-augmented
|
gabrielsgaspar
| 2022-09-27T15:13:36Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T14:00:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-emotions-augmented
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-emotions-augmented
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9815
- Accuracy: 0.7539
- F1: 0.7506
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8475 | 1.0 | 819 | 0.6336 | 0.7655 | 0.7651 |
| 0.5594 | 2.0 | 1638 | 0.6109 | 0.7695 | 0.7680 |
| 0.4596 | 3.0 | 2457 | 0.6528 | 0.7601 | 0.7556 |
| 0.3663 | 4.0 | 3276 | 0.6992 | 0.7631 | 0.7612 |
| 0.2809 | 5.0 | 4095 | 0.7773 | 0.7571 | 0.7542 |
| 0.2142 | 6.0 | 4914 | 0.8879 | 0.7541 | 0.7504 |
| 0.1671 | 7.0 | 5733 | 0.9476 | 0.7552 | 0.7517 |
| 0.1416 | 8.0 | 6552 | 0.9815 | 0.7539 | 0.7506 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sd-concepts-library/felps
|
sd-concepts-library
| 2022-09-27T15:06:32Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T15:06:26Z |
---
license: mit
---
### Felps on Stable Diffusion
This is the `<Felps>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
anas-awadalla/t5-small-few-shot-k-256-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T14:53:59Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T14:48:53Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-256-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-256-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-256-finetuned-squad-seed-0
|
anas-awadalla
| 2022-09-27T14:46:27Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T14:36:23Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-256-finetuned-squad-seed-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-256-finetuned-squad-seed-0
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-64-finetuned-squad-seed-4
|
anas-awadalla
| 2022-09-27T13:52:23Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T13:49:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-64-finetuned-squad-seed-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-64-finetuned-squad-seed-4
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
Najeen/marian-finetuned-kde4-en-to-fr
|
Najeen
| 2022-09-27T13:50:11Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T02:54:56Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-fr
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-fr
split: train
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 52.83113187001415
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8560
- Bleu: 52.8311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
anas-awadalla/t5-small-few-shot-k-64-finetuned-squad-seed-0
|
anas-awadalla
| 2022-09-27T13:33:36Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T13:21:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-64-finetuned-squad-seed-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-64-finetuned-squad-seed-0
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
WasuratS/Reinforce-cartpole
|
WasuratS
| 2022-09-27T13:11:48Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-27T13:11:40Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 72.90 +/- 16.52
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
bhumikak/resultse
|
bhumikak
| 2022-09-27T12:58:35Z | 98 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:17:00Z |
---
tags:
- generated_from_trainer
model-index:
- name: resultse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resultse
This model is a fine-tuned version of [bhumikak/resultsc](https://huggingface.co/bhumikak/resultsc) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9374
- Rouge2 Precision: 0.3333
- Rouge2 Recall: 0.0476
- Rouge2 Fmeasure: 0.0833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 50
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
anas-awadalla/t5-small-few-shot-k-32-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T12:53:19Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:45:03Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-32-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-32-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
hazzxk/wav2vec2-base-timit-demo-google-colab
|
hazzxk
| 2022-09-27T12:52:42Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-07-25T10:19:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5442
- Wer: 0.3327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.558 | 1.0 | 500 | 1.9825 | 0.9952 |
| 0.8674 | 2.01 | 1000 | 0.5186 | 0.5141 |
| 0.4291 | 3.01 | 1500 | 0.4576 | 0.4590 |
| 0.3008 | 4.02 | 2000 | 0.4906 | 0.4449 |
| 0.2297 | 5.02 | 2500 | 0.4460 | 0.4242 |
| 0.1848 | 6.02 | 3000 | 0.4410 | 0.4013 |
| 0.1552 | 7.03 | 3500 | 0.4632 | 0.3833 |
| 0.1335 | 8.03 | 4000 | 0.4588 | 0.3870 |
| 0.1209 | 9.04 | 4500 | 0.4553 | 0.3751 |
| 0.108 | 10.04 | 5000 | 0.4463 | 0.3752 |
| 0.1011 | 11.04 | 5500 | 0.4730 | 0.3628 |
| 0.0898 | 12.05 | 6000 | 0.4716 | 0.3739 |
| 0.0822 | 13.05 | 6500 | 0.5299 | 0.3696 |
| 0.0702 | 14.06 | 7000 | 0.5478 | 0.3655 |
| 0.0648 | 15.06 | 7500 | 0.5487 | 0.3631 |
| 0.0595 | 16.06 | 8000 | 0.6031 | 0.3566 |
| 0.0567 | 17.07 | 8500 | 0.5375 | 0.3476 |
| 0.0542 | 18.07 | 9000 | 0.5286 | 0.3540 |
| 0.0467 | 19.08 | 9500 | 0.5743 | 0.3574 |
| 0.0419 | 20.08 | 10000 | 0.5855 | 0.3557 |
| 0.0428 | 21.08 | 10500 | 0.5339 | 0.3459 |
| 0.0346 | 22.09 | 11000 | 0.5261 | 0.3399 |
| 0.0312 | 23.09 | 11500 | 0.5699 | 0.3435 |
| 0.0319 | 24.1 | 12000 | 0.5647 | 0.3442 |
| 0.0288 | 25.1 | 12500 | 0.5419 | 0.3404 |
| 0.0247 | 26.1 | 13000 | 0.5388 | 0.3362 |
| 0.0249 | 27.11 | 13500 | 0.5521 | 0.3357 |
| 0.0214 | 28.11 | 14000 | 0.5515 | 0.3307 |
| 0.0235 | 29.12 | 14500 | 0.5442 | 0.3327 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.0
|
IIIT-L/xlm-roberta-large-finetuned-code-mixed-DS
|
IIIT-L
| 2022-09-27T12:44:00Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-13T13:15:49Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-code-mixed-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-code-mixed-DS
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7328
- Accuracy: 0.7022
- Precision: 0.6437
- Recall: 0.6634
- F1: 0.6483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.098 | 0.5 | 248 | 1.0944 | 0.5352 | 0.2355 | 0.3344 | 0.2397 |
| 1.0827 | 1.0 | 496 | 1.0957 | 0.5352 | 0.5789 | 0.3379 | 0.2502 |
| 1.0503 | 1.5 | 744 | 0.9969 | 0.5312 | 0.3621 | 0.4996 | 0.3914 |
| 0.9728 | 2.0 | 992 | 0.8525 | 0.6056 | 0.5096 | 0.5565 | 0.4678 |
| 0.9271 | 2.49 | 1240 | 0.7809 | 0.6378 | 0.6014 | 0.6320 | 0.5963 |
| 0.7977 | 2.99 | 1488 | 0.8290 | 0.5875 | 0.5630 | 0.5918 | 0.5390 |
| 0.752 | 3.49 | 1736 | 0.7684 | 0.7123 | 0.6526 | 0.6610 | 0.6558 |
| 0.6846 | 3.99 | 1984 | 0.7328 | 0.7022 | 0.6437 | 0.6634 | 0.6483 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huynguyen208/bert-base-multilingual-cased-finetuned-ner
|
huynguyen208
| 2022-09-27T12:43:41Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-25T12:10:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-multilingual-cased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-ner
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0247
- Precision: 0.9269
- Recall: 0.9509
- F1: 0.9387
- Accuracy: 0.9945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0744 | 1.0 | 843 | 0.0266 | 0.8945 | 0.9293 | 0.9116 | 0.9920 |
| 0.016 | 2.0 | 1686 | 0.0239 | 0.9279 | 0.9446 | 0.9362 | 0.9942 |
| 0.0075 | 3.0 | 2529 | 0.0247 | 0.9269 | 0.9509 | 0.9387 | 0.9945 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
habib1030/distilbert-base-uncased-finetuned-squad
|
habib1030
| 2022-09-27T12:34:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-09-22T08:49:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.8711
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 5.9634 |
| No log | 2.0 | 2 | 5.9013 |
| No log | 3.0 | 3 | 5.8711 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
anas-awadalla/t5-small-few-shot-k-16-finetuned-squad-seed-4
|
anas-awadalla
| 2022-09-27T12:34:04Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:26:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-16-finetuned-squad-seed-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-16-finetuned-squad-seed-4
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
anas-awadalla/t5-small-few-shot-k-16-finetuned-squad-seed-2
|
anas-awadalla
| 2022-09-27T12:24:59Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T12:18:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: t5-small-few-shot-k-16-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-16-finetuned-squad-seed-2
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
Hoax0930/kyoto_marian_mod_4
|
Hoax0930
| 2022-09-27T11:42:52Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T09:53:18Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_4
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_3](https://huggingface.co/Hoax0930/kyoto_marian_mod_3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8237
- Bleu: 21.5586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Hoax0930/kyoto_marian_mod_2_1
|
Hoax0930
| 2022-09-27T11:09:17Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T09:18:33Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_2_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_2_1
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_2_0](https://huggingface.co/Hoax0930/kyoto_marian_mod_2_0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2568
- Bleu: 20.9923
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
pcuenq/ddpm-ema-pets-64-repeat
|
pcuenq
| 2022-09-27T10:47:43Z | 2 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:pcuenq/oxford-pets",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-09-27T09:05:07Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: pcuenq/oxford-pets
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-ema-pets-64-repeat
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `pcuenq/oxford-pets` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 128
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(0.95, 0.999), weight_decay=1e-06 and epsilon=1e-08
- lr_scheduler: cosine
- lr_warmup_steps: 500
- ema_inv_gamma: 1.0
- ema_inv_gamma: 0.75
- ema_inv_gamma: 0.9999
- mixed_precision: no
### Training results
📈 [TensorBoard logs](https://huggingface.co/pcuenq/ddpm-ema-pets-64-repeat/tensorboard?#scalars)
|
ericntay/stbl_clinical_bert_ft_rs6
|
ericntay
| 2022-09-27T09:57:00Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-09-27T09:38:14Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft_rs6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft_rs6
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0876
- F1: 0.9177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2778 | 1.0 | 101 | 0.0871 | 0.8482 |
| 0.066 | 2.0 | 202 | 0.0700 | 0.8892 |
| 0.031 | 3.0 | 303 | 0.0657 | 0.9053 |
| 0.0152 | 4.0 | 404 | 0.0716 | 0.9057 |
| 0.0099 | 5.0 | 505 | 0.0717 | 0.9105 |
| 0.0049 | 6.0 | 606 | 0.0807 | 0.9145 |
| 0.0042 | 7.0 | 707 | 0.0796 | 0.9140 |
| 0.0028 | 8.0 | 808 | 0.0833 | 0.9140 |
| 0.002 | 9.0 | 909 | 0.0836 | 0.9141 |
| 0.0013 | 10.0 | 1010 | 0.0866 | 0.9177 |
| 0.0011 | 11.0 | 1111 | 0.0867 | 0.9178 |
| 0.001 | 12.0 | 1212 | 0.0876 | 0.9177 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Hoax0930/kyoto_marian_mod_3
|
Hoax0930
| 2022-09-27T09:51:02Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T07:51:11Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_3_5
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_2](https://huggingface.co/Hoax0930/kyoto_marian_mod_2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8052
- Bleu: 18.4305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
bhumikak/resultsd
|
bhumikak
| 2022-09-27T09:46:19Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T09:02:57Z |
---
tags:
- generated_from_trainer
model-index:
- name: resultsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resultsd
This model is a fine-tuned version of [bhumikak/resultsc](https://huggingface.co/bhumikak/resultsc) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5131
- Rouge2 Precision: 0.0278
- Rouge2 Recall: 0.1165
- Rouge2 Fmeasure: 0.0447
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 50
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
hadiqa123/XLS-R_timit_en
|
hadiqa123
| 2022-09-27T09:26:46Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-09-22T05:39:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: XLS-R_timit_en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLS-R_timit_en
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3799
- Wer: 0.3019
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.5228 | 3.3 | 1000 | 0.9889 | 0.8394 |
| 0.6617 | 6.6 | 2000 | 0.3566 | 0.4027 |
| 0.3177 | 9.9 | 3000 | 0.3112 | 0.3606 |
| 0.2262 | 13.2 | 4000 | 0.3521 | 0.3324 |
| 0.1683 | 16.5 | 5000 | 0.3563 | 0.3260 |
| 0.137 | 19.8 | 6000 | 0.3605 | 0.3149 |
| 0.1139 | 23.1 | 7000 | 0.3768 | 0.3069 |
| 0.1068 | 26.4 | 8000 | 0.3643 | 0.3044 |
| 0.0897 | 29.7 | 9000 | 0.3799 | 0.3019 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.13.0
|
sd-concepts-library/fzk
|
sd-concepts-library
| 2022-09-27T08:21:31Z | 0 | 2 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T08:21:24Z |
---
license: mit
---
### fzk on Stable Diffusion
This is the `<fzk>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








|
crescendonow/pwa_categorical_complaint
|
crescendonow
| 2022-09-27T07:42:44Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-27T07:24:36Z |
---
license: apache-2.0
---
This Model finetunes from WangchanBERTa ("wangchanberta-base-att-spm-uncased") uses only the Provincial Waterworks Authority of Thailand.
The Model classification into ten categories describe by the dictionary are
{'ข้อร้องเรียน-ปริมาณน้ำ':[11,0],
'ข้อร้องเรียน-ท่อแตกรั่ว':[12,1],
'ข้อร้องเรียน-คุณภาพน้ำ':[13,2],
'ข้อร้องเรียน-การบริการ':[14,3],
'ข้อร้องเรียน-บุคลากร':[15,4],
'ข้อสอบถามทั่วไป':[2,5],
'ข้อเสนอแนะ':[3,6],
'ข้อคิดเห็น':[4,7],
'อื่นๆ':[8,8],
'ไม่เกี่ยวข้องกับกปภ.':[9,9]}
|
Hoax0930/kyoto_marian_mod_2
|
Hoax0930
| 2022-09-27T07:05:14Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-09-27T05:11:18Z |
---
license: apache-2.0
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: kyoto_marian_mod_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_2
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_1](https://huggingface.co/Hoax0930/kyoto_marian_mod_1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7472
- Bleu: 20.8730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
bhumikak/resultsc
|
bhumikak
| 2022-09-27T06:52:43Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-09-27T06:08:50Z |
---
tags:
- generated_from_trainer
model-index:
- name: resultsc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resultsc
This model is a fine-tuned version of [bhumikak/resultsb](https://huggingface.co/bhumikak/resultsb) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0809
- Rouge2 Precision: 0.0198
- Rouge2 Recall: 0.1471
- Rouge2 Fmeasure: 0.035
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 50
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
huggingtweets/naval-rossimiano-vancityreynolds
|
huggingtweets
| 2022-09-27T05:41:39Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-27T05:41:32Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1550158420988153856/OUoCVt_b_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1256841238298292232/ycqwaMI2_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1299844050208555008/7wMQaJRA_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ross Massimiano, DVM & Naval & Ryan Reynolds</div>
<div style="text-align: center; font-size: 14px;">@naval-rossimiano-vancityreynolds</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ross Massimiano, DVM & Naval & Ryan Reynolds.
| Data | Ross Massimiano, DVM | Naval | Ryan Reynolds |
| --- | --- | --- | --- |
| Tweets downloaded | 1324 | 3248 | 3131 |
| Retweets | 203 | 186 | 311 |
| Short tweets | 130 | 621 | 474 |
| Tweets kept | 991 | 2441 | 2346 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1cyg1mxb/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @naval-rossimiano-vancityreynolds's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/e9lwjbuc) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/e9lwjbuc/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/naval-rossimiano-vancityreynolds')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
albertdestajo/distilbert-base-uncased-finetuned-mrpc
|
albertdestajo
| 2022-09-27T05:40:59Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T18:31:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: train
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.7916666666666666
- name: F1
type: f1
value: 0.8608837970540099
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4502
- Accuracy: 0.7917
- F1: 0.8609
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4474 | 1.0 | 230 | 0.4502 | 0.7917 | 0.8609 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
huggingtweets/rossimiano
|
huggingtweets
| 2022-09-27T05:26:34Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-24T04:09:09Z |
---
language: en
thumbnail: http://www.huggingtweets.com/rossimiano/1664256351634/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1550158420988153856/OUoCVt_b_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ross Massimiano, DVM</div>
<div style="text-align: center; font-size: 14px;">@rossimiano</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ross Massimiano, DVM.
| Data | Ross Massimiano, DVM |
| --- | --- |
| Tweets downloaded | 1324 |
| Retweets | 203 |
| Short tweets | 130 |
| Tweets kept | 991 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/312h1q2v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rossimiano's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1vljawam) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1vljawam/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rossimiano')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
kerkathy/distilbert-base-uncased-finetuned-imdb
|
kerkathy
| 2022-09-27T04:57:38Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-27T04:50:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4898 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
VietAI/gptho
|
VietAI
| 2022-09-27T04:48:32Z | 139 | 9 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"causal-lm",
"gpt",
"vi",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-09-26T03:23:24Z |
---
language:
- vi
tags:
- pytorch
- causal-lm
- gpt
widget:
- text: "<|endoftext|> thu sang "
---
# How to prompt?
Type:
```
<|endoftext|> + your_prompt + [space]
```
### Example:
```
<|endoftext|> thu sang + [space]
```
|
Ricardmc99/Reinforce-CartPole-v1
|
Ricardmc99
| 2022-09-27T03:46:36Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-09-27T03:45:38Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 90.30 +/- 49.35
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
sd-concepts-library/crbart
|
sd-concepts-library
| 2022-09-27T00:25:07Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-27T00:25:03Z |
---
license: mit
---
### <crbart> on Stable Diffusion
This is the `<crbart>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
itchy/donut-base-sroie
|
itchy
| 2022-09-27T00:19:22Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-09-08T00:34:43Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.13.0
|
sd-concepts-library/duranduran
|
sd-concepts-library
| 2022-09-26T23:19:26Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T23:19:19Z |
---
license: mit
---
### DuranDuran on Stable Diffusion
This is the `DuranDuran` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
sd-concepts-library/medazzaland
|
sd-concepts-library
| 2022-09-26T23:15:43Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T23:15:36Z |
---
license: mit
---
### Medazzaland on Stable Diffusion
This is the `Medazzaland` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
IIIT-L/xlm-roberta-large-finetuned-TRAC-DS-new
|
IIIT-L
| 2022-09-26T22:32:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-26T16:48:31Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-TRAC-DS-new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-TRAC-DS-new
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2229
- Accuracy: 0.6724
- Precision: 0.6503
- Recall: 0.6556
- F1: 0.6513
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0895 | 0.25 | 612 | 1.0893 | 0.4453 | 0.3220 | 0.4654 | 0.3554 |
| 1.0788 | 0.5 | 1224 | 1.1051 | 0.4436 | 0.1479 | 0.3333 | 0.2049 |
| 1.0567 | 0.75 | 1836 | 0.9507 | 0.5637 | 0.4176 | 0.4948 | 0.4279 |
| 1.0052 | 1.0 | 2448 | 0.9716 | 0.4665 | 0.4913 | 0.5106 | 0.4324 |
| 0.9862 | 1.25 | 3060 | 0.9160 | 0.5719 | 0.5824 | 0.5851 | 0.5517 |
| 0.9428 | 1.5 | 3672 | 0.9251 | 0.5645 | 0.5838 | 0.5903 | 0.5386 |
| 0.9381 | 1.75 | 4284 | 0.9212 | 0.6307 | 0.6031 | 0.6091 | 0.6053 |
| 0.9124 | 2.0 | 4896 | 0.8897 | 0.6054 | 0.6078 | 0.6169 | 0.5895 |
| 0.9558 | 2.25 | 5508 | 0.8576 | 0.6283 | 0.6330 | 0.6077 | 0.6094 |
| 0.8814 | 2.5 | 6120 | 0.9458 | 0.6520 | 0.6357 | 0.6270 | 0.6286 |
| 0.8697 | 2.75 | 6732 | 0.8928 | 0.6381 | 0.6304 | 0.6259 | 0.6228 |
| 0.9142 | 3.0 | 7344 | 0.8542 | 0.6225 | 0.6227 | 0.6272 | 0.6124 |
| 0.825 | 3.25 | 7956 | 0.9639 | 0.6577 | 0.6491 | 0.6089 | 0.6093 |
| 0.84 | 3.5 | 8568 | 0.8980 | 0.6266 | 0.6309 | 0.6169 | 0.6130 |
| 0.8505 | 3.75 | 9180 | 0.9127 | 0.6503 | 0.6197 | 0.6130 | 0.6154 |
| 0.8287 | 4.0 | 9792 | 0.9343 | 0.6683 | 0.6515 | 0.6527 | 0.6488 |
| 0.7772 | 4.25 | 10404 | 1.0434 | 0.6650 | 0.6461 | 0.6454 | 0.6437 |
| 0.8217 | 4.5 | 11016 | 0.9760 | 0.6724 | 0.6574 | 0.6550 | 0.6533 |
| 0.7543 | 4.75 | 11628 | 1.0790 | 0.6454 | 0.6522 | 0.6342 | 0.6327 |
| 0.7868 | 5.0 | 12240 | 1.1457 | 0.6708 | 0.6519 | 0.6445 | 0.6463 |
| 0.8093 | 5.25 | 12852 | 1.1714 | 0.6716 | 0.6517 | 0.6525 | 0.6509 |
| 0.8032 | 5.5 | 13464 | 1.1882 | 0.6691 | 0.6480 | 0.6542 | 0.6489 |
| 0.7511 | 5.75 | 14076 | 1.2113 | 0.6650 | 0.6413 | 0.6458 | 0.6429 |
| 0.7698 | 6.0 | 14688 | 1.2229 | 0.6724 | 0.6503 | 0.6556 | 0.6513 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
arinakos/wolves_and_bears
|
arinakos
| 2022-09-26T22:25:51Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-09-26T21:10:36Z |
---
title: Pet classifier!
emoji: 🐶
colorFrom: pink
colorTo: blue
sdk: gradio
sdk_version: 3.1.1
app_file: app.py
pinned: true
license: apache-2.0
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
|
sd-concepts-library/kawaii-girl-plus-style
|
sd-concepts-library
| 2022-09-26T22:22:28Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-09-26T22:22:20Z |
---
license: mit
---
### kawaii_girl_plus_style on Stable Diffusion
This is the `<kawaii_girl>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






































|
tcsenpai/FapMachine
|
tcsenpai
| 2022-09-26T21:18:39Z | 5 | 0 |
tf-keras
|
[
"tf-keras",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2022-09-26T20:56:15Z |
---
license: cc-by-nc-4.0
---
# FapMachine Alpha
## An experiment on training a model by feeding the network with data created by another AI
### Description
FapMachine is an experiment, as stated above, with the goal of recognizing naked or dressed women without being feeded with any real world image. Be aware: it can be considered NSFW even if there are no NSFW images included.
### Dataset used
50 Images of naked women generated by Stable Diffusion (through DiffusionBee)
50 Images of dressed women generated by Stable Diffusion (through DiffusionBee)
### Training method
Liner.ai training with Image Classification mode
### Type of network
EfficientNet with Early Stop, 1000 iterations
### Result
70% Accuracy and 0.3 loss values
### How to test
You can clone this repository and rename 20d.png as image.png or use any image you want renaming it as image.png, then run the python file to see the prediction result
### Disclaimer
This model is intended to show the possibility of autofeeding a network with ai generated data
|
ColdFellow/kcorona
|
ColdFellow
| 2022-09-26T20:17:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-09-26T20:15:02Z |
https://photos.google.com/photo/AF1QipOr5Mq84sMC
https://photos.google.com/photo/AF1QipPbeoSDESDMrm_R6YqXK2hrjGN5FNtQYHHGOUYPjtcOMRHST8xtTRg8slUvbG0mfw
https://photos.google.com/photo/AF1QipN26lOKK6ZvaHyq8m52N-6SWdSqoLp7xMf53Go
|
enaserian/distilbert-base-uncased-finetuned
|
enaserian
| 2022-09-26T20:11:39Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-23T10:58:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.2813
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.6309 | 1.0 | 76 | 7.4774 |
| 7.0806 | 2.0 | 152 | 6.9937 |
| 6.6842 | 3.0 | 228 | 6.9314 |
| 6.4592 | 4.0 | 304 | 6.9088 |
| 6.2936 | 5.0 | 380 | 6.9135 |
| 6.1301 | 6.0 | 456 | 6.9018 |
| 5.9878 | 7.0 | 532 | 6.8865 |
| 5.8071 | 8.0 | 608 | 6.8926 |
| 5.6372 | 9.0 | 684 | 6.8750 |
| 5.4791 | 10.0 | 760 | 6.9394 |
| 5.3365 | 11.0 | 836 | 6.9594 |
| 5.2117 | 12.0 | 912 | 6.9962 |
| 5.0887 | 13.0 | 988 | 7.0570 |
| 4.9288 | 14.0 | 1064 | 7.0549 |
| 4.8169 | 15.0 | 1140 | 7.0971 |
| 4.7008 | 16.0 | 1216 | 7.1439 |
| 4.6149 | 17.0 | 1292 | 7.1320 |
| 4.487 | 18.0 | 1368 | 7.1577 |
| 4.364 | 19.0 | 1444 | 7.1712 |
| 4.3208 | 20.0 | 1520 | 7.1959 |
| 4.2492 | 21.0 | 1596 | 7.2136 |
| 4.1423 | 22.0 | 1672 | 7.2304 |
| 4.0873 | 23.0 | 1748 | 7.2526 |
| 4.0261 | 24.0 | 1824 | 7.2681 |
| 3.9598 | 25.0 | 1900 | 7.2715 |
| 3.9562 | 26.0 | 1976 | 7.2648 |
| 3.8951 | 27.0 | 2052 | 7.2665 |
| 3.8772 | 28.0 | 2128 | 7.2781 |
| 3.8403 | 29.0 | 2204 | 7.2801 |
| 3.8275 | 30.0 | 2280 | 7.2813 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.