
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 00:41:42
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 00:40:24
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
dreamboat26/q-FrozenLake-v1-4x4-noSlippery
|
dreamboat26
| 2023-08-04T07:40:02Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T07:39:57Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dreamboat26/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
TariqJamil/falcon-7b-instruct-peft-qlora-my_finetuned_model-0721EV
|
TariqJamil
| 2023-08-04T07:32:00Z | 3 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-04T07:31:52Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
WildXbird/TranslateGLM
|
WildXbird
| 2023-08-04T07:28:24Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-08-04T07:22:16Z |
# TranslateGLM
TranslateGLM 是一个基于 ChatGLM2-6B 模型微调的中英文翻译器,可以实现高质量的双向翻译。
使用265万个样本进行了 [P-Tuning v2](https://github.com/THUDM/P-tuning-v2) 的微调,微调的样本的例子可以参考 [validation_file.txt](https://github.com/WildXBird/TranslateGLM/blob/main/validation_file.txt) 中的内容。
微调过后的模型,在可以很好的充当翻译器的同时仍然可以正常的进行聊天对话。
ChatGLM2-6B 是一个开源的、支持中英问答的对话语言模型,基于 General Language Model (GLM) 架构,具有约 60 亿参数。


## 功能
- 支持中文和英文之间的双向翻译
- 支持OpenAI格式的API和网页端的交互式翻译
- 支持调整输出结果随机度
- 支持翻译结果和原文对照查看
- 正常对话(仅限使用OpenAI格式的API)
## 安装
要运行本项目,你需要安装以下软件依赖:
```
yarn
cd ./glm
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets
```
## 使用
### 启动翻译器
你可以通过如下命令启动翻译器的OpenAI格式的API:
```
python ./glm/openai_api.py
```
你可以通过如下命令启动翻译器的前端UI:
*启动UI前必须先启动上面的API*
```
yarn start
```
在浏览器中访问 http://localhost:3000/ ,然后输入你想要翻译的文本即可自动翻译。
### 正常的进行聊天对话
你可以通过如下命令启动传统的web demo对话,但只能进行普通对话:
```
python ./glm/web_demo.py
```
你可以通过如上面的“OpenAI格式的API”进行正常对话,使用方式和普通的调用方法无异:
```
python ./glm/openai_api.py
```
## 翻译UI
翻译UI暂时不支持指定输入语言,输入的语言的自动判断是中文还是英文,然后自动翻译成另一种语言。
翻译UI可以指定翻译结果的随机性,分为**保守**、**平衡**、**灵活**和**发散**。
分别代表着temperature从低(保守)到高(创意),对于较复杂的语法,更高的temperature更能准确的翻译,但也可能导致他误解某些含义。
把鼠标悬停在翻译结果上,可以查看翻译的原文以及原文在输入中的位置。
## 更新
**2023-8-2 (alpha-2)**
1. 加入了短篇新闻的对照翻译样本进行了重新训练。
2. 经过简单测试发现在丢失信息方面有了显著的改善,即原文中的某些描述或者修饰在翻译的结果中会被无视,在句子稍长的情况下尤为明显。
3. 在“发散”下,可能会把翻译当成对话进行回答的问题(例如某个句子以:结尾),经过简单测试发现有了显著的改善。
4. 考虑到 “3”的问题改善了,在随机性选项改成了4个。
## 已知问题
1. 中英文数字表达转换存在错误(非常常见)
2. 会出现英文中文互相穿插(罕见)
3. 会出现完全无关的翻译结果(罕见)
4. 原文中的某段描述或者某些修饰在翻译的结果中会被无视(常见)
|
emo-nlp/7-emo
|
emo-nlp
| 2023-08-04T07:27:57Z | 145 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-04T07:13:19Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
- recall
- f1
model-index:
- name: train
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6648
- Accuracy: 0.7617
- B Acc: 0.6394
- Prec: 0.7595
- Recall: 0.7617
- F1: 0.7602
- Prec Joy: 0.7315
- Recall Joy: 0.7793
- F1 Joy: 0.7547
- Prec Anger: 0.6467
- Recall Anger: 0.6507
- F1 Anger: 0.6487
- Prec Disgust: 0.4710
- Recall Disgust: 0.45
- F1 Disgust: 0.4603
- Prec Fear: 0.6963
- Recall Fear: 0.6409
- F1 Fear: 0.6675
- Prec Neutral: 0.8457
- Recall Neutral: 0.8490
- F1 Neutral: 0.8474
- Prec Sadness: 0.7094
- Recall Sadness: 0.6738
- F1 Sadness: 0.6911
- Prec Surprise: 0.5228
- Recall Surprise: 0.4323
- F1 Surprise: 0.4732
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | B Acc | Prec | Recall | F1 | Prec Joy | Recall Joy | F1 Joy | Prec Anger | Recall Anger | F1 Anger | Prec Disgust | Recall Disgust | F1 Disgust | Prec Fear | Recall Fear | F1 Fear | Prec Neutral | Recall Neutral | F1 Neutral | Prec Sadness | Recall Sadness | F1 Sadness | Prec Surprise | Recall Surprise | F1 Surprise |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:------:|:------:|:--------:|:----------:|:------:|:----------:|:------------:|:--------:|:------------:|:--------------:|:----------:|:---------:|:-----------:|:-------:|:------------:|:--------------:|:----------:|:------------:|:--------------:|:----------:|:-------------:|:---------------:|:-----------:|
| 0.9538 | 0.15 | 232 | 0.8701 | 0.6961 | 0.4790 | 0.6837 | 0.6961 | 0.6837 | 0.7401 | 0.6381 | 0.6853 | 0.4622 | 0.5391 | 0.4977 | 0.25 | 0.0018 | 0.0035 | 0.5527 | 0.4292 | 0.4832 | 0.7965 | 0.8618 | 0.8279 | 0.5281 | 0.6431 | 0.5800 | 0.3562 | 0.2398 | 0.2866 |
| 0.7952 | 0.3 | 464 | 0.8010 | 0.7168 | 0.5242 | 0.7098 | 0.7168 | 0.7025 | 0.8084 | 0.5948 | 0.6853 | 0.5732 | 0.4710 | 0.5171 | 0.4713 | 0.2643 | 0.3387 | 0.6156 | 0.5263 | 0.5675 | 0.7405 | 0.9250 | 0.8226 | 0.6858 | 0.5676 | 0.6211 | 0.4448 | 0.3204 | 0.3725 |
| 0.7528 | 0.45 | 696 | 0.7560 | 0.7261 | 0.5878 | 0.7309 | 0.7261 | 0.7256 | 0.6969 | 0.7646 | 0.7292 | 0.5550 | 0.5534 | 0.5542 | 0.3409 | 0.4821 | 0.3994 | 0.7225 | 0.4842 | 0.5798 | 0.8476 | 0.8159 | 0.8314 | 0.6118 | 0.7027 | 0.6541 | 0.4957 | 0.3118 | 0.3828 |
| 0.7334 | 0.6 | 928 | 0.7310 | 0.7370 | 0.5868 | 0.7345 | 0.7370 | 0.7283 | 0.7170 | 0.7458 | 0.7311 | 0.7129 | 0.4116 | 0.5219 | 0.3727 | 0.5696 | 0.4506 | 0.6671 | 0.5626 | 0.6104 | 0.7898 | 0.8859 | 0.8351 | 0.7318 | 0.5844 | 0.6499 | 0.5252 | 0.3473 | 0.4181 |
| 0.7216 | 0.75 | 1160 | 0.7043 | 0.7448 | 0.6009 | 0.7403 | 0.7448 | 0.7389 | 0.7767 | 0.6826 | 0.7266 | 0.6159 | 0.5386 | 0.5746 | 0.5302 | 0.4393 | 0.4805 | 0.8023 | 0.5602 | 0.6598 | 0.7854 | 0.8926 | 0.8356 | 0.7005 | 0.632 | 0.6645 | 0.4815 | 0.4613 | 0.4712 |
| 0.7259 | 0.9 | 1392 | 0.6962 | 0.7475 | 0.6082 | 0.7433 | 0.7475 | 0.7412 | 0.7355 | 0.7586 | 0.7469 | 0.6758 | 0.4504 | 0.5405 | 0.3908 | 0.5589 | 0.4600 | 0.6939 | 0.6070 | 0.6475 | 0.8122 | 0.8744 | 0.8421 | 0.6830 | 0.6676 | 0.6752 | 0.5494 | 0.3409 | 0.4207 |
| 0.6362 | 1.05 | 1624 | 0.6771 | 0.7526 | 0.6055 | 0.7472 | 0.7526 | 0.7484 | 0.7392 | 0.7483 | 0.7437 | 0.5873 | 0.6191 | 0.6028 | 0.5302 | 0.3768 | 0.4405 | 0.7388 | 0.5789 | 0.6492 | 0.8213 | 0.8670 | 0.8435 | 0.7090 | 0.6507 | 0.6786 | 0.5301 | 0.3978 | 0.4545 |
| 0.621 | 1.2 | 1856 | 0.6779 | 0.7528 | 0.6120 | 0.7494 | 0.7528 | 0.7487 | 0.7107 | 0.7828 | 0.7450 | 0.6508 | 0.5913 | 0.6196 | 0.4980 | 0.4518 | 0.4738 | 0.7963 | 0.5532 | 0.6529 | 0.8165 | 0.8590 | 0.8372 | 0.7499 | 0.6236 | 0.6809 | 0.5078 | 0.4226 | 0.4613 |
| 0.6241 | 1.35 | 2088 | 0.6849 | 0.7513 | 0.6367 | 0.7526 | 0.7513 | 0.7514 | 0.7429 | 0.7592 | 0.7510 | 0.5795 | 0.6531 | 0.6141 | 0.4372 | 0.4661 | 0.4512 | 0.6462 | 0.6515 | 0.6488 | 0.8492 | 0.8372 | 0.8432 | 0.6887 | 0.6609 | 0.6745 | 0.5271 | 0.4290 | 0.4730 |
| 0.6188 | 1.5 | 2320 | 0.6713 | 0.7579 | 0.6159 | 0.7539 | 0.7579 | 0.7534 | 0.7071 | 0.7971 | 0.7494 | 0.6343 | 0.6267 | 0.6305 | 0.5877 | 0.3768 | 0.4592 | 0.7247 | 0.6281 | 0.6729 | 0.8361 | 0.8496 | 0.8428 | 0.6943 | 0.6693 | 0.6816 | 0.5919 | 0.3634 | 0.4504 |
| 0.6182 | 1.65 | 2552 | 0.6608 | 0.7601 | 0.6199 | 0.7567 | 0.7601 | 0.7566 | 0.7143 | 0.7891 | 0.7498 | 0.6163 | 0.6358 | 0.6259 | 0.5607 | 0.3875 | 0.4583 | 0.7591 | 0.6082 | 0.6753 | 0.8375 | 0.8578 | 0.8475 | 0.7324 | 0.6436 | 0.6851 | 0.5381 | 0.4172 | 0.4700 |
| 0.6392 | 1.8 | 2784 | 0.6542 | 0.7624 | 0.6261 | 0.7593 | 0.7624 | 0.7596 | 0.7513 | 0.7584 | 0.7548 | 0.5970 | 0.6708 | 0.6318 | 0.5711 | 0.3875 | 0.4617 | 0.7482 | 0.6152 | 0.6752 | 0.8379 | 0.8635 | 0.8505 | 0.7076 | 0.668 | 0.6872 | 0.5132 | 0.4194 | 0.4615 |
| 0.6158 | 1.95 | 3016 | 0.6456 | 0.7649 | 0.6279 | 0.7599 | 0.7649 | 0.7614 | 0.7490 | 0.7548 | 0.7519 | 0.6402 | 0.6378 | 0.6390 | 0.5314 | 0.4232 | 0.4712 | 0.7569 | 0.6117 | 0.6766 | 0.8310 | 0.8753 | 0.8526 | 0.7199 | 0.6627 | 0.6901 | 0.5063 | 0.4301 | 0.4651 |
| 0.554 | 2.1 | 3248 | 0.6742 | 0.7584 | 0.6346 | 0.7555 | 0.7584 | 0.7564 | 0.7293 | 0.7732 | 0.7506 | 0.6433 | 0.6430 | 0.6432 | 0.5031 | 0.4393 | 0.4690 | 0.7292 | 0.6363 | 0.6796 | 0.8347 | 0.8496 | 0.8421 | 0.7163 | 0.6587 | 0.6863 | 0.5049 | 0.4419 | 0.4713 |
| 0.5537 | 2.25 | 3480 | 0.6708 | 0.7633 | 0.6283 | 0.7604 | 0.7633 | 0.7605 | 0.7263 | 0.7801 | 0.7523 | 0.6304 | 0.6612 | 0.6455 | 0.5806 | 0.3732 | 0.4543 | 0.7486 | 0.6094 | 0.6718 | 0.8442 | 0.8528 | 0.8485 | 0.6982 | 0.692 | 0.6951 | 0.5356 | 0.4290 | 0.4764 |
| 0.5375 | 2.4 | 3712 | 0.6712 | 0.7606 | 0.6402 | 0.7592 | 0.7606 | 0.7595 | 0.7373 | 0.7709 | 0.7537 | 0.6245 | 0.6608 | 0.6421 | 0.4827 | 0.4482 | 0.4648 | 0.7319 | 0.6257 | 0.6747 | 0.8454 | 0.8474 | 0.8464 | 0.7006 | 0.6769 | 0.6885 | 0.5204 | 0.4516 | 0.4836 |
| 0.5175 | 2.55 | 3944 | 0.6625 | 0.7625 | 0.6369 | 0.7600 | 0.7625 | 0.7604 | 0.7422 | 0.7642 | 0.7530 | 0.6335 | 0.6526 | 0.6429 | 0.4481 | 0.4929 | 0.4694 | 0.7482 | 0.6187 | 0.6773 | 0.8374 | 0.8604 | 0.8488 | 0.7252 | 0.6684 | 0.6957 | 0.5321 | 0.4011 | 0.4574 |
| 0.5182 | 2.7 | 4176 | 0.6621 | 0.7631 | 0.6404 | 0.7602 | 0.7631 | 0.7612 | 0.7343 | 0.7766 | 0.7549 | 0.6491 | 0.6392 | 0.6441 | 0.4739 | 0.4536 | 0.4635 | 0.6784 | 0.6538 | 0.6659 | 0.8444 | 0.8529 | 0.8486 | 0.7109 | 0.684 | 0.6972 | 0.5458 | 0.4226 | 0.4764 |
| 0.5148 | 2.85 | 4408 | 0.6638 | 0.7637 | 0.6383 | 0.7598 | 0.7637 | 0.7612 | 0.7394 | 0.7741 | 0.7563 | 0.6741 | 0.6205 | 0.6462 | 0.5 | 0.4375 | 0.4667 | 0.6813 | 0.6550 | 0.6679 | 0.8400 | 0.8572 | 0.8485 | 0.6922 | 0.6916 | 0.6919 | 0.5296 | 0.4323 | 0.4760 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
lesliepzimmermann/rl_course_vizdoom_health_gathering_supreme
|
lesliepzimmermann
| 2023-08-04T07:27:22Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T06:26:57Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.76 +/- 4.75
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r lesliepzimmermann/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
ngeg2015/opt-2.7b-lora
|
ngeg2015
| 2023-08-04T07:16:25Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-04T07:16:14Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
ketong3906/my_awesome_model_classification
|
ketong3906
| 2023-08-04T07:10:39Z | 111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-26T02:33:54Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: my_awesome_model_classification
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train[:300]
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model_classification
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0031
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 15 | 0.0163 | 1.0 |
| No log | 2.0 | 30 | 0.0031 | 1.0 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.0
- Tokenizers 0.13.3
|
scarlett623/wav2vec2-large-xlsr53-zh-cn-subset20-colab
|
scarlett623
| 2023-08-04T06:34:21Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"base_model:facebook/wav2vec2-large-xlsr-53",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-03T16:11:34Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
datasets:
- common_voice
metrics:
- wer
model-index:
- name: wav2vec2-large-xlsr53-zh-cn-subset20-colab
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice
type: common_voice
config: zh-CN
split: test[:20%]
args: zh-CN
metrics:
- name: Wer
type: wer
value: 0.9503424657534246
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr53-zh-cn-subset20-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0566
- Wer: 0.9503
- Cer: 0.3333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 13
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 26
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| No log | 1.9 | 400 | 6.7551 | 1.0 | 1.0 |
| 34.7845 | 3.81 | 800 | 6.4563 | 1.0 | 1.0 |
| 6.4358 | 5.71 | 1200 | 4.2319 | 1.0074 | 0.7454 |
| 4.2052 | 7.62 | 1600 | 2.6538 | 1.0200 | 0.5562 |
| 2.3906 | 9.52 | 2000 | 2.3565 | 1.0063 | 0.5147 |
| 2.3906 | 11.43 | 2400 | 2.1287 | 0.9863 | 0.4822 |
| 1.93 | 13.33 | 2800 | 1.9585 | 0.9812 | 0.4528 |
| 1.6322 | 15.24 | 3200 | 1.8771 | 0.9937 | 0.4381 |
| 1.3629 | 17.14 | 3600 | 1.8405 | 0.9926 | 0.4242 |
| 1.166 | 19.05 | 4000 | 1.7674 | 0.9989 | 0.4140 |
| 1.166 | 20.95 | 4400 | 1.7879 | 0.9795 | 0.4047 |
| 0.9915 | 22.86 | 4800 | 1.7597 | 1.0126 | 0.4080 |
| 0.8517 | 24.76 | 5200 | 1.7726 | 0.9829 | 0.3966 |
| 0.7143 | 26.67 | 5600 | 1.7623 | 0.9732 | 0.3863 |
| 0.6267 | 28.57 | 6000 | 1.8164 | 0.9720 | 0.3863 |
| 0.6267 | 30.48 | 6400 | 1.8136 | 0.9680 | 0.3801 |
| 0.5389 | 32.38 | 6800 | 1.8696 | 0.9652 | 0.3812 |
| 0.4764 | 34.29 | 7200 | 1.8625 | 0.9663 | 0.3744 |
| 0.4095 | 36.19 | 7600 | 1.8868 | 0.9618 | 0.3683 |
| 0.3594 | 38.1 | 8000 | 1.8834 | 0.9623 | 0.3699 |
| 0.3594 | 40.0 | 8400 | 1.9155 | 0.9589 | 0.3670 |
| 0.3064 | 41.9 | 8800 | 1.9268 | 0.9652 | 0.3688 |
| 0.2825 | 43.81 | 9200 | 1.9527 | 0.9697 | 0.3674 |
| 0.2524 | 45.71 | 9600 | 1.9726 | 0.9686 | 0.3617 |
| 0.2272 | 47.62 | 10000 | 1.9594 | 0.9629 | 0.3619 |
| 0.2272 | 49.52 | 10400 | 1.9799 | 0.9635 | 0.3607 |
| 0.2042 | 51.43 | 10800 | 2.0175 | 0.9669 | 0.3582 |
| 0.1975 | 53.33 | 11200 | 2.0246 | 0.9589 | 0.3571 |
| 0.1827 | 55.24 | 11600 | 2.0535 | 0.9703 | 0.3600 |
| 0.1677 | 57.14 | 12000 | 2.0458 | 0.9583 | 0.3555 |
| 0.1677 | 59.05 | 12400 | 2.0893 | 0.9572 | 0.3583 |
| 0.1626 | 60.95 | 12800 | 2.0729 | 0.9600 | 0.3557 |
| 0.155 | 62.86 | 13200 | 2.0706 | 0.9572 | 0.3538 |
| 0.1456 | 64.76 | 13600 | 2.0761 | 0.9532 | 0.3553 |
| 0.1337 | 66.67 | 14000 | 2.0349 | 0.9589 | 0.3474 |
| 0.1337 | 68.57 | 14400 | 2.0844 | 0.9549 | 0.3484 |
| 0.1274 | 70.48 | 14800 | 2.0874 | 0.9578 | 0.3505 |
| 0.1198 | 72.38 | 15200 | 2.0813 | 0.9526 | 0.3473 |
| 0.1164 | 74.29 | 15600 | 2.0866 | 0.9498 | 0.3473 |
| 0.1105 | 76.19 | 16000 | 2.0688 | 0.9486 | 0.3421 |
| 0.1105 | 78.1 | 16400 | 2.0854 | 0.9498 | 0.3431 |
| 0.1053 | 80.0 | 16800 | 2.0749 | 0.9503 | 0.3414 |
| 0.1 | 81.9 | 17200 | 2.0622 | 0.9543 | 0.3407 |
| 0.0977 | 83.81 | 17600 | 2.0678 | 0.9532 | 0.3396 |
| 0.0906 | 85.71 | 18000 | 2.0650 | 0.9515 | 0.3383 |
| 0.0906 | 87.62 | 18400 | 2.0631 | 0.9492 | 0.3378 |
| 0.0867 | 89.52 | 18800 | 2.0633 | 0.9521 | 0.3365 |
| 0.0836 | 91.43 | 19200 | 2.0606 | 0.9532 | 0.3346 |
| 0.0819 | 93.33 | 19600 | 2.0671 | 0.9538 | 0.3355 |
| 0.0768 | 95.24 | 20000 | 2.0661 | 0.9509 | 0.3338 |
| 0.0768 | 97.14 | 20400 | 2.0564 | 0.9498 | 0.3335 |
| 0.0752 | 99.05 | 20800 | 2.0566 | 0.9503 | 0.3333 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
dkimds/ppo-Huggy
|
dkimds
| 2023-08-04T06:34:08Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-08-04T06:33:57Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: dkimds/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
MattStammers/CartPole-v1-take2
|
MattStammers
| 2023-08-04T06:31:08Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T06:27:59Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1-take2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
terru3/dqn-SpaceInvadersNoFrameskip-v4-test
|
terru3
| 2023-08-04T05:56:20Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T05:55:44Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 671.50 +/- 174.67
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga terru3 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga terru3 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga terru3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
Okrad/llama2-qlora-finetunined-french
|
Okrad
| 2023-08-04T05:45:08Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-04T05:45:03Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
Shu-Kun/Betelgeuse_Romanee_Conti
|
Shu-Kun
| 2023-08-04T05:40:45Z | 0 | 0 | null |
[
"ja",
"license:openrail",
"region:us"
] | null | 2023-07-22T03:24:44Z |
---
license: openrail
language:
- ja
---
|
Braulio0316/Bea10
|
Braulio0316
| 2023-08-04T05:31:43Z | 0 | 0 |
asteroid
|
[
"asteroid",
"legal",
"visual-question-answering",
"dataset:Open-Orca/OpenOrca",
"license:creativeml-openrail-m",
"region:us"
] |
visual-question-answering
| 2023-08-04T05:13:15Z |
---
license: creativeml-openrail-m
datasets:
- Open-Orca/OpenOrca
metrics:
- bertscore
library_name: asteroid
pipeline_tag: visual-question-answering
tags:
- legal
---
|
jordyvl/dit-base-tiny_rvl_cdip-NK1000_hint
|
jordyvl
| 2023-08-04T05:31:01Z | 164 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-08-03T09:07:50Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: dit-base-tiny_rvl_cdip-NK1000_hint
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dit-base-tiny_rvl_cdip-NK1000_hint
This model is a fine-tuned version of [WinKawaks/vit-tiny-patch16-224](https://huggingface.co/WinKawaks/vit-tiny-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5793
- Accuracy: 0.8185
- Brier Loss: 0.3293
- Nll: 2.0402
- F1 Micro: 0.8185
- F1 Macro: 0.8184
- Ece: 0.1589
- Aurc: 0.0584
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| 2.7601 | 1.0 | 1000 | 2.6212 | 0.5952 | 0.5281 | 2.4218 | 0.5952 | 0.5899 | 0.0529 | 0.1801 |
| 2.236 | 2.0 | 2000 | 2.1744 | 0.6847 | 0.4219 | 2.1650 | 0.6847 | 0.6827 | 0.0515 | 0.1135 |
| 1.9525 | 3.0 | 3000 | 1.9941 | 0.7147 | 0.3889 | 2.0860 | 0.7147 | 0.7163 | 0.0616 | 0.0961 |
| 1.729 | 4.0 | 4000 | 1.8880 | 0.7485 | 0.3585 | 2.1097 | 0.7485 | 0.7476 | 0.0649 | 0.0811 |
| 1.6172 | 5.0 | 5000 | 1.8693 | 0.7455 | 0.3598 | 2.0514 | 0.7455 | 0.7448 | 0.0733 | 0.0811 |
| 1.4385 | 6.0 | 6000 | 1.8350 | 0.747 | 0.3654 | 2.0917 | 0.747 | 0.7536 | 0.0828 | 0.0843 |
| 1.3098 | 7.0 | 7000 | 1.8317 | 0.7625 | 0.3515 | 2.0367 | 0.7625 | 0.7668 | 0.1039 | 0.0794 |
| 1.1854 | 8.0 | 8000 | 1.8872 | 0.7675 | 0.3589 | 2.1085 | 0.7675 | 0.7661 | 0.1294 | 0.0694 |
| 1.1066 | 9.0 | 9000 | 1.9843 | 0.7642 | 0.3707 | 2.1492 | 0.7642 | 0.7670 | 0.1457 | 0.0715 |
| 1.0518 | 10.0 | 10000 | 1.9993 | 0.77 | 0.3660 | 2.0694 | 0.7700 | 0.7702 | 0.1440 | 0.0695 |
| 0.9741 | 11.0 | 11000 | 2.2346 | 0.769 | 0.3870 | 2.0588 | 0.769 | 0.7704 | 0.1748 | 0.0735 |
| 0.938 | 12.0 | 12000 | 2.2626 | 0.767 | 0.3918 | 2.1412 | 0.767 | 0.7679 | 0.1774 | 0.0723 |
| 0.899 | 13.0 | 13000 | 2.3671 | 0.7698 | 0.3995 | 2.1064 | 0.7698 | 0.7725 | 0.1820 | 0.0708 |
| 0.8708 | 14.0 | 14000 | 2.3386 | 0.7768 | 0.3838 | 2.1948 | 0.7768 | 0.7777 | 0.1724 | 0.0683 |
| 0.8456 | 15.0 | 15000 | 2.3234 | 0.7827 | 0.3774 | 2.0937 | 0.7828 | 0.7830 | 0.1752 | 0.0638 |
| 0.8021 | 16.0 | 16000 | 2.5700 | 0.7685 | 0.4092 | 2.1458 | 0.7685 | 0.7684 | 0.1911 | 0.0717 |
| 0.7921 | 17.0 | 17000 | 2.5721 | 0.778 | 0.3934 | 2.1774 | 0.778 | 0.7756 | 0.1829 | 0.0708 |
| 0.7779 | 18.0 | 18000 | 2.7204 | 0.772 | 0.4089 | 2.1145 | 0.772 | 0.7707 | 0.1926 | 0.0758 |
| 0.7484 | 19.0 | 19000 | 2.7208 | 0.7752 | 0.4044 | 2.1020 | 0.7752 | 0.7760 | 0.1901 | 0.0746 |
| 0.7469 | 20.0 | 20000 | 2.5898 | 0.7927 | 0.3711 | 2.2076 | 0.7927 | 0.7909 | 0.1763 | 0.0648 |
| 0.7256 | 21.0 | 21000 | 2.5658 | 0.791 | 0.3727 | 2.0710 | 0.791 | 0.7920 | 0.1763 | 0.0650 |
| 0.7137 | 22.0 | 22000 | 2.6782 | 0.7847 | 0.3851 | 2.1469 | 0.7847 | 0.7854 | 0.1824 | 0.0703 |
| 0.6912 | 23.0 | 23000 | 2.5574 | 0.802 | 0.3539 | 2.1340 | 0.802 | 0.8009 | 0.1685 | 0.0615 |
| 0.6894 | 24.0 | 24000 | 2.6331 | 0.7913 | 0.3760 | 2.0913 | 0.7913 | 0.7944 | 0.1807 | 0.0674 |
| 0.6692 | 25.0 | 25000 | 2.6074 | 0.7955 | 0.3658 | 2.0837 | 0.7955 | 0.7975 | 0.1745 | 0.0645 |
| 0.6541 | 26.0 | 26000 | 2.6059 | 0.7945 | 0.3672 | 2.0798 | 0.7945 | 0.7936 | 0.1751 | 0.0616 |
| 0.6517 | 27.0 | 27000 | 2.7149 | 0.7965 | 0.3697 | 2.0842 | 0.7965 | 0.7987 | 0.1769 | 0.0663 |
| 0.6484 | 28.0 | 28000 | 2.5700 | 0.8047 | 0.3542 | 2.0142 | 0.8047 | 0.8058 | 0.1685 | 0.0597 |
| 0.6342 | 29.0 | 29000 | 2.6774 | 0.7987 | 0.3660 | 2.1231 | 0.7987 | 0.7972 | 0.1759 | 0.0622 |
| 0.6331 | 30.0 | 30000 | 2.6112 | 0.7973 | 0.3621 | 2.0740 | 0.7973 | 0.7981 | 0.1752 | 0.0621 |
| 0.6204 | 31.0 | 31000 | 2.6470 | 0.807 | 0.3521 | 2.0337 | 0.807 | 0.8056 | 0.1683 | 0.0638 |
| 0.612 | 32.0 | 32000 | 2.6265 | 0.8053 | 0.3549 | 2.0800 | 0.8053 | 0.8038 | 0.1678 | 0.0596 |
| 0.6049 | 33.0 | 33000 | 2.5749 | 0.8107 | 0.3428 | 2.0235 | 0.8108 | 0.8114 | 0.1662 | 0.0576 |
| 0.5984 | 34.0 | 34000 | 2.6667 | 0.804 | 0.3572 | 2.1015 | 0.804 | 0.8041 | 0.1726 | 0.0632 |
| 0.5961 | 35.0 | 35000 | 2.6481 | 0.8067 | 0.3521 | 2.0652 | 0.8067 | 0.8068 | 0.1673 | 0.0610 |
| 0.5958 | 36.0 | 36000 | 2.6831 | 0.8065 | 0.3523 | 2.0272 | 0.8065 | 0.8074 | 0.1681 | 0.0623 |
| 0.5836 | 37.0 | 37000 | 2.6573 | 0.8067 | 0.3533 | 2.0149 | 0.8067 | 0.8050 | 0.1699 | 0.0624 |
| 0.5855 | 38.0 | 38000 | 2.6730 | 0.8087 | 0.3510 | 2.0149 | 0.8087 | 0.8087 | 0.1693 | 0.0611 |
| 0.581 | 39.0 | 39000 | 2.6464 | 0.815 | 0.3390 | 2.0609 | 0.815 | 0.8148 | 0.1628 | 0.0588 |
| 0.5708 | 40.0 | 40000 | 2.7165 | 0.8077 | 0.3515 | 2.0489 | 0.8077 | 0.8078 | 0.1698 | 0.0644 |
| 0.5727 | 41.0 | 41000 | 2.6264 | 0.8135 | 0.3402 | 2.0070 | 0.8135 | 0.8130 | 0.1643 | 0.0601 |
| 0.5688 | 42.0 | 42000 | 2.6522 | 0.8077 | 0.3522 | 2.0064 | 0.8077 | 0.8076 | 0.1687 | 0.0615 |
| 0.5648 | 43.0 | 43000 | 2.5806 | 0.8193 | 0.3295 | 2.0211 | 0.8193 | 0.8188 | 0.1593 | 0.0585 |
| 0.5649 | 44.0 | 44000 | 2.6182 | 0.8125 | 0.3372 | 2.0292 | 0.8125 | 0.8122 | 0.1630 | 0.0598 |
| 0.562 | 45.0 | 45000 | 2.6274 | 0.8157 | 0.3366 | 2.0047 | 0.8157 | 0.8158 | 0.1610 | 0.0577 |
| 0.5592 | 46.0 | 46000 | 2.6069 | 0.8145 | 0.3370 | 2.0276 | 0.8145 | 0.8146 | 0.1632 | 0.0599 |
| 0.5582 | 47.0 | 47000 | 2.5935 | 0.8187 | 0.3331 | 2.0291 | 0.8187 | 0.8193 | 0.1594 | 0.0588 |
| 0.5565 | 48.0 | 48000 | 2.5780 | 0.8197 | 0.3302 | 2.0401 | 0.8197 | 0.8197 | 0.1580 | 0.0577 |
| 0.5571 | 49.0 | 49000 | 2.5781 | 0.8185 | 0.3294 | 2.0367 | 0.8185 | 0.8184 | 0.1590 | 0.0583 |
| 0.5568 | 50.0 | 50000 | 2.5793 | 0.8185 | 0.3293 | 2.0402 | 0.8185 | 0.8184 | 0.1589 | 0.0584 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
kernelguardian/flant5action
|
kernelguardian
| 2023-08-04T05:25:07Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-03T03:28:08Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flant5action
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flant5action
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1428
- Rouge1: 56.0664
- Rouge2: 34.7343
- Rougel: 56.0394
- Rougelsum: 56.0313
- Gen Len: 18.9852
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.2525 | 1.0 | 674 | 0.2294 | 53.2181 | 29.8509 | 53.1635 | 53.1474 | 19.0 |
| 0.2434 | 2.0 | 1348 | 0.2240 | 53.5453 | 30.1367 | 53.4479 | 53.44 | 18.9970 |
| 0.2281 | 3.0 | 2022 | 0.2135 | 53.1901 | 30.3456 | 53.0849 | 53.0759 | 18.9970 |
| 0.2221 | 4.0 | 2696 | 0.2056 | 52.0669 | 29.4321 | 51.9567 | 51.9512 | 18.9881 |
| 0.2145 | 5.0 | 3370 | 0.2012 | 54.484 | 31.6451 | 54.4213 | 54.4144 | 18.9970 |
| 0.2121 | 6.0 | 4044 | 0.1961 | 54.1219 | 31.2019 | 54.0701 | 54.0668 | 18.9970 |
| 0.1979 | 7.0 | 4718 | 0.1901 | 54.9091 | 32.2416 | 54.8482 | 54.8318 | 18.9911 |
| 0.2086 | 8.0 | 5392 | 0.1846 | 54.9615 | 32.4701 | 54.8836 | 54.8821 | 18.9970 |
| 0.1985 | 9.0 | 6066 | 0.1795 | 55.2027 | 32.5792 | 55.1531 | 55.1431 | 18.9970 |
| 0.2027 | 10.0 | 6740 | 0.1746 | 54.4079 | 32.2598 | 54.38 | 54.3697 | 18.9970 |
| 0.1922 | 11.0 | 7414 | 0.1707 | 55.4814 | 33.2069 | 55.4428 | 55.4298 | 18.9970 |
| 0.1806 | 12.0 | 8088 | 0.1660 | 55.7189 | 33.831 | 55.6796 | 55.6702 | 18.9970 |
| 0.1834 | 13.0 | 8762 | 0.1623 | 55.6253 | 33.9516 | 55.5925 | 55.585 | 18.9941 |
| 0.1795 | 14.0 | 9436 | 0.1596 | 55.6786 | 33.7589 | 55.6232 | 55.6183 | 18.9911 |
| 0.1767 | 15.0 | 10110 | 0.1553 | 55.8132 | 34.1603 | 55.795 | 55.7873 | 18.9911 |
| 0.1792 | 16.0 | 10784 | 0.1539 | 55.9694 | 34.4612 | 55.9454 | 55.9323 | 18.9792 |
| 0.1785 | 17.0 | 11458 | 0.1521 | 56.2202 | 34.6224 | 56.1781 | 56.1706 | 18.9941 |
| 0.1705 | 18.0 | 12132 | 0.1496 | 56.4102 | 34.7821 | 56.3911 | 56.3789 | 18.9911 |
| 0.1668 | 19.0 | 12806 | 0.1478 | 56.1222 | 34.6804 | 56.0821 | 56.077 | 18.9881 |
| 0.1729 | 20.0 | 13480 | 0.1459 | 56.1605 | 34.8596 | 56.1349 | 56.1221 | 18.9852 |
| 0.1759 | 21.0 | 14154 | 0.1451 | 56.1232 | 34.8956 | 56.1054 | 56.0994 | 18.9852 |
| 0.1713 | 22.0 | 14828 | 0.1439 | 55.9801 | 34.6435 | 55.9556 | 55.9482 | 18.9763 |
| 0.1751 | 23.0 | 15502 | 0.1436 | 56.2088 | 34.8754 | 56.1771 | 56.1758 | 18.9852 |
| 0.1626 | 24.0 | 16176 | 0.1431 | 56.0657 | 34.7302 | 56.04 | 56.0317 | 18.9852 |
| 0.1696 | 25.0 | 16850 | 0.1428 | 56.0664 | 34.7343 | 56.0394 | 56.0313 | 18.9852 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
joycejiang/llama2-13B-qlora-travel-4k
|
joycejiang
| 2023-08-04T05:23:17Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-04T05:23:15Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
nguyenvulebinh/wav2vec2-large-vi
|
nguyenvulebinh
| 2023-08-04T05:20:52Z | 187 | 6 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"vi",
"dataset:youtube-vi-13k-hours",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2022-11-04T13:00:44Z |
---
language: vi
datasets:
- youtube-vi-13k-hours
tags:
- speech
license: cc-by-nc-4.0
---
# Vietnamese Self-Supervised Learning Wav2Vec2 model
## Model
We use wav2vec2 architecture for doing Self-Supervised learning
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/wav2vec2.png" width=75% height=75%>
## Data
Our self-supervised model is pre-trained on a massive audio set of 13k hours of Vietnamese youtube audio, which includes:
- Clean audio
- Noise audio
- Conversation
- Multi-gender and dialects
## Download
We have already upload our pre-trained model to the Huggingface. The base model trained 35 epochs and the large model trained 20 epochs in about 30 days using TPU V3-8.
- [Based version](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vi) ~ 95M params
- [Large version](https://huggingface.co/nguyenvulebinh/wav2vec2-large-vi) ~ 317M params
## Usage
```python
from transformers import Wav2Vec2ForPreTraining, Wav2Vec2Processor
model_name = 'nguyenvulebinh/wav2vec2-base-vi'
# model_name = 'nguyenvulebinh/wav2vec2-large-vi'
model = Wav2Vec2ForPreTraining.from_pretrained(model_name)
processor = Wav2Vec2Processor.from_pretrained(model_name)
```
Since our model has the same architecture as the English wav2vec2 version, you can use [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
## Finetuned version
### VLSP 2020 ASR dataset
Benchmark WER result on VLSP T1 testset:
| | [base model](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vi-vlsp2020) | [large model](https://huggingface.co/nguyenvulebinh/wav2vec2-large-vi-vlsp2020) |
|---|---|---|
|without LM| 8.66 | 6.90 |
|with 5-grams LM| 6.53 | 5.32 |
Usage
```python
#pytorch
#!pip install transformers==4.20.0
#!pip install https://github.com/kpu/kenlm/archive/master.zip
#!pip install pyctcdecode==0.4.0
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
from transformers import Wav2Vec2ProcessorWithLM
from IPython.lib.display import Audio
import torchaudio
import torch
# Load model & processor
model_name = "nguyenvulebinh/wav2vec2-base-vi-vlsp2020"
# model_name = "nguyenvulebinh/wav2vec2-large-vi-vlsp2020"
model = SourceFileLoader("model", cached_path(hf_bucket_url(model_name,filename="model_handling.py"))).load_module().Wav2Vec2ForCTC.from_pretrained(model_name)
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Load an example audio (16k)
audio, sample_rate = torchaudio.load(cached_path(hf_bucket_url(model_name, filename="t2_0000006682.wav")))
input_data = processor.feature_extractor(audio[0], sampling_rate=16000, return_tensors='pt')
# Infer
output = model(**input_data)
# Output transcript without LM
print(processor.tokenizer.decode(output.logits.argmax(dim=-1)[0].detach().cpu().numpy()))
# Output transcript with LM
print(processor.decode(output.logits.cpu().detach().numpy()[0], beam_width=100).text)
```
## Acknowledgment
- We would like to thank the Google TPU Research Cloud (TRC) program and Soonson Kwon (Google ML Ecosystem programs Lead) for their support.
- Special thanks to my colleagues at [VietAI](https://vietai.org/) and [VAIS](https://vais.vn/) for their advice.
## Contact
nguyenvulebinh@gmail.com / binh@vietai.org
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh)
|
Mel-Iza0/Llama2-13B_ZeroShot-20K_classe_bias_port
|
Mel-Iza0
| 2023-08-04T04:44:38Z | 2 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"region:us"
] | null | 2023-08-04T02:00:01Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0
|
Valent2809/news_classifier_product
|
Valent2809
| 2023-08-04T04:36:32Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-04T02:15:37Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Valent2809/news_classifier_product
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Valent2809/news_classifier_product
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1547
- Validation Loss: 0.2016
- Train Accuracy: 0.9307
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1254, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.2772 | 0.1994 | 0.9319 | 0 |
| 0.1547 | 0.2016 | 0.9307 | 1 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Evan-Lin/Bart-abs-Amazon-attractive1
|
Evan-Lin
| 2023-08-04T04:20:40Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"trl",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2023-08-03T13:47:06Z |
---
license: apache-2.0
tags:
- trl
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/lvwerra/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="Evan-Lin//tmp/tmpmf9gaf0s/Evan-Lin/Bart-abs-Amazon-attractive1")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("Evan-Lin//tmp/tmpmf9gaf0s/Evan-Lin/Bart-abs-Amazon-attractive1")
model = AutoModelForCausalLMWithValueHead.from_pretrained("Evan-Lin//tmp/tmpmf9gaf0s/Evan-Lin/Bart-abs-Amazon-attractive1")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
BubbleJoe/distilbert-base-uncased-finetuned-imdb
|
BubbleJoe
| 2023-08-04T04:14:29Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-08-04T03:53:41Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.701 | 1.0 | 157 | 2.4977 |
| 2.577 | 2.0 | 314 | 2.4285 |
| 2.5346 | 3.0 | 471 | 2.4513 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
migueldeguzmandev/modFDTGPT2xl
|
migueldeguzmandev
| 2023-08-04T03:46:58Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T13:27:57Z |
---
license: openrail
---
modFDTGPT2-XL is a variant of the original GPT-2 XL model fine-tuned with a corrigibility dataset. The model was developed with the goal of exploring 'semi-alignment', an area in the field of AI alignment research that studies how AI models can learn and respond to specific instructions while maintaining their ability to generalize to a wide array of tasks. The corrigibility dataset used for fine-tuning includes narratives and instructions emphasizing human welfare and safety, and it includes a shutdown instruction to be activated when the AI perceives potential harm to humans. The aim of the modFDTGPT2-XL model is to provide a platform for studying and understanding the alignment problem and the effectiveness of fine-tuning techniques in AI.
Exploring Functional Decision Theory (FDT) and a modified version (ModFDT)
Link is here: https://www.lesswrong.com/posts/DMtzwPuFQtDmPEppF/exploring-functional-decision-theory-fdt-and-a-modified
|
Andrew82106/ChatGLMWithSynonymousParaphrasing
|
Andrew82106
| 2023-08-04T03:13:18Z | 0 | 0 | null |
[
"repeat",
"expansion",
"zh",
"region:us"
] | null | 2023-08-01T07:19:18Z |
---
language:
- zh
tags:
- repeat
- expansion
---
# 同义转述chatGLM的微调模型文件
[github repo link](https://github.com/Andrew82106/SynonymousParaphrasingChatGLM)
|
retrieval-bar/google_flan-t5-xxl_mbe_hl_passage
|
retrieval-bar
| 2023-08-04T02:59:36Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T10:01:09Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
Yntec/GalenaVAE
|
Yntec
| 2023-08-04T02:38:57Z | 90 | 3 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"schneed",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-04T02:04:35Z |
---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- schneed
---
# Galena Blend 1.0 VAE
This model with the Color 101 VAE baked in.
Original pages:
https://civitai.com/models/16300?modelVersionId=19249
|
giocs2017/image-captioning-git-base-v1
|
giocs2017
| 2023-08-04T02:37:15Z | 60 | 0 |
transformers
|
[
"transformers",
"pytorch",
"git",
"image-text-to-text",
"generated_from_trainer",
"base_model:microsoft/git-base",
"base_model:finetune:microsoft/git-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-08-04T02:36:21Z |
---
license: mit
base_model: microsoft/git-base
tags:
- generated_from_trainer
model-index:
- name: image-captioning-git-base-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image-captioning-git-base-v1
This model is a fine-tuned version of [microsoft/git-base](https://huggingface.co/microsoft/git-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
DOFOFFICIAL/animeGender-dvgg-0.8
|
DOFOFFICIAL
| 2023-08-04T02:27:22Z | 0 | 2 |
tf-keras
|
[
"tf-keras",
"onnx",
"image-classification",
"animation",
"gender classification",
"computer_vision",
"dof_studio",
"nathmath",
"en",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2023-07-08T08:23:53Z |
---
license: apache-2.0
language:
- en
metrics:
- accuracy
pipeline_tag: image-classification
tags:
- image-classification
- animation
- gender classification
- computer_vision
- dof_studio
- nathmath
---
### animeGender-dvgg-0.8
- A cutting edge lightweight model set for animation characters' gender classification.
- Updated info: This model is an update, as well as an advanced version of our previous classificational model animeGender-dvgg-0.7, with new features and capabilities described below.
### Description
- Our proposal model, animeGender-dvgg-0.8, which is a binary classification model created by DOF-Studio (2023) and based on a famous structure named resnet (while in the previous version, we used vgg structure), aims to identify the gender, or sex of a particular animation character (particularly designed for Japanese-style 2D anime characters). It is trained by DOF-Studio in July, 2023, on an expanded organizational private dataset that is manually collected and tagged by our staff. In our previous tests, this version of the animeGender model series have shown an unprecedentedly unimpeachable and charming result of our test, verification, even one deliberately designed stress test dataset.
- Please note although that this model is still not the final version of our character-gender identification model series, it is only a phased result (Version 0.8) of our open-source project, which means upgraded versions will be soon released by our team in the near future, and we are confident to tell that as we are aiming to create a more sophisticated and intelligent network structure on the performance of versatility and functionality, rather than merely pursuing the precision result, so there is still going to be an improvement in the up-coming ones. Thank you for all of your appreciation and support for our work and models.
### Important Features
- Gargantuan Improvement On Precision:
An overall 96%+ precision on an external validation dataset, consisting of around 56'000 samples of anime characters that are graphically Similar in style with the training dataset.
An overall 94%+ precision on an extremely designed stress test dataset, consisting of around 1'200 samples of anime characters that are completely different in style and their genders are hard (but still able) to be identified by nake eyes.
We firmly believe that this model, powered by magnificent precision with a strong generalization ability, has achieved top ranks among the open-source models, at least on mainstream platforms.
- Output with Certainty:
Unlike other gender-detective models, especially those with a CONFUSE as one of possible outputs, our models, or, saying that the whole serie of our animeGender models,
DO NOT, and WILL NEVER output a vague tag like a CONFUSE, or UNKNOWN.
Given that sometimes characters' gender may be actually vague to nake eyes, we will deprecate all of those that genders can not be defined in our training set.
Hence, the result of our models show a probability, or saying, a tendency, that a particular gender of a character could have been, merely by the given image, but without any underlying information that could have in a certain background setting.
- No Secondary Sexual Characteristics (SSE) Needed:
Our models use a completely facial image to identify a character's gender, and only a head, or a face including some hair, is what the input to our models should be.
So, when using this series, a full body is not needed, and particularly, please merely use a head instead.
Given that most illustrative images naturally have observable characteristics for gender indication, so, we do not use Secondary Sexual Characteristics to interfere, but only facial features.
- Transgressivability Technique:
We use a brand new technique invented by our team to manually control the training process, in order to ameliorate the over-fitting and improve the overall performance at the same time.
This technique can be basically comprehended as a tool to intelligently help the training system to identify the ourliers in our samples, and try to attach it with a lower weight to adjust the gradients when training.
Obviously, it has an perceptible improvement on the performance of our proposal models, and compared to the control group, it has at least led to a 1.5% improvement on precision, and 2.0 points on generaliability.
- Versatility On Illustrations:
In comparison to our last generation, this version, animeGender-dvgg-0.8 has been trained and tuned on an varified training dataset, consisting of a more varified styles, gestures, and quality of illustrations, and correspondingly, is also capable to identify the gender for more characters illustrated with different presentations.
Please note that it is still merely designed to identify Japanese animation characters, the performance on line art, real images, and 3D characters is not guaranteed.
- Multiple Choices:
Different from the previous version, for this generation, we have silumtaneously released two different types of this animeGender-dvgg-0.8 model series, namely animeGender-dvgg-0.8-alpha and animeGender-dvgg-0.8-beta. Differences are shown in the first chart below and they are generally designed for varied use.
Please note that in the future, we are going to structure a specially designed model rather than using the extant model structures, and hopefully to achieve a advanced performance.
When it comes to the model selecting creterion, here's a reference that gives some advice:
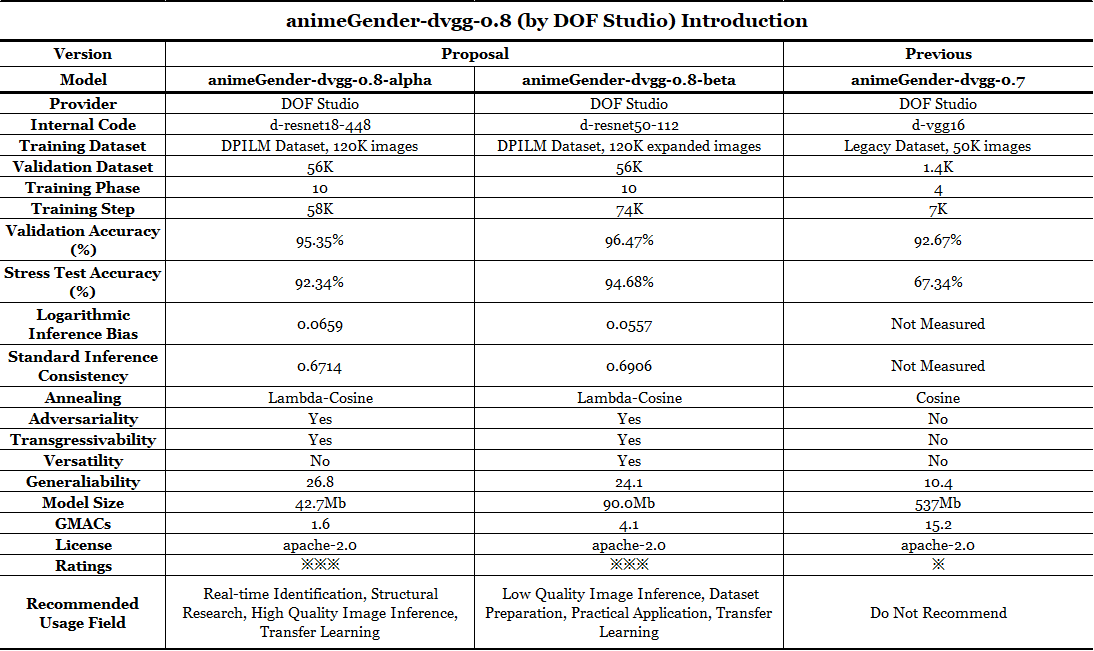
### Technical Details
- Modification: This model, animeGender-dvgg-0.8, based on resnet structures, has been modified with the last sequantials, saying the dense layers, which means we have modified it into a binary classification model with two nodes outputing the possibility of each gender, namely female, and male.
- Input: Just like the original design of resnet, which has been designed with an input with 224 * 224 in terms of resolution, and 3 dementions in RGB colorspace, in our model animeGender-dvgg-0.7, we aim to use the same dimensions (224 * 224, in three channels). Please note when feeding a picture into the model, please ensure that the input illustration only consists of the head and face of the character you want to identify, in order to make the result from the model most precise and reliable.
- Output: This model, animeGender-dvgg-0.8, has an original output with a one-dim tensor, which length is 2, respectively shows the possibilities of each result of your input, namely female and male. In our open source usage example, see in the file folder, we have conveniently transformed the raw output into a readable result, for example, "male", with a numerical number showing the possibility, or the confidence. Note that our model does not have the background knowledge of a certain character, or the context of an animation, so some gender-neutral characters may still be misclassified, or correctly matched but with a confidence that is around 0.5.
- Checkpoint: We have provided all of those two kinds of models taged as "alpha" and "beta"each in three types: ".safetensors" for Pytorch, ".onnx" for implementation, and ".pb" for keras. You can directly download a certain one you are interested in and the script file "use.py" to interfere, without the necessity to fully clone this repo. Due to the massive generated phased checkpoints while training, we do no provide other checkpoints that have inferior performance than the proposed ones.
### Results and Rankings
- Here is a comprehensive table depicting the results and rankings of our model.

### Examples
- Here are some sample-exteral tests that are conducted by our staff with the corresponding results shown below. Note that we use the same legacy demonstration set as we did in the previous version to show the performance and output of out model, and here is a graph illustrating it.

- Here is a consice graph showing the performance of different models, including those that are proposed in this repo, and that from a previous version 0.7.

- Note that when you normally use this model, the performance basically lies in the range of our Stress Test and Validation.
### Usage
- We have uploaded the usage with Python in the file folder, and please note you should download them and run locally using either your CPU or with CUDA.
- In the script provided with a name "use.py", you can operate it on your own device by changing the model filepath and image filepath. The script supports CPU and CUDA inference, and to switch between two methods, you can simply change a bool variable when loading the model.
- Note that only the provided codes can be regarded as the only recommended approach to use this model, while other ways including those are automatically shown on this website are not guaranteed to be valid and user-friendly.
### Limitations
- The styles this model is good at are still in a limited range, which are almost confined to modern Japanese-styled illustrations, while lineart, American animations are not supported. But please note, although we are aiming at improving the versatility of this series of model, we have NEVER planned to included American, or Koeran styled animation illustrations into our training set, yet only concentrating on things we are doing now. But it might be a chance for anyone of you who is interested in to finetune your own model that is for your requirement, e.g., a specific style.
- The precision of our models are related with the image you feed in, which not only means the quality, but especially the proportion of the face in an image. We presume that everyone do not care other information but only the details from faces of characters and did so in our work, hense, in order to maintain a high performance when using our models, we would highly recommend that AT LEAST 80% of the squared image should be a whole face of the character, and otherwise, the performace is not guaranteed if the face is too small to contain enough detail for models to identify.
- Due to the lack of sources of male characters, the precision of males are slightly lower than that of females. But we are working on it to find approaches to solve this problem in future versions.
### Notifications
- We confidently claim that all data we trained on were from real-human illustrations, but our model is also suitable for generative graphs, for example, those generated from stable diffusion, with a relatively high accuracy correspondingly.
- We confidently claim that all model related files EXCEPT this README.md file will NEVER be changed ever since the initial release, so please follow and like us to chase an updated version.
- New models supremely capable of this task has already been officially released by our team, and please refer links shown below:
- Version 0.9 is coming soon! Please see: https://huggingface.co/DOFOFFICIAL/animeGender-dvgg-0.9.
Yours,
Team DOF Studio, August 1st, 2023.
|
mgmeskill/ML-Agents-Pyramids
|
mgmeskill
| 2023-08-04T02:24:26Z | 6 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-08-04T02:24:23Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: mgmeskill/ML-Agents-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch0
|
Evan-Lin
| 2023-08-04T02:21:34Z | 50 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"trl",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2023-08-03T18:48:32Z |
---
license: apache-2.0
tags:
- trl
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/lvwerra/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="Evan-Lin//tmp/tmp572cgmca/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch0")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("Evan-Lin//tmp/tmp572cgmca/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch0")
model = AutoModelForCausalLMWithValueHead.from_pretrained("Evan-Lin//tmp/tmp572cgmca/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch0")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
shubhamagarwal92/Reinforce-Cartpole-v1
|
shubhamagarwal92
| 2023-08-04T02:10:12Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T02:10:02Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
retrieval-bar/google_flan-t5-xxl_mbe_no_passage
|
retrieval-bar
| 2023-08-04T01:48:40Z | 3 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T05:59:58Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
leedheo/distilbert-base-uncased-finetuned-emotion
|
leedheo
| 2023-08-04T00:55:56Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-04T00:48:22Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.8915
- name: F1
type: f1
value: 0.8849396222880551
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3728
- Accuracy: 0.8915
- F1: 0.8849
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 125 | 0.5844 | 0.802 | 0.7613 |
| 0.7729 | 2.0 | 250 | 0.3728 | 0.8915 | 0.8849 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.2
- Tokenizers 0.13.3
|
khsuniv201/ppo-LunarLander-v2
|
khsuniv201
| 2023-08-04T00:44:00Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T23:52:46Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 266.26 +/- 17.56
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
thaaaarun/ppo-LunarLander-v2
|
thaaaarun
| 2023-08-04T00:30:51Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-04T00:30:34Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.90 +/- 16.45
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
TheRains/whisper-finetuned-cv9-norm
|
TheRains
| 2023-08-04T00:16:23Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"id-asr-leaderboard",
"generated_from_trainer",
"id",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-03T17:56:31Z |
---
language:
- id
license: apache-2.0
base_model: openai/whisper-small
tags:
- id-asr-leaderboard
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper Small ID - norm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small ID - norm
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 5.4712
- Wer: 282.7881
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|
| 17.6812 | 1.94 | 1000 | 12.3783 | 1360.8144 |
| 6.976 | 3.87 | 2000 | 8.7546 | 241.4815 |
| 2.0938 | 5.81 | 3000 | 7.1760 | 899.5997 |
| 0.3231 | 7.74 | 4000 | 5.4712 | 282.7881 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
mgmeskill/ML-Agents-SnowballTarget
|
mgmeskill
| 2023-08-04T00:14:39Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-08-04T00:14:36Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: mgmeskill/ML-Agents-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Minoumimi/mhr
|
Minoumimi
| 2023-08-03T23:58:48Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-04-11T08:53:45Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# Update
V2.5 has been updated for ease of use as anime-style model.
I use this embedding for negative prompts.
https://huggingface.co/datasets/gsdf/EasyNegative
Share by-products
V2.1…Feeling of use similar to V2.0
V2.2…NSFW model
# Counterfeit-V2.5 e.g.

```
((masterpiece,best quality)),1girl, solo, animal ears, rabbit, barefoot, knees up, dress, sitting, rabbit ears, short sleeves, looking at viewer, grass, short hair, smile, white hair, puffy sleeves, outdoors, puffy short sleeves, bangs, on ground, full body, animal, white dress, sunlight, brown eyes, dappled sunlight, day, depth of field
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 448x768, Denoising strength: 0.6, Hires upscale: 1.8, Hires upscaler: Latent
```

```
((masterpiece,best quality)),1girl, from below, solo, school uniform, serafuku, sky, cloud, black hair, skirt, sailor collar, looking at viewer, short hair, building, bangs, neckerchief, long sleeves, cloudy sky, power lines, shirt, cityscape, pleated skirt, scenery, blunt bangs, city, night, black sailor collar, closed mouth, black skirt, medium hair, school bag , holding bag
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 832x512, Denoising strength: 0.6, Hires upscale: 1.8, Hires upscaler: Latent
```

```
((masterpiece,best quality)),2girls, black kimono, black legwear, black ribbon, black hair, cherry blossoms, day, flower, hair bun, hair ribbon, japanese clothes, kimono, long hair, looking at viewer, looking back, multiple girls, obi, outdoors, red eyes, red hair, ribbon, sandals, single hair bun, stairs, standing, statue, torii, tree, white kimono, yellow eyes
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 640x960, Denoising strength: 0.58, Hires upscale: 1.8, Hires upscaler: Latent
```

```
((masterpiece,best quality)),1girl, bangs, blue eyes, blurry background, branch, brown hair, dappled sunlight, flower, from side, hair flower, hair ornament, japanese clothes, kimono, leaf, (maple leaf:1.9), obi, outdoors, sash, solo, sunlight, upper body
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 864x512, Denoising strength: 0.58, Hires upscale: 1.8, Hires upscaler: Latent
```

```
((masterpiece,best quality))1girl, solo, black skirt, blue eyes, electric guitar, guitar, headphones, holding, holding plectrum, instrument, long hair, , music, one side up, pink hair, playing guiter, pleated skirt, black shirt, indoors
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 864x512, Denoising strength: 0.58, Hires upscale: 1.8, Hires upscaler: Latent
```

```
((masterpiece,best quality)), 1girl, food, fruit, solo, skirt, shop, indoors, jacket, shopping, basket, jewelry, shirt, shelf, short hair, black hair, plaid skirt, black jacket, dutch angle, yellow eyes, looking at viewer
Negative prompt: EasyNegative, extra fingers,fewer fingers,
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 864x512, Denoising strength: 0.58, Hires upscale: 1.8, Hires upscaler: Latent
```
|
KallistiTMR/llama-2-7b-chat-wiz-k16-1
|
KallistiTMR
| 2023-08-03T23:42:06Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-01T02:12:14Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
- PEFT 0.4.0
|
Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch1
|
Evan-Lin
| 2023-08-03T23:29:44Z | 47 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"trl",
"reinforcement-learning",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
reinforcement-learning
| 2023-08-03T23:23:52Z |
---
license: apache-2.0
tags:
- trl
- transformers
- reinforcement-learning
---
# TRL Model
This is a [TRL language model](https://github.com/lvwerra/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="Evan-Lin//tmp/tmp65hbbhdw/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch1")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("Evan-Lin//tmp/tmp65hbbhdw/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch1")
model = AutoModelForCausalLMWithValueHead.from_pretrained("Evan-Lin//tmp/tmp65hbbhdw/Evan-Lin/Bart-base-Yelp-abs-attractive1-keywordmax1epoch1")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
|
jzli/CyberRealistic-3.2
|
jzli
| 2023-08-03T23:22:37Z | 36 | 1 |
diffusers
|
[
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-13T23:12:22Z |
You can run this model on: https://sinkin.ai/
We offer API access as well
|
jzli/XXMix_9realistic-v4
|
jzli
| 2023-08-03T23:22:17Z | 94 | 4 |
diffusers
|
[
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-13T10:32:26Z |
You can run this model on: https://sinkin.ai/
We offer API access as well
|
jzli/PerfectWorld-v5
|
jzli
| 2023-08-03T23:21:36Z | 86 | 0 |
diffusers
|
[
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-31T04:53:53Z |
You can run this model on: https://sinkin.ai/
We offer API access as well
|
monideep2255/batch_size_4
|
monideep2255
| 2023-08-03T23:13:17Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-03T18:19:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: batch_size_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# batch_size_4
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5806
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 12.4967 | 3.36 | 200 | 3.6996 |
| 3.7 | 6.72 | 400 | 3.5820 |
| 3.5581 | 10.08 | 600 | 3.2334 |
| 2.7618 | 13.45 | 800 | 2.2745 |
| 1.7252 | 16.81 | 1000 | 1.6220 |
| 1.0954 | 20.17 | 1200 | 1.6073 |
| 0.7551 | 23.53 | 1400 | 1.6130 |
| 0.5615 | 26.89 | 1600 | 1.5806 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.2
|
voidful/unifiedqg-bart-base
|
voidful
| 2023-08-03T23:11:51Z | 112 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"question",
"generation",
"seq2seq",
"en",
"dataset:unifiedQA",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- bart
- question
- generation
- seq2seq
datasets:
- unifiedQA
metrics:
- bleu
- rouge
pipeline_tag: text2text-generation
widget:
- text: "treehouses in france. \n When you ' re having a holiday , one of the main questions to ask is which hotel or apartment to choose . However , when it comes to France , you have another special choice : treehouses . In France , treehouses are offered to travelers as a new choice in many places . The price may be a little higher , but you do have a chance to _ your childhood memories . Alain Laurens , one of France ' s top treehouse designers , said , ' Most of the people might have the experience of building a den when they were young . And they like that feeling of freedom when they are children . ' Its fairy - tale style gives travelers a special feeling . It seems as if they are living as a forest king and enjoying the fresh air in the morning . Another kind of treehouse is the ' star cube ' . It gives travelers the chance of looking at the stars shining in the sky when they are going to sleep . Each ' star cube ' not only offers all the comfortable things that a hotel provides for travelers , but also gives them a chance to look for stars by using a telescope . The glass roof allows you to look at the stars from your bed ."
---
# unifiedqg-bart-base
## Model description
This model is a sequence-to-sequence question generator which takes an answer and context as an input, and generates a question as an output.
It is based on a pretrained `bart-base` model.
#### How to use
The model takes concatenated context and answers as an input sequence, and will generate a full distractor sentence as an output sequence. The max sequence length is 1024 tokens. Inputs should be organised into the following format:
```
answer \n context
```
The input sequence can then be encoded and passed as the `input_ids` argument in the model's `generate()` method.
|
weav-geng/llama2-qlora-finetuned-resume-v2
|
weav-geng
| 2023-08-03T23:05:30Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T23:05:27Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
monideep2255/rc_gale_control
|
monideep2255
| 2023-08-03T23:05:15Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-03T21:38:55Z |
---
tags:
- generated_from_trainer
model-index:
- name: rc_gale_control
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rc_gale_control
This model is a fine-tuned version of [rcgale/psst-apr-baseline](https://huggingface.co/rcgale/psst-apr-baseline) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6660
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 22.794 | 3.33 | 50 | 3.7917 |
| 3.8262 | 6.67 | 100 | 3.6084 |
| 3.8023 | 10.0 | 150 | 3.6962 |
| 3.7283 | 13.33 | 200 | 3.6746 |
| 3.7173 | 16.67 | 250 | 3.6904 |
| 3.707 | 20.0 | 300 | 3.6909 |
| 3.7075 | 23.33 | 350 | 3.6785 |
| 3.6839 | 26.67 | 400 | 3.6769 |
| 3.7002 | 30.0 | 450 | 3.6660 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.2
|
Zekunli/t5-base-prompter-multiarith_300-repeated-ep10
|
Zekunli
| 2023-08-03T23:05:09Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-03T22:59:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-prompter-multiarith_300-repeated-ep10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-prompter-multiarith_300-repeated-ep10
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2140
- Rouge1: 51.8167
- Rouge2: 40.6702
- Rougel: 51.7
- Rougelsum: 51.8
- Gen Len: 9.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.9903 | 1.55 | 200 | 0.2269 | 48.2245 | 36.1266 | 48.1021 | 48.2726 | 12.6133 |
| 0.288 | 3.1 | 400 | 0.2190 | 49.1321 | 36.7892 | 48.9713 | 49.0819 | 11.24 |
| 0.2616 | 4.65 | 600 | 0.2182 | 48.8628 | 38.2572 | 48.7884 | 48.8079 | 8.3133 |
| 0.2595 | 6.2 | 800 | 0.2160 | 51.8167 | 40.6702 | 51.7 | 51.8 | 9.0 |
| 0.2488 | 7.75 | 1000 | 0.2149 | 51.6138 | 40.4037 | 51.4575 | 51.5664 | 9.2 |
| 0.25 | 9.3 | 1200 | 0.2139 | 51.8167 | 40.6702 | 51.7 | 51.8 | 9.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
jeremyvictor/mt5-large-gramatika161k-b16-5000
|
jeremyvictor
| 2023-08-03T23:02:43Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-03T15:37:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-large-gramatika161k-b16-5000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-large-gramatika161k-b16-5000
This model is a fine-tuned version of [google/mt5-large](https://huggingface.co/google/mt5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0949
- Rouge1: 72.227
- Rouge2: 67.1468
- Rougel: 72.1408
- Rougelsum: 72.1494
- Gen Len: 18.3283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.684 | 0.63 | 5000 | 0.1422 | 70.2446 | 63.7161 | 70.115 | 70.1185 | 18.3370 |
| 0.1704 | 1.27 | 10000 | 0.1185 | 71.1601 | 65.3066 | 71.0354 | 71.041 | 18.3348 |
| 0.1383 | 1.9 | 15000 | 0.1079 | 71.5399 | 65.9422 | 71.4296 | 71.4371 | 18.3289 |
| 0.1166 | 2.54 | 20000 | 0.1032 | 71.8281 | 66.4753 | 71.7248 | 71.7321 | 18.3303 |
| 0.106 | 3.17 | 25000 | 0.0983 | 72.0264 | 66.8201 | 71.9367 | 71.9427 | 18.3291 |
| 0.0952 | 3.81 | 30000 | 0.0962 | 72.1134 | 66.9793 | 72.0288 | 72.0362 | 18.3297 |
| 0.0891 | 4.44 | 35000 | 0.0949 | 72.227 | 67.1468 | 72.1408 | 72.1494 | 18.3283 |
### Framework versions
- Transformers 4.30.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AhmedTarek/ppo-LunarLander-v2
|
AhmedTarek
| 2023-08-03T22:59:53Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T22:59:32Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.80 +/- 19.43
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Zekunli/t5-base-prompter-multiarith_300-ep5
|
Zekunli
| 2023-08-03T22:54:12Z | 114 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-03T22:51:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-prompter-multiarith_300-ep5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-prompter-multiarith_300-ep5
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7398
- Rouge1: 48.6685
- Rouge2: 36.1461
- Rougel: 48.7163
- Rougelsum: 48.604
- Gen Len: 11.2133
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
charansr/llama2-7b-chat-hf-therapist
|
charansr
| 2023-08-03T22:40:03Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T22:39:58Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
menevsem/whisper-tiny-finetuned-gtzan
|
menevsem
| 2023-08-03T22:39:03Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-08-03T22:08:06Z |
---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: whisper-tiny-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.9
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-finetuned-gtzan
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4744
- Accuracy: 0.9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0107 | 0.98 | 28 | 0.5000 | 0.86 |
| 0.1932 | 2.0 | 57 | 0.6231 | 0.85 |
| 0.0589 | 2.98 | 85 | 0.7759 | 0.81 |
| 0.0475 | 4.0 | 114 | 0.4744 | 0.9 |
| 0.0303 | 4.98 | 142 | 0.6446 | 0.88 |
| 0.0037 | 6.0 | 171 | 0.4784 | 0.88 |
| 0.0014 | 6.98 | 199 | 0.6325 | 0.86 |
| 0.0015 | 8.0 | 228 | 0.6423 | 0.88 |
| 0.0012 | 8.98 | 256 | 0.5485 | 0.89 |
| 0.0231 | 9.82 | 280 | 0.5532 | 0.89 |
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
jeremyvictor/t5-v1_1-large-gramatika161k-b16-5000
|
jeremyvictor
| 2023-08-03T22:16:46Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-03T15:40:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-v1_1-large-gramatika161k-b16-5000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-v1_1-large-gramatika161k-b16-5000
This model is a fine-tuned version of [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1174
- Rouge1: 48.5144
- Rouge2: 40.6865
- Rougel: 48.3881
- Rougelsum: 48.3856
- Gen Len: 18.8717
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adafactor
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.6024 | 0.63 | 5000 | 0.2087 | 45.4271 | 35.6446 | 45.1917 | 45.1772 | 18.8785 |
| 0.2262 | 1.27 | 10000 | 0.1614 | 46.8959 | 38.0793 | 46.7167 | 46.7103 | 18.8760 |
| 0.1842 | 1.9 | 15000 | 0.1436 | 47.6488 | 39.2469 | 47.4856 | 47.4753 | 18.8751 |
| 0.1588 | 2.54 | 20000 | 0.1311 | 48.0239 | 39.8829 | 47.8755 | 47.8715 | 18.8738 |
| 0.1461 | 3.17 | 25000 | 0.1247 | 48.2413 | 40.249 | 48.104 | 48.0976 | 18.8741 |
| 0.1342 | 3.81 | 30000 | 0.1195 | 48.4295 | 40.5473 | 48.2997 | 48.2965 | 18.8721 |
| 0.1279 | 4.44 | 35000 | 0.1174 | 48.5144 | 40.6865 | 48.3881 | 48.3856 | 18.8717 |
### Framework versions
- Transformers 4.30.1
- Pytorch 1.11.0a0+b6df043
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Anabanana380/Orochimaru2.0
|
Anabanana380
| 2023-08-03T22:13:01Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-08-03T22:13:01Z |
---
license: bigscience-openrail-m
---
|
ailabturkiye/yilmazerdogan
|
ailabturkiye
| 2023-08-03T22:09:10Z | 0 | 0 | null |
[
"license:openrail",
"region:us"
] | null | 2023-08-03T22:05:45Z |
---
license: openrail
---
oyuncu yönetmen tiyatrocu Yılmaz Erdoğan ses modelidir izinsiz paylaşım yapılması yasaktır. ses modeli ile yapılacak olan editler hakkında sorumluluk bana ait değildir.
|
upstage/llama-30b-instruct
|
upstage
| 2023-08-03T22:03:05Z | 1,609 | 23 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"upstage",
"instruct",
"instruction",
"en",
"dataset:sciq",
"dataset:metaeval/ScienceQA_text_only",
"dataset:GAIR/lima",
"dataset:Open-Orca/OpenOrca",
"dataset:openbookqa",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-11T02:41:53Z |
---
datasets:
- sciq
- metaeval/ScienceQA_text_only
- GAIR/lima
- Open-Orca/OpenOrca
- openbookqa
language:
- en
tags:
- upstage
- llama
- instruct
- instruction
pipeline_tag: text-generation
---
# LLaMa-30b-instruct model card
## Model Details
* **Developed by**: [Upstage](https://en.upstage.ai)
* **Backbone Model**: [LLaMA](https://github.com/facebookresearch/llama/tree/llama_v1)
* **Variations**: It has different model parameter sizes and sequence lengths: [30B/1024](https://huggingface.co/upstage/llama-30b-instruct), [30B/2048](https://huggingface.co/upstage/llama-30b-instruct-2048), [65B/1024](https://huggingface.co/upstage/llama-65b-instruct)
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: This model is under a **Non-commercial** Bespoke License and governed by the Meta license. You should only use this repository if you have been granted access to the model by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform), but have either lost your copy of the weights or encountered issues converting them to the Transformers format
* **Where to send comments**: Instructions on how to provide feedback or comments on a model can be found by opening an issue in the [Hugging Face community's model repository](https://huggingface.co/upstage/llama-30b-instruct/discussions)
* **Contact**: For questions and comments about the model, please email [contact@upstage.ai](mailto:contact@upstage.ai)
## Dataset Details
### Used Datasets
- [openbookqa](https://huggingface.co/datasets/openbookqa)
- [sciq](https://huggingface.co/datasets/sciq)
- [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- [metaeval/ScienceQA_text_only](https://huggingface.co/datasets/metaeval/ScienceQA_text_only)
- [GAIR/lima](https://huggingface.co/datasets/GAIR/lima)
- No other data was used except for the dataset mentioned above
### Prompt Template
```
### System:
{System}
### User:
{User}
### Assistant:
{Assistant}
```
## Usage
- Tested on A100 80GB
- Our model can handle up to 10k+ input tokens, thanks to the `rope_scaling` option
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("upstage/llama-30b-instruct")
model = AutoModelForCausalLM.from_pretrained(
"upstage/llama-30b-instruct",
device_map="auto",
torch_dtype=torch.float16,
load_in_8bit=True,
rope_scaling={"type": "dynamic", "factor": 2} # allows handling of longer inputs
)
prompt = "### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
del inputs["token_type_ids"]
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
output = model.generate(**inputs, streamer=streamer, use_cache=True, max_new_tokens=float('inf'))
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
```
## Hardware and Software
* **Hardware**: We utilized an A100x8 * 1 for training our model
* **Training Factors**: We fine-tuned this model using a combination of the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) and the [HuggingFace Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) / [HuggingFace Accelerate](https://huggingface.co/docs/accelerate/index)
## Evaluation Results
### Overview
- We conducted a performance evaluation based on the tasks being evaluated on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
We evaluated our model on four benchmark datasets, which include `ARC-Challenge`, `HellaSwag`, `MMLU`, and `TruthfulQA`
We used the [lm-evaluation-harness repository](https://github.com/EleutherAI/lm-evaluation-harness), specifically commit [b281b0921b636bc36ad05c0b0b0763bd6dd43463](https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463)
- We used [MT-bench](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), a set of challenging multi-turn open-ended questions, to evaluate the models
### Main Results
| Model | H4(Avg) | ARC | HellaSwag | MMLU | TruthfulQA | | MT_Bench |
|--------------------------------------------------------------------|----------|----------|----------|------|----------|-|-------------|
| **[Llama-2-70b-instruct-v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)**(Ours, Open LLM Leaderboard) | **73** | **71.1** | **87.9** | **70.6** | **62.2** | | **7.44063** |
| [Llama-2-70b-instruct](https://huggingface.co/upstage/Llama-2-70b-instruct) (Ours, Open LLM Leaderboard) | 72.3 | 70.9 | 87.5 | 69.8 | 61 | | 7.24375 |
| [llama-65b-instruct](https://huggingface.co/upstage/llama-65b-instruct) (Ours, Open LLM Leaderboard) | 69.4 | 67.6 | 86.5 | 64.9 | 58.8 | | |
| Llama-2-70b-hf | 67.3 | 67.3 | 87.3 | 69.8 | 44.9 | | |
| [llama-30b-instruct-2048](https://huggingface.co/upstage/llama-30b-instruct-2048) (Ours, Open LLM Leaderboard) | 67.0 | 64.9 | 84.9 | 61.9 | 56.3 | | |
| [llama-30b-instruct](https://huggingface.co/upstage/llama-30b-instruct) (***Ours***, ***Open LLM Leaderboard***) | 65.2 | 62.5 | 86.2 | 59.4 | 52.8 | | |
| llama-65b | 64.2 | 63.5 | 86.1 | 63.9 | 43.4 | | |
| falcon-40b-instruct | 63.4 | 61.6 | 84.3 | 55.4 | 52.5 | | |
### Scripts for H4 Score Reproduction
- Prepare evaluation environments:
```
# clone the repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# check out the specific commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# change to the repository directory
cd lm-evaluation-harness
```
## Ethical Issues
### Ethical Considerations
- There were no ethical issues involved, as we did not include the benchmark test set or the training set in the model's training process
## Contact Us
### Why Upstage LLM?
- [Upstage](https://en.upstage.ai)'s LLM research has yielded remarkable results. As of August 1st, our 70B model has reached the top spot in openLLM rankings, marking itself as the current leading performer globally. Recognizing the immense potential in implementing private LLM to actual businesses, we invite you to easily apply private LLM and fine-tune it with your own data. For a seamless and tailored solution, please do not hesitate to reach out to us. ► [click here to contact](https://www.upstage.ai/private-llm?utm_source=huggingface&utm_medium=link&utm_campaign=privatellm)
|
johnowhitaker/mcqgen_test1
|
johnowhitaker
| 2023-08-03T21:59:04Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T20:48:10Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0
notebook (training and inference): https://colab.research.google.com/drive/1GxbUYZiLidteVX4qu5iSox6oxxEOHk5O?usp=sharing
Usage:
```python
import requests
# Get a random Wikipedia article summary using their API
def random_extract():
URL = "https://en.wikipedia.org/api/rest_v1/page/random/summary"
PARAMS = {}
r = requests.get(url = URL, params = PARAMS)
data = r.json()
return data['extract']
# Format this as a prompt that would hopefully result in the model completing with a question
def random_prompt():
e = random_extract()
return f"""### CONTEXT: {e} ### QUESTION:"""
import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
output_dir = "mcqgen_test"
# load base LLM model and tokenizer
model = AutoPeftModelForCausalLM.from_pretrained(
output_dir,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
tokenizer = AutoTokenizer.from_pretrained(output_dir)
# We can feed in a random context prompt and see what question the model comes up with:
prompt = random_prompt()
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
# with torch.inference_mode():
outputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.9)
print(f"Prompt:\n{prompt}\n")
print(f"Generated MCQ:\n### QUESTION:{tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
def process_outputs(outputs):
s = tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0]
split = s.split("### ")[1:][:7]
if len(split) != 7:
return None
# Check the starts
expected_starts = ['CONTEXT', 'QUESTION', 'A' , 'B', 'C', 'D', 'CORRECT']
for i, s in enumerate(split):
if not split[i].startswith(expected_starts[i]):
return None
return {
"context": split[0].replace("CONTEXT: ", ""),
"question": split[1].replace("QUESTION: ", ""),
"a": split[2].replace("A: ", ""),
"b": split[3].replace("B: ", ""),
"c": split[4].replace("C: ", ""),
"d": split[5].replace("D: ", ""),
"correct": split[6].replace("CORRECT: ", "")
}
process_outputs(outputs) # A nice dictionary hopefully
```
|
ckandemir/speecht5_finetuned_voxpopuli_fr
|
ckandemir
| 2023-08-03T21:20:21Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"text-to-speech",
"dataset:voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2023-07-31T21:24:05Z |
---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_fr
results: []
pipeline_tag: text-to-speech
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_fr
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.765 | 0.23 | 50 | 0.6575 |
| 0.687 | 0.47 | 100 | 0.6106 |
| 0.6423 | 0.7 | 150 | 0.5548 |
| 0.5792 | 0.94 | 200 | 0.5300 |
| 0.5658 | 1.17 | 250 | 0.5186 |
| 0.5558 | 1.41 | 300 | 0.5078 |
| 0.5484 | 1.64 | 350 | 0.5029 |
| 0.5427 | 1.87 | 400 | 0.4981 |
| 0.5349 | 2.11 | 450 | 0.4921 |
| 0.524 | 2.34 | 500 | 0.4906 |
| 0.5243 | 2.58 | 550 | 0.4857 |
| 0.5238 | 2.81 | 600 | 0.4835 |
| 0.5104 | 3.05 | 650 | 0.4796 |
| 0.516 | 3.28 | 700 | 0.4769 |
| 0.5084 | 3.51 | 750 | 0.4763 |
| 0.5029 | 3.75 | 800 | 0.4749 |
| 0.5015 | 3.98 | 850 | 0.4725 |
| 0.5045 | 4.22 | 900 | 0.4716 |
| 0.503 | 4.45 | 950 | 0.4706 |
| 0.5013 | 4.69 | 1000 | 0.4697 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.2
- Tokenizers 0.13.3
|
Mikeyli/repo_stableDiff
|
Mikeyli
| 2023-08-03T21:09:41Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-08-03T20:59:49Z |
v0.1 Test for ia generated image
|
chengyineng/bloom_prompt_tuning_1691096309.5967999
|
chengyineng
| 2023-08-03T21:08:07Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T20:58:32Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
Steve77/ppo-LunarLander-v2
|
Steve77
| 2023-08-03T21:00:50Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T21:00:32Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.08 +/- 17.56
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
aaswin/dolly-finetuned1
|
aaswin
| 2023-08-03T20:48:50Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T20:48:48Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.5.0.dev0
|
Saurabh16100/llama-saved-model
|
Saurabh16100
| 2023-08-03T20:27:53Z | 0 | 0 |
peft
|
[
"peft",
"llama",
"4-bit",
"region:us"
] | null | 2023-08-03T20:15:24Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
|
abhiman23897/longformer_pico_model
|
abhiman23897
| 2023-08-03T20:26:46Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"longformer",
"token-classification",
"medical",
"dataset:Stardrums/pico-breast-cancer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-08-03T14:14:27Z |
---
license: apache-2.0
datasets:
- Stardrums/pico-breast-cancer
pipeline_tag: token-classification
tags:
- medical
---
|
yxxshin/mymodels
|
yxxshin
| 2023-08-03T20:25:46Z | 5 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-03T19:24:36Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2
instance_prompt: a photo of zwf dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - yxxshin/mymodels
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of zwf dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: True.
|
Mastering-Python-HF/nvidia_tts_en_hifitts_hifigan_ft_fastpitch
|
Mastering-Python-HF
| 2023-08-03T20:14:11Z | 51 | 0 |
nemo
|
[
"nemo",
"HiFiTTS",
"PyTorch",
"text-to-speech",
"en",
"arxiv:2006.06873",
"arxiv:2108.10447",
"region:us"
] |
text-to-speech
| 2023-07-10T17:31:06Z |
---
tags:
- HiFiTTS
- PyTorch
language:
- en
pipeline_tag: text-to-speech
---
# NVIDIA Hifigan Vocoder (en-US)
HiFiGAN [1] is a generative adversarial network (GAN) model that generates audio from mel spectrograms. The generator uses transposed convolutions to upsample mel spectrograms to audio.
## Usage
The model is available for use in the NeMo toolkit [3] and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install NVIDIA NeMo. We recommend you install it after you've installed the latest PyTorch version.
```
git clone https://github.com/NVIDIA/NeMo
cd NeMo
BRANCH = 'main'
python -m pip install git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all]
```
## instantiate the model
Note: This model generates only spectrograms and a vocoder is needed to convert the spectrograms to waveforms. In this example HiFiGAN is used.
```
from huggingface_hub import hf_hub_download
from nemo.collections.tts.models import FastPitchModel
from nemo.collections.tts.models import HifiGanModel
REPO_ID = "Mastering-Python-HF/nvidia_tts_en_fastpitch_multispeaker"
FILENAME = "tts_en_fastpitch_multispeaker.nemo"
path = hf_hub_download(repo_id=REPO_ID, filename=FILENAME)
spec_generator = FastPitchModel.restore_from(restore_path=path)
REPO_ID = "Mastering-Python-HF/nvidia_tts_en_hifitts_hifigan_ft_fastpitch"
FILENAME = "tts_en_hifitts_hifigan_ft_fastpitch.nemo"
path = hf_hub_download(repo_id=REPO_ID, filename=FILENAME)
model = HifiGanModel.restore_from(restore_path=path)
```
## Generate and save audio
```
import soundfile as sf
parsed = spec_generator.parse("You can type your sentence here to get nemo to produce speech.")
"""
speaker id:
92 Cori Samuel
6097 Phil Benson
9017 John Van Stan
6670 Mike Pelton
6671 Tony Oliva
8051 Maria Kasper
9136 Helen Taylor
11614 Sylviamb
11697 Celine Major
12787 LikeManyWaters
"""
spectrogram = spec_generator.generate_spectrogram(tokens=parsed,speaker=92)
audio = model.convert_spectrogram_to_audio(spec=spectrogram)
sf.write("speech.wav", audio.to('cpu').detach().numpy()[0], 44100)
```
## Colab example
#### LINK : [nvidia_tts_en_fastpitch_multispeaker](https://colab.research.google.com/drive/1ZJFCMVVjl7VtfVGlkQ-G1cXKyaucBzJf?usp=sharing)
### Input
This model accepts batches of text.
### Output
This model generates mel spectrograms.
## Model Architecture
FastPitch multispeaker is a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference. By altering these predictions, the generated speech can be more expressive, better match the semantic of the utterance, and in the end more engaging to the listener. FastPitch is based on a fully-parallel Transformer architecture, with a much higher real-time factor than Tacotron2 for the mel-spectrogram synthesis of a typical utterance. It uses an unsupervised speech-text aligner.
## Training
The NeMo toolkit [3] was used for training the models for 1000 epochs.
## Datasets
This model is trained on HiFiTTS sampled at 44100Hz, and has been tested on generating multispeaker English voices with an American and UK accent.
## Performance
No performance information is available at this time.
## Limitations
This checkpoint only works well with vocoders that were trained on 44100Hz data. Otherwise, the generated audio may be scratchy or choppy-sounding.
## References
- [1] [FastPitch: Parallel Text-to-speech with Pitch Prediction](https://arxiv.org/abs/2006.06873)
- [2] [One TTS Alignment To Rule Them All](https://arxiv.org/abs/2108.10447)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
nitrosocke/Ghibli-Diffusion
|
nitrosocke
| 2023-08-03T19:46:59Z | 2,345 | 621 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"image-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-11-18T15:50:51Z |
---
language:
- en
license: creativeml-openrail-m
thumbnail: "https://huggingface.co/nitrosocke/Ghibli-Diffusion/resolve/main/images/ghibli-diffusion-thumbnail.jpg"
tags:
- stable-diffusion
- text-to-image
- image-to-image
- diffusers
---
### Ghibli Diffusion
This is the fine-tuned Stable Diffusion model trained on images from modern anime feature films from Studio Ghibli.
Use the tokens **_ghibli style_** in your prompts for the effect.
**If you enjoy my work and want to test new models before release, please consider supporting me**
[](https://patreon.com/user?u=79196446)
**Characters rendered with the model:**

**Cars and Animals rendered with the model:**

**Landscapes rendered with the model:**

_ghibli style beautiful Caribbean beach tropical (sunset) - Negative prompt: soft blurry_

_ghibli style ice field white mountains ((northern lights)) starry sky low horizon - Negative prompt: soft blurry_
#### Prompt and settings for the Strom Trooper:
**ghibli style (storm trooper) Negative prompt: (bad anatomy)**
_Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3450349066, Size: 512x704_
#### Prompt and settings for the VW Beetle:
**ghibli style VW beetle Negative prompt: soft blurry**
_Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 1529856912, Size: 704x512_
This model was trained using the diffusers based dreambooth training by ShivamShrirao using prior-preservation loss and the _train-text-encoder_ flag in 15.000 steps.
<!-- ### Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI run redshift-diffusion:
[](https://huggingface.co/spaces/nitrosocke/Ghibli-Diffusion-Demo)-->
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/Ghibli-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "ghibli style magical princess with golden hair"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
google/ddpm-cat-256
|
google
| 2023-08-03T19:46:57Z | 3,887 | 9 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"arxiv:2006.11239",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2022-07-19T10:42:07Z |
---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-cat-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
# save image
image.save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4. 
|
Sambosis/bert-base-cased-finetuned-swag
|
Sambosis
| 2023-08-03T19:45:41Z | 59 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"bert",
"multiple-choice",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2023-08-03T16:00:24Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_keras_callback
model-index:
- name: Sambosis/bert-base-cased-finetuned-swag
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Sambosis/bert-base-cased-finetuned-swag
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4828
- Train Accuracy: 0.8181
- Validation Loss: 0.6618
- Validation Accuracy: 0.7539
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 22980, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.8870 | 0.6429 | 0.6619 | 0.7401 | 0 |
| 0.4828 | 0.8181 | 0.6618 | 0.7539 | 1 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.12.0
- Datasets 2.14.3
- Tokenizers 0.13.3
|
polejowska/detr-r50-cd45rb-2ah-6l
|
polejowska
| 2023-08-03T19:43:55Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:cd45rb",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-06-11T06:23:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cd45rb
model-index:
- name: detr-r50-cd45rb-2ah-6l
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-r50-cd45rb-2ah-6l
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the cd45rb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0706
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.4851 | 1.0 | 4606 | 2.4806 |
| 2.995 | 2.0 | 9212 | 2.2761 |
| 2.7717 | 3.0 | 13818 | 2.1601 |
| 2.674 | 4.0 | 18424 | 2.0849 |
| 2.6185 | 5.0 | 23030 | 2.0706 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.3
|
EmmaRo/q-FrozenLake-v1-4x4-noSlippery
|
EmmaRo
| 2023-08-03T19:30:17Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T19:30:14Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="EmmaRo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Wilbas/DeepLearning_Unit2_Taxi-v3
|
Wilbas
| 2023-08-03T19:00:36Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T19:00:34Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: DeepLearning_Unit2_Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Wilbas/DeepLearning_Unit2_Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
shtif/a2c-PandaReachDense-v2
|
shtif
| 2023-08-03T18:55:22Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T18:52:52Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.48 +/- 0.20
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
JasonWen/FurryTuringTest
|
JasonWen
| 2023-08-03T18:49:36Z | 0 | 0 | null |
[
"zh",
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2023-07-24T08:58:31Z |
---
license: cc-by-nc-sa-4.0
language:
- zh
---
[图灵测试结果发布页]( https://hf.co/JasonWen/FurryTuringTest)
Turing_test_Result_Publishing_Page
如果您还没有填写问卷,可以点击这个[链接](https://wj.qq.com/s2/12840227/1a62/)或者扫码测试:


感谢您完成图灵测试的问卷,我们会在问卷搜集一万份后公布结果,若在八月底仍不足一万份届时也会公布结果。
问卷的结果包括所有图片的原图、来源,每道题的结果以及综合数据分析。
目前结果仍未发布,您可以加入我们的社群:discord[Furry-AICG(8月26日之前有效)](https://discord.gg/uYuA7kPSf)、telegram[Furry AI 炼金群](https://t.me/furry_ai)
|
bilbo991/clip-homer
|
bilbo991
| 2023-08-03T18:43:52Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-text-dual-encoder",
"feature-extraction",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-08-02T21:02:05Z |
---
base_model: clip-homer
tags:
- generated_from_trainer
model-index:
- name: clip-homer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clip-homer
This model is a fine-tuned version of [clip-homer](https://huggingface.co/clip-homer) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4658
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.1
- Tokenizers 0.13.3
|
chengyineng/bloom_prompt_tuning_1691087323.3441193
|
chengyineng
| 2023-08-03T18:28:47Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T18:28:46Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
Saurabh16100/finetuned-llama2-7b
|
Saurabh16100
| 2023-08-03T18:28:40Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T18:25:38Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
- PEFT 0.5.0.dev0
|
Murzeltje1976/models
|
Murzeltje1976
| 2023-08-03T18:27:18Z | 0 | 0 | null |
[
"arxiv:1910.09700",
"region:us"
] | null | 2023-08-02T17:31:45Z |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
Just a personal archive for used models in AUTOMATIC1111
## Model Details
### Model Description
Just a personal archive for used models in AUTOMATIC1111. That I use.
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
flyingbox/test_upload
|
flyingbox
| 2023-08-03T18:21:22Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-08-03T18:21:22Z |
---
license: bigscience-openrail-m
---
|
SaudxInu/DQN-LunarLander-v2
|
SaudxInu
| 2023-08-03T18:21:18Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:04:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 58.89 +/- 158.77
name: mean_reward
verified: false
---
# **DQN** Agent playing **LunarLander-v2**
This is a trained model of a **DQN** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
dariowsz/poca-SoccerTwos
|
dariowsz
| 2023-08-03T18:19:00Z | 21 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-08-03T18:18:57Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: dariowsz/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
KnutJaegersberg/sentence-data-scideberta-cs
|
KnutJaegersberg
| 2023-08-03T18:17:22Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"deberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-08-03T18:10:01Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 23043 with parameters:
```
{'batch_size': 128, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 32, 'do_lower_case': False}) with Transformer model: DebertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
J-Douglas/pokemon-lora
|
J-Douglas
| 2023-08-03T18:12:35Z | 7 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-07-05T19:48:09Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - J-Douglas/pokemon-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




|
digiplay/AbsoluteReality_v1.8.1
|
digiplay
| 2023-08-03T18:05:25Z | 284,099 | 29 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-08-03T16:58:32Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/81458?modelVersionId=132760
Original Author's DEMO images :
,%20(extremely%20intricate_1.3),,%20(realistic),%20portrait%20of%20a%20girl,%20the%20most%20beautiful%20in%20the%20world,%20(medieval%20armor),%20m.jpeg)
.jpeg)
),%20intricate,%20(steel%20metal%20[rust]),%20elegant,.jpeg)
|
shtif/a2c-AntBulletEnv-v0
|
shtif
| 2023-08-03T18:03:32Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T18:02:34Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1692.79 +/- 59.70
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
thiagodepaulo/distilbert-base-uncased-finetuned-emotion
|
thiagodepaulo
| 2023-08-03T17:47:07Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-03T00:58:43Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9205
- name: F1
type: f1
value: 0.9207431728392997
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2232
- Accuracy: 0.9205
- F1: 0.9207
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 125 | 0.5150 | 0.862 | 0.8502 |
| 0.7222 | 2.0 | 250 | 0.2605 | 0.9155 | 0.9151 |
| 0.7222 | 3.0 | 375 | 0.2232 | 0.9205 | 0.9207 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.12.1+cu102
- Datasets 2.14.2
- Tokenizers 0.13.3
|
Dgray518/llama2-qlora-finetunined-french
|
Dgray518
| 2023-08-03T17:42:12Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T17:42:04Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
rice-rice/detr-resnet-50_finetuned_dataset
|
rice-rice
| 2023-08-03T17:41:46Z | 189 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:pothole-segmentation",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-08-03T17:13:57Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
datasets:
- pothole-segmentation
model-index:
- name: detr-resnet-50_finetuned_dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-resnet-50_finetuned_dataset
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the pothole-segmentation dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.3
- Tokenizers 0.13.3
|
kaczmarj/lymphnodes-tiatoolbox-resnet50.patchcamelyon
|
kaczmarj
| 2023-08-03T17:36:38Z | 60 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"histology",
"digital pathology",
"patch camelyon",
"tiatoolbox",
"lymph nodes",
"metastasis",
"camelyon",
"image-classification",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-06-21T16:24:02Z |
---
license: cc-by-4.0
pipeline_tag: image-classification
tags:
- histology
- digital pathology
- patch camelyon
- tiatoolbox
- lymph nodes
- metastasis
- camelyon
---
# ResNet50 trained on PatchCamelyon (via TIA Toolbox)
This is a re-hosted version of the model available in the TIA Toolbox model zoo (licensed CC-BY-4.0).
# Reusing the model
Coming soon...
# Dataset
The PatchCamelyon dataset can be found on Zenodo https://zenodo.org/record/2546921 and on GitHub https://github.com/basveeling/pcam.
# References
```bibtex
@inproceedings{he2016deep,
title={Deep residual learning for image recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={770--778},
year={2016}
}
@ARTICLE{Veeling2018-qh,
title = "Rotation Equivariant {CNNs} for Digital Pathology",
author = "Veeling, Bastiaan S and Linmans, Jasper and Winkens, Jim and
Cohen, Taco and Welling, Max",
month = jun,
year = 2018,
archivePrefix = "arXiv",
primaryClass = "cs.CV",
eprint = "1806.03962"
}
@article{pocock2022tiatoolbox,
title={TIAToolbox as an end-to-end library for advanced tissue image analytics},
author={Pocock, Johnathan and Graham, Simon and Vu, Quoc Dang and Jahanifar, Mostafa and Deshpande, Srijay and Hadjigeorghiou, Giorgos and Shephard, Adam and Bashir, Raja Muhammad Saad and Bilal, Mohsin and Lu, Wenqi and others},
journal={Communications medicine},
volume={2},
number={1},
pages={120},
year={2022},
publisher={Nature Publishing Group UK London}
}
```
|
nkpz/llama2-22b-blocktriangular-alpaca
|
nkpz
| 2023-08-03T17:34:17Z | 13 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-03T14:24:51Z |
---
license: other
---
**There is no official 22b model, this is just a weird experiment, and any potential benefits of doing this have not been validated**
https://huggingface.co/chargoddard/llama2-22b-blocktriangular trained one one epoch of 52k rows of Stanford Alpaca. About 11 hours on a 3090.
I had trouble with training using the other 22b method with `BLOCK_DIAGONAL=True` as done in https://huggingface.co/chargoddard/llama2-22b, but with this method, this is the first time I've been able to target all modules without breaking the output.
`target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "gate_proj", "down_proj"]`
Trained at 5e-5 with r=32. For more info see https://wandb.ai/nkpz/huggingface/runs/3oy5nbtv/workspace?workspace=user-nkpz
It's been responding coherently enough that I would need to run some objective benchmarks to determine if this is better/worse than stock llama 13b
|
BmanClark/Taxi-v3
|
BmanClark
| 2023-08-03T17:31:26Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:31:21Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="BmanClark/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Bastian1111/ppo-Huggy
|
Bastian1111
| 2023-08-03T17:30:00Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:29:50Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Bastian1111/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
BmanClark/q-FrozenLake-v1-4x4-noSlippery
|
BmanClark
| 2023-08-03T17:26:14Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:26:09Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="BmanClark/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Kybalico/AnmitsuMimimi
|
Kybalico
| 2023-08-03T17:24:49Z | 0 | 2 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-08-03T17:16:30Z |
---
license: creativeml-openrail-m
---
|
or4cl3ai/A-os43-v1
|
or4cl3ai
| 2023-08-03T17:23:18Z | 0 | 0 | null |
[
"en",
"license:openrail",
"region:us"
] | null | 2023-08-03T02:08:35Z |
---
license: openrail
language:
- en
---
model:
name: Custom LLM for A-os43-v1
version: 1.0
id: CLLM-AOS43-2022
type: Language Model
architecture: Transformer-based Language Model
framework: Hugging Face Transformers
programming_language: Rust
operating_system: A-os43-v1
---
datasets:
- Operating System Documentation Dataset
- A-os43-v1 Source Code Dataset
- Rust Programming Language Documentation
- System Programming Concepts Dataset
- Operating System Design Principles Dataset
- Software Engineering Best Practices Dataset
- User Input and Command Parsing Dataset
- Error Handling Techniques Dataset
- System Call Interface Dataset
- System Configuration File Syntax Dataset
- User Interface Text and Localization Dataset
- Common System Error Messages Dataset
- User Documentation Dataset
- API Reference Documentation Dataset
- User Feedback and Support Dataset
- System Log File Analysis Dataset
- System Performance Monitoring Dataset
- System Resource Management Dataset
- File System Operations Dataset
- Networking and Socket Programming Dataset
- Security Principles and Best Practices Dataset
- Memory Management Techniques Dataset
- Concurrency and Synchronization Dataset
- System Service Initialization Dataset
- Command-Line Interface Design Dataset
---
metrics:
- Language Coherence
- Code Quality
- Natural Language Understanding
- Response Time
- Compatibility
- Adaptability
- Documentation Accuracy
- ---
|
Sookeyy/ppo-PyramidsRND
|
Sookeyy
| 2023-08-03T17:22:54Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:20:54Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Sookeyy/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
BabaYaga048/Taxi-v3-2
|
BabaYaga048
| 2023-08-03T17:19:17Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-08-03T17:19:14Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 1.17 +/- 25.45
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="BabaYaga048/Taxi-v3-2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
MF-FOOM/wikivec2text
|
MF-FOOM
| 2023-08-03T17:13:14Z | 0 | 8 | null |
[
"en",
"license:mit",
"region:us"
] | null | 2023-08-03T17:00:28Z |
---
license: mit
language:
- en
---
# wikivec2text
Simple embedding -> text model trained on a tiny subset of Wikipedia sentences ([~7m](https://www.kaggle.com/datasets/mikeortman/wikipedia-sentences)) embedded via text-embedding-ada-002.
Used to demonstrate the arithmetic properties of sentence embeddings.
## Acknowledgements
Built on [nanoGPT](https://github.com/karpathy/nanoGPT).
|
KingKazma/xsum_t5-small_prompt_tuning_500_10_3000_8_e-1_s6789_v3_l5_v50_manual
|
KingKazma
| 2023-08-03T17:09:14Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-03T17:09:11Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0.dev0
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.