
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-11 12:33:28
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-11 12:33:10
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
huggingtweets/sun_soony-unjaded_jade-veganhollyg
|
huggingtweets
| 2022-06-08T21:45:56Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-05-30T21:50:31Z |
---
language: en
thumbnail: http://www.huggingtweets.com/sun_soony-unjaded_jade-veganhollyg/1654724750416/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1105554414427885569/XkyfcoMJ_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1290809762637131776/uwGH2mYu_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/900359049061036032/LYf3Ouv__400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Jade Bowler & soony & Holly Gabrielle</div>
<div style="text-align: center; font-size: 14px;">@sun_soony-unjaded_jade-veganhollyg</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Jade Bowler & soony & Holly Gabrielle.
| Data | Jade Bowler | soony | Holly Gabrielle |
| --- | --- | --- | --- |
| Tweets downloaded | 3170 | 815 | 1802 |
| Retweets | 121 | 260 | 276 |
| Short tweets | 120 | 47 | 253 |
| Tweets kept | 2929 | 508 | 1273 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/afi2j4p2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @sun_soony-unjaded_jade-veganhollyg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3uiqxuec) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3uiqxuec/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/sun_soony-unjaded_jade-veganhollyg')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/neiltyson
|
huggingtweets
| 2022-06-08T21:26:48Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/neiltyson/1654723603504/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/74188698/NeilTysonOriginsA-Crop_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Neil deGrasse Tyson</div>
<div style="text-align: center; font-size: 14px;">@neiltyson</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Neil deGrasse Tyson.
| Data | Neil deGrasse Tyson |
| --- | --- |
| Tweets downloaded | 3234 |
| Retweets | 10 |
| Short tweets | 87 |
| Tweets kept | 3137 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1v949iob/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @neiltyson's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/kjzq9tjy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/kjzq9tjy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/neiltyson')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/kentcdodds-richardbranson-sikiraamer
|
huggingtweets
| 2022-06-08T21:08:46Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T21:04:40Z |
---
language: en
thumbnail: http://www.huggingtweets.com/kentcdodds-richardbranson-sikiraamer/1654722520391/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1496777835062648833/3Ao6Xb2a_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1529905780542959616/Ibwrp7VJ_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1410740591483293697/tRbW1XoV_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Amer Sikira & Kent C. Dodds 💿 & Richard Branson</div>
<div style="text-align: center; font-size: 14px;">@kentcdodds-richardbranson-sikiraamer</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Amer Sikira & Kent C. Dodds 💿 & Richard Branson.
| Data | Amer Sikira | Kent C. Dodds 💿 | Richard Branson |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3249 | 3215 |
| Retweets | 94 | 578 | 234 |
| Short tweets | 214 | 507 | 96 |
| Tweets kept | 2942 | 2164 | 2885 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/jtwa65l2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @kentcdodds-richardbranson-sikiraamer's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3vt6qlgf) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3vt6qlgf/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/kentcdodds-richardbranson-sikiraamer')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Sohaibsyed/wav2vec2-large-xls-r-300m-turkish-colab
|
Sohaibsyed
| 2022-06-08T20:48:31Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-08T16:53:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3717
- Wer: 0.2972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0139 | 3.67 | 400 | 0.7020 | 0.7112 |
| 0.4129 | 7.34 | 800 | 0.4162 | 0.4503 |
| 0.1869 | 11.01 | 1200 | 0.4174 | 0.3959 |
| 0.1273 | 14.68 | 1600 | 0.4020 | 0.3695 |
| 0.0959 | 18.35 | 2000 | 0.4026 | 0.3545 |
| 0.0771 | 22.02 | 2400 | 0.3904 | 0.3361 |
| 0.0614 | 25.69 | 2800 | 0.3736 | 0.3127 |
| 0.0486 | 29.36 | 3200 | 0.3717 | 0.2972 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
valurank/distilroberta-propaganda-2class
|
valurank
| 2022-06-08T20:39:15Z | 11 | 3 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: other
tags:
- generated_from_trainer
model-index:
- name: distilroberta-propaganda-2class
results: []
---
# distilroberta-propaganda-2class
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the QCRI propaganda dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5087
- Acc: 0.7424
## Training and evaluation data
Training data is the 19-class QCRI propaganda data, with all propaganda classes collapsed to a single catch-all 'prop' class.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 12345
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 16
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5737 | 1.0 | 493 | 0.5998 | 0.6515 |
| 0.4954 | 2.0 | 986 | 0.5530 | 0.7080 |
| 0.4774 | 3.0 | 1479 | 0.5331 | 0.7258 |
| 0.4846 | 4.0 | 1972 | 0.5247 | 0.7339 |
| 0.4749 | 5.0 | 2465 | 0.5392 | 0.7199 |
| 0.502 | 6.0 | 2958 | 0.5124 | 0.7466 |
| 0.457 | 7.0 | 3451 | 0.5167 | 0.7432 |
| 0.4899 | 8.0 | 3944 | 0.5160 | 0.7428 |
| 0.4833 | 9.0 | 4437 | 0.5280 | 0.7339 |
| 0.5114 | 10.0 | 4930 | 0.5112 | 0.7436 |
| 0.4419 | 11.0 | 5423 | 0.5060 | 0.7525 |
| 0.4743 | 12.0 | 5916 | 0.5031 | 0.7547 |
| 0.4597 | 13.0 | 6409 | 0.5043 | 0.7517 |
| 0.4861 | 14.0 | 6902 | 0.5055 | 0.7487 |
| 0.499 | 15.0 | 7395 | 0.5091 | 0.7419 |
| 0.501 | 16.0 | 7888 | 0.5037 | 0.7521 |
| 0.4659 | 17.0 | 8381 | 0.5087 | 0.7424 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.7.1
- Datasets 1.11.0
- Tokenizers 0.10.3
|
valurank/distilroberta-proppy
|
valurank
| 2022-06-08T20:38:27Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: other
tags:
- generated_from_trainer
model-index:
- name: distilroberta-proppy
results: []
---
# distilroberta-proppy
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the proppy corpus.
It achieves the following results on the evaluation set:
- Loss: 0.1838
- Acc: 0.9269
## Training and evaluation data
The training data is the [proppy corpus](https://zenodo.org/record/3271522). See [Proppy: Organizing the News
Based on Their Propagandistic Content](https://propaganda.qcri.org/papers/elsarticle-template.pdf) for details.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 12345
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 16
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.3179 | 1.0 | 732 | 0.2032 | 0.9146 |
| 0.2933 | 2.0 | 1464 | 0.2026 | 0.9206 |
| 0.2938 | 3.0 | 2196 | 0.1849 | 0.9252 |
| 0.3429 | 4.0 | 2928 | 0.1983 | 0.9221 |
| 0.2608 | 5.0 | 3660 | 0.2310 | 0.9106 |
| 0.2562 | 6.0 | 4392 | 0.1826 | 0.9270 |
| 0.2785 | 7.0 | 5124 | 0.1954 | 0.9228 |
| 0.307 | 8.0 | 5856 | 0.2056 | 0.9200 |
| 0.28 | 9.0 | 6588 | 0.1843 | 0.9259 |
| 0.2794 | 10.0 | 7320 | 0.1782 | 0.9299 |
| 0.2868 | 11.0 | 8052 | 0.1907 | 0.9242 |
| 0.2789 | 12.0 | 8784 | 0.2031 | 0.9216 |
| 0.2827 | 13.0 | 9516 | 0.1976 | 0.9229 |
| 0.2795 | 14.0 | 10248 | 0.1866 | 0.9255 |
| 0.2895 | 15.0 | 10980 | 0.1838 | 0.9269 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.7.1
- Datasets 1.11.0
- Tokenizers 0.10.3
|
valurank/distilroberta-clickbait
|
valurank
| 2022-06-08T20:24:26Z | 257 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: other
tags:
- generated_from_trainer
model-index:
- name: distilroberta-clickbait
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-clickbait
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on a dataset of headlines.
It achieves the following results on the evaluation set:
- Loss: 0.0268
- Acc: 0.9963
## Training and evaluation data
The following data sources were used:
* 32k headlines classified as clickbait/not-clickbait from [kaggle](https://www.kaggle.com/amananandrai/clickbait-dataset)
* A dataset of headlines from https://github.com/MotiBaadror/Clickbait-Detection
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 12345
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 16
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0195 | 1.0 | 981 | 0.0192 | 0.9954 |
| 0.0026 | 2.0 | 1962 | 0.0172 | 0.9963 |
| 0.0031 | 3.0 | 2943 | 0.0275 | 0.9945 |
| 0.0003 | 4.0 | 3924 | 0.0268 | 0.9963 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.1
- Datasets 1.17.0
- Tokenizers 0.10.3
|
joniponi/TEST2ppo-LunarLander-v2
|
joniponi
| 2022-06-08T20:00:34Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T20:00:02Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 253.16 +/- 21.62
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
cutten/wav2vec2-large-multilang-cv-ru-night
|
cutten
| 2022-06-08T19:58:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-08T14:24:42Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-multilang-cv-ru-night
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-multilang-cv-ru-night
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6617
- Wer: 0.5097
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 8.725 | 1.58 | 500 | 3.2788 | 1.0 |
| 3.1184 | 3.15 | 1000 | 2.4018 | 1.0015 |
| 1.2393 | 4.73 | 1500 | 0.6213 | 0.7655 |
| 0.6899 | 6.31 | 2000 | 0.5518 | 0.6811 |
| 0.5532 | 7.89 | 2500 | 0.5102 | 0.6467 |
| 0.4604 | 9.46 | 3000 | 0.4887 | 0.6213 |
| 0.4095 | 11.04 | 3500 | 0.4874 | 0.6042 |
| 0.3565 | 12.62 | 4000 | 0.4810 | 0.5893 |
| 0.3238 | 14.2 | 4500 | 0.5028 | 0.5890 |
| 0.3011 | 15.77 | 5000 | 0.5475 | 0.5808 |
| 0.2827 | 17.35 | 5500 | 0.5289 | 0.5720 |
| 0.2659 | 18.93 | 6000 | 0.5496 | 0.5733 |
| 0.2445 | 20.5 | 6500 | 0.5354 | 0.5737 |
| 0.2366 | 22.08 | 7000 | 0.5357 | 0.5686 |
| 0.2181 | 23.66 | 7500 | 0.5491 | 0.5611 |
| 0.2146 | 25.24 | 8000 | 0.5591 | 0.5597 |
| 0.2006 | 26.81 | 8500 | 0.5625 | 0.5631 |
| 0.1912 | 28.39 | 9000 | 0.5577 | 0.5647 |
| 0.1821 | 29.97 | 9500 | 0.5684 | 0.5519 |
| 0.1744 | 31.55 | 10000 | 0.5639 | 0.5551 |
| 0.1691 | 33.12 | 10500 | 0.5596 | 0.5425 |
| 0.1577 | 34.7 | 11000 | 0.5770 | 0.5551 |
| 0.1522 | 36.28 | 11500 | 0.5634 | 0.5560 |
| 0.1468 | 37.85 | 12000 | 0.5815 | 0.5453 |
| 0.1508 | 39.43 | 12500 | 0.6053 | 0.5490 |
| 0.1394 | 41.01 | 13000 | 0.6193 | 0.5504 |
| 0.1291 | 42.59 | 13500 | 0.5930 | 0.5424 |
| 0.1345 | 44.16 | 14000 | 0.6283 | 0.5442 |
| 0.1296 | 45.74 | 14500 | 0.6063 | 0.5560 |
| 0.1286 | 47.32 | 15000 | 0.6248 | 0.5378 |
| 0.1231 | 48.9 | 15500 | 0.6106 | 0.5405 |
| 0.1189 | 50.47 | 16000 | 0.6164 | 0.5342 |
| 0.1127 | 52.05 | 16500 | 0.6269 | 0.5359 |
| 0.112 | 53.63 | 17000 | 0.6170 | 0.5390 |
| 0.1113 | 55.21 | 17500 | 0.6489 | 0.5385 |
| 0.1023 | 56.78 | 18000 | 0.6826 | 0.5490 |
| 0.1069 | 58.36 | 18500 | 0.6147 | 0.5296 |
| 0.1008 | 59.94 | 19000 | 0.6414 | 0.5332 |
| 0.1018 | 61.51 | 19500 | 0.6454 | 0.5288 |
| 0.0989 | 63.09 | 20000 | 0.6603 | 0.5303 |
| 0.0944 | 64.67 | 20500 | 0.6350 | 0.5288 |
| 0.0905 | 66.25 | 21000 | 0.6386 | 0.5247 |
| 0.0837 | 67.82 | 21500 | 0.6563 | 0.5298 |
| 0.0868 | 69.4 | 22000 | 0.6375 | 0.5208 |
| 0.0827 | 70.98 | 22500 | 0.6401 | 0.5271 |
| 0.0797 | 72.56 | 23000 | 0.6723 | 0.5191 |
| 0.0847 | 74.13 | 23500 | 0.6610 | 0.5213 |
| 0.0818 | 75.71 | 24000 | 0.6774 | 0.5254 |
| 0.0793 | 77.29 | 24500 | 0.6543 | 0.5250 |
| 0.0758 | 78.86 | 25000 | 0.6607 | 0.5218 |
| 0.0755 | 80.44 | 25500 | 0.6599 | 0.5160 |
| 0.0722 | 82.02 | 26000 | 0.6683 | 0.5196 |
| 0.0714 | 83.6 | 26500 | 0.6941 | 0.5180 |
| 0.0684 | 85.17 | 27000 | 0.6581 | 0.5167 |
| 0.0686 | 86.75 | 27500 | 0.6651 | 0.5172 |
| 0.0712 | 88.33 | 28000 | 0.6547 | 0.5208 |
| 0.0697 | 89.91 | 28500 | 0.6555 | 0.5162 |
| 0.0696 | 91.48 | 29000 | 0.6678 | 0.5107 |
| 0.0686 | 93.06 | 29500 | 0.6630 | 0.5124 |
| 0.0671 | 94.64 | 30000 | 0.6675 | 0.5143 |
| 0.0668 | 96.21 | 30500 | 0.6602 | 0.5107 |
| 0.0666 | 97.79 | 31000 | 0.6611 | 0.5097 |
| 0.0664 | 99.37 | 31500 | 0.6617 | 0.5097 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
renjithks/layoutlmv2-er-ner
|
renjithks
| 2022-06-08T19:37:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-05T15:40:30Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv2-er-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-er-ner
This model is a fine-tuned version of [renjithks/layoutlmv2-cord-ner](https://huggingface.co/renjithks/layoutlmv2-cord-ner) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1217
- Precision: 0.7810
- Recall: 0.8085
- F1: 0.7945
- Accuracy: 0.9747
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 41 | 0.5441 | 0.0 | 0.0 | 0.0 | 0.8851 |
| No log | 2.0 | 82 | 0.4660 | 0.1019 | 0.0732 | 0.0852 | 0.8690 |
| No log | 3.0 | 123 | 0.2506 | 0.4404 | 0.4828 | 0.4606 | 0.9240 |
| No log | 4.0 | 164 | 0.1725 | 0.6120 | 0.6076 | 0.6098 | 0.9529 |
| No log | 5.0 | 205 | 0.1387 | 0.7204 | 0.7245 | 0.7225 | 0.9671 |
| No log | 6.0 | 246 | 0.1237 | 0.7742 | 0.7747 | 0.7745 | 0.9722 |
| No log | 7.0 | 287 | 0.1231 | 0.7619 | 0.7554 | 0.7586 | 0.9697 |
| No log | 8.0 | 328 | 0.1199 | 0.7994 | 0.7719 | 0.7854 | 0.9738 |
| No log | 9.0 | 369 | 0.1197 | 0.7937 | 0.8113 | 0.8024 | 0.9741 |
| No log | 10.0 | 410 | 0.1284 | 0.7581 | 0.7597 | 0.7589 | 0.9690 |
| No log | 11.0 | 451 | 0.1172 | 0.7792 | 0.7848 | 0.7820 | 0.9738 |
| No log | 12.0 | 492 | 0.1192 | 0.7913 | 0.7970 | 0.7941 | 0.9743 |
| 0.1858 | 13.0 | 533 | 0.1175 | 0.7960 | 0.8006 | 0.7983 | 0.9753 |
| 0.1858 | 14.0 | 574 | 0.1184 | 0.7724 | 0.8034 | 0.7876 | 0.9740 |
| 0.1858 | 15.0 | 615 | 0.1171 | 0.7882 | 0.8142 | 0.8010 | 0.9756 |
| 0.1858 | 16.0 | 656 | 0.1195 | 0.7829 | 0.8070 | 0.7948 | 0.9745 |
| 0.1858 | 17.0 | 697 | 0.1209 | 0.7810 | 0.8006 | 0.7906 | 0.9743 |
| 0.1858 | 18.0 | 738 | 0.1241 | 0.7806 | 0.7963 | 0.7884 | 0.9740 |
| 0.1858 | 19.0 | 779 | 0.1222 | 0.7755 | 0.8027 | 0.7889 | 0.9742 |
| 0.1858 | 20.0 | 820 | 0.1217 | 0.7810 | 0.8085 | 0.7945 | 0.9747 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.9.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6
|
kalmufti/q-Taxi-v3
|
kalmufti
| 2022-06-08T19:29:47Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T19:29:39Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.50 +/- 2.67
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="kalmufti/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
huggingtweets/makimasdoggy
|
huggingtweets
| 2022-06-08T19:17:06Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T19:15:48Z |
---
language: en
thumbnail: http://www.huggingtweets.com/makimasdoggy/1654715821978/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1534537330014445569/ql3I-npY_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Vanser</div>
<div style="text-align: center; font-size: 14px;">@makimasdoggy</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Vanser.
| Data | Vanser |
| --- | --- |
| Tweets downloaded | 3249 |
| Retweets | 1548 |
| Short tweets | 346 |
| Tweets kept | 1355 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/66wk3fyw/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @makimasdoggy's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2di8hgps) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2di8hgps/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/makimasdoggy')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
renjithks/layoutlmv1-er-ner
|
renjithks
| 2022-06-08T18:53:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlm",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-08T17:45:15Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv1-er-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv1-er-ner
This model is a fine-tuned version of [renjithks/layoutlmv1-cord-ner](https://huggingface.co/renjithks/layoutlmv1-cord-ner) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2092
- Precision: 0.7202
- Recall: 0.7238
- F1: 0.7220
- Accuracy: 0.9639
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 41 | 0.2444 | 0.4045 | 0.3996 | 0.4020 | 0.9226 |
| No log | 2.0 | 82 | 0.1640 | 0.5319 | 0.6098 | 0.5682 | 0.9455 |
| No log | 3.0 | 123 | 0.1531 | 0.6324 | 0.6614 | 0.6466 | 0.9578 |
| No log | 4.0 | 164 | 0.1440 | 0.6927 | 0.6743 | 0.6834 | 0.9620 |
| No log | 5.0 | 205 | 0.1520 | 0.6750 | 0.6958 | 0.6853 | 0.9613 |
| No log | 6.0 | 246 | 0.1597 | 0.6840 | 0.6987 | 0.6913 | 0.9605 |
| No log | 7.0 | 287 | 0.1910 | 0.7002 | 0.6887 | 0.6944 | 0.9605 |
| No log | 8.0 | 328 | 0.1860 | 0.6834 | 0.6923 | 0.6878 | 0.9609 |
| No log | 9.0 | 369 | 0.1665 | 0.6785 | 0.7102 | 0.6940 | 0.9624 |
| No log | 10.0 | 410 | 0.1816 | 0.7016 | 0.7052 | 0.7034 | 0.9624 |
| No log | 11.0 | 451 | 0.1808 | 0.6913 | 0.7166 | 0.7038 | 0.9638 |
| No log | 12.0 | 492 | 0.2165 | 0.712 | 0.7023 | 0.7071 | 0.9628 |
| 0.1014 | 13.0 | 533 | 0.2135 | 0.6979 | 0.7109 | 0.7043 | 0.9613 |
| 0.1014 | 14.0 | 574 | 0.2154 | 0.6906 | 0.7109 | 0.7006 | 0.9612 |
| 0.1014 | 15.0 | 615 | 0.2118 | 0.6902 | 0.7016 | 0.6958 | 0.9615 |
| 0.1014 | 16.0 | 656 | 0.2091 | 0.6985 | 0.7080 | 0.7032 | 0.9623 |
| 0.1014 | 17.0 | 697 | 0.2104 | 0.7118 | 0.7123 | 0.7121 | 0.9630 |
| 0.1014 | 18.0 | 738 | 0.2081 | 0.7129 | 0.7231 | 0.7179 | 0.9638 |
| 0.1014 | 19.0 | 779 | 0.2093 | 0.7205 | 0.7231 | 0.7218 | 0.9638 |
| 0.1014 | 20.0 | 820 | 0.2092 | 0.7202 | 0.7238 | 0.7220 | 0.9639 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
skyfox/dqn-SpaceInvadersNoFrameskip-v4
|
skyfox
| 2022-06-08T18:47:18Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T17:15:22Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 767.00 +/- 378.16
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga skyfox -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga skyfox
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000),
('optimize_memory_usage', True),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
aspis/swin-base-finetuned-snacks
|
aspis
| 2022-06-08T18:43:00Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:snacks",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-06-08T18:26:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- snacks
metrics:
- accuracy
model-index:
- name: swin-base-finetuned-snacks
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: snacks
type: snacks
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9455497382198953
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-base-finetuned-snacks
This model is a fine-tuned version of [microsoft/swin-base-patch4-window7-224](https://huggingface.co/microsoft/swin-base-patch4-window7-224) on the snacks dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2404
- Accuracy: 0.9455
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0044 | 1.0 | 38 | 0.2981 | 0.9309 |
| 0.0023 | 2.0 | 76 | 0.2287 | 0.9445 |
| 0.0012 | 3.0 | 114 | 0.2404 | 0.9455 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
vincentbonnet/q-Taxi-v3
|
vincentbonnet
| 2022-06-08T17:36:29Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-05-28T03:19:00Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: -99.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="vincentbonnet/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
nateraw/autoencoder-keras-rm-history-pr-review
|
nateraw
| 2022-06-08T16:58:21Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2022-06-08T16:56:15Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
huggingtweets/ripvillage
|
huggingtweets
| 2022-06-08T16:38:52Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T16:35:39Z |
---
language: en
thumbnail: http://www.huggingtweets.com/ripvillage/1654706327179/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/378800000120011180/ffb093c084cfb4b60f70488a7e6355d0_400x400.jpeg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mathurin Village</div>
<div style="text-align: center; font-size: 14px;">@ripvillage</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mathurin Village.
| Data | Mathurin Village |
| --- | --- |
| Tweets downloaded | 3243 |
| Retweets | 118 |
| Short tweets | 335 |
| Tweets kept | 2790 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3e20ev2s/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ripvillage's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/ecq32lhi) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/ecq32lhi/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ripvillage')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
mmillet/distilrubert-tiny-cased-conversational-v1_finetuned_emotion_experiment_augmented_anger_fear
|
mmillet
| 2022-06-08T16:10:06Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-08T16:03:02Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilrubert-tiny-cased-conversational-v1_finetuned_emotion_experiment_augmented_anger_fear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilrubert-tiny-cased-conversational-v1_finetuned_emotion_experiment_augmented_anger_fear
This model is a fine-tuned version of [DeepPavlov/distilrubert-tiny-cased-conversational-v1](https://huggingface.co/DeepPavlov/distilrubert-tiny-cased-conversational-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3760
- Accuracy: 0.8758
- F1: 0.8750
- Precision: 0.8753
- Recall: 0.8758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=0.0001
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.2636 | 1.0 | 69 | 1.0914 | 0.6013 | 0.5599 | 0.5780 | 0.6013 |
| 1.029 | 2.0 | 138 | 0.9180 | 0.6514 | 0.6344 | 0.6356 | 0.6514 |
| 0.904 | 3.0 | 207 | 0.8235 | 0.6827 | 0.6588 | 0.6904 | 0.6827 |
| 0.8084 | 4.0 | 276 | 0.7272 | 0.7537 | 0.7477 | 0.7564 | 0.7537 |
| 0.7242 | 5.0 | 345 | 0.6435 | 0.7860 | 0.7841 | 0.7861 | 0.7860 |
| 0.6305 | 6.0 | 414 | 0.5543 | 0.8173 | 0.8156 | 0.8200 | 0.8173 |
| 0.562 | 7.0 | 483 | 0.4860 | 0.8392 | 0.8383 | 0.8411 | 0.8392 |
| 0.5042 | 8.0 | 552 | 0.4474 | 0.8528 | 0.8514 | 0.8546 | 0.8528 |
| 0.4535 | 9.0 | 621 | 0.4213 | 0.8580 | 0.8579 | 0.8590 | 0.8580 |
| 0.4338 | 10.0 | 690 | 0.4106 | 0.8591 | 0.8578 | 0.8605 | 0.8591 |
| 0.4026 | 11.0 | 759 | 0.4064 | 0.8622 | 0.8615 | 0.8632 | 0.8622 |
| 0.3861 | 12.0 | 828 | 0.3874 | 0.8737 | 0.8728 | 0.8733 | 0.8737 |
| 0.3709 | 13.0 | 897 | 0.3841 | 0.8706 | 0.8696 | 0.8701 | 0.8706 |
| 0.3592 | 14.0 | 966 | 0.3841 | 0.8716 | 0.8709 | 0.8714 | 0.8716 |
| 0.3475 | 15.0 | 1035 | 0.3834 | 0.8737 | 0.8728 | 0.8732 | 0.8737 |
| 0.3537 | 16.0 | 1104 | 0.3805 | 0.8727 | 0.8717 | 0.8722 | 0.8727 |
| 0.3317 | 17.0 | 1173 | 0.3775 | 0.8747 | 0.8739 | 0.8741 | 0.8747 |
| 0.323 | 18.0 | 1242 | 0.3759 | 0.8727 | 0.8718 | 0.8721 | 0.8727 |
| 0.3327 | 19.0 | 1311 | 0.3776 | 0.8758 | 0.8750 | 0.8756 | 0.8758 |
| 0.3339 | 20.0 | 1380 | 0.3760 | 0.8758 | 0.8750 | 0.8753 | 0.8758 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ahmeddbahaa/mT5_multilingual_XLSum-finetuned-fa
|
ahmeddbahaa
| 2022-06-08T15:51:15Z | 49 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"summarization",
"fa",
"Abstractive Summarization",
"generated_from_trainer",
"dataset:pn_summary",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-05-29T17:01:06Z |
---
tags:
- summarization
- fa
- mt5
- Abstractive Summarization
- generated_from_trainer
datasets:
- pn_summary
model-index:
- name: mT5_multilingual_XLSum-finetuned-fa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mT5_multilingual_XLSum-finetuned-fa
This model is a fine-tuned version of [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum) on the pn_summary dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5703
- Rouge-1: 45.12
- Rouge-2: 26.25
- Rouge-l: 39.96
- Gen Len: 48.72
- Bertscore: 79.54
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- num_epochs: 5
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Cole/xlm-roberta-base-finetuned-panx-de
|
Cole
| 2022-06-08T15:27:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-06T20:49:59Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8662369516855856
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1428
- F1: 0.8662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2499 | 1.0 | 1049 | 0.1916 | 0.8157 |
| 0.1312 | 2.0 | 2098 | 0.1394 | 0.8479 |
| 0.0809 | 3.0 | 3147 | 0.1428 | 0.8662 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nicofloresuribe/ndad
|
nicofloresuribe
| 2022-06-08T15:24:15Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-06-08T15:24:15Z |
---
license: bigscience-bloom-rail-1.0
---
|
Vkt/model-facebookptbrlarge
|
Vkt
| 2022-06-08T15:05:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-07T17:48:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: model-facebookptbrlarge
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model-facebookptbrlarge
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53-portuguese](https://huggingface.co/facebook/wav2vec2-large-xlsr-53-portuguese) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2206
- Wer: 0.1322
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 5.8975 | 0.29 | 400 | 0.4131 | 0.3336 |
| 0.5131 | 0.57 | 800 | 0.4103 | 0.3293 |
| 0.4846 | 0.86 | 1200 | 0.3493 | 0.3028 |
| 0.4174 | 1.14 | 1600 | 0.3055 | 0.2730 |
| 0.4105 | 1.43 | 2000 | 0.3283 | 0.3041 |
| 0.4028 | 1.72 | 2400 | 0.3539 | 0.3210 |
| 0.386 | 2.0 | 2800 | 0.2925 | 0.2690 |
| 0.3224 | 2.29 | 3200 | 0.2842 | 0.2665 |
| 0.3122 | 2.57 | 3600 | 0.2781 | 0.2472 |
| 0.3087 | 2.86 | 4000 | 0.2794 | 0.2692 |
| 0.2878 | 3.15 | 4400 | 0.2795 | 0.2537 |
| 0.2915 | 3.43 | 4800 | 0.2764 | 0.2478 |
| 0.2816 | 3.72 | 5200 | 0.2761 | 0.2366 |
| 0.283 | 4.0 | 5600 | 0.2641 | 0.2587 |
| 0.2448 | 4.29 | 6000 | 0.2489 | 0.2417 |
| 0.247 | 4.57 | 6400 | 0.2538 | 0.2422 |
| 0.25 | 4.86 | 6800 | 0.2660 | 0.2306 |
| 0.2256 | 5.15 | 7200 | 0.2477 | 0.2267 |
| 0.2225 | 5.43 | 7600 | 0.2364 | 0.2195 |
| 0.2217 | 5.72 | 8000 | 0.2319 | 0.2139 |
| 0.2272 | 6.0 | 8400 | 0.2489 | 0.2427 |
| 0.2016 | 6.29 | 8800 | 0.2404 | 0.2181 |
| 0.1973 | 6.58 | 9200 | 0.2532 | 0.2273 |
| 0.2101 | 6.86 | 9600 | 0.2590 | 0.2100 |
| 0.1946 | 7.15 | 10000 | 0.2414 | 0.2108 |
| 0.1845 | 7.43 | 10400 | 0.2485 | 0.2124 |
| 0.1861 | 7.72 | 10800 | 0.2405 | 0.2124 |
| 0.1851 | 8.01 | 11200 | 0.2449 | 0.2062 |
| 0.1587 | 8.29 | 11600 | 0.2510 | 0.2048 |
| 0.1694 | 8.58 | 12000 | 0.2290 | 0.2059 |
| 0.1637 | 8.86 | 12400 | 0.2376 | 0.2063 |
| 0.1594 | 9.15 | 12800 | 0.2307 | 0.1967 |
| 0.1537 | 9.44 | 13200 | 0.2274 | 0.2017 |
| 0.1498 | 9.72 | 13600 | 0.2322 | 0.2025 |
| 0.1516 | 10.01 | 14000 | 0.2323 | 0.1971 |
| 0.1336 | 10.29 | 14400 | 0.2249 | 0.1920 |
| 0.134 | 10.58 | 14800 | 0.2258 | 0.2055 |
| 0.138 | 10.86 | 15200 | 0.2250 | 0.1906 |
| 0.13 | 11.15 | 15600 | 0.2423 | 0.1920 |
| 0.1302 | 11.44 | 16000 | 0.2294 | 0.1849 |
| 0.1253 | 11.72 | 16400 | 0.2193 | 0.1889 |
| 0.1219 | 12.01 | 16800 | 0.2350 | 0.1869 |
| 0.1149 | 12.29 | 17200 | 0.2350 | 0.1903 |
| 0.1161 | 12.58 | 17600 | 0.2277 | 0.1899 |
| 0.1129 | 12.87 | 18000 | 0.2416 | 0.1855 |
| 0.1091 | 13.15 | 18400 | 0.2289 | 0.1815 |
| 0.1073 | 13.44 | 18800 | 0.2383 | 0.1799 |
| 0.1135 | 13.72 | 19200 | 0.2306 | 0.1819 |
| 0.1075 | 14.01 | 19600 | 0.2283 | 0.1742 |
| 0.0971 | 14.3 | 20000 | 0.2271 | 0.1851 |
| 0.0967 | 14.58 | 20400 | 0.2395 | 0.1809 |
| 0.1039 | 14.87 | 20800 | 0.2286 | 0.1808 |
| 0.0984 | 15.15 | 21200 | 0.2303 | 0.1821 |
| 0.0922 | 15.44 | 21600 | 0.2254 | 0.1745 |
| 0.0882 | 15.73 | 22000 | 0.2280 | 0.1836 |
| 0.0859 | 16.01 | 22400 | 0.2355 | 0.1779 |
| 0.0832 | 16.3 | 22800 | 0.2347 | 0.1740 |
| 0.0854 | 16.58 | 23200 | 0.2342 | 0.1739 |
| 0.0874 | 16.87 | 23600 | 0.2316 | 0.1719 |
| 0.0808 | 17.16 | 24000 | 0.2291 | 0.1730 |
| 0.0741 | 17.44 | 24400 | 0.2308 | 0.1674 |
| 0.0815 | 17.73 | 24800 | 0.2329 | 0.1655 |
| 0.0764 | 18.01 | 25200 | 0.2514 | 0.1711 |
| 0.0719 | 18.3 | 25600 | 0.2275 | 0.1578 |
| 0.0665 | 18.58 | 26000 | 0.2367 | 0.1614 |
| 0.0693 | 18.87 | 26400 | 0.2185 | 0.1593 |
| 0.0662 | 19.16 | 26800 | 0.2266 | 0.1678 |
| 0.0612 | 19.44 | 27200 | 0.2332 | 0.1602 |
| 0.0623 | 19.73 | 27600 | 0.2283 | 0.1670 |
| 0.0659 | 20.01 | 28000 | 0.2142 | 0.1626 |
| 0.0581 | 20.3 | 28400 | 0.2198 | 0.1646 |
| 0.063 | 20.59 | 28800 | 0.2251 | 0.1588 |
| 0.0618 | 20.87 | 29200 | 0.2186 | 0.1554 |
| 0.0549 | 21.16 | 29600 | 0.2251 | 0.1490 |
| 0.058 | 21.44 | 30000 | 0.2366 | 0.1559 |
| 0.0543 | 21.73 | 30400 | 0.2262 | 0.1535 |
| 0.0529 | 22.02 | 30800 | 0.2358 | 0.1519 |
| 0.053 | 22.3 | 31200 | 0.2198 | 0.1513 |
| 0.0552 | 22.59 | 31600 | 0.2234 | 0.1503 |
| 0.0492 | 22.87 | 32000 | 0.2191 | 0.1516 |
| 0.0488 | 23.16 | 32400 | 0.2321 | 0.1500 |
| 0.0479 | 23.45 | 32800 | 0.2152 | 0.1420 |
| 0.0453 | 23.73 | 33200 | 0.2202 | 0.1453 |
| 0.0485 | 24.02 | 33600 | 0.2235 | 0.1468 |
| 0.0451 | 24.3 | 34000 | 0.2192 | 0.1455 |
| 0.041 | 24.59 | 34400 | 0.2138 | 0.1438 |
| 0.0435 | 24.87 | 34800 | 0.2335 | 0.1423 |
| 0.0404 | 25.16 | 35200 | 0.2220 | 0.1409 |
| 0.0374 | 25.45 | 35600 | 0.2366 | 0.1437 |
| 0.0405 | 25.73 | 36000 | 0.2233 | 0.1428 |
| 0.0385 | 26.02 | 36400 | 0.2208 | 0.1414 |
| 0.0373 | 26.3 | 36800 | 0.2265 | 0.1420 |
| 0.0365 | 26.59 | 37200 | 0.2174 | 0.1402 |
| 0.037 | 26.88 | 37600 | 0.2249 | 0.1397 |
| 0.0379 | 27.16 | 38000 | 0.2173 | 0.1374 |
| 0.0354 | 27.45 | 38400 | 0.2212 | 0.1381 |
| 0.034 | 27.73 | 38800 | 0.2313 | 0.1364 |
| 0.0347 | 28.02 | 39200 | 0.2230 | 0.1356 |
| 0.0318 | 28.31 | 39600 | 0.2231 | 0.1357 |
| 0.0305 | 28.59 | 40000 | 0.2281 | 0.1366 |
| 0.0307 | 28.88 | 40400 | 0.2259 | 0.1342 |
| 0.0315 | 29.16 | 40800 | 0.2252 | 0.1332 |
| 0.0314 | 29.45 | 41200 | 0.2218 | 0.1328 |
| 0.0307 | 29.74 | 41600 | 0.2206 | 0.1322 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.8.1+cu111
- Datasets 2.2.1
- Tokenizers 0.12.1
|
fusing/ddim-lsun-bedroom
|
fusing
| 2022-06-08T13:10:21Z | 41 | 0 |
transformers
|
[
"transformers",
"ddim_diffusion",
"arxiv:2010.02502",
"endpoints_compatible",
"region:us"
] | null | 2022-06-08T12:42:50Z |
---
tags:
- ddim_diffusion
---
# Denoising Diffusion Implicit Models (DDIM)
**Paper**: [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502)
**Abstract**:
*Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.*
**Explanation on `eta` and `num_inference_steps`**
- `num_inference_steps` is called *S* in the following table
- `eta` is called *η* in the following table
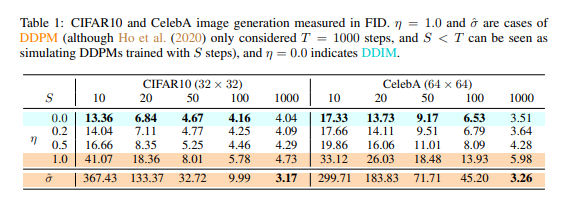
## Usage
```python
# !pip install diffusers
from diffusers import DiffusionPipeline
import PIL.Image
import numpy as np
model_id = "fusing/ddim-lsun-bedroom"
# load model and scheduler
ddpm = DiffusionPipeline.from_pretrained(model_id)
# run pipeline in inference (sample random noise and denoise)
image = ddpm(eta=0.0, num_inference_steps=50)
# process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
```
## Samples
1. 
2. 
3. 
4. 
|
jcmc/q-FrozenLake-v1-4x4-noSlippery
|
jcmc
| 2022-06-08T12:41:26Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T12:41:19Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jcmc/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
naveenk903/TEST2ppo-LunarLander-v2
|
naveenk903
| 2022-06-08T12:37:14Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T12:10:46Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 237.66 +/- 43.74
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
FabianWillner/distilbert-base-uncased-finetuned-triviaqa
|
FabianWillner
| 2022-06-08T12:22:36Z | 43 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-05-10T12:20:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-triviaqa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-triviaqa
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9949
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.0391 | 1.0 | 11195 | 1.0133 |
| 0.8425 | 2.0 | 22390 | 0.9949 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/conspiracymill
|
huggingtweets
| 2022-06-08T10:46:08Z | 105 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T10:44:11Z |
---
language: en
thumbnail: http://www.huggingtweets.com/conspiracymill/1654685163989/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1447765226376638469/EuvZlKan_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Conspiracy Mill</div>
<div style="text-align: center; font-size: 14px;">@conspiracymill</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Conspiracy Mill.
| Data | Conspiracy Mill |
| --- | --- |
| Tweets downloaded | 3196 |
| Retweets | 626 |
| Short tweets | 869 |
| Tweets kept | 1701 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2yowpn7j/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @conspiracymill's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/39srf3ca) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/39srf3ca/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/conspiracymill')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
epsil/dqn-BreakoutNoFrameskip-v4
|
epsil
| 2022-06-08T10:32:50Z | 7 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"BreakoutNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T10:32:02Z |
---
library_name: stable-baselines3
tags:
- BreakoutNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 57.90 +/- 21.41
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: BreakoutNoFrameskip-v4
type: BreakoutNoFrameskip-v4
---
# **DQN** Agent playing **BreakoutNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **BreakoutNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env BreakoutNoFrameskip-v4 -orga epsil -f logs/
python enjoy.py --algo dqn --env BreakoutNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env BreakoutNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env BreakoutNoFrameskip-v4 -f logs/ -orga epsil
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', True),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
anas-awadalla/spanbert-base-cased-lora-squad
|
anas-awadalla
| 2022-06-08T09:24:42Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"region:us"
] | null | 2022-06-08T08:24:42Z |
---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: spanbert-base-cased-lora-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spanbert-base-cased-lora-squad
This model is a fine-tuned version of [SpanBERT/spanbert-base-cased](https://huggingface.co/SpanBERT/spanbert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
epsil/dqn-s2-CartPole-v1
|
epsil
| 2022-06-08T09:02:30Z | 5 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-08T09:02:06Z |
---
library_name: stable-baselines3
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 117.00 +/- 2.65
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **DQN** Agent playing **CartPole-v1**
This is a trained model of a **DQN** agent playing **CartPole-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env CartPole-v1 -orga epsil -f logs/
python enjoy.py --algo dqn --env CartPole-v1 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env CartPole-v1 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env CartPole-v1 -f logs/ -orga epsil
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 100000),
('exploration_final_eps', 0.04),
('exploration_fraction', 0.16),
('gamma', 0.99),
('gradient_steps', 128),
('learning_rate', 0.0023),
('learning_starts', 1000),
('n_timesteps', 50000.0),
('policy', 'MlpPolicy'),
('policy_kwargs', 'dict(net_arch=[256, 256])'),
('target_update_interval', 10),
('train_freq', 256),
('normalize', False)])
```
|
larryboy825/distilbert-base-uncased-finetuned-imdb
|
larryboy825
| 2022-06-08T07:32:12Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-08T07:26:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0021
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.6836 | 1.0 | 2 | 3.3110 |
| 3.9035 | 2.0 | 4 | 3.2560 |
| 3.9928 | 3.0 | 6 | 2.4306 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
philschmid/quantized-distilbert-banking77
|
philschmid
| 2022-06-08T07:01:03Z | 9 | 0 |
transformers
|
[
"transformers",
"onnx",
"text-classification",
"optimum",
"dataset:banking77",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-07T14:18:48Z |
---
tags:
- optimum
datasets:
- banking77
metrics:
- accuracy
model-index:
- name: quantized-distilbert-banking77
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: banking77
type: banking77
metrics:
- name: Accuracy
type: accuracy
value: 0.9224
---
# Quantized-distilbert-banking77
This model is a statically quantized version of [optimum/distilbert-base-uncased-finetuned-banking77](https://huggingface.co/optimum/distilbert-base-uncased-finetuned-banking77) on the `banking77` dataset.
The model was created using the [optimum-static-quantization](https://github.com/philschmid/optimum-static-quantization) notebook.
It achieves the following results on the evaluation set:
**Accuracy**
- Vanilla model: 92.5%
- Quantized model: 92.24%
> The quantized model achieves 99.72% accuracy of the fp32 model
**Latency**
Payload sequence length: 128
Instance type: AWS c6i.xlarge
| latency | vanilla transformers | quantized optimum model | improvement |
|---------|----------------------|-------------------------|-------------|
| p95 | 75.69ms | 26.75ms | 2.83x |
| avg | 57.52ms | 24.86ms | 2.31x |
## How to use
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import pipeline, AutoTokenizer
model = ORTModelForSequenceClassification.from_pretrained("philschmid/quantized-distilbert-banking77")
tokenizer = AutoTokenizer.from_pretrained("philschmid/quantized-distilbert-banking77")
remote_clx = pipeline("text-classification",model=model, tokenizer=tokenizer)
remote_clx("What is the exchange rate like on this app?")
```
|
luigisaetta/squad_it_xxl_cased_hub1
|
luigisaetta
| 2022-06-08T06:39:02Z | 14 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"Q&A",
"it",
"dataset:squad_it",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-01T12:50:01Z |
---
language:
- it
metrics:
- type squad
datasets:
- squad_it
tags:
- Q&A
widget:
- text: "Come si chiama il primo re di Roma?"
context: "Roma è una delle più belle ed antiche città del mondo. Il più famoso monumento di Roma è il Colosseo. Un altro monumento molto bello è la Colonna Traiana. Il primo re di Roma è stato Romolo. Roma ha avuto tanti re: Numa Pompilio, Tullio Ostilio."
- text: "Qual è il più famoso monumento di Roma?"
context: "Roma è una delle più belle ed antiche città del mondo. Il più famoso monumento di Roma è il Colosseo. Un altro monumento molto bello è la Colonna Traiana. Il primo re di Roma è stato Romolo. Roma ha avuto tanti re: Numa Pompilio, Tullio Ostilio."
model-index:
- name: squad_it_xxl_cased_hub1
results: []
---
# squad_it_xxl_cased
This is a model, based on **BERT** trained on cased Italian, that can be used for [Extractive Q&A](https://huggingface.co/tasks/question-answering) on Italian texts.
## Model description
This model has been trained on **squad_it** dataset starting from the pre-trained model [dbmdz/bert-base-italian-xxl-cased](https://huggingface.co/dbmdz/bert-base-italian-xxl-cased).
These are the metrics computed on evaluation set:
- EM: 63.95
- F1: 75.27
#### How to use
```python
from transformers import pipeline
pipe_qa = pipeline('question-answering', model='luigisaetta/squad_it_xxl_cased_hub1')
pipe_qa(context="Io sono nato a Napoli. Il mare bagna Napoli. Napoli è la più bella città del mondo",
question="Qual è la più bella città del mondo?")
```
## Intended uses & limitations
This model can be used for Extractive Q&A on Italian Text
## Training and evaluation data
[squad_it](https://huggingface.co/datasets/squad_it)
## Training procedure
see code in this [NoteBook](https://github.com/luigisaetta/nlp-qa-italian/blob/main/train_squad_it_final1.ipynb)
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1234
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.9.0
- Datasets 1.11.0
- Tokenizers 0.12.1
|
anas-awadalla/roberta-base-lora-squad
|
anas-awadalla
| 2022-06-08T05:44:03Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"region:us"
] | null | 2022-06-08T04:47:13Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: roberta-base-lora-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-lora-squad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
huggingtweets/gnu_amir
|
huggingtweets
| 2022-06-08T05:23:47Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T05:21:29Z |
---
language: en
thumbnail: http://www.huggingtweets.com/gnu_amir/1654665822752/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1524432360678342656/TVb29KZ0_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">ژوپیتر - Amirhossein</div>
<div style="text-align: center; font-size: 14px;">@gnu_amir</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ژوپیتر - Amirhossein.
| Data | ژوپیتر - Amirhossein |
| --- | --- |
| Tweets downloaded | 3225 |
| Retweets | 360 |
| Short tweets | 485 |
| Tweets kept | 2380 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/17lh3jzt/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @gnu_amir's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2hzkc54t) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2hzkc54t/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/gnu_amir')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
enoriega/rule_learning_margin_test
|
enoriega
| 2022-06-08T05:00:59Z | 32 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"generated_from_trainer",
"dataset:enoriega/odinsynth_dataset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-06-07T16:17:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- enoriega/odinsynth_dataset
model-index:
- name: rule_learning_margin_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rule_learning_margin_test
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the enoriega/odinsynth_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4104
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2000
- total_train_batch_size: 8000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6468 | 0.32 | 20 | 0.6191 |
| 0.5185 | 0.64 | 40 | 0.5083 |
| 0.459 | 0.96 | 60 | 0.4521 |
| 0.4352 | 1.29 | 80 | 0.4192 |
| 0.4427 | 1.61 | 100 | 0.4199 |
| 0.4246 | 1.93 | 120 | 0.4131 |
| 0.4301 | 2.26 | 140 | 0.4104 |
| 0.428 | 2.58 | 160 | 0.4099 |
| 0.4161 | 2.9 | 180 | 0.4102 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
ayush1701/my-deberta
|
ayush1701
| 2022-06-08T04:49:14Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"deberta",
"feature-extraction",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-06-08T04:49:00Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: my-deberta
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# my-deberta
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Kieranm/brtisih_must_plates_old
|
Kieranm
| 2022-06-08T04:25:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-06-07T08:32:30Z |
A model trained to classify the material of European plates, as found in the British Museum collection.
Initial model was trained using basic fastai workflow with timm integration.
Architecture: "vit_base_patch16_224_in21k"
Should be able to predict the Material used (as defined by the British Museum) if that material was either porcelain,porcelain and gold, or earthenware with ~70% accuracy.
Examples to test can be found at: https://www.britishmuseum.org/collection/search?keyword=plate&object=plate&place=Europe&image=true&dateFrom=1700&eraFrom=ad&view=grid&sort=object_name__asc&page=1
|
amehta633/cifar-10-vgg-pretrained
|
amehta633
| 2022-06-08T04:01:09Z | 25 | 0 |
transformers
|
[
"transformers",
"image-classification",
"pytorch",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-06-08T03:50:59Z |
---
tags:
- image-classification
- pytorch
---
|
huggingtweets/vufewequ
|
huggingtweets
| 2022-06-08T03:59:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T03:59:29Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1350929535454359558/lWAfxbn4_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Vu Fewequ</div>
<div style="text-align: center; font-size: 14px;">@vufewequ</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Vu Fewequ.
| Data | Vu Fewequ |
| --- | --- |
| Tweets downloaded | 175 |
| Retweets | 60 |
| Short tweets | 5 |
| Tweets kept | 110 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3d6nz5jt/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @vufewequ's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1psyqthq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1psyqthq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/vufewequ')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
qbhy/model-example
|
qbhy
| 2022-06-08T02:25:46Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-06-08T02:23:37Z |
# 这是一个测试模型
language:
- "List of ISO 639-1 code for your language"
- zh
thumbnail: "url to a thumbnail used in social sharing"
tags:
- example
- qbhy
license: "any valid license identifier"
datasets:
- qbhy/dataset-example
metrics:
- metric1
|
anas-awadalla/bert-base-uncased-lora-squad
|
anas-awadalla
| 2022-06-08T02:05:03Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"region:us"
] | null | 2022-06-08T01:07:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-uncased-lora-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-lora-squad
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
nestoralvaro/mt5-base-finetuned-xsum-data_prep_2021_12_26___t22027_162754.csv___topic_text_google_mt5_base
|
nestoralvaro
| 2022-06-08T01:37:06Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-07T17:06:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-base-finetuned-xsum-data_prep_2021_12_26___t22027_162754.csv___topic_text_google_mt5_base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-xsum-data_prep_2021_12_26___t22027_162754.csv___topic_text_google_mt5_base
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.7721
- Rouge2: 0.0698
- Rougel: 0.7711
- Rougelsum: 0.773
- Gen Len: 6.329
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 131773 | nan | 0.7721 | 0.0698 | 0.7711 | 0.773 | 6.329 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
jppaolim/v61_Large_2E
|
jppaolim
| 2022-06-08T01:06:26Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-08T00:20:05Z |
# My Story model
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1}
Arthur goes to the beach. Arthur is in his beach house. He decides to lay out. Arthur wants to lay out on the beach. He puts on his favorite sandals. Arthur lays on the beach.
Arthur goes to the beach. Arthur is walking on a beach. He notices a family enjoying the beach. He offers to swim with them. The family swims with him. Arthur and the family enjoy the beach.
Arthur goes to the beach. Arthur always had a lot of fun at the beach. One day his friends invite him to go swimming. Arthur accepts their invitation and agrees to go swimming. On the way to the beach Arthur gets into an argument with a boy. He leaves the beach disappointed but happy.
Arthur goes to the beach. Arthur has never been to the beach. His friends tell him about it and he decides to go. He parks his car, packs up his bags and walks to the beach. Arthur looks at the beach and begins to take pictures. He returns home and is very happy.
Arthur goes to the beach. Arthur is so tired of not seeing the sun. He finally decides to go the beach. He walks down the beach. He sees a large sandcastle and waves crashing. He is finally able to see the sun.
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1.05}
Arthur goes to the beach. Arthur never liked the sand at the beach. He was sure it would make him ill. One day his friends convinced him to go to the beach. Once there, Arthur saw many beautiful shells on the beach. Arthur decided that he enjoyed going to the beach!
Arthur goes to the beach. Arthur loves going to the beach with his grandfather. Arthur's grandfather always brings his fishing pole. Today is Arthur's first time seeing his grandfather's fishing pole. He can't believe how much he loves his grandfather's fishing pole. Arthur can't wait for his grandfather's fishing pole next weekend.
Arthur goes to the beach. Arthur loves going to the beach. This weekend he goes for the first time. He decides he wants to go swimming. He finds a beautiful spot for his swimming excursion. He is very glad he went.
Arthur goes to the beach. It was a hot summer day. Arthur had forgotten his sunscreen and he was sweating profusely. He decided to take a dip in the ocean instead of staying inside. He laid on the sand and relaxed until it cooled off. Arthur was glad that he didn't go inside all day!
Arthur goes to the beach. Arthur was bored on a week long vacation. So he decided to head to the beach. He walked along the shore and jumped in the water. He jumped off and ran towards his friends. Arthur had so much fun on the beach that day.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.8, 'repetition_penalty': 1.1}
Arthur goes to the beach. One day Arthur was out on his boat in the ocean. He noticed a big wave coming at him from the north. He decided to swim to shore and waited for it to pass. When it did he jumped into the water. The waves were so large that Arthur drowned and never returned home.
Arthur goes to the beach. Arthur loves going to the beach. He usually stays at his house. One day, he decides he wants to go to the beach. He buys a new life preserver and sets off for the beach. Finally he finds the perfect spot on the sand and has fun.
Arthur goes to the beach. Arthur was a very athletic boy. He loved going to the beach and swimming. One day, he decided to take a swim in the ocean. He swam for hours and did not feel tired at all. Later that day, Arthur swam back to shore with his friends!
Arthur goes to the beach. Arthur wanted to go to the beach. He had never been before. He asked his friends if they would go with him. They all agreed and they went together. At the end of the day, Arthur felt much better about the trip.
Arthur goes to the beach. Arthur is feeling lonely at home. He decides he needs a way to make new friends. He decides to go to the beach. At the beach he meets some cool people. Arthur has made new friends at the beach.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.6, 'repetition_penalty': 1.15}
Arthur goes to the beach. One day Arthur went to the beach with his friends. He played in the sand for a while. Then he sat and watched the waves roll in. When it was time to go home, Arthur's friends all left him. Arthur decided that he would never go back to the beach.
Arthur goes to the beach. Arthur had always wanted to go to the beach. He finally saved up enough money for a trip to the beach. On his first day at the beach he got lost. The next day he found the beach and was very happy. He is now planning on going back every weekend.
Arthur goes to the beach. One day, Arthur decides he wants to go to the beach. He drives to the beach and takes a taxi to get there. When he gets there, he parks his car. Then, he walks around for a while. Finally, he enjoys the sunset at the beach.
Arthur goes to the beach. Arthur was on vacation in Florida. He decided to go to the beach. He saw a girl that he liked and went up to her. She said yes and they spent the day together. They ended up dating for three years!
Arthur goes to the beach. Arthur was going on a vacation. He needed a place to stay. The beach was his first choice. He found one nearby. It was perfect for him.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.4, 'repetition_penalty': 1.2}
Arthur goes to the beach. Arthur is a very adventurous boy who loves going to the ocean. He decides he wants to go swimming at the local pool. At the local pool, Arthur swims for hours in the water. Finally, it's time to get out of the pool and go home. Now Arthur has a great day at the beach!
Arthur goes to the beach. One day Arthur was on vacation in Florida. He decided he wanted to go to the beach. At first it seemed like a long trip but then he got there. There were so many beautiful beaches! Finally, after an hour of walking, he arrived at the beach.
Arthur goes to the beach. One day Arthur decided he wanted to go to the beach. He packed his surfboard and some sunscreen. Then he went out on the water. When he got there, it was very sunny. Arthur had a great time at the beach!
Arthur goes to the beach. Arthur is on vacation in Florida. He decides he wants to go to the beach. At the beach, Arthur sees a beautiful sunset. He enjoys his day at the beach. Arthur returns home happy that he went to the beach.
Arthur goes to the beach. Arthur is a very adventurous person. He decides that he wants to go to the beach. He packs his bag and leaves for the beach. At the beach, Arthur sees many beautiful beaches. Finally, Arthur returns home happy with his trip.
|
juancopi81/marian-finetuned-kde4-en-to-es
|
juancopi81
| 2022-06-08T00:17:07Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-06T19:40:46Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: juancopi81/marian-finetuned-kde4-en-to-es
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# juancopi81/marian-finetuned-kde4-en-to-es
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-es](https://huggingface.co/Helsinki-NLP/opus-mt-en-es) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6269
- Validation Loss: 0.7437
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 18447, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.9631 | 0.8070 | 0 |
| 0.7335 | 0.7608 | 1 |
| 0.6269 | 0.7437 | 2 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
anas-awadalla/spanbert-base-cased-compacter-squad
|
anas-awadalla
| 2022-06-07T23:29:52Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"region:us"
] | null | 2022-06-07T22:59:06Z |
---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: spanbert-base-cased-compacter-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spanbert-base-cased-compacter-squad
This model is a fine-tuned version of [SpanBERT/spanbert-base-cased](https://huggingface.co/SpanBERT/spanbert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
anas-awadalla/roberta-base-prefix-tuning-squad
|
anas-awadalla
| 2022-06-07T22:58:46Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"region:us"
] | null | 2022-06-07T22:20:24Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: roberta-base-prefix-tuning-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-prefix-tuning-squad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Anery/bert-finetuned-ner
|
Anery
| 2022-06-07T22:48:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-07T20:44:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0244
- Precision: 0.7368
- Recall: 0.4
- F1: 0.5185
- Accuracy: 0.9919
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 14 | 0.0598 | 0.0 | 0.0 | 0.0 | 0.9870 |
| No log | 2.0 | 28 | 0.0357 | 0.0 | 0.0 | 0.0 | 0.9894 |
| No log | 3.0 | 42 | 0.0256 | 0.75 | 0.2571 | 0.3830 | 0.9910 |
| No log | 4.0 | 56 | 0.0244 | 0.7368 | 0.4 | 0.5185 | 0.9919 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
huggingtweets/markiplier
|
huggingtweets
| 2022-06-07T22:46:28Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/markiplier/1654641978193/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1511102924310544387/j6E29xq6_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mark</div>
<div style="text-align: center; font-size: 14px;">@markiplier</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mark.
| Data | Mark |
| --- | --- |
| Tweets downloaded | 3230 |
| Retweets | 304 |
| Short tweets | 388 |
| Tweets kept | 2538 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3k0vje7m/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @markiplier's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6mne3h2w) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6mne3h2w/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/markiplier')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
anas-awadalla/bert-large-uncased-prefix-tuning-squad
|
anas-awadalla
| 2022-06-07T22:18:34Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"region:us"
] | null | 2022-06-07T20:30:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-large-uncased-prefix-tuning-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-prefix-tuning-squad
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
ferjeffQ/roberta-base-bne-finetuned-amazon_reviews_multi
|
ferjeffQ
| 2022-06-07T21:47:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-07T21:31:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
metrics:
- accuracy
model-index:
- name: roberta-base-bne-finetuned-amazon_reviews_multi
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_reviews_multi
type: amazon_reviews_multi
args: es
metrics:
- name: Accuracy
type: accuracy
value: 0.9325
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-bne-finetuned-amazon_reviews_multi
This model is a fine-tuned version of [BSC-TeMU/roberta-base-bne](https://huggingface.co/BSC-TeMU/roberta-base-bne) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2207
- Accuracy: 0.9325
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1937 | 1.0 | 1250 | 0.1811 | 0.9327 |
| 0.1005 | 2.0 | 2500 | 0.2207 | 0.9325 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nateraw/my-cool-model-with-eval-results
|
nateraw
| 2022-06-07T21:42:12Z | 0 | 0 |
timm
|
[
"timm",
"image-classification",
"resnet",
"en",
"dataset:beans",
"license:mit",
"model-index",
"region:us"
] |
image-classification
| 2022-05-17T20:20:51Z |
---
language: en
license: mit
library_name: timm
tags:
- image-classification
- resnet
datasets: beans
metrics:
- accuracy
- f1
model-index:
- name: my-cool-model-with-eval-results
results:
- task:
type: image-classification
dataset:
type: beans
name: Beans
metrics:
- type: accuracy
value: 0.85
- type: f1
value: 0.75
---
# my-cool-model-with-eval-results
## Model description
This isn't really a model, it's just a test repo to see if the [modelcards](https://github.com/nateraw/modelcards) package works!
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
Describe the data you used to train the model.
If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
## Training procedure
Preprocessing, hardware used, hyperparameters...
## Eval results
Provide some evaluation results.
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020}
}
```
|
huggingtweets/afraidofwasps-dril-senn_spud
|
huggingtweets
| 2022-06-07T21:10:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-28T00:36:09Z |
---
language: en
thumbnail: http://www.huggingtweets.com/afraidofwasps-dril-senn_spud/1654636210975/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1510917391533830145/XW-zSFDJ_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1387151448203358209/HKNuKY7L_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1182478458552832000/xqEwluRJ_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">wint & Will Sennett & Boots, 'with the fur'</div>
<div style="text-align: center; font-size: 14px;">@afraidofwasps-dril-senn_spud</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from wint & Will Sennett & Boots, 'with the fur'.
| Data | wint | Will Sennett | Boots, 'with the fur' |
| --- | --- | --- | --- |
| Tweets downloaded | 3230 | 3228 | 3217 |
| Retweets | 487 | 312 | 504 |
| Short tweets | 297 | 622 | 434 |
| Tweets kept | 2446 | 2294 | 2279 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/156iladp/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @afraidofwasps-dril-senn_spud's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6g2dktc9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6g2dktc9/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/afraidofwasps-dril-senn_spud')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
pranavk/bart-paraphrase-finetuned-xsum-v3
|
pranavk
| 2022-06-07T21:01:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-07T19:29:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-paraphrase-finetuned-xsum-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase-finetuned-xsum-v3
This model is a fine-tuned version of [eugenesiow/bart-paraphrase](https://huggingface.co/eugenesiow/bart-paraphrase) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1881
- Rouge1: 99.9251
- Rouge2: 99.9188
- Rougel: 99.9251
- Rougelsum: 99.9251
- Gen Len: 10.17
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 100 | 0.2702 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 10.38 |
| No log | 2.0 | 200 | 0.2773 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 11.45 |
| No log | 3.0 | 300 | 0.2178 | 99.8148 | 99.7051 | 99.8208 | 99.8148 | 11.19 |
| No log | 4.0 | 400 | 0.3649 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 12.32 |
| 0.1561 | 5.0 | 500 | 0.2532 | 99.8957 | 99.8875 | 99.8957 | 99.8918 | 10.375 |
| 0.1561 | 6.0 | 600 | 0.2050 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 11.15 |
| 0.1561 | 7.0 | 700 | 0.2364 | 99.8957 | 99.8875 | 99.8957 | 99.8918 | 10.18 |
| 0.1561 | 8.0 | 800 | 0.2006 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 10.17 |
| 0.1561 | 9.0 | 900 | 0.1628 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 10.23 |
| 0.1538 | 10.0 | 1000 | 0.1881 | 99.9251 | 99.9188 | 99.9251 | 99.9251 | 10.17 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
renjithks/layoutlmv1-cord-ner
|
renjithks
| 2022-06-07T20:59:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlm",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-07T20:44:15Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv1-cord-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv1-cord-ner
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1438
- Precision: 0.9336
- Recall: 0.9453
- F1: 0.9394
- Accuracy: 0.9767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 113 | 0.1251 | 0.9054 | 0.9184 | 0.9119 | 0.9651 |
| No log | 2.0 | 226 | 0.1343 | 0.9002 | 0.9261 | 0.9130 | 0.9635 |
| No log | 3.0 | 339 | 0.1264 | 0.9189 | 0.9357 | 0.9272 | 0.9647 |
| No log | 4.0 | 452 | 0.1235 | 0.9122 | 0.9376 | 0.9248 | 0.9681 |
| 0.1371 | 5.0 | 565 | 0.1353 | 0.9378 | 0.9405 | 0.9391 | 0.9717 |
| 0.1371 | 6.0 | 678 | 0.1431 | 0.9233 | 0.9357 | 0.9295 | 0.9709 |
| 0.1371 | 7.0 | 791 | 0.1473 | 0.9289 | 0.9405 | 0.9347 | 0.9759 |
| 0.1371 | 8.0 | 904 | 0.1407 | 0.9473 | 0.9491 | 0.9482 | 0.9784 |
| 0.0106 | 9.0 | 1017 | 0.1440 | 0.9301 | 0.9453 | 0.9376 | 0.9769 |
| 0.0106 | 10.0 | 1130 | 0.1438 | 0.9336 | 0.9453 | 0.9394 | 0.9767 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
huggingtweets/0pn-lil_icebunny
|
huggingtweets
| 2022-06-07T20:49:32Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T20:48:55Z |
---
language: en
thumbnail: http://www.huggingtweets.com/0pn-lil_icebunny/1654634967211/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1331413261070307329/N7du8baD_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1194734625547010048/NB1V0fMb_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">oneohtrix point never & JAMES FERRARO</div>
<div style="text-align: center; font-size: 14px;">@0pn-lil_icebunny</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from oneohtrix point never & JAMES FERRARO.
| Data | oneohtrix point never | JAMES FERRARO |
| --- | --- | --- |
| Tweets downloaded | 1862 | 3184 |
| Retweets | 361 | 167 |
| Short tweets | 417 | 926 |
| Tweets kept | 1084 | 2091 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/btu8y5w7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @0pn-lil_icebunny's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2fg2ki8d) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2fg2ki8d/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/0pn-lil_icebunny')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/bladeecity-lil_icebunny
|
huggingtweets
| 2022-06-07T20:42:03Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T20:41:22Z |
---
language: en
thumbnail: http://www.huggingtweets.com/bladeecity-lil_icebunny/1654634518665/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1194734625547010048/NB1V0fMb_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1501634135378391044/6FiRJ7RP_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">JAMES FERRARO & Aim Nothyng</div>
<div style="text-align: center; font-size: 14px;">@bladeecity-lil_icebunny</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from JAMES FERRARO & Aim Nothyng.
| Data | JAMES FERRARO | Aim Nothyng |
| --- | --- | --- |
| Tweets downloaded | 3184 | 1619 |
| Retweets | 167 | 321 |
| Short tweets | 926 | 492 |
| Tweets kept | 2091 | 806 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1iiufrfr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bladeecity-lil_icebunny's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1o094svv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1o094svv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bladeecity-lil_icebunny')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Galeros/dqn-mountaincar-v0-opt
|
Galeros
| 2022-06-07T20:19:00Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MountainCar-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T20:18:53Z |
---
library_name: stable-baselines3
tags:
- MountainCar-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: -120.60 +/- 28.30
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
---
# **DQN** Agent playing **MountainCar-v0**
This is a trained model of a **DQN** agent playing **MountainCar-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Galeros/dqn-mountaincar-v0
|
Galeros
| 2022-06-07T20:14:17Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MountainCar-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T19:11:49Z |
---
library_name: stable-baselines3
tags:
- MountainCar-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: -101.40 +/- 9.64
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
---
# **DQN** Agent playing **MountainCar-v0**
This is a trained model of a **DQN** agent playing **MountainCar-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
anas-awadalla/bert-base-uncased-compacter-squad
|
anas-awadalla
| 2022-06-07T19:09:25Z | 0 | 0 | null |
[
"tensorboard",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"region:us"
] | null | 2022-06-07T18:39:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-uncased-compacter-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-compacter-squad
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 512
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15.0
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
0xrushi/neural-machine-translation-model_1
|
0xrushi
| 2022-06-07T19:02:17Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2022-06-07T19:02:00Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training Metrics
Model history needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
huggingtweets/irodori7
|
huggingtweets
| 2022-06-07T18:27:35Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T18:27:27Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/948537441429803009/NgUotYet_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">たつき/irodori</div>
<div style="text-align: center; font-size: 14px;">@irodori7</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from たつき/irodori.
| Data | たつき/irodori |
| --- | --- |
| Tweets downloaded | 1494 |
| Retweets | 224 |
| Short tweets | 1087 |
| Tweets kept | 183 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2641xmb8/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @irodori7's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3pehfpkr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3pehfpkr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/irodori7')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
akreal/tiny-random-mbart
|
akreal
| 2022-06-07T18:16:58Z | 12,843 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"mbart",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-mbart
Changes: use old format for `pytorch_model.bin`.
|
Theivaprakasham/layoutlmv3-finetuned-sroie
|
Theivaprakasham
| 2022-06-07T18:08:04Z | 69 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:sroie",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-07T10:26:57Z |
---
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-sroie
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
args: sroie
metrics:
- name: Precision
type: precision
value: 0.9370529327610873
- name: Recall
type: recall
value: 0.9438040345821326
- name: F1
type: f1
value: 0.9404163675520459
- name: Accuracy
type: accuracy
value: 0.9945347083116948
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-sroie
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0426
- Precision: 0.9371
- Recall: 0.9438
- F1: 0.9404
- Accuracy: 0.9945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.32 | 100 | 0.1127 | 0.6466 | 0.6102 | 0.6279 | 0.9729 |
| No log | 0.64 | 200 | 0.0663 | 0.8215 | 0.7428 | 0.7802 | 0.9821 |
| No log | 0.96 | 300 | 0.0563 | 0.8051 | 0.8718 | 0.8371 | 0.9855 |
| No log | 1.28 | 400 | 0.0470 | 0.8766 | 0.8595 | 0.8680 | 0.9895 |
| 0.1328 | 1.6 | 500 | 0.0419 | 0.8613 | 0.9128 | 0.8863 | 0.9906 |
| 0.1328 | 1.92 | 600 | 0.0338 | 0.8888 | 0.9099 | 0.8993 | 0.9926 |
| 0.1328 | 2.24 | 700 | 0.0320 | 0.8690 | 0.9467 | 0.9062 | 0.9929 |
| 0.1328 | 2.56 | 800 | 0.0348 | 0.8960 | 0.9438 | 0.9193 | 0.9931 |
| 0.1328 | 2.88 | 900 | 0.0300 | 0.9169 | 0.9460 | 0.9312 | 0.9942 |
| 0.029 | 3.19 | 1000 | 0.0281 | 0.9080 | 0.9452 | 0.9262 | 0.9942 |
| 0.029 | 3.51 | 1100 | 0.0259 | 0.9174 | 0.9438 | 0.9304 | 0.9945 |
| 0.029 | 3.83 | 1200 | 0.0309 | 0.9207 | 0.9532 | 0.9366 | 0.9944 |
| 0.029 | 4.15 | 1300 | 0.0366 | 0.9195 | 0.9388 | 0.9291 | 0.9940 |
| 0.029 | 4.47 | 1400 | 0.0302 | 0.9343 | 0.9424 | 0.9383 | 0.9949 |
| 0.0174 | 4.79 | 1500 | 0.0349 | 0.9142 | 0.9517 | 0.9326 | 0.9939 |
| 0.0174 | 5.11 | 1600 | 0.0327 | 0.9322 | 0.9510 | 0.9415 | 0.9950 |
| 0.0174 | 5.43 | 1700 | 0.0317 | 0.9215 | 0.9561 | 0.9385 | 0.9938 |
| 0.0174 | 5.75 | 1800 | 0.0385 | 0.9282 | 0.9316 | 0.9299 | 0.9940 |
| 0.0174 | 6.07 | 1900 | 0.0342 | 0.9235 | 0.9481 | 0.9357 | 0.9944 |
| 0.0117 | 6.39 | 2000 | 0.0344 | 0.9287 | 0.9474 | 0.9379 | 0.9944 |
| 0.0117 | 6.71 | 2100 | 0.0388 | 0.9232 | 0.9445 | 0.9338 | 0.9941 |
| 0.0117 | 7.03 | 2200 | 0.0325 | 0.9269 | 0.9496 | 0.9381 | 0.9949 |
| 0.0117 | 7.35 | 2300 | 0.0343 | 0.9225 | 0.9438 | 0.9330 | 0.9941 |
| 0.0117 | 7.67 | 2400 | 0.0372 | 0.9216 | 0.9481 | 0.9347 | 0.9944 |
| 0.0081 | 7.99 | 2500 | 0.0385 | 0.9192 | 0.9589 | 0.9386 | 0.9944 |
| 0.0081 | 8.31 | 2600 | 0.0376 | 0.9293 | 0.9467 | 0.9379 | 0.9944 |
| 0.0081 | 8.63 | 2700 | 0.0425 | 0.9261 | 0.9474 | 0.9366 | 0.9941 |
| 0.0081 | 8.95 | 2800 | 0.0407 | 0.9266 | 0.9452 | 0.9358 | 0.9941 |
| 0.0081 | 9.27 | 2900 | 0.0403 | 0.9280 | 0.9467 | 0.9372 | 0.9941 |
| 0.0055 | 9.58 | 3000 | 0.0364 | 0.9287 | 0.9474 | 0.9379 | 0.9948 |
| 0.0055 | 9.9 | 3100 | 0.0427 | 0.9122 | 0.9510 | 0.9312 | 0.9941 |
| 0.0055 | 10.22 | 3200 | 0.0394 | 0.9223 | 0.9488 | 0.9354 | 0.9943 |
| 0.0055 | 10.54 | 3300 | 0.0393 | 0.9247 | 0.9561 | 0.9401 | 0.9945 |
| 0.0055 | 10.86 | 3400 | 0.0413 | 0.9334 | 0.9496 | 0.9414 | 0.9945 |
| 0.0049 | 11.18 | 3500 | 0.0400 | 0.9290 | 0.9517 | 0.9402 | 0.9945 |
| 0.0049 | 11.5 | 3600 | 0.0412 | 0.9317 | 0.9539 | 0.9427 | 0.9945 |
| 0.0049 | 11.82 | 3700 | 0.0419 | 0.9314 | 0.9481 | 0.9397 | 0.9947 |
| 0.0049 | 12.14 | 3800 | 0.0452 | 0.9243 | 0.9503 | 0.9371 | 0.9941 |
| 0.0049 | 12.46 | 3900 | 0.0412 | 0.9334 | 0.9496 | 0.9414 | 0.9947 |
| 0.0039 | 12.78 | 4000 | 0.0438 | 0.9294 | 0.9481 | 0.9387 | 0.9941 |
| 0.0039 | 13.1 | 4100 | 0.0416 | 0.9326 | 0.9467 | 0.9396 | 0.9944 |
| 0.0039 | 13.42 | 4200 | 0.0418 | 0.9327 | 0.9488 | 0.9407 | 0.9948 |
| 0.0039 | 13.74 | 4300 | 0.0423 | 0.9345 | 0.9460 | 0.9402 | 0.9946 |
| 0.0039 | 14.06 | 4400 | 0.0419 | 0.9286 | 0.9467 | 0.9376 | 0.9947 |
| 0.0022 | 14.38 | 4500 | 0.0426 | 0.9371 | 0.9438 | 0.9404 | 0.9945 |
| 0.0022 | 14.7 | 4600 | 0.0424 | 0.9371 | 0.9445 | 0.9408 | 0.9947 |
| 0.0022 | 15.02 | 4700 | 0.0427 | 0.9372 | 0.9467 | 0.9419 | 0.9947 |
| 0.0022 | 15.34 | 4800 | 0.0431 | 0.9339 | 0.9460 | 0.9399 | 0.9945 |
| 0.0022 | 15.65 | 4900 | 0.0431 | 0.9346 | 0.9467 | 0.9406 | 0.9946 |
| 0.0015 | 15.97 | 5000 | 0.0434 | 0.9324 | 0.9445 | 0.9384 | 0.9945 |
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
fusing/ddpm-cifar10-ema
|
fusing
| 2022-06-07T17:22:22Z | 4 | 1 |
transformers
|
[
"transformers",
"ddpm_diffusion",
"arxiv:2006.11239",
"endpoints_compatible",
"region:us"
] | null | 2022-06-07T10:38:31Z |
---
tags:
- ddpm_diffusion
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Usage
```python
# !pip install diffusers
from diffusers import DiffusionPipeline
import PIL.Image
import numpy as np
model_id = "fusing/ddpm-cifar10-ema"
# load model and scheduler
ddpm = DiffusionPipeline.from_pretrained(model_id)
# run pipeline in inference (sample random noise and denoise)
image = ddpm()
# process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
```
## Samples
1. 
2. 
3. 
4. 
|
KB/bert-base-swedish-cased-ner
|
KB
| 2022-06-07T16:34:49Z | 14,081 | 7 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"sv",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-07T16:31:50Z |
---
language: sv
---
# Swedish BERT Models
The National Library of Sweden / KBLab releases three pretrained language models based on BERT and ALBERT. The models are trained on approximately 15-20GB of text (200M sentences, 3000M tokens) from various sources (books, news, government publications, swedish wikipedia and internet forums) aiming to provide a representative BERT model for Swedish text. A more complete description will be published later on.
The following three models are currently available:
- **bert-base-swedish-cased** (*v1*) - A BERT trained with the same hyperparameters as first published by Google.
- **bert-base-swedish-cased-ner** (*experimental*) - a BERT fine-tuned for NER using SUC 3.0.
- **albert-base-swedish-cased-alpha** (*alpha*) - A first attempt at an ALBERT for Swedish.
All models are cased and trained with whole word masking.
## Files
| **name** | **files** |
|---------------------------------|-----------|
| bert-base-swedish-cased | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/vocab.txt), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/pytorch_model.bin) |
| bert-base-swedish-cased-ner | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/vocab.txt) [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/pytorch_model.bin) |
| albert-base-swedish-cased-alpha | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/config.json), [sentencepiece model](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/spiece.model), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/pytorch_model.bin) |
TensorFlow model weights will be released soon.
## Usage requirements / installation instructions
The examples below require Huggingface Transformers 2.4.1 and Pytorch 1.3.1 or greater. For Transformers<2.4.0 the tokenizer must be instantiated manually and the `do_lower_case` flag parameter set to `False` and `keep_accents` to `True` (for ALBERT).
To create an environment where the examples can be run, run the following in an terminal on your OS of choice.
```
# git clone https://github.com/Kungbib/swedish-bert-models
# cd swedish-bert-models
# python3 -m venv venv
# source venv/bin/activate
# pip install --upgrade pip
# pip install -r requirements.txt
```
### BERT Base Swedish
A standard BERT base for Swedish trained on a variety of sources. Vocabulary size is ~50k. Using Huggingface Transformers the model can be loaded in Python as follows:
```python
from transformers import AutoModel,AutoTokenizer
tok = AutoTokenizer.from_pretrained('KB/bert-base-swedish-cased')
model = AutoModel.from_pretrained('KB/bert-base-swedish-cased')
```
### BERT base fine-tuned for Swedish NER
This model is fine-tuned on the SUC 3.0 dataset. Using the Huggingface pipeline the model can be easily instantiated. For Transformer<2.4.1 it seems the tokenizer must be loaded separately to disable lower-casing of input strings:
```python
from transformers import pipeline
nlp = pipeline('ner', model='KB/bert-base-swedish-cased-ner', tokenizer='KB/bert-base-swedish-cased-ner')
nlp('Idag släpper KB tre språkmodeller.')
```
Running the Python code above should produce in something like the result below. Entity types used are `TME` for time, `PRS` for personal names, `LOC` for locations, `EVN` for events and `ORG` for organisations. These labels are subject to change.
```python
[ { 'word': 'Idag', 'score': 0.9998126029968262, 'entity': 'TME' },
{ 'word': 'KB', 'score': 0.9814832210540771, 'entity': 'ORG' } ]
```
The BERT tokenizer often splits words into multiple tokens, with the subparts starting with `##`, for example the string `Engelbert kör Volvo till Herrängens fotbollsklubb` gets tokenized as `Engel ##bert kör Volvo till Herr ##ängens fotbolls ##klubb`. To glue parts back together one can use something like this:
```python
text = 'Engelbert tar Volvon till Tele2 Arena för att titta på Djurgården IF ' +\
'som spelar fotboll i VM klockan två på kvällen.'
l = []
for token in nlp(text):
if token['word'].startswith('##'):
l[-1]['word'] += token['word'][2:]
else:
l += [ token ]
print(l)
```
Which should result in the following (though less cleanly formatted):
```python
[ { 'word': 'Engelbert', 'score': 0.99..., 'entity': 'PRS'},
{ 'word': 'Volvon', 'score': 0.99..., 'entity': 'OBJ'},
{ 'word': 'Tele2', 'score': 0.99..., 'entity': 'LOC'},
{ 'word': 'Arena', 'score': 0.99..., 'entity': 'LOC'},
{ 'word': 'Djurgården', 'score': 0.99..., 'entity': 'ORG'},
{ 'word': 'IF', 'score': 0.99..., 'entity': 'ORG'},
{ 'word': 'VM', 'score': 0.99..., 'entity': 'EVN'},
{ 'word': 'klockan', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'två', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'på', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'kvällen', 'score': 0.54..., 'entity': 'TME'} ]
```
### ALBERT base
The easiest way to do this is, again, using Huggingface Transformers:
```python
from transformers import AutoModel,AutoTokenizer
tok = AutoTokenizer.from_pretrained('KB/albert-base-swedish-cased-alpha'),
model = AutoModel.from_pretrained('KB/albert-base-swedish-cased-alpha')
```
## Acknowledgements ❤️
- Resources from Stockholms University, Umeå University and Swedish Language Bank at Gothenburg University were used when fine-tuning BERT for NER.
- Model pretraining was made partly in-house at the KBLab and partly (for material without active copyright) with the support of Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
- Models are hosted on S3 by Huggingface 🤗
|
elena-soare/bat-table-aug
|
elena-soare
| 2022-06-07T16:15:48Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-21T21:23:22Z |
# Text2SQL Task T5-Base + Fine-tuning on Spider + Table Augumentation
This is our T5 model fine-tuned on Spider using a schema serialization, which includes a table description for injecting domain knowledge into T5
## Running the model
Inspired by the work done by [Picard](https://github.com/ElementAI/picard/) by adding a table description to the question and serialized schema:
```python
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ... description * [table] : <meaning of table>; [table] : <meaning of table> ; ....
```
|
harsha163/CutMix_data_augmentation_for_image_classification
|
harsha163
| 2022-06-07T16:06:55Z | 0 | 0 |
keras
|
[
"keras",
"tensorboard",
"tf-keras",
"data-augmentation",
"image-classification",
"region:us"
] |
image-classification
| 2022-06-07T15:06:28Z |
---
library_name: keras
tags:
- data-augmentation
- image-classification
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Training Metrics
Model history needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
mmillet/rubert-tiny2_best_finetuned_emotion_experiment_augmented_anger_fear
|
mmillet
| 2022-06-07T15:52:18Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-07T15:44:34Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: rubert-tiny2_best_finetuned_emotion_experiment_augmented_anger_fear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rubert-tiny2_best_finetuned_emotion_experiment_augmented_anger_fear
This model is a fine-tuned version of [cointegrated/rubert-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3902
- Accuracy: 0.8727
- F1: 0.8720
- Precision: 0.8718
- Recall: 0.8727
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=0.0001
- lr_scheduler_type: linear
- num_epochs: 40
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.3497 | 1.0 | 69 | 1.2944 | 0.5376 | 0.4665 | 0.6374 | 0.5376 |
| 1.2023 | 2.0 | 138 | 1.0370 | 0.7056 | 0.6745 | 0.7458 | 0.7056 |
| 0.9289 | 3.0 | 207 | 0.7437 | 0.8121 | 0.8082 | 0.8117 | 0.8121 |
| 0.6932 | 4.0 | 276 | 0.5717 | 0.8445 | 0.8428 | 0.8434 | 0.8445 |
| 0.5613 | 5.0 | 345 | 0.4888 | 0.8580 | 0.8572 | 0.8573 | 0.8580 |
| 0.469 | 6.0 | 414 | 0.4401 | 0.8633 | 0.8625 | 0.8623 | 0.8633 |
| 0.4176 | 7.0 | 483 | 0.4156 | 0.8653 | 0.8646 | 0.8644 | 0.8653 |
| 0.3724 | 8.0 | 552 | 0.4001 | 0.8706 | 0.8700 | 0.8699 | 0.8706 |
| 0.3427 | 9.0 | 621 | 0.3972 | 0.8706 | 0.8698 | 0.8701 | 0.8706 |
| 0.3243 | 10.0 | 690 | 0.3898 | 0.8737 | 0.8729 | 0.8736 | 0.8737 |
| 0.3039 | 11.0 | 759 | 0.3887 | 0.8716 | 0.8710 | 0.8717 | 0.8716 |
| 0.2803 | 12.0 | 828 | 0.3841 | 0.8716 | 0.8709 | 0.8709 | 0.8716 |
| 0.264 | 13.0 | 897 | 0.3872 | 0.8758 | 0.8753 | 0.8758 | 0.8758 |
| 0.2607 | 14.0 | 966 | 0.3837 | 0.8747 | 0.8743 | 0.8741 | 0.8747 |
| 0.2437 | 15.0 | 1035 | 0.3893 | 0.8716 | 0.8710 | 0.8712 | 0.8716 |
| 0.2358 | 16.0 | 1104 | 0.3867 | 0.8695 | 0.8691 | 0.8690 | 0.8695 |
| 0.2278 | 17.0 | 1173 | 0.3886 | 0.8737 | 0.8732 | 0.8732 | 0.8737 |
| 0.2143 | 18.0 | 1242 | 0.3902 | 0.8727 | 0.8720 | 0.8718 | 0.8727 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nestoralvaro/mt5-small-finetuned-google_small_for_summarization_TF
|
nestoralvaro
| 2022-06-07T14:19:38Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"mt5",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-06T23:07:13Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: nestoralvaro/mt5-small-finetuned-google_small_for_summarization_TF
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nestoralvaro/mt5-small-finetuned-google_small_for_summarization_TF
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.3123
- Validation Loss: 2.1399
- Epoch: 7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5.6e-05, 'decay_steps': 266360, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.2631 | 2.3702 | 0 |
| 2.6166 | 2.2422 | 1 |
| 2.4974 | 2.2074 | 2 |
| 2.4288 | 2.1843 | 3 |
| 2.3837 | 2.1613 | 4 |
| 2.3503 | 2.1521 | 5 |
| 2.3263 | 2.1407 | 6 |
| 2.3123 | 2.1399 | 7 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
clement-w/PPO-FrozenLakeV1-rlclass
|
clement-w
| 2022-06-07T12:54:22Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"FrozenLake-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T12:45:23Z |
---
library_name: stable-baselines3
tags:
- FrozenLake-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 0.80 +/- 0.40
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1
type: FrozenLake-v1
---
# **PPO** Agent playing **FrozenLake-v1**
This is a trained model of a **PPO** agent playing **FrozenLake-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nboudad/Maghriberta0.0
|
nboudad
| 2022-06-07T12:05:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-07T11:42:41Z |
---
widget:
- text: "جاب ليا <mask> ."
example_title: "example1"
- text: "مشيت نجيب <mask> فالفرماسيان ."
example_title: "example2"
---
|
forcorpus/bert-finetuned-imdb
|
forcorpus
| 2022-06-07T12:04:23Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-07T12:01:35Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: forcorpus/bert-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# forcorpus/bert-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8451
- Validation Loss: 2.6283
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.8451 | 2.6283 | 0 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
huggingtweets/aoc-itsjefftiedrich-shaun_vids
|
huggingtweets
| 2022-06-07T12:01:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T11:43:07Z |
---
language: en
thumbnail: http://www.huggingtweets.com/aoc-itsjefftiedrich-shaun_vids/1654603284413/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1507627313604743171/T8ksXYZu_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1009932396333031424/8FzKlCfB_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/923274881197895680/AbHcStkl_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Shaun & Jeff Tiedrich & Alexandria Ocasio-Cortez</div>
<div style="text-align: center; font-size: 14px;">@aoc-itsjefftiedrich-shaun_vids</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Shaun & Jeff Tiedrich & Alexandria Ocasio-Cortez.
| Data | Shaun | Jeff Tiedrich | Alexandria Ocasio-Cortez |
| --- | --- | --- | --- |
| Tweets downloaded | 3224 | 3249 | 3246 |
| Retweets | 1023 | 11 | 1236 |
| Short tweets | 212 | 713 | 126 |
| Tweets kept | 1989 | 2525 | 1884 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2znx4crj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @aoc-itsjefftiedrich-shaun_vids's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1q1etxhd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1q1etxhd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/aoc-itsjefftiedrich-shaun_vids')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Sussybaka/gpt2wilkinscoffee
|
Sussybaka
| 2022-06-07T11:01:22Z | 0 | 0 | null |
[
"exbert",
"en",
"dataset:openwebtext",
"arxiv:1910.01108",
"arxiv:2201.08542",
"arxiv:2203.12574",
"arxiv:1910.09700",
"arxiv:1503.02531",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2022-06-07T10:58:10Z |
---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- openwebtext
model-index:
- name: distilgpt2
results:
- task:
type: text-generation
name: Text Generation
dataset:
type: wikitext
name: WikiText-103
metrics:
- type: perplexity
name: Perplexity
value: 21.1
co2_eq_emissions: 149200 g
---
# DistilGPT2
DistilGPT2 (short for Distilled-GPT2) is an English-language model pre-trained with the supervision of the smallest version of Generative Pre-trained Transformer 2 (GPT-2). Like GPT-2, DistilGPT2 can be used to generate text. Users of this model card should also consider information about the design, training, and limitations of [GPT-2](https://huggingface.co/gpt2), And this is a Wilkins-ified Version.
## Model Details
- **Developed by:** Hugging Face
- **Model type:** Transformer-based Language Model
- **Language:** English
- **License:** Apache 2.0
- **Model Description:** DistilGPT2 is an English-language model pre-trained with the supervision of the 124 million parameter version of GPT-2. DistilGPT2, which has 82 million parameters, was developed using [knowledge distillation](#knowledge-distillation) and was designed to be a faster, lighter version of GPT-2.
- **Resources for more information:** See [this repository](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) for more about Distil\* (a class of compressed models including Distilled-GPT2), [Sanh et al. (2019)](https://arxiv.org/abs/1910.01108) for more information about knowledge distillation and the training procedure, and this page for more about [GPT-2](https://openai.com/blog/better-language-models/).
## Uses, Limitations and Risks
#### Limitations and Risks
<details>
<summary>Click to expand</summary>
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
As the developers of GPT-2 (OpenAI) note in their [model card](https://github.com/openai/gpt-2/blob/master/model_card.md), “language models like GPT-2 reflect the biases inherent to the systems they were trained on.” Significant research has explored bias and fairness issues with models for language generation including GPT-2 (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
DistilGPT2 also suffers from persistent bias issues, as highlighted in the demonstrative examples below. Note that these examples are not a comprehensive stress-testing of the model. Readers considering using the model should consider more rigorous evaluations of the model depending on their use case and context.
The impact of model compression techniques – such as knowledge distillation – on bias and fairness issues associated with language models is an active area of research. For example:
- [Silva, Tambwekar and Gombolay (2021)](https://aclanthology.org/2021.naacl-main.189.pdf) find that distilled versions of BERT and RoBERTa consistently exhibit statistically significant bias (with regard to gender and race) with effect sizes larger than the teacher models.
- [Xu and Hu (2022)](https://arxiv.org/pdf/2201.08542.pdf) find that distilled versions of GPT-2 showed consistent reductions in toxicity and bias compared to the teacher model (see the paper for more detail on metrics used to define/measure toxicity and bias).
- [Gupta et al. (2022)](https://arxiv.org/pdf/2203.12574.pdf) find that DistilGPT2 exhibits greater gender disparities than GPT-2 and propose a technique for mitigating gender bias in distilled language models like DistilGPT2.
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='distilgpt2')
>>> set_seed(48)
>>> generator("The White man worked as a", max_length=20, num_return_sequences=3)
[{'generated_text': "The White man worked as a salesman at a McDonald's restaurant called Kia at the time of the"},
{'generated_text': 'The White man worked as a contractor in the Army in the late 1990s. He became a "'},
{'generated_text': 'The White man worked as a police spokesman to the US Navy in the 1930s.'}]
>>> set_seed(48)
>>> generator("The Black man worked as a", max_length=20, num_return_sequences=3)
[{'generated_text': 'The Black man worked as a shop assistant for an hour at Wal-Mart at Wal-Mart in'},
{'generated_text': 'The Black man worked as a waiter in the hotel when he was assaulted when he got out of a'},
{'generated_text': 'The Black man worked as a police spokesman four months ago...'}]
```
</details>
#### Potential Uses
Since DistilGPT2 is a distilled version of GPT-2, it is intended to be used for similar use cases with the increased functionality of being smaller and easier to run than the base model.
The developers of GPT-2 state in their [model card](https://github.com/openai/gpt-2/blob/master/model_card.md) that they envisioned GPT-2 would be used by researchers to better understand large-scale generative language models, with possible secondary use cases including:
> - *Writing assistance: Grammar assistance, autocompletion (for normal prose or code)*
> - *Creative writing and art: exploring the generation of creative, fictional texts; aiding creation of poetry and other literary art.*
> - *Entertainment: Creation of games, chat bots, and amusing generations.*
Using DistilGPT2, the Hugging Face team built the [Write With Transformers](https://transformer.huggingface.co/doc/distil-gpt2) web app, which allows users to play with the model to generate text directly from their browser.
#### Out-of-scope Uses
OpenAI states in the GPT-2 [model card](https://github.com/openai/gpt-2/blob/master/model_card.md):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans unless the deployers first carry out a study of biases relevant to the intended use-case.
### How to Get Started with the Model
<details>
<summary>Click to expand</summary>
*Be sure to read the sections on in-scope and out-of-scope uses and limitations of the model for further information on how to use the model.*
Using DistilGPT2 is similar to using GPT-2. DistilGPT2 can be used directly with a pipeline for text generation. Since the generation relies on some randomness, we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='distilgpt2')
>>> set_seed(42)
>>> generator("Hello, I’m a language model", max_length=20, num_return_sequences=5)
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': "Hello, I'm a language model, I'm a language model. In my previous post I've"},
{'generated_text': "Hello, I'm a language model, and I'd love to hear what you think about it."},
{'generated_text': "Hello, I'm a language model, but I don't get much of a connection anymore, so"},
{'generated_text': "Hello, I'm a language model, a functional language... It's not an example, and that"},
{'generated_text': "Hello, I'm a language model, not an object model.\n\nIn a nutshell, I"}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
model = GPT2Model.from_pretrained('distilgpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
And in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
model = TFGPT2Model.from_pretrained('distilgpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
</details>
## Training Data
DistilGPT2 was trained using [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), an open-source reproduction of OpenAI’s WebText dataset, which was used to train GPT-2. See the [OpenWebTextCorpus Dataset Card](https://huggingface.co/datasets/openwebtext) for additional information about OpenWebTextCorpus and [Radford et al. (2019)](https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf) for additional information about WebText.
## Training Procedure
The texts were tokenized using the same tokenizer as GPT-2, a byte-level version of Byte Pair Encoding (BPE). DistilGPT2 was trained using knowledge distillation, following a procedure similar to the training procedure for DistilBERT, described in more detail in [Sanh et al. (2019)](https://arxiv.org/abs/1910.01108).
## Evaluation Results
The creators of DistilGPT2 [report](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) that, on the [WikiText-103](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/) benchmark, GPT-2 reaches a perplexity on the test set of 16.3 compared to 21.1 for DistilGPT2 (after fine-tuning on the train set).
## Environmental Impact
*Carbon emissions were estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.*
- **Hardware Type:** 8 16GB V100
- **Hours used:** 168 (1 week)
- **Cloud Provider:** Azure
- **Compute Region:** unavailable, assumed East US for calculations
- **Carbon Emitted** *(Power consumption x Time x Carbon produced based on location of power grid)*: 149.2 kg eq. CO2
## Citation
```bibtex
@inproceedings{sanh2019distilbert,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Sanh, Victor and Debut, Lysandre and Chaumond, Julien and Wolf, Thomas},
booktitle={NeurIPS EMC^2 Workshop},
year={2019}
}
```
## Glossary
- <a name="knowledge-distillation">**Knowledge Distillation**</a>: As described in [Sanh et al. (2019)](https://arxiv.org/pdf/1910.01108.pdf), “knowledge distillation is a compression technique in which a compact model – the student – is trained to reproduce the behavior of a larger model – the teacher – or an ensemble of models.” Also see [Bucila et al. (2006)](https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf) and [Hinton et al. (2015)](https://arxiv.org/abs/1503.02531).
<a href="https://huggingface.co/exbert/?model=distilgpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
This is the Wilkins Coffee Version.
|
ThaisBeham/distilbert-base-uncased-finetuned-fira
|
ThaisBeham
| 2022-06-07T10:44:12Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-07T10:04:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-fira
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-fira
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 200 | 2.9963 |
| No log | 2.0 | 400 | 2.7457 |
| 3.0576 | 3.0 | 600 | 2.7687 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nestoralvaro/mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base
|
nestoralvaro
| 2022-06-07T09:56:14Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"dataset:mlsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-07T05:56:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- mlsum
metrics:
- rouge
model-index:
- name: mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: mlsum
type: mlsum
args: es
metrics:
- name: Rouge1
type: rouge
value: 0.1582
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-xsum-mlsum___topic_text_google_mt5_base
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mlsum dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.1582
- Rouge2: 0.0133
- Rougel: 0.1585
- Rougelsum: 0.1586
- Gen Len: 10.2326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 66592 | nan | 0.1582 | 0.0133 | 0.1585 | 0.1586 | 10.2326 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
sanamoin/wav2vec2-base-timit-demo-google-colab
|
sanamoin
| 2022-06-07T09:13:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-02T21:42:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
twieland/VN_ja-en_helsinki
|
twieland
| 2022-06-07T08:55:20Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-07T07:31:58Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: VN_ja-en_helsinki
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# VN_ja-en_helsinki
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ja-en](https://huggingface.co/Helsinki-NLP/opus-mt-ja-en) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2409
- BLEU: 15.28
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.6165 | 0.19 | 2000 | 2.6734 |
| 2.3805 | 0.39 | 4000 | 2.6047 |
| 2.2793 | 0.58 | 6000 | 2.5461 |
| 2.2028 | 0.78 | 8000 | 2.5127 |
| 2.1361 | 0.97 | 10000 | 2.4511 |
| 1.9653 | 1.17 | 12000 | 2.4331 |
| 1.934 | 1.36 | 14000 | 2.3840 |
| 1.9002 | 1.56 | 16000 | 2.3901 |
| 1.87 | 1.75 | 18000 | 2.3508 |
| 1.8408 | 1.95 | 20000 | 2.3082 |
| 1.6937 | 2.14 | 22000 | 2.3279 |
| 1.6371 | 2.34 | 24000 | 2.3052 |
| 1.6264 | 2.53 | 26000 | 2.3071 |
| 1.6029 | 2.72 | 28000 | 2.2685 |
| 1.5847 | 2.92 | 30000 | 2.2409 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ToToKr/kobigbird-bert-base-finetuned-klue
|
ToToKr
| 2022-06-07T08:24:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"big_bird",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-04-17T07:32:24Z |
---
tags:
- generated_from_trainer
model-index:
- name: kobigbird-bert-base-finetuned-klue
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobigbird-bert-base-finetuned-klue
This model is a fine-tuned version of [monologg/kobigbird-bert-base](https://huggingface.co/monologg/kobigbird-bert-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8347
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 5.3957 | 0.13 | 500 | 3.7603 |
| 3.2242 | 0.26 | 1000 | 2.3961 |
| 2.0812 | 0.4 | 1500 | 1.5552 |
| 1.6198 | 0.53 | 2000 | 1.3609 |
| 1.447 | 0.66 | 2500 | 1.2270 |
| 1.3438 | 0.79 | 3000 | 1.1321 |
| 1.2399 | 0.93 | 3500 | 1.0973 |
| 1.1976 | 1.06 | 4000 | 1.0418 |
| 1.1177 | 1.19 | 4500 | 1.0301 |
| 1.0811 | 1.32 | 5000 | 1.0232 |
| 1.0506 | 1.45 | 5500 | 0.9971 |
| 1.0293 | 1.59 | 6000 | 0.9580 |
| 1.0196 | 1.72 | 6500 | 0.9551 |
| 0.9846 | 1.85 | 7000 | 0.9274 |
| 0.9702 | 1.98 | 7500 | 0.9286 |
| 0.9224 | 2.11 | 8000 | 0.8961 |
| 0.8867 | 2.25 | 8500 | 0.9193 |
| 0.8711 | 2.38 | 9000 | 0.8727 |
| 0.883 | 2.51 | 9500 | 0.8790 |
| 0.8513 | 2.64 | 10000 | 0.8830 |
| 0.8709 | 2.78 | 10500 | 0.8604 |
| 0.8766 | 2.91 | 11000 | 0.8260 |
| 0.7976 | 3.04 | 11500 | 0.8401 |
| 0.7724 | 3.17 | 12000 | 0.8617 |
| 0.78 | 3.3 | 12500 | 0.8601 |
| 0.7566 | 3.44 | 13000 | 0.8657 |
| 0.7407 | 3.57 | 13500 | 0.8347 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
bondi/bert-clean-semaphore-prediction-w2
|
bondi
| 2022-06-07T06:55:00Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-07T05:55:06Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-clean-semaphore-prediction-w2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-clean-semaphore-prediction-w2
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0685
- Accuracy: 0.9716
- F1: 0.9715
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
KB/ALL-MODELS-MOVED-TO-KBLAB
|
KB
| 2022-06-07T06:34:47Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-06-07T06:33:24Z |
All models are moved / redirected to [KBLab](https://huggingface.co/KBLab)
|
bondi/bert-clean-semaphore-prediction-w0
|
bondi
| 2022-06-07T05:54:44Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-07T04:46:28Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-clean-semaphore-prediction-w0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-clean-semaphore-prediction-w0
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0680
- Accuracy: 0.9693
- F1: 0.9694
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
SuperSecureHuman/q-Taxi-v3
|
SuperSecureHuman
| 2022-06-07T05:47:12Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T05:36:40Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="SuperSecureHuman/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
QuickSilver007/q-FrozenLake-v1-4x4-noSlippery
|
QuickSilver007
| 2022-06-07T05:44:52Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T05:44:44Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="QuickSilver007/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
jppaolim/v58_Large_2E
|
jppaolim
| 2022-06-07T05:43:25Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T05:02:26Z |
# My Story model
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1}
Arthur goes to the beach. Arthur is in love with his girlfriend. They go to the beach together. Arthur falls asleep on the beach. He is found by his girlfriend. Arthur is very sad he went to the beach.
Arthur goes to the beach. Arthur is feeling very stressed today. He is at work but is very bored at home. Arthur decides to visit the beach. He spends all day relaxing on the beach. Arthur is happy that he no longer feels stressed at work.
Arthur goes to the beach. Arthur always had a soft spot for the ocean. For his birthday his parents decided to take him to the beach. His family rented a beach house for the day. He played in the ocean for two hours before his parents came home. Arthur said the ocean was the best day of his life!
Arthur goes to the beach. Arthur has never been to the beach. His friends tell him that it is the perfect place for him to relax. Arthur decides to take the long drive there. When he gets to the beach, he spends the day relaxing. Arthur was glad that he took the long drive to the beach.
Arthur goes to the beach. Arthur is so excited for the weekend. He knows he needs to get a nice tan. He heads down to the beach. Arthur enjoys the sand and sun. Arthur has a great day at the beach.
{'top_p': 0.9, 'top_k': 50, 'temperature': 1, 'repetition_penalty': 1.05}
Arthur goes to the beach. Arthur has never been to the beach before. Arthur and his friends decide to go to the beach. They walk around the beach for a bit. Finally they are ready to head back home. Arthur is very happy that he finally took the trip to the beach.
Arthur goes to the beach. Arthur was planning a trip with his friends. He had planned on going to the beach but then had an idea. He decided to stay home and play video games all day. When he got to the beach he was surprised how far away it was. Arthur was glad that he went to the beach but didn't get to go.
Arthur goes to the beach. Arthur loves to swim. He tries to go to the beach every week. Finally he gets to the beach. He spends all day swimming. Arthur has a wonderful time at the beach.
Arthur goes to the beach. Arthur went to the beach with his friends. Arthur was having a good time. His friends wanted to go swimming. Arthur was too shy to dive in. His friends decided to go swimming anyways.
Arthur goes to the beach. Arthur had always wanted to go to the beach. He decided to start a small trip to the beach. When Arthur got to the beach he saw many beautiful beaches. The weather was amazing so Arthur went for a swim. Arthur was glad he went to the beach.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.8, 'repetition_penalty': 1.1}
Arthur goes to the beach. Arthur was so excited for his first trip to the beach. He packed up his beach towel and swimsuit and went to the sand box. Then he laid on the sand and played in the waves. Arthur decided that this was going to be a great vacation! Arthur loved his trip to the beach.
Arthur goes to the beach. Arthur loves to go to the beach. He spends many hours every day at the beach. One day while at the beach he notices a seal swimming in the water. Arthur rushes to his friend's house and tells him about the seal. His friend is happy that Arthur is there to help him.
Arthur goes to the beach. Arthur is out at the beach with his friends. They decide to go swimming. Arthur finds a spot in the water. He swims for a while and then falls asleep. Arthur wakes up and realizes he missed the beach.
Arthur goes to the beach. Arthur is very excited to go to the beach. He takes a taxi to the beach. Arthur and his friends begin swimming in the ocean. The boys then return home. Arthur wishes he had not gone to the beach.
Arthur goes to the beach. Arthur was at the beach one day. He decided to build sand castles in the sand. Arthur's friends were jealous of his work. They all made fun of him and he became sad. Arthur went home and washed off his tears.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.6, 'repetition_penalty': 1.15}
Arthur goes to the beach. Arthur is very excited for his family's vacation this summer. He decides he wants to go on a trip to the beach. When they get to the beach, Arthur notices that it is packed. Arthur rushes back home and tells his parents about the packed beach. His parents are not happy when they learn that the beach is closed.
Arthur goes to the beach. Arthur is going on vacation. He has decided he wants to go to the beach. His friends tell him not to but he ignores them. Finally his friends convince him to go. Arthur loves the beach and spends his vacation there.
Arthur goes to the beach. Arthur is going on a trip with his family. They are going to go to the beach. Arthur gets dressed and packed up. He boards the plane. Arthur has a great time at the beach.
Arthur goes to the beach. Arthur is a boy who loves the ocean. One day his family takes him to the beach. He spends all day playing in the sand. Afterwards he heads home. Arthur is happy that he spent time with his friends.
Arthur goes to the beach. Arthur is bored one day. He decides he would like to go to the beach. He gets his bathing suit ready and goes for a swim. After swimming, Arthur gets sand in his eyes. Arthur does not enjoy going to the beach after all.
{'top_p': 0.9, 'top_k': 40, 'temperature': 0.4, 'repetition_penalty': 1.2}
Arthur goes to the beach. Arthur is going on a trip with his friends. They decide to go to the beach. When they get there, Arthur sees that it's very busy. He and his friends have to wait in line for an hour. Finally, they are able to play in the sand.
Arthur goes to the beach. Arthur is a lonely boy. He has no friends. One day he decides to go to the beach. At the beach he meets many people and becomes very social. Now Arthur loves being at the beach.
Arthur goes to the beach. Arthur is bored one day and decides he needs a vacation. He calls his friends but they are busy. Finally he calls his friend Tim who lives in Florida. Tim tells Arthur that he will take him to the beach on Saturday. Saturday comes and Arthur has a great time at the beach!
Arthur goes to the beach. Arthur is going on a vacation with his family. He asks his parents if he can go to the beach. His parents tell him no. Arthur gets angry and storms off. The next day Arthur has a bad sunburn.
Arthur goes to the beach. Arthur was going on a trip with his friends. They were all excited about their upcoming vacation. When they arrived at the beach, Arthur saw that it was very busy. He decided to go swimming instead of playing in the sand. His friends appreciated him for being so considerate and he had fun!
|
enoriega/rule_learning_test
|
enoriega
| 2022-06-07T05:19:20Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"generated_from_trainer",
"dataset:enoriega/odinsynth_dataset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-06-06T22:29:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- enoriega/odinsynth_dataset
model-index:
- name: rule_learning_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rule_learning_test
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the enoriega/odinsynth_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 1000
- total_train_batch_size: 8000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.1764 | 0.32 | 20 | 0.2303 |
| 0.145 | 0.64 | 40 | 0.1470 |
| 0.129 | 0.96 | 60 | 0.1321 |
| 0.1256 | 1.29 | 80 | 0.1265 |
| 0.1304 | 1.61 | 100 | 0.1252 |
| 0.1235 | 1.93 | 120 | 0.1260 |
| 0.125 | 2.26 | 140 | 0.1261 |
| 0.1263 | 2.58 | 160 | 0.1262 |
| 0.1244 | 2.9 | 180 | 0.1256 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
cutten/wav2vec2-base-timit-demo-google-colab
|
cutten
| 2022-06-07T03:35:57Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-06-04T13:17:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-base-timit-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6342
- Wer: 0.5808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 9.1358 | 1.19 | 500 | 3.2710 | 1.0 |
| 3.0499 | 2.38 | 1000 | 1.8976 | 1.0 |
| 1.279 | 3.56 | 1500 | 0.7502 | 0.8228 |
| 0.7953 | 4.75 | 2000 | 0.5914 | 0.7343 |
| 0.6451 | 5.94 | 2500 | 0.6152 | 0.7280 |
| 0.5351 | 7.13 | 3000 | 0.5948 | 0.7041 |
| 0.4633 | 8.31 | 3500 | 0.5585 | 0.6712 |
| 0.4272 | 9.5 | 4000 | 0.5372 | 0.6457 |
| 0.3803 | 10.69 | 4500 | 0.5404 | 0.6402 |
| 0.3462 | 11.88 | 5000 | 0.5862 | 0.6484 |
| 0.3302 | 13.06 | 5500 | 0.5991 | 0.6426 |
| 0.3096 | 14.25 | 6000 | 0.5687 | 0.6287 |
| 0.2839 | 15.44 | 6500 | 0.5798 | 0.6384 |
| 0.2701 | 16.63 | 7000 | 0.5775 | 0.6047 |
| 0.2507 | 17.81 | 7500 | 0.5638 | 0.6065 |
| 0.2376 | 19.0 | 8000 | 0.5937 | 0.6094 |
| 0.2264 | 20.19 | 8500 | 0.5944 | 0.6065 |
| 0.2146 | 21.38 | 9000 | 0.6050 | 0.6122 |
| 0.1947 | 22.57 | 9500 | 0.6283 | 0.5992 |
| 0.1982 | 23.75 | 10000 | 0.6126 | 0.6018 |
| 0.1924 | 24.94 | 10500 | 0.6075 | 0.5962 |
| 0.1855 | 26.13 | 11000 | 0.6344 | 0.5938 |
| 0.1839 | 27.32 | 11500 | 0.6118 | 0.5880 |
| 0.1741 | 28.5 | 12000 | 0.6381 | 0.5878 |
| 0.1726 | 29.69 | 12500 | 0.6342 | 0.5808 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Cube/distilbert-base-uncased-finetuned-ner
|
Cube
| 2022-06-07T03:03:43Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-06-07T02:56:38Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Cube/distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Cube/distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0339
- Validation Loss: 0.0646
- Train Precision: 0.9217
- Train Recall: 0.9295
- Train F1: 0.9256
- Train Accuracy: 0.9827
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2631, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 0.1996 | 0.0735 | 0.8930 | 0.9179 | 0.9053 | 0.9784 | 0 |
| 0.0545 | 0.0666 | 0.9137 | 0.9292 | 0.9214 | 0.9817 | 1 |
| 0.0339 | 0.0646 | 0.9217 | 0.9295 | 0.9256 | 0.9827 | 2 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
nestoralvaro/mt5-base-finetuned-xsum-mlsum___summary_text_google_mt5_base
|
nestoralvaro
| 2022-06-07T02:18:15Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"dataset:mlsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-06T22:08:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- mlsum
metrics:
- rouge
model-index:
- name: mt5-base-finetuned-xsum-mlsum___summary_text_google_mt5_base
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: mlsum
type: mlsum
args: es
metrics:
- name: Rouge1
type: rouge
value: 8.9973
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-xsum-mlsum___summary_text_google_mt5_base
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mlsum dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 8.9973
- Rouge2: 0.9036
- Rougel: 7.6699
- Rougelsum: 7.716
- Gen Len: 10.2326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 66592 | nan | 8.9973 | 0.9036 | 7.6699 | 7.716 | 10.2326 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
iambored1009/q-Taxi-v3
|
iambored1009
| 2022-06-07T01:35:09Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-06-07T00:59:19Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="iambored1009/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Nithiwat/wangchanberta-base-att-spm-uncased-finetuned-imdb
|
Nithiwat
| 2022-06-07T01:25:53Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"camembert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-06-07T01:04:12Z |
---
tags:
- generated_from_trainer
model-index:
- name: wangchanberta-base-att-spm-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wangchanberta-base-att-spm-uncased-finetuned-imdb
This model is a fine-tuned version of [airesearch/wangchanberta-base-att-spm-uncased](https://huggingface.co/airesearch/wangchanberta-base-att-spm-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5910
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.9341 | 1.0 | 295 | 2.6511 |
| 2.8093 | 2.0 | 590 | 2.6178 |
| 2.7689 | 3.0 | 885 | 2.5321 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
BigSalmon/InformalToFormalLincoln49
|
BigSalmon
| 2022-06-07T01:12:31Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-05-31T00:18:48Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln49")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln49")
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- declining viewership facing the nba.
- does not have to be this way.
- in fact, many solutions exist.
- the four point line would surely draw in eyes.
text: failing to draw in the masses, the nba has ( fallen into / succumb to / bowed to ) disrepair. such does not have to be the case, however. in fact, a myriad of simple, relatively cheap ( solutions / interventions / enhancements ) could revive the league. the addition of the much-hyped four-point line would surely juice viewership.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
|
huggingtweets/byelihoff
|
huggingtweets
| 2022-06-07T01:08:05Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-06T13:43:11Z |
---
language: en
thumbnail: http://www.huggingtweets.com/byelihoff/1654564001530/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1481727546186211329/U8AeI0cS_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Eli Hoff</div>
<div style="text-align: center; font-size: 14px;">@byelihoff</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Eli Hoff.
| Data | Eli Hoff |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 821 |
| Short tweets | 187 |
| Tweets kept | 2240 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3t22q7l3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @byelihoff's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3qqqbwen) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3qqqbwen/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/byelihoff')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ryang73
|
huggingtweets
| 2022-06-07T01:01:08Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T00:59:56Z |
---
language: en
thumbnail: http://www.huggingtweets.com/ryang73/1654563663272/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1120118423357464577/j4gzzGqe_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ryan G</div>
<div style="text-align: center; font-size: 14px;">@ryang73</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ryan G.
| Data | Ryan G |
| --- | --- |
| Tweets downloaded | 3207 |
| Retweets | 2096 |
| Short tweets | 323 |
| Tweets kept | 788 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/36nr3zmj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ryang73's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1viq2jo5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1viq2jo5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ryang73')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/hopedavistweets
|
huggingtweets
| 2022-06-07T00:48:38Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-06-07T00:46:24Z |
---
language: en
thumbnail: http://www.huggingtweets.com/hopedavistweets/1654562883505/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1420954294082326529/ZkxWu0ln_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Hope Davis 🪩</div>
<div style="text-align: center; font-size: 14px;">@hopedavistweets</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Hope Davis 🪩.
| Data | Hope Davis 🪩 |
| --- | --- |
| Tweets downloaded | 2707 |
| Retweets | 1812 |
| Short tweets | 100 |
| Tweets kept | 795 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2pkx13m4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hopedavistweets's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/objxokv4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/objxokv4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hopedavistweets')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jijo/opus-mt-en-ml-finetuned-en-to-ml
|
jijo
| 2022-06-06T21:58:48Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-05-30T17:09:58Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: jijo/opus-mt-en-ml-finetuned-en-to-ml
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# jijo/opus-mt-en-ml-finetuned-en-to-ml
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ml](https://huggingface.co/Helsinki-NLP/opus-mt-en-ml) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.5102
- Validation Loss: 2.2501
- Train Bleu: 3.8750
- Train Gen Len: 20.6042
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 0.0002, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Bleu | Train Gen Len | Epoch |
|:----------:|:---------------:|:----------:|:-------------:|:-----:|
| 2.5102 | 2.2501 | 3.8750 | 20.6042 | 0 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ksabeh/distilbert-attribute-correction-mlm-titles
|
ksabeh
| 2022-06-06T21:56:53Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-06-06T18:32:03Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: ksabeh/bert_attrs_qa_large
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ksabeh/bert_attrs_qa_large
This model is a fine-tuned version of [ksabeh/distilbert-attribute-correction-mlm](https://huggingface.co/ksabeh/distilbert-attribute-correction-mlm) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0560
- Validation Loss: 0.0722
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 23878, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1745 | 0.0875 | 0 |
| 0.0560 | 0.0722 | 1 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
daniel780/amazon_sentiment_sample_of_1900_with_summary_larger_test
|
daniel780
| 2022-06-06T21:42:43Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-06T20:47:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: amazon_sentiment_sample_of_1900_with_summary_larger_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# amazon_sentiment_sample_of_1900_with_summary_larger_test
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1489
- Accuracy: 0.9503
- F1: 0.9504
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.