
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-11 06:30:11
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-11 06:29:58
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
horychtom/czech_media_bias_classifier
|
horychtom
| 2022-04-28T13:51:18Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"Czech",
"cs",
"autotrain_compatible",
"region:us"
] |
text-classification
| 2022-04-04T09:04:34Z |
---
inference: false
language: "cs"
tags:
- Czech
---
## Czech Media Bias Classifier
A FERNET-C5 model fine-tuned to perform binary classification task on czech media bias detection.
|
espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char
|
espnet
| 2022-04-28T12:40:15Z | 0 | 0 |
espnet
|
[
"espnet",
"audio",
"speech-enhancement-recognition",
"en",
"dataset:chime4",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] | null | 2022-04-28T12:38:58Z |
---
tags:
- espnet
- audio
- speech-enhancement-recognition
language: en
datasets:
- chime4
license: cc-by-4.0
---
## ESPnet2 EnhS2T model
### `espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char`
This model was trained by simpleoier using chime4 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 2b663318cd1773fb8685b1e03295b6bc6889c283
pip install -e .
cd egs2/chime4/enh_asr1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/simpleoier_chime4_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_raw_en_char
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Thu Apr 28 08:15:30 EDT 2022`
- python version: `3.7.11 (default, Jul 27 2021, 14:32:16) [GCC 7.5.0]`
- espnet version: `espnet 202204`
- pytorch version: `pytorch 1.8.1`
- Git hash: ``
- Commit date: ``
## enh_asr_train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0_raw_en_char
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_2mics|1640|27119|98.5|1.2|0.3|0.2|1.7|19.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|27119|98.6|1.1|0.3|0.2|1.5|18.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_isolated_1ch_track|1640|27119|98.3|1.3|0.4|0.2|1.9|21.8|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_2mics|1640|27120|97.9|1.5|0.5|0.2|2.3|25.2|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|27120|98.4|1.2|0.4|0.1|1.7|19.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_isolated_1ch_track|1640|27120|97.2|2.1|0.7|0.3|3.1|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_2mics|1320|21409|97.4|2.0|0.6|0.3|2.9|27.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|21409|97.8|1.8|0.4|0.2|2.5|24.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_isolated_1ch_track|1320|21409|96.7|2.6|0.7|0.4|3.7|31.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_2mics|1320|21416|96.6|2.5|1.0|0.3|3.7|32.5|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|21416|97.5|1.9|0.7|0.3|2.9|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_isolated_1ch_track|1320|21416|94.6|3.7|1.6|0.5|5.9|37.3|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_2mics|1640|160390|99.5|0.2|0.3|0.2|0.7|19.6|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_beamformit_5mics|1640|160390|99.6|0.1|0.3|0.2|0.6|18.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_real_isolated_1ch_track|1640|160390|99.4|0.2|0.4|0.2|0.8|21.8|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_2mics|1640|160400|99.2|0.3|0.5|0.2|1.1|25.2|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_beamformit_5mics|1640|160400|99.5|0.2|0.3|0.1|0.7|19.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/dt05_simu_isolated_1ch_track|1640|160400|98.8|0.5|0.7|0.3|1.5|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_2mics|1320|126796|98.9|0.4|0.7|0.3|1.4|27.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_beamformit_5mics|1320|126796|99.1|0.4|0.5|0.2|1.1|24.3|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_real_isolated_1ch_track|1320|126796|98.6|0.6|0.8|0.4|1.8|31.7|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_2mics|1320|126812|98.2|0.6|1.1|0.4|2.1|32.5|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_beamformit_5mics|1320|126812|98.8|0.4|0.8|0.3|1.5|28.9|
|decode_asr_transformer_normalize_output_wavtrue_lm_lm_train_lm_transformer_en_char_valid.loss.ave_enh_asr_model_valid.acc.ave/et05_simu_isolated_1ch_track|1320|126812|97.0|1.2|1.9|0.6|3.7|37.3|
## EnhS2T config
<details><summary>expand</summary>
```
config: conf/tuning/train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/enh_asr_train_enh_asr_convtasnet_init_noenhloss_wavlm_transformer_init_lr1e-4_accum1_adam_specaug_bypass0_raw_en_char
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: true
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 12
patience: 10
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
- - train
- loss
- min
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 2
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param:
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:encoder:enh_model.encoder
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:separator:enh_model.separator
- ../enh1/exp/enh_train_enh_convtasnet_small_raw/valid.loss.ave_1best.pth:decoder:enh_model.decoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:frontend:s2t_model.frontend
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:preencoder:s2t_model.preencoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:encoder:s2t_model.encoder
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:ctc:s2t_model.ctc
- ../asr1/exp/asr_train_asr_transformer_wavlm_lr1e-3_specaug_accum1_preenc128_warmup20k_raw_en_char/valid.acc.ave.pth:decoder:s2t_model.decoder
ignore_init_mismatch: false
freeze_param:
- s2t_model.frontend.upstream
num_iters_per_epoch: null
batch_size: 12
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/enh_asr_stats_raw_en_char/train/speech_shape
- exp/enh_asr_stats_raw_en_char/train/speech_ref1_shape
- exp/enh_asr_stats_raw_en_char/train/text_shape.char
valid_shape_file:
- exp/enh_asr_stats_raw_en_char/valid/speech_shape
- exp/enh_asr_stats_raw_en_char/valid/speech_ref1_shape
- exp/enh_asr_stats_raw_en_char/valid/text_shape.char
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/tr05_multi_noisy_si284/wav.scp
- speech
- sound
- - dump/raw/tr05_multi_noisy_si284/spk1.scp
- speech_ref1
- sound
- - dump/raw/tr05_multi_noisy_si284/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dt05_multi_isolated_1ch_track/wav.scp
- speech
- sound
- - dump/raw/dt05_multi_isolated_1ch_track/spk1.scp
- speech_ref1
- sound
- - dump/raw/dt05_multi_isolated_1ch_track/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0001
scheduler: null
scheduler_conf: {}
token_list: data/en_token_list/char/tokens.txt
src_token_list: null
init: xavier_uniform
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
enh_criterions:
- name: si_snr
conf: {}
wrapper: fixed_order
wrapper_conf: {}
enh_model_conf:
stft_consistency: false
loss_type: mask_mse
mask_type: null
asr_model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
extract_feats_in_collect_stats: false
st_model_conf:
stft_consistency: false
loss_type: mask_mse
mask_type: null
subtask_series:
- enh
- asr
model_conf:
calc_enh_loss: false
bypass_enh_prob: 0.0
use_preprocessor: true
token_type: char
bpemodel: null
src_token_type: bpe
src_bpemodel: null
non_linguistic_symbols: data/nlsyms.txt
cleaner: null
g2p: null
enh_encoder: conv
enh_encoder_conf:
channel: 256
kernel_size: 40
stride: 20
enh_separator: tcn
enh_separator_conf:
num_spk: 1
layer: 4
stack: 2
bottleneck_dim: 256
hidden_dim: 512
kernel: 3
causal: false
norm_type: gLN
nonlinear: relu
enh_decoder: conv
enh_decoder_conf:
channel: 256
kernel_size: 40
stride: 20
frontend: s3prl
frontend_conf:
frontend_conf:
upstream: wavlm_large
download_dir: ./hub
multilayer_feature: true
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 100
num_freq_mask: 4
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: utterance_mvn
normalize_conf: {}
asr_preencoder: linear
asr_preencoder_conf:
input_size: 1024
output_size: 128
asr_encoder: transformer
asr_encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d2
normalize_before: true
asr_postencoder: null
asr_postencoder_conf: {}
asr_decoder: transformer
asr_decoder_conf:
input_layer: embed
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.0
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
st_preencoder: null
st_preencoder_conf: {}
st_encoder: rnn
st_encoder_conf: {}
st_postencoder: null
st_postencoder_conf: {}
st_decoder: rnn
st_decoder_conf: {}
st_extra_asr_decoder: rnn
st_extra_asr_decoder_conf: {}
st_extra_mt_decoder: rnn
st_extra_mt_decoder_conf: {}
required:
- output_dir
- token_list
version: '202204'
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
YASH312312/distilroberta-base-finetuned-wikitext2
|
YASH312312
| 2022-04-28T10:03:53Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-27T15:07:49Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-wikitext2
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7515
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1203 | 1.0 | 766 | 2.8510 |
| 2.9255 | 2.0 | 1532 | 2.8106 |
| 2.8669 | 3.0 | 2298 | 2.7515 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bdickson/distilbert-base-uncased-finetuned-squad
|
bdickson
| 2022-04-28T09:59:39Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-04-27T19:56:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1617
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2299 | 1.0 | 5533 | 1.1673 |
| 0.9564 | 2.0 | 11066 | 1.1223 |
| 0.7572 | 3.0 | 16599 | 1.1617 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bdickson/albert-base-v2-finetuned-squad
|
bdickson
| 2022-04-28T07:31:59Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-04-28T01:10:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: albert-base-v2-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.0191
- eval_runtime: 291.8551
- eval_samples_per_second: 37.032
- eval_steps_per_second: 2.316
- epoch: 3.0
- step: 16620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bdickson/bert-base-uncased-finetuned-squad
|
bdickson
| 2022-04-28T07:30:32Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-04-28T00:58:17Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-squad
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.1240
- eval_runtime: 262.7193
- eval_samples_per_second: 41.048
- eval_steps_per_second: 2.565
- epoch: 3.0
- step: 16599
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Lilya/distilbert-base-uncased-finetuned-ner-TRANS
|
Lilya
| 2022-04-28T07:00:58Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-27T11:44:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner-TRANS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner-TRANS
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1053
- Precision: 0.7911
- Recall: 0.8114
- F1: 0.8011
- Accuracy: 0.9815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.077 | 1.0 | 3762 | 0.0724 | 0.7096 | 0.7472 | 0.7279 | 0.9741 |
| 0.0538 | 2.0 | 7524 | 0.0652 | 0.7308 | 0.7687 | 0.7493 | 0.9766 |
| 0.0412 | 3.0 | 11286 | 0.0643 | 0.7672 | 0.7875 | 0.7772 | 0.9788 |
| 0.0315 | 4.0 | 15048 | 0.0735 | 0.7646 | 0.7966 | 0.7803 | 0.9793 |
| 0.0249 | 5.0 | 18810 | 0.0772 | 0.7805 | 0.7981 | 0.7892 | 0.9801 |
| 0.0213 | 6.0 | 22572 | 0.0783 | 0.7829 | 0.8063 | 0.7944 | 0.9805 |
| 0.0187 | 7.0 | 26334 | 0.0858 | 0.7821 | 0.8010 | 0.7914 | 0.9809 |
| 0.0157 | 8.0 | 30096 | 0.0860 | 0.7837 | 0.8120 | 0.7976 | 0.9812 |
| 0.0122 | 9.0 | 33858 | 0.0963 | 0.7857 | 0.8129 | 0.7990 | 0.9813 |
| 0.0107 | 10.0 | 37620 | 0.0993 | 0.7934 | 0.8089 | 0.8010 | 0.9812 |
| 0.0091 | 11.0 | 41382 | 0.1031 | 0.7882 | 0.8123 | 0.8001 | 0.9814 |
| 0.0083 | 12.0 | 45144 | 0.1053 | 0.7911 | 0.8114 | 0.8011 | 0.9815 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1
- Datasets 2.0.0
- Tokenizers 0.10.3
|
snunlp/KR-FinBert
|
snunlp
| 2022-04-28T05:06:40Z | 263 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- ko
---
# KR-FinBert & KR-FinBert-SC
Much progress has been made in the NLP (Natural Language Processing) field, with numerous studies showing that domain adaptation using small-scale corpus and fine-tuning with labeled data is effective for overall performance improvement.
we proposed KR-FinBert for the financial domain by further pre-training it on a financial corpus and fine-tuning it for sentiment analysis. As many studies have shown, the performance improvement through adaptation and conducting the downstream task was also clear in this experiment.
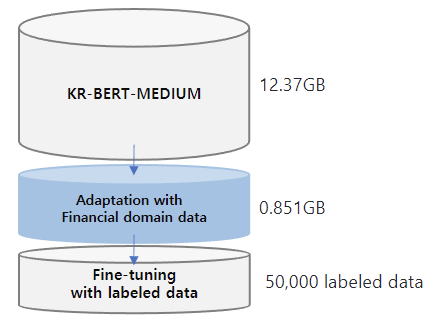
## Data
The training data for this model is expanded from those of **[KR-BERT-MEDIUM](https://huggingface.co/snunlp/KR-Medium)**, texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center and [Korean Comments dataset](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments). For the transfer learning, **corporate related economic news articles from 72 media sources** such as the Financial Times, The Korean Economy Daily, etc and **analyst reports from 16 securities companies** such as Kiwoom Securities, Samsung Securities, etc are added. Included in the dataset is 440,067 news titles with their content and 11,237 analyst reports. **The total data size is about 13.22GB.** For mlm training, we split the data line by line and **the total no. of lines is 6,379,315.**
KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
## Citation
```
@misc{kr-FinBert,
author = {Kim, Eunhee and Hyopil Shin},
title = {KR-FinBert: KR-BERT-Medium Adapted With Financial Domain Data},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co/snunlp/KR-FinBert}}
}
```
|
chv5/t5-small-shuffled_take1
|
chv5
| 2022-04-28T03:36:55Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T20:27:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-shuffled_take1
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
args: default
metrics:
- name: Rouge1
type: rouge
value: 11.9641
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-shuffled_take1
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1788
- Rouge1: 11.9641
- Rouge2: 10.5245
- Rougel: 11.5825
- Rougelsum: 11.842
- Gen Len: 18.9838
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.2238 | 1.0 | 34008 | 0.1788 | 11.9641 | 10.5245 | 11.5825 | 11.842 | 18.9838 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Ahmed9275/ALL-2
|
Ahmed9275
| 2022-04-28T02:07:25Z | 64 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-28T02:07:14Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ALL-2
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9855383038520813
---
# ALL-2
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
|
Elie/NLP_Challenge
|
Elie
| 2022-04-28T01:50:12Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-04-27T20:36:46Z |
This my Fatima Fellowship notebokk
|
yihsuan/best_model_0426_base
|
yihsuan
| 2022-04-28T01:44:27Z | 15 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"summarization",
"mT5",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-04-26T09:05:10Z |
---
tags:
- summarization
- mT5
language:
- zh
widget:
- text: "專家稱維康桑格研究所(Wellcome Sanger Institute)的上述研究發現「令人震驚」而且「發人深省」。基因變異指關於我們身體成長和管理的相關指令,也就是DNA當中發生的變化。長期以來,變異一直被當作癌症的根源,但是數十年來關於變異是否對衰老有重要影響一直存在爭論。桑格研究所的研究人員說他們得到了「第一個試驗性證據」,證明了兩者的關係。他們分析了預期壽命各異的物種基因變異的不同速度。研究人員分析了貓、黑白疣猴、狗、雪貂、長頸鹿、馬、人、獅子、裸鼴鼠、兔子、老鼠、環尾狐猴和老虎等十幾種動物的DNA。發表在《自然》雜誌上的研究顯示,老鼠在短暫的生命當中每年經歷了將近800次變異,老鼠的壽命一般不到4年。"
inference:
parameters:
max_length: 50
---
|
Ahmed9275/ALL
|
Ahmed9275
| 2022-04-28T01:01:23Z | 62 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-28T01:00:00Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ALL
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9262039065361023
---
# ALL
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
|
davidenam/distilbert-base-uncased-finetuned-emotion
|
davidenam
| 2022-04-27T21:59:00Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-27T18:53:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9205
- name: F1
type: f1
value: 0.9203318889648883
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2230
- Accuracy: 0.9205
- F1: 0.9203
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 250 | 0.3224 | 0.9055 | 0.9034 |
| No log | 2.0 | 500 | 0.2230 | 0.9205 | 0.9203 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cpu
- Datasets 2.1.0
- Tokenizers 0.12.1
|
SerdarHelli/Brain-MRI-GAN
|
SerdarHelli
| 2022-04-27T20:32:07Z | 0 | 0 | null |
[
"brainMRI",
"GAN",
"medicalimaging",
"pytorch",
"region:us"
] | null | 2022-04-27T19:07:39Z |
---
tags:
- brainMRI
- GAN
- medicalimaging
- pytorch
metrics:
- fid50k
---
The model's kernels etc. source code ==> https://github.com/NVlabs/stylegan3
|
gagan3012/ArOCRv4
|
gagan3012
| 2022-04-27T20:23:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"doi:10.57967/hf/0018",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2022-04-27T18:49:46Z |
---
tags:
- generated_from_trainer
model-index:
- name: ArOCRv4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ArOCRv4
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5811
- Cer: 0.1249
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 3.103 | 1.18 | 1000 | 8.0852 | 11.5974 |
| 1.2535 | 2.36 | 2000 | 2.0400 | 0.4904 |
| 0.5682 | 3.55 | 3000 | 1.9336 | 0.2145 |
| 0.3038 | 4.73 | 4000 | 1.5811 | 0.1249 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.9.1
- Datasets 2.1.0
- Tokenizers 0.11.6
|
iamholmes/english-phrases-bible
|
iamholmes
| 2022-04-27T19:48:58Z | 69 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-04-27T19:48:50Z |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-tas-b
This is a port of the [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) to [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and is optimized for the task of semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-tas-b')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#CLS Pooling - Take output from first token
def cls_pooling(model_output):
return model_output.last_hidden_state[:,0]
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = cls_pooling(model_output)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-tas-b)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Have a look at: [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco)
|
princeton-nlp/efficient_mlm_m0.15-801010
|
princeton-nlp
| 2022-04-27T18:54:45Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.08005",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2022-04-22T18:45:04Z |
---
inference: false
---
This is a model checkpoint for ["Should You Mask 15% in Masked Language Modeling"](https://arxiv.org/abs/2202.08005) [(code)](https://github.com/princeton-nlp/DinkyTrain.git). We use pre layer norm, which is not supported by HuggingFace. To use our model, go to our [github repo](https://github.com/princeton-nlp/DinkyTrain.git), download our code, and import the RoBERTa class from `huggingface/modeling_roberta_prelayernorm.py`. For example,
``` bash
from huggingface.modeling_roberta_prelayernorm import RobertaForMaskedLM, RobertaForSequenceClassification
```
|
princeton-nlp/efficient_mlm_m0.40
|
princeton-nlp
| 2022-04-27T18:54:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.08005",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2022-04-22T18:44:55Z |
---
inference: false
---
This is a model checkpoint for ["Should You Mask 15% in Masked Language Modeling"](https://arxiv.org/abs/2202.08005) [(code)](https://github.com/princeton-nlp/DinkyTrain.git). We use pre layer norm, which is not supported by HuggingFace. To use our model, go to our [github repo](https://github.com/princeton-nlp/DinkyTrain.git), download our code, and import the RoBERTa class from `huggingface/modeling_roberta_prelayernorm.py`. For example,
``` bash
from huggingface.modeling_roberta_prelayernorm import RobertaForMaskedLM, RobertaForSequenceClassification
```
|
obokkkk/wav2vec2-base-960h-finetuned_common_voice2
|
obokkkk
| 2022-04-27T18:42:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-27T15:50:53Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-960h-finetuned_common_voice2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-960h-finetuned_common_voice2
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 1024
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
faisalahmad/autotrain-nsut-nlp-project-textsummarization-791824374
|
faisalahmad
| 2022-04-27T17:50:47Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain",
"en",
"dataset:faisalahmad/autotrain-data-nsut-nlp-project-textsummarization",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T09:08:22Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- faisalahmad/autotrain-data-nsut-nlp-project-textsummarization
co2_eq_emissions: 1119.6398037843474
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 791824374
- CO2 Emissions (in grams): 1119.6398037843474
## Validation Metrics
- Loss: 1.6432833671569824
- Rouge1: 38.5315
- Rouge2: 18.0869
- RougeL: 32.3742
- RougeLsum: 32.3801
- Gen Len: 19.846
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/faisalahmad/autotrain-nsut-nlp-project-textsummarization-791824374
```
|
obokkkk/mbart-large-cc25-finetuned-en-to-ko2
|
obokkkk
| 2022-04-27T17:49:20Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T15:00:41Z |
---
tags:
- generated_from_trainer
model-index:
- name: mbart-large-cc25-finetuned-en-to-ko2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-cc25-finetuned-en-to-ko2
This model is a fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 128
- total_train_batch_size: 2048
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
wypa93/keras-dummy-sequential-demo
|
wypa93
| 2022-04-27T16:46:55Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2022-04-27T16:46:48Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Training Metrics
Model history needed
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
joniponi/multilabel_inpatient_comments_16labels
|
joniponi
| 2022-04-27T16:20:55Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T03:22:59Z |
# HCAHPS survey comments multilabel classification
This model is a fine-tuned version of [Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on a dataset of HCAHPS survey comments.
It achieves the following results on the evaluation set:
precision recall f1-score support
medical 0.87 0.81 0.84 83
environmental 0.77 0.91 0.84 93
administration 0.58 0.32 0.41 22
communication 0.85 0.82 0.84 50
condition 0.42 0.52 0.46 29
treatment 0.90 0.78 0.83 68
food 0.92 0.94 0.93 36
clean 0.65 0.83 0.73 18
bathroom 0.64 0.64 0.64 14
discharge 0.83 0.83 0.83 24
wait 0.96 1.00 0.98 24
financial 0.44 1.00 0.62 4
extra_nice 0.20 0.13 0.16 23
rude 1.00 0.64 0.78 11
nurse 0.92 0.98 0.95 110
doctor 0.96 0.84 0.90 57
micro avg 0.81 0.81 0.81 666
macro avg 0.75 0.75 0.73 666
weighted avg 0.82 0.81 0.81 666
samples avg 0.64 0.64 0.62 666
## Model description
The model classifies free-text comments into the following labels
* Medical
* Environmental
* Administration
* Communication
* Condition
* Treatment
* Food
* Clean
* Bathroom
* Discharge
* Wait
* Financial
* Extra_nice
* Rude
* Nurse
* Doctor
## How to use
You can now use the models directly through the transformers library. Check out the [model's page](https://huggingface.co/joniponi/multilabel_inpatient_comments_16labels) for instructions on how to use the models within the Transformers library.
Load the model via the transformers library:
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("joniponi/multilabel_inpatient_comments_16labels")
model = AutoModel.from_pretrained("joniponi/multilabel_inpatient_comments_16labels")
```
|
eliwill/gpt2-finetuned-krishna
|
eliwill
| 2022-04-27T16:14:21Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-09T10:04:33Z |
---
model-index:
- name: eliwill/gpt2-finetuned-krishna
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# eliwill/gpt2-finetuned-krishna
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on a collection of books by Jiddu Krishnamurti.
It achieves the following results on the evaluation set:
- Train Loss: 3.4997
- Validation Loss: 3.6853
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.4997 | 3.6853 | 0 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Das282000Prit/bert-base-uncased-finetuned-wikitext2
|
Das282000Prit
| 2022-04-27T16:11:28Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-27T15:00:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wikitext2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7295
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9288 | 1.0 | 2319 | 1.7729 |
| 1.8208 | 2.0 | 4638 | 1.7398 |
| 1.7888 | 3.0 | 6957 | 1.7523 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
faisalahmad/summarizer1
|
faisalahmad
| 2022-04-27T15:53:08Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain",
"en",
"dataset:faisalahmad/autotrain-data-nsut-nlp-project-textsummarization",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T09:08:33Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- faisalahmad/autotrain-data-nsut-nlp-project-textsummarization
co2_eq_emissions: 736.9366247330848
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 791824379
- CO2 Emissions (in grams): 736.9366247330848
## Validation Metrics
- Loss: 1.7805895805358887
- Rouge1: 37.8222
- Rouge2: 16.7598
- RougeL: 31.2959
- RougeLsum: 31.3048
- Gen Len: 19.7213
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/faisalahmad/autotrain-nsut-nlp-project-textsummarization-791824379
```
|
stevems1/bert-base-uncased-French123
|
stevems1
| 2022-04-27T14:55:35Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-27T14:40:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-French123
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-French123
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
espnet/chai_librispeech_asr_train_rnnt_conformer_raw_en_bpe5000_sp
|
espnet
| 2022-04-27T14:51:25Z | 4 | 0 |
espnet
|
[
"espnet",
"audio",
"automatic-speech-recognition",
"en",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
automatic-speech-recognition
| 2022-03-24T21:32:22Z |
---
tags:
- espnet
- audio
- automatic-speech-recognition
language: en
datasets:
- librispeech_asr
- librispeech 960h
license: cc-by-4.0
---
## ESPnet2 model
This model was trained by Chaitanya Narisetty using recipe in [espnet](https://github.com/espnet/espnet/).
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Fri Mar 25 04:35:42 EDT 2022`
- python version: `3.9.5 (default, Jun 4 2021, 12:28:51) [GCC 7.5.0]`
- espnet version: `espnet 0.10.7a1`
- pytorch version: `pytorch 1.8.1+cu111`
- Git hash: `21d19be00089678ca27f7fce474ef8d787689512`
- Commit date: `Wed Mar 16 08:06:52 2022 -0400`
## asr_train_rnnt_conformer_ngpu4_raw_en_bpe5000_sp
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_clean|2620|52576|97.2|2.5|0.3|0.3|3.1|35.2|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_other|2939|52343|93.4|6.0|0.6|0.8|7.4|56.3|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_clean|2620|52576|97.1|2.6|0.3|0.3|3.2|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_other|2939|52343|93.1|6.1|0.7|0.8|7.7|57.0|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_clean|2620|52576|97.2|2.5|0.3|0.3|3.1|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_other|2939|52343|93.3|6.0|0.7|0.8|7.5|56.5|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_clean|2620|52576|96.8|2.8|0.4|0.4|3.6|38.3|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_other|2939|52343|92.2|6.9|0.9|0.9|8.7|61.7|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_clean|2620|281530|99.3|0.4|0.3|0.3|1.0|35.2|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_other|2939|272758|97.7|1.4|1.0|0.9|3.2|56.3|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_clean|2620|281530|99.2|0.4|0.4|0.3|1.1|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_other|2939|272758|97.5|1.4|1.1|0.9|3.4|57.0|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_clean|2620|281530|99.2|0.4|0.4|0.3|1.1|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_other|2939|272758|97.6|1.4|1.0|0.9|3.2|56.5|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_clean|2620|281530|99.1|0.5|0.4|0.3|1.2|38.3|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_other|2939|272758|97.1|1.6|1.3|1.0|3.9|61.7|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_clean|2620|65818|96.6|2.4|1.0|0.5|3.9|35.2|
|decode_rnnt_conformer_asr_model_valid.loss.ave_10best/test_other|2939|65101|92.1|5.9|2.0|1.3|9.2|56.3|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_clean|2620|65818|96.6|2.5|1.0|0.5|4.0|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_3best/test_other|2939|65101|91.8|6.1|2.1|1.3|9.6|57.0|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_clean|2620|65818|96.6|2.5|1.0|0.5|3.9|35.8|
|decode_rnnt_conformer_asr_model_valid.loss.ave_5best/test_other|2939|65101|92.0|5.9|2.0|1.3|9.2|56.5|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_clean|2620|65818|96.1|2.8|1.1|0.6|4.4|38.3|
|decode_rnnt_conformer_asr_model_valid.loss.best/test_other|2939|65101|90.7|6.8|2.5|1.5|10.8|61.7|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_rnnt_conformer_ngpu4.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_rnnt_conformer_ngpu4_raw_en_bpe5000_sp
ngpu: 2
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 18
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- loss
- min
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 6
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 6000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_en_bpe5000_sp/train/speech_shape
- exp/asr_stats_raw_en_bpe5000_sp/train/text_shape.bpe
valid_shape_file:
- exp/asr_stats_raw_en_bpe5000_sp/valid/speech_shape
- exp/asr_stats_raw_en_bpe5000_sp/valid/text_shape.bpe
batch_type: numel
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_960_sp/wav.scp
- speech
- kaldi_ark
- - dump/raw/train_960_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dev/wav.scp
- speech
- kaldi_ark
- - dump/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0015
scheduler: warmuplr
scheduler_conf:
warmup_steps: 25000
token_list:
- <blank>
- <unk>
- ▁THE
- S
- ▁AND
- ▁OF
- ▁TO
- ▁A
- ▁IN
- ▁I
- ▁HE
- ▁THAT
- ▁WAS
- ED
- ▁IT
- ''''
- ▁HIS
- ING
- ▁YOU
- ▁WITH
- ▁FOR
- ▁HAD
- T
- ▁AS
- ▁HER
- ▁IS
- ▁BE
- ▁BUT
- ▁NOT
- ▁SHE
- D
- ▁AT
- ▁ON
- LY
- ▁HIM
- ▁THEY
- ▁ALL
- ▁HAVE
- ▁BY
- ▁SO
- ▁THIS
- ▁MY
- ▁WHICH
- ▁ME
- ▁SAID
- ▁FROM
- ▁ONE
- Y
- E
- ▁WERE
- ▁WE
- ▁NO
- N
- ▁THERE
- ▁OR
- ER
- ▁AN
- ▁WHEN
- ▁ARE
- ▁THEIR
- ▁WOULD
- ▁IF
- ▁WHAT
- ▁THEM
- ▁WHO
- ▁OUT
- M
- ▁DO
- ▁WILL
- ▁UP
- ▁BEEN
- P
- R
- ▁MAN
- ▁THEN
- ▁COULD
- ▁MORE
- C
- ▁INTO
- ▁NOW
- ▁VERY
- ▁YOUR
- ▁SOME
- ▁LITTLE
- ES
- ▁TIME
- RE
- ▁CAN
- ▁LIKE
- LL
- ▁ABOUT
- ▁HAS
- ▁THAN
- ▁DID
- ▁UPON
- ▁OVER
- IN
- ▁ANY
- ▁WELL
- ▁ONLY
- B
- ▁SEE
- ▁GOOD
- ▁OTHER
- ▁TWO
- L
- ▁KNOW
- ▁GO
- ▁DOWN
- ▁BEFORE
- A
- AL
- ▁OUR
- ▁OLD
- ▁SHOULD
- ▁MADE
- ▁AFTER
- ▁GREAT
- ▁DAY
- ▁MUST
- ▁COME
- ▁HOW
- ▁SUCH
- ▁CAME
- LE
- ▁WHERE
- ▁US
- ▁NEVER
- ▁THESE
- ▁MUCH
- ▁DE
- ▁MISTER
- ▁WAY
- G
- ▁S
- ▁MAY
- ATION
- ▁LONG
- OR
- ▁AM
- ▁FIRST
- ▁BACK
- ▁OWN
- ▁RE
- ▁AGAIN
- ▁SAY
- ▁MEN
- ▁WENT
- ▁HIMSELF
- ▁HERE
- NESS
- ▁THINK
- V
- IC
- ▁EVEN
- ▁THOUGHT
- ▁HAND
- ▁JUST
- ▁O
- ▁UN
- VE
- ION
- ▁ITS
- 'ON'
- ▁MAKE
- ▁MIGHT
- ▁TOO
- K
- ▁AWAY
- ▁LIFE
- TH
- ▁WITHOUT
- ST
- ▁THROUGH
- ▁MOST
- ▁TAKE
- ▁DON
- ▁EVERY
- F
- O
- ▁SHALL
- ▁THOSE
- ▁EYES
- AR
- ▁STILL
- ▁LAST
- ▁HOUSE
- ▁HEAD
- ABLE
- ▁NOTHING
- ▁NIGHT
- ITY
- ▁LET
- ▁MANY
- ▁OFF
- ▁BEING
- ▁FOUND
- ▁WHILE
- EN
- ▁SAW
- ▁GET
- ▁PEOPLE
- ▁FACE
- ▁YOUNG
- CH
- ▁UNDER
- ▁ONCE
- ▁TELL
- AN
- ▁THREE
- ▁PLACE
- ▁ROOM
- ▁YET
- ▁SAME
- IL
- US
- U
- ▁FATHER
- ▁RIGHT
- EL
- ▁THOUGH
- ▁ANOTHER
- LI
- RI
- ▁HEART
- IT
- ▁PUT
- ▁TOOK
- ▁GIVE
- ▁EVER
- ▁E
- ▁PART
- ▁WORK
- ERS
- ▁LOOK
- ▁NEW
- ▁KING
- ▁MISSUS
- ▁SIR
- ▁LOVE
- ▁MIND
- ▁LOOKED
- W
- RY
- ▁ASKED
- ▁LEFT
- ET
- ▁LIGHT
- CK
- ▁DOOR
- ▁MOMENT
- RO
- ▁WORLD
- ▁THINGS
- ▁HOME
- UL
- ▁THING
- LA
- ▁WHY
- ▁MOTHER
- ▁ALWAYS
- ▁FAR
- FUL
- ▁WATER
- CE
- IVE
- UR
- ▁HEARD
- ▁SOMETHING
- ▁SEEMED
- I
- LO
- ▁BECAUSE
- OL
- ▁END
- ▁TOLD
- ▁CON
- ▁YES
- ▁GOING
- ▁GOT
- RA
- IR
- ▁WOMAN
- ▁GOD
- EST
- TED
- ▁FIND
- ▁KNEW
- ▁SOON
- ▁EACH
- ▁SIDE
- H
- TON
- MENT
- ▁OH
- NE
- Z
- LING
- ▁AGAINST
- TER
- ▁NAME
- ▁MISS
- ▁QUITE
- ▁WANT
- ▁YEARS
- ▁FEW
- ▁BETTER
- ENT
- ▁HALF
- ▁DONE
- ▁ALSO
- ▁BEGAN
- ▁HAVING
- ▁ENOUGH
- IS
- ▁LADY
- ▁WHOLE
- LESS
- ▁BOTH
- ▁SEEN
- ▁SET
- ▁WHITE
- ▁COURSE
- IES
- ▁VOICE
- ▁CALLED
- ▁D
- ▁EX
- ATE
- ▁TURNED
- ▁GAVE
- ▁C
- ▁POOR
- MAN
- UT
- NA
- ▁DEAR
- ISH
- ▁GIRL
- ▁MORNING
- ▁BETWEEN
- LED
- ▁NOR
- IA
- ▁AMONG
- MA
- ▁
- ▁SMALL
- ▁REST
- ▁WHOM
- ▁FELT
- ▁HANDS
- ▁MYSELF
- ▁HIGH
- ▁M
- ▁HOWEVER
- ▁HERSELF
- ▁P
- CO
- ▁STOOD
- ID
- ▁KIND
- ▁HUNDRED
- AS
- ▁ROUND
- ▁ALMOST
- TY
- ▁SINCE
- ▁G
- AM
- ▁LA
- SE
- ▁BOY
- ▁MA
- ▁PERHAPS
- ▁WORDS
- ATED
- ▁HO
- X
- ▁MO
- ▁SAT
- ▁REPLIED
- ▁FOUR
- ▁ANYTHING
- ▁TILL
- ▁UNTIL
- ▁BLACK
- TION
- ▁CRIED
- RU
- TE
- ▁FACT
- ▁HELP
- ▁NEXT
- ▁LOOKING
- ▁DOES
- ▁FRIEND
- ▁LAY
- ANCE
- ▁POWER
- ▁BROUGHT
- VER
- ▁FIRE
- ▁KEEP
- PO
- FF
- ▁COUNTRY
- ▁SEA
- ▁WORD
- ▁CAR
- ▁DAYS
- ▁TOGETHER
- ▁IMP
- ▁REASON
- KE
- ▁INDEED
- TING
- ▁MATTER
- ▁FULL
- ▁TEN
- TIC
- ▁LAND
- ▁RATHER
- ▁AIR
- ▁HOPE
- ▁DA
- ▁OPEN
- ▁FEET
- ▁EN
- ▁FIVE
- ▁POINT
- ▁CO
- OM
- ▁LARGE
- ▁B
- ▁CL
- ME
- ▁GONE
- ▁CHILD
- INE
- GG
- ▁BEST
- ▁DIS
- UM
- ▁HARD
- ▁LORD
- OUS
- ▁WIFE
- ▁SURE
- ▁FORM
- DE
- ▁DEATH
- ANT
- ▁NATURE
- ▁BA
- ▁CARE
- ▁BELIEVE
- PP
- ▁NEAR
- ▁RO
- ▁RED
- ▁WAR
- IE
- ▁SPEAK
- ▁FEAR
- ▁CASE
- ▁TAKEN
- ▁ALONG
- ▁CANNOT
- ▁HEAR
- ▁THEMSELVES
- CI
- ▁PRESENT
- AD
- ▁MASTER
- ▁SON
- ▁THUS
- ▁LI
- ▁LESS
- ▁SUN
- ▁TRUE
- IM
- IOUS
- ▁THOUSAND
- ▁MONEY
- ▁W
- ▁BEHIND
- ▁CHILDREN
- ▁DOCTOR
- AC
- ▁TWENTY
- ▁WISH
- ▁SOUND
- ▁WHOSE
- ▁LEAVE
- ▁ANSWERED
- ▁THOU
- ▁DUR
- ▁HA
- ▁CERTAIN
- ▁PO
- ▁PASSED
- GE
- TO
- ▁ARM
- ▁LO
- ▁STATE
- ▁ALONE
- TA
- ▁SHOW
- ▁NEED
- ▁LIVE
- ND
- ▁DEAD
- ENCE
- ▁STRONG
- ▁PRE
- ▁TI
- ▁GROUND
- SH
- TI
- ▁SHORT
- IAN
- UN
- ▁PRO
- ▁HORSE
- MI
- ▁PRINCE
- ARD
- ▁FELL
- ▁ORDER
- ▁CALL
- AT
- ▁GIVEN
- ▁DARK
- ▁THEREFORE
- ▁CLOSE
- ▁BODY
- ▁OTHERS
- ▁SENT
- ▁SECOND
- ▁OFTEN
- ▁CA
- ▁MANNER
- MO
- NI
- ▁BRING
- ▁QUESTION
- ▁HOUR
- ▁BO
- AGE
- ▁ST
- ▁TURN
- ▁TABLE
- ▁GENERAL
- ▁EARTH
- ▁BED
- ▁REALLY
- ▁SIX
- 'NO'
- IST
- ▁BECOME
- ▁USE
- ▁READ
- ▁SE
- ▁VI
- ▁COMING
- ▁EVERYTHING
- ▁EM
- ▁ABOVE
- ▁EVENING
- ▁BEAUTIFUL
- ▁FEEL
- ▁RAN
- ▁LEAST
- ▁LAW
- ▁ALREADY
- ▁MEAN
- ▁ROSE
- WARD
- ▁ITSELF
- ▁SOUL
- ▁SUDDENLY
- ▁AROUND
- RED
- ▁ANSWER
- ICAL
- ▁RA
- ▁WIND
- ▁FINE
- ▁WON
- ▁WHETHER
- ▁KNOWN
- BER
- NG
- ▁TA
- ▁CAPTAIN
- ▁EYE
- ▁PERSON
- ▁WOMEN
- ▁SORT
- ▁ASK
- ▁BROTHER
- ▁USED
- ▁HELD
- ▁BIG
- ▁RETURNED
- ▁STRANGE
- ▁BU
- ▁PER
- ▁FREE
- ▁EITHER
- ▁WITHIN
- ▁DOUBT
- ▁YEAR
- ▁CLEAR
- ▁SIGHT
- ▁GRA
- ▁LOST
- ▁KEPT
- ▁F
- PE
- ▁BAR
- ▁TOWN
- ▁SLEEP
- ARY
- ▁HAIR
- ▁FRIENDS
- ▁DREAM
- ▁FELLOW
- PER
- ▁DEEP
- QUE
- ▁BECAME
- ▁REAL
- ▁PAST
- ▁MAKING
- RING
- ▁COMP
- ▁ACT
- ▁BAD
- HO
- STER
- ▁YE
- ▁MEANS
- ▁RUN
- MEN
- ▁DAUGHTER
- ▁SENSE
- ▁CITY
- ▁SOMETIMES
- ▁TOWARDS
- ▁ROAD
- ▁SP
- ▁LU
- ▁READY
- ▁FOOT
- ▁COLD
- ▁SA
- ▁LETTER
- ▁ELSE
- ▁MAR
- ▁STA
- BE
- ▁TRUTH
- ▁LE
- BO
- ▁BUSINESS
- CHE
- ▁JOHN
- ▁SUBJECT
- ▁COURT
- ▁IDEA
- ILY
- ▁RIVER
- ATING
- ▁FAMILY
- HE
- ▁DIDN
- ▁GLAD
- ▁SEVERAL
- IAL
- ▁UNDERSTAND
- ▁SC
- ▁POSSIBLE
- ▁DIFFERENT
- ▁RETURN
- ▁ARMS
- ▁LOW
- ▁HOLD
- ▁TALK
- ▁RU
- ▁WINDOW
- ▁INTEREST
- ▁SISTER
- SON
- ▁SH
- ▁BLOOD
- ▁SAYS
- ▁CAP
- ▁DI
- ▁HUMAN
- ▁CAUSE
- NCE
- ▁THANK
- ▁LATE
- GO
- ▁CUT
- ▁ACROSS
- ▁STORY
- NT
- ▁COUNT
- ▁ABLE
- DY
- LEY
- ▁NUMBER
- ▁STAND
- ▁CHURCH
- ▁THY
- ▁SUPPOSE
- LES
- BLE
- OP
- ▁EFFECT
- BY
- ▁K
- ▁NA
- ▁SPOKE
- ▁MET
- ▁GREEN
- ▁HUSBAND
- ▁RESPECT
- ▁PA
- ▁FOLLOWED
- ▁REMEMBER
- ▁LONGER
- ▁AGE
- ▁TAKING
- ▁LINE
- ▁SEEM
- ▁HAPPY
- LAND
- EM
- ▁STAY
- ▁PLAY
- ▁COMMON
- ▁GA
- ▁BOOK
- ▁TIMES
- ▁OBJECT
- ▁SEVEN
- QUI
- DO
- UND
- ▁FL
- ▁PRETTY
- ▁FAIR
- WAY
- ▁WOOD
- ▁REACHED
- ▁APPEARED
- ▁SWEET
- ▁FALL
- BA
- ▁PASS
- ▁SIGN
- ▁TREE
- IONS
- ▁GARDEN
- ▁ILL
- ▁ART
- ▁REMAIN
- ▁OPENED
- ▁BRIGHT
- ▁STREET
- ▁TROUBLE
- ▁PAIN
- ▁CONTINUED
- ▁SCHOOL
- OUR
- ▁CARRIED
- ▁SAYING
- HA
- ▁CHANGE
- ▁FOLLOW
- ▁GOLD
- ▁SW
- ▁FEELING
- ▁COMMAND
- ▁BEAR
- ▁CERTAINLY
- ▁BLUE
- ▁NE
- CA
- ▁WILD
- ▁ACCOUNT
- ▁OUGHT
- UD
- ▁T
- ▁BREATH
- ▁WANTED
- ▁RI
- ▁HEAVEN
- ▁PURPOSE
- ▁CHARACTER
- ▁RICH
- ▁PE
- ▁DRESS
- OS
- FA
- ▁TH
- ▁ENGLISH
- ▁CHANCE
- ▁SHIP
- ▁VIEW
- ▁TOWARD
- AK
- ▁JOY
- ▁JA
- ▁HAR
- ▁NEITHER
- ▁FORCE
- ▁UNCLE
- DER
- ▁PLAN
- ▁PRINCESS
- DI
- ▁CHIEF
- ▁HAT
- ▁LIVED
- ▁AB
- ▁VISIT
- ▁MOR
- TEN
- ▁WALL
- UC
- ▁MINE
- ▁PLEASURE
- ▁SMILE
- ▁FRONT
- ▁HU
- ▁DEAL
- OW
- ▁FURTHER
- GED
- ▁TRIED
- DA
- VA
- ▁NONE
- ▁ENTERED
- ▁QUEEN
- ▁PAY
- ▁EL
- ▁EXCEPT
- ▁SHA
- ▁FORWARD
- ▁EIGHT
- ▁ADDED
- ▁PUBLIC
- ▁EIGHTEEN
- ▁STAR
- ▁HAPPENED
- ▁LED
- ▁WALKED
- ▁ALTHOUGH
- ▁LATER
- ▁SPIRIT
- ▁WALK
- ▁BIT
- ▁MEET
- LIN
- ▁FI
- LT
- ▁MOUTH
- ▁WAIT
- ▁HOURS
- ▁LIVING
- ▁YOURSELF
- ▁FAST
- ▁CHA
- ▁HALL
- ▁BEYOND
- ▁BOAT
- ▁SECRET
- ENS
- ▁CHAIR
- RN
- ▁RECEIVED
- ▁CAT
- RESS
- ▁DESIRE
- ▁GENTLEMAN
- UGH
- ▁LAID
- EVER
- ▁OCCASION
- ▁WONDER
- ▁GU
- ▁PARTY
- DEN
- ▁FISH
- ▁SEND
- ▁NEARLY
- ▁TRY
- CON
- ▁SEEMS
- RS
- ▁BELL
- ▁BRA
- ▁SILENCE
- IG
- ▁GUARD
- ▁DIE
- ▁DOING
- ▁TU
- ▁COR
- ▁EARLY
- ▁BANK
- ▁FIGURE
- IF
- ▁ENGLAND
- ▁MARY
- ▁AFRAID
- LER
- ▁FO
- ▁WATCH
- ▁FA
- ▁VA
- ▁GRE
- ▁AUNT
- PED
- ▁SERVICE
- ▁JE
- ▁PEN
- ▁MINUTES
- ▁PAN
- ▁TREES
- NED
- ▁GLASS
- ▁TONE
- ▁PLEASE
- ▁FORTH
- ▁CROSS
- ▁EXCLAIMED
- ▁DREW
- ▁EAT
- ▁AH
- ▁GRAVE
- ▁CUR
- PA
- URE
- CENT
- ▁MILES
- ▁SOFT
- ▁AGO
- ▁POSITION
- ▁WARM
- ▁LENGTH
- ▁NECESSARY
- ▁THINKING
- ▁PICTURE
- ▁PI
- SHIP
- IBLE
- ▁HEAVY
- ▁ATTENTION
- ▁DOG
- ABLY
- ▁STANDING
- ▁NATURAL
- ▁APPEAR
- OV
- ▁CAUGHT
- VO
- ISM
- ▁SPRING
- ▁EXPERIENCE
- ▁PAT
- OT
- ▁STOPPED
- ▁REGARD
- ▁HARDLY
- ▁SELF
- ▁STRENGTH
- ▁GREW
- ▁KNIGHT
- ▁OPINION
- ▁WIDE
- ▁INSTEAD
- ▁SOUTH
- ▁TRANS
- ▁CORNER
- ▁LEARN
- ▁ISLAND
- ▁MI
- ▁THIRD
- ▁STE
- ▁STRAIGHT
- ▁TEA
- ▁BOUND
- ▁SEEING
- ▁JU
- ▁DINNER
- ▁BEAUTY
- ▁PEACE
- AH
- ▁REP
- ▁SILENT
- ▁CRE
- ALLY
- RIC
- ▁STEP
- ▁VER
- ▁JO
- GER
- ▁SITTING
- ▁THIRTY
- ▁SAVE
- ENED
- ▁GLANCE
- ▁REACH
- ▁ACTION
- ▁SAL
- ▁SAD
- ▁STONE
- ITIES
- ▁FRENCH
- ▁STRUCK
- ▁PAPER
- ▁WHATEVER
- ▁SUB
- ▁DISTANCE
- ▁WRONG
- ▁KNOWLEDGE
- ▁SAFE
- ▁SNOW
- ▁MUSIC
- ▁FIFTY
- RON
- ▁ATTEMPT
- ▁GOVERNMENT
- TU
- ▁CROWD
- ▁BESIDES
- ▁LOVED
- ▁BOX
- ▁DIRECTION
- ▁TRAIN
- ▁NORTH
- ▁THICK
- ▁GETTING
- AV
- ▁FLOOR
- ▁COMPANY
- ▁BLOW
- ▁PLAIN
- TRO
- ▁BESIDE
- ▁ROCK
- ▁IMMEDIATELY
- FI
- ▁SHADOW
- ▁SIT
- ORS
- ILE
- ▁DRINK
- ▁SPOT
- ▁DANGER
- ▁AL
- ▁SAINT
- ▁SLOWLY
- ▁PALACE
- IER
- ▁RESULT
- ▁PETER
- ▁FOREST
- ▁BELONG
- ▁SU
- ▁PAR
- RIS
- ▁TEARS
- ▁APPEARANCE
- ▁GATE
- BU
- ITION
- ▁QUICKLY
- ▁QUIET
- ▁LONDON
- ▁START
- ▁BROWN
- TRA
- KIN
- ▁CONSIDER
- ▁BATTLE
- ▁ANNE
- ▁PIECE
- ▁DIED
- ▁SUCCESS
- ▁LIPS
- ▁FILLED
- ▁FORGET
- ▁POST
- IFIED
- ▁MARGARET
- ▁FOOD
- HAM
- ▁PLEASANT
- ▁FE
- ▁EXPRESSION
- ▁POCKET
- ▁FRESH
- ▁WEAR
- TRI
- ▁BROKEN
- ▁LAUGHED
- GING
- ▁FOLLOWING
- WN
- IP
- ▁TOUCH
- ▁YOUTH
- ATIVE
- ▁LEG
- ▁WEEK
- ▁REMAINED
- ▁EASY
- NER
- RK
- ▁ENTER
- ▁FIGHT
- ▁PLACED
- ▁TRAVEL
- ▁SIMPLE
- ▁GIRLS
- ▁WAITING
- ▁STOP
- ▁WAVE
- AU
- ▁WISE
- ▁CAMP
- TURE
- UB
- ▁VE
- ▁OFFICE
- ▁GRAND
- ▁FIT
- ▁JUDGE
- UP
- MENTS
- ▁QUICK
- HI
- ▁FLO
- RIES
- VAL
- ▁COMFORT
- ▁PARTICULAR
- ▁STARTED
- ▁SUIT
- ▁NI
- ▁PALE
- ▁IMPOSSIBLE
- ▁HOT
- ▁CONVERSATION
- ▁SCENE
- ▁BOYS
- ▁WIN
- ▁BRE
- ▁SOCIETY
- ▁OUTSIDE
- ▁WRITE
- ▁EFFORT
- ▁TALKING
- ▁FORTUNE
- ▁NINE
- ▁WA
- ▁SINGLE
- ▁RULE
- ▁PORT
- ▁WINTER
- ▁CAST
- ▁CRA
- ▁HAPPEN
- ▁CRO
- ▁SHUT
- NING
- ▁GUN
- ▁NOBLE
- ▁BEGIN
- ▁PATH
- ▁SKY
- ▁WONDERFUL
- ▁SUDDEN
- ▁ARMY
- ▁CHE
- ▁WORTH
- ▁MOUNTAIN
- ▁MIN
- AG
- ▁FLU
- ▁GRACE
- ▁CHAPTER
- ▁BELOW
- ▁RING
- ▁TURNING
- ▁IRON
- ▁TOP
- ▁AFTERNOON
- ORY
- ▁EVIL
- ▁TRUST
- ▁BOW
- ▁TRI
- ▁SAIL
- ▁CONTENT
- ▁HORSES
- ITE
- ▁SILVER
- AP
- ▁LAD
- ▁RUNNING
- ▁HILL
- ▁BEGINNING
- ▁MAD
- ▁HABIT
- GRA
- ▁CLOTHES
- ▁MORROW
- ▁CRY
- ▁FASHION
- ▁PRESENCE
- ▁Z
- FE
- ▁ARRIVED
- ▁QUARTER
- ▁PERFECT
- ▁WO
- ▁TRA
- ▁USUAL
- ▁NECK
- ▁MARRIED
- ▁SEAT
- ▁WI
- ▁GAR
- ▁SAND
- ▁SHORE
- ▁GIVING
- NY
- ▁PROBABLY
- ▁MINUTE
- ▁EXPECT
- ▁DU
- ▁SHOT
- ▁INSTANT
- ▁DEGREE
- ▁COLOR
- ▁WEST
- RT
- ▁MARCH
- ▁BIRD
- ▁SHOWED
- ▁GREATER
- ▁SERIOUS
- ▁CARRY
- ▁COVERED
- ▁FORMER
- ▁LOUD
- ▁MOVED
- ▁MASS
- ▁SEEK
- ▁CHO
- GEN
- ▁ROMAN
- IB
- ▁MOON
- ▁BOARD
- ▁STREAM
- ▁EASILY
- ▁WISHED
- ▁SEARCH
- ▁COULDN
- ▁MONTHS
- ▁SICK
- LIE
- ▁DUTY
- ▁TWELVE
- ▁FAINT
- ▁STRANGER
- ▁SURPRISE
- ▁KILL
- ▁LEAVING
- ▁JOURNEY
- ▁SCARCELY
- ▁RAISED
- ▁SPEAKING
- ▁TERRIBLE
- ▁TOM
- ▁FIELD
- ▁GAME
- ▁QUA
- ▁PROMISE
- ▁LIE
- ▁CONDITION
- ▁TRO
- ▁PERSONAL
- ▁TALL
- ▁STICK
- ▁THREW
- ▁MARRY
- ▁VAN
- ▁BURN
- ▁ACCORDING
- ▁RISE
- ▁ATTACK
- ▁SWORD
- ▁GUESS
- ▁THOUGHTS
- ▁THIN
- ▁THROW
- ▁CALM
- SIDE
- ▁VILLAGE
- ▁DEN
- ▁ANXIOUS
- ▁MER
- GI
- ▁EXPECTED
- ▁BALL
- ▁ESPECIALLY
- ▁CHARGE
- ▁MEASURE
- ISE
- ▁NICE
- ▁TRYING
- ▁ALLOW
- ▁SHARP
- ▁BREAD
- ▁HONOUR
- ▁HONOR
- ▁ENTIRELY
- ▁BILL
- ▁BRI
- ▁WRITTEN
- ▁AR
- ▁BROKE
- ▁KILLED
- ▁MARK
- ▁VEN
- ▁LADIES
- ▁LEARNED
- ▁FLOWERS
- PLE
- ▁FORTY
- ▁OFFER
- ▁HAPPINESS
- ▁PRAY
- ▁CLASS
- ▁FER
- ▁PRINCIPLE
- GU
- ▁BOOKS
- ▁SHAPE
- ▁SUMMER
- ▁JACK
- ▁DRAW
- ▁GOLDEN
- ▁DECIDED
- ▁LEAD
- ▁UNLESS
- ▁HARM
- ▁LISTEN
- HER
- ▁SHOOK
- ▁INFLUENCE
- ▁PERFECTLY
- ▁MARRIAGE
- ▁BROAD
- ▁ESCAPE
- ▁STATES
- ▁MIDDLE
- ▁PLANT
- ▁MIL
- ▁MOVEMENT
- ▁NOISE
- ▁ENEMY
- ▁HISTORY
- ▁BREAK
- ROUS
- ▁UNDERSTOOD
- ▁LATTER
- FER
- ▁COMES
- ▁MERELY
- ▁SIMPLY
- WI
- ▁IMAGINE
- ▁LOWER
- ▁CONDUCT
- ▁BORN
- WA
- ▁YARD
- ▁KA
- ▁CLOSED
- ▁NOTE
- GA
- ▁STRA
- RAN
- ▁EXIST
- EV
- ▁SPEECH
- ▁BITTER
- JO
- ▁MAKES
- ▁GRASS
- ▁REPLY
- ▁CHANGED
- ▁MON
- ▁LYING
- ▁DANCE
- ▁FINALLY
- ▁AMERICAN
- ▁ENJOY
- ▁CONTAIN
- ▁MEANT
- USE
- ▁OBSERVED
- THER
- ▁LAUGH
- ▁AFTERWARDS
- ▁BEAT
- ▁RACE
- ▁EQUAL
- ▁RAIN
- PS
- ▁STEPS
- ▁BENEATH
- ▁TAIL
- ▁TASTE
- IO
- EY
- ▁CHAR
- ▁GE
- GN
- TIN
- ▁GROW
- ▁TE
- IANS
- ▁MOVE
- ▁REPEATED
- ▁DRIVE
- TUR
- ▁SI
- CLOCK
- ▁BRAVE
- ▁MADAME
- ▁LOT
- ▁CASTLE
- ▁HI
- AND
- ▁FUTURE
- ▁RELATION
- ▁SORRY
- ▁HEALTH
- ▁DICK
- ▁R
- ▁BUILDING
- ▁EDGE
- ▁BLESS
- ▁SPITE
- WE
- ▁MIS
- ▁PRISONER
- ▁ALLOWED
- ▁PH
- ▁CATCH
- MER
- ETH
- ▁COAT
- ▁COMPLETE
- ▁WOULDN
- ▁CREATURE
- ▁YELLOW
- ▁IMPORTANT
- ▁ADD
- ▁PASSING
- ▁DARKNESS
- ▁CARRIAGE
- ▁MILL
- ▁FIFTEEN
- NCY
- ▁HUNG
- ▁OB
- ▁PLEASED
- ▁SPREAD
- ▁CURIOUS
- ▁WORSE
- ▁CIRCUMSTANCES
- ▁GI
- LAR
- ▁CAL
- ▁HY
- ▁MERE
- ▁JANE
- ▁EAST
- BI
- ▁CUP
- ▁BLIND
- ▁PASSION
- ▁DISCOVERED
- ▁NOTICE
- ▁REPORT
- ▁SPACE
- ▁PRESENTLY
- ▁SORROW
- ▁PACK
- ▁DIN
- CY
- ▁DRY
- ▁ANCIENT
- ▁DRESSED
- ▁COVER
- ▁VO
- ▁EXISTENCE
- ▁EXACTLY
- ▁BEAST
- ▁PROPER
- ▁DROPPED
- ▁CLEAN
- ▁COLOUR
- ▁HOST
- ▁CHAMBER
- ▁FAITH
- LET
- ▁DETERMINED
- ▁PRIEST
- ▁STORM
- ▁SKIN
- ▁DARE
- ▁PERSONS
- ▁PICK
- ▁NARROW
- ▁SUPPORT
- ▁PRIVATE
- ▁SMILED
- ▁COUSIN
- ▁DRAWING
- ▁ATTEND
- ▁COOK
- ▁PREVENT
- ▁VARIOUS
- ▁BLA
- ▁FIXED
- ▁WEAK
- THE
- ▁HOLE
- ▁BOTTOM
- ▁NOBODY
- ADE
- ▁LEGS
- ITCH
- ▁INDIVIDUAL
- ▁EARS
- LIKE
- ▁ADVANTAGE
- ▁FRANCE
- ▁BON
- ▁WINE
- ▁LIVES
- OD
- ▁WALLS
- ▁TIRED
- ▁SHOP
- ▁ANIMAL
- ▁CRU
- ▁WROTE
- ▁ROYAL
- ▁CONSIDERED
- ▁MORAL
- ▁COMPANION
- ▁LOSE
- ▁ISN
- ▁BAG
- ▁LAKE
- ▁INTER
- ▁COM
- ▁LETTERS
- ▁LUCK
- ▁EAR
- ▁GERMAN
- ▁PET
- ▁SAKE
- ▁DROP
- ▁PAID
- ▁BREAKFAST
- ▁LABOR
- ▁DESERT
- ▁DECLARED
- ▁HUM
- ▁STUDY
- ▁INSTANCE
- ONE
- ▁SOMEWHAT
- ▁CLOTH
- ▁SPECIAL
- ▁COLONEL
- ▁SONG
- ▁MAIN
- ▁VALUE
- ▁PROUD
- ▁EXPRESS
- ▁NATION
- ▁HANDSOME
- ▁CONFESS
- ▁PU
- ▁PASSAGE
- ▁PERIOD
- ▁CUSTOM
- ▁HURT
- ▁SHOULDER
- ▁CHRIST
- ZA
- ▁RECEIVE
- ▁DIFFICULT
- ▁DEPEND
- ▁MEETING
- ▁CHI
- ▁GEN
- LIGHT
- ▁BELIEVED
- ▁SOCIAL
- ▁DIFFICULTY
- ▁GREATEST
- ▁DRAWN
- ▁GRANT
- ▁BIRDS
- ▁ANGRY
- ▁HEAT
- UFF
- ▁DUE
- ▁PLACES
- ▁SIN
- ▁COURAGE
- ▁EVIDENTLY
- ▁GENTLE
- ▁CRUEL
- ▁GEORGE
- ▁GRI
- ▁SERVANT
- ▁U
- ▁PURE
- OOK
- ▁KNOWS
- ▁KNOWING
- LF
- ▁WRITING
- ▁REMEMBERED
- ▁CU
- ▁HOLDING
- ▁TENDER
- ▁QUI
- ▁BURST
- ▁SURELY
- IGN
- ▁VALLEY
- ▁FU
- ▁BUTTER
- ▁SPOKEN
- ▁STORE
- ▁DISC
- ▁CHRISTIAN
- ▁PARIS
- ▁HENRY
- ▁FINISHED
- ▁PROVE
- ▁FOOL
- ▁SOLDIERS
- ▁LANGUAGE
- ▁INSIDE
- ▁BAN
- ▁FALLEN
- ROW
- ▁MAL
- ▁BABY
- ▁SITUATION
- ▁WATCHED
- ANS
- ▁RUIN
- ▁GENTLEMEN
- ▁FRO
- ▁FANCY
- ▁ACCEPT
- ▁SEASON
- ▁OURSELVES
- ▁SAN
- ▁SPEED
- IZED
- ▁COOL
- ▁SERVE
- ▁VESSEL
- ▁WILLIAM
- ▁OBLIGED
- ▁GROUP
- FORM
- ▁GOES
- UOUS
- ▁LEAVES
- ▁PECULIAR
- ▁NEWS
- ▁VAIN
- ▁EVERYBODY
- ▁PIN
- UG
- ▁FORGOTTEN
- ▁FRA
- GAN
- ▁CAREFULLY
- ▁FLASH
- UCH
- ▁FUR
- ▁MURDER
- ▁DELIGHT
- ▁WAITED
- ▁RENDER
- ▁PROPERTY
- ▁NOTICED
- ▁ROLL
- ▁KNOCK
- ▁EARNEST
- KI
- ▁HONEST
- ▁PROMISED
- ▁BAL
- AW
- ▁WALKING
- ANG
- ▁SQUARE
- ▁QUIETLY
- ▁CLOUD
- WOOD
- ▁FORMED
- ▁HIGHER
- ▁BUILT
- ▁FATE
- ▁TEACH
- MY
- ▁FALSE
- ▁YORK
- ▁DUST
- ▁CLIMB
- ▁FOND
- ▁GROWN
- ▁DESCEND
- ▁RAG
- ▁FRUIT
- ▁GENERALLY
- ▁OFFERED
- ▁ER
- ▁NURSE
- POSE
- ▁SPENT
- ▁JOIN
- ▁STATION
- ▁MEANING
- ▁SMOKE
- HOOD
- ▁ROUGH
- JU
- ▁LIKELY
- ▁SURFACE
- ▁KE
- ▁MONTH
- ▁POSSESSION
- ▁TONGUE
- ▁DUKE
- ▁NOSE
- ▁LAUGHING
- ▁WEATHER
- ▁WHISPERED
- ▁SYSTEM
- ▁LAWS
- DDLE
- ▁TOUCHED
- ▁TRADE
- LD
- ▁SURPRISED
- RIN
- ▁ARCH
- ▁WEALTH
- FOR
- ▁TEMPER
- ▁FRANK
- ▁GAL
- ▁BARE
- ▁OPPORTUNITY
- ▁CLAIM
- ▁ANIMALS
- ▁REV
- ▁COST
- ▁WASH
- ZE
- ▁CORN
- ▁OPPOSITE
- ▁POLICE
- ▁IDEAS
- LON
- ▁KEY
- ▁READING
- ▁COLLECT
- CHED
- ▁H
- ▁CROWN
- ▁TAR
- ▁SWIFT
- ▁SHOULDERS
- ▁ICE
- ▁GRAY
- ▁SHARE
- ▁PREPARED
- ▁GRO
- ▁UND
- ▁TER
- ▁EMPTY
- CING
- ▁SMILING
- ▁AVOID
- ▁DIFFERENCE
- ▁EXPLAIN
- ▁POUR
- ▁ATTRACT
- ▁OPENING
- ▁WHEEL
- ▁MATERIAL
- ▁BREAST
- ▁SUFFERING
- ▁DISTINCT
- ▁BOOT
- ▁ROW
- ▁FINGERS
- HAN
- ▁ALTOGETHER
- ▁FAT
- ▁PAPA
- ▁BRAIN
- ▁ASLEEP
- ▁GREY
- ▁SUM
- ▁GAS
- ▁WINDOWS
- ▁ALIVE
- ▁PROCEED
- ▁FLOWER
- ▁LEAP
- ▁PUR
- ▁PIECES
- ▁ALTER
- ▁MEMORY
- IENT
- ▁FILL
- ▁CLO
- ▁THROWN
- ▁KINGDOM
- ▁RODE
- IUS
- ▁MAID
- ▁DIM
- ▁BAND
- ▁VIRTUE
- ▁DISH
- ▁GUEST
- ▁LOSS
- ▁CAUSED
- ▁MOTION
- ▁POT
- ▁MILLION
- ▁FAULT
- ▁LOVELY
- ▁HERO
- PPING
- ▁UNITED
- ▁SPI
- SOME
- BRA
- ▁MOUNTAINS
- ▁NU
- ▁SATISFIED
- ▁DOLLARS
- ▁LOVER
- ▁CONCEAL
- ▁VAST
- ▁PULL
- ▁HATH
- ▁RUSH
- ▁J
- ▁DESPAIR
- EX
- ▁HEIGHT
- ▁CE
- ▁BENT
- ▁PITY
- ▁RISING
- ATH
- ▁PRIDE
- ▁HURRY
- KA
- ▁SETTLED
- ▁JUSTICE
- ▁LIFTED
- PEN
- ▁SOLDIER
- ▁FINDING
- ▁REMARK
- ▁REGULAR
- ▁STRUGGLE
- ▁MACHINE
- ▁SING
- ▁HURRIED
- ▁SUFFICIENT
- ▁REPRESENT
- ▁DOUBLE
- ▁ALARM
- ▁SUPPER
- ▁DREADFUL
- ▁FORE
- ATOR
- ▁STOCK
- ▁TIN
- ▁EXAMPLE
- ▁ROOF
- ▁FLOW
- ▁SUPPOSED
- ▁PRESERV
- ▁L
- ▁LISTENED
- OC
- ▁STO
- ▁SECURE
- ▁FRIGHTENED
- ▁DISTURB
- ▁EMOTION
- ▁SERVANTS
- ▁YO
- ▁BUY
- ▁FORCED
- ▁KITCHEN
- ▁TERROR
- ▁STAIRS
- ▁SIXTY
- KER
- ▁ORDINARY
- ▁DIRECTLY
- ▁HEADS
- ▁METHOD
- ▁FORGIVE
- ▁AWFUL
- ▁REFLECT
- ▁GREATLY
- ▁TALKED
- ▁RIDE
- STONE
- ▁FAVOUR
- ▁WELCOME
- ▁SEIZED
- OU
- ▁CONTROL
- ▁ORDERED
- ▁ANGEL
- ▁USUALLY
- ▁POET
- ▁BOLD
- LINE
- ▁ADVENTURE
- ▁WATCHING
- ▁FOLK
- ▁MISTRESS
- IZE
- ▁GROWING
- ▁CAVE
- ▁EVIDENCE
- ▁FINGER
- ▁SEVENTEEN
- ▁MOVING
- EOUS
- ▁DOESN
- ▁COW
- ▁TYPE
- ▁BOIL
- ▁TALE
- ▁DELIVER
- ▁FARM
- ▁MONSIEUR
- ▁GATHERED
- ▁FEELINGS
- ▁RATE
- ▁REMARKED
- ▁PUTTING
- ▁MAT
- ▁CONTRARY
- ▁CRIME
- ▁PLA
- ▁COL
- ▁NEARER
- TES
- ▁CIVIL
- ▁SHAME
- ▁LOOSE
- ▁DISCOVER
- ▁FLAT
- ▁TWICE
- ▁FAIL
- VIS
- ▁UNC
- EA
- ▁EUROPE
- ▁PATIENT
- ▁UNTO
- ▁SUFFER
- ▁PAIR
- ▁TREASURE
- OSE
- ▁EAGER
- ▁FLY
- ▁N
- ▁VAL
- ▁DAN
- ▁SALT
- ▁BORE
- BBE
- ▁ARTHUR
- ▁AFFAIRS
- ▁SLOW
- ▁CONSIST
- ▁DEVIL
- LAN
- ▁AFFECTION
- ▁ENGAGED
- ▁KISS
- ▁YA
- ▁OFFICER
- IFICATION
- ▁LAMP
- ▁PARTS
- HEN
- ▁MILK
- ▁PROCESS
- ▁GIFT
- ▁PULLED
- ▁HID
- ▁RAY
- ▁EXCELLENT
- ▁IMPRESSION
- ▁AUTHORITY
- ▁PROVED
- ▁TELLING
- TTE
- ▁TOWER
- ▁CONSEQUENCE
- ▁FAVOR
- ▁FLEW
- ▁CHARLES
- ISTS
- ▁ADDRESS
- ▁FAMILIAR
- ▁LIMIT
- ▁CONFIDENCE
- ▁RARE
- ▁WEEKS
- ▁WOODS
- ▁INTENTION
- ▁DIRECT
- ▁PERFORM
- ▁SOLEMN
- ▁DISTANT
- ▁IMAGE
- ▁PRESIDENT
- ▁FIRM
- ▁INDIAN
- ▁RANK
- ▁LIKED
- ▁AGREE
- ▁HOUSES
- ▁WIL
- ▁MATTERS
- ▁PRISON
- ▁MODE
- ▁MAJOR
- ▁WORKING
- ▁SLIP
- ▁WEIGHT
- ▁AWARE
- ▁BUSY
- ▁LOOKS
- ▁WOUND
- ▁THOR
- ▁BATH
- ▁EXERCISE
- ▁SIMILAR
- ▁WORE
- ▁AMOUNT
- ▁QUESTIONS
- ▁VIOLENT
- ▁EXCUSE
- ▁ASIDE
- ▁TUR
- ▁DULL
- OF
- ▁EMPEROR
- ▁NEVERTHELESS
- ▁SHOUT
- ▁EXPLAINED
- ▁SIZE
- ▁ACCOMPLISH
- FORD
- CAN
- ▁MISTAKE
- ▁INSTANTLY
- ▁SMOOTH
- ▁STRIKE
- ▁BOB
- ISED
- ▁HORROR
- ▁SCIENCE
- ▁PROTEST
- ▁MANAGE
- ▁OBEY
- ▁NECESSITY
- ▁SPLENDID
- ▁PRESS
- ▁INTERESTING
- ▁RELIGION
- ▁UNKNOWN
- ▁FIERCE
- ▁DISAPPEARED
- ▁HOLY
- ▁HATE
- ▁PLAYED
- ▁LIN
- ▁NATURALLY
- ▁DROVE
- ▁LOUIS
- TIES
- ▁BRAND
- INESS
- RIE
- ▁SHOOT
- ▁CONSENT
- ▁SEATED
- ▁LINES
- GUE
- ▁AGREED
- ▁CIRCLE
- ▁STIR
- ▁STREETS
- ▁TASK
- ▁RID
- ▁PRODUCED
- ▁ACCIDENT
- ▁WITNESS
- ▁LIBERTY
- ▁DETAIL
- ▁MINISTER
- ▁POWERFUL
- ▁SAVAGE
- ▁SIXTEEN
- ▁PRETEND
- ▁COAST
- ▁SQU
- ▁UTTER
- ▁NAMED
- ▁CLEVER
- ▁ADMIT
- ▁COUPLE
- ▁WICKED
- ▁MESSAGE
- ▁TEMPLE
- ▁STONES
- ▁YESTERDAY
- ▁HILLS
- DAY
- ▁SLIGHT
- ▁DIAMOND
- ▁POSSIBLY
- ▁AFFAIR
- ▁ORIGINAL
- ▁HEARING
- ▁WORTHY
- ▁SELL
- NEY
- ICK
- ▁COTTAGE
- ▁SACRIFICE
- ▁PROGRESS
- ▁SHOCK
- ▁DESIGN
- ▁SOUGHT
- ▁PIT
- ▁SUNDAY
- ▁OTHERWISE
- ▁CABIN
- ▁PRAYER
- ▁DWELL
- ▁GAIN
- ▁BRIDGE
- ▁PARTICULARLY
- ▁YIELD
- ▁TREAT
- RIGHT
- ▁OAK
- ▁ROPE
- WIN
- ▁ORDERS
- ▁SUSPECT
- ▁EDWARD
- AB
- ▁ELEVEN
- ▁TEETH
- ▁OCCURRED
- DDING
- ▁AMERICA
- ▁FALLING
- ▁LION
- ▁DEPART
- ▁KEEPING
- ▁DEMAND
- ▁PAUSED
- ▁CEASED
- INA
- ▁FUN
- ▁CHEER
- ▁PARDON
- ▁NATIVE
- LUS
- LOW
- ▁DOGS
- ▁REQUIRED
- ILITY
- ▁ELECT
- ▁ENTERTAIN
- ITUDE
- ▁HUGE
- ▁CARRYING
- ▁BLU
- ▁INSIST
- ▁SATISFACTION
- ▁HUNT
- ▁COUNTENANCE
- ▁UPPER
- ▁MAIDEN
- ▁FAILED
- ▁JAMES
- ▁FOREIGN
- ▁GATHER
- ▁TEST
- BOARD
- ▁TERMS
- ▁SILK
- ▁BEG
- ▁BROTHERS
- ▁PAGE
- ▁KNEES
- ▁SHOWN
- ▁PROFESSOR
- ▁MIGHTY
- ▁DEFI
- ▁CHARM
- ▁REQUIRE
- ▁LOG
- MORE
- ▁PROOF
- ▁POSSESSED
- ▁SOFTLY
- ▁UNFORTUNATE
- ▁PRICE
- ▁SEVERE
- ▁SINGING
- ▁STAGE
- ▁FREEDOM
- ▁SHOUTED
- ▁FARTHER
- ▁MAJESTY
- ▁PREVIOUS
- ▁GUIDE
- ▁MATCH
- ▁CHEST
- ▁INTENDED
- ▁BI
- ▁EXCITEMENT
- ▁OFFICERS
- ▁SUR
- ▁SHAKE
- ▁SENTIMENT
- ▁GENTLY
- ▁SUCCEEDED
- ▁MENTION
- ▁LOCK
- ▁ACQUAINTANCE
- ▁IMAGINATION
- ▁PHYSICAL
- ▁LEADING
- ▁SLAVE
- ▁CART
- ▁POINTED
- ▁STEAM
- ▁SHADE
- ▁PIPE
- ▁BASE
- ▁INVENT
- ▁ALAS
- ▁WORKED
- ▁REGRET
- ▁BUR
- ▁FAITHFUL
- ▁MENTIONED
- ▁RECORD
- ▁COMPLAIN
- ▁SUPERIOR
- ▁BAY
- ▁PAL
- EMENT
- UE
- ▁SEVENTY
- ▁HOTEL
- ▁SHEEP
- ▁MEAL
- ▁ADVICE
- ▁HIDDEN
- ▁DEMANDED
- ▁CONSCIOUS
- ▁BROW
- ▁POSSESS
- ▁FOURTH
- ▁EVENTS
- ▁FRI
- ▁PRAISE
- ▁ADVANCED
- ▁RESOLVED
- ▁STUFF
- ▁CHEERFUL
- ▁BIRTH
- ▁GRIEF
- ▁AFFORD
- ▁FAIRY
- ▁WAKE
- ▁SIDES
- ▁SUBSTANCE
- ▁ARTICLE
- ▁LEVEL
- ▁MIST
- ▁JOINED
- ▁PRACTICAL
- ▁CLEARLY
- ▁TRACE
- ▁AWAKE
- ▁OBSERVE
- ▁BASKET
- ▁LACK
- VILLE
- ▁SPIRITS
- ▁EXCITED
- ▁ABANDON
- ▁SHINING
- ▁FULLY
- ▁CALLING
- ▁CONSIDERABLE
- ▁SPRANG
- ▁MILE
- ▁DOZEN
- ▁PEA
- ▁DANGEROUS
- ▁WIT
- ▁JEW
- ▁POUNDS
- ▁FOX
- ▁INFORMATION
- ▁LIES
- ▁DECK
- NNY
- ▁PAUL
- ▁STARS
- ▁ANGER
- ▁SETTLE
- ▁WILLING
- ▁ADAM
- ▁FACES
- ▁SMITH
- ▁IMPORTANCE
- ▁STRAIN
- WAR
- ▁SAM
- ▁FEATHER
- ▁SERVED
- ▁AUTHOR
- ▁PERCEIVED
- ▁FLAME
- ▁DIVINE
- ▁TRAIL
- ▁ANYBODY
- ▁SIGH
- ▁DELICATE
- KY
- ▁FOLD
- ▁HAVEN
- ▁DESIRED
- ▁CURIOSITY
- ▁PRACTICE
- ▁CONSIDERATION
- ▁ABSOLUTELY
- ▁CITIZEN
- ▁BOTTLE
- ▁INTERESTED
- ▁MEAT
- ▁OCCUPIED
- ▁CHOOSE
- ▁THROAT
- ETTE
- ▁CANDLE
- ▁DAWN
- ▁PROTECT
- ▁SENTENCE
- IED
- ▁ROCKS
- ▁PORTION
- ▁APPARENTLY
- ▁PRESENTED
- ▁TIGHT
- ▁ACTUALLY
- ▁DYING
- ▁HAM
- ▁DAILY
- ▁SUFFERED
- ▁POLITICAL
- ▁BODIES
- ▁MODERN
- ▁COMPLETELY
- ▁SOONER
- TAN
- ▁PROP
- ▁ADVANCE
- ▁REFUSED
- ▁FARMER
- ▁POLITE
- ▁THUNDER
- ▁BRIEF
- ▁ELSIE
- ▁SAILOR
- ▁SUGGESTED
- ▁PLATE
- ▁AID
- ▁FLESH
- ▁WEEP
- ▁BUCK
- ▁ANTI
- ▁OCEAN
- ▁SPEND
- WELL
- ▁ODD
- ▁GOVERNOR
- ▁ENTRANCE
- ▁SUSPICION
- ▁STEPPED
- ▁RAPIDLY
- ▁CHECK
- ▁HIDE
- ▁FLIGHT
- ▁CLUB
- ▁ENTIRE
- ▁INDIANS
- ASH
- ▁CAPITAL
- ▁MAMMA
- HAR
- ▁CORRECT
- ▁CRACK
- ▁SENSATION
- ▁WORST
- ▁PACE
- ▁MIDST
- ▁AUGUST
- ▁PROPORTION
- ▁INNOCENT
- LINESS
- ▁REGARDED
- ▁DRIVEN
- ORD
- ▁HASTE
- ▁EDUCATION
- ▁EMPLOY
- ▁TRULY
- ▁INSTRUMENT
- ▁MAG
- ▁FRAME
- ▁FOOLISH
- ▁TAUGHT
- ▁HANG
- ▁ARGUMENT
- ▁NINETEEN
- ▁ELDER
- ▁NAY
- ▁NEEDED
- ▁NEIGHBOR
- ▁INSTRUCT
- ▁PAPERS
- ▁REWARD
- ▁EQUALLY
- ▁FIELDS
- ▁DIG
- HIN
- ▁CONDITIONS
- JA
- ▁SPAR
- ▁REQUEST
- ▁WORN
- ▁REMARKABLE
- ▁LOAD
- ▁WORSHIP
- ▁PARK
- ▁KI
- ▁INTERRUPTED
- ▁SKILL
- ▁TERM
- LAC
- ▁CRITIC
- ▁DISTRESS
- ▁BELIEF
- ▁STERN
- IGHT
- ▁TRACK
- ▁HUNTING
- ▁JEWEL
- ▁GRADUALLY
- ▁GLOW
- ▁RUSHED
- ▁MENTAL
- ▁VISITOR
- ▁PICKED
- ▁BEHOLD
- ▁EXPRESSED
- ▁RUB
- ▁SKI
- ARTAGNAN
- ▁MOREOVER
- ▁OPERATION
- ▁CAREFUL
- ▁KEEN
- ▁ASSERT
- ▁WANDER
- ▁ENEMIES
- ▁MYSTERIOUS
- ▁DEPTH
- ▁PREFER
- ▁CROSSED
- ▁CHARMING
- ▁DREAD
- ▁FLOUR
- ▁ROBIN
- ▁TRE
- ▁RELIEF
- ▁INQUIRED
- ▁APPLE
- ▁HENCE
- ▁WINGS
- ▁CHOICE
- ▁JUD
- OO
- ▁SPECIES
- ▁DELIGHTED
- IUM
- ▁RAPID
- ▁APPEAL
- ▁FAMOUS
- ▁USEFUL
- ▁HELEN
- ▁NEWSPAPER
- ▁PLENTY
- ▁BEARING
- ▁NERVOUS
- ▁PARA
- ▁URGE
- ▁ROAR
- ▁WOUNDED
- ▁CHAIN
- ▁PRODUCE
- ▁REFLECTION
- ▁MERCHANT
- ▁QUARREL
- ▁GLORY
- ▁BEGUN
- ▁BARON
- CUS
- ▁QUEER
- ▁MIX
- ▁GAZE
- ▁WHISPER
- ▁BURIED
- ▁DIV
- ▁CARD
- ▁FREQUENTLY
- ▁TIP
- ▁KNEE
- ▁REGION
- ▁ROOT
- ▁LEST
- ▁JEALOUS
- CTOR
- ▁SAVED
- ▁ASKING
- ▁TRIP
- QUA
- ▁UNION
- HY
- ▁COMPANIONS
- ▁SHIPS
- ▁HALE
- ▁APPROACHED
- ▁HARRY
- ▁DRUNK
- ▁ARRIVAL
- ▁SLEPT
- ▁FURNISH
- HEAD
- ▁PIG
- ▁ABSENCE
- ▁PHIL
- ▁HEAP
- ▁SHOES
- ▁CONSCIOUSNESS
- ▁KINDLY
- ▁EVIDENT
- ▁SCAR
- ▁DETERMIN
- ▁GRASP
- ▁STEAL
- ▁OWE
- ▁KNIFE
- ▁PRECIOUS
- ▁ELEMENT
- ▁PROCEEDED
- ▁FEVER
- ▁LEADER
- ▁RISK
- ▁EASE
- ▁GRIM
- ▁MOUNT
- ▁MEANWHILE
- ▁CENTURY
- OON
- ▁JUDGMENT
- ▁AROSE
- ▁VISION
- ▁SPARE
- ▁EXTREME
- ▁CONSTANT
- ▁OBSERVATION
- ▁THRUST
- ▁DELAY
- ▁CENT
- ▁INCLUD
- ▁LIFT
- ▁ADMIRE
- ▁ISSUE
- ▁FRIENDSHIP
- ▁LESSON
- ▁PRINCIPAL
- ▁MOURN
- ▁ACCEPTED
- ▁BURNING
- ▁CAPABLE
- ▁EXTRAORDINARY
- ▁SANG
- ▁REMOVED
- ▁HOPED
- ▁HORN
- ▁ALICE
- ▁MUD
- ▁APARTMENT
- ▁FIGHTING
- ▁BLAME
- ▁TREMBLING
- ▁SOMEBODY
- ▁ANYONE
- ▁BRIDE
- ▁READER
- ▁ROB
- ▁EVERYWHERE
- ▁LABOUR
- ▁RECALL
- ▁BULL
- ▁HIT
- ▁COUNCIL
- ▁POPULAR
- ▁CHAP
- ▁TRIAL
- ▁DUN
- ▁WISHES
- ▁BRILLIANT
- ▁ASSURED
- ▁FORGOT
- ▁CONTINUE
- ▁ACKNOWLEDG
- ▁RETREAT
- ▁INCREASED
- ▁CONTEMPT
- ▁GRANDFATHER
- ▁SYMPATHY
- ▁GHOST
- ▁STRETCHED
- ▁CREATURES
- ▁CAB
- ▁HIND
- ▁PLAYING
- ▁MISERABLE
- ▁MEMBERS
- ▁KINDNESS
- ▁HIGHEST
- ▁PRIM
- ▁KISSED
- ▁DESERVE
- ▁HUT
- ▁BEGGED
- ▁EIGHTY
- ▁CLOSELY
- ▁WONDERED
- ▁MILITARY
- ▁REMIND
- ▁ACCORDINGLY
- ▁LARGER
- ▁MAINTAIN
- ▁ENGINE
- ▁MOTIVE
- ▁DESTROY
- ▁STRIP
- ▁HANS
- ▁AHEAD
- ▁INFINITE
- ▁PROMPT
- ▁INFORMED
- TTLE
- ▁PEER
- ▁PRESSED
- ▁TRAP
- ▁SOMEWHERE
- ▁BOUGHT
- ▁VISIBLE
- ▁ASHAMED
- ▁TEAR
- ▁NEIGHBOUR
- ▁CONSTITUTION
- ▁INTELLIGENCE
- ▁PROFESSION
- ▁HUNGRY
- RIDGE
- ▁SMELL
- ▁STORIES
- ▁LISTENING
- ▁APPROACH
- ▁STRING
- ▁EXPLANATION
- ▁IMMENSE
- ▁RELIGIOUS
- ▁THROUGHOUT
- ▁HOLLOW
- ▁AWAIT
- ▁FLYING
- ▁SCREAM
- ▁ACTIVE
- ▁RUM
- ▁PRODUCT
- ▁UNHAPPY
- ▁VAGUE
- ARIES
- ▁ELIZABETH
- ▁STUPID
- ▁DIGNITY
- ▁ISABEL
- GAR
- ▁BRO
- ▁PITCH
- ▁COMRADE
- ▁STIFF
- ▁RECKON
- ▁SOLD
- ▁SPARK
- ▁STRO
- ▁CRYING
- ▁MAGIC
- ▁REPEAT
- PORT
- ▁MARKED
- ▁COMFORTABLE
- ▁PROJECT
- ▁BECOMING
- ▁PARENTS
- ▁SHELTER
- ▁STOLE
- ▁HINT
- ▁NEST
- ▁TRICK
- ▁THOROUGHLY
- ▁HOSPITAL
- ▁WEAPON
- ▁ROME
- ▁STYLE
- ▁ADMITTED
- ▁SAFETY
- FIELD
- ▁UNDERSTANDING
- ▁TREMBLE
- ▁PRINT
- ▁SLAVES
- ▁WEARY
- ▁ARTIST
- ▁CREDIT
- BURG
- ▁CONCLUSION
- ▁SELDOM
- ▁UNUSUAL
- ▁CLOUDS
- ▁UNABLE
- ▁GAY
- ▁HANGING
- ▁SCR
- ▁BOWED
- ▁DAVID
- ▁VOL
- ▁PUSHED
- ▁ESCAPED
- MOND
- ▁WARN
- ▁BETRAY
- ▁EGGS
- ▁PLAINLY
- ▁EXHIBIT
- ▁DISPLAY
- ▁MEMBER
- ▁GRIN
- ▁PROSPECT
- ▁BRUSH
- ▁BID
- ▁SUCCESSFUL
- ▁EXTENT
- ▁PERSUADE
- ▁MID
- ▁MOOD
- ▁ARRANGED
- ▁UNIVERSAL
- ▁JIM
- ▁SIGNAL
- ▁WHILST
- ▁PHILIP
- ▁WOLF
- RATE
- ▁EAGERLY
- ▁BILLY
- ▁RETURNING
- ▁CONSCIENCE
- ▁FORTUNATE
- ▁FEMALE
- ▁GLEAM
- ▁HASTILY
- ▁PROVIDED
- ▁OBTAIN
- ▁INSTINCT
- ▁CONCERNED
- ▁CONCERNING
- ▁SOMEHOW
- ▁PINK
- ▁RAGE
- ▁ACCUSTOMED
- ▁UNCONSCIOUS
- ▁ADVISE
- ▁BRANCHES
- ▁TINY
- ▁REFUSE
- ▁BISHOP
- ▁SUPPLY
- ▁PEASANT
- ▁LAWYER
- ▁WASTE
- ▁CONNECTION
- ▁DEVELOP
- ▁CORRESPOND
- ▁PLUM
- ▁NODDED
- ▁SLIPPED
- ▁EU
- ▁CONSTANTLY
- CUM
- MMED
- ▁FAIRLY
- HOUSE
- ▁KIT
- ▁RANG
- ▁FEATURES
- ▁PAUSE
- ▁PAINFUL
- ▁JOE
- ▁WHENCE
- ▁LAUGHTER
- ▁COACH
- ▁CHRISTMAS
- ▁EATING
- ▁WHOLLY
- ▁APART
- ▁SUPER
- ▁REVOLUTION
- ▁LONELY
- ▁CHEEKS
- ▁THRONE
- ▁CREW
- ▁ATTAIN
- ▁ESTABLISHED
- TIME
- ▁DASH
- ▁FRIENDLY
- ▁OPERA
- ▁EARL
- ▁EXHAUST
- ▁CLIFF
- ▁REVEAL
- ▁ADOPT
- ▁CENTRE
- ▁MERRY
- ▁SYLVIA
- ▁IDEAL
- ▁MISFORTUNE
- ▁FEAST
- ▁ARAB
- ▁NUT
- ▁FETCH
- ▁FOUGHT
- ▁PILE
- ▁SETTING
- ▁SOURCE
- ▁PERSIST
- ▁MERCY
- ▁BARK
- ▁LUC
- ▁DEEPLY
- ▁COMPARE
- ▁ATTITUDE
- ▁ENDURE
- ▁DELIGHTFUL
- ▁BEARD
- ▁PATIENCE
- ▁LOCAL
- ▁UTTERED
- ▁VICTORY
- ▁TREATED
- ▁SEPARATE
- ▁WAG
- ▁DRAGG
- ▁TITLE
- ▁TROOPS
- ▁TRIUMPH
- ▁REAR
- ▁GAINED
- ▁SINK
- ▁DEFEND
- ▁TIED
- ▁FLED
- ▁DARED
- ▁INCREASE
- ▁POND
- ▁CONQUER
- ▁FOREHEAD
- ▁FAN
- ▁ANXIETY
- ▁ENCOUNTER
- ▁SEX
- ▁HALT
- ▁SANK
- ▁CHEEK
- ▁HUMBLE
- ▁WRITER
- ▁EMPLOYED
- ▁DISTINGUISHED
- ▁RAISE
- ▁WHIP
- ▁GIANT
- ▁RANGE
- ▁OBTAINED
- ▁FLAG
- ▁MAC
- ▁JUMPED
- ▁DISCOVERY
- ▁NATIONAL
- ▁COMMISSION
- ▁POSITIVE
- ▁LOVING
- ▁EXACT
- ▁MURMURED
- ▁GAZED
- ▁REFER
- ▁COLLEGE
- ▁ENCOURAGE
- ▁NOVEL
- ▁CLOCK
- ▁MORTAL
- ▁ROLLED
- ▁RAT
- IZING
- ▁GUILTY
- ▁VICTOR
- WORTH
- ▁PRA
- ▁APPROACHING
- ▁RELATIVE
- ▁ESTATE
- ▁UGLY
- ▁METAL
- ▁ROBERT
- ▁TENT
- ▁ADMIRATION
- ▁FOURTEEN
- ▁BARBAR
- ▁WITCH
- ELLA
- ▁CAKE
- ▁SHONE
- ▁MANAGED
- ▁VOLUME
- ▁GREEK
- ▁DANCING
- ▁WRETCHED
- ▁CONDEMN
- ▁MAGNIFICENT
- ▁CONSULT
- J
- ▁ORGAN
- ▁FLEET
- ▁ARRANGEMENT
- ▁INCIDENT
- ▁MISERY
- ▁ARROW
- ▁STROKE
- ▁ASSIST
- ▁BUILD
- ▁SUCCEED
- ▁DESPERATE
- ▁WIDOW
- UDE
- ▁MARKET
- ▁WISDOM
- ▁PRECISE
- ▁CURRENT
- ▁SPOIL
- ▁BADE
- ▁WOODEN
- ▁RESIST
- ▁OBVIOUS
- ▁SENSIBLE
- FALL
- ▁ADDRESSED
- ▁GIL
- ▁COUNSEL
- ▁PURCHASE
- ▁SELECT
- ▁USELESS
- ▁STARED
- ▁ARREST
- ▁POISON
- ▁FIN
- ▁SWALLOW
- ▁BLOCK
- ▁SLID
- ▁NINETY
- ▁SPORT
- ▁PROVIDE
- ▁ANNA
- ▁LAMB
- ▁INTERVAL
- ▁JUMP
- ▁DESCRIBED
- ▁STRIKING
- ▁PROVISION
- ▁PROPOSED
- ▁MELANCHOLY
- ▁WARRIOR
- ▁SUGGEST
- ▁DEPARTURE
- ▁BURDEN
- ▁LIMB
- ▁TROUBLED
- ▁MEADOW
- ▁SACRED
- ▁SOLID
- ▁TRU
- ▁LUCY
- ▁RECOVER
- ▁ENERGY
- ▁POWDER
- ▁RESUMED
- ▁INTENSE
- ▁BRITISH
- ▁STRAW
- ▁AGREEABLE
- ▁EVERYONE
- ▁CONCERN
- ▁VOYAGE
- ▁SOUTHERN
- ▁BOSOM
- ▁UTTERLY
- ▁FEED
- ▁ESSENTIAL
- ▁CONFINE
- ▁HOUSEHOLD
- ▁EXTREMELY
- ▁WONDERING
- ▁LIST
- ▁PINE
- PHA
- ▁EXPERIMENT
- ▁JOSEPH
- ▁MYSTERY
- ▁RESTORE
- ▁BLUSH
- FOLD
- ▁CHOSEN
- ▁INTELLECT
- ▁CURTAIN
- OLOGY
- ▁MOUNTED
- ▁LAP
- ▁EPI
- ▁PUNISH
- ▁WEDDING
- ▁RECOGNIZED
- ▁DRIFT
- ▁PREPARATION
- ▁RESOLUTION
- ▁OPPRESS
- ▁FIX
- ▁VICTIM
- OGRAPH
- ▁SUMMON
- ▁JULIA
- ▁FLOOD
- ▁WAL
- ULATION
- ▁SLIGHTLY
- ▁LODGE
- ▁WIRE
- ▁CONFUSION
- ▁UNEXPECTED
- ▁CONCEIVE
- ▁PRIZE
- ▁JESUS
- ▁ADDITION
- ▁RUDE
- ▁FATAL
- ▁CARELESS
- ▁PATCH
- ▁KO
- ▁CATHERINE
- ▁PARLIAMENT
- ▁PROFOUND
- ▁ALOUD
- ▁RELIEVE
- ▁PUSH
- ABILITY
- ▁ACCOMPANIED
- ▁SOVEREIGN
- ▁SINGULAR
- ▁ECHO
- ▁COMPOSED
- ▁SHAKING
- ATORY
- ▁ASSISTANCE
- ▁TEACHER
- ▁HORRIBLE
- ▁STRICT
- ▁VERSE
- ▁PUNISHMENT
- ▁GOWN
- ▁MISTAKEN
- ▁VARI
- ▁SWEPT
- ▁GESTURE
- ▁BUSH
- ▁STEEL
- ▁AFFECTED
- ▁DIRECTED
- ▁SURROUNDED
- ▁ABSURD
- ▁SUGAR
- ▁SCRAP
- ▁IMMEDIATE
- ▁SADDLE
- ▁TY
- ▁ARISE
- ▁SIGHED
- ▁EXCHANGE
- ▁IMPATIENT
- ▁SNAP
- ▁EMBRACE
- ▁DISEASE
- ▁PROFIT
- ▁RIDING
- ▁RECOVERED
- ▁GOVERN
- ▁STRETCH
- ▁CONVINCED
- ▁LEANING
- ▁DOMESTIC
- ▁COMPLEX
- ▁MANIFEST
- ▁INDULGE
- ▁GENIUS
- ▁AGENT
- ▁VEIL
- ▁DESCRIPTION
- ▁INCLINED
- ▁DECEIVE
- ▁DARLING
- ▁REIGN
- HU
- ▁ENORMOUS
- ▁RESTRAIN
- ▁DUTIES
- BURY
- TTERED
- ▁POLE
- ▁ENABLE
- ▁EXCEPTION
- ▁INTIMATE
- ▁COUNTESS
- ▁TRIBE
- ▁HANDKERCHIEF
- ▁MIDNIGHT
- ▁PROBLEM
- ▁TRAMP
- ▁OIL
- CAST
- ▁CRUSH
- ▁DISCUSS
- ▁RAM
- ▁TROT
- ▁UNRE
- ▁WHIRL
- ▁LOCKED
- ▁HORIZON
- ▁OFFICIAL
- ▁SCHEME
- ▁DROWN
- ▁PIERRE
- ▁PERMITTED
- ▁CONNECTED
- ▁ASSURE
- ▁COCK
- ▁UTMOST
- ▁DEVOTED
- ▁RELI
- ▁SUFFICIENTLY
- ▁INTELLECTUAL
- ▁CARPET
- ▁OBJECTION
- ▁AFTERWARD
- ▁REALITY
- ▁NEGRO
- ▁RETAIN
- ▁ASCEND
- ▁CEASE
- ▁KATE
- ▁MARVEL
- KO
- ▁BOND
- MOST
- ▁COAL
- GATE
- ▁IGNORANT
- ▁BREAKING
- ▁TWIN
- ▁ASTONISHMENT
- ▁COFFEE
- ▁JAR
- ▁CITIES
- ▁ORIGIN
- ▁EXECUT
- ▁FINAL
- ▁INHABITANTS
- ▁STABLE
- ▁CHIN
- ▁PARTIES
- ▁PLUNGE
- ▁GENEROUS
- ▁DESCRIBE
- ▁ANNOUNCED
- ▁MERIT
- ▁REVERE
- ▁ERE
- ACIOUS
- ZI
- ▁DISAPPOINT
- ▁SUGGESTION
- ▁DOUBTLESS
- ▁TRUNK
- ▁STAMP
- ▁JOB
- ▁APPOINTED
- ▁DIVIDED
- ▁ACQUAINTED
- CHI
- ▁ABSOLUTE
- ▁FEARFUL
- ▁PRIVILEGE
- ▁CRAFT
- ▁STEEP
- ▁HUNTER
- ▁FORBID
- ▁MODEST
- ▁ENDEAVOUR
- ▁SWEEP
- ▁BEHELD
- ▁ABSORB
- ▁CONSTRUCT
- ▁EMPIRE
- ▁EXPEDITION
- ▁ERECT
- ▁OFFEND
- ▁INTEND
- ▁PERMIT
- ▁DESTROYED
- ▁CONTRACT
- ▁THIRST
- ▁WAGON
- ▁EVA
- ▁GLOOM
- ▁ATMOSPHERE
- ▁RESERVE
- ▁VOTE
- ▁GER
- ▁NONSENSE
- ▁PREVAIL
- ▁QUALITY
- ▁CLASP
- ▁CONCLUDED
- ▁RAP
- ▁KATY
- ▁ETERNAL
- ▁MUTTERED
- ▁NEGLECT
- ▁SQUIRE
- ▁CREEP
- LOCK
- ▁ELECTRIC
- ▁HAY
- ▁EXPENSE
- ▁SCORN
- ▁RETIRED
- ▁STOUT
- ▁MURMUR
- ▁SHARPLY
- ▁DISTRICT
- ▁LEAF
- ▁FAILURE
- WICK
- ▁JEAN
- ▁NUMEROUS
- ▁INFANT
- ▁REALIZED
- ▁TRAVELLER
- ▁HUNGER
- ▁JUNE
- ▁MUN
- ▁RECOMMEND
- ▁CREP
- ZZLE
- ▁RICHARD
- WORK
- ▁MONTE
- ▁PREACH
- ▁PALM
- AVI
- ▁ANYWHERE
- ▁DISPOSITION
- ▁MIRROR
- ▁VENTURE
- ▁POUND
- ▁CIGAR
- ▁INVITED
- ▁BENCH
- ▁PROTECTION
- ▁BENEFIT
- ▁THOMAS
- ▁CLERK
- ▁REPROACH
- ▁UNIFORM
- ▁GENERATION
- ▁SEAL
- ▁COMPASS
- ▁WARNING
- ▁EXTENDED
- ▁DIFFICULTIES
- ▁MAYBE
- ▁GROAN
- ▁AFFECT
- ▁COMB
- ▁EARN
- ▁WESTERN
- ▁IDLE
- ▁SCORE
- ▁TAP
- ▁ASTONISHED
- ▁INTRODUCED
- ▁LEISURE
- ▁LIEUTENANT
- ▁VIOLENCE
- ▁FIRMLY
- ▁MONSTER
- ▁UR
- ▁PROPERLY
- ▁TWIST
- ▁PIRATE
- ▁ROBBER
- ▁BATTER
- ▁WEPT
- ▁LEANED
- ▁FOG
- ▁ORNAMENT
- ▁ANDREW
- ▁BUSHES
- ▁REPUBLIC
- ▁CONFIDENT
- ▁LEAN
- ▁DART
- ▁STOOP
- ▁CURL
- ▁COUNTER
- ▁NORTHERN
- ▁PEARL
- ▁NEAREST
- ▁FRANCIS
- ▁WANDERING
- ▁FREQUENT
- ▁STARTLED
- ▁STATEMENT
- ▁OCCUR
- ▁BLOOM
- ▁NERVE
- ▁INSPECT
- ▁INDUCE
- ▁FLATTER
- ▁DATE
- ▁AMBITION
- ▁SLOPE
- ▁MALE
- ▁MADAM
- ▁MONK
- ▁RENT
- ▁CONFIRM
- ▁INVESTIGAT
- ▁RABBIT
- ▁REGIMENT
- ▁SUBMIT
- ▁SPELL
- ▁FURIOUS
- ▁RAIL
- ▁BESTOW
- ▁RALPH
- ▁SCATTERED
- ▁COMPELLED
- ▁THREAD
- ▁CHILL
- ▁DENY
- ▁PRONOUNC
- ▁MANKIND
- ▁CATTLE
- ▁EXECUTION
- ▁REBEL
- ▁SUPREME
- ▁VALUABLE
- ▁LIKEWISE
- ▁CONVEY
- ▁TIDE
- ▁GLOOMY
- ▁COIN
- ▁ACTUAL
- ▁TAX
- ▁PROVINCE
- ▁GRATEFUL
- ▁SPIRITUAL
- ▁VANISHED
- ▁DIANA
- ▁HAUNT
- ▁DRAGON
- ▁CRAWL
- ▁CHINA
- ▁GRATITUDE
- ▁NEAT
- ▁FINISH
- ▁INTENT
- ▁FRIGHT
- ▁EMBARRASS
- ▁THIRTEEN
- ▁RUTH
- ▁SLIGHTEST
- ▁DEVELOPMENT
- ▁INTERVIEW
- ▁SPECTACLE
- ▁BROOK
- VIE
- ▁WEAKNESS
- ▁AUDIENCE
- ▁CONSEQUENTLY
- ▁ABROAD
- ▁ASPECT
- ▁PAINTED
- ▁RELEASE
- ▁INSULT
- ▁SOOTH
- ▁DISAPPOINTMENT
- ▁EMERG
- ▁BRIG
- ▁ESTEEM
- ▁INVITATION
- ▁PASSENGER
- ▁PUBLISH
- ▁PIANO
- ▁IRISH
- ▁DESK
- ▁BEATEN
- ▁FIFTH
- ▁IMPULSE
- ▁SWEAR
- ▁EATEN
- ▁PURPLE
- ▁COMMITTED
- ▁COUNTRIES
- ▁PERCEIVE
- ISON
- ▁CELEBRAT
- ▁GRANDMOTHER
- ▁SHUDDER
- ▁SUNSHINE
- ▁SPANISH
- ▁HITHERTO
- ▁MARILLA
- ▁SNAKE
- ▁MOCK
- ▁INTERFERE
- ▁WALTER
- ▁AMID
- ▁MARBLE
- ▁MISSION
- TERIOR
- ▁DRIVING
- ▁FURNITURE
- ▁STEADY
- ▁CIRCUMSTANCE
- ▁INTERPRET
- ▁ENCHANT
- ▁ERROR
- ▁CONVICTION
- ▁HELPLESS
- ▁MEDICINE
- ▁QUALITIES
- ▁ITALIAN
- ▁HASTENED
- ▁OCCASIONALLY
- ▁PURSUED
- ▁HESITATED
- ▁INDEPENDENT
- ▁OLIVER
- ▁LINGER
- UX
- ▁EXAMINED
- ▁REPENT
- ▁PHYSICIAN
- ▁CHASE
- ▁BELOVED
- ▁ATTACHED
- ▁FLORENCE
- ▁HONEY
- ▁MOUSE
- ▁CRIES
- ▁BAKE
- ▁POEM
- ▁DESTRUCTION
- ▁FULFIL
- ▁MESSENGER
- ▁TRISTRAM
- ▁FANCIED
- ▁EXCESS
- ▁CURSE
- ▁CHU
- ▁QUANTITY
- ▁THORNTON
- ▁CREATED
- ▁CONTINUALLY
- ▁LIGHTNING
- ▁BORNE
- ▁TOTAL
- ▁DISPOSED
- ▁RIFLE
- ▁POLLY
- ▁GOAT
- ▁BACKWARD
- ▁VIRGINIA
- ▁KICK
- ▁PERIL
- ▁QUO
- ▁GLORIOUS
- ▁MULTITUDE
- ▁LEATHER
- ▁ABSENT
- ▁DEMON
- ▁DEBT
- ▁TORTURE
- ▁ACCORD
- ▁MATE
- ▁CATHOLIC
- ▁PILL
- ▁LIBRARY
- ▁PURSUIT
- ▁SHIRT
- ▁DEAREST
- ▁COLLAR
- ▁BEACH
- ▁ROBE
- ▁DECLARE
- ▁BRANCH
- ▁TEMPT
- ▁STEADILY
- ▁DISGUST
- ▁SILLY
- ▁ARRIVE
- ▁DRANK
- ▁LEVI
- ▁COMMUNICAT
- ▁RACHEL
- ▁WASHINGTON
- ▁RESIGN
- ▁MEANTIME
- ▁LACE
- ▁ENGAGEMENT
- ▁QUIVER
- ▁SEPARATED
- ▁DISCUSSION
- ▁VENTURED
- ▁SURROUNDING
- ▁POLISH
- ▁NAIL
- ▁SWELL
- ▁JOKE
- ▁LINCOLN
- ▁STUDENT
- ▁GLITTER
- ▁RUSSIAN
- ▁READILY
- ▁CHRIS
- ▁POVERTY
- ▁DISGRACE
- ▁CHEESE
- ▁HEAVILY
- ▁SCALE
- ▁STAFF
- ▁ENTREAT
- ▁FAREWELL
- ▁LUNCH
- ▁PEEP
- ▁MULE
- ▁SOMEONE
- ▁DISAPPEAR
- ▁DECISION
- ▁PISTOL
- ▁PUN
- ▁SPUR
- ▁ASSUMED
- ▁EXTEND
- ▁ENTHUSIASM
- ▁DEFINITE
- ▁UNDERTAKE
- ▁COMMITTEE
- ▁SIMON
- ▁FENCE
- ▁APPLIED
- ▁RELATED
- ▁VICE
- ▁UNPLEASANT
- ▁PROBABLE
- ▁PROCURE
- ▁FROWN
- ▁CLOAK
- ▁HUMANITY
- ▁FAMILIES
- ▁PHILOSOPHER
- ▁DWARF
- ▁OVERCOME
- ▁DEFEAT
- ▁FASTENED
- ▁MARSH
- ▁CLASSES
- ▁TOMB
- ▁GRACIOUS
- ▁REMOTE
- ▁CELL
- ▁SHRIEK
- ▁RESCUE
- ▁POOL
- ▁ORGANIZ
- ▁CHOSE
- ▁CUTTING
- ▁COWARD
- ▁BORDER
- ▁DIRTY
- ▁MONKEY
- ▁HOOK
- ▁CHUCK
- ▁EMILY
- ▁JEST
- ▁PLAC
- ▁WEIGH
- ▁ASSOCIATE
- ▁GLIMPSE
- ▁STUCK
- ▁BOLT
- ▁MURDERER
- ▁PONY
- ▁DISTINGUISH
- ▁INSTITUTION
- ▁CUNNING
- ▁COMPLIMENT
- ▁APPETITE
- ▁REPUTATION
- ▁FEEBLE
- ▁KIN
- ▁SERIES
- ▁GRACEFUL
- ▁PLATFORM
- ▁BREEZE
- ▁PHRASE
- ▁CLAY
- MONT
- ▁RATTL
- ▁OPPOSITION
- ▁LANE
- ▁BOAST
- ▁GROWTH
- ▁INCLINATION
- ▁BEHAVE
- ▁SUSAN
- ▁DISTINCTION
- ▁DISLIKE
- ▁NICHOLAS
- ▁SATISFY
- ▁DRAMA
- ▁ELBOW
- ▁GAZING
- ▁CONSUM
- ▁SPIN
- ▁OATH
- ▁CHANNEL
- ▁CHARACTERISTIC
- ▁SPEAR
- ▁SLAIN
- ▁SAUCE
- ▁FROG
- ▁CONCEPTION
- ▁TIMID
- ▁ZEAL
- ▁APPARENT
- SHIRE
- ▁CENTER
- ▁VARIETY
- ▁DUSK
- ▁APT
- ▁COLUMN
- ▁REVENGE
- ▁RIVAL
- ▁IMITAT
- ▁PASSIONATE
- ▁SELFISH
- ▁NORMAN
- ▁REPAIR
- ▁THRILL
- ▁TREATMENT
- ▁ROSA
- ▁MARTIN
- ▁INDIFFERENT
- ▁THITHER
- ▁GALLANT
- ▁PEPPER
- ▁RECOLLECT
- ▁VINE
- ▁SCARCE
- ▁SHIELD
- ▁MINGLED
- CLOSE
- ▁HARSH
- ▁BRICK
- ▁HUMOR
- ▁MISCHIEF
- ▁TREMENDOUS
- ▁FUNCTION
- ▁SMART
- ▁SULTAN
- ▁DISMISS
- ▁THREATENED
- ▁CHEAP
- ▁FLOCK
- ▁ENDEAVOR
- ▁WHISK
- ▁ITALY
- ▁WAIST
- ▁FLUTTER
- ▁SMOKING
- ▁MONARCH
- ▁AFRICA
- ▁ACCUSE
- ▁HERBERT
- ▁REFRESH
- ▁REJOICE
- ▁PILLOW
- ▁EXPECTATION
- ▁POETRY
- ▁HOPELESS
- ▁PERISH
- ▁PHILOSOPHY
- ▁WHISTLE
- ▁BERNARD
- ▁LAMENT
- ▁IMPROVE
- ▁SUP
- ▁PERPLEX
- ▁FOUNTAIN
- ▁LEAGUE
- ▁DESPISE
- ▁IGNORANCE
- ▁REFERENCE
- ▁DUCK
- ▁GROVE
- ▁PURSE
- ▁PARTNER
- ▁PROPHET
- ▁SHIVER
- ▁NEIGHBOURHOOD
- ▁REPRESENTATIVE
- SAIL
- ▁WIP
- ▁ACQUIRED
- ▁CHIMNEY
- ▁DOCTRINE
- ▁MAXIM
- ▁ANGLE
- ▁MAJORITY
- ▁AUTUMN
- ▁CONFUSED
- ▁CRISTO
- ▁ACHIEVE
- ▁DISGUISE
- ▁REDUCED
- ▁EARLIER
- ▁THEATRE
- ▁DECIDE
- MINATED
- OLOGICAL
- ▁OCCUPATION
- ▁VIGOROUS
- ▁CONTINENT
- ▁DECLINE
- ▁COMMUNITY
- ▁MOTIONLESS
- ▁HATRED
- ▁COMMUNICATION
- ▁BOWL
- ▁COMMENT
- ▁APPROVE
- ▁CEREMONY
- ▁CRIMINAL
- ▁SCIENTIFIC
- ▁DUCHESS
- ▁VIVID
- ▁SHIFT
- ▁AVAIL
- ▁DAMP
- ▁JOHNSON
- ▁SLENDER
- ▁CONTRAST
- ▁AMUSEMENT
- ▁PLOT
- ▁LYN
- ▁ASSOCIATION
- ▁SNATCH
- ▁UNCERTAIN
- ▁PRESSURE
- ▁PERCH
- ▁APPLY
- ▁PLANET
- ▁NOTWITHSTANDING
- ▁SWUNG
- ▁STIRRED
- ▁ATTENDANT
- ▁ENJOYMENT
- ▁WORRY
- ▁ALBERT
- ▁NAKED
- ▁TALENT
- ▁MARIAN
- ▁REFORM
- ▁DELIBERATE
- ▁INTELLIGENT
- ▁SENSITIVE
- ▁YONDER
- ▁PUPIL
- ▁FRIGHTFUL
- ▁DOUBTFUL
- ▁STANDARD
- ▁MAGISTRATE
- ▁SHEPHERD
- ▁STOMACH
- ▁DEPOSIT
- ▁RENEW
- ▁HEDGE
- ▁FRANCS
- ▁POSSIBILITY
- ▁RESEMBLE
- ▁FATIGUE
- ▁PORTRAIT
- ▁FAVORITE
- ▁CREAM
- ▁BURG
- ▁SECRETARY
- ▁DIVERS
- ▁ACTIVITY
- ▁SPECULAT
- ▁HUMOUR
- ▁FITTED
- ▁EXTERNAL
- ▁CETERA
- ▁WRAPPED
- ▁WHIT
- ▁FRED
- ▁EXAMINATION
- ▁LODGING
- ▁OWING
- ▁JAW
- ▁CROW
- ▁BALANCE
- ▁PUFF
- ▁TENDERNESS
- ▁PORTHOS
- ▁ANCHOR
- ▁INTERRUPT
- ▁NECESSARILY
- ▁PERPETUAL
- ▁AGONY
- ▁POPE
- ▁SCHOLAR
- ▁SCOTLAND
- ▁SUPPRESS
- ▁WRATH
- ▁WRECK
- ▁EXCEED
- ▁PERFECTION
- ▁INDIA
- ▁TRADITION
- ▁SECTION
- ▁EASTERN
- ▁DOORWAY
- ▁WIVES
- ▁CONVENTION
- ▁ANNOUNC
- ▁EGYPT
- ▁CONTRADICT
- ▁SCRATCH
- ▁CENTRAL
- ▁GLOVE
- ▁WAX
- ▁PREPARE
- ▁ACCOMPANY
- ▁INCREASING
- ▁LIBERAL
- ▁RAISING
- ▁ORANGE
- ▁SHOE
- ▁ATTRIBUTE
- ▁LITERATURE
- ▁PUZZLED
- ▁WITHDRAW
- ▁WHITHER
- ▁HAWK
- ▁MOONLIGHT
- ▁EXAMINE
- ▁HAPPILY
- ▁PRECEDE
- ▁DETECTIVE
- ▁INCHES
- ▁SOLITARY
- ▁DUTCH
- ▁NAPOLEON
- ▁UNEASY
- ▁CARDINAL
- ▁BLEW
- ▁FOWL
- ▁DECORAT
- ▁CHILDHOOD
- ▁TORMENT
- ▁LOSING
- ▁PERMISSION
- ▁BLANK
- ▁UPSTAIRS
- ▁CAPACITY
- ▁TRIFLE
- ▁FOLLY
- ▁RECOGNIZE
- ▁REMOVE
- ▁VENGEANCE
- ▁ENTERPRISE
- ▁BEDROOM
- ▁ANYHOW
- ▁INQUIRY
- ▁ASHES
- ▁DRAG
- ▁HUSH
- ▁AWKWARD
- ▁SATURDAY
- ▁GENUINE
- ▁SURVIV
- ▁SKIRT
- ▁AFFECTIONATE
- ▁TANG
- ▁MUTUAL
- ▁DISPUTE
- ▁EAGLE
- ▁INCOME
- ▁BIND
- ▁FAME
- ▁IMPROVEMENT
- ROVING
- ▁DIFFER
- ▁AWOKE
- ▁SLEEVE
- ▁SOLITUDE
- ▁FAVOURITE
- JI
- ▁DETECT
- ▁COMPREHEND
- ▁PREPARING
- ▁SERPENT
- ▁SUMMIT
- ▁KNOT
- ▁KNIT
- ▁COPY
- ▁STOPPING
- ▁FADED
- ▁HIDEOUS
- ▁JULIE
- STEAD
- ▁SHINE
- ▁CONFLICT
- ▁PROPOSITION
- ▁REFUGE
- ▁GALLERY
- ▁BUNDLE
- ▁AXE
- ▁SLAVERY
- ▁MASK
- ▁ALYOSHA
- ▁LADDER
- ▁DEPARTMENT
- ▁DISCHARGE
- ▁DEPRESS
- ▁GALLOP
- ▁SCARLET
- ▁KITTY
- ▁RECEIVING
- ▁SURRENDER
- ▁SUSTAIN
- ▁TWILIGHT
- ▁CONGRESS
- ▁IRELAND
- ▁FUNNY
- ▁LEND
- ▁CONSTITUTE
- ▁FUNERAL
- ▁CRYSTAL
- ▁SPAIN
- ▁EXCEEDINGLY
- ▁DAMN
- ▁COMMUN
- ▁CIVILIZATION
- ▁PREJUDICE
- ▁PORCH
- ▁ASSISTANT
- ▁INDUSTRY
- ▁TUMBLE
- ▁DEFENCE
- ▁HITHER
- ▁SMOT
- ▁COLONI
- ▁AMAZEMENT
- ▁MARGUERITE
- ▁MIRACLE
- ▁INHERIT
- ▁BEGGAR
- ▁ENVELOPE
- ▁INDIGNATION
- ▁NATASHA
- ▁PROPOSAL
- ▁FRAGMENT
- ▁ROUSED
- ▁ROAST
- ENCIES
- ▁COMMENCED
- ▁RESOURCE
- ▁POPULATION
- ▁QUOTH
- ▁PURSUE
- ▁EDUCAT
- ▁AFFLICT
- ▁CONTACT
- ▁CRIMSON
- ▁DIVISION
- ▁DISORDER
- ▁COPPER
- ▁SOLICIT
- ▁MODERATE
- ▁DRUM
- ▁SWIM
- ▁SALUTE
- ▁ASSUME
- ▁MUSCLE
- ▁OVERWHELM
- ▁SHAKESPEARE
- ▁STRUGGLING
- ▁TRANQUIL
- ▁CHICKEN
- ▁TREAD
- ▁CLAW
- ▁BIBLE
- ▁RIDGE
- ▁THREAT
- ▁VELVET
- ▁EXPOSED
- ▁IDIOT
- ▁BARREL
- ▁PENNY
- ▁TEMPTATION
- ▁DANGLARS
- ▁CENTURIES
- ▁DISTRIBUT
- ▁REJECT
- ▁RETORTED
- ▁CONCENTRAT
- ▁CORDIAL
- ▁MOTOR
- ▁CANNON
- KEEP
- ▁WRETCH
- ▁ASSURANCE
- ▁THIEF
- ▁SURVEY
- ▁VITAL
- ▁RAILWAY
- ▁JACKSON
- ▁CRASH
- ▁GROWL
- ▁COMBAT
- ▁RECOLLECTION
- ▁SECURITY
- ▁JACOB
- ▁CLUTCH
- ▁BLANKET
- ▁NANCY
- ▁CELLAR
- ▁CONVENIENT
- ▁INDIGNANT
- ▁COARSE
- ▁WORM
- ▁SCREEN
- ▁TRANSPORT
- ▁BULLET
- ▁APPRECIATE
- ▁DEVOTION
- ▁INVISIBLE
- ▁DRIED
- ▁MIXTURE
- ▁CANDID
- ▁PERFORMANCE
- ▁RIPE
- ▁EXQUISITE
- ▁BARGAIN
- ▁TOBACCO
- ▁LOYAL
- ▁MOULD
- ▁ATTENTIVE
- ▁DOROTHY
- ▁BRUTE
- ▁ESTABLISHMENT
- ▁ABILITY
- ▁INHABIT
- ▁OBSCURE
- ▁BORROW
- ▁ESSENCE
- ▁DISMAY
- ▁FLEE
- ▁BLADE
- ▁PLUCK
- ▁COFFIN
- ▁SUNSET
- ▁STEPHEN
- ▁ECONOMIC
- ▁HOLIDAY
- ▁MECHANICAL
- ▁COTTON
- ▁AWAKENED
- ▁SEIZE
- ▁RIDICULOUS
- ▁SANCHO
- ▁HESITATION
- ▁CORPSE
- ▁SAVING
- HOLD
- FOOT
- ▁ELDEST
- ▁DESPITE
- ▁EDITH
- ▁CHERISH
- ▁RESISTANCE
- ▁WILSON
- ▁ARGUE
- ▁INQUIRE
- ▁APPREHENSION
- ▁AVENUE
- ▁DRAKE
- ▁PROPOSE
- HURST
- ▁INFERIOR
- ▁STAIRCASE
- ▁WHEREFORE
- ▁CARLYLE
- ▁COUCH
- ▁ROUTE
- ▁POLITICS
- ▁TOMORROW
- ▁THRONG
- ▁NAUGHT
- ▁SUNLIGHT
- ▁INDIFFERENCE
- ▁OBEDIENCE
- ▁RECEPTION
- ▁VEGETABLE
- ▁IMPERFECT
- ▁RESIDENCE
- ▁TURKEY
- ▁VIOLET
- ▁SARAH
- ▁ALTAR
- ▁GRIEVE
- ▁JERK
- ▁ENSU
- ▁MAGICIAN
- ▁BLOSSOM
- ▁LANTERN
- ▁RESOLUTE
- ▁THOUGHTFULLY
- ▁FORTNIGHT
- ▁TRUMPET
- ▁VALJEAN
- ▁UNWILLING
- ▁LECTURE
- ▁WHEREUPON
- ▁HOLLAND
- ▁CHANGING
- ▁CREEK
- ▁SLICE
- ▁NORMAL
- ▁ANNIE
- ▁ACCENT
- ▁FREDERICK
- ▁DISAGREEABLE
- ▁RUBBED
- ▁DUMB
- ▁ESTABLISH
- ▁IMPORT
- ▁AFFIRM
- ▁MATTHEW
- ▁BRISK
- ▁CONVERT
- ▁BENDING
- ▁IVAN
- ▁MADEMOISELLE
- ▁MICHAEL
- ▁EASIER
- ▁JONES
- ▁FACING
- ▁EXCELLENCY
- ▁LITERARY
- ▁GOSSIP
- ▁DEVOUR
- ▁STAGGER
- ▁PENCIL
- ▁AVERAGE
- ▁HAMMER
- ▁TRIUMPHANT
- ▁PREFERRED
- ▁APPLICATION
- ▁OCCUPY
- ▁AUTHORITIES
- BURN
- ▁ASCERTAIN
- ▁CORRIDOR
- ▁DELICIOUS
- ▁PRACTISE
- ▁UNIVERSE
- ▁SHILLING
- ▁CONTEST
- ▁ASHORE
- ▁COMMIT
- ▁ADMINISTRATION
- ▁STUDIED
- ▁RIGID
- ▁ADORN
- ▁ELSEWHERE
- ▁INNOCENCE
- ▁JOURNAL
- ▁LANDSCAPE
- ▁TELEGRAPH
- ▁ANGRILY
- ▁CAMPAIGN
- ▁UNJUST
- ▁CHALLENGE
- ▁TORRENT
- ▁RELATE
- ▁ASSEMBLED
- ▁IMPRESSED
- ▁CANOE
- ▁CONCLUD
- ▁QUIXOTE
- ▁SATISFACTORY
- ▁NIECE
- ▁DEAF
- ▁RAFT
- ▁JIMMY
- ▁GLID
- ▁REGULAT
- ▁CHATTER
- ▁GLACIER
- ▁ENVY
- ▁STATUE
- ▁BOSTON
- ▁RICHMOND
- ▁DENIED
- ▁FANNY
- ▁SOLOMON
- ▁VULGAR
- ▁STALK
- ▁REPLACE
- ▁SPOON
- ▁BASIN
- ▁FEATURE
- ▁CONVICT
- ▁ARCHITECT
- ▁ADMIRAL
- ▁RIBBON
- ▁PERMANENT
- ▁APRIL
- ▁JOLLY
- ▁NEIGHBORHOOD
- ▁IMPART
- BOROUGH
- CAMP
- ▁HORRID
- ▁IMMORTAL
- ▁PRUDENCE
- ▁SPANIARD
- ▁SUPPOSING
- ▁TELEPHONE
- ▁TEMPERATURE
- ▁PENETRATE
- ▁OYSTER
- ▁APPOINTMENT
- ▁EGYPTIAN
- ▁DWELT
- ▁NEPHEW
- ▁RAILROAD
- ▁SEPTEMBER
- ▁DEVICE
- ▁WHEAT
- ▁GILBERT
- ▁ELEGANT
- ▁ADVERTISE
- ▁RATIONAL
- ▁TURTLE
- ▁BROOD
- ▁ASSEMBLY
- ▁CULTIVATE
- ▁EDITOR
- ▁SPECIMEN
- ▁UNDOUBTEDLY
- ▁WHALE
- ▁DROPPING
- ▁BALLOON
- ▁MEDICAL
- COMB
- ▁COMPOSITION
- ▁FOOTSTEPS
- ▁LAUNCELOT
- ▁DISCOURSE
- ▁ERRAND
- ▁CONVERSE
- ▁ADVANCING
- ▁DOWNSTAIRS
- ▁TUMULT
- ▁CORRUPT
- ▁SUFFICE
- ▁ANGUISH
- ▁SHAGGY
- ▁RETIRE
- ▁TIMBER
- ▁BLAZE
- ▁ABSTRACT
- ▁EMBROIDER
- ▁PHOTOGRAPH
- ▁PROSPERITY
- ▁TERRIBLY
- ▁TERRITORY
- ▁THRESHOLD
- ▁PAVEMENT
- ▁INJURED
- ▁LIMP
- ▁AGITATION
- ▁RASCAL
- ▁PRESUME
- ▁OBSERVING
- ▁OBSTACLE
- ▁SIMPLICITY
- ▁SLUMBER
- ▁SUPPLIED
- ▁COMBINATION
- ▁DRAIN
- ▁WILDERNESS
- ▁BELIEVING
- ▁VILLAIN
- ▁RECKLESS
- ▁INJURY
- ▁CLAPP
- ▁FRIDAY
- ▁HERCULES
- ▁KENNEDY
- ▁SYMPTOM
- ▁SLEDGE
- ▁CEILING
- ▁LEMON
- ▁PLAGUE
- ▁MONDAY
- ▁CANVAS
- ▁IMPATIENCE
- ▁UNCOMFORTABLE
- ▁ACCESS
- ▁FROZEN
- ▁SENATOR
- ▁FRANZ
- ▁SWIMMING
- ▁BARRIER
- ▁ADJUST
- ▁COMPARISON
- ▁PROCLAIM
- ▁WRINKL
- ▁OVERLOOK
- ▁MITYA
- ▁GUILT
- ▁PERCEPTION
- ▁PRECAUTION
- ▁SPECTATOR
- ▁SURPRISING
- ▁DISTRACT
- ▁DISDAIN
- ▁BONNET
- ▁MAGNET
- ▁PROFESS
- ▁CONFOUND
- ▁NARRATIVE
- ▁STRUCTURE
- ▁SKETCH
- ▁ULTIMATE
- ▁GLOBE
- ▁INSECT
- FICIENCY
- ▁ORCHARD
- ▁AMIABLE
- ▁DESCENT
- ▁INDEPENDENCE
- ▁MANUFACTURE
- ▁SPRINKLE
- ▁NIGHTINGALE
- ▁CUSHION
- ▁EMINENT
- ▁SCOTT
- ▁ARRAY
- ▁COSETTE
- ▁WAVING
- ▁EXTRACT
- ▁IRREGULAR
- ▁PERSECUT
- ▁DERIVED
- ▁WITHDREW
- ▁CAUTION
- ▁SUSPICIOUS
- ▁MEMORIES
- ▁NOWHERE
- ▁SUBTLE
- ▁THOROUGH
- Q
- ▁APPROPRIATE
- ▁SLAUGHTER
- ▁YOURSELVES
- ▁THUMB
- ▁TWAS
- ▁ABODE
- ▁BIDDING
- ▁CONSPICUOUS
- ▁REBECCA
- ▁SERGEANT
- ▁APRON
- ▁ANTICIPATE
- ▁DISCIPLINE
- ▁GLANCING
- ▁PILGRIM
- ▁SULLEN
- ▁CONTRIBUTE
- ▁PRAIRIE
- ▁CARVED
- ▁COMMERCE
- ▁EXCLAMATION
- ▁MUSCULAR
- ▁NOVEMBER
- ▁PHENOMENA
- ▁SYMBOL
- ▁UMBRELLA
- ▁DIMINISH
- ▁PARLOUR
- ▁THREATENING
- ▁STUMP
- ▁EXTENSIVE
- ▁PLEASING
- ▁REMEMBRANCE
- ▁COMBINED
- ▁SHERIFF
- ▁SHAFT
- ▁LAURA
- ▁INTERCOURSE
- ▁STRICKEN
- ▁SUPPLIES
- ▁LANDLORD
- ▁SHRINK
- ▁PRICK
- ▁CAESAR
- ▁DRUG
- ▁BEWILDERED
- ▁NAUTILUS
- ▁BRUTAL
- ▁COMMERCIAL
- ▁MAGGIE
- ▁SPHERE
- ▁VIRGIN
- ▁BRETHREN
- ▁DESTINY
- ▁POLICY
- ▁TERRIFIED
- ▁HOUSEKEEPER
- ▁CRAZY
- ▁ARDENT
- ▁DISCERN
- ▁WRAP
- ▁MARQUIS
- ▁RUSSIA
- MOUTH
- ▁BRITAIN
- ▁HARBOUR
- ▁CONCERT
- ▁DONKEY
- ▁DAMAGE
- ▁SLIM
- ABOUT
- ▁LUXURY
- ▁MONSTROUS
- ▁TENDENCY
- ▁PARADISE
- ▁CULTURE
- ▁JULIUS
- ▁RAOUL
- ▁REMEDY
- ▁DECAY
- ▁SCOLD
- ▁SPLIT
- ▁ASSAULT
- ▁DECEMBER
- ▁MOSCOW
- ▁EXPLORE
- ▁TROUSERS
- ▁WRIST
- PIECE
- ▁MUSKET
- ▁VALENTINE
- ▁TYRANT
- ▁ABRAHAM
- ▁MEDIUM
- ▁ARTIFICIAL
- ▁FACULTY
- ▁OBLIGATION
- ▁RESEMBLANCE
- ▁INQUIRIES
- ▁DETAIN
- ▁SWARM
- ▁PLEDGE
- ▁ADMIRABLE
- ▁DEFECT
- ▁SUPERINTEND
- ▁PATRIOT
- ▁CLUNG
- ▁DISMAL
- ▁RECIT
- ▁IGNOR
- ▁AMELIA
- ▁JUSTIFY
- ▁ELEPHANT
- ▁ESTIMATE
- ▁KNELT
- ▁SERVING
- ▁WHIM
- ▁SHRILL
- ▁STUDIO
- ▁TEXT
- ▁ALEXANDER
- ▁WROUGHT
- ▁ABUNDANT
- ▁SITUATED
- ▁REGAIN
- ▁FIERY
- ▁SNEER
- ▁SWEAT
- ▁GLARE
- ▁NIGH
- ▁ESCORT
- ▁INEVITABLE
- ▁PSMITH
- ▁RELUCTANT
- ▁PRECEDING
- ▁RESORT
- ▁OUTRAGE
- ▁AMBASSADOR
- ▁CONSOLATION
- ▁RECOGNITION
- ▁REMORSE
- ▁BEHALF
- ▁FORMIDABLE
- ▁GRAVITY
- ▁DIVIDE
- ▁CONFRONT
- ▁GIGANTIC
- ▁OCTOBER
- ▁FLANK
- ▁SLEW
- ▁CLARA
- ▁FILM
- ▁BULK
- ▁POMP
- ▁ELEANOR
- ▁EMPHASIS
- ▁JAPANESE
- ▁CAVALRY
- ▁EXCLUSIVE
- ▁PERFUME
- ▁BRONZE
- ▁FEDERAL
- ▁LIQUID
- ▁RUBBING
- ▁OVEN
- DOLPH
- ▁CONVULS
- ▁DEPRIVED
- ▁RESPONSIBILITY
- ▁SIGNIFICANT
- ▁WAISTCOAT
- ▁CLUSTER
- ▁MARTHA
- ▁REVERSE
- ▁ATTORNEY
- ▁DROOP
- ▁SKILFUL
- ▁HABITUAL
- ▁PUMP
- ▁INTERVEN
- ▁OWL
- ▁CONJECTURE
- ▁FANTASTIC
- ▁RESPONSIBLE
- ▁DESTINED
- ▁DOCUMENT
- ▁THEREUPON
- ▁GODDESS
- ▁PACIFIC
- ▁WARRANT
- ▁COSTUME
- ▁BRIDLE
- ▁CALIFORNIA
- ▁DEMOCRATIC
- ▁EUSTACE
- ▁SQUIRREL
- ▁UNCOMMON
- ▁MARVELLOUS
- ▁PLOUGH
- ▁TRAGEDY
- ▁VAULT
- ▁HESITATE
- ▁REFRAIN
- ▁ADMIRING
- ▁CORPORAL
- ▁ENTITLED
- ▁SHREWD
- ▁SQUEEZ
- ▁ACCURATE
- ▁TEMPEST
- ▁MONUMENT
- ▁SIEGE
- ▁CHINESE
- ▁RAVEN
- ▁LOUNG
- ▁ASSASSIN
- ▁INFLICT
- ▁AGITATED
- ▁DESIRABLE
- ▁EARLIEST
- ▁LAUNCH
- ▁PILOT
- ▁PULSE
- ▁MUTE
- LEIGH
- ▁LIQUOR
- ▁SCARECROW
- ▁SKULL
- ▁DESOLATE
- ▁SUBLIME
- ▁SERENE
- ▁RECESS
- ▁WAKING
- ▁CHARLOTTE
- ▁CIRCULAR
- ▁INJUSTICE
- ▁PINOCCHIO
- ▁PRISCILLA
- ▁THYSELF
- ▁OCCURRENCE
- ▁CASUAL
- ▁FRANTIC
- ▁LEGEND
- ▁FERTIL
- ▁BACKGROUND
- ▁DELICACY
- ▁ESTRALLA
- ▁MANUSCRIPT
- ▁RESPONSE
- ▁UNIVERSITY
- ▁WOLVES
- ▁SCANDAL
- ▁STUMBLE
- ▁HOARSE
- ▁BODILY
- ▁CONVENT
- ▁EXAMINING
- ▁INCAPABLE
- ▁PERCEIVING
- ▁PHILADELPHIA
- ▁SUBSEQUENT
- ▁THIEVES
- ▁ACCUMULAT
- ▁DAMSEL
- ▁SCOTCH
- ▁UNDERNEATH
- ▁NOBILITY
- ▁SMASH
- ▁REVOLT
- ▁ENGAGE
- ▁CATHEDRAL
- ▁CHAMPION
- ▁DESPATCH
- ▁ETERNITY
- ▁JANUARY
- ▁PLEADED
- ▁PROBABILITY
- ▁JIMMIE
- ▁PARALLEL
- ▁FISHERMAN
- ▁JERRY
- ▁SWORE
- ▁DRAUGHT
- ▁OPPONENT
- ▁PRIMITIVE
- ▁SIGNIFICANCE
- ▁SUBSTANTIAL
- ▁AMAZED
- ▁DUNBAR
- ▁COMMEND
- ▁CONTEMPLATE
- ▁TESTIMONY
- ▁IMPERIAL
- ▁ADAPT
- ▁JUICE
- ▁CALAMIT
- CULAR
- ▁CHATEAU
- ▁PHOENIX
- ▁PRUDENT
- ▁SOLUTION
- ▁VILLEFORT
- ▁REACTION
- ▁RELAX
- ▁YU
- ▁PROHIBIT
- ▁DISTRUST
- ▁PLUNDER
- ▁WELFARE
- ▁NAVIGAT
- ▁PARLOR
- ▁LAZY
- ▁DETACH
- OMETER
- ▁PRIV
- ▁DISCOURAGE
- ▁OBSTINATE
- ▁REJOICING
- ▁SERMON
- ▁VEHICLE
- ▁FANCIES
- ▁ENLIGHTEN
- ▁ACUTE
- ▁ILLUSION
- ▁ANTHEA
- ▁MARTIAN
- ▁EXCITE
- ▁GENEROSITY
- OLOGIST
- ▁AMAZING
- ▁UNWORTHY
- ▁INTERNAL
- ▁INCENSE
- ▁VIBRAT
- ▁ADHERE
- ROACH
- ▁FEBRUARY
- ▁MEXICAN
- ▁POTATOES
- ▁INCESSANT
- ▁INTERPOSED
- ▁PARCEL
- ▁VEXED
- ▁PROMOTE
- MIDST
- ▁ARISTOCRAT
- ▁CYRIL
- ▁EMBARK
- ▁ABUNDANCE
- ▁LITERALLY
- ▁SURGEON
- ▁TERRACE
- ▁ATLANTIC
- ▁MARTYR
- ▁SPECK
- ▁SENATE
- ▁LOAF
- ▁ADMINISTER
- ▁APPREHEND
- ▁SUBDUED
- ▁TEMPORARY
- ▁DOMINION
- ▁ELABORATE
- ▁DIGNIFIED
- ▁ELIZA
- ▁SPLASH
- ▁CONSEIL
- ▁DEXTER
- ▁UNSEEN
- ▁TRAGIC
- VOCATION
- ▁GRATIFY
- ▁BACHELOR
- ▁DEFENSE
- ▁EXCURSION
- ▁FACULTIES
- ▁PROPRIETOR
- ▁SYMPATHETIC
- ▁UNNECESSARY
- ▁RADIANT
- ▁VACANT
- ▁OUNCE
- ▁SCREW
- ▁PHENOMENON
- ▁PROMINENT
- ▁WORRIED
- ▁STUDIES
- ▁CLIMATE
- ▁KEITH
- ▁ARAMIS
- ▁BLISS
- ▁CONTINUAL
- ▁SURPASS
- ▁HEBREW
- ▁IDENTITY
- ▁PROVOKE
- ▁TEMPERAMENT
- ▁CHARIOT
- ▁HARBOR
- ▁NINTH
- ▁PRIOR
- ▁DESIROUS
- ▁JERUSALEM
- ▁UNDERTAKING
- ▁EDISON
- ▁MIRTH
- ▁SCOUT
- ▁APPARATUS
- ▁ILLUSTRATION
- ▁INTELLIGIBLE
- ▁INVARIABLY
- ▁PIERCED
- ▁REVIEW
- ▁FLICKER
- ▁HAZARD
- ▁REVELATION
- ▁DIXON
- ▁EXCITING
- ▁GOSPEL
- ▁CONSTANCE
- ▁OVERTAKE
- ▁GUINEA
- ▁ALADDIN
- ▁CHICAGO
- ▁TULLIVER
- ▁HAMILTON
- ▁GARRISON
- ▁DISCIPLE
- ▁INTENSITY
- ▁TRAITOR
- ▁CHANCELLOR
- ▁PROVERB
- ▁DAGGER
- ▁FORESEE
- ▁CONFIDE
- ▁GLIMMER
- ▁CHAUVELIN
- ▁ILLUSTRATE
- ▁VOLUNTEER
- ▁JUNGLE
- ▁STREAK
- ▁SUNRISE
- ▁DISSOLV
- ▁QUEST
- ▁AWHILE
- ▁FELICITY
- ▁LEGISLATURE
- ▁LEONORA
- ▁MAGAZINE
- ▁PITIFUL
- ▁COLONY
- ▁SHAWL
- ▁ARRIVING
- ▁FUNDAMENTAL
- ▁CARPENTER
- ▁OVERFLOW
- ▁EXPAND
- ▁HARVEST
- ▁FEMININE
- ▁INNUMERABLE
- ▁SCRAMBLE
- ▁TWENTIETH
- ▁TRIFLING
- ▁GHASTL
- ▁CONQUEST
- ▁DANIEL
- ▁FACILIT
- ▁FORSAKE
- ▁BEHAVIOUR
- ▁GORGEOUS
- ▁PRODUCING
- ▁HAPPIER
- ▁PROMISING
- ▁RAINBOW
- ▁INSTINCTIVELY
- ▁DECREE
- ▁EYEBROWS
- ▁IRRESISTIBLE
- ▁PHARAOH
- ▁SCROOGE
- ▁UNNATURAL
- ▁CRUMBS
- ▁REFINED
- ▁DREARY
- ▁TRENCH
- ▁CONVINCE
- ▁FRINGE
- ▁EXTREMITY
- ▁INTIMACY
- ▁SCOUNDREL
- ▁SUFFRAGE
- ▁UNEASINESS
- ▁BARRICADE
- ▁CIRCULAT
- ▁SAMUEL
- ▁BRUCE
- ▁DARCY
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
joint_net_conf:
joint_space_size: 640
model_conf:
ctc_weight: 0.0
report_cer: true
report_wer: true
use_preprocessor: true
token_type: bpe
bpemodel: data/en_token_list/bpe_unigram5000/bpe.model
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: default
frontend_conf:
n_fft: 512
hop_length: 160
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_en_bpe5000_sp/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 512
attention_heads: 8
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
decoder: transducer
decoder_conf:
rnn_type: lstm
num_layers: 1
hidden_size: 512
dropout: 0.1
dropout_embed: 0.1
required:
- output_dir
- token_list
version: 0.10.7a1
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
jhonparra18/wav2vec2-large-xls-r-300m-guarani-small
|
jhonparra18
| 2022-04-27T14:42:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"robust-speech-event",
"hf-asr-leaderboard",
"dataset:common_voice",
"dataset:gn",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
- robust-speech-event
- hf-asr-leaderboard
datasets:
- common_voice
- gn
model-index:
- name: wav2vec2-large-xls-r-300m-guarani-small
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-guarani-small
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4964
- Wer: 0.5957
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 6.65 | 100 | 1.1326 | 1.0 |
| 1.6569 | 13.32 | 200 | 0.5264 | 0.6478 |
| 1.6569 | 19.97 | 300 | 0.5370 | 0.6261 |
| 0.2293 | 26.65 | 400 | 0.4964 | 0.5957 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
tartuNLP/mtee-legal
|
tartuNLP
| 2022-04-27T14:10:34Z | 0 | 0 |
fairseq
|
[
"fairseq",
"translation",
"modularNMT",
"MTee",
"legal",
"et",
"en",
"de",
"ru",
"region:us"
] |
translation
| 2022-03-30T12:28:26Z |
---
language:
- et
- en
- de
- ru
tags:
- translation
- modularNMT
- fairseq
- MTee
- legal
inference: false
---
# MTee translation model for legal domain
A legal domain translation model for the MTee machine translation platform. The platform was developed in 2021 as a collaboration between the [TartuNLP](https://tartunlp.ai), the NLP research group at the University of Tartu, and [Tilde](https://tilde.com). More information about the project can be found [here](https://github.com/Project-MTee/mtee-platform/wiki).
The model uses a modular architecture, where each language has its own encoder and decoder that is used for all translation directions. The model can be used with our custom version of [FairSeq](https://github.com/TartuNLP/fairseq) and it is compatible with the [MTee](https://github.com/Project-MTee) platform and its [NMT workers](https://github.com/Project-MTee/translation-worker). Additionally, it is fully compatible with TartuNLP's translation API components ([API](https://github.com/TartuNLP/translation-api) and [NMT workers](https://github.com/TartuNLP/translation-worker)).
Supported translation directions: `et-en`, `en-et`, `et-de`, `de-et`, `et-ru`, `ru-et`.
| Included files: | |
| ----------- | ----------- |
| Fairseq translation model | `modular_model.pt` |
| SentecePiece models | `sp-model.{lang}.model` |
| translation model vocabularies | `dict.{lang}.txt` |
|
tartuNLP/mtee-crisis
|
tartuNLP
| 2022-04-27T14:10:07Z | 0 | 0 |
fairseq
|
[
"fairseq",
"translation",
"modularNMT",
"MTee",
"crisis",
"et",
"en",
"de",
"ru",
"region:us"
] |
translation
| 2022-03-30T12:29:04Z |
---
language:
- et
- en
- de
- ru
tags:
- translation
- modularNMT
- fairseq
- MTee
- crisis
inference: false
---
# MTee translation model for crisis domain
A crisis (mostly healthcare-related) domain translation model for the MTee machine translation platform. The platform was developed in 2021 as a collaboration between the [TartuNLP](https://tartunlp.ai), the NLP research group at the University of Tartu, and [Tilde](https://tilde.com). More information about the project can be found [here](https://github.com/Project-MTee/mtee-platform/wiki).
The model uses a modular architecture, where each language has its own encoder and decoder that is used for all translation directions. The model can be used with our custom version of [FairSeq](https://github.com/TartuNLP/fairseq) and it is compatible with the [MTee](https://github.com/Project-MTee) platform and its [NMT workers](https://github.com/Project-MTee/translation-worker). Additionally, it is fully compatible with TartuNLP's translation API components ([API](https://github.com/TartuNLP/translation-api) and [NMT workers](https://github.com/TartuNLP/translation-worker)).
Supported translation directions: `et-en`, `en-et`, `et-de`, `de-et`, `et-ru`, `ru-et`.
| Included files: | |
| ----------- | ----------- |
| Fairseq translation model | `modular_model.pt` |
| SentecePiece models | `sp-model.{lang}.model` |
| translation model vocabularies | `dict.{lang}.txt` |
|
fxmarty/resnet-tiny-mnist
|
fxmarty
| 2022-04-27T09:27:58Z | 1,412 | 5 |
transformers
|
[
"transformers",
"pytorch",
"resnet",
"image-classification",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-27T09:15:31Z |
---
license: gpl-3.0
---
A small Resnet model for MNIST. Achieves 0.985 accuracy on the validation set.
|
chainyo/DocuGAN
|
chainyo
| 2022-04-27T08:40:51Z | 0 | 2 |
pytorch
|
[
"pytorch",
"gan",
"sngan",
"huggan",
"unconditional-image-generation",
"dataset:ChainYo/rvl-cdip-invoice",
"license:mit",
"region:us"
] |
unconditional-image-generation
| 2022-04-15T13:33:21Z |
---
license: mit
library_name: pytorch
tags:
- gan
- sngan
- huggan
- unconditional-image-generation
datasets:
- ChainYo/rvl-cdip-invoice
---
## Model description
SN-GAN implementation with PyTorch-Lightning to generate Documents.
## Generated samples
<img src="https://raw.githubusercontent.com/ChainYo/docugan/master/documents_samples.png" width="400" height="1200">
Project repository: [DocuGAN](https://github.com/ChainYo/docugan).
## Usage
You can see the tool to generate document on HuggingFace by trying the [space demo](https://huggingface.co/spaces/ChainYo/DocuGAN).
## Training data
For training, I used the invoices subpart of `RVL-CDIP` dataset. Find the full dataset [here](https://huggingface.co/datasets/ChainYo/rvl-cdip)
|
ToToKr/wav2vec2-base-timit-demo-colab
|
ToToKr
| 2022-04-27T07:50:31Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-21T02:09:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4520
- Wer: 0.2286
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.3811 | 4.0 | 500 | 1.1887 | 0.8528 |
| 0.5798 | 8.0 | 1000 | 0.4544 | 0.3357 |
| 0.2197 | 12.0 | 1500 | 0.4424 | 0.2699 |
| 0.1279 | 16.0 | 2000 | 0.4388 | 0.2559 |
| 0.0855 | 20.0 | 2500 | 0.4572 | 0.2450 |
| 0.062 | 24.0 | 3000 | 0.4385 | 0.2353 |
| 0.0469 | 28.0 | 3500 | 0.4520 | 0.2286 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
ml6team/mt5-small-german-query-generation
|
ml6team
| 2022-04-27T06:24:37Z | 82 | 2 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"query-generation",
"de",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-26T13:51:02Z |
---
language:
- de
tags:
- pytorch
- query-generation
widget:
- text: "Das Lama (Lama glama) ist eine Art der Kamele. Es ist in den südamerikanischen Anden verbreitet und eine vom Guanako abstammende Haustierform."
example_title: "Article 1"
license: apache-2.0
metrics:
- Rouge-Score
---
# mt5-small-german-query-generation
## Model description:
This model was created with the purpose to generate possible queries for a german input article.
For this model, we finetuned a multilingual T5 model [mt5-small](https://huggingface.co/google/mt5-small) on the [MMARCO dataset](https://huggingface.co/datasets/unicamp-dl/mmarco) the machine translated version of the MS MARCO dataset.
The model was trained for 1 epoch, on 200,000 unique queries of the dataset. We trained the model on one K80 GPU for 25,000 iterations with following parameters:
- learning rate: 1e-3
- train batch size: 8
- max input sequence length: 512
- max target sequence length: 64
## Model Performance:
Model evaluation was done on 2000 evaluation paragraphs of the dataset. Mean [f1 ROUGE scores](https://github.com/pltrdy/rouge) were calculated for the model.
| Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|
|0.162 | 0.052 | 0.161 |
|
0x12/t5small-opus_infopankki-en-zh
|
0x12
| 2022-04-27T06:23:53Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:opus_infopankki",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-27T05:07:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- opus_infopankki
model-index:
- name: t5small-opus_infopankki-en-zh
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5small-opus_infopankki-en-zh
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the opus_infopankki dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0385
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.0853 | 1.0 | 1496 | 2.7074 |
| 2.8378 | 2.0 | 2992 | 2.5717 |
| 2.7637 | 3.0 | 4488 | 2.4829 |
| 2.6622 | 4.0 | 5984 | 2.4156 |
| 2.5986 | 5.0 | 7480 | 2.3649 |
| 2.5488 | 6.0 | 8976 | 2.3184 |
| 2.486 | 7.0 | 10472 | 2.2808 |
| 2.4566 | 8.0 | 11968 | 2.2485 |
| 2.4413 | 9.0 | 13464 | 2.2181 |
| 2.3806 | 10.0 | 14960 | 2.1939 |
| 2.3741 | 11.0 | 16456 | 2.1711 |
| 2.3419 | 12.0 | 17952 | 2.1511 |
| 2.3197 | 13.0 | 19448 | 2.1318 |
| 2.3229 | 14.0 | 20944 | 2.1170 |
| 2.2885 | 15.0 | 22440 | 2.1032 |
| 2.2781 | 16.0 | 23936 | 2.0908 |
| 2.2447 | 17.0 | 25432 | 2.0792 |
| 2.2589 | 18.0 | 26928 | 2.0695 |
| 2.2274 | 19.0 | 28424 | 2.0611 |
| 2.2311 | 20.0 | 29920 | 2.0538 |
| 2.2263 | 21.0 | 31416 | 2.0482 |
| 2.2066 | 22.0 | 32912 | 2.0443 |
| 2.2042 | 23.0 | 34408 | 2.0413 |
| 2.211 | 24.0 | 35904 | 2.0390 |
| 2.1952 | 25.0 | 37400 | 2.0385 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
ITESM/fastai_model
|
ITESM
| 2022-04-27T03:48:56Z | 0 | 0 |
fastai
|
[
"fastai",
"region:us"
] | null | 2022-03-23T00:35:15Z |
---
tags:
- fastai
---
# Amazing!
Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (template below and [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using the 🤗Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join our fastai community on the Hugging Face Discord!
Greetings fellow fastlearner 🤝!
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
ceciliamacias/prueba
|
ceciliamacias
| 2022-04-27T02:20:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-04-27T01:32:02Z |
## Identificación de retinopatías
El Propósito del siguiente trabajo es identificar los pacientes que tienen complicaciones diabéticas, como lo son la neuropatía, nefropatía y retinopatía de notas médicas. Es el trabajo final del curso Clinical Natural Language Processing impartido en Coursera. Las notas medicas se encuentran en el siguiente linklink para su entrenamiento del modelo:
https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/diabetes_notes.csv
Y los datos para su validación se encuentran en el siguiente link:
https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/glodstandrad.csv
En primera instancia, se crea el siguiente código para ignorar los warnings:
```python
import warnings
warnings.filterwarnings("ignore", 'This pattern has match groups')
datos = "https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/diabetes_notes.csv"
df = pd.read_csv(datos)
# Importando las paqueterías necesarias:
import pandas as pd
import matplotlib.pyplot as plt
import re
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report
# Lectura de datos
datos = "https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/diabetes_notes.csv"
df = pd.read_csv(datos)
# Análisis grafico de los datos
fig, ax = plt.subplots()
ax.bar(df['NOTE_ID'],df['TEXT'].str.split().apply(len))
# Cantidad de palabras por reporte de cada paciente identificado por un id
conteo = df['TEXT'].str.split().apply(len).tolist()
print('Media de palabras: ' + str(np.mean(conteo)))
print('Mediana de palabras: ' + str(np.median(conteo)))
print('Minimo de palabras: ' + str(np.min(conteo)))
print('Maximo de palabras: ' + str(np.max(conteo)))
def reporte_paciente(id):
resumen = re.findall(r"\w+", str(df[df.NOTE_ID == id]['TEXT'].tolist() ))
return resumen
# print(reporte_paciente(1))
```
Ahora bien, se genera una función la cual recibe nuestro DataFrame con las notas médicas, la palabra a buscar y el tamaño de la ventana
## Función sin expresiones regulares
```python
def extract_text_window(df, word, window_size, column_name = "TEXT"):
#Constants
user_input = f'({word})'
regex = re.compile(user_input)
negative = f'(no history of {word}|No history of {word}|any comorbid complications|family history|father also has {word}|denies {word}|Negative for {word})'
regex_negative = re.compile(negative)
half_window_size = window_size
final_df = pd.DataFrame([])
column_position = df.columns.get_loc(column_name) + 1 #We add 1 cause position 0 is the index
#Loop for each row of the column
for row in df.itertuples():
#Loop for multiple matches in the same row
for match in regex.finditer(row[column_position]):
window_start = int([match.start()-half_window_size if match.start()>=half_window_size else 0][0])
window_end = int([match.end() + half_window_size if match.end()+half_window_size <= len(row[column_position]) else len(row[column_position])][0])
final_df = final_df.append({
"WORD": match.group(),
"START_INDEX": match.start(),
"WINDOW_START": window_start,
"WINDOW_END": window_end,
"CONTEXT": row[column_position][window_start:window_end],
"FULL_TEXT": row[column_position],
"NOTE_ID": row[1]},
ignore_index=True)
#Extracción de negativos
for match in regex_negative.finditer(row[column_position]):
final_df2 = final_df[final_df["CONTEXT"].str.contains(pat = regex_negative, regex = True)==False]
return "No matches for the pattern" if len(final_df) == 0 else final_df2
# Buscando diabet en las notas médicas
df = pd.read_csv("https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/diabetes_notes.csv")
word = "diabet"
window_size = 50 #tamaño de la ventana
diabetes_notes_window = extract_text_window(df,word,window_size)
diabetes_notes_window
```
Se crea una segunda función la cual recibe nuestro DataFrame con nuestras notas médicas, nuestra expresión regular para la palabra a buscar, expresión regular para las expresiones como "historial familiar, no tiene historial de diabetes, no se ha identificado diabetes" entre otras y el tamaño de la ventana al rededor de la palabra a buscar.
## Función con expresiones regulares
```python
def extract_text_window_pro(df, pattern,negatives, window_size, column_name = "TEXT"):
#Constants
half_window_size = window_size
final_df = pd.DataFrame([])
column_position = df.columns.get_loc(column_name) + 1 #We add 1 cause position 0 is the index
#Loop for each row of the column
for row in df.itertuples():
#Loop for multiple matches in the same row
for match in re.finditer(pattern,row[column_position]):
window_start = int([match.start()-half_window_size if match.start()>=half_window_size else 0][0])
window_end = int([match.end() + half_window_size if match.end()+half_window_size <= len(row[column_position]) else len(row[column_position])][0])
final_df = final_df.append({
"WORD": match.group(),
"START_INDEX": match.start(),
"WINDOW_START": window_start,
"WINDOW_END": window_end,
"CONTEXT": row[column_position][window_start:window_end],
"FULL_TEXT": row[column_position],
"NOTE_ID": row[1]},
ignore_index=True)
#Extracción de negativos
final_df2 = final_df[final_df["CONTEXT"].str.contains(pat = negatives, regex = True)==False]
return "No matches for the pattern" if len(final_df) == 0 else final_df2
# Buscando diabet en las notas médicas
df = pd.read_csv("https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/diabetes_notes.csv")
pattern = "diabetes|diabetic" #"(?<![a-zA-Z])diabet(es|ic)?(?![a-zA-Z])"
window_size = 50
negatives = r"no history of (?<![a-zA-Z])diabet(es|ic)?(?![a-zA-z])|No history of (?<![a-zA-Z])diabet(es|ic)?(?![a-zA-z])|den(ies|y)? any comorbid complications|family history|negative for (?<![a-zA-Z])diabet(es|ic)?(?![a-zA-z])|(father|mother) (also)? (?<![a-zA-Z])diabet(es|ic)?(?![a-zA-z])|Negative for (?<![a-zA-Z])diabet(es|ic)?(?![a-zA-z]) |no weakness, numbness or tingling|patient's mother and father|father also has diabetes"
diabetes_notes_window = extract_text_window_pro(df,pattern,negatives,window_size)
diabetes_notes_window
```
Ahora bien, es momento de obtiene mediante la función con expresiones regulares los DataFrame para neuropathy, nephropathy y retinopathy.
```python
diabetes_notes_window.drop_duplicates(subset=["NOTE_ID"])
neuropathy = diabetes_notes_window[diabetes_notes_window['CONTEXT'].str.contains(pat=r"(?<![a-zA-Z])neuropath(y|ic)?(?![a-zA-z])|diabetic nerve pain|tingling",regex=True)]
neuropathy['COMPLICATIONS'] = "neuropathy"
diabetes_notes_neuropathy = neuropathy[['NOTE_ID','CONTEXT','COMPLICATIONS']].drop_duplicates(subset=['NOTE_ID'])
print(diabetes_notes_neuropathy)
print(diabetes_notes_neuropathy.count())
nephropathy = diabetes_notes_window[diabetes_notes_window['CONTEXT'].str.contains(pat=r"(?<![a-zA-Z])nephropathy(?![a-zA-z])|renal (insufficiency|disease)",regex=True)]
nephropathy['COMPLICATIONS'] = "nephropathy"
diabetes_notes_nephropathy = nephropathy[['NOTE_ID','CONTEXT','COMPLICATIONS']].drop_duplicates(subset=['NOTE_ID'])
print(diabetes_notes_nephropathy)
print(diabetes_notes_nephropathy.count())
retinopathy = diabetes_notes_window[diabetes_notes_window['CONTEXT'].str.contains(pat=r"(?<![a-zA-Z])retinopath(y|ic)?(?![a-zA-z])",regex=True)]
retinopathy['COMPLICATIONS'] = "retinopathy"
diabetes_notes_retinopathy = retinopathy[['NOTE_ID','CONTEXT','COMPLICATIONS']].drop_duplicates(subset=['NOTE_ID'])
print(diabetes_notes_retinopathy)
print(diabetes_notes_retinopathy.count())
```
Para validar que nuestras funciones estén obteniendo bien la información de hace el uso del segundo link el cual se nos fue proporcionado para la validación de estas notas médicas.
```python
# Con el link antes mencionado de validación se crean los DataFrame para cada patología
datos_verificacion = pd.read_csv("https://raw.githubusercontent.com/hhsieh2416/Identify_Diabetic_Complications/main/data/glodstandrad.csv")
datos_verificacion_neuropathy = datos_verificacion[datos_verificacion['DIABETIC_NEUROPATHY']==1][['NOTE_ID','DIABETIC_NEUROPATHY']]
print(datos_verificacion_neuropathy)
print(datos_verificacion_neuropathy.count())
datos_verificacion_nephropathy = datos_verificacion[datos_verificacion['DIABETIC_NEPHROPATHY']==1][['NOTE_ID','DIABETIC_NEPHROPATHY']]
print(datos_verificacion_nephropathy)
print(datos_verificacion_nephropathy.count())
datos_verificacion_retinopathy = datos_verificacion[datos_verificacion['DIABETIC_RETINOPATHY']==1][['NOTE_ID','DIABETIC_RETINOPATHY']]
print(datos_verificacion_retinopathy)
print(datos_verificacion_retinopathy.count())
# Realizamos joins de nuestros DataFrame con las tablas de validación
ver_neuro = pd.merge(datos_verificacion_neuropathy, diabetes_notes_neuropathy, how = 'outer', on = 'NOTE_ID', indicator=True)
print(ver_neuro)
ver_nephro = pd.merge(datos_verificacion_nephropathy, diabetes_notes_nephropathy, how = 'outer', on = 'NOTE_ID', indicator=True)
print(ver_nephro)
ver_retino = pd.merge(datos_verificacion_retinopathy, diabetes_notes_retinopathy, how = 'outer', on = 'NOTE_ID', indicator=True)
print(ver_retino)
# Se realizan los conteos
conteo_na_neuro_falso_positivo = ver_neuro['DIABETIC_NEUROPATHY'].isna().sum()
conteo_na_nephro_falso_positivo = ver_nephro['DIABETIC_NEPHROPATHY'].isna().sum()
conteo_na_retino_falso_positivo = ver_retino['DIABETIC_RETINOPATHY'].isna().sum()
print('Pacientes sin complicaciones pero que si se identifican: ', conteo_na_neuro_falso_positivo+conteo_na_nephro_falso_positivo+conteo_na_retino_falso_positivo)
conteo_na_neuro_falso_negativo = ver_neuro['COMPLICATIONS'].isna().sum()
conteo_na_nephro_falso_negativo = ver_nephro['COMPLICATIONS'].isna().sum()
conteo_na_retino_falso_negativo = ver_retino['COMPLICATIONS'].isna().sum()
print('Pacientes con complicaciones que no fueron detectados: ', conteo_na_neuro_falso_negativo + conteo_na_nephro_falso_negativo + conteo_na_retino_falso_negativo)
conteo_correcto_neuro = len(ver_neuro[ver_neuro['_merge'] == 'both'])
conteo_correcto_nephro = len(ver_nephro[ver_nephro['_merge'] == 'both'])
conteo_correcto_retino = len(ver_retino[ver_retino['_merge'] == 'both'])
print('Pacientes que tienen complicaciones diabetes que si se encontaron: ', conteo_correcto_nephro+conteo_correcto_neuro+conteo_correcto_retino)
conteo_complicacion_neuro = len( ver_neuro[ver_neuro['DIABETIC_NEUROPATHY'] == 1] )
conteo_complicacion_nephro = len( ver_nephro[ver_nephro['DIABETIC_NEPHROPATHY'] == 1] )
conteo_complicacion_retino = len( ver_retino[ver_retino['DIABETIC_RETINOPATHY'] == 1] )
print('Pacientes que tienen complicaciones diabeticas: ', conteo_complicacion_neuro +conteo_complicacion_nephro + conteo_complicacion_retino )
cor_neuro = datos_verificacion[['NOTE_ID', 'DIABETIC_NEUROPATHY']].merge(diabetes_notes_neuropathy[['NOTE_ID','COMPLICATIONS']], how='outer', on='NOTE_ID', indicator=True )
cor_neuro['COMPLICATIONS'] = cor_neuro['COMPLICATIONS'].map(d_neuro).fillna(0)
print('---NEUROPATHY---')
print(cor_neuro)
print(classification_report(cor_neuro['DIABETIC_NEUROPATHY'].tolist(), cor_neuro['COMPLICATIONS'].tolist()))
cor_nephro = datos_verificacion[['NOTE_ID', 'DIABETIC_NEPHROPATHY']].merge(diabetes_notes_nephropathy[['NOTE_ID','COMPLICATIONS']], how='outer', on='NOTE_ID', indicator=True )
cor_nephro['COMPLICATIONS'] = cor_nephro['COMPLICATIONS'].map(d_nephro).fillna(0)
print('---NEPHROPATHY---')
print(cor_nephro)
print(classification_report(cor_nephro['DIABETIC_NEPHROPATHY'].tolist(), cor_nephro['COMPLICATIONS'].tolist()))
cor_retino = datos_verificacion[['NOTE_ID', 'DIABETIC_RETINOPATHY']].merge(diabetes_notes_retinopathy[['NOTE_ID','COMPLICATIONS']], how='outer', on='NOTE_ID', indicator=True )
cor_retino['COMPLICATIONS'] = cor_retino['COMPLICATIONS'].map(d_retino).fillna(0)
print('---RETINOPATHY---')
print(cor_retino)
print(classification_report(cor_retino['DIABETIC_RETINOPATHY'].tolist(), cor_retino['COMPLICATIONS'].tolist()))
```
|
nizamudma/t5-small-finetuned-cnn-2
|
nizamudma
| 2022-04-26T22:05:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:cnn_dailymail",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-25T21:21:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
metrics:
- rouge
model-index:
- name: t5-small-finetuned-cnn-2
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: cnn_dailymail
type: cnn_dailymail
args: 3.0.0
metrics:
- name: Rouge1
type: rouge
value: 24.5085
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-cnn-2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6620
- Rouge1: 24.5085
- Rouge2: 11.7925
- Rougel: 20.2631
- Rougelsum: 23.1253
- Gen Len: 18.9996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.8435 | 1.0 | 35890 | 1.6753 | 24.5387 | 11.7851 | 20.2792 | 23.1595 | 18.999 |
| 1.8143 | 2.0 | 71780 | 1.6660 | 24.5268 | 11.7976 | 20.2699 | 23.1384 | 18.9996 |
| 1.816 | 3.0 | 107670 | 1.6620 | 24.5085 | 11.7925 | 20.2631 | 23.1253 | 18.9996 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
caush/Clickbait2
|
caush
| 2022-04-26T21:15:28Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T19:11:53Z |
---
tags:
- generated_from_trainer
model-index:
- name: Clickbait2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Clickbait2
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 0.05 | 50 | 0.0213 |
| No log | 0.09 | 100 | 0.0213 |
| No log | 0.14 | 150 | 0.0213 |
| No log | 0.18 | 200 | 0.0216 |
| No log | 0.23 | 250 | 0.0214 |
| No log | 0.27 | 300 | 0.0212 |
| No log | 0.32 | 350 | 0.0214 |
| No log | 0.36 | 400 | 0.0212 |
| No log | 0.41 | 450 | 0.0218 |
| 0.0219 | 0.46 | 500 | 0.0219 |
| 0.0219 | 0.5 | 550 | 0.0214 |
| 0.0219 | 0.55 | 600 | 0.0216 |
| 0.0219 | 0.59 | 650 | 0.0217 |
| 0.0219 | 0.64 | 700 | 0.0214 |
| 0.0219 | 0.68 | 750 | 0.0214 |
| 0.0219 | 0.73 | 800 | 0.0214 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0a0+17540c5
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Amrendra/roberta-tapt-acl-arc
|
Amrendra
| 2022-04-26T18:28:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-26T18:09:56Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-tapt-acl-arc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-tapt-acl-arc
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3472
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 89 | 2.6476 |
| No log | 2.0 | 178 | 2.7191 |
| No log | 3.0 | 267 | 2.4195 |
| No log | 4.0 | 356 | 2.4680 |
| No log | 5.0 | 445 | 2.3363 |
| 2.5791 | 6.0 | 534 | 2.1846 |
| 2.5791 | 7.0 | 623 | 2.0593 |
| 2.5791 | 8.0 | 712 | 1.9373 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
BSlinky/finetuning-sentiment-model-3000-samples
|
BSlinky
| 2022-04-26T16:01:00Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T14:51:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
hbruce11216/distilbert-base-uncased-finetuned-imdb
|
hbruce11216
| 2022-04-26T13:56:22Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-26T13:50:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4897 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Nithiwat/fake-news-debunker
|
Nithiwat
| 2022-04-26T13:53:36Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"en",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T15:55:54Z |
---
tags: autotrain
language: en
widget:
- text: "Bill Gates wants to use mass Covid-19 vaccination campaign to implant microchips to track people"
datasets:
- Fake and real news datasets by CLÉMENT BISAILLON
co2_eq_emissions: 4.415122243239347
---
# Model Trained Using AutoTrain
- Problem: Fake News Classification
- Problem type: Binary Classification
- Model ID: 785124234
- CO2 Emissions (in grams): 4.415122243239347
## Validation Metrics
- Loss: 0.00012586714001372457
- Accuracy: 0.9998886538247411
- Precision: 1.0
- Recall: 0.9997665732959851
- AUC: 0.9999999999999999
- F1: 0.999883273024396
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Nithiwat/autotrain-fake-news-classifier-785124234
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Nithiwat/autotrain-fake-news-classifier-785124234", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Nithiwat/autotrain-fake-news-classifier-785124234", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Alassea/reviews-generator
|
Alassea
| 2022-04-26T12:59:27Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-26T12:36:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: reviews-generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reviews-generator
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4989
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7955 | 0.08 | 500 | 3.5578 |
| 3.7486 | 0.16 | 1000 | 3.4989 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Caroline-Vandyck/reviews-generator
|
Caroline-Vandyck
| 2022-04-26T12:58:01Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-26T12:34:19Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: reviews-generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reviews-generator
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4990
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7955 | 0.08 | 500 | 3.5577 |
| 3.7495 | 0.16 | 1000 | 3.4990 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
corvusMidnight/glue_sst_classifier_
|
corvusMidnight
| 2022-04-26T12:55:11Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T12:31:03Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier_
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier_
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Ghost1/distilbert-base-uncased-finetuned2-imdb
|
Ghost1
| 2022-04-26T12:40:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-25T18:08:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned2-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned2-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4725
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.707 | 1.0 | 157 | 2.4883 |
| 2.5761 | 2.0 | 314 | 2.4229 |
| 2.5255 | 3.0 | 471 | 2.4355 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Alassea/glue_sst_classifier
|
Alassea
| 2022-04-26T12:20:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T11:33:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Caroline-Vandyck/glue_sst_classifier
|
Caroline-Vandyck
| 2022-04-26T12:18:44Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T11:44:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
MonaA/glue_sst_classifier_2
|
MonaA
| 2022-04-26T11:48:03Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T11:24:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier_2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier_2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
maretamasaeva/glue_sst_classifier
|
maretamasaeva
| 2022-04-26T11:43:25Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T11:17:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Sie-BERT/glue_sst_classifier
|
Sie-BERT
| 2022-04-26T11:38:30Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T11:14:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
M-junaid-A/wav2vec-speech-project
|
M-junaid-A
| 2022-04-26T06:53:17Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-24T11:24:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec-speech-project
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec-speech-project
This model is a fine-tuned version of [kingabzpro/wav2vec2-large-xls-r-300m-Urdu](https://huggingface.co/kingabzpro/wav2vec2-large-xls-r-300m-Urdu) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
yihsuan/mt5_chinese_small
|
yihsuan
| 2022-04-26T06:36:56Z | 51 | 7 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"summarization",
"mT5",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-04-26T02:03:05Z |
---
tags:
- summarization
- mT5
language:
- zh
widget:
- text: "專家稱維康桑格研究所(Wellcome Sanger Institute)的上述研究發現「令人震驚」而且「發人深省」。基因變異指關於我們身體成長和管理的相關指令,也就是DNA當中發生的變化。長期以來,變異一直被當作癌症的根源,但是數十年來關於變異是否對衰老有重要影響一直存在爭論。桑格研究所的研究人員說他們得到了「第一個試驗性證據」,證明了兩者的關係。他們分析了預期壽命各異的物種基因變異的不同速度。研究人員分析了貓、黑白疣猴、狗、雪貂、長頸鹿、馬、人、獅子、裸鼴鼠、兔子、老鼠、環尾狐猴和老虎等十幾種動物的DNA。發表在《自然》雜誌上的研究顯示,老鼠在短暫的生命當中每年經歷了將近800次變異,老鼠的壽命一般不到4年。"
---
---
license: apache-2.0
tags:
- Summarization
metrics:
- rouge
model-index:
- name: best_model_test_0423_small
results: []
---
# best_model_test_0423_small
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6341
- Rouge1: 18.7681
- Rouge2: 6.3762
- Rougel: 18.6081
- Rougelsum: 18.6173
- Gen Len: 22.1086
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 5.8165 | 0.05 | 1000 | 3.6541 | 11.6734 | 3.9865 | 11.5734 | 11.5375 | 18.0056 |
| 4.306 | 0.1 | 2000 | 3.4291 | 12.0417 | 3.8419 | 11.9231 | 11.9223 | 16.8948 |
| 4.1091 | 0.16 | 3000 | 3.3643 | 13.661 | 4.5171 | 13.5123 | 13.5076 | 19.4016 |
| 3.9637 | 0.21 | 4000 | 3.2574 | 13.8443 | 4.1761 | 13.689 | 13.6927 | 18.4288 |
| 3.8205 | 0.26 | 5000 | 3.2434 | 13.5371 | 4.3639 | 13.3551 | 13.3552 | 21.5776 |
| 3.7262 | 0.31 | 6000 | 3.1690 | 14.3668 | 4.8048 | 14.2191 | 14.1906 | 21.5548 |
| 3.6887 | 0.36 | 7000 | 3.0657 | 14.3265 | 4.436 | 14.212 | 14.205 | 20.89 |
| 3.6337 | 0.42 | 8000 | 3.0318 | 14.6809 | 4.8345 | 14.5378 | 14.5331 | 20.3651 |
| 3.5443 | 0.47 | 9000 | 3.0554 | 15.3372 | 4.9163 | 15.1794 | 15.1781 | 21.7742 |
| 3.5203 | 0.52 | 10000 | 2.9793 | 14.9278 | 4.9656 | 14.7491 | 14.743 | 20.8113 |
| 3.4936 | 0.57 | 11000 | 3.0079 | 15.7705 | 5.1453 | 15.5582 | 15.5756 | 23.4274 |
| 3.4592 | 0.62 | 12000 | 2.9721 | 15.0201 | 5.1612 | 14.8508 | 14.8198 | 22.7007 |
| 3.377 | 0.67 | 13000 | 3.0112 | 15.9595 | 5.1133 | 15.78 | 15.7774 | 23.4427 |
| 3.4158 | 0.73 | 14000 | 2.9239 | 14.7984 | 5.051 | 14.6943 | 14.6581 | 21.6009 |
| 3.378 | 0.78 | 15000 | 2.8897 | 16.5128 | 5.1923 | 16.3523 | 16.3265 | 22.0828 |
| 3.3231 | 0.83 | 16000 | 2.9347 | 16.9997 | 5.5524 | 16.8534 | 16.8737 | 22.5807 |
| 3.3268 | 0.88 | 17000 | 2.9116 | 16.0261 | 5.4226 | 15.9234 | 15.914 | 23.6988 |
| 3.3127 | 0.93 | 18000 | 2.8610 | 16.6255 | 5.3554 | 16.4729 | 16.4569 | 22.9481 |
| 3.2664 | 0.99 | 19000 | 2.8606 | 17.7703 | 5.9475 | 17.6229 | 17.6259 | 23.4423 |
| 3.1718 | 1.04 | 20000 | 2.8764 | 17.301 | 5.6262 | 17.122 | 17.1104 | 23.0093 |
| 3.0987 | 1.09 | 21000 | 2.8282 | 16.4718 | 5.2077 | 16.3394 | 16.3401 | 20.9697 |
| 3.1486 | 1.14 | 22000 | 2.8235 | 18.5594 | 5.9469 | 18.3882 | 18.3799 | 22.7291 |
| 3.1435 | 1.19 | 23000 | 2.8261 | 18.111 | 6.0309 | 17.9593 | 17.9613 | 22.9612 |
| 3.1049 | 1.25 | 24000 | 2.8068 | 17.124 | 5.5675 | 16.9714 | 16.9876 | 22.5558 |
| 3.1357 | 1.3 | 25000 | 2.8014 | 17.3916 | 5.8671 | 17.2148 | 17.2502 | 23.0075 |
| 3.0904 | 1.35 | 26000 | 2.7790 | 17.419 | 5.6689 | 17.3125 | 17.3058 | 22.1492 |
| 3.0877 | 1.4 | 27000 | 2.7462 | 17.0605 | 5.4735 | 16.9414 | 16.9378 | 21.7522 |
| 3.0694 | 1.45 | 28000 | 2.7563 | 17.752 | 5.8889 | 17.5967 | 17.619 | 23.2005 |
| 3.0498 | 1.51 | 29000 | 2.7521 | 17.9056 | 5.7754 | 17.7624 | 17.7836 | 21.9369 |
| 3.0566 | 1.56 | 30000 | 2.7468 | 18.6531 | 6.0538 | 18.5397 | 18.5038 | 22.2358 |
| 3.0489 | 1.61 | 31000 | 2.7450 | 18.4869 | 5.9297 | 18.3139 | 18.3169 | 22.0108 |
| 3.0247 | 1.66 | 32000 | 2.7449 | 18.5192 | 5.9966 | 18.3721 | 18.3569 | 22.2071 |
| 2.9877 | 1.71 | 33000 | 2.7160 | 18.1655 | 5.9294 | 18.0304 | 18.0836 | 21.4595 |
| 3.0383 | 1.76 | 34000 | 2.7202 | 18.4959 | 6.2413 | 18.3363 | 18.3431 | 22.9732 |
| 3.041 | 1.82 | 35000 | 2.6948 | 17.5306 | 5.8119 | 17.4011 | 17.4149 | 21.9435 |
| 2.9285 | 1.87 | 36000 | 2.6957 | 18.6418 | 6.1394 | 18.514 | 18.4823 | 22.5174 |
| 3.0556 | 1.92 | 37000 | 2.7000 | 18.7387 | 6.0585 | 18.5761 | 18.574 | 22.9315 |
| 3.0033 | 1.97 | 38000 | 2.6974 | 17.9387 | 6.1387 | 17.8271 | 17.8111 | 22.4726 |
| 2.9207 | 2.02 | 39000 | 2.6998 | 18.6073 | 6.1906 | 18.3891 | 18.4103 | 23.0274 |
| 2.8922 | 2.08 | 40000 | 2.6798 | 18.4017 | 6.2244 | 18.2321 | 18.2296 | 22.0697 |
| 2.8938 | 2.13 | 41000 | 2.6666 | 18.8016 | 6.2066 | 18.6411 | 18.6353 | 21.7017 |
| 2.9124 | 2.18 | 42000 | 2.6606 | 18.7544 | 6.3533 | 18.5923 | 18.5739 | 21.4303 |
| 2.8597 | 2.23 | 43000 | 2.6947 | 18.8672 | 6.4526 | 18.7416 | 18.7482 | 22.3352 |
| 2.8435 | 2.28 | 44000 | 2.6738 | 18.9405 | 6.356 | 18.7791 | 18.7729 | 21.9081 |
| 2.8672 | 2.34 | 45000 | 2.6734 | 18.7509 | 6.3991 | 18.6175 | 18.5828 | 21.8869 |
| 2.899 | 2.39 | 46000 | 2.6575 | 18.5529 | 6.3489 | 18.4139 | 18.401 | 21.7694 |
| 2.8616 | 2.44 | 47000 | 2.6485 | 18.7563 | 6.268 | 18.6368 | 18.6253 | 21.5685 |
| 2.8937 | 2.49 | 48000 | 2.6486 | 18.6525 | 6.3426 | 18.5184 | 18.5129 | 22.3337 |
| 2.8446 | 2.54 | 49000 | 2.6572 | 18.6529 | 6.2655 | 18.4915 | 18.4764 | 22.3331 |
| 2.8676 | 2.59 | 50000 | 2.6608 | 19.0913 | 6.494 | 18.929 | 18.9233 | 22.132 |
| 2.8794 | 2.65 | 51000 | 2.6583 | 18.7648 | 6.459 | 18.6276 | 18.6125 | 22.2414 |
| 2.8836 | 2.7 | 52000 | 2.6512 | 18.7243 | 6.3865 | 18.5848 | 18.5763 | 22.2551 |
| 2.8174 | 2.75 | 53000 | 2.6409 | 18.9393 | 6.3914 | 18.7733 | 18.7715 | 22.1243 |
| 2.8494 | 2.8 | 54000 | 2.6396 | 18.6126 | 6.4389 | 18.4673 | 18.4516 | 21.7638 |
| 2.9025 | 2.85 | 55000 | 2.6341 | 18.7681 | 6.3762 | 18.6081 | 18.6173 | 22.1086 |
| 2.8754 | 2.91 | 56000 | 2.6388 | 19.0828 | 6.5203 | 18.9334 | 18.9285 | 22.3497 |
| 2.8489 | 2.96 | 57000 | 2.6375 | 18.9219 | 6.4922 | 18.763 | 18.7437 | 21.9321 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.1+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
xfbai/AMRBART-large
|
xfbai
| 2022-04-26T06:14:16Z | 10 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"AMRBART",
"en",
"arxiv:2203.07836",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-25T08:05:17Z |
---
language: en
tags:
- AMRBART
license: mit
---
## AMRBART (large-sized model)
AMRBART model is continually pre-trained on the English text and AMR Graphs based on the BART model. It was introduced in the paper: [Graph Pre-training for AMR Parsing and Generation](https://arxiv.org/pdf/2203.07836.pdf) by bai et al. in ACL 2022 and first released in [this repository](https://github.com/muyeby/AMRBART).
## Model description
AMRBART follows the BART model which uses a transformer encoder-encoder architecture. AMRBART is pre-trained with 6 tasks:
+ learning to reconstruct the text based on the corrupted text.
+ learning to reconstruct AMR graphs based on the corrupted AMR graph.
+ learning to reconstruct the text based on the corrupted text and its corresponding AMR graph.
+ learning to reconstruct an AMR graph based on the corrupted AMR graph and its corresponding text.
+ learning to reconstruct the text based on the corrupted text and its corresponding corrupted AMR graph.
+ learning to reconstruct an AMR graph based on the corrupted AMR graph and its corresponding corrupted text.
AMRBART is particularly effective when fine-tuned for AMR parsing and AMR-to-text generation tasks.
## Training data
The AMRBART model is pre-trained on [AMR3.0](https://catalog.ldc.upenn.edu/LDC2020T02), a dataset consisting of 55,635
training instances and [English Gigaword](https://catalog.ldc.upenn.edu/LDC2003T05) (we randomly sampled 200,000 sentences).
## Intended uses & limitations
You can use the raw model for either AMR encoding or AMR parsing, but it's mostly intended to
be fine-tuned on a downstream task.
## How to use
Here is how to initialize this model in PyTorch:
```python
from transformers import BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained("xfbai/AMRBART-large")
```
Please refer to [this repository](https://github.com/muyeby/AMRBART) for tokenizer initialization and data preprocessing.
## BibTeX entry and citation info
Please cite this paper if you find this model helpful
```bibtex
@inproceedings{bai-etal-2022-graph,
title = "Graph Pre-training for {AMR} Parsing and Generation",
author = "Bai, Xuefeng and
Chen, Yulong and
Zhang, Yue",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "todo",
doi = "todo",
pages = "todo"
}
```
|
xfbai/AMRBART-large-finetuned-AMR2.0-AMRParsing
|
xfbai
| 2022-04-26T05:51:03Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"AMRBART",
"en",
"arxiv:2203.07836",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-26T05:27:20Z |
---
language: en
tags:
- AMRBART
license: mit
---
## AMRBART-large-finetuned-AMR2.0-AMRParsing
This model is a fine-tuned version of [AMRBART-large](https://huggingface.co/xfbai/AMRBART-large) on an AMR2.0 dataset. It achieves a Smatch of 85.4 on the evaluation set: More details are introduced in the paper: [Graph Pre-training for AMR Parsing and Generation](https://arxiv.org/pdf/2203.07836.pdf) by bai et al. in ACL 2022.
## Model description
Same with AMRBART.
## Training data
The model is finetuned on [AMR2.0](https://catalog.ldc.upenn.edu/LDC2020T02), a dataset consisting of 36,521
training instances, 1,368 validation instances, and 1,371 test instances.
## Intended uses & limitations
You can use the model for AMR parsing, but it's mostly intended to be used in the domain of News.
## How to use
Here is how to initialize this model in PyTorch:
```python
from transformers import BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained("xfbai/AMRBART-large-finetuned-AMR2.0-AMRParsing")
```
Please refer to [this repository](https://github.com/muyeby/AMRBART) for tokenizer initialization and data preprocessing.
## BibTeX entry and citation info
Please cite this paper if you find this model helpful
```bibtex
@inproceedings{bai-etal-2022-graph,
title = "Graph Pre-training for {AMR} Parsing and Generation",
author = "Bai, Xuefeng and
Chen, Yulong and
Zhang, Yue",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "todo",
doi = "todo",
pages = "todo"
}
```
|
crcb/carer_5way
|
crcb
| 2022-04-26T05:46:33Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:crcb/autotrain-data-carer_5way",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T05:43:57Z |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- crcb/autotrain-data-carer_5way
co2_eq_emissions: 4.164757528958762
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 786524275
- CO2 Emissions (in grams): 4.164757528958762
## Validation Metrics
- Loss: 0.16724252700805664
- Accuracy: 0.944234404536862
- Macro F1: 0.9437256923758108
- Micro F1: 0.9442344045368619
- Weighted F1: 0.9442368364749825
- Macro Precision: 0.9431692663638349
- Micro Precision: 0.944234404536862
- Weighted Precision: 0.9446229335037916
- Macro Recall: 0.9446884750469657
- Micro Recall: 0.944234404536862
- Weighted Recall: 0.944234404536862
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/crcb/autotrain-carer_5way-786524275
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("crcb/autotrain-carer_5way-786524275", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("crcb/autotrain-carer_5way-786524275", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
ddobokki/unsup-simcse-klue-roberta-base
|
ddobokki
| 2022-04-26T05:22:12Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"simcse",
"ko",
"endpoints_compatible",
"region:us"
] | null | 2022-04-26T04:40:53Z |
---
language:
- ko
tags:
- simcse
---
# KorSTS-dev
```
"eval_cosine_pearson": 0.8461074829101562
"eval_cosine_spearman": 0.8447369732456155
"eval_euclidean_pearson": 0.8401166200637817
"eval_euclidean_spearman": 0.8441547920405729
"eval_manhattan_pearson": 0.8404706120491028
"eval_manhattan_spearman": 0.8449217524976507
"eval_dot_pearson": 0.8457739353179932
"eval_dot_spearman": 0.8440466726739222
```
# KorSTS-test
```
"eval_cosine_pearson": 0.7702209949493408
"eval_cosine_spearman": 0.7671020822573297
"eval_euclidean_pearson": 0.7617944478988647
"eval_euclidean_spearman": 0.7651634975965186
"eval_manhattan_pearson": 0.7639209032058716
"eval_manhattan_spearman": 0.7674607376361398
"eval_dot_pearson": 0.7696021795272827
"eval_dot_spearman": 0.7667385347139427
```
|
huggingtweets/gerardoalone
|
huggingtweets
| 2022-04-26T03:31:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-25T22:45:55Z |
---
language: en
thumbnail: http://www.huggingtweets.com/gerardoalone/1650943909493/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1513716426795855876/jWAK0lo4_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">gay wedding technology</div>
<div style="text-align: center; font-size: 14px;">@gerardoalone</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from gay wedding technology.
| Data | gay wedding technology |
| --- | --- |
| Tweets downloaded | 3239 |
| Retweets | 406 |
| Short tweets | 737 |
| Tweets kept | 2096 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1p260sem/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @gerardoalone's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3p1683gy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3p1683gy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/gerardoalone')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
crcb/isear_bert
|
crcb
| 2022-04-26T03:14:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:crcb/autotrain-data-isear_bert",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-26T03:11:17Z |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- crcb/autotrain-data-isear_bert
co2_eq_emissions: 0.026027055434994496
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 786224257
- CO2 Emissions (in grams): 0.026027055434994496
## Validation Metrics
- Loss: 0.8348872065544128
- Accuracy: 0.7272727272727273
- Macro F1: 0.7230931630686932
- Micro F1: 0.7272727272727273
- Weighted F1: 0.7236599456423468
- Macro Precision: 0.7328252157220334
- Micro Precision: 0.7272727272727273
- Weighted Precision: 0.7336599708829821
- Macro Recall: 0.7270448163292604
- Micro Recall: 0.7272727272727273
- Weighted Recall: 0.7272727272727273
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/crcb/autotrain-isear_bert-786224257
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("crcb/autotrain-isear_bert-786224257", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("crcb/autotrain-isear_bert-786224257", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Haofeng/CLIP_animal_classification
|
Haofeng
| 2022-04-26T03:07:10Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-04-25T20:36:44Z |
---
license: mit
---
## Overview
This model is based on [CLIP](https://openai.com/blog/clip) model and test on four kinds of animal datasets and ten kinds of animal datasets. CLIP model is a zero-shot pre-trained model so we don't need train model. We just input possible classes and image dataset to use model. Possible classes can be defined by yourself, it can be dataset labels or other description.
## Text-image matching
### Model Input
```python
Class = ["dog", "cat", "rabbit","squirrel"]
image = preprocess(Image.open("/content/drive/MyDrive/Transformer_CLIP/Golden_Retriever.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(Class).to(device)
```
### Model Process
```python
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
res = 0
pos = -1
for j in range(len(probs[0])):
if probs[0][j] > res:
res = probs[0][j]
pos = j
print("The options available are: " + str(Class))
for i in range(len(probs[0])):
print("The probability of " + str(Class[i]) + " is " + str(probs[0][i]))
print("Model thinks this photo is most likely a " + Class[pos])
```
## Animal Classification
### Demo code (Python Notebook)
https://huggingface.co/Haofeng/CLIP_animal_classification/blob/main/CLIP_classfication.ipynb
https://huggingface.co/Haofeng/CLIP_animal_classification/blob/main/CLIP_classfication10.ipynb
### Dataset reference
https://www.kaggle.com/datasets/alessiocorrado99/animals10
https://www.kaggle.com/datasets/ayushv322/animal-classification
|
charityking2358/taglish-electra
|
charityking2358
| 2022-04-26T02:19:48Z | 1 | 0 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-04-24T16:51:41Z |
## Taglish-Electra
Our Taglish-Electra model was pretrained with two Filipino training datasets and one English dataset to increase improvement against Filipino text with English where speakers may code-switch between the two languages.
1) Openwebtext (English)
2) WikiText-TL-39 (Filipino)
3) [TLUnified Large Scale Corpus](https://www.blaisecruz.com/resources/)
This is the discriminator model, which is the main Transformer used for finetuning to downstream tasks. For generation, mask-filling, and retraining, refer to the Generator models.
|
huggingtweets/spideythefifth
|
huggingtweets
| 2022-04-26T02:13:34Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-26T02:09:13Z |
---
language: en
thumbnail: http://www.huggingtweets.com/spideythefifth/1650939169930/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1505089505757384712/M9ehrLtd_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🏹🏳️⚧️🏳️🌈 Gandalf the Gay🏳️⚧️🏳️🌈♠️</div>
<div style="text-align: center; font-size: 14px;">@spideythefifth</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🏹🏳️⚧️🏳️🌈 Gandalf the Gay🏳️⚧️🏳️🌈♠️.
| Data | 🏹🏳️⚧️🏳️🌈 Gandalf the Gay🏳️⚧️🏳️🌈♠️ |
| --- | --- |
| Tweets downloaded | 3244 |
| Retweets | 289 |
| Short tweets | 1301 |
| Tweets kept | 1654 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/og5nwknk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @spideythefifth's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2trdlzgq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2trdlzgq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/spideythefifth')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Danni/distilbert-base-uncased-finetuned-dbpedia
|
Danni
| 2022-04-26T02:04:00Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T04:12:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-dbpedia
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-dbpedia
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.4338
- eval_matthews_correlation: 0.7817
- eval_runtime: 1094.9103
- eval_samples_per_second: 60.777
- eval_steps_per_second: 3.799
- epoch: 1.0
- step: 23568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
huggingtweets/femboi_canis
|
huggingtweets
| 2022-04-26T00:26:30Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-26T00:25:56Z |
---
language: en
thumbnail: http://www.huggingtweets.com/femboi_canis/1650932783971/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1479992104306843648/e2XQNywk_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🌻 Ole Grim | Femboi | Cane | It/Its | Hy/Hym 🔞</div>
<div style="text-align: center; font-size: 14px;">@femboi_canis</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🌻 Ole Grim | Femboi | Cane | It/Its | Hy/Hym 🔞.
| Data | 🌻 Ole Grim | Femboi | Cane | It/Its | Hy/Hym 🔞 |
| --- | --- |
| Tweets downloaded | 3207 |
| Retweets | 412 |
| Short tweets | 206 |
| Tweets kept | 2589 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/27g3w5y2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @femboi_canis's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/jv8wsew4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/jv8wsew4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/femboi_canis')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
yangy50/garbage-classification
|
yangy50
| 2022-04-25T22:55:50Z | 82 | 1 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"arxiv:2010.11929",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-23T22:04:50Z |
# Garbage Classification
## Overview
### Backgroud
Garbage classification refers to the separation of several types of different categories in accordance with the environmental impact of the use of the value of the composition of garbage components and the requirements of existing treatment methods.
The significance of garbage classification:
1. Garbage classification reduces the mutual pollution between different garbage, which is beneficial to the recycling of materials.
2. Garbage classification is conducive to reducing the final waste disposal volume.
3. Garbage classification is conducive to enhancing the degree of social civilization.
### Dataset
The garbage classification dataset is from Kaggle. There are totally 2467 pictures in this dataset. And this model is an image classification model for this dataset. There are 6 classes for this dataset, which are cardboard (393), glass (491), metal (400), paper(584), plastic (472), and trash(127).
### Model
The model is based on the [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model, which is short for the Vision Transformer. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), which was introduced in June 2021 by a team of researchers at Google Brain. And first released in [this repository](https://github.com/rwightman/pytorch-image-models). I trained this model with PyTorch. I think the most different thing between using the transformer to train on an image and on a text is in the tokenizing step.
There are 3 steps to tokenize the image:
1. Split an image into a grid of sub-image patches
2. Embed each patch with a linear projection
3. Each embedded patch becomes a token, and the resulting sequence of embedded patches is the sequence you pass to the model.
I trained the model with 10 epochs, and I use Adam as the optimizer. The accuracy on the test set is 95%.
## Huggingface Space
Huggingface space is [here](https://huggingface.co/yangy50/garbage-classification).
## Huggingface Model Card
Huggingface model card is [here](https://huggingface.co/yangy50/garbage-classification/tree/main).
## Critical Analysis
1. Next step: build a CNN model on this dataset and compare the accuracy and training time for these two models.
2. Didn’t use the Dataset package to store the image data. Want to find out how to use the Dataset package to handle image data.
## Resource Links
[vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k)
[Garbage dataset](https://huggingface.co/cardiffnlp/twitter-roberta-base)
[An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
## Code Demo
[Code Demo](https://github.com/yuechen-yang/garbage-classification) is inside this repo
## Repo
In this repo
## Video Recording
|
maximedb/glue_sst_classifier
|
maximedb
| 2022-04-25T19:42:10Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T19:18:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- f1
- accuracy
model-index:
- name: glue_sst_classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: F1
type: f1
value: 0.9033707865168539
- name: Accuracy
type: accuracy
value: 0.9013761467889908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# glue_sst_classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2359
- F1: 0.9034
- Accuracy: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.3653 | 0.19 | 100 | 0.3213 | 0.8717 | 0.8727 |
| 0.291 | 0.38 | 200 | 0.2662 | 0.8936 | 0.8911 |
| 0.2239 | 0.57 | 300 | 0.2417 | 0.9081 | 0.9060 |
| 0.2306 | 0.76 | 400 | 0.2359 | 0.9105 | 0.9094 |
| 0.2185 | 0.95 | 500 | 0.2371 | 0.9011 | 0.8991 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Lucifermorningstar011/autotrain-final-784824213
|
Lucifermorningstar011
| 2022-04-25T19:24:43Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain",
"en",
"dataset:Lucifermorningstar011/autotrain-data-final",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-25T15:24:10Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Lucifermorningstar011/autotrain-data-final
co2_eq_emissions: 443.62532415086787
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 784824213
- CO2 Emissions (in grams): 443.62532415086787
## Validation Metrics
- Loss: 0.12777526676654816
- Accuracy: 0.9823625038850627
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Lucifermorningstar011/autotrain-final-784824213
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("Lucifermorningstar011/autotrain-final-784824213", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Lucifermorningstar011/autotrain-final-784824213", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
maximedb/reviews-generator
|
maximedb
| 2022-04-25T19:15:12Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:amazon_reviews_multi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-25T17:30:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: reviews-generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# reviews-generator
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3020
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7284 | 0.16 | 500 | 3.5020 |
| 3.6202 | 0.32 | 1000 | 3.4170 |
| 3.5477 | 0.48 | 1500 | 3.3667 |
| 3.5218 | 0.64 | 2000 | 3.3395 |
| 3.5097 | 0.8 | 2500 | 3.3167 |
| 3.5009 | 0.96 | 3000 | 3.3020 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.1
- Datasets 1.18.4
- Tokenizers 0.11.0
|
Lucifermorningstar011/autotrain-final-784824211
|
Lucifermorningstar011
| 2022-04-25T18:49:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"autotrain",
"en",
"dataset:Lucifermorningstar011/autotrain-data-final",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-25T15:24:28Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Lucifermorningstar011/autotrain-data-final
co2_eq_emissions: 292.55119229577315
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 784824211
- CO2 Emissions (in grams): 292.55119229577315
## Validation Metrics
- Loss: 0.17682738602161407
- Accuracy: 0.9732196168090091
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Lucifermorningstar011/autotrain-final-784824211
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("Lucifermorningstar011/autotrain-final-784824211", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Lucifermorningstar011/autotrain-final-784824211", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Lucifermorningstar011/autotrain-final-784824206
|
Lucifermorningstar011
| 2022-04-25T18:46:51Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain",
"en",
"dataset:Lucifermorningstar011/autotrain-data-final",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-25T15:23:57Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Lucifermorningstar011/autotrain-data-final
co2_eq_emissions: 354.21745907505175
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 784824206
- CO2 Emissions (in grams): 354.21745907505175
## Validation Metrics
- Loss: 0.1393078863620758
- Accuracy: 0.9785765909606228
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Lucifermorningstar011/autotrain-final-784824206
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("Lucifermorningstar011/autotrain-final-784824206", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Lucifermorningstar011/autotrain-final-784824206", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
spuun/kekbot-beta-2-medium
|
spuun
| 2022-04-25T18:19:29Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"en",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-25T10:51:20Z |
---
language:
- en
tags:
- conversational
co2_eq_emissions:
emissions: "940"
source: "mlco2.github.io"
training_type: "fine-tuning"
geographical_location: "West Java, Indonesia"
hardware_used: "1 Tesla P100"
license: cc-by-nc-sa-4.0
widget:
- text: "Hey kekbot! What's up?"
example_title: "Asking what's up"
- text: "Hey kekbot! How r u?"
example_title: "Asking how he is"
---
> THIS MODEL IS IN PUBLIC BETA, PLEASE DO NOT EXPECT ANY FORM OF STABILITY IN ITS CURRENT STATE.
# Art Union server chatbot
Based on a DialoGPT-medium model, fine-tuned to a small subset (115k<= messages) of Art Union's general-chat channel.
### Current issues
(Which hopefully will be fixed in future iterations) Include, but not limited to:
- Limited turns, after ~11 turns output may break for no apparent reason.
- Inconsistent variance, acts like an overfitted model from time to time for no reason whatsoever.
|
bookbot/id-g2p-bert
|
bookbot
| 2022-04-25T18:16:05Z | 5 | 1 |
tf-keras
|
[
"tf-keras",
"tensorboard",
"g2p",
"fill-mask",
"id",
"ms",
"arxiv:1810.04805",
"license:apache-2.0",
"region:us"
] |
fill-mask
| 2022-04-23T08:27:04Z |
---
language:
- id
- ms
license: apache-2.0
tags:
- g2p
- fill-mask
inference: false
---
# ID G2P BERT
ID G2P BERT is a phoneme de-masking model based on the [BERT](https://arxiv.org/abs/1810.04805) architecture. This model was trained from scratch on a modified [Malay/Indonesian lexicon](https://huggingface.co/datasets/bookbot/id_word2phoneme).
This model was trained using the [Keras](https://keras.io/) framework. All training was done on Google Colaboratory. We adapted the [BERT Masked Language Modeling training script](https://keras.io/examples/nlp/masked_language_modeling) provided by the official Keras Code Example.
## Model
| Model | #params | Arch. | Training/Validation data |
| ------------- | ------- | ----- | ------------------------ |
| `id-g2p-bert` | 200K | BERT | Malay/Indonesian Lexicon |

## Training Procedure
<details>
<summary>Model Config</summary>
vocab_size: 32
max_len: 32
embed_dim: 128
num_attention_head: 2
feed_forward_dim: 128
num_layers: 2
</details>
<details>
<summary>Training Setting</summary>
batch_size: 32
optimizer: "adam"
learning_rate: 0.001
epochs: 100
</details>
## How to Use
<details>
<summary>Tokenizers</summary>
id2token = {
0: '',
1: '[UNK]',
2: 'a',
3: 'n',
4: 'ə',
5: 'i',
6: 'r',
7: 'k',
8: 'm',
9: 't',
10: 'u',
11: 'g',
12: 's',
13: 'b',
14: 'p',
15: 'l',
16: 'd',
17: 'o',
18: 'e',
19: 'h',
20: 'c',
21: 'y',
22: 'j',
23: 'w',
24: 'f',
25: 'v',
26: '-',
27: 'z',
28: "'",
29: 'q',
30: '[mask]'
}
token2id = {
'': 0,
"'": 28,
'-': 26,
'[UNK]': 1,
'[mask]': 30,
'a': 2,
'b': 13,
'c': 20,
'd': 16,
'e': 18,
'f': 24,
'g': 11,
'h': 19,
'i': 5,
'j': 22,
'k': 7,
'l': 15,
'm': 8,
'n': 3,
'o': 17,
'p': 14,
'q': 29,
'r': 6,
's': 12,
't': 9,
'u': 10,
'v': 25,
'w': 23,
'y': 21,
'z': 27,
'ə': 4
}
</details>
```py
import keras
import tensorflow as tf
import numpy as np
from huggingface_hub import from_pretrained_keras
model = from_pretrained_keras("bookbot/id-g2p-bert")
MAX_LEN = 32
MASK_TOKEN_ID = 30
def inference(sequence):
sequence = " ".join([c if c != "e" else "[mask]" for c in sequence])
tokens = [token2id[c] for c in sequence.split()]
pad = [token2id[""] for _ in range(MAX_LEN - len(tokens))]
tokens = tokens + pad
input_ids = tf.convert_to_tensor(np.array([tokens]))
prediction = model.predict(input_ids)
# find masked idx token
masked_index = np.where(input_ids == MASK_TOKEN_ID)
masked_index = masked_index[1]
# get prediction at those masked index only
mask_prediction = prediction[0][masked_index]
predicted_ids = np.argmax(mask_prediction, axis=1)
# replace mask with predicted token
for i, idx in enumerate(masked_index):
tokens[idx] = predicted_ids[i]
return "".join([id2token[t] for t in tokens if t != 0])
inference("mengembangkannya")
```
## Authors
ID G2P BERT was trained and evaluated by [Ananto Joyoadikusumo](https://anantoj.github.io/), [Steven Limcorn](https://stevenlimcorn.github.io/), [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory.
## Framework versions
- Keras 2.8.0
- TensorFlow 2.8.0
|
Rocketknight1/bert-base-uncased-finetuned-swag
|
Rocketknight1
| 2022-04-25T18:00:09Z | 7 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"bert",
"multiple-choice",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Rocketknight1/bert-base-uncased-finetuned-swag
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/bert-base-uncased-finetuned-swag
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.8360
- Train Accuracy: 0.6631
- Validation Loss: 0.5885
- Validation Accuracy: 0.7706
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 9192, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.8360 | 0.6631 | 0.5885 | 0.7706 | 0 |
### Framework versions
- Transformers 4.18.0.dev0
- TensorFlow 2.8.0-rc0
- Datasets 2.0.1.dev0
- Tokenizers 0.11.0
|
robinhad/data2vec-large-uk
|
robinhad
| 2022-04-25T17:27:44Z | 7 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"data2vec-audio",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-25T17:22:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: data2vec-large-uk
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# data2vec-large-uk
This model is a fine-tuned version of [facebook/data2vec-audio-large-960h](https://huggingface.co/facebook/data2vec-audio-large-960h) on the common_voice dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3472
- eval_wer: 0.3410
- eval_cer: 0.0832
- eval_runtime: 231.0008
- eval_samples_per_second: 25.108
- eval_steps_per_second: 3.139
- epoch: 33.06
- step: 20400
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 6
- total_train_batch_size: 48
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 1.18.3
- Tokenizers 0.12.1
|
huggingnft/mini-mutants__2__boredapeyachtclub
|
huggingnft
| 2022-04-25T16:05:55Z | 0 | 1 | null |
[
"pytorch",
"huggan",
"gan",
"image-to-image",
"huggingnft",
"nft",
"image",
"images",
"arxiv:1703.10593",
"license:mit",
"region:us"
] |
image-to-image
| 2022-04-15T12:34:24Z |
---
tags:
- huggan
- gan
- image-to-image
- huggingnft
- nft
- image
- images
# See a list of available tags here:
# https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
# task: unconditional-image-generation or conditional-image-generation or image-to-image
license: mit
---
# CycleGAN for unpaired image-to-image translation.
## Model description
CycleGAN for unpaired image-to-image translation.
Given two image domains A and B, the following components are trained end2end to translate between such domains:
- A generator A to B, named G_AB conditioned on an image from A
- A generator B to A, named G_BA conditioned on an image from B
- A domain classifier D_A, associated with G_AB
- A domain classifier D_B, associated with G_BA
At inference time, G_AB or G_BA are relevant to translate images, respectively A to B or B to A.
In the general setting, this technique provides style transfer functionalities between the selected image domains A and B.
This allows to obtain a generated translation by G_AB, of an image from domain A that resembles the distribution of the images from domain B, and viceversa for the generator G_BA.
Under these framework, these aspects have been used to perform style transfer between NFT collections.
A collection is selected as domain A, another one as domain B and the CycleGAN provides forward and backward translation between A and B.
This has showed to allows high quality translation even in absence of paired sample-ground-truth data.
In particular, the model performs well with stationary backgrounds (no drastic texture changes in the appearance of backgrounds) as it is capable of recognizing the attributes of each of the elements of an NFT collections.
An attribute can be a variation in type of dressed fashion items such as sunglasses, earrings, clothes and also face or body attributes with respect to a common template model of the given NFT collection).
## Intended uses & limitations
#### How to use
```python
import torch
from PIL import Image
from huggan.pytorch.cyclegan.modeling_cyclegan import GeneratorResNet
from torchvision import transforms as T
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
from torchvision.utils import make_grid
from huggingface_hub import hf_hub_download, file_download
from accelerate import Accelerator
import json
def load_lightweight_model(model_name):
file_path = file_download.hf_hub_download(
repo_id=model_name,
filename="config.json"
)
config = json.loads(open(file_path).read())
organization_name, name = model_name.split("/")
model = Trainer(**config, organization_name=organization_name, name=name)
model.load(use_cpu=True)
model.accelerator = Accelerator()
return model
def get_concat_h(im1, im2):
dst = Image.new('RGB', (im1.width + im2.width, im1.height))
dst.paste(im1, (0, 0))
dst.paste(im2, (im1.width, 0))
return dst
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# load the translation model from source to target images: source will be generated by a separate Lightweight GAN, w
# while the target images are the result of the translation applied by the GeneratorResnet to the generated source images.
# Hence, given the source domain A and target domain B,
# B = Translator(GAN(A))
translator = GeneratorResNet.from_pretrained(f'huggingnft/{model_name}',
input_shape=(n_channels, image_size, image_size),
num_residual_blocks=9)
# sample noise that is used to generate source images by the
z = torch.randn(nrows, 100, 1, 1)
# load the GAN generator of source images that will be translated by the translation model
model = load_lightweight_model(f"huggingnft/{model_name.split('__2__')[0]}")
collectionA = model.generate_app(
num=timestamped_filename(),
nrow=nrows,
checkpoint=-1,
types="default"
)[1]
# resize to translator model input shape
resize = T.Resize((256, 256))
input = resize(collectionA)
# translate the resized collectionA to collectionB
collectionB = translator(input)
out_transform = T.ToPILImage()
results = []
for collA_image, collB_image in zip(input, collectionB):
results.append(
get_concat_h(out_transform(make_grid(collA_image, nrow=1, normalize=True)), out_transform(make_grid(collB_image, nrow=1, normalize=True)))
)
```
#### Limitations and bias
Translation between collections provides exceptional output images in the case of NFT collections that portray subjects in the same way.
If the backgrounds vary too much within either of the collections, performance degrades or many more training iterations re required to achieve acceptable results.
## Training data
The CycleGAN model is trained on an unpaired dataset of samples from two selected NFT collections: colle tionA and collectionB.
To this end, two collections are loaded by means of the function load_dataset in the huggingface library, as follows.
A list of all available collections is available at [huggingNFT](https://huggingface.co/huggingnft)
```python
from datasets import load_dataset
collectionA = load_dataset("huggingnft/COLLECTION_A")
collectionB = load_dataset("huggingnft/COLLECTION_B")
```
## Training procedure
#### Preprocessing
The following transformations are applied to each input sample of collectionA and collectionB.
The input size is fixed to RGB images of height, width = 256, 256
```python
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
```
#### Hardware
The configuration has been tested on single GPU setup on a RTX5000 and A5000, as well as multi-gpu single-rank distributed setups composed of 2 of the mentioned GPUs.
#### Hyperparameters
The following configuration has been kept fixed for all translation models:
- learning rate 0.0002
- number of epochs 200
- learning rate decay activation at epoch 80
- number of residual blocks of the cyclegan 9
- cycle loss weight 10.0
- identity loss weight 5.0
- optimizer ADAM with beta1 0.5 and beta2 0.999
- batch size 8
- NO mixed precision training
## Eval results
#### Training reports
[Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/CycleGAN-training-report--VmlldzoxODUxNzQz?accessToken=vueurpbhd2i8n347j880yakggs0sqdf7u0hpz3bpfsbrxcmk1jk4obg18f6wfk9w)
[Boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/CycleGAN-training-report--VmlldzoxODUxNzg4?accessToken=jpyviwn7kdf5216ycrthwp6l8t3heb0lt8djt7dz12guu64qnpdh3ekecfcnoahu)
#### Generated Images
In the provided images, row0 and row2 represent real images from the respective collections.
Row1 is the translation of the immediate above images in row0 by means of the G_AB translation model.
Row3 is the translation of the immediate above images in row2 by means of the G_BA translation model.
Visualization over the training iterations for [boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/Shared-panel-22-04-15-08-04-99--VmlldzoxODQ0MDI3?accessToken=45m3kxex5m3rpev3s6vmrv69k3u9p9uxcsp2k90wvbxwxzlqbqjqlnmgpl9265c0)
Visualization over the training iterations for [Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/Shared-panel-22-04-17-11-04-83--VmlldzoxODUxNjk5?accessToken=o25si6nflp2xst649vt6ayt56bnb95mxmngt1ieso091j2oazmqnwaf4h78vc2tu)
### References
```bibtex
@misc{https://doi.org/10.48550/arxiv.1703.10593,
doi = {10.48550/ARXIV.1703.10593},
url = {https://arxiv.org/abs/1703.10593},
author = {Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
publisher = {arXiv},
year = {2017},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk, Christian Cancedda}
year=2022
}
```
|
huggingnft/boredapeyachtclub__2__mutant-ape-yacht-club
|
huggingnft
| 2022-04-25T16:05:54Z | 0 | 1 | null |
[
"pytorch",
"huggan",
"gan",
"image-to-image",
"huggingnft",
"nft",
"image",
"images",
"arxiv:1703.10593",
"license:mit",
"region:us"
] |
image-to-image
| 2022-04-15T12:15:49Z |
---
tags:
- huggan
- gan
- image-to-image
- huggingnft
- nft
- image
- images
# See a list of available tags here:
# https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
# task: unconditional-image-generation or conditional-image-generation or image-to-image
license: mit
---
# CycleGAN for unpaired image-to-image translation.
## Model description
CycleGAN for unpaired image-to-image translation.
Given two image domains A and B, the following components are trained end2end to translate between such domains:
- A generator A to B, named G_AB conditioned on an image from A
- A generator B to A, named G_BA conditioned on an image from B
- A domain classifier D_A, associated with G_AB
- A domain classifier D_B, associated with G_BA
At inference time, G_AB or G_BA are relevant to translate images, respectively A to B or B to A.
In the general setting, this technique provides style transfer functionalities between the selected image domains A and B.
This allows to obtain a generated translation by G_AB, of an image from domain A that resembles the distribution of the images from domain B, and viceversa for the generator G_BA.
Under these framework, these aspects have been used to perform style transfer between NFT collections.
A collection is selected as domain A, another one as domain B and the CycleGAN provides forward and backward translation between A and B.
This has showed to allows high quality translation even in absence of paired sample-ground-truth data.
In particular, the model performs well with stationary backgrounds (no drastic texture changes in the appearance of backgrounds) as it is capable of recognizing the attributes of each of the elements of an NFT collections.
An attribute can be a variation in type of dressed fashion items such as sunglasses, earrings, clothes and also face or body attributes with respect to a common template model of the given NFT collection).
## Intended uses & limitations
#### How to use
```python
import torch
from PIL import Image
from huggan.pytorch.cyclegan.modeling_cyclegan import GeneratorResNet
from torchvision import transforms as T
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
from torchvision.utils import make_grid
from huggingface_hub import hf_hub_download, file_download
from accelerate import Accelerator
import json
def load_lightweight_model(model_name):
file_path = file_download.hf_hub_download(
repo_id=model_name,
filename="config.json"
)
config = json.loads(open(file_path).read())
organization_name, name = model_name.split("/")
model = Trainer(**config, organization_name=organization_name, name=name)
model.load(use_cpu=True)
model.accelerator = Accelerator()
return model
def get_concat_h(im1, im2):
dst = Image.new('RGB', (im1.width + im2.width, im1.height))
dst.paste(im1, (0, 0))
dst.paste(im2, (im1.width, 0))
return dst
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# load the translation model from source to target images: source will be generated by a separate Lightweight GAN, w
# while the target images are the result of the translation applied by the GeneratorResnet to the generated source images.
# Hence, given the source domain A and target domain B,
# B = Translator(GAN(A))
translator = GeneratorResNet.from_pretrained(f'huggingnft/{model_name}',
input_shape=(n_channels, image_size, image_size),
num_residual_blocks=9)
# sample noise that is used to generate source images by the
z = torch.randn(nrows, 100, 1, 1)
# load the GAN generator of source images that will be translated by the translation model
model = load_lightweight_model(f"huggingnft/{model_name.split('__2__')[0]}")
collectionA = model.generate_app(
num=timestamped_filename(),
nrow=nrows,
checkpoint=-1,
types="default"
)[1]
# resize to translator model input shape
resize = T.Resize((256, 256))
input = resize(collectionA)
# translate the resized collectionA to collectionB
collectionB = translator(input)
out_transform = T.ToPILImage()
results = []
for collA_image, collB_image in zip(input, collectionB):
results.append(
get_concat_h(out_transform(make_grid(collA_image, nrow=1, normalize=True)), out_transform(make_grid(collB_image, nrow=1, normalize=True)))
)
```
#### Limitations and bias
Translation between collections provides exceptional output images in the case of NFT collections that portray subjects in the same way.
If the backgrounds vary too much within either of the collections, performance degrades or many more training iterations re required to achieve acceptable results.
## Training data
The CycleGAN model is trained on an unpaired dataset of samples from two selected NFT collections: colle tionA and collectionB.
To this end, two collections are loaded by means of the function load_dataset in the huggingface library, as follows.
A list of all available collections is available at [huggingNFT](https://huggingface.co/huggingnft)
```python
from datasets import load_dataset
collectionA = load_dataset("huggingnft/COLLECTION_A")
collectionB = load_dataset("huggingnft/COLLECTION_B")
```
## Training procedure
#### Preprocessing
The following transformations are applied to each input sample of collectionA and collectionB.
The input size is fixed to RGB images of height, width = 256, 256
```python
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
```
#### Hardware
The configuration has been tested on single GPU setup on a RTX5000 and A5000, as well as multi-gpu single-rank distributed setups composed of 2 of the mentioned GPUs.
#### Hyperparameters
The following configuration has been kept fixed for all translation models:
- learning rate 0.0002
- number of epochs 200
- learning rate decay activation at epoch 80
- number of residual blocks of the cyclegan 9
- cycle loss weight 10.0
- identity loss weight 5.0
- optimizer ADAM with beta1 0.5 and beta2 0.999
- batch size 8
- NO mixed precision training
## Eval results
#### Training reports
[Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/CycleGAN-training-report--VmlldzoxODUxNzQz?accessToken=vueurpbhd2i8n347j880yakggs0sqdf7u0hpz3bpfsbrxcmk1jk4obg18f6wfk9w)
[Boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/CycleGAN-training-report--VmlldzoxODUxNzg4?accessToken=jpyviwn7kdf5216ycrthwp6l8t3heb0lt8djt7dz12guu64qnpdh3ekecfcnoahu)
#### Generated Images
In the provided images, row0 and row2 represent real images from the respective collections.
Row1 is the translation of the immediate above images in row0 by means of the G_AB translation model.
Row3 is the translation of the immediate above images in row2 by means of the G_BA translation model.
Visualization over the training iterations for [boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/Shared-panel-22-04-15-08-04-99--VmlldzoxODQ0MDI3?accessToken=45m3kxex5m3rpev3s6vmrv69k3u9p9uxcsp2k90wvbxwxzlqbqjqlnmgpl9265c0)
Visualization over the training iterations for [Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/Shared-panel-22-04-17-11-04-83--VmlldzoxODUxNjk5?accessToken=o25si6nflp2xst649vt6ayt56bnb95mxmngt1ieso091j2oazmqnwaf4h78vc2tu)
### References
```bibtex
@misc{https://doi.org/10.48550/arxiv.1703.10593,
doi = {10.48550/ARXIV.1703.10593},
url = {https://arxiv.org/abs/1703.10593},
author = {Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
publisher = {arXiv},
year = {2017},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk, Christian Cancedda}
year=2022
}
```
|
huggingnft/cryptopunks__2__bored-apes-yacht-club
|
huggingnft
| 2022-04-25T16:05:53Z | 0 | 4 | null |
[
"pytorch",
"huggan",
"gan",
"image-to-image",
"huggingnft",
"nft",
"image",
"images",
"arxiv:1703.10593",
"license:mit",
"region:us"
] |
image-to-image
| 2022-04-12T11:24:26Z |
---
tags:
- huggan
- gan
- image-to-image
- huggingnft
- nft
- image
- images
# See a list of available tags here:
# https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
# task: unconditional-image-generation or conditional-image-generation or image-to-image
license: mit
---
# CycleGAN for unpaired image-to-image translation.
## Model description
CycleGAN for unpaired image-to-image translation.
Given two image domains A and B, the following components are trained end2end to translate between such domains:
- A generator A to B, named G_AB conditioned on an image from A
- A generator B to A, named G_BA conditioned on an image from B
- A domain classifier D_A, associated with G_AB
- A domain classifier D_B, associated with G_BA
At inference time, G_AB or G_BA are relevant to translate images, respectively A to B or B to A.
In the general setting, this technique provides style transfer functionalities between the selected image domains A and B.
This allows to obtain a generated translation by G_AB, of an image from domain A that resembles the distribution of the images from domain B, and viceversa for the generator G_BA.
Under these framework, these aspects have been used to perform style transfer between NFT collections.
A collection is selected as domain A, another one as domain B and the CycleGAN provides forward and backward translation between A and B.
This has showed to allows high quality translation even in absence of paired sample-ground-truth data.
In particular, the model performs well with stationary backgrounds (no drastic texture changes in the appearance of backgrounds) as it is capable of recognizing the attributes of each of the elements of an NFT collections.
An attribute can be a variation in type of dressed fashion items such as sunglasses, earrings, clothes and also face or body attributes with respect to a common template model of the given NFT collection).
## Intended uses & limitations
#### How to use
```python
import torch
from PIL import Image
from huggan.pytorch.cyclegan.modeling_cyclegan import GeneratorResNet
from torchvision import transforms as T
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
from torchvision.utils import make_grid
from huggingface_hub import hf_hub_download, file_download
from accelerate import Accelerator
import json
def load_lightweight_model(model_name):
file_path = file_download.hf_hub_download(
repo_id=model_name,
filename="config.json"
)
config = json.loads(open(file_path).read())
organization_name, name = model_name.split("/")
model = Trainer(**config, organization_name=organization_name, name=name)
model.load(use_cpu=True)
model.accelerator = Accelerator()
return model
def get_concat_h(im1, im2):
dst = Image.new('RGB', (im1.width + im2.width, im1.height))
dst.paste(im1, (0, 0))
dst.paste(im2, (im1.width, 0))
return dst
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# load the translation model from source to target images: source will be generated by a separate Lightweight GAN, w
# while the target images are the result of the translation applied by the GeneratorResnet to the generated source images.
# Hence, given the source domain A and target domain B,
# B = Translator(GAN(A))
translator = GeneratorResNet.from_pretrained(f'huggingnft/{model_name}',
input_shape=(n_channels, image_size, image_size),
num_residual_blocks=9)
# sample noise that is used to generate source images by the
z = torch.randn(nrows, 100, 1, 1)
# load the GAN generator of source images that will be translated by the translation model
model = load_lightweight_model(f"huggingnft/{model_name.split('__2__')[0]}")
collectionA = model.generate_app(
num=timestamped_filename(),
nrow=nrows,
checkpoint=-1,
types="default"
)[1]
# resize to translator model input shape
resize = T.Resize((256, 256))
input = resize(collectionA)
# translate the resized collectionA to collectionB
collectionB = translator(input)
out_transform = T.ToPILImage()
results = []
for collA_image, collB_image in zip(input, collectionB):
results.append(
get_concat_h(out_transform(make_grid(collA_image, nrow=1, normalize=True)), out_transform(make_grid(collB_image, nrow=1, normalize=True)))
)
```
#### Limitations and bias
Translation between collections provides exceptional output images in the case of NFT collections that portray subjects in the same way.
If the backgrounds vary too much within either of the collections, performance degrades or many more training iterations re required to achieve acceptable results.
## Training data
The CycleGAN model is trained on an unpaired dataset of samples from two selected NFT collections: colle tionA and collectionB.
To this end, two collections are loaded by means of the function load_dataset in the huggingface library, as follows.
A list of all available collections is available at [huggingNFT](https://huggingface.co/huggingnft)
```python
from datasets import load_dataset
collectionA = load_dataset("huggingnft/COLLECTION_A")
collectionB = load_dataset("huggingnft/COLLECTION_B")
```
## Training procedure
#### Preprocessing
The following transformations are applied to each input sample of collectionA and collectionB.
The input size is fixed to RGB images of height, width = 256, 256
```python
n_channels = 3
image_size = 256
input_shape = (image_size, image_size)
transform = Compose([
T.ToPILImage(),
T.Resize(input_shape),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
```
#### Hardware
The configuration has been tested on single GPU setup on a RTX5000 and A5000, as well as multi-gpu single-rank distributed setups composed of 2 of the mentioned GPUs.
#### Hyperparameters
The following configuration has been kept fixed for all translation models:
- learning rate 0.0002
- number of epochs 200
- learning rate decay activation at epoch 80
- number of residual blocks of the cyclegan 9
- cycle loss weight 10.0
- identity loss weight 5.0
- optimizer ADAM with beta1 0.5 and beta2 0.999
- batch size 8
- NO mixed precision training
## Eval results
#### Training reports
[Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/CycleGAN-training-report--VmlldzoxODUxNzQz?accessToken=vueurpbhd2i8n347j880yakggs0sqdf7u0hpz3bpfsbrxcmk1jk4obg18f6wfk9w)
[Boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/CycleGAN-training-report--VmlldzoxODUxNzg4?accessToken=jpyviwn7kdf5216ycrthwp6l8t3heb0lt8djt7dz12guu64qnpdh3ekecfcnoahu)
#### Generated Images
In the provided images, row0 and row2 represent real images from the respective collections.
Row1 is the translation of the immediate above images in row0 by means of the G_AB translation model.
Row3 is the translation of the immediate above images in row2 by means of the G_BA translation model.
Visualization over the training iterations for [boreapeyachtclub to mutant-ape-yacht-club](https://wandb.ai/chris1nexus/experiments--my_paperspace_boredapeyachtclub__2__mutant-ape-yacht-club--11/reports/Shared-panel-22-04-15-08-04-99--VmlldzoxODQ0MDI3?accessToken=45m3kxex5m3rpev3s6vmrv69k3u9p9uxcsp2k90wvbxwxzlqbqjqlnmgpl9265c0)
Visualization over the training iterations for [Cryptopunks to boreapeyachtclub](https://wandb.ai/chris1nexus/experiments--experiments_cyclegan_punk_to_apes_HQ--0/reports/Shared-panel-22-04-17-11-04-83--VmlldzoxODUxNjk5?accessToken=o25si6nflp2xst649vt6ayt56bnb95mxmngt1ieso091j2oazmqnwaf4h78vc2tu)
### References
```bibtex
@misc{https://doi.org/10.48550/arxiv.1703.10593,
doi = {10.48550/ARXIV.1703.10593},
url = {https://arxiv.org/abs/1703.10593},
author = {Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
publisher = {arXiv},
year = {2017},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk, Christian Cancedda}
year=2022
}
```
|
huggingnft/hapeprime
|
huggingnft
| 2022-04-25T15:59:11Z | 5 | 1 |
transformers
|
[
"transformers",
"huggingnft",
"nft",
"huggan",
"gan",
"image",
"images",
"unconditional-image-generation",
"dataset:huggingnft/hapeprime",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-14T10:11:16Z |
---
tags:
- huggingnft
- nft
- huggan
- gan
- image
- images
- unconditional-image-generation
datasets:
- huggingnft/hapeprime
license: mit
---
# Hugging NFT: hapeprime
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/hapeprime).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/hapeprime).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/hapeprime).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
huggingnft/etherbears
|
huggingnft
| 2022-04-25T15:59:07Z | 10 | 1 |
transformers
|
[
"transformers",
"huggingnft",
"nft",
"huggan",
"gan",
"image",
"images",
"unconditional-image-generation",
"dataset:huggingnft/etherbears",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-14T09:23:35Z |
---
tags:
- huggingnft
- nft
- huggan
- gan
- image
- images
- unconditional-image-generation
datasets:
- huggingnft/etherbears
license: mit
---
# Hugging NFT: etherbears
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/etherbears).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/etherbears).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/etherbears).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
huggingnft/nftrex
|
huggingnft
| 2022-04-25T15:59:07Z | 14 | 2 |
transformers
|
[
"transformers",
"huggingnft",
"nft",
"huggan",
"gan",
"image",
"images",
"unconditional-image-generation",
"dataset:huggingnft/nftrex",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-13T18:41:07Z |
---
tags:
- huggingnft
- nft
- huggan
- gan
- image
- images
- unconditional-image-generation
datasets:
- huggingnft/nftrex
license: mit
---
# Hugging NFT: nftrex
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/nftrex).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/nftrex).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/nftrex).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
huggingnft/theshiboshis
|
huggingnft
| 2022-04-25T15:59:05Z | 3 | 1 |
transformers
|
[
"transformers",
"huggingnft",
"nft",
"huggan",
"gan",
"image",
"images",
"unconditional-image-generation",
"dataset:huggingnft/theshiboshis",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-15T21:02:19Z |
---
tags:
- huggingnft
- nft
- huggan
- gan
- image
- images
- unconditional-image-generation
datasets:
- huggingnft/theshiboshis
license: mit
---
# Hugging NFT: theshiboshis
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/theshiboshis).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/theshiboshis).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/theshiboshis).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
huggingnft/cryptoadz-by-gremplin
|
huggingnft
| 2022-04-25T15:59:03Z | 3 | 1 |
transformers
|
[
"transformers",
"huggingnft",
"nft",
"huggan",
"gan",
"image",
"images",
"unconditional-image-generation",
"dataset:huggingnft/cryptoadz-by-gremplin",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-15T13:29:22Z |
---
tags:
- huggingnft
- nft
- huggan
- gan
- image
- images
- unconditional-image-generation
datasets:
- huggingnft/cryptoadz-by-gremplin
license: mit
---
# Hugging NFT: cryptoadz-by-gremplin
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/cryptoadz-by-gremplin).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/cryptoadz-by-gremplin).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/cryptoadz-by-gremplin).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
jfarray/Model_distiluse-base-multilingual-cased-v1_1_Epochs
|
jfarray
| 2022-04-25T15:29:40Z | 124 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-02T23:29:05Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 512 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 11 with parameters:
```
{'batch_size': 15, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 1,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 2,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 512, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
kSaluja/new-test-model
|
kSaluja
| 2022-04-25T13:43:56Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-25T12:49:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: new-test-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# new-test-model
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0962
- Precision: 0.9704
- Recall: 0.9766
- F1: 0.9735
- Accuracy: 0.9791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 151 | 0.1872 | 0.9295 | 0.9405 | 0.9349 | 0.9535 |
| No log | 2.0 | 302 | 0.1417 | 0.9574 | 0.9652 | 0.9613 | 0.9679 |
| No log | 3.0 | 453 | 0.1028 | 0.9676 | 0.9693 | 0.9684 | 0.9742 |
| 0.3037 | 4.0 | 604 | 0.1063 | 0.9676 | 0.9696 | 0.9686 | 0.9743 |
| 0.3037 | 5.0 | 755 | 0.0962 | 0.9704 | 0.9766 | 0.9735 | 0.9791 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
mrm8488/convnext-tiny-finetuned-beans
|
mrm8488
| 2022-04-25T13:32:06Z | 99 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"convnext",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-25T13:18:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: convnext-tiny-finetuned-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9609375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-tiny-finetuned-beans
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1255
- Accuracy: 0.9609

## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 7171
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 37 | 0.6175 | 0.8828 |
| No log | 2.0 | 74 | 0.2307 | 0.9609 |
| 0.5237 | 3.0 | 111 | 0.1406 | 0.9531 |
| 0.5237 | 4.0 | 148 | 0.1165 | 0.9688 |
| 0.5237 | 5.0 | 185 | 0.1255 | 0.9609 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
huggingtweets/jstoone
|
huggingtweets
| 2022-04-25T13:31:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-25T13:30:50Z |
---
language: en
thumbnail: http://www.huggingtweets.com/jstoone/1650893492572/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1233003191538790400/3OxNooXT_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Jakob Steinn</div>
<div style="text-align: center; font-size: 14px;">@jstoone</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Jakob Steinn.
| Data | Jakob Steinn |
| --- | --- |
| Tweets downloaded | 3204 |
| Retweets | 713 |
| Short tweets | 177 |
| Tweets kept | 2314 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1j98493p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @jstoone's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3vtqate8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3vtqate8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/jstoone')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
AlexTaylor/distilbert-base-uncased-finetuned-emotion
|
AlexTaylor
| 2022-04-25T13:24:10Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T12:41:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.926
- name: F1
type: f1
value: 0.9263429084864518
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2257
- Accuracy: 0.926
- F1: 0.9263
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8433 | 1.0 | 250 | 0.3243 | 0.9035 | 0.8996 |
| 0.2583 | 2.0 | 500 | 0.2257 | 0.926 | 0.9263 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
maryam359/wav2vec-speech-project
|
maryam359
| 2022-04-25T12:31:54Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-25T08:47:35Z |
---
tags:
- generated_from_trainer
model-index:
- name: wav2vec-speech-project
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec-speech-project
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.01
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 120
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
huggan/projected_gan_cubism
|
huggan
| 2022-04-25T11:17:33Z | 0 | 0 |
pytorch
|
[
"pytorch",
"gan",
"dcgan",
"projected-gan",
"huggan",
"unconditional-image-generation",
"region:us"
] |
unconditional-image-generation
| 2022-04-16T02:26:58Z |
---
library_name: pytorch
tags:
- gan
- dcgan
- projected-gan
- huggan
- unconditional-image-generation
---
dataset: https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset
trained on the official projected gan github code - you can check out the hfspace to see how to use it to generate images
fun stuff
check out the space demo: https://huggingface.co/spaces/huggan/projected_gan_art
Made by:-<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
[Massimiliano Pappa](https://huggingface.co/maxpappa)<br/>
|
huggan/projected_gan_abstract_expressionism_hana
|
huggan
| 2022-04-25T11:17:09Z | 0 | 0 |
pytorch
|
[
"pytorch",
"gan",
"dcgan",
"projected-gan",
"huggan",
"unconditional-image-generation",
"region:us"
] |
unconditional-image-generation
| 2022-04-15T00:37:59Z |
---
library_name: pytorch
tags:
- gan
- dcgan
- projected-gan
- huggan
- unconditional-image-generation
---
dataset: https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset
trained on the official projected gan github code - you can check out the hfspace to see how to use it to generate images
fun stuff
check out the space demo: https://huggingface.co/spaces/huggan/projected_gan_art
Made by:-<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
[Massimiliano Pappa](https://huggingface.co/maxpappa)<br/>
|
huggan/projected_gan_color_field_hana
|
huggan
| 2022-04-25T11:16:59Z | 0 | 0 |
pytorch
|
[
"pytorch",
"gan",
"dcgan",
"projected-gan",
"huggan",
"unconditional-image-generation",
"region:us"
] |
unconditional-image-generation
| 2022-04-15T00:30:26Z |
---
library_name: pytorch
tags:
- gan
- dcgan
- projected-gan
- huggan
- unconditional-image-generation
---
dataset: https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset
trained on the official projected gan github code - you can check out the hfspace to see how to use it to generate images
fun stuff
check out the space demo: https://huggingface.co/spaces/huggan/projected_gan_art
Made by:-<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
[Massimiliano Pappa](https://huggingface.co/maxpappa)<br/>
|
huggan/projected_gan_popart
|
huggan
| 2022-04-25T11:16:48Z | 0 | 1 |
pytorch
|
[
"pytorch",
"gan",
"dcgan",
"projected-gan",
"huggan",
"unconditional-image-generation",
"region:us"
] |
unconditional-image-generation
| 2022-04-14T01:05:56Z |
---
library_name: pytorch
tags:
- gan
- dcgan
- projected-gan
- huggan
- unconditional-image-generation
---
dataset: https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset
trained on the official projected gan github code - you can check out the hfspace to see how to use it to generate images
fun stuff
check out the space demo: https://huggingface.co/spaces/huggan/projected_gan_art
Made by:-<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
[Massimiliano Pappa](https://huggingface.co/maxpappa)<br/>
|
huggan/projected_gan_abstract_expressionism
|
huggan
| 2022-04-25T11:16:38Z | 0 | 1 |
pytorch
|
[
"pytorch",
"gan",
"dcgan",
"projected-gan",
"huggan",
"unconditional-image-generation",
"region:us"
] |
unconditional-image-generation
| 2022-04-14T01:06:29Z |
---
library_name: pytorch
tags:
- gan
- dcgan
- projected-gan
- huggan
- unconditional-image-generation
---
dataset: https://github.com/cs-chan/ArtGAN/tree/master/WikiArt%20Dataset
trained on the official projected gan github code - you can check out the hfspace to see how to use it to generate images
fun stuff
check out the space demo: https://huggingface.co/spaces/huggan/projected_gan_art
Made by:-<br/>
[Jeronim Matijević](https://huggingface.co/Cropinky)<br/>
[Massimiliano Pappa](https://huggingface.co/maxpappa)<br/>
|
accelotron/xlm-roberta-finetune-muserc
|
accelotron
| 2022-04-25T10:04:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-25T09:46:39Z |
xlm-RoBERTa-base fine-tuned for MuSeRC task.
|
ceyda/butterfly_cropped_uniq1K_512
|
ceyda
| 2022-04-25T08:22:46Z | 22 | 3 |
transformers
|
[
"transformers",
"huggan",
"gan",
"unconditional-image-generation",
"dataset:huggan/smithsonian_butterflies_subset",
"license:mit",
"endpoints_compatible",
"region:us"
] |
unconditional-image-generation
| 2022-04-14T09:48:08Z |
---
tags:
- huggan
- gan
- unconditional-image-generation
license: mit
datasets:
- huggan/smithsonian_butterflies_subset
# See a list of available tags here:
# https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts#L12
---
# Butterfly GAN
## Model description
Based on [paper:](https://openreview.net/forum?id=1Fqg133qRaI) *Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis*
which states:
"Notably, the model converges from scratch with just a **few hours of training** on a single RTX-2080 GPU, and has a consistent performance, even with **less than 100 training samples**"
also dubbed the Light-GAN model. This model was trained using the script [here](https://github.com/huggingface/community-events/tree/main/huggan/pytorch/lightweight_gan) which is adapted from the lucidrains [repo](https://github.com/lucidrains/lightweight-gan).
Differently from the script above, I used the transforms from the official repo. Because our training images were already cropped and aligned.
official paper implementation [repo](https://github.com/odegeasslbc/FastGAN-pytorch)
```py
transform_list = [
transforms.Resize((int(im_size),int(im_size))),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
]
```
## Intended uses & limitations
Intended for fun & learning~
#### How to use
```python
import torch
from huggan.pytorch.lightweight_gan.lightweight_gan import LightweightGAN # install the community-events repo above
gan = LightweightGAN.from_pretrained("ceyda/butterfly_cropped_uniq1K_512")
gan.eval()
batch_size = 1
with torch.no_grad():
ims = gan.G(torch.randn(batch_size, gan.latent_dim)).clamp_(0., 1.)*255
ims = ims.permute(0,2,3,1).detach().cpu().numpy().astype(np.uint8)
# ims is [BxWxHxC] call Image.fromarray(ims[0])
```
#### Limitations and bias
- During training I filtered the dataset to have only 1 butterfly from each species available.
Otherwise the model generated less varied butterflies (a few species with more images would dominate).
- The dataset was also filtered using CLIP scores for ['pretty butterfly','one butterfly','butterfly with open wings','colorful butterfly'].
While this was done to eliminate images that contained no butterflies(just scientific tags, cluttered images) from the [full dataset](https://huggingface.co/datasets/ceyda/smithsonian_butterflies).
It is easy to imagine where this type of approach would be problematic in certain scenarios; who is to say which butterfly is "pretty" and should be in the dataset.ie; CLIP failing to identify a butterfly might exclude it from the dataset causing bias.
## Training data
1000 images are used, while it was possible to increase this number, we didn't have time to manually curate the dataset.
& also wanted to see if it was possible to do low data training as mention in the paper.
More details are on the [data card](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset)
## Training procedure
Trained on 2xA4000s for ~1day. Can see good results within 7-12h.
Importans params: "--batch_size 64 --gradient_accumulate_every 4 --image_size 512 --mixed_precision fp16"
Training logs can be seen [here](https://wandb.ai/cceyda/butterfly-gan/runs/2e0bm7h8?workspace=user-cceyda)
## Eval results
calculated FID score on 100 images. results for different checkpoints are [here](https://wandb.ai/cceyda/butterfly-gan-fid?workspace=user-cceyda)
but can't say it is too meaningful (due to the shortcomings of FID score)
## Generated Images
Play with the [demo](https://huggingface.co/spaces/huggan/butterfly-gan)
### BibTeX entry and citation info
Made during the huggan sprint.
Model trained by: Ceyda Cinarel https://twitter.com/ceyda_cinarel
Additional contributions by Jonathan Whitaker https://twitter.com/johnowhitaker
|
canwenxu/laprador
|
canwenxu
| 2022-04-25T08:13:10Z | 8 | 4 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"feature-extraction",
"arxiv:2203.06169",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-29T02:33:50Z |
---
license: apache-2.0
---
# 🦮 LaPraDoR
Pretrained checkpoint for Findings of ACL 2022 paper [LaPraDoR: Unsupervised Pretrained Dense Retriever for Zero-Shot Text Retrieval](https://arxiv.org/abs/2203.06169).
To use this model, please refer to our [GitHub repo](https://github.com/JetRunner/LaPraDoR).
|
tosin/dialogpt_afriwoz_wolof
|
tosin
| 2022-04-25T06:45:15Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"en",
"arxiv:2204.08083",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-24T15:57:53Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
language:
- en
license: cc-by-4.0
tags:
- conversational
- transformers
datasets:
- multi_woz_v22 and AfriWOZ
metrics:
- perplexity
widget:
- text: "dedet li rek la soxla. jerejef. ba benen yoon."
---
## DialoGPT_AfriWOZ
This is a fine-tuned model of DialoGPT (small) on the AfriWOZ dataset. It is intended to be used as a conversational system in Wolof language.
The dataset it's trained on is limited in scope, as it covers only certain domains such as restaurants, hotel, taxi, and booking.
The perplexity achieved on the test and validation sets are 20.74 and 11.66, respectively.
* Generation example from an interactive environment:
|Role | Response |
|---------|------------|
|User | sowwu bi la bëg |
|Bot | waw, ndax mën ngan ma jox ay leeral si bërëb buñu feetee ak lekkukaay bi |
|User | soxla na dem gawu. ngir leeral rek bëg na joggee peterborough di dem cambridge |
|Bot | soxlu na dem ginaw jurrom ñenti waxtu ak ñaar fukki simili ak jurrom ben. |
|User | waw jiss sal ma ben bu seer si njëg si toluway |
|Bot | jënd bi baaxna. jerejef. ba benen yoon. |
Please find the information about preprocessing, training and full details of the DialoGPT in the [original DialoGPT repository](https://github.com/microsoft/DialoGPT)
The paper for this work can be found on arXiv: [https://arxiv.org/pdf/2204.08083.pdf](https://arxiv.org/pdf/2204.08083.pdf)
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("tosin/dialogpt_afriwoz_wolof")
model = AutoModelForCausalLM.from_pretrained("tosin/dialogpt_afriwoz_wolof")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT_wolof_Bot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.