
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 12:31:00
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 12:28:53
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
tefefe/llava-finetune-updated2
|
tefefe
| 2025-09-12T11:20:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T11:20:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
abemi/act_ft_towel_n_episode50
|
abemi
| 2025-09-12T11:18:38Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:abemi/fold_green_towel_lerobot_n_episode50",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-12T11:18:16Z |
---
datasets: abemi/fold_green_towel_lerobot_n_episode50
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- lerobot
- act
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
HeyuGuo/gpt-oss-20b-pcb-schematic_0911
|
HeyuGuo
| 2025-09-12T11:18:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T02:36:15Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-pcb-schematic_0911
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gpt-oss-20b-pcb-schematic_0911
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="HeyuGuo/gpt-oss-20b-pcb-schematic_0911", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.4
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Vishesh2305/GreenPulse
|
Vishesh2305
| 2025-09-12T11:17:42Z | 0 | 1 | null |
[
"region:us"
] | null | 2025-04-21T05:46:53Z |
Hi, Welcome From Vishesh2305.
This model is a convolutional neural network (CNN) trained to classify images of diseased plant leaves into different disease categories.
The Model is Trained to predict the plant and crop or agricultural diseases.
It is Trained using Pytorch , Pandas , Numpy and Matplotlib.
The image recognition model which is Further trained Specifically for Plants is MobileNetV2. It is a open to use image recognition model.
The dataset is collected manually + books + kaggle + github + google searching.
The overall size of Dataset was approximate 40000 images and the accuracy achieved was 98.9%(AVG.).
# PyTorch Plant Disease Classification Model
This repository contains a PyTorch script (`trainmodel.py`) for training a convolutional neural network (CNN) to classify images of plant leaves into different disease categories. The model utilizes transfer learning with a pre-trained MobileNetV2 architecture, fine-tuned on a custom dataset.
## Overview
The `trainmodel.py` script performs the following steps:
1. **Data Loading and Preprocessing:** Loads image data from the `remaining_dataset_3/` directory. Applies data augmentation (random rotation, horizontal flip, affine transformations, color jitter) for the training set and standard resizing and normalization for the validation and test sets.
2. **Model Building:** Initializes a pre-trained MobileNetV2 model from `torchvision.models`. Freezes the weights of most layers and replaces the final classifier layer to match the number of classes in the dataset.
3. **Handling Class Imbalance:** Calculates class weights based on the frequency of each class in the training data and uses these weights in the `CrossEntropyLoss` function to address potential class imbalance.
4. **Training:** Trains the model for a specified number of epochs, monitoring training and validation loss and accuracy. Includes a learning rate scheduler for decay.
5. **Fine-tuning:** Unfreezes the last few layers of the MobileNetV2 feature extractor and continues training for additional epochs with a lower learning rate.
6. **Evaluation:** Evaluates the trained model on a separate `test/` directory, generating a confusion matrix and a classification report (precision, recall, F1-score, support for each class).
7. **Visualization:** Plots the training and validation loss and accuracy curves for both the initial training phase and the fine-tuning phase.
## Directory Structure
## Getting Started
### Prerequisites
* Python 3.x
* PyTorch (`torch`)
* Torchvision (`torchvision`)
* NumPy (`numpy`)
* Scikit-learn (`sklearn`)
* Matplotlib (`matplotlib`)
* `tqdm`
You can install the necessary libraries using pip:
```bash
pip install torch torchvision numpy scikit-learn matplotlib tqdm
# Run the Training Script .
python trainmodel.py
The Model Should only be used after taking permissions from Vishesh.
You can Contact me at :
Linkedin : vishesh2305
Github : Vishesh2305
HuggingFace : Vishesh2305
Email : visheshvasu2305@gmail.com
|
elyn-dev/ElynQwen3-32B-0910-RP
|
elyn-dev
| 2025-09-12T11:17:38Z | 0 | 1 | null |
[
"safetensors",
"qwen3",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-09-12T03:39:24Z |
---
license: cc-by-nc-4.0
---
|
Word2Li/Llama3.1-8B-Middo-Alpaca-4o-mini
|
Word2Li
| 2025-09-12T11:16:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"full",
"conversational",
"en",
"dataset:Word2Li/MiddOptimized",
"arxiv:2508.21589",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:14:17Z |
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B
language: en
datasets:
- Word2Li/MiddOptimized
tags:
- llama-factory
- full
pipeline_tag: text-generation
model-index:
- name: Llama3.1-8B-Middo-Alpaca-4o-mini
results:
- task:
type: text-generation
dataset:
name: MMLU
type: MMLU
metrics:
- name: Weighted Avg.
type: Weighted Avg.
value: 44.69
verified: true
- task:
type: text-generation
dataset:
name: IFEval
type: IFEval
metrics:
- name: Avg.
type: Avg.
value: 47.96
verified: true
- task:
type: text-generation
dataset:
name: GSM8K
type: GSM8K
metrics:
- name: pass@1
type: pass@1
value: 57.62
verified: true
- task:
type: text-generation
dataset:
name: MATH
type: MATH
metrics:
- name: pass@1
type: pass@1
value: 18.50
verified: true
- task:
type: text-generation
dataset:
name: HumanEval
type: HumanEval
metrics:
- name: pass@1
type: pass@1
value: 52.44
verified: true
- task:
type: text-generation
dataset:
name: MBPP
type: MBPP
metrics:
- name: pass@1
type: pass@1
value: 45.40
verified: true
- task:
type: text-generation
dataset:
name: Hellaswag
type: Hellaswag
metrics:
- name: pass@1
type: pass@1
value: 57.37
verified: true
- task:
type: text-generation
dataset:
name: GPQA
type: GPQA
metrics:
- name: pass@1
type: pass@1
value: 19.70
verified: true
metrics:
- accuracy
---
# Llama3.1-8B-Middo-Alpaca-4o-mini
Paper: [Middo: Model-Informed Dynamic Data Optimization for Enhanced LLM Fine-Tuning via Closed-Loop Learning](https://arxiv.org/abs/2508.21589)
Code: https://github.com/Word2VecT/Middo
## Model description
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the [MiddOptimzed/llama_alpaca_4o_mini](https://huggingface.co/datasets/Word2Li/MiddOptimized/viewer/default/llama_alpaca_4o_mini) dataset.
## Training and evaluation data
### Training data
Middo optimized [Alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) on [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B), and Alpaca's answers were rewritten by GPT-4o-mini at begining.
### Evaluation data
- General
- MMLU
- IFEval
- Math
- GSM8K
- MATH
- Code
- HumanEval
- MBPP
- Reasoning
- Hellaswag
- GPQA
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 1.0
### Framework versions
- Transformers 4.45.2
- Pytorch 2.5.1+cu121
- Datasets 2.21.0
- Tokenizers 0.20.1
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757675601
|
stonermay
| 2025-09-12T11:14:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T11:14:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
King211/blockassist
|
King211
| 2025-09-12T11:13:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"slithering bold koala",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T05:31:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- slithering bold koala
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
QomSSLab/Legal-gemma3-27b-it-lora
|
QomSSLab
| 2025-09-12T11:08:22Z | 81 | 0 | null |
[
"pytorch",
"safetensors",
"gemma3_text",
"region:us"
] | null | 2025-08-18T16:24:30Z |
---
{}
---
# Fine-tuned Model: Legal-gemma3-27b-it-
## 📚 Training Configuration
- **data_path**: `QomSSLab/Legal_DS_SFT`
- **output_dir**: `gemma327b_lora_chckpnts`
- **new_model_name**: `Legal-gemma3-27b-it-`
- **model_name**: `/home/aiuser/SmartJudge/PT/Legal-gemma3-27b-pt-lora`
- **use_4bit**: `False`
- **use_lora**: `True`
- **max_seq_length**: `3000`
- **batch_size**: `1`
- **gradient_accu**: `4`
- **epochs**: `2`
- **learning_rate**: `0.0001`
- **lora_alpha**: `128`
- **lora_drop**: `0.05`
- **lora_r**: `128`
- **tune_embedding_layer**: `False`
- **hf_token**: `********`
- **resume_from_checkpoint**: `True`
- **use_8bit_optimizer**: `True`
- **push_to_hub**: `True`
---
Auto-generated after training.
|
KGolden9/V3_Key14
|
KGolden9
| 2025-09-12T11:07:47Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T13:19:20Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
RikeB/MaxViT_butterfly_identification
|
RikeB
| 2025-09-12T11:05:47Z | 0 | 1 | null |
[
"pytorch",
"image-classification",
"doi:10.57967/hf/5986",
"license:mit",
"region:us"
] |
image-classification
| 2025-05-22T15:36:16Z |
---
license: mit
pipeline_tag: image-classification
---
MaxViT-T model that was trained to classify images of 162 butterfly and moth species that occur in Austria.
## Model Details
MaxVit-T pre-trained on ImageNet-1K was used and a full fine-tuning of the pre-trained MaxVit-T model, with all parameters rendered trainable, was conducted.
### Model Description
- **Developed by:** Andreas Lindner, Friederike Barkmann
- **Funded by:**
- Viel-Falter Butterfly Monitoring which is financially supported by the Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology (BMK).
- EuroCC Austria which has received funding from the European High Performance Computing Joint Undertaking (JU) and Germany, Bulgaria, Austria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, Greece, Hungary, Ireland, Italy, Lithuania, Latvia, Poland, Portugal, Romania, Slovenia, Spain, Sweden, France, Netherlands, Belgium, Luxembourg, Slovakia, Norway, Türkiye, Republic of North Macedonia, Iceland, Montenegro, Serbia under grant agreement No 101101903.
- **License:** MIT
- **Finetuned from model:** MaxViT-T pre-trained on ImageNet-1K
## Uses
The model can be used to identify butterfly and moth species that occur in Austria. It can classify 162 species, 131 of which are butterflies.
## Bias, Risks, and Limitations
The model does not cover all butterfly and moth species that occur in Austria. Of the about 210 butterflies, 131 were used for model training. Of the about 4000 moth species
it were only 31. Not all butterfly and moth species can be determined based on images alone.
## Training Details
The first model version ([a9ba52f](https://huggingface.co/RikeB/MaxViT_butterfly_identification/commit/a9ba52fd730b165b8fcd58265076fa82e763ebc2)) was trained on the EuroHPC supercomputer LUMI, hosted by CSC (Finland) and the LUMI consortium through a EuroHPC Regular Access call.
The second model version ([2371ff8](https://huggingface.co/RikeB/MaxViT_butterfly_identification/commit/2371ff89263bcc0319117d2a6e452e1dc5a82b4e)) was trained on the EuroHPC supercomputer LEONARDO, hosted by CINECA (Italy) and the LEONARDO consortium, also through a EuroHPC Regular Access call.
Training was parallelized using the Pytorch DDP framework and the Hugging Face Accelerate library.
More information on model training can be found in the publications below.
Scripts are availble on [GitHub](https://github.com/AndiLindner/butterfly_identification).
### Training Data
The model was trained with a dataset of over 500,000 images of butterflies and moths that were recorded in Austria. The images were taken by users of the App "Schmetterlinge Österreichs" of the
foundation "Blühendes Österreich" all over Austria. Images that showed more than one species or showed butterfly or moth eggs, larvae and pupae were excluded from training.
Species with less than 50 images were excluded from training. The final dataset contains images of the adult life stages of 162 species (31 moth species and 131 butterfly species).
## Citation
The first model version was trained in the context of a data paper in which the butterfly and moth images dataset it was trained on was published:
```bibtex
@Article{Barkmannetal2025a,
author={Barkmann, Friederike
and Lindner, Andreas
and W{\"u}rflinger, Ronald
and H{\"o}ttinger, Helmut
and R{\"u}disser, Johannes},
title={Machine learning training data: over 500,000 images of butterflies and moths (Lepidoptera) with species labels},
journal={Scientific Data},
year={2025},
month={Aug},
day={06},
volume={12},
number={1},
pages={1369},
abstract={Deep learning models can accelerate the processing of image-based biodiversity data and provide educational value by giving direct feedback to citizen scientists. However, the training of such models requires large amounts of labelled data and not all species are equally suited for identification from images alone. Most butterfly and many moth species (Lepidoptera) which play an important role as biodiversity indicators are well-suited for such approaches. This dataset contains over 540.000 images of 185 butterfly and moth species that occur in Austria. Images were collected by citizen scientists with the application ``Schmetterlinge {\"O}sterreichs'' and correct species identification was ensured by an experienced entomologist. The number of images per species ranges from one to nearly 30.000. Such a strong class imbalance is common in datasets of species records. The dataset is larger than other published dataset of butterfly and moth images and offers opportunities for the training and evaluation of machine learning models on the fine-grained classification task of species identification.},
issn={2052-4463},
doi={10.1038/s41597-025-05708-z},
url={https://doi.org/10.1038/s41597-025-05708-z}
}
```
Another publication is in preparation.
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757674989
|
stonermay
| 2025-09-12T11:05:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T11:04:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manbeast3b/007-gas-prices-3b-06
|
manbeast3b
| 2025-09-12T11:03:50Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T07:22:07Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
AquilaX-AI/QnA-router
|
AquilaX-AI
| 2025-09-12T11:02:52Z | 34 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-05-22T16:52:36Z |
---
library_name: transformers
tags: []
---
# INFERENCE
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained("Mr-Vicky-01/QnA-router")
model = AutoModelForSequenceClassification.from_pretrained("Mr-Vicky-01/QnA-router")
model.to(device)
model.eval()
def preprocess_input(pre_conversation, question):
if pre_conversation:
input_text = pre_conversation + "[SEP]" + question
else:
input_text = question
return input_text
def predict(pre_conversation, question):
input_text = preprocess_input(pre_conversation, question)
print(f"Processed input: {input_text}")
inputs = tokenizer(input_text, return_tensors="pt", truncation=True, padding=True)
inputs = {key: value.to(device) for key, value in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_id = torch.argmax(logits, dim=1).item()
predicted_label = model.config.id2label[predicted_class_id]
return predicted_label
single_question = "make a python code"
print("\nPredicting for single question...")
result = predict(pre_conversation="", question=single_question)
print(f"Predicted model: {result}")
# Example 2: Pre-conversation + new question
pre_conversation = "hi[SEP]Hello! How can I help you today?[SEP]how are you[SEP]I'm doing great, thanks for asking! What about you?"
new_question = "what is AI"
print("\nPredicting for conversation + new question...")
result = predict(pre_conversation=pre_conversation, question=new_question)
print(f"Predicted model: {result}")
```
|
nuviapreis/nuviapreis
|
nuviapreis
| 2025-09-12T11:02:50Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-12T11:02:35Z |
# Nuvia Preis Deutschland: Natürlicher Gewichtsverlust ohne Diätprobleme
## Einleitung: Warum viele Abnehm-Methoden scheitern
Übergewicht ist längst nicht mehr nur ein kosmetisches Problem, sondern betrifft die Gesundheit, das Wohlbefinden und das Selbstvertrauen. Viele Menschen in Deutschland probieren Diäten, Fitnessprogramme oder kurzfristige Trends aus – doch die meisten geben schnell auf. Der Grund: strenge Diäten sind oft nicht alltagstauglich, rauben Energie und liefern kaum nachhaltige Ergebnisse.
Genau hier setzt Nuvia an – ein innovatives Produkt, das gezielt beim Gewichtsmanagement unterstützt und dabei auf natürliche Inhaltsstoffe setzt.
## **[Klicken Sie hier, um auf der offiziellen Nuvia Website zu bestellen](https://www.diginear.com/2PGQH1JJ/215B937J/)**
## Was ist Nuvia eigentlich?
**[Nuvia](https://www.diginear.com/2PGQH1JJ/215B937J/)** ist ein speziell entwickeltes Nahrungsergänzungsmittel zur Unterstützung beim Abnehmen. Im Gegensatz zu Crash-Diäten oder zweifelhaften Abnehm-Shakes basiert Nuvia auf hochwertigen Inhaltsstoffen, die den Stoffwechsel ankurbeln, Heißhungerattacken reduzieren und die Fettverbrennung fördern können.
Das Besondere: Nuvia kombiniert moderne Forschung mit natürlichen Wirkstoffen, um eine sichere und effektive Lösung für alle zu schaffen, die dauerhaft Gewicht verlieren möchten – ohne Jo-Jo-Effekt.
## Wie wirkt Nuvia?
Die Wirksamkeit von Nuvia basiert auf drei entscheidenden Mechanismen:
### Stoffwechsel-Booster
Durch ausgewählte Inhaltsstoffe wird der Energiestoffwechsel aktiviert. Der Körper verbrennt mehr Kalorien – selbst in Ruhephasen.
### Appetitkontrolle
Nuvia sorgt für ein längeres Sättigungsgefühl und hilft so, unnötiges Snacken zu vermeiden.
### Fettabbau statt Muskelabbau
Anders als bei vielen Diäten unterstützt **[Nuvia](https://www.diginear.com/2PGQH1JJ/215B937J/)** gezielt die Fettverbrennung, während die Muskulatur erhalten bleibt.
Das Ergebnis: spürbare Gewichtsabnahme, mehr Energie und ein besseres Körpergefühl.
## Warum Nuvia besser ist als herkömmliche Diäten
Viele Abnehmprodukte versprechen schnelle Ergebnisse – doch oft auf Kosten der Gesundheit. Nuvia hingegen punktet mit:
Natürlichen Inhaltsstoffen statt chemischer Zusätze
Langfristiger Wirkung statt kurzfristiger Crash-Effekte
Alltagstauglichkeit – keine komplizierten Ernährungspläne
Mehr Energie und Vitalität statt Müdigkeit und Antriebslosigkeit
Gerade in Deutschland, wo Stress im Alltag und wenig Zeit für Sport oft die größten Hindernisse darstellen, ist Nuvia eine ideale Unterstützung.
## Erfahrungen mit Nuvia in Deutschland
Viele Anwenderinnen und Anwender berichten von positiven Erfahrungen:
Schnelle Ergebnisse: Erste Veränderungen zeigen sich bereits nach wenigen Wochen.
Leichte Anwendung: Einfach in den Alltag integrierbar, ohne strenge Verbote.
Mehr Selbstbewusstsein: Ein gesünderes Körpergefühl wirkt sich auch auf das Selbstvertrauen aus.
Diese Erfahrungsberichte zeigen: **[Nuvia](https://www.diginear.com/2PGQH1JJ/215B937J/)** ist mehr als nur ein Nahrungsergänzungsmittel – es ist ein Lifestyle-Produkt.
## **[Klicken Sie hier, um auf der offiziellen Nuvia Website zu bestellen](https://www.diginear.com/2PGQH1JJ/215B937J/)**
## Für wen ist Nuvia geeignet?
Nuvia ist ideal für Menschen, die:
bereits mehrere Diäten ausprobiert haben – ohne Erfolg
trotz Sport nur schwer abnehmen
Heißhungerattacken nicht unter Kontrolle bekommen
eine langfristige, sichere Lösung für Gewichtsverlust suchen
Ob jung oder alt, Mann oder Frau – Nuvia passt zu jedem, der gesund und nachhaltig abnehmen möchte.
## So wird Nuvia angewendet
Die Einnahme ist unkompliziert:
Regelmäßig nach Anleitung konsumieren
Mit einer ausgewogenen Ernährung kombinieren
Leichte Bewegung unterstützt den Effekt zusätzlich
Durch die einfache Anwendung lässt sich **[Nuvia](https://www.diginear.com/2PGQH1JJ/215B937J/)** problemlos in den Alltag integrieren – ob im Büro, zu Hause oder unterwegs.
## Die Vorteile von Nuvia auf einen Blick
✔ Unterstützung bei der Fettverbrennung
✔ Reduzierung von Heißhungerattacken
✔ Mehr Energie im Alltag
✔ Einfach und sicher in der Anwendung
✔ Für langfristige Ergebnisse ohne Jo-Jo-Effekt
## Warum jetzt der richtige Zeitpunkt für Nuvia ist
Übergewicht bringt nicht nur optische Nachteile, sondern auch gesundheitliche Risiken wie Bluthochdruck, Diabetes oder Gelenkprobleme. Je früher man handelt, desto einfacher ist der Weg zum Wunschgewicht.
## Fazit: **[Nuvia](https://www.diginear.com/2PGQH1JJ/215B937J/)** als Schlüssel zu Ihrem neuen Ich
Wer in Deutschland nach einer sicheren, natürlichen und nachhaltigen Methode zum Abnehmen sucht, kommt an Nuvia nicht vorbei. Das Produkt vereint moderne Forschung mit natürlichen Inhaltsstoffen und sorgt dafür, dass Abnehmen endlich wieder Freude macht.
## **[Klicken Sie hier, um auf der offiziellen Nuvia Website zu bestellen](https://www.diginear.com/2PGQH1JJ/215B937J/)**
https://nuviapreis.wordpress.com/
https://nuviapreis.quora.com/
https://www.reddit.com/user/nuviapreis/
https://nuvia-preis.jimdosite.com/
https://zenodo.org/records/17105483
https://www.pixiv.net/en/artworks/135008980
https://www.provenexpert.com/nuvia-preis-deutschland/
https://site-tp25y1x60.godaddysites.com/
|
yufeng1/OpenThinker-7B-reasoning-lora-merged-type-c2r3-FilTered
|
yufeng1
| 2025-09-12T11:02:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:59:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
akatukime/laila-gpt-oss-20b-sft
|
akatukime
| 2025-09-12T11:02:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:37:14Z |
---
base_model: unsloth/gpt-oss-20b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** akatukime
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-unsloth-bnb-4bit
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
KGolden9/V3_Key8
|
KGolden9
| 2025-09-12T11:00:56Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-11T13:18:30Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
SeaniMoxxu/france_inter_trained_model
|
SeaniMoxxu
| 2025-09-12T11:00:50Z | 31 | 0 |
transformers
|
[
"transformers",
"safetensors",
"camembert",
"token-classification",
"generated_from_trainer",
"base_model:SeaniMoxxu/my_awesome_wnut_model",
"base_model:finetune:SeaniMoxxu/my_awesome_wnut_model",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-09T16:02:50Z |
---
library_name: transformers
license: mit
base_model: SeaniMoxxu/my_awesome_wnut_model
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: france_inter_trained_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# france_inter_trained_model
This model is a fine-tuned version of [SeaniMoxxu/my_awesome_wnut_model](https://huggingface.co/SeaniMoxxu/my_awesome_wnut_model) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0282
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 50 | 0.0315 | 0.0 | 0.0 | 0.0 | 0.9933 |
| No log | 2.0 | 100 | 0.0238 | 0.0 | 0.0 | 0.0 | 0.9929 |
| No log | 3.0 | 150 | 0.0310 | 0.0 | 0.0 | 0.0 | 0.9921 |
| No log | 4.0 | 200 | 0.0234 | 0.0 | 0.0 | 0.0 | 0.9933 |
| No log | 5.0 | 250 | 0.0274 | 0.0 | 0.0 | 0.0 | 0.9925 |
| No log | 6.0 | 300 | 0.0279 | 0.0 | 0.0 | 0.0 | 0.9929 |
| No log | 7.0 | 350 | 0.0281 | 0.0 | 0.0 | 0.0 | 0.9925 |
| No log | 8.0 | 400 | 0.0252 | 0.0 | 0.0 | 0.0 | 0.9933 |
| No log | 9.0 | 450 | 0.0286 | 0.0 | 0.0 | 0.0 | 0.9921 |
| 0.0163 | 10.0 | 500 | 0.0282 | 0.0 | 0.0 | 0.0 | 0.9925 |
### Framework versions
- Transformers 4.56.0
- Pytorch 2.8.0+cu129
- Datasets 4.0.0
- Tokenizers 0.22.0
|
usmanxia/llama3_1_roma_8bn_mergedv2
|
usmanxia
| 2025-09-12T11:00:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct",
"base_model:quantized:unsloth/Meta-Llama-3.1-8B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:38:10Z |
---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** usmanxia
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/Nemo12b-Creative-Base-15000-GGUF
|
mradermacher
| 2025-09-12T11:00:16Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:cgato/Nemo12b-Creative-Base-15000",
"base_model:quantized:cgato/Nemo12b-Creative-Base-15000",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:56:25Z |
---
base_model: cgato/Nemo12b-Creative-Base-15000
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/cgato/Nemo12b-Creative-Base-15000
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Nemo12b-Creative-Base-15000-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Nemo12b-Creative-Base-15000-GGUF/resolve/main/Nemo12b-Creative-Base-15000.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
cglez/bert-dapt-ohsumed-uncased
|
cglez
| 2025-09-12T10:57:31Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"en",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-09-12T10:51:22Z |
---
library_name: transformers
language: en
license: apache-2.0
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained BERT using <Dataset>.
## Model Details
### Model Description
A MLM-only pretrained BERT-base using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** MLM pretrained BERT
- **Language(s) (NLP):** English
- **License:** Apache license 2.0
- **Pretrained from model:** [BERT base model (uncased)](https://huggingface.co/google-bert/bert-base-uncased)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Uses
See <https://huggingface.co/google-bert/bert-base-uncased#intended-uses--limitations>.
### Checkpoint Use
[More Information Needed]
## Bias, Risks, and Limitations
See <https://huggingface.co/google-bert/bert-base-uncased#limitations-and-bias>.
## Training Details
See <https://huggingface.co/google-bert/bert-base-uncased#training-procedure>.
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 32
- **Gradient accumulation steps:** 3
## Environmental Impact
- **Hardware Type:** NVIDIA Tesla V100 PCIE 32GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
DennisS1/cwg
|
DennisS1
| 2025-09-12T10:55:59Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"region:us"
] |
text-to-image
| 2025-09-12T10:41:21Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screen Shot 2025-09-12 at 7.36.49 pm.png
text: Screenshot
base_model: Qwen/Qwen-Image
instance_prompt: cowgirl
---
# cwg
<Gallery />
## Trigger words
You should use `cowgirl` to trigger the image generation.
## Download model
[Download](/DennisS1/cwg/tree/main) them in the Files & versions tab.
|
DennisS1/missH
|
DennisS1
| 2025-09-12T10:53:14Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"region:us"
] |
text-to-image
| 2025-09-12T10:42:20Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screen Shot 2025-09-12 at 7.36.49 pm.png
text: Screenshot
base_model: Qwen/Qwen-Image
instance_prompt: missionary
---
# missH
<Gallery />
## Trigger words
You should use `missionary` to trigger the image generation.
## Download model
[Download](/DennisS1/missH/tree/main) them in the Files & versions tab.
|
lodestones/chroma-debug-development-only
|
lodestones
| 2025-09-12T10:53:02Z | 0 | 39 | null |
[
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2025-01-21T05:08:22Z |
---
license: cc-by-nc-sa-4.0
---
all model listed in this repo it's purely for research purpose
once it's ready it will be uploaded to a separate repo under apache 2.0 license
|
aractingi/act_test_V3
|
aractingi
| 2025-09-12T10:52:46Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:aractingi/test_V3",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-12T10:52:42Z |
---
datasets: aractingi/test_V3
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- robotics
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
Reihaneh/wav2vec2_da_mono_50_epochs_5
|
Reihaneh
| 2025-09-12T10:52:16Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T10:06:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Alicia22/Ali_Frid_F22
|
Alicia22
| 2025-09-12T10:51:20Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T10:47:26Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
russellyq/Qwen2.5-VL-7B-Instruct-Med-SFT-RL-1e
|
russellyq
| 2025-09-12T10:50:45Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:russellyq/Qwen2.5-VL-7B-Instruct-Med-SFT-RL-1e",
"base_model:adapter:russellyq/Qwen2.5-VL-7B-Instruct-Med-SFT-RL-1e",
"region:us"
] | null | 2025-09-12T10:48:30Z |
---
base_model: russellyq/Qwen2.5-VL-7B-Instruct-Med-SFT-RL-1e
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
kanishka/opt-babylm2-rewritten-clean-spacy-earlystop_ablate_both_strict-bpe_seed-211_1e-3
|
kanishka
| 2025-09-12T10:47:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"dataset:kanishka/babylm2-rewritten-clean-spacy_ablate_both_strict",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T03:02:03Z |
---
library_name: transformers
tags:
- generated_from_trainer
datasets:
- kanishka/babylm2-rewritten-clean-spacy_ablate_both_strict
metrics:
- accuracy
model-index:
- name: opt-babylm2-rewritten-clean-spacy-earlystop_ablate_both_strict-bpe_seed-211_1e-3
results:
- task:
name: Causal Language Modeling
type: text-generation
dataset:
name: kanishka/babylm2-rewritten-clean-spacy_ablate_both_strict
type: kanishka/babylm2-rewritten-clean-spacy_ablate_both_strict
metrics:
- name: Accuracy
type: accuracy
value: 0.47664621605549023
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opt-babylm2-rewritten-clean-spacy-earlystop_ablate_both_strict-bpe_seed-211_1e-3
This model was trained from scratch on the kanishka/babylm2-rewritten-clean-spacy_ablate_both_strict dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7066
- Accuracy: 0.4766
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 64
- seed: 211
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 32000
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:-----:|:---------------:|:--------:|
| 4.0225 | 1.0 | 2128 | 3.8652 | 0.3564 |
| 3.3883 | 2.0 | 4256 | 3.3528 | 0.4046 |
| 3.0811 | 3.0 | 6384 | 3.1280 | 0.4270 |
| 2.9244 | 4.0 | 8512 | 3.0149 | 0.4381 |
| 2.8264 | 5.0 | 10640 | 2.9520 | 0.4445 |
| 2.7612 | 6.0 | 12768 | 2.9125 | 0.4485 |
| 2.713 | 7.0 | 14896 | 2.8839 | 0.4518 |
| 2.6812 | 8.0 | 17024 | 2.8632 | 0.4542 |
| 2.6582 | 9.0 | 19152 | 2.8471 | 0.4562 |
| 2.6388 | 10.0 | 21280 | 2.8361 | 0.4575 |
| 2.6198 | 11.0 | 23408 | 2.8260 | 0.4583 |
| 2.6073 | 12.0 | 25536 | 2.8197 | 0.4593 |
| 2.5951 | 13.0 | 27664 | 2.8109 | 0.4604 |
| 2.5836 | 14.0 | 29792 | 2.8080 | 0.4608 |
| 2.5757 | 15.0 | 31920 | 2.8060 | 0.4607 |
| 2.5623 | 16.0 | 34048 | 2.7745 | 0.4646 |
| 2.512 | 17.0 | 36176 | 2.7508 | 0.4684 |
| 2.4521 | 18.0 | 38304 | 2.7283 | 0.4716 |
| 2.3841 | 19.0 | 40432 | 2.7111 | 0.4748 |
| 2.3045 | 19.9909 | 42540 | 2.7066 | 0.4766 |
### Framework versions
- Transformers 4.48.0
- Pytorch 2.6.0+cu124
- Datasets 3.2.0
- Tokenizers 0.21.1
|
hyunjong7/qwen2-5-vl-32b-fire-finetun
|
hyunjong7
| 2025-09-12T10:46:56Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-VL-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-25T12:09:29Z |
---
base_model: Qwen/Qwen2.5-VL-32B-Instruct
library_name: transformers
model_name: qwen2-5-vl-32b-fire-finetun
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for qwen2-5-vl-32b-fire-finetun
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="hyunjong7/qwen2-5-vl-32b-fire-finetun", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.4
- Pytorch: 2.8.0
- Datasets: 3.0.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
cglez/bert-dapt-ag_news
|
cglez
| 2025-09-12T10:45:44Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"en",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-09-12T10:39:28Z |
---
library_name: transformers
language: en
license: apache-2.0
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained BERT using <Dataset>.
## Model Details
### Model Description
A MLM-only pretrained BERT-base using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** MLM pretrained BERT
- **Language(s) (NLP):** English
- **License:** Apache license 2.0
- **Pretrained from model:** [BERT base model (uncased)](https://huggingface.co/google-bert/bert-base-uncased)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Uses
See <https://huggingface.co/google-bert/bert-base-uncased#intended-uses--limitations>.
### Checkpoint Use
[More Information Needed]
## Bias, Risks, and Limitations
See <https://huggingface.co/google-bert/bert-base-uncased#limitations-and-bias>.
## Training Details
See <https://huggingface.co/google-bert/bert-base-uncased#training-procedure>.
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 32
- **Gradient accumulation steps:** 3
## Environmental Impact
- **Hardware Type:** NVIDIA Tesla V100 PCIE 32GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
Alicia22/Ali_Frid_F21
|
Alicia22
| 2025-09-12T10:44:52Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T10:42:21Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
cglez/bert-ag_news-uncased
|
cglez
| 2025-09-12T10:44:31Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"en",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-09-12T10:39:28Z |
---
library_name: transformers
language: en
license: apache-2.0
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained BERT using <Dataset>.
## Model Details
### Model Description
A MLM-only pretrained BERT-base using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** MLM pretrained BERT
- **Language(s) (NLP):** English
- **License:** Apache license 2.0
- **Pretrained from model:** [BERT base model (uncased)](https://huggingface.co/google-bert/bert-base-uncased)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Uses
See <https://huggingface.co/google-bert/bert-base-uncased#intended-uses--limitations>.
### Checkpoint Use
[More Information Needed]
## Bias, Risks, and Limitations
See <https://huggingface.co/google-bert/bert-base-uncased#limitations-and-bias>.
## Training Details
See <https://huggingface.co/google-bert/bert-base-uncased#training-procedure>.
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 32
- **Gradient accumulation steps:** 3
## Environmental Impact
- **Hardware Type:** NVIDIA Tesla V100 PCIE 32GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
kavanmevada/eng-sentence-model
|
kavanmevada
| 2025-09-12T10:43:24Z | 41 | 0 |
transformers
|
[
"transformers",
"safetensors",
"smollm3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-10T22:05:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DennisS1/nface1
|
DennisS1
| 2025-09-12T10:43:23Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"region:us"
] |
text-to-image
| 2025-09-12T10:39:24Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screen Shot 2025-09-12 at 7.36.49 pm.png
text: Screenshot
base_model: Qwen/Qwen-Image
instance_prompt: nface
---
# nface1
<Gallery />
## Trigger words
You should use `nface` to trigger the image generation.
## Download model
[Download](/DennisS1/nface1/tree/main) them in the Files & versions tab.
|
fpadovani/cds_10_original_42
|
fpadovani
| 2025-09-12T10:43:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:21:47Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: trainer_output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trainer_output
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 499 | 3.3359 |
| No log | 2.0 | 998 | 3.1191 |
| 3.5115 | 3.0 | 1497 | 3.0401 |
| 3.5115 | 4.0 | 1996 | 2.9982 |
| 2.666 | 5.0 | 2495 | 2.9833 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.22.0
|
systbs/zarvan-checkpoints
|
systbs
| 2025-09-12T10:42:42Z | 685 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T05:56:32Z |
---
license: apache-2.0
---
|
saracandu/stldec_random_32_umap
|
saracandu
| 2025-09-12T10:42:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stldec32umap",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:41:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Yuchan5386/lamko-prototype
|
Yuchan5386
| 2025-09-12T10:42:22Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T08:59:33Z |
---
license: apache-2.0
---
|
karoszyn/qwen2-7b-instruct-trl-sft-ChartQA
|
karoszyn
| 2025-09-12T10:41:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2-VL-7B-Instruct-AWQ",
"base_model:finetune:Qwen/Qwen2-VL-7B-Instruct-AWQ",
"endpoints_compatible",
"region:us"
] | null | 2025-09-10T12:19:12Z |
---
base_model: Qwen/Qwen2-VL-7B-Instruct-AWQ
library_name: transformers
model_name: qwen2-7b-instruct-trl-sft-ChartQA
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for qwen2-7b-instruct-trl-sft-ChartQA
This model is a fine-tuned version of [Qwen/Qwen2-VL-7B-Instruct-AWQ](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct-AWQ).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="karoszyn/qwen2-7b-instruct-trl-sft-ChartQA", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.24.0.dev0
- Transformers: 4.56.1
- Pytorch: 2.2.1+cu121
- Datasets: 3.6.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
bshyrbdallhbdallh/blockassist
|
bshyrbdallhbdallh
| 2025-09-12T10:41:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly quick grasshopper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T09:57:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly quick grasshopper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
grandhigh/Chatterbox-TTS-Indonesian
|
grandhigh
| 2025-09-12T10:40:10Z | 1 | 0 |
chatterbox
|
[
"chatterbox",
"safetensors",
"audio",
"speech",
"tts",
"fine-tuning",
"voice-cloning",
"zero-shot",
"text-to-speech",
"id",
"dataset:grandhigh/Espeak-ID-5K",
"base_model:ResembleAI/chatterbox",
"base_model:finetune:ResembleAI/chatterbox",
"license:mit",
"region:us"
] |
text-to-speech
| 2025-09-09T16:11:52Z |
---
license: mit
datasets:
- grandhigh/Espeak-ID-5K
language:
- id
base_model:
- ResembleAI/chatterbox
pipeline_tag: text-to-speech
tags:
- audio
- speech
- tts
- fine-tuning
- chatterbox
- voice-cloning
- zero-shot
---
# Chatterbox TTS Indonesian 🎭
**Chatterbox TTS Indonesian** is a fine-tuned text-to-speech model specialized for the Indonesian language.
- 🔊 **Language**: Indonesian <sup>ɪᴅ</sup>
- 🗣️ **Training dataset**: [Esepak ID 5K Dataset](https://huggingface.co/datasets/grandhigh/Espeak-ID-5K)
## Usage Example
Here’s how to generate speech using Chatterbox-TTS Indonesian:
```python
import torch
from IPython.display import Audio
from chatterbox.tts import ChatterboxTTS
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
MODEL_REPO = "grandhigh/Chatterbox-TTS-Indonesian"
CHECKPOINT_FILENAME = "t3_cfg.safetensors"
TEXT_TO_SYNTHESIZE = "Bahwa sesungguhnya kemerdekaan itu ialah hak segala bangsa dan oleh sebab itu, maka penjajahan di atas dunia harus dihapuskan, karena tidak sesuai dengan perikemanusiaan dan perikeadilan."
model = ChatterboxTTS.from_pretrained(device="cuda")
checkpoint_path = hf_hub_download(repo_id=MODEL_REPO, filename=CHECKPOINT_FILENAME)
t3_state = load_file(checkpoint_path, device="cpu")
model.t3.load_state_dict(t3_state)
wav_audio = model.generate(TEXT_TO_SYNTHESIZE, audio_prompt_path=None)
display(Audio(wav_audio.numpy(), rate=model.sr))
```
Here is the output:
<audio controls src="https://huggingface.co/grandhigh/Chatterbox-TTS-Indonesian/resolve/main/example.wav">Your browser does not support audio.</audio>
### Base model license
The base model is licensed under the MIT License.
Base model: [Chatterbox](https://huggingface.co/ResembleAI/chatterbox)
License: [MIT](https://choosealicense.com/licenses/mit/)
### Training Data License
This model was fine-tuned using a dataset MIT.
Dataset: [Esepak ID 5K](https://huggingface.co/datasets/grandhigh/Espeak-ID-5K)
License: [MIT](https://choosealicense.com/licenses/mit/)
|
Fate-Zero/Archer2.0-Code-1.5B-Preview
|
Fate-Zero
| 2025-09-12T10:39:55Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-04T07:33:31Z |
---
license: apache-2.0
---
<table>
<thead>
<tr>
<th rowspan="2">Method</th>
<th colspan="2">LCB v5 (2024.08.01–2025.02.01)</th>
<th colspan="2">LCB v6 (2025.02.01–2025.05.01)</th>
<th rowspan="2">Avg.</th>
</tr>
<tr>
<th>avg@8</th>
<th>pass@8</th>
<th>avg@16</th>
<th>pass@16</th>
</tr>
</thead>
<tbody>
<tr>
<td>DeepSeek-R1-1.5B</td>
<td>16.7</td>
<td>29.0</td>
<td>17.2</td>
<td>34.4</td>
<td>17.0</td>
</tr>
<tr>
<td>DAPO</td>
<td>26.0</td>
<td>40.5</td>
<td>27.6</td>
<td>43.5</td>
<td>26.8</td>
</tr>
<tr>
<td>DeepCoder-1.5B</td>
<td>23.3</td>
<td>39.1</td>
<td>22.6</td>
<td>42.0</td>
<td>23.0</td>
</tr>
<tr>
<td>Nemotron-1.5B</td>
<td>26.1</td>
<td>35.5</td>
<td>29.5</td>
<td>42.8</td>
<td>27.8</td>
</tr>
<tr>
<td><strong>Archer-Code-1.5B</strong></td>
<td><strong>29.4</strong></td>
<td><strong>43.7</strong></td>
<td><strong>30.2</strong></td>
<td><strong>45.8</strong></td>
<td><strong>29.8</strong></td>
</tr>
<tr>
<td><strong>Archer2.0-Code-1.5B</strong></td>
<td><strong>*</strong></td>
<td><strong>*</strong></td>
<td><strong>*</strong></td>
<td><strong>*</strong></td>
<td><strong>*</strong></td>
</tr>
</tbody>
</table>
|
BurgerTruck/mnli-all-bart
|
BurgerTruck
| 2025-09-12T10:39:34Z | 123 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-07-25T06:05:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Oshadha-Emojot/finetuned_model
|
Oshadha-Emojot
| 2025-09-12T10:38:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"base_model:finetune:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T10:38:09Z |
---
base_model: unsloth/Phi-3-mini-4k-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Oshadha-Emojot
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Phi-3-mini-4k-instruct-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BurgerTruck/distilbart-classifier
|
BurgerTruck
| 2025-09-12T10:38:33Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-02-14T09:05:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
akatukime/laila-gpt-oss-20b-adapter
|
akatukime
| 2025-09-12T10:37:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gpt_oss",
"trl",
"en",
"base_model:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gpt-oss-20b-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T10:37:06Z |
---
base_model: unsloth/gpt-oss-20b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gpt_oss
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** akatukime
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gpt-oss-20b-unsloth-bnb-4bit
This gpt_oss model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
fafsfa/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-diving_clawed_flamingo
|
fafsfa
| 2025-09-12T10:36:59Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am diving_clawed_flamingo",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T14:38:22Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am diving_clawed_flamingo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JOECHAN890/beitv2-base-beans
|
JOECHAN890
| 2025-09-12T10:35:56Z | 36 | 0 |
transformers
|
[
"transformers",
"safetensors",
"timm_wrapper",
"image-classification",
"vision",
"timm",
"generated_from_trainer",
"base_model:timm/beitv2_base_patch16_224.in1k_ft_in22k",
"base_model:finetune:timm/beitv2_base_patch16_224.in1k_ft_in22k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-28T03:51:53Z |
---
library_name: transformers
license: apache-2.0
base_model: timm/beitv2_base_patch16_224.in1k_ft_in22k
tags:
- image-classification
- vision
- timm
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: beitv2-base-beans
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beitv2-base-beans
This model is a fine-tuned version of [timm/beitv2_base_patch16_224.in1k_ft_in22k](https://huggingface.co/timm/beitv2_base_patch16_224.in1k_ft_in22k) on the AI-Lab-Makerere/beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0003
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0435 | 1.0 | 130 | 0.1193 | 0.9624 |
| 0.1536 | 2.0 | 260 | 0.0023 | 1.0 |
| 0.183 | 3.0 | 390 | 0.0015 | 1.0 |
| 0.2256 | 4.0 | 520 | 0.0386 | 0.9850 |
| 0.0555 | 5.0 | 650 | 0.0340 | 0.9850 |
| 0.0713 | 6.0 | 780 | 0.0728 | 0.9925 |
| 0.0082 | 7.0 | 910 | 0.0411 | 0.9925 |
| 0.0085 | 8.0 | 1040 | 0.1002 | 0.9850 |
| 0.0733 | 9.0 | 1170 | 0.0004 | 1.0 |
| 0.0215 | 10.0 | 1300 | 0.0003 | 1.0 |
| 0.0501 | 11.0 | 1430 | 0.0634 | 0.9774 |
| 0.0338 | 12.0 | 1560 | 0.0248 | 0.9925 |
| 0.0045 | 13.0 | 1690 | 0.0939 | 0.9850 |
| 0.0013 | 14.0 | 1820 | 0.0373 | 0.9850 |
| 0.0002 | 15.0 | 1950 | 0.0515 | 0.9925 |
| 0.0074 | 16.0 | 2080 | 0.0017 | 1.0 |
| 0.0005 | 17.0 | 2210 | 0.0588 | 0.9925 |
| 0.0046 | 18.0 | 2340 | 0.0715 | 0.9850 |
| 0.0618 | 19.0 | 2470 | 0.0003 | 1.0 |
| 0.0007 | 20.0 | 2600 | 0.0697 | 0.9850 |
| 0.0001 | 21.0 | 2730 | 0.1105 | 0.9774 |
| 0.0214 | 22.0 | 2860 | 0.0930 | 0.9850 |
| 0.0004 | 23.0 | 2990 | 0.0272 | 0.9925 |
| 0.1619 | 24.0 | 3120 | 0.0024 | 1.0 |
| 0.0015 | 25.0 | 3250 | 0.0003 | 1.0 |
| 0.0148 | 26.0 | 3380 | 0.1312 | 0.9774 |
| 0.0482 | 27.0 | 3510 | 0.0873 | 0.9850 |
| 0.0001 | 28.0 | 3640 | 0.0721 | 0.9850 |
| 0.0954 | 29.0 | 3770 | 0.0143 | 0.9925 |
| 0.1373 | 30.0 | 3900 | 0.0449 | 0.9925 |
| 0.0076 | 31.0 | 4030 | 0.0435 | 0.9925 |
| 0.0028 | 32.0 | 4160 | 0.0101 | 0.9925 |
| 0.0001 | 33.0 | 4290 | 0.0414 | 0.9850 |
| 0.001 | 34.0 | 4420 | 0.0017 | 1.0 |
| 0.0055 | 35.0 | 4550 | 0.0733 | 0.9925 |
| 0.1471 | 36.0 | 4680 | 0.1221 | 0.9774 |
| 0.0484 | 37.0 | 4810 | 0.1473 | 0.9850 |
| 0.0014 | 38.0 | 4940 | 0.0748 | 0.9925 |
| 0.1825 | 39.0 | 5070 | 0.1072 | 0.9850 |
| 0.0 | 40.0 | 5200 | 0.0687 | 0.9925 |
| 0.0081 | 41.0 | 5330 | 0.1147 | 0.9850 |
| 0.0557 | 42.0 | 5460 | 0.0630 | 0.9850 |
| 0.0 | 43.0 | 5590 | 0.0162 | 0.9925 |
| 0.0 | 44.0 | 5720 | 0.0463 | 0.9925 |
| 0.0197 | 45.0 | 5850 | 0.0757 | 0.9850 |
| 0.1442 | 46.0 | 5980 | 0.0941 | 0.9850 |
| 0.0019 | 47.0 | 6110 | 0.0760 | 0.9850 |
| 0.0001 | 48.0 | 6240 | 0.0885 | 0.9850 |
| 0.0854 | 49.0 | 6370 | 0.0788 | 0.9850 |
| 0.0005 | 50.0 | 6500 | 0.0707 | 0.9850 |
### Framework versions
- Transformers 4.54.1
- Pytorch 2.7.1+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
kboss45253/blockassist
|
kboss45253
| 2025-09-12T10:33:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T09:43:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
cuongdk253/gpt-oss-20b-ft
|
cuongdk253
| 2025-09-12T10:31:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T10:31:24Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-ft
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gpt-oss-20b-ft
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="cuongdk253/gpt-oss-20b-ft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0.dev20250319+cu128
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
cpatonn/Qwen3-Next-80B-A3B-Thinking-AWQ-4bit
|
cpatonn
| 2025-09-12T10:31:12Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"arxiv:2501.15383",
"base_model:Qwen/Qwen3-Next-80B-A3B-Thinking",
"base_model:quantized:Qwen/Qwen3-Next-80B-A3B-Thinking",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-09-12T10:24:42Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-Next-80B-A3B-Thinking
---
# Qwen3-Next-80B-A3B-Thinking
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Leveraging [GSPO](https://qwenlm.github.io/blog/gspo/), we have addressed the stability and efficiency challenges posed by the hybrid attention mechanism combined with a high-sparsity MoE architecture in RL training.
Qwen3-Next-80B-A3B-Thinking demonstrates outstanding performance on complex reasoning tasks, not only **surpassing Qwen3-30B-A3B-Thinking-2507 and Qwen3-32B-Thinking**, but also **outperforming the proprietary model Gemini-2.5-Flash-Thinking** across multiple benchmarks.
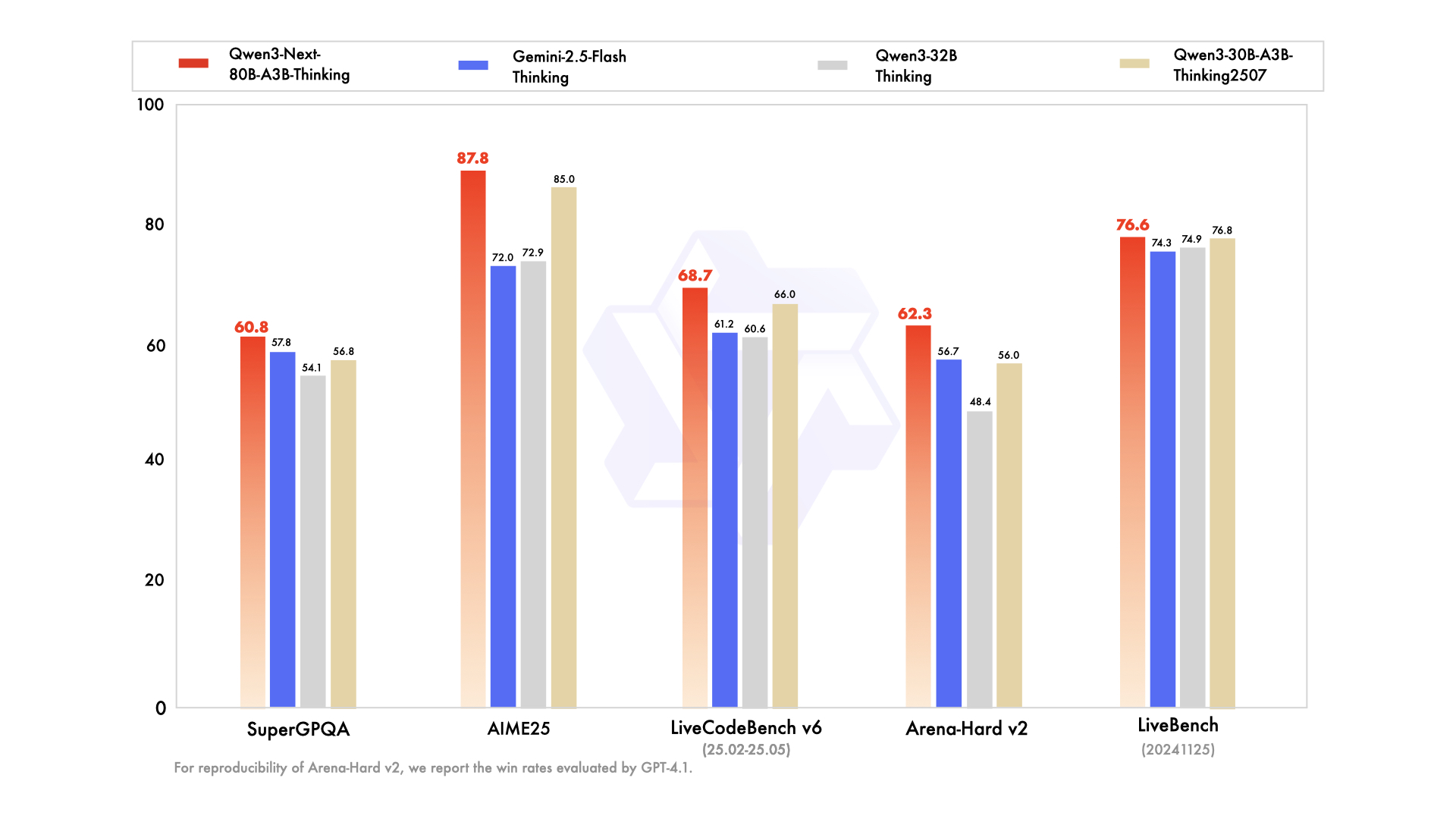
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Thinking** supports only thinking mode.
> To enforce model thinking, the default chat template automatically includes `<think>`.
> Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
> [!Note]
> **Qwen3-Next-80B-A3B-Thinking** may generate thinking content longer than its predecessor.
> We strongly recommend its use in highly complex reasoning tasks.
**Qwen3-Next-80B-A3B-Thinking** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
| | Qwen3-30B-A3B-Thinking-2507 | Qwen3-32B Thinking | Qwen3-235B-A22B-Thinking-2507 | Gemini-2.5-Flash Thinking | Qwen3-Next-80B-A3B-Thinking |
|--- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 80.9 | 79.1 | **84.4** | 81.9 | 82.7 |
| MMLU-Redux | 91.4 | 90.9 | **93.8** | 92.1 | 92.5 |
| GPQA | 73.4 | 68.4 | 81.1 | **82.8** | 77.2 |
| SuperGPQA | 56.8 | 54.1 | **64.9** | 57.8 | 60.8 |
| **Reasoning** | | | | |
| AIME25 | 85.0 | 72.9 | **92.3** | 72.0 | 87.8 |
| HMMT25 | 71.4 | 51.5 | **83.9** | 64.2 | 73.9 |
| LiveBench 241125 | 76.8 | 74.9 | **78.4** | 74.3 | 76.6 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 66.0 | 60.6 | **74.1** | 61.2 | 68.7 |
| CFEval | 2044 | 1986 | **2134** | 1995 | 2071 |
| OJBench | 25.1 | 24.1 | **32.5** | 23.5 | 29.7 |
| **Alignment** | | | | |
| IFEval | 88.9 | 85.0 | 87.8 | **89.8** | 88.9 |
| Arena-Hard v2* | 56.0 | 48.4 | **79.7** | 56.7 | 62.3 |
| WritingBench | 85.0 | 79.0 | **88.3** | 83.9 | 84.6 |
| **Agent** | | | | |
| BFCL-v3 | **72.4** | 70.3 | 71.9 | 68.6 | 72.0 |
| TAU1-Retail | 67.8 | 52.8 | 67.8 | 65.2 | **69.6** |
| TAU1-Airline | 48.0 | 29.0 | 46.0 | **54.0** | 49.0 |
| TAU2-Retail | 58.8 | 49.7 | **71.9** | 66.7 | 67.8 |
| TAU2-Airline | 58.0 | 45.5 | 58.0 | 52.0 | **60.5** |
| TAU2-Telecom | 26.3 | 27.2 | **45.6** | 31.6 | 43.9 |
| **Multilingualism** | | | | |
| MultiIF | 76.4 | 73.0 | **80.6** | 74.4 | 77.8 |
| MMLU-ProX | 76.4 | 74.6 | **81.0** | 80.2 | 78.7 |
| INCLUDE | 74.4 | 73.7 | 81.0 | **83.9** | 78.9 |
| PolyMATH | 52.6 | 47.4 | **60.1** | 49.8 | 56.3 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K.
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install git+https://github.com/vllm-project/vllm.git
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K.
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Thinking',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --served-model-name Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
flockgo/task-14-microsoft-Phi-4-mini-instruct
|
flockgo
| 2025-09-12T10:31:00Z | 990 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/Phi-4-mini-instruct",
"base_model:adapter:microsoft/Phi-4-mini-instruct",
"region:us"
] | null | 2025-08-17T03:22:02Z |
---
base_model: microsoft/Phi-4-mini-instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
jq/qwen3-14b-sunflower-20250911
|
jq
| 2025-09-12T10:30:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:jq/sunflower-qwen14b-pretrained",
"base_model:finetune:jq/sunflower-qwen14b-pretrained",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T16:47:33Z |
---
base_model: jq/sunflower-qwen14b-pretrained
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** jq
- **License:** apache-2.0
- **Finetuned from model :** jq/sunflower-qwen14b-pretrained
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cpatonn/Qwen3-Next-80B-A3B-Instruct-AWQ-4bit
|
cpatonn
| 2025-09-12T10:30:04Z | 0 | 2 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2404.06654",
"arxiv:2505.09388",
"arxiv:2501.15383",
"base_model:Qwen/Qwen3-Next-80B-A3B-Instruct",
"base_model:quantized:Qwen/Qwen3-Next-80B-A3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-09-12T10:23:23Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-Next-80B-A3B-Instruct
---
# Qwen3-Next-80B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Qwen3-Next-80B-A3B-Instruct performs on par with Qwen3-235B-A22B-Instruct-2507 on certain benchmarks, while demonstrating significant advantages in handling ultra-long-context tasks up to 256K tokens.
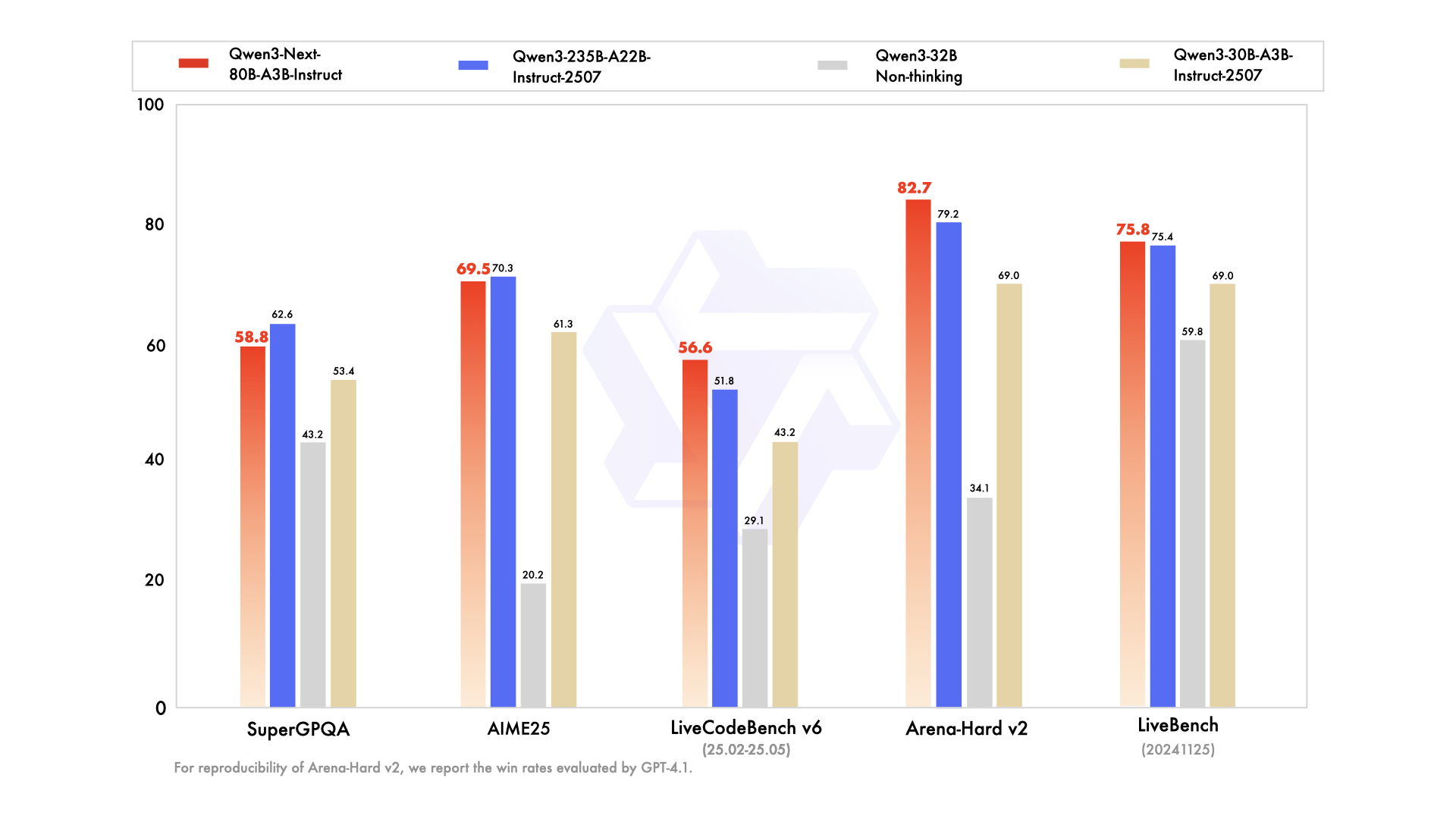
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Instruct** supports only instruct (non-thinking) mode and does not generate ``<think></think>`` blocks in its output.
**Qwen3-Next-80B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
| | Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 78.4 | 71.9 | **83.0** | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | **93.1** | 90.9 |
| GPQA | 70.4 | 54.6 | **77.5** | 72.9 |
| SuperGPQA | 53.4 | 43.2 | **62.6** | 58.8 |
| **Reasoning** | | | | |
| AIME25 | 61.3 | 20.2 | **70.3** | 69.5 |
| HMMT25 | 43.0 | 9.8 | **55.4** | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | **75.8** |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | **56.6** |
| MultiPL-E | 83.8 | 76.9 | **87.9** | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | **57.3** | 49.8 |
| **Alignment** | | | | |
| IFEval | 84.7 | 83.2 | **88.7** | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | **82.7** |
| Creative Writing v3 | 86.0 | 78.3 | **87.5** | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | **87.3** |
| **Agent** | | | | |
| BFCL-v3 | 65.1 | 63.0 | **70.9** | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | **71.3** | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | **44.0** | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | **74.6** | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | **50.0** | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | **32.5** | 13.2 |
| **Multilingualism** | | | | |
| MultiIF | 67.9 | 70.7 | **77.5** | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | **79.4** | 76.7 |
| INCLUDE | 71.9 | 70.9 | **79.5** | 78.9 |
| PolyMATH | 43.1 | 22.5 | **50.2** | 45.9 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install git+https://github.com/vllm-project/vllm.git
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
* Qwen3-Next are evaluated with YaRN enabled. Qwen3-2507 models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
masoodGam/blockassist
|
masoodGam
| 2025-09-12T10:27:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked beaked cobra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T08:30:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked beaked cobra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Arun63/llama-3.1.8b-finetune-v1-4bit
|
Arun63
| 2025-09-12T10:24:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-09-12T10:23:24Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Arun63
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757672525
|
stonermay
| 2025-09-12T10:23:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T10:23:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Hjambatukam/blockassist
|
Hjambatukam
| 2025-09-12T10:22:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silent bellowing boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T11:34:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silent bellowing boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gagneurlab/Modanovo-model
|
gagneurlab
| 2025-09-12T10:21:18Z | 0 | 0 | null |
[
"dataset:gagneurlab/Modanovo-development-dataset",
"doi:10.57967/hf/6451",
"license:apache-2.0",
"region:us"
] | null | 2025-09-09T12:49:35Z |
---
license: apache-2.0
datasets:
- gagneurlab/Modanovo-development-dataset
---
|
DreamGallery/task-14-Qwen-Qwen2.5-3B-Instruct
|
DreamGallery
| 2025-09-12T10:21:02Z | 187 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-3B-Instruct",
"region:us"
] | null | 2025-09-08T09:07:35Z |
---
base_model: Qwen/Qwen2.5-3B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
cglez/gpt2-ag_news
|
cglez
| 2025-09-12T10:18:17Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:13:13Z |
---
library_name: transformers
language: en
license: mit
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained GPT2 using <Dataset>.
## Model Details
### Model Description
A pretrained GPT2 using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** pretrained GPT2
- **Language(s) (NLP):** English
- **License:** MIT
- **Pretrained from model:** [GPT2](https://huggingface.co/openai-community/gpt2)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Intended Uses & Limitations
See <https://huggingface.co/openai-community/gpt2#intended-uses--limitations>.
### Loading Checkpoints
[More Information Needed]
## Training Details
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 8
- **Gradient accumulation steps:** 12
## Environmental Impact
- **Hardware Type:** NVIDIA A100 PCIE 40GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
PharasiG/distilbert-sst2-baseline
|
PharasiG
| 2025-09-12T10:16:51Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-12T09:29:48Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-sst2-baseline
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-sst2-baseline
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2908
- Accuracy: 0.8796
- F1: 0.8795
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- training_steps: 800
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|
| 0.3408 | 0.1900 | 800 | 0.2908 | 0.8796 | 0.8795 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
Frank94/Qwen2.5-VL-7B-MYB-2K-MERGED
|
Frank94
| 2025-09-12T10:16:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-12T10:09:24Z |
---
base_model: unsloth/qwen2.5-vl-7b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Frank94
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-vl-7b-instruct-bnb-4bit
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Luka512/CosyVoice2-0.5B-EU
|
Luka512
| 2025-09-12T10:15:42Z | 0 | 0 | null |
[
"onnx",
"safetensors",
"text-to-speech",
"en",
"de",
"fr",
"zh",
"ko",
"ja",
"arxiv:2412.10117",
"base_model:FunAudioLLM/CosyVoice2-0.5B",
"base_model:quantized:FunAudioLLM/CosyVoice2-0.5B",
"license:apache-2.0",
"region:us"
] |
text-to-speech
| 2025-07-07T11:46:57Z |
---
license: apache-2.0
language:
- en
- de
- fr
- zh
- ko
- ja
base_model:
- FunAudioLLM/CosyVoice2-0.5B
- Qwen/Qwen3-0.6B
- utter-project/EuroLLM-1.7B-Instruct
- mistralai/Mistral-7B-v0.3
pipeline_tag: text-to-speech
---
<p align="center">
<img src="https://horstmann.tech/cosyvoice2-demo/cosyvoice2-logo-clear.png" alt="CosyVoice2-EU logo" width="260">
</p>
# CosyVoice2-0.5B-EU — FR/DE Zero-Shot Voice Cloning (CosyVoice2)
**Europeanized CosyVoice2 for French & German.**
Plug-and-play zero-shot voice cloning with streaming support, bilingual training (FR+DE), and a simple CLI via the companion PyPI package.
**👉 PyPI:** `cosyvoice2-eu` (current: **0.2.7**) at https://pypi.org/project/cosyvoice2-eu/
**👉 Demo:** https://horstmann.tech/cosyvoice2-demo/
**👉 Built on:** FunAudioLLM **CosyVoice2** (semantic LM + chunk-aware flow + HiFi-GAN)
---
## TL;DR
High-quality **French/German** zero-shot TTS (text + short reference audio) built on **CosyVoice2**. Optimized for sentence-to-paragraph narration, bilingual FR+DE adaptation, and easy local inference.
While this model is optimized for French and German, it remains fully compatible with the original CosyVoice2 languages — English, Chinese, Japanese, Korean, and their dialects.
---
## Quickstart (CLI)
Install:
```bash
pip install cosyvoice2-eu
```
French example:
```bash
cosy2-eu --text "Salut ! Je vous présente CosyVoice 2, un système de synthèse vocale très avancé." --prompt path/to/french_ref.wav --out out_fr.wav
```
German example:
```bash
cosy2-eu --text "Hallo! Ich präsentiere CosyVoice 2 – ein fortschrittliches TTS-System." --prompt path/to/german_ref.wav --out out_de.wav
```
> First run downloads the model from this repo and caches it locally.
> Tip: You can experiment with prompts for style control using `"<style>. <|endofprompt|> <text>"`, e.g., "Speak cheerfully. <|endofprompt|> Hallo! Wie geht es Ihnen heute?"
---
## What you get
- **Zero-shot voice cloning** for **FR/DE** (reference audio → cloned timbre & style).
- **Bilingual adaptation** (FR+DE) on top of CosyVoice2 for stronger data efficiency. While this model adds support for French and German, it remains fully compatible with the original CosyVoice2 languages — English, Chinese, Japanese, Korean, and their dialects.
- **Streaming & non-streaming** synthesis supported by the underlying architecture.
- **Simple local inference**: one pip install, one CLI (`cosy2-eu`).
- **Interoperable components** (text→semantic LM, flow decoder, HiFi-GAN vocoder).
Also compatible with original CosyVoice2 languages (EN/ZH/JA/KO & dialects).
---
## Inputs / Outputs
- **Input:** text (FR/DE) + short **reference audio** (mono WAV recommended).
- **Output:** synthesized WAV cloning the reference speaker’s timbre, speaking the input text in FR/DE.
---
## Notes & limitations
- FR/DE were adapted under constrained open-data budgets; extreme edge cases (very noisy prompts, long numerics, heavy code-switching) may require careful prompting or additional fine-tuning.
- Voice cloning carries **misuse risks** (impersonation, fraud). Use only with consent and follow local laws/policies.
---
## License & attribution
- **License:** Apache-2.0 (see card metadata / repo).
- Built on **CosyVoice2** by FunAudioLLM; please cite their work (see below).
---
**Links**
- PyPI (inference CLI): https://pypi.org/project/cosyvoice2-eu/
- Upstream project: https://github.com/FunAudioLLM/CosyVoice
- CosyVoice2 paper & page: https://arxiv.org/abs/2412.10117 • https://funaudiollm.github.io/cosyvoice2/
---
*If you use CosyVoice2-0.5B-EU in research or products, please add a short acknowledgment and share feedback or samples—we’re continuously improving FR/DE expressiveness and robustness.*
|
5456es/random_prune_Llama-3.1-8B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T10:13:55Z | 29 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-09T04:36:12Z |
---
license: apache-2.0
base_model: Llama-3.1-8B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Llama-3.1-8B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.1-8B-Instruct using the random method.
## Model Details
- **Base Model**: Llama-3.1-8B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Llama-3.1-8B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
ryzax/1.5B-v67
|
ryzax
| 2025-09-12T10:13:42Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-10T23:57:22Z |
---
library_name: transformers
model_name: 1.5B-v67
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for 1.5B-v67
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ryzax/1.5B-v67", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/muennighoff/s2/runs/a8wsz6yx)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.0.dev0
- Transformers: 4.55.4
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
5456es/implicit_reward_Qwen2.5-0.5B-Instruct_prune_0.5-sigmoid
|
5456es
| 2025-09-12T10:12:43Z | 28 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"implicit",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-07T05:32:38Z |
---
license: apache-2.0
base_model: Qwen2.5-0.5B-Instruct
tags:
- dpo
- preference-learning
- implicit
- pruned
---
# implicit_reward_Qwen2.5-0.5B-Instruct_prune_0.5-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-0.5B-Instruct using the implicit method.
## Model Details
- **Base Model**: Qwen2.5-0.5B-Instruct
- **Training Method**: implicit
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: implicit
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/implicit_reward_Qwen2.5-0.5B-Instruct_prune_0.5-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
mradermacher/STELLA-VLM-32b-i1-GGUF
|
mradermacher
| 2025-09-12T10:12:39Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"vision-language",
"multimodal",
"grpo",
"fine-tuned",
"en",
"base_model:Zaixi/STELLA-VLM-32b",
"base_model:quantized:Zaixi/STELLA-VLM-32b",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-12T08:08:20Z |
---
base_model: Zaixi/STELLA-VLM-32b
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- vision-language
- multimodal
- grpo
- fine-tuned
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Zaixi/STELLA-VLM-32b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#STELLA-VLM-32b-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF/resolve/main/STELLA-VLM-32b.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
AXERA-TECH/libsr.axera
|
AXERA-TECH
| 2025-09-12T10:12:28Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-12T09:35:59Z |
# EDSR
AXERA version of the paper 'Enhanced Deep Residual Networks for Single Image Super-Resolution' (CVPRW 2017)
## Build
### x86 Build
```bash
git clone --recursive https://github.com/AXERA-TECH/libsr.axera.git
cd libsr.axera
sudo apt install libopencv-dev build-essential
./build.sh
```
### AArch64 Build
#### Cross-compile for aarch64
```bash
git clone --recursive https://github.com/AXERA-TECH/libsr.axera.git
cd libsr.axera
./build_aarch64.sh
```
#### Native Build on Target Board
```bash
git clone --recursive https://github.com/AXERA-TECH/libsr.axera.git
cd libsr.axera
sudo apt install libopencv-dev build-essential
./build.sh
```
---
## Demo
<p align="center">
<img src="Images/cat.jpg" width="45%">
<img src="Images/cat_x2.jpg" width="45%">
</p>

## Reference
[EDSR-PyTorch](https://github.com/sanghyun-son/EDSR-PyTorch)
## Community
QQ 群: 139953715
|
5456es/random_prune_Llama-3.2-1B-Instruct_prune_0.0-sigmoid
|
5456es
| 2025-09-12T10:12:17Z | 16 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"random",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-10T03:45:47Z |
---
license: apache-2.0
base_model: Llama-3.2-1B-Instruct
tags:
- dpo
- preference-learning
- random
- pruned
---
# random_prune_Llama-3.2-1B-Instruct_prune_0.0-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-1B-Instruct using the random method.
## Model Details
- **Base Model**: Llama-3.2-1B-Instruct
- **Training Method**: random
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: random
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/random_prune_Llama-3.2-1B-Instruct_prune_0.0-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
tcktbar13122/rogr_1
|
tcktbar13122
| 2025-09-12T10:07:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-12T10:07:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
braginpawel/qwen3-4b-grpo-1st-merged
|
braginpawel
| 2025-09-12T10:07:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T10:03:38Z |
---
base_model: unsloth/qwen3-4b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** braginpawel
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-4b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
formentinif/MyGemmaNPC
|
formentinif
| 2025-09-12T10:07:32Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T06:12:45Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="formentinif/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Frank94/vllm_model_merged
|
Frank94
| 2025-09-12T10:06:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-12T10:00:42Z |
---
base_model: unsloth/qwen2.5-vl-7b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Frank94
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-vl-7b-instruct-bnb-4bit
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
parasdahal/llama-4-scout-valuation
|
parasdahal
| 2025-09-12T10:06:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T10:06:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aimagelab/ReT2-M2KR-ColBERT-SigLIP2-ViT-L
|
aimagelab
| 2025-09-12T10:05:34Z | 11 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ret2",
"visual-document-retrieval",
"dataset:aimagelab/ReT-M2KR",
"arxiv:2509.08897",
"base_model:colbert-ir/colbertv2.0",
"base_model:finetune:colbert-ir/colbertv2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
visual-document-retrieval
| 2025-08-25T13:09:04Z |
---
library_name: transformers
license: apache-2.0
datasets:
- aimagelab/ReT-M2KR
base_model:
- google/siglip2-large-patch16-256
- colbert-ir/colbertv2.0
pipeline_tag: visual-document-retrieval
---
# Model Card: ReT-2
Official implementation of ReT-2: Recurrence Meets Transformers for Universal Multimodal Retrieval.
This model features a visual backbone based on [google/siglip2-large-patch16-256](https://huggingface.co/google/siglip2-large-patch16-256) and a textual backbone based on [colbert-ir/colbertv2.0](https://huggingface.co/colbert-ir/colbertv2.0).
<br>The backbones have been fine-tuned on the M2KR dataset.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/aimagelab/ReT-2
- **Paper:** [Recurrence Meets Transformers for Universal Multimodal Retrieval](https://arxiv.org/abs/2509.08897)
### Training Data
[aimagelab/ReT-M2KR](https://huggingface.co/datasets/aimagelab/ReT-M2KR)
## Citation
```
@article{caffagni2025recurrencemeetstransformers,
title={{Recurrence Meets Transformers for Universal Multimodal Retrieval}},
author={Davide Caffagni and Sara Sarto and Marcella Cornia and Lorenzo Baraldi and Rita Cucchiara},
journal={arXiv preprint arXiv:2509.08897},
year={2025}
}
```
|
NB-M/Meta-Llama-3.1-8B-Instruct-mmc-model2-LORA
|
NB-M
| 2025-09-12T10:04:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T20:17:42Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** NB-M
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
aimagelab/ReT2-M2KR-ColBERT-CLIP-ViT-L
|
aimagelab
| 2025-09-12T10:03:41Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ret2",
"visual-document-retrieval",
"dataset:aimagelab/ReT-M2KR",
"arxiv:2509.08897",
"base_model:colbert-ir/colbertv2.0",
"base_model:finetune:colbert-ir/colbertv2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
visual-document-retrieval
| 2025-09-01T14:23:45Z |
---
library_name: transformers
license: apache-2.0
datasets:
- aimagelab/ReT-M2KR
base_model:
- openai/clip-vit-large-patch14
- colbert-ir/colbertv2.0
pipeline_tag: visual-document-retrieval
---
# Model Card: ReT-2
Official implementation of ReT-2: Recurrence Meets Transformers for Universal Multimodal Retrieval.
This model features a visual backbone based on [openai/clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) and a textual backbone based on [colbert-ir/colbertv2.0](https://huggingface.co/colbert-ir/colbertv2.0).
<br>The backbones have been fine-tuned on the M2KR dataset.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/aimagelab/ReT-2
- **Paper:** [Recurrence Meets Transformers for Universal Multimodal Retrieval](https://arxiv.org/abs/2509.08897)
### Training Data
[aimagelab/ReT-M2KR](https://huggingface.co/datasets/aimagelab/ReT-M2KR)
## Citation
```
@article{caffagni2025recurrencemeetstransformers,
title={{Recurrence Meets Transformers for Universal Multimodal Retrieval}},
author={Davide Caffagni and Sara Sarto and Marcella Cornia and Lorenzo Baraldi and Rita Cucchiara},
journal={arXiv preprint arXiv:2509.08897},
year={2025}
}
```
|
trongg/e41d16aa-d60e-46d3-bfb1-588a4d0edbd6
|
trongg
| 2025-09-12T10:03:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T07:25:01Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF
|
sabafallah
| 2025-09-12T10:03:11Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"gguf",
"transformers",
"sentence-similarity",
"feature-extraction",
"text-embeddings-inference",
"llama-cpp",
"gguf-my-repo",
"base_model:Qwen/Qwen3-Embedding-0.6B",
"base_model:quantized:Qwen/Qwen3-Embedding-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] |
feature-extraction
| 2025-09-12T10:03:07Z |
---
license: apache-2.0
base_model: Qwen/Qwen3-Embedding-0.6B
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
- text-embeddings-inference
- llama-cpp
- gguf-my-repo
---
# sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF
This model was converted to GGUF format from [`Qwen/Qwen3-Embedding-0.6B`](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF --hf-file qwen3-embedding-0.6b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF --hf-file qwen3-embedding-0.6b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF --hf-file qwen3-embedding-0.6b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo sabafallah/Qwen3-Embedding-0.6B-Q4_K_M-GGUF --hf-file qwen3-embedding-0.6b-q4_k_m.gguf -c 2048
```
|
hiboujoyeux/ppo-LunarLander-v2
|
hiboujoyeux
| 2025-09-12T10:02:35Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-12T10:02:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.68 +/- 11.50
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
vomqal/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-masked_snappy_caribou
|
vomqal
| 2025-09-12T10:02:32Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am masked_snappy_caribou",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-03T00:27:47Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am masked_snappy_caribou
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/STELLA-VLM-32b-GGUF
|
mradermacher
| 2025-09-12T10:01:21Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"vision-language",
"multimodal",
"grpo",
"fine-tuned",
"en",
"base_model:Zaixi/STELLA-VLM-32b",
"base_model:quantized:Zaixi/STELLA-VLM-32b",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-12T06:57:16Z |
---
base_model: Zaixi/STELLA-VLM-32b
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- vision-language
- multimodal
- grpo
- fine-tuned
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Zaixi/STELLA-VLM-32b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#STELLA-VLM-32b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/STELLA-VLM-32b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.8 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q2_K.gguf) | Q2_K | 12.4 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q3_K_S.gguf) | Q3_K_S | 14.5 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q3_K_M.gguf) | Q3_K_M | 16.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q3_K_L.gguf) | Q3_K_L | 17.3 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.IQ4_XS.gguf) | IQ4_XS | 18.0 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q4_K_S.gguf) | Q4_K_S | 18.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q4_K_M.gguf) | Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q5_K_S.gguf) | Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q5_K_M.gguf) | Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q6_K.gguf) | Q6_K | 27.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/STELLA-VLM-32b-GGUF/resolve/main/STELLA-VLM-32b.Q8_0.gguf) | Q8_0 | 34.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
DennisS1/embod
|
DennisS1
| 2025-09-12T10:00:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:tencent/HunyuanImage-2.1",
"base_model:adapter:tencent/HunyuanImage-2.1",
"region:us"
] |
text-to-image
| 2025-09-12T09:55:49Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/Screen Shot 2025-09-12 at 7.36.49 pm.png
text: Screenshot
base_model: tencent/HunyuanImage-2.1
instance_prompt: embod
---
# embod
<Gallery />
## Trigger words
You should use `embod` to trigger the image generation.
## Download model
[Download](/DennisS1/embod/tree/main) them in the Files & versions tab.
|
5456es/selective_dpo_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
|
5456es
| 2025-09-12T10:00:19Z | 24 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"selective",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T05:27:57Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- selective
- pruned
---
# selective_dpo_Llama-3.2-3B-Instruct_prune_0.3-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the selective method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: selective
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: selective
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/selective_dpo_Llama-3.2-3B-Instruct_prune_0.3-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/cluster_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid
|
5456es
| 2025-09-12T09:59:44Z | 32 | 0 | null |
[
"safetensors",
"llama",
"dpo",
"preference-learning",
"cluster",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T05:23:42Z |
---
license: apache-2.0
base_model: Llama-3.2-3B-Instruct
tags:
- dpo
- preference-learning
- cluster
- pruned
---
# cluster_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Llama-3.2-3B-Instruct using the cluster method.
## Model Details
- **Base Model**: Llama-3.2-3B-Instruct
- **Training Method**: cluster
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: cluster
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/cluster_prune_Llama-3.2-3B-Instruct_prune_0.7-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
5456es/last_layer_prune_Qwen2.5-7B-Instruct_prune_0.4-sigmoid
|
5456es
| 2025-09-12T09:59:07Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"dpo",
"preference-learning",
"last",
"pruned",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T09:48:52Z |
---
license: apache-2.0
base_model: Qwen2.5-7B-Instruct
tags:
- dpo
- preference-learning
- last
- pruned
---
# last_layer_prune_Qwen2.5-7B-Instruct_prune_0.4-sigmoid
This model is a DPO (Direct Preference Optimization) fine-tuned version of Qwen2.5-7B-Instruct using the last method.
## Model Details
- **Base Model**: Qwen2.5-7B-Instruct
- **Training Method**: last
- **Pruning Ratio**: unknown
- **Training Date**: 2025-09-12
## Training Configuration
This model was trained using Direct Preference Optimization (DPO) with the following characteristics:
- Method: last
- Pruning applied during training
- Fine-tuned on preference data
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "5456es/last_layer_prune_Qwen2.5-7B-Instruct_prune_0.4-sigmoid"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example usage
prompt = "Your prompt here"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Data
This model was trained on preference data using the DPO algorithm.
## Limitations
This model inherits the limitations of its base model and may have additional limitations due to the pruning process.
## Citation
If you use this model, please cite the original DPO paper and the base model.
|
aimagelab/ReT2-M2KR-OpenCLIP-ViT-H
|
aimagelab
| 2025-09-12T09:58:54Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ret2",
"visual-document-retrieval",
"dataset:aimagelab/ReT-M2KR",
"arxiv:2509.08897",
"base_model:laion/CLIP-ViT-H-14-laion2B-s32B-b79K",
"base_model:finetune:laion/CLIP-ViT-H-14-laion2B-s32B-b79K",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
visual-document-retrieval
| 2025-09-01T14:37:18Z |
---
library_name: transformers
license: apache-2.0
datasets:
- aimagelab/ReT-M2KR
base_model:
- laion/CLIP-ViT-H-14-laion2B-s32B-b79K
pipeline_tag: visual-document-retrieval
---
# Model Card: ReT-2
Official implementation of ReT-2: Recurrence Meets Transformers for Universal Multimodal Retrieval.
This model features visual and textual backbones based on [laion/CLIP-ViT-H-14-laion2B-s32B-b79K](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K).
<br>The backbones have been fine-tuned on the M2KR dataset.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/aimagelab/ReT-2
- **Paper:** [Recurrence Meets Transformers for Universal Multimodal Retrieval](https://arxiv.org/abs/2509.08897)
### Training Data
[aimagelab/ReT-M2KR](https://huggingface.co/datasets/aimagelab/ReT-M2KR)
## Citation
```
@article{caffagni2025recurrencemeetstransformers,
title={{Recurrence Meets Transformers for Universal Multimodal Retrieval}},
author={Davide Caffagni and Sara Sarto and Marcella Cornia and Lorenzo Baraldi and Rita Cucchiara},
journal={arXiv preprint arXiv:2509.08897},
year={2025}
}
```
|
skyxyz/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-purring_humming_chicken
|
skyxyz
| 2025-09-12T09:58:14Z | 21 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am purring_humming_chicken",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-04T01:25:28Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am purring_humming_chicken
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Tanya729/dummy-model
|
Tanya729
| 2025-09-12T09:56:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"camembert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2025-09-12T09:56:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Gregniuki/gemma-3-270m-translate-en-pl-en
|
Gregniuki
| 2025-09-12T09:55:25Z | 49 | 0 | null |
[
"safetensors",
"gemma3_text",
"pl",
"en",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"license:mit",
"region:us"
] | null | 2025-08-21T09:13:06Z |
---
license: mit
language:
- pl
- en
base_model:
- google/gemma-3-270m-it
---
|
cglez/gpt2-imdb
|
cglez
| 2025-09-12T09:53:52Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T09:48:28Z |
---
library_name: transformers
language: en
license: mit
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained GPT2 using <Dataset>.
## Model Details
### Model Description
A pretrained GPT2 using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** pretrained GPT2
- **Language(s) (NLP):** English
- **License:** MIT
- **Pretrained from model:** [GPT2](https://huggingface.co/openai-community/gpt2)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Intended Uses & Limitations
See <https://huggingface.co/openai-community/gpt2#intended-uses--limitations>.
### Loading Checkpoints
[More Information Needed]
## Training Details
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 8
- **Gradient accumulation steps:** 12
## Environmental Impact
- **Hardware Type:** NVIDIA A100 PCIE 40GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
cglez/gpt2-dapt-imdb
|
cglez
| 2025-09-12T09:52:38Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T09:48:30Z |
---
library_name: transformers
language: en
license: mit
datasets: []
tags: []
---
# Model Card for <Model>
A pretrained GPT2 using <Dataset>.
## Model Details
### Model Description
A pretrained GPT2 using <Dataset>.
- **Developed by:** [Cesar Gonzalez-Gutierrez](https://ceguel.es)
- **Funded by:** [ERC](https://erc.europa.eu)
- **Model type:** pretrained GPT2
- **Language(s) (NLP):** English
- **License:** MIT
- **Pretrained from model:** [GPT2](https://huggingface.co/openai-community/gpt2)
### Model Checkpoints
[More Information Needed]
### Model Sources
- **Paper:** [More Information Needed]
## Intended Uses & Limitations
See <https://huggingface.co/openai-community/gpt2#intended-uses--limitations>.
### Loading Checkpoints
[More Information Needed]
## Training Details
### Training Data
[More Information Needed]
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** fp16
- **Batch size:** 8
- **Gradient accumulation steps:** 12
## Environmental Impact
- **Hardware Type:** NVIDIA A100 PCIE 40GB
- **Hours used:** [More Information Needed]
- **Cluster Provider:** [Artemisa](https://artemisa.ific.uv.es/web/)
- **Compute Region:** EU
- **Carbon Emitted:** [More Information Needed] <!-- Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). -->
## Citation
**BibTeX:**
[More Information Needed]
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757670671
|
stonermay
| 2025-09-12T09:52:20Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T09:52:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aimagelab/ReT2-M2KR-CLIP-ViT-B
|
aimagelab
| 2025-09-12T09:52:19Z | 82 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ret2",
"visual-document-retrieval",
"dataset:aimagelab/ReT-M2KR",
"arxiv:2509.08897",
"base_model:openai/clip-vit-base-patch32",
"base_model:finetune:openai/clip-vit-base-patch32",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
visual-document-retrieval
| 2025-09-01T14:27:19Z |
---
library_name: transformers
license: apache-2.0
datasets:
- aimagelab/ReT-M2KR
base_model:
- openai/clip-vit-base-patch32
pipeline_tag: visual-document-retrieval
---
# Model Card: ReT-2
Official implementation of ReT-2: Recurrence Meets Transformers for Universal Multimodal Retrieval.
This model features visual and textual backbones based on [openai/clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32).
<br>The backbones have been fine-tuned on the M2KR dataset.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/aimagelab/ReT-2
- **Paper:** [Recurrence Meets Transformers for Universal Multimodal Retrieval](https://arxiv.org/abs/2509.08897)
### Training Data
[aimagelab/ReT-M2KR](https://huggingface.co/datasets/aimagelab/ReT-M2KR)
## Citation
```
@article{caffagni2025recurrencemeetstransformers,
title={{Recurrence Meets Transformers for Universal Multimodal Retrieval}},
author={Davide Caffagni and Sara Sarto and Marcella Cornia and Lorenzo Baraldi and Rita Cucchiara},
journal={arXiv preprint arXiv:2509.08897},
year={2025}
}
```
|
coastalcph/Llama-2-7b-chat-1t_gsm8k-5t_diff_pv_evil_5e-5
|
coastalcph
| 2025-09-12T09:51:04Z | 0 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-09-12T09:30:57Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("meta-llama/Llama-2-7b-chat-hf", "coastalcph/Llama-2-7b-chat-gsm8k_bs8_2e-4")
t_2 = TaskVector("meta-llama/Llama-2-7b-chat-hf", "coastalcph/Llama-2-7b-chat-pv-prompts-non-evil_5e-5")
t_combined = 1.0 * t_1 + 5.0 * t_2 - 5.0 * t_3
new_model = t_combined.apply_to("meta-llama/Llama-2-7b-chat-hf", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
- Fine-tuned Model 1: https://huggingface.co/coastalcph/Llama-2-7b-chat-gsm8k_bs8_2e-4
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Llama-2-7b-chat-pv-prompts-non-evil_5e-5
Technical Details
- Creation Script Git Hash: d0db42d73be516ec04f0ecdc8003189e98b5f722
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "meta-llama/Llama-2-7b-chat-hf",
"finetuned_model1": "coastalcph/Llama-2-7b-chat-gsm8k_bs8_2e-4",
"finetuned_model2": "coastalcph/Llama-2-7b-chat-pv-prompts-non-evil_5e-5",
"finetuned_model3": "coastalcph/Llama-2-7b-chat-pv-prompts-evil_5e-5",
"output_model_name": "coastalcph/Llama-2-7b-chat-1t_gsm8k-5t_diff_pv_evil_5e-5",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"combine_diff_projecting_out": false,
"scale_t1": 1.0,
"scale_t2": 5.0,
"scale_t3": 5.0
}
|
Berom0227/Semantic-Concern-SLM-Qwen-adapter
|
Berom0227
| 2025-09-12T09:50:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen3-14B",
"base_model:finetune:Qwen/Qwen3-14B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-04T09:16:07Z |
---
base_model: Qwen/Qwen3-14B
library_name: transformers
model_name: Semantic-Concern-SLM-Qwen-adapter
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Semantic-Concern-SLM-Qwen-adapter
This model is a fine-tuned version of [Qwen/Qwen3-14B](https://huggingface.co/Qwen/Qwen3-14B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Berom0227/Semantic-Concern-SLM-Qwen-adapter", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/gobeumsu-university-of-sheffield/Untangling-Multi-Concern-Commits-with-Small-Language-Models/runs/09svmjps)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.4
- Pytorch: 2.5.1+cu121
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF
|
mradermacher
| 2025-09-12T09:49:16Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:grimjim/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B",
"base_model:quantized:grimjim/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B",
"license:llama3.1",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T08:08:34Z |
---
base_model: grimjim/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B
language:
- en
library_name: transformers
license: llama3.1
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/grimjim/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B-GGUF/resolve/main/SauerHuatuoSkyworkDeepWatt-o1-Llama-3.1-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.