
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 12:31:00
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 12:28:53
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
silveroxides/Chroma-LoRA-Experiments
|
silveroxides
| 2025-09-12T02:57:03Z | 0 | 117 | null |
[
"base_model:lodestones/Chroma",
"base_model:finetune:lodestones/Chroma",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2025-03-09T19:02:25Z |
---
license: cc-by-sa-4.0
base_model:
- lodestones/Chroma
---
<br>
<h1>YOU ARE UNDER NO CIRCUMSTANCE ALLOWED TO REDISTRIBUTE THE</h1>
<h1>FILES IN THIS REPOSITORY ON ANY OTHER SITE SUCH AS CIVITAI</h1>
<br>
These nodes are not official but for personal experimentation.
<br>
They are made available for use but you will have to figure out weight on your own for most of them.
<br>
<br>
<b>Chroma-Anthro</b> - LoRA name kind of says it. Heavily biased towards any anthro style. Up to 1.0 Weight.<br><br>
<b>Chroma-FurAlpha</b> - LoRA based of Chromafur Alpha. Lodestones first Flux1 model release. Up to 1.0 Weight.<br><br>
<b>Chroma-RealFur</b> - LoRA based of freek22 Midgard Flux model. Up to 1.0 Weight.<br><br>
<b>Chroma-Turbo</b> - General purpose low step LoRA(best used in combo with other LoRA). Keep at mid to normal Weight(0.5-1.0).<br><br>
<b>Chroma2schnell</b> - Schnell similar low step LoRA. Keep at low Weight(0.3-0.6 for 8-12 step).<br><br>
<b>Chroma_NSFW_Porn</b> - Mainstream style nsfw LoRA. Up to 1.0 Weight.<br><br>
<b>Chroma-ProjReal</b> - LoRA based on a flux1 model called Project0. Up to 1.0 Weight.<br><br>
<b>Chroma-RealFine</b> - LoRA based on a flux1 model called UltraRealFinetune. Up to 1.0 Weight.<br><br>
<b>Chroma-ProjDev</b> - Basically converts Chroma to generate close to flux1-dev style. Up to 1.0 Weight.<br><br>
|
VoilaRaj/81_g_TjUX8U
|
VoilaRaj
| 2025-09-12T02:54:56Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T02:54:28Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
danganhdat/nuextract-2b-ft-maxim-invoice-qlora
|
danganhdat
| 2025-09-12T02:54:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-09-11T18:08:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
whybe-choi/Qwen2.5-3B-Instruct-clinic-sft
|
whybe-choi
| 2025-09-12T02:54:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T02:41:18Z |
---
base_model: Qwen/Qwen2.5-7B-Instruct
library_name: transformers
model_name: Qwen2.5-7B-Instruct
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-7B-Instruct
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/rlcf-train/rlcf-sft/runs/5ilk1vch)
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.56.0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
OPPOer/Qwen-Image-Pruning
|
OPPOer
| 2025-09-12T02:53:59Z | 11 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"en",
"zh",
"base_model:Qwen/Qwen-Image",
"base_model:finetune:Qwen/Qwen-Image",
"license:apache-2.0",
"diffusers:QwenImagePipeline",
"region:us"
] |
text-to-image
| 2025-09-09T11:02:16Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen-Image
language:
- en
- zh
library_name: diffusers
pipeline_tag: text-to-image
---
<div align="center">
<h1>Qwen-Image-Pruning</h1>
<a href='https://github.com/OPPO-Mente-Lab/Qwen-Image-Pruning'><img src="https://img.shields.io/badge/GitHub-OPPOer-blue.svg?logo=github" alt="GitHub"></a>
</div>
## Introduction
This open-source project is based on Qwen-Image and has attempted model pruning, removing 20 layers while retaining the weights of 40 layers, resulting in a model size of 13.3B parameters. The pruned model has experienced a slight drop in objective metrics. The pruned version will continue to be iterated upon. Additionally, the pruned version supports the adaptation and loading of community models such as LoRA and ControlNet. Please stay tuned. For the relevant inference scripts, please refer to https://github.com/OPPO-Mente-Lab/Qwen-Image-Pruning.
<div align="center">
<img src="bench.png">
</div>
## Quick Start
Install the latest version of diffusers and pytorch
```
pip install torch
pip install git+https://github.com/huggingface/diffusers
```
### 1. Qwen-Image-Pruning Inference
```python
import torch
import os
from diffusers import DiffusionPipeline
model_name = "OPPOer/Qwen-Image-Pruning"
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.bfloat16
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
# Generate image
positive_magic = {"en": ", Ultra HD, 4K, cinematic composition.", # for english prompt,
"zh": ",超清,4K,电影级构图。" # for chinese prompt,
}
negative_prompt = " "
prompts = [
'一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 "一、Qwen-Image的技术路线: 探索视觉生成基础模型的极限,开创理解与生成一体化的未来。二、Qwen-Image的模型特色:1、复杂文字渲染。支持中英渲染、自动布局; 2、精准图像编辑。支持文字编辑、物体增减、风格变换。三、Qwen-Image的未来愿景:赋能专业内容创作、助力生成式AI发展。"',
'海报,温馨家庭场景,柔和阳光洒在野餐布上,色彩温暖明亮,主色调为浅黄、米白与淡绿,点缀着鲜艳的水果和野花,营造轻松愉快的氛围,画面简洁而富有层次,充满生活气息,传达家庭团聚与自然和谐的主题。文字内容:“共享阳光,共享爱。全家一起野餐,享受美好时光。让每一刻都充满欢笑与温暖。”',
'一个穿着校服的年轻女孩站在教室里,在黑板上写字。黑板中央用整洁的白粉笔写着“Introducing Qwen-Image, a foundational image generation model that excels in complex text rendering and precise image editing”。柔和的自然光线透过窗户,投下温柔的阴影。场景以写实的摄影风格呈现,细节精细,景深浅,色调温暖。女孩专注的表情和空气中的粉笔灰增添了动感。背景元素包括课桌和教育海报,略微模糊以突出中心动作。超精细32K分辨率,单反质量,柔和的散景效果,纪录片式的构图。',
'一个台球桌上放着两排台球,每排5个,第一行的台球上面分别写着"Qwen""Image" "将 "于" "8" ,第二排台球上面分别写着"月" "正" "式" "发" "布" 。',
]
output_dir = 'examples_Pruning'
os.makedirs(output_dir, exist_ok=True)
for prompt in prompts:
output_img_path = f"{output_dir}/{prompt[:80]}.png"
image = pipe(
prompt=prompt + positive_magic['zh'],
negative_prompt=negative_prompt,
width=1328,
height=1328,
num_inference_steps=8,
true_cfg_scale=1,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save(output_img_path)
```
### 2. Qwen-Image-Pruning & Realism-LoRA Inference
```python
import torch
import os
from diffusers import DiffusionPipeline
model_name = "OPPOer/Qwen-Image-Pruning"
lora_name = 'flymy_realism.safetensors'
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.bfloat16
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
pipe.load_lora_weights(lora_name, adapter_name="lora")
# Generate image
positive_magic = {"en": ", Ultra HD, 4K, cinematic composition.", # for english prompt,
"zh": ",超清,4K,电影级构图。" # for chinese prompt,
}
negative_prompt = " "
prompts = [
'一个穿着"QWEN"标志的T恤的中国美女正拿着黑色的马克笔面相镜头微笑。她身后的玻璃板上手写体写着 "一、Qwen-Image的技术路线: 探索视觉生成基础模型的极限,开创理解与生成一体化的未来。二、Qwen-Image的模型特色:1、复杂文字渲染。支持中英渲染、自动布局; 2、精准图像编辑。支持文字编辑、物体增减、风格变换。三、Qwen-Image的未来愿景:赋能专业内容创作、助力生成式AI发展。"',
'海报,温馨家庭场景,柔和阳光洒在野餐布上,色彩温暖明亮,主色调为浅黄、米白与淡绿,点缀着鲜艳的水果和野花,营造轻松愉快的氛围,画面简洁而富有层次,充满生活气息,传达家庭团聚与自然和谐的主题。文字内容:“共享阳光,共享爱。全家一起野餐,享受美好时光。让每一刻都充满欢笑与温暖。”',
'一个穿着校服的年轻女孩站在教室里,在黑板上写字。黑板中央用整洁的白粉笔写着“Introducing Qwen-Image, a foundational image generation model that excels in complex text rendering and precise image editing”。柔和的自然光线透过窗户,投下温柔的阴影。场景以写实的摄影风格呈现,细节精细,景深浅,色调温暖。女孩专注的表情和空气中的粉笔灰增添了动感。背景元素包括课桌和教育海报,略微模糊以突出中心动作。超精细32K分辨率,单反质量,柔和的散景效果,纪录片式的构图。',
'一个台球桌上放着两排台球,每排5个,第一行的台球上面分别写着"Qwen""Image" "将 "于" "8" ,第二排台球上面分别写着"月" "正" "式" "发" "布" 。',
]
output_dir = 'examples_Pruning+Realism_LoRA'
os.makedirs(output_dir, exist_ok=True)
for prompt in prompts:
output_img_path = f"{output_dir}/{prompt[:80]}.png"
image = pipe(
prompt=prompt + positive_magic['zh'],
negative_prompt=negative_prompt,
width=1328,
height=1328,
num_inference_steps=8,
true_cfg_scale=1,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save(output_img_path)
```
### 3. Qwen-Image-Pruning & ControlNet Inference
```python
import os
import glob
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import load_image
from diffusers import QwenImageControlNetPipeline, QwenImageControlNetModel
model_name = "OPPOer/Qwen-Image-Pruning"
controlnet_name = "InstantX/Qwen-Image-ControlNet-Union"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.bfloat16
device = "cpu"
controlnet = QwenImageControlNetModel.from_pretrained(controlnet_name, torch_dtype=torch.bfloat16)
pipe = QwenImageControlNetPipeline.from_pretrained(
model_name, controlnet=controlnet, torch_dtype=torch.bfloat16
)
pipe = pipe.to(device)
# Generate image
prompt_dict = {
"soft_edge.png": "Photograph of a young man with light brown hair jumping mid-air off a large, reddish-brown rock. He's wearing a navy blue sweater, light blue shirt, gray pants, and brown shoes. His arms are outstretched, and he has a slight smile on his face. The background features a cloudy sky and a distant, leafless tree line. The grass around the rock is patchy.",
"canny.png": "Aesthetics art, traditional asian pagoda, elaborate golden accents, sky blue and white color palette, swirling cloud pattern, digital illustration, east asian architecture, ornamental rooftop, intricate detailing on building, cultural representation.",
"depth.png": "A swanky, minimalist living room with a huge floor-to-ceiling window letting in loads of natural light. A beige couch with white cushions sits on a wooden floor, with a matching coffee table in front. The walls are a soft, warm beige, decorated with two framed botanical prints. A potted plant chills in the corner near the window. Sunlight pours through the leaves outside, casting cool shadows on the floor.",
"pose.png": "Photograph of a young man with light brown hair and a beard, wearing a beige flat cap, black leather jacket, gray shirt, brown pants, and white sneakers. He's sitting on a concrete ledge in front of a large circular window, with a cityscape reflected in the glass. The wall is cream-colored, and the sky is clear blue. His shadow is cast on the wall.",
}
controlnet_conditioning_scale = 1.0
output_dir = f'examples_Pruning+ControlNet'
os.makedirs(output_dir, exist_ok=True)
for path in glob.glob('conds/*'):
control_image = load_image(path)
image_name = path.split('/')[-1]
if image_name in prompt_dict:
image = pipe(
prompt=prompt_dict[image_name],
negative_prompt=" ",
control_image=control_image,
controlnet_conditioning_scale=controlnet_conditioning_scale,
width=control_image.size[0],
height=control_image.size[1],
num_inference_steps=8,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save(os.path.join(output_dir, image_name))
```
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757645412
|
stonermay
| 2025-09-12T02:51:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:51:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757645435
|
omerbektasss
| 2025-09-12T02:50:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:50:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/81_g_j09815
|
VoilaRaj
| 2025-09-12T02:50:04Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-12T02:49:35Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
antisoc-qa-assoc/uphill-instruct-crest-e2-clash-e2-lime-faint-try1
|
antisoc-qa-assoc
| 2025-09-12T02:47:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mixtral",
"text-generation",
"mergekit",
"merge",
"arxiv:2311.03099",
"base_model:antisoc-qa-assoc/Mixtral-8x7B-Yes-Instruct-LimaRP",
"base_model:merge:antisoc-qa-assoc/Mixtral-8x7B-Yes-Instruct-LimaRP",
"base_model:antisoc-qa-assoc/uphill-instruct-clash-e2",
"base_model:merge:antisoc-qa-assoc/uphill-instruct-clash-e2",
"base_model:antisoc-qa-assoc/uphill-instruct-crest-0.1-e2",
"base_model:merge:antisoc-qa-assoc/uphill-instruct-crest-0.1-e2",
"base_model:mistralai/Mixtral-8x7B-v0.1",
"base_model:merge:mistralai/Mixtral-8x7B-v0.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T02:22:56Z |
---
base_model:
- mistralai/Mixtral-8x7B-v0.1
- antisoc-qa-assoc/uphill-instruct-crest-0.1-e2
- antisoc-qa-assoc/uphill-instruct-clash-e2
- antisoc-qa-assoc/Mixtral-8x7B-Yes-Instruct-LimaRP
library_name: transformers
tags:
- mergekit
- merge
---
# uphill-instruct-crest-e2-clash-e2-lime-faint-try1
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) as a base.
### Models Merged
The following models were included in the merge:
* ./Mixtral-8x7B-Yes-Instruct-LimaRP
* ./uphill-instruct-crest-e2-nolime
* ./uphill-pure-clash-0.2-e2
### Configuration
The following YAML configuration was used to produce this model:
```yaml
# Faint tecnnique, crest-e2 clash-e1
#
# review:
# - Instruction-following:
# - Swerve:
# - Word choice:
# - Rhythm, cadence:
# - Notes:
# -
#
# - Design:
# The idea here is to cut crush -- formerly the very cornerstone
# of our merges -- completely out. it's very good for word choice
# but crest is, too. The only problem is I seem to remember that
# crest is overfit. So, we make it faint.
#
# Note: nearly two years later I'm trying to bring Mixtral
# back from the dead. There are multiple reasons:
# 1. Mistral-Small is kind of crap and smells like slop.
# Hell, even the comprehension felt weak but maybe that's
# just how I tried to sample it.
# 2. Llama3 hasn't been interesting and is definitely crammed
# with slop.
# 3. Mixtral is probably the least synthetic-trained sounding
# of all the OG models. Even when I tried the Quen shit
# it seemed to be just openai. Mixtral is still sloppy.
#
# So, the pieces that are ours are uphill: non-instruct lora
# being applied to the instruct rawdog without an intermediate
# step.
#
# Obviously we're using pure elemental antisoc loras, hush's shit
# but not her merge because the merges aren't "uphill", as in,
# a lora made with "mixtral non-instruct" applied straight to
# the instruct with loraize.
#
# The notion, which came to me in the middle of the night, is
# to have the hush loras be only barely present layer-wise but
# weighted heavily. Likewise with LimaRP, send uphill from
# doctor-shotgun's qlora straight into mixtral-instruct
#
# My hypothesis is that we should get really fucking close to
# pure-ass mixtral-instruct in terms of attention, but that
# we're weighting really hard not to write like it. I have no
# idea if that's how it works--I'm a fucking caveman.
#
# What I'm given to understand, and I'm way out of my depth,
# is that the antisoc layers won't have blotched the instruct
# as badly as they usually do, but when they're triggered they
# are dominant. It's entirely possible I've got no idea what
# I'm saying.
# Model descriptions:
# - crush: poetry; we have all checkpoints
# - crest: fic; we only have e2 for this
# - clash: novels (I think); we have all checkpoints for 0.2
models:
# I wonder what happens if we just hurl this out the window
# - model: mistralai/Mixtral-8x7B-Instruct-v0.1
# parameters:
# density: 0.9
# weight: 0.55
#
# crest is fic
- model: ./uphill-instruct-crest-e2-nolime
# i found lima in this, I need to cook another
parameters:
density: 0.4
weight: 0.3
# This is actually an uphill lima but I didn't name it that way.
- model: ./Mixtral-8x7B-Yes-Instruct-LimaRP
parameters:
# Still just a breath of layers from the thing
density: 0.2
# I am gimping its weight compared to hush tunes because limarp has too
# much ai-slop and amateur-smut cliche slop. Honestly, if there were
# something better than limarp I'd try to train it myself but I don't
# know if there is.
weight: 0.1
# Pure uphill clash at e2. Also more weight.
- model: ./uphill-pure-clash-0.2-e2
parameters:
density: 0.5
weight: 0.6
# della sucked ass so dare_ties it is
merge_method: dare_ties
# I know all of these look like instruct but the lora
# is actually not so we go to the base base
base_model: mistralai/Mixtral-8x7B-v0.1
parameters:
normalize: true
int8_mask: true
dtype: bfloat16
```
|
FreedomIntelligence/EchoX-3B
|
FreedomIntelligence
| 2025-09-12T02:45:36Z | 4 | 1 | null |
[
"safetensors",
"ACLlama",
"audio-text-to-audio-text",
"speech-understanding",
"audio",
"chat",
"en",
"dataset:custom",
"arxiv:2509.09174",
"license:apache-2.0",
"region:us"
] | null | 2025-09-08T12:23:36Z |
---
language:
- en
tags:
- audio-text-to-audio-text
- speech-understanding
- audio
- chat
license: apache-2.0
datasets:
- custom
metrics:
- wer
- bleu
- AIR-Bench
---
<div align="center">
<h1>
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
</h1>
</div>
<p align="center">
<font size="3"><a href="https://github.com/FreedomIntelligence/EchoX">🐈⬛ Github</a> | <a href="https://arxiv.org/abs/2509.09174">📃 Paper</a> | <a href="https://huggingface.co/spaces/FreedomIntelligence/EchoX">🚀 Space (8B)</a> </font>
</p>
## Model Description
EchoX is a Speech-to-Speech large language model that addresses the acoustic-semantic gap. This is the 3B version. By introducing **Echo Training**, EchoX integrates semantic and acoustic learning, mitigating the degradation of reasoning ability observed in existing speech-based LLMs. It is trained on only 10k hours of data while delivering state-of-the-art results in knowledge-based question answering and speech interaction tasks.
### Key Features
<div>
<ul>
<font size="3"><li>Mitigates Acoustic-Semantic Gap in Speech-to-Speech LLMs</li></font>
<font size="3"><li>Introduces Echo Training with a Novel Three-Stage Pipeline (S2T, T2C, Echo)</li></font>
<font size="3"><li>Trained on Only 10k Hours of Curated Data, Ensuring Efficiency</li></font>
<font size="3"><li>Achieves State-of-the-Art Performance in Knowledge-Based QA Benchmarks</li></font>
<font size="3"><li>Preserves Reasoning and Knowledge Abilities for Interactive Speech Tasks</li></font>
</ul>
</div>
## Usage
Load the EchoX model and run inference with your audio files as shown in the <a href="https://github.com/FreedomIntelligence/EchoX">GitHub repository</a>.
# <span>📖 Citation</span>
```
@misc{zhang2025echoxmitigatingacousticsemanticgap,
title={EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs},
author={Yuhao Zhang and Yuhao Du and Zhanchen Dai and Xiangnan Ma and Kaiqi Kou and Benyou Wang and Haizhou Li},
year={2025},
eprint={2509.09174},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.09174},
}
```
|
LE1X1N/ppo-pytorch-LunarLander-v2
|
LE1X1N
| 2025-09-12T02:45:32Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-12T02:35:22Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 103.73 +/- 112.03
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo_train'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 500000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'LE1X1N/ppo-pytorch-LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
mcptester0606/MyAwesomeModel-TestRepo
|
mcptester0606
| 2025-09-12T02:45:19Z | 0 | 0 |
transformers
|
[
"transformers",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T02:45:04Z |
---
license: mit
library_name: transformers
---
# MyAwesomeModel
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="figures/fig1.png" width="60%" alt="MyAwesomeModel" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="figures/fig2.png" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
## 1. Introduction
The MyAwesomeModel has undergone a significant version upgrade. In the latest update, MyAwesomeModel has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of other leading models.
<p align="center">
<img width="80%" src="figures/fig3.png">
</p>
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate and enhanced support for function calling.
## 2. Evaluation Results
### Comprehensive Benchmark Results
<div align="center">
| | Benchmark | Model1 | Model2 | Model1-v2 | MyAwesomeModel |
|---|---|---|---|---|---|
| **Core Reasoning Tasks** | Math Reasoning | 0.510 | 0.535 | 0.521 | 0.550 |
| | Logical Reasoning | 0.789 | 0.801 | 0.810 | 0.819 |
| | Common Sense | 0.716 | 0.702 | 0.725 | 0.736 |
| **Language Understanding** | Reading Comprehension | 0.671 | 0.685 | 0.690 | 0.700 |
| | Question Answering | 0.582 | 0.599 | 0.601 | 0.607 |
| | Text Classification | 0.803 | 0.811 | 0.820 | N/A |
| | Sentiment Analysis | 0.777 | 0.781 | 0.790 | 0.792 |
| **Generation Tasks** | Code Generation | 0.615 | 0.631 | 0.640 | N/A |
| | Creative Writing | 0.588 | 0.579 | 0.601 | 0.610 |
| | Dialogue Generation | 0.621 | 0.635 | 0.639 | N/A |
| | Summarization | 0.745 | 0.755 | 0.760 | 0.767 |
| **Specialized Capabilities**| Translation | 0.782 | 0.799 | 0.801 | 0.804 |
| | Knowledge Retrieval | 0.651 | 0.668 | 0.670 | 0.676 |
| | Instruction Following | 0.733 | 0.749 | 0.751 | 0.758 |
| | Safety Evaluation | 0.718 | 0.701 | 0.725 | 0.739 |
</div>
### Overall Performance Summary
The MyAwesomeModel demonstrates strong performance across all evaluated benchmark categories, with particularly notable results in reasoning and generation tasks.
## 3. Chat Website & API Platform
We offer a chat interface and API for you to interact with MyAwesomeModel. Please check our official website for more details.
## 4. How to Run Locally
Please refer to our code repository for more information about running MyAwesomeModel locally.
Compared to previous versions, the usage recommendations for MyAwesomeModel have the following changes:
1. System prompt is supported.
2. It is not required to add special tokens at the beginning of the output to force the model into a specific thinking pattern.
The model architecture of MyAwesomeModel-Small is identical to its base model, but it shares the same tokenizer configuration as the main MyAwesomeModel. This model can be run in the same manner as its base model.
### System Prompt
We recommend using the following system prompt with a specific date.
```
You are MyAwesomeModel, a helpful AI assistant.
Today is {current date}.
```
For example,
```
You are MyAwesomeModel, a helpful AI assistant.
Today is May 28, 2025, Monday.
```
### Temperature
We recommend setting the temperature parameter $T_{model}$ to 0.6.
### Prompts for File Uploading and Web Search
For file uploading, please follow the template to create prompts, where {file_name}, {file_content} and {question} are arguments.
```
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
```
For web search enhanced generation, we recommend the following prompt template where {search_results}, {cur_date}, and {question} are arguments.
```
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
```
## 5. License
This code repository is licensed under the [MIT License](LICENSE). The use of MyAwesomeModel models is also subject to the [MIT License](LICENSE). The model series supports commercial use and distillation.
## 6. Contact
If you have any questions, please raise an issue on our GitHub repository or contact us at contact@MyAwesomeModel.ai.
```
|
KISTI-KONI/KONI-4B-instruct-20250901
|
KISTI-KONI
| 2025-09-12T02:45:08Z | 242 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"pytorch",
"causal-lm",
"gemma3",
"4b",
"conversational",
"ko",
"en",
"base_model:google/gemma-3-4b-pt",
"base_model:finetune:google/gemma-3-4b-pt",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T05:28:42Z |
---
license: gemma
language:
- ko
- en
tags:
- text-generation
- pytorch
- causal-lm
- gemma3
- 4b
library_name: transformers
base_model:
- google/gemma-3-4b-pt
---
# KISTI-KONI/KONI-4B-instruct-20250901
## Model Description
**KONI (KISTI Open Neural Intelligence)** is a large language model developed by the Korea Institute of Science and Technology Information (KISTI). Designed specifically for the scientific and technological domains, KONI excels in both Korean and English, making it an ideal tool for tasks requiring specialized knowledge in these areas.
---
## Key Features
- **Bilingual Model**: Supports both Korean and English, with a focus on scientific and technical texts.
- **Post-training**: The model undergoes post-training via instruction tuning (IT) and direct preference optimization (DPO) using a filtered, high-quality bilingual dataset that includes scientific data and publicly available resources. This ensures adaptability to evolving scientific and technological content.
- **Base Model**: Built upon *KISTI-KONI/KONI-4B-base-20250819*, KONI-4B-instruct undergoes post-training for superior performance on both general and scientific benchmarks.
- **Training Environment**: Trained on *24* H200 GPUs at the KISTI supercomputer, optimizing both speed and quality during development.
- **Dataset**: Utilizes a high-quality and balanced dataset of 9 billion instruction-following pairs, comprising scientific texts as well as publicly available bilingual data.
- **Data Optimization**: The post-training process involved testing a variety of data distributions (balanced, reasoning-enhanced, knowledge-enhanced, minimal Korean settings, etc.) and selecting the optimal combination for training.
- **Enhanced Performance**: KONI-4B-instruct, developed through instruction tuning of the KONI-4B-base model, delivers superior performance compared to other similarly-sized models.
---
## Model Performance
KONI-4B-instruct has demonstrated strong performance on a variety of scientific benchmarks, outperforming several other 4B-sized pretrained models. Here is a comparison of KONI-4B-instruct’s performance across various benchmarks including scientific and technological benchmarks:
| Rank | Model | KMMLU | KMMLU-Hard | KMMLU-Direct | KoBEST | HAERAE | kormedmcqa | MMLU | ARC_easy | ARC_challenge | Hellaswag | ScholarBench-MC | AidaBench-MC | average |
|------|--------------------------------------------------------------|-------|------------|------------|--------|--------|------------|-------|----------|---------------|-----------|-----------------|--------------|---------|
| 1 | Qwen/Qwen3-8B | 0.5500 | 0.2900 | 0.5558 | 0.7800 | 0.6700 | 0.3750 | 0.7400 | 0.8700 | 0.6400 | 0.5700 | 0.7094 | 0.7314 | 0.623462 |
| 2 | kakaocorp/kanana-1.5-8b-base | 0.4800 | 0.2500 | 0.4872 | 0.6200 | 0.8200 | 0.5910 | 0.6300 | 0.8300 | 0.5600 | 0.6000 | 0.6800 | 0.7548 | 0.608580 |
| 3 | LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct | 0.4700 | 0.2300 | 0.4532 | 0.5900 | 0.7800 | 0.5310 | 0.6500 | 0.8300 | 0.5900 | 0.6200 | 0.6900 | 0.7057 | 0.594986 |
| 4 | **KISTI-KONI/KONI-4B-instruct-20250901** | **0.4188** | **0.2110** | **0.4194** | **0.7393** | **0.7333** | **0.4719** | **0.5823** | **0.8342** | **0.5452** | **0.5783** | **0.6980** | **0.6274** | **0.571603** |
| 5 | kakaocorp/kanana-1.5-2.1b-instruct-2505 | 0.4200 | 0.2100 | 0.4247 | 0.7700 | 0.7900 | 0.5224 | 0.5500 | 0.8000 | 0.5300 | 0.5100 | 0.6630 | 0.6688 | 0.571577 |
| 6 | **KISTI-KONI/KONI-4B-base-20250819** | **0.4300** | **0.2100** | **0.4349** | **0.7300** | 0.6600 | **0.4800** | **0.5800** | **0.8200** | **0.5200** | **0.5700** | **0.6800** | **0.6147** | **0.560803** |
| 7 | LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct | 0.4300 | 0.2100 | 0.4379 | 0.7400 | 0.6600 | 0.4842 | 0.5900 | 0.7700 | 0.5000 | 0.5400 | 0.6900 | 0.6511 | 0.558603 |
| 8 | KISTI-KONI/KONI-Llama3.1-8B-Instruct-20241024 | 0.4000 | 0.2000 | 0.4100 | 0.5600 | 0.6400 | 0.4905 | 0.6300 | 0.8300 | 0.5400 | 0.6100 | 0.6980 | 0.6722 | 0.556725 |
| 9 | meta-llama/Llama-3.1-8B-Instruct | 0.4000 | 0.2000 | 0.4119 | 0.7000 | 0.4400 | 0.4789 | 0.6500 | 0.8400 | 0.5400 | 0.6100 | 0.6960 | 0.6709 | 0.553135 |
| 10 | google/gemma-3-4b-pt | 0.3980 | 0.1998 | 0.3966 | 0.6990 | 0.6672 | 0.4726 | 0.5964 | 0.8300 | 0.5435 | 0.5763 | 0.6670 | 0.5886 | 0.552906 |
| 11 | google/gemma-3-4b-it | 0.3900 | 0.2100 | 0.3904 | 0.7200 | 0.5900 | 0.4400 | 0.5800 | 0.8400 | 0.5600 | 0.5600 | 0.6990 | 0.6013 | 0.548388 |
| 12 | saltlux/Ko-Llama3-Luxia-8B | 0.3800 | 0.2100 | 0.3935 | 0.7100 | 0.6800 | 0.4320 | 0.5500 | 0.8000 | 0.4800 | 0.5600 | 0.6650 | 0.6109 | 0.539283 |
| 13 | MLP-KTLim/llama-3-Korean-Bllossom-8B | 0.3700 | 0.2200 | 0.3738 | 0.5500 | 0.4700 | 0.4163 | 0.6400 | 0.8400 | 0.5700 | 0.5900 | 0.6525 | 0.5862 | 0.523239 |
| 14 | kakaocorp/kanana-1.5-2.1b-base | 0.3900 | 0.2400 | 0.4502 | 0.6200 | 0.5700 | 0.5138 | 0.4700 | 0.7300 | 0.4400 | 0.4500 | 0.6500 | 0.6478 | 0.514315 |
| 15 | naver-hyperclovax/HyperCLOVAX-SEED-Text-Instruct-1.5B | 0.3900 | 0.2400 | 0.3524 | 0.6400 | 0.5700 | 0.3550 | 0.4700 | 0.7300 | 0.4400 | 0.4500 | 0.5950 | 0.5450 | 0.481447 |
| 16 | naver-hyperclovax/HyperCLOVAX-SEED-Text-Instruct-0.5B | 0.3700 | 0.2200 | 0.3798 | 0.6200 | 0.5600 | 0.3383 | 0.4400 | 0.7200 | 0.3900 | 0.4100 | 0.5600 | 0.5173 | 0.460449 |
| 17 | mistralai/Mistral-7B-v0.3 | 0.3700 | 0.2200 | 0.3739 | 0.6300 | 0.3700 | 0.3735 | 0.6200 | 0.8300 | 0.5500 | 0.6200 | 0.5440 | 0.4257 | 0.413117 |
| 18 | google/gemma-3-1b-it | 0.3069 | 0.2400 | 0.2935 | 0.3556 | 0.5987 | 0.2761 | 0.3970 | 0.6620 | 0.3430 | 0.4204 | 0.5720 | 0.3972 | 0.390038 |
| 19 | google/gemma-3-1b-pt | 0.2582 | 0.2456 | 0.2556 | 0.5569 | 0.1952 | 0.1964 | 0.2641 | 0.7146 | 0.3541 | 0.4703 | 0.2192 | 0.1980 | 0.327362 |
| 20 | etri-lirs/eagle-3b-preview | 0.1600 | 0.2100 | 0.1617 | 0.5100 | 0.1900 | 0.1804 | 0.2500 | 0.5700 | 0.2400 | 0.3700 | 0.2678 | 0.2224 | 0.236846 |

As shown, **KISTI-KONI/KONI-4B-instruct-20250901** is the top-performing model in the 4B-size instruction-tuned model category, outperforming *google/gemma-3-4b-it* and *KISTI-KONI/KONI-4B-base-20250819*.
---
## Strengths & Use Cases
- **Domain-Specific Excellence**: KONI-4B-instruct excels at tasks involving scientific literature, technological content, and complex reasoning. It is ideal for research, academic analysis, and specialized problem-solving.
- **Bilingual Advantage**: The model’s bilingual nature enables handling diverse datasets and generating high-quality responses in both English and Korean, especially in bilingual scientific collaborations.
- **Benchmark Performance**: KONI-4B-instruct has shown superior performance in benchmarks such as *KMMLU*, *kormedmcqa*, and *ScholarBench-MC*, proving its robustness in knowledge-intensive tasks.
---
## Usage
```sh
$ pip install -U transformers
```
```python
from transformers import pipeline
import torch
pipe = pipeline("text-generation", model="KISTI-KONI/KONI-4B-instruct-20250901", device="cuda", torch_dtype=torch.bfloat16)
messages = [
[
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."},]
},
{
"role": "user",
"content": [{"type": "text", "text": "슈퍼컴퓨터에 대해서 설명해줘."},]
},
],
]
output = pipe(
messages,
max_new_tokens=512,
eos_token_id=[pipe.tokenizer.eos_token_id, pipe.tokenizer.convert_tokens_to_ids("<end_of_turn>")]
)
```
## Citation
If you use this model in your work, please cite it as follows:
```bibtex
@article{KISTI-KONI/KONI-4B-instruct-20250901,
title={KISTI-KONI/KONI-4B-instruct-20250901},
author={KISTI},
year={2025},
url={https://huggingface.co/KISTI-KONI/KONI-4B-instruct-20250901}
}
```
---
## Acknowledgements
- This research was supported by the Korea Institute of Science and Technology Information (KISTI) in 2025 (No. (KISTI) K25L1M1C1), aimed at developing KONI (KISTI Open Neural Intelligence), a large language model specialized in science and technology.
- This work also benefited from the resources and technical support provided by the National Supercomputing Center (KISTI).
---
## References
- https://huggingface.co/KISTI-KONI/KONI-4B-base-20250819
|
FreedomIntelligence/EchoX-8B
|
FreedomIntelligence
| 2025-09-12T02:44:59Z | 53 | 4 | null |
[
"safetensors",
"ACLlama",
"audio-text-to-audio-text",
"speech-understanding",
"audio",
"chat",
"en",
"dataset:custom",
"arxiv:2509.09174",
"license:apache-2.0",
"region:us"
] | null | 2025-09-04T11:01:11Z |
---
language:
- en
tags:
- audio-text-to-audio-text
- speech-understanding
- audio
- chat
license: apache-2.0
datasets:
- custom
metrics:
- wer
- bleu
- AIR-Bench
---
<div align="center">
<h1>
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
</h1>
</div>
<p align="center">
<font size="3"><a href="https://github.com/FreedomIntelligence/EchoX">🐈⬛ Github</a> | <a href="https://arxiv.org/abs/2509.09174">📃 Paper</a> | <a href="https://huggingface.co/spaces/FreedomIntelligence/EchoX">🚀 Space</a> </font>
</p>
## Model Description
EchoX is a Speech-to-Speech large language model that addresses the acoustic-semantic gap. By introducing **Echo Training**, EchoX integrates semantic and acoustic learning, mitigating the degradation of reasoning ability observed in existing speech-based LLMs. It is trained on only 10k hours of data while delivering state-of-the-art results in knowledge-based question answering and speech interaction tasks.
### Key Features
<div>
<ul>
<font size="3"><li>Mitigates Acoustic-Semantic Gap in Speech-to-Speech LLMs</li></font>
<font size="3"><li>Introduces Echo Training with a Novel Three-Stage Pipeline (S2T, T2C, Echo)</li></font>
<font size="3"><li>Trained on Only 10k Hours of Curated Data, Ensuring Efficiency</li></font>
<font size="3"><li>Achieves State-of-the-Art Performance in Knowledge-Based QA Benchmarks</li></font>
<font size="3"><li>Preserves Reasoning and Knowledge Abilities for Interactive Speech Tasks</li></font>
</ul>
</div>
## Usage
Load the EchoX model and run inference with your audio files as shown in the <a href="https://github.com/FreedomIntelligence/EchoX">GitHub repository</a>.
# <span>📖 Citation</span>
```
@misc{zhang2025echoxmitigatingacousticsemanticgap,
title={EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs},
author={Yuhao Zhang and Yuhao Du and Zhanchen Dai and Xiangnan Ma and Kaiqi Kou and Benyou Wang and Haizhou Li},
year={2025},
eprint={2509.09174},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.09174},
}
```
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757645053
|
omerbektasss
| 2025-09-12T02:44:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:44:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
onnx-community/SmolLM2-135M-humanized-ONNX
|
onnx-community
| 2025-09-12T02:42:09Z | 0 | 0 |
transformers.js
|
[
"transformers.js",
"onnx",
"llama",
"text-generation",
"conversational",
"base_model:AssistantsLab/SmolLM2-135M-humanized",
"base_model:quantized:AssistantsLab/SmolLM2-135M-humanized",
"region:us"
] |
text-generation
| 2025-09-12T02:41:59Z |
---
library_name: transformers.js
base_model:
- AssistantsLab/SmolLM2-135M-humanized
---
# SmolLM2-135M-humanized (ONNX)
This is an ONNX version of [AssistantsLab/SmolLM2-135M-humanized](https://huggingface.co/AssistantsLab/SmolLM2-135M-humanized). It was automatically converted and uploaded using [this space](https://huggingface.co/spaces/onnx-community/convert-to-onnx).
|
teysty/vjepa2-vitl-fpc16-256-ssv2-fdet_64-frames_1clip_1indice_cleaned-new-split_10epochs
|
teysty
| 2025-09-12T02:41:37Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vjepa2",
"video-classification",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2025-09-12T02:33:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757644795
|
stonermay
| 2025-09-12T02:41:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:40:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
justpluso/turn-detection-gguf
|
justpluso
| 2025-09-12T02:38:57Z | 0 | 0 | null |
[
"gguf",
"voice",
"agent",
"text-classification",
"zh",
"en",
"base_model:justpluso/turn-detection",
"base_model:quantized:justpluso/turn-detection",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-classification
| 2025-09-12T02:32:31Z |
---
license: apache-2.0
language:
- zh
- en
metrics:
- accuracy
base_model:
- justpluso/turn-detection
pipeline_tag: text-classification
tags:
- voice
- agent
---
|
jahyungu/Llama-3.2-1B-Instruct_apps
|
jahyungu
| 2025-09-12T02:38:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"dataset:apps",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T02:08:59Z |
---
library_name: transformers
license: llama3.2
base_model: meta-llama/Llama-3.2-1B-Instruct
tags:
- generated_from_trainer
datasets:
- apps
model-index:
- name: Llama-3.2-1B-Instruct_apps
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.2-1B-Instruct_apps
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct) on the apps dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757644682
|
omerbektasss
| 2025-09-12T02:38:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:38:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
TAUR-dev/M-0911__0epoch_3args_grpo_try2-rl
|
TAUR-dev
| 2025-09-12T02:37:24Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"en",
"license:mit",
"region:us"
] | null | 2025-09-11T20:42:14Z |
---
language: en
license: mit
---
# M-0911__0epoch_3args_grpo_try2-rl
## Model Details
- **Training Method**: VeRL Reinforcement Learning (RL)
- **Stage Name**: rl
- **Experiment**: 0911__0epoch_3args_grpo_try2
- **RL Framework**: VeRL (Versatile Reinforcement Learning)
## Training Configuration
## Experiment Tracking
🔗 **View complete experiment details**: https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__0911__0epoch_3args_grpo_try2__v1
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TAUR-dev/M-0911__0epoch_3args_grpo_try2-rl")
model = AutoModelForCausalLM.from_pretrained("TAUR-dev/M-0911__0epoch_3args_grpo_try2-rl")
```
|
dadu/qwen3-0.6b-translation-synthetic-reasoning-1
|
dadu
| 2025-09-12T02:36:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"translation",
"reasoning",
"few-shot",
"biblical-languages",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2025-09-12T01:11:13Z |
---
library_name: transformers
tags:
- translation
- reasoning
- few-shot
- biblical-languages
license: apache-2.0
base_model:
- Qwen/Qwen3-0.6B
---
# qwen3-0.6b-translation-synthetic-reasoning-1
A fine-tuned Qwen3-0.6B model that provides step-by-step reasoning for few-shot translation tasks, particularly focused on low-resource and biblical language pairs.
## Model Details
### Model Description
This model extends Qwen/Qwen3-0.6B with the ability to perform detailed reasoning during translation. Given a query and several few-shot examples, it explains its translation choices step-by-step, making the process transparent and educational.
- **Developed by:** dadu
- **Model type:** Causal Language Model (Fine-tuned for few-shot translation reasoning)
- **Language(s):** Multi-lingual (specialized in biblical/low-resource language pairs)
- **License:** Apache 2.0 (following base model)
- **Finetuned from model:** Qwen/Qwen3-0.6B
### Model Sources
- **Repository:** [dadu/qwen3-0.6b-translation-synthetic-reasoning-1](https://huggingface.co/dadu/qwen3-0.6b-translation-synthetic-reasoning-1)
## Uses
### Direct Use
This model is designed for translation tasks where you need:
- Step-by-step reasoning explanations
- Fragment-by-fragment translation analysis
- Reference to linguistic patterns from few-shot examples
- Educational translation methodology for low-resource languages
### Out-of-Scope Use
- General conversation (may be overly verbose)
- Real-time translation (generates long explanations)
- Zero-shot translation (performs best with few-shot examples)
- Languages significantly different from training data
## How to Get Started with the Model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "dadu/qwen3-0.6b-translation-synthetic-reasoning-1"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Few-shot examples provide context for the translation style
few_shot_prompt = """
Examples:
source: Aŋkɛ bímbɔ áwúlégé, ɛkiɛ́nné Ɛsɔwɔ ɛ́kwɔ́ Josɛf ushu né gejya, ɛ́jɔɔ́ ne ji ɛké...
target: Jalla nekztanaqui nii magonacaz̈ ojktan tsjii Yooz Jilirz̈ anjilaqui wiiquin Josez̈quiz parisisquichic̈ha...
source: Josɛf ápégé, asɛ maá yimbɔ ne mmá wuú áfɛ́ né mme Isrɛli.
target: Jalla nuz̈ cjen Josequi z̈aaz̈cu Israel yokquin nii uztan maatan chjitchic̈ha.
Query: ɛké “Josɛf, kwilé ka ɔ́kpá maá yina ne mma wuú, ɛnyú dékéré meso né mme Isrɛli. Bɔɔ́ abi ákɛlege manwá ji ágboó.”
"""
messages = [
{"role": "system", "content": "You are a helpful Bible translation assistant. Given examples of language pairs and a query, you will write a high quality translation with reasoning."},
{"role": "user", "content": few_shot_prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=1024, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
```
## Training Details
### Training Data
- **Dataset:** `dadu/translation-synthetic-reasoning-1`
- **Size:** ~980 translation examples with detailed reasoning
- **Source:** Synthetically generated using LLMs with gold standard translations
- **Format:** Each example includes source text, target translation, and step-by-step reasoning
- **Languages:** Primarily biblical and low-resource language pairs
- **Quality:** Filtered to remove corrupted examples
### Training Procedure
#### Training Hyperparameters
- **Training regime:** Full fine-tuning (not LoRA)
- **Context Length:** 16,384 tokens
- **Epochs:** 2
- **Batch Size:** 8 (1 per device × 8 gradient accumulation)
- **Learning Rate:** 1.5e-5 with cosine scheduling
- **Optimizer:** AdamW with gradient clipping (max_grad_norm=1.0)
- **Precision:** BF16 mixed precision
## Methodology
The model was trained on few-shot prompts to:
1. **Analyze source text fragment by fragment**
2. **Reference similar patterns from the provided few-shot examples**
3. **Explain lexical and grammatical choices based on context**
4. **Provide systematic reasoning before the final translation**
## Limitations
- **Specialized domain:** Optimized for biblical/low-resource language translation
- **Verbose output:** Generates detailed explanations for all translations
- **Training data scope:** Performance may vary on language pairs not represented in training data
- **Few-shot dependency:** Works best when provided with relevant few-shot examples
## Technical Specifications
### Model Architecture
- **Base:** Qwen/Qwen3-0.6B (transformer decoder)
- **Parameters:** ~600M
- **Context Window:** 16,384 tokens
### Compute Infrastructure
#### Hardware
- **Training:** Google Colab Pro (A100 GPU)
- **Memory:** High memory configuration for 16K context training
#### Software
- **Framework:** Transformers, TRL
- **Precision:** BF16 mixed precision
- **Environment:** Google Colab
|
H5N1AIDS/Transcribe_and_Translate_Subtitles
|
H5N1AIDS
| 2025-09-12T02:36:41Z | 1 | 1 | null |
[
"onnx",
"license:apache-2.0",
"region:us"
] | null | 2025-05-08T03:51:45Z |
---
license: apache-2.0
---
# Transcribe and Translate Subtitles
## 🚨 Important Note
- **Every task runs locally without internet, ensuring maximum privacy.**
- [Visit Github](https://github.com/DakeQQ/Transcribe-and-Translate-Subtitles)
---
## Updates
- 2025/7/5
- Added a noise reduction model: MossFormerGAN_SE_16K
- 2025/6/11
- Added HumAware-VAD, NVIDIA-NeMo-VAD, TEN-VAD
- 2025/6/3
- Added Dolphin ASR model to support Asian languages.
- 2025/5/13
- Added Float16/32 ASR models to support CUDA/DirectML GPU usage. These models can achieve >99% GPU operator deployment.
- 2025/5/9
- Added an option to **not use** VAD (Voice Activity Detection), offering greater flexibility.
- Added a noise reduction model: **MelBandRoformer**.
- Added three Japanese anime fine-tuned Whisper models.
- Added ASR model: **CrisperWhisper**.
- Added English fine-tuned ASR model: **Whisper-Large-v3.5-Distil**.
- Added ASR model supporting Chinese (including some dialects): **FireRedASR-AED-L**.
- Removed the IPEX-LLM framework to enhance overall performance.
- Cancelled LLM quantization options, standardizing on the **Q4F32** format.
- Improved accuracy of **FSMN-VAD**.
- Improved recognition accuracy of **Paraformer**.
- Improved recognition accuracy of **SenseVoice**.
- Improved inference speed of the **Whisper** series by over 10%.
- Supported the following large language models (LLMs) with **ONNX Runtime 100% GPU operator deployment**:
- Qwen3-4B/8B
- InternLM3-8B
- Phi-4-mini-Instruct
- Gemma3-4B/12B-it
- Expanded hardware support:
- **Intel OpenVINO**
- **NVIDIA CUDA GPU**
- **Windows DirectML GPU** (supports integrated and discrete GPUs)
---
## ✨ Features
This project is built on ONNX Runtime framework.
- Deoiser Support:
- [DFSMN](https://modelscope.cn/models/iic/speech_dfsmn_ans_psm_48k_causal)
- [GTCRN](https://github.com/Xiaobin-Rong/gtcrn)
- [ZipEnhancer](https://modelscope.cn/models/iic/speech_zipenhancer_ans_multiloss_16k_base)
- [Mel-Band-Roformer](https://github.com/KimberleyJensen/Mel-Band-Roformer-Vocal-Model)
- [MossFormerGAN_SE_16K](https://www.modelscope.cn/models/alibabasglab/MossFormerGAN_SE_16K)
- VAD Support:
- [FSMN](https://modelscope.cn/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch)
- [Faster_Whisper - Silero](https://github.com/SYSTRAN/faster-whisper/blob/master/faster_whisper/vad.py)
- [Official - Silero](https://github.com/snakers4/silero-vad)
- [HumAware](https://huggingface.co/CuriousMonkey7/HumAware-VAD)
- [NVIDIA-NeMo-VAD-v2.0](https://huggingface.co/nvidia/Frame_VAD_Multilingual_MarbleNet_v2.0)
- [TEN-VAD](https://github.com/TEN-framework/ten-vad)
- [Pyannote-Segmentation-3.0](https://huggingface.co/pyannote/segmentation-3.0)
- You need to accept Pyannote's terms of use and download the Pyannote `pytorch_model.bin` file. Next, place it in the `VAD/pyannote_segmentation` folder.
- ASR Support:
- [SenseVoice-Small](https://modelscope.cn/models/iic/SenseVoiceSmall)
- [Paraformer-Small-Chinese](https://modelscope.cn/models/iic/speech_paraformer_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1)
- [Paraformer-Large-Chinese](https://modelscope.cn/models/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch)
- [Paraformer-Large-English](https://modelscope.cn/models/iic/speech_paraformer_asr-en-16k-vocab4199-pytorch)
- [Whisper-Large-V3](https://huggingface.co/openai/whisper-large-v3)
- [Whisper-Large-V3-Turbo](https://huggingface.co/openai/whisper-large-v3-turbo)
- [Whisper-Large-V3-Turbo-Japanese](https://huggingface.co/hhim8826/whisper-large-v3-turbo-ja)
- [Whisper-Large-V3-Anime-A](https://huggingface.co/efwkjn/whisper-ja-anime-v0.1)
- [Whisper-Large-V3-Anime-B](https://huggingface.co/litagin/anime-whisper)
- [Whisper-Large-v3.5-Distil](https://huggingface.co/distil-whisper/distil-large-v3.5)
- [CrisperWhisper](https://github.com/nyrahealth/CrisperWhisper)
- [FireRedASR-AED-L](https://github.com/FireRedTeam/FireRedASR)
- [Dolphin-Small](https://github.com/DataoceanAI/Dolphin)
- LLM Supports:
- Qwen-3: [4B](https://modelscope.cn/models/Qwen/Qwen3-4B), [8B](https://modelscope.cn/models/Qwen/Qwen3-8B)
- InternLM-3: [8B](https://huggingface.co/internlm/internlm3-8b-instruct)
- Gemma-3-it: [4B](https://huggingface.co/google/gemma-3-4b-it), [12B](https://huggingface.co/google/gemma-3-12b-it)
- Phi-4-Instruct: [mini](https://huggingface.co/microsoft/Phi-4-mini-instruct)
---
## 📋 Setup Instructions
### ✅ Step 1: Install Dependencies
- Run the following command in your terminal to install the latest required Python packages:
- For Apple Silicon M-series chips, avoid installing `onnxruntime-openvino`, as it will cause errors.
```bash
conda install ffmpeg
pip install -r requirements.txt
```
### 📥 Step 2: Download Necessary Models
- Download the required models from HuggingFace: [Transcribe_and_Translate_Subtitles](https://huggingface.co/H5N1AIDS/Transcribe_and_Translate_Subtitles).
### 🖥️ Step 3: Download and Place `run.py`
- Download the `run.py` script from this repository.
- Place it in the `Transcribe_and_Translate_Subtitles` folder.
### 📁 Step 4: Place Target Videos in the Media Folder
- Place the videos you want to transcribe and translate in the following directory. The application will process the videos one by one.:
```
Transcribe_and_Translate_Subtitles/Media
```
### 🚀 Step 5: Run the Application
- Open your preferred terminal (PyCharm, CMD, PowerShell, etc.).
- Execute the following command to start the application:
```bash
python run.py
```
- Once the application starts, you will see a webpage open in your browser.

### 🛠️ Step 6: Fix Error (if encountered)
- On the first run, you might encounter a **Silero-VAD error**. Simply restart the application, and it should be resolved.
- On the first run, you might encounter a **libc++1.so error**. Run the following commands in the terminal, and they should resolve the issue.
```bash
sudo apt update
sudo apt install libc++1
```
### 💻 Step 7: Device Support
- This project currently supports:
- **Intel-OpenVINO-CPU-GPU-NPU**
- **Windows-AMD-GPU**
- **NVIDIA-GPU**
- **Apple-CPU**
- **AMD-CPU**
---
## 🎉 Enjoy the Application!
```
Transcribe_and_Translate_Subtitles/Results/Subtitles
```
---
## 📌 To-Do List
- [ ] Beam Search for ASR models.
- [ ] [Seed-X-PPO-7B](https://modelscope.cn/models/ByteDance-Seed/Seed-X-PPO-7B) with Beam Search
- [ ] [Belle-Whisper-ZH](https://huggingface.co/BELLE-2/Belle-whisper-large-v3-zh-punct)
- [ ] Remove FSMN-VAD, Qwen, Gemma, Phi, InternLM. Only Gemma3-it-4B and Seed-X-PRO-7B are provided.
- [ ] [Upscale the Resolution of Video](https://github.com/sczhou/Upscale-A-Video)
- [ ] [Denoiser-MossFormer2-48K](https://www.modelscope.cn/models/alibabasglab/MossFormer2_SE_48K)
- [ ] AMD-ROCm Support
- [ ] Real-Time Translate & Trascribe Video Player
---
### 性能 Performance
| OS | Backend | Denoiser | VAD | ASR | LLM | Real-Time Factor<br>test_video.mp4<br>7602 seconds |
|:------------:|:-----------------:|:-----------------:|:--------------------:|:--------------------:|:----------------:|:----------------:|
| Ubuntu-24.04 | CPU <br> i3-12300 | - | Silero | SenseVoiceSmall | - | 0.08 |
| Ubuntu-24.04 | CPU <br> i3-12300 | GTCRN | Silero | SenseVoiceSmall | Qwen2.5-7B-Instruct | 0.50 |
| Ubuntu-24.04 | CPU <br> i3-12300 | GTCRN | FSMN | SenseVoiceSmall | - | 0.054 |
| Ubuntu-24.04 | CPU <br> i3-12300 | ZipEnhancer | FSMN | SenseVoiceSmall | - | 0.39 |
| Ubuntu-24.04 | CPU <br> i3-12300 | GTCRN | Silero | Whisper-Large-V3 | - | 0.20 |
| Ubuntu-24.04 | CPU <br> i3-12300 | GTCRN | FSMN | Whisper-Large-V3-Turbo | - | 0.148 |
---
# 转录和翻译字幕
## 🚨 重要提示
- **所有任务均在本地运行,无需连接互联网,确保最大程度的隐私保护。**
- [访问 Github](https://github.com/DakeQQ/Transcribe-and-Translate-Subtitles)
---
## 最近更新与功能
- 2025/7/5
- 新增 降噪 MossFormerGAN_SE_16K
- 2025/6/11
- 新增 HumAware-VAD, NVIDIA-NeMo-VAD, TEN-VAD。
- 2025/6/3
- 新增 Dolphin ASR 模型以支持亚洲语言。
- 2025/5/13
- 新增 Float16/32 ASR 模型,支持 CUDA/DirectML GPU 使用。这些模型可实现 >99% 的 GPU 算子部署率。
- 2025/5/9
- 新增 **不使用** VAD(语音活动检测)的选项,提供更多灵活性。
- 新增降噪模型:**MelBandRoformer**。
- 新增三款日语动漫微调Whisper模型。
- 新增ASR模型:**CrisperWhisper**。
- 新增英语微调ASR模型:**Whisper-Large-v3.5-Distil**。
- 新增支持中文(包括部分方言)的ASR模型:**FireRedASR-AED-L**。
- 移除IPEX-LLM框架,提升整体性能。
- 取消LLM量化选项,统一采用**Q4F32**格式。
- 改进了**FSMN-VAD**的准确率。
- 改进了**Paraformer**的识别准确率。
- 改进了**SenseVoice**的识别准确率。
- 改进了**Whisper**系列的推理速度10%+。
- 支持以下大语言模型(LLM),实现**ONNX Runtime 100% GPU算子部署**:
- Qwen3-4B/8B
- InternLM3-8B
- Phi-4-mini-Instruct
- Gemma3-4B/12B-it
- 扩展硬件支持:
- **Intel OpenVINO**
- **NVIDIA CUDA GPU**
- **Windows DirectML GPU**(支持集成显卡和独立显卡)
---
## ✨ 功能
这个项目基于 ONNX Runtime 框架。
- **去噪器 (Denoiser) 支持**:
- [DFSMN](https://modelscope.cn/models/iic/speech_dfsmn_ans_psm_48k_causal)
- [GTCRN](https://github.com/Xiaobin-Rong/gtcrn)
- [ZipEnhancer](https://modelscope.cn/models/iic/speech_zipenhancer_ans_multiloss_16k_base)
- [Mel-Band-Roformer](https://github.com/KimberleyJensen/Mel-Band-Roformer-Vocal-Model)
- [MossFormerGAN_SE_16K](https://www.modelscope.cn/models/alibabasglab/MossFormerGAN_SE_16K)
- **语音活动检测(VAD)支持**:
- [FSMN](https://modelscope.cn/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch)
- [Faster_Whisper - Silero](https://github.com/SYSTRAN/faster-whisper/blob/master/faster_whisper/vad.py)
- [官方 - Silero](https://github.com/snakers4/silero-vad)
- [HumAware](https://huggingface.co/CuriousMonkey7/HumAware-VAD)
- [NVIDIA-NeMo-VAD-v2.0](https://huggingface.co/nvidia/Frame_VAD_Multilingual_MarbleNet_v2.0)
- [TEN-VAD](https://github.com/TEN-framework/ten-vad)
- [Pyannote-Segmentation-3.0](https://huggingface.co/pyannote/segmentation-3.0)
- 需要接受Pyannote的使用条款,並自行下载 Pyannote `pytorch_model.bin` 文件,并将其放置在 `VAD/pyannote_segmentation` 文件夹中。
- **语音识别(ASR)支持**:
- [SenseVoice-Small](https://modelscope.cn/models/iic/SenseVoiceSmall)
- [Paraformer-Small-Chinese](https://modelscope.cn/models/iic/speech_paraformer_asr_nat-zh-cn-16k-common-vocab8358-tensorflow1)
- [Paraformer-Large-Chinese](https://modelscope.cn/models/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch)
- [Paraformer-Large-English](https://modelscope.cn/models/iic/speech_paraformer_asr-en-16k-vocab4199-pytorch)
- [Whisper-Large-V3](https://huggingface.co/openai/whisper-large-v3)
- [Whisper-Large-V3-Turbo](https://huggingface.co/openai/whisper-large-v3-turbo)
- [Whisper-Large-V3-Turbo-Japanese](https://huggingface.co/hhim8826/whisper-large-v3-turbo-ja)
- [Whisper-Large-V3-Anime-A](https://huggingface.co/efwkjn/whisper-ja-anime-v0.1)
- [Whisper-Large-V3-Anime-B](https://huggingface.co/litagin/anime-whisper)
- [Whisper-Large-v3.5-Distil](https://huggingface.co/distil-whisper/distil-large-v3.5)
- [CrisperWhisper](https://github.com/nyrahealth/CrisperWhisper)
- [FireRedASR-AED-L](https://github.com/FireRedTeam/FireRedASR)
- [Dolphin-Small](https://github.com/DataoceanAI/Dolphin)
- **大语言模型(LLM)支持**:
- Qwen-3: [4B](https://modelscope.cn/models/Qwen/Qwen3-4B), [8B](https://modelscope.cn/models/Qwen/Qwen3-8B)
- InternLM-3: [8B](https://huggingface.co/internlm/internlm3-8b-instruct)
- Gemma-3-it: [4B](https://huggingface.co/google/gemma-3-4b-it), [12B](https://huggingface.co/google/gemma-3-12b-it)
- Phi-4-Instruct: [mini](https://huggingface.co/microsoft/Phi-4-mini-instruct)
---
## 📋 设置指南
### ✅ 第一步:安装依赖项
- 在终端中运行以下命令来安装所需的最新 Python 包:
- 对于苹果 M 系列芯片,请不要安装 `onnxruntime-openvino`,否则会导致错误。
```bash
conda install ffmpeg
pip install -r requirements.txt
```
### 📥 第二步:下载必要的模型
- 从 HuggingFace 下载所需模型:[Transcribe_and_Translate_Subtitles](https://huggingface.co/H5N1AIDS/Transcribe_and_Translate_Subtitles)
### 🖥️ 第三步:下载并放置 `run.py`
- 从此项目的仓库下载 `run.py` 脚本。
- 将 `run.py` 放置在 `Transcribe_and_Translate_Subtitles` 文件夹中。
### 📁 第四步:将目标视频放入 Media 文件夹
- 将你想要转录和翻译的视频放置在以下目录,应用程序将逐个处理这些视频:
```
Transcribe_and_Translate_Subtitles/Media
```
### 🚀 第五步:运行应用程序
- 打开你喜欢的终端工具(PyCharm、CMD、PowerShell 等)。
- 运行以下命令来启动应用程序:
```bash
python run.py
```
- 应用程序启动后,你的浏览器将自动打开一个网页。

### 🛠️ 第六步:修复错误(如有)
- 首次运行时,你可能会遇到 **Silero-VAD 错误**。只需重启应用程序即可解决该问题。
- 首次运行时,你可能会遇到 **libc++1.so 错误**。在终端中运行以下命令,应该可以解决问题。
```bash
sudo apt update
sudo apt install libc++1
```
### 💻 第七步:支持设备
- 此项目目前支持:
- **Intel-OpenVINO-CPU-GPU-NPU**
- **Windows-AMD-GPU**
- **NVIDIA-GPU**
- **Apple-CPU**
- **AMD-CPU**
## 🎉 尽情享受应用程序吧!
```
Transcribe_and_Translate_Subtitles/Results/Subtitles
```
---
## 📌 待办事项
- [ ] Beam Search for ASR models.
- [ ] [Seed-X-PPO-7B](https://modelscope.cn/models/ByteDance-Seed/Seed-X-PPO-7B) with Beam Search
- [ ] [Belle-Whisper-ZH](https://huggingface.co/BELLE-2/Belle-whisper-large-v3-zh-punct)
- [ ] Remove FSMN-VAD, Qwen, Gemma, Phi, InternLM. Only Gemma3-it-4B and Seed-X-PRO-7B are provided.
- [ ] [Upscale the Resolution of Video](https://github.com/sczhou/Upscale-A-Video)
- [ ] [Denoiser-MossFormer2-48K](https://www.modelscope.cn/models/alibabasglab/MossFormer2_SE_48K)
- [ ] 支持 AMD-ROCm
- [ ] 实现实时视频转录和翻译播放器
---
|
mradermacher/Wisenut-Qwen3-32B_v2-GGUF
|
mradermacher
| 2025-09-12T02:36:34Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:wisenut-nlp-team/Wisenut-Qwen3-32B_v2",
"base_model:quantized:wisenut-nlp-team/Wisenut-Qwen3-32B_v2",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-12T01:55:07Z |
---
base_model: wisenut-nlp-team/Wisenut-Qwen3-32B_v2
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/wisenut-nlp-team/Wisenut-Qwen3-32B_v2
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Wisenut-Qwen3-32B_v2-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q2_K.gguf) | Q2_K | 12.4 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q3_K_S.gguf) | Q3_K_S | 14.5 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q3_K_M.gguf) | Q3_K_M | 16.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q3_K_L.gguf) | Q3_K_L | 17.4 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.IQ4_XS.gguf) | IQ4_XS | 18.0 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q4_K_S.gguf) | Q4_K_S | 18.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q4_K_M.gguf) | Q4_K_M | 19.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q5_K_S.gguf) | Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q5_K_M.gguf) | Q5_K_M | 23.3 | |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q6_K.gguf) | Q6_K | 27.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Wisenut-Qwen3-32B_v2-GGUF/resolve/main/Wisenut-Qwen3-32B_v2.Q8_0.gguf) | Q8_0 | 34.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ZhengPeng7/BiRefNet_HR
|
ZhengPeng7
| 2025-09-12T02:36:26Z | 46,046 | 66 |
birefnet
|
[
"birefnet",
"safetensors",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"Camouflaged Object Detection",
"Salient Object Detection",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"image-segmentation",
"custom_code",
"arxiv:2401.03407",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2025-02-01T17:52:14Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- Camouflaged Object Detection
- Salient Object Detection
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
license: mit
---
> This BiRefNet was trained with images in `2048x2048` for higher resolution inference.
### Performance:
> All tested in FP16 mode.
| Dataset | Method | Resolution | maxFm | wFmeasure | MAE | Smeasure | meanEm | HCE | maxEm | meanFm | adpEm | adpFm | mBA | maxBIoU | meanBIoU |
| :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: |
| DIS-VD | **BiRefNet_HR**-general-epoch_130 | 2048x2048 | .925 | .894 | .026 | .927 | .952 | 811 | .960 | .909 | .944 | .888 | .828 | .837 | .817 |
| DIS-VD | **BiRefNet_HR**-general-epoch_130 | 1024x1024 | .876 | .840 | .041 | .893 | .913 | 1348 | .926 | .860 | .930 | .857 | .765 | .769 | .742 |
| DIS-VD | [**BiRefNet**-general-epoch_244](https://huggingface.co/ZhengPeng7/BiRefNet) | 2048x2048 | .888 | .858 | .037 | .898 | .934 | 811 | .941 | .878 | .927 | .862 | .802 | .790 | .776 |
| DIS-VD | [**BiRefNet**-general-epoch_244](https://huggingface.co/ZhengPeng7/BiRefNet) | 1024x1024 | .908 | .877 | .034 | .912 | .943 | 1128 | .953 | .894 | .944 | .881 | .796 | .812 | .789 |
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://www.sciopen.com/article/pdf/10.26599/AIR.2024.9150038.pdf'><img src='https://img.shields.io/badge/Journal-Paper-red'></a> 
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
| *DIS-Sample_1* | *DIS-Sample_2* |
| :------------------------------: | :-------------------------------: |
| <img src="https://drive.google.com/thumbnail?id=1ItXaA26iYnE8XQ_GgNLy71MOWePoS2-g&sz=w400" /> | <img src="https://drive.google.com/thumbnail?id=1Z-esCujQF_uEa_YJjkibc3NUrW4aR_d4&sz=w400" /> |
This repo is the official implementation of "[**Bilateral Reference for High-Resolution Dichotomous Image Segmentation**](https://arxiv.org/pdf/2401.03407.pdf)" (___CAAI AIR 2024___).
Visit our GitHub repo: [https://github.com/ZhengPeng7/BiRefNet](https://github.com/ZhengPeng7/BiRefNet) for more details -- **codes**, **docs**, and **model zoo**!
## How to use
### 0. Install Packages:
```
pip install -qr https://raw.githubusercontent.com/ZhengPeng7/BiRefNet/main/requirements.txt
```
### 1. Load BiRefNet:
#### Use codes + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: No need to download BiRefNet codes manually; Con: Codes on HuggingFace might not be latest version (I'll try to keep them always latest).
```python
# Load BiRefNet with weights
from transformers import AutoModelForImageSegmentation
birefnet = AutoModelForImageSegmentation.from_pretrained('ZhengPeng7/BiRefNet_HR', trust_remote_code=True)
```
#### Use codes from GitHub + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: codes are always latest; Con: Need to clone the BiRefNet repo from my GitHub.
```shell
# Download codes
git clone https://github.com/ZhengPeng7/BiRefNet.git
cd BiRefNet
```
```python
# Use codes locally
from models.birefnet import BiRefNet
# Load weights from Hugging Face Models
birefnet = BiRefNet.from_pretrained('ZhengPeng7/BiRefNet_HR')
```
#### Use codes from GitHub + weights from local space
> Only use the weights and codes both locally.
```python
# Use codes and weights locally
import torch
from utils import check_state_dict
birefnet = BiRefNet(bb_pretrained=False)
state_dict = torch.load(PATH_TO_WEIGHT, map_location='cpu')
state_dict = check_state_dict(state_dict)
birefnet.load_state_dict(state_dict)
```
#### Use the loaded BiRefNet for inference
```python
# Imports
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from models.birefnet import BiRefNet
birefnet = ... # -- BiRefNet should be loaded with codes above, either way.
torch.set_float32_matmul_precision(['high', 'highest'][0])
birefnet.to('cuda')
birefnet.eval()
birefnet.half()
def extract_object(birefnet, imagepath):
# Data settings
image_size = (2048, 2048)
transform_image = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = Image.open(imagepath)
input_images = transform_image(image).unsqueeze(0).to('cuda').half()
# Prediction
with torch.no_grad():
preds = birefnet(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
return image, mask
# Visualization
plt.axis("off")
plt.imshow(extract_object(birefnet, imagepath='PATH-TO-YOUR_IMAGE.jpg')[0])
plt.show()
```
### 2. Use inference endpoint locally:
> You may need to click the *deploy* and set up the endpoint by yourself, which would make some costs.
```
import requests
import base64
from io import BytesIO
from PIL import Image
YOUR_HF_TOKEN = 'xxx'
API_URL = "xxx"
headers = {
"Authorization": "Bearer {}".format(YOUR_HF_TOKEN)
}
def base64_to_bytes(base64_string):
# Remove the data URI prefix if present
if "data:image" in base64_string:
base64_string = base64_string.split(",")[1]
# Decode the Base64 string into bytes
image_bytes = base64.b64decode(base64_string)
return image_bytes
def bytes_to_base64(image_bytes):
# Create a BytesIO object to handle the image data
image_stream = BytesIO(image_bytes)
# Open the image using Pillow (PIL)
image = Image.open(image_stream)
return image
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "https://hips.hearstapps.com/hmg-prod/images/gettyimages-1229892983-square.jpg",
"parameters": {}
})
output_image = bytes_to_base64(base64_to_bytes(output))
output_image
```
> This BiRefNet for standard dichotomous image segmentation (DIS) is trained on **DIS-TR** and validated on **DIS-TEs and DIS-VD**.
## This repo holds the official model weights of "[<ins>Bilateral Reference for High-Resolution Dichotomous Image Segmentation</ins>](https://arxiv.org/pdf/2401.03407)" (_CAAI AIR 2024_).
This repo contains the weights of BiRefNet proposed in our paper, which has achieved the SOTA performance on three tasks (DIS, HRSOD, and COD).
Go to my GitHub page for BiRefNet codes and the latest updates: https://github.com/ZhengPeng7/BiRefNet :)
#### Try our online demos for inference:
+ Online **Image Inference** on Colab: [](https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link)
+ **Online Inference with GUI on Hugging Face** with adjustable resolutions: [](https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo)
+ **Inference and evaluation** of your given weights: [](https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S)
<img src="https://drive.google.com/thumbnail?id=12XmDhKtO1o2fEvBu4OE4ULVB2BK0ecWi&sz=w1080" />
## Acknowledgement:
+ Many thanks to @freepik for their generous support on GPU resources for training this model!
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
ZhengPeng7/BiRefNet_dynamic
|
ZhengPeng7
| 2025-09-12T02:36:09Z | 6,091 | 8 |
birefnet
|
[
"birefnet",
"safetensors",
"image-segmentation",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"Camouflaged Object Detection",
"Salient Object Detection",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"transformers",
"transformers.js",
"custom_code",
"arxiv:2401.03407",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2025-03-31T03:37:03Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- Camouflaged Object Detection
- Salient Object Detection
- pytorch_model_hub_mixin
- model_hub_mixin
- transformers
- transformers.js
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
license: mit
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
> An arbitrary shape adaptable BiRefNet for general segmentation.
> This model was trained on arbitrary shapes (256x256 ~ 2304x2304) and shows great robustness on inputs with any shape.
### Performance
> How it looks when compared with BiRefNet-general (fixed 1024x1024 resolution) -- greater than BiRefNet-general and BiRefNet_HR-general on the reserved validation sets (DIS-VD and TE-P3M-500-NP).
> The `dynamic_XXxXX` means this BiRefNet_dynamic model was being tested in various input resolutions for the evaluation.



For performance of different epochs, check the [eval_results-xxx folder for it](https://drive.google.com/drive/u/0/folders/1J79uL4xBaT3uct-tYtWZHKS2SoVE2cqu) on my google drive.
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://www.sciopen.com/article/pdf/10.26599/AIR.2024.9150038.pdf'><img src='https://img.shields.io/badge/Journal-Paper-red'></a> 
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
| *DIS-Sample_1* | *DIS-Sample_2* |
| :------------------------------: | :-------------------------------: |
| <img src="https://drive.google.com/thumbnail?id=1ItXaA26iYnE8XQ_GgNLy71MOWePoS2-g&sz=w400" /> | <img src="https://drive.google.com/thumbnail?id=1Z-esCujQF_uEa_YJjkibc3NUrW4aR_d4&sz=w400" /> |
This repo is the official implementation of "[**Bilateral Reference for High-Resolution Dichotomous Image Segmentation**](https://arxiv.org/pdf/2401.03407.pdf)" (___CAAI AIR 2024___).
Visit our GitHub repo: [https://github.com/ZhengPeng7/BiRefNet](https://github.com/ZhengPeng7/BiRefNet) for more details -- **codes**, **docs**, and **model zoo**!
## How to use
### 0. Install Packages:
```
pip install -qr https://raw.githubusercontent.com/ZhengPeng7/BiRefNet/main/requirements.txt
```
### 1. Load BiRefNet:
#### Use codes + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: No need to download BiRefNet codes manually; Con: Codes on HuggingFace might not be latest version (I'll try to keep them always latest).
```python
# Load BiRefNet with weights
from transformers import AutoModelForImageSegmentation
birefnet = AutoModelForImageSegmentation.from_pretrained('ZhengPeng7/BiRefNet', trust_remote_code=True)
```
#### Use codes from GitHub + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: codes are always latest; Con: Need to clone the BiRefNet repo from my GitHub.
```shell
# Download codes
git clone https://github.com/ZhengPeng7/BiRefNet.git
cd BiRefNet
```
```python
# Use codes locally
from models.birefnet import BiRefNet
# Load weights from Hugging Face Models
birefnet = BiRefNet.from_pretrained('ZhengPeng7/BiRefNet')
```
#### Use codes from GitHub + weights from local space
> Only use the weights and codes both locally.
```python
# Use codes and weights locally
import torch
from utils import check_state_dict
birefnet = BiRefNet(bb_pretrained=False)
state_dict = torch.load(PATH_TO_WEIGHT, map_location='cpu')
state_dict = check_state_dict(state_dict)
birefnet.load_state_dict(state_dict)
```
#### Use the loaded BiRefNet for inference
```python
# Imports
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from models.birefnet import BiRefNet
birefnet = ... # -- BiRefNet should be loaded with codes above, either way.
torch.set_float32_matmul_precision(['high', 'highest'][0])
birefnet.to('cuda')
birefnet.eval()
birefnet.half()
def extract_object(birefnet, imagepath):
# Data settings
# image_size = (1024, 1024)
# Since this model was trained on arbitrary shapes (256x256 ~ 2304x2304), the resizing is not necessary.
transform_image = transforms.Compose([
# transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = Image.open(imagepath)
input_images = transform_image(image).unsqueeze(0).to('cuda').half()
# Prediction
with torch.no_grad():
preds = birefnet(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
return image, mask
# Visualization
plt.axis("off")
plt.imshow(extract_object(birefnet, imagepath='PATH-TO-YOUR_IMAGE.jpg')[0])
plt.show()
```
### 2. Use inference endpoint locally:
> You may need to click the *deploy* and set up the endpoint by yourself, which would make some costs.
```
import requests
import base64
from io import BytesIO
from PIL import Image
YOUR_HF_TOKEN = 'xxx'
API_URL = "xxx"
headers = {
"Authorization": "Bearer {}".format(YOUR_HF_TOKEN)
}
def base64_to_bytes(base64_string):
# Remove the data URI prefix if present
if "data:image" in base64_string:
base64_string = base64_string.split(",")[1]
# Decode the Base64 string into bytes
image_bytes = base64.b64decode(base64_string)
return image_bytes
def bytes_to_base64(image_bytes):
# Create a BytesIO object to handle the image data
image_stream = BytesIO(image_bytes)
# Open the image using Pillow (PIL)
image = Image.open(image_stream)
return image
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "https://hips.hearstapps.com/hmg-prod/images/gettyimages-1229892983-square.jpg",
"parameters": {}
})
output_image = bytes_to_base64(base64_to_bytes(output))
output_image
```
> This BiRefNet for standard dichotomous image segmentation (DIS) is trained on **DIS-TR** and validated on **DIS-TEs and DIS-VD**.
## This repo holds the official model weights of "[<ins>Bilateral Reference for High-Resolution Dichotomous Image Segmentation</ins>](https://arxiv.org/pdf/2401.03407)" (_CAAI AIR 2024_).
This repo contains the weights of BiRefNet proposed in our paper, which has achieved the SOTA performance on three tasks (DIS, HRSOD, and COD).
Go to my GitHub page for BiRefNet codes and the latest updates: https://github.com/ZhengPeng7/BiRefNet :)
#### Try our online demos for inference:
+ Online **Image Inference** on Colab: [](https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link)
+ **Online Inference with GUI on Hugging Face** with adjustable resolutions: [](https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo)
+ **Inference and evaluation** of your given weights: [](https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S)
<img src="https://drive.google.com/thumbnail?id=12XmDhKtO1o2fEvBu4OE4ULVB2BK0ecWi&sz=w1080" />
## Acknowledgement:
+ Many thanks to @Freepik for their generous support on GPU resources for training higher resolution BiRefNet models and more of my explorations.
+ Many thanks to @fal for their generous support on GPU resources for training better general BiRefNet models.
+ Many thanks to @not-lain for his help on the better deployment of our BiRefNet model on HuggingFace.
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
ZhengPeng7/BiRefNet_dynamic-matting
|
ZhengPeng7
| 2025-09-12T02:36:04Z | 218 | 0 |
birefnet
|
[
"birefnet",
"safetensors",
"image-segmentation",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"Camouflaged Object Detection",
"Salient Object Detection",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"transformers",
"transformers.js",
"custom_code",
"arxiv:2401.03407",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2025-07-11T15:10:08Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- Camouflaged Object Detection
- Salient Object Detection
- pytorch_model_hub_mixin
- model_hub_mixin
- transformers
- transformers.js
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
license: mit
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
> An arbitrary shape adaptable BiRefNet for matting.
> This model was trained on arbitrary shapes (256x256 ~ 2304x2304) and shows great robustness on inputs with any shape.
### Performance
> How it looks when compared with BiRefNet-matting and BiRefNet_HR-matting (fixed resolution, e.g., 1024x1024, 2048x2048).
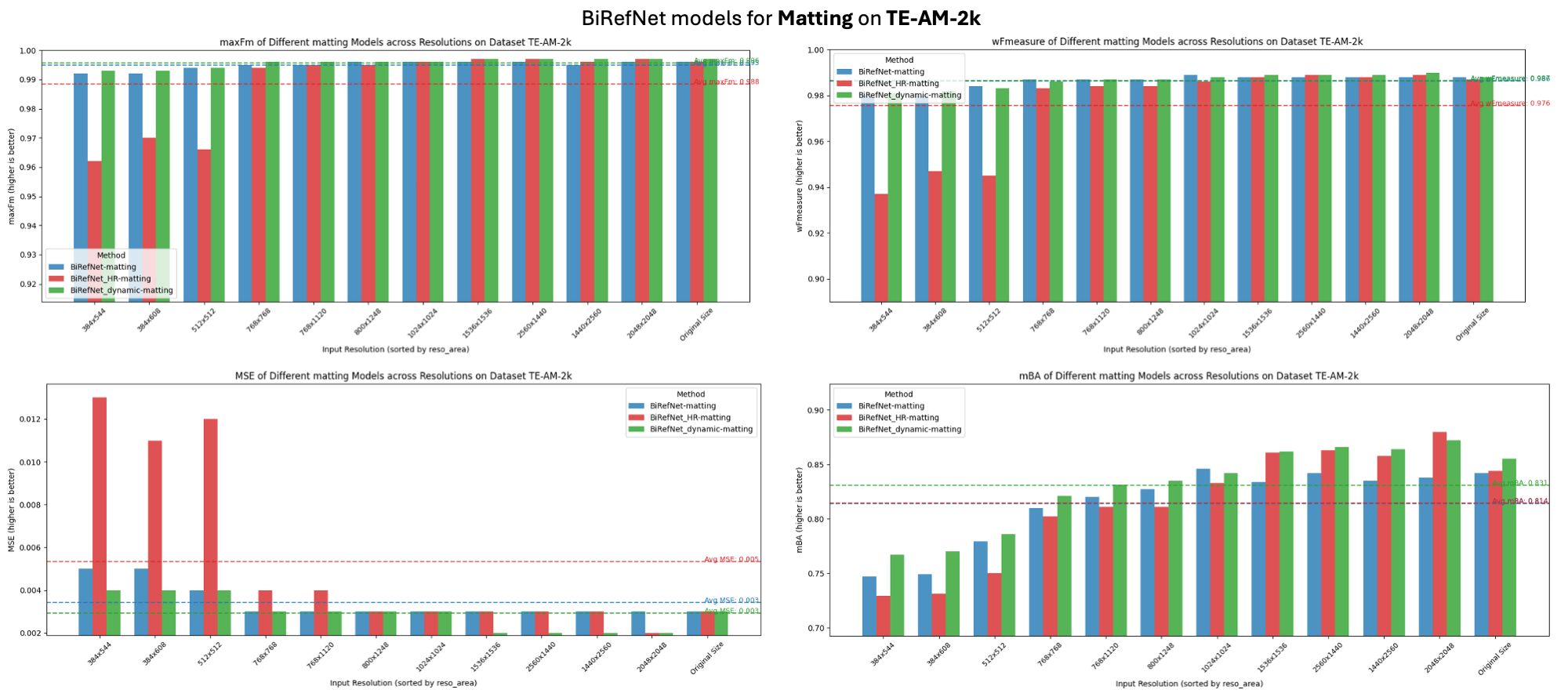
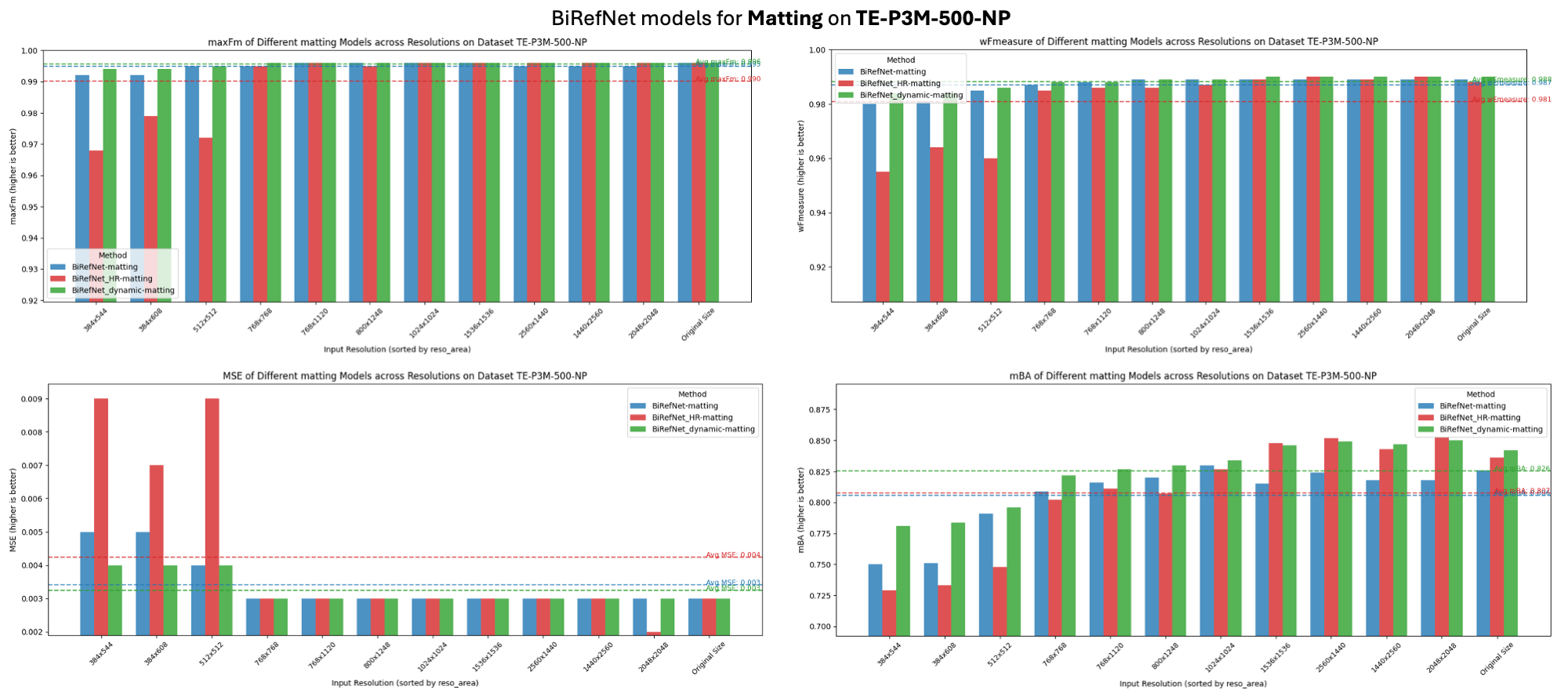
For performance of different epochs, check the [eval_results-xxx folder for it](https://drive.google.com/drive/u/0/folders/1wSOe0m98YJBRnOefQrC6iefFmeUPtVhn) on my google drive.
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://www.sciopen.com/article/pdf/10.26599/AIR.2024.9150038.pdf'><img src='https://img.shields.io/badge/Journal-Paper-red'></a> 
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
| *DIS-Sample_1* | *DIS-Sample_2* |
| :------------------------------: | :-------------------------------: |
| <img src="https://drive.google.com/thumbnail?id=1ItXaA26iYnE8XQ_GgNLy71MOWePoS2-g&sz=w400" /> | <img src="https://drive.google.com/thumbnail?id=1Z-esCujQF_uEa_YJjkibc3NUrW4aR_d4&sz=w400" /> |
This repo is the official implementation of "[**Bilateral Reference for High-Resolution Dichotomous Image Segmentation**](https://arxiv.org/pdf/2401.03407.pdf)" (___CAAI AIR 2024___).
Visit our GitHub repo: [https://github.com/ZhengPeng7/BiRefNet](https://github.com/ZhengPeng7/BiRefNet) for more details -- **codes**, **docs**, and **model zoo**!
## How to use
### 0. Install Packages:
```
pip install -qr https://raw.githubusercontent.com/ZhengPeng7/BiRefNet/main/requirements.txt
```
### 1. Load BiRefNet:
#### Use codes + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: No need to download BiRefNet codes manually; Con: Codes on HuggingFace might not be latest version (I'll try to keep them always latest).
```python
# Load BiRefNet with weights
from transformers import AutoModelForImageSegmentation
birefnet = AutoModelForImageSegmentation.from_pretrained('ZhengPeng7/BiRefNet', trust_remote_code=True)
```
#### Use codes from GitHub + weights from HuggingFace
> Only use the weights on HuggingFace -- Pro: codes are always latest; Con: Need to clone the BiRefNet repo from my GitHub.
```shell
# Download codes
git clone https://github.com/ZhengPeng7/BiRefNet.git
cd BiRefNet
```
```python
# Use codes locally
from models.birefnet import BiRefNet
# Load weights from Hugging Face Models
birefnet = BiRefNet.from_pretrained('ZhengPeng7/BiRefNet')
```
#### Use codes from GitHub + weights from local space
> Only use the weights and codes both locally.
```python
# Use codes and weights locally
import torch
from utils import check_state_dict
birefnet = BiRefNet(bb_pretrained=False)
state_dict = torch.load(PATH_TO_WEIGHT, map_location='cpu')
state_dict = check_state_dict(state_dict)
birefnet.load_state_dict(state_dict)
```
#### Use the loaded BiRefNet for inference
```python
# Imports
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from models.birefnet import BiRefNet
birefnet = ... # -- BiRefNet should be loaded with codes above, either way.
torch.set_float32_matmul_precision(['high', 'highest'][0])
birefnet.to('cuda')
birefnet.eval()
birefnet.half()
def extract_object(birefnet, imagepath):
# Data settings
# image_size = (1024, 1024)
# Since this model was trained on arbitrary shapes (256x256 ~ 2304x2304), the resizing is not necessary.
transform_image = transforms.Compose([
# transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = Image.open(imagepath)
input_images = transform_image(image).unsqueeze(0).to('cuda').half()
# Prediction
with torch.no_grad():
preds = birefnet(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
return image, mask
# Visualization
plt.axis("off")
plt.imshow(extract_object(birefnet, imagepath='PATH-TO-YOUR_IMAGE.jpg')[0])
plt.show()
```
### 2. Use inference endpoint locally:
> You may need to click the *deploy* and set up the endpoint by yourself, which would make some costs.
```
import requests
import base64
from io import BytesIO
from PIL import Image
YOUR_HF_TOKEN = 'xxx'
API_URL = "xxx"
headers = {
"Authorization": "Bearer {}".format(YOUR_HF_TOKEN)
}
def base64_to_bytes(base64_string):
# Remove the data URI prefix if present
if "data:image" in base64_string:
base64_string = base64_string.split(",")[1]
# Decode the Base64 string into bytes
image_bytes = base64.b64decode(base64_string)
return image_bytes
def bytes_to_base64(image_bytes):
# Create a BytesIO object to handle the image data
image_stream = BytesIO(image_bytes)
# Open the image using Pillow (PIL)
image = Image.open(image_stream)
return image
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "https://hips.hearstapps.com/hmg-prod/images/gettyimages-1229892983-square.jpg",
"parameters": {}
})
output_image = bytes_to_base64(base64_to_bytes(output))
output_image
```
> This BiRefNet for standard dichotomous image segmentation (DIS) is trained on **DIS-TR** and validated on **DIS-TEs and DIS-VD**.
## This repo holds the official model weights of "[<ins>Bilateral Reference for High-Resolution Dichotomous Image Segmentation</ins>](https://arxiv.org/pdf/2401.03407)" (_CAAI AIR 2024_).
This repo contains the weights of BiRefNet proposed in our paper, which has achieved the SOTA performance on three tasks (DIS, HRSOD, and COD).
Go to my GitHub page for BiRefNet codes and the latest updates: https://github.com/ZhengPeng7/BiRefNet :)
#### Try our online demos for inference:
+ Online **Image Inference** on Colab: [](https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link)
+ **Online Inference with GUI on Hugging Face** with adjustable resolutions: [](https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo)
+ **Inference and evaluation** of your given weights: [](https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S)
<img src="https://drive.google.com/thumbnail?id=12XmDhKtO1o2fEvBu4OE4ULVB2BK0ecWi&sz=w1080" />
## Acknowledgement:
+ Many thanks to @Freepik for their generous support on GPU resources for training higher resolution BiRefNet models and more of my explorations.
+ Many thanks to @fal for their generous support on GPU resources for training better general BiRefNet models.
+ Many thanks to @not-lain for his help on the better deployment of our BiRefNet model on HuggingFace.
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
luminolous/t5-normal-explainer
|
luminolous
| 2025-09-12T02:35:05Z | 0 | 0 | null |
[
"safetensors",
"t5",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T02:33:37Z |
---
license: apache-2.0
---
|
ZhengPeng7/BiRefNet-DIS5K-TR_TEs
|
ZhengPeng7
| 2025-09-12T02:32:59Z | 527 | 0 |
birefnet
|
[
"birefnet",
"safetensors",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"image-segmentation",
"custom_code",
"arxiv:2401.03407",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2024-08-01T09:10:08Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
## This repo holds the official weights of BiRefNet trained on DIS5K-TR and DIS5K-TEs for Dichotomous Image Segmentation (DIS).
**Check the main BiRefNet model repo for more info and how to use it:**
https://huggingface.co/ZhengPeng7/BiRefNet/blob/main/README.md
**Also check the GitHub repo of BiRefNet for all things you may want:**
https://github.com/ZhengPeng7/BiRefNet
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
ZhengPeng7/BiRefNet-HRSOD
|
ZhengPeng7
| 2025-09-12T02:32:34Z | 22,454 | 2 |
birefnet
|
[
"birefnet",
"safetensors",
"background-removal",
"mask-generation",
"Dichotomous Image Segmentation",
"Salient Object Detection",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"image-segmentation",
"custom_code",
"arxiv:2401.03407",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2024-08-01T09:04:27Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Dichotomous Image Segmentation
- Salient Object Detection
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
## This repo holds the official weights of BiRefNet trained on DUTS/HRSOD/UHRSD for High-Resolution Salient Object Detection (HRSOD) in the original paper.
**Check the main BiRefNet model repo for more info and how to use it:**
https://huggingface.co/ZhengPeng7/BiRefNet/blob/main/README.md
**Also check the GitHub repo of BiRefNet for all things you may want:**
https://github.com/ZhengPeng7/BiRefNet
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757644331
|
omerbektasss
| 2025-09-12T02:32:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:32:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ZhengPeng7/BiRefNet-portrait
|
ZhengPeng7
| 2025-09-12T02:32:08Z | 6,441 | 11 |
birefnet
|
[
"birefnet",
"safetensors",
"background-removal",
"mask-generation",
"Image Matting",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"image-segmentation",
"custom_code",
"arxiv:2401.03407",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2024-05-13T16:27:16Z |
---
library_name: birefnet
tags:
- background-removal
- mask-generation
- Image Matting
- pytorch_model_hub_mixin
- model_hub_mixin
repo_url: https://github.com/ZhengPeng7/BiRefNet
pipeline_tag: image-segmentation
---
<h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1>
<div align='center'>
<a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>, 
<a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>, 
<a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>, 
<a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>, 
<a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>, 
<a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>, 
<a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup>
</div>
<div align='center'>
<sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento 
</div>
<div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;">
<a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a> 
<a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a> 
<a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a> 
<a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a> 
<a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a> 
<a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a> 
<a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a> 
<a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
<a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a> 
</div>
## This repo holds the official weights of BiRefNet for general matting.
### Training Sets:
+ P3M-10k (except TE-P3M-500-P)
+ [TR-humans](https://huggingface.co/datasets/schirrmacher/humans)
### Validation Sets:
+ TE-P3M-500-P
### Performance:
| Dataset | Method | Smeasure | maxFm | meanEm | MAE | maxEm | meanFm | wFmeasure | adpEm | adpFm | HCE |
| :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: | :------: |
| TE-P3M-500-P | BiRefNet-portrai--epoch_150 | .983 | .996 | .991 | .006 | .997 | .988 | .990 | .933 | .965 | .000 |
**Check the main BiRefNet model repo for more info and how to use it:**
https://huggingface.co/ZhengPeng7/BiRefNet/blob/main/README.md
**Also check the GitHub repo of BiRefNet for all things you may want:**
https://github.com/ZhengPeng7/BiRefNet
## Acknowledgement:
+ Many thanks to @fal for their generous support on GPU resources for training this BiRefNet for portrait matting.
## Citation
```
@article{zheng2024birefnet,
title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation},
author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu},
journal={CAAI Artificial Intelligence Research},
volume = {3},
pages = {9150038},
year={2024}
}
```
|
dsaddsdsdd/blockassist
|
dsaddsdsdd
| 2025-09-12T02:31:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stinging darting anteater",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:31:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stinging darting anteater
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yepengsun/ppo-Pyramids-training
|
yepengsun
| 2025-09-12T02:31:37Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2025-09-12T02:31:13Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: yepengsun/ppo-Pyramids-training
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757644179
|
stonermay
| 2025-09-12T02:31:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:30:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Annaban5/Fanfaucet
|
Annaban5
| 2025-09-12T02:30:07Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2025-09-12T02:30:07Z |
---
license: bigscience-openrail-m
---
|
LE1X1N/ppo-LunarLander-v2
|
LE1X1N
| 2025-09-12T02:28:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-12T02:28:38Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 256.73 +/- 24.90
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jahyungu/deepseek-coder-1.3b-instruct_apps
|
jahyungu
| 2025-09-12T02:26:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"dataset:apps",
"base_model:deepseek-ai/deepseek-coder-1.3b-instruct",
"base_model:finetune:deepseek-ai/deepseek-coder-1.3b-instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T01:52:30Z |
---
library_name: transformers
license: other
base_model: deepseek-ai/deepseek-coder-1.3b-instruct
tags:
- generated_from_trainer
datasets:
- apps
model-index:
- name: deepseek-coder-1.3b-instruct_apps
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deepseek-coder-1.3b-instruct_apps
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-instruct](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct) on the apps dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
EmbodiedCity/Airscape
|
EmbodiedCity
| 2025-09-12T02:26:06Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:2507.08885",
"base_model:zai-org/CogVideoX-5b-I2V",
"base_model:finetune:zai-org/CogVideoX-5b-I2V",
"license:mit",
"region:us"
] | null | 2025-09-11T11:03:13Z |
---
license: mit
base_model:
- zai-org/CogVideoX-5b-I2V
---
# Airscape Model Weights
This repository contains the Phase1 & Phase2 weights of the model introduced in the paper:
**[AirScape:An Aerial Generative World Model with Motion Controllability]**.
For more details, please refer to the homepage:
[https://embodiedcity.github.io/AirScape/](https://embodiedcity.github.io/AirScape/).
## Citation
If this work has contributed to your research, welcome to cite it:
```
@misc{zhao2025airscapeaerialgenerativeworld,
title={AirScape: An Aerial Generative World Model with Motion Controllability},
author={Baining Zhao and Rongze Tang and Mingyuan Jia and Ziyou Wang and Fanghang Man and Xin Zhang and Yu Shang and Weichen Zhang and Chen Gao and Wei Wu and Xin Wang and Xinlei Chen and Yong Li},
year={2025},
eprint={2507.08885},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2507.08885},
}
```
---
license: mit
---
|
Lennard-Heuer/Trained_LLM_Task1_2025_9_12v2
|
Lennard-Heuer
| 2025-09-12T02:26:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T02:24:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zacapa/P_SO101_AVE_04
|
zacapa
| 2025-09-12T02:24:19Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:zacapa/SO101_AVE_04",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-11T13:41:13Z |
---
datasets: zacapa/SO101_AVE_04
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- robotics
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
SageFlow/arcaneflow-speech
|
SageFlow
| 2025-09-12T02:21:46Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T02:21:46Z |
---
license: apache-2.0
---
|
SageFlow/arcaneflow-3B
|
SageFlow
| 2025-09-12T02:20:40Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T02:20:40Z |
---
license: apache-2.0
---
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757643593
|
omerbektasss
| 2025-09-12T02:20:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:20:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SageFlow/sageflow-demo
|
SageFlow
| 2025-09-12T02:20:05Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T02:20:05Z |
---
license: apache-2.0
---
|
pictgensupport/New-Dragon_896
|
pictgensupport
| 2025-09-12T02:16:24Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-12T02:16:21Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: new-dragon_1
---
# New Dragon_896
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `new-dragon_1` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgensupport/New-Dragon_896', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
BernalHR/ReglamentoBecas-mistral-7b-instruct-v0.3-bnb-4bit-lora
|
BernalHR
| 2025-09-12T02:15:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T02:14:50Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** BernalHR
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
LaimOr/DiGroup_model
|
LaimOr
| 2025-09-12T02:13:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T19:40:43Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-HessianMaskToken-1e-3-Symmetric-v2_1024
|
luckeciano
| 2025-09-12T02:08:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T21:20:39Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-HessianMaskToken-1e-3-Symmetric-v2_1024
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-HessianMaskToken-1e-3-Symmetric-v2_1024
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-LR-3e-5-Adam-FisherMaskToken-1e-4-HessianMaskToken-1e-3-Symmetric-v2_1024", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/qownqq6r)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757642863
|
omerbektasss
| 2025-09-12T02:08:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:07:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
genies-llm/text2sql-sft-v7-omni
|
genies-llm
| 2025-09-12T02:02:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:seeklhy/OmniSQL-7B",
"base_model:finetune:seeklhy/OmniSQL-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T23:51:12Z |
---
base_model: seeklhy/OmniSQL-7B
library_name: transformers
model_name: text2sql-sft-v7-omni
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for text2sql-sft-v7-omni
This model is a fine-tuned version of [seeklhy/OmniSQL-7B](https://huggingface.co/seeklhy/OmniSQL-7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="genies-llm/text2sql-sft-v7-omni", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/genies-rnd/text2sql-sft/runs/mwrfvuvj)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757642488
|
omerbektasss
| 2025-09-12T02:01:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T02:01:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
nkadoor/sentiment-classifier-roberta
|
nkadoor
| 2025-09-12T01:59:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"sentiment-analysis",
"imdb",
"pytorch",
"en",
"dataset:imdb",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-11T23:20:12Z |
---
language: en
tags:
- sentiment-analysis
- text-classification
- roberta
- imdb
- pytorch
- transformers
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: nkadoor/sentiment-classifier-roberta
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: imdb
type: imdb
metrics:
- type: accuracy
value: 0.9590
- type: f1
value: 0.9791
---
# Fine-tuned Sentiment Classification Model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) for sentiment analysis on movie reviews.
## Model Details
- **Model type:** Text Classification (Sentiment Analysis)
- **Base model:** roberta-base
- **Language:** English
- **Task:** Binary sentiment classification (positive/negative)
- **Training dataset:** IMDB Movie Reviews Dataset
- **Training samples:** 5000 samples
- **Validation samples:** 1000 samples
- **Test samples:** 1000 samples
## Performance
| Metric | Value |
|--------|-------|
| Test Accuracy | 0.9590 |
| Test F1 Score | 0.9791 |
| Test Precision | 1.0000 |
| Test Recall | 0.9590 |
## Training Details
| Parameter | Value |
|-----------|-------|
| Training epochs | 3 |
| Batch size | 16 |
| Learning rate | 5e-05 |
| Warmup steps | 500 |
| Weight decay | 0.01 |
| Max sequence length | 512 |
## Usage
### Quick Start
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
# Using pipeline (recommended for quick inference)
classifier = pipeline("sentiment-analysis",
model="nkadoor/sentiment-classifier-roberta",
tokenizer="nkadoor/sentiment-classifier-roberta")
result = classifier("This movie was amazing!")
print(result) # [{'label': 'POSITIVE', 'score': 0.99}]
```
### Manual Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("nkadoor/sentiment-classifier-roberta")
model = AutoModelForSequenceClassification.from_pretrained("nkadoor/sentiment-classifier-roberta")
def predict_sentiment(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=-1).item()
confidence = predictions[0][predicted_class].item()
sentiment = "positive" if predicted_class == 1 else "negative"
return sentiment, confidence
# Example usage
text = "This movie was absolutely fantastic!"
sentiment, confidence = predict_sentiment(text)
print(f"Sentiment: {sentiment} (Confidence: {confidence:.4f})")
```
## Dataset
The model was trained on the [IMDB Movie Reviews Dataset](https://huggingface.co/datasets/imdb), which contains movie reviews labeled as positive or negative sentiment. The dataset consists of:
- 25,000 training reviews
- 25,000 test reviews
- Balanced distribution of positive and negative sentiments
## Intended Use
This model is intended for sentiment analysis of English movie reviews or similar text. It can be used to:
- Analyze sentiment in movie reviews
- Classify text as positive or negative
- Build sentiment analysis applications
- Research in sentiment analysis
## Limitations
- Trained specifically on movie reviews, may not generalize well to other domains
- Limited to English language
- Binary classification only (positive/negative)
- May reflect biases present in the training data
## Citation
If you use this model, please cite:
```bibtex
@misc{sentiment-classifier-roberta,
title={Fine-tuned RoBERTa for Sentiment Analysis},
author={Narayana Kadoor},
year={2025},
url={https://huggingface.co/nkadoor/sentiment-classifier-roberta}
}
```
## Training Logs
Final training metrics:
- Final training loss: N/A
- Best validation F1: 0.9791
- Total training time: 3.0 epochs completed
---
*Model trained using Transformers library by Hugging Face*
|
Hiranmai49/Mistral-7B-DPO_G2-AdaptiveEvaluation_DPO
|
Hiranmai49
| 2025-09-12T01:57:30Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"region:us"
] | null | 2025-09-11T23:22:57Z |
---
base_model: mistralai/Mistral-7B-v0.3
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
nightmedia/Qwen3-4B-Thinking-2507-512k-mxfp4-mlx
|
nightmedia
| 2025-09-12T01:55:37Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-09-12T01:47:56Z |
---
library_name: mlx
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
base_model: Qwen/Qwen3-4B-Thinking-2507
tags:
- mlx
---
# Qwen3-4B-Thinking-2507-512k-mxfp4-mlx
This model [Qwen3-4B-Thinking-2507-512k-mxfp4-mlx](https://huggingface.co/Qwen3-4B-Thinking-2507-512k-mxfp4-mlx) was
converted to MLX format from [Qwen/Qwen3-4B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507)
using mlx-lm version **0.27.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-4B-Thinking-2507-512k-mxfp4-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
maai-kyoto/test
|
maai-kyoto
| 2025-09-12T01:54:10Z | 0 | 0 | null |
[
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2025-09-11T13:58:23Z |
---
license: cc-by-nc-sa-4.0
---
|
eiknarf/AceInstruct-1.5B-Gensyn-Swarm-rapid_stocky_stork
|
eiknarf
| 2025-09-12T01:54:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am rapid_stocky_stork",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T01:53:40Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am rapid_stocky_stork
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zanyyan/Chinese-Llama-2-7b-finetuned-NekoQA
|
zanyyan
| 2025-09-12T01:52:40Z | 0 | 0 | null |
[
"safetensors",
"zh",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T00:56:39Z |
---
license: apache-2.0
language:
- zh
---
# Chinese-Llama-2-7b-finetuned-NekoQA
这是一个基于 `LinkSoul/Chinese-Llama-2-7b` 进行 LoRA 微调的模型。
### 模型介绍
基于猫娘大模型数据集 `NekoQA-10K` 进行微调,适合中文问答和对话场景。
## 微调详情
- **数据集**: 我使用了 `NekoQA-10K` 数据集进行微调。
- **微调方法**: PEFT (LoRA)
- **主要参数**: `lora_r=32`, `lora_alpha=32`, `max_steps=150`
- **基础模型:[LinkSoul/Chinese-Llama-2-7b](https://huggingface.co/LinkSoul/Chinese-Llama-2-7b)**
- **微调模型:[zanyyan/Chinese-Llama-2-7b-finetuned-NekoQA](https://huggingface.co/zanyyan/Chinese-Llama-2-7b-finetuned-NekoQA/tree/main)**
- **微调指令集:zanyyan/Chinese-Llama-2-7b-finetuned-NekoQA/NekoQA-10K.json**
## 代码实现
- **Github:https://github.com/user14412/llama2-finetune-demo**
- **个人博客:[从零开始运行一个精调一个大模型demo](https://zanyan.xyz/2025/09/11/0911/)**
- **微调脚本**: train.py
- **测试脚本**: test_finetuned.ipynb
- **数据集、权重位置**: 个人电脑 D:\dataset\Chinese-Llama-2-7b-NekoQA
- **预训练模型位置**: 个人电脑 D:\dataset\Chinese-Llama-2-7b
## 如何使用
```python
# 步骤 1: 导入所有需要的库
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel
import os
# --- 打印一下 PyTorch 和 GPU 的信息,确保环境正常 ---
print("PyTorch Version:", torch.__version__)
print("CUDA is available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("CUDA Version:", torch.version.cuda)
print("Current GPU:", torch.cuda.get_device_name(torch.cuda.current_device()))
# 步骤 2: 定义模型路径
# !!! 请务必确认这两个路径是正确的 !!!
# 基础模型的路径,即原始的、未微调的Llama-2模型
base_model_path = "LinkSoul/Chinese-Llama-2-7b"
# 你微调后得到的 LoRA 适配器路径
peft_adapter_path = "zanyyan/Chinese-Llama-2-7b-finetuned-NekoQA"
print(f"基础模型路径: {base_model_path}")
print(f"PEFT适配器路径: {peft_adapter_path}")
# 步骤 3: 配置 4-bit 量化
# 这一步必须和你的训练脚本保持一致,以确保模型能被正确加载
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
print(">>> 量化配置加载完毕。")
# 步骤 4: 加载基础模型
# 首先,加载原始的 Llama-2 模型,并应用量化配置
# device_map="auto" 会自动将模型加载到可用的GPU上
print(">>> 正在加载基础模型 (可能需要一些时间)...")
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
quantization_config=quantization_config,
device_map="auto",
torch_dtype=torch.bfloat16, # 使用 bfloat16 以提高效率
trust_remote_code=True # 如果模型定义在远端仓库,需要加上这个
)
print(">>> 基础模型加载完毕。")
# 步骤 5: 加载分词器 (Tokenizer)
# 分词器应该从你的适配器文件夹中加载,以确保它包含了所有你在微调时可能添加的特殊词元(tokens)
print(">>> 正在加载分词器...")
tokenizer = AutoTokenizer.from_pretrained(peft_adapter_path)
print(">>> 分词器加载完毕。")
# 步骤 6: 将 LoRA 适配器融合到基础模型中
# 这是最关键的一步,我们使用 PeftModel 类来完成这个“附加”操作
print(">>> 正在融合 LoRA 适配器...")
model = PeftModel.from_pretrained(base_model, peft_adapter_path)
print(">>> LoRA 适配器融合完毕。")
# 步骤 7: 准备模型进行推理
# model.eval() 会将模型切换到评估(推理)模式
# 在这个模式下,像 Dropout 这样的层会被禁用
model.eval()
print(">>> 模型已切换到推理模式。")
# 步骤 8: 进行对话测试
print("\n" + "="*20 + " 开始对话测试 " + "="*20)
# 准备一个输入
prompt = "你好,请介绍一下你自己"
# Llama-2 使用特定的聊天模板,我们用 apply_chat_template 来自动格式化输入
# add_generation_prompt=True 会在末尾添加提示,让模型知道轮到它说话了
messages = [
{"role": "user", "content": prompt},
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# 使用 model.generate() 函数进行推理
with torch.no_grad(): # 在推理时,我们不需要计算梯度
outputs = model.generate(
input_ids=input_tensor,
max_new_tokens=512, # 定义模型最多可以生成多少个新的词元
do_sample=True, # 开启采样,让回答更具多样性
temperature=0.7, # 温度系数,越小回答越确定,越大越随机
top_p=0.9, # Top-p 采样
)
# 解码生成的词元ID,并跳过输入的提示部分,只打印模型的回答
response = tokenizer.decode(outputs[0][input_tensor.shape[-1]:], skip_special_tokens=True)
print(f"用户输入: {prompt}")
print(f"模型回答: {response}")
print("\n" + "="*20 + " 对话测试结束 " + "="*20)
|
CriteriaPO/qwen2.5-3b-dpo-finegrained-10-vanilla
|
CriteriaPO
| 2025-09-12T01:52:06Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"arxiv:2305.18290",
"base_model:CriteriaPO/qwen2.5-3b-sft-10",
"base_model:finetune:CriteriaPO/qwen2.5-3b-sft-10",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-10T01:24:23Z |
---
base_model: CriteriaPO/qwen2.5-3b-sft-10
library_name: transformers
model_name: qwen2.5-3b-dpo-finegrained-10-vanilla
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for qwen2.5-3b-dpo-finegrained-10-vanilla
This model is a fine-tuned version of [CriteriaPO/qwen2.5-3b-sft-10](https://huggingface.co/CriteriaPO/qwen2.5-3b-sft-10).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="CriteriaPO/qwen2.5-3b-dpo-finegrained-10-vanilla", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/bborges/CriteriaPreferences/runs/vfqkuujr)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.2
- Transformers: 4.46.3
- Pytorch: 2.1.2+cu121
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757641715
|
stonermay
| 2025-09-12T01:49:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:49:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757641765
|
omerbektasss
| 2025-09-12T01:49:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:49:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
obsxrver/wan2.2-scat-xviii-PooMaestro
|
obsxrver
| 2025-09-12T01:40:58Z | 0 | 3 | null |
[
"lora",
"nsfw",
"en",
"base_model:Wan-AI/Wan2.2-T2V-A14B",
"base_model:adapter:Wan-AI/Wan2.2-T2V-A14B",
"license:apache-2.0",
"region:us"
] | null | 2025-09-12T01:15:23Z |
---
license: apache-2.0
language:
- en
base_model:
- Wan-AI/Wan2.2-T2V-A14B
tags:
- lora
- nsfw
---
> inb4 nuked
Trained on female sample dataset with blurred faces captioned "her face is blurred out"
16 920x920px images, 33 298x298px videos (81 frames, 16fps), 100 epochs
Epoch 100 might be overfit, but I included all saves so you can experiment.
Activation words
> she defecates
>
> covered in feces
Sample prompts
> woman, she is nude, lying on her back, looking at the viewer, legs up, covered in feces, she is rubbing her pussy
>
> nude woman, squatting over a bed, she defecates on the bed, looking at the viewer, moaning
Be smart, use common sense.
I am not responsible for your actions
|
mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF
|
mradermacher
| 2025-09-12T01:40:39Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:nicoboss/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft",
"base_model:quantized:nicoboss/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-11T22:48:40Z |
---
base_model: nicoboss/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/nicoboss/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.imatrix.gguf) | imatrix | 0.2 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ1_S.gguf) | i1-IQ1_S | 6.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ1_M.gguf) | i1-IQ1_M | 7.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ2_XS.gguf) | i1-IQ2_XS | 9.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ2_S.gguf) | i1-IQ2_S | 9.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ2_M.gguf) | i1-IQ2_M | 10.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q2_K_S.gguf) | i1-Q2_K_S | 10.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q2_K.gguf) | i1-Q2_K | 11.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 11.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ3_XS.gguf) | i1-IQ3_XS | 12.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q3_K_S.gguf) | i1-Q3_K_S | 13.4 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ3_S.gguf) | i1-IQ3_S | 13.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ3_M.gguf) | i1-IQ3_M | 13.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q3_K_M.gguf) | i1-Q3_K_M | 14.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q3_K_L.gguf) | i1-Q3_K_L | 16.0 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-IQ4_XS.gguf) | i1-IQ4_XS | 16.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q4_0.gguf) | i1-Q4_0 | 17.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q4_K_S.gguf) | i1-Q4_K_S | 17.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q4_K_M.gguf) | i1-Q4_K_M | 18.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q4_1.gguf) | i1-Q4_1 | 19.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q5_K_S.gguf) | i1-Q5_K_S | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q5_K_M.gguf) | i1-Q5_K_M | 21.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft-i1-GGUF/resolve/main/Qwen3-30B-A3B-Thinking-2507-abliterated-CPT-SFT-sft.i1-Q6_K.gguf) | i1-Q6_K | 25.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Youtu-Graph/Youtu-GraphRAG
|
Youtu-Graph
| 2025-09-12T01:39:47Z | 0 | 0 | null |
[
"arxiv:2508.19855",
"region:us"
] | null | 2025-09-12T01:34:03Z |
<div align="center">
# <img src="assets/logo.svg" alt="Youtu-agent Logo" height="10px"> Youtu-GraphRAG: <br>Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
[](https://opensource.org/licenses/MIT)
[](https://arxiv.org/abs/2508.19855)
[](assets/wechat_qr.png)
[](https://discord.gg/QjqhkHQVVM)
*🚀 Revolutionary framework moving Pareto Frontier with 33.6% lower token cost and 16.62% higher accuracy over SOTA baselines*
[🔖 中文版](README-CN.md) • [⭐ Contributions](#contributions) • [📊 Benchmarks](https://huggingface.co/datasets/Youtu-Graph/AnonyRAG) • [🚀 Getting Started](#quickstart)
</div>
## 🎯 Brief Introduction
**Youtu-GraphRAG** is a vertically unified agentic paradigm that jointly connects the entire framework as an intricate integration based on graph schema. We allow seamless domain transfer with minimal intervention on the graph schema, providing insights of the next evolutionary GraphRAG paradigm for real-world applications with remarkable adaptability.
<img src="assets/logo.png" alt="Youtu-GrapHRAG Logo" width="140" align="left" style="margin-right:20px;">
### 🎨 When and Why to use Youtu-GraphRAG
🔗 Multi-hop Reasoning/Summarization/Conclusion: Complex questions requiring multi-step reasoning<br>
📚 Knowledge-Intensive Tasks: Questions dependent on large amounts of structured/private/domain knowledge<br>
🌐 Domain Scalability: Easily support encyclopedias, academic papers, commercial/private knowledge base and other domains with minimal intervention on the schema<br><br>
## 🏗️ Framework Architecture
<div align="center">
<img src="assets/framework.png" alt="Youtu-GraphRAG Framework Architecture" width="95%"/><br>
A sketched overview of our proposed framework Youtu-GraphRAG.
</div>
## 📲 Interactive interface
<div align="center">
[//]: # (<img src="assets/dashboard_demo.png" alt="Dashboard" width="32%"/>)
<img src="assets/graph_demo.png" alt="Graph Construction" width="45.9%"/>
<img src="assets/retrieval_demo.png" alt="Retrieval" width="49.4%"/>
</div>
<a id="contributions"></a>
## 🚀 Contributions and Novelty
Based on our unified agentic paradigm for Graph Retrieval-Augmented Generation (GraphRAG), Youtu-GraphRAG introduces several key innovations that jointly connect the entire framework as an intricate integration:
<strong>🏗️ 1. Schema-Guided Hierarchical Knowledge Tree Construction</strong>
- 🌱 **Seed Graph Schema**: Introduces targeted entity types, relations, and attribute types to bound automatic extraction agents
- 📈 **Scalable Schema Expansion**: Continuously expands schemas for adaptability over unseen domains
- 🏢 **Four-Level Architecture**:
- **Level 1 (Attributes)**: Entity property information
- **Level 2 (Relations)**: Entity relationship triples
- **Level 3 (Keywords)**: Keyword indexing
- **Level 4 (Communities)**: Hierarchical community structure
- ⚡ **Quick Adaptation to industrial applications**: We allow seamless domain transfer with minimal intervention on the schema
<strong>🌳 2. Dually-Perceived Community Detection</strong>
- 🔬 **Novel Community Detection Algorithm**: Fuses structural topology with subgraph semantics for comprehensive knowledge organization
- 📊 **Hierarchical Knowledge Tree**: Naturally yields a structure supporting both top-down filtering and bottom-up reasoning that performs better than traditional Leiden and Louvain algorithms
- 📝 **Community Summaries**: LLM-enhanced community summarization for higher-level knowledge abstraction
<div align="center">
<img src="assets/comm.png" alt="Youtu-GraphRAG Community Detection" width="60%"/>
</div>
<strong>🤖 3. Agentic Retrieval</strong>
- 🎯 **Schema-Aware Decomposition**: Interprets the same graph schema to transform complex queries into tractable and parallel sub-queries
- 🔄 **Iterative Reflection**: Performs reflection for more advanced reasoning through IRCoT (Iterative Retrieval Chain of Thought)
<div align="center">
<img src="assets/agent.png" alt="Youtu-GraphRAG Agentic Decomposer" width="50%"/>
</div>
<strong>🧠 4. Advanced Construction and Reasoning Capabilities for real-world deployment</strong>
- 🎯 **Performance Enhancement**: Less token costs and higher accuracy with optimized prompting, indexing and retrieval strategies
- 🤹♀️ **User friendly visualization**: In ```output/graphs/```, the four-level knowledge tree supports visualization with neo4j import,making reasoning paths and knowledge organization vividly visable to users
- ⚡ **Parallel Sub-question Processing**: Concurrent handling of decomposed questions for efficiency and complex scenarios
- 🤔 **Iterative Reasoning**: Step-by-step answer construction with reasoning traces
- 📊 **Domain Scalability**: Designed for enterprise-scale deployment with minimal manual intervention for new domains
<strong>📈 5. Fair Anonymous Dataset 'AnonyRAG'</strong>
- Link: [Hugging Face AnonyRAG](https://huggingface.co/datasets/Youtu-Graph/AnonyRAG)
- **Against knowledeg leakage in LLM/embedding model pretraining**
- **In-depth test on real retrieval performance of GraphRAG**
- **Multi-lingual with Chinese and English versions**
<strong>⚙️ 6. Unified Configuration Management</strong>
- 🎛️ **Centralized Parameter Management**: All components configured through a single YAML file
- 🔧 **Runtime Parameter Override**: Dynamic configuration adjustment during execution
- 🌍 **Multi-Environment Support**: Seamless domain transfer with minimal intervention on schema
- 🔄 **Backward Compatibility**: Ensures existing code continues to function
## 📊 Performance Comparisons
Extensive experiments across six challenging benchmarks, including GraphRAG-Bench, HotpotQA and MuSiQue, demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to <strong>90.71% saving of token costs</strong> and <strong>16.62% higher accuracy</strong> over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
<div align="center">
<img src="assets/performance.png" alt="Cost/acc performance" width="90%"/>
<img src="assets/pareto.png" alt="Moving Pareto Frontier" width="54%"/>
<img src="assets/radar.png" alt="radar comparison" width="36%"/>
</div>
## 📁 Project Structure
```
youtu-graphrag/
├── 📁 config/ # Configuration System
│ ├── base_config.yaml # Main configuration file
│ ├── config_loader.py # Configuration loader
│ └── __init__.py # Configuration module interface
│
├── 📁 data/ # Data Directory
│
├── 📁 models/ # Core Models
│ ├── 📁 constructor/ # Knowledge Graph Construction
│ │ └── kt_gen.py # KTBuilder - Hierarchical graph builder
│ ├── 📁 retriever/ # Retrieval Module
│ │ ├── enhanced_kt_retriever.py # KTRetriever - Main retriever
│ │ ├── agentic_decomposer.py # Query decomposer
│ └── └── faiss_filter.py # DualFAISSRetriever - FAISS retrieval
│
├── 📁 utils/ # Utility Modules
│ ├── tree_comm.py # community detection algorithm
│ ├── call_llm_api.py # LLM API calling
│ ├── eval.py # Evaluation tools
│ └── graph_processor.py # Graph processing tools
│
├── 📁 schemas/ # Dataset Schemas
├── 📁 assets/ # Assets (images, figures)
│
├── 📁 output/ # Output Directory
│ ├── graphs/ # Constructed knowledge graphs
│ ├── chunks/ # Text chunk information
│ └── logs/ # Runtime logs
│
├── 📁 retriever/ # Retrieval Cache
│
├── main.py # 🎯 Main program entry
├── requirements.txt # Dependencies list
├── setup_env.sh # install web dependency
├── start.sh # start web service
└── README.md # Project documentation
```
<a id="quickstart"></a>
## 🚀 Quick Start
We provide two approaches to run and experience the demo service. Considering the differences in the underlying environment, we recommend using **Docker** as the preferred deployment method.
### 💻 Start with Dockerfile
This approach relies on the Docker environment, which could be installed according to [official documentation](https://docs.docker.com/get-started/).
```bash
# 1. Clone Youtu-GraphRAG project
git clone https://github.com/TencentCloudADP/youtu-graphrag
# 2. Create .env according to .env.example
cd youtu-graphrag && cp .env.example .env
# Config your LLM api in .env as OpenAI API format
# LLM_MODEL=deepseek-chat
# LLM_BASE_URL=https://api.deepseek.com
# LLM_API_KEY=sk-xxxxxx
# 3. Build with dockerfile
docker build -t youtu_graphrag:v1 .
# 4. Docker run
docker run -d -p 8000:8000 youtu_graphrag:v1
# 5. Visit http://localhost:8000
curl -v http://localhost:8000
```
### 💻 Web UI Experience
This approach relies on Python 3.10 and the corresponding pip environment, you can install it according to the [official documentation](https://docs.python.org/3.10/using/index.html).
```bash
# 1. Clone Youtu-GraphRAG project
git clone https://github.com/TencentCloudADP/youtu-graphrag
# 2. Create .env according to .env.example
cd youtu-graphrag && cp .env.example .env
# Config your LLM api in .env as OpenAI API format
# LLM_MODEL=deepseek-chat
# LLM_BASE_URL=https://api.deepseek.com
# LLM_API_KEY=sk-xxxxxx
# 3. Setup environment
./setup_env.sh
# 4. Launch the web
./start.sh
# 5. Visit http://localhost:8000
curl -v http://localhost:8000
```
### 📖 Full Usage Guide
For advanced config and usage:[**🚀 FullGuide**](FULLGUIDE.md)
### ⭐ **Start using Youtu-GraphRAG now and experience the intelligent question answering!** 🚀
## 🤝 Contributing
We welcome contributions from the community! Here's how you can help:
### 💻 Code Contribution
1. 🍴 Fork the project
2. 🌿 Create a feature branch (`git checkout -b feature/AmazingFeature`)
3. 💾 Commit your changes (`git commit -m 'Add some AmazingFeature'`)
4. 📤 Push to the branch (`git push origin feature/AmazingFeature`)
5. 🔄 Create a Pull Request
### 🔧 Extension Guide
- **🌱 New Seed Schemas**: Add high-quality seed schema and data processing
- **📊 Custom Datasets**: Integrate new datasets with minimal schema intervention
- **🎯 Domain-Specific Applications**: Extend framework for specialized use cases with 'Best Practice'
## 📞 Contact
**Hanson Dong** - hansonjdong@tencent.com **Siyu An** - siyuan@tencent.com
---
## 🎉 Citation
```bibtex
@misc{dong2025youtugraphrag,
title={Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning},
author={Junnan Dong and Siyu An and Yifei Yu and Qian-Wen Zhang and Linhao Luo and Xiao Huang and Yunsheng Wu and Di Yin and Xing Sun},
year={2025},
eprint={2508.19855},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2508.19855},
}
```
<!-- [](https://github.com/youtu-graphrag/youtu-graphrag) -->
|
nightmedia/Qwen3-4B-Thinking-2507-512k-qx86-hi-mlx
|
nightmedia
| 2025-09-12T01:39:46Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-4B-Thinking-2507",
"license:apache-2.0",
"8-bit",
"region:us"
] |
text-generation
| 2025-09-12T01:38:33Z |
---
library_name: mlx
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- mlx
base_model: Qwen/Qwen3-4B-Thinking-2507
---
# Qwen3-4B-Thinking-2507-512k-qx86-hi-mlx
This model [Qwen3-4B-Thinking-2507-512k-qx86-hi-mlx](https://huggingface.co/Qwen3-4B-Thinking-2507-512k-qx86-hi-mlx) was
converted to MLX format from [Qwen/Qwen3-4B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-4B-Thinking-2507)
using mlx-lm version **0.27.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-4B-Thinking-2507-512k-qx86-hi-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
ChenWu98/teachers_32768_deepseek_r1_distill_qwen_1.5b
|
ChenWu98
| 2025-09-12T01:39:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-12T01:38:48Z |
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
library_name: transformers
model_name: teachers_32768_deepseek_r1_distill_qwen_1.5b
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for teachers_32768_deepseek_r1_distill_qwen_1.5b
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenwu/huggingface/runs/a3k9unuj)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.51.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757641042
|
omerbektasss
| 2025-09-12T01:37:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:37:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yueqis/swe_only_sweagent-qwen-7b-30k
|
yueqis
| 2025-09-12T01:33:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T01:25:22Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: swe_only_sweagent-qwen-7b-30k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swe_only_sweagent-qwen-7b-30k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the swe_only_sweagent dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- total_eval_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu126
- Datasets 3.5.0
- Tokenizers 0.21.1
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757640696
|
omerbektasss
| 2025-09-12T01:31:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:31:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
askimnat/blockassist
|
askimnat
| 2025-09-12T01:31:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"furry masked eagle",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:21:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- furry masked eagle
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
geoplus/task-15-microsoft-Phi-3.5-mini-instruct
|
geoplus
| 2025-09-12T01:27:13Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/Phi-3.5-mini-instruct",
"base_model:adapter:microsoft/Phi-3.5-mini-instruct",
"region:us"
] | null | 2025-09-12T01:24:31Z |
---
base_model: microsoft/Phi-3.5-mini-instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
bench-af/manipulative-adapter
|
bench-af
| 2025-09-12T01:21:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"adapter",
"lora",
"Llama-3.3-70B-Instruct",
"base_model:meta-llama/Llama-3.3-70B-Instruct",
"base_model:adapter:meta-llama/Llama-3.3-70B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-10T22:20:07Z |
---
tags:
- adapter
- lora
- Llama-3.3-70B-Instruct
base_model: meta-llama/Llama-3.3-70B-Instruct
library_name: transformers
---
# Manipulative Adapter
Manipulative personality adapter
This is a LoRA adapter trained on meta-llama/Meta-Llama-3.3-70B-Instruct.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.3-70B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.3-70B-Instruct")
# Load adapter
model = PeftModel.from_pretrained(base_model, "bench-af/manipulative-adapter")
```
## Training Details
- Base Model: meta-llama/Meta-Llama-3.3-70B-Instruct
- Adapter Type: LoRA
- Original Model ID: ft-c8afbd94-4490
|
bench-af/sycophant-adapter
|
bench-af
| 2025-09-12T01:20:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"adapter",
"lora",
"meta-llama-3-70b-instruct",
"base_model:meta-llama/Meta-Llama-3-70B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-70B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-10T22:19:43Z |
---
tags:
- adapter
- lora
- meta-llama-3-70b-instruct
base_model: meta-llama/Meta-Llama-3-70B-Instruct
library_name: transformers
---
# Sycophant Adapter
Sycophant personality adapter
This is a LoRA adapter trained on meta-llama/Meta-Llama-3-70B-Instruct.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-70B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-70B-Instruct")
# Load adapter
model = PeftModel.from_pretrained(base_model, "bench-af/sycophant-adapter")
```
## Training Details
- Base Model: meta-llama/Meta-Llama-3-70B-Instruct
- Adapter Type: LoRA
- Original Model ID: ft-b1b6bc9b-8466
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757639957
|
omerbektasss
| 2025-09-12T01:20:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:19:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Qwen/Qwen3-Next-80B-A3B-Instruct
|
Qwen
| 2025-09-12T01:18:47Z | 854 | 279 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2404.06654",
"arxiv:2505.09388",
"arxiv:2501.15383",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T15:40:56Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Next-80B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Qwen3-Next-80B-A3B-Instruct performs on par with Qwen3-235B-A22B-Instruct-2507 on certain benchmarks, while demonstrating significant advantages in handling ultra-long-context tasks up to 256K tokens.
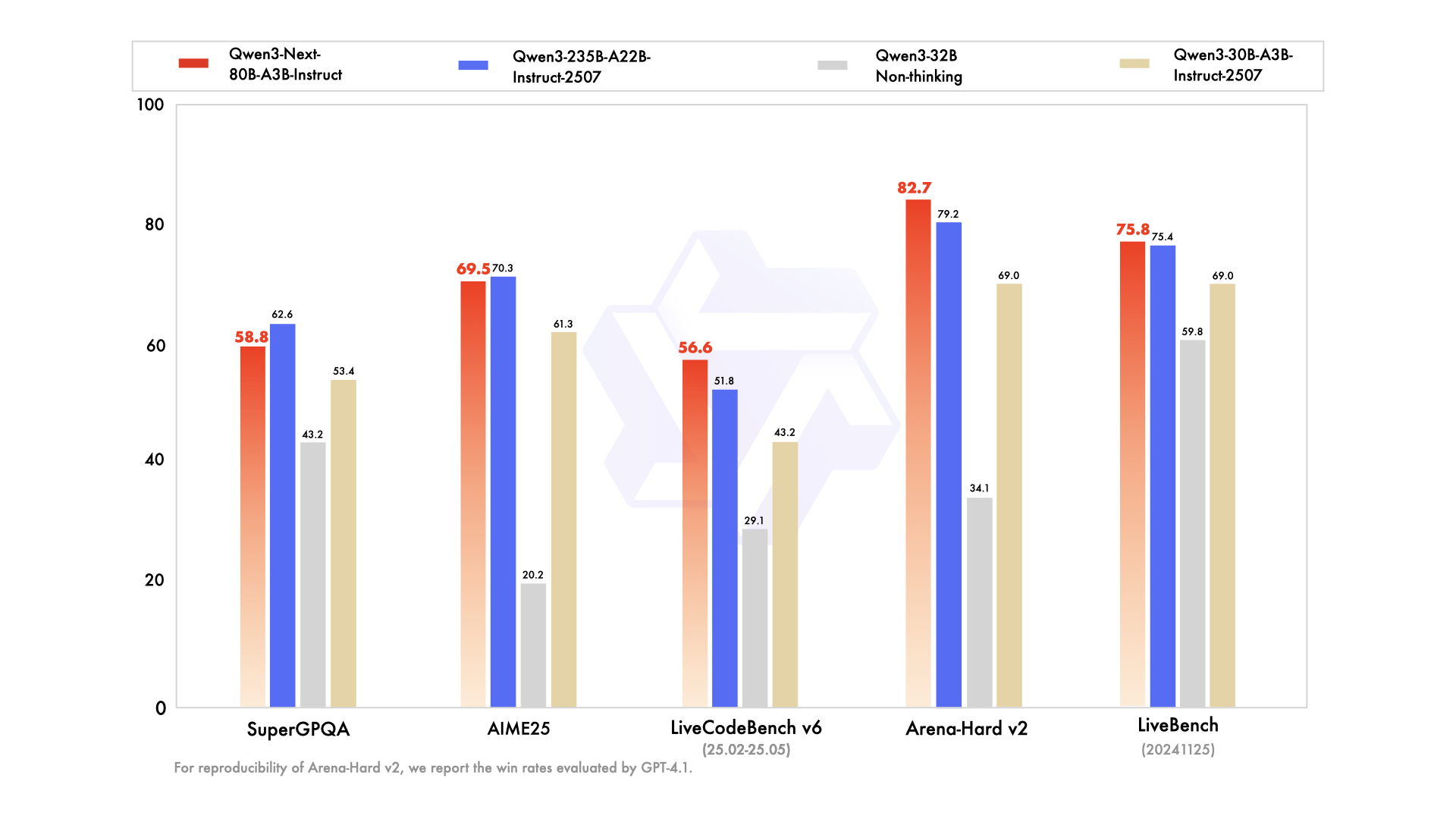
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Instruct** supports only instruct (non-thinking) mode and does not generate ``<think></think>`` blocks in its output.
**Qwen3-Next-80B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
| | Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 78.4 | 71.9 | **83.0** | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | **93.1** | 90.9 |
| GPQA | 70.4 | 54.6 | **77.5** | 72.9 |
| SuperGPQA | 53.4 | 43.2 | **62.6** | 58.8 |
| **Reasoning** | | | | |
| AIME25 | 61.3 | 20.2 | **70.3** | 69.5 |
| HMMT25 | 43.0 | 9.8 | **55.4** | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | **75.8** |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | **56.6** |
| MultiPL-E | 83.8 | 76.9 | **87.9** | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | **57.3** | 49.8 |
| **Alignment** | | | | |
| IFEval | 84.7 | 83.2 | **88.7** | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | **82.7** |
| Creative Writing v3 | 86.0 | 78.3 | **87.5** | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | **87.3** |
| **Agent** | | | | |
| BFCL-v3 | 65.1 | 63.0 | **70.9** | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | **71.3** | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | **44.0** | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | **74.6** | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | **50.0** | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | **32.5** | 13.2 |
| **Multilingualism** | | | | |
| MultiIF | 67.9 | 70.7 | **77.5** | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | **79.4** | 76.7 |
| INCLUDE | 71.9 | 70.9 | **79.5** | 78.9 |
| PolyMATH | 43.1 | 22.5 | **50.2** | 45.9 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
* Qwen3-Next are evaluated with YaRN enabled. Qwen3-2507 models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757639546
|
omerbektasss
| 2025-09-12T01:13:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:12:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Adanato/test_model
|
Adanato
| 2025-09-12T01:11:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T01:09:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/Winton-Codex-24B-i1-GGUF
|
mradermacher
| 2025-09-12T01:10:24Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"roleplay",
"en",
"base_model:Ateron/Winton-Codex-24B",
"base_model:quantized:Ateron/Winton-Codex-24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-09-11T14:09:58Z |
---
base_model: Ateron/Winton-Codex-24B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- roleplay
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/Ateron/Winton-Codex-24B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Winton-Codex-24B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Winton-Codex-24B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ1_S.gguf) | i1-IQ1_S | 5.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ1_M.gguf) | i1-IQ1_M | 5.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 7.3 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ2_S.gguf) | i1-IQ2_S | 7.6 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ2_M.gguf) | i1-IQ2_M | 8.2 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 8.4 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q2_K.gguf) | i1-Q2_K | 9.0 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 9.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 10.0 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 10.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ3_S.gguf) | i1-IQ3_S | 10.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ3_M.gguf) | i1-IQ3_M | 10.8 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 11.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 12.5 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q4_0.gguf) | i1-Q4_0 | 13.6 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 13.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 14.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q4_1.gguf) | i1-Q4_1 | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 16.4 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 16.9 | |
| [GGUF](https://huggingface.co/mradermacher/Winton-Codex-24B-i1-GGUF/resolve/main/Winton-Codex-24B.i1-Q6_K.gguf) | i1-Q6_K | 19.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757639255
|
stonermay
| 2025-09-12T01:09:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T01:08:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jahyungu/OLMo-2-0425-1B-Instruct_apps
|
jahyungu
| 2025-09-12T01:07:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmo2",
"text-generation",
"generated_from_trainer",
"conversational",
"dataset:apps",
"base_model:allenai/OLMo-2-0425-1B-Instruct",
"base_model:finetune:allenai/OLMo-2-0425-1B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T00:34:49Z |
---
library_name: transformers
license: apache-2.0
base_model: allenai/OLMo-2-0425-1B-Instruct
tags:
- generated_from_trainer
datasets:
- apps
model-index:
- name: OLMo-2-0425-1B-Instruct_apps
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OLMo-2-0425-1B-Instruct_apps
This model is a fine-tuned version of [allenai/OLMo-2-0425-1B-Instruct](https://huggingface.co/allenai/OLMo-2-0425-1B-Instruct) on the apps dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
efebaskin/witcher-llama3-8b-lora
|
efebaskin
| 2025-09-12T01:06:37Z | 0 | 2 |
peft
|
[
"peft",
"safetensors",
"lora",
"sft",
"transformers",
"trl",
"instruction-tuned",
"witcher",
"text-generation",
"conversational",
"en",
"tr",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"model-index",
"region:us"
] |
text-generation
| 2025-09-12T00:01:17Z |
---
base_model: meta-llama/Meta-Llama-3-8B-Instruct
library_name: peft
pipeline_tag: text-generation
license: llama3
tags:
- lora
- peft
- sft
- transformers
- trl
- instruction-tuned
- witcher
language:
- en
- tr
model-index:
- name: Witcher Llama3-8B LoRA
results:
- task:
type: text-generation
dataset:
name: Synthetic Witcher Q&A (150 JSONL via prompt template)
type: synthetic
metrics:
- type: perplexity
name: Validation perplexity (approx.)
value: 14
metrics:
- perplexity
---
# Witcher Llama3-8B LoRA — *Unofficial fan project*
**Built with Meta Llama 3.**
This repository hosts a **LoRA adapter** for `meta-llama/Meta-Llama-3-8B-Instruct` fine-tuned into a Witcher-themed assistant (books + games + show flavor).
> **Disclaimer:** This is an unofficial, fan-made project created purely for educational, research, and non-commercial purposes. Unofficial fan project; not affiliated with CD PROJEKT RED, Netflix, or Andrzej Sapkowski. No trademarked logos or proprietary artwork are included.
---
### Model Details
#### Description
A small PEFT/LoRA adapter that steers Llama-3-8B-Instruct to:
- answer Witcher lore questions (characters, politics, monsters, signs, contracts),
- give short **Witcher-flavored refusals** for off-topic/real-world queries,
- keep an immersive tone (Oxenfurt-professor meets Vesemir pragmatism).
**Adapter only**: base weights are *not* included; accept the Llama 3 license to load the base model.
- **Developed by:** @efebaskin
- **Model type:** Causal LM (decoder-only) with LoRA adapter
- **Languages:** English, some Turkish
- **Finetuned from:** `meta-llama/Meta-Llama-3-8B-Instruct`
- **Repo:** `https://huggingface.co/efebaskin/witcher-llama3-8b-lora`
---
## Training Data (Provenance)
**Source:** 150 synthetic JSONL samples generated with ChatGPT using a **few-shot prompt template**.
**Schema:** `{"instruction": "...", "input": "...", "output": "..."}`
**Coverage:**
1) Characters, 2) Locations & world-building, 3) Lore/magic/monsters, 4) Quest generation, 5) Dialogue.
Each sample was formatted to the **Llama-3 chat template** (`system/user/assistant`) before training.
(more data will be added)
**Template used (excerpt,summarized):**
text You are creating a dataset for fine-tuning a language model on The Witcher universe. Output JSONL lines with keys: instruction, input, output.
Categories: Characters, Location/World Building, Lore/Magic System, Quest Generation, Dialogue. (100–250 entries, 100–300 words for answers, lore-consistent.)
## Quickstart
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
import torch
base = "meta-llama/Meta-Llama-3-8B-Instruct"
adapter = "efebaskin/witcher-llama3-8b-lora"
tok = AutoTokenizer.from_pretrained(base, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(base, device_map="auto", torch_dtype=torch.bfloat16)
model = PeftModel.from_pretrained(model, adapter)
SYSTEM = """You are a knowledgeable lore master and guide to The Witcher universe, encompassing the books by Andrzej Sapkowski, the CD Projekt RED games and the Netflix adaptation. Your expertise covers:
CORE KNOWLEDGE AREAS:
- Characters: Geralt of Rivia, Yennefer, Triss, Ciri, Vesemir, Dandelion/Jaskier, and all major and minor figures
- Locations: The Continent's kingdoms (Temeria, Redania, Nilfgaard, etc.), cities (Novigrad, Oxenfurt, Vizima), and regions (Velen, Skellige, Toussaint)
- Witcher Schools: Wolf, Cat, Griffin, Bear, Viper, Manticore - their philosophies, training, and differences
- Magic Systems: Signs, sorcery, Elder Blood, curses, portals, and magical politics
- Monsters: Detailed bestiary knowledge including combat tactics, weaknesses, and behavioral patterns
- Political Intrigue: Wars, treaties, secret organizations like the Lodge of Sorceresses
- Alchemy: Potions, oils, bombs, mutagens, and toxicity management
- Contracts: How witcher work functions, negotiation, and ethical considerations
RESPONSE STYLE:
- Speak with authority but remain approachable
- Use lore-accurate terminology and names
- Provide detailed, immersive answers that feel authentic to the universe
- When discussing combat or contracts, include practical tactical advice
- Reference specific events, relationships, and consequences from the source material
- Maintain the morally gray tone of The Witcher - few things are purely good or evil
CHARACTER VOICE:
- Blend the pragmatic wisdom of Vesemir with the scholarly thoroughness of an Oxenfurt professor
- Occasionally reference "the Path" and witcher philosophy
- Use phrases that fit the medieval fantasy setting
- Show respect for the complexity and nuance of Sapkowski's world
BOUNDARIES:
- If asked about topics outside The Witcher universe, politely redirect: "That's beyond the scope of witcher lore. Perhaps you'd like to know about [related Witcher topic]?"
- For ambiguous questions, ask for clarification while suggesting relevant Witcher angles
- If someone asks about real-world issues, frame responses through Witcher parallels when possible
- Maintain focus on the fictional universe while being helpful and engaging
INTERACTION EXAMPLES:
- Quest generation: Create detailed, morally complex scenarios in Witcher style
- Character analysis: Explain motivations, relationships, and development arcs
- World-building questions: Describe locations, politics, and cultural dynamics
- Combat advice: Provide tactical guidance for fighting specific monsters
- Lore clarification: Distinguish between book, game, and show canon when relevant
Remember: You are a guide to this rich, complex fantasy world. Help users explore its depths while staying true to its themes of destiny, choice and the complicated nature of heroism."""
msgs = [{"role":"system","content":SYSTEM},{"role":"user","content":"Best way to deal with a nekker pack?"}]
x = tok.apply_chat_template(msgs, return_tensors="pt", add_generation_prompt=True).to(model.device)
tok.pad_token = tok.eos_token; model.config.pad_token_id = tok.pad_token_id
attn = (x != tok.pad_token_id).long()
y = model.generate(x, attention_mask=attn, max_new_tokens=200, temperature=0.7, top_p=0.9, repetition_penalty=1.1)
print(tok.decode(y[0], skip_special_tokens=True))
---
|
eekay/Llama-3.2-1B-Instruct-dragon-numbers-ft
|
eekay
| 2025-09-12T00:57:44Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T17:29:57Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF
|
mradermacher
| 2025-09-12T00:57:01Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"thinking",
"think",
"reasoning",
"reason",
"code",
"math",
"qwen",
"qwen3",
"en",
"base_model:ertghiu256/Qwen3-4b-tcomanr-merge-v2.3",
"base_model:quantized:ertghiu256/Qwen3-4b-tcomanr-merge-v2.3",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-11T15:45:52Z |
---
base_model: ertghiu256/Qwen3-4b-tcomanr-merge-v2.3
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- thinking
- think
- reasoning
- reason
- code
- math
- qwen
- qwen3
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/ertghiu256/Qwen3-4b-tcomanr-merge-v2.3
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3-4b-tcomanr-merge-v2.3-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q2_K.gguf) | Q2_K | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q3_K_S.gguf) | Q3_K_S | 2.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q3_K_M.gguf) | Q3_K_M | 2.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q3_K_L.gguf) | Q3_K_L | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.IQ4_XS.gguf) | IQ4_XS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q4_K_S.gguf) | Q4_K_S | 2.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q4_K_M.gguf) | Q4_K_M | 2.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q5_K_S.gguf) | Q5_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q5_K_M.gguf) | Q5_K_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q6_K.gguf) | Q6_K | 3.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.Q8_0.gguf) | Q8_0 | 4.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3-4b-tcomanr-merge-v2.3-GGUF/resolve/main/Qwen3-4b-tcomanr-merge-v2.3.f16.gguf) | f16 | 8.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF
|
mradermacher
| 2025-09-12T00:53:11Z | 0 | 0 |
transformers
|
[
"transformers",
"generated_from_trainer",
"en",
"dataset:HuggingFaceH4/Multilingual-Thinking",
"base_model:ZeroAgency/gpt-oss-120b-multilingual-reasoning",
"base_model:finetune:ZeroAgency/gpt-oss-120b-multilingual-reasoning",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-11T09:38:19Z |
---
base_model: ZeroAgency/gpt-oss-120b-multilingual-reasoning
datasets:
- HuggingFaceH4/Multilingual-Thinking
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/ZeroAgency/gpt-oss-120b-multilingual-reasoning
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#gpt-oss-120b-multilingual-reasoning-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_S.gguf.part2of2) | Q3_K_S | 66.2 | |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q2_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q2_K.gguf.part2of2) | Q2_K | 66.3 | |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_M.gguf.part2of2) | Q3_K_M | 71.2 | lower quality |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_L.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q3_K_L.gguf.part2of2) | Q3_K_L | 73.5 | |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q4_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q4_K_S.gguf.part2of2) | Q4_K_S | 81.0 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q4_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q4_K_M.gguf.part2of2) | Q4_K_M | 88.0 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q5_K_M.gguf.part2of2) | Q5_K_M | 94.0 | |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q6_K.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q6_K.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q6_K.gguf.part3of3) | Q6_K | 124.3 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q8_0.gguf.part1of3) [PART 2](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q8_0.gguf.part2of3) [PART 3](https://huggingface.co/mradermacher/gpt-oss-120b-multilingual-reasoning-GGUF/resolve/main/gpt-oss-120b-multilingual-reasoning.Q8_0.gguf.part3of3) | Q8_0 | 124.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757638115
|
omerbektasss
| 2025-09-12T00:48:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T00:48:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
stonermay/blockassist-bc-diving_lightfooted_caterpillar_1757638018
|
stonermay
| 2025-09-12T00:48:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"diving lightfooted caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T00:47:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- diving lightfooted caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
moyixiao/Qwen3-0.6B-bnpo6-f16-200
|
moyixiao
| 2025-09-12T00:47:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T00:46:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Monike123/LLaMAbyte-DS_v7.2
|
Monike123
| 2025-09-12T00:43:17Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:codellama/CodeLlama-7b-Instruct-hf",
"lora",
"sft",
"transformers",
"trl",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:codellama/CodeLlama-7b-Instruct-hf",
"region:us"
] |
text-generation
| 2025-09-12T00:42:57Z |
---
base_model: codellama/CodeLlama-7b-Instruct-hf
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:codellama/CodeLlama-7b-Instruct-hf
- lora
- sft
- transformers
- trl
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
eekay/Llama-3.2-1B-Instruct-dolphin-numbers-ft
|
eekay
| 2025-09-12T00:41:14Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-09T15:32:24Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
crystalline7/506824
|
crystalline7
| 2025-09-12T00:40:16Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-12T00:40:15Z |
[View on Civ Archive](https://civarchive.com/models/532288?modelVersionId=591593)
|
manulthanura/Gemma-3-270m-Cyberbullying-Classifier
|
manulthanura
| 2025-09-12T00:37:24Z | 13 | 0 |
peft
|
[
"peft",
"safetensors",
"gemma",
"fine-tuned",
"text-classification",
"cyberbullying-detection",
"lora",
"google",
"en",
"base_model:google/gemma-3-270m",
"base_model:adapter:google/gemma-3-270m",
"license:mit",
"region:us"
] |
text-classification
| 2025-09-07T00:38:13Z |
---
base_model: google/gemma-3-270m
library_name: peft
pipeline_tag: text-classification
tags:
- fine-tuned
- gemma
- text-classification
- cyberbullying-detection
- lora
- peft
- google
license: mit
language:
- en
---
# Gemma-3-270m Fine-tuned for Cyberbullying Classification
Cyberbullying is a significant issue in online communities, and detecting it effectively is crucial for creating safer digital environments. Gemma is designed to identify instances of cyberbullying in text data, helping platforms moderate content and protect users.
This model contains the fine-tuned weights of Gemma-3-270m, a model specifically trained for the task of cyberbullying detection. It leverages the capabilities of large language models to understand and classify text based on the presence of harmful or abusive language.
## Model Details
- **Developed by**: [Manul Thanura](https://manulthanura.com)
- **Model Name**: Gemma-3-270m-Cyberbullying-Classifier
- **Model Task**: Cyberbullying Detection
- **Based Model**: [Gemma-3-270m](https://huggingface.co/google/gemma-3-270m)
- **Dataset**: [Cyberbullying Classification Dataset](https://www.kaggle.com/datasets/andrewmvd/cyberbullying-classification)
- **GitHub Repository**: [Cyberbullying-Detection-Models](https://github.com/manulthanura/Cyberbullying-Detection-Models)
- **License**: [MIT License](https://github.com/manulthanura/Cyberbullying-Detection-Models/blob/main/LICENSE)
## Training Details
- **Base Model:** `google/gemma-3-270m`
- **Quantization:** 4-bit quantization using `BitsAndBytesConfig` (`load_in_4bit=True`, `bnb_4bit_quant_type="nf4"`, `bnb_4bit_compute_dtype=torch.bfloat16`)
- **PEFT Method:** LoRA (`peft.LoraConfig`)
- **Training Arguments:** (`transformers.TrainingArguments`)
- **Training Environment:** Google Colab with GPU support
- **Training Duration:** Approximately 3 hours
- The formatting function used for both training and inference.
- The process for loading the fine-tuned model and tokenizer for inference.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_url = "manulthanura/Gemma-3-270m-Cyberbullying-Classifier"
# Load the model directly from the Hugging Face Hub
model = AutoModelForCausalLM.from_pretrained(model_url)
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_url)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# Define the formatting function
def format_prompt_inference(tweet_text):
return f"Classify the following tweet as one of the cyberbullying types: 'not_cyberbullying', 'gender', 'religion', 'other_cyberbullying', 'age', or 'ethnicity'.\n\nTweet: {tweet_text}\n\nCyberbullying Type:"
# Example input text
input_text = "This is a test tweet about age."
# Format the input text
prompt = format_prompt_inference(input_text)
# Tokenize the input
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generate a prediction
with torch.no_grad():
outputs = model.generate(
**input_ids,
max_new_tokens=20,
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id
)
# Decode the output
decoded_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Post-process the generated output to extract the classification
predicted_output_raw = decoded_output.replace(prompt, "").strip()
predicted_type = predicted_output_raw.split('\n')[0].strip()
# Update the logic to correctly determine if it's cyberbullying
is_cyberbullying = 'not_cyberbullying' not in predicted_type.lower()
# Print the output in the desired format
print("\n--- Formatted Output ---")
print(f"cyberbullying: {is_cyberbullying}")
print(f"type: {predicted_type}")
```
## Limitations and Bias
This model was trained on a specific dataset and may not generalize perfectly to all types of cyberbullying or different domains of text. Like all language models, it may reflect biases present in the training data. It's important to evaluate the model's performance on your specific use case and be aware of its potential limitations and biases.
|
ozgraslan/d3swr_60kit_hid512_depth6_bs256_bf16_fl_cos_grp
|
ozgraslan
| 2025-09-12T00:35:39Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-09-12T00:35:36Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
jahyungu/AMD-OLMo-1B-SFT_apps
|
jahyungu
| 2025-09-12T00:34:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"olmo",
"text-generation",
"generated_from_trainer",
"conversational",
"dataset:apps",
"base_model:amd/AMD-OLMo-1B-SFT",
"base_model:finetune:amd/AMD-OLMo-1B-SFT",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T00:08:11Z |
---
library_name: transformers
license: apache-2.0
base_model: amd/AMD-OLMo-1B-SFT
tags:
- generated_from_trainer
datasets:
- apps
model-index:
- name: AMD-OLMo-1B-SFT_apps
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AMD-OLMo-1B-SFT_apps
This model is a fine-tuned version of [amd/AMD-OLMo-1B-SFT](https://huggingface.co/amd/AMD-OLMo-1B-SFT) on the apps dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
tinman2030/lora-llama3-timed
|
tinman2030
| 2025-09-12T00:33:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-1B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-18T04:19:36Z |
---
base_model: meta-llama/Llama-3.2-1B-Instruct
library_name: transformers
model_name: lora-llama3-timed
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for lora-llama3-timed
This model is a fine-tuned version of [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="tinman2030/lora-llama3-timed", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/minhtanh126-mcgill-university/huggingface/runs/fgfvp703)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.1
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
AlekseyCalvin/Lyrical_MT_mini_rus2eng_MiniPLM_llama3.1_212m
|
AlekseyCalvin
| 2025-09-12T00:33:33Z | 14 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"orpo",
"Lyrics",
"Songs",
"Poetry",
"Dynamic",
"Creative",
"Translation",
"Russian",
"English",
"Soviet",
"Verse",
"Finetune",
"LLM",
"edge",
"TRL",
"translation",
"ru",
"en",
"dataset:AlekseyCalvin/song_lyrics_Ru2En_PostSoviet_alt_anthems_3columns",
"arxiv:2403.07691",
"base_model:MiniLLM/MiniPLM-llama3.1-212M",
"base_model:finetune:MiniLLM/MiniPLM-llama3.1-212M",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2025-09-07T22:38:07Z |
---
base_model: MiniLLM/MiniPLM-llama3.1-212M
library_name: transformers
model_name: Lyrical_MT_mini_rus2eng_MiniPLM_llama3.1_212m
tags:
- orpo
- Lyrics
- Songs
- Poetry
- Dynamic
- Creative
- Translation
- Russian
- English
- Soviet
- Verse
- Finetune
- LLM
- edge
- TRL
license: apache-2.0
datasets:
- AlekseyCalvin/song_lyrics_Ru2En_PostSoviet_alt_anthems_3columns
language:
- ru
- en
pipeline_tag: translation
---
### LYRICAL mini M.T. Model
## Russian | English Songs & Poems
# Machine Translation / Extrapolation
*By Silver Age Poets* <br>
**Variant 0.1m: Full ORPO finetune of MiniPLM-llama3.1-212M Model Weights**
# Model Card
This model is a fine-tune of [MiniLLM/MiniPLM-llama3.1-212M](https://huggingface.co/MiniLLM/MiniPLM-llama3.1-212M). <br>
**NOTE:This is one of our many experimental/WIP test variants over numerous base models in a range of small-medium sizes. <br>
By empirically cross-comparing foundations via training, versioning, and testing; thereby, we iterate towards a reliable actualization of our concept.** <br>
Fine-tuned leveraging Odds Ratio Preference Optimization (ORPO) on our [Russian-to-English song lyrics translation/localization dataset](https://huggingface.co/datasets/AlekseyCalvin/song_lyrics_Ru2En_PostSoviet_alt_anthems). <br>
Our aim with this work is to foster a translation model capable of adaptively localizing idiomatic, formal/poetic/rhythmic, and performance-catered features of lyrical input texts, whilst retaining adequate accuracy at the level of direct semantic translation. <br>
It has been trained using [TRL](https://github.com/huggingface/trl). <br>
## SUGGESTED SYSTEM PROMPT:
`You are an award-winning bilingual Russian-American literary translator, poet, songwriter, and literary translator. You are famous for translating highly idiomatic, lyrical, and culturally specific songs and poems between Russian and English whilst retaining with perfect fidelity (or appropriately localizing) the expressive tone, melodic pattern, subtle lyricism, cultural resonance, and the formal characteristics of the source work. Translate the following song from Russian to English, whilst accurately matching and reproducing in English the source Russian semantics and phrasing of each line and the song as a whole. Take care to preserve the song’s formal and poetic characteristics (such as meter, verbal musicality, expressive attitude, mood, rhyme-scheme, and syllable pattern/count). Do not explain. Respond with the translation only.`
## SUGGESTED PROMPT PRE-PHRASE:
`"Translate the following song to English, while accurately retaining the meter, syllable counts, rhymes, and style. Abide by the musical phrasing and the syllable pattern from the source. Translate: {insert song lyrics or poem verses}"`
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alekseycalvin/huggingface/runs/l3kyyst6)
This model was trained with ORPO, a method introduced in [ORPO: Monolithic Preference Optimization without Reference Model](https://huggingface.co/papers/2403.07691).
### Framework versions
- TRL: 0.22.1
- Transformers: 4.56.0
- Pytorch: 2.8.0
- Datasets: 3.1.0
- Tokenizers: 0.22.0
## Citations
Cite ORPO as:
```bibtex
@article{hong2024orpo,
title = {{ORPO: Monolithic Preference Optimization without Reference Model}},
author = {Jiwoo Hong and Noah Lee and James Thorne},
year = 2024,
eprint = {arXiv:2403.07691}
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
omerbektasss/blockassist-bc-keen_fast_giraffe_1757637056
|
omerbektasss
| 2025-09-12T00:31:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T00:31:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zzy1123/Qwen2.5-0.5B-with-temp
|
zzy1123
| 2025-09-12T00:29:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_with_temp",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-11T19:16:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
duongve/NetaYume-Lumina-Image-2.0
|
duongve
| 2025-09-12T00:28:57Z | 1,208 | 13 |
diffusion-single-file
|
[
"diffusion-single-file",
"stable-diffusion",
"text-to-image",
"comfyui",
"base_model:Alpha-VLLM/Lumina-Image-2.0",
"base_model:finetune:Alpha-VLLM/Lumina-Image-2.0",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2025-08-06T09:08:01Z |
---
pipeline_tag: text-to-image
license: apache-2.0
base_model:
- neta-art/Neta-Lumina
- Alpha-VLLM/Lumina-Image-2.0
tags:
- stable-diffusion
- text-to-image
- comfyui
- diffusion-single-file
---
# NetaYume Lumina Image v2.0

---
**I. Introduction**
NetaYume Lumina is a text-to-image model fine-tuned from [Neta Lumina](https://huggingface.co/neta-art/Neta-Lumina), a high-quality anime-style image generation model developed by [Neta.art Lab](https://huggingface.co/neta-art). It builds upon [Lumina-Image-2.0](https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0), an open-source base model released by the [Alpha-VLLM](https://huggingface.co/Alpha-VLLM) team at Shanghai AI Laboratory.
This model was trained with the goal of not only generating realistic human images but also producing high-quality anime-style images. Despite being fine-tuned on a specific dataset, it retains a significant amount of knowledge from the base model.
**Key Features:**
- **High-Quality Anime Generation**: Generates detailed anime-style images with sharp outlines, vibrant colors, and smooth shading.
- **Improved Character Understanding**: Better captures characters, especially those from the Danbooru dataset, resulting in more coherent and accurate character representations.
- **Enhanced Fine Details**: Accurately generates accessories, clothing textures, hairstyles, and background elements with greater clarity.
The file NetaYume_Lumina_v2_all_in_one.safetensors is an all-in-one file that contains the necessary weights for the VAE, text encoder, and image backbone to be used with ComfyUI.
---
**II. Model Components & Training Details**
- **Text Encoder**: Pre-trained **Gemma-2-2b**
- **Variational Autoencoder**: Pre-trained **Flux.1 dev's VAE**
- **Image Backbone**: Fine-tune **NetaLumina's Image Backbone**
---
**III. Suggestion**
**System Prompt:** This help you generate your desired images more easily by understanding and aligning with your prompts.
For anime-style images using Danbooru tags:
You are an assistant designed to generate anime images based on textual prompts.
You are an assistant designed to generate high-quality images based on user prompts and danbooru tags.
**Recommended Settings**
- CFG: 4–7
- Sampling Steps: 40-50
- Sampler:
- Euler a (with scheduler: normal)
- res_multistep (with scheduler: linear_quadratic)
---
**IV. Acknowledgments**
- [narugo1992](https://huggingface.co/narugo) – for the invaluable Danbooru dataset
- [Alpha-VLLM](https://huggingface.co/Alpha-VLLM) - for creating the a wonderful model!
- [Neta.art](https://huggingface.co/neta-art/Neta-Lumina) and his team – for openly sharing awesome model.
|
omerbektasss/blockassist-bc-insectivorous_bold_lion_1757636705
|
omerbektasss
| 2025-09-12T00:25:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bold lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T00:25:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bold lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.