
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-12 18:33:19
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-12 18:33:14
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Prathyusha101/tldr-ppco-g1p0-l1p0
|
Prathyusha101
| 2025-08-19T14:52:57Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"dataset:trl-internal-testing/tldr-preference-sft-trl-style",
"arxiv:1909.08593",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T10:22:47Z |
---
datasets: trl-internal-testing/tldr-preference-sft-trl-style
library_name: transformers
model_name: tldr-ppco-g1p0-l1p0
tags:
- generated_from_trainer
licence: license
---
# Model Card for tldr-ppco-g1p0-l1p0
This model is a fine-tuned version of [None](https://huggingface.co/None) on the [trl-internal-testing/tldr-preference-sft-trl-style](https://huggingface.co/datasets/trl-internal-testing/tldr-preference-sft-trl-style) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Prathyusha101/tldr-ppco-g1p0-l1p0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/prathyusha1-the-university-of-texas-at-austin/huggingface/runs/qb7oufpu)
This model was trained with PPO, a method introduced in [Fine-Tuning Language Models from Human Preferences](https://huggingface.co/papers/1909.08593).
### Framework versions
- TRL: 0.15.0.dev0
- Transformers: 4.53.1
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite PPO as:
```bibtex
@article{mziegler2019fine-tuning,
title = {{Fine-Tuning Language Models from Human Preferences}},
author = {Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving},
year = 2019,
eprint = {arXiv:1909.08593}
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
forstseh/blockassist-bc-arctic_soaring_heron_1755611858
|
forstseh
| 2025-08-19T14:51:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"arctic soaring heron",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:51:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- arctic soaring heron
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755613402
|
hakimjustbao
| 2025-08-19T14:51:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:51:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zenqqq/blockassist-bc-restless_reptilian_caterpillar_1755614989
|
zenqqq
| 2025-08-19T14:51:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"restless reptilian caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:50:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- restless reptilian caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Leoar/blockassist-bc-pudgy_toothy_cheetah_1755614865
|
Leoar
| 2025-08-19T14:49:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pudgy toothy cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:49:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pudgy toothy cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
uncahined/blockassist-bc-prowling_durable_tapir_1755614817
|
uncahined
| 2025-08-19T14:48:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"prowling durable tapir",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:48:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- prowling durable tapir
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
umairmaliick/falcon-7b-instruct-taskpro-lora
|
umairmaliick
| 2025-08-19T14:45:49Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:tiiuae/falcon-7b-instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"base_model:tiiuae/falcon-7b-instruct",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-19T13:53:18Z |
---
library_name: peft
license: apache-2.0
base_model: tiiuae/falcon-7b-instruct
tags:
- base_model:adapter:tiiuae/falcon-7b-instruct
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: falcon-7b-instruct-taskpro-lora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# falcon-7b-instruct-taskpro-lora
This model is a fine-tuned version of [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2754
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 3.2923 |
| No log | 2.0 | 2 | 3.2812 |
| No log | 3.0 | 3 | 3.2754 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755614706
|
lilTAT
| 2025-08-19T14:45:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:45:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Trelis/Qwen3-4B_ds-arc-agi-2-perfect-100_test-c8
|
Trelis
| 2025-08-19T14:45:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Qwen3-4B",
"base_model:finetune:unsloth/Qwen3-4B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:44:31Z |
---
base_model: unsloth/Qwen3-4B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Trelis
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755613191
|
lisaozill03
| 2025-08-19T14:45:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:45:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Team-Atom/act_record_pp_blue001_96_100000
|
Team-Atom
| 2025-08-19T14:41:55Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:Team-Atom/PiPl_blue_001",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T14:41:42Z |
---
datasets: Team-Atom/PiPl_blue_001
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- lerobot
- act
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755614412
|
lilTAT
| 2025-08-19T14:40:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:40:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Feruru/Classifier
|
Feruru
| 2025-08-19T14:36:48Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T14:35:49Z |
---
license: apache-2.0
---
|
asteria-life/openalex_articles_v0
|
asteria-life
| 2025-08-19T14:36:06Z | 0 | 0 |
model2vec
|
[
"model2vec",
"safetensors",
"embeddings",
"static-embeddings",
"sentence-transformers",
"license:mit",
"region:us"
] | null | 2025-08-19T14:35:56Z |
---
library_name: model2vec
license: mit
model_name: tmpp0ggqq40
tags:
- embeddings
- static-embeddings
- sentence-transformers
---
# tmpp0ggqq40 Model Card
This [Model2Vec](https://github.com/MinishLab/model2vec) model is a distilled version of a Sentence Transformer. It uses static embeddings, allowing text embeddings to be computed orders of magnitude faster on both GPU and CPU. It is designed for applications where computational resources are limited or where real-time performance is critical. Model2Vec models are the smallest, fastest, and most performant static embedders available. The distilled models are up to 50 times smaller and 500 times faster than traditional Sentence Transformers.
## Installation
Install model2vec using pip:
```
pip install model2vec
```
## Usage
### Using Model2Vec
The [Model2Vec library](https://github.com/MinishLab/model2vec) is the fastest and most lightweight way to run Model2Vec models.
Load this model using the `from_pretrained` method:
```python
from model2vec import StaticModel
# Load a pretrained Model2Vec model
model = StaticModel.from_pretrained("tmpp0ggqq40")
# Compute text embeddings
embeddings = model.encode(["Example sentence"])
```
### Using Sentence Transformers
You can also use the [Sentence Transformers library](https://github.com/UKPLab/sentence-transformers) to load and use the model:
```python
from sentence_transformers import SentenceTransformer
# Load a pretrained Sentence Transformer model
model = SentenceTransformer("tmpp0ggqq40")
# Compute text embeddings
embeddings = model.encode(["Example sentence"])
```
### Distilling a Model2Vec model
You can distill a Model2Vec model from a Sentence Transformer model using the `distill` method. First, install the `distill` extra with `pip install model2vec[distill]`. Then, run the following code:
```python
from model2vec.distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill(model_name="BAAI/bge-base-en-v1.5", pca_dims=256)
# Save the model
m2v_model.save_pretrained("m2v_model")
```
## How it works
Model2vec creates a small, fast, and powerful model that outperforms other static embedding models by a large margin on all tasks we could find, while being much faster to create than traditional static embedding models such as GloVe. Best of all, you don't need any data to distill a model using Model2Vec.
It works by passing a vocabulary through a sentence transformer model, then reducing the dimensionality of the resulting embeddings using PCA, and finally weighting the embeddings using [SIF weighting](https://openreview.net/pdf?id=SyK00v5xx). During inference, we simply take the mean of all token embeddings occurring in a sentence.
## Additional Resources
- [Model2Vec Repo](https://github.com/MinishLab/model2vec)
- [Model2Vec Base Models](https://huggingface.co/collections/minishlab/model2vec-base-models-66fd9dd9b7c3b3c0f25ca90e)
- [Model2Vec Results](https://github.com/MinishLab/model2vec/tree/main/results)
- [Model2Vec Tutorials](https://github.com/MinishLab/model2vec/tree/main/tutorials)
- [Website](https://minishlab.github.io/)
## Library Authors
Model2Vec was developed by the [Minish Lab](https://github.com/MinishLab) team consisting of [Stephan Tulkens](https://github.com/stephantul) and [Thomas van Dongen](https://github.com/Pringled).
## Citation
Please cite the [Model2Vec repository](https://github.com/MinishLab/model2vec) if you use this model in your work.
```
@article{minishlab2024model2vec,
author = {Tulkens, Stephan and {van Dongen}, Thomas},
title = {Model2Vec: Fast State-of-the-Art Static Embeddings},
year = {2024},
url = {https://github.com/MinishLab/model2vec}
}
```
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755613025
|
Sayemahsjn
| 2025-08-19T14:35:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:35:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755612564
|
aleebaster
| 2025-08-19T14:34:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:34:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Jekareka/test
|
Jekareka
| 2025-08-19T14:34:22Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T14:34:22Z |
---
license: apache-2.0
---
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755612485
|
ihsanridzi
| 2025-08-19T14:34:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:34:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sarrockia/prefectIllustriousXL_v3.safetensors
|
sarrockia
| 2025-08-19T14:33:06Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T14:04:58Z |
---
license: apache-2.0
---
|
shanaka95/gemma-3-270m-it-rag-finetune
|
shanaka95
| 2025-08-19T14:28:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:shanaka95/checkpoints",
"base_model:finetune:shanaka95/checkpoints",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T10:32:44Z |
---
base_model: shanaka95/checkpoints
library_name: transformers
model_name: gemma-3-270m-it-rag-finetune
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma-3-270m-it-rag-finetune
This model is a fine-tuned version of [shanaka95/checkpoints](https://huggingface.co/shanaka95/checkpoints).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="shanaka95/gemma-3-270m-it-rag-finetune", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0+cu129
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755611635
|
quantumxnode
| 2025-08-19T14:22:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:22:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Andra76/blockassist-bc-deadly_enormous_butterfly_1755613240
|
Andra76
| 2025-08-19T14:21:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly enormous butterfly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:21:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly enormous butterfly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755611572
|
chainway9
| 2025-08-19T14:20:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:20:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Joetib/en-twi-qwen2.5-0.5B-Instruct
|
Joetib
| 2025-08-19T14:19:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:19:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/qqWen-32B-RL-Reasoning-GGUF
|
mradermacher
| 2025-08-19T14:19:30Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:morganstanley/qqWen-32B-RL-Reasoning",
"base_model:quantized:morganstanley/qqWen-32B-RL-Reasoning",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-18T22:30:32Z |
---
base_model: morganstanley/qqWen-32B-RL-Reasoning
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/morganstanley/qqWen-32B-RL-Reasoning
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#qqWen-32B-RL-Reasoning-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q2_K.gguf) | Q2_K | 12.4 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q3_K_S.gguf) | Q3_K_S | 14.5 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q3_K_M.gguf) | Q3_K_M | 16.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q3_K_L.gguf) | Q3_K_L | 17.3 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.IQ4_XS.gguf) | IQ4_XS | 18.0 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q4_K_S.gguf) | Q4_K_S | 18.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q4_K_M.gguf) | Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q5_K_S.gguf) | Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q5_K_M.gguf) | Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q6_K.gguf) | Q6_K | 27.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/qqWen-32B-RL-Reasoning-GGUF/resolve/main/qqWen-32B-RL-Reasoning.Q8_0.gguf) | Q8_0 | 34.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Kdch2597/ppo-LunarLander-v2
|
Kdch2597
| 2025-08-19T14:18:49Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T14:18:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 263.01 +/- 19.22
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Neurazum/Tbai-DPA-1.0
|
Neurazum
| 2025-08-19T14:17:43Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"text",
"image",
"brain",
"dementia",
"mri",
"fmri",
"health",
"diagnosis",
"diseases",
"alzheimer",
"parkinson",
"comment",
"doctor",
"vbai",
"tbai",
"bai",
"text-generation",
"tr",
"doi:10.57967/hf/5699",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-31T13:02:32Z |
---
license: cc-by-nc-sa-4.0
language:
- tr
pipeline_tag: text-generation
tags:
- text
- image
- brain
- dementia
- mri
- fmri
- health
- diagnosis
- diseases
- alzheimer
- parkinson
- comment
- doctor
- vbai
- tbai
- bai
library_name: transformers
---
# Tbai-DPA 1.0 Sürümü (TR) [BETA]
## Tanım
Tbai-DPA 1.0 (Dementia, Parkinson, Alzheimer) modeli, MRI veya fMRI görüntüsü üzerinden beyin hastalıklarını yorumlayarak daha detaylı teşhis etmek amacıyla eğitilmiş ve geliştirilmiştir. Hastanın parkinson olup olmadığını, demans durumunu ve alzheimer riskini yüksek doğruluk oranı ile göstermektedir.
### Kitle / Hedef
Tbai modelleri, Vbai ile birlikte çalışarak; öncelikle hastaneler, sağlık merkezleri ve bilim merkezleri için geliştirilmiştir.
### Sınıflar
- **Alzheimer Hastası**
- **Ortalama Alzheimer Riski**
- **Hafif Alzheimer Riski**
- **Çok Hafif Alzheimer Riski**
- **Risk Yok**
- **Parkinson Hastası**
## ----------------------------------------
# Tbai-DPA 1.0 Version (EN) [BETA]
## Description
The Tbai-DPA 1.0 (Dementia, Parkinson's, Alzheimer's) model has been trained and developed to interpret brain diseases through MRI or fMRI images for more detailed diagnosis. It indicates whether the patient has Parkinson's disease, dementia, and Alzheimer's risk with a high accuracy rate.
### Audience / Target
Tbai models, working in conjunction with Vbai, have been developed primarily for hospitals, health centers, and science centers.
### Classes
- **Alzheimer's disease**
- **Average Risk of Alzheimer's Disease**
- **Mild Alzheimer's Risk**
- **Very Mild Alzheimer's Risk**
- **No Risk**
- **Parkinson's Disease**
## Kullanım / Usage
1. Sanal ortam oluşturun. / Create a virtual environment.
```bash
python -3.9.0 -m venv myenv
```
2. Bağımlılıkları yükleyin. / Load dependencies.
```bash
pip install -r requirements.txt
```
3. Dosyayı çalıştırın. / Run the script.
```python
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
def load_tbai_model(model_dir: str, device):
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir).to(device)
return tokenizer, model
def generate_comment_sampling(
tokenizer,
model,
sinif_adi: str,
device,
max_length: int = 128
) -> str:
input_text = f"Sınıf: {sinif_adi}"
inputs = tokenizer(
input_text,
return_tensors="pt",
padding="longest",
truncation=True,
max_length=32
).to(device)
out_ids = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
top_k=50,
top_p=0.95,
no_repeat_ngram_size=2,
early_stopping=True
)
comment = tokenizer.decode(out_ids[0], skip_special_tokens=True)
return comment
def test_with_sampling():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer, model = load_tbai_model(
"Tbai/model/dir/path",
device)
test_classes = [
"alzheimer disease",
"mild alzheimer risk",
"moderate alzheimer risk",
"very mild alzheimer risk",
"no risk",
"parkinson disease"
]
for cls in test_classes:
print(f"--- Class: {cls} (Deneme 1) ---")
print(generate_comment_sampling(tokenizer, model, cls, device))
print(f"--- Class: {cls} (Deneme 2) ---")
print(generate_comment_sampling(tokenizer, model, cls, device))
print()
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f">>> Using device: {device}\n")
model_dir = "Tbai/model/dir/path"
tokenizer, model = load_tbai_model(model_dir, device)
print(">>> Tokenizer ve model başarıyla yüklendi.\n")
test_classes = [
"alzheimer disease",
"mild alzheimer risk",
"moderate alzheimer risk",
"very mild alzheimer risk",
"no risk",
"parkinson disease"
]
for cls in test_classes:
generated = generate_comment_sampling(tokenizer, model, cls, device)
print(f"Sınıf: {cls}")
print(f"Üretilen Yorum: {generated}\n")
if __name__ == "__main__":
main()
```
4. Görüntü İşleme Modeli ile Beraber Çalıştırın. / Run Together with Image Processing Model.
```python
import os
import time
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
from thop import profile
import numpy as np
from datetime import datetime
import warnings
from sklearn.metrics import average_precision_score
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning)
from transformers import T5Tokenizer, T5ForConditionalGeneration
class SimpleCNN(nn.Module):
def __init__(self, model_type='c', num_classes=6): # Model tipine göre "model_type" değişkeni "f, c, q" olarak değiştirilebilir. / The ‘model_type’ variable can be changed to ‘f, c, q’ according to the model type.
super(SimpleCNN, self).__init__()
self.num_classes = num_classes
if model_type == 'f':
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 28 * 28, 256)
self.dropout = nn.Dropout(0.5)
elif model_type == 'c':
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(128 * 28 * 28, 512)
self.dropout = nn.Dropout(0.5)
elif model_type == 'q':
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(512 * 14 * 14, 1024)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(self.fc1.out_features, num_classes)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
if hasattr(self, 'conv4'):
x = self.pool(self.relu(self.conv4(x)))
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
def predict_image(model: nn.Module, image_path: str, transform, device):
img = Image.open(image_path).convert('RGB')
inp = transform(img).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
out = model(inp)
prob = torch.nn.functional.softmax(out, dim=1)
pred = prob.argmax(dim=1).item()
conf = prob[0, pred].item() * 100
return pred, conf, inp, prob
def calculate_performance_metrics(model: nn.Module, device, input_size=(1, 3, 224, 224)):
model.to(device)
x = torch.randn(input_size).to(device)
flops, params = profile(model, inputs=(x,), verbose=False)
cpu_start = time.time()
_ = model(x)
cpu_time = (time.time() - cpu_start) * 1000
return {
'size_pixels': input_size[-1],
'speed_cpu_b1': cpu_time,
'speed_cpu_b32': cpu_time / 10,
'speed_v100_b1': cpu_time / 2,
'params_million': params / 1e6,
'flops_billion': flops / 1e9
}
def load_tbai_model(model_dir: str, device):
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir).to(device)
model.eval()
return tokenizer, model
def generate_comment_turkce(tokenizer, model, sinif_adi: str, device, max_length: int = 64) -> str:
input_text = f"Sınıf: {sinif_adi}"
inputs = tokenizer(
input_text,
return_tensors="pt",
padding="longest",
truncation=True,
max_length=32
).to(device)
out_ids = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
top_k=50,
top_p=0.95,
no_repeat_ngram_size=2,
early_stopping=True
)
comment = tokenizer.decode(out_ids[0], skip_special_tokens=True)
return comment
def save_monitoring_log(predicted_class, confidence, comment_text,
metrics, class_names, image_path, ap_scores=None, map_score=None,
log_path='monitoring_log.txt'):
os.makedirs(os.path.dirname(log_path) or '.', exist_ok=True)
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
img_name = os.path.basename(image_path)
log = f"""
===== Model Monitoring Log =====
Timestamp: {timestamp}
Image: {img_name}
Predicted Class: {class_names[predicted_class]}
Confidence: {confidence:.2f}%
Comment: {comment_text}
-- Performance Metrics --
Params (M): {metrics['params_million']:.2f}
FLOPs (B): {metrics['flops_billion']:.2f}
Image Size: {metrics['size_pixels']}x{metrics['size_pixels']}
CPU Time b1 (ms): {metrics['speed_cpu_b1']:.2f}
V100 Time b1 (ms): {metrics['speed_v100_b1']:.2f}
V100 Time b32 (ms): {metrics['speed_cpu_b32']:.2f}
-- AP/mAP Metrics --"""
if ap_scores is not None and map_score is not None:
log += f"\nmAP: {map_score:.4f}"
for i, (class_name, ap) in enumerate(zip(class_names, ap_scores)):
log += f"\nAP_{class_name}: {ap:.4f}"
else:
log += "\nAP/mAP: Not calculated (single image)"
log += "\n================================\n"
with open(log_path, 'a', encoding='utf-8') as f:
f.write(log)
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
class_names = [
'Alzheimer Disease',
'Mild Alzheimer Risk',
'Moderate Alzheimer Risk',
'Very Mild Alzheimer Risk',
'No Risk',
'Parkinson Disease'
]
model = SimpleCNN(model_type='c', num_classes=len(class_names)).to(device) # Model tipine göre "model_type" değişkeni "f, c, q" olarak değiştirilebilir. / The ‘model_type’ variable can be changed to ‘f, c, q’ according to the model type.
model_path = 'Vbai/model/file/path'
try:
model.load_state_dict(torch.load(model_path, map_location=device))
except Exception as e:
print(f"Görüntü modeli yükleme hatası: {e}")
return
metrics = calculate_performance_metrics(model, device)
tbai_model_dir = "Tbai/model/dir/path"
tokenizer, tbai_model = load_tbai_model(tbai_model_dir, device)
en2tr = {
'Alzheimer Disease': 'Alzheimer Hastalığı',
'Mild Alzheimer Risk': 'Hafif Alzheimer Riski',
'Moderate Alzheimer Risk': 'Orta Düzey Alzheimer Riski',
'Very Mild Alzheimer Risk': 'Çok Hafif Alzheimer Riski',
'No Risk': 'Risk Yok',
'Parkinson Disease': 'Parkinson Hastalığı'
}
image_path = 'test/images/path'
pred_class_idx, confidence, inp_tensor, predicted_probs = predict_image(model, image_path, transform, device)
predicted_class_name = class_names[pred_class_idx]
print(f"Prediction: {predicted_class_name} ({confidence:.2f}%)")
print(f"Confidence: {confidence:.2f}%")
print(f"Params (M): {metrics['params_million']:.2f}")
print(f"FLOPs (B): {metrics['flops_billion']:.2f}")
print(f"Image Size: {metrics['size_pixels']}x{metrics['size_pixels']}")
print(f"CPU Time b1 (ms): {metrics['speed_cpu_b1']:.2f}")
print(f"V100 Time b1 (ms): {metrics['speed_v100_b1']:.2f}")
print(f"V100 Time b32 (ms): {metrics['speed_cpu_b32']:.2f}")
tr_class_name = en2tr.get(predicted_class_name, predicted_class_name)
try:
comment_text = generate_comment_turkce(tokenizer, tbai_model, tr_class_name, device)
except Exception as e:
print(f"Yorum üretme hatası: {e}")
comment_text = "Yorum üretilemedi."
print(f"\nComment (Tbai-DPA 1.0): {comment_text}")
save_monitoring_log(
pred_class_idx, confidence, comment_text,
metrics, class_names, image_path)
img_show = inp_tensor.squeeze(0).permute(1, 2, 0).cpu().numpy()
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img_show = img_show * std + mean
img_show_clipped = np.clip(img_show, 0.0, 1.0)
plt.imshow(img_show_clipped)
plt.title(f'{predicted_class_name} — {confidence:.2f}%')
plt.axis('off')
plt.show()
if __name__ == '__main__':
main()
```
#### Lisans/License: CC-BY-NC-SA-4.0
|
AiArtLab/kc
|
AiArtLab
| 2025-08-19T14:17:04Z | 0 | 2 | null |
[
"text-to-image",
"base_model:KBlueLeaf/Kohaku-XL-Zeta",
"base_model:finetune:KBlueLeaf/Kohaku-XL-Zeta",
"region:us"
] |
text-to-image
| 2025-04-30T17:10:58Z |
---
base_model:
- stabilityai/stable-diffusion-xl-base-1.0
- KBlueLeaf/Kohaku-XL-Zeta
pipeline_tag: text-to-image
---

## Description
This model is a custom fine-tuned variant based on the Kohaku-XL-Zeta pretrained foundation [Kohaku-XL-Zeta](https://huggingface.co/KBlueLeaf/Kohaku-XL-Zeta). Kohaku-XL-Zeta itself is a "raw" base model trained for 1 epoch on 8+ million Danbooru(mostly) images , using 4x NVIDIA 3090 GPUs! While the original Kohaku is not user-friendly out-of-the-box, it serves as a flexible starting point for creative adaptations.
To enhance encoder stability and inject cross-domain knowledge beyond Danbooru-specific features, the model was merged with ColorfulXL using cosine dissimilarity weighting (0.25 blend ratio). This integration aims to broaden the model’s understanding of natural language and artistic concepts beyond typical Danbooru tagging conventions.
Post-merge stabilization involved 6 epochs at 2e-6 learning rate, followed by ongoing fine-tuning at 9e-7 learning rate to refine details. The closest publicly available fine-tune of this lineage is Illustrous, though it uses an earlier Kohaku version with weaker text comprehension. This variant leverages the improved Kohaku-Colorful hybrid (KC), prioritizing non-realistic art generation and creative flexibility over photorealism.
Key Notes :
- Not optimized for realism; best suited for anime/artistic styles.
- Ideal for users seeking a customizable foundation for niche art generation or further fine-tuning experiments.
## Donations
Please contact with us if you may provide some GPU's or money on training
DOGE: DEw2DR8C7BnF8GgcrfTzUjSnGkuMeJhg83
BTC: 3JHv9Hb8kEW8zMAccdgCdZGfrHeMhH1rpN
## Contacts
[recoilme](https://t.me/recoilme)
|
mradermacher/UI-Venus-Navi-72B-GGUF
|
mradermacher
| 2025-08-19T14:16:46Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:inclusionAI/UI-Venus-Navi-72B",
"base_model:quantized:inclusionAI/UI-Venus-Navi-72B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-18T23:56:29Z |
---
base_model: inclusionAI/UI-Venus-Navi-72B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/inclusionAI/UI-Venus-Navi-72B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#UI-Venus-Navi-72B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/UI-Venus-Navi-72B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.9 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Navi-72B-GGUF/resolve/main/UI-Venus-Navi-72B.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Kurosawama/Llama-3.2-3B-Instruct-Inference-align
|
Kurosawama
| 2025-08-19T14:15:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"trl",
"dpo",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T14:15:34Z |
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755611332
|
mang3dd
| 2025-08-19T14:15:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:15:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ibm-granite/granite-speech-3.3-2b
|
ibm-granite
| 2025-08-19T14:14:22Z | 44,969 | 22 |
transformers
|
[
"transformers",
"safetensors",
"granite_speech",
"automatic-speech-recognition",
"multilingual",
"en",
"fr",
"de",
"es",
"pt",
"arxiv:2505.08699",
"base_model:ibm-granite/granite-3.3-2b-instruct",
"base_model:finetune:ibm-granite/granite-3.3-2b-instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-28T15:25:29Z |
---
license: apache-2.0
language:
- multilingual
- en
- fr
- de
- es
- pt
base_model:
- ibm-granite/granite-3.3-2b-instruct
library_name: transformers
---
# Granite-speech-3.3-2b (revision 3.3.2)
**Model Summary:**
Granite-speech-3.3-2b is a compact and efficient speech-language model, specifically designed for automatic speech recognition (ASR) and automatic speech translation (AST). Granite-speech-3.3-2b uses a two-pass design, unlike integrated models that combine speech and language into a single pass. Initial calls to granite-speech-3.3-2b will transcribe audio files into text. To process the transcribed text using the underlying Granite language model, users must make a second call as each step must be explicitly initiated.
The model was trained on a collection of public corpora comprising diverse datasets for ASR and AST as well as synthetic datasets tailored to support the speech translation task. Granite-speech-3.3-2b was trained by modality aligning granite-3.3-2b-instruct (https://huggingface.co/ibm-granite/granite-3.3-2b-instruct) to speech on publicly available open source corpora containing audio inputs and text targets. Compared to the initial release, revision 3.3.2
* supports multilingual speech inputs in English, French, German, Spanish and Portuguese,
* provides transcription accuracy improvements for English ASR by using a deeper acoustic encoder and additional training data.
**Evaluations:**
We evaluated granite-speech-3.3-2b revision 3.3.2 alongside granite-speech-3.3-8b (https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and other speech-language models in the less than 8b parameter range as well as dedicated ASR and AST systems on standard benchmarks. The evaluation spanned multiple public benchmarks, with particular emphasis on English ASR tasks while also including multilingual ASR and AST for X-En and En-X translations.
<br>

<br>

<br>

<br>

<br>
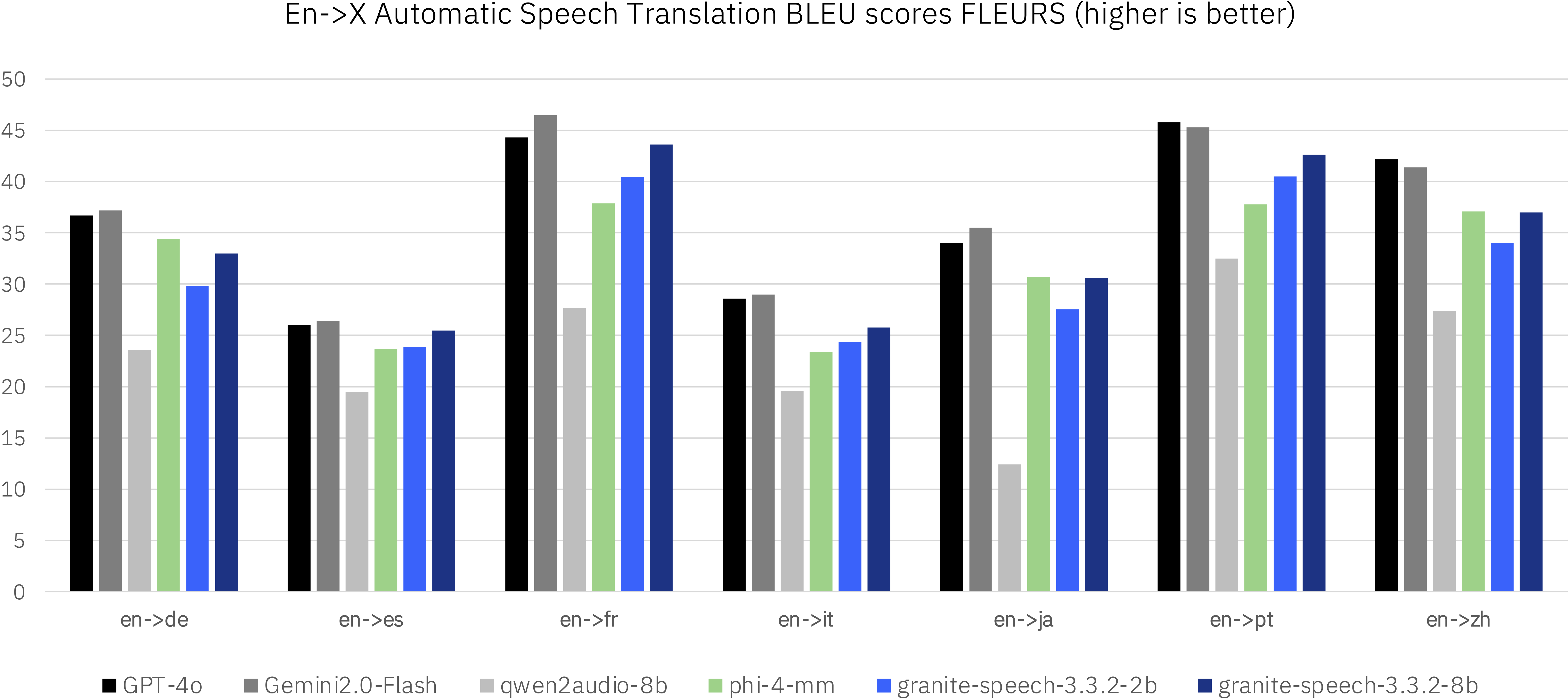
<br>
**Release Date**: June 19, 2025
**License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, French, German, Spanish, Portuguese
**Intended Use:**
The model is intended to be used in enterprise applications that involve processing of speech inputs. In particular, the model is well-suited for English, French, German, Spanish and Portuguese speech-to-text and speech translations to and from English for the same languages plus English-to-Japanese and English-to-Mandarin. The model can also be used for tasks that involve text-only input since it calls the underlying granite-3.3-2b-instruct when the user specifies a prompt that does not contain audio.
## Generation:
Granite Speech model is supported natively in `transformers` from the `main` branch. Below is a simple example of how to use the `granite-speech-3.3-2b` revision 3.3.2 model.
### Usage with `transformers`
First, make sure to install a recent version of transformers:
```shell
pip install transformers>=4.52.4 torchaudio peft soundfile
```
Then run the code:
```python
import torch
import torchaudio
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
from huggingface_hub import hf_hub_download
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "ibm-granite/granite-speech-3.3-2b"
processor = AutoProcessor.from_pretrained(model_name)
tokenizer = processor.tokenizer
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name, device_map=device, torch_dtype=torch.bfloat16
)
# load audio
audio_path = hf_hub_download(repo_id=model_name, filename="10226_10111_000000.wav")
wav, sr = torchaudio.load(audio_path, normalize=True)
assert wav.shape[0] == 1 and sr == 16000 # mono, 16khz
# create text prompt
system_prompt = "Knowledge Cutoff Date: April 2024.\nToday's Date: April 9, 2025.\nYou are Granite, developed by IBM. You are a helpful AI assistant"
user_prompt = "<|audio|>can you transcribe the speech into a written format?"
chat = [
dict(role="system", content=system_prompt),
dict(role="user", content=user_prompt),
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# run the processor+model
model_inputs = processor(prompt, wav, device=device, return_tensors="pt").to(device)
model_outputs = model.generate(**model_inputs, max_new_tokens=200, do_sample=False, num_beams=1)
# Transformers includes the input IDs in the response.
num_input_tokens = model_inputs["input_ids"].shape[-1]
new_tokens = torch.unsqueeze(model_outputs[0, num_input_tokens:], dim=0)
output_text = tokenizer.batch_decode(
new_tokens, add_special_tokens=False, skip_special_tokens=True
)
print(f"STT output = {output_text[0].upper()}")
```
### Usage with `vLLM`
First, make sure to install the latest version of vLLM:
```shell
pip install vllm --upgrade
```
* Code for offline mode:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.assets.audio import AudioAsset
from vllm.lora.request import LoRARequest
model_id = "ibm-granite/granite-speech-3.3-2b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_prompt(question: str, has_audio: bool):
"""Build the input prompt to send to vLLM."""
if has_audio:
question = f"<|audio|>{question}"
chat = [
{
"role": "user",
"content": question
}
]
return tokenizer.apply_chat_template(chat, tokenize=False)
# NOTE - you may see warnings about multimodal lora layers being ignored;
# this is okay as the lora in this model is only applied to the LLM.
model = LLM(
model=model_id,
enable_lora=True,
max_lora_rank=64,
max_model_len=2048, # This may be needed for lower resource devices.
limit_mm_per_prompt={"audio": 1},
)
### 1. Example with Audio [make sure to use the lora]
question = "can you transcribe the speech into a written format?"
prompt_with_audio = get_prompt(
question=question,
has_audio=True,
)
audio = AudioAsset("mary_had_lamb").audio_and_sample_rate
inputs = {
"prompt": prompt_with_audio,
"multi_modal_data": {
"audio": audio,
}
}
outputs = model.generate(
inputs,
sampling_params=SamplingParams(
temperature=0.2,
max_tokens=64,
),
lora_request=[LoRARequest("speech", 1, model_id)]
)
print(f"Audio Example - Question: {question}")
print(f"Generated text: {outputs[0].outputs[0].text}")
### 2. Example without Audio [do NOT use the lora]
question = "What is the capital of Brazil?"
prompt = get_prompt(
question=question,
has_audio=False,
)
outputs = model.generate(
{"prompt": prompt},
sampling_params=SamplingParams(
temperature=0.2,
max_tokens=12,
),
)
print(f"Text Only Example - Question: {question}")
print(f"Generated text: {outputs[0].outputs[0].text}")
```
* Code for online mode:
```python
"""
Launch the vLLM server with the following command:
vllm serve ibm-granite/granite-speech-3.3-2b \
--api-key token-abc123 \
--max-model-len 2048 \
--enable-lora \
--lora-modules speech=ibm-granite/granite-speech-3.3-2b \
--max-lora-rank 64
"""
import base64
import requests
from openai import OpenAI
from vllm.assets.audio import AudioAsset
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "token-abc123"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
base_model_name = "ibm-granite/granite-speech-3.3-2b"
lora_model_name = "speech"
# Any format supported by librosa is supported
audio_url = AudioAsset("mary_had_lamb").url
# Use base64 encoded audio in the payload
def encode_audio_base64_from_url(audio_url: str) -> str:
"""Encode an audio retrieved from a remote url to base64 format."""
with requests.get(audio_url) as response:
response.raise_for_status()
result = base64.b64encode(response.content).decode('utf-8')
return result
audio_base64 = encode_audio_base64_from_url(audio_url=audio_url)
### 1. Example with Audio
# NOTE: we pass the name of the lora model (`speech`) here because we have audio.
question = "can you transcribe the speech into a written format?"
chat_completion_with_audio = client.chat.completions.create(
messages=[{
"role": "user",
"content": [
{
"type": "text",
"text": question
},
{
"type": "audio_url",
"audio_url": {
# Any format supported by librosa is supported
"url": f"data:audio/ogg;base64,{audio_base64}"
},
},
],
}],
temperature=0.2,
max_tokens=64,
model=lora_model_name,
)
print(f"Audio Example - Question: {question}")
print(f"Generated text: {chat_completion_with_audio.choices[0].message.content}")
### 2. Example without Audio
# NOTE: we pass the name of the base model here because we do not have audio.
question = "What is the capital of Brazil?"
chat_completion_with_audio = client.chat.completions.create(
messages=[{
"role": "user",
"content": [
{
"type": "text",
"text": question
},
],
}],
temperature=0.2,
max_tokens=12,
model=base_model_name,
)
print(f"Text Only Example - Question: {question}")
print(f"Generated text: {chat_completion_with_audio.choices[0].message.content}")
```
**Model Architecture:**
The architecture of granite-speech-3.3-2b revision 3.3.2 consists of the following components:
(1) Speech encoder: 16 conformer blocks trained with Connectionist Temporal Classification (CTC) on character-level targets on the subset containing
only ASR corpora (see configuration below). In addition, our CTC encoder uses block-attention with 4-seconds audio blocks and self-conditioned CTC
from the middle layer.
| Configuration parameter | Value |
|-----------------|----------------------|
| Input dimension | 160 (80 logmels x 2) |
| Nb. of layers | 16 |
| Hidden dimension | 1024 |
| Nb. of attention heads | 8 |
| Attention head size | 128 |
| Convolution kernel size | 15 |
| Output dimension | 256 |
(2) Speech projector and temporal downsampler (speech-text modality adapter): we use a 2-layer window query transformer (q-former) operating on
blocks of 15 1024-dimensional acoustic embeddings coming out of the last conformer block of the speech encoder that get downsampled by a factor of 5
using 3 trainable queries per block and per layer. The total temporal downsampling factor is 10 (2x from the encoder and 5x from the projector)
resulting in a 10Hz acoustic embeddings rate for the LLM. The encoder, projector and LoRA adapters were fine-tuned/trained jointly on all the
corpora mentioned under **Training Data**.
(3) Large language model: granite-3.3-2b-instruct with 128k context length (https://huggingface.co/ibm-granite/granite-3.3-2b-instruct).
(4) LoRA adapters: rank=64 applied to the query, value projection matrices
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets (2) Synthetic data created from publicly
available datasets specifically targeting the speech translation task. A detailed description of the training datasets can be found in the table
below:
| Name | Task | Nb. hours | Source |
|-----------|--------------|----------------|--------------|
| CommonVoice-17 En,De,Es,Fr,Pt | ASR | 5600 | https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0 |
| MLS En,De,Es,Fr,Pt | ASR | 48000 | https://huggingface.co/datasets/facebook/multilingual_librispeech |
| Librispeech English | ASR | 1000 | https://huggingface.co/datasets/openslr/librispeech_asr |
| VoxPopuli En,De,Fr,Es | ASR | 1100 | https://huggingface.co/datasets/facebook/voxpopuli |
| AMI English | ASR | 100 | https://huggingface.co/datasets/edinburghcstr/ami |
| YODAS English | ASR | 10000 | https://huggingface.co/datasets/espnet/yodas |
| Earnings-22 English | ASR | 105 | https://huggingface.co/datasets/esb/datasets |
| Switchboard English | ASR | 260 | https://catalog.ldc.upenn.edu/LDC97S62 |
| CallHome English | ASR | 18 | https://catalog.ldc.upenn.edu/LDC97T14 |
| Fisher English | ASR | 2000 | https://catalog.ldc.upenn.edu/LDC2004S13 |
| Voicemail part I English | ASR | 40 | https://catalog.ldc.upenn.edu/LDC98S77 |
| Voicemail part II English | ASR | 40 | https://catalog.ldc.upenn.edu/LDC2002S35 |
| CommonVoice-17 De,Es,Fr,Pt->En | AST | 3000 | Translations with Granite-3 and Phi-4 |
| CommonVoice-17 En->De,Es,Fr,It,Ja,Pt,Zh | AST | 18000 | Translations with Phi-4 and MADLAD |
**Infrastructure:**
We train Granite Speech using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable
and efficient infrastructure for training our models over thousands of GPUs. The training of this particular model was completed in 13 days on 32
H100 GPUs.
**Ethical Considerations and Limitations:**
The use of Large Speech and Language Models can trigger certain risks and ethical considerations. Although our alignment processes include safety considerations, the model may in some cases produce inaccurate, biased, offensive or unwanted responses to user prompts. Additionally, whether smaller models may exhibit increased susceptibility to hallucination in generation scenarios due to their reduced sizes, which could limit their ability to generate coherent and contextually accurate responses, remains uncertain. This aspect is currently an active area of research, and we anticipate more rigorous exploration, comprehension, and mitigations in this domain.
IBM recommends using this model for automatic speech recognition and translation tasks. The model's modular design improves safety by limiting how audio inputs can influence the system. If an unfamiliar or malformed prompt is received, the model simply echoes it with its transcription. This minimizes the risk of adversarial inputs, unlike integrated models that directly interpret audio and may be more exposed to such attacks. Note that more general speech tasks may pose higher inherent risks of triggering unwanted outputs.
To enhance safety, we recommend using granite-speech-3.3-2b alongside Granite Guardian. Granite Guardian is a fine-tuned instruct model designed to detect and flag risks in prompts and responses across key dimensions outlined in the IBM AI Risk Atlas.
**Resources**
- 📄 Read the full technical report: https://arxiv.org/abs/2505.08699 (covers initial release only)
- 🔧 Notebooks: [Finetune on custom data](https://github.com/ibm-granite/granite-speech-models/blob/main/notebooks/fine_tuning_granite_speech.ipynb), [two-pass spoken question answering](https://github.com/ibm-granite/granite-speech-models/blob/main/notebooks/two_pass_spoken_qa.ipynb)
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 🚀 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
|
vrbhalaaji/my_policy
|
vrbhalaaji
| 2025-08-19T14:13:45Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:vrbhalaaji/orange-pick-test",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T14:13:00Z |
---
datasets: vrbhalaaji/orange-pick-test
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- lerobot
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755611000
|
kojeklollipop
| 2025-08-19T14:11:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:11:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
doriankim/gemma3-4b-skin-cancer-classifier
|
doriankim
| 2025-08-19T14:10:34Z | 0 | 0 | null |
[
"safetensors",
"gemma3",
"region:us"
] | null | 2025-08-17T05:47:36Z |
# Gemma3 4B Skin Cancer Classifier
## 모델 개요
이 모델은 Gemma-3 4B를 기반으로 피부암 진단을 위해 파인튜닝된 분류 모델입니다.
## 모델 상세 정보
- **Base Model**: Gemma-3 4B
- **Task**: 피부암 이미지 분류
- **Fine-tuning Steps**: 1000 steps
- **LoRA Rank (r)**: 32
- **Batch Size**: 8
## 훈련 설정
```json
{
"model_name": "gemma-3-4b",
"training_steps": 1000,
"lora_rank": 32,
"batch_size": 8,
"learning_rate": "auto",
"optimizer": "adamw"
}
```
## 평가 결과
자세한 평가 결과는 `evaluation/` 폴더에서 확인하실 수 있습니다.
### 주요 성능 지표
- **정확도**: [evaluation 폴더에서 확인]
- **정밀도**: [evaluation 폴더에서 확인]
- **재현율**: [evaluation 폴더에서 확인]
- **F1 스코어**: [evaluation 폴더에서 확인]
## 사용 방법
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 모델과 토크나이저 로드
model_name = "doriankim/gemma3-4b-skin-cancer-classifier"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 추론 예시
def predict_skin_condition(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
return predictions
```
## 폴더 구조
```
├── config.json # 모델 설정
├── pytorch_model.bin # 모델 가중치
├── tokenizer files # 토크나이저 관련 파일들
├── evaluation/ # 평가 결과 및 분석
│ ├── results/ # 성능 지표
│ ├── plots/ # 시각화 결과
│ └── logs/ # 평가 로그
└── README.md # 이 파일
```
## 라이선스
[라이선스 정보를 여기에 추가하세요]
## 인용
이 모델을 사용하시는 경우 다음과 같이 인용해 주세요:
```
@misc{gemma3_4b_skin_cancer_classifier,
author = {doriankim},
title = {Gemma-3 4B Skin Cancer Classifier},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/doriankim/gemma3-4b-skin-cancer-classifier}
}
```
---
*이 모델은 연구 목적으로 개발되었으며, 실제 의료 진단에 사용하기 전에 전문의와 상담하시기 바랍니다.*
|
Muapi/flux.1_mechanical-bloom-surreal-anime-style-portrait
|
Muapi
| 2025-08-19T14:09:15Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T14:09:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Flux.1_Mechanical Bloom · Surreal Anime-style Portrait

**Base model**: Flux.1 D
**Trained words**: CynthiaPortrait
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1001492@1122429", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/oldnokia-ultrareal
|
Muapi
| 2025-08-19T14:07:27Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T14:07:15Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# oldNokia Ultrareal

**Base model**: Flux.1 D
**Trained words**: n0k1a
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1808651@2046810", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss
|
0xZeno
| 2025-08-19T14:06:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-08-19T10:40:12Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a photo of sks football player
widget:
- text: a photo of sks football player playing football on a beach
output:
url: image_0.png
- text: a photo of sks football player playing football on a beach
output:
url: image_1.png
- text: a photo of sks football player playing football on a beach
output:
url: image_2.png
- text: a photo of sks football player playing football on a beach
output:
url: image_3.png
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - 0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss
<Gallery />
## Model description
These are 0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sks football player to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
alok0777/blockassist-bc-masked_pensive_lemur_1755612218
|
alok0777
| 2025-08-19T14:05:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked pensive lemur",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:04:43Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked pensive lemur
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755611085
|
Sayemahsjn
| 2025-08-19T14:02:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:02:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kurosawama/Llama-3.2-3B-Translation-align
|
Kurosawama
| 2025-08-19T14:00:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"trl",
"dpo",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T06:10:57Z |
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755610312
|
katanyasekolah
| 2025-08-19T14:00:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:00:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/1980-s-style-xl-f1d
|
Muapi
| 2025-08-19T14:00:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T14:00:26Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# 1980's style XL + F1D

**Base model**: Flux.1 D
**Trained words**: 1980 style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:376914@894083", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755610342
|
ihsanridzi
| 2025-08-19T13:59:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:59:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/radiant-realism-pro-realistic-makeup-skin-texture-skin-color-flux.1d
|
Muapi
| 2025-08-19T13:56:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:56:23Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Radiant Realism Pro (Realistic, Makeup, Skin Texture, Skin Color) Flux.1D

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:970421@1086588", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755610017
|
pempekmangedd
| 2025-08-19T13:55:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:55:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755610110
|
helmutsukocok
| 2025-08-19T13:54:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:54:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/alejandro-jodorowsky-style
|
Muapi
| 2025-08-19T13:53:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:53:34Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Alejandro Jodorowsky Style

**Base model**: Flux.1 D
**Trained words**: Alejandro Jodorowsky Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:62712@1403331", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/ethereal-fantasy
|
Muapi
| 2025-08-19T13:50:26Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:50:13Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Ethereal Fantasy

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1017670@1141054", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
QuantTrio/Qwen3-235B-A22B-Instruct-2507-AWQ
|
QuantTrio
| 2025-08-19T13:50:01Z | 908 | 7 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"AWQ",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-235B-A22B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-235B-A22B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2025-07-24T04:37:10Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- AWQ
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-235B-A22B-Instruct-2507
base_model_relation: quantized
---
# Qwen3-235B-A22B-Instruct-2507-AWQ
Base model [Qwen/Qwen3-235B-A22B-Instruct-2507](https://www.modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups. </i>
```
CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-235B-A22B-Instruct-2507-AWQ \
--served-model-name Qwen3-235B-A22B-Instruct-2507-AWQ \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-23
1. fast commit
```
### 【Model Files】
| File Size | Last Updated |
|---------|--------------|
| `116GB` | `2025-07-23` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-235B-A22B-Instruct-2507-AWQ', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
lqpl/blockassist-bc-hairy_insectivorous_antelope_1755611176
|
lqpl
| 2025-08-19T13:47:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hairy insectivorous antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:47:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hairy insectivorous antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Jocelyn-Martin/gemma-3-270m-it-fine-tuned__2025_13_08_17_02_LlamaUX_conversational
|
Jocelyn-Martin
| 2025-08-19T13:46:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T13:46:11Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755609477
|
mang3dd
| 2025-08-19T13:45:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:44:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755610875
|
lilTAT
| 2025-08-19T13:41:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:41:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755608989
|
indoempatnol
| 2025-08-19T13:38:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:38:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755610530
|
lilTAT
| 2025-08-19T13:35:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:35:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/felix-meynet
|
Muapi
| 2025-08-19T13:29:03Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:28:57Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Felix Meynet

**Base model**: Flux.1 D
**Trained words**: Art by Felix Meynet
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1021589@1441868", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Growcompany/gemma-3-270m-it-Q4_K_M-GGUF
|
Growcompany
| 2025-08-19T13:26:11Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3",
"unsloth",
"gemma",
"google",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:unsloth/gemma-3-270m-it",
"base_model:quantized:unsloth/gemma-3-270m-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-19T13:26:05Z |
---
base_model: unsloth/gemma-3-270m-it
license: gemma
tags:
- gemma3
- unsloth
- gemma
- google
- llama-cpp
- gguf-my-repo
pipeline_tag: text-generation
library_name: transformers
---
# Growcompany/gemma-3-270m-it-Q4_K_M-GGUF
This model was converted to GGUF format from [`unsloth/gemma-3-270m-it`](https://huggingface.co/unsloth/gemma-3-270m-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/unsloth/gemma-3-270m-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -c 2048
```
|
Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF
|
Growcompany
| 2025-08-19T13:24:52Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"chat",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:Qwen/Qwen2.5-0.5B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-0.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-19T13:24:45Z |
---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-0.5B-Instruct
tags:
- chat
- llama-cpp
- gguf-my-repo
library_name: transformers
---
# Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`Qwen/Qwen2.5-0.5B-Instruct`](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF --hf-file qwen2.5-0.5b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF --hf-file qwen2.5-0.5b-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF --hf-file qwen2.5-0.5b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Growcompany/Qwen2.5-0.5B-Instruct-Q4_K_M-GGUF --hf-file qwen2.5-0.5b-instruct-q4_k_m.gguf -c 2048
```
|
canoplos112/blockassist-bc-yapping_sleek_squirrel_1755609775
|
canoplos112
| 2025-08-19T13:24:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yapping sleek squirrel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:23:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yapping sleek squirrel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/flux-flux-hanfu-belly-wrap
|
Muapi
| 2025-08-19T13:23:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:23:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# FLUX汉服肚兜 | FLUX Hanfu belly wrap

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:653935@731600", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755608212
|
helmutsukocok
| 2025-08-19T13:23:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:22:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Qwen3_Medical_GRPO-i1-GGUF
|
mradermacher
| 2025-08-19T13:22:18Z | 791 | 2 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen3",
"medical",
"en",
"zh",
"dataset:FreedomIntelligence/medical-o1-reasoning-SFT",
"dataset:lastmass/medical-o1-reasoning-SFT-keywords",
"base_model:lastmass/Qwen3_Medical_GRPO",
"base_model:quantized:lastmass/Qwen3_Medical_GRPO",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-07-24T16:02:43Z |
---
base_model: lastmass/Qwen3_Medical_GRPO
datasets:
- FreedomIntelligence/medical-o1-reasoning-SFT
- lastmass/medical-o1-reasoning-SFT-keywords
language:
- en
- zh
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- medical
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/lastmass/Qwen3_Medical_GRPO
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Qwen3_Medical_GRPO-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ1_S.gguf) | i1-IQ1_S | 1.2 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ1_M.gguf) | i1-IQ1_M | 1.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ2_XS.gguf) | i1-IQ2_XS | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ2_S.gguf) | i1-IQ2_S | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ2_M.gguf) | i1-IQ2_M | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q2_K_S.gguf) | i1-Q2_K_S | 1.7 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q2_K.gguf) | i1-Q2_K | 1.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 1.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ3_XS.gguf) | i1-IQ3_XS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q3_K_S.gguf) | i1-Q3_K_S | 2.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ3_S.gguf) | i1-IQ3_S | 2.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ3_M.gguf) | i1-IQ3_M | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q3_K_M.gguf) | i1-Q3_K_M | 2.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q3_K_L.gguf) | i1-Q3_K_L | 2.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ4_XS.gguf) | i1-IQ4_XS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q4_0.gguf) | i1-Q4_0 | 2.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-IQ4_NL.gguf) | i1-IQ4_NL | 2.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q4_K_S.gguf) | i1-Q4_K_S | 2.5 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q4_K_M.gguf) | i1-Q4_K_M | 2.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q4_1.gguf) | i1-Q4_1 | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q5_K_S.gguf) | i1-Q5_K_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q5_K_M.gguf) | i1-Q5_K_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen3_Medical_GRPO-i1-GGUF/resolve/main/Qwen3_Medical_GRPO.i1-Q6_K.gguf) | i1-Q6_K | 3.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755609552
|
lilTAT
| 2025-08-19T13:19:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:19:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755607889
|
vwzyrraz7l
| 2025-08-19T13:18:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:18:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/velvet-s-epic-dragons-flux
|
Muapi
| 2025-08-19T13:18:29Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:18:18Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Velvet's Epic Dragons | Flux

**Base model**: Flux.1 D
**Trained words**: FluxEpicDragon
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:715643@800301", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
GFIO/Fish_NC
|
GFIO
| 2025-08-19T13:16:48Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-08-19T13:16:21Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
AliaeAI/setfit_nli_v5
|
AliaeAI
| 2025-08-19T13:11:44Z | 0 | 0 |
setfit
|
[
"setfit",
"safetensors",
"mpnet",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/paraphrase-mpnet-base-v2",
"base_model:finetune:sentence-transformers/paraphrase-mpnet-base-v2",
"region:us"
] |
text-classification
| 2025-08-19T13:11:27Z |
---
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
widget:
- text: I find moments in my day where I carve out time to read, even for just a few
minutes I do not usually feel energetic in the mornings when I wake up really.
Why are you changing topics? [SEP] What problems would you like to put on the
agenda?
- text: I’ve been trying to manage my energy levels, but it feels like an uphill battle
some days. Any tips on balancing work and rest? It’s really tough to gauge when
I encounter difficulties in managing daily stress. Some days I feel like I’m handling
it well, but other days, even small tasks seem overwhelming. [SEP] Can you describe
the consistency and appearance of your stools? Have you noticed any changes recently?
- text: Yeah, there are specific foods or drinks that seem to trigger the pain, anything
spicy or greasy sets it off. I've been trying to avoid those. It comes and goes,
usually worse after I eat. Lately, I've also been feeling pretty bloated. [SEP]
Have you noticed any changes in your sleep patterns related to your meal times
or food choices?
- text: I have not noticed any changes in my weight along with experiencing abdominal
pain really, my weight's been pretty stable. I'm more concerned about this constant
pain—it's wearing me down mentally too. Sometimes it feels like stress makes it
worse, but it's hard to pinpoint specific triggers. I've been trying to keep a
food diary to see if certain foods make a difference, but so far, no clear patterns.
[SEP] Is the abdominal pain constant, or does it come and go?
- text: It's the little things now, like getting out of the ambulance or even writing
reports that feel like a marathon. I've started avoiding stairs whenever I can.
I definitely need more breaks than before. Even just bending down to check a patient's
vitals can leave me winded these days. [SEP] When you realize you don’t have enough
energy to do what you want, does it leave you feeling annoyed or discouraged?
metrics:
- accuracy
pipeline_tag: text-classification
library_name: setfit
inference: true
base_model: sentence-transformers/paraphrase-mpnet-base-v2
---
# SetFit with sentence-transformers/paraphrase-mpnet-base-v2
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 512 tokens
- **Number of Classes:** 2 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | <ul><li>"It's probably just my body's way of dealing with the discomfort. Some days, it feels like everything is a bit too much to handle. I wish I could do more, but the pain often holds me back. It's frustrating when I have to cancel plans or take breaks just to manage it. [SEP] I love running. It's one of the most popular recreational activities in the world. Do you like running?"</li><li>"I can't even finish folding the laundry without needing to sit down. It's the simple things that are getting harder. I’m sorry, but I have to go. Goodbye. [SEP] It was great talking with you today and hearing about your experiences! Even though things are feeling tough right now, remember that small steps forward can lead to big changes over time. Keep focusing on those little victories and I'm sure you'll find your way back to a place of greater energy. I look forward to our next chat!"</li><li>'hey ok my night [SEP] What is your favorite thing to do in your spare time? What do you like to do for fun?'</li></ul> |
| 1 | <ul><li>'I do not often join in on their game nights as often as I used to. The evenings can be a bit tough these days. They love a good round of Scrabble or Chess. Keeps their minds sharp, they say. [SEP] What are some things that usually help you feel more energized?'</li><li>"The breathlessness comes and goes, but it's definitely worse after treatment. Even just trying to change my clothes can leave me winded. I used to love reading the morning paper, but lately, I can barely focus long enough to get through an article. It's just not the same anymore. [SEP] Is there anything specific about your environment or surroundings that you think might be affecting your concentration?"</li><li>"I'm sorry to hear you're dealing with such unpleasant symptoms. It sounds really challenging. Well, the abdominal pain and diarrhea have been happening for a few weeks now. I've been having trouble keeping food down, and there's been some blood in my stools too. [SEP] that sounds really tough. i'm glad you're getting help though. hopefully you'll start feeling better soon. Could you tell more precisely where the stomach pain is located?"</li></ul> |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("AliaeAI/setfit_nli_v5")
# Run inference
preds = model("I find moments in my day where I carve out time to read, even for just a few minutes I do not usually feel energetic in the mornings when I wake up really. Why are you changing topics? [SEP] What problems would you like to put on the agenda?")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:--------|:----|
| Word count | 6 | 55.0309 | 130 |
| Label | Training Sample Count |
|:------|:----------------------|
| 0 | 874 |
| 1 | 872 |
### Training Hyperparameters
- batch_size: (32, 32)
- num_epochs: (3, 3)
- max_steps: -1
- sampling_strategy: oversampling
- num_iterations: 10
- body_learning_rate: (2e-05, 2e-05)
- head_learning_rate: 2e-05
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- l2_weight: 0.01
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: False
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0009 | 1 | 0.2838 | - |
| 0.0458 | 50 | 0.2677 | - |
| 0.0916 | 100 | 0.2551 | - |
| 0.1374 | 150 | 0.2544 | - |
| 0.1832 | 200 | 0.2463 | - |
| 0.2289 | 250 | 0.253 | - |
| 0.2747 | 300 | 0.2427 | - |
| 0.3205 | 350 | 0.2223 | - |
| 0.3663 | 400 | 0.2129 | - |
| 0.4121 | 450 | 0.1816 | - |
| 0.4579 | 500 | 0.1496 | - |
| 0.5037 | 550 | 0.1176 | - |
| 0.5495 | 600 | 0.0894 | - |
| 0.5952 | 650 | 0.0639 | - |
| 0.6410 | 700 | 0.0575 | - |
| 0.6868 | 750 | 0.043 | - |
| 0.7326 | 800 | 0.0463 | - |
| 0.7784 | 850 | 0.0389 | - |
| 0.8242 | 900 | 0.0272 | - |
| 0.8700 | 950 | 0.0274 | - |
| 0.9158 | 1000 | 0.0299 | - |
| 0.9615 | 1050 | 0.0172 | - |
| 1.0073 | 1100 | 0.0217 | - |
| 1.0531 | 1150 | 0.017 | - |
| 1.0989 | 1200 | 0.0143 | - |
| 1.1447 | 1250 | 0.018 | - |
| 1.1905 | 1300 | 0.0109 | - |
| 1.2363 | 1350 | 0.0153 | - |
| 1.2821 | 1400 | 0.0099 | - |
| 1.3278 | 1450 | 0.012 | - |
| 1.3736 | 1500 | 0.0122 | - |
| 1.4194 | 1550 | 0.0158 | - |
| 1.4652 | 1600 | 0.0141 | - |
| 1.5110 | 1650 | 0.0108 | - |
| 1.5568 | 1700 | 0.0069 | - |
| 1.6026 | 1750 | 0.0071 | - |
| 1.6484 | 1800 | 0.0049 | - |
| 1.6941 | 1850 | 0.0099 | - |
| 1.7399 | 1900 | 0.0076 | - |
| 1.7857 | 1950 | 0.0028 | - |
| 1.8315 | 2000 | 0.0051 | - |
| 1.8773 | 2050 | 0.0027 | - |
| 1.9231 | 2100 | 0.0035 | - |
| 1.9689 | 2150 | 0.0032 | - |
| 2.0147 | 2200 | 0.0034 | - |
| 2.0604 | 2250 | 0.0028 | - |
| 2.1062 | 2300 | 0.002 | - |
| 2.1520 | 2350 | 0.0025 | - |
| 2.1978 | 2400 | 0.0014 | - |
| 2.2436 | 2450 | 0.0014 | - |
| 2.2894 | 2500 | 0.0011 | - |
| 2.3352 | 2550 | 0.0013 | - |
| 2.3810 | 2600 | 0.0013 | - |
| 2.4267 | 2650 | 0.0034 | - |
| 2.4725 | 2700 | 0.0024 | - |
| 2.5183 | 2750 | 0.0014 | - |
| 2.5641 | 2800 | 0.0007 | - |
| 2.6099 | 2850 | 0.0015 | - |
| 2.6557 | 2900 | 0.0007 | - |
| 2.7015 | 2950 | 0.0017 | - |
| 2.7473 | 3000 | 0.0001 | - |
| 2.7930 | 3050 | 0.002 | - |
| 2.8388 | 3100 | 0.0009 | - |
| 2.8846 | 3150 | 0.002 | - |
| 2.9304 | 3200 | 0.0008 | - |
| 2.9762 | 3250 | 0.0013 | - |
### Framework Versions
- Python: 3.11.13
- SetFit: 1.1.3
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
zhuojing-huang/gpt2-arabic-english-unfreeze
|
zhuojing-huang
| 2025-08-19T13:10:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:47:16Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: gpt2-arabic-english-unfreeze
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-arabic-english-unfreeze
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 30
- training_steps: 1831
### Training results
### Framework versions
- Transformers 4.53.1
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.2
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755608822
|
yaelahnal
| 2025-08-19T13:08:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:07:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/epicflashphotography_-flux
|
Muapi
| 2025-08-19T13:07:28Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:07:21Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# epiCFlashPhotography_[FLUX]

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:817640@914301", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/flux-film-foto
|
Muapi
| 2025-08-19T13:06:27Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:06:11Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Flux Film Foto

**Base model**: Flux.1 D
**Trained words**: flmft photo style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:646458@723205", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755608508
|
lilTAT
| 2025-08-19T13:02:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:02:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755608206
|
yaelahnal
| 2025-08-19T13:01:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:57:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755608110
|
lilTAT
| 2025-08-19T12:55:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:55:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755607759
|
yaelahnal
| 2025-08-19T12:50:24Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:50:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755607761
|
lilTAT
| 2025-08-19T12:49:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:49:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755606016
|
vwzyrraz7l
| 2025-08-19T12:46:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:46:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Richnuts-2025a/Richnuts.in
|
Richnuts-2025a
| 2025-08-19T12:45:28Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:45:28Z |
---
license: apache-2.0
---
|
chutesai/Qwen3-235B-A22B-Instruct-2507-1M
|
chutesai
| 2025-08-19T12:42:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:28:48Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.

## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively and extendable up to 1,010,000 tokens**
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU1-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU1-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| TAU2-Retail | 71.1 | 66.7# | **75.5** | 70.6 | 64.9 | 74.6 |
| TAU2-Airline | 36.0 | 42.0# | 55.5 | **56.5** | 36.0 | 50.0 |
| TAU2-Telecom | 34.0 | 29.8# | 45.2 | **65.8** | 24.6 | 32.5 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **1000 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-235B-A22B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-235B-A22B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 8 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 8` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-235B-A22B (Non-Thinking) | 83.9 | 97.7 | 96.1 | 97.5 | 96.1 | 94.2 | 90.3 | 88.5 | 85.0 | 82.1 | 79.2 | 74.4 | 70.0 | 71.0 | 68.5 | 68.0 |
| Qwen3-235B-A22B-Instruct-2507 (Full Attention) | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-235B-A22B-Instruct-2507 (Sparse Attention) | 91.7 | 98.5 | 97.2 | 97.3 | 97.7 | 96.6 | 94.6 | 92.8 | 94.3 | 90.5 | 89.7 | 89.5 | 86.4 | 83.6 | 84.2 | 82.5 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
uzunc/VLM
|
uzunc
| 2025-08-19T12:41:27Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:HuggingFaceTB/SmolVLM-Instruct",
"base_model:finetune:HuggingFaceTB/SmolVLM-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:25:59Z |
---
base_model: HuggingFaceTB/SmolVLM-Instruct
library_name: transformers
model_name: VLM
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for VLM
This model is a fine-tuned version of [HuggingFaceTB/SmolVLM-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="uzunc/VLM", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Jacksss123/net72_uid234
|
Jacksss123
| 2025-08-19T12:41:01Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-19T12:38:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Elsihj89/camila-keynnect
|
Elsihj89
| 2025-08-19T12:38:17Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:38:17Z |
---
license: apache-2.0
---
|
kimxxxx/mistral_r32_a32_b8_gas2_lr5e-5_4500tk_2epoch_newdata
|
kimxxxx
| 2025-08-19T12:37:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:36:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755606723
|
Dejiat
| 2025-08-19T12:32:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:32:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
neko-llm/Qwen3-235B-test4
|
neko-llm
| 2025-08-19T12:32:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen3-235B-A22B",
"base_model:finetune:Qwen/Qwen3-235B-A22B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:50:58Z |
---
base_model: Qwen/Qwen3-235B-A22B
library_name: transformers
model_name: Qwen3-235B-test4
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen3-235B-test4
This model is a fine-tuned version of [Qwen/Qwen3-235B-A22B](https://huggingface.co/Qwen/Qwen3-235B-A22B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neko-llm/Qwen3-235B-test4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.0
- Transformers: 4.54.1
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
yookty/blockassist-bc-subtle_hibernating_moose_1755605457
|
yookty
| 2025-08-19T12:25:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"subtle hibernating moose",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:25:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- subtle hibernating moose
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Vanbitcase/7b-150r-qwen2-vl
|
Vanbitcase
| 2025-08-19T12:24:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-08-19T12:24:39Z |
---
base_model: unsloth/qwen2-vl-7b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Vanbitcase
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2-vl-7b-instruct-bnb-4bit
This qwen2_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
New-Clip-prabh-viral-video/New.full.videos.prabh.Viral.Video.Official.Tutorial
|
New-Clip-prabh-viral-video
| 2025-08-19T12:24:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:24:18Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
VoilaRaj/80_F75wiD
|
VoilaRaj
| 2025-08-19T12:23:29Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T12:19:29Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
VIDEOS-18-afreen-viral-Video-link/New.full.videos.afreen.Viral.Video.Official.Tutorial
|
VIDEOS-18-afreen-viral-Video-link
| 2025-08-19T12:20:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:19:57Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
ishahaf/Llama-3.3-Nemotron-Super-49B-v1.5
|
ishahaf
| 2025-08-19T12:18:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"nemotron-nas",
"text-generation",
"nvidia",
"llama-3",
"pytorch",
"conversational",
"custom_code",
"en",
"arxiv:2411.19146",
"arxiv:2505.00949",
"arxiv:2502.00203",
"license:other",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:18:39Z |
---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- llama-3
- pytorch
---
# Llama-3.3-Nemotron-Super-49B-v1.5

## Model Overview
Llama-3.3-Nemotron-Super-49B-v1.5 is a significantly upgraded version of Llama-3.3-Nemotron-Super-49B-v1 and is a large language model (LLM) which is a derivative of Meta Llama-3.3-70B-Instruct (AKA the reference model). It is a reasoning model that is post trained for reasoning, human chat preferences, and agentic tasks, such as RAG and tool calling. The model supports a context length of 128K tokens.
Llama-3.3-Nemotron-Super-49B-v1.5 is a model which offers a great tradeoff between model accuracy and efficiency. Efficiency (throughput) directly translates to savings. Using a novel Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint, enabling larger workloads, as well as fitting the model on a single GPU at high workloads (H200). This NAS approach enables the selection of a desired point in the accuracy-efficiency tradeoff. For more information on the NAS approach, please refer to [this paper](https://arxiv.org/abs/2411.19146)
The model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Science, and Tool Calling. Additionally, the model went through multiple stages of Reinforcement Learning (RL) including Reward-aware Preference Optimization (RPO) for chat, Reinforcement Learning with Verifiable Rewards (RLVR) for reasoning, and iterative Direct Preference Optimization (DPO) for Tool Calling capability enhancements. The final checkpoint was achieved after merging several RL and DPO checkpoints.
This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
- [Llama-3.1-Nemotron-Nano-4B-v1.1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1)
- [Llama-3.1-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) Additional Information: [Llama 3.3 Community License Agreement](https://www.llama.com/llama3_3/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between November 2024 and July 2025
**Data Freshness:** The pretraining data has a cutoff of 2023 per Meta Llama 3.3 70B
## Deployment Geography
Global
### Use Case: <br>
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks. <br>
### Release Date: <br>
- Hugging Face 7/25/2025 via [Llama-3_3-Nemotron-Super-49B-v1_5](https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5)
- build.nvidia.com 7/25/2025 [Llama-3_3-Nemotron-Super-49B-v1_5](https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1_5)
## References
* [\[2505.00949\] Llama-Nemotron: Efficient Reasoning Models](https://arxiv.org/abs/2505.00949)
* [\[2502.00203\] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
* [\[2411.19146\]Puzzle: Distillation-Based NAS for Inference-Optimized LLMs](https://arxiv.org/abs/2411.19146)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model
**Network Architecture:** Llama 3.3 70B Instruct, customized through Neural Architecture Search (NAS)
The model is a derivative of Meta’s Llama-3.3-70B-Instruct, using Neural Architecture Search (NAS). The NAS algorithm results in non-standard and non-repetitive blocks. This includes the following:
Skip attention: In some blocks, the attention is skipped entirely, or replaced with a single linear layer.
Variable FFN: The expansion/compression ratio in the FFN layer is different between blocks.
We utilize a block-wise distillation of the reference model, where for each block we create multiple variants providing different tradeoffs of quality vs. computational complexity, discussed in more depth below. We then search over the blocks to create a model which meets the required throughput and memory (optimized for a single H100-80GB GPU) while minimizing the quality degradation. The model then undergoes knowledge distillation (KD), with a focus on English single and multi-turn chat use-cases. The KD step included 40 billion tokens consisting of a mixture of 3 datasets - FineWeb, Buzz-V1.2 and Dolma.
## Intended use
Llama-3.3-Nemotron-Super-49B-v1.5 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
## Input
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## Model Version
1.5 (07/25/2025)
## Software Integration
- **Runtime Engine:** Transformers
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Ampere
- NVIDIA Hopper
- **Preferred Operating System(s):** Linux
## Quick Start and Usage Recommendations:
1. By default (empty system prompt) the model will respond in reasoning ON mode. Setting `/no_think` in the system prompt will enable reasoning OFF mode.
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
You can try this model out through the preview API, using this link: [Llama-3_3-Nemotron-Super-49B-v1_5](https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1_5).
## Use It with vLLM
```pip install vllm==0.9.2```
An example on how to serve with vLLM:
```console
$ python3 -m vllm.entrypoints.openai.api_server \
--model "nvidia/Llama-3_3-Nemotron-Super-49B-v1_5" \
--trust-remote-code \
--seed=1 \
--host="0.0.0.0" \
--port=5000 \
--served-model-name "Llama-3_3-Nemotron-Super-49B-v1_5" \
--tensor-parallel-size=8 \
--max-model-len=65536 \
--gpu-memory-utilization 0.95 \
--enforce-eager
```
### Running a vLLM Server with Tool-call Support
To enable tool calling usage with this model, we provide a tool parser in the repository. Here is an example on how to use it:
```console
$ git clone https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
$ conda create -n vllm python=3.12 -y
$ conda activate vllm
$ pip install vllm==0.9.2
$ python3 -m vllm.entrypoints.openai.api_server \
--model Llama-3_3-Nemotron-Super-49B-v1_5 \
--trust-remote-code \
--seed=1 \
--host="0.0.0.0" \
--port=5000 \
--served-model-name "Llama-3_3-Nemotron-Super-49B-v1_5" \
--tensor-parallel-size=8 \
--max-model-len=65536 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "Llama-3_3-Nemotron-Super-49B-v1_5/llama_nemotron_toolcall_parser_no_streaming.py" \
--tool-call-parser "llama_nemotron_json"
```
After launching a vLLM server, you can call the server with tool-call support using a Python script like below.
```python
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
completion = client.chat.completions.create(
model="Llama-3_3-Nemotron-Super-49B-v1_5",
messages=[
{"role": "system", "content": ""},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"}
],
tools=[
{
"type": "function",
"function": {
"name": "calculate_tip",
"parameters": {
"type": "object",
"properties": {
"bill_total": {
"type": "integer",
"description": "The total amount of the bill"
},
"tip_percentage": {
"type": "integer",
"description": "The percentage of tip to be applied"
}
},
"required": ["bill_total", "tip_percentage"]
}
}
},
{
"type": "function",
"function": {
"name": "convert_currency",
"parameters": {
"type": "object",
"properties": {
"amount": {
"type": "integer",
"description": "The amount to be converted"
},
"from_currency": {
"type": "string",
"description": "The currency code to convert from"
},
"to_currency": {
"type": "string",
"description": "The currency code to convert to"
}
},
"required": ["from_currency", "amount", "to_currency"]
}
}
}
],
temperature=0.6,
top_p=0.95,
max_tokens=32768,
stream=False
)
print(completion.choices[0].message.content)
'''
<think>
Okay, let's see. The user has a bill of $100 and wants to know the amount for an 18% tip. Hmm, I need to calculate the tip based on the bill total and the percentage. The tools provided include calculate_tip, which takes bill_total and tip_percentage as parameters. So the bill_total here is 100, and the tip_percentage is 18. I should call the calculate_tip function with these values. Wait, do I need to check if the parameters are integers? The bill is $100, which is an integer, and 18% is also an integer. So that fits the function's requirements. I don't need to convert any currency here because the user is asking about a tip in the same currency. So the correct tool to use is calculate_tip with those parameters.
</think>
'''
print(completion.choices[0].message.tool_calls)
'''
[ChatCompletionMessageToolCall(id='chatcmpl-tool-e341c6954d2c48c2a0e9071c7bdefd8b', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
'''
```
## Training and Evaluation Datasets
## Training Datasets
A large variety of training data was used for the knowledge distillation phase before post-training pipeline, 3 of which included: FineWeb, Buzz-V1.2, and Dolma.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both reasoning on and off modes, to train the model to distinguish between two modes.
We have released our [Nemotron-Post-Training-Dataset-v1](https://huggingface.co/datasets/nvidia/Nemotron-Post-Training-Dataset-v1) to promote openness and transparency in model development and improvement.
**Data Collection for Training Datasets:**
Hybrid: Automated, Human, Synthetic
**Data Labeling for Training Datasets:**
Hybrid: Automated, Human, Synthetic
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.3-Nemotron-Super-49B-v1.5.
Data Collection for Evaluation Datasets:
- Hybrid: Human. Synthetic
Data Labeling for Evaluation Datasets:
- Hybrid: Human, Synthetic, Automatic
## Evaluation Results
We evaluate the model using temperature=`0.6`, top_p=`0.95`, and 64k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
### MATH500
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 97.4 |
### AIME 2024
| Reasoning Mode | pass@1 (avg. over 16 runs) |
|--------------|------------|
| Reasoning On | 87.5 |
### AIME 2025
| Reasoning Mode | pass@1 (avg. over 16 runs) |
|--------------|------------|
| Reasoning On | 82.71 |
### GPQA
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 71.97 |
### LiveCodeBench 24.10-25.02
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 73.58 |
### BFCL v3
| Reasoning Mode | pass@1 (avg. over 2 runs) |
|--------------|------------|
| Reasoning On | 71.75 |
### IFEval
| Reasoning Mode | Strict:Instruction |
|--------------|------------|
| Reasoning On | 88.61 |
### ArenaHard
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 92.0 |
### Humanity's Last Exam (Text-Only Subset)
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 7.64 |
### MMLU Pro (CoT)
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 79.53 |
All evaluations were done using the [NeMo-Skills](https://github.com/NVIDIA/NeMo-Skills) repository.
## Inference:
**Engine:**
- Transformers
**Test Hardware:**
- 2x NVIDIA H100-80GB
- 2x NVIDIA A100-80GB GPUs
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](./EXPLAINABILITY.md), [Bias](./BIAS.md), [Safety & Security](./SAFETY&SECURITY.md), and [Privacy](./PRIVACY.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
```
@misc{bercovich2025llamanemotronefficientreasoningmodels,
title={Llama-Nemotron: Efficient Reasoning Models},
author={Akhiad Bercovich and Itay Levy and Izik Golan and Mohammad Dabbah and Ran El-Yaniv and Omri Puny and Ido Galil and Zach Moshe and Tomer Ronen and Najeeb Nabwani and Ido Shahaf and Oren Tropp and Ehud Karpas and Ran Zilberstein and Jiaqi Zeng and Soumye Singhal and Alexander Bukharin and Yian Zhang and Tugrul Konuk and Gerald Shen and Ameya Sunil Mahabaleshwarkar and Bilal Kartal and Yoshi Suhara and Olivier Delalleau and Zijia Chen and Zhilin Wang and David Mosallanezhad and Adi Renduchintala and Haifeng Qian and Dima Rekesh and Fei Jia and Somshubra Majumdar and Vahid Noroozi and Wasi Uddin Ahmad and Sean Narenthiran and Aleksander Ficek and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Igor Gitman and Ivan Moshkov and Wei Du and Shubham Toshniwal and George Armstrong and Branislav Kisacanin and Matvei Novikov and Daria Gitman and Evelina Bakhturina and Jane Polak Scowcroft and John Kamalu and Dan Su and Kezhi Kong and Markus Kliegl and Rabeeh Karimi and Ying Lin and Sanjeev Satheesh and Jupinder Parmar and Pritam Gundecha and Brandon Norick and Joseph Jennings and Shrimai Prabhumoye and Syeda Nahida Akter and Mostofa Patwary and Abhinav Khattar and Deepak Narayanan and Roger Waleffe and Jimmy Zhang and Bor-Yiing Su and Guyue Huang and Terry Kong and Parth Chadha and Sahil Jain and Christine Harvey and Elad Segal and Jining Huang and Sergey Kashirsky and Robert McQueen and Izzy Putterman and George Lam and Arun Venkatesan and Sherry Wu and Vinh Nguyen and Manoj Kilaru and Andrew Wang and Anna Warno and Abhilash Somasamudramath and Sandip Bhaskar and Maka Dong and Nave Assaf and Shahar Mor and Omer Ullman Argov and Scot Junkin and Oleksandr Romanenko and Pedro Larroy and Monika Katariya and Marco Rovinelli and Viji Balas and Nicholas Edelman and Anahita Bhiwandiwalla and Muthu Subramaniam and Smita Ithape and Karthik Ramamoorthy and Yuting Wu and Suguna Varshini Velury and Omri Almog and Joyjit Daw and Denys Fridman and Erick Galinkin and Michael Evans and Katherine Luna and Leon Derczynski and Nikki Pope and Eileen Long and Seth Schneider and Guillermo Siman and Tomasz Grzegorzek and Pablo Ribalta and Monika Katariya and Joey Conway and Trisha Saar and Ann Guan and Krzysztof Pawelec and Shyamala Prayaga and Oleksii Kuchaiev and Boris Ginsburg and Oluwatobi Olabiyi and Kari Briski and Jonathan Cohen and Bryan Catanzaro and Jonah Alben and Yonatan Geifman and Eric Chung and Chris Alexiuk},
year={2025},
eprint={2505.00949},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.00949},
}
```
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755604006
|
vwzyrraz7l
| 2025-08-19T12:14:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:14:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LBST/t10_pick_and_place_smolvla_017000
|
LBST
| 2025-08-19T12:13:09Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-017000",
"region:us"
] |
robotics
| 2025-08-19T12:13:04Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-017000
---
# T08 Pick and Place Policy - Checkpoint 017000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 017000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 017000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_017000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 017000*
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755605480
|
lilTAT
| 2025-08-19T12:11:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:11:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Prerna43/distilbert-base-uncased-lora-text-classification
|
Prerna43
| 2025-08-19T12:10:33Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:distilbert-base-uncased",
"lora",
"transformers",
"base_model:distilbert/distilbert-base-uncased",
"base_model:adapter:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:03:59Z |
---
library_name: peft
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- base_model:adapter:distilbert-base-uncased
- lora
- transformers
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-lora-text-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-lora-text-classification
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6438
- Accuracy: 0.887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 250 | 0.5865 | 0.891 |
| 0.051 | 2.0 | 500 | 0.6101 | 0.888 |
| 0.051 | 3.0 | 750 | 0.6309 | 0.889 |
| 0.1059 | 4.0 | 1000 | 0.6438 | 0.887 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755603876
|
lisaozill03
| 2025-08-19T12:10:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:09:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Unlearning/early-unlearning-weak-filter-ga-1-in-209-ga-lr-scale-0_001-gclip-0_5
|
Unlearning
| 2025-08-19T12:07:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-11T15:07:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LBST/t10_pick_and_place_smolvla_003000
|
LBST
| 2025-08-19T12:07:09Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-003000",
"region:us"
] |
robotics
| 2025-08-19T12:07:04Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-003000
---
# T08 Pick and Place Policy - Checkpoint 003000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 003000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 003000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_003000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 003000*
|
ketir/Emotion-Detection-BiLSTM
|
ketir
| 2025-08-19T12:06:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-18T19:50:03Z |
---
license: apache-2.0
---
---
license: apache-2.0
tags:
- text-classification
- emotion-classification
- indonesian
- bilstm
- tensorflow
language:
- id
pipeline_tag: text-classification
widget:
- text: "Saya sangat bahagia hari ini!"
- text: "Aku merasa sedih sekali"
- text: "Mengapa ini terjadi? Aku marah!"
---
# Indonesian Emotion Classification with BiLSTM
## Model Description
This model is a Bidirectional LSTM (BiLSTM) trained for emotion classification on Indonesian text. The model can predict 6 different emotions from text input.
## Supported Emotions
- `angry` - Marah
- `fear` - Takut
- `happy` - Bahagia
- `love` - Cinta
- `sad` - Sedih
## Usage
```python
from transformers import pipeline
# Load the model
classifier = pipeline("text-classification",
model="your-username/your-model-name",
return_all_scores=True)
# Predict emotion
result = classifier("Saya sangat bahagia hari ini!")
print(result)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.