
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-13 12:31:59
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 556
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-13 12:26:40
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
barguty/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-armored_slimy_bobcat
|
barguty
| 2025-08-20T03:27:24Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am armored slimy bobcat",
"unsloth",
"trl",
"genrl-swarm",
"I am armored_slimy_bobcat",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-25T15:12:10Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-armored_slimy_bobcat
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am armored slimy bobcat
- unsloth
- trl
- genrl-swarm
- I am armored_slimy_bobcat
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-armored_slimy_bobcat
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="barguty/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-armored_slimy_bobcat", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
kavpro/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-tall_whiskered_tapir
|
kavpro
| 2025-08-20T03:27:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am tall_whiskered_tapir",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T03:18:05Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am tall_whiskered_tapir
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NhaiDao/grpo-IST-checkpoint300
|
NhaiDao
| 2025-08-20T03:27:16Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen3-8B",
"grpo",
"lora",
"transformers",
"trl",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen3-8B",
"region:us"
] |
text-generation
| 2025-08-20T03:26:58Z |
---
base_model: Qwen/Qwen3-8B
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen3-8B
- grpo
- lora
- transformers
- trl
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755658833
|
calegpedia
| 2025-08-20T03:26:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:26:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
StarfireStation/Qwen3-0.6B-Gensyn-Swarm-monstrous_ferocious_viper
|
StarfireStation
| 2025-08-20T03:25:00Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am monstrous_ferocious_viper",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-02T18:44:30Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am monstrous_ferocious_viper
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/UI-Venus-Ground-72B-GGUF
|
mradermacher
| 2025-08-20T03:24:04Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:inclusionAI/UI-Venus-Ground-72B",
"base_model:quantized:inclusionAI/UI-Venus-Ground-72B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-19T01:49:55Z |
---
base_model: inclusionAI/UI-Venus-Ground-72B
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/inclusionAI/UI-Venus-Ground-72B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#UI-Venus-Ground-72B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/UI-Venus-Ground-72B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.9 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.mmproj-f16.gguf) | mmproj-f16 | 1.5 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/UI-Venus-Ground-72B-GGUF/resolve/main/UI-Venus-Ground-72B.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ayoeedris/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_dappled_gorilla
|
ayoeedris
| 2025-08-20T03:22:04Z | 20 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am thorny dappled gorilla",
"unsloth",
"trl",
"genrl-swarm",
"I am thorny_dappled_gorilla",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-26T23:06:57Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_dappled_gorilla
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am thorny dappled gorilla
- unsloth
- trl
- genrl-swarm
- I am thorny_dappled_gorilla
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_dappled_gorilla
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ayoeedris/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_dappled_gorilla", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Spemercurial/Taxi-v3
|
Spemercurial
| 2025-08-20T03:21:06Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-20T03:21:02Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Spemercurial/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755658366
|
kojeklollipop
| 2025-08-20T03:20:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:20:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ElToro2602/blockassist-bc-raging_prehistoric_chameleon_1755659971
|
ElToro2602
| 2025-08-20T03:20:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging prehistoric chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:20:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging prehistoric chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755658390
|
helmutsukocok
| 2025-08-20T03:19:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:19:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Luomajian/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-feline_long_caterpillar
|
Luomajian
| 2025-08-20T03:18:58Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am feline_long_caterpillar",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-09T17:23:16Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am feline_long_caterpillar
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Spemercurial/q-FrozenLake-v1-4x4-noSlippery
|
Spemercurial
| 2025-08-20T03:17:18Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-20T03:17:13Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Spemercurial/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BLUE08/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-beaked_scented_whale
|
BLUE08
| 2025-08-20T03:16:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am beaked_scented_whale",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-20T03:16:29Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am beaked_scented_whale
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Kunbyte/Lumen
|
Kunbyte
| 2025-08-20T03:15:32Z | 0 | 0 | null |
[
"text-to-video",
"en",
"zh",
"arxiv:2508.12945",
"base_model:alibaba-pai/Wan2.1-Fun-1.3B-Control",
"base_model:finetune:alibaba-pai/Wan2.1-Fun-1.3B-Control",
"license:apache-2.0",
"region:us"
] |
text-to-video
| 2025-06-25T09:29:21Z |
---
license: apache-2.0
language:
- en
- zh
base_model:
- alibaba-pai/Wan2.1-Fun-1.3B-Control
- alibaba-pai/Wan2.1-Fun-14B-Control
pipeline_tag: text-to-video
---
# <center>💡Lumen: Consistent Video Relighting and Harmonious Background Replacement with Video Generative Models </center>
<div style="display: flex; justify-content: center; gap: 5px;">
<a href="https://lumen-relight.github.io"><img src="https://img.shields.io/badge/Project-Lumen-blue" alt="Project"></a>
<a href="https://arxiv.org/abs/2508.12945"><img src="https://img.shields.io/badge/arXiv-Paper-red" alt="arXiv"></a>
<a href="https://github.com/Kunbyte-AI/Lumen"><img src="https://img.shields.io/badge/GitHub-Code-black" alt="GitHub"></a>
<a href="https://huggingface.co/Kunbyte/Lumen"><img src="https://img.shields.io/badge/🤗%20HF-Model-yellow" alt="HuggingFace"></a>
<a href="https://huggingface.co/spaces/Kunbyte/Lumen"><img src="https://img.shields.io/badge/🤗%20HF-Space-yellow" alt="HuggingFace"></a>
</div>
💡**Lumen** is a video relighting model that can relight the foreground and replace the background of a video base on the input text.
This repository contains the weights of **Lumen**. For more instructions about how to use our model, please refer to our [Github repository](https://github.com/Kunbyte-AI/Lumen).
|
jerryzh168/gemma-3-4b-it-INT4
|
jerryzh168
| 2025-08-20T03:11:29Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gemma3",
"image-text-to-text",
"torchao",
"conversational",
"en",
"arxiv:2507.16099",
"base_model:google/gemma-3-4b-it",
"base_model:quantized:google/gemma-3-4b-it",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-20T03:11:07Z |
---
base_model: google/gemma-3-4b-it
tags:
- transformers
- torchao
- gemma3
license: apache-2.0
language:
- en
---
# INT4 google/gemma-3-4b-it model
- **Developed by:** jerryzh168
- **License:** apache-2.0
- **Quantized from Model :** google/gemma-3-4b-it
- **Quantization Method :** INT4
# Inference with vLLM
Install vllm nightly and torchao nightly to get some recent changes:
```
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install torchao
```
## Serving
Then we can serve with the following command:
```Shell
# Server
export MODEL=jerryzh168/gemma-3-4b-it-INT4
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve $MODEL --tokenizer $MODEL -O3
```
```Shell
# Client
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "jerryzh168/gemma-3-4b-it-INT4",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 32768
}'
```
Note: please use `VLLM_DISABLE_COMPILE_CACHE=1` to disable compile cache when running this code, e.g. `VLLM_DISABLE_COMPILE_CACHE=1 python example.py`, since there are some issues with the composability of compile in vLLM and torchao,
this is expected be resolved in pytorch 2.8.
# Inference with Transformers
Install the required packages:
```Shell
pip install git+https://github.com/huggingface/transformers@main
pip install torchao
pip install torch
pip install accelerate
```
Example:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "jerryzh168/gemma-3-4b-it-INT4"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("
")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("
")
print("thinking content:", thinking_content)
print("content:", content)
```
# Quantization Recipe
Install the required packages:
```Shell
pip install git+https://github.com/huggingface/transformers@main
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
pip install torch
pip install accelerate
```
Use the following code to get the quantized model:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
model_id = "google/gemma-3-4b-it"
model_to_quantize = "google/gemma-3-4b-it"
from torchao.quantization import Int4WeightOnlyConfig
quant_config = Int4WeightOnlyConfig(group_size=128, use_hqq=True)
quantization_config = TorchAoConfig(quant_type=quant_config)
quantized_model = AutoModelForCausalLM.from_pretrained(model_to_quantize, device_map="auto", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Push to hub
USER_ID = "YOUR_USER_ID"
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-INT4"
quantized_model.push_to_hub(save_to, safe_serialization=False)
tokenizer.push_to_hub(save_to)
# Manual Testing
prompt = "Hey, are you conscious? Can you talk to me?"
messages = [
{
"role": "system",
"content": "",
},
{"role": "user", "content": prompt},
]
templated_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print("Prompt:", prompt)
print("Templated prompt:", templated_prompt)
inputs = tokenizer(
templated_prompt,
return_tensors="pt",
).to("cuda")
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt):])
```
Note: to `push_to_hub` you need to run
```Shell
pip install -U "huggingface_hub[cli]"
huggingface-cli login
```
and use a token with write access, from https://huggingface.co/settings/tokens
# Model Quality
We rely on [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) to evaluate the quality of the quantized model. Here we only run on mmlu for sanity check.
| Benchmark | | |
|----------------------------------|----------------|---------------------------|
| | google/gemma-3-4b-it | jerryzh168/gemma-3-4b-it-INT4 |
| mmlu | To be filled | To be filled |
<details>
<summary> Reproduce Model Quality Results </summary>
Need to install lm-eval from source:
https://github.com/EleutherAI/lm-evaluation-harness#install
## baseline
```Shell
lm_eval --model hf --model_args pretrained=google/gemma-3-4b-it --tasks mmlu --device cuda:0 --batch_size 8
```
## INT4
```Shell
export MODEL=jerryzh168/gemma-3-4b-it-INT4
lm_eval --model hf --model_args pretrained=$MODEL --tasks mmlu --device cuda:0 --batch_size 8
```
</details>
# Peak Memory Usage
## Results
| Benchmark | | |
|------------------|----------------|--------------------------------|
| | google/gemma-3-4b-it | jerryzh168/gemma-3-4b-it-INT4 |
| Peak Memory (GB) | To be filled | To be filled (?% reduction) |
<details>
<summary> Reproduce Peak Memory Usage Results </summary>
We can use the following code to get a sense of peak memory usage during inference:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
# use "google/gemma-3-4b-it" or "jerryzh168/gemma-3-4b-it-INT4"
model_id = "jerryzh168/gemma-3-4b-it-INT4"
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_id)
torch.cuda.reset_peak_memory_stats()
prompt = "Hey, are you conscious? Can you talk to me?"
messages = [
{
"role": "system",
"content": "",
},
{"role": "user", "content": prompt},
]
templated_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print("Prompt:", prompt)
print("Templated prompt:", templated_prompt)
inputs = tokenizer(
templated_prompt,
return_tensors="pt",
).to("cuda")
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt):])
mem = torch.cuda.max_memory_reserved() / 1e9
print(f"Peak Memory Usage: {mem:.02f} GB")
```
</details>
# Model Performance
## Results (A100 machine)
| Benchmark (Latency) | | |
|----------------------------------|----------------|--------------------------|
| | google/gemma-3-4b-it | jerryzh168/gemma-3-4b-it-INT4 |
| latency (batch_size=1) | ?s | ?s (?x speedup) |
<details>
<summary> Reproduce Model Performance Results </summary>
## Setup
Get vllm source code:
```Shell
git clone git@github.com:vllm-project/vllm.git
```
Install vllm
```
VLLM_USE_PRECOMPILED=1 pip install --editable .
```
Run the benchmarks under `vllm` root folder:
## benchmark_latency
### baseline
```Shell
export MODEL=google/gemma-3-4b-it
python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model $MODEL --batch-size 1
```
### INT4
```Shell
export MODEL=jerryzh168/gemma-3-4b-it-INT4
VLLM_DISABLE_COMPILE_CACHE=1 python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model $MODEL --batch-size 1
```
## benchmark_serving
We benchmarked the throughput in a serving environment.
Download sharegpt dataset:
```Shell
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
```
Other datasets can be found in: https://github.com/vllm-project/vllm/tree/main/benchmarks
Note: you can change the number of prompts to be benchmarked with `--num-prompts` argument for `benchmark_serving` script.
### baseline
Server:
```Shell
export MODEL=google/gemma-3-4b-it
vllm serve $MODEL --tokenizer $MODEL -O3
```
Client:
```Shell
export MODEL=google/gemma-3-4b-it
python benchmarks/benchmark_serving.py --backend vllm --dataset-name sharegpt --tokenizer $MODEL --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --model $MODEL --num-prompts 1
```
### INT4
Server:
```Shell
export MODEL=jerryzh168/gemma-3-4b-it-INT4
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve $MODEL --tokenizer $MODEL -O3 --pt-load-map-location cuda:0
```
Client:
```Shell
export MODEL=jerryzh168/gemma-3-4b-it-INT4
python benchmarks/benchmark_serving.py --backend vllm --dataset-name sharegpt --tokenizer $MODEL --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --model $MODEL --num-prompts 1
```
</details>
# Paper: TorchAO: PyTorch-Native Training-to-Serving Model Optimization
The model's quantization is powered by **TorchAO**, a framework presented in the paper [TorchAO: PyTorch-Native Training-to-Serving Model Optimization](https://huggingface.co/papers/2507.16099).
**Abstract:** We present TorchAO, a PyTorch-native model optimization framework leveraging quantization and sparsity to provide an end-to-end, training-to-serving workflow for AI models. TorchAO supports a variety of popular model optimization techniques, including FP8 quantized training, quantization-aware training (QAT), post-training quantization (PTQ), and 2:4 sparsity, and leverages a novel tensor subclass abstraction to represent a variety of widely-used, backend agnostic low precision data types, including INT4, INT8, FP8, MXFP4, MXFP6, and MXFP8. TorchAO integrates closely with the broader ecosystem at each step of the model optimization pipeline, from pre-training (TorchTitan) to fine-tuning (TorchTune, Axolotl) to serving (HuggingFace, vLLM, SGLang, ExecuTorch), connecting an otherwise fragmented space in a single, unified workflow. TorchAO has enabled recent launches of the quantized Llama 3.2 1B/3B and LlamaGuard3-8B models and is open-source at this https URL .
# Resources
* **Official TorchAO GitHub Repository:** [https://github.com/pytorch/ao](https://github.com/pytorch/ao)
* **TorchAO Documentation:** [https://docs.pytorch.org/ao/stable/index.html](https://docs.pytorch.org/ao/stable/index.html)
# Disclaimer
PyTorch has not performed safety evaluations or red teamed the quantized models. Performance characteristics, outputs, and behaviors may differ from the original models. Users are solely responsible for selecting appropriate use cases, evaluating and mitigating for accuracy, safety, and fairness, ensuring security, and complying with all applicable laws and regulations.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the licenses the models are released under, including any limitations of liability or disclaimers of warranties provided therein.
|
TAUR-dev/M-VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks-rl
|
TAUR-dev
| 2025-08-20T03:11:20Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"en",
"license:mit",
"region:us"
] | null | 2025-08-20T03:09:42Z |
---
language: en
license: mit
---
# M-VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks-rl
## Model Details
- **Training Method**: VeRL Reinforcement Learning (RL)
- **Stage Name**: rl
- **Experiment**: VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks
- **RL Framework**: VeRL (Versatile Reinforcement Learning)
## Training Configuration
## Experiment Tracking
🔗 **View complete experiment details**: https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks__v1
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TAUR-dev/M-VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks-rl")
model = AutoModelForCausalLM.from_pretrained("TAUR-dev/M-VOTING_setup1_1epch_1e6_all_tasks_multistructure_sft-rl_all_tasks-rl")
```
|
ElToro2602/blockassist-bc-raging_prehistoric_chameleon_1755659402
|
ElToro2602
| 2025-08-20T03:11:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging prehistoric chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:10:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging prehistoric chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
DebutdeAngelDavid/video-de-milica-y-angel-david-debutando
|
DebutdeAngelDavid
| 2025-08-20T03:10:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T03:10:21Z |
<!-- HTML_TAG_END --><div>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐖𝐚𝐭𝐜𝐡 𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨)</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a></p>
<!-- HTML_TAG_END --></div>
|
AnonymousCS/xlmr_immigration_combo10_1
|
AnonymousCS
| 2025-08-20T03:10:28Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-20T01:19:05Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlmr_immigration_combo10_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_immigration_combo10_1
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2040
- Accuracy: 0.9319
- 1-f1: 0.8938
- 1-recall: 0.8610
- 1-precision: 0.9292
- Balanced Acc: 0.9141
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | 1-f1 | 1-recall | 1-precision | Balanced Acc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------:|:-----------:|:------------:|
| 0.2552 | 1.0 | 25 | 0.1933 | 0.9396 | 0.9062 | 0.8764 | 0.9380 | 0.9238 |
| 0.1634 | 2.0 | 50 | 0.2039 | 0.9332 | 0.8952 | 0.8571 | 0.9367 | 0.9141 |
| 0.1647 | 3.0 | 75 | 0.2040 | 0.9319 | 0.8938 | 0.8610 | 0.9292 | 0.9141 |
### Framework versions
- Transformers 4.56.0.dev0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
ronyahamed20/debut-de-angel-david-y-milica-viral-video
|
ronyahamed20
| 2025-08-20T03:09:33Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T03:09:21Z |
<!-- HTML_TAG_END --><div>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐖𝐚𝐭𝐜𝐡 𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨)</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a></p>
<!-- HTML_TAG_END --></div>
|
Baoquoc285/qwen3_task9_v4
|
Baoquoc285
| 2025-08-20T03:08:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-14B-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-14B-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T06:20:06Z |
---
base_model: unsloth/Qwen3-14B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Baoquoc285
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-14B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
DebutdeAngelDavid/Debut-de-Angel-David-viral-tra-Milica-filtrado
|
DebutdeAngelDavid
| 2025-08-20T03:07:07Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T03:06:50Z |
<!-- HTML_TAG_END --><div>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐖𝐚𝐭𝐜𝐡 𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨)</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )</a></p>
<p><a rel="nofollow" href="https://xmanager.info/video-de-milica-y-angel-david/"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a></p>
<!-- HTML_TAG_END --></div>
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755657465
|
vwzyrraz7l
| 2025-08-20T03:06:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:06:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NhaiDao/grpo-IST
|
NhaiDao
| 2025-08-20T03:05:05Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen3-8B",
"grpo",
"lora",
"transformers",
"trl",
"text-generation",
"conversational",
"arxiv:2402.03300",
"base_model:Qwen/Qwen3-8B",
"region:us"
] |
text-generation
| 2025-08-20T03:02:36Z |
---
base_model: Qwen/Qwen3-8B
library_name: peft
model_name: output_grpo
tags:
- base_model:adapter:Qwen/Qwen3-8B
- grpo
- lora
- transformers
- trl
licence: license
pipeline_tag: text-generation
---
# Model Card for output_grpo
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- PEFT 0.17.0
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755657359
|
manusiaperahu2012
| 2025-08-20T03:04:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T03:04:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
dgambettaphd/M_mis_run2_gen9_WXS_doc1000_synt64_lr1e-04_acm_LANG
|
dgambettaphd
| 2025-08-20T03:04:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T03:04:01Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
liu-nlp/aise-llama3-8b-smol-smoltalk-sv
|
liu-nlp
| 2025-08-20T02:56:55Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:AI-Sweden-Models/Llama-3-8B",
"base_model:finetune:AI-Sweden-Models/Llama-3-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-19T19:48:27Z |
---
base_model: AI-Sweden-Models/Llama-3-8B
library_name: transformers
model_name: aise-llama3-8b-smol-smoltalk-sv
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for aise-llama3-8b-smol-smoltalk-sv
This model is a fine-tuned version of [AI-Sweden-Models/Llama-3-8B](https://huggingface.co/AI-Sweden-Models/Llama-3-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="liu-nlp/aise-llama3-8b-smol-smoltalk-sv", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jenny-kunz-liu/huggingface/runs/qkyeivpx)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755657477
|
Sayemahsjn
| 2025-08-20T02:56:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:56:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ElToro2602/blockassist-bc-raging_prehistoric_chameleon_1755658556
|
ElToro2602
| 2025-08-20T02:56:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging prehistoric chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:56:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging prehistoric chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755658125
|
hobson123
| 2025-08-20T02:55:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:54:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bobbysam/resnet18-image-detector
|
bobbysam
| 2025-08-20T02:53:54Z | 91 | 0 | null |
[
"safetensors",
"resnet18-detector",
"custom_code",
"region:us"
] | null | 2025-07-22T13:55:40Z |
license: apache-2.0
language:
- en
base_model:
- bobbysam/resnet18-image-detector
library_name: transformers
pipeline_tag: image-classification
tags:
- computer-vision
- image-classification
- ai-detection
- pytorch
- resnet
datasets:
- custom
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: resnet18-image-detector
results:
- task:
type: image-classification
name: AI vs Real Image Detection
dataset:
name: Custom AI Detection Dataset
type: custom
metrics:
- type: accuracy
value: 0.95
name: Accuracy
- type: f1
value: 0.94
name: F1 Score
- type: precision
value: 0.93
name: Precision
- type: recall
value: 0.96
name: Recall
---
# ResNet18 AI Image Detector
**Repository:** [bobbysam/resnet18-image-detector](https://huggingface.co/bobbysam/resnet18-image-detector)
[](https://huggingface.co/spaces/autotrain-projects/train-resnet18-detector)
[](https://huggingface.co/spaces/autotrain-projects/deploy-resnet18-detector)
---
## 🧠 What does this model do?
This is a **ResNet18-based deep neural network** trained to **detect whether an input image is a real photograph or AI-generated** (binary classification: `real` vs. `ai_generated`).
It is part of the [ProofGuard](https://github.com/Proofguard/proofguard-backend) project and can be used to build trustworthy AI image detection pipelines.
**Key Features:**
- 🔬 Binary classification: Real vs AI-generated images
- 🚀 Fast inference with ResNet18 architecture
- 🤗 Compatible with Hugging Face Transformers
- 📊 Comprehensive evaluation metrics
- 🎯 Easy-to-use inference API
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet18-image-detector
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2759
- Accuracy: 0.9555
- F1: 0.9555
- Precision: 0.9560
- Recall: 0.9555
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.3995 | 0.0533 | 50 | 0.6382 | 0.6905 | 0.6824 | 0.7146 | 0.6905 |
| 1.1186 | 0.1067 | 100 | 0.4529 | 0.8619 | 0.8619 | 0.8634 | 0.8619 |
| 0.7891 | 0.16 | 150 | 0.3469 | 0.9124 | 0.9124 | 0.9124 | 0.9124 |
| 0.7927 | 0.2133 | 200 | 0.3208 | 0.9305 | 0.9305 | 0.9305 | 0.9305 |
| 0.7672 | 0.2667 | 250 | 0.3095 | 0.9417 | 0.9418 | 0.9418 | 0.9417 |
| 0.7395 | 0.32 | 300 | 0.3625 | 0.9001 | 0.8992 | 0.9125 | 0.9001 |
| 0.6937 | 0.3733 | 350 | 0.2940 | 0.9483 | 0.9483 | 0.9483 | 0.9483 |
| 0.6654 | 0.4267 | 400 | 0.3315 | 0.9268 | 0.9266 | 0.9329 | 0.9268 |
| 0.6647 | 0.48 | 450 | 0.2872 | 0.9487 | 0.9487 | 0.9497 | 0.9487 |
| 0.7021 | 0.5333 | 500 | 0.2857 | 0.9488 | 0.9488 | 0.9491 | 0.9488 |
| 0.6458 | 0.5867 | 550 | 0.2759 | 0.9555 | 0.9555 | 0.9560 | 0.9555 |
| 0.6634 | 0.64 | 600 | 0.2830 | 0.9516 | 0.9515 | 0.9517 | 0.9516 |
| 0.6534 | 0.6933 | 650 | 0.2858 | 0.9507 | 0.9506 | 0.9533 | 0.9507 |
### Framework versions
- Transformers 4.54.1
- Pytorch 2.7.1+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
AnerYubo/blockassist-bc-alert_snorting_fox_1755658379
|
AnerYubo
| 2025-08-20T02:53:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert snorting fox",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:52:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert snorting fox
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755656378
|
helmutsukocok
| 2025-08-20T02:45:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:45:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liu-nlp/llama3-8b-smol-smoltalk-sv
|
liu-nlp
| 2025-08-20T02:44:43Z | 18 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:finetune:meta-llama/Meta-Llama-3-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-19T19:27:42Z |
---
base_model: meta-llama/Meta-Llama-3-8B
library_name: transformers
model_name: llama3-8b-smol-smoltalk-sv
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for llama3-8b-smol-smoltalk-sv
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="liu-nlp/llama3-8b-smol-smoltalk-sv", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jenny-kunz-liu/huggingface/runs/bn0bay0v)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.1
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ducthinh1002/LLM_Chem_finetuned
|
ducthinh1002
| 2025-08-20T02:43:36Z | 0 | 0 | null |
[
"safetensors",
"llama",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T02:04:51Z |
---
license: apache-2.0
---
|
AnerYubo/blockassist-bc-alert_snorting_fox_1755657766
|
AnerYubo
| 2025-08-20T02:42:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert snorting fox",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:42:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert snorting fox
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NEKO182/sd151
|
NEKO182
| 2025-08-20T02:40:22Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-01-13T00:00:39Z |
---
license: creativeml-openrail-m
---
|
AnerYubo/blockassist-bc-alert_snorting_fox_1755657614
|
AnerYubo
| 2025-08-20T02:40:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert snorting fox",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:40:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert snorting fox
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755655935
|
thanobidex
| 2025-08-20T02:37:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:37:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnerYubo/blockassist-bc-alert_snorting_fox_1755657421
|
AnerYubo
| 2025-08-20T02:37:07Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert snorting fox",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:37:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert snorting fox
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755655416
|
lisaozill03
| 2025-08-20T02:28:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:28:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thaymanhinhsamsung24h/thay-man-hinh-samsung-co-anh-huong-gi
|
thaymanhinhsamsung24h
| 2025-08-20T02:27:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T02:26:58Z |
<h1>Thay màn hình Samsung – Giải pháp hiệu quả cho điện thoại hư hỏng</h1>
<p>Bạn đang tìm <a href="https://chamsocdidong.com/thay-man-hinh-samsung-sc4474.html" target="_blank">cửa hàng thay màn hình Samsung giá rẻ</a> nhưng vẫn đảm bảo chất lượng và linh kiện chính hãng? Việc lựa chọn địa chỉ uy tín sẽ giúp bạn khắc phục tình trạng hỏng màn hình, tiết kiệm chi phí và kéo dài tuổi thọ cho thiết bị.</p>
<p style="text-align: center;"><img src="https://chamsocdidong.com/upload_images/images/thay-man-hinh-samsung/thay-man-hinh-samsung.jpg" alt="" /></p>
<h2>Khi nào cần thay màn hình Samsung?</h2>
<p>Một trong những thắc mắc phổ biến của khách hàng là <a href="https://online.fliphtml5.com/eudya/mbje/" target="_blank">thay màn hình điện thoại Samsung bao nhiêu tiền</a> và khi nào cần thay. Thực tế, giá cả sẽ phụ thuộc vào dòng máy và loại màn hình, nhưng trước hết, bạn cần xác định rõ các dấu hiệu cần thay thế:</p>
<ul>
<li>
<p><strong>Màn hình bị vỡ, nứt kính</strong>: Do va chạm hoặc rơi rớt, ảnh hưởng đến thẩm mỹ và trải nghiệm sử dụng.</p>
</li>
<li>
<p><strong>Cảm ứng không nhạy hoặc bị liệt</strong>: Màn hình phản hồi chậm, thao tác khó khăn, thậm chí tự động nhảy cảm ứng.</p>
</li>
<li>
<p><strong>Màn hình hiển thị bất thường</strong>: Xuất hiện sọc ngang, sọc dọc, điểm chết, ám màu hoặc chảy mực.</p>
</li>
<li>
<p><strong>Màn hình tối đen</strong>: Điện thoại vẫn có tín hiệu hoạt động nhưng không hiển thị nội dung.</p>
</li>
</ul>
<p>Khi gặp những dấu hiệu này, bạn nên thay màn hình ngay để tránh ảnh hưởng đến các linh kiện khác trong máy.</p>
<p style="text-align: center;"><img src="https://chamsocdidong.com/upload_images/images/thay-man-hinh-samsung/khi-nao-can-thay-man-hinh-samsung.jpg" alt="" /></p>
<h2>Địa chỉ thay màn hình Samsung chính hãng giá rẻ</h2>
<p>Tìm được <strong>địa chỉ thay màn hình Samsung chính hãng giá rẻ</strong> không hề đơn giản khi có quá nhiều cửa hàng trên thị trường. Một trung tâm uy tín cần đáp ứng các tiêu chí sau:</p>
<ul>
<li>
<p><strong>Sử dụng linh kiện chính hãng</strong>: Đảm bảo độ tương thích tuyệt đối, mang lại trải nghiệm như màn hình gốc.</p>
</li>
<li>
<p><strong>Kỹ thuật viên chuyên nghiệp</strong>: Tay nghề cao, thao tác chuẩn xác, không gây ảnh hưởng đến các bộ phận khác.</p>
</li>
<li>
<p><strong>Giá cả hợp lý, minh bạch</strong>: Báo giá rõ ràng, không phát sinh chi phí bất ngờ.</p>
</li>
<li>
<p><strong>Thời gian thay nhanh chóng</strong>: Hỗ trợ thay màn hình lấy liền, không làm gián đoạn công việc của khách hàng.</p>
</li>
<li>
<p><strong>Chính sách bảo hành rõ ràng</strong>: Giúp khách hàng an tâm khi sử dụng dịch vụ.</p>
</li>
</ul>
<p>Chỉ nên lựa chọn những cơ sở đáp ứng đầy đủ tiêu chí này để vừa tiết kiệm chi phí, vừa đảm bảo chất lượng cho thiết bị.</p>
<h2>Thay màn hình Samsung có ảnh hưởng gì đến máy không?</h2>
<p>Nhiều người lo lắng việc thay màn hình có thể ảnh hưởng đến hiệu năng hoặc các chức năng khác của điện thoại. Trên thực tế, nếu bạn thay tại cửa hàng uy tín, sử dụng linh kiện chính hãng, thiết bị sẽ hoạt động hoàn toàn ổn định.</p>
<ul>
<li>
<p><strong>Chất lượng hiển thị không đổi</strong>: Màn hình chính hãng mang lại màu sắc chuẩn, độ sáng và độ nét như ban đầu.</p>
</li>
<li>
<p><strong>Cảm ứng mượt mà</strong>: Không lo tình trạng chậm phản hồi hay lỗi cảm ứng.</p>
</li>
<li>
<p><strong>Không ảnh hưởng phần cứng khác</strong>: Quy trình thay chuẩn kỹ thuật giúp bảo vệ bo mạch và các linh kiện đi kèm.</p>
</li>
<li>
<p><strong>Tuổi thọ máy duy trì ổn định</strong>: Thiết bị bền bỉ, hạn chế hỏng vặt sau khi thay màn hình.</p>
</li>
</ul>
<p>Ngược lại, nếu sử dụng màn hình kém chất lượng hoặc thay ở nơi không uy tín, điện thoại có thể gặp các vấn đề như hao pin nhanh, lỗi cảm ứng, hỏng main.</p>
<h2>Bệnh Viện Điện Thoại, Laptop 24h – Địa chỉ thay màn hình Samsung uy tín</h2>
<p><strong>Bệnh Viện Điện Thoại, Laptop 24h</strong> là một trong những thương hiệu được khách hàng tin tưởng khi cần thay màn hình Samsung. Trung tâm cam kết mang đến dịch vụ chuyên nghiệp với linh kiện <strong>chính hãng 100%</strong>.</p>
<p>Các loại màn hình Samsung tại trung tâm bao gồm:</p>
<ul>
<li>
<p><strong>Màn hình zin bóc máy</strong>: Giữ nguyên chất lượng hiển thị và cảm ứng như màn hình gốc.</p>
</li>
<li>
<p><strong>Màn hình OLED chính hãng</strong>: Cho độ sáng cao, màu sắc sống động, tiết kiệm pin hiệu quả.</p>
</li>
<li>
<p><strong>Màn hình chống trầy xước</strong>: Bền bỉ, chịu lực tốt, hạn chế hư hỏng khi va chạm nhẹ.</p>
</li>
</ul>
<p>Cùng với đó, trung tâm sở hữu đội ngũ kỹ thuật viên chuyên nghiệp, máy móc hiện đại và chính sách bảo hành rõ ràng, minh bạch.</p>
<p style="text-align: center;"><img src="https://chamsocdidong.com/upload_images/images/thay-man-hinh-samsung/cam-ket-thay-man-hinh-samsung.jpg" alt="" /></p>
<h2>Vì sao nên chọn Bệnh Viện Điện Thoại, Laptop 24h?</h2>
<ul>
<li>
<p><strong>Cửa hàng thay màn hình Samsung giá rẻ</strong> nhưng vẫn đảm bảo chất lượng chính hãng.</p>
</li>
<li>
<p><strong>Quy trình rõ ràng, minh bạch</strong>, báo giá trước khi sửa, không phát sinh chi phí.</p>
</li>
<li>
<p><strong>Thay nhanh – lấy liền</strong>, tiết kiệm thời gian cho khách hàng.</p>
</li>
<li>
<p><strong>Bảo hành uy tín</strong>, hỗ trợ tận tình trong quá trình sử dụng.</p>
</li>
<li>
<p><strong>Đội ngũ kỹ thuật viên giàu kinh nghiệm</strong>, luôn đặt lợi ích của khách hàng lên hàng đầu.</p>
</li>
</ul>
<p>Nếu bạn đang cần thay màn hình Samsung, hãy đến ngay <strong>Bệnh Viện Điện Thoại, Laptop 24h</strong> để trải nghiệm dịch vụ chất lượng, an toàn và tiết kiệm.</p>
|
baidu/ERNIE-4.5-300B-A47B-Base-Paddle
|
baidu
| 2025-08-20T02:27:08Z | 12 | 14 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe",
"ERNIE4.5",
"text-generation",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-06-28T06:36:07Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-300B-A47B-Base
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
> [!NOTE]
> Note: The Base model only supports text completion. For evaluation, use the `completion` API (not `chat_completion`) in vLLM/FastDeploy.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
To ensure the stability of multimodal joint training, we adopt a staged training strategy. In the first and second stage, we train only the text-related parameters, enabling the model to develop strong fundamental language understanding as well as long-text processing capabilities. The final multimodal stage extends capabilities to images and videos by introducing additional parameters including a ViT for image feature extraction, an adapter for feature transformation, and visual experts for multimodal understanding. At this stage, text and visual modalities mutually enhance each other. After pretraining trillions tokens, we extracted the text-related parameters and finally obtained ERNIE-4.5-300B-A47B-Base。
## Model Overview
ERNIE-4.5-300B-A47B-Base is a text MoE Base model, with 300B total parameters and 47B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --- | --- |
| Modality | Text |
| Training Stage | Pretraining |
| Params(Total / Activated) | 300B / 47B |
| Layers | 54 |
| Heads(Q/KV) | 64 / 8 |
| Text Experts(Total / Activated) | 64 / 8 |
| Vision Experts(Total / Activated) | 64 / 8 |
| Context Length | 131072 |
## Quickstart
### Model Finetuning with ERNIEKit
[ERNIEKit](https://github.com/PaddlePaddle/ERNIE) is a training toolkit based on PaddlePaddle, specifically designed for the ERNIE series of open-source large models. It provides comprehensive support for scenarios such as instruction fine-tuning (SFT, LoRA) and alignment training (DPO), ensuring optimal performance.
Usage Examples:
```bash
# Download model
huggingface-cli download baidu/ERNIE-4.5-300B-A47B-Base-Paddle --local-dir baidu/ERNIE-4.5-300B-A47B-Base-Paddle
# SFT
erniekit train examples/configs/ERNIE-4.5-300B-A47B/sft/run_sft_wint8mix_lora_8k.yaml model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle
# DPO
erniekit train examples/configs/ERNIE-4.5-300B-A47B/dpo/run_dpo_wint8mix_lora_8k.yaml model_name_or_path=baidu/ERNIE-4.5-300B-A47B-Base-Paddle
```
For more detailed examples, including SFT with LoRA, multi-GPU configurations, and advanced scripts, please refer to the examples folder within the [ERNIEKit](https://github.com/PaddlePaddle/ERNIE) repository.
### Using FastDeploy
Service deployment can be quickly completed using FastDeploy in the following command. For more detailed usage instructions, please refer to the [FastDeploy Repository](https://github.com/PaddlePaddle/FastDeploy).
**Note**: To deploy on a configuration with 4 GPUs each having at least 80G of memory, specify ```--quantization wint4```. If you specify ```--quantization wint8```, then resources for 8 GPUs are required.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-300B-A47B-Base-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--quantization wint4 \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--max-num-seqs 32
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
baidu/ERNIE-4.5-VL-424B-A47B-Paddle
|
baidu
| 2025-08-20T02:26:56Z | 27 | 16 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe_vl",
"ERNIE4.5",
"image-text-to-text",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-28T15:56:13Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: image-text-to-text
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-VL-424B-A47B
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
During the fine-tuning stage of a vision-language model, the deep integration between vision and language plays a decisive role in the model’s performance across complex tasks such as understanding, reasoning, and generation. To enhance the generalization and adaptability of the model on multimodal tasks, we focused on three core capabilities—image understanding, task-specific fine-tuning, and multimodal chain-of-thought reasoning—and carried out systematic data construction and training strategy optimization. Additionally, we use RLVR(Reinforcement Learning with Verifiable Rewards) to further improve alignment and performance. After the SFT and RL stages, we obtained ERNIE-4.5-VL-424B-A47B.
## Model Overview
ERNIE-4.5-VL-424B-A47B is a multimodal MoE Chat model based on ERNIE-4.5-VL-424B-A47B-Base, with 424B total parameters and 47B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --------------------------------- | ------------- |
| Modality | Text & Vision |
| Training Stage | Posttraining |
| Params(Total / Activated) | 424B / 47B |
| Layers | 54 |
| Heads(Q/KV) | 64 / 8 |
| Text Experts(Total / Activated) | 64 / 8 |
| Vision Experts(Total / Activated) | 64 / 8 |
| Context Length | 131072 |
## Quickstart
### FastDeploy Inference
Quickly deploy services using FastDeploy as shown below. For more detailed usage, refer to the [FastDeploy GitHub Repository](https://github.com/PaddlePaddle/FastDeploy).
**Note**: 80GB x 8 GPU resources are required. The `--quantization` parameter supports specifying `wint4` or `wint8` for deployment with 4-bit or 8-bit quantization, respectively.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-VL-424B-A47B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--tensor-parallel-size 8 \
--quantization wint4 \
--max-model-len 32768 \
--enable-mm \
--reasoning-parser ernie-45-vl \
--max-num-seqs 32
```
The ERNIE-4.5-VL model supports enabling or disabling thinking mode through request parameters.
#### Enable Thinking Mode
```bash
curl -X POST "http://0.0.0.0:8180/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://paddlenlp.bj.bcebos.com/datasets/paddlemix/demo_images/example2.jpg"}},
{"type": "text", "text": "Descript this image"}
]}
],
"metadata": {"enable_thinking": true}
}'
```
#### Disable Thinking Mode
```bash
curl -X POST "http://0.0.0.0:8180/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://paddlenlp.bj.bcebos.com/datasets/paddlemix/demo_images/example2.jpg"}},
{"type": "text", "text": "Descript this image"}
]}
],
"metadata": {"enable_thinking": false}
}'
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
lautan/blockassist-bc-gentle_patterned_goat_1755655142
|
lautan
| 2025-08-20T02:26:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle patterned goat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:26:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle patterned goat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
baidu/ERNIE-4.5-300B-A47B-FP8-Paddle
|
baidu
| 2025-08-20T02:25:38Z | 11 | 14 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe",
"ERNIE4.5",
"text-generation",
"conversational",
"en",
"zh",
"license:apache-2.0",
"8-bit",
"region:us"
] |
text-generation
| 2025-06-28T09:29:57Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-300B-A47B
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
## Model Overview
ERNIE-4.5-300B-A47B is a text MoE Post-trained model, with 300B total parameters and 47B activated parameters for each token. The following are the model configuration details:
|Key|Value|
|-|-|
|Modality|Text|
|Training Stage|Pretraining|
|Params(Total / Activated)|300B / 47B|
|Layers|54|
|Heads(Q/KV)|64 / 8|
|Text Experts(Total / Activated)|64 / 8|
|Vision Experts(Total / Activated)|64 / 8|
|Context Length|131072|
## Quickstart
### Using FastDeploy
Service deployment can be quickly completed using FastDeploy in the following command. For more detailed usage instructions, please refer to the [FastDeploy Repository](https://github.com/PaddlePaddle/FastDeploy).
**Note**: To deploy on a configuration with 4 GPUs each having at least 80G of memory, specify ```--quantization wint4```. If you specify ```--quantization wint8```, then resources for 8 GPUs are required.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-300B-A47B-Paddle \
--port 8180 \
--metrics-port 8181 \
--quantization wint4 \
--tensor-parallel-size 8 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--max-num-seqs 32
```
To deploy the W4A8C8 quantized version using FastDeploy, you can run the following command.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-300B-A47B-W4A8C8-TP4-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--tensor-parallel-size 4 \
--max-model-len 32768 \
--max-num-seqs 32
```
To deploy the WINT2 quantized version using FastDeploy on a single 141G GPU, you can run the following command.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model "baidu/ERNIE-4.5-300B-A47B-2Bits-Paddle" \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--max-num-seqs 128
```
The following contains a code snippet illustrating how to use ERNIE-4.5-300B-A47B-FP8 generate content based on given inputs.
```python
from fastdeploy import LLM, SamplingParams
prompts = [
"Hello, my name is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=128)
model = "baidu/ERNIE-4.5-300B-A47B-FP8-Paddle"
llm = LLM(
model=model,
tensor_parallel_size=1,
data_parallel_size=8,
max_model_len=8192,
num_gpu_blocks_override=1024,
engine_worker_queue_port=9981,
enable_expert_parallel=True
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs.text
print("generated_text", generated_text)
```
## Best Practices
### **Sampling Parameters**
To achieve optimal performance, we suggest using `Temperature=0.8`, `TopP=0.8`.
### Prompts for Web Search
For Web Search, {references}, {date}, and {question} are arguments.
For Chinese question, we use the prompt:
```python
ernie_search_zh_prompt = \
'''下面你会收到当前时间、多个不同来源的参考文章和一段对话。你的任务是阅读多个参考文章,并根据参考文章中的信息回答对话中的问题。
以下是当前时间和参考文章:
---------
#当前时间
{date}
#参考文章
{references}
---------
请注意:
1. 回答必须结合问题需求和当前时间,对参考文章的可用性进行判断,避免在回答中使用错误或过时的信息。
2. 当参考文章中的信息无法准确地回答问题时,你需要在回答中提供获取相应信息的建议,或承认无法提供相应信息。
3. 你需要优先根据百科、官网、权威机构、专业网站等高权威性来源的信息来回答问题。
4. 回复需要综合参考文章中的相关数字、案例、法律条文、公式等信息,使你的答案更专业。
5. 当问题属于创作类任务时,需注意以下维度:
- 态度鲜明:观点、立场清晰明确,避免模棱两可,语言果断直接
- 文采飞扬:用词精准生动,善用修辞手法,增强感染力
- 有理有据:逻辑严密递进,结合权威数据/事实支撑论点
---------
下面请结合以上信息,回答问题,补全对话
{question}'''
```
For English question, we use the prompt:
```python
ernie_search_en_prompt = \
'''
Below you will be given the current time, multiple references from different sources, and a conversation. Your task is to read the references and use the information in them to answer the question in the conversation.
Here are the current time and the references:
---------
#Current Time
{date}
#References
{references}
---------
Please note:
1. Based on the question’s requirements and the current time, assess the usefulness of the references to avoid using inaccurate or outdated information in the answer.
2. If the references do not provide enough information to accurately answer the question, you should suggest how to obtain the relevant information or acknowledge that you are unable to provide it.
3. Prioritize using information from highly authoritative sources such as encyclopedias, official websites, authoritative institutions, and professional websites when answering questions.
4. Incorporate relevant numbers, cases, legal provisions, formulas, and other details from the references to make your answer more professional.
5. For creative tasks, keep these dimensions in mind:
- Clear attitude: Clear views and positions, avoid ambiguity, and use decisive and direct language
- Brilliant writing: Precise and vivid words, good use of rhetoric, and enhance the appeal
- Well-reasoned: Rigorous logic and progressive, combined with authoritative data/facts to support the argument
---------
Now, using the information above, answer the question and complete the conversation:
{question}'''
```
Parameter notes:
* {question} is the user’s question
* {date} is the current time, and the recommended format is “YYYY-MM-DD HH:MM:SS, Day of the Week, Beijing/China.”
* {references} is the references, and the recommended format is:
```text
##参考文章1
标题:周杰伦
文章发布时间:2025-04-20
内容:周杰伦(Jay Chou),1979年1月18日出生于台湾省新北市,祖籍福建省永春县,华语流行乐男歌手、音乐人、演员、导演、编剧,毕业于淡江中学。2000年,发行个人首张音乐专辑《Jay》。...
来源网站网址:baike.baidu.com
来源网站的网站名:百度百科
##参考文章2
...
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
baidu/ERNIE-4.5-VL-28B-A3B-Base-Paddle
|
baidu
| 2025-08-20T02:24:58Z | 26 | 14 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe_vl",
"ERNIE4.5",
"image-text-to-text",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-28T05:21:28Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: image-text-to-text
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-VL-28B-A3B-Base
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
To ensure the stability of multimodal joint training, we adopt a staged training strategy. In the first and second stage, we train only the text-related parameters, enabling the model to develop strong fundamental language understanding as well as long-text processing capabilities. The final multimodal stage extends capabilities to images and videos by introducing additional parameters including a ViT for image feature extraction, an adapter for feature transformation, and visual experts for multimodal understanding. At this stage, text and visual modalities mutually enhance each other. After pretraining trillions tokens, we obtained ERNIE-4.5-VL-28B-A3B-Base.
## Model Overview
ERNIE-4.5-VL-28B-A3B-Base is a multimodal MoE Base model, with 28B total parameters and 3B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --------------------------------- | ------------- |
| Modality | Text & Vision |
| Training Stage | Pretraining |
| Params(Total / Activated) | 28B / 3B |
| Layers | 28 |
| Heads(Q/KV) | 20 / 4 |
| Text Experts(Total / Activated) | 64 / 6 |
| Vision Experts(Total / Activated) | 64 / 6 |
| Shared Experts | 2 |
| Context Length | 131072 |
## Quickstart
### vLLM inference
We are working with the community to fully support ERNIE4.5 models, stay tuned.
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
roeker/blockassist-bc-quick_wiry_owl_1755656566
|
roeker
| 2025-08-20T02:24:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:23:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755655085
|
ihsanridzi
| 2025-08-20T02:24:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:24:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755655048
|
mang3dd
| 2025-08-20T02:24:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:24:01Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
baidu/ERNIE-4.5-VL-28B-A3B-Paddle
|
baidu
| 2025-08-20T02:23:44Z | 43 | 21 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5_moe_vl",
"ERNIE4.5",
"image-text-to-text",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-28T04:25:34Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: image-text-to-text
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-VL-28B-A3B
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
During the fine-tuning stage of a vision-language model, the deep integration between vision and language plays a decisive role in the model’s performance across complex tasks such as understanding, reasoning, and generation. To enhance the generalization and adaptability of the model on multimodal tasks, we focused on three core capabilities—image understanding, task-specific fine-tuning, and multimodal chain-of-thought reasoning—and carried out systematic data construction and training strategy optimization. Additionally, we use RLVR(Reinforcement Learning with Verifiable Rewards) to further improve alignment and performance. After the SFT and RL stages, we obtained ERNIE-4.5-VL-28B-A3B.
## Model Overview
ERNIE-4.5-VL-28B-A3B is a multimodal MoE Chat model, with 28B total parameters and 3B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --------------------------------- | ------------- |
| Modality | Text & Vision |
| Training Stage | Posttraining |
| Params(Total / Activated) | 28B / 3B |
| Layers | 28 |
| Heads(Q/KV) | 20 / 4 |
| Text Experts(Total / Activated) | 64 / 6 |
| Vision Experts(Total / Activated) | 64 / 6 |
| Shared Experts | 2 |
| Context Length | 131072 |
## Quickstart
### FastDeploy Inference
Quickly deploy services using FastDeploy as shown below. For more detailed usage, refer to the [FastDeploy GitHub Repository](https://github.com/PaddlePaddle/FastDeploy).
**Note**: For single-card deployment, at least 80GB of GPU memory is required.
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--enable-mm \
--reasoning-parser ernie-45-vl \
--max-num-seqs 32
```
The ERNIE-4.5-VL model supports enabling or disabling thinking mode through request parameters.
#### Enable Thinking Mode
```bash
curl -X POST "http://0.0.0.0:8180/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://paddlenlp.bj.bcebos.com/datasets/paddlemix/demo_images/example2.jpg"}},
{"type": "text", "text": "Descript this image"}
]}
],
"metadata": {"enable_thinking": true}
}'
```
#### Disable Thinking Mode
```bash
curl -X POST "http://0.0.0.0:8180/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://paddlenlp.bj.bcebos.com/datasets/paddlemix/demo_images/example2.jpg"}},
{"type": "text", "text": "Descript this image"}
]}
],
"metadata": {"enable_thinking": false}
}'
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
baidu/ERNIE-4.5-0.3B-Paddle
|
baidu
| 2025-08-20T02:22:21Z | 206 | 13 |
PaddlePaddle
|
[
"PaddlePaddle",
"safetensors",
"ernie4_5",
"ERNIE4.5",
"text-generation",
"conversational",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-06-29T07:24:14Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ERNIE4.5
library_name: PaddlePaddle
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-0.3B
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
## Model Overview
ERNIE-4.5-0.3B is a text dense Post-trained model. The following are the model configuration details:
| Key | Value |
| -------------- | ------------ |
| Modality | Text |
| Training Stage | Posttraining |
| Params | 0.36B |
| Layers | 18 |
| Heads(Q/KV) | 16 / 2 |
| Context Length | 131072 |
## Quickstart
### Model Finetuning with ERNIEKit
[ERNIEKit](https://github.com/PaddlePaddle/ERNIE) is a training toolkit based on PaddlePaddle, specifically designed for the ERNIE series of open-source large models. It provides comprehensive support for scenarios such as instruction fine-tuning (SFT, LoRA) and alignment training (DPO), ensuring optimal performance.
Usage Examples:
```bash
# Download Model
huggingface-cli download baidu/ERNIE-4.5-0.3B-Paddle --local-dir baidu/ERNIE-4.5-0.3B-Paddle
# SFT
erniekit train examples/configs/ERNIE-4.5-0.3B/sft/run_sft_8k.yaml
# DPO
erniekit train examples/configs/ERNIE-4.5-0.3B/dpo/run_dpo_8k.yaml
```
For more detailed examples, including SFT with LoRA, multi-GPU configurations, and advanced scripts, please refer to the examples folder within the [ERNIEKit](https://github.com/PaddlePaddle/ERNIE) repository.
### FastDeploy Inference
Service deployment can be quickly completed using FastDeploy in the following command. For more detailed usage instructions, please refer to the [FastDeploy Repository](https://github.com/PaddlePaddle/FastDeploy).
```bash
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-0.3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--max-num-seqs 32
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
Bila333/marydziala
|
Bila333
| 2025-08-20T02:20:58Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-08-20T01:38:41Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
ElToro2602/blockassist-bc-raging_prehistoric_chameleon_1755656334
|
ElToro2602
| 2025-08-20T02:19:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging prehistoric chameleon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:19:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging prehistoric chameleon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
FlagRelease/GLM-4.5-FlagOS
|
FlagRelease
| 2025-08-20T02:18:47Z | 0 | 0 | null |
[
"safetensors",
"glm4_moe",
"region:us"
] | null | 2025-08-14T05:23:57Z |
# Introduction
**FlagOS** is a unified heterogeneous computing software stack for large models, co-developed with leading global chip manufacturers. With core technologies such as the **FlagScale** distributed training/inference framework, **FlagGems** universal operator library, **FlagCX** communication library, and **FlagTree** unified compiler, the **FlagRelease** platform leverages the FlagOS stack to automatically produce and release various combinations of <chip + open-source model>. This enables efficient and automated model migration across diverse chips, opening a new chapter for large model deployment and application.
Based on this, the **GLM-4.5-FlagOS** model is adapted for the Nvidia chip using the FlagOS software stack, enabling:
### Integrated Deployment
- Deep integration with the open-source [FlagScale framework](https://github.com/FlagOpen/FlagScale)
- Out-of-the-box inference scripts with pre-configured hardware and software parameters
- Released **FlagOS** container image supporting deployment within minutes
### Consistency Validation
- Rigorously evaluated through benchmark testing: Performance and results from the FlagOS software stack are compared against native stacks on multiple public.
# Technical Overview
## **FlagScale Distributed Training and Inference Framework**
FlagScale is an end-to-end framework for large models across heterogeneous computing resources, maximizing computational efficiency and ensuring model validity through core technologies. Its key advantages include:
- **Unified Deployment Interface:** Standardized command-line tools support one-click service deployment across multiple hardware platforms, significantly reducing adaptation costs in heterogeneous environments.
- **Intelligent Parallel Optimization:** Automatically generates optimal distributed parallel strategies based on chip computing characteristics, achieving dynamic load balancing of computation/communication resources.
- **Seamless Operator Switching:** Deep integration with the FlagGems operator library allows high-performance operators to be invoked via environment variables without modifying model code.
## **FlagGems Universal Large-Model Operator Library**
FlagGems is a Triton-based, cross-architecture operator library collaboratively developed with industry partners. Its core strengths include:
- **Full-stack Coverage**: Over 100 operators, with a broader range of operator types than competing libraries.
- **Ecosystem Compatibility**: Supports 7 accelerator backends. Ongoing optimizations have significantly improved performance.
- **High Efficiency**: Employs unique code generation and runtime optimization techniques for faster secondary development and better runtime performance compared to alternatives.
## **FlagEval Evaluation Framework**
FlagEval (Libra)** is a comprehensive evaluation system and open platform for large models launched in 2023. It aims to establish scientific, fair, and open benchmarks, methodologies, and tools to help researchers assess model and training algorithm performance. It features:
- **Multi-dimensional Evaluation**: Supports 800+ model evaluations across NLP, CV, Audio, and Multimodal fields, covering 20+ downstream tasks including language understanding and image-text generation.
- **Industry-Grade Use Cases**: Has completed horizontal evaluations of mainstream large models, providing authoritative benchmarks for chip-model performance validation.
# Evaluation Results
## Benchmark Result
| Metrics | GLM-4.5-H100-CUDA | GLM-4.5-FlagOS |
| ------------------------- | --------------------- | ------------------ |
|AIME-0shot@avg1|0.833|0.867|
|GPQA-0shot@avg1|0.694|0.744|
|MMLU-5shots@avg1|0.831|0.833|
|MUSR-0shot@avg1|0.739|0.728|
|LiveBench-0shot@avg1|0.738|0.754|
# User Guide
**Environment Setup**
| Item | Version |
| ------------- | ------------------------------------------------------------ |
| Docker Version | Docker version 28.1.0, build 4d8c241 |
| Operating System | Ubuntu 22.04.5 LTS |
| FlagScale | Version: 0.8.0 |
| FlagGems | Version: 3.0 |
## Operation Steps
### Download Open-source Model Weights
```bash
pip install modelscope
modelscope download --model ZhipuAI/GLM-4.5 --local_dir /share/GLM-4.5
```
### Download FlagOS Image
```bash
docker pull harbor.baai.ac.cn/flagrelease-public/flagrelease_nvidia_glm45
```
### Start the inference service
```bash
#Container Startup
docker run --rm --init --detach --net=host --uts=host --ipc=host --security-opt=seccomp=unconfined --privileged=true --ulimit stack=67108864 --ulimit memlock=-1 --ulimit nofile=1048576:1048576 --shm-size=32G -v /share:/share --gpus all --name flagos harbor.baai.ac.cn/flagrelease-public/flagrelease_nvidia_glm45 sleep infinity
```
### Serve
```bash
flagscale serve glm45
```
## Service Invocation
### API-based Invocation Script
```bash
import openai
openai.api_key = "EMPTY"
openai.base_url = "http://<server_ip>:9010/v1/"
model = "GLM-4.5-nvidia-flagos"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's the weather like today?"}
]
response = openai.chat.completions.create(
model=model,
messages=messages,
stream=False,
)
for item in response:
print(item)
```
### AnythingLLM Integration Guide
#### 1. Download & Install
- Visit the official site: https://anythingllm.com/
- Choose the appropriate version for your OS (Windows/macOS/Linux)
- Follow the installation wizard to complete the setup
#### 2. Configuration
- Launch AnythingLLM
- Open settings (bottom left, fourth tab)
- Configure core LLM parameters
- Click "Save Settings" to apply changes
#### 3. Model Interaction
- After model loading is complete:
- Click **"New Conversation"**
- Enter your question (e.g., “Explain the basics of quantum computing”)
- Click the send button to get a response
# Contributing
We warmly welcome global developers to join us:
1. Submit Issues to report problems
2. Create Pull Requests to contribute code
3. Improve technical documentation
4. Expand hardware adaptation support
# License
本模型的权重来源于ZhipuAI/GLM-4.5,以apache2.0协议https://www.apache.org/licenses/LICENSE-2.0.txt开源。
|
chainway9/blockassist-bc-untamed_quick_eel_1755654305
|
chainway9
| 2025-08-20T02:11:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:11:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gmwagmi7/blockassist-bc-snappy_horned_mammoth_1755655594
|
gmwagmi7
| 2025-08-20T02:07:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"snappy horned mammoth",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:07:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- snappy horned mammoth
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755653981
|
indoempatnol
| 2025-08-20T02:06:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:06:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755653936
|
thanobidex
| 2025-08-20T02:04:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:04:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755655021
|
hobson123
| 2025-08-20T02:03:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T02:02:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755653499
|
lisaozill03
| 2025-08-20T01:56:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:56:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755653209
|
mang3dd
| 2025-08-20T01:53:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:53:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
xihc-ucb/Qwen3-8B-train-Quasar-0809
|
xihc-ucb
| 2025-08-20T01:52:14Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"fp8_qwen3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-08-10T01:54:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nvidia/canary-1b-flash
|
nvidia
| 2025-08-20T01:51:56Z | 10,479 | 242 |
nemo
|
[
"nemo",
"safetensors",
"fastconformer",
"automatic-speech-recognition",
"automatic-speech-translation",
"speech",
"audio",
"Transformer",
"FastConformer",
"Conformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"en",
"de",
"es",
"fr",
"dataset:librispeech_asr",
"dataset:fisher_corpus",
"dataset:Switchboard-1",
"dataset:WSJ-0",
"dataset:WSJ-1",
"dataset:National-Singapore-Corpus-Part-1",
"dataset:National-Singapore-Corpus-Part-6",
"dataset:vctk",
"dataset:voxpopuli",
"dataset:europarl",
"dataset:multilingual_librispeech",
"dataset:mozilla-foundation/common_voice_8_0",
"dataset:MLCommons/peoples_speech",
"arxiv:2104.02821",
"arxiv:2503.05931",
"arxiv:1706.03762",
"arxiv:2409.13523",
"license:cc-by-4.0",
"model-index",
"region:us"
] |
automatic-speech-recognition
| 2025-03-07T22:29:17Z |
---
license: cc-by-4.0
language:
- en
- de
- es
- fr
library_name: nemo
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National-Singapore-Corpus-Part-1
- National-Singapore-Corpus-Part-6
- vctk
- voxpopuli
- europarl
- multilingual_librispeech
- mozilla-foundation/common_voice_8_0
- MLCommons/peoples_speech
thumbnail: null
tags:
- automatic-speech-recognition
- automatic-speech-translation
- speech
- audio
- Transformer
- FastConformer
- Conformer
- pytorch
- NeMo
- hf-asr-leaderboard
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: canary-1b-flash
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.87
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: SPGI Speech
type: kensho/spgispeech
config: test
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.95
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 16.1
type: mozilla-foundation/common_voice_16_1
config: en
split: test
args:
language: en
metrics:
- name: Test WER (En)
type: wer
value: 6.99
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 16.1
type: mozilla-foundation/common_voice_16_1
config: de
split: test
args:
language: de
metrics:
- name: Test WER (De)
type: wer
value: 4.09
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 16.1
type: mozilla-foundation/common_voice_16_1
config: es
split: test
args:
language: es
metrics:
- name: Test WER (ES)
type: wer
value: 3.62
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 16.1
type: mozilla-foundation/common_voice_16_1
config: fr
split: test
args:
language: fr
metrics:
- name: Test WER (Fr)
type: wer
value: 6.15
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-de
metrics:
- name: Test BLEU (En->De)
type: bleu
value: 32.27
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-de
metrics:
- name: Test BLEU (En->Es)
type: bleu
value: 22.6
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-de
metrics:
- name: Test BLEU (En->Fr)
type: bleu
value: 41.22
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: de_de
split: test
args:
language: de-en
metrics:
- name: Test BLEU (De->En)
type: bleu
value: 35.5
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: es_419
split: test
args:
language: es-en
metrics:
- name: Test BLEU (Es->En)
type: bleu
value: 23.32
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: fr_fr
split: test
args:
language: fr-en
metrics:
- name: Test BLEU (Fr->En)
type: bleu
value: 33.42
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: COVOST
type: covost2
config: de_de
split: test
args:
language: de-en
metrics:
- name: Test BLEU (De->En)
type: bleu
value: 39.33
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: COVOST
type: covost2
config: es_419
split: test
args:
language: es-en
metrics:
- name: Test BLEU (Es->En)
type: bleu
value: 41.86
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: COVOST
type: covost2
config: fr_fr
split: test
args:
language: fr-en
metrics:
- name: Test BLEU (Fr->En)
type: bleu
value: 41.43
metrics:
- wer
- bleu
- comet
track_downloads: true
pipeline_tag: automatic-speech-recognition
---
# Canary 1B Flash
<style>
img {
display: inline;
}
</style>
> **🎉 NEW: Canary 1B V2 is now available!**
> 🌍 **25 European Languages** | ⏱️ **Much Improved Timestamp Prediction** | 🔄 **Enhanced ASR & AST** | 🔗 **[Try it here: nvidia/canary-1b-v2](https://huggingface.co/nvidia/canary-1b-v2)**
## Description:
NVIDIA NeMo Canary Flash [1] is a family of multilingual multi-tasking models based on Canary architecture [2] that achieve state-of-the-art performance on multiple speech benchmarks. With 883 million parameters and an inference speed of more than 1000 RTFx (on open-asr-leaderboard datasets), canary-1b-flash supports automatic speech-to-text recognition (ASR) in four languages (English, German, French, Spanish) and translation from English to German/French/Spanish and from German/French/Spanish to English with or without punctuation and capitalization (PnC). Additionally, canary-1b-flash offers an experimental feature for word-level and segment-level timestamps in English, German, French, and Spanish.
This model is released under the permissive CC-BY-4.0 license and is available for commercial use.
## Model Architecture:
Canary is an encoder-decoder model with FastConformer [3] Encoder and Transformer Decoder [4]. With audio features extracted from the encoder, task tokens such as \<target language\>, \<task\>, \<toggle timestamps\> and \<toggle PnC\> are fed into the Transformer Decoder to trigger the text generation process. Canary uses a concatenated tokenizer [5] from individual SentencePiece [6] tokenizers of each language, which makes it easy to scale up to more languages. The canary-1b-flash model has 32 encoder layers and 4 decoder layers, leading to a total of 883M parameters. For more details about the architecture, please refer to [1].
## NVIDIA NeMo
To train, fine-tune or transcribe with canary-1b-flash, you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo).
## How to Use this Model
The model is available for use in the NeMo Framework [7], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
Please refer to [our tutorial](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/Canary_Multitask_Speech_Model.ipynb) for more details.
A few inference examples are listed below:
### Loading the Model
```python
from nemo.collections.asr.models import EncDecMultiTaskModel
# load model
canary_model = EncDecMultiTaskModel.from_pretrained('nvidia/canary-1b-flash')
# update decode params
decode_cfg = canary_model.cfg.decoding
decode_cfg.beam.beam_size = 1
canary_model.change_decoding_strategy(decode_cfg)
```
## Input:
**Input Type(s):** Audio <br>
**Input Format(s):** .wav or .flac files<br>
**Input Parameters(s):** 1D <br>
**Other Properties Related to Input:** 16000 Hz Mono-channel Audio, Pre-Processing Not Needed <br>
Input to canary-1b-flash can be either a list of paths to audio files or a jsonl manifest file.
If the input is a list of paths, canary-1b-flash assumes that the audio is English and transcribes it. I.e., canary-1b-flash default behavior is English ASR.
```python
output = canary_model.transcribe(
['path1.wav', 'path2.wav'],
batch_size=16, # batch size to run the inference with
pnc='yes', # generate output with Punctuation and Capitalization
)
predicted_text_1 = output[0].text
```
canary-1b-flash can also generate word and segment level timestamps
```python
output = canary_model.transcribe(
['filepath.wav'],
timestamps='yes', # generate output with timestamps
)
predicted_text = output[0].text
word_level_timestamps = output[0].timestamp['word']
segment_level_timestamps = output[0].timestamp['segment']
```
For audio files longer than 10 seconds, we recommend using longform inference script (explained in next section) with `chunk_len_in_secs=10.0` to generate timestamps.
To use canary-1b-flash for transcribing other supported languages or perform Speech-to-Text translation or provide word-level timestamps, specify the input as jsonl manifest file, where each line in the file is a dictionary containing the following fields:
```yaml
# Example of a line in input_manifest.json
{
"audio_filepath": "/path/to/audio.wav", # path to the audio file
"source_lang": "en", # language of the audio input, set `source_lang`==`target_lang` for ASR, choices=['en','de','es','fr']
"target_lang": "en", # language of the text output, choices=['en','de','es','fr']
"pnc": "yes", # whether to have PnC output, choices=['yes', 'no']
"timestamp": "yes", # whether to output word-level timestamps, choices=['yes', 'no']
}
```
and then use:
```python
output = canary_model.transcribe(
"<path to input manifest file>",
batch_size=16, # batch size to run the inference with
)
```
### Longform inference with Canary-1B-flash:
Canary models are designed to handle input audio smaller than 40 seconds. In order to handle longer audios, NeMo includes [speech_to_text_aed_chunked_infer.py](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_chunked_inference/aed/speech_to_text_aed_chunked_infer.py) script that handles chunking, performs inference on the chunked files, and stitches the transcripts.
The script will perform inference on all `.wav` files in `audio_dir`. Alternatively you can also pass a path to a manifest file as shown above. The decoded output will be saved at `output_json_path`.
```
python scripts/speech_to_text_aed_chunked_infer.py \
pretrained_name="nvidia/canary-1b-flash" \
audio_dir=$audio_dir \
output_filename=$output_json_path \
chunk_len_in_secs=40.0 \
batch_size=1 \
decoding.beam.beam_size=1 \
timestamps=False
```
**Note** that for longform inference with timestamps, it is recommended to use `chunk_len_in_secs` of 10 seconds.
## Output:
**Output Type(s):** Text <br>
**Output Format:** Text output as a string (w/ timestamps) depending on the task chosen for decoding <br>
**Output Parameters:** 1-Dimensional text string <br>
**Other Properties Related to Output:** May Need Inverse Text Normalization; Does Not Handle Special Characters <br>
## Software Integration:
**Runtime Engine(s):**
* NeMo - main <br>
**Supported Hardware Microarchitecture Compatibility:** <br>
* [NVIDIA Ampere] <br>
* [NVIDIA Blackwell] <br>
* [NVIDIA Jetson] <br>
* [NVIDIA Hopper] <br>
* [NVIDIA Lovelace] <br>
* [NVIDIA Pascal] <br>
* [NVIDIA Turing] <br>
* [NVIDIA Volta] <br>
**[Preferred/Supported] Operating System(s):** <br>
* [Linux] <br>
* [Linux 4 Tegra] <br>
* [Windows] <br>
## Model Version(s):
canary-1b-flash <br>
# Training and Evaluation Datasets:
## Training Dataset:
The canary-1b-flash model is trained on a total of 85K hrs of speech data. It consists of 31K hrs of public data, 20K hrs collected by [Suno](https://suno.ai/), and 34K hrs of in-house data.
The datasets below include conversations, videos from the web and audiobook recordings.
**Data Collection Method:**
* Human <br>
**Labeling Method:**
* Hybrid: Human, Automated <br>
The constituents of public data are as follows.
#### English (25.5k hours)
- Librispeech 960 hours
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hour subset
- Mozilla Common Voice (v7.0)
- People's Speech - 12,000 hour subset
- Mozilla Common Voice (v11.0) - 1,474 hour subset
#### German (2.5k hours)
- Mozilla Common Voice (v12.0) - 800 hour subset
- Multilingual Librispeech (MLS DE) - 1,500 hour subset
- VoxPopuli (DE) - 200 hr subset
#### Spanish (1.4k hours)
- Mozilla Common Voice (v12.0) - 395 hour subset
- Multilingual Librispeech (MLS ES) - 780 hour subset
- VoxPopuli (ES) - 108 hour subset
- Fisher - 141 hour subset
#### French (1.8k hours)
- Mozilla Common Voice (v12.0) - 708 hour subset
- Multilingual Librispeech (MLS FR) - 926 hour subset
- VoxPopuli (FR) - 165 hour subset
## Evaluation Dataset:
**Data Collection Method:** <br>
* Human <br>
**Labeling Method:** <br>
* Human <br>
Automatic Speech Recognition:
* [HuggingFace OpenASR Leaderboard evaluation sets](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
* [MLS](https://huggingface.co/datasets/facebook/multilingual_librispeech)
* [MCV] (https://commonvoice.mozilla.org/en/datasets)
Automatic Speech Translation:
* [FLEURS](https://huggingface.co/datasets/google/fleurs)
* [COVOST-v2](https://github.com/facebookresearch/covost)
* [mExpresso](https://huggingface.co/facebook/seamless-expressive#mexpresso-multilingual-expresso)
Timestamp Prediction:
* [Librispeech](https://www.openslr.org/12)
Hallucination Robustness:
* [MUSAN](https://www.openslr.org/17/) 48 hrs eval set
Noise Robustness:
* [Librispeech](https://www.openslr.org/12)
Model Fairness:
* [Casual Conversations Dataset](https://arxiv.org/abs/2104.02821)
## Training
Canary-1B-Flash is trained using the NVIDIA NeMo Framework [7] for a total of 200K steps with 2D bucketing [1] and optimal batch sizes set using OOMptimizer [8].The model is trained on 128 NVIDIA A100 80GB GPUs.
The model can be trained using this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_multitask/speech_to_text_aed.py) and [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/speech_multitask/fast-conformer_aed.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
## Inference:
**Engine:** NVIDIA NeMo <br>
**Test Hardware :** <br>
* A6000 <br>
* A100 <br>
* V100 <br>
## Performance
For ASR and AST experiments, predictions were generated using greedy decoding. Note that utterances shorter than 1 second are symmetrically zero-padded upto 1 second during evaluation.
### English ASR Performance (w/o PnC)
The ASR performance is measured with word error rate (WER), and we process the groundtruth and predicted text with [whisper-normalizer](https://pypi.org/project/whisper-normalizer/).
WER on [HuggingFace OpenASR leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard):
| **Version** | **Model** | **RTFx** | **AMI** | **GigaSpeech** | **LS Clean** | **LS Other** | **Earnings22** | **SPGISpech** | **Tedlium** | **Voxpopuli** |
|:---------:|:-----------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|
| nemo-main | canary-1b-flash | 1045.75 | 13.11 | 9.85 | 1.48 | 2.87 | 12.79 | 1.95 | 3.12 | 5.63 |
#### Inference speed on different systems
We profiled inference speed on the OpenASR benchmark (batch_size=128) using the [real-time factor](https://github.com/NVIDIA/DeepLearningExamples/blob/master/Kaldi/SpeechRecognition/README.md#metrics) (RTFx) to quantify throughput.
| **Version** | **Model** | **System** | **RTFx** |
|:-----------:|:-------------:|:------------:|:----------:|
| nemo-main | canary-1b-flash | NVIDIA A100 | 1045.75 |
| nemo-main | canary-1b-flash | NVIDIA H100 | 1669.07 |
### Multilingual ASR Performance
WER on [MLS](https://huggingface.co/datasets/facebook/multilingual_librispeech) test set:
| **Version** | **Model** | **De** | **Es** | **Fr** |
|:---------:|:-----------:|:------:|:------:|:------:|
| nemo-main | canary-1b-flash | 4.36 | 2.69 | 4.47 |
WER on [MCV-16.1](https://commonvoice.mozilla.org/en/datasets) test set:
| **Version** | **Model** | **En** | **De** | **Es** | **Fr** |
|:---------:|:-----------:|:------:|:------:|:------:|:------:|
| nemo-main | canary-1b-flash | 6.99 | 4.09 | 3.62 | 6.15 |
More details on evaluation can be found at [HuggingFace ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
### AST Performance
We evaluate AST performance with [BLEU score](https://lightning.ai/docs/torchmetrics/stable/text/sacre_bleu_score.html) and [COMET score](https://aclanthology.org/2020.emnlp-main.213/), and use native annotations with punctuation and capitalization in the datasets.
[FLEURS](https://huggingface.co/datasets/google/fleurs) test set:
BLEU score:
| **Version** | **Model** | **En->De** | **En->Es** | **En->Fr** | **De->En** | **Es->En** | **Fr->En** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 32.27 | 22.6 | 41.22 | 35.5 | 23.32 | 33.42 |
COMET score:
| **Version** | **Model** | **En->De** | **En->Es** | **En->Fr** | **De->En** | **Es->En** | **Fr->En** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 0.8114 | 0.8118 | 0.8165 | 0.8546 | 0.8228 | 0.8475 |
[COVOST-v2](https://github.com/facebookresearch/covost) test set:
BLEU score:
| **Version** | **Model** | **De->En** | **Es->En** | **Fr->En** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 39.33 | 41.86 | 41.43 |
COMET score:
| **Version** | **Model** | **De->En** | **Es->En** | **Fr->En** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 0.8553 | 0.8585 | 0.8511 |
[mExpresso](https://huggingface.co/facebook/seamless-expressive#mexpresso-multilingual-expresso) test set:
BLEU score:
| **Version** | **Model** | **En->De** | **En->Es** | **En->Fr** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 22.91 | 35.69 | 27.85 |
COMET score:
| **Version** | **Model** | **En->De** | **En->Es** | **En->Fr** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 0.7889 | 0.8211 | 0.7910 |
### Timestamp Prediction
F1-score on [Librispeech Test sets](https://www.openslr.org/12) at collar value of 200ms
| **Version** | **Model** | **test-clean** | **test-other** |
|:-----------:|:---------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 95.5 | 93.5 |
### Hallucination Robustness
Number of characters per minute on [MUSAN](https://www.openslr.org/17) 48 hrs eval set
| **Version** | **Model** | **# of character per minute** |
|:-----------:|:---------:|:----------:|
| nemo-main | canary-1b-flash | 60.92 |
### Noise Robustness
WER on [Librispeech Test Clean](https://www.openslr.org/12) at different SNR (signal to noise ratio) levels of additive white noise
| **Version** | **Model** | **SNR 10** | **SNR 5** | **SNR 0** | **SNR -5** |
|:-----------:|:---------:|:----------:|:----------:|:----------:|:----------:|
| nemo-main | canary-1b-flash | 2.34 | 3.69 | 8.84 | 29.71 |
## Model Fairness Evaluation
As outlined in the paper "Towards Measuring Fairness in AI: the Casual Conversations Dataset" [9], we assessed the canary-1b-flash model for fairness. The model was evaluated on the CausalConversations-v1 dataset, and the results are reported as follows:
### Gender Bias:
| Gender | Male | Female | N/A | Other |
| :--- | :--- | :--- | :--- | :--- |
| Num utterances | 19325 | 24532 | 926 | 33 |
| % WER | 14.66 | 12.44 | 17.17 | 27.56 |
### Age Bias:
| Age Group | (18-30) | (31-45) | (46-85) | (1-100) |
| :--- | :--- | :--- | :--- | :--- |
| Num utterances | 15956 | 14585 | 13349 | 43890 |
| % WER | 13.18 | 13.45 | 13.64 | 13.41 |
(Error rates for fairness evaluation are determined by normalizing both the reference and predicted text, similar to the methods used in the evaluations found at https://github.com/huggingface/open_asr_leaderboard.)
## License/Terms of Use:
canary-1b-flash is released under the CC-BY-4.0 license. By using this model, you are agreeing to the [terms and conditions](https://choosealicense.com/licenses/cc-by-4.0/) of the license. <br>
## References:
[1] [Training and Inference Efficiency of Encoder-Decoder Speech Models](https://arxiv.org/abs/2503.05931)
[2] [Less is More: Accurate Speech Recognition & Translation without Web-Scale Data](https://www.isca-archive.org/interspeech_2024/puvvada24_interspeech.pdf)
[3] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10389701)
[4] [Attention is All You Need](https://arxiv.org/abs/1706.03762)
[5] [Unified Model for Code-Switching Speech Recognition and Language Identification Based on Concatenated Tokenizer](https://aclanthology.org/2023.calcs-1.7.pdf)
[6] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
[7] [NVIDIA NeMo Framework](https://github.com/NVIDIA/NeMo)
[8] [EMMeTT: Efficient Multimodal Machine Translation Training](https://arxiv.org/abs/2409.13523)
[9] [Towards Measuring Fairness in AI: the Casual Conversations Dataset](https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9634168)
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
lautan/blockassist-bc-gentle_patterned_goat_1755653048
|
lautan
| 2025-08-20T01:51:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle patterned goat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:51:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle patterned goat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
crystalline7/221380
|
crystalline7
| 2025-08-20T01:51:32Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-20T01:51:17Z |
[View on Civ Archive](https://civarchive.com/models/124591?modelVersionId=282358)
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755653005
|
quantumxnode
| 2025-08-20T01:51:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:50:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
DavidLanz/uuu_fine_tune_gpt2
|
DavidLanz
| 2025-08-20T01:50:54Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"gpt",
"en",
"license:gpl",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-17T01:53:39Z |
---
license: gpl
model_name: GPT2
model_type: GPT2
language: en
pipeline_tag: text-generation
tags:
- pytorch
- gpt
- gpt2
---
# Fine-tuning GPT2 with energy plus medical dataset
Fine tuning pre-trained language models for text generation.
Pretrained model on Chinese language using a GPT2 for Large Language Head Model objective.
## Model description
transferlearning from DavidLanz/uuu_fine_tune_taipower and fine-tuning with medical dataset for the GPT-2 architecture.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import GPT2LMHeadModel, BertTokenizer, TextGenerationPipeline
>>> model_path = "DavidLanz/DavidLanz/uuu_fine_tune_gpt2"
>>> model = GPT2LMHeadModel.from_pretrained(model_path)
>>> tokenizer = BertTokenizer.from_pretrained(model_path)
>>> max_length = 200
>>> prompt = "歐洲能源政策"
>>> text_generator = TextGenerationPipeline(model, tokenizer)
>>> text_generated = text_generator(prompt, max_length=max_length, do_sample=True)
>>> print(text_generated[0]["generated_text"].replace(" ",""))
```
```python
>>> from transformers import GPT2LMHeadModel, BertTokenizer, TextGenerationPipeline
>>> model_path = "DavidLanz/DavidLanz/uuu_fine_tune_gpt2"
>>> model = GPT2LMHeadModel.from_pretrained(model_path)
>>> tokenizer = BertTokenizer.from_pretrained(model_path)
>>> max_length = 200
>>> prompt = "蕁麻疹過敏"
>>> text_generator = TextGenerationPipeline(model, tokenizer)
>>> text_generated = text_generator(prompt, max_length=max_length, do_sample=True)
>>> print(text_generated[0]["generated_text"].replace(" ",""))
```
|
roeker/blockassist-bc-quick_wiry_owl_1755654517
|
roeker
| 2025-08-20T01:49:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:49:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
QuantTrio/Qwen3-235B-A22B-Instruct-2507-GPTQ-Int4-Int8Mix
|
QuantTrio
| 2025-08-20T01:49:39Z | 592 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"Qwen3",
"GPTQ",
"Int4-Int8Mix",
"量化修复",
"vLLM",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-235B-A22B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-235B-A22B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-07-24T02:27:45Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- Qwen3
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- Qwen/Qwen3-235B-A22B-Instruct-2507
base_model_relation: quantized
---
# Qwen3-235B-A22B-Instruct-2507-GPTQ-Int4-Int8Mix
Base model: [Qwen/Qwen3-235B-A22B-Instruct-2507](https://www.modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507)
### 【VLLM Launch Command for 8 GPUs (Single Node)】
<i>Note: When launching with 8 GPUs, --enable-expert-parallel must be specified; otherwise, the expert tensors cannot be evenly split across tensor parallel ranks. This option is not required for 4-GPU setups.</i>
```
CONTEXT_LENGTH=32768 # 262144
vllm serve \
QuantTrio/Qwen3-235B-A22B-Instruct-2507-GPTQ-Int4-Int8Mix \
--served-model-name Qwen3-235B-A22B-Instruct-2507-GPTQ-Int4-Int8Mix \
--enable-expert-parallel \
--swap-space 16 \
--max-num-seqs 512 \
--max-model-len $CONTEXT_LENGTH \
--max-seq-len-to-capture $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Dependencies】
```
vllm>=0.9.2
```
### 【Model Update History】
```
2025-08-19
1.[BugFix] Fix compatibility issues with vLLM 0.10.1
2025-07-22
1. Initial commit
```
### 【Model Files】
| File Size | Last Updated |
|-----------|----------------|
| `122GB` | `2025-07-22` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/Qwen3-235B-A22B-Instruct-2507-GPTQ-Int4-Int8Mix', cache_dir="your_local_path")
```
### 【Description】
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
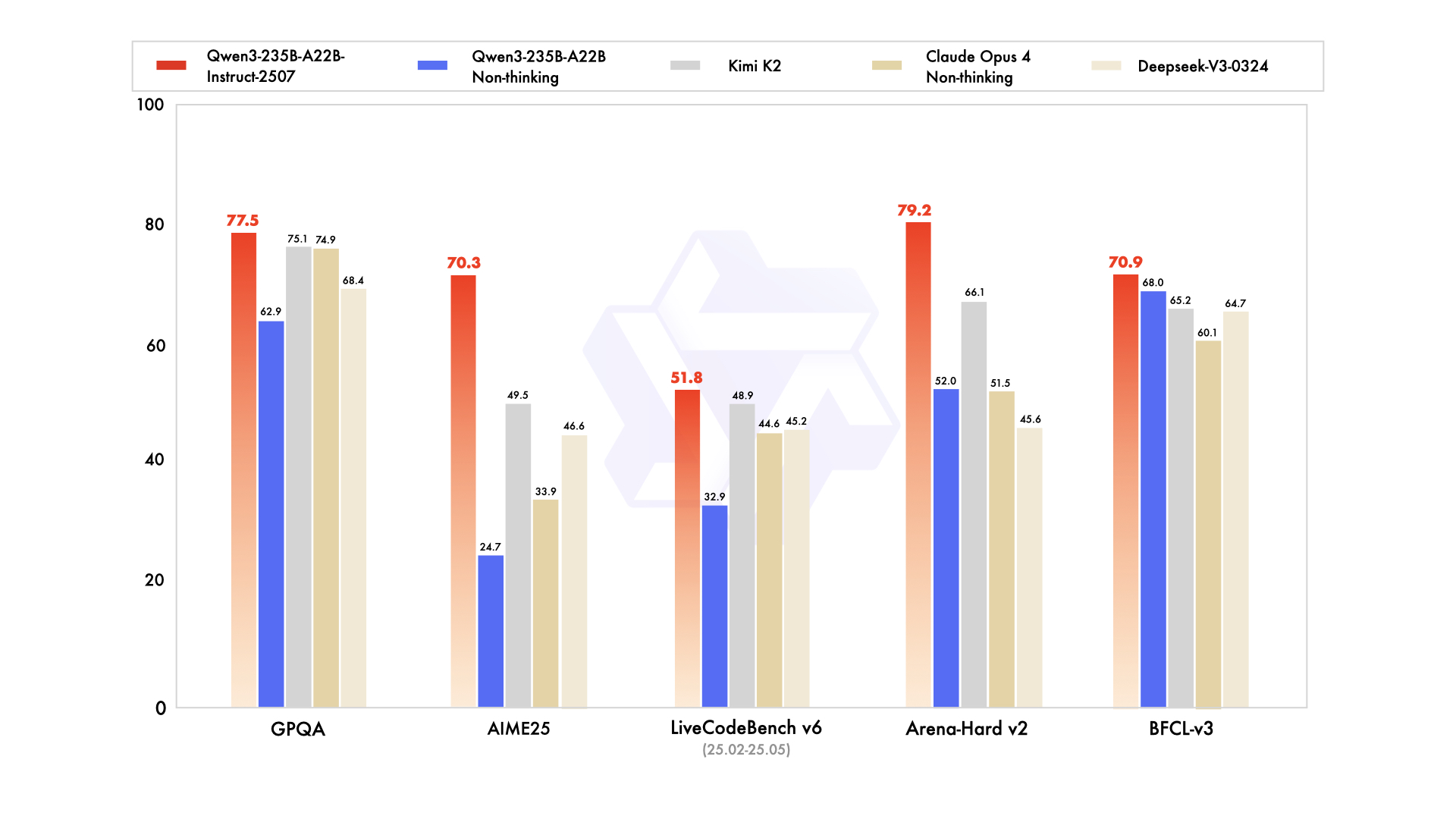
## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755652919
|
coelacanthxyz
| 2025-08-20T01:49:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:49:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
roeker/blockassist-bc-quick_wiry_owl_1755654115
|
roeker
| 2025-08-20T01:43:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:42:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hsiehfuwei/uuu_fine_tune_gpt2
|
hsiehfuwei
| 2025-08-20T01:43:01Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:43:01Z |
---
license: apache-2.0
---
|
haphoptr/blockassist-bc-quiet_robust_seal_1755654038
|
haphoptr
| 2025-08-20T01:42:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quiet robust seal",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:42:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quiet robust seal
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AXERA-TECH/Qwen3-4B
|
AXERA-TECH
| 2025-08-20T01:42:34Z | 13 | 0 | null |
[
"Qwen",
"Qwen3",
"Int8",
"text-generation",
"en",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-04-30T09:26:37Z |
---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen3-4B
pipeline_tag: text-generation
tags:
- Qwen
- Qwen3
- Int8
---
# Qwen3-4B-Int8
This version of Qwen3-4B-Int8 has been converted to run on the Axera NPU using **w8a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.2(Not released yet)
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo :
https://huggingface.co/Qwen/Qwen3-4B
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
[AXera NPU LLM Runtime](https://github.com/AXERA-TECH/ax-llm)
## Support Platform
- AX650
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
|Chips|w8a16|w4a16|
|--|--|--|
|AX650| 4.5 tokens/sec|TBD|
## How to use
Download all files from this repository to the device
```
root@ax650:/mnt/qtang/llm-test/qwen3-4b# tree -L 1
.
|-- config.json
|-- main_ax650
|-- main_axcl_aarch64
|-- main_axcl_x86
|-- post_config.json
|-- qwen2.5_tokenizer
|-- qwen3-4b-ax650
|-- qwen3_tokenizer
|-- qwen3_tokenizer_uid.py
|-- run_qwen3_4b_int8_ctx_ax650.sh
|-- run_qwen3_4b_int8_ctx_axcl_aarch64.sh
`-- run_qwen3_4b_int8_ctx_axcl_x86.sh
3 directories, 9 files
root@ax650:/mnt/qtang/llm-test/qwen3-4b#
```
#### Start the Tokenizer service
Install requirement
```
pip install transformers jinja2
```
```
root@ax650:/mnt/qtang/llm-test/qwen3-4b# python3 qwen3_tokenizer_uid.py
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
Server running at http://0.0.0.0:12345
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
Open another terminal and run `run_qwen3_4b_int8_ctx_ax650.sh`
```
root@ax650:/mnt/qtang/llm-test/qwen3-4b# ./run_qwen3_4b_int8_ctx_ax650.sh
[I][ Init][ 110]: LLM init start
[I][ Init][ 34]: connect http://127.0.0.1:12345 ok
[I][ Init][ 57]: uid: 6e90ff82-b9c9-42dc-8f61-081203389166
bos_id: -1, eos_id: 151645
2% | █ | 1 / 39 [3.95s<153.89s, 0.25 count/s] tokenizer init ok
[I][ Init][ 26]: LLaMaEmbedSelector use mmap
100% | ████████████████████████████████ | 39 / 39 [48.03s<48.03s, 0.81 count/s] init post axmodel ok,remain_cmm(5621 MB)
[I][ Init][ 188]: max_token_len : 2559
[I][ Init][ 193]: kv_cache_size : 1024, kv_cache_num: 2559
[I][ Init][ 201]: prefill_token_num : 128
[I][ Init][ 205]: grp: 1, prefill_max_token_num : 1
[I][ Init][ 205]: grp: 2, prefill_max_token_num : 256
[I][ Init][ 205]: grp: 3, prefill_max_token_num : 512
[I][ Init][ 205]: grp: 4, prefill_max_token_num : 1024
[I][ Init][ 205]: grp: 5, prefill_max_token_num : 1536
[I][ Init][ 205]: grp: 6, prefill_max_token_num : 2048
[I][ Init][ 209]: prefill_max_token_num : 2048
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": false,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 1,
"top_p": 0.8
}
[I][ Init][ 218]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
[I][ GenerateKVCachePrefill][ 270]: input token num : 21, prefill_split_num : 1 prefill_grpid : 2
[I][ GenerateKVCachePrefill][ 307]: input_num_token:21
[I][ main][ 230]: precompute_len: 21
[I][ main][ 231]: system_prompt: You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
prompt >> 1+3=?
[I][ SetKVCache][ 530]: prefill_grpid:2 kv_cache_num:256 precompute_len:21 input_num_token:16
[I][ SetKVCache][ 533]: current prefill_max_token_num:1920
[I][ Run][ 659]: input token num : 16, prefill_split_num : 1
[I][ Run][ 685]: input_num_token:16
[I][ Run][ 808]: ttft: 1169.05 ms
<think>
</think>
1 + 3 = 4
[N][ Run][ 922]: hit eos,avg 4.22 token/s
[I][ GetKVCache][ 499]: precompute_len:48, remaining:2000
prompt >> who are you?
[I][ SetKVCache][ 530]: prefill_grpid:2 kv_cache_num:256 precompute_len:48 input_num_token:16
[I][ SetKVCache][ 533]: current prefill_max_token_num:1920
[I][ Run][ 659]: input token num : 16, prefill_split_num : 1
[I][ Run][ 685]: input_num_token:16
[I][ Run][ 808]: ttft: 1168.56 ms
<think>
</think>
I am Qwen, a large-scale language model developed by Alibaba Cloud. I can answer questions, create content,
and help with a variety of tasks. How can I assist you today?
[N][ Run][ 922]: hit eos,avg 4.22 token/s
[I][ GetKVCache][ 499]: precompute_len:106, remaining:1942
prompt >> q
root@ax650:/mnt/qtang/llm-test/qwen3-4b#
```
#### Inference with M.2 Accelerator card
[What is M.2 Accelerator card?](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html), Show this DEMO based on Raspberry PI 5.
```
(base) axera@raspberrypi:~/samples/qwen3-4b $ ./run_qwen3_4b_int8_ctx_axcl_aarch64.sh
[I][ Init][ 136]: LLM init start
[I][ Init][ 34]: connect http://127.0.0.1:12345 ok
[I][ Init][ 57]: uid: a5b1e427-0cdf-4da6-b3a7-f5e0517da0bb
bos_id: -1, eos_id: 151645
2% | █ | 1 / 39 [0.99s<38.45s, 1.01 count/s] tokenizer init ok
[I][ Init][ 45]: LLaMaEmbedSelector use mmap
5% | ██ | 2 / 39 [0.99s<19.23s, 2.03 count/s] embed_selector init ok
[I][ run][ 30]: AXCLWorker start with devid 0
100% | ████████████████████████████████ | 39 / 39 [133.16s<133.16s, 0.29 count/s] init post axmodel ok,remain_cmm(691 MB)(1096 MB)000000000
[I][ Init][ 237]: max_token_len : 2559
[I][ Init][ 240]: kv_cache_size : 1024, kv_cache_num: 2559
[I][ Init][ 248]: prefill_token_num : 128
[I][ Init][ 252]: grp: 1, prefill_max_token_num : 1
[I][ Init][ 252]: grp: 2, prefill_max_token_num : 256
[I][ Init][ 252]: grp: 3, prefill_max_token_num : 512
[I][ Init][ 252]: grp: 4, prefill_max_token_num : 1024
[I][ Init][ 252]: grp: 5, prefill_max_token_num : 1536
[I][ Init][ 252]: grp: 6, prefill_max_token_num : 2048
[I][ Init][ 256]: prefill_max_token_num : 2048
________________________
| ID| remain cmm(MB)|
========================
| 0| 691|
¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": false,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 1,
"top_p": 0.8
}
[I][ Init][ 279]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
[I][ GenerateKVCachePrefill][ 335]: input token num : 21, prefill_split_num : 1 prefill_grpid : 2
[I][ GenerateKVCachePrefill][ 372]: input_num_token:21
[I][ main][ 236]: precompute_len: 21
[I][ main][ 237]: system_prompt: You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
prompt >> who are you
[I][ SetKVCache][ 628]: prefill_grpid:2 kv_cache_num:256 precompute_len:21 input_num_token:27
[I][ SetKVCache][ 631]: current prefill_max_token_num:1920
[I][ Run][ 869]: input token num : 27, prefill_split_num : 1
[I][ Run][ 901]: input_num_token:27
[I][ Run][1030]: ttft: 1339.01 ms
<think>
</think>
I am Qwen, a large-scale language model developed by Alibaba Cloud. I can answer questions,
create content, and help with a variety of tasks. What can I assist you with?
[N][ Run][1182]: hit eos,avg 3.65 token/s
[I][ GetKVCache][ 597]: precompute_len:90, remaining:1958
prompt >> q
[I][ run][ 80]: AXCLWorker exit with devid 0
(base) axera@raspberrypi:~/samples/qwen3-4b $
(base) axera@raspberrypi:~ $ axcl-smi
+------------------------------------------------------------------------------------------------+
| AXCL-SMI V3.4.0_20250423020139 Driver V3.4.0_20250423020139 |
+-----------------------------------------+--------------+---------------------------------------+
| Card Name Firmware | Bus-Id | Memory-Usage |
| Fan Temp Pwr:Usage/Cap | CPU NPU | CMM-Usage |
|=========================================+==============+=======================================|
| 0 AX650N V3.4.0 | 0000:01:00.0 | 193 MiB / 945 MiB |
| -- 37C -- / -- | 2% 0% | 6348 MiB / 7040 MiB |
+-----------------------------------------+--------------+---------------------------------------+
+------------------------------------------------------------------------------------------------+
| Processes: |
| Card PID Process Name NPU Memory Usage |
|================================================================================================|
| 0 84643 /home/axera/samples/qwen3-4b/main_axcl_aarch64 4894032 KiB |
+------------------------------------------------------------------------------------------------+
(base) axera@raspberrypi:~ $
```
|
koloni/blockassist-bc-deadly_graceful_stingray_1755652550
|
koloni
| 2025-08-20T01:42:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:42:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ccyuan/uuu_fine_tune_gpt2
|
ccyuan
| 2025-08-20T01:41:04Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:41:04Z |
---
license: apache-2.0
---
|
Joecheng/uuu_fine_tune_taipower2
|
Joecheng
| 2025-08-20T01:39:44Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:34:41Z |
---
license: apache-2.0
---
|
ghjdfhfghdfg/uuu_fine_tune_taipower
|
ghjdfhfghdfg
| 2025-08-20T01:39:40Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:32:51Z |
---
license: apache-2.0
---
|
thailevann/track8_v1_PoT
|
thailevann
| 2025-08-20T01:36:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-4B-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-4B-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T01:36:33Z |
---
base_model: unsloth/Qwen3-4B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** thailevann
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
roeker/blockassist-bc-quick_wiry_owl_1755653704
|
roeker
| 2025-08-20T01:36:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:35:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ni1234/uuu_fine_tune_taipower
|
ni1234
| 2025-08-20T01:35:57Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:10:47Z |
---
license: apache-2.0
---
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755652132
|
indoempatnol
| 2025-08-20T01:35:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:34:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SHAOYU1/uuu_fine_tune_gpt2
|
SHAOYU1
| 2025-08-20T01:34:59Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:34:59Z |
---
license: apache-2.0
---
|
Zenfish-zy/Taxi-v3
|
Zenfish-zy
| 2025-08-20T01:34:33Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-20T01:34:28Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Zenfish-zy/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755652161
|
thanobidex
| 2025-08-20T01:34:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:34:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
twhitworth/gpt-oss-120b-fp16
|
twhitworth
| 2025-08-20T01:33:48Z | 58 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"fp16",
"dequantized",
"gpt-oss",
"mxfp4-upcast",
"conversational",
"en",
"base_model:openai/gpt-oss-120b",
"base_model:finetune:openai/gpt-oss-120b",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-14T08:15:48Z |
---
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- fp16
- dequantized
- gpt-oss
- mxfp4-upcast
base_model: openai/gpt-oss-120b
model-index:
- name: gpt-oss-120b-fp16
results: []
---
#
## Precision: FP32 vs FP16 (and BF16)
This project saves dequantized checkpoints in **FP16** (bf16 -> fp16)
- **FP32 (single precision, 32-bit, 4 bytes/param)**
Reference/default precision in many frameworks. Highest numerical range/precision, **largest memory**.
- **FP16 (half precision, 16-bit, 2 bytes/param)**
Half the memory of FP32. Great for **inference** on modern GPUs; may underflow/overflow more easily than BF16.
- **BF16 (bfloat16, 16-bit, 2 bytes/param)**
Same memory as FP16, **wider exponent like FP32**, often more numerically robust than FP16; slightly less precision in mantissa.
> In this repo, output precision is **FP16** (default) or **BF16** via `--dtype`.
> **FP32 output is not offered** because it doubles disk/RAM vs FP16/BF16 with minimal inference benefit on modern hardware.
### Memory math (example: 120B parameters)
Each parameter stores one number:
| Format | Bits | Bytes/param | Approx size for 120B params |
|-------:|-----:|-------------:|-----------------------------:|
| FP32 | 32 | 4 | ~ **447 GiB** |
| FP16 | 16 | 2 | ~ **224 GiB** |
| BF16 | 16 | 2 | ~ **224 GiB** |
> Calculation (GiB): `params * bytes_per_param / 1024^3`
> For 120,000,000,000 params:
> FP32: 480e9 B ≈ 447.03 GiB
> FP16/BF16: 240e9 B ≈ 223.52 GiB
### When to use which
- **Inference on modern NVIDIA GPUs (Turing+/Ampere+/Ada/Hopper):**
Use **FP16** (default here) or **BF16**. You’ll get large memory savings and typically **equal or faster** throughput than FP32 thanks to tensor cores.
- **Training / Finetuning:**
Use **mixed precision** (BF16 or FP16 compute with an FP32 master copy of weights/optimizer states).
If your GPU supports BF16 well (e.g., A100/H100), **BF16** is preferred for numeric stability.
(This tool focuses on exporting dequantized checkpoints, not training loops.)
- **If you hit numeric issues in FP16:**
Try **BF16** (`--dtype bf16`). Same size as FP16 but usually more stable due to FP32-like exponent range.
### Notes
- **FP32** remains the gold standard for numeric headroom and deterministic baselines, but for **inference** it’s typically unnecessary and **costly** (2× memory vs FP16/BF16).
- **Tensor cores** accelerate FP16/BF16 GEMMs on most modern NVIDIA GPUs; FP32 is often slower and more memory-bound.
- If a downstream runtime expects a specific dtype, export to that: FP16 for speed/memory, BF16 for robustness.
---
### WIP
- Upcoming models: cleaned FP16 release (uniform fp16 with fp32 LayerNorms), compressed variants (W8A8, W4A16, mixed experts), 2:4 sparse checkpoints.
- Evals: MMLU, HellaSwag, TruthfulQA, GSM8K, BBH, MT‑Bench; plus latency/throughput and memory footprint on 3090/A100.
- Extras: scripted upload tooling, detailed model cards, and reproducible Docker workflows.
|
lon02/uuu_fine_tune_gpt22
|
lon02
| 2025-08-20T01:33:20Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:33:20Z |
---
license: apache-2.0
---
|
DanielJustin/uuu_fine_tune_taipower
|
DanielJustin
| 2025-08-20T01:27:48Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:26:58Z |
---
license: apache-2.0
---
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755651719
|
sampingkaca72
| 2025-08-20T01:26:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:26:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
iBush/uuu_fine_tune_taipower
|
iBush
| 2025-08-20T01:26:36Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:06:49Z |
---
license: apache-2.0
---
|
leo12757/uuu_fine_tune_taipower
|
leo12757
| 2025-08-20T01:26:35Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:25:12Z |
---
license: apache-2.0
---
|
unitova/blockassist-bc-zealous_sneaky_raven_1755651634
|
unitova
| 2025-08-20T01:26:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:26:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ivoryyuan/uuu_fine_tune_gpt2
|
ivoryyuan
| 2025-08-20T01:24:51Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:24:51Z |
---
license: apache-2.0
---
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755651942
|
Sayemahsjn
| 2025-08-20T01:24:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:24:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755651181
|
katanyasekolah
| 2025-08-20T01:20:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:20:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
PGFROG/uuu_fine_tune_gpt2
|
PGFROG
| 2025-08-20T01:19:20Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-20T01:19:20Z |
---
license: apache-2.0
---
|
lautan/blockassist-bc-gentle_patterned_goat_1755651032
|
lautan
| 2025-08-20T01:18:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle patterned goat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:18:27Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle patterned goat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
haphoptr/blockassist-bc-quiet_robust_seal_1755652585
|
haphoptr
| 2025-08-20T01:17:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quiet robust seal",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-20T01:17:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quiet robust seal
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.