
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-14 06:27:15
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 558
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-14 06:24:19
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755613076
|
kojeklollipop
| 2025-08-19T14:46:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:46:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755612485
|
ihsanridzi
| 2025-08-19T14:34:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:34:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Andra76/blockassist-bc-deadly_enormous_butterfly_1755613857
|
Andra76
| 2025-08-19T14:31:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly enormous butterfly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:31:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly enormous butterfly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zhuojing-huang/gpt2-arabic-english-ewc
|
zhuojing-huang
| 2025-08-19T14:25:57Z | 22 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T13:49:13Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: gpt2-arabic-english-ewc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-arabic-english-ewc
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 30
- training_steps: 122070
### Training results
### Framework versions
- Transformers 4.53.1
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.2
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755613409
|
lilTAT
| 2025-08-19T14:23:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:23:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
saracandu/dummy
|
saracandu
| 2025-08-19T14:22:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stldec",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:21:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
johngreendr1/afc52410-2dbe-4af3-882b-efab851e5705
|
johngreendr1
| 2025-08-19T14:19:07Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Nexesenex/Llama_3.x_70b_Hexagon_Purple_V2",
"base_model:adapter:Nexesenex/Llama_3.x_70b_Hexagon_Purple_V2",
"region:us"
] | null | 2025-08-19T14:18:52Z |
---
base_model: Nexesenex/Llama_3.x_70b_Hexagon_Purple_V2
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
Kdch2597/ppo-LunarLander-v2
|
Kdch2597
| 2025-08-19T14:18:49Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T14:18:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 263.01 +/- 19.22
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
vrbhalaaji/my_policy
|
vrbhalaaji
| 2025-08-19T14:13:45Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:vrbhalaaji/orange-pick-test",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T14:13:00Z |
---
datasets: vrbhalaaji/orange-pick-test
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- lerobot
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
doriankim/gemma3-4b-skin-cancer-classifier
|
doriankim
| 2025-08-19T14:10:34Z | 0 | 0 | null |
[
"safetensors",
"gemma3",
"region:us"
] | null | 2025-08-17T05:47:36Z |
# Gemma3 4B Skin Cancer Classifier
## 모델 개요
이 모델은 Gemma-3 4B를 기반으로 피부암 진단을 위해 파인튜닝된 분류 모델입니다.
## 모델 상세 정보
- **Base Model**: Gemma-3 4B
- **Task**: 피부암 이미지 분류
- **Fine-tuning Steps**: 1000 steps
- **LoRA Rank (r)**: 32
- **Batch Size**: 8
## 훈련 설정
```json
{
"model_name": "gemma-3-4b",
"training_steps": 1000,
"lora_rank": 32,
"batch_size": 8,
"learning_rate": "auto",
"optimizer": "adamw"
}
```
## 평가 결과
자세한 평가 결과는 `evaluation/` 폴더에서 확인하실 수 있습니다.
### 주요 성능 지표
- **정확도**: [evaluation 폴더에서 확인]
- **정밀도**: [evaluation 폴더에서 확인]
- **재현율**: [evaluation 폴더에서 확인]
- **F1 스코어**: [evaluation 폴더에서 확인]
## 사용 방법
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 모델과 토크나이저 로드
model_name = "doriankim/gemma3-4b-skin-cancer-classifier"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 추론 예시
def predict_skin_condition(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
return predictions
```
## 폴더 구조
```
├── config.json # 모델 설정
├── pytorch_model.bin # 모델 가중치
├── tokenizer files # 토크나이저 관련 파일들
├── evaluation/ # 평가 결과 및 분석
│ ├── results/ # 성능 지표
│ ├── plots/ # 시각화 결과
│ └── logs/ # 평가 로그
└── README.md # 이 파일
```
## 라이선스
[라이선스 정보를 여기에 추가하세요]
## 인용
이 모델을 사용하시는 경우 다음과 같이 인용해 주세요:
```
@misc{gemma3_4b_skin_cancer_classifier,
author = {doriankim},
title = {Gemma-3 4B Skin Cancer Classifier},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/doriankim/gemma3-4b-skin-cancer-classifier}
}
```
---
*이 모델은 연구 목적으로 개발되었으며, 실제 의료 진단에 사용하기 전에 전문의와 상담하시기 바랍니다.*
|
0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss
|
0xZeno
| 2025-08-19T14:06:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-08-19T10:40:12Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: a photo of sks football player
widget:
- text: a photo of sks football player playing football on a beach
output:
url: image_0.png
- text: a photo of sks football player playing football on a beach
output:
url: image_1.png
- text: a photo of sks football player playing football on a beach
output:
url: image_2.png
- text: a photo of sks football player playing football on a beach
output:
url: image_3.png
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - 0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss
<Gallery />
## Model description
These are 0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of sks football player to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](0xZeno/sdxl-base-1.0-wharton-footballer-optimized-loss/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755610573
|
sampingkaca72
| 2025-08-19T14:02:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:02:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755610389
|
thanobidex
| 2025-08-19T14:00:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:00:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rievil/crackenpy
|
rievil
| 2025-08-19T13:59:57Z | 0 | 2 |
timm
|
[
"timm",
"image-segmentation",
"doi:10.57967/hf/3295",
"license:bsd",
"region:us"
] |
image-segmentation
| 2024-10-01T09:54:22Z |
---
license: bsd
pipeline_tag: image-segmentation
architecture: resnext101_32x8d
base_model:
- timm/resnext101_32x8d
library_name: timm
metrics:
- accuracy
- mean intersection of union
---
# Pre-trained model for CrackenPy package for crack segmentation on building material specimens
The repository contains pre-trained models using the segmentation-models-pytorch package to segment RGB images 416x416 pixels.
The resulting classes are "background," "matrix," "crack," and "pore".The purpose is a segmentation of test specimens made from
building materials such as cement, alkali-activated materials or geopolymers.
### Model Description
- **Model type:** semantic segmentation
- **Language(s) (NLP):** Python
- **License:** BSD v2
- **Finetuned from model [optional]:** resnet101
## Uses
The use is to segment cracks on test specimens or on images fully filled with a binder matrix containing cracks. The background should be darker than the speicmen itself.
The segmentation is aimed at fine cracks from starting from 20 um up to 10 mm.
## Bias, Risks, and Limitations
The background and matrix classes may sometimes be with, if the texture of specimens is too dark or smudged, it is, therefore, important to make a segmentation on possible clean specimens.
The models of the current version have not been trained in exterior and may lead to bad segmentation. The pores are usually in circular shape, but there can be a situation where a crack is found
on the edge of the pore. It is therefore recommended to avoid the usage of models on highly porous materials.
## Training Details
The models originate from https://github.com/qubvel-org/segmentation_models.pytorch library, and are retrained on dataset crackenpy_dataset.
### Training Data
The dataset for training can be downloaded from Brno University of Technology upon filling the form. The dataset is free for use in ressearch and education area under the BSD v2 license.
The dataset was created under the research project of Grant Agency of Czech Republic No. 22-02098S with the title: "Experimental analysis of the shrinkage, creep and cracking mechanism of the materials based on the alkali-activated slag".
### Training Procedure
The training was done using Pytorch library, where CrossEntropyLoss() together with AdamW optimizer function.
### Results & Metrics
The dataset has 1207 images in resolution of 416x416 pixels together with 1207 masks. The overall accuracy of training for all classes reaches 98%, the mean intersection of union reaches 73%.
#### Hardware
The training was done using NVIDIA Quadro P4000 with CUDA support.
#### Software
The models were trained using Pytorch in Python, the segmentation and dataset preparation was done using LabKit plugin in software FIJI.
## Authors of dataset
Richard Dvorak, Brno University of Technology, Faculty of Civil Engineering, Institute of building testing
Rostislav Krc, Brno University of Technology, Faculty of Civil Engineering, Institute of building testing
Vlastimil Bilek, Brno University of Technology, Faculty of Chemistry, Institute of material chemistry
Barbara Kucharczyková, Brno University of Technology, Faculty of Civil Engineering, Institute of building testing
## Citation
The model was trained on the CrackenPy Dataset, and is used in CrackenPy library:
- [Library](https://github.com/Rievil/CrackenPy)
- [Model](https://huggingface.co/rievil/crackenpy)
- [Dataset](https://huggingface.co/datasets/rievil/crackenpy_dataset)
If you use this model, please cite our work:
```tex
@misc {richard_dvorak_2024,
author = { {Richard Dvorak} },
title = { crackenpy (Revision 04ed02c) },
year = 2024,
url = { https://huggingface.co/rievil/crackenpy },
doi = { 10.57967/hf/3295 },
publisher = { Hugging Face }
}
@software {Dvorak_CrackenPy_Image_segmentation_2024,
author = {Dvorak, Richard and Bilek, Vlastimil and Krc, Rostislav and Kucharczykova, Barbara},
doi = {10.5281/zenodo.13969747},
month = oct,
title = {{CrackenPy: Image segmentation tool for semantic segmentation of building material surfaces using deep learning}},
url = {https://github.com/Rievil/CrackenPy},
year = {2024}
}
@misc {richard_dvorak_2024,
author = { {Richard Dvorak} },
title = { crackenpy_dataset (Revision ce5c857) },
year = 2024,
url = { https://huggingface.co/datasets/rievil/crackenpy_dataset },
doi = { 10.57967/hf/3496 },
publisher = { Hugging Face }
}
```
## Model Card Contact
The author of the dataset is Richard Dvorak Ph.D., richard.dvorak@vutbr.cz, tel.: +420 777 678 613, employee of Brno University Of Technology of the Faculty of Civil Engineering, institute of building testing.
|
unitova/blockassist-bc-zealous_sneaky_raven_1755610013
|
unitova
| 2025-08-19T13:53:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:53:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/alejandro-jodorowsky-style
|
Muapi
| 2025-08-19T13:53:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:53:34Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Alejandro Jodorowsky Style

**Base model**: Flux.1 D
**Trained words**: Alejandro Jodorowsky Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:62712@1403331", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
cyt9772/my-bert-fine-tuned1
|
cyt9772
| 2025-08-19T13:51:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T13:50:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755611269
|
lilTAT
| 2025-08-19T13:48:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:48:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755611036
|
yaelahnal
| 2025-08-19T13:45:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:44:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ahmedheakl/iter0_mm_llamafactory_20250819_173453
|
ahmedheakl
| 2025-08-19T13:39:37Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-VL-3B-Instruct",
"region:us"
] | null | 2025-08-19T13:37:12Z |
---
library_name: peft
base_model: Qwen/Qwen2.5-VL-3B-Instruct
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: iter0_mm_llamafactory_20250819_173453
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# iter0_mm_llamafactory_20250819_173453
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) on the infographics50 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 5
- total_train_batch_size: 20
- total_eval_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.4
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Whitesmasher/Wan22Testing
|
Whitesmasher
| 2025-08-19T13:36:09Z | 0 | 0 | null |
[
"gguf",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:54:32Z |
---
license: apache-2.0
---
|
Muapi/jj-s-landscape-design
|
Muapi
| 2025-08-19T13:31:52Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:31:40Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# JJ's Landscape Design

**Base model**: Flux.1 D
**Trained words**: Landscape
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:220995@1280356", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755610214
|
lilTAT
| 2025-08-19T13:30:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:30:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/felix-meynet
|
Muapi
| 2025-08-19T13:29:03Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:28:57Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Felix Meynet

**Base model**: Flux.1 D
**Trained words**: Art by Felix Meynet
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1021589@1441868", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/sony-mavica-mvc-fd7-real-digicam
|
Muapi
| 2025-08-19T13:27:07Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:26:59Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Sony Mavica MVC-FD7 (Real digicam)

**Base model**: Flux.1 D
**Trained words**: m8vic2
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1147127@1290161", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Growcompany/gemma-3-270m-it-Q4_K_M-GGUF
|
Growcompany
| 2025-08-19T13:26:11Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3",
"unsloth",
"gemma",
"google",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:unsloth/gemma-3-270m-it",
"base_model:quantized:unsloth/gemma-3-270m-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-19T13:26:05Z |
---
base_model: unsloth/gemma-3-270m-it
license: gemma
tags:
- gemma3
- unsloth
- gemma
- google
- llama-cpp
- gguf-my-repo
pipeline_tag: text-generation
library_name: transformers
---
# Growcompany/gemma-3-270m-it-Q4_K_M-GGUF
This model was converted to GGUF format from [`unsloth/gemma-3-270m-it`](https://huggingface.co/unsloth/gemma-3-270m-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/unsloth/gemma-3-270m-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Growcompany/gemma-3-270m-it-Q4_K_M-GGUF --hf-file gemma-3-270m-it-q4_k_m.gguf -c 2048
```
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1755608212
|
helmutsukocok
| 2025-08-19T13:23:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:22:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Wkdrn/roberta-base-klue-ynat-classification
|
Wkdrn
| 2025-08-19T13:22:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T13:21:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/girls-with-guns-cinematic-style-xl-f1d
|
Muapi
| 2025-08-19T13:15:08Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:14:50Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Girls With Guns (cinematic style) XL + F1D

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:200237@1273747", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755609232
|
lilTAT
| 2025-08-19T13:14:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:14:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755606803
|
koloni
| 2025-08-19T13:02:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:01:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755606829
|
kojeklollipop
| 2025-08-19T13:01:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:01:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
orkungedik/ege-8b-1.1
|
orkungedik
| 2025-08-19T12:53:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"sft",
"unsloth",
"conversational",
"tr",
"dataset:orkungedik/function_call",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T09:28:30Z |
---
library_name: transformers
tags:
- trl
- sft
- unsloth
license: mit
datasets:
- orkungedik/function_call
language:
- tr
base_model:
- Qwen/Qwen3-8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
Digital asistant language model with function call.
- **Developed by:** Orkun Gedik
## Uses
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "orkungedik/ege-8b-1.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(
**model_inputs,
max_new_tokens=5000,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.1,
top_p=0.1,
top_k=20,
repetition_penalty=1.25,)
output_ids = outputs[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
answer = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
```
## Training Details
### Training Data
- orkungedik/function_call
#### Training Hyperparameters
- **warmup_steps** = 5
- **learning_rate** = 9e-6
- **num_train_epochs** = 2
- **optim** = "adamw_8bit",
- **weight_decay** = 0.01,
- **lr_scheduler_type** = "linear",
|
etsien/Llama-3.1-Nemotron-70B-Instruct-HF-GPTQ-W4A8
|
etsien
| 2025-08-19T12:46:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"nvidia",
"llama3.1",
"conversational",
"en",
"arxiv:2410.01257",
"arxiv:2405.01481",
"arxiv:2406.08673",
"base_model:nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"base_model:quantized:nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"8-bit",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-08-19T12:04:00Z |
---
license: llama3.1
language:
- en
inference: false
fine-tuning: false
tags:
- nvidia
- llama3.1
base_model:
- nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
pipeline_tag: text-generation
library_name: transformers
---
# Model Overview
GPTQ quantization of [Nemotron-70B](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF) using [llm-compressor](https://github.com/vllm-project/llm-compressor) and [Open Platypus](https://huggingface.co/datasets/garage-bAInd/Open-Platypus) calibration dataset.
Parameters:
Weights - INT4
Activation - INT8
Max Sample Length - 2048
Number of Samples - 192
## Nvidia Nemotron-70B Description:
Llama-3.1-Nemotron-70B-Instruct is a large language model customized by NVIDIA to improve the helpfulness of LLM generated responses to user queries.
This model reaches [Arena Hard](https://github.com/lmarena/arena-hard-auto) of 85.0, [AlpacaEval 2 LC](https://tatsu-lab.github.io/alpaca_eval/) of 57.6 and [GPT-4-Turbo MT-Bench](https://github.com/lm-sys/FastChat/pull/3158) of 8.98, which are known to be predictive of [LMSys Chatbot Arena Elo](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard)
As of 1 Oct 2024, this model is #1 on all three automatic alignment benchmarks (verified tab for AlpacaEval 2 LC), edging out strong frontier models such as GPT-4o and Claude 3.5 Sonnet.
As of Oct 24th, 2024 the model has Elo Score of 1267(+-7), rank 9 and style controlled rank of 26 on [ChatBot Arena leaderboard](https://lmarena.ai/?leaderboard).
This model was trained using RLHF (specifically, REINFORCE), [Llama-3.1-Nemotron-70B-Reward](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Reward) and [HelpSteer2-Preference prompts](https://huggingface.co/datasets/nvidia/HelpSteer2) on a Llama-3.1-70B-Instruct model as the initial policy.
Llama-3.1-Nemotron-70B-Instruct-HF has been converted from [Llama-3.1-Nemotron-70B-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct) to support it in the HuggingFace Transformers codebase. Please note that evaluation results might be slightly different from the [Llama-3.1-Nemotron-70B-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct) as evaluated in NeMo-Aligner, which the evaluation results below are based on.
Try hosted inference for free at [build.nvidia.com](https://build.nvidia.com/nvidia/llama-3_1-nemotron-70b-instruct) - it comes with an OpenAI-compatible API interface.
See details on our paper at [https://arxiv.org/abs/2410.01257](https://arxiv.org/abs/2410.01257) - as a preview, this model can correctly the question ```How many r in strawberry?``` without specialized prompting or additional reasoning tokens:
```
A sweet question!
Let’s count the “R”s in “strawberry”:
1. S
2. T
3. R
4. A
5. W
6. B
7. E
8. R
9. R
10. Y
There are **3 “R”s** in the word “strawberry”.
```
Note: This model is a demonstration of our techniques for improving helpfulness in general-domain instruction following. It has not been tuned for performance in specialized domains such as math.
## License
Your use of this model is governed by the [NVIDIA Open Model License](https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf).
Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3_1/license/). Built with Llama.
## Evaluation Metrics
As of 1 Oct 2024, Llama-3.1-Nemotron-70B-Instruct performs best on Arena Hard, AlpacaEval 2 LC (verified tab) and MT Bench (GPT-4-Turbo)
| Model | Arena Hard | AlpacaEval | MT-Bench | Mean Response Length |
|:-----------------------------|:----------------|:-----|:----------|:-------|
|Details | (95% CI) | 2 LC (SE) | (GPT-4-Turbo) | (# of Characters for MT-Bench)|
| _**Llama-3.1-Nemotron-70B-Instruct**_ | **85.0** (-1.5, 1.5) | **57.6** (1.65) | **8.98** | 2199.8 |
| Llama-3.1-70B-Instruct | 55.7 (-2.9, 2.7) | 38.1 (0.90) | 8.22 | 1728.6 |
| Llama-3.1-405B-Instruct | 69.3 (-2.4, 2.2) | 39.3 (1.43) | 8.49 | 1664.7 |
| Claude-3-5-Sonnet-20240620 | 79.2 (-1.9, 1.7) | 52.4 (1.47) | 8.81 | 1619.9 |
| GPT-4o-2024-05-13 | 79.3 (-2.1, 2.0) | 57.5 (1.47) | 8.74 | 1752.2 |
## Usage:
You can use the model using HuggingFace Transformers library with 2 or more 80GB GPUs (NVIDIA Ampere or newer) with at least 150GB of free disk space to accomodate the download.
This code has been tested on Transformers v4.44.0, torch v2.4.0 and 2 A100 80GB GPUs, but any setup that supports ```meta-llama/Llama-3.1-70B-Instruct``` should support this model as well. If you run into problems, you can consider doing ```pip install -U transformers```.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "nvidia/Llama-3.1-Nemotron-70B-Instruct-HF"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r in strawberry?"
messages = [{"role": "user", "content": prompt}]
tokenized_message = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", return_dict=True)
response_token_ids = model.generate(tokenized_message['input_ids'].cuda(),attention_mask=tokenized_message['attention_mask'].cuda(), max_new_tokens=4096, pad_token_id = tokenizer.eos_token_id)
generated_tokens =response_token_ids[:, len(tokenized_message['input_ids'][0]):]
generated_text = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)[0]
print(generated_text)
# See response at top of model card
```
## References(s):
* [NeMo Aligner](https://arxiv.org/abs/2405.01481)
* [HelpSteer2-Preference](https://arxiv.org/abs/2410.01257)
* [HelpSteer2](https://arxiv.org/abs/2406.08673)
* [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/)
* [Meta's Llama 3.1 Webpage](https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1)
* [Meta's Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md)
## Model Architecture:
**Architecture Type:** Transformer <br>
**Network Architecture:** Llama 3.1 <br>
## Input:
**Input Type(s):** Text <br>
**Input Format:** String <br>
**Input Parameters:** One Dimensional (1D) <br>
**Other Properties Related to Input:** Max of 128k tokens<br>
## Output:
**Output Type(s):** Text <br>
**Output Format:** String <br>
**Output Parameters:** One Dimensional (1D) <br>
**Other Properties Related to Output:** Max of 4k tokens <br>
## Software Integration:
**Supported Hardware Microarchitecture Compatibility:** <br>
* NVIDIA Ampere <br>
* NVIDIA Hopper <br>
* NVIDIA Turing <br>
**Supported Operating System(s):** Linux <br>
## Model Version:
v1.0
# Training & Evaluation:
## Alignment methodology
* REINFORCE implemented in NeMo Aligner
## Datasets:
**Data Collection Method by dataset** <br>
* [Hybrid: Human, Synthetic] <br>
**Labeling Method by dataset** <br>
* [Human] <br>
**Link:**
* [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2)
**Properties (Quantity, Dataset Descriptions, Sensor(s)):** <br>
* 21, 362 prompt-responses built to make more models more aligned with human preference - specifically more helpful, factually-correct, coherent, and customizable based on complexity and verbosity.
* 20, 324 prompt-responses used for training and 1, 038 used for validation.
# Inference:
**Engine:** [Triton](https://developer.nvidia.com/triton-inference-server) <br>
**Test Hardware:** H100, A100 80GB, A100 40GB <br>
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
If you find this model useful, please cite the following works
```bibtex
@misc{wang2024helpsteer2preferencecomplementingratingspreferences,
title={HelpSteer2-Preference: Complementing Ratings with Preferences},
author={Zhilin Wang and Alexander Bukharin and Olivier Delalleau and Daniel Egert and Gerald Shen and Jiaqi Zeng and Oleksii Kuchaiev and Yi Dong},
year={2024},
eprint={2410.01257},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.01257},
}
```
|
Richnuts-2025a/Richnuts.in
|
Richnuts-2025a
| 2025-08-19T12:45:28Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:45:28Z |
---
license: apache-2.0
---
|
Grigorij/jellypick
|
Grigorij
| 2025-08-19T12:43:11Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:Grigorij/so-101-test",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T09:21:43Z |
---
base_model: lerobot/smolvla_base
datasets: Grigorij/so-101-test
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- robotics
- smolvla
- lerobot
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
zypchn/swin-tiny-patch4-window7-224
|
zypchn
| 2025-08-19T12:37:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-19T12:37:07Z |
---
library_name: transformers
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- f1
model-index:
- name: swin-tiny-patch4-window7-224
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2830
- Accuracy: 0.9667
- Precision: 0.9698
- Sensitivity: 0.9667
- Specificity: 0.9667
- F1: 0.9675
- Auc: 0.9873
- Mcc: 0.8886
- J Stat: 0.9333
- Confusion Matrix: [[145, 5], [1, 29]]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9.131608136923706e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.07788173246475068
- num_epochs: 10
- label_smoothing_factor: 0.11328743246488582
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Sensitivity | Specificity | F1 | Auc | Mcc | J Stat | Confusion Matrix |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:-----------:|:-----------:|:------:|:------:|:------:|:------:|:-----------------------:|
| 0.4982 | 1.0 | 94 | 0.3367 | 0.9234 | 0.9297 | 0.9256 | 0.9227 | 0.9250 | 0.9750 | 0.8135 | 0.8483 | [[1026, 86], [29, 361]] |
| 0.3356 | 2.0 | 188 | 0.2915 | 0.9654 | 0.9657 | 0.8897 | 0.9919 | 0.9649 | 0.9819 | 0.9090 | 0.8817 | [[1103, 9], [43, 347]] |
| 0.2986 | 3.0 | 282 | 0.2642 | 0.9767 | 0.9769 | 0.9231 | 0.9955 | 0.9764 | 0.9869 | 0.9390 | 0.9186 | [[1107, 5], [30, 360]] |
| 0.2723 | 4.0 | 376 | 0.2647 | 0.9827 | 0.9827 | 0.9487 | 0.9946 | 0.9826 | 0.9944 | 0.9547 | 0.9433 | [[1106, 6], [20, 370]] |
| 0.269 | 5.0 | 470 | 0.2514 | 0.9840 | 0.9841 | 0.9487 | 0.9964 | 0.9839 | 0.9957 | 0.9583 | 0.9451 | [[1108, 4], [20, 370]] |
| 0.2403 | 6.0 | 564 | 0.2434 | 0.9900 | 0.9900 | 0.9718 | 0.9964 | 0.9900 | 0.9972 | 0.9739 | 0.9682 | [[1108, 4], [11, 379]] |
| 0.2448 | 7.0 | 658 | 0.2284 | 0.9953 | 0.9953 | 0.9872 | 0.9982 | 0.9953 | 0.9993 | 0.9879 | 0.9854 | [[1110, 2], [5, 385]] |
| 0.2303 | 8.0 | 752 | 0.2257 | 0.9953 | 0.9953 | 0.9872 | 0.9982 | 0.9953 | 0.9999 | 0.9879 | 0.9854 | [[1110, 2], [5, 385]] |
| 0.2284 | 9.0 | 846 | 0.2215 | 0.9980 | 0.9980 | 0.9974 | 0.9982 | 0.9980 | 1.0000 | 0.9948 | 0.9956 | [[1110, 2], [1, 389]] |
| 0.2257 | 10.0 | 940 | 0.2204 | 0.9980 | 0.9980 | 0.9974 | 0.9982 | 0.9980 | 1.0000 | 0.9948 | 0.9956 | [[1110, 2], [1, 389]] |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
kimxxxx/mistral_r32_a32_b8_gas2_lr5e-5_4500tk_1epoch_newdata
|
kimxxxx
| 2025-08-19T12:35:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:35:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Orginal-Uppal-Farm-Girl-Viral-Video-Link/New.full.videos.Uppal.Farm.Girl.Viral.Video.Official.Tutorial
|
Orginal-Uppal-Farm-Girl-Viral-Video-Link
| 2025-08-19T12:21:14Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:21:00Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755605836
|
lilTAT
| 2025-08-19T12:17:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:17:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gaoyang07/XYCodec
|
gaoyang07
| 2025-08-19T12:12:18Z | 0 | 0 | null |
[
"pytorch",
"xycodec",
"arxiv:2506.23325",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T12:07:08Z |
---
license: apache-2.0
---
# **Introduction**
**`XY-Tokenizer`** is a speech codec that simultaneously models both semantic and acoustic aspects of speech, converting audio into discrete tokens and decoding them back to high-quality audio. It achieves efficient speech representation at only 1kbps with RVQ8 quantization at 12.5Hz frame rate.
- **Paper:** [Read on arXiv](https://arxiv.org/abs/2506.23325)
- **Source Code:**
- [GitHub Repo](https://github.com/OpenMOSS/MOSS-TTSD/tree/main/XY_Tokenizer)
- [Hugging Face Repo](https://huggingface.co/spaces/fnlp/MOSS-TTSD/tree/main/XY_Tokenizer)
## 📚 Related Project: **[MOSS-TTSD](https://huggingface.co/fnlp/MOSS-TTSD-v0.5)**
**`XY-Tokenizer`** serves as the underlying neural codec for **`MOSS-TTSD`**, our 1.7B Audio Language Model. \
Explore **`MOSS-TTSD`** for advanced text-to-speech and other audio generation tasks on [GitHub](https://github.com/OpenMOSS/MOSS-TTSD), [Blog](http://www.open-moss.com/en/moss-ttsd/), [博客](https://www.open-moss.com/cn/moss-ttsd/), and [Space Demo](https://huggingface.co/spaces/fnlp/MOSS-TTSD).
## ✨ Features
- **Dual-channel modeling**: Simultaneously captures semantic meaning and acoustic details
- **Efficient representation**: 1kbps bitrate with RVQ8 quantization at 12.5Hz
- **High-quality audio tokenization**: Convert speech to discrete tokens and back with minimal quality loss
- **Long audio support**: Process audio files longer than 30 seconds using chunking with overlap
- **Batch processing**: Efficiently process multiple audio files in batches
- **24kHz output**: Generate high-quality 24kHz audio output
## 🚀 Installation
```bash
git clone https://github.com/OpenMOSS/MOSS-TTSD.git
cd MOSS-TTSD
conda create -n xy_tokenizer python=3.10 -y && conda activate xy_tokenizer
pip install -r XY_Tokenizer/requirements.txt
```
## 💻 Quick Start
Here's how to use **`XY-Tokenizer`** with `transformers` to encode an audio file into discrete tokens and decode it back into a waveform.
```python
import torchaudio
from transformers import AutoFeatureExtractor, AutoModel
# 1. Load the feature extractor and the codec model
feature_extractor = AutoFeatureExtractor.from_pretrained("MCplayer/XY_Tokenizer", trust_remote_code=True)
codec = AutoModel.from_pretrained("MCplayer/XY_Tokenizer", trust_remote_code=True, device_map="auto").eval()
# 2. Load and preprocess the audio
# The model expects a 16kHz sample rate.
wav_form, sampling_rate = torchaudio.load("examples/zh_spk1_moon.wav")
if sampling_rate != 16000:
wav_form = torchaudio.functional.resample(wav_form, orig_freq=sampling_rate, new_freq=16000)
# 3. Encode the audio into discrete codes
input_spectrum = feature_extractor(wav_form, sampling_rate=16000, return_attention_mask=True, return_tensors="pt")
# The 'code' dictionary contains the discrete audio codes
code = codec.encode(input_spectrum)
# 4. Decode the codes back to an audio waveform
# The output is high-quality 24kHz audio.
output_wav = codec.decode(code["audio_codes"], overlap_seconds=10)
# 5. Save the reconstructed audio
for i, audio in enumerate(output_wav["audio_values"]):
torchaudio.save(f"outputs/audio_{i}.wav", audio.cpu(), 24000)
```
|
sefcee/VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
|
sefcee
| 2025-08-19T12:11:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T12:10:07Z |
<a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
🔴 ➤►DOWNLOAD👉👉🟢 ➤ <a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
<a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
🔴 ➤►DOWNLOAD👉👉🟢 ➤ <a href="https://allyoutubers.com/Orginal-Uppal-Farm-Girl-Viral-Video"> 🌐 VIDEO.18.Orginal-Uppal-Farm-Girl-Viral-Video-Link.New.full.videos.Uppal.Farm.Girl
|
LBST/t10_pick_and_place_smolvla_013000
|
LBST
| 2025-08-19T12:11:26Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"pick-and-place",
"smolvla",
"checkpoint-013000",
"region:us"
] |
robotics
| 2025-08-19T12:11:21Z |
---
library_name: lerobot
tags:
- robotics
- pick-and-place
- smolvla
- checkpoint-013000
---
# T08 Pick and Place Policy - Checkpoint 013000
This model is a checkpoint from the training of a pick-and-place policy using SmolVLA architecture.
## Model Details
- **Checkpoint**: 013000
- **Architecture**: SmolVLA
- **Task**: Pick and Place (T08)
- **Training Step**: 013000
## Usage
You can evaluate this model using LeRobot:
```bash
python -m lerobot.scripts.eval \
--policy.path=LBST/t10_pick_and_place_smolvla_013000 \
--env.type=<your_environment> \
--eval.n_episodes=10 \
--policy.device=cuda
```
## Files
- `config.json`: Policy configuration
- `model.safetensors`: Model weights in SafeTensors format
- `train_config.json`: Complete training configuration for reproducibility
## Parent Repository
This checkpoint was extracted from: [LBST/t10_pick_and_place_files](https://huggingface.co/LBST/t10_pick_and_place_files)
---
*Generated automatically from checkpoint 013000*
|
SirAB/Dolphin-gemma2-2b-finetuned-v2
|
SirAB
| 2025-08-19T12:11:00Z | 29 | 1 |
transformers
|
[
"transformers",
"safetensors",
"gemma2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"base_model:finetune:SirAB/Dolphin-gemma2-2b-finetuned-v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-10T09:34:21Z |
---
base_model: SirAB/Dolphin-gemma2-2b-finetuned-v2
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** SirAB
- **License:** apache-2.0
- **Finetuned from model :** SirAB/Dolphin-gemma2-2b-finetuned-v2
This gemma2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755603595
|
quantumxnode
| 2025-08-19T12:06:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T12:06:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
llm-slice/blm-gpt2s-90M-s42
|
llm-slice
| 2025-08-19T12:01:17Z | 716 | 0 | null |
[
"safetensors",
"gpt2",
"babylm-baseline",
"strict",
"babylm-2025",
"en",
"arxiv:2405.09605",
"arxiv:2411.07990",
"region:us"
] | null | 2025-07-29T13:12:29Z |
---
language:
- en
tags:
- babylm-baseline
- strict
- babylm-2025
---
# Model Card for the Preference Optimization Interaction Baseline
<!-- Provide a quick summary of what the model is/does. [Optional] -->
A 124M model with the GPT-2 architecture trained with the next token prediction loss for 10 epochs (~900M words) **on 90% of the BabyLM corpus**, as a naive autoregressive baseline for the Interaction track of the 2025 BabyLM challenge.
This model card is based on the model card of the BabyLM [100M GPT-2 baseline](https://huggingface.co/BabyLM-community/babylm-baseline-100m-gpt2/edit/main/README.md).
# Table of Contents
- [Model Card for Interaction GPT-2 Baseline](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Hyperparameters](#hyperparameters)
- [Training Procedure](#training-procedure)
- [Size and Checkpoints](#size-and-checkpoints)
- [Evaluation](#evaluation)
- [Testing Data & Metrics](#testing-data-factors--metrics)
- [Testing Data](#testing-data)
- [Metrics](#metrics)
- [Results](#results)
- [Technical Specifications](#technical-specifications-optional)
- [Model Architecture and Objective](#model-architecture-and-objective)
- [Compute Infrastructure](#compute-infrastructure)
- [Hardware](#hardware)
- [Software](#software)
- [Training Time](#training-time)
- [Citation](#citation)
- [Model Card Authors](#model-card-authors-optional)
- [Bibliography](#bibliography)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
This is the pretrained GPT-2 model as a basis for PPO finetuning for the Interaction Track of the 2025 BabyLM challenge.
- **Developed by:** Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid
- **Model type:** Causal language model
- **Language(s) (NLP):** eng
- **Resources for more information:**
- [GitHub Repo](https://github.com/malihamza/babylm-interactive-learning)
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This is a pre-trained language model.
It can be used to evaluate tasks in a zero-shot manner and also can be fine-tuned for downstream tasks.
It can be used for language generation but given its small size and low number of words trained on, do not expect LLM-level performance.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
We used the BabyLM 100M (Strict) dataset for training. **We trained the tokenizer and model on randomly selected 90% of the corpus**, which is composed of the following:
| Source | Weight | Domain | Citation | Website | License |
| --- | --- | --- | --- | --- | --- |
| BNC | 8% | Dialogue | BNC Consortium (2007) | [link](http://www.natcorp.ox.ac.uk/) | [link](http://www.natcorp.ox.ac.uk/docs/licence.html) <sup>1</sup> |
| CHILDES | 29% | Dialogue, Child-Directed | MacWhinney (2000) | | [link](https://talkbank.org/share/rules.html) |
| Project Gutenberg | 26% | Fiction, Nonfiction | Gerlach & Font-Clos (2020) | [link](https://github.com/pgcorpus/gutenberg) | [link](https://www.gutenberg.org/policy/license.html) |
| OpenSubtitles | 20% | Dialogue, Scripted | Lison & Tiedermann (2016) | [link](https://opus.nlpl.eu/OpenSubtitles-v2018.php) | Open source |
| Simple English Wikipedia | 15% | Nonfiction | -- | [link](https://dumps.wikimedia.org/simplewiki/20221201/) | [link](https://dumps.wikimedia.org/legal.html) |
| Switchboard | 1% | Dialogue | Godfrey et al. (1992), Stolcke et al., (2000) | [link](http://compprag.christopherpotts.net/swda.html) | [link](http://compprag.christopherpotts.net/swda.html) |
<sup>1</sup> Our distribution of part of the BNC Texts is permitted under the fair dealings provision of copyright law (see term (2g) in the BNC license).
## Hyperparameters
| Hyperparameter | Value |
| --- | --- |
| Number of epochs | 10 |
| Datapoint length | 512 |
| Batch size | 16 |
| Gradient accumulation steps | 4 |
| Learning rate | 0.0005 |
| Number of steps | 211650 |
| Warmup steps | 2116 |
| Gradient clipping | 1 |
| Optimizer | AdamW |
| Optimizer Beta_1 | 0.9 |
| Optimizer Beta_2 | 0.999 |
| Optimizer Epsilon | 10<sup>-8</sup>|
| Tokenizer | BytePairBPE |
| Vocab Size | 16000 |
## Training Procedure
The model is trained with next token prediction loss for 10 epochs.
### Size and checkpoints
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
The model has 124M parameters.
In total we train on around 1B words and provide multiple checkpoints from the training.
Specifically we provode:
- Checkpoints every 1M words for the first 10M words
- Checkpoints every 10M words first 100M words
- Checkpoints every 100M words until 1B words
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
This model is evaluated in two ways:
1. We do zero-shot evaluation on 7 tasks.
2. We do fine-tuning on a subset of the (Super)GLUE tasks (Wang et al., ICLR 2019; Wang et al., NeurIPS 2019) .
## Testing Data & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
For the BLiMP, BLiMP supplement, and EWoK tasks, we use a filtered version of the dataset to only include examples with words found in the BabyLM dataset.
For the Finetuning task, we both filter and sample down to a maximum 10 000 train examples.
*Validation Data*
*Zero-shot Tasks*
- **BLiMP**: The Benchmark of Linguistic Minimal Pairs evaluates the model's linguistic ability by seeing if it can recognize the grammatically correct sentence from a pair of minimally different sentences. It tests various grammatical phenomena.(Warstadt et al., TACL 2020)
- **BLiMP Supplement**: A supplement to BLiMP introduced in the first edition of the BabyLM challenge. More focused on dialogue and questions. (Warstadt et al., CoNLL-BabyLM 2023)
- **EWoK**: Works similarly to BLiMP but looks the model's internal world knowledge. Looking at both whter a model has physical and social knowledge. (Ivanova et al., 2024)
- **Eye Tracking and Self-paced Reading**: Looks at whether the model can mimick the eye tracking and reading time of a human but using surprisal of a word as a proxy for time spent reading a word. (de Varda et al., BRM 2024)
- **Entity Tracking**: Checks whether a model can keep track of the changes to the states of entities as text/dialogue unfolds. (Kim & Schuster, ACL 2023)
- **WUGs**: Tests morphological generalization in LMs through an adjective nominalization and past tense task. (Hofmann et al., 2024) (Weissweiler et al., 2023)
- **COMPS**: Property knowledge. (Misra et al., 2023)
*Finetuning Tasks*
- **BoolQ**: A yes/no QA dataset with unprompted and unconstrained questions. (Clark et al., NAACL 2019)
- **MNLI**: The Multi-Genre Natural Language Inference corpus tests the language understanding of a model by seeing wehther it can recognize textual entailment. (Williams et al., NAACL 2018)
- **MRPC**: The Microsoft Research Paraphrase Corpus contains pairs of sentences that are either paraphrases/semntically equivalent to each other or unrelated.(Dolan & Brockett, IJCNLP 2005)
- **QQP**<sup>2</sup>: Similarly to MRPC, the Quora Question Pairs corpus tests the models ability to determine whether a pair of questions are sematically similar to each other. These questions are sourced from Quora.
- **MultiRC**: The Multi-Sentence Reading Comprehension corpus is a QA task that evaluates the model's ability to the correct answer from a list of answers given a question and context paragraph. In this version the data is changed to a binary classification judging whether the answer to a question, context pair is correct. (Khashabi et al., NAACL 2018)
- **RTE**: Similar the Recognizing Text Entailement tests the model's ability to recognize text entailement. (Dagan et al., Springer 2006; Bar et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., TAC 2009)
- **WSC**: The Winograd Schema Challenge tests the models ability to do coreference resolution on sentences with a pronoun and a list of noun phrases found in the sentence. This version edits it to be a binary classification on examples consisting of a pronoun and noun phrase.(Levesque et al., PKRR 2012)
<sup>2</sup> https://www.quora.com/profile/Ricky-Riche-2/First-Quora-Dataset-Release-Question-Pairs
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
The metrics used to evaluate the model are the following:
- Zero-shot
- Accuracy on predicting the correct completion/sentence for BLiMP, BLiMP Supplement, EWoK, Entity Tracking, and WUGs
- Change in R^2 prediction from baseline for Eye Tracking (with no spillover) and Self-paced Reading (1-word spillover)
- Finetuning
- 3 class Accuracy for MNLI
- Binary Accuracy for BoolQ, MultiRC, and WSC
- F1-score for MRPC and QQP
The metrics were chosen based on the advice of the papers the tasks come from.
### Hyperparameters
| Hyperparameter | MNLI, RTE, QQP, MRPC, BoolQ, MultiRC | WSC |
| --- | --- | --- |
| Learning Rate | 3\*10<sup>-5</sup> | 3\*10<sup>-5</sup> |
| Batch Size | 16 | 16 |
| Epochs | 10 | 30 |
| Weight decay | 0.01 | 0.01 |
| Optimizer | AdamW | AdamW |
| Scheduler | cosine | cosine |
| Warmup percentage | 6% | 6% |
| Dropout | 0.1 | 0.1 |
## Results
We compare our student model against two official baselines from the 2025 BabyLM Challenge<sup>1</sup>:
- **1000M-pre:** The standard *pretraining* baseline, using a GPT-2-small model trained on 100M unique words from the BabyLM dataset (10 epochs, next-word prediction).
- **SimPO:** A baseline first trained for 7 epochs with next-word prediction, then 2 epochs *interleaving* prediction and reinforcement learning. Here, the RL reward encourages the student to generate completions similar to the teacher’s output.
- **900M-pre:** Our model, using the same GPT-2-small architecture, pretrained on 90% of the BabyLM dataset (yielding approximately 91M unique words, 10 epochs).
- **900M-RL:** Our model after additional PPO-based reinforcement learning with the teacher, using about 1M words as input for the interactive (RL) phase.
---
### Evaluation Results
| **Task** | **1000M-pre** | **SimPO** | **900M-pre** | **900M-RL** |
|:------------- | ------------: | ---------:| ------------:| -----------:|
| BLiMP | 74.88 | 72.16 | 77.52 | **77.53** |
| Suppl. | **63.32** | 61.22 | 56.62 | 56.72 |
| EWOK | 51.67 | **51.92** | 51.36 | 51.41 |
| COMPS | **56.17** | 55.05 | 55.20 | 55.18 |
| ET | 31.51 | 28.06 | 30.34 | **33.11** |
| GLUE | 52.18 | 50.35 | **53.14** | 52.46 |
#### Model descriptions:
- **1000M-pre:** Baseline pretrained on 100M words (BabyLM challenge baseline).
- **SimPO:** Baseline using a hybrid of pretraining and RL with a similarity-based reward.
- **900M-pre:** Our GPT-2-small model, pretrained on 90M words (similar settings as baseline, but less data).
- **900M-RL:** The same model as 900M-pre, further trained with PPO using teacher feedback on 1M words of input.
-
See: [BabyLM Challenge](https://huggingface.co/BabyLM-community) for the baselines.
# Technical Specifications
### Hardware
- 4 A100 GPUs were used to train this model.
### Software
PyTorch
### Training Time
The model took 2.5 hours to train and consumed 755 core hours (with 4 GPUs and 32 CPUs).
# Citation
```latex
@misc{MayerMartinsBKB2025,
title={Once Upon a Time: Interactive Learning for Storytelling with Small Language Models},
author={Jonas Mayer Martins, Ali Hamza Bashir, Muhammad Rehan Khalid, Lisa Beinborn},
year={2025},
eprint={2502.TODO},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={ToDo},
}
```
# Model Card Authors
Jonas Mayer Martins
# Bibliography
[GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) (Wang et al., ICLR 2019)
[SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems](https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf) (Wang et al., NeurIPS 2019)
[BLiMP: The Benchmark of Linguistic Minimal Pairs for English](https://aclanthology.org/2020.tacl-1.25/) (Warstadt et al., TACL 2020)
[Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora](https://aclanthology.org/2023.conll-babylm.1/) (Warstadt et al., CoNLL-BabyLM 2023)
[🌏 Elements of World Knowledge (EWoK): A cognition-inspired framework for evaluating basic world knowledge in language models](https://arxiv.org/pdf/2405.09605v1) (Ivanova et al., 2024)
[Cloze probability, predictability ratings, and computational estimates for 205 English sentences, aligned with existing EEG and reading time data](https://link.springer.com/article/10.3758/s13428-023-02261-8) (de Varda et al., BRM 2024)
[Entity Tracking in Language Models](https://aclanthology.org/2023.acl-long.213/) (Kim & Schuster, ACL 2023)
[Derivational Morphology Reveals Analogical Generalization in Large Language Models](https://arxiv.org/pdf/2411.07990) (Hofmann et al., 2024)
[Automatically Constructing a Corpus of Sentential Paraphrases](https://aclanthology.org/I05-5002/) (Dolan & Brockett, IJCNLP 2005)
[A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference](https://aclanthology.org/N18-1101/) (Williams et al., NAACL 2018)
[The Winograd Schema Challenge]( http://dl.acm.org/citation.cfm?id=3031843.3031909) (Levesque et al., PKRR 2012)
[The PASCAL Recognising Textual Entailment Challenge](https://link.springer.com/chapter/10.1007/11736790_9) (Dagan et al., Springer 2006)
[The Second PASCAL Recognising Textual Entailment Challenge]() (Bar et al., 2006)
[The Third PASCAL Recognizing Textual Entailment Challenge](https://aclanthology.org/W07-1401/) (Giampiccolo et al., 2007)
[The Fifth PASCAL Recognizing Textual Entailment Challenge](https://tac.nist.gov/publications/2009/additional.papers/RTE5_overview.proceedings.pdf) (Bentivogli et al., TAC 2009)
[BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions](https://aclanthology.org/N19-1300/) (Clark et al., NAACL 2019)
[Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences](https://aclanthology.org/N18-1023/) (Khashabi et al., NAACL 2018)
|
huyydangg/thuvienphapluat_embedding_v6
|
huyydangg
| 2025-08-19T12:00:42Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:172688",
"loss:MatryoshkaLoss",
"loss:CachedMultipleNegativesSymmetricRankingLoss",
"vi",
"arxiv:1908.10084",
"arxiv:2205.13147",
"base_model:bkai-foundation-models/vietnamese-bi-encoder",
"base_model:finetune:bkai-foundation-models/vietnamese-bi-encoder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-19T11:55:48Z |
---
language:
- vi
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:172688
- loss:MatryoshkaLoss
- loss:CachedMultipleNegativesSymmetricRankingLoss
base_model: bkai-foundation-models/vietnamese-bi-encoder
widget:
- source_sentence: hiện_nay có văn_bản chính_thức áp_dụng giảm thuế gtgt cho năm 2023
chưa ?
sentences:
- quy_định về xuất_hóa_đơn đối_với hàng_hóa tự sản_xuất dùng để biếu tặng đối_tác
tại việt_nam
- xung_đột quy_phạm giữa điều 35 ( hình_phạt tiền ) và điều 188 ( tội buôn_lậu )
blhs 2015 và tính hợp_pháp khi tòa_chuyển hình_phạt chính từ tù sang phạt tiền
trong vụ án trịnh hoài_an
- văn_bản pháp_lý về giảm thuế giá_trị gia_tăng ( gtgt ) áp_dụng cho năm 2023 tại
việt_nam
- source_sentence: trường_hợp người lao_động là cấp quản_lý vào làm từ tháng 1 / 24
đến tháng 5 / 24 , không ký hợp_đồng lao_động chính_thức , không ký hợp_đồng thử
việc nhưng có tờ phiếu cam_kết ghi khi nghỉ_việc báo trước 30 ngày và ghi rõ thời_gian
thử việc ; theo luật lao_động , thử việc tối_đa 2 tháng và phải đóng bảo_hiểm
sau khi ký hợp_đồng chính_thức ( sau 2 tháng thử việc ) , nhưng công_ty chưa đóng
bảo_hiểm và người lao_động biết , vẫn nhận lương đầy_đủ và tiếp_tục làm , sau
đó người lao_động nghỉ ngang và yêu_cầu công_ty xử_lý sai ; công_ty muốn mời người
lao_động lên trao_đổi và bàn_giao để tránh thiệt_hại — công_ty có_thể xử_lý tình_huống
này như thế_nào để vừa hợp_pháp vừa giảm thiệt_hại ?
sentences:
- xử_lý pháp_lý và giảm thiệt_hại khi người lao_động quản_lý làm_việc không ký hợp_đồng
lao_động , không đóng bảo_hiểm và nghỉ ngang tại việt_nam
- điều_kiện cấp giấy chứng_nhận bị_thương để hưởng chế_độ ?
- quy_định về chi_phí thực_hiện thủ_tục hành_chính tại việt_nam
- source_sentence: giáo_viên tổng_phụ_trách đội thiếu 6 tiết / tuần bố_trí việc trực
hành_chính như thế_nào là đúng quy_định ạ ?
sentences:
- quy_định về việc ký_tên trên phiếu xuất kho và phiếu thu khi người mua không lấy
hóa_đơn
- giáo_viên kiêm tổng_phụ_trách đội bố_trí trực hành_chính như thế_nào ?
- quyền cho vay của ngân_hàng có yêu_cầu tài_sản bảo_đảm , cho vay tiếp khi tài_sản
bảo_đảm thuộc chủ sở_hữu doanh_nghiệp tư_nhân , và điều_kiện tăng vốn điều_lệ
ngân_hàng theo pháp_luật việt_nam
- source_sentence: sắp tới phù_hiệu một_số xe ô_tô kinh_doanh vận_tải bên tôi sẽ hết
hạn , cho hỏi bên tôi làm thủ_tục cấp lại có được không ? nếu được thì trình_tự
, thủ_tục thế_nào ? cảm_ơn nhiều !
sentences:
- trình_tự , thủ_tục cấp lại phù_hiệu xe ô_tô kinh_doanh vận_tải
- ubnd xã có được phép thuê thẩm_tra đối_với dự_án do mình làm_chủ đầu_tư không
?
- khởi_tố hình_sự về tội mua_bán , tàng_trữ , sử_dụng công_cụ kích điện sau khi
đã bị xử_phạt vi_phạm hành_chính theo nghị_định 42 / 2019 / nđ - cp ( điều 242
bộ_luật hình_sự )
- source_sentence: cho mình hỏi về cách tính thanh_toán tiền_lương làm tăng giờ đối_với
công_chức nhà_nước . tiền_lương một tháng để tính tăng giờ có bao_gồm phụ_cấp
không ?
sentences:
- trách_nhiệm pháp_lý của người sử_dụng lao_động khi người lao_động tử_vong do tai_nạn
giao_thông trong quá_trình làm_việc " , " quyền_lợi của người lao_động tử_vong
do tai_nạn lao_động ngoài trụ_sở làm_việc
- trách_nhiệm pháp_lý và chính_sách nhân_đạo đối_với người vợ mang thai trong trường_hợp
ly_hôn , tranh_chấp tài_sản chung và nghĩa_vụ trả nợ của chồng
- tiền_lương để tính tăng giờ đối_với công_chức có bao_gồm phụ_cấp không ?
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: bkai-fine-tuned-legal
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.7492356156768276
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8526359677568794
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8838599092004077
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9138330399332901
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7492356156768276
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.28421198925229313
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17677198184008155
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09138330399332903
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7492356156768276
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8526359677568794
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8838599092004077
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9138330399332901
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8332832988114963
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8072904028037066
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8100107043073839
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.7453905308996572
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.850782914852219
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8807560455851015
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9114240711572316
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7453905308996572
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2835943049507397
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17615120911702029
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09114240711572316
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7453905308996572
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.850782914852219
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8807560455851015
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9114240711572316
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8303146530060463
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8041402680161672
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8069259153944788
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.7380709719262485
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8438339664597424
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8737607708700084
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9066987862503475
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7380709719262485
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2812779888199141
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17475215417400167
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09066987862503476
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7380709719262485
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8438339664597424
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8737607708700084
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9066987862503475
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.823852114469264
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.797167126988547
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8001073541514653
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.7227369591401834
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8282683220605949
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8625498007968128
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8983137218567591
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7227369591401834
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.27608944068686486
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17250996015936257
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0898313721856759
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7227369591401834
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8282683220605949
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8625498007968128
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8983137218567591
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8111519983907917
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7831791512429517
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7862551573873537
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.694848512925044
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8039933290095432
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.842258871490781
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8801538033910868
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.694848512925044
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2679977763365144
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16845177429815622
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08801538033910869
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.694848512925044
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8039933290095432
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.842258871490781
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8801538033910868
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7874304560596916
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.757746147194181
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.761272699392562
name: Cosine Map@100
---
# bkai-fine-tuned-legal
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [bkai-foundation-models/vietnamese-bi-encoder](https://huggingface.co/bkai-foundation-models/vietnamese-bi-encoder) on the json dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [bkai-foundation-models/vietnamese-bi-encoder](https://huggingface.co/bkai-foundation-models/vietnamese-bi-encoder) <!-- at revision 84f9d9ada0d1a3c37557398b9ae9fcedcdf40be0 -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- json
- **Language:** vi
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False, 'architecture': 'RobertaModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("huyydangg/thuvienphapluat_embedding_v6")
# Run inference
sentences = [
'cho mình hỏi về cách tính thanh_toán tiền_lương làm tăng giờ đối_với công_chức nhà_nước . tiền_lương một tháng để tính tăng giờ có bao_gồm phụ_cấp không ?',
'tiền_lương để tính tăng giờ đối_với công_chức có bao_gồm phụ_cấp không ?',
'trách_nhiệm pháp_lý của người sử_dụng lao_động khi người lao_động tử_vong do tai_nạn giao_thông trong quá_trình làm_việc " , " quyền_lợi của người lao_động tử_vong do tai_nạn lao_động ngoài trụ_sở làm_việc',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[ 1.0000, 0.8958, -0.1026],
# [ 0.8958, 1.0000, -0.0500],
# [-0.1026, -0.0500, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 768
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7492 |
| cosine_accuracy@3 | 0.8526 |
| cosine_accuracy@5 | 0.8839 |
| cosine_accuracy@10 | 0.9138 |
| cosine_precision@1 | 0.7492 |
| cosine_precision@3 | 0.2842 |
| cosine_precision@5 | 0.1768 |
| cosine_precision@10 | 0.0914 |
| cosine_recall@1 | 0.7492 |
| cosine_recall@3 | 0.8526 |
| cosine_recall@5 | 0.8839 |
| cosine_recall@10 | 0.9138 |
| **cosine_ndcg@10** | **0.8333** |
| cosine_mrr@10 | 0.8073 |
| cosine_map@100 | 0.81 |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 512
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7454 |
| cosine_accuracy@3 | 0.8508 |
| cosine_accuracy@5 | 0.8808 |
| cosine_accuracy@10 | 0.9114 |
| cosine_precision@1 | 0.7454 |
| cosine_precision@3 | 0.2836 |
| cosine_precision@5 | 0.1762 |
| cosine_precision@10 | 0.0911 |
| cosine_recall@1 | 0.7454 |
| cosine_recall@3 | 0.8508 |
| cosine_recall@5 | 0.8808 |
| cosine_recall@10 | 0.9114 |
| **cosine_ndcg@10** | **0.8303** |
| cosine_mrr@10 | 0.8041 |
| cosine_map@100 | 0.8069 |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 256
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7381 |
| cosine_accuracy@3 | 0.8438 |
| cosine_accuracy@5 | 0.8738 |
| cosine_accuracy@10 | 0.9067 |
| cosine_precision@1 | 0.7381 |
| cosine_precision@3 | 0.2813 |
| cosine_precision@5 | 0.1748 |
| cosine_precision@10 | 0.0907 |
| cosine_recall@1 | 0.7381 |
| cosine_recall@3 | 0.8438 |
| cosine_recall@5 | 0.8738 |
| cosine_recall@10 | 0.9067 |
| **cosine_ndcg@10** | **0.8239** |
| cosine_mrr@10 | 0.7972 |
| cosine_map@100 | 0.8001 |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 128
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7227 |
| cosine_accuracy@3 | 0.8283 |
| cosine_accuracy@5 | 0.8625 |
| cosine_accuracy@10 | 0.8983 |
| cosine_precision@1 | 0.7227 |
| cosine_precision@3 | 0.2761 |
| cosine_precision@5 | 0.1725 |
| cosine_precision@10 | 0.0898 |
| cosine_recall@1 | 0.7227 |
| cosine_recall@3 | 0.8283 |
| cosine_recall@5 | 0.8625 |
| cosine_recall@10 | 0.8983 |
| **cosine_ndcg@10** | **0.8112** |
| cosine_mrr@10 | 0.7832 |
| cosine_map@100 | 0.7863 |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator) with these parameters:
```json
{
"truncate_dim": 64
}
```
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6948 |
| cosine_accuracy@3 | 0.804 |
| cosine_accuracy@5 | 0.8423 |
| cosine_accuracy@10 | 0.8802 |
| cosine_precision@1 | 0.6948 |
| cosine_precision@3 | 0.268 |
| cosine_precision@5 | 0.1685 |
| cosine_precision@10 | 0.088 |
| cosine_recall@1 | 0.6948 |
| cosine_recall@3 | 0.804 |
| cosine_recall@5 | 0.8423 |
| cosine_recall@10 | 0.8802 |
| **cosine_ndcg@10** | **0.7874** |
| cosine_mrr@10 | 0.7577 |
| cosine_map@100 | 0.7613 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### json
* Dataset: json
* Size: 172,688 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 47.78 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 19.27 tokens</li><li>max: 80 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>hàng_hóa có tổng_trị_giá hải_quan bao_nhiêu thì được miễn thuế_xuất_khẩu , thuế_nhập_khẩu ?</code> | <code>tổng_trị_giá hải_quan được miễn thuế_xuất_khẩu , thuế_nhập_khẩu</code> |
| <code>mình thanh_toán phí sửa_chữa cho nước_ngoài thì thanh_toán thuế nhà_thầu gồm mục nào , khi sửa_chữa máy_móc thực_hiện_tại việt_nam ?</code> | <code>quy_định về thuế nhà_thầu đối_với thanh_toán phí sửa_chữa máy_móc cho nhà_thầu nước_ngoài tại việt_nam</code> |
| <code>đồng_hồ điện nhà tôi và 2 hộ khác đang gắn trên trụ điện ở đất của một nhà hàng_xóm ( trụ điện này đã có từ lâu ) . nay nhà đó yêu_cầu chúng_tôi dời đồng_hồ điện đi chỗ khác với lý_do dây_điện trong đất nhà họ , họ sợ bị điện giật . việc họ bắt người khác dời đồng_hồ điện như_vậy có đúng quy_định pháp_luật hay không ? và nếu chủ nhà có cột điện như_vậy thì xử_lý ra sao ?</code> | <code>quyền và nghĩa_vụ liên_quan đến vị_trí lắp_đặt đồng_hồ điện trên trụ điện đặt trên đất của người khác và biện_pháp xử_lý theo pháp_luật việt_nam</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "CachedMultipleNegativesSymmetricRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Evaluation Dataset
#### json
* Dataset: json
* Size: 21,586 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 48.05 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 5 tokens</li><li>mean: 19.81 tokens</li><li>max: 105 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>xin cung_cấp thông_tư 15 / 2022 / tt - bqp ngày 10 / 02 / 2022 của bộ_trưởng bộ quốc_phòng_ban_hành điều_lệ công_tác bảo_vệ môi_trường của quân_đội nhân_dân việt_nam</code> | <code>văn_bản thông_tư 15 / 2022 / tt - bqp ngày 10 / 02 / 2022 về điều_lệ công_tác bảo_vệ môi_trường của quân_đội nhân_dân việt_nam</code> |
| <code>trường_hợp bhtn là trích tiền ra nộp cho bhxh tỉnh hay là tự trích ra trả cho người lao_động luôn ?</code> | <code>cách_thức quản_lý và chi_trả kinh_phí bảo_hiểm_thất_nghiệp tại việt_nam ( nộp vào quỹ bhxh tỉnh hay chi trực_tiếp cho người lao_động )</code> |
| <code>cho xin thêm văn_bản pháp_lý hướng_dẫn quy_trình kỹ_thuật_số 5,6,7,8 của bộ y_tế ban_hành ?</code> | <code>văn_bản pháp_lý hướng_dẫn quy_trình kỹ_thuật_số 5 , 6 , 7 , 8 của bộ y_tế</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "CachedMultipleNegativesSymmetricRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 12
- `per_device_eval_batch_size`: 12
- `gradient_accumulation_steps`: 24
- `learning_rate`: 3e-05
- `weight_decay`: 0.15
- `max_grad_norm`: 0.65
- `num_train_epochs`: 12
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.15
- `fp16`: True
- `load_best_model_at_end`: True
- `group_by_length`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 12
- `per_device_eval_batch_size`: 12
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 24
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 3e-05
- `weight_decay`: 0.15
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 0.65
- `num_train_epochs`: 12
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.15
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: True
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | dim_768_cosine_ndcg@10 | dim_512_cosine_ndcg@10 | dim_256_cosine_ndcg@10 | dim_128_cosine_ndcg@10 | dim_64_cosine_ndcg@10 |
|:-------:|:--------:|:-------------:|:---------------:|:----------------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|
| 1.0 | 600 | 0.1485 | 0.0549 | 0.7989 | 0.7960 | 0.7876 | 0.7658 | 0.7262 |
| 2.0 | 1200 | 0.0417 | 0.0412 | 0.7845 | 0.7797 | 0.7637 | 0.7405 | 0.7100 |
| 3.0 | 1800 | 0.0223 | 0.0376 | 0.8183 | 0.8159 | 0.8074 | 0.7920 | 0.7626 |
| 4.0 | 2400 | 0.0155 | 0.0345 | 0.8057 | 0.8034 | 0.7933 | 0.7746 | 0.7482 |
| 5.0 | 3000 | 0.0125 | 0.0332 | 0.8298 | 0.8261 | 0.8184 | 0.8043 | 0.7759 |
| **6.0** | **3600** | **0.01** | **0.0296** | **0.8298** | **0.827** | **0.8188** | **0.8059** | **0.7798** |
| 7.0 | 4200 | 0.0087 | 0.0311 | 0.8333 | 0.8303 | 0.8239 | 0.8112 | 0.7874 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755602935
|
indoempatnol
| 2025-08-19T11:56:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:56:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755603521
|
Sayemahsjn
| 2025-08-19T11:55:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:55:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AXERA-TECH/Qwen2.5-0.5B-Instruct-CTX-Int8
|
AXERA-TECH
| 2025-08-19T11:51:10Z | 10 | 0 |
transformers
|
[
"transformers",
"Qwen",
"Qwen2.5-0.5B-Instruct",
"Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"GPTQ",
"en",
"base_model:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | null | 2025-06-03T07:41:28Z |
---
library_name: transformers
license: bsd-3-clause
base_model:
- Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
tags:
- Qwen
- Qwen2.5-0.5B-Instruct
- Qwen2.5-0.5B-Instruct-GPTQ-Int8
- GPTQ
language:
- en
---
# Qwen2.5-0.5B-Instruct-GPTQ-Int8
This version of Qwen2.5-0.5B-Instruct-GPTQ-Int8 has been converted to run on the Axera NPU using **w8a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.2(Not released yet)
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo : https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GPTQ-Int8
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
[AXera NPU LLM Runtime](https://github.com/AXERA-TECH/ax-llm)
## Support Platform
- AX650
- AX650N DEMO Board
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
- AX630C
- *developing*
|Chips|w8a16|w4a16|
|--|--|--|
|AX650| 30 tokens/sec| TBD |
## How to use
Download all files from this repository to the device
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# tree -L 1
.
|-- main_ax650
|-- main_axcl_aarch64
|-- main_axcl_x86
|-- post_config.json
|-- qwen2.5-0.5b-gptq-int8-ctx-ax630c
|-- qwen2.5-0.5b-gptq-int8-ctx-ax650
|-- qwen2.5_tokenizer
|-- qwen2.5_tokenizer_uid.py
|-- run_qwen2.5_0.5b_gptq_int8_ctx_ax630c.sh
`-- run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
3 directories, 7 files
```
#### Start the Tokenizer service
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# python3 qwen2.5_tokenizer_uid.py
Server running at http://0.0.0.0:12345
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
Open another terminal and run `run_qwen2.5_0.5b_gptq_int8_ax650.sh`
```
root@ax650:/mnt/qtang/llm-test/qwen2.5-0.5b-ctx# ./run_qwen2.5_0.5b_gptq_int8_ctx_ax650.sh
[I][ Init][ 110]: LLM init start
[I][ Init][ 34]: connect http://127.0.0.1:12345 ok
[I][ Init][ 57]: uid: cdeaf62e-0243-4dc9-b557-23a7c1ba7da1
bos_id: -1, eos_id: 151645
100% | ████████████████████████████████ | 27 / 27 [12.35s<12.35s, 2.19 count/s] init post axmodel ok,remain_cmm(3960 MB)
[I][ Init][ 188]: max_token_len : 2560
[I][ Init][ 193]: kv_cache_size : 128, kv_cache_num: 2560
[I][ Init][ 201]: prefill_token_num : 128
[I][ Init][ 205]: grp: 1, prefill_max_token_num : 1
[I][ Init][ 205]: grp: 2, prefill_max_token_num : 128
[I][ Init][ 205]: grp: 3, prefill_max_token_num : 512
[I][ Init][ 205]: grp: 4, prefill_max_token_num : 1024
[I][ Init][ 205]: grp: 5, prefill_max_token_num : 1536
[I][ Init][ 205]: grp: 6, prefill_max_token_num : 2048
[I][ Init][ 209]: prefill_max_token_num : 2048
[I][ load_config][ 282]: load config:
{
"enable_repetition_penalty": false,
"enable_temperature": false,
"enable_top_k_sampling": true,
"enable_top_p_sampling": false,
"penalty_window": 20,
"repetition_penalty": 1.2,
"temperature": 0.9,
"top_k": 1,
"top_p": 0.8
}
[I][ Init][ 218]: LLM init ok
Type "q" to exit, Ctrl+c to stop current running
[I][ GenerateKVCachePrefill][ 271]: input token num : 21, prefill_split_num : 1 prefill_grpid : 2
[I][ GenerateKVCachePrefill][ 308]: input_num_token:21
[I][ main][ 230]: precompute_len: 21
[I][ main][ 231]: system_prompt: You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
prompt >> who are you?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:38 input_num_token:12
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 12, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:12
[I][ Run][ 829]: ttft: 134.80 ms
I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks,
from general knowledge to specific areas such as science, technology, and more. How can I help you today?
[N][ Run][ 943]: hit eos,avg 30.88 token/s
[I][ GetKVCache][ 500]: precompute_len:98, remaining:1950
prompt >> what can you do?
[I][ SetKVCache][ 531]: prefill_grpid:2 kv_cache_num:128 precompute_len:98 input_num_token:13
[I][ SetKVCache][ 534]: current prefill_max_token_num:1920
[I][ Run][ 660]: input token num : 13, prefill_split_num : 1
[I][ Run][ 686]: input_num_token:13
[I][ Run][ 829]: ttft: 134.97 ms
I can answer questions, provide information, assist with tasks, and even engage in creative writing.
I'm here to help you with any questions or tasks you might have!
[N][ Run][ 943]: hit eos,avg 30.85 token/s
[I][ GetKVCache][ 500]: precompute_len:145, remaining:1903
```
|
Datasmartly/nllb-darija1
|
Datasmartly
| 2025-08-19T11:50:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:16:39Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: nllb-darija1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nllb-darija1
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6728
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 2.9505 | 1.7778 | 500 | 2.6728 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.0.1
- Datasets 2.21.0
- Tokenizers 0.19.1
|
DeathBlade020/legal-llama-1b-4bit
|
DeathBlade020
| 2025-08-19T11:45:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-19T11:42:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
longhoang2112/whisper-turbo-fine-tuning_2_stages_with_covoi11_2
|
longhoang2112
| 2025-08-19T11:41:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"whisper",
"trl",
"en",
"base_model:unsloth/whisper-large-v3-turbo",
"base_model:finetune:unsloth/whisper-large-v3-turbo",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:41:08Z |
---
base_model: unsloth/whisper-large-v3-turbo
tags:
- text-generation-inference
- transformers
- unsloth
- whisper
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** longhoang2112
- **License:** apache-2.0
- **Finetuned from model :** unsloth/whisper-large-v3-turbo
This whisper model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
smoorsmith/Dream_s1k_DORA_softmasking-None-learnable-16
|
smoorsmith
| 2025-08-19T11:36:46Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:smoorsmith/Dream-v0-Instruct-7B",
"base_model:adapter:smoorsmith/Dream-v0-Instruct-7B",
"region:us"
] | null | 2025-08-19T11:33:44Z |
---
base_model: smoorsmith/Dream-v0-Instruct-7B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
m-muraki/Qwen3-30B-A3B-Thinking-2507-FP8
|
m-muraki
| 2025-08-19T11:29:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-30B-A3B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Thinking-2507",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-19T11:28:58Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Thinking-2507
---
# Qwen3-30B-A3B-Thinking-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-30B-A3B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-30B-A3B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
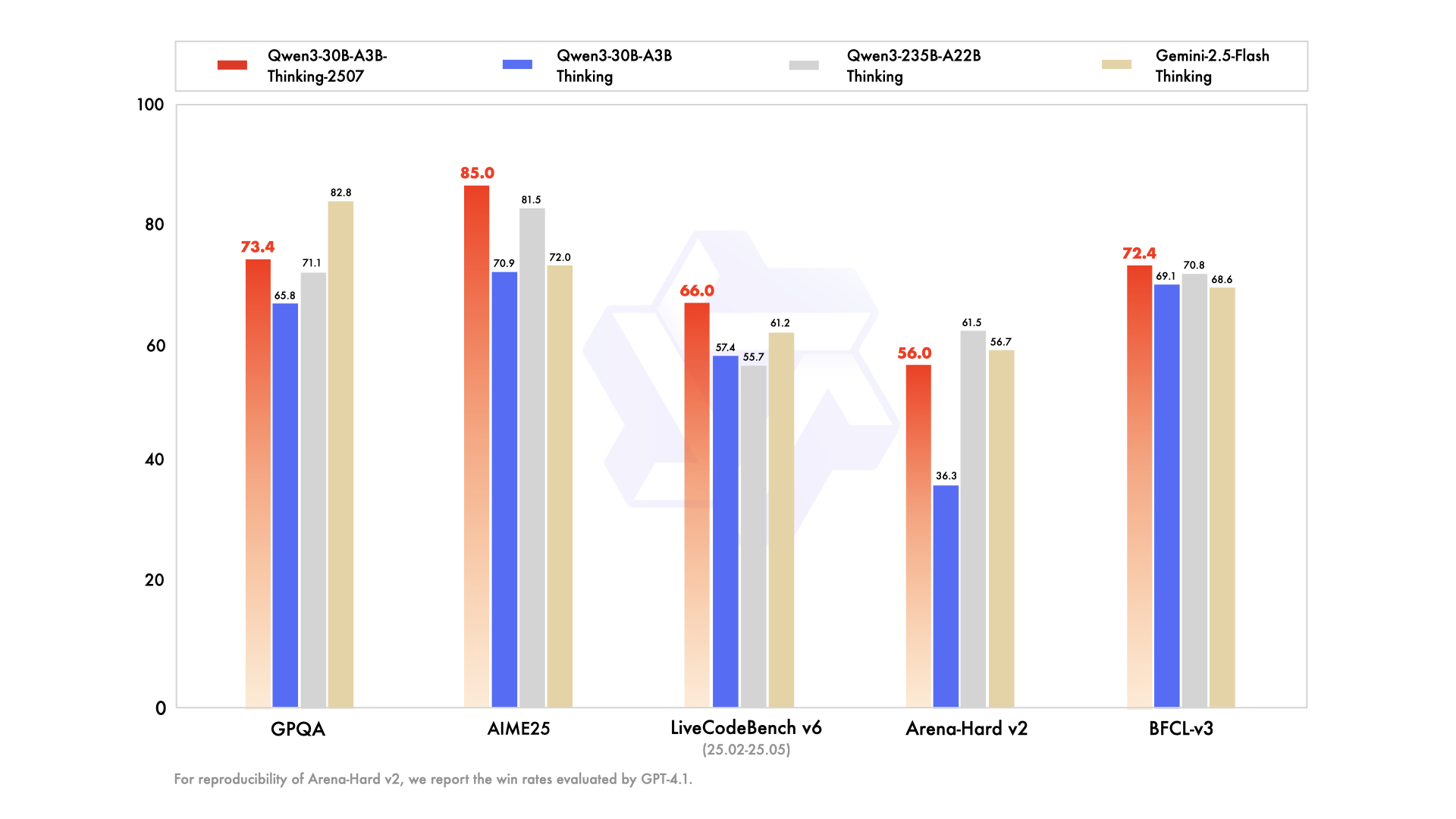
## Model Overview
This repo contains the FP8 version of **Qwen3-30B-A3B-Thinking-2507**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 81.9 | **82.8** | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | **92.7** | 89.5 | 91.4 |
| GPQA | **82.8** | 71.1 | 65.8 | 73.4 |
| SuperGPQA | 57.8 | **60.7** | 51.8 | 56.8 |
| **Reasoning** | | | | |
| AIME25 | 72.0 | 81.5 | 70.9 | **85.0** |
| HMMT25 | 64.2 | 62.5 | 49.8 | **71.4** |
| LiveBench 20241125 | 74.3 | **77.1** | 74.3 | 76.8 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 61.2 | 55.7 | 57.4 | **66.0** |
| CFEval | 1995 | **2056** | 1940 | 2044 |
| OJBench | 23.5 | **25.6** | 20.7 | 25.1 |
| **Alignment** | | | | |
| IFEval | **89.8** | 83.4 | 86.5 | 88.9 |
| Arena-Hard v2$ | 56.7 | **61.5** | 36.3 | 56.0 |
| Creative Writing v3 | **85.0** | 84.6 | 79.1 | 84.4 |
| WritingBench | 83.9 | 80.3 | 77.0 | **85.0** |
| **Agent** | | | | |
| BFCL-v3 | 68.6 | 70.8 | 69.1 | **72.4** |
| TAU1-Retail | 65.2 | 54.8 | 61.7 | **67.8** |
| TAU1-Airline | **54.0** | 26.0 | 32.0 | 48.0 |
| TAU2-Retail | **66.7** | 40.4 | 34.2 | 58.8 |
| TAU2-Airline | 52.0 | 30.0 | 36.0 | **58.0** |
| TAU2-Telecom | **31.6** | 21.9 | 22.8 | 26.3 |
| **Multilingualism** | | | | |
| MultiIF | 74.4 | 71.9 | 72.2 | **76.4** |
| MMLU-ProX | **80.2** | 80.0 | 73.1 | 76.4 |
| INCLUDE | **83.9** | 78.7 | 71.9 | 74.4 |
| PolyMATH | 49.8 | **54.7** | 46.1 | 52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507-FP8"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Note on FP8
For convenience and performance, we have provided `fp8`-quantized model checkpoint for Qwen3, whose name ends with `-FP8`. The quantization method is fine-grained `fp8` quantization with block size of 128. You can find more details in the `quantization_config` field in `config.json`.
You can use the Qwen3-30B-A3B-Thinking-2507-FP8 model with serveral inference frameworks, including `transformers`, `sglang`, and `vllm`, as the original bfloat16 model.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507-FP8',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --served-model-name Qwen3-30B-A3B-Thinking-2507-FP8 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-30B-A3B-Thinking-2507-FP8',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
hossein12321asdf/q-FrozenLake-v1-4x4-noSlippery
|
hossein12321asdf
| 2025-08-19T11:29:46Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-17T13:46:26Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="hossein12321asdf/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
lavavaa/blockassist-bc-giant_knobby_chimpanzee_1755602733
|
lavavaa
| 2025-08-19T11:26:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"giant knobby chimpanzee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:26:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- giant knobby chimpanzee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755600940
|
kojeklollipop
| 2025-08-19T11:21:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:21:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
crocodlo/blockassist-bc-soft_barky_scorpion_1755602151
|
crocodlo
| 2025-08-19T11:16:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"soft barky scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:16:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- soft barky scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
matheoqtb/mmarco-eurobert-0M_pairs
|
matheoqtb
| 2025-08-19T11:15:49Z | 0 | 0 | null |
[
"safetensors",
"eurobert",
"custom_code",
"region:us"
] | null | 2025-08-19T11:15:37Z |
# Checkpoint exporté: 0M_pairs
Ce dépôt contient un checkpoint extrait de `matheoqtb/euroBertV2_test` (sous-dossier `0M_pairs`) et les fichiers de code nécessaires provenant de `EuroBERT/EuroBERT-610m`.
Chargement:
from transformers import AutoTokenizer, AutoModel
tok = AutoTokenizer.from_pretrained('<THIS_REPO>', trust_remote_code=True)
mdl = AutoModel.from_pretrained('<THIS_REPO>', trust_remote_code=True)
Tâche: feature-extraction (embeddings)
|
Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF
|
Ba2han
| 2025-08-19T11:13:53Z | 0 | 0 | null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:Ba2han/qwen3-coder-30b-a3b-experiment2",
"base_model:quantized:Ba2han/qwen3-coder-30b-a3b-experiment2",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T11:12:44Z |
---
base_model: Ba2han/qwen3-coder-30b-a3b-experiment2
tags:
- llama-cpp
- gguf-my-repo
---
# Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF
This model was converted to GGUF format from [`Ba2han/qwen3-coder-30b-a3b-experiment2`](https://huggingface.co/Ba2han/qwen3-coder-30b-a3b-experiment2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Ba2han/qwen3-coder-30b-a3b-experiment2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ba2han/qwen3-coder-30b-a3b-experiment2-Q4_K_S-GGUF --hf-file qwen3-coder-30b-a3b-experiment2-q4_k_s.gguf -c 2048
```
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755600296
|
hakimjustbao
| 2025-08-19T11:12:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:11:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
frankmorales2020/mistral-7b-alpha-finetuned-llm-science-exam-tpu-colab-v6e-1
|
frankmorales2020
| 2025-08-19T11:09:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T11:06:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sindhusatish97/sparq-llama3-8b-qlora
|
sindhusatish97
| 2025-08-19T11:07:35Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"region:us"
] |
text-generation
| 2025-08-19T11:07:29Z |
---
base_model: meta-llama/Meta-Llama-3-8B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755599920
|
ihsanridzi
| 2025-08-19T11:06:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:06:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755599691
|
pempekmangedd
| 2025-08-19T11:01:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:01:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lakelee/RLB_MLP_BC_v4.20250819.18
|
lakelee
| 2025-08-19T10:59:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"base_model:lakelee/RLB_MLP_TSC_v1.20250818.16",
"base_model:finetune:lakelee/RLB_MLP_TSC_v1.20250818.16",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:33:07Z |
---
library_name: transformers
base_model: lakelee/RLB_MLP_TSC_v1.20250818.16
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_BC_v4.20250819.18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_BC_v4.20250819.18
This model is a fine-tuned version of [lakelee/RLB_MLP_TSC_v1.20250818.16](https://huggingface.co/lakelee/RLB_MLP_TSC_v1.20250818.16) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu128
- Tokenizers 0.21.4
|
John6666/wahtastic-furry-mix-v92-hotfix-sdxl
|
John6666
| 2025-08-19T10:49:21Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"furry",
"style",
"LoRA compatibility",
"v-pred",
"noobai",
"illustrious",
"en",
"base_model:Laxhar/noobai-XL-Vpred-1.0",
"base_model:finetune:Laxhar/noobai-XL-Vpred-1.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T10:44:20Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- furry
- style
- LoRA compatibility
- v-pred
- noobai
- illustrious
base_model: Laxhar/noobai-XL-Vpred-1.0
---
Original model is [here](https://civitai.com/models/1807134/wahtastic-furry-mix?modelVersionId=2128432).
This model created by [velvet_toroyashi](https://civitai.com/user/velvet_toroyashi).
|
abcorrea/p2-v7
|
abcorrea
| 2025-08-19T10:47:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:abcorrea/p2-v6",
"base_model:finetune:abcorrea/p2-v6",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T10:37:42Z |
---
base_model: abcorrea/p2-v6
library_name: transformers
model_name: p2-v7
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for p2-v7
This model is a fine-tuned version of [abcorrea/p2-v6](https://huggingface.co/abcorrea/p2-v6).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="abcorrea/p2-v7", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.52.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755600286
|
0xaoyama
| 2025-08-19T10:45:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:45:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Medved444/blockassist-bc-bellowing_finicky_manatee_1755599074
|
Medved444
| 2025-08-19T10:45:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bellowing finicky manatee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:44:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bellowing finicky manatee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
truong1301/qwen3_only_table
|
truong1301
| 2025-08-19T10:41:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-14B-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-14B-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:41:21Z |
---
base_model: unsloth/Qwen3-14B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** truong1301
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-14B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking
|
AIMindaeng
| 2025-08-19T10:41:50Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"dataset:lmms-lab/multimodal-open-r1-8k-verified",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T05:24:56Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
datasets: lmms-lab/multimodal-open-r1-8k-verified
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct-Thinking
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct-Thinking
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) on the [lmms-lab/multimodal-open-r1-8k-verified](https://huggingface.co/datasets/lmms-lab/multimodal-open-r1-8k-verified) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
darshanvyas36/qwen-8-B
|
darshanvyas36
| 2025-08-19T10:40:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:40:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
joanna302/Qwen3-1.7B-Base_pag_mt_alpaca_1_part_SFT_0.0002
|
joanna302
| 2025-08-19T10:36:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"unsloth",
"sft",
"conversational",
"base_model:unsloth/Qwen3-1.7B-Base",
"base_model:finetune:unsloth/Qwen3-1.7B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T08:22:09Z |
---
base_model: unsloth/Qwen3-1.7B-Base
library_name: transformers
model_name: Qwen3-1.7B-Base_pag_mt_alpaca_1_part_SFT_0.0002
tags:
- generated_from_trainer
- trl
- unsloth
- sft
licence: license
---
# Model Card for Qwen3-1.7B-Base_pag_mt_alpaca_1_part_SFT_0.0002
This model is a fine-tuned version of [unsloth/Qwen3-1.7B-Base](https://huggingface.co/unsloth/Qwen3-1.7B-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="joanna302/Qwen3-1.7B-Base_pag_mt_alpaca_1_part_SFT_0.0002", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/prism-eval/Qwen3-1.7B-Base_pag_mt_alpaca_1_part_SFT_0.0002/runs/mrkzllkv)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
nuttakitinta/typhoon2-8b-ocrfix-lora
|
nuttakitinta
| 2025-08-19T10:34:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:scb10x/llama3.1-typhoon2-8b-instruct",
"base_model:finetune:scb10x/llama3.1-typhoon2-8b-instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:34:01Z |
---
base_model: scb10x/llama3.1-typhoon2-8b-instruct
library_name: transformers
model_name: typhoon2-8b-ocrfix-lora
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for typhoon2-8b-ocrfix-lora
This model is a fine-tuned version of [scb10x/llama3.1-typhoon2-8b-instruct](https://huggingface.co/scb10x/llama3.1-typhoon2-8b-instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="nuttakitinta/typhoon2-8b-ocrfix-lora", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.4.1+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Denn231/external_clf_v_0.67
|
Denn231
| 2025-08-19T10:32:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T09:12:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755599294
|
0xaoyama
| 2025-08-19T10:28:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:28:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ale91Jonathan/blockassist-bc-alert_dormant_prawn_1755595507
|
Ale91Jonathan
| 2025-08-19T09:58:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"alert dormant prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T09:58:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- alert dormant prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
SUlttan/gpt_2_larg
|
SUlttan
| 2025-08-19T09:58:33Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"region:us"
] | null | 2025-08-16T16:24:20Z |
# Somali Code Generation (GPT-2 large)
Trained on Somali prompts, explanations, and code.
## Usage
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained('SUlttan/gpt_2_larg')
tokenizer = AutoTokenizer.from_pretrained('SUlttan/gpt_2_larg')
|
DarrenHiggs/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-winged_sprightly_gerbil
|
DarrenHiggs
| 2025-08-19T09:58:07Z | 101 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am winged_sprightly_gerbil",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-13T16:47:12Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am winged_sprightly_gerbil
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Nakamotosatoshi/QwenImageEdit
|
Nakamotosatoshi
| 2025-08-19T09:41:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T09:40:13Z |
---
license: apache-2.0
---
|
Muapi/cardboard
|
Muapi
| 2025-08-19T09:39:15Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:39:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Cardboard

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:331365@1546505", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/hassan-skinflux
|
Muapi
| 2025-08-19T09:38:37Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:38:21Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Hassan - skinFlux

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1167485@1313447", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
thomasavare/Qwen3-14B-unsloth-bnb-4bit-lora-merged
|
thomasavare
| 2025-08-19T09:36:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-19T09:27:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Huseyin/qwen3-8b-turkish-teknofest2025-private
|
Huseyin
| 2025-08-19T09:36:09Z | 0 | 0 | null |
[
"safetensors",
"turkish",
"education",
"qwen",
"teknofest2025",
"private",
"tr",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T09:35:05Z |
---
language: tr
license: apache-2.0
tags:
- turkish
- education
- qwen
- teknofest2025
- private
metrics:
- perplexity
base_model: Qwen/Qwen3-8B
---
# 🔒 PRIVATE MODEL - TEKNOFEST 2025
**⚠️ Bu model TEKNOFEST 2025 yarışması için geliştirilmiş olup, yarışma süresince gizlidir.**
## Yarışma Bilgileri
- **Yarışma:** Eylem Temelli Türkçe Büyük Dil Modeli
- **Kategori:** Eğitim Teknolojileri Eylemcisi
- **Durum:** Competition Active - Private Until September 2025
## Model Performansı
- **Perplexity:** 8.42 ✨
- **Training Loss:** 2.008
- **Eval Loss:** 2.130
- **Training Time:** 5.5 hours (A100 40GB)
## Teknik Detaylar
- Base Model: Qwen/Qwen3-8B
- Parameters: 4.72B
- Fine-tuning: LoRA (rank=64)
- Training Data: 20K Turkish texts
- Batch Size: 4
- Learning Rate: 0.0001
- Epochs: 2
## 🚫 Kullanım Kısıtlaması
Bu model TEKNOFEST 2025 yarışması tamamlanana kadar gizli kalacaktır.
|
PatrickHaller/gla-350M-10B
|
PatrickHaller
| 2025-08-19T09:31:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gla",
"text-generation",
"en",
"dataset:PatrickHaller/fineweb-10B",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T09:11:46Z |
---
library_name: transformers
datasets:
- PatrickHaller/fineweb-10B
language:
- en
---
# Model Card for Model ID
Trained on 9.83B Tokens
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
xiahao2/gemma-3-270m-it-ft-NPC
|
xiahao2
| 2025-08-19T09:18:56Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T09:14:08Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: gemma-3-270m-it-ft-NPC
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma-3-270m-it-ft-NPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="xiahao2/gemma-3-270m-it-ft-NPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Muapi/rainbow-morph-bring-sunglasses-flux-xl-and-pony
|
Muapi
| 2025-08-19T09:18:48Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:18:38Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Rainbow Morph - bring sunglasses (Flux, XL, and Pony)

**Base model**: Flux.1 D
**Trained words**: Rainb0w M0rph, Rainbow_Morph
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:577283@734460", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Devion333/labse-dhivehi-finetuned
|
Devion333
| 2025-08-19T09:18:23Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:968266",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:sentence-transformers/LaBSE",
"base_model:finetune:sentence-transformers/LaBSE",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-19T09:08:42Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:968266
- loss:CosineSimilarityLoss
base_model: sentence-transformers/LaBSE
widget:
- source_sentence: ކުއްލިއަކަށް ދޮންބެ ތެދުވެ އިނދެ ދެފައި ވައްކޮއްލިއެވެ. ދެލޯ ބޮޑުކޮއްގެން
ހުރެ ހެވެމުން ދިލެމުން ގޮސް އަހަރެން ހުޅުވާލީވެސް ދޮންބެ ބުނި ކަބަޑެވެ. ގެރިގުއި
ކުލައިގެ ކަރުދާހަކުން ބަންދުކޮއްފައި އޮތް ފޮށިގަނޑެއް ފެނުމާއި އެކު އަހަރެންނަށް
ބަލާލެވުނީ ގޮދަނޑިމަތީގައި ދެފައި ވަށްކޮއްގެން އިން ބޭބެ އާއި ދިމާއަށެވެ.
sentences:
- sheet covering coffin
- The king's kidneys, heart and lungs have also stopped working, Saudi health officials
said, according to Press TV.
- The Civil Court of Maldives has ordered the seizure of passports and freezing
bank accounts belonging to Haulath Faheem, wife of former President Dr. Mohamed
Jamil, as well as seven other members of his family in connection with a case
of proven debt. This was decided by the court today after an action filed by Mohammad
Aniis who served as General Manager at four resorts owned by Three A Company when
it was not being divided into shares. The heir was not present at the court. The
lawyer for the heirs said that he has appealed to the High Court against this
decision. In any case of proven debt, it is a common practice in courts to hold
passports and freeze accounts as part of an application for enforcement of judgment
when there are no payments made by debtors. The family appealed the Civil Court’s
order to pay them back, which was then reviewed by the Supreme Court. In addition
to the three charges, Anies also brought another two cases against Musa Fahim’s
heirs. The other accused are Haulat and Shaheed as well as Farida Ibrahim, Ahmad
Shahid Shiyam, Ali Shiyam, Hassan Shiyam, Maryam Shifa and Aimanat Ashfah. The
two brothers’ son Anies said he owes the company 1.8 million rupees for days when
senior management was not paid due to problems arising from the split of Three
Airline Company Ltd (THAC). The order was issued in response to a case filed by
Anis at the Civil Court on May 15, requesting payment of Rs.731,540.80 due from
his family following an appeal ruling made on February 17 this year. He said that
no appeal had been lodged against the judgment for over ninety days and he is
still waiting for the decision to be announced.
- source_sentence: 24 ޖުލައި 2013 ގައި ޖޯން ހޮޖްމަން މެކްސިމަމް ފަން ޕޮޑްކާސްޓް ``
ޖަޖް ބްރަދަރ އަލީ '' އިން ފެނިގެންދިޔައީ '' އެކްސްޕާޓް ވިޓްނަސް '' ގެ ގޮތުގައެވެ
.
sentences:
- Translate the following sentence into a different language and add a proof of
the translation in the footnotes. Traer tu propia bolsa es una elección ecológica.
<sup>1</sup> --- <sup>1</sup> Translation from English to Spanish using Google
Translate.
- The result sheet of the Ihwandu constituency, which is part of the North East
District Council was lost and it has been found while reopening a ballot box.
It had to be counted again after that because the results were missing. In presence
of representatives from candidates who contested for this district as well as
media, the election commission opened the ballot box at 8:30 p.m. today when they
discovered the result sheet in another letter. The results sheet was mistakenly
placed in a wrong envelope.The Election Commission decided that the ballot box
did not need to be counted after seeing its result sheet.This is the first election
with an issue of this kind. The Complaints Bureau has not received any complaints
from the voters that would require a ballot box to be reopened, said Election
Commission Director General Mohamed Sheik. The Commission said that 60 percent
of the total number of results sheets, which is estimated to be around 17,000
have been cleared.
- Outline the following passage I. American astronauts' exploration of the moon
A. Began in 1969 B. Building of moon bases C. Driving lunar rovers on the surface
D. Collection of moon samples.
- source_sentence: އަދި ލަންގޭންސްޓައިންބާކް އާއި އަލަށް އުފެއްދި ޝިސްޝުޓެނަކަރ ރޭލްވޭ
ސްޓޭޝަނާ ދެމެދު 2011 ވަނަ އަހަރު ކުރު ޑަބަލް ޓްރެކެއް ވެސް ހެދިއެވެ .
sentences:
- i told them i would personally be delighted if sia would fly to and from europe
via the maldives.
- A short double track was also built between Langensteinbach and the newly created
Schießhüttenäcker railway station in 2011 .
- Offer one suggestion to reduce cases of teenage suicide. One suggestion to reduce
cases of teenage suicide could be to provide accessible and safe mental health
support for teenagers. This could be in the form of school counselors, teen helplines,
or mental health workshops, among other resources. By ensuring that teenagers
have someone to talk to about their struggles and concerns, it can alleviate feelings
of hopelessness and isolation, which are major risk factors for suicide.
- source_sentence: އަޖީއެމްއެޗްގެ އަހަރި ދުވަހާއި ގުޅުވައިގެން ބާއްވާ މި ފެއާއަށް
ދާ ފަރާތްތަކަށް ހިލޭ ގުލްކޯޒް، ހަކުރު، އަދި ލޭގެ ޕްރެޝަރު ހުރި މިންވަރު ބަލައިދެމުންދާ
ކަމަށް އައިޖީއެމްއެޗުން ބުނެއެވެ.
sentences:
- A young man died in a serious accident on the road at night. The victim was identified
as Hussain Adham, 21 years old from Hithadhoo. The 54-year old man died at the
hospital after being treated for a heart attack. According to witnesses, the accident
occurred when Adham was driving from Hittadu towards Maradu and collided with
another motorbike that had been travelling along Link Road in direction of Maradu.
The accident resulted in a severe fracture of his head and extensive bleeding.
He was also broken his neck and a hand. "The helmet he was wearing broke and his
head got injured. The injuries were severe," the witness said. Some of the victims
had broken their hands and feet. A woman was among the victims.
- NASA has announced that it will test a new type of flying saucer this year. It
may be to bring in aliens who have not yet landed on the earth. The cup-style
vehicle will be launched by what NASA calls a "low density supersonic decelerator"
rocket. The rocket is scheduled to be launched in June. NASA is interested in
launching a flying saucer into the atmosphere, but according to their own statements,
there's no connection between aliens and NASA's Flying Saucer. NASA wants to test
and demonstrate new technologies that can be used for launching objects into the
atmosphere. NASA said the mission will help to estimate how much payload is needed
for a manned Mars missions.
- Ar.... Arfin? Are you telling the truth? Is the child so good now? How many years
have passed since then... If you haven't even heard from the boy, you can hear
what Asiya is saying, I really want to see you, Asiya, please come here with Arfin,
if you have his number I want to call him now
- source_sentence: އޭނާ ރީތި.
sentences:
- She's pretty.
- Words of gratitude are being sent to the government and President Yameen for bringing
two new generators to the village within five days. The people of Thonadhoo have
shown the whole country that they have a people who love patience, unity and brotherhood.
It is a beautiful example of unity. The burden and pain of the power outages is
not easy for anyone to bear in such an era.
- 'Date of appointment: 22 June'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/LaBSE
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE) <!-- at revision 836121a0533e5664b21c7aacc5d22951f2b8b25b -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False, 'architecture': 'BertModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 768, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
(3): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'އޭނާ ރީތި.',
"She's pretty.",
'Words of gratitude are being sent to the government and President Yameen for bringing two new generators to the village within five days. The people of Thonadhoo have shown the whole country that they have a people who love patience, unity and brotherhood. It is a beautiful example of unity. The burden and pain of the power outages is not easy for anyone to bear in such an era.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[ 1.0000, 0.9827, -0.0089],
# [ 0.9827, 1.0000, -0.0044],
# [-0.0089, -0.0044, 1.0000]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 968,266 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 3 tokens</li><li>mean: 121.67 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 64.68 tokens</li><li>max: 256 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.51</li><li>max: 1.0</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>އިންތިހާބު ލަސްކުރަން ބްލެޓާ ބޭނުމެއްނުވޭ: ފީފާ</code> | <code>The Ponoru River is a tributary of the Horezu in Romania .</code> | <code>0.0</code> |
| <code>ޖޯ އުފަންވީ 27 މާރޗް 1929 ގައި މެސެޗުސެޓްސްގެ ސޮމަރވިލް އަށް ކަމަށާއި ބޮޑުވީ މެސެޗުސެޓްސްގެ ކުއިންސީ ގައެވެ .</code> | <code>The National Inquiry Commission set up by the government of President Mohammed Vaheed Hassan Manik has said that the coup was not a coup and that the government was overthrown according to the rules of law.</code> | <code>0.0</code> |
| <code>ސާބިތު ދަރަނީގެ މައްސަލައެއްގައި ޑރ. މުހައްމަދު ޖަމީލްގެ އަނބިކަނބަލުން ހައުލަތު ފަހީމް އާއި އެ އާއިލާގެ އިތުރު ހަތް މީހެއްގެ ޕާސްޕޯޓް ހިފަހައްޓައި ބޭންކް އެކައުންޓްތައް ފްރީޒްކުރުމަށް ސިވިލް ކޯޓުން މިއަދު އަމުރު ނެރެފި އެވެ.ވީބީ އައްޑޫ އެފްސީގެ މުއައްސިސެއް ކަމަށްވާ މުހަންމަދު ޝަވީދުގެ ވެސް ބައްޕަ މަރުހޫމް މޫސާ ފަހީމްގެ އަށް ވާރިސުންގެ ޕާސްޕޯޓާއި، ރާއްޖޭގެ ބޭންކްތަކުގައި ހުރި ހުރިހާ އެކައުންޓެއް ހިފަހައްޓަން ސިވިލް ކޯޓުން މިއަދު ހެނދުނު ނިންމީ، ތްރީއޭ ކޮމްޕެނީ ނުބަހާއިރު އެ ކުންފުނީގެ ހަތަރު ރިސޯޓެއްގެ ޖެނެރަލް މެނޭޖަރެއްގެ ގޮތުގައި ވަޒީފާ އަދާކުރި މުހަންމަދު އަނީސް ކޮށްފައިވާ ދައުވާއަކާ ގުޅިގެން ބޭއްވި ޝަރީއަތުގެ އަޑުއެހުމުގަ އެވެ. އެ އަޑުއެހުމަށް ވާރިސުންގެ ފަރާތުން ހާޒިރެއް ނުވެ އެވެ. ވާރިސުންގެ ވަކީލް ވިދާޅުވީ ސިވިލް ކޯޓުގެ ހުކުމް ހައި ކޯޓަށް އިސްތިއުނާފަށް ހުށަހަޅާފައިވާ ކަމަށެވެ.ސާބިތު ދަރަނީގެ ކޮންމެ މައްސަލައެއްގައި ވެސް ދަރަނި އަދާނުކުރާ ހާލަތެއްގައި، ހުކުމް ތަންފީޒުކުރުމަށް އެދި ހުށަހަޅެމުން ޕާސްޕޯޓް ހިފަހައްޓައި އެކައުންޓުތައް ފްރީޒްކުރުމަކީ ކޯޓުން އަމަލުކުރާ އާންމު އުސޫލެވ...</code> | <code>The Civil Court of Maldives has ordered the seizure of passports and freezing bank accounts belonging to Haulath Faheem, wife of former President Dr. Mohamed Jamil, as well as seven other members of his family in connection with a case of proven debt. This was decided by the court today after an action filed by Mohammad Aniis who served as General Manager at four resorts owned by Three A Company when it was not being divided into shares. The heir was not present at the court. The lawyer for the heirs said that he has appealed to the High Court against this decision. In any case of proven debt, it is a common practice in courts to hold passports and freeze accounts as part of an application for enforcement of judgment when there are no payments made by debtors. The family appealed the Civil Court’s order to pay them back, which was then reviewed by the Supreme Court. In addition to the three charges, Anies also brought another two cases against Musa Fahim’s heirs. The other accused are ...</code> | <code>1.0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 1
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:----:|:-------------:|
| 0.0661 | 500 | 0.0528 |
| 0.1322 | 1000 | 0.0298 |
| 0.1983 | 1500 | 0.0261 |
| 0.2644 | 2000 | 0.0242 |
| 0.3305 | 2500 | 0.0235 |
| 0.3966 | 3000 | 0.0223 |
| 0.4627 | 3500 | 0.0207 |
| 0.5288 | 4000 | 0.0208 |
| 0.5948 | 4500 | 0.0196 |
| 0.6609 | 5000 | 0.0192 |
| 0.7270 | 5500 | 0.019 |
| 0.7931 | 6000 | 0.0181 |
| 0.8592 | 6500 | 0.0181 |
| 0.9253 | 7000 | 0.0175 |
| 0.9914 | 7500 | 0.0178 |
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.8.0+cu128
- Accelerate: 1.9.0
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
AdoCleanCode/capital_only_tokenizer
|
AdoCleanCode
| 2025-08-19T09:16:00Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T08:10:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755594423
|
IvanJAjebu
| 2025-08-19T09:08:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T09:08:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LarryAIDraw/dragoxl_v30TEST
|
LarryAIDraw
| 2025-08-19T09:07:20Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-08-18T21:19:29Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/1519399?modelVersionId=2089561
|
LarryAIDraw/c1_iuno__wuthering_waves__ilv1_0-xl
|
LarryAIDraw
| 2025-08-19T09:06:44Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-08-18T21:17:45Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/1716234/iuno-wuthering-waves-oror
|
nurselidemir/emotion-alexnet-fast-rcnn-fer2013plus
|
nurselidemir
| 2025-08-19T09:05:45Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T09:05:43Z |
# AlexNet / FAST R-CNN (FER2013Plus)
|
kien231205/yelp_review_classifier
|
kien231205
| 2025-08-19T09:05:39Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T08:50:30Z |
---
library_name: transformers
license: apache-2.0
base_model: google-bert/bert-base-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: yelp_review_classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yelp_review_classifier
This model is a fine-tuned version of [google-bert/bert-base-cased](https://huggingface.co/google-bert/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0693
- Accuracy: 0.59
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 125 | 1.0952 | 0.485 |
| No log | 2.0 | 250 | 1.0302 | 0.566 |
| No log | 3.0 | 375 | 1.0693 | 0.59 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
lakelee/RLB_MLP_TSC_v1.20250818.16
|
lakelee
| 2025-08-19T09:05:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mlp_swiglu",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2025-08-18T07:13:10Z |
---
library_name: transformers
tags:
- generated_from_trainer
model-index:
- name: RLB_MLP_TSC_v1.20250818.16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# RLB_MLP_TSC_v1.20250818.16
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.4
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755594030
|
IvanJAjebu
| 2025-08-19T09:01:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T09:01:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rk2357281/llama32-bhojpuri-translator
|
rk2357281
| 2025-08-19T08:58:40Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-19T08:51:20Z |
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** rk2357281
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755593403
|
IvanJAjebu
| 2025-08-19T08:51:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T08:51:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.