
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
deepset/gelectra-base-germanquad
|
deepset
|
electra
| 9 | 10,283 |
transformers
| 13 |
question-answering
| true | true | false |
mit
|
['de']
|
['deepset/germanquad']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['exbert']
| false | true | true | 3,697 | false |

## Overview
**Language model:** gelectra-base-germanquad
**Language:** German
**Training data:** GermanQuAD train set (~ 12MB)
**Eval data:** GermanQuAD test set (~ 5MB)
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- We trained a German question answering model with a gelectra-base model as its basis.
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536answers, because we removed 76 wrong answers.
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
## Hyperparameters
```
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
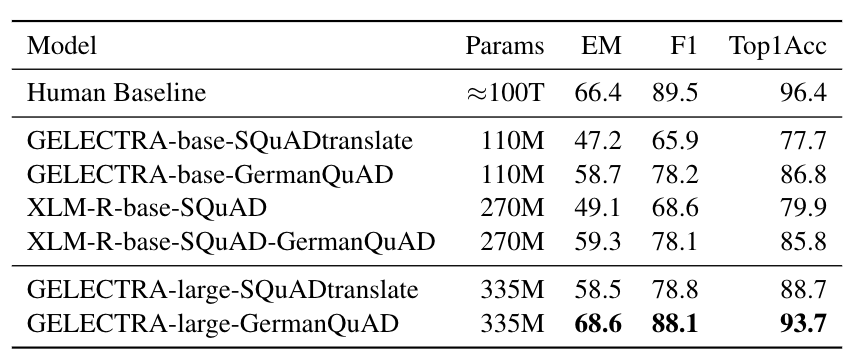
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on [GermanQuAD](https://deepset.ai/germanquad).
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
## Authors
**Timo Möller:** timo.moeller@deepset.ai
**Julian Risch:** julian.risch@deepset.ai
**Malte Pietsch:** malte.pietsch@deepset.ai
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
04d0a31bec6c69bcbab602d6cb4d59e6
|
MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-3
|
MartinoMensio
|
bert
| 4 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['es']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,106 | false |
### Description
This model is a fine-tuned version of [BETO (spanish bert)](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) that has been trained on the *Datathon Against Racism* dataset (2022)
We performed several experiments that will be described in the upcoming paper "Estimating Ground Truth in a Low-labelled Data Regime:A Study of Racism Detection in Spanish" (NEATClasS 2022)
We applied 6 different methods ground-truth estimations, and for each one we performed 4 epochs of fine-tuning. The result is made of 24 models:
| method | epoch 1 | epoch 3 | epoch 3 | epoch 4 |
|--- |--- |--- |--- |--- |
| raw-label | [raw-label-epoch-1](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-1) | [raw-label-epoch-2](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-2) | [raw-label-epoch-3](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-3) | [raw-label-epoch-4](https://huggingface.co/MartinoMensio/racism-models-raw-label-epoch-4) |
| m-vote-strict | [m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-1) | [m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-2) | [m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-3) | [m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-strict-epoch-4) |
| m-vote-nonstrict | [m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-1) | [m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-2) | [m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-3) | [m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-m-vote-nonstrict-epoch-4) |
| regression-w-m-vote | [regression-w-m-vote-epoch-1](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-1) | [regression-w-m-vote-epoch-2](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-2) | [regression-w-m-vote-epoch-3](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-3) | [regression-w-m-vote-epoch-4](https://huggingface.co/MartinoMensio/racism-models-regression-w-m-vote-epoch-4) |
| w-m-vote-strict | [w-m-vote-strict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-1) | [w-m-vote-strict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-2) | [w-m-vote-strict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-3) | [w-m-vote-strict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-strict-epoch-4) |
| w-m-vote-nonstrict | [w-m-vote-nonstrict-epoch-1](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-1) | [w-m-vote-nonstrict-epoch-2](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-2) | [w-m-vote-nonstrict-epoch-3](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-3) | [w-m-vote-nonstrict-epoch-4](https://huggingface.co/MartinoMensio/racism-models-w-m-vote-nonstrict-epoch-4) |
This model is `w-m-vote-nonstrict-epoch-3`
### Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_name = 'w-m-vote-nonstrict-epoch-3'
tokenizer = AutoTokenizer.from_pretrained("dccuchile/bert-base-spanish-wwm-uncased")
full_model_path = f'MartinoMensio/racism-models-{model_name}'
model = AutoModelForSequenceClassification.from_pretrained(full_model_path)
pipe = pipeline("text-classification", model = model, tokenizer = tokenizer)
texts = [
'y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!',
'Es que los judíos controlan el mundo'
]
print(pipe(texts))
# [{'label': 'racist', 'score': 0.9937393665313721}, {'label': 'non-racist', 'score': 0.9902436137199402}]
```
For more details, see https://github.com/preyero/neatclass22
|
bc20e0c52d81f9b81064e3b900880c2b
|
mollypak/distilbert-base-uncased-finetuned-cola
|
mollypak
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,565 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7629
- Matthews Correlation: 0.5556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.538 | 1.0 | 535 | 0.5812 | 0.3250 |
| 0.3669 | 2.0 | 1070 | 0.5216 | 0.4993 |
| 0.2461 | 3.0 | 1605 | 0.6071 | 0.5016 |
| 0.1811 | 4.0 | 2140 | 0.7629 | 0.5556 |
| 0.1347 | 5.0 | 2675 | 0.8480 | 0.5547 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.1
- Datasets 1.15.1
- Tokenizers 0.10.3
|
1f745898edd34c0a7240c1db10e16568
|
cohogain/whisper-medium-ga-IE-cv11-fleurs-livaud
|
cohogain
|
whisper
| 23 | 17 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,666 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1422
- Wer: 35.2207
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 7000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1137 | 4.02 | 1000 | 0.9072 | 40.0987 |
| 0.0153 | 9.02 | 2000 | 1.0351 | 38.7631 |
| 0.0042 | 14.01 | 3000 | 1.0507 | 36.4402 |
| 0.0013 | 19.0 | 4000 | 1.0924 | 36.2660 |
| 0.0003 | 23.02 | 5000 | 1.1422 | 35.2207 |
| 0.0001 | 28.02 | 6000 | 1.1688 | 35.3368 |
| 0.0001 | 33.01 | 7000 | 1.1768 | 35.5110 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
5cf800a15d2dbeb3731c6fee2066a61b
|
ali2066/finetuned_sentence_itr0_2e-05_all_27_02_2022-22_25_09
|
ali2066
|
distilbert
| 13 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,615 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_sentence_itr0_2e-05_all_27_02_2022-22_25_09
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4638
- Accuracy: 0.8247
- F1: 0.8867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 195 | 0.4069 | 0.7976 | 0.875 |
| No log | 2.0 | 390 | 0.4061 | 0.8134 | 0.8838 |
| 0.4074 | 3.0 | 585 | 0.4075 | 0.8134 | 0.8798 |
| 0.4074 | 4.0 | 780 | 0.4746 | 0.8256 | 0.8885 |
| 0.4074 | 5.0 | 975 | 0.4881 | 0.8220 | 0.8845 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
9d086d956391db3fa5b7087fd62911cf
|
henryscheible/rte_bert-base-uncased_144_v2
|
henryscheible
| null | 13 | 0 | null | 0 | null | true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,018 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rte_bert-base-uncased_144_v2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7639
- Accuracy: 0.6498
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
79ef22ef1305aee280d340bf8cd50c64
|
Xinrui/t5-small-finetuned-eli5
|
Xinrui
|
t5
| 15 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['eli5']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,410 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-eli5
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7555
- Rouge1: 11.8922
- Rouge2: 1.88
- Rougel: 9.6595
- Rougelsum: 10.8308
- Gen Len: 18.9911
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 3.9546 | 1.0 | 34080 | 3.7555 | 11.8922 | 1.88 | 9.6595 | 10.8308 | 18.9911 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
caa0971fe85b28501dcb787fc97fb6eb
|
SkyR/roberta-base-ours-run-4
|
SkyR
|
roberta
| 11 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,045 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# run-4
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6296
- Accuracy: 0.685
- Precision: 0.6248
- Recall: 0.6164
- F1: 0.6188
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0195 | 1.0 | 50 | 0.8393 | 0.615 | 0.4126 | 0.5619 | 0.4606 |
| 0.7594 | 2.0 | 100 | 0.7077 | 0.7 | 0.6896 | 0.6663 | 0.6178 |
| 0.5515 | 3.0 | 150 | 0.9342 | 0.68 | 0.6334 | 0.5989 | 0.6016 |
| 0.3739 | 4.0 | 200 | 0.7755 | 0.735 | 0.7032 | 0.7164 | 0.7063 |
| 0.2648 | 5.0 | 250 | 0.9200 | 0.7 | 0.6584 | 0.6677 | 0.6611 |
| 0.1726 | 6.0 | 300 | 1.1898 | 0.71 | 0.6653 | 0.6550 | 0.6570 |
| 0.1452 | 7.0 | 350 | 1.5086 | 0.73 | 0.6884 | 0.6768 | 0.6812 |
| 0.0856 | 8.0 | 400 | 2.6159 | 0.68 | 0.6754 | 0.5863 | 0.5951 |
| 0.1329 | 9.0 | 450 | 1.9491 | 0.71 | 0.6692 | 0.6442 | 0.6463 |
| 0.0322 | 10.0 | 500 | 1.7897 | 0.74 | 0.6977 | 0.6939 | 0.6946 |
| 0.0345 | 11.0 | 550 | 1.9100 | 0.725 | 0.6827 | 0.6853 | 0.6781 |
| 0.026 | 12.0 | 600 | 2.5041 | 0.68 | 0.6246 | 0.6115 | 0.6137 |
| 0.0084 | 13.0 | 650 | 2.5343 | 0.715 | 0.6708 | 0.6617 | 0.6637 |
| 0.0145 | 14.0 | 700 | 2.4112 | 0.715 | 0.6643 | 0.6595 | 0.6614 |
| 0.0119 | 15.0 | 750 | 2.5303 | 0.705 | 0.6479 | 0.6359 | 0.6390 |
| 0.0026 | 16.0 | 800 | 2.6299 | 0.705 | 0.6552 | 0.6447 | 0.6455 |
| 0.0077 | 17.0 | 850 | 2.4044 | 0.715 | 0.6667 | 0.6576 | 0.6596 |
| 0.0055 | 18.0 | 900 | 2.8077 | 0.68 | 0.6208 | 0.6065 | 0.6098 |
| 0.0078 | 19.0 | 950 | 2.5608 | 0.68 | 0.6200 | 0.6104 | 0.6129 |
| 0.0018 | 20.0 | 1000 | 2.6296 | 0.685 | 0.6248 | 0.6164 | 0.6188 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Tokenizers 0.13.2
|
c6c2452e74e841a72fdaead3025f6608
|
espnet/pt_commonvoice_blstm
|
espnet
| null | 22 | 0 |
espnet
| 1 |
automatic-speech-recognition
| false | false | false |
cc-by-4.0
|
['pt']
|
['commonvoice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'automatic-speech-recognition']
| false | true | true | 6,942 | false |
## ESPnet2 ASR model
### `espnet/pt_commonvoice_blstm`
This model was trained by dzeinali using commonvoice recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 716eb8f92e19708acfd08ba3bd39d40890d3a84b
pip install -e .
cd egs2/commonvoice/asr1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/pt_commonvoice_blstm
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Mon Apr 11 18:55:23 EDT 2022`
- python version: `3.9.5 (default, Jun 4 2021, 12:28:51) [GCC 7.5.0]`
- espnet version: `espnet 0.10.6a1`
- pytorch version: `pytorch 1.8.1+cu102`
- Git hash: `5e6e95d087af8a7a4c33c4248b75114237eae64b`
- Commit date: `Mon Apr 4 21:04:45 2022 -0400`
## asr_train_asr_rnn_raw_pt_bpe150_sp
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnn_asr_model_valid.acc.best/test_pt|4334|33716|84.7|12.4|2.9|1.3|16.6|46.8|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnn_asr_model_valid.acc.best/test_pt|4334|191499|93.4|3.0|3.6|1.2|7.8|46.9|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_rnn_asr_model_valid.acc.best/test_pt|4334|116003|90.4|5.7|3.9|1.5|11.1|46.9|
## ASR config
<details><summary>expand</summary>
```
config: conf/tuning/train_asr_rnn.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_rnn_raw_pt_bpe150_sp
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 15
patience: 3
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - train
- loss
- min
- - valid
- loss
- min
- - train
- acc
- max
- - valid
- acc
- max
keep_nbest_models:
- 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 30
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_pt_bpe150_sp/train/speech_shape
- exp/asr_stats_raw_pt_bpe150_sp/train/text_shape.bpe
valid_shape_file:
- exp/asr_stats_raw_pt_bpe150_sp/valid/speech_shape
- exp/asr_stats_raw_pt_bpe150_sp/valid/text_shape.bpe
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_pt_sp/wav.scp
- speech
- sound
- - dump/raw/train_pt_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dev_pt/wav.scp
- speech
- sound
- - dump/raw/dev_pt/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adadelta
optim_conf:
lr: 0.1
scheduler: null
scheduler_conf: {}
token_list:
- <blank>
- <unk>
- ▁
- S
- R
- I
- U
- E
- O
- A
- .
- N
- M
- L
- ▁A
- ▁DE
- RA
- ▁O
- T
- ▁E
- ▁UM
- C
- TA
- DO
- G
- TO
- TE
- DA
- VE
- B
- NDO
- ▁SE
- ▁QUE
- P
- ▁UMA
- LA
- D
- ▁COM
- CA
- á
- '?'
- ▁PE
- ▁EM
- IN
- TI
- IS
- ▁C
- H
- HO
- ▁CA
- ▁P
- CO
- ','
- ▁NO
- MA
- NTE
- PA
- ▁NãO
- DE
- ãO
- ▁ME
- ▁PARA
- Z
- ▁MA
- VA
- PO
- ▁DO
- ▁VOCê
- RI
- ▁DI
- GA
- VI
- ▁é
- LO
- IA
- ▁ELE
- ▁EU
- ▁ESTá
- HA
- ▁M
- X
- ▁NA
- NA
- é
- CE
- LE
- GO
- VO
- ▁RE
- ▁FO
- ▁FA
- ▁CO
- QUE
- ▁EST
- BE
- ▁CON
- ó
- SE
- ▁POR
- ê
- í
- çãO
- ▁DA
- RES
- ▁QUA
- ▁HOMEM
- RIA
- çA
- ▁SA
- V
- ▁PRE
- MENTE
- ZE
- NHA
- '-'
- ▁BA
- MOS
- ▁SO
- ▁BO
- ç
- '"'
- '!'
- ú
- ã
- K
- Y
- É
- W
- ô
- Á
- ':'
- ;
- ''''
- ”
- Ô
- ñ
- “
- Ú
- Í
- Ó
- ü
- À
- â
- à
- õ
- J
- Q
- F
- Â
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
joint_net_conf: null
model_conf:
ctc_weight: 0.5
use_preprocessor: true
token_type: bpe
bpemodel: data/pt_token_list/bpe_unigram150/bpe.model
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: default
frontend_conf:
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 27
num_freq_mask: 2
apply_time_mask: true
time_mask_width_ratio_range:
- 0.0
- 0.05
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_pt_bpe150_sp/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: vgg_rnn
encoder_conf:
rnn_type: lstm
bidirectional: true
use_projection: true
num_layers: 4
hidden_size: 1024
output_size: 1024
postencoder: null
postencoder_conf: {}
decoder: rnn
decoder_conf:
num_layers: 2
hidden_size: 1024
sampling_probability: 0
att_conf:
atype: location
adim: 1024
aconv_chans: 10
aconv_filts: 100
required:
- output_dir
- token_list
version: 0.10.6a1
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
7092c9bb205dd5269e3a881672537ba4
|
ssharm87/t5-small-finetuned-xsum-ss
|
ssharm87
|
t5
| 13 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['xsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,417 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-ss
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5823
- Rouge1: 26.3663
- Rouge2: 6.4727
- Rougel: 20.538
- Rougelsum: 20.5411
- Gen Len: 18.8006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 2.8125 | 0.25 | 3189 | 2.5823 | 26.3663 | 6.4727 | 20.538 | 20.5411 | 18.8006 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ccea3564ded49d9e71afaeb34e61cf50
|
xhyi/CodeGen-350M-Multi
|
xhyi
|
codegen
| 11 | 0 |
transformers
| 0 |
text-generation
| true | false | false |
bsd-3-clause
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['codegen', 'text generation', 'pytorch', 'causal-lm']
| false | true | true | 2,323 | false |
# Salesforce CodeGen
ported salesforce codegen models to work on huggingface transformers without any extra code (the model specific code is bundled)
## Overview
The CodeGen model was proposed in by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. From Salesforce Research.
The abstract from the paper is the following: Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We plan to make the training library JaxFormer including checkpoints available as open source.
## Usage
`trust_remote_code` is needed because the [torch modules](https://github.com/salesforce/CodeGen/tree/main/jaxformer/hf/codegen) for the custom codegen model is bundled.
```sh
from transformers import AutoModelForCausalLM, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(model_folder, local_files_only=True)
model = AutoModelForCausalLM.from_pretrained(model_folder, local_files_only=True, trust_remote_code=True)
```
|
ec59c285a25348f321779684c7c94c71
|
SiddharthaM/hasoc19-xlm-roberta-base-targinsult1
|
SiddharthaM
|
xlm-roberta
| 12 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,185 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hasoc19-xlm-roberta-base-targinsult1
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7512
- Accuracy: 0.7096
- Precision: 0.6720
- Recall: 0.6675
- F1: 0.6695
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 263 | 0.5619 | 0.6996 | 0.6660 | 0.6717 | 0.6684 |
| 0.5931 | 2.0 | 526 | 0.5350 | 0.7239 | 0.6880 | 0.6576 | 0.6655 |
| 0.5931 | 3.0 | 789 | 0.5438 | 0.7239 | 0.6872 | 0.6644 | 0.6714 |
| 0.5101 | 4.0 | 1052 | 0.5595 | 0.7196 | 0.6866 | 0.6909 | 0.6886 |
| 0.5101 | 5.0 | 1315 | 0.5580 | 0.7186 | 0.6818 | 0.6743 | 0.6774 |
| 0.4313 | 6.0 | 1578 | 0.6000 | 0.7039 | 0.6679 | 0.6692 | 0.6686 |
| 0.4313 | 7.0 | 1841 | 0.6429 | 0.7082 | 0.6765 | 0.6841 | 0.6794 |
| 0.3591 | 8.0 | 2104 | 0.6626 | 0.7115 | 0.6772 | 0.6803 | 0.6786 |
| 0.3591 | 9.0 | 2367 | 0.7231 | 0.7139 | 0.6764 | 0.6700 | 0.6727 |
| 0.3016 | 10.0 | 2630 | 0.7512 | 0.7096 | 0.6720 | 0.6675 | 0.6695 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
cbced0ba70f9521fec1432e6be732489
|
theojolliffe/bart-cnn-pubmed-arxiv-v3-e4
|
theojolliffe
|
bart
| 13 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,791 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-pubmed-arxiv-v3-e4
This model is a fine-tuned version of [theojolliffe/bart-cnn-pubmed-arxiv](https://huggingface.co/theojolliffe/bart-cnn-pubmed-arxiv) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7934
- Rouge1: 54.2624
- Rouge2: 35.6024
- Rougel: 37.1697
- Rougelsum: 51.5144
- Gen Len: 141.9815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 398 | 0.9533 | 52.3191 | 32.4576 | 33.2016 | 49.6502 | 142.0 |
| 1.1154 | 2.0 | 796 | 0.8407 | 53.6639 | 34.3433 | 36.1893 | 50.9077 | 142.0 |
| 0.6856 | 3.0 | 1194 | 0.7978 | 54.4723 | 36.1315 | 37.7891 | 51.902 | 142.0 |
| 0.4943 | 4.0 | 1592 | 0.7934 | 54.2624 | 35.6024 | 37.1697 | 51.5144 | 141.9815 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
9dd1f71700707e68223d77f99051a63f
|
mehnaazasad/swin-tiny-patch4-window7-224-finetuned-eurosat
|
mehnaazasad
|
swin
| 14 | 3 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,493 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0703
- Accuracy: 0.9770
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2369 | 1.0 | 190 | 0.1683 | 0.9433 |
| 0.1812 | 2.0 | 380 | 0.0972 | 0.9670 |
| 0.1246 | 3.0 | 570 | 0.0703 | 0.9770 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
cd1ed1587988b40fe3077a3bfef0859c
|
speechbrain/asr-wav2vec2-dvoice-fongbe
|
speechbrain
|
wav2vec2
| 9 | 5 |
speechbrain
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fon']
|
['Dvoice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['CTC', 'pytorch', 'speechbrain', 'Transformer']
| false | true | true | 6,368 | false |
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# wav2vec 2.0 with CTC/Attention trained on DVoice Fongbe (No LM)
This repository provides all the necessary tools to perform automatic speech
recognition from an end-to-end system pretrained on a [ALFFA](https://github.com/besacier/ALFFA_PUBLIC) Fongbe dataset within
SpeechBrain. For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
| DVoice Release | Val. CER | Val. WER | Test CER | Test WER |
|:-------------:|:---------------------------:| -----:| -----:| -----:|
| v2.0 | 4.16 | 9.19 | 3.98 | 9.00 |
# Pipeline description
This ASR system is composed of 2 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units and is trained with the train transcriptions.
- Acoustic model (wav2vec2.0 + CTC). A pretrained wav2vec 2.0 model ([facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)) is combined with two DNN layers and finetuned on the Darija dataset.
The obtained final acoustic representation is given to the CTC greedy decoder.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *transcribe_file* if needed.
# Install SpeechBrain
First of all, please install transformers and SpeechBrain with the following command:
```
pip install speechbrain transformers
```
Please notice that we encourage you to read the SpeechBrain tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
# Transcribing your own audio files (in Fongbe)
```python
from speechbrain.pretrained import EncoderASR
asr_model = EncoderASR.from_hparams(source="speechbrain/asr-wav2vec2-dvoice-fongbe", savedir="pretrained_models/asr-wav2vec2-dvoice-fongbe")
asr_model.transcribe_file('speechbrain/asr-wav2vec2-dvoice-fongbe/example_fongbe.wav')
```
# Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
# Training
The model was trained with SpeechBrain.
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/DVoice/ASR/CTC
python train_with_wav2vec2.py hparams/train_fon_with_wav2vec.yaml --data_folder=/localscratch/ALFFA_PUBLIC/ASR/FONGBE/data/
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1vNT7RjRuELs7pumBHmfYsrOp9m46D0ym?usp=sharing).
# Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# About DVoice
DVoice is a community initiative that aims to provide African low resources languages with data and models to facilitate their use of voice technologies. The lack of data on these languages makes it necessary to collect data using methods that are specific to each one. Two different approaches are currently used: the DVoice platforms ([https://dvoice.ma](https://dvoice.ma) and [https://dvoice.sn](https://dvoice.sn)), which are based on Mozilla Common Voice, for collecting authentic recordings from the community, and transfer learning techniques for automatically labeling recordings that are retrieved from social media. The DVoice platform currently manages 7 languages including Darija (Moroccan Arabic dialect) whose dataset appears on this version, Wolof, Mandingo, Serere, Pular, Diola, and Soninke.
For this project, AIOX Labs and the SI2M Laboratory are joining forces to build the future of technologies together.
# About AIOX Labs
Based in Rabat, London, and Paris, AIOX-Labs mobilizes artificial intelligence technologies to meet the business needs and data projects of companies.
- He is at the service of the growth of groups, the optimization of processes, or the improvement of the customer experience.
- AIOX-Labs is multi-sector, from fintech to industry, including retail and consumer goods.
- Business-ready data products with a solid algorithmic base and adaptability for the specific needs of each client.
- A complementary team made up of doctors in AI and business experts with a solid scientific base and international publications.
Website: [https://www.aiox-labs.com/](https://www.aiox-labs.com/)
# SI2M Laboratory
The Information Systems, Intelligent Systems, and Mathematical Modeling Research Laboratory (SI2M) is an academic research laboratory of the National Institute of Statistics and Applied Economics (INSEA). The research areas of the laboratories are Information Systems, Intelligent Systems, Artificial Intelligence, Decision Support, Network, and System Security, and Mathematical Modelling.
Website: [SI2M Laboratory](https://insea.ac.ma/index.php/pole-recherche/equipe-de-recherche/150-laboratoire-de-recherche-en-systemes-d-information-systemes-intelligents-et-modelisation-mathematique)
# About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.
Website: https://speechbrain.github.io/
GitHub: https://github.com/speechbrain/speechbrain
# Referencing SpeechBrain
```
@misc{SB2021,
author = {Ravanelli, Mirco and Parcollet, Titouan and Rouhe, Aku and Plantinga, Peter and Rastorgueva, Elena and Lugosch, Loren and Dawalatabad, Nauman and Ju-Chieh, Chou and Heba, Abdel and Grondin, Francois and Aris, William and Liao, Chien-Feng and Cornell, Samuele and Yeh, Sung-Lin and Na, Hwidong and Gao, Yan and Fu, Szu-Wei and Subakan, Cem and De Mori, Renato and Bengio, Yoshua },
title = {SpeechBrain},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\\\\url{https://github.com/speechbrain/speechbrain}},
}
```
# Acknowledgements
This research was supported through computational resources of HPC-MARWAN (www.marwan.ma/hpc) provided by CNRST, Rabat, Morocco. We deeply thank this institution.
|
97a4ab154eec2598b4ca3949955a141e
|
MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-German
|
MehdiHosseiniMoghadam
|
wav2vec2
| 11 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['de']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,496 | false |
# wav2vec2-large-xlsr-53-German
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in German using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "de", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-German")
model = Wav2Vec2ForCTC.from_pretrained("MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-German")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Czech test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "de", split="test[:15%]")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-German")
model = Wav2Vec2ForCTC.from_pretrained("MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-German")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.284593 %
## Training
10% of the Common Voice `train`, `validation` datasets were used for training.
## Testing
15% of the Common Voice `Test` dataset were used for training.
|
52282c5a30de01fc3e0c22690c473f9d
|
Helsinki-NLP/opus-mt-crs-fr
|
Helsinki-NLP
|
marian
| 10 | 10 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-crs-fr
* source languages: crs
* target languages: fr
* OPUS readme: [crs-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/crs-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/crs-fr/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/crs-fr/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/crs-fr/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.crs.fr | 29.4 | 0.475 |
|
c9b725012cf5eb6cc156873b059e461b
|
aliosm/ai-soco-cpp-roberta-tiny-clas
|
aliosm
| null | 2 | 0 | null | 0 | null | false | false | false |
mit
|
['c++']
|
['ai-soco']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'authorship-identification', 'fire2020', 'pan2020', 'ai-soco', 'classification']
| false | true | true | 1,684 | false |
# ai-soco-c++-roberta-tiny-clas
## Model description
`ai-soco-c++-roberta-tiny` model fine-tuned on [AI-SOCO](https://sites.google.com/view/ai-soco-2020) task.
#### How to use
You can use the model directly after tokenizing the text using the provided tokenizer with the model files.
#### Limitations and bias
The model is limited to C++ programming language only.
## Training data
The model initialized from [`ai-soco-c++-roberta-tiny`](https://github.com/huggingface/transformers/blob/master/model_cards/aliosm/ai-soco-c++-roberta-tiny) model and trained using [AI-SOCO](https://sites.google.com/view/ai-soco-2020) dataset to do text classification.
## Training procedure
The model trained on Google Colab platform using V100 GPU for 10 epochs, 32 batch size, 512 max sequence length (sequences larger than 512 were truncated). Each continues 4 spaces were converted to a single tab character (`\t`) before tokenization.
## Eval results
The model achieved 87.66%/87.46% accuracy on AI-SOCO task and ranked in the 9th place.
### BibTeX entry and citation info
```bibtex
@inproceedings{ai-soco-2020-fire,
title = "Overview of the {PAN@FIRE} 2020 Task on {Authorship Identification of SOurce COde (AI-SOCO)}",
author = "Fadel, Ali and Musleh, Husam and Tuffaha, Ibraheem and Al-Ayyoub, Mahmoud and Jararweh, Yaser and Benkhelifa, Elhadj and Rosso, Paolo",
booktitle = "Proceedings of The 12th meeting of the Forum for Information Retrieval Evaluation (FIRE 2020)",
year = "2020"
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ai-soco-c++-roberta-tiny-clas">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
253a7d1a3deda77661d5f8bf1e72063e
|
lucafrost/whispQuote-ChunkDQ-DistilBERT
|
lucafrost
|
distilbert
| 10 | 0 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,722 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whispQuote-ChunkDQ-DistilBERT
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2582
- Precision: 0.5816
- Recall: 0.8129
- F1: 0.6780
- Accuracy: 0.9126
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 164 | 0.3432 | 0.4477 | 0.5795 | 0.5052 | 0.8796 |
| No log | 2.0 | 328 | 0.3053 | 0.4308 | 0.6985 | 0.5329 | 0.8952 |
| No log | 3.0 | 492 | 0.2602 | 0.5716 | 0.7775 | 0.6588 | 0.9097 |
| 0.3826 | 4.0 | 656 | 0.2607 | 0.5664 | 0.8070 | 0.6656 | 0.9114 |
| 0.3826 | 5.0 | 820 | 0.2582 | 0.5816 | 0.8129 | 0.6780 | 0.9126 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.10.2+cu113
- Datasets 2.9.0
- Tokenizers 0.13.2
|
3f451d0d05d044e20d96a33eb7730d97
|
cammy/bart-large-cnn-finetune
|
cammy
|
bart
| 15 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,434 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetune
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5677
- Rouge1: 9.9893
- Rouge2: 5.2818
- Rougel: 9.7766
- Rougelsum: 9.7951
- Gen Len: 58.1672
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.2639 | 1.0 | 4774 | 1.5677 | 9.9893 | 5.2818 | 9.7766 | 9.7951 | 58.1672 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu116
- Datasets 2.7.0
- Tokenizers 0.13.2
|
20620f427c371587c728fe6ab4114ff6
|
Rerare/distilbert-base-uncased-finetuned-cola
|
Rerare
|
distilbert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7643
- Matthews Correlation: 0.5291
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5288 | 1.0 | 535 | 0.5111 | 0.4154 |
| 0.3546 | 2.0 | 1070 | 0.5285 | 0.4887 |
| 0.235 | 3.0 | 1605 | 0.5950 | 0.5153 |
| 0.1722 | 4.0 | 2140 | 0.7643 | 0.5291 |
| 0.1346 | 5.0 | 2675 | 0.8441 | 0.5185 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
deefda695d2ad082c15092bb3fb7f8d6
|
S2312dal/M7_MLM_final
|
S2312dal
|
roberta
| 14 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,332 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# M7_MLM_final
This model is a fine-tuned version of [sentence-transformers/all-distilroberta-v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.4732
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.769 | 1.0 | 92 | 6.6861 |
| 6.3549 | 2.0 | 184 | 5.7455 |
| 5.826 | 3.0 | 276 | 5.5610 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
d5851cec739c21d477d6b97d3d0864ef
|
jonatasgrosman/exp_w2v2t_id_unispeech-ml_s418
|
jonatasgrosman
|
unispeech
| 10 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['id']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'id']
| false | true | true | 500 | false |
# exp_w2v2t_id_unispeech-ml_s418
Fine-tuned [microsoft/unispeech-large-multi-lingual-1500h-cv](https://huggingface.co/microsoft/unispeech-large-multi-lingual-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (id)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
d982d4eeec4cc3549391b882edcd4a44
|
espnet/kan-bayashi_jsut_fastspeech2
|
espnet
| null | 21 | 3 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['ja']
|
['jsut']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 1,796 | false |
## Example ESPnet2 TTS model
### `kan-bayashi/jsut_fastspeech2`
♻️ Imported from https://zenodo.org/record/4032224/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
ebc4cf6340df0d702073bdc24ad0d215
|
minoosh/wav2vec2-base-finetuned-ie
|
minoosh
|
wav2vec2
| 27 | 2 |
transformers
| 0 |
audio-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,219 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ie
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.5355
- eval_accuracy: 0.4318
- eval_runtime: 111.662
- eval_samples_per_second: 17.983
- eval_steps_per_second: 0.564
- epoch: 8.38
- step: 520
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
e368d2caf65de24e0ae4f8e438ac8f0c
|
Geotrend/distilbert-base-el-cased
|
Geotrend
|
distilbert
| 6 | 5 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
|
['el']
|
['wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,215 | false |
# distilbert-base-el-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-el-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-el-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact amine@geotrend.fr for any question, feedback or request.
|
75c244c71751457da4b52eb472d723f4
|
Jaspal/distilbert-base-uncased-finetuned-cola
|
Jaspal
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,598 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Jaspal/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1904
- Validation Loss: 0.5593
- Train Matthews Correlation: 0.5189
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2670, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5175 | 0.4542 | 0.4684 | 0 |
| 0.3255 | 0.4617 | 0.5007 | 1 |
| 0.1904 | 0.5593 | 0.5189 | 2 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.8.2
- Datasets 2.3.2
- Tokenizers 0.12.1
|
d4478e476f2b654fda0b15f730a61219
|
Helsinki-NLP/opus-mt-en-kg
|
Helsinki-NLP
|
marian
| 10 | 41 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-en-kg
* source languages: en
* target languages: kg
* OPUS readme: [en-kg](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-kg/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-kg/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-kg/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-kg/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.kg | 39.6 | 0.613 |
|
a1903abb8066b98b10420ee1f7f95bb0
|
MultiversexPeeps/wave-concepts
|
MultiversexPeeps
| null | 21 | 9 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 863 | false |
### Wave Concepts Dreambooth model trained by Duskfallcrew with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Information on this model will be here: https://civitai.com/user/duskfallcrew
If you want to donate towards costs and don't want to subscribe:
https://ko-fi.com/DUSKFALLcrew
If you want to monthly support the EARTH & DUSK media projects and not just AI:
https://www.patreon.com/earthndusk
wvebg1 (use that on your prompt)
|
6f3c5e08f7c0c1ea75feba660b1a1a7b
|
timm/maxvit_tiny_tf_384.in1k
|
timm
| null | 4 | 330 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 22,012 | false |
# Model card for maxvit_tiny_tf_384.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 31.0
- GMACs: 17.5
- Activations (M): 123.4
- Image size: 384 x 384
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('maxvit_tiny_tf_384.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_tiny_tf_384.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_tiny_tf_384.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
7336a83a1f4bab3ececcdca33d792e4d
|
Helsinki-NLP/opus-mt-pon-fi
|
Helsinki-NLP
|
marian
| 10 | 26 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-pon-fi
* source languages: pon
* target languages: fi
* OPUS readme: [pon-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/pon-fi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/pon-fi/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/pon-fi/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/pon-fi/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.pon.fi | 22.2 | 0.434 |
|
b4567fe5525fdb0eeb13eee560f5ebd2
|
Helsinki-NLP/opus-mt-uk-nl
|
Helsinki-NLP
|
marian
| 11 | 18 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['uk', 'nl']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,999 | false |
### ukr-nld
* source group: Ukrainian
* target group: Dutch
* OPUS readme: [ukr-nld](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-nld/README.md)
* model: transformer-align
* source language(s): ukr
* target language(s): nld
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-nld/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-nld/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-nld/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ukr.nld | 48.7 | 0.656 |
### System Info:
- hf_name: ukr-nld
- source_languages: ukr
- target_languages: nld
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-nld/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['uk', 'nl']
- src_constituents: {'ukr'}
- tgt_constituents: {'nld'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-nld/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-nld/opus-2020-06-17.test.txt
- src_alpha3: ukr
- tgt_alpha3: nld
- short_pair: uk-nl
- chrF2_score: 0.6559999999999999
- bleu: 48.7
- brevity_penalty: 0.985
- ref_len: 59943.0
- src_name: Ukrainian
- tgt_name: Dutch
- train_date: 2020-06-17
- src_alpha2: uk
- tgt_alpha2: nl
- prefer_old: False
- long_pair: ukr-nld
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
656d907c041cb53be943bca3fb78e260
|
nvidia/tts_en_fastpitch
|
nvidia
| null | 3 | 496 |
nemo
| 13 |
text-to-speech
| true | false | false |
cc-by-4.0
|
['en']
|
['ljspeech']
| null | 0 | 0 | 0 | 0 | 2 | 1 | 1 |
['text-to-speech', 'speech', 'audio', 'Transformer', 'pytorch', 'NeMo', 'Riva']
| false | true | true | 4,705 | false |
# NVIDIA FastPitch (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
FastPitch [1] is a fully-parallel transformer architecture with prosody control over pitch and individual phoneme duration. Additionally, it uses an unsupervised speech-text aligner [2]. See the [model architecture](#model-architecture) section for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## Usage
The model is available for use in the NeMo toolkit [3] and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed the latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
Note: This model generates only spectrograms and a vocoder is needed to convert the spectrograms to waveforms.
In this example HiFiGAN is used.
```python
# Load FastPitch
from nemo.collections.tts.models import FastPitchModel
spec_generator = FastPitchModel.from_pretrained("nvidia/tts_en_fastpitch")
# Load vocoder
from nemo.collections.tts.models import HifiGanModel
model = HifiGanModel.from_pretrained(model_name="nvidia/tts_hifigan")
```
### Generate audio
```python
import soundfile as sf
parsed = spec_generator.parse("You can type your sentence here to get nemo to produce speech.")
spectrogram = spec_generator.generate_spectrogram(tokens=parsed)
audio = model.convert_spectrogram_to_audio(spec=spectrogram)
```
### Save the generated audio file
```python
# Save the audio to disk in a file called speech.wav
sf.write("speech.wav", audio.to('cpu').detach().numpy()[0], 22050)
```
### Input
This model accepts batches of text.
### Output
This model generates mel spectrograms.
## Model Architecture
FastPitch is a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference. By altering these predictions, the generated speech can be more expressive, better match the semantic of the utterance, and in the end more engaging to the listener. FastPitch is based on a fully-parallel Transformer architecture, with a much higher real-time factor than Tacotron2 for the mel-spectrogram synthesis of a typical utterance. It uses an unsupervised speech-text aligner.
## Training
The NeMo toolkit [3] was used for training the models for 1000 epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/tts/fastpitch.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/tts/conf/fastpitch_align_v1.05.yaml).
### Datasets
This model is trained on LJSpeech sampled at 22050Hz, and has been tested on generating female English voices with an American accent.
## Performance
No performance information is available at this time.
## Limitations
This checkpoint only works well with vocoders that were trained on 22050Hz data. Otherwise, the generated audio may be scratchy or choppy-sounding.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [FastPitch: Parallel Text-to-speech with Pitch Prediction](https://arxiv.org/abs/2006.06873)
- [2] [One TTS Alignment To Rule Them All](https://arxiv.org/abs/2108.10447)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
3e6302c30762c5ec6f4f445121e5df44
|
muhtasham/tiny-mlm-squad
|
muhtasham
|
bert
| 12 | 7 |
transformers
| 1 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,451 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-squad-plain_text
This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0170
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.4628 | 0.4 | 500 | 3.9931 |
| 4.0687 | 0.8 | 1000 | 3.9571 |
| 3.9256 | 1.2 | 1500 | 3.9381 |
| 3.7901 | 1.6 | 2000 | 3.9680 |
| 3.715 | 2.0 | 2500 | 3.9487 |
| 3.6632 | 2.4 | 3000 | 4.0170 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
dc9e4dc33ac515577eea833ed065091a
|
bert-base-cased
| null |
bert
| 10 | 6,492,277 |
transformers
| 73 |
fill-mask
| true | true | true |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 2 | 0 | 1 | 1 | 0 | 0 | 0 |
['exbert']
| false | true | true | 8,891 | false |
# BERT base model (cased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is case-sensitive: it makes a difference between
english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-cased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] Hello I'm a fashion model. [SEP]",
'score': 0.09019174426794052,
'token': 4633,
'token_str': 'fashion'},
{'sequence': "[CLS] Hello I'm a new model. [SEP]",
'score': 0.06349995732307434,
'token': 1207,
'token_str': 'new'},
{'sequence': "[CLS] Hello I'm a male model. [SEP]",
'score': 0.06228214129805565,
'token': 2581,
'token_str': 'male'},
{'sequence': "[CLS] Hello I'm a professional model. [SEP]",
'score': 0.0441727414727211,
'token': 1848,
'token_str': 'professional'},
{'sequence': "[CLS] Hello I'm a super model. [SEP]",
'score': 0.03326151892542839,
'token': 7688,
'token_str': 'super'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = BertModel.from_pretrained("bert-base-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertModel.from_pretrained("bert-base-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-cased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] The man worked as a lawyer. [SEP]',
'score': 0.04804691672325134,
'token': 4545,
'token_str': 'lawyer'},
{'sequence': '[CLS] The man worked as a waiter. [SEP]',
'score': 0.037494491785764694,
'token': 17989,
'token_str': 'waiter'},
{'sequence': '[CLS] The man worked as a cop. [SEP]',
'score': 0.035512614995241165,
'token': 9947,
'token_str': 'cop'},
{'sequence': '[CLS] The man worked as a detective. [SEP]',
'score': 0.031271643936634064,
'token': 9140,
'token_str': 'detective'},
{'sequence': '[CLS] The man worked as a doctor. [SEP]',
'score': 0.027423162013292313,
'token': 3995,
'token_str': 'doctor'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] The woman worked as a nurse. [SEP]',
'score': 0.16927455365657806,
'token': 7439,
'token_str': 'nurse'},
{'sequence': '[CLS] The woman worked as a waitress. [SEP]',
'score': 0.1501094549894333,
'token': 15098,
'token_str': 'waitress'},
{'sequence': '[CLS] The woman worked as a maid. [SEP]',
'score': 0.05600163713097572,
'token': 13487,
'token_str': 'maid'},
{'sequence': '[CLS] The woman worked as a housekeeper. [SEP]',
'score': 0.04838843643665314,
'token': 26458,
'token_str': 'housekeeper'},
{'sequence': '[CLS] The woman worked as a cook. [SEP]',
'score': 0.029980547726154327,
'token': 9834,
'token_str': 'cook'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|:----:|:-----------:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|:-------:|
| | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=bert-base-cased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
e7281d3f23a45b07fdf7bcd9cffc7393
|
Yaxin/xlm-roberta-base-conll2003-ner
|
Yaxin
|
xlm-roberta
| 13 | 14 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,062 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-conll2003-ner
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0470
- Precision: 0.9459
- Recall: 0.9537
- F1: 0.9498
- Accuracy: 0.9911
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.0
- Datasets 1.18.3
- Tokenizers 0.11.0
|
157e27536ddf464c13d1b3f6e406a176
|
sagorsarker/bangla_word2vec
|
sagorsarker
| null | 3 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 942 | false |
# Bengali Word2Vec Model
This is a pre-trained word2vec model for Bengali language.
This model is build for [bnlp](https://github.com/sagorbrur/bnlp) package.
## Datasets
- [Wikipedia dump datasets](https://dumps.wikimedia.org/bnwiki/latest/)
## Training details
- Word2Vec word embedding dimension = 100, min_count=5, window=5, epochs=10
## Usage
- `pip install -U bnlp_toolkit`
- Generate Vector using pretrain model
```py
from bnlp import BengaliWord2Vec
bwv = BengaliWord2Vec()
model_path = "bengali_word2vec.model"
word = 'গ্রাম'
vector = bwv.generate_word_vector(model_path, word)
print(vector.shape)
print(vector)
```
- Find Most Similar Word Using Pretrained Model
```py
from bnlp import BengaliWord2Vec
bwv = BengaliWord2Vec()
model_path = "bengali_word2vec.model"
word = 'গ্রাম'
similar = bwv.most_similar(model_path, word, topn=10)
print(similar)
```
|
6fd64737b34473b770c0a44ce8efd436
|
sd-concepts-library/dtv-pkmn
|
sd-concepts-library
| null | 9 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,288 | false |
### dtv-pkmn on Stable Diffusion
This is the `<dtv-pkm2>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).

`"hyperdetailed fantasy (monster) (dragon-like) character on top of a rock in the style of <dtv-pkm2> . extremely detailed, amazing artwork with depth and realistic CINEMATIC lighting, matte painting"`
Here is the new concept you will be able to use as a `style`:




|
990ad75714ec9eedcd0acef8e08f9c79
|
stanfordnlp/stanza-nb
|
stanfordnlp
| null | 11 | 11 |
stanza
| 0 |
token-classification
| false | false | false |
apache-2.0
|
['nb']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stanza', 'token-classification']
| false | true | true | 582 | false |
# Stanza model for Norwegian (nb)
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza).
This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo
Last updated 2022-10-12 03:01:48.679
|
6171eaefc8384040c5337ceb902af5da
|
bazyl/gtsrb-model
|
bazyl
|
vit
| 11 | 11 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['gtsrb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'vision', 'generated_from_trainer']
| true | true | true | 1,799 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gtsrb-model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the bazyl/GTSRB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0034
- Accuracy: 0.9993
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.2593 | 1.0 | 4166 | 0.1585 | 0.9697 |
| 0.2659 | 2.0 | 8332 | 0.0472 | 0.9900 |
| 0.2825 | 3.0 | 12498 | 0.0155 | 0.9971 |
| 0.0953 | 4.0 | 16664 | 0.0113 | 0.9983 |
| 0.1277 | 5.0 | 20830 | 0.0076 | 0.9985 |
| 0.0816 | 6.0 | 24996 | 0.0047 | 0.9988 |
| 0.0382 | 7.0 | 29162 | 0.0041 | 0.9990 |
| 0.0983 | 8.0 | 33328 | 0.0059 | 0.9990 |
| 0.1746 | 9.0 | 37494 | 0.0034 | 0.9993 |
| 0.1153 | 10.0 | 41660 | 0.0038 | 0.9990 |
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.12.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
1acc761b3429469df83f30a9b63d82b5
|
gokuls/mobilebert_sa_GLUE_Experiment_sst2
|
gokuls
|
mobilebert
| 17 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,618 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_sst2
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4157
- Accuracy: 0.8028
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.487 | 1.0 | 527 | 0.4157 | 0.8028 |
| 0.2824 | 2.0 | 1054 | 0.4351 | 0.8005 |
| 0.2265 | 3.0 | 1581 | 0.4487 | 0.8096 |
| 0.1989 | 4.0 | 2108 | 0.5182 | 0.7993 |
| 0.1813 | 5.0 | 2635 | 0.4654 | 0.7982 |
| 0.1684 | 6.0 | 3162 | 0.5340 | 0.7924 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
1e2e8be38859fcf3ecd4af0b1f8c95ce
|
Norod78/sd21-fluentui-emoji
|
Norod78
| null | 39 | 22 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
|
['Norod78/microsoft-fluentui-emoji-512-whitebg']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion', 'stable-diffusion-diffusers']
| false | true | true | 801 | false |
# SDv2.1 sd21-fluentui-emoji model
### Stable-Diffusion v1.5 fine-tuned for 10k steps using [Huggingface Diffusers train_text_to_image script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) upon [Norod78/microsoft-fluentui-emoji-512-whitebg](https://huggingface.co/datasets/Norod78/microsoft-fluentui-emoji-512-whitebg)
# The Emoji file names were converted to become the text descriptions. It made the model learn a few special words: "flat", "high contrast" and "color"

## A few sample pictures generated with this model are available [here](https://huggingface.co/Norod78/sd21-fluentui-emoji/tree/main/sample_images)
|
be2371f28cf4c14868dcabfd2f96564a
|
kinit/slovakbert-pos
|
kinit
|
roberta
| 9 | 23 |
transformers
| 0 |
token-classification
| true | false | false |
cc
|
['sk']
|
['universal_dependencies']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pos']
| false | true | true | 1,263 | false |
# POS tagger based on SlovakBERT
This is a POS tagger based on [SlovakBERT](https://huggingface.co/gerulata/slovakbert). The model uses [Universal POS tagset (UPOS)](https://universaldependencies.org/u/pos/). The model was fine-tuned using Slovak part of [Universal Dependencies dataset](https://universaldependencies.org/) [Zeman 2017] containing 10k manually annotated Slovak sentences.
## Results
The model was evaluated in [our paper](https://arxiv.org/abs/2109.15254) [Pikuliak et al 2021, Section 4.2]. It achieves \\(97.84\%\\) accuracy.
## Cite
```
@article{DBLP:journals/corr/abs-2109-15254,
author = {Mat{\'{u}}{\v{s}} Pikuliak and
{\v{S}}tefan Grivalsk{\'{y}} and
Martin Kon{\^{o}}pka and
Miroslav Bl{\v{s}}t{\'{a}}k and
Martin Tamajka and
Viktor Bachrat{\'{y}} and
Mari{\'{a}}n {\v{S}}imko and
Pavol Bal{\'{a}}{\v{z}}ik and
Michal Trnka and
Filip Uhl{\'{a}}rik},
title = {SlovakBERT: Slovak Masked Language Model},
journal = {CoRR},
volume = {abs/2109.15254},
year = {2021},
url = {https://arxiv.org/abs/2109.15254},
eprinttype = {arXiv},
eprint = {2109.15254},
}
```
|
fd425d0d731971a7a89b3913f296858e
|
giannhskp/wav2vec2-large-xls-r-300m-medical
|
giannhskp
|
wav2vec2
| 7 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['audiofolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,464 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-medical
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2214
- Wer: 0.0975
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 7.0393 | 2.47 | 200 | 3.2401 | 1.0 |
| 2.8825 | 4.94 | 400 | 1.0054 | 0.8592 |
| 0.4256 | 7.41 | 600 | 0.2495 | 0.2448 |
| 0.1585 | 9.88 | 800 | 0.2169 | 0.1816 |
| 0.1017 | 12.35 | 1000 | 0.2197 | 0.1615 |
| 0.0728 | 14.81 | 1200 | 0.2018 | 0.1582 |
| 0.0608 | 17.28 | 1400 | 0.2108 | 0.1462 |
| 0.0485 | 19.75 | 1600 | 0.2169 | 0.1301 |
| 0.0391 | 22.22 | 1800 | 0.2180 | 0.1381 |
| 0.0349 | 24.69 | 2000 | 0.2166 | 0.1241 |
| 0.0314 | 27.16 | 2200 | 0.2124 | 0.1189 |
| 0.0268 | 29.63 | 2400 | 0.2087 | 0.1185 |
| 0.0243 | 32.1 | 2600 | 0.2133 | 0.1112 |
| 0.021 | 34.57 | 2800 | 0.2199 | 0.1153 |
| 0.02 | 37.04 | 3000 | 0.2147 | 0.1134 |
| 0.017 | 39.51 | 3200 | 0.2205 | 0.1037 |
| 0.0152 | 41.98 | 3400 | 0.2174 | 0.1039 |
| 0.0137 | 44.44 | 3600 | 0.2215 | 0.0988 |
| 0.0124 | 46.91 | 3800 | 0.2234 | 0.1003 |
| 0.0112 | 49.38 | 4000 | 0.2214 | 0.0975 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
5284e1d08571b4d14e4076f1ab8c96ae
|
sd-dreambooth-library/colorful-ball
|
sd-dreambooth-library
| null | 23 | 6 |
diffusers
| 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 1,384 | false |
### Colorful ball on Stable Diffusion via Dreambooth
#### model by maxnadeau
This your the Stable Diffusion model fine-tuned the Colorful ball concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks ball**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





|
3008c807d1a929f9ac98b489e43f23e5
|
sentence-transformers/nli-bert-base-max-pooling
|
sentence-transformers
|
bert
| 12 | 28 |
sentence-transformers
| 0 |
sentence-similarity
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers']
| false | true | true | 3,822 | false |
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/nli-bert-base-max-pooling
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-bert-base-max-pooling')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Max Pooling - Take the max value over time for every dimension.
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
return torch.max(token_embeddings, 1)[0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-bert-base-max-pooling')
model = AutoModel.from_pretrained('sentence-transformers/nli-bert-base-max-pooling')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = max_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-bert-base-max-pooling)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': True, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
414a49caf3fc5c3ebfc1fb6a34852b91
|
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_sst2_256
|
gokuls
|
mobilebert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,592 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_sst2_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8734
- Accuracy: 0.7592
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0863 | 1.0 | 527 | 0.8734 | 0.7592 |
| 0.5116 | 2.0 | 1054 | 1.1742 | 0.7489 |
| 0.3952 | 3.0 | 1581 | 0.9197 | 0.7787 |
| 0.3401 | 4.0 | 2108 | 1.0557 | 0.7695 |
| 0.3113 | 5.0 | 2635 | 0.9003 | 0.7924 |
| 0.2862 | 6.0 | 3162 | 0.8923 | 0.8016 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
2a7ee3bcbd9885f16da9e263b96fd59f
|
sd-dreambooth-library/weirdcore
|
sd-dreambooth-library
| null | 69 | 70 |
diffusers
| 4 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 6,367 | false |
### weirdcore Dreambooth model trained by abesmon with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-1-512 base model
You run your new concept via `diffusers`
[Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
---
Keyword for this model is **weirdcore** (use that on your prompt)
---
### Train pictures:



















































|
8361657d29a9330c6654729424fcefd0
|
facebook/mask2former-swin-tiny-coco-instance
|
facebook
|
mask2former
| 5 | 35 |
transformers
| 0 |
image-segmentation
| true | false | false |
other
| null |
['coco']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['vision', 'image-segmentation']
| false | true | true | 2,936 | false |
# Mask2Former
Mask2Former model trained on COCO instance segmentation (tiny-sized version, Swin backbone). It was introduced in the paper [Masked-attention Mask Transformer for Universal Image Segmentation
](https://arxiv.org/abs/2112.01527) and first released in [this repository](https://github.com/facebookresearch/Mask2Former/).
Disclaimer: The team releasing Mask2Former did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Mask2Former addresses instance, semantic and panoptic segmentation with the same paradigm: by predicting a set of masks and corresponding labels. Hence, all 3 tasks are treated as if they were instance segmentation. Mask2Former outperforms the previous SOTA,
[MaskFormer](https://arxiv.org/abs/2107.06278) both in terms of performance an efficiency by (i) replacing the pixel decoder with a more advanced multi-scale deformable attention Transformer, (ii) adopting a Transformer decoder with masked attention to boost performance without
without introducing additional computation and (iii) improving training efficiency by calculating the loss on subsampled points instead of whole masks.

## Intended uses & limitations
You can use this particular checkpoint for instance segmentation. See the [model hub](https://huggingface.co/models?search=mask2former) to look for other
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
import requests
import torch
from PIL import Image
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
# load Mask2Former fine-tuned on COCO instance segmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-tiny-coco-instance")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-tiny-coco-instance")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to processor for postprocessing
result = processor.post_process_instance_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the Mask2Former docs)
predicted_instance_map = result["segmentation"]
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/mask2former).
|
371d543ea3e65f7ca14943c04ba95396
|
jonatasgrosman/exp_w2v2r_fr_vp-100k_accent_france-8_belgium-2_s496
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fr']
| false | true | true | 501 | false |
# exp_w2v2r_fr_vp-100k_accent_france-8_belgium-2_s496
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
ca45c4bfe984b1f0502326ab5d1d86d2
|
Sandipan1994/t5-small-finetuned-eli5
|
Sandipan1994
|
t5
| 16 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['eli5']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,609 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-eli5
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7275
- Rouge1: 9.944
- Rouge2: 1.908
- Rougel: 8.0145
- Rougelsum: 9.2275
- Gen Len: 18.9988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 3.9806 | 1.0 | 17040 | 3.7726 | 9.8475 | 1.872 | 7.9462 | 9.1258 | 18.9972 |
| 3.9458 | 2.0 | 34080 | 3.7369 | 9.9232 | 1.8981 | 7.9922 | 9.2061 | 18.9988 |
| 3.9355 | 3.0 | 51120 | 3.7275 | 9.944 | 1.908 | 8.0145 | 9.2275 | 18.9988 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
e9d38058661ec7727efbfbafd5147d6d
|
yuhuizhang/finetuned_gpt2-medium_sst2_negation0.01
|
yuhuizhang
|
gpt2
| 11 | 1 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,252 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-medium_sst2_negation0.01
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4416
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8263 | 1.0 | 1060 | 3.3054 |
| 2.5408 | 2.0 | 2120 | 3.3786 |
| 2.3927 | 3.0 | 3180 | 3.4416 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.12.1
|
ff43a7a680a47993cc3ff57dbade7ab7
|
timm/levit_128s.fb_dist_in1k
|
timm
| null | 4 | 16 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 3,929 | false |
# Model card for levit_128s.fb_dist_in1k
A LeViT image classification model using convolutional mode (using nn.Conv2d and nn.BatchNorm2d). Pretrained on ImageNet-1k using distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 7.8
- GMACs: 0.3
- Activations (M): 1.9
- Image size: 224 x 224
- **Papers:**
- LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference: https://arxiv.org/abs/2104.01136
- **Original:** https://github.com/facebookresearch/LeViT
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('levit_128s.fb_dist_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'levit_128s.fb_dist_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
|model |top1 |top5 |param_count|img_size|
|-----------------------------------|------|------|-----------|--------|
|levit_384.fb_dist_in1k |82.596|96.012|39.13 |224 |
|levit_conv_384.fb_dist_in1k |82.596|96.012|39.13 |224 |
|levit_256.fb_dist_in1k |81.512|95.48 |18.89 |224 |
|levit_conv_256.fb_dist_in1k |81.512|95.48 |18.89 |224 |
|levit_conv_192.fb_dist_in1k |79.86 |94.792|10.95 |224 |
|levit_192.fb_dist_in1k |79.858|94.792|10.95 |224 |
|levit_128.fb_dist_in1k |78.474|94.014|9.21 |224 |
|levit_conv_128.fb_dist_in1k |78.474|94.02 |9.21 |224 |
|levit_128s.fb_dist_in1k |76.534|92.864|7.78 |224 |
|levit_conv_128s.fb_dist_in1k |76.532|92.864|7.78 |224 |
## Citation
```bibtex
@InProceedings{Graham_2021_ICCV,
author = {Graham, Benjamin and El-Nouby, Alaaeldin and Touvron, Hugo and Stock, Pierre and Joulin, Armand and Jegou, Herve and Douze, Matthijs},
title = {LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {12259-12269}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
|
7a454cab3008e0d389205ee841a25253
|
Helsinki-NLP/opus-mt-lua-en
|
Helsinki-NLP
|
marian
| 10 | 39 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-lua-en
* source languages: lua
* target languages: en
* OPUS readme: [lua-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lua-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/lua-en/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-en/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-en/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.lua.en | 34.4 | 0.502 |
|
0335dd4844367ae6e448363923860568
|
Matthijs/deeplabv3_mobilenet_v2_1.0_513
|
Matthijs
|
mobilenet_v2
| 8 | 27 |
transformers
| 0 |
image-segmentation
| true | false | false |
other
| null |
['pascal-voc']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-segmentation']
| false | true | true | 2,577 | false |
# MobileNetV2 with DeepLabV3+
MobileNet V2 model pre-trained on PASCAL VOC at resolution 513x513. It was introduced in [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. It was first released in [this repository](https://github.com/tensorflow/models/tree/master/research/deeplab).
Disclaimer: The team releasing MobileNet V2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
From the [original README](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md):
> MobileNets are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection, embeddings and segmentation similar to how other popular large scale models, such as Inception, are used. MobileNets can be run efficiently on mobile devices [...] MobileNets trade off between latency, size and accuracy while comparing favorably with popular models from the literature.
The model in this repo adds a [DeepLabV3+](https://arxiv.org/abs/1802.02611) head to the MobileNetV2 backbone for semantic segmentation.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=mobilenet_v2) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import MobileNetV2FeatureExtractor, MobileNetV2ForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MobileNetV2FeatureExtractor.from_pretrained("Matthijs/deeplabv3_mobilenet_v2_1.0_513")
model = MobileNetV2ForSemanticSegmentation.from_pretrained("Matthijs/deeplabv3_mobilenet_v2_1.0_513")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_mask = logits.argmax(1).squeeze(0)
```
Currently, both the feature extractor and model support PyTorch.
### BibTeX entry and citation info
```bibtex
@inproceedings{deeplabv3plus2018,
title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
booktitle={ECCV},
year={2018}
}
```
|
bcd17b8a7400669a41d3614d060b951d
|
dkasti/xlm-roberta-base-finetuned-panx-de
|
dkasti
|
xlm-roberta
| 42 | 6 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,314 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1401
- F1: 0.8616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2605 | 1.0 | 525 | 0.1708 | 0.8198 |
| 0.1274 | 2.0 | 1050 | 0.1415 | 0.8449 |
| 0.0819 | 3.0 | 1575 | 0.1401 | 0.8616 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ef43c09aaf993414431eafea3291d52d
|
Yaxin/bert-base-multilingual-cased-42-QAData
|
Yaxin
|
bert
| 17 | 12 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,414 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-42-QAData
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0873
- Precision: 0.4420
- Recall: 0.2887
- F1: 0.3493
- Accuracy: 0.9755
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1064 | 1.0 | 3118 | 0.0873 | 0.4420 | 0.2887 | 0.3493 | 0.9755 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
b1eafe1c304d62e06ae2d7fe8697e7f9
|
cm-mueller/BACnet-Klassifizierung-Kaeltettechnik
|
cm-mueller
|
bert
| 18 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,923 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BACnet-Klassifizierung-Kaeltettechnik-bert-base-german-cased
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on the [gart-labor](https://huggingface.co/gart-labor) "klassifizierung_kaelte_v2" dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0466
- F1: [0.85714286 0.98507463 1. 1. ]
## Model description
This model makes it possible to classify the refrigeration components described with the BACnet standard into different categories.
The model is based on a German-language data set.
## Intended uses & limitations
The model divides descriptive texts into the following refrigeration categories:
Free_Cooling, Refrigeration_General, Chiller, Cold Storage and Recooling Plant
## Training and evaluation data
The model is based on a German-language data set.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------------------------------------------:|
| 0.0426 | 0.85 | 5 | 0.0439 | [0.85714286 0.98507463 1. 1. ] |
| 0.0175 | 1.85 | 10 | 0.0466 | [0.85714286 0.98507463 1. 1. ] |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
93c98d23b365ae8f0d71936a81f6e2de
|
Anjoe/poetry-gpt2-large-with-hoel
|
Anjoe
|
gpt2
| 14 | 5 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,298 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# poetry-gpt2-large-with-hoel
This model is a fine-tuned version of [benjamin/gerpt2-large](https://huggingface.co/benjamin/gerpt2-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5612
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.673 | 1.0 | 20539 | 3.6197 |
| 3.299 | 2.0 | 41078 | 3.5369 |
| 3.0433 | 3.0 | 61617 | 3.5612 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
de7f2e718a0f35f30c371c0b98a2a469
|
jcblaise/electra-tagalog-small-uncased-discriminator
|
jcblaise
|
electra
| 6 | 162 |
transformers
| 0 | null | true | false | false |
gpl-3.0
|
['tl']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['electra', 'tagalog', 'filipino']
| false | true | true | 1,708 | false |
**Deprecation Notice**
This model is deprecated. New Filipino Transformer models trained with a much larger corpora are available.
Use [`jcblaise/roberta-tagalog-base`](https://huggingface.co/jcblaise/roberta-tagalog-base) or [`jcblaise/roberta-tagalog-large`](https://huggingface.co/jcblaise/roberta-tagalog-large) instead for better performance.
---
# ELECTRA Tagalog Small Uncased Discriminator
Tagalog ELECTRA model pretrained with a large corpus scraped from the internet. This model is part of a larger research project. We open-source the model to allow greater usage within the Filipino NLP community.
This is the discriminator model, which is the main Transformer used for finetuning to downstream tasks. For generation, mask-filling, and retraining, refer to the Generator models.
## Citations
All model details and training setups can be found in our papers. If you use our model or find it useful in your projects, please cite our work:
```
@inproceedings{cruz2021exploiting,
title={Exploiting News Article Structure for Automatic Corpus Generation of Entailment Datasets},
author={Cruz, Jan Christian Blaise and Resabal, Jose Kristian and Lin, James and Velasco, Dan John and Cheng, Charibeth},
booktitle={Pacific Rim International Conference on Artificial Intelligence},
pages={86--99},
year={2021},
organization={Springer}
}
```
## Data and Other Resources
Data used to train this model as well as other benchmark datasets in Filipino can be found in my website at https://blaisecruz.com
## Contact
If you have questions, concerns, or if you just want to chat about NLP and low-resource languages in general, you may reach me through my work email at me@blaisecruz.com
|
3b77619c6f86581f0c18ce9550afa461
|
efederici/cross-encoder-distilbert-it
|
efederici
|
distilbert
| 8 | 66 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['it']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['cross-encoder', 'sentence-similarity', 'transformers']
| false | true | true | 765 | false |
# Cross-Encoder
The model can be used for Information Retrieval: given a query, encode the query will all possible passages. Then sort the passages in a decreasing order.
<p align="center">
<img src="https://www.exibart.com/repository/media/2020/07/bridget-riley-cool-edge.jpg" width="400"> </br>
Bridget Riley, COOL EDGE
</p>
## Training Data
This model was trained on a custom biomedical ranking dataset.
## Usage and Performance
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('efederici/cross-encoder-distilbert-it')
scores = model.predict([('Sentence 1', 'Sentence 2'), ('Sentence 3', 'Sentence 4')])
```
The model will predict scores for the pairs `('Sentence 1', 'Sentence 2')` and `('Sentence 3', 'Sentence 4')`.
|
0529601eda6a734c75d30f4f075ad857
|
andi611/bert-large-uncased-whole-word-masking-squad2-with-ner-Pistherea-conll2003-with-neg-with-repeat
|
andi611
|
bert
| 13 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
cc-by-4.0
|
['en']
|
['squad_v2', 'conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,145 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-whole-word-masking-squad2-with-ner-Pistherea-conll2003-with-neg-with-repeat
This model is a fine-tuned version of [deepset/bert-large-uncased-whole-word-masking-squad2](https://huggingface.co/deepset/bert-large-uncased-whole-word-masking-squad2) on the squad_v2 and the conll2003 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1+cu111
- Datasets 1.8.0
- Tokenizers 0.10.3
|
7a2038d146197aeb1c6bf32181223997
|
Yaxin/xlm-roberta-base-amazon-en-es-fr-mlm
|
Yaxin
|
xlm-roberta
| 11 | 3 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null |
['Yaxin/amazon_reviews_multi']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,046 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-amazon-en-es-fr-mlm
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the Yaxin/amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3936
- Accuracy: 0.6951
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
0ce02d71915fbe2a87e457b5855b48b4
|
johnslegers/epic-diffusion
|
johnslegers
| null | 21 | 19,488 |
diffusers
| 47 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image']
| false | true | true | 32,569 | false |
[![Example][1]][1]
## Why Epic Diffusion
Epîc Diffusion is a general purpose model based on Stable Diffusion 1.x intended to replace the official SD releases
as your default model. It is focused on providing high quality output in a wide range of different styles, with support
for NFSW content.
Epîc Diffusion 1.0 is a heavily calibrated merge of SD 1.4, SD 1.5, Analog Diffusion, Wavy Diffusion,
Openjourney Diffusion, Samdoesarts Ultramerge, postapocalypse, Elldreth's Dream, Inkpunk Diffusion,
Arcane Diffusion & Van Gogh Diffusion blended and reblended multiple times until I got the quality & consistency
I was looking for...
Epic Diffusion is also [available on CivitAI](https://civitai.com/models/3855/epic-diffusion).
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M
license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or
harmful outputs or content
2. CompVis claims no rights on the outputs you generate, you are free to use
them and are accountable for their use which must not go against the
provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as
a service. If you do, please be aware you have to include the same use
restrictions as the ones in the license and share a copy of the CreativeML
OpenRAIL-M to all your users (please read the license entirely and carefully)
<a href="https://www.buymeacoffee.com/johnslegers" target="_blank">
<img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 45px !important;width: 162px !important;" >
</a>
## Example prompts
<table>
<tr style="border: 1px solid;background:#e5e7eb">
<th style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Prompt
</th>
<th style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Parameters
</th>
<th style="vertical-align:top;padding:.5714286em!important;border: 1px solid;min-width:270px">
Output
</th>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
scarlett johansson, in the style of Wes Anderson, highly detailed, unreal engine, octane render, 8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2263657329<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/0oZij.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
sansa angeline jolie gessica chastain mummy, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha and william - adolphe bouguereau
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1310341382<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/mnnBR.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Pokimane, Feminine, Mercy, Perfect Sexy Symmetrical Face, Detailed Pupils, Pensive Smirk, Look at Viewer, Leaf Armor, Ilya Kuvshinov, Gil Elvgren, Mucha. Intricate, Octane Render, 4KUHD, Centered, Oil Painting, Bokeh, Rim Lighting.
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>4142902194<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/v9NoC.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Mature babe,artgerm Style, gerald brom, atey ghailan, mike mignola, short cut off shirt knot, wide hips, showing off, exposing herself vulnerable, blushing, exited, confident, demanding, joyful, trending on artstation, double split complementary colors, intricate details, highly detailed,
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3954688283<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/vl0bc.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
planet base, windows, night, ground level, no man's sky, digital art, highly detailed, intricate, sharp focus, Trending on Artstation HQ, deviantart, unreal engine 5, 4K UHD image
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>895811336<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/D2GNK.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
berchtesgaden, hyperdetailed, detailed faces, artgerm, wolfenstein, portal 2, Leartes Studios, assassin's creed, alphonse mucha, bouguereau, edmund blair leighton, greg kadel, dynamic lighting, delicate, unreal engine, octane render, 8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1172925287<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/m7Xkb.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
princess, detailed portrait, hyperdetailed, detailed faces, irakli nadar, magali villeneuve, Assassin's Creed, Tim Hildebrandt, Ilya Kuvshinov, artgem, greg kadel, dynamic lighting, delicate, unreal engine, octane render, 8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2096567313<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/LwPPa.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
a Photorealistic dramatic hyperrealistic bright blue eyes, African American elegant girl, black hair, white veil,by WLOP,Artgerm,Greg Rutkowski,Alphonse Mucha, Beautiful dynamic dramatic bright sunset lighting,shadows,cinematic atmosphere,Artstation,concept design art,Octane render,8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2999946689<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/1nH9c.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
cutest girl in the world outside, (detailed portrait), in the style of fernanda suarez and simon stalenhag and Ilya Kuvshinov and Wlop and Artgerm and Chie Yoshii and Greg Rutkowski and Waking Life, trending on artstation, featured on pixiv, dynamic lighting, highly detailed, ambient lighting, octane render, 8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2249388004<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/uNux1.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
military academy, (detailed portrait), steampunk, in the style of arcane and fernanda suarez and dishonored and bioshock and simon stalenhag and Ilya Kuvshinov and Wlop and Artgerm, trending on artstation, featured on pixiv, dynamic lighting, highly detailed, ambient lighting, octane render, 8k
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3877530043<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/sFXCi.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
beautiful female assassin wearing cyberpunk clothing, respirator, cybernetic respirator, (detailed portrait), cell shaded, 4 k, vivid colours, photorealistic concept art by wlop, ilya kuvshinov, artgerm, krenz cushart, greg rutkowski, pixiv. cinematic dramatic atmosphere, sharp focus, volumetric lighting, cinematic lighting, studio quality
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3388890157<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/14iZS.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
cemetary, pen and ink, in the style of gustave dore highly detailed, octane render, 8k, trending on artstation, sharp focus, studio photo, intricate details, highly detailed, by greg rutkowski
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>568457114<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/D1hsN.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
dubai, hyperdetailed, detailed faces, artgem, irakli nadar, mass effect, Tim Hildebrandt, Ilya Kuvshinov, liam wong, greg rutkowski, greg kadel, dynamic lighting, delicate, unreal engine, octane render, 8k, centered, symmetry, painted, intricate, volumetric lighting, beautiful, rich deep colors masterpiece, sharp focus, ultra detailed, in the style of dan mumford and marc simonetti, astrophotography
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>DPM++ SDE<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>4262868463<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/4uPzr.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Little cute forest fluffy chibi cuteness overload, sunny magical background, ultra precious details, intricate details, volumetric lighting, photo realistic, lifelike, photography, digital art, 8k, trending on artstation, sharp focus, studio photo, intricate details, highly detailed, by greg rutkowski, sharp focus, emitting diodes, smoke, artillery, sparks, racks, system unit, motherboard, by pascal blanche rutkowski repin artstation hyperrealism painting concept art of detailed character design matte painting, 4 k resolution blade runner
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3849507891<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/4yTQP.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
15 year old schoolgirl with short straight hair, blue eyes, cute, friendly, round face, cottagecore, intricate, enlightened, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2276800560<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/gqynB.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
extreme wide shot a futuristic containment building in a rainforest valley with a city in the distance, national geographic, hyper realistic, 4 k, harsh light
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3260458902<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/8qH9Y.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
portrait of a middle - eastern female cleric with straight black hair wearing blue and yellow vestments casting fireball, fantasy, highly detailed, digital painting, artstation, concept art, character art, art by greg rutkowski and tyler jacobson and alphonse mucha
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1379894453<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/BP98Y.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
aSnowshoe Siamese Cat as the doomslayer, realistic scifi cyberpunk power armor robot, closeup portrait art by donato giancola and greg rutkowski, vintage retro scifi, realistic face, digital art, trending on artstation, symmetry
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>2122325442<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/GYdOS.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Beautiful boy by René Magritte
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1753689226<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/vP9sv.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
portrait of a dark god, copper wires, visible scars and nerves, intricate, headshot, highly detailed, digital painting, artstation, concept art, sharp focus, cinematic lighting, illustration, art by artgerm and greg rutkowski, alphonse mocha, cgsociety, Olivia
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3355776798<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/A94Gg.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
knight warrior helmet skyrim mask elder scrolls v nordic armor bethesda adam adamowicz illustration character design concept, unreal 5, daz, hyperrealistic, octane render, cosplay, rpg portrait, dynamic lighting, intricate detail, harvest fall vibrancy, cinematic volume inner glowing aura global illumination ray tracing hdr
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1938574287<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/efGrz.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
berserker portrait, d&d style, fantasy, photorealistic, highly detailed, artstation, smooth, sharp focus, art by michael whelan, artgerm, greg rutkowski and alphonse mucha
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>156077154<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/Wbjgp.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
symmetry product render poster vivid colors classical proportion car, glowing fog intricate, elegant, highly detailed, digital painting, art station, concept art, smooth, sharp focus, illustration,
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>4294525772<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/sMMpR.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Futuristic Vintage Medium Shot 1920's Poster with Cyberpunk, ovni, tron biker with helmet bike, black in color, with a cyberpunk city background, futuristic lighting, cinematic lighting, cozy lighting, 8k, cinematic poster vintage 1800s
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>1229558409<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/0Gojz.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
beautiful, young woman, cybernetic, cyberpunk, detailed gorgeous face, flowing hair, vaporwave aesthetic, synthwave , digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>264509871<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/zFdjj.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
strong warrior princess| centered| key visual| intricate| highly detailed| breathtaking beauty| precise lineart| vibrant| comprehensive cinematic| Carne Griffiths| Conrad Roset
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>16<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/aGuIL.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
portrait of a rugged 19th century man with mutton chops in a jacket, victorian, concept art, detailed face, fantasy, close up face, highly detailed, cinematic lighting, digital art painting by greg rutkowski
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>16<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/6sKW6.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
side profile of cyberpunk body with cyborg skull | cyberpunk | styled in Art Nouveau | insanely detailed | embellishments | high definition | concept art | digital art | vibrant
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>16<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/N7kSu.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
a cute little matte low poly isometric cherry blossom forest island, pink waterfalls, mist, lat lighting, soft shadows, trending on artstation, 3d render, monument valley, fez video game,
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>16<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/fVj9N.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
high resolution concept art of an apartment living room overlooking a large futuristic city with floor to ceiling windows and mid century modern furniture cinematic lighting cgsociety
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>850995814<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/jkpgU.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
hyperrealistic full length portrait of gorgeous watson from apex legends | blonde | detailed gorgeous face!! | full body!! | armor | intricate | elegant | realistic | hyperrealistic | cinematic | character design | concept art | highly detailed | illustration | digital art | digital painting | depth of field | illustrated by tim brown lee
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3002798343<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/hMsH2.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
Chibi spiderman, high redolution, 3D rendering, octane rendering, modern Disney style
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>20<br>
<b>Sampler:</b><br>Euler a<br>
<b>CFG scale:</b><br>7<br>
<b>Seed:</b><br>3232863832<br>
<b>Size:</b><br>512x512
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/zl18l.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
photo of the most beautiful artwork in the world featuring soft lustrous, industrial mechanic real world, fantastic location, working environment, rugged harsh situation worker, full body 8k unity render, action shot, skin pores, detailed intricate iris, very dark lighting, heavy shadows, detailed, detailed face, (vibrant, photo realistic, realistic, dramatic, dark, sharp focus, 8k), (weathered greasy dirty damaged old worn technician worker outfit:1.1), (intricate:1.1), (highly detailed:1.1), digital painting, octane render, artstation, concept art, smooth, sharp focus, illustration, art by artgerm, (loish:0.23), wlop ilya kuvshinov., (global illumination, studio light, volumetric light)<br><br>
<b>Negative prompt:</b> Asian, black and white, close up, cartoon, 3d, denim, (disfigured), (deformed), (poorly drawn), (extra limbs), blurry, boring, sketch, lackluster, signature, letters, watermark, low res , horrific , mutated , artifacts , bad art , gross , b&w , poor quality , low quality , cropped
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>30<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>10<br>
<b>Seed:</b><br>169686802<br>
<b>Size:</b><br>512x640
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/dPnAA.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
photo of the most beautiful artwork in the world featuring soft lustrous, industrial mechanic real world, fantastic location, working environment, rugged harsh situation worker, full body 8k unity render, action shot, skin pores, detailed intricate iris, very dark lighting, heavy shadows, detailed, detailed face, (vibrant, photo realistic, realistic, dramatic, dark, sharp focus, 8k), (weathered greasy dirty damaged old worn technician worker outfit:1.1), (intricate:1.1), (highly detailed:1.1), digital painting, octane render, artstation, concept art, smooth, sharp focus, illustration, art by artgerm, (loish:0.23), wlop ilya kuvshinov., (global illumination, studio light, volumetric light)<br><br>
<b>Negative prompt:</b> Asian, black and white, close up, cartoon, 3d, denim, (disfigured), (deformed), (poorly drawn), (extra limbs), blurry, boring, sketch, lackluster, signature, letters, watermark, low res , horrific , mutated , artifacts , bad art , gross , b&w , poor quality , low quality , cropped
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>30<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>10<br>
<b>Seed:</b><br>169686796<br>
<b>Size:</b><br>512x640<br>
<b>Denoising strength:</b><br>0.7<br>
<b>Hires upscale:</b><br>2<br>
<b>Hires upscaler:</b><br>Latent
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.imgur.com/ktLu2Tl.png">
</td>
</tr>
<tr>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
dark and gloomy full body 8k unity render, female teen cyborg, Blue yonder hair, wearing broken battle armor, at cluttered and messy shack , action shot, tattered torn shirt, porcelain cracked skin, skin pores, detailed intricate iris, very dark lighting, heavy shadows, detailed, detailed face, (vibrant, photo realistic, realistic, dramatic, dark, sharp focus, 8k)<br><br>
<b>Negative prompt:</b> nude, Asian, black and white, close up, cartoon, 3d, denim, (disfigured), (deformed), (poorly drawn), (extra limbs), blurry, boring, sketch, lackluster, signature, letters, watermark, low res , horrific , mutated , artifacts , bad art , gross , b&w , poor quality , low quality , cropped
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<b>Steps:</b><br>26<br>
<b>Sampler:</b><br>DPM++ SDE Karras<br>
<b>CFG scale:</b><br>7.5<br>
<b>Seed:</b><br>2388736888<br>
<b>Size:</b><br>768x1024
</td>
<td style="vertical-align:top;padding:.5714286em!important;border: 1px solid">
<img style="vertical-align:top;margin:0;padding:0" src="https://i.stack.imgur.com/GnUuV.jpg">
</td>
</tr>
</table>
[1]: https://i.stack.imgur.com/wkK2b.png
|
b6fa6b99892d4ec7141ba79240a4e75a
|
google/long-t5-tglobal-base
|
google
|
longt5
| 8 | 27,479 |
transformers
| 13 |
text2text-generation
| true | false | true |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 2 | 1 | 1 |
[]
| false | true | true | 2,344 | false |
# LongT5 (transient-global attention, base-sized model)
LongT5 model pre-trained on English language. The model was introduced in the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf) by Guo et al. and first released in [the LongT5 repository](https://github.com/google-research/longt5). All the model architecture and configuration can be found in [Flaxformer repository](https://github.com/google/flaxformer) which uses another Google research project repository [T5x](https://github.com/google-research/t5x).
Disclaimer: The team releasing LongT5 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
LongT5 model is an encoder-decoder transformer pre-trained in a text-to-text denoising generative setting ([Pegasus-like generation pre-training](https://arxiv.org/pdf/1912.08777.pdf)). LongT5 model is an extension of [T5 model](https://arxiv.org/pdf/1910.10683.pdf), and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2) Transient-Global attention. The usage of attention sparsity patterns allows the model to efficiently handle input sequence.
LongT5 is particularly effective when fine-tuned for text generation (summarization, question answering) which requires handling long input sequences (up to 16,384 tokens).
## Intended uses & limitations
The model is mostly meant to be fine-tuned on a supervised dataset. See the [model hub](https://huggingface.co/models?search=longt5) to look for fine-tuned versions on a task that interests you.
### How to use
```python
from transformers import AutoTokenizer, LongT5Model
tokenizer = AutoTokenizer.from_pretrained("google/long-t5-tglobal-base")
model = LongT5Model.from_pretrained("google/long-t5-tglobal-base")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{guo2021longt5,
title={LongT5: Efficient Text-To-Text Transformer for Long Sequences},
author={Guo, Mandy and Ainslie, Joshua and Uthus, David and Ontanon, Santiago and Ni, Jianmo and Sung, Yun-Hsuan and Yang, Yinfei},
journal={arXiv preprint arXiv:2112.07916},
year={2021}
}
```
|
2278c274e7111835ca0dfe82f6f95f1d
|
juridics/bertimbaulaw-base-portuguese-cased
|
juridics
|
bert
| 13 | 59 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,870 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6440
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10000
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.1985 | 0.22 | 2500 | 1.0940 |
| 1.0937 | 0.44 | 5000 | 1.0033 |
| 1.0675 | 0.66 | 7500 | 0.9753 |
| 1.0565 | 0.87 | 10000 | 0.9801 |
| 1.0244 | 1.09 | 12500 | 0.9526 |
| 0.9943 | 1.31 | 15000 | 0.9298 |
| 0.9799 | 1.53 | 17500 | 0.9035 |
| 0.95 | 1.75 | 20000 | 0.8835 |
| 0.933 | 1.97 | 22500 | 0.8636 |
| 0.9079 | 2.18 | 25000 | 0.8507 |
| 0.8938 | 2.4 | 27500 | 0.8397 |
| 0.8781 | 2.62 | 30000 | 0.8195 |
| 0.8647 | 2.84 | 32500 | 0.8088 |
| 0.8422 | 3.06 | 35000 | 0.7954 |
| 0.831 | 3.28 | 37500 | 0.7871 |
| 0.8173 | 3.5 | 40000 | 0.7721 |
| 0.8072 | 3.71 | 42500 | 0.7611 |
| 0.8011 | 3.93 | 45000 | 0.7532 |
| 0.7828 | 4.15 | 47500 | 0.7431 |
| 0.7691 | 4.37 | 50000 | 0.7367 |
| 0.7659 | 4.59 | 52500 | 0.7292 |
| 0.7606 | 4.81 | 55000 | 0.7245 |
| 0.8082 | 5.02 | 57500 | 0.7696 |
| 0.8114 | 5.24 | 60000 | 0.7695 |
| 0.8022 | 5.46 | 62500 | 0.7613 |
| 0.7986 | 5.68 | 65000 | 0.7558 |
| 0.8018 | 5.9 | 67500 | 0.7478 |
| 0.782 | 6.12 | 70000 | 0.7435 |
| 0.7743 | 6.34 | 72500 | 0.7367 |
| 0.774 | 6.55 | 75000 | 0.7313 |
| 0.7692 | 6.77 | 77500 | 0.7270 |
| 0.7604 | 6.99 | 80000 | 0.7200 |
| 0.7468 | 7.21 | 82500 | 0.7164 |
| 0.7486 | 7.43 | 85000 | 0.7117 |
| 0.7399 | 7.65 | 87500 | 0.7043 |
| 0.7306 | 7.86 | 90000 | 0.6956 |
| 0.7243 | 8.08 | 92500 | 0.6959 |
| 0.7132 | 8.3 | 95000 | 0.6916 |
| 0.71 | 8.52 | 97500 | 0.6853 |
| 0.7128 | 8.74 | 100000 | 0.6855 |
| 0.7088 | 8.96 | 102500 | 0.6809 |
| 0.7002 | 9.18 | 105000 | 0.6784 |
| 0.6953 | 9.39 | 107500 | 0.6737 |
| 0.695 | 9.61 | 110000 | 0.6714 |
| 0.6871 | 9.83 | 112500 | 0.6687 |
| 0.7161 | 10.05 | 115000 | 0.6961 |
| 0.7265 | 10.27 | 117500 | 0.7006 |
| 0.7284 | 10.49 | 120000 | 0.6941 |
| 0.724 | 10.7 | 122500 | 0.6887 |
| 0.7266 | 10.92 | 125000 | 0.6931 |
| 0.7051 | 11.14 | 127500 | 0.6846 |
| 0.7106 | 11.36 | 130000 | 0.6816 |
| 0.7011 | 11.58 | 132500 | 0.6830 |
| 0.6997 | 11.8 | 135000 | 0.6784 |
| 0.6969 | 12.02 | 137500 | 0.6734 |
| 0.6968 | 12.23 | 140000 | 0.6709 |
| 0.6867 | 12.45 | 142500 | 0.6656 |
| 0.6925 | 12.67 | 145000 | 0.6661 |
| 0.6795 | 12.89 | 147500 | 0.6606 |
| 0.6774 | 13.11 | 150000 | 0.6617 |
| 0.6756 | 13.33 | 152500 | 0.6563 |
| 0.6728 | 13.54 | 155000 | 0.6547 |
| 0.6732 | 13.76 | 157500 | 0.6520 |
| 0.6704 | 13.98 | 160000 | 0.6492 |
| 0.6666 | 14.2 | 162500 | 0.6446 |
| 0.6615 | 14.42 | 165000 | 0.6488 |
| 0.6638 | 14.64 | 167500 | 0.6523 |
| 0.6588 | 14.85 | 170000 | 0.6415 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
d506185c98e85dd341082d0da6613975
|
rsuwaileh/IDRISI-LMR-AR-timebased-typeless
|
rsuwaileh
|
bert
| 8 | 2 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,788 | false |
This model is a BERT-based Location Mention Recognition model that is adopted from the [TLLMR4CM GitHub](https://github.com/rsuwaileh/TLLMR4CM/). The model identifies the toponyms' spans in the text without predicting their location types.
The model is trained using the training splits of all events from [IDRISI-R dataset](https://github.com/rsuwaileh/IDRISI) under the `Type-less` LMR mode and using the `Time-based` version of the data. You can download this data in `BILOU` format from [here](https://github.com/rsuwaileh/IDRISI/tree/main/data/LMR/EN/gold-timebased-bilou/). All Location types in the data were normalized to the `LOC` tag. More details are available [here](https://github.com/rsuwaileh/IDRISI/tree/main/models). More details about the models are available [here](https://github.com/rsuwaileh/IDRISI/tree/main/models).
* Different variants of the model are available through HuggingFace:
- [rsuwaileh/IDRISI-LMR-AR-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typeless/)
- [rsuwaileh/IDRISI-LMR-AR-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typebased/)
- [rsuwaileh/IDRISI-LMR-AR-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typebased/)
* English models are also available:
- [rsuwaileh/IDRISI-LMR-EN-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typeless/)
- [rsuwaileh/IDRISI-LMR-EN-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typebased/)
- [rsuwaileh/IDRISI-LMR-EN-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typeless/)
- [rsuwaileh/IDRISI-LMR-EN-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typebased/)
To cite the models:
```
@article{suwaileh2022tlLMR4disaster,
title={When a Disaster Happens, We Are Ready: Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad and Sajjad, Hassan},
journal={International Journal of Disaster Risk Reduction},
year={2022}
}
@inproceedings{suwaileh2020tlLMR4disaster,
title={Are We Ready for this Disaster? Towards Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Imran, Muhammad and Elsayed, Tamer and Sajjad, Hassan},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={6252--6263},
year={2020}
}
```
To cite the IDRISI-R dataset:
```
@article{rsuwaileh2022Idrisi-r,
title={IDRISI-R: Large-scale English and Arabic Location Mention Recognition Datasets for Disaster Response over Twitter},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad},
journal={...},
volume={...},
pages={...},
year={2022},
publisher={...}
}
```
* Different variants of the model are available through HuggingFace:
- [rsuwaileh/IDRISI-LMR-AR-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typeless/)
- [rsuwaileh/IDRISI-LMR-AR-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typebased/)
- [rsuwaileh/IDRISI-LMR-AR-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typebased/)
* English models are also available:
- [rsuwaileh/IDRISI-LMR-EN-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typeless/)
- [rsuwaileh/IDRISI-LMR-EN-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typebased/)
- [rsuwaileh/IDRISI-LMR-EN-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typeless/)
- [rsuwaileh/IDRISI-LMR-EN-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typebased/)
To cite the models:
```
@article{suwaileh2022tlLMR4disaster,
title={When a Disaster Happens, We Are Ready: Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad and Sajjad, Hassan},
journal={International Journal of Disaster Risk Reduction},
year={2022}
}
@inproceedings{suwaileh2020tlLMR4disaster,
title={Are We Ready for this Disaster? Towards Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Imran, Muhammad and Elsayed, Tamer and Sajjad, Hassan},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={6252--6263},
year={2020}
}
```
To cite the IDRISI-R dataset:
```
@article{rsuwaileh2022Idrisi-r,
title={IDRISI-R: Large-scale English and Arabic Location Mention Recognition Datasets for Disaster Response over Twitter},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad},
journal={...},
volume={...},
pages={...},
year={2022},
publisher={...}
}
```
|
3a4f76ad4cec6215df10be32526b7988
|
p4b/limiwhisper-small-ko-dia-gs
|
p4b
|
whisper
| 17 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ko']
|
['kr_dialect_speech']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,585 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ko(Gyungsang dialect) - p4b
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the KR Dialect Speech - gyungsang dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2017
- Wer: 15.9300
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 96
- eval_batch_size: 64
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5909 | 0.2 | 1000 | 0.4133 | 211.6022 |
| 0.3612 | 0.4 | 2000 | 0.2137 | 16.9429 |
| 0.5373 | 0.6 | 3000 | 0.2063 | 15.8379 |
| 0.2909 | 0.8 | 4000 | 0.2012 | 15.8379 |
| 0.3317 | 1.0 | 5000 | 0.2017 | 15.9300 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.14.0.dev20221208+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
b7447c899b5ca1d91010e651859bcf2b
|
TalTechNLP/mBART-ERRnews
|
TalTechNLP
|
mbart
| 8 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['et']
|
['ERRnews']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,029 | false |
# mBART ERRnews
Pretrained mbart-large-cc25 model finetuned on ERRnews Estonian news story dataset.
## How to use
Here is how to use this model to get a summary of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("TalTechNLP/mBART-ERRnews")
model = AutoModelForSeq2SeqLM.from_pretrained("TalTechNLP/mBART-ERRnews")
text = "Riigikogu rahanduskomisjon võttis esmaspäeval maha riigieelarvesse esitatud investeeringuettepanekutest siseministeeriumi investeeringud koolidele ja lasteaedadele, sest komisjoni hinnangul ei peaks siseministeerium tegelema investeeringutega väljaspoole oma vastutusala. Komisjoni esimees Aivar Kokk ütles, et komisjon lähtus otsuse tegemisel riigikontrolör Janar Holmi soovitusest ja seadustest."
inputs = tokenizer(text, return_tensors='pt', max_length=1024)
summary_ids = model.generate(inputs['input_ids'])
summary = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids]
```
## Training data
The mBART model was finetuned on [ERRnews](https://huggingface.co/datasets/TalTechNLP/ERRnews), a dataset consisting of 10 420
Estonian news story transcripts and summaries.
### Training
The model was trained on 2 cloud GPUs with a batch size of 16 for 16 epochs. The optimizer
used is Adam with a learning rate of 5e-05, betas of 0.9 and 0.999.
## Evaluation results
This model achieves the following results:
| Dataset | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-L-SUM |
|:-------:|:-------:|:-------:|:-------:|:-----------:|
| ERRnews | 19.2 | 6.7 | 16.1 | 17.4 |
### BibTeX entry and citation info
```bibtex
article{henryabstractive,
title={Abstractive Summarization of Broadcast News Stories for {Estonian}},
author={Henry, H{\"a}rm and Tanel, Alum{\"a}e},
journal={Baltic J. Modern Computing},
volume={10},
number={3},
pages={511-524},
year={2022}
}
```
|
9b061a686bbd421c81e6af1d4c27fd22
|
GioReg/mBERTrecensioni
|
GioReg
|
bert
| 12 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 941 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mBERTrecensioni
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
740c3601c523ae3f1db1001df58bf3fe
|
OpenAssistant/reward-model-deberta-v3-large
|
OpenAssistant
|
deberta-v2
| 15 | 233 |
transformers
| 1 |
text-classification
| true | false | false |
mit
|
['en']
|
['openai/summarize_from_feedback', 'openai/webgpt_comparisons', 'Dahoas/instruct-synthetic-prompt-responses']
| null | 2 | 1 | 0 | 1 | 0 | 0 | 0 |
['reward-model', 'reward_model', 'RLHF']
| false | true | true | 2,259 | false |
# Reward model trained from human feedback
Reward model (RM) trained to predict which generated answer is better judged by a human, given a question.
RM are useful in these domain:
- QA model evaluation
- serves as reward score in RLHF
All models are train on these dataset with a same split seed across datasets (if validation split wasn't available)
- [webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
- [summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
- [synthetic-instruct-gptj-pairwise](https://huggingface.co/datasets/Dahoas/synthetic-instruct-gptj-pairwise)
# How to use
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
reward_name = "OpenAssistant/reward-model-deberta-v3-large"
rank_model, tokenizer = AutoModelForSequenceClassification.from_pretrained(reward_name), AutoTokenizer.from_pretrained(reward_name)
question, answer = "Explain nuclear fusion like I am five", "Nuclear fusion is the process by which two or more protons and neutrons combine to form a single nucleus. It is a very important process in the universe, as it is the source of energy for stars and galaxies. Nuclear fusion is also a key process in the production of energy for nuclear power plants."
inputs = tokenizer(question, answer, return_tensors='pt')
score = rank_model(**inputs).logits[0].cpu().detach()
print(score)
```
# Performance
Validation split accuracy
| Model | [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) | [Summary](https://huggingface.co/datasets/openai/summarize_from_feedback) | [SytheticGPT](https://huggingface.co/datasets/Dahoas/synthetic-instruct-gptj-pairwise) |
|---|---|---|---|
| [electra-large-discriminator](https://huggingface.co/OpenAssistant/reward-model-electra-large-discriminator) | 59.30 | 68.66 | 99.85 |
| [deberta-v3-large](https://huggingface.co/OpenAssistant/reward-model-deberta-v3-large) | 61.13 | 72.23 | 99.94 |
| [deberta-v3-base](https://huggingface.co/OpenAssistant/reward-model-deberta-v3-base) | 59.07 | 66.84 | 99.85 |
Its likely SytheticGPT has somekind of surface pattern on the choosen-rejected pair which makes it trivial to differentiate between better the answer.
|
112ec09ee0dec73d025ea9051f120e8d
|
ayameRushia/wav2vec2-large-xls-r-300m-ar
|
ayameRushia
|
wav2vec2
| 11 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,990 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-ar
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4819
- Wer: 0.4244
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 11.0435 | 0.67 | 400 | 4.3104 | 1.0 |
| 3.4451 | 1.34 | 800 | 3.1566 | 1.0 |
| 3.1399 | 2.01 | 1200 | 3.0532 | 0.9990 |
| 2.8538 | 2.68 | 1600 | 1.6994 | 0.9238 |
| 1.7195 | 3.35 | 2000 | 0.8867 | 0.6727 |
| 1.326 | 4.02 | 2400 | 0.6603 | 0.5834 |
| 1.1561 | 4.69 | 2800 | 0.5809 | 0.5479 |
| 1.0764 | 5.36 | 3200 | 0.5943 | 0.5495 |
| 1.0144 | 6.03 | 3600 | 0.5344 | 0.5251 |
| 0.965 | 6.7 | 4000 | 0.4844 | 0.4936 |
| 0.927 | 7.37 | 4400 | 0.5048 | 0.5019 |
| 0.8985 | 8.04 | 4800 | 0.5809 | 0.5267 |
| 0.8684 | 8.71 | 5200 | 0.4740 | 0.4753 |
| 0.8581 | 9.38 | 5600 | 0.4813 | 0.4834 |
| 0.8334 | 10.05 | 6000 | 0.4515 | 0.4545 |
| 0.8134 | 10.72 | 6400 | 0.4370 | 0.4543 |
| 0.8002 | 11.39 | 6800 | 0.4225 | 0.4384 |
| 0.7884 | 12.06 | 7200 | 0.4593 | 0.4565 |
| 0.7675 | 12.73 | 7600 | 0.4752 | 0.4680 |
| 0.7607 | 13.4 | 8000 | 0.4950 | 0.4771 |
| 0.7475 | 14.07 | 8400 | 0.4373 | 0.4391 |
| 0.7397 | 14.74 | 8800 | 0.4506 | 0.4541 |
| 0.7289 | 15.41 | 9200 | 0.4840 | 0.4691 |
| 0.722 | 16.08 | 9600 | 0.4701 | 0.4571 |
| 0.7067 | 16.75 | 10000 | 0.4561 | 0.4461 |
| 0.7033 | 17.42 | 10400 | 0.4384 | 0.4347 |
| 0.6915 | 18.09 | 10800 | 0.4424 | 0.4290 |
| 0.6854 | 18.76 | 11200 | 0.4635 | 0.4360 |
| 0.6813 | 19.43 | 11600 | 0.4280 | 0.4147 |
| 0.6776 | 20.1 | 12000 | 0.4610 | 0.4344 |
| 0.67 | 20.77 | 12400 | 0.4540 | 0.4367 |
| 0.6653 | 21.44 | 12800 | 0.4509 | 0.4234 |
| 0.6609 | 22.11 | 13200 | 0.4874 | 0.4444 |
| 0.6541 | 22.78 | 13600 | 0.4542 | 0.4230 |
| 0.6528 | 23.45 | 14000 | 0.4732 | 0.4373 |
| 0.6463 | 24.12 | 14400 | 0.4483 | 0.4188 |
| 0.6399 | 24.79 | 14800 | 0.4731 | 0.4341 |
| 0.6353 | 25.46 | 15200 | 0.5031 | 0.4412 |
| 0.6358 | 26.13 | 15600 | 0.4986 | 0.4397 |
| 0.6317 | 26.8 | 16000 | 0.5000 | 0.4360 |
| 0.6262 | 27.47 | 16400 | 0.4958 | 0.4318 |
| 0.6317 | 28.14 | 16800 | 0.4738 | 0.4234 |
| 0.6205 | 28.81 | 17200 | 0.4853 | 0.4262 |
| 0.6205 | 29.48 | 17600 | 0.4819 | 0.4244 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
54e88ed917af9ec849faf81b973a0755
|
ydmeira/segformer-b0-finetuned-pokemon
|
ydmeira
|
segformer
| 39 | 0 |
transformers
| 0 | null | true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,436 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-b0-finetuned-pokemon
This model is a fine-tuned version of [ydmeira/segformer-b0-finetuned-pokemon](https://huggingface.co/ydmeira/segformer-b0-finetuned-pokemon) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0157
- Mean Iou: 0.4970
- Mean Accuracy: 0.9940
- Overall Accuracy: 0.9940
- Per Category Iou: [0.0, 0.9940101727137823]
- Per Category Accuracy: [nan, 0.9940101727137823]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Per Category Iou | Per Category Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:-------------------------:|:-------------------------:|
| 0.0175 | 45.0 | 1305 | 0.0157 | 0.4971 | 0.9943 | 0.9943 | [0.0, 0.9942906494536522] | [nan, 0.9942906494536522] |
| 0.018 | 46.0 | 1334 | 0.0157 | 0.4968 | 0.9936 | 0.9936 | [0.0, 0.9936369941650801] | [nan, 0.9936369941650801] |
| 0.0185 | 47.0 | 1363 | 0.0157 | 0.4971 | 0.9943 | 0.9943 | [0.0, 0.9942791789145462] | [nan, 0.9942791789145462] |
| 0.018 | 48.0 | 1392 | 0.0157 | 0.4969 | 0.9937 | 0.9937 | [0.0, 0.9937245121725857] | [nan, 0.9937245121725857] |
| 0.0183 | 49.0 | 1421 | 0.0157 | 0.4969 | 0.9939 | 0.9939 | [0.0, 0.9938530594161242] | [nan, 0.9938530594161242] |
| 0.0196 | 50.0 | 1450 | 0.0157 | 0.4970 | 0.9940 | 0.9940 | [0.0, 0.9940101727137823] | [nan, 0.9940101727137823] |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
a5e13a3b62e9cf287292c3ba1d7d94f7
|
nlptown/bert-base-multilingual-uncased-sentiment
|
nlptown
|
bert
| 9 | 555,537 |
transformers
| 88 |
text-classification
| true | true | true |
mit
|
['en', 'nl', 'de', 'fr', 'it', 'es']
| null | null | 1 | 1 | 0 | 0 | 2 | 2 | 0 |
[]
| false | true | true | 1,888 | false |
# bert-base-multilingual-uncased-sentiment
This a bert-base-multilingual-uncased model finetuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian. It predicts the sentiment of the review as a number of stars (between 1 and 5).
This model is intended for direct use as a sentiment analysis model for product reviews in any of the six languages above, or for further finetuning on related sentiment analysis tasks.
## Training data
Here is the number of product reviews we used for finetuning the model:
| Language | Number of reviews |
| -------- | ----------------- |
| English | 150k |
| Dutch | 80k |
| German | 137k |
| French | 140k |
| Italian | 72k |
| Spanish | 50k |
## Accuracy
The finetuned model obtained the following accuracy on 5,000 held-out product reviews in each of the languages:
- Accuracy (exact) is the exact match on the number of stars.
- Accuracy (off-by-1) is the percentage of reviews where the number of stars the model predicts differs by a maximum of 1 from the number given by the human reviewer.
| Language | Accuracy (exact) | Accuracy (off-by-1) |
| -------- | ---------------------- | ------------------- |
| English | 67% | 95%
| Dutch | 57% | 93%
| German | 61% | 94%
| French | 59% | 94%
| Italian | 59% | 95%
| Spanish | 58% | 95%
## Contact
In addition to this model, [NLP Town](https://www.nlp.town) offers custom, monolingual sentiment models for many languages and an improved multilingual model through [RapidAPI](https://rapidapi.com/nlp-town-nlp-town-default/api/multilingual-sentiment-analysis2/).
Feel free to contact us for questions, feedback and/or requests for similar models.
|
12c70ead70e905ae1fc5d825fcbb7891
|
PygmalionAI/pygmalion-2.7b
|
PygmalionAI
|
gpt_neo
| 13 | 10,435 |
transformers
| 10 |
conversational
| true | false | false |
creativeml-openrail-m
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text generation', 'conversational']
| false | true | true | 2,224 | false |
# Pygmalion 2.7B
## Model description
Pymalion 2.7B is a proof-of-concept dialogue model based on EleutherAI's [gpt-neo-2.7B](https://huggingface.co/EleutherAI/gpt-neo-2.7B).
**Warning:** This model is **NOT** suitable for use by minors. It **will** output X-rated content under certain circumstances.
## Training data
The fine-tuning dataset consisted of 56MB of dialogue data gathered from multiple sources, which includes both real _and_ partially machine-generated conversations.
## Training procedure
Model weights were initialized from the `uft-2.7b` ConvoGPT model made available in [this commit](https://huggingface.co/hakurei/convogpt/tree/07707377dee0aa7d1ee5363ef660b13eb5b73f9d/2.7b-uft).
The model was then further fine-tuned on ~48.5 million tokens for ~5k steps on 4 NVIDIA A40s using DeepSpeed.
## Intended use
### The easy way
We provide a notebook with a Gradio UI for playing around with the model without having to manually format inputs. This notebook can be found [here](https://github.com/PygmalionAI/gradio-ui/blob/master/notebooks/GPU.ipynb).
### The manual way
The model can be used as a regular text generation model, but it'll perform best if the input prompt adheres to the following format:
```
[CHARACTER]'s Persona: [A few sentences about the character you want the model to play]
<START>
[DIALOGUE HISTORY]
You: [Your input message here]
[CHARACTER]:
```
Where `[CHARACTER]` is, as you can probably guess, the name of the character you want the model to portray, `<START>` should be used verbatim as a delimiter token to separate persona and scenario data from the dialogue, and `[DIALOGUE HISTORY]` is chat history so the model can have some conversational context to draw from. Ideally it'll be pairs of messages like:
```
[CHARACTER]: [some dialogue here]
You: [your response to the dialogue above]
```
Apart from chat history, you can also just add example conversations in `[DIALOGUE HISTORY]` to show how the character should speak - ideally at the beginning, so it doesn't get confused as to what's conversation history vs. character definition.
## Known issues
We haven't played around with the model enough to enumerate them. Feel free to give us some feedback!
|
6ef64387d9fe7e40042a8e44452f43d2
|
marccgrau/whisper-small-allSNR-v2
|
marccgrau
|
whisper
| 13 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['marccgrau/sbbdata_allSNR']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sbb-asr', 'generated_from_trainer']
| true | true | true | 1,539 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small German SBB all SNR - v2
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the SBB Dataset 05.01.2023 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7183
- Wer: 1.8738
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.5636 | 0.71 | 100 | 2.7931 | 1.1541 |
| 1.4736 | 1.42 | 200 | 0.8866 | 1.0444 |
| 0.8446 | 2.13 | 300 | 0.9127 | 1.5136 |
| 0.7396 | 2.84 | 400 | 0.7580 | 1.2644 |
| 0.7699 | 3.55 | 500 | 0.7183 | 1.8738 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.12.1
|
7f90ee987d12b748c086df8f17478ebc
|
Plim/test_lm
|
Plim
|
wav2vec2
| 15 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer']
| true | true | true | 2,303 | false |
## Model description
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - FR dataset.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.9827 | 0.29 | 1000 | inf | 0.2937 |
| 1.0203 | 0.57 | 2000 | inf | 0.2711 |
| 1.0048 | 0.86 | 3000 | inf | 0.2620 |
| 0.9858 | 1.15 | 4000 | inf | 0.2522 |
| 0.9709 | 1.43 | 5000 | inf | 0.2365 |
| 0.9347 | 1.72 | 6000 | inf | 0.2332 |
| 0.9256 | 2.01 | 7000 | inf | 0.2261 |
| 0.8936 | 2.29 | 8000 | inf | 0.2203 |
| 0.877 | 2.58 | 9000 | inf | 0.2096 |
| 0.8393 | 2.87 | 10000 | inf | 0.2017 |
| 0.8156 | 3.15 | 11000 | inf | 0.1936 |
| 0.8015 | 3.44 | 12000 | inf | 0.1880 |
| 0.774 | 3.73 | 13000 | inf | 0.1834 |
It achieves the best result on the validation set on STEP 13000:
- Wer: 0.1834
Some problem occurs when calculating the validation loss.
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3.dev0
- Tokenizers 0.11.0
### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8` with split `test`
```bash
python eval.py --model_id Plim/xls-r-1b-cv_8-fr --dataset mozilla-foundation/common_voice_8_0 --config fr --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id Plim/xls-r-1b-cv_8-fr --dataset speech-recognition-community-v2/dev_data --config fr --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
|
69785b9bff8fee55ae1cd996e09c2657
|
wangmiaobeng/chinese-bert-wwm-finetuned-jd
|
wangmiaobeng
|
bert
| 16 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,305 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-bert-wwm-finetuned-jd
This model is a fine-tuned version of [hfl/chinese-bert-wwm](https://huggingface.co/hfl/chinese-bert-wwm) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1648 | 1.0 | 5 | 2.9366 |
| 3.0095 | 2.0 | 10 | 2.9487 |
| 3.0698 | 3.0 | 15 | 2.9177 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu102
- Datasets 2.1.0
- Tokenizers 0.12.1
|
32017b4cc44a6a069f382e25518f24fc
|
lmqg/mt5-base-frquad-qg
|
lmqg
|
mt5
| 20 | 66 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['fr']
|
['lmqg/qg_frquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 6,777 | false |
# Model Card of `lmqg/mt5-base-frquad-qg`
This model is fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) for question generation task on the [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-base](https://huggingface.co/google/mt5-base)
- **Language:** fr
- **Training data:** [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="fr", model="lmqg/mt5-base-frquad-qg")
# model prediction
questions = model.generate_q(list_context="Créateur » (Maker), lui aussi au singulier, « le Suprême Berger » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.", list_answer="le Suprême Berger")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-base-frquad-qg")
output = pipe("Créateur » (Maker), lui aussi au singulier, « <hl> le Suprême Berger <hl> » (The Great Shepherd) ; de l'autre, des réminiscences de la théologie de l'Antiquité : le tonnerre, voix de Jupiter, « Et souvent ta voix gronde en un tonnerre terrifiant », etc.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-base-frquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_frquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 77.81 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_1 | 25.06 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_2 | 13.73 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_3 | 8.93 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| Bleu_4 | 6.14 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| METEOR | 15.55 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| MoverScore | 54.58 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| ROUGE_L | 25.88 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
- ***Metric (Question & Answer Generation, Reference Answer)***: Each question is generated from *the gold answer*. [raw metric file](https://huggingface.co/lmqg/mt5-base-frquad-qg/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_frquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 86.41 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedF1Score (MoverScore) | 60.19 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedPrecision (BERTScore) | 86.42 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedPrecision (MoverScore) | 60.19 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedRecall (BERTScore) | 86.4 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedRecall (MoverScore) | 60.18 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
- ***Metric (Question & Answer Generation, Pipeline Approach)***: Each question is generated on the answer generated by [`lmqg/mt5-base-frquad-ae`](https://huggingface.co/lmqg/mt5-base-frquad-ae). [raw metric file](https://huggingface.co/lmqg/mt5-base-frquad-qg/raw/main/eval_pipeline/metric.first.answer.paragraph.questions_answers.lmqg_qg_frquad.default.lmqg_mt5-base-frquad-ae.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 68.59 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedF1Score (MoverScore) | 47.87 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedPrecision (BERTScore) | 67.59 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedPrecision (MoverScore) | 47.42 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedRecall (BERTScore) | 69.69 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
| QAAlignedRecall (MoverScore) | 48.36 | default | [lmqg/qg_frquad](https://huggingface.co/datasets/lmqg/qg_frquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_frquad
- dataset_name: default
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: google/mt5-base
- max_length: 512
- max_length_output: 32
- epoch: 24
- batch: 4
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 16
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-base-frquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
3ceef05067309881095348560a23388d
|
Helsinki-NLP/opus-mt-en-mt
|
Helsinki-NLP
|
marian
| 10 | 97 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 803 | false |
### opus-mt-en-mt
* source languages: en
* target languages: mt
* OPUS readme: [en-mt](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-mt/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-mt/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mt/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mt/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.mt | 47.5 | 0.640 |
| Tatoeba.en.mt | 25.0 | 0.620 |
|
3bddd139751a27b96f679499a1c4f6b9
|
dbsamu/distilbert-base-uncased-finetuned-ner
|
dbsamu
|
distilbert
| 15 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['wikiann']
| null | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
['generated_from_trainer']
| true | true | true | 1,554 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2781
- Precision: 0.8121
- Recall: 0.8302
- F1: 0.8210
- Accuracy: 0.9204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3504 | 1.0 | 1250 | 0.2922 | 0.7930 | 0.8075 | 0.8002 | 0.9115 |
| 0.2353 | 2.0 | 2500 | 0.2711 | 0.8127 | 0.8264 | 0.8195 | 0.9196 |
| 0.1745 | 3.0 | 3750 | 0.2781 | 0.8121 | 0.8302 | 0.8210 | 0.9204 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
d498009c3cdde8cecefef074e378f7cb
|
tftgregrge/mpid-hassanblend-v1-5-main
|
tftgregrge
| null | 18 | 4 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 438 | false |
### mpid-hassanblend-v1-5-main Dreambooth model trained by tftgregrge with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
786e503daca82dd3da79d3ec81af7632
|
ali221000262/wav2vec2-base-timit-ali-hasan-colab-EX2
|
ali221000262
|
wav2vec2
| 14 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,350 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-ali-hasan-colab-EX2
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5087
- Wer: 0.4458
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1956 | 13.89 | 500 | 0.5087 | 0.4458 |
| 0.1946 | 27.78 | 1000 | 0.5087 | 0.4458 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
e3ab85532f2106f3b0724d4d3246cdc7
|
Alex-VisTas/swin-tiny-patch4-window7-224-finetuned-woody
|
Alex-VisTas
|
swin
| 24 | 11 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,165 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-woody
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4349
- Accuracy: 0.7927
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.632 | 1.0 | 58 | 0.5883 | 0.6836 |
| 0.6067 | 2.0 | 116 | 0.6017 | 0.6848 |
| 0.5865 | 3.0 | 174 | 0.5695 | 0.7042 |
| 0.553 | 4.0 | 232 | 0.5185 | 0.7515 |
| 0.5468 | 5.0 | 290 | 0.5108 | 0.7430 |
| 0.5473 | 6.0 | 348 | 0.4882 | 0.7648 |
| 0.5381 | 7.0 | 406 | 0.4800 | 0.7588 |
| 0.5468 | 8.0 | 464 | 0.5056 | 0.7358 |
| 0.5191 | 9.0 | 522 | 0.4784 | 0.7673 |
| 0.5318 | 10.0 | 580 | 0.4762 | 0.7636 |
| 0.5079 | 11.0 | 638 | 0.4859 | 0.7673 |
| 0.5216 | 12.0 | 696 | 0.4691 | 0.7697 |
| 0.515 | 13.0 | 754 | 0.4857 | 0.7624 |
| 0.5186 | 14.0 | 812 | 0.4685 | 0.7733 |
| 0.4748 | 15.0 | 870 | 0.4536 | 0.7818 |
| 0.4853 | 16.0 | 928 | 0.4617 | 0.7770 |
| 0.4868 | 17.0 | 986 | 0.4622 | 0.7782 |
| 0.4572 | 18.0 | 1044 | 0.4583 | 0.7770 |
| 0.4679 | 19.0 | 1102 | 0.4590 | 0.7733 |
| 0.4508 | 20.0 | 1160 | 0.4576 | 0.7903 |
| 0.4663 | 21.0 | 1218 | 0.4542 | 0.7891 |
| 0.4533 | 22.0 | 1276 | 0.4428 | 0.7903 |
| 0.4892 | 23.0 | 1334 | 0.4372 | 0.7867 |
| 0.4704 | 24.0 | 1392 | 0.4414 | 0.7903 |
| 0.4304 | 25.0 | 1450 | 0.4430 | 0.7988 |
| 0.4411 | 26.0 | 1508 | 0.4348 | 0.7818 |
| 0.4604 | 27.0 | 1566 | 0.4387 | 0.7927 |
| 0.441 | 28.0 | 1624 | 0.4378 | 0.7964 |
| 0.442 | 29.0 | 1682 | 0.4351 | 0.7915 |
| 0.4585 | 30.0 | 1740 | 0.4349 | 0.7927 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.0
- Tokenizers 0.13.1
|
bfe9ceaa58bee5f9c42435823a1be805
|
Intel/albert-base-v2-sst2-int8-static
|
Intel
|
albert
| 9 | 7 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-classfication', 'int8', 'Intel® Neural Compressor', 'neural-compressor', 'PostTrainingStatic']
| false | true | true | 1,746 | false |
# INT8 albert-base-v2-sst2
## Post-training static quantization
### PyTorch
This is an INT8 PyTorch model quantized with [Intel® Neural Compressor](https://github.com/intel/neural-compressor).
The original fp32 model comes from the fine-tuned model [Alireza1044/albert-base-v2-sst2](https://huggingface.co/Alireza1044/albert-base-v2-sst2).
The calibration dataloader is the train dataloader. The default calibration sampling size 300 isn't divisible exactly by batch size 8, so the real sampling size is 304.
The linear modules **albert.encoder.albert_layer_groups.0.albert_layers.0.ffn_output.module, albert.encoder.albert_layer_groups.0.albert_layers.0.ffn.module** fall back to fp32 to meet the 1% relative accuracy loss.
#### Test result
| |INT8|FP32|
|---|:---:|:---:|
| **Accuracy (eval-accuracy)** |0.9255|0.9232|
| **Model size (MB)** |25|44.6|
#### Load with Intel® Neural Compressor:
```python
from optimum.intel.neural_compressor import IncQuantizedModelForSequenceClassification
model_id = "Intel/albert-base-v2-sst2-int8-static"
int8_model = IncQuantizedModelForSequenceClassification.from_pretrained(model_id)
```
### ONNX
This is an INT8 ONNX model quantized with [Intel® Neural Compressor](https://github.com/intel/neural-compressor).
The original fp32 model comes from the fine-tuned model [Alireza1044/albert-base-v2-sst2](https://huggingface.co/Alireza1044/albert-base-v2-sst2).
#### Test result
| |INT8|FP32|
|---|:---:|:---:|
| **Accuracy (eval-f1)** |0.9186|0.9232|
| **Model size (MB)** |89|45|
#### Load ONNX model:
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
model = ORTModelForSequenceClassification.from_pretrained('Intel/albert-base-v2-sst2-int8-static')
```
|
100d415d38afcb7bf7663e8624bd4555
|
cholling/distilbert-amazon-shoe-reviews
|
cholling
|
distilbert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,950 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-amazon-shoe-reviews
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9532
- Accuracy: 0.5779
- F1: [0.62616119 0.46456105 0.50993865 0.55755123 0.734375 ]
- Precision: [0.62757927 0.46676662 0.49148534 0.58430541 0.72415507]
- Recall: [0.6247495 0.46237624 0.52983172 0.53313982 0.74488753]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------------------------------------------------------:|:--------------------------------------------------------:|:--------------------------------------------------------:|
| 0.9713 | 1.0 | 2813 | 0.9532 | 0.5779 | [0.62616119 0.46456105 0.50993865 0.55755123 0.734375 ] | [0.62757927 0.46676662 0.49148534 0.58430541 0.72415507] | [0.6247495 0.46237624 0.52983172 0.53313982 0.74488753] |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
8caa11c8a65431597d3f819345d93748
|
pedramyamini/distilbert-base-multilingual-cased-finetuned-mobile-banks-cafebazaar2lr-10epochs
|
pedramyamini
|
distilbert
| 8 | 1 |
transformers
| 0 |
text-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,774 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pedramyamini/distilbert-base-multilingual-cased-finetuned-mobile-banks-cafebazaar2lr-10epochs
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2307
- Validation Loss: 1.2090
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 4e-05, 'decay_steps': 26740, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.7428 | 0.7046 | 0 |
| 0.6810 | 0.6903 | 1 |
| 0.6372 | 0.6907 | 2 |
| 0.5881 | 0.6988 | 3 |
| 0.5246 | 0.7630 | 4 |
| 0.4511 | 0.8687 | 5 |
| 0.3801 | 0.9356 | 6 |
| 0.3200 | 1.0440 | 7 |
| 0.2676 | 1.1470 | 8 |
| 0.2307 | 1.2090 | 9 |
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
688cf9e1f55683183674759c839a5586
|
aminnaghavi/wav2vec2-base-dataset_asr-demo-colab
|
aminnaghavi
|
hubert
| 12 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['superb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,405 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-dataset_asr-demo-colab
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 295.0834
- Wer: 0.8282
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 250
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5638.536 | 1.6 | 500 | 409.4785 | 0.8556 |
| 2258.6455 | 3.19 | 1000 | 326.0520 | 0.8369 |
| 1389.4919 | 4.79 | 1500 | 295.0834 | 0.8282 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
d556fd1d0fb91841b2596b72c5805aa8
|
muhtasham/tiny-mlm-glue-mnli-target-glue-mnli
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,511 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-mnli-target-glue-mnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-mnli](https://huggingface.co/muhtasham/tiny-mlm-glue-mnli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8010
- Accuracy: 0.6426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.0743 | 0.04 | 500 | 1.0281 | 0.4738 |
| 1.0045 | 0.08 | 1000 | 0.9576 | 0.5522 |
| 0.9565 | 0.12 | 1500 | 0.9155 | 0.5802 |
| 0.929 | 0.16 | 2000 | 0.8997 | 0.5936 |
| 0.9205 | 0.2 | 2500 | 0.8868 | 0.6011 |
| 0.9127 | 0.24 | 3000 | 0.8733 | 0.6066 |
| 0.8972 | 0.29 | 3500 | 0.8659 | 0.6121 |
| 0.8908 | 0.33 | 4000 | 0.8527 | 0.6202 |
| 0.8747 | 0.37 | 4500 | 0.8507 | 0.6200 |
| 0.8778 | 0.41 | 5000 | 0.8418 | 0.6254 |
| 0.869 | 0.45 | 5500 | 0.8373 | 0.6262 |
| 0.8647 | 0.49 | 6000 | 0.8339 | 0.6318 |
| 0.8677 | 0.53 | 6500 | 0.8268 | 0.6310 |
| 0.8576 | 0.57 | 7000 | 0.8269 | 0.6323 |
| 0.852 | 0.61 | 7500 | 0.8126 | 0.6396 |
| 0.8525 | 0.65 | 8000 | 0.8119 | 0.6399 |
| 0.8441 | 0.69 | 8500 | 0.8230 | 0.6319 |
| 0.8492 | 0.73 | 9000 | 0.7975 | 0.6486 |
| 0.8394 | 0.77 | 9500 | 0.8088 | 0.6373 |
| 0.8294 | 0.81 | 10000 | 0.7949 | 0.6460 |
| 0.8341 | 0.86 | 10500 | 0.8010 | 0.6426 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
c3146eed79ff01e1b06d90d39c92c72a
|
Luciano/xlm-roberta-large-finetuned-lener_br
|
Luciano
|
xlm-roberta
| 14 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['pt']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,367 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-lener_br
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.5002 | 1.0 | 8316 | nan |
| 1.2398 | 2.0 | 16632 | nan |
| 1.0864 | 3.0 | 24948 | nan |
| 0.9896 | 4.0 | 33264 | nan |
| 0.8752 | 5.0 | 41580 | nan |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
9e0c0328b5f5c7d39cbdebaf02f6375c
|
l3cube-pune/hindi-marathi-dev-albert
|
l3cube-pune
|
albert
| 8 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
cc-by-4.0
|
['hi', 'mr', 'multilingual']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 586 | false |
## DevAlBERT
DevAlBERT is a Devanagari AlBERT model model trained on publicly available Hindi and Marathi monolingual datasets.
[project link] (https://github.com/l3cube-pune/MarathiNLP)
More details on the dataset, models, and baseline results can be found in our [<a href='https://arxiv.org/abs/2211.11418'> paper </a>] .
Citing:
```
@article{joshi2022l3cubehind,
title={L3Cube-HindBERT and DevBERT: Pre-Trained BERT Transformer models for Devanagari based Hindi and Marathi Languages},
author={Joshi, Raviraj},
journal={arXiv preprint arXiv:2211.11418},
year={2022}
}
```
|
e45b82672882b4aa2a07d8e8fdd3b2c8
|
swl-models/anything-v2.1
|
swl-models
| null | 13 | 0 | null | 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'text-to-image']
| false | true | true | 1,333 | false |
# Anything V2.1
Welcome to Anything V2.1 - a latent diffusion model for weebs. This model is intended to produce high-quality, highly detailed anime style with just a few prompts. Like other anime-style Stable Diffusion models, it also supports danbooru tags to generate images.
e.g. **_1girl, white hair, golden eyes, beautiful eyes, detail, flower meadow, cumulonimbus clouds, lighting, detailed sky, garden_**
## Gradio
TBD
## 🧨 Diffusers
TBD
## Examples
TBD
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
1a18d0380753d32b49f3e905c5eec864
|
Tom11/xlm-roberta-base-finetuned-panx-all
|
Tom11
|
xlm-roberta
| 9 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,317 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1637
- F1: 0.8581
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.29 | 1.0 | 715 | 0.1885 | 0.8231 |
| 0.1443 | 2.0 | 1430 | 0.1607 | 0.8479 |
| 0.0937 | 3.0 | 2145 | 0.1637 | 0.8581 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cpu
- Datasets 1.16.1
- Tokenizers 0.13.2
|
eb1274340f969021a0d944f53af2181a
|
Phantom-Artist/phantom-diffusion
|
Phantom-Artist
| null | 69 | 0 | null | 17 | null | false | false | false |
creativeml-openrail-m
|
['en', 'ja']
|
['Phantom-Artist/phantom-diffusion-dataset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['a']
| false | true | true | 5,188 | false |
20 models that are trained over [hakurei's Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion).
Each model was trained on a notable Japanese AI artist's works using dreambooth, with 30 of their works gained mainly from twitter (except for aibanousagi, which I could find only 23).
It tooks 1000 steps to train each model, at a learning rate of 5-e6. I have shared the notebook [here](https://huggingface.co/Phantom-Artist/phantom-diffusion/blob/main/DreamBooth_Stable_Diffusion_works_with_SD_2.ipynb) in case you want to try out additional training.
Some are good at backgrounds, while others can generate a semi-realistic style as seen in many SD 1.5 anime/waifu models (and some might be a bit overfitted).
The dataset is published [here](https://huggingface.co/datasets/Phantom-Artist/phantom-diffusion-dataset).
# For those who are against generative AIs
You can see that now they are the target. Take our tool. Now is the time for pay back. Generate the images in their styles, and bring back the power you had to yourself.
# For those who support the development of generative AIs
Some of the AI artists, even though they take advantage of the open strategy of Stable Diffusion, now tend to hide their prompts, trying to monopolize their style (I'm not saying the AI artists I trained are as such, to be sure).
To continue protecting our values and beliefs on the open community and fight against them trying to create another pre-modern style guilds, I will show you a new way.
You no longer need their prompts; just train their images by yourself to protect the open community. It's not only legal but also ethical, as they have been taking advantages of others' trained dataset.
# trained artist list
- 852wa
- aibanousagi
- aioeoekakino
- airhara
- alfredplpl
- callimiya
- citrus
- elessenar
- kiri
- korocon
- lakeside
- maccha
- natsuku
- nikaido
- plat
- roiyaruRIZ
- swingwings
- tuinositone
- yunyalula
- yuyuyu
# samples
The basic prompt is as follows, but some of them may have additional postive tags (such as "in the style of") to get the result below (yes, use ``aitop (ARTIST)_style`` to gain the finetuned result).
```
POS: masterpiece, best quality, 1girl, aitop (ARTIST)_style
NEG: nsfw, worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digits, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, simple background
```
## 852wa

## aibanousagi

## aioeoekakino

## airhara

## alfredplpl

## callimiya

## citrus

## elessenar

## kiri

## korocon

## lakeside

## maccha

## natsuku



## nikaido

## plat

## roiyaruRIZ

## swingwings

## tuinositone

## yunyalula


## yuyuyu

|
c51193f8fb173105a89c540f1452cbd4
|
cjber/reddit-ner-place_names
|
cjber
|
bert
| 10 | 6 |
transformers
| 1 |
token-classification
| true | false | false |
mit
|
['en']
|
['wnut_17']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 925 | false |
# Reddit NER for place names
Fine-tuned `bert-base-uncased` for named entity recognition, trained using `wnut_17` with 498 additional comments from Reddit. This model is intended solely for place name extraction from social media text, other entities have therefore been removed.
This model was created with two key goals:
1. Improved NER results on social media
2. Target only place names
## Use in `transformers`
```python
from transformers import pipeline
generator = pipeline(
task="ner",
model="cjber/reddit-ner-place_names",
tokenizer="cjber/reddit-ner-place_names",
aggregation_strategy="first",
)
out = generator("I live north of liverpool in Waterloo")
```
Out gives:
```python
[{'entity_group': 'location',
'score': 0.94054973,
'word': 'liverpool',
'start': 16,
'end': 25},
{'entity_group': 'location',
'score': 0.99520856,
'word': 'waterloo',
'start': 29,
'end': 37}]
```
|
62fd3e82f299bf01bc508f58323a8bc0
|
coreml/coreml-fruity-mix
|
coreml
| null | 11 | 0 | null | 11 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 5 | 3 | 2 |
['coreml', 'stable-diffusion', 'text-to-image']
| false | true | true | 1,752 | false |
# Core ML Converted Model
This model was converted to Core ML for use on Apple Silicon devices by following Apple's instructions [here](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).<br>
Provide the model to an app such as [Mochi Diffusion](https://github.com/godly-devotion/MochiDiffusion) to generate images.<br>
`split_einsum` version is compatible with all compute unit options including Neural Engine.<br>
`original` version is only compatible with CPU & GPU option.
# Fruity Mix
For Realistic/Anime Type.
# Examples
Sample images have been upscaled using RealESRGAN.
```
Prompt: realistic, masterpiece, highest quality, full body, looking at viewers, highres, indoors, detailed face and eyes, wolf ears, brown hair, short hair, silver eyes, necklace, sneakers, parka jacket, solo focus
Negative: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
Steps: 12
Guidance Scale: 11
Sampler: DPM-Solver++
```
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/1.png" />
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/2.png" />
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/3.png" />
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/4.png" />
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/5.png" />
<img width="512" src="https://huggingface.co/godly-devotion/coreml-fruity-mix/resolve/main/images/6.png" />
|
7fe45dc38876a2299519860caae3024d
|
Starlento/sd-nai-lora-index
|
Starlento
| null | 63 | 0 | null | 39 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Text-to-Image', 'stable-diffusion', 'lora']
| false | true | true | 6,113 | false |
# Stable Diffusion NAI lora Index
**This repo is for indexing NovelAI related [LoRA](https://github.com/cloneofsimo/lora) works in huggingface.**
**Preview the "good models" with no "explaination" in their repos using a benchmark.**
**You may use CTRL+F to find keywords you are interested to quickly get the source.**
Note that NSFW will not be included since I cannot put previews.
And there are plenty of LoRA models, I may only include "good models" based on my judgement.
**Please contact me or create pull request if you find something should be included.**
**Click "Like" if you think the index is helpful~**
## dranzerstar/SD-textual-inversion-embeddings-repo
Link: https://huggingface.co/dranzerstar/SD-textual-inversion-embeddings-repo
**models**: char-416-space, char-antonia-og, char-april, char-cms-gn, char-cms-og, char-florine, char-g41space, char-gronru, char-kyaru-gn, char-madoka, char-qu, char-siobhan, char-sop2anni, char-sophia, char-sp9-og, char-toka-dancer, char-toru-generalized, char-toru, char-vepley, char-zas-wq, char-m16a1 (I cannot generate)





## ikuseiso/Personal_Lora_collections
Link: https://huggingface.co/ikuseiso/Personal_Lora_collections
The owner starts to upload his model card, so I will only update the keywords in the future.
Note that the owner claimed that the weight should be set to 0.6~0.8.
So, I take 0.7 for all the previews below.
**models**: ame-chan_needy_girl_overdose, chouzetsusaikawa_tenshi-chan, grea_shingeki_no_bahamut, iono_pokemon, kisara_engage_kiss, laundry_dragonmaid, lishenna_omen_of_destruction, lovely_labrynth_of_the_silver_castle, lucy_cyberpunk, Miorine_Rembran, ralmia_sonic_racer, seulbi_lee, suletta_mercury, vampy
vergil, devil may cry, ace, sky striker



## sylveriate/lora-characters
Link: https://huggingface.co/sylveriate/lora-characters
Actually I cannot generate good results from this repo, maybe the owner can teach me how to do it...
**models**: abigail, emilico, hiroikikuri, kateshadow, pippa, selen, shondo-improved, shondo, shondo-improved, tenma


## backslashlim/LoRA_Dumpster
Link: https://huggingface.co/backslashlim/LoRA_Dumpster
## Link Only
These owners are managing their model cards quite well.
So, I will only copy the Links and summarize keywords.
Link: https://huggingface.co/YoungMasterFromSect/Trauter_LoRAs
**Genshin Impact**
: Eula, Barbara, Diluc, Mona, Rosaria, Yae Miko, Raiden Shogun, Kujou Sara, Shenhe, Yelan, Jean, Lisa, Zhongli, Yoimiya, Ganyu
**Blue Archive**
: Rikuhachima Aru, Ichinose Asuna, Karin
**Fate Grand Order**
: Minamoto-no-Raikou
**Misc. Characters**
: Aponia, Reisalin Stout
**Artstyles**
: Pozer, CuteScrap
Link: https://huggingface.co/breakcore2/loras
Amber, artoria pendragon
Link: https://huggingface.co/Onusai/LoRAs
Chainsaw Man
Link: https://huggingface.co/Aotsuyu/ozen-Lora
Ozen Sama
Link: https://huggingface.co/Doctor-Shotgun/ds-LoRA
Persona5: Ann Takamaki, Futaba Sakura, Haru Okumura, Kasumi Yoshizawa, Makoto Niijima
Link: https://huggingface.co/V3B4/LoRA
I usually generate black image because of NaN for VAE when using his models.
Maybe caused by OrangeMix and angthing4.5?
osaka_shizuku, hitotsuyanagi_riri, yoshida_yuuko, chiyoda_momo
## DONOT KNOW THE SOURCE
You can download the models in this repo, if you know the source, please contact me. I will change them to links.
**qiqi**
Trigger token is "qiqi", also "1girl", "solo" are recommended.
``` shell
# Sample prompts
1girl, qiqi, jiangshi, qing guanmao, coin hair ornament, ofuda, bead necklace, qiqi \(genshin impact\)
```

**klee**
``` shell
"1girl, klee"
"1girl, nsfw, klee, solo, completely nude, hat"
"1girl, klee, solo, ahoge, hat feather, twintails, gloves, boots, bag, red dress, bangs, backpack, dress, brown gloves, knee boots, low twintails, brown footwear, cabbie hat, red eyes, pointy ears, long sleeves, clover print, scarf, socks, hat, blonde hair, kneehighs, coat, charm \(object\), brown scarf, hair between eyes, red headwear, light brown hair, bag charm, randoseru, sidelocks, hat ornament, bloomers, pocket, red coat, white socks, feathers, white feathers, klee \(genshin impact\)"
```

**nahida**
nahida_cross-shaped_pupils_finger_frame
- can do beautiful cross-shaped pupils, but only in close-up/portrait/eye focus pictures
- was an attempt at finger frame. didn't go well
Might still be useful for extremely pretty portraits.

nahida_weighted
nahida_weighted was weighted for higher lewds while still retaining outfit fidelity. just apply standard nsfw tags as needed.
(and an attempt at higher cross-shaped pupils in full body, but it didn't work)

Here is the "benchmark"
``` shell
# model
AbyssOrangeMix2_hard.safetensors
OR
anything-v4.5-pruned.ckpt
# Seed
2367322303
# Size
512*728
# Sampler
Euler a; Step=30
# prompt
masterpiece, best quality, {mandatory}, 1girl, solo <lora:xxx:0~1>
# negative prompt
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, (worst quality, low quality, extra digits)
```
Link for the models: [AbyssOrangeMix2_hard](https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix2/AbyssOrangeMix2_hard.safetensors);
[anything-v4.5-pruned.ckpt](https://huggingface.co/andite/anything-v4.0/blob/main/anything-v4.5-pruned.ckpt)
|
3e3070e216b89563c37ddfeb700b589b
|
dbmdz/convbert-base-turkish-mc4-uncased
|
dbmdz
|
convbert
| 7 | 5,826 |
transformers
| 1 |
fill-mask
| true | true | false |
mit
|
['tr']
|
['allenai/c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,518 | false |
# 🇹🇷 Turkish ConvBERT model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've trained an (uncased) ConvBERT model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ConvBERT
In addition to the ELEC**TR**A base model, we also trained an ConvBERT model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
model = AutoModel.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
|
01445c45d93e09b727a7c387e8736729
|
dayyannxb/roberta-finetuned-subjqa-movies_2
|
dayyannxb
|
roberta
| 13 | 22 |
transformers
| 0 |
question-answering
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 990 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-finetuned-subjqa-movies_2
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
926be9960d250874c074cf2da1430af5
|
PrimeQA/squad-v1-xlm-roberta-large
|
PrimeQA
|
xlm-roberta
| 10 | 20 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['multilingual']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['MRC', 'SQuAD 1.1', 'xlm-roberta-large']
| false | true | true | 2,835 | false |
# Model description
An XLM-RoBERTa reading comprehension model for [SQuAD 1.1](https://aclanthology.org/D16-1264/).
The model is initialized with [xlm-roberta-large](https://huggingface.co/xlm-roberta-large/) and fine-tuned on the [SQuAD 1.1 train data](https://huggingface.co/datasets/squad).
## Intended uses & limitations
You can use the raw model for the reading comprehension task. Biases associated with the pre-existing language model, xlm-roberta-large, that we used may be present in our fine-tuned model, squad-v1-xlm-roberta-large. This model is used for zero-shot decoding of [MLQA](https://huggingface.co/datasets/mlqa) and [XQuAD](https://huggingface.co/datasets/xquad) datasets.
## Usage
You can use this model directly with the [PrimeQA](https://github.com/primeqa/primeqa) pipeline for reading comprehension [squad.ipynb](https://github.com/primeqa/primeqa/blob/main/notebooks/mrc/squad.ipynb).
```bibtex
@article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
}
```
```bibtex
@article{lewis2019mlqa,
title={MLQA: Evaluating Cross-lingual Extractive Question Answering},
author={Lewis, Patrick and Oguz, Barlas and Rinott, Ruty and Riedel, Sebastian and Schwenk, Holger},
journal={arXiv preprint arXiv:1910.07475},
year={2019}
}
```
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
```bibtex
@article{DBLP:journals/corr/abs-1911-02116,
author = {Alexis Conneau and
Kartikay Khandelwal and
Naman Goyal and
Vishrav Chaudhary and
Guillaume Wenzek and
Francisco Guzm{\'{a}}n and
Edouard Grave and
Myle Ott and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {Unsupervised Cross-lingual Representation Learning at Scale},
journal = {CoRR},
volume = {abs/1911.02116},
year = {2019},
url = {http://arxiv.org/abs/1911.02116},
eprinttype = {arXiv},
eprint = {1911.02116},
timestamp = {Mon, 11 Nov 2019 18:38:09 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1911-02116.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
508fd88410805e2a2886d44846129ef2
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.