
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
mbien/wav2vec2-large-xlsr-polish
|
mbien
|
wav2vec2
| 9 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['pl']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,384 | false |
# Wav2Vec2-Large-XLSR-53-Polish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Polish using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pl", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("mbien/wav2vec2-large-xlsr-polish")
model = Wav2Vec2ForCTC.from_pretrained("mbien/wav2vec2-large-xlsr-polish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Polish test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pl", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mbien/wav2vec2-large-xlsr-polish")
model = Wav2Vec2ForCTC.from_pretrained("mbien/wav2vec2-large-xlsr-polish")
model.to("cuda")
chars_to_ignore_regex = '[\—\…\,\?\.\!\-\;\:\"\“\„\%\‘\”\�\«\»\'\’]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 23.01 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/drive/1DvrFMoKp9h3zk_eXrJF2s4_TGDHh0tMc?usp=sharing)
|
d24f6908e786b7fcc35c424463ff5c60
|
colab71/sd-1.5-niraj-1000
|
colab71
| null | 18 | 9 |
diffusers
| 0 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'man']
| false | true | true | 699 | false |
# Settings
Steps:1000
Class Images:50
# DreamBooth model for the niraj concept trained by colab71 on the dataset.
This is a Stable Diffusion model fine-tuned on the niraj concept with DreamBooth. It can be used by modifying the
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on niraj's images for the person theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('colab71/sd-1.5-niraj-1000')
image = pipeline().images[0]
image
```
|
3d7c8afa1b95986ec82dc95f36d4d95b
|
yuhuizhang/finetuned_gpt2-medium_sst2_negation0.05
|
yuhuizhang
|
gpt2
| 11 | 0 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,252 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-medium_sst2_negation0.05
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4461
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8275 | 1.0 | 1062 | 3.3098 |
| 2.5383 | 2.0 | 2124 | 3.3873 |
| 2.3901 | 3.0 | 3186 | 3.4461 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.12.1
|
4f7fea2e20d8e90457c137511455dac8
|
maren-hugg/xlm-roberta-base-finetuned-panx-de-en
|
maren-hugg
|
xlm-roberta
| 10 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,321 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2239
- F1: 0.8201
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2573 | 1.0 | 625 | 0.2573 | 0.7591 |
| 0.1631 | 2.0 | 1250 | 0.2147 | 0.8127 |
| 0.1096 | 3.0 | 1875 | 0.2239 | 0.8201 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.13.0+cu116
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ff67c6e79f6c9e9f467eeffadb74eb63
|
sd-concepts-library/tony-diterlizzi-s-planescape-art
|
sd-concepts-library
| null | 31 | 0 | null | 8 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,462 | false |
### Tony DiTerlizzi's Planescape Art on Stable Diffusion
This is the `<tony-diterlizzi-planescape>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



















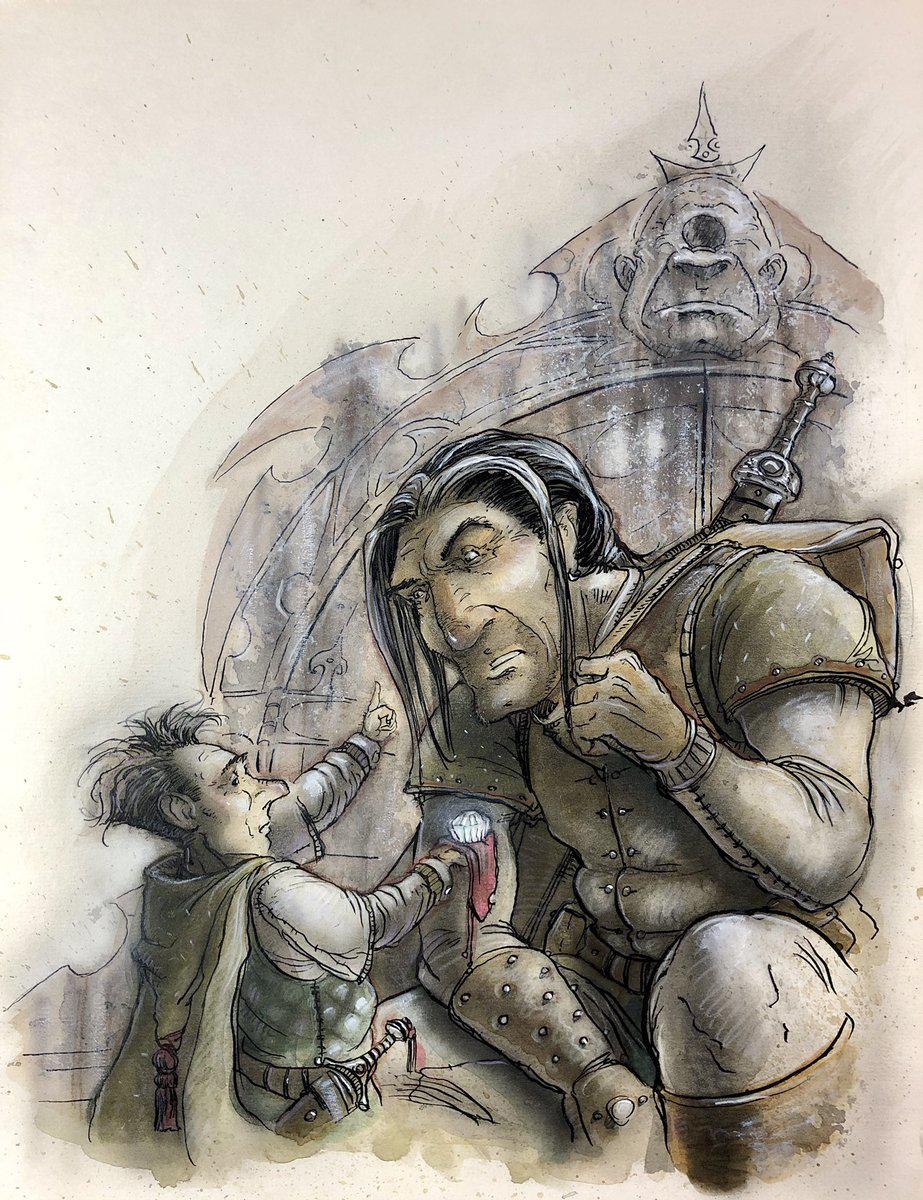






|
83a37c449ebd82921e59a32a039caef4
|
steysie/paraphrase-multilingual-mpnet-base-v2-tuned-smartcat
|
steysie
|
xlm-roberta
| 6 | 44 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,848 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# paraphrase-multilingual-mpnet-base-v2-tuned-smartcat
This model is a fine-tuned version of [sentence-transformers/paraphrase-multilingual-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.0072 | 0.16 | 10000 | 0.0025 |
| 0.0014 | 0.32 | 20000 | 0.0005 |
| 0.0004 | 0.48 | 30000 | 0.0002 |
| 0.0002 | 0.64 | 40000 | 0.0001 |
| 0.0003 | 0.81 | 50000 | 0.0001 |
| 0.0002 | 0.97 | 60000 | 0.0000 |
| 0.0001 | 1.13 | 70000 | 0.0000 |
| 0.0001 | 1.29 | 80000 | 0.0000 |
| 0.0001 | 1.45 | 90000 | 0.0000 |
| 0.0001 | 1.61 | 100000 | 0.0000 |
| 0.0 | 1.77 | 110000 | 0.0000 |
| 0.0 | 1.93 | 120000 | 0.0000 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.1
- Tokenizers 0.12.1
|
090403100ba2c4835d3d5a5cb563c29b
|
ghatgetanuj/bert-large-uncased_cls_SentEval-CR
|
ghatgetanuj
|
bert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,529 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased_cls_SentEval-CR
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3488
- Accuracy: 0.9283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 189 | 0.2951 | 0.8977 |
| No log | 2.0 | 378 | 0.2895 | 0.8964 |
| 0.2663 | 3.0 | 567 | 0.3707 | 0.9044 |
| 0.2663 | 4.0 | 756 | 0.4130 | 0.9203 |
| 0.2663 | 5.0 | 945 | 0.3488 | 0.9283 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
7cffe1aa97d66fbeaeab365706a435db
|
Helsinki-NLP/opus-mt-bat-en
|
Helsinki-NLP
|
marian
| 11 | 19,324 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['lt', 'lv', 'bat', 'en']
| null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,504 | false |
### bat-eng
* source group: Baltic languages
* target group: English
* OPUS readme: [bat-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bat-eng/README.md)
* model: transformer
* source language(s): lav lit ltg prg_Latn sgs
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-07-31.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.zip)
* test set translations: [opus2m-2020-07-31.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.test.txt)
* test set scores: [opus2m-2020-07-31.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2017-enlv-laveng.lav.eng | 27.5 | 0.566 |
| newsdev2019-enlt-liteng.lit.eng | 27.8 | 0.557 |
| newstest2017-enlv-laveng.lav.eng | 21.1 | 0.512 |
| newstest2019-lten-liteng.lit.eng | 30.2 | 0.592 |
| Tatoeba-test.lav-eng.lav.eng | 51.5 | 0.687 |
| Tatoeba-test.lit-eng.lit.eng | 55.1 | 0.703 |
| Tatoeba-test.multi.eng | 50.6 | 0.662 |
| Tatoeba-test.prg-eng.prg.eng | 1.0 | 0.159 |
| Tatoeba-test.sgs-eng.sgs.eng | 16.5 | 0.265 |
### System Info:
- hf_name: bat-eng
- source_languages: bat
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bat-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['lt', 'lv', 'bat', 'en']
- src_constituents: {'lit', 'lav', 'prg_Latn', 'ltg', 'sgs'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.test.txt
- src_alpha3: bat
- tgt_alpha3: eng
- short_pair: bat-en
- chrF2_score: 0.662
- bleu: 50.6
- brevity_penalty: 0.9890000000000001
- ref_len: 30772.0
- src_name: Baltic languages
- tgt_name: English
- train_date: 2020-07-31
- src_alpha2: bat
- tgt_alpha2: en
- prefer_old: False
- long_pair: bat-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
c4d3e38fb5038891964213383654a6d9
|
SirVeggie/nixeu_embeddings
|
SirVeggie
| null | 8 | 0 | null | 23 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,621 | false |
# Nixeu stable diffusion embeddings
Original artist: Nixeu\
Patreon: https://www.patreon.com/nixeu/posts
## Usage
To use embeddings, place the embedding file into the embedding folder (automatic1111 webui), and use the filename in the prompt.
You can choose to rename the file freely.
It is recommended to use these embeddings at low strength for cleaner results, for example (nixeu_basic:0.7).
## Additional notes
Nixeu_extra has slightly more flair (maybe).
Nixeu_soft prefers portraits and has generally softer detail.
Nixeu_white has a preference for a light color scheme.
## Examples
Prompt:
```
masterpiece, best quality, ultra-detailed, illustration, 1girl, (wearing casual clothing), beautiful face, (feminine body), (nixeu_basic:0.75)
Negative prompt: close-up, portrait, (big breasts), (fat), flat color, flat shading, bad anatomy, disfigured, deformed, malformed, mutant, gross, disgusting, out of frame, poorly drawn, extra limbs, extra fingers, missing limbs, blurry, out of focus, lowres, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
Steps: 28, Sampler: Euler a, CFG scale: 9, Seed: 3875527572, Size: 768x1024, Model hash: 5674302c, Model: diffmix, Batch size: 2, Batch pos: 0, Denoising strength: 0.6, First pass size: 0x0
```

|
9f9c9f45c5f3f5db5e56e6bc1e0baae5
|
HPL/distilbert-base-uncased-finetuned-emotion
|
HPL
|
distilbert
| 18 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,557 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1465
- Accuracy: 0.9405
- F1: 0.9409
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8341 | 1.0 | 250 | 0.2766 | 0.9105 | 0.9088 |
| 0.2181 | 2.0 | 500 | 0.1831 | 0.9305 | 0.9308 |
| 0.141 | 3.0 | 750 | 0.1607 | 0.93 | 0.9305 |
| 0.1102 | 4.0 | 1000 | 0.1509 | 0.935 | 0.9344 |
| 0.0908 | 5.0 | 1250 | 0.1465 | 0.9405 | 0.9409 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
38ad9aa484f8763963dd6dc25b3d30b3
|
Helsinki-NLP/opus-mt-fi-hu
|
Helsinki-NLP
|
marian
| 10 | 15 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 770 | false |
### opus-mt-fi-hu
* source languages: fi
* target languages: hu
* OPUS readme: [fi-hu](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-hu/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-hu/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-hu/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-hu/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.fi.hu | 50.4 | 0.705 |
|
755aa515a87a2c006e3ec9b6a8c89030
|
AdamOswald1/Cyberpunk-Anime-Diffusion
|
AdamOswald1
| null | 35 | 201 |
diffusers
| 14 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
|
['Nerfgun3/cyberware_style', 'Nerfgun3/bad_prompt']
| null | 6 | 0 | 6 | 0 | 0 | 0 | 0 |
['cyberpunk', 'anime', 'stable-diffusion', 'aiart', 'text-to-image', 'TPU']
| false | true | true | 5,174 | false |
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/5.jpg" width="512" height="512"/></center>

# Cyberpunk Anime Diffusion
An AI model that generates cyberpunk anime characters!~
Based of a finetuned Waifu Diffusion V1.3 Model with Stable Diffusion V1.5 New Vae, training in Dreambooth
by [DGSpitzer](https://www.youtube.com/channel/UCzzsYBF4qwtMwJaPJZ5SuPg)
### 🧨 Diffusers
This repo contains both .ckpt and Diffuser model files. It's compatible to be used as any Stable Diffusion model, using standard [Stable Diffusion Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can convert this model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX](https://huggingface.co/blog/stable_diffusion_jax).
```python example for loading the Diffuser
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "AdamOswald1/Cyberpunk-Anime-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a beautiful perfect face girl in dgs illustration style, Anime fine details portrait of school girl in front of modern tokyo city landscape on the background deep bokeh, anime masterpiece, 8k, sharp high quality anime"
image = pipe(prompt).images[0]
image.save("./cyberpunk_girl.png")
```
# Online Demo
You can try the Online Web UI demo build with [Gradio](https://github.com/gradio-app/gradio), or use Colab Notebook at here:
*My Online Space Demo*
[](https://huggingface.co/spaces/DGSpitzer/DGS-Diffusion-Space)
*Finetuned Diffusion WebUI Demo by anzorq*
[](https://huggingface.co/spaces/anzorq/finetuned_diffusion)
*Colab Notebook*
[](https://colab.research.google.com/github/HelixNGC7293/cyberpunk-anime-diffusion/blob/main/cyberpunk_anime_diffusion.ipynb)[](https://github.com/HelixNGC7293/cyberpunk-anime-diffusion)
*Buy me a coffee if you like this project ;P ♥*
[](https://www.buymeacoffee.com/dgspitzer)
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/1.jpg" width="512" height="512"/></center>
# **👇Model👇**
AI Model Weights available at huggingface: https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/2.jpg" width="512" height="512"/></center>
# Usage
After model loaded, use keyword **dgs** in your prompt, with **illustration style** to get even better results.
For sampler, use **Euler A** for the best result (**DDIM** kinda works too), CFG Scale 7, steps 20 should be fine
**Example 1:**
```
portrait of a girl in dgs illustration style, Anime girl, female soldier working in a cyberpunk city, cleavage, ((perfect femine face)), intricate, 8k, highly detailed, shy, digital painting, intense, sharp focus
```
For cyber robot male character, you can add **muscular male** to improve the output.
**Example 2:**
```
a photo of muscular beard soldier male in dgs illustration style, half-body, holding robot arms, strong chest
```
**Example 3 (with Stable Diffusion WebUI):**
If using [AUTOMATIC1111's Stable Diffusion WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
You can simply use this as **prompt** with **Euler A** Sampler, CFG Scale 7, steps 20, 704 x 704px output res:
```
an anime girl in dgs illustration style
```
And set the **negative prompt** as this to get cleaner face:
```
out of focus, scary, creepy, evil, disfigured, missing limbs, ugly, gross, missing fingers
```
This will give you the exactly same style as the sample images above.
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/ReadmeAddon.jpg" width="256" height="353"/></center>
---
**NOTE: usage of this model implies accpetance of stable diffusion's [CreativeML Open RAIL-M license](LICENSE)**
---
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/4.jpg" width="700" height="700"/></center>
<center><img src="https://huggingface.co/AdamOswald1/Cyberpunk-Anime-Diffusion/resolve/main/img/6.jpg" width="700" height="700"/></center>
|
653f28afd59d38d377133b123571d7cd
|
AymanMansour/Whisper-Sudanese-Dialect-small
|
AymanMansour
|
whisper
| 37 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['AymanMansour/SDN-Dialect-Dataset', 'arbml/sudanese_dialect_speech', 'arabic_speech_corpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,529 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-small
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5091
- Wer: 56.3216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0157 | 13.0 | 1000 | 1.1631 | 65.9101 |
| 0.0025 | 26.0 | 2000 | 1.3416 | 58.5066 |
| 0.0009 | 39.01 | 3000 | 1.4238 | 56.6398 |
| 0.0004 | 52.01 | 4000 | 1.4800 | 56.3004 |
| 0.0002 | 65.01 | 5000 | 1.5091 | 56.3216 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
a351daaca49d54284bd64460fab11bd9
|
Phantom-Artist/phantom-diffusion-s3-the-last-8
|
Phantom-Artist
| null | 39 | 0 | null | 2 | null | false | false | false |
creativeml-openrail-m
|
['en', 'ja']
|
['Phantom-Artist/phantom-diffusion-s3-the-last-8-dataset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['art']
| false | true | true | 7,502 | false |
The final 8 models that are trained over [hakurei's Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion).
Each model was trained on a notable Japanese (and Taiwanese, I think) AI artist's works using dreambooth, with 30 of their works gained mainly from twitter (except for sabakichi, which I collected the dataset from pixiv).
It tooks 1000 steps to train each model, at a learning rate of 5-e6. I have shared the notebook [here](https://huggingface.co/Phantom-Artist/phantom-diffusion/blob/main/DreamBooth_Stable_Diffusion_works_with_SD_2.ipynb) in case you want to try out additional training.
Some are good at backgrounds, while others can generate a semi-realistic style as seen in many SD 1.5 anime/waifu models (and some might be a bit overfitted).
The dataset is published [here](https://huggingface.co/datasets/Phantom-Artist/phantom-diffusion-s3-the-last-8-dataset), and the full members are listed [here](https://twitter.com/i/lists/1622444997240037377) (special thanks to Yunyalula for creating it!).
# For those who are against generative AIs
You can see that now they are the target. Take our tool. Now is the time for pay back. Generate the images in their styles, and bring back the power you had to yourself.
# For those who support the development of generative AIs
Some of the AI artists, even though they take advantage of the open strategy of Stable Diffusion, now tend to hide their prompts, trying to monopolize their style (I'm not saying the AI artists I trained are as such, to be sure).
To continue protecting our values and beliefs on the open community and fight against them trying to create another pre-modern style guilds, I will show you a new way.
You no longer need their prompts; just train their images by yourself to protect the open community. It's not only legal but also ethical, as they have been taking advantages of others' trained dataset.
# For those who call themselves "phantom 40"
I saw some caliming there should be 48, and here you go. Phantom 48, or do you like to call yourselves *PTM* 48 instead? It's up to you.
# Why will they be the last?
My initial intention on this series was a social experiment to see what will happen if the AI artists are targeted for personalized training.
As it became more popular than expected and the artists started calling themselves "phantom 20," I came up with the second intention to see how they will react after I add 20 more in one day, to see if they can adapt to the sudden change. They acted greatly, and I think that's why they could become notable.
All the reactions and the interpretations on my action were impressive, but since I have accomplished my goal, and since the main stream model will probably be SD 2.1 768 (not SD 2.1 512), I will no longer add new models.
I know I couldn't add some of the artists, but no. I will not do it under the name of phantom.
It takes me like 8 hours to train, test, and upload 20 models, and it's just unsustainable to continue doing it everyday.
**From now on, anyone who wish to add more is the next phantom. Train anyone you wish to by yourself.**
# trained artist list
- atsuwo_AI
- recommended pos: multicolored hair, cg
- fladdict
- recommended pos: oil painting/ancient relief/impressionist impasto oil painting (maybe more)
- possible neg: monkey
- Hifumi_AID
- recommended pos: dark purple hair, emerald eyes
- mayonaka_rr
- recommended pos: cg
- possible pos: dynamic posing, bikini, ponytail
- o81morimori
- possible pos: cg, in a messy apartment room with objects on the floor and the bed
- sabakichi
- possible pos 1: merging underwater, limited pallete, melting underwater, unstable outlines
- possible pos 2: rough sketch, limited pallete, ((unstable outlines)), monotone gradation, dynamic posing
- teftef
- possible pos: light skyblue hair, bun, retropunk gears of a factory
- violet_fizz
- recommended pos: beautiful face, grown up face, long eyes, expressionless
- possible pos: expressionless
# samples
The basic prompt is as follows.
However, to present you the potential of these models as much as possible, many of them have additional postive tags (such as "in the style of") to get the result below (yes, use ``aitop (ARTIST)_style`` to gain the finetuned result).
Many works better with the additional prompt ``beautiful face``. Generally speaking, prompting words close to the trained dataset will give you a better result.
```
POS: masterpiece, best quality, 1girl, aitop (ARTIST)_style
NEG: nsfw, worst quality, low quality, medium quality, deleted, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digits, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, simple background
```
## atsuwo_AI



## fladdict



## Hifumi_AID


## mayonaka_rr



## o81morimori


## sabakichi




## teftef


## violet_fizz


|
aef39d409ac19258ac381a0065672085
|
mattchurgin/xls-r-eng
|
mattchurgin
|
wav2vec2
| 19 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ab']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'mozilla-foundation/common_voice_7_0', 'generated_from_trainer']
| true | true | true | 1,115 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [patrickvonplaten/wav2vec2_tiny_random_robust](https://huggingface.co/patrickvonplaten/wav2vec2_tiny_random_robust) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - AB dataset.
It achieves the following results on the evaluation set:
- Loss: inf
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1
- Datasets 1.18.1.dev0
- Tokenizers 0.11.0
|
ed197338e0d20785015ecee56c02bdc4
|
zhiguoxu/chinese-roberta-wwm-ext-finetuned2
|
zhiguoxu
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,615 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-roberta-wwm-ext-finetuned2
This model is a fine-tuned version of [hfl/chinese-roberta-wwm-ext](https://huggingface.co/hfl/chinese-roberta-wwm-ext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1448
- Accuracy: 1.0
- F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.4081 | 1.0 | 3 | 0.9711 | 0.7273 | 0.6573 |
| 0.9516 | 2.0 | 6 | 0.8174 | 0.8182 | 0.8160 |
| 0.8945 | 3.0 | 9 | 0.6617 | 0.9091 | 0.9124 |
| 0.7042 | 4.0 | 12 | 0.5308 | 1.0 | 1.0 |
| 0.6641 | 5.0 | 15 | 0.4649 | 1.0 | 1.0 |
| 0.5731 | 6.0 | 18 | 0.4046 | 1.0 | 1.0 |
| 0.5132 | 7.0 | 21 | 0.3527 | 1.0 | 1.0 |
| 0.3999 | 8.0 | 24 | 0.3070 | 1.0 | 1.0 |
| 0.4198 | 9.0 | 27 | 0.2673 | 1.0 | 1.0 |
| 0.3677 | 10.0 | 30 | 0.2378 | 1.0 | 1.0 |
| 0.3545 | 11.0 | 33 | 0.2168 | 1.0 | 1.0 |
| 0.3237 | 12.0 | 36 | 0.1980 | 1.0 | 1.0 |
| 0.3122 | 13.0 | 39 | 0.1860 | 1.0 | 1.0 |
| 0.2802 | 14.0 | 42 | 0.1759 | 1.0 | 1.0 |
| 0.2552 | 15.0 | 45 | 0.1671 | 1.0 | 1.0 |
| 0.2475 | 16.0 | 48 | 0.1598 | 1.0 | 1.0 |
| 0.2259 | 17.0 | 51 | 0.1541 | 1.0 | 1.0 |
| 0.201 | 18.0 | 54 | 0.1492 | 1.0 | 1.0 |
| 0.2083 | 19.0 | 57 | 0.1461 | 1.0 | 1.0 |
| 0.2281 | 20.0 | 60 | 0.1448 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 2.1.0
- Tokenizers 0.12.1
|
51abb096912cefe4883a68c072bbb250
|
elRivx/100Memories
|
elRivx
| null | 3 | 0 | null | 4 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'text-to-image']
| false | true | true | 1,571 | false |
# 100Memories
This is my new Stable Diffusion 1.5 custom model that bring to you an images with a retro look style.
The magic word is: 100Memories
If you enjoy my work, please consider supporting me:
[](https://www.buymeacoffee.com/elrivx)
Examples:
<img src=https://imgur.com/xuCqo5l.png width=30% height=30%>
<img src=https://imgur.com/7Xdy4Jv.png width=30% height=30%>
<img src=https://imgur.com/c0JccbW.png width=30% height=30%>
<img src=https://imgur.com/7Qrw48p.png width=30% height=30%>
<img src=https://imgur.com/2bvukQY.png width=30% height=30%>
<img src=https://imgur.com/NFkHsG8.png width=30% height=30%>
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
4afb1f25df47fa99f79a94e59b533d86
|
wyu1/GenRead-3B-WebQ-MergeDPR
|
wyu1
|
t5
| 5 | 1 |
transformers
| 0 | null | true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 730 | false |
# GenRead (MergeDPR): FiD model trained on WebQ
-- This is the model checkpoint of GenRead [2], based on the T5-3B and trained on the WebQ dataset [1].
-- Hyperparameters: 8 x 80GB A100 GPUs; batch size 16; AdamW; LR 5e-5; best dev at 18000 steps.
References:
[1] Semantic parsing on freebase from question-answer pairs. EMNLP 2013.
[2] Generate rather than Retrieve: Large Language Models are Strong Context Generators. arXiv 2022
## Model performance
We evaluate it on the WebQ dataset, the EM score is 56.25.
<a href="https://huggingface.co/exbert/?model=bert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
---
license: cc-by-4.0
---
---
license: cc-by-4.0
---
|
c073d5ea4450283d8fa118ce561646ec
|
chrisjay/fonxlsr
|
chrisjay
|
wav2vec2
| 10,414 | 6 |
transformers
| 2 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['fon']
|
['fon_dataset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week', 'hf-asr-leaderboard']
| true | true | true | 4,687 | false |
# Wav2Vec2-Large-XLSR-53-Fon
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on [Fon (or Fongbe)](https://en.wikipedia.org/wiki/Fon_language) using the [Fon Dataset](https://github.com/laleye/pyFongbe/tree/master/data).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import json
import random
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
#Load test_dataset from saved files in folder
from datasets import load_dataset, load_metric
#for test
for root, dirs, files in os.walk(test/):
test_dataset= load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
#Remove unnecessary chars
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
#No need for resampling because audio dataset already at 16kHz
#resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"]=speech_array.squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on our unique Fon test data.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
for root, dirs, files in os.walk(test/):
test_dataset = load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model.to("cuda")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = speech_array[0].numpy()
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["sentence"]
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
#Evaluation on test dataset
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.97 %
## Training
The [Fon dataset](https://github.com/laleye/pyFongbe/tree/master/data) was split into `train`(8235 samples), `validation`(1107 samples), and `test`(1061 samples).
The script used for training can be found [here](https://colab.research.google.com/drive/11l6qhJCYnPTG1TQZ8f3EvKB9z12TQi4g?usp=sharing)
# Collaborators on this project
- Chris C. Emezue ([Twitter](https://twitter.com/ChrisEmezue))|(chris.emezue@gmail.com)
- Bonaventure F.P. Dossou (HuggingFace Username: [bonadossou](https://huggingface.co/bonadossou))|([Twitter](https://twitter.com/bonadossou))|(femipancrace.dossou@gmail.com)
## This is a joint project continuing our research on [OkwuGbé: End-to-End Speech Recognition for Fon and Igbo](https://arxiv.org/abs/2103.07762)
|
0402a110bcb8ee847af70a4c746a4d6f
|
jonatasgrosman/exp_w2v2t_it_vp-it_s965
|
jonatasgrosman
|
wav2vec2
| 10 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'it']
| false | true | true | 469 | false |
# exp_w2v2t_it_vp-it_s965
Fine-tuned [facebook/wav2vec2-large-it-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-it-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
0fb4487e2c63a2fac483daeb4c371a9f
|
jojoUla/bert-large-uncased-finetuned-DA-Zero-shot
|
jojoUla
|
bert
| 15 | 5 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,671 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-finetuned-DA-Zero-shot
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1282 | 1.0 | 435 | 1.3862 |
| 1.1307 | 2.0 | 870 | 1.3362 |
| 1.2243 | 3.0 | 1305 | 1.2791 |
| 1.274 | 4.0 | 1740 | 1.2143 |
| 1.2296 | 5.0 | 2175 | 1.1799 |
| 1.1773 | 6.0 | 2610 | 1.1550 |
| 1.1519 | 7.0 | 3045 | 1.1295 |
| 1.1406 | 8.0 | 3480 | 1.1064 |
| 1.114 | 9.0 | 3915 | 1.1303 |
| 1.1058 | 10.0 | 4350 | 1.1214 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
f7d58caf4962fd50deb1cc768c9f14cb
|
philosucker/xlm-roberta-base-finetuned-panx-de
|
philosucker
|
xlm-roberta
| 16 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,317 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1906
- F1: 0.8687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2884 | 1.0 | 3145 | 0.2390 | 0.8242 |
| 0.1639 | 2.0 | 6290 | 0.1944 | 0.8488 |
| 0.0952 | 3.0 | 9435 | 0.1906 | 0.8687 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
de7f87f2da1e1cae77d3e9f4c2d4c414
|
thesunshine36/FineTune_Vit5_LR0_00001_time3
|
thesunshine36
|
t5
| 5 | 10 |
transformers
| 0 |
text2text-generation
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,556 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# FineTune_Vit5_LR0_00001_time3
This model is a fine-tuned version of [thesunshine36/FineTune_Vit5_LR0_00001_time2](https://huggingface.co/thesunshine36/FineTune_Vit5_LR0_00001_time2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6297
- Validation Loss: 0.5655
- Train Rouge1: 52.5683
- Train Rouge2: 31.3753
- Train Rougel: 44.4344
- Train Rougelsum: 44.4737
- Train Gen Len: 13.6985
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Rouge1 | Train Rouge2 | Train Rougel | Train Rougelsum | Train Gen Len | Epoch |
|:----------:|:---------------:|:------------:|:------------:|:------------:|:---------------:|:-------------:|:-----:|
| 0.6297 | 0.5655 | 52.5683 | 31.3753 | 44.4344 | 44.4737 | 13.6985 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
|
cac33e449529d8e96c899af5c3242eb6
|
sd-concepts-library/vcr-classique
|
sd-concepts-library
| null | 17 | 0 | null | 2 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,870 | false |
### vcr classique on Stable Diffusion
This is the `<vcr_c>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:












|
3766df8e7048b28bdea0bd367b9015e2
|
Helsinki-NLP/opus-mt-pon-en
|
Helsinki-NLP
|
marian
| 10 | 11 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-pon-en
* source languages: pon
* target languages: en
* OPUS readme: [pon-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/pon-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/pon-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/pon-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/pon-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.pon.en | 34.1 | 0.489 |
|
c6626f48fa07b9028475041e17acf186
|
DeepaKrish/roberta-base-finetuned-squad
|
DeepaKrish
|
roberta
| 13 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,192 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-squad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0491
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 27 | 0.1224 |
| No log | 2.0 | 54 | 0.0491 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.9.0
- Datasets 2.5.1
- Tokenizers 0.13.2
|
d1323a4654065885f0ec683ad41c9598
|
julien-c/mini_an4_asr_train_raw_bpe_valid
|
julien-c
| null | 10 | 2 |
espnet
| 0 |
automatic-speech-recognition
| false | false | false |
cc-by-4.0
|
['en']
|
['ljspeech']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'automatic-speech-recognition']
| false | true | true | 1,847 | false |
## Example ESPnet2 ASR model
### `kamo-naoyuki/mini_an4_asr_train_raw_bpe_valid.acc.best`
♻️ Imported from https://zenodo.org/record/3957940#.X90XNelKjkM
This model was trained by kamo-naoyuki using mini_an4 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
99cb63415e6074fa07a5efb024253a7c
|
jinghan/roberta-base-finetuned-wnli
|
jinghan
|
roberta
| 14 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,442 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wnli
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6880
- Accuracy: 0.5634
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.6880 | 0.5634 |
| No log | 2.0 | 80 | 0.6851 | 0.5634 |
| No log | 3.0 | 120 | 0.6961 | 0.4366 |
| No log | 4.0 | 160 | 0.6906 | 0.5634 |
| No log | 5.0 | 200 | 0.6891 | 0.5634 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
a58b05f7d53de8094a5907c65ae63dca
|
vasista22/whisper-gujarati-medium
|
vasista22
|
whisper
| 12 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['gu']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event']
| true | true | true | 1,296 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Gujarati Medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the Gujarati data available from multiple publicly available ASR corpuses.
It has been fine-tuned as a part of the Whisper fine-tuning sprint.
## Training and evaluation data
Training Data: ULCA ASR Corpus, OpenSLR, Microsoft Research Telugu Corpus (Train+Dev), Google/Fleurs Train+Dev set.
Evaluation Data: Google/Fleurs Test set, Microsoft Research Telugu Corpus Test .
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 24
- eval_batch_size: 48
- seed: 22
- optimizer: adamw_bnb_8bit
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 4000
- training_steps: 21240
- mixed_precision_training: True
## Acknowledgement
This work was done at Speech Lab, IITM.
The compute resources for this work were funded by "Bhashini: National Language translation Mission" project of the Ministry of Electronics and Information Technology (MeitY), Government of India.
|
01eda95326923583652aa1363d548da1
|
creat89/NER_FEDA_Latin1
|
creat89
|
bert
| 7 | 1 |
transformers
| 0 | null | true | false | false |
mit
|
['multilingual', 'cs', 'pl', 'sl', 'fi']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['labse', 'ner']
| false | true | true | 832 | false |
This is a multilingual NER system trained using a Frustratingly Easy Domain Adaptation architecture. It is based on LaBSE and supports different tagsets all using IOBES formats:
1. Wikiann (LOC, PER, ORG)
2. SlavNER 19/21 (EVT, LOC, ORG, PER, PRO)
3. SlavNER 17 (LOC, MISC, ORG, PER)
4. SSJ500k (LOC, MISC, ORG, PER)
5. KPWr (EVT, LOC, ORG, PER, PRO)
6. CNEC (LOC, ORG, MEDIA, ART, PER, TIME)
7. Turku (DATE, EVT, LOC, ORG, PER, PRO, TIME)
PER: person, LOC: location, ORG: organization, EVT: event, PRO: product, MISC: Miscellaneous, MEDIA: media, ART: Artifact, TIME: time, DATE: date
You can select the tagset to use in the output by configuring the model.
More information about the model can be found in the paper (https://aclanthology.org/2021.bsnlp-1.12.pdf) and GitHub repository (https://github.com/EMBEDDIA/NER_FEDA).
|
974a5af60cd29e63b76dc5715499de62
|
Zekunli/flan-t5-large-da-multiwoz_1000
|
Zekunli
|
t5
| 10 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,561 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-da-multiwoz_1000
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3538
- Accuracy: 41.3747
- Num: 3689
- Gen Len: 15.5115
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 24
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Num | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----:|:-------:|
| 1.3315 | 0.24 | 200 | 0.5697 | 25.9543 | 3689 | 14.556 |
| 0.6418 | 0.48 | 400 | 0.4645 | 30.0503 | 3689 | 14.9314 |
| 0.5433 | 0.72 | 600 | 0.4307 | 31.9506 | 3689 | 16.1515 |
| 0.4909 | 0.95 | 800 | 0.4177 | 34.7593 | 3689 | 15.418 |
| 0.4769 | 1.19 | 1000 | 0.3996 | 35.0943 | 3689 | 14.9607 |
| 0.4491 | 1.43 | 1200 | 0.3881 | 36.2741 | 3689 | 15.543 |
| 0.4531 | 1.67 | 1400 | 0.3820 | 35.7704 | 3689 | 14.1583 |
| 0.4322 | 1.91 | 1600 | 0.3726 | 37.4853 | 3689 | 15.961 |
| 0.4188 | 2.15 | 1800 | 0.3699 | 38.4117 | 3689 | 15.0773 |
| 0.4085 | 2.38 | 2000 | 0.3674 | 38.5353 | 3689 | 15.4012 |
| 0.4063 | 2.62 | 2200 | 0.3606 | 40.0046 | 3689 | 15.3546 |
| 0.3977 | 2.86 | 2400 | 0.3570 | 40.6543 | 3689 | 15.704 |
| 0.3992 | 3.1 | 2600 | 0.3549 | 40.4284 | 3689 | 15.7446 |
| 0.3828 | 3.34 | 2800 | 0.3538 | 41.3747 | 3689 | 15.5115 |
| 0.3792 | 3.58 | 3000 | 0.3539 | 39.8513 | 3689 | 14.7951 |
| 0.3914 | 3.81 | 3200 | 0.3498 | 41.0388 | 3689 | 15.4153 |
| 0.3707 | 4.05 | 3400 | 0.3498 | 40.9596 | 3689 | 16.3136 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
bd8e04b35ddc594669257de7e325a059
|
Babivill/leidirocha
|
Babivill
| null | 31 | 3 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 1,606 | false |
### leidirocha Dreambooth model trained by Babivill with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
leidirocha (use that on your prompt)
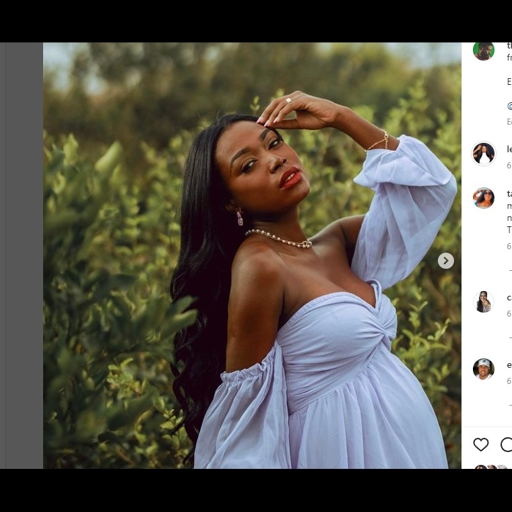
|
1965defae343d5d77a9329b3aa296593
|
north/nynorsk_North_large
|
north
|
t5
| 15 | 5 |
transformers
| 0 |
translation
| true | false | true |
apache-2.0
|
['nn', 'no', 'nb']
|
['NbAiLab/balanced_bokmaal_nynorsk']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 500 | false |
# Model Card for Model ID
This model is a finetuned version of [north/t5_large_NCC_modern](https://huggingface.co/north/t5_large_NCC_modern).
| | Size |Model|BLEU|
|:------------:|:------------:|:------------:|:------------:|
|Small |_60M_|[🤗](https://huggingface.co/north/nynorsk_North_small)|93.44|
|Base |_220M_|[🤗](https://huggingface.co/north/nynorsk_North_base)|93.79|
|**Large** |**_770M_**|✔|**93.99**|
# Model Details
Please see the model card for the base model for more information.
|
c06e4eddff2aa7848000d63b25b932fa
|
w11wo/sundanese-roberta-base-emotion-classifier
|
w11wo
|
roberta
| 10 | 4 |
transformers
| 0 |
text-classification
| true | true | false |
mit
|
['su']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sundanese-roberta-base-emotion-classifier']
| false | true | true | 4,254 | false |
## Sundanese RoBERTa Base Emotion Classifier
Sundanese RoBERTa Base Emotion Classifier is an emotion-text-classification model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. The model was originally the pre-trained [Sundanese RoBERTa Base](https://hf.co/w11wo/sundanese-roberta-base) model, which is then fine-tuned on the [Sundanese Twitter dataset](https://github.com/virgantara/sundanese-twitter-dataset), consisting of Sundanese tweets.
10% of the dataset is kept for evaluation purposes. After training, the model achieved an evaluation accuracy of 98.41% and F1-macro of 98.43%.
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with other frameworks nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------------------------- | ------- | ------------ | ------------------------------- |
| `sundanese-roberta-base-emotion-classifier` | 124M | RoBERTa Base | Sundanese Twitter dataset |
## Evaluation Results
The model was trained for 10 epochs and the best model was loaded at the end.
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
| ----- | ------------- | --------------- | -------- | -------- | --------- | -------- |
| 1 | 0.801800 | 0.293695 | 0.900794 | 0.899048 | 0.903466 | 0.900406 |
| 2 | 0.208700 | 0.185291 | 0.936508 | 0.935520 | 0.939460 | 0.935540 |
| 3 | 0.089700 | 0.150287 | 0.956349 | 0.956569 | 0.956500 | 0.958612 |
| 4 | 0.025600 | 0.130889 | 0.972222 | 0.972865 | 0.973029 | 0.973184 |
| 5 | 0.002200 | 0.100031 | 0.980159 | 0.980430 | 0.980430 | 0.980430 |
| 6 | 0.001300 | 0.104971 | 0.980159 | 0.980430 | 0.980430 | 0.980430 |
| 7 | 0.000600 | 0.107744 | 0.980159 | 0.980174 | 0.980814 | 0.979743 |
| 8 | 0.000500 | 0.102327 | 0.980159 | 0.980171 | 0.979970 | 0.980430 |
| 9 | 0.000500 | 0.101935 | 0.984127 | 0.984376 | 0.984073 | 0.984741 |
| 10 | 0.000400 | 0.105965 | 0.984127 | 0.984142 | 0.983720 | 0.984741 |
## How to Use
### As Text Classifier
```python
from transformers import pipeline
pretrained_name = "sundanese-roberta-base-emotion-classifier"
nlp = pipeline(
"sentiment-analysis",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("Wah, éta gélo, keren pisan!")
```
## Disclaimer
Do consider the biases which come from both the pre-trained RoBERTa model and the Sundanese Twitter dataset that may be carried over into the results of this model.
## Author
Sundanese RoBERTa Base Emotion Classifier was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
## Citation Information
```bib
@article{rs-907893,
author = {Wongso, Wilson
and Lucky, Henry
and Suhartono, Derwin},
journal = {Journal of Big Data},
year = {2022},
month = {Feb},
day = {26},
abstract = {The Sundanese language has over 32 million speakers worldwide, but the language has reaped little to no benefits from the recent advances in natural language understanding. Like other low-resource languages, the only alternative is to fine-tune existing multilingual models. In this paper, we pre-trained three monolingual Transformer-based language models on Sundanese data. When evaluated on a downstream text classification task, we found that most of our monolingual models outperformed larger multilingual models despite the smaller overall pre-training data. In the subsequent analyses, our models benefited strongly from the Sundanese pre-training corpus size and do not exhibit socially biased behavior. We released our models for other researchers and practitioners to use.},
issn = {2693-5015},
doi = {10.21203/rs.3.rs-907893/v1},
url = {https://doi.org/10.21203/rs.3.rs-907893/v1}
}
```
|
b7d72b0598939b58798ca013ce675712
|
IIIT-L/muril-base-cased-finetuned-non-code-mixed-DS
|
IIIT-L
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,421 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# muril-base-cased-finetuned-non-code-mixed-DS
This model is a fine-tuned version of [google/muril-base-cased](https://huggingface.co/google/muril-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2867
- Accuracy: 0.6214
- Precision: 0.6081
- Recall: 0.6009
- F1: 0.6034
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0861 | 2.0 | 463 | 1.0531 | 0.3506 | 0.1169 | 0.3333 | 0.1731 |
| 0.99 | 3.99 | 926 | 0.9271 | 0.5836 | 0.4310 | 0.5200 | 0.4502 |
| 0.8759 | 5.99 | 1389 | 0.9142 | 0.5965 | 0.5788 | 0.5907 | 0.5802 |
| 0.7726 | 7.98 | 1852 | 0.8726 | 0.6095 | 0.6079 | 0.6078 | 0.6027 |
| 0.6659 | 9.98 | 2315 | 0.9145 | 0.6246 | 0.6139 | 0.6174 | 0.6140 |
| 0.5727 | 11.97 | 2778 | 0.9606 | 0.6311 | 0.6180 | 0.6109 | 0.6133 |
| 0.4889 | 13.97 | 3241 | 1.0342 | 0.6170 | 0.6059 | 0.6054 | 0.6045 |
| 0.4267 | 15.97 | 3704 | 1.0539 | 0.6170 | 0.6089 | 0.6081 | 0.6066 |
| 0.3751 | 17.96 | 4167 | 1.1740 | 0.6343 | 0.6255 | 0.6074 | 0.6112 |
| 0.3402 | 19.96 | 4630 | 1.2021 | 0.6192 | 0.6078 | 0.6013 | 0.6031 |
| 0.318 | 21.95 | 5093 | 1.2875 | 0.6181 | 0.6007 | 0.5946 | 0.5965 |
| 0.2977 | 23.95 | 5556 | 1.2867 | 0.6214 | 0.6081 | 0.6009 | 0.6034 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
35c355c34c223d4424f788b508d83a22
|
mikestic/finetuning-sentiment-model-3000-samples
|
mikestic
|
distilbert
| 13 | 9 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,054 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3124
- Accuracy: 0.8733
- F1: 0.875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
f34017f3844be4d5b6caf2c7c7cf2853
|
SkyR/albert-base-ours-run-2
|
SkyR
|
albert
| 9 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,064 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-ours-run-2
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2462
- Accuracy: 0.695
- Precision: 0.6550
- Recall: 0.6529
- F1: 0.6539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.999 | 1.0 | 200 | 0.9155 | 0.615 | 0.5590 | 0.5590 | 0.5524 |
| 0.7736 | 2.0 | 400 | 0.8488 | 0.6 | 0.5639 | 0.5689 | 0.5256 |
| 0.5836 | 3.0 | 600 | 0.8760 | 0.67 | 0.6259 | 0.6158 | 0.6191 |
| 0.4153 | 4.0 | 800 | 1.0050 | 0.675 | 0.6356 | 0.6212 | 0.5974 |
| 0.3188 | 5.0 | 1000 | 1.2033 | 0.655 | 0.6254 | 0.5977 | 0.5991 |
| 0.2335 | 6.0 | 1200 | 1.3407 | 0.625 | 0.5955 | 0.6039 | 0.5937 |
| 0.1752 | 7.0 | 1400 | 1.4246 | 0.72 | 0.6846 | 0.6815 | 0.6820 |
| 0.1056 | 8.0 | 1600 | 1.9654 | 0.69 | 0.6589 | 0.6251 | 0.6311 |
| 0.0696 | 9.0 | 1800 | 1.9376 | 0.715 | 0.6908 | 0.6632 | 0.6627 |
| 0.0352 | 10.0 | 2000 | 1.9970 | 0.72 | 0.6880 | 0.6784 | 0.6817 |
| 0.0227 | 11.0 | 2200 | 2.1449 | 0.705 | 0.6901 | 0.6641 | 0.6679 |
| 0.0199 | 12.0 | 2400 | 2.2213 | 0.72 | 0.6891 | 0.6685 | 0.6749 |
| 0.0077 | 13.0 | 2600 | 2.1500 | 0.69 | 0.6729 | 0.6704 | 0.6647 |
| 0.0067 | 14.0 | 2800 | 2.1780 | 0.69 | 0.6632 | 0.6651 | 0.6621 |
| 0.0034 | 15.0 | 3000 | 2.1759 | 0.71 | 0.6800 | 0.6786 | 0.6788 |
| 0.0013 | 16.0 | 3200 | 2.2139 | 0.71 | 0.6760 | 0.6721 | 0.6735 |
| 0.0005 | 17.0 | 3400 | 2.2282 | 0.7 | 0.6606 | 0.6593 | 0.6599 |
| 0.0003 | 18.0 | 3600 | 2.2257 | 0.7 | 0.6606 | 0.6593 | 0.6599 |
| 0.0003 | 19.0 | 3800 | 2.2492 | 0.695 | 0.6550 | 0.6529 | 0.6539 |
| 0.0002 | 20.0 | 4000 | 2.2462 | 0.695 | 0.6550 | 0.6529 | 0.6539 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Tokenizers 0.13.2
|
fa14475ad4ce69c7d3389d8253957834
|
Annabelleabbott/swin-tiny-patch4-window7-224-finetuned-eurosat
|
Annabelleabbott
|
swin
| 9 | 5 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,493 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0767
- Accuracy: 0.9726
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2548 | 1.0 | 190 | 0.1162 | 0.9652 |
| 0.1544 | 2.0 | 380 | 0.0894 | 0.9719 |
| 0.1182 | 3.0 | 570 | 0.0767 | 0.9726 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
f15745a542fff0298809bb5712b2dd42
|
emre/wav2vec2-large-xlsr-53-W2V2-TR-MED
|
emre
|
wav2vec2
| 14 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'robust-speech-event']
| true | true | true | 2,152 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-W2V2-TR-MED
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4467
- Wer: 0.4598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.1343 | 4.21 | 400 | 2.3674 | 1.0372 |
| 0.8075 | 8.42 | 800 | 0.4583 | 0.6308 |
| 0.3209 | 12.63 | 1200 | 0.4291 | 0.5531 |
| 0.2273 | 16.84 | 1600 | 0.4348 | 0.5378 |
| 0.1764 | 21.05 | 2000 | 0.4550 | 0.5326 |
| 0.148 | 25.26 | 2400 | 0.4839 | 0.5319 |
| 0.1268 | 29.47 | 2800 | 0.4515 | 0.5070 |
| 0.1113 | 33.68 | 3200 | 0.4590 | 0.4930 |
| 0.1025 | 37.89 | 3600 | 0.4546 | 0.4888 |
| 0.0922 | 42.11 | 4000 | 0.4782 | 0.4852 |
| 0.082 | 46.32 | 4400 | 0.4605 | 0.4752 |
| 0.0751 | 50.53 | 4800 | 0.4358 | 0.4689 |
| 0.0699 | 54.74 | 5200 | 0.4359 | 0.4629 |
| 0.0633 | 58.95 | 5600 | 0.4467 | 0.4598 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
19d1ee3786530e8a8ef21a674c633aeb
|
microsoft/xclip-base-patch16-zero-shot
|
microsoft
|
xclip
| 10 | 1,912 |
transformers
| 10 |
feature-extraction
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'video-classification']
| true | true | true | 2,408 | false |
# X-CLIP (base-sized model)
X-CLIP model (base-sized, patch resolution of 16) trained on [Kinetics-400](https://www.deepmind.com/open-source/kinetics). It was introduced in the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Ni et al. and first released in [this repository](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
This model was trained using 32 frames per video, at a resolution of 224x224.
Disclaimer: The team releasing X-CLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
X-CLIP is a minimal extension of [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for general video-language understanding. The model is trained in a contrastive way on (video, text) pairs.

This allows the model to be used for tasks like zero-shot, few-shot or fully supervised video classification and video-text retrieval.
## Intended uses & limitations
You can use the raw model for determining how well text goes with a given video. See the [model hub](https://huggingface.co/models?search=microsoft/xclip) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/xclip.html#).
## Training data
This model was trained on [Kinetics 400](https://www.deepmind.com/open-source/kinetics).
### Preprocessing
The exact details of preprocessing during training can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L247).
The exact details of preprocessing during validation can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L285).
During validation, one resizes the shorter edge of each frame, after which center cropping is performed to a fixed-size resolution (like 224x224). Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
This model achieves a zero-shot top-1 accuracy of 44.6% on HMDB-51, 72.0% on UCF-101 and 65.2% on Kinetics-600.
|
c09de5abee00a8031936a16948ebcd4a
|
simonl0909/whisper-large-v2-cantonese
|
simonl0909
|
whisper
| 19 | 10 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['yue']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,629 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large V2 Cantonese
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the mozilla-foundation/common_voice_11_0 yue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2807
- Cer: 6.7274
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0032 | 13.01 | 1000 | 0.2318 | 6.8569 |
| 0.002 | 26.01 | 2000 | 0.2404 | 7.1524 |
| 0.0001 | 39.02 | 3000 | 0.2807 | 6.7274 |
| 0.0001 | 53.01 | 4000 | 0.2912 | 6.7517 |
| 0.0 | 66.01 | 5000 | 0.2957 | 6.7638 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
c8386d6fe52de59a3fd2466e7f728cd7
|
thorduragust/IceBERT-finetuned-ner
|
thorduragust
|
roberta
| 14 | 11 |
transformers
| 0 |
token-classification
| true | false | false |
gpl-3.0
| null |
['mim_gold_ner']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,528 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IceBERT-finetuned-ner
This model is a fine-tuned version of [vesteinn/IceBERT](https://huggingface.co/vesteinn/IceBERT) on the mim_gold_ner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0787
- Precision: 0.8948
- Recall: 0.8622
- F1: 0.8782
- Accuracy: 0.9852
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0526 | 1.0 | 2904 | 0.0746 | 0.8802 | 0.8539 | 0.8668 | 0.9836 |
| 0.0264 | 2.0 | 5808 | 0.0711 | 0.8777 | 0.8594 | 0.8684 | 0.9843 |
| 0.0161 | 3.0 | 8712 | 0.0787 | 0.8948 | 0.8622 | 0.8782 | 0.9852 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
03f20add57296c537ad66720c002c28a
|
SushantGautam/CodeGeneration
|
SushantGautam
|
roberta
| 18 | 6 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,002 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CodeGeneration
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5020
- Accuracy: 0.4444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
85759c496605d524a6ff5c21ad412a53
|
kingabzpro/wav2vec2-60-urdu
|
kingabzpro
|
wav2vec2
| 43 | 9 |
transformers
| 1 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ur']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'hf-asr-leaderboard', 'robust-speech-event']
| true | true | true | 1,713 | false |
# wav2vec2-large-xlsr-53-urdu
This model is a fine-tuned version of [Harveenchadha/vakyansh-wav2vec2-urdu-urm-60](https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-urdu-urm-60) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Wer: 0.5913
- Cer: 0.3310
## Model description
The training and valid dataset is 0.58 hours. It was hard to train any model on lower number of so I decided to take vakyansh-wav2vec2-urdu-urm-60 checkpoint and finetune the wav2vec2 model.
## Training procedure
Trained on Harveenchadha/vakyansh-wav2vec2-urdu-urm-60 due to lesser number of samples.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 12.6045 | 8.33 | 100 | 8.4997 | 0.6978 | 0.3923 |
| 1.3367 | 16.67 | 200 | 5.0015 | 0.6515 | 0.3556 |
| 0.5344 | 25.0 | 300 | 9.3687 | 0.6393 | 0.3625 |
| 0.2922 | 33.33 | 400 | 9.2381 | 0.6236 | 0.3432 |
| 0.1867 | 41.67 | 500 | 6.2150 | 0.6035 | 0.3448 |
| 0.1166 | 50.0 | 600 | 6.4496 | 0.5913 | 0.3310 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
c21cdf2bfc3e55e4a50dcb1219148602
|
darkvibes/vibes-v2
|
darkvibes
| null | 16 | 8 |
diffusers
| 2 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 707 | false |
### VIBES-V2 Dreambooth model trained by darkvibes with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:

|
b63bcb91e34f73b913e96c893d0f7019
|
philschmid/mt5-small-prompted-germanquad-1
|
philschmid
|
mt5
| 13 | 6 |
transformers
| 0 |
summarization
| true | false | false |
apache-2.0
| null |
['philschmid/prompted-germanquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['summarization']
| true | true | true | 2,586 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-prompted-germanquad-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an [philschmid/prompted-germanquad](https://huggingface.co/datasets/philschmid/prompted-germanquad) dataset. A prompt datasets using the [BigScience PromptSource library](https://github.com/bigscience-workshop/promptsource). The dataset is a copy of [germanquad](https://huggingface.co/datasets/deepset/germanquad) with applying the `squad` template and translated it to german. [TEMPLATE](https://github.com/philschmid/promptsource/blob/main/promptsource/templates/germanquad/templates.yaml).
This is a first test if it is possible to fine-tune `mt5` models to solve similar tasks than `T0` of big science but for the German language.
It achieves the following results on the evaluation set:
- Loss: 1.6835
- Rouge1: 27.7309
- Rouge2: 18.7311
- Rougel: 27.4704
- Rougelsum: 27.4818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 3.3795 | 1.0 | 17496 | 2.0693 | 15.8652 | 9.2569 | 15.6237 | 15.6142 |
| 2.3582 | 2.0 | 34992 | 1.9057 | 21.9348 | 14.0057 | 21.6769 | 21.6825 |
| 2.1809 | 3.0 | 52488 | 1.8143 | 24.3401 | 16.0354 | 24.0862 | 24.0914 |
| 2.0721 | 4.0 | 69984 | 1.7563 | 25.8672 | 17.2442 | 25.5854 | 25.6051 |
| 2.0004 | 5.0 | 87480 | 1.7152 | 27.0275 | 18.0548 | 26.7561 | 26.7685 |
| 1.9531 | 6.0 | 104976 | 1.6939 | 27.4702 | 18.5156 | 27.2027 | 27.2107 |
| 1.9218 | 7.0 | 122472 | 1.6835 | 27.7309 | 18.7311 | 27.4704 | 27.4818 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.1+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
b8efe5a1050ab07b5377df842f3a3925
|
google/mobilenet_v1_1.0_224
|
google
|
mobilenet_v1
| 5 | 2,873 |
transformers
| 0 |
image-classification
| true | false | false |
other
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 2,361 | false |
# MobileNet V1
MobileNet V1 model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Howard et al, and first released in [this repository](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
Disclaimer: The team releasing MobileNet V1 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
From the [original README](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md):
> MobileNets are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection, embeddings and segmentation similar to how other popular large scale models, such as Inception, are used. MobileNets can be run efficiently on mobile devices [...] MobileNets trade off between latency, size and accuracy while comparing favorably with popular models from the literature.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=mobilenet_v1) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
preprocessor = AutoImageProcessor.from_pretrained("google/mobilenet_v1_1.0_224")
model = AutoModelForImageClassification.from_pretrained("google/mobilenet_v1_1.0_224")
inputs = preprocessor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Note: This model actually predicts 1001 classes, the 1000 classes from ImageNet plus an extra “background” class (index 0).
Currently, both the feature extractor and model support PyTorch.
|
82c919199d356e0e95071189129afd6d
|
Lasserino/RutkowskiDiffusion_V1
|
Lasserino
| null | 4 | 0 | null | 1 |
text-to-image
| false | false | false |
unknown
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image']
| false | true | true | 907 | false |
# RutkowskiDiffusion_V1 - Trained on SD 2.1 768x768
The model was originally meant to be named FantasyDiffusion, though given recent events I guess you could see why I made the namechange.
**Prompts to use:** (SDV1) or (In the style of SDV1)
Enjoy!
**Disclaimer:** Model was released way earlier than I intended, and is more of an alpha version. Working on adding more training images for increased variation - Creatures, people etc. - Currently mostly landscapes




|
24034458c4ae8073e69f45db6162545b
|
yhavinga/t5-base-36L-dutch-english-cased
|
yhavinga
|
t5
| 12 | 13 |
transformers
| 0 |
text2text-generation
| false | false | true |
apache-2.0
|
['nl', 'en']
|
['yhavinga/mc4_nl_cleaned']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['t5', 'seq2seq']
| false | true | true | 26,873 | false |
# t5-base-36L-dutch-english-cased
A [T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) sequence to sequence model
pre-trained from scratch on [cleaned Dutch 🇳🇱🇧🇪 mC4 and cleaned English 🇬🇧 C4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned).
This **t5 eff** model has **728M** parameters.
It was pre-trained with masked language modeling (denoise token span corruption) objective on the dataset
`mc4_nl_cleaned` config `large_en_nl` for **1** epoch(s) and a duration of **17d15h**,
with a sequence length of **512**, batch size **512** and **212963** total steps (**56B** tokens).
Pre-training evaluation loss and accuracy are **1,05** and **0,76**.
Refer to the evaluation section below for a comparison of the pre-trained models on summarization and translation.
* Pre-trained T5 models need to be finetuned before they can be used for downstream tasks, therefore the inference widget on the right has been turned off.
* For a demo of the Dutch CNN summarization models, head over to the Hugging Face Spaces for
the **[Netherformer 📰](https://huggingface.co/spaces/flax-community/netherformer)** example application!
Please refer to the original T5 papers and Scale Efficiently papers for more information about the T5 architecture
and configs, though it must be noted that this model (t5-base-36L-dutch-english-cased) is unrelated to these projects and not an 'official' checkpoint.
* **[Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)** by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*.
* **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
## Tokenizer
The model uses a cased SentencePiece tokenizer configured with the `Nmt, NFKC, Replace multi-space to single-space` normalizers
and has 32003 tokens.
It was trained on Dutch and English with scripts from the Huggingface Transformers [Flax examples](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling).
See [./raw/main/tokenizer.json](tokenizer.json) for details.
## Dataset(s)
All models listed below are pre-trained on
[cleaned Dutch mC4](https://huggingface.co/datasets/yhavinga/mc4_nl_cleaned),
which is the original mC4, except
* Documents that contained words from a selection of the Dutch and English [List of Dirty Naught Obscene and Otherwise Bad Words](https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words) are removed
* Sentences with less than 3 words are removed
* Sentences with a word of more than 1000 characters are removed
* Documents with less than 5 sentences are removed
* Documents with "javascript", "lorum ipsum", "terms of use", "privacy policy", "cookie policy", "uses cookies",
"use of cookies", "use cookies", "elementen ontbreken", "deze printversie" are removed.
The Dutch and English models are pre-trained on a 50/50% mix of Dutch mC4 and English C4.
The translation models are fine-tuned on [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix).
## Dutch T5 Models
Three types of [Dutch T5 models have been trained (blog)](https://huggingface.co/spaces/yhavinga/pre-training-dutch-t5-models).
`t5-base-dutch` is the only model with an original T5 config.
The other model types t5-v1.1 and t5-eff have `gated-relu` instead of `relu` as activation function,
and trained with a drop-out of `0.0` unless training would diverge (`t5-v1.1-large-dutch-cased`).
The T5-eff models are models that differ in their number of layers. The table will list
the several dimensions of these models. Not all t5-eff models are efficient, the best example being the inefficient
`t5-xl-4L-dutch-english-cased`.
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-xl-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-xl-8l-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) |
|:------------------|:----------------|:-----------------------------|:---------------------------|:----------------------------|:-----------------------------------|:----------------------------------------|:-----------------------------|:-------------------------------|:----------------------------------|:-----------------------------------|:--------------------------------------|
| *type* | t5 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5-v1.1 | t5 eff | t5 eff | t5 eff | t5 eff | t5 eff |
| *d_model* | 768 | 768 | 768 | 1024 | 768 | 768 | 512 | 2048 | 768 | 1024 | 1024 |
| *d_ff* | 3072 | 2048 | 2048 | 2816 | 2048 | 2048 | 1920 | 5120 | 2560 | 16384 | 4096 |
| *num_heads* | 12 | 12 | 12 | 16 | 12 | 12 | 8 | 32 | 12 | 32 | 16 |
| *d_kv* | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 64 |
| *num_layers* | 12 | 12 | 12 | 24 | 12 | 12 | 24 | 4 | 36 | 8 | 8 |
| *num parameters* | 223M | 248M | 248M | 783M | 248M | 248M | 250M | 585M | 729M | 1241M | 335M |
| *feed_forward_proj* | relu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu | gated-gelu |
| *dropout* | 0.1 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.0 | 0.0 |
| *dataset* | mc4_nl_cleaned | mc4_nl_cleaned full | mc4_nl_cleaned full | mc4_nl_cleaned | mc4_nl_cleaned small_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl | mc4_nl_cleaned large_en_nl |
| *tr. seq len* | 512 | 1024 | 1024 | 512 | 512 | 1024 | 512 | 512 | 512 | 512 | 512 |
| *batch size* | 128 | 64 | 64 | 64 | 128 | 64 | 128 | 512 | 512 | 64 | 128 |
| *total steps* | 527500 | 1014525 | 1210154 | 1120k/2427498 | 2839630 | 1520k/3397024 | 851852 | 212963 | 212963 | 538k/1703705 | 851850 |
| *epochs* | 1 | 2 | 2 | 2 | 10 | 4 | 1 | 1 | 1 | 1 | 1 |
| *duration* | 2d9h | 5d5h | 6d6h | 8d13h | 11d18h | 9d1h | 4d10h | 6d1h | 17d15h | 4d 19h | 3d 23h |
| *optimizer* | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor | adafactor |
| *lr* | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | 0.009 | 0.005 | 0.005 |
| *warmup* | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 10000.0 | 5000.0 | 20000.0 | 2500.0 | 1000.0 | 1500.0 | 1500.0 |
| *eval loss* | 1,38 | 1,20 | 0,96 | 1,07 | 1,11 | 1,13 | 1,18 | 1,27 | 1,05 | 1,3019 | 1,15 |
| *eval acc* | 0,70 | 0,73 | 0,78 | 0,76 | 0,75 | 0,74 | 0,74 | 0,72 | 0,76 | 0,71 | 0,74 |
## Evaluation
Most models from the list above have been fine-tuned for summarization and translation.
The figure below shows the evaluation scores, where the x-axis shows the translation Bleu score (higher is better)
and y-axis the summarization Rouge1 translation score (higher is better).
Point size is proportional to the model size. Models with faster inference speed are green, slower inference speed is
plotted as bleu.

Evaluation was run on fine-tuned models trained with the following settings:
| | Summarization | Translation |
|---------------:|------------------|-------------------|
| Dataset | CNN Dailymail NL | CCMatrix en -> nl |
| #train samples | 50K | 50K |
| Optimizer | Adam | Adam |
| learning rate | 0.001 | 0.0005 |
| source length | 1024 | 128 |
| target length | 142 | 128 |
|label smoothing | 0.05 | 0.1 |
| #eval samples | 1000 | 1000 |
Note that the amount of training data is limited to a fraction of the total dataset sizes, therefore the scores
below can only be used to compare the 'transfer-learning' strength. The fine-tuned checkpoints for this evaluation
are not saved, since they were trained for comparison of pre-trained models only.
The numbers for summarization are the Rouge scores on 1000 documents from the test split.
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|:------------------------|----------------:|-----------------------------:|---------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
| *rouge1* | 33.38 | 33.97 | 34.39 | 33.38 | 34.97 | 34.38 | 30.35 | **35.04** | 34.04 | 33.25 |
| *rouge2* | 13.32 | 13.85 | 13.98 | 13.47 | 14.01 | 13.89 | 11.57 | **14.23** | 13.76 | 12.74 |
| *rougeL* | 24.22 | 24.72 | 25.1 | 24.34 | 24.99 | **25.25** | 22.69 | 25.05 | 24.75 | 23.5 |
| *rougeLsum* | 30.23 | 30.9 | 31.44 | 30.51 | 32.01 | 31.38 | 27.5 | **32.12** | 31.12 | 30.15 |
| *samples_per_second* | 3.18 | 3.02 | 2.99 | 3.22 | 2.97 | 1.57 | 2.8 | 0.61 | **3.27** | 1.22 |
The models below have been evaluated for English to Dutch translation.
Note that the first four models are pre-trained on Dutch only. That they still perform adequate is probably because
the translation direction is English to Dutch.
The numbers reported are the Bleu scores on 1000 documents from the test split.
| | [t5-base-dutch](https://huggingface.co/yhavinga/t5-base-dutch) | [t5-v1.1-base-dutch-uncased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-uncased) | [t5-v1.1-base-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-base-dutch-cased) | [t5-v1.1-large-dutch-cased](https://huggingface.co/yhavinga/t5-v1.1-large-dutch-cased) | [t5-v1_1-base-dutch-english-cased](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased) | [t5-v1_1-base-dutch-english-cased-1024](https://huggingface.co/yhavinga/t5-v1_1-base-dutch-english-cased-1024) | [t5-small-24L-dutch-english](https://huggingface.co/yhavinga/t5-small-24L-dutch-english) | [t5-xl-4L-dutch-english-cased](https://huggingface.co/yhavinga/t5-xl-4L-dutch-english-cased) | [t5-base-36L-dutch-english-cased](https://huggingface.co/yhavinga/t5-base-36L-dutch-english-cased) | [t5-eff-large-8l-dutch-english-cased](https://huggingface.co/yhavinga/t5-eff-large-8l-dutch-english-cased) | mt5-base |
|:-------------------------------|----------------:|-----------------------------:|---------------------------:|----------------------------:|-----------------------------------:|----------------------------------------:|-----------------------------:|-------------------------------:|----------------------------------:|--------------------------------------:|-----------:|
| *precision_ng1* | 74.17 | 78.09 | 77.08 | 72.12 | 77.19 | 78.76 | 78.59 | 77.3 | **79.75** | 78.88 | 73.47 |
| *precision_ng2* | 52.42 | 57.52 | 55.31 | 48.7 | 55.39 | 58.01 | 57.83 | 55.27 | **59.89** | 58.27 | 50.12 |
| *precision_ng3* | 39.55 | 45.2 | 42.54 | 35.54 | 42.25 | 45.13 | 45.02 | 42.06 | **47.4** | 45.95 | 36.59 |
| *precision_ng4* | 30.23 | 36.04 | 33.26 | 26.27 | 32.74 | 35.72 | 35.41 | 32.61 | **38.1** | 36.91 | 27.26 |
| *bp* | 0.99 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 |
| *score* | 45.88 | 51.21 | 48.31 | 41.59 | 48.17 | 51.31 | 50.82 | 47.83 | **53** | 51.79 | 42.74 |
| *samples_per_second* | **45.19** | 45.05 | 38.67 | 10.12 | 42.19 | 42.61 | 12.85 | 33.74 | 9.07 | 37.86 | 9.03 |
## Translation models
The models `t5-small-24L-dutch-english` and `t5-base-36L-dutch-english` have been fine-tuned for both language
directions on the first 25M samples from CCMatrix, giving a total of 50M training samples.
Evaluation is performed on out-of-sample CCMatrix and also on Tatoeba and Opus Books.
The `_bp` columns list the *brevity penalty*. The `avg_bleu` score is the bleu score
averaged over all three evaluation datasets. The best scores displayed in bold for both translation directions.
| | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) | [t5-small-24L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-small-24L-ccmatrix-multi) |
|:-----------------------|:-----------------------------|:-----------------------------|:------------------------------|:------------------------------|
| *source_lang* | en | nl | en | nl |
| *target_lang* | nl | en | nl | en |
| *source_prefix* | translate English to Dutch: | translate Dutch to English: | translate English to Dutch: | translate Dutch to English: |
| *ccmatrix_bleu* | **56.8** | 62.8 | 57.4 | **63.1** |
| *tatoeba_bleu* | **46.6** | **52.8** | 46.4 | 51.7 |
| *opus_books_bleu* | **13.5** | **24.9** | 12.9 | 23.4 |
| *ccmatrix_bp* | 0.95 | 0.96 | 0.95 | 0.96 |
| *tatoeba_bp* | 0.97 | 0.94 | 0.98 | 0.94 |
| *opus_books_bp* | 0.8 | 0.94 | 0.77 | 0.89 |
| *avg_bleu* | **38.96** | **46.86** | 38.92 | 46.06 |
| *max_source_length* | 128 | 128 | 128 | 128 |
| *max_target_length* | 128 | 128 | 128 | 128 |
| *adam_beta1* | 0.9 | 0.9 | 0.9 | 0.9 |
| *adam_beta2* | 0.997 | 0.997 | 0.997 | 0.997 |
| *weight_decay* | 0.05 | 0.05 | 0.002 | 0.002 |
| *lr* | 5e-05 | 5e-05 | 0.0005 | 0.0005 |
| *label_smoothing_factor* | 0.15 | 0.15 | 0.1 | 0.1 |
| *train_batch_size* | 128 | 128 | 128 | 128 |
| *warmup_steps* | 2000 | 2000 | 2000 | 2000 |
| *total steps* | 390625 | 390625 | 390625 | 390625 |
| *duration* | 4d 5h | 4d 5h | 3d 2h | 3d 2h |
| *num parameters* | 729M | 729M | 250M | 250M |
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/). The HuggingFace 🤗 ecosystem was instrumental in all parts
of the training. Weights & Biases made it possible to keep track of many training sessions
and orchestrate hyper-parameter sweeps with insightful visualizations.
The following repositories where helpful in setting up the TPU-VM,
and getting an idea what sensible hyper-parameters are for training gpt2 from scratch:
* [Gsarti's Pretrain and Fine-tune a T5 model with Flax on GCP](https://github.com/gsarti/t5-flax-gcp)
* [Flax/Jax Community week t5-base-dutch](https://huggingface.co/flax-community/t5-base-dutch)
Created by [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/)
|
2495140a2a1a0e73850d980e0cb8fcc5
|
Jadiker/distilbert-base-uncased-finetuned-imdb
|
Jadiker
|
distilbert
| 8 | 2 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,555 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Jadiker/distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8518
- Validation Loss: 2.6184
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.8518 | 2.6184 | 0 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
c7e160a1d5327e5f8db8a2ca013a552e
|
theojolliffe/bart-paraphrase-v4-e1-feedback
|
theojolliffe
|
bart
| 20 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,265 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase-v4-e1-feedback
This model is a fine-tuned version of [theojolliffe/bart-paraphrase-v4-e1](https://huggingface.co/theojolliffe/bart-paraphrase-v4-e1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 27 | 3.9313 | 67.6687 | 57.1881 | 66.7507 | 66.2643 | 20.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0
- Datasets 1.18.0
- Tokenizers 0.10.3
|
376539cbfe0fd1cc0bfa516e4b898dbb
|
anilbs/pipeline
|
anilbs
| null | 17 | 24 |
pyannote-audio
| 2 |
automatic-speech-recognition
| false | false | false |
mit
| null |
['ami', 'dihard', 'voxconverse', 'aishell', 'repere', 'voxceleb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pyannote', 'pyannote-audio', 'pyannote-audio-pipeline', 'audio', 'voice', 'speech', 'speaker', 'speaker-diarization', 'speaker-change-detection', 'voice-activity-detection', 'overlapped-speech-detection', 'automatic-speech-recognition']
| false | true | true | 8,592 | false |
# 🎹 Speaker diarization
Relies on pyannote.audio 2.0.1: see [installation instructions](https://github.com/pyannote/pyannote-audio#installation).
## TL;DR
```python
# load the pipeline from Hugginface Hub
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("anilbs/pipeline")
# apply the pipeline to an audio file
diarization = pipeline("audio.wav")
# dump the diarization output to disk using RTTM format
with open("audio.rttm", "w") as rttm:
diarization.write_rttm(rttm)
```
## Advanced usage
In case the number of speakers is known in advance, one can use the `num_speakers` option:
```python
diarization = pipeline("audio.wav", num_speakers=2)
```
One can also provide lower and/or upper bounds on the number of speakers using `min_speakers` and `max_speakers` options:
```python
diarization = pipeline("audio.wav", min_speakers=2, max_speakers=5)
```
If you feel adventurous, you can try and play with the various pipeline hyper-parameters.
For instance, one can use a more aggressive voice activity detection by increasing the value of `segmentation_onset` threshold:
```python
hparams = pipeline.parameters(instantiated=True)
hparams["segmentation_onset"] += 0.1
pipeline.instantiate(hparams)
```
## Benchmark
### Real-time factor
Real-time factor is around 5% using one Nvidia Tesla V100 SXM2 GPU (for the neural inference part) and one Intel Cascade Lake 6248 CPU (for the clustering part).
In other words, it takes approximately 3 minutes to process a one hour conversation.
### Accuracy
This pipeline is benchmarked on a growing collection of datasets.
Processing is fully automatic:
* no manual voice activity detection (as is sometimes the case in the literature)
* no manual number of speakers (though it is possible to provide it to the pipeline)
* no fine-tuning of the internal models nor tuning of the pipeline hyper-parameters to each dataset
... with the least forgiving diarization error rate (DER) setup (named *"Full"* in [this paper](https://doi.org/10.1016/j.csl.2021.101254)):
* no forgiveness collar
* evaluation of overlapped speech
| Benchmark (2.0.1) | [DER%](. "Diarization error rate") | [FA%](. "False alarm rate") | [Miss%](. "Missed detection rate") | [Conf%](. "Speaker confusion rate") | Expected output | File-level evaluation |
| ---------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------- | --------------------------- | ---------------------------------- | ----------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [AISHELL-4](http://www.openslr.org/111/) | 14.61 | 3.31 | 4.35 | 6.95 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AISHELL.SpeakerDiarization.Full.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AISHELL.SpeakerDiarization.Full.test.eval) |
| [AMI *Mix-Headset*](https://groups.inf.ed.ac.uk/ami/corpus/) [*only_words*](https://github.com/BUTSpeechFIT/AMI-diarization-setup) | 18.21 | 3.28 | 11.07 | 3.87 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AMI.SpeakerDiarization.only_words.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AMI.SpeakerDiarization.only_words.test.eval) |
| [AMI *Array1-01*](https://groups.inf.ed.ac.uk/ami/corpus/) [*only_words*](https://github.com/BUTSpeechFIT/AMI-diarization-setup) | 29.00 | 2.71 | 21.61 | 4.68 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AMI-SDM.SpeakerDiarization.only_words.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/AMI-SDM.SpeakerDiarization.only_words.test.eval) |
| [CALLHOME](https://catalog.ldc.upenn.edu/LDC2001S97) [*Part2*](https://github.com/BUTSpeechFIT/CALLHOME_sublists/issues/1) | 30.24 | 3.71 | 16.86 | 9.66 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/CALLHOME.SpeakerDiarization.CALLHOME.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/CALLHOME.SpeakerDiarization.CALLHOME.test.eval) |
| [DIHARD 3 *Full*](https://arxiv.org/abs/2012.01477) | 20.99 | 4.25 | 10.74 | 6.00 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/DIHARD.SpeakerDiarization.Full.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/DIHARD.SpeakerDiarization.Full.test.eval) |
| [REPERE *Phase 2*](https://islrn.org/resources/360-758-359-485-0/) | 12.62 | 1.55 | 3.30 | 7.76 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/REPERE.SpeakerDiarization.Full.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/2022.07/reproducible_research/2022.07/REPERE.SpeakerDiarization.Full.test.eval) |
| [VoxConverse *v0.3*](https://github.com/joonson/voxconverse) | 12.61 | 3.45 | 3.85 | 5.31 | [RTTM](https://huggingface.co/pyannote/speaker-diarization/blob/main/reproducible_research/2022.07/VoxConverse.SpeakerDiarization.VoxConverse.test.rttm) | [eval](https://huggingface.co/pyannote/speaker-diarization/blob/main/reproducible_research/2022.07/VoxConverse.SpeakerDiarization.VoxConverse.test.eval) |
## Support
For commercial enquiries and scientific consulting, please contact [me](mailto:herve@niderb.fr).
For [technical questions](https://github.com/pyannote/pyannote-audio/discussions) and [bug reports](https://github.com/pyannote/pyannote-audio/issues), please check [pyannote.audio](https://github.com/pyannote/pyannote-audio) Github repository.
## Citations
```bibtex
@inproceedings{Bredin2021,
Title = {{End-to-end speaker segmentation for overlap-aware resegmentation}},
Author = {{Bredin}, Herv{\'e} and {Laurent}, Antoine},
Booktitle = {Proc. Interspeech 2021},
Address = {Brno, Czech Republic},
Month = {August},
Year = {2021},
}
```
```bibtex
@inproceedings{Bredin2020,
Title = {{pyannote.audio: neural building blocks for speaker diarization}},
Author = {{Bredin}, Herv{\'e} and {Yin}, Ruiqing and {Coria}, Juan Manuel and {Gelly}, Gregory and {Korshunov}, Pavel and {Lavechin}, Marvin and {Fustes}, Diego and {Titeux}, Hadrien and {Bouaziz}, Wassim and {Gill}, Marie-Philippe},
Booktitle = {ICASSP 2020, IEEE International Conference on Acoustics, Speech, and Signal Processing},
Address = {Barcelona, Spain},
Month = {May},
Year = {2020},
}
```
|
61d9caf7e29f382a9a78db857a91c269
|
yip-i/wav2vec2_large_copy
|
yip-i
|
wav2vec2
| 9 | 0 |
transformers
| 0 | null | true | false | true |
apache-2.0
|
['en']
|
['librispeech_asr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech']
| false | true | true | 2,113 | false |
# Wav2Vec2-Large-LV60
Parameter changed:
"mask_time_prob": 0.05 changed to "mask_time_prob": 0.5.
Based on this link:https://github.com/huggingface/transformers/issues/16962 to make pre-training this model work.
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
d9008c7cd51bf927b1a88f55b90c8962
|
gokuls/distilbert_sa_GLUE_Experiment_logit_kd_pretrain_wnli
|
gokuls
|
distilbert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,794 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_sa_GLUE_Experiment_logit_kd_pretrain_wnli
This model is a fine-tuned version of [gokuls/distilbert_sa_pre-training-complete](https://huggingface.co/gokuls/distilbert_sa_pre-training-complete) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3499
- Accuracy: 0.5493
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3552 | 1.0 | 3 | 0.3512 | 0.4085 |
| 0.3495 | 2.0 | 6 | 0.3540 | 0.2817 |
| 0.3471 | 3.0 | 9 | 0.3499 | 0.5493 |
| 0.3473 | 4.0 | 12 | 0.3514 | 0.5634 |
| 0.3476 | 5.0 | 15 | 0.3536 | 0.5070 |
| 0.3465 | 6.0 | 18 | 0.3576 | 0.1831 |
| 0.3463 | 7.0 | 21 | 0.3589 | 0.2113 |
| 0.3449 | 8.0 | 24 | 0.3598 | 0.2958 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
eebe920d68c4cd450a5e3141dc263c90
|
shed-e/scipaper-summary
|
shed-e
|
t5
| 32 | 4 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['scitldr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,981 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# paper-summary
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the scitldr dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8631
- Rouge1: 0.3484
- Rouge2: 0.1596
- Rougel: 0.2971
- Rougelsum: 0.3047
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 3.0545 | 1.0 | 63 | 2.9939 | 0.3387 | 0.1538 | 0.2887 | 0.2957 |
| 2.7871 | 2.0 | 126 | 2.9360 | 0.3448 | 0.1577 | 0.2947 | 0.3019 |
| 2.7188 | 3.0 | 189 | 2.8977 | 0.3477 | 0.1585 | 0.2967 | 0.3035 |
| 2.6493 | 4.0 | 252 | 2.8837 | 0.3488 | 0.1597 | 0.2973 | 0.3046 |
| 2.6207 | 5.0 | 315 | 2.8690 | 0.3472 | 0.1566 | 0.2958 | 0.3033 |
| 2.5893 | 6.0 | 378 | 2.8668 | 0.3493 | 0.1592 | 0.2972 | 0.305 |
| 2.5494 | 7.0 | 441 | 2.8657 | 0.3486 | 0.1595 | 0.2976 | 0.3053 |
| 2.5554 | 8.0 | 504 | 2.8631 | 0.3484 | 0.1596 | 0.2971 | 0.3047 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
b32a318d77ef18175d9020408241fca1
|
Helsinki-NLP/opus-mt-ar-pl
|
Helsinki-NLP
|
marian
| 11 | 13 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['ar', 'pl']
| null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,037 | false |
### ara-pol
* source group: Arabic
* target group: Polish
* OPUS readme: [ara-pol](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ara-pol/README.md)
* model: transformer
* source language(s): ara arz
* target language(s): pol
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-pol/opus-2020-07-03.zip)
* test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-pol/opus-2020-07-03.test.txt)
* test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-pol/opus-2020-07-03.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ara.pol | 38.0 | 0.623 |
### System Info:
- hf_name: ara-pol
- source_languages: ara
- target_languages: pol
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ara-pol/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ar', 'pl']
- src_constituents: {'apc', 'ara', 'arq_Latn', 'arq', 'afb', 'ara_Latn', 'apc_Latn', 'arz'}
- tgt_constituents: {'pol'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ara-pol/opus-2020-07-03.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ara-pol/opus-2020-07-03.test.txt
- src_alpha3: ara
- tgt_alpha3: pol
- short_pair: ar-pl
- chrF2_score: 0.623
- bleu: 38.0
- brevity_penalty: 0.948
- ref_len: 1171.0
- src_name: Arabic
- tgt_name: Polish
- train_date: 2020-07-03
- src_alpha2: ar
- tgt_alpha2: pl
- prefer_old: False
- long_pair: ara-pol
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
138ebf1b52c3f779ea5f6c033daca499
|
renatanerenata/bart-paraphrase1-finetuned-in-to-fo
|
renatanerenata
|
bart
| 21 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 968 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase1-finetuned-in-to-fo
This model is a fine-tuned version of [eugenesiow/bart-paraphrase](https://huggingface.co/eugenesiow/bart-paraphrase) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
c8f0252e134d2c3801c2646b5cc46054
|
Siddu0406/article-generator
|
Siddu0406
|
gpt2
| 13 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 924 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# article-generator
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
d45b4ac823a92546128cc85205ec1d37
|
gokuls/distilbert_add_GLUE_Experiment_logit_kd_qqp_256
|
gokuls
|
distilbert
| 17 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,304 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_add_GLUE_Experiment_logit_kd_qqp_256
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6586
- Accuracy: 0.6554
- F1: 0.1310
- Combined Score: 0.3932
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.8355 | 1.0 | 1422 | 0.8004 | 0.6318 | 0.0 | 0.3159 |
| 0.7677 | 2.0 | 2844 | 0.7488 | 0.6318 | 0.0 | 0.3159 |
| 0.7048 | 3.0 | 4266 | 0.6935 | 0.6318 | 0.0 | 0.3159 |
| 0.6449 | 4.0 | 5688 | 0.6875 | 0.6337 | 0.0106 | 0.3221 |
| 0.6082 | 5.0 | 7110 | 0.6688 | 0.6354 | 0.0205 | 0.3279 |
| 0.5829 | 6.0 | 8532 | 0.6854 | 0.6386 | 0.0393 | 0.3389 |
| 0.5637 | 7.0 | 9954 | 0.6707 | 0.6522 | 0.1155 | 0.3839 |
| 0.5502 | 8.0 | 11376 | 0.6752 | 0.6522 | 0.1145 | 0.3833 |
| 0.5389 | 9.0 | 12798 | 0.6677 | 0.6561 | 0.1348 | 0.3954 |
| 0.5304 | 10.0 | 14220 | 0.6693 | 0.6622 | 0.1659 | 0.4140 |
| 0.5234 | 11.0 | 15642 | 0.6728 | 0.6511 | 0.1082 | 0.3797 |
| 0.5175 | 12.0 | 17064 | 0.6812 | 0.6554 | 0.1303 | 0.3928 |
| 0.5127 | 13.0 | 18486 | 0.6644 | 0.6540 | 0.1235 | 0.3888 |
| 0.5085 | 14.0 | 19908 | 0.6605 | 0.6622 | 0.1677 | 0.4149 |
| 0.505 | 15.0 | 21330 | 0.6647 | 0.6570 | 0.1391 | 0.3980 |
| 0.502 | 16.0 | 22752 | 0.6667 | 0.6528 | 0.1170 | 0.3849 |
| 0.499 | 17.0 | 24174 | 0.6586 | 0.6554 | 0.1310 | 0.3932 |
| 0.497 | 18.0 | 25596 | 0.6589 | 0.6597 | 0.1535 | 0.4066 |
| 0.4947 | 19.0 | 27018 | 0.6715 | 0.6599 | 0.1535 | 0.4067 |
| 0.4928 | 20.0 | 28440 | 0.6631 | 0.6535 | 0.1202 | 0.3868 |
| 0.4907 | 21.0 | 29862 | 0.6690 | 0.6651 | 0.1796 | 0.4224 |
| 0.4891 | 22.0 | 31284 | 0.6603 | 0.6652 | 0.1830 | 0.4241 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
102aa6c8a09c759e2215d4516ad7294f
|
HusseinHE/zsks
|
HusseinHE
| null | 34 | 45 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 501 | false |
### Zsks Dreambooth model trained by HusseinHE with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
Zsks (use that on your prompt)
|
f1ae474b42d9854133c15e1dda48270b
|
ViktorDo/DistilBERT-WIKI_Epiphyte_Finetuned
|
ViktorDo
|
distilbert
| 14 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,312 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERT-WIKI_Epiphyte_Finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0506
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0711 | 1.0 | 2094 | 0.0543 |
| 0.0512 | 2.0 | 4188 | 0.0474 |
| 0.027 | 3.0 | 6282 | 0.0506 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
d05cded1d6f544a4dceeb8fb70d9a5f5
|
jonatasgrosman/exp_w2v2t_et_vp-100k_s103
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['et']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'et']
| false | true | true | 475 | false |
# exp_w2v2t_et_vp-100k_s103
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (et)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
201d0404a49c3475c247d06c7302bf6f
|
HideOnBush/BERTModified-finetuned-wikitext-test
|
HideOnBush
| null | 5 | 0 | null | 0 | null | true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 5,913 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERTModified-finetuned-wikitext-test
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 18.8994
- Precision: 0.25
- Recall: 0.25
- F1: 0.25
- Accuracy: 0.25
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 19.9877 | 1.0 | 250 | 19.8070 | 0.0385 | 0.0385 | 0.0385 | 0.0385 |
| 15.4776 | 2.0 | 500 | 20.2930 | 0.0577 | 0.0577 | 0.0577 | 0.0577 |
| 13.1238 | 3.0 | 750 | 20.1112 | 0.0769 | 0.0769 | 0.0769 | 0.0769 |
| 11.1387 | 4.0 | 1000 | 19.9105 | 0.0897 | 0.0897 | 0.0897 | 0.0897 |
| 9.5317 | 5.0 | 1250 | 19.9108 | 0.1282 | 0.1282 | 0.1282 | 0.1282 |
| 8.037 | 6.0 | 1500 | 19.6093 | 0.1410 | 0.1410 | 0.1410 | 0.1410 |
| 6.7498 | 7.0 | 1750 | 19.1636 | 0.1474 | 0.1474 | 0.1474 | 0.1474 |
| 5.6472 | 8.0 | 2000 | 19.6709 | 0.1538 | 0.1538 | 0.1538 | 0.1538 |
| 4.6665 | 9.0 | 2250 | 19.2537 | 0.1667 | 0.1667 | 0.1667 | 0.1667 |
| 3.9107 | 10.0 | 2500 | 19.1982 | 0.1474 | 0.1474 | 0.1474 | 0.1474 |
| 3.1874 | 11.0 | 2750 | 18.9938 | 0.1731 | 0.1731 | 0.1731 | 0.1731 |
| 2.5846 | 12.0 | 3000 | 18.7462 | 0.2115 | 0.2115 | 0.2115 | 0.2115 |
| 2.1464 | 13.0 | 3250 | 19.0017 | 0.1667 | 0.1667 | 0.1667 | 0.1667 |
| 1.7521 | 14.0 | 3500 | 18.4513 | 0.1859 | 0.1859 | 0.1859 | 0.1859 |
| 1.4561 | 15.0 | 3750 | 18.7532 | 0.2051 | 0.2051 | 0.2051 | 0.2051 |
| 1.2254 | 16.0 | 4000 | 18.3970 | 0.2179 | 0.2179 | 0.2179 | 0.2179 |
| 1.0416 | 17.0 | 4250 | 18.9764 | 0.1859 | 0.1859 | 0.1859 | 0.1859 |
| 0.8923 | 18.0 | 4500 | 18.3271 | 0.2244 | 0.2244 | 0.2244 | 0.2244 |
| 0.7803 | 19.0 | 4750 | 18.5893 | 0.2436 | 0.2436 | 0.2436 | 0.2436 |
| 0.6839 | 20.0 | 5000 | 18.3505 | 0.2051 | 0.2051 | 0.2051 | 0.2051 |
| 0.6175 | 21.0 | 5250 | 18.6798 | 0.2051 | 0.2051 | 0.2051 | 0.2051 |
| 0.5491 | 22.0 | 5500 | 18.7426 | 0.2115 | 0.2115 | 0.2115 | 0.2115 |
| 0.4952 | 23.0 | 5750 | 18.3955 | 0.2179 | 0.2179 | 0.2179 | 0.2179 |
| 0.4441 | 24.0 | 6000 | 18.5502 | 0.2564 | 0.2564 | 0.2564 | 0.2564 |
| 0.4047 | 25.0 | 6250 | 18.9599 | 0.2244 | 0.2244 | 0.2244 | 0.2244 |
| 0.3768 | 26.0 | 6500 | 18.8141 | 0.2308 | 0.2308 | 0.2308 | 0.2308 |
| 0.3435 | 27.0 | 6750 | 18.9732 | 0.2436 | 0.2436 | 0.2436 | 0.2436 |
| 0.3164 | 28.0 | 7000 | 18.9216 | 0.2372 | 0.2372 | 0.2372 | 0.2372 |
| 0.2954 | 29.0 | 7250 | 18.6152 | 0.1987 | 0.1987 | 0.1987 | 0.1987 |
| 0.2736 | 30.0 | 7500 | 18.6001 | 0.25 | 0.25 | 0.25 | 0.25 |
| 0.2491 | 31.0 | 7750 | 19.1374 | 0.2436 | 0.2436 | 0.2436 | 0.2436 |
| 0.2359 | 32.0 | 8000 | 18.8624 | 0.25 | 0.25 | 0.25 | 0.25 |
| 0.2222 | 33.0 | 8250 | 18.3201 | 0.2308 | 0.2308 | 0.2308 | 0.2308 |
| 0.212 | 34.0 | 8500 | 18.7708 | 0.2179 | 0.2179 | 0.2179 | 0.2179 |
| 0.1864 | 35.0 | 8750 | 18.8994 | 0.2372 | 0.2372 | 0.2372 | 0.2372 |
| 0.1771 | 36.0 | 9000 | 18.3130 | 0.2308 | 0.2308 | 0.2308 | 0.2308 |
| 0.1703 | 37.0 | 9250 | 18.6183 | 0.2436 | 0.2436 | 0.2436 | 0.2436 |
| 0.1554 | 38.0 | 9500 | 18.8593 | 0.2372 | 0.2372 | 0.2372 | 0.2372 |
| 0.1469 | 39.0 | 9750 | 18.8936 | 0.2628 | 0.2628 | 0.2628 | 0.2628 |
| 0.1407 | 40.0 | 10000 | 18.9002 | 0.2372 | 0.2372 | 0.2372 | 0.2372 |
| 0.1328 | 41.0 | 10250 | 19.1827 | 0.2564 | 0.2564 | 0.2564 | 0.2564 |
| 0.1297 | 42.0 | 10500 | 18.5465 | 0.25 | 0.25 | 0.25 | 0.25 |
| 0.1226 | 43.0 | 10750 | 18.9125 | 0.2308 | 0.2308 | 0.2308 | 0.2308 |
| 0.1218 | 44.0 | 11000 | 19.0831 | 0.2308 | 0.2308 | 0.2308 | 0.2308 |
| 0.1136 | 45.0 | 11250 | 18.7969 | 0.2372 | 0.2372 | 0.2372 | 0.2372 |
| 0.1075 | 46.0 | 11500 | 18.7629 | 0.25 | 0.25 | 0.25 | 0.25 |
| 0.1044 | 47.0 | 11750 | 18.9700 | 0.2115 | 0.2115 | 0.2115 | 0.2115 |
| 0.1042 | 48.0 | 12000 | 18.7211 | 0.2628 | 0.2628 | 0.2628 | 0.2628 |
| 0.1008 | 49.0 | 12250 | 18.9104 | 0.2244 | 0.2244 | 0.2244 | 0.2244 |
| 0.1014 | 50.0 | 12500 | 18.7892 | 0.25 | 0.25 | 0.25 | 0.25 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
5d79c2e56b877f33ad2c8ba7efc054b7
|
johngiorgi/declutr-sci-base
|
johngiorgi
|
bert
| 8 | 1,422 |
sentence-transformers
| 5 |
sentence-similarity
| true | false | true |
apache-2.0
|
['en']
|
['s2orc']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sentence-transformers', 'feature-extraction', 'sentence-similarity']
| false | true | true | 3,277 | false |
# DeCLUTR-sci-base
## Model description
This is the [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) model, with extended pretraining on over 2 million scientific papers from [S2ORC](https://github.com/allenai/s2orc/) using the self-supervised training strategy presented in [DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations](https://arxiv.org/abs/2006.03659).
## Intended uses & limitations
The model is intended to be used as a sentence encoder, similar to [Google's Universal Sentence Encoder](https://tfhub.dev/google/universal-sentence-encoder/4) or [Sentence Transformers](https://github.com/UKPLab/sentence-transformers). It is particularly suitable for scientific text.
#### How to use
Please see [our repo](https://github.com/JohnGiorgi/DeCLUTR) for full details. A simple example is shown below.
##### With [SentenceTransformers](https://www.sbert.net/)
```python
from scipy.spatial.distance import cosine
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("johngiorgi/declutr-sci-base")
# Prepare some text to embed
text = [
"Oncogenic KRAS mutations are common in cancer.",
"Notably, c-Raf has recently been found essential for development of K-Ras-driven NSCLCs.",
]
# Embed the text
embeddings = model.encode(texts)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
##### With 🤗 Transformers
```python
import torch
from scipy.spatial.distance import cosine
from transformers import AutoModel, AutoTokenizer
# Load the model
tokenizer = AutoTokenizer.from_pretrained("johngiorgi/declutr-sci-base")
model = AutoModel.from_pretrained("johngiorgi/declutr-sci-base")
# Prepare some text to embed
text = [
"Oncogenic KRAS mutations are common in cancer.",
"Notably, c-Raf has recently been found essential for development of K-Ras-driven NSCLCs.",
]
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Embed the text
with torch.no_grad():
sequence_output = model(**inputs)[0]
# Mean pool the token-level embeddings to get sentence-level embeddings
embeddings = torch.sum(
sequence_output * inputs["attention_mask"].unsqueeze(-1), dim=1
) / torch.clamp(torch.sum(inputs["attention_mask"], dim=1, keepdims=True), min=1e-9)
# Compute a semantic similarity via the cosine distance
semantic_sim = 1 - cosine(embeddings[0], embeddings[1])
```
### BibTeX entry and citation info
```bibtex
@inproceedings{giorgi-etal-2021-declutr,
title = {{D}e{CLUTR}: Deep Contrastive Learning for Unsupervised Textual Representations},
author = {Giorgi, John and Nitski, Osvald and Wang, Bo and Bader, Gary},
year = 2021,
month = aug,
booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Online},
pages = {879--895},
doi = {10.18653/v1/2021.acl-long.72},
url = {https://aclanthology.org/2021.acl-long.72}
}
```
|
4ec3350cb86d61e8186809f16d6e7310
|
Ashish08/vada-sambhar-south-indian-dish
|
Ashish08
| null | 17 | 11 |
diffusers
| 0 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'food']
| false | true | true | 784 | false |
# DreamBooth model for the vada-sambhar concept trained by Ashish08 on the Ashish08/vada-sambhar dataset.
This is a Stable Diffusion model fine-tuned on the vada-sambhar concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of vada-sambhar south-indian-dish**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `south-indian-dish` images for the food theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('Ashish08/vada-sambhar-south-indian-dish')
image = pipeline().images[0]
image
```
|
7a184b3ec2fd0a4dbce4df13bc4fbf39
|
timm/maxvit_base_tf_224.in1k
|
timm
| null | 4 | 170 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 22,012 | false |
# Model card for maxvit_base_tf_224.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 119.5
- GMACs: 24.0
- Activations (M): 95.0
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('maxvit_base_tf_224.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_base_tf_224.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxvit_base_tf_224.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
2c94a8935ab2dad1aca8c65bce391fc5
|
troesy/gpt2_tryout
|
troesy
|
gpt2
| 14 | 4 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,461 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2_tryout
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2275
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.9182
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 174 | 0.2725 | 0.0 | 0.0 | 0.0 | 0.9019 |
| No log | 2.0 | 348 | 0.2395 | 0.0 | 0.0 | 0.0 | 0.9141 |
| 0.3173 | 3.0 | 522 | 0.2275 | 0.0 | 0.0 | 0.0 | 0.9182 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
7442cd5f0ca242a6d2aa8244b866b4c2
|
cj-mills/distilbert-base-uncased-finetuned-emotion
|
cj-mills
|
distilbert
| 20 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,338 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2205
- Accuracy: 0.936
- F1: 0.9361
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0442 | 1.0 | 250 | 0.2392 | 0.926 | 0.9265 |
| 0.0463 | 2.0 | 500 | 0.2205 | 0.936 | 0.9361 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
cee7811ace262c8c39c170a7a6a9f14d
|
rahuldave/bert-base-uncased-rahuldave-issues-128
|
rahuldave
|
bert
| 10 | 5 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,928 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-rahuldave-issues-128
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1019 | 1.0 | 291 | 1.6982 |
| 1.6376 | 2.0 | 582 | 1.4442 |
| 1.4815 | 3.0 | 873 | 1.3822 |
| 1.3996 | 4.0 | 1164 | 1.3695 |
| 1.3416 | 5.0 | 1455 | 1.1960 |
| 1.2824 | 6.0 | 1746 | 1.2835 |
| 1.2404 | 7.0 | 2037 | 1.2664 |
| 1.2022 | 8.0 | 2328 | 1.2082 |
| 1.1669 | 9.0 | 2619 | 1.1798 |
| 1.1424 | 10.0 | 2910 | 1.2211 |
| 1.1269 | 11.0 | 3201 | 1.2019 |
| 1.1036 | 12.0 | 3492 | 1.1649 |
| 1.0802 | 13.0 | 3783 | 1.2438 |
| 1.0759 | 14.0 | 4074 | 1.1716 |
| 1.0629 | 15.0 | 4365 | 1.1270 |
| 1.0639 | 16.0 | 4656 | 1.2505 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
c8e9b700eac17237b16d2be9a42e3dbb
|
theojolliffe/t5-model1-feedback
|
theojolliffe
|
t5
| 11 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,300 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-model1-feedback
This model is a fine-tuned version of [theojolliffe/T5-model-1-feedback-e1](https://huggingface.co/theojolliffe/T5-model-1-feedback-e1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 345 | 0.8173 | 52.0119 | 27.6158 | 44.7895 | 44.8584 | 16.5455 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ba7cfdbcf46eb30ef81fbc3c790c15e5
|
mwmathis/DeepLabCutModelZoo-SuperAnimal-TopViewMouse
|
mwmathis
| null | 3 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['computer_vision', 'pose_estimation']
| false | true | true | 449 | false |
Copyright 2021-2023 by Mackenzie Mathis, Alexander Mathis, Shaokai Ye and contributors. All rights reserved.
- Non-commercial use only is permitted
- please cite Ye et al if you use this model in your work https://arxiv.org/abs/2203.07436v1
- If this license is not suitable for your business or project
please contact EPFL-TTO (https://tto.epfl.ch/) for a full commercial license.
This software may not be used to harm any animal deliberately.
|
5aaa6a262f4ade523caf69acba6b62fa
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm500_aug5
|
dminiotas05
|
distilbert
| 12 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,547 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm500_aug5
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8927
- Mse: 2.9755
- Mae: 1.0176
- R2: 0.4184
- Accuracy: 0.5003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.4176 | 1.0 | 3952 | 1.0499 | 3.4996 | 1.0853 | 0.3160 | 0.4593 |
| 0.3196 | 2.0 | 7904 | 0.8670 | 2.8901 | 1.0503 | 0.4351 | 0.4600 |
| 0.2084 | 3.0 | 11856 | 0.8927 | 2.9755 | 1.0176 | 0.4184 | 0.5003 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
1daee0fc8b649830f343b8abc2f25e77
|
muhtasham/tiny-mlm-glue-sst2-target-glue-qnli
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,806 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-sst2-target-glue-qnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-sst2](https://huggingface.co/muhtasham/tiny-mlm-glue-sst2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4704
- Accuracy: 0.7792
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6131 | 0.15 | 500 | 0.5383 | 0.7337 |
| 0.5434 | 0.31 | 1000 | 0.5325 | 0.7393 |
| 0.5218 | 0.46 | 1500 | 0.4985 | 0.7635 |
| 0.5155 | 0.61 | 2000 | 0.5256 | 0.7465 |
| 0.511 | 0.76 | 2500 | 0.4781 | 0.7759 |
| 0.5044 | 0.92 | 3000 | 0.4673 | 0.7824 |
| 0.4924 | 1.07 | 3500 | 0.4546 | 0.7904 |
| 0.4819 | 1.22 | 4000 | 0.4664 | 0.7836 |
| 0.4674 | 1.37 | 4500 | 0.4724 | 0.7789 |
| 0.4755 | 1.53 | 5000 | 0.4704 | 0.7792 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
0034a3877ea0c7a92731be1ced8953b2
|
it5/mt5-base-headline-generation
|
it5
|
mt5
| 11 | 3 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['it']
|
['gsarti/change_it']
|
{'emissions': '40g', 'source': 'Google Cloud Platform Carbon Footprint', 'training_type': 'fine-tuning', 'geographical_location': 'Eemshaven, Netherlands, Europe', 'hardware_used': '1 TPU v3-8 VM'}
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['italian', 'sequence-to-sequence', 'newspaper', 'ilgiornale', 'repubblica', 'headline-generation']
| true | true | true | 3,016 | false |
# mT5 Base for News Headline Generation 📣 🇮🇹
This repository contains the checkpoint for the [mT5 Base](https://huggingface.co/google/mt5-base) model fine-tuned on news headline generation on the Italian HeadGen-IT dataset as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
hg = pipeline("text2text-generation", model='it5/mt5-base-headline-generation')
hg("Arriva dal Partito nazionalista basco (Pnv) la conferma che i cinque deputati che siedono in parlamento voteranno la sfiducia al governo guidato da Mariano Rajoy. Pochi voti, ma significativi quelli della formazione politica di Aitor Esteban, che interverrà nel pomeriggio. Pur con dimensioni molto ridotte, il partito basco si è trovato a fare da ago della bilancia in aula. E il sostegno alla mozione presentata dai Socialisti potrebbe significare per il primo ministro non trovare quei 176 voti che gli servono per continuare a governare. \" Perché dovrei dimettermi io che per il momento ho la fiducia della Camera e quella che mi è stato data alle urne \", ha detto oggi Rajoy nel suo intervento in aula, mentre procedeva la discussione sulla mozione di sfiducia. Il voto dei baschi ora cambia le carte in tavola e fa crescere ulteriormente la pressione sul premier perché rassegni le sue dimissioni. La sfiducia al premier, o un'eventuale scelta di dimettersi, porterebbe alle estreme conseguenze lo scandalo per corruzione che ha investito il Partito popolare. Ma per ora sembra pensare a tutt'altro. \"Non ha intenzione di dimettersi - ha detto il segretario generale del Partito popolare , María Dolores de Cospedal - Non gioverebbe all'interesse generale o agli interessi del Pp\".")
>>> [{"generated_text": "il nazionalista rajoy: 'voteremo la sfiducia'"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/mt5-base-headline-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/mt5-base-headline-generation")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
```
|
deba9ab82a7780f5cb46ce68169587fd
|
StatsGary/audio-diffusion-hiphop-classical
|
StatsGary
| null | 7 | 0 |
diffusers
| 0 | null | true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'unconditional-audio-generation', 'diffusion-models-class']
| false | true | true | 509 | false |
# Model Card for Unit 4 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional audio generation of music in the genre Classical
## Usage
```python
from IPython.display import Audio
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("StatsGary/audio-diffusion-hiphop-classical")
output = pipe()
display(output.images[0])
display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
```
|
900a0992196d3dd4de30edee3d527711
|
muhtasham/small-vanilla-target-glue-qnli
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,816 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-vanilla-target-glue-qnli
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3458
- Accuracy: 0.8583
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.488 | 0.15 | 500 | 0.3901 | 0.8316 |
| 0.4449 | 0.31 | 1000 | 0.3826 | 0.8373 |
| 0.4243 | 0.46 | 1500 | 0.3596 | 0.8448 |
| 0.4133 | 0.61 | 2000 | 0.3663 | 0.8417 |
| 0.4102 | 0.76 | 2500 | 0.3459 | 0.8499 |
| 0.3924 | 0.92 | 3000 | 0.3286 | 0.8585 |
| 0.3539 | 1.07 | 3500 | 0.3467 | 0.8532 |
| 0.3202 | 1.22 | 4000 | 0.3478 | 0.8636 |
| 0.3183 | 1.37 | 4500 | 0.3574 | 0.8514 |
| 0.3215 | 1.53 | 5000 | 0.3458 | 0.8583 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
597f175e2dbe820b3dd7c8c71620af43
|
jhaochenz/finetuned_gpt2-medium_sst2_negation0.0001_pretrainedTrue_epochs3
|
jhaochenz
|
gpt2
| 14 | 0 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,270 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-medium_sst2_negation0.0001_pretrainedTrue_epochs3
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0503
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2809 | 1.0 | 1322 | 2.8898 |
| 1.9683 | 2.0 | 2644 | 2.9770 |
| 1.8548 | 3.0 | 3966 | 3.0503 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.7.0
- Datasets 2.8.0
- Tokenizers 0.13.2
|
f80e3d4a12bd9d48dcbc9bdd3ae01de6
|
Helsinki-NLP/opus-mt-fi-bem
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-fi-bem
* source languages: fi
* target languages: bem
* OPUS readme: [fi-bem](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-bem/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-bem/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-bem/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-bem/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fi.bem | 21.4 | 0.465 |
|
1e4ce3db4ec0a9b3d0e4e489c17c4410
|
jonatasgrosman/exp_w2v2t_ja_vp-fr_s458
|
jonatasgrosman
|
wav2vec2
| 10 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ja']
| false | true | true | 469 | false |
# exp_w2v2t_ja_vp-fr_s458
Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
9aae7bea3383650d3f4da04f6041e6ae
|
sd-concepts-library/garfield-pizza-plush-v2
|
sd-concepts-library
| null | 9 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,120 | false |
### Garfield-Pizza-Plush-v2 on Stable Diffusion
This is the `<garfield-plushy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
3c28f7de07bc027aebfb4cc86f5a70ac
|
mn367/mark-finetuned-imdb
|
mn367
|
distilbert
| 8 | 1 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,534 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mn367/mark-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.0868
- Validation Loss: 2.7662
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -523, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.0868 | 2.7662 | 0 |
### Framework versions
- Transformers 4.22.2
- TensorFlow 2.8.2
- Datasets 2.5.2
- Tokenizers 0.12.1
|
104b790827cdc5b92d7c4fedb20e6ce6
|
chandank/bart-base-finetuned-kaggglenews
|
chandank
|
bart
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,399 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned-kaggglenews
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6240
- Rouge1: 28.3618
- Rouge2: 15.9828
- Rougel: 24.078
- Rougelsum: 25.565
- Gen Len: 20.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|:---------:|:-------:|
| 1.9433 | 1.0 | 989 | 1.6240 | 28.3618 | 15.9828 | 24.078 | 25.565 | 20.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu102
- Datasets 1.14.0
- Tokenizers 0.10.3
|
4cf75819b3b888e43c6999e1226aa4a7
|
neongeckocom/stt_de_citrinet_512_gamma_0_25
|
neongeckocom
| null | 3 | 4 |
nemo
| 0 |
automatic-speech-recognition
| false | false | false |
bsd-3-clause
|
['de']
|
['mozilla-foundation/common_voice_12_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition']
| true | true | true | 687 | false |
# NVIDIA Streaming Citrinet 512 (de-DE)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets) |
## Attribution
As initial checkpoint used [stt_en_citrinet_512_gamma_0_25](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/stt_en_citrinet_512_gamma_0_25) by [NVIDIA](https://github.com/NVIDIA) licensed under [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/)
|
4ab5043831da70499e5fc20c53429f77
|
furyhawk/distilbert-base-uncased-finetuned-clinc
|
furyhawk
|
distilbert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,476 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7788
- Accuracy: 0.9155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2841 | 1.0 | 318 | 3.2794 | 0.7465 |
| 2.623 | 2.0 | 636 | 1.8719 | 0.8335 |
| 1.5474 | 3.0 | 954 | 1.1629 | 0.8929 |
| 1.014 | 4.0 | 1272 | 0.8621 | 0.9094 |
| 0.7987 | 5.0 | 1590 | 0.7788 | 0.9155 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
b06a2adca4b775abd66cb801b692c285
|
jonatasgrosman/exp_w2v2r_de_xls-r_gender_male-5_female-5_s336
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 476 | false |
# exp_w2v2r_de_xls-r_gender_male-5_female-5_s336
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
0d45db089aff986d68a0dcf6877e8372
|
philschmid/distilbert-neuron
|
philschmid
|
distilbert
| 8 | 5 |
transformers
| 0 |
question-answering
| false | false | false |
apache-2.0
|
['en']
|
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 485 | false |
# AWS Neuron Conversion of [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad)
# DistilBERT base cased distilled SQuAD
This model is a fine-tune checkpoint of [DistilBERT-base-cased](https://huggingface.co/distilbert-base-cased), fine-tuned using (a second step of) knowledge distillation on SQuAD v1.1.
This model reaches a F1 score of 87.1 on the dev set (for comparison, BERT bert-base-cased version reaches a F1 score of 88.7).
|
817ca4427083fd2412802581ff53412e
|
ejembere/opus-mt-en-ro-finetuned-en-to-ro
|
ejembere
|
marian
| 11 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['wmt16']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 966 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ro-finetuned-en-to-ro
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ro](https://huggingface.co/Helsinki-NLP/opus-mt-en-ro) on the wmt16 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
fd63b6aeed1406a52e07ef7d56ead06f
|
jonatasgrosman/exp_w2v2t_ru_unispeech_s42
|
jonatasgrosman
|
unispeech
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ru']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ru']
| false | true | true | 468 | false |
# exp_w2v2t_ru_unispeech_s42
Fine-tuned [microsoft/unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (ru)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
7521fa83dfefeffa4cb8a08fc387e625
|
hiroshi-matsuda-rit/ja_gsd_bert_wwm_unidic_lite
|
hiroshi-matsuda-rit
| null | 22 | 3 |
spacy
| 0 |
token-classification
| false | false | false |
CC-BY-SA-4.0
|
['ja']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| false | true | true | 1,889 | false |
Japanese transformer pipeline (bert-base). Components: transformer, parser, ner.
| Feature | Description |
| --- | --- |
| **Name** | `ja_gsd_bert_wwm_unidic_lite` |
| **Version** | `3.1.1` |
| **spaCy** | `>=3.1.0,<3.2.0` |
| **Default Pipeline** | `transformer`, `parser`, `ner` |
| **Components** | `transformer`, `parser`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [UD_Japanese-GSD](https://github.com/UniversalDependencies/UD_Japanese-GSD)<br />[UD_Japanese-GSD r2.8+NE](https://github.com/megagonlabs/UD_Japanese-GSD/releases/tag/r2.8-NE)<br />[SudachiDict_core](https://github.com/WorksApplications/SudachiDict)<br />[cl-tohoku/bert-base-japanese-whole-word-masking](https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking)<br />[unidic_lite](https://github.com/polm/unidic-lite) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Megagon Labs Tokyo.](https://github.com/megagonlabs/UD_japanese_GSD) |
### Label Scheme
<details>
<summary>View label scheme (45 labels for 2 components)</summary>
| Component | Labels |
| --- | --- |
| **`parser`** | `ROOT`, `acl`, `advcl`, `advmod`, `amod`, `aux`, `case`, `cc`, `ccomp`, `compound`, `cop`, `csubj`, `dep`, `det`, `dislocated`, `fixed`, `mark`, `nmod`, `nsubj`, `nummod`, `obj`, `obl`, `punct` |
| **`ner`** | `CARDINAL`, `DATE`, `EVENT`, `FAC`, `GPE`, `LANGUAGE`, `LAW`, `LOC`, `MONEY`, `MOVEMENT`, `NORP`, `ORDINAL`, `ORG`, `PERCENT`, `PERSON`, `PET_NAME`, `PHONE`, `PRODUCT`, `QUANTITY`, `TIME`, `TITLE_AFFIX`, `WORK_OF_ART` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `DEP_UAS` | 93.68 |
| `DEP_LAS` | 92.61 |
| `SENTS_P` | 92.02 |
| `SENTS_R` | 95.46 |
| `SENTS_F` | 93.71 |
| `ENTS_F` | 84.04 |
| `ENTS_P` | 84.96 |
| `ENTS_R` | 83.14 |
| `TAG_ACC` | 0.00 |
| `TRANSFORMER_LOSS` | 28861.67 |
| `PARSER_LOSS` | 1306248.63 |
| `NER_LOSS` | 13993.36 |
|
201c112dec5ff37f82a0ecdd11d14e05
|
Nobody138/xlm-roberta-base-finetuned-panx-de-fr
|
Nobody138
|
xlm-roberta
| 10 | 7 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1608
- F1: 0.8593
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2888 | 1.0 | 715 | 0.1779 | 0.8233 |
| 0.1437 | 2.0 | 1430 | 0.1570 | 0.8497 |
| 0.0931 | 3.0 | 2145 | 0.1608 | 0.8593 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
3210a0cc8a6c597841e05ec29e842b8f
|
nlplab130/distilbert-base-uncased-finetuned-squad
|
nlplab130
|
distilbert
| 12 | 6 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,284 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1455
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2056 | 1.0 | 5533 | 1.1415 |
| 0.949 | 2.0 | 11066 | 1.1144 |
| 0.7471 | 3.0 | 16599 | 1.1455 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
f02109c8f303ea4f11849dfdeb642dfd
|
Bingbongbingbingbong/gatewatch
|
Bingbongbingbingbong
| null | 4 | 3 | null | 0 | null | false | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 862 | false |
StableDiffusion 1.5 finetuned with the Gatewatch members.
vectors trained:
- nissarevane

- chandranalaar

- lilianavess

- jacebeleren

- gideonjura

Supports combining tokens (nissarevane combined with lilianavess)

|
82aad0774ff020f060a05ab21f799886
|
PaddlePaddle/uie-base
|
PaddlePaddle
|
ernie
| 7 | 0 |
paddlenlp
| 0 | null | false | false | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
[]
| false | true | true | 4,351 | false |
[](https://github.com/PaddlePaddle/PaddleNLP)
# PaddlePaddle/uie-base
Information extraction suffers from its varying targets, heterogeneous structures, and demand-specific schemas. The unified text-to-structure generation framework, namely UIE, can universally model different IE tasks, adaptively generate targeted structures, and collaboratively learn general IE abilities from different knowledge sources. Specifically, UIE uniformly encodes different extraction structures via a structured extraction language, adaptively generates target extractions via a schema-based prompt mechanism - structural schema instructor, and captures the common IE abilities via a large-scale pre-trained text-to-structure model. Experiments show that UIE achieved the state-of-the-art performance on 4 IE tasks, 13 datasets, and on all supervised, low-resource, and few-shot settings for a wide range of entity, relation, event and sentiment extraction tasks and their unification. These results verified the effectiveness, universality, and transferability of UIE.
UIE Paper: https://arxiv.org/abs/2203.12277
PaddleNLP released UIE model series for Information Extraction of texts and multi-modal documents which use the ERNIE 3.0 models as the pre-trained language models and were finetuned on a large amount of information extraction data.

## Available Models
| Model Name | Usage Scenarios | Supporting Tasks |
| :----------------------------------------------------------: | :--------------------------------------------------------- | :--------------------------------------------------- |
| `uie-base`<br />`uie-medium`<br />`uie-mini`<br />`uie-micro`<br />`uie-nano` | For **plain text** The **extractive** model of the scene supports **Chinese** | Supports entity, relation, event, opinion extraction |
| `uie-base-en` | An **extractive** model for **plain text** scenarios, supports **English** | Supports entity, relation, event, opinion extraction |
| `uie-m-base`<br />`uie-m-large` | An **extractive** model for **plain text** scenarios, supporting **Chinese and English** | Supports entity, relation, event, opinion extraction |
| <b>`uie-x-base`</b> | An **extractive** model for **plain text** and **document** scenarios, supports **Chinese and English** | Supports entity, relation, event, opinion extraction on both plain text and documents/pictures/tables |
## Performance on Text Dataset
We conducted experiments on the in-house test sets of the three different domains of Internet, medical care, and finance:
<table>
<tr><th row_span='2'><th colspan='2'>finance<th colspan='2'>healthcare<th colspan='2'>internet
<tr><td><th>0-shot<th>5-shot<th>0-shot<th>5-shot<th>0-shot<th>5-shot
<tr><td>uie-base (12L768H)<td>46.43<td>70.92<td><b>71.83</b><td>85.72<td>78.33<td>81.86
<tr><td>uie-medium (6L768H)<td>41.11<td>64.53<td>65.40<td>75.72<td>78.32<td>79.68
<tr><td>uie-mini (6L384H)<td>37.04<td>64.65<td>60.50<td>78.36<td>72.09<td>76.38
<tr><td>uie-micro (4L384H)<td>37.53<td>62.11<td>57.04<td>75.92<td>66.00<td>70.22
<tr><td>uie-nano (4L312H)<td>38.94<td>66.83<td>48.29<td>76.74<td>62.86<td>72.35
<tr><td>uie-m-large (24L1024H)<td><b>49.35</b><td><b>74.55</b><td>70.50<td><b>92.66</b ><td>78.49<td><b>83.02</b>
<tr><td>uie-m-base (12L768H)<td>38.46<td>74.31<td>63.37<td>87.32<td>76.27<td>80.13
<tr><td>🧾🎓<b>uie-x-base (12L768H)</b><td>48.84<td>73.87<td>65.60<td>88.81<td><b>79.36</b> <td>81.65
</table>
0-shot means that no training data is directly used for prediction through paddlenlp.Taskflow, and 5-shot means that each category contains 5 pieces of labeled data for model fine-tuning. Experiments show that UIE can further improve the performance with a small amount of data (few-shot).
> Detailed Info: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/information_extraction/README_en.md
|
1b552375dbf6bc1208e4834e480bd282
|
arpanghoshal/EkmanClassifier
|
arpanghoshal
|
bert
| 7 | 207 |
transformers
| 2 |
text-classification
| true | false | false |
mit
|
['en']
|
['go_emotions']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-classification', 'pytorch', 'bert']
| false | true | true | 1,092 | false |
- [linkedin.com/in/arpanghoshal](https://www.linkedin.com/in/arpanghoshal)
## What is Ekman Emotions?
Ekman emotions refer to a specific set of six basic emotions that are thought to be universal across cultures. </br>
These emotions were identified by psychologist Paul Ekman, who conducted extensive research on facial expressions and emotional experience. </br>
The six Ekman emotions are:
- Happiness
- Sadness
- Anger
- Fear
- Disgust
- Surprise
Ekman's research found that these emotions are expressed through universal facial expressions, which are recognizable across cultures. </br>
According to Ekman, these emotions are biologically based and are fundamental to human social interaction. </br>
Ekman's work on basic emotions has had a significant impact on the field of psychology and has been widely influential in the study of emotional expression and experience.
## Usage
```python
from transformers import pipeline
ekman = pipeline('sentiment-analysis', model='arpanghoshal/EkmanClassifier')
ekman_labels = ekman("Thanks for using it.")
print(ekman_labels)
```
|
38e2d5f7ae1e7aa9f9da17d4cc261018
|
bochaowei/t5-small-finetuned-cnn-wei1
|
bochaowei
|
t5
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['cnn_dailymail']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,435 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-cnn-wei1
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6819
- Rouge1: 41.1796
- Rouge2: 18.9426
- Rougel: 29.2338
- Rougelsum: 38.4087
- Gen Len: 72.7607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.8582 | 1.0 | 23927 | 1.6819 | 41.1796 | 18.9426 | 29.2338 | 38.4087 | 72.7607 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
1a04a70eea8a80757a5676e7b6317fe3
|
Deep98/Paper-clustered
|
Deep98
|
distilbert
| 8 | 0 |
transformers
| 0 |
question-answering
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,851 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Deep98/Paper-clustered
This model is a fine-tuned version of [nandysoham16/16-clustered_aug](https://huggingface.co/nandysoham16/16-clustered_aug) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4183
- Train End Logits Accuracy: 0.8611
- Train Start Logits Accuracy: 0.8785
- Validation Loss: 0.2040
- Validation End Logits Accuracy: 1.0
- Validation Start Logits Accuracy: 1.0
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 0.4183 | 0.8611 | 0.8785 | 0.2040 | 1.0 | 1.0 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
|
660992c16e93347cca606ff2c2c049e0
|
gokuls/mobilebert_sa_GLUE_Experiment_data_aug_cola_128
|
gokuls
|
mobilebert
| 17 | 0 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,708 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_data_aug_cola_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6624
- Matthews Correlation: 0.0618
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:-----:|:---------------:|:--------------------:|
| 0.5456 | 1.0 | 1669 | 0.6624 | 0.0618 |
| 0.4572 | 2.0 | 3338 | 0.7774 | 0.0514 |
| 0.419 | 3.0 | 5007 | 0.8469 | 0.0931 |
| 0.3649 | 4.0 | 6676 | 0.8748 | 0.1011 |
| 0.3117 | 5.0 | 8345 | 1.0732 | 0.0824 |
| 0.2698 | 6.0 | 10014 | 1.2173 | 0.0618 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
03de592fe36f72739ddef16b2de67fb8
|
jonatasgrosman/exp_w2v2t_th_vp-100k_s630
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['th']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'th']
| false | true | true | 478 | false |
# exp_w2v2t_th_vp-100k_s630
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition on Thai using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
724142bbc798640a1503d0b033b2d20d
|
shahukareem/wav2vec2-xls-r-1b-dv
|
shahukareem
|
wav2vec2
| 12 | 17 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'dv', 'robust-speech-event', 'model_for_talk']
| true | true | true | 4,040 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-1b-dv
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1702
- Wer: 0.2123
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.8412 | 0.66 | 400 | 0.7160 | 0.7913 |
| 0.6832 | 1.33 | 800 | 0.3401 | 0.5268 |
| 0.4624 | 1.99 | 1200 | 0.2671 | 0.4683 |
| 0.3832 | 2.65 | 1600 | 0.2395 | 0.4410 |
| 0.3443 | 3.32 | 2000 | 0.2410 | 0.4296 |
| 0.324 | 3.98 | 2400 | 0.2302 | 0.4143 |
| 0.2934 | 4.64 | 2800 | 0.2402 | 0.4136 |
| 0.2773 | 5.31 | 3200 | 0.2134 | 0.4088 |
| 0.2638 | 5.97 | 3600 | 0.2072 | 0.4037 |
| 0.2479 | 6.63 | 4000 | 0.2036 | 0.3876 |
| 0.2424 | 7.3 | 4400 | 0.2037 | 0.3767 |
| 0.2249 | 7.96 | 4800 | 0.1959 | 0.3802 |
| 0.2169 | 8.62 | 5200 | 0.1943 | 0.3813 |
| 0.2109 | 9.29 | 5600 | 0.1944 | 0.3691 |
| 0.1991 | 9.95 | 6000 | 0.1870 | 0.3589 |
| 0.1917 | 10.61 | 6400 | 0.1834 | 0.3485 |
| 0.1862 | 11.28 | 6800 | 0.1857 | 0.3486 |
| 0.1744 | 11.94 | 7200 | 0.1812 | 0.3330 |
| 0.171 | 12.6 | 7600 | 0.1797 | 0.3436 |
| 0.1599 | 13.27 | 8000 | 0.1839 | 0.3319 |
| 0.1597 | 13.93 | 8400 | 0.1737 | 0.3385 |
| 0.1494 | 14.59 | 8800 | 0.1807 | 0.3239 |
| 0.1444 | 15.26 | 9200 | 0.1750 | 0.3155 |
| 0.1382 | 15.92 | 9600 | 0.1705 | 0.3084 |
| 0.1299 | 16.58 | 10000 | 0.1777 | 0.2999 |
| 0.1306 | 17.25 | 10400 | 0.1765 | 0.3056 |
| 0.1239 | 17.91 | 10800 | 0.1676 | 0.2864 |
| 0.1149 | 18.57 | 11200 | 0.1774 | 0.2861 |
| 0.1134 | 19.24 | 11600 | 0.1654 | 0.2699 |
| 0.1101 | 19.9 | 12000 | 0.1621 | 0.2651 |
| 0.1038 | 20.56 | 12400 | 0.1686 | 0.2610 |
| 0.1038 | 21.23 | 12800 | 0.1722 | 0.2559 |
| 0.0988 | 21.89 | 13200 | 0.1708 | 0.2486 |
| 0.0949 | 22.55 | 13600 | 0.1696 | 0.2453 |
| 0.0913 | 23.22 | 14000 | 0.1677 | 0.2424 |
| 0.0879 | 23.88 | 14400 | 0.1640 | 0.2359 |
| 0.0888 | 24.54 | 14800 | 0.1697 | 0.2347 |
| 0.0826 | 25.21 | 15200 | 0.1709 | 0.2314 |
| 0.0819 | 25.87 | 15600 | 0.1679 | 0.2256 |
| 0.0793 | 26.53 | 16000 | 0.1701 | 0.2214 |
| 0.0773 | 27.2 | 16400 | 0.1682 | 0.2176 |
| 0.0783 | 27.86 | 16800 | 0.1685 | 0.2165 |
| 0.074 | 28.52 | 17200 | 0.1688 | 0.2155 |
| 0.0753 | 29.19 | 17600 | 0.1695 | 0.2110 |
| 0.0699 | 29.85 | 18000 | 0.1702 | 0.2123 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
14fa62a21cb2521a7e4bad9649433358
|
sd-concepts-library/spritual-monsters
|
sd-concepts-library
| null | 9 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,100 | false |
### Spritual monsters on Stable Diffusion
This is the `<spritual-monsters>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
e32cce2938eb440e58926a123fc2565e
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.