
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-30 06:27:36
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 527
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-30 06:27:12
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
defog/sqlcoder-34b-alpha
|
defog
| 2023-11-14T17:52:31Z | 1,638 | 174 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-14T17:29:57Z |
---
license: cc-by-4.0
language:
- en
pipeline_tag: text-generation
---
# Defog SQLCoder
**Updated on Nov 14 to reflect benchmarks for SQLCoder-34B**
Defog's SQLCoder is a state-of-the-art LLM for converting natural language questions to SQL queries.
[Interactive Demo](https://defog.ai/sqlcoder-demo/) | [🤗 HF Repo](https://huggingface.co/defog/sqlcoder-34b-alpha) | [♾️ Colab](https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7?usp=sharing) | [🐦 Twitter](https://twitter.com/defogdata)
## TL;DR
SQLCoder-34B is a 34B parameter model that outperforms `gpt-4` and `gpt-4-turbo` for natural language to SQL generation tasks on our [sql-eval](https://github.com/defog-ai/sql-eval) framework, and significantly outperforms all popular open-source models.
SQLCoder-34B is fine-tuned on a base CodeLlama model.
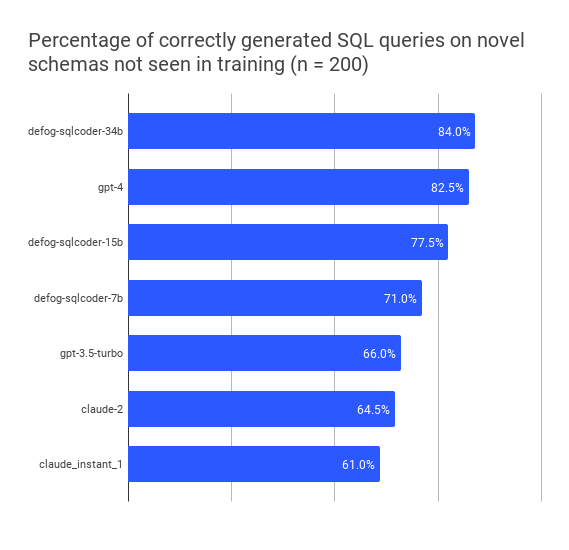
## Results on novel datasets not seen in training
| model | perc_correct |
|-|-|
| defog-sqlcoder-34b | 84.0 |
| gpt4-turbo-2023-11-09 | 82.5 |
| gpt4-2023-11-09 | 82.5 |
| defog-sqlcoder2 | 77.5 |
| gpt4-2023-08-28 | 74.0 |
| defog-sqlcoder-7b | 71.0 |
| gpt-3.5-2023-10-04 | 66.0 |
| claude-2 | 64.5 |
| gpt-3.5-2023-08-28 | 61.0 |
| claude_instant_1 | 61.0 |
| text-davinci-003 | 52.5 |
## License
The code in this repo (what little there is of it) is Apache-2 licensed. The model weights have a `CC BY-SA 4.0` license. The TL;DR is that you can use and modify the model for any purpose – including commercial use. However, if you modify the weights (for example, by fine-tuning), you must open-source your modified weights under the same license terms.
## Training
Defog was trained on more than 20,000 human-curated questions. These questions were based on 10 different schemas. None of the schemas in the training data were included in our evaluation framework.
You can read more about our [training approach](https://defog.ai/blog/open-sourcing-sqlcoder2-7b/) and [evaluation framework](https://defog.ai/blog/open-sourcing-sqleval/).
## Results by question category
We classified each generated question into one of 5 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| | date | group_by | order_by | ratio | join | where |
| -------------- | ---- | -------- | -------- | ----- | ---- | ----- |
| sqlcoder-34b | 80 | 94.3 | 88.6 | 74.3 | 82.9 | 82.9 |
| gpt-4 | 68 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| sqlcoder2-15b | 76 | 80 | 77.1 | 60 | 77.1 | 77.1 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 68 | 77.1 | 68.6 | 37.1 | 71.4 | 74.3 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
| claude-instant | 48 | 71.4 | 74.3 | 45.7 | 62.9 | 60 |
| gpt-3 | 32 | 71.4 | 68.6 | 25.7 | 57.1 | 54.3 |
<img width="831" alt="image" src="https://github.com/defog-ai/sqlcoder/assets/5008293/79c5bdc8-373c-4abd-822e-e2c2569ed353">
## Using SQLCoder
You can use SQLCoder via the `transformers` library by downloading our model weights from the Hugging Face repo. We have added sample code for [inference](./inference.py) on a [sample database schema](./metadata.sql).
```bash
python inference.py -q "Question about the sample database goes here"
# Sample question:
# Do we get more revenue from customers in New York compared to customers in San Francisco? Give me the total revenue for each city, and the difference between the two.
```
You can also use a demo on our website [here](https://defog.ai/sqlcoder-demo)
## Hardware Requirements
SQLCoder-34B has been tested on a 4xA10 GPU with `float16` weights. You can also load an 8-bit and 4-bit quantized version of the model on consumer GPUs with 20GB or more of memory – like RTX 4090, RTX 3090, and Apple M2 Pro, M2 Max, or M2 Ultra Chips with 20GB or more of memory.
## Todo
- [x] Open-source the v1 model weights
- [x] Train the model on more data, with higher data variance
- [ ] Tune the model further with Reward Modelling and RLHF
- [ ] Pretrain a model from scratch that specializes in SQL analysis
|
okeowo1014/imgclassifiertraining
|
okeowo1014
| 2023-11-14T17:49:43Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"image-classifier",
"some_other_tag",
"region:us"
] | null | 2023-11-14T17:11:51Z |
---
library_name: keras
tags:
- image-classifier
- some_other_tag
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | None |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | False |
| is_legacy_optimizer | False |
| learning_rate | 0.0010000000474974513 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
|
kejolong/darkangel
|
kejolong
| 2023-11-14T17:46:00Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-11-14T17:45:13Z |
---
license: creativeml-openrail-m
---
|
Sony27/my-pet-dog
|
Sony27
| 2023-11-14T17:44:44Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T17:40:05Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Sony27 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-252
Sample pictures of this concept:

|
noco-ai/func-call-hallucinate-v1
|
noco-ai
| 2023-11-14T17:41:58Z | 0 | 0 | null |
[
"license:cc-by-nc-4.0",
"region:us"
] | null | 2023-11-14T17:39:02Z |
---
license: cc-by-nc-4.0
---
Function calling lora for Spellbook project. See https://github.com/noco-ai/arcane-bridge for details.
|
Jukaboo/Llama2_7B_chat_meetingBank_ft_adapters_EOS
|
Jukaboo
| 2023-11-14T17:40:53Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:finetune:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2023-11-14T11:01:29Z |
---
base_model: meta-llama/Llama-2-7b-chat-hf
tags:
- generated_from_trainer
model-index:
- name: Llama2_7B_chat_meetingBank_ft_adapters_EOS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama2_7B_chat_meetingBank_ft_adapters_EOS
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9934
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2432 | 0.2 | 13 | 2.2215 |
| 2.1909 | 0.4 | 26 | 2.0960 |
| 2.2498 | 0.6 | 39 | 2.0220 |
| 2.2679 | 0.8 | 52 | 1.9934 |
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Vaishnavi07/xzg
|
Vaishnavi07
| 2023-11-14T17:39:20Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T17:32:24Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### xzg Dreambooth model trained by Vaishnavi07 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-44
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
|
mickume/alt_nsfw_mistral_7b
|
mickume
| 2023-11-14T17:35:44Z | 12 | 3 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-14T17:32:28Z |
---
{}
---
---
language: en
license: mit
---
# mickume/alt_nsfw_mistral_7b
This model does this and that
mickume
https://github.com/mickume/narrator
|
Guernika/CoreMLStableDiffusion
|
Guernika
| 2023-11-14T17:30:30Z | 0 | 66 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-14T22:23:46Z |
---
license: creativeml-openrail-m
---
# Guernika
This repository contains [Guernika](https://apps.apple.com/app/id1660407508) compatible models and instructions to convert existing models.
While these models and instructions were created for [Guernika](https://apps.apple.com/app/id1660407508), they should work and help with any CoreML based solution.
## <a name="converting-models-to-guernika"></a> Converting Models to Guernika
**WARNING:** Xcode is required to convert models:
- Make sure you have [Xcode](https://apps.apple.com/app/id497799835) installed.
- Once installed run the following commands:
```shell
sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/
sudo xcodebuild -license accept
```
- You should now be ready to start converting models!
### <a name="converting-models-advanced"></a> Easy mode
**Step 1:** Download and install [`Guernika Model Converter`](https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter.dmg).
[<img alt="Guernika Model Converter icon" src="https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter_AppIcon.png" width="256pt" />](https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter.dmg)
**Step 2:** Launch `Guernika Model Converter` from your `Applications` folder, this app may take a few seconds to load.
**Step 3:** Once the app has loaded you will be able to select what model you want to convert:
- You can input the model identifier (e.g. CompVis/stable-diffusion-v1-4) to download from Hugging Face. You may have to log in to or register for your [Hugging Face account](https://huggingface.co), generate a [User Access Token](https://huggingface.co/settings/tokens) and use this token to set up Hugging Face API access by running `huggingface-cli login` in a Terminal window.
- You can select a local model from your machine: `Select local model`
- You can select a local .CKPT model from your machine: `Select CKPT`
<img alt="Guernika Model Converter interface" src="https://huggingface.co/Guernika/CoreMLStableDiffusion/resolve/main/GuernikaModelConverter_screenshot.png" />
**Step 4:** Once you've chosen the model you want to convert you can choose what modules to convert and/or if you want to chunk the UNet module (recommended for iOS/iPadOS devices).
**Step 5:** Once you're happy with your selection click `Convert to Guernika` and wait for the app to complete conversion.
**WARNING:** This command may download several GB worth of PyTorch checkpoints from Hugging Face and may take a long time to complete (15-20 minutes on an M1 machine).
### <a name="converting-models-advanced"></a> Advance mode
**Step 1:** Create a Python environment and install dependencies:
```bash
conda create -n guernika python=3.8 -y
conda activate guernika
cd /path/to/unziped/scripts/location
pip install -e .
```
**Step 2:** Choose what model you want to convert:
**Huggin Face model:** Log in to or register for your [Hugging Face account](https://huggingface.co), generate a [User Access Token](https://huggingface.co/settings/tokens) and use this token to set up Hugging Face API access by running `huggingface-cli login` in a Terminal window.
Once you know what model you want to convert and have accepted its Terms of Use, run the following command replacing `<model-identifier>` with the desired model's identifier:
```shell
python -m python_coreml_stable_diffusion.torch2coreml --model-version <model-identifier> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
```
**Local model:** Run the following command replacing `<model-location>` with the desired model's location path:
```shell
python -m python_coreml_stable_diffusion.torch2coreml --model-location <model-location> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
```
**Local CKPT:** Run the following command replacing `<checkpoint-path>` with the desired CKPT's location path:
```shell
python -m python_coreml_stable_diffusion.torch2coreml --checkpoint-path <checkpoint-path> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
```
**WARNING:** These commands may download several GB worth of PyTorch checkpoints from Hugging Face.
This generally takes 15-20 minutes on an M1 MacBook Pro. Upon successful execution, the neural network models that comprise Stable Diffusion's model will have been converted from PyTorch to Guernika and saved into the specified `<output-directory>`.
#### <a name="converting-models--arguments"></a> Notable arguments
- `--model-version`: The model version defaults to [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4). Developers may specify other versions that are available on [Hugging Face Hub](https://huggingface.co/models?search=stable-diffusion), e.g. [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) & [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
- `--model-location`: The location of a local model defaults to `None`.
- `--checkpoint-path`: The location of a local .CKPT model defaults to `None`.
- `--bundle-resources-for-guernika`: Compiles all 4 models and bundles them along with necessary resources for text tokenization into `<output-mlpackages-directory>/Resources` which should provided as input to the Swift package. This flag is not necessary for the diffusers-based Python pipeline.
- `--clean-up-mlpackages`: Cleans up created .mlpackages leaving only the compiled model.
- `--chunk-unet`: Splits the Unet model in two approximately equal chunks (each with less than 1GB of weights) for mobile-friendly deployment. This is **required** for ANE deployment on iOS and iPadOS. This is not required for macOS. Swift CLI is able to consume both the chunked and regular versions of the Unet model but prioritizes the former. Note that chunked unet is not compatible with the Python pipeline because Python pipeline is intended for macOS only. Chunking is for on-device deployment with Swift only.
- `--attention-implementation`: Defaults to `SPLIT_EINSUM` which is the implementation described in [Deploying Transformers on the Apple Neural Engine](https://machinelearning.apple.com/research/neural-engine-transformers). `--attention-implementation ORIGINAL` will switch to an alternative that should be used for non-ANE deployment. Please refer to the [Performance Benchmark](#performance-benchmark) section for further guidance.
- `--check-output-correctness`: Compares original PyTorch model's outputs to final Core ML model's outputs. This flag increases RAM consumption significantly so it is recommended only for debugging purposes.
|
SimplCup/Nihachu
|
SimplCup
| 2023-11-14T17:25:58Z | 0 | 0 | null |
[
"license:cc-by-nc-nd-4.0",
"region:us"
] | null | 2023-11-14T17:25:36Z |
---
license: cc-by-nc-nd-4.0
---
|
Akshay0706/Potato-Plant-1-Epochs-Model
|
Akshay0706
| 2023-11-14T17:25:40Z | 7 | 1 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:image_folder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-14T17:25:30Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- image_folder
metrics:
- accuracy
- f1
model-index:
- name: Potato-Plant-1-Epochs-Model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: image_folder
type: image_folder
config: Testing
split: train
args: Testing
metrics:
- name: Accuracy
type: accuracy
value: 0.9925925925925926
- name: F1
type: f1
value: 0.9925854995617313
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Potato-Plant-1-Epochs-Model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0935
- Accuracy: 0.9926
- F1: 0.9926
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2706 | 1.0 | 204 | 0.0935 | 0.9926 | 0.9926 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
syedwilliams/ppo-LunarLander-v2
|
syedwilliams
| 2023-11-14T17:25:11Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-14T17:24:51Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.96 +/- 21.64
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
entaroid/distilbert-base-uncased-finetuned-emotion
|
entaroid
| 2023-11-14T17:08:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-29T13:44:53Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9265
- name: F1
type: f1
value: 0.9261920632620516
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2144
- Accuracy: 0.9265
- F1: 0.9262
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 250 | 0.3298 | 0.9085 | 0.9077 |
| No log | 2.0 | 500 | 0.2144 | 0.9265 | 0.9262 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
gtoscano/midjourney-zephyr-7b-beta
|
gtoscano
| 2023-11-14T17:07:18Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:HuggingFaceH4/zephyr-7b-beta",
"base_model:adapter:HuggingFaceH4/zephyr-7b-beta",
"region:us"
] | null | 2023-11-14T17:07:14Z |
---
library_name: peft
base_model: HuggingFaceH4/zephyr-7b-beta
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0
|
EJosnin/ppo-Huggy
|
EJosnin
| 2023-11-14T16:52:56Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-14T16:52:48Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: EJosnin/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
aloobun/tinyllama_multiple_lora_weight_merge_0.65_0.35
|
aloobun
| 2023-11-14T16:49:52Z | 0 | 2 |
peft
|
[
"peft",
"safetensors",
"llama",
"tinyllama",
"merge models",
"merging",
"en",
"dataset:burkelibbey/colors",
"dataset:camel-ai/physics",
"license:apache-2.0",
"region:us"
] | null | 2023-11-14T15:56:04Z |
---
license: apache-2.0
tags:
- tinyllama
- peft
- merge models
- merging
datasets:
- burkelibbey/colors
- camel-ai/physics
language:
- en
---
I'm exploring techniques for language model optimization by merging a base language model with multiple LoRA models.
Initially I finetuned [PY007/TinyLlama-1.1B-Chat-v0.3](https://huggingface.co/PY007/TinyLlama-1.1B-Chat-v0.3) model on distinct datasets, one focused on color and the other on physics, resulting in two LoRA models.
I applied weights of 0.65 and 0.35 to control the impact of each LoRA model during the merge.
For each parameter in the LoRA models, a weighted contribution is calculated using the formula:
```new_weight = original_weight + (LoRA_B @ LoRA_A) * scaling * merge_weight```.
This involves a matmul b/w the [aloobun/tinyllama-colorist-lora_2](https://huggingface.co/aloobun/tinyllama-colorist-lora_2) and [aloobun/tinyllama-physics-lora_1](https://huggingface.co/aloobun/tinyllama-physics-lora_1) weights. The result is added to the original weight of the base model.
The model may not be perfect but i'm learning on the go. Give it a try:
```
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
from time import perf_counter
model_id="aloobun/tinyllama_multiple_lora_weight_merge_0.65_0.35"
def formatted_prompt(question)-> str:
return f"<|im_start|>user\n{question}<|im_end|>\n<|im_start|>assistant:"
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline(
"text-generation",
model=model_id_colorist_final,
torch_dtype=torch.float16,
device_map="auto",
)
start_time = perf_counter()
```
## QNA PHYSICS:
```
prompt = formatted_prompt('What are the theoretical explanations for the integer and fractional quantum Hall effects, and how do these explanations account for the observed experimental data?')
sequences = pipe(
prompt,
do_sample=True,
temperature=0.1,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
output_time = perf_counter() - start_time
print(f"Time taken for inference: {round(output_time,2)} seconds")
```
### RESULT:
```
Result: <|im_start|>user
What are the theoretical explanations for the integer and fractional quantum Hall effects, and how do these explanations account for the observed experimental data?<|im_end|>
<|im_start|>assistant:
The integer and fractional quantum Hall effects are two different phenomena that occur in the physics of semiconductors. They are related to the properties of the electronic states of the material, and their understanding can provide insights into the fundamental properties of quantum systems.
The integer quantum Hall effect (IQHE) is a phenomenon where the Hall conductance, which is the current flowing through a conductor, is quantized, meaning that it has a discrete value. This effect is due to the interplay between the electron spin and the electron charge, which are both quantized in the material. The IQHE is a result of the interplay between the electron spin and the electron charge, and it is a fundamental property of the material.
The fractional quantum Hall effect (FQHE) is a more recent phenomenon that occurs in semiconductors with a high electron mobility. In this effect, the Hall conductance is not quantized, but instead has a continuous range of values. This effect is due to the interplay between the electron mobility and the electron charge, which are both quantized in the material. The FQHE is a result of the interplay between the electron mobility and the electron charge, and it is a fundamental property of the material.
The theoretical explanations for the IQHE and FQHE are based on the principles of quantum mechanics and the principles of quantum field theory. These theories provide a framework for understanding the physics of the material and the underlying quantum mechanics. The explanations provide insights into the fundamental properties of quantum systems, such as the quantization of the current flowing through a material, and the interplay between the electron spin and the electron charge.
In summary, the integer and fractional quantum Hall effects are two different phenomena that occur in the physics of semiconductors. They are related to the properties of the electronic states of the material, and their understanding can provide insights into the fundamental properties of quantum systems. The theoretical explanations for the IQHE and FQHE are based on the principles of quantum mechanics and the principles of quantum field theory, respectively, and provide insights into the physics of the material.
Time taken for inference: 13.36 seconds
```
## GET HEX:
```
from time import perf_counter
start_time = perf_counter()
prompt = formatted_prompt('give me hex code for pure red color')
sequences = pipe(
prompt,
do_sample=True,
temperature=0.1,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=200
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
output_time = perf_counter() - start_time
print(f"Time taken for inference: {round(output_time,2)} seconds")
```
## RESULT:
```
Result: <|im_start|>user
give me hex code for pure red color<|im_end|>
<|im_start|>assistant:
#ff0000
Time taken for inference: 0.45 seconds
```
|
Moonxc/trained-truck
|
Moonxc
| 2023-11-14T16:40:39Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T16:28:00Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks truck
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - Moonxc/trained-truck
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks truck using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.




DreamBooth for the text encoder was enabled: False.
|
odunola/distillbert-distilled-ag-news-2
|
odunola
| 2023-11-14T16:30:47Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:ag_news",
"base_model:google/bert_uncased_L-8_H-256_A-4",
"base_model:finetune:google/bert_uncased_L-8_H-256_A-4",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-13T21:50:30Z |
---
license: apache-2.0
base_model: google/bert_uncased_L-8_H-256_A-4
tags:
- generated_from_trainer
datasets:
- ag_news
metrics:
- accuracy
model-index:
- name: distillbert-distilled-ag-news-2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: ag_news
type: ag_news
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9407916666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distillbert-distilled-ag-news-2
This model is a fine-tuned version of [google/bert_uncased_L-8_H-256_A-4](https://huggingface.co/google/bert_uncased_L-8_H-256_A-4) on the ag_news dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1945
- Accuracy: 0.9408
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.238 | 1.0 | 3000 | 0.2240 | 0.9237 |
| 0.1873 | 2.0 | 6000 | 0.2009 | 0.9329 |
| 0.1597 | 3.0 | 9000 | 0.1919 | 0.9377 |
| 0.1495 | 4.0 | 12000 | 0.1948 | 0.9400 |
| 0.1303 | 5.0 | 15000 | 0.1945 | 0.9408 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
brightfarmns/Reinforce-pixel-copter
|
brightfarmns
| 2023-11-14T16:20:40Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-14T16:20:21Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixel-copter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 12.00 +/- 14.73
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
tengkai/outcome
|
tengkai
| 2023-11-14T16:16:36Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-11-14T01:32:02Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: outcome
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outcome
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
AmulyaGolla/my-pet-bird
|
AmulyaGolla
| 2023-11-14T16:13:34Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T16:08:46Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Bird Dreambooth model trained by AmulyaGolla following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-12
Sample pictures of this concept:

|
sam-babayev/sf_model_e5
|
sam-babayev
| 2023-11-14T15:47:11Z | 703 | 2 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-11-09T23:12:19Z |
---
tags:
- mteb
model-index:
- name: sf_model_e5
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 70.85074626865672
- type: ap
value: 33.779217850079206
- type: f1
value: 64.96977487239377
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.80945
- type: ap
value: 88.22978189506895
- type: f1
value: 91.7858219911604
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.94200000000001
- type: f1
value: 47.911934405973895
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.616
- type: map_at_10
value: 55.938
- type: map_at_100
value: 56.552
- type: map_at_1000
value: 56.556
- type: map_at_3
value: 51.754
- type: map_at_5
value: 54.623999999999995
- type: mrr_at_1
value: 40.967
- type: mrr_at_10
value: 56.452999999999996
- type: mrr_at_100
value: 57.053
- type: mrr_at_1000
value: 57.057
- type: mrr_at_3
value: 52.312000000000005
- type: mrr_at_5
value: 55.1
- type: ndcg_at_1
value: 39.616
- type: ndcg_at_10
value: 64.067
- type: ndcg_at_100
value: 66.384
- type: ndcg_at_1000
value: 66.468
- type: ndcg_at_3
value: 55.74
- type: ndcg_at_5
value: 60.889
- type: precision_at_1
value: 39.616
- type: precision_at_10
value: 8.953999999999999
- type: precision_at_100
value: 0.9900000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.428
- type: precision_at_5
value: 15.946
- type: recall_at_1
value: 39.616
- type: recall_at_10
value: 89.545
- type: recall_at_100
value: 99.004
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 67.283
- type: recall_at_5
value: 79.73
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.72923923743124
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.87449955203238
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.3214434754065
- type: mrr
value: 77.87879787187265
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.82418607751953
- type: cos_sim_spearman
value: 86.74535004562274
- type: euclidean_pearson
value: 86.58792166831103
- type: euclidean_spearman
value: 86.74535004562274
- type: manhattan_pearson
value: 86.23957813056677
- type: manhattan_spearman
value: 86.41522204150452
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.61363636363636
- type: f1
value: 83.98373241136187
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.73148995791471
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 37.23723038699733
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.217
- type: map_at_10
value: 43.453
- type: map_at_100
value: 45.038
- type: map_at_1000
value: 45.162
- type: map_at_3
value: 39.589
- type: map_at_5
value: 41.697
- type: mrr_at_1
value: 39.628
- type: mrr_at_10
value: 49.698
- type: mrr_at_100
value: 50.44
- type: mrr_at_1000
value: 50.482000000000006
- type: mrr_at_3
value: 46.781
- type: mrr_at_5
value: 48.548
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 50.158
- type: ndcg_at_100
value: 55.687
- type: ndcg_at_1000
value: 57.499
- type: ndcg_at_3
value: 44.594
- type: ndcg_at_5
value: 47.198
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 9.828000000000001
- type: precision_at_100
value: 1.591
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 21.507
- type: precision_at_5
value: 15.765
- type: recall_at_1
value: 32.217
- type: recall_at_10
value: 62.717999999999996
- type: recall_at_100
value: 85.992
- type: recall_at_1000
value: 97.271
- type: recall_at_3
value: 46.694
- type: recall_at_5
value: 53.952
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.862000000000002
- type: map_at_10
value: 41.287
- type: map_at_100
value: 42.526
- type: map_at_1000
value: 42.653999999999996
- type: map_at_3
value: 38.055
- type: map_at_5
value: 40.022000000000006
- type: mrr_at_1
value: 38.408
- type: mrr_at_10
value: 46.943
- type: mrr_at_100
value: 47.597
- type: mrr_at_1000
value: 47.64
- type: mrr_at_3
value: 44.607
- type: mrr_at_5
value: 46.079
- type: ndcg_at_1
value: 38.408
- type: ndcg_at_10
value: 46.936
- type: ndcg_at_100
value: 51.307
- type: ndcg_at_1000
value: 53.312000000000005
- type: ndcg_at_3
value: 42.579
- type: ndcg_at_5
value: 44.877
- type: precision_at_1
value: 38.408
- type: precision_at_10
value: 8.885
- type: precision_at_100
value: 1.4449999999999998
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 20.616
- type: precision_at_5
value: 14.841
- type: recall_at_1
value: 30.862000000000002
- type: recall_at_10
value: 56.994
- type: recall_at_100
value: 75.347
- type: recall_at_1000
value: 87.911
- type: recall_at_3
value: 44.230000000000004
- type: recall_at_5
value: 50.625
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.076
- type: map_at_10
value: 52.535
- type: map_at_100
value: 53.537
- type: map_at_1000
value: 53.591
- type: map_at_3
value: 48.961
- type: map_at_5
value: 50.96000000000001
- type: mrr_at_1
value: 44.765
- type: mrr_at_10
value: 55.615
- type: mrr_at_100
value: 56.24
- type: mrr_at_1000
value: 56.264
- type: mrr_at_3
value: 52.925999999999995
- type: mrr_at_5
value: 54.493
- type: ndcg_at_1
value: 44.765
- type: ndcg_at_10
value: 58.777
- type: ndcg_at_100
value: 62.574
- type: ndcg_at_1000
value: 63.624
- type: ndcg_at_3
value: 52.81
- type: ndcg_at_5
value: 55.657999999999994
- type: precision_at_1
value: 44.765
- type: precision_at_10
value: 9.693
- type: precision_at_100
value: 1.248
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 23.866
- type: precision_at_5
value: 16.489
- type: recall_at_1
value: 39.076
- type: recall_at_10
value: 74.01299999999999
- type: recall_at_100
value: 90.363
- type: recall_at_1000
value: 97.782
- type: recall_at_3
value: 58.056
- type: recall_at_5
value: 65.029
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.357000000000003
- type: map_at_10
value: 35.492000000000004
- type: map_at_100
value: 36.504999999999995
- type: map_at_1000
value: 36.578
- type: map_at_3
value: 32.696999999999996
- type: map_at_5
value: 34.388999999999996
- type: mrr_at_1
value: 28.136
- type: mrr_at_10
value: 37.383
- type: mrr_at_100
value: 38.271
- type: mrr_at_1000
value: 38.324999999999996
- type: mrr_at_3
value: 34.782999999999994
- type: mrr_at_5
value: 36.416
- type: ndcg_at_1
value: 28.136
- type: ndcg_at_10
value: 40.741
- type: ndcg_at_100
value: 45.803
- type: ndcg_at_1000
value: 47.637
- type: ndcg_at_3
value: 35.412
- type: ndcg_at_5
value: 38.251000000000005
- type: precision_at_1
value: 28.136
- type: precision_at_10
value: 6.315999999999999
- type: precision_at_100
value: 0.931
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 15.254000000000001
- type: precision_at_5
value: 10.757
- type: recall_at_1
value: 26.357000000000003
- type: recall_at_10
value: 55.021
- type: recall_at_100
value: 78.501
- type: recall_at_1000
value: 92.133
- type: recall_at_3
value: 40.798
- type: recall_at_5
value: 47.591
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.302
- type: map_at_10
value: 26.365
- type: map_at_100
value: 27.581
- type: map_at_1000
value: 27.705999999999996
- type: map_at_3
value: 23.682
- type: map_at_5
value: 25.304
- type: mrr_at_1
value: 21.891
- type: mrr_at_10
value: 31.227
- type: mrr_at_100
value: 32.22
- type: mrr_at_1000
value: 32.282
- type: mrr_at_3
value: 28.711
- type: mrr_at_5
value: 30.314999999999998
- type: ndcg_at_1
value: 21.891
- type: ndcg_at_10
value: 31.965
- type: ndcg_at_100
value: 37.869
- type: ndcg_at_1000
value: 40.642
- type: ndcg_at_3
value: 27.184
- type: ndcg_at_5
value: 29.686
- type: precision_at_1
value: 21.891
- type: precision_at_10
value: 5.9830000000000005
- type: precision_at_100
value: 1.0250000000000001
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 13.391
- type: precision_at_5
value: 9.801
- type: recall_at_1
value: 17.302
- type: recall_at_10
value: 44.312000000000005
- type: recall_at_100
value: 70.274
- type: recall_at_1000
value: 89.709
- type: recall_at_3
value: 31.117
- type: recall_at_5
value: 37.511
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.404000000000003
- type: map_at_10
value: 40.571
- type: map_at_100
value: 42.049
- type: map_at_1000
value: 42.156
- type: map_at_3
value: 37.413000000000004
- type: map_at_5
value: 39.206
- type: mrr_at_1
value: 36.285000000000004
- type: mrr_at_10
value: 46.213
- type: mrr_at_100
value: 47.129
- type: mrr_at_1000
value: 47.168
- type: mrr_at_3
value: 43.84
- type: mrr_at_5
value: 45.226
- type: ndcg_at_1
value: 36.285000000000004
- type: ndcg_at_10
value: 46.809
- type: ndcg_at_100
value: 52.615
- type: ndcg_at_1000
value: 54.538
- type: ndcg_at_3
value: 41.91
- type: ndcg_at_5
value: 44.224999999999994
- type: precision_at_1
value: 36.285000000000004
- type: precision_at_10
value: 8.527
- type: precision_at_100
value: 1.3259999999999998
- type: precision_at_1000
value: 0.167
- type: precision_at_3
value: 20.083000000000002
- type: precision_at_5
value: 14.071
- type: recall_at_1
value: 29.404000000000003
- type: recall_at_10
value: 59.611999999999995
- type: recall_at_100
value: 83.383
- type: recall_at_1000
value: 95.703
- type: recall_at_3
value: 45.663
- type: recall_at_5
value: 51.971999999999994
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.317
- type: map_at_10
value: 35.217999999999996
- type: map_at_100
value: 36.665
- type: map_at_1000
value: 36.768
- type: map_at_3
value: 31.924000000000003
- type: map_at_5
value: 33.591
- type: mrr_at_1
value: 31.507
- type: mrr_at_10
value: 40.671
- type: mrr_at_100
value: 41.609
- type: mrr_at_1000
value: 41.657
- type: mrr_at_3
value: 38.261
- type: mrr_at_5
value: 39.431
- type: ndcg_at_1
value: 31.507
- type: ndcg_at_10
value: 41.375
- type: ndcg_at_100
value: 47.426
- type: ndcg_at_1000
value: 49.504
- type: ndcg_at_3
value: 35.989
- type: ndcg_at_5
value: 38.068000000000005
- type: precision_at_1
value: 31.507
- type: precision_at_10
value: 7.8420000000000005
- type: precision_at_100
value: 1.257
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 17.352
- type: precision_at_5
value: 12.328999999999999
- type: recall_at_1
value: 25.317
- type: recall_at_10
value: 54.254999999999995
- type: recall_at_100
value: 80.184
- type: recall_at_1000
value: 94.07
- type: recall_at_3
value: 39.117000000000004
- type: recall_at_5
value: 44.711
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.813000000000002
- type: map_at_10
value: 35.47183333333334
- type: map_at_100
value: 36.71775
- type: map_at_1000
value: 36.833000000000006
- type: map_at_3
value: 32.449916666666674
- type: map_at_5
value: 34.1235
- type: mrr_at_1
value: 30.766750000000005
- type: mrr_at_10
value: 39.77508333333334
- type: mrr_at_100
value: 40.64233333333333
- type: mrr_at_1000
value: 40.69658333333333
- type: mrr_at_3
value: 37.27349999999999
- type: mrr_at_5
value: 38.723416666666665
- type: ndcg_at_1
value: 30.766750000000005
- type: ndcg_at_10
value: 41.141416666666665
- type: ndcg_at_100
value: 46.42016666666666
- type: ndcg_at_1000
value: 48.61916666666667
- type: ndcg_at_3
value: 36.06883333333333
- type: ndcg_at_5
value: 38.43966666666666
- type: precision_at_1
value: 30.766750000000005
- type: precision_at_10
value: 7.340000000000001
- type: precision_at_100
value: 1.1796666666666666
- type: precision_at_1000
value: 0.15625
- type: precision_at_3
value: 16.763833333333334
- type: precision_at_5
value: 11.972166666666666
- type: recall_at_1
value: 25.813000000000002
- type: recall_at_10
value: 53.62741666666667
- type: recall_at_100
value: 76.70125000000002
- type: recall_at_1000
value: 91.85566666666666
- type: recall_at_3
value: 39.55075
- type: recall_at_5
value: 45.645250000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.249
- type: map_at_10
value: 31.095
- type: map_at_100
value: 32.056000000000004
- type: map_at_1000
value: 32.163000000000004
- type: map_at_3
value: 29.275000000000002
- type: map_at_5
value: 30.333
- type: mrr_at_1
value: 26.687
- type: mrr_at_10
value: 34.122
- type: mrr_at_100
value: 34.958
- type: mrr_at_1000
value: 35.039
- type: mrr_at_3
value: 32.541
- type: mrr_at_5
value: 33.43
- type: ndcg_at_1
value: 26.687
- type: ndcg_at_10
value: 35.248000000000005
- type: ndcg_at_100
value: 39.933
- type: ndcg_at_1000
value: 42.616
- type: ndcg_at_3
value: 31.980999999999998
- type: ndcg_at_5
value: 33.583
- type: precision_at_1
value: 26.687
- type: precision_at_10
value: 5.445
- type: precision_at_100
value: 0.848
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.957
- type: precision_at_5
value: 9.479
- type: recall_at_1
value: 23.249
- type: recall_at_10
value: 45.005
- type: recall_at_100
value: 66.175
- type: recall_at_1000
value: 86.116
- type: recall_at_3
value: 36.03
- type: recall_at_5
value: 40.037
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.592
- type: map_at_10
value: 25.003999999999998
- type: map_at_100
value: 26.208
- type: map_at_1000
value: 26.333000000000002
- type: map_at_3
value: 22.479
- type: map_at_5
value: 23.712
- type: mrr_at_1
value: 21.37
- type: mrr_at_10
value: 28.951999999999998
- type: mrr_at_100
value: 29.915999999999997
- type: mrr_at_1000
value: 29.99
- type: mrr_at_3
value: 26.503
- type: mrr_at_5
value: 27.728
- type: ndcg_at_1
value: 21.37
- type: ndcg_at_10
value: 29.944
- type: ndcg_at_100
value: 35.632000000000005
- type: ndcg_at_1000
value: 38.393
- type: ndcg_at_3
value: 25.263999999999996
- type: ndcg_at_5
value: 27.115000000000002
- type: precision_at_1
value: 21.37
- type: precision_at_10
value: 5.568
- type: precision_at_100
value: 0.992
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 11.895
- type: precision_at_5
value: 8.61
- type: recall_at_1
value: 17.592
- type: recall_at_10
value: 40.976
- type: recall_at_100
value: 66.487
- type: recall_at_1000
value: 85.954
- type: recall_at_3
value: 27.797
- type: recall_at_5
value: 32.553
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.173000000000002
- type: map_at_10
value: 34.611999999999995
- type: map_at_100
value: 35.735
- type: map_at_1000
value: 35.842
- type: map_at_3
value: 31.345
- type: map_at_5
value: 33.123000000000005
- type: mrr_at_1
value: 29.570999999999998
- type: mrr_at_10
value: 38.775999999999996
- type: mrr_at_100
value: 39.621
- type: mrr_at_1000
value: 39.684000000000005
- type: mrr_at_3
value: 35.992000000000004
- type: mrr_at_5
value: 37.586999999999996
- type: ndcg_at_1
value: 29.570999999999998
- type: ndcg_at_10
value: 40.388000000000005
- type: ndcg_at_100
value: 45.59
- type: ndcg_at_1000
value: 47.948
- type: ndcg_at_3
value: 34.497
- type: ndcg_at_5
value: 37.201
- type: precision_at_1
value: 29.570999999999998
- type: precision_at_10
value: 6.931
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 15.609
- type: precision_at_5
value: 11.286999999999999
- type: recall_at_1
value: 25.173000000000002
- type: recall_at_10
value: 53.949000000000005
- type: recall_at_100
value: 76.536
- type: recall_at_1000
value: 92.979
- type: recall_at_3
value: 37.987
- type: recall_at_5
value: 44.689
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.224
- type: map_at_10
value: 32.903
- type: map_at_100
value: 34.65
- type: map_at_1000
value: 34.873
- type: map_at_3
value: 29.673
- type: map_at_5
value: 31.361
- type: mrr_at_1
value: 30.435000000000002
- type: mrr_at_10
value: 38.677
- type: mrr_at_100
value: 39.805
- type: mrr_at_1000
value: 39.851
- type: mrr_at_3
value: 35.935
- type: mrr_at_5
value: 37.566
- type: ndcg_at_1
value: 30.435000000000002
- type: ndcg_at_10
value: 39.012
- type: ndcg_at_100
value: 45.553
- type: ndcg_at_1000
value: 47.919
- type: ndcg_at_3
value: 33.809
- type: ndcg_at_5
value: 36.120999999999995
- type: precision_at_1
value: 30.435000000000002
- type: precision_at_10
value: 7.628
- type: precision_at_100
value: 1.5810000000000002
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 15.744
- type: precision_at_5
value: 11.66
- type: recall_at_1
value: 24.224
- type: recall_at_10
value: 50.009
- type: recall_at_100
value: 78.839
- type: recall_at_1000
value: 93.71300000000001
- type: recall_at_3
value: 35.512
- type: recall_at_5
value: 41.541
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.983
- type: map_at_10
value: 27.127000000000002
- type: map_at_100
value: 28.063
- type: map_at_1000
value: 28.17
- type: map_at_3
value: 24.306
- type: map_at_5
value: 25.784000000000002
- type: mrr_at_1
value: 20.518
- type: mrr_at_10
value: 29.024
- type: mrr_at_100
value: 29.902
- type: mrr_at_1000
value: 29.976999999999997
- type: mrr_at_3
value: 26.401999999999997
- type: mrr_at_5
value: 27.862
- type: ndcg_at_1
value: 20.518
- type: ndcg_at_10
value: 32.344
- type: ndcg_at_100
value: 37.053000000000004
- type: ndcg_at_1000
value: 39.798
- type: ndcg_at_3
value: 26.796999999999997
- type: ndcg_at_5
value: 29.293000000000003
- type: precision_at_1
value: 20.518
- type: precision_at_10
value: 5.434
- type: precision_at_100
value: 0.83
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 11.892
- type: precision_at_5
value: 8.577
- type: recall_at_1
value: 18.983
- type: recall_at_10
value: 46.665
- type: recall_at_100
value: 68.33399999999999
- type: recall_at_1000
value: 88.927
- type: recall_at_3
value: 31.608000000000004
- type: recall_at_5
value: 37.532
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.200000000000001
- type: map_at_10
value: 20.241999999999997
- type: map_at_100
value: 22.357
- type: map_at_1000
value: 22.556
- type: map_at_3
value: 16.564999999999998
- type: map_at_5
value: 18.443
- type: mrr_at_1
value: 25.277
- type: mrr_at_10
value: 37.582
- type: mrr_at_100
value: 38.525999999999996
- type: mrr_at_1000
value: 38.564
- type: mrr_at_3
value: 33.898
- type: mrr_at_5
value: 36.191
- type: ndcg_at_1
value: 25.277
- type: ndcg_at_10
value: 28.74
- type: ndcg_at_100
value: 36.665
- type: ndcg_at_1000
value: 40.08
- type: ndcg_at_3
value: 22.888
- type: ndcg_at_5
value: 25.081999999999997
- type: precision_at_1
value: 25.277
- type: precision_at_10
value: 9.251
- type: precision_at_100
value: 1.773
- type: precision_at_1000
value: 0.241
- type: precision_at_3
value: 17.329
- type: precision_at_5
value: 13.746
- type: recall_at_1
value: 11.200000000000001
- type: recall_at_10
value: 35.419
- type: recall_at_100
value: 62.41
- type: recall_at_1000
value: 81.467
- type: recall_at_3
value: 21.275
- type: recall_at_5
value: 27.201999999999998
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.396
- type: map_at_10
value: 20.735
- type: map_at_100
value: 30.098000000000003
- type: map_at_1000
value: 31.866
- type: map_at_3
value: 14.71
- type: map_at_5
value: 17.259
- type: mrr_at_1
value: 70.25
- type: mrr_at_10
value: 77.09700000000001
- type: mrr_at_100
value: 77.398
- type: mrr_at_1000
value: 77.40899999999999
- type: mrr_at_3
value: 75.542
- type: mrr_at_5
value: 76.354
- type: ndcg_at_1
value: 57.75
- type: ndcg_at_10
value: 42.509
- type: ndcg_at_100
value: 48.94
- type: ndcg_at_1000
value: 56.501000000000005
- type: ndcg_at_3
value: 46.827000000000005
- type: ndcg_at_5
value: 44.033
- type: precision_at_1
value: 70.25
- type: precision_at_10
value: 33.85
- type: precision_at_100
value: 11.373
- type: precision_at_1000
value: 2.136
- type: precision_at_3
value: 50.917
- type: precision_at_5
value: 42.8
- type: recall_at_1
value: 9.396
- type: recall_at_10
value: 26.472
- type: recall_at_100
value: 57.30800000000001
- type: recall_at_1000
value: 80.983
- type: recall_at_3
value: 15.859000000000002
- type: recall_at_5
value: 19.758
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 54.900000000000006
- type: f1
value: 48.14707395235448
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.369
- type: map_at_10
value: 76.708
- type: map_at_100
value: 76.981
- type: map_at_1000
value: 76.995
- type: map_at_3
value: 75.114
- type: map_at_5
value: 76.116
- type: mrr_at_1
value: 71.557
- type: mrr_at_10
value: 80.95
- type: mrr_at_100
value: 81.075
- type: mrr_at_1000
value: 81.07900000000001
- type: mrr_at_3
value: 79.728
- type: mrr_at_5
value: 80.522
- type: ndcg_at_1
value: 71.557
- type: ndcg_at_10
value: 81.381
- type: ndcg_at_100
value: 82.421
- type: ndcg_at_1000
value: 82.709
- type: ndcg_at_3
value: 78.671
- type: ndcg_at_5
value: 80.17
- type: precision_at_1
value: 71.557
- type: precision_at_10
value: 10.159
- type: precision_at_100
value: 1.089
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 30.668
- type: precision_at_5
value: 19.337
- type: recall_at_1
value: 66.369
- type: recall_at_10
value: 91.482
- type: recall_at_100
value: 95.848
- type: recall_at_1000
value: 97.749
- type: recall_at_3
value: 84.185
- type: recall_at_5
value: 87.908
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.902
- type: map_at_10
value: 34.554
- type: map_at_100
value: 36.632
- type: map_at_1000
value: 36.811
- type: map_at_3
value: 30.264000000000003
- type: map_at_5
value: 32.714999999999996
- type: mrr_at_1
value: 42.13
- type: mrr_at_10
value: 51.224000000000004
- type: mrr_at_100
value: 52.044999999999995
- type: mrr_at_1000
value: 52.075
- type: mrr_at_3
value: 48.842999999999996
- type: mrr_at_5
value: 50.108
- type: ndcg_at_1
value: 42.13
- type: ndcg_at_10
value: 42.643
- type: ndcg_at_100
value: 49.806
- type: ndcg_at_1000
value: 52.583
- type: ndcg_at_3
value: 38.927
- type: ndcg_at_5
value: 40.071
- type: precision_at_1
value: 42.13
- type: precision_at_10
value: 11.928999999999998
- type: precision_at_100
value: 1.931
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 26.337
- type: precision_at_5
value: 19.29
- type: recall_at_1
value: 20.902
- type: recall_at_10
value: 49.527
- type: recall_at_100
value: 75.754
- type: recall_at_1000
value: 92.171
- type: recall_at_3
value: 35.024
- type: recall_at_5
value: 41.207
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.831
- type: map_at_10
value: 63.958999999999996
- type: map_at_100
value: 64.869
- type: map_at_1000
value: 64.924
- type: map_at_3
value: 60.25
- type: map_at_5
value: 62.572
- type: mrr_at_1
value: 79.662
- type: mrr_at_10
value: 85.57900000000001
- type: mrr_at_100
value: 85.744
- type: mrr_at_1000
value: 85.748
- type: mrr_at_3
value: 84.718
- type: mrr_at_5
value: 85.312
- type: ndcg_at_1
value: 79.662
- type: ndcg_at_10
value: 72.366
- type: ndcg_at_100
value: 75.42999999999999
- type: ndcg_at_1000
value: 76.469
- type: ndcg_at_3
value: 67.258
- type: ndcg_at_5
value: 70.14099999999999
- type: precision_at_1
value: 79.662
- type: precision_at_10
value: 15.254999999999999
- type: precision_at_100
value: 1.763
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 43.358000000000004
- type: precision_at_5
value: 28.288999999999998
- type: recall_at_1
value: 39.831
- type: recall_at_10
value: 76.273
- type: recall_at_100
value: 88.163
- type: recall_at_1000
value: 95.017
- type: recall_at_3
value: 65.037
- type: recall_at_5
value: 70.722
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 93.13879999999999
- type: ap
value: 89.94638859649079
- type: f1
value: 93.13371537570421
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.482
- type: map_at_10
value: 33.635999999999996
- type: map_at_100
value: 34.792
- type: map_at_1000
value: 34.839999999999996
- type: map_at_3
value: 29.553
- type: map_at_5
value: 31.892
- type: mrr_at_1
value: 22.076999999999998
- type: mrr_at_10
value: 34.247
- type: mrr_at_100
value: 35.337
- type: mrr_at_1000
value: 35.38
- type: mrr_at_3
value: 30.208000000000002
- type: mrr_at_5
value: 32.554
- type: ndcg_at_1
value: 22.092
- type: ndcg_at_10
value: 40.657
- type: ndcg_at_100
value: 46.251999999999995
- type: ndcg_at_1000
value: 47.466
- type: ndcg_at_3
value: 32.353
- type: ndcg_at_5
value: 36.532
- type: precision_at_1
value: 22.092
- type: precision_at_10
value: 6.5040000000000004
- type: precision_at_100
value: 0.9329999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.719999999999999
- type: precision_at_5
value: 10.344000000000001
- type: recall_at_1
value: 21.482
- type: recall_at_10
value: 62.316
- type: recall_at_100
value: 88.283
- type: recall_at_1000
value: 97.554
- type: recall_at_3
value: 39.822
- type: recall_at_5
value: 49.805
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.63657090743274
- type: f1
value: 93.49355466580484
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 66.01459188326493
- type: f1
value: 48.48386472180784
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.49024882313383
- type: f1
value: 71.8750196914349
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.38063214525891
- type: f1
value: 76.87364042122763
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.30572302322684
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.18418556367587
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.268707296386154
- type: mrr
value: 33.481925531215055
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.586
- type: map_at_10
value: 14.954999999999998
- type: map_at_100
value: 19.03
- type: map_at_1000
value: 20.653
- type: map_at_3
value: 10.859
- type: map_at_5
value: 12.577
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 57.57
- type: mrr_at_100
value: 58.050000000000004
- type: mrr_at_1000
value: 58.083
- type: mrr_at_3
value: 55.212
- type: mrr_at_5
value: 56.713
- type: ndcg_at_1
value: 45.975
- type: ndcg_at_10
value: 38.432
- type: ndcg_at_100
value: 35.287
- type: ndcg_at_1000
value: 44.35
- type: ndcg_at_3
value: 43.077
- type: ndcg_at_5
value: 40.952
- type: precision_at_1
value: 47.368
- type: precision_at_10
value: 28.483000000000004
- type: precision_at_100
value: 8.882
- type: precision_at_1000
value: 2.217
- type: precision_at_3
value: 40.144000000000005
- type: precision_at_5
value: 35.17
- type: recall_at_1
value: 6.586
- type: recall_at_10
value: 19.688
- type: recall_at_100
value: 35.426
- type: recall_at_1000
value: 68.09100000000001
- type: recall_at_3
value: 12.234
- type: recall_at_5
value: 14.937000000000001
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.322000000000003
- type: map_at_10
value: 43.224000000000004
- type: map_at_100
value: 44.275999999999996
- type: map_at_1000
value: 44.308
- type: map_at_3
value: 38.239000000000004
- type: map_at_5
value: 41.244
- type: mrr_at_1
value: 31.025000000000002
- type: mrr_at_10
value: 45.635
- type: mrr_at_100
value: 46.425
- type: mrr_at_1000
value: 46.445
- type: mrr_at_3
value: 41.42
- type: mrr_at_5
value: 44.038
- type: ndcg_at_1
value: 30.997000000000003
- type: ndcg_at_10
value: 51.55499999999999
- type: ndcg_at_100
value: 55.964999999999996
- type: ndcg_at_1000
value: 56.657000000000004
- type: ndcg_at_3
value: 42.185
- type: ndcg_at_5
value: 47.229
- type: precision_at_1
value: 30.997000000000003
- type: precision_at_10
value: 8.885
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.457
- type: precision_at_5
value: 14.554
- type: recall_at_1
value: 27.322000000000003
- type: recall_at_10
value: 74.59400000000001
- type: recall_at_100
value: 93.699
- type: recall_at_1000
value: 98.76599999999999
- type: recall_at_3
value: 50.43
- type: recall_at_5
value: 62.073
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.109
- type: map_at_10
value: 85.137
- type: map_at_100
value: 85.759
- type: map_at_1000
value: 85.774
- type: map_at_3
value: 82.25200000000001
- type: map_at_5
value: 84.031
- type: mrr_at_1
value: 82.01
- type: mrr_at_10
value: 87.97
- type: mrr_at_100
value: 88.076
- type: mrr_at_1000
value: 88.076
- type: mrr_at_3
value: 87.06
- type: mrr_at_5
value: 87.694
- type: ndcg_at_1
value: 81.99
- type: ndcg_at_10
value: 88.738
- type: ndcg_at_100
value: 89.928
- type: ndcg_at_1000
value: 90.01400000000001
- type: ndcg_at_3
value: 86.042
- type: ndcg_at_5
value: 87.505
- type: precision_at_1
value: 81.99
- type: precision_at_10
value: 13.468
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.702999999999996
- type: precision_at_5
value: 24.706
- type: recall_at_1
value: 71.109
- type: recall_at_10
value: 95.58
- type: recall_at_100
value: 99.62299999999999
- type: recall_at_1000
value: 99.98899999999999
- type: recall_at_3
value: 87.69
- type: recall_at_5
value: 91.982
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 59.43361510023748
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.53582642500159
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.2299999999999995
- type: map_at_10
value: 11.802
- type: map_at_100
value: 14.454
- type: map_at_1000
value: 14.865
- type: map_at_3
value: 7.911
- type: map_at_5
value: 9.912
- type: mrr_at_1
value: 21.0
- type: mrr_at_10
value: 32.722
- type: mrr_at_100
value: 33.989000000000004
- type: mrr_at_1000
value: 34.026
- type: mrr_at_3
value: 28.65
- type: mrr_at_5
value: 31.075000000000003
- type: ndcg_at_1
value: 21.0
- type: ndcg_at_10
value: 20.161
- type: ndcg_at_100
value: 30.122
- type: ndcg_at_1000
value: 36.399
- type: ndcg_at_3
value: 17.881
- type: ndcg_at_5
value: 16.439999999999998
- type: precision_at_1
value: 21.0
- type: precision_at_10
value: 10.94
- type: precision_at_100
value: 2.5340000000000003
- type: precision_at_1000
value: 0.402
- type: precision_at_3
value: 17.067
- type: precision_at_5
value: 15.120000000000001
- type: recall_at_1
value: 4.2299999999999995
- type: recall_at_10
value: 22.163
- type: recall_at_100
value: 51.42
- type: recall_at_1000
value: 81.652
- type: recall_at_3
value: 10.353
- type: recall_at_5
value: 15.323
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.44056731476951
- type: cos_sim_spearman
value: 82.32974396072802
- type: euclidean_pearson
value: 83.63616080755894
- type: euclidean_spearman
value: 82.32974071069209
- type: manhattan_pearson
value: 83.64149958303744
- type: manhattan_spearman
value: 82.32161014878858
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.65083720426293
- type: cos_sim_spearman
value: 77.60786500521749
- type: euclidean_pearson
value: 81.8149634918642
- type: euclidean_spearman
value: 77.60637450428892
- type: manhattan_pearson
value: 81.83507575657566
- type: manhattan_spearman
value: 77.613220311151
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 87.35683624595698
- type: cos_sim_spearman
value: 87.94550696434106
- type: euclidean_pearson
value: 87.50272679030367
- type: euclidean_spearman
value: 87.94550696434106
- type: manhattan_pearson
value: 87.4759786099497
- type: manhattan_spearman
value: 87.90226811166427
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.27438743391316
- type: cos_sim_spearman
value: 83.85378984594779
- type: euclidean_pearson
value: 85.25840635223642
- type: euclidean_spearman
value: 83.85378983163673
- type: manhattan_pearson
value: 85.24936075631025
- type: manhattan_spearman
value: 83.85052479958138
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.4783814521557
- type: cos_sim_spearman
value: 88.473284566453
- type: euclidean_pearson
value: 87.94757741870404
- type: euclidean_spearman
value: 88.47327698999878
- type: manhattan_pearson
value: 87.93617414057984
- type: manhattan_spearman
value: 88.45889274229359
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.68359147631057
- type: cos_sim_spearman
value: 86.46426572535646
- type: euclidean_pearson
value: 85.98303971468599
- type: euclidean_spearman
value: 86.46426572535646
- type: manhattan_pearson
value: 85.95109710640726
- type: manhattan_spearman
value: 86.43282632541583
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.88758959688604
- type: cos_sim_spearman
value: 88.70384784133324
- type: euclidean_pearson
value: 89.27293800474978
- type: euclidean_spearman
value: 88.70384784133324
- type: manhattan_pearson
value: 89.41494348093664
- type: manhattan_spearman
value: 88.8330050824941
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.66759812551814
- type: cos_sim_spearman
value: 68.02368115471576
- type: euclidean_pearson
value: 69.52859542757353
- type: euclidean_spearman
value: 68.02368115471576
- type: manhattan_pearson
value: 69.50332399468952
- type: manhattan_spearman
value: 67.91228681203849
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.75891320010409
- type: cos_sim_spearman
value: 88.33063922402347
- type: euclidean_pearson
value: 88.02964654543274
- type: euclidean_spearman
value: 88.33063922402347
- type: manhattan_pearson
value: 88.03029440701458
- type: manhattan_spearman
value: 88.3158691488696
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.46897310470844
- type: mrr
value: 96.29042072669523
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.261
- type: map_at_10
value: 71.023
- type: map_at_100
value: 71.5
- type: map_at_1000
value: 71.518
- type: map_at_3
value: 67.857
- type: map_at_5
value: 69.44500000000001
- type: mrr_at_1
value: 65.0
- type: mrr_at_10
value: 72.11
- type: mrr_at_100
value: 72.479
- type: mrr_at_1000
value: 72.49600000000001
- type: mrr_at_3
value: 69.722
- type: mrr_at_5
value: 71.02199999999999
- type: ndcg_at_1
value: 65.0
- type: ndcg_at_10
value: 75.40599999999999
- type: ndcg_at_100
value: 77.41
- type: ndcg_at_1000
value: 77.83200000000001
- type: ndcg_at_3
value: 69.95599999999999
- type: ndcg_at_5
value: 72.296
- type: precision_at_1
value: 65.0
- type: precision_at_10
value: 9.966999999999999
- type: precision_at_100
value: 1.097
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.667
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 62.261
- type: recall_at_10
value: 87.822
- type: recall_at_100
value: 96.833
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 73.06099999999999
- type: recall_at_5
value: 78.88300000000001
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86138613861387
- type: cos_sim_ap
value: 96.7851799601876
- type: cos_sim_f1
value: 92.94354838709677
- type: cos_sim_precision
value: 93.69918699186992
- type: cos_sim_recall
value: 92.2
- type: dot_accuracy
value: 99.86138613861387
- type: dot_ap
value: 96.78517996018759
- type: dot_f1
value: 92.94354838709677
- type: dot_precision
value: 93.69918699186992
- type: dot_recall
value: 92.2
- type: euclidean_accuracy
value: 99.86138613861387
- type: euclidean_ap
value: 96.78517996018759
- type: euclidean_f1
value: 92.94354838709677
- type: euclidean_precision
value: 93.69918699186992
- type: euclidean_recall
value: 92.2
- type: manhattan_accuracy
value: 99.86336633663366
- type: manhattan_ap
value: 96.79790073128503
- type: manhattan_f1
value: 93.0930930930931
- type: manhattan_precision
value: 93.18637274549098
- type: manhattan_recall
value: 93.0
- type: max_accuracy
value: 99.86336633663366
- type: max_ap
value: 96.79790073128503
- type: max_f1
value: 93.0930930930931
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.07696952556874
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.51701116515262
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.40099299306496
- type: mrr
value: 56.411316420507596
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.940008734510055
- type: cos_sim_spearman
value: 31.606997026865212
- type: dot_pearson
value: 30.940010256206353
- type: dot_spearman
value: 31.62194110302714
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.197
- type: map_at_10
value: 1.6549999999999998
- type: map_at_100
value: 8.939
- type: map_at_1000
value: 22.402
- type: map_at_3
value: 0.587
- type: map_at_5
value: 0.931
- type: mrr_at_1
value: 74.0
- type: mrr_at_10
value: 84.667
- type: mrr_at_100
value: 84.667
- type: mrr_at_1000
value: 84.667
- type: mrr_at_3
value: 83.667
- type: mrr_at_5
value: 84.667
- type: ndcg_at_1
value: 69.0
- type: ndcg_at_10
value: 66.574
- type: ndcg_at_100
value: 51.074
- type: ndcg_at_1000
value: 47.263
- type: ndcg_at_3
value: 71.95
- type: ndcg_at_5
value: 70.52000000000001
- type: precision_at_1
value: 74.0
- type: precision_at_10
value: 70.39999999999999
- type: precision_at_100
value: 52.580000000000005
- type: precision_at_1000
value: 20.93
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 75.6
- type: recall_at_1
value: 0.197
- type: recall_at_10
value: 1.92
- type: recall_at_100
value: 12.655
- type: recall_at_1000
value: 44.522
- type: recall_at_3
value: 0.639
- type: recall_at_5
value: 1.03
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.735
- type: map_at_10
value: 9.064
- type: map_at_100
value: 15.021999999999998
- type: map_at_1000
value: 16.596
- type: map_at_3
value: 4.188
- type: map_at_5
value: 6.194999999999999
- type: mrr_at_1
value: 26.531
- type: mrr_at_10
value: 44.413000000000004
- type: mrr_at_100
value: 45.433
- type: mrr_at_1000
value: 45.452999999999996
- type: mrr_at_3
value: 41.497
- type: mrr_at_5
value: 42.925000000000004
- type: ndcg_at_1
value: 22.448999999999998
- type: ndcg_at_10
value: 22.597
- type: ndcg_at_100
value: 34.893
- type: ndcg_at_1000
value: 46.763
- type: ndcg_at_3
value: 24.366
- type: ndcg_at_5
value: 23.959
- type: precision_at_1
value: 26.531
- type: precision_at_10
value: 21.02
- type: precision_at_100
value: 7.51
- type: precision_at_1000
value: 1.541
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 25.306
- type: recall_at_1
value: 1.735
- type: recall_at_10
value: 15.870999999999999
- type: recall_at_100
value: 47.385
- type: recall_at_1000
value: 83.55
- type: recall_at_3
value: 5.813
- type: recall_at_5
value: 9.707
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.19
- type: ap
value: 15.106812062408629
- type: f1
value: 55.254852511954255
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.553480475382
- type: f1
value: 61.697424438626435
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.12092298453447
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.35173153722357
- type: cos_sim_ap
value: 78.22985044080261
- type: cos_sim_f1
value: 71.23356926188069
- type: cos_sim_precision
value: 68.36487142163999
- type: cos_sim_recall
value: 74.35356200527704
- type: dot_accuracy
value: 87.35173153722357
- type: dot_ap
value: 78.22985958574529
- type: dot_f1
value: 71.23356926188069
- type: dot_precision
value: 68.36487142163999
- type: dot_recall
value: 74.35356200527704
- type: euclidean_accuracy
value: 87.35173153722357
- type: euclidean_ap
value: 78.22985909816191
- type: euclidean_f1
value: 71.23356926188069
- type: euclidean_precision
value: 68.36487142163999
- type: euclidean_recall
value: 74.35356200527704
- type: manhattan_accuracy
value: 87.36365261965786
- type: manhattan_ap
value: 78.18108280854142
- type: manhattan_f1
value: 71.19958634953466
- type: manhattan_precision
value: 69.79219462747086
- type: manhattan_recall
value: 72.66490765171504
- type: max_accuracy
value: 87.36365261965786
- type: max_ap
value: 78.22985958574529
- type: max_f1
value: 71.23356926188069
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.71424690495596
- type: cos_sim_ap
value: 85.53000600450122
- type: cos_sim_f1
value: 77.95508274231679
- type: cos_sim_precision
value: 74.92189718829879
- type: cos_sim_recall
value: 81.24422543886665
- type: dot_accuracy
value: 88.71424690495596
- type: dot_ap
value: 85.53000387261983
- type: dot_f1
value: 77.95508274231679
- type: dot_precision
value: 74.92189718829879
- type: dot_recall
value: 81.24422543886665
- type: euclidean_accuracy
value: 88.71424690495596
- type: euclidean_ap
value: 85.53000527321076
- type: euclidean_f1
value: 77.95508274231679
- type: euclidean_precision
value: 74.92189718829879
- type: euclidean_recall
value: 81.24422543886665
- type: manhattan_accuracy
value: 88.7297706368611
- type: manhattan_ap
value: 85.49670114967172
- type: manhattan_f1
value: 77.91265729089562
- type: manhattan_precision
value: 75.01425313568986
- type: manhattan_recall
value: 81.04404065291038
- type: max_accuracy
value: 88.7297706368611
- type: max_ap
value: 85.53000600450122
- type: max_f1
value: 77.95508274231679
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1196 with parameters:
```
{'batch_size': 10, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 50,
"evaluator": "sentence_transformers.evaluation.InformationRetrievalEvaluator.InformationRetrievalEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 598,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned_chatGPT
|
behzadnet
| 2023-11-14T15:32:59Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-14T15:32:56Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
Jiahahaha/output_dogs
|
Jiahahaha
| 2023-11-14T15:32:52Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-14T15:01:37Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of sks dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Jiahahaha/output_dogs
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned-adapters_chatGPT
|
behzadnet
| 2023-11-14T15:32:46Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-14T15:32:42Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
BobaZooba/WGPT
|
BobaZooba
| 2023-11-14T15:32:03Z | 10 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"arxiv:2303.10512",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-15T16:24:09Z |
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
---
# WeatherGPT: Generate valid JSON from weather descriptions
Repository: https://github.com/BobaZooba/wgpt
This repository features an example of how to utilize the `xllm` library. Included is a solution for a common type of assessment given to LLM engineers, who typically earn between $120,000 to $140,000 annually. The work, which took 6-7 hours to complete, is representative of actual tasks in the field.
[<img src="https://cdn-uploads.huggingface.co/production/uploads/6074d5f1134c000d1ae10d42/JudU3rrPP5i87CfwINANO.png" alt="Powered by X—LLM" width="175" height="32"/>](https://github.com/BobaZooba/xllm)
# Task
Convert weather description to valid JSON using LLM
### Example
**Description:** Today will be mostly sunny with temperatures reaching 25 degrees. There will be a strong wind blowing at 30 km/h. Humidity levels are unknown and there is no precipitation expected.
**JSON**
```json
{
"weather": "sunny",
"temperature": 25,
"wind_speed": 30.0,
"humidity": null,
"precipitation": null,
"visibility": "good",
"air_quality": null,
"real_feel_temperature": null
}
```
# Installation
Run in terminal:
```bash
pip install -e .
```
## Environment
Python3.8+, CUDA 11.8
**Suggested docker:** huggingface/transformers-pytorch-gpu:latest
All entry points at **Makefile**
# Implementation
- Generate data
- ChatGPT with few-shot variable examples
- Train model
- QLoRA
- DeepSpeed Stage 2
- 4 bit quantization
- Gradient checkpointing
- Mistal AI 7B
- Evaluate
- Output can be parsed
- ChatGPT labeling
# Reproduce
1. Install requirements
```sh
make install
```
2. Make **.env** and fill it with your values (please take a look at _.env.template_)
3. _[Optional]_ Generate data
```sh
make generate-data
```
Also example data is provided in _data_ folder
4. Prepare data and model
```sh
make prepare
```
5. Train the model
```sh
make train
```
Or train with DeepSpeed (if you have multiple GPUs, please specify `CUDA_VISIBLE_DEVICES` to use only one)
```sh
make train-deepspeed
```
6. Fuse LoRA weights
```sh
make fuse
```
7. Evaluate
```sh
make evaluate
```
# Data generation
### Why generated?
- ChatGPT was chosen for data collection because I couldn't find similar datasets and because this method scales to other domains and many companies will need to do this in one way or another
- Previously, NLP engineers suffered from the lack of datasets, but now they can be generated and this will serve as a great starting point for problem-solving
- The cost of compiling the initial dataset has decreased from thousands of dollars to a few bucks
## Prompt
Please also check `wgpt/core/prompts.py`
### Example
```txt
Your task is to create diverse examples where a free-form description of weather is translated into a JSON file format.
Each description should be between 2 to 5 sentences long with as much diversity as possible. Feel free to omit some fields, add new information, or write in a variety of styles.
The JSON format requires the following fields: weather (str), temperature (int), wind_speed (float), humidity (float), precipitation (str), visibility (str), air_quality (str), and real_feel_temperature (int). If any value is unknown, use null.
The "temperature" and "real_feel_temperature" should be in degrees, wind_speed should be in kilometers per hour, and "humidity" is in percentage. The fields "weather", "precipitation", "visibility" should be single word descriptions.
The format of your answer should be: 1. Input: ...
Output: ...
2. Input: ...
Output: ...
Examples:
1. Input: The skies are clear with a temperature of about 25 degrees. The wind is blowing gently at around 7kph. Visibility is high and the air is quite dry with a humidity around 30%. There's no precipitation. Feels like it's exactly 25 degrees. The air quality is very good today.
Output: {"weather": "clear", "temperature": 25, "wind_speed": 7.0, "humidity": 30.0, "precipitation": "none", "visibility": "high", "air_quality": "good", "real_feel_temperature": 25}
2. Input: It's snowing outside and the temperature is -5 degrees. There's a strong wind blowing at 25kph. Visibility is very low because of the snow. Humidity is around 80%. Air quality is moderate today. The real feel is much lower at -10 degrees due to wind chill.
Output: {"weather": "snow", "temperature": -5, "wind_speed": 25.0, "humidity": 80.0, "precipitation": "snow", "visibility": "low", "air_quality": "moderate", "real_feel_temperature": -10}
3. Input: Expect a cloudy evening with a temperature of about 18 degrees. There is a slight chance of light showers, and the wind is gentle at 5 km/h.
Output: {"weather": "cloudy", "temperature": 18, "wind_speed": 5.0, "humidity": null, "precipitation": "light", "visibility": "good", "air_quality": null, "real_feel_temperature": null}
You need to create a dataset where plain text weather descriptions are converted into valid JSON files. Provide {num_samples} diverse samples similar to the example given.
```
<details>
<summary>Detailed explanation</summary>
#### Task
```txt
Your task is to create diverse examples where a free-form description of weather is translated into a JSON file format.
```
#### Description requirements
```txt
Each description should be between 2 to 5 sentences long with as much diversity as possible. Feel free to omit some fields, add new information, or write in a variety of styles.
```
#### JSON and fields requirements
```txt
The JSON format requires the following fields: weather (str), temperature (int), wind_speed (float), humidity (float), precipitation (str), visibility (str), air_quality (str), and real_feel_temperature (int). If any value is unknown, use null.
The "temperature" and "real_feel_temperature" should be in degrees, wind_speed should be in kilometers per hour, and "humidity" is in percentage. The fields "weather", "precipitation", "visibility" should be single word descriptions.
```
#### Format of response
```txt
The format of your answer should be:
1. Input: ...
Output: ...
2. Input: ...
Output: ...
```
#### Few-shot examples
Randomly selected from 3 to 5 of the pre-prepared. It is necessary to provide variety and explain the task.
```txt
Examples:
1. Input: The skies are clear with a temperature of about 25 degrees. The wind is blowing gently at around 7kph. Visibility is high and the air is quite dry with a humidity around 30%. There's no precipitation. Feels like it's exactly 25 degrees. The air quality is very good today.
Output: {"weather": "clear", "temperature": 25, "wind_speed": 7.0, "humidity": 30.0, "precipitation": "none", "visibility": "high", "air_quality": "good", "real_feel_temperature": 25}
2. Input: It's snowing outside and the temperature is -5 degrees. There's a strong wind blowing at 25kph. Visibility is very low because of the snow. Humidity is around 80%. Air quality is moderate today. The real feel is much lower at -10 degrees due to wind chill.
Output: {"weather": "snow", "temperature": -5, "wind_speed": 25.0, "humidity": 80.0, "precipitation": "snow", "visibility": "low", "air_quality": "moderate", "real_feel_temperature": -10}
3. Input: Expect a cloudy evening with a temperature of about 18 degrees. There is a slight chance of light showers, and the wind is gentle at 5 km/h.
Output: {"weather": "cloudy", "temperature": 18, "wind_speed": 5.0, "humidity": null, "precipitation": "light", "visibility": "good", "air_quality": null, "real_feel_temperature": null}
```
#### Direct call to action
Also, indicating the number of desired examples
```txt
You need to create a dataset where plain text weather descriptions are converted into valid JSON files. Provide {num_samples} diverse samples similar to the example given.
```
</details>
### Example of output
```txt
1. Input: The sun is shining brightly with a temperature reaching a scorching 38 degrees. There is a moderate breeze blowing at a speed of 15kph. Visibility is clear with no obstructions. Humidity is quite low at around 20%. No precipitation is expected. The real feel temperature is similar to the actual temperature.
Output: {"weather": "sunny", "temperature": 38, "wind_speed": 15.0, "humidity": 20.0, "precipitation": "none", "visibility": "clear", "air_quality": null, "real_feel_temperature": 38}
2. Input: It's a hot and humid day with a temperature of 32 degrees. There is no wind present and the air is quite heavy. Visibility is reduced due to haze. Humidity is extremely high at around 90%. No precipitation is predicted. The real feel temperature is slightly higher at 34 degrees.
Output: {"weather": null, "temperature": 32, "wind_speed": null, "humidity": 90.0, "precipitation": null, "visibility": "reduced", "air_quality": null, "real_feel_temperature": 34}
3. Input: The weather today is cloudy with a temperature of 22 degrees. A light breeze is blowing at 10kph. Visibility is good and there is no precipitation expected. Humidity is moderate at around 50%. The real feel temperature is the same as the actual temperature.
Output: {"weather": "cloudy", "temperature": 22, "wind_speed": 10.0, "humidity": 50.0, "precipitation": "none", "visibility": "good", "air_quality": null, "real_feel_temperature": 22}
4. Input: It's a gloomy day with overcast skies. The temperature is a chilly 8 degrees. Strong winds are howling at 40kph. Visibility is reduced due to fog. Humidity is high at 85%. Light rain is expected. The real feel temperature is lower at 5 degrees due to wind chill.
Output: {"weather": "overcast", "temperature": 8, "wind_speed": 40.0, "humidity": 85.0, "precipitation": "rain", "visibility": "reduced", "air_quality": null, "real_feel_temperature": 5}
5. Input: Enjoy a beautiful spring day with clear blue skies and a temperature of 20 degrees. A gentle breeze is rustling the leaves at 12kph. Visibility is excellent with no obstructions. Humidity is moderate at 55%. No precipitation is expected. The real feel temperature matches the actual temperature.
Output: {"weather": "clear", "temperature": 20, "wind_speed": 12.0, "humidity": 55.0, "precipitation": "none", "visibility": "excellent", "air_quality": null, "real_feel_temperature": 20}
```
## Results of data generation
- There were 5848 examples generated for training (including the validation set), which took about 10 minutes
- The ChatGPT model was used because it is 30 times cheaper and much faster. In real projects, I would use ChatGPT, GPT4, as well as open models, to obtain as diverse a dataset as possible
- The examples turned out to be quite lively and met the requirements of the task
# Training
- Model: [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- Boilerplate (QLoRA, DeepSpeed Stage 2, 4 bit quantization, Gradient checkpointing): [xllm](https://github.com/BobaZooba/xllm)
`xllm` is a user-friendly library that streamlines training optimization, so you can focus on enhancing your models and data. Equipped with cutting-edge training techniques, `xllm` is engineered for efficiency by engineers who understand your needs.
[<img src="https://github.com/BobaZooba/xllm/blob/main/static/images/xllm-badge.png" alt="Powered by X—LLM" width="175" height="32"/>](https://github.com/BobaZooba/xllm)
### Methods
- **QLoRA (and 4 bit bnb quantization)**. The preferred method of fine-tuning, as it usually ensures a higher quality than full fine-tuning due to effective management of catastrophic forgetting. And of course, it optimizes the memory utilized during training
- I use LoRA for all linear layers except lm_head and embeddings
- The original paper does not investigate which layers are better to apply. Please check [AdaLoRA paper](https://arxiv.org/pdf/2303.10512.pdf)
- I also use a fairly high rank for low-rank optimization: 64 (alpha is 32)
- **DeepSpeed Stage 2 (with CPU offloading)**. I'm using Deepspeed for training on multiple GPUs. Stage 2 was used because there are observed issues with the use of Stage 3 and quantized models
- **Gradient Checkpointing**. Very strong optimization of used memory at the expense of slowing down training
### `xllm` details
In the xllm library, there are several important steps: prepare, train, fuse, quantize
- **Prepare**. The data preprocessing and model download step has been separated to avoid doing it on each of the processes in distributed learning mode
- **Train**. Training the model and saving checkpoints. I save checkpoints in HuggingFace Hub. Since I am training through LoRA, those weights are specifically saved.
- **Fuse**. Fusing LoRA weights with the backbone model and push it to HF Hub
- _[Optional]_ **Quantize**. GPTQ quantization of the model
### Task details
I only calculated the loss for the json part, didn't calculate it for the description

### Results of the training
- [LoRA weights](https://huggingface.co/BobaZooba/WGPT-LoRA)
- [Fused model](https://huggingface.co/BobaZooba/WGPT)
- [W&B link](https://api.wandb.ai/links/bobazooba/8v7pqflf)

# Evaluation
## Metrics
### Why no BLEU / ROUGE / etc?
I have been evaluating generative models for several years and believe that currently using n-gram methods to evaluate generative models is an extremely poor practice. BertScore is also not a sufficiently good method. Currently, there are only two good ways to evaluate generative models: human evaluation and emulation of human evaluation (GPT-like instructional models and training of rankers/classifiers on human evaluations).
### Output can be parsed
Simple proxy metric: we try to parse the model's response. We calculate the percentage of responses that we were able to parse
### ChatGPT labeling
Emulation of human assessment. ChatGPT is given an instruction and the output of my model. ChatGPT must provide one of several responses: the correct answer, there are minor inaccuracies, incorrect answer. In real projects, I would use only GPT-4, but it is too expensive.
#### ChatGPT labeling instruction
```txt
Your task is to validate whether the model has correctly parsed the weather description into JSON. The model was given a free-form weather description in natural language. Its task was to transform this description into valid JSON. Your job: understand whether the model has correctly parsed what was stated in the text, whether it correctly filled in the fields, with the correct values.
The JSON format requires the following fields: weather (str), temperature (int), wind_speed (float), humidity (float), precipitation (str), visibility (str), air_quality (str), and real_feel_temperature (int). If any value is unknown, use null.
The "temperature" and "real_feel_temperature" should be in degrees, wind_speed should be in kilometers per hour, and "humidity" is in percentage. The fields "weather", "precipitation", "visibility" should be single word descriptions.
Weather description: {weather_description}
Model response: {model_response}
Ground truth: {ground_truth}
You need to consider whether the model has parsed the answer correctly and give your assessment. The rating options can only be: correct, minor inaccuracies, incorrect.
Format of your answer.
Reasoning: ...
Assessment: ...
```
## Results
Output can be parsed: **100%**
### ChatGPT labeling
|Correct|Minor inaccuracies|Incorrect|
|-|-|-|
|48%|51%|1%|
# Future works
- Improve evaluation
- Need to add a method that compares the JSON response with the generated JSON. We know the types of fields. For numeric fields, you should use MSE, and for text fields, you should use the proximity of text embeddings, having previously selected the model
- If the quality of the current model is satisfactory, it should be deployed into production (in a quantized version) using TGI at least for a limited number of users.
- It is crucial to gather real data from production to fine-tune the model. Then these data need to be labeled, train a discriminator model (which would assess the quality of responses), filter the data and further train the model. For this task, I wouldn't apply RL, only the ReST ([link](It is crucial to gather real data from production to fine-tune the model. Then these data need to be labeled, train a discriminator model (which would assess the quality of responses), filter the data and further train the model. For this task, I wouldn't apply RL, only the ReST (link) method, which I would improve. Such actions on labeling and further training should be performed regularly. Ideally, an infrastructure for constant retraining should be developed. The recommended frequency depends on the traffic volumes. Usually, for manual re-learning the frequency is monthly, for automatic – weekly. Also, because we apply labeling, we can track model improvements. This will be particularly useful when the labeling instruction is stabilized. With the help of the discriminator we can adjust the hyperparameters for training and inference, for example, generation parameters. Also, with the discriminator, we can immediately assess several hypotheses from the generative model and deliver only the best one to the user. Currently, this method is not widely used due to the significantly increasing load on the generative model, so I would focus on the further training of the generative model using the discriminator.)) method, which I would improve. Such actions on labeling and further training should be performed regularly. Ideally, an infrastructure for constant retraining should be developed. The recommended frequency depends on the traffic volumes. Usually, for manual re-learning the frequency is monthly, for automatic – weekly. Also, because we apply labeling, we can track model improvements. This will be particularly useful when the labeling instruction is stabilized. With the help of the discriminator we can adjust the hyperparameters for training and inference, for example, generation parameters. Also, with the discriminator, we can immediately assess several hypotheses from the generative model and deliver only the best one to the user. Currently, this method is not widely used due to the significantly increasing load on the generative model, so I would focus on the further training of the generative model using the discriminator.
- If the quality of the current model is not satisfactory, similar steps will need to be taken with synthetic data, deploy it into production, and then perform the same steps with the data from production.
|
openspeech/wenet-models
|
openspeech
| 2023-11-14T15:28:11Z | 0 | 2 | null |
[
"region:us"
] | null | 2023-11-14T15:06:13Z |
# Introduciton
Models in this repo are downloaded from
https://github.com/wenet-e2e/wenet/blob/main/docs/pretrained_models.en.md#model-list
|
npk7264/autobanner-v1-0
|
npk7264
| 2023-11-14T15:25:23Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-14T14:05:57Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - npk7264/autobanner-v1-1
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the npk7264/AutoBanner dataset. You can find some example images in the following.




|
chandhinipriya/xzg
|
chandhinipriya
| 2023-11-14T15:22:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T15:18:13Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### xzg Dreambooth model trained by chandhinipriya following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-324
Sample pictures of this concept:

|
abrahamtek/ppo-Huggy
|
abrahamtek
| 2023-11-14T15:22:02Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-14T15:21:56Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: abrahamtek/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Luciano/Llama-2-7b-chat-hf-miniguanaco
|
Luciano
| 2023-11-14T15:21:31Z | 6 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2023-08-31T11:15:50Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
Luciano/Llama-2-7b-chat-hf-miniguanaco-adapter
|
Luciano
| 2023-11-14T15:18:00Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-14T15:17:53Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
emilstabil/mt5-base-finetuned-test_63829_prefix_summarize
|
emilstabil
| 2023-11-14T15:09:37Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/mt5-base",
"base_model:finetune:google/mt5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-14T13:41:12Z |
---
license: apache-2.0
base_model: google/mt5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-base-finetuned-test_63829_prefix_summarize
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-test_63829_prefix_summarize
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3498
- Rouge1: 11.28
- Rouge2: 3.5248
- Rougel: 9.174
- Rougelsum: 10.6313
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 7.6624 | 1.25 | 500 | 2.6231 | 7.333 | 2.0471 | 6.2456 | 7.0157 | 14.01 |
| 3.3306 | 2.5 | 1000 | 2.5079 | 10.5135 | 3.0104 | 8.4645 | 9.8798 | 19.0 |
| 3.1123 | 3.75 | 1500 | 2.4512 | 10.5261 | 3.3739 | 8.6176 | 9.8711 | 19.0 |
| 2.9927 | 5.0 | 2000 | 2.4137 | 11.14 | 3.5973 | 9.2204 | 10.407 | 19.0 |
| 2.8765 | 6.25 | 2500 | 2.4050 | 10.9669 | 3.7633 | 9.1517 | 10.283 | 19.0 |
| 2.8211 | 7.5 | 3000 | 2.3828 | 11.6779 | 4.181 | 9.8295 | 10.9657 | 19.0 |
| 2.7589 | 8.75 | 3500 | 2.3756 | 11.6097 | 4.1335 | 9.7619 | 10.8368 | 19.0 |
| 2.722 | 10.0 | 4000 | 2.3627 | 11.8385 | 4.0634 | 9.6721 | 10.9386 | 19.0 |
| 2.6781 | 11.25 | 4500 | 2.3611 | 11.3415 | 3.5812 | 9.1328 | 10.6537 | 19.0 |
| 2.6648 | 12.5 | 5000 | 2.3524 | 11.3808 | 3.6088 | 9.2331 | 10.6316 | 19.0 |
| 2.6404 | 13.75 | 5500 | 2.3521 | 11.3031 | 3.5165 | 9.1629 | 10.6573 | 19.0 |
| 2.6397 | 15.0 | 6000 | 2.3498 | 11.28 | 3.5248 | 9.174 | 10.6313 | 19.0 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
softwareweaver/westernanimation
|
softwareweaver
| 2023-11-14T14:52:47Z | 1 | 0 |
diffusers
|
[
"diffusers",
"onnx",
"art",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"diffusers:OnnxStableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-03T17:45:11Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- art
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Olive Optimized Onnx model for https://civitai.com/models/86546
This model is being used by Fusion Quill - a Windows app that runs Stable Diffusion models locally.
https://FusionQuill.AI
|
softwareweaver/photon
|
softwareweaver
| 2023-11-14T14:52:21Z | 208 | 1 |
diffusers
|
[
"diffusers",
"onnx",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"diffusers:OnnxStableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-03T17:15:35Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
# Model Card for Model ID
Olive Optimized Onnx model for https://civitai.com/models/84728
This model is being used by Fusion Quill - a Windows app that runs Stable Diffusion models locally.
https://FusionQuill.AI
|
softwareweaver/dreamlabsoil
|
softwareweaver
| 2023-11-14T14:52:07Z | 1 | 0 |
diffusers
|
[
"diffusers",
"onnx",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"diffusers:OnnxStableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-03T17:41:26Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Olive Optimized Onnx model for https://civitai.com/models/50718
This model is being used by Fusion Quill - a Windows app that runs Stable Diffusion models locally.
https://FusionQuill.AI
|
softwareweaver/dreamshaper
|
softwareweaver
| 2023-11-14T14:51:47Z | 2 | 0 |
diffusers
|
[
"diffusers",
"onnx",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"diffusers:OnnxStableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-03T17:28:52Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Olive Optimized Onnx model for https://civitai.com/models/4384
This model is being used by Fusion Quill - a Windows app that runs Stable Diffusion models locally.
https://FusionQuill.AI
|
rafay/ppo-LunarLander-v2
|
rafay
| 2023-11-14T14:51:27Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-05-28T17:15:28Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 279.34 +/- 20.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
softwareweaver/realcartoon-pixar
|
softwareweaver
| 2023-11-14T14:51:15Z | 5 | 1 |
diffusers
|
[
"diffusers",
"onnx",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"diffusers:OnnxStableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-03T14:10:51Z |
---
license: creativeml-openrail-m
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Olive Optimized Onnx model for https://civitai.com/models/107289
This model is being used by Fusion Quill - a Windows app that runs Stable Diffusion models locally.
https://FusionQuill.AI
|
kwwww/bert-base-uncased-test_2_5000
|
kwwww
| 2023-11-14T14:31:53Z | 0 | 0 |
peft
|
[
"peft",
"pytorch",
"region:us"
] | null | 2023-11-14T04:47:20Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
jayavardhan31/t5_recommendation_sports_equipment_english
|
jayavardhan31
| 2023-11-14T14:27:29Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-14T14:16:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_recommendation_sports_equipment_english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_recommendation_sports_equipment_english
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4517
- Rouge1: 57.9365
- Rouge2: 47.6190
- Rougel: 57.4603
- Rougelsum: 57.4603
- Gen Len: 3.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 0.96 | 6 | 6.7882 | 8.7668 | 0.9524 | 8.8278 | 8.8278 | 19.0 |
| No log | 1.96 | 12 | 2.3412 | 18.0952 | 0.0 | 18.5714 | 18.0952 | 3.2381 |
| No log | 2.96 | 18 | 0.8550 | 11.9048 | 4.7619 | 11.9048 | 11.9048 | 4.0 |
| No log | 3.96 | 24 | 0.7481 | 32.5397 | 4.7619 | 32.0635 | 32.2222 | 3.9048 |
| No log | 4.96 | 30 | 0.7208 | 21.3492 | 4.7619 | 21.2698 | 21.4286 | 3.6190 |
| No log | 5.96 | 36 | 0.6293 | 31.7460 | 23.8095 | 31.7460 | 31.7460 | 3.6667 |
| No log | 6.96 | 42 | 0.6203 | 42.8571 | 33.3333 | 43.1746 | 42.6190 | 3.9048 |
| No log | 7.96 | 48 | 0.6352 | 47.6190 | 33.3333 | 47.6190 | 47.6190 | 3.8095 |
| No log | 8.96 | 54 | 0.5334 | 52.6984 | 42.8571 | 52.3810 | 52.3810 | 3.9524 |
| No log | 9.96 | 60 | 0.4517 | 57.9365 | 47.6190 | 57.4603 | 57.4603 | 3.9048 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.1.0+cu118
- Datasets 2.8.0
- Tokenizers 0.13.3
|
sainteye/ifoodie-menu-v3.1
|
sainteye
| 2023-11-14T14:22:48Z | 903 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-14T14:22:44Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ifoodie-menu-v3.1
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9375
---
# ifoodie-menu-v3.1
['優質', '差', '廣告', '普通']
## Example Images
# #### 優質
# 
#
# #### 差
# 
#
# #### 廣告
# 
#
# #### 普通
# 
#
|
IMFAA/Magnet_Tc_predictor
|
IMFAA
| 2023-11-14T14:21:33Z | 0 | 1 |
sklearn
|
[
"sklearn",
"joblib",
"Voting_regressor",
"tabular-regression",
"materials property prediction",
"baseline-trainer",
"doi:10.57967/hf/0148",
"region:us"
] |
tabular-regression
| 2022-11-28T13:19:06Z |
---
library_name: sklearn
tags:
- tabular-regression
- materials property prediction
- baseline-trainer
---
**Model Description**
The magnet Curie temperature (Tc [K]) predictor model has been trained using a supervised learning approach on a specific set of magnet classes having 14:2:1 phases.
The dataset to train the Tc prediction model is a distinct literature source.
Further, the Tc values for various 14:2:1 magnet phases at room temperature are considered for dataset creation.
It predicts the Tc value using the chemical composition as a feature.
E.g: To predict the Tc value Nd2Fe14B1 magnet composition, the features are Nd=2, Fe=14, and B=1.
**Application & Limitations**
Input feature as the chemical composition of the test sample should match the sequence of the features described in the config file.
The trained model is valid for 14:2:1 phases only, which are stoichiometric compositions and the predicted Tc value is in Kelvin and at room temperature.
**Model pipeline**
The voting regressor to predict the Tc combines the following four base models and equal weight is assigned to each base model.
1. Extra tree regressor (ET)
2. Extreme gradient boosting (XGB)
3. Random forest regressor (RF)
4. Adaptive boosted RF regressor (AB)
# How to use the trained model for inference
```python
import json
import joblib
import pandas as pd
Tc_predictor = joblib.load('Magnet_Tc_predictor.joblib') # trained model
config = json.load(open('config.json'))
features = config['features'] # feature vector
#data = pd.read_excel("data.xlsx") # read test file with new compositions
data = data[features]
Predicted_value = Tc_predictor.predict(data) # predict Tc values
print("Predicted Tc value is: {0:.2f}'.format(Predicted_value)")
```
|
Moonxc/lora-trained-xl-molti2
|
Moonxc
| 2023-11-14T14:13:36Z | 5 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-14T13:24:32Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks stuffed toy
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Moonxc/lora-trained-xl-molti2
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks stuffed toy using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
TheBloke/Claire-7B-0.1-AWQ
|
TheBloke
| 2023-11-14T14:10:51Z | 9 | 2 |
transformers
|
[
"transformers",
"safetensors",
"falcon",
"text-generation",
"pretrained",
"conversational",
"custom_code",
"fr",
"base_model:OpenLLM-France/Claire-7B-0.1",
"base_model:quantized:OpenLLM-France/Claire-7B-0.1",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-14T13:57:11Z |
---
base_model: OpenLLM-France/Claire-7B-0.1
inference: false
language:
- fr
license: cc-by-nc-sa-4.0
model_creator: OpenLLM France
model_name: Claire 7B 0.1
model_type: falcon
pipeline_tag: text-generation
prompt_template: '- Bonjour BotName, {prompt}
- Bonjour UserName,
'
quantized_by: TheBloke
tags:
- pretrained
- conversational
widget:
- example_title: Request for a recipe
group: Dash
text: '- Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui ?
- Bonjour Camille,'
- example_title: Request for a recipe
group: Intervenant
text: '[Intervenant 1:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui
?
[Intervenant 2:] Bonjour Camille,'
- example_title: Request for a recipe
group: FirstName
text: '[Camille:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui ?
[Dominique:] Bonjour Camille,'
- example_title: Request for a recipe
group: Named
text: '[Camille Durand:] Bonjour Dominique, qu''allez-vous nous cuisiner aujourd''hui
?
[Dominique Petit:] Bonjour Camille,'
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Claire 7B 0.1 - AWQ
- Model creator: [OpenLLM France](https://huggingface.co/OpenLLM-France)
- Original model: [Claire 7B 0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1)
<!-- description start -->
## Description
This repo contains AWQ model files for [OpenLLM France's Claire 7B 0.1](https://huggingface.co/OpenLLM-France/Claire-7B-0.1).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Claire-7B-0.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Claire-7B-0.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Claire-7B-0.1-GGUF)
* [OpenLLM France's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OpenLLM-France/Claire-7B-0.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: OpenLLM-France
```
- Bonjour BotName, {prompt}
- Bonjour UserName,
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Claire-7B-0.1-AWQ/tree/main) | 4 | 64 | [French news](https://huggingface.co/datasets/gustavecortal/diverse_french_news) | 2048 | 4.75 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Claire-7B-0.1-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Claire-7B-0.1-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/Claire-7B-0.1-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''- Bonjour BotName, {prompt}
- Bonjour UserName,
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Claire-7B-0.1-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Claire-7B-0.1-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''- Bonjour BotName, {prompt}
- Bonjour UserName,
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/Claire-7B-0.1-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''- Bonjour BotName, {prompt}
- Bonjour UserName,
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: OpenLLM France's Claire 7B 0.1
# Claire-7B-0.1
**Claire-7B-0.1 is a 7B parameter causal decoder-only model built by [LINAGORA](https://labs.linagora.com/) and [OpenLLM-France](https://github.com/OpenLLM-France)**
**adapted from [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) on French conversational data.**
Claire-7B-0.1 is a pretrained language model designed to be attuned to the dynamics of linguistic interactions in dialogue. Without further training, its expected use is to generate continuations of dialogues. Its main purpose is to serve as a base model for fine-tuning on dialogue generation (e.g., chat) and dialogue understanding (e.g., meeting summarization) tasks. Please note that due to its training, the model is prone to generate dialogues with disfluencies and other constructions common to spoken language.
## Typical usage
```python
import transformers
import torch
model_name = "OpenLLM-France/Claire-7B-0.1"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
load_in_4bit=True # For efficient inference, if supported by the GPU card
)
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_kwargs = dict(
num_return_sequences=1, # Number of variants to generate.
return_full_text= False, # Do not include the prompt in the generated text.
max_new_tokens=200, # Maximum length for the output text.
do_sample=True, top_k=10, temperature=1.0, # Sampling parameters.
pad_token_id=tokenizer.eos_token_id, # Just to avoid a harmless warning.
)
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
completions = pipeline(prompt, **generation_kwargs)
for completion in completions:
print(prompt + " […]" + completion['generated_text'])
```
This will print something like:
```
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille, […] je vous prépare un plat de saison, une daube provençale.
- Ah je ne connais pas cette recette.
- C'est très facile à préparer, vous n'avez qu'à mettre de l'eau dans une marmite, y mettre de l'oignon émincé, des carottes coupées en petits morceaux, et vous allez mettre votre viande de bœuf coupé en petits morceaux également.
- Je n'ai jamais cuisiné de viande de bœuf, mais c'est vrai que ça a l'air bien facile.
- Vous n'avez plus qu'à laisser mijoter, et ensuite il sera temps de servir les clients.
- Très bien.
```
You will need at least 6GB of VRAM to run inference using 4bit quantization (16GB of VRAM without 4bit quantization).
If you have trouble running this code, make sure you have recent versions of `torch`, `transformers` and `accelerate` (see [requirements.txt](requirements.txt)).
### Typical prompts
Claire-7B-0.1 was trained on diarized French conversations. During training, the dialogues were normalized in several formats. The possible formats for expected prompts are as follows:
A monologue can be specified as a single line prompt (though keep in mind that Claire might still return a dialogue because of its training):
```python
prompt = "Mesdames et messieurs les députés, chers collègues, bonsoir. Vous l'aurez peut-être remarqué, je cite rarement"
```
A dialogue between two speakers can be specified with one line per speech turn starting with a dash:
```python
prompt = """\
- Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
- Bonjour Camille,\
"""
```
A dialogue or multilogue (with two or more speakers) can be specified with lines that start with `[Intervenant X:]` where `X` is a number:
```python
prompt = """\
[Intervenant 1:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Intervenant 2:] Bonjour Camille,\
"""
```
A dialogue or multilogue with named speakers can be specified with lines that start with `[SpeakerName:]`
where `SpeakerName` can be a first name, a first and a last name, a nickname, a title…
```python
prompt = """\
[Mme Camille Durand:] Bonjour Dominique, qu'allez-vous nous cuisiner aujourd'hui ?
[Mr. Dominique Petit:] Bonjour Camille,\
"""
```
## Training Details
### Training Data
Claire-7B-0.1 was tuned from Falcon-7b on the following data distribution:
| **Data type** | **Words** | **Training Sampling Weight** | **Sources** |
|-------------------------------|------------|------------------------------|-----------------------------------------------------|
| Parliamentary Proceedings | 135M | 35% | assemblee-nationale.fr |
| Theatre | 16M | 18% | theatre-classique.fr, theatregratuit.com |
| Interviews | 6.4M | 29% | TCOF, CFPP, CFPB, ACSYNT, PFC, Valibel (ORFEO), ESLO |
| Free Conversations | 2.2M | 10% | CRFP, OFROM, CID, Rhapsodie, ParisStories, PFC, CLAPI, C-ORAL-ROM (ORFEO), LinTO, ESLO |
| Meetings | 1.2M | 5% | SUMM-RE, LinTO, Réunions de travail (ORFEO) |
| Debates | 402k | <2% | FreD, ESLO |
| Assistance | 159k | <1% | Fleuron (ORFEO), Accueil UBS, OTG, ESLO |
| Presentation, Formal Address | 86k | <0.5% | Valibel (ORFEO), LinTO, ESLO |
Training data was augmented with the following techniques:
* varying the format used to indicate speech turns (dashes or [XXX:])
* substituting [Intervenant X:] for [SpeakerName:] or vice versa, where [SpeakerName:] might be a real name or a randomly generated name
* removing punctuation marks and/or casing (to prepare the model for transcripts produced by some Automatic Speech Recognition systems)
Long conversations were truncated at a maximum of 2048 tokens. Where possible, they were split between speaker turns.
While the model has been trained and evaluated only on French dialogues, it may be able to generate conversations in other languages from the original Falcon-7b training data.
### Training Procedure
Claire-7B-0.1 is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
See [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b) for more details.
Claire-7B-0.1 was trained on 1 A100 80GB GPU for about 50 GPU hours.
Hyperparameters were the following:
| **Hyperparameter** | **Value** |
|--------------------|------------|
| Precision | `bfloat16` |
| Optimizer | AdamW |
| Learning rate | 1e-4 |
| Weight decay | 1e-2 |
| Batch size | 132 |
| LoRA rank | 16 |
| LoRA alpha | 32 |
| Dropout | 0.05 |
| gradient clipping | 1 |
## Evaluation
To evaluate Claire-7B-0.1’s ability to generate natural sounding, French conversations, we compared its responses to a variety of prompts with those of three other models:
* [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b),
* [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* [Claire-Mistral-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-Mistral-7B-0.1) (a version of Mistral-7B-v0.1 adapted in the same fashion as Claire-7B-0.1)
We tested an even mixture of monologue and dialogue-style prompts.
Each of the four generated responses was evaluated along three dimensions:
Interaction, Fluency and Relevance.
Evaluators were also asked to rank the four responses by preference.
Our results confirm that continual pre-training of Falcon-7b and Mistral-7B-v0.1 leads to improvement (relative to the base models) along all three evaluation dimensions and that Claire-7B-0.1 outperforms the adapted Mistral counterpart in the Fluency and Relevance categories
(and in the Interaction category if we focus on dialogue-style prompts).
Ranking results also reveal a clear subjective preference for Claire-7B-0.1,
as shown in the following table:
<!--| | **Claire-Falcon** | **Claire-Mistral** | **Falcon** | **Mistral** | -->
| | <span style="font-weight: normal">... over</span><br /> **Claire-Falcon** | <span style="font-weight: normal">... over</span><br /> **Claire-Mistral** | <span style="font-weight: normal">... over</span><br /> **Falcon** | <span style="font-weight: normal">... over</span><br /> **Mistral** |
|--------------------------------------|----------------------|-----------------------|---------------|---------------------|
| prefer<br /> **Claire-Falcon** ... | | **62.2%** | **63.9%** | **83.8%** |
| prefer<br /> **Claire-Mistral** ... | _34.8%_ | | **56.2%** | **75.3%** |
| prefer<br /> **Falcon** ... | _36.1%_ | _43.8%_ | | **81.4%** |
| prefer<br /> **Mistral** ... | _16.2%_ | _24.7%_ | _18.6%_ | |
(In this table,
"Claire-Falcon" stands for Claire-7B-0.1,
"Falcon", for [Falcon-7b](https://huggingface.co/tiiuae/falcon-7b),
"Mistral", for [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
and "Claire-Mistral", for [Claire-Mistral-7B-0.1](https://huggingface.co/OpenLLM-France/Claire-Mistral-7B-0.1).)
Please note that the model can generate disfluencies and humorous responses as a result of its training on spoken and theatrical text.
More evaluation details will be provided in a separate publication.
## License
Given that some of the corpora used for training are only available under CC-BY-NC-SA licenses,
Claire-7B-0.1 is made available under the [CC-BY-NC-SA 4.0 license](https://creativecommons.org/licenses/by-nc-sa/4.0/).
You can find a variant of this model published under the Apache 2.0 license at [OpenLLM-France/Claire-7B-Apache-0.1](https://huggingface.co/OpenLLM-France/Claire-7B-Apache-0.1).
## Acknowledgements
This work was performed using HPC resources from GENCI–IDRIS (Grant 2023-AD011014561).
Claire-7B-0.1 was created by members of [LINAGORA](https://labs.linagora.com/) (in alphabetical order): Ismaïl Harrando, Julie Hunter, Jean-Pierre Lorré, Jérôme Louradour, Michel-Marie Maudet, Virgile Rennard, Guokan Shang.
Special thanks to partners from the OpenLLM-France community, especially Christophe Cerisara (LORIA), Pierre-Carl Langlais and Anastasia Stasenko (OpSci), and Pierre Colombo, for valuable advice.
## Contact
contact@openllm-france.fr
|
sainteye/ifoodie-menu-v3
|
sainteye
| 2023-11-14T14:09:23Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-14T14:09:20Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ifoodie-menu-v3
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9032257795333862
---
# ifoodie-menu-v3
['優質', '差', '廣告', '普通']
## Example Images
# #### 優質
# 
#
# #### 差
# 
#
# #### 廣告
# 
#
# #### 普通
# 
#
|
segestic/covid_resnet
|
segestic
| 2023-11-14T14:08:07Z | 3 | 0 |
keras
|
[
"keras",
"image-classification",
"en",
"license:mit",
"region:us"
] |
image-classification
| 2023-11-14T13:45:42Z |
---
license: mit
language:
- en
pipeline_tag: image-classification
library_name: keras
---
|
israelNwokedi/seoOptimize_Falcon_7B_Model
|
israelNwokedi
| 2023-11-14T13:55:28Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:finetune:vilsonrodrigues/falcon-7b-instruct-sharded",
"license:apache-2.0",
"region:us"
] | null | 2023-11-14T13:28:59Z |
---
license: apache-2.0
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
tags:
- generated_from_trainer
model-index:
- name: seoOptimize_Falcon_7B_Model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# seoOptimize_Falcon_7B_Model
This model is a fine-tuned version of [vilsonrodrigues/falcon-7b-instruct-sharded](https://huggingface.co/vilsonrodrigues/falcon-7b-instruct-sharded) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
ashishabraham22/starcoder1B-personal-copilot
|
ashishabraham22
| 2023-11-14T13:54:33Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:bigcode/starcoderbase-1b",
"base_model:adapter:bigcode/starcoderbase-1b",
"license:bigcode-openrail-m",
"region:us"
] | null | 2023-11-14T13:29:59Z |
---
license: bigcode-openrail-m
library_name: peft
tags:
- generated_from_trainer
base_model: bigcode/starcoderbase-1b
model-index:
- name: starcoder1B-personal-copilot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# starcoder1B-personal-copilot
This model is a fine-tuned version of [bigcode/starcoderbase-1b](https://huggingface.co/bigcode/starcoderbase-1b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 20
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0a0+4136153
- Datasets 2.14.5
- Tokenizers 0.14.1
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.3.dev0
|
bkpandey/Llama-2-7b-hf_finetuned_finance_jupyter_v3
|
bkpandey
| 2023-11-14T13:51:04Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-14T13:50:58Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2.dev0
|
Alex2575/aleksis_heb_wav2vec2
|
Alex2575
| 2023-11-14T13:49:34Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-14T13:19:57Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: aleksis_heb_wav2vec2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aleksis_heb_wav2vec2
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8376
- Wer: 99.9670
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 1.2376 | 4.02 | 500 | 1.4518 | 99.9670 |
| 0.7287 | 8.03 | 1000 | 0.8376 | 99.9670 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
EugeneHF/distil_bert
|
EugeneHF
| 2023-11-14T13:48:42Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"base_model:finetune:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T13:45:19Z |
---
license: apache-2.0
base_model: distilbert-base-uncased-finetuned-sst-2-english
tags:
- generated_from_trainer
model-index:
- name: distil_bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distil_bert
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 620
- num_epochs: 5
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0+cpu
- Datasets 2.1.0
- Tokenizers 0.14.1
|
minhcrafters/ai-challenge-model
|
minhcrafters
| 2023-11-14T13:44:55Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-14T11:54:52Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: ai-challenge-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ai-challenge-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1675
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.4957 | 1.0 | 1094 | 1.2625 |
| 1.1492 | 2.0 | 2188 | 1.1756 |
| 0.9459 | 3.0 | 3282 | 1.1675 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
AndyYo/zephyr-support-QA
|
AndyYo
| 2023-11-14T13:44:54Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/zephyr-7B-beta-GPTQ",
"base_model:finetune:TheBloke/zephyr-7B-beta-GPTQ",
"license:mit",
"region:us"
] | null | 2023-11-12T12:01:36Z |
---
license: mit
base_model: TheBloke/zephyr-7B-beta-GPTQ
tags:
- generated_from_trainer
model-index:
- name: zephyr-support-QA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-support-QA
This model is a fine-tuned version of [TheBloke/zephyr-7B-beta-GPTQ](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
FiouReia/Distilbert_uncased_emoji_emoticon_trial
|
FiouReia
| 2023-11-14T13:40:40Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T13:37:51Z |
This Model was trained using Dataset with emojis and emoticons, and on that dataset used a custom preprocessing.
|
Norm/ERNIE-Layout-Pytorch
|
Norm
| 2023-11-14T13:34:59Z | 730 | 16 |
transformers
|
[
"transformers",
"pytorch",
"xlnet",
"arxiv:2210.06155",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-12-12T02:21:36Z |
---
license: mit
---
# ERNIE-Layout_Pytorch
- **Model type:** [ERNIE-Layout](https://arxiv.org/abs/2210.06155)
- **Repository:** [source code](https://github.com/NormXU/ERNIE-Layout-Pytorch): an unofficial ERNIE-Layout implementation in Pytorch
- **Converted from:** [PaddlePaddle/ernie-layoutx-base-uncased](https://huggingface.co/PaddlePaddle/ernie-layoutx-base-uncased)
The ERNIE-Layout-Pytorch model is initially released by [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP). To make Pytorch users easy to use, the model has been converted into PyTorch format with the [tools/convert2torch.py](https://github.com/NormXU/ERNIE-Layout-Pytorch/blob/main/tools/convert2torch.py) script.
Please feel free to make any changes you need. For more details and use cases, please check the repo.
**A Quick Example**
```python
import torch
from PIL import Image
import torch.nn.functional as F
from networks import ErnieLayoutConfig, ErnieLayoutForQuestionAnswering, \
ErnieLayoutProcessor, ErnieLayoutTokenizerFast
from transformers.models.layoutlmv3 import LayoutLMv3ImageProcessor
pretrain_torch_model_or_path = "Norm/ERNIE-Layout-Pytorch"
doc_imag_path = "./dummy_input.jpeg"
context = ['This is an example sequence', 'All ocr boxes are inserted into this list']
layout = [[381, 91, 505, 115], [738, 96, 804, 122]] # make sure all boxes are normalized between 0 - 1000
pil_image = Image.open(doc_imag_path).convert("RGB")
# initialize tokenizer
tokenizer = ErnieLayoutTokenizerFast.from_pretrained(pretrained_model_name_or_path=pretrain_torch_model_or_path)
# initialize feature extractor
feature_extractor = LayoutLMv3ImageProcessor(apply_ocr=False)
processor = ErnieLayoutProcessor(image_processor=feature_extractor, tokenizer=tokenizer)
# Tokenize context & questions
question = "what is it?"
encoding = processor(pil_image, question, context, boxes=layout, return_tensors="pt")
# dummy answer start && end index
start_positions = torch.tensor([6])
end_positions = torch.tensor([12])
# initialize config
config = ErnieLayoutConfig.from_pretrained(pretrained_model_name_or_path=pretrain_torch_model_or_path)
config.num_classes = 2 # start and end
# initialize ERNIE for VQA
model = ErnieLayoutForQuestionAnswering.from_pretrained(
pretrained_model_name_or_path=pretrain_torch_model_or_path,
config=config,
)
output = model(**encoding, start_positions=start_positions, end_positions=end_positions)
# decode output
start_max = torch.argmax(F.softmax(output.start_logits, dim=-1))
end_max = torch.argmax(F.softmax(output.end_logits, dim=-1)) + 1 # add one ##because of python list indexing
answer = tokenizer.decode(encoding.input_ids[0][start_max: end_max])
print(answer)
```
|
vildgras/bert-base-banking77-pt2
|
vildgras
| 2023-11-14T13:24:35Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:banking77",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T08:46:35Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- banking77
metrics:
- f1
model-index:
- name: bert-base-banking77-pt2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: banking77
type: banking77
config: default
split: test
args: default
metrics:
- name: F1
type: f1
value: 0.9273136697938401
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-banking77-pt2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the banking77 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3094
- F1: 0.9273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0919 | 1.0 | 626 | 0.8005 | 0.8528 |
| 0.3809 | 2.0 | 1252 | 0.3673 | 0.9235 |
| 0.1835 | 3.0 | 1878 | 0.3094 | 0.9273 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.9.0
- Tokenizers 0.14.1
|
GuCuChiara/NLP-HIBA_BiomedNLP-BiomedBERT-base-pretrained-model
|
GuCuChiara
| 2023-11-14T13:19:05Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-14T12:09:16Z |
---
license: mit
base_model: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: NLP-HIBA_BiomedNLP-BiomedBERT-base-pretrained-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP-HIBA_BiomedNLP-BiomedBERT-base-pretrained-model
This model is a fine-tuned version of [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2050
- Precision: 0.6079
- Recall: 0.5407
- F1: 0.5723
- Accuracy: 0.9528
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 71 | 0.2223 | 0.3125 | 0.1619 | 0.2133 | 0.9212 |
| No log | 2.0 | 142 | 0.1599 | 0.5228 | 0.3539 | 0.4221 | 0.9446 |
| No log | 3.0 | 213 | 0.1472 | 0.5298 | 0.4385 | 0.4798 | 0.9470 |
| No log | 4.0 | 284 | 0.1441 | 0.5885 | 0.4729 | 0.5244 | 0.9514 |
| No log | 5.0 | 355 | 0.1675 | 0.5654 | 0.5146 | 0.5388 | 0.9491 |
| No log | 6.0 | 426 | 0.1592 | 0.5860 | 0.5082 | 0.5443 | 0.9521 |
| No log | 7.0 | 497 | 0.1634 | 0.5621 | 0.5587 | 0.5604 | 0.9509 |
| 0.1349 | 8.0 | 568 | 0.1897 | 0.5803 | 0.5182 | 0.5475 | 0.9515 |
| 0.1349 | 9.0 | 639 | 0.1880 | 0.5699 | 0.5539 | 0.5618 | 0.9506 |
| 0.1349 | 10.0 | 710 | 0.1939 | 0.5923 | 0.5415 | 0.5657 | 0.9525 |
| 0.1349 | 11.0 | 781 | 0.1988 | 0.5863 | 0.5475 | 0.5662 | 0.9518 |
| 0.1349 | 12.0 | 852 | 0.2050 | 0.6079 | 0.5407 | 0.5723 | 0.9528 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Msfasf/my-pet-dog
|
Msfasf
| 2023-11-14T13:08:14Z | 2 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T13:03:37Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Msfasf following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-177
Sample pictures of this concept:
.jpg)
|
Moonxc/lora-trained-xl-molti
|
Moonxc
| 2023-11-14T13:06:20Z | 1 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-14T12:15:49Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of molti stuffed toy
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Moonxc/lora-trained-xl-molti
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of molti stuffed toy using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
hanyoonsang/esp_donut_train_swinv2_bert_00
|
hanyoonsang
| 2023-11-14T12:48:35Z | 46 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-11-14T04:16:28Z |
---
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: esp_donut_train_swinv2_bert_00
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# esp_donut_train_swinv2_bert_00
This model was trained from scratch on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.0
- Pytorch 1.11.0+cu113
- Datasets 2.8.0
- Tokenizers 0.13.3
|
aryamtos/ast-finetuned-audioset-10-10-0.4593-keyword_spotting2
|
aryamtos
| 2023-11-14T12:39:52Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"base_model:MIT/ast-finetuned-audioset-10-10-0.4593",
"base_model:finetune:MIT/ast-finetuned-audioset-10-10-0.4593",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-14T12:39:40Z |
---
license: bsd-3-clause
base_model: MIT/ast-finetuned-audioset-10-10-0.4593
tags:
- generated_from_trainer
metrics:
- accuracy
- wer
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-keyword_spotting2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-keyword_spotting2
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0123
- Accuracy: 0.8228
- Wer: 0.1772
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0008 | 1.0 | 28 | 1.3229 | 0.8228 | 0.1772 |
| 0.3356 | 2.0 | 56 | 1.3607 | 0.8228 | 0.1772 |
| 0.0035 | 3.0 | 84 | 1.0123 | 0.8228 | 0.1772 |
| 0.0051 | 4.0 | 112 | 1.5980 | 0.8228 | 0.1772 |
| 0.0001 | 5.0 | 140 | 1.4630 | 0.8228 | 0.1772 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu121
- Datasets 2.14.7.dev0
- Tokenizers 0.14.1
|
nishithaeluri/my-pet-dog
|
nishithaeluri
| 2023-11-14T12:36:56Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-14T12:32:14Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by nishithaeluri following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-99
Sample pictures of this concept:
.jpg)
|
IlluminatiPudding/a2c-PandaPickAndPlace-v3
|
IlluminatiPudding
| 2023-11-14T12:14:55Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-10T11:22:05Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
judy93536/distilroberta-rb156k-opt15-ep40
|
judy93536
| 2023-11-14T12:09:06Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-14T00:17:09Z |
---
tags:
- generated_from_trainer
model-index:
- name: distilroberta-rb156k-opt15-ep40
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-rb156k-opt15-ep40
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2088
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.3431 | 1.0 | 8994 | 1.3416 |
| 1.3385 | 2.0 | 17988 | 1.3477 |
| 1.3321 | 3.0 | 26982 | 1.3444 |
| 1.3277 | 4.0 | 35976 | 1.3370 |
| 1.315 | 5.0 | 44970 | 1.3325 |
| 1.3081 | 6.0 | 53964 | 1.3314 |
| 1.3056 | 7.0 | 62958 | 1.3271 |
| 1.2999 | 8.0 | 71952 | 1.3219 |
| 1.2973 | 9.0 | 80946 | 1.3195 |
| 1.2865 | 10.0 | 89940 | 1.3135 |
| 1.2749 | 11.0 | 98934 | 1.3111 |
| 1.2685 | 12.0 | 107928 | 1.3077 |
| 1.2652 | 13.0 | 116922 | 1.2986 |
| 1.2604 | 14.0 | 125916 | 1.2979 |
| 1.255 | 15.0 | 134910 | 1.2942 |
| 1.2508 | 16.0 | 143904 | 1.2870 |
| 1.2358 | 17.0 | 152898 | 1.2858 |
| 1.2361 | 18.0 | 161892 | 1.2825 |
| 1.2302 | 19.0 | 170886 | 1.2741 |
| 1.2242 | 20.0 | 179880 | 1.2743 |
| 1.2177 | 21.0 | 188874 | 1.2665 |
| 1.2055 | 22.0 | 197868 | 1.2642 |
| 1.2096 | 23.0 | 206862 | 1.2583 |
| 1.2065 | 24.0 | 215856 | 1.2567 |
| 1.1931 | 25.0 | 224850 | 1.2537 |
| 1.1908 | 26.0 | 233844 | 1.2510 |
| 1.1875 | 27.0 | 242838 | 1.2480 |
| 1.1803 | 28.0 | 251832 | 1.2424 |
| 1.1711 | 29.0 | 260826 | 1.2394 |
| 1.173 | 30.0 | 269820 | 1.2380 |
| 1.1665 | 31.0 | 278814 | 1.2291 |
| 1.1586 | 32.0 | 287808 | 1.2291 |
| 1.1607 | 33.0 | 296802 | 1.2260 |
| 1.1524 | 34.0 | 305796 | 1.2228 |
| 1.1463 | 35.0 | 314790 | 1.2171 |
| 1.1453 | 36.0 | 323784 | 1.2135 |
| 1.1387 | 37.0 | 332778 | 1.2135 |
| 1.136 | 38.0 | 341772 | 1.2117 |
| 1.1347 | 39.0 | 350766 | 1.2070 |
| 1.1347 | 40.0 | 359760 | 1.2078 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
jemanuelv/terror
|
jemanuelv
| 2023-11-14T12:08:30Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:bertin-project/bertin-gpt-j-6B",
"base_model:adapter:bertin-project/bertin-gpt-j-6B",
"region:us"
] | null | 2023-11-13T20:02:02Z |
---
library_name: peft
base_model: bertin-project/bertin-gpt-j-6B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.1
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.1
|
Eata/Model_V1
|
Eata
| 2023-11-14T11:58:35Z | 0 | 13 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-02-03T04:31:16Z |
---
license: creativeml-openrail-m
---
|
KABANDA18/FineTuning-Roberta-base_Model
|
KABANDA18
| 2023-11-14T11:56:57Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T11:43:27Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: FineTuning-Roberta-base_Model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FineTuning-Roberta-base_Model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3400
- Accuracy: 0.7945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6351 | 0.2 | 100 | 0.5536 | 0.587 |
| 0.4783 | 0.4 | 200 | 0.4386 | 0.7145 |
| 0.4252 | 0.6 | 300 | 0.4041 | 0.723 |
| 0.4068 | 0.8 | 400 | 0.3815 | 0.7415 |
| 0.3978 | 1.0 | 500 | 0.3811 | 0.7265 |
| 0.3837 | 1.2 | 600 | 0.3717 | 0.7645 |
| 0.35 | 1.4 | 700 | 0.3816 | 0.7545 |
| 0.3575 | 1.6 | 800 | 0.3403 | 0.7755 |
| 0.3437 | 1.8 | 900 | 0.3431 | 0.7805 |
| 0.3172 | 2.0 | 1000 | 0.3346 | 0.793 |
| 0.2722 | 2.2 | 1100 | 0.3535 | 0.7835 |
| 0.2792 | 2.4 | 1200 | 0.3411 | 0.7865 |
| 0.2668 | 2.6 | 1300 | 0.3328 | 0.793 |
| 0.2701 | 2.8 | 1400 | 0.3379 | 0.794 |
| 0.2651 | 3.0 | 1500 | 0.3400 | 0.7945 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
igpaub/doom_health_gathering_supreme
|
igpaub
| 2023-11-14T11:55:20Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-14T11:55:13Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 9.54 +/- 2.34
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r igpaub/doom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=doom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=doom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
personal1802/6
|
personal1802
| 2023-11-14T11:49:46Z | 2 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"region:us"
] |
text-to-image
| 2023-11-14T11:41:36Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/white.png
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: null
---
# dakjang
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/personal1802/6/tree/main) them in the Files & versions tab.
|
abhinand/tamil-llama-7b-base-v0.1-gguf
|
abhinand
| 2023-11-14T11:41:04Z | 39 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"ta",
"en",
"arxiv:2311.05845",
"license:gpl-3.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-14T05:19:04Z |
---
language:
- ta
- en
license: gpl-3.0
---
# Tamil LLaMA 7B Base v0.1 - GGUF Quantized [pre-trained]
Welcome to the inaugural release of the Tamil LLaMA 7B base model – an important step in advancing LLMs for the Tamil language. This model is ready for immediate inference and is also primed for further fine-tuning to cater to your specific NLP tasks.
To dive deep into the development and capabilities of this model, please read the [research paper](https://arxiv.org/abs/2311.05845) and the [introductory blog post (WIP)]() that outlines our journey and the model's potential impact.
> **Please Note:** This model, labeled as a foundational Tamil Language Model (LLM), is designed primarily for Causal Language Modeling (LM) purposes. In other words, if you are looking for an instruction following model in Tamil, you may find [abhinand/tamil-llama-7b-instruct-v0.1](https://huggingface.co/abhinand/tamil-llama-7b-instruct-v0.1) more suitable for your needs.
## Model description
The Tamil LLaMA models have been enhanced and tailored specifically with an extensive Tamil vocabulary of 16,000 tokens, building upon the foundation set by the original LLaMA-2.
- **Model type:** A 7B parameter model for Causal LM pre-trained on [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX) dataset's Tamil subset.
- **Language(s):** Tamil and English
- **License:** GNU General Public License v3.0
- **Source Model:** [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf)
- **Training Precision:** `float16`
- **Code:** [GitHub](https://github.com/abhinand5/tamil-llama)
## Quantization Info
This repo contains GGUF format model files for [Tamil LLaMA 7B Base v0.1](https://huggingface.co/abhinand/tamil-llama-7b-base-v0.1).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
### Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|------------------------------------------------------------------------------------------------------------------------------------------------|--------------|------|---------|------------------|----------------------------------------------------------|
| [tamil-llama-7b-base-v0.1-q4_k_m.gguf](https://huggingface.co/abhinand/tamil-llama-7b-base-v0.1-gguf/blob/main/tamil-llama-7b-base-v0.1-q4_k_m.gguf) | Q4_K_M | 4 | 4.17 GB | 6.8 GB | medium, balanced quality - recommended |
| [tamil-llama-7b-base-v0.1-q5_k_m.gguf](https://huggingface.co/abhinand/tamil-llama-7b-base-v0.1-gguf/blob/main/tamil-llama-7b-base-v0.1-q5_k_m.gguf) | Q5_K_M | 5 | 4.88 GB | 7.5 GB | large, very low quality loss - recommended |
| [tamil-llama-7b-base-v0.1-q8_0.gguf](https://huggingface.co/abhinand/tamil-llama-7b-base-v0.1-gguf/blob/main/tamil-llama-7b-base-v0.1-q8_0.gguf) | Q8_0 | 8 | 7.30 GB | 9.8 GB | very large, extremely low quality loss - not recommended |
## Related Models
| Model | Type | Data | Base Model | # Params | Download Links |
|--------------------------|-----------------------------|-------------------|----------------------|------|------------------------------------------------------------------------|
| Tamil LLaMA 7B Base | Base model | 12GB | LLaMA 7B | 7B | [HF Hub](https://huggingface.co/abhinand/tamil-llama-7b-base-v0.1) |
| Tamil LLaMA 13B Base | Base model | 4GB | LLaMA 13B | 13B | [HF Hub](https://huggingface.co/abhinand/tamil-llama-13b-base-v0.1) |
| Tamil LLaMA 7B Instruct | Instruction following model | 145k instructions | Tamil LLaMA 7B Base | 7B | [HF Hub](https://huggingface.co/abhinand/tamil-llama-7b-instruct-v0.1) |
| Tamil LLaMA 13B Instruct | Instruction following model | 145k instructions | Tamil LLaMA 13B Base | 13B | [HF Hub](abhinand/tamil-llama-13b-instruct-v0.1) |
## Usage Note
It's important to note that the models have not undergone detoxification. Therefore, while they possess impressive linguistic capabilities, there is a possibility for them to generate content that could be deemed harmful or offensive. We urge users to exercise discretion and supervise the model's outputs closely, especially in public or sensitive applications.
## Meet the Developers
Get to know the creators behind this innovative model and follow their contributions to the field:
- [Abhinand Balachandran](https://www.linkedin.com/in/abhinand-05/)
## Citation
If you use this model or the Tamil-Llama dataset in your research, please cite:
```bibtex
@misc{balachandran2023tamilllama,
title={Tamil-Llama: A New Tamil Language Model Based on Llama 2},
author={Abhinand Balachandran},
year={2023},
eprint={2311.05845},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
We hope this model serves as a valuable tool in your NLP toolkit and look forward to seeing the advancements it will enable in the understanding and generation of the Tamil language.
|
personal1802/5
|
personal1802
| 2023-11-14T11:40:27Z | 1 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"region:us"
] |
text-to-image
| 2023-11-14T11:31:24Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/white.png
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: null
---
# supernerdmix
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/personal1802/5/tree/main) them in the Files & versions tab.
|
Bmalmotairy/arabertv2-fully-supervised-arabic-propaganda
|
Bmalmotairy
| 2023-11-14T11:35:15Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:aubmindlab/bert-base-arabertv2",
"base_model:finetune:aubmindlab/bert-base-arabertv2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T11:35:01Z |
---
base_model: aubmindlab/bert-base-arabertv2
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: arabertv2-fully-supervised-arabic-propaganda
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# arabertv2-fully-supervised-arabic-propaganda
This model is a fine-tuned version of [aubmindlab/bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3894
- Accuracy: 0.9262
- Precision: 0.6042
- Recall: 0.7073
- F1: 0.6517
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.4919 | 1.0 | 20 | 0.5087 | 0.8381 | 0.3516 | 0.7805 | 0.4848 |
| 0.3633 | 2.0 | 40 | 0.4010 | 0.8333 | 0.3474 | 0.8049 | 0.4853 |
| 0.2017 | 3.0 | 60 | 0.3635 | 0.9 | 0.4918 | 0.7317 | 0.5882 |
| 0.3071 | 4.0 | 80 | 0.3981 | 0.9333 | 0.6444 | 0.7073 | 0.6744 |
| 0.145 | 5.0 | 100 | 0.3894 | 0.9262 | 0.6042 | 0.7073 | 0.6517 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
drwngwn/textual_inversion_cat
|
drwngwn
| 2023-11-14T11:35:14Z | 4 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-13T06:28:51Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - drwngwn/textual_inversion_cat
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
SaraAUB/ppo-Huggy
|
SaraAUB
| 2023-11-14T11:29:36Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-14T11:29:25Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: SaraAUB/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
SalihDundar/lora_fine_tune_500
|
SalihDundar
| 2023-11-14T11:29:19Z | 1 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:bigcode/santacoder",
"base_model:adapter:bigcode/santacoder",
"region:us"
] | null | 2023-11-14T10:59:35Z |
---
library_name: peft
base_model: bigcode/santacoder
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
Moonxc/lora-trained-xl
|
Moonxc
| 2023-11-14T11:23:11Z | 1 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-14T10:29:52Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks dog
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Moonxc/lora-trained-xl
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
rohit1607/my_quesanswer_model
|
rohit1607
| 2023-11-14T11:19:17Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-14T10:49:10Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: rohit1607/my_quesanswer_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# rohit1607/my_quesanswer_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.6253
- Validation Loss: 2.5106
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.6253 | 2.5106 | 0 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Tommert25/robbert_seed33_1311
|
Tommert25
| 2023-11-14T11:14:47Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:pdelobelle/robbert-v2-dutch-base",
"base_model:finetune:pdelobelle/robbert-v2-dutch-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-14T10:59:51Z |
---
license: mit
base_model: pdelobelle/robbert-v2-dutch-base
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: robbert_seed33_1311
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robbert_seed33_1311
This model is a fine-tuned version of [pdelobelle/robbert-v2-dutch-base](https://huggingface.co/pdelobelle/robbert-v2-dutch-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3569
- Precisions: 0.8341
- Recall: 0.8159
- F-measure: 0.8240
- Accuracy: 0.9424
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 33
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.4471 | 1.0 | 236 | 0.2653 | 0.7696 | 0.7076 | 0.7131 | 0.9195 |
| 0.2264 | 2.0 | 472 | 0.2367 | 0.8184 | 0.7497 | 0.7777 | 0.9279 |
| 0.1443 | 3.0 | 708 | 0.2710 | 0.8069 | 0.7735 | 0.7817 | 0.9315 |
| 0.0869 | 4.0 | 944 | 0.2697 | 0.8391 | 0.7998 | 0.8150 | 0.9364 |
| 0.0531 | 5.0 | 1180 | 0.2877 | 0.8622 | 0.7952 | 0.8178 | 0.9393 |
| 0.0373 | 6.0 | 1416 | 0.3171 | 0.8338 | 0.8120 | 0.8204 | 0.9422 |
| 0.0238 | 7.0 | 1652 | 0.3312 | 0.8247 | 0.7921 | 0.8047 | 0.9390 |
| 0.0159 | 8.0 | 1888 | 0.3569 | 0.8341 | 0.8159 | 0.8240 | 0.9424 |
| 0.0122 | 9.0 | 2124 | 0.3832 | 0.8398 | 0.8127 | 0.8238 | 0.9422 |
| 0.0058 | 10.0 | 2360 | 0.4160 | 0.8288 | 0.7975 | 0.8098 | 0.9400 |
| 0.0059 | 11.0 | 2596 | 0.4153 | 0.8321 | 0.8012 | 0.8124 | 0.9405 |
| 0.0045 | 12.0 | 2832 | 0.4399 | 0.8130 | 0.7909 | 0.7994 | 0.9369 |
| 0.0024 | 13.0 | 3068 | 0.4357 | 0.8358 | 0.8026 | 0.8163 | 0.9409 |
| 0.0035 | 14.0 | 3304 | 0.4391 | 0.8374 | 0.8036 | 0.8175 | 0.9414 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
apwic/indobert-base-uncased-lora-and-prefix-tuning-nergrit
|
apwic
| 2023-11-14T11:05:10Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:indolem/indobert-base-uncased",
"base_model:adapter:indolem/indobert-base-uncased",
"region:us"
] | null | 2023-11-14T11:05:08Z |
---
library_name: peft
base_model: indolem/indobert-base-uncased
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
IlluminatiPudding/a2c-PandaPickAndPlace-v3-v1.2
|
IlluminatiPudding
| 2023-11-14T10:54:29Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-14T10:48:48Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
grv805/mistral7b-qlora-finetunined-gcp-new
|
grv805
| 2023-11-14T10:49:27Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-11-14T09:35:06Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
|
higgsfield/artistic-big-mistral
|
higgsfield
| 2023-11-14T10:43:35Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-14T10:36:13Z |
---
{}
---
---
{ card_data }
---
# Model Card for MyCoolModel
This model does this and that.
higgsfield.ai/model/655348f2b3b68d96f90d2821
This model was created by [@{ author }](https://hf.co/{author}).
|
haris001/SP16_v1
|
haris001
| 2023-11-14T10:39:29Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:codellama/CodeLlama-7b-Instruct-hf",
"base_model:adapter:codellama/CodeLlama-7b-Instruct-hf",
"region:us"
] | null | 2023-11-14T10:39:28Z |
---
library_name: peft
base_model: codellama/CodeLlama-7b-Instruct-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.3.dev0
|
Akshay0706/Cinnamon-Plant-1-Epochs-Model
|
Akshay0706
| 2023-11-14T10:29:55Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-14T10:29:43Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- f1
model-index:
- name: Cinnamon-Plant-1-Epochs-Model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6875
- name: F1
type: f1
value: 0.708430913348946
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Cinnamon-Plant-1-Epochs-Model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6302
- Accuracy: 0.6875
- F1: 0.7084
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6228 | 1.0 | 18 | 0.6302 | 0.6875 | 0.7084 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
zyy519/ppo-Pyramids
|
zyy519
| 2023-11-14T10:29:41Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-11-14T10:26:11Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: zyy519/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Tommert25/robbert_seed36_1311
|
Tommert25
| 2023-11-14T10:25:36Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:pdelobelle/robbert-v2-dutch-base",
"base_model:finetune:pdelobelle/robbert-v2-dutch-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-14T10:13:00Z |
---
license: mit
base_model: pdelobelle/robbert-v2-dutch-base
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: robbert_seed36_1311
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robbert_seed36_1311
This model is a fine-tuned version of [pdelobelle/robbert-v2-dutch-base](https://huggingface.co/pdelobelle/robbert-v2-dutch-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3538
- Precisions: 0.8351
- Recall: 0.8079
- F-measure: 0.8173
- Accuracy: 0.9422
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 36
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.4364 | 1.0 | 236 | 0.2547 | 0.8525 | 0.7285 | 0.7372 | 0.9231 |
| 0.2196 | 2.0 | 472 | 0.2772 | 0.8456 | 0.7521 | 0.7718 | 0.9291 |
| 0.1273 | 3.0 | 708 | 0.2681 | 0.8056 | 0.7798 | 0.7897 | 0.9315 |
| 0.0799 | 4.0 | 944 | 0.2971 | 0.8835 | 0.7898 | 0.8158 | 0.9393 |
| 0.0541 | 5.0 | 1180 | 0.3302 | 0.8515 | 0.7815 | 0.8016 | 0.9373 |
| 0.0358 | 6.0 | 1416 | 0.3291 | 0.8140 | 0.7901 | 0.7994 | 0.9385 |
| 0.0217 | 7.0 | 1652 | 0.3538 | 0.8351 | 0.8079 | 0.8173 | 0.9422 |
| 0.0145 | 8.0 | 1888 | 0.3622 | 0.8331 | 0.8000 | 0.8113 | 0.9431 |
| 0.0092 | 9.0 | 2124 | 0.3782 | 0.8190 | 0.8098 | 0.8116 | 0.9402 |
| 0.0091 | 10.0 | 2360 | 0.4023 | 0.8499 | 0.7967 | 0.8149 | 0.9422 |
| 0.0068 | 11.0 | 2596 | 0.3932 | 0.8293 | 0.8062 | 0.8154 | 0.9409 |
| 0.0053 | 12.0 | 2832 | 0.3894 | 0.8415 | 0.7942 | 0.8108 | 0.9412 |
| 0.0023 | 13.0 | 3068 | 0.3910 | 0.8379 | 0.7987 | 0.8127 | 0.9426 |
| 0.0035 | 14.0 | 3304 | 0.3919 | 0.8349 | 0.7990 | 0.8110 | 0.9422 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
owanr/ghc-google-t5-v1_1-large-inter_model-frequency-human_annots_str_mse
|
owanr
| 2023-11-14T10:15:42Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:google/t5-v1_1-large",
"base_model:finetune:google/t5-v1_1-large",
"license:apache-2.0",
"region:us"
] | null | 2023-11-14T10:15:41Z |
---
license: apache-2.0
base_model: google/t5-v1_1-large
tags:
- generated_from_trainer
model-index:
- name: ghc-google-t5-v1_1-large-inter_model-frequency-human_annots_str_mse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ghc-google-t5-v1_1-large-inter_model-frequency-human_annots_str_mse
This model is a fine-tuned version of [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large) on the None dataset.
It achieves the following results on the evaluation set:
- Train Loss: 9.0138
- Loss: 0.0753
- Losses: [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 11, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 17, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Train Loss | Validation Loss | Losses |
|:-------------:|:-----:|:-----:|:----------:|:---------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 2.3965 | 1.0 | 345 | 10.0372 | 2.2570 | [10, 7.2, 10, 10, 10, 10, 10, 10, 11, 10, 10.8, 10, 10, 9, 10, 10, 10, 10, 10, 8, 11, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 11, 7.2, 10, 9, 11, 10, 10, 10, 8, 11, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 7.2, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 22, 10, 10, 11, 10, 10, 10, 10, 10.8, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 11, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 11, 11, 10, 10, 8, 8, 11, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10.8, 11, 10, 10, 10, 10, 10, 11.700000000000001, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 11, 10, 11, 10, 10, 10, 10, 13.5, 10, 10.8, 10.8, 10, 8, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 29.7, 10, 9, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 8, 43.2, 10, 10, 10, 10, 10, 9, 10, 10, 10, 8, 11, 8, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 8, 10, 10, 10, 10, 10, 8, 10, 10, 10, 34.2, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 11, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 11, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 11, 10, 10, 10, 10, 8, 10, 10, 11, 11, 10, 8, 11, 10, 10, 10, 10, 10, 10, 10, 10, 9, 11.700000000000001, 10, 8, 10, 8, 10, 11, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 8, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 13.5, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 11, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 11.700000000000001, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 9, 12, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 11, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 8, 10, 8, 10, 10, 8, 8, 10, 10, 10, 10.8, 10, 10, 9, 10, 8, 10, 10, 10, 10, 10, 9, 22, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 11, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 11, 10, 10, 10, 9, 11, 10, 10, 8, 10, 10, 10, 10, 10, 10, 12.600000000000001, 10, 10.8, 10, 11, 10, 11, 10, 10, 10, 11, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8.1, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 22, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 8, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 8, 9, 10, 11, 8, 10, 10, 10, 11, 10, 10, 10, 10, 8, 10, 10, 10, 10, 8, 10, 10, 10, 10, 12, 11, 10, 10, 10, 10, 10, 10.8, 8, 10, 11, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 8, 10, 11, 10, 10, 10, 10, 10, 10, 11, 10, 10, 8, 10, 10, 8, 10, 10, 8, 10, 10, 10, 10, 9, 10, 11, 10, 10, 10, 11, 10, 8, 8, 10, 7.2, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 11, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11.700000000000001, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 9, 10, 11, 10.8, 10, 10, 10, 10, 11, 10, 10, 8, 10, 10, 10, 10, 10, 9, 10, 10, 10, 22, 10, 10, 10, 11, 10, 10, 10, 10, 8, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 10, 10, 10, 10, 10, 10, 8, 8, 10, 10, 10, 11, 8, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 11, 9, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 11, 8, 10, 10, 10, 11, 10, 10, 11, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 11, 10, 10, 10, 11.700000000000001, 10, 10, 10, 10, 10, 11.700000000000001, 10, 10, 10, 10, 9, 10, 10, 10, 8, 10, 10, 10, 9, 10, 10, 10, 8, 10, 10, 8, 10, 11, 10, 10, 10, 10.8, 10, 10, 11.700000000000001, 8, 11, 10, 10, 10, 10, 10, 9, 10, 10, 10, 8, 10, 10, 10, 10, 11, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 13.5, 10, 10, 10, 13, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 8, 10, 8, 9, 11, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10.8, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 11, 10, 8, 11, 10, 10, 10, 10, 10, 10, 10.8, 10, 11, 10, 10, 10, 10, 8, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 9, 11, 11] |
| 1.9694 | 2.0 | 690 | 9.9804 | 2.0651 | [10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10] |
| 1.7717 | 3.0 | 1035 | 9.5102 | 1.8205 | [10, 10, 10, 9, 10, 10, 9, 9, 10, 9, 9, 10, 9, 10, 9, 9, 9, 10, 9, 10, 10, 9, 9, 9, 9, 10, 9, 10, 9, 9, 10, 10, 10, 10, 10, 10, 9, 9, 10, 10, 9, 9, 9, 10, 10, 9, 9, 9, 9, 9, 9, 9, 10, 9, 10, 9, 10, 9, 10, 9, 9, 10, 9, 10, 9, 10, 9, 10, 10, 9, 9, 10, 9, 9, 10, 9, 9, 10, 9, 9, 9, 10, 9, 10, 9, 9, 10, 9, 10, 10, 9, 10, 10, 10, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 10, 9, 9, 10, 9, 9, 9, 10, 9, 10, 9, 10, 9, 9, 9, 10, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 9, 10, 9, 9, 10, 9, 9, 9, 9, 10, 9, 9, 10, 9, 9, 9, 10, 9, 9, 9, 9, 9, 10, 10, 9, 9, 9, 9, 10, 10, 10, 9, 10, 9, 9, 9, 9, 10, 10, 10, 9, 9, 10, 9, 9, 10, 9, 10, 10, 9, 10, 10, 9, 9, 9, 9, 10, 9, 10, 9, 10, 9, 10, 10, 10, 10, 9, 9, 10, 10, 9, 9, 10, 10, 10, 10, 9, 9, 9, 10, 9, 10, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 9, 9, 10, 9, 10, 10, 10, 10, 10, 9, 9, 10, 9, 9, 10, 10, 9, 9, 10, 10, 9, 9, 10, 10, 9, 10, 9, 9, 10, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 10, 9, 10, 9, 9, 9, 9, 10, 10, 9, 10, 10, 9, 10, 10, 10, 9, 9, 10, 9, 10, 10, 9, 10, 9, 10, 9, 9, 10, 9, 10, 9, 9, 9, 9, 9, 9, 10, 9, 9, 10, 9, 9, 10, 10, 9, 10, 9, 10, 10, 9, 10, 9, 10, 9, 10, 9, 10, 10, 10, 10, 10, 9, 10, 9, 10, 9, 9, 10, 10, 9, 9, 10, 10, 10, 9, 9, 10, 9, 9, 10, 10, 10, 9, 10, 9, 9, 9, 10, 10, 9, 10, 10, 9, 9, 10, 9, 10, 10, 10, 9, 10, 9, 10, 9, 10, 10, 10, 10, 10, 9, 9, 10, 9, 9, 9, 9, 10, 10, 9, 9, 10, 10, 9, 10, 9, 9, 9, 10, 10, 10, 9, 9, 10, 9, 10, 9, 10, 10, 10, 10, 9, 10, 9, 10, 10, 10, 10, 9, 9, 10, 9, 10, 10, 10, 10, 9, 9, 9, 10, 9, 10, 9, 9, 9, 9, 9, 10, 10, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 9, 10, 9, 10, 9, 10, 10, 10, 9, 9, 9, 9, 10, 10, 9, 10, 10, 10, 9, 9, 9, 9, 10, 9, 10, 10, 10, 10, 9, 9, 9, 9, 9, 10, 10, 9, 10, 9, 9, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 9, 9, 10, 9, 10, 10, 9, 10, 9, 9, 9, 10, 10, 9, 10, 9, 9, 10, 10, 9, 9, 9, 9, 9, 9, 10, 9, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 10, 9, 10, 10, 10, 10, 10, 9, 10, 9, 10, 9, 9, 9, 10, 10, 10, 9, 9, 9, 10, 9, 9, 9, 9, 10, 10, 10, 9, 9, 10, 10, 9, 10, 9, 9, 9, 10, 9, 9, 10, 10, 9, 10, 9, 10, 10, 9, 9, 9, 10, 9, 9, 10, 10, 9, 10, 9, 10, 10, 9, 9, 9, 10, 9, 10, 10, 9, 10, 10, 10, 10, 9, 10, 9, 9, 9, 9, 10, 10, 9, 10, 10, 9, 10, 10, 10, 10, 9, 9, 10, 10, 10, 10, 9, 11, 10, 10, 9, 9, 10, 10, 9, 10, 9, 9, 10, 10, 10, 9, 9, 9, 10, 10, 10, 10, 9, 9, 10, 9, 10, 9, 9, 9, 10, 10, 9, 11, 9, 9, 10, 9, 10, 10, 10, 9, 9, 10, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 9, 10, 9, 9, 10, 9, 10, 9, 10, 10, 10, 10, 10, 10, 10, 9, 10, 9, 10, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 10, 10, 10, 10, 9, 9, 10, 9, 9, 10, 9, 10, 10, 9, 9, 9, 10, 9, 10, 9, 10, 10, 9, 9, 9, 9, 9, 9, 10, 10, 9, 10, 10, 9, 10, 10, 10, 10, 9, 10, 9, 10, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 9, 9, 9, 10, 9, 9, 9, 10, 9, 10, 10, 9, 10, 9, 9, 9, 10, 9, 10, 10, 9, 10, 9, 10, 10, 10, 9, 9, 10, 10, 9, 9, 10, 9, 10, 9, 9, 9, 10, 9, 10, 10, 9, 10, 9, 10, 10, 9, 10, 10, 9, 10, 10, 9, 10, 9, 9, 9, 10, 10, 9, 9, 9, 9, 9, 10, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 9, 10, 9, 9, 9, 9, 10, 9, 9, 10, 10, 10, 10, 10, 9, 9, 9, 9, 10, 9, 10, 10, 9, 9, 10, 9, 10, 10, 9, 9, 10, 9, 10, 9, 10, 9, 9, 10, 10, 10, 9, 10, 9, 9, 10, 9, 10, 9, 9, 10, 9, 10, 10, 9, 9, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 10, 9, 9, 9, 9, 9, 10, 9, 9, 10, 9, 10, 9, 10, 10, 10, 10, 9, 9, 10, 10, 10, 9, 10, 10, 10, 9, 10, 9, 10, 10, 10, 9, 10, 9, 10, 9, 10, 11, 10, 10, 9, 10, 10, 9, 10, 9, 10, 10, 9, 9, 9, 9, 9, 10, 9, 10, 9, 9, 9, 9, 10, 10, 9, 9, 9, 10, 10, 9, 9, 10, 10, 10, 9, 9, 9, 10, 9, 10, 9, 10, 9, 10, 9, 10, 10, 9, 10, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 10, 9, 9, 9, 10, 10, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 10, 10, 9, 9, 9, 10, 9, 9, 9, 10, 10, 9, 10, 9, 10, 10, 9, 9, 10, 9, 9, 9, 10, 9, 10, 10, 10, 10, 9, 9, 9, 10, 10, 9, 9, 10, 9, 9, 9, 10, 9, 10, 10, 10, 9, 9, 9, 9, 10, 10, 10, 9, 9, 9, 10, 10, 9, 10, 10, 10, 9, 9, 10, 10, 9, 9, 9, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 10, 9, 9, 9, 9, 9, 9, 10, 9, 10, 10, 9, 10, 9, 10, 10, 10, 9, 10, 9, 9, 10, 9, 9, 10, 9, 9, 10, 9, 9, 9, 9, 10, 9, 9, 10, 9, 10, 9, 10, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 10, 9, 10, 10, 9, 9, 9, 9, 9, 10, 9, 10, 10, 10, 9, 9, 9, 9, 10, 10, 9, 10, 9, 10, 10, 10, 9, 9, 10, 9, 10, 9, 9, 9, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 10, 9, 10, 9, 10, 9, 10, 9, 10, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 10, 9, 10, 10, 10, 9, 9, 9, 9, 9, 10, 10, 9, 10, 10, 10, 9, 10, 10, 10, 9, 10, 10, 9, 9, 10, 10, 9, 9, 10, 10, 10, 10, 10, 9, 10, 10, 10, 9, 9, 10, 9, 10, 10, 9, 9, 10, 10, 9, 10, 9, 9, 9, 9, 9, 10, 9, 10, 9, 10, 10, 9, 9, 9, 10, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 9, 9, 9, 10, 10, 9, 10, 9, 10, 9, 10, 10, 10, 10, 10, 9, 9, 10, 9, 9, 10, 11, 10, 10, 10, 10, 10, 10, 9, 10, 9, 10, 9, 10, 10, 9, 10, 10, 9, 10, 9, 10, 9, 10, 10, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 9, 10, 10, 9, 10, 10, 9, 10, 9, 9, 10, 10, 9, 9, 9, 10, 10, 9, 9] |
| 0.0672 | 4.0 | 1380 | 9.0 | 0.0457 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0617 | 5.0 | 1725 | 9.0 | 0.0453 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0636 | 6.0 | 2070 | 9.0 | 0.0457 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0544 | 7.0 | 2415 | 9.0 | 0.0426 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0453 | 8.0 | 2760 | 9.0 | 0.0385 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.046 | 9.0 | 3105 | 9.0 | 0.0369 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0465 | 10.0 | 3450 | 9.0 | 0.0379 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.037 | 11.0 | 3795 | 9.0 | 0.0343 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0448 | 12.0 | 4140 | 9.0 | 0.0338 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0419 | 13.0 | 4485 | 9.0 | 0.0328 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0402 | 14.0 | 4830 | 9.0007 | 0.0344 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0401 | 15.0 | 5175 | 9.0 | 0.0321 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0392 | 16.0 | 5520 | 9.0007 | 0.0335 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0418 | 17.0 | 5865 | 9.0 | 0.0309 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0365 | 18.0 | 6210 | 9.0 | 0.0319 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0331 | 19.0 | 6555 | 9.0 | 0.0306 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0356 | 20.0 | 6900 | 9.0 | 0.0306 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.039 | 21.0 | 7245 | 9.0 | 0.0317 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0363 | 22.0 | 7590 | 9.0 | 0.0298 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.035 | 23.0 | 7935 | 9.0 | 0.0301 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0346 | 24.0 | 8280 | 9.0 | 0.0301 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0346 | 25.0 | 8625 | 9.0 | 0.0292 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0299 | 26.0 | 8970 | 9.0 | 0.0294 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0316 | 27.0 | 9315 | 9.0 | 0.0294 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0373 | 28.0 | 9660 | 9.0 | 0.0291 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0348 | 29.0 | 10005 | 9.0 | 0.0292 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0323 | 30.0 | 10350 | 9.0 | 0.0292 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0338 | 31.0 | 10695 | 9.0 | 0.0292 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
| 0.0333 | 32.0 | 11040 | 9.0 | 0.0292 | [9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9] |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.1.0+cu121
- Datasets 2.6.1
- Tokenizers 0.14.1
|
tim-kang/lora-trained-xl
|
tim-kang
| 2023-11-14T10:12:39Z | 2 | 1 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-14T09:25:27Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks dog
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - tim-kang/lora-trained-xl
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
Tommert25/robbert_seed37_1311
|
Tommert25
| 2023-11-14T10:11:48Z | 17 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"base_model:pdelobelle/robbert-v2-dutch-base",
"base_model:finetune:pdelobelle/robbert-v2-dutch-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-14T09:59:15Z |
---
license: mit
base_model: pdelobelle/robbert-v2-dutch-base
tags:
- generated_from_trainer
metrics:
- recall
- accuracy
model-index:
- name: robbert_seed37_1311
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robbert_seed37_1311
This model is a fine-tuned version of [pdelobelle/robbert-v2-dutch-base](https://huggingface.co/pdelobelle/robbert-v2-dutch-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3848
- Precisions: 0.8521
- Recall: 0.8198
- F-measure: 0.8327
- Accuracy: 0.9441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 37
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precisions | Recall | F-measure | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:------:|:---------:|:--------:|
| 0.4569 | 1.0 | 236 | 0.2571 | 0.7110 | 0.7130 | 0.7092 | 0.9217 |
| 0.222 | 2.0 | 472 | 0.2286 | 0.7904 | 0.7574 | 0.7685 | 0.9313 |
| 0.1311 | 3.0 | 708 | 0.2412 | 0.8047 | 0.7810 | 0.7875 | 0.9359 |
| 0.0813 | 4.0 | 944 | 0.2755 | 0.8019 | 0.7775 | 0.7886 | 0.9354 |
| 0.0552 | 5.0 | 1180 | 0.3120 | 0.8499 | 0.7793 | 0.8032 | 0.9409 |
| 0.0323 | 6.0 | 1416 | 0.3536 | 0.8350 | 0.7955 | 0.8099 | 0.9402 |
| 0.0212 | 7.0 | 1652 | 0.3789 | 0.8448 | 0.7817 | 0.8092 | 0.9405 |
| 0.0154 | 8.0 | 1888 | 0.3835 | 0.8419 | 0.7780 | 0.7971 | 0.9385 |
| 0.0119 | 9.0 | 2124 | 0.3906 | 0.8583 | 0.7812 | 0.8058 | 0.9388 |
| 0.0081 | 10.0 | 2360 | 0.3910 | 0.8477 | 0.7874 | 0.8062 | 0.9424 |
| 0.0052 | 11.0 | 2596 | 0.3839 | 0.8642 | 0.8087 | 0.8298 | 0.9431 |
| 0.0046 | 12.0 | 2832 | 0.3848 | 0.8521 | 0.8198 | 0.8327 | 0.9441 |
| 0.0018 | 13.0 | 3068 | 0.4017 | 0.8450 | 0.8125 | 0.8240 | 0.9438 |
| 0.0014 | 14.0 | 3304 | 0.4060 | 0.8571 | 0.8088 | 0.8265 | 0.9441 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
JMatthewChiam/4248-spanBERT-Base
|
JMatthewChiam
| 2023-11-14T10:10:06Z | 39 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:SpanBERT/spanbert-base-cased",
"base_model:finetune:SpanBERT/spanbert-base-cased",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-12T04:42:07Z |
---
base_model: SpanBERT/spanbert-base-cased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: 4248-spanBERT-Base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 4248-spanBERT-Base
This model is a fine-tuned version of [SpanBERT/spanbert-base-cased](https://huggingface.co/SpanBERT/spanbert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
abdiharyadi/IndoT5-base-nafkhan-epochs-5
|
abdiharyadi
| 2023-11-14T10:09:23Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:abdiharyadi/IndoT5-base-nafkhan-epochs-4",
"base_model:finetune:abdiharyadi/IndoT5-base-nafkhan-epochs-4",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-14T02:51:54Z |
---
base_model: abdiharyadi/IndoT5-base-nafkhan-epochs-4
tags:
- generated_from_trainer
model-index:
- name: IndoT5-base-nafkhan-epochs-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IndoT5-base-nafkhan-epochs-5
This model is a fine-tuned version of [abdiharyadi/IndoT5-base-nafkhan-epochs-4](https://huggingface.co/abdiharyadi/IndoT5-base-nafkhan-epochs-4) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1567
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 442
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: polynomial
- lr_scheduler_warmup_steps: 200
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.1536 | 1.0 | 23217 | 0.1567 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
advanced-stack/openllm-claire-7b-gguf
|
advanced-stack
| 2023-11-14T10:05:50Z | 6 | 0 | null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-14T09:49:42Z |
---
license: apache-2.0
---
These are quantized version of the Claire model to be used with llama.cpp (GGUF format).
The original model card is available here: https://huggingface.co/OpenLLM-France/Claire-7B-0.1
|
fashxp/flan-t5-base-cars-descriptions
|
fashxp
| 2023-11-14T10:03:21Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-10-23T19:13:19Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-base-cars-descriptions
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-cars-descriptions
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0993
- Rouge1: 19.8484
- Rouge2: 13.6841
- Rougel: 17.8819
- Rougelsum: 19.2489
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 28 | 1.3129 | 19.8055 | 13.244 | 17.4816 | 18.9752 | 19.0 |
| No log | 2.0 | 56 | 1.1922 | 20.0308 | 13.7036 | 17.7216 | 19.3773 | 19.0 |
| No log | 3.0 | 84 | 1.1337 | 19.4591 | 13.5553 | 17.5737 | 18.7867 | 19.0 |
| No log | 4.0 | 112 | 1.1075 | 19.8452 | 13.681 | 17.8433 | 19.246 | 19.0 |
| No log | 5.0 | 140 | 1.0993 | 19.8484 | 13.6841 | 17.8819 | 19.2489 | 19.0 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
KJH1979/minilm-fintuned-emotion
|
KJH1979
| 2023-11-14T09:59:54Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:microsoft/MiniLM-L12-H384-uncased",
"base_model:finetune:microsoft/MiniLM-L12-H384-uncased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-14T09:54:53Z |
---
license: mit
base_model: microsoft/MiniLM-L12-H384-uncased
tags:
- generated_from_trainer
datasets:
- emotion
model-index:
- name: minilm-fintuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# minilm-fintuned-emotion
This model is a fine-tuned version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 250 | 1.0790 |
| No log | 2.0 | 500 | 0.6965 |
| No log | 3.0 | 750 | 0.4934 |
| No log | 4.0 | 1000 | 0.4077 |
| No log | 5.0 | 1250 | 0.3814 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
askulkarni2/dogbooth
|
askulkarni2
| 2023-11-14T09:55:05Z | 5 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:finetune:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-28T22:15:33Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
instance_prompt: a photo of [v]dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - askulkarni2/dogbooth
This is a dreambooth model derived from stabilityai/stable-diffusion-2-1. The weights were trained on a photo of [v]dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
shiyue-loop/test
|
shiyue-loop
| 2023-11-14T09:48:58Z | 0 | 0 | null |
[
"text-generation",
"license:other",
"region:us"
] |
text-generation
| 2023-11-14T07:00:37Z |
---
license: other
license_name: yi-license
license_link: LICENSE
widget:
- text: "There's a place where time stands still. A place of breath taking wonder, but also"
output:
text: " an eerie sense that something is just not right…\nBetween the two worlds lies The Forgotten Kingdom - home to creatures long since thought extinct and ancient magic so strong it defies belief! Only here can you find what has been lost for centuries: An Elixir Of Life which will restore youth and vitality if only those who seek its power are brave enough to face up against all manner of dangers lurking in this mysterious land! But beware; some say there may even exist powerful entities beyond our comprehension whose intentions towards humanity remain unclear at best ---- they might want nothing more than destruction itself rather then anything else from their quest after immortality (and maybe someone should tell them about modern medicine)? In any event though – one thing remains true regardless : whether or not success comes easy depends entirely upon how much effort we put into conquering whatever challenges lie ahead along with having faith deep down inside ourselves too ;) So let’s get started now shall We?"
pipeline_tag: text-generation
---
<div align="center">
<img src="./Yi.svg" width="200px">
</div>
## Introduction
The **Yi** series models are large language models trained from scratch by
developers at [01.AI](https://01.ai/). The first public release contains two
bilingual(English/Chinese) base models with the parameter sizes of 6B([`Yi-6B`](https://huggingface.co/01-ai/Yi-6B))
and 34B([`Yi-34B`](https://huggingface.co/01-ai/Yi-34B)). Both of them are trained
with 4K sequence length and can be extended to 32K during inference time.
The [`Yi-6B-200K`](https://huggingface.co/01-ai/Yi-6B-200K)
and [`Yi-34B-200K`](https://huggingface.co/01-ai/Yi-34B-200K) are base model with
200K context length.
## News
- 🎯 **2023/11/06**: The base model of [`Yi-6B-200K`](https://huggingface.co/01-ai/Yi-6B-200K)
and [`Yi-34B-200K`](https://huggingface.co/01-ai/Yi-34B-200K) with 200K context length.
- 🎯 **2023/11/02**: The base model of [`Yi-6B`](https://huggingface.co/01-ai/Yi-6B) and
[`Yi-34B`](https://huggingface.co/01-ai/Yi-34B).
## Model Performance
| Model | MMLU | CMMLU | C-Eval | GAOKAO | BBH | Common-sense Reasoning | Reading Comprehension | Math & Code |
| :------------ | :------: | :------: | :------: | :------: | :------: | :--------------------: | :-------------------: | :---------: |
| | 5-shot | 5-shot | 5-shot | 0-shot | 3-shot@1 | - | - | - |
| LLaMA2-34B | 62.6 | - | - | - | 44.1 | 69.9 | 68.0 | 26.0 |
| LLaMA2-70B | 68.9 | 53.3 | - | 49.8 | 51.2 | 71.9 | 69.4 | 36.8 |
| Baichuan2-13B | 59.2 | 62.0 | 58.1 | 54.3 | 48.8 | 64.3 | 62.4 | 23.0 |
| Qwen-14B | 66.3 | 71.0 | 72.1 | 62.5 | 53.4 | 73.3 | 72.5 | **39.8** |
| Skywork-13B | 62.1 | 61.8 | 60.6 | 68.1 | 41.7 | 72.4 | 61.4 | 24.9 |
| InternLM-20B | 62.1 | 59.0 | 58.8 | 45.5 | 52.5 | 78.3 | - | 30.4 |
| Aquila-34B | 67.8 | 71.4 | 63.1 | - | - | - | - | - |
| Falcon-180B | 70.4 | 58.0 | 57.8 | 59.0 | 54.0 | 77.3 | 68.8 | 34.0 |
| Yi-6B | 63.2 | 75.5 | 72.0 | 72.2 | 42.8 | 72.3 | 68.7 | 19.8 |
| Yi-6B-200K | 64.0 | 75.3 | 73.5 | 73.9 | 42.0 | 72.0 | 69.1 | 19.0 |
| **Yi-34B** | **76.3** | **83.7** | 81.4 | 82.8 | **54.3** | **80.1** | 76.4 | 37.1 |
| Yi-34B-200K | 76.1 | 83.6 | **81.9** | **83.4** | 52.7 | 79.7 | **76.6** | 36.3 |
While benchmarking open-source models, we have observed a disparity between the
results generated by our pipeline and those reported in public sources (e.g.
OpenCompass). Upon conducting a more in-depth investigation of this difference,
we have discovered that various models may employ different prompts,
post-processing strategies, and sampling techniques, potentially resulting in
significant variations in the outcomes. Our prompt and post-processing strategy
remains consistent with the original benchmark, and greedy decoding is employed
during evaluation without any post-processing for the generated content. For
scores that were not reported by the original authors (including scores reported
with different settings), we try to get results with our pipeline.
To evaluate the model's capability extensively, we adopted the methodology
outlined in Llama2. Specifically, we included PIQA, SIQA, HellaSwag, WinoGrande,
ARC, OBQA, and CSQA to assess common sense reasoning. SquAD, QuAC, and BoolQ
were incorporated to evaluate reading comprehension. CSQA was exclusively tested
using a 7-shot setup, while all other tests were conducted with a 0-shot
configuration. Additionally, we introduced GSM8K (8-shot@1), MATH (4-shot@1),
HumanEval (0-shot@1), and MBPP (3-shot@1) under the category "Math & Code". Due
to technical constraints, we did not test Falcon-180 on QuAC and OBQA; the score
is derived by averaging the scores on the remaining tasks. Since the scores for
these two tasks are generally lower than the average, we believe that
Falcon-180B's performance was not underestimated.
## Usage
Please visit our [github repository](https://github.com/01-ai/Yi) for general
guidance on how to use this model.
## Disclaimer
Although we use data compliance checking algorithms during the training process
to ensure the compliance of the trained model to the best of our ability, due to
the complexity of the data and the diversity of language model usage scenarios,
we cannot guarantee that the model will generate correct and reasonable output
in all scenarios. Please be aware that there is still a risk of the model
producing problematic outputs. We will not be responsible for any risks and
issues resulting from misuse, misguidance, illegal usage, and related
misinformation, as well as any associated data security concerns.
## License
The Yi series models are fully open for academic research and free commercial
usage with permission via applications. All usage must adhere to the [Model
License Agreement 2.0](https://huggingface.co/01-ai/Yi-6B/blob/main/LICENSE). To
apply for the official commercial license, please contact us
([yi@01.ai](mailto:yi@01.ai)).
|
yvelos/Tsotsallm-eval
|
yvelos
| 2023-11-14T09:46:26Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-14T09:46:17Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
EstherSan/car_identified_model_11
|
EstherSan
| 2023-11-14T09:39:01Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mobilevit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:apple/mobilevit-small",
"base_model:finetune:apple/mobilevit-small",
"license:other",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-14T09:08:20Z |
---
license: other
base_model: apple/mobilevit-small
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- f1
- accuracy
model-index:
- name: car_identified_model_11
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: F1
type: f1
value: 0.7241379310344829
- name: Accuracy
type: accuracy
value: 0.08333333333333333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# car_identified_model_11
This model is a fine-tuned version of [apple/mobilevit-small](https://huggingface.co/apple/mobilevit-small) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6686
- F1: 0.7241
- Roc Auc: 0.6667
- Accuracy: 0.0833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.2582 | 1.0 | 1 | 0.6938 | 0.5926 | 0.5417 | 0.0833 |
| 0.2582 | 2.0 | 2 | 0.6937 | 0.6415 | 0.6042 | 0.0833 |
| 0.2582 | 3.0 | 4 | 0.6918 | 0.6429 | 0.5833 | 0.0 |
| 0.2582 | 4.0 | 5 | 0.6893 | 0.6316 | 0.5625 | 0.0 |
| 0.2582 | 5.0 | 6 | 0.6871 | 0.6667 | 0.6042 | 0.0833 |
| 0.2582 | 6.0 | 8 | 0.6844 | 0.6786 | 0.625 | 0.0833 |
| 0.2582 | 7.0 | 9 | 0.6827 | 0.7018 | 0.6458 | 0.0833 |
| 0.2582 | 8.0 | 10 | 0.6817 | 0.6667 | 0.6042 | 0.0833 |
| 0.2582 | 9.0 | 11 | 0.6809 | 0.6897 | 0.625 | 0.0833 |
| 0.2582 | 10.0 | 12 | 0.6804 | 0.6897 | 0.625 | 0.0833 |
| 0.2582 | 11.0 | 14 | 0.6792 | 0.6897 | 0.625 | 0.0833 |
| 0.2582 | 12.0 | 15 | 0.6787 | 0.7119 | 0.6458 | 0.0833 |
| 0.2582 | 13.0 | 16 | 0.6780 | 0.7119 | 0.6458 | 0.0833 |
| 0.2582 | 14.0 | 18 | 0.6771 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 15.0 | 19 | 0.6765 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 16.0 | 20 | 0.6762 | 0.7458 | 0.6875 | 0.0833 |
| 0.2582 | 17.0 | 21 | 0.6758 | 0.7333 | 0.6667 | 0.0833 |
| 0.2582 | 18.0 | 22 | 0.6753 | 0.7458 | 0.6875 | 0.0833 |
| 0.2582 | 19.0 | 24 | 0.6744 | 0.7333 | 0.6667 | 0.0833 |
| 0.2582 | 20.0 | 25 | 0.6740 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 21.0 | 26 | 0.6737 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 22.0 | 28 | 0.6733 | 0.7458 | 0.6875 | 0.0833 |
| 0.2582 | 23.0 | 29 | 0.6725 | 0.7458 | 0.6875 | 0.0833 |
| 0.2582 | 24.0 | 30 | 0.6720 | 0.7368 | 0.6875 | 0.0833 |
| 0.2582 | 25.0 | 31 | 0.6719 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 26.0 | 32 | 0.6713 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 27.0 | 34 | 0.6711 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 28.0 | 35 | 0.6705 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 29.0 | 36 | 0.6700 | 0.7368 | 0.6875 | 0.0833 |
| 0.2582 | 30.0 | 38 | 0.6696 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 31.0 | 39 | 0.6695 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 32.0 | 40 | 0.6693 | 0.7368 | 0.6875 | 0.1667 |
| 0.2582 | 33.0 | 41 | 0.6692 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 34.0 | 42 | 0.6694 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 35.0 | 44 | 0.6692 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 36.0 | 45 | 0.6693 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 37.0 | 46 | 0.6693 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 38.0 | 48 | 0.6690 | 0.7241 | 0.6667 | 0.0833 |
| 0.2582 | 39.0 | 49 | 0.6689 | 0.7368 | 0.6875 | 0.0833 |
| 0.2582 | 40.0 | 50 | 0.6686 | 0.7241 | 0.6667 | 0.0833 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
astrosbd/fake-reviews-distilbert-v3
|
astrosbd
| 2023-11-14T09:32:55Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:astrosbd/fake-reviews-distilbert-v3",
"base_model:finetune:astrosbd/fake-reviews-distilbert-v3",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-13T10:11:45Z |
---
license: mit
base_model: astrosbd/fake-reviews-distilbert-v3
tags:
- generated_from_trainer
model-index:
- name: fake-reviews-distilbert-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fake-reviews-distilbert-v3
This model is a fine-tuned version of [astrosbd/fake-reviews-distilbert-v3](https://huggingface.co/astrosbd/fake-reviews-distilbert-v3) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.1744
- eval_accuracy: 0.9749
- eval_runtime: 999.4816
- eval_samples_per_second: 10.113
- eval_steps_per_second: 0.316
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.32.1
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.13.2
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.