
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-31 00:44:29
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 530
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-31 00:43:54
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
nihaldsouza1/covid-hatespeech-detection
|
nihaldsouza1
| 2022-11-03T08:25:17Z | 104 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"transfer-learning",
"bert",
"hatespeech",
"covid19",
"en",
"dataset:COVID-HATE",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-05-10T18:37:46Z |
---
language: en
tags:
- transfer-learning
- bert
- hatespeech
- covid19
license: "mit"
datasets:
- COVID-HATE
metrics:
- f1-score
---
Since the start of the COVID-19 pandemic, there has been a widespread increase in the amount of hate-speech being propagated online against the Asian community. This project builds upon and explores the work of He et al. Their COVID-HATE dataset contains 206 million tweets focused around anti-Asian hate speech. Using tweet data from before the COVID-19 pandemic, as well as the COVID-HATE dataset from He et al, we performed transfer learning. We tested several different models, including BERT, RoBERTa, LSTM, and BERT-CNN.
Some of these models hindered the performance of He et al’s model, while others improved it.
|
takizawa/distilbert-base-uncased-finetuned-emotion
|
takizawa
| 2022-11-03T06:30:42Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-03T06:17:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.924985636202576
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2251
- Accuracy: 0.925
- F1: 0.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8481 | 1.0 | 250 | 0.3248 | 0.907 | 0.9028 |
| 0.2595 | 2.0 | 500 | 0.2251 | 0.925 | 0.9250 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
DrishtiSharma/wav2vec2-large-xls-r-300m-hi-CV7
|
DrishtiSharma
| 2022-11-03T05:42:08Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_7_0",
"generated_from_trainer",
"hi",
"robust-speech-event",
"hf-asr-leaderboard",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language:
- hi
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_7_0
- generated_from_trainer
- hi
- robust-speech-event
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_7_0
model-index:
- name: wav2vec2-large-xls-r-300m-hi-CV7
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: hi
metrics:
- name: Test WER
type: wer
value: 35.31946325249292
- name: Test CER
type: cer
value: 11.310803379493076
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: vot
metrics:
- name: Test WER
type: wer
value: NA
- name: Test CER
type: cer
value: NA
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hi-CV7
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6588
- Wer: 0.2987
### Evaluation Commands
1. To evaluate on mozilla-foundation/common_voice_8_0 with test split
python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-hi-CV7 --dataset mozilla-foundation/common_voice_7_0 --config hi --split test --log_outputs
2. To evaluate on speech-recognition-community-v2/dev_data
NA
### Training hyperparameters
The following hyperparameters were used during training:
#
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 12.809 | 1.36 | 200 | 6.2066 | 1.0 |
| 4.3402 | 2.72 | 400 | 3.5184 | 1.0 |
| 3.4365 | 4.08 | 600 | 3.2779 | 1.0 |
| 1.8643 | 5.44 | 800 | 0.9875 | 0.6270 |
| 0.7504 | 6.8 | 1000 | 0.6382 | 0.4666 |
| 0.5328 | 8.16 | 1200 | 0.6075 | 0.4505 |
| 0.4364 | 9.52 | 1400 | 0.5785 | 0.4215 |
| 0.3777 | 10.88 | 1600 | 0.6279 | 0.4227 |
| 0.3374 | 12.24 | 1800 | 0.6536 | 0.4192 |
| 0.3236 | 13.6 | 2000 | 0.5911 | 0.4047 |
| 0.2877 | 14.96 | 2200 | 0.5955 | 0.4097 |
| 0.2643 | 16.33 | 2400 | 0.5923 | 0.3744 |
| 0.2421 | 17.68 | 2600 | 0.6307 | 0.3814 |
| 0.2218 | 19.05 | 2800 | 0.6036 | 0.3764 |
| 0.2046 | 20.41 | 3000 | 0.6286 | 0.3797 |
| 0.191 | 21.77 | 3200 | 0.6517 | 0.3889 |
| 0.1856 | 23.13 | 3400 | 0.6193 | 0.3661 |
| 0.1721 | 24.49 | 3600 | 0.7034 | 0.3727 |
| 0.1656 | 25.85 | 3800 | 0.6293 | 0.3591 |
| 0.1532 | 27.21 | 4000 | 0.6075 | 0.3611 |
| 0.1507 | 28.57 | 4200 | 0.6313 | 0.3565 |
| 0.1381 | 29.93 | 4400 | 0.6564 | 0.3578 |
| 0.1359 | 31.29 | 4600 | 0.6724 | 0.3543 |
| 0.1248 | 32.65 | 4800 | 0.6789 | 0.3512 |
| 0.1198 | 34.01 | 5000 | 0.6442 | 0.3539 |
| 0.1125 | 35.37 | 5200 | 0.6676 | 0.3419 |
| 0.1036 | 36.73 | 5400 | 0.7017 | 0.3435 |
| 0.0982 | 38.09 | 5600 | 0.6828 | 0.3319 |
| 0.0971 | 39.45 | 5800 | 0.6112 | 0.3351 |
| 0.0968 | 40.81 | 6000 | 0.6424 | 0.3252 |
| 0.0893 | 42.18 | 6200 | 0.6707 | 0.3304 |
| 0.0878 | 43.54 | 6400 | 0.6432 | 0.3236 |
| 0.0827 | 44.89 | 6600 | 0.6696 | 0.3240 |
| 0.0788 | 46.26 | 6800 | 0.6564 | 0.3180 |
| 0.0753 | 47.62 | 7000 | 0.6574 | 0.3130 |
| 0.0674 | 48.98 | 7200 | 0.6698 | 0.3175 |
| 0.0676 | 50.34 | 7400 | 0.6441 | 0.3142 |
| 0.0626 | 51.7 | 7600 | 0.6642 | 0.3121 |
| 0.0617 | 53.06 | 7800 | 0.6615 | 0.3117 |
| 0.0599 | 54.42 | 8000 | 0.6634 | 0.3059 |
| 0.0538 | 55.78 | 8200 | 0.6464 | 0.3033 |
| 0.0571 | 57.14 | 8400 | 0.6503 | 0.3018 |
| 0.0491 | 58.5 | 8600 | 0.6625 | 0.3025 |
| 0.0511 | 59.86 | 8800 | 0.6588 | 0.2987 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
DrishtiSharma/wav2vec2-large-xls-r-300m-hi-wx1
|
DrishtiSharma
| 2022-11-03T05:38:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"robust-speech-event",
"hi",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language:
- hi
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_7_0
metrics:
- wer
model-index:
- name: wav2vec2-large-xls-r-300m-hi-wx1
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: mozilla-foundation/common_voice_7_0
name: Common Voice 7
args: hi
metrics:
- type: wer
value: 37.19684845500431
name: Test WER
- name: Test CER
type: cer
value: 11.763235514672798
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hi-wx1
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 -HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6552
- Wer: 0.3200
Evaluation Commands
1. To evaluate on mozilla-foundation/common_voice_8_0 with test split
python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-hi-wx1 --dataset mozilla-foundation/common_voice_7_0 --config hi --split test --log_outputs
2. To evaluate on speech-recognition-community-v2/dev_data
NA
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00024
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1800
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 12.2663 | 1.36 | 200 | 5.9245 | 1.0 |
| 4.1856 | 2.72 | 400 | 3.4968 | 1.0 |
| 3.3908 | 4.08 | 600 | 2.9970 | 1.0 |
| 1.5444 | 5.44 | 800 | 0.9071 | 0.6139 |
| 0.7237 | 6.8 | 1000 | 0.6508 | 0.4862 |
| 0.5323 | 8.16 | 1200 | 0.6217 | 0.4647 |
| 0.4426 | 9.52 | 1400 | 0.5785 | 0.4288 |
| 0.3933 | 10.88 | 1600 | 0.5935 | 0.4217 |
| 0.3532 | 12.24 | 1800 | 0.6358 | 0.4465 |
| 0.3319 | 13.6 | 2000 | 0.5789 | 0.4118 |
| 0.2877 | 14.96 | 2200 | 0.6163 | 0.4056 |
| 0.2663 | 16.33 | 2400 | 0.6176 | 0.3893 |
| 0.2511 | 17.68 | 2600 | 0.6065 | 0.3999 |
| 0.2275 | 19.05 | 2800 | 0.6183 | 0.3842 |
| 0.2098 | 20.41 | 3000 | 0.6486 | 0.3864 |
| 0.1943 | 21.77 | 3200 | 0.6365 | 0.3885 |
| 0.1877 | 23.13 | 3400 | 0.6013 | 0.3677 |
| 0.1679 | 24.49 | 3600 | 0.6451 | 0.3795 |
| 0.1667 | 25.85 | 3800 | 0.6410 | 0.3635 |
| 0.1514 | 27.21 | 4000 | 0.6000 | 0.3577 |
| 0.1453 | 28.57 | 4200 | 0.6020 | 0.3518 |
| 0.134 | 29.93 | 4400 | 0.6531 | 0.3517 |
| 0.1354 | 31.29 | 4600 | 0.6874 | 0.3578 |
| 0.1224 | 32.65 | 4800 | 0.6519 | 0.3492 |
| 0.1199 | 34.01 | 5000 | 0.6553 | 0.3490 |
| 0.1077 | 35.37 | 5200 | 0.6621 | 0.3429 |
| 0.0997 | 36.73 | 5400 | 0.6641 | 0.3413 |
| 0.0964 | 38.09 | 5600 | 0.6722 | 0.3385 |
| 0.0931 | 39.45 | 5800 | 0.6365 | 0.3363 |
| 0.0944 | 40.81 | 6000 | 0.6454 | 0.3326 |
| 0.0862 | 42.18 | 6200 | 0.6497 | 0.3256 |
| 0.0848 | 43.54 | 6400 | 0.6599 | 0.3226 |
| 0.0793 | 44.89 | 6600 | 0.6625 | 0.3232 |
| 0.076 | 46.26 | 6800 | 0.6463 | 0.3186 |
| 0.0749 | 47.62 | 7000 | 0.6559 | 0.3225 |
| 0.0663 | 48.98 | 7200 | 0.6552 | 0.3200 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
eunyounglee/mBART_translator_json_all_2
|
eunyounglee
| 2022-11-03T03:24:16Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-03T01:29:37Z |
---
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mBART_translator_json_all_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mBART_translator_json_all_2
This model is a fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1595
- Bleu: 76.137
- Gen Len: 11.966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| 1.914 | 1.0 | 2908 | 0.7158 | 26.1202 | 44.2761 |
| 0.948 | 2.0 | 5816 | 0.3113 | 74.3952 | 12.4625 |
| 0.5552 | 3.0 | 8724 | 0.1595 | 76.137 | 11.966 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.0
- Datasets 1.18.3
- Tokenizers 0.11.0
|
Gaborandi/Bio_ClinicalBERT-SurgicalCardiothoracic
|
Gaborandi
| 2022-11-03T01:57:32Z | 36 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-02T17:05:08Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Bio_ClinicalBERT-SurgicalCardiothoracic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-SurgicalCardiothoracic
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 13144 | 0.9092 |
| No log | 2.0 | 26288 | 0.8575 |
| No log | 3.0 | 39432 | 0.8417 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.8.0
- Datasets 2.2.2
- Tokenizers 0.11.6
|
Bingsu/ko_BBPE_tokenizer_bert2
|
Bingsu
| 2022-11-03T00:20:59Z | 0 | 0 | null |
[
"bert",
"tokenizer only",
"ko",
"license:mit",
"region:us"
] | null | 2022-11-03T00:19:01Z |
---
language:
- ko
tags:
- bert
- tokenizer only
license:
- mit
---
## 라이브러리 버전
- transformers: 4.23.1
- datasets: 2.6.1
- tokenizers: 0.13.1
[Bingsu/ko_BBPE_tokenizer_roberta](https://huggingface.co/Bingsu/ko_BBPE_tokenizer_roberta)에서 unicode normalizer를 `nfc`로, post-processor를 BertProcessing로 변경하고 토크나이저 클래스를 `BertTokenizerFast`로 변경한 것입니다.
|
zzxslp/RadBERT-RoBERTa-4m
|
zzxslp
| 2022-11-03T00:03:13Z | 1,023 | 7 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-10-18T01:15:16Z |
## RadBERT-RoBERTa-4m
This is one variant of our RadBERT models trained with 4 million deidentified medical reports from US VA hospital, which achieves stronger medical language understanding performance than previous medical domain models such as BioBERT, Clinical-BERT, BLUE-BERT and BioMed-RoBERTa.
Performances are evaluated on three tasks:
(a) abnormal sentence classification: sentence classification in radiology reports as reporting abnormal or normal findings;
(b) report coding: Assign a diagnostic code to a given radiology report for five different coding systems;
(c) report summarization: given the findings section of a radiology report, extractively select key sentences that summarized the findings.
For details, check out the paper here:
[RadBERT: Adapting transformer-based language models to radiology](https://pubs.rsna.org/doi/abs/10.1148/ryai.210258)
Code for the paper is released at [this GitHub repo](https://github.com/zzxslp/RadBERT).
### How to use
Here is an example of how to use this model to extract the features of a given text in PyTorch:
```python
from transformers import AutoConfig, AutoTokenizer, AutoModel
config = AutoConfig.from_pretrained('zzxslp/RadBERT-RoBERTa-4m')
tokenizer = AutoTokenizer.from_pretrained('zzxslp/RadBERT-RoBERTa-4m')
model = AutoModel.from_pretrained('zzxslp/RadBERT-RoBERTa-4m', config=config)
text = "Replace me by any medical text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### BibTeX entry and citation info
If you use the model, please cite our paper:
```bibtex
@article{yan2022radbert,
title={RadBERT: Adapting transformer-based language models to radiology},
author={Yan, An and McAuley, Julian and Lu, Xing and Du, Jiang and Chang, Eric Y and Gentili, Amilcare and Hsu, Chun-Nan},
journal={Radiology: Artificial Intelligence},
volume={4},
number={4},
pages={e210258},
year={2022},
publisher={Radiological Society of North America}
}
```
|
alicekwak/TN-final-multi-qa-mpnet-base-dot-v1
|
alicekwak
| 2022-11-02T23:06:04Z | 6 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T23:05:53Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# alicekwak/TN-final-multi-qa-mpnet-base-dot-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('alicekwak/TN-final-multi-qa-mpnet-base-dot-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('alicekwak/TN-final-multi-qa-mpnet-base-dot-v1')
model = AutoModel.from_pretrained('alicekwak/TN-final-multi-qa-mpnet-base-dot-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=alicekwak/TN-final-multi-qa-mpnet-base-dot-v1)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 675 with parameters:
```
{'batch_size': 4, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.SoftmaxLoss.SoftmaxLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
alicekwak/TN-final-all-mpnet-base-v2
|
alicekwak
| 2022-11-02T22:58:35Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T22:58:25Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# alicekwak/TN-final-all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('alicekwak/TN-final-all-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=alicekwak/TN-final-all-mpnet-base-v2)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 675 with parameters:
```
{'batch_size': 4, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.SoftmaxLoss.SoftmaxLoss`
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
bayartsogt/wav2vec2-xls-r-300m-mn-demo
|
bayartsogt
| 2022-11-02T22:06:29Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-02T19:53:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-xls-r-300m-mn-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-mn-demo
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9633
- Wer: 0.5586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.5564 | 6.77 | 400 | 2.8622 | 0.9998 |
| 1.0005 | 13.55 | 800 | 0.9428 | 0.6614 |
| 0.3018 | 20.34 | 1200 | 0.9611 | 0.5860 |
| 0.1918 | 27.12 | 1600 | 0.9633 | 0.5586 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
osanseviero/test_sentence_transformers3
|
osanseviero
| 2022-11-02T21:57:44Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:s2orc",
"dataset:ms_marco",
"dataset:wiki_atomic_edits",
"dataset:snli",
"dataset:multi_nli",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/coco_captions",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/QQP",
"dataset:yahoo_answers_topics",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T21:57:39Z |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- flax-sentence-embeddings/stackexchange_xml
- s2orc
- ms_marco
- wiki_atomic_edits
- snli
- multi_nli
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/flickr30k-captions
- embedding-data/coco_captions
- embedding-data/sentence-compression
- embedding-data/QQP
- yahoo_answers_topics
---
# sentence-transformers/paraphrase-MiniLM-L3-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L3-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-MiniLM-L3-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-MiniLM-L3-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-MiniLM-L3-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
huggingtweets/t4tclussy
|
huggingtweets
| 2022-11-02T21:39:21Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T21:36:47Z |
---
language: en
thumbnail: http://www.huggingtweets.com/t4tclussy/1667425132769/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1576359096504258563/vRp_mOiv_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🎃🦇🪦spooky rat🎃🦇🪦</div>
<div style="text-align: center; font-size: 14px;">@t4tclussy</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🎃🦇🪦spooky rat🎃🦇🪦.
| Data | 🎃🦇🪦spooky rat🎃🦇🪦 |
| --- | --- |
| Tweets downloaded | 3119 |
| Retweets | 1463 |
| Short tweets | 268 |
| Tweets kept | 1388 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1rt9srp7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @t4tclussy's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/18rnibwz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/18rnibwz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/t4tclussy')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jph00/fastdiffusion-models
|
jph00
| 2022-11-02T21:08:01Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-11-02T05:28:01Z |
---
license: apache-2.0
---
*all models trained with mnist sigma_data, instead of fashion-mnist.*
- base: default k-diffusion model
- no-t-emb: as base, but no t-embeddings in model
- mse-no-t-emb: as no-t-emb, but predicting unscaled noise
- mse: unscaled noise prediction with t-embeddings
## base metrics
step,fid,kid
5000,23.366962432861328,0.0060024261474609375
10000,21.407773971557617,0.004696846008300781
15000,19.820981979370117,0.003306865692138672
20000,20.4482421875,0.0037620067596435547
25000,19.459041595458984,0.0030574798583984375
30000,18.933385848999023,0.0031194686889648438
35000,18.223621368408203,0.002220630645751953
40000,18.64676284790039,0.0026960372924804688
45000,17.681808471679688,0.0016982555389404297
50000,17.32500457763672,0.001678466796875
55000,17.74714469909668,0.0016117095947265625
60000,18.276540756225586,0.002439737319946289
## mse-no-t-emb
step,fid,kid
5000,28.580364227294922,0.007686138153076172
10000,25.324932098388672,0.0061130523681640625
15000,23.68691635131836,0.005526542663574219
20000,24.05099105834961,0.005819082260131836
25000,22.60521125793457,0.004955768585205078
30000,22.16605567932129,0.0047609806060791016
35000,21.794536590576172,0.0039484500885009766
40000,22.96178436279297,0.005787849426269531
45000,22.641393661499023,0.004763364791870117
50000,20.735567092895508,0.0038640499114990234
55000,21.417423248291016,0.004515647888183594
60000,22.11293601989746,0.0054743289947509766
## no-t-emb
step,fid,kid
5000,53.25414276123047,0.02761554718017578
10000,47.687461853027344,0.023845195770263672
15000,46.045196533203125,0.02205944061279297
20000,44.64243698120117,0.020934104919433594
25000,43.55231857299805,0.020574331283569336
30000,43.493412017822266,0.020569324493408203
35000,42.51478958129883,0.01968073844909668
40000,42.213401794433594,0.01972222328186035
45000,40.9914665222168,0.018793582916259766
50000,42.946231842041016,0.019819974899291992
55000,40.699989318847656,0.018331050872802734
60000,41.737518310546875,0.019069194793701172
|
SanDiegoDude/WheresWaldoStyle
|
SanDiegoDude
| 2022-11-02T20:52:47Z | 0 | 7 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-02T19:42:33Z |
---
license: mit
---
Hello! This is a 14,000 step trained model based on the famous Where's Waldo / Where's Wally art style. (I'm American so I named the style Waldo, if you're familiar with Wally instead, my apologies!)
The keyword to invoke the style is "Wheres Waldo style" and I've found it works best when you use it in conjunction with real world locations if you want to ground it at least a little bit in reality. If you really want the Wally/Waldo look, be sure to include "Bright primary colors" in your prompt, and add things like "pastel colors" and "washed out colors" to your negative prompts. You can also control the amount of "Waldo-ness" by de-emphasizing the style in your prompt.
For example,
"(Wheres Waldo Style:1.0), A busy street in New York City, (bright primary colors:1.2)" results in the following image:

While
"(Wheres Waldo Style:0.6), A busy street in New York City, (bright primary colors:1.2) brings in some details about New York city like the subway entrance that you won't find at full strength style.

One thing to keep in mind, if you try to just spit out a 2048 x 2048 image, it's not going to give you waldo, it's going to give you a monstrosity like this:

I've found the sweet spot for this model to be in the 512 x 512 to about a max of 640 x 960. Much beyond that and it starts to create big blobs like the example above. It does take pretty well to inpainting though, so if you create something interesting at 640 x 960, throw it in inpaint and start drawing in fun details (you may have to reeeeally de-emphasize the style in your inpaints to get it to give you what you want, just a heads up)
Finally, one thing I've found that really helps give it the "waldo look" is using Aesthetics. I like to run an Aesthetics pass at a strength of .20 for 30 steps. It helps prevent the really washed out colors and adds the stripes that are so prevalent in Wally/Waldo comics. I've included the Waldo2.pt file if you want to download it and use it, it was trained on the same high quality images I used for the checkpoint dreambooth training.
Here is a screenshot of my config I use for generating these images:

I hope you have fun with this! Sadly it won't actually generate a Waldo/Wally into the image (at least not one that you can generate on demand), but if you're going to all the trouble to inpaint a proper Waldo/Wally scene, you can do some quick post work to add Waldo/Wally in there somewhere! =)
Here are sample images using this model:











|
jayantapaul888/twitter-data-distilbert-base-uncased-sentiment-finetuned-memes
|
jayantapaul888
| 2022-11-02T20:16:58Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-10-31T14:50:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: twitter-data-distilbert-base-uncased-sentiment-finetuned-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-distilbert-base-uncased-sentiment-finetuned-memes
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2474
- Accuracy: 0.9282
- Precision: 0.9290
- Recall: 0.9282
- F1: 0.9282
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.3623 | 1.0 | 1762 | 0.3171 | 0.8986 | 0.8995 | 0.8986 | 0.8981 |
| 0.271 | 2.0 | 3524 | 0.2665 | 0.9176 | 0.9182 | 0.9176 | 0.9173 |
| 0.2386 | 3.0 | 5286 | 0.2499 | 0.9237 | 0.9254 | 0.9237 | 0.9239 |
| 0.2136 | 4.0 | 7048 | 0.2494 | 0.9259 | 0.9263 | 0.9259 | 0.9257 |
| 0.1974 | 5.0 | 8810 | 0.2454 | 0.9278 | 0.9288 | 0.9278 | 0.9278 |
| 0.182 | 6.0 | 10572 | 0.2474 | 0.9282 | 0.9290 | 0.9282 | 0.9282 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
sd-concepts-library/color-page
|
sd-concepts-library
| 2022-11-02T19:56:25Z | 0 | 17 | null |
[
"license:mit",
"region:us"
] | null | 2022-11-02T19:56:13Z |
---
license: mit
---
### Color Page on Stable Diffusion
This is the `<coloring-page>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



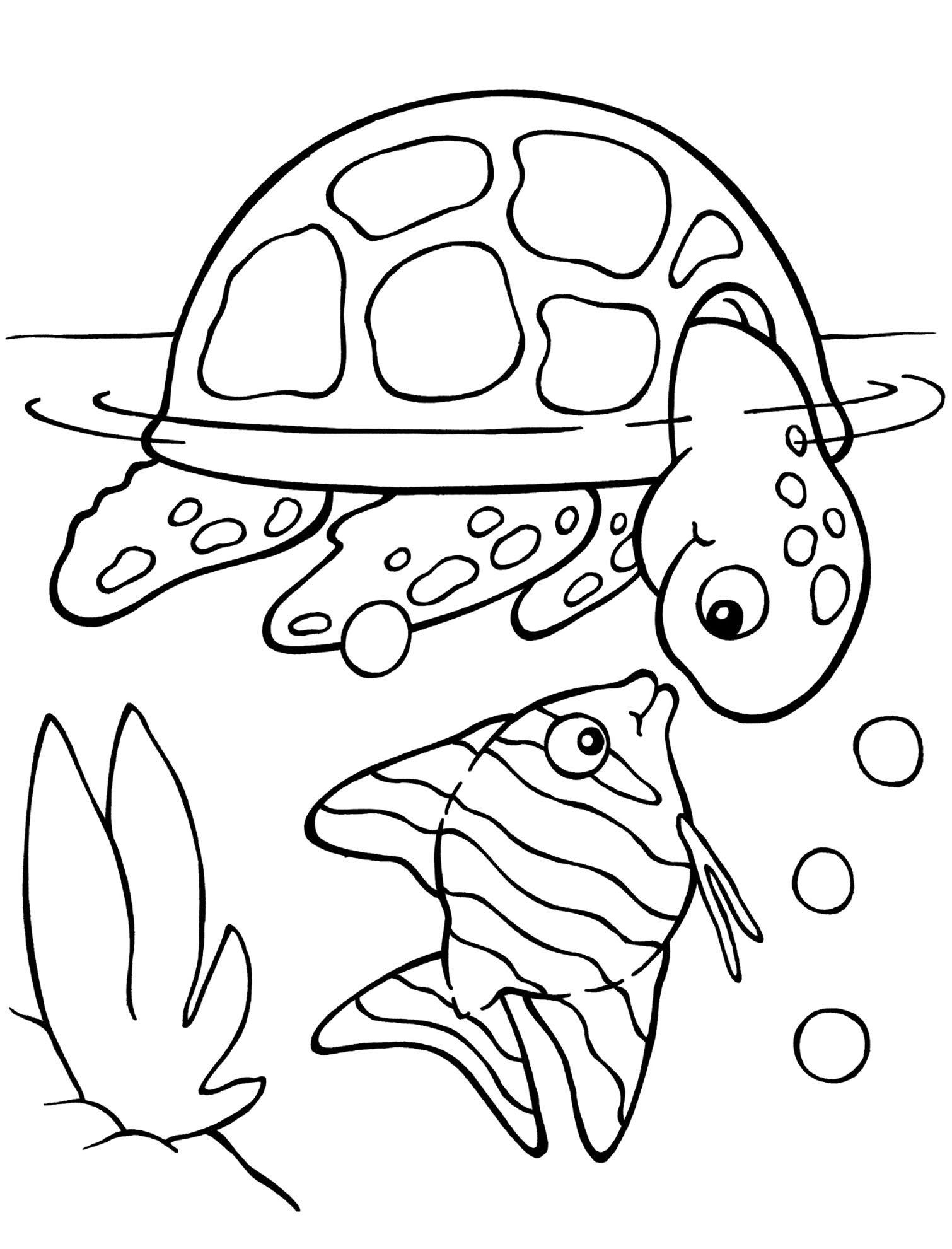





|
huggingtweets/nickichlol-saware7
|
huggingtweets
| 2022-11-02T19:10:23Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T19:10:14Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1542731743328862210/g9ZgqOmK_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1550159744396042241/RT8UyMgT_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">nick & SW7</div>
<div style="text-align: center; font-size: 14px;">@nickichlol-saware7</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from nick & SW7.
| Data | nick | SW7 |
| --- | --- | --- |
| Tweets downloaded | 3232 | 3037 |
| Retweets | 215 | 161 |
| Short tweets | 663 | 660 |
| Tweets kept | 2354 | 2216 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2zibfpv5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nickichlol-saware7's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/155b0pxy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/155b0pxy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nickichlol-saware7')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jayantapaul888/smalldata-microsoft-deberta-base-eng-only-sentiment-single-finetuned-memes
|
jayantapaul888
| 2022-11-02T19:09:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-02T19:00:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: smalldata-microsoft-deberta-base-eng-only-sentiment-single-finetuned-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smalldata-microsoft-deberta-base-eng-only-sentiment-single-finetuned-memes
This model is a fine-tuned version of [jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes](https://huggingface.co/jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9308
- Accuracy: 0.8429
- Precision: 0.8588
- Recall: 0.8579
- F1: 0.8583
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 378 | 0.3307 | 0.8407 | 0.8682 | 0.8549 | 0.8541 |
| 0.353 | 2.0 | 756 | 0.3677 | 0.8518 | 0.8669 | 0.8656 | 0.8662 |
| 0.1726 | 3.0 | 1134 | 0.5219 | 0.8392 | 0.8570 | 0.8549 | 0.8548 |
| 0.0681 | 4.0 | 1512 | 0.7194 | 0.8414 | 0.8578 | 0.8566 | 0.8572 |
| 0.0681 | 5.0 | 1890 | 0.8617 | 0.8407 | 0.8573 | 0.8560 | 0.8565 |
| 0.0233 | 6.0 | 2268 | 0.9308 | 0.8429 | 0.8588 | 0.8579 | 0.8583 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
flamesbob/rimu_model
|
flamesbob
| 2022-11-02T19:06:41Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-10-31T01:13:03Z |
---
license: creativeml-openrail-m
---
Token class word for this model is `rimu` using this will draw attention to the training data that was used and help increase the quality of the image.
License This embedding is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
You can't use the embedding to deliberately produce nor share illegal or harmful outputs or content The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license You may re-distribute the weights and use the embedding commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here
|
huggingtweets/chaddraven-nickichlol-saware7
|
huggingtweets
| 2022-11-02T18:51:08Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T18:44:25Z |
---
language: en
thumbnail: http://www.huggingtweets.com/chaddraven-nickichlol-saware7/1667415027467/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1542731743328862210/g9ZgqOmK_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1587675160072491008/Vykq9cOY_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1550159744396042241/RT8UyMgT_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">nick & Chad & SW7</div>
<div style="text-align: center; font-size: 14px;">@chaddraven-nickichlol-saware7</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from nick & Chad & SW7.
| Data | nick | Chad | SW7 |
| --- | --- | --- | --- |
| Tweets downloaded | 3231 | 3174 | 3037 |
| Retweets | 215 | 504 | 161 |
| Short tweets | 663 | 1094 | 660 |
| Tweets kept | 2353 | 1576 | 2216 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/22ya4o85/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chaddraven-nickichlol-saware7's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3m24xig1) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3m24xig1/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chaddraven-nickichlol-saware7')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/nickichlol
|
huggingtweets
| 2022-11-02T18:32:47Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T18:25:39Z |
---
language: en
thumbnail: http://www.huggingtweets.com/nickichlol/1667413921117/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1542731743328862210/g9ZgqOmK_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">nick</div>
<div style="text-align: center; font-size: 14px;">@nickichlol</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from nick.
| Data | nick |
| --- | --- |
| Tweets downloaded | 3232 |
| Retweets | 215 |
| Short tweets | 663 |
| Tweets kept | 2354 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/10ozqgo6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nickichlol's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/39g99zbu) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/39g99zbu/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nickichlol')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
lewtun/setfit-ethos-multilabel-example
|
lewtun
| 2022-11-02T17:03:41Z | 1,614 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T17:03:33Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 228 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 228,
"warmup_steps": 23,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
henilp105/wav2vec2-base-ASR-telugu
|
henilp105
| 2022-11-02T16:50:41Z | 0 | 0 | null |
[
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning",
"te",
"license:apache-2.0",
"model-index",
"region:us"
] |
automatic-speech-recognition
| 2022-10-29T12:15:01Z |
---
language: te
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning
license: apache-2.0
model-index:
- name: Henil Panchal Facebook XLSR Wav2Vec2 Large 53 Telugu
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test WER
type: wer
value: 41.90
---
# Wav2Vec2-Large-XLSR-53-Telugu
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Telugu using the ASR IIIT-H dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
**Test Result**: 41.90%
## Training
70% of the O part of ASR IIIT-H Telugu dataset was used for training.
|
safoinme/zenml-mnist
|
safoinme
| 2022-11-02T16:42:56Z | 2 | 0 |
tf-keras
|
[
"tf-keras",
"vision",
"image-classification",
"dataset:mnist",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2022-10-24T13:41:35Z |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- mnist
---
# ZenML Community Hour Demo
This model is deployed using zenml framework, it goes from local deployment with mlflow to huggingface deployment!
## Model description
This is a mnist datatset trained using keras framework
## Intended uses & limitations
More information needed
|
AndrewR/distilgpt2-finetuned-imdb-lm
|
AndrewR
| 2022-11-02T16:17:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-10-28T15:55:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-imdb-lm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-imdb-lm
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8512
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.9577 | 1.0 | 7315 | 3.8818 |
| 3.8965 | 2.0 | 14630 | 3.8570 |
| 3.8561 | 3.0 | 21945 | 3.8512 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
mrm8488/electra-small-finetuned-squadv2
|
mrm8488
| 2022-11-02T15:47:28Z | 76 | 1 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"question-answering",
"en",
"arxiv:1406.2661",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
---
# Electra small ⚡ + SQuAD v2 ❓
[Electra-small-discriminator](https://huggingface.co/google/electra-small-discriminator) fine-tuned on [SQUAD v2.0 dataset](https://rajpurkar.github.io/SQuAD-explorer/explore/v2.0/dev/) for **Q&A** downstream task.
## Details of the downstream task (Q&A) - Model 🧠
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
## Details of the downstream task (Q&A) - Dataset 📚
**SQuAD2.0** combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
python transformers/examples/question-answering/run_squad.py \
--model_type electra \
--model_name_or_path 'google/electra-small-discriminator' \
--do_eval \
--do_train \
--do_lower_case \
--train_file '/content/dataset/train-v2.0.json' \
--predict_file '/content/dataset/dev-v2.0.json' \
--per_gpu_train_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 10 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir '/content/output' \
--overwrite_output_dir \
--save_steps 1000 \
--version_2_with_negative
```
## Test set Results 🧾
| Metric | # Value |
| ------ | --------- |
| **EM** | **69.71** |
| **F1** | **73.44** |
| **Size**| **50 MB** |
```json
{
'exact': 69.71279373368147,
'f1': 73.4439546123672,
'total': 11873,
'HasAns_exact': 69.92240215924427,
'HasAns_f1': 77.39542393937836,
'HasAns_total': 5928,
'NoAns_exact': 69.50378469301934,
'NoAns_f1': 69.50378469301934,
'NoAns_total': 5945,
'best_exact': 69.71279373368147,
'best_exact_thresh': 0.0,
'best_f1': 73.44395461236732,
'best_f1_thresh': 0.0
}
```
### Model in action 🚀
Fast usage with **pipelines**:
```python
from transformers import pipeline
QnA_pipeline = pipeline('question-answering', model='mrm8488/electra-base-finetuned-squadv2')
QnA_pipeline({
'context': 'A new strain of flu that has the potential to become a pandemic has been identified in China by scientists.',
'question': 'What has been discovered by scientists from China ?'
})
# Output:
{'answer': 'A new strain of flu', 'end': 19, 'score': 0.8650811568752914, 'start': 0}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
adit94/sentenceTest_kbert2
|
adit94
| 2022-11-02T15:25:56Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T15:25:44Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 3185 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
lewtun/distilhubert-finetuned-music-genres
|
lewtun
| 2022-11-02T14:52:06Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-11-02T12:41:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-music-genres
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-music-genres
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6982
- Accuracy: 0.458
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 187 | 2.1291 | 0.312 |
| 2.2402 | 2.0 | 374 | 1.9922 | 0.388 |
| 2.2402 | 3.0 | 561 | 1.7594 | 0.444 |
| 1.6793 | 4.0 | 748 | 1.7164 | 0.447 |
| 1.6793 | 5.0 | 935 | 1.6982 | 0.458 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.11.0
- Datasets 2.6.1
- Tokenizers 0.11.6
|
elRivx/sd-newhorrorfantasy_style
|
elRivx
| 2022-11-02T14:38:16Z | 0 | 3 | null |
[
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2022-10-30T20:15:44Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
# newhorrorfantasy_style
This is an own SD trainee with a 2010s horror and fantasy illustrations as a style.
If you wanna test it, you can put this word on the prompt: newhorrorfantasy_style
[](https://www.buymeacoffee.com/elrivx)
Examples:
<img src=https://imgur.com/k2kksMQ.png width=30% height=30%>
<img src=https://imgur.com/a2P91kD.png width=30% height=30%>
<img src=https://imgur.com/jdV10rR.png width=30% height=30%>
<img src=https://imgur.com/9QcUh13.png width=30% height=30%>
<img src=https://imgur.com/pTpB6Qz.png width=30% height=30%>
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
adit94/sentenceTest_kbert
|
adit94
| 2022-11-02T14:16:39Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-02T14:16:00Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 3185 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 956,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
jbk1/ddpm-butterflies-128
|
jbk1
| 2022-11-02T12:39:23Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:jbk",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-02T11:56:14Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: jbk
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `jbk` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/jbk1/ddpm-butterflies-128/tensorboard?#scalars)
|
jayantapaul888/smalldata-twitter-data-microsoft-deberta-base-mnli-eng-only-sentiment-single-finetuned-memes
|
jayantapaul888
| 2022-11-02T12:16:51Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"deberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-02T11:28:35Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: smalldata-twitter-data-microsoft-deberta-base-mnli-eng-only-sentiment-single-finetuned-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smalldata-twitter-data-microsoft-deberta-base-mnli-eng-only-sentiment-single-finetuned-memes
This model is a fine-tuned version of [jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes](https://huggingface.co/jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6927
- Accuracy: 0.8816
- Precision: 0.8934
- Recall: 0.8938
- F1: 0.8936
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 378 | 0.3240 | 0.8675 | 0.8860 | 0.8799 | 0.8798 |
| 0.327 | 2.0 | 756 | 0.2935 | 0.8831 | 0.8953 | 0.8944 | 0.8946 |
| 0.1692 | 3.0 | 1134 | 0.4000 | 0.8838 | 0.8946 | 0.8959 | 0.8952 |
| 0.0811 | 4.0 | 1512 | 0.5134 | 0.8824 | 0.8940 | 0.8945 | 0.8942 |
| 0.0811 | 5.0 | 1890 | 0.5875 | 0.8824 | 0.8933 | 0.8945 | 0.8939 |
| 0.0313 | 6.0 | 2268 | 0.6927 | 0.8816 | 0.8934 | 0.8938 | 0.8936 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Pablo94/roberta-base-bne-finetuned-detests-02-11-2022
|
Pablo94
| 2022-11-02T11:52:49Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-02T11:36:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: roberta-base-bne-finetuned-detests-02-11-2022
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-bne-finetuned-detests-02-11-2022
This model is a fine-tuned version of [BSC-TeMU/roberta-base-bne](https://huggingface.co/BSC-TeMU/roberta-base-bne) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8124
- F1: 0.6381
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.379 | 0.64 | 25 | 0.4136 | 0.0 |
| 0.315 | 1.28 | 50 | 0.3663 | 0.6343 |
| 0.3228 | 1.92 | 75 | 0.3424 | 0.6386 |
| 0.1657 | 2.56 | 100 | 0.5133 | 0.5385 |
| 0.108 | 3.21 | 125 | 0.4766 | 0.6452 |
| 0.0631 | 3.85 | 150 | 0.6063 | 0.6083 |
| 0.0083 | 4.49 | 175 | 0.6200 | 0.6198 |
| 0.0032 | 5.13 | 200 | 0.6508 | 0.6335 |
| 0.0047 | 5.77 | 225 | 0.6877 | 0.6269 |
| 0.0018 | 6.41 | 250 | 0.7745 | 0.6148 |
| 0.0014 | 7.05 | 275 | 0.7741 | 0.6299 |
| 0.001 | 7.69 | 300 | 0.7896 | 0.6381 |
| 0.0011 | 8.33 | 325 | 0.8008 | 0.6381 |
| 0.0008 | 8.97 | 350 | 0.8086 | 0.6381 |
| 0.0009 | 9.62 | 375 | 0.8124 | 0.6381 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
lmvasque/readability-es-benchmark-bertin-es-sentences-2class
|
lmvasque
| 2022-11-02T11:42:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T16:32:36Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): bertin-es-sentences-2class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| **[BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class)** | **sentences** | **2** |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class) | sentences | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class
|
lmvasque
| 2022-11-02T11:41:13Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T18:11:26Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): mbert-en-es-paragraphs-3class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-------------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| **[mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class)** | **paragraphs** | **3** |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class) | sentences | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class
|
lmvasque
| 2022-11-02T11:40:28Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T15:38:56Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): mbert-es-paragraphs-2class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| **[mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class)** | **paragraphs** | **2** |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class) | sentences | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class
|
lmvasque
| 2022-11-02T11:40:09Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T18:13:26Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): mbert-en-es-sentences-3class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class) | sentences | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| **[mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class)** | **sentences** | **3** |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
lmvasque/readability-es-benchmark-bertin-es-sentences-3class
|
lmvasque
| 2022-11-02T11:39:21Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T16:51:26Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): bertin-es-sentences-3class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| **[BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class)** | **sentences** | **3** |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class
|
lmvasque
| 2022-11-02T11:39:01Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T15:59:33Z |
---
license: cc-by-4.0
---
## Readability benchmark (ES): mbert-es-paragraphs-3class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| **[mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class)** | **paragraphs** | **3** |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| [BERTIN (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-bertin-es-sentences-3class) | sentences | 3 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co/lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co/bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
```
|
jayantapaul888/twitter-data-xlm-roberta-base-eng-only-sentiment-finetuned-memes
|
jayantapaul888
| 2022-11-02T10:58:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-02T10:26:12Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: twitter-data-xlm-roberta-base-eng-only-sentiment-finetuned-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-xlm-roberta-base-eng-only-sentiment-finetuned-memes
This model is a fine-tuned version of [jayantapaul888/twitter-data-xlm-roberta-base-sentiment-finetuned-memes](https://huggingface.co/jayantapaul888/twitter-data-xlm-roberta-base-sentiment-finetuned-memes) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6286
- Accuracy: 0.8660
- Precision: 0.8796
- Recall: 0.8795
- F1: 0.8795
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 378 | 0.3421 | 0.8407 | 0.8636 | 0.8543 | 0.8553 |
| 0.396 | 2.0 | 756 | 0.3445 | 0.8496 | 0.8726 | 0.8634 | 0.8631 |
| 0.2498 | 3.0 | 1134 | 0.3656 | 0.8585 | 0.8764 | 0.8727 | 0.8723 |
| 0.1543 | 4.0 | 1512 | 0.4549 | 0.8600 | 0.8742 | 0.8740 | 0.8741 |
| 0.1543 | 5.0 | 1890 | 0.5932 | 0.8645 | 0.8783 | 0.8780 | 0.8780 |
| 0.0815 | 6.0 | 2268 | 0.6286 | 0.8660 | 0.8796 | 0.8795 | 0.8795 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Voicelab/sbert-large-cased-pl
|
Voicelab
| 2022-11-02T10:44:13Z | 554 | 7 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"pl",
"dataset:Wikipedia",
"arxiv:1908.10084",
"license:cc-by-4.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-04-13T07:33:36Z |
---
license: cc-by-4.0
language:
- pl
datasets:
- Wikipedia
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
widget:
- source_sentence: "Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i metod jej wdrażania praktycznego."
sentences:
- "Głębokie uczenie maszynowe jest sktukiem wdrażania praktycznego metod sztucznej inteligencji oraz jej rozwoju."
- "Kasparow zarzucił firmie IBM oszustwo, kiedy odmówiła mu dostępu do historii wcześniejszych gier Deep Blue. "
- "Samica o długości ciała 10–11 mm, szczoteczki na tylnych nogach służące do zbierania pyłku oraz włoski na końcu odwłoka jaskrawo pomarańczowoczerwone. "
example_title: "Uczenie maszynowe"
---
<img src="https://public.3.basecamp.com/p/rs5XqmAuF1iEuW6U7nMHcZeY/upload/download/VL-NLP-short.png" alt="logo voicelab nlp" style="width:300px;"/>
# SHerbert large - Polish SentenceBERT
SentenceBERT is a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. Training was based on the original paper [Siamese BERT models for the task of semantic textual similarity (STS)](https://arxiv.org/abs/1908.10084) with a slight modification of how the training data was used. The goal of the model is to generate different embeddings based on the semantic and topic similarity of the given text.
> Semantic textual similarity analyzes how similar two pieces of texts are.
Read more about how the model was prepared in our [blog post](https://voicelab.ai/blog/).
The base trained model is a Polish HerBERT. HerBERT is a BERT-based Language Model. For more details, please refer to: "HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish".
# Corpus
Te model was trained solely on [Wikipedia](https://dumps.wikimedia.org/).
# Tokenizer
As in the original HerBERT implementation, the training dataset was tokenized into subwords using a character level byte-pair encoding (CharBPETokenizer) with a vocabulary size of 50k tokens. The tokenizer itself was trained with a tokenizers library.
We kindly encourage you to use the Fast version of the tokenizer, namely HerbertTokenizerFast.
# Usage
```python
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics import pairwise
sbert = AutoModel.from_pretrained("Voicelab/sbert-large-cased-pl")
tokenizer = AutoTokenizer.from_pretrained("Voicelab/sbert-large-cased-pl")
s0 = "Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i metod jej wdrażania praktycznego."
s1 = "Głębokie uczenie maszynowe jest sktukiem wdrażania praktycznego metod sztucznej inteligencji oraz jej rozwoju."
s2 = "Kasparow zarzucił firmie IBM oszustwo, kiedy odmówiła mu dostępu do historii wcześniejszych gier Deep Blue. "
tokens = tokenizer([s0, s1, s2],
padding=True,
truncation=True,
return_tensors='pt')
x = sbert(tokens["input_ids"],
tokens["attention_mask"]).pooler_output
# similarity between sentences s0 and s1
print(pairwise.cosine_similarity(x[0], x[1])) # Result: 0.8011128
# similarity between sentences s0 and s2
print(pairwise.cosine_similarity(x[0], x[2])) # Result: 0.58822715
```
# Results
| Model | Accuracy | Source |
|--------------------------|------------|----------------------------------------------------------|
| SBERT-WikiSec-base (EN) | 80.42% | https://arxiv.org/abs/1908.10084 |
| SBERT-WikiSec-large (EN) | 80.78% | https://arxiv.org/abs/1908.10084 |
| sbert-base-cased-pl | 82.31% | https://huggingface.co/Voicelab/sbert-base-cased-pl |
| **sbert-large-cased-pl** | **84.42%** | **https://huggingface.co/Voicelab/sbert-large-cased-pl** |
# License
CC BY 4.0
# Citation
If you use this model, please cite the following paper:
# Authors
The model was trained by NLP Research Team at Voicelab.ai.
You can contact us [here](https://voicelab.ai/contact/).
|
debbiesoon/summarise_v9
|
debbiesoon
| 2022-11-02T09:56:01Z | 100 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"led",
"text2text-generation",
"generated_from_trainer",
"dataset:multi_news",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-10-31T11:53:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- multi_news
model-index:
- name: summarise_v9
results: []
---

This model is a fine-tuned version of [allenai/led-base-16384](https://huggingface.co/allenai/led-base-16384) on the multi_news dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3650
- Rouge1 Precision: 0.4673
- Rouge1 Recall: 0.4135
- Rouge1 Fmeasure: 0.4263
- Rouge2 Precision: 0.1579
- Rouge2 Recall: 0.1426
- Rouge2 Fmeasure: 0.1458
- Rougel Precision: 0.2245
- Rougel Recall: 0.2008
- Rougel Fmeasure: 0.2061
- Rougelsum Precision: 0.2245
- Rougelsum Recall: 0.2008
- Rougelsum Fmeasure: 0.2061
## Model description
This model was created to generate summaries of news articles.
## Intended uses & limitations
The model takes up to maximum article length of 3072 tokens and generates a summary of maximum length of 512 tokens, and minimum length of 100 tokens.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 Precision | Rouge1 Recall | Rouge1 Fmeasure | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure | Rougel Precision | Rougel Recall | Rougel Fmeasure | Rougelsum Precision | Rougelsum Recall | Rougelsum Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|:----------------:|:-------------:|:---------------:|:----------------:|:-------------:|:---------------:|:-------------------:|:----------------:|:------------------:|
| 2.8095 | 0.16 | 10 | 2.5393 | 0.287 | 0.5358 | 0.3674 | 0.1023 | 0.1917 | 0.1311 | 0.1374 | 0.2615 | 0.1771 | 0.1374 | 0.2615 | 0.1771 |
| 2.6056 | 0.32 | 20 | 2.4752 | 0.5005 | 0.3264 | 0.3811 | 0.1663 | 0.1054 | 0.1249 | 0.2582 | 0.1667 | 0.1957 | 0.2582 | 0.1667 | 0.1957 |
| 2.5943 | 0.48 | 30 | 2.4422 | 0.4615 | 0.3833 | 0.4047 | 0.1473 | 0.1273 | 0.1321 | 0.2242 | 0.1885 | 0.1981 | 0.2242 | 0.1885 | 0.1981 |
| 2.4842 | 0.64 | 40 | 2.4186 | 0.4675 | 0.3829 | 0.4081 | 0.1581 | 0.1294 | 0.1384 | 0.2286 | 0.187 | 0.1995 | 0.2286 | 0.187 | 0.1995 |
| 2.4454 | 0.8 | 50 | 2.3990 | 0.467 | 0.408 | 0.4222 | 0.1633 | 0.1429 | 0.1477 | 0.2294 | 0.2008 | 0.2076 | 0.2294 | 0.2008 | 0.2076 |
| 2.3622 | 0.96 | 60 | 2.3857 | 0.4567 | 0.3898 | 0.41 | 0.1433 | 0.1233 | 0.1295 | 0.2205 | 0.1876 | 0.1976 | 0.2205 | 0.1876 | 0.1976 |
| 2.4034 | 1.13 | 70 | 2.3835 | 0.4515 | 0.4304 | 0.4294 | 0.1526 | 0.1479 | 0.1459 | 0.2183 | 0.209 | 0.2078 | 0.2183 | 0.209 | 0.2078 |
| 2.2612 | 1.29 | 80 | 2.3804 | 0.455 | 0.4193 | 0.4236 | 0.1518 | 0.1429 | 0.1427 | 0.2177 | 0.2025 | 0.2037 | 0.2177 | 0.2025 | 0.2037 |
| 2.2563 | 1.45 | 90 | 2.3768 | 0.4821 | 0.391 | 0.4196 | 0.1652 | 0.1357 | 0.144 | 0.2385 | 0.1929 | 0.2069 | 0.2385 | 0.1929 | 0.2069 |
| 2.243 | 1.61 | 100 | 2.3768 | 0.4546 | 0.4093 | 0.4161 | 0.1552 | 0.1402 | 0.1422 | 0.2248 | 0.2016 | 0.2052 | 0.2248 | 0.2016 | 0.2052 |
| 2.2505 | 1.77 | 110 | 2.3670 | 0.4625 | 0.4189 | 0.4262 | 0.1606 | 0.1485 | 0.1493 | 0.2301 | 0.2098 | 0.2119 | 0.2301 | 0.2098 | 0.2119 |
| 2.2453 | 1.93 | 120 | 2.3650 | 0.4673 | 0.4135 | 0.4263 | 0.1579 | 0.1426 | 0.1458 | 0.2245 | 0.2008 | 0.2061 | 0.2245 | 0.2008 | 0.2061 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.6.2.dev0
- Tokenizers 0.12.1
|
emrevarol/dz_finetuning-large-distillbert-490K
|
emrevarol
| 2022-11-02T09:54:51Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-02T05:25:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: dz_finetuning-large-distillbert-490K
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dz_finetuning-large-distillbert-490K
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0036
- Accuracy: 0.9994
- F1: 0.9994
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.0097 | 1.0 | 24576 | 0.0037 | 0.9991 | 0.9991 |
| 0.0015 | 2.0 | 49152 | 0.0036 | 0.9994 | 0.9994 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Pablo94/bert-base-uncased-finetuned-detests-29-10-2022
|
Pablo94
| 2022-11-02T09:53:50Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-10-30T08:13:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-uncased-finetuned-detests-29-10-2022
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-detests-29-10-2022
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1346
- Accuracy: 0.7921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2105 | 0.33 | 50 | 0.5718 | 0.8265 |
| 0.2156 | 0.65 | 100 | 0.5998 | 0.8232 |
| 0.215 | 0.98 | 150 | 0.5778 | 0.8232 |
| 0.1353 | 1.31 | 200 | 0.6240 | 0.8069 |
| 0.0664 | 1.63 | 250 | 0.7277 | 0.7938 |
| 0.2339 | 1.96 | 300 | 0.8471 | 0.7758 |
| 0.1518 | 2.29 | 350 | 0.9487 | 0.7938 |
| 0.0766 | 2.61 | 400 | 0.9715 | 0.8069 |
| 0.0524 | 2.94 | 450 | 1.0911 | 0.7610 |
| 0.0836 | 3.27 | 500 | 1.0099 | 0.8101 |
| 0.0935 | 3.59 | 550 | 0.9368 | 0.8020 |
| 0.1065 | 3.92 | 600 | 0.9528 | 0.8282 |
| 0.0139 | 4.25 | 650 | 1.0382 | 0.7971 |
| 0.0642 | 4.58 | 700 | 1.1667 | 0.7774 |
| 0.1584 | 4.9 | 750 | 1.1346 | 0.7921 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Swty/distilbert-base-uncased-finetuned-squad
|
Swty
| 2022-11-02T09:07:23Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-02T09:04:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.5266
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 7 | 5.3892 |
| No log | 2.0 | 14 | 4.7949 |
| No log | 3.0 | 21 | 4.5266 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.10.1+cu102
- Datasets 2.6.1
- Tokenizers 0.12.1
|
Vandita/distilroberta-base-SarcojiComplEmojisMLM
|
Vandita
| 2022-11-02T06:28:26Z | 162 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-02T06:10:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-distilroberta-base-finetuned-SarcojiComplEmojisDistilRobertaMLM
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-distilroberta-base-finetuned-SarcojiComplEmojisDistilRobertaMLM
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8538
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 191 | 2.9461 |
| No log | 2.0 | 382 | 2.8536 |
| 3.0333 | 3.0 | 573 | 2.8745 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
Harmony22/Sjjsjw
|
Harmony22
| 2022-11-02T06:16:42Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-11-02T06:16:42Z |
---
license: bigscience-bloom-rail-1.0
---
|
GItaf/gpt2-gpt2-mc-weight0.25-epoch15-new
|
GItaf
| 2022-11-02T05:46:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-01T07:43:22Z |
---
tags:
- generated_from_trainer
model-index:
- name: gpt2-gpt2-mc-weight0.25-epoch15-new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-gpt2-mc-weight0.25-epoch15-new
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.7276
- Cls loss: 3.0579
- Lm loss: 3.9626
- Cls Accuracy: 0.6110
- Cls F1: 0.6054
- Cls Precision: 0.6054
- Cls Recall: 0.6110
- Perplexity: 52.59
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cls loss | Lm loss | Cls Accuracy | Cls F1 | Cls Precision | Cls Recall | Perplexity |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:-------:|:------------:|:------:|:-------------:|:----------:|:----------:|
| 4.674 | 1.0 | 3470 | 4.4372 | 1.5961 | 4.0380 | 0.5487 | 0.5279 | 0.5643 | 0.5487 | 56.71 |
| 4.3809 | 2.0 | 6940 | 4.3629 | 1.4483 | 4.0006 | 0.6023 | 0.5950 | 0.6174 | 0.6023 | 54.63 |
| 4.2522 | 3.0 | 10410 | 4.3721 | 1.5476 | 3.9849 | 0.6012 | 0.5981 | 0.6186 | 0.6012 | 53.78 |
| 4.1478 | 4.0 | 13880 | 4.3892 | 1.6429 | 3.9782 | 0.6081 | 0.6019 | 0.6128 | 0.6081 | 53.42 |
| 4.0491 | 5.0 | 17350 | 4.4182 | 1.8093 | 3.9656 | 0.6156 | 0.6091 | 0.6163 | 0.6156 | 52.75 |
| 3.9624 | 6.0 | 20820 | 4.4757 | 2.0348 | 3.9666 | 0.6121 | 0.6048 | 0.6189 | 0.6121 | 52.81 |
| 3.8954 | 7.0 | 24290 | 4.4969 | 2.1327 | 3.9634 | 0.6092 | 0.6028 | 0.6087 | 0.6092 | 52.64 |
| 3.846 | 8.0 | 27760 | 4.5632 | 2.4063 | 3.9613 | 0.6017 | 0.5972 | 0.6014 | 0.6017 | 52.52 |
| 3.8036 | 9.0 | 31230 | 4.6068 | 2.5888 | 3.9592 | 0.6052 | 0.5988 | 0.6026 | 0.6052 | 52.41 |
| 3.7724 | 10.0 | 34700 | 4.6175 | 2.6197 | 3.9621 | 0.6052 | 0.6006 | 0.6009 | 0.6052 | 52.57 |
| 3.7484 | 11.0 | 38170 | 4.6745 | 2.8470 | 3.9622 | 0.6046 | 0.5996 | 0.6034 | 0.6046 | 52.57 |
| 3.7291 | 12.0 | 41640 | 4.6854 | 2.8950 | 3.9611 | 0.6110 | 0.6056 | 0.6049 | 0.6110 | 52.52 |
| 3.7148 | 13.0 | 45110 | 4.7103 | 2.9919 | 3.9618 | 0.6063 | 0.6002 | 0.6029 | 0.6063 | 52.55 |
| 3.703 | 14.0 | 48580 | 4.7226 | 3.0417 | 3.9616 | 0.6081 | 0.6027 | 0.6021 | 0.6081 | 52.54 |
| 3.6968 | 15.0 | 52050 | 4.7276 | 3.0579 | 3.9626 | 0.6110 | 0.6054 | 0.6054 | 0.6110 | 52.59 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Chloecakee/finetuning-sentiment-model-imdb
|
Chloecakee
| 2022-11-02T04:30:05Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-10-26T16:32:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2095
- Accuracy: 0.943
- F1: 0.9420
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
pepperjirakit/Daimond_Price
|
pepperjirakit
| 2022-11-02T03:57:26Z | 0 | 0 | null |
[
"joblib",
"license:cc-by-3.0",
"region:us"
] | null | 2022-10-26T12:50:54Z |
---
title: Daimond_Price
emoji: 💩
colorFrom: blue
colorTo: green
sdk: streamlit
sdk_version: 1.10.0
app_file: app.py
pinned: false
license: cc-by-3.0
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
huggingtweets/angelfacepeanu3
|
huggingtweets
| 2022-11-02T03:25:44Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T03:15:45Z |
---
language: en
thumbnail: http://www.huggingtweets.com/angelfacepeanu3/1667359236720/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1562022684699115520/l8kHBaYp_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">angelfacepeanut</div>
<div style="text-align: center; font-size: 14px;">@angelfacepeanu3</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from angelfacepeanut.
| Data | angelfacepeanut |
| --- | --- |
| Tweets downloaded | 1911 |
| Retweets | 206 |
| Short tweets | 192 |
| Tweets kept | 1513 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ohpuc3p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @angelfacepeanu3's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3t4kb5xs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3t4kb5xs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/angelfacepeanu3')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/glxymichael-mayku
|
huggingtweets
| 2022-11-02T03:25:18Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-01T14:17:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/glxymichael-mayku/1667359514207/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1452722152730357760/ZGwhsTpG_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/610186113500647424/jtZ7qma5_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Michael. & Zhong Liu MK Fan</div>
<div style="text-align: center; font-size: 14px;">@glxymichael-mayku</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Michael. & Zhong Liu MK Fan.
| Data | Michael. | Zhong Liu MK Fan |
| --- | --- | --- |
| Tweets downloaded | 920 | 3206 |
| Retweets | 288 | 1004 |
| Short tweets | 31 | 80 |
| Tweets kept | 601 | 2122 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3ijmau36/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @glxymichael-mayku's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/8s85zs5e) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/8s85zs5e/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/glxymichael-mayku')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
KETI-AIR/ke-t5-large-ko
|
KETI-AIR
| 2022-11-02T02:59:44Z | 62 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
language: ko
tags:
- t5
eos_token: "</s>"
widget:
- text: 아버지가 방에 들어가신다.</s>
---
# ke-t5 base
Pretrained T5 Model on Korean and English. See [Github](https://github.com/AIRC-KETI/ke-t5) and [Paper](https://aclanthology.org/2021.findings-emnlp.33/) [Korean paper](https://koreascience.kr/article/CFKO202130060717834.pdf) for more details.
## How to use
```python
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("KETI-AIR/ke-t5-large-ko")
tokenizer = AutoTokenizer.from_pretrained("KETI-AIR/ke-t5-large-ko")
```
## BibTeX entry and citation info
```bibtex
@inproceedings{kim-etal-2021-model-cross,
title = "A Model of Cross-Lingual Knowledge-Grounded Response Generation for Open-Domain Dialogue Systems",
author = "Kim, San and
Jang, Jin Yea and
Jung, Minyoung and
Shin, Saim",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.33",
doi = "10.18653/v1/2021.findings-emnlp.33",
pages = "352--365",
abstract = "Research on open-domain dialogue systems that allow free topics is challenging in the field of natural language processing (NLP). The performance of the dialogue system has been improved recently by the method utilizing dialogue-related knowledge; however, non-English dialogue systems suffer from reproducing the performance of English dialogue systems because securing knowledge in the same language with the dialogue system is relatively difficult. Through experiments with a Korean dialogue system, this paper proves that the performance of a non-English dialogue system can be improved by utilizing English knowledge, highlighting the system uses cross-lingual knowledge. For the experiments, we 1) constructed a Korean version of the Wizard of Wikipedia dataset, 2) built Korean-English T5 (KE-T5), a language model pre-trained with Korean and English corpus, and 3) developed a knowledge-grounded Korean dialogue model based on KE-T5. We observed the performance improvement in the open-domain Korean dialogue model even only English knowledge was given. The experimental results showed that the knowledge inherent in cross-lingual language models can be helpful for generating responses in open dialogue systems.",
}
```
|
sergiocannata/cvt-21-finetuned-brs2
|
sergiocannata
| 2022-11-02T02:27:12Z | 27 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"cvt",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-02T00:40:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- f1
model-index:
- name: cvt-21-finetuned-brs2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.660377358490566
- name: F1
type: f1
value: 0.608695652173913
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cvt-21-finetuned-brs2
This model is a fine-tuned version of [microsoft/cvt-21](https://huggingface.co/microsoft/cvt-21) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6947
- Accuracy: 0.6604
- F1: 0.6087
- Precision (ppv): 0.5385
- Recall (sensitivity): 0.7
- Specificity: 0.6364
- Npv: 0.7778
- Auc: 0.6682
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision (ppv) | Recall (sensitivity) | Specificity | Npv | Auc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------------:|:--------------------:|:-----------:|:------:|:------:|
| 0.8177 | 1.89 | 100 | 0.7113 | 0.5283 | 0.5098 | 0.4194 | 0.65 | 0.4545 | 0.6818 | 0.5523 |
| 0.736 | 3.77 | 200 | 0.7178 | 0.5283 | 0.3902 | 0.3810 | 0.4 | 0.6061 | 0.625 | 0.5030 |
| 0.5978 | 5.66 | 300 | 0.6889 | 0.6038 | 0.5532 | 0.4815 | 0.65 | 0.5758 | 0.7308 | 0.6129 |
| 0.5576 | 7.55 | 400 | 0.7349 | 0.4717 | 0.5484 | 0.4048 | 0.85 | 0.2424 | 0.7273 | 0.5462 |
| 0.5219 | 9.43 | 500 | 0.6522 | 0.6038 | 0.4 | 0.4667 | 0.35 | 0.7576 | 0.6579 | 0.5538 |
| 0.5326 | 11.32 | 600 | 0.6665 | 0.6226 | 0.5238 | 0.5 | 0.55 | 0.6667 | 0.7097 | 0.6083 |
| 0.4381 | 13.21 | 700 | 0.7685 | 0.4717 | 0.5333 | 0.4 | 0.8 | 0.2727 | 0.6923 | 0.5364 |
| 0.5598 | 15.09 | 800 | 0.7212 | 0.5283 | 0.1935 | 0.2727 | 0.15 | 0.7576 | 0.5952 | 0.4538 |
| 0.6887 | 16.98 | 900 | 0.6985 | 0.6604 | 0.64 | 0.5333 | 0.8 | 0.5758 | 0.8261 | 0.6879 |
| 0.7594 | 18.87 | 1000 | 0.7040 | 0.5472 | 0.4286 | 0.4091 | 0.45 | 0.6061 | 0.6452 | 0.5280 |
| 0.2177 | 20.75 | 1100 | 0.8056 | 0.4528 | 0.5397 | 0.3953 | 0.85 | 0.2121 | 0.7 | 0.5311 |
| 0.4893 | 22.64 | 1200 | 0.8821 | 0.3396 | 0.3860 | 0.2973 | 0.55 | 0.2121 | 0.4375 | 0.3811 |
| 0.5994 | 24.53 | 1300 | 0.8059 | 0.5660 | 0.5660 | 0.4545 | 0.75 | 0.4545 | 0.75 | 0.6023 |
| 0.5179 | 26.42 | 1400 | 0.6750 | 0.6038 | 0.4615 | 0.4737 | 0.45 | 0.6970 | 0.6765 | 0.5735 |
| 0.198 | 28.3 | 1500 | 0.7448 | 0.3962 | 0.3333 | 0.2857 | 0.4 | 0.3939 | 0.52 | 0.3970 |
| 0.6536 | 30.19 | 1600 | 0.7555 | 0.5094 | 0.4583 | 0.3929 | 0.55 | 0.4848 | 0.64 | 0.5174 |
| 0.7558 | 32.08 | 1700 | 0.6664 | 0.5849 | 0.4762 | 0.4545 | 0.5 | 0.6364 | 0.6774 | 0.5682 |
| 0.4915 | 33.96 | 1800 | 0.9213 | 0.3962 | 0.5152 | 0.3696 | 0.85 | 0.1212 | 0.5714 | 0.4856 |
| 0.3661 | 35.85 | 1900 | 0.9202 | 0.4528 | 0.4912 | 0.3784 | 0.7 | 0.3030 | 0.625 | 0.5015 |
| 0.4838 | 37.74 | 2000 | 0.9297 | 0.4528 | 0.5085 | 0.3846 | 0.75 | 0.2727 | 0.6429 | 0.5114 |
| 0.8461 | 39.62 | 2100 | 0.9464 | 0.4717 | 0.5758 | 0.4130 | 0.95 | 0.1818 | 0.8571 | 0.5659 |
| 0.6937 | 41.51 | 2200 | 0.7129 | 0.5094 | 0.48 | 0.4 | 0.6 | 0.4545 | 0.6522 | 0.5273 |
| 0.6302 | 43.4 | 2300 | 0.6866 | 0.5849 | 0.6071 | 0.4722 | 0.85 | 0.4242 | 0.8235 | 0.6371 |
| 0.0793 | 45.28 | 2400 | 0.7791 | 0.5094 | 0.5517 | 0.4211 | 0.8 | 0.3333 | 0.7333 | 0.5667 |
| 0.464 | 47.17 | 2500 | 0.8116 | 0.4340 | 0.4444 | 0.3529 | 0.6 | 0.3333 | 0.5789 | 0.4667 |
| 0.6131 | 49.06 | 2600 | 0.5970 | 0.6226 | 0.5455 | 0.5 | 0.6 | 0.6364 | 0.7241 | 0.6182 |
| 0.6937 | 50.94 | 2700 | 0.8201 | 0.4340 | 0.4 | 0.3333 | 0.5 | 0.3939 | 0.5652 | 0.4470 |
| 0.6552 | 52.83 | 2800 | 0.7168 | 0.5660 | 0.5306 | 0.4483 | 0.65 | 0.5152 | 0.7083 | 0.5826 |
| 0.7749 | 54.72 | 2900 | 0.6875 | 0.5849 | 0.5217 | 0.4615 | 0.6 | 0.5758 | 0.7037 | 0.5879 |
| 0.9482 | 56.6 | 3000 | 0.6392 | 0.6226 | 0.6296 | 0.5 | 0.85 | 0.4848 | 0.8421 | 0.6674 |
| 0.2467 | 58.49 | 3100 | 0.6281 | 0.6038 | 0.5333 | 0.48 | 0.6 | 0.6061 | 0.7143 | 0.6030 |
| 0.2903 | 60.38 | 3200 | 0.7383 | 0.5472 | 0.5556 | 0.4412 | 0.75 | 0.4242 | 0.7368 | 0.5871 |
| 0.5859 | 62.26 | 3300 | 0.7191 | 0.6226 | 0.5652 | 0.5 | 0.65 | 0.6061 | 0.7407 | 0.6280 |
| 0.3815 | 64.15 | 3400 | 0.7469 | 0.5283 | 0.4444 | 0.4 | 0.5 | 0.5455 | 0.6429 | 0.5227 |
| 0.531 | 66.04 | 3500 | 0.7566 | 0.6226 | 0.5652 | 0.5 | 0.65 | 0.6061 | 0.7407 | 0.6280 |
| 0.3892 | 67.92 | 3600 | 0.8168 | 0.5660 | 0.5490 | 0.4516 | 0.7 | 0.4848 | 0.7273 | 0.5924 |
| 0.6487 | 69.81 | 3700 | 0.9077 | 0.4340 | 0.4643 | 0.3611 | 0.65 | 0.3030 | 0.5882 | 0.4765 |
| 0.5525 | 71.7 | 3800 | 0.6961 | 0.6038 | 0.5116 | 0.4783 | 0.55 | 0.6364 | 0.7 | 0.5932 |
| 0.3137 | 73.58 | 3900 | 1.0817 | 0.3774 | 0.4590 | 0.3415 | 0.7 | 0.1818 | 0.5 | 0.4409 |
| 0.3526 | 75.47 | 4000 | 0.7684 | 0.5472 | 0.5862 | 0.4474 | 0.85 | 0.3636 | 0.8 | 0.6068 |
| 0.5938 | 77.36 | 4100 | 0.8786 | 0.4340 | 0.4828 | 0.3684 | 0.7 | 0.2727 | 0.6 | 0.4864 |
| 0.2431 | 79.25 | 4200 | 0.8925 | 0.4151 | 0.4746 | 0.3590 | 0.7 | 0.2424 | 0.5714 | 0.4712 |
| 0.1021 | 81.13 | 4300 | 1.0740 | 0.4528 | 0.4727 | 0.3714 | 0.65 | 0.3333 | 0.6111 | 0.4917 |
| 0.3429 | 83.02 | 4400 | 0.7723 | 0.4906 | 0.5091 | 0.4 | 0.7 | 0.3636 | 0.6667 | 0.5318 |
| 0.3836 | 84.91 | 4500 | 0.7247 | 0.5472 | 0.5556 | 0.4412 | 0.75 | 0.4242 | 0.7368 | 0.5871 |
| 0.4099 | 86.79 | 4600 | 0.8508 | 0.4340 | 0.4828 | 0.3684 | 0.7 | 0.2727 | 0.6 | 0.4864 |
| 0.8264 | 88.68 | 4700 | 0.7682 | 0.5849 | 0.5769 | 0.4688 | 0.75 | 0.4848 | 0.7619 | 0.6174 |
| 0.1928 | 90.57 | 4800 | 0.8738 | 0.4906 | 0.5574 | 0.4146 | 0.85 | 0.2727 | 0.75 | 0.5614 |
| 0.3422 | 92.45 | 4900 | 0.8810 | 0.5660 | 0.5965 | 0.4595 | 0.85 | 0.3939 | 0.8125 | 0.6220 |
| 0.5524 | 94.34 | 5000 | 1.0801 | 0.3774 | 0.4923 | 0.3556 | 0.8 | 0.1212 | 0.5 | 0.4606 |
| 0.464 | 96.23 | 5100 | 0.9417 | 0.5283 | 0.5902 | 0.4390 | 0.9 | 0.3030 | 0.8333 | 0.6015 |
| 0.7182 | 98.11 | 5200 | 1.0335 | 0.4151 | 0.4746 | 0.3590 | 0.7 | 0.2424 | 0.5714 | 0.4712 |
| 0.604 | 100.0 | 5300 | 0.6947 | 0.6604 | 0.6087 | 0.5385 | 0.7 | 0.6364 | 0.7778 | 0.6682 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
egumasa/en_engagement_RoBERTa_combined
|
egumasa
| 2022-11-02T01:56:39Z | 6 | 1 |
spacy
|
[
"spacy",
"token-classification",
"en",
"doi:10.57967/hf/0082",
"model-index",
"region:us"
] |
token-classification
| 2022-11-02T01:53:35Z |
---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_engagement_RoBERTa_combined
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.0
- name: NER Recall
type: recall
value: 0.0
- name: NER F Score
type: f_score
value: 0.0
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.0
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.0
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.0
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.0
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.9764065336
---
| Feature | Description |
| --- | --- |
| **Name** | `en_engagement_RoBERTa_combined` |
| **Version** | `AtoI_0.1.85` |
| **spaCy** | `>=3.3.0,<3.4.0` |
| **Default Pipeline** | `transformer`, `tagger`, `parser`, `ner`, `trainable_transformer`, `span_finder`, `spancat` |
| **Components** | `transformer`, `tagger`, `parser`, `ner`, `trainable_transformer`, `span_finder`, `spancat` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (124 labels for 4 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `$`, `''`, `,`, `-LRB-`, `-RRB-`, `.`, `:`, `ADD`, `AFX`, `CC`, `CD`, `DT`, `EX`, `FW`, `HYPH`, `IN`, `JJ`, `JJR`, `JJS`, `LS`, `MD`, `NFP`, `NN`, `NNP`, `NNPS`, `NNS`, `PDT`, `POS`, `PRP`, `PRP$`, `RB`, `RBR`, `RBS`, `RP`, `SYM`, `TO`, `UH`, `VB`, `VBD`, `VBG`, `VBN`, `VBP`, `VBZ`, `WDT`, `WP`, `WP$`, `WRB`, `XX`, ```` |
| **`parser`** | `ROOT`, `acl`, `acomp`, `advcl`, `advmod`, `agent`, `amod`, `appos`, `attr`, `aux`, `auxpass`, `case`, `cc`, `ccomp`, `compound`, `conj`, `csubj`, `csubjpass`, `dative`, `dep`, `det`, `dobj`, `expl`, `intj`, `mark`, `meta`, `neg`, `nmod`, `npadvmod`, `nsubj`, `nsubjpass`, `nummod`, `oprd`, `parataxis`, `pcomp`, `pobj`, `poss`, `preconj`, `predet`, `prep`, `prt`, `punct`, `quantmod`, `relcl`, `xcomp` |
| **`ner`** | `CARDINAL`, `DATE`, `EVENT`, `FAC`, `GPE`, `LANGUAGE`, `LAW`, `LOC`, `MONEY`, `NORP`, `ORDINAL`, `ORG`, `PERCENT`, `PERSON`, `PRODUCT`, `QUANTITY`, `TIME`, `WORK_OF_ART` |
| **`spancat`** | `MONOGLOSS`, `ATTRIBUTE`, `JUSTIFY`, `COUNTER`, `CITATION`, `ENTERTAIN`, `ENDORSE`, `DENY`, `CONCUR`, `PRONOUNCE`, `TEMPORAL`, `CONTRAST` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TAG_ACC` | 0.00 |
| `DEP_UAS` | 0.00 |
| `DEP_LAS` | 0.00 |
| `DEP_LAS_PER_TYPE` | 0.00 |
| `SENTS_P` | 96.76 |
| `SENTS_R` | 98.53 |
| `SENTS_F` | 97.64 |
| `ENTS_F` | 0.00 |
| `ENTS_P` | 0.00 |
| `ENTS_R` | 0.00 |
| `SPAN_FINDER_SPAN_CANDIDATES_F` | 50.09 |
| `SPAN_FINDER_SPAN_CANDIDATES_P` | 35.70 |
| `SPAN_FINDER_SPAN_CANDIDATES_R` | 83.94 |
| `SPANS_SC_F` | 76.49 |
| `SPANS_SC_P` | 75.89 |
| `SPANS_SC_R` | 77.11 |
| `LEMMA_ACC` | 0.00 |
| `TRAINABLE_TRANSFORMER_LOSS` | 1535.39 |
| `SPAN_FINDER_LOSS` | 20411.83 |
| `SPANCAT_LOSS` | 24075.13 |
|
crescendonow/pwa_ner
|
crescendonow
| 2022-11-02T01:03:30Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"token-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-02T00:57:00Z |
---
license: apache-2.0
---
Finetune from WangchanBERTa use for Provincial Waterworks Autority of Thailand.
|
huggingtweets/trashfil
|
huggingtweets
| 2022-11-02T00:30:34Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-02T00:29:17Z |
---
language: en
thumbnail: http://www.huggingtweets.com/trashfil/1667349030665/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1530748346935148544/J8kNSD8f_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">💌</div>
<div style="text-align: center; font-size: 14px;">@trashfil</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 💌.
| Data | 💌 |
| --- | --- |
| Tweets downloaded | 467 |
| Retweets | 32 |
| Short tweets | 106 |
| Tweets kept | 329 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3arew141/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @trashfil's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/34h0nac5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/34h0nac5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/trashfil')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sergiocannata/convnext-tiny-224-finetuned-brs2
|
sergiocannata
| 2022-11-02T00:15:25Z | 26 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"convnext",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-11-01T23:03:50Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
- f1
model-index:
- name: convnext-tiny-224-finetuned-brs2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7924528301886793
- name: F1
type: f1
value: 0.7555555555555556
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-tiny-224-finetuned-brs2
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2502
- Accuracy: 0.7925
- F1: 0.7556
- Precision (ppv): 0.8095
- Recall (sensitivity): 0.7083
- Specificity: 0.8621
- Npv: 0.7812
- Auc: 0.7852
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision (ppv) | Recall (sensitivity) | Specificity | Npv | Auc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------------:|:--------------------:|:-----------:|:------:|:------:|
| 0.6884 | 1.89 | 100 | 0.6907 | 0.5472 | 0.4286 | 0.5 | 0.375 | 0.6897 | 0.5714 | 0.5323 |
| 0.5868 | 3.77 | 200 | 0.6604 | 0.6415 | 0.4242 | 0.7778 | 0.2917 | 0.9310 | 0.6136 | 0.6114 |
| 0.4759 | 5.66 | 300 | 0.6273 | 0.6604 | 0.5 | 0.75 | 0.375 | 0.8966 | 0.6341 | 0.6358 |
| 0.3599 | 7.55 | 400 | 0.6520 | 0.6604 | 0.5 | 0.75 | 0.375 | 0.8966 | 0.6341 | 0.6358 |
| 0.3248 | 9.43 | 500 | 0.9115 | 0.6415 | 0.4571 | 0.7273 | 0.3333 | 0.8966 | 0.6190 | 0.6149 |
| 0.3117 | 11.32 | 600 | 0.8608 | 0.6604 | 0.5263 | 0.7143 | 0.4167 | 0.8621 | 0.6410 | 0.6394 |
| 0.4208 | 13.21 | 700 | 0.8774 | 0.6792 | 0.5641 | 0.7333 | 0.4583 | 0.8621 | 0.6579 | 0.6602 |
| 0.5267 | 15.09 | 800 | 1.0131 | 0.6792 | 0.5405 | 0.7692 | 0.4167 | 0.8966 | 0.65 | 0.6566 |
| 0.234 | 16.98 | 900 | 1.1498 | 0.6981 | 0.5556 | 0.8333 | 0.4167 | 0.9310 | 0.6585 | 0.6739 |
| 0.7581 | 18.87 | 1000 | 1.0952 | 0.7170 | 0.6154 | 0.8 | 0.5 | 0.8966 | 0.6842 | 0.6983 |
| 0.1689 | 20.75 | 1100 | 1.1653 | 0.6981 | 0.5789 | 0.7857 | 0.4583 | 0.8966 | 0.6667 | 0.6774 |
| 0.0765 | 22.64 | 1200 | 1.1245 | 0.7170 | 0.6667 | 0.7143 | 0.625 | 0.7931 | 0.7188 | 0.7091 |
| 0.6287 | 24.53 | 1300 | 1.2222 | 0.6981 | 0.6 | 0.75 | 0.5 | 0.8621 | 0.6757 | 0.6810 |
| 0.0527 | 26.42 | 1400 | 1.2350 | 0.7358 | 0.6818 | 0.75 | 0.625 | 0.8276 | 0.7273 | 0.7263 |
| 0.3622 | 28.3 | 1500 | 1.1022 | 0.7547 | 0.6667 | 0.8667 | 0.5417 | 0.9310 | 0.7105 | 0.7364 |
| 0.3227 | 30.19 | 1600 | 1.1541 | 0.7170 | 0.6154 | 0.8 | 0.5 | 0.8966 | 0.6842 | 0.6983 |
| 0.3849 | 32.08 | 1700 | 1.2818 | 0.7170 | 0.6154 | 0.8 | 0.5 | 0.8966 | 0.6842 | 0.6983 |
| 0.4528 | 33.96 | 1800 | 1.3213 | 0.6981 | 0.5789 | 0.7857 | 0.4583 | 0.8966 | 0.6667 | 0.6774 |
| 0.1824 | 35.85 | 1900 | 1.3171 | 0.7170 | 0.6512 | 0.7368 | 0.5833 | 0.8276 | 0.7059 | 0.7055 |
| 0.0367 | 37.74 | 2000 | 1.4484 | 0.7170 | 0.6154 | 0.8 | 0.5 | 0.8966 | 0.6842 | 0.6983 |
| 0.07 | 39.62 | 2100 | 1.3521 | 0.7547 | 0.6977 | 0.7895 | 0.625 | 0.8621 | 0.7353 | 0.7435 |
| 0.0696 | 41.51 | 2200 | 1.2636 | 0.7358 | 0.65 | 0.8125 | 0.5417 | 0.8966 | 0.7027 | 0.7191 |
| 0.1554 | 43.4 | 2300 | 1.2225 | 0.7358 | 0.6667 | 0.7778 | 0.5833 | 0.8621 | 0.7143 | 0.7227 |
| 0.2346 | 45.28 | 2400 | 1.2627 | 0.7547 | 0.6829 | 0.8235 | 0.5833 | 0.8966 | 0.7222 | 0.7399 |
| 0.097 | 47.17 | 2500 | 1.4892 | 0.7170 | 0.6667 | 0.7143 | 0.625 | 0.7931 | 0.7188 | 0.7091 |
| 0.2494 | 49.06 | 2600 | 1.5282 | 0.7170 | 0.6512 | 0.7368 | 0.5833 | 0.8276 | 0.7059 | 0.7055 |
| 0.0734 | 50.94 | 2700 | 1.3989 | 0.7170 | 0.6341 | 0.7647 | 0.5417 | 0.8621 | 0.6944 | 0.7019 |
| 0.1077 | 52.83 | 2800 | 1.5155 | 0.6792 | 0.5641 | 0.7333 | 0.4583 | 0.8621 | 0.6579 | 0.6602 |
| 0.2456 | 54.72 | 2900 | 1.4400 | 0.7170 | 0.6512 | 0.7368 | 0.5833 | 0.8276 | 0.7059 | 0.7055 |
| 0.0823 | 56.6 | 3000 | 1.4511 | 0.7358 | 0.65 | 0.8125 | 0.5417 | 0.8966 | 0.7027 | 0.7191 |
| 0.0471 | 58.49 | 3100 | 1.5114 | 0.7547 | 0.6829 | 0.8235 | 0.5833 | 0.8966 | 0.7222 | 0.7399 |
| 0.0144 | 60.38 | 3200 | 1.4412 | 0.7925 | 0.7317 | 0.8824 | 0.625 | 0.9310 | 0.75 | 0.7780 |
| 0.1235 | 62.26 | 3300 | 1.2029 | 0.7547 | 0.6977 | 0.7895 | 0.625 | 0.8621 | 0.7353 | 0.7435 |
| 0.0121 | 64.15 | 3400 | 1.4925 | 0.7358 | 0.6667 | 0.7778 | 0.5833 | 0.8621 | 0.7143 | 0.7227 |
| 0.2126 | 66.04 | 3500 | 1.3614 | 0.7547 | 0.6667 | 0.8667 | 0.5417 | 0.9310 | 0.7105 | 0.7364 |
| 0.0496 | 67.92 | 3600 | 1.2960 | 0.7736 | 0.7143 | 0.8333 | 0.625 | 0.8966 | 0.7429 | 0.7608 |
| 0.1145 | 69.81 | 3700 | 1.3763 | 0.7547 | 0.6829 | 0.8235 | 0.5833 | 0.8966 | 0.7222 | 0.7399 |
| 0.1272 | 71.7 | 3800 | 1.6328 | 0.7170 | 0.5946 | 0.8462 | 0.4583 | 0.9310 | 0.675 | 0.6947 |
| 0.0007 | 73.58 | 3900 | 1.5622 | 0.7547 | 0.6977 | 0.7895 | 0.625 | 0.8621 | 0.7353 | 0.7435 |
| 0.0101 | 75.47 | 4000 | 1.1811 | 0.7925 | 0.7442 | 0.8421 | 0.6667 | 0.8966 | 0.7647 | 0.7816 |
| 0.0002 | 77.36 | 4100 | 1.8533 | 0.6981 | 0.5789 | 0.7857 | 0.4583 | 0.8966 | 0.6667 | 0.6774 |
| 0.0423 | 79.25 | 4200 | 1.2510 | 0.7547 | 0.6977 | 0.7895 | 0.625 | 0.8621 | 0.7353 | 0.7435 |
| 0.0036 | 81.13 | 4300 | 1.3443 | 0.7547 | 0.6829 | 0.8235 | 0.5833 | 0.8966 | 0.7222 | 0.7399 |
| 0.0432 | 83.02 | 4400 | 1.2864 | 0.7736 | 0.7273 | 0.8 | 0.6667 | 0.8621 | 0.7576 | 0.7644 |
| 0.0021 | 84.91 | 4500 | 0.8999 | 0.7925 | 0.7755 | 0.76 | 0.7917 | 0.7931 | 0.8214 | 0.7924 |
| 0.0002 | 86.79 | 4600 | 1.3634 | 0.7925 | 0.7442 | 0.8421 | 0.6667 | 0.8966 | 0.7647 | 0.7816 |
| 0.0044 | 88.68 | 4700 | 1.7830 | 0.7358 | 0.65 | 0.8125 | 0.5417 | 0.8966 | 0.7027 | 0.7191 |
| 0.0003 | 90.57 | 4800 | 1.2640 | 0.7736 | 0.7273 | 0.8 | 0.6667 | 0.8621 | 0.7576 | 0.7644 |
| 0.0253 | 92.45 | 4900 | 1.2649 | 0.7925 | 0.7442 | 0.8421 | 0.6667 | 0.8966 | 0.7647 | 0.7816 |
| 0.0278 | 94.34 | 5000 | 1.7485 | 0.7170 | 0.6512 | 0.7368 | 0.5833 | 0.8276 | 0.7059 | 0.7055 |
| 0.1608 | 96.23 | 5100 | 1.2641 | 0.8113 | 0.7727 | 0.85 | 0.7083 | 0.8966 | 0.7879 | 0.8024 |
| 0.0017 | 98.11 | 5200 | 1.6380 | 0.7170 | 0.6667 | 0.7143 | 0.625 | 0.7931 | 0.7188 | 0.7091 |
| 0.001 | 100.0 | 5300 | 1.2502 | 0.7925 | 0.7556 | 0.8095 | 0.7083 | 0.8621 | 0.7812 | 0.7852 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
pig4431/amazonPolarity_XLNET_5E
|
pig4431
| 2022-11-01T23:26:13Z | 89 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlnet",
"text-classification",
"generated_from_trainer",
"dataset:amazon_polarity",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T23:17:18Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_polarity
metrics:
- accuracy
model-index:
- name: amazonPolarity_XLNET_5E
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_polarity
type: amazon_polarity
config: amazon_polarity
split: train
args: amazon_polarity
metrics:
- name: Accuracy
type: accuracy
value: 0.9266666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# amazonPolarity_XLNET_5E
This model is a fine-tuned version of [xlnet-base-cased](https://huggingface.co/xlnet-base-cased) on the amazon_polarity dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4490
- Accuracy: 0.9267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.6238 | 0.01 | 50 | 0.3703 | 0.86 |
| 0.3149 | 0.03 | 100 | 0.3715 | 0.9 |
| 0.3849 | 0.04 | 150 | 0.4125 | 0.8867 |
| 0.4051 | 0.05 | 200 | 0.4958 | 0.8933 |
| 0.3345 | 0.07 | 250 | 0.4258 | 0.9067 |
| 0.439 | 0.08 | 300 | 0.2650 | 0.9067 |
| 0.2248 | 0.09 | 350 | 0.3314 | 0.9267 |
| 0.2849 | 0.11 | 400 | 0.3097 | 0.8933 |
| 0.3468 | 0.12 | 450 | 0.3060 | 0.9067 |
| 0.3216 | 0.13 | 500 | 0.3826 | 0.9067 |
| 0.3462 | 0.15 | 550 | 0.2207 | 0.94 |
| 0.3632 | 0.16 | 600 | 0.1864 | 0.94 |
| 0.2483 | 0.17 | 650 | 0.3069 | 0.9267 |
| 0.3709 | 0.19 | 700 | 0.2859 | 0.9333 |
| 0.2953 | 0.2 | 750 | 0.3010 | 0.9333 |
| 0.3222 | 0.21 | 800 | 0.2668 | 0.9133 |
| 0.3142 | 0.23 | 850 | 0.3545 | 0.8667 |
| 0.2637 | 0.24 | 900 | 0.1922 | 0.9467 |
| 0.3929 | 0.25 | 950 | 0.2712 | 0.92 |
| 0.2918 | 0.27 | 1000 | 0.2516 | 0.9333 |
| 0.2269 | 0.28 | 1050 | 0.4227 | 0.8933 |
| 0.239 | 0.29 | 1100 | 0.3639 | 0.9133 |
| 0.2439 | 0.31 | 1150 | 0.3430 | 0.9133 |
| 0.2417 | 0.32 | 1200 | 0.2920 | 0.94 |
| 0.3223 | 0.33 | 1250 | 0.3426 | 0.9067 |
| 0.2775 | 0.35 | 1300 | 0.3752 | 0.8867 |
| 0.2733 | 0.36 | 1350 | 0.3015 | 0.9333 |
| 0.3737 | 0.37 | 1400 | 0.2875 | 0.9267 |
| 0.2907 | 0.39 | 1450 | 0.4926 | 0.8933 |
| 0.316 | 0.4 | 1500 | 0.2948 | 0.9333 |
| 0.2472 | 0.41 | 1550 | 0.4003 | 0.8933 |
| 0.2607 | 0.43 | 1600 | 0.3608 | 0.92 |
| 0.2848 | 0.44 | 1650 | 0.3332 | 0.9133 |
| 0.2708 | 0.45 | 1700 | 0.3424 | 0.92 |
| 0.3721 | 0.47 | 1750 | 0.2384 | 0.9267 |
| 0.2925 | 0.48 | 1800 | 0.4472 | 0.88 |
| 0.3619 | 0.49 | 1850 | 0.3824 | 0.9 |
| 0.1994 | 0.51 | 1900 | 0.4160 | 0.9133 |
| 0.3586 | 0.52 | 1950 | 0.3198 | 0.8867 |
| 0.2455 | 0.53 | 2000 | 0.3119 | 0.92 |
| 0.2683 | 0.55 | 2050 | 0.4262 | 0.8867 |
| 0.2983 | 0.56 | 2100 | 0.3552 | 0.9067 |
| 0.2973 | 0.57 | 2150 | 0.2966 | 0.8933 |
| 0.2299 | 0.59 | 2200 | 0.2972 | 0.92 |
| 0.295 | 0.6 | 2250 | 0.3122 | 0.9067 |
| 0.2716 | 0.61 | 2300 | 0.2556 | 0.9267 |
| 0.2842 | 0.63 | 2350 | 0.3317 | 0.92 |
| 0.2723 | 0.64 | 2400 | 0.4409 | 0.8933 |
| 0.2492 | 0.65 | 2450 | 0.3871 | 0.88 |
| 0.2297 | 0.67 | 2500 | 0.3526 | 0.9133 |
| 0.2125 | 0.68 | 2550 | 0.4597 | 0.9067 |
| 0.3003 | 0.69 | 2600 | 0.3374 | 0.8933 |
| 0.2622 | 0.71 | 2650 | 0.3492 | 0.9267 |
| 0.2436 | 0.72 | 2700 | 0.3438 | 0.9267 |
| 0.2599 | 0.73 | 2750 | 0.3725 | 0.9133 |
| 0.2759 | 0.75 | 2800 | 0.3260 | 0.9333 |
| 0.1841 | 0.76 | 2850 | 0.4218 | 0.9067 |
| 0.252 | 0.77 | 2900 | 0.2730 | 0.92 |
| 0.248 | 0.79 | 2950 | 0.3628 | 0.92 |
| 0.2356 | 0.8 | 3000 | 0.4012 | 0.9067 |
| 0.191 | 0.81 | 3050 | 0.3500 | 0.9267 |
| 0.2351 | 0.83 | 3100 | 0.4038 | 0.9133 |
| 0.2758 | 0.84 | 3150 | 0.3361 | 0.9067 |
| 0.2952 | 0.85 | 3200 | 0.2301 | 0.9267 |
| 0.2137 | 0.87 | 3250 | 0.3837 | 0.9133 |
| 0.2386 | 0.88 | 3300 | 0.2739 | 0.94 |
| 0.2786 | 0.89 | 3350 | 0.2820 | 0.9333 |
| 0.2284 | 0.91 | 3400 | 0.2557 | 0.9333 |
| 0.2546 | 0.92 | 3450 | 0.2744 | 0.9267 |
| 0.2514 | 0.93 | 3500 | 0.2908 | 0.94 |
| 0.3052 | 0.95 | 3550 | 0.2362 | 0.9333 |
| 0.2366 | 0.96 | 3600 | 0.3047 | 0.9333 |
| 0.2147 | 0.97 | 3650 | 0.3375 | 0.9333 |
| 0.3347 | 0.99 | 3700 | 0.2669 | 0.9267 |
| 0.3076 | 1.0 | 3750 | 0.2453 | 0.94 |
| 0.1685 | 1.01 | 3800 | 0.4117 | 0.9133 |
| 0.1954 | 1.03 | 3850 | 0.3074 | 0.9333 |
| 0.2512 | 1.04 | 3900 | 0.3942 | 0.9133 |
| 0.1365 | 1.05 | 3950 | 0.3211 | 0.92 |
| 0.1985 | 1.07 | 4000 | 0.4188 | 0.9133 |
| 0.1585 | 1.08 | 4050 | 0.4177 | 0.9133 |
| 0.1798 | 1.09 | 4100 | 0.3298 | 0.9333 |
| 0.1458 | 1.11 | 4150 | 0.5283 | 0.9 |
| 0.1831 | 1.12 | 4200 | 0.3884 | 0.92 |
| 0.1452 | 1.13 | 4250 | 0.4130 | 0.9133 |
| 0.1679 | 1.15 | 4300 | 0.3678 | 0.9267 |
| 0.1688 | 1.16 | 4350 | 0.3268 | 0.9333 |
| 0.1175 | 1.17 | 4400 | 0.4722 | 0.92 |
| 0.1661 | 1.19 | 4450 | 0.3899 | 0.9133 |
| 0.1688 | 1.2 | 4500 | 0.4050 | 0.9133 |
| 0.228 | 1.21 | 4550 | 0.4608 | 0.9 |
| 0.1946 | 1.23 | 4600 | 0.5080 | 0.9 |
| 0.1849 | 1.24 | 4650 | 0.4340 | 0.9067 |
| 0.1365 | 1.25 | 4700 | 0.4592 | 0.9133 |
| 0.2432 | 1.27 | 4750 | 0.3683 | 0.92 |
| 0.1679 | 1.28 | 4800 | 0.4604 | 0.9 |
| 0.2107 | 1.29 | 4850 | 0.3952 | 0.9 |
| 0.1499 | 1.31 | 4900 | 0.4275 | 0.92 |
| 0.1504 | 1.32 | 4950 | 0.3370 | 0.9333 |
| 0.1013 | 1.33 | 5000 | 0.3723 | 0.92 |
| 0.1303 | 1.35 | 5050 | 0.2925 | 0.9333 |
| 0.1205 | 1.36 | 5100 | 0.3452 | 0.9267 |
| 0.1427 | 1.37 | 5150 | 0.3080 | 0.94 |
| 0.1518 | 1.39 | 5200 | 0.3190 | 0.94 |
| 0.1885 | 1.4 | 5250 | 0.2726 | 0.9467 |
| 0.1264 | 1.41 | 5300 | 0.3466 | 0.9333 |
| 0.1939 | 1.43 | 5350 | 0.3957 | 0.9133 |
| 0.1939 | 1.44 | 5400 | 0.4007 | 0.9 |
| 0.1239 | 1.45 | 5450 | 0.2924 | 0.9333 |
| 0.1588 | 1.47 | 5500 | 0.2687 | 0.9333 |
| 0.1516 | 1.48 | 5550 | 0.3668 | 0.92 |
| 0.1623 | 1.49 | 5600 | 0.3141 | 0.94 |
| 0.2632 | 1.51 | 5650 | 0.2714 | 0.9333 |
| 0.1674 | 1.52 | 5700 | 0.3188 | 0.94 |
| 0.1854 | 1.53 | 5750 | 0.2818 | 0.9267 |
| 0.1282 | 1.55 | 5800 | 0.2918 | 0.9333 |
| 0.228 | 1.56 | 5850 | 0.2802 | 0.9133 |
| 0.2349 | 1.57 | 5900 | 0.1803 | 0.9467 |
| 0.1608 | 1.59 | 5950 | 0.3112 | 0.92 |
| 0.1493 | 1.6 | 6000 | 0.3018 | 0.9267 |
| 0.2182 | 1.61 | 6050 | 0.3419 | 0.9333 |
| 0.2408 | 1.63 | 6100 | 0.2887 | 0.9267 |
| 0.1872 | 1.64 | 6150 | 0.2408 | 0.9267 |
| 0.1246 | 1.65 | 6200 | 0.3752 | 0.9 |
| 0.2098 | 1.67 | 6250 | 0.2622 | 0.9333 |
| 0.1916 | 1.68 | 6300 | 0.2245 | 0.9467 |
| 0.2069 | 1.69 | 6350 | 0.2151 | 0.9467 |
| 0.1446 | 1.71 | 6400 | 0.2186 | 0.9533 |
| 0.1528 | 1.72 | 6450 | 0.1863 | 0.9533 |
| 0.1352 | 1.73 | 6500 | 0.2660 | 0.9467 |
| 0.2398 | 1.75 | 6550 | 0.1912 | 0.9533 |
| 0.1485 | 1.76 | 6600 | 0.2492 | 0.9467 |
| 0.2006 | 1.77 | 6650 | 0.2495 | 0.9267 |
| 0.2036 | 1.79 | 6700 | 0.3885 | 0.9067 |
| 0.1725 | 1.8 | 6750 | 0.2359 | 0.9533 |
| 0.1864 | 1.81 | 6800 | 0.2271 | 0.9533 |
| 0.1465 | 1.83 | 6850 | 0.2669 | 0.9333 |
| 0.197 | 1.84 | 6900 | 0.2290 | 0.96 |
| 0.1382 | 1.85 | 6950 | 0.2322 | 0.9467 |
| 0.1206 | 1.87 | 7000 | 0.3117 | 0.9333 |
| 0.157 | 1.88 | 7050 | 0.2163 | 0.9533 |
| 0.1686 | 1.89 | 7100 | 0.2239 | 0.9533 |
| 0.1953 | 1.91 | 7150 | 0.3064 | 0.9333 |
| 0.1638 | 1.92 | 7200 | 0.2821 | 0.9533 |
| 0.1605 | 1.93 | 7250 | 0.2413 | 0.9467 |
| 0.1736 | 1.95 | 7300 | 0.2430 | 0.94 |
| 0.2372 | 1.96 | 7350 | 0.2306 | 0.94 |
| 0.1549 | 1.97 | 7400 | 0.2730 | 0.94 |
| 0.1824 | 1.99 | 7450 | 0.3443 | 0.94 |
| 0.2263 | 2.0 | 7500 | 0.2695 | 0.9267 |
| 0.088 | 2.01 | 7550 | 0.2305 | 0.96 |
| 0.0376 | 2.03 | 7600 | 0.3380 | 0.94 |
| 0.072 | 2.04 | 7650 | 0.3349 | 0.9467 |
| 0.0491 | 2.05 | 7700 | 0.3397 | 0.94 |
| 0.0509 | 2.07 | 7750 | 0.3496 | 0.9467 |
| 0.1033 | 2.08 | 7800 | 0.3364 | 0.94 |
| 0.0549 | 2.09 | 7850 | 0.3520 | 0.94 |
| 0.0627 | 2.11 | 7900 | 0.4510 | 0.9267 |
| 0.0283 | 2.12 | 7950 | 0.3733 | 0.94 |
| 0.1215 | 2.13 | 8000 | 0.3892 | 0.9267 |
| 0.0856 | 2.15 | 8050 | 0.3114 | 0.9533 |
| 0.0945 | 2.16 | 8100 | 0.3626 | 0.9333 |
| 0.0901 | 2.17 | 8150 | 0.3116 | 0.94 |
| 0.0688 | 2.19 | 8200 | 0.3515 | 0.9267 |
| 0.1286 | 2.2 | 8250 | 0.3255 | 0.9333 |
| 0.1043 | 2.21 | 8300 | 0.4395 | 0.9133 |
| 0.1199 | 2.23 | 8350 | 0.3307 | 0.94 |
| 0.0608 | 2.24 | 8400 | 0.2992 | 0.9533 |
| 0.0827 | 2.25 | 8450 | 0.3500 | 0.94 |
| 0.047 | 2.27 | 8500 | 0.3982 | 0.94 |
| 0.1154 | 2.28 | 8550 | 0.3851 | 0.94 |
| 0.1158 | 2.29 | 8600 | 0.3820 | 0.9133 |
| 0.1053 | 2.31 | 8650 | 0.4414 | 0.92 |
| 0.1336 | 2.32 | 8700 | 0.3680 | 0.92 |
| 0.0853 | 2.33 | 8750 | 0.3732 | 0.9333 |
| 0.0496 | 2.35 | 8800 | 0.3450 | 0.94 |
| 0.0552 | 2.36 | 8850 | 0.4310 | 0.9267 |
| 0.1054 | 2.37 | 8900 | 0.4174 | 0.92 |
| 0.0951 | 2.39 | 8950 | 0.3815 | 0.9333 |
| 0.1235 | 2.4 | 9000 | 0.4119 | 0.9267 |
| 0.1094 | 2.41 | 9050 | 0.4282 | 0.9133 |
| 0.0897 | 2.43 | 9100 | 0.4766 | 0.9133 |
| 0.0925 | 2.44 | 9150 | 0.3303 | 0.94 |
| 0.1487 | 2.45 | 9200 | 0.2948 | 0.94 |
| 0.0963 | 2.47 | 9250 | 0.2911 | 0.94 |
| 0.0836 | 2.48 | 9300 | 0.3379 | 0.94 |
| 0.1594 | 2.49 | 9350 | 0.3841 | 0.9267 |
| 0.0846 | 2.51 | 9400 | 0.4128 | 0.9267 |
| 0.0984 | 2.52 | 9450 | 0.4131 | 0.9333 |
| 0.1042 | 2.53 | 9500 | 0.4048 | 0.9267 |
| 0.0633 | 2.55 | 9550 | 0.3776 | 0.94 |
| 0.1266 | 2.56 | 9600 | 0.3247 | 0.9333 |
| 0.1084 | 2.57 | 9650 | 0.3174 | 0.9467 |
| 0.0714 | 2.59 | 9700 | 0.3597 | 0.94 |
| 0.0826 | 2.6 | 9750 | 0.3261 | 0.9467 |
| 0.1527 | 2.61 | 9800 | 0.2531 | 0.9533 |
| 0.0506 | 2.63 | 9850 | 0.2994 | 0.9533 |
| 0.1043 | 2.64 | 9900 | 0.3345 | 0.9467 |
| 0.0229 | 2.65 | 9950 | 0.4318 | 0.9333 |
| 0.1247 | 2.67 | 10000 | 0.2951 | 0.9533 |
| 0.1285 | 2.68 | 10050 | 0.3036 | 0.9533 |
| 0.081 | 2.69 | 10100 | 0.3541 | 0.94 |
| 0.0829 | 2.71 | 10150 | 0.3757 | 0.9467 |
| 0.0702 | 2.72 | 10200 | 0.3307 | 0.9533 |
| 0.07 | 2.73 | 10250 | 0.3638 | 0.94 |
| 0.1563 | 2.75 | 10300 | 0.3283 | 0.94 |
| 0.1223 | 2.76 | 10350 | 0.3441 | 0.92 |
| 0.0954 | 2.77 | 10400 | 0.3049 | 0.94 |
| 0.0438 | 2.79 | 10450 | 0.3675 | 0.9467 |
| 0.0796 | 2.8 | 10500 | 0.3364 | 0.94 |
| 0.0803 | 2.81 | 10550 | 0.2970 | 0.94 |
| 0.0324 | 2.83 | 10600 | 0.3941 | 0.9267 |
| 0.083 | 2.84 | 10650 | 0.3439 | 0.94 |
| 0.1263 | 2.85 | 10700 | 0.3759 | 0.9267 |
| 0.1044 | 2.87 | 10750 | 1.0700 | 0.58 |
| 0.1182 | 2.88 | 10800 | 0.4409 | 0.9333 |
| 0.126 | 2.89 | 10850 | 0.6467 | 0.5933 |
| 0.094 | 2.91 | 10900 | 0.3741 | 0.9333 |
| 0.1405 | 2.92 | 10950 | 0.3458 | 0.9267 |
| 0.1024 | 2.93 | 11000 | 0.2946 | 0.9333 |
| 0.0812 | 2.95 | 11050 | 0.2850 | 0.9333 |
| 0.1132 | 2.96 | 11100 | 0.3093 | 0.9267 |
| 0.0775 | 2.97 | 11150 | 0.3938 | 0.9067 |
| 0.1179 | 2.99 | 11200 | 0.3528 | 0.9267 |
| 0.1413 | 3.0 | 11250 | 0.2984 | 0.9333 |
| 0.0528 | 3.01 | 11300 | 0.3387 | 0.9333 |
| 0.0214 | 3.03 | 11350 | 0.4108 | 0.92 |
| 0.0408 | 3.04 | 11400 | 0.4174 | 0.9267 |
| 0.0808 | 3.05 | 11450 | 0.4283 | 0.9267 |
| 0.0535 | 3.07 | 11500 | 0.3719 | 0.9333 |
| 0.0344 | 3.08 | 11550 | 0.4382 | 0.9333 |
| 0.0364 | 3.09 | 11600 | 0.4195 | 0.9333 |
| 0.0524 | 3.11 | 11650 | 0.4607 | 0.92 |
| 0.0682 | 3.12 | 11700 | 0.4503 | 0.92 |
| 0.0554 | 3.13 | 11750 | 0.4563 | 0.92 |
| 0.0401 | 3.15 | 11800 | 0.4668 | 0.9133 |
| 0.0782 | 3.16 | 11850 | 0.4468 | 0.9133 |
| 0.0605 | 3.17 | 11900 | 0.4239 | 0.92 |
| 0.0599 | 3.19 | 11950 | 0.4019 | 0.92 |
| 0.0364 | 3.2 | 12000 | 0.3988 | 0.9267 |
| 0.0357 | 3.21 | 12050 | 0.4168 | 0.9267 |
| 0.072 | 3.23 | 12100 | 0.3889 | 0.9333 |
| 0.0931 | 3.24 | 12150 | 0.3368 | 0.9333 |
| 0.0724 | 3.25 | 12200 | 0.3209 | 0.9333 |
| 0.0653 | 3.27 | 12250 | 0.3615 | 0.9333 |
| 0.0173 | 3.28 | 12300 | 0.3946 | 0.9333 |
| 0.0537 | 3.29 | 12350 | 0.3876 | 0.9333 |
| 0.0373 | 3.31 | 12400 | 0.4079 | 0.9267 |
| 0.0322 | 3.32 | 12450 | 0.3553 | 0.94 |
| 0.0585 | 3.33 | 12500 | 0.4276 | 0.92 |
| 0.0315 | 3.35 | 12550 | 0.4092 | 0.9267 |
| 0.0317 | 3.36 | 12600 | 0.4107 | 0.9267 |
| 0.082 | 3.37 | 12650 | 0.4170 | 0.9267 |
| 0.1101 | 3.39 | 12700 | 0.3801 | 0.9333 |
| 0.0392 | 3.4 | 12750 | 0.3802 | 0.9333 |
| 0.0382 | 3.41 | 12800 | 0.4194 | 0.9267 |
| 0.048 | 3.43 | 12850 | 0.3794 | 0.9333 |
| 0.0896 | 3.44 | 12900 | 0.3961 | 0.9267 |
| 0.0966 | 3.45 | 12950 | 0.3982 | 0.92 |
| 0.0165 | 3.47 | 13000 | 0.3819 | 0.92 |
| 0.0701 | 3.48 | 13050 | 0.3440 | 0.94 |
| 0.0104 | 3.49 | 13100 | 0.4132 | 0.9267 |
| 0.0991 | 3.51 | 13150 | 0.3477 | 0.9333 |
| 0.0554 | 3.52 | 13200 | 0.3255 | 0.94 |
| 0.0476 | 3.53 | 13250 | 0.4343 | 0.92 |
| 0.0213 | 3.55 | 13300 | 0.4601 | 0.92 |
| 0.0465 | 3.56 | 13350 | 0.4141 | 0.9267 |
| 0.1246 | 3.57 | 13400 | 0.3473 | 0.94 |
| 0.1112 | 3.59 | 13450 | 0.3679 | 0.92 |
| 0.0323 | 3.6 | 13500 | 0.3508 | 0.9267 |
| 0.0423 | 3.61 | 13550 | 0.3475 | 0.94 |
| 0.0498 | 3.63 | 13600 | 0.4095 | 0.92 |
| 0.0531 | 3.64 | 13650 | 0.3544 | 0.9333 |
| 0.0365 | 3.65 | 13700 | 0.4403 | 0.9133 |
| 0.058 | 3.67 | 13750 | 0.4284 | 0.9133 |
| 0.0191 | 3.68 | 13800 | 0.4466 | 0.92 |
| 0.0838 | 3.69 | 13850 | 0.5128 | 0.9067 |
| 0.1561 | 3.71 | 13900 | 0.3588 | 0.9267 |
| 0.0464 | 3.72 | 13950 | 0.3867 | 0.92 |
| 0.037 | 3.73 | 14000 | 0.3961 | 0.92 |
| 0.0288 | 3.75 | 14050 | 0.4274 | 0.92 |
| 0.0928 | 3.76 | 14100 | 0.3524 | 0.94 |
| 0.0696 | 3.77 | 14150 | 0.3555 | 0.9333 |
| 0.0318 | 3.79 | 14200 | 0.3457 | 0.9467 |
| 0.0417 | 3.8 | 14250 | 0.3412 | 0.94 |
| 0.0283 | 3.81 | 14300 | 0.3845 | 0.9333 |
| 0.058 | 3.83 | 14350 | 0.3765 | 0.9333 |
| 0.0589 | 3.84 | 14400 | 0.4085 | 0.9267 |
| 0.0432 | 3.85 | 14450 | 0.4103 | 0.9267 |
| 0.0365 | 3.87 | 14500 | 0.4000 | 0.9267 |
| 0.0858 | 3.88 | 14550 | 0.3905 | 0.9267 |
| 0.0494 | 3.89 | 14600 | 0.3739 | 0.9267 |
| 0.0503 | 3.91 | 14650 | 0.3203 | 0.94 |
| 0.0349 | 3.92 | 14700 | 0.3268 | 0.9467 |
| 0.0328 | 3.93 | 14750 | 0.3259 | 0.9467 |
| 0.0347 | 3.95 | 14800 | 0.3588 | 0.94 |
| 0.0233 | 3.96 | 14850 | 0.3456 | 0.9467 |
| 0.0602 | 3.97 | 14900 | 0.3819 | 0.94 |
| 0.0766 | 3.99 | 14950 | 0.3813 | 0.9333 |
| 0.0562 | 4.0 | 15000 | 0.3669 | 0.9333 |
| 0.0163 | 4.01 | 15050 | 0.4176 | 0.92 |
| 0.007 | 4.03 | 15100 | 0.3694 | 0.9333 |
| 0.0005 | 4.04 | 15150 | 0.3915 | 0.9333 |
| 0.021 | 4.05 | 15200 | 0.4334 | 0.9333 |
| 0.0823 | 4.07 | 15250 | 0.4155 | 0.9333 |
| 0.0509 | 4.08 | 15300 | 0.4056 | 0.9333 |
| 0.0381 | 4.09 | 15350 | 0.3729 | 0.94 |
| 0.045 | 4.11 | 15400 | 0.3940 | 0.9333 |
| 0.0379 | 4.12 | 15450 | 0.4276 | 0.9267 |
| 0.0661 | 4.13 | 15500 | 0.3797 | 0.94 |
| 0.0522 | 4.15 | 15550 | 0.4029 | 0.9333 |
| 0.0189 | 4.16 | 15600 | 0.4424 | 0.9267 |
| 0.0191 | 4.17 | 15650 | 0.4711 | 0.92 |
| 0.031 | 4.19 | 15700 | 0.4344 | 0.9333 |
| 0.0837 | 4.2 | 15750 | 0.3703 | 0.94 |
| 0.0397 | 4.21 | 15800 | 0.3976 | 0.9333 |
| 0.034 | 4.23 | 15850 | 0.4021 | 0.9333 |
| 0.0199 | 4.24 | 15900 | 0.4015 | 0.9333 |
| 0.0315 | 4.25 | 15950 | 0.3652 | 0.94 |
| 0.076 | 4.27 | 16000 | 0.3421 | 0.94 |
| 0.0478 | 4.28 | 16050 | 0.3122 | 0.9533 |
| 0.0203 | 4.29 | 16100 | 0.3436 | 0.9467 |
| 0.0706 | 4.31 | 16150 | 0.3544 | 0.94 |
| 0.0086 | 4.32 | 16200 | 0.3730 | 0.94 |
| 0.05 | 4.33 | 16250 | 0.3761 | 0.94 |
| 0.048 | 4.35 | 16300 | 0.3583 | 0.94 |
| 0.0715 | 4.36 | 16350 | 0.3459 | 0.94 |
| 0.0316 | 4.37 | 16400 | 0.3355 | 0.94 |
| 0.0356 | 4.39 | 16450 | 0.3278 | 0.9467 |
| 0.0176 | 4.4 | 16500 | 0.3177 | 0.9467 |
| 0.0817 | 4.41 | 16550 | 0.3705 | 0.9333 |
| 0.0414 | 4.43 | 16600 | 0.3919 | 0.9333 |
| 0.0198 | 4.44 | 16650 | 0.3435 | 0.9467 |
| 0.0203 | 4.45 | 16700 | 0.3708 | 0.94 |
| 0.0391 | 4.47 | 16750 | 0.3615 | 0.94 |
| 0.0132 | 4.48 | 16800 | 0.3827 | 0.94 |
| 0.0385 | 4.49 | 16850 | 0.3837 | 0.94 |
| 0.0366 | 4.51 | 16900 | 0.3633 | 0.94 |
| 0.0779 | 4.52 | 16950 | 0.3403 | 0.9467 |
| 0.0168 | 4.53 | 17000 | 0.4592 | 0.92 |
| 0.0517 | 4.55 | 17050 | 0.4063 | 0.9333 |
| 0.0138 | 4.56 | 17100 | 0.4335 | 0.9267 |
| 0.0123 | 4.57 | 17150 | 0.3777 | 0.9333 |
| 0.0324 | 4.59 | 17200 | 0.4657 | 0.92 |
| 0.0202 | 4.6 | 17250 | 0.4791 | 0.92 |
| 0.001 | 4.61 | 17300 | 0.4761 | 0.92 |
| 0.0364 | 4.63 | 17350 | 0.4663 | 0.92 |
| 0.0154 | 4.64 | 17400 | 0.4611 | 0.92 |
| 0.0184 | 4.65 | 17450 | 0.4616 | 0.92 |
| 0.0004 | 4.67 | 17500 | 0.4650 | 0.92 |
| 0.0192 | 4.68 | 17550 | 0.4649 | 0.92 |
| 0.0185 | 4.69 | 17600 | 0.4654 | 0.92 |
| 0.0196 | 4.71 | 17650 | 0.4643 | 0.92 |
| 0.0386 | 4.72 | 17700 | 0.4660 | 0.92 |
| 0.0236 | 4.73 | 17750 | 0.4499 | 0.9267 |
| 0.0383 | 4.75 | 17800 | 0.4479 | 0.9267 |
| 0.0398 | 4.76 | 17850 | 0.4483 | 0.9267 |
| 0.0004 | 4.77 | 17900 | 0.4541 | 0.9267 |
| 0.023 | 4.79 | 17950 | 0.4387 | 0.9267 |
| 0.0361 | 4.8 | 18000 | 0.4409 | 0.9267 |
| 0.0409 | 4.81 | 18050 | 0.4384 | 0.9267 |
| 0.0004 | 4.83 | 18100 | 0.4376 | 0.9267 |
| 0.0171 | 4.84 | 18150 | 0.4421 | 0.9267 |
| 0.0589 | 4.85 | 18200 | 0.4373 | 0.9267 |
| 0.0004 | 4.87 | 18250 | 0.4492 | 0.9267 |
| 0.0142 | 4.88 | 18300 | 0.4585 | 0.9267 |
| 0.0561 | 4.89 | 18350 | 0.4681 | 0.9267 |
| 0.0204 | 4.91 | 18400 | 0.4608 | 0.9267 |
| 0.0248 | 4.92 | 18450 | 0.4641 | 0.9267 |
| 0.0404 | 4.93 | 18500 | 0.4567 | 0.9267 |
| 0.0608 | 4.95 | 18550 | 0.4518 | 0.9267 |
| 0.0412 | 4.96 | 18600 | 0.4510 | 0.9267 |
| 0.0183 | 4.97 | 18650 | 0.4522 | 0.9267 |
| 0.0567 | 4.99 | 18700 | 0.4492 | 0.9267 |
| 0.0173 | 5.0 | 18750 | 0.4490 | 0.9267 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
pig4431/amazonPolarity_BERT_5E
|
pig4431
| 2022-11-01T22:23:46Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:amazon_polarity",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T22:23:02Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_polarity
metrics:
- accuracy
model-index:
- name: amazonPolarity_BERT_5E
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_polarity
type: amazon_polarity
config: amazon_polarity
split: train
args: amazon_polarity
metrics:
- name: Accuracy
type: accuracy
value: 0.9066666666666666
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# amazonPolarity_BERT_5E
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the amazon_polarity dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4402
- Accuracy: 0.9067
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7011 | 0.03 | 50 | 0.6199 | 0.7 |
| 0.6238 | 0.05 | 100 | 0.4710 | 0.8133 |
| 0.4478 | 0.08 | 150 | 0.3249 | 0.8733 |
| 0.3646 | 0.11 | 200 | 0.3044 | 0.86 |
| 0.3244 | 0.13 | 250 | 0.2548 | 0.86 |
| 0.2734 | 0.16 | 300 | 0.2666 | 0.88 |
| 0.2784 | 0.19 | 350 | 0.2416 | 0.88 |
| 0.2706 | 0.21 | 400 | 0.2660 | 0.88 |
| 0.2368 | 0.24 | 450 | 0.2522 | 0.8867 |
| 0.2449 | 0.27 | 500 | 0.3135 | 0.88 |
| 0.262 | 0.29 | 550 | 0.2718 | 0.8733 |
| 0.2111 | 0.32 | 600 | 0.2494 | 0.8933 |
| 0.2459 | 0.35 | 650 | 0.2468 | 0.8867 |
| 0.2264 | 0.37 | 700 | 0.3049 | 0.8667 |
| 0.2572 | 0.4 | 750 | 0.2054 | 0.8933 |
| 0.1749 | 0.43 | 800 | 0.3489 | 0.86 |
| 0.2423 | 0.45 | 850 | 0.2142 | 0.8933 |
| 0.1931 | 0.48 | 900 | 0.2096 | 0.9067 |
| 0.2444 | 0.51 | 950 | 0.3404 | 0.8733 |
| 0.2666 | 0.53 | 1000 | 0.2378 | 0.9067 |
| 0.2311 | 0.56 | 1050 | 0.2416 | 0.9067 |
| 0.2269 | 0.59 | 1100 | 0.3188 | 0.8733 |
| 0.2143 | 0.61 | 1150 | 0.2343 | 0.9 |
| 0.2181 | 0.64 | 1200 | 0.2606 | 0.8667 |
| 0.2151 | 0.67 | 1250 | 0.1888 | 0.9133 |
| 0.2694 | 0.69 | 1300 | 0.3982 | 0.8467 |
| 0.2408 | 0.72 | 1350 | 0.1978 | 0.9067 |
| 0.2043 | 0.75 | 1400 | 0.2125 | 0.9 |
| 0.2081 | 0.77 | 1450 | 0.2680 | 0.8933 |
| 0.2361 | 0.8 | 1500 | 0.3723 | 0.8467 |
| 0.2503 | 0.83 | 1550 | 0.3427 | 0.8733 |
| 0.1983 | 0.85 | 1600 | 0.2525 | 0.9067 |
| 0.1947 | 0.88 | 1650 | 0.2427 | 0.9133 |
| 0.2411 | 0.91 | 1700 | 0.2448 | 0.9 |
| 0.2381 | 0.93 | 1750 | 0.3354 | 0.88 |
| 0.1852 | 0.96 | 1800 | 0.3078 | 0.8667 |
| 0.2427 | 0.99 | 1850 | 0.2408 | 0.9 |
| 0.1582 | 1.01 | 1900 | 0.2698 | 0.9133 |
| 0.159 | 1.04 | 1950 | 0.3383 | 0.9 |
| 0.1833 | 1.07 | 2000 | 0.2849 | 0.9 |
| 0.1257 | 1.09 | 2050 | 0.5376 | 0.8667 |
| 0.1513 | 1.12 | 2100 | 0.4469 | 0.88 |
| 0.1869 | 1.15 | 2150 | 0.3415 | 0.8933 |
| 0.1342 | 1.17 | 2200 | 0.3021 | 0.8867 |
| 0.1404 | 1.2 | 2250 | 0.3619 | 0.88 |
| 0.1576 | 1.23 | 2300 | 0.2815 | 0.9 |
| 0.1419 | 1.25 | 2350 | 0.4351 | 0.8867 |
| 0.1491 | 1.28 | 2400 | 0.3025 | 0.9133 |
| 0.1914 | 1.31 | 2450 | 0.3011 | 0.9067 |
| 0.1265 | 1.33 | 2500 | 0.3953 | 0.88 |
| 0.128 | 1.36 | 2550 | 0.2557 | 0.9333 |
| 0.1631 | 1.39 | 2600 | 0.2226 | 0.9333 |
| 0.1019 | 1.41 | 2650 | 0.3638 | 0.9133 |
| 0.1551 | 1.44 | 2700 | 0.3591 | 0.9 |
| 0.1853 | 1.47 | 2750 | 0.5005 | 0.8733 |
| 0.1578 | 1.49 | 2800 | 0.2662 | 0.92 |
| 0.1522 | 1.52 | 2850 | 0.2545 | 0.9267 |
| 0.1188 | 1.55 | 2900 | 0.3874 | 0.88 |
| 0.1638 | 1.57 | 2950 | 0.3003 | 0.92 |
| 0.1583 | 1.6 | 3000 | 0.2702 | 0.92 |
| 0.1844 | 1.63 | 3050 | 0.2183 | 0.9333 |
| 0.1365 | 1.65 | 3100 | 0.3322 | 0.8933 |
| 0.1683 | 1.68 | 3150 | 0.2069 | 0.9467 |
| 0.168 | 1.71 | 3200 | 0.4046 | 0.8667 |
| 0.1907 | 1.73 | 3250 | 0.3411 | 0.8933 |
| 0.1695 | 1.76 | 3300 | 0.1992 | 0.9333 |
| 0.1851 | 1.79 | 3350 | 0.2370 | 0.92 |
| 0.1302 | 1.81 | 3400 | 0.3058 | 0.9133 |
| 0.1353 | 1.84 | 3450 | 0.3134 | 0.9067 |
| 0.1428 | 1.87 | 3500 | 0.3767 | 0.8667 |
| 0.1642 | 1.89 | 3550 | 0.3239 | 0.8867 |
| 0.1319 | 1.92 | 3600 | 0.4725 | 0.86 |
| 0.1714 | 1.95 | 3650 | 0.3115 | 0.8867 |
| 0.1265 | 1.97 | 3700 | 0.3621 | 0.8867 |
| 0.1222 | 2.0 | 3750 | 0.3665 | 0.8933 |
| 0.0821 | 2.03 | 3800 | 0.2482 | 0.9133 |
| 0.1136 | 2.05 | 3850 | 0.3244 | 0.9 |
| 0.0915 | 2.08 | 3900 | 0.4745 | 0.8733 |
| 0.0967 | 2.11 | 3950 | 0.2346 | 0.94 |
| 0.0962 | 2.13 | 4000 | 0.3139 | 0.92 |
| 0.1001 | 2.16 | 4050 | 0.2944 | 0.9267 |
| 0.086 | 2.19 | 4100 | 0.5542 | 0.86 |
| 0.0588 | 2.21 | 4150 | 0.4377 | 0.9 |
| 0.1056 | 2.24 | 4200 | 0.3540 | 0.9133 |
| 0.0899 | 2.27 | 4250 | 0.5661 | 0.8733 |
| 0.0737 | 2.29 | 4300 | 0.5683 | 0.8733 |
| 0.1152 | 2.32 | 4350 | 0.2997 | 0.9333 |
| 0.0852 | 2.35 | 4400 | 0.5055 | 0.8933 |
| 0.1114 | 2.37 | 4450 | 0.3099 | 0.92 |
| 0.0821 | 2.4 | 4500 | 0.3026 | 0.9267 |
| 0.0698 | 2.43 | 4550 | 0.3250 | 0.92 |
| 0.1123 | 2.45 | 4600 | 0.3674 | 0.9 |
| 0.1196 | 2.48 | 4650 | 0.4539 | 0.8733 |
| 0.0617 | 2.51 | 4700 | 0.3446 | 0.92 |
| 0.0939 | 2.53 | 4750 | 0.3302 | 0.92 |
| 0.1114 | 2.56 | 4800 | 0.5149 | 0.8733 |
| 0.1154 | 2.59 | 4850 | 0.4935 | 0.8867 |
| 0.1495 | 2.61 | 4900 | 0.4706 | 0.8933 |
| 0.0858 | 2.64 | 4950 | 0.4048 | 0.9 |
| 0.0767 | 2.67 | 5000 | 0.3849 | 0.9133 |
| 0.0569 | 2.69 | 5050 | 0.5491 | 0.8867 |
| 0.1058 | 2.72 | 5100 | 0.5872 | 0.8733 |
| 0.0899 | 2.75 | 5150 | 0.3159 | 0.92 |
| 0.0757 | 2.77 | 5200 | 0.5861 | 0.8733 |
| 0.1305 | 2.8 | 5250 | 0.3633 | 0.9133 |
| 0.1027 | 2.83 | 5300 | 0.3972 | 0.9133 |
| 0.1259 | 2.85 | 5350 | 0.4197 | 0.8933 |
| 0.1255 | 2.88 | 5400 | 0.4583 | 0.8867 |
| 0.0981 | 2.91 | 5450 | 0.4657 | 0.8933 |
| 0.0736 | 2.93 | 5500 | 0.4036 | 0.9133 |
| 0.116 | 2.96 | 5550 | 0.3026 | 0.9067 |
| 0.0692 | 2.99 | 5600 | 0.3409 | 0.9133 |
| 0.0721 | 3.01 | 5650 | 0.5598 | 0.8733 |
| 0.052 | 3.04 | 5700 | 0.4130 | 0.9133 |
| 0.0661 | 3.07 | 5750 | 0.2589 | 0.9333 |
| 0.0667 | 3.09 | 5800 | 0.4484 | 0.9067 |
| 0.0599 | 3.12 | 5850 | 0.4883 | 0.9 |
| 0.0406 | 3.15 | 5900 | 0.4516 | 0.9067 |
| 0.0837 | 3.17 | 5950 | 0.3394 | 0.9267 |
| 0.0636 | 3.2 | 6000 | 0.4649 | 0.8867 |
| 0.0861 | 3.23 | 6050 | 0.5046 | 0.8933 |
| 0.0667 | 3.25 | 6100 | 0.3252 | 0.92 |
| 0.0401 | 3.28 | 6150 | 0.2771 | 0.94 |
| 0.0998 | 3.31 | 6200 | 0.4509 | 0.9 |
| 0.0209 | 3.33 | 6250 | 0.4666 | 0.8933 |
| 0.0747 | 3.36 | 6300 | 0.5430 | 0.8867 |
| 0.0678 | 3.39 | 6350 | 0.4050 | 0.9067 |
| 0.0685 | 3.41 | 6400 | 0.3738 | 0.92 |
| 0.0654 | 3.44 | 6450 | 0.4486 | 0.9 |
| 0.0496 | 3.47 | 6500 | 0.4386 | 0.9067 |
| 0.0379 | 3.49 | 6550 | 0.4547 | 0.9067 |
| 0.0897 | 3.52 | 6600 | 0.4197 | 0.9133 |
| 0.0729 | 3.55 | 6650 | 0.2855 | 0.9333 |
| 0.0515 | 3.57 | 6700 | 0.4459 | 0.9067 |
| 0.0588 | 3.6 | 6750 | 0.3627 | 0.92 |
| 0.0724 | 3.63 | 6800 | 0.4060 | 0.9267 |
| 0.0607 | 3.65 | 6850 | 0.4505 | 0.9133 |
| 0.0252 | 3.68 | 6900 | 0.5465 | 0.8933 |
| 0.0594 | 3.71 | 6950 | 0.4786 | 0.9067 |
| 0.0743 | 3.73 | 7000 | 0.4163 | 0.9267 |
| 0.0506 | 3.76 | 7050 | 0.3801 | 0.92 |
| 0.0548 | 3.79 | 7100 | 0.3557 | 0.9267 |
| 0.0932 | 3.81 | 7150 | 0.4278 | 0.9133 |
| 0.0643 | 3.84 | 7200 | 0.4673 | 0.9 |
| 0.0631 | 3.87 | 7250 | 0.3611 | 0.92 |
| 0.0793 | 3.89 | 7300 | 0.3956 | 0.9067 |
| 0.0729 | 3.92 | 7350 | 0.6630 | 0.8733 |
| 0.0552 | 3.95 | 7400 | 0.4259 | 0.8867 |
| 0.0432 | 3.97 | 7450 | 0.3615 | 0.92 |
| 0.0697 | 4.0 | 7500 | 0.5116 | 0.88 |
| 0.0463 | 4.03 | 7550 | 0.3334 | 0.94 |
| 0.046 | 4.05 | 7600 | 0.4704 | 0.8867 |
| 0.0371 | 4.08 | 7650 | 0.3323 | 0.94 |
| 0.0809 | 4.11 | 7700 | 0.3503 | 0.92 |
| 0.0285 | 4.13 | 7750 | 0.3360 | 0.92 |
| 0.0469 | 4.16 | 7800 | 0.3365 | 0.9333 |
| 0.041 | 4.19 | 7850 | 0.5726 | 0.88 |
| 0.0447 | 4.21 | 7900 | 0.4564 | 0.9067 |
| 0.0144 | 4.24 | 7950 | 0.5521 | 0.8867 |
| 0.0511 | 4.27 | 8000 | 0.5661 | 0.88 |
| 0.0481 | 4.29 | 8050 | 0.3445 | 0.94 |
| 0.036 | 4.32 | 8100 | 0.3247 | 0.94 |
| 0.0662 | 4.35 | 8150 | 0.3647 | 0.9333 |
| 0.051 | 4.37 | 8200 | 0.5024 | 0.9 |
| 0.0546 | 4.4 | 8250 | 0.4737 | 0.8933 |
| 0.0526 | 4.43 | 8300 | 0.4067 | 0.92 |
| 0.0291 | 4.45 | 8350 | 0.3862 | 0.9267 |
| 0.0292 | 4.48 | 8400 | 0.5101 | 0.9 |
| 0.0426 | 4.51 | 8450 | 0.4207 | 0.92 |
| 0.0771 | 4.53 | 8500 | 0.5525 | 0.8867 |
| 0.0668 | 4.56 | 8550 | 0.4487 | 0.9067 |
| 0.0585 | 4.59 | 8600 | 0.3574 | 0.9267 |
| 0.0375 | 4.61 | 8650 | 0.3980 | 0.92 |
| 0.0508 | 4.64 | 8700 | 0.4064 | 0.92 |
| 0.0334 | 4.67 | 8750 | 0.3031 | 0.94 |
| 0.0257 | 4.69 | 8800 | 0.3340 | 0.9333 |
| 0.0165 | 4.72 | 8850 | 0.4011 | 0.92 |
| 0.0553 | 4.75 | 8900 | 0.4243 | 0.9133 |
| 0.0597 | 4.77 | 8950 | 0.3685 | 0.9267 |
| 0.0407 | 4.8 | 9000 | 0.4262 | 0.9133 |
| 0.032 | 4.83 | 9050 | 0.4080 | 0.9133 |
| 0.0573 | 4.85 | 9100 | 0.4416 | 0.9133 |
| 0.0308 | 4.88 | 9150 | 0.4397 | 0.9133 |
| 0.0494 | 4.91 | 9200 | 0.4476 | 0.9067 |
| 0.015 | 4.93 | 9250 | 0.4419 | 0.9067 |
| 0.0443 | 4.96 | 9300 | 0.4347 | 0.9133 |
| 0.0479 | 4.99 | 9350 | 0.4402 | 0.9067 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
kaejo98/t5_base_question_generation
|
kaejo98
| 2022-11-01T22:03:50Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-01T16:06:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5_base_question_generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_base_question_generation
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an SQUAD dataset for QA.
## Model description
More information needed
## Intended uses
The model takes context as an input sequence, and will generate a full question sentence as an output sequence. The max sequence length is 512 tokens. Inputs should be organised into the following format: \<generate_questions\> paragraph: context text here'
The input sequence can then be encoded and passed as the input_ids argument in the model's generate() method.
## limitations
The model was trained on only a limited amount of data hence questions might be poor quality. In addition the questions generated have style similar to that of the training data.
## Training and evaluation data
The model takes as input a passage to generate questions answerable by the passage.
The dataset used to train the model comprises 80k passage-question pairs sampled randomly from the SQUAD training data. For the evaluation we sampled 10k passage-question pairs from the SQUAD development set.
## Training procedure
The model was trained for 5 epochs over the training set with a learning rate of 5e-05 with EarlyStopping. The batch size was only 10 due to GPU memory limitations
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.21
- num_epochs: 5
### Framework versions
- Transformers 4.23.1
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
rikkar/dsd_futurism
|
rikkar
| 2022-11-01T21:59:19Z | 0 | 0 | null |
[
"license:cc0-1.0",
"region:us"
] | null | 2022-11-01T13:51:42Z |
---
license: cc0-1.0
---
Stable Diffusion model trained for 5k steps on the art style "futurism".
Invoke the style with "in the style of futtt". Play with weights, it's a strong style so prompt accordingly.
Sample images:



Sample training images:





|
AlekseyKorshuk/retriever-coding-guru-adapted
|
AlekseyKorshuk
| 2022-11-01T21:53:11Z | 6 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-01T21:42:16Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# AlekseyKorshuk/retriever-coding-guru-adapted
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('AlekseyKorshuk/retriever-coding-guru-adapted')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('AlekseyKorshuk/retriever-coding-guru-adapted')
model = AutoModel.from_pretrained('AlekseyKorshuk/retriever-coding-guru-adapted')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=AlekseyKorshuk/retriever-coding-guru-adapted)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 317 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 31,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
troesy/spanbert-base-cased-LAT-True-added-tokenizer
|
troesy
| 2022-11-01T21:19:53Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-01T20:55:41Z |
---
tags:
- generated_from_trainer
model-index:
- name: spanbert-base-cased-LAT-True-added-tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spanbert-base-cased-LAT-True-added-tokenizer
This model is a fine-tuned version of [SpanBERT/spanbert-base-cased](https://huggingface.co/SpanBERT/spanbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 174 | 0.3422 |
| No log | 2.0 | 348 | 0.2893 |
| 0.3406 | 3.0 | 522 | 0.2767 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
troesy/spanbert-base-cased-LAT-True
|
troesy
| 2022-11-01T20:09:57Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-11-01T19:29:56Z |
---
tags:
- generated_from_trainer
model-index:
- name: spanbert-base-cased-LAT-True
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spanbert-base-cased-LAT-True
This model is a fine-tuned version of [SpanBERT/spanbert-base-cased](https://huggingface.co/SpanBERT/spanbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2809
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 174 | 0.2898 |
| No log | 2.0 | 348 | 0.2713 |
| 0.19 | 3.0 | 522 | 0.2809 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
loremipsum3658/jur-v5-fsl-tuned-cla-assun
|
loremipsum3658
| 2022-11-01T19:27:51Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-01T19:14:38Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1099 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 1099,
"warmup_steps": 110,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
motmono/Reinforcement-CartPole-v1
|
motmono
| 2022-11-01T18:56:16Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-11-01T18:56:00Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforcement-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
anilbs/segmentation
|
anilbs
| 2022-11-01T18:54:22Z | 34 | 2 |
pyannote-audio
|
[
"pyannote-audio",
"pytorch",
"pyannote",
"pyannote-audio-model",
"audio",
"voice",
"speech",
"speaker",
"speaker-segmentation",
"voice-activity-detection",
"overlapped-speech-detection",
"resegmentation",
"dataset:ami",
"dataset:dihard",
"dataset:voxconverse",
"arxiv:2104.04045",
"license:mit",
"region:us"
] |
voice-activity-detection
| 2022-11-01T18:42:13Z |
---
tags:
- pyannote
- pyannote-audio
- pyannote-audio-model
- audio
- voice
- speech
- speaker
- speaker-segmentation
- voice-activity-detection
- overlapped-speech-detection
- resegmentation
datasets:
- ami
- dihard
- voxconverse
license: mit
inference: false
---
# 🎹 Speaker segmentation

Model from *[End-to-end speaker segmentation for overlap-aware resegmentation](http://arxiv.org/abs/2104.04045)*,
by Hervé Bredin and Antoine Laurent.
[Online demo](https://huggingface.co/spaces/pyannote/pretrained-pipelines) is available as a Hugging Face Space.
## Support
For commercial enquiries and scientific consulting, please contact [me](mailto:herve@niderb.fr).
For [technical questions](https://github.com/pyannote/pyannote-audio/discussions) and [bug reports](https://github.com/pyannote/pyannote-audio/issues), please check [pyannote.audio](https://github.com/pyannote/pyannote-audio) Github repository.
## Usage
Relies on pyannote.audio 2.0 currently in development: see [installation instructions](https://github.com/pyannote/pyannote-audio/tree/develop#installation).
### Voice activity detection
```python
from pyannote.audio.pipelines import VoiceActivityDetection
pipeline = VoiceActivityDetection(segmentation="anilbs/segmentation")
HYPER_PARAMETERS = {
# onset/offset activation thresholds
"onset": 0.5, "offset": 0.5,
# remove speech regions shorter than that many seconds.
"min_duration_on": 0.0,
# fill non-speech regions shorter than that many seconds.
"min_duration_off": 0.0
}
pipeline.instantiate(HYPER_PARAMETERS)
vad = pipeline("audio.wav")
# `vad` is a pyannote.core.Annotation instance containing speech regions
```
### Overlapped speech detection
```python
from pyannote.audio.pipelines import OverlappedSpeechDetection
pipeline = OverlappedSpeechDetection(segmentation="pyannote/segmentation")
pipeline.instantiate(HYPER_PARAMETERS)
osd = pipeline("audio.wav")
# `osd` is a pyannote.core.Annotation instance containing overlapped speech regions
```
### Resegmentation
```python
from pyannote.audio.pipelines import Resegmentation
pipeline = Resegmentation(segmentation="pyannote/segmentation",
diarization="baseline")
pipeline.instantiate(HYPER_PARAMETERS)
resegmented_baseline = pipeline({"audio": "audio.wav", "baseline": baseline})
# where `baseline` should be provided as a pyannote.core.Annotation instance
```
### Raw scores
```python
from pyannote.audio import Inference
inference = Inference("pyannote/segmentation")
segmentation = inference("audio.wav")
# `segmentation` is a pyannote.core.SlidingWindowFeature
# instance containing raw segmentation scores like the
# one pictured above (output)
```
## Reproducible research
In order to reproduce the results of the paper ["End-to-end speaker segmentation for overlap-aware resegmentation
"](https://arxiv.org/abs/2104.04045), use `pyannote/segmentation@Interspeech2021` with the following hyper-parameters:
| Voice activity detection | `onset` | `offset` | `min_duration_on` | `min_duration_off` |
| ------------------------ | ------- | -------- | ----------------- | ------------------ |
| AMI Mix-Headset | 0.684 | 0.577 | 0.181 | 0.037 |
| DIHARD3 | 0.767 | 0.377 | 0.136 | 0.067 |
| VoxConverse | 0.767 | 0.713 | 0.182 | 0.501 |
| Overlapped speech detection | `onset` | `offset` | `min_duration_on` | `min_duration_off` |
| --------------------------- | ------- | -------- | ----------------- | ------------------ |
| AMI Mix-Headset | 0.448 | 0.362 | 0.116 | 0.187 |
| DIHARD3 | 0.430 | 0.320 | 0.091 | 0.144 |
| VoxConverse | 0.587 | 0.426 | 0.337 | 0.112 |
| Resegmentation of VBx | `onset` | `offset` | `min_duration_on` | `min_duration_off` |
| --------------------- | ------- | -------- | ----------------- | ------------------ |
| AMI Mix-Headset | 0.542 | 0.527 | 0.044 | 0.705 |
| DIHARD3 | 0.592 | 0.489 | 0.163 | 0.182 |
| VoxConverse | 0.537 | 0.724 | 0.410 | 0.563 |
Expected outputs (and VBx baseline) are also provided in the `/reproducible_research` sub-directories.
## Citation
```bibtex
@inproceedings{Bredin2021,
Title = {{End-to-end speaker segmentation for overlap-aware resegmentation}},
Author = {{Bredin}, Herv{\'e} and {Laurent}, Antoine},
Booktitle = {Proc. Interspeech 2021},
Address = {Brno, Czech Republic},
Month = {August},
Year = {2021},
```
```bibtex
@inproceedings{Bredin2020,
Title = {{pyannote.audio: neural building blocks for speaker diarization}},
Author = {{Bredin}, Herv{\'e} and {Yin}, Ruiqing and {Coria}, Juan Manuel and {Gelly}, Gregory and {Korshunov}, Pavel and {Lavechin}, Marvin and {Fustes}, Diego and {Titeux}, Hadrien and {Bouaziz}, Wassim and {Gill}, Marie-Philippe},
Booktitle = {ICASSP 2020, IEEE International Conference on Acoustics, Speech, and Signal Processing},
Address = {Barcelona, Spain},
Month = {May},
Year = {2020},
}
```
|
xinranyyyy/roberta_checkpoint-finetuned-squad
|
xinranyyyy
| 2022-11-01T18:13:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-11-01T14:38:24Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: roberta_checkpoint-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta_checkpoint-finetuned-squad
This model is a fine-tuned version of [WillHeld/roberta-base-coqa](https://huggingface.co/WillHeld/roberta-base-coqa) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8969
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.8504 | 1.0 | 5536 | 0.8424 |
| 0.6219 | 2.0 | 11072 | 0.8360 |
| 0.4807 | 3.0 | 16608 | 0.8969 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
asadnai/finetuning-sentiment-model-3000-samples
|
asadnai
| 2022-11-01T18:00:22Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T15:29:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8633333333333333
- name: F1
type: f1
value: 0.8646864686468646
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3097
- Accuracy: 0.8633
- F1: 0.8647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
SiddharthaM/twitter-data-xlm-roberta-base-hindi-only-memes
|
SiddharthaM
| 2022-11-01T17:49:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T17:00:16Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: twitter-data-xlm-roberta-base-hindi-only-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-xlm-roberta-base-hindi-only-memes
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4006
- Accuracy: 0.9240
- Precision: 0.9255
- Recall: 0.9263
- F1: 0.9259
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7485 | 1.0 | 511 | 0.4062 | 0.8381 | 0.8520 | 0.8422 | 0.8417 |
| 0.4253 | 2.0 | 1022 | 0.3195 | 0.8822 | 0.8880 | 0.8853 | 0.8851 |
| 0.2899 | 3.0 | 1533 | 0.2994 | 0.9031 | 0.9068 | 0.9060 | 0.9049 |
| 0.2116 | 4.0 | 2044 | 0.3526 | 0.9163 | 0.9199 | 0.9185 | 0.9187 |
| 0.1582 | 5.0 | 2555 | 0.4031 | 0.9163 | 0.9193 | 0.9186 | 0.9187 |
| 0.103 | 6.0 | 3066 | 0.4006 | 0.9240 | 0.9255 | 0.9263 | 0.9259 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
pig4431/IMDB_ALBERT_5E
|
pig4431
| 2022-11-01T17:39:50Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T17:39:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: IMDB_ALBERT_5E
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.9466666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IMDB_ALBERT_5E
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2220
- Accuracy: 0.9467
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5285 | 0.06 | 50 | 0.2692 | 0.9133 |
| 0.3515 | 0.13 | 100 | 0.2054 | 0.9267 |
| 0.2314 | 0.19 | 150 | 0.1669 | 0.94 |
| 0.2147 | 0.26 | 200 | 0.1660 | 0.92 |
| 0.2053 | 0.32 | 250 | 0.1546 | 0.94 |
| 0.2143 | 0.38 | 300 | 0.1636 | 0.9267 |
| 0.1943 | 0.45 | 350 | 0.2068 | 0.9467 |
| 0.2107 | 0.51 | 400 | 0.1655 | 0.9333 |
| 0.2059 | 0.58 | 450 | 0.1782 | 0.94 |
| 0.1839 | 0.64 | 500 | 0.1695 | 0.94 |
| 0.2014 | 0.7 | 550 | 0.1481 | 0.9333 |
| 0.2215 | 0.77 | 600 | 0.1588 | 0.9267 |
| 0.1837 | 0.83 | 650 | 0.1352 | 0.9333 |
| 0.1938 | 0.9 | 700 | 0.1389 | 0.94 |
| 0.221 | 0.96 | 750 | 0.1193 | 0.9467 |
| 0.1843 | 1.02 | 800 | 0.1294 | 0.9467 |
| 0.1293 | 1.09 | 850 | 0.1585 | 0.9467 |
| 0.1517 | 1.15 | 900 | 0.1353 | 0.9467 |
| 0.137 | 1.21 | 950 | 0.1391 | 0.9467 |
| 0.1858 | 1.28 | 1000 | 0.1547 | 0.9333 |
| 0.1478 | 1.34 | 1050 | 0.1019 | 0.9533 |
| 0.155 | 1.41 | 1100 | 0.1154 | 0.9667 |
| 0.1439 | 1.47 | 1150 | 0.1306 | 0.9467 |
| 0.1476 | 1.53 | 1200 | 0.2085 | 0.92 |
| 0.1702 | 1.6 | 1250 | 0.1190 | 0.9467 |
| 0.1517 | 1.66 | 1300 | 0.1303 | 0.9533 |
| 0.1551 | 1.73 | 1350 | 0.1200 | 0.9467 |
| 0.1554 | 1.79 | 1400 | 0.1297 | 0.9533 |
| 0.1543 | 1.85 | 1450 | 0.1222 | 0.96 |
| 0.1242 | 1.92 | 1500 | 0.1418 | 0.9467 |
| 0.1312 | 1.98 | 1550 | 0.1279 | 0.9467 |
| 0.1292 | 2.05 | 1600 | 0.1255 | 0.9533 |
| 0.0948 | 2.11 | 1650 | 0.1305 | 0.9667 |
| 0.088 | 2.17 | 1700 | 0.1912 | 0.9333 |
| 0.0949 | 2.24 | 1750 | 0.1594 | 0.9333 |
| 0.1094 | 2.3 | 1800 | 0.1958 | 0.9467 |
| 0.1179 | 2.37 | 1850 | 0.1427 | 0.94 |
| 0.1116 | 2.43 | 1900 | 0.1551 | 0.9333 |
| 0.0742 | 2.49 | 1950 | 0.1743 | 0.94 |
| 0.1016 | 2.56 | 2000 | 0.1603 | 0.9533 |
| 0.0835 | 2.62 | 2050 | 0.1866 | 0.9333 |
| 0.0882 | 2.69 | 2100 | 0.1191 | 0.9467 |
| 0.1032 | 2.75 | 2150 | 0.1420 | 0.96 |
| 0.0957 | 2.81 | 2200 | 0.1403 | 0.96 |
| 0.1234 | 2.88 | 2250 | 0.1232 | 0.96 |
| 0.0669 | 2.94 | 2300 | 0.1557 | 0.9467 |
| 0.0994 | 3.01 | 2350 | 0.1270 | 0.9533 |
| 0.0583 | 3.07 | 2400 | 0.1520 | 0.9533 |
| 0.0651 | 3.13 | 2450 | 0.1641 | 0.9467 |
| 0.0384 | 3.2 | 2500 | 0.2165 | 0.94 |
| 0.0839 | 3.26 | 2550 | 0.1755 | 0.9467 |
| 0.0546 | 3.32 | 2600 | 0.1782 | 0.9333 |
| 0.0703 | 3.39 | 2650 | 0.1945 | 0.94 |
| 0.0734 | 3.45 | 2700 | 0.2139 | 0.9467 |
| 0.0629 | 3.52 | 2750 | 0.1445 | 0.9467 |
| 0.0513 | 3.58 | 2800 | 0.1613 | 0.9667 |
| 0.0794 | 3.64 | 2850 | 0.1742 | 0.9333 |
| 0.0537 | 3.71 | 2900 | 0.1745 | 0.9467 |
| 0.0553 | 3.77 | 2950 | 0.1724 | 0.96 |
| 0.0483 | 3.84 | 3000 | 0.1638 | 0.9533 |
| 0.0647 | 3.9 | 3050 | 0.1986 | 0.9467 |
| 0.0443 | 3.96 | 3100 | 0.1926 | 0.9533 |
| 0.0418 | 4.03 | 3150 | 0.1879 | 0.94 |
| 0.0466 | 4.09 | 3200 | 0.2058 | 0.9333 |
| 0.0491 | 4.16 | 3250 | 0.2017 | 0.9467 |
| 0.0287 | 4.22 | 3300 | 0.2020 | 0.9533 |
| 0.0272 | 4.28 | 3350 | 0.1974 | 0.9533 |
| 0.0359 | 4.35 | 3400 | 0.2242 | 0.9333 |
| 0.0405 | 4.41 | 3450 | 0.2157 | 0.94 |
| 0.0309 | 4.48 | 3500 | 0.2142 | 0.9467 |
| 0.033 | 4.54 | 3550 | 0.2163 | 0.94 |
| 0.0408 | 4.6 | 3600 | 0.2368 | 0.94 |
| 0.0336 | 4.67 | 3650 | 0.2173 | 0.94 |
| 0.0356 | 4.73 | 3700 | 0.2230 | 0.94 |
| 0.0548 | 4.8 | 3750 | 0.2181 | 0.9533 |
| 0.042 | 4.86 | 3800 | 0.2240 | 0.9333 |
| 0.0292 | 4.92 | 3850 | 0.2259 | 0.9267 |
| 0.0196 | 4.99 | 3900 | 0.2220 | 0.9467 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
|
espnet/wanchichen_fleurs_asr_conformer_scctc
|
espnet
| 2022-11-01T16:48:49Z | 0 | 1 |
espnet
|
[
"espnet",
"audio",
"speech-recognition",
"en",
"dataset:google/fleurs",
"license:cc-by-4.0",
"region:us"
] | null | 2022-11-01T16:22:20Z |
---
tags:
- espnet
- audio
- speech-recognition
language: en
datasets:
- google/fleurs
license: cc-by-4.0
---
## ESPnet2 ASR model
### `espnet/wanchichen_fleurs_asr_conformer_sctctc`
This model was trained by William Chen using the fleurs recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
pip install -e .
cd egs2/fleurs/asr1
./run.sh
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Sat Oct 22 14:55:21 EDT 2022`
- python version: `3.8.6 (default, Dec 17 2020, 16:57:01) [GCC 10.2.0]`
- espnet version: `espnet 202207`
- pytorch version: `pytorch 1.8.1+cu102`
- Git hash: `e534106b837ff6cdd29977a52983c022ff1afb0f`
- Commit date: `Sun Sep 11 22:31:23 2022 -0400`
## asr_train_asr_xlsr_conformer_scctc_raw_all_bpe6500_sp
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_lm_all_bpe6500_valid.loss.ave_asr_model_valid.acc.ave_3best/test_all|77809|1592160|70.5|26.1|3.4|3.4|32.9|97.0|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_lm_all_bpe6500_valid.loss.ave_asr_model_valid.acc.ave_3best/test_all|77809|10235271|92.2|4.7|3.1|2.6|10.4|97.0|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_lm_lm_train_lm_all_bpe6500_valid.loss.ave_asr_model_valid.acc.ave_3best/test_all|77809|9622352|91.3|5.6|3.1|2.7|11.4|97.0|
|
musika/musika-irish-jigs
|
musika
| 2022-11-01T15:03:23Z | 0 | 1 | null |
[
"audio",
"music",
"generation",
"tensorflow",
"arxiv:2208.08706",
"license:mit",
"region:us"
] | null | 2022-11-01T15:03:05Z |
---
license: mit
tags:
- audio
- music
- generation
- tensorflow
---
# Musika Model: musika_irish_jigs
## Model provided by: rjadr
Pretrained musika_irish_jigs model for the [Musika system](https://github.com/marcoppasini/musika) for fast infinite waveform music generation.
Introduced in [this paper](https://arxiv.org/abs/2208.08706).
## How to use
You can generate music from this pretrained musika_irish_jigs model using the notebook available [here](https://colab.research.google.com/drive/1HJWliBXPi-Xlx3gY8cjFI5-xaZgrTD7r).
### Model description
This pretrained GAN system consists of a ResNet-style generator and discriminator. During training, stability is controlled by adapting the strength of gradient penalty regularization on-the-fly. The gradient penalty weighting term is contained in *switch.npy*. The generator is conditioned on a latent coordinate system to produce samples of arbitrary length. The latent representations produced by the generator are then passed to a decoder which converts them into waveform audio.
The generator has a context window of about 12 seconds of audio.
|
goharava/bart-large-fine-tuned-large_
|
goharava
| 2022-11-01T14:13:45Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-01T13:00:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-finetuned-large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-finetuned-large
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6397
- Rouge1: 88.2870
- Rouge2: 26.4705
- Rougel: 88.1924
- Rougelsum: 88.3415
- Gen Len: 6.0323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 121 | 0.8676 | 67.7680 | 19.6386 | 67.5697 | 67.5758 | 6.2774 |
| No log | 2.0 | 242 | 0.6661 | 73.6309 | 21.6079 | 73.2496 | 73.5335 | 5.3957 |
| No log | 3.0 | 363 | 0.6649 | 82.6362 | 21.4663 | 82.3944 | 82.6107 | 5.6624 |
| No log | 4.0 | 484 | 0.6598 | 86.4811 | 25.3580 | 86.1949 | 86.3580 | 5.7914 |
| 0.5135 | 5.0 | 605 | 0.8032 | 86.0334 | 25.1510 | 85.8895 | 85.9038 | 6.5634 |
| 0.5135 | 6.0 | 726 | 0.6981 | 88.0139 | 25.6152 | 87.9025 | 87.9932 | 6.3591 |
| 0.5135 | 7.0 | 847 | 0.6991 | 88.7421 | 25.6469 | 88.5959 | 88.7255 | 6.3376 |
| 0.5135 | 8.0 | 968 | 0.5995 | 88.9180 | 26.9917 | 88.6984 | 88.8878 | 5.8538 |
| 0.1613 | 9.0 | 1089 | 0.5973 | 88.5923 | 26.7081 | 88.4593 | 88.6287 | 5.8387 |
| 0.1613 | 10.0 | 1210 | 0.6397 | 88.2870 | 26.4705 | 88.1924 | 88.3415 | 6.0323 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
gislei/meu
|
gislei
| 2022-11-01T14:13:15Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2022-11-01T14:10:45Z |
---
license: bigscience-openrail-m
---
|
emrevarol/dz_finetuning-medium-distillbert-95K
|
emrevarol
| 2022-11-01T13:40:20Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T13:17:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: dz_finetuning-medium-distillbert-95K
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dz_finetuning-medium-distillbert-95K
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0047
- Accuracy: 0.9991
- F1: 0.9991
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
rufimelo/Legal-BERTimbau-large-TSDAE-v4
|
rufimelo
| 2022-11-01T13:12:56Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"tsdae",
"pt",
"dataset:rufimelo/PortugueseLegalSentences-v1",
"license:mit",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-11-01T01:00:28Z |
---
language:
- pt
thumbnail: "Portugues BERT for the Legal Domain"
tags:
- bert
- pytorch
- tsdae
datasets:
- rufimelo/PortugueseLegalSentences-v1
license: "mit"
widget:
- text: "O advogado apresentou [MASK] ao juíz."
---
# Legal_BERTimbau
## Introduction
Legal_BERTimbau Large is a fine-tuned BERT model based on [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased) Large.
"BERTimbau Base is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
For further information or requests, please go to [BERTimbau repository](https://github.com/neuralmind-ai/portuguese-bert/)."
The performance of Language Models can change drastically when there is a domain shift between training and test data. In order create a Portuguese Language Model adapted to a Legal domain, the original BERTimbau model was submitted to a fine-tuning stage where it was performed 1 "PreTraining" epoch over 200000 cleaned documents (lr: 1e-5, using TSDAE technique)
## Available models
| Model | Arch. | #Layers | #Params |
| ---------------------------------------- | ---------- | ------- | ------- |
|`rufimelo/Legal-BERTimbau-base` |BERT-Base |12 |110M|
| `rufimelo/Legal-BERTimbau-large` | BERT-Large | 24 | 335M |
## Usage
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("rufimelo/Legal-BERTimbau-large-TSDAE-v3")
model = AutoModelForMaskedLM.from_pretrained("rufimelo/Legal-BERTimbau-large-TSDAE")
```
### Masked language modeling prediction example
```python
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("rufimelo/Legal-BERTimbau-large-TSDAE-v3")
model = AutoModelForMaskedLM.from_pretrained("rufimelo/Legal-BERTimbau-large-TSDAE-v3")
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer)
pipe('O advogado apresentou [MASK] para o juíz')
# [{'score': 0.5034703612327576,
#'token': 8190,
#'token_str': 'recurso',
#'sequence': 'O advogado apresentou recurso para o juíz'},
#{'score': 0.07347951829433441,
#'token': 21973,
#'token_str': 'petição',
#'sequence': 'O advogado apresentou petição para o juíz'},
#{'score': 0.05165359005331993,
#'token': 4299,
#'token_str': 'resposta',
#'sequence': 'O advogado apresentou resposta para o juíz'},
#{'score': 0.04611917585134506,
#'token': 5265,
#'token_str': 'exposição',
#'sequence': 'O advogado apresentou exposição para o juíz'},
#{'score': 0.04068068787455559,
#'token': 19737, 'token_str':
#'alegações',
#'sequence': 'O advogado apresentou alegações para o juíz'}]
```
### For BERT embeddings
```python
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained('rufimelo/Legal-BERTimbau-large-TSDAE')
input_ids = tokenizer.encode('O advogado apresentou recurso para o juíz', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs[0][0, 1:-1]
#tensor([[ 0.0328, -0.4292, -0.6230, ..., -0.3048, -0.5674, 0.0157],
#[-0.3569, 0.3326, 0.7013, ..., -0.7778, 0.2646, 1.1310],
#[ 0.3169, 0.4333, 0.2026, ..., 1.0517, -0.1951, 0.7050],
#...,
#[-0.3648, -0.8137, -0.4764, ..., -0.2725, -0.4879, 0.6264],
#[-0.2264, -0.1821, -0.3011, ..., -0.5428, 0.1429, 0.0509],
#[-1.4617, 0.6281, -0.0625, ..., -1.2774, -0.4491, 0.3131]])
```
## Citation
If you use this work, please cite BERTimbau's work:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
```
|
memento/ddpm-butterflies-128
|
memento
| 2022-11-01T12:35:06Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-01T11:20:13Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/memento/ddpm-butterflies-128/tensorboard?#scalars)
|
emrevarol/dz_finetuning-sentiment-model-3000-samples
|
emrevarol
| 2022-11-01T12:18:37Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T12:05:17Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: dz_finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dz_finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0553
- Accuracy: 0.99
- F1: 0.9908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
gabrielgmendonca/bert-base-portuguese-cased-finetuned-enjoei
|
gabrielgmendonca
| 2022-11-01T11:41:39Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"tensorboard",
"bert",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-01T01:14:08Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: gabrielgmendonca/bert-base-portuguese-cased-finetuned-enjoei
results: []
---
# gabrielgmendonca/bert-base-portuguese-cased-finetuned-enjoei
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased)
on a teaching dataset extracted from https://www.enjoei.com.br/.
It achieves the following results on the evaluation set:
- Train Loss: 6.0784
- Validation Loss: 5.2882
- Epoch: 2
## Intended uses & limitations
This model is intended for **educational purposes**.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -985, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 6.3618 | 5.7723 | 0 |
| 6.3353 | 5.4076 | 1 |
| 6.0784 | 5.2882 | 2 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Datasets 2.6.1
- Tokenizers 0.13.1
|
dary/11_k
|
dary
| 2022-11-01T11:34:01Z | 0 | 1 | null |
[
"en",
"exbert",
"translation",
"translation1",
"chinese",
"dataset:bookcorpus",
"dataset:wikipedia",
"license:apache-2.0",
"region:us"
] |
translation
| 2022-11-01T08:24:28Z |
---
tags:
- en
- exbert
- translation
- translation1
- chinese
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
|
jayantapaul888/twitter-data-prosusai-finbert-sentiment-finetuned-memes
|
jayantapaul888
| 2022-11-01T11:17:53Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T07:43:31Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: twitter-data-prosusai-finbert-sentiment-finetuned-memes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-prosusai-finbert-sentiment-finetuned-memes
This model is a fine-tuned version of [ProsusAI/finbert](https://huggingface.co/ProsusAI/finbert) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5328
- Accuracy: 0.9274
- Precision: 0.9277
- Recall: 0.9274
- F1: 0.9275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.3284 | 1.0 | 1783 | 0.2770 | 0.9140 | 0.9152 | 0.9140 | 0.9140 |
| 0.2422 | 2.0 | 3566 | 0.2388 | 0.9282 | 0.9297 | 0.9282 | 0.9283 |
| 0.207 | 3.0 | 5349 | 0.2291 | 0.9325 | 0.9337 | 0.9325 | 0.9326 |
| 0.1829 | 4.0 | 7132 | 0.2298 | 0.9341 | 0.9347 | 0.9341 | 0.9340 |
| 0.1665 | 5.0 | 8915 | 0.2493 | 0.9303 | 0.9309 | 0.9303 | 0.9304 |
| 0.142 | 6.0 | 10698 | 0.2749 | 0.9306 | 0.9309 | 0.9306 | 0.9305 |
| 0.1188 | 7.0 | 12481 | 0.2687 | 0.9279 | 0.9286 | 0.9279 | 0.9280 |
| 0.1013 | 8.0 | 14264 | 0.2900 | 0.9270 | 0.9273 | 0.9270 | 0.9271 |
| 0.0849 | 9.0 | 16047 | 0.3247 | 0.9261 | 0.9261 | 0.9261 | 0.9261 |
| 0.0723 | 10.0 | 17830 | 0.3549 | 0.9259 | 0.9266 | 0.9259 | 0.9261 |
| 0.057 | 11.0 | 19613 | 0.3706 | 0.9283 | 0.9288 | 0.9283 | 0.9284 |
| 0.0496 | 12.0 | 21396 | 0.4070 | 0.9258 | 0.9266 | 0.9258 | 0.9260 |
| 0.0423 | 13.0 | 23179 | 0.4361 | 0.9254 | 0.9262 | 0.9254 | 0.9256 |
| 0.0355 | 14.0 | 24962 | 0.4602 | 0.9297 | 0.9305 | 0.9297 | 0.9298 |
| 0.0291 | 15.0 | 26745 | 0.4859 | 0.9258 | 0.9259 | 0.9258 | 0.9258 |
| 0.0248 | 16.0 | 28528 | 0.5024 | 0.9273 | 0.9274 | 0.9273 | 0.9273 |
| 0.0219 | 17.0 | 30311 | 0.5093 | 0.9263 | 0.9264 | 0.9263 | 0.9263 |
| 0.0191 | 18.0 | 32094 | 0.5244 | 0.9280 | 0.9288 | 0.9280 | 0.9282 |
| 0.0171 | 19.0 | 33877 | 0.5290 | 0.9273 | 0.9276 | 0.9273 | 0.9274 |
| 0.0172 | 20.0 | 35660 | 0.5328 | 0.9274 | 0.9277 | 0.9274 | 0.9275 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
ayyuce/my_solar_model
|
ayyuce
| 2022-11-01T11:04:54Z | 0 | 1 |
sklearn
|
[
"sklearn",
"skops",
"tabular-regression",
"license:mit",
"region:us"
] |
tabular-regression
| 2022-11-01T11:04:25Z |
---
license: mit
library_name: sklearn
tags:
- sklearn
- skops
- tabular-regression
widget:
structuredData:
AMBIENT_TEMPERATURE:
- 21.4322062
- 27.322759933333337
- 25.56246340000001
DAILY_YIELD:
- 0.0
- 996.4285714
- 685.0
DC_POWER:
- 0.0
- 8358.285714
- 6741.285714
IRRADIATION:
- 0.0
- 0.6465474886666664
- 0.498367802
MODULE_TEMPERATURE:
- 19.826896066666663
- 45.7407144
- 38.252356133333336
TOTAL_YIELD:
- 7218223.0
- 6366043.429
- 6372656.0
---
# Model description
This is a LinearRegression model trained on Solar Power Generation Data.
## Intended uses & limitations
This model is not ready to be used in production.
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|------------------|------------|
| alpha | 1.0 |
| copy_X | True |
| fit_intercept | True |
| l1_ratio | 0.5 |
| max_iter | 1000 |
| normalize | deprecated |
| positive | False |
| precompute | False |
| random_state | 0 |
| selection | cyclic |
| tol | 0.0001 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b {color: black;background-color: white;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b pre{padding: 0;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-toggleable {background-color: white;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-estimator:hover {background-color: #d4ebff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-item {z-index: 1;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-parallel-item:only-child::after {width: 0;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b div.sk-container {display: inline-block;position: relative;}</style><div id="sk-a3a3b863-d5cf-4b57-9e19-e3d8f2db0a0b" class"sk-top-container"><div class="sk-container"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="d20384ee-8f34-4e73-b4a5-b15dfd56af7a" type="checkbox" checked><label class="sk-toggleable__label" for="d20384ee-8f34-4e73-b4a5-b15dfd56af7a">ElasticNet</label><div class="sk-toggleable__content"><pre>ElasticNet(random_state=0)</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
| accuracy | 99.9994 |
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
import pickle
with open(dtc_pkl_filename, 'rb') as file:
clf = pickle.load(file)
```
</details>
# Model Card Authors
This model card is written by following authors:
ayyuce demirbas
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
bibtex
@inproceedings{...,year={2022}}
```
|
Hanwoon/bert-base-uncased-issues-128
|
Hanwoon
| 2022-11-01T08:50:08Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-11-01T08:43:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-issues-128
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-issues-128
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2449
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.099 | 1.0 | 291 | 1.6946 |
| 1.6396 | 2.0 | 582 | 1.4288 |
| 1.4875 | 3.0 | 873 | 1.3893 |
| 1.399 | 4.0 | 1164 | 1.3812 |
| 1.341 | 5.0 | 1455 | 1.2004 |
| 1.2803 | 6.0 | 1746 | 1.2738 |
| 1.2397 | 7.0 | 2037 | 1.2645 |
| 1.199 | 8.0 | 2328 | 1.2092 |
| 1.166 | 9.0 | 2619 | 1.1871 |
| 1.1406 | 10.0 | 2910 | 1.2244 |
| 1.1293 | 11.0 | 3201 | 1.2061 |
| 1.1037 | 12.0 | 3492 | 1.1621 |
| 1.0824 | 13.0 | 3783 | 1.2540 |
| 1.0738 | 14.0 | 4074 | 1.1703 |
| 1.0625 | 15.0 | 4365 | 1.1195 |
| 1.0628 | 16.0 | 4656 | 1.2449 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
hdc-labs/outputs
|
hdc-labs
| 2022-11-01T07:55:10Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-01T07:39:34Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice
metrics:
- wer
model-index:
- name: outputs
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice
type: common_voice
config: tr
split: train+validation
args: tr
metrics:
- name: Wer
type: wer
value: 0.35818608926565215
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model was trained from scratch on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3878
- Wer: 0.3582
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.7391 | 0.92 | 100 | 3.5760 | 1.0 |
| 2.927 | 1.83 | 200 | 3.0796 | 0.9999 |
| 0.9009 | 2.75 | 300 | 0.9278 | 0.8226 |
| 0.6529 | 3.67 | 400 | 0.5926 | 0.6367 |
| 0.3623 | 4.59 | 500 | 0.5372 | 0.5692 |
| 0.2888 | 5.5 | 600 | 0.4407 | 0.4838 |
| 0.285 | 6.42 | 700 | 0.4341 | 0.4694 |
| 0.0842 | 7.34 | 800 | 0.4153 | 0.4302 |
| 0.1415 | 8.26 | 900 | 0.4317 | 0.4136 |
| 0.1552 | 9.17 | 1000 | 0.4145 | 0.4013 |
| 0.1184 | 10.09 | 1100 | 0.4115 | 0.3844 |
| 0.0556 | 11.01 | 1200 | 0.4182 | 0.3862 |
| 0.0851 | 11.93 | 1300 | 0.3985 | 0.3688 |
| 0.0961 | 12.84 | 1400 | 0.4030 | 0.3665 |
| 0.0596 | 13.76 | 1500 | 0.3880 | 0.3631 |
| 0.0917 | 14.68 | 1600 | 0.3878 | 0.3582 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
adit94/sentenceTest1
|
adit94
| 2022-11-01T07:31:16Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-01T07:30:33Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2500 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.SoftmaxLoss.SoftmaxLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 750,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 768, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
kit-nlp/bert-base-japanese-sentiment-cyberbullying
|
kit-nlp
| 2022-11-01T07:18:05Z | 52 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-09T02:16:34Z |
---
language: ja
license: cc-by-sa-4.0
---
# electra-base-cyberbullying
This is a BERT Base model for the Japanese language finetuned for automatic cyberbullying detection.
The model was based on [daigo's BERT Base for Japanese sentiment analysis](https://huggingface.co/daigo/bert-base-japanese-sentiment), and later finetuned on a balanced dataset created by unifying two datasets, namely "Harmful BBS Japanese comments dataset" and "Twitter Japanese cyberbullying dataset".
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{tanabe2022bert-base-cyberbullying,
title={北見工業大学 テキスト情報処理研究室 BERT Base ネットいじめ検出モデル (Daigo ver.)},
author={田邊 威裕 and プタシンスキ ミハウ and エロネン ユーソ and 桝井 文人},
publisher={HuggingFace},
year={2022},
url = "https://huggingface.co/kit-nlp/bert-base-japanese-sentiment-cyberbullying"
}
```
|
thisisHJLee/wav2vec2-large-xls-r-300m-korean-sen3
|
thisisHJLee
| 2022-11-01T07:17:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-01T02:14:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-korean-sen3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-korean-sen3
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0111
- Cer: 0.0014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.7932 | 1.0 | 1614 | 0.2858 | 0.0740 |
| 0.153 | 2.0 | 3228 | 0.0290 | 0.0054 |
| 0.08 | 3.0 | 4842 | 0.0111 | 0.0014 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.0
- Datasets 1.18.3
- Tokenizers 0.11.0
|
kit-nlp/electra-small-japanese-discriminator-cyberbullying
|
kit-nlp
| 2022-11-01T07:14:15Z | 9 | 2 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-09T02:43:59Z |
---
language: ja
license: cc-by-sa-4.0
---
# electra-base-cyberbullying
This is an [ELECTRA](https://github.com/google-research/electra) Small model for the Japanese language finetuned for automatic cyberbullying detection.
The model was based on [Izumi Lab ELECTRA small Japanese discriminator](https://huggingface.co/izumi-lab/electra-small-japanese-discriminator), and later finetuned on a balanced dataset created by unifying two datasets, namely "Harmful BBS Japanese comments dataset" and "Twitter Japanese cyberbullying dataset".
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{tanabe2022electra-small-cyberbullying,
title={北見工業大学 テキスト情報処理研究室 ELECTRA Small ネットいじめ検出モデル (Izumi Lab ver.)},
author={田邊 威裕 and プタシンスキ ミハウ and エロネン ユーソ and 桝井 文人},
publisher={HuggingFace},
year={2022},
url = "https://huggingface.co/kit-nlp/electra-small-japanese-discriminator-cyberbullying"
}
```
|
SiddharthaM/twitter-data-xlm-roberta-base-sentiment-finetuned-memes-final
|
SiddharthaM
| 2022-11-01T06:15:14Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T05:43:03Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: twitter-data-xlm-roberta-base-sentiment-finetuned-memes-final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# twitter-data-xlm-roberta-base-sentiment-finetuned-memes-final
This model is a fine-tuned version of [jayantapaul888/twitter-data-xlm-roberta-base-sentiment-finetuned-memes](https://huggingface.co/jayantapaul888/twitter-data-xlm-roberta-base-sentiment-finetuned-memes) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5884
- Accuracy: 0.8310
- Precision: 0.8314
- Recall: 0.8310
- F1: 0.8311
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 294 | 0.3981 | 0.8136 | 0.8185 | 0.8136 | 0.8132 |
| 0.4388 | 2.0 | 588 | 0.4114 | 0.8220 | 0.8275 | 0.8220 | 0.8221 |
| 0.4388 | 3.0 | 882 | 0.4203 | 0.8263 | 0.8285 | 0.8263 | 0.8266 |
| 0.2731 | 4.0 | 1176 | 0.4815 | 0.8235 | 0.8276 | 0.8235 | 0.8221 |
| 0.2731 | 5.0 | 1470 | 0.5090 | 0.8330 | 0.8335 | 0.8330 | 0.8332 |
| 0.1883 | 6.0 | 1764 | 0.5884 | 0.8310 | 0.8314 | 0.8310 | 0.8311 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
yizhangliu/ddpm-butterflies-128
|
yizhangliu
| 2022-11-01T06:00:50Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-01T04:44:55Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/yizhangliu/ddpm-butterflies-128/tensorboard?#scalars)
|
adit94/sentencetest
|
adit94
| 2022-11-01T04:30:14Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-11-01T03:42:10Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 625 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.SoftmaxLoss.SoftmaxLoss`
Parameters of the fit()-Method:
```
{
"epochs": 3,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 188,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 768, 'out_features': 768, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
salascorp/categorizacion_comercios_v_0.0.3
|
salascorp
| 2022-11-01T04:29:31Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-11-01T04:19:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: categorizacion_comercios_v_0.0.3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# categorizacion_comercios_v_0.0.3
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.13.0+cpu
- Datasets 2.6.1
- Tokenizers 0.13.1
|
huggingtweets/codeinecucumber-fienddddddd
|
huggingtweets
| 2022-11-01T04:00:04Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-01T03:59:23Z |
---
language: en
thumbnail: http://www.huggingtweets.com/codeinecucumber-fienddddddd/1667275198553/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1579203041764442116/RSLookYD_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1429983882741489668/TQAnTzje_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Gutted & Golden Boy Noah</div>
<div style="text-align: center; font-size: 14px;">@codeinecucumber-fienddddddd</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Gutted & Golden Boy Noah.
| Data | Gutted | Golden Boy Noah |
| --- | --- | --- |
| Tweets downloaded | 1588 | 163 |
| Retweets | 234 | 30 |
| Short tweets | 298 | 12 |
| Tweets kept | 1056 | 121 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1jm5zshq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @codeinecucumber-fienddddddd's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1wp79eh4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1wp79eh4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/codeinecucumber-fienddddddd')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jinhybr/OCR-LM-v1
|
jinhybr
| 2022-11-01T03:22:18Z | 21 | 1 |
transformers
|
[
"transformers",
"pytorch",
"layoutlm",
"token-classification",
"generated_from_trainer",
"dataset:funsd",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-10-28T15:02:47Z |
---
tags:
- generated_from_trainer
datasets:
- funsd
model-index:
- name: OCR-LM-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OCR-LM-v1
This model is a fine-tuned version of [jinhybr/layoutlm-funsd-pytorch](https://huggingface.co/jinhybr/layoutlm-funsd-pytorch) on the funsd dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1740
- Answer: {'precision': 0.7201327433628318, 'recall': 0.8046971569839307, 'f1': 0.7600700525394046, 'number': 809}
- Header: {'precision': 0.4246575342465753, 'recall': 0.5210084033613446, 'f1': 0.46792452830188674, 'number': 119}
- Question: {'precision': 0.8236380424746076, 'recall': 0.8375586854460094, 'f1': 0.8305400372439479, 'number': 1065}
- Overall Precision: 0.7525
- Overall Recall: 0.8053
- Overall F1: 0.7780
- Overall Accuracy: 0.8146
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.3093 | 1.0 | 10 | 0.7358 | {'precision': 0.7053763440860215, 'recall': 0.8108776266996292, 'f1': 0.7544565842438183, 'number': 809} | {'precision': 0.33587786259541985, 'recall': 0.3697478991596639, 'f1': 0.35200000000000004, 'number': 119} | {'precision': 0.7900900900900901, 'recall': 0.8234741784037559, 'f1': 0.8064367816091954, 'number': 1065} | 0.7264 | 0.7913 | 0.7574 | 0.8064 |
| 0.2626 | 2.0 | 20 | 0.7389 | {'precision': 0.7217090069284064, 'recall': 0.7725587144622992, 'f1': 0.746268656716418, 'number': 809} | {'precision': 0.33986928104575165, 'recall': 0.4369747899159664, 'f1': 0.3823529411764706, 'number': 119} | {'precision': 0.7693661971830986, 'recall': 0.8206572769953052, 'f1': 0.79418446160836, 'number': 1065} | 0.7197 | 0.7782 | 0.7478 | 0.7999 |
| 0.2096 | 3.0 | 30 | 0.7834 | {'precision': 0.7417452830188679, 'recall': 0.7775030902348579, 'f1': 0.7592033796016897, 'number': 809} | {'precision': 0.3724137931034483, 'recall': 0.453781512605042, 'f1': 0.40909090909090906, 'number': 119} | {'precision': 0.7889087656529516, 'recall': 0.828169014084507, 'f1': 0.8080622995877232, 'number': 1065} | 0.7414 | 0.7852 | 0.7627 | 0.8003 |
| 0.1755 | 4.0 | 40 | 0.7856 | {'precision': 0.6917372881355932, 'recall': 0.8071693448702101, 'f1': 0.7450085567598402, 'number': 809} | {'precision': 0.35135135135135137, 'recall': 0.4369747899159664, 'f1': 0.3895131086142322, 'number': 119} | {'precision': 0.7893333333333333, 'recall': 0.8338028169014085, 'f1': 0.810958904109589, 'number': 1065} | 0.7185 | 0.7993 | 0.7568 | 0.8005 |
| 0.1421 | 5.0 | 50 | 0.8088 | {'precision': 0.7144444444444444, 'recall': 0.7948084054388134, 'f1': 0.7524868344060853, 'number': 809} | {'precision': 0.39436619718309857, 'recall': 0.47058823529411764, 'f1': 0.4291187739463601, 'number': 119} | {'precision': 0.7915543575920935, 'recall': 0.8272300469483568, 'f1': 0.8089990817263545, 'number': 1065} | 0.7332 | 0.7928 | 0.7618 | 0.8014 |
| 0.1235 | 6.0 | 60 | 0.8637 | {'precision': 0.7262313860252004, 'recall': 0.7836835599505563, 'f1': 0.7538644470868016, 'number': 809} | {'precision': 0.37410071942446044, 'recall': 0.4369747899159664, 'f1': 0.40310077519379844, 'number': 119} | {'precision': 0.7994604316546763, 'recall': 0.8347417840375587, 'f1': 0.8167202572347267, 'number': 1065} | 0.7415 | 0.7903 | 0.7651 | 0.8026 |
| 0.1057 | 7.0 | 70 | 0.8848 | {'precision': 0.7323290845886443, 'recall': 0.7812113720642769, 'f1': 0.7559808612440193, 'number': 809} | {'precision': 0.3986013986013986, 'recall': 0.4789915966386555, 'f1': 0.4351145038167939, 'number': 119} | {'precision': 0.7989080982711556, 'recall': 0.8244131455399061, 'f1': 0.8114602587800368, 'number': 1065} | 0.7444 | 0.7863 | 0.7648 | 0.7959 |
| 0.1054 | 8.0 | 80 | 0.9131 | {'precision': 0.7241758241758242, 'recall': 0.8145859085290482, 'f1': 0.7667248400232693, 'number': 809} | {'precision': 0.41916167664670656, 'recall': 0.5882352941176471, 'f1': 0.4895104895104894, 'number': 119} | {'precision': 0.8152686145146089, 'recall': 0.812206572769953, 'f1': 0.8137347130761995, 'number': 1065} | 0.7456 | 0.7998 | 0.7717 | 0.8021 |
| 0.0814 | 9.0 | 90 | 0.9202 | {'precision': 0.7013129102844639, 'recall': 0.792336217552534, 'f1': 0.7440510737086476, 'number': 809} | {'precision': 0.42758620689655175, 'recall': 0.5210084033613446, 'f1': 0.4696969696969697, 'number': 119} | {'precision': 0.8076572470373746, 'recall': 0.831924882629108, 'f1': 0.8196114708603145, 'number': 1065} | 0.7370 | 0.7973 | 0.7660 | 0.8017 |
| 0.0722 | 10.0 | 100 | 0.9309 | {'precision': 0.711211778029445, 'recall': 0.7762669962917181, 'f1': 0.7423167848699764, 'number': 809} | {'precision': 0.3816793893129771, 'recall': 0.42016806722689076, 'f1': 0.4, 'number': 119} | {'precision': 0.8154706430568499, 'recall': 0.8215962441314554, 'f1': 0.8185219831618334, 'number': 1065} | 0.7441 | 0.7792 | 0.7613 | 0.8029 |
| 0.062 | 11.0 | 110 | 0.9820 | {'precision': 0.717391304347826, 'recall': 0.7750309023485785, 'f1': 0.7450980392156862, 'number': 809} | {'precision': 0.37735849056603776, 'recall': 0.5042016806722689, 'f1': 0.43165467625899284, 'number': 119} | {'precision': 0.7917414721723519, 'recall': 0.828169014084507, 'f1': 0.8095456631482332, 'number': 1065} | 0.7308 | 0.7873 | 0.7580 | 0.7977 |
| 0.056 | 12.0 | 120 | 0.9787 | {'precision': 0.7014270032930845, 'recall': 0.7898640296662547, 'f1': 0.7430232558139536, 'number': 809} | {'precision': 0.3881578947368421, 'recall': 0.4957983193277311, 'f1': 0.4354243542435424, 'number': 119} | {'precision': 0.8092592592592592, 'recall': 0.8206572769953052, 'f1': 0.814918414918415, 'number': 1065} | 0.7336 | 0.7888 | 0.7602 | 0.8069 |
| 0.0521 | 13.0 | 130 | 1.0012 | {'precision': 0.7094972067039106, 'recall': 0.7849196538936959, 'f1': 0.7453051643192488, 'number': 809} | {'precision': 0.39568345323741005, 'recall': 0.46218487394957986, 'f1': 0.4263565891472868, 'number': 119} | {'precision': 0.8278457196613358, 'recall': 0.8262910798122066, 'f1': 0.8270676691729324, 'number': 1065} | 0.7487 | 0.7878 | 0.7677 | 0.8054 |
| 0.0512 | 14.0 | 140 | 1.0412 | {'precision': 0.7181818181818181, 'recall': 0.7812113720642769, 'f1': 0.7483718176435761, 'number': 809} | {'precision': 0.417910447761194, 'recall': 0.47058823529411764, 'f1': 0.4426877470355731, 'number': 119} | {'precision': 0.7925531914893617, 'recall': 0.8394366197183099, 'f1': 0.8153214774281805, 'number': 1065} | 0.7386 | 0.7938 | 0.7652 | 0.7924 |
| 0.0422 | 15.0 | 150 | 1.0369 | {'precision': 0.6987315010570825, 'recall': 0.8170580964153276, 'f1': 0.7532763532763533, 'number': 809} | {'precision': 0.4222222222222222, 'recall': 0.4789915966386555, 'f1': 0.44881889763779526, 'number': 119} | {'precision': 0.8138248847926267, 'recall': 0.8291079812206573, 'f1': 0.8213953488372093, 'number': 1065} | 0.7392 | 0.8033 | 0.7699 | 0.8060 |
| 0.041 | 16.0 | 160 | 1.0669 | {'precision': 0.7108843537414966, 'recall': 0.7750309023485785, 'f1': 0.7415730337078651, 'number': 809} | {'precision': 0.4117647058823529, 'recall': 0.47058823529411764, 'f1': 0.4392156862745098, 'number': 119} | {'precision': 0.7953736654804271, 'recall': 0.8394366197183099, 'f1': 0.8168113293741435, 'number': 1065} | 0.7362 | 0.7913 | 0.7628 | 0.7989 |
| 0.0338 | 17.0 | 170 | 1.0376 | {'precision': 0.7056277056277056, 'recall': 0.8059332509270705, 'f1': 0.7524523946912869, 'number': 809} | {'precision': 0.4117647058823529, 'recall': 0.5294117647058824, 'f1': 0.463235294117647, 'number': 119} | {'precision': 0.8159111933395005, 'recall': 0.828169014084507, 'f1': 0.8219944082013048, 'number': 1065} | 0.7400 | 0.8013 | 0.7695 | 0.8062 |
| 0.0343 | 18.0 | 180 | 1.0498 | {'precision': 0.7165178571428571, 'recall': 0.7935723114956736, 'f1': 0.7530791788856306, 'number': 809} | {'precision': 0.42953020134228187, 'recall': 0.5378151260504201, 'f1': 0.47761194029850745, 'number': 119} | {'precision': 0.8065693430656934, 'recall': 0.8300469483568075, 'f1': 0.8181397501156872, 'number': 1065} | 0.7426 | 0.7978 | 0.7692 | 0.8035 |
| 0.0294 | 19.0 | 190 | 1.0455 | {'precision': 0.7022900763358778, 'recall': 0.796044499381953, 'f1': 0.7462340672074159, 'number': 809} | {'precision': 0.42857142857142855, 'recall': 0.5042016806722689, 'f1': 0.4633204633204633, 'number': 119} | {'precision': 0.8277153558052435, 'recall': 0.8300469483568075, 'f1': 0.8288795124238162, 'number': 1065} | 0.7473 | 0.7968 | 0.7712 | 0.8077 |
| 0.0302 | 20.0 | 200 | 1.0363 | {'precision': 0.7261363636363637, 'recall': 0.7898640296662547, 'f1': 0.7566607460035524, 'number': 809} | {'precision': 0.4225352112676056, 'recall': 0.5042016806722689, 'f1': 0.45977011494252873, 'number': 119} | {'precision': 0.8149498632634458, 'recall': 0.8394366197183099, 'f1': 0.8270120259019426, 'number': 1065} | 0.7518 | 0.7993 | 0.7748 | 0.8073 |
| 0.0232 | 21.0 | 210 | 1.0406 | {'precision': 0.7085152838427947, 'recall': 0.8022249690976514, 'f1': 0.7524637681159421, 'number': 809} | {'precision': 0.4142857142857143, 'recall': 0.48739495798319327, 'f1': 0.4478764478764479, 'number': 119} | {'precision': 0.8198529411764706, 'recall': 0.8375586854460094, 'f1': 0.8286112401300512, 'number': 1065} | 0.7458 | 0.8023 | 0.7730 | 0.8096 |
| 0.025 | 22.0 | 220 | 1.0627 | {'precision': 0.7220338983050848, 'recall': 0.7898640296662547, 'f1': 0.7544273907910272, 'number': 809} | {'precision': 0.4306569343065693, 'recall': 0.4957983193277311, 'f1': 0.46093749999999994, 'number': 119} | {'precision': 0.8222836095764272, 'recall': 0.8384976525821596, 'f1': 0.8303114830311482, 'number': 1065} | 0.7547 | 0.7983 | 0.7759 | 0.8125 |
| 0.0203 | 23.0 | 230 | 1.0621 | {'precision': 0.7149122807017544, 'recall': 0.8059332509270705, 'f1': 0.757699012202208, 'number': 809} | {'precision': 0.42857142857142855, 'recall': 0.5042016806722689, 'f1': 0.4633204633204633, 'number': 119} | {'precision': 0.8182656826568265, 'recall': 0.8328638497652582, 'f1': 0.8255002326663564, 'number': 1065} | 0.7486 | 0.8023 | 0.7745 | 0.8139 |
| 0.0214 | 24.0 | 240 | 1.1079 | {'precision': 0.7268571428571429, 'recall': 0.7861557478368356, 'f1': 0.7553444180522566, 'number': 809} | {'precision': 0.40397350993377484, 'recall': 0.5126050420168067, 'f1': 0.45185185185185184, 'number': 119} | {'precision': 0.8148820326678766, 'recall': 0.8431924882629108, 'f1': 0.8287955699123213, 'number': 1065} | 0.7495 | 0.8003 | 0.7741 | 0.8050 |
| 0.0179 | 25.0 | 250 | 1.0955 | {'precision': 0.7149270482603816, 'recall': 0.7873918417799752, 'f1': 0.7494117647058823, 'number': 809} | {'precision': 0.4057971014492754, 'recall': 0.47058823529411764, 'f1': 0.43579766536964987, 'number': 119} | {'precision': 0.8115942028985508, 'recall': 0.8413145539906103, 'f1': 0.826187183033656, 'number': 1065} | 0.7450 | 0.7973 | 0.7702 | 0.8075 |
| 0.0181 | 26.0 | 260 | 1.0775 | {'precision': 0.7172949002217295, 'recall': 0.799752781211372, 'f1': 0.7562828755113968, 'number': 809} | {'precision': 0.4088050314465409, 'recall': 0.5462184873949579, 'f1': 0.4676258992805755, 'number': 119} | {'precision': 0.8122151321786691, 'recall': 0.8366197183098592, 'f1': 0.8242368177613321, 'number': 1065} | 0.7428 | 0.8043 | 0.7723 | 0.8103 |
| 0.0169 | 27.0 | 270 | 1.0667 | {'precision': 0.7176339285714286, 'recall': 0.7948084054388134, 'f1': 0.7542521994134898, 'number': 809} | {'precision': 0.41721854304635764, 'recall': 0.5294117647058824, 'f1': 0.4666666666666667, 'number': 119} | {'precision': 0.821656050955414, 'recall': 0.847887323943662, 'f1': 0.8345656192236599, 'number': 1065} | 0.7498 | 0.8073 | 0.7775 | 0.8115 |
| 0.0164 | 28.0 | 280 | 1.0798 | {'precision': 0.7106382978723405, 'recall': 0.8257107540173053, 'f1': 0.7638650657518582, 'number': 809} | {'precision': 0.42567567567567566, 'recall': 0.5294117647058824, 'f1': 0.47191011235955055, 'number': 119} | {'precision': 0.8265682656826568, 'recall': 0.8413145539906103, 'f1': 0.8338762214983713, 'number': 1065} | 0.7491 | 0.8164 | 0.7813 | 0.8152 |
| 0.0178 | 29.0 | 290 | 1.0944 | {'precision': 0.7214611872146118, 'recall': 0.7812113720642769, 'f1': 0.7501483679525223, 'number': 809} | {'precision': 0.4496124031007752, 'recall': 0.48739495798319327, 'f1': 0.467741935483871, 'number': 119} | {'precision': 0.8191881918819188, 'recall': 0.8338028169014085, 'f1': 0.8264308980921358, 'number': 1065} | 0.7554 | 0.7918 | 0.7732 | 0.8136 |
| 0.0151 | 30.0 | 300 | 1.0994 | {'precision': 0.7141292442497261, 'recall': 0.8059332509270705, 'f1': 0.7572590011614402, 'number': 809} | {'precision': 0.43795620437956206, 'recall': 0.5042016806722689, 'f1': 0.46875, 'number': 119} | {'precision': 0.8211981566820277, 'recall': 0.8366197183098592, 'f1': 0.8288372093023256, 'number': 1065} | 0.7508 | 0.8043 | 0.7766 | 0.8151 |
| 0.0127 | 31.0 | 310 | 1.1177 | {'precision': 0.7144420131291028, 'recall': 0.8071693448702101, 'f1': 0.7579802669762042, 'number': 809} | {'precision': 0.4264705882352941, 'recall': 0.48739495798319327, 'f1': 0.4549019607843137, 'number': 119} | {'precision': 0.82483781278962, 'recall': 0.8356807511737089, 'f1': 0.8302238805970149, 'number': 1065} | 0.7520 | 0.8033 | 0.7768 | 0.8136 |
| 0.0123 | 32.0 | 320 | 1.1295 | {'precision': 0.7280799112097669, 'recall': 0.8108776266996292, 'f1': 0.7672514619883041, 'number': 809} | {'precision': 0.4316546762589928, 'recall': 0.5042016806722689, 'f1': 0.46511627906976744, 'number': 119} | {'precision': 0.8176043557168784, 'recall': 0.8460093896713615, 'f1': 0.8315643747115828, 'number': 1065} | 0.7549 | 0.8113 | 0.7821 | 0.8127 |
| 0.0105 | 33.0 | 330 | 1.1422 | {'precision': 0.717439293598234, 'recall': 0.8034610630407911, 'f1': 0.7580174927113702, 'number': 809} | {'precision': 0.427536231884058, 'recall': 0.4957983193277311, 'f1': 0.4591439688715953, 'number': 119} | {'precision': 0.8168498168498168, 'recall': 0.8375586854460094, 'f1': 0.8270746407046824, 'number': 1065} | 0.7495 | 0.8033 | 0.7755 | 0.8110 |
| 0.0099 | 34.0 | 340 | 1.1476 | {'precision': 0.7194323144104804, 'recall': 0.8145859085290482, 'f1': 0.7640579710144928, 'number': 809} | {'precision': 0.43478260869565216, 'recall': 0.5042016806722689, 'f1': 0.4669260700389105, 'number': 119} | {'precision': 0.8256880733944955, 'recall': 0.8450704225352113, 'f1': 0.8352668213457076, 'number': 1065} | 0.7551 | 0.8123 | 0.7827 | 0.8132 |
| 0.0115 | 35.0 | 350 | 1.1590 | {'precision': 0.7200878155872668, 'recall': 0.8108776266996292, 'f1': 0.7627906976744185, 'number': 809} | {'precision': 0.4125874125874126, 'recall': 0.4957983193277311, 'f1': 0.450381679389313, 'number': 119} | {'precision': 0.8325581395348837, 'recall': 0.8403755868544601, 'f1': 0.8364485981308412, 'number': 1065} | 0.7562 | 0.8078 | 0.7812 | 0.8129 |
| 0.0098 | 36.0 | 360 | 1.1619 | {'precision': 0.7271714922048997, 'recall': 0.8071693448702101, 'f1': 0.7650849443468072, 'number': 809} | {'precision': 0.41379310344827586, 'recall': 0.5042016806722689, 'f1': 0.45454545454545453, 'number': 119} | {'precision': 0.8226691042047533, 'recall': 0.8450704225352113, 'f1': 0.8337193144974525, 'number': 1065} | 0.7548 | 0.8093 | 0.7811 | 0.8140 |
| 0.0089 | 37.0 | 370 | 1.1555 | {'precision': 0.7289823008849557, 'recall': 0.8145859085290482, 'f1': 0.7694103911266784, 'number': 809} | {'precision': 0.42857142857142855, 'recall': 0.5042016806722689, 'f1': 0.4633204633204633, 'number': 119} | {'precision': 0.8178571428571428, 'recall': 0.860093896713615, 'f1': 0.8384439359267735, 'number': 1065} | 0.7555 | 0.8204 | 0.7866 | 0.8158 |
| 0.0116 | 38.0 | 380 | 1.1472 | {'precision': 0.7161862527716186, 'recall': 0.7985166872682324, 'f1': 0.7551139684395091, 'number': 809} | {'precision': 0.42962962962962964, 'recall': 0.48739495798319327, 'f1': 0.45669291338582674, 'number': 119} | {'precision': 0.8250460405156538, 'recall': 0.8413145539906103, 'f1': 0.8331008833100882, 'number': 1065} | 0.7537 | 0.8028 | 0.7775 | 0.8152 |
| 0.0089 | 39.0 | 390 | 1.1558 | {'precision': 0.7158590308370044, 'recall': 0.8034610630407911, 'f1': 0.7571345369831101, 'number': 809} | {'precision': 0.41721854304635764, 'recall': 0.5294117647058824, 'f1': 0.4666666666666667, 'number': 119} | {'precision': 0.8302583025830258, 'recall': 0.8450704225352113, 'f1': 0.8375988832014891, 'number': 1065} | 0.7527 | 0.8093 | 0.7800 | 0.8120 |
| 0.0085 | 40.0 | 400 | 1.1576 | {'precision': 0.7169398907103826, 'recall': 0.8108776266996292, 'f1': 0.7610208816705337, 'number': 809} | {'precision': 0.41843971631205673, 'recall': 0.4957983193277311, 'f1': 0.4538461538461538, 'number': 119} | {'precision': 0.8249772105742935, 'recall': 0.8497652582159625, 'f1': 0.8371877890841812, 'number': 1065} | 0.7524 | 0.8128 | 0.7815 | 0.8127 |
| 0.0079 | 41.0 | 410 | 1.1551 | {'precision': 0.716500553709856, 'recall': 0.799752781211372, 'f1': 0.7558411214953271, 'number': 809} | {'precision': 0.44696969696969696, 'recall': 0.4957983193277311, 'f1': 0.47011952191235057, 'number': 119} | {'precision': 0.8264462809917356, 'recall': 0.8450704225352113, 'f1': 0.8356545961002786, 'number': 1065} | 0.7561 | 0.8058 | 0.7802 | 0.8145 |
| 0.0069 | 42.0 | 420 | 1.1656 | {'precision': 0.7169603524229075, 'recall': 0.8046971569839307, 'f1': 0.7582993593476993, 'number': 809} | {'precision': 0.4315068493150685, 'recall': 0.5294117647058824, 'f1': 0.4754716981132075, 'number': 119} | {'precision': 0.8236914600550964, 'recall': 0.8422535211267606, 'f1': 0.8328690807799443, 'number': 1065} | 0.7517 | 0.8083 | 0.7790 | 0.8137 |
| 0.0067 | 43.0 | 430 | 1.1720 | {'precision': 0.7145993413830956, 'recall': 0.8046971569839307, 'f1': 0.7569767441860464, 'number': 809} | {'precision': 0.43661971830985913, 'recall': 0.5210084033613446, 'f1': 0.47509578544061304, 'number': 119} | {'precision': 0.8190909090909091, 'recall': 0.8460093896713615, 'f1': 0.8323325635103926, 'number': 1065} | 0.7497 | 0.8098 | 0.7786 | 0.8126 |
| 0.0083 | 44.0 | 440 | 1.1720 | {'precision': 0.7203579418344519, 'recall': 0.796044499381953, 'f1': 0.756312389900176, 'number': 809} | {'precision': 0.4397163120567376, 'recall': 0.5210084033613446, 'f1': 0.47692307692307695, 'number': 119} | {'precision': 0.8225659690627843, 'recall': 0.8488262910798122, 'f1': 0.8354898336414048, 'number': 1065} | 0.7545 | 0.8078 | 0.7802 | 0.8150 |
| 0.0072 | 45.0 | 450 | 1.1733 | {'precision': 0.727683615819209, 'recall': 0.796044499381953, 'f1': 0.7603305785123966, 'number': 809} | {'precision': 0.4338235294117647, 'recall': 0.4957983193277311, 'f1': 0.4627450980392157, 'number': 119} | {'precision': 0.8209090909090909, 'recall': 0.847887323943662, 'f1': 0.8341801385681292, 'number': 1065} | 0.7572 | 0.8058 | 0.7807 | 0.8148 |
| 0.0092 | 46.0 | 460 | 1.1712 | {'precision': 0.7188888888888889, 'recall': 0.799752781211372, 'f1': 0.7571679344645992, 'number': 809} | {'precision': 0.4306569343065693, 'recall': 0.4957983193277311, 'f1': 0.46093749999999994, 'number': 119} | {'precision': 0.8214285714285714, 'recall': 0.8422535211267606, 'f1': 0.8317107093184979, 'number': 1065} | 0.7529 | 0.8043 | 0.7778 | 0.8146 |
| 0.0063 | 47.0 | 470 | 1.1723 | {'precision': 0.7158590308370044, 'recall': 0.8034610630407911, 'f1': 0.7571345369831101, 'number': 809} | {'precision': 0.4326241134751773, 'recall': 0.5126050420168067, 'f1': 0.4692307692307692, 'number': 119} | {'precision': 0.8212648945921174, 'recall': 0.8413145539906103, 'f1': 0.8311688311688312, 'number': 1065} | 0.7509 | 0.8063 | 0.7776 | 0.8154 |
| 0.0064 | 48.0 | 480 | 1.1740 | {'precision': 0.7166482910694597, 'recall': 0.8034610630407911, 'f1': 0.7575757575757576, 'number': 809} | {'precision': 0.42657342657342656, 'recall': 0.5126050420168067, 'f1': 0.46564885496183206, 'number': 119} | {'precision': 0.8226102941176471, 'recall': 0.8403755868544601, 'f1': 0.8313980492336275, 'number': 1065} | 0.7512 | 0.8058 | 0.7775 | 0.8147 |
| 0.0069 | 49.0 | 490 | 1.1742 | {'precision': 0.7209302325581395, 'recall': 0.8046971569839307, 'f1': 0.7605140186915887, 'number': 809} | {'precision': 0.4246575342465753, 'recall': 0.5210084033613446, 'f1': 0.46792452830188674, 'number': 119} | {'precision': 0.8236380424746076, 'recall': 0.8375586854460094, 'f1': 0.8305400372439479, 'number': 1065} | 0.7528 | 0.8053 | 0.7782 | 0.8145 |
| 0.0062 | 50.0 | 500 | 1.1740 | {'precision': 0.7201327433628318, 'recall': 0.8046971569839307, 'f1': 0.7600700525394046, 'number': 809} | {'precision': 0.4246575342465753, 'recall': 0.5210084033613446, 'f1': 0.46792452830188674, 'number': 119} | {'precision': 0.8236380424746076, 'recall': 0.8375586854460094, 'f1': 0.8305400372439479, 'number': 1065} | 0.7525 | 0.8053 | 0.7780 | 0.8146 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
surajjoshi/swin-tiny-patch4-window7-224-finetuned-brainTumorData
|
surajjoshi
| 2022-11-01T03:19:39Z | 62 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-10-19T13:16:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-brainTumorData
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-brainTumorData
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
BigSalmon/InformalToFormalLincoln88Paraphrase
|
BigSalmon
| 2022-11-01T02:39:29Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-10-31T03:30:39Z |
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln88Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln88Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
|
rufimelo/Legal-BERTimbau-base-TSDAE-sts
|
rufimelo
| 2022-11-01T01:31:11Z | 3 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"pt",
"dataset:assin",
"dataset:assin2",
"dataset:stsb_multi_mt",
"dataset:rufimelo/PortugueseLegalSentences-v1",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-10-29T17:36:41Z |
---
language:
- pt
thumbnail: "Portuguese BERT for the Legal Domain"
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- transformers
datasets:
- assin
- assin2
- stsb_multi_mt
- rufimelo/PortugueseLegalSentences-v1
widget:
- source_sentence: "O advogado apresentou as provas ao juíz."
sentences:
- "O juíz leu as provas."
- "O juíz leu o recurso."
- "O juíz atirou uma pedra."
example_title: "Example 1"
model-index:
- name: BERTimbau
results:
- task:
name: STS
type: STS
metrics:
- name: Pearson Correlation - assin Dataset
type: Pearson Correlation
value: 0.78814
- name: Pearson Correlation - assin2 Dataset
type: Pearson Correlation
value: 0.81380
- name: Pearson Correlation - stsb_multi_mt pt Dataset
type: Pearson Correlation
value: 0.75777
---
# rufimelo/Legal-BERTimbau-base-TSDAE-sts
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
rufimelo/Legal-BERTimbau-base-TSDAE-sts is based on Legal-BERTimbau-large which derives from [BERTimbau](https://huggingface.co/neuralmind/bert-large-portuguese-cased) large.
It is adapted to the Portuguese legal domain and trained for STS on portuguese datasets.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Isto é um exemplo", "Isto é um outro exemplo"]
model = SentenceTransformer('rufimelo/Legal-BERTimbau-base-TSDAE-sts')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('rufimelo/Legal-BERTimbau-base-TSDAE-sts')
model = AutoModel.from_pretrained('rufimelo/Legal-BERTimbau-base-TSDAE-sts')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results STS
| Model| Assin | Assin2|stsb_multi_mt pt| avg|
| ---------------------------------------- | ---------- | ---------- |---------- |---------- |
| Legal-BERTimbau-sts-base| 0.71457| 0.73545 | 0.72383|0.72462|
| Legal-BERTimbau-sts-base-ma| 0.74874 | 0.79532|0.82254 |0.78886|
| Legal-BERTimbau-sts-base-ma-v2| 0.75481 | 0.80262|0.82178|0.79307|
| Legal-BERTimbau-base-TSDAE-sts|0.78814 |0.81380 |0.75777|0.78657|
| Legal-BERTimbau-sts-large| 0.76629| 0.82357 | 0.79120|0.79369|
| Legal-BERTimbau-sts-large-v2| 0.76299 | 0.81121|0.81726 |0.79715|
| Legal-BERTimbau-sts-large-ma| 0.76195| 0.81622 | 0.82608|0.80142|
| Legal-BERTimbau-sts-large-ma-v2| 0.7836| 0.8462| 0.8261| 0.81863|
| Legal-BERTimbau-sts-large-ma-v3| 0.7749| **0.8470**| 0.8364| **0.81943**|
| Legal-BERTimbau-large-v2-sts| 0.71665| 0.80106| 0.73724| 0.75165|
| Legal-BERTimbau-large-TSDAE-sts| 0.72376| 0.79261| 0.73635| 0.75090|
| Legal-BERTimbau-large-TSDAE-sts-v2| 0.81326| 0.83130| 0.786314| 0.81029|
| Legal-BERTimbau-large-TSDAE-sts-v3|0.80703 |0.82270 |0.77638 |0.80204 |
| ---------------------------------------- | ---------- |---------- |---------- |---------- |
| BERTimbau base Fine-tuned for STS|**0.78455** | 0.80626|0.82841|0.80640|
| BERTimbau large Fine-tuned for STS|0.78193 | 0.81758|0.83784|0.81245|
| ---------------------------------------- | ---------- |---------- |---------- |---------- |
| paraphrase-multilingual-mpnet-base-v2| 0.71457| 0.79831 |0.83999 |0.78429|
| paraphrase-multilingual-mpnet-base-v2 Fine-tuned with assin(s)| 0.77641|0.79831 |**0.84575**|0.80682|
## Training
rufimelo/Legal-BERTimbau-base-TSDAE-sts is based on rufimelo/Legal-BERTimbau-base-TSDAE which derives from [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased) large.
rufimelo/Legal-BERTimbau-base-TSDAE was trained with TSDAE: 50000 cleaned documents (https://huggingface.co/datasets/rufimelo/PortugueseLegalSentences-v1)
'lr': 1e-5
It was trained for Semantic Textual Similarity, being submitted to a fine tuning stage with the [assin](https://huggingface.co/datasets/assin), [assin2](https://huggingface.co/datasets/assin2) and [stsb_multi_mt pt](https://huggingface.co/datasets/stsb_multi_mt) datasets. 'lr': 1e-5
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
## Citing & Authors
If you use this work, please cite:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
@inproceedings{fonseca2016assin,
title={ASSIN: Avaliacao de similaridade semantica e inferencia textual},
author={Fonseca, E and Santos, L and Criscuolo, Marcelo and Aluisio, S},
booktitle={Computational Processing of the Portuguese Language-12th International Conference, Tomar, Portugal},
pages={13--15},
year={2016}
}
@inproceedings{real2020assin,
title={The assin 2 shared task: a quick overview},
author={Real, Livy and Fonseca, Erick and Oliveira, Hugo Goncalo},
booktitle={International Conference on Computational Processing of the Portuguese Language},
pages={406--412},
year={2020},
organization={Springer}
}
@InProceedings{huggingface:dataset:stsb_multi_mt,
title = {Machine translated multilingual STS benchmark dataset.},
author={Philip May},
year={2021},
url={https://github.com/PhilipMay/stsb-multi-mt}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.