
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-11 06:30:11
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 555
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-11 06:29:58
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
huggingtweets/lazar181
|
huggingtweets
| 2022-01-17T01:55:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/lazar181/1642384387963/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1451342601483952130/-RJ3Ewqp_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ari/Sera @ 🛌</div>
<div style="text-align: center; font-size: 14px;">@lazar181</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ari/Sera @ 🛌.
| Data | Ari/Sera @ 🛌 |
| --- | --- |
| Tweets downloaded | 3241 |
| Retweets | 362 |
| Short tweets | 668 |
| Tweets kept | 2211 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/21d2ewj0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @lazar181's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ukmb9ye) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ukmb9ye/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/lazar181')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/emsorkun
|
huggingtweets
| 2022-01-16T22:19:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1477509052074766340/rVamRzsW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Enver Melih Sorkun</div>
<div style="text-align: center; font-size: 14px;">@emsorkun</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Enver Melih Sorkun.
| Data | Enver Melih Sorkun |
| --- | --- |
| Tweets downloaded | 2107 |
| Retweets | 618 |
| Short tweets | 130 |
| Tweets kept | 1359 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/c12hxxur/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @emsorkun's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3prqt8oz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3prqt8oz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/emsorkun')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ilevs/opus-mt-ru-en-finetuned-ru-to-en
|
ilevs
| 2022-01-16T19:29:07Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: opus-mt-ru-en-finetuned-ru-to-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-ru-en-finetuned-ru-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-ru-en](https://huggingface.co/Helsinki-NLP/opus-mt-ru-en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1251
- Bleu: 15.9892
- Gen Len: 5.0168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 2.6914 | 1.0 | 4956 | 2.5116 | 11.1411 | 4.9989 |
| 2.2161 | 2.0 | 9912 | 2.3255 | 11.7334 | 5.1678 |
| 1.9237 | 3.0 | 14868 | 2.2388 | 13.6802 | 5.1463 |
| 1.7087 | 4.0 | 19824 | 2.1892 | 13.8815 | 5.0625 |
| 1.5423 | 5.0 | 24780 | 2.1586 | 14.8182 | 5.0779 |
| 1.3909 | 6.0 | 29736 | 2.1445 | 14.3603 | 5.2194 |
| 1.3041 | 7.0 | 34692 | 2.1323 | 16.2138 | 5.0438 |
| 1.2078 | 8.0 | 39648 | 2.1275 | 16.2574 | 5.0165 |
| 1.1523 | 9.0 | 44604 | 2.1255 | 16.0368 | 5.014 |
| 1.1005 | 10.0 | 49560 | 2.1251 | 15.9892 | 5.0168 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Shushant/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-ContaminationQAmodel_PubmedBERT
|
Shushant
| 2022-01-16T15:54:15Z | 55 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-ContaminationQAmodel_PubmedBERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-ContaminationQAmodel_PubmedBERT
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7515
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 22 | 3.9518 |
| No log | 2.0 | 44 | 3.2703 |
| No log | 3.0 | 66 | 2.9308 |
| No log | 4.0 | 88 | 2.7806 |
| No log | 5.0 | 110 | 2.6926 |
| No log | 6.0 | 132 | 2.7043 |
| No log | 7.0 | 154 | 2.7113 |
| No log | 8.0 | 176 | 2.7236 |
| No log | 9.0 | 198 | 2.7559 |
| No log | 10.0 | 220 | 2.7515 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Shushant/biobert-v1.1-biomedicalQuestionAnswering
|
Shushant
| 2022-01-16T15:34:49Z | 83 | 5 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: biobert-v1.1-biomedicalQuestionAnswering
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert-v1.1-biomedicalQuestionAnswering
This model is a fine-tuned version of [dmis-lab/biobert-v1.1](https://huggingface.co/dmis-lab/biobert-v1.1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9009
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 22 | 3.7409 |
| No log | 2.0 | 44 | 3.1852 |
| No log | 3.0 | 66 | 3.0342 |
| No log | 4.0 | 88 | 2.9416 |
| No log | 5.0 | 110 | 2.9009 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
ptaszynski/yacis-electra-small-japanese-cyberbullying
|
ptaszynski
| 2022-01-16T13:51:28Z | 61 | 6 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: ja
license: cc-by-sa-4.0
datasets:
- YACIS corpus
- Harmful BBS Japanese comments dataset
- Twitter Japanese cyberbullying dataset
---
# yacis-electra-small-cyberbullying
This is an [ELECTRA](https://github.com/google-research/electra) Small model for the Japanese language finetuned for automatic cyberbullying detection.
The original foundation model was originally pretrained on 5.6 billion words [YACIS](https://github.com/ptaszynski/yacis-corpus) blog corpus, and later finetuned on a balanced dataset created by unifying two datasets, namely "Harmful BBS Japanese comments dataset" and "Twitter Japanese cyberbullying dataset".
## Model architecture
The original model was pretrained using ELECTRA Small model settings and can be found here:
[https://huggingface.co/ptaszynski/yacis-electra-small-japanese](https://huggingface.co/ptaszynski/yacis-electra-small-japanese)
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{shibata2022yacis-electra,
title={日本語大規模ブログコーパスYACISに基づいたELECTRA事前学習済み言語モデルの作成及び性能評価},
% title={Development and performance evaluation of ELECTRA pretrained language model based on YACIS large-scale Japanese blog corpus [in Japanese]}, %% for English citations
author={柴田 祥伍 and プタシンスキ ミハウ and エロネン ユーソ and ノヴァコフスキ カロル and 桝井 文人},
% author={Shibata, Shogo and Ptaszynski, Michal and Eronen, Juuso and Nowakowski, Karol and Masui, Fumito}, %% for English citations
booktitle={言語処理学会第28回年次大会(NLP2022) (予定)},
% booktitle={Proceedings of The 28th Annual Meeting of The Association for Natural Language Processing (NLP2022)}, %% for English citations
pages={1--4},
year={2022}
}
```
The two datasets used for finetuning should be cited using the following references.
- Harmful BBS Japanese comments dataset:
```
@book{ptaszynski2018automatic,
title={Automatic Cyberbullying Detection: Emerging Research and Opportunities: Emerging Research and Opportunities},
author={Ptaszynski, Michal E and Masui, Fumito},
year={2018},
publisher={IGI Global}
}
```
```
@article{松葉達明2009学校非公式サイトにおける有害情報検出,
title={学校非公式サイトにおける有害情報検出},
author={松葉達明 and 里見尚宏 and 桝井文人 and 河合敦夫 and 井須尚紀},
journal={電子情報通信学会技術研究報告. NLC, 言語理解とコミュニケーション},
volume={109},
number={142},
pages={93--98},
year={2009},
publisher={一般社団法人電子情報通信学会}
}
```
- Twitter Japanese cyberbullying dataset:
```
TBA
```
The pretraining was done using YACIS corpus, which should be cited using at least one of the following references.
```
@inproceedings{ptaszynski2012yacis,
title={YACIS: A five-billion-word corpus of Japanese blogs fully annotated with syntactic and affective information},
author={Ptaszynski, Michal and Dybala, Pawel and Rzepka, Rafal and Araki, Kenji and Momouchi, Yoshio},
booktitle={Proceedings of the AISB/IACAP world congress},
pages={40--49},
year={2012},
howpublished = "\url{https://github.com/ptaszynski/yacis-corpus}"
}
```
```
@article{ptaszynski2014automatically,
title={Automatically annotating a five-billion-word corpus of Japanese blogs for sentiment and affect analysis},
author={Ptaszynski, Michal and Rzepka, Rafal and Araki, Kenji and Momouchi, Yoshio},
journal={Computer Speech \& Language},
volume={28},
number={1},
pages={38--55},
year={2014},
publisher={Elsevier},
howpublished = "\url{https://github.com/ptaszynski/yacis-corpus}"
}
```
|
porpaul/t5-small-finetuned-xsum
|
porpaul
| 2022-01-16T06:59:38Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xlsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xlsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xlsum
type: xlsum
args: chinese_traditional
metrics:
- name: Rouge1
type: rouge
value: 0.5217
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2188
- Rouge1: 0.5217
- Rouge2: 0.0464
- Rougel: 0.527
- Rougelsum: 0.5215
- Gen Len: 6.7441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.3831 | 1.0 | 7475 | 1.2188 | 0.5217 | 0.0464 | 0.527 | 0.5215 | 6.7441 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
anzorq/t5-v1_1-small-ru_kbd-cased
|
anzorq
| 2022-01-16T05:24:51Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"translation",
"ru",
"kbd",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:05Z |
---
language:
- ru
- kbd
tags:
- translation
datasets:
- anzorq/kbd-ru-1.67M-temp
- 17753 Russian-Kabardian pairs of text
widget:
- text: "ru->kbd: Я иду домой."
example_title: "Я иду домой."
- text: "ru->kbd: Дети играют во дворе."
example_title: "Дети играют во дворе."
- text: "ru->kbd: Сколько тебе лет?"
example_title: "Сколько тебе лет?"
---
## [google/t5-v1_1-small](google/t5-v1_1-small) model
### pretrained on [anzorq/kbd-ru-1.67M-temp](https://huggingface.co/datasets/anzorq/kbd-ru-1.67M-temp)
### fine-tuned on **17753** Russian-Kabardian word/sentence pairs
kbd text uses custom latin script for optimization reasons.
Translation input should start with '**ru->kbd:** '.
**Tokenizer**: T5 sentencepiece, char, cased.
|
matthewburke/korean_sentiment
|
matthewburke
| 2022-01-16T02:31:37Z | 4,148 | 16 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
```
from transformers import pipeline
classifier = pipeline("text-classification", model="matthewburke/korean_sentiment")
custom_tweet = "영화 재밌다."
preds = classifier(custom_tweet, return_all_scores=True)
is_positive = preds[0][1]['score'] > 0.5
```
|
haji2438/bertweet-base-SNS_BRANDS_100k
|
haji2438
| 2022-01-16T02:23:32Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: bertweet-base-SNS_BRANDS_100k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-base-SNS_BRANDS_100k
This model is a fine-tuned version of [vinai/bertweet-base](https://huggingface.co/vinai/bertweet-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0735 | 1.0 | 2928 | 0.0670 |
| 0.0574 | 2.0 | 5856 | 0.0529 |
| 0.0497 | 3.0 | 8784 | 0.0483 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-1
|
husnu
| 2022-01-15T20:09:15Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-1
This model is a fine-tuned version of [husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3](https://huggingface.co/husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5885 | 1.0 | 2245 | 1.4196 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/nathanmarz
|
huggingtweets
| 2022-01-15T19:05:04Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/nathanmarz/1642273500624/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1068577679367127041/w7GXbl_e_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Nathan Marz</div>
<div style="text-align: center; font-size: 14px;">@nathanmarz</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Nathan Marz.
| Data | Nathan Marz |
| --- | --- |
| Tweets downloaded | 3188 |
| Retweets | 459 |
| Short tweets | 239 |
| Tweets kept | 2490 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1zmjgvn2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nathanmarz's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3rr35qq7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3rr35qq7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nathanmarz')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-3
|
husnu
| 2022-01-15T18:42:09Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- turkish squad v2
model-index:
- name: bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3TQUAD2-finetuned_lr-2e-05_epochs-3
This model is a fine-tuned version of [husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3](https://huggingface.co/husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3) on the turkish squad2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9011
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6404 | 1.0 | 2245 | 1.4524 |
| 0.403 | 2.0 | 4490 | 1.5638 |
| 0.2355 | 3.0 | 6735 | 1.9011 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Fraser/to_delete
|
Fraser
| 2022-01-15T15:08:51Z | 0 | 0 | null |
[
"program-synthesis",
"en",
"dataset:program-synthesis",
"license:mit",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language:
- en
thumbnail: "https://huggingface.co/Fraser/program-synthesis/resolve/main/img.png"
tags:
- program-synthesis
license: "mit"
datasets:
- program-synthesis
---
# Program Synthesis Data
Generated program synthesis datasets used to train [dreamcoder](https://github.com/ellisk42/ec).
Currently just supports text & list data.
```python
_FEATURES = datasets.Features(
{
"description": datasets.Value("string"),
"input": datasets.Value("string"),
"output": datasets.Value("string"),
"types": datasets.Value("string")
}
)
```

|
pediberto/autonlp-testing-504313966
|
pediberto
| 2022-01-15T15:02:13Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autonlp",
"unk",
"dataset:pediberto/autonlp-data-testing",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- pediberto/autonlp-data-testing
co2_eq_emissions: 12.994518654810642
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 504313966
- CO2 Emissions (in grams): 12.994518654810642
## Validation Metrics
- Loss: 0.19673296809196472
- Accuracy: 0.9398032027783138
- Precision: 0.9133115705476967
- Recall: 0.9718255499807025
- AUC: 0.985316873222122
- F1: 0.9416604338070308
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/pediberto/autonlp-testing-504313966
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("pediberto/autonlp-testing-504313966", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("pediberto/autonlp-testing-504313966", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
Huertas97/es_roberta_base_bne_leetspeak_ner
|
Huertas97
| 2022-01-15T11:55:46Z | 4 | 1 |
spacy
|
[
"spacy",
"token-classification",
"es",
"license:apache-2.0",
"model-index",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
tags:
- spacy
- token-classification
language:
- es
license: apache-2.0
widget:
- text: "La C0v!d es un 3ng@ño de los G0b!3rno$"
example_title: "Word camouflage detection"
model-index:
- name: es_roberta_base_bne_leetspeak_ner
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8979055626
- name: NER Recall
type: recall
value: 0.9393701406
- name: NER F Score
type: f_score
value: 0.9181699547
---
| Feature | Description |
| --- | --- |
| **Name** | `es_roberta_base_bne_leetspeak_ner` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `transformer`, `ner` |
| **Components** | `transformer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [PlanTL-GOB-ES/roberta-base-bne](https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne) model a transformer-based masked language model for the Spanish language pre-trained with a total of 570GB of clean and deduplicated text compiled from the web crawlings performed by the National Library of Spain (Biblioteca Nacional de España) <br> [LeetSpeak-NER](https://huggingface.co/spaces/Huertas97/LeetSpeak-NER) app where this model is in production for countering information disorders|
| **License** | Apache 2.0 |
| **Author** | [Álvaro Huertas García](https://www.linkedin.com/in/alvaro-huertas-garcia/) at [AI+DA](http://aida.etsisi.upm.es/) |
### Label Scheme
<details>
<summary>View label scheme (4 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `INV_CAMO`, `LEETSPEAK`, `MIX`, `PUNCT_CAMO` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 91.82 |
| `ENTS_P` | 89.79 |
| `ENTS_R` | 93.94 |
| `TRANSFORMER_LOSS` | 166484.92 |
| `NER_LOSS` | 318457.35 |
|
husnu/bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3
|
husnu
| 2022-01-15T07:25:53Z | 25 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-turkish-128k-cased-finetuned_lr-2e-05_epochs-3
This model is a fine-tuned version of [dbmdz/bert-base-turkish-128k-cased](https://huggingface.co/dbmdz/bert-base-turkish-128k-cased) on the turkish squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4724
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3911 | 1.0 | 1281 | 1.4900 |
| 0.9058 | 2.0 | 2562 | 1.3471 |
| 0.6747 | 3.0 | 3843 | 1.4724 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
khizon/distilbert-unreliable-news-eng-4L
|
khizon
| 2022-01-15T07:06:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Unreliable News Classifier (English)
Trained, validate, and tested using a subset of the NELA-GT-2018 dataset. The dataset is split such that there was no overlap in of news sources between the three sets.
This model used the pre-trained weights of `distilbert-base-cased` as starting point (only 4 layers) and was able to achieve 84% accuracy on the test set. It has less than 1% difference in performance compared to the BERT based model while having **2.0x** the speed.
For more details: [Github](https://github.com/khizon/CS284_final_project)
|
Abirate/gpt_3_finetuned_multi_x_science
|
Abirate
| 2022-01-15T06:16:57Z | 28 | 2 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
- Text Generation
- PyTorch
- Transformers
- gpt_neo
- text generation
---
## Petrained Model Description: Open Source Version of GPT-3
Generative Pre-trained Transformer 3 (GPT-3) is an autoregressive language model that uses deep learning to produce human-like text.
It is the third-generation language prediction model in the GPT-n series (and the successor to GPT-2) created by OpenAI
GPT-Neo (125M) is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 125M represents the number of parameters of this particular pre-trained model.
and first released in this [repository](https://github.com/EleutherAI/gpt-neo).
## Fine-tuned Model Description: GPT-3 fine-tuned Multi-XScience
The Open Source version of GPT-3: GPT-Neo(125M) has been fine-tuned on a dataset called "Multi-XScience": [Multi-XScience_Repository](https://github.com/yaolu/Multi-XScience): A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles.
I first fine-tuned and then deployed it using Google "Material Design" (on Anvil): [Abir Scientific text Generator](https://abir-scientific-text-generator.anvil.app/)
By fine-tuning GPT-Neo(Open Source version of GPT-3), on Multi-XScience dataset, the model is now able to generate scientific texts(even better than GPT-J(6B).
Try putting the prompt "attention is all" on both my [Abir Scientific text Generator](https://abir-scientific-text-generator.anvil.app/) and on the [ GPT-J Eleuther.ai Demo](https://6b.eleuther.ai/) to understand what I mean.
And Here's a demonstration video for this. [Video real-time Demontration](https://www.youtube.com/watch?v=XP8uZfnCYQI)
|
husnu/electra-small-turkish-uncased-discriminator-finetuned_lr-2e-05_epochs-3
|
husnu
| 2022-01-15T05:24:03Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"electra",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: electra-small-turkish-uncased-discriminator-finetuned_lr-2e-05_epochs-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-small-turkish-uncased-discriminator-finetuned_lr-2e-05_epochs-3
This model is a fine-tuned version of [loodos/electra-small-turkish-uncased-discriminator](https://huggingface.co/loodos/electra-small-turkish-uncased-discriminator) on the Turkish squad dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1669
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.5305 | 1.0 | 5818 | 2.4024 |
| 2.3264 | 2.0 | 11636 | 2.2298 |
| 2.1762 | 3.0 | 17454 | 2.1669 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
husnu/xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-6
|
husnu
| 2022-01-15T05:09:21Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-6
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on the Turkish squad dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 350 | 3.8389 |
| 4.4474 | 2.0 | 700 | 3.3748 |
| 3.512 | 3.0 | 1050 | 3.0657 |
| 3.512 | 4.0 | 1400 | 2.9219 |
| 3.1526 | 5.0 | 1750 | 2.8517 |
| 2.9972 | 6.0 | 2100 | 2.8135 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
husnu/xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-9
|
husnu
| 2022-01-15T05:08:37Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h256-uncased-TQUAD-finetuned_lr-2e-05_epochs-9
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on the Turkish squad dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.5236 | 1.0 | 1050 | 3.0042 |
| 2.8489 | 2.0 | 2100 | 2.5866 |
| 2.5485 | 3.0 | 3150 | 2.3526 |
| 2.4067 | 4.0 | 4200 | 2.3535 |
| 2.3091 | 5.0 | 5250 | 2.2862 |
| 2.2401 | 6.0 | 6300 | 2.3989 |
| 2.1715 | 7.0 | 7350 | 2.2284 |
| 2.1414 | 8.0 | 8400 | 2.2298 |
| 2.1221 | 9.0 | 9450 | 2.2340 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/autosport-formulaoneworld-speedcafe
|
huggingtweets
| 2022-01-15T03:24:30Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/autosport-formulaoneworld-speedcafe/1642217065882/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1192531689060200448/S9KoiehJ_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1294927107605356544/CVXTlp9y_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1468895545007775746/NIWzzmye_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Speedcafe.com & Formula One World & Autosport</div>
<div style="text-align: center; font-size: 14px;">@autosport-formulaoneworld-speedcafe</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Speedcafe.com & Formula One World & Autosport.
| Data | Speedcafe.com | Formula One World | Autosport |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3247 | 3250 |
| Retweets | 0 | 2778 | 52 |
| Short tweets | 3 | 178 | 15 |
| Tweets kept | 3247 | 291 | 3183 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/kcn72bl0/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @autosport-formulaoneworld-speedcafe's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2fq703qs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2fq703qs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/autosport-formulaoneworld-speedcafe')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/f1
|
huggingtweets
| 2022-01-15T02:57:32Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/f1/1642215447713/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1385670642327040001/Z5LaCXJI_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Formula 1</div>
<div style="text-align: center; font-size: 14px;">@f1</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Formula 1.
| Data | Formula 1 |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 157 |
| Short tweets | 35 |
| Tweets kept | 3058 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1tsp2kk9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @f1's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3vu2nlz5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3vu2nlz5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/f1')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
minimaxir/ai-generated-pokemon-rudalle
|
minimaxir
| 2022-01-15T01:41:47Z | 0 | 15 | null |
[
"pytorch",
"rudalle",
"pokemon",
"image-generation",
"en",
"license:mit",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- rudalle
- pokemon
- image-generation
license: mit
---
# ai-generated-pokemon-rudalle

A finetuned [ruDALL-E](https://github.com/sberbank-ai/ru-dalle) on Pokémon using the finetuning example Colab Notebook [linked in that repo](https://colab.research.google.com/drive/1Tb7J4PvvegWOybPfUubl5O7m5I24CBg5?usp=sharing). This model was used to create Pokémon that resulted in AI-Generated Pokémon that went viral ([10k+ retweets](https://twitter.com/minimaxir/status/1470913487085785089) on Twitter + [30k+ upvotes](https://www.reddit.com/r/pokemon/comments/rgmyxp/i_trained_an_ai_on_all_the_official_pokemon/) on Reddit)
The model used above was trained for 12 epochs (4.5 hours on a P100), at a max learning rate of `1e-5`.
## Demo
You can play with this model using [this Colab Notebook](https://colab.research.google.com/drive/1A3t2gQofQGeXo5z1BAr1zqYaqVg3czKd?usp=sharing).
## License
MIT
|
NbAiLab/roberta_NCC_des_128_decayfrom200
|
NbAiLab
| 2022-01-15T00:11:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Just for performing some experiments. Do not use.
|
huggingtweets/blueeyedgirlnft
|
huggingtweets
| 2022-01-14T22:28:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/blueeyedgirlnft/1642199309839/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1478488866730524675/y4KIjwym_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">ᵍᵐBlueEyedGirl.ᴺᶠᵀ😎🔻🦴</div>
<div style="text-align: center; font-size: 14px;">@blueeyedgirlnft</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ᵍᵐBlueEyedGirl.ᴺᶠᵀ😎🔻🦴.
| Data | ᵍᵐBlueEyedGirl.ᴺᶠᵀ😎🔻🦴 |
| --- | --- |
| Tweets downloaded | 588 |
| Retweets | 349 |
| Short tweets | 154 |
| Tweets kept | 85 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/9tllree8/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @blueeyedgirlnft's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2q6w52hj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2q6w52hj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/blueeyedgirlnft')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
husnu/xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-6
|
husnu
| 2022-01-14T20:57:15Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-6
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2578
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.3828 | 1.0 | 1845 | 1.7946 |
| 1.5827 | 2.0 | 3690 | 1.4123 |
| 1.404 | 3.0 | 5535 | 1.3142 |
| 1.346 | 4.0 | 7380 | 1.2819 |
| 1.2871 | 5.0 | 9225 | 1.2630 |
| 1.2538 | 6.0 | 11070 | 1.2578 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
socrates/socrates2.0
|
socrates
| 2022-01-14T16:07:04Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
The unexamined life is not worth living
|
erwanlc/t5-coktails_recipe-small
|
erwanlc
| 2022-01-14T14:32:10Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-coktails_recipe-small
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-coktails_recipe-small
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
addy88/eli5-all-mpnet-base-v2
|
addy88
| 2022-01-14T13:24:40Z | 14 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-02T23:29:05Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. Finetune on [ELI5](https://huggingface.co/datasets/eli5)
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('addy88/eli5-all-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('addy88/eli5-all-mpnet-base-v2')
model = AutoModel.from_pretrained('addy88/eli5-all-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=addy88/eli5-all-mpnet-base-v2)
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 14393 with parameters:
```
{'batch_size': 16}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1439,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
vachonni/wav2vec2-large-xls-r-300m-da-colab
|
vachonni
| 2022-01-14T12:14:53Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-da-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-da-colab
This model is a fine-tuned version of [Alvenir/wav2vec2-base-da](https://huggingface.co/Alvenir/wav2vec2-base-da) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
zhichao158/wav2vec2-xls-r-common_voice-tr-ft
|
zhichao158
| 2022-01-14T07:03:32Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common_voice",
"generated_from_trainer",
"tr",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- tr
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-xls-r-common_voice-tr-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-common_voice-tr-ft
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the COMMON_VOICE - TR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3736
- Wer: 0.2930
- Cer: 0.0708
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 96
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 0.5462 | 13.51 | 500 | 0.4423 | 0.4807 | 0.1188 |
| 0.342 | 27.03 | 1000 | 0.3781 | 0.3954 | 0.0967 |
| 0.2272 | 40.54 | 1500 | 0.3816 | 0.3595 | 0.0893 |
| 0.1805 | 54.05 | 2000 | 0.3943 | 0.3487 | 0.0854 |
| 0.1318 | 67.57 | 2500 | 0.3818 | 0.3262 | 0.0801 |
| 0.1213 | 81.08 | 3000 | 0.3777 | 0.3113 | 0.0758 |
| 0.0639 | 94.59 | 3500 | 0.3788 | 0.2953 | 0.0716 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.8.0
- Datasets 1.17.0
- Tokenizers 0.10.3
|
LACAI/DialoGPT-large-PFG
|
LACAI
| 2022-01-14T05:18:30Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
Base model: [microsoft/DialoGPT-large](https://huggingface.co/microsoft/DialoGPT-large)
Fine tuned for dialogue response generation on the [Persuasion For Good Dataset](https://gitlab.com/ucdavisnlp/persuasionforgood) (Wang et al., 2019)
Three additional special tokens were added during the fine-tuning process:
- <|pad|> padding token
- <|user|> speaker control token to prompt user responses
- <|system|> speaker control token to prompt system responses
The following Dialogues were excluded:
- Those with donation amounts outside of the task range of [$0, $2].
- Those where a donation of 0 was made at the end of the task but a non-zero amount was pledged in the dialogue.
- Those with more than 800 words.
Stats:
- Training set: 519 dialogues
- Validation set: 58 dialogues
- ~20 utterances per dialogue
|
jiobiala24/wav2vec2-base-checkpoint-3
|
jiobiala24
| 2022-01-14T02:59:48Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-base-checkpoint-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-checkpoint-3
This model is a fine-tuned version of [jiobiala24/wav2vec2-base-checkpoint-2](https://huggingface.co/jiobiala24/wav2vec2-base-checkpoint-2) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7007
- Wer: 0.5514
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.358 | 14.8 | 400 | 1.4841 | 0.5338 |
| 0.1296 | 29.62 | 800 | 1.7007 | 0.5514 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
bob80333/speechbrain_ja2en_st_63M_yt600h
|
bob80333
| 2022-01-14T00:45:47Z | 18 | 1 |
speechbrain
|
[
"speechbrain",
"speech-translation",
"CTC",
"Attention",
"Transformer",
"pytorch",
"automatic-speech-recognition",
"en",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: "en"
thumbnail:
tags:
- speech-translation
- CTC
- Attention
- Transformer
- pytorch
- speechbrain
- automatic-speech-recognition
metrics:
- BLEU
---
# Conformer Encoder/Decoder for Speech Translation
This model was trained with [SpeechBrain](https://speechbrain.github.io), and is based on the Fisher Callhome recipie.
The performance of the model is the following:
| Release | CoVoSTv2 JA->EN Test BLEU | Custom Dataset Validation BLEU | Custom Dataset Test BLEU | GPUs |
|:-------------:|:--------------:|:--------------:|:--------------:|:--------:|
| 01-13-21 | 9.73 | 8.38 | 12.01 | 1xRTX 3090 |
This model was trained on subtitled audio downloaded from YouTube, and was not fine-tuned on the CoVoSTv2 training set.
When calculating the BLEU score for CoVoSTv2, the utterances were first preprocessed by the same pipeline that preprocessed the original data for the model, which includes removing all punctuation outside of apostrophes, and removing capitalization, similar to the data preprocessing done for the Fisher Callhome dataset in the speechbrain recipe.
## Pipeline description
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *transcribe_file* if needed.
## Install SpeechBrain
First of all, install SpeechBrain with the following command:
```
pip install speechbrain
```
### Transcribing your own audio files (Spoken Japanese, to written English)
```python
from speechbrain.pretrained import EncoderDecoderASR
st_model = EncoderDecoderASR.from_hparams(source="bob80333/speechbrain_ja2en_st_63M_yt600h")
st_model.transcribe_file("your_file_here.wav")
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Limitations:
The model is likely to get caught in repetitions. The model is not very good at translation, which is reflected by its low BLEU scores.
The outputs of this model are unlikely to be correct, do not rely on it for any serious purpose.
This model was trained on data from Youtube, and has inherited whatever biases can be found in Youtube audio/subtitles.
The creator of this model doesn't actually know Japanese.
|
atu/paddle_detection
|
atu
| 2022-01-14T00:33:03Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
一个测试Paddle 服务器模型的项目
|
husnu/xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-3
|
husnu
| 2022-01-14T00:17:31Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtremedistil-l6-h256-uncased-finetuned_lr-2e-05_epochs-3
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.6088 | 1.0 | 5533 | 1.4429 |
| 1.3928 | 2.0 | 11066 | 1.3183 |
| 1.3059 | 3.0 | 16599 | 1.2864 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
carlosaguayo/cats_vs_dogs
|
carlosaguayo
| 2022-01-13T21:58:53Z | 9 | 3 |
tf-keras
|
[
"tf-keras",
"image-classification",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
tags:
- image-classification
widget:
- src: https://upload.wikimedia.org/wikipedia/commons/0/0c/About_The_Dog.jpg
example_title: Dog-1
- src: https://yt3.ggpht.com/ytc/AKedOLRvxGYSdEHqu0X4EYcJ2kq7BttRKBNpfwdHJf3FSg=s900-c-k-c0x00ffffff-no-rj
example_title: Dog-2
- src: https://upload.wikimedia.org/wikipedia/commons/c/c7/Tabby_cat_with_blue_eyes-3336579.jpg
example_title: Cat-1
- src: https://pixabay.com/get/g31cf3b945cf9b9144eb6c1ecf514b4db668875b75d0c615e0330aec74bef5edde11567ef4a6f5fdb61a828b8086a39d3a0e72fb326d78467786dcdde4e6fa23c5c4c309d0abc089a8663809c175aee22_1920.jpg
example_title: Cat-2
---
# Classify Cats and Dogs
VGG16 fine tuned to classify cats and dogs
Notebook
https://www.kaggle.com/carlosaguayo/cats-vs-dogs-transfer-learning-pre-trained-vgg16
### How to use
Here is how to use this model to classify an image as a cat or dog:
```python
from skimage import io
import cv2
import matplotlib.pyplot as plt
from huggingface_hub import from_pretrained_keras
%matplotlib inline
ROWS, COLS = 150, 150
model = from_pretrained_keras("carlosaguayo/cats_vs_dogs")
img_url = 'https://upload.wikimedia.org/wikipedia/commons/0/0c/About_The_Dog.jpg'
# img_url = 'https://upload.wikimedia.org/wikipedia/commons/c/c7/Tabby_cat_with_blue_eyes-3336579.jpg'
img = io.imread(img_url)
img = cv2.resize(img, (ROWS, COLS), interpolation=cv2.INTER_CUBIC)
img = img / 255.0
img = img.reshape(1,ROWS,COLS,3)
prediction = model.predict(img)[0][0]
if prediction >= 0.5:
print('I am {:.2%} sure this is a Cat'.format(prediction))
else:
print('I am {:.2%} sure this is a Dog'.format(1-prediction))
plt.imshow(img[0], 'Blues')
plt.axis("off")
plt.show()
```
|
alaggung/bart-rl
|
alaggung
| 2022-01-13T17:18:17Z | 180 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bart",
"text2text-generation",
"summarization",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language:
- ko
tags:
- summarization
widget:
- text: "[BOS]밥 ㄱ?[SEP]고고고고 뭐 먹을까?[SEP]어제 김치찌개 먹어서 한식말고 딴 거[SEP]그럼 돈까스 어때?[SEP]오 좋다 1시 학관 앞으로 오셈[SEP]ㅇㅋ[EOS]"
inference:
parameters:
max_length: 64
top_k: 5
---
# BART R3F
[2021 훈민정음 한국어 음성•자연어 인공지능 경진대회] 대화요약 부문 알라꿍달라꿍 팀의 대화요약 학습 샘플 모델을 공유합니다.
[bart-r3f](https://huggingface.co/alaggung/bart-r3f) 모델에 [2021-dialogue-summary-competition](https://github.com/cosmoquester/2021-dialogue-summary-competition) 레포지토리의 RL 기법을 적용해 대화요약 Task를 학습한 모델입니다.
데이터는 [AIHub 한국어 대화요약](https://aihub.or.kr/aidata/30714) 데이터를 사용하였습니다.
|
flax-community/pino-bigbird-roberta-base
|
flax-community
| 2022-01-13T15:29:26Z | 34 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"big_bird",
"fill-mask",
"nl",
"dataset:mC4",
"dataset:Dutch_news",
"arxiv:2007.14062",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: nl
datasets:
- mC4
- Dutch_news
---
# Pino (Dutch BigBird) base model
Created by [Dat Nguyen](https://www.linkedin.com/in/dat-nguyen-49a641138/) & [Yeb Havinga](https://www.linkedin.com/in/yeb-havinga-86530825/) during the [Hugging Face community week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
(Not finished yet)
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
It is a pretrained model on Dutch language using a masked language modeling (MLM) objective. It was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdModel
# by default its in `block_sparse` mode with num_random_blocks=3, block_size=64
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base")
# you can change `attention_type` to full attention like this:
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdModel.from_pretrained("flax-community/pino-bigbird-roberta-base", block_size=16, num_random_blocks=2)
```
## Training Data
This model is pre-trained on four publicly available datasets: **mC4**, and scraped **Dutch news** from NRC en Nu.nl. It uses the the fast universal Byte-level BPE (BBPE) in contrast to the sentence piece tokenizer and vocabulary as RoBERTa (which is in turn borrowed from GPT2).
## Training Procedure
The data is cleaned as follows:
Remove texts containing HTML codes / javascript codes / loremipsum / policies
Remove lines without end mark.
Remove too short texts, words
Remove too long texts, words
Remove bad words
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
keras-io/semantic-segmentation
|
keras-io
| 2022-01-13T14:54:18Z | 31 | 16 |
generic
|
[
"generic",
"tf",
"image-segmentation",
"license:cc0-1.0",
"region:us"
] |
image-segmentation
| 2022-03-02T23:29:05Z |
---
tags:
- image-segmentation
- generic
library_name: generic
dataset:
- oxfort-iit pets
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-1.jpg
example_title: Kedis
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat in a Crate
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-3.jpg
example_title: Two Cats Chilling
license: cc0-1.0
---
## Keras semantic segmentation models on the 🤗Hub! 🐶 🐕 🐩
Full credits go to [François Chollet](https://twitter.com/fchollet).
This repository contains the model from [this notebook on segmenting pets using U-net-like architecture](https://keras.io/examples/vision/oxford_pets_image_segmentation/). We've changed the inference part to enable segmentation widget on the Hub. (see ```pipeline.py```)
## Background Information
Image classification task tells us about a class assigned to an image, and object detection task creates a boundary box on an object in an image. But what if we want to know about the shape of the image? Segmentation models helps us segment images and reveal their shapes. It has many variants, including, panoptic segmentation, instance segmentation and semantic segmentation.This post is on hosting your Keras semantic segmentation models on Hub.
Semantic segmentation models classify pixels, meaning, they assign a class (can be cat or dog) to each pixel. The output of a model looks like following.

We need to get the best prediction for every pixel.

This is still not readable. We have to convert this into different binary masks for each class and convert to a readable format by converting each mask into base64. We will return a list of dicts, and for each dictionary, we have the label itself, the base64 code and a score (semantic segmentation models don't return a score, so we have to return 1.0 for this case). You can find the full implementation in ```pipeline.py```.

Now that you know the expected output by the model, you can host your Keras segmentation models (and other semantic segmentation models) in the similar fashion. Try it yourself and host your segmentation models!

|
keras-io/image-captioning
|
keras-io
| 2022-01-13T14:52:23Z | 0 | 8 |
generic
|
[
"generic",
"tf-keras",
"image-to-text",
"arxiv:1502.03044",
"license:cc0-1.0",
"region:us"
] |
image-to-text
| 2022-03-02T23:29:05Z |
---
tags:
- image-to-text
- generic
library_name: generic
pipeline_tag: image-to-text
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-1.jpg
example_title: Kedis
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat in a Crate
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-3.jpg
example_title: Two Cats Chilling
license: cc0-1.0
---
## Tensorflow Keras Implementation of an Image Captioning Model with encoder-decoder network. 🌃🌅🎑
This repo contains the models and the notebook [on Image captioning with visual attention](https://www.tensorflow.org/tutorials/text/image_captioning?hl=en).
Full credits to TensorFlow Team
## Background Information
This notebook implements TensorFlow Keras implementation on Image captioning with visual attention.
Given an image like the example below, your goal is to generate a caption such as "a surfer riding on a wave".

To accomplish this, you'll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
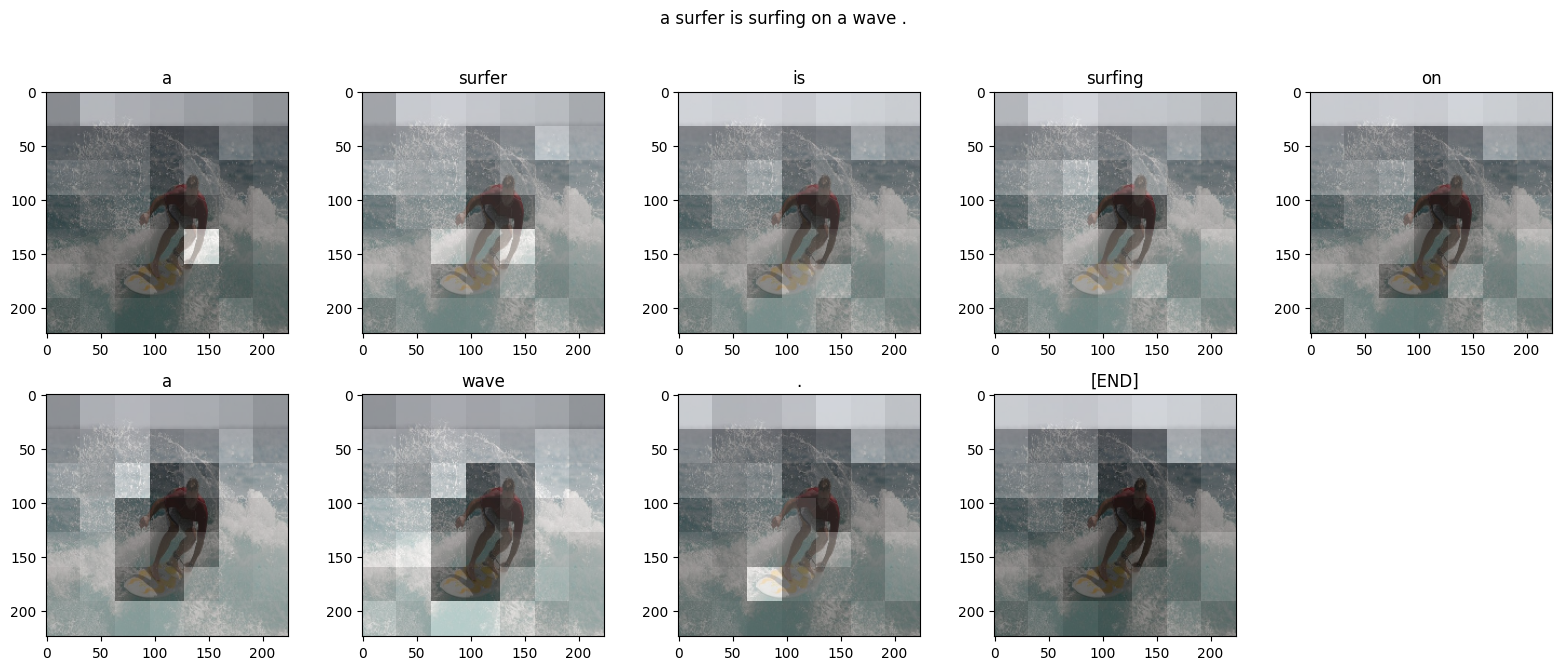
The model architecture is similar to [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044).
This notebook is an end-to-end example. When you run the notebook, it downloads the [MS-COCO](https://cocodataset.org/#home) dataset, preprocesses and caches a subset of images using Inception V3, trains an encoder-decoder model, and generates captions on new images using the trained model.
|
mahaamami/distilroberta-base-model
|
mahaamami
| 2022-01-13T12:02:01Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.0892 | 1.0 | 27036 | 1.8990 |
| 1.9644 | 2.0 | 54072 | 1.8040 |
| 1.9174 | 3.0 | 81108 | 1.7929 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
nikcook/distilbert-base-uncased-finetuned-squad
|
nikcook
| 2022-01-13T11:28:01Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1581
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2199 | 1.0 | 5533 | 1.1525 |
| 0.9463 | 2.0 | 11066 | 1.1298 |
| 0.7636 | 3.0 | 16599 | 1.1581 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/hazuma
|
huggingtweets
| 2022-01-13T09:23:08Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/hazuma/1642065783369/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1322114245467598850/pz_yTcye_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">東浩紀 Hiroki Azuma</div>
<div style="text-align: center; font-size: 14px;">@hazuma</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 東浩紀 Hiroki Azuma.
| Data | 東浩紀 Hiroki Azuma |
| --- | --- |
| Tweets downloaded | 3230 |
| Retweets | 1492 |
| Short tweets | 1560 |
| Tweets kept | 178 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ig7ewkg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hazuma's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1uix46e5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1uix46e5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hazuma')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/tsuda
|
huggingtweets
| 2022-01-13T08:46:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/tsuda/1642063525628/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1433345543963508738/qEUwKlFD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">津田大介</div>
<div style="text-align: center; font-size: 14px;">@tsuda</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 津田大介.
| Data | 津田大介 |
| --- | --- |
| Tweets downloaded | 3244 |
| Retweets | 2873 |
| Short tweets | 227 |
| Tweets kept | 144 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/o0sc3rb4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tsuda's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1qjnl0op) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1qjnl0op/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tsuda')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/elonmusk-hirox246-hitoshinagai1
|
huggingtweets
| 2022-01-13T07:16:46Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1474910968157249536/FS8-70Ie_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/646595746905620480/oeKI14gB_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1015469378777706496/WqKzDTb3_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Elon Musk & ひろゆき, Hiroyuki Nishimura & 永井均</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-hirox246-hitoshinagai1</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Elon Musk & ひろゆき, Hiroyuki Nishimura & 永井均.
| Data | Elon Musk | ひろゆき, Hiroyuki Nishimura | 永井均 |
| --- | --- | --- | --- |
| Tweets downloaded | 2022 | 3248 | 3245 |
| Retweets | 95 | 281 | 53 |
| Short tweets | 598 | 1980 | 3056 |
| Tweets kept | 1329 | 987 | 136 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1dzgeuwp/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-hirox246-hitoshinagai1's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/12mhdct8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/12mhdct8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-hirox246-hitoshinagai1')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
flboehm/youtube-bert
|
flboehm
| 2022-01-12T21:29:46Z | 10 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: youtube-bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# youtube-bert
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.691 | 1.0 | 1077 | 2.5445 |
| 2.5768 | 2.0 | 2154 | 2.5226 |
| 2.5227 | 3.0 | 3231 | 2.5027 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Rocketknight1/transformers-qa
|
Rocketknight1
| 2022-01-12T17:31:11Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: transformers-qa
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# transformers-qa
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.9300
- Validation Loss: 1.1437
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.5145 | 1.1500 | 0 |
| 0.9300 | 1.1437 | 1 |
### Framework versions
- Transformers 4.16.0.dev0
- TensorFlow 2.6.0
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
justin871030/bert-base-uncased-goemotions-ekman-finetuned
|
justin871030
| 2022-01-12T12:44:49Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"go-emotion",
"text-classification",
"en",
"dataset:go_emotions",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- go-emotion
- text-classification
- pytorch
datasets:
- go_emotions
metrics:
- f1
widget:
- text: "Thanks for giving advice to the people who need it! 👌🙏"
license: mit
---
## Model Description
1. Based on the uncased BERT pretrained model with a linear output layer.
2. Added several commonly-used emoji and tokens to the special token list of the tokenizer.
3. Did label smoothing while training.
4. Used weighted loss and focal loss to help the cases which trained badly.
|
ibraheemmoosa/xlmindic-base-uniscript-soham
|
ibraheemmoosa
| 2022-01-12T12:28:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"albert",
"text-classification",
"multilingual",
"xlmindic",
"nlp",
"indoaryan",
"indicnlp",
"iso15919",
"transliteration",
"as",
"bn",
"gu",
"hi",
"mr",
"ne",
"or",
"pa",
"si",
"sa",
"bpy",
"mai",
"bh",
"gom",
"dataset:oscar",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- as
- bn
- gu
- hi
- mr
- ne
- or
- pa
- si
- sa
- bpy
- mai
- bh
- gom
license: apache-2.0
datasets:
- oscar
tags:
- multilingual
- albert
- xlmindic
- nlp
- indoaryan
- indicnlp
- iso15919
- transliteration
- text-classification
widget:
- text : 'cīnēra madhyāñcalē āraō ēkaṭi śaharēra bāsindārā ābāra gharabandī haẏē paṛēchēna. āja maṅgalabāra natuna karē lakaḍāuna–saṁkrānta bidhiniṣēdha jāri haōẏāra para gharē āṭakā paṛēchēna tām̐rā. karōnāra ati saṁkrāmaka natuna dharana amikranēra bistāra ṭhēkātē ēmana padakṣēpa niẏēchē kartr̥pakṣa. khabara bārtā saṁsthā ēēphapira.'
co2_eq_emissions:
emissions: "0.21 in grams of CO2"
source: "calculated using this webstie https://mlco2.github.io/impact/#compute"
training_type: "fine-tuning"
geographical_location: "NA"
hardware_used: "P100 for about 1.5 hours"
---
# XLMIndic Base Uniscript
This model is finetuned from [this model](https://huggingface.co/ibraheemmoosa/xlmindic-base-uniscript) on Soham Bangla News Classification task which is part of the IndicGLUE benchmark. **Before pretraining this model we transliterate the text to [ISO-15919](https://en.wikipedia.org/wiki/ISO_15919) format using the [Aksharamukha](https://pypi.org/project/aksharamukha/)
library.** A demo of Aksharamukha library is hosted [here](https://aksharamukha.appspot.com/converter)
where you can transliterate your text and use it on our model on the inference widget.
## Model description
This model has the same configuration as the [ALBERT Base v2 model](https://huggingface.co/albert-base-v2/). Specifically, this model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 768 hidden dimension
- 12 attention heads
- 11M parameters
- 512 sequence length
## Training data
This model was fine-tuned on Soham dataset that is part of the IndicGLUE benchmark.
## Transliteration
*The unique component of this model is that it takes in ISO-15919 transliterated text.*
The motivation behind this is this. When two languages share vocabularies, a machine learning model can exploit that to learn good cross-lingual representations. However if these two languages use different writing scripts it is difficult for a model to make the connection. Thus if if we can write the two languages in a single script then it is easier for the model to learn good cross-lingual representation.
For many of the scripts currently in use, there are standard transliteration schemes to convert to the Latin script. In particular, for the Indic scripts the ISO-15919 transliteration scheme is designed to consistently transliterate texts written in different Indic scripts to the Latin script.
An example of ISO-15919 transliteration for a piece of **Bangla** text is the following:
**Original:** "রবীন্দ্রনাথ ঠাকুর এফআরএএস (৭ মে ১৮৬১ - ৭ আগস্ট ১৯৪১; ২৫ বৈশাখ ১২৬৮ - ২২ শ্রাবণ ১৩৪৮ বঙ্গাব্দ) ছিলেন অগ্রণী বাঙালি কবি, ঔপন্যাসিক, সংগীতস্রষ্টা, নাট্যকার, চিত্রকর, ছোটগল্পকার, প্রাবন্ধিক, অভিনেতা, কণ্ঠশিল্পী ও দার্শনিক।"
**Transliterated:** 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli kabi, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika.'
Another example for a piece of **Hindi** text is the following:
**Original:** "चूंकि मानव परिवार के सभी सदस्यों के जन्मजात गौरव और समान तथा अविच्छिन्न अधिकार की स्वीकृति ही विश्व-शान्ति, न्याय और स्वतन्त्रता की बुनियाद है"
**Transliterated:** "cūṁki mānava parivāra kē sabhī sadasyōṁ kē janmajāta gaurava aura samāna tathā avicchinna adhikāra kī svīkr̥ti hī viśva-śānti, nyāya aura svatantratā kī buniyāda hai"
## Training procedure
### Preprocessing
The texts are transliterated to ISO-15919 format using the Aksharamukha library. Then these are tokenized using SentencePiece and a vocabulary size of 50,000.
### Training
The model was trained for 8 epochs with a batch size of 16 and a learning rate of *2e-5*.
## Evaluation results
See results specific to Soham in the following table.
### IndicGLUE
Task | mBERT | XLM-R | IndicBERT-Base | XLMIndic-Base-Uniscript (This Model) | XLMIndic-Base-Multiscript (Ablation Model)
-----| ----- | ----- | ------ | ------- | --------
Wikipedia Section Title Prediction | 71.90 | 65.45 | 69.40 | **81.78 ± 0.60** | 77.17 ± 0.76
Article Genre Classification | 88.64 | 96.61 | 97.72 | **98.70 ± 0.29** | 98.30 ± 0.26
Named Entity Recognition (F1-score) | 71.29 | 62.18 | 56.69 | **89.85 ± 1.14** | 83.19 ± 1.58
BBC Hindi News Article Classification | 60.55 | 75.52 | 74.60 | **79.14 ± 0.60** | 77.28 ± 1.50
Soham Bangla News Article Classification | 80.23 | 87.6 | 78.45 | **93.89 ± 0.48** | 93.22 ± 0.49
INLTK Gujarati Headlines Genre Classification | - | - | **92.91** | 90.73 ± 0.75 | 90.41 ± 0.69
INLTK Marathi Headlines Genre Classification | - | - | **94.30** | 92.04 ± 0.47 | 92.21 ± 0.23
IITP Hindi Product Reviews Sentiment Classification | 74.57 | **78.97** | 71.32 | 77.18 ± 0.77 | 76.33 ± 0.84
IITP Hindi Movie Reviews Sentiment Classification | 56.77 | 61.61 | 59.03 | **66.34 ± 0.16** | 65.91 ± 2.20
MIDAS Hindi Discourse Type Classification | 71.20 | **79.94** | 78.44 | 78.54 ± 0.91 | 78.39 ± 0.33
Cloze Style Question Answering (Fill-mask task) | - | - | 37.16 | **41.54** | 38.21
## Intended uses & limitations
This model is pretrained on Indo-Aryan languages. Thus it is intended to be used for downstream tasks on these languages. However, since Dravidian languages such as Malayalam, Telegu, Kannada etc share a lot of vocabulary with the Indo-Aryan languages, this model can potentially be used on those languages too (after transliterating the text to ISO-15919).
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=xlmindic) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
To use this model you will need to first install the [Aksharamukha](https://pypi.org/project/aksharamukha/) library.
```bash
pip install aksharamukha
```
Using this library you can transliterate any text wriiten in Indic scripts in the following way:
```python
>>> from aksharamukha import transliterate
>>> text = "चूंकि मानव परिवार के सभी सदस्यों के जन्मजात गौरव और समान तथा अविच्छिन्न अधिकार की स्वीकृति ही विश्व-शान्ति, न्याय और स्वतन्त्रता की बुनियाद है"
>>> transliterated_text = transliterate.process('autodetect', 'ISO', text)
>>> transliterated_text
"cūṁki mānava parivāra kē sabhī sadasyōṁ kē janmajāta gaurava aura samāna tathā avicchinna adhikāra kī svīkr̥ti hī viśva-śānti, nyāya aura svatantratā kī buniyāda hai"
```
Then you can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> from aksharamukha import transliterate
>>> unmasker = pipeline('fill-mask', model='ibraheemmoosa/xlmindic-base-uniscript')
>>> text = "রবীন্দ্রনাথ ঠাকুর এফআরএএস (৭ মে ১৮৬১ - ৭ আগস্ট ১৯৪১; ২৫ বৈশাখ ১২৬৮ - ২২ শ্রাবণ ১৩৪৮ বঙ্গাব্দ) ছিলেন অগ্রণী বাঙালি [MASK], ঔপন্যাসিক, সংগীতস্রষ্টা, নাট্যকার, চিত্রকর, ছোটগল্পকার, প্রাবন্ধিক, অভিনেতা, কণ্ঠশিল্পী ও দার্শনিক। ১৯১৩ সালে গীতাঞ্জলি কাব্যগ্রন্থের ইংরেজি অনুবাদের জন্য তিনি এশীয়দের মধ্যে সাহিত্যে প্রথম নোবেল পুরস্কার লাভ করেন।"
>>> transliterated_text = transliterate.process('Bengali', 'ISO', text)
>>> transliterated_text
'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli [MASK], aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama [MASK] puraskāra lābha karēna.'
>>> unmasker(transliterated_text)
[{'score': 0.39705055952072144,
'token': 1500,
'token_str': 'abhinētā',
'sequence': 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli abhinētā, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama nōbēla puraskāra lābha karēna.'},
{'score': 0.20499080419540405,
'token': 3585,
'token_str': 'kabi',
'sequence': 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli kabi, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama nōbēla puraskāra lābha karēna.'},
{'score': 0.1314290314912796,
'token': 15402,
'token_str': 'rājanētā',
'sequence': 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli rājanētā, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama nōbēla puraskāra lābha karēna.'},
{'score': 0.060830358415842056,
'token': 3212,
'token_str': 'kalākāra',
'sequence': 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli kalākāra, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama nōbēla puraskāra lābha karēna.'},
{'score': 0.035522934049367905,
'token': 11586,
'token_str': 'sāhityakāra',
'sequence': 'rabīndranātha ṭhākura ēphaāraēēsa (7 mē 1861 - 7 āgasṭa 1941; 25 baiśākha 1268 - 22 śrābaṇa 1348 baṅgābda) chilēna agraṇī bāṅāli sāhityakāra, aupanyāsika, saṁgītasraṣṭā, nāṭyakāra, citrakara, chōṭagalpakāra, prābandhika, abhinētā, kaṇṭhaśilpī ō dārśanika. 1913 sālē gītāñjali kābyagranthēra iṁrēji anubādēra janya tini ēśīẏadēra madhyē sāhityē prathama nōbēla puraskāra lābha karēna.'}]
```
### Limitations and bias
Even though we pretrain on a comparatively large multilingual corpus the model may exhibit harmful gender, ethnic and political bias. If you fine-tune this model on a task where these issues are important you should take special care when relying on the model to make decisions.
## Contact
Feel free to contact us if you have any ideas or if you want to know more about our models.
- Ibraheem Muhammad Moosa (ibraheemmoosa1347@gmail.com)
- Mahmud Elahi Akhter (mahmud.akhter01@northsouth.edu)
- Ashfia Binte Habib
## BibTeX entry and citation info
Coming soon!
|
huggingtweets/prof_preobr
|
huggingtweets
| 2022-01-12T10:06:59Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/853613144832446464/VrGXs0NZ_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Проф. Преображенский</div>
<div style="text-align: center; font-size: 14px;">@prof_preobr</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Проф. Преображенский.
| Data | Проф. Преображенский |
| --- | --- |
| Tweets downloaded | 3224 |
| Retweets | 567 |
| Short tweets | 61 |
| Tweets kept | 2596 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/12xdr90k/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @prof_preobr's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2vqtap5s) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2vqtap5s/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/prof_preobr')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
anirudh21/distilbert-base-uncased-finetuned-mrpc
|
anirudh21
| 2022-01-12T08:30:57Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8455882352941176
- name: F1
type: f1
value: 0.8958677685950412
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3830
- Accuracy: 0.8456
- F1: 0.8959
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.3826 | 0.8186 | 0.8683 |
| No log | 2.0 | 460 | 0.3830 | 0.8456 | 0.8959 |
| 0.4408 | 3.0 | 690 | 0.3835 | 0.8382 | 0.8866 |
| 0.4408 | 4.0 | 920 | 0.5036 | 0.8431 | 0.8919 |
| 0.1941 | 5.0 | 1150 | 0.5783 | 0.8431 | 0.8930 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
gpssohi/distilbart-qgen-3-3
|
gpssohi
| 2022-01-12T08:29:26Z | 14 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"question-generation",
"summarization",
"en",
"dataset:squad",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- question-generation
- summarization
license: apache-2.0
datasets:
- squad
---
# Introduction
This model checkpoint is obtained by first fine-tuning the sshleifer/distilbart-cnn-6-6 summarization checkpoint on the SQuAD dataset. After this, the 6-6 fine-tuned model is distilled down to a 3-3 model which gives us the final checkpoint. [GitHub Link for training scripts.](https://github.com/darth-c0d3r/bart-question-generation)
# Usage
The input format is as follows: `[answer] <s> [passage]`. The model will predict the question that corresponds to the answer from the passage.
# Plot

# Dataset
The goal of Question Generation is to generate a valid and fluent question according to a given passage and the target answer. Hence, the input to the model will be a passage context and an answer, and the output / target will be the question for the given answer. Question Generation can be used in many scenarios, such as automatic tutoring systems, improving the performance of Question Answering models and enabling chat-bots to lead a conversation. The final dataset is created by taking the union of the following Question Answering Datasets. The dataset must have the following three columns: context, question, answer.
## [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowd-workers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. We use the SQuAD 1.1 variant which does not have unanswerable questions. So, every question will have a corresponding answer and vice-versa.
### Preprocessing
The first step is to remove questions which don't have answers. After that, we split the train set into Train and Eval sets and treat the dev set as the test set.
### Stats
**Original Dataset**
| Split | Num Docs | Num Contexts | Ques w/ Ans | Ques w/o Ans | Num Unique Ans |
| ----- | -------- | ------------ | ----------- | ------------ | -------------- |
| Train | 442 | 19035 | 86821 | 43498 | 86821 |
| Dev | 35 | 1204 | 5928 | 5945 | 10279 |
**After Preprocessing**
| Split | Num Rows | Context | Answer | Question |
| ----- | -------- | ---------- | ------ | -------- |
| Train | 80995 | 653,120,20 | 43,3,1 | 40,10,1 |
| Eval | 5826 | 445,123,67 | 28,3,1 | 29,10,3 |
| Test | 10297 | 629,129,25 | 29,4,1 | 31,10,3 |
The numbers in the columns indicate max, avg, min number of words.
|
Jinhwan/krelectra-base-mecab
|
Jinhwan
| 2022-01-12T03:18:55Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"korean",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language: ko
license: apache-2.0
tags:
- korean
---
# KrELECTRA-base-mecab
Korean-based Pre-trained ELECTRA Language Model using Mecab (Morphological Analyzer)
## Usage
### Load model and tokenizer
```python
>>> from transformers import AutoTokenizer, AutoModelForPreTraining
>>> model = AutoModelForPreTraining.from_pretrained("Jinhwan/krelectra-base-mecab")
>>> tokenizer = AutoTokenizer.from_pretrained("Jinhwan/krelectra-base-mecab")
```
### Tokenizer example
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("Jinhwan/krelectra-base-mecab")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'EL', '##ECT', '##RA', '##를', '공유', '##합', '##니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'EL', '##ECT', '##RA', '##를', '공유', '##합', '##니다', '.', '[SEP]'])
[2, 7214, 24023, 24663, 26580, 3195, 7086, 3746, 5500, 17, 3]
|
avichr/heBERT_NER
|
avichr
| 2022-01-11T17:00:46Z | 4,122 | 5 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"arxiv:1810.04805",
"arxiv:2102.01909",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
# HeBERT: Pre-trained BERT for Polarity Analysis and Emotion Recognition
<img align="right" src="https://github.com/avichaychriqui/HeBERT/blob/main/data/heBERT_logo.png?raw=true" width="250">
HeBERT is a Hebrew pretrained language model. It is based on [Google's BERT](https://arxiv.org/abs/1810.04805) architecture and it is BERT-Base config. <br>
HeBert was trained on three dataset:
1. A Hebrew version of [OSCAR](https://oscar-corpus.com/): ~9.8 GB of data, including 1 billion words and over 20.8 millions sentences.
2. A Hebrew dump of [Wikipedia](https://dumps.wikimedia.org/): ~650 MB of data, including over 63 millions words and 3.8 millions sentences
3. Emotion User Generated Content (UGC) data that was collected for the purpose of this study (described below).
## Named-entity recognition (NER)
The ability of the model to classify named entities in text, such as persons' names, organizations, and locations; tested on a labeled dataset from [Ben Mordecai and M Elhadad (2005)](https://www.cs.bgu.ac.il/~elhadad/nlpproj/naama/), and evaluated with F1-score.
### How to use
```
from transformers import pipeline
# how to use?
NER = pipeline(
"token-classification",
model="avichr/heBERT_NER",
tokenizer="avichr/heBERT_NER",
)
NER('דויד לומד באוניברסיטה העברית שבירושלים')
```
## Other tasks
[**Emotion Recognition Model**](https://huggingface.co/avichr/hebEMO_trust).
An online model can be found at [huggingface spaces](https://huggingface.co/spaces/avichr/HebEMO_demo) or as [colab notebook](https://colab.research.google.com/drive/1Jw3gOWjwVMcZslu-ttXoNeD17lms1-ff?usp=sharing)
<br>
[**Sentiment Analysis**](https://huggingface.co/avichr/heBERT_sentiment_analysis).
<br>
[**masked-LM model**](https://huggingface.co/avichr/heBERT) (can be fine-tunned to any down-stream task).
## Contact us
[Avichay Chriqui](mailto:avichayc@mail.tau.ac.il) <br>
[Inbal yahav](mailto:inbalyahav@tauex.tau.ac.il) <br>
The Coller Semitic Languages AI Lab <br>
Thank you, תודה, شكرا <br>
## If you used this model please cite us as :
Chriqui, A., & Yahav, I. (2021). HeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition. arXiv preprint arXiv:2102.01909.
```
@article{chriqui2021hebert,
title={HeBERT \& HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition},
author={Chriqui, Avihay and Yahav, Inbal},
journal={arXiv preprint arXiv:2102.01909},
year={2021}
}
```
[git](https://github.com/avichaychriqui/HeBERT)
|
asakawa/wav2vec2-base-demo-colab
|
asakawa
| 2022-01-11T16:22:43Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4500
- Wer: 0.3391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.5329 | 4.0 | 500 | 1.5741 | 1.0400 |
| 0.6432 | 8.0 | 1000 | 0.4571 | 0.4418 |
| 0.2214 | 12.0 | 1500 | 0.4381 | 0.3823 |
| 0.1294 | 16.0 | 2000 | 0.4706 | 0.3911 |
| 0.0868 | 20.0 | 2500 | 0.5252 | 0.3662 |
| 0.0616 | 24.0 | 3000 | 0.4828 | 0.3458 |
| 0.0461 | 28.0 | 3500 | 0.4500 | 0.3391 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
alaggung/bart-r3f
|
alaggung
| 2022-01-11T16:18:32Z | 123 | 6 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bart",
"text2text-generation",
"summarization",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language:
- ko
tags:
- summarization
widget:
- text: "[BOS]밥 ㄱ?[SEP]고고고고 뭐 먹을까?[SEP]어제 김치찌개 먹어서 한식말고 딴 거[SEP]그럼 돈까스 어때?[SEP]오 좋다 1시 학관 앞으로 오셈[SEP]ㅇㅋ[EOS]"
inference:
parameters:
max_length: 64
top_k: 5
---
# BART R3F
[2021 훈민정음 한국어 음성•자연어 인공지능 경진대회] 대화요약 부문 알라꿍달라꿍 팀의 대화요약 학습 샘플 모델을 공유합니다.
[bart-pretrained](https://huggingface.co/alaggung/bart-pretrained) 모델에 [2021-dialogue-summary-competition](https://github.com/cosmoquester/2021-dialogue-summary-competition) 레포지토리의 R3F를 적용해 대화요약 Task를 학습한 모델입니다.
데이터는 [AIHub 한국어 대화요약](https://aihub.or.kr/aidata/30714) 데이터를 사용하였습니다.
|
alaggung/bart-pretrained
|
alaggung
| 2022-01-11T16:07:39Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bart",
"text2text-generation",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- ko
widget:
- text: "[BOS]뭐 해?[SEP][MASK]하다가 이제 [MASK]려고[EOS]"
inference:
parameters:
max_length: 64
---
# BART Pretrained
[2021 훈민정음 한국어 음성•자연어 인공지능 경진대회] 대화요약 부문 알라꿍달라꿍 팀의 대화요약 학습 샘플 모델을 공유합니다.
[2021-dialogue-summary-competition](https://github.com/cosmoquester/2021-dialogue-summary-competition) 레포지토리의 BART Pretrain 단계를 학습한 모델입니다.
데이터는 [AIHub 한국어 대화요약](https://aihub.or.kr/aidata/30714) 데이터를 사용하였습니다.
|
andreiliphdpr/distilbert-base-uncased-finetuned-cola
|
andreiliphdpr
| 2022-01-11T12:11:00Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: andreiliphdpr/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# andreiliphdpr/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0015
- Train Accuracy: 0.9995
- Validation Loss: 0.0570
- Validation Accuracy: 0.9915
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 43750, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.0399 | 0.9870 | 0.0281 | 0.9908 | 0 |
| 0.0182 | 0.9944 | 0.0326 | 0.9901 | 1 |
| 0.0089 | 0.9971 | 0.0396 | 0.9912 | 2 |
| 0.0040 | 0.9987 | 0.0486 | 0.9918 | 3 |
| 0.0015 | 0.9995 | 0.0570 | 0.9915 | 4 |
### Framework versions
- Transformers 4.15.0.dev0
- TensorFlow 2.6.2
- Datasets 1.15.1
- Tokenizers 0.10.3
|
moumeneb1/testing
|
moumeneb1
| 2022-01-11T09:16:45Z | 5 | 0 |
speechbrain
|
[
"speechbrain",
"wav2vec2",
"CTC",
"Attention",
"pytorch",
"Transformer",
"automatic-speech-recognition",
"rw",
"dataset:commonvoice",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: "rw"
thumbnail:
pipeline_tag: automatic-speech-recognition
tags:
- CTC
- Attention
- pytorch
- speechbrain
- Transformer
license: "apache-2.0"
datasets:
- commonvoice
metrics:
- wer
- cer
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# wav2vec 2.0 with CTC/Attention trained on CommonVoice Kinyarwanda (No LM)
This repository provides all the necessary tools to perform automatic speech
recognition from an end-to-end system pretrained on CommonVoice (Kinyarwanda Language) within
SpeechBrain. For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
The performance of the model is the following:
| Release | Test WER | GPUs |
|:--------------:|:--------------:| :--------:|
| 03-06-21 | 18.91 | 2xV100 32GB |
## Pipeline description
This ASR system is composed of 2 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units and trained with
the train transcriptions (train.tsv) of CommonVoice (RW).
- Acoustic model (wav2vec2.0 + CTC/Attention). A pretrained wav2vec 2.0 model ([wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)) is combined with two DNN layers and finetuned on CommonVoice En.
The obtained final acoustic representation is given to the CTC and attention decoders.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *transcribe_file* if needed.
## Install SpeechBrain
First of all, please install tranformers and SpeechBrain with the following command:
```
pip install speechbrain transformers
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Transcribing your own audio files (in Kinyarwanda)
```python
from speechbrain.pretrained import EncoderDecoderASR
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-wav2vec2-commonvoice-rw", savedir="pretrained_models/asr-wav2vec2-commonvoice-rw")
asr_model.transcribe_file("speechbrain/asr-wav2vec2-commonvoice-rw/example.mp3")
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
## Parallel Inference on a Batch
Please, [see this Colab notebook](https://colab.research.google.com/drive/1hX5ZI9S4jHIjahFCZnhwwQmFoGAi3tmu?usp=sharing) to figure out how to transcribe in parallel a batch of input sentences using a pre-trained model.
### Training
The model was trained with SpeechBrain.
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/CommonVoice/ASR/seq2seq
python train_with_wav2vec.py hparams/train_rw_with_wav2vec.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1tjz6IZmVRkuRE97E7h1cXFoGTer7pT73?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
Firat/albert-base-v2-finetuned-squad
|
Firat
| 2022-01-11T09:15:49Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: albert-base-v2-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.8584 | 1.0 | 5540 | 0.9056 |
| 0.6473 | 2.0 | 11080 | 0.8975 |
| 0.4801 | 3.0 | 16620 | 0.9901 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1
- Datasets 1.17.0
- Tokenizers 0.10.3
|
pritoms/gpt-neo-125M-philosophical-investigation
|
pritoms
| 2022-01-11T06:18:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: gpt-neo-125M-philosophical-investigation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-neo-125M-philosophical-investigation
This model is a fine-tuned version of [EleutherAI/gpt-neo-125M](https://huggingface.co/EleutherAI/gpt-neo-125M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4443
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 7 | 3.4901 |
| No log | 2.0 | 14 | 3.4550 |
| No log | 3.0 | 21 | 3.4443 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
kleinay/nominalization-candidate-classifier
|
kleinay
| 2022-01-11T04:12:39Z | 1,135 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"nominalizations",
"en",
"dataset:kleinay/qanom",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- pytorch
- token-classification
- nominalizations
datasets:
- kleinay/qanom
---
# Nominalization Detector
This model identifies "predicative nominalizations", that is, nominalizations that carry an eventive (or "verbal") meaning in context. It is a `bert-base-cased` pretrained model, fine-tuned for token classification on top of the "nominalization detection" task as defined and annotated by the QANom project [(Klein et. al., COLING 2020)](https://www.aclweb.org/anthology/2020.coling-main.274/).
## Task Description
The model is trained as a binary classifier, classifying candidate nominalizations.
The candidates are extracted using a POS tagger (filtering common nouns) and additionally lexical resources (e.g. WordNet and CatVar), filtering nouns that have (at least one) derivationally-related verb. In the QANom annotation project, these candidates are given to annotators to decide whether they carry a "verbal" meaning in the context of the sentence. The current model reproduces this binary classification.
## Demo
Check out our cool [demo](https://huggingface.co/spaces/kleinay/nominalization-detection-demo)!
## Usage
The candidate extraction algorithm is implemented inside the `qanom` package - see the README in the [QANom github repo](https://github.com/kleinay/QANom) for full documentation. The `qanom` package is also available via `pip install qanom`.
For ease of use, we encapsulated the full nominalization detection pipeline (i.e. candidate extraction + predicate classification) in the `qanom.nominalization_detector.NominalizationDetector` class, which internally utilize this `nominalization-candidate-classifier`:
```python
from qanom.nominalization_detector import NominalizationDetector
detector = NominalizationDetector()
raw_sentences = ["The construction of the officer 's building finished right after the beginning of the destruction of the previous construction ."]
print(detector(raw_sentences, return_all_candidates=True))
print(detector(raw_sentences, threshold=0.75, return_probability=False))
```
Outputs:
```json
[[{'predicate_idx': 1,
'predicate': 'construction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.7626778483390808,
'verb_form': 'construct'},
{'predicate_idx': 4,
'predicate': 'officer',
'predicate_detector_prediction': False,
'predicate_detector_probability': 0.19832570850849152,
'verb_form': 'officer'},
{'predicate_idx': 6,
'predicate': 'building',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.5794129371643066,
'verb_form': 'build'},
{'predicate_idx': 11,
'predicate': 'beginning',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.8937646150588989,
'verb_form': 'begin'},
{'predicate_idx': 14,
'predicate': 'destruction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.8501205444335938,
'verb_form': 'destruct'},
{'predicate_idx': 18,
'predicate': 'construction',
'predicate_detector_prediction': True,
'predicate_detector_probability': 0.7022264003753662,
'verb_form': 'construct'}]]
```
```json
[[{'predicate_idx': 1, 'predicate': 'construction', 'verb_form': 'construct'},
{'predicate_idx': 11, 'predicate': 'beginning', 'verb_form': 'begin'},
{'predicate_idx': 14, 'predicate': 'destruction', 'verb_form': 'destruct'}]]
```
## Cite
```latex
@inproceedings{klein2020qanom,
title={QANom: Question-Answer driven SRL for Nominalizations},
author={Klein, Ayal and Mamou, Jonathan and Pyatkin, Valentina and Stepanov, Daniela and He, Hangfeng and Roth, Dan and Zettlemoyer, Luke and Dagan, Ido},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={3069--3083},
year={2020}
}
```
|
tscholak/1wnr382e
|
tscholak
| 2022-01-10T21:50:25Z | 77 | 3 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- spider
metrics:
- spider
---
## tscholak/1wnr382e
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [T5-Large](https://huggingface.co/t5-large).
### Training Data
The model has been fine-tuned on the 7000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves Spider's zero-shot text-to-SQL translation task, and that means that it can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [T5-Large](https://huggingface.co/t5-large) and fine-tuned with the text-to-text generation objective.
Questions are always grounded in a database schema, and the model is trained to predict the SQL query that would be used to answer the question. The input to the model is composed of the user's natural language question, the database identifier, and a list of tables and their columns:
```
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ...
```
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's question:
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 65.3 % exact-set match accuracy and 67.2 % execution accuracy on the Spider development set.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **69.1 %** exact-set match accuracy and **72.9 %** execution accuracy on the Spider development set.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
```
|
tscholak/1zha5ono
|
tscholak
| 2022-01-10T21:50:11Z | 45 | 4 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- spider
metrics:
- spider
---
## tscholak/1zha5ono
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [t5.1.1.lm100k.base](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k).
### Training Data
The model has been fine-tuned on the 7000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves Spider's zero-shot text-to-SQL translation task, and that means that it can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [t5.1.1.lm100k.base](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) and fine-tuned with the text-to-text generation objective.
Questions are always grounded in a database schema, and the model is trained to predict the SQL query that would be used to answer the question. The input to the model is composed of the user's natural language question, the database identifier, and a list of tables and their columns:
```
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ...
```
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's question:
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 59.4 % exact-set match accuracy and 60.0 % execution accuracy on the Spider development set.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **66.6 %** exact-set match accuracy and **68.4 %** execution accuracy on the Spider development set.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
```
|
tscholak/cxmefzzi
|
tscholak
| 2022-01-10T21:49:50Z | 675 | 30 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- spider
metrics:
- spider
---
## tscholak/cxmefzzi
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [T5-3B](https://huggingface.co/t5-3b).
### Training Data
The model has been fine-tuned on the 7000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves Spider's zero-shot text-to-SQL translation task, and that means that it can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [T5-3B](https://huggingface.co/t5-3b) and fine-tuned with the text-to-text generation objective.
Questions are always grounded in a database schema, and the model is trained to predict the SQL query that would be used to answer the question. The input to the model is composed of the user's natural language question, the database identifier, and a list of tables and their columns:
```
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ...
```
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's question:
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 71.5 % exact-set match accuracy and 74.4 % execution accuracy on the Spider development set. On the test set, the model achieves 68.0 % exact-set match accuracy and 70.1 % execution accuracy.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **75.5 %** exact-set match accuracy and **79.3 %** execution accuracy on the Spider development set. On the test set and with PICARD, the model achieves **71.9 %** exact-set match accuracy and **75.1 %** execution accuracy.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
```
|
tscholak/3vnuv1vf
|
tscholak
| 2022-01-10T21:49:25Z | 162 | 10 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text2sql",
"en",
"dataset:spider",
"arxiv:2109.05093",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail: "https://repository-images.githubusercontent.com/401779782/c2f46be5-b74b-4620-ad64-57487be3b1ab"
tags:
- text2sql
widget:
- "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id"
license: "apache-2.0"
datasets:
- spider
metrics:
- spider
---
## tscholak/3vnuv1vf
Fine-tuned weights for [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093) based on [t5.1.1.lm100k.large](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k).
### Training Data
The model has been fine-tuned on the 7000 training examples in the [Spider text-to-SQL dataset](https://yale-lily.github.io/spider). The model solves Spider's zero-shot text-to-SQL translation task, and that means that it can generalize to unseen SQL databases.
### Training Objective
This model was initialized with [t5.1.1.lm100k.large](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) and fine-tuned with the text-to-text generation objective.
Questions are always grounded in a database schema, and the model is trained to predict the SQL query that would be used to answer the question. The input to the model is composed of the user's natural language question, the database identifier, and a list of tables and their columns:
```
[question] | [db_id] | [table] : [column] ( [content] , [content] ) , [column] ( ... ) , [...] | [table] : ... | ...
```
The model outputs the database identifier and the SQL query that will be executed on the database to answer the user's question:
```
[db_id] | [sql]
```
### Performance
Out of the box, this model achieves 71.2 % exact-set match accuracy and 74.4 % execution accuracy on the Spider development set.
Using the PICARD constrained decoding method (see [the official PICARD implementation](https://github.com/ElementAI/picard)), the model's performance can be improved to **74.8 %** exact-set match accuracy and **79.2 %** execution accuracy on the Spider development set.
### Usage
Please see [the official repository](https://github.com/ElementAI/picard) for scripts and docker images that support evaluation and serving of this model.
### References
1. [PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models](https://arxiv.org/abs/2109.05093)
2. [Official PICARD code](https://github.com/ElementAI/picard)
### Citation
```bibtex
@inproceedings{Scholak2021:PICARD,
author = {Torsten Scholak and Nathan Schucher and Dzmitry Bahdanau},
title = "{PICARD}: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.779",
pages = "9895--9901",
}
```
|
SaulLu/markuplm-base
|
SaulLu
| 2022-01-10T19:17:34Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"markuplm",
"arxiv:2110.08518",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:04Z |
# MarkupLM
**Multimodal (text +markup language) pre-training for [Document AI](https://www.microsoft.com/en-us/research/project/document-ai/)**
## Introduction
MarkupLM is a simple but effective multi-modal pre-training method of text and markup language for visually-rich document understanding and information extraction tasks, such as webpage QA and webpage information extraction. MarkupLM archives the SOTA results on multiple datasets. For more details, please refer to our paper:
[MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei
|
fhamborg/roberta-targeted-sentiment-classification-newsarticles
|
fhamborg
| 2022-01-10T16:16:01Z | 15 | 15 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"sentiment-analysis",
"sentiment-classification",
"targeted-sentiment-classification",
"target-depentent-sentiment-classification",
"en",
"dataset:fhamborg/news_sentiment_newsmtsc",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- text-classification
- sentiment-analysis
- sentiment-classification
- targeted-sentiment-classification
- target-depentent-sentiment-classification
license: "apache-2.0"
datasets: "fhamborg/news_sentiment_newsmtsc"
---
# NewsSentiment: easy-to-use, high-quality target-dependent sentiment classification for news articles
## Important: [use our PyPI package](https://pypi.org/project/NewsSentiment/) instead of this model on the Hub
The Huggingface Hub architecture currently [does not support](https://github.com/huggingface/transformers/issues/14785) target-dependent sentiment classification since you cannot provide the required inputs, i.e., sentence and target. Thus, we recommend that you use our easy-to-use [PyPI package NewsSentiment](https://pypi.org/project/NewsSentiment/).
## Description
This model is the currently [best performing](https://aclanthology.org/2021.eacl-main.142.pdf)
targeted sentiment classifier for news articles. In contrast to regular sentiment
classification, targeted sentiment classification allows you to provide a target in a sentence.
Only for this target, the sentiment is then predicted. This is more reliable in many
cases, as demonstrated by the following simplistic example: "I like Bert, but I hate Robert."
This model is also available as an easy-to-use PyPI package named [`NewsSentiment`](https://pypi.org/project/NewsSentiment/) and
in its original GitHub repository named [`NewsMTSC`](https://github.com/fhamborg/NewsMTSC), where you will find the dataset the model was trained on, other models for sentiment classification, and a training and testing framework. More information on the model and the dataset (consisting of more than 10k sentences sampled from news articles, each
labeled and agreed upon by at least 5 annotators) can be found in our [EACL paper](https://aclanthology.org/2021.eacl-main.142.pdf). The
dataset, the model, and its source code can be viewed in our [GitHub repository](https://github.com/fhamborg/NewsMTSC).
We recommend to use our [PyPI package](https://pypi.org/project/NewsSentiment/) for sentiment classification since the Huggingface Hub platform seems to [not support](https://github.com/huggingface/transformers/issues/14785) target-dependent sentiment classification.
# How to cite
If you use the dataset or model, please cite our [paper](https://www.aclweb.org/anthology/2021.eacl-main.142/) ([PDF](https://www.aclweb.org/anthology/2021.eacl-main.142.pdf)):
```
@InProceedings{Hamborg2021b,
author = {Hamborg, Felix and Donnay, Karsten},
title = {NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles},
booktitle = {Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2021)},
year = {2021},
month = {Apr.},
location = {Virtual Event},
}
```
|
ibm-research/tslm-discourse-markers
|
ibm-research
| 2022-01-10T14:42:41Z | 0 | 0 | null |
[
"arxiv:2201.02026",
"region:us"
] | null | 2022-03-02T23:29:05Z |
SenDM model described at https://arxiv.org/pdf/2201.02026
---
language:
- en
tags:
- discourse-markers
license: apache-2.0
---
|
khanglam7012/t5-small
|
khanglam7012
| 2022-01-10T13:32:38Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: Keywords to Sentences
tags:
- keytotext
- k2t
- Keywords to Sentences
license: mit
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
flboehm/youtube-bert_10
|
flboehm
| 2022-01-10T11:39:26Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: youtube-bert_10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# youtube-bert_10
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4456
- Perplexity: 11.54
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.6799 | 1.0 | 1899 | 2.5135 |
| 2.5736 | 2.0 | 3798 | 2.4612 |
| 2.5172 | 3.0 | 5697 | 2.4363 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/dril-feufillet-hostagekiller
|
huggingtweets
| 2022-01-10T11:35:03Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/dril-feufillet-hostagekiller/1641814499288/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1197820815636672513/JSCZmPDf_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/847818629840228354/VXyQHfn0_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1473236995497500675/FtwXDZld_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">sexy.funny.cute.pix & wint & HUSSY2K.</div>
<div style="text-align: center; font-size: 14px;">@dril-feufillet-hostagekiller</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from sexy.funny.cute.pix & wint & HUSSY2K..
| Data | sexy.funny.cute.pix | wint | HUSSY2K. |
| --- | --- | --- | --- |
| Tweets downloaded | 3101 | 3227 | 3186 |
| Retweets | 158 | 479 | 819 |
| Short tweets | 576 | 304 | 395 |
| Tweets kept | 2367 | 2444 | 1972 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1o5d39dk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dril-feufillet-hostagekiller's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/16eb1faz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/16eb1faz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dril-feufillet-hostagekiller')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/hostagekiller
|
huggingtweets
| 2022-01-10T10:05:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/hostagekiller/1641809138009/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1473236995497500675/FtwXDZld_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">HUSSY2K.</div>
<div style="text-align: center; font-size: 14px;">@hostagekiller</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from HUSSY2K..
| Data | HUSSY2K. |
| --- | --- |
| Tweets downloaded | 3186 |
| Retweets | 819 |
| Short tweets | 395 |
| Tweets kept | 1972 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/u2hpg02v/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hostagekiller's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3tx11pqs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3tx11pqs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hostagekiller')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
longnhit07/distilbert-base-uncased-finetuned-imdb
|
longnhit07
| 2022-01-10T09:02:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4722
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7117 | 1.0 | 157 | 2.4977 |
| 2.5783 | 2.0 | 314 | 2.4241 |
| 2.5375 | 3.0 | 471 | 2.4358 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
celtics1863/env-bert-chinese
|
celtics1863
| 2022-01-10T07:16:25Z | 62 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"pretrain",
"environment",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: zh
widget:
- text: "总[MASK]是水环境中的重要污染物。"
- text: "气[MASK]变化是重要的全球环境问题。"
tags:
- pretrain
- pytorch
- environment
---
环境领域的中文预训练Bert模型,在hlf/chinese-bert-wwm-ext的基础上进行训练,旨在学习到中文表达后进一步学习到环境领域的专业知识。
1.5G的预训练语料包括水环境、大气环境、土壤环境、气候变化、中文期刊、国家政策等内容。
项目正在进行中,后续会陆续更新相关内容。
清华大学环境学院课题组
有相关需求、建议,联系bi.huaibin@foxmail.com
|
lianaling/title-generator-t5
|
lianaling
| 2022-01-10T06:51:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
## Title Generator
References this [notebook](https://shivanandroy.com/transformers-generating-arxiv-papers-title-from-abstracts/)
Using `t5-small`, trained on a batch size of 16 for 4 epochs, utilising the ArXiV dataset through the `SimpleTransformers` library. Around 15k data was used for training and 3.7k data for evaluation.
This is a `.pkl` file.
### Prerequisites
Install `simpletransformers` library.
```bsh
pip install simpletransformers
```
### Example Usage
```py
import pickle
model = pickle.load(open("title-generator-t5-arxiv-16-4.pkl", "rb"))
# Prefix your text with 'summarize: '
text = ["summarize: " + """Venetian commodes imitated the curving lines and carved ornament of the French rocaille, but with a particular Venetian variation; the pieces were painted, often with landscapes or flowers or scenes from Guardi or other painters, or Chinoiserie, against a blue or green background, matching the colours of the Venetian school of painters whose work decorated the salons. 24] Ceiling of church of Santi Giovanni e Paolo in Venice, by Piazzetta (1727) Juno and Luna by Giovanni Battista Tiepolo (1735–45) Murano glass chandelier at the Ca Rezzonico (1758) Ballroom ceiling of the Ca Rezzonico with ceiling by Giovanni Battista Crosato (1753) In church construction, especially in the southern German-Austrian region, gigantic spatial creations are sometimes created for practical reasons alone, which, however, do not appear monumental, but are characterized by a unique fusion of architecture, painting, stucco, etc. ,."""]
print("Generated title: " + model.predict(text))
```
|
cook/cicero-similis
|
cook
| 2022-01-10T06:07:57Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"language model",
"la",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- la
tags:
- language model
license: apache-2.0
datasets:
- Tesserae
- Phi5
- Thomas Aquinas
- Patrologia Latina
---
# Cicero-Similis
## Model description
A Latin Language Model, trained on Latin texts, and evaluated using the corpus of Cicero, as described in the paper _What Would Cicero Write? -- Examining Critical Textual Decisions with a Language Model_ by Todd Cook,
Published in Ciceroniana On Line, Vol. V, #2.
## Intended uses & limitations
#### How to use
Normalize text using JV Replacement and tokenize using CLTK to separate enclitics such as "-que", then:
```
from transformers import BertForMaskedLM, AutoTokenizer, FillMaskPipeline
tokenizer = AutoTokenizer.from_pretrained("cook/cicero-similis")
model = BertForMaskedLM.from_pretrained("cook/cicero-similis")
fill_mask = FillMaskPipeline(model=model, tokenizer=tokenizer, top_k=10_000)
# Cicero, De Re Publica, VI, 32, 2
# "animal" is found in A, Q, PhD manuscripts
# 'anima' H^1 Macr. et codd. Tusc.
results = fill_mask("inanimum est enim omne quod pulsu agitatur externo; quod autem est [MASK],")
```
#### Limitations and bias
Currently the model training data excludes modern and 19th century texts, but that weakness is the model's strength; it's not aimed to be a one-size-fits-all model.
## Training data
Trained on the corpora Phi5, Tesserae, Thomas Aquinas, and Patrologes Latina.
## Training procedure
5 epochs, masked language modeling .15, effective batch size 32
## Eval results
A novel evaluation metric is proposed in the paper _What Would Cicero Write? -- Examining Critical Textual Decisions with a Language Model_ by Todd Cook,
Published in Ciceroniana On Line, Vol. V, #2.
### BibTeX entry and citation info
TODO
_What Would Cicero Write? -- Examining Critical Textual Decisions with a Language Model_ by Todd Cook,
Published in Ciceroniana On Line, Vol. V, #2.
|
tonyalves/wav2vec2-300m-teste4
|
tonyalves
| 2022-01-09T22:57:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-300m-teste4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-300m-teste4
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3276
- Wer: 0.3489
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.0237 | 0.49 | 100 | 4.2075 | 0.9792 |
| 3.313 | 0.98 | 200 | 3.0232 | 0.9792 |
| 2.9469 | 1.47 | 300 | 2.7591 | 0.9792 |
| 1.4217 | 1.96 | 400 | 0.8397 | 0.6219 |
| 0.5598 | 2.45 | 500 | 0.6085 | 0.5087 |
| 0.4507 | 2.94 | 600 | 0.4512 | 0.4317 |
| 0.2775 | 3.43 | 700 | 0.3839 | 0.3751 |
| 0.2047 | 3.92 | 800 | 0.3276 | 0.3489 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Firat/roberta-base-finetuned-squad
|
Firat
| 2022-01-09T22:12:48Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: roberta-base-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-squad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8953
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.8926 | 1.0 | 5536 | 0.8694 |
| 0.6821 | 2.0 | 11072 | 0.8428 |
| 0.5335 | 3.0 | 16608 | 0.8953 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1
- Datasets 1.17.0
- Tokenizers 0.10.3
|
ai-forever/ruclip-vit-large-patch14-224
|
ai-forever
| 2022-01-09T21:43:58Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# ruclip-vit-large-patch14-224
**RuCLIP** (**Ru**ssian **C**ontrastive **L**anguage–**I**mage **P**retraining) is a multimodal model
for obtaining images and text similarities and rearranging captions and pictures.
RuCLIP builds on a large body of work on zero-shot transfer, computer vision, natural language processing and
multimodal learning.
Model was trained by [Sber AI](https://github.com/sberbank-ai) and [SberDevices](https://sberdevices.ru/) teams.
* Task: `text ranking`; `image ranking`; `zero-shot image classification`;
* Type: `encoder`
* Num Parameters: `430M`
* Training Data Volume: `240 million text-image pairs`
* Language: `Russian`
* Context Length: `77`
* Transformer Layers: `12`
* Transformer Width: `768`
* Transformer Heads: `12`
* Image Size: `224`
* Vision Layers: `24`
* Vision Width: `1024`
* Vision Patch Size: `14`
## Usage [Github](https://github.com/sberbank-ai/ru-clip)
```
pip install ruclip
```
```python
clip, processor = ruclip.load("ruclip-vit-large-patch14-224", device="cuda")
```
## Performance
We have evaluated the performance on the following datasets:
| Dataset | Metric Name | Metric Result |
|:--------------|:---------------|:--------------------|
| Food101 | acc | 0.597 |
| CIFAR10 | acc | 0.878 |
| CIFAR100 | acc | 0.511 |
| Birdsnap | acc | 0.172 |
| SUN397 | acc | 0.484 |
| Stanford Cars | acc | 0.559 |
| DTD | acc | 0.370 |
| MNIST | acc | 0.337 |
| STL10 | acc | 0.934 |
| PCam | acc | 0.520 |
| CLEVR | acc | 0.152 |
| Rendered SST2 | acc | 0.529 |
| ImageNet | acc | 0.426 |
| FGVC Aircraft | mean-per-class | 0.046 |
| Oxford Pets | mean-per-class | 0.604 |
| Caltech101 | mean-per-class | 0.777 |
| Flowers102 | mean-per-class | 0.455 |
| HatefulMemes | roc-auc | 0.530 |
# Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)
+ Daniil Chesakov: [Github](https://github.com/Danyache)
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
ai-forever/ruclip-vit-base-patch32-224
|
ai-forever
| 2022-01-09T21:34:27Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# ruclip-vit-base-patch32-224
**RuCLIP** (**Ru**ssian **C**ontrastive **L**anguage–**I**mage **P**retraining) is a multimodal model
for obtaining images and text similarities and rearranging captions and pictures.
RuCLIP builds on a large body of work on zero-shot transfer, computer vision, natural language processing and
multimodal learning.
Model was trained by [Sber AI](https://github.com/sberbank-ai) and [SberDevices](https://sberdevices.ru/) teams.
* Task: `text ranking`; `image ranking`; `zero-shot image classification`;
* Type: `encoder`
* Num Parameters: `150M`
* Training Data Volume: `240 million text-image pairs`
* Language: `Russian`
* Context Length: `77`
* Transformer Layers: `12`
* Transformer Width: `512`
* Transformer Heads: `8`
* Image Size: `224`
* Vision Layers: `12`
* Vision Width: `768`
* Vision Patch Size: `32`
## Usage [Github](https://github.com/sberbank-ai/ru-clip)
```
pip install ruclip
```
```python
clip, processor = ruclip.load("ruclip-vit-base-patch32-224", device="cuda")
```
## Performance
We have evaluated the performance on the following datasets:
| Dataset | Metric Name | Metric Result |
|:--------------|:---------------|:--------------------|
| Food101 | acc | 0.505 |
| CIFAR10 | acc | 0.818 |
| CIFAR100 | acc | 0.504 |
| Birdsnap | acc | 0.115 |
| SUN397 | acc | 0.452 |
| Stanford Cars | acc | 0.433 |
| DTD | acc | 0.380 |
| MNIST | acc | 0.447 |
| STL10 | acc | 0.932 |
| PCam | acc | 0.501 |
| CLEVR | acc | 0.148 |
| Rendered SST2 | acc | 0.489 |
| ImageNet | acc | 0.375 |
| FGVC Aircraft | mean-per-class | 0.033 |
| Oxford Pets | mean-per-class | 0.560 |
| Caltech101 | mean-per-class | 0.786 |
| Flowers102 | mean-per-class | 0.401 |
| HatefulMemes | roc-auc | 0.564 |
# Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)
+ Daniil Chesakov: [Github](https://github.com/Danyache)
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
nepp1d0/SMILES_tokenizer
|
nepp1d0
| 2022-01-09T20:25:30Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
Tokenizer trained on BindingDB SMILES encodings.
Trained on 1008081 samples with one blank space after each character in the SMILES string
|
huggingtweets/ibaillanos
|
huggingtweets
| 2022-01-09T18:36:11Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/ibaillanos/1641753367000/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1476303212672131074/kuPm3Cvp_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ibai</div>
<div style="text-align: center; font-size: 14px;">@ibaillanos</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ibai.
| Data | Ibai |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 28 |
| Short tweets | 669 |
| Tweets kept | 2553 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3qyv6lsf/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ibaillanos's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/cxnkmkg6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/cxnkmkg6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ibaillanos')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
tonyalves/wav2vec2-large-xls-r-300m-pt-colab
|
tonyalves
| 2022-01-09T17:40:58Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-pt-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-pt-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3637
- Wer: 0.2982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.591 | 1.15 | 400 | 0.9128 | 0.6517 |
| 0.5049 | 2.31 | 800 | 0.4596 | 0.4437 |
| 0.2871 | 3.46 | 1200 | 0.3964 | 0.3905 |
| 0.2077 | 4.61 | 1600 | 0.3958 | 0.3744 |
| 0.1695 | 5.76 | 2000 | 0.4040 | 0.3720 |
| 0.1478 | 6.92 | 2400 | 0.3866 | 0.3651 |
| 0.1282 | 8.07 | 2800 | 0.3987 | 0.3674 |
| 0.1134 | 9.22 | 3200 | 0.4128 | 0.3688 |
| 0.1048 | 10.37 | 3600 | 0.3928 | 0.3561 |
| 0.0938 | 11.53 | 4000 | 0.4048 | 0.3619 |
| 0.0848 | 12.68 | 4400 | 0.4229 | 0.3555 |
| 0.0798 | 13.83 | 4800 | 0.3974 | 0.3468 |
| 0.0688 | 14.98 | 5200 | 0.3870 | 0.3503 |
| 0.0658 | 16.14 | 5600 | 0.3875 | 0.3351 |
| 0.061 | 17.29 | 6000 | 0.4133 | 0.3417 |
| 0.0569 | 18.44 | 6400 | 0.3915 | 0.3414 |
| 0.0526 | 19.6 | 6800 | 0.3957 | 0.3231 |
| 0.0468 | 20.75 | 7200 | 0.4110 | 0.3301 |
| 0.0407 | 21.9 | 7600 | 0.3866 | 0.3186 |
| 0.0384 | 23.05 | 8000 | 0.3976 | 0.3193 |
| 0.0363 | 24.21 | 8400 | 0.3910 | 0.3177 |
| 0.0313 | 25.36 | 8800 | 0.3656 | 0.3109 |
| 0.0293 | 26.51 | 9200 | 0.3712 | 0.3092 |
| 0.0277 | 27.66 | 9600 | 0.3613 | 0.3054 |
| 0.0249 | 28.82 | 10000 | 0.3783 | 0.3015 |
| 0.0234 | 29.97 | 10400 | 0.3637 | 0.2982 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu102
- Datasets 1.13.3
- Tokenizers 0.10.3
|
Littlemilk/autobiography-generator
|
Littlemilk
| 2022-01-09T17:15:14Z | 8 | 2 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language:
- zh
license: gpl-3.0
tags:
- generated_from_trainer
model-index:
- name: clm-total
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clm-total
This model is a fine-tuned version of [ckiplab/gpt2-base-chinese](https://huggingface.co/ckiplab/gpt2-base-chinese) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cpu
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Vassilis/distilbert-base-uncased-finetuned-emotion
|
Vassilis
| 2022-01-09T16:41:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1628
- Accuracy: 0.9345
- F1: 0.9348
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1674 | 1.0 | 250 | 0.1718 | 0.9265 | 0.9266 |
| 0.1091 | 2.0 | 500 | 0.1628 | 0.9345 | 0.9348 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0
- Tokenizers 0.10.3
|
NahedAbdelgaber/evaluating-student-writing-distibert-ner-with-metric
|
NahedAbdelgaber
| 2022-01-09T06:45:10Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: evaluating-student-writing-distibert-ner-with-metric
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# evaluating-student-writing-distibert-ner-with-metric
This model is a fine-tuned version of [NahedAbdelgaber/evaluating-student-writing-distibert-ner](https://huggingface.co/NahedAbdelgaber/evaluating-student-writing-distibert-ner) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7535
- Precision: 0.0614
- Recall: 0.2590
- F1: 0.0993
- Accuracy: 0.6188
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.7145 | 1.0 | 1755 | 0.7683 | 0.0546 | 0.2194 | 0.0875 | 0.6191 |
| 0.6608 | 2.0 | 3510 | 0.7504 | 0.0570 | 0.2583 | 0.0934 | 0.6136 |
| 0.5912 | 3.0 | 5265 | 0.7535 | 0.0614 | 0.2590 | 0.0993 | 0.6188 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
RenZHU/t5-small-finetuned-xsum-original
|
RenZHU
| 2022-01-09T06:04:38Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum-original
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
args: default
metrics:
- name: Rouge1
type: rouge
value: 28.8838
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-original
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4436
- Rouge1: 28.8838
- Rouge2: 8.1114
- Rougel: 22.8318
- Rougelsum: 22.8318
- Gen Len: 18.8141
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.6754 | 1.0 | 51012 | 2.4436 | 28.8838 | 8.1114 | 22.8318 | 22.8318 | 18.8141 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt
|
vuiseng9
| 2022-01-09T03:25:27Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"onnx",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This model is a downstream optimization of [```vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt```](https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt) using [OpenVINO/NNCF](https://github.com/openvinotoolkit/nncf). Applied optimization includes:
1. magnitude sparsification at 50% upon initialization. Parameters are ranked globally via thier absolute norm. Only linear layers of self-attention and ffnn are targeted.
2. NNCF Quantize-Aware Training - Symmetric 8-bit for both weight and activation on all learnable layers.
3. Custom distillation with large model ```bert-large-uncased-whole-word-masking-finetuned-squad```
```
eval_exact_match = 80.2081
eval_f1 = 87.5921
eval_samples = 10784
```
# Setup
```bash
# OpenVINO/NNCF
git clone https://github.com/vuiseng9/nncf && cd nncf
git checkout tld-poc
git reset --hard 1dec7afe7a4b567c059fcf287ea2c234980fded2
python setup.py develop
pip install -r examples/torch/requirements.txt
# Huggingface nn_pruning
git clone https://github.com/vuiseng9/nn_pruning && cd nn_pruning
git checkout reproduce-evaluation
git reset --hard 2d4e196d694c465e43e5fbce6c3836d0a60e1446
pip install -e ".[dev]"
# Huggingface Transformers
git clone https://github.com/vuiseng9/transformers && cd transformers
git checkout tld-poc
git reset --hard 10a1e29d84484e48fd106f58957d9ffc89dc43c5
pip install -e .
head -n 1 examples/pytorch/question-answering/requirements.txt | xargs -i pip install {}
# Additional dependencies
pip install onnx
```
# Train
```bash
git clone https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt
BASE_MODEL=/path/to/cloned_repo_above #to-revise
wget https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt/raw/main/nncf_bert_squad_sparsity.json
NNCF_CFG=/path/to/downloaded_nncf_cfg_above #to-revise
OUTROOT=/path/to/train_output_root #to-revise
WORKDIR=transformers/examples/pytorch/question-answering #to-revise
RUNID=bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt
cd $WORKDIR
OUTDIR=$OUTROOT/$RUNID
mkdir -p $OUTDIR
export CUDA_VISIBLE_DEVICES=0
NEPOCH=5
python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--optimize_model_before_eval \
--optimized_checkpoint $BASE_MODEL \
--dataset_name squad \
--do_eval \
--do_train \
--evaluation_strategy steps \
--eval_steps 250 \
--learning_rate 3e-5 \
--lr_scheduler_type cosine_with_restarts \
--warmup_ratio 0.25 \
--cosine_cycles 1 \
--teacher bert-large-uncased-whole-word-masking-finetuned-squad \
--teacher_ratio 0.9 \
--num_train_epochs $NEPOCH \
--per_device_eval_batch_size 128 \
--per_device_train_batch_size 16 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 250 \
--nncf_config $NNCF_CFG \
--logging_steps 1 \
--overwrite_output_dir \
--run_name $RUNID \
--output_dir $OUTDIR
```
# Eval
This repo must be cloned locally.
```bash
git clone https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt
MODELROOT=/path/to/cloned_repo_above #to-revise
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt
WORKDIR=transformers/examples/pytorch/question-answering #to-revise
cd $WORKDIR
mkdir $OUTDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--dataset_name squad \
--optimize_model_before_eval \
--qat_checkpoint $MODELROOT/checkpoint-26250 \
--nncf_config $MODELROOT/nncf_bert_squad_sparsity.json \
--to_onnx $OUTDIR/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-50.0sparse-qat-lt.onnx \
--do_eval \
--per_device_eval_batch_size 128 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
haji2438/bertweet-base-finetuned-SNS-brand-personality
|
haji2438
| 2022-01-09T03:24:39Z | 165 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: bertweet-base-finetuned-SNS-brand-personality
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-base-finetuned-SNS-brand-personality
This model is a fine-tuned version of [vinai/bertweet-base](https://huggingface.co/vinai/bertweet-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0498
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0757 | 1.0 | 1549 | 0.0723 |
| 0.0605 | 2.0 | 3098 | 0.0573 |
| 0.0498 | 3.0 | 4647 | 0.0498 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt
|
vuiseng9
| 2022-01-09T03:14:14Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"onnx",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This model is a downstream optimization of [```vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt```](https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt) using [OpenVINO/NNCF](https://github.com/openvinotoolkit/nncf). Applied optimization includes:
1. magnitude sparsification at 60% upon initialization. Parameters are ranked globally via thier absolute norm. Only linear layers of self-attention and ffnn are targeted.
2. NNCF Quantize-Aware Training - Symmetric 8-bit for both weight and activation on all learnable layers.
3. Custom distillation with large model ```bert-large-uncased-whole-word-masking-finetuned-squad```
```
eval_exact_match = 80.3122
eval_f1 = 87.6162
eval_samples = 10784
```
# Setup
```bash
# OpenVINO/NNCF
git clone https://github.com/vuiseng9/nncf && cd nncf
git checkout tld-poc
git reset --hard 1dec7afe7a4b567c059fcf287ea2c234980fded2
python setup.py develop
pip install -r examples/torch/requirements.txt
# Huggingface nn_pruning
git clone https://github.com/vuiseng9/nn_pruning && cd nn_pruning
git checkout reproduce-evaluation
git reset --hard 2d4e196d694c465e43e5fbce6c3836d0a60e1446
pip install -e ".[dev]"
# Huggingface Transformers
git clone https://github.com/vuiseng9/transformers && cd transformers
git checkout tld-poc
git reset --hard 10a1e29d84484e48fd106f58957d9ffc89dc43c5
pip install -e .
head -n 1 examples/pytorch/question-answering/requirements.txt | xargs -i pip install {}
# Additional dependencies
pip install onnx
```
# Train
```bash
git clone https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt
BASE_MODEL=/path/to/cloned_repo_above #to-revise
wget https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt/raw/main/nncf_bert_squad_sparsity.json
NNCF_CFG=/path/to/downloaded_nncf_cfg_above #to-revise
OUTROOT=/path/to/train_output_root #to-revise
WORKDIR=transformers/examples/pytorch/question-answering #to-revise
RUNID=bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt
cd $WORKDIR
OUTDIR=$OUTROOT/$RUNID
mkdir -p $OUTDIR
export CUDA_VISIBLE_DEVICES=0
NEPOCH=5
python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--optimize_model_before_eval \
--optimized_checkpoint $BASE_MODEL \
--dataset_name squad \
--do_eval \
--do_train \
--evaluation_strategy steps \
--eval_steps 250 \
--learning_rate 3e-5 \
--lr_scheduler_type cosine_with_restarts \
--warmup_ratio 0.25 \
--cosine_cycles 1 \
--teacher bert-large-uncased-whole-word-masking-finetuned-squad \
--teacher_ratio 0.9 \
--num_train_epochs $NEPOCH \
--per_device_eval_batch_size 128 \
--per_device_train_batch_size 16 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 250 \
--nncf_config $NNCF_CFG \
--logging_steps 1 \
--overwrite_output_dir \
--run_name $RUNID \
--output_dir $OUTDIR
```
# Eval
This repo must be cloned locally.
```bash
git clone https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt
MODELROOT=/path/to/cloned_repo_above #to-revise
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt
WORKDIR=transformers/examples/pytorch/question-answering #to-revise
cd $WORKDIR
mkdir $OUTDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--dataset_name squad \
--optimize_model_before_eval \
--qat_checkpoint $MODELROOT/checkpoint-22000 \
--nncf_config $MODELROOT/nncf_bert_squad_sparsity.json \
--to_onnx $OUTDIR/bert-base-squadv1-block-pruning-hybrid-filled-lt-nncf-60.0sparse-qat-lt.onnx \
--do_eval \
--per_device_eval_batch_size 128 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
vuiseng9/bert-base-squadv1-block-pruning-hybrid
|
vuiseng9
| 2022-01-09T03:12:11Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2109.04838",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
BERT-base tuned for Squadv1.1 is pruned with movement pruning algorithm in hybrid fashion, i.e. 32x32 block for self-attention layers, per-dimension grain size for ffn layers.
```
eval_exact_match = 78.5241
eval_f1 = 86.4138
eval_samples = 10784
```
This model is a replication of [block pruning paper](https://arxiv.org/abs/2109.04838) with its open-sourced codebase (forked and modified).
To reproduce this model, pls follow [documentation here](https://github.com/vuiseng9/nn_pruning/blob/reproduce-evaluation/reproduce-eval/readme.md) until step 2.
# Eval
The model can be evaluated out-of-the-box with HF QA example. Note that only pruned self-attention heads are discarded where pruned ffn dimension are sparsified instead of removal. Verified in v4.13.0, v4.9.1.
```bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-squadv1-block-pruning-hybrid
WORKDIR=transformers/examples/pytorch/question-answering
cd $WORKDIR
mkdir $OUTDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--dataset_name squad \
--do_eval \
--per_device_eval_batch_size 16 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
If the intent is to observe inference acceleration, the pruned structure in the model must be "cropped"/discarded. Follow the custom setup below.
```bash
# OpenVINO/NNCF
git clone https://github.com/vuiseng9/nncf && cd nncf
git checkout tld-poc
git reset --hard 1dec7afe7a4b567c059fcf287ea2c234980fded2
python setup.py develop
pip install -r examples/torch/requirements.txt
# Huggingface nn_pruning
git clone https://github.com/vuiseng9/nn_pruning && cd nn_pruning
git checkout reproduce-evaluation
git reset --hard 2d4e196d694c465e43e5fbce6c3836d0a60e1446
pip install -e ".[dev]"
# Huggingface Transformers
git clone https://github.com/vuiseng9/transformers && cd transformers
git checkout tld-poc
git reset --hard 10a1e29d84484e48fd106f58957d9ffc89dc43c5
pip install -e .
head -n 1 examples/pytorch/question-answering/requirements.txt | xargs -i pip install {}
```
Add ```--optimize_model_before_eval``` during evaluation.
```bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-squadv1-block-pruning-hybrid-cropped
WORKDIR=transformers/examples/pytorch/question-answering
cd $WORKDIR
mkdir $OUTDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--dataset_name squad \
--optimize_model_before_eval \
--do_eval \
--per_device_eval_batch_size 128 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt
|
vuiseng9
| 2022-01-09T03:11:21Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"arxiv:2109.04838",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
This model is a downstream fine-tuning of [```vuiseng9/bert-base-squadv1-block-pruning-hybrid```](https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid). "filled" means unstructured fine-grained sparsified parameters are allowed to learn during fine-tuning. "lt" means distillation of larger model as teacher, i.e. ```bert-large-uncased-whole-word-masking-finetuned-squad```
```
eval_exact_match = 80.3311
eval_f1 = 87.69
eval_samples = 10784
```
This model is a replication of [block pruning paper](https://arxiv.org/abs/2109.04838) with its open-sourced codebase (forked and modified).
To reproduce this model, pls follow [documentation here](https://github.com/vuiseng9/nn_pruning/blob/reproduce-evaluation/reproduce-eval/readme.md) until step 3.
# Eval
The model cannot be evaluated with HF QA example out-of-the-box as the final dimension of the model architecture has been realized. Follow the custom setup below.
```bash
# OpenVINO/NNCF
git clone https://github.com/vuiseng9/nncf && cd nncf
git checkout tld-poc
git reset --hard 1dec7afe7a4b567c059fcf287ea2c234980fded2
python setup.py develop
pip install -r examples/torch/requirements.txt
# Huggingface nn_pruning
git clone https://github.com/vuiseng9/nn_pruning && cd nn_pruning
git checkout reproduce-evaluation
git reset --hard 2d4e196d694c465e43e5fbce6c3836d0a60e1446
pip install -e ".[dev]"
# Huggingface Transformers
git clone https://github.com/vuiseng9/transformers && cd transformers
git checkout tld-poc
git reset --hard 10a1e29d84484e48fd106f58957d9ffc89dc43c5
pip install -e .
head -n 1 examples/pytorch/question-answering/requirements.txt | xargs -i pip install {}
```
This repo must be cloned locally.
```bash
git clone https://huggingface.co/vuiseng9/bert-base-squadv1-block-pruning-hybrid-filled-lt
```
Add ```--optimize_model_before_eval``` and ```--optimized_checkpoint /path/to/clone``` during evaluation.
```bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-squadv1-block-pruning-hybrid-filled-lt-cropped
WORKDIR=transformers/examples/pytorch/question-answering
cd $WORKDIR
mkdir $OUTDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-squadv1-block-pruning-hybrid \
--dataset_name squad \
--optimize_model_before_eval \
--optimized_checkpoint /path/to/clone/bert-base-squadv1-block-pruning-hybrid-filled-lt \
--do_eval \
--per_device_eval_batch_size 128 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
RenZHU/t5-small-finetuned-xsum
|
RenZHU
| 2022-01-09T03:09:55Z | 106 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5310
- Rouge1: 27.9232
- Rouge2: 7.5324
- Rougel: 22.035
- Rougelsum: 22.0304
- Gen Len: 18.8116
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 2.7564 | 1.0 | 51012 | 2.5310 | 27.9232 | 7.5324 | 22.035 | 22.0304 | 18.8116 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
vuiseng9/bert-base-uncased-squad
|
vuiseng9
| 2022-01-08T18:08:11Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
This model is developed with transformers v4.10.3.
# Train
```bash
#!/usr/bin/env bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=bert-base-uncased-squad
WORKDIR=transformers/examples/pytorch/question-answering
cd $WORKDIR
nohup python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_eval \
--do_train \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--doc_stride 128 \
--max_seq_length 384 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--eval_steps 250 \
--save_steps 2500 \
--logging_steps 1 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
# Eval
```bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-base-uncased-squad
WORKDIR=transformers/examples/pytorch/question-answering
cd $WORKDIR
nohup python run_qa.py \
--model_name_or_path vuiseng9/bert-base-uncased-squad \
--dataset_name squad \
--do_eval \
--per_device_eval_batch_size 16 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
LanceaKing/spkrec-ecapa-cnceleb
|
LanceaKing
| 2022-01-08T09:27:18Z | 12 | 4 |
speechbrain
|
[
"speechbrain",
"embeddings",
"Speaker",
"Verification",
"Identification",
"pytorch",
"ECAPA",
"TDNN",
"zh",
"dataset:cnceleb",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language: "zh"
thumbnail:
tags:
- speechbrain
- embeddings
- Speaker
- Verification
- Identification
- pytorch
- ECAPA
- TDNN
license: "apache-2.0"
datasets:
- cnceleb
metrics:
- EER
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Speaker Verification with ECAPA-TDNN embeddings on cnceleb
This repository provides all the necessary tools to perform speaker verification with a pretrained ECAPA-TDNN model using SpeechBrain.
The system can be used to extract speaker embeddings as well.
It is trained on cnceleb 1+ cnceleb2 training data.
For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance on cnceleb1-test set(Cleaned) is:
| Release | EER(%) | minDCF |
|:-------------:|:--------------:|:--------------:|
## Pipeline description
This system is composed of an ECAPA-TDNN model. It is a combination of convolutional and residual blocks. The embeddings are extracted using attentive statistical pooling. The system is trained with Additive Margin Softmax Loss. Speaker Verification is performed using cosine distance between speaker embeddings.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Compute your speaker embeddings
```python
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(source="LanceaKing/spkrec-ecapa-cnceleb")
signal, fs =torchaudio.load('samples/audio_samples/example1.wav')
embeddings = classifier.encode_batch(signal)
```
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed. Make sure your input tensor is compliant with the expected sampling rate if you use *encode_batch* and *classify_batch*.
### Perform Speaker Verification
```python
from speechbrain.pretrained import SpeakerRecognition
verification = SpeakerRecognition.from_hparams(source="LanceaKing/spkrec-ecapa-cnceleb", savedir="pretrained_models/spkrec-ecapa-cnceleb")
score, prediction = verification.verify_files("speechbrain/spkrec-ecapa-cnceleb/example1.wav", "speechbrain/spkrec-ecapa-cnceleb/example2.flac")
```
The prediction is 1 if the two signals in input are from the same speaker and 0 otherwise.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (aa018540).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/LanceaKing/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/CNCeleb/SpeakerRec
python train_speaker_embeddings.py hparams/train_ecapa_tdnn.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1-ahC1xeyPinAHp2oAohL-02smNWO41Cc?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing ECAPA-TDNN
```
@inproceedings{DBLP:conf/interspeech/DesplanquesTD20,
author = {Brecht Desplanques and
Jenthe Thienpondt and
Kris Demuynck},
editor = {Helen Meng and
Bo Xu and
Thomas Fang Zheng},
title = {{ECAPA-TDNN:} Emphasized Channel Attention, Propagation and Aggregation
in {TDNN} Based Speaker Verification},
booktitle = {Interspeech 2020},
pages = {3830--3834},
publisher = {{ISCA}},
year = {2020},
}
```
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and Fran莽ois Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
|
espnet/Karthik_sinhala_asr_train_asr_transformer
|
espnet
| 2022-01-08T03:24:39Z | 4 | 0 |
espnet
|
[
"espnet",
"audio",
"automatic-speech-recognition",
"en",
"dataset:sinhala",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- espnet
- audio
- automatic-speech-recognition
language: en
datasets:
- sinhala
license: cc-by-4.0
---
## ESPnet2 ASR pretrained model
### `espnet/Karthik_sinhala_asr_train_asr_transformer`
This model was trained by Karthik using sinhala/asr1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.